Методика учета утверждена приказом ФГБУ «ФНИЦ Охота» от 14 ноября 2022 года № 74
Общие положения
1. Методика учета численности охотничьих ресурсов методом зимнего маршрутного учета (далее – методика) включает планирование учетных маршрутов,
проведение полевых работ на учетных маршрутах и расчет численности охотничьих ресурсов.
2. Зимний маршрутный учет (далее – ЗМУ) проводится в субъектах Центрального, Северо-Западного (за исключением Калининградской области), Северо-Кавказского (за исключением Республики Дагестан, Ставропольского края), Приволжского, Уральского, Сибирского и Дальневосточного федеральных округов, а также в Республике Адыгея и Астраханской области, при наличии на территории данных субъектов снежного покрова в период проведения полевых работ, установленный в пункте 4 методики. ЗМУ проводится на исследуемых территориях, площадь которых составляет 8 тыс. га и более, и применяется для определения численности лося, европейской и сибирской косуль, благородного оленя, пятнистого оленя, дикого северного оленя лесной популяции, кабарги, рыси, а также кабана, волка, лисицы, корсака, куниц, хорей, росомахи, горностая, колонка, белки, зайца беляка, зайца русака (далее – звери), а также рябчика, тетерева, глухарей, куропаток, фазана (далее – птицы).
3. К исследуемым территориям относятся отдельные закрепленные и общедоступные охотничьи угодья, каждое из которых расположено в единых границах, а также иные территории, являющиеся средой обитания охотничьих ресурсов (не являющиеся охотничьими угодьями, в том числе особо охраняемые природные территории регионального значения) (далее – иная территория), каждая из которых также расположена в единых границах. Если закрепленное, общедоступное охотничье угодье, иная территория состоят из нескольких участков, не имеющих общих границ, то каждый участок охотничьего угодья, участок иной территории (далее – участок закрепленного охотничьего угодья, участок общедоступного охотничьего угодья, участок иной территории соответственно) рассматривается как отдельная исследуемая территория.
Юридическому лицу, имеющему несколько охотничьих угодий и осуществляющему свою деятельность на основании разных охотхозяйственных соглашений, по согласованию с уполномоченным органом допускается объединить для учета эти охотничьи угодья, при условии наличия между ними общих границ, в одну исследуемую территорию (далее – объединенная исследуемая территория) с последующим распределением численности учитываемых видов охотничьих ресурсов, рассчитанной на эту территорию, по охотничьим угодьям, входящим в объединенную исследуемую территорию. Площадь объединенной исследуемой территории должна составляет не менее 8 тыс. га.
4. Срок (период) проведения ЗМУ должен быть завершен не позднее 25 марта и включает период планирования полевых работ на учетных маршрутах,
периоды проведения полевых работ и определения численности зверей и птиц.
Полевые работы проводятся в период с 15 января по 15 марта в дни с благоприятными погодными условиями при наличии снежного покрова (далее —
период проведения полевых работ).
Период полевых работ может быть сокращен по решению лица, ответственного за учет, предусмотренного в пункте 5 методики.
При неблагоприятных погодных условиях: в метель, в снегопад, при сильном ветре или при образовании плотного наста, если следы заметаются или невозможно определить их видовую принадлежность, полевые работы на учетных маршрутах не проводятся.
5. Планирование учетных маршрутов и полевых работ на них, включая принятие решений о применении спутниковых навигаторов, видеоаппаратуры, транспортных средств, а также оценка качества материалов учета и расчет численности зверей и птиц обеспечивается:
5.1. в закрепленном охотничьем угодье (участке), в котором пользование охотничьими ресурсами осуществляется на основании охотхозяйственного соглашения (далее — ОХС) или в объединенной исследуемой территории – лицом, ответственным за учет в закрепленном охотничьем угодье (участке).
В случае проведения полевых работ (затирка, учет следов) совместно с представителем уполномоченного государственного органа по его предварительному письменному запросу, ведомость зимнего маршрутного учета (Приложение 2 к методике) оценивается и подписывается совместно лицом, ответственным за учет, и представителем уполномоченного государственного органа.
5.2. в закрепленном охотничьем угодье (участке), в котором пользование охотничьими ресурсами осуществляется на основании долгосрочной лицензии на пользование объектами животного мира в отношении охотничьих ресурсов (далее — ДЛ), – совместно лицом, ответственным за учет в закрепленном охотничьем угодье (участке), и должностным лицом уполномоченного государственного органа.
5.3. в общедоступных охотничьих угодьях (ОДУ) (участках), на иных территориях (участках) — должностным лицом уполномоченного государственного органа или государственного учреждения, ответственным (ответственными) за учет численности в ОДУ (участках), на иных территориях (участках).
5.4. на иных территориях, являющихся особо охраняемыми природными территориями федерального значения – должностным лицом федерального государственного бюджетного учреждения, осуществляющего управление особо охраняемыми природными территориями, ответственным (ответственными) за учет численности на иных территориях (участках).
6. При проведении ЗМУ на исследуемых территориях формируются материалы учета численности зверей и птиц, содержащие данные о численности зверей и птиц (далее – данные учета), которые включают: список учетных маршрутов, запланированных на исследуемой территории (Приложение 1 к методике), ведомости зимнего маршрутного учета (Приложение 2 к методике), ведомости расчета численности зверей и птиц на исследуемой территории (Приложения 7 и 8 к методике), схему исследуемой территории, подготовленную в электронном виде с нанесенными на нее схемами учетных маршрутов (пункты 8-16 методики), электронные файлы электронных треков с электронными файлами маршрутных точек с их расшифровкой (при применении спутниковых навигаторов при учете следов на маршрутах), материалы видеозаписи (при применении видеоаппаратуры при учете следов на маршруте). Расшифровка путевых отметок обеспечивается в формате Word, либо в иных совместимых с ним форматах.
Список учетных маршрутов после их предварительного прохождения на исследуемой территории и ведомости зимнего маршрутного учета формируются в формате Word и/или Excel, либо в иных совместимых с ними форматах, ведомости расчета численности зверей и птиц на исследуемой территории формируются в формате Excel, либо в иных совместимых с ним форматах. Электронная схема исследуемой территории с нанесенными на нее схемами учетных маршрутов — в формате, предусмотренном используемой программой.
Данные учета формируются в электронном виде, сохраняются в виде электронных файлов и подписываются усиленной квалифицированной электронной подписью (ЭЦП). Если данные учета не были подписаны ЭЦП, то к электронным файлам, содержащим данные учета, должны прилагаться данные учета, подписанные на бумажных носителях.
6.1. При проведении ЗМУ на объединенной исследуемой территории формируются материалы учета численности зверей, содержащие данные о численности зверей в соответствии с пунктом 6 методики, а также ведомостей распределения численности учитываемых видов зверей в охотничьих угодьях, входивших в объединенную исследуемую территорию (Приложение 7.1 к методике), которые формируются в формате Word или Excel, или в иных совместимых с ними форматах.
Планирование учетных маршрутов и подготовка схемы
исследуемой территории
7. До начала периода проведения полевых работ лица, ответственные за учет, предусмотренные пунктом 5 методики, осуществляют мероприятия, в соответствии с пунктами 8 — 16 методики.
8. Определяется площадь каждой категории среды обитания, указанной в Приложении к Требованиям к составу и структуре схемы размещения, использования и охраны охотничьих угодий на территории субъекта Российской Федерации, утвержденным приказом Министерства природных ресурсов и экологии Российской Федерации от 31.08.2010 № 335.
Категории среды обитания распределяются в категорию «лес», категорию «поле», категорию «болото».
В площадь категории «лес» объединяются площади категорий среды обитания:
- леса; молодняки и кустарники; пойменные комплексы (класс: с преобладанием леса (более 80%), смешанный лесной, смешанный кустарниковый);
- преобразованные и поврежденные участки леса (гари, ветровалы, торфоразработки).
В площадь категории «поле» объединяются площади категорий среды обитания:
- лугово-степные комплексы; сельскохозяйственные угодья; пойменные комплексы (класс: с преобладанием травянистой растительности, где лес и кустарники занимают до 20% площади);
- береговые комплексы; тундры; альпийские луга; участки с почвенным покровом, нарушенным в результате добычи полезных ископаемых и других техногенных воздействий, внутренние водоемы.
В площадь категории «болото» входит площадь категории среды обитания болото.
Определяется площадь исследуемой территории как сумма площадей категории «лес», категории «поле», категории «болото», имеющихся на данной исследуемой территории.
По согласованию с уполномоченным государственным органом в закрепленном охотничьем угодье (участке) из площади категории «лес», категории «поле», категории «болото» ответственным за учет может быть исключена площадь одной или нескольких категорий среды обитания или часть их площадей. В общедоступном охотничьем угодье (участке), на иной территории (участке) исключение при необходимости площадей осуществляется уполномоченным государственным органом. На территории ООПТ решение принимает – руководство ООПТ. В этом случае площадь исследуемой территории определяется как сумма площадей категории «лес», категории «поле», категории «болото» за вычетом исключенной из них площади одной или нескольких категорий среды обитания или их частей.
Исключенная площадь не обследуется и не используется для расчета численности учитываемых видов зверей и птиц.
9. Определяется для исследуемой территории общая длина учетных маршрутов (далее – запланированная общая длина учетных маршрутов) исходя из условия, что запланированная общая длина учетных маршрутов должна быть не меньше минимально необходимой общей длины учетных маршрутов, рассчитанной в соответствии с пунктом 10 методики.
