Непараметрические
критерии статистики — свободны
от допущения о законе распределения
выборок и базируются на предположении
о независимости наблюдений.
В
группу параметрических
критериев методов
математической статистики входят
методы для вычисления описательных
статистик, построения графиков на
нормальность распределения, проверка
гипотез о принадлежности двух выборок
одной совокупности. Эти методы
основываются на предположении о том,
что распределение выборок подчиняется
нормальному (гауссовому) закону
распределения. Среди параметрических
критериев статистики нами будут
рассмотрены критерий Стьюдента и Фишера.
6.1.1 Методы проверки выборки на нормальность
Чтобы
определить, имеем ли мы дело с
нормальным распределением, можно
применять следующие методы:
1)
в пределах осей можно нарисовать полигон
частоты (эмпирическую функцию
распределения) и кривую нормального
распределения на основе данных
исследования. Исследуя формы кривой
нормального распределения и графика
эмпирической функции распределения,
можно выяснить те параметры, которыми
последняя кривая отличается от первой;
2)
вычисляется среднее, медиана и мода и
на основе этого определяется отклонение
от нормального распределения. Если
мода, медиана и среднее арифметическое
друг от друга значительно не отличаются,
мы имеем дело с нормальным распределением.
Если медиана значительно отличается
от среднего, то мы имеем дело с асимметричной
выборкой.
3)
эксцесс кривой распределения должен
быть равен 0.
Кривые с положительным эксцессом значительно вертикальнее
кривой нормального распределения.
Кривые с отрицательным эксцессом
являются более покатистыми по сравнению
с кривой нормального распределения;
4)
после определения среднего
значения распределения частоты и
стандартного oтклонения находят следующие
четыре интервала распределения сравнивают
их с действительными данными ряда:
а) ![]() —
—
к интервалу должно относиться около
25% частоты совокупности,
б) ![]() —
—
к интервалу должно относиться около
50% частоты совокупности,
в) ![]() —
—
к интервалу должно относиться около
75% частоты совокупности,
г) ![]() —
—
к интервалу должно относиться около
100% частоты совокупности.
6.1.2 Критерий Стьюдента (t-критерий)
Критерий
позволяет найти вероятность того, что
оба средних значения в выборке относятся
к одной и той же совокупности. Данный
критерий наиболее часто используется
для проверки гипотезы: «Средние двух
выборок относятся к одной и той же
совокупности».
При
использовании критерия можно выделить
два случая. В первом случае его применяют
для проверки гипотезы о равенстве
генеральных средних
двух независимых, несвязанныхвыборок
(так называемый двухвыборочный t-критерий).
В этом случае есть контрольная группа
и экспериментальная (опытная) группа,
количество испытуемых в группах может
быть различно.
Во
втором случае, когда одна и та же группа
объектов порождает числовой материал
для проверки гипотез о средних,
используется так называемый парный
t-критерий.
Выборки при этом называют зависимыми, связанными.
а)
случай независимых выборок
Статистика
критерия для случая несвязанных,
независимых выборок равна:
![]() (1)
(1)
где ![]() ,
,![]() —
—
средние арифметические в экспериментальной
и контрольной группах,
![]() —
—
стандартная ошибка разности средних
арифметических. Находится из формулы:
![]() , (2)
, (2)
где n1 и n2 соответственно
величины первой и второй выборки.
Если n1=n2,
то стандартная ошибка разности средних
арифметических будет считаться по
формуле:
 (3)
(3)
где
n величина выборки.
Подсчет числа
степеней свободы осуществляется
по формуле:
k
= n1 +
n2 –
2. (4)
При
численном равенстве выборок k =
2n —
2.
Далее
необходимо сравнить полученное
значение tэмп с
теоретическим значением t—распределения
Стьюдента (см. приложение к учебникам
статистики). Если tэмп<tкрит,
то гипотезаH0 принимается,
в противном случае нулевая гипотеза
отвергается и принимается альтернативная
гипотеза.
Рассмотрим
пример использования t-критерия
Стьюдента для несвязных и неравных по
численности выборок.
Пример 1. В
двух группах учащихся — экспериментальной
и контрольной — получены следующие
результаты по учебному предмету
(тестовые баллы; см. табл. 1).[1]
Таблица
1. Результаты эксперимента
|
Первая |
Вторая N2=9 |
|
12 14 13 16 11 9 13 15 15 18 14 |
13 9 11 10 7 6 8 10 11 |
Общее
количество членов выборки: n1=11, n2=9.
