Материал из MachineLearning.
Перейти к: навигация, поиск
Содержание
- 1 Введение
- 2 Распространение ошибок
- 2.1 Абсолютная ошибка
- 2.2 Относительная ошибка
- 3 Графы вычислительных процессов
- 3.1 Примеры
- 4 Памятка программисту
- 5 Список литературы
- 6 См. также
Введение
Одним из наиболее важных вопросов в численном анализе является вопрос о том, как ошибка, возникшая в определенном месте в ходе вычислений, распространяется дальше, то есть становится ли ее влияние больше или меньше по мере того, как производятся последующие операции. Крайним случаем является вычитание двух почти равных чисел: даже при очень маленьких ошибках обоих этих чисел относительная ошибка разности может оказаться очень большой. Такая относительная ошибка будет распространяться дальше при выполнении всех последующих арифметических операций.
Одним из источников вычислительных погрешностей (ошибок) является приближенное представление вещественных чисел в ЭВМ, обусловленное конечностью разрядной сетки. Хотя исходные данные представляются в ЭВМ с большой точностью накопление погрешностей округления в процессе счета может привести к значительной результирующей погрешности, а некоторые алгоритмы могут оказаться и вовсе непригодными для реального счета на ЭВМ. Подробнее о представлении вещественных чисел в ЭВМ можно узнать здесь.
Распространение ошибок
В качестве первого шага при рассмотрении такого вопроса, как распространение ошибок, необходимо найти выражения для абсолютной и относительной ошибок результата каждого из четырех арифметических действий как функции величин, участвющих в операции, и их ошибок.
Абсолютная ошибка
Сложение
Имеются два приближения  и к двум величинам и , а также соответствующие абсолютные ошибки и . Тогда в результате сложения имеем
и к двум величинам и , а также соответствующие абсолютные ошибки и . Тогда в результате сложения имеем
- .
Ошибка суммы, которую мы обозначим через , будет равна
- .
Вычитание
Тем же путем получаем
- .
Умножение
При умножении мы имеем
- .
Поскольку ошибки обычно гораздо меньше самих величин, пренебрегаем произведением ошибок:
- .
Ошибка произведения будет равна
- .
Деление
Имеем
- .
Преобразовываем это выражение к виду
- .
Множитель, стоящий в скобках, при можно разложить в ряд
- .
Перемножая и пренебрегая всеми членами, которые содержат произведения ошибок или степени ошибок выше первой, имеем
- .
Следовательно,
- .
Необходимо четко понимать, что знак ошибки бывает известен только в очень редких случаях. Не факт, например, что ошибка увеличивается при сложении и уменьшается при вычитании потому, что в формуле для сложения стоит плюс, а для вычитания — минус. Если, например, ошибки двух чисел имеют противоположные знаки, то дело будет обстоять как раз наоборот, то есть ошибка уменьшится при сложении и увеличится при вычитании этих чисел.
Относительная ошибка
После того, как мы вывели формулы для распространения абсолютных ошибок при четырех арифметических действиях, довольно просто вывести соответствующие формулы для относительных ошибок. Для сложения и вычитания формулы были преобразованы с тем, чтобы в них входила в явном виде относительная ошибка каждого исходного числа.
Сложение
- .
Вычитание
- .
Умножение
- .
Деление
- .
Мы начинаем арифметическую операцию, имея в своем распоряжении два приближенных значения и с соответствующими ошибками и . Ошибки эти могут быть любого происхождения. Величины и могут быть экспериментальными результатами, содержащими ошибки; они могут быть результатами предварительного вычисления согласно какому-либо бесконечному процессу и поэтому могут содержать ошибки ограничения; они могут быть результатами предшествующих арифметических операций и могут содержать ошибки округления. Естественно, они могут также содержать в различных комбинациях и все три вида ошибок.
Вышеприведенные формулы дают выражение ошибки результата каждого из четырех арифметических действий как функции от ; ошибка округления в данном арифметическом действии при этом не учитывается. Если же в дальнейшем необходимо будет подсчитать, как распространяется в последующих арифметических операциях ошибка этого результата, то необходимо к вычисленной по одной из четырех формул ошибке результата прибавить отдельно ошибку округления.
Графы вычислительных процессов
Теперь рассмотрим удобный способ подсчета распространения ошибки в каком-либо арифметическом вычислении. С этой целью мы будем изображать последовательность операций в вычислении с помощью графа и будем писать около стрелок графа коэффициенты, которые позволят нам сравнительно легко определить общую ошибку окончательного результата. Метод этот удобен еще и тем, что позволяет легко определить вклад любой ошибки, возникшей в процессе вычислений, в общую ошибку.
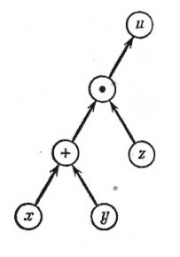
![]()
Рис.1. Граф вычислительного процесса
На рис.1 изображен граф вычислительного процесса . Граф следует читать снизу вверх, следуя стрелкам. Сначала выполняются операции, расположенные на каком-либо горизонтальном уровне, после этого — операции, расположенные на более высоком уровне, и т. д. Из рис.1, например, ясно, что x и y сначала складываются, а потом умножаются на z. Граф, изображенный на рис.1, является только изображением самого вычислительного процесса. Для подсчета общей ошибки результата необходимо дополнить этот граф коэффициентами, которые пишутся около стрелок согласно следующим правилам.
Сложение
Пусть две стрелки, которые входят в кружок сложения, выходят из двух кружков с величинами и . Эти величины могут быть как исходными, так и результатами предыдущих вычислений. Тогда стрелка, ведущая от к знаку + в кружке, получает коэффициент , стрелка же, ведущая от к знаку + в кружке, получает коэффициент .
Вычитание
Если выполняется операция , то соответствующие стрелки получают коэффициенты и .
Умножение
Обе стрелки, входящие в кружок умножения, получают коэффициент +1.
Деление
Если выполняется деление , то стрелка от к косой черте в кружке получает коэффициент +1, а стрелка от к косой черте в кружке получает коэффициент −1.
Смысл всех этих коэффициентов следующий: относительная ошибка результата любой операции (кружка) входит в результат следующей операции, умножаясь на коэффициенты у стрелки, соединяющей эти две операции.
Примеры
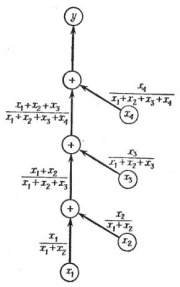
![]()
Рис.2. Граф вычислительного процесса для сложения , причем
Применим теперь методику графов к примерам и проиллюстрируем, что означает распространение ошибки в практических вычислениях.
Пример 1
Рассмотрим задачу сложения четырех положительных чисел:
- ,
где
- .
Граф этого процесса изображен на рис.2. Предположим, что все исходные величины заданы точно и не имеют ошибок, и пусть , и являются относительными ошибками округления после каждой следующей операции сложения. Последовательное применение правила для подсчета полной ошибки окончательного результата приводит к формуле
- .
Сокращая сумму в первом члене и умножая все выражение на , получаем
- .
