






RSS




The ESXi booting troubleshooting topics provide solutions to problems that you might encounter during the ESXi booting.
check-circle-line
exclamation-circle-line
close-line

09.03.21 г. вышел релиз ESXi 7.0U2, и его первоначальное тестирование показало ряд разной степени критичности ошибок и сопутствующих проблем. Ниже мы их распишем во всех подробностях, а также, по возможности, приведем методы устранения, для удобства разбив всю проблематику по категориям воздействия.
Проблемы с сетью
- Issue: Паравиртуальные сетевые адаптеры RDMA (PVRDMA) не поддерживают сетевые политики NSX. Если настроить распределенный виртуальный порт NSX для использования трафика PVRDMA, трафик протокола RDMA через сетевые адаптеры PVRDMA несовместим с сетевыми политиками NSX.
Resolve: Не настраивать распределенный виртуальный порт NSX для использования трафика PVRDMA.
- Issue: Сетевые адаптеры Solarflare x2542 и x2541, настроенные в режиме порта 1x100G, достигают пропускной способности до 70 Гбит/с в среде vSphere. Несмотря на то, что vSphere 7.0U2 поддерживает такие сетевые адаптеры, можно наблюдать ограничение по «железу» в устройствах.
Resolve: нет.
- Issue: После перезагрузки NIC трафик VLAN может упасть. NIC с PCI идентификатором устройства 8086:1537 может перестать посылать и получать тэггированные VLAN пакеты после перезагрузки, например, с командой: «vsish -e set /net/pNics/vmnic0/reset 1»
Resolve: Избегать перезагрузки NIC. Если же проблема все-таки случилась, использовать для восстановления возможностей VLAN команды (пример для vmnic0):
# esxcli network nic software set –tagging=1 -n vmnic0
# esxcli network nic software set –tagging=0 -n vmnic0
- Issue: Любое изменение в параметрах NetQueue балансера с помощью команды:
esxcli/localcli network nic queue loadbalancer set -n <nicname> –<lb_setting>
ведет к выключению NetQueue после перезагрузки ESXi-хоста.
Resolve: После всего проделанного использовать команду:
configstorecli config current get -c esx -g network -k nics
для получения данных ConfigStore для подтверждения, работает ли «/esx/network/nics/net_queue/load_balancer/enable» как ожидается. Вывод должен быть примерно таким:
{
“mac”: “02:00:0e:6d:14:3e”,
“name”: “vmnic1”,
“net_queue”: {
“load_balancer”: {
“dynamic_pool”: true,
“enable”: true
}
},
“virtual_mac”: “00:50:56:5a:21:11”
}
Если же в нем встречается, например, «load_balancer”: “enable”: false», запустить следующее:
esxcli/localcli network nic queue loadbalancer state set -n <nicname> -e true
- Issue: Задержка чтения адаптеров QLogic 16Gb Fibre Channel, поддерживаемых драйвером qlnativefc, растет при некоторых условиях. Если ВМ зашифрована, задержка последовательного чтения увеличивается на 8% в ESXi 7.0 Update 2 по сравнению с тем, что было актуально для ESXi 7.0 Update 1. Для незашифрованных машин она растет на 15-23%.
Resolve: нет.
Безопасность
- Issue: Выключение службы Service Location Protocol на ESXi (slpd) для предотвращения потенциальных пробоев в безопасности. Некоторые службы ESXi, работающие поверх операционной системы хоста, включая slpd, брокер объектов CIM, sfcbd и родственные openwsmand службы, доказали свою уязвимость в плане безопасности. Все подобные выявляемые уязвимости адресуются в VMSA-2019-0022 и VMSA-2020-0023 и, по мере возможностей, VMware старается их исправлять. Однако, если sfcbd и openwsmand по дефолту на ESXi выключены, slpd, напротив, включена, и, если в ней нет необходимости, рекомендуется ее выключить, чтобы предотвратить возможные будущие уязвимости после апгрейдов.
Resolve: Чтобы выключить службу slpd, использовать команды:
$ Get-VMHost | Get-VmHostService | Where-Object {$_.key -eq “slpd”} | Set-VMHostService -policy “off”
$ Get-VMHost | Get-VmHostService | Where-Object {$_.key -eq “slpd”} | Stop-VMHostService -Confirm:$false
Альтернативно, можно запустить: «chkconfig slpd off && /etc/init.d/slpd stop».
Стоит отметить, что служба openwsmand не представлена в списке служб ESXi, но, проверить ее статус можно командами:
$esx=(Get-EsxCli -vmhost xx.xx.xx.xx -v2)
$esx.system.process.list.invoke() | where CommandLine -like ‘*openwsman*’ | select commandline
А служба sfcbd там есть, но представлена как «sfcbd-watchdog». Больше информации по этой теме можно получить из этого и этого КБ.
Разные проблемы
- Issue: Не получается снять снэпшот ВМ из-за ошибки о сбое в операции дайджеста. Изредка, плавающее условие, при котором состояние All-Paths-Down (APD) появляется в процессе обновления файла дайджеста Content Based Read Cache (CBRC), может привести к несоответствию в дайджесте файла. Из-за этого нельзя снять снэпшот машин и видна ошибка:
An error occurred while saving the snapshot: A digest operation has failed
Resolve: Запустить цикл включения ВМ для вызова повторного вычисления хэшей CBRC и очистки несоответствий в файле дайджеста.
- Issue: ESXi-хост падает в фиолетовый диагностический экран из-за редкого условия в драйвере qedentv. Проблема появляется, когда полное прерывание Rx случается сразу после уничтожения пары очередей (QP) General Services Interface (GSI). Например, во время выгрузки драйвера qedentv или завершения работы системы. В таком случае этот драйвер не может получить доступ к уже освободившемуся адресу QP, в результате чего PF исключается. Известно для хостов ESXi, подключенных к занятому физическому свитчу с интенсивным не запрошенным трафиком GSI. В трассировке будут сообщения:
cpu4:2107287)0x45389609bcb0:[0x42001d3e6f72]qedrntv_ll2_rx_cb@(qedrntv)#<None>+0x1be stack: 0x45b8f00a7740, 0x1e146d040, 0x432d65738d40, 0x0, 0x
2021-02-11T03:31:53.882Z cpu4:2107287)0x45389609bd50:[0x42001d421d2a]ecore_ll2_rxq_completion@(qedrntv)#<None>+0x2ab stack: 0x432bc20020ed, 0x4c1e74ef0, 0x432bc2002000,
2021-02-11T03:31:53.967Z cpu4:2107287)0x45389609bdf0:[0x42001d1296d0]ecore_int_sp_dpc@(qedentv)#<None>+0x331 stack: 0x0, 0x42001c3bfb6b, 0x76f1e5c0, 0x2000097, 0x14c2002
2021-02-11T03:31:54.039Z cpu4:2107287)0x45389609be60:[0x42001c0db867]IntrCookieBH@vmkernel#nover+0x17c stack: 0x45389609be80, 0x40992f09ba, 0x43007a436690, 0x43007a43669
2021-02-11T03:31:54.116Z cpu4:2107287)0x45389609bef0:[0x42001c0be6b0]BH_Check@vmkernel#nover+0x121 stack: 0x98ba, 0x33e72f6f6e20, 0x0, 0x8000000000000000, 0x430000000001
2021-02-11T03:31:54.187Z cpu4:2107287)0x45389609bf70:[0x42001c28370c]NetPollWorldCallback@vmkernel#nover+0x129 stack: 0x61, 0x42001d0e0000, 0x42001c283770, 0x0, 0x0
2021-02-11T03:31:54.256Z cpu4:2107287)0x45389609bfe0:[0x42001c380bad]CpuSched_StartWorld@vmkernel#nover+0x86 stack: 0x0, 0x42001c0c2b44, 0x0, 0x0, 0x0
2021-02-11T03:31:54.319Z cpu4:2107287)0x45389609c000:[0x42001c0c2b43]Debug_IsInitialized@vmkernel#nover+0xc stack: 0x0, 0x0, 0x0, 0x0, 0x0
2021-02-11T03:31:54.424Z cpu4:2107287)^[[45m^[[33;1mVMware ESXi 7.0.2 [Releasebuild-17435195 x86_64]^[[0m
#PF Exception 14 in world 2107287:vmnic7-pollW IP 0x42001d3e6f72 addr 0x1c
Resolve: нет.
