Размер шрифта:
Шрифт:
Известно, что участники проекта программного изделия (ПИ) в ходе его выполнения всегда допускают ошибки [1]. Допустимое количество ошибок в проекте ПИ зависит от уровня качества разработки, от размера нового кода ПИ и уровня качества поставляемого ПИ [2]. Часть допущенных ошибок в проекте ПИ находится и устраняется на фазах жизненного цикла разработки ПИ во время проведения плановых обзоров продуктов проекта [3], а оставшаяся часть ошибок превращается в дефекты разработки, которые переходят в дефекты программного кода ПИ и дефекты сопровождающей этот код документации (переходят в дефекты ПИ).
 Для обнаружения оставшихся в ПИ дефектов с целью их последующего устранения сами разработчики подвергают ПИ нескольким видам тестирования [5]: модульному, интеграционному и тестированию работоспособности. Эти виды тестирования предназначены для отладки сборки версии ПИ и подтверждения соответствия отлаженной версии ПИ спецификациям функционального проектирования. В литературе процесс модульного, интеграционного тестирования и тестирования работоспособности называют верификацией ПИ.
Для обнаружения оставшихся в ПИ дефектов с целью их последующего устранения сами разработчики подвергают ПИ нескольким видам тестирования [5]: модульному, интеграционному и тестированию работоспособности. Эти виды тестирования предназначены для отладки сборки версии ПИ и подтверждения соответствия отлаженной версии ПИ спецификациям функционального проектирования. В литературе процесс модульного, интеграционного тестирования и тестирования работоспособности называют верификацией ПИ.
ПИ также подвергают системному тестированию. Этот вид тестирования используют для подтверждения работоспособности поставляемого ПИ и его соответствия требованиям заказчика. Системное тестирование, как правило, выполняет специальная группа системного тестирования. Процесс системного тестирования в литературе часто называют валидацией ПИ.
Рассмотрим более подробно процесс обнаружения дефектов во время проведения всех видов тестирования. Для этого обратимся к рисункам 1 и 2.
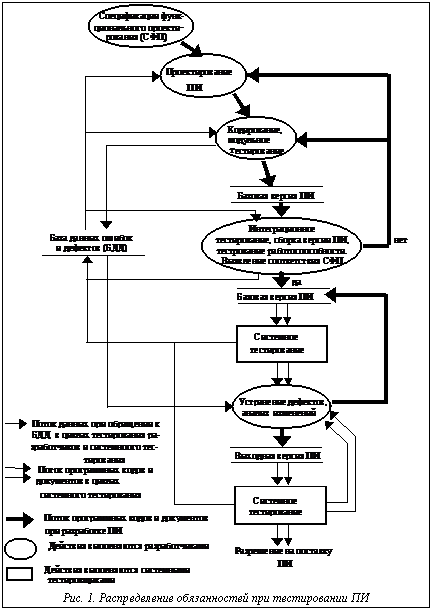
На рисунке 1 представлено распределение обязанностей между разработчиками ПИ и системными тестировщиками во время тестирования ПИ, принятое в АОЗТ ИДУ.
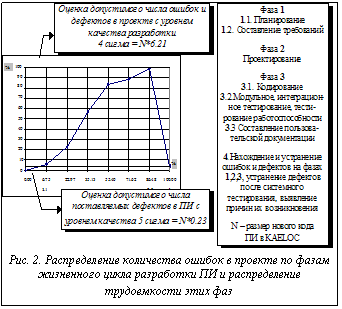
На рисунке 2 представлено распределение трудоемкости отдельных фаз жизненного цикла разработки ПИ и распределение количества ошибок, которое допускают участники проекта на этих фазах. Распределения получены на реальных данных АОЗТ ИДУ [2]. График представлен для случая выполнения разработки ПИ с уровнем качества 4 сигма и уровнем качества поставляемого ПИ 5 сигма [6].
По оси абсцисс последовательно отложены трудоемкости (в %) фаз жизненного цикла разработки ПИ (без учета фазы «Системное тестирование»). Отдельно выделен этап 4. Трудоемкость этапа 4 представляет собой сумму трудоемкости выявления и устранения ошибок в проекте; выявления и устранения некоторого числа, необязательно всех дефектов на каждой из фаз разработки ПИ (модульное и интеграционное тестирование, тестирование работоспособности); устранения всех дефектов, обнаруженных в процессе системного тестирования.
Трудоемкость выявления ошибок на фазах 1, 2, 3 представляет собой сумму трудоемкости проведения обзоров продуктов проекта, трудоемкости выявления и анализа причин возникновения ошибок в прошлом и трудоемкости по выработке мер для устранения обнаруженных причин возникновения ошибок в будущем.
По оси ординат графика отложены значения оценок допустимого на различных фазах разработки ПИ числа ошибок (в % от величины оценки допустимого количества ошибок в проекте) – возрастающая часть графика – и оценка количества обнаруженных и устраненных ошибок и дефектов на тех же фазах – нисходящая часть графика.
Первым видом тестирования, которому подвергается ПИ разработчиками (рис. 1), является модульное тестирование. Вероятность обнаружения дефектов в модулях достаточно велика, поскольку ошибок и дефектов еще много (рис. 2). После завершения модульного тестирования, когда устранены все обнаруженные дефекты в тестируемых программных модулях, вероятность присутствия каждого из оставшихся дефектов в модулях повышается. Однако вероятность обнаружения оставшихся дефектов в ПИ на этапе интеграционного тестирования за счет уменьшения их коли-чества меньше, чем на этапе модульного тестирования.
Тестирование работоспособности ПИ является заключительным этапом отладки (рис. 1) и предназначено для выяснения работоспособности ПИ и соответствия его спецификациям проектирования (осуществляется окончательная верификация ПИ). При этом вероятность обнаружения оставшихся дефектов меньше, чем на этапе интеграционного тестирования, также за счет уменьшения их числа в программном коде.
 После завершения отладки базовой версии ПИ (рис. 1) в ней, как правило, устранены все обнаруженные дефекты. Вероятность присутствия каждого из оставшихся дефектов в отлаженной базовой версии ПИ, передаваемой на системное тестирование, увеличивается по сравнению с вероятностью присутствия каждого дефекта в сборке ПИ на этапе ее отладки. Однако вероятность обнаружения дефектов в ней уменьшается.
После завершения отладки базовой версии ПИ (рис. 1) в ней, как правило, устранены все обнаруженные дефекты. Вероятность присутствия каждого из оставшихся дефектов в отлаженной базовой версии ПИ, передаваемой на системное тестирование, увеличивается по сравнению с вероятностью присутствия каждого дефекта в сборке ПИ на этапе ее отладки. Однако вероятность обнаружения дефектов в ней уменьшается.
Теоретически это происходит потому, что дефекты, присутствующие в ПИ, сколько бы их ни было, можно рассматривать как случайные несовместные события, составляющие полную группу [6]. Таким образом, сумма вероятностей присутствия оставшихся дефектов в сборке ПИ всегда равна единице:
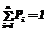 , (1)
, (1)
где Pi – вероятность присутствия i-го оставшегося дефекта в сборке ПИ; n – число оставшихся дефектов.
Несовместность оставшихся в ПИ дефектов как случайных событий заключается в том, что на одной позиции программного кода или сопроводительной документации ПИ может проявиться случайное событие только в виде одного дефекта. А полную группу составляют случайные события (оставшиеся дефекты), потому что при проведении опыта, который заключается в установлении факта присутствия дефекта на какой-либо позиции из всех позиций программного кода или сопроводительной документации ПИ, с вероятностью единица такой факт будет установлен.
Как следует из рисунка 2, после модульного тестирования 0.23N<< n <6.21N, а после интеграционного тестирования и тестирования работоспособности число оставшихся дефектов в ПИ становится меньше этого значения. Поэтому вероятность обнаружения любого из оставшихся дефектов в сборке ПИ на этапе системного тестирования меньше, чем на этапе отладки. И эта вероятность тем меньше, чем меньше осталось дефектов в сборке ПИ после ее отладки:
 (2)
(2)
где Pk – вероятность обнаружения одного оставшегося дефекта в сборке ПИ на этапе системного тестирования; Pi – вероятность присутствия i-го оставшегося дефекта в сборке ПИ, переданной для проведения системного тестирования; n – число оставшихся дефектов в сборке ПИ, переданной для проведения системного тестирования, 0.23N> n (рис. 2).
Из соотношения (2) видно, что при проведении модульного тестирования, когда в программном коде еще много невыявленных дефектов, вероятность обнаружения любого из них достаточно велика. Кроме того, количество дефектов в модуле при заданном его качестве пропорционально размеру его программного кода. Поэтому при малом размере программного кода модуля (рис. 2) возможно выявление всех присутствующих в нем дефектов.
 Соотношение (2) показывает также, что с увеличением числа обнаруженных при системном тестировании дефектов вероятность обнаружения оставшихся в ПИ дефектов уменьшается (это справедливо для ПИ большого размера – сотни и тысячи KELOC). Когда в сборке ПИ в результате системного тестирования остается очень мало дефектов (n < 0.23N), сумма вероятностей их присутствия в сборке все равно равна единице, а вероятность обнаружения любого из них близка к нулю. Поэтому практически невозможно выявить все дефекты в тестируемом ПИ, а системное тестирование выполняется циклически, и для принятия решения об окончании системного тестирования используют специальные критерии [4].
Соотношение (2) показывает также, что с увеличением числа обнаруженных при системном тестировании дефектов вероятность обнаружения оставшихся в ПИ дефектов уменьшается (это справедливо для ПИ большого размера – сотни и тысячи KELOC). Когда в сборке ПИ в результате системного тестирования остается очень мало дефектов (n < 0.23N), сумма вероятностей их присутствия в сборке все равно равна единице, а вероятность обнаружения любого из них близка к нулю. Поэтому практически невозможно выявить все дефекты в тестируемом ПИ, а системное тестирование выполняется циклически, и для принятия решения об окончании системного тестирования используют специальные критерии [4].