10. Минимально необходимая общая длина учетных маршрутов на исследуемой территории должна составлять:
— для площади от 8 тыс. га включительно до 30 тыс. га включительно не менее 80 км, при этом количество учетных маршрутов должно быть не менее 4, которые допускается проходить повторно, с учетом пункта 15.1 методики;
— для площади от 30 тыс. га до 50 тыс. га включительно не менее 100 км, при этом количество учетных маршрутов должно быть не менее 7, которые допускается проходить повторно с учетом пункта 15.2 методики;
— для площади свыше 50 тыс. га и до 100 тыс. га включительно не менее величины, определяемой по формуле:
DL=100+(S-50)×k, при k = 1,6, где:
DL – минимально необходимая общая длина учетных маршрутов, км;
S – площадь исследуемой территории, тыс. га;
k – коэффициент, км/тыс. га;
— для площади свыше 100 тыс. га и до 200 тыс. га включительно не менее величины, определяемой по формуле:
DL= 180+(S-100)×k, при k = 0,7;
— для исследуемых территорий площадью свыше 200 тыс. га в субъектах Российской Федерации, входящих в состав Центрального федерального округа, Приволжского федерального округа (за исключением Республики Башкортостан, Пермского края, Кировской области, Оренбургской области), Северо-Кавказского федерального округа (за исключением Республики Дагестан, Ставропольского края), Северо-Западного федерального округа (за исключением Республики Карелия, Республики Коми, Архангельской области, Мурманской области, Ненецкого автономного округа), а также Республики Адыгея и Астраханской области не менее величины, определяемой по формуле:
DL=250+(S-200)×k, при k = 0,6;
— для исследуемых территорий субъектов Российской Федерации, входящих в состав Уральского федерального округа (за исключением Ханты-Мансийского автономного округа-Югры, Ямало-Ненецкого автономного округа), а также Республики Башкортостан, Пермского края, Астраханской области, Кировской области, Оренбургской области, Кемеровской области, Новосибирской области, Омской области:
для площади свыше 200 тыс. га до 1000 тыс. га включительно не менее величины, определяемой по формуле:
DL=250+(S-200)×k, при k = 0,5;
для площади свыше 1000 тыс. га не менее величины, определяемой по формуле:
DL=650+(S-1000)×k, при k = 0,1;
— для исследуемых территорий субъектов Российской Федерации, входящих в состав Дальневосточного федерального округа, Сибирского федерального округа (за исключением Кемеровской области, Новосибирской области, Омской области), а также для Республики Карелия, Республики Коми, Архангельской области, Мурманской области, Ненецкого автономного округа, Ханты-Мансийского автономного округа-Югры, Ямало-Ненецкого автономного округа:
для площади свыше 200 тыс. га до 1000 тыс. га включительно не менее величины, определяемой по формуле:
DL=250+(S-200)×k, при k = 0,1;
для площади свыше 1000 тыс. га не менее величины, определяемой по формуле:
DL=330+(S-1000)×k, при k = 0,08.
11. Общее количество учетных маршрутов на исследуемой территории определяется исходя из условия, что длина каждого учетного маршрута должна составлять не менее 5 км и не более 15 км, за исключением горной месnности, где допускается уменьшение длины учетного маршрута до 3 км.
12. Общая длина учетных маршрутов по категории «лес», категории «поле», категории «болото», имеющихся на исследуемой территории, определяется исходя из условия, что запланированная общая длина учетных маршрутов распределяется по категории «лес», категории «поле», категории «болото» пропорционально их площади (далее – запланированная длина учетных маршрутов в категории «лес», запланированная длина учетных маршрутов в категории «поле», запланированная длина учетных маршрутов в категории «болото»).
Распределение общей длины учетных маршрутов по категории «лес», категории «поле», категории «болото» производится с учетом формул:

где:
DLлес – протяженность всех учетных маршрутов по категории «лес», км;
DLполе – протяженность всех учетных маршрутов по категории «поле», км;
DLболото – протяженность всех учетных маршрутов по категории «болото», км;
Qлес – площадь категории «лес», тыс. га;
Qполе – площадь категории «поле», тыс. га;
Qболото – площадь категории «болото», тыс. га.
13. Подготовка электронной схемы исследуемой территории и планируемых на ней треков (конфигураций) учетных маршрутов осуществляется с применением специального программного обеспечения, позволяющего работать с пространственными данными, полученными с применением спутниковых навигаторов. Образец возможного варианта схемы исследуемой территории с запланированными на ней учетными маршрутами приведен в Приложении 1.1 к методике. Планирование учетных маршрутов осуществляется в соответствии с пунктами 8 — 12, 14 методики.
14. Учетные маршруты размещаются на схеме исследуемой территории равномерно, разнонаправленно и с соблюдением следующих условий:
14.1. Конфигурация учетных маршрутов может быть произвольной формы (прямолинейная, ломаная, замкнутая) (Приложение 11 к методике). На исследуемой территории рекомендуется планировать учетные маршруты примерно одинаковой конфигурации.
14.2. Углы между последовательно соединенными отрезками учетного маршрута должны быть не менее 70 градусов.
14.3. Отрезки учетного маршрута не должны пересекаться.
14.4. Расстояние между параллельными отрезками одного и того же учетного маршрута должно быть не менее 1 км (если планируется ломаная, замкнутая форма учетного маршрута).
14.5. Расстояние между соседними учетными маршрутами должно быть не менее 1 км друг от друга. На исследуемой территории с площадью до 30 тыс. га включительно соседние учетные маршруты могут сближаться между собой на протяжении всей их длины или в отдельных точках на расстояние менее 1 км, если полевые работы на этих маршрутах планируется проводить в разные дни.
14.6. При планировании пересекающихся учётных маршрутов необходимо учитывать, что проведение полевых работ на этих маршрутах должно осуществляться в разные дни.
14.7. Учетные маршруты или их отрезки по возможности не должны планироваться и проходить:
по линейным объектам шириной более 10 метров (просеки, автомобильные и железные дороги, линии электропередач), а также вдоль них на расстоянии ближе, чем 100 метров;
по опушкам, водотокам, оврагам, а также вдоль них на расстоянии ближе, чем 100 метров. В горной местности разрешается планирование учетных маршрутов по водотокам или вдоль них, при этом длина учетных маршрутов вдоль водотоков должна составлять не более половины от общей длины учетных маршрутов на исследуемой территории.
15. Не допускается повторное проведение полевых работ на учетных маршрутах, за исключением исследуемой территории, расположенной в горной местности, и исследуемой территории с площадью до 50 тыс. га включительно, за исключением случаев, предусмотренных пунктами 15.1 и 15.2 методики.
15.1. На исследуемой территории с площадью от 8 тыс. га включительно до 30 тыс. га включительно допускается повторное проведение полевых работ (затирка и учет следов) на всех запланированных учетных маршрутах. В этом случае день учета следов может использоваться как затирка при повторном проведении учета следов на следующий день.
Повторное проведение полевых работ на одном и том же учетном маршруте проводится также в случае, указанном в пункте 25 методики.
15.2. На исследуемой территории с площадью от 30 тыс. га до 50 тыс. га включительно, допускается повторное проведение полевых работ (затирка и учет следов) на выборочных учетных маршрутах. В этом случае день учета следов может использоваться как затирка при повторном проведении учета следов на следующий день. Также допускается повторное проведение полевых работ на выборочных учетных маршрутах для исследуемой территории, расположенной в горной местности с площадью от 30 тыс. га и более.
При повторном проведении полевых работ на выборочных учетных маршрутах должно соблюдаться условие, что длина выборочных учетных маршрутов в каждой категории, имеющейся на исследуемой территории, должна быть пропорциональна площади данной категории (допускается отклонение суммарной длины учетных маршрутов по соответствующей категории от площади данной категории на ± 10%).
16. После окончания планирования треков учетных маршрутов они должны быть загружены в спутниковый навигатор (конвертированы в соответствующий электронный формат для применения спутниковых навигаторов) и предварительно пройдены в любой период времени до начала полевых работ на исследуемой территории или до начала полевых работ на данном учетном маршруте. После чего, записанные на спутниковый навигатор электронные треки пройденных учетных маршрутов (далее — схемы учетных маршрутов) переносятся на электронную схему исследуемой территории.
Схема учетного маршрута сохраняется в виде электронного файла.
Схемой учетного маршрута может также являться электронный трек учетного маршрута, записанный на спутниковый навигатор, при прохождении маршрута при проведении ЗМУ в прошедших годах при условии, что в текущем году не планируется менять его конфигурацию и/или место расположения на местности.
Общая длина учетного маршрута при его предварительном прохождении может иметь незначительное расхождение от общей запланированной длины
учетного маршрута на исследуемой территории, но не менее минимально необходимой общей длины учетных маршрутов.
Для расчета численности вида охотничьих ресурсов используется длина учетного маршрута по категории «лес», категории «поле», категории «болото»,
полученная при его предварительном прохождении.
17. В случае объединения охотничьих угодий в объединенную исследуемую территорию в соответствии с пунктом 3 методики, ее площадь определяется как
сумма площадей категории «лес», категории «поле», категории «болото», имеющихся в охотничьих угодьях, входящих в объединенную исследуемую
территорию. При этом площади категории «лес», категории «поле», категории «болото» каждого охотничьего угодья определяются в соответствии с пунктом методики.
Запланированная общая длина учетных маршрутов на объединенной исследуемой территории определяется суммированием запланированных общих длин учетных маршрутов, определенных на каждое охотничье угодье, входящее в объединенную исследуемую территорию, в соответствии с пунктом 9 методики. При этом запланированная общая длина учетных маршрутов для охотничьего угодья площадью менее 8 тыс. га определяется также как для исследуемой территории площадью от 8 тыс. га включительно до 30 тыс. га включительно.
Распределение общей длины учетных маршрутов, полученной на объединенную исследуемую территорию, осуществляется с учетом пунктов 11 -16 методики.