Проблемы хранилища
- Issue: Если NVMe-устройство добавлено и удалено на горячую практически подряд, ESXi-хост падает в фиолетовый диагностический экран. Драйвер NVMe не может инициализировать NVMe-контроллер из-за времени истечения команды. В результате драйвер может попробовать достучаться до памяти, которая уже освобождается в процессе очистки. В трассировке будет значиться:
WARNING: NVMEDEV: NVMEInitializeController:4045: Failed to get controller identify data, status: Timeout.
Случается, что в этом случае хост падает в фиолет с ошибкой, вида:
#PF Exception … in world …:vmkdevmgr
Resolve: Выполнять операции замены на горячую исключительно после завершения предыдущей операции. Например, если нужно запустить удаление после добавления, следует дождаться создания HBA и обнаружения LUN. Для альтернативного сценария (добавление после удаления) важно дождаться, пока все LUN и HBA не будут удалены.
Проблемы с управлением ВМ
- Issue: UEFI HTTP-загрузка ВМ на хостах версий, древнее 7.0U2, может дать сбой.
Resolve: Использовать UEFI HTTP-загрузку только для ВМ с «железом» версии 19 или свежее. При этом хосты должны иметь ESXi 7.0U2 или более новые.
Проблемы с vSAN
- Issue: Если поменять предпочтительный сайт в растянутом кластере vSAN, некоторые объекты могут некорректно отображаться как соответствующие. Это происходит потому, что параметры политики таких объектов могут не меняться автоматически. Например, если настроить ВМ на хранение данных на предпочитаемом сайте, при смене этого сайта на другой, данные могут остаться на не предпочитаемом.
Resolve: Перед сменой предпочитаемого сайта в Advanced Settings, уменьшить параметр «ClomMaxCrawlCycleMinutes» до 15 минут, чтобы политики объектов успели проапдейтиться. После изменения восстановить эту опцию до прежнего значения.
Проблемы с инсталляцией, апгрейдом и миграцией
- Issue: UEFI-загрузка ESXi-хостов может остановиться с ошибкой при апдейте до ESXi 7.0U2 с более ранних версий «семерки». Ошибка вида:
Loading /boot.cfg
Failed to load crypto64.efi
Fatal error: 15 (Not found)
Resolve: Использовать baseline обновления хостов после импорта образа актуальной версии в инвентарь vCenter Server, если его еще нет в хранилище vLCM. Больше информации в КБ.
- Issue: Если старые VIB все еще используются на ESXi-хосте, vLCM не может извлечь желаемую спецификацию софта в сид нового кластера. В vCenter Server 7.0U2 можно создавать новые кластера импортированием спецификации софта из единственного эталонного хоста. Но, если старые VIB все еще в деле, в «/var/log/lifecycle.log» можно получить сообщение вида:
020-11-11T06:54:03Z lifecycle: 1000082644: HostSeeding:499 ERROR Extract depot failed: Checksum doesn’t match. Calculated 5b404e28e83b1387841bb417da93c8c796ef2497c8af0f79583fd54e789d8826, expected: 0947542e30b794c721e21fb595f1851b247711d0619c55489a6a8cae6675e796 2020-11-11T06:54:04Z lifecycle: 1000082644: imagemanagerctl:366 ERROR Extract depot failed. 2020-11-11T06:54:04Z lifecycle: 1000082644: imagemanagerctl:145 ERROR [VibChecksumError]
Resolve: Воспользоваться рекомендациями из КБ.
- Issue: Может наблюдаться краткое наращивание активности сообщений в syslog.log после каждой загрузки ESXi, например, показывается такое:
2021-01-19T22:44:22Z watchdog-vaai-nasd: ‘/usr/lib/vmware/nfs/bin/vaai-nasd -f’ exited after 0 seconds (quick failure 127) 1
2021-01-19T22:44:22Z watchdog-vaai-nasd: Executing ‘/usr/lib/vmware/nfs/bin/vaai-nasd -f’
2021-01-19T22:44:22.990Z aainasd[1000051135]: Log for VAAI-NAS Daemon for NFS version=1.0 build=build-00000 option=DEBUG
2021-01-19T22:44:22.990Z vaainasd[1000051135]: DictionaryLoadFile: No entries loaded by dictionary.
2021-01-19T22:44:22.990Z vaainasd[1000051135]: DictionaryLoad: Cannot open file “/usr/lib/vmware/config”: No such file or directory.
2021-01-19T22:44:22.990Z vaainasd[1000051135]: DictionaryLoad: Cannot open file “//.vmware/config”: No such file or directory.
2021-01-19T22:44:22.990Z vaainasd[1000051135]: DictionaryLoad: Cannot open file “//.vmware/preferences”: No such file or directory.
2021-01-19T22:44:22.990Z vaainasd[1000051135]: Switching to VMware syslog extensions
2021-01-19T22:44:22.992Z vaainasd[1000051135]: Loading VAAI-NAS plugin(s).
2021-01-19T22:44:22.992Z vaainasd[1000051135]: DISKLIB-PLUGIN : Not loading plugin /usr/lib/vmware/nas_plugins/lib64: Not a shared library.
Resolve: Смысловой нагрузки не несет. Можно игнорировать.
- Issue: Показываются предупреждения о пропущенных VIB в отчетах проверки совместимости vSphere Quick Boot после обновления до последней версии гипервизора и использования команды «/usr/lib/vmware/loadesx/bin/loadESXCheckCompat.py», вида:
Cannot find VIB(s) … in the given VIB collection.
Ignoring missing reserved VIB(s) …, they are removed from reserved VIB IDs.
Resolve: Можно спокойно не обращать внимания. Проблему совместимости не отражают. Конечная строка вывода команды «loadESXCheckCompat» покажет совместимость хоста.
- Issue: Автоматическая загрузка кластера, управляемого с помощью образа vSphere Lifecycle Manager, завершается ошибкой:
2021-02-11T19:37:43Z Host Profiles[265671 opID=MainThread]: ERROR: EngineModule::ApplyHostConfig. Exception: [Errno 30] Read-only file system
Resolve: Следовать гайдам вендора по очистке VMFS-партиций на целевом хосте и повторить операцию. Альтернативно использовать чистый диск. Больше узнать об этом поможет КБ.
Если по перечисленным проблемам без решения появятся какие-то дельные пути их устранения, а также, если обнаружатся дополнительные, связанные с новой версией гипервизора, ошибки, эта статья непременно будет соответствующим образом дополнена.

