Поиск ошибок и различных проблем. Помощь в решении
Therac 25 ошибка
Время на прочтение
5 мин
Количество просмотров 46K
Программный код начал убивать людей при помощи машин еще в 1985 году.
Типичная разовая терапевтическая доза радиации составляет до 200 рад.
1000 рад — смертельная доза. Восставшая машина фигачила в беззащитных землян 20 000 рад.
Рассмотрим случай, когда поэтапное, но не согласованное внедрение улушений софта привело к системной ошибке. К худшей в истории программной ошибке.
В Therac-25 аппаратная защита была убрана и функции безопасности были возложены на программное обеспечение.
Как проводилось расследование, что должны намотать на ус проектировщики ИТ-систем, программисты, тестировщики, чтобы не допустить подобного.
Убийца
Therac-25 — аппарат лучевой терапии, медицинский ускоритель созданный канадской государственной организацией Atomic Energy of Canada Limited.
Реклама аппарата для домохозяек.
Убийство
С июня 1985 года по январь 1987 года этот аппарат стал причиной шести передозировок радиации, некоторые пациенты получили дозы в десятки тысяч рад. Как минимум двое умерли непосредственно от передозировок.
Медсестра вспомнила, что в тот день она заменяла «x» на «e». Выяснилось, что если сделать это достаточно быстро, переоблучение случалось практически со 100-процентной вероятностью.
Расследование
Во время ведения судебных дел против AECL прокуратура штата Техас обратилась к Нэнси Ливесон (профессор компьютерных наук Калифорнийского Университета в Ирвайне) как к эксперту для расследования. Она внесла весомый вклад в компьютерную безопасность. Нэнси с Кларком Тёрнером в течение трех лет занимались сбором материалов и реконструкцией событий, связанных с Therac-25. Данный результат важен, так как в большинстве инцидентов по безопасности информация является неполной, противоречивой и неверной.
Канадская государственная организация «Atomic Energy of Canada Limited» (далее AECL) выпустила три версии: Therac-6, Therac-20 и Therac-25. 6 и 20 были произведены совместно с французской компанией CGR. Партнёрство прекратилось перед проектировкой Therac-25, но у обеих компаний остался доступ к проектам и исходным кодам ранних моделей.
Программный код в Therac-20 основывался на коде Therac-6. На всех трёх аппаратах был установлен компьютер PDP-11. Предыдущим моделям он не требовался, так как они были спроектированы как автономные устройства. Техник по лучевой терапии настраивал различные параметры вручную, в том числе и положение поворотного диска для настройки режима работы аппарата.
В электронном режиме отклоняющие магниты распределяли луч так, чтобы электроны покрыли большую площадь. В рентгеновском режиме мишень располагалась на пути излучения, электроны наносили по ней удар, чтобы произвести фотоны рентгеновского излучения, направленные на пациента. Наконец, на пути ускорителя можно было расположить отражатель, с помощью которого рентгенотехник мог навести излучение точно на больное место. Если отражатель был на пути, электронный луч не запускался.
На Therac-6 и 20 аппаратные механизмы блокировки не позволяли оператору сделать что-то опасное, скажем, выбрать электронный пучок высокой мощности без рентгеновской мишени на месте.
Попытка активировать ускоритель в неправильном режиме приводила к срабатыванию предохранителей и остановке работы. PDP-11 и сопутствующее оборудование были встроены для удобства. Техник мог ввести рецепт в терминал VT-100, и компьютер, используя сервоприводы, автоматически настраивал поворотный диск и другие устройства.
Сотрудникам больниц нравилось, что компьютер настраивает всё быстрее, чем человек. Чем меньше времени уходило на настройку, тем больше пациентов можно было принять за день.
Когда пришло время сделать Therac-25, AECL решили оставить только компьютерное управление. Они отказались от устройств ручного управления и от аппаратных механизмов блокировки. Компьютер должен был следить за настройками устройства и, в случае обнаружения неполадок, должен был отключать питание всей машины.
Ну ну.
В программном обеспечении Therac-25 были найдены как минимум четыре ошибки, которые могли привести к переоблучению.
Одна и та же переменная применялась как для анализа введённых чисел, так и для определения положения поворотного круга. Поэтому при быстром вводе данных через терминал Therac-25 мог иметь дело с неправильным положением поворотного круга (состояние гонки).
Настройка положения отклоняющих магнитов занимает около 8 секунд. Если за это время параметры типа и мощности излучения были изменены, а курсор установлен на финальную позицию, то система не обнаруживала изменений.
Деление на величину излучения, приводящее в некоторых случаях к ошибке деления на ноль и к соответствующему увеличению величины облучения до максимально возможной.
Установка булевской переменной (однобайтовой) в значение «истина» производилось командой «x=x+1». Поэтому с вероятностью 1/256 при нажатии кнопки «Set» программа могла пропустить информацию о некорректном положении диска.
Были выявлены потенциальные ошибки — в многозадачной операционной системе не было никакой синхронизации.
Исправления
Все прерывания, относящиеся к системе дозиметрии, останавливали процедуру, а не ставили ее на паузу. Оператор был обязан заново вводить все параметры.
Добавлено софтовое выключение «в один клик».
Добавлено независимое хардверное выключение «в один клик».
Кодированные сообщения об ошибках заменены осмысленными и на экране выводился текущий уровень облучения.
Добавили потенциометр, который определяет положение поворотного диска.
Изменение положения диска и других частей аппарата теперь возможно только тогда, когда оператор удерживает специальную педаль (deadman switch) .
В режиме рентгеновской терапии отклоняющие магниты для электронной терапии устанавливаются в такую конфигурацию, что отклоняют пучок электронов на 270°.
Производитель сообщил, что программное и аппаратное обеспечение протестировано в течение многих лет. Однако, при разбирательстве выяснилось, что программное обеспечение было проверено минимальным количеством тестов на симуляторе, а большинство времени тестировалась вся система в целом. Таким образом, модульным тестированием пренебрегали, а проводили только интеграционное тестирование.
Было выдвинуто наивное предположение, что повторное использование кода или коробочного продукта увеличит безопасность программного обеспечения в силу длительности их успешного применения. Повторное использование кода не гарантирует безопасность модуля в новой системе, так как её проектирование имеет свои особенности. Переписывание с нуля позволяет получить более простую и прозрачную систему, и как следствие, более безопасную.
В данном случае имело место повторное использование программного кода с Therac-6 и Therac-20. В Therac-6 вообще не было рентгеновской терапии, в Therac-20 применялся механический блокиратор.
После несчастных случаев Therac-25 FDA изменило своё отношение к множеству проблем систем, связанных с безопасностью, и особенно в отношении к программному обеспечению. Как результат, FDA запустило процесс улучшения своих процедур, директив и системы отчетности, и включило в них программное обеспечение. Данный урок был важным не только для FDA, но и для всех промышленных систем, критичных к безопасности.
Еще материалы по теме Therac-25
My professor investigated the Therac-25 incident and was a part of the prosecution. Got any questions for me to ask him?
What is the name of the programmer who wrote the Therac-25 software?
Fatal Defect: Chasing Killer Computer Bugs
Nancy Leveson, Clark S. Turner An Investigation of the Therac-25 Accidents
Nancy G. Leveson, Therac-25 Accidents
Nancy G. Leveson Safeware: System Safety and Computer
Infusion Pump Software Safety Research at FDA
Заключение
Software Engineering Institute говорит о среднем числе в 1 баг на каждые 100 строк кода и 98% случаев сбоев устройств, случающихся по причинам багов в ПО, легко можно было бы избежать при должном уровне тестирования кода. Зная об этом, хочется примкнуть к движению «дайте код посмотреть». Вроде бы меры после громких случаев приняты, но все равно не очень хочется столкнуться с бормашиной, где в переменной, отвечающей за угловую скорость, «ошиблись на нолик». Уважаемые тестировщики (программисты, разработчики), делайте свою работу хорошо.
UPD
The University of California, Berkeley: Computer Science 61A — Lecture 35: Therac-25
В 1984 году на экраны вышел фильм «Терминатор» с Арнольдом Шварценеггером в главной роли. Персонаж стал посланником злобного искусственного интеллекта, который стремится уничтожить все живое на Земле или подчинить его своей воле. С чего все началось? Вероятно, с ошибки программистов, которые в коде не там поставили запятую и предоставили Skynet слишком много свободы.
Мы не станем изучать искусственный интеллект, а обратим внимание на историю, которая привела к трагическим последствиям. Источником всех бед в ней стал именно человек, машина была лишь инструментом.
Содержание
Аппарат для лечения агрессивных форм рака
Оптимизация разработки
Начало «неприятностей»
Отрицание
Признать ошибку и остановить работу
Аппарат для лечения агрессивных форм рака
Лучевую терапию применяют давно и достаточно успешно, инженеры и медики совершенствуют технологии и оборудование, которое призвано помочь в борьбе со злокачественными образованиями. То и дело появляются революционные решения — сегодня они могут казаться устаревшими, но 30—40 лет назад считались прорывом.
В конце 1970-х годов канадское правительство инициировало разработку полностью компьютеризированной системы Therac-25 — аппарата лучевой терапии для лечения агрессивных форм рака, более эффективного с медицинской и экономической точки зрения, нежели предшественники Therac-6 и Therac-20.
Медицинский линейный ускоритель мог работать в двух режимах: с небольшой интенсивностью излучения и высокой (это упрощенное описание) в зависимости от того, на какой глубине в тканях находился очаг. Одним из ключевых отличий Therac-25 от Therac-20 стал переход на полностью программное управление.
Потенциальных покупателей системы именно этим и пытались заинтересовать: ведь вместо дорогостоящих сенсоров и аппаратных решений для защиты применялось сравнительно дешевое ПО. В прошлых же версиях системы для предотвращения неверных конфигураций применялись всевозможные ограничители, датчики, сенсоры и механизмы, обеспечивающие безопасность процедуры.
Оптимизация разработки
Чтобы оптимизировать разработку, создатели Therac-25 использовали старый код — написанный для предыдущих «тераков». Тот, в свою очередь, по данным ряда источников, был написан программистом-самоучкой, который не имел профильного образования. Возможно, по этой причине он не стал сопровождать код комментариями — разобраться в нюансах было непросто, а создавать программную платформу с нуля не захотели.
Поставки Therac-25 в медучреждения США и Канады начались в 1983 году, и первое время информации о сбоях не было. Системе было несложно пройти все инстанции и получить разрешения от регуляторов — в машине применялось уже существующее ПО, поэтому его пропустили без особых вопросов. В то время около 94% медицинского оборудования попадало на рынок именно таким образом, что упрощало, ускоряло и удешевляло вывод новых устройств. А как все это работало, вопрос другой.
Для проверки степени опасности и рисков выхода системы из строя применялся Fault Tree Analysis (или «анализ дерева отказов»). В процессе определялись те самые «опасные последствия», условия, которые к ним приведут, и предпринятые шаги в этой цепочке. Затем оценивался шанс возникновения ситуаций. Вновь подчеркнем — это упрощенное описание подхода.
Главное заключалось в том, что анализ решили не проводить, так как программное обеспечение «зарекомендовало себя как безопасное во время работы на Therac-6 и Therac-20». То, что Therac-25 значительно отличается от предыдущих поколений медицинских ускорителей, решили опустить. Компания-разработчик оценила шанс неправильной работы как почти несуществующий, а возможные ошибки в ПО проигнорировала.
Позже оказалось, что в ПО существовала уйма критических ошибок. Одну из них называют race condition. В случае с Therac-25 использовалась одна и та же переменная для двух команд, которые могли выполняться в произвольном порядке, что для описываемого аппарата неприемлемо.
К примеру, в одном из режимов при максимальной интенсивности излучения между пациентом и электронной пушкой должен был устанавливаться «рассеиватель», распределяющий поток. Машина же выполняла не ту последовательность, и на человека обрушивался мощнейший луч. Проверяющая система, в свою очередь, из-за неверной команды (которая, опять же, не проверялась дублирующими системами) неправильно оценивала уровень радиации и «стреляла» вновь.
Были и другие программные недочеты: некорректные операции с нулем приводили к выводу мощности излучения на максимум, а неверно описанная переменная генерировала неправильное положение поворотного диска с набором инструментов (для разных режимов работы и настройки) 1 раз из 256, что могло привести к многократно завышенному уровню облучения.
Свою роль играла работа магнитов, которые позиционировали поворотный диск с «прицелами» для разных видов терапии. Если оператор вносил корректировку в мощность и тип излучения слишком быстро, машина не успевала перевести диск. Тогда шансы получить высокую дозу составляли 50 на 50. Если принять во внимание все возможные ошибки, то окажется, что Therac-25 представлял собой чуть ли не русскую рулетку с радиацией вместо пуль.
Начало «неприятностей»
Основные «неприятности» аппарат лучевой терапии принес в период с 1985 по 1987 год шести людям (это те, о которых есть информация). Первый смертельный исход был зафиксирован в 1986 году.
Жертвой стал пациент, проходивший девятую для него процедуру облучения. Оператор, внося команду, допустила опечатку — вместо Е (электронная терапия) она указала Х (рентгеновская терапия). Заметив это, она вернулась на пункт выше и поставила верную букву. В этот момент в системе произошла ошибка — их случались десятки в день, так что «ничего странного».
Аппарат продолжил работу, а оператор, приняв уведомление за индикацию низкой дозы, повторила процесс облучения. Так как пациент находился в защищенном помещении вне поля зрения сотрудника, а предусмотренные системы связи были неисправными, оператор не знала, что человек за стеной скорчился от боли. Через некоторое время мужчина вскочил со стола и бросился к двери, пытаясь привлечь внимание человека за стеной.
Но «разряды» уже нанесли непоправимый вред: отказали левая рука, на которую пришлась доза облучения, и обе ноги, пациент потерял речь, а спустя пять месяцев умер от ряда осложнений.
Второй фатальный случай произошел в том же медицинском учреждении с участием того же оператора спустя месяц после предыдущего. Некоторые источники описывают техника как поднаторевшую во вводе команд в Therac-25 сотрудницу, и якобы именно стремительность ее действий стала одной из причин сбоев.
На этот раз интерком работал и оператор услышала стоны пациента, чье лицо оказалось под ударом радиации. Спасти человека не удалось — мужчина впал в кому и умер спустя три недели после инцидента.
Третья жертва неверно написанного ПО, отсутствия тестирования и, вероятно, желания сэкономить умерла в январе 1987 года. Вновь речь шла о сбоях, ошибках в работе системы, ее перезагрузке и отчете компьютера о дозе в 7 рад, что не соответствовало действительности. Пациент жаловался на жжение в области облучения, это «как бы приняли к сведению», а спустя три месяца он умер от последствий лучевой болезни.
Отрицание
Три других случая завершились чуть менее трагично. Самое странное, что все они произошли до трех фатальных инцидентов, однако действенных мер предпринято не было — какие-то изменения по требованию экспертов вносились, но система была настолько несовершенной, что результата это не принесло.
В июне 1985 года 61-летняя женщина проходила терапию после удаления раковой опухоли в груди. После сеанса лучевой терапии с использованием аппарата Therac-25 ее плечо и рука оказались парализованы, а грудь пришлось удалить. Канадская государственная корпорация AECL, которая выступала заказчиком ускорителей, отказалась признать вину.
«Этого не может быть, ошибки и некорректная работа Therac-25 исключены. Возникновение отека — это нормально», — примерно так говорилось в их заявлении.
Второй инцидент произошел спустя примерно месяц в другом медучреждении. На этот раз под излучателем оказалась 40-летняя пациентка. Во время сеанса машина сообщила о нулевой интенсивности излучения. Оператор ставил систему на паузу и возобновлял процедуру — аппарат был направлен в область таза. Это повторилось пять раз, потому что Therac-25 продолжал выдавать одно и то же уведомление — нулевая доза.
Прибывший по вызову техник отрапортовал: «Все в порядке, неисправностей нет». Пациентку госпитализировали, а позже она умерла — причиной стало развитие рака. Но останься она живой, женщине как минимум бы потребовалась замена тазобедренного сустава, уничтоженного ускорителем.
Третий инцидент имел место в том же 1985 году. Пациентка получила шрамы, но выжила. Сперва недомогание списали на основное заболевание, возможность радиационного «овердоза» начали рассматривать лишь год спустя. Вред здоровью был нанесен, но в сравнении с другими случаями — «незначительный».
Первое время AECL категорически отрицала возможность чрезмерного облучения пациентов аппаратом Therac-25 — «ведь мы проводили многолетнее тестирование». Позже были отсылки к неким экспертам, которые пришли к аналогичным выводам, — «но мы не можем назвать их имена». Независимое изучение вопроса показало, что это не так. Канадскую государственную корпорацию вынудили начать собственное настоящее расследование лишь после пятого инцидента.
В AECL до последнего пытались найти ошибки в «железе», практически не принимая во внимание код. В то же время, как утверждают некоторые специалисты, чтобы достичь заявленного уровня безопасности, инженерам компании пришлось бы тестировать систему на протяжении 100 тыс. лет. На деле же, по их словам, к тестированию относились спустя рукава, после внедрения исправлений софт не прогоняли через всевозможные испытания. А ведь шанс того, что что-то «сломается» после патча, достаточно велик — 50 на 50.
Наконец выяснилось, что все ошибки достались Therac-25 от Therac-20 и, вероятно, даже от Therac-6 (в котором рентгеновского режима не было вовсе). На старых системах баги никак не проявляли себя из-за аппаратных решений обеспечения безопасности. А в новой «продвинутой» системе стали очевидны — ничто не могло их «прехватить». И вот при разовой терапевтической дозе до 200 рад пациенты, как утверждают некоторые источники, получали до 20—25 тыс. рад (точечно, так как смертельная доза для всей поверхности тела в разы меньше).
Признать ошибку и остановить работу
В 1987 году американский и канадский регуляторы потребовали остановить работу всех Therac-25 (их насчитывалось чуть менее полутора десятков в США и Канаде) до выяснения обстоятельств. За полгода AECL составила план и утвердила его, внедрив аппаратные системы защиты и доработав ПО. Оставшиеся в живых жертвы и их родственники подали иски, однако все вопросы были улажены сторонами в досудебном порядке.
Остается открытым вопрос, кто тот программист-самоучка, который работал то ли на полную ставку, то ли на аутсорсе, то ли «халтурил» по вечерам? История тщательно скрывает этот момент. Может, он просто не имел опыта разработки систем, функционирующих в режиме реального времени, однако в жизни был хорошим парнем?
Ну а история Therac-25 стала уроком о том, как нельзя проектировать системы с повышенными требованиями к безопасности.
Список источников: Bugsnag, Hackaday, California Polytechnic State University, Stanford University, IEEE Computer Society, How Not To Code, ComputingCases, Wikibooks, Interesting Engineering, Virginia Tech.
Читайте также:
Жил в доме без горячей воды и «бежал от коммунизма». История украинского основателя WhatsApp Яна Кума
Sonnengewehr, или Как нацисты лучом света из космоса хотели сжигать города
Наш канал в Telegram. Присоединяйтесь!
Быстрая связь с редакцией: читайте паблик-чат Onliner и пишите нам в Viber!
Читайте нас в Дзене
Перепечатка текста и фотографий Onliner без разрешения редакции запрещена. nak@onliner.by
The Therac-25 was a computer-controlled radiation therapy machine produced by Atomic Energy of Canada Limited (AECL) in 1982 after the Therac-6 and Therac-20 units (the earlier units had been produced in partnership with Compagnie générale de radiologie (CGR) of France).
It was involved in at least six accidents between 1985 and 1987, in which patients were given massive overdoses of radiation.[1]: 425 Because of concurrent programming errors (also known as race conditions), it sometimes gave its patients radiation doses that were hundreds of times greater than normal, resulting in death or serious injury.[2] These accidents highlighted the dangers of software control of safety-critical systems, and they have become a standard case study in health informatics, software engineering, and computer ethics. Additionally, the overconfidence of the engineers[1]: 428 and lack of proper due diligence to resolve reported software bugs are highlighted as an extreme case where the engineers’ overconfidence in their initial work and failure to believe the end users’ claims caused drastic repercussions.
History[edit]
Linear accelerator.Animation of the operation of a medical use linear accelerator.
The French company CGR manufactured the Neptune and Sagittaire linear accelerators.
In the early 1970s, CGR and the Canadian public company Atomic Energy Commission Limited (AECL) collaborated on the construction of linear accelerators controlled by a DEC PDP-11 minicomputer: the Therac-6, which produced X-rays of up to 6 MeV, and the Therac-20, which could produce X-rays or electrons of up to 20 MeV. The computer added some ease of use because the accelerator could operate without it. CGR developed the software for the Therac-6 and reused some subroutines for the Therac-20.[3]
In 1981, the two companies ended their collaboration agreement. AECL developed a new double pass concept for electron acceleration in a more confined space, changing its energy source from klystron to magnetron. In certain techniques, the electrons produced are used directly, while in others they are made to collide against a tungsten anode to produce X-ray beams. This dual accelerator concept was applied to the Therac-20 and Therac-25, with the latter being much more compact, versatile, and easy to use. It was also more economical for a hospital to have a dual machine that could apply treatments of electrons and X-rays, instead of two machines.
