S: Назовите
ученого, описавшего закон пирамиды
энергий
+: Линдеман
S: Применение в
экологических исследованиях методов
математической статистики определяется
тем, что…
+: экосистемы
являются стохастически-детерминированными
системами
-: экосистемы
являются динамическими системами
-: экосистемы
являются саморегулирующими системами
S: Первичная
статистическая обработка данных
включает в себя следующие процедуры…
+: отображение
переменных в той или иной шкале
+: статистическое
описание исходных совокупностей
(определение пределов варьирования,
построение эмпирических распределений)
+: восстановление
пропущенных наблюдений
+: унификация типов
переменных (перевод признаков в одну
шкалу)
+: анализ законов
распределений
-: построение
динамической модели
-: проверка модели
на адекватность
S: Для характеристики
номинальных данных наиболее часто
используются…
+: пропорция и
процентное отношение
-: абсолютные
величины
-: логарифмы чисел
S: Порядковые
шкалы соответствуют таким качественным
переменным, для которых характерна …
+: упорядоченность,
-: непрерывность
-: дискретность
S: Флуктуирующая
асимметрия – это …
+: мелкие ненаправленные
нарушения гомеостаза развития, являющиеся
ответом организма на состояние окружающей
среды.
-: точное соответствие
между правой и левой половинами тела
-: отклонения в
промерах между правой и левой половинами
тела
S: Для анализа
состояния наземных экосистем по методу
флуктуирующей асимметрии используются
следующие виды-индикаторы…
+: береза повислая
-: тополь
-: ель
+: полевая мышь
-: белка
S: Для состояния
водных экосистем по методу флуктуирующей
асимметрии используются следующие
виды-индикаторы …
+: плотва
+: окунь
+: лещ
+: лягушка
-: сом
-: судак
-: уж
S: Для оценки
качества среды по методу флуктуирующей
асимметрии используется
+: пятибалльная
шкала
-: десятибалльная
шкала
-: восьмибалльная
шкала
S: Статистическая
значимость различий между выборками
по величине интегрального показателя
стабильности развития определяется
по…
+: по t — критерию
Стьюдента
-: по критерию
Фишера
-: по критерию хи
-квадрат
S: Правильные
значения, оценивающие показатель
плотности популяции следующие…
+: кг/га
-: экз/м
+: экз/л
+: экз/кв.м
+: экз/куб.м
S: Ошибка при
оценке плотности популяции должна
составлять не более…
-: 5%
-: 10%
+: 20%
-: 30%
S: Правильные
значения, оценивающие показатель обилия
популяции следующие…
+: %
+: экз/час
-: штук
-: кг/кв.м
S: Встречаемость
– это…
+: процент пробных
площадок, на которых встречается данный
вид
-: процентное
содержание вида на данной площадке
+: процент пробных
площадок, на которых встречается набор
видов
-: процентное
содержание группы видов на данной
площадке
S: Встречаемость
вида считается высокой, если он
встречается в …
+: 51% площадок
+: 70% площадок
-: 45% площадок
+: 90% площадок
Q: Установите
соответствие между типом распределения
особей в пространстве и значением
индекса Одума
L1: равномерное
R1: IO < 1
L2: случайное
R2: IO = 1
L3: агрегированное
R3: IO > 1
L4: дискретное
R4:
Q: Правильное
соответствие между методом измерения
плотности и категорией организмов, для
которых она рассчитывается следующее…
L1: Тотальный учет
R1: Малоподвижные
животные
L2: Метод мечения
с повторным отловом
R2: Для подвижных
животных
L3: Метод пробных
площадок
R3: Для мелких
неподвижных организмов
L4:
R4: Деревья
S: Репрезентативностью
выборки — это…
+: Степень соответствия
характеристик выборки истинным
характеристикам биологического объекта
-: Степень не
соответствия характеристик выборки
истинным характеристикам биологического
объекта
-: Точность
исследования
-: Способ, когда
изучается лишь небольшая группа объектов
Q: Правильное
соответствие между вариантом размещения
площадок и правилами их отбора для
достижения репрезентативности выборок
следующее…
L1: Случайный отбор
R1: Независимость
каждой пробы от всех остальных
L2: Систематический
или регулярный отбор
R2: Места расположения
площадок определяются по заранее
намеченному плану
L3: Стратифицированный
отбор образцов
R3: Сначала отбирают
по относительно большие группы (массивы
проб), а из них осуществляют отбор
нескольких проб для обследования
S: Фиксированный
размер площадок важен при…
+: оценке
биоразнообразия
-: при описании
растительности на фитоценотическом
уровне
-: при описании
мелких неподвижных организмов
-: при описании
деревьев
S: Назовите автора
следующего принципа:Скопление особей
популяции, с одной стороны, усиливает
конкуренцию между ними за пищевые
ресурсы и жизненное пространство, с
другой – приводит к повышению способности
группы в целом к выживанию
+: Олли
-: Барри Коммонер
-: Шельфорд
-: Дарвин
S: Гипотезе
Вильямса заключается в том, что…
+: при возрастании
обследуемой площади увеличивается
числа видов
-: при возрастании
обследуемой площади числа видов
уменьшается
-: зависимость
между числом видов и обследованной
площадью выражается экспоненциальной
кривой
S: Математическим
описанием связи число видов — площадь
чаще всего является …
+: степная функция
-: экспоненциальная
функция
-: парабола
-: синусоидальная
кривая
Q: Правильное
соответствие между встречаемостью и
размером пробы…
L1: либо незначительная,
либо высокая встречаемость, а видов с
встречаемостью 40 — 60% очень мало
R1: удачный подбор
размера пробы
L2: большинство
видов встречается во всех пробах
R2: размер пробы
слишком велик
L3: встречаемость
большинства видов низка
R3: размер пробы
мал
Q: Соответствие
между шкалой измеряемого признака и
показателем средней тенденции …
L1: Номинальная
шкала
R1: Мода
L2: Порядковая
(ранговая) шкалы
R2: Медиана
L3: Интервальная
шкала
R3: Среднее
арифметическое
S: К качественным
измерениям признаков относятся следующие
шкалы…
+: номинальная
шкала
+: ранговая шкала
-: интервальная
шкала
S: Из всех
перечисленных статистических
характеристик параметров популяции
меры вариации следующие…
-: средняя
арифметическая
+: дисперсия
+: коэффициент
вариации
+: стандартное
отклонение
-: мода
-: медиана
S: Величина ошибки
измерения параметров популяции зависит
от…
+: изменчивости
признака
+: размеров выборки
-: численности
популяции
-: величины
генеральной совокупности
S: Какое из этих
исследований должно проводиться
раньше?…
+: Исследование
особенностей распределения особей в
пределах сообщества
-: Определения
численности
S: Больше проб
или их размеров требуется в учете…
-: случайного
распределения организмов
+: контагиозного
распределения организмов
S: Примерами
равномерного распределения могут
быть…
+: деревья в лесу
+: посадки деревьев
в парках
+: кустарники в
пустыне
-: личинки мучных
хрущаков
S: Адекватность
моделей распределения популяций
проверяют с помощью критерия…
-: Стьюдента
+: хи-квадрат
-: Фишера
S: Наиболее
пригодной для сравнения видов в
сообществе является…
-: плотность
+: продукция
-: проектное покрытие
-: встречаемость
-: биомасса
Q: Соответствие
между моделью распределения видов в
сообществе и ситуацией, которую она
описывает следующее…
L1: Геометрический
ряд И. Мотомуры
R1: Каждый последующий
вид занимает ровно половину доступного
пространства ниши
L2: Модель
«разломанного стержня» Р. Мак-Артура
R2: Виды разделяют
среду случайно между собой так, что они
занимают неперекрывающиеся ниши
L3: Лог-нормальное
распределение
R3: Ниши многомерны
и перекрываются
S: Ранговое
распределение устанавливает зависимость
между
+: числом особей
каждого вида и числом видов
-: обилием и рангом
вида
+: обилием вида и
рангом вида по обилию
-: числом особей
каждого вида и числом видов
S: В стабильных
ненарушенных сообществах кривая для
численности лежит… кривой для биомассы
-: выше
+: ниже
Q: Правильное
соответствие между объектом и
характеризующим его типом разнообразия
следующее…
L1: Местообитание
или одного сообщество
R1: альфа-разнообразие
L2: Местообитания
или сообщества
R2: бета-разнообразие
L3: Ландшафты
R3: гамма -разнообразие
S: Постоянство –
это…
+: отношение числа
содержащих изучаемый вид выборок (p) к
общему числу выборок (P), выраженное в
процентах
-: отношение числа
особей одного вида (n) к общей численности
особей (N)
-: число особей на
единицу площади или объема
Q: Правильное
соответствие между категорией вида по
степени привязанности к экосистеме и
качественными характеристиками вида
следующее…
L1: характерные
R1: свойственные
исключительно одной экологической
системе и представленные в ней гораздо
обильнее, чем в других экосистемах
L2: преферентные
R2: встречающиеся
в нескольких смежных системах, но
предпочитающих одну из них
L3: чуждые
R3: случайно попавшие
в сообщество, к которому они не принадлежат
L4: индифферентные
R4: способные
существовать с равным успехом во многих
экосистемах
Q: Правильное
соответствие между характеристиками
видового комплекса и значением индекса
доминирования Палия — Ковнацки
следующее…
L1: доминанты
R1: 10 < Di < 100
L2: субдоминанты
R2: 1 < Di < 10
L3: субдоминанты
первого порядка
R3: 0,1 < Di < 1
L4: второстепенные
члены
R4: 0,01 < Di < 0,1
S: Нумерическое
видовое богатство — это…
+: число видов на
строго оговоренное число особей или
на определенную биомассу
-: число составляющих
его видов
-: число составляющих
его особей
S: Нумерическое
видовое богатство применяется если…
+: не имеется полного
списка видов сообщества
+: исследуются
экологические воздействия на сообщества
рыб
+: исследуются
водные объекты
-: имеется полный
список видов сообщества
Q: Правильное
соответствие между постоянством и
категорией вида следующее…
L1: постоянные
R1: более чем в 50%
выборок
L2: добавочные
R2: в 25-50% выборок
L3: случайные
R3: менее чем в 25%
выборок
Q: Введите
правильный ответ
S: Назовите фамилию
ученого, сформулировавшего законы
разнообразия (биоценотические принципы)
+: Тинеман
S: Лучшим среди
индексов, оценивающим доминирование
видов в сообществе считается индекс…
-: Индекс Маргалефа
-: Индекс Шеннона
-: Индекс выровненности
+: Индекс Симпсона
-: Индекс Менхиника
Q: Правильная
последовательность процедур для анализа
данных по разнообразию видов следующая…
1: Формирование
выборок
2: Графический
анализ данных
3: Проверка
эмпирических данных теоретической
модели
4: Расчет индексов
разнообразия
5: Проверка
статистических гипотез значимости
различий между сообществами
S: Для сравнения
с результатами исследований по
разнообразию сообществ других авторов
предпочтительнее использовать…
+: индекса Шеннона
-: индекс Симпсона
-: индекс Маргалефа
S: Индекс Шеннона
может принять следующее значение…
-: 1,1
+: 1,6
-: 10
+: 3,8
S: Индекс
выравненности принимает значения в
промежутке…
+: [0; 1]
-: [0; 2]
-: [-1; 1]
-: [0,5; 1]
-: [1; 3]
V1: {{4}} МОДЕЛИ
ФАКТОРИАЛЬНОЙ ЭКОЛОГИИ
S: Какие по
отношению к массе виды являются лучшими
индикаторами?
+: Более крупные
-: Более мелкие
S: Выравненность
– это…
+: равномерность
распределения видов по их обилию в
сообществе
-: число видов,
отнесенное к определенной площади
-: число видов на
строго оговоренное число особей
S: Законы
толерантности относятся к …
+: физиологическим
факторам
-: к ресурсным
факторам
S: Укажите из
перечисленных факторов антропогенные
стрессоры
+: химическое
загрязнения
-: температурный
режим
+: шум
-: ветер
-: паразитизм
S: Можно ли
утверждать следующее высказывание:«Лимитирующие
факторы для сообщества всегда потребляются
из окружающей среды полностью»
+: да
-: нет
S: Модель роста
растения Полетаева формализует следующий
закон:
+: Закон Либиха
-: Закон Ферхюльста
-: Закон Митчерлиха
S: Кто автор
принципа совокупного действия факторов?
+: Митчерлих
-: Алехин
-: Полетаев
-: Одум
S: Функция
зависимости количественных оценок
характеристик экосистемы от важнейших
экологических факторов называется…
-: функцией
правдоподобия
+: функцией отклика
-: функцией
благополучия
S: Математическим
аппаратом метода функции отклика
является …
+: нелинейный
регрессионный анализ
-: системы
дифференциальных уравнений
-: матричная алгебра
S: В математической
формулировке лимитирующим называется
тот фактор, по которому для достижения
заданного относительного изменения
функции отклика необходимо….
