We are doing some load testing on our servers and I’m using tshark to capture some data to a pcap file then using the wireshark GUI to see what errors or warnings are showing up by going to Analyze -> expert Info with my pcap loaded in..
I’m seeing various things that I’m not sure or do not completely understand yet..
Under Warnings I have:
779 Warnings for TCP: ACKed segment that wasn’t captured (common at capture start)
446 TCP: Previous segment not captured (common at capture start)
An example is :
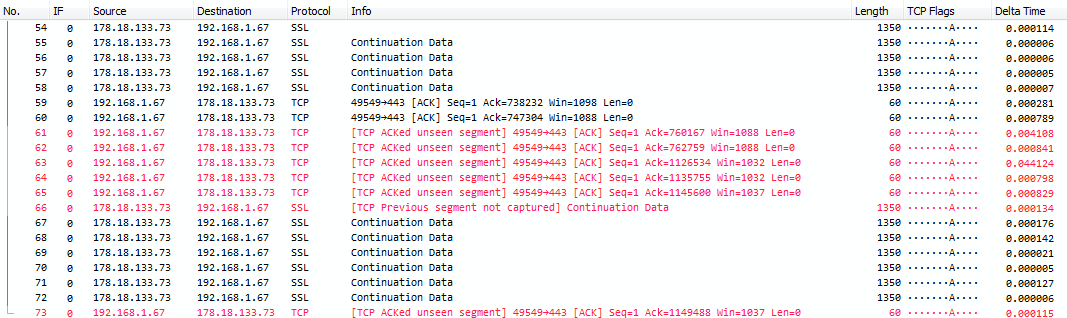
40292 0.000 xxx xxx TCP 90 [TCP ACKed unseen segment] [TCP Previous segment not captured] 11210 > 37586 [PSH, ACK] Seq=3812 Ack=28611 Win=768 Len=24 TSval=199317872 TSecr=4506547
We also ran the pcap file though a nice command that creates a command line column of data
command
tshark -i 1 -w file.pcap -c 500000
basically just saw a few things in the tcp.analysis.lost_segment column but not many..\
Anyone enlighten what might be going on? tshark not able to keep up with writing data, some other issue? False positive?
asked Aug 20, 2013 at 1:19
![]()
That very well may be a false positive. Like the warning message says, it is common for a capture to start in the middle of a tcp session. In those cases it does not have that information. If you are really missing acks then it is time to start looking upstream from your host for where they are disappearing. It is possible that tshark can not keep up with the data and so it is dropping some metrics. At the end of your capture it will tell you if the «kernel dropped packet» and how many. By default tshark disables dns lookup, tcpdump does not. If you use tcpdump you need to pass in the «-n» switch. If you are having a disk IO issue then you can do something like write to memory /dev/shm. BUT be careful because if your captures get very large then you can cause your machine to start swapping.
My bet is that you have some very long running tcp sessions and when you start your capture you are simply missing some parts of the tcp session due to that. Having said that, here are some of the things that I have seen cause duplicate/missing acks.
- Switches — (very unlikely but sometimes they get in a sick state)
- Routers — more likely than switches, but not much
- Firewall — More likely than routers. Things to look for here are resource exhaustion (license, cpu, etc)
- Client side filtering software — antivirus, malware detection etc.
answered Aug 20, 2013 at 16:26
![]()
dtorgodtorgo
2,0661 gold badge16 silver badges10 bronze badges
Another cause of «TCP ACKed Unseen» is the number of packets that may get dropped in a capture. If I run an unfiltered capture for all traffic on a busy interface, I will sometimes see a large number of ‘dropped’ packets after stopping tshark.
On the last capture I did when I saw this, I had 2893204 packets captured, but once I hit Ctrl-C, I got a 87581 packets dropped message. Thats a 3% loss, so when wireshark opens the capture, its likely to be missing packets and report «unseen» packets.
As I mentioned, I captured a really busy interface with no capture filter, so tshark had to sort all packets, when I use a capture filter to remove some of the noise, I no longer get the error.
answered Sep 5, 2014 at 16:07
![]()
Acked Unseen sample
Hi guys! Just some observations from what I just found in my capture:
On many occasions, the packet capture reports “ACKed segment that wasn’t captured” on the client side, which alerts of the condition that the client PC has sent a data packet, the server acknowledges receipt of that packet, but the packet capture made on the client does not include the packet sent by the client
Initially, I thought it indicates a failure of the PC to record into the capture a packet it sends because “e.g., machine which is running Wireshark is slow” (https://osqa-ask.wireshark.org/questions/25593/tcp-previous-segment-not-captured-is-that-a-connectivity-issue)
However, then I noticed every time I see this “ACKed segment that wasn’t captured” alert I can see a record of an “invalid” packet sent by the client PC
-
In the capture example above, frame 67795 sends an ACK for 10384
-
Even though wireshark reports Bogus IP length (0), frame 67795 is
reported to have length 13194 - Frame 67800 sends an ACK for 23524
- 10384+13194 = 23578
- 23578 – 23524 = 54
- 54 is in fact length of the
Ethernet / IP / TCP headers (14 for Ethernt, 20 for IP, 20 for TCP) - So in fact, the frame 67796 does represent a large TCP packets (13194
bytes) which operating system tried to put on the wore- NIC driver will fragment it into smaller 1500 bytes pieces in order to transmit over the network
- But Wireshark running on my PC fails to understand it is a valid packet and parse it. I believe Wireshark running on 2012 Windows
server reads these captures correctly
- So after all, these “Bogus IP
length” and “ACKed segment that wasn’t captured” alerts were in fact
false positives in my case
answered Dec 21, 2017 at 0:24
![]()
I just came across this and would like to share my observation of TCP ACKed unseen segment. In my case the client was trying to initiate connection on same source port and destination port it used previously and thus the server was confused and replied with old TCP SEQ number saying I havent seen this new packet