Учитывая, что ошибка округления равна (в данном случае предполагается, что действительное число в ЭВМ представляется в виде десятичной дроби с t значищими цифрами), окончательно имеем
- .
Из этой формулы ясно, что максимально возможная ошибка (абсолютная или относительная), обусловленная округлением, становится меньше, если сначала складывать меньшие числа. Результат довольно удивительный, так как вся классическая математика основана на предположении, что при перемене мест слагаемых или их группировке сумма не изменяется. Разница заключается в том, что ЭВМ не может производить вычисления с бесконечно большой точностью, а именно такие вычисления рассматриваются в классической математике.
Пример 2
Вычитание двух почти равных чисел. Предположим, что необходимо вычислить . Тогда из формулы распространения ошибки при вычитании имеем
- .
Предположим, кроме того, что x и y являются соответствующим образом округленными положительными числами, так что
- и .
Если разность x-y мала, то относительная ошибка z может стать большой, даже если абсолютная ошибка мала. Так как в дальнейших вычислениях эта большая относительная ошибка будет распространяться, то она может поставить под сомнение точность окончательного результата вычислений.
Рассмотрим простой пример:
Тогда
Зная x и y, мы можем написать
Как видим, относительные ошибки x и y малы. Однако
Эта относительная ошибка очень велика, и, что важнее всего, она будет распространяться в ходе последующих вычислений.
Памятка программисту
Выводы, полученные выше, можно свести в краткий перечень рекомендаций для практической организации вычислений.
- Если необходимо произвести сложение-вычитание длинной последовательности чисел, работайте сначала с наименьшими числами.
- Если возможно, избегайте вычитания двух почти равных чисел. Формулы, содержащие такое вычитание, часто можно преобразовать так, чтобы избежать подобной операции.
- Выражение вида можно написать в виде , а выражение вида можно написать в виде . Если числа в разности почти равны друг другу, производите вычитание до умножения или деления. При этом задача не будет осложнена дополнительными ошибками округления.
- В любом случае сводите к минимуму число необходимых арифметических операций.
Список литературы
- Д.Мак-Кракен, У.Дорн. Численные методы и программирование на Фортране. Москва «Мир», 1977
- А. А. Самарский, А. В. Гулин. Численные методы. Москва «Наука», 1989.
См. также
- Практикум ММП ВМК, 4й курс, осень 2008
Нейронные сети обучаются с помощью тех или иных модификаций градиентного спуска, а чтобы применять его, нужно уметь эффективно вычислять градиенты функции потерь по всем обучающим параметрам. Казалось бы, для какого-нибудь запутанного вычислительного графа это может быть очень сложной задачей, но на помощь спешит метод обратного распространения ошибки.
Открытие метода обратного распространения ошибки стало одним из наиболее значимых событий в области искусственного интеллекта. В актуальном виде он был предложен в 1986 году Дэвидом Э. Румельхартом, Джеффри Э. Хинтоном и Рональдом Дж. Вильямсом и независимо и одновременно красноярскими математиками С. И. Барцевым и В. А. Охониным. С тех пор для нахождения градиентов параметров нейронной сети используется метод вычисления производной сложной функции, и оценка градиентов параметров сети стала хоть сложной инженерной задачей, но уже не искусством. Несмотря на простоту используемого математического аппарата, появление этого метода привело к значительному скачку в развитии искусственных нейронных сетей.
Суть метода можно записать одной формулой, тривиально следующей из формулы производной сложной функции: если $f(x) = g_m(g_{m-1}(\ldots (g_1(x)) \ldots))$, то $\frac{\partial f}{\partial x} = \frac{\partial g_m}{\partial g_{m-1}}\frac{\partial g_{m-1}}{\partial g_{m-2}}\ldots \frac{\partial g_2}{\partial g_1}\frac{\partial g_1}{\partial x}$. Уже сейчас мы видим, что градиенты можно вычислять последовательно, в ходе одного обратного прохода, начиная с $\frac{\partial g_m}{\partial g_{m-1}}$ и умножая каждый раз на частные производные предыдущего слоя.
Backpropagation в одномерном случае
В одномерном случае всё выглядит особенно просто. Пусть $w_0$ — переменная, по которой мы хотим продифференцировать, причём сложная функция имеет вид
$$f(w_0) = g_m(g_{m-1}(\ldots g_1(w_0)\ldots)),$$
где все $g_i$ скалярные. Тогда
$$f'(w_0) = g_m'(g_{m-1}(\ldots g_1(w_0)\ldots))\cdot g’_{m-1}(g_{m-2}(\ldots g_1(w_0)\ldots))\cdot\ldots \cdot g’_1(w_0)$$
Суть этой формулы такова. Если мы уже совершили forward pass, то есть уже знаем
$$g_1(w_0), g_2(g_1(w_0)),\ldots,g_{m-1}(\ldots g_1(w_0)\ldots),$$
то мы действуем следующим образом:
-
берём производную $g_m$ в точке $g_{m-1}(\ldots g_1(w_0)\ldots)$;
-
умножаем на производную $g_{m-1}$ в точке $g_{m-2}(\ldots g_1(w_0)\ldots)$;
-
и так далее, пока не дойдём до производной $g_1$ в точке $w_0$.
Проиллюстрируем это на картинке, расписав по шагам дифференцирование по весам $w_i$ функции потерь логистической регрессии на одном объекте (то есть для батча размера 1):

Собирая все множители вместе, получаем:
$$\frac{\partial f}{\partial w_0} = (-y)\cdot e^{-y(w_0 + w_1x_1 + w_2x_2)}\cdot\frac{-1}{1 + e^{-y(w_0 + w_1x_1 + w_2x_2)}}$$
$$\frac{\partial f}{\partial w_1} = x_1\cdot(-y)\cdot e^{-y(w_0 + w_1x_1 + w_2x_2)}\cdot\frac{-1}{1 + e^{-y(w_0 + w_1x_1 + w_2x_2)}}$$
$$\frac{\partial f}{\partial w_2} = x_2\cdot(-y)\cdot e^{-y(w_0 + w_1x_1 + w_2x_2)}\cdot\frac{-1}{1 + e^{-y(w_0 + w_1x_1 + w_2x_2)}}$$
Таким образом, мы видим, что сперва совершается forward pass для вычисления всех промежуточных значений (и да, все промежуточные представления нужно будет хранить в памяти), а потом запускается backward pass, на котором в один проход вычисляются все градиенты.
Почему же нельзя просто пойти и начать везде вычислять производные?