Здесь необходимо заметить, что во время системного тестирования для обнаружения дефекта всегда приходится много раз (иногда десятки тысяч раз и более) охватывать тестами весь объем кода ПИ. Это происходит потому, что во время системного тестирования ПИ тестированию подвергаются многие (иногда практически все) пути ветвления программы, а при высокой логической сложности ПИ таких путей может быть десятки и сотни тысяч.
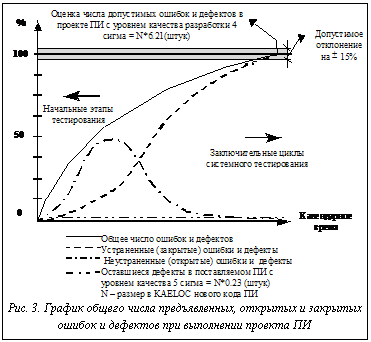
Наш опыт показывает, что для достижения целей системного тестирования, обеспечения высокого качества поставляемого ПИ и эффективного управления процессом обнаружения и устранения ошибок и дефектов в проекте ПИ следует ввести специальные метрики разработки ПИ. В соответствии с рисунком 2 – это число найденных (предъявленных), неустраненных (открытых) и устраненных (закрытых) ошибок и дефектов. Необходимо также обеспечить регулярный сбор этих метрик во время выполнения проекта ПИ с его начала и до его окончания, а по результатам метрических данных строить график (рис. 3).
График целесообразно обновлять еженедельно. При этом следует стремиться к тому, чтобы к окончанию любой фазы жизненного цикла разработки, показанной на рисунке 2, было найдено и закрыто такое количество ошибок и дефектов, которое соответствовало бы метрикам стандартного процесса этой фазы [4].
При управлении проектом ПИ график предоставляет возможность наглядного отслеживания динамики изменения оценки количества оставшихся дефектов в ПИ во время выполнения всех видов тестирования, а также количества оставшихся дефектов в ПИ во время проведения и после завершения системного тестирования. Наличие такой возможности существенно облегчает управление процессом тестирования ПИ и управление качеством ПИ. Кроме того, в этом случае руководство приобретает возможность принятия своевременных мер для достижения требуемого уровня качества поставляемого ПИ, так как отставание от установленных требований по качеству обнаруживается на ранних этапах выполнения проекта ПИ.
В заключение отметим, поскольку во время системного тестирования ПИ большого размера (сотни тысяч KAELOC) вероятность обнаружения последних дефектов очень мала, то для их обнаружения потребуется очень много времени. Поэтому практически нецелесообразно выполнять системное тестирование до победного конца, то есть до обнаружения последнего дефекта. А для определения момента завершения системного тестирования следует использовать специальные критерии, например так, как изложено в [6].
Список литературы
1. Barry W. Boehm. Software Engineering Economics. 1981 by Prentice-Hall, Inc., Englewood Cliffs, N.J. 07632.
2. Баранов С.Н., Домарацкий А.Н., Ласточкин Н.К., Морозов В.П. Предотвращение дефектов при разработке ПИ. //Программные продукты и системы. – 1998. — №2. — С.2-6.
3. Домарацкий А.Н. Управление улучшением стандартного процесса и качеством программных изделий. //Программные продукты и системы. – 1998. — № 4. — С. 20-24.
4. Домарацкий А.Н., Никифоров В.В. Критерии завершения тестирования ПИ. //Там же . — С. 30-33.
5. Myers G.J. The Art of Software Testing. — New York: John Wiley & Sons, 1979. — 177 p.
6. Пугачев В.С. Теория случайных функций. — М.: Гос. изд. физ.-мат. лит., 1960. — 883 с.
Предупреждение,
обнаружение, исправление ошибок,
обеспечение устойчивости к ошибкам.
Тестирование, доказательство, контроль,
испытание, аттестация, отладка.
ПРОВЕРКА
ПРАВИЛЬНОСТИ ПРОГРАММ.
Программу
нельзя использовать до тех пор, пока не
будет уверенности в ее надежности.
Надежность — это свойство программы,
более строгое, чем корректность, поскольку
программа может быть корректной, но не
быть надежной. Программа является
корректной, если удовлетворяет внешним
спецификациям, т.е. выдает ожидаемые
ответы на определенные комбинации
значений входных данных. Программа
является надежной, если она корректна,
приемлемо реагирует на неточные входные
данные и удовлетворительно функционирует
в необычных условиях.
В
процессе создания программы программист
старается предвидеть все возможные
ситуации и написать программу так, чтобы
она реагировала на них вполне
удовлетворительно. Этап тестирования
является последней попыткой определить
надежность и корректность программы.
Проверка надежности включает в себя
просмотр проектной документации и
текста программы, анализ текста программы,
тестирование и, наконец, демонстрацию
заказчику того, что программа работает
надежно.
Все
принципы и методы разработки надежного
программного обеспечения можно разбить
на четыре группы:
1.
Предупреждение ошибок.
2.
Обнаружение ошибок.
3.
Исправление ошибок.
4.
Обеспечение устойчивости к ошибкам.
Предупреждение
ошибок.
К этой группе относятся принципы и
методы, цель которых — не допустить
появление ошибок в готовой программе.
Большинство методов концентрируется
на отдельных процессах перевода и
направлено на предупреждение ошибок в
этих процессах (упрощение программ,
достижение большей точности при переводе,
немедленное обнаружение и устранение
ошибок).
Обнаружение
ошибок.
Если предполагать, что в программном
обеспечении какие-то ошибки все же
будут, то лучшая стратегия в этом случае
— включить средства обнаружения ошибок
в само программное обеспечение.
Немедленное обнаружение имеет два
преимущества: можно минимизировать как
влияние ошибки, так и последующие
затруднения для человека, которому
придется извлекать информацию об этой
ошибке, находить ее место и исправлять.
Исправление
ошибок.
После того, как ошибка обнаружена, либо
она сама, либо ее последствия должны
быть исправлены программным обеспечением.
Некоторые устройства способны обнаружить
неисправные компоненты и перейти к
использованию резервных. Другой метод
— восстановление информации (например,
при сбое питания).
Устойчивость
к ошибкам.
Методы этой группы ставят своей целью
обеспечит функционирование программной
системы при наличии в ней ошибок. Они
разбиваются на три подгруппы: динамическая
избыточность (методы голосования,
резервных копий); методы отступления
(когда необходимо корректно закончить
работу — например, закрыть базу данных);
изоляция ошибок (основная идея — не дать
последствиям ошибки выйти за пределы
как можно меньшей части системы
программного обеспечения, так, чтобы
если ошибка возникнет, то не вся система
оказалась бы неработоспособной).
8.1.
Основные определения.
Тестирование
— процесс выполнения программы с
намерением найти ошибки. Если Ваша цель
— показать отсутствие ошибок, Вы их
найдете не слишком много. Если же Ваша
цель — показать наличие ошибок, Вы найдете
значительную их часть.
Доказательство
— попытка найти ошибки в программе
безотносительно к внешней для программы
среде. Большинство методов доказательства
предполагает формулировку утверждений
о поведении программы и затем вывод и
доказательство математических теорем
о правильности программы. Доказательства
могут рассматриваться как форма
тестирования, хотя они и не предполагают
прямого выполнения программы.
Контроль
— попытка найти ошибки, выполняя программу
в тестовой, или моделируемой, среде.
Испытание
— попытка найти ошибки, выполняя программу
в заданной реальной среде.
Аттестация
— авторитетное подтверждение правильности
программы. При тестировании с целью
аттестации выполняется сравнение с
некоторым заранее определенным
стандартом.
Отладка
— не является разновидностью тестирования.
Хотя слова «отладка» и «тестирование»
часто используются как синонимы, под
ними подразумеваются разные виды
деятельности. Тестирование — деятельность,
направленная на обнаружение ошибок;
отладка направлена на установление
точной природы известной ошибки, а затем
— на исправление этой ошибки. Эти два
вида деятельности связаны — результаты
тестирования являются исходными данными
для отладки.
Тестирование
модуля, или автономное тестирование —
контроль отдельного программного
модуля, обычно в изолированной среде.
Тестирование модуля иногда включает
также математическое доказательство.
Тестирование
сопряжений — контроль сопряжений между
частями системы (модулями, компонентами,
подсистемами).
Тестирование
внешних функций — контроль внешнего
поведения системы, определенного
внешними спецификациями.
Комплексное
тестирование — контроль и испытание
системы по отношению к исходным целям.
Комплексное тестирование является
процессом испытания, если выполняется
в среде реальной, жизненной.
Тестирование
приемлемости — проверка соответствия
программы требованиям пользователя.
Тестирование
настройки — проверка соответствия
каждого конкретного варианта установки
системы с целью выявить любые ошибки,
возникшие в процессе настройки системы.
8.2.
Базовые правила тестирования.
Обсудим
некоторые из важнейших аксиом тестирования.
они приведены в настоящем разделе и
являются фундаментальными принципами
тестирования.
Хорош
тот тест, для которого высока вероятность
обнаружить ошибку, а не тот, который
демонстрирует правильную работу
программы. Поскольку невозможно показать,
что программа не имеет ошибок и, значит,
все такие попытки бесплодны, процесс
тестирования должен представлять собой
попытки обнаружить а программе прежде
не найденные ошибки.
Одна
из самых сложных проблем при тестировании
— решить, когда нужно закончить. Как уже
говорилось, исчерпывающее тестирование
(т.е. испытание всех входных значений)
невозможно. Таким образом, при тестировании
мы сталкиваемся с экономической
проблемой: как выбрать конечное число
тестов, которое дает максимальную отдачу
(вероятность обнаружения ошибок) для
данных затрат. Известно слишком много
случаев, когда написанные тесты имели
крайне малую вероятность обнаружения
новых ошибок, в то время как довольно
очевидные хорошие тесты оставались
незамеченными.
Невозможно
тестировать свою собственную программу.