answered Dec 16, 2022 at 8:45
![]()
Two days ago, I met such a strange phenomenon: when I send an HTTP request to a service, there will be packet loss in probability
The screenshot is as follows:
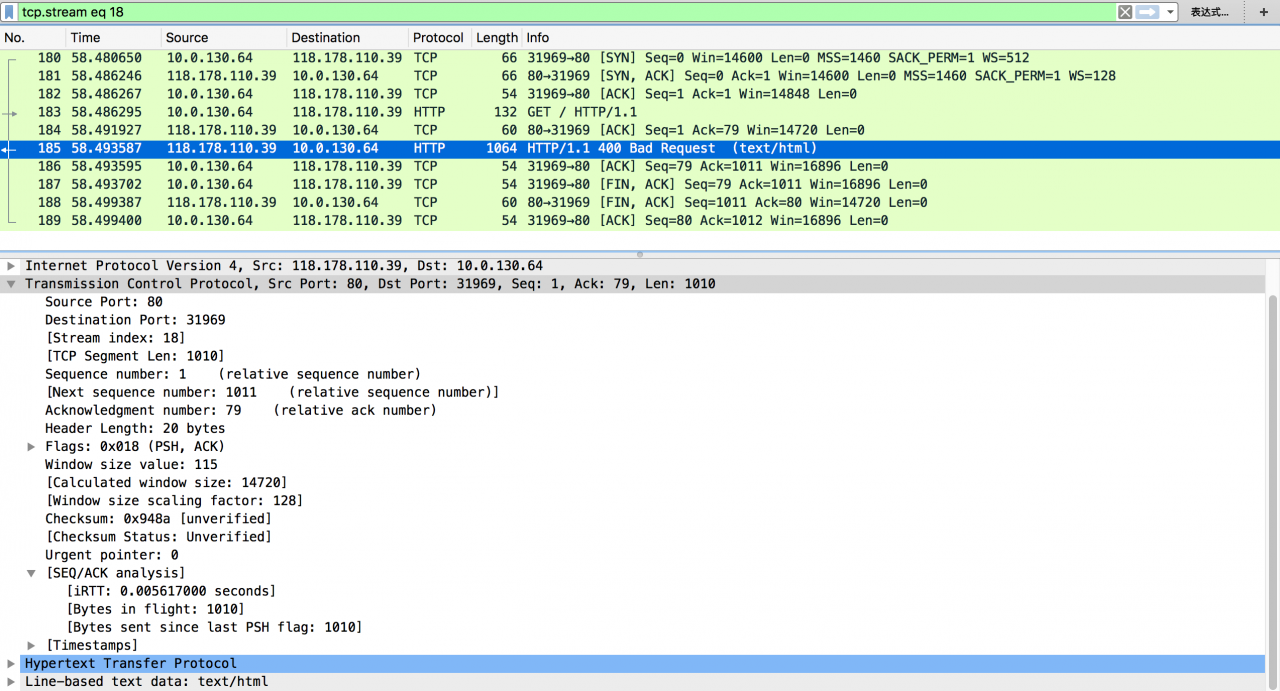
Under normal circumstances, the server will respond quickly after receiving the HTTP request, and the TCP connection closure is initiated by the client side
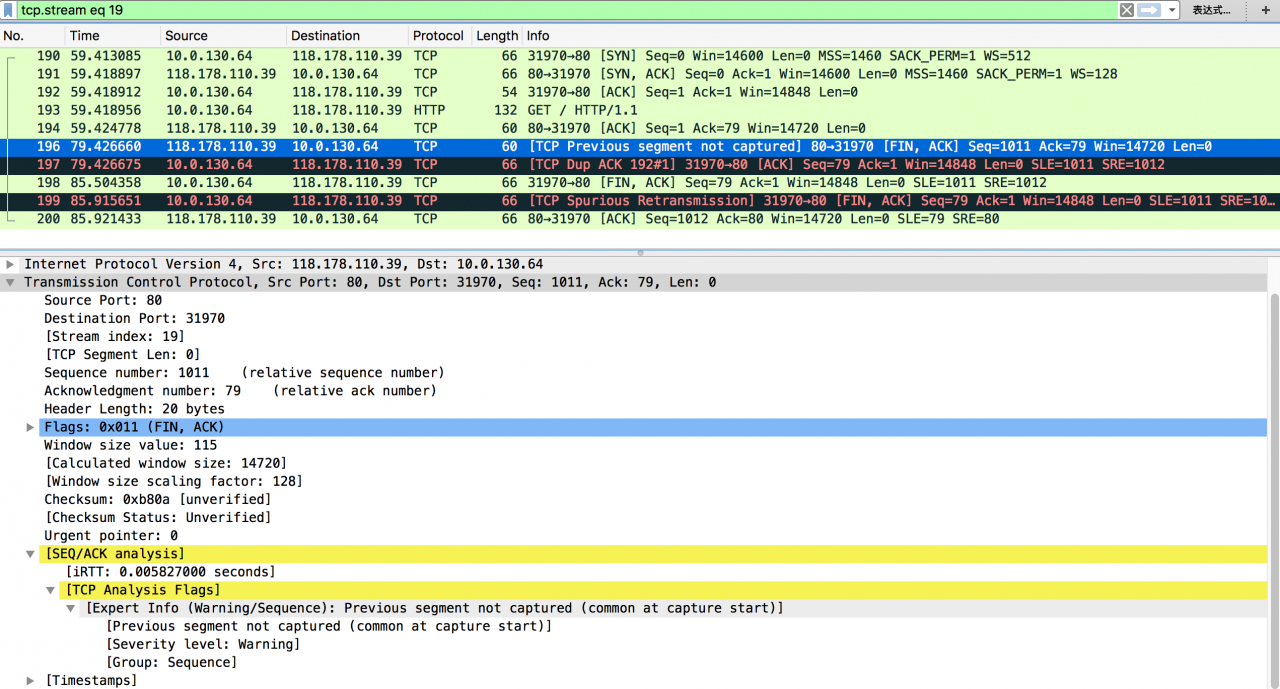
In abnormal cases, we can see that the server actively closes the TCP connection after 20 seconds, and Wireshark’s expert information tells us that there are packets that have not been captured (TCP previous segment not captured)
It should be noted that: the above two screenshots are captured during continuous testing through curl, and the recurrence probability of the problem is very high; because the server is in the cloud, it can only perform packet capture analysis on the local client side
For the abnormal data packets, the analysis is as follows:
Packet No. 196 indicates that the server thinks that it has completed the service request, but the client does not actively close the connection, so it has to actively close the connection after 20 seconds; packet No. 196 shows “TCP previous segment not captured” and “SEQ = 1011” in the packet, while the last server side packet we caught needs to be “SEQ = 1”, indicating that there is 1010 in it We didn’t catch the byte packet
Package 197 indicates that the client thinks that it has received a packet out of order after receiving “SEQ = 1011”, so it tries to make the server retransmit the missing 1010 sub section through “TCP DUP ACK 192#1” and “ack = 1”
Package 198 indicates that the client found that package 196 carried the “fin” flag, so (after about 6S) the connection was closed after four handshakes
Packet No. 199 indicates that the client has also conducted a “TCP spurious retransmission” for “fin” for some reason
From the above analysis, it can be seen that although there are several abnormal packets, the most critical one is “TCP previous segment not captured”, because the problem is probabilistic, and the packet size is also conventional. In addition, according to relevant personnel, there is no CPU on the server side And the network card traffic is also in the normal range. Therefore, the problem looks like intermittent “exhaust”. Then, what situation will lead to the appearance of “TCP previous segment not captured”?
During packet capture analysis, you may see the following information:
Capturing packets in the middle stage of TCP session leads to the loss of some information
The speed of packet capture cannot meet the speed of packet arrival (it can be adjusted by capture filter)
Switches, routers and firewalls can cause the above problems in some cases
Antivirus software and malware monitoring program may also cause the above problems
There may be some bugs in the old TCP stack
In addition, according to the official website of Wireshark, there are the following explanations:
TCP Previous segment lost – Occurs when a packet arrives with a sequence number greater than the “next expected sequence number” on that connection, indicating that one or more packets prior to the flagged packet did not arrive. This event is a good indicator of packet loss and will likely be accompanied by “TCP Retransmission” events.
In a word, the cause of the problem can not be determined at present, but it is suspected that it is related to the firewall and other equipment, and the conclusion will be updated after further progress
General analysis instructions found on the Internet
As described by the alarm information, this is often the case when the packet capture behavior starts in the middle stage of a TCP session. If the real situation is caused by the loss of acks, you need to check how the packet is lost relative to the upstream of your host
It is very likely that tshark’s packet capture speed can’t keep up with the speed of packet arrival, and then, of course, some metrics will be lost; when packet capture stops, there will be corresponding information to tell you whether there is a situation of “ kernel dropped packet ” and drop By default, tshark will disable DNS queries, while tcpdump will not; if you use tcpdump to capture packets, you need to use “- n” switch to disable DNS queries to reduce overhead; if you are faced with insufficient disk IO, you can write the contents of packet capture to/dev/SHM But this usage needs to be careful, because once the content of the packet is too large, it will lead the machine into the swapping dilemma
A common situation is that if your application uses some long-running TCP sessions, some information of these TCP sessions will be lost when the subsequent packet capture behavior is started
Specifically, some typical situations that I have seen and lead to duplicate/missing acks are as follows:
switches – it is not possible in general, but sometimes the switch is in the sick state
routes – it is more likely than the switch to have problems, but it is not very high
firewall – it is more likely than router to have problems, and the common reasons are related to resource exhaustion (license, CPU, etc.)
