Предыстория
Будучи любителем ретро железа, приобрёл я как-то у продавца из Великобритании ZX Spectrum+. В комплекте с самим компьютером мне достались несколько аудиокассет с играми (в оригинальной упаковке с инструкциями), а также программами, записанными на кассеты без особых обозначений. На удивление данные с кассет 40-летней давности хорошо читались и мне удалось загрузить почти все игры и программы с них.

Однако, на некоторых кассетах я обнаружил записи, сделанные явно не компьютером ZX Spectrum. Звучали они совершенно по-другому и, в отличие от записей с упомянутого компьютера, не начинались с короткого BASIC загрузчика, который обычно присутствует в записях всех программ и игр.
Какое-то время мне не давало это покоя — очень хотелось узнать, что скрыто в них. Если бы получилось прочитать аудио сигнал как последовательность байтов, можно было бы поискать в них символы или что-то, что указывает на происхождение сигнала. Своего рода ретро-археология.
Сейчас, когда я прошёл весь путь и смотрю на этикетки самих кассет, я улыбаюсь, потому что
ответ был прямо перед глазами всё это время
На этикетке левой кассеты — название компьютера TRS-80, и чуть ниже название производителя: «Manufactured by Radio Shack in USA»
(Если хотите сохранить интригу до конца, не заходите под спойлер)
Сравнение аудио сигналов
Первым делом оцифруем аудиозаписи. Можно послушать как это звучит:
И как обычно звучит запись с компьютера ZX Spectrum:
В обоих случаях в начале записи присутствует так называемый пилотный тон — звук одной частоты (на первой записи он очень короткий <1 сек, однако различим). Пилотный тон служит сигналом компьютеру, что необходимо подготовиться к получению данных. Как правило каждый компьютер распознает только «свой» пилотный тон по форме сигнала и его частоте.
Надо сказать о самой форме сигнала. Например, на ZX Spectrum его форма прямоугольная:
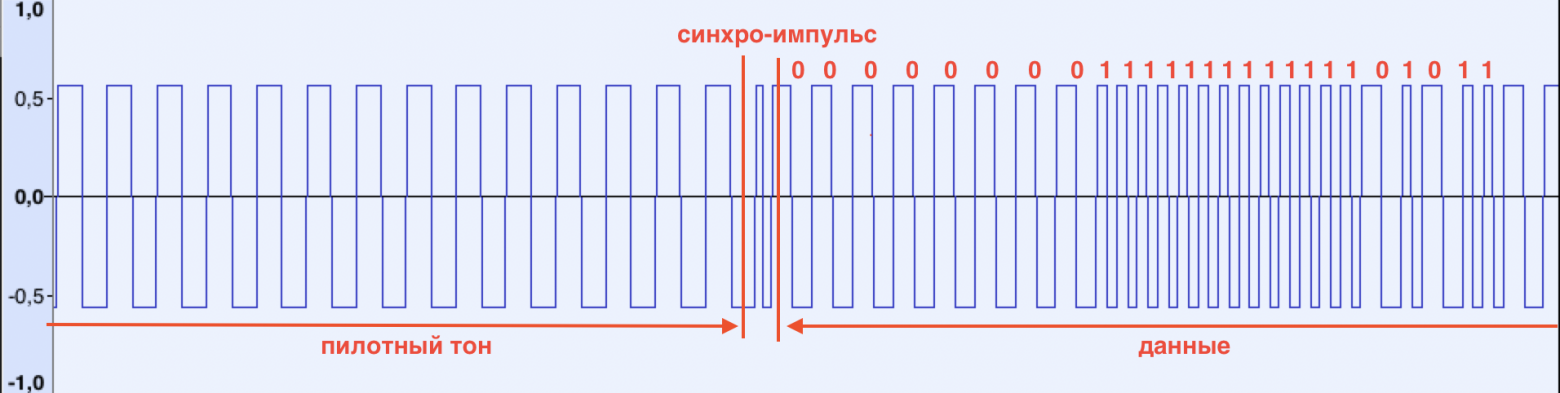
При обнаружении пилотного тона ZX Spectrum отображает чередующиеся красно-голубые полоски на бордюрной части экрана, показывая, что сигнал распознан. Пилотный тон заканчивается синхро-импульсом, который сигнализирует компьютеру о том, что следует начинать принимать данные. Он характеризуется меньшей (по сравнению с пилотным тоном и последующими данными) длительностью (см. рисунок)
После того, как синхро-импульс получен, компьютер фиксирует каждый подъём/спуск сигнала, измеряя его длительность. Если длительность меньше опредёленной границы, в память записывается бит 1, иначе 0. Биты собираются в байты и процесс повторяется до тех пор пока не будет получено N байт. Число N, как правило, берётся из заголовка загружаемого файла. Последовательность загрузки следующая:
- пилотный тон
- заголовок (фиксированной длины), содержит размер загружаемых данных (N), имя и тип файла
- пилотный тон
- сами данные
Чтобы удостовериться, что данные загружены верно, ZX Spectrum последним байтом читает так называемый байт чётности (parity byte), который вычисляется при сохранении файла операцией XOR над всеми байтами записанных данных. При чтении файла компьютер вычисляет байт чётности из полученных данных и, если результат отличается от сохранённого, выводит сообщение об ошибке «R Tape loading error». Строго говоря, компьютер может выдать это сообщение и раньше, если при чтении не может распознать импульс (пропущен или его длительность не соответствует определённым границам)
Итак, посмотрим теперь, как выглядит неизвестный сигнал:
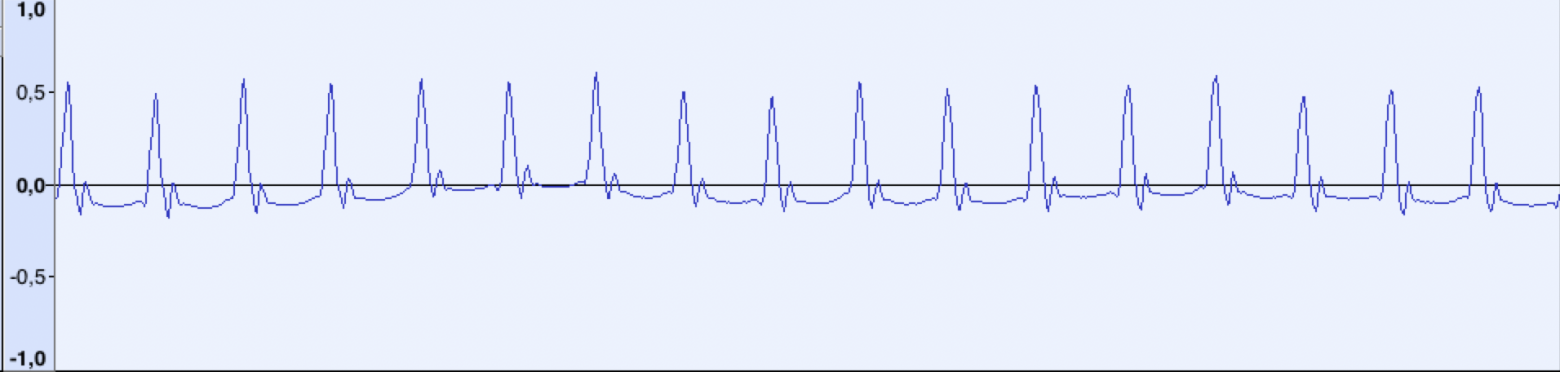
Это пилотный тон. Форма сигнала значительно отличается, но видно что сигнал состоит из повторяющихся коротких импульсов определённой частоты. При частоте дискретизации 44100 Гц, расстояние между «пиками» примерно равно 48 сэмплов (что соответствует частоте ~918 Гц) Запомним эту цифру.