Ни один программист не должен пытаться
тестировать свою собственную программу.
Тестирование должно быть в высшей
степени разрушительным процессом, но
имеются глубокие психологические
причины, по которым программист не может
относится к своей программе как
разрушитель.
Необходимая
часть всякого теста — описание ожидаемых
выходных данных или результатов. Одна
из самых распространенных ошибок при
тестировании состоит в том, что результаты
каждого теста не прогнозируются до его
выполнения. Ожидаемые результаты нужно
определять заранее, чтобы не возникла
ситуация, когда «глаз видит то, что
хочет увидеть». Чтобы совсем исключить
такую возможность, лучше разрабатывать
самопроверяющиеся тесты, либо пользоваться
инструментами тестирования, способными
автоматически сверять ожидаемые и
фактические результаты.
Избегайте
невоспроизводимых тестов, не тестируйте
«с лету». В условиях диалога
программист слишком часто выполняет
тестирование «с лету», т.е., сидя за
терминалом, задает конкретные значения
и выполняет программу, чтобы посмотреть,
что получится. Это -неряшливая и
нежелательная форма тестирования.
Основной ее недостаток в том, что такие
тесты мимолетны; они исчезают по окончании
их выполнения. Никогда не используйте
тестов, которые тут же выбрасываются.
Готовьте
тесты как для правильных, так и для
неправильных входных данных. Многие
программисты ориентируются в своих
тестах на «разумные» условия на
входе, забывая о последствиях появления
непредусмотренных или ошибочных входных
данных. Однако многие ошибки, которые
потом неожиданно обнаруживаются в
работающих программах, проявляются
вследствии никак не предусмотренных
действий пользователя программы. Тесты,
представляющие неожиданные или
неправильные входные данные, часто
лучше обнаруживают ошибки, чем «правильные»
тесты.
Детально
изучите результаты каждого теста. Самые
изощренные тесты ничего не стоят, если
их результаты удостаиваются лишь беглого
взгляда. Тестирование программы означает
большее, нежели выполнение достаточного
количества тестов; оно также предполагает
изучение результатов каждого теста.
По
мере того как число ошибок, обнаруженных
в некоторой компоненте программного
обеспечения увеличивается, растет также
относительная вероятность существования
в ней необнаруженных ошибок. Этот феномен
наблюдался во многих системах. Его
понимание способно повысить качество
тестирования, обеспечивая обратную
связь между результатами прогона тестов
и их проектированием. Если конкретная
часть системы окажется при тестировании
полной ошибок, для нее следует подготовить
дополнительные тесты.
Поручайте
тестирование самым способным программистам.
Тестирование, и в особенности проектирование
тестов, — этап в разработке программного
обеспечения, требующий особенно
творческого подхода. К сожалению, во
многих организациях на тестирование
смотрят совсем не так. Его часто считают
рутинной, нетворческой работой. Однако
практика показывает, что проектирование
тестов требует даже больше творчества,
чем разработка архитектуры и проектирование
программного обеспечения.
Считайте
тестируемость ключевой задачей Вашей
разработки. Хотя «тестируемость»
и не фигурировала явно в «проектных»
главах, сложность тестирования программы
напрямую зависит от ее структуры и
качества проектирования. Несмотря на
то, что эта связь осознана еще недостаточно
глубоко, можно утверждать, что многие
характеристики хорошего проекта
(например, небольшие, в значительной
степени независимые модули и независимые
подсистемы), улучшают и тестируемость
программы.
Никогда
не изменяйте программу, чтобы облегчить
ее тестируемость. Часто возникает
соблазн изменить программу, чтобы было
легче ее тестировать. Например,
программист, тестируя модуль, содержащий
цикл, который должен повторяться 100 раз,
меняет его так, чтобы цикл повторялся
только 10 раз.
8.3.
Отладка.
Рекомендуемый
подход к методам отладки аналогичен
особенностям проектирования и включает
в себя следующие этапы:
1.
Поймите задачу. Многие программисты
начинают процесс отладки бессистемно,
пропуская жизненно важный этап детального
анализа имеющихся данных. Первым делом
нужно тщательно исследовать, что в
программе выполнено правильно, а что —
неправильно, чтобы выработать одну или
несколько гипотез о природе ошибки.
Одна из самых распространенных причин
затруднений при отладке — не учтен
какой-нибудь существенный фактор в
выходных данных программы. Важно
исследовать данные в поисках противоречий
гипотезе (например, ошибка возникает
только в каждой второй записи), потому
что это поведет к уточнению гипотезы
или, возможно, покажет, что имеется не
одна причина ошибки.
2.
Разработайте план. Следующий шаг —
построить одну или несколько гипотез
об ошибке и разработать план проверки
этих гипотез.
3.
Выполните план. Следуя своему плану,
пытайтесь доказать гипотезу. Если план
включает несколько шагов, нужно проверить
каждый.
4.
Проверьте решение. Если кажется, что
точное местоположение ошибки обнаружено,
необходимо выполнить еще несколько
проверок, прежде чем пытаться исправить
ошибку. Проанализируйте, может ли
предполагаемая ошибка давать в точности
известные симптомы. Убедитесь, что
найденная причина полностью объясняет
все симптомы, а не только их часть.
Проверьте, не вызовет ли ее исправление
новой ошибки.
Главная
причина затруднений при отладке — такая
психологическая установка, когда разум
видит то, что он ожидает увидеть, а совсем
не то, что имеет место в действительности.
Один из способов преодоления такой
установки — скептицизм в отношении
всего, что Вы изучаете, в особенности
комментариев и документации. Опытные
специалисты по отладке, изучая модуль,
часто закрывают комментарии, поскольку
комментарии нередко описывают, что
программа делает, по мнению ее создателя.
Обратный просмотр (чтение программы в
обратном направлении) — еще один полезный
тактический прием, поскольку он помогает
по-новому взглянуть на алгоритм.
Еще
одна трудность при отладке — такое
состояние, когда все идеи зашли в тупик
и найти местоположение ошибки кажется
просто невозможно. Это означает, что Вы
либо смотрите не туда, куда нужно, и
следует еще раз изучить симптомы и
построить новую гипотезу, либо подозрения
правильные, но разум уже не способен
заметить ошибку. Если кажется, что именно
так и есть , то лучший принцип — «утро
вечера мудренее». Переключите внимание
на другую деятельность, и пусть над
задачей работает Ваше подсознание.
Многие программисты признают, что самые
трудные свои задачи они решают во время
бритья или по дороге на работу.
Когда
Вы найдете и проверите ошибку и убедитесь
в том, что нашли ее правильно, не забудьте
о том, что вероятность других ошибок в
этой части программы теперь выше. Изучите
программу в окрестности найденной
ошибки в поисках новых неприятностей.
Проверьте, не была ли сделана такая же
ошибка в других местах программы.
Исследования
методов отладки вначале концентрировались
на сравнении отладки в пакетном и
диалоговом режимах, причем большинство
исследований приходило к выводу, что
диалоговый режим предпочтительнее.
Однако более поздняя работа показала,
что, вероятно, наилучший способ отладки
— просто читать программу и изо всех сил
стараться вникнуть в алгоритм, хотя это
требует усердия и собранности.
Важно
подчеркнуть, что многие из методов
проектирования помогают и в процессе
отладки, такие методы, как структурное
программирование и хороший стиль
программирования не только уменьшают
исходное количество ошибок, но и облегчают
отладку, делая программу более простой
для понимания.
После
того, как точно установлено, где находится
ошибка, надо ее исправить. Самая большая
трудность на этом шаге — суметь охватить
проблему целиком; самая распространенная
неприятность — устранить только некоторые
симптомы ошибки. Избегайте «экспериментальных»
исправлений; они показывают, что Вы еще
недостаточно подготовлены к отладке
этой программы, поскольку не понимаете
ее.
В
деле исправления ошибок очень важно
понимать, что оно возвращает нас назад,
к стадии проектирования. Обидно, если
после завершения хорошо организованного
проектирования весь его строгий порядок
нарушается, когда вносятся поправки.
Исправления должны выполняться по
крайней мере так же строго, как
первоначальное выполнение программы.
Если необходимо, следует обновить
документацию, поправки должны проходить
сквозной структурный контроль или
другие формы контрольного чтения
программы. Ни одна поправка не «мала»
настолько, чтобы не нуждаться в
тестировании.
По
самой своей природе исправления всегда
имеют некоторое отрицательное влияние
на структуру программы и легкость ее
чтения. Тот факт, что они делаются в
условиях жесткого давления, усиливает
это влияние. Опыт показывает, что при
исправлении довольно высока вероятность
внесения в программу новой ошибки
(обычно от 20 до 50).
Из этого следует, что отладка должна
выполняться лучшими программистами
проекта.
Изучение
процесса отладки.
Один
из лучших способов повысить надежность
программного обеспечения в нынешних
или в будущих проектах — очевидный, но
часто упускаемый из виду процесс обучения
на сделанных ошибках. Каждую ошибку
следует внимательно изучить, чтобы
понять, почему она возникла и что должно
было бы сделано, чтобы ее предотвратить
или обнаружить раньше. Редко можно
встретить программиста или организацию,
которые выполняли бы такой полезный
анализ, а когда он проводится, то обычно
имеет поверхностный характер и сводится,
например, к классификации ошибок: ошибки
проектирования, логические ошибки,
ошибки сопряжения или другие, не имеющие
особого смысла категории.
Нужно
уделять время изучению природы каждой
обнаруженной ошибки. Необходимо
подчеркнуть, что анализ ошибок должен
быть в значительной мере качественным
и не сводиться просто к упражнению в
количественном подсчете. Чтобы понять
причины , лежащие в основе ошибок, и
усовершенствовать процессы проектирования
и тестирования, нужно ответить на
следующие вопросы:
1.
Почему возникла именно такая ошибка? В
ответе должны быть указаны как
первоисточник, так и непосредственный
источник ошибки. Например, ошибка могла
быть сделана при программировании
конкретного модуля, но в ее основе могла
лежать неоднозначность в спецификациях
или исправление другой ошибки.