client side filtering software – anti virus software, malware detection software, etc
If all network traffic is captured in unfiltered mode on busy interface, a large number of packets will be displayed as “dropped” when tshark is stopped, because in this case, tshark needs to sort all captured packets; once an appropriate capture filter is set to reduce the capture of non target packets, there will be a problem The probability of ‘dropped’ is greatly reduced
The following figure is a special case given by netizens: serial number error caused by TCP stack bug
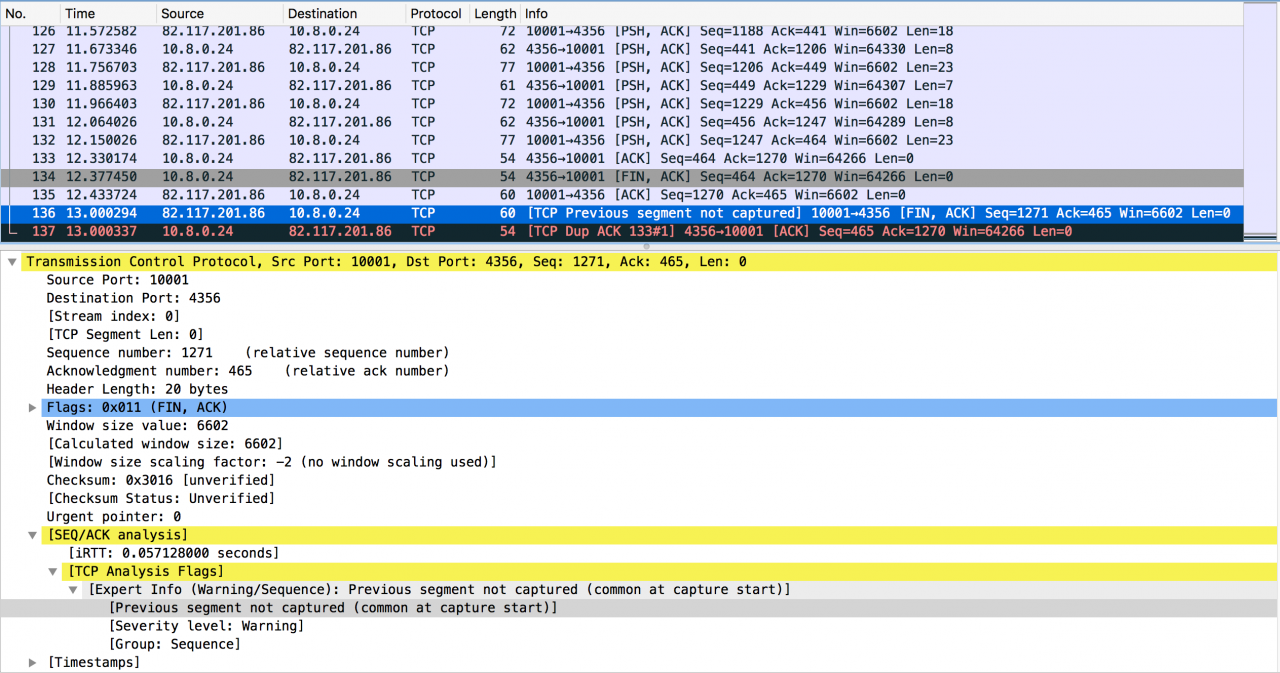
Package address: here
It is obvious from the above packet capture that the packet from server address 82.117.201.86 does not follow the TCP RFC protocol stack implementation: when closing the TCP session, the fin packet should carry the next expected sequence packet, and when the fin packet is acked, the corresponding ACK packet needs to be one byte occupied by the fin However, the actual situation of the above packet is that the sequence number in the fin packet sent by the server has exceeded the length of one byte; this behavior is obviously wrong, so the client correctly sends a duplicate ack to request the packet with the correct sequence number
Therefore, the possible reasons for the above packet capture are either that a byte of data is sent and then lost, or that there is a bug in the TCP stack on the server side
“TCP previous segment not captured” is the expert information provided by Wireshark software, which is used to inform that some packets are missing in the current packet capture. The alarm information was described as “TCP previous segment lost” before. The basic meaning of the alarm is: either the packet does not appear (packet loss), or Wireshark The action of catching bags is not fast enough to record the arrival of bags
Reference article:
Understanding [TCP ACKed unseen segment] [TCP Previous segment not captured]
TCP previous segment not captured, why?
Actually, in networking you never know if a packet got lost or not if you are only watching the end-points. This is due to the fact that you cannot distinguish between a lost packet (dropped by router or even corrupted on the link layer) and a extremely delayed transmission (packet is still on the wire or in a queue but is not processed).
A TCP duplicate ACK indicates: You received an acknowledgement from the server but it gives the same sequence number that the last ACK had. This means that an intermediate packet is lost (as the receiver ACKed the number twice) or extremely delay. But as you have received another ACK (the duplicate ACK) this means that the network path is not completely congested. Consequently, if you get multiple ACKs in a row, you can assume that the ACKed packet is lost as the other packets come through. Many TCP implementations then do what is called a Fast Retransmit, so that they don’t wait for the retransmit timeout but instead resend the first unacked packet. This also has some implications regarding the congestion window.
The message «Expert Info (Warn/Sequence): Previous segment not captured (common at capture start)» means the following: On the receiver side you capture an outgoing ACK packet for a sequence number where you haven’t seen the respective segment. This is common, as it might be possible that a segment arrived, you started the capture and afterwards your TCP stack replied with an ACK. So there was no way to see the incoming packet. This does not necessarily indicate a loss.
[TOC]
Wireshark analysis art [описание чтения]
1. Фактическая работа Wireshark
Анализ работы интерфейса
Один из трех приемов: просмотр статистики и атрибутивной информации
Одна из трех осей анализа производительности:
[Статистика -> Захват атрибутов файла] Статистика -> Сводка, просмотр информации об атрибутах файла, такой как средняя скорость, размер пакета, количество пакетов и т. Д.
Определите, высокий или низкий расход, и не перегружен ли он
Второй из трех способов: просмотр и анализ экспертной информации.
Анализ производительности по трем осям:
[Анализировать -> Информация для экспертов] Wireshark -> Анализировать -> Информация для экспертов -> Заметки, просматривать статистику перехваченных пакетов
Проверьте, есть ли такая информация, как примечания, предупреждения, ошибки, проверьте наличие связанных предупреждений и ошибок, оцените качество сети, нарушение повторной передачи и т. Д.
Три хитрости: просмотрите время ответа службы
Третий из трех приемов анализа производительности:
[Статистика -> Время ответа службы] статистика -> Время ответа службы -> xxxxx (например: ONC-RPC -> Программа: NFS)
Проверьте время отклика службы для каждой операции, чтобы определить, не перегружена ли она.
Используйте относительные значения для seq вместо истинных значений
Правка-> Настройки-> Протоколы-> TCP, отметьте относительные порядковые номера.
Это относительное значение до включения.
Просмотр TCP StreamGraph
Statistics -> TCP StreamGraph -> TCP Sequence Graph(Stevens)
Проверьте ситуацию передачи данных, например, является ли передача ровной, есть ли TCP Zero Windows и т. Д.
Значение поля и подсказка
Значение поля — это некоторая оперативная информация wirehark, то есть некоторая информационная информация о захваченных пакетах wirehark, эта подсказка отражается в столбце «Информация».
1,[Packer size limited during caputre]
Если пакет отмечен как подсказка[Packer size limited during caputre], Это означает, что этот пакет не захвачен, вы можете проверить информацию о кадре ниже. Как правило, эта ситуация такова, что положение сумки неправильное. В некоторых операционных системах tcpdump по умолчанию захватывает только первые 96 байтов каждого кадра, поэтому, когда tcpdump захватывает пакеты, вы можете указать количество байтов для захвата с помощью параметра -s
2,[TCP ACKed unseen segment]
Если wirehark обнаружит, что пакет Ack не был перехвачен, он предложит[TCP ACKed unseen segment], Но в большинстве случаев это приглашение можно проигнорировать. Потому что в большинстве случаев, когда пакет был впервые захвачен, был захвачен только задний Ack, а передний ACK не был захвачен.
3,[TCP Previous segment not captured]
При передаче данных TCP, в дополнение к трехэтапному и четырехстороннему рукопожатию, сегмент данных, отправленный одним и тем же компьютером, должен быть непрерывным, то есть Seq следующего пакета равен Seq + Len предыдущего пакета. Это правильная ситуация; если Если будет обнаружено, что Seq последнего пакета больше, чем Seq + Len предыдущего пакета, это означает, что часть данных потеряна в середине. Если потерянные данные не найдены во всем сетевом пакете, Wireshark предложит[TCP Previous segment not captured],
В этой ситуации есть две возможности:
- Пакет действительно потерян
- Пакет данных на самом деле не потерян, но инструмент захвата пакетов пропустил
- Если подтверждено, что пакет Ack содержит пакет, который не был перехвачен, значит, инструмент захвата пакетов пропустил его, в противном случае он действительно потерян.
4,[TCP Out-of-Order]
При передаче данных TCP, в дополнение к трехэтапному и четырехэтапному рукопожатию, сегмент данных, отправленный одной и той же машиной, должен быть непрерывным, то есть Seq следующего пакета равняется Seq + Len предыдущего пакета, что должно быть правильным случаем; или Говорят, что Seq последнего пакета должен быть больше или равен Seq + Len предыдущего пакета. Если Wireshark обнаруживает, что Seq последнего пакета меньше, чем Seq + Len предыдущего пакета, то он считается неисправным, и он запрашивает[TCP Out-of-Order]。
Вообще говоря, расстройство малого размаха имеет незначительный эффект, а расстройство большого размаха вызывает быстрые повторные передачи. Например, если порядок пакетов — 1, 2, 3, 4, 5, и он перетасовывается в 2, 1, 3, 4, 5, это беспорядок небольшого промежутка времени и мало влияет; если он перетасовывается в 2, 3 , 4, 5, 1, вызовет достаточное количество Dup ACK, что вызовет повторную передачу пакета 1.
5,[TCP Dup ACK]
Когда происходит нарушение последовательности или потеря пакетов, получатель получит несколько пакетов с порядковым номером, превышающим ожидаемое значение. Протокол TCP будет подтверждать ожидаемое значение Seq каждый раз, когда он получает пакет этого типа, и таким образом информирует отправителя. Были какие-то повторные Ак. Wireshark подскажет, поймает ли он эти повторяющиеся Ack[TCP Dup ACK].