Посмотрим теперь на фрагмент с данными:
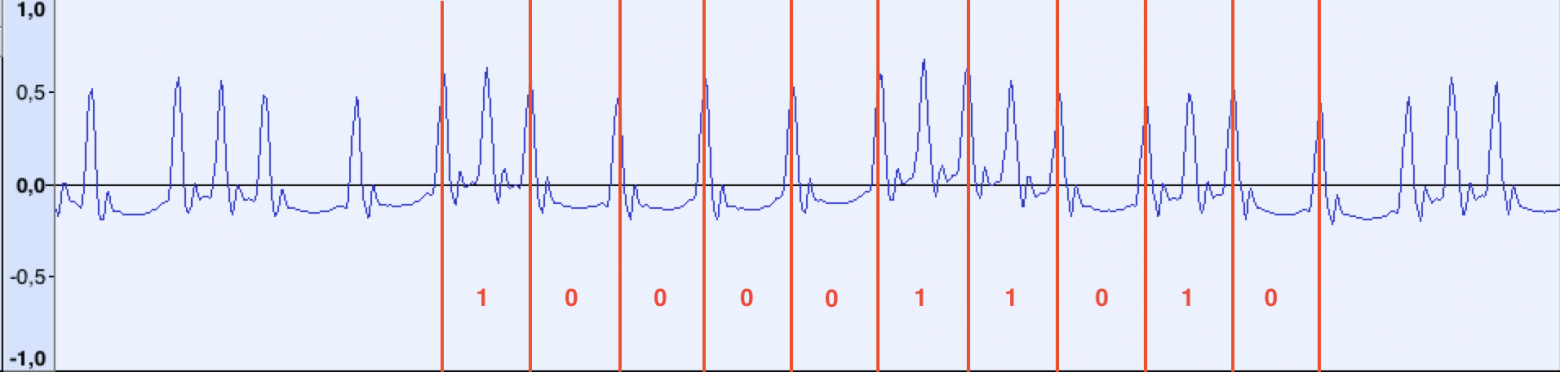
Если измерить расстояние между отдельными импульсами, окажется, что между «длинными» импульсами расстояние по-прежнему в ~48 сэмплов, а между короткими — ~24. Немного забегая вперёд, скажу, что в итоге выяснилось, «опорные» импульсы с частотой 918 Гц следуют непрерывно, от начала и до конца файла. Можно предположить, что при передаче данных, если между опорными импульсами встречается дополнительный импульс, считаем его за бит 1, иначе 0.
Что с синхро-импульсом? Посмотрим на начало данных:
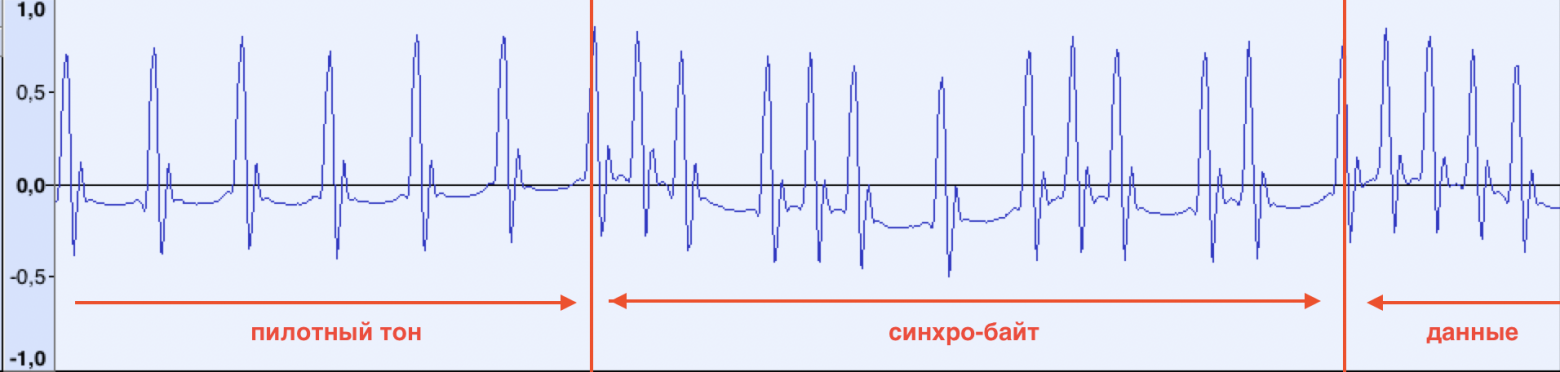
Пилотный тон заканчивается и сразу начинаются данные. Чуть позже, проанализировав несколько разных аудио записей, удалось обнаружить, что первый байт данных всегда один и тот же (10100101b, A5h). Возможно, компьютер начинает считывать данные, после того как получит его.
Можно также обратить внимание на сдвиг первого опорного импульса сразу после последней 1-цы в синхробайте. Его удалось обнаружить значительно позже в процессе разработки программы для распознавания данных, когда данные в начале файла не могли стабильно считаться.
Теперь попробуем описать алгоритм, который обработает аудио файл и загрузит данные.