2.
Как и когда ошибка была обнаружена?
Поскольку мы только что добились
значительного успеха, почему бы нам не
воспользоваться приобретенным опытом?
3.
Почему эта ошибка не была обнаружена
при проектировании, контроле или на
предыдущей фазе тестирования?
4.
Что следовало сделать при проектировании
или тестировании, чтобы предупредить
появление этой ошибки или обнаружить
ее раньше?
Собирать
эту информацию нужно не только для того,
чтобы учиться на ошибках. Официально
отчетность об ошибках и об их исправлении
необходима и для того, чтобы гарантировать,
что обнаруженные ошибки в работающих
или тестируемых системах не упущены и
что исправления выполнены в соответствии
с принятыми нормами.
Другой
способ обучения на ошибках в программном
обеспечении — учиться на опыте других
организаций. К сожалению, это не жизненный
вариант, поскольку даже в лучшие времена
научного книгоиздания, такие материалы
если и встречались то крайне редко.

Елена Игоревна Комиссарова
Эксперт по предмету «Бухгалтерский учет и аудит»
Предложить статью
Определение 1
Аудиторский риск – это вероятное наличие в бух. отчетности не найденных ошибок или искажений информации уже после подтверждения ее достоверности или вероятное признание наличия искажения в отчетности, тогда как признанные искажения в ней отсутствуют.
Требования стандартов
Задача теории аудита заключается в разработке и обосновании методов оценки вероятности определения аудиторского риска или ожидаемой ошибки.
При любых проверках (сплошных или выборочных) при определении ожидаемой ошибки присутствует элемент случайности. Например, элемент случайности может быть таким: аудитор не заметил ошибку или неверно истолковал содержание хозяйственной операции и т.д. В качестве вывода можно сказать, что определение любой ожидаемой ошибки всегда происходит с какой-то вероятностью. По-другому эта вероятность называется аудиторским риском.
Существуют требования федеральных и международных аудиторских стандартов в соответствии, с которыми аудитор должен производить оценку аудиторского риска и разрабатывать процедуры, которые потребуются для снижения риска до самого низкого уровня. Стандарты устанавливают еще одни требования, а именно, что аудитору необходимо производить оценку риска на общем уровне отчетности, на уровне групп однотипных операций, а также на уровне сальдо по счетам.
Определение аудиторского риска
В стандартах аудиторский риск отражается как возможное выражение аудитором ошибочного мнения, хотя в бухгалтерской отчетности будут присутствовать существенные ошибки или искажения. Данное определение считается концептуальным и малопригодным для практической работы.
Представим строгое определение аудиторского риска. Для данного определения потребуется ввести некоторые обозначения: S (руб.) – уровень существенности базового показателя; К (руб.) – наиболее вероятная ошибка, содержащаяся в статье бух. отчетности с установленным уровнем существенности; Q (руб.) – действительная ошибка, которая содержится в данной статье бух. отчетности.
«Вероятность определения ожидаемой ошибки в аудите (аудиторский риск)» 👇
Рассмотрим аудиторский риск на разных уровнях:
- на общем уровне отчетности – это вероятность события, которое заключается в том, что как минимум для 1 статьи бух. отчетности будет выполняться неравенство $K$ $S$. Расшифровать можно следующим образом – одновременно должны выполняться 2 условия: уровень существенности больше ожидаемой ошибки и меньше действительной.
- на уровне сальдо определенного счета – это вероятность события, которое заключается в том, что неравенства $K$ $S$ выполняются для конкретной статьи баланса.
- на уровне оборота по определенному счету – это вероятность события, которое заключается в том, что неравенства $K$ $S$ выполняются для генеральной совокупности операций, составляющей оборот данного счета. Для данного случая обозначения будут являться: $S$ — уровнем существенности, $K$ — ожидаемой ошибкой, $Q$ – действительной ошибкой.
Исходя из вышеперечисленного, можно дать определение аудиторского риска – это вероятность наступления какого-либо события. Вероятность – это математическая величина, которая определяется количественным значением. Но согласно стандартам есть возможность определения в виде качественной оценки. Для выбора способа оценки, необходимо определить природу аудиторского риска.
Аудиторский риск на уровне сальдо и оборотов по счетам при применении выборочных процедур, основанных на статистических методах – это статистическая вероятность, которую можно определить, численно используя при этом закон распределения случайной величины.
Во всех остальных случаях аудиторский риск – это субъективная вероятность, т. е. вероятность, которая основана на суждении экспертов (аудиторов), учитывающих имеющийся опыт, влияние различных факторов и т. д.
Находи статьи и создавай свой список литературы по ГОСТу
Поиск по теме
Продолжаем говорить о техниках тест-дизайна. Сегодня речь пойдет о технике предугадывания ошибок. Она подойдет в том случае, когда мы уже знакомы с продуктом и имеем определенный опыт в тестировании подобного функционала.
Суть техники в том, что чтобы найти все способы, которые могут сломать тестируемый продукт.
По традиции начну с определения. Немного информации из ISTQB:
Предположение об ошибках – это способ предотвращения ошибок, дефектов и отказов, основанный на знаниях тестировщика, включающих:
— Историю работы приложения в прошлом.
— Наиболее вероятные типы дефектов, допускаемых при разработке.
— Типы дефектов, которые были обнаружены в схожих приложениях.
Структурированный подход к предположению об ошибках предполагает создание списка всех возможных ошибок, дефектов и отказов с последующей разработкой тестов, направленных на поиск дефектов из этого списка. Списки отказов и дефектов могут быть построены на основе опыта, исторических данных об отказах и ошибках, а также на общих знаниях о причинах отказа программ.
Получается, что предугадывание ошибки — это когда тест аналитик использует свои знания системы и способность к интерпретации спецификации на предмет того, чтобы «предугадать» при каких входных условиях система может выдать ошибку.
Например, в программе я вижу: «для подтверждения заказа введите свой номер телефона в формате +7(…)… ….» И я, как тестировщик, начинаю думать: «А если не вводить телефон?», «А если ввести в формате не +7, а просто 8? «, и так далее. Это и есть предугадывание ошибки.
Давайте посмотрим на конкретных примерах, как можно использовать этот метод.
Уже знакомая нам игра с молокозаводом
Возьмем объекты, которые нам необходимо построить. Например, каким образом можно сломать курятник на этапе покупки?
- Можно попробовать поставить его на другой объект

2. Или за границу доступного поля

3. За границей поля тоже не получается.. А давайте попробуем поставить на воду? Вдруг разработчики не учли этот момент?

Тоже никак, все работает как надо… Ладно поставим пока курятник на место. Теперь попробуем проверить, все ли нормально с его работой.
4. В курятник можно покупать и сажать кур. А что если попробовать вместо кур поместить коров?

5. Или попробовать кур поместить на территорию вне курятника

6. Или попробовать зайти в магазин, пока покупаем кур

«Ладно, видимо не в этот раз» — говорим мы себе и закрываем игру…
Таким образом, путем предугадывания ошибок, мы с вами нашли 6 случаев, при которых возможны проблемы в работе приложения.
А теперь посмотрим на примере сайта
Возьмем один из элементов сайта — форму регистрации. Посмотрим на нее внимательно и подумаем, как мы можем ее «сломать».

Мне на ум приходят вот какие варианты:
- Указать e-mail c несуществующим доменом на конце.
- Указать e-mail без знака «@».
- Заполнить поле «Пароль» без использования обязательных символов. Например, если программа требует, чтобы в пароле были заглавные и строчные буквы, то пробуем ввести пароль без использования заглавных букв.
- В поле «Пароль еще раз» ввести символы отличные от символов в поле «Пароль».
- Снять галочку «Я принимаю условия Пользовательского соглашения».
- Ввести неверные символы с картинки.
- Оставить одно поле незаполненным.
________________________________
Таким образом, суть данного метода заключается в том, чтобы найти как можно больше ошибок, попытаться сломать работающий функционал. Название техники уже говорит само за себя.
________________________________
В предугадывании ошибок нет четкой и логической схемы, которая позволила бы нам составить тест-кейсы. Т.е. нельзя сказать, что сделав сначала Шаг №1, затем Шаг №2 и т.д. мы на выходе получим готовые проверки с максимально полным покрытием.
Наоборот, эта техника основывается на опыте тестировщика и на его умении думать креативно и деструктивно.
Основные показатели надежности программного обеспечения (ПО). Математические модели оценки надежности ПО.
13.1. Основные показатели надежности программного обеспечения (ПО).
Надежность программного обеспечения отличается от надежности технических средств следующим:
- элементы ПО не стареют от износа;
- число способов контроля ПО значительно больше числа способов контроля аппаратуры;
- в ПО значительно больше объектов для контроля, чем в аппаратуре;
- вПО гораздо проще вносить исправления и дополнения, чем в аппаратуру, но это трудно делать корректно и безошибочно.
Основные понятия, связанные с надежностью программного обеспечения:
- ошибки в программах и признаки их наличия;
- количество оставшихся в программе ошибок (ошибок, дошедших до пользователя); вероятность безотказной работы программы;
- интенсивность обнаружения ошибок (или функция риска);
- прогон программы;
- отказ программы.
Дать строгое определение программной ошибки непросто, поскольку это определение, является функцией от самой программы, то есть зависит от того, какого функционирования ожидает от программы пользователь. По этой причине вместо строгого определения будут перечислены только признаки, указывающие на наличие ошибки в программе:
- при выполнении программы появилась ошибочная операция;
- использование некорректного операнда в программе;
- несоответствие функций, выполняемых программой, ее спецификации;
- ошибки в самой спецификации, которые вызывают необходимость корректирования программы;
- ошибки в вычислениях (например, переполнение и т.п.);
- ошибки интерфейса программы с пользователем.
Этот список можно считать открытым, поскольку он может быть продолжен разработчиками по мере накопления ими опыта в повышении надежности программного обеспечения.