The Therac-25 was designed as a machine controlled by a computer, and some safety mechanisms switched from hardware to software. AECL decided not to duplicate some safety mechanisms. AECL reused modules and code routines from the Therac-20 for the Therac-25.
The first prototype of the Therac-25 was built in 1976. It began to be marketed at the end of 1982.
The software for the Therac-25 was developed by one person over several years using PDP-11 assembly language. It was an evolution of the Therac-6 software. In 1986, the programmer left AECL. In a lawsuit, lawyers could not identify the programmer or learn about his qualification and experience.
Five machines were installed in the United States and six in Canada.[3]
After the accidents, in 1988 AECL dissolved the AECL Medical section and the company Theratronics International Ltd took over the maintenance of the installed Therac-25 machines.[4]
Design[edit]
The machine had three modes of operation, with a turntable moving some apparatus into position for each of those modes: either a light, some scan magnets, or a tungsten target and flattener.[5]
A «field light» mode, which allowed the patient and collimator to be correctly positioned by illuminating the treatment area with visible light.
Direct electron-beam therapy, in which a narrow, low-current beam of high-energy (5 to 25 MeV (0.80 to 4.01 pJ)) electrons was scanned over the treatment area by magnets;[5]
Megavolt X-ray (or photon) therapy, which delivered a beam of 25 MeV X-ray photons. The X-ray photons are produced by colliding a high current, narrow beam of electrons with a tungsten target. The X-rays are then passed through a flattening filter, and then measured using an X-ray ion chamber. The flattening filter resembles an inverted ice-cream cone, and it shapes and attenuates the X-rays. The electron beam current required to produce the X-rays is about 100 times greater than that used for electron therapy.[5]
Turntable rotation.
The patient is placed on a fixed stretcher. Above them is a turntable to which the components that modify the electron beam are fixed. The turntable has a position for the X-ray mode (photons), another position for the electron mode and a third position for making adjustments using visible light. In this position an electron beam is not expected, and a light that is reflected in a stainless steel mirror simulates the beam. In this position there is no ion chamber acting as a radiation dosimeter because the radiation beam is not expected to function.
The turntable has some microswitches that indicate the position to the computer. When the plate is in one of the three allowed fixed positions a plunger locks it by interlocking. In this type of machine, electromechanical locks were traditionally used to ensure that the turntable was in the correct position before starting treatment. In the Therac-25, these were replaced by software checks.[5]
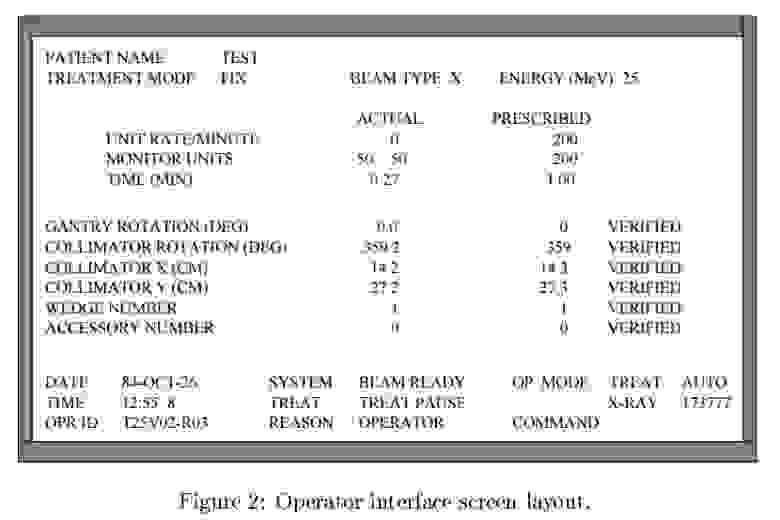
Problem description[edit]
Simulated Therac-25 user interface
The six documented accidents occurred when the high-current electron beam generated in X-ray mode was delivered directly to patients. Two software faults were to blame.[5] One, when the operator incorrectly selected X-ray mode before quickly changing to electron mode, which allowed the electron beam to be set for X-ray mode without the X-ray target being in place. A second fault allowed the electron beam to activate during field-light mode, during which no beam scanner was active or target was in place.
Previous models had hardware interlocks to prevent such faults, but the Therac-25 had removed them, depending instead on software checks for safety.
The high-current electron beam struck the patients with approximately 100 times the intended dose of radiation, and over a narrower area, delivering a potentially lethal dose of beta radiation. The feeling was described by patient Ray Cox as «an intense electric shock», causing him to scream and run out of the treatment room.[6] Several days later, radiation burns appeared, and the patients showed the symptoms of radiation poisoning; in three cases, the injured patients later died as a result of the overdose.[7]
Radiation overexposure incidents[edit]
Kennestone Regional Oncology Center, 1985[edit]
A Therac-25 had been in operation for six months in Marietta, Georgia at the Kennestone Regional Oncology Center when, on June 3, 1985, applied radiation therapy treatment following a lumpectomy was being performed on a 61-year-old woman. The patient was set to receive a 10-MeV dose of electron therapy to her clavicle. When therapy began, she stated she experienced a «tremendous force of heat…this red-hot sensation.» The technician entered the room, to whom the patient stated, «you burned me.» The technician assured her this was not possible. The patient returned home where, in the following days, she experienced reddening of the treatment area. Shortly after, her shoulder became locked in place and she experienced spasms. Within two weeks, the aforementioned redness spread from her chest to her back, indicating that the source of the burn had passed through her, which is the case with radiation burns. The staff at the treatment center did not believe it was possible for the Therac-25 to cause such an injury, and it was treated as a symptom of her cancer. Later, the hospital physicist consulted the AECL about the incident. He calculated that the applied dose was between 15,000 and 20,000 rad (radiation absorbed dose) when she should have been dosed with 200 rad. A dose of 1000 rad can be fatal. In October 1985, the patient sued the hospital and the manufacturer of the machine. In November 1985, the AECL was notified of the lawsuit. It was not until March 1986, after another incident involving the Therac-25, that the AECL informed the FDA that it had received a complaint from the patient.
Due to the radiation overdose, her breast had to be surgically removed, an arm and shoulder were immobilized, and she was in constant pain. The treatment printout function was not activated at the time of treatment and there was no record of the applied radiation data. An out-of-court settlement was reached to resolve the lawsuit.[2]
Ontario Cancer Foundation, 1985[edit]
Terminal DEC VT-100.
The Therac-25 had been in operation in the clinic for six months when, on July 26, 1985 a 40-year-old patient was receiving her 24th treatment for cervical cancer. The operator activated the treatment, but after five seconds the machine stopped with the error message «H-tilt», the treatment pause indication and the dosimeter indicating that no radiation had been applied. The operator pressed the P key (Proceed : continue). The machine stopped again. The operator repeated the process five times until the machine stopped the treatment. A technician was called and found no problem. The machine treated six other patients on the same day.
The patient complained of burning and swelling in the area and was hospitalized on July 30. She was suspected of a radiation overdose and the machine was taken out of service. On November 3, 1985 the patient herself died of cancer, although the autopsy mentioned that if she had not died then, she would have had to have a hip replacement due to damage from the radiation overdose. A technician estimated that she received between 13,000 and 17,000 rad.
The incident was reported to the FDA and the Canadian Radiation Protection Bureau.
The AECL suspected that there might be an error with three microswitches that reported the position of the turntable. The AECL was unable to replicate a failure of the microswitches and microswitch testing was inconclusive. They then changed the method to be tolerant of one failure and modified the software to check if the turntable was moving or in the treatment position.
Afterward, the AECL claimed that the modifications represented a five-order-of-magnitude increase in safety.[2]
Yakima Valley Memorial Hospital, 1985[edit]
In December 1985 a woman developed an erythema with a parallel band pattern after receiving treatment from a Therac-25 unit. Hospital staff sent a letter on January 31, 1986 to the AECL about the incident. The AECL responded in two pages detailing the reasons why radiation overdose was impossible on the Therac-25, stating both machine failure and operator error were not possible.
Six months later, the patient developed chronic ulcers under the skin due to tissue necrosis. She had surgery and skin grafts were placed. The patient continued to live with minor sequelae. [2]
East Texas Cancer Center, Tyler, March 1986[edit]
Over two years, this hospital treated more than 500 patients with the Therac-25 with no incident. On March 21, 1986, a patient presented for his ninth treatment session for a tumor on his back. The treatment was set to be 22-MeV of electrons with a dose of 180 rad in an area of 10×17 cm, with an accumulated radiation in 6 weeks of 6000 rad.
The experienced operator entered the session data and realized that she had written an X instead of an E as the type of treatment. With the cursor she went up and changed the X to an E and since the rest of the parameters were correct she pressed ↵ Enter until she got down to the command box. All parameters were marked «Verified» and the message «Rays ready» was displayed. She hit the B key («Beam on»). The machine stopped and displayed the message «Malfunction 54» (error 54). It also showed ‘Treatment pause’. The manual said that the «Malfunction 54» message was a «dose input 2» error. A technician later testified that «dose input 2» meant that the radiation delivered was either too high or too low.
The radiation monitor (dosimeter) marked 6 units supplied when it had demanded 202 units. The operator pressed P ( Proceed : continue). The machine stopped again with the message «Malfunction 54» (error 54) and the dosimeter indicated that it had delivered fewer units than required. The surveillance camera in the radiation room was offline and the intercom had been broken that day.
With the first dose the patient felt an electric shock and heard a crackle from the machine. Since it was his ninth session, he realized that it was not normal. He started to get up from the table to ask for help. At that moment the operator pressed P to continue the treatment. The patient felt a shock of electricity through his arm, as if his hand was torn off. He reached the door and began to bang on it until the operator opened it. A physician was immediately called to the scene, where they observed intense erythema in the area, suspecting that it had been a simple electric shock. He sent the patient home. The hospital physicist checked the machine and, because it was calibrated to the correct specification, it continued to treat patients throughout the day. The technicians were unaware that the patient had received a massive dose of radiation between 16,500 to 25,000 rads in less than a second over an area of one cm². The crackling of the machine had been produced by saturation of the ionization chambers, which had the consequence that they indicated that the applied radiation dose had been very low.
Over the following weeks the patient experienced paralysis of the left arm, nausea, vomiting, and ended up being hospitalized for radiation-induced myelitis of the spinal cord. His legs, mid-diaphragm and vocal cords ended up paralyzed. He also had recurrent herpes simplex skin infections. He died five months after the overdose.
From the day after the accident, AECL technicians checked the machine and were unable to replicate error 54. They checked the grounding of the machine to rule out electric shock as the cause. The machine was back in operation on April 7, 1986.[2]
East Texas Cancer Center, Tyler, April 1986[edit]
On April 11, 1986, a patient was to receive electron treatment for skin cancer on the face. The prescription was 10 MeV for an area of 7×10 cm. The operator was the same as the one in the March incident, three weeks earlier. After filling in all the treatment data he realized that he had to change the mode from X to E. He did so and pressed ↵ Enter to go down to the command box. As «Beam ready» was displayed, he pressed P (Proceed : continue). The machine produced a loud noise, which was heard through the intercom. Error 54 was displayed. The operator entered the room and the patient described a burning sensation on his face. The patient died on May 1, 1986. The autopsy showed severe radiation damage to the right temporal lobe and brain stem.
The hospital physicist stopped the machine treatments and notified the AECL. After strenuous work, the physicist and operator were able to reproduce the error 54 message. They determined that speed in editing the data entry was a key factor in producing error 54. After much practice, he was able to reproduce the error 54 at will. The AECL stated they could not reproduce the error and they only got it after following the instructions of the physicist so that the data entry was very rapid.[2]
Yakima Valley Memorial Hospital, 1987[edit]
On January 17, 1987 a patient was to receive a treatment with two film-verification exposures of 4 and 3 rads, plus a 79-rad photon treatment for a total exposure of 86 rads. Film was placed under the patient and 4 rads were administered through a 22×18 cm opening. The machine was stopped, the aperture was opened to 35×35 cm and a dose of 3 rad was administered. The machine stopped. The operator entered the room to remove the film plates and adjust the patient’s position. He used the hand control inside the room to adjust the turntable. He left the room, forgetting the film plates. In the control room, after seeing the «Beam ready» message, he pressed the B key to fire the beams. After 5 seconds the machine stopped and displayed a message that quickly disappeared. Since the machine was paused, the operator pressed P (Proceed : continue). The machine stopped, showing «Flatness» as the reason. The operator heard the patient on the intercom, but could not understand him, and entered the room. The patient had felt a severe burning sensation in his chest. The screen showed that he had only been given 7 rad. A few hours later, the patient showed burns on the skin in the area. Four days later the reddening of the area had a banded pattern similar to that produced in the incident the previous year, and for which they had not found the cause. The AECL began an investigation, but was unable to reproduce the event.
The hospital physicist conducted tests with film plates to see if he could recreate the incident. Two X-ray parameters with the turntable in field-light position. The film appeared to match the film that was left by mistake under the patient during the accident. It was found the patient was exposed to between 8,000 and 10,000 rad instead of the prescribed 86 rad. The patient died in April 1987 from complications due to radiation overdose. The relatives filed a lawsuit that ended with an out-of-court settlement.[2]
Root causes[edit]
A commission attributed the primary cause to general poor software design and development practices rather than single-out specific coding errors. In particular, the software was designed so that it was realistically impossible to test it in a rigorous, automated way.[5]: 48 [additional citation(s) needed]
Researchers who investigated the accidents found several contributing causes. These included the following institutional causes:
AECL did not have the software code independently reviewed and chose to rely on in-house code, including the operating system.
AECL did not consider the design of the software during its assessment of how the machine might produce the desired results and what failure modes existed, focusing purely on hardware and asserting that the software was free of bugs.
Machine operators were reassured by AECL personnel that overdoses were impossible, leading them to dismiss the Therac-25 as the potential cause of many incidents.[1]: 428
AECL had never tested the Therac-25 with the combination of software and hardware until it was assembled at the hospital.
The researchers also found several engineering issues:
Several error messages merely displayed the word «MALFUNCTION» followed by a number from 1 to 64. The user manual did not explain or even address the error codes, nor give any indication that these errors could pose a threat to patient safety.
The system distinguished between errors that halted the machine, requiring a restart, and errors which merely paused the machine (which allowed operators to continue with the same settings using a keypress). However, some errors which endangered the patient merely paused the machine, and the frequent occurrence of minor errors caused operators to become accustomed to habitually unpausing the machine.
One failure occurred when a particular sequence of keystrokes was entered on the VT-100 terminal which controlled the PDP-11 computer: if the operator were to press «X» to (erroneously) select 25 MeV photon mode, then use «cursor up» to edit the input to «E» to (correctly) select 25 MeV Electron mode, then «Enter», all within eight seconds of the first keypress, well within the capability of an experienced user of the machine. These edits were not noticed as it would take 8 seconds for startup, so it would go with the default setup.[5]
The design did not have any hardware interlocks to prevent the electron-beam from operating in its high-energy mode without the target in place.
The engineer had reused software from the Therac-6 and Therac-20, which used hardware interlocks that masked their software defects. Those hardware safeties had no way of reporting that they had been triggered, so preexisting errors were overlooked.
The hardware provided no way for the software to verify that sensors were working correctly. The table-position system was the first implicated in Therac-25’s failures; the manufacturer revised it with redundant switches to cross-check their operation.
The software set a flag variable by incrementing it, rather than by setting it to a fixed non-zero value. Occasionally an arithmetic overflow occurred, causing the flag to return to zero and the software to bypass safety checks.
Leveson notes that a lesson to be drawn from the incident is to not assume that reused software is safe:[8] «A naive assumption is often made that reusing software or using commercial off-the-shelf software will increase safety because the software will have been exercised extensively. Reusing software modules does not guarantee safety in the new system to which they are transferred…»[5] In response to incidents like those associated with Therac-25, the IEC 62304 standard was created, which introduces development life cycle standards for medical device software and specific guidance on using software of unknown pedigree.[9]
See also[edit]
Clinic of Zaragoza radiotherapy accident
Computer ethics
High integrity software
IEC 62304
Ionizing radiation
List of civilian radiation accidents
Nuclear and radiation accidents
Radiation protection
References[edit]
^ abcBaase, Sara (5 August 2012). «8.2 Case Study: The Therac-25». A Gift of Fire: Social, Legal, and Ethical Issues for Computing Technology(application/ld+json) (4th ed.). Pearson Prentice Hall. pp. 425–430. ISBN 978-0132492676. LCCN 2012020988. OCLC 840390999. OL 25355635M – via Internet Archive.
^ abcdefgLeveson, Nancy G.; Turner, Clark S. (1 July 1993). «An Investigation of the Therac-25 Accidents». Computer. IEEE Computer Society. 26 (7): 18–41. doi:10.1109/MC.1993.274940. eISSN 1558-0814. ISSN 0018-9162. LCCN 74648480. OCLC 2240099. S2CID 9691171.
^ abLeveson, Nancy G. (1 July 1993). «An Investigation of the Therac-25 Accidents» (PDF). Archived from the original (PDF) on 28 November 2004. Retrieved 20 May 2020.
^Rose, Barbara Wade (1 June 1994). «Fatal Dose. Radiation Deaths linked to AECL Computer Errors». Retrieved 25 May 2020.
^ abcdefghLeveson, Nancy G. (17 April 1995). «Appendix A: Medical Devices: The Therac-25» (PDF). Safeware: System Safety and Computers (1st ed.). Addison-Wesley. ISBN 978-0201119725. OCLC 841117551. OL 7406745M – via University of Central Florida.
^Casey, Steven (1 January 1998). Set Phasers on Stun: And Other True Tales of Design, Technology, and Human Error (2nd ed.). Aegean Publishing Company. pp. 11–16. ISBN 978-0963617880. LCCN 97077875. OCLC 476275373. OL 712024M.
^Rose, Barbara Wade (1 June 1994). «Fatal Dose — Radiation Deaths linked to AECL Computer Errors». Saturday Night. ISSN 0036-4975. OCLC 222180972. Archived from the original on 24 November 2021. Retrieved 27 December 2021 – via Canadian Coalition for Nuclear Responsibility (CCNR).
^Leveson, Nancy G. (1 November 2017). «The Therac-25: 30 Years Later». Computer. IEEE Computer Society. 50 (11): 8–11. doi:10.1109/MC.2017.4041349. eISSN 1558-0814. ISSN 0018-9162. LCCN 74648480. OCLC 2240099.
^Hall, Ken (1 June 2010). «Developing Medical Device Software to IEC 62304». MD&DI. ISSN 0194-844X. OCLC 647577709. Retrieved 24 December 2021.
Further reading[edit]
Gallagher, Troy. THERAC-25: Computerized Radiation Therapy. Archived from the original on 2007-12-12. (short summary of the Therac-25 Accidents)
Хостинг с DDoS защитой от 2.5$ + Бесплатный SSL и Домен
SSD VPS в Нидерландах под различные задачи от 2.6$
Выделенные серверы: в Европе / в России.
Виртуальные серверы: в Европе / в России.
Партнерская программа
2005 г.