+: минимальное
относительное изменение значения
фактора
-: максимальное
относительное изменение значения
фактора
S: При отсутствии
(или дефиците) кальция многие моллюски
при строительстве своих раковин заменяют
его на стронций. Какую гипотезу
факториальной экологии подтверждает
это наблюдение?
+: Гипотезу
компенсации экологических факторов
-: Гипотезу
незаменимости фундаментальных факторов
-: Принцип совокупности
экологических факторов
S: Одним из
вариантов формализации закона минимума
Либиха является…
+: модель роста
растения Полетаева.
-: модель функции
отклика
-: модель
Ферхюльста-Пирла
S: Основные
процессы превращения вещества и энергии
в растениях, учтенные в модели роста
растения Полетаева следующие…
+: процесс возрастания
биомассы (роста), идущий за счет
фотосинтеза и поглощения веществ из
почвы и атмосферы
+: процесс основного
обмена (дыхания)
-: выделение
продуктов обмена
Q: Правильное
соответствие между степенью толерантности
и приставкой к слову, выражающему
фактор, по отношению к которому выявляется
эта толерантность следующее…
L1: стено-
R1: узкий, тесный
L2: эври-
R2: широкий
L3: поли-
R3: многий,
многочисленный
L4: олиго-
R4: немногий,
незначительный
S: Частная функция
отклика представляет собой…
+: функцию одной
переменной
-: функцию двух
переменных
-: функцию многих
переменных
S: Лучшими
биоиндикаторами являются…
+: Стенотопные виды
-: Эвритопные виды
S: Обобщенной
функцией отклика Fk называется функция….
+: зависимости
значений k-го показателя или процесса
от всех рассматриваемых экологических
факторов
+: представленная
как комбинация частных функций отклика
-: зависимости
значений k-го показателя или процесса
от одного из рассматриваемых экологических
факторов
S: Конкуренция
между двумя популяциями разных видов
возрастает при условии, когда:
-: одна популяция
более многочисленна, чем другая
-: два вида тесно
взаимосвязаны
+: экологические
ниши конкурирующих видов перекрываются
в больших масштабах
-: у видов сходная
плодовитость
S: Что является
более надежным индикатором?
-: Численность
одного вида
+: Численное
отношение разных видов
S: Укажите все
категории экологических ниш
+: пространственная
+: трофическая
+: многомерная
+: фундаментальная
+: реализованная
-: прямоугольная
Q: Укажите
соответствие между термином экологическая
ниша и его автором
L1: Пространственная
ниша
R1: Дж. Гриннел
L2: Тип питания
(место в трофических цепях)
R2: Ч. Элтон
L3: Многомерная
(сумма всех абиотических и биотических
связей)
R3: Дж. Хатчинсон
L4:
R4: Одум
S: Заполнение ниш
происходит по следующей схеме:
-: Крупный сменяет
мелкого
+: Мелкий сменяет
крупного
+: Менее организованный
сменяет высокоорганизованного
-: Высокоорганизованный
сменяет менее организованного
+: Генетически
изменчивый сменяет менее изменчивого
S: Концепция
одномерной иерархической ниши более
актуальна по отношению к …
+: Животному миру
-: Растительному
миру
S: Принцип
классификации сообществ по Браун-Бланке
заключается…
+: В преобразовании
матрицы данных к блочной форме
-: В анализе матрицы
корреляций между видами
Populations
In statistics the term “population” has a slightly different meaning from the one given to it in ordinary speech. It need not refer only to people or to animate creatures – the population of Britain, for instance or the dog population of London. Statisticians also speak of a population of objects, or events, or procedures, or observations, including such things as the quantity of lead in urine, visits to the doctor, or surgical operations. A population is thus an aggregate of creatures, things, cases and so on.
Although a statistician should clearly define the population he or she is dealing with, they may not be able to enumerate it exactly. For instance, in ordinary usage the population of England denotes the number of people within England’s boundaries, perhaps as enumerated at a census. But a physician might embark on a study to try to answer the question “What is the average systolic blood pressure of Englishmen aged 40-59?” But who are the “Englishmen” referred to here? Not all Englishmen live in England, and the social and genetic background of those that do may vary. A surgeon may study the effects of two alternative operations for gastric ulcer. But how old are the patients? What sex are they? How severe is their disease? Where do they live? And so on. The reader needs precise information on such matters to draw valid inferences from the sample that was studied to the population being considered. Statistics such as averages and standard deviations, when taken from populations are referred to as population parameters. They are often denoted by Greek letters: the population mean is denoted by μ(mu) and the standard deviation denoted by ς (low case sigma)
Samples
A population commonly contains too many individuals to study conveniently, so an investigation is often restricted to one or more samples drawn from it. A well chosen sample will contain most of the information about a particular population parameter but the relation between the sample and the population must be such as to allow true inferences to be made about a population from that sample.
Consequently, the first important attribute of a sample is that every individual in the population from which it is drawn must have a known non-zero chance of being included in it; a natural suggestion is that these chances should be equal. We would like the choices to be made independently; in other words, the choice of one subject will not affect the chance of other subjects being chosen. To ensure this we make the choice by means of a process in which chance alone operates, such as spinning a coin or, more usually, the use of a table of random numbers. A limited table is given in the Table F (Appendix), and more extensive ones have been published.(1-4) A sample so chosen is called a random sample.The word “random” does not describe the sample as such but the way in which it is selected.
To draw a satisfactory sample sometimes presents greater problems than to analyse statistically the observations made on it. A full discussion of the topic is beyond the scope of this book, but guidance is readily available(1)(2). In this book only an introduction is offered.
Before drawing a sample the investigator should define the population from which it is to come. Sometimes he or she can completely enumerate its members before beginning analysis – for example, all the livers studied at necropsy over the previous year, all the patients aged 20-44 admitted to hospital with perforated peptic ulcer in the previous 20 months. In retrospective studies of this kind numbers can be allotted serially from any point in the table to each patient or specimen. Suppose we have a population of size 150, and we wish to take a sample of size five. contains a set of computer generated random digits arranged in groups of five. Choose any row and column, say the last column of five digits. Read only the first three digits, and go down the column starting with the first row. Thus we have 265, 881, 722, etc. If a number appears between 001 and 150 then we include it in our sample. Thus, in order, in the sample will be subjects numbered 24, 59, 107, 73, and 65. If necessary we can carry on down the next column to the left until the full sample is chosen.
The use of random numbers in this way is generally preferable to taking every alternate patient or every fifth specimen, or acting on some other such regular plan. The regularity of the plan can occasionally coincide by chance with some unforeseen regularity in the presentation of the material for study – for example, by hospital appointments being made from patients from certain practices on certain days of the week, or specimens being prepared in batches in accordance with some schedule.
As susceptibility to disease generally varies in relation to age, sex, occupation, family history, exposure to risk, inoculation state, country lived in or visited, and many other genetic or environmental factors, it is advisable to examine samples when drawn to see whether they are, on average, comparable in these respects. The random process of selection is intended to make them so, but sometimes it can by chance lead to disparities. To guard against this possibility the sampling may be stratified.This means that a framework is laid down initially, and the patients or objects of the study in a random sample are then allotted to the compartments of the framework. For instance, the framework might have a primary division into males and females and then a secondary division of each of those categories into five age groups, the result being a framework with ten compartments. It is then important to bear in mind that the distributions of the categories on two samples made up on such a framework may be truly comparable, but they will not reflect the distribution of these categories in the population from which the sample is drawn unless the compartments in the framework have been designed with that in mind. For instance, equal numbers might be admitted to the male and female categories, but males and females are not equally numerous in the general population, and their relative proportions vary with age. This is known as stratified random sampling.For taking a sample from a long list a compromise between strict theory and practicalities is known as a systematic random sample.In this case we choose subjects a fixed interval apart on the list, say every tenth subject, but we choose the starting point within the first interval at random.
Unbiasedness and precision
The terms unbiased and precision have acquired special meanings in statistics. When we say that a measurement is unbiased we mean that the average of a large set of unbiased measurements will be close to the true value. When we say it is precise we mean that it is repeatable. Repeated measurements will be close to one another, but not necessarily close to the true value. We would like a measurement that is both accurate and precise. Some authors equate unbiasedness with accuracy,but this is not universal and others use the term accuracy to mean a measurement that is both unbiased and precise. Strike (5) gives a good discussion of the problem.
An estimate of a parameter taken from a random sample is known to be unbiased. As the sample size increases, it gets more precise.
Randomisation
Another use of random number tables is to randomise the allocation of treatments to patients in a clinical trial. This ensures that there is no bias in treatment allocation and, in the long run, the subjects in each treatment group are comparable in both known and unknown prognostic factors. A common method is to use blocked randomisation. This is to ensure that at regular intervals there are equal numbers in the two groups. Usual sizes for blocks are two, four, six, eight, and ten. Suppose we chose a block size of ten. A simple method using Table F (Appendix) is to choose the first five unique digits in any row. If we chose the first row, the first five unique digits are 3, 5, 6, 8, and 4. Thus we would allocate the third, fourth, fifth, sixth, and eighth subjects to one treatment and the first, second, seventh, ninth, and tenth to the other. If the block size was less than ten we would ignore digits bigger than the block size. To allocate further subjects to treatment, we carry on along the same row, choosing the next five unique digits for the first treatment. In randomised controlled trials it is advisable to change the block size from time to time to make it more difficult to guess what the next treatment is going to be.
It is important to realise that patients in a randomised trial are not a random sample from the population of people with the disease in question but rather a highly selected set of eligible and willing patients. However, randomisation ensures that in the long run any differences in outcome in the two treatment groups are due solely to differences in treatment.
Variation between samples
Even if we ensure that every member of a population has a known, and usually an equal, chance of being included in a sample, it does not follow that a series of samples drawn from one population and fulfilling this criterion will be identical. They will show chance variations from one to another, and the variation may be slight or considerable. For example, a series of samples of the body temperature of healthy people would show very little variation from one to another, but the variation between samples of the systolic blood pressure would be considerable. Thus the variation between samples depends partly on the amount of variation in the population from which they are drawn.
Furthermore, it is a matter of common observation that a small sample is a much less certain guide to the population from which it was drawn than a large sample. In other words, the more members of a population that are included in a sample the more chance will that sample have of accurately representing the population, provided a random process is used to construct the sample. A consequence of this is that, if two or more samples are drawn from a population, the larger they are the more likely they are to resemble each other – again provided that the random technique is followed. Thus the variation between samples depends partly also on the size of the sample. Usually, however, we are not in a position to take a random sample; our sample is simply those subjects available for study. This is a “convenience” sample. For valid generalisations to be made we would like to assert that our sample is in some way representative of the population as a whole and for this reason the first stage in a report is to describe the sample, say by age, sex, and disease status, so that other readers can decide if it is representative of the type of patients they encounter.
Standard error of the mean
If we draw a series of samples and calculate the mean of the observations in each, we have a series of means. These means generally conform to a Normal distribution, and they often do so even if the observations from which they were obtained do not (see Exercise 3.3). This can be proven mathematically and is known as the “Central Limit Theorem”. The series of means, like the series of observations in each sample, has a standard deviation. The standard error of the mean of one sample is an estimate of the standard deviation that would be obtained from the means of a large number of samples drawn from that population.
As noted above, if random samples are drawn from a population their means will vary from one to another. The variation depends on the variation of the population and the size of the sample. We do not know the variation in the population so we use the variation in the sample as an estimate of it. This is expressed in the standard deviation. If we now divide the standard deviation by the square root of the number of observations in the sample we have an estimate of the standard error of the mean, ![]() . It is important to realise that we do not have to take repeated samples in order to estimate the standard error, there is sufficient information within a single sample. However, the conception is that ifwe were to take repeated random samples from the population, this is how we would expect the mean to vary, purely by chance.
. It is important to realise that we do not have to take repeated samples in order to estimate the standard error, there is sufficient information within a single sample. However, the conception is that ifwe were to take repeated random samples from the population, this is how we would expect the mean to vary, purely by chance.
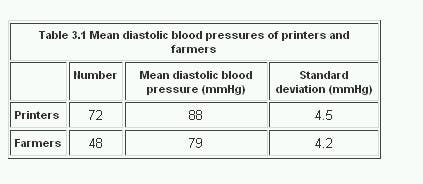
A general practitioner in Yorkshire has a practice which includes part of a town with a large printing works and some of the adjacent sheep farming country. With her patients’ informed consent she has been investigating whether the diastolic blood pressure of men aged 20-44 differs between the printers and the farm workers. For this purpose she has obtained a random sample of 72 printers and 48 farm workers and calculated the mean and standard deviations, as shown in Table 3.1.