Расчет
средних арифметических: Хср=13,636; Yср=9,444
Стандартное
отклонение: sx=2,460; sy=2,186
По
формуле (2) рассчитываем стандартную
ошибку разности арифметических средних:
![]()
Считаем
статистику критерия:
![]()
Сравниваем
полученное в эксперименте значение t с
табличным значением с учетом степеней
свободы, равных по формуле (4) числу
испытуемых минус два (18).
Табличное
значение tкрит равняется
2,1 при допущении возможности риска
сделать ошибочное суждение в пяти
случаях из ста (уровень значимости=5 %
или 0,05).
Если
полученное в эксперименте эмпирическое
значение t превышает табличное, то
есть основания принять альтернативную
гипотезу (H1)
о том, что учащиеся экспериментальной
группы показывают в среднем более
высокий уровень знаний. В эксперименте
t=3,981, табличное t=2,10, 3,981>2,10, откуда
следует вывод о преимуществе
экспериментального обучения.
Здесь
могут возникнуть такие вопросы:
1.
Что если полученное в опыте значение t
окажется меньше табличного? Тогда надо
принять нулевую гипотезу.
2.
Доказано ли преимущество экспериментального
метода? Не столько доказано, сколько
показано, потому что с самого начала
допускается риск ошибиться в пяти
случаях из ста (р=0,05). Наш эксперимент
мог быть одним из этих пяти случаев. Но
95% возможных случаев говорит в пользу
альтернативной гипотезы, а это достаточно
убедительный аргумент в статистическом
доказательстве.
3.
Что если в контрольной группе результаты
окажутся выше, чем в экспериментальной?
Поменяем, например, местами, сделав ![]() средней
средней
арифметической экспериментальной
группы, a![]() —
—
контрольной:
![]()
Отсюда
следует вывод, что новый метод пока не
проявил себя с хорошей стороны по
разным, возможно, причинам. Поскольку
абсолютное значение 3,9811>2,1, принимается
вторая альтернативная гипотеза (Н2)
о преимуществе традиционного метода.
б)
случай связанных (парных) выборок
В
случае связанных выборок с равным числом
измерений в каждой можно использовать
более простую формулу t-критерия
Стьюдента.
Вычисление
значения t осуществляется по формуле:
![]() (5)
(5)
где ![]() —
—
разности между соответствующими
значениями переменной X и переменной
У, аd —
среднее этих разностей;
Sd
вычисляется по следующей формуле:
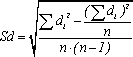 (6)
(6)
Число
степеней свободы k определяется
по формуле k=n-1.
Рассмотрим пример использования t-критерия
Стьюдента для связных и, очевидно, равных
по численности выборок.
Если tэмп<tкрит,
то нулевая гипотеза принимается, в
противном случае принимается
альтернативная.
Пример
2.
Изучался уровень ориентации учащихся
на художественно-эстетические
ценности. С целью активизации формирования
этой ориентации в экспериментальной
группе проводились беседы, выставки
детских рисунков, были организованы
посещения музеев и картинных галерей,
проведены встречи с музыкантами,
художниками и др. Закономерно встает
вопрос: какова эффективность проведенной
работы? С целью проверки эффективности
этой работы до начала эксперимента и
после давался тест. Из методических
соображений в таблице 2 приводятся
результаты небольшого числа
испытуемых.[2]
Таблица
2. Результаты эксперимента
|
Ученики (n=10) |
Баллы |
Вспомогательные |
||
|
до |
в эксперимента |
d |
d2 |
|
|
Иванов |
14 |
18 |
4 |
16 |
|
Новиков |
20 |
19 |
-1 |
1 |
|
Сидоров |
15 |
22 |
7 |
49 |
|
Пирогов |
11 |
17 |
6 |
36 |
|
Агапов |
16 |
24 |
8 |
64 |
|
Суворов |
13 |
21 |
8 |
64 |
|
Рыжиков |
16 |
25 |
9 |
81 |
|
Серов |
19 |
26 |
7 |
49 |
|
Топоров |
15 |
24 |
9 |
81 |
|
Быстров |
9 |
15 |
6 |
36 |
|
å |
148 |
211 |
63 |
477 |
|
Среднее |
14,8 |
21,1 |
Вначале
произведем расчет по формуле:
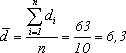
Затем
применим формулу (6), получим:
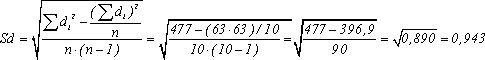
И,
наконец, следует применить формулу (5).