18. Схема исследуемой территории (объединенной исследуемой территории) с нанесенными на нее схемами учетных маршрутов обновляется не реже 1 раза в 10 лет. В случае изменения в этот период конфигурации одного или нескольких учетных маршрутов или изменения их места расположения на местности схема исследуемой территории (объединенной исследуемой территории) с нанесенными на нее схемами учетных маршрутов должна быть обновлена с учетом этих изменений.
19. Составляется список учетных маршрутов на исследуемой территории (объединенной исследуемой территории) с указанием общих длин учетных маршрутов, а также по категории «лес», категории «поле», категории «болото», полученных при их предварительном прохождении со спутниковым навигатором (Приложение 1 к методике).
Проведение полевых работ на учетных маршрутах
20. Полевые работы на учетном маршруте проводятся в два дня.
20.1. В первый день проведения полевых работ на учетном маршруте следы и тропы зверей засыпаются снегом или нарушается целостность следа зверей (веткой, палкой, лыжей и т.п.) (далее – затирка) таким образом, чтобы во второй день можно было определить вновь появившиеся на учетном маршруте следы зверей.
На бумажном носителе (в блокноте) отмечается каждая встреча птиц (группы птиц), их вид, количество, расстояние по прямой от учетчика до центра группы птиц или до одиночной птицы в соответствующей категории «лес», категории «поле», категории «болото», где они были встречены;
На бумажном носителе (в блокноте) дополнительно могут отмечаться пересечения следов волка, рыси, росомахи с указанием их количества и примерной давности (в днях) оставленного следа.
20.2. Во второй день проведения полевых работ (далее — учет следов) учетный маршрут проходится в том же направлении, что и при затирке. Интервал между затиркой и учетом следов на всем протяжении учетного маршрута должен укладываться в суточный интервал (24 часа). Допускается уменьшение суточного интервала между затиркой и учетом следов на учетном маршруте до 20 часов или его увеличение до 28 часов.
Допускается прохождение учетного маршрута при учете следов в противоположном по сравнению с затиркой направлении. При этом суточный интервал в 24 часа между затиркой и учетом следов может быть увеличен, но не более чем на 8 часов (до 32 часов) между временем начала затирки на маршруте накануне и временем окончания учета следов на данном маршруте на следующий день, а суточный интервал в 24 часа может быть сокращен, но не более чем на 8 часов (до 16 часов) между временем окончания затирки накануне и временем начала учета следов на следующий день (например, затирка на маршруте проводилась с 8 до 16 часов, учет следов в противоположном от затирки направлении может начаться на следующий день не раньше 8 часов и закончиться не позже 16 часов).
20.3. При учете следов на учетном маршруте осуществляется подсчет пересечений следов зверей учетного маршрута и встреч птиц (групп птиц) и отмечается на бумажном носителе (в блокноте) каждое пересечение следов зверей и встреч птиц (групп птиц) в соответствующей категории «лес», категории «поле», категории «болото», где следы зверей и встречи птиц (групп птиц) были зафиксированы, с указанием количества и видовой принадлежности зверей и птиц.
Пересечения следов лося, благородного оленя, пятнистого оленя, дикого северного оленя лесной популяции, рыси, волка, росомахи, встреченные на учетном маршруте в категории «поле» на расстоянии не более 100 м от границы категории «лес», отмечаются с пометкой «лес».
Пересечения следов лося, благородного оленя, пятнистого оленя, рыси, дикого северного оленя лесной популяции, волка, росомахи, встреченные на учетном маршруте в категории «поле» на расстоянии не более 100 м от категории «болото», отмечаются с пометкой «болото».
Отмечается на бумажном носителе (в блокноте) каждая встреча птиц (группы птиц), их вид и количество, расстояние по прямой от учетчика до центра группы птиц или до одиночной птицы в соответствующей категории «лес», категории «поле», категории «болото», где они были встречены.
21. В случае принятия решения о применении спутникового навигатора на него производится запись прохождения учетного маршрута (далее – электронный трек).
Электронный трек должен иметь следующие параметры: географические координаты точек электронного трека, значения высот точек электронного трека, дату и время их записи.
В спутниковом навигаторе точками фиксируются все пересечения следами зверей (лося, косуль, благородного оленя, пятнистого оленя, дикого северного оленя лесной популяции, кабарги, росомахи, рыси, волка) учетного маршрута (далее – маршрутные точки).
Количество учитываемых видов зверей, пересечения следов которых фиксируется в спутниковый навигатор, может быть изменено по усмотрению ответственного за учет.
Маршрутные точки должны иметь расшифровку, которая производится в спутниковом навигаторе и/или на бумажном носителе с указанием количества пересечений следов зверей учитываемого вида в соответствующей категории «лес», категории «поле», категории «болото», и их видовая принадлежность.
21.1. В случае применения видеоаппаратуры при учете следов на нее производится запись прохождения учетного маршрута и фиксация пересечений следов зверей учитываемого вида, которая сохраняется в виде электронного файла (далее – материалы видеозаписи учета). Количество пересечений следов и вид зверей, зафиксированных на видеоаппаратуру, указывается при оформлении ведомости ЗМУ.
21.2. В случае применения при затирке и/или учете следов транспортных средств, скорость движения транспортного средства по учетному маршруту не должна превышать 40 км/час.
22. Допускается по решению ответственного (ответственных) за учет, указанных в пункте 5 методики, проведение полевых работ на учетном маршруте в один день, без затирки, если в предыдущие сутки (за 24 часа) до начала полевых работ на учетном маршруте выпал снег (далее – пороша).
Допускается уменьшение суточного интервала между окончанием пороши и началом учета следов до 20 часов и/или его увеличение между окончанием пороши и окончанием учета следов на учетном маршруте до 28 часов (например, пороша закончилась в 12 часов утра, учет следов может начаться не ранее 8 часов утра следующего дня и закончиться не позднее 16 часов этого же дня или пороша закончилась в 8 часов, учет следов может начаться в 8 часов следующего дня и закончиться не позднее 16 часов этого же дня).
23. При проведении полевых работ на учетных маршрутах запрещается осуществлять охоту, находиться с собакой.
24. При встрече на учетном маршруте при проведении учета следов пересечений следов нескольких зверей учитываемого вида, прошедших одной тропой, необходимо пройти по тропе до места, где звери разошлись, и определить точное их количество.
Если при учете следов установлено, что зверь (лисица, волк, рысь, росомаха), подойдя к учетному маршруту и не пересекая его, повернул обратно, то такой подход отмечается как одно пересечение учетного маршрута (Приложение 2 к методике).
25. Если во время затирки возникли неблагоприятные погодные условия, указанные в пункте 4 методики, и не прекратились после ее завершения, или эти же условия возникли во время учета следов, то полевые работы на данном маршруте прекращаются. Полевые работы на данном учетном маршруте проводятся заново после установления благоприятных для их проведения погодных условий.
Порядок оформления ведомостей ЗМУ
26. Ведомости ЗМУ (Приложение 2 к методике) заполняются учетчиком в следующем порядке:
а) заполняются все графы, предусмотренные в ведомости ЗМУ;
б) в таблице 1 указывается:
- общая длина учетного маршрута, в том числе по категории «лес», категории «поле», категории «болото», полученная при его предварительном прохождении (в соответствии с Приложением 1 к методике);
- суммарное количество пересечений следов зверей учитываемого вида, отмеченных в день учета следов на учетном маршруте в соответствующей категории «лес», категории «поле», категории «болото», где следы были встречены;
- количество пересечений следов зверей с пометкой «лес» отмечается в категории «лес»;
- количество пересечений следов зверей с пометкой «болото» отмечается в категории «болото»;
в) в таблице 2 указываются сведения о пересечениях следов волка, рыси, росомахи и других видов зверей (определяются по усмотрению ответственного за учет), отмеченных при затирке, с указанием их количества и примерной давности (в днях) оставленного следа;
г) в таблице 3 указываются сведения о каждой встрече птиц (группы птиц) учитываемого вида, отмеченной в день затирки и в день учета следов в категории «лес», категории «поле», категории «болото», где птицы были встречены.
д) на оборотной стороне ведомости ЗМУ отображается схема учетного маршрута (электронный трек учетного маршрута, записанный при его предварительном прохождении) с указанием его номера. На схеме учетного маршрута отображается (от руки или с помощью графического изображения, сделанного на компьютере) каждое пересечение следов зверей учитываемых видов с указанием их количества и видовой принадлежности в соответствующей категории «лес», категории «поле», категории «болото», где следы были встречены.
Допускается на схеме учетного маршрута при оформлении ведомости ЗМУ объединение многочисленных пересечений следов зверей учитываемого вида, встреченных на участке учетного маршрута, длина которого не превышает 1 км, в какой-либо из категорий (например, на участке учетного маршрута в 500 м, проходящего по категории «лес», было зафиксировано 7 пересечений следов лосей;
в этом случае на схеме учетного маршрута можно указать Ло(7) — лес.
При применении при учете следов спутникового навигатора допускается на схеме учетного маршрута не отображать пересечения следов зверей учитываемых видов с указанием их количества и видовой принадлежности. В этом случае к ведомости ЗМУ должен быть прикреплен распечатанный на отдельном листе электронный трек учетного маршрута с нанесенными на него маршрутными точками с их расшифровкой или должен быть приложен записанный на электронный носитель электронный файл электронного трека с электронным файлом маршрутных точек с их расшифровкой.
Оценка полноты и качества данных учета на исследуемой территории
(объединенной исследуемой территории)
27. Оценка полноты и качества данных учета и обоснование принятого решения осуществляется ответственными за учет, предусмотренными пунктом 5 методики.