В главе, посвящённой матричным дифференцированиям, мы поднимаем вопрос о том, что вычислять частные производные по отдельности — это зло, лучше пользоваться матричными вычислениями. Но есть и ещё одна причина: даже и с матричной производной в принципе не всегда хочется иметь дело. Рассмотрим простой пример. Допустим, что $X^r$ и $X^{r+1}$ — два последовательных промежуточных представления $N\times M$ и $N\times K$, связанных функцией $X^{r+1} = f^{r+1}(X^r)$. Предположим, что мы как-то посчитали производную $\frac{\partial\mathcal{L}}{\partial X^{r+1}_{ij}}$ функции потерь $\mathcal{L}$, тогда
$$\frac{\partial\mathcal{L}}{\partial X^{r}_{st}} = \sum_{i,j}\frac{\partial f^{r+1}_{ij}}{\partial X^{r}_{st}}\frac{\partial\mathcal{L}}{\partial X^{r+1}_{ij}}$$
И мы видим, что, хотя оба градиента $\frac{\partial\mathcal{L}}{\partial X_{ij}^{r+1}}$ и $\frac{\partial\mathcal{L}}{\partial X_{st}^{r}}$ являются просто матрицами, в ходе вычислений возникает «четырёхмерный кубик» $\frac{\partial f_{ij}^{r+1}}{\partial X_{st}^{r}}$, даже хранить который весьма болезненно: уж больно много памяти он требует ($N^2MK$ по сравнению с безобидными $NM + NK$, требуемыми для хранения градиентов). Поэтому хочется промежуточные производные $\frac{\partial f^{r+1}}{\partial X^{r}}$ рассматривать не как вычисляемые объекты $\frac{\partial f_{ij}^{r+1}}{\partial X_{st}^{r}}$, а как преобразования, которые превращают $\frac{\partial\mathcal{L}}{\partial X_{ij}^{r+1}}$ в $\frac{\partial\mathcal{L}}{\partial X_{st}^{r}}$. Целью следующих глав будет именно это: понять, как преобразуется градиент в ходе error backpropagation при переходе через тот или иной слой.
Вы спросите себя: надо ли мне сейчас пойти и прочитать главу учебника про матричное дифференцирование?
Встречный вопрос. Найдите производную функции по вектору $x$:
$$f(x) = x^TAx,\ A\in Mat_{n}{\mathbb{R}}\text{ — матрица размера }n\times n$$
А как всё поменяется, если $A$ тоже зависит от $x$? Чему равен градиент функции, если $A$ является скаляром? Если вы готовы прямо сейчас взять ручку и бумагу и посчитать всё, то вам, вероятно, не надо читать про матричные дифференцирования. Но мы советуем всё-таки заглянуть в эту главу, если обозначения, которые мы будем дальше использовать, покажутся вам непонятными: единой нотации для матричных дифференцирований человечество пока, увы, не изобрело, и переводить с одной на другую не всегда легко.
Мы же сразу перейдём к интересующей нас вещи: к вычислению градиентов сложных функций.
Градиент сложной функции
Напомним, что формула производной сложной функции выглядит следующим образом:
$$\left[D_{x_0} (\color{#5002A7}{u} \circ \color{#4CB9C0}{v}) \right](h) = \color{#5002A7}{\left[D_{v(x_0)} u \right]} \left( \color{#4CB9C0}{\left[D_{x_0} v\right]} (h)\right)$$
Теперь разберёмся с градиентами. Пусть $f(x) = g(h(x))$ – скалярная функция. Тогда
$$\left[D_{x_0} f \right] (x-x_0) = \langle\nabla_{x_0} f, x-x_0\rangle.$$
С другой стороны,
$$\left[D_{h(x_0)} g \right] \left(\left[D_{x_0}h \right] (x-x_0)\right) = \langle\nabla_{h_{x_0}} g, \left[D_{x_0} h\right] (x-x_0)\rangle = \langle\left[D_{x_0} h\right]^* \nabla_{h(x_0)} g, x-x_0\rangle.$$
То есть $\color{#FFC100}{\nabla_{x_0} f} = \color{#348FEA}{\left[D_{x_0} h \right]}^* \color{#FFC100}{\nabla_{h(x_0)}}g$ — применение сопряжённого к $D_{x_0} h$ линейного отображения к вектору $\nabla_{h(x_0)} g$.
Эта формула — сердце механизма обратного распространения ошибки. Она говорит следующее: если мы каким-то образом получили градиент функции потерь по переменным из некоторого промежуточного представления $X^k$ нейронной сети и при этом знаем, как преобразуется градиент при проходе через слой $f^k$ между $X^{k-1}$ и $X^k$ (то есть как выглядит сопряжённое к дифференциалу слоя между ними отображение), то мы сразу же находим градиент и по переменным из $X^{k-1}$:

Таким образом слой за слоем мы посчитаем градиенты по всем $X^i$ вплоть до самых первых слоёв.
Далее мы разберёмся, как именно преобразуются градиенты при переходе через некоторые распространённые слои.
Градиенты для типичных слоёв
Рассмотрим несколько важных примеров.
Примеры
-
$f(x) = u(v(x))$, где $x$ — вектор, а $v(x)$ – поэлементное применение $v$:
$$v\begin{pmatrix}
x_1 \\
\vdots\\
x_N
\end{pmatrix}
= \begin{pmatrix}
v(x_1)\\
\vdots\\
v(x_N)
\end{pmatrix}$$Тогда, как мы знаем,
$$\left[D_{x_0} f\right] (h) = \langle\nabla_{x_0} f, h\rangle = \left[\nabla_{x_0} f\right]^T h.$$
Следовательно,
$$
\left[D_{v(x_0)} u\right] \left( \left[ D_{x_0} v\right] (h)\right) = \left[\nabla_{v(x_0)} u\right]^T \left(v'(x_0) \odot h\right) =\\
$$$$
= \sum\limits_i \left[\nabla_{v(x_0)} u\right]_i v'(x_{0i})h_i
= \langle\left[\nabla_{v(x_0)} u\right] \odot v'(x_0), h\rangle.
,$$где $\odot$ означает поэлементное перемножение. Окончательно получаем
$$\color{#348FEA}{\nabla_{x_0} f = \left[\nabla_{v(x_0)}u\right] \odot v'(x_0) = v'(x_0) \odot \left[\nabla_{v(x_0)} u\right]}$$
Отметим, что если $x$ и $h(x)$ — это просто векторы, то мы могли бы вычислять всё и по формуле $\frac{\partial f}{\partial x_i} = \sum_j\big(\frac{\partial z_j}{\partial x_i}\big)\cdot\big(\frac{\partial h}{\partial z_j}\big)$. В этом случае матрица $\big(\frac{\partial z_j}{\partial x_i}\big)$ была бы диагональной (так как $z_j$ зависит только от $x_j$: ведь $h$ берётся поэлементно), и матричное умножение приводило бы к тому же результату. Однако если $x$ и $h(x)$ — матрицы, то $\big(\frac{\partial z_j}{\partial x_i}\big)$ представлялась бы уже «четырёхмерным кубиком», и работать с ним было бы ужасно неудобно.
