![]() Резервное копирование виртуальной машины с SharePoint Server 2019 в Veeam Backup & Replication v12 выполнялось успешно до тех пор, пока в SharePoint не была настроена и запущена служба поиска Search Service Application. Каждое последующее задание резервного копирования ВМ стало завершаться ошибкой создания контрольной точки Hyper-V production checkpoint следующего вида:
Резервное копирование виртуальной машины с SharePoint Server 2019 в Veeam Backup & Replication v12 выполнялось успешно до тех пор, пока в SharePoint не была настроена и запущена служба поиска Search Service Application. Каждое последующее задание резервного копирования ВМ стало завершаться ошибкой создания контрольной точки Hyper-V production checkpoint следующего вида:
Failed to create VM recovery checkpoint (mode: Veeam application-aware processing) Details: Failed to create VM (ID: ba7b4b0c-3fbd-4c51-8737-2ae39aee005f) recovery checkpoint. Job failed ('Checkpoint operation for 'KOM-WEB01' failed. (Virtual machine ID BA7B4B0C-3FBD-4C51-8737-2AE39AEE005F) 'KOM-WEB01' could not initiate a checkpoint operation: %%2147754996 (0x800423F4). (Virtual machine ID BA7B4B0C-3FBD-4C51-8737-2AE39AEE005F)'). Error code: '32768'.
Retrying snapshot creation attempt (Failed to create production checkpoint.)
Task has been rescheduled
Unable to allocate processing resources. Error: Failed to create production checkpoint.
Анализ логов на сервере SharePoint в момент выполнения задания в VBR показал наличие ошибки с кодом Event ID 8194:
Log Name: Application
Source: VSS
Date: 29.04.2023 3:12:51
Event ID: 8194
Level: Error
Keywords: Classic
Computer: KOM-WEB01.holding.com
Description: Volume Shadow Copy Service error: Unexpected error querying for the IVssWriterCallback interface. hr = 0x80070005, Access is denied. This is often caused by incorrect security settings in either the writer or requestor process.
Operation: PrepareForSnapshot Event
Context:
Execution Context: Writer
Writer Class Id: {0ff1ce16-0201-0000-0000-000000000000}
Writer Name: OSearch16 VSS Writer
Writer Instance Name: OSearch Replication Service
Writer Instance ID: {4ce2a6c6-2cf2-4f58-872f-9ce95adf804a}
Попытка создать контрольную точку ВМ вручную в консоли Hyper-V Manager также приводила к ошибке «could not initiate a checkpoint operation: %%2147754996 (0x800423F4)«
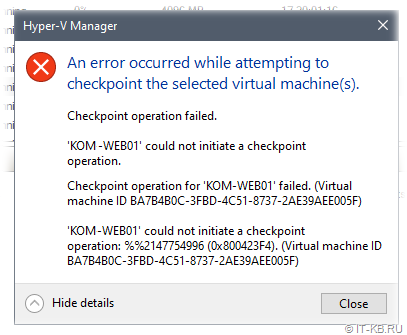
При этом в логе Application фиксировалась аналогичная ошибка с кодом 8194.
Команда листинга модулей записи теневого копирования на сервере SharePoint показала ошибочное состояние модуля «OSearch16 VSS Writer«:
vssadmin list writers
...
Writer name: 'OSearch16 VSS Writer'
Writer Id: {0ff1ce16-0201-0000-0000-000000000000}
Writer Instance Id: {268f99a2-1231-41d2-81e2-8f3ee565ee8e}
State: [8] Failed
Last error: Non-retryable error
...
Так как в тексте ошибки в event-логе фигурирует информация о нехватке прав («…0x80070005, Access is denied…»), в первую очередь нужно понять о какой учётной записи идёт речь.
Если посмотреть на стандартные поля в событии об ошибке, то в поле User мы не увидим информации о пользователе:
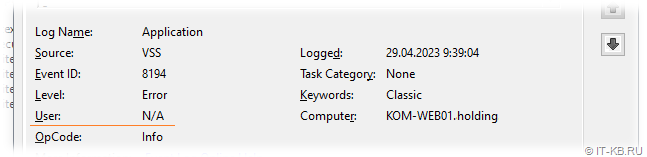
Однако, если переключиться на отображение подробностей на вкладке Details, то в варианте просмотра Friendly View в разделе с листингом бинарных данных мы сможем увидеть имя учётной записи, в контексте которой возникла шибка:
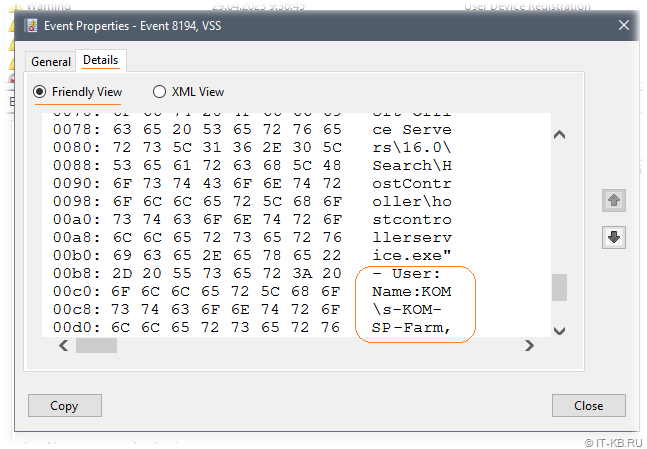
В нашем случае, это учётная запись фермы SharePoint (Farm account). И в контексте именно этой учётной записи у нас выполняется служба поиска SharePoint. При этом данная учётная запись не имеет полных административных прав на сервере.