27.1. Проверяется комплектность данных учета, предусмотренная пунктом 6 методики, с исследуемой территории или объединенной исследуемой территории;
27.2. Ведомости ЗМУ признаются не соответствующими требованиям методики в случае установления одного и более несоответствий:
- не соблюдено требование, предусмотренное пунктами 20.2, 20.3, 21, 22 методики;
- количество пересечений следов зверей учитываемых видов (лося, косуль, благородного оленя, пятнистого оленя, дикого северного оленя лесной популяции, кабарги, росомахи, рыси, волка), отмеченное на схеме учетного маршрута в соответствующей категории «лес», категории «поле», категории «болото», не соответствует количеству пересечений следов зверей данных видов в соответствующей категории «лес», категории «поле», категории «болото», указанному в таблице 1 ведомости ЗМУ.
27.3. Если при применении спутникового навигатора:
- отсутствует прикрепленный к ведомости ЗМУ распечатанный на отдельном листе электронный трек с нанесенными на него маршрутными точками (если
фиксировались) и их расшифровка; - у ведомости ЗМУ отсутствует записанный на электронном носителе электронный файл электронного трека и/или электронный файл с маршрутными
точками и их расшифровкой.
27.4. Если при применении видеоаппаратуры на видеозаписи при проведении учета следов количество пересечений следов зверей учитываемых видов не соответствует количеству следов зверей учитываемых видов, указанных в ведомости ЗМУ (на схеме учетного маршрута и/или в таблице 1).
28. По результатам оценки качества ведомостей ЗМУ, произведенной с учетом пункта 27 методики, в них проставляется запись «ведомость принята» или «ведомость не принята» лицами, ответственными за учет, предусмотренными пунктом 5 методики, и обосновывается принятое решение.
Расчет численности зверей и птиц на исследуемой территории (объединенной исследуемой территории)
29. Расчет численности учитываемых видов зверей и птиц на исследуемой территории (объединенной исследуемой территории) осуществляется ответственными за учет, предусмотренными пунктом 5 методики.
30. Ведомости ЗМУ, признанные не соответствующими требованиям, предусмотренным в пунктах 27.2 — 27.4 методики, и в которых на этом основании была проставлена запись «ведомость не принята», не используются для расчета численности учитываемых видов зверей и птиц.
31. Расчет численности учитываемых видов зверей и птиц на исследуемой территории (объединенной исследуемой территории) не осуществляется, если данные учета содержат не весь объем, предусмотренный пунктом 6 методики и/или если после оценки качества ведомостей ЗМУ, произведенной должностным лицом уполномоченного государственного органа в соответствии с разграничением полномочий, предусмотренных пунктом 5 методики, общая запланированная длина учетных маршрутов на исследуемой территории (объединенной исследуемой территории) не соответствует требованиям пункта 10 методики.
32. Расчет численности учитываемых видов зверей на исследуемой территории (объединенной исследуемой территории) осуществляется с использованием стандартного или специализированного программного обеспечения по следующему алгоритму:
32.1. Численность учитываемого вида зверей в соответствующей категории «лес», категории «поле», категории «болото» на исследуемой территории (объединенной исследуемой территории) рассчитывается по формуле:
Nru=Dru× Qru,
где:
r – исследуемая территория (объединенная исследуемая территория);
u – соответствующая категория «лес», категория «поле», категория «болото»;
Nru – численность учитываемого вида зверей в соответствующей категории «лес», категории «поле», категории «болото», особей;
Dru – плотность населения учитываемого вида зверей в соответствующей категории «лес», категории «поле», категории «болото», особей/1000 га;
Qru – площадь соответствующей категории «лес», категории «поле», категории «болото», тыс. га.
32.2. Плотность населения учитываемого вида зверей в соответствующей категории «лес», категории «поле», категории «болото» рассчитывается по формуле:
Dru=Aru×K,
где:
Аru – показатель учета учитываемого вида зверей в соответствующей категории «лес», категории «поле», категории «болото»;
K – пересчетный коэффициент для учитываемого вида зверей (Приложения 3, 4, 5, 6 к методике).
32.3. Показатель учета учитываемого вида зверей в соответствующей категории «лес», категории «поле», категории «болото» рассчитывается по формуле:

Xru – количество пересечений следов учитываемого вида зверей в соответствующей категории «лес», категории «поле», категории «болото», единиц;
Lru — длина всех частей учетных маршрутов, проходящих в соответствующей категории «лес», категории «поле», категории «болото», полученная при их предварительном прохождении, км;
Mr – количество учетных маршрутов в соответствующей категории, единиц;
Хruj – количество пересечений следов учитываемого вида зверей на части j учетного маршрута, проходящего в соответствующей категории «лес», категории «поле», категории «болото», единиц;
Lruj –длина части j учетного маршрута, проходящей в соответствующей категории «лес», категории «поле», категории «болото», полученная при его предварительном прохождении, км.
Округление в расчетных показателях плотности населения учитываемого вида зверей производится до 2 знаков после запятой, площадей по категории «лес», категории «поле», категории «болото» и общей площади указанных категорий — до 3 знаков после запятой.
Округление расчетных показателей численности учитываемого вида зверей производится по правилам математического округления.
32.4. Дополнительно может быть рассчитана относительная статистическая ошибка показателя учета учитываемого вида зверей в соответствующей категории «лес», категории «поле», категории «болото» на исследуемой территории (объединенной исследуемой территории) по формуле:

Ca𝑟𝑢 – относительная статистическая ошибка показателя учета учитываемого вида зверей в соответствующей категории «лес», категории «поле», категории «болото»;
Аruj – показатель учета учитываемого вида зверей для части j учетного маршрута, проходящей в соответствующей категории «лес», категории «поле»,
категории «болото;
33. Расчет численности учитываемых видов птиц на исследуемой территории (объединенной исследуемой территории) осуществляется с использованием
стандартного или специализированного программного обеспечения по следующему алгоритму:
33.1. Численность учитываемого вида птиц в соответствующей категории «лес», категории «поле», категории «болото» по формуле:
Zru=Pru×Qru, где:
Zru – численность учитываемого вида птиц в соответствующей категории «лес», категории «поле», категории «болото», особей;
Pru – плотность населения учитываемого вида птиц в соответствующей категории «лес», категории «поле», категории «болото», особей/1000 га.
33.2. Плотность населения учитываемого вида птиц в соответствующей категории «лес», категории «поле», категории «болото» рассчитывается по формуле:

где:
Yruj — число птиц учитываемого вида, отмеченных на учетном маршруте (его части) в соответствующей категории «лес», категории «поле», категории «болото» (по данным таблицы 3 ведомости ЗМУ), особей;
Yru — суммарное число птиц учитываемого вида, отмеченных на учетных маршрутах при затирке и при учете следов в соответствующей категории «лес»,
категории «поле», категории «болото», особей;
Eruj – удвоенная длина части учетного маршрута, проходящая в соответствующей категории «лес», категории «поле», категории «болото»,
полученная при его предварительном прохождении, км. При проведении ЗМУ в один день (с использованием пороши вместо затирки) длина части учетного
маршрута не удваивается;
Eru — длина всех частей учетных маршрутов, проходящих в соответствующей категории «лес», категории «поле», категории «болото», полученная при его
предварительном прохождении;
Bru – ширина учетной полосы для учитываемого вида птиц в соответствующей категории «лес», категории «поле», категории «болото», км;
Tru – общее число встреч групп птиц и одиночных птиц учитываемого вида в соответствующей категории «лес», категории «поле», категории «болото», единиц;
Rrui – расстояние от учетчика до центра группы птиц учитываемого вида или до одиночной птицы учитываемого вида для каждой i встречи в соответствующей категории «лес», категории «поле», категории «болото», км.
Округление в расчетах плотности населения учитываемого вида птиц производится до 2 знаков после запятой, ширины учетной полосы, площадей по категории «лес», категории «поле», категории «болото» и общей площади указанных категорий, производится до 3 знаков после запятой. Округление расчетных показателей численности учитываемого вида птиц производится по правилам математического округления.
34. Численность учитываемого вида зверей на исследуемой территории рассчитывается путем суммирования численности учитываемого вида зверей, рассчитанной в соответствующей категории «лес», категории «поле», категории «болото» данной исследуемой территории с заполнением ведомости расчета численности зверей на исследуемой территории (Приложение 7 к методике).
35. Численность учитываемого вида птиц на исследуемой территории (объединенной исследуемой территории) рассчитывается путем суммирования численности учитываемого вида птиц, рассчитанной в соответствующей категории «лес», категории «поле», категории «болото» данной исследуемой территории (объединенной исследуемой территории) с заполнением ведомости расчета численности птиц на исследуемой территории (объединенной исследуемой территории) (Приложение 8 к методике).
36. Расчет численности учитываемого вида зверей на объединенной исследуемой территории, в которую были объединены охотничьи угодья в соответствии с пунктом 3 методики, и распределение полученной численности по отдельным охотничьим угодьям осуществляется с использованием стандартного или специализированного программного обеспечения по следующему алгоритму
(В.А. Кузякин, Н.Г. Челинцев «Учет охотничьих ресурсов», 2005)
36.1. Рассчитывается численность учитываемого вида зверей на объединенную исследуемую территорию (Nru) в соответствующей категории «лес», категории «поле», категории «болото» в соответствии с пунктом 32 методики.
