Гетероскедастичность
Случайной ошибкой
называется отклонение в линейной модели
множественной регрессии:
εi=yi–β0–β1x1i–…–βmxmi
В связи с тем, что
величина случайной ошибки модели
регрессии является неизвестной величиной,
рассчитывается выборочная оценка
случайной ошибки модели регрессии по
формуле:
![]()
где ei – остатки
модели регрессии.
Термин
гетероскедастичность в широком смысле
понимается как предположение о дисперсии
случайных ошибок модели регрессии.
При построении
нормальной линейной модели регрессии
учитываются следующие условия, касающиеся
случайной ошибки модели регрессии:
6) математическое
ожидание случайной ошибки модели
регрессии равно нулю во всех наблюдениях:
![]()
7) дисперсия случайной
ошибки модели регрессии постоянна для
всех наблюдений:
![]()
 между значениями
между значениями
случайных ошибок модели регрессии в
любых двух наблюдениях отсутствует
систематическая взаимосвязь, т. е.
случайные ошибки модели регрессии не
коррелированны между собой (ковариация
случайных ошибок любых двух разных
наблюдений равна нулю):
![]()
Второе условие
![]()
означает
гомоскедастичность (homoscedasticity – однородный
разброс) дисперсий случайных ошибок
модели регрессии.
Под гомоскедастичностью
понимается предположение о том, что
дисперсия случайной ошибки βi является
известной постоянной величиной для
всех наблюдений.
Но на практике
предположение о гомоскедастичности
случайной ошибки βi или остатков модели
регрессии ei выполняется не всегда.
Под гетероскедастичностью
(heteroscedasticity – неоднородный разброс)
понимается предположение о том, что
дисперсии случайных ошибок являются
разными величинами для всех наблюдений,
что означает нарушение второго условия
нормальной линейной модели множественной
регрессии:
![]()
Гетероскедастичность
можно записать через ковариационную
матрицу случайных ошибок модели
регрессии:

Тогда можно
утверждать, что случайная ошибка модели
регрессии βi подчиняется нормальному
закону распределения с нулевым
математическим ожиданием и дисперсией
G2Ω:
εi~N(0; G2Ω),
где Ω – матрица
ковариаций случайной ошибки.
Если дисперсии
случайных ошибок
![]()
модели регрессии
известны заранее, то проблема
гетероскедастичности легко устраняется.
Однако в большинстве случаев неизвестными
являются не только дисперсии случайных
ошибок, но и сама функция регрессионной
зависимости y=f(x), которую предстоит
построить и оценить.
Для обнаружения
гетероскедастичности остатков модели
регрессии необходимо провести их анализ.
При этом проверяются следующие гипотезы.
Основная гипотеза
H0 предполагает постоянство дисперсий
случайных ошибок модели регрессии, т.
е. присутствие в модели условия
гомоскедастичности:
![]()
Альтернативная
гипотеза H1 предполагает непостоянство
дисперсиий случайных ошибок в различных
наблюдениях, т. е. присутствие в модели
условия гетероскедастичности:
![]()
Гетероскедастичность
остатков модели регрессии может привести
к негативным последствиям:
1) оценки неизвестных
коэффициентов нормальной линейной
модели регрессии являются несмещёнными
и состоятельными, но при этом теряется
свойство эффективности;
2) существует большая
вероятность того, что оценки стандартных
ошибок коэффициентов модели регрессии
будут рассчитаны неверно, что конечном
итоге может привести к утверждению
неверной гипотезы о значимости
коэффициентов регрессии и значимости
модели регрессии в целом.
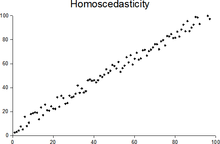
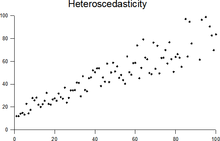
Гомоскедастичность
Гомоскедастичность
остатков означает, что дисперсия каждого
отклонения одинакова для всех значений
x. Если это условие не соблюдается, то
имеет место гетероскедастичность.
Наличие гетероскедастичности можно
наглядно видеть из поля корреляции.


Т.к. дисперсия
характеризует отклонение то из рисунков
видно, что в первом случае дисперсия
остатков растет по мере увеличения x, а
во втором – дисперсия остатков достигает
максимальной величины при средних
значениях величины x и уменьшается при
минимальных и максимальных значениях
x. Наличие гетероскедастичности будет
сказываться на уменьшении эффективности
оценок параметров уравнения регрессии.
Наличие гомоскедастичности или
гетероскедастичности можно определять
также по графику зависимости остатков
от теоретических значений
![]() .
.

Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Гомоскедастичность – допущение линейной регрессии об «одинаковости» Дисперсии (Variance). Иными словами, разность между реальным Ypred и предсказанным Yactual значениями, скажем, Линейной регрессии (Linear Regresion) остается в определенном известном диапазоне, что позволяет в принципе использовать такую Модель (Model). В случае такого единообразия ошибок Наблюдения (Observation) с большими значениями будут иметь то же влияние на предсказывающий Алгоритм (Algorithm), что и наблюдения с меньшими значениями:

Линейная регрессия базируется на предположении, что для всех случаев ошибки будут одинаковыми и с очень малой дисперсией.
Пример. У нас есть две переменные – высота дерева навскидку и реальный его рост. Естественно, по мере увеличения оценочной высоты реальные тоже растут. Итак, мы подбираем модель линейной регрессии и видим, что ошибки имеют одинаковую дисперсию:

Прогнозы почти совпадают с линейной регрессией и имеют одинаковую известную дисперсию повсюду. Кроме того, если мы нанесем эти остатки на ось X, мы увидим их вдоль прямой линии, параллельной оси X. Это явный признак гомоскедастичности.