6,[TCP Fast Retransmission]
Когда отправитель получает 3 или более подряд[TCP Dup ACK]В то время я понял, что ранее отправленный пакет может быть потерян, поэтому он начнет быстро повторно передавать в соответствии с RFC.[TCP Dup ACK]Это получатель отвечает отправителю, поэтому отправитель может его воспринять и начать быструю повторную передачу, когда он получает более трех сообщений подряд.
Алгоритм быстрой повторной передачи предусматривает, что, пока отправитель получает 3 повторяющихся подтверждения подряд, он должен немедленно повторно передать сегмент сообщения, который другой стороной не получил, не дожидаясь истечения установленного времени счетчика повторной передачи.
7,[TCP Retransmission]
Если пакет действительно потерян, и никакие последующие пакеты не могут вызвать [Dup Ack] на получателе, тогда быстрая повторная передача не будет включена.В этом случае отправитель может только дождаться тайм-аута перед отправкой повторной передачи. Пакет будет отмечен wirehark и подсказкой[TCP Retransmission]
Тайм-аут TCP и повторная передача должны быть одними из самых сложных частей TCP. Тайм-аут повторной передачи является основой TCP для обеспечения надежной передачи. Когда TCP отправляет данные, данные и подтверждение могут быть потеряны, поэтому TCP решает эту проблему, устанавливая таймер при отправке. Если таймер переполняется и не получил подтверждения, он повторно передает данные. Ключевым моментом является стратегия тайм-аута и повторной передачи. Необходимо учитывать два аспекта:
- Настройка тайм-аута
- Частота ретрансляции (количество раз)
В более поздних версиях ядра Linux, таких как 3.15, есть как минимум 9 таймеров: таймер повторной передачи тайм-аута, непрерывный таймер, таймер задержки ER, таймер PTO, таймер задержки ACK, таймер SYNACK, Таймер поддержания активности, таймер FIN_WAIT2, таймер TIME_WAIT.
8,[TCP zerowindow]
«Win = xxx» в пакете TCP представляет размер окна приема, который указывает, сколько буферов отправитель этого пакета может принять в данный момент. Когда wirehark публикует «win = 0» в пакете, он отмечает приглашение[TCP zerowindow], Это означает, что буфер заполнен и больше не может принимать данные.
Как правило, размер окна следует постепенно уменьшать до заполнения буфера.
9,[TCP window Full]
Если отправитель пакета исчерпал размер окна приема, заявленный другой стороной, он будет помечен wirehark как[TCP window Full]. Например, определенный конец объявляет, что его окно приема составляет только 65535 во время рукопожатия, что означает, что противоположный конец может отправить ему только 65535 байтов данных без подтверждения, то есть «количество байтов в пути» может быть не более 65535. Когда wirehark Это приглашение появится, если будет подсчитано, что 65535 байтов противоположного конца не подтверждены.
[TCP window Full] и указанное выше [TCP zerowindow] легко перепутать. Первое означает, что отправитель этого пакета не имеет возможности отправлять какие-либо данные в данный момент; второй означает, что отправитель этого пакета больше не может получать данные; оба будут Приостановить передачу данных
10,[TCP segment of reassembled PDU]
Доступно только в меню Edit-> Preferences-> Protocols-> TCPAllow sub dissector to reassemble TCP streamsПосле этого можно получить это приглашение. Это представление может виртуально собирать TCP-пакеты, принадлежащие одному PDU прикладного уровня.
11,[Continuation to #]
Закрывается только в меню Edit-> Preferences-> Protocols-> TCPAllow sub dissector to reassemble TCP streamsПосле этого можно получить это приглашение.
12,[Time-to-live-exceeded(Fragment reasembly time execeeded)]
(Превышено время повторной сборки фрагмента) указывает на то, что отправитель этого пакета уже получил некоторые фрагменты раньше, но по некоторым причинам сборка задерживалась.
Например, если некоторые фрагменты потеряны во время передачи, получатель не может их собрать, а затем отправитель уведомляется этим методом ICMP.
ICMP — это протокол управляющих сообщений Интернета (Internet Control Message Protocol). Это подпротокол набора протоколов TCP / IP, используемый для передачи управляющих сообщений между IP-узлами и маршрутизаторами. Управляющее сообщение относится к сообщению самой сети, например, о недоступности сети, о том, доступен ли хост и доступен ли маршрут. Хотя эти управляющие сообщения не передают пользовательские данные, они играют важную роль в передаче пользовательских данных.
Во-вторых, Wireshark анализирует протокол TCP.
Основы протокола захвата пакетов TCP
Поле управления TCP
На уровне TCP есть поле FLAGS со следующими идентификаторами: SYN, FIN, ACK, PSH, RST, URG.
Форма поля управления, отображаемого при захвате пакета, следующая:
[SYN]: установить соединение, запустить пакет [FIN]: закрыть соединение, завершить пакет [PSH]: передача данных DATA [ACK]: ответ ACK [RST]: RESET, сброс соединения
Два других часто используемых поля:
[Len]: длина пакета [Seq]: порядковый номер пакета.
ACK может использоваться одновременно с SYN, FIN и т. Д. Например, SYN и ACK могут быть 1 одновременно, это означает, что ответ после установления соединения, если это только один SYN, это означает, что установлено только соединение
Когда появляется пакет FIN или RST, мы думаем, что клиент отключен от сервера. Когда появляются пакеты SYN и SYN + ACK, мы думаем, что клиент установил соединение с сервером.
Направление захвата пакета (клиент или сервер)
- При захвате пакетов, независимо от того, захватываете ли вы пакеты с помощью wirehark или tcpdump, вам нужно видеть, захватываются ли пакеты со стороны клиента или со стороны сервера.Ситуация захвата пакетов полностью различается в разных направлениях. Потому что в сети (общедоступная сеть, реальная среда) возникает много ненормальных ситуаций.
TCP Ack
В соответствии с http это обычно запрос-> ответ, один вопрос и один ответ. Но для TCP не каждый пакет будет ACK. TCP ACK — это совокупный ACK, что означает, что все остальные ACK до моего ACK были подтверждены для получения.
Например, ACK пакета 97 = 65701 и Seq + Len = 64273 + 1428 = 65701 пакета 96, тогда это означает, что ACK 97 является ответом на 96, то есть другие ACK до 96 не отображаются. Фактически, пакеты прошли ACK пакета 97, поэтому отправитель также знает, что все пакеты, отправленные до 96, были получены и подтверждены другой стороной.
MSL、TTL、RTT
-
MSL (Максимальное время жизни сегмента), что означает «Максимальное время жизни сегмента сообщений», — это наибольшее время, в течение которого все сообщения следуют в сети. Сообщения, превышающие это время, будут отброшены.
- RFC 793 предусматривает, что MSL составляет 2 минуты. В практических приложениях обычно используются 30 секунд, 1 минута и 2 минуты.
- 2MSL вдвое больше MSL, а состояние TIME_WAIT TCP также называется состоянием ожидания 2MSL.
-
TTL (время жизни), что означает время жизни, является полем в заголовке ip. Время жизни устанавливается исходным хостом для установки начального значения, но TTL — это не конкретное сохраненное время, а максимальное количество маршрутов, которые можно пройти.
- Согласно RFC 1812, каждый раз, когда TTL сетевого пакета вычитается на 1, это означает, что он был маршрутизирован один раз. Как правило, начальное значение TTL равно 64. Если TTL пакета ACK составляет 62, это означает, что он отправляется устройством на расстоянии двух переходов от этого устройства.
- Форма TTL в пакете захвата wirehark выглядит следующим образом
Time to live: 62 - TTL = 0, дейтаграмма будет отброшена, и будет отправлено сообщение ICMP для уведомления хоста-источника.
- Как правило, TTL также используется в кэше и пульсе соединения. Он отличается от TTL в протоколе TCP. TTL в кэше и пульсе соединения указывает оставшееся время кеширования данных или.
-
RTT (время приема-передачи), что означает время, необходимое для передачи данных от клиента к серверу и обратно. TCP содержит алгоритм для динамической оценки RTT.
- TCP будет продолжать оценивать RTT данного соединения, потому что RTT подвержен изменениям в процедурах перегрузки сети.
Разрешение MAC-адреса
Протокол = ARP Источник и место назначения имеют формат MAC-адреса, например 00: 60: 48: ff: 12: 31.
При анализе захвата пакетов, если сеть заблокирована, ACK не может быть получен и т. Д., Необходимо дополнительно проверить правильность MAC-адреса каждого пакета.Напротив, есть некоторые проблемы, вызванные несколькими MAC-адресами.