36.2. Рассчитывается показатель учета учитываемого вида зверей в соответствующей категории «лес», категории «поле», категории «болото» в данном охотничьем угодье на основании учетных данных, полученных на учетных маршрутах, приходящихся на данное охотничье угодье, по формуле:

где:
Aоu – показатель учета учитываемого вида зверей в соответствующей категории «лес», категории «поле», категории «болото» в данном охотничьем угодье;
Xоu – количество пересечений следов учитываемого вида зверей в соответствующей категории «лес», категории «поле», категории «болото» в данном охотничьем угодье, единиц;
Lоu – длина всех частей учетных маршрутов, проходящих в соответствующей категории «лес», категории «поле», категории «болото» в данном охотничьем угодье, полученная при их предварительном прохождении, км;
Lоuj — длина части j учетного маршрута, проходящего в соответствующей категории «лес», категории «поле», категории «болото», полученная при его предварительном прохождении, км;
Rо – количество учетных маршрутов или их частей в соответствующей категории «лес», категории «поле», категории «болото» в данном охотничьем угодье, единиц;
Хоuj – количество пересечений следов учитываемого вида зверей на части j учетного маршрута, проходящего в соответствующей категории «лес», категории «поле», категории «болото» в данном охотничьем угодье, единиц;
36.3. Рассчитывается для каждого охотничьего угодья показатель условных единиц для учитываемого вида зверей в соответствующей категории «лес», категории «поле», категории «болото» по формуле:
Поu= Qоu× Aоu , где
Qоu – площадь соответствующей категории «лес», категории «поле», категории «болото» в данном охотничьем угодье, тыс. га;
Поu — показатель условных единиц для учитываемого вида зверей в соответствующей категории «лес», категории «поле», категории «болото» данного
охотничьего угодья.
36.4. Рассчитывается суммарный показатель условных единиц для учитываемого вида зверей для всех охотничьих угодий, входящих в объединенную исследуемую территорию, в соответствующей категории «лес», категории «поле», категории «болото» (Пи), путем суммирования показателей условных единиц, определенных для каждого охотничьего угодья в соответствующей категории «лес», категории «поле», категории «болото» (Поu).
36.5. Рассчитывается количество условных единиц, которое приходится на учитываемый вид зверей всех охотничьих угодий, входящих в объединенную исследуемую территорию, в соответствующей категории «лес», категории «поле», категории «болото» по формуле:
Yи=Пu / N ru , где
Nru – численность учитываемого вида зверей в соответствующей категории «лес», категории «поле», категории «болото», рассчитанная на объединенную исследуемую территорию, особей;
Yи — количество условных единиц, которое приходится на учитываемый вид зверей в соответствующей категории «лес», категории «поле», категории «болото» всех охотничьих угодий, входящих в объединенную исследуемую территорию.
36.6. Распределение численности учитываемого вида зверей по каждому охотничьему угодью, входящих в объединенную исследуемую территорию, в соответствующей категории «лес», категории «поле», категории «болото» производится по формуле:
Nou= Пou / Yи
Пример распределения численности учитываемого вида зверей, полученной на объединенную исследуемую территорию по отдельным охотничьим угодьям, входящим в объединенную исследуемую территорию, приведен в Приложении 12 к методике.
36.7. Численность учитываемого вида зверей в каждом охотничьем угодье, входящем в объединенную исследуемую территорию, рассчитывается суммированием численности учитываемого вида зверей в соответствующей категории «лес», категории «поле», категории «болото» данного охотничьего
угодья.
36.8. Плотность населения учитываемого вида зверей в соответствующей категории «лес», категории «поле», категории «болото» данного охотничьего угодья (Dou) рассчитывается как отношение численности учитываемого вида зверей в соответствующей категории «лес», категории «поле», категории «болото» (Nou) к площади соответствующей категории (Qоu).
36.9. По результатам распределения численности и расчета плотности населения учитываемого вида зверей заполняется ведомость распределения численности учитываемого вида зверей в охотничьих угодьях, входящих в объединенную исследуемую территорию (Приложение 7.1 к методике).
37. Уполномоченный государственный орган до 15 апреля:
— проверяет комплектность данных учета, представленных с исследуемых территорий (объединенных исследуемых территорий) субъекта Российской Федерации, на соответствие пункту 6 методики;
— формирует сводный список учетных маршрутов по субъекту Российской Федерации путем обобщения списков учетных маршрутов с исследуемых территорий (объединенных исследуемых территорий) (Приложение 1.2 к методике);
— обобщает и анализирует данные из ведомостей расчета численности зверей на исследуемых территориях и ведомостей распределения численности зверей в охотничьем угодье, входящих в объединенную исследуемую территорию, полученных с использованием стандартного или специализированного программного обеспечения, и формирует итоговую ведомость расчета численности зверей методом ЗМУ в субъекте Российской Федерации. Численность учитываемого вида зверей в субъекте Российской Федерации определяется суммированием численности учитываемого вида зверей в соответствующей категории «лес», категории «поле», категории «болото» на исследуемых территориях (если объединение не производилось) и в охотничьих угодьях (при произведенном объединении) в разрезе муниципальных образований (районов) данного субъекта Российской Федерации (Приложение 9 к методике).
— обобщает и анализирует данные из ведомостей расчета численности птиц на исследуемых территориях, полученных с использованием стандартного или специализированного программного обеспечения, и формирует итоговую ведомость расчета численности птиц в субъекте Российской Федерации. Численность учитываемого вида птиц в субъекте Российской Федерации определяется путем суммирования численности учитываемого вида птиц в соответствующей категории «лес», категории «поле», категории «болото» на исследуемых территориях в разрезе муниципальных образований (районов) данного субъекта Российской Федерации (Приложение 10 к методике).
В случае отсутствия с исследуемой территории полного комплекта данных учета, предусмотренного в пункте 6 методики, показатели численности зверей и птиц по данной исследуемой территории не включаются в итоговую ведомость расчета численности зверей и итоговую ведомость расчета численности птиц в субъекте Российской Федерации.
В случае отсутствия с объединенной исследуемой территории полного комплекта данных учета, предусмотренного пунктом 6 методики, показатели численности зверей по охотничьим угодьям, входящим в объединенную исследуемую территорию, не включаются в итоговую ведомость расчета численности зверей в субъекте Российской Федерации.
Программа для заполнения ведомостей (карточек):
Программа для заполнения ведомостей (карточек)
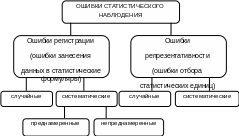
Ошибка
статистического наблюдения – это
отклонение расчетных значений показателей
от фактических. Классификация различных
видов ошибок представлена на схеме 2.1.
Ошибки
регистрации
– это просто ошибки записей при заполнении
статистических формуляров. Такие ошибки
встречаются при любых видах наблюдений.
Ошибки
репрезентативности
(то есть представительности)1
характерны только для так называемых
выборочных
наблюдений (которые более подробно
будут изучаться в дальнейшем). Их суть
заключается в том, что статистические
единицы, отобранные для проведения
наблюдения (включенные в выборочную
совокупность или «выборку») недостаточно
полно представляют всю (генеральную)
статистическую совокупность. Например,
при проведении социологического опроса
были собраны данные о среднедушевом
доходе только у лиц в возрасте от 30 до
50 лет, и не были охвачены другие категории
населения.
Случайные
ошибки
бывают всегда,
а процент систематических
ошибок
можно уменьшить
за счет улучшения организации самого
наблюдения. Однако, если эти ошибки
являются преднамеренными
(например, скрываются данные о доходах,
чтобы снизить величину налоговых
отчислений), то снизить процент таких
ошибок можно, только выходя за рамки
компетенции статистических органов.
Схема
2.1
Классификация ошибок статистического наблюдения
3. Организационные формы, виды и способы статистического наблюдения
Существует
три основных организационных формы
статистического наблюдения:
-
Официальная
статистическая отчетность; -
Специально
организованные наблюдения; -
Регистры
(регистрационная форма наблюдения)
Роль
официальной статистической отчетности
для статистических исследований в том,
что она позволяет в течение длительного
промежутка времени накапливать
статистические данные, представленные
в виде единообразного, официально
утвержденного перечня показателей. Эти
показатели обычно комплексно характеризуют
развитие отдельных социально-экономических
процессов во времени. Однако с переходом
к рыночной экономике в нашей стране
существенно изменились многие формы
статистической отчетности. Поэтому,
как правило, статистические ряды данных,
сформированные в период до начала 1990-х
годов, фактически несопоставимы с той
статистической информацией, которая
была накоплена в течение последнего
десятилетия.
Официальная
статистическая отчетность является
обязательной,
документально обоснованной, периодической.
Все
сведения в отчетности должны быть
юридически заверены подписью руководителя
предприятия.
Официальная
статистическая отчетность делится на:
1)
типовую (обязательную для всех
предприятий),
2) специальную
(заполняют только предприятия одной
отрасли).
Специально
организованные наблюдения –
это те, для которых всякий раз, независимо
от их периодичности и сроков проведения,
разрабатывается специальная программа
(например, к таким наблюдениям относится
перепись, опросы общественного мнения
и т.д.)
Регистр
– это особая форма непрерывного
наблюдения за социально-экономическими
процессами, имеющими фиксированное
начало и фиксированный конец. Проще
говоря, регистр – это список, в который
заносятся статистические единицы с
определенными признаками, некоторые
из которых имеют постоянное значение,
а другие изменяются. Все эти изменения
фиксируются и также заносятся в регистр.
Примером такого наблюдения является
регистрация актов гражданского состояния
или регистрация всех предприятий,
создаваемых на территории Российской
Федерации.
Кроме
того, все статистические наблюдения
разделяют на различные виды, в зависимости
от периодичности их проведения:
-
Периодические
(которые проводятся через равные
промежутки времени, например, через
год, месяц, квартал): примером такого
наблюдения является официальная
статистическая отчетность); -
Непрерывные
(или текущие),
которые фиксируют все факты, имеющие
отношения к данному социально-экономическому
явлению, независимо от момента времени,
когда происходят соответствующие
события: примером такого наблюдения
является регистрация дорожно-транспортных
происшествий; -
Разовые
или единовременные,
которые могут больше не повториться:
например, опрос общественного мнения
перед выборами.
В
зависимости от степени охвата
статистических единиц, статистические
наблюдения также разделяют на сплошные
и несплошные
наблюдения. В свою очередь, несплошные
наблюдения разделяют на выборочные,
обследования
основного массива
и монографические
исследования.