Изучение знаменитых (и не очень знаменитых) ошибок
Глава из книги «Наука отладки»
Мэтт Тэллес, Юань Хсих
Пер. с англ. С. Лунин, науч.ред. С. Брудков
Издательство: КУДИЦ-ОБРАЗ
Полное содержание книги
Глава 2
Yuan Hsieh
Сценарий
Распределенные компьютерные системы из «реальной жизни»
ИСТОРИЯ: КОМПАНИЯ Y
ИСТОРИЯ: КОМПАНИЯ Х
ВЫВОДЫ
Therac-25
ИСТОРИЯ
Kennestone Regional Oncologyl Center, г Кенстоун, округ Мариетта, штат Джорджия (Kennestone, Marietta, Georgia). Июнь 1985
Ontario Cancer Foundation, Хемилтон, провинция Онтарио, Канада (Hamilton, Ontario, Canada)
Yakima Valley Memorial Hospital, Якима, штат Вашингтон (Yakima, Washington), декабрь 1985
East Texas Cancer Center (Восточно-Техасский онкологический центр), г Тайлер, штат Техас (Tyler, Texas). Март 1986
East Texas Cancer Center (Восточно-Техасский онкологический центр), г Тайлер, штат Техас (Tyler, Texas). Апрель 1986
Yakima Valley Memorial Hospital, г Якима, штат Вашингтон (Yakima, Washington), Январь 1987
Выводы
Зарисовка #1
ОШИБКА В ПРОЦЕССОРЕ INTEL PENTIUM
ИСТОРИЯ
ВЫВОД
Зарисовка #2
Ariane 5 Ошибка операнда
ИСТОРИЯ
ВЫВОД
Зарисовка #3
Аппарат для исследования климата Марса
История
Вывод
Зарисовка #4
Авария на телефонной компании AT&T
История: Авария 1990 года
Вывод: Авария 1990 года
История: Авария 1998 года
Вывод: Авария 1998 года
Переполнение буфера
История
Вывод
Заключение
Задача
Представьте, что сейчас 1986 год. И представьте, что вы — ныне покойный Ричард Фейнман (Richard Feynman). Звонит телефон, вы поднимаете трубку. Звонит Уильям Грэхэм (William Graham), исполняющий обязанности администратора в NASA1. Вы знаете, что это не может быть просто дружеский звонок, поскольку космический челнок Челленджер потерпел катастрофу несколько дней назад, 28 января 1986 года. Вы правы. Он звонит для того, чтобы просить вас принять участие в работе комиссии по исследованию причин катастрофы Челленджера. В сущности, NASA просит вас, свежеиспеченного Нобелевского лауреата, выступить в роли главного исследователя неисправностей для одного из самых печальных инцидентов в NASA в современной истории2. Вы принимаете предложение с трепетом. В конце концов, вы можете быть Нобелевским лауреатом, но вы не специалист по ракетам. Вы не участвовали в разработке космического челнока. Вы не знакомы с компонентами и системами космического корабля. Вы не имеете представления, какого рода информация записывалась в ходе рокового полета Челленджера. Вы не представляете себе состояние или полезность документации. Единственный ключ, который у вас есть, — это ваши визуальные наблюдения, что пламя, как кажется, выходило из правого топливного бака. Как вы будете решать задачу по поиску причины катастрофы?
В действительности, доктор Фейнман обнаружил причину инцидента, перемещаясь по всей стране и беседуя с инженерами и персоналом и не поддаваясь политическому давлению. В конечном итоге он провел свой знаменитый настольный эксперимент с образцом от одного из уплотнительных колец с челнока и стаканом ледяной воды для доказательства своей теории3 в ходе пресс-конференции в прямом эфире4.
К счастью, наша работа по устранению ошибок в программных системах намного легче той задачи, с которой столкнулся доктор Фейнман. В большинстве случаев мы можем попытаться воспроизвести ошибку, чтобы удостовериться, что мы полностью понимаем ее причины и следствия. Ученые NASA не имели такого преимущества. Они не могли воспроизвести ошибку, взорвав другой космический корабль. Более того, доктор Фейнман должен был представить формальный отчет о своих открытиях для общественной поверки и, что еще хуже, должен был бороться с политическим давлением со стороны официальных лиц NASA. Когда в последний раз мы должны были делать нечто подобное при устранении ошибок? В индустрии программного обеспечения мы очень мало делаем того, что можно назвать посмертным анализом ошибки. Мы не задаем таких вопросов, как, каким образом ошибка была обнаружена, как она возникла и что мы можем сделать, чтобы предотвратить ее. Если мы все же проводим посмертный анализ, мы так редко документируем наши открытия, что наше знание недоступно другим людям.
Во многих смыслах наша книга — это кульминация многих лет посмертного анализа ошибок, о которых мы узнали и которые провели сами. В главе 12 мы покажем вам, как анализировать ошибки, как увеличить ваше коллективное знание о процессах формирования ошибок и как это знание поможет нам избежать одних и тех же ошибок и создавать лучшее программное обеспечение в будущем. Действительно ли посмертный анализ ошибки поможет нам создать лучший продукт? Мы считаем, что ответ на этот вопрос — да! В 1981 году фирма NEC осуществила план, призванный помочь разработчикам программ и менеджерам проектов учиться на ошибках. Был создан каталог ошибок, наблюдавшихся во многих корпоративных проектах. Это поддержало разработчиков в поисках причин отказов программ и в предотвращении их повторного появления. За 10 лет, прошедших с запуска проекта, разработчики извлекли много уроков и стали способны применять этот опыт для повышения своей производительности и понижения числа ошибок5.
Инициатива NEC началась с каталога проблем и решений. После, обучившись находить причинно-следственные связи между проблемами, разработчики стали способны формулировать контрмеры для решения этих проблем. Мы начнем с того же.
Сценарий
В этой главе мы собрали для изучения набор программных ошибок. Большинство этих ошибок довольно хорошо известны и, как правило, хорошо описаны, поскольку их появление было общественно-значимым событием и многие имели серьезные последствия. Хотя достаточно банальные и избитые, эти ошибки все же способствуют наилучшему изучению конкретных случаев. Проблема состоит в том, что далеко не каждый связан с проектами такого масштаба и столь же критичными для безопасности, так что трудности, которые испытали эти программисты, могут показаться чем-то не связанным с вашими повседневными задачами, поэтому мы также включили несколько примеров ошибок из нашей собственной практики разработки программного обеспечения. Наши персональные ошибки являются более приземленными и не связаны с взрывами и потерями многих миллиардов долларов. Тем не менее в этой книге мы показываем ошибки, созданные другими, для иллюстрации различных положений. Мы показываем эти ошибки не для забавы. Наша цель — изучить события, окружающие эти знаменитые и не очень знаменитые ошибки, для того чтобы мы могли на них учиться.
Распределенные компьютерные системы из «реальной жизни»
Парад ошибок начинается примерами с двух моих предыдущих мест работы. Первая ошибка просуществовала несколько часов и была быстро устранена. Это был урок для второй ошибки. Девять месяцев спустя, вскоре после того как я начал работать в другом месте, я столкнулся с похожей ошибкой. Однако в новой компании проблема проявила себя за два месяца до моего прихода. Серьезность первой ошибки была такова, что она нарушала работу всей системы. Вторая ошибка, хотя и устойчивая, не была фатальной, она просто вызывала легкое раздражение, а не общую катастрофу.
История: компания Y
Был конец 1999 года, и я работал в одной Интернет-компании, которая обслуживала финансовые отчеты в Интернете. Назовем ее компания Y. Архитектура систем, обслуживающих финансовые отчеты, очень проста: Web-запрос приходит через один из многочисленных Web-серверов. Web-сервер передает запрос менеджеру нагрузки, и менеджер нагрузки доставляет запрос к одному из четырех серверов отчетов циклическим образом. Сервер отчета выбирает информацию из базы данных для генерации отчета.
Однажды сигналы тревоги начали сыпаться со всех сторон. Сервера отчетов выходили из строя один за другим. Сервер останавливался, перезапускался несколькими минутами позже и снова останавливался через несколько минут. Это случалось со всеми серверами. Частота поступления запросов не была очень высокой, не была она и какой-то необычной. Перезагрузка машины, кажется, не помогала. Сетевые операторы не имели представления, что вызвало этот хаос, и была вызвана команда разработчиков. Поскольку я разрабатывал и реализовывал коммуникационную инфраструктуру, используемую внутренними серверами, меня попросили помочь. Команда разработчиков подозревала, что модуль распределения нагрузки в коммуникационной инфраструктуре был неисправен и сервера останавливались из-за перегрузки.
Коммуникационная инфраструктура имела встроенные возможности протоколирования и трассировки, которые были деактивированы в конечном продукте. Первое, что я сделал, это включил эти возможности, чтобы определить, что же система делает. Протокол, сформированный сервером отчетов, мало что прояснил для меня. В протоколе была масса сообщений об ошибках, но ни одно из этих сообщений ничего не описывало. Однако сразу перед тем, как сервер отчетов претерпевал сбой и перезапускался, в протокол попадало сообщение, что сервер отчета остановлен. Я спросил у инженера, что означает это сообщение, но его ответ был несколько загадочным. Это было что-то о том, что программа перезапускает себя, когда считает, что есть какая-то проблема. В это время я рассматривал файлы протоколов, полученных от менеджера нагрузки, и увидел, что он все время обращается к одному и тому же серверу. Я немедленно предположил, что механизм распределения нагрузки работает неправильно и что менеджер загрузки перегружает сервер отчета, заставляя его перезапускать себя.
Я проинформировал группу о моих предположениях и вернулся к своему столу, проверять код, выискивая потенциальные ошибки. Ничего не бросалось в глаза, и я подумал о замечании инженера, что сервер отчета разработан так, чтобы перезапускаться, когда он считает, что существует проблема. Я решил выяснить, какого рода проблемы могли бы вынудить сервер перезапуститься. По существу сервер отчетов поддерживал 20 потоков одновременно и каждый запрос к серверу занимал 1 процесс. Ожидалось, что в нормальных условиях каждый процесс заканчивает обработку в течение 1-2 секунд. Данный сервер отчета не считался очень стабильным и имел факты подверженности ошибкам. Поэтому в сервер была встроена логика «безопасности», так, что, если в момент, когда все 20 процессов были заняты, поступал 21-й запрос, этот последний должен был ожидать освобождения потока в течение 5 секунд. Если срок ожидания у этого запроса истекал, сервер отчета считал, что что-то не так и что все 20 потоков зависли. Единственным действием дальше становилась остановка и перезагрузка сервера.
Услышав это, я вернулся к своему столу, чтобы все обдумать. Через несколько минут все встало на свои места. Я проверил свои размышления файлами протоколов и трассировок и сообщил мою гипотезу группе, обслуживающей сервер отчетов.
Причина того, что менеджер нагрузки работал только с одним сервером отчетов, была не в том, что алгоритм распределения нагрузки был ошибочным. Он работал только с одним, поскольку остальные были недоступны. Они все перезапускались. Это было легко проверить, взглянув на временные отметки файлов протокола с серверов отчета и менеджера нагрузки.
Протоколы серверов отчета показывали, что запускалась логика «безопасности». Это подразумевало, что у каждого сервера было по 21 конкурирующему процессу. Это означало, что в некоторый момент времени к системе поступило 84 запроса, поскольку к моменту инцидента работали 4 сервера отчетов.
В конечном итоге один из серверов перезапускался из-за запуска логики «безопасности». Это в результате снижало пропускную способность системы до 63 запросов. Однако скорость поступления запросов оставалась постоянной. Это еще увеличивало нагрузку на оставшиеся 3 сервера, и в конечном итоге другой сервер перезапускался из-за логики «безопасности». Пропускная способность падала до 42 запросов. К тому времени, когда первый сервер заканчивал перезагрузку, останавливался и начинал перезапуск третий. Этот эффект мог сохраняться сколь угодно долго, если ничего не менялось, и скорость поступления запросов и скорость ответа оставались постоянными.
Эта гипотеза соответствовала наблюдениям, что сервера перезапускались последовательно, и тому, что они просто не были способны оставаться функциональными. Однако нам еще следовало определить причину перегрузки 84 запросами. Мы уже проверяли, что нагрузка не была чрезвычайно высокой. Оставалась только одна возможность. Проблема должна была быть связана с допущением того, что каждый запрос обрабатывается за 1-2 секунды и что 21-й запрос должен подождать только 5 секунд. Это выбранное значение, по-видимому, было ошибочно. Это допущение является верным в нормальных условиях работы. В начале этого описания я сказал, что сервер при генерации отчета зависит от базы данных. В данном случае база данных претерпевала что-то вроде деградации (meltdown). Мы так и не смогли определить причины такой деградации. Простая команда SELECT вместо десятых долей секунды занимала до 10 секунд. Сильное падение производительности базы данных проявило ошибку проектирования системы, и ситуация быстро ухудшалась. Поскольку каждый сервер отчета, который останавливался, снижал общую пропускную способность, большая нагрузка оказывалась на оставшиеся рабочие сервера. Если не вмешиваться, то проблема просто бы исчезла, когда нагрузка упала бы до величин, меньших 20 одновременно обрабатываемых запросов ко всей системе.
Как только было определено, что сервер базы данных работает неверно, перезагрузка SQL сервера решила проблему.
История: компания Х
В середине 2000 года я начал работать в другой Интернет-компании, которая занималась картографической и деловой информацией, а также электронной коммерцией. Назовем ее Компанией Х. Системная инфраструктура в Компании Х была сходна с инфраструктурой в Компании Y: Web-сервера обращались к менеджерам нагрузки, которые обращались к агентам баз данных, которые и связывались с базами. Однако существовало небольшое усложнение в том, что Компания Х предоставляла интерфейс интерактивного голосового ответа (Interactive Voice Response, IVR), который позволял клиентам осуществлять доступ к системе через обычный телефон. Инфраструктура, которая реализовывала IVR, просто замещала Web-сервер IVR-сервером, который связывался с менеджером нагрузки таким же образом, как и Web-сервера. Другое отличие состояло в том, что Компания Х задействовала два отдельных центра данных. Обычно IVR-сервер использовал один центр в качестве первичной и активной системы. Когда возникали сложности с активным центром, IVR-сервер переключался на другой, запасной центр.
Однажды руководитель технического отдела Компании Х пришел, чтобы попросить меня поговорить с группой, обслуживающей IVR-сервер, и помочь им исследовать недавний выход службы из строя. Несколькими днями ранее работа IVR-системы была нарушена более чем на восемь часов. Когда я пришел поговорить с группой, выяснилось, что для продолжения работы информации очень мало. Были файлы протокола с IVR-сервера на момент выхода его из строя, но они были удалены из-за проблем коммуникации с Центром сетевых операций. Люди, занимавшиеся обслуживанием системы, подозревали, что ошибка была связана с какой-то малопонятной сетевой проблемой центра данных. Однако это не объясняло, почему не использовался запасной центр. После дальнейших исследований оказалось, что проблема в IVR-сервере возникала при соединении с одним из центров данных. Эта проблема сохранялась в течение двух месяцев.
Поскольку я был не знаком с системой, я попросил показать мне сгенерированные файлы протоколов. Я хотел быть способным зафиксировать поведение системы, когда (и если) сбой возникнет опять. Файл протокола, хотя и полезный для просмотра ошибок, не очень помогает в описании действий системы. Он только отображает статус каждого запроса, после того как он был обработан. Если бы какой-нибудь запрос вызвал ошибку, файл протокола никогда не показал бы состояние IVR-сервера в момент сбоя. Более того, IVR-сервер не выходил из строя при сбое системы. Не было ни одного базового файла, который можно было бы использовать. Однако файл протокола показывал относительно большое число событий при переключении IVR-сервера от одного центра данных к другому. Каждое событие переключения центров данных имело корреляцию с серией из трех запросов со статусом кода ошибки -3, кода, который означал, что время ожидания у запроса истекло, когда IVR-сервер пытался соединиться с менеджером нагрузки. В Компании Х каждый запрос имел уникальный идентификатор (ID), который заносился в файл протокола на любом сервере, к которому этот запрос обращался, так что была возможность проследить путь запроса в системе. Однако IVR-сервер не записывал ID запроса в свой протокол, так что мы не могли выяснить, почему истекло время ожидания.
Наученный опытом, полученным в Компании Y, я спросил о стратегии преодоления ошибок на IVR-сервере. Оказалось, что IVR имеет требования к быстродействию — в отличие от использования Web-сайтов, при использовании телефона люди не любят ждать. Поэтому IVR должен ответить в течение определенного времени. IVR-сервер должен был получить данные от менеджера нагрузки в течение трех секунд. После трех последовательных, закончившихся неудачей попыток сервер автоматически переключался на запасной центр данных. Оставаясь соединенным с запасным центром данных, IVR-сервер через 2 часа пытался восстановить соединение с первичным центром данных. Если попытка оказывалась успешной, сервер вновь переключался на первичный центр данных.
К этому времени у меня были две довольно разумные гипотезы, которые объясняли все наблюдения. (1) Поскольку проблемы на IVR-сервере были при соединении с одним из центров данных, по всей видимости, IVR-сервер работал без резерва. Если бы на центре данных, к которому он был подключен, возникли проблемы, служба IVR оказалась бы недоступной. И (2) причина того, что IVR-сервер не мог поддерживать соединение с центром данных, была точно записана в существующем файле протокола. Это было истечение времени ожидания его запросов. Чтобы определить, почему время ожидания заканчивается так часто, нам следовало проследить путь запросов, которые вызывали его.
Не было, однако, протоколов или другой информации, чтобы проверить мои гипотезы, поэтому я совместно с командой обслуживания IVR-сервера начал работу по генерации более полезного протокола. Как только мы оказались способны проследить поток запросов через систему, сразу стало видно, где здесь узкое место. Один из серверов базы данных тратил необычно долгое время на обработку запросов. Этот сервер делал несколько SQL запросов к базе данных, которая располагалась на той же машине, что и сам сервер. Продолжительность вызовов была существенно выше, чем ожидалось. Поскольку на сервере базы данных была видна необычно высокая загрузка процессора, было сделано предположение, что машина слишком перегружена и, возможно, необходимо дополнительное оборудование. Другая гипотеза состояла в том, что SQL-операторы, как они были реализованы, являлись неэффективными. Это необходимо было проверить. Еще несколько дней исследований выявили, что база данных обновлялась за 2 месяца до инцидента. Однако администратор базы данных забыл переиндексировать базу, и каждый запрос занимал в 10 раз больше времени на обработку, чем обычно. Сильная нагрузка на процессор просто отражала выполнение SQL-операторов на неиндексированной базе. База на «рабочем» центре данных была обновлена и переиндексирована, поэтому никаких неприятностей не возникло. Мы никогда бы не смогли правильно объяснить причины сбоя, поскольку не было информации для исследований. Однако главной причиной сбоя было отсутствие запасного сервера данных.
Выводы
Сходство между предыдущими двумя случаями поразительно. В обоих случаях участвовали системы, которые были работоспособными долгое время. Обе системы работали как положено и не содержали ошибок реализации. Устранение проблемы в обоих случаях (по крайней мере, быстрое) состояло просто в перезапуске или переиндексировании базы данных. Обе проблемы проявились, поскольку ответы баз данных занимали больше времени, чем ожидалось. Причины проблем были хорошо видны в файлах протокола. Однако было трудно отследить в файлах и понять эти причины. Почему?
Компонентное мышление. — В обоих случаях инженеры концентрировались главным образом на компонентах. Они никогда не рассматривали наблюдения в контексте целой системы. Наладка в распределенной компьютерной среде требует целостного подхода. Каждый компонент системы может влиять на поведение другого компонента и системы в целом. Взаимосвязи между компонентами могут быть очень сложными и часто непонятными интуитивно. Когда вы интересуетесь, почему компонент вышел из строя, может быть, полезно задать вопрос: «Какой другой компонент системы мог вызвать сбой этого компонента?»
Ориентировка по вторичным признакам. — Несколько лет назад я участвовал в занятиях по лавинной безопасности. Одной темой этих занятий было проведение поиска с помощью радиомаяков. Идея такого поиска заключалась в том, что, если жертву засыпало снегом, ее радиомаяк посылал радиосигнал, который приемник на другом радиомаяке мог принять. В приемнике радиосигнал преобразовывался в звуковой сигнал. Чем громче был звук, тем ближе была жертва. Первоначально у меня были проблемы с поиском. Вместо того чтобы слушать звуковой сигнал и следовать по нему, я искал видимые признаки. Как только мне удалось отбросить все мои прочие чувства и сфокусироваться на звуке, спасение жертвы у меня существенно ускорилось. Тот же самый совет будет полезен при наладке приложений. В обоих наших примерах инженеры игнорировали подсказки, которые давали им их системы. Вместо того чтобы следовать этим подсказкам, они выбрали ориентировку по вторичным признакам и создавали некорректные гипотезы, не объяснявшие всех наблюдений. Все подсказки и все наблюдения нужно принять во внимание при создании гипотезы.
Игнорирование подсказок. — Важные подсказки игнорировались. В компании Х повышенную нагрузку на процессор у сервера базы данных нужно было исследовать, поскольку скорость поступления запросов не превышала нормальной. Неприемлемое время вызова и обработки запроса у сервера базы записывались в файлы протокола в течение двух месяцев, пока проблема сохранялась. Было множество предупреждений, что нечто плохое потенциально может случиться. Однако из-за недостатка времени, ресурсов и инфраструктуры на эти предупреждения не обращали внимания, пока не случилась катастрофа.
В этих двух инцидентах не были задействованы программные ошибки в традиционном смысле этого слова, хотя даже разработчики были поставлены в тупик. Проблемы, с которыми столкнулись Компании Х и Y, можно было предотвратить, если бы обслуживающий персонал был лучше информирован. Каким образом?
Лучшие инструменты мониторинга. — В обоих случаях, если бы обслуживающий персонал смог обнаружить и зафиксировать необычное поведение сервера базы данных, возможно, они смогли бы предпринять действия для корректировки сервера базы данных. Проблемы, с которыми мы столкнулись, могли бы никогда не проявиться.
Следование правилам. — В Компании Х существовало стандартное правило переиндексировать базу данных после ее обновления. В данном случае переиндексирование не было произведено и не было никаких записей об обновлении.
Недостаток записей сделал трудным определение изменений в окружении и в системе для нужд наладки.