Протокол установления связи TCP и волновой протокол
Пакет трехстороннего подтверждения TCP и ответного суждения
-
Соглашение о трехстороннем рукопожатии
- client->server : [SYN] Seq=X win=xxx Len=0 MSS=xxx
- server->client : [SYN, ACK] Seq=Y,ACK=X+1 win=xxx Len=0 MSS=xxx
- client->server : [ACK] Seq=X+1,Ack=Y+1 win=xxx Len=0
-
Захват пакетных данных, как определить, является ли пакет пакетом возврата предыдущего пакета? Согласно протоколу TCP, если значение Ack следующего пакета равно Seq + Len предыдущего пакета, это означает, что пакет возвращается.
- Предыдущий и следующий во многих случаях не являются непрерывными, а следующий ответный пакет намного длиннее предыдущего из-за повторной передачи и задержки.
-
Во время трехстороннего рукопожатия все MSS будут объявлены друг другу.
ПТС четыре раза махнул и трижды
-
Четырехволновой протокол TCP
- client->server : FIN Seq=X,ACK=Y
- server->client : Seq=Y,ACK=X+1
- server->client : FIN Seq=Y,ACK=X+1
- client->server : Seq=X+1,Ack=Y+1
-
Обычно таких волн будет четыре, но если есть задержка с подтверждением, тогда четыре волны станут тремя волнами, сохраняя вторую сумку из четырех волн.
- client->server : FIN Seq=X,ACK=Y
- server->client : FIN Seq=Y,ACK=X+1
- client->server : Seq=X+1,Ack=Y+1
Алгоритм контроля перегрузки TCP
Количество байтов в пути
- Количество байтов в пути [байтов в пути] означает количество байтов, которые были отправлены, но не были подтверждены. Это подтверждение относится к подтверждению ACK, отправленному противоположной стороной. Это так называемая пропускная способность сети; если байты находятся в пути Если число превышает пропускную способность сети, произойдет потеря пакета и повторная передача
- Количество байтов в пути = [Seq + Len] текущего отправителя- [ACK] текущего получателя
- Этот «текущий» можно увидеть только по серийному номеру сетевого пакета в захваченном пакете. Он не обязательно должен быть связан с двумя пакетами. Именно потому, что два пакета не связаны между собой, рассчитывается количество байтов в пути. путь
- Этот Len, вообще говоря, не должен превышать MSS (максимальное поле данных) TCP, это значение 1388, обратите внимание на сравнение MTU (1500)
- Количество байтов в пути = [Seq + Len] текущего отправителя- [ACK] текущего получателя
Перегрузка сети
- Точка перегрузки сети: перегрузка сети, вызванная превышением пропускной способности сети. Количество байтов в пути при возникновении перегрузки является точкой перегрузки сети в данный момент. Чтобы оценить точку перегрузки сети, вам нужно просто найти количество байтов в пути во время перегрузки.
- Перегрузка характеризуется серией потерь и повторной передачи пакетов после потери пакетов; инструменты захвата пакетов, такие как wirehark и tcpdump, могут идентифицировать повторно переданные пакеты.
- Согласно инструменту захвата пакетов найдите первый пакет в серии повторно переданных пакетов, а затем найдите соответствующий исходный пакет в соответствии со значением Seq повторной передачи пакета. Наконец, вычислите количество байтов в пути во время отправки исходного пакета. Это идентифицирует текущий Точка перегрузки
- Если Seq + Len-Ack = 103122, эта единица измерения представляет байты, что составляет 100 КБ. Эти 100 КБ — самое большое окно отправки, поэтому вам необходимо установить значение окна отправки в системе Linux.
- Wireshark -> Анализировать -> Информация об эксперте -> Меню заметок
- Количество байтов в пути используется только для оценки точки перегрузки сети, что не обязательно очень точно. Вы можете выполнить несколько выборок и найти подходящее значение; данные после нескольких выборок должны быть минимальным значением, а не средним значением, если оно является консервативным.
- Минимальное значение связано с тем, что это наиболее консервативное значение, чтобы действительно гарантировать, что сеть не будет перегружена; после его принятия вы должны установить окно отправки Linux
- Как упоминалось ранее, максимальное значение Len пакета данных не должно превышать 1388, но в процессе анализа фактического захвата пакетов выясняется, что фактическое значение Len может быть дважды или N умножено на 1338. В чем причина? Это потому, что существует так называемый LSO.
- Общий метод работы сети: уровень приложения передает сгенерированные данные на уровень TCP, и сегментация TCP выполняется в соответствии с размером MSS, сегментация выполняется ЦП, и, наконец, она доставляется на сетевую карту.
- Если LSO включен: уровень TCP напрямую доставляет блоки данных, размер которых превышает MSS, на сетевую карту, а сетевая карта отвечает за сегментацию.
- С точки зрения отправителя это равносильно тому, что он находится с точки зрения ЦП, так что при захвате пакета пакет должен быть виден до сегментации. С точки зрения получателя это эквивалентно стоянию с точки зрения сетевой карты, тогда вы должны увидеть несколько небольших пакетов после сегментации.
- Важность появления LSO заключается в том, что современные сетевые карты часто имеют гигабитный или 10-гигабитный формат, поэтому нагрузка на ЦП очень велика. Например, для сетевого трафика 625 МБ / с требуется ЦП с частотой около 5 ГГц, поэтому, чтобы уменьшить нагрузку на ЦП, некоторые работы по сегментации передаются для выполнения непосредственно сетевой карте.
Фактический боевой опыт подсказывает нам,Wireshark ->Analyze -> Expert Info -> NotesЕсли частота ретрансляции в статистике превышает 0,1%, необходимо принять какие-то меры. Однако в реальной сетевой среде практически невозможно ретранслировать менее 0,01%.
Окно отправки
- Два фактора окна отправки клиента: окно перегрузки (cwnd) в сети и окно приема на сервере
- Метод роста cwnd: сначала «медленный старт», а затем «предотвращение перегрузки». Первый имеет низкую начальную точку, но может быстро расти, а второй имеет высокую начальную точку, но только один MSS может быть добавлен для каждого RTT (RTT относится к времени приема-передачи, то есть к следующему Пакет, переданный в одном направлении)
- Согласно полученным данным, нажмите на детали и проверьте его значение «Байт в полете», которое может быть просто эквивалентом cwnd
- Если это фаза «медленного старта», то cwnd следующего пакета RTT должно быть намного больше, чем cwnd предыдущего пакета.
- Если это фаза «предотвращения перегрузки», то cwnd следующего пакета RTT следует увеличить на один MSS (MSS в Ethernet составляет около 1460 байт).
- Если два вышеуказанных условия не выполняются, например, cwnd растет очень медленно, то его необходимо проанализировать в соответствии с методом расчета cwnd
Алгоритм TCP Nagle и отложенный ACK
- Алгоритм Нэгла:
-
Это необходимо для уменьшения количества небольших пакетов в глобальной сети, тем самым уменьшая вероятность перегрузки сети;
-
Алгоритм требует, чтобы в TCP-соединении мог быть не более одного неподтвержденного небольшого пакета, и никакие другие небольшие пакеты не могли быть отправлены до прибытия пакета подтверждения. TCP должен собирать эти небольшие пакеты и отправлять небольшой пакет, когда приходит подтверждение. Отправляйте сообщения группами; определение малой группы — это любая группа, меньшая, чем MSS;
-
Преимущество этого алгоритма в том, что он адаптивен. Чем быстрее приходит подтверждение, тем быстрее будут отправлены данные. В низкоскоростной глобальной сети, которая хочет уменьшить количество небольших пакетов, будет отправлено меньше пакетов;
-
if there is new data to send
if the window size >= MSS and available data is >= MSS
send complete MSS segment now
else
if there is unconfirmed data still in the pipe
enqueue data in the buffer until an acknowledge is received
else
send data immediately
end if
end if
end if
Скопировать код- Отложенный ACK:
Если tcp отправляет подтверждение подтверждения для каждого пакета данных, то отправка подтверждения для одного пакета данных обходится дороже, поэтому TCP будет задерживаться на определенный период времени. Если в течение этого периода на противоположный конец будут отправлены данные, они будут отправлены с совмещением. ack, если будет обнаружено, что подтверждение не было отправлено при срабатывании таймера отложенного подтверждения, оно будет отправлено отдельно немедленно;
Преимущества отложенного ACK:
(1) Избегайте синдрома запутанного окна; (2) При отправке данных отправляйте подтверждение с совмещением вместо отправки подтверждения отдельно; (3) Если Если в течение времени задержки поступает несколько сегментов данных, стеку протоколов разрешается отправить подтверждение для подтверждения нескольких сегментов сообщения;
- Когда Нэгл обнаруживает отложенное ACK:
Представьте себе следующую типичную операцию, запись-запись-чтение, то есть отправка одной логической операции одноранговому узлу через несколько небольших фрагментов записи данных. Длина двух записываемых данных меньше MSS. Когда первые данные записи поступают на одноранговый узел, одноранговый узел задерживает подтверждение , Не отправлять подтверждение, и поскольку длина отправляемых данных меньше MSS, алгоритм Нэгла работает, данные не будут отправлены немедленно, но дождитесь первого подтверждения данных, отправленного партнером; в этом случае вам нужно Подождите, пока одноранговый узел отправит подтверждение с течением времени, а затем этот абзац может отправить записанные данные во второй раз, что вызывает задержку;
- Отключите алгоритм Нэгла:
Используйте параметр сокета TCP TCP_NODELAY, чтобы отключить параметр сокета;
Рассмотрите возможность отключения алгоритма Нэгла в следующих случаях:
(1) Противоположный конец не отправляет данные на локальный конец, и операция более чувствительна к задержке; этот вид операции не может переносить подтверждение; (2) Операция записи-записи-чтения, как указано выше; В этом случае вместо отключения алгоритма Нэгла предпочтительнее использовать другие методы:
Разница и сравнение TCP и UDP
Главное отличие
Разница между TCP и UDP в том, что TCP надежен, а UDP ненадежен, но какова реальная производительность? Что ненадежно? В чем разница между ACK конкретного протокола?