Загрузка данных
Сперва рассмотрим несколько допущений, чтобы не усложнять алгоритм:
- Будем рассматривать файлы только в формате WAV;
- Аудиофайл должен начинаться с пилотного тона и не должен содержать тишину в начале
- Исходный файл должен иметь частоту дискретизации 44100 Гц. В таком случае расстояние между опорными импульсами в 48 сэмплов уже определено и нам не нужно программно его рассчитывать;
- Формат сэмплов может быть любой (8/16 бит/с плавающей точкой) — так как при чтении мы можем сконвертировать его в нужный;
- Предполагаем, что исходный файл нормализован по амплитуде, что должно стабилизировать результат;
Алгоритм чтения будет следующий:
- Читаем файл в память, одновременно конвертируем формат сэмплов в 8 бит;
- Определяем позицию первого импульса в аудиоданных. Для этого нужно вычислить номер сэмпла с максимальной амплитудой. Для простоты посчитаем его один раз вручную. Сохраним в переменную prev_pos;
- Прибавляем к позиции последнего импульса 48 (pos := prev_pos + 48)
- Так как увеличение позиции на 48 не гарантирует, что мы попадём в позицию следующего опорного импульса (дефекты ленты, нестабильная работа лентопротяжного механизма и прочее), нужно откорректировать позицию импульса pos. Для этого возьмем небольшой отрезок данных (pos-8;pos+8) и найдем на нём максимум значения амплитуды. Позицию, соответствующую максимуму, сохраним в pos. Здесь 8 = 48/6 — экспериментально полученная константа, которая гарантирует что мы определим верный максимум и не затронем другие импульсы, которые могут идти рядом. В очень плохих случаях, когда расстояние между импульсами сильно меньше или больше 48, можно реализовать принудительный поиск импульса, но в рамках статьи я не буду описывать это в алгоритме;
- На предыдущем шаге также необходимо бы проверить, что опорный импульс вообще найден. То есть, если просто искать максимум, это не гарантирует что импульс в данном отрезке присутствует. В своей последней реализации программы чтения я проверяю разницу между максимальным и минимальным значением амплитуды на отрезке, и если она превышает некоторую границу, засчитываю наличие импульса. Вопрос также, что делать если опорный импульс не найден. Тут 2 варианта: либо данные закончились и далее следует тишина, либо это следует рассматривать как ошибку чтения. Однако опустим это для упрощения алгоритма;
- На следующем шаге нужно определить наличие импульса данных (бит 0 или 1), для этого возьмем середину отрезка (prev_pos;pos) middle_pos равную middle_pos := (prev_pos+pos)/2 и в некоторой окрестности middle_pos на отрезке (middle_pos-8;middle_pos+8) посчитаем максимум и минимум амплитуды. Если разница между ними больше 10, записываем в результат бит 1 иначе 0. 10 — константа полученная опытным путём;
- Сохраняем текущую позицию в prev_pos (prev_pos := pos)
- Повторяем начиная с шага 3, пока не прочитаем весь файл;
- Полученный битовый массив необходимо сохранить как набор байт. Поскольку мы не учли синхро-байт при чтении, количество битов может оказаться не кратно 8, а также неизвестно необходимое смещение в битах. В первой реализации алгоритма я не знал о существовании синхро-байта и потому просто сохранял 8 файлов с разным количеством бит смещения. Один из них содержал корректные данные. В финальном алгоритме я просто удаляю все биты до A5h, что позволяет сразу получать корректный файл на выходе
Алгоритм на Ruby, кому интересно
В качестве языка для написания программы я выбрал Ruby, т.к. бОльшую часть времени программирую на нём. Вариант не высокопроизводительный, однако задача сделать скорость чтения максимально быстрой не стоит.
# Используем gem 'wavefile'
require 'wavefile'
reader = WaveFile::Reader.new('input.wav')
samples = []
format = WaveFile::Format.new(:mono, :pcm_8, 44100)
# Читаем WAV файл, конвертируем в формат Mono, 8 bit
# Массив samples будет состоять из байт со значениями 0-255
reader.each_buffer(10000) do |buffer|
samples += buffer.convert(format).samples
end
# Позиция первого импульса (вместо 0)
prev_pos = 0
# Расстояние между импульсами
distance = 48
# Значение расстояния для окрестности поиска локального максимума
delta = (distance / 6).floor
# Биты будем сохранять в виде строки из "0" и "1"
bits = ""
loop do
# Рассчитываем позицию следующего импульса
pos = prev_pos + distance
# Выходим из цикла если данные закончились
break if pos + delta >= samples.size
# Корректируем позицию pos обнаружением максимума на отрезке [pos - delta;pos + delta]
(pos - delta..pos + delta).each { |p| pos = p if samples[p] > samples[pos] }
# Находим середину отрезка [prev_pos;pos]
middle_pos = ((prev_pos + pos) / 2).floor
# Берем окрестность в середине
sample = samples[middle_pos - delta..middle_pos + delta]
# Определяем бит как "1" если разница между максимальным и минимальным значением на отрезке превышает 10
bit = sample.max - sample.min > 10
bits += bit ? "1" : "0"
end
# Определяем синхро-байт и заменяем все предшествующие биты на 256 бит нулей (согласно спецификации формата)
bits.gsub! /^[01]*?10100101/, ("0" * 256) + "10100101"
# Сохраняем выходной файл, упаковывая биты в байты
File.write "output.cas", [bits].pack("B*")
Результат
Перепробовав несколько вариантов алгоритма и констант, мне повезло получить что-то в крайней степени интересное:

Итак, судя по символьным строкам, мы имеем программу для построения графиков. Однако в тексте программы отсутствуют ключевые слова. Все ключевые слова закодированы в виде байтов (значение каждого > 80h). Теперь нужно выяснить, какой компьютер из 80-х мог сохранять программы в таком формате.
На самом деле это очень похоже на программу на языке BASIC. Примерно в таком же формате компьютер ZX Spectrum хранит в памяти и сохраняет программы на ленту. На всякий случай я проверил ключевые слова на соответствие с таблицей. Однако результат, очевидно, оказался отрицательным.
Также я проверил ключевые слова BASIC популярных в то время компьютеров Atari, Commodore 64 и нескольких других, на которые удалось найти документацию, однако безуспешно — мои познания в разновидностях ретро-компьютеров оказались не столь широки.
Тогда я решил пойти по списку, и тут мой взгляд упал на название производителя Radio Shack и компьютера TRS-80. Именно эти названия были написаны на этикетках кассет, которые лежали у меня на столе! Я ведь не знал ранее эти названия и не был знаком с компьютером TRS-80, поэтому мне казалось, что Radio Shack это производитель аудиокассет, такой кaк BASF, Sony или TDK, a TRS-80 — длительность воспроизведения. Почему нет?