Теперь относительного того, куда именно не может получить доступ учётная запись.
При проблемах с резервным копированием службы поиска SharePoint, в качестве одного из моментов, на который стоит обращать внимание, является состояние ключа реестра для службы «Volume Shadow Copy» (VSS):
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\VSS
Как минимум, в этом ключе:
1) В под-ключе \VssAccessControl должен присутствовать параметр REG_DWORD с именем учётной записи, в контексте которой работает ферма/служба поиска, и значением «1»;
2) В под-ключе \Diag должен присутствовать под-ключ с именем VSS модуля для службы поиска SharePoint (в нашем случае должен быть под-ключ с именем «OSearch16 VSS Writer«):
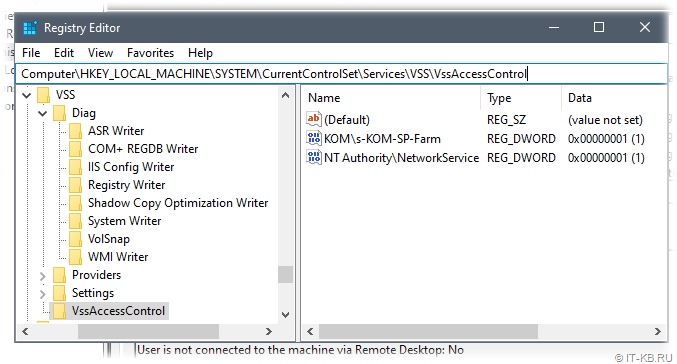
В нашем случае обнаружилось, что под-ключа «OSearch16 VSS Writer» нет.
В такой ситуации некоторые граждане предлагают выдать полные права доступа для учётной записи фермы/службы поиска на под-ключ \Diag. Однако, если присмотреться к действующим разрешениям на этот ключ реестра, то можно заметить, что запись в него разрешена локальной группе безопасности «Backup Operators«.
Включаем учётную запись фермы/службы поиска в эту группу на нашем виртуальном сервере SharePoint со службой поиска и перезагружаем этот сервер.
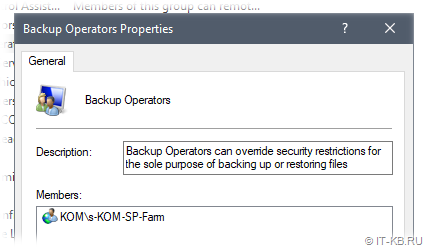
После перезагрузки удостоверимся в наличии ключа реестра «OSearch16 VSS Writer» и увидим, что владельцем этого ключа является учётная запись, включенная нами ранее в группу «Backup Operators».
После этого снова попробуем создать контрольную точку виртуальной машины в оснастке Hyper-V Manager.
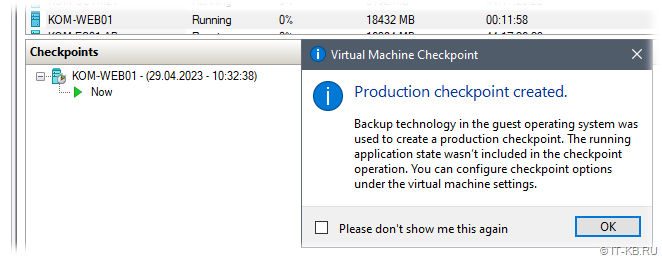
В нашем случае контрольная точка создалась успешно и в гостевой системе виртуального сервера SharePoint ошибка с кодом 8194 больше не появляется.
Теперь можно проверить, как изменилась ситуация в Veeam Backup & Replication. Убеждаемся в том, что в ходе выполнения задания резервного копирования для ВМ успешно создаётся, а затем автоматически удаляется временная контрольная точка, и, как следствие задание VBR отрабатывает без ошибок.