Получим:

Число
степеней свободы: k=10-1=9
и по таблице Приложения 1 находим
tкрит =2.262,
экспериментальное t=6,678, откуда следует
возможность принятия альтернативной
гипотезы (H1)
о достоверных различиях средних
арифметических, т. е. делается вывод об
эффективности экспериментального
воздействия.
В
терминах статистических гипотез
полученный результат будет звучать
так: на 5% уровне гипотеза Н0 отклоняется
и принимается гипотеза Н1 .
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Критерий Стьюдента применяется для проверки равенства средних значений двух выборок, сравнение количественных значений только двух выборок с нормальным распределением случайной величины.
Критерий Стьюдента определяется по формуле:
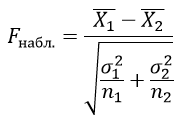
$\bar{X_1}$ – выборочные средние значения первой выборки;
$\bar{X_2}$ – выборочные средние значения второй выборки;
n1 – объем первой выборки;
n2 – объем второй выборки;
σ1 и σ2 – среднее квадратическое отклонение в соответствующих выборках и находятся из формулы:
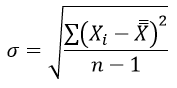
Число степеней свободы определяется по формуле:
k=n1+n2−2
Fкр(α, k) определяется по таблице
При Fнабл<Fкр нулевая гипотеза принимается.
Формула критерия Стьюдента для несвязанных независимых выборок:
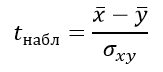
Формула для определения стандартной ошибки разности средних арифметических σxy:
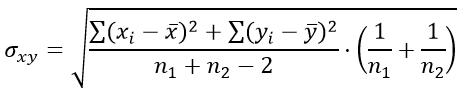
Число степеней свободы определяется выражением:
k=n1+n2–2
При n1=n2 число степеней свободы находится по формуле:
k=2n-2
а стандартная ошибка разности средних арифметических σxy задаётся выражением:
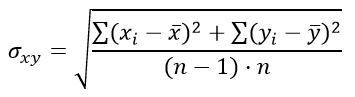
Пример
Даны две выборки.
В первой выборки продажа товара со скидкой, а во второй без скидки.
| № п/п | X | Y |
| 1 | 25 | 19 |
| 2 | 34 | 31 |
| 3 | 23 | 17 |
| 4 | 35 | 24 |
| 5 | 33 | 28 |
| 6 | 25 | 31 |
| 7 | 45 | 39 |
| 8 | 41 | 32 |
| 9 | 27 | 38 |
| 10 | 54 | 43 |
| 11 | 32 | 21 |
| 12 | 32 |
По критерию Стьюдента определить зависит ли спрос на товар от скидок на него при p=0.99?
Решение
В соответствии с таблицей n1=12, n2=11
Вычислим дисперсии D(X), D(Y)
| № п/п | X | Y | D(X) | D(Y) |
| 1 | 25 | 19 | 78,028 | 107,4 |
| 2 | 34 | 31 | 0,0278 | 2,6777 |
| 3 | 23 | 17 | 117,36 | 152,86 |
| 4 | 35 | 24 | 1,3611 | 28,769 |
| 5 | 33 | 28 | 0,6944 | 1,8595 |
| 6 | 25 | 31 | 78,028 | 2,6777 |
| 7 | 45 | 39 | 124,69 | 92,86 |
| 8 | 41 | 32 | 51,361 | 6,9504 |
| 9 | 27 | 38 | 46,694 | 74,587 |
| 10 | 54 | 43 | 406,69 | 185,95 |
| 11 | 32 | 21 | 3,3611 | 69,95 |
| 12 | 32 | 3,3611 | ||
| Сумма | 406 | 323 | 911,67 | 726,55 |
| Среднее | 33,833 | 29,364 |
Подставим значения в формулу стандартной ошибки разности средних арифметических σxy:
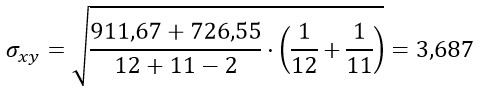
Вычисляем критерий Стьюдента:
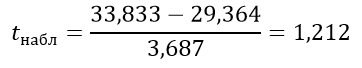
Число степеней свободы равно:
k=12+11–2=21
По таблице Стьюдента находим критическое значение:
tкрит=2,8310
Отсюда tкрит> tнабл, следовательно, зависит.