Компьютер Tandy/Radio Shack TRS-80
Очень вероятно, что рассматриваемая аудиозапись, которую я привёл в качестве примера в начале статьи, сделана на таком компьютере:

Оказалось, что данный компьютер и его разновидности (Model I/Model III/Model IV и т.д.) были очень популярны в свое время (конечно, не в России). Примечательно, что процессор, которых в них использовался — тоже Z80. По данному компьютеру в Интернете можно найти много информации. В 80-х годах информация о компьютере распространялась в журналах. На данный момент существует несколько эмуляторов компьютера под разные платформы.
Я загрузил эмулятор trs80gp и мне впервые удалось посмотреть как работал этот компьютер. Конечно, компьютер не поддерживал вывод цвета, разрешение экрана всего 128х48 точек, но существовало множество расширений и модификаций которые могли увеличивать разрешение экрана. Также существовало множество вариантов операционных систем для данного компьютера и вариантов реализации языка BASIC (который, в отличие от ZX Spectrum, в некоторых моделях даже не был «прошит» в ПЗУ и любой вариант мог загружаться с дискеты, также как и сама ОС)
Также я нашёл утилиту для конвертирования аудиозаписей в формат CAS, которых поддерживается эмуляторами, однако прочитать с их помощью записи с моих кассет по каким-то причинам не удалось.
Разобравшись с форматом файла CAS (который оказался просто побитовой копией данных с ленты, которая у меня уже имелась на руках, за исключением заголовка с наличием синхро-байта), я внес несколько изменений в свою программу и смог получить на выходе рабочий CAS файл, который заработал в эмуляторе (TRS-80 Model III):
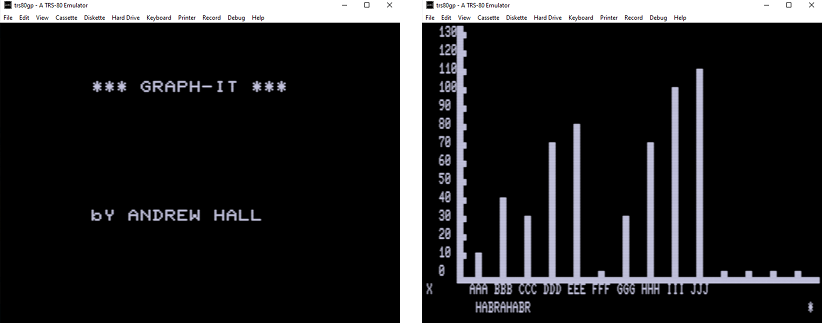
Последний вариант утилиты для конвертации с автоматическим определением первого импульса и расстоянием между опорными импульсами я оформил в виде GEM пакета, исходный код доступен на Github.
Заключение
Пройденный путь оказался увлекательным путешествием в прошлое, и я рад что в итоге нашёл разгадку. Помимо прочего я:
- Разобрался с форматом сохранения данных в ZX Spectrum и изучил встроенные в ПЗУ подпрограммы сохранения/чтения данных с аудиокассет
- Познакомился с компьютером TRS-80 и его разновидностями, изучил операционную систему, посмотрел примеры программ и даже имел возможность заняться отладкой в машинных кодах (всё-таки все мнемоники Z80 мне хорошо знакомы)
- Написал полноценную утилиту для конвертирования аудио записей в CAS формат, которая может считывать данные, нераспознаваемые «официальной» утилитой
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
- Pick a username
- Email Address
- Password
By clicking “Sign up for GitHub”, you agree to our terms of service and
privacy statement. We’ll occasionally send you account related emails.
Already on GitHub?
Sign in
to your account
 In the first part I showed how the Sinclair ZX Spectrum stored data on tape. This second part explains what is stored, and what causes a tape loading error.
In the first part I showed how the Sinclair ZX Spectrum stored data on tape. This second part explains what is stored, and what causes a tape loading error.
The ZX Spectrum BASIC offers a SAVE command for saving all kind of data. It can be used to save a BASIC program, variable arrays, but also arbitrary parts of memory. These files are always saved in two separate blocks. The first block is called header. It contains the file name, data type, and other meta information. The second block follows about a second later and contains the data itself.
The internal structure of each block is identical. The first byte distinguishes between header ($00) and data blocks ($FF). The final byte is a parity checksum. Everything between these two bytes is the payload.
A header block always contains a payload of 17 bytes. The first byte identifies the file type, followed by the file name (10 characters), followed by the length of the data block, and closed by two optional parameters that have different meanings depending on the file type. The length and the two parameters consume two bytes each, with the lower byte coming first because the Z80 CPU is little endian.
This is an example header block of a screenshot:
00 |
$00 = Header | |
| 00 | 03 |
$03 = Binary file (Code or SCREEN$) |
| 01 | 53 |
S |
| 02 | 68 |
h |
| 03 | 72 |
r |
| 04 | 65 |
e |
| 05 | 64 |
d |
| 06 | 2E |
. |
| 07 | 7A |
z |
| 08 | 6F |
o |
| 09 | 6E |
n |
| 10 | 65 |
e |
| 11 | 001B |
Length: 6912 bytes ($1B00) |
| 13 | 0040 |
Parameter 1, here: starting address ($4000) |
| 15 | 0000 |
Parameter 2, here: unused |
20 |
Parity |
A screenshot is actually just a memory dump that starts at address $4000 (which is the starting address of the screen buffer) and is exactly 6912 bytes long (the ZX Spectrum has a resolution of 256×192 monochrome pixels plus 32×24 bytes color attributes, giving a screen buffer size of 6912 bytes).
For other file types, the two optional parameters have different meanings. For example, a BASIC program file stores the line number to start at after loading.
The final byte is the parity. It is used for error detection, and computed just by XOR-ing all the bytes that have been read. The result must be $00, otherwise a «R Tape loading error» is reported.
This kind of error detection is rather weak. Due to the nature of the XOR operation, two wrongs give a right. This means that when the block contains an even number of bad bits at the same position, they will be undetected. It is also not possible to correct reading errors, as the XOR operation only allows to identify the position of the bad bit, but not the actual byte that contained the error. More sophisticated error correction algorithms would have slowed down the loading process, though.
The parity is computed as a final step, after all the bytes have been read from the block on tape. For that reason, the loader can only decide at the end of the recording whether the loading was successful or not.
But then, why does the tape loading error sometimes appear while the block is still loading? Well, in the first part I have explained that the loading routine just reads an unknown number of bytes. It ends when waiting for a pulse change took to long. Now, if there is an audio gap on tape, the signal seems to end just in the middle of the block. It is then very likely that the parity checksum is wrong because there are still bytes missing.
Some simple copy protections made use of the way the Spectrum loads data from tape. A very common way were “headerless” files, where the header block was left out and only the data block was recorded on tape. The BASIC LOAD command was unable to read those files because of the missing header.