Therac-25
Ошибка аппарата Therac-25 была, пожалуй, самой дорогой ошибкой в современной истории. Как известно, с июня 1985 по январь 1987 года шесть пациентов получили передозировку радиации, что привело к гибели троих из них. Здесь мы полностью полагаемся на отчет, опубликованный Leveson и Turner в 1993 году после нескольких лет расследования. Этот отчет содержит наиболее тщательную и детальную оценку причин и следствий инцидента с Therac-25 и охватывает все аспекты безопасности системы. Однако, поскольку наша книга посвящена программным ошибкам, мы ограничим наше изложение и анализ результатами, связанными с программным обеспечением6.
История
Therac-25 представлял собой компьютеризированную машину для радиационной терапии, построенную компанией Atomic Energy of Canada Limited (AECL). Предшественниками Therac-25 были Therac-6, который представлял собой ускоритель на 6 миллионов электрон-вольт (МэВ), способный испускать только рентгеновские лучи, и Therac-20, рентгеновский излучатель и ускоритель электронов на 20 МэВ. Все три машины использовали мини-компьютер DEC PDP-11. И в Therac-6, и в Therac-20 использовались некоторые аппаратные возможности для предотвращения небезопасных операций. Некоторые программные модули из Therac-6 были использованы вновь в Therac-20 и Therac-25. Кроме того, в Therac-25 были использованы программные модули Therac-20 для электронного режима.
Therac-25 был усовершенствованием Therac-20. Он был способен испускать фотоны или электроны с энергией 25 МэВ с возможностью переключения уровней. Он был меньше, имел больше возможностей и был легче в использовании. Также он был сконструирован так, чтобы компьютерное управление было более полным, чем в его предшественниках. Программное обеспечение, разработанное для Therac-25, было способно осуществлять контроль состояния и управление оборудованием. Поэтому решено было удалить аппаратные средства безопасности и полагаться в этом вопросе на программное обеспечение.
Therac-25 поступил в продажу в конце 1982 года, и 11 таких машин были установлены в Северной Америке, 5 — в США и 6 — в Канаде. Шесть несчастных случаев с большими передозировками произошли между 1985 и 1987 годами7.
Kennestone Regional Oncologyl Center, г. Кенстоун, округ Мариетта, штат Джорджия (Kennestone, Marietta, Georgia). Июнь 1985
Женщина в возрасте 61 года была направлена в онкологический центр для дополнительного лечения аппаратом Therac-25 после хирургического удаления молочной железы. Как считается, пациентка получила одну или две дозы радиации от 15 000 до 20 000 рад (поглощенная доза радиации). Для сравнения, типичная разовая терапевтическая доза радиации составляет до 200 рад. Кенстоунская клиника использовала Therac-25 с 1983 года без происшествий. Техники и фирма AECL не поверили, что эта проблема может быть вызвана Therac-25. В конечном итоге пациентка потеряла грудь, а также возможность пользоваться руками и плечами из-за радиационного поражения.
Ontario Cancer Foundation, Хемилтон, провинция Онтарио, Канада (Hamilton, Ontario, Canada)
Клиника в Хэмилтоне использовала Therac-25 в течение шести месяцев до инцидента с передозировкой. Сорокалетняя женщина поступила в клинику на 24-й сеанс лечения аппаратом Therac-25. Аппарат отключился через пять секунд после того, как оператор запустил его. Операторы были знакомы с частыми неполадками машины. Эти неполадки, вероятно, не имели серьезных последствий для пациента. Поскольку машина показывала, что облучение не было произведено, оператор попытался повторить его. Были произведены пять попыток. После пятой попытки был вызван техник, не обнаруживший проблем в аппарате.
Об инциденте сообщили в AECL, но воспроизвести неполадку и сделать заключение о причинах такого поведения Therac-25 не удалось. Однако благодаря этому сообщению фирма AECL обнаружила некоторые слабости конструкции и потенциальные механические проблемы в позиционировании поворотной платформы Therac-25 и были сделаны исправления. Пациентка умерла через пять месяцев. Результаты вскрытия показали, что смерть наступила от рака, а не от передозировки радиации. Однако вскрытие также выявило серьезные поражения бедра, вызванные радиационным воздействием. Как было позже определено, пациентка получила дозу порядка 13 000 — 17 000 рад8.
Yakima Valley Memorial Hospital, Якима, штат Вашингтон (Yakima, Washington). Декабрь 1985
После лечения аппаратом Therac-25 у женщины развилось сильное покраснение кожи в форме параллельных полос. Персонал клиники считал, что это явление мог вызвать Therac-25. Однако они не смогли воспроизвести конфигурацию оборудования, которая была использована при лечении пациентки. Персонал проинформировал AECL о потенциальной передозировке. В AECL снова посчитали, что передозировка при использовании аппарата Therac-25 невозможна. Персонал клиники не был осведомлен о двух предыдущих случаях и не имел возможности расследовать инцидент, поэтому они не стали продолжать дело после ответа из AECL. Пациентка, вероятно, получила более низкую дозу радиации, чем два предыдущих пострадавших, и она не испытала серьезных последствий в результате передозировки9 .
East Texas Cancer Center (Восточно-техасский онкологический центр), г. Тайлер, штат Техас (Tyler, Texas). Март 1986
Восточно-техасский онкологический центр использовал аппарат Therac-25 с 1984 года и применял его при лечении более 500 пациентов. 21 марта 1986 года пациент (мужчина) был направлен на дополнительное лечение. Оператор, которая осуществляла лечение, была знакома с Therac-25 и хорошо разбиралась в его свойствах и в процессе использования. Когда она вводила данные пациента и врачебные предписания, она допустила ошибку, которую быстро исправила и начала лечение. Спустя мгновение машина отключилась, и дисплей отобразил сообщения об ошибках. Как обычно происходит в программных системах, сообщение об ошибке представляло собой код, который никто не смог бы расшифровать. «Ошибка 54» расшифровывалась в печатном перечне ошибок как «ввод дозы 2». Восточно-техасский онкологический центр не располагал другой документацией, которая объясняла бы смысл выражения «ввод дозы 2». Дисплей показал также очень малую дозу облучения и, поскольку оператор была знакома с капризами Therac-25, она немедленно запустила повторное лечение. Машина снова отключилась с теми же сообщениями об ошибках.
Клиника связалась с AECL по поводу этой проблемы. Техники фирмы, направленные в Восточно-техасский онкологический центр, не смогли воспроизвести неисправность, и AECL все так же считала, что передозировка на Therac 25 невозможна. Пациент умер от осложнений передозировки через пять месяцев после этих событий10 .
East Texas Cancer Center (Восточно-техасский онкологический центр), г. Тайлер, штат Техас (Tyler, Texas). Апрель 1986
Три недели спустя другой мужчина поступил для лечения с помощью Therac 25. Та же женщина-оператор, которая участвовала в прошлом инциденте, была ответственной за лечение. Как и в предыдущем случае, она сделала ошибку при вводе данных, и, почти столь же быстро исправив ошибку, она запустила лечение. Машина ответила сообщением «ошибка 54» и отключилась. Однако пациент уже получил передозировку, и оператор побежала за помощью. Therac-25 был отключен, и клиника проинформировала AECL о втором случае передозировки.
Физик клиники, Фриц Хэгер (Fritz Hager), совместно с оператором научились воспроизводить сообщение «ошибка 54» произвольно. Оказалось, что передозировка возникала, если данные врачебного предписания редактировались в быстром темпе. Люди из AECL наконец смогли воспроизвести ошибку и признали, что передозировка была возможна11.
Как же было возможно, что быстрое редактирование вызывало передозировку? Аппарат Therac-25 мог работать в одном из двух режимов — фотонном или электронном. В электронном режиме оператору было необходимо ввести уровень энергии. Если же был выбран фотонный режим, по умолчанию энергия фотонов принималась за 25 МеV. Ошибки, совершенные оператором в обоих случаях, были одни и те же. Для двоих пациентов, которые получили передозировку, требовался электронный режим. Однако, поскольку большинству пациентов нужен фотонный режим, оператор привыкла выбирать последний. В этих двух случаях оператор первоначально выбирала фотонный режим, а затем исправляла свою ошибку. Физическая калибровка и настройка магнитов занимает около 6 секунд. Программный модуль, который проверяет завершение ввода данных, должен произвести калибровку магнитов, как только были установлены параметры режима и уровня энергии. Другой программный модуль был ответственен за проверку изменения входных данных. Если изменения были произведены, настройка магнита сбрасывалась и калибровка начиналась заново с новыми параметрами. Однако логическая ошибка в этом модуле вызывала то, что он был не способен распознать изменения данных, если они производились в течение восьми секунд после того, как были введены первоначально. (Это чрезвычайно упрощенное описание программного алгоритма. Советую читателю обратиться к отчету Levenson and Clark за дополнительными подробностями.) В этих двух случаях, когда оператор выбирала фотонный режим в первый раз, машина подготавливала к использованию уровень энергии в 25 MeV в фотонном режиме. А когда оператор изменила режим на электронный в течение восьми секунд, параметры магнитов не были сброшены и давалась неверная доза.
Когда в фирме AECL поняли ошибку, фирма немедленно разослала письмо к пользователям, в котором рекомендовала временные меры, заключавшиеся в том, чтобы не редактировать данные в ходе процесса их ввода.
Пациент скончался через три недели после инцидента от передозировки радиации12.
Yakima Valley Memorial Hospital, г. Якима, штат Вашингтон (Yakima, Washington). Январь 1987
К этому времени проблемы с машиной Therac-25 были преданы широкой гласности, по крайней мере в сообществе пользователей. Операторы знали о запрете редактировать данные. В то время когда AECL совместно с Управлением по контролю за продуктами и лекарствами (FDA) активно занималась планом работ по устранению неполадок, случился шестой инцидент. В данном случае пациент должен был получить три дозы облучения. Первые две дозы составляли 4 и 3 рад. Следующая доза составляла 79 рад в фотонном режиме. Первые два сеанса прошли без осложнений. После второй дозы оператор вошел в комнату облучения, чтобы повернуть поворотную платформу, чтобы проверить положение лучевого пучка относительно тела пациента. Оператор нажал кнопку возле поворотной платформы для указания того, что контроль произведен. Установив платформу, оператор запустил процесс лечения. Машина остановилась через 5-6 секунд, и поэтому оператор запустил лечение снова. И снова машина отключилась и отобразила «маловразумительную» причину остановки. Возникло предположение о передозировке, однако дисплей показал только облучение в 7 рад от двух первых сеансов.
Через неделю AECL обнаружила недостаток в программном обеспечении, который смог объяснить это поведение. Этот программный дефект отличался от того, который был обнаружен в Восточно-техасском онкологическом центре в деталях. Однако оба дефекта были вызваны неожиданными зависимостями от скорости в программных модулях. В данном случае существовала разделяемая переменная, названная Class3, содержащая однобайтовое значение. Это значение указывало, соответствуют ли параметры машины параметрам лечения. Если значение Class3 было ненулевым, параметры считались несоответствующими, и пучок лучей подавлялся. Эта переменная инициализировалась в модуле, который готовил машину к лечению. Однако инициализация заканчивалась инкрементированием данной переменной. Поскольку переменная была однобайтовой, через каждые 256 итераций значение ее доходило до нуля, программный модуль, проводивший инициализацию, запускался все время в зависимости от других событий в системе. Если кнопка на поворотной платформе была нажата именно в тот момент, когда переменная Class3 была равна нулю, проверка соответствия не производилась, и машина могла облучить пациента электронным пучком дозой до 25МеV.
Пациент умер в апреле 1987 году от осложнений, вызванных передозировкой. Машина была отозвана вскоре после этого13.
Выводы
За короткую жизнь Therac-25 было обнаружено два программных дефекта:
Логическая ошибка в обновлении параметров, когда оператор менял состояние машины.
Проверка безопасности не срабатывала, когда 8-битный счетчик переполнялся и достигал нуля каждые 256 итераций.
Однако с точки зрения безопасности систем самое уязвимое место — это доверие к программному обеспечению. Очевидно, что тот же дефект, который вызвал передозировки в Therac-25, присутствовал и в Therac-20. Та же ошибка в Therac-20 приводила к отключению машины без передозировки, поскольку в Therac-20 применялись независимые аппаратные устройства безопасности, которые предотвращали ее.
Ошибки, связанные с зависимостью от скорости, очень трудно обнаружить и воспроизвести. В первом случае две причины точно должны были присутствовать, чтобы активировать ошибку.
Оператор должен сделать изменения в параметрах режима и уровня энергии.
Оператор должен сделать изменения в течение восьми секунд.
В случае второго дефекта все зависит от случайности. Ошибка активируется, если клавиша нажимается в тот момент, когда счетчик достигает нуля. Вот почему, несмотря на врожденный дефект в продукте, было отмечено только шесть несчастных случаев. Если бы ошибка была более явной и ее было бы легче запустить, несомненно, она была бы выявлена на AECL в ходе обычных процедур тестирования и проверки качества, и тогда о ней никогда не узнало бы общество. Если ошибку трудно активировать, ее также трудно будет выявить в ходе обычного процесса тестирования. Трудно найти ошибки, если не можешь их воспроизвести.
Замечание
Большинство аварий — аварии системные, то есть они происходят в результате сложных взаимодействий между различными компонентами и процессами. Приписывать аварии какой-либо одной причине — обычно серьезное заблуждение.14
Кроме двух главных ошибок, описанных выше, существовали многочисленные другие, которые мы наблюдали в отношении этой истории и которые, возможно, внесли свой вклад в длительное существование этих главных ошибок.
Аппарат Therac-25 имел много неполадок, которые, по-видимому, не причиняли вреда, и операторы научились игнорировать эти капризы. Это напоминает историю о мальчике, который кричал «волк!». Люди научились не обращать на него внимания. Частые отключения и остановки машины беспокоили операторов. Однако операторы никогда не видели никаких вредных последствий для пациентов из-за этих отключений, поэтому они научились игнорировать их. Нечто, что может иметь серьезные последствия, игнорировалось. Постоянные неполадки также демонстрировали внутреннюю нестабильность и небезопасность машины.
Когда проявлялась неполадка, Therac-25 выдавал непонятные сообщения, которые не давали обслуживающему персоналу никаких ключей к причинам и следствиям системной ошибки. Конструкция системы не предусматривала адекватной обратной связи, и персонал не мог понять, что происходит. Информация проходила от оператора через программное обеспечение к оборудованию. Когда связь нарушалась, пользователь не имел способов узнать состояние оборудования, поскольку построение программ не позволяло опрашивать оборудование. Ошибка при вводе данных ясно показывает последствия недостатка обратной связи. Например, вместо того, чтобы просто позволить оператору включать пучок лучей после изменения параметров, программы могли быть сделаны так, чтобы облучение не могло начаться до тех пор, пока программа не опросит оборудование о его состоянии и не предоставит эту информацию оператору для проверки.
Когда клиники связывались с AECL по поводу потенциальных проблем, фирма не принимала эти проблемы всерьез. Поскольку люди из AECL не могли воспроизвести неисправность, они считали, что проблема не может быть связана с машиной. Более того, поскольку Therac-25 базировался на Therac-20 и Therac-6, машинах, прошедших полевые испытания, они были слишком самоуверенны в отношении потенциального риска. Ошибки были трудны для обнаружения, но, проявив достаточно внимания, их можно было найти. Инциденты в г. Якима 1985 и 1987 годов являются тому яркими примерами. Когда о проблеме впервые сообщили в 1985 году, фирма AECL провела только поверхностное расследование. Она сообщила, что ошибка невоспроизводима и, следовательно, проблемы нет. Однако в 1987 году фирма приняла сообщение всерьез и обнаружила возможную причину некорректного поведения в течение нескольких недель. Как только AECL оказалась готова признать, что ее продукт может содержать дефекты, она оказалась способна взглянуть на проблему с другой точки зрения.
Когда была обнаружена ошибка ввода данных, видимо, не было сделано ни единой попытки оценить безопасность системы в целом. В то время поступили сообщения о пяти случаях, а ошибка ввода данных могла объяснить только два из них — случаи в Восточно-техасском онкологическом центре. Первые три передозировки нельзя объяснить этой ошибкой. Это указывает на то, что в системе были другие дефекты, не принятые в расчет, и машина, по-видимому, могла и далее передозировать облучение по другим причинам. Через восемь месяцев произошел второй случай в г. Якима.
В Therac-25 было вновь использовано программное обеспечение его предшественников. Повторное использование программ позволило фирме AECL быстрее вывести Therac-25 на рынок, но внушило им ложную самоуверенность по поводу запаса прочности системы. Повторное использование программ приветствуется ведущими специалистами в индустрии в качестве пути к повышению продуктивности и снижению числа дефектов. Это так, но, с другой стороны, это означает, что программные ошибки воспроизводятся. Кроме того, повторное использование создает новые взаимодействия между ранее не связанными компонентами в новом окружении. Эти взаимодействия могут проявить скрытые дефекты и сформировать новые. Дефект, который не проявляет себя в одном случае, может внезапно возникнуть в другой среде. Также, программы обычно плохо документируются, и пользователям трудно понять нюансы повторного использования программных модулей. Массированное использование таких модулей может также привести к неудобному и небезопасному дизайну.
Зарисовка #1
В апреле 2000 года секретный девятистраничный документ НАТО, датированный 23 сентября 1999 года, попал в одну лондонскую издательскую фирму. В ходе Косовского конфликта компьютеры НАТО подвергались атакам со стороны сербов. Ученые НАТО, в поисках путей защиты от дальнейших вирусных атак, создавали вирусы для моделирования различных режимов атаки. Однако эксперимент пошел не так, как планировалось. Экспериментальные вирусы сделали в точности то, что и должны были сделать. Они извлекли документы с жестких дисков инфицированного компьютера и разослали их в качестве невидимых приложений к электронной почте. Так были разосланы секретные документы15.
Ошибка в данном случае представляла собой не вирус, разработанный и реализованный специалистами НАТО. Ошибки были в сетевом окружении и процессе тестирования, которые и позволили разослать секретные материалы. Разве вам не нравится, когда компьютер делает то, что вы от него требуете?
Ошибка в процессоре Intel Pentium
В 1993 году корпорация Intel представила новый процессор Pentium™, который обещал стать самым лучшим процессором на рынке персональных компьютеров в то время. Через год после выпуска профессор Томас Найсели (Thomas Nicely) из Линчбергского колледжа (Lynchburg College) обнаружил ошибку и сообщил о ней в Intel. Это стало совершенным кошмаром для Intel, и в конечном итоге фирма согласилась заменять микросхему автоматически по требованию. Популярная пресса заставила нас поверить, что эта ошибка вызвана глупостью инженеров Intel, — в конце концов, разве трудно проверить каждое значение по справочной таблице? Как обычно, реальность намного сложнее, чем жирные заголовки газетных статей.
История
Профессор Томас Найсели — математик. В период 1993-1994 годов он работал над исследовательским проектом в области, называемой вычислительной теорией чисел (computational number theory). Одной из его целей было продемонстрировать полезность настольных персональных компьютеров. Для своего исследования он заставил большое число персональных компьютеров вычислять простые числа, пары простых чисел, триплеты и квадраплеты простых чисел для всех положительных целых до 6 x 1012. Простые числа — это целые, которые делятся только на единицу и сами на себя (например, 3). Пары простых чисел — это два последовательных нечетных целых, которые также являются простыми (например, 3 и 5). Триплеты простых — это три последовательных целых нечетных простых числа (3, 5, 7). При вычислениях его программа предпринимала некоторое число проверок, в которых уже известные, опубликованные в литературе числа просчитывались, чтобы проверить правильность вычислений. Машина с процессором Pentium приняла участие в вычислениях в марте 1994, а 13 июня 1994 года проверка закончилась неожиданным значением. После четырех месяцев поиска профессор Найсели смог определить ошибку в блоке вычисления чисел с плавающей запятой (floating-point unit, FPU) процессора Pentium. В публичном сообщении, сделанном 9 декабря 1994 года, он описал свои трудности и исследования причины ошибок16.
24 октября 1994 года, после того как профессор окончательно уверился в результатах анализа, он послал в службу технической поддержки Intel сообщение об ошибке. Когда Intel не ответила на сообщение, 30 октября 1994 года профессор Найсели написал письмо некоторым своим коллегам, объявив об открытии ошибки деления чисел с плавающей запятой в процессоре Intel Pentium. В электронном письме он описал свои наблюдения:
Если коротко, FPU процессора Pentium возвращает ошибочное значение для некоторых операций деления. Например,
1/824633702441,0
вычисляется некорректно (ошибочны все цифры после восьмой значащей цифры)17.
Вскоре сообщение об ошибке уже циркулировало на форуме CompuServe и в группах новостей Интернета. Александр Вулф (Alexander Wolf), репортер EE Times, подхватил эту историю и написал статью, которая появилась в номере EE Times от 7 ноября 1994 года. Отвечая на запрос репортера, Intel заявила, что они обнаружили эту ошибку летом 1994 года, и она была исправлена в процессорах, выпущенных позднее. Однако Intel не смогла определить число выпущенных дефектных процессоров, и они попытались сгладить важность этой ошибки.