Когда это условие нарушается, в модели присутствует Гетероскедастичность (Heteroscedasticity). Предположим, что для деревьев с меньшей приблизительной высотой разность между прогнозируемым и реальным значением меньше, чем для высоких представителей флоры. По мере увеличения высоты дисперсия в прогнозах увеличивается, что приводит к увеличению значения ошибки или Остатка (Residual). Когда мы снова построим график остатков, то увидим типичную коническую кривую, которая четко указывает на наличие гетероскедастичности в модели:

Гетероскедастичность – это систематическое увеличение или уменьшение дисперсии остатков в диапазоне независимых переменных. Это проблема, потому нарушается базовое предположение о линейной регрессии: все ошибки должны иметь одинаковую дисперсию.
Как узнать, присутствует ли гетероскедастичность?
Проще говоря, самый простой способ узнать, присутствует ли гетероскедастичность, – построить график остатков. Если вы видите какую-либо закономерность, значит, есть гетероскедастичность. Обычно значения увеличиваются, образуя конусообразную кривую.
Причины гетероскедастичности
- Есть большая разница в переменной. Другими словами, когда наименьшее и наибольшее значения переменной слишком экстремальны. Это также могут быть Выбросы (Outlier).
- Мы выбираем неправильную модель. Если вы подгоните модель линейной регрессии к нелинейным данным, это приведет к гетероскедастичности.
- Когда масштаб значений в переменной некорректен (например, стоит рассматривать данные по сезонам, а не по дням).
- Когда для регрессии используется неправильное преобразование данных.
- Когда в данных присутствует Скошенность (Skewness).
Чистая и нечистая гетероскедастичности
Когда мы подбираем правильную модель (линейную или нелинейную) и все же есть видимый образец в остатках, это называется чистой гетероскедастичностью.
Однако, если мы подбираем неправильную модель, а затем наблюдаем закономерность в остатках, то это случай нечистой гетероскедастичности. В зависимости от типа гетероскедастичности необходимо принять меры для ее преодоления. Это зависит и от сферы, в которой мы работаем.
Эффекты гетероскедастичности в Машинном обучении
Как мы обсуждали ранее, модель линейной регрессии делает предположение о наличии гомоскедастичности в данных. Если это предположение неверно, мы не сможем доверять полученным результатам.
Наличие гетероскедастичности делает коэффициенты менее точными, и, следовательно, правильные находятся дальше от значения Генеральной совокупности (Population).
Как лечить гетероскедастичность?
Если мы обнаружили гетероскедастичность, есть несколько способов справиться с ней. Во-первых, давайте рассмотрим пример, в котором у нас есть две переменные: население города и количество заражений COVID-19.
В этом примере будет огромная разница в количестве заражений в крупных мегаполисах по сравнению с небольшими городами. Переменная «Количество инфекций» будет Целевой переменной (Target Variable), а «Население города» – Предиктором (Predictor Variable). Мы знаем, что в модели присутствует гетероскедастичность, и ее необходимо исправить.
В нашем случае, источник проблемы – это переменная с большой дисперсией (Население). Есть несколько способов справиться с подобным неоднообразием остатков, мы же рассмотрим три таких метода.
Управление переменными
Мы можем внести некоторые изменения в имеющиеся переменные, чтобы уменьшить влияние этой большой дисперсии на прогнозы модели. Один из способов сделать это – осуществить Нормализацию (Normalization), то есть привести значения Признака (Feature) к диапазону от 0 до 1. Это заставит признаки передавать немного другую информацию. От проблемы и данных будет зависеть, можно ли реализовать такой подход.
Этот метод требует минимальных модификаций и часто помогает решить проблему, а в некоторых случаях даже повысить производительность модели.
В нашем случае, мы изменим параметр «Количество инфекций» на «Скорость заражения». Это поможет уменьшить дисперсию, поскольку совершенно очевидно, что число инфекций в городах с большой численностью населения будет большим.
Взвешенная регрессия
Взвешенная регрессия – это модификация нормальной регрессии, при которой точкам данных присваиваются определенные Веса (Weights) в соответствии с их дисперсией. Те, у которых есть бо́льшая дисперсия, получают небольшой вес, а те, у которых меньшая дисперсия, получают бо́льший вес.
Таким образом, когда веса возведены в квадрат, это позволяет снизить влияние остатков с большой дисперсией.
Когда используются правильные веса, гетероскедастичность заменяется гомоскедастичностью. Но как найти правильный вес? Один из быстрых способов – использовать инверсию этой переменной в качестве веса (население города превратится в дробь 1/n, где n – число жителей).
Трансформация
Преобразование данных – последнее средство, поскольку при этом вы теряете интерпретируемость функции. Это означает, что вы больше не сможете легко объяснить, что показывает признак. Один из способов – взятие логарифма. Воспринять новые значения высоты дерева (например, 16 метров превратятся в ≈2.772) будет сложнее.
Фото: @sorasagano
Автор оригинальной статьи: Pavan Vadapalli
From Wikipedia, the free encyclopedia
In statistics, a sequence (or a vector) of random variables is homoscedastic () if all its random variables have the same finite variance; this is also known as homogeneity of variance. The complementary notion is called heteroscedasticity, also known as heterogeneity of variance. The spellings homoskedasticity and heteroskedasticity are also frequently used.[1][2][3]
Assuming a variable is homoscedastic when in reality it is heteroscedastic () results in unbiased but inefficient point estimates and in biased estimates of standard errors, and may result in overestimating the goodness of fit as measured by the Pearson coefficient.