Независимо от того, TCP это или UDP, он может быть фрагментированным, что определяется MSS Ethernet; разница заключается в обработке фрагментированной передачи:
- Для UDP, если передача фрагмента приводит к потере некоторых фрагментов, получатель не может завершить повторную сборку, поэтому отправитель повторно передает все фрагменты.Если повторная передача происходит, эффективность будет относительно низкой.
- Это ненадежность UDP. Не существует механизма, обеспечивающего безопасную доставку данных, а уровень приложения должен отвечать за повторную передачу.
- Что касается TCP, механизм сегментации TCP может разбивать пакеты данных на несколько пакетов и затем избегать фрагментации на сетевом уровне. Что касается повторной передачи, TCP нужно только повторно передать потерянный пакет, а не повторно передать весь пакет
- В этом также заключается надежность TCP. TCP имеет механизм, обеспечивающий безопасную доставку данных, без необходимости для прикладного уровня обрабатывать повторные передачи.
- Поскольку TCP повторно передает только потерянный пакет, а не весь пакет, эффективность повторной передачи намного выше, чем у UDP.
UDP больше подходит для голоса, чем TCP
Сценарий голосового вызова заключается в том, что задержка не может быть принята, но качество звука немного хуже. В этом случае во время передачи UDP, если некоторые пакеты потеряны, прикладной уровень может игнорировать и продолжать передавать другие пакеты. Потеря некоторых пакетов повлияет только на качество звука, но обеспечит плавность. Что касается TCP, каждый пакет будет передан повторно, и пока пакет будет потерян, он будет повторно передаваться. Это вызовет определенную задержку. Если есть задержка в голосе, это нежелательно.
Следовательно, TCP и UDP имеют свои подходящие сценарии. Для голоса и видео больше подходит UDP.Как голосовая сеть и linphone, UDP используется для обработки аудио и видео. TCP должен использоваться при взаимодействии базового и основного протоколов.
Эффективность TCP и UDP
TCP требуется время приема-передачи для подтверждения во время передачи, которое является ACK, в то время как UDP не требует подтверждения, так что UDP более эффективен, чем TCP? Это не обязательно верно. Хотя UDP может продолжать отправлять пакеты, не дожидаясь ACK, но TCP имеет окно отправки. Если окно отправки небольшое и не занимает всю полосу пропускания, оно должно быть ограничено временем приема-передачи и немного снизить эффективность. , Но если окно достаточно велико и подходит для работы с полной полосой пропускания, TCP также может непрерывно передавать данные, не ограничиваясь временем приема-передачи.
Пример: по дороге взад и вперед едет только одна машина. Процесс возврата эквивалентен пустому пробегу (обратный путь эквивалентен ACK TCP), поэтому эффективность TCP, конечно, низкая. Однако, если вы попытаетесь увеличить количество транспортных средств при отсутствии заторов, транспортные средства на дороге будут просто заполнены, поэтому общая эффективность передачи улучшится, а ACK обратного рейса не будет затронут.
Фрагментация пакетов, MTU, MSS
Фрагментация и повторная сборка пакетов
Коммутация пакетов разделяет большие данные на маленькие пакеты, так что совместное использование ссылок может быть реализовано без блокировки всех из-за одной стороны. Поскольку он должен быть разделен на небольшие пакеты, необходимо определить максимальный размер пакета — это максимальная единица передачи MTU (Maximum Transmission Unit), которая составляет 1500 байт. Если удалить 20-байтовую структуру заголовка, максимальный размер пакета IP составляет 1500-20 = 1480 байтов. Если передаваемый блок данных превышает 1480 байт, сетевой уровень фрагментирует его и инкапсулирует в несколько сетевых пакетов для передачи. Для TCP уровень протокола TCP будет активно разделять данные на небольшие сегменты, а затем передавать их на сетевой уровень. Максимальный размер сегмента TCP называется MSS (максимальный размер сегмента). Для этого MSS задано значение MTU минус заголовок IP и заголовок TCP. После размера он может соответствовать одному MTU. Поскольку UDP не имеет концепции MSS, его можно передать на сетевой уровень только для обработки фрагментации.
Но следует отметить, что в некоторых сетях в настоящее время есть такие устройства, как Jumbo Frame (jumbo frame) или PPPOE, поэтому их MTU не составляет 1500 байтов. В настоящее время у отправителя нет хорошего механизма для определения оптимального размера фрагмента, и он должен стараться поддерживать согласованность MTU устройств в сети. Если MTU устройств в сети несовместимо, как протокол TCP адаптируется к MTU? Мы знаем, что когда TCP устанавливает соединение, сначала должно быть выполнено трехстороннее рукопожатие. TCP взаимно объявит свой собственный MSS в первых двух пакетах подтверждения. Если клиентская сторона объявляет свой собственный MSS = 8960 (jumbo-фрейм), а серверная сторона объявляет свой собственный MSS = 1460, то клиент знает MSS сервера после трехстороннего рукопожатия, поэтому, когда клиент хочет отправить пакет, превышающий MSS сервера Будет предпринята инициатива по уменьшению собственного MSS до размера MSS на стороне сервера, чтобы адаптироваться к MTU получателя. Видно, что уровень протокола TCP проделал большую оптимизацию и обработку.
Поскольку существует фрагментация, получатель должен выполнить фрагментацию и реорганизацию. С помощью инструмента захвата пакетов можно узнать, что каждый пакет фрагмента содержитoff=xxx,ID=xxxИмея такую информацию, получатель реорганизует фрагменты с тем же идентификатором в соответствии с смещением выключения. Итак, как получатель узнает, какой пакет является последним фрагментом? Когда начнется реорганизация? Здесь последний пакет фрагмента имеет специальный флаг, называемыйMore fragment = 0, Форма выражения в захвате:..0. ... = More fragment: Not set, Это означает, что это последний фрагмент, и тогда пакет можно реорганизовать. Если это другой пакет фрагментов, он выглядит как..1. ... = More fragment: setЭто означает, что получателю необходимо выполнить буферизацию и дождаться передачи других фрагментов.
Настоящая битва MTU
Если MTU клиента = 9000, а MTU сервера = 1500, тогда, когда клиент запрашивает сервер, пакет клиента будет либо потерян, либо фрагментирован при прохождении через маршрутизатор. Если этот пакет jumbo-кадра несет на сетевом уровне флаг DF (Don’t Fragment), он будет отброшен (его установка означает, что фрагментация не разрешена), если он не установлен, будет выполнена передача фрагмента. Следует отметить, что в этом случае, если пакет потерян, а повторная передача все еще отбрасывается, он становится черной дырой.
В тесте вы можете смоделировать эту ситуацию с помощью команды ping:
Успех:
ping xxx.xxx.xxx.xxx -l 1472 -f -n 1
Не удалось:
ping xxx.xxx.xxx.xxx -l 1473 -f -n 1
Скопировать код-f параметр означает установку флага DF -l параметр означает запрос байтов
Когда байт запроса установлен в 1472, поскольку заголовок ICMP составляет 8 байтов, а заголовок IP — 20 байтов, 1472 + 8 + 20 = 1500, что является MTU, поэтому эхо-запрос может быть успешным. Но вторые 1473 + 8 + 20 = 1501 байт превышают MTU, и поскольку установлен флаг DF, указывающий, что фрагментация не разрешена, передача не выполняется. Как правило, в этом случае маршрутизатор ответитPacket needs to be fragmented but DF set。
При захвате пакетов, если вы обнаружите, что он был повторно передан, и определенные относительно большие пакеты (проверьте значение Len) будут повторно переданы, вы можете передатьping xxx.xxx.xxx.xxx -l [Len] -fЗначение проверяется и проверяется, и правило можно найти по изменению размера [Len], заданному этим эхо-запросом, и может быть обнаружено, что MTU определенного устройства в сети не равно 1500, что приводит к феномену повторной передачи, если оно превышает это значение.