Стоит отметить, что описанная проблема является не проблемой VBR, а проблемой корректной настройки прав доступа для сервисных учётных записей SharePoint. При этом в официальном документе «Plan for administrative and service accounts in SharePoint Server» мне не удалось найти каких-либо явных указаний по включению сервисных учётных записей SharePoint в группу «Backup Operators» или каких-либо схожих по смыслу рекомендаций.
To solve the issue, the wrong disk ID should be removed from the used Veeam database. We recommend backing up your database prior to making any changes. To apply the query, follow the next steps:
1. From SQL Management Studio, connect to the instance containing the Veeam configuration database (default names are VEEAM, VEEAMSQL2008R2 or VEEAMSQL2012);
2. Expand “Databases”;
3. Right-click “VeeamBackup” > New query;
4. Paste the appropriate query (below) and press “execute” or F5
DELETE FROM Physhost_disk WHERE disk_id = ‘GUID’
You will need to paste the GUID from the error message in the job to the query. For example, if the error message looks like:Failed to create processing task for VM Error: Disk '3f8688c2-d5ae-4ac8-be11-2257097f8eb9' not found.
The query should look like:DELETE FROM Physhost_disk WHERE disk_id = '3f8688c2-d5ae-4ac8-be11-2257097f8eb9'
5. Close the Veeam GUI and run Veeam again to force the GUI to update.
NOTE: This is an operation that Veeam Support is happy to walk through with you and this KB is provided mostly as a convenience for customers wishing to perform the above operations themselves. If you would like to walk through this process with a representative of Veeam Customer Support, please do not hesitate to open a case with us via the Customer Portal.
In some circumstances there may be multiple orphaned disk references in the database, the error shown in the GUI will only display the first problematic GUID the software comes across. With this in mind it is advised to run a test job after running the above query, if the test jobs fails with another GUID error run the query again for that GUID. Repeat the test process till no errors occur.
есть две виртуальные машины с debian 10 на Hyper-V , и внешний usb диск. в одной из них примонтирован жесткий диск, настроена Samba , и сетевая общая папка, размером 1ТБ, занято примерно 700Гб . Пытаюсь создать бэкап на съемный диск, места достаточно 1 Тб. процесс длился более суток, но так и осталось 0% выполнено. Переключил съемный диск на другую машину , примонтировал сетевой диск . и nfv пробую создать бекап нескольких папок, все получилось довольно быстро. Выбрал все папки, но процесс так и не пошел , прошло уже 14 часов.
в логе вижу таки строчки:
log
[07.05.2021 21:15:03.869] <140277216487168> lpbcore| Initializing CBT indices. ok.
[07.05.2021 21:15:03.869] <140277216487168> lpbcore| The following snapshot storage files should be excluded from backup
[07.05.2021 21:15:03.893] <140277216487168> vmb | Backup compression level: [Lz4].
[07.05.2021 21:15:03.893] <140277216487168> vmb | [3afc] >> : setTrafficCompressionLevel\n5
[07.05.2021 21:15:03.893] <140277216487168> vmb | [3afc] out:
[07.05.2021 21:15:03.894] <140277216487168> lpbcore| Performing file-level backup: [/mnt/uatiS1/UATI].
[07.05.2021 21:15:03.894] <140277216487168> vmb | [SessionLog][processing] Backing up files /mnt/uatiS1/UATI.
[07.05.2021 21:15:04.123] <140277216487168> lpbdeve| ERR |Failed to create DeviceInfoEx for device [/dev/sr0].
[07.05.2021 21:15:04.123] <140277216487168> lpbdeve| >> |Носитель не найден
[07.05.2021 21:15:04.123] <140277216487168> lpbdeve| >> |Failed to probe device [/dev/sr0].
[07.05.2021 21:15:04.123] <140277216487168> lpbdeve| >> |—tr:CRealBlkidAccessor: Failed to probe device [/dev/sr0].
но вот есть — Agent.Target.log
а там такое
[07.05.2021 21:35:06.414] <140609411962624> cli | WARN|MTA invoke thread : timed out for backup events. Wait cycle will be resumed for ‘336’ hours.
[07.05.2021 21:35:17.134] <140608438007552> cli | WARN|MTA invoke thread : timed out for backup events. Wait cycle will be resumed for ‘336’ hours.
[07.05.2021 21:35:17.147] <140608412829440> cli | WARN|MTA invoke thread : timed out for backup events. Wait cycle will be resumed for ‘336’ hours.
[07.05.2021 21:35:17.282] <140608261826304> cli | WARN|MTA invoke thread : timed out for backup events. Wait cycle will be resumed for ‘336’ hours.
[07.05.2021 22:15:01.972] <140609437140736> srv | There was no finalized server sessions during the last 60 minutes.
[07.05.2021 23:15:02.178] <140609437140736> srv | There was no finalized server sessions during the last 60 minutes.