The existence of heteroscedasticity is a major concern in regression analysis and the analysis of variance, as it invalidates statistical tests of significance that assume that the modelling errors all have the same variance. While the ordinary least squares estimator is still unbiased in the presence of heteroscedasticity, it is inefficient and inference based on the assumption of homoskedasticity is misleading. In that case, generalized least squares (GLS) was frequently used in the past.[4][5] Nowadays, standard practice in econometrics is to include Heteroskedasticity-consistent standard errors instead of using GLS, as GLS can exhibit strong bias in small samples if the actual Skedastic function is unknown.[6]
Because heteroscedasticity concerns expectations of the second moment of the errors, its presence is referred to as misspecification of the second order.[7]
The econometrician Robert Engle was awarded the 2003 Nobel Memorial Prize for Economics for his studies on regression analysis in the presence of heteroscedasticity, which led to his formulation of the autoregressive conditional heteroscedasticity (ARCH) modeling technique.[8]
Definition[edit]
Consider the linear regression equation  where the dependent random variable
where the dependent random variable  equals the deterministic variable
equals the deterministic variable  times coefficient
times coefficient  plus a random disturbance term
plus a random disturbance term  that has mean zero. The disturbances are homoscedastic if the variance of is a constant
that has mean zero. The disturbances are homoscedastic if the variance of is a constant  ; otherwise, they are heteroscedastic. In particular, the disturbances are heteroscedastic if the variance of depends on
; otherwise, they are heteroscedastic. In particular, the disturbances are heteroscedastic if the variance of depends on  or on the value of . One way they might be heteroscedastic is if
or on the value of . One way they might be heteroscedastic is if  (an example of a scedastic function), so the variance is proportional to the value of
(an example of a scedastic function), so the variance is proportional to the value of  .
.
More generally, if the variance-covariance matrix of disturbance across has a nonconstant diagonal, the disturbance is heteroscedastic.[9] The matrices below are covariances when there are just three observations across time. The disturbance in matrix A is homoscedastic; this is the simple case where OLS is the best linear unbiased estimator. The disturbances in matrices B and C are heteroscedastic. In matrix B, the variance is time-varying, increasing steadily across time; in matrix C, the variance depends on the value of . The disturbance in matrix D is homoscedastic because the diagonal variances are constant, even though the off-diagonal covariances are non-zero and ordinary least squares is inefficient for a different reason: serial correlation.

Examples[edit]
Heteroscedasticity often occurs when there is a large difference among the sizes of the observations.
A classic example of heteroscedasticity is that of income versus expenditure on meals. A wealthy person may eat inexpensive food sometimes and expensive food at other times. A poor person will almost always eat inexpensive food. Therefore, people with higher incomes exhibit greater variability in expenditures on food.
At a rocket launch, an observer measures the distance traveled by the rocket once per second. In the first couple of seconds, the measurements may be accurate to the nearest centimeter. After five minutes, the accuracy of the measurements may be good only to 100 m, because of the increased distance, atmospheric distortion, and a variety of other factors. So the measurements of distance may exhibit heteroscedasticity.
Consequences[edit]
One of the assumptions of the classical linear regression model is that there is no heteroscedasticity. Breaking this assumption means that the Gauss–Markov theorem does not apply, meaning that OLS estimators are not the Best Linear Unbiased Estimators (BLUE) and their variance is not the lowest of all other unbiased estimators.
Heteroscedasticity does not cause ordinary least squares coefficient estimates to be biased, although it can cause ordinary least squares estimates of the variance (and, thus, standard errors) of the coefficients to be biased, possibly above or below the true of population variance. Thus, regression analysis using heteroscedastic data will still provide an unbiased estimate for the relationship between the predictor variable and the outcome, but standard errors and therefore inferences obtained from data analysis are suspect. Biased standard errors lead to biased inference, so results of hypothesis tests are possibly wrong. For example, if OLS is performed on a heteroscedastic data set, yielding biased standard error estimation, a researcher might fail to reject a null hypothesis at a given significance level, when that null hypothesis was actually uncharacteristic of the actual population (making a type II error).
Under certain assumptions, the OLS estimator has a normal asymptotic distribution when properly normalized and centered (even when the data does not come from a normal distribution). This result is used to justify using a normal distribution, or a chi square distribution (depending on how the test statistic is calculated), when conducting a hypothesis test. This holds even under heteroscedasticity. More precisely, the OLS estimator in the presence of heteroscedasticity is asymptotically normal, when properly normalized and centered, with a variance-covariance matrix that differs from the case of homoscedasticity. In 1980, White proposed a consistent estimator for the variance-covariance matrix of the asymptotic distribution of the OLS estimator.[2] This validates the use of hypothesis testing using OLS estimators and White’s variance-covariance estimator under heteroscedasticity.
Heteroscedasticity is also a major practical issue encountered in ANOVA problems.[10]
The F test can still be used in some circumstances.[11]
However, it has been said that students in econometrics should not overreact to heteroscedasticity.[3] One author wrote, «unequal error variance is worth correcting only when the problem is severe.»[12] In addition, another word of caution was in the form, «heteroscedasticity has never been a reason to throw out an otherwise good model.»[3][13] With the advent of heteroscedasticity-consistent standard errors allowing for inference without specifying the conditional second moment of error term, testing conditional homoscedasticity is not as important as in the past.[6]
For any non-linear model (for instance Logit and Probit models), however, heteroscedasticity has more severe consequences: the maximum likelihood estimates (MLE) of the parameters will usually be biased, as well as inconsistent (unless the likelihood function is modified to correctly take into account the precise form of heteroscedasticity or the distribution is a member of the linear exponential family and the conditional expectation function is correctly specified).[14][15] Yet, in the context of binary choice models (Logit or Probit), heteroscedasticity will only result in a positive scaling effect on the asymptotic mean of the misspecified MLE (i.e. the model that ignores heteroscedasticity).[16] As a result, the predictions which are based on the misspecified MLE will remain correct. In addition, the misspecified Probit and Logit MLE will be asymptotically normally distributed which allows performing the usual significance tests (with the appropriate variance-covariance matrix). However, regarding the general hypothesis testing, as pointed out by Greene, “simply computing a robust covariance matrix for an otherwise inconsistent estimator does not give it redemption. Consequently, the virtue of a robust covariance matrix in this setting is unclear.”[17]
Correction[edit]
There are several common corrections for heteroscedasticity. They are:
- A stabilizing transformation of the data, e.g. logarithmized data. Non-logarithmized series that are growing exponentially often appear to have increasing variability as the series rises over time. The variability in percentage terms may, however, be rather stable.