Особый контроль потока и пропускная способность
На стороне клиента и сервера должны быть коммутаторы, маршрутизаторы и другое оборудование. Если на стороне сервера используется сетевая карта 10 Gigabit, а на стороне клиента — сетевая карта Gigabit, это может привести к слишком быстрой отправке сервером и блокировке данных на коммутаторе, так что коммутатор будет заблокирован после его заполнения. Произошла потеря пакета. Но вообще говоря, полоса пропускания сервера должна быть больше, чем у клиента. Во избежание перегрузки необходим механизм управления потоком, позволяющий коммутатору сообщать серверу о замедлении или приостановке передачи при перегрузке.
Существует своего рода «кадр паузы», который может удовлетворить это требование: когда буфер коммутатора собирается заполниться, на сервер отправляется кадр паузы, и сервер некоторое время ждет, чтобы отправить его снова, чтобы избежать переполнения и потери пакетов. Повторная передача после потери пакета. Время ожидания на стороне сервера определяется параметром pause_time в кадре паузы, так что серверная сторона начнет отправку после ожидания pause_time. Конечно, коммутатор также может отправить на сервер кадр паузы с pause_time = 0, чтобы сообщить серверу, что я его обработал и могу отправить немедленно.
Обратите внимание, что управление потоком здесь отличается от управления потоком TCP.
В-третьих, используйте методологию анализа Wireshark.
-
Чтобы устранить проблему с помощью wirehark, вам необходимо проанализировать сетевой пакет, найти некоторые подсказки в сетевом пакете, а затем сделать вывод на основе сетевого протокола, затем отменить один за другим и, наконец, найти проблему.
-
Необходимо уметь понимать основной протокол TCP и смысл каждого поля.
-
Используйте некоторые инструменты статистики и анализа Wireshark, фильтры и т. Д.
-
Существует большая разница между отправкой и получением захвата пакетов
-
Используйте «три оси» рабочего процесса и шагов для анализа проблемы.
В первой части серии мы прошлись взглядом по типичным схемам сетей Ethernet и различным ситуациям при захвате трафика. Поэтому в текущей статье (и во всех последующих!) я буду считать, что вы ознакомились с предыдущими частями. Сегодня давайте обсудим, в каком случае скорость интерфейса и режим дуплекса становятся очень важны, и что такое эти «дропы».
Скорость и дуплекс
Есть 2 режима дуплекса, которые можно встретить при работе с сетью Ethernet:
- Полудуплекс, также известный как «HDX», «Half Duplex». Он означает, что только один передатчик может отправлять данные в определенный момент времени, иначе возникнут проблемы (они же «коллизии»).
- Полный дуплекс («Full duplex», «FDX»). В этом режиме возможна двусторонняя коммуникация, то есть и передача, и прием возможны одновременно.
Ну так и что же случится, если одна сторона работает в режиме FDX, а вторая всего лишь в HDX? Ничего хорошего. Узел, который использует FDX, будет думать, что он спокойно может передавать данные когда только пожелает, не понимая, что это вызовет коллизию, если вдруг случится так, что HDX-сосед как раз в этот момент отправляет что-то свое. Называется такая ситуация «duplex mismatch». Что в результате? Скорость передачи упадет до совсем печального уровня (уточним: это считанные килобайты в секунду вместо мегабайтов в секунду на линке в 100 Мбит/с).
Интересный факт 1: Автосогласование
Иногда люди думают, что “10/100 автосогласование” на одной стороне окажется достаточно разумным алгоритмом, чтобы распознать параметры второй стороны, настроенной вручную. Типа: «так, я поставлю на одной стороне 100 Мбит/с + полный дуплекс самостоятельно, а вторая сторона должна это увидеть и подстроиться». Давайте рассмотрим это на примере. Сторона номер 1 (обычно коммутатор) настроена принудительно на “100/полный дуплекс”, сторона номер 2 (обычно ПК) – выставлена на “автосогласование”. Что получится? Правильно, несоответствие, именно этот duplex mismatch:

Почему так происходит? Сторона 2 (ПК, настроенный в “авто”), сообщает: «я могу 10Мбит/с полудуплекс; 10Мбит/с полный дуплекс; 100Мбит/с полудуплекс; 100Мбит/с полный дуплекс». Ну, то есть, перечисляет все свои возможные режимы. А что говорит сторона 1 – коммутатор? А вообще ничего, он же настроен жестко. Из-за этого ПК, который ничего не слышит, на всякий случай переходит в режим полудуплекса (предполагает худшее). И это ещё хорошо, что скорость он все же может обнаружить и все-таки выставит себе 100Мбит/с, а иначе мы бы получили полный сбой соединения – стороны с несогласованной скоростью порта не могут общаться вообще никак!
Поэтому существует такое правило: ставим или обе стороны на авто, или обе вручную! По крайней мере, так было, пока не вышла спецификация 1Гбит/с (IEEE 802.3z), которая содержит небольшое, но важное предписание сообщать о параметрах, даже если узел настроен статически вручную.
По этой причине в последнее время, когда все стали переходить на гигабит и больше, количество проблем с duplex mismatch пошло на убыль.
Интересный факт 2: Полудуплекс на гигабите!
Да, есть такой стандарт: 1Гбит/с, полудуплекс. Ходят слухи, что инженеры (естественно, зная, что полудуплекс – дело прошлого) все равно должны были описать этот режим, чтобы стандарт формально остался в группе 802.3. Которая называется «CSMA-CD», и где CD означает «Collision Detection», а для этого Collision Detection нужен полудуплекс, иначе откуда там взяться коллизиям? 🙂
Что? Опять про дуплекс?
Могу себе представить, что некоторые читатели, снова смотря на главу про полный/полудуплекс, скажут: «чувак, об этом надо было помнить лет 10-15 назад, но сейчас? Сейчас все на полном дуплексе!» Ну, во-первых, этот цикл создавался для начинающих. А, во-вторых, давайте зададим простой, но важный вопрос более знающим читателям:
Сможете ли вы захватить полностью загруженный гигабитный полнодуплексный канал, используя один такой же полнодуплексный порт гигабитной сетевой карты?
И ответ… нет, не сможете.
И так как я уверен, что многие сейчас чешут затылок в размышлениях, давайте углубимся в этот вопрос ещё немного, потому что это по-настоящему важно. Ключевое слово в моем вопросе – «полнодуплексный» гигабитный канал. Как мы помним, это значит, что узел может отправлять и получать данные одновременно.
Ну так что это означает, если мы говорим про гигабитный полнодуплексный канал? 1 гигабит в секунду на прием и 1 гигабит в секудну на отправку (а совсем не 500Мбит/с на прием и 500Мбит/с на отправку, как часто неправильно думают мои ученики на курсах по Wireshark). Итого, когда мы говорим про полнодуплексный гигабитный канал, по факту мы имеем дело с общей скоростью передачи 2 гигабита в секунду (да-да, конечно, если он полностью загружен). То же относится и к 10Гбит FDX – это по сути 20Гбит. 25Гбит означает 50Гбит, 40 означает 80, 100 означает 200, если мы имеем дело с полным дуплексом.
Но все же, и почему мы не сможем захватить такой канал одним портом гигабитной карты? Она же тоже полнодуплексная, правда?
Оно-то так, но карта захвата может только получать трафик, но не отправлять (точнее, не должна бы отправлять, или, по моему мнению, не должна отправлять ни в коем случае). Итак, скорость карты захвата на передачу нам становится полностью неважна и бесполезна. И все, что нас интересует – это скорость карты захвата на прием, а она равна 1 Гбит/с. Выходит, что такой карты мало, для того, чтобы захватить полнодуплексный гигабитный загруженный канал. Потому что он будет иметь в сумме скорость 2 Гбит/с. А мы сможем принять из них только 1 Гбит/с. Нам придется с этим столкнуться ещё позже, но если уже сейчас вы подумали «вот же…», то вы на правильном пути.