Troubleshooting VMWare ESXi Virtual Machine ‘Invalid Status’
Let’s troubleshoot VM Invalid status
You can see multiple “invalid” VM machines in the image below. Here status is showing invalid.
Reason of Invalid VM Machine status could be related to the storage of underlying machine has been moved or changed, or corrupted, deleted and it moved to another storage device and as a result of which VMware ESXi hosts no longer knows what it is and consider VM Machines as invalid.
You need to delete the invalid VM Machines and add it manually if the machine does exist.
Please consider below points before deleting any VMware Machine
- Check .vmx file for configuration of the host. It should be accessible to replicate the new VM after deleting invalid host.
- Check if .vmx file is in unlock state
- Check VM tools for installation like SSH/putty
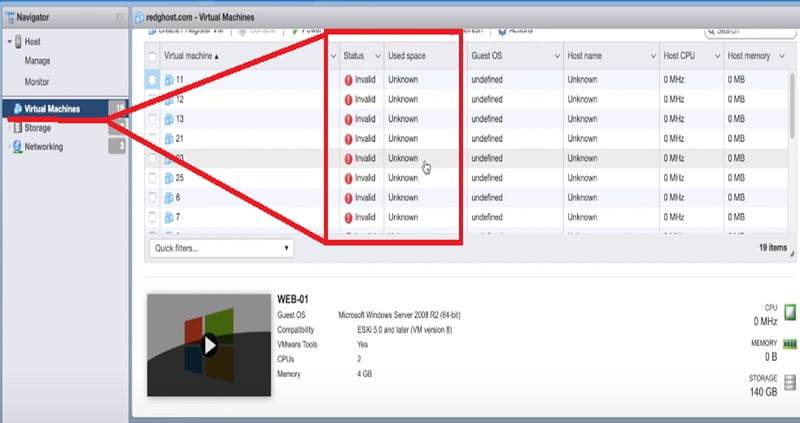
There -> Navigator -> Virtual Machines -> Select VM
Click on Action -> Right Click the Action Tab -> It will give you so many options to allow, delete, and unregister you the VMware Machine.
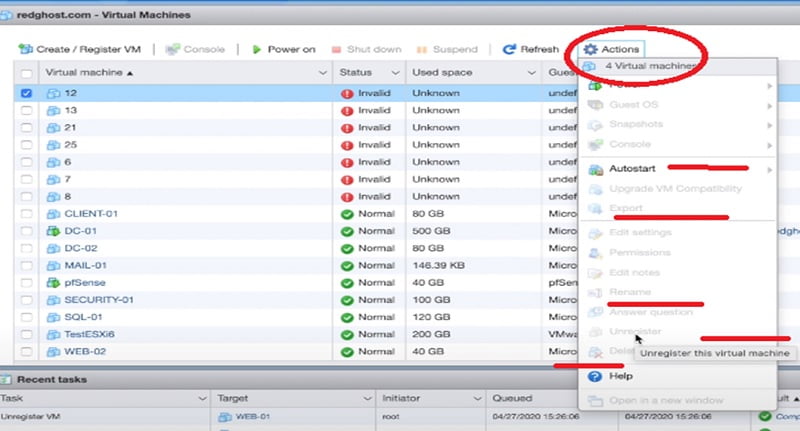
You can select unregister Tab to remove the device from here. However if you find the options in greyed-out colour then you need to unregister the devices from SSH access.
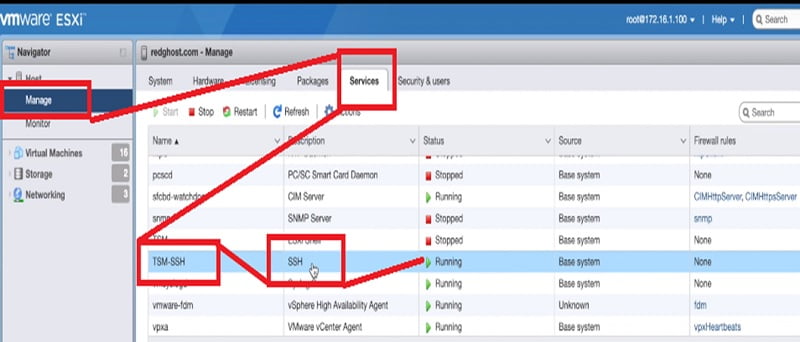
First you need to enable SSH for VMware ESXi machines and then connect to the machines by using a putty session.
Go to Manage -> Services -> TSM-SSH -> SSH -> Action -> Select Start
And apply a running option to enable the SSH application for the host.
Login to Putty session from Windows Machine.
Make sure you can login as a root user.
Once you login into putty session type below command to provide the overview what is running in the ESXi host
# vim-cmd /vmsvc/getallvms
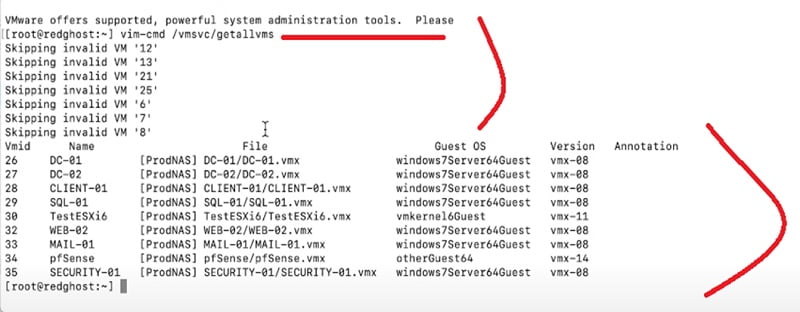
You can see that the output of the command can show you the list of VM IDs. You can pick the list of VM IDs which you want to remove from the VM host.
Now further you can check the list of VM IDs with invalid status along with ID number.
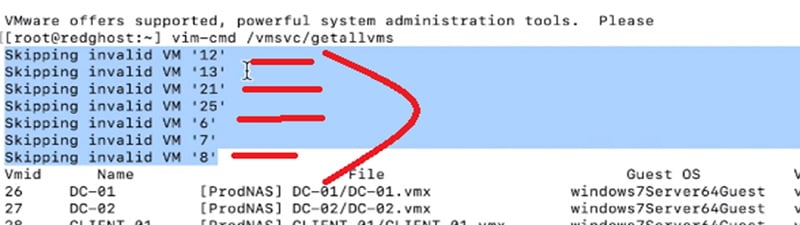
Case 1: Reload VM to recover from invalid state
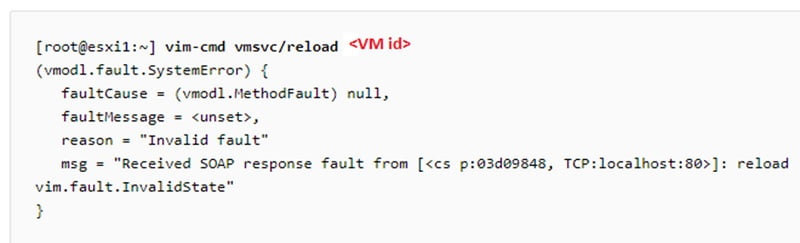
Here first, we will try to recover the host by reloading the configuration. We can try to reload the VM as to rectify the issue but if it fails then we have to unregister the VM (case-2)
# vmsvc/reload <VM id>
Case 2: Unregister VM Host
Now we need to unregister the above invalid VM IDs from CLI by running below command followed by VM ID number
#vim –cm /vmsvc/unregister <VM id>

Further you can cross verify the removal of VM IDs from the Web GUI of host as well.