-
$f(X) = g(XW)$, где $X$ и $W$ — матрицы. Как мы знаем,
$$\left[D_{X_0} f \right] (X-X_0) = \text{tr}, \left(\left[\nabla_{X_0} f\right]^T (X-X_0)\right).$$
Тогда
$$
\left[ D_{X_0W} g \right] \left(\left[D_{X_0} \left( \ast W\right)\right] (H)\right) =
\left[ D_{X_0W} g \right] \left(HW\right)=\\
$$ $$
= \text{tr}\, \left( \left[\nabla_{X_0W} g \right]^T \cdot (H) W \right) =\\
$$ $$
=
\text{tr} \, \left(W \left[\nabla_{X_0W} (g) \right]^T \cdot (H)\right) = \text{tr} \, \left( \left[\left[\nabla_{X_0W} g\right] W^T\right]^T (H)\right)
$$Здесь через $\ast W$ мы обозначили отображение $Y \hookrightarrow YW$, а в предпоследнем переходе использовалось следующее свойство следа:
$$
\text{tr} , (A B C) = \text{tr} , (C A B),
$$где $A, B, C$ — произвольные матрицы подходящих размеров (то есть допускающие перемножение в обоих приведённых порядках). Следовательно, получаем
$$\color{#348FEA}{\nabla_{X_0} f = \left[\nabla_{X_0W} (g) \right] \cdot W^T}$$
-
$f(W) = g(XW)$, где $W$ и $X$ — матрицы. Для приращения $H = W — W_0$ имеем
$$
\left[D_{W_0} f \right] (H) = \text{tr} , \left( \left[\nabla_{W_0} f \right]^T (H)\right)
$$Тогда
$$
\left[D_{XW_0} g \right] \left( \left[D_{W_0} \left(X \ast\right) \right] (H)\right) = \left[D_{XW_0} g \right] \left( XH \right) = \
$$ $$
= \text{tr} , \left( \left[\nabla_{XW_0} g \right]^T \cdot X (H)\right) =
\text{tr}, \left(\left[X^T \left[\nabla_{XW_0} g \right] \right]^T (H)\right)
$$Здесь через $X \ast$ обозначено отображение $Y \hookrightarrow XY$. Значит,
$$\color{#348FEA}{\nabla_{X_0} f = X^T \cdot \left[\nabla_{XW_0} (g)\right]}$$
-
$f(X) = g(softmax(X))$, где $X$ — матрица $N\times K$, а $softmax$ — функция, которая вычисляется построчно, причём для каждой строки $x$
$$softmax(x) = \left(\frac{e^{x_1}}{\sum_te^{x_t}},\ldots,\frac{e^{x_K}}{\sum_te^{x_t}}\right)$$
В этом примере нам будет удобно воспользоваться формализмом с частными производными. Сначала вычислим $\frac{\partial s_l}{\partial x_j}$ для одной строки $x$, где через $s_l$ мы для краткости обозначим $softmax(x)_l = \frac{e^{x_l}} {\sum_te^{x_t}}$. Нетрудно проверить, что
$$\frac{\partial s_l}{\partial x_j} = \begin{cases}
s_j(1 — s_j),\ & j = l,\
-s_ls_j,\ & j\ne l
\end{cases}$$Так как softmax вычисляется независимо от каждой строчки, то
$$\frac{\partial s_{rl}}{\partial x_{ij}} = \begin{cases}
s_{ij}(1 — s_{ij}),\ & r=i, j = l,\
-s_{il}s_{ij},\ & r = i, j\ne l,\
0,\ & r\ne i
\end{cases},$$где через $s_{rl}$ мы обозначили для краткости $softmax(X)_{rl}$.
Теперь пусть $\nabla_{rl} = \nabla g = \frac{\partial\mathcal{L}}{\partial s_{rl}}$ (пришедший со следующего слоя, уже известный градиент). Тогда
$$\frac{\partial\mathcal{L}}{\partial x_{ij}} = \sum_{r,l}\frac{\partial s_{rl}}{\partial x_{ij}} \nabla_{rl}$$
Так как $\frac{\partial s_{rl}}{\partial x_{ij}} = 0$ при $r\ne i$, мы можем убрать суммирование по $r$:
$$\ldots = \sum_{l}\frac{\partial s_{il}}{\partial x_{ij}} \nabla_{il} = -s_{i1}s_{ij}\nabla_{i1} — \ldots + s_{ij}(1 — s_{ij})\nabla_{ij}-\ldots — s_{iK}s_{ij}\nabla_{iK} =$$
$$= -s_{ij}\sum_t s_{it}\nabla_{it} + s_{ij}\nabla_{ij}$$
Таким образом, если мы хотим продифференцировать $f$ в какой-то конкретной точке $X_0$, то, смешивая математические обозначения с нотацией Python, мы можем записать:
$$\begin{multline*}
\color{#348FEA}{\nabla_{X_0}f =}\\
\color{#348FEA}{= -softmax(X_0) \odot \text{sum}\left(
softmax(X_0)\odot\nabla_{softmax(X_0)}g, \text{ axis = 1}
\right) +}\\
\color{#348FEA}{softmax(X_0)\odot \nabla_{softmax(X_0)}g}
\end{multline*}
$$
Backpropagation в общем виде
Подытожим предыдущее обсуждение, описав алгоритм error backpropagation (алгоритм обратного распространения ошибки). Допустим, у нас есть текущие значения весов $W^i_0$ и мы хотим совершить шаг SGD по мини-батчу $X$. Мы должны сделать следующее:
- Совершить forward pass, вычислив и запомнив все промежуточные представления $X = X^0, X^1, \ldots, X^m = \widehat{y}$.
- Вычислить все градиенты с помощью backward pass.
- С помощью полученных градиентов совершить шаг SGD.
Проиллюстрируем алгоритм на примере двуслойной нейронной сети со скалярным output’ом. Для простоты опустим свободные члены в линейных слоях.
 Обучаемые параметры – матрицы $U$ и $W$. Как найти градиенты по ним в точке $U_0, W_0$?
Обучаемые параметры – матрицы $U$ и $W$. Как найти градиенты по ним в точке $U_0, W_0$?
$$\nabla_{W_0}\mathcal{L} = \nabla_{W_0}{\left({\vphantom{\frac12}\mathcal{L}\circ h\circ\left[W\mapsto g(XU_0)W\right]}\right)}=$$
$$=g(XU_0)^T\nabla_{g(XU_0)W_0}(\mathcal{L}\circ h) = \underbrace{g(XU_0)^T}_{k\times N}\cdot
\left[\vphantom{\frac12}\underbrace{h’\left(\vphantom{\int_0^1}g(XU_0)W_0\right)}_{N\times 1}\odot
\underbrace{\nabla_{h\left(\vphantom{\int_0^1}g(XU_0)W_0\right)}\mathcal{L}}_{N\times 1}\right]$$
Итого матрица $k\times 1$, как и $W_0$
$$\nabla_{U_0}\mathcal{L} = \nabla_{U_0}\left(\vphantom{\frac12}
\mathcal{L}\circ h\circ\left[Y\mapsto YW_0\right]\circ g\circ\left[ U\mapsto XU\right]
\right)=$$
$$=X^T\cdot\nabla_{XU^0}\left(\vphantom{\frac12}\mathcal{L}\circ h\circ [Y\mapsto YW_0]\circ g\right) =$$
$$=X^T\cdot\left(\vphantom{\frac12}g'(XU_0)\odot
\nabla_{g(XU_0)}\left[\vphantom{\in_0^1}\mathcal{L}\circ h\circ[Y\mapsto YW_0\right]
\right)$$
$$=\ldots = \underset{D\times N}{X^T}\cdot\left(\vphantom{\frac12}
\underbrace{g'(XU_0)}_{N\times K}\odot
\underbrace{\left[\vphantom{\int_0^1}\left(
\underbrace{h’\left(\vphantom{\int_0^1}g(XU_0)W_0\right)}_{N\times1}\odot\underbrace{\nabla_{h(\vphantom{\int_0^1}g\left(XU_0\right)W_0)}\mathcal{L}}_{N\times 1}
\right)\cdot \underbrace{W^T}_{1\times K}\right]}_{N\times K}
\right)$$
Итого $D\times K$, как и $U_0$
Схематически это можно представить следующим образом:

Backpropagation для двуслойной нейронной сети
Подробнее о предыдущих вычисленияхЕсли вы не уследили за вычислениями в предыдущем примере, давайте более подробно разберём его чуть более конкретную версию (для $g = h = \sigma$).