To calculate the standard errors of the two mean blood pressures the standard deviation of each sample is divided by the square root of the number of the observations in the sample.
![]()
![]()
These standard errors may be used to study the significance of the difference between the two means, as described in successive chapters
Table 3.1
Standard error of a proportion or a percentage
Just as we can calculate a standard error associated with a mean so we can also calculate a standard error associated with a percentage or a proportion. Here the size of the sample will affect the size of the standard error but the amount of variation is determined by the value of the percentage or proportion in the population itself, and so we do not need an estimate of the standard deviation. For example, a senior surgical registrar in a large hospital is investigating acute appendicitis in people aged 65 and over. As a preliminary study he examines the hospital case notes over the previous 10 years and finds that of 120 patients in this age group with a diagnosis confirmed at operation 73 (60.8%) were women and 47 (39.2%) were men.
If p represents one percentage, 100 p represents the other. Then the standard error of each of these percentages is obtained by (1) multiplying them together, (2) dividing the product by the number in the sample, and (3) taking the square root:
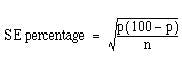
which for the appendicitis data given above is as follows:
Problems with non-random samples
In general we do not have the luxury of a random sample; we have to make do with what is available, a “convenience sample“. In order to be able to make generalisations we should investigate whether biases could have crept in, which mean that the patients available are not typical. Common biases are:
- hospital patients are not the same as ones seen in the community;
- volunteers are not typical of non-volunteers;
- patients who return questionnaires are different from those who do not.
In order to persuade the reader that the patients included are typical it is important to give as much detail as possible at the beginning of a report of the selection process and some demographic data such as age, sex, social class and response rate.
Common questions
Given measurements on a sample, what is the difference between a standard deviation and a standard error?
A standard deviation is a sample estimate of the population parameter; that is, it is an estimate of the variability of the observations. Since the population is unique, it has a unique standard deviation, which may be large or small depending on how variable the observations are. We would not expect the sample standard deviation to get smaller because the sample gets larger. However, a large sample would provide a more precise estimate of the population standard deviation than a small sample.
A standard error, on the other hand, is a measure of precision of an estimate of a population parameter. A standard error is always attached to a parameter, and one can have standard errors of any estimate, such as mean, median, fifth centile, even the standard error of the standard deviation. Since one would expect the precision of the estimate to increase with the sample size, the standard error of an estimate will decrease as the sample size increases.
When should I use a standard deviation to describe data and when should I use a standard error?
It is a common mistake to try and use the standard error to describe data. Usually it is done because the standard error is smaller, and so the study appears more precise. If the purpose is to describe the data (for example so that one can see if the patients are typical) and if the data are plausibly Normal, then one should use the standard deviation (mnemonic D for Description and D for Deviation). If the purpose is to describe the outcome of a study, for example to estimate the prevalence of a disease, or the mean height of a group, then one should use a standard error (or, better, a confidence interval; see Chapter 4) (mnemonic E for Estimate and E for Error).
References
- Altman DG. Practical Statistics for Medical Research.London: Chapman & Hall, 1991
- Armitage P, Berry G. Statistical Methods in Medical Research.Oxford: Blackwell Scientific Publications, 1994.
- Campbell MJ, Machin D. Medical Statistics: A Commonsense Approach.2nd ed. Chichester: John Wiley, 1993.
- Fisher RA, Yates F. Statistical Tables for Biological, Agricultural and Medical Research,6th ed. London: Longman, 1974.
- Strike PW. Measurement and control. Statistical Methods in Laboratory Medicine.Oxford: Butterworth-Heinemann, 1991:255.
Exercises
Exercise 3.1
The mean urinary lead concentration in 140 children was 2.18 mol/24 h, with standard deviation 0.87. What is the standard error of the mean?
Exercise 3.2
In Table F (Appendix), what is the distribution of the digits, and what are the mean and standard deviation?
Exercise 3.3
For the first column of five digits in Table F take the mean value of the five digits and do this for all rows of five digits in the column.
What would you expect a histogram of the means to look like?
What would you expect the mean and standard deviation to be?
1
1. Как организовать и провести популяционное исследование по изучению факторов риска НИЗ Р.А. Потемкина Государственный научно- исследовательский центр профилактической медицины МЗ РФ Ведущий научный сотрудник, Кандидат медицинских наук
2
2 3-й шаг в принятии решений Кратко определить проблему и подходы по ее решению Установить, что известно из научной литературы Выразить проблему в количественных показателях Разработать возможные программы или политику для решения проблемы Разработать план действий для осуществления программы или политики Оценить программу или политику
3
3 Мониторирование показателей в программе CINDI
4
4 Что такое одномоментное эпидемиологическое исследование? Под одномоментным эпидемиологическим или популяционным* исследованием понимается исследование, проводимое на основе случайной** репрезентативной выборки населения *Популяция – группа лиц, определяемая каким-либо общим признаком **Случайная выборка –это такая выборка, при котором каждый индивидуум имеет равную возможность быть отобранным
5
5 Для чего нужна выборка? Популяция большого размера, невозможно обследовать каждого; Правильно сформированная случайная выборка отражает особенности всей популяции (является репрезентативной); На данных полученных из обследования популяции основываются выводы о всей популяции%
6
6 Представительные одномоментные исследования Цель – представить распространенность НИЗ или их факторов риска среди населения на определенный момент времени
7
7 Представительные одномоментные исследования Используют стандартные методы исследования; Проводятся на случайных выборках; Оценивают частоту (распространенность) факторов риска НИЗ; Оценивают показатели среди всего населения
8
8 Распространенность АГ (%), стандартизованной по возрасту (мужчины лет)
9
9 Мониторирующие исследования Позволяют оценить динамику распространенности факторов риска НИЗ Позволяют оценить эффективность профилактических программ
10
10 Динамика среднего САД (мм. рт. ст.) населения г. Электросталь
11
11 Клинические исследования Преимущества: – Подробное изучение болезни; – Проверка этиологических гипотез заболевания; Недостатки – Изучение характеристик лиц, уже имеющих заболевания; – Невозможность сравнения с другими группами населения или популяции в целом; – Невозможно дать характеристику популяции, к которой относятся эти больные.
12
12 Зачем нужны выборочные исследования? Быстрота получение результатов Ниже стоимость Единственный путь получения информации о факторах риска НИЗ Более точные измерения Ошибки выборки могут быть заданы и определены
13
13 Уровень формирования выборки Национальная выборка Выборка, сформированная по территориальному принципу Выборка, сформированная по профессиональному и производственному принципу
14
14 Этапы проведения исследования Подготовка исследования: Планирование: Обоснование необходимости исследования и постановка цели Создание таблиц для занесения результата Определение популяции и размера выборки Выбор метода обследования Подготовка инструментов Обучение персонала Формирование выборки
15
15 Предварительная разработка таблиц: распределение обследованных по уровню факторов риска НИЗ %N %N%N%N%N Низкая физическая активность Ожирение Гиперхолесте- ринемия Курение Артериальная гипертония Всего Факторы риска/Возраст- ные группы
16
16 Определение размера выборки Зависит от распространенности изучаемых факторов риска в популяции Зависит от величины динамики изменения изучаемых факторов риска Зависит от числа изучаемых групп в выборке (возраст, пол, образование и т.п.)
17
17 Определение размера выборки Возраст/ Пол Всего М Ж Всего
18
18 Формирование выборки для проведения телефонного опроса в Москве в 2000 году СтатусРаспределение N*% Лица, не подходящие по возрасту ( 64 лет) ,1 Офисные номера 54 1,8 Лица, отсутствующие на весь период проведения обследования 10 0,3 Число лиц, подлежащих опросу (окончательная выборка) ,8 Всего ,0 N – абсолютное число телефонных номеров Офисные номера Лица, не подходящие по возрасту ( 64 лет) Лица, отсутствуюшие на весь период проведения обследования Число лиц, подлежащих опросу (окончательная выборка)
19
19 Неадекватная выборка – один из самых главных источников ошибок!
20
20 Ошибки измерения Низкий отклик Величина ошибки зависит от частоты признака в выборке в целом Процента отказавшихся от обследования Степени их различий от остальной части выборки по распространению изучаемого показателя Случайная Систематическая Нестандартные исследования Неадекватные методы
21
21 Как достичь высокого отклика? Опрос должен быть Интересным Легким Конфиденциальным Использование СМИ для информирования населения Учреждение призов (лотерея) и т.п.
22
22 Источники формирования списков для выборок Регистр популяции Список избирателей Списки страховых кампаний Списки жителей, прикрепленных к поликлиникам Телефонные номера Другие источники
23
23 Методы формирования выборок Простая случайная выборка* Стратифицированная выборка Кустовая выборка * Простая случайная выборка отличается от стратифицированной выборки
24
24 Методы эпидемиологического исследования* Обследование (измерение) Персональный опрос Почтовый опрос Телефонный опрос Опрос в Интернете Смешанные методы *Для изучения трендов методы исследования должны быть одинаковыми
25
25 Почтовый опрос Рассылка писем День рассылки Конверт с обратным адресом Пояснительное письмо Содержание опросника Напоминания
26
26 Распространенность АГ по данным опроса и обследования населения г. Электросталь в 1997 г.
27
27 Основные принципы разработки опросников Всегда помнить, с какой целью разрабатывается опросник Обдумать, что конкретно нужно выяснить Демографические данные Факторы риска Уровень знаний Выбрать форму, в которой будет проводиться опрос
28
28 Стандартизация исследований Обучить персонал использованию данной методики Разработать инструкции для интервьюеров Контролировать выполнение методики в целом и каждым исследователем в отдельности Документировать все этапы работы Анализировать и представлять результаты в форме, обеспечивающей сопоставимость с результатами аналогичных работ
29
29 Этапы проведения исследования Проведение исследования Ввод и обработка данных Анализ и интерпретация результатов Составление отчета ИСПОЛЬЗОВАНИЕ РЕЗУЛЬТАТОВ
Введение
Определение флуктуирующей асимметрии (незначительные ненаправленные отличия в проявлении признаков на симметричных сторонах биологического объекта), также как и ее статистическая характеристика (распределение отличия сторон имеет нулевое среднее значение и подчиняется нормальному закону), говорит о стохастичном характере этого явления. Показатели асимметрии характеризуют случайную изменчивость развития в пределах нормы реакции особи и используются для характеристики «стабильности развития» и «онтогенетического шума» (Thoday, 1956; Soule, 1967; Рalmer, Strobeck, 1986, 1992; Захаров, 1987, 2000; Mitton, 1993; Рalmer, 1994). Считается, что данная форма асимметрии показывает относительную неэффективность организменных систем контроля процессов развития (Palmer, 1996; Leung, Forbes, 1997). Уровень асимметрии используют не только для описания процессов развития отдельных особей, но и их групп. Показатели асимметрии применяют при оценке состояния природных популяций в популяционной биологии (Захаров, 1987), для изучения микроэволюционных преобразований (Soule, 1967; Захаров, 2001), для определения качества среды в целях биомониторинга (Palmer, Strobeck, 1986; Методические…, 2003) и т. д. Однако результаты, получаемые при изучении закономерностей в изменении величины флуктуирующей асимметрии, нередко противоречат друг другу. Например, показатели асимметрии рекомендуется использовать в качестве индикаторов отклонения условий среды от оптимальных значений (Методические…, 2003). Считается, что чем сильнее негативное (стрессовое) воздействие, тем больше величина флуктуирующей асимметрии как в природных популяциях, так и в контролируемых лабораторных группах особей (Захаров, 1987, 2001; Parsons, 1992; Clarke, 1993; Naugler, Leech, 1994; Kozlov et al., 1996). Однако данная закономерность не всегда подтверждается эмпирическими данными (Clarke, McKenzie, 1992; Graham, Freeman, Emlen, 1993; Manning, Chamberlain, 1993; Zvereva et al., 1997; Kellner, Alford, 2003; Гилева и др., 2007). Поэтому результаты, получаемые при анализе изменения величины асимметрии, рекомендуется подтверждать традиционными методами мониторинга состояния природных популяций и среды (Leary, Allendorf, 1989; Graham et al., 1993 ). Одна из актуальных проблем практического использования уровня флуктуирующей асимметрии — выбор нужного метода ее оценки с последующей интерпретацией получаемых на ее основе результатов (Palmer, Strobeck, 1986). В данной статье приводится краткий обзор наиболее распространенных и используемых в настоящее время показателей и индексов асимметрии, описывается их многообразие, характеризуются статистические и индикационные свойства некоторых оценок асимметрии, включая их нормальную изменчивость.