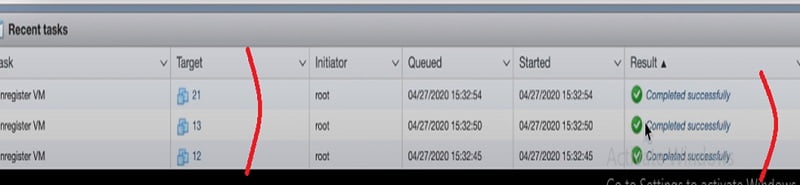
You can reconfigure the VM hosts once removing the VM IDs.
Thanks for reading!!!
Continue Reading:
Hyper V vs VMware : Detailed Comparison
What is VMware Horizon?
![]()
I am here to share my knowledge and experience in the field of networking with the goal being — «The more you share, the more you learn.»
I am a biotechnologist by qualification and a Network Enthusiast by interest. I developed interest in networking being in the company of a passionate Network Professional, my husband.
I am a strong believer of the fact that «learning is a constant process of discovering yourself.»
— Rashmi Bhardwaj (Author/Editor)
Время на прочтение
7 мин
Количество просмотров 12K
Многие администраторы VMware ESXi сталкивались с такой проблемой, как «фиолетовый экран смерти». Самое неприятное в этой проблеме, что у вас возникает недоверие к своей собственной инфраструктуре. В голове постоянно крутятся мысли о том, что такая же проблема может повториться и на другом сервере.
Что такое PSOD?
PSOD расшифровывается, как Purple Screen of Diagnostics, часто называемый Purple Screen of Death от более известного Blue Screen of Death, встречающегося в Microsoft Windows.
Это диагностический экран, отображаемый VMware ESXi, когда ядро обнаруживает фатальную ошибку, при которой оно либо не может безопасно восстановиться, либо не может продолжать работу.
Он показывает состояние памяти во время сбоя, а также дополнительные сведения, которые важны для устранения причины сбоя: версия и сборка ESXi, тип исключения, дамп регистра, обратную трассировку, время безотказной работы сервера, сообщения об ошибках и информацию о дампе ядра. (файл, созданный после ошибки, содержащий дополнительную диагностическую информацию).
Данный экран отображается в консоли сервера. Чтобы увидеть его, вам нужно будет либо находиться в центре обработки данных и подключить монитор, либо подключиться удаленно с помощью внеполосного управления сервером (iLO, iDRAC, IMM и т.д. в зависимости от вашего вендора).

Почему появляется PSOD?
PSOD — это сбой в ядре. Все мы знаем, что ESXi не основан на UNIX, но механика сбоя соответствует определению UNIX. Ядро ESXi (vmkernel) запускает эту меру безопасности в ответ на события или ошибки, которые невозможно исправить, это будет означать, что продолжение работы может создать высокий риск для служб и виртуальных машин. Проще говоря: когда хосты ESXi чувствуют, что они повреждены, они совершают «харакири» и, истекая пурпурной кровью, пишут «предсмертную записку» с подробным описанием причин, по которым они это сделали!
Наиболее частые причины PSOD:
1. Аппаратные сбои, в основном связанные с RAM или CPU. Обычно они выдают ошибку «MCE» или «NMI».
«MCE» — исключение проверки компьютера, которое представляет собой механизм в ЦП для обнаружения и сообщения о проблемах с оборудованием. В кодах, отображаемых на фиолетовом экране, есть важные детали для определения основной причины проблемы.
«NMI» — немаскируемое прерывание, то есть аппаратное прерывание, которое не может игнорироваться процессором. Поскольку NMI является очень важным сообщением об отказе HW, ответ по умолчанию, начиная с ESXi 5.0 и более поздних версий, должен запускать PSOD. Более ранние версии просто регистрировали ошибку и продолжали. Как и в случае с MCE, фиолетовый экран, вызванный NMI, предоставляет важные коды, которые имеют решающее значение для устранения неполадок.
2. Программные ошибки
· неверное взаимодействие между компонентами ESXi SW (см. KB2105711)
· условия гонки (см. KB2136430 )
· из ресурсов: память, динамическая область памяти, буфер (см. KB2034111, KB2150280)
· бесконечный цикл + переполнение стека (см. KB2105522 )
· неверные или неподдерживаемые параметры конфигурации (см. KB2012125, KB2127997)
3. Некорректно функционирующие драйвера; ошибки в драйверах, которые пытаются получить доступ к некорректному индексу или несуществующему методу (см. KB2146526, KB2148123)
Какое влияние оказывает PSOD?
Когда возникает сбой, хост выходит из строя и завершает работу всех служб, работающих на нем, вместе со всеми размещенными виртуальными машинами. Виртуальные машины отключаются резко и не завершают свою работу корректно. Если хост является частью кластера и вы настроили HA, эти виртуальные машины будут запущены на других хостах в кластере. Помимо простоя и недоступности виртуальных машин во время их простоя, «грязное» завершение может повлиять на некоторые критически важные приложения, такие как серверы баз данных, очереди сообщений или задания резервного копирования.
Кроме того, все другие службы, предоставляемые хостом, будут прекращены, поэтому, если ваш хост является частью кластера VSAN, PSOD также повлияет на vSAN.
Что делать?
1. Проанализируйте сообщение на фиолетовом экране.
Одна из самых важных вещей, которые нужно сделать при появлении фиолетового экрана — это сделать снимок экрана. Если вы подключаетесь к консоли удаленно (IMM, iLO, iDRAC, …), будет легко сделать снимок экрана, если нет такой возможности, хотя сфотографируйте экран на телефон. На этом экране много полезной информации о причине сбоя.

2. Обратитесь в службу поддержки VMware.
Прежде чем приступить к дальнейшему исследованию и устранению неполадок, рекомендуется обратиться в службу поддержки VMware, если у вас есть контракт на поддержку. Параллельно с вашим расследованием они смогут помочь вам в проведении корневого анализа причин (RCA).
3. Перезагрузите затронутый хост ESXi.
Чтобы восстановить сервер, вам необходимо перезагрузить его. Я бы также посоветовал оставить его в режиме обслуживания, пока вы не выполните полный анализ RCA, пока не будет определена и исправлена ошибка. Если вы не можете позволить себе держать его в режиме обслуживания, по крайней мере, точно настройте свои правила DRS, чтобы на нем работали только второстепенные виртуальные машины, чтобы в случае возникновения другого PSOD влияние было минимальным.
4. Получите coredump
После загрузки сервера вы должны собрать дамп ядра — coredump. Coredump, также называемый vmkernel-zdump, представляет собой файл, содержащий журналы с более подробной информацией, чем та, что отображается на фиолетовом экране диагностики, и будет использоваться при дальнейшем устранении неполадок. Даже если причина сбоя может показаться очевидной из сообщения PSOD, которое вы проанализировали на шаге 1, рекомендуется подтвердить ее, просмотрев журналы из coredump.
В зависимости от вашей конфигурации у вас может быть дамп ядра в одной из следующих форм:
а. Во временном разделе
b. В виде файла .dump в одном из хранилищ данных хоста
c. В виде файла .dump на vCenter — через службу netdump
Coredump становится особенно важным, если конфигурация хоста должна автоматически сбрасываться после PSOD , и в этом случае вы не увидите сообщение на экране. Вы можете скопировать файл дампа с хоста ESXi с помощью SCP, а затем открыть его с помощью текстового редактора (например, Notepad ++). Он будет вмещать содержимое памяти на момент сбоя, и первые его части будут содержать сообщения, которые вы видели на фиолетовом экране. Служба поддержки VMware может запросить весь файл, но у вас лишь будет возможность извлечь только журнал vmkernel, который более нагляден:

5. Расшифруйте ошибку.