Рассмотрим двуслойную нейронную сеть для классификации. Мы уже встречали ее ранее при рассмотрении линейно неразделимой выборки. Предсказания получаются следующим образом:
$$
\widehat{y} = \sigma(X^1 W^2) = \sigma\Big(\big(\sigma(X^0 W^1 )\big) W^2 \Big).
$$
Пусть $W^1_0$ и $W^2_0$ — текущее приближение матриц весов. Мы хотим совершить шаг по градиенту функции потерь, и для этого мы должны вычислить её градиенты по $W^1$ и $W^2$ в точке $(W^1_0, W^2_0)$.
Прежде всего мы совершаем forward pass, в ходе которого мы должны запомнить все промежуточные представления: $X^1 = X^0 W^1_0$, $X^2 = \sigma(X^0 W^1_0)$, $X^3 = \sigma(X^0 W^1_0) W^2_0$, $X^4 = \sigma(\sigma(X^0 W^1_0) W^2_0) = \widehat{y}$. Они понадобятся нам дальше.
Для полученных предсказаний вычисляется значение функции потерь:
$$
l = \mathcal{L}(y, \widehat{y}) = y \log(\widehat{y}) + (1-y) \log(1-\widehat{y}).
$$
Дальше мы шаг за шагом будем находить производные по переменным из всё более глубоких слоёв.
-
Градиент $\mathcal{L}$ по предсказаниям имеет вид
$$
\nabla_{\widehat{y}}l = \frac{y}{\widehat{y}} — \frac{1 — y}{1 — \widehat{y}} = \frac{y — \widehat{y}}{\widehat{y} (1 — \widehat{y})},
$$где, напомним, $ \widehat{y} = \sigma(X^3) = \sigma\Big(\big(\sigma(X^0 W^1_0 )\big) W^2_0 \Big)$ (обратите внимание на то, что $W^1_0$ и $W^2_0$ тут именно те, из которых мы делаем градиентный шаг).
-
Следующий слой — поэлементное взятие $\sigma$. Как мы помним, при переходе через него градиент поэлементно умножается на производную $\sigma$, в которую подставлено предыдущее промежуточное представление:
$$
\nabla_{X^3}l = \sigma'(X^3)\odot\nabla_{\widehat{y}}l = \sigma(X^3)\left( 1 — \sigma(X^3) \right) \odot \frac{y — \widehat{y}}{\widehat{y} (1 — \widehat{y})} =
$$$$
= \sigma(X^3)\left( 1 — \sigma(X^3) \right) \odot \frac{y — \sigma(X^3)}{\sigma(X^3) (1 — \sigma(X^3))} =
y — \sigma(X^3)
$$ -
Следующий слой — умножение на $W^2_0$. В этот момент мы найдём градиент как по $W^2$, так и по $X^2$. При переходе через умножение на матрицу градиент, как мы помним, умножается с той же стороны на транспонированную матрицу, а значит:
$$
\color{blue}{\nabla_{W^2_0}l} = (X^2)^T\cdot \nabla_{X^3}l = (X^2)^T\cdot(y — \sigma(X^3)) =
$$$$
= \color{blue}{\left( \sigma(X^0W^1_0) \right)^T \cdot (y — \sigma(\sigma(X^0W^1_0)W^2_0))}
$$Аналогичным образом
$$
\nabla_{X^2}l = \nabla_{X^3}l\cdot (W^2_0)^T = (y — \sigma(X^3))\cdot (W^2_0)^T =
$$$$
= (y — \sigma(X^2W_0^2))\cdot (W^2_0)^T
$$ -
Следующий слой — снова взятие $\sigma$.
$$
\nabla_{X^1}l = \sigma'(X^1)\odot\nabla_{X^2}l = \sigma(X^1)\left( 1 — \sigma(X^1) \right) \odot \left( (y — \sigma(X^2W_0^2))\cdot (W^2_0)^T \right) =
$$$$
= \sigma(X^1)\left( 1 — \sigma(X^1) \right) \odot\left( (y — \sigma(\sigma(X^1)W_0^2))\cdot (W^2_0)^T \right)
$$ -
Наконец, последний слой — это умножение $X^0$ на $W^1_0$. Тут мы дифференцируем только по $W^1$:
$$
\color{blue}{\nabla_{W^1_0}l} = (X^0)^T\cdot \nabla_{X^1}l = (X^0)^T\cdot \big( \sigma(X^1) \left( 1 — \sigma(X^1) \right) \odot (y — \sigma(\sigma(X^1)W_0^2))\cdot (W^2_0)^T\big) =
$$$$
= \color{blue}{(X^0)^T\cdot\big(\sigma(X^0W^1_0)\left( 1 — \sigma(X^0W^1_0) \right) \odot (y — \sigma(\sigma(X^0W^1_0)W_0^2))\cdot (W^2_0)^T\big) }
$$
Итоговые формулы для градиентов получились страшноватыми, но они были получены друг из друга итеративно с помощью очень простых операций: матричного и поэлементного умножения, в которые порой подставлялись значения заранее вычисленных промежуточных представлений.
Автоматизация и autograd
Итак, чтобы нейросеть обучалась, достаточно для любого слоя $f^k: X^{k-1}\mapsto X^k$ с параметрами $W^k$ уметь:
- превращать $\nabla_{X^k_0}\mathcal{L}$ в $\nabla_{X^{k-1}_0}\mathcal{L}$ (градиент по выходу в градиент по входу);
- считать градиент по его параметрам $\nabla_{W^k_0}\mathcal{L}$.
При этом слою совершенно не надо знать, что происходит вокруг. То есть слой действительно может быть запрограммирован как отдельная сущность, умеющая внутри себя делать forward pass и backward pass, после чего слои механически, как кубики в конструкторе, собираются в большую сеть, которая сможет работать как одно целое.
Более того, во многих случаях авторы библиотек для глубинного обучения уже о вас позаботились и создали средства для автоматического дифференцирования выражений (autograd). Поэтому, программируя нейросеть, вы почти всегда можете думать только о forward-проходе, прямом преобразовании данных, предоставив библиотеке дифференцировать всё самостоятельно. Это делает код нейросетей весьма понятным и выразительным (да, в реальности он тоже бывает большим и страшным, но сравните на досуге код какой-нибудь разухабистой нейросети и код градиентного бустинга на решающих деревьях и почувствуйте разницу).