Аналитический обзор
«Удостоверение» флуктуирующей асимметрии
Статистическая характеристика флуктуирующей асимметрии проявляется как нормальное для метрических, и биномиальное для меристических признаков распределение отличия сторон (Lij – Rij) с нулевым средним значением (M(Lij – Rij)= 0) (рис. 1, А). Данный тип асимметрии установлен для многих билатеральных характеристик особей, включая размеры и строение частей скелета и черепа млекопитающих (Leamy, 1992; Захаров, 2001; Гилева и др., 2007) и птиц, признаки ящериц (Гелашвили и др., 2004) и рыб (Методические…, 2003), характеристики крыльев насекомых (Van Valen, 1962; Mason et al., 1967), антенн диптер, губных щупальцев и сифонных сосочков пресноводных моллюсков (Palmer, Strobeck, 1986), признаки вегетативных и генеративных органов сосудистых растений (Sakai, Shimamoto, 1965; Kozlov et al., 1996, 2002) и т. д.
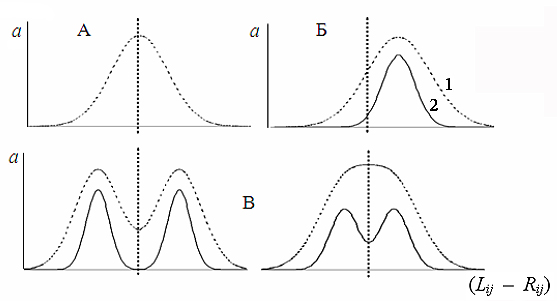
Рис. 1. Формы билатеральной асимметрии пластических признаков (Palmer, Strobeck, 1992): “A” – флуктуирующая асимметрия, “Б” – направленная асимметрия, “В” – антисимметрия; 1 – проявление фенотипа, 2 – изменчивость генотипа; a – частота. (Lij – Rij) – отличие в величине j‑го признака (j = 1, 2… m) на левой (Lij) и на правой (Rij) сторонах тела i-й особи (i = 1, 2… n)
Fig. 1. Forms of bilateral asymmetry of plastic signs (Palmer, Strobeck, 1992): “A” – fluctuating asymmetry, “Б” – directed asymmetry, “В” – anti-symmetry; 1 – phenotype manifestation, 2 – genotype variability; a – frequency. (Lij – Rij) – difference in j-sign value (j = 1, 2… m) on the left (Lij) and on the right (Rij) body sides of i-individual (i = 1, 2… n)
В отличие от флуктуирующей, направленная асимметрия и антисимметрия имеют адаптивное значение и наследственно детерминированы. При направленной асимметрии (преобладание выраженности признака на одной из сторон тела особей в выборке) средняя арифметическая нормального (биномиального) распределения разности сторон (Lij – Rij) не равна нулю (M(Lij – Rij) ≠ 0; рис. 1, Б). В качестве образца направленной асимметрии приводят асимметрию расположения сердца млекопитающих, лево- и правостороннюю асимметрию в строении тела камбалообразных, закрученность раковины у брюхоногих моллюсков и т. д. (Van Valen, 1962; Soule, 1967). Антисимметрии присуще бимодальное распределение разности сторон или распределение с эксцессом меньше нормального при нулевом среднем значении M(Lij – Rij) = 0 (рис. 1, В). Экстремальные формы антисимметрии можно наблюдать на примере сигнальных клешней крабов Uca sp. (Захаров, 1987; Palmer, Strobeck, 1992), когда одна клешня намного больше, чем другая, но «правши» и «левши» попадаются примерно с одинаковой частотой у всех видов.
Объединение нескольких форм асимметрий или нескольких выборок с одной и той же формой асимметрии, но разной степенью ее проявления, приводят к формированию сложных видов распределения показателя (Lij – Rij) (рис. 2).
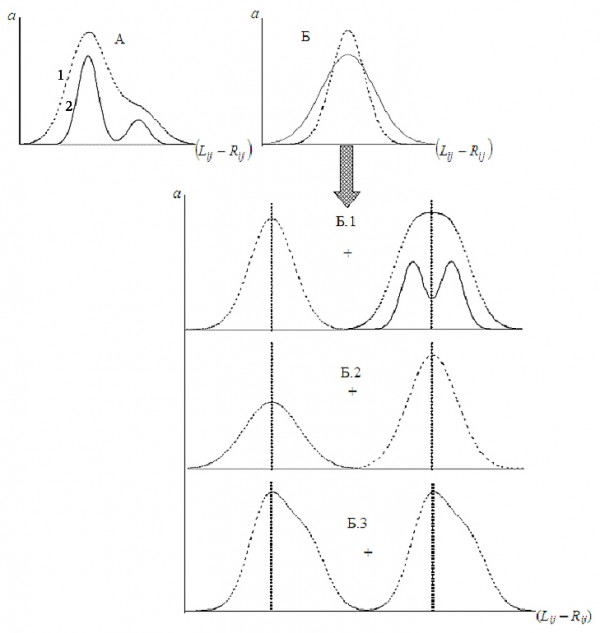
Рис. 2. Сложные виды распределения показателя отличия сторон (Palmer, Strobeck, 1992): “А” – асимметрия и “Б” – эксцесс распределения и причины его возникновения; 1 – проявление фенотипа, 2 – изменчивость генотипа; a – частота
Fig. 2. Complicated types of distribution of side difference indicator (Palmer, Strobeck, 1992): “A” – asymmetry and “Б” – an excess of distribution and the causes of its emergence; 1 – phenotype manifestation, 2 – genotype variability; a – frequency
Асимметричное распределение отличия сторон может возникать, если в выборке особей с флуктуирующей асимметрией присутствует незначительная доля вариант с направленной асимметрией (рис. 2, А). Протяженность и направление скоса сложных распределений будет зависеть от величины направленной асимметрии и антисимметрии, направления асимметрий, относительной доли разных форм асимметрий в смешанной выборке.
Если признаки, распределение отличия сторон которых асимметрично или с отрицательным эксцессом, обычно исключаются из анализа, то с положительным эксцессом активно используются (Polak, 1993; Leung, Forbes, 1997) без рассмотрения его происхождения. Тем не менее распределение показателя (Lij – Rij) с эксцессом больше нормального (рис. 2, Б) может проявляться как минимум в результате четырех различных причин (Palmer, Strobeck, 1992; Leung, Forbes, 1997):
- Выборка включает две группы вариант: для первой (большинство) характерна только флуктуирующая асимметрия, для второй дополнительно отмечается наличие антисимметрии (рис. 2, Б.1).
- Выборка включает две группы вариант: для первой характерен высокий уровень флуктуирующей асимметрии, для второй – низкий (рис. 2, Б.2).
- Статистические особенности распределения самого признака как на левой, так и на правой сторонах тела организма (рис. 2, Б.3).
- Высокая доля в выборке симметричных особей ((Lij – Rij) ≈ 0), т. е. в случае «оптимального» фенотипа.
Флуктуирующая асимметрия составляет около 1% (Palmer, 1996) от величины признака и 2—25 % (Mason et al., 1967; Зорина, 2009) от общей фенотипической его изменчивости, что затрудняет ее выявление. Более того, в общую величину изменчивости асимметрии могут вносить существенный вклад не только наличие генетически детерминированной асимметрии, но и ошибки измерения. По некоторым данным, на долю ошибки измерения метрических и меристических признаков рыб приходится 10—22 % от общей изменчивости показателей асимметрии (Ames et al., 1979), для признаков вегетативных органов березы повислой и пушистой доля составляет от 4 до 12 % (Зорина, 2009), у дентальных признаков мелких млекопитающих – до 11—25 % (Bader, 1965) и до 33—76 % у признаков пятнистости и длины крыльев бабочек нимфалид (Mason et al., 1967). Ошибки измерений сказываются на показателях асимметрии и могут служить причиной появления достоверных отличий между выборками.
Методические проблемы
Величина флуктуирующей асимметрии обычно очень мала по сравнению с общей фенотипической изменчивостью признаков и любая стохастичность, дополнительно привнесенная в процессе получения и обработки данных, будет оказывать значительное влияние на биологические выводы. Все разнообразие методических проблем, связанных с применением флуктуирующей асимметрии, можно свести к следующим:
- Выбор биообъектов, их признаков и комплексов признаков.
- Доказательство флуктуирующего характера асимметрии с последующей отбраковкой признаков.
- Выбор показателей и индексов асимметрии.
- Выбор параметрических или непараметрических критериев, проведение статистического анализа и интерпретация получаемых на его основе результатов.
- Выявление закономерностей в изменении величины асимметрии.
Выбор биообъектов, их признаков и комплексов признаков определяются в основном целями и задачами конкретного исследования. Широко используются билатеральные признаки: метрические (расстояние между фиксированными точками, длина, ширина, угол и пр.), их индексы (отношение ширины к длине и пр.), меристические (многие краниологические признаки; особенности жилкования крыльев насекомых и т.д.), качественные (наличие или отсутствие асимметричного проявления признака). Для более надежной характеристики процессов развития целого объекта используют данные по асимметрии нескольких его признаков (Van Valen, 1978; Mitton, 1993; Захаров, 2000; Гелашвили и др., 2004; Трубянов, 2010).
При доказательстве флуктуирующего характера асимметрии признака проводят проверку на наличие других форм асимметрии, оценивают долю ошибки измерения в общей морфологической изменчивости, устанавливают зависимость величины асимметрии от размера признака. При наличии направленной асимметрии, антисимметрии или значительной доли ошибки измерения, признаки предлагается удалять из анализа флуктуирующей асимметрии. С увеличением размера объекта может увеличиваться и величина асимметрии. Сильная «размер-зависимость» оказывает влияние как на форму распределения значений асимметрии, так и на статистические характеристики выборки (Гелашвили и др., 2004), поэтому для ее учета в формулы показателей асимметрии вводят разные способы нормирования.
Особое место занимает проблема разнообразия показателей и индексов асимметрии (способов количественной оценки величины асимметрии биообъекта). Еще в 1986 году A. R. Palmer и C. Strobeck (1986) обобщили информацию по 22 показателям асимметрии, которые свели к 9 основным. В дальнейшем число показателей асимметрии отдельных признаков и интегральных индексов асимметрии комплекса признаков значительно возросло. Нередко в одной работе применяют сразу несколько способов оценки (Pankakoski, 1985; Kimball, 1997; Kellner, Alford, 2003), результаты статистического сравнения по которым не всегда совпадают. Публикуются также специализированные обзоры существующих и предлагаемых показателей и индексов (Кожара, 1985; Zhivotovsky, 1992; Palmer, Strobeck, 2003; Гелашвили и др., 2004).
Для установления различий между выборками и выявления закономерностей в изменении величины асимметрии часто используют сравнительный, регрессионный и корреляционный анализы. Выбор параметрических или непараметрических критериев должен определяться типом распределения используемых показателей. Иногда применяют различные дополнительные преобразования для перевода ненормально распределенных показателей в форму нормального распределения (например, логарифмические трансформации). Распределения многих показателей и индексов асимметрии, как правило, не подчиняются нормальному закону, поэтому для их сравнения приходится использовать непараметрические методы статистики (Гелашвили и др., 2004), имеющие меньшую мощность, чем параметрические (Урбах, 1964).
Модель изменчивости билатерального признака
A. R. Palmer и C. Strobeck (1986, 1992) предложили простую алгебраическую модель (без учета ошибки измерения) для иллюстрации того, за какую долю фенотипической изменчивости билатерального признака отвечает флуктуирующая асимметрия:
Rij = Mj + sij + Dj / 2 · Aij + αij / 2 + rij и Lij = Mj + sij – Dj / 2 · Aij – αij/2 + lij,
где Mj = (∑Rij + ∑Lij) / 2n – популяционная средняя величина признака, –Sj / 2 < sijSj / 2 – нормальная изменчивость размера признака (генетическая или средовая), Dj = (∑(i=1→n)(Lij – Rij)) / n – популяционная оценка направленной асимметрии и ее изменчивости αij, Aij – уровень антисимметрии, который имеет значение от +1 до –1 с вероятностью p (может изменяться от 0 до 1) и q = 1 – p.
Когда антисимметрия отсутствует, p = 1, когда антисимметрия присутствует и соотношение особей с преобладанием L и R примерно одинаково, тогда p = q = 0.5 и т. д. Отсюда среднее значение M(Aij) = 2p – 1 с бимодальной генетической или средовой изменчивостью S(Aij) = 4pq. Индексы rij и lij характеризуют процессы развития правой и левой сторон.
При наличии зависимости между величиной флуктуирующей асимметрии и размером признака, модель будет выглядеть следующим образом:
Rij = Mj + sij + Dj / 2 · Aij + αij / 2 + (K(Mj + sij)(rij)) и Lij = Mj + sij – Dj / 2 · Aij – αij / 2 + (K(Mj + sij)(lij)),
где К – константа пропорциональности.