- Use a different specification for the model (different X variables, or perhaps non-linear transformations of the X variables).
- Apply a weighted least squares estimation method, in which OLS is applied to transformed or weighted values of X and Y. The weights vary over observations, usually depending on the changing error variances. In one variation the weights are directly related to the magnitude of the dependent variable, and this corresponds to least squares percentage regression.[18]
- Heteroscedasticity-consistent standard errors (HCSE), while still biased, improve upon OLS estimates.[2] HCSE is a consistent estimator of standard errors in regression models with heteroscedasticity. This method corrects for heteroscedasticity without altering the values of the coefficients. This method may be superior to regular OLS because if heteroscedasticity is present it corrects for it, however, if the data is homoscedastic, the standard errors are equivalent to conventional standard errors estimated by OLS. Several modifications of the White method of computing heteroscedasticity-consistent standard errors have been proposed as corrections with superior finite sample properties.
- Wild bootstrapping can be used as a Resampling method that respects the differences in the conditional variance of the error term. An alternative is resampling observations instead of errors. Note resampling errors without respect for the affiliated values of the observation enforces homoskedasticity and thus yields incorrect inference.
- Use MINQUE or even the customary estimators
 (for independent samples with observations each), whose efficiency losses are not substantial when the number of observations per sample is large (), especially for small number of independent samples.[19]
(for independent samples with observations each), whose efficiency losses are not substantial when the number of observations per sample is large (), especially for small number of independent samples.[19]




Testing[edit]

Residuals can be tested for homoscedasticity using the Breusch–Pagan test,[20] which performs an auxiliary regression of the squared residuals on the independent variables. From this auxiliary regression, the explained sum of squares is retained, divided by two, and then becomes the test statistic for a chi-squared distribution with the degrees of freedom equal to the number of independent variables.[21] The null hypothesis of this chi-squared test is homoscedasticity, and the alternative hypothesis would indicate heteroscedasticity. Since the Breusch–Pagan test is sensitive to departures from normality or small sample sizes, the Koenker–Bassett or ‘generalized Breusch–Pagan’ test is commonly used instead.[22][additional citation(s) needed] From the auxiliary regression, it retains the R-squared value which is then multiplied by the sample size, and then becomes the test statistic for a chi-squared distribution (and uses the same degrees of freedom). Although it is not necessary for the Koenker–Bassett test, the Breusch–Pagan test requires that the squared residuals also be divided by the residual sum of squares divided by the sample size.[22] Testing for groupwise heteroscedasticity can be done with the Goldfeld–Quandt test.[23]
Due to the standard use of heteroskedasticity-consistent Standard Errors and the problem of Pre-test, econometricians nowadays rarely use tests for conditional heteroskedasticity.[6]
List of tests[edit]
Although tests for heteroscedasticity between groups can formally be considered as a special case of testing within regression models, some tests have structures specific to this case.
Generalisations[edit]
Homoscedastic distributions[edit]
Two or more normal distributions,  are both homoscedastic and lack Serial correlation if they share the same diagonals in their covariance matrix,
are both homoscedastic and lack Serial correlation if they share the same diagonals in their covariance matrix,  and their non-diagonal entries are zero. Homoscedastic distributions are especially useful to derive statistical pattern recognition and machine learning algorithms. One popular example of an algorithm that assumes homoscedasticity is Fisher’s linear discriminant analysis.
and their non-diagonal entries are zero. Homoscedastic distributions are especially useful to derive statistical pattern recognition and machine learning algorithms. One popular example of an algorithm that assumes homoscedasticity is Fisher’s linear discriminant analysis.
The concept of homoscedasticity can be applied to distributions on spheres.[27]
Multivariate data[edit]
The study of homescedasticity and heteroscedasticity has been generalized to the multivariate case, which deals with the covariances of vector observations instead of the variance of scalar observations. One version of this is to use covariance matrices as the multivariate measure of dispersion. Several authors have considered tests in this context, for both regression and grouped-data situations.[28][29] Bartlett’s test for heteroscedasticity between grouped data, used most commonly in the univariate case, has also been extended for the multivariate case, but a tractable solution only exists for 2 groups.[30] Approximations exist for more than two groups, and they are both called Box’s M test.
See also[edit]
- Heterogeneity
- Spherical error
- Heteroskedasticity-consistent standard errors
References[edit]
- ^ For the Greek etymology of the term, see McCulloch, J. Huston (1985). «On Heteros*edasticity». Econometrica. 53 (2): 483. JSTOR 1911250.
- ^ a b c d
White, Halbert (1980). «A heteroskedasticity-consistent covariance matrix estimator and a direct test for heteroskedasticity». Econometrica. 48 (4): 817–838. CiteSeerX 10.1.1.11.7646. doi:10.2307/1912934. JSTOR 1912934. - ^ a b c
Gujarati, D. N.; Porter, D. C. (2009). Basic Econometrics (Fifth ed.). Boston: McGraw-Hill Irwin. p. 400. ISBN 9780073375779. - ^ Goldberger, Arthur S. (1964). Econometric Theory. New York: John Wiley & Sons. pp. 238–243. ISBN 9780471311010.
- ^ Johnston, J. (1972). Econometric Methods. New York: McGraw-Hill. pp. 214–221.
- ^ a b c Angrist, Joshua D.; Pischke, Jörn-Steffen (2009-12-31). Mostly Harmless Econometrics: An Empiricist’s Companion. Princeton University Press. doi:10.1515/9781400829828. ISBN 978-1-4008-2982-8.