Все же чаще всего под ошибкой (или отказом) программы понимают всякое невыполнение программой функций, которые были предусмотрены в техническом задании на ее разработку или вытекают непосредственно из инструкций пользователю. Является некорректным относить к ошибкам, например, необходимость написания программного кода, заменяющего какую-либо временно отсутствующую часть программы, или же необходимость рекомпиляции, вызванную изменениями в других модулях.
Количество оставшихся в программе ошибок – это количество ошибок, которые потенциально могут быть обнаружены на последующих стадиях жизненного цикла программы, после исправлений, внесенных в программу на текущей стадии ее жизненного цикла. Это количество оставшихся в программе ошибок (обозначаемое далее как B) – один из важнейших показателей надежности ПО.
Пусть P(t) — вероятность того, что ни одной ошибки не будет обнаружено на временном интервале [0,t]. Тогда вероятность хотя бы одного отказа за этот период будет Q(t) = 1 – P(t), и плотность вероятности можно записать как
Рассмотрим функцию риска R(t), как условную плотность вероятности отказа программы в момент времени t, при условии, что до этого момента отказов не было
(13.1)
Функция риска имеет размерность [1/время] и она очень полезна при классификации основных распределений отказов. Распределения с возрастающей функцией риска соответствуют тем ситуациям, когда статистические характеристики надежности ухудшаются со временем. И наоборот, распределения с убывающей функцией риска соответствуют обратной ситуации, когда надежность улучшается со временем в результате процесса обнаружения и коррекции ошибок.
Из выражения (13.1), ясно, что , и, следовательно,
или
(13.2)
Равенство (13.2) является одним из самых важных в теории надежности. В дальнейшем будет показано, что различные виды поведения функции риска во времени порождают различные возможности для построения моделей надежности ПО. Интенсивность обнаружения ошибок (функция риска), вместе с вероятностью безотказной работы программы и количеством оставшихся в программе ошибок, являются важнейшими показателями надежности программ.
Прогон программы – это набор действий, включающий в себя: ввод в программу одной из возможных комбинаций Ei пространства входных данных E (); выполнение программы, которое заканчивается либо получением результата F(Ei), либо отказом.
Для некоторых наборов входных данных Ei, отклонение полученного на выходе результата (F’(Ei)) от требуемого результата F(Ei) находится в пределах допустимого отклонения , то есть выполняется следующее неравенство
()
а для всех остальных Ei из подмножества , выполнение программы не дает приемлемого результата, то есть
()
Случаи, описанные неравенством (13.4), называются отказами программы.
Рассмотрим дихотомическую переменную :
Тогда статистическая оценка вероятности отказа программы в течении m прогонов будет равна:
()
Обозначим через приемлемую ошибку оценки вероятности отказа . Тогда требуемое количество прогонов программы m должно быть пропорционально значению , где Q – заданная вероятность отказа программы. Это означает, что если, например, требуемая относительная ошибка оценки (13.5) , и требуемое (желаемое) значение , тогда количество независимых прогонов программы m одлжно быть не меньше, чем , что, конечно, нелегко реализовать на практике. Решением этой проблемы может быть использование процедуры последовательного анализа Вальда.
И наконец, еще один показатель надежности ПО, который тоже будет использоваться в этой работе – среднее время наработки программы до отказа:
Опыт разработки ПО показывает, что выявление ошибок и их исправление связано с определенными затратами, которые составляют цену ошибки. По мере перехода к более поздним стадиям разработки цена ошибки возрастает:
- Этап разработки спецификаций 140$;
- Программирование 1100$;
- Комплексная отладка 7000$;
- Этап сопровождения от 14000$ до 140 000$;
13.2. Математические модели оценки надежности ПО.
Модели надежности ПО служат для предсказания значений метрик, позволяющих оценить надежность на различных этапах тестирования программного продукта. Например, в том случае, если к некоторому моменту тестирования количество обнаруженных и исправленных ошибок уже достаточно велико, это может создать впечатление, что тестирование продукта близится к завершению, то есть ошибок в программе осталось немного. Однако, это может совершенно не соответствовать действительности, и как раз использование моделей надежности программ может помочь прояснить подобную ситуацию.
Математические модели надежности программ можно разбить на группы по следующим признакам:
- Вид «функции риска», определяющей временную структуру появления ошибок в программе;
- Сложность разработки программы;
- Способы «посева» ошибок и оценки числа исходных ошибок по соотношению исходных и внесенных;
- Сравнение числа успешных прогонов программы и общего числа прогонов для различных структур пространства входных данных.
Модели, основанные на использовании функции риска
Модель Джелинского-Моранды.
Это одна из первых и простейших моделей классического типа, послужившая основой для дальнейших разработок в этом направлении. Модель была использована при разработке таких значительных программных проектов, как программа Аполло (некоторых ее модулей). Модель Джелинского-Моранды основана на следующих предположениях:
- Интенсивность обнаружения ошибок R(t) пропорциональна текущему количеству ошибок в программе, то есть изначальному количеству ошибок за вычетом количества ошибок, уже обнаруженных на данный момент.
- Все ошибки в программе равновероятны и не зависят друг от друга.
- Все ошибки имеют одинаковую степень важности.
- Время до следующего отказа программы распределено экспоненциально.
- Исправление ошибок происходит без внесения в программу новых ошибок.
- R(t) = const в промежутке между любыми двумя соседними моментами обнаружения ошибок.
Согласно этим предположениям, функция риска будет представлена как:
В этой формуле t – это произвольный момент времени между обнаружением (i-1)-й и i-й ошибок; K – неизвестный коэффициент масштабирования; B – начальное количество оставшихся в программе ошибок (также неизвестное). Таким образом, если в течении времени t было обнаружено (i-1) ошибок, это означает, что в программе еще остается B-(i-1) необнаруженных ошибок. Полагая, что
и используя предпосылку 6, а также равенство (13.2), можно заключить, что все Xi имеют экспоненциальное распределение
и плотность вероятности отказа, соответственно, равна
Тогда функцию правдоподобия (согласно предпосылке 2) можно записать как
или, переходя к логарифму функции правдоподобия, имеем
(13.2)
Максимум функции правдоподобия можно найти, используя следующие условия
(13.3)
(13.4)
Из формулы (13.3) получается оценка максимального правдоподобия для K
(13.5)
Подставляя выражение (13.5) в (13.4), находим нелинейное уравнение для вычисления –оценки максимального правдоподобия для B
(13.6)
Это уравнение можно упростить перед тем, как искать его решение, если записать его с использованием следующих обозначений
(13.7)
где
Поскольку имеют смысл лишь целочисленные значения , функции из выражения (13.7) можно рассматривать только для целочисленных аргументов. Более того, , поскольку n ошибок с программе уже обнаружено. Таким образом, оценка максимального правдоподобия для B может быть получена с помощью вычисления начальных значений функций fn(m) и gn(m) для m=n+1, n+2…, и анализа разницы |fn(m)-gn(m)|.
Поскольку правая и левая части выражения (13.7) одинаково монотонны, это порождает проблему единственности решения, а также проблему его существования. Конечное решение в области существует тогда и только тогда, когда выполняется неравенство
(13.8)
В противном случае оценка максимального правдоподобия будет Условие (13.8) можно переписать в более удобном виде
(13.9)
где A – то же самое выражение, что и в формуле (13.7). Необходимо отметить, что, A является интегральной характеристикой n встретившихся в программе за время тестирования ошибок, и представляет (в статистическом смысле) набор интервалов Xi между ошибками.
Рассмотрим пример использования модели Джелинского-Моранды, в котором она применяется к следующим экспериментальным данным: в течение 250 дней было обнаружено 26 ошибок, интервалы между обнаружением которых представлены в таблице 13.1. Для этих данных мы имеем n=26 и . Условие (13.9) выполняется, и, таким образом, оценка максимального правдоподобия имеет единственное решение. В таблице 13.2 представлены начальные значения функций, входящих в уравнение (13.7), для множества аргументов
Наилучшим решением для уравнения (13.7) является m=32 (соответствующая строка в таблице дает минимальное значение разницы функций по модулю, то есть максимально приближает ее к нулю, что нам и требуется), то есть = m-1=31. Из выражения (13.5) находим = 0.007.
Среднее время (время, оставшееся до обнаружения (n+1)-й ошибки) есть инвертированная оценка интенсивности для предыдущей ошибки:
В этом примере, , и время до полного завершения тестирования
Таблица 10. Интервалы между обнаружением ошибок.
| I | Xi | I | Xi | i | Xi | i | Xi |
| 1 | 9 | 8 | 8 | 15 | 4 | 21 | 11 |
| 2 | 12 | 9 | 5 | 16 | 1 | 22 | 33 |
| 3 | 11 | 10 | 7 | 17 | 3 | 23 | 7 |
| 4 | 4 | 11 | 1 | 18 | 3 | 24 | 91 |
| 5 | 7 | 12 | 6 | 19 | 6 | 25 | 2 |
| 6 | 2 | 13 | 1 | 20 | 1 | 26 | 1 |
| 7 | 5 | 14 | 9 |
Таблица 11. Значения функций.
| m | |||
| 27 | 3.854 | 2.608 | 1.246 |
| 28 | 2.891 | 2.371 | 0.520 |
| 29 | 2.427 | 2.172 | 0.255 |
| 30 | 2.128 | 2.005 | 0.123 |
| 31 | 1.912 | 1.861 | 0.051 |
| 32 | 1.744 | 1.737 | 0.007 |
| 33 | 1.608 | 1.628 | -0.020 |
| 34 | 1.496 | 1.532 | -0.036 |
Простая экспоненциальная модель.
Основное различие между этой моделью и моделью Джелинского-Моранды, рассмотренной в предыдущем разделе, в том, что эта модель не использует предположение 6, и, таким образом, допускает, что функция риска может меняться между моментами обнаружения ошибок, то есть она больше не является константой на этих интервалах. Пусть N(t) – число ошибок, обнаруженных к моменту времени, и пусть функция риска пропорциональна количеству ошибок, оставшихся в программе после момента t.