Смит (Smith), представитель Intel, подчеркнул, что этот дефект не повлияет на среднего пользователя. Говоря о Найсели, Смит сказал: «Это исключительный пользователь. Он круглосуточно проводит вычисления обратных величин. То, что он обнаружил после многих месяцев вычислений, является примером того, что восемь десятичных чисел правильны и только девятая отображается неверно. То есть ошибка у вас будет только в девятом знаке справа от точки. Я думаю, что, даже если вы инженер, вы этого не заметите».18
CNN распространила это заявление 22 ноября 1994 года, и вскоре оно было во всех главных средствах массовой информации, таких, как New York Times и Associated Press. В других интервью Intel повторяла свое раннее заявление о том, что ошибка несущественна для среднего пользователя.
В среду Intel заявила, что они не считают необходимым отзывать процессор, утверждая, что обычный пользователь имеет только один шанс из девяти миллиардов получить неверный результат из-за этой ошибки и таким образом не будет никаких заметных последствий для компьютеров дома и в офисе. Компания заявляет, что она продолжает поставлять сборщикам компьютеров процессоры Pentium, сделанные до того, как проблема была обнаружена19 .
28 ноября 1994 года Тим Коу (Tim Coe) из компании Vitess Semiconductor опубликовал статью в группе новостей comp.sys.intel, в которой он путем анализа восстановил реализацию алгоритма и предложил модель поведения процессора Pentium. Через несколько дней появились аппаратные и программные «заплатки» для ошибки. 3 декабря 1994 года Воэн Пратт (Vaughan R. Pratt) из Стэндфордского университета опубликовал письмо в группах новостей comp.arch и comp.sys.intel, в котором оспаривал точку зрения Intel о том, что вероятность встречи с ошибкой составляет «один раз в 27 000 лет». Он смог продемонстрировать возможность активации ошибки один раз в каждые 3 миллисекунды в достаточно правдоподобном сценарии. А также он продемонстрировал, что достаточно безобидно выглядящее деление 4,999999/14,999999 приводило к отклонению от правильного результата на 0,00000407 при использовании дефектного процессора20.
12 декабря 1994 года фирма IBM выпустила сообщение, в котором также был подвергнут сомнению анализ Intel о том, что вероятность обнаружения ошибки составляет один к девяти миллионам21.
14 декабря 1994 года Intel опубликовала официальное сообщение, которое было датировано 30 ноября 1994 года22.
В этом сообщении рассматривалась данная ошибка, обсуждались ее последствия, и этот документ был, очевидно, источником многих заявлений Intel. В этом отчете определялось, что вероятность встречи с ошибкой составляет «один к девяти миллиардам» и что среднее время появления ошибки — «один раз в 27 000 лет». Далее Intel описывала причину ошибки и алгоритм работы FPU. Инженеры компании избрали в качестве алгоритма деления процессора SRT алгоритм23 по основанию 4 (radix 4 SRT algorithm), чтобы скорость деления могла быть удвоена, по сравнению с 486-м процессором. Полное описание SRT алгоритма, использованного в процессоре Pentium, находится за рамками этой книги. Детали можно найти в работе Edelman, Sharangpani и Bryant24.
Однако главная причина ошибки в том, что SRT-алгоритм требует справочную таблицу для определения частного. Значение в справочной таблице генерируется численно и загружается в программируемый справочный массив. Дефект скрипта привел к тому, что несколько элементов в справочной таблице были пропущены. Когда выполнялась операция деления, которая требовала эти значения, извлекалось неверное число, и точность вычисленного результата частного оказывалась сниженной.
В конечном счете 20 декабря 1994 года фирма Intel объявила, что она начинает заменять процессоры Pentium по требованию. Это существенно снизило ажиотаж вокруг ошибки в процессоре. Однако это не остановило тех, кто анализировал эту ошибку. 19 сентября 1995 года Алан Эдельман (Alan Edelman) опубликовал отчет, в котором провел детальный анализ этой ошибки25.
В своем отчете он определил, что было только два способа, с помощью которых можно было осуществить доступ к ошибочным данным и использовать их при вычислениях. Ошибочное значение извлекалось, только если делитель содержал шесть последовательных бит, от 5-го до 10-го, установленных в единицу. Таким образом, ошибочные табличные значения могли не извлекаться при тестах, основанных на случайной выборке значения; тест, способный выявить ошибку, должен работать лучше, чем простая случайная выборка. Он также показал, что максимальная абсолютная ошибка в данном случае не могла превышать 0,00005.
Вывод
Ошибка в процессоре Pentium — это ошибка, которую легко совершить, но которую трудно обнаружить в силу двух причин. Во-первых, ошибка в результате операции деления, проведенной дефектным процессором, не превышает 0,00005. Как много из нас придрались бы к различию между 0,33332922 и 0,33333329? Более того, если бы мы использовали эти значения в приложениях, которые автоматически округляют их до двух значащих цифр, мы бы никогда и не узнали о таких небольших различиях. Воэн Пратт писал в своем сообщении:
Эта ошибка наиболее коварна: она почти столь же коварна, как если бы вовсе не вызывала тревоги у людей при просмотре ими колонок своих данных. Таким образом, крошечные ошибки в одну стотысячную могут в течение долгого времени проникать в триллионы вычислений, совершаемых по всему миру, и практически нет способа определить их, кроме как осуществляя массированную проверку на ошибку в FPU, которая совершенно не является необходимой для надежно работающего процессора26.
Вторая причина того, что ошибку трудно найти, состоит в том, что дефект проявляется чрезвычайно редко27.
Шанс того, что неверное значение будет извлечено из справочной таблицы в тестах по случайной выборке, чрезвычайно низок. Intel, используя эти тесты, независимо от других идентифицировала ошибку через год после выпуска процессора. Это ясно говорит о трудностях тестирования и обнаружения этого дефекта.
Для профессора Найсели процесс поиска ошибки начался, поскольку он заметил небольшие несоответствия. Но причина того, что он оказался в состоянии заметить несоответствия, состоит в том, что он поместил операцию проверки вычислений в свой код. Без этих проверок он мог и не заметить проблему так рано, и его вычисления простых чисел могли быть ошибочными. Как только он понял, что проблема существует, он начал систематически убирать ее возможные причины, пока поиск не сузился до FPU процессора Pentium.
Уроков, которые мы можем извлечь за счет Intel, довольно много:
Тестирование должно не только следовать спецификации, оно для полноты также должно учитывать использованные алгоритмы.
Мы должны использовать в программах средства для постоянного контроля над правильностью программы. Это даст нам возможность найти потенциальные ошибки настолько рано, насколько возможно.
Все неожиданные результаты нужно ставить под сомнение и проверять до тех пор, пока мы не объясним их причину. Ошибка может оказаться скрытой.
Обнаружение потенциальной фундаментальной причины ошибки — это систематический процесс. Сначала нужно построить гипотезу о возможной причине, а затем проводить эксперименты для ее проверки.
Создание упрощенного воспроизводимого опыта может все изменить. Тот факт, что профессор Найсели смог активировать ошибку простой операцией деления, позволил ему протестировать другие системы и конфигурации, что позволило ему опровергнуть неверные гипотезы.
Зарисовка #2
Согласно легенде, ранние конструкции торпед имели устройства безопасности, предохраняющие подводную лодку от повреждения, когда торпеда была запущена. Торпеда была сконструирована так, чтобы самоуничтожение запускалось, если торпеда поворачивалась на 180? . Идея была в том, что повернувшаяся на 180? торпеда может повредить выпустившую ее лодку. Однажды, капитан подводной лодки решил выпустить торпеду. Однако торпеда застряла в пусковой камере, и ее не смогли удалить. Капитан решил вернуться в порт для ремонта. Когда субмарина развернулась на 180 градусов, торпеда взорвалась и потопила лодку.
В данном случае ошибка заключалась в конструкции торпеды. Когда-то кто-то решил, что неплохо было бы встроить в торпеду некий предохранитель так, чтобы она не смогла потопить запустившую ее лодку. Идея была хорошей, а вот ее реализация — нет. Конструктор не учел тот самый случай, который и потопил субмарину. Однако остается неясным, на самом ли деле на заре конструирования вооружения для субмарин такой случай произошел или это всего лишь легенда. Но он показался нам достаточно реалистичным и поучительным, так что мы решили его привести.
Ariane 5. Ошибка операнда
Если коротко, несчастный случай с Arian 5 был вызван необработанным исключением при преобразовании 64-битного значения с плавающей запятой в 16 битное целое значение со знаком. Значение с плавающей запятой, вызвавшее исключение (или ошибку операнда, как она была названа в официальном сообщении), оказалось больше, чем значение, которое может быть представлено 16 битным целым. Однако более полная версия этой истории гораздо более интересна и поучительна28.
История
Ракета-носитель Ariane 5 была ответом попыткам Европейского космического агентства (European Space Agency) стать лидером в запусках ракет на коммерческом космическом рынке. Стоившая 7 миллиардов долларов и строившаяся в течение 10 лет, Arian 5 могла вывести на орбиту два трехтонных спутника.
При своем первом полете ракета Ariane 5 взорвалась через 40 секунд после старта утром 4 июня 1996 года. Анализ данных полета быстро показал, что ракета вела себя нормально до того момента, когда она вдруг отклонилась от курса и самоуничтожилась. Погода в то утро была приемлемой, так что она не могла оказать влияние. Полетные данные также показывали, что активная система и первичная Инерционная система ориентировки (Inertial Reference System), которые влияли на управление соплами твердотопливного ускорителя, более или менее одновременно отказали прямо перед разрушением ракеты.
После инцидента была сформирована комиссия по его расследованию. Комиссия для решения своей задачи располагала телеметрическими данными ракеты, данными о траектории с радиолокационных станций, оптическими наблюдениями ракеты и упавших обломков и восстановленной Инерционной системой ориентировки. Кроме того, комиссия располагала отдельными компонентами ракеты и системами программ, использованных в ней, для тестирований и осмотра. Получив эту информацию, комиссия смогла реконструировать последовательность событий 4 июня 1996 года.
Программный модуль, в котором в итоге возникла ошибка, был унаследован от ракеты-носителя Arian 4. Этот модуль производил выравнивание инерционной платформы для того, чтобы оценить точность измерений, проведенных Инерционной системой ориентировки. После старта данный модуль более не служил в Ariane 5 никаким целям. Однако в Ariane 4 этот модуль работал в течение еще полных 50 секунд. Начальная часть траектории полета Ariane 5 существенно отличалась от траектории Ariane 4, и этот программный модуль никогда соответствующим образом не тестировался.
Вскоре после старта ошибочный программный модуль попытался посчитать значение, основанное на горизонтальной скорости ракеты. Поскольку для Ariane 5 это значение было существенно больше, чем то, которое ожидалось для Ariane 4, возникла ошибка и на активной, и на запасной Инерционной системе ориентировки. Допустимость такого преобразования не была проверена, поскольку ожидалось, что такого никогда не случится.
Спецификация обработки ошибок в системе указывала, что контекст ошибок должен быть сохранен в постоянной памяти (ПЗУ) до отключения процессора. После ошибки операнда Инерционная система ориентировки сохранила контекст ошибки, как было установлено. Эти данные были прочитаны бортовым компьютером. На основе этих данных компьютер отдал команду соплам твердотопливного ускорителя и главному двигателю. Команда требовала полного отклонения сопел, что вызвало то, что ракета вышла на запредельную траекторию.
На новой траектории ракета подверглась запредельной аэродинамической нагрузке и начала разрушаться. Стартовые двигатели отделились от ракеты, что запустило ее самоуничтожение.
Несомненно, глупая ошибка, но интересен такой вопрос: как эта ошибка миновала стадию тестирования? В аэрокосмической индустрии обычно строгие стандарты и скрупулезные процессы и процедуры, направленные на проверку безопасности из-за высокой цены ошибок. Комиссия по расследованию задала тот же вопрос, и команда обслуживания Ariane 5 представила следующие объяснения:
Команда Ariane 5 решила не защищать некоторые переменные от возможной ошибки операнда, поскольку они считали, что значения этих переменных либо ограничены физическими факторами, либо имеют существенный запас по максимальной величине.
Команда Ariane 5 решила не включать данные о траектории в функциональные требования для Инерционной системы ориентировки. Следовательно, данные о траектории Ariane 5 не использовались при тестировании.
Из-за физических законов трудно осуществить реалистичный полетный тест Инерционной системы ориентировки. При функциональном имитационном тестировании полетных программ было решено не включать в тест эту систему главным образом по той причине, что она должна быть проверена при тестировании аппаратного уровня, а также потому, что было бы трудно достигнуть необходимой точности при имитационном тестировании, если бы была использована реальная Инерционная система ориентировки.
Вывод
Как и в случае других ошибок, которые мы обсуждали, дефект на Ariane 5 не был вызван одной причиной. В ходе всей разработки и процессов тестирования существовало много стадий, на которых данный дефект мог быть выявлен.
Программный модуль был повторно использован в новой среде, где условия функционирования отличались от требований программного модуля. Эти требования не были пересмотрены.
Система выявила и распознала ошибку. К несчастью, спецификация механизма обработки ошибок была несоответственной и вызвала окончательное разрушение.
Ошибочный модуль никогда должным образом не тестировался в новом окружении — ни на уровне оборудования, ни на уровне системной интеграции. Следовательно, ошибочность разработки и реализации не была обнаружена.
Отчет комиссии по расследованию содержит следующее наблюдение, которое мы считаем очень подходящим для всей индустрии программного обеспечения, а не только для разработчиков программ для Ariane 5.
Главной задачей при разработке Ariane 5 является уклон в сторону уменьшения случайной аварии. …Возникшее исключение, объясняется не случайной аварией, но ошибкой конструкции. Исключение было обнаружено, но обработано неверно, поскольку была принята точка зрения, что программу следует рассматривать как правильную, пока не показано обратное. …Комиссия придерживается противоположной точки зрения, что программное обеспечение нужно считать ошибочным, пока использование признанных в настоящее время наилучшими практических методов не продемонстрирует его правильность29.
Однако одна из причин того, что комиссия по расследованию смогла успешно определить виновного, — в сборе данных измерений, в имитационных средах и в документации. Без метеорологических данных было бы трудно исключить влияние погоды. Без телеметрии и полетных данных было бы трудно определить временные параметры изменения траектории и ошибку Инерционной системы ориентации, что позволило комиссии быстро сузить область потенциальных дефектов. Послеполетные имитационные исследования были проведены с использованием реальных данных о траектории полета Ariane 5, и моделирование точно воспроизвело цепь событий, приведших к аварии системы. Комиссия смогла воспроизвести ошибку!
Зарисовка #3
Интернет — это великий источник информации. К сожалению, слово «великий» не используется здесь как прилагательное, описывающее качество информации. «Великий» обозначает количество информации — слишком большое количество информации, которая при некоторых обстоятельствах нежелательна и которую мы называем спам. В других случаях доступ к некоторым специфическим формам информации, таким, как порнография, намеренно блокируется и подвергается цензуре по различным причинам. В любом случае существует некоторое число инструментов, чья функция — служить в роли фильтров для удаления потенциально нежелательных электронных писем и блокировать запросы к некоторым Web-сайтам. Эти средства могут быть источниками большого раздражения. Например:
Только что услышал сообщение по сетевому радио CBS о том, что футбольные фанаты по всей стране не смогли узнать по Интернету результаты воскресного Суперкубка. Оказалось, что программы-фильтры доступа в Web, установленные на браузерах (например, в некоторых публичных библиотеках), рассматривали «ХХХ» в словах «Суперкубок XXXIV» как ссылку на порносайт30.
В другом примере чрезмерная цензура потенциально оскорбительных слов может сделать вполне безобидное сообщение неразборчивым и забавным. Так Интернет-служба BBC подвергла цензуре такое предложение:
Я надеюсь, вы сохраните пристрастие к острым словечкам, когда я заскочу к вам в класс в субботу в Сканторп, Эссекс. «I hope you still have your appetite for scraps of dickens when I bump into you in class in Scunthorpe, Essex, on Saturday».
Программа превратила его в
«I hope you still have your appetite for s****s of dickens when I ***p into you in class in S****horpe, Es***, on Sa****ay»31, 32
Однако наибольшее раздражение вызывает программное обеспечение, направленное против спама, которое может удалить важные электронные письма, поскольку ошибочно классифицирует их как спам.
Я недавно провел обновление (?) MS Office до MS Office 2000, который среди прочих возможностей позволяет устанавливать более 8 фильтров электронной корреспонденции. Я радостно начал запускать все эти возможности, включая фильтрацию почты. Сюрприз! Я обнаружил, что 8-10 важных сообщений, которые все являлись ответами на запросы, посланные на адреса из личной адресной книги, были перенесены в папку для почты-спама.
Что же случилось? Я участвовал в благотворительной велосипедной гонке, и мне необходимо было сообщить спонсорам, что мне нужны их деньги. Я выслал им электронные письма с просьбой прислать мне чеки. Конечно, это сообщение содержало, по крайней мере, один знак «$», а также, поскольку я возбудимый человек, содержало, по крайней мере, один двойной восклицательный знак «!!». В конце я просил моего респондента выполнить мою гиперболизированную версию его обещания:
>>Марк, ты не обещал мне 5,000$ или что-то около того?
Мы также встретили здесь волшебную фразу «,000». Недавно замечательные люди из Редмонда33 (Redmond) определили, что, если эти три элемента одновременно присутствуют, значит, вы получили спам. Текущее правило (взятое с их Web-сайта) гласит:
Текст содержит «,000» AND текст содержит «!!» AND текст содержит «$»
Кто бы мог подумать? Даже взглянув на список их фильтров, я далеко не сразу понял, какое правило я нарушил (ОК, иногда я медленно соображаю)34.
Это ошибки программы или ошибки пользователя? Во всех трех случаях программное обеспечение функционирует в точности так, как предписывает алгоритм, и производители не посчитали бы эти случаи за ошибки. Однако иногда действие алгоритма — это не то, что хочет конечный пользователь. Поэтому, как конечные пользователи мы выключаем фильтрующее и противоспамное программное обеспечение или же находим пути обойти неверный алгоритм. В главе 3 мы исследуем природу ошибок, что может помочь нам определить точно, что такое ошибка.
Аппарат для исследования климата Марса
Аппарат для исследования климата Марса (Mars Climate Orbiter) является частью программы Mars Surveyor по изучению и картографированию Марса. Ожидалось, что программа Mars Surveyor продлится в течение 10 лет и в рамках программы будет запускаться одна экспедиция в год. Первыми двумя экспедициями были миссии аппаратов Mars Pathfinder и Mars Global Surveyor в 1996 году. Аппарат Mars Climate Orbiter был запущен 11 декабря 1998 года. Следом за ним был также запущен Mars Polar Lander — 3 января 1999. Оба аппарата были потеряны вскоре после того, как они достигли красной планеты. Эти два космических корабля стоили NASA около 327,6 миллиона долларов, потраченных на их создание и функционирование. Эти аварии заставили NASA пересмотреть свои цели и методы в Марсианской программе, чтобы быть уверенными в успехе будущих миссий. Причину аварии Mars Polar Lander определить все еще нельзя. Однако причина потери Mars Climate Orbiter выяснена, поэтому мы сконцентрируем наше исследование на этом аппарате.
История
Mars Climate Orbiter был запущен 11 декабря 1998 года с помощью ракеты-носителя Delta 11 с космодрома на мысе Канаверал (Canaveral) во Флориде. После девяти с половиной месяцев космического полета 23 сентября 1999 года, его планировалось вывести на орбиту вокруг Марса. Однако, когда пришло назначенное время, что-то произошло.
Сегодня, ранним утром, около 2:00 утра по летнему тихоокеанскому времени, аппарат включил главный двигатель для выхода на орбиту вокруг планеты. Вся информация, приходившая до этого момента с борта космического корабля, выглядела нормально. Запуск двигателя начался как планировалось, за пять минут до того, как аппарат оказался за планетой (если смотреть с Земли). Управление полетом не зафиксировало сигнала, когда ожидалось, что аппарат должен был выйти из-за планеты35.
Mars Climate Orbiter разрабатывался объединенной командой инженеров и ученых в двух местах — Лаборатории реактивных двигателей (Jet Propulsion Laboratory, JPL), расположенной в Пасадене (Pasadena), штат Калифорния, и на заводе Lockheed Martin Astronautics, LMA в Денвере, штат Колорадо. Завод LMA был ответственен за планирование и разработку Mars Climate Orbiter с точки зрения интеграции и тестирования полетных систем, а также за операцию запуска. Лаборатория JPL несла ответственность за управление проектом, за управление разработкой космического аппарата и приборов, за системотехнику, за планирование миссии, навигацию, разработку операционной системы миссии, разработку наземной системы сбора данных и гарантии безопасности36.