Но это лишь начало
Метод обратного распространения ошибки позволяет удобно посчитать градиенты, но дальше с ними что-то надо делать, и старый добрый SGD едва ли справится с обучением современной сетки. Так что же делать? О некоторых приёмах мы расскажем в следующей главе.
From Wikipedia, the free encyclopedia
Error diffusion is a type of halftoning in which the quantization residual is distributed to neighboring pixels that have not yet been processed. Its main use is to convert a multi-level image into a binary image, though it has other applications.
Unlike many other halftoning methods, error diffusion is classified as an area operation, because what the algorithm does at one location influences what happens at other locations. This means buffering is required, and complicates parallel processing. Point operations, such as ordered dither, do not have these complications.
Error diffusion has the tendency to enhance edges in an image. This can make text in images more readable than in other halftoning techniques.

Early history[edit]
Richard Howland Ranger received United States patent 1790723 for his invention, «Facsimile system». The patent, which issued in 1931, describes a system for transmitting images over telephone or telegraph lines, or by radio.[1] Ranger’s invention permitted continuous-tone photographs to be converted first into black and white, then transmitted to remote locations, which had a pen moving over a piece of paper. To render black, the pen was lowered to the paper; to produce white, the pen was raised. Shades of gray were rendered by intermittently raising and lowering the pen, depending upon the luminance of the gray desired.
Ranger’s invention used capacitors to store charges, and vacuum tube comparators to determine when the present luminance, plus any accumulated error, was above a threshold (causing the pen to be raised) or below (causing the pen to be lowered). In this sense, it was an analog version of error diffusion.
Digital era[edit]
Floyd and Steinberg described a system for performing error diffusion on digital images based on a simple kernel[2]

where « » denotes a pixel in the current row which has already been processed (hence diffusing error to it would be pointless), and «#» denotes the pixel currently being processed.
» denotes a pixel in the current row which has already been processed (hence diffusing error to it would be pointless), and «#» denotes the pixel currently being processed.
Nearly concurrently, J. F. Jarvis, C. N. Judice, and W. H. Ninke of Bell Labs disclosed a similar method, which they termed «minimized average error» using a larger kernel[3]

Algorithm description[edit]
Error diffusion takes a monochrome or color image and reduces the number of quantization levels.[4] A popular application of error diffusion involves reducing the number of quantization states to just two per channel. This makes the image suitable for printing on binary printers such as black and white laser printers.
In the discussion which follows, it is assumed that the number of quantization states in the error diffused image is two per channel, unless otherwise stated.
One-dimensional error diffusion[edit]
The simplest form of the algorithm scans the image one row at a time and one pixel at a time. The current pixel is compared to a half-gray value. If it is above the value a white pixel is generated in the resulting image. If the pixel is below the half way brightness, a black pixel is generated. Different methods may be used if the target palette is not monochrome, such as thresholding with two values if the target palette is black, gray and white. The generated pixel is either full bright, or full black, so there is an error in the image. The error is then added to the next pixel in the image and the process repeats.
Two-dimensional error diffusion[edit]
One-dimensional error diffusion tends to have severe image artifacts that show up as distinct vertical lines. Two-dimensional error diffusion reduces the visual artifacts. The simplest algorithm is exactly like one-dimensional error diffusion, except that half the error is added to the next pixel, and half of the error is added to the pixel on the next line below.
The kernel is

where «#» denotes the pixel currently being processed.
Further refinement can be had by dispersing the error further away from the current pixel, as in the matrices given above in Digital era. The sample image at the start of this article is an example of two-dimensional error diffusion.
Color error diffusion[edit]
The same algorithms may be applied to each of the red, green, and blue (or cyan, magenta, yellow, black) channels of a color image to achieve a color effect on printers such as color laser printers that can only print single color values.
However, better visual results may be obtained by first converting the color channels into a perceptive color model that will separate lightness, hue and saturation channels, so that a higher weight for error diffusion will be given to the lightness channel, than to the hue channel. The motivation for this conversion is that human vision better perceives small differences of lightness in small local areas, than similar differences of hue in the same area, and even more than similar differences of saturation on the same area.
For example, if there is a small error in the green channel that cannot be represented, and another small error in the red channel in the same case, the properly weighted sum of these two errors may be used to adjust a perceptible lightness error, that can be represented in a balanced way between all three color channels (according to their respective statistical contribution to the lightness), even if this produces a larger error for the hue when converting the green channel. This error will be diffused in the neighboring pixels.
In addition, gamma correction may be needed on each of these perceptive channels, if they don’t scale linearly with the human vision, so that error diffusion can be accumulated linearly to these gamma-corrected linear channels, before computing the final color channels of the rounded pixel colors, using a reverse conversion to the native non gamma-corrected image format and from which the new residual error will be computed and converted again to be distributed to the next pixels.
Error diffusion with several gray levels[edit]
Error Diffusion may also be used to produce output images with more than two levels (per channel, in the case of color images). This has application in displays and printers which can produce 4, 8, or 16 levels in each image plane, such as electrostatic printers and displays in compact mobile telephones. Rather than use a single threshold to produce binary output, the closest permitted level is determined, and the error, if any, is diffused as described above.
Printer considerations[edit]
Most printers overlap the black dots slightly, so there is not an exact one-to-one relationship to dot frequency (in dots per unit area) and lightness. Tone scale linearization may be applied to the source image to get the printed image to look correct.
Edge enhancement versus lightness preservation[edit]
When an image has a transition from light to dark, the error-diffusion algorithm tends to
make the next generated pixel be black. Dark-to-light transitions tend to result in the next
generated pixel being white. This causes an edge-enhancement effect at the expense of gray-level reproduction accuracy. This results in error diffusion having a higher apparent resolution than other halftone methods. This is especially beneficial with images with text in them, such as the typical facsimile.
This effect shows fairly well in the picture at the top of this article. The grass detail and the text on the sign is well preserved,
and the lightness in the sky, containing little detail. A cluster-dot halftone image of the same resolution would be much less sharp.
See also[edit]
- Floyd–Steinberg dithering
- Halftone
References[edit]
- ^ Richard Howland Ranger, «Facsimile system». United States Patent 1790723, issued 3 February 1931.
- ^ Floyd, Robert W.; Steinberg, Louis (1976). «An Adaptive Algorithm for Spatial Grayscale». Proceedings of the Society for Information Display. 17 (2): 75–77.
- ^ J. F. Jarvis, C. N. Judice, and W. H. Ninke, «A survey of techniques for the display of continuous tone pictures on bilevel displays». Computer Graphics and Image Processing, 5:1:13–40 (1976).
- ^ «Error Diffusion — an overview | ScienceDirect Topics». www.sciencedirect.com. Retrieved 2022-05-09.
External links[edit]
- Error diffusion in Matlab
Распространение
ошибок
|
Содержание [убрать]
|
Введение
Одним
из наиболее важных вопросов в численном
анализе является вопрос о том, как
ошибка, возникшая в определенном месте
в ходе вычислений, распространяется
дальше, то есть становится ли ее влияние
больше или меньше по мере того, как
производятся последующие операции.