[08.05.2021 00:15:02.206] <140609437140736> srv | There was no finalized server sessions during the last 60 minutes.
[08.05.2021 01:15:02.251] <140609437140736> srv | There was no finalized server sessions during the last 60 minutes.
[08.05.2021 02:15:02.276] <140609437140736> srv | There was no finalized server sessions during the last 60 minutes.
[08.05.2021 03:15:02.317] <140609437140736> srv | There was no finalized server sessions during the last 60 minutes.
[08.05.2021 04:15:02.338] <140609437140736> srv | There was no finalized server sessions during the last 60 minutes.
[08.05.2021 05:15:02.368] <140609437140736> srv | There was no finalized server sessions during the last 60 minutes.
[08.05.2021 06:15:02.423] <140609437140736> srv | There was no finalized server sessions during the last 60 minutes.
[08.05.2021 07:15:02.466] <140609437140736> srv | There was no finalized server sessions during the last 60 minutes.
[08.05.2021 08:15:02.507] <140609437140736> srv | There was no finalized server sessions during the last 60 minutes.
[08.05.2021 09:15:02.549] <140609437140736> srv | There was no finalized server sessions during the last 60 minutes.
[08.05.2021 10:15:02.589] <140609437140736> srv | There was no finalized server sessions during the last 60 minutes.
[08.05.2021 11:15:02.639] <140609437140736> srv | There was no finalized server sessions during the last 60 minutes.
Recently encountered this issue after attempting to install Veeam B&R v9 on a server that at one stage in its life had an instance of Veeam B&R installed then uninstalled.
I cannot comment on how it was uninstalled but my first installation of Veeam B&R went smoothly, I utilised the existing Veeam DB and ran a couple of backup jobs. Unfortunately, after a couple of days, several issues started to happen. Essentially the existing DB was no good and I needed to wipe the slate clean.
After several unsuccessful installations later, Veeam was now having a problem when creating the database during installation.
The exact error was ‘Failed to create database VeeamBackup.Create failed for database VeeamBackup’
What finally fixed the problem was to uninstall the Veeam B&R Server perform the following steps to clean up SQL.
Step 1. Open the directory C:\Program Files\Microsoft SQL Server\MSSQL11.VEEAMSQL2012\MSSQL\DATA
Step 2. Find the below files and delete them
-Veeam Backup
-Veeam Backup-log
Step 3. Reinstall Veeam B&R
If the above fails to work try uninstalling all SQL components and then manually delete the left-over Microsoft SQL folder in the program files. Once completed, reinstall the Veeam B&R Server.
Knowledge Base
-
Home
-
Knowledge Base
-
Windows Agent Backups
-
Agent Job Errors
-
Troubleshooting: Job Errors
-
Home
-
Knowledge Base
-
Virtual Machine Backups
-
VM Job Errors
-
Troubleshooting: Job Errors
-
Home
-
Knowledge Base
-
Troubleshooting
-
Troubleshooting: Job Errors
General Troubleshooting: Veeam Backup Job Errors
Below are common host and backup job error messages you may encounter and what they mean.
This article is organized by Alarm Type:
- Backup Agent Job State Errors
- Job Session State Errors
- Job Status Errors
- Computer/VM Not Backed Up
- Miscellaneous
For Additional Errors Not Listed Below, Consult the Veeam Knowledge Base and/or Forums:
- Veeam Knowledge Base – https://www.veeam.com/kb_search_results.html
- Veeam Community Forums – https://forums.veeam.com/
1. Backup Agent Job State Errors
Error: write: An existing connection was forcibly closed by the remote host Failed to upload disk. Agent failed to process method {DataTransfer.SyncDisk}.
What This Means
- The last backup job was unsuccessful because the remote host (machine backing up) closed the connection to eSilo while the backup was running.
Possible Causes
- The machine was powered down during the backup. Upon shutdown, the active snapshot taken at the start of the backup is lost.
Troubleshooting Steps
- No user intervention is typically required. When the computer is powered back on, a new snapshot will be taken at the next scheduled backup time, and a new backup job will begin. (Note: If the machine is put to Sleep or Standby during a backup, it should resume when it wakes up. It is only when the machine is completely powered down that this error happens).
Error: Task failed unexpectedly
What This Means
- The job was terminated suddenly, resulting in an incomplete backup and restore point.
Possible Causes
- Host rebooted during the backup, resulting in the loss of the active snapshot.
Troubleshooting Steps
- Check host’s Event Viewer Windows System logs to see if there was a reboot.
- Rerun the backup job.
Error: Root element missing
What This Means
- The VBM file associated with the backup job has become corrupted.
Possible Causes
- This may be caused by a connection issue during the backup job or the Veeam repository had an error.