Формула дает возможность наглядно представить компоненты изменчивости, которые будут входить в величину разности сторон (Rij – Lij) = DjAij + αij + rij – lij. Следует отметить, что при введении поправки на направленность асимметрии сохраняется соответствующая ей компонента αij. При отсутствии генетически детерминированных форм асимметрий, показатель отличия сторон будет характеризовать только флуктуирующую асимметрию. При наличии «масштабного эффекта» показатель разности сторон будет включать зависимость уровня асимметрии от величины признака (Rij – Lij) = [K(Mj + sij)( rij – lij)].
В моделях представлены все основные компоненты фенотипической изменчивости, которые могут оказывать влияние на распределение показателя отличия сторон, кроме ошибки измерения. Флуктуирующая асимметрия пластических признаков обнаруживается в форме нормального распределения разности между промерами сторон признака (Rij– Lij), при этом показатели асимметрии, эксцесса и среднее значение равны нулю (Van Valen, 1962). Для проверки распределения на нормальность предлагается использовать несколько критериев, например, Колмогорова – Смирнова или χ2 Пирсона, а при проверке на значимость эксцесса и антисимметрии – t-Стьюдента. Для выявления направленной асимметрии можно провести сравнение величины признака на левой и правой сторонах. В случае нормального распределения признака используют, например, критерий t-Стьюдента. Если распределение признаков не подчиняется нормальному закону, то сравнение проводят с помощью непараметрических критериев (Уилкоксона – Манна – Уитни, Уайта и т. д.). Также возможно сравнение левой и правой сторон по частотному распределению признака, например с применением критерия χ2. Индикатором антисимметрии служит отрицательный эксцесс или бимодальность (Palmer, Strobeck, 1992; Developmental…, 2003; Гелашвили и др., 2004).
Другой способ верификации флуктуирующего характера асимметрии основан на анализе морфологической изменчивости билатерального признака и заключается в декомпозиции ее дисперсии с помощью дисперсионного анализа или теста ANOVA. A. R. Palmer и C. Strobeck (1986) подробно рассмотрели процесс декомпозиции для случаев, когда есть возможность оценить все компоненты изменчивости, то есть когда стабильность развития одного и того же генотипа может быть оценена по нескольким онтогенетически эквивалентным особям или частям (несколько оценок отличия сторон для одного и того же генотипа). Такое возможно в двух случаях: 1) когда несколько особей имеют идентичный генотип, что происходит при образовании клонов у партеногенетических особей (редкое явление); 2) когда у особи присутствуют два или более гомологичных органов (колониальные беспозвоночные или растения).
Модель общей изменчивости морфологического признака растений с несколькими онтогенетически эквивалентными органами – метамерами (например, листья, иголки и т. д.) имеет следующие компоненты:
MSобщ.= MSг + MSс + MSвнутри,
где MS – это соответствующая компонента дисперсии (средний квадрат) или S2.
Достоверное влияние фактора «сторона» (MSс) свидетельствует о направленной асимметрии. Значимость фактора «генотип» (MSг) говорит о влиянии размера признака (особи) на величину отличия сторон, что указывает на необходимость учитывать масштабный эффект. Достоверное взаимодействие между факторами (MSгс) указывает на наличие антисимметрии. Случайная компонента дисперсии MSвнутри и представляет собой флуктуирующую асимметрию. Получается, что в рамках теста ANOVA проводится анализ компонентов морфологической изменчивости, характеристика их соотношения и значимости, а также оценка самой флуктуирующей асимметрии MSвнутри = faj. Сравнение выборок по данному показателю асимметрии группы особей по одному признаку, проводится с помощью параметрического критерия Фишера. A. R. Palmer и C. Strobeck (1986) отмечают высокую точность и надежность данного показателя (наиболее высокую из 22 рассмотренных ими способов оценки асимметрии) при выявлении отличий между выборками.
Однако у большинства организмов (особенно животных) нет идентичных органов, на основе которых можно было бы получить несколько оценок показателя отличия сторон признака (Rij– Lij) для характеристики одного и того же генотипа. В случае когда один генотип соответствует одной особи и одной оценке разности между промерами сторон признака, для характеристики компонентов морфологической изменчивости признака используется двухфакторный дисперсионный анализ без повторностей:
MSобщ.= MSг + MSс + MSпогрешн. Изменчивость, обусловленная взаимодействием факторов, будет объединена со случайной компонентой дисперсии, и для выявления антисимметрии потребуются дополнительный анализ распределения показателя отличия сторон (в частности, проверка на значимость эксцесса или бимодальности). Если антисимметрия не будет доказана, показателем флуктуирующей асимметрии выступит компонента дисперсии «погрешность» MSпогрешн = faj.
Если есть повторные промеры признака на каждой стороне, то с помощью дисперсионного анализа также можно оценить долю изменчивости, которая приходится на ошибку измерения. При этом формируется таблица двухфакторного равномерного дисперсионного комплекса с двукратной повторностью (повторные промеры признака на каждой стороне). Таблица включает две градации по фактору «сторона» (левая и правая стороны) и n (количество особей в выборке) градаций по фактору «генотип». Тогда декомпозиция общей морфологической изменчивости признака примет следующий вид: MSобщ.= MSг + MSс + MSвзаим + MSвнутри. При этом показателем флуктуирующей асимметрии выступает дисперсия, обусловленная взаимодействием факторов MSвзаим = faj (если нет антисимметрии), а ошибка измерения представляет собой корень квадратный из случайной компоненты дисперсии √(MSвнутри) = ОИj (Гилева и др., 2007).
Для того чтобы понять, какая доля в изменчивости показателя асимметрии имеет методическую природу, а какая действительно обусловлена биологически, ошибки измерения рекомендуется оценивать в каждом исследовании. О значимости ошибки измерения обычно судят по отношению показателей асимметрии faj и ошибки ОИj. Согласно A. R. Palmer и C. Strobeck (2003) необходимо, чтобы средняя абсолютная разность между промерами сторон признака превышала ошибку измерения хотя бы двукратно. Ошибку предлагается отнимать от оценок асимметрии (Palmer, Strobeck, 1986). Другие исследователи считают, что величина ошибки измерения «укладывается в рамки допустимого», если между двумя выборками показателей асимметрии, полученными на основе повторных промеров, нет достоверных отличий (Swaddle, Witter, 1997). Иногда для оценки значимости ошибки измерения вычисляют коэффициент корреляции между выборками повторных промеров, высокая величина которого (r > 0.95) считается удовлетворительной для обычной (нормы) ошибки (Mason et al., 1967).
Многообразие показателей асимметрии
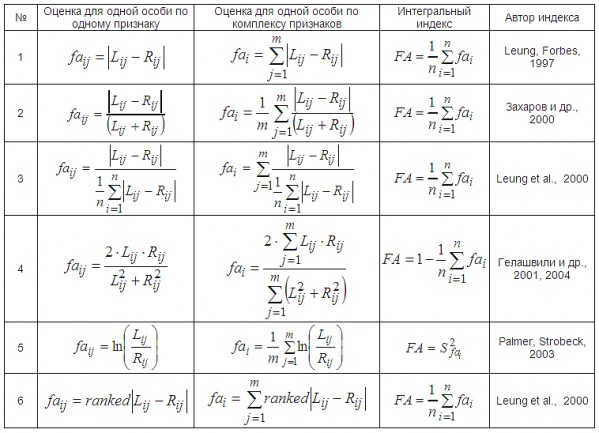
Рассмотренный выше способ оценки асимметрии с помощью дисперсионного анализа характеризует уровень асимметрии группы особей по одному признаку. В целом представленные в литературе показатели условно можно разбить для наглядности и простоты понимания на четыре иерархических уровня: 1 – оценки флуктуирующей асимметрии у отдельной особи (варианты) по одному признаку, 2 – оценки асимметрии для группы (выборки) особей по одному признаку, 3 – оценки асимметрии у отдельной особи по комплексу признаков (комплексные показатели асимметрии) и 4 – оценки асимметрии для группы (выборки) особей по комплексу признаков (интегральные индексы). Все они характеризуют изменчивость, т. к. средняя величина для значений разности между билатеральными промерами равна нулю. При расчете показателей и индексов используется большое количество способов преобразования исходных данных (значений признаков на левой и правой сторонах тела особей), включая модуль, возведение в квадрат, логарифмирование и т. д. (табл. 1).
Таблица 1. Показатели флуктуирующей асимметрии отдельной особи по одному признаку
Table 1. The indicators of fluctuating asymmetry of an individual based on one sign
(Palmer, Strobeck, 1986; Zhivotovsky, 1992; Leung et al., 2000; Developmental …, 2003)

Структура формулы оценки асимметрии одного признака у отдельной особи определяется выбором показателя отличия сторон dij= Lij – Rij (просто разница между сторонами, абсолютное отличие сторон или деление величины признака одной стороны на другую) и способом нормирования (деление на величину признака, логарифмирование и пр.). Когда сам показатель отличия сторон выступает оценкой асимметрии (табл. 1: 1), нормирование не используется: faij = dij.
При изучении флуктуирующей асимметрии особо отмечается проблема «масштабного эффекта». Корреляцию между размером признака и величиной асимметрии пытаются учесть с помощью различных способов нормирования, среди которых используют деление показателя асимметрии особи на величину промера или логарифмирование значений: faij = dij / xij, где процедура деления на xij характеризует нормирование на размер признака отдельной особи, например деление на xij = (Lij + Rij) / 2 или на xij = (Lij + Rij) (табл. 1: 2).
Отличия выборок по величине и изменчивости признаков может оказывать влияние на изменчивость показателей асимметрии. Нормирование на среднюю величину размера признака в выборке компенсирует «масштабный эффект» выборок: faij = dij / M. Величина M в знаменателе характеризует нормирование на среднюю величину размера признака в выборке (учет отличий между группами особей по величине признака), например M = Mj или M = MRj, где Mj = 1 / (2n)∙ ∑(i=1 → n)(Lij + Rij) = 1 / n ∙ ∑(i=1 → n)(xij) и M(Rj) = 1 / n ∙ ∑(i=1 → n)(Rij) (табл. 1: 3).
Величина флуктуирующей асимметрии одного признака в той или иной мере отличается от величины показателя для другого признака. Для компенсации отличий между показателями асимметрии разных признаков нормирование проводят путем деления величины асимметрии отдельной особи по одному признаку на общую характеристику признака или его асимметрии в выборке: faij = dij / S или faij = dij / M(faj), где S используется для нормирования на общую изменчивость признака в выборке (или стандартное отклонение, или дисперсия), а Mfa характеризует нормирование на средний уровень асимметрии признака, рассчитанный по всем выборкам, участвующим в сравнении M(faj) = 1 / N ∙ ∑(i=1 → N)(faij) (табл. 1: 4).
Структура формулы показателя асимметрии одного признака у группы (выборки) особей (групповые показатели faj) определяется формой показателя асимметрии для отдельной особи (faij) и представляет собой сумму, среднюю величину значений faij для всех особей выборки или характеристику изменчивости распределения индивидуальных показателей (дисперсия, стандартное отклонение). Если оценка асимметрии отдельной особи по одному признаку основана на модуле отличия сторон (dij = |Lij – Rij|), то групповой показатель асимметрии представляет собой суммирование индивидуальных оценок асимметрии всех особей выборки faj = ∑(i=1 → n)(faij) или усреднение faj = 1 / n ∙ ∑(i=1 → n)(faij). Для случая обычной разности между сторонами (с сохранением знака – dij = (Lij – Rij)) форма групповой оценки определяется типом распределения индивидуального показателя. В случае нормального распределения показателя faij, оценивается его изменчивость для выборки особей в виде стандартного отклонения faj = S(faij) или дисперсии faj = S2(faij) или faj = 1 / 2 ∙ S2(faij) (иногда оценка изменчивости умножается на 100 %). Иногда групповой показатель усложняют, вводя в формулу процедуру деление дисперсии асимметрии на среднюю характеристику величины признака в выборке
faj = S2(faij) / M2(j) или faj = S2(faij) / M(j) (Developmental…, 2003). Когда показатель faij не подчиняется нормальному закону, оценки асимметрии по выборке особей просто усредняются faj = 1 / n ∙ ∑(i=1 → n)(faij), например faj = 1 / n ∙ ∑(i=1 → n)(Lij – Rij)2 или faj = 1 / n ∙ ∑(i=1 → n)((Lij – Rij) / M(Rj)) ∙ 100 %. Если для расчета индивидуальной оценки асимметрии используют показатель отличия сторон в виде их отношения друг к другу (Lij / Rij) или логарифмирования, то групповой оценкой асимметрии признака выступает дисперсия faj = S2(faij).