Устранение неполадок и анализ причин позволяют почувствовать себя Шерлоком Холмсом. Самый важный симптом, с которого вам следует начать, — это сообщение об ошибке, создаваемое фиолетовым экраном. К счастью, количество выдаваемых сообщений об ошибках ограничено:
Exception Type 0 #DE: Divide ErrorException Type 1 #DB: Debug ExceptionException Type 2 NMI: Non-Maskable InterruptException Type 3 #BP: Breakpoint ExceptionException Type 4 #OF: Overflow (INTO instruction)Exception Type 5 #BR: Bounds check (BOUND instruction)Exception Type 6 #UD: Invalid OpcodeException Type 7 #NM: Coprocessor not availableException Type 8 #DF: Double FaultException Type 10 #TS: Invalid TSSException Type 11 #NP: Segment Not PresentException Type 12 #SS: Stack Segment FaultException Type 13 #GP: General Protection FaultException Type 14 #PF: Page FaultException Type 16 #MF: Coprocessor errorException Type 17 #AC: Alignment CheckException Type 18 #MC: Machine Check ExceptionException Type 19 #XF: SIMD Floating-Point ExceptionException Type 20-31: ReservedException Type 32-255: User-defined (clock scheduler)
Поскольку сбой в ядре обрабатывается процессором, для получения дополнительной информации об этих исключениях см. Руководство разработчика программного обеспечения для архитектур Intel 64 и IA-32, том 1: Базовая архитектура и Руководство разработчика программного обеспечения для архитектур Intel 64 и IA-32, том 3A.
Наиболее распространенные случаи описаны в отдельных статьях базы знаний VMware. Поэтому используйте эту таблицу в качестве индекса для ошибок PSOD:
6. Проверьте журналы
Может случиться так, что причина не очень очевидна при просмотре фиолетового сообщения на экране или журнала дампа ядра, поэтому следующее место, где искать подсказки, — это журналы хоста, особенно во временном интервале, непосредственно предшествующем PSOD. Даже если вы чувствуете, что нашли причину, все же рекомендуется подтвердить ее, просмотрев журналы.
Если вы администрируете корпоративную среду, вероятно, у вас под рукой есть специализированное решение для управления журналами (например, VMware Log Insight или SolarWinds LEM ), поэтому их будет легко просматривать, но если у вас нет управления журналами, вы можете легко экспортировать их .
Наиболее интересные файлы журналов для изучения:
|
Компоненты |
Место расположения |
Что это такое |
|
Системные сообщения |
/var/log/syslog.log |
Содержит все общие сообщения журнала и может использоваться для устранения неполадок. |
|
VMkernel |
/var/log/vmkernel.log |
Записывает действия, связанные с виртуальными машинами и ESXi. Большинство записей, относящихся к PSOD, будет в этом журнале, поэтому обратите на него особое внимание. |
|
Журнал агента хоста ESXi |
/var/log/hostd.log |
Содержит информацию об агенте, который управляет и настраивает хост ESXi и о его виртуальных машинах. |
|
Предупреждения VMkernel |
/var/log/vmkwarning.log |
Записывает действия, связанные с виртуальными машинами. Следит за записями журнала, связанными с истощение динамической области памяти (Heap WorkHeap). |
|
Журнал агента vCenter |
/var/log/vpxa.log |
Содержит информацию об агенте, который обменивается данными с vCenter, поэтому вы можете использовать его для обнаружения задач, запускаемых vCenter и могущих вызвать PSOD. |
|
Журнал shell |
/var/log/shell.log |
Содержит запись всех набранных команд, так что вы можете соотнести PSOD с выполненной командой. |
Рассказываем, как проверять ресурсы ВМ на ошибки и даем ключевые метрики, на которые можно опираться.
В этой статье мы расскажем, как искать иголку в стоге сена причину проблем с производительностью ВМ на ESXi. Главным способом будет то, что так не любят многие администраторы: планомерная проверка всех ресурсов на утилизацию, сатурацию и ошибки. Мы приведем ключевые метрики, на которые следует обратить внимание, их краткое описание и значения, на которые можно ориентироваться, как на норму. При этом важно понимать, что разные системы имеют разные требования к производительности. Следовательно, то, что приемлемо для одной системы, для другой может являться признаком аварийного состояния.
Кроме собственных наработок, мы использовали материалы из разных англоязычных источников. По некоторым вопросам описания тянут на отдельные статьи, поэтому на них приводим ссылки.
Нашим первым шагом должна быть быстрая базовая проверка основных параметров – ее сценарий описан в начале статьи. Если базовая проверка не нашла причины проблем, то, скорее всего, укажет направление, в котором мы запустим расширенную проверку. В любом случае, более глубокая расширенная проверка всех доступных параметров поможет в итоге найти корень проблем. С этим обнадеживающим фактом давайте приступим. Напоминаем, что проверяемые параметры стоит фиксировать скриншотами.
Выясняем симптомы проблемы
Вот краткий список ключевых вопросов, на которые нужно ответить:
1. Как проявляются проблемы производительности? Описываем словами, снимками, прикладываем графики.
2. Когда работало хорошо и когда начало работать плохо? Вспоминаем даты и время.
3. Были ли какие-то аппаратные, программные или нагрузочные изменения?
4. Охватывает ли проблема другие системы или только одну, например: ВМ, vApp, группу ВМ, кластер, группу кластеров и т. д.
Часть 1. Базовая проверка
Цель базовой проверки – быстро выяснить направление, в котором находится источник проблем производительности. Учитывайте, что графики в vSphere Client усредняют значения со временем, и лучше собирать максимум информации в любую стороннюю систему мониторинга (Prometeus, Zabbix, VMware vRealize Operation Manager и т. д.). Если такой системы нет, то воспроизводим проблему в реальном времени и наблюдаем за ней со стороны гипервизора. По результатам базовой проверки решаем, нужно ли дальнейшее расследование.
Проверяем ВМ из vSphere Client
- Triggered Alarms, Tasks и Events не должны содержать событий, коррелирующих с проблемой.
- CPU
-
Usage не должен превышать 90%.
Usage – процент активно задействованных мощностей виртуальных CPU. Это среднее значение загруженности CPU в виртуальной машине. Например, если виртуальная машина с одним виртуальным CPU работает на хосте, имеющем четыре физических CPU, и Usage виртуального CPU составляет 100%, то виртуальная машина полностью использует один физический CPU.
Usage виртуального CPU = usagemhz / кол-во виртуальных CPU x частота ядра.
-
Ready не должен превышать 10% на ядро.
Ready показывает время, в течение которого виртуальная машина была готова к использованию, но не могла быть запущена на физическом CPU из-за нехватки ресурсов. Ready % зависит от количества виртуальных машин на хосте и загруженности их CPU.
-
- Memory
-
Ballooned должен быть равен 0.
Этот параметр указывает на объем памяти, захваченной драйвером управления памятью ВМ (vmmemctl), который установлен в гостевую ОС вместе с VMware Tools. Данный объем перераспределяется от ВМ к гипервизору в условиях её нехватки. То же самое происходит, когда неверно выставлен Memory Limit на ВМ или ресурсный пул – это тоже ухудшает производительность ВМ.