![]() 19866
19866
Критерий Стьюдента применяется для проверки равенства средних значений двух выборок, сравнение количественных значений только двух выборок с нормальным распределением случайной величины.
Критерий Стьюдента определяется по формуле:
$bar{X_1}$ – выборочные средние значения первой выборки;
$bar{X_2}$ – выборочные средние значения второй выборки;
n1 – объем первой выборки;
n2 – объем второй выборки;
σ1 и σ2 – среднее квадратическое отклонение в соответствующих выборках и находятся из формулы:
Число степеней свободы определяется по формуле:
k=n1+n2−2
Fкр(α, k) определяется по таблице
При Fнабл<Fкр нулевая гипотеза принимается.
Формула критерия Стьюдента для несвязанных независимых выборок:
Формула для определения стандартной ошибки разности средних арифметических σxy:
Число степеней свободы определяется выражением:
k=n1+n2–2
При n1=n2 число степеней свободы находится по формуле:
k=2n-2
а стандартная ошибка разности средних арифметических σxy задаётся выражением:
Пример
Даны две выборки.
В первой выборки продажа товара со скидкой, а во второй без скидки.
| № п/п | X | Y |
| 1 | 25 | 19 |
| 2 | 34 | 31 |
| 3 | 23 | 17 |
| 4 | 35 | 24 |
| 5 | 33 | 28 |
| 6 | 25 | 31 |
| 7 | 45 | 39 |
| 8 | 41 | 32 |
| 9 | 27 | 38 |
| 10 | 54 | 43 |
| 11 | 32 | 21 |
| 12 | 32 |
По критерию Стьюдента определить зависит ли спрос на товар от скидок на него при p=0.99?
Решение
В соответствии с таблицей n1=12, n2=11
Вычислим дисперсии D(X), D(Y)
| № п/п | X | Y | D(X) | D(Y) |
| 1 | 25 | 19 | 78,028 | 107,4 |
| 2 | 34 | 31 | 0,0278 | 2,6777 |
| 3 | 23 | 17 | 117,36 | 152,86 |
| 4 | 35 | 24 | 1,3611 | 28,769 |
| 5 | 33 | 28 | 0,6944 | 1,8595 |
| 6 | 25 | 31 | 78,028 | 2,6777 |
| 7 | 45 | 39 | 124,69 | 92,86 |
| 8 | 41 | 32 | 51,361 | 6,9504 |
| 9 | 27 | 38 | 46,694 | 74,587 |
| 10 | 54 | 43 | 406,69 | 185,95 |
| 11 | 32 | 21 | 3,3611 | 69,95 |
| 12 | 32 | 3,3611 | ||
| Сумма | 406 | 323 | 911,67 | 726,55 |
| Среднее | 33,833 | 29,364 |
Подставим значения в формулу стандартной ошибки разности средних арифметических σxy:
Вычисляем критерий Стьюдента:
Число степеней свободы равно:
k=12+11–2=21
По таблице Стьюдента находим критическое значение:
tкрит=2,8310
Отсюда tкрит> tнабл, следовательно, зависит.
![]() 18953
18953
Условное обозначение средней ошибки среднего арифметического — т. Следует помнить, что под «ошибкой» в статистике понимается не ошибка исследования, а мера представительства данной величины, т. е. мера, которой средняя арифметическая величина, полученная на выборочной совокупности (в нашем примере — на 125 детях), отличается от истинной средней арифметической величины, которая была бы получена на генеральной совокупности (в нашем примере это были бы все дети аналогичного возраста, уровня подготовленности и т. д.). Например, в приведенном ранее примере определялась точность попадания малым мячом в цель у 125 детей и была получена средняя арифметическая величина примерно равная 5,6 см. Теперь надо установить, в какой мере эта величина будет характерна, если взять для исследования 200, 300, 500 и больше аналогичных детей. Ответ на этот вопрос и даст вычисление средней ошибки среднего арифметического, которое производится по формуле:
Для приведенного примера величина средней ошибки среднего арифметического будет равна:
Следовательно, M±m = 5,6±0,38. Это означает, что полученная средняя арифметическая величина (M = 5,6) может иметь в других аналогичных исследованиях значения от 5,22 (5,6 — 0,38 = 5,22) до 5,98 (5,6+0,38 = 5,98).