Продифференцируем обе части этого уравнения по времени:
Учитывая, что — это R(t) (количество ошибок, обнаруживаемых в единицу времени), получаем дифференциальное уравнение для R(t)
(13.10)
Если рассмотреть начальные значения N(0)=0, R(0)=KB, то решением уравнения (3.10) будет
(13.11)
Оценки параметров К и В можно получить аналогично модели Джелинского-Моранды и затем с помощью оценки функции риска можно спрогнозировать ситуацию на следующие этапы отладки.
Модель Шика-Уолвертона.
Эта модель основана на предположении, что функция риска пропорциональна не только количеству ошибок в программе, но и продолжительности процесса тестирования. Кроме того, предполагается, что чем дольше ПО тестируется, тем больше появляется шансов на обнаружение последующих ошибок, поскольку в процессе отладки некоторые участки программы «подчищаются», что облегчает ее дальнейшее тестирование.
Модель основана на следующих предположениях:
- Все ошибки в программе равновероятны и независимы друг от друга.
- Все ошибки считаются одинаково серьезными.
- Исправление ошибок происходит без внесения в программу новых ошибок.
Функция риска для данной модели:
В этой формуле Xi — время между моментом обнаружения (i-1)-й ошибки до текущего момента .
Вероятность безотказного функционирования программы на интервале Xi равна:
,
что дает плотность вероятности отказа
Модели Липова
Эти модели являются обобщением моделей Джелинского-Моранды и Шика-Уолвертона. В отличие от этих моделей, модели Липова допускают более одной ошибки в интервале тестирования, и кроме того, допускают, что не все из ошибок, обнаруженных а этом интервале, могут быть исправлены. Первая модель Липова (обобщение модели Джелинского-Моранды) основана на следующих предположениях:
- Все ошибки равновероятны и независимы друг от друга.
- Все ошибки считаются одинаково серьезными.
- Интенсивность обнаружения ошибок постоянна на всем интервале тестирования.
- На i-том интервале тестирования обнаруживается ошибок, но только из них исправляется.
Последнее предположение значительно отличает данную модель от всех моделей, рассмотренных ранее. Таким образом, функция риска определяется следующим выражением: где — общее количество ошибок, исправленных к моменту времени , а — это время окончания i-го интервала тестирования (измеренное обычным способом или таймером процессора). Еще одно отличие данной модели от модели Джелинского-Моранды в том, что интервалы фиксированные, а не произвольные.
Вторая модель Липова (обобщение модели Шика-Уолвертона) основана на следующих предположениях. Интенсивность обнаружения ошибок пропорциональна текущему количеству ошибок вПО и общему времени, затраченному на его тестирование, включая также «среднее» время поиска ошибки, обнаруженной на интервале тестирования. С учетом этих предположений, функция риска задается следующим выражением:
(13.12)
где — общее количество ошибок, исправленных к моменту времени . Формула (13.12) отличается от первой модели Липова вторым множителем — , отражающем изменение интервала тестирования.
Геометрические модели
В этом разделе рассмотрен пример геометрической модели, предложенной П. Б. Морандой и являющейся модификацией модели Джелинского-Моранды.
Модель основана на предположении, что начальное количество ошибок в программе B не является фиксированным значением (не ограничено), более того, не все ошибки встречаются с одинаковой вероятностью. Также предполагается, что чем дольше длится процесс отладки ПО, тем труднее становится обнаруживать в нем ошибки, и , таким образом, ПО никогда полностью не освобождается от ошибок. Основные предположения в этой модели следующие:
- Общее количество ошибок в программе неограниченно;
- Ошибки встречаются с разной вероятностью;
- Процесс обнаружения ошибок не зависит от самих ошибок;
- Интенсивность обнаружения ошибок изменяется по закону геометрической прогрессии, но между моментами обнаружения ошибок интенсивность постоянна.
Исходя из этих предположений, функцию риска можно записать следующим выражением:
где t – временной интервал между обнаружением (i-1)-ой и i-той ошибок. Начальное значение этой функции R(0) = D, и функция риска убывает со скоростью геометрической прогрессии (0<K<1) по ходу процесса обнаружения ошибок. Скорость изменения R(t) пропорциональна инвертированному значению константы K:
что приводит к убыванию шага изменения R(t) в процессе обнаружения ошибок. Таким образом, более поздние ошибки труднее обнаружить, и они оказывают меньшее влияние на уменьшение потока ошибок, чем предыдущие ошибки. Если снова положить (временной интервал между обнаружением (i-1)-ой и i-той ошибок), тогда, согласно второму и третьему предположению, Xi распределены экспоненциально с плотностью распределения
Эта модель не позволяет определить, сколько ошибок осталось в ПО, но с ее помощью можно найти его «уровень чистоты». “Уровень чистоты” — это отношение
(13.13)
Оценка максимального правдоподобия для этого значения будет
Модель Шнейдевинда
Эта модель основана на подходе, что чем позже встречаются ошибки, тем большее значение они имеют для процесса предсказания ошибок в программе. Предположим, что есть m интервалов тестирования, и пускай на i-том интервале обнаружено ошибок. Тогда возможно три различных подхода:
- Использовать данные об ошибках на всех интервалах;
- Не рассматривать данные об ошибках, обнаруженных на первых (s-1) интервалах, и использовать только данные с s-того по m-тый;
- Использовать суммарное количество ошибок, обнаруженных с первого по (s-1)-ый интервал, т.е. , и отдельные ошибки с s-того по m-тый интервалы.
Подход 1 предлагается использовать в тех случаях, когда для предсказания будущего состояния ПО необходимы данные со всех интервалов тестирования. Подход 2 – когда есть причины полагать, что произошел некий перелом в процессе обнаружения ошибок, и только данные последних m – (s-1) интервалов имеет смысл учитывать в прогнозах на будущее. И наконец, подход 3 является компромиссом между первыми двумя подходами.
Модель основана на следующих предположениях:
- Количество ошибок на интервале тестирования не зависит от количества ошибок на остальных интервалах;
- Количество обнаруженных ошибок убывает от одного интервала к другому;
- Все интервалы тестирования имеют одинаковую длину;
- Интенсивность обнаружения ошибок пропорциональна количеству ошибок, содержащихся в программе в текущий момент времени.
Лекция 14. Модели, основанные на методе «посева» и разметки ошибок, и модели на основе учета структуры входных данных
Методы оценки надежности программ, основанные на моделях «посева» и разметки ошибок, рассмотрены на примере трех моделей: Милза, Бейзина и простой эвристической модели. Согласно методике, предложенной Милзом, программа изначально “засевается” известным количеством некоторых ошибок — M. Главное предположение модели в том, что «засеянные» ошибки распределены таким же образом, как и естественные ошибки программы, и, следовательно, вероятность обнаружения для «засеянной» ошибки такая же, как и для естественной. После этого начинается процесс тестирования ПО. Пусть во время тестирования было обнаружено (m+v) ошибок, из которых m ошибок было искусственно «засеяно», а v ошибок содержалось в ПО изначально. Тогда, согласно методу максимального правдоподобия, начальное количество ошибок в программе можно оценить следующим образом: .
Серьезным недостатком этой модели является предположение об одинаковости распределения сгенерированных и естественных ошибок, которое невозможно проверить, особенно на более поздних стадиях разработки ПО, когда многие простые ошибки (такие, как синтаксические ошибки, например) уже исправлены, и только наиболее сложные для обнаружения ошибки еще остаются в ПО.
Теперь рассмотрим модель Бейзина. Пусть программный продукт содержит Nk команд. Из этих Nk команд произвольно выбираются n команд, и в каждую из этих n команд заносится ошибка. После этого для тестирования случайным образом выбирается r команд. Если в процессе тестирования было случайным образом обнаружено m “засеянных” и v естественных ошибок, это означает, что, согласно методу максимального правдоподобия, начальное количество ошибок в программе можно оценить следующим образом:
где скобками ][ обозначена целая часть числа.
При использовании такой процедуры уровень пометки (т.е. среднее количество помеченных команд) должен превышать 20, чтобы полученную оценку можно было считать достаточно объективной. Эти процедуры могут применяться на любой стадии после того, как написание кода программы закончено.
Теперь рассмотрим простую эвристическую модель. Эта модель была предложена Б. Руднером. Она позволяет избавиться от главного недостатка модели Милза. Здесь тестирование производится параллельно, двумя независимыми группами разработчиков ПО.
Пусть и — количество ошибок, обнаруженных, соответственно, первой и второй группами, а — количество общих ошибок, то есть обнаруженных обеими группами, первой и второй. Начальное количество ошибок, содержащихся в программе, можно оценить, используя гипергеометрическое распределение и метод максимального правдоподобия
Модели, основанные на использовании структуры входных данных
В основе методов, использующих структуру входных данных, лежит модель, предложенная Нельсоном, которая начала применяться на практике только после ее доработки, связанной с применением последовательного анализа Вальда. Также к этой группе относится модель, разработанная фирмой IBM.
Модель Нельсона. Применение последовательного анализа Вальда для снижения количества прогонов программы.
Модель, предложенная Е. Нельсоном, основана на использовании структуры входных данных программы. В простейшем случае набор входных данных Ei, произвольно выбранный из пространства входных данных E, имеет равную априорную вероятность с другими наборами, входящими в E, и это дает оценку вероятности отказа по формуле (13.5).
Если рассмотреть также и случай различных вероятностей для каждого набора данных, то оценка (13.5) изменится следующим образом.
что позволяет записать следующее выражение для вероятности успешного прогона:
(14.1)
Тогда вероятность успешного выполнения m прогонов, при условии, что набор входных данных для каждого прогона выбирается независимо и в соответствии с распределением, заданным формулой (14.1), будет равна:
(14.2)
Модель (14.2) позволяет дать следующее определение надежности ПО: надежность ПО – это вероятность его m безотказных прогонов.