Troubleshooting Steps
- Locate the VBM file associated with the backup job and rename the file, such as by adding “.old” to end of the file name.
- Start a new backup job to generate a new VBM file.
- After the new VBM file gets created, the old file can be safely deleted without waiting for the running job to complete.
Unable to allocate processing resources. Error: Job session with id [STRING] does not exist
What This Means
- Host requested but was not assigned processing resources by eSilo cloud connect. This happens because the maximum number of concurrent backup jobs was already reached.
Possible Causes
- eSilo limits the number of concurrent backup jobs from a single Company when their bandwidth is lower than recommended thresholds. This max limit ensures hosts queue their backup jobs sequentially (vs. all machines at once) and avoids network slowdowns for the customer.
- When the first few machines’ backup jobs run long, they can cause subsequent hosts’ jobs to time out while waiting for their turn to backup.
Troubleshooting Steps
- Hosts should automatically retry backups at their next scheduled interval. No user intervention is typically required.
- If this is a persistent issue, or if your hosts are connecting from multiple locations (and thus there is little concern that multiple backups may saturate a site’s connection), contact eSilo Support to request the concurrent task limit be increased for your Company.
Failed to start a backup job. Failed to perform the operation. Invalid job configuration: Connection over network is blocked by network throttling rules
What This Means
- Backup job was unable to complete due to network restrictions.
Possible Causes
- The host is on a metered connection (ex: hot spot), or on a WiFi connection that has “Set as a metered connection” toggled on in the properties for the currently active WiFi connection. By default, eSilo Backup Jobs are set to “Disable backups over a metered connection”.
- Temporary network congestion may also cause this error.
- Firewall rules that limit or severely restrict certain types of traffic.
Troubleshooting Steps
- To check if the current WiFi connection is flagged as “metered” by Windows, the user can navigate to the Properties of their WiFi Network, and scroll to “Metered Connection” to verify if this is toggled ON. The preferred setting is to turn this OFF. Alternatively, if you don’t have remote access to the machine, uncheck the “Disable backups over metered connection” setting in the backup job and rerun it.

- Wait until the next scheduled backup run to see if the issue persists or was temporary.
- Contact the network or IT administrator for the site to investigate if there were recent firewall rule changes or upgrades that may have introduced new blocking or throttling settings.
Unable to allocate processing resources. Error: Authentication failed because the remote party has closed the transport stream.
What This Means
- The backup job failed due to an authentication error between the client machine backing up and the eSilo infrastructure.
Possible Causes
- Client machine is behind on Windows Updates which include authentication and security enhancements, or they have not checked the box in Windows Update Settings to include updates for other Microsoft Products, such as .NET Framework.
Troubleshooting Steps
- Apply latest Windows Security updates and .NET Framework updates
- Check if at the time of the above error on the tenant side, the eSilo Svc.VeeamCloudConnect.log log file displays the following error: “A call to SSPI failed, see inner exception“. If so, the issue may be related to a Windows Update enforcing a new .Net Framework security check. This check does not allow the client to establish a secure connection between their Veeam backup servers or agents and the eSilo Cloud Connect service, if there is a weak Diffie-Hellman Ephemeral (DHE) key. See this help article from Veeam on the steps needed to confirm and resolve. https://www.veeam.com/kb3208
- Subsequent job reattempts may complete successfully without user intervention, although this error may still sporadically cause jobs to fail.
Error: Failed to connect to the port [DNS_Name:Port].
What This Means
- Host unable to connect to eSilo cloud connect at the specified gateway and port address.
Possible Causes
- If this issue is occurring for only one or two machines (most common), and not all machines connecting to the eSilo cloud connect infrastructure, it may be indicative of a network issue on the client side.
Troubleshooting Steps
- The host should reattempt the job at the next scheduled interval. You can also manually start a backup to reattempt the job. No other user intervention is typically required.
Error: Insufficient quota to complete the requested service. Asynchronous read operation failed Failed to upload disk. Agent failed to process method {DataTransfer.SyncDisk}. Exception from server: Insufficient quota to complete the requested service. Asynchronous read operation failed Unable to retrieve next block transmission command. Number of already processed blocks: [#]. Failed to download disk ‘[LONG_ID]’.
What This Means
- The error description may be misleading. We’ve observed this error previously, and it was unrelated to the Tenant’s Quota, which was well within limits.
Possible Causes
- When this was observed on an internal testing VM, the cause was that the source VM in the backup job was very low on memory (RAM) resources and was unresponsive. Restarting the VM brought it back online, and the next automatic job try was successful.
Troubleshooting Steps
- Verify the source machine is online and responsive. Ensure resource levels look good.
- Host will reattempt job at the next scheduled interval. No user intervention is typically required.
Error: Invalid backup cache synchronization state.