Непосредственная оценка группового показателя асимметрии признака без предварительного расчета величины асимметрии отдельно для каждой особи была рассмотрена нами в предыдущем разделе при декомпозиции общей изменчивости морфологического признака с помощью дисперсионного анализа. Еще один подобный пример – коэффициент корреляции между величиной признака на левой и правой сторонах тела особей faj = r и различные его модификации, например, faj = 1 – r или faj = 1 – r2. Если показатель асимметрии, вычисляемый как компонента дисперсии, используется достаточно часто, то групповой показатель асимметрии в виде коэффициента корреляции в последнее время практически не используется (Palmer, Strobeck, 1986).
Групповые оценки асимметрии отдельных признаков (faj) редко сами участвуют при проведении сравнения. Обычно различия между выборками устанавливаются при сопоставлении двух распределений faij с помощью непараметрических критериев (Developmental…, 2003; Гелашвили и др., 2004) или с использованием критерия t‑Стьюдента (Захаров и др., 2000). Исключения составляют показатели faj в виде дисперсии или стандартного отклонения, которые могут непосредственно использоваться при сравнении выборок с помощью критерия Фишера. Основное применение оценки асимметрии для группы особей по одному признаку (faj) находят при исследовании согласованности в изменении асимметрий признаков по разным группам, при разработке балльных шкал, определении условной нормы, критических порогов, выявлении трендов и установлении моделей изменчивости показателей асимметрии.
Для характеристики согласованной изменчивости групповых оценок асимметрии разных признаков применяется коэффициент W конкордации Кендала (Soule, 1967; Mason, 1967), для вычисления которого показатели асимметрии ранжируют (faj = Rkj, где k – количество выборок, участвующих в анализе, для каждой из которых рассчитана оценка faj). Пример ранжированных групповых оценок асимметрий представлен в таблице 2.
Таблица 2. Ранги групповых показателей асимметрий для расчета коэффициента конкордации
Table 2. The ranks of group indicators of asymmetry for the calculation of a concordance index

Коэффициент конкордации Кендала рассчитывается по формуле
W = (12 ∙ ∑d2) / (m2 ∙ (N3 – N)), где dk = ∑(j=1→m)(Rk) – 1 / N ∙ ∑(k=1→N)(∑(j=1→m)Rk).
Значения коэффициента варьирует в пределах от 0 (нет согласованности между показателями асимметрии разных признаков) до 1. Обычно о сильной согласованности в изменчивости показателей асимметрии признаков говорят, когда коэффициент не ниже 0.6, однако в силу малого количества групповых оценок, используемых в анализе (редко больше десяти групп особей или популяций), о статистической значимости коэффициента судят по критерию χ2 = m ∙ (N – 1) ∙ W (Mason, 1967). Если эмпирическая величина критерия больше теоретического значения χ2(0.05,N-2), то говорят о согласованной изменчивости показателей асимметрии признаков по группам особей. Достоверность коэффициента W может означать, что оценки асимметрии разных признаков биообъектов отражают один определенный феномен, лежащий в основе изменчивости процессов развития разных выборок (популяций). Таким феноменом может выступать всеобщая коадаптация генетических элементов (Soule, 1967), отличия в генотипической структуре популяций (Palmer, Strobeck, 1986), изменчивость метаболической эффективности (Захаров, 1987), разная степень онтогенетического шума (Palmer, Strobeck, 1986).
Иногда коэффициент конкордации Кендала используется для установления согласованности в изменчивости оценок асимметрии разных признаков в пределах группы особей; в этом случае ранжируются индивидуальные показатели асимметрии faij = Rij. С помощью этого теста было доказано отсутствие «общеорганизменного свойства асимметрии» (Van Valen, 1962; Mason et al., 1967; Leamy, 1992).
Интегральные индексы
Разработка и использование интегральных индексов асимметрии выборки особей по комплексу признаков ведутся с 80-х гг. XX в. Предполагается, что подобные комплексные показатели точнее и надежнее характеризуют процессы развития целого объекта (отдельную особь или популяцию), повышают вероятность выявления закономерностей в изменчивости асимметрии биообъектов, позволяют детальнее изучить влияние факторов на реализацию процессов развития (Zhivotovsky, 1992; Leung et al., 2000; Гелашвили и др., 2004).
Структура формулы интегрального индекса зависит от формы показателя асимметрии для отдельной особи по одному признаку (табл. 1), а также от способа объединения показателей асимметрии отдельных признаков в новый (сложный) признак, который будет характеризовать одну особь по комплексу свойств. Оценки асимметрии всех m признаков у одной особи (fai) усредняются или просто суммируются. Для расчета интегрального индекса FA асимметрии комплекса признаков для группы (выборки) особей используются усреднение, суммирование, вычисление дисперсии или стандартного отклонения распределения показателей fai (табл. 3). Д. Б. Гелашвили (Гелашвили и др., 2004) при вычислении индекса асимметрии предлагает проводить одновременно и суммирование, и нормирование отличий между сторонами по всем признакам (табл. 3: 4). B. Leung (2000) акцентирует внимание на отличии признаков друг от друга по процессам стабильности развития. Для того чтобы признаки оказывали равноценный вклад в интегральную оценку, при расчете индивидуальных показателей автор вводит нормирование на среднюю величину асимметрии признака в выборке (табл. 3: 3). B. Leung (2000) также считает, что одним из наиболее надежных способов учета отличий между асимметриями разных признаков выступает ранжирование оценок асимметрий по каждому признаку с последующим суммированием рангов (табл. 3: 6).
Таблица 3. Оценки флуктуирующей асимметрии по комплексу признаков
Table 3. The estimates of fluctuating asymmetry based on a signs complex
Представленные формулы позволяют рассчитывать комплексные показатели асимметрии у отдельных особей по нескольким признакам. Сравнение выборок обычно проводится с помощью непараметрических критериев, когда сопоставляются распределения показателей fai двух выборок (Гелашвили и др., 2004), реже предлагается использовать критерий t‑Стьюдента и тест-ANOVA (Leung et al., 2000).
Принципиально иной способ оценки интегральных индексов основан на применении разных методов многомерного анализа. Например, L. A. Zhivotovsky (1992) предлагает алгоритм вычисления «обобщенной изменчивости асимметрии» комплекса признаков FA = G ∙ (detS)1/k. При расчете детерминант (detS) для каждой выборки создается матрица «изменчивость – ковариация», включающая показатели асимметрии всех признаков. L. A. Zhivotovsky приводит формулы поправочного коэффициента G и краткую таблицу уровней G при определенном числе степеней свободы. Сравнение выборок проводится с помощью F-теста. Однако, A. R. Palmer (1994) отмечает сложность предыдущего показателя и предлагает обычный двухфакторный дисперсионный анализ в качестве альтернативы.
Среди новых работ следует отметить недавно предложенный подход, определяющий степень псевдосимметричности (приблизительной симметрии) биообъектов на основе теории групп (Гелашвили и др., 2010; Нижегородцев, 2010). Метод учитывает не только разные типы асимметрии билатеральных признаков, но и включает другие возможные преобразования (повороты, инверсии, трансляции и др.). Авторы разработали комплекс программных продуктов BioPs для автоматической оценки степени псевдосимметрии биообъектов на основе алгоритма свертки. В расчетах используются числа, задающие яркости пикселов цифрового изображения объектов. Выражение интегральной свертки, предложенной Гелашвили и др. (2004) для оценки псевдосимметрии приобретает вид конечной суммы:
η = ∑(i,j)(Ai,j ∙ Bi,j) / ∑(i,j)(A2i,j), где η – степень симметричности, A – матрица яркостей исходного изображения, В – матрица яркостей, полученная в результате отражения матрицы A относительно выбранной плоскости.
Показатели асимметрии неметрических признаков
В соответствии с распространенной классификацией признаков (Животовский, 1991), к качественным относят те свойства (вариации, морфы, фенотипы и т. д.), при использовании которых совокупность особей можно однозначно разделить на четко различимые группы. Количественными называются признаки, степень выраженности которых можно охарактеризовать числом. Выделяют три типа количественных признаков. Дискретные признаки (счетные или меристические) определяются путем подсчета (число позвонков у рыб, щетинок у мух, пульс и т. д.). Непрерывные признаки (метрические, пластические) определяются путем измерений (размеры и вес особей, активность ферментов и т. д.). Для меристического признака величина асимметрии определяется по различию числа структур слева и справа, а для качественного свойства просто учитывается симметрично или асимметрично проявление признака. Обзор литературы показал, что те показатели, которые применяются для характеристики флуктуирующей асимметрии пластических признаков, также используются и для неметрических признаков организмов.
Один из немногих примеров разграничения оценок асимметрии по типу признака можно найти в работах A. R. Palmer и C. Strobeck (2003). В частности, они особо отмечают показатели, основанные на «дискретизированном» значении асимметрии (bij = 0, если Lij = Rij, bij = 1, если Lij ≠ Rij), и предлагают их использовать только при оценке асимметрии неметрических признаков. Групповым показателем в данном случае выступает усредненная величина асимметричного проявления признака в выборке faj = 1 / n ∙ ∑(i=1→n)(bij) (Захаров, 2000). В качестве комплексного показателя асимметрии особи по нескольким признакам рассчитывается средняя величина асимметрично проявившихся признаков у одной особи fai = 1 / m ∙ ∑(j=1→m)(bij), а формула интегрального индекса будет включать двойное усреднение:
FA = (1 / (n ∙ m)) ∙ ∑(i=1→n)(∑(j=1→m)(bij)) = 1 / n ∙ ∑(i=1→n)(fai) (Захаров, 2000; Гелашвили и др., 2004). A. R. Palmer и C. Strobeck (2003) предлагают вместо процедуры усреднения использовать простое суммирование при расчете показателя асимметрии особи по комплексу признаков.
Другая оценка асимметрии предложена А. Г. Васильевым (2007) на основе формул R. R. Sokal и P. H. A. Sneath (1973). Формулы позволяют вычислить дисперсию общей асимметричности, которую А. Г. Васильев обозначил ТА2, и двух ее компонент: DA2 – направленную и FA2 – флуктуирующую асимметрии (Васильев и др., 2007). Дисперсию общей асимметричности комплекса признаков для отдельной особи предложено вычислять по формуле ТА2 = 1 / m ∙ ∑(j=1→m)(Lij – Rij)2. Дисперсия направленной асимметрии будет равна:
DА2 = 1 / m2∙[∑(j=1→m)(Lij – Rij)]2, тогда вторая компонента – флуктуирующая асимметрия вычисляется так: FА2 = TА2 – DА2. Однако, несмотря на то, что данные показатели апробированы только на дискретных признаках, предлагается их более широкое применение (Васильев и др., 2007).
Анализ работоспособности показателей и индексов
Многообразие показателей асимметрии создает проблему выбора способа оценки для конкретного исследования. Какому показателю следует отдать предпочтение и каковы преимущества той или иной оценки? В ряде работ проводятся сравнения показателей друг с другом, анализируются их свойства и работоспособность, которые позволяют провести ранжирование в порядке убывания их «качества».
В основном исследования направлены на анализ чувствительности показателей, т. е. их способности улавливать реальные отличия по величине асимметрии между выборками (анализ индикационных способностей). Оценка работоспособности показателей проведена в рамках имитационных моделей на искусственно созданных данных. Например, A. R. Palmer и C. Strobeck (1986) при характеристике относительной чувствительности девяти индексов наблюдали изменение точности показателей асимметрии при изменении таких факторов, как фенотипическая изменчивость признака, направленная асимметрия, антисимметрия, степень зависимости величины флуктуирующей асимметрии от размера признака. Способность каждого показателя выявлять отличия между выборками они оценивали с помощью дисперсионного анализа логарифмированных переменных.
A. R. Palmer и C. Strobeck (1986) установили, что индексы, основанные на коэффициенте корреляции, проявляют высокую чувствительность к изменению величины признака и поэтому неэффективны. При отсутствии «масштабного эффекта», наилучшей работоспособностью обладают оценки, основанные на обычном показателе отличия сторон (Lij – Rij) и его дисперсии. При увеличении зависимости уровня асимметрии от размера признака, более надежными становятся оценки, которые также основаны на показателе (Lij – Rij), только с учетом масштабного эффекта, например вида faij = 2 ∙ (Lij – Rij) / (Lij + Rij). A. R. Palmer и C. Strobeck (1986) подчеркивают большую эффективность оценок на основе разности между сторонами (Lij – Rij) по сравнению с абсолютными отличиями |Lij – Rij|.