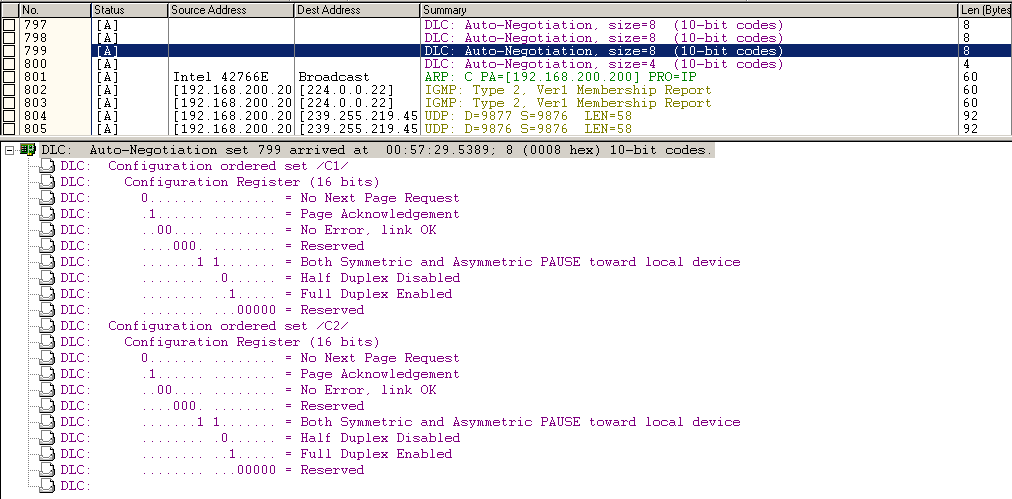
Захватываем преамбулу и протокол автосогласования
Захватить преамбулу и делимитер Ethernet-кадра, которые передаются перед самим кадром, практически невозможно. Может, удастся их увидеть на экране осциллографа в медленной сети (10Мбит/с), или получится захватить коллизию (смотрите в предыдущей статье).
А причина в том факте, что сетевая карта передает компьютеру только сами кадры. Ей незачем передавать также всякие служебные вещи, которые происходят где-то в проводах, потому что попросту эти вещи никому кроме самой сетевой карты не нужны и никакого смысла загружать ими ПК нет. Если все-таки очень хочется увидеть эти данные, понадобится как минимум специализированная (читайте: профессиональная и очень дорогая) карта захвата. Никакая обычная потребительская сетевая карта не позволит этого сделать.
Если вы обладатель профессиональной карты захвата совместно с TAP, то вы как минимум сможете захватить импульсы протокола автосогласования, как на рисунке ниже (это только часть, ещё многое происходит позже, но, как видите, эта часть происходит как раз перед переходом в состояние “link up”). Захватывался этот дамп на специализированном устройстве Network General S6040 в комбинации с полнодуплексным оптическим ТАР:
«Дропы»
«Дроп», он же «отброшенный пакет» – это пакет, который по факту был в сети и должен был быть захвачен, но не захватился. Разница «потерянного» (lost) и «отброшенного» (drop) пакетов в том, что потерянный пакет пропал где-то в сети (то есть, на входе нашего порта его уже не было), и в случае, если у нас ТСР, то такой пакет будет переотправлен заново отправителем. Если же пакет не захватился, в дампе отсутствует, но в сети он был, дошел до получателя и никуда по пути не пропал – то это «дроп» То есть отбросили его мы. Примерно ситуация с дропами выглядит так:
 |
| Пример дропов в дампе |
Если вы видите в Wireshark сообщение “TCP ACKed unseen segment” (это сообщение генерируется модулем-анализатором ТСР) – это верный признак дропов при захвате: Wireshark видит, что в дампе присутствует ACK (подтверждение) для какого-то пакета данных, а вот самого пакета не видит. Так как узел, участвующий в обмене данными, подтвердил прием, следовательно, пакет с данными дошел до получателя нормально. Просто этот пакет с данными не добрался до нас, до самого Wireshark’а. Всего две основных причины могут быть связаны с этим:
- Дропы. Производительность устройства захвата была недостаточной, чтобы обработать весь входящий поток без потерь.
- Асинхронный маршрут. Случается так, что загруженные пакеты с данными идут к получателю одним путем, в то время, как АСК-подтверждения от получателя возвращаются по другому маршруту, на котором вы не захватываете трафик. В этой ситуации пропавшие пакеты не являются дропами, ведь мы их не отбрасывали. Это легко заметить по тому признаку, что у вас в итоге получается «односторонний дамп», и вы вообще не видите обратного потока.
Но все же больше, чем в 95% случаев причиной “недолета” пакетов является первая – было недостаточно производительности устройства захвата. Кстати, ещё один признак дропов – это сообщения “TCP Previous segment not captured”, после которых нет переотправленных пакетов с данными. Подумайте об этом.
Причины дропов
Возможны несколько причин, но все они попадают в категорию «ваше устройство захвата было недостаточно быстро, чтобы захватить весь трафик без потерь». Дропы могут возникнуть по вине коммутатора, ответвителя ТАР, сетевой карты, жесткого диска и даже ЦП или памяти вашего ПК (к примеру, если ваш софт недостаточно оптимизирован). Подведем итог: всё, что угодно, – любое устройство или схема – которые находятся между пакетом в проводе и диском, куда пишется дамп, может стать причиной дропов. Что-то из этого виновато чаще, что-то реже. (Дорогие производители ТАР, следите за своим давлением, мы будем рассматривать ТАР позже, и тогда же уточним, почему дропы могут возникнуть и здесь).
В зависимости от ситуации, дропы могут иметь разную степень критичности.
Критичные дропы
Считаются таковыми, если вам нужна полная информация, и вы не можете себе позволить ни одного потерянного пакета. Зачастую это касается задач сетевой безопасности, когда необходима реконструкция контента, переданного по сети. Если у вас пропал один или несколько пакетов, которые были частью переданного вредоносного файла – вы уже не сможете этот файл полностью восстановить, и его реверс-инжиниринг будет невозможен (или как минимум затруднен).
В другой ситуации у вас может быть задача исследовать причину потерь пакетов – и дропы приведут вас к ложным выводам, просто потому, что вы думали, что пакет был потерян в сети (packet loss), а на самом деле он дропнулся на вашем устройстве захвата. (В случае с ТСР об этом хотя бы косвенно можно догадаться, как написано выше. А вот UDP и другие уже не дадут таких подсказок. – прим. перев.)
Некритичные дропы
Дропы могут раздражать, но быть не настолько критичными, если их влияние в конкретной задаче траблшутинга предсказуемо. Как правило, это требует навыка анализа выше среднего уровня, так как аналитик должен иметь достаточно опыта, чтобы найти причину сбоев даже в присутствии отвлекающих внимание паразитных дропов. Но эти товарищи могут увести неопытного аналитика по ложному пути.
Как пример можно взять анализ ТСР-соединения, которое страдает от симптома «низкая производительность (bad performance)». Здесь аналитик сможет пережить редкие дропы, потому что он видит, что TCP ACK на эти «как бы потерянные» пакеты есть, а значит, эти пакеты потеряли мы сами.
В обратном случае (исследование места реальных потерь пакетов в сети, packet loss), где задача – найти сбойное сетевое устройство, вызывающее потери, вы не можете себе позволить дропы, потому что они исказят всю картину. Вы можете быть не в состоянии разграничить, был ли этот пакет реально потерян кем-то другим, или виновник – вы же сами.
Несущественные дропы
Дропы становятся несущественными, если аналитику и так не нужен был каждый пакет. Например, если он делает снимок характеристик трафика в сети (baselining). Если просто нужно собрать некоторую статистику сети (например, распределение протоколов, «какой процент от всех пакетов у нас НТТР?»), вы можете запросто пережить дропы. Они особо не повлияют на конечный результат (ну, конечно, если у вас их не огромное количество) 🙂
Заключение
Да, я помню, что в первой части говорил, что сегодня мы рассмотрим и сетевые карты, но не хотелось бы делать очень длинную статью, и потому я отложил их на потом. Иначе пришлось бы сокращать другой материал, а это нежелательно. Зато теперь сетевые карты займут свою собственную целую статью.
Что стоит вынести из данной статьи:
– дропы могут быть как большой проблемой, так и не очень;
– полный дуплекс – это скорость больше, чем она кажется на первый взгляд, и если канал загружен, а у вас карта захвата только с одним портом…
Статья переведена и опубликована с разрешения автора (Jasper Bongertz) только для сайта packettrain.net
Использование материала статьи без согласования запрещено!
Оригинал статьи находится по адресу: https://blog.packet-foo.com/2016/10/the-network-capture-playbook-part-2-speed-duplex-and-drops/
This article has been translated and published with author’s (Jasper Bongertz) permission. For packettrain.net website only!
Original article can be found at: https://blog.packet-foo.com/2016/10/the-network-capture-playbook-part-2-speed-duplex-and-drops/