В ходе девяти с половиной месяцев полета наземные службы отслеживали и сравнивали наблюдаемую траекторию аппарата с расчетной. Также наземные службы проверяли все события, происходящие на борту Mars Climate Orbiter. Одним из таких событий было уменьшение углового момента (Angular Momentum Desaturation, AMD). Событие AMD возникало, когда аппарат запускал двигатели малой тяги для устранения углового момента, накопившегося в его маховиках. В основе своей — это калибровочный маневр для поддержания функционирования системных компонентов в заданном диапазоне. Когда возникало событие AMD, происходила следующая последовательность событий:
Аппарат посылал значимые данные на наземную станцию.
Данные обрабатывались программным модулем, называвшимся SM-FORCE.
Результаты работы модуля SM-FORCE помещались в файл, называемый файл AMD.
Данные файла AMD использовались для вычисления изменения скорости аппарата.
Вычисленное значение изменения скорости использовалось для моделирования траектории корабля.
Согласно спецификации модуль SM-FORCE должен формировать данные, помещаемые в файл AMD, используя метрические единицы, то есть ньютон-секунды. Однако по тем или иным причинам модуль SM-FORCE на наземной станции выводил данные, используя английские единицы (фунт-секунды) (в официальном отчете причина не указывалась, и мы не будем строить предположения по этому поводу). Программный модуль, который рассчитывал изменение скорости с использованием данных из файла AMD, ожидал, что они будут в метрических единицах, согласно спецификации. На борту аппарата модуль, который создавал файл AMD, использовал метрические единицы. Это привело к различию между траекториями, вычисленными космическим аппаратом и наземной станцией, а именно параметры траектории, вычисленные наземной станцией, были в 4,45 раза меньше, поскольку 1 фунт-секунда равен 4,45 ньютон-секундам.
Корабль периодически передавал вычисленную модель траектории на наземную станцию для сравнения. Теоретически быстрое сопоставление моделей, полученных кораблем и наземной станцией, должно было поднять тревогу. Однако несколько осложняющих факторов помешали наземному персоналу осознать ошибку.
В программном обеспечении наземной станции было несколько ошибок, и персонал не мог использовать модуль SM-FORCE для расчета траектории корабля. Эти ошибки были исправлены только к четвертому месяцу полета, в районе апреля 1999 года.
Персонал, ответственный за навигацию, не знал о том, что данные об изменении скорости с борта корабля были доступны для сравнения в течение долгого времени после запуска.
Линия обзора между аппаратом и Землей не давала персоналу точно моделировать траекторию корабля, используя наблюдения.
Если бы событие AMD возникало нечасто, коэффициент 4,45 мог и не иметь таких серьезных последствий. Однако из-за формы корабля это событие возникало в 10-14 раз чаще, чем ожидалось. Более того, когда были обнаружены различия в моделях наземной станции, космического корабля и данных наблюдений, неофициальный отчет об этих различиях был отправлен по электронной почте, без использования стандартной процедуры для таких случаев. В конечном итоге эти различия не были устранены до потери космического аппарата.
8 сентября 1999 года персонал наземной станции рассчитал маневр для вывода корабля на орбиту Марса. Это вычисление было сделано с использованием неверной модели. Целью этого маневра была коррекция траектории корабля таким образом, чтобы точка наибольшего приближения к Марсу составляла 226 километров. 23 сентября маневр был выполнен. Запуск двигателя произошел в 09:00:46 по Всемирному координированному времени (UTC), более известному как время по Гринвичу (GMT). Спустя четыре минуты и шесть секунд наземная станция потеряла сигнал с аппарата. Потеря сигнала была вызвана тем, что Orbiter находился за планетой. Но это событие произошло на 49 секунд раньше, чем было предсказано моделью траектории. Поскольку была использована ошибочная модель траектории, корабль оказался в действительности ближе к поверхности планеты, чем ожидалось. Действительная точка максимального сближения оказалась приблизительно 57 километров. По оценке, такая высота оказалась слишком мала для аппарата.
Вывод
«Люди иногда делают ошибки», — заявил доктор Эдвард Уэйлер (Edward Weiler), первый заместитель главы NASA по науке о космосе. «Данная проблема — это не ошибка, это неудача системотехники и систем проверки в наших технологиях, предназначенных для обнаружения ошибки. Вот почему мы потеряли космический аппарат»37.
Одна ошибка была допущена в одной из частей программного обеспечения. Однако целая серия ошибок на протяжении девяти с половиной месяцев полета привела в конечном итоге к потере аппарата. Назвать первоначальную ошибку фундаментальной причиной аварии мешает тот факт, что данный инцидент не был результатом только одной ошибки. Вот три главных составляющих аварии Mars Climate Orbiter:
Если бы было проведено соответствующее тестирование, такая ошибка могла быть быстро обнаружена и исправлена.
Однако, поскольку программное обеспечение наземной станции не было хорошо протестировано, после запуска космического аппарата проявились дополнительные ошибки. Эти ошибки отсрочили наблюдения над проблемой. Вместо девяти месяцев из-за дополнительных ошибок персонал имел только пять месяцев на выяснение причины несоответствий.
Когда несоответствие в итоге было обнаружено, оно так и не было правильно объяснено. Первоначальная причина так и не была выяснена, а это дало бы персоналу информацию о надвигающейся катастрофе.
В отчете комиссии по расследованию первой фазы ее работы также были указаны следующие факторы неудачи и сделаны некоторые дополнительные рекомендации38. Эти факторы и рекомендации главным образом касаются методов и технологий проекта, которые могли быть полезны для программного обеспечения наземных служб.
Обмен информацией. — Обмен информацией является главной проблемой в проекте большого масштаба, программном или любом другом. В случае с Mars Climate Orbiter команды, работавшие над проектами, не связывались действенным образом друг с другом. Команда наземного обслуживания не сообщала о своем беспокойстве по поводу различия траекторий команде управления космическим аппаратом и органам управления проектом. Важная информация от одной команды не передавалась другим командам, что внесло свой вклад в аварию.
Обучение и переход от стадии разработки к стадии функционирования. — Одна из причин того, что различия в моделях траекторий так и не были полностью объяснены, пока не случилась катастрофа, состоит в том, что обслуживающий персонал не был полностью обучен. Переход от разработки к функционированию не был тщательно спланирован и осуществлен. В разработке программного обеспечения это можно приравнять к тому, как если бы команда разработчиков перебросила готовую систему команде сетевых операторов, не снабдив их соответствующими инструментами и не проведя обучение особенностям и поведению системы.
Проанализируй, что может выйти из строя. — Исследователи считают, что предварительный анализ критических условий системы может помочь предотвратить будущие аварии. Это сходно с анализом отказоустойчивости, анализом процедур восстановления после ошибки и планированием нагрузки, проводимым в распределенных компьютерных средах, обычно встречающихся в системе Интернета.
Самоуверенность. — Комиссия по расследованию обнаружила, что персонал проекта считал посылку космического аппарата на орбиту вокруг Марса легкой задачей, поскольку JPL имела тридцатилетний опыт безошибочной межпланетной навигации. Эта самоуверенность может объяснить недостаток соответствующего тестирования в программных модулях.
Зарисовка #4
Этот инцидент не связан с какой-либо программной ошибкой. В действительности в этой истории программное обеспечение не участвует вовсе. Однако эта история поучительна и забавна и заслуживает места в этой главе. Это укороченная версия истории, в которой описывается субподрядчик, который выполнял работу по прокладке волоконно-оптического кабеля для одной местной телефонной компании. Перед описываемым инцидентом субподрядчик отключил телефонную линию и воспользовался машиной-канавокопателем для прорытия канавы в земле. Однако земля была мокрой от утренней росы, и канавокопатель соскользнул по откосу дороги и столкнул субподрядчика в яму глубиной 10-15 футов. Человек, заметивший этот несчастный случай, подъехал к ближайшему дому, чтобы вызвать по телефону помощь, но телефон не работал. Почему? Потому что телефонная линия была отключена субподрядчиком для проведения работы. Что еще более курьезно, в машине субподрядчика был сотовый телефон, но товарищи раненого по работе совершенно забыли о нем в момент инцидента. В конце концов другой свидетель смог позвонить в службу спасения из другого дома, и инцидент закончился благополучно. Пострадавший был отправлен в больницу без серьезных повреждений. Канавокопатель извлекли из ямы, и общество получило волоконно-оптические кабели39.
Какой урок мы можем извлечь из этого инцидента, который можно было бы применить к наладке программного обеспечения? Главный вывод — всегда имейте резервную копию. Часто в азарте исправления и изменения кода мы чувствуем такую уверенность в своих изменениях, что принимаем их без должного тестирования. Принятые изменения — это такие модификации, которые трудно вернуть в первоначальное состояние, и мы оказываемся в тупике, если возникает проблема. Это напоминает историю с субподрядчиком, который отключил телефонную линию, не подумав о возможности того, что что-то может случиться, и, когда это действительно случилось, он остался без телефона.
Создание резервной копии кода, комментирование40 кода при его замене вместо удаления, создание копии старой функции с другим именем и использование инструментов управления конфигурацией — вот некоторые советы, которые вы можете использовать, чтобы сохранять пути отступления до того, как вы серьезно протестируете ваши изменения. Однако эти пути бесполезны, если вы не помните, что они у вас есть. В описанной истории помощь могла быть вызвана раньше, если бы кто-нибудь вспомнил о сотовом телефоне в машине. В нашей работе опасность не в том, что мы забудем, что у нас есть путь отступления, а в попытках определить, какая версия старого кода (или какая комбинация версий из разных модулей) соответствует последней работающей версии системы.
Авария на телефонной компании AT&T
Для большинства из нас авария на телефонной станции означает то, что мы не можем пользоваться телефонами: не можем звонить сами, и люди не могут звонить нам. Аварии — это ожидаемый и принимаемый риск в этой индустрии. Ураганы могут повредить телефонные линии, подземные кабели могут быть повреждены из-за человеческой ошибки или землетрясения или же возможны ошибки в программном обеспечении, которое управляет сетью.
К 15 января 1990 года в компании AT&T произошла авария, охватившая всю страну и продолжавшаяся девять часов. Причина состояла в ошибке в программном обеспечении, которое должно было сделать эту систему более эффективной. Восемь лет спустя, 13 апреля 1998 года, на AT&T произошла другая крупная авария в сети ретрансляции кадров (frame relay network), которая затронула банкоматы, операции с кредитными картами и другие службы, связанные с передачей бизнес-данных. Авария длилась 26 часов. И опять ошибка была внесена при обновлении программного обеспечения.
Сделала ли AT&T одну и ту же ошибку дважды или здесь было что-то еще?
История: авария 1990 года
В 1990 году телефонная сеть AT&T состояла из 114 соединенных между собой систем коммутирования вызовов 4ESS (4ESS toll switching systems) (это представление является упрощением). Для нашего обсуждения мы мысленно смоделируем сеть AT&T в виде схемы. В этой схеме существует 114 узлов (точек пересечения) и каждый узел представляет один из 114 коммутаторов 4ESS. Линии, нарисованные между узлами, изображают коммуникационные каналы между ними.
В такой телефонной сети, когда один из узлов сталкивается с проблемой, он посылает сообщение «не беспокоить» всем узлам, с которыми он соединен. Это сообщение информирует соседний узел о том, что данный узел не может обрабатывать новые вызовы и просит соседний узел считать его не работающим. Тем временем аварийный узел активирует процесс восстановления после сбоя, который длится от четырех до шести секунд. По окончании процесса восстановления аварийный узел посылает сообщение, известное как Начальное адресное сообщение (Initial Address Message, IAM), всем соседним узлам, сообщая им о своем новом статусе и требуя направлять вызовы на восстановленный узел.
В середине декабря 1989 года AT&T произвела обновление программного обеспечения на коммутаторах 4ESS с целью увеличения производительности системы и введения быстрого процесса восстановления после ошибки. Приблизительно в 2:30 по Восточному стандартному времени (EST) 15 января 1990 года на 4ESS коммутаторе в Нью-Йорке возникла небольшая аппаратная проблема, и коммутатор начал процесс восстановления, как было описано выше. После того как Нью-Йоркский коммутатор исправил проблему, он послал сообщение IAM для уведомления соседних коммутаторов, что он готов продолжать работу. Однако обновление программ, проведенное в середине декабря, внесло в действия ошибку. Эта ошибка проявилась, когда коммутатор получил два IAM сообщения с интервалом 1/100 секунды. Некоторые данные в коммутаторе оказались искажены, и он прекратил обслуживание, перейдя к инициализации. Когда соседние узлы выходили из строя, они запускали тот же самый процесс восстановления. Поскольку все коммутаторы были одинаковы, та же последовательность событий каскадом распространялась от одного коммутатора к другому и вывела из строя всю систему.
В течение дня инженеры AT&T смогли стабилизировать сеть, уменьшив нагрузку на нее. К 23:30 EST они смогли очистить все звенья сети, и система практически вернулась к нормальному состоянию.
Во вторник, 16 января 1990 года, инженеры AT&T смогли идентифицировать и выделить ошибку, которая была отслежена до набора ошибочных кодов. Этот код активировался в ходе процедуры восстановления коммутатора. Отрывок кода, который вызвал аварию, представлен ниже41:
В данном случае виновным оказался оператор break в строке 7. Согласно реализации, если logical_test прошел успешно, программа переходит к строке 6 для выполнения расположенных там операторов. Когда выполнение программы доходит до строки 7, оператор break заставляет программу покинуть блок оператора switch, расположенного между 3 и 15 строками, и исполнять код начиная со строки 16. Однако эта часть исполнения не входила в намерения программиста. Программист желал, чтобы оператор break в седьмой строке прерывал выполнение условного оператора if-then и чтобы после исполнения седьмой строки исполнение продолжилось со строки 11. В таблице 2.1 показаны различия в исполнении программы, как это было задумано и как это было реализовано.
Таблица 2.1. Желаемые и реализованные последовательности инструкций, которые привели к аварии в телефонной сети AT&T 1990 года
ход выполнения
реализация
ожидалось
шаг 1
строка 2
строка 2
шаг 2
строка 3
строка 3
шаг 3
строка 4
строка 4
шаг 4
строка 5
строка 5
шаг 5
строка 6
строка 6
шаг 6
строка 7
строка 7
шаг 7
строка 16
строка 11 (не верно)
шаг 8
строка 17
строка 12 (не верно)
шаг 9
—
строка 16 (не верно)
Вывод: авария 1990 года
Программная ошибка, приведшая к аварии 1990 года, — это типичная ошибка новичка. Но ошибки делаем все мы, и даже ветеран с 20-летним стажем может совершить случайно глупую ошибку. Если ошибки неизбежны, вопрос состоит в том, что мы можем сделать для того, чтобы отыскать ошибку до того, как она станет достоянием общества? У нас нет никакого знания из первых рук о внутренней кухне разработки программ в AT&T в 1990 году. Следовательно, мы не можем оценить вклад других причин. В официальном отчете AT&T говорилось:
Мы считаем, что процессы планирования, разработки и тестирования программ, которые мы используем, базируются на прочных и качественных основах. Все будущие программы будут также скрупулезно тестироваться. Мы используем опыт, приобретенный при решении этой проблемы, для дальнейшего улучшения наших методов42.
Мы не считаем возможным обвинять в аварии 1990 года процесс разработки программного обеспечения в AT&T и не имеем оснований считать, что AT&T не протестировала тщательно обновление для своих программ. Оглядываясь назад, легко говорить, что, если бы разработчики только протестировали свои программы, они сразу увидели бы эту ошибку. Или то, что, если бы они проверили код, они, возможно, обнаружили бы дефект. Проверка кода может быть и помогла бы в данном случае. Однако единственный случай, когда проверка кода помогла бы найти данную ошибку, если бы другой специалист увидел именно эту строку кода и спросил первого программиста, входил ли этот код в его (ее) намерения. А единственная причина, по которой этот специалист мог бы задать такой вопрос, — знакомство со спецификацией к этому конкретному блоку кода.
Ошибки такого рода обычно нелегко выявить при тестировании в обычной тестовой среде. Такую ошибку можно воспроизвести, как только вы поймете ее и создадите последовательность действий для ее активации. Однако шанс создать правильную последовательность событий случайным образом очень мал, особенно если система будет использоваться в крупномасштабной среде реального времени, которую трудно имитировать в лабораторных условиях. Более того, новое программное обеспечение работало правильно примерно в течение месяца, что соответствует нескольким миллиардам обработанных вызовов. В программном обеспечении был дефект, но этот дефект требовал целого набора специфических событий и факторов, для того чтобы пробудиться к жизни.
Эта ошибка требовала, чтобы нагрузка на сеть была продолжительной. Когда нагрузка на сеть уменьшалась, действие дефекта, по существу, исчезало43.
Эта ошибка зависела от временных параметров. Чтобы ошибка активировалась, было необходимо, чтобы были получены два IAM сообщения от одного и того же коммутатора с интервалом менее 10 миллисекунд.
Тот факт, что на всех коммутаторах было установлено одинаковое программное обеспечение, делал систему расширяемой. Однако был риск в том, что, если на всех коммутаторах был один и тот же дефект, они все оказывались чувствительными к одной и той же ошибке.
История: авария 1998 года
13 апреля 1998 года в 2:30 после полудня к коммутатору системы ретрансляции кадров Cisco Stratacom BPX был направлен техник для обновления транк-карты (trunk-card)44. Коммутатор Stratacom BPX содержал две транк-карты, одна из которых была активной, тогда как другая находилась в ждущем режиме и выполняла функцию резерва. Фирма AT&T использовала две процедуры обновления транк-карт. Одна процедура использовалась, если коммутатор был в текущее время подключен к сети и активен, тогда как другая процедура применялась, если коммутатор был изолирован, то есть не соединен с сетью.
Согласно первому сценарию, то есть когда коммутатор считался активным, процедура требовала, чтобы техник заменил сначала карту, находящуюся в ждущем режиме. Как только становилось ясно, что состояние новой карты стабильно, старая активная карта переводилась в ждущий режим, а новая карта становилась активной. Проведя эту операцию, техник мог заменить оставшуюся карту (теперь находящуюся в ждущем режиме). При второй процедуре предполагалось, что коммутатор отключен от сети и техник мог менять обе карты одновременно.
Когда техник прибыл на место, он посчитал, что коммутатор, которому требуется обновление, не подключен к сети, поскольку казалось, что через него не проходил никакой сетевой трафик. Однако коммутатор был подключен к сети и активен. К несчастью для техника и для AT&T, обе карты имели дефекты. Как только карты были установлены и активированы, они немедленно выслали коммутатору поток сообщений об ошибках. Эти сообщения от транк-карт активировали ошибку в программном модуле коммутатора. Этот дефект вызвал распространение передачи сообщений об ошибках к другим коммутаторам сети, ко всем 145. Объем этих посланий был достаточно велик, для того чтобы быстро перегрузить все коммутаторы, что очень действенно вывело из строя всю систему приблизительно к 3:00 пополудни45.
Информации об ошибках в программном обеспечении транк-карт и коммутатора Cisco немного. Элка Ярвис (Alka Jarvis), менеджер по программному обеспечению Cisco Systems, 28 мая 1998 года на заседании сессии Международной недели качества программного обеспечения (International Software Quality Week) прокомментировал, что код, который вызвал аварию в сети AT&T, являлся наследством прошлого46.
Компания AT&T смогла быстро изолировать аварийный коммутатор, к 23:00 он был отключен от сети. Оставшаяся задача состояла в том, чтобы просто перестроить всю сеть, одну часть за другой. К 2:00 пополудни 14 апреля 1998 года 99,9 % сети ретрансляции кадров были снова работоспособны. Однако определение причины аварии заняло у AT&T около недели, и 22 апреля 1998 года фирма выпустила отчет, очерчивающий причину выхода сети из строя.
Вывод: авария 1998 года
Хотя в аварии 1998 года и участвовало программное обеспечение, существует множество причин, внесших свой вклад в данное происшествие. Эта авария отличалась от аварии 1990 года тем, что процедурная ошибка в ходе обновления запустила скрытые программные дефекты. Однако сходств очень много.
Установка нового программного обеспечения запустила ошибку. Программы, и старые и новые, имели многочисленные скрытые дефекты, которые не были обнаружены в ходе обычных тестовых процедур. Наличие скрытых дефектов изменило функциональную среду и запустило дефект, вызвавший аварию.
Ошибочный код не был проверен должным образом. При аварии 1990 года это был новый код от AT&T. При аварии 1998 года — старый код от Cisco Systems.
Программные дефекты в обоих случаях представляли собой проблемы со скрытыми граничными условиями, которые было трудно протестировать и которые, по всей вероятности, так и не были протестированы.
Авария 1998 года в сети AT&T выявила многочисленные просчеты в процедурах и процессах обслуживания сети и продемонстрировала трудности в разработке и поддержании в рабочем состоянии надежной сети. Очевидно, AT&T извлекла урок из своих ошибок и исправила многочисленные процедурные и функциональные недостатки и ввела многочисленные планы для восстановления после аварий, чтобы минимизировать риск другой общесистемной аварии47.
