![]()
93
![]()
2
17.01.2015 11:05
Скачал прогу, запустил, вылезло окошко с ошибкой. Полазил маленько по настройкам, вроде заработало. Объясняю действия пошагово, без картинок.
1. запускаем прогу
2. приветсвенное окно — жмём далее
3. задаём имя, категорию проекта, папку загрузки — далее
4. в окошке вводим адрес сайта, не забудьте указать протокол http://
здесь же жмём кнопку «задать параметры». Вкладка «Фильтры» — ставим галочки на все типы, вкладка «Качалка» — ставим галочку «использовать http: версии 1,0 (не1,1)»
5. Жмём «Готово» — хдём, когда сайт загрузится. Вроде всё. 
Содержание
- HTTrack Website Copier
- Как скачивать сайт целиком
- Примечание
- Как просмотреть то, что мы скачали
Наиболее известны такие программы как:
- Offline Explorer ($59.95) и Offline Explorer Pro ($149.95)
- Teleport Pro ($49.95)
- Webcopier ($30)
- И даже такие архаичные как Wget (бесплатна), но необходимо уметь работы с консолью операционной системы.
- Есть даже бесплатный русский сервис Site2Zip.com (я ставил на закачку, но он ничего не скачал).
- HTTrack Website Copier (бесплатна)
А теперь подробнее о последней программе.
HTTrack Website Copier
Выбор небольшой, поэтому наиболее подходящей программой для скачивания сайта будет HTTrack Website Copier. К тому она вполне неплохо справляется с данной задачей.
Есть различные версии программы, которые совместимы с:
- 32-разрядной Windows 2000/XP/Vista/Seven/8
- 64-разрядной Windows Vista/7/8
В настройках можно выбрать русский язык.
Скачать нужную версию мы сможете прямо с официального сайта
Как скачивать сайт целиком
1. Установить программу на свой компьютер.
2. Выберите в настройках русский язык и перезагрузите программу, чтобы интерфейс обновился.
3. Создайте новый проект
- Укажите название проекта.
- В какую папку на ваш компьютер сохранить сайт.
- И нажмите кнопку «Далее».
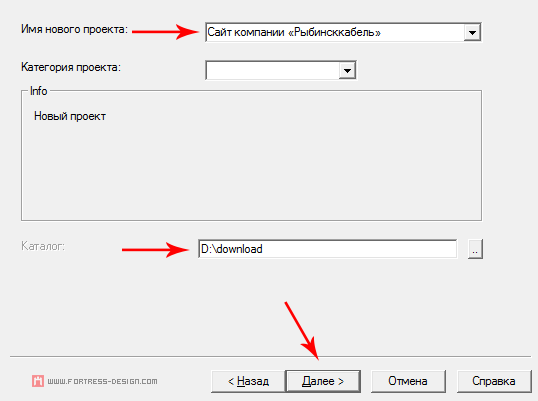
4. В поле «Веб адреса: (URL)» укажите адрес сайта, который надо скопировать и нажмите на кнопку «Задать параметры».

5. В появившемся окне выставляем параметры скачивания.
Если у вас нет прокси оставляем все как есть и переходим к следующей вкладке «Фильтры».
Внимание: если возникли проблемы со скачиванием — попробуйте снять флажок с опции «Использовать прокси для ftp-закачки».

6. Здесь мы избавляемся от мусора и говорим какие файлы нам скачивать не нужно.
Ставим флажки напротив архивов и видео-файлов. Все расширения добавятся автоматически.

7. Переходим на вкладку «Ограничения».
Я задал максимальную глубину загрузки сайта до трех уровне вложенности. Вы можете указывать другое значение, в зависимости от ваших потребностей.
Максимальную глубину внешних рекомендую устанавливать в нуль, если, конечно, вы не хотите попытаться скачать весь интернет ))

8. Идем на вкладку «Линки».
Можете поставить также все флажки как на этом скриншоте, чтобы скачивание сайта происходило максимально быстро.

9. На вкладке «Структура» выбираем тип локальной структуры зеркала. Я выбрал структуру сайта по умолчанию.

10. Нажимаем кнопку «ОК» и видим такое окно.
Здесь вы можете разорвать соединение после скачивания сайта, если у вас интернет не безлимитный. А также поставить флажок напротив пункта «Shutdown PC when finished», если хотите, чтобы HTTrack сам выключил компьютер, когда сольёт весь сайт.
Можем начать скачивание прямо сейчас или сделать это позже. Нажимаем кнопку «ОК».

11. Начался процесс скачивания сайта.