Несколько слов о ZX Spectrum
ZX Spectrum — компьютер, созданный более 30 лет назад с 3.5 МГц процессором и всего лишь 48 Кб ОЗУ, под который написано огромное
количество игр (да и прикладного софта тоже), в которые интересно играть даже сегодня. При том, что эти игры часто представляют
собой мегашедевры с точки зрения программирования и оптимизации кода, их разработчики умудрялись вмещать огромные игровые миры
в эти скромные 48 Кб.
Программы в те времена загружались с магнитофонной ленты. Причем, в отличии от самого Spectrum-а, магнитофоны и процесс загрузки с них
вызывают гораздо меньше теплых воспоминаний — загрузка не всегда заканчивалась успешно, иногда игрушку приходилось грузить
по несколько раз получая ошибку «R Tape loading error» регулируя положение головки магнитофона, прочищая ее поверхность одеколоном,
либо, если совсем не повезло, вытаскивать из магнитофона «зажеванную» им кассету при этом с трудом сдерживая желание сильно стукнуть виновника
апстену 
Вообщем, если сам компьютер по сей день совсем не утратил своей актуальности и его хочется иметь в коллекции (причем,
именно настоящий компьютер, а не эмулятор) чтобы запускать такие игры, как Elite, Saboteur, Exolon и т.д., то связываться с кассетным магнитофоном
для загрузки программ хочется гораздо меньше (да к тому же, аудиокассеты сейчас достать уже не так просто).
В качестве альтернативы можно использовать либо mp3-плеер, либо смартфон со специальной программой. Первый вариант неудобен тем, что
в mp3-формате программы занимают гораздо больше места, чем в tap-файлы, оба варианта неудобны тем, что позволяют только воспроизводить, но
не записывать TAP-файлы. А уметь сохранять TAP-файлы нужно хотя бы для того, чтобы сохранить свою набранную на бейсике программку или свое состояние
в игре.
В качестве альтернативы аудиокассетам в наши дни напрашивается карта памяти, содержащая файлы программ в форматах TAP и TZX.
А в качестве альтернативы магнитофону — микроконтроллерное устройство, способное эти файлы воспроизводить и записывать.
Схема магнитофона
Схема такого устройства приведена ниже:
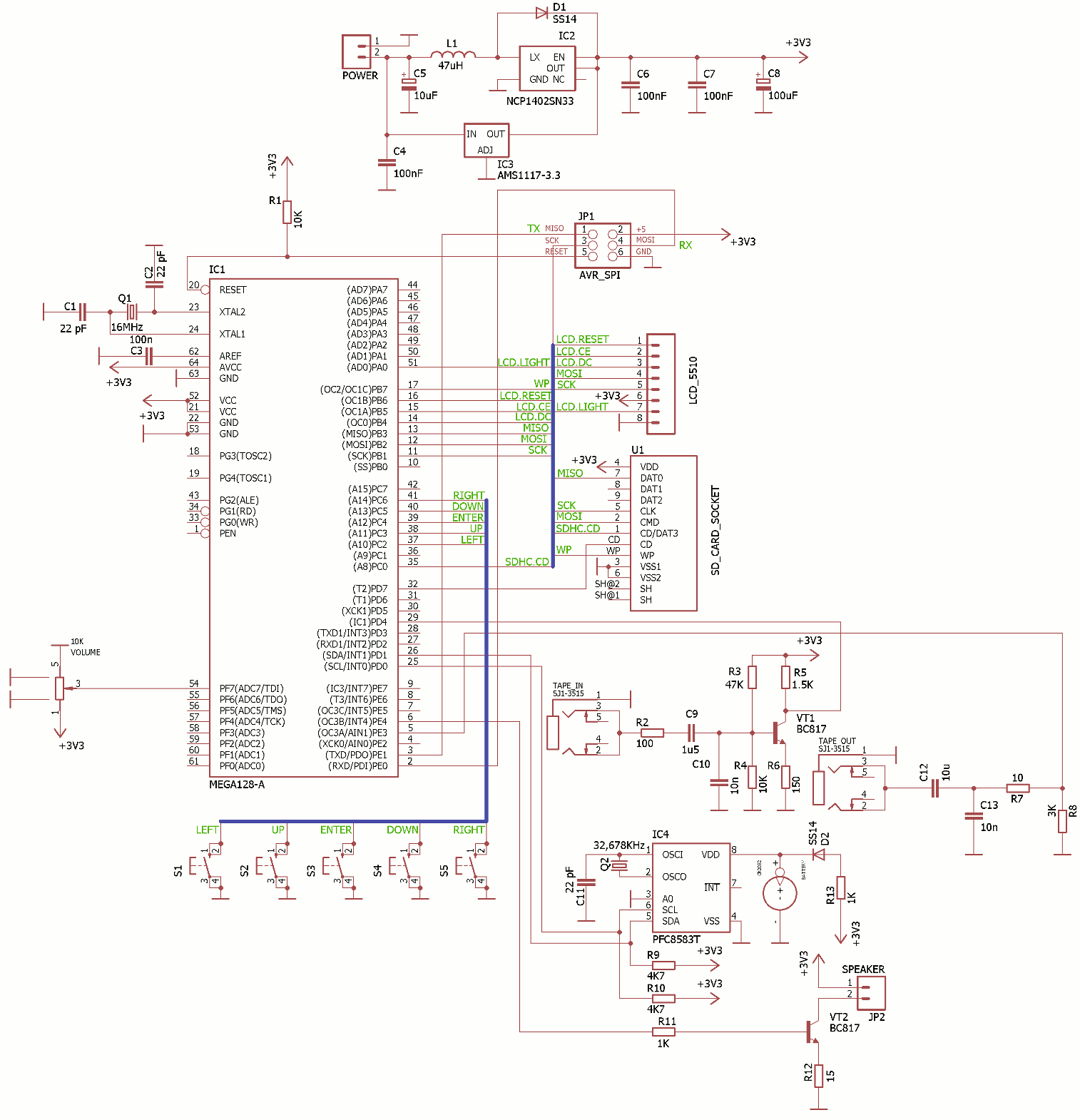
Мангитофон выполнен на микроконтроллере ATMega128, работающий на тактовой частоте 16 МГц. Ресурсов этого МК должно быть вполне достаточно для
реализации всего необходимого функционала и его совершенствованию в будущем.