4. Вычисление средней ошибки разности
Условное обозначение средней ошибки разности — t. Таким образом, установлены основные статистические параметры, характеризующие количественную сторону эффективности одной из методик обучения метанию малых мячей в цель. Но в приведенном примере речь шла о сравнительном эксперименте, в котором сопоставлялись две методики обучения. Предположим, что вычисленные параметры характеризуют методику «А». Тогда для методики «Б» также необходимо вычислить аналогичные статистические параметры. Допустим, они будут равны:
МБ 4,7; σБ ± 3,67 mБ ± 0,33
Теперь есть числовые характеристики двух разных методик обучения. Необходимо установить, насколько эти характеристики достоверно различны, т. е. установить статистически реальную значимость разницы между ними. Условно принято считать, что если разница равна трем своим ошибкам или больше, то она является достоверной:
В приведенном примере:
0,9<1,5
Следовательно, найденные количественные характеристики двух методик обучения не имеют достоверных различий и объясняются не закономерными, а случайными факторами. Поэтому можно сделать следующий педагогический вывод: обе методики обучения равноценны по своей эффективности; новая методика расширяет существующие способы решения данной педагогической задачи.
Подобное вычисление средней ошибки разности применяется в тех случаях, когда имеются количественно значительные показатели п (т. е. при большом числе вариант). Если же в распоряжении экспериментатора имеется небольшое число наблюдений (менее 20), то целесообразно вычислять среднюю ошибку разности по формулам:
где С — число степеней свободы вариаций от 1 до ∞, которые равны числу наблюдений без единицы (С = п — 1).
В виде примера можно привести исследование, в котором оценивалась разница в величине становой динамометрии боксеров двух весовых категорий (А. Г. Жданова, 1961). Были получены следующие исходные данные: тяжелый вес — п1 = 12 человек, легкий вес — п2 = 15человек.
М1 = 139,2 кг M2 = 135,0 кг
σ1 = ± 4,2 кг σ2 = ±4,0 кг
m1 = ± 1,23 кг m2 = ± 1,69 кг
Если подставить эти значения в формулы, то получится:
Далее достоверность различия определяют по таблице вероятностей P/t/≥/t1/ по распределению Стьюдента (t — критерий Стьюдента).
В данной таблице столбец t является нормированным отклонением и содержит числа, которые показывают, во сколько раз разница больше средней ошибки. По вычисленным показателям t и С в таблице определяется число Р, которое показывает вероятность разницы между М1 и М2. Чем больше Р, тем менее существенна разница, тем меньше достоверность различий.
В приведенном примере при значении t 2,0 и С = 25 число Р будет равняться 0,0455 (в таблице оно расположено на пересечении строки, соответствующей t 2,0, и столбца, соответствующего С = ∞). Это свидетельствует о том, что реальная разница весьма вероятна.
В тех случаях, когда расчеты показывают отсутствие достоверности различия, преждевременно считать, что между изучаемыми явлениями вообще не может быть различия. Можно лишь утверждать, что нет различия при данных условиях исследования. При увеличении объема выборки достоверность в различии может появиться. Это положение является главным доказательством важности правильного определения необходимого числа исследований до начала эксперимента.
СПИСОК ЛИТЕРАТУРЫ
-
Масальгин Н.А. Математико-статистические методы в спорте. М., ФиС, 1974.
-
Методика и техника статистической обработки первичной социологической информации. Отв. ред. Г.В. Осипов. М., «Наука», 1968.
-
Начинская С.В. Основы спортивной статистики. — К.: Вища шк., 1987. — 189 с.
-
Толоконцев Н.А. Вычисление среднего квадратичного отклонения по размаху. Сравнение с общепринятым методом. Тезисы докладов третьего совещания по применению математических методов в биологии. ЛГУ, 1961, стр. 83 — 85.