Следующим шагом в развитии этой модели будет признать, что, как правило, предположение о том, что выбор входных данных происходит независимо для каждого прогона, на практике неверно. Исключение могут составлять только последовательности прогонов с постепенным увеличением значения входной переменной, или с использованием определенной последовательности процедур (как в системах реального времени).
Принимая во внимание эти обстоятельства, необходимо переопределить распределение (14.1) в терминах вероятностей pij выбора набора данных Ei для j-того прогона программы из некоторой последовательности прогонов. Тогда вероятность отказа на j-том прогоне будет
Соответственно, вероятность безотказного выполнения m прогонов можно оценить следующим выражением:
Это выражение можно записать в виде
и если Qi<<1, тогда
Обозначим — время выполнения j-того прогона программы, и — суммарное время, потраченное на выполнение j прогонов, и будем использовать следующее выражение для функции риска
тогда мы имеем
Если , то сумма превращается в интеграл, и формула (14.3) превращается в фундаментальное отношение (13.2):
основного правила надежности.
При использовании модели Нельсона на практике встречаются две категории трудностей. Первая связана с нахождением — параметров распределения входных данных. Вторая связана с необходимостью выполнения значительного количества прогонов программы (десятки и сотни тысяч) для получения приемлемой точности для соответствующих оценок вероятности (отказа или безотказной работы). Последняя проблема решается применением хорошо известного в статистике метода последовательного анализа, предложенного Вальдом.
Модель, разработанная специалистами компании IBM.
Во время эксплуатации пользователем текущей версии ПОразработчики, как правило, занимаются активным сопровождением этого программного продукта, то есть вносят некоторые улучшения или исправления в данную версию, не дожидаясь, пока пользователь этого потребует. И это сопровождение может включать в себя также добавление новых функций в ПО. С некоторого момента, когда разработчик считает свою задачу выполненной, начинается, так называемое, пассивное сопровождение, когда исправления вносятся уже только по запросу пользователя.
В течение сопровождения вПО вносится значительное количество новых ошибок в каждой новой версии, вместе с доработками, изменениями и исправлениями, что требует исправлений также и в следующей версии. Разработчики известной компании IBM попытались предсказать количество подобных исправлений от версии к версии, основываясь на большом количестве экспериментальных данных, собранных в ходе сопровождения операционной системы OS/360. Модель, предложенная специалистами IBM, основана на наблюдении за ходом разработки этого программного продукта, и на гипотезе о статистической стабильности зависимости между параметрами, характеризующими различные версии системы. В качестве основной единицы измерения сложности ПО был выбран программный модуль. Были стандартизованы правила создания модулей.
Объем i-той версии выражается количеством модулей Mi, входящих в данную версию. При выпуске i –той версии системы изменялся параметра СИМi (количества старых исправляемых модулей), и добавление некоторого числа новых модулей НМi , так что .
При доработке i-й версии (в период подготовки (i+1)-й) происходит дальнейшая коррекция модулей. Эти исправленный модули делятся на две группы: первая группа характеризуется параметром MИMi – многократно изменяемые модули (10 или более исправлений на модуль), и вторая группа – ИMi, модули с числом исправлений меньше 10.Эта классификация необходима для упрощения вычислений, а также из-за того факта, что небольшое число исправлений характерно для большинства модулей.
Также необходимо отметить, что группа ИM не требуют особых средств отладки, в то время как группа MИM может потребовать некоторых дополнительных усилий при отладке.
В ходе анализа истории сопровождения OS/360 фирмы IBM было установлено, что существует значительная зависимость между параметрами, характеризующими масштабы изменений и (соответственно) уровень содержания ошибок (в группах ИM и MCM), и параметрами, характеризующими сложность и объем следующей версии (СИМ, НМ). В применении к OS/VS1 это соотношение выглядело следующим образом.
(14.7)
(14.8)
Если предположить, что термины “исправление” и “ошибка” идентичны, то тогда модель для оценивания общего количества ошибок в программе, предложенная специалистами из IBM и основанная на приведенных выше объяснениях, записывается следующим образом:
(14.9)
где ИЗМi — общее количество исправлений, внесенное в модули (или, другими словами, общее количество ожидаемых ошибок), а коэффициенты 23 и 2 – среднее количество исправлений на модуль для групп MИM и ИM, соответственно.
Прогноз основывается на запланированном количестве исправлений в старых модулях и на количестве добавляемых модулей (СИМi, НМi) для реализации новых требуемых функций ПО. Если количество действительно внесенных исправлений меньше, чем предсказанное количество исправлений, то можно сделать вывод, что в ПО существует еще некое количество необнаруженных ошибок. Модель фирмы IBM позволяет сделать следующие выводы:
- на этапе пассивного сопровождения ПО (ИMi = 0, СИМi невелико) количество исправляемых модулей и количество исправлений внутри модулей быстро убывает от версии к версии;
- количество ожидаемых ошибок в следующей версии может увеличится по сравнению с прошлой версией, если достаточно много старых модулей было изменено (СИМ), и/или было добавлено много новых модулей (НМ).
- Добавление новых модулей оказывает более сильное влияние на рост числа новых ошибок, чем исправления, вносимые в старые модули; в то же время, если есть возможность создать новый модуль вместо изменения старых модулей (5 или более), то это снижает ожидаемое количество ошибок. Другими словами, на некотором этапе сопровождения ПО изменение уже существующих модулей теряет свою эффективность, и требуется добавление вместо этого нового модуля.
Лекция 15. Методы повышения надежности программ и оценка эффективности их применения.
15.1. Влияние избыточности на повышение надежности программ
Так как в программах нет необходимости “ремонта” компонент с участием человека, то можно добиваться высокой автоматизации программного восстановления. Главной задачей становится восстановление за время, не превышающее порогового значения между сбоем и отказом. Автоматизируя процесс и сокращая время восстановления, можно преобразовать отказы в сбои и тем самым улучшить показатели надежности функционирования системы.
Комплексы программ в процессе функционирования находятся под воздействием шумов-возмущений различных типов. Для снижения их влияния на результаты следует применять фильтры, позволяющие обнаруживать искажения, устранять или уменьшать их вредные последствия. Разнообразие видов искажений приводит к необходимости построения систем фильтров, каждый из которых способен селектировать некоторые виды искажений.
Для реализации фильтров, обеспечивающих повышение надежности функционирования программ и защиту вычислительного процесса и информации программно-алгоритмическими методами, используется программная, информационная и временнаяизбыточность.Основная задача ввода избыточности состоит в исключении возможности аварийных последствий от возмущений, соответствующих отказу системы. Любые аномалии при исполнении программ необходимо сводить до уровня сбоя путем быстрого восстановления.
Временная избыточность состоит в использовании некоторой части производительности ЭВМ для контроля исполнения программ и восстановления вычислительного процесса. Величина временной избыточности зависит от требований к надежности функционирования системы и находится в пределах от 5-10% производительности однопроцессорной ЭВМ до трех-четырех кратного дублирования производительности машины. Временная избыточность используется на обнаружение искажений, их диагностику и на реализацию операций восстановления. На это требуется в общем случае небольшой интервал времени, который выделяется либо за счет резерва, либо за счет сокращения времени решения функциональных задач.
Информационная избыточность состоит в дублировании накопленных исходных и промежуточных данных, обрабатываемых комплексом программ. Избыточность используется для сохранения достоверности данных, которые в наибольшей степени влияют на нормальное функционирование программ или требуют значительного времени восстановления.Для менее важных данных информационная избыточность используется в виде помехозащитных кодов, позволяющих только обнаружить искажение.
Программная избыточность используется для контроля и обеспечения достоверности наиболее важных решений по управлению и обработке информации. Она заключается в применении нескольких вариантов программ, различающихся методами решения задачи или программной реализацией одного и того же метода. Программная избыточность необходима также для реализации программ контроля и восстановления данных с использованием информационной избыточности и для функционирования всех средств защит, использующих временную избыточность.
Эффективность применения избыточности для повышения надежности комплексов программ.
Выше рассмотрены принципы использования временной, информационной и программной избыточности для обеспечения надежности программ. Здесь представлены некоторые рекомендации, позволяющие оценить эффективность использования избыточности. Наибольшее внимание уделяется временной избыточности, которая эффективно используется для оперативной защиты при отказовых ситуациях и непосредственно влияет на надежность функционирования программ.
Для реализации стратегий резервирования программ необходима временная избыточность. При этом временная избыточность используется в основном для оперативного контроля состояния данных и вычислительного процесса а также для автоматического восстановления при возникновении отказовых ситуаций Резерв времени для выполнения этих операций можно считать достаточным независимо от числа предыдущих отказов времени на их устранение и наработки на отказ Кроме того суммарное время восстановления работоспособности обычно не ограничено
Эффективность оперативного использования временной избыточности для повышения надежности функционирования программ определяется затратами на контрольно-восстановительные операции изменением показателей надежности в зависимости от затрат и связью этих изменений с отлаженностью программ В результате для оценки эффективности введения временной избыточности в программе необходимо
* определить совокупные затраты на контроль на работу при необнаруженном искажении и на восстановление обеспечивающие заданную вероятность обнаружения отказовой ситуации при исполнении программ
* определить основные показатели надежности функционирования программ в зависимости от совокупных затрат на оперативный контроль и восстановление
* оптимизировать суммарные затраты на отладку программ и оперативную защиту от искажений для обеспечения заданной надежности функционирования комплекса программ
При решении последней задачи источниками искажений предполагаются только невыявленные ошибки в программах
Влияние оперативного контроля и восстановления на производительность ЭВМ
Использование времени функционирования ЭВМ для контроля работоспособности исправления искажений и восстановления при отказовых ситуациях приводит к снижению затрат производительности ЭВМ на исполнение комплекса программ в процессе эксплуатации В результате сокращаются ресурсы ЭВМ доступные для выполнения основных функций системы Это сокращение ресурсов можно отразить коэффициентом простоя ЭВМ Кп = 1 — Кг характеризующим относительные затраты времени на задачи повышения помехозащищенности программ По мере совершенствования и углубления средств помехозащиты программ возрастают затраты времени ЭВМ на их исполнение что отражается на снижении реальной эффективности функционирования комплекса программ
Целесообразно исследовать влияние использования временной избыточности на сокращение полезной производительности ЭВМ для решения функциональных задач а также на снижение потерь вследствие отказов После определения этих составляющих можно провести их совместный анализ для оптимизации глубины помехозащиты программ с учетом затрат на ее реализацию
Методы обеспечения надежности программ.