Стабилизатор напряжения питания может быть выполнен либо на микросхеме IC2 либо на микросхеме IC3. На схеме изображены обе эти
микросхемы, но в реальном устройстве должна быть установлена только одна из них, в зависимости от требуемого способа питания. Если устройство
предполагается встроить непосредственно в компьютер либо питать от блока питания с напряжением не менее 5В, то микросхему IC2 (а также
дроссель L1 и диод D1) надо исключить из схемы. Если же планируется питание от батареек / аккумуляторов, то из схемы следует
исключить микросхему IC3. В последнем случае будет использоваться повышающий стабилизатор на микросхеме IC2, а для питания схемы
будет достаточно одной-двух батареек / аккумуляторов на 1.5В. Однако, не смотря на то, что схема сможет работать от напряжения всего в 1В,
рекомендую все же питать ее от двух аккумуляторов с суммарным напряжением 2.4В, т.к. только в этом случае схема работает устойчиво при включении
светодиодной подсветки экрана (если же подсветка не нужна, то одного аккумулятора на 1.2В будет достаточно).
В качестве экрана используется дисплей от телефона Nokia 5110 с алиэкспресса, смонтированный на печатную плату. Для навигации по экранному меню служит 5-кнопочный
джойстик.
Поскольку магнитофон может не только воспроизводить TAP-файлы, но и записывать их на SD-карту памяти, ему необходимы часы реального времени с
автономным питанием чтобы проставлять дату-время модификации файла. Часы выполнены на микросхеме IC4, в качестве которой можно использовать
PCF8583T либо PCF8563T (для чего разработаны две разные версии прошивки).
Устройство имеет динамик для прослушивания записываемых / воспроизводимых файлов. Громкость динамика можно регулировать переменным резистором.
Но вообще, управление динамиком полностью программное и переменный резистор можно будет исключить а громкость настраивать в меню в будущих
версиях прошивки.
Для подключения к Spectrum-у есть два разъема «мини-джек» — вход и выход.
После отладки схемы на макете были заказаны печатные платы в Китае. Внешний вид собранной платы спереди и сзади:


Магнитофон в сборе:

Прошивка и интерфейс
При включении магнитофона отображается главное меню:

Тут можно перейти, соответственно
- к воспроизведению TAP-файла с SD-карты
- к его сохранению с компьютера на карту
- к настройкам интерфейса магнитофона и параметров таймингов сигналов
- к просмотру информации об установленной SD-карте (размер и тип карты, свободное и занятое место, производитель и т.д.)
- к просмотру информации о магнитофоне и номера установленной версии прошивки
При выборе первого пункта следует переход к списку файлов и директорий на карте памяти. Из файлов показываются только .tap файлы, из директорий
не показываются те, что начинаются с точки (т.е. скрытые директории).

После выбора файла начинается его загрузка. Тут можно видеть количество блоков в TAP-файле и текущий блок а также время, прошедшее с начала загрузки.
Загрузку можно приостановить нажав Pause, при этом в режиме паузы клавишами вверх-вниз можно выбрать блок, с которого будет начато воспроизведение
(актуально для игр с дозагружаемыми уровнями).

При сохранении файла на карту сначала вводится имя файла:

Перемещение по экранной клавиатуре — курсором, ввод символа — центральная клавиша. Для отмены сохранения ввести пустое имя.
После ввода имени устройство будет ожидать начала передачи с компьютера. Затем, на экране будут выводиться номера и размеры принятых блоков.
На экране настроек можно выбрать язык интерфейса (английский или русский), настроить звуки при нажатии клавиш, при воспроизведении и сохранении
TAP-ов. Настройка подсветки экрана: всегда выключена, всегда включена и авто-режим — включается при нажатии на клавиши. Еще тут можно настроить скорость
воспроизведения (x1, x2, x4, x8), ввести текущую дату и перейти к настройке временных параметров сигнала:

На экране настроек временных параметров сигнала можно изменить
- Pause: задержка между блоками в миллисекундах
- Pilot: длительность сигнала пилота в миллисекундах
- Pilot.l: длительность импульсов пилота в микросекундах
- Sync 1: длительность первого синхроимпульса в микросекундах
- Sync 2: длительность второго синхроимпульса в микросекундах
- Data: длительность импульса данных (длительность передачи бита 0, бит 1 будет в два раза дольше)
- Capture: режим захвата при получении данных от компьютера (по фронту или спаду импульса)
Так же тут можно сбросить параметры в значения по умолчанию или определить их по форме сигнала с компьютера.

Предварительная настройка устройства
После первого включения магнитофона или обновления прошивки, возможно, потребуется настроить контрастность дисплея. Хотя, некоторые дисплеи показывают
одинаково хорошо, вне зависимости от выбранного контраста. Если при включении экран дисплея показывает чёрный квадрат, или, наоборот, ничего не показывает,
то настроить контрастность через меню не получится. В этом случае надо отключить питание, затем нажать и удерживать три клавиши — влево, вправо и среднюю
одновременно включая питание. В случае успеха произвчит мелодия и магнитофон перейдёт в инженерное меню, где кнопками вверх/вниз можно точно выставить
желаемый контраст, а средней кнопкой можно быстро менять его с шагом 10. Контраст меняется в диапазоне от 0 до 128. Затем, изменённое значение можно
сохранить нажатием клавиши вправо.
Файлы
Далее по ссылкам можно скачать проект Eagle и прошивки.
 zx-tape-loader-v1.1.3.zip (самая свежая)
zx-tape-loader-v1.1.3.zip (самая свежая)
zx-tape-loader-v1.1.2.zip
zx-tape-loader_8563_v1.1.hex (прошивка для PCF8563T)
zx-tape-loader_8583_v1.1.hex (прошивка для PCF8583T)
zx-tape-loader_8563_v1.1.1.hex (прошивка для PCF8583T)
Проект Eagle
Схема в pdf
Схема в png в большом разрешении
Фьюзы
Как я восстанавливал данные в неизвестном формате с магнитной ленты
Время на прочтение
8 мин
Количество просмотров 38K
Предыстория
Будучи любителем ретро железа, приобрёл я как-то у продавца из Великобритании ZX Spectrum+. В комплекте с самим компьютером мне достались несколько аудиокассет с играми (в оригинальной упаковке с инструкциями), а также программами, записанными на кассеты без особых обозначений. На удивление данные с кассет 40-летней давности хорошо читались и мне удалось загрузить почти все игры и программы с них.
Однако, на некоторых кассетах я обнаружил записи, сделанные явно не компьютером ZX Spectrum. Звучали они совершенно по-другому и, в отличие от записей с упомянутого компьютера, не начинались с короткого BASIC загрузчика, который обычно присутствует в записях всех программ и игр.
Какое-то время мне не давало это покоя — очень хотелось узнать, что скрыто в них. Если бы получилось прочитать аудио сигнал как последовательность байтов, можно было бы поискать в них символы или что-то, что указывает на происхождение сигнала. Своего рода ретро-археология.