- ^ Long, J. Scott; Trivedi, Pravin K. (1993). «Some Specification Tests for the Linear Regression Model». In Bollen, Kenneth A.; Long, J. Scott (eds.). Testing Structural Equation Models. London: Sage. pp. 66–110. ISBN 978-0-8039-4506-7.
- ^ Engle, Robert F. (July 1982). «Autoregressive Conditional Heteroscedasticity with Estimates of the Variance of United Kingdom Inflation». Econometrica. 50 (4): 987–1007. doi:10.2307/1912773. ISSN 0012-9682. JSTOR 1912773.
- ^ Peter Kennedy, A Guide to Econometrics, 5th edition, p. 137.
- ^ Jinadasa, Gamage; Weerahandi, Sam (1998). «Size performance of some tests in one-way anova». Communications in Statistics — Simulation and Computation. 27 (3): 625. doi:10.1080/03610919808813500.
- ^ Bathke, A (2004). «The ANOVA F test can still be used in some balanced designs with unequal variances and nonnormal data». Journal of Statistical Planning and Inference. 126 (2): 413–422. doi:10.1016/j.jspi.2003.09.010.
- ^ Fox, J. (1997). Applied Regression Analysis, Linear Models, and Related Methods. California: Sage Publications. p. 306. (Cited in Gujarati et al. 2009, p. 400)
- ^ Mankiw, N. G. (1990). «A Quick Refresher Course in Macroeconomics». Journal of Economic Literature. 28 (4): 1645–1660 [p. 1648]. doi:10.3386/w3256. JSTOR 2727441.
- ^ Giles, Dave (May 8, 2013). «Robust Standard Errors for Nonlinear Models». Econometrics Beat.
- ^ Gourieroux, C.; Monfort, A.; Trognon, A. (1984). «Pseudo Maximum Likelihood Methods: Theory». Econometrica. 52 (3): 681–700. doi:10.2307/1913471. ISSN 0012-9682.
- ^ Ginker, T.; Lieberman, O. (2017). «Robustness of binary choice models to conditional heteroscedasticity». Economics Letters. 150: 130–134. doi:10.1016/j.econlet.2016.11.024.
- ^ Greene, William H. (2012). «Estimation and Inference in Binary Choice Models». Econometric Analysis (Seventh ed.). Boston: Pearson Education. pp. 730–755 [p. 733]. ISBN 978-0-273-75356-8.
- ^ Tofallis, C (2008). «Least Squares Percentage Regression». Journal of Modern Applied Statistical Methods. 7: 526–534. doi:10.2139/ssrn.1406472. SSRN 1406472.
- ^ J. N. K. Rao (March 1973). «On the Estimation of Heteroscedastic Variances». Biometrics. 29 (1): 11–24. doi:10.2307/2529672. JSTOR 2529672.
- ^ Breusch, T. S.; Pagan, A. R. (1979). «A Simple Test for Heteroscedasticity and Random Coefficient Variation». Econometrica. 47 (5): 1287–1294. doi:10.2307/1911963. ISSN 0012-9682. JSTOR 1911963.
- ^ Ullah, Muhammad Imdad (2012-07-26). «Breusch Pagan Test for Heteroscedasticity». Basic Statistics and Data Analysis. Retrieved 2020-11-28.
- ^ a b Pryce, Gwilym. «Heteroscedasticity: Testing and Correcting in SPSS» (PDF). pp. 12–18. Archived (PDF) from the original on 2017-03-27. Retrieved 26 March 2017.
- ^ Baum, Christopher F. (2006). «Stata Tip 38: Testing for Groupwise Heteroskedasticity». The Stata Journal: Promoting Communications on Statistics and Stata. 6 (4): 590–592. doi:10.1177/1536867X0600600412. ISSN 1536-867X. S2CID 117349246.
- ^ R. E. Park (1966). «Estimation with Heteroscedastic Error Terms». Econometrica. 34 (4): 888. doi:10.2307/1910108. JSTOR 1910108.
- ^ Glejser, H. (1969). «A new test for heteroscedasticity». Journal of the American Statistical Association. 64 (325): 316–323. doi:10.1080/01621459.1969.10500976.
- ^ Machado, José A. F.; Silva, J. M. C. Santos (2000). «Glejser’s test revisited». Journal of Econometrics. 97 (1): 189–202. doi:10.1016/S0304-4076(00)00016-6.
- ^ Hamsici, Onur C.; Martinez, Aleix M. (2007) «Spherical-Homoscedastic Distributions: The Equivalency of Spherical and Normal Distributions in Classification», Journal of Machine Learning Research, 8, 1583-1623
- ^
- ^ Gupta, A. K.; Tang, J. (1984). «Distribution of likelihood ratio statistic for testing equality of covariance matrices of multivariate Gaussian models». Biometrika. 71 (3): 555–559. doi:10.1093/biomet/71.3.555. JSTOR 2336564.
- ^ d’Agostino, R. B.; Russell, H. K. (2005). «Multivariate Bartlett Test». Encyclopedia of Biostatistics. doi:10.1002/0470011815.b2a13048. ISBN 978-0470849071.
Further reading[edit]
Most statistics textbooks will include at least some material on homoscedasticity and heteroscedasticity. Some examples are:
- Asteriou, Dimitros; Hall, Stephen G. (2011). Applied Econometrics (Second ed.). Palgrave MacMillan. pp. 109–147. ISBN 978-0-230-27182-1.
- Davidson, Russell; MacKinnon, James G. (1993). Estimation and Inference in Econometrics. New York: Oxford University Press. pp. 547–582. ISBN 978-0-19-506011-9.
- Dougherty, Christopher (2011). Introduction to Econometrics. New York: Oxford University Press. pp. 280–299. ISBN 978-0-19-956708-9.
- Gujarati, Damodar N.; Porter, Dawn C. (2009). Basic Econometrics (Fifth ed.). New York: McGraw-Hill Irwin. pp. 365–411. ISBN 978-0-07-337577-9.