-
Swapped должен быть равен 0.
Это текущий объем гостевой физической памяти, которую VMkernel выгрузил в файл подкачки ВМ. Выгруженная память остается на диске до тех пор, пока она не понадобится ВМ, либо пока не будет запущен принудительный механизм unswap. Подробнее расписано тут: https://www.yellow-bricks.com/2016/06/02/memory-pages-swapped-can-unswap/
-
- Virtual Disk
- Нормально, если отсутствуют мгновенные снимки старше 24 часов.
-
Highest latency не должен превышать приемлемых для приложения значений.
Это наибольшее значение задержки среди всех дисков, используемых ВМ. Измеряет время, необходимое для обработки команды SCSI, которое гостевая ОС предоставила виртуальной машине. Задержка ядра – это время, которое требуется VMkernel для обработки запроса ввода/вывода. Задержка устройства – это время, которое требуется оборудованию для обработки запроса.
Есть прямая зависимость от размера блока ввода/вывода (Write request size и Read request size) с временем задержки, за которое этот блок будет обработан подсистемой хранения.
-
Write request size и Read request size не должны коррелировать с Highest latency.
Важным нюансом этой метрики является то, что vSphere не отображает размеры блока более 512 КБ: вы увидите рост задержек вследствие роста размера блока выше 512 КБ, но при этом не будете видеть рост размера самого блока. Увидеть его можно только через утилиту хоста ESXi vscsiStats.
Подробнее о vscsiStats здесь: https://communities.vmware.com/t5/Storage-Performance/Using-vscsiStats-for-Storage-Performance-Analysis/ta-p/2796805
Здесь можно превратить вывод команды в гистограмму: https://www.virten.net/vmware/vscsistats-grapher/
- Average commands issued per second не должен превышать IOPS Limit.
- Commands aborted и Bus resets должны равняться 0.
- Network
-
Usage не должен достигать предела (vmnic хоста, политик коммутирующего оборудования или маршрутизатора).
Этот параметр отображает объем данных, переданных и полученных всеми виртуальными сетевыми картами, подключенными к виртуальной машине.
- Receive packets dropped и Transmit packets dropped должен равняться 0.
- Packets received и Packets transmitted не должны содержать скачков, коррелирующих с проблемой в разбивке по типам Broadcast, Unicast и Multicast.
-
Проверяем хост из vSphere Client
- Triggered Alarms, Tasks и Events не должны содержать событий, коррелирующих с проблемой.
- CPU
- Usage по всему хосту не должен превышать 80%.
- Ready не должен превышать 10% на ядро (как перевести из summation в проценты подробно читайте тут: https://kb.vmware.com/s/article/2002181).
- Memory
-
Balloned должен равняться 0.
Это сумма значений vmmemctl для всех включенных ВМ и служб vSphere на хосте. Если целевой размер balloon (дословно переводится как «шар») больше, чем текущий, VMkernel «раздувает» balloon внутри ВМ, в результате чего освобождается больше памяти хоста. Если целевой размер balloon меньше, чем текущий, VMkernel «сдувает» balloon, что позволяет процессам внутри ВМ при необходимости использовать больше памяти. Подробнее про ballooning тут: https://docs.vmware.com/en/VMware-vSphere/8.0/vsphere-resource-management/GUID-2B1086F3-B3F5-426C-9162-3C3CDD23A5DF.html
-
Swap consumed должен быть равен 0.
Это объем памяти, которая используется для подкачки всех включенных ВМ и служб vSphere на хосте.
-
Page-fault latency должно равняться 0.
Это время ожидания виртуальной машиной доступа к сжатой памяти или файлу подкачки.
-
- Storage adapter
- Write rate и Read rate не должны превышать пропускную способность vmhba, коммутирующего оборудования до хранилища или пропускной способности хранилища.
-
Write latency и Read latency должны примерно равняться по всем активным vmhba.
Если какая-то из vmhba сильно выбивается по задержкам или нагрузке, то следует удостовериться, что политика мультипасинга выставлена корректно. Подробнее о политиках тут: https://kb.vmware.com/s/article/1011340. Большинство современных хранилищ позволяют применять политику Round Robin. После проверки политики стоит обратить внимание на качество соединения.
- Network
-
Usage не должен превышать пределов vmnic
Это суммарный объем данных, которые передают и получают все физические сетевые карты, подключенные к хосту.
- Receive packets dropped и Transmit packets dropped должны равняться 0.
- Packets received и Packets transmitted недолжны содержать скачков, коррелирующих с проблемой в разбивке по типам Broadcast, Unicast и Multicast.
-
Часть 2. Расширенная проверка
Если результаты базовой проверки не указали на главную причину проблем с производительностью, делаем расширенную проверку.
Проверяем ВМ и хост
Здесь большая часть метрик берется из утилиты хоста ESXi esxtop. Очень кстати вывод esxtop можно записывать в csv-файл. Формат csv позволяет открыть его, к примеру, в PerfMon на Windows и проанализировать не только мгновенные значения, но и их изменение во времени.
Запись одной тысячи точек с шагом раз в две секунды можно выполнить так:
esxtop -a -b -d 2 -n 1000 > esxtop-output.csv- Должны отсутствовать ошибки в vmware.log ВМ, vmkernel.log хоста, в журнале IPMI хоста и во внешних системах журналирования по объектам, релевантным проблеме.
- CPU в esxtop (клавиша ‘c’)
-
CPU load average не должен превышать 1.
Это среднее арифметическое значение загрузки CPU за 1 минуту, 5 минут и 15 минут, основанное на 6-секундных выборках.
-
%USED не должен превышать 90 на ядро.
Это процент физического процессорного времени, приходящийся на world. В эту величину входит метрика %RUN, обозначающая процент времени, когда world вычислялся на физическом CPU. Дополнительно сюда засчитывается %SYS, обозначающая процент времени, при котором VMkernel обрабатывал прерывания и выполнял иные системные действия для данного world. Метрика же %OVRLP вычитается из данной и отражает процент времени, которое world провел в очереди на выполнение, ожидая завершения системных действий в отношении других world.
%USED = %RUN + %SYS — %OVRLP.
-
%RDY не должен превышать 10.
Это процент времени, в течение которого world был готов к запуску.
Поясню: world, который стоит в очереди, ожидает, пока планировщик разрешит ему запуск на физическом CPU. %RDY – процент от этого времени, поэтому он всегда меньше 100%.
Если в настройках ресурсов ВМ установлен CPU Limit, то планировщик не станет размещать ВМ на физическом CPU, когда она израсходует выделенный ей ресурс CPU. Это может произойти даже при наличии большого количества свободных тактов CPU. Время, в течение которого планировщик намеренно удерживает ВМ, отображается в параметре %MLMTD, который мы опишем дальше. Обратите внимание, что параметр %RDY включает в себя %MLMTD. Для определения задержки процессора мы будем использовать формулу: %RDY – %MLMTD. Поэтому, если показатель %RDY – %MLMTD высокий, например больше 10%, вы можете столкнуться с проблемой нехватки мощностей CPU.
Рекомендуемый порог зависит от обстоятельств. Для пробы можно начать с 10%. Если скорость работы приложения в ВМ в порядке, то оставьте порог как есть. В противном случае – снизьте порог.
Закономерный вопрос: а что составляет 100% времени?