What This Means
- Host is currently saving backups to Local Backup Cache. An attempt to sync cached backups to the eSilo cloud repository failed, due to a mismatch between what the Veeam Agent for Windows had in its local database for expected restore points and what was actually found in the repository and/or local backup cache.
Possible Causes
- If an in-progress backup is abruptly stopped, for example due to power failure, Veeam will discard any partially written restore points. However, if all references to those now discarded restore points are not cleared from the database (which should happen automatically), this can cause a job error on the next run, which highlights a mismatch between restore points expected on disk and what was found.
Troubleshooting Steps
- In most cases where this has been observed, the job will complete successfully the next time it is run, without any user intervention.
- If this error persists more than once, contact eSilo Support for assistance troubleshooting Backup Cache issues.
Job session for “[JOB_NAME]” finished with error. Job [JOB_NAME] cannot be started. SessionId: [ID], Timeout: [XX sec]
What This Means
- The Veeam job could not start due to too many active sessions or jobs running on the host consuming all available memory.
Possible Causes
- Too many running sessions causes Veeam services to be impacted by the host’s Desktop Heap limitation. This is because the Desktop Heap size for services is much smaller than that for applications.
Troubleshooting Steps
- To resolve this issue the Desktop Heap size must be increased via a registry modification.
- See this Veeam Knowledge Base article for detailed resolution steps: KB1909
Error: The system cannot find the file specified. Failed to open I/O device Failed to open emulated disk. Failed to open disk for read. Failed to upload disk. Agent failed to process method {DataTransfer.SyncDisk}
What This Means
- An expected disk on the client machine (machine to backup) was unable to be opened and read during the backup job.
Possible Causes
- Not known at this time.
Troubleshooting Steps
- The host will reattempt job at the next scheduled interval. No user intervention is typically required.
Error: Oib is complete and cannot be continued
What This Means
- The “oib” stands for “objects in backup” and is a unique identifier used by Veeam.
- The error indicates there is a discrepancy; a job is attempting to write to an oib that is already complete or finalized.
Possible Causes
- This may occur on a backup cache sync job that was interrupted right at very end, during the finalization stage. The error indicates that the oib was finalized by the previous job (“oib is complete”), however the current job is trying to modify or append to it, which is not allowed.
Troubleshooting Steps
- This error should resolve itself on next job run. If not, contact eSilo support.
Job session for “[JOB_NAME]” finished with error. Backup cache size has been exceeded
What This Means
- The size of the local backup cache has exceeded the maximum allowed size as configured in the backup job, preventing new restore points from being saved to the cache.
Possible Causes
- Persistent network disruptions may be preventing cached restore points from syncing, or uploading, to the eSilo Backup Cloud and thus they are not rotated out of the local backup cache. Restore points accumulate until the backup cache location is full.
- Service provider resources are busy or unable to be allocated to this host, preventing the syncing of cached restore points.
Troubleshooting Steps
- The Backup Cache Sync should resume in time, once the originating network or resource issues are resolved.
- The maximum Backup Cache size can be increased in the job settings, so long as there is sufficient local space.
- For more detail on advanced resolution steps, see this eSilo KB article: How to Resolve Backup Cache Size Exceeded Error
Error: Failed to create snapshot: Backup job failed. Cannot create a shadow copy of the volumes containing writer’s data. A VSS critical writer has failed. Writer name: [NAME]. Class ID: [ID]. Instance ID: [ID]. Writer’s state: [VSS_WS_FAILED_AT_PREPARE_SNAPSHOT]. Error code: [0x800423f0].
What This Means
- There is an issue with the built-in Windows VSS (Volume Shadow Copy service) on the host machine. Specifically, the VSS writer mentioned was not available at the time of the backup.
- eSilo Backups powered by Veeam use VSS writers to backup files that may be in-use, open or locked at the time of backup. This is particularly useful for databases, allowing backups to complete without downtime. If a writer is not in the proper state and functioning as expected, the backup snapshot will fail. VSS writer issues must be resolved on the host, and can usually be corrected by restarting the associated service.
Possible Causes
- The VSS service and/or the VSS Providers service is disabled
- The VSS writer is not in the Stable state, indicating it is ready and waiting to perform a backup. Below are alternative states:
- Failed or Unstable – the Writer encountered a problem, and must be reset .
- In-Progress or Waiting for Completion – the Writer is currently in use by a backup process. When the backup is finished, the Writer will revert to back to Stable state. However, if you see this state when no backups are running, the Writer needs to be reset.
Troubleshooting Options
- Verify the Volume Shadow Copy and Microsoft Software Shadow Copy Provider services are not disabled in services.msc.