- Kmenta, Jan (1986). Elements of Econometrics (Second ed.). New York: Macmillan. pp. 269–298. ISBN 978-0-02-365070-3.
- Maddala, G. S.; Lahiri, Kajal (2009). Introduction to Econometrics (Fourth ed.). New York: Wiley. pp. 211–238. ISBN 978-0-470-01512-4.
External links[edit]
- Econometrics lecture (topic: heteroscedasticity) on YouTube by Mark Thoma
Гомоскедастичность
-
Гомоскедастичность (англ. homoscedasticity) — однородная вариативность значений наблюдений, выражающаяся в относительной стабильности, гомогенности дисперсии случайной ошибки регрессионной модели. Явление, противоположное гетероскедастичности. Является обязательным предусловием применения метода наименьших квадратов, который может быть использован только для гомоскедастичных наблюдений.
Иногда говорят о скедастичности (англ. scedasticity) как свойстве, отражающем вариативность наблюдений, принимающей форму гомоскедастичности при однородных случайных ошибках, и гетероскедастичности в противном случае.
Источник: Википедия
Связанные понятия
Робастность (англ. robustness, от robust — «крепкий», «сильный», «твёрдый», «устойчивый») — свойство статистического метода, характеризующее независимость влияния на результат исследования различного рода выбросов, устойчивости к помехам. Выбросоустойчивый (робастный) метод — метод, направленный на выявление выбросов, снижение их влияния или исключение их из выборки.
Фа́кторный анализ — многомерный метод, применяемый для изучения взаимосвязей между значениями переменных. Предполагается, что известные переменные зависят от меньшего количества неизвестных переменных и случайной ошибки.
Экзогенность — буквально «внешнее происхождение» — свойство факторов (и важнейшее требование, предъявляемое к ним) эконометрических моделей, заключающееся в предопределённости, заданности их значений, независимости от функционирования моделируемой системы (явления, процесса). Экзогенность противоположна эндогенности. Значения экзогенных переменных определяется вне модели, и на их основе в рамках рассматриваемой модели определяются значения эндогенных переменных.
Гауссовский процесс назван так в честь Карла Фридриха Гаусса, поскольку в его основе лежит понятие гауссовского распределения (нормального распределения). Гауссовский процесс может рассматриваться как бесконечномерное обобщение многомерных нормальных распределений. Эти процессы применяются в статистическом моделировании; в частности используются свойства нормальности. Например, если случайный процесс моделируется как гауссовский, то распределения различных производных величин, такие как среднее значение…
Гетероскедастичность (англ. heteroscedasticity) — понятие, используемое в прикладной статистике (чаще всего — в эконометрике), означающее неоднородность наблюдений, выражающуюся в неодинаковой (непостоянной) дисперсии случайной ошибки регрессионной (эконометрической) модели. Гетероскедастичность противоположна гомоскедастичности, означающей однородность наблюдений, то есть постоянство дисперсии случайных ошибок модели.
Стационарность или постоянство — свойство процесса не менять свои характеристики со временем. Понятие используется в нескольких разделах науки.
Корреляционная функция — функция времени и пространственных координат, которая задает корреляцию в системах со случайными процессами.
Случайные сигналы — сигналы, мгновенные значения которых (в отличие от детерминированных сигналов) не известны, а могут быть лишь предсказаны с некоторой вероятностью, меньшей единицы. Характеристики таких сигналов являются статистическими, то есть имеют вероятностный вид.
Подробнее: Случайный сигнал
Конти́нуум в физике обозначает некоторую сплошную среду, в которой исследуются процессы/поведение этой среды при различных внешних условиях. Вводится на основании гипотезы сплошности, в рамках которой пренебрегают структурой исследуемых тел и сред, усредняя их микроструктурные характеристики по физически малому объёму. Непрерывным континуумом можно считать как обычные материальные тела, так и различные поля, например, электромагнитное поле.
Модель бинарного выбора — применяемая в эконометрике модель зависимости бинарной переменной (принимающей всего два значения — 0 и 1) от совокупности факторов. Построение обычной линейной регрессии для таких переменных теоретически некорректно, так как условное математическое ожидание таких переменных равно вероятности того, что зависимая переменная примет значение 1, а линейная регрессия допускает и отрицательные значения и значения выше 1. Поэтому обычно используются некоторые интегральные функции…
Пра́вило фаз (или правило фаз Гиббса) — соотношение, связывающее число компонентов, фаз и термодинамических степеней свободы в равновесной термодинамической системе. Роль правила фаз особенно велика при рассмотрении гетерогенных равновесий в многофазных многокомпонентных системах.
Логистическая регрессия или логит-регрессия (англ. logit model) — это статистическая модель, используемая для прогнозирования вероятности возникновения некоторого события путём подгонки данных к логистической кривой.
Система одновременных уравнений — совокупность эконометрических уравнений (часто линейных), определяющих взаимозависимость экономических переменных. Важным отличительным признаком системы «одновременных» уравнений от прочих систем уравнений является наличие одних и тех же переменных в правых и левых частях разных уравнений системы (речь идет о так называемой структурной форме модели, см. ниже).
Аддитивность (лат. additivus — прибавляемый) — свойство величин, состоящее в том, что значение величины, соответствующее целому объекту, равно сумме значений величин, соответствующих его частям, в некотором классе возможных разбиений объекта на части. Например, аддитивность объёма означает, что объём целого тела равен сумме объёмов составляющих его частей.
Автокорреляция — статистическая взаимосвязь между последовательностями величин одного ряда, взятыми со сдвигом, например, для случайного процесса — со сдвигом по времени.