Переполнение буфера
18 июля 2000 года через список рассылки BugTraq было опубликовано детальное описание уязвимости систем безопасности Microsoft Outlook и Outlook Express. BugTruq — это список рассылки (mailing list), посвященный обсуждению компьютерной безопасности. Указанная уязвимость, по существу, обеспечивается ошибкой, обычно называемой в программной индустрии переполнение буфера (buffer overflow). В наиболее простой форме переполнение буфера случается, когда программа старается поместить данные в область памяти, которая слишком мала для их хранения. Следующий отрывок кода представляет собой пример на языке С:
Размер массива составляет 10 символов, а сообщение: «Это вызовет переполнение буфера» состоит из 31 символа. Функция strcpy() пытается скопировать 31 символ в область, размеры которой позволяют хранить только 10 символов, и, таким образом, часть сообщения пишется за пределами разрешенной области. Когда такое случается, программа иногда претерпевает сбой. В другой раз программа может продолжать работу в течение некоторого времени без побочных эффектов. Но если сообщение составлено подходящим образом, это может привести к выполнению встроенного в сообщение «вируса», что вызовет заражение компьютера этим вирусом.
До настоящего момента наибольшую заботу о безопасности компьютера вызывали многообразные вирусы, которые требовали от пользователей предпринять некоторые действия для осуществления заражения. К таким вирусам относятся такие, как «ILOVEYOU» в 1999 году и «Melissa» в 1998 году. В обоих случаях для активации вируса пользователя хитростью заставляли запустить программу или открыть файл. Однако ошибка переполнения буфера в Outlook не требует вмешательства конечного пользователя. Для того чтобы вы подверглись атаке, достаточно просто получить электронное письмо, и это делает атаку особенно трудной для отражения.
В отличие от прочих случаев, описанных в этой главе, эта ошибка не ограничивается программой Microsoft Outlook. Как ошибка, переполнение буфера существует последние 10 лет, и это хорошо известное уязвимое место систем безопасности. Вне пределов проблем безопасности сетей переполнение буфера также очень распространенная ошибка — вероятно, каждый создавал такой дефект в какой-то момент своей карьеры. Когда бы вы использовали переменную фиксированного размера, такую, как массив, вы рискуете создать ошибку переполнения буфера. Поскольку эта проблема так распространена, вместо того чтобы детально описывать ошибку в Microsoft Outlook, мы поговорим об ошибке переполнения буфера вообще — как эта ошибка создается, какого рода риск для безопасности она может представлять и что мы можем сделать, чтобы избежать ее.
История
Причину переполнения буфера понять легко. Оно происходит, когда мы пытаемся записать слишком много данных в фиксированную область памяти (буфер). Чтобы понять, как переполнение буфера может вызвать сбой программы или стать уязвимым местом в системе безопасности, мы должны проникнуть во внутреннюю логику работы компьютера.
Когда вы пишете программу на языке высокого уровня, таком, как С, компилятор переводит программу в машинный код. Машинный код, по существу, представляет собой последовательность инструкций низкого уровня и данных. Например, рассмотрим следующую основную программу:
1.main(){
2.printf("Hello World");
3.}
Знаменитая программа «Здравствуй, мир» создает 300 294 байта исполняемого кода при использовании компилятора ‘С’ GNU (GCC) в Windows NT, и это выглядит примерно так:
Что-то довольно непонятное, не так ли? Эти числа — это то, что компьютер использует, когда исполняет написанную вами программу. Числа в этом коде представлены в шестнадцатеричном виде. Первая колонка представляет собой адрес памяти, где находится программа, а оставшиеся колонки показывают содержимое этих адресов памяти. Каждая колонка увеличивает значение адреса на единицу. Таким образом, по адресу 401000 хранится значение 55, по адресу 401001 хранится значение 89 и так далее. Некоторые из этих чисел — команды, которые говорят компьютеру, что делать, другие представляют собой данные, используемые компьютером. В данном случае компьютер берет первое значение, 55, и интерпретирует его как команду выполнить некоторое действие. Затем он переходит к следующему значению — 89. Компьютер знает, что команда 89 требует параметр, который хранится в следующем адресе и имеет значение е5. Таким образом, компьютер выполняет команду 89 е5 и затем переходит к значению, идущему следом за е5. Так компьютер исполняет эти команды по одной за раз. В программе «Здравствуй, мир» строка «Hello, world» представляет собой данные. Если вы можете прочитать шестнадцатеричные значения и знаете коды ASCII, вы можете увидеть, что строка «Hello, world» расположена по адресу 0х401040.
Этот набор чисел выглядит совершенно неотличимым от другого набора чисел. Что же не дает компьютеру рассматривать эти числа, как последовательность команд? Ничего, кроме логики, реализованной в программе и которая является главной проблемой при ошибке переполнения буфера. Если вы совершаете ошибку, компьютер считает эти данные командами и исполняет их как таковые. У него нет способа узнать, что эти значения относятся к данным. Такие команды бессмысленны, и программа, наиболее вероятно, остановится. Таким образом, задача потенциального нарушителя — использовать эту ошибку, чтобы заставить компьютер исполнять те данные, которые он ему предоставит. Следовательно, нарушители, которые хотят атаковать ваш компьютер с помощью ваших программ, должны сделать две вещи:
Вставить свой код в память.
Заставить компьютер исполнять этот код.
Ошибка переполнения буфера дает хакеру возможность сделать и то и другое. Поскольку программа не проверяет размер буфера, когда пишет в него, нарушитель может поместить произвольное содержимое в область памяти, идущую за буфером, — и сражение наполовину выиграно. Вторая половина будет выиграна, когда потенциальный хакер определит, как можно заставить компьютер выполнить код, который он вставил в вашу программу48.
Вывод
Из всех случаев, изученных в данной главе, переполнение буфера, вероятно, самый простой для понимания и объяснения. Он все время рядом, но тем не менее он все еще так распространен. Научимся ли мы чему-нибудь, как индустрия? Почему мы продолжаем делать эти ошибки?
Не помогают языки программирования. Ошибки переполнения буфера приобрели характер эпидемии в тех языках, в которых нет встроенных средств проверки границ, таких, как С и С++. Эти языки дают программистам возможность манипулировать компьютером произвольно. Эта сила доверяется программистам, и от них ждут, что они будут программировать корректно и безопасно. Ожидается также, что они будут проводить явные проверки границ, если это необходимо. С другой стороны, такие языки, как Java, проводят явные проверки границ, и вероятность того, что ошибка переполнения буфера может быть использована, очень низка. Однако язык Java ограничивает возможности программиста. Он отнимает у него возможность напрямую манипулировать пространством памяти машины. Нельзя сказать, что переполнение буфера невозможно в программе на Java. Это просто означает, что программист должен внести серьезные искажения, чтобы вызвать переполнение буфера на Java. Когда это случается, определить причину крайне тяжело. И поскольку большая часть виртуальной машины Java написана на С и С++, всегда существует опасность ошибки переполнения буфера в виртуальной машине Java.
Программистам нельзя доверять. Программисты — люди, а люди делают ошибки. Я по невнимательности много раз за свою жизнь создавал ошибки переполнения буфера. Много раз ошибки возникали, поскольку я создавал макет программного модуля и проверка границ массивов — это последнее, о чем я думал. Но макет имеет обыкновение находить способ проникать в продукт. В другой раз ошибки возникали, потому что я делал допущения по поводу кода и процесса функционирования и считал, что переполнение буфера невозможно. Как это обычно бывает, как только я делаю какие-либо допущения, что-нибудь показывает мне мою неправоту. Часто ошибки появляются из-за моей лени. Написание кода проверки на переполнение буфера — задача в большинстве случаев легкая, но обработка условий обнаружения нарушений границ может оказаться трудным и надоедливым делом. Могу ли я просто прервать выполнение программы? Или я должен сообщить об ошибке вызываемой функции? Как эта функция будет обрабатывать эту ошибку? Прерываю ли я выполнение программы в вызываемой функции до бесконечности? Проще всего не иметь с этим дела и допустить, что такого не случится. Я займусь этим, если те, кто тестируют программы, докажут, что я не прав.
Языковые конструкции делают это сложным. Проведение проверки границ в некоторых языках может оказаться трудным делом — на ум приходит использование функции sprintf(). Поскольку sprintf() принимает переменное число аргументов, при использовании этих аргументов от программиста требуется посчитать размеры буфера. Это может легко вызвать переполнение, поскольку вы не понимаете нюансов языка. В С и С++ строка «Hello World» требует 12 символов памяти, потому что язык определяет, что строка должна оканчиваться символом с кодом «0». Иными словами, код «0» добавляется в строке после символа «d». Если вы выделили буфер размером в 11 символов, считая, что он вместит в себя всю строку, то использование любых строковых функций, таких, как strcpy(), приведет к ошибке переполнения буфера, и это ударит по вам, когда вы меньше всего ожидаете.
Легко говорить о способах окончательного избавления от ошибок переполнения буфера. Например, прекратите использовать небезопасные языки, такие, как С и С++, и приучите себя писать программы с позиций «оборонительного программирования»49. Мы понимаем, что это легче сказать, чем сделать. Если мы примем то, что ошибка переполнения буфера неизбежна, и то, что нам необходимо использовать небезопасные языки программирования, тогда единственным решением будет поиск ошибки. Чем раньше мы обнаружим ошибку, тем меньше шанс, что она огорчит нас в будущем.
С точки зрения безопасности ошибка не беспокоит нас, если программа зависает, но беспокоит, если ее можно использовать. Теперь сделаем ударение на том как предотвратить ошибку переполнения буфера от использования злоумышленником. Есть многочисленные исследовательские проекты и коммерческие продукты, касающиеся этой темы, и мы считаем, что читателям нужно ознакомиться с этими документами для получения дальнейшей информации50.
Заключение
Ошибки, обсуждаемые в этой главе, за несколькими исключениями, существовали или существуют в настоящее время. Сейчас тысячи разработчиков программ устраняют ошибки, работая сверхурочно. Некоторые из этих ошибок забавны, тогда как другие — подлые или трагичные. Тем не менее это совсем не забавно, если вы — один из тех, кто работает по выходным, устраняя ошибки. Однако цена, которую платят разработчики программ, мизерна по сравнению с последствиями этих ошибок. В этой главе мы узнали, что цена ошибки может быть астрономической. Миллионы долларов, затраченные на оборудование и работу, исчезают без следа. Человеческая боль и страдания, даже смерть могут быть вызваны простой ошибкой в программе.
Мы узнали, что, несмотря на все тестирование, технологии и процедуры, ошибки неизбежны. И сбои, проявляющиеся в конечном продукте, как правило, являются результатом целой серии ошибок. Обычно не существует какой-то одной причины. Вместо этого есть целая коллекция причин, предотвращающих обнаружение и удаление ошибки до рокового финала. Например, простая ошибка программирования привела к аварии на AT&T в 1990 году. Однако, если бы был проведен тест по исполнению кода в ошибочной его части, дефект был бы выявлен раньше, и это спасло бы AT&T от аварии телефонной сети общенациональных масштабов. Является ли главной причиной ошибки программист, написавший неверный код, или отдел тестирования, который позволил дефекту проникнуть в код конечного продукта?
Мы узнали, что способность находить ошибки также важна, как способность предотвращать их. Чем раньше мы сможем найти ошибку, тем дешевле нам встанет ее исправить. Мы узнали, что программное обеспечение может функционировать в точности так, как указывает спецификация, и все же мы будем считать его дефектным, хотя оно работает именно так, как ему указали. Мы узнали, что мы должны понимать подсказки, которые дает нам система, и должны всегда задаваться вопросами, оценивать и понимать причины, стоящие за этими подсказками. Но что наиболее важно, мы узнали, что перед лицом проблем нам следует быть скромными. Неспособность признать, что ошибки возможны и вера без сомнений в наши создания может сделать нас слепыми перед лицом потенциальных аварий программ. Вот объяснение того, что гордость — один их смертных грехов.
Мы определили много причин тех ошибок, о которых рассказано в этой главе. Эти причины кратко перечислены и обобщены ниже.
Недостаток понимания инструментов и конструкций языка:
Случаи — авария 1990 года на AT&T, ошибка переполнения буфера.
Описание — дефект возникает, когда программист неправильно понимает конструкции языка. При аварии на AT&T 1990 года ошибка заключалась в неверном расположении оператора break. Типичная ошибка переполнения буфера может быть вызвана непониманием средств манипуляции со строками в стандартных функциях С и С++.
Повторное использование модулей без понимания:
Случай — Ariane-5.
Описание — унаследованный программный модуль был использован повторно, но наблюдался недостаток понимания требований этого модуля. Не было сделано попыток оценить правомерность использования.
Изменения и обновления программ:
Случаи — аварии на AT&T 1990 и 1998 годов.
Описание — ошибка проявилась в ходе и после окончания обновления программ, которое было направлено на повышение производительности системы.
Игнорирование неожиданных результатов:
Случаи — Mars Climate Orbiter, Therac-25.
Описание — в обоих случаях была масса предупреждений и подсказок из различных источников о том, что что-то не так. Предупреждения проявлялись как неожиданные результаты и поведение. Но эти предупреждения регулярно игнорировались, и должное расследование не было проведено. В случае Mars Climate Orbiter проблема состояла в несовпадении между рассчитанными моделями с борта космического корабля и с наземной станции. В случае с Therac-25 проблема была в постоянных неполадках и Therac-20, и Therac-25.
Непонимание подсказок:
Случаи — Mars Climate Orbiter, Therac-25, Компания Х, Компания Y.
Описание — ключи, указывающие на потенциальные ошибки, не интерпретировались корректно, что в конечном счете привело ко всем описанным авариям. И в случае с Компанией Х, и в случае с Компанией Y подсказки прекрасно описывали причину симптомов, но эти подсказки первоначально не были приняты во внимание.
Недостаток подходящих средств мониторинга:
Случаи — Mars Climate Orbiter, Therac-25, Компания Х, Компания Y.
Описание — хорошие средства мониторинга могут помочь обслуживающему персоналу обнаружить и решить проблему до того, как она приобретет серьезные последствия. Может быть, несправедливо относить в эту категорию Mars Climate Orbiter, поскольку ученые были ограничены технологиями и законами физики в том, что они могли наблюдать. Тот факт, что они не могли наблюдать действительную траекторию космического аппарата, ограничивал их возможности в определении правильности их модели. В случае Therac-25 сообщения об ошибках не имели достаточно описательного характера, чтобы встревожить операторов потенциальными проблемами в машине. Так же наблюдался явный недостаток обратной связи, позволяющей оператору точно знать, что делает машина. Проблемы в Компаниях Х и Y могли бы быть минимизированы, если бы обслуживающий персонал смог определить падение производительности базы данных до аварии.
Неверная или бедная спецификация:
Случай — Ariane 5.
Описание — спецификация обработки ошибки определяла, чтобы ошибочное значение было помещено в память, используемую навигационным компьютером. Реализация программного обеспечения точно соответствовала спецификации. Навигационный компьютер использовал это значение для осуществления маневра с использованием двигателей, что вызвало катастрофу. В данном случае спецификация обработки ошибки была ошибочна и вызвала крушение.
Отклонение от спецификации:
Случай — Mars Climate Orbiter.
Описание — спецификация для Mars Climate Orbiter была очень ясной: единицы измерения должны быть метрическими, а не английскими.
Унаследованные ошибки:
Случаи — Therac-25, авария на AT&T 1998 года.
Описание — унаследованные программные модули содержали ошибки, которые не были обнаружены в их предыдущем воплощении.
Отклонение от должной процедуры:
Случаи — авария на AT&T 1998 года, компания Х.
Описание — процедуры были разработаны для того, чтобы помешать нам сделать ошибку, а когда процедуре не следуют, а идут коротким путем, возникают нежелательные эффекты.
Небезопасные средства:
Случай — переполнение буфера.
Описание — одной из главных причин ошибки переполнения буфера является «небезопасность» таких программных языков, как С и С++, в которых программа зависит от того, провел ли программист явную проверку границ массивов для предотвращения этих ошибок.
Человеческий фактор:
Случай — переполнение буфера.
Описание — мы все знаем, как предотвращать ошибки, и все же мы продолжаем их делать.
Эго и самоуверенность:
Случаи — Therac-25, Mars Climate Orbiter.
Описание — эго может встать на пути объективной оценки систем. Самоуверенность может заставить нас не подвергать сомнению наши допущения. Результатом такого отношения станет то, что мы не будем обращать внимания на имеющиеся ключи, которые указывают на потенциальные дефекты программ.
Неполное тестирование:
Случаи: Ariane 5, Mars Climate Orbiter, Pentium, авария на AT&T 1990 года.
Описание — легко рассуждать, глядя в прошлое, но большая часть этих ошибок могла бы быть обнаружена при «правильном» тестировании. В случае Ariane 5 неполнота требований и недостаток возможностей по имитации функциональной среды привели к тому, что инженеры вынуждены были отказаться от теста, который обнаружил бы ошибку. Неясно, проводилось ли тестирование в случае с Mars Climate Orbiter, поскольку персонал в ходе космического полета все еще занимался устранением ошибок. В случаях ошибки в процессоре Pentium и аварии на AT&T 1990 года проведенные тесты не принимали во внимание особенности алгоритма, поэтому некоторая часть кода не была протестирована. В случае с ошибкой в Pentium тестирование на основе случайной выборки не было достаточным для оценки всех значений в справочной таблице. При аварии на AT&T 1990 года тест не охватывал сценарий восстановления коммутатора.
Задача
Вы тестировали набор Web-страниц на Web-сайте вашей компании. Вы нажали на ссылку на Web-страницу А, и все прошло великолепно. Вы продолжили тестирование других Web-страниц на сайте и случайно вернулись на Web-страницу А опять. Но в этот раз ее содержимое оказалось устаревшим. Вы недоуменно посмотрели на страницу и перезагрузили ее. Теперь она снова выглядела нормально. Не доверяя тому, что вы видите, вы опять перезагрузили страницу, и страница снова оказалась правильной. Полагая, что три — это число магическое, вы подумали про себя, что если страница и теперь окажется правильной, значит, то, что вы видели, — это просто случайность. Вы перезагрузили страницу еще раз, и оказалось, что ее содержимое снова является устаревшим. Вы боднули головой монитор. После 10 минут, проведенных в перезагрузке этой страницы снова и снова, вы определили, что она загружается правильно 34 раза и неправильно 12 раз. Что может быть причиной ошибки?
Вот некоторые подсказки, которые помогут вам поразмышлять о причине ошибки. Архитектурно есть пять Web-серверов, обрабатывающих запросы браузера. Каждый Web-сервер может связываться с одним из четырех серверов приложений. Сервер приложений извлекает данные из базы данных и реализует бизнес-правила. Для ускорения работы каждый сервер хранит данные в локальном кэше.
1 Национальный комитет no аэронавтике и исследованию космического пространства, НАСА (США). — Примеч. пер.
2 Gleick, James. Genius, The Life and Science of Richard Feynman. Vintage Books, New-York, New York, 1992.
3 Опустив уплотнительное кольцо в ледяную воду, Р. Фейнман продемонстрировал широкоизвестный факт, что при низких температурах жесткость резины увеличивается, что привело к ослаблению уплотнительных свойств прокладки, утечке топлива и в конце концов к взрыву. — Примеч. науч. ред.
4 Feynman, Richard P. The Pleasure of Finding Things Out. Perseus Books, Cambridge, Massachusetts, 1999.
5 Kajihara, J., Amamiya, G., and Saya, T. «Learning from Bugs», IEEE Software, p. 46-54, September 1993.
6 Leveson, Nancy, and Turner, Clark S. «An Investigation of the Therac-25 Accidents», IEEE Computer, Vol. 26, No. 7, p. 18-41, July 1993.
7 Там же.
8 Там же.
9 Там же.
10 Там же.
11 Там же.
12 Там же.
13 Там же.
14 Там же.
15 Nathan, Adam. «NATO Creates Computer Virus That Reveals Its Secrets», The Sunday Times, June 18, 2000. www.thetimes.co.uk/news/pages/sti/2000/06/18/stinwenws01024.html.
16 Nicely, Thomas R. Pentium FPU Bug, Memo available on acavax.lynchburg.edu.
17 Nicely, Thomas R. Letter to Intel, October 30, 1994.
18 Wolfe, Alexander. EE Times, Issue 822, p. 1, November 7, 1994.
19 Markoff, John. «Circuit Flaw Causes Pentium Chip to Miscalculate, Intel Admits,» New York Times. November 24, 1994.
20 Pratt, V. R. «A natural scenario with high FDIV bug probability (was: In Intel’s Defense…)», comp.arch newsgroup, December 3, 1994, 15:20:17 UTC.