Крайним случаем является вычитание
двух почти равных чисел: даже при очень
маленьких ошибках обоих этих чисел
относительная ошибка разности может
оказаться очень большой. Такая
относительная ошибка будет распространяться
дальше при выполнении всех последующих
арифметических операций.
Одним
из источников вычислительных погрешностей
(ошибок) является приближенное
представление вещественных чисел в
ЭВМ, обусловленное конечностью разрядной
сетки. Хотя исходные данные представляются
в ЭВМ с большой точностью накопление
погрешностей округления в процессе
счета может привести к значительной
результирующей погрешности, а некоторые
алгоритмы могут оказаться и вовсе
непригодными для реального счета на
ЭВМ. Подробнее о представлении вещественных
чисел в ЭВМ можно узнать здесь.
Распространение
ошибок
В
качестве первого шага при рассмотрении
такого вопроса, как распространение
ошибок, необходимо найти выражения для
абсолютной и относительной ошибок
результата каждого из четырех
арифметических действий как функции
величин, участвющих в операции, и их
ошибок.
Абсолютная
ошибка
Сложение
Имеются
два приближения
![]() и
и
![]() к
к
двум величинам
![]() и
и
![]() ,
,
а также соответствующие абсолютные
ошибки
![]() и
и
![]() .
.
Тогда в результате сложения имеем
![]() .
.
Ошибка
суммы, которую мы обозначим через
![]() ,
,
будет равна
![]() .
.
Вычитание
Тем
же путем получаем
![]() .
.
Умножение
При
умножении мы имеем
![]() .
.
Поскольку
ошибки обычно гораздо меньше самих
величин, пренебрегаем произведением
ошибок:
![]() .
.
Ошибка
произведения будет равна
![]() .
.
Деление
Имеем
![]() .
.
Преобразовываем
это выражение к виду
![]() .
.
Множитель,
стоящий в скобках, при
![]() можно
можно
разложить в ряд
![]() .
.
Перемножая
и пренебрегая всеми членами, которые
содержат произведения ошибок или степени
ошибок выше первой, имеем
![]() .
.
Следовательно,
![]() .
.
Необходимо
четко понимать, что знак ошибки бывает
известен только в очень редких случаях.
Не факт, например, что ошибка увеличивается
при сложении и уменьшается при вычитании
потому, что в формуле для сложения стоит
плюс, а для вычитания — минус. Если,
например, ошибки двух чисел имеют
противоположные знаки, то дело будет
обстоять как раз наоборот, то есть ошибка
уменьшится при сложении и увеличится
при вычитании этих чисел.
Относительная
ошибка
После
того, как мы вывели формулы для
распространения абсолютных ошибок при
четырех арифметических действиях,
довольно просто вывести соответствующие
формулы для относительных ошибок. Для
сложения и вычитания формулы были
преобразованы с тем, чтобы в них входила
в явном виде относительная ошибка
каждого исходного числа.
Сложение
.
Вычитание
.
Умножение
![]() .
.
Деление
![]() .
.
Мы
начинаем арифметическую операцию, имея
в своем распоряжении два приближенных
значения
![]() и
и
![]() с
с
соответствующими ошибками
![]() и
и
![]() .
.
Ошибки эти могут быть любого происхождения.
Величины
![]() и
и
![]() могут
могут
быть экспериментальными результатами,
содержащими ошибки; они могут быть
результатами предварительного вычисления
согласно какому-либо бесконечному
процессу и поэтому могут содержать
ошибки ограничения; они могут быть
результатами предшествующих арифметических
операций и могут содержать ошибки
округления. Естественно, они могут также
содержать в различных комбинациях и
все три вида ошибок.
Вышеприведенные
формулы дают выражение ошибки результата
каждого из четырех арифметических
действий как функции от
![]() ;
;
ошибка округления в данном арифметическом
действии при этом не
учитывается.
Если же в дальнейшем необходимо будет
подсчитать, как распространяется в
последующих арифметических операциях
ошибка этого результата, то необходимо
к вычисленной по одной из четырех формул
ошибке результата прибавить
отдельно ошибку округления.
Графы
вычислительных процессов
Теперь
рассмотрим удобный способ подсчета
распространения ошибки в каком-либо
арифметическом вычислении. С этой целью
мы будем изображать последовательность
операций в вычислении с помощью графа
и будем писать около стрелок графа
коэффициенты, которые позволят нам
сравнительно легко определить общую
ошибку окончательного результата. Метод
этот удобен еще и тем, что позволяет
легко определить вклад любой ошибки,
возникшей в процессе вычислений, в общую
ошибку.

![]()
Рис.1.
Граф вычислительного процесса
![]()
На
рис.1
изображен граф вычислительного процесса
![]() .
.
Граф следует читать снизу вверх, следуя
стрелкам. Сначала выполняются операции,
расположенные на каком-либо горизонтальном
уровне, после этого — операции,
расположенные на более высоком уровне,
и т. д. Из рис.1, например, ясно, что
x
и y
сначала складываются, а потом умножаются
на z.
Граф, изображенный на рис.1,
является только изображением самого
вычислительного процесса. Для подсчета
общей ошибки результата необходимо
дополнить этот граф коэффициентами,
которые пишутся около стрелок согласно
следующим правилам.
Сложение
Пусть
две стрелки, которые входят в кружок
сложения, выходят из двух кружков с
величинами
![]() и
и
![]() .
.
Эти величины могут быть как исходными,
так и результатами предыдущих вычислений.
Тогда стрелка, ведущая от
![]() к
к
знаку + в кружке, получает коэффициент
![]() ,
,
стрелка же, ведущая от
![]() к
к
знаку + в кружке, получает коэффициент
![]() .
.
Вычитание
Если
выполняется операция
![]() ,
,
то соответствующие стрелки получают
коэффициенты
![]() и
и
![]() .
.
Умножение
Обе
стрелки, входящие в кружок умножения,
получают коэффициент +1.
Деление
Если
выполняется деление
![]() ,
,
то стрелка от
![]() к
к
косой черте в кружке получает коэффициент
+1, а стрелка от
![]() к
к
косой черте в кружке получает коэффициент
−1.
Смысл
всех этих коэффициентов следующий:
относительная
ошибка результата любой операции
(кружка) входит в результат следующей
операции, умножаясь на коэффициенты у
стрелки, соединяющей эти две операции.
Примеры

![]()
Рис.2.
Граф вычислительного процесса для
сложения
![]() ,
,
причем
![]()
Применим
теперь методику графов к примерам и
проиллюстрируем, что означает
распространение ошибки в практических
вычислениях.
Пример
1
Рассмотрим
задачу сложения четырех положительных
чисел:
![]() ,
,
где
![]() .
.
Граф
этого процесса изображен на рис.2.
Предположим, что все исходные величины
заданы точно и не имеют ошибок, и пусть
![]() ,
,
![]() и
и
![]() являются
являются
относительными ошибками округления
после каждой следующей операции сложения.