Выборка по значимости (англ. importance sampling, далее ВЗ) — один из методов уменьшения дисперсии случайной величины, который используется для улучшения сходимости процесса моделирования какой-либо величины методом Монте-Карло. Идея ВЗ основывается на том, что некоторые значения случайной величины в процессе моделирования имеют бо́льшую значимость (вероятность) для оцениваемой функции (параметра), чем другие. Если эти «более вероятные» значения будут появляться в процессе выбора случайной величины…
Вариа́ция — различие значений какого-либо признака у разных единиц совокупности за один и тот же промежуток времени. Причиной возникновения вариации являются различные условия существования разных единиц совокупности. Вариация — необходимое условие существования и развития массовых явлений.
Дисперсионный анализ — метод в математической статистике, направленный на поиск зависимостей в экспериментальных данных путём исследования значимости различий в средних значениях. В отличие от t-критерия, позволяет сравнивать средние значения трёх и более групп. Разработан Р. Фишером для анализа результатов экспериментальных исследований. В литературе также встречается обозначение ANOVA (от англ. ANalysis Of VAriance).
Погрешность измерения — отклонение измеренного значения величины от её истинного (действительного) значения. Погрешность измерения является характеристикой точности измерения.
Многочасти́чный фильтр (МЧФ, англ. particle filter — «фильтр частиц», «частичный фильтр», «корпускулярный фильтр») — последовательный метод Монте-Карло — рекурсивный алгоритм для численного решения проблем оценивания (фильтрации, сглаживания), особенно для нелинейных и не-гауссовских случаев. Со времени описания в 1993 году Н. Гордоном, Д. Салмондом и А. Смитом используется в различных областях — навигации, робототехнике, компьютерном зрении.
Фиксированные эффекты с разложением вектора (англ. Fixed-effects vector decomposition, FEVD) — разновидность регрессионного анализа на панельных данных с фиксированными эффектами, позволяющая измерять эффекты не изменяющихся во времени предикторов вместе с фиксированными эффектами групп наблюдений (стандартные FE-оценки не позволяют оценивать не различающиеся во времени предикторы). Первоначально метод был предложен в статье (Plümper, Troeger, 2007).
Закон сравнительных суждений — психофизический закон, определяющий отношение между двумя объектами в психическом пространстве человека. Сформулирован Л. Л. Терстоуном.
В статистической термодинамике энтропия Цаллиса — обобщение стандартной энтропии Больцмана—Гиббса, предложенное Константино Цаллисом (Constantino Tsallis) в 1988 г. для случая неэкстенсивных (неаддитивных) систем. Его гипотеза базируется на предположении, что сильное взаимодействие в термодинамически аномальной системе приводит к новым степеням свободы, к совершенно иной статистической физике небольцмановского типа.
Фазовые переходы второго рода — фазовые переходы, при которых вторые производные термодинамических потенциалов по давлению и температуре изменяются скачкообразно, тогда как их первые производные изменяются постепенно. Отсюда следует, в частности, что энергия и объём вещества при фазовом переходе второго рода не изменяются, но изменяются его теплоёмкость, сжимаемость, различные восприимчивости и т. д.
Надёжностью называется один из критериев качества теста, его устойчивость по отношению к погрешностям измерения. Различают два вида надёжности — надёжность как устойчивость и надёжность как внутреннюю согласованность.
Подробнее: Надёжность психологического теста
Т-критерий Вилкоксона — (также используются названия Т-критерий Уилкоксона, критерий Вилкоксона, критерий знаковых рангов Уилкоксона, критерий суммы рангов Уилкоксона) непараметрический статистический тест (критерий), используемый для проверки различий между двумя выборками парных или независимых измерений по уровню какого-либо количественного признака, измеренного в непрерывной или в порядковой шкале.. Впервые предложен Фрэнком Уилкоксоном. Другие названия — W-критерий Вилкоксона, критерий знаковых…
Подробнее: Критерий Уилкоксона
Обучение на примерах (англ. Learning from Examples) — вид обучения, при котором интеллектуальной системе предъявляется набор положительных и отрицательных примеров, связанных с какой-либо заранее неизвестной закономерностью. В интеллектуальных системах вырабатываются решающие правила, с помощью которых происходит разделение множества примеров на положительные и отрицательные. Качество разделения, как правило, проверяется экзаменационной выборкой примеров.
В обучении машин и распознавании образов признак — это индивидуальное измеримое свойство или характеристика наблюдаемого явления. Выбор информативных, отличительных и независимых признаков является критическим шагом для эффективных алгоритмов в распознавании образов, классификации и регрессии. Признаки обычно являются числовыми, но структурные признаки, такие как строки и графы, используются в синтаксическом распознавании образов.
Подробнее: Признак (обучение машин)
Пара́метр (от др.-греч. παραμετρέω — «отмеривающий»; где παρά: «рядом», «второстепенный», «вспомогательный», «подчинённый»; и μέτρον: «измерение») — величина, значения которой служат для различения элементов некоторого множества между собой.. Параметр — величина, постоянная в пределах данного явления или задачи, но при переходе к другому явлению или задаче могущая изменить своё значение. Иногда параметрами называют также величины, очень медленно изменяющиеся по сравнению с другими величинами (переменными…
Авторегрессионная условная гетероскедастичность (англ. ARCH; AutoRegressive Conditional Heteroscedasticity) — применяемая в эконометрике модель для анализа временных рядов (в первую очередь финансовых), у которых условная (по прошлым значениям ряда) дисперсия ряда зависит от прошлых значений ряда, прошлых значений этих дисперсий и иных факторов. Данные модели предназначены для «объяснения» кластеризации волатильности на финансовых рынках, когда периоды высокой волатильности длятся некоторое время…
Частотное распределение — метод статистического описания данных (измеренных значений, характерных значений). Математически распределение частот является функцией, которая в первую очередь определяет для каждого показателя идеальное значение, так как эта величина обычно уже измерена. Такое распределение можно представить в виде таблицы или графика, моделируя функциональные уравнения. В описательной статистике частота распределения имеет ряд математических функций, которые используются для выравнивания…
Ме́тод вы́борочных обсле́дований — способ определения свойств группы объектов (генеральной совокупности) на основании статистического исследования её части (выборки).