B. Leung (2000) на основе имитационного моделирования сделал попытку оценить свойства интегральных индексов. Работоспособность индексов он проверяет по двум критериям: 1 – достоверность отличий между выборками, которые взяты из одной генеральной совокупности (правомерность применения индекса за счет учета ошибки первого рода); 2 – значимость отличий между выборками, которые взяты из разных генеральных совокупностей (оценка силы или чувствительности индекса). Было показано, что интегральные индексы, учитывающие несколько признаков, обладают большей чувствительностью по сравнению с выборочными показателями, оценивающими асимметрию отдельного признака. «Сила» индексов зависит от количества признаков, входящих в состав индекса, от размера выборки особей, от степени отклонения распределений показателей асимметрии отдельных признаков от нормального закона, от ошибки измерения. При увеличении согласованности в изменении показателей асимметрии признаков в пределах выборки чувствительность индексов уменьшается. На повышение вероятности появления ошибки первого рода могут оказывать влияние положительный эксцесс распределения показателей асимметрии отдельных признаков, наличие корреляции между показателями асимметрии разных признаков. Из всего разнообразия интегральных индексов B. Leung (2000) отдает предпочтение тем, при расчете которых индивидуальные оценки включают нормирование на средний уровень асимметрии признака в выборке или ранжирование показателей асимметрии по каждому признаку.
Рассмотренные работы по анализу работоспособности показателей и индексов асимметрии проводятся на основе модельных выборок с заранее заданными распределениями и известными параметрами. Появляются работы по оценке чувствительности показателей и анализу их статистических свойств с использованием значительного объема эмпирического материала (Зорина, Коросов 2009; Зорина, 2009; Трубянов, 2010; Трубянов, Глотов, 2010). В таблице 4 представлены наиболее отличающиеся друг от друга показатели и индексы флуктуирующей асимметрии, которые часто используются в работах по исследованию качества среды в целях биомониторинга или введены в последнее время.
Таблица 4. Формулы расчета оценок флуктуирующей асимметрии, используемых в сравнении
Table 4. The formulas for the calculation of the estimates of fluctuating asymmetrybsed in comparison

*Примечание к таблице 4: Mj и Sj – средняя арифметическая и стандартное отклонение j-го билатерального признака по всем выборкам, участвующим в сравнении, N – суммарный объем выборок (N=n1+…+nx).
Простейшая оценка флуктуирующей асимметрии отдельного билатерального признака представляет собой дисперсию разности сторон faj(1) = S2(Lij – Rij) (Кожара, 1985; Palmer, Strobeck, 1992). Формулы показателей faij(3), faij(4), faij(5), faij(6), faij(7), faij(8), faij(9) и соответствующих индексов, представленные в литературе (Palmer, Strobeck, 1986, 2003; Zhivotovsky, 1992; Leung et al, 2000; Захаров, 2001; Гелашвили и др., 2004; Зорина, Коросов, 2009), используют различные преобразования для перевода промеров признаков или их билатеральной разности в относительные величины.
С технической точки зрения расчеты всех показателей и индексов выполняются в несколько этапов. Сначала для каждой i-й особи по каждому j-му признаку вычисляют отличие сторон faij. Усредняя значения faij (или вычисляя дисперсию) для всех особей выборки (в столбце) по каждому признаку, получают свой показатель асимметрии faj. Усредняя значения faij для всех признаков данной особи (в строке), получают интегральную оценку асимметрии fai для каждой особи. Усредняя индивидуальные оценки fai (или вычисляя дисперсию) по всей выборке особей (в столбце), получают интегральный индекс асимметрии FA для всех особей по всем признакам.
Итоги сравнения работоспособности оценок асимметрии показали, что на основании одних и тех же данных разные показатели асимметрии могут давать разные результаты (Зорина, Коросов, 2009; Зорина, 2009). Одна из возможных причин – отличие форм распределения оценок асимметрии, что наблюдается при изучении нормальной изменчивости показателей или индексов. На этой основе строится весь последующий статистический анализ — выбор непараметрических или параметрических критериев и выявление закономерностей. Изучение статистических свойств и закономерностей нормальной изменчивости показателей и индексов флуктуирующей асимметрии признаков биообъектов проводилось на основе использования «чистых» выборок растений и животных, характеризующихся значительными объемами и относительной однородностью материала.
Изначально нормальное распределение разности сторон (Lij – Rij) признаков сохраняется для показателей faij(4), faij(5), faij(7), faij(9); распределение остальных оценок (faij(2), faij(3), faij(6), faij(8)) не подчиняется нормальному закону. Модуль разности |Lij – Rij|, использованный в формулах 2, 3 и 6 (табл. 4) превращает все отклонения билатеральных промеров в положительные и приводит их распределение к правосторонней асимметрии (рис. 3: 2, 3, 6). Для преобразования абсолютной разности |Lij – Rij| в разряд относительных показателей, выражающих пропорции (faij(6)), применяется деление на сумму промеров |Lij – Rij| / (Lij + Rij). Распределению подобных относительных индексов присуще нарушение симметрии (Шварц и др., 1968) и приближение к форме логнормального (Дэвис, 1977) (рис. 3: 6). К похожему эффекту ведет возведение в квадрат (Тьюки, 1981): большие значения случайной величины возрастают сильнее небольших и обеспечивают положительную асимметрию распределению. Если же квадрат стоит в знаменателе показателя (faij(8)), получим обратный результат – левостороннюю асимметрию (рис. 3: 8).
Рис. 3. Эмпирические частоты распределения показателей асимметрии (faij) метрического признака листовой пластинки березы повислой (1) и кривые нормального распределения с теми же параметрами (2) (указан уровень значимости соответствия нормальному закону по критерию W Шапиро – Уилкса)
Fig. 3. The mpirical frequencies of asymmetry indicator distributions (faij) of metric sign of Bétula péndula leave plate (1) and the curves of normal distribution with the same parameters (2) (the significance value of compliance with the normal law according to the W Shapiro – Wilks criterion is specified)
Одно из последствий нарушения исходного нормального распределения билатеральной разности (Lij – Rij) показателями faij(2), faij(3), faij(6), faij(8) – это запрет на сравнение выборочных значений с помощью точных параметрических критериев. Более того, показатели с ненормальным распределением переносят незначительные отличия между выборками на одну сторону гистограммы и усиливают их (Зорина, Коросов, 2009). Они повышают значимость редких случайных отклонений и выдают их за существенные (включая методические огрехи).
Наконец, сам способ нормирования может привнести дополнительную компоненту изменчивости в уровень асимметрии, и отличия между выборками будут иметь совершенно иную природу происхождения (не связанную с нарушением онтогенеза особей). Один из примеров – это когда разность промеров делится на их сумму, т. е. характеристика изменчивости относится к характеристике величины признака (некий аналог коэффициента вариации) в показателях faij(6), faij(7), faij(8), faij(9). Поскольку между дисперсией и средней величиной морфологических признаков нет однозначной зависимости (Яблоков, 1966), то появляется еще одна компонента, закономерности изменчивости которой отдельно не обсуждаются, но которая вводится в оценку уровня асимметрии признака. То же самое касается нормирования на характеристику изменчивости признака (в частности, на стандартное отклонение распределения билатерального признака в показателе faij(5)). Зависимость между фенотипической изменчивостью признака и показателем отличия сторон (Lij – Rij) носит сложный неоднозначных характер (Кожара, 1985; Palmer, Strobeck, 2003). Нормирование может приводить к отличиям между выборками, которые сложно интерпретировать.
Считается, что флуктуирующую асимметрию целого объекта полнее характеризуют интегральные индексы, и их сравнение позволяет делать более надежные выводы, чем при анализе отдельных признаков (Developmental …, 2003). Однако в большинстве случаев индексы рассчитываются путем простого объединения показателей асимметрии отдельных признаков и сохраняют их недостатки, например нарушение нормального распределения. Есть вопросы и к способу расчета индексов FA, которым рекомендуется простое усреднение значений faij (табл. 4), тогда как при объединении асимметричных распределений наиболее представительной и устойчивой характеристикой выступает медиана (Животовский, 1991).
Индексы никак не учитывают различие статистических характеристик показателей асимметрии отдельных промеров – значения частных показателей просто усредняются для каждой особи. Разные признаки имеют разную форму распределений и разные уровни статистических параметров. Их объединение означает, что наибольшую роль в общей средней особи будут играть только те показатели асимметрии, которые имеют самые большие значения.
Вопрос о правомочности процедуры усреднения относительных показателей асимметрии для m разных исходных признаков актуален и для оценок fai(5), fai(7), fai(9) (табл. 4). Для расчета величин данных показателей используются нормированные значения faij, которые в силу безразмерности усредняются. При этом неявно и неоправданно предполагается, что между величиной всех изучаемых промеров и уровнем их билатеральной асимметрии сохраняется примерно одинаковая пропорция, которую и выражают нормированные показатели. Однако асимметрия мелко- и крупноразмерных билатеральных органов (признаков), как правило, имеет не только разный порядок различий, но и несходные механизмы возникновения и разную стоимость их проявления. Нередки ситуации, когда варьирование крупного органа на разных сторонах тела (наибольшее по абсолютной величине) при нормировании приобретает невысокие относительные оценки, которые вносят неоправданно малый вклад в интегральный индекс FA. В свою очередь, оценки изменчивости малозначимых мелкоразмерных структур могут обеспечить существенный вклад в относительный индекс. Поэтому при расчетах интегральных показателей следует в большей степени ориентироваться на оценки различий в абсолютном масштабе.
Отдельно стоит рассмотреть вопрос о количественном и качественном составе показателей асимметрии отдельных признаков, объединяемых в интегральные индексы. Обычно в состав индексов входят показатели асимметрии одной категории признаков: или только качественные, или меристические, или пластические (Методические…, 2003, Гелашвили и др., 2004). Однако и в пределах этих групп асимметрия одних признаков может оказывать более существенное влияние на интегральную оценку, чем других. Например, предполагается (Leung, 2000), что при увеличении согласованной изменчивости асимметрий признаков в пределах выборки чувствительность индексов уменьшается. Наличие корреляции между показателями асимметрии разных признаков также может оказывать влияние на повышение вероятности появления ошибок первого рода.
Базовый способ нормировки статистических данных, нормированное отклонение (x – M) / S (используется в показателе faij(4), табл. 4: 4), выступает альтернативой рассмотренных показателей и индексов асимметрии. Эта универсальная величина независимо от исследуемого признака показывает, на каком расстоянии (в единицах стандартного отклонения) находится его конкретное значение от центра распределения. С ее помощью можно сравнивать объекты разного качества (организмы разных видов, пород, возрастов и т. д.) по нескольким свойствам (Ивантер, Коросов, 2003). Процедура сохраняет исходно нормальное распределение признаков (в нашем случае – разницы между лево- и правосторонними промерами, показатель faij(4) на рис. 3: 4), приводит все признаки к одинаковому диапазону изменчивости (примерно ±3) и позволяет выполнять их суммирование с признанием равной информационной значимости. Это дает возможность проводить сравнение выборок с использованием точных параметрических критериев (Зорина, Коросов, 2009; Зорина, 2009).
Процедура нормирования сохраняет нормальное распределение разницы сторон и для индекса FA4. Чем больше признаков объекта исследования имеет массовые проявления ненаправленной асимметрии, то есть чем шире основания распределения faij(4) для каждого признака, тем больше будет размах колебаний интегрального показателя fai(4) и выше значение его дисперсии FA4 = S2(fai(4)). Таким образом, показатель, основанный на нормированном отклонении, учитывает массовые проявления флуктуирующей асимметрии и в меньшей мере зависит от случайностей при формировании выборок.
Иногда при определении величины флуктуирующей асимметрии используют оценки, которые по своей структуре и особенностям расчета существенно отличаются от рассмотренных выше показателей и индексов асимметрии. Например, Трубянов (Трубянов, Глотов, 2010) вводит новый показатель флуктуирующей асимметрии − показатель «ковариации — корреляции» (CVR), который в явном виде и в равной степени включает коэффициент вариации признака слева (или справа) (CV) и коэффициент корреляции между значениями признака слева и справа (ρ) (Трубянов, 2010): CVR = CV ∙ (1 — ρ2). Интегральный индекс на основе данного показателя асимметрии имеет следующий вид: CVR(FA) = CV(ср) ∙ (1 — r2(ср)). Средний коэффициент вариации (CV(ср)) оценивается при помощи медианы средних Уолша, а средний коэффициент корреляции (r(ср)) при помощи z-преобразования. Распределение данного показателя близко к нормальному.
Автор считает, что информативность показателя CVR заключается не только в количественном значении самого показателя, но и его компонент. Коэффициент корреляции показывает степень структурной взаимосвязи и целостности организма, а коэффициент вариации показывает степень изменчивости признака, обусловленную внутренними или внешними по отношению к организму причинами (Трубянов, 2010).