Последовательное применение правила
для подсчета полной ошибки окончательного
результата приводит к формуле
![]() .
.
Сокращая
сумму
![]() в
в
первом члене и умножая все выражение
на
![]() ,
,
получаем
![]() .
.
Учитывая,
что ошибка округления равна
![]() (в
(в
данном случае предполагается, что
действительное число в ЭВМ представляется
в виде десятичной дроби с t
значищими цифрами), окончательно имеем
![]() .
.
Из
этой формулы ясно, что максимально
возможная ошибка (абсолютная или
относительная), обусловленная округлением,
становится меньше, если сначала складывать
меньшие числа. Результат довольно
удивительный, так как вся классическая
математика основана на предположении,
что при перемене мест слагаемых или их
группировке сумма не изменяется. Разница
заключается в том, что ЭВМ не может
производить вычисления с бесконечно
большой точностью, а именно такие
вычисления рассматриваются в классической
математике.
Пример
2
Вычитание
двух почти равных чисел. Предположим,
что необходимо вычислить
![]() .
.
Тогда из формулы распространения ошибки
при вычитании имеем
![]() .
.
Предположим,
кроме того, что x
и y
являются соответствующим образом
округленными положительными числами,
так что
![]() и
и
![]() .
.
Если
разность x-y
мала, то относительная ошибка z
может стать большой, даже если абсолютная
ошибка мала. Так как в дальнейших
вычислениях эта большая относительная
ошибка будет распространяться, то она
может поставить под сомнение точность
окончательного результата вычислений.
Рассмотрим
простой пример:
![]()
![]()
Тогда
![]()
Зная
x
и y,
мы можем написать
![]()
![]()
Как
видим, относительные ошибки x
и y
малы. Однако
![]()
Эта
относительная ошибка очень велика, и,
что важнее всего, она будет распространяться
в ходе последующих вычислений.
Памятка
программисту
Выводы,
полученные выше, можно свести в краткий
перечень рекомендаций для практической
организации вычислений.
-
Если
необходимо произвести сложение-вычитание
длинной последовательности чисел,
работайте сначала с наименьшими числами. -
Если
возможно, избегайте вычитания двух
почти равных чисел. Формулы, содержащие
такое вычитание, часто можно преобразовать
так, чтобы избежать подобной операции. -
Выражение
вида
 можно
можно
написать в виде
 ,
,
а выражение вида
 можно
можно
написать в виде
.
Если числа в разности почти равны друг
другу, производите
вычитание до умножения или деления.
При этом задача не будет осложнена
дополнительными ошибками округления. -
В
любом случае сводите к минимуму число
необходимых арифметических операций.
Список
литературы
-
Д.Мак-Кракен,
У.Дорн.
Численные методы и программирование
на Фортране. Москва «Мир», 1977 -
А. А. Самарский,
А. В. Гулин.
Численные методы. Москва «Наука», 1989.
Соседние файлы в папке вычМатКурсач
- #
- #
- #
- #
- #
- #
Что такое распространение ошибок? (Определение и пример)
читать 2 мин
Распространение ошибки происходит, когда вы измеряете некоторые величины a , b , c , … с неопределенностями δ a , δ b , δc …, а затем хотите вычислить какую-то другую величину Q , используя измерения a , b , c и т. д.
Получается, что неопределенности δa , δb , δc будут распространяться (т.е. «растягиваться») на неопределенность Q.
Для вычисления неопределенности Q , обозначаемой δ Q , мы можем использовать следующие формулы.
Примечание. Для каждой из приведенных ниже формул предполагается, что величины a , b , c и т. д. имеют случайные и некоррелированные ошибки.
Сложение или вычитание
Если Q = a + b + … + c – (x + y + … + z)
Тогда δ Q = √ (δa) 2 + (δb) 2 + … + (δc) 2 + (δx) 2 + (δy) 2 + … + (δz) 2
Пример. Предположим, вы измеряете длину человека от земли до талии как 40 дюймов ± 0,18 дюйма. Затем вы измеряете длину человека от талии до макушки как 30 дюймов ± 0,06 дюйма.
Предположим, вы затем используете эти два измерения для расчета общего роста человека. Высота будет рассчитана как 40 дюймов + 30 дюймов = 70 дюймов. Неопределенность в этой оценке будет рассчитываться как:
- δ Q = √ (δa) 2 + (δb) 2 + … + (δc) 2 + (δx) 2 + (δy) 2 + … + (δz) 2
- δ Q = √ (.18) 2 + (.06) 2
- δ Q = 0,1897
Это дает нам окончательное измерение 70 ± 0,1897 дюйма.
Умножение или деление
Если Q = (ab…c) / (xy…z)
Тогда δ Q = |Q| * √ (δa/a) 2 + (δb/b) 2 + … + (δc/c) 2 + (δx/x) 2 + (δy/y) 2 + … + (δz/z) 2
Пример: Предположим, вы хотите измерить отношение длины элемента a к элементу b.Вы измеряете длину a как 20 дюймов ± 0,34 дюйма, а длину b как 15 дюймов ± 0,21 дюйма.
Отношение, определенное как Q = a/b , будет рассчитано как 20/15 = 1,333.Неопределенность в этой оценке будет рассчитываться как:
- δQ = | Q | * √ (δa/a) 2 + (δb/b) 2 + … + (δc/c) 2 + (δx/x) 2 + (δy/y) 2 + … + (δz/z) 2
- δ Q = |1,333| * √ (0,34/20) 2 + (0,21/15) 2
- δ Q = 0,0294
Это дает нам окончательное соотношение 1,333 ± 0,0294 дюйма.
Измеренное количество, умноженное на точное число
Если A точно известно и Q = A x
Тогда δ Q = |A|δx
Пример: предположим, что вы измеряете диаметр круга как 5 метров ± 0,3 метра. Затем вы используете это значение для вычисления длины окружности c = πd .
Длина окружности будет рассчитана как c = πd = π*5 = 15,708.Неопределенность в этой оценке будет рассчитываться как:
- δ Q = |A|δx
- δ = | π | * 0,3
- δ Q = 0,942
Таким образом, длина окружности равна 15,708 ± 0,942 метра.
Неуверенность в силе
Если n — точное число и Q = x n
Тогда δ Q = | Вопрос | * | н | * (δ х/х )
Пример: предположим, что вы измеряете сторону куба как s = 2 дюйма ± 0,02 дюйма. Затем вы используете это значение для вычисления объема куба v = s 3 .
Объем будет рассчитан как v = s 3 = 2 3 = 8 дюймов 3.Неопределенность в этой оценке будет рассчитываться как:
- δ = | Вопрос | * | н | * (δ х/х )
- δ Q = |8| * |3| * (.02/2)
- δ Q = 0,24
Таким образом, объем куба равен 8 ± 0,24 дюйма 3 .
Общая формула распространения ошибок
Если Q = Q(x) является любой функцией от x , то общая формула распространения ошибок может быть определена как:
δ Q = |dQ / dX |δx
Обратите внимание, что вам редко придется выводить эти формулы с нуля, но может быть полезно знать общую формулу, используемую для их вывода.