Анализ независимых компонент (АНК, англ. Independent Component Analysis, ICA), называемый также Метод независимых компонент (МНК) — это вычислительный метод в обработке сигналов для разделения многомерного сигнала на аддитивные подкомпоненты. Этот метод применяется при предположении, что подкомпоненты являются негауссовыми сигналами и что они статистически независимы друг от друга. АНК является специальным случаем слепого разделения сигнала. Типичным примером приложения является «Задача о шумной…
В статистике, машинном обучении и теории информации снижение размерности — это преобразование данных, состоящее в уменьшении числа переменных путём получения главных переменных. Преобразование может быть разделено на отбор признаков и выделение признаков.
Подробнее: Снижение размерности
Ядерная оценка плотности (ЯОП, англ. Kernel Density Estimation, KDE) — это непараметрический способ оценки плотности случайной величины. Ядерная оценка плотности является задачей сглаживания данных, когда делается заключение о совокупности, основываясь на конечных выборках данных. В некоторых областях, таких как обработка сигналов и математическая экономика, метод называется также методом окна Парзена-Розенблатта. Как считается, Эммануэль Парзен и Мюррей Розенблатт независимо создали метод в существующем…
Эмердже́нтность или эмерге́нтность (от англ. emergent «возникающий, неожиданно появляющийся») в теории систем — наличие у какой-либо системы особых свойств, не присущих её элементам, а также сумме элементов, не связанных особыми системообразующими связями; несводимость свойств системы к сумме свойств её компонентов; синонимы — синергичность, холизм, системный эффект, сверхаддитивный эффект.
Анализ размерности (чаще говорят «соображения размерности» или «метрические соображения») — инструмент, используемый в физике, химии, технике и нескольких направлениях экономики для построения обоснованных гипотез о взаимосвязи различных параметров сложной системы. Неоднократно применялся физиками на интуитивном уровне не позже XIX века.
Q-критерий Розенбаума — простой непараметрический статистический критерий, используемый для оценки различий между двумя выборками по уровню какого-либо признака, измеренного количественно.
Отбор признаков, известный также как отбор переменных, отбор атрибутов или отбор поднабора переменных, это процесс отбора подмножества значимых признаков (переменных зависимых и независимых) для использования в построении модели. Техники отбора признаков используются по четырём причинам…
В статистике под латентными или скрытыми переменными понимают такие переменные, которые не могут быть измерены в явном виде, а могут быть только выведены через математические модели с использованием наблюдаемых переменных. Скрытые переменные используются во многих областях, включая психологию, экономику, машинное обучение, биоинформатику, обработку естественного языка и социальные науки.
Подробнее: Скрытая переменная
В математической статистике семплирование — обобщенное название методов манипулирования начальной выборкой при известной цели моделирования, которые позволяют выполнить структурно-параметрическую идентификацию наилучшей статистической модели стационарного эргодического случайного процесса.
Фу́нкция поле́зности — функция, с помощью которой можно представить предпочтения на некотором множестве альтернатив. Функция полезности является очень удобным вспомогательным средством, которое открывает возможность использования теории оптимизации при решении задачи потребителя. Без использования функции полезности решение такой задачи с математической точки зрения может быть затруднительным. С другой стороны, не каждое предпочтение может быть представлено с помощью функции полезности. Тем не менее…
Анализ полных наблюдений (англ. listwise/casewise deletion, реже англ. complete-case analysis) — статистический метод обработки пропущенных данных, основанный на удалении всех наблюдений с неполными признаковыми описаниями. Считается самым простым способом разрешения проблемы пропущенных данных.
Аппроксима́ция (от лат. proxima — ближайшая) или приближе́ние — научный метод, состоящий в замене одних объектов другими, в каком-то смысле близкими к исходным, но более простыми.
Качественная, дискретная, или категорийная переменная — это переменная, которая может принимать одно из ограниченного и, обычно, фиксированного числа возможных значений, назначая каждую единицу наблюдения определённой группе или номинальной категории на основе некоторого качественного свойства. В информатике и некоторых других ветвях математики качественные переменные называются перечислениями или перечисляемыми типами. Обычно (хотя не в этой статье), каждое из возможных значений качественной переменной…
Фиксированные эффекты с индивидуальными наклонами (англ. Fixed effects with invidual-specific slopes, fixed effects with individual slopes, FEIS, FE-IS) — разновидность регрессионного анализа на панельных данных с фиксированными эффектами, позволяющая получать оценки не только индивидуального эффекта в общей константе модели (как делает стандартная FE-модель), но и вводить характерные для индивидов в выборке наклоны для независимой переменной. FEIS-оценки были впервые введены в статье (Polachek…
Метод главных компонент (англ. principal component analysis, PCA) — один из основных способов уменьшить размерность данных, потеряв наименьшее количество информации. Изобретён Карлом Пирсоном в 1901 году. Применяется во многих областях, в том числе, в эконометрике, биоинформатике, обработке изображений, для сжатия данных, в общественных науках.
Функция предельного правдоподобия (англ. Marginal Likelihood Function) или интегрированное правдоподобие (англ. integrated likelihood) — это функция правдоподобия, в которой некоторые переменные параметры исключены. В контексте байесовской статистики, функция может называться обоснованностью (англ. evidence) или обоснованностью модели (англ. model evidence).
Подробнее: Предельное правдоподобие
Масштабно-инвариантная трансформация признаков (англ. scale-invariant feature transform, SIFT) является алгоритмом выявления признаков в компьютерном зрении для выявления и описания локальных признаков в изображениях.
Коэффициент сходства (также мера сходства, индекс сходства) — безразмерный показатель сходства сравниваемых объектов. Также известен под названиями «мера ассоциации», «мера подобия» и др.