- Check the state of VSS Writers using the following syntax in an admin command prompt. Also check the Windows Event Viewer for additional error information.
vssadmin list writers
-
- For the specified Writer in the error message, verify it is in a Stable state. If not, restart the respective Service related to that writer as mentioned in the table here. Then run the above command a second time to ensure the writer has returned to a stable state.
- Note that Services often have dependencies on one another. When one service is reset it may require others to be reset as well. Restarting a service will momentarily disrupt any application services that rely on it. For example, while resetting the MEIS service (Microsoft Exchange Information Store), MS Exchange will be unable to send and receive emails.
- A system reboot can also resolve most VSS writer problems, although it requires downtime.
- This Veeam KB article can also be useful in troubleshooting VSS issues for servers.
Job Session for [JOB_NAME] finished with error. Job [JOB_NAME] cannot be started. SessionID: [ID], Timeout: [VALUE]
What This Means:
- The job could not start, due to timeout waiting for required Veeam resources
Possible Causes:
- The Concurrent Task limit set at the Company level is too low for the number of hosts and disks schedule to be backup within a defined backup window.
Troubleshooting Options:
- Increase the number of concurrent tasks (e.g. disks that can be processed at once). This setting can be found in the eSilo Backup Portal under Companies >> Edit >> Bandwidth >> Max Concurrent Tasks. The minimum value should be 2, but greater numbers may be needed based on the timing and staggering of host backups.
Job session for “[JOB_NAME]” finished with error.
Error: Service provider side storage commander failed to perform an operation: CreateStorage
What this Means:
- eSilo was not able to allocate repository storage for the backup job.
Possible Causes:
- The assigned repository quota for this Tenant has been exceeded, thus preventing new backups from initiating.
Troubleshooting Options:
- Increase the Company’s repository quota.
- Remove existing backup chains or reduce the retention period to free space.
Job Status Warning: Unable to truncate SQL server transaction logs. Details: Failed to truncate SQL server transaction logs for instances: [MSSQLSERVER].
What this Means:
- Veeam was unable to truncate SQL server logs as specified in the job settings.
Possible Causes:
- This most commonly due to a permissions issue.
Troubleshooting Options:
- This Veeam Helpcenter article discusses the Log Truncation settings.
- You can confirm if this is a permissions issue by reviewing the Backup Job log for Warning items. Ex: Description = The server principal “[HOST]\[ACCOUNT]” is not able to access the database “[HOSTNAME]” under the current security context.
- Grant necessary permissions and rerun the job.
- Alternatively, you can modify the Backup Job settings to not truncate SQL Logs.
- Edit the Backup Job
- Under Guest Processing, click to “Customize application handling options for individual applications…”
- On the SQL tab, select the option for “Do not truncate logs”
2. Job Session State Errors (for VMs)
Host [LOCAL_IP] is not available. Error: Cannot complete login due to an incorrect user name or password. Virtual Machine [NAME] is unavailable and will be skipped from processing. Nothing to process. [#] machines were excluded from task list.
What This Means
- Veeam Backup and Replication was unable to access the Virtual Machine (VM) to perform the backup.
Possible Causes
- Incorrect user name or password specified to access the source VM. The password may have expired or the account credentials or permissions may have been changed.
Troubleshooting Steps
- Contact the IT Administrator for the VM to troubleshoot the credentials saved in the Backup Job.
3. Job Status Errors
SQL VSS Writer is missing: databases will be backed up in crash-consistent state and transaction log processing will be skipped
What This Means
- The SQL Writer for the Windows Volume Shadow Copy Service (VSS) is not available on the host machine, or is not configured with adequate permissions. This issue is related to the setup of the SQL database, and not specific to eSilo provided software or the backup itself.
Steps to Confirm the Issue
- Running ‘vssadmin list writers’ in an Administrator Command Prompt shows that SqlServerWriter is not in the list, or is in a State other than ‘Stable’.
Possible Causes
- The SQL instance has at least one database with name starting or ending in a space character
- The account under which SQL VSS Writer service is running doesn’t have sysadmin role on a SQL server – most frequently encountered
- SQL VSS Writer service is stuck in an invalid state, e.g. other than ‘Stable’
Troubleshooting Steps
- Depending on a particular cause:
- Rename the database to a new name (without a space in it). To check if your database has space in the name you can run the following query:
select name from sys.databases where name like '% '
If you notice any spaces in the database names, then you will need to remove the spaces from the database names.
- Grant the SQL VSS Writer service user a sysadmin role (Instructions in KB here: https://www.veeam.com/kb1978)
- Restart SQL VSS Writer service (Instructions in KB here: https://www.veeam.com/kb2041)
- In the case of SBS machines that are also Domain Controllers, ensure that the SQL Writer is running as a domain administrator and not local system.
- Allow the SQL Writer service account access to the Volume Shadow Copy service via the registry:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\VSS\VssAccessControl- If the DWORD value “NT SERVICE\SQLWriter” is present in this key, it must be set to 1.