Основные факторы, определяющие надежность программ.
Надежность функционирования комплексов программ зависит от многих факторов, которые можно объединить в три группы (табл.. 12).
n факторы,непосредственно определяющие возникновение отказов, и характеристики надежности программ;
n методы, способствующие проектированию корректных программ, снижающие вероятность программных ошибок и отказовых ситуаций при исполнении программ;
n метод, активно влияющие на повышение надежности функционирования программ позволяющие контролировать и поддерживать заданные показатели надежности.
Таблица 12.
|
Факторы, непосредственно определяющие надежность программ |
Методы проектирования корректных программ |
Методы контроля и обеспечения надежности программ |
|
Особенности внешних абонентов и пользователей результатов программ |
Структурное проектирование программ и данных |
Методы использования избыточности |
|
Требования к показателям надежности |
Структурное проектирование программных модулей |
Временной
Информационной Программной |
|
Инерционность внешних абонентов |
Структурное проектирование взаимодействия модулей |
Методы контроля программ, данных и вычислительного процесса |
|
Необходимое время отклика на входные данные |
Структурирование данных |
Предпусковой контроль
Оперативный контроль |
|
Искажения исходных данных |
Тестирование программ |
Методы программного восстановления |
| Искажения данных поступающих от человека |
Детерминированное тестирование |
Восстановление текстов программ Исправление данных |
| Искажения данных поступающих по телекодовым каналам связи |
Статистическое тестирование |
Корректировка вычислительного процесса |
| Искажения данных в процессе накопления и хранения в ЭВМ |
Динамическое тестирование и контроль пропускной способности в реальном времени |
Методы испытаний на надежность Форсированные испытания |
|
Ошибки в программах и их проявление |
Испытания в нормальных условиях эксплуатации | |
|
Статистические характеристики ошибок и искажений: |
Расчетно-экспериментальные методы определения надежности | |
| Программ |
Методы обеспечения надежности при сопровождении |
|
| массивов данных | Обеспечение сохранности программ эталонных версий | |
| Вычислительного процесса | Обеспечение корректности внесения изменений и развития версий |
Отказы при функционировании программ возникают вследствие взаимодействия данных и ошибок в программе. Характеристики ошибок в значительной степени определяются методами проектирования программ.Активные методы обнаружения и локализации программных ошибок базируются на тестировании различных видов: детерминированном, статистическом и динамическом. Однако все виды тестирования не гарантируют отсутствие ошибок в комплексах программ и высокую надежность. Для этого применяются методы контроля и обеспечения надежности программ путем использования программной, временной и информационной избыточности.
Ситуации проявления ошибок при исполнении программ можно разделить на три группы:
n Отказ — искажения вычислительного процесса, данных или программ, вызывающие полное прекращение выполнения функций системой;
n Искажения, кратковременно прерывающие функционирование системы — отказовые ситуации или сбои, характеризующиеся быстрым восстановлением без длительной потери работоспособности;
n Искажения, мало отражающиеся на вычислительном процессе — сбои и искажения, не создающие отказовые ситуации.
Основным показателем при классификации конкретных видов искажений является возможное время восстановления и степень проявления последствий произошедшего сбоя или отказовой ситуации:
n зацикливание, т.е. последовательная повторяющаяся реализация некоторой группы команд, не прекращающаяся без внешнего (для данного цикла) вмешательства;
n останов исполнения программ и прекращение решения функциональных задач;
n полная самоблокировка вычислительного процесса (клинч) из-за последовательного прекрестного обращения разных программ к одним и тем же ресурсам ЭВМ без освобождения ранее занятых ресурсов;
n прекращение или значительное снижение темпа решения некоторых задач вследствие перегрузки ЭВМ по пропускной способности;
n значительное искажение или полная потеря накопленной информации о текущем состоянии управляемого процесса или внешних абонентов;
n искажение процессов взаимного прерывания программ, приводящее к блокировке возможности некоторых типов прерываний.
Методы программного восстановления.
Выбор метода оперативного восстановления происходит в условиях неопределенности сведений о характере отказовой ситуации и степени ее влияния на работоспособность программ.
Каждый метод восстановления характеризуется следующими статическими параметрами:
n вероятность полного восстановления нормального функционирования комплекса программ при данном методе (p3);
n затратами ресурсов ЭВМ на проведение процедуры восстановительных работ выбранным методом (b3);
n длительностью проведения работ по восстановлению — суммарным временем выбора метода восстановления и временем его реализации(t3)
Показатели восстановления p3и t3непосредственно влияют на показатели надежности функционирования комплекса программ. Если операции по восстановлению работоспособности комплекса программ при отказовой ситуации полностью завершаются за время меньше tд и после этого продолжается нормальное функционирование, то происшедшее искажение в работе программ не учитывается как отказ и не влияет на основные показатели надежности.
Процесс функционирования комплекса программ на однопроцессорной ЭВМ в реальном масштабе времени с учетом операций контроля и восстановления можно представить графом состояний, дуги которого соответствуют возможным переходам между состояниями за некоторый интервал времени.
Основные состояния следующие:
0- состояние соответствует нормальному функционированию работоспособного комплекса программ при полном отсутствии искажений — полезная работа;
1- состояние имеет место при переходе комплекса программ в режим контроля функционирования и обнаружения ошибок — состояние контроля;
2- состояние соответствует функционированию программ при наличии искажений, не обнаруженных средствами контроля — состояние необнаруженного искажения данных или вычислительного процесса, которое, в частности может соответствовать отказу;
3- состояние характеризуется функционированием группы программ восстановления режима полезной работы и устранения последствий искажения — восстановление после действительного искажения;
4- состояние соответствует также восстановлению режима полезной работы, но после ложного обнаружения проявления искажения, когда в действительности состояние полезной работы не нарушалось — восстановление после ложной тревоги.
Переходы между состояниями могут происходить в некоторых направлениях случайно или коррелированно с предыдущем переходом (рис. 5.3, диаграмма 1 ). Пребывание во всех состояниях, кроме нулевого, сопряжено с затратами производительности ЭВМ на выполнение операций, не связанных с прямыми функциональными задачами, и может рассматриваться как снижение общей эффективности комплекса программ и производительности ЭВМ. При определении показателей надежности учитывается только такая цепочка последовательных состояний вне работоспособности, которая оказывается протяженности больше. Все остальные более короткие выходы из нулевого состояния не влияют на показатели надежности.
Методы испытаний программ на надежность.
В теории надежности разработан ряд методов, позволяющих определить характеристики надежности сложных систем. Эти методы можно свести к трем основным группам:
n прямые экспериментальные методы определения показателей надежности систем в условиях нормального функционирования;
n форсированные методы испытаний реальных систем на надежность;
n расчетно-экспериментальные методы, при использовании которых ряд исходных данных для компонент получается экспериментально, а окончательные показатели надежности систем надежности рассчитываются с использованием этих данных.
Прямые экспериментальные методы определения показателей надежности программ в нормальных условиях функционирования в ряде случаев трудно использовать из-за больших значений времени наработки на отказ (сотни и тысячи часов).
Форсированные методы испытаний надежности программ значительно отличаются от традиционных методов испытаний аппаратуры. Форсирование испытаний может выполняться путем повышения интенсивности искажений исходных данных, а также специальным увеличением загрузки комплекса программ выше нормальной.
Особым видом форсированных испытаний является проверка эффективности средств контроля и восстановления программ, данных и вычислительного процесса. Для этого имитируются запланированные экстремальные условия функционирования программ, при которых в наибольшей степени стимулируется работа испытываемого средства программного контроля или восстановления.
Расчетно-экспериментальные методы . При анализе надежности программ применение расчетно-экспериментальных методов более ограничено, чем при анализе аппаратуры. Это обусловлено неоднородностью надежностных характеристик основных компонент: программных модулей, групп программ, массивов данных и т.д. Однако в некоторых случаях расчетным путем можно оценить характеристики надежности комплексов программ. Сочетание экспериментальных и аналитических методов применяется также для определения пропускной способности комплекса программ на конкретной ЭВМ и влияние перегрузки на надежность его функционирования.
Методы обеспечения надежности комплексов программ при сопровождении.
В этой стадии жизненного цикла программ расширяются условия их использования и характеристики исходных данных, вследствие чего могут потребоваться изменения в программах. Для сохранения и улучшения показателей надежности комплексов программ в процессе длительного сопровождения необходимо четко регламентировать передачу комплексов программ пользователям. Целесообразно накапливать необходимые изменения в программах и вводить их группами, формируя очередную версию комплекса программ с измененными характеристиками. Версии комплекса программ можно разделить на эталонные и пользовательские (или конкретного объекта).
Эталонные версииразвиваются, дорабатываются и модернизируются основными разработчиками комплекса программ или специалистами, выделенными для их сопровождения. Они снабжаются откорректированной технической документацией, полностью соответствующей программам, и точным перечнем всех изменений введенных в данную версию по сравнению с предыдущей.
Пользовательские версии. Необходимы также общие проверки работоспособности и сохранности всех программ комплекса. Для корректности выполнения изменений они снабжаются методиками проверки и правилами подготовки контролирующих тестов..Целесообразно ограничивать доступ широких пользователей к технологической документации, хранящей подробные сведения о содержании и логике функционирования программ. Такие меры в некоторой степени предотвращают возможность резкого ухудшения показателей надежности.