World может находиться в разных состояниях: он запланирован к запуску, готов к запуску, но не запланирован, или не готов к запуску, то есть ожидает какое-либо событие.
100% = %RUN + %RDY + %CSTP + %WAIT.
-
%CSTP не должен превышать 3.
Это процент времени, в течение которого world находится в состоянии co-schedule. Состояние co-schedule применимо только для многопроцессорных виртуальных машин. Планировщик CPU ESXi намеренно переводит виртуальный CPU в это состояние, если этот виртуальный CPU опережает в вычислениях другие виртуальные CPU данной ВМ.
Высокий показатель %CSTP означает, что ВМ неравномерно использует виртуальные CPU. Приложение использует CPU с высоким %CSTP внутри ВМ гораздо чаще, чем остальные её CPU.
-
%MLMTD должен равняться 0.
Это процент времени, в течение которого world был готов к запуску, но не запущен планировщиком из-за настроек CPU Limit.
Обратите внимание, что параметр %MLMTD уже учтен в расчете %RDY. Показатель %MLMTD высок, когда ВМ не может быть запущена из-за настройки CPU Limit. Если вы хотите повысить производительность этой ВМ, то увеличьте этот лимит. В целом, использование CPU Limit не рекомендуется.
-
%SWPWT должен равняться 0.
Это процент времени, в течение которого world ожидает, пока VMkernel завершит подкачку памяти. Время %SWPWT (ожидание подкачки) включено в %WAIT.
-
- Memory в esxtop (клавиша ‘m’)
- Memory хоста в состоянии High. Про memory state подробно написано здесь: https://www.yellow-bricks.com/2015/03/02/what-happens-at-which-vsphere-memory-state/.
-
MCTLSZ должен равняться 0.
Это объем гостевой физической памяти, перераспределенной balloon-драйвером.
Высокий показатель MCTLSZ означает, что много гостевой физической памяти этой виртуальной машины «украдено», чтобы уменьшить нагрузку на память хоста.
Как тогда узнать, что виртуальная машина работает в режиме ballooning? Если показатель MCTLSZ изменяется, balloon-драйвер активно освобождает память хоста, раздувая «шар памяти» в ВМ. Скорость ballooning в краткосрочной перспективе можно оценить по изменению MCTLSZ в какую-либо сторону.
-
SWCUR должно равняться 0.
Это общее количество мегабайт подкачки, которые используются в файле vswp ВМ или в системном файле подкачки, а также миграционном файле подкачки. ВМ в состоянии vMotion использует миграционный файл подкачки для удержания выгруженной памяти на целевом узле, если целевому узлу не хватает памяти.
Для ВМ это текущий объем гостевой физической памяти, выгруженной в зарезервированное хранилище. Обратите внимание, что эта статистика относится к своппингу VMkernel, а не к своппингу гостевой ОС внутри ВМ.
Высокий показатель SWCUR у ВМ означает, что гостевая физическая память ВМ находится не в оперативной памяти, а на диске. .
-
N%L должен быть больше 80.
Это процент объема виртуальной памяти ВМ, который находится в локальной для её виртуальных CPU NUMA Node. Низкий процент N%L означает, что, с высокой вероятностью, какие-то запросы виртуальных процессоров ВМ используют данные оперативной памяти ВМ через межпроцессорное соединение.
Подробнее об этом можно почитать в цикле статей от Frank Denneman: https://frankdenneman.nl/2016/07/06/introduction-2016-numa-deep-dive-series/.
- Disk ВМ в esxtop (клавиша ‘v’)
- LAT/rd и LAT/wr не должны превышать приемлемых для приложения значений.
- CMDS/s не должен достигать IOPS Limit.
- MBREAD/s + MBWRTN/s не должна достигать пределов vmhba.
- Disk Adapter в esxtop (клавиша ‘d’)
-
QAVG/cmd должно быть около 0 и не превышать KAVG/cmd.
Это среднее время ожидания в очереди.
QAVG должен входить в KAVG. Но при проблемах с физическим устройством или соединительными линиями QAVG может превышать KAVG. Если показатель QAVG высокий, то следует обратить внимание на глубину очередей на каждом уровне стека хранения.
-
GAVG/cmd, KAVG/cmd и DAVG/cmd не должны превышать приемлемые значения для данного хранилища данных.
- GAVG – это круговая задержка для всех запросов ввода/вывода, которые гостевая система отправляет на виртуальное устройство хранения. Параметр GAVG = KAVG + DAVG.
-
KAVG – этот параметр отслеживает задержки, связанные с работой VMkernel.
Значение KAVG должно быть намного меньше значения DAVG и близко к нулю. Когда в ESXi много очередей, KAVG может быть таким же высоким или даже выше, чем DAVG. Если это произошло, проверьте статистику очередей и лимиты политики хранения или виртуального диска.
-
DAVG – это задержка, наблюдаемая на уровне драйвера устройства. Она включает в себя время приема-передачи между HBA и хранилищем.
DAVG – хороший индикатор производительности хранилища. Если есть подозрения, что задержки ввода/вывода являются причиной проблем с производительностью, то следует проверить DAVG. Сравните задержки ввода/вывода с соответствующими данными из массива. Если они сходятся, проверьте массив на предмет неправильной конфигурации или неисправностей. Если нет, то сравните DAVG с соответствующими данными из точек между массивом и сервером ESXi, например, FC-коммутаторов. Если эти промежуточные данные также совпадают со значениями DAVG, вероятно, приложению не хватает ресурсов для корректной работы в этом хранилище. В таких случаях может помочь добавление накопителей или изменение уровня RAID.
- MBREAD/s + MBWRTN/s не должна достигать пределов vmhba.
-
FCMDS/s, ABRTS/s, RESETS/s должны равняться 0.
- FCMDS/s – это количество команд в секунду, завершившихся ошибкой. Может указывать на проблемы с контроллером хранения, состоянием соединения до хранилища или непосредственно с хранилищем.
- ABRTS/s – это количество прерванных команд в секунду. Параметр может указывать на то, что система хранения данных не удовлетворяет требованиям гостевой ОС. Гостевая система прерывает обработку команды, если хранилище не отвечает в течение приемлемого времени (может быть настроено в гостевой ОС, в том числе и в результате установки VMware Tools). Кроме того, гостевая ОС может прервать все команды, выполняемые на ее виртуальном SCSI-адаптере.
- RESETS/s – это количество сброшенных команд в секунду. Указывает на число отброшенных команд в результате сброса состояния адаптера. Сброс может быть вызван драйвером как реакция на какие-либо события в сети хранения данных.
-
- FC
- Вывод команды
esxcli storage san fc stats getне должен содержать ошибок. - Мониторинг портов сети хранения данных не должен содержать ошибок.
- Вывод команды
- Disk device в esxtop (клавиша ‘u’)
- QAVG/cmd должно быть около 0 и не превышать KAVG/cmd.
- KAVG/cmd должно быть около 0.
- DAVG/cmd, GAVG/cmd не должны превышать приемлемых для приложения значений.
-
DQLEN должен быть более 32 (кроме устройств USB и CDROM).
Глубина очереди (queue depth) – одна из ключевых характеристик подсистемы ввода/вывода, особенно в виртуализации, где требуется высокий параллелизм операций. Глубина очереди определяет число команд ввода/вывода, которые подсистема может осуществлять одновременно. На глубину очереди влияют протоколы, аппаратные возможности устройств, прошивки и драйверы.