- If the Volume Shadow Copy service is running, stop it after changing this registry value. Do not disable it.
For More Information
See this Veeam Knowledgebase article: https://www.veeam.com/kb2095
Microsoft documentation states that the SQL Writer service must run as Local System.
- In SQL Server 2008R2 and earlier, this means that the writer service account appears to SQL Server as “NT AUTHORITY\System”.
- In SQL Server 2012 and later, the writer service account appears to SQL Server as “NT Service\SQLWriter”.
4. Computer/VM Not Backed Up Errors
Backup Agent ‘[HOSTNAME]’ has fallen out of the configured RPO interval ([#]days). Last backup: [#] days, [#] hours ago.
What This Means
- The host’s most recent eSilo cloud backup is greater than the specified RPO (Recovery Point Objective) interval.
Possible Causes
- Host has been powered off or offline.
- Backups are being saved to the host’s Local Backup Cache and all restore points in the cache have not yet synced to the eSilo Cloud Repository (e.g. eSilo has not yet received the backups).
- Veeam Backup Agent Service or Veeam Management Agent Service is not running on host.
- The backups and/or backup schedule have been manually disabled (uncommon).
Troubleshooting Steps
- Verify host is online and connected to network.
- Check Backup Job to determine if Backup Cache is enabled. View cache folder on host to see if populated with recent restore points (default location: C:\VeeamCache).
- Verify ‘VeeamManagementAgentSvc’ service is running on host. Status should be ‘Running’ and Startup Type should be ‘Automatic (Delayed Start)’. If the service is ‘Stopped’, check the Event Viewer for possible error details. See this article for more troubleshooting steps.
- Verify ‘VeeamEndpointBackupSvc’ service is running on host. Status should be ‘Running’ and Startup Type should be ‘Automatic’. Restart or reinstall if necessary.
- Check Backup Job to verify schedule and ensure not ‘Disabled’
Other Errors – Full Details Coming Soon
Error: Reconnectable protocol device was closed. Agent failed to process method {FileBackup.SyncDirs}. Exception from server: Reconnectable protocol device was closed.
Troubleshooting Steps
- Host will reattempt job at the next scheduled interval. No user intervention is typically required.
Error: A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond.
Troubleshooting Steps
- Host will reattempt job at the next scheduled interval. No user intervention is typically required.
[In Backup Job Log] Error: [CStorageLinksHelper] Link Id=[LONG_ID] doesn’t exist for storage [JOBNAME_SUBTENANTNAME]yyy-mm-ddTxxxxxx.vib
What This Means
- While the restore point exists on the repository, the Link ID to that restore point in the metadata (.vbm) file is missing.
- Note: If the Backup Job is configured to use Backup Cache, this error does not by itself trigger a Backup Job Failure, since the restore points are successfully written to local cache. You will notice it however, because the eSilo Backup Portal will warn that a new restore point has not been uploaded in X days (according to the RPO alarm thresholds set for this tenant).
Possible Causes
- This can be a symptom of a network drop, where a handshake was missed in the final stages of job completion for the last restore point uploaded to eSilo. The local Veeam Agent database (on the subtenant’s machine) saw the restore point created, but the finalization step didn’t update the metadata file on the repository side with eSilo.
Troubleshooting Steps
- In the repository, we will force the job to recreate the metadata file by editing the existing metadata file to append “.old” at the end. At the next job run, this will force a recheck of all restore points in the backup chain and recreate the metadata file from that chain.
[In Svc.VeeamEndpointBackup.log] Error: Warning [CertificateError] Validation complete with warnings, AND/OR Warning Remote certificate chain errors, AND/OR Warning WarningRevocationStatusUnknown (The revocation function was unable to check revocation for the certificate.
What This Means
- The subtenant was unable to validate the eSilo Cloud Connect server’s certificate.
Possible Causes
- If this is happening for only one tenant, as opposed to all tenants, it suggests an issue with how this specific subtenant is connecting to eSilo.
- If no firewall or other changes have been made recently, you can recheck the credentials used by the subtenant in the backup job.
- This Veeam KB article is also helpful for investigating common causes of certificate errors: https://www.veeam.com/kb2323
Troubleshooting Steps
- Verify the Management Agent status shows as Connected. You can force a reconnect by changing a property in the dialog box, then changing it back and clicking “Apply“.
- Pause and unpause sync of Backup Cache files by right-clicking on the Veeam Backup Agent icon in the taskbar.
- Edit the Backup Job to specify the correct sub-tenant login credentials. Save and rerun the job. Upon the next job run, you should see “Uploading cached restore points” when you hover over the Veeam Backup Agent icon in the taskbar.
Was this article helpful?
Related Articles
Page load link
Go to Top