Следует отметить, что автор не принял во внимание логические основы создания и статистические характеристики тех коэффициентов, которые он использует при построении нового показателя асимметрии. Если новый показатель и учитывает корреляцию, связанную с фактической изменчивостью флуктуирующей асимметрии, то никак не вычленяет ее из общей корреляционной изменчивости признаков. Например, высокая корреляция признаков слева и справа возникает в том случае, когда анализируется выборка объектов разного размера (при высокой точности промеров даже небольшие отличия объектов по размеру будут существенны), что не имеет никакого отношения к флуктуирующей асимметрии. «Загрязнение» нового показателя возможно и другими видами корреляции, связанными с неравномерностью роста частей самого листа (аллометрией), методическими ошибками и т. д. Во-вторых, следует отметить, что коэффициент вариации признаков, используемый в новом показателе асимметрии, зависит, кроме собственно варьирования, еще и от величины признака, что также не учитывается при проведении расчетов. Поэтому, чтобы ввести в широкое использование данный показатель асимметрии, следует изначально пересмотреть теоретические и статистические основы его построения и провести дополнительные исследования на основе большого объема фактического материала.
Заключение
Выбор неадекватного метода оценки флуктуирующей асимметрии может привести к неточному установлению закономерностей в изменении величины асимметрии биологических систем. На основании одних и тех же данных разные показатели асимметрии могут давать разные результаты. Арифметические и статистические преобразования исходных данных (включая разные способы их нормирования) определяют чувствительность и работоспособность показателей асимметрии.
Нарушение изначально нормального распределения разности сторон признаков приводит к необходимости использования грубых непараметрических критериев. Показатели с ненормальным распределением повышают значимость редких случайных отклонений и выдают их за существенные (включая методические огрехи). Сам способ нормирования может приводить к отличиям между выборками, которые сложно интерпретировать.
Индексы рассчитываются путем простого объединения показателей асимметрии отдельных признаков и не учитывают различие их статистических характеристик. Как одно из последствий – нарушение нормального распределения (индексы сохраняют недостатки показателей). Объединение признаков с разным уровнем статистических параметров означает, что наибольшую роль в общей средней особи будут играть только те показатели асимметрии, которые имеют наибольшие значения. Рассматриваются и обычные статистические ошибки, например, когда при объединении показателей с асимметричным распределением применяется процедура усреднения вместо вычисления медианы.
Как альтернатива рассмотренным оценкам асимметрии отмечается показатель и индекс, основанные на нормированном отклонении. Процедура нормирования сохраняет нормальное распределение разницы сторон, и с ее помощью можно сравнивать объекты разного качества.
Библиография
Васильев А. Г., Васильева И. А., Большаков В. Н. Феногенетическая изменчивость и методы ее изучения: Учебное пособие. Екатеринбург: Изд-во Уральского университета, 2007. 280 с.
Гелашвили Д. Б., Чупрунов Е. В., Иудин Д. И. Структурные и биоиндикационные аспекты флуктуирующей асимметрии билатерально симметричных организмов // Журн. общ. биол. 2004. Т. 65. №5. С. 433–441.
Гелашвили Д. Б., Чупрунов Е. В., Марычев М. О., Сомов Н. В., Широков А. И., Нижегородцев А. А. Приложение теории групп к описанию псевдосимметрии биологических объектов // Журн. общ. биол. 2010. Т. 71. №6. С. 497–513.
Гелашвили Д. Б., Якимов В. Н., Логинов В. В., Епланова Г. В. Статистический анализ флуктуирующей асимметрии билатеральных признаков разноцветной ящурки // Актуальные проблемы герпетологии и токсинологии: Сборник научных трудов. Тольятти. 2004. Вып. 7. С. 45–59.
Гилева Э. А., Ялковская Л. Э., Бородин А. В., Зыков С. В., Кшнясев И. А. Флуктуирующая асимметрия краниометрических признаков у грызунов (Mammalia: Rodentia): межвидовые и межпопуляционные сравнения // Журнал общей биологии. 2007. Т. 68. № 3. С. 221–230.
Дэвис Дж. Статистический анализ данных в геологии . М.: Мир, 1977. 573 с.
Животовский Л. А. Популяционная биометрия . М.: Наука, 1991. 271 с.
Захаров В. М. Асимметрия животных (популяционно-феногенетический подход). М.: Наука, 1987. 216 с.
Захаров В. М. Онтогенез и популяция // Экология. 2001. № 3. С. 164–168.
Захаров В. М., Чубинишвили А. Т., Дмитриев С. Г., Баранов А. С., Борисов В. И., Валецкий А. В., Крысанов Е. Ю., Кряжева Н. Г., Пронин А. В., Чистякова Е. К. Здоровье среды: практика оценки . М.: Центр экологической политики России. 2000. 320 с.
Зорина А. А. Нормальная изменчивость флуктуирующей асимметрии растений и животных : Автореф. дис. … канд. биол. наук. Тольятти, 2009. 20 c.
Зорина А. А., Коросов А. В. Изменчивость показателей и индексов асимметрии признаков листа в кроне Вetula pendula (Betulaceae) // Ботанический журнал. 2009. Т. 94. №8. С. 1172–1192.
Ивантер Э. В., Коросов А. В. Введение в количественную биологию . Петрозаводск: Изд-во ПетрГУ, 2003. 304 с.
Кожара А. В. Структура показателя флуктуирующей асимметрии и его пригодность для популяционных исследований // Биологические науки. 1985. № 6. С. 100–104.
Методические рекомендации по выполнению оценки качества среды по состоянию живых существ (оценка стабильности развития живых организмов по уровню асимметрии морфологических структур). Распоряжение Росэкологии от 16.10.2003. № 460–р. М. 2003. 28 с.
Нижегородцев А. А. Псевдосимметрия растительных объектов как биоиндикационный показатель: теоретическое обоснование, автоматизация оценок, апробация : Автореф. дис. … канд. биол. наук. Нижний Новгород, 2010. 24 с.
Трубянов А. Б. Анализ показателей флуктуирующей асимметрии : Автореф. дис. … канд. биол. наук. Нижний Новгород, 2010. 23 с.
Трубянов А. Б., Глотов Н. В. Флуктуирующая асимметрия: вариация признака и корреляция левое-правое . ДАН. 2010. Т. 431. №2. С.283–285.
Тьюки Дж. Анализ результатов наблюдений . М.: Мир, 1981. 694 с.
Урбах В. Ю. Биометрические методы . М.: Наука, 1964. 415 с.
Шварц С. С., Смирнов В. С., Добринский А. Н. Метод морфофизиологических индикаторов в экологии наземных позвоночных . Свердловск, 1968. 387 с.
Яблоков А. В. Изменчивость млекопитающих . М.: Наука, 1966. 364 с.
Ames L., Felley J., Smith M. H. Amount of asymmetry in centrarchid fish inhabiting heated and nonheated reservoirs // Trans. Am. Fish. Soc. 1979. N 108. P. 489–495.
Bader R. S. Fluctuating asymmetry in the dentition of the house mouse // Growth. 1965. N 29. P. 291–300.
Clarke G. M. The genetic basis of developmental stability: 1. Relationships between stability, heterozygosity and genomic coadaptation // Genetica. 1993. N 89. P. 15–23.
Clarke G. M., McKenzie L. J. Fluctuating asymmetry as a quality control indicator for insect mass rearing processes // Journal of Economic Entomology. 1992. N 85. P. 2045–2050.
Developmental instability: causes and consequences / ed. Polak M. N.Y.: Oxford Univ. Press. 2003. 500 p.
Graham J. H., Freeman D. C., Emlen J. M. Antisymmetry, directional asymmetry, and dynamic morpogenesis // Genetica. 1993. N 89. P. 121–137.
Graham J. H., Roe K. E., West T. B. Effects of lead and benzene on developmental stability of Drosophila melanogaster // Ecotoxicology. 1993. N 2. P. 185–195.
Kellner J. R., Alford R. A. The ontogeny of fluctuating asymmetry // Amer. Natur. 2003. Vol. 161. N 6. P. 931–947.
Kimball R. T., Ligon J. D., Merola–Zwartjes M. Fluctuating asymmetry in red jungle fowl // Journal of Evolutionary Biology. 1997. N 10. P. 441–457.
Kozlov M. V., Niemelä P., Junttila J. Needle fluctuating asymmetry is a sensitive indicator of pollution impact on Scots pine (Pinus sylvestris) // Ecological Indicators. 2002. N 1. P. 271–277.
Kozlov M. V., Wilsey B. J, Koricheva J., Haukioja E. Fluctuation asymmetry of birch leaves increases under pollution impact // Journal of Applied Ecology. 1996. N 33. P. 489–495.
Leamy L. J. Morphometric studies in inbred and hybrid house mice. 7. Heterosis in fluctuating asymmetry at different ages // Acta Zool. Fennica. 1992. N 191. P. 111–119.
Leary R. F., Allendorf F. W. Fluctuating asymmetry as an indicator of stress in conservation biology // Trends in Ecology and Evolution. 1989. N 4. P. 214–217.
Leung B., Forbes M. R. Modelling fluctuating asymmetry in relation to stress and fitness // Oikos. 1997. N 78. P. 397–405.
Leung B., Forbes N. R., Houle D. Fluctuating asymmetry as a bioindicator of stress: comparing efficacy of analyses involving multiple traits // The American naturalist. 2000. Vol. 155. N 1. P. 101–115.
Manning J. T., Chamberlain A. T. Fluctuating asymmetry, sexual selection and canine teeth in primates // Proc. R. Soc. Lond. 1993. B 251. P. 83–87.
Mason G. L., Ehrlich P. R, Emmel T. C. The population biology of the butterfly, Euphydryas editha. 5. Character clusters and asymmetry // Evolution. 1967. N 21. P. 85–91.
Mitton J. B. Enzyme heterozygosity, metabolism and developmental stability // Genetica. 1993. N 89. P. 47–65.
Naugler C. T., Leech S. M. Fluctuating asymmetry and survival ability in the forest tent caterpillar moth Malacosoma disstria: implications for pest management // Entomol. Exp. Appl. 1994. N 70. P. 295–298.
Palmer A. R. Waltzing with asymmetry // Bioscience. 1996. Vol. 46. Issue 7. P. 518–532.
Palmer A. R., Strobeck C. Fluctuating asymmetry analyses revisited // Developmental instability: causes and consequences. N.Y.: Oxford Univ. Press. 2003. P. 279–319.
Palmer A. R., Strobeck C. Fluctuating asymmetry: measurement, analysis, patterns // Annual Review of Ecology and Systematics. 1986. Vol. 17. P. 391–421.
Palmer A. R., Strobeck C. Fluctuation asymmetry as a measure of developmental stability: implications of non–normal distributions and power of statistical tests // Acta Zool. Fennica. 1992. N 191. P. 57–72.
Pankakoski E. Epigenetic asymetry as an ecological indicator in myskrats // J. Mammal. 1985. Vol. 66. N 1. P. 52–57.
Parsons P. A. Fluctuating asymmetry: a biological monitor of environmental and genomic stress // Heredity. 1992. N 68. P. 361–364.
Polak M. Parasites increase fluctuating asymmetry of male Drosophila nigrospiracula: implications for sexual selection // Genetica. 1993. N 89. P. 255–265.
Sakai K., Shimamoto Y. Developmental instability in leaves and flowers of Nicotiana tabacum // Genetic. 1965. N 51. P. 801–813.
Sokal R. R., Sneath P. H. A. Numerical taxonomy. The principles and practice of numerical classification. San Francisco: W. H. Freeman and Company, 1973. 573 p.
Soule M. Phenetics of natural populations. Asymmetry and evolution in a lizard // The American naturalist. 1967. Vol. 101. N 918. P. 141–160.
Swaddle J. P., Witter M. S. On the ontogeny of developmental stability in a stabilized trait // Proc. Roy. Soc. London. 1997. N 264. P. 329–334.
Thoday J. M. Balance, heterozygosity and developmental stability // Cold Spring Harb. Symp. Quant. Biol. 1956. N 21. P. 318–326.
Van Valen L. A study of fluctuating asymmetry // Evolution. 1962. N 16. P. 125 142.
Van Valen L. The statistics of variation // Evol. Theory. 1978. N 4. P. 33–43.
Zhivotovsky L. A. A measure of fluctuating asymmetry for a set of characters // Acta Zoologica Fennica. 1992. N 191. P. 73–77.
Zvereva E. L., Kozlov M. V., Niemela P., Haukioja E. Delayed induced resistance and increase in leaf fluctuating asymmetry as responses of Salix borealis to insect herbivory // Oecologia. 1997. N 109. P. 368–373.
Благодарности
Автор благодарен А. В. Коросову за разностороннюю помощь в работе.