Примечание
Если вы хотите прервать скачивание, то нажмите кнопку «Отмена». В появившемся окне подтвердите остановку процесса, после чего HTTrack докачает текущие файлы, а новые скачивать не будет.
Сохраниет этот проект у себя на компьютере. Потом, чтобы докачать сайт, снова откроете этот проект и возобновите скачивание.
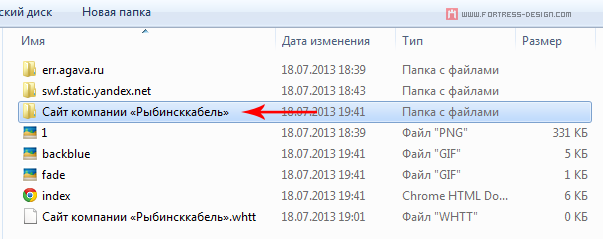
Вот как это выглядит на диске. Стрелкой отмечена папка, в которой находится скачанный сайт.
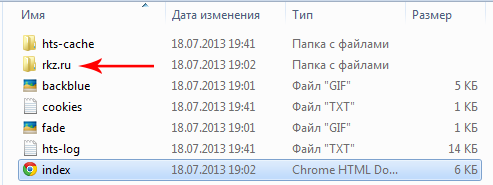
Если вы зайдете в нее, то увидите такую структуру.
Как просмотреть то, что мы скачали
Скачанный сайт можно запустить любым способом, например:
- зайти в папку, в которую сохраняли проект, кликнув по файлу
index.html. После этого откроется страница со списком всех проектов. Нужно выбрать нужный. - или войти в папку с названием проекта, кликнув по файлу
index.html, чтобы открылся сайт сразу.
Всё. Поздравляю, теперь на вашем компьютере точно такая копия сайта как и в интернете. Пользуйтесь на здоровье!
Напишите, пожалуйста, в комментариях, всё ли понятно написано? Скажите, какими программами вы пользуетесь, когда вам надо бесплатно скачать сайт на компьютер?
Фото: Rawpixel / Shutterstock.com
whenever i am trying to download: http://www.computerhope.com/
a dialog box appears saying following:
**MIRROR ERROR!**
HTTrack has detected that the curent mirror is empty. if it was an
update,the previos mirror has been restored.
reason: the first page(s) either could not found, or a connection
problem occured.
=> Ensure that the website stil exits, and/or check your proxy settings
<=
i am using 3.47-27 version of httrack in chrome browser on windows 8.
one additional information.......
log file says following.....
HTTrack3.47-27+htsswf+htsjava launched on Wed, 05 Feb 2014 11:58:17 at
http://www.computerhope.com/ +*.png +*.gif +*.jpg +*.css +*.js
-ad.doubleclick.net/* -mime:application/foobar
(winhttrack -qwC2%Ps2u1%s%uN0%I0p3DaK0H0%kf2A25000%f#f -F "Mozilla/4.5
(compatible; HTTrack 3.0x; Windows 98)" -%F "<!-- Mirrored from %s%s by HTTrack
Website Copier/3.x [XR&CO'2013], %s -->" -%l "en, *"
http://www.computerhope.com/ -O1 "C:\My Web Sites\aboutcomputer" +*.png +*.gif
+*.jpg +*.css +*.js -ad.doubleclick.net/* -mime:application/foobar )
Information, Warnings and Errors reported for this mirror:
note: the hts-log.txt file, and hts-cache folder, may contain sensitive
information,
such as username/password authentication for websites mirrored in this project
do not share these files/folders if you want these information to remain private
11:58:18 Error: "Forbidden" (403) at link www.computerhope.com/ (from
primary/primary)
11:58:18 Warning: No data seems to have been transferred during this session!
: restoring previous one!
Original issue reported on code.google.com by rahulhit...@gmail.com on 5 Feb 2014 at 6:45
Solution 1
I was apparently using an older version of Mozilla as the browser within HTTrack. I changed the version to 4.0 and it worked fine.
Solution 2
I hate to kick up old threads, but I have run into the same problem.
HTTrack version: 3.48-19
My solution was to use the browser identity of:
HyperBrowser (Cray;I;OrganicOS 9.7.42beta-27)
I have never used this identity before, but it has definitely started the mirror.
Solution 3
For me the solution was to use a current and existing User-Agent. I retrieved the one of my real browser by visiting https://www.whatismybrowser.com/detect/what-is-my-user-agent
Related videos on Youtube

01 : 42
HTTrack Empty Mirror Error (3 Solutions!!)
01 : 58
Fix 100% Success Mirror Error HTTrack Website Copier | Cách Khắc Phục Lỗi Mirror Error HTTrack

01 : 34
HTTrack Website Copier Mirror Error Problem Solve

02 : 19
WinHTTrack Web Copier Error Solved
![Httrack Mirror empty problem alternative | Use IDM Grabber To download Templates [Free 100%]](https://i.ytimg.com/vi/WL4HRuNrbgY/hq720.jpg?sqp=-oaymwEcCNAFEJQDSFXyq4qpAw4IARUAAIhCGAFwAcABBg==&rs=AOn4CLDNSEgyn2x5oXAywht_b0mJeK6TAQ)
09 : 17
Httrack Mirror empty problem alternative | Use IDM Grabber To download Templates [Free 100%]
Comments
-
I’m trying to download the following site: http://www.interneto-parduotuve.lt/
However, no matter what I try to do (get rid of the www, try other options than the «download website» one, etc) I keep getting a «HTTrack has detected that the current mirror is empty.» error. Does anyone know how to resolve this?
Recents
Related
Я пытаюсь загрузить следующий сайт: http://www.interneto-parduotuve.lt/
Тем не менее, независимо от того, что я пытаюсь сделать (избавиться от www, попробовать другие варианты, кроме как «скачать сайт» и т.д.), Я получаю «HTTrack обнаружил, что текущее зеркало пусто». ошибка. Кто-нибудь знает, как решить эту проблему?
Я очевидно использовал старую версию Mozilla в качестве браузера в HTTrack. Я изменил версию на 4.0, и она работала нормально.
Я ненавижу поднимать старые темы, но столкнулся с той же проблемой.
Версия HTTrack: 3.48-19
Мое решение состояло в том, чтобы использовать идентификатор браузера:
HyperBrowser (Cray; I; OrganicOS 9.7.42бета-27)
Я никогда не использовал эту личность раньше, но это определенно положило начало зеркалу.
Этот инструмент будет работать только на основе ссылок между страницами. Если на странице нет других страниц, указывающих на нее, она невидима для HTTrack (и других инструментов- пауков ). Если вы знаете URL-адреса этих несвязанных страниц, вы добавляете их вручную.