Сейчас, когда я прошёл весь путь и смотрю на этикетки самих кассет, я улыбаюсь, потому что
ответ был прямо перед глазами всё это время
На этикетке левой кассеты — название компьютера TRS-80, и чуть ниже название производителя: «Manufactured by Radio Shack in USA»
(Если хотите сохранить интригу до конца, не заходите под спойлер)
Сравнение аудио сигналов
Первым делом оцифруем аудиозаписи. Можно послушать как это звучит:
И как обычно звучит запись с компьютера ZX Spectrum:
В обоих случаях в начале записи присутствует так называемый пилотный тон — звук одной частоты (на первой записи он очень короткий <1 сек, однако различим). Пилотный тон служит сигналом компьютеру, что необходимо подготовиться к получению данных. Как правило каждый компьютер распознает только «свой» пилотный тон по форме сигнала и его частоте.
Надо сказать о самой форме сигнала. Например, на ZX Spectrum его форма прямоугольная:
При обнаружении пилотного тона ZX Spectrum отображает чередующиеся красно-голубые полоски на бордюрной части экрана, показывая, что сигнал распознан. Пилотный тон заканчивается синхро-импульсом, который сигнализирует компьютеру о том, что следует начинать принимать данные. Он характеризуется меньшей (по сравнению с пилотным тоном и последующими данными) длительностью (см. рисунок)
После того, как синхро-импульс получен, компьютер фиксирует каждый подъём/спуск сигнала, измеряя его длительность. Если длительность меньше опредёленной границы, в память записывается бит 1, иначе 0. Биты собираются в байты и процесс повторяется до тех пор пока не будет получено N байт. Число N, как правило, берётся из заголовка загружаемого файла. Последовательность загрузки следующая:
- пилотный тон
- заголовок (фиксированной длины), содержит размер загружаемых данных (N), имя и тип файла
- пилотный тон
- сами данные
Чтобы удостовериться, что данные загружены верно, ZX Spectrum последним байтом читает так называемый байт чётности (parity byte), который вычисляется при сохранении файла операцией XOR над всеми байтами записанных данных. При чтении файла компьютер вычисляет байт чётности из полученных данных и, если результат отличается от сохранённого, выводит сообщение об ошибке «R Tape loading error». Строго говоря, компьютер может выдать это сообщение и раньше, если при чтении не может распознать импульс (пропущен или его длительность не соответствует определённым границам)
Итак, посмотрим теперь, как выглядит неизвестный сигнал:
Это пилотный тон. Форма сигнала значительно отличается, но видно что сигнал состоит из повторяющихся коротких импульсов определённой частоты. При частоте дискретизации 44100 Гц, расстояние между «пиками» примерно равно 48 сэмплов (что соответствует частоте ~918 Гц) Запомним эту цифру.
Посмотрим теперь на фрагмент с данными:
Если измерить расстояние между отдельными импульсами, окажется, что между «длинными» импульсами расстояние по-прежнему в ~48 сэмплов, а между короткими — ~24. Немного забегая вперёд, скажу, что в итоге выяснилось, «опорные» импульсы с частотой 918 Гц следуют непрерывно, от начала и до конца файла. Можно предположить, что при передаче данных, если между опорными импульсами встречается дополнительный импульс, считаем его за бит 1, иначе 0.
Что с синхро-импульсом? Посмотрим на начало данных:
Пилотный тон заканчивается и сразу начинаются данные. Чуть позже, проанализировав несколько разных аудио записей, удалось обнаружить, что первый байт данных всегда один и тот же (10100101b, A5h). Возможно, компьютер начинает считывать данные, после того как получит его.
Можно также обратить внимание на сдвиг первого опорного импульса сразу после последней 1-цы в синхробайте. Его удалось обнаружить значительно позже в процессе разработки программы для распознавания данных, когда данные в начале файла не могли стабильно считаться.
Теперь попробуем описать алгоритм, который обработает аудио файл и загрузит данные.
Загрузка данных
Сперва рассмотрим несколько допущений, чтобы не усложнять алгоритм:
- Будем рассматривать файлы только в формате WAV;
- Аудиофайл должен начинаться с пилотного тона и не должен содержать тишину в начале
- Исходный файл должен иметь частоту дискретизации 44100 Гц. В таком случае расстояние между опорными импульсами в 48 сэмплов уже определено и нам не нужно программно его рассчитывать;
- Формат сэмплов может быть любой (8/16 бит/с плавающей точкой) — так как при чтении мы можем сконвертировать его в нужный;
- Предполагаем, что исходный файл нормализован по амплитуде, что должно стабилизировать результат;
Алгоритм чтения будет следующий:
- Читаем файл в память, одновременно конвертируем формат сэмплов в 8 бит;
- Определяем позицию первого импульса в аудиоданных. Для этого нужно вычислить номер сэмпла с максимальной амплитудой. Для простоты посчитаем его один раз вручную. Сохраним в переменную prev_pos;
- Прибавляем к позиции последнего импульса 48 (pos := prev_pos + 48)
- Так как увеличение позиции на 48 не гарантирует, что мы попадём в позицию следующего опорного импульса (дефекты ленты, нестабильная работа лентопротяжного механизма и прочее), нужно откорректировать позицию импульса pos. Для этого возьмем небольшой отрезок данных (pos-8;pos+8) и найдем на нём максимум значения амплитуды. Позицию, соответствующую максимуму, сохраним в pos. Здесь 8 = 48/6 — экспериментально полученная константа, которая гарантирует что мы определим верный максимум и не затронем другие импульсы, которые могут идти рядом. В очень плохих случаях, когда расстояние между импульсами сильно меньше или больше 48, можно реализовать принудительный поиск импульса, но в рамках статьи я не буду описывать это в алгоритме;
- На предыдущем шаге также необходимо бы проверить, что опорный импульс вообще найден. То есть, если просто искать максимум, это не гарантирует что импульс в данном отрезке присутствует. В своей последней реализации программы чтения я проверяю разницу между максимальным и минимальным значением амплитуды на отрезке, и если она превышает некоторую границу, засчитываю наличие импульса. Вопрос также, что делать если опорный импульс не найден. Тут 2 варианта: либо данные закончились и далее следует тишина, либо это следует рассматривать как ошибку чтения. Однако опустим это для упрощения алгоритма;
- На следующем шаге нужно определить наличие импульса данных (бит 0 или 1), для этого возьмем середину отрезка (prev_pos;pos) middle_pos равную middle_pos := (prev_pos+pos)/2 и в некоторой окрестности middle_pos на отрезке (middle_pos-8;middle_pos+8) посчитаем максимум и минимум амплитуды. Если разница между ними больше 10, записываем в результат бит 1 иначе 0. 10 — константа полученная опытным путём;
- Сохраняем текущую позицию в prev_pos (prev_pos := pos)
- Повторяем начиная с шага 3, пока не прочитаем весь файл;
- Полученный битовый массив необходимо сохранить как набор байт. Поскольку мы не учли синхро-байт при чтении, количество битов может оказаться не кратно 8, а также неизвестно необходимое смещение в битах. В первой реализации алгоритма я не знал о существовании синхро-байта и потому просто сохранял 8 файлов с разным количеством бит смещения. Один из них содержал корректные данные. В финальном алгоритме я просто удаляю все биты до A5h, что позволяет сразу получать корректный файл на выходе
Алгоритм на Ruby, кому интересно
В качестве языка для написания программы я выбрал Ruby, т.к. бОльшую часть времени программирую на нём. Вариант не высокопроизводительный, однако задача сделать скорость чтения максимально быстрой не стоит.