Нередко
всякие наблюдения, не являющиеся
сплошными, называют выборочными. Однако
выборочные
наблюдения
– это только одна
из нескольких возможных разновидностей
несплошных наблюдений. При выборочных
наблюдениях
отбор обследуемых единиц осуществляется
с помощью особых, научно обоснованных
способов формирования выборочной
совокупности единиц. Другой формой
несплошных наблюдений являются
обследования основного
массива, при которых
отбирается такая часть статистических
единиц, которая дает наибольший вклад
в итоговый показатель. (Например,
отбираются предприятия с наибольшим
объемом реализованной продукции или
магазины с наибольшим объемом
товарооборота). Наконец, при монографических
исследованиях обычно обследуется совсем
немного статистических единиц, но очень
детально, по чрезвычайно широкому
перечню признаков. Например, изучаются
только те предприятия, где внедрена
совершенно новая форма оплаты труда,
но необходимо очень тщательно изучить
влияние этой новой формы на результаты
работы предприятия (с привлечением
большого числа показателей, характеризующих
деятельность предприятия).
В
зависимости от способа проведения
статистического наблюдения выделяют:
-
непосредственное
наблюдение (подсчет, измерение,
взвешивание); -
наблюдение
на основе документальных источников
первичной информации (например, на
основе форм бухгалтерского учета и
отчетности); -
опрос
(письменный или устный).
Таблица 2.1
Классификация форм, видов и способов
статистических наблюдений
|
Признаки классификации |
|||||
|
Организацион-ная наблюдения |
Вид |
Способ |
|||
|
По времени регистрации актов |
По степени |
Непосредственное |
Документальный |
Опрос (письменный или устный) |
|
|
Официальная |
Периоди-ческие |
Сплошные |
Саморе-гистрация |
||
|
Специально организован-ные |
Разовые |
Выбороч-ные |
Экспеди-ционный |
||
|
Регистры |
Непрерыв-ные |
Основного массива |
Корреспон-дентский |
||
|
Моногра-фические |
Лекция
№3.
Сводка
и группировка статистических материалов
Введение
На
предыдущих лекциях мы изучили
содержание
трех этапов статистического исследования
и
более подробно ознакомились
с
основным
методом сбора информации на первом
этапе исследования, то есть со
статистическим наблюдением, его основными
видами и формами.
На
втором этапе статистического исследования
основную
роль играют такие методы обработки
статистической информации, как сводка
и группировка. Это давно известные в
статистике методы, исторически
сформировавшиеся еще в позапрошлом
веке.
Но
раньше эти методы использовались для
сложного и трудоемкого процесса обработки
данных вручную. В настоящее время те же
самые процессы осуществляются с
использованием современных компьютерных
программ.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Ошибки при статистическом анализе: какие бывают и чем вызваны
Статистический анализ данных применительно к медицине – серьёзная наука, которая подчиняется определённым законам. И если им не следовать, результат будет неудовлетворительным. Статическая обработка данных в научном исследовании, продумывается ещё на этапе его планирования. Если же вспомнить о ней только по окончанию основной части работы, то систематизировать полученные данные будет практически невозможно. Даже специалистам будет весьма проблематично выудить из «кучи мусора» действительно важные показатели, чтобы исследователь получил ожидаемый результат. Поэтому, если вы не можете похвастаться высоким уровнем квалификации в биостатистике, обратиться за помощью к профессионалам в данном направлении, стоит ещё до начала экспериментальной работы. Это позволит избежать ошибок, которые могут поставить под сомнение результаты всего процесса.
Статистические ошибки – какими они бывают
 Проведение любого эксперимента требует создания статистической выборке. О том, какими они бывают, на каких принципах строятся и их характеристики, вы можете прочесть в нашей статье. Статистическая обработка данных в научном исследовании и проводится на основании результатов, полученных в данных выборках. А затем, перекладывается на всю популяцию.
Проведение любого эксперимента требует создания статистической выборке. О том, какими они бывают, на каких принципах строятся и их характеристики, вы можете прочесть в нашей статье. Статистическая обработка данных в научном исследовании и проводится на основании результатов, полученных в данных выборках. А затем, перекладывается на всю популяцию.
Объём выборки, напрямую связан с вероятностью появления статистических ошибок. Они бывают первого и второго рода.
- Статистические ошибки первого рода. Они могут появляться из-за того, что в процессе исследования, осуществляется изучение не всей популяции, а только её части. Таким образом, ошибка первого рода является ошибочным отклонением от нулевой гипотезы. При этом, важно понимать, что собой представляет сама нулевая гипотеза. Это предположение, что все изучаемые группы взяты из одной генеральной совокупности, а значит, любые различия или напротив – связи между ними, являются случайными. По аналогии с диагностическим тестированием, можно говорить, что ошибка первого рода – это ложноположительный результат.
- Статистические ошибки второго рода. Они являются неверным отклонением альтернативной гипотезы. В свою очередь, альтернативная гипотеза говорит о том, что совпадения или различия между группами не случайны, а обусловлены влиянием изучаемых факторов. Если снова затронуть диагностическую ошибку, то в данном случае, результат будет ложноотрицательным. При таком результате, в силу вступает понятие мощности, определяющее насколько подобранный статистический метод является эффективным для конкретных условий. Для вычисления мощности используется формула 1-β, где β – это вероятность ошибки второго рода.
Что касается ошибки второго рода, то показатель мощности, в большинстве случаев, имеет прямую зависимость от численности выборки. В больших по объёму группах, ниже вероятность ошибки второго рода и выше мощность статистических критериев. Данная зависимость является не менее чем квадратичной. Это значит, что при уменьшении объема выборки в два раза, последует падение мощности не менее чем в 4 раза. При этом, минимально допустимая мощность должна составлять не менее 80%, а максимально допустимый уровень ошибки – не выше 5%.
Стоит учитывать, что чётких границ не существует. Задаются они произвольно и в зависимости от особенностей исследования, его целей и характера, могут быть изменены. В большинстве случаев, научное сообщество произвольное изменение мощности, однако в подавляющем большинстве случаев уровень ошибки первого рода не может превышать 5%.
Особенности процедуры анализа
 Статистическая обработка данных в научном исследовании предполагает соблюдение процедуры анализа. Он может осуществляться с использованием двух разновидностей техник – описательной или доказательной, которую ещё называют аналитической. Что касается описательных техник, то с их помощью, данные можно предоставить в компактном и понятном виде. Это могут быть графики, таблицы, абсолютные и относительные частоты, меры центральной тенденции, меры разброса данных и другие. Все они дают характеристику изучаемым выборкам.
Статистическая обработка данных в научном исследовании предполагает соблюдение процедуры анализа. Он может осуществляться с использованием двух разновидностей техник – описательной или доказательной, которую ещё называют аналитической. Что касается описательных техник, то с их помощью, данные можно предоставить в компактном и понятном виде. Это могут быть графики, таблицы, абсолютные и относительные частоты, меры центральной тенденции, меры разброса данных и другие. Все они дают характеристику изучаемым выборкам.
Описание групп осуществляется по чётким критериям, и специалисты подбирают их совокупность индивидуально. Таким образом, результат получается максимально объективным. По завершению данного процесса, требуется выявить взаимоотношения между группами и, если это возможно, перенести результаты исследования на всю популяцию. Здесь в дело вступают аналитические методы биостатистики. Традиционно, данный этап специалисты называют «тестирование статистических гипотез».
При тестировании гипотез, все задачи разделяются на две большие группы. Работая с первой, необходимо выявить, есть ли различия между группами по уровню определённого показателя. Например – печеночных трансаминаз среди здоровых реципиентов и людей с подтверждённым гепатитом. А работая со второй группой, наличие связей исследуется уже не по одному, а нескольким параметрам. Для примера – функции печени и иммунной системы.
Если переменная, которая подлежит изучению, является качественной, сравниваются между собой две группы, то эффективно используется критерий «хи-квадрат». Стоит учитывать, что если наблюдений недостаточно, он будет непоказательным. В таком случае, применяются такие методы как поправка Йейтса на непрерывность и точный метод Фишера.
Что касается количественной переменной, то применяется один из двух видов статистических критериев. Так, критерии первого вида основываются на конкретном типе распределения генеральной совокупности и оперируют параметрами этой совокупности. Они имеют название «параметрические». А вот критерии второго вида – непараметрические, основываются на теории о типе распределения генеральной совокупности, и они не используют ее параметры. Иногда, их называют свободными от распределения. При этом важно учитывать, что распределения во всех сравниваемых группах должны быть идентичными, чтобы не получить ложноположительный результат.
Ошибки в статистике
Ошибки в статистике (сплошных и выборочных) могут возникнуть ошибки двух видов: репрезентативности и регистрации.
Ошибки репрезентативности характерны только для выборочного наблюдения и возникают в результате того, что выборочная совокупность не полностью воспроизводит генеральную. Они определяются как расхождение между значениями показателей, полученных по выборке, и значениями показателей этих же величин, которые были бы получены при проведенном сплошном наблюдении с одинаковой степенью точности.
Ошибки регистрации могут иметь случайный, систематический и непреднамеренный характер.
Случайные ошибки часто уравновешивают друг друга, так как они не имеют преимущественного направления в сторону преувеличения (преуменьшении) значения изучаемого показателя. Данные ошибки имеют объективный характер и возникают в следствии случайных различий между единицами, попавшими в выборку, и единицами генеральной совокупности. В результате и структуры этих совокупностей чаще всего не совпадают. Научным обоснованием случайных ошибок являются теория вероятностей и ее предельные теоремы.
Систематические ошибки направлены в одну сторону в результате предумышленного нарушения правил отбора. Их можно избежать при правильной организации и проведении наблюдения.