21 IBM, Pentium Study, IBM Memo, December 12, 1994.
22 Sharangpani, H. P., and Barton, M. L. «Statistical Analysis of Floating Point Flaw in the Pentium Processor (1994)», Intel White Paper, November 30, 1994.
23 По первым буквам имен авторов Sweeney, Robertson и Tocher, которые независимо друг от друга опубликовали его в 1994 году. — Примеч. науч. ред.
24 Bryant, R. «Bit-level analysis of an SRT circuit», CMU technical report, CMU-CS-95-140, 1995.
Sharangpani, H. P., and Barton, M. L. «Statistical Analysis of Floating Point Flaw in the Pentium Processor (1994)», Intel White Paper, November 30, 1994.
25 Edelman, Alan. «The Mathematics of the Pentium Division Bug», 1995. Available from www-math.mit.edu/-edelman/.
Also appears in SIAM Review, March 1997.
26 Pratt, V. R. «A natural scenario with high FDIV bug probability (was: In Intel’s Defense…)», comp.arch newsgroup, December 3, 1994, 15:20:17 UTC.
27 Edelman, Alan. «The Mathematics of the Pentium Division Bug», 1995. Available from www-math.mit.edu/-edelman/.
Also appears in SIAM Review, March 1997.
28 Lions, J. L., et al. «ARIANE 5 Flight 501 Failure», Report by the Inquiry Board. Paris, July 19, 1996. Available at www.csrin.esa.int/htdocs/tidc/Press/Press96/ariane5rep.html.
29 Lions, J. L., et al. «ARIANE 5 Flight 501 Failure», Report by the Inquiry Board. Paris, July 19, 1996. Available at www.csrin.esa.int/htdocs/tidc/Press/Press96/ariane5rep.html.
30 Wharton, J. «Super Bowl XXXIV Web-Filtered: Adult Porn?», Risk Digest, Vol 20, No. 77. January 26, 2000. catless.ncl.ac.uk/Risks.
31 Программа замещает звездочками части слов, которые интерпретирует как отдельные слова с оскорбительным смыслом — Прим. пер.
32 McWilliams, P. «BBC Censorship», rec.humor.funny, December 3, 1999.
www.netfunny.com/rhf/jokes/99/Dec/censorship.html.
33 Город, где располагается штаб-квартира корпорации Майкрософт — Прим. пер.
35 Media Relations Office, Jet Propulsion Laboratory. «NASA’s Mars Climate Orbiter Believed to Be Lost». NASA Press Release. September 23, 1999.
36 Mars Climate Orbiter Mishap Investigation Board, Phase 1 Report, November 10, 1999.
37 Isbell, Douglas; Hardin, Mary; and Underwood, Joan. «Mars Climate Orbiter Team Finds Likely Cause of Loss», NASA Press Release 99-113, September 30, 1999.
38 Mars Climate Orbiter Mishap Investigation Board, Phase 1 Report, November 10, 1999.
40 Термин, означающий добавление к части кода специальных символов комментария, чтобы компилятор рассматривал эту часть не как код программы, а как комментарий программиста. — Прим. пер.
41 Neumann, Peter. «Risks to the Public in Computers and Related Systems», ACM SIGSOFT Software Engineering Notes, Vol. 15, No. 2, p. 11ff, April 1990.
42 Neumann, Peter. «Risks to the Public in Computers and Related Systems», ACM SIGSOFT Software Engineering Notes, Vol. 15, No. 2, p. 11ff, April 1990.
43 Neumann, Peter G. Computer Related Risks. Addison-Wesley, New York, New York, 1995.
44 Trunk — устройство или канал, соединяющий две точки, каждая из которых является коммутационным центром или точкой распределения; обычно транк работает с несколькими каналами одновременно. — Примеч. пер.
45 «AT&T Announces Cause of Frame-Relay Network Outage», AT&T Press Release, April 22, 1998. McCartney, Laton. «One Year Later: A Behind-the-Scenes Look at the Causes of and Fallout from AT&T’s Devastating Frame-Relay Outage», Network World, March 22, 1999.
46 Bernstein, L., and Yuhas, C. M. «Chinks in the Armor: Will a Hybrid IP/ATM Architecture Protect the Network from Node Failures?» America’s Network Magazine, July 1, 1998.
47 Bernstein, L., and Yuhas, C. M. «Chinks in the Armor: Will a Hybrid IP/ATM Architecture Protect the Network from Node Failures?» America’s Network Magazine, July 1, 1998
48 «Aleph One», Smashing the Stack for Fun and Profit, Phrack, 7(49), November 1996.
49 Термин «оборонительное программирование» представляет подход, при котором программист при написании кода сразу же принимает все меры, направленные на обнаружение и исправление всех ошибок, которые могут возникнуть при выполнении этого кода. — Примеч. науч. ред.
50 Cowan, C., et al. «Buffer Overflows: Attacks and Defenses for the Vulnerability of the Decade», Proceedings of DARPA Information Survivability Conference and Expo. Available from www.wirex.com/~Crispin.
VPS в 21 локации
От 104 рублей в месяц
Безлимитный трафик. Защита от ДДоС.
🔥 VPS до 5.7 ГГц под любые задачи с AntiDDoS в 7 локациях
💸 Гифткод CITFORUM (250р на баланс) и попробуйте уже сейчас!
🛒 Скидка 15% на первый платеж (в течение 24ч)
☁️ Виртуальные серверы от 95 ₽
🖥 Хостинг сайтов PHP от 25 ₽
💰 Скидка 15% по промокоду CITFORUM на первый платёж!
Виртуальные VPS серверы в РФ и ЕС
Dedicated серверы в РФ и ЕС
По промокоду CITFORUM скидка 30% на заказ VPS\VDS
Новости мира IT:
21.09 — В России дронам выделили новые радиочастоты, но совместимых с ними беспилотников в стране нет
21.09 — NVIDIA стала крупнейшим разработчиком чипов в мире по объёму выручки — AMD и Qualcomm остались далеко позади
21.09 — Планшет Amazon Fire Max 11 получил поддержку управления одними лишь глазами
19.09 — Биткоин впервые за сентябрь поднялся выше $27 тысяч
19.09 — Intel анонсировала первый в мире 288-ядерный x86-процессор — Xeon Sierra Forest на малых E-ядрах
19.09 — Исследовательская лаборатория ВВС США получила суперкомпьютер мощностью 12 Пфлопс
19.09 — Intel представила первый в мире процессор с UCIe — в нём объединены чиплеты от разных производителей
19.09 — В России появится единый закон для регулирования сферы ИТ и связи
19.09 — Выполнен первый в истории 5G-звонок через спутник с помощью обычного смартфона
15.09 — Роскомнадзор создаст реестр хостеров — тем, кто в него не попадёт, запретят оказывать услуги
15.09 — ФАС проверит законность повышения тарифов МТС
15.09 — МТС протянула ВОЛС на остров Русский
15.09 — Европейские антимонопольщики готовят официальную жалобу на Microsoft из-за Teams
15.09 — Ёмкость российских дата-центров в 2023 выросла более чем на 20 %
13.09 — Российские ретейлеры, дистрибьюторы и импортёры объединились в ассоциацию Р.А.Д.И. Видеоигр — зачем она нужна и чем будет заниматься
13.09 — Google предстала перед судом за монополизацию рынка поисковиков
13.09 — iOS 17 выйдет 18 сентября для всех совместимых iPhone — режим настольных часов, интерактивные виджеты и другие новшества
13.09 — Финальный релиз watchOS 10 состоится 18 сентября
11.09 — Российский IT-рынок вырастет более чем в два раза к 2030 году
11.09 — WhatsApp начала работу над совместимостью с другими мессенджерами — этого требует новый закон ЕС
Внимание! Любой из материалов, опубликованных на этом сервере, не может быть воспроизведен в какой бы то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских прав. Подробнее…
Вы столкнулись со страшной бедой, и этот аппарат — ваш последний шанс на спасение. Доверите ли вы ему свою жизнь?
Therac–25 не из тех устройств, при виде которых люди радуются. Это аппарат лучевой терапии. Говоря простыми словами, «цеппер для рака», линейный ускоритель, чья мишень — человек. Используя рентгеновские лучи или пучки электронов, аппараты лучевой терапии уничтожают раковые клетки даже глубоко внутри организма. Эти аппараты размером с комнату всегда наносят побочный ущерб здоровым тканям вокруг опухолей. Как и в случае с химиотерапией, ставка делается на то, что суммарный эффект окажет пациенту больше пользы, нежели вреда. Но в 1986 и 1987 Therac–25 сделал немыслимое: аппарат подверг шестерых пациентов радиоактивной передозировке, в результате которой четверо из них погибли, а двое получили увечья на всю жизнь. В ходе расследования было установлено, что, во–первых, в программном обеспечении аппарата содержались ошибки, которые оказались смертельными. Во–вторых, конструкция аппарата в плане безопасности опиралась только лишь на управляющий компьютер. В самой конструкции не были предусмотрены механизмы блокировки или контрольные схемы, которые гарантировали бы, что ошибка в программном обеспечении не приведёт к катастрофическим сбоям.
В программном обеспечении Therac–25 содержался один из самых известных багов–убийц в истории. Несколько университетов приводят этот случай в качестве предостережения о том, что может пойти не так и как расследования могут вводить в заблуждение. Наибольший вклад в изучение этой проблемы сделала Нэнси Левенсон, эксперт безопасности программного обеспечения, она провела исчерпывающие исследования несчастных случаев и связанных с ними судебных исков. Большая часть информации, опубликованной о Therac–25 (включая эту статью), основана на её исследовании, проведённом совместно с Кларком Тёрнером, под названием «Расследование аварий Therac–25».
История и разработка
Therac–25 был создан канадской государственной организацией «Atomic Energy of Canada Limited» (далее AECL). Это был третий аппарат лучевой терапии на счету компании, предшествующие Therac–6 и Therac–20 были произведены совместно с французской компанией CGR. Когда пришло время проектировать Therac–25, партнёрство прекратилось. Тем не менее, у обеих компаний остался доступ к проектам и исходным кодам ранних моделей.
Программный код в Therac–20 основывался на коде Therac–6. На всех трёх аппаратах был установлен компьютер PDP–11. Однако предыдущим моделям он не требовался, так как они были спроектированы как автономные устройства. Техник по лучевой терапии настраивал различные параметры вручную, в том числе и положение поворотного диска для настройки режима работы аппарата.
В электронном режиме отклоняющие магниты распределяли луч так, чтобы электроны покрыли большую площадь. В рентгеновском режиме мишень располагалась на пути излучения, электроны наносили по ней удар, чтобы произвести фотоны рентгеновского излучения, направленные на пациента. Наконец, на пути ускорителя можно было расположить отражатель, с помощью которого рентгенотехник мог навести излучение точно на больное место. Если отражатель был на пути, электронный луч не запускался.
На Therac–6 и 20 аппаратные механизмы блокировки не позволяли оператору сделать что–то опасное, скажем, выбрать электронный пучок высокой мощности без рентгеновской мишени на месте.
Попытка активировать ускоритель в неправильном режиме приводила к срабатыванию предохранителей и остановке работы. PDP–11 и сопутствующее оборудование были встроены для удобства. Техник мог ввести рецепт в терминал VT–100, и компьютер, используя сервоприводы, автоматически настраивал поворотный диск и другие устройства. Сотрудникам больниц нравилось, что компьютер настраивает всё быстрее, чем человек. Чем меньше времени уходило на настройку, тем больше пациентов можно было принять за день на аппарате ценой в несколько миллионов долларов.
Когда пришло время сделать Therac–25, AECL решили оставить только компьютерное управление. Они не только отказались от устройств ручного управления, но также и от аппаратных механизмов блокировки. Компьютер должен был следить за настройками устройства и, в случае обнаружения неполадок, должен был отключать питание всей машины.
Происшествия
Therac–25 ввели в эксплуатацию в 1983 году. За несколько лет он обслужил тысячи пациентов без каких–либо проблем. 3 июня 1985 года одна женщина проходила курс лечения от рака груди. Ей прописали 200 поглощённых доз ионизирующего излучения (рад) в виде электронного пучка 10 МэВ. Когда машина запустилась, пациентка почувствовала очень сильный ожог. Позже было уставлено, что она подверглась дозе от 10000 до 20000 рад. Пациентка выжила, но лишилась левой груди и руки из–за радиации.
Второй несчастный случай произошёл 26 июля в онкологическом Институте Онтарио в Канаде. Пациентка скончалась в ноябре того же года. Вскрытие установило, что смерть наступила в результате рака шейки матки. Но если бы пациентка выжила, ей понадобилось бы полное эндопротезирование тазобедренного сустава, чтобы исправить травму, нанесённую Therac–25.
В декабре 1985 произошёл третий несчастный случай в Якиме, штат Вашингтон. У пациентки на бедре остались ожоги в виде узора, который повторял полосы на аппарате, предназначенные для блокировки излучения. Пациентка выжила, но ей потребовалась кожные трансплантаты, чтобы залечить раны от радиационных ожогов.
21 марта 1986 года пациенту в Тайлере, штат Техас, назначили девятый сеанс лучевой терапии на Therac–25. Ему прописали 180 рад для лечения небольшой опухоли в спине. Когда аппарат включился, пациент почувствовал жар и боль, что было неожиданно, так как лучевая терапия обычно проходит безболезненно. Therac–25 стал издавать нехарактерный гудящий звук. Пациент попытался встать с процедурного стола и получил второй радиационный ожог. После чего он начал стучать по двери. Он получил сильную передозировку. Его госпитализировали с лучевой болезнью, и через пять месяцев он скончался.
11 апреля 1986 года в Тайлере снова произошёл несчастный случай. На этот раз пациент лечился от рака кожи уха. Аппаратом управлял тот же самый оператор, что и во время происшествия 21 марта 1986. Когда начался сеанс терапии, пациент увидел яркий свет и услышал звук, с которым жарится яичница на сковороде. У него было чувство, словно его лицо горит. Пациент умер спустя три недели от радиационных ожогов в правой части височной доли и стволе головного мозга.
Последний случай передозировки произошёл намного позже в больнице Якима Вэлли в январе 1987 года. Пациент скончался в результате полученных повреждений.
Расследование
После каждого несчастного случая дозиметрист местной больницы связывался с AECL и управлением медицинского регулирования в соответствующих странах. Сначала AECL отрицал, что Therac–25 был способен вызывать передозировки излучения.
В аппарате было столько защитных гарантий, что он часто выдавал коды ошибок и приостанавливал свою работу, давая меньше назначенной дозы. После инцидента в Онтарио стало очевидно, что что–то не так. Единственная причина, по которой могла случиться такая передозировка — неправильное расположение поворотного диска. Если бы сканирующие магниты или рентгеновская мишень были в неправильном положении, пациента бы поразил луч радиации, подобный лазерному.
AECL проводили тестирование за тестированием, но не могли воспроизвести такую ошибку. Единственная возможная причина, которая приходила им в голову — временный отказ работы трёх микропереключателей, которые определяли положение поворотной платформы. Сеть микропереключателей была переконструирована таким образом, чтобы неполадки в работе любого из них определялись компьютером. Эту модификацию быстро добавили, но она не помогла предотвратить последующие инциденты.
Если в этой истории и есть герой, то это Фриц Хагер, дозиметрист онкологического центра в Тайлере. После второго происшествия на его объекте он решил докопаться до корня проблемы. В обоих случаях Therac–25 выводил на экран компьютера сообщение о «Неисправности–54». В пользовательском руководстве такая ошибка не упоминалась. AECL объяснили, что неисправность–54 указывала на то, что компьютер не мог определить, недостаточна ли дозировка излучения или, наоборот, она превышается.
В обоих случаях аппаратом управляла одна и та же женщина–техник лучевой терапии, и Фриц дал ей указание попробовать воссоздать такой случай в комнате управления. Вдвоём они «заперли двери» (прим пер.: среди работников НАСА эта кодовая фраза означает наступление нештатной ситуации, при которой никому не разрешается покидать помещение пультовой или входить в него, чтобы можно было сохранить всю имеющуюся информацию для последующего расследования) и всю ночь и все выходные пытались воссоздать проблему. Вместе они должны были обнаружить неполадки.
Консоль виртуального терминала, которая используется для ввода команд, разрешает перемещение курсора с помощью кнопок вверх и вниз.
При выборе рентгеновского режима аппарат начинал настраивать устройство для мощного рентгеновского излучения. Этот процесс занимал около восьми секунд. Если в течение этих восьми секунд оператор переключал аппарат в электронный режим, поворотный диск принимал неправильное положение.
Важно отметить, что все тестирования до этого момента проводились медленно и тщательно, как можно было ожидать. Из–за природы этой ошибки результаты таких тестирований никогда бы не смогли определить причину происшествий. Для этого требовался кто–то, кто хорошо знал аппарат, кто–то, кто работал с системой ввода данных каждый день до того, как нашли ошибку. Фриц продолжал работать до тех пор, пока не смог вызывать «Неисправность–54» по собственной воле. Даже с таким неопровержимым доказательством ему понадобилось совершить несколько звонков и отправить несколько факсов с подробными инструкциями для того, чтобы AECL смогли добиться подобного поведения аппарата в лабораторных условиях. Фрэнк Боргер, дозиметрист онкологического центра в Чикаго, доказал, что эта ошибка также существовала и в программном обеспечении Therac–20. Введя алгоритм задач, который установил Фриц на предыдущей модели аппарата, Боргер получил подобную ошибку, но в аппарате срабатывал предохранитель. Предохранитель был частью системы блокировки, от которой отказались в Therac–25.
По мере того, как продвигалось судебные разбирательства и расследование, программное обеспечение Therac–25 рассматривалось самым пристальным образом. PDP–11, установленный на Therac–25, был полностью запрограммирован на языке ассемблера. Не только приложение, но и лежащая в основе операционная система. Задачей компьютера было управление аппаратом в реальном времени, он отвечал как за эксплуатацию в обычном режиме, так и за систему безопасности. Сегодня с таким типом работы справляется один или два микроконтроллера, а компьютер обеспечивает работу графического пользовательского интерфейса.
AECL не выкладывала исходный код в открытый доступ, но несколько экспертов, в том числе Нэнси Левинсон, получили доступ для проведения расследования. То, что они обнаружили, их шокировало. Программное обеспечение было написано программистом, у которого почти не было опыта работы с системами, работающими в реальном времени. Со стороны компании было несколько заявлений, но никаких доказательств того, что проводился временной анализ. Согласно AECL, всё программное обеспечение написал один программист, взяв за основу код Therac–6 и 20. Однако он больше не работал в компании, и найти его не удалось.
Последствия
Управление по санитарному надзору объявило о том, что Therac–25 неисправен. AECL выпустили патчи и обновления для оборудования, которые в итоге позволили аппаратам вернуться на службу. Все иски были урегулированы во внесудебном порядке. Казалось, что все проблемы решены, пока 17 января 1987 года ещё один пациент не получил передозировку в Якиме, штат Вашингтон. На этот раз проблема была в другом: переполнение счётчика. Если оператор отправлял команду в момент, когда счётчик переполнялся, машина пропускала некоторые настройки излучения, например, не приводила в правильное положение стальной отражатель системы наведения. В результате чего луч не считывался, что приводило к передозировке. Пациент умер спустя три месяца.
Важно отметить, что софт был основополагающим фактором в Therac–25, а не главной причиной. Весь проект системы был одной большой проблемой. Компьютерная система подвергалась критическим, с точки зрения безопасности, нагрузкам, на которые не была рассчитана. Временной анализ не проводился, как и модульное тестирование. Не составлялись диаграммы всех возможных последствий несрабатывания системы ни для софта, ни для железа. За это должны были отвечать не только специалисты по программному обеспечению, но и инженеры–разработчики систем по проекту. Therac–25 уже давно списали, но его наследие будет жить. Это было эпохальное событие, которое наглядно всем продемонстрировало, что может пойти не так, если софт для жизненно важных систем не проектируется должным образом и не тестируется как следует.



 Во время ведения судебных дел против AECL прокуратура штата Техас обратилась к Нэнси Ливесон (профессор компьютерных наук Калифорнийского Университета в Ирвайне) как к эксперту для расследования. Она внесла весомый вклад в компьютерную безопасность. Нэнси с Кларком Тёрнером в течение трех лет занимались сбором материалов и реконструкцией событий, связанных с Therac-25. Данный результат важен, так как в большинстве инцидентов по безопасности информация является неполной, противоречивой и неверной.
Во время ведения судебных дел против AECL прокуратура штата Техас обратилась к Нэнси Ливесон (профессор компьютерных наук Калифорнийского Университета в Ирвайне) как к эксперту для расследования. Она внесла весомый вклад в компьютерную безопасность. Нэнси с Кларком Тёрнером в течение трех лет занимались сбором материалов и реконструкцией событий, связанных с Therac-25. Данный результат важен, так как в большинстве инцидентов по безопасности информация является неполной, противоречивой и неверной.