Регулируется, как минимум, в следующих местах:
- в драйвере HBA глобально на хост: https://kb.vmware.com/s/article/1267
- на каждом LUN есть два параметра: https://kb.vmware.com/s/article/1268
- Device Max Queue Depth наследуется от Queue Depth драйвера HBA (предыдущий шаг). Однако может быть занижено такими технологиями, как SIOCv1 (включается в vSphere Client на Datastore) и Adaptive Queue Depth (подробнее тут: https://kb.vmware.com/s/article/1008113), которая включается расширенными настройками QFullSampleSize и QFullThreshold.
- No of outstanding IOs with competing worlds (DSNRO) по умолчанию равняется 32. Это глубина очереди к LUN, если с ним одновременно работают более одной ВМ.
- на контроллере и диске ВМ: https://kb.vmware.com/s/article/2053145.
Важно: если параллелизм операций с хостов ESXi превысит допустимый параллелизм нижележащих HBA, SAN или СХД, то есть совокупная глубина очереди выполняемых в настоящий момент операций ВМ превысит глубину очереди инфраструктуры, то хост будет получать SCSI-примитивы QFULL или BUSY, и в журнале vmkernel.log будут регистрироваться такие события:
- H:0x0 D:0x28 P:0x0 Valid sense data: 0x## 0x## 0x##
- H:0x0 D:0x08 P:0x0 Valid sense data: 0x## 0x## 0x##
- H:0x0 D:0x8 P:0x0 Valid sense data: 0x## 0x## 0x##
-
QUED должно равняться 0.
Это количество команд VMkernel, которые находятся в очереди. Статистика применима только к world и LUN.
Большое количество команд в очереди может быть признаком того, что система хранения перегружена. Постоянно высокое значение счетчика QUED сигнализирует об узком месте (bottleneck, дословно – «бутылочное горлышко») в системе хранения, которое в некоторых случаях можно устранить, увеличив глубину очереди. После увеличения глубины очереди проверьте, что LOAD меньше 1. Это должно увеличить количество обработанных команд в секунду и повысить производительность.
-
%USD не должно превышать 60.
Это процент глубины очереди, используемой активными командами VMKernel. Эта статистика применима только к world и LUN.
%USD = ACTV / QLEN * 100%
Чтобы рассчитать статистику по world, в качестве знаменателя используйте WQLEN. Для статистики LUN (устройства) в качестве знаменателя используйте LQLEN.
%USD показывает, сколько доступных слотов очереди команд задействованы. Высокие значения говорят о возможности образования очередей. Тогда вам потребуется настроить глубину очередей для HBA, если QUED также постоянно больше 1. Размеры очередей можно настроить в нескольких местах на пути ввода/вывода. Это помогает смягчить проблемы с производительностью, вызванные большими задержками.
- FCMDS/s, ABRTS/s, RESETS/s должны равняться 0.
-
ATSF должен быть значительно меньше ATS.
Примитив VAAI Atomic Test and Set позволяет ускорить ряд операций с подсистемой хранения. Ниже приведены две статьи, подробно объясняющие каждую операцию. Множество неудавшихся операций ATS могут стать причиной проблем в работе подсистемы хранения.
Про ATS heartbeat: https://kb.vmware.com/s/article/2113956.
Про ATS lock: https://kb.vmware.com/s/article/2146451.
- Политика мультипасинга должна быть рекомендована вендором СХД.
- No of outstanding IOs with competing worlds (DSNRO) должно равняться Queue Depth.
- Network в esxtop (клавиша ‘n’)
-
MbTX/s, MbRX/s не должны превышать vmnic.
Это мегабиты, передаваемые (MbTX) или принимаемые (MbRX) в секунду.
В зависимости от рабочей нагрузки MbRX/s может не совпадать с PKTRX/s, потому что размер пакетов может быть разным. Средний размер пакета можно рассчитать по формуле: средний размер пакета = MbRX/s / PKTRX/s. Увеличение размера пакетов может повысить эффективность обработки пакетов процессором. Однако потенциально это также может увеличить задержку.
-
%DRPTX, %DRPRX должны равняться 0.
%DRPTX – это процент потерянных исходящих пакетов.
%DRPTX = потерянные исходящие пакеты / (успешно отправленные исходящие пакеты + потерянные исходящие пакеты).
Высокое значение %DRPTX обычно указывает на проблемы с отправкой данных. Проверьте, полностью ли используются возможности физических сетевых карт. Возможно, нужно заменить сетевые карты на карты с лучшей производительностью. Или вы можете подключить еще несколько сетевых карт и настроить политику балансировки нагрузки, чтобы равномерно распределить нагрузку по всем картам.
%DRPRX – это процент потерянных входящих пакетов. Вычисляется по формуле: %DRPRX = потерянные входящие пакеты / (успешные принятые входящие пакеты + потерянные входящие пакеты).
Высокое значение %DRPRX обычно указывает на проблемы с приемом входящего трафика. Стоит выделить больше ресурсов CPU для затронутой ВМ или увеличить размер ring buffer.
-
- Network
- Вывод команды
esxcli network nic stats get -n vmnicXне должен содержать ошибок. -
Статистика релевантных портов vsish не должна содержать ошибок и дропов.
Бывает так, что ВМ испытывает резкие скачки входящего трафика, способные переполнить Rx Ring Buffers. Расследовать такие ситуации можно, выяснив PORT-ID сетевой карточки ВМ через раздел network утилиты esxtop или командой
esxcli network vm list-> посмотреть World ID нужной ВМ ->esxcli network vm port list -w <World ID>.Затем в vsish:
cd/net/portsets/<vSwitch-NAME>/ports/<PORT-ID>/ cat stats packet stats { pktsTx:823080899 pktsTxMulticast:18571 pktsTxBroadcast:1908 pktsRx:961804917 pktsRxMulticast:48602 pktsRxBroadcast:1947286 droppedTx:0 droppedRx:27314 }Ненулевое значение droppedRx может означать превышение Rx Ring Buffers. Расследуем дальше:
cd /net/portsets/vSwitch0/ports/<PORT-ID>/vmxnet3 cat rxSummary stats of a vmxnet3 vNICrx queue { ... 1st ring size:1024 2nd ring size:64 # of times the 1st ring is full:349 # of times the 2nd ring is full:0 ... }Здесь мы видим размеры ring buffers и сколько раз они были переполнены. Ненулевое значение – хороший повод увеличить ring size. Там же есть директория rxqueues, в которой может быть одна или более поддиректорий. Если включена NetQueue или RSS, то в данных директориях можно посмотреть статистику каждой очереди по отдельности.
- Вывод команды arp-scan подсети не должен содержать дубликатов IP и MAC-адресов.
- Запись трафика в момент воспроизведения проблемы не должна содержать аномалий. Об этом подробнее тут: https://docs.vmware.com/en/VMware-vSphere/8.0/vsphere-networking/GUID-C1CEBDDF-1E6E-42A8-A026-0C067DD16AE7.html.
- Вывод команды
В этой статье был приведен список ключевых точек для исследования при поиске проблем с производительностью ВМ и их краткое описание. Если требуется более глубокое погружение в материал, то рекомендуем обратиться к циклу наших прошлых статей по данной теме:
- Анализ производительности ВМ в VMware vSphere. Часть 1: CPU
- Анализ производительности ВМ в VMware vSphere. Часть 2: Memory
- Анализ производительности ВМ в VMware vSphere. Часть 3: Storage