Ошибка выборки в статистике
Ошибка выборки или ошибка репрезентативности определяется как разница между значением показателя, который был получен по выборке, и генеральным параметром. Она характерна только для выборочных наблюдений. Чем больше значение этой ошибки, тем в большей степени выборочные показатели отличаются от соответствующих им генеральных показателей.
Ошибку выборки часто определяют по формулам:
1. Для среднего количественного признака:

где первое — среднее значение признака в генеральной совокупности или генеральная средняя;
второе — выборочная средняя.
2. Для доли (альтернативного признака):

где w — выборочная доля;
р — генеральная доля, или доля единиц, обладающих данным значением признака в общем числе единиц генеральной совокупности.
Ошибки выборки возникают вследствие двух причин из-за нарушения принципа случайности как основного принципа выборки (систематические ошибки) и в результате случайного отбора (случайные ошибки). Выборки являются случайными величинами и могут принимать разные значения.
Источник: Балинова B.C. Статистика в вопросах и ответах: Учеб. пособие. — М.: ТК. Велби, Изд-во Проспект, 2004. — 344 с.
Статистическая погрешность — это та неопределенность в оценке истинного значения измеряемой величины, которая возникает из-за того, что несколько повторных измерений тем же самым инструментом дали различающиеся результаты. Возникает она, как правило, из-за того, что результаты измерения в микромире не фиксированы, а вероятностны. Она тесно связана с объемом статистики: обычно чем больше данных, тем меньше статистическая погрешность и тем точнее результат измерения. Среди всех типов погрешностей она, пожалуй, самая безобидная: понятно, как ее считать, и понятно, как с ней бороться.
Статистическая погрешность: чуть подробнее
Предположим, что ваш детектор может очень точно измерить какую-то величину в каждом конкретном столкновении. Это может быть энергия или импульс какой-то родившейся частицы, или дискретная величина (например, сколько мюонов родилось в событии), или вообще элементарный ответ «да» или «нет» на какой-то вопрос (например, родилась ли в этом событии хоть одна частица с импульсом больше 100 ГэВ).
Это конкретное число, полученное в одном столкновении, почти бессмысленно. Скажем, взяли вы одно событие и выяснили, что в нём хиггсовский бозон не родился. Никакой научной пользы от такого единичного факта нет. Законы микромира вероятностны, и если вы организуете абсолютно такое же столкновение протонов, то картина рождения частиц вовсе не обязана повторяться, она может оказаться совсем другой. Если бозон не родился сейчас, не родился в следующем столкновении, то это еще ничего не говорит о том, может ли он родиться вообще и как это соотносится с теоретическими предсказаниями. Для того, чтобы получить какое-то осмысленное число в экспериментах с элементарными частицами, надо повторить эксперимент много раз и набрать статистику одинаковых столкновений. Всё свое рабочее время коллайдеры именно этим и занимаются, они накапливают статистику, которую потом будут обрабатывать экспериментаторы.
В каждом конкретном столкновении результат измерения может быть разный. Наберем статистику столкновений и усредним по ней результат. Этот средний результат, конечно, тоже не фиксирован, он может меняться в зависимости от статистики, но он будет намного стабильнее, он не будет так сильно прыгать от одной статистической выборки к другой. У него тоже есть некая неопределенность (в статистическом анализе она так и называется: «неопределенность среднего»), но она обычно небольшая. Вот эта величина и называется статистической погрешностью измерения.
Итак, когда экспериментаторы предъявляют измерение какой-то величины, то они сообщают результат усреднения этой величины по всей набранной статистике столкновений и сопровождают его статистической погрешностью. Именно такие средние значения имеют физический смысл, только их может предсказывать теория.
Есть, конечно, и иной источник статистической погрешности: недостаточный контроль условий эксперимента при повторном измерении. Если в физике частиц этот источник можно попытаться устранить, по крайней мере, в принципе, то в других разделах естественных наук он выходит на первый план; например, в медицинских исследованиях каждый человек отличается от другого по большому числу параметров.
Как считать статистическую погрешность?
Существует теория расчета статистической погрешности, в которую мы, конечно, вдаваться не будем. Но есть одно очень простое правило, которое легко запомнить и которое срабатывает почти всегда. Пусть у вас есть статистическая выборка из N столкновений и в ней присутствует n событий какого-то определенного типа. Тогда в другой статистической выборке из N событий, набранной в тех же условиях, можно ожидать примерно n ± √n таких событий. Поделив это на N, мы получим среднюю вероятность встретить такое событие и погрешность среднего: n/N ± √n/N. Оценка истинного значения вероятности такого типа события примерно соответствует этому выражению.
Сразу же, впрочем, подчеркнем, что эта простая оценка начинает сильно «врать», когда количество событий очень мало. В науке обсчета маленькой статистики есть много дополнительных тонкостей.
Более серьезное (но умеренно краткое) введение в методы статистической обработки данных в применении к экспериментам на LHC см. в лекциях arXiv.1307.2487.
Именно поэтому эксперименты в физике элементарных частиц стараются оптимизировать не только по энергии, но и по светимости. Ведь чем больше светимость, тем больше столкновений будет произведено — значит, тем больше будет статистическая выборка. И уже это позволит сделать измерения более точными — даже без каких-либо улучшений в эксперименте. Примерная зависимость тут такая: если вы увеличите статистику в k раз, то относительные статистические погрешности уменьшатся примерно в √k раз.
Этот пример — некая симуляция того, как могло бы происходить измерение массы ρ-мезона свыше полувека назад, на заре адронной физики, если бы он был вначале обнаружен в процессе e+e– → π+π–. А теперь перенесемся в наше время.

Сейчас этот процесс изучен вдоль и поперек, статистика набрана огромная (миллионы событий), а значит, и масса ρ-мезона сейчас определена несравнимо точнее. На рис. 3 показано современное состояние дел в этой области масс. Если ранние эксперименты еще имели какие-то существенные погрешности, то сейчас они практически неразличимы глазом. Огромная статистика позволила не только измерить массу (примерно равна 775 МэВ с точностью в десятые доли МэВ), но и заметить очень странную форму этого пика. Такая форма получается потому, что практически в том же месте на шкале масс находится и другой мезон, ω(782), который «вмешивается» в процесс и искажает форму ρ-мезонного пика.
Другой, гораздо более реальный пример влияния статистики на процесс поиска и изучения хиггсовского бозона обсуждался в новости Анимации показывают, как в данных LHC зарождался хиггсовский сигнал.
Статистические ошибки
Использование
методов биометрии позволяет исследователю
на ограниченном по численности материале
делать заключения о проявлении признака,
его изменчивости и других параметрах
в генеральной совокупности. Но так
как выборочная совокупность — часть
генеральной и ее формируют методом
случайного отбора, то в выборку могут
попасть животные с более низкими
продуктивными качествами, или несколько
лучшие особи. В этом случае вычисленные
значения M, б, Cv и
других биометрических величин будут
отличаться от значений этих величин в
генеральной совокупности, то есть
выборка отражает генеральную совокупность
с ошибкой. Эти ошибки, связанные с
методом выборочности, называются
статистическими и устранить их нельзя.
Ошибки не будет лишь в том случае, когда
в обработку включаются все члены
генеральной совокупности. Величины
статистических ошибок зависят от
изменчивости признаков и объема выборки:
чем более изменчив признак, тем больше
ошибка, и чем больше объем выборки, тем
она меньше. Ошибки статистических
величин в биометрии принято обозначать
буквой m.
Ошибки
имеют все статистические величины.
Вычисляют их по формулам:
![]()
Все
ошибки измеряют в тех же единицах, что
и сами показатели, и записывают обычно
рядом с ними.
Статистические
ошибки указывают интервал, в котором
находится величина того или иного
статистического показателя в генеральной
совокупности. Зная среднее значение
признака (М) и его ошибку (m), можно
установить доверительные границы
средней величины в генеральной
совокупности по формуле: Мген.=Мв.
tm, где t — нормированное отклонение,
которое зависит от уровня вероятности
и объема выборки. Цифровое значение t
для каждого конкретного случая находят
с помощью специальной таблицы. Например,
нас интересует средняя частота пульса
у овец породы прекос. Для изучения этого
показателя была сформирована выборка
в количестве 50 голов и определена у
этих животных средняя частота пульса.
Оказалось, что этот показатель равен
75 ударов в минуту, изменчивость его б =
12 ударов. Ошибка средней арифметической
величины в этом случае составит:
б
12
m
= ──── = ──── = 1,7 (уд./мин).
n
50
Итоговая
запись будет иметь вид: М
m или 75
1,7, то есть частота пульса 75 ударов в
минуту — среднее значение для 50 голов.
Чтобы определить среднюю частоту пульса
в генеральной совокупности животных,
возьмем в качестве доверительной
вероятности P = 0,95. В этом случае, исходя
из таблицы, t = 2,01. Определим доверительные
границы частоты пульса в генеральной
совокупности M
tm.
75,0
+ 2,01 x 1,7 = 75,0 + 3,4 = 78,4 (уд./мин)
75,0
— 2,01 x 1,7 = 75,0 — 3,4 = 71,6 (уд./мин)
Таким
образом, средняя частота пульса для
генеральной совокупности будет в
пределах от 71,6 до 78,4 ударов в минуту.
Зная
величину статистических ошибок,
устанавливают также, правильно ли
выборочная совокупность отражает тот
или иной параметр генеральной, то есть
устанавливают критерий доверительности
выборочных величин.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Содержание
- Расчет ошибки средней арифметической
- Способ 1: расчет с помощью комбинации функций
- Способ 2: применение инструмента «Описательная статистика»
- Вопросы и ответы

Стандартная ошибка или, как часто называют, ошибка средней арифметической, является одним из важных статистических показателей. С помощью данного показателя можно определить неоднородность выборки. Он также довольно важен при прогнозировании. Давайте узнаем, какими способами можно рассчитать величину стандартной ошибки с помощью инструментов Microsoft Excel.