# Используем gem 'wavefile'
require 'wavefile'
reader = WaveFile::Reader.new('input.wav')
samples = []
format = WaveFile::Format.new(:mono, :pcm_8, 44100)
# Читаем WAV файл, конвертируем в формат Mono, 8 bit
# Массив samples будет состоять из байт со значениями 0-255
reader.each_buffer(10000) do |buffer|
samples += buffer.convert(format).samples
end
# Позиция первого импульса (вместо 0)
prev_pos = 0
# Расстояние между импульсами
distance = 48
# Значение расстояния для окрестности поиска локального максимума
delta = (distance / 6).floor
# Биты будем сохранять в виде строки из "0" и "1"
bits = ""
loop do
# Рассчитываем позицию следующего импульса
pos = prev_pos + distance
# Выходим из цикла если данные закончились
break if pos + delta >= samples.size
# Корректируем позицию pos обнаружением максимума на отрезке [pos - delta;pos + delta]
(pos - delta..pos + delta).each { |p| pos = p if samples[p] > samples[pos] }
# Находим середину отрезка [prev_pos;pos]
middle_pos = ((prev_pos + pos) / 2).floor
# Берем окрестность в середине
sample = samples[middle_pos - delta..middle_pos + delta]
# Определяем бит как "1" если разница между максимальным и минимальным значением на отрезке превышает 10
bit = sample.max - sample.min > 10
bits += bit ? "1" : "0"
end
# Определяем синхро-байт и заменяем все предшествующие биты на 256 бит нулей (согласно спецификации формата)
bits.gsub! /^[01]*?10100101/, ("0" * 256) + "10100101"
# Сохраняем выходной файл, упаковывая биты в байты
File.write "output.cas", [bits].pack("B*")
Результат
Перепробовав несколько вариантов алгоритма и констант, мне повезло получить что-то в крайней степени интересное:
Итак, судя по символьным строкам, мы имеем программу для построения графиков. Однако в тексте программы отсутствуют ключевые слова. Все ключевые слова закодированы в виде байтов (значение каждого > 80h). Теперь нужно выяснить, какой компьютер из 80-х мог сохранять программы в таком формате.
На самом деле это очень похоже на программу на языке BASIC. Примерно в таком же формате компьютер ZX Spectrum хранит в памяти и сохраняет программы на ленту. На всякий случай я проверил ключевые слова на соответствие с таблицей. Однако результат, очевидно, оказался отрицательным.
Также я проверил ключевые слова BASIC популярных в то время компьютеров Atari, Commodore 64 и нескольких других, на которые удалось найти документацию, однако безуспешно — мои познания в разновидностях ретро-компьютеров оказались не столь широки.
Тогда я решил пойти по списку, и тут мой взгляд упал на название производителя Radio Shack и компьютера TRS-80. Именно эти названия были написаны на этикетках кассет, которые лежали у меня на столе! Я ведь не знал ранее эти названия и не был знаком с компьютером TRS-80, поэтому мне казалось, что Radio Shack это производитель аудиокассет, такой кaк BASF, Sony или TDK, a TRS-80 — длительность воспроизведения. Почему нет?
Компьютер Tandy/Radio Shack TRS-80
Очень вероятно, что рассматриваемая аудиозапись, которую я привёл в качестве примера в начале статьи, сделана на таком компьютере:
Оказалось, что данный компьютер и его разновидности (Model I/Model III/Model IV и т.д.) были очень популярны в свое время (конечно, не в России). Примечательно, что процессор, которых в них использовался — тоже Z80. По данному компьютеру в Интернете можно найти много информации. В 80-х годах информация о компьютере распространялась в журналах. На данный момент существует несколько эмуляторов компьютера под разные платформы.
Я загрузил эмулятор trs80gp и мне впервые удалось посмотреть как работал этот компьютер. Конечно, компьютер не поддерживал вывод цвета, разрешение экрана всего 128х48 точек, но существовало множество расширений и модификаций которые могли увеличивать разрешение экрана. Также существовало множество вариантов операционных систем для данного компьютера и вариантов реализации языка BASIC (который, в отличие от ZX Spectrum, в некоторых моделях даже не был «прошит» в ПЗУ и любой вариант мог загружаться с дискеты, также как и сама ОС)
Также я нашёл утилиту для конвертирования аудиозаписей в формат CAS, которых поддерживается эмуляторами, однако прочитать с их помощью записи с моих кассет по каким-то причинам не удалось.
Разобравшись с форматом файла CAS (который оказался просто побитовой копией данных с ленты, которая у меня уже имелась на руках, за исключением заголовка с наличием синхро-байта), я внес несколько изменений в свою программу и смог получить на выходе рабочий CAS файл, который заработал в эмуляторе (TRS-80 Model III):
Последний вариант утилиты для конвертации с автоматическим определением первого импульса и расстоянием между опорными импульсами я оформил в виде GEM пакета, исходный код доступен на Github.
Заключение
Пройденный путь оказался увлекательным путешествием в прошлое, и я рад что в итоге нашёл разгадку. Помимо прочего я:
- Разобрался с форматом сохранения данных в ZX Spectrum и изучил встроенные в ПЗУ подпрограммы сохранения/чтения данных с аудиокассет
- Познакомился с компьютером TRS-80 и его разновидностями, изучил операционную систему, посмотрел примеры программ и даже имел возможность заняться отладкой в машинных кодах (всё-таки все мнемоники Z80 мне хорошо знакомы)
- Написал полноценную утилиту для конвертирования аудио записей в CAS формат, которая может считывать данные, нераспознаваемые «официальной» утилитой