Расчет ошибки средней арифметической
Одним из показателей, которые характеризуют цельность и однородность выборки, является стандартная ошибка. Эта величина представляет собой корень квадратный из дисперсии. Сама дисперсия является средним квадратном от средней арифметической. Средняя арифметическая вычисляется делением суммарной величины объектов выборки на их общее количество.
В Экселе существуют два способа вычисления стандартной ошибки: используя набор функций и при помощи инструментов Пакета анализа. Давайте подробно рассмотрим каждый из этих вариантов.
Способ 1: расчет с помощью комбинации функций
Прежде всего, давайте составим алгоритм действий на конкретном примере по расчету ошибки средней арифметической, используя для этих целей комбинацию функций. Для выполнения задачи нам понадобятся операторы СТАНДОТКЛОН.В, КОРЕНЬ и СЧЁТ.
Для примера нами будет использована выборка из двенадцати чисел, представленных в таблице.

- Выделяем ячейку, в которой будет выводиться итоговое значение стандартной ошибки, и клацаем по иконке «Вставить функцию».
- Открывается Мастер функций. Производим перемещение в блок «Статистические». В представленном перечне наименований выбираем название «СТАНДОТКЛОН.В».
- Запускается окно аргументов вышеуказанного оператора. СТАНДОТКЛОН.В предназначен для оценивания стандартного отклонения при выборке. Данный оператор имеет следующий синтаксис:
=СТАНДОТКЛОН.В(число1;число2;…)«Число1» и последующие аргументы являются числовыми значениями или ссылками на ячейки и диапазоны листа, в которых они расположены. Всего может насчитываться до 255 аргументов этого типа. Обязательным является только первый аргумент.
Итак, устанавливаем курсор в поле «Число1». Далее, обязательно произведя зажим левой кнопки мыши, выделяем курсором весь диапазон выборки на листе. Координаты данного массива тут же отображаются в поле окна. После этого клацаем по кнопке «OK».
- В ячейку на листе выводится результат расчета оператора СТАНДОТКЛОН.В. Но это ещё не ошибка средней арифметической. Для того, чтобы получить искомое значение, нужно стандартное отклонение разделить на квадратный корень от количества элементов выборки. Для того, чтобы продолжить вычисления, выделяем ячейку, содержащую функцию СТАНДОТКЛОН.В. После этого устанавливаем курсор в строку формул и дописываем после уже существующего выражения знак деления (/). Вслед за этим клацаем по пиктограмме перевернутого вниз углом треугольника, которая располагается слева от строки формул. Открывается список недавно использованных функций. Если вы в нем найдете наименование оператора «КОРЕНЬ», то переходите по данному наименованию. В обратном случае жмите по пункту «Другие функции…».
- Снова происходит запуск Мастера функций. На этот раз нам следует посетить категорию «Математические». В представленном перечне выделяем название «КОРЕНЬ» и жмем на кнопку «OK».
- Открывается окно аргументов функции КОРЕНЬ. Единственной задачей данного оператора является вычисление квадратного корня из заданного числа. Его синтаксис предельно простой:
=КОРЕНЬ(число)
Как видим, функция имеет всего один аргумент «Число». Он может быть представлен числовым значением, ссылкой на ячейку, в которой оно содержится или другой функцией, вычисляющей это число. Последний вариант как раз и будет представлен в нашем примере.
Устанавливаем курсор в поле «Число» и кликаем по знакомому нам треугольнику, который вызывает список последних использованных функций. Ищем в нем наименование «СЧЁТ». Если находим, то кликаем по нему. В обратном случае, опять же, переходим по наименованию «Другие функции…».
- В раскрывшемся окне Мастера функций производим перемещение в группу «Статистические». Там выделяем наименование «СЧЁТ» и выполняем клик по кнопке «OK».
- Запускается окно аргументов функции СЧЁТ. Указанный оператор предназначен для вычисления количества ячеек, которые заполнены числовыми значениями. В нашем случае он будет подсчитывать количество элементов выборки и сообщать результат «материнскому» оператору КОРЕНЬ. Синтаксис функции следующий:
=СЧЁТ(значение1;значение2;…)В качестве аргументов «Значение», которых может насчитываться до 255 штук, выступают ссылки на диапазоны ячеек. Ставим курсор в поле «Значение1», зажимаем левую кнопку мыши и выделяем весь диапазон выборки. После того, как его координаты отобразились в поле, жмем на кнопку «OK».
- После выполнения последнего действия будет не только рассчитано количество ячеек заполненных числами, но и вычислена ошибка средней арифметической, так как это был последний штрих в работе над данной формулой. Величина стандартной ошибки выведена в ту ячейку, где размещена сложная формула, общий вид которой в нашем случае следующий:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13))Результат вычисления ошибки средней арифметической составил 0,505793. Запомним это число и сравним с тем, которое получим при решении поставленной задачи следующим способом.










Но дело в том, что для малых выборок (до 30 единиц) для большей точности лучше применять немного измененную формулу. В ней величина стандартного отклонения делится не на квадратный корень от количества элементов выборки, а на квадратный корень от количества элементов выборки минус один. Таким образом, с учетом нюансов малой выборки наша формула приобретет следующий вид:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13)-1)

Урок: Статистические функции в Экселе
Способ 2: применение инструмента «Описательная статистика»
Вторым вариантом, с помощью которого можно вычислить стандартную ошибку в Экселе, является применение инструмента «Описательная статистика», входящего в набор инструментов «Анализ данных» («Пакет анализа»). «Описательная статистика» проводит комплексный анализ выборки по различным критериям. Одним из них как раз и является нахождение ошибки средней арифметической.
Но чтобы воспользоваться данной возможностью, нужно сразу активировать «Пакет анализа», так как по умолчанию в Экселе он отключен.
- После того, как открыт документ с выборкой, переходим во вкладку «Файл».
- Далее, воспользовавшись левым вертикальным меню, перемещаемся через его пункт в раздел «Параметры».
- Запускается окно параметров Эксель. В левой части данного окна размещено меню, через которое перемещаемся в подраздел «Надстройки».
- В самой нижней части появившегося окна расположено поле «Управление». Выставляем в нем параметр «Надстройки Excel» и жмем на кнопку «Перейти…» справа от него.
- Запускается окно надстроек с перечнем доступных скриптов. Отмечаем галочкой наименование «Пакет анализа» и щелкаем по кнопке «OK» в правой части окошка.
- После выполнения последнего действия на ленте появится новая группа инструментов, которая имеет наименование «Анализ». Чтобы перейти к ней, щелкаем по названию вкладки «Данные».
- После перехода жмем на кнопку «Анализ данных» в блоке инструментов «Анализ», который расположен в самом конце ленты.
- Запускается окошко выбора инструмента анализа. Выделяем наименование «Описательная статистика» и жмем на кнопку «OK» справа.
- Запускается окно настроек инструмента комплексного статистического анализа «Описательная статистика».
В поле «Входной интервал» необходимо указать диапазон ячеек таблицы, в которых находится анализируемая выборка. Вручную это делать неудобно, хотя и можно, поэтому ставим курсор в указанное поле и при зажатой левой кнопке мыши выделяем соответствующий массив данных на листе. Его координаты тут же отобразятся в поле окна.
В блоке «Группирование» оставляем настройки по умолчанию. То есть, переключатель должен стоять около пункта «По столбцам». Если это не так, то его следует переставить.
Галочку «Метки в первой строке» можно не устанавливать. Для решения нашего вопроса это не важно.
Далее переходим к блоку настроек «Параметры вывода». Здесь следует указать, куда именно будет выводиться результат расчета инструмента «Описательная статистика»:
- На новый лист;
- В новую книгу (другой файл);
- В указанный диапазон текущего листа.
Давайте выберем последний из этих вариантов. Для этого переставляем переключатель в позицию «Выходной интервал» и устанавливаем курсор в поле напротив данного параметра. После этого клацаем на листе по ячейке, которая станет верхним левым элементом массива вывода данных. Её координаты должны отобразиться в поле, в котором мы до этого устанавливали курсор.
Далее следует блок настроек определяющий, какие именно данные нужно вводить:
- Итоговая статистика;
- К-ый наибольший;
- К-ый наименьший;
- Уровень надежности.
Для определения стандартной ошибки обязательно нужно установить галочку около параметра «Итоговая статистика». Напротив остальных пунктов выставляем галочки на свое усмотрение. На решение нашей основной задачи это никак не повлияет.
После того, как все настройки в окне «Описательная статистика» установлены, щелкаем по кнопке «OK» в его правой части.
- После этого инструмент «Описательная статистика» выводит результаты обработки выборки на текущий лист. Как видим, это довольно много разноплановых статистических показателей, но среди них есть и нужный нам – «Стандартная ошибка». Он равен числу 0,505793. Это в точности тот же результат, который мы достигли путем применения сложной формулы при описании предыдущего способа.










Урок: Описательная статистика в Экселе
Как видим, в Экселе можно произвести расчет стандартной ошибки двумя способами: применив набор функций и воспользовавшись инструментом пакета анализа «Описательная статистика». Итоговый результат будет абсолютно одинаковый. Поэтому выбор метода зависит от удобства пользователя и поставленной конкретной задачи. Например, если ошибка средней арифметической является только одним из многих статистических показателей выборки, которые нужно рассчитать, то удобнее воспользоваться инструментом «Описательная статистика». Но если вам нужно вычислить исключительно этот показатель, то во избежание нагромождения лишних данных лучше прибегнуть к сложной формуле. В этом случае результат расчета уместится в одной ячейке листа.