-
Фаламеев А.И., Выдрин В.М. Научно-исследовательская работа в тяжелой атлетике. ГДОИФК им. П. Ф. Лесгафта, 1974.
Оценка разности двух показателей
При оценке
существенности разности двух показателей
вначале находят разность
двух показателей
α
по формуле:
![]()
После этого
вычисляют среднюю
ошибку разности Sα
и
коэффициент доверительности tα
по формулам:
![]()
,
![]()
Пример:
Из 125 студентов у 43 (pЭГ
= 34,40%) выявлен высокий уровень личностной
тревожности в экспериментальной группе
(ЭГ). В контрольной группе (КГ) из 125
студентов – высокий уровень личностной
тревожности у 59 (pКГ
= 47,20%). Необходимо определить, имеются
ли существенные различия между
показателями экспериментальной (pЭГ)
и контрольной (pКГ)
групп.
В нашем примере α
= 12,80, Sα
= 6,16, tα
= 2,08. Разность показателей α
превышает
свою ошибку Sα
более, чем в 2 раза (tα
= 2,08).
По таблице Стьюдента
находим, что эмпирическое значение tα
(2,08) превышает табличное для вероятности
ошибки P
= 0,05 (5%). Значение коэффициента Стьюдента
зависит не только от вероятности P
, но и от объема выборки. Число
степеней свободы n‘
при оценке
одного показателя равняется n
– 1, при
оценке достоверности разности двух
показателей n‘
= n1
+ n2
– 2. Так как
эмпирическое значение tα
(2,08) превышает табличное для вероятности
ошибки P
= 0,05 (5%), следовательно, имеются существенные
различия в показателях высоких уровней
личностной тревожности среди студентов
экспериментальной и контрольной групп.
Таблица 2 – Значения
критерия t
(по Стьюденту)
|
Число степеней |
Вероятность |
|||
|
0,05 = 5% |
0,02 = 2% |
0,01 = 1% |
0,001 = 0,1% |
|
|
30 |
2,042 |
2,457 |
2,750 |
3,64 |
|
∞ |
1,957 |
2,326 |
2,575 |
3,29 |
Определение средней ошибки показателей равных или близких к нулю или 100%
Величина средней
ошибки рассчитывается по формуле:
![]()
где
Sp
– величина
средней ошибки;
t
– доверительный
коэффициент;
n
– число
наблюдений (объем выборки).
Пример:
По данным минутной пробы Н.И Моисеевой
– В.М. Сысуева у всех 35 студентов
зарегистрирован средний уровень
способности к адаптации и ориентации
во времени (p
= 100%). Значит ли это, что в данной группе
отсутствуют студенты, имеющие высокие
или низкие способности к адаптации?
Принимаем
доверительный коэффициент t
= 2, что соответствует вероятности ошибки
меньше 5% (0,05), тогда средняя ошибка
показателя Sp
= 10,3%.
Следовательно,
при последующих испытаниях число лиц,
имеющих средние способности к адаптации
и ориентации во времени, может быть p
= 100% –
10,3% = 89,7%.
Если необходимо
увеличить надежность вывода, можно
принять t
= 3.
Критерий х2
Часто возникает
задача сравнения частных (например,
процентных) распределений
данных. В этом случае можно воспользоваться
статистикой, именуемой х2-критерий:
![]()
где
Pk
–
частоты
результатов наблюдений до эксперимента;
Vk
–
частоты результатов наблюдений после
эксперимента;
S
–
общее
число групп, на которые разделились
результаты наблюдений.
Полученное
расчетным путем значение х2
сопоставляется
с табличным и в случае его превышения
или равенства делается вывод о значимости
различий с определенной вероятностью
допустимой
ошибки.
Таблица 3 – Граничные
(критические)
значения х2-критерия
|
Число |
Вероятность |
||
|
0,05 |
0,01 |
0,001 |
|
|
1 |
3,84 |
6,64 |
10,83 |
|
2 |
5,99 |
9,21 |
13,82 |
|
3 |
7,81 |
11,34 |
16,27 |
|
4 |
9,49 |
13,23 |
18,46 |
|
5 |
11,07 |
15,09 |
20,52 |
|
6 |
12,59 |
16,81 |
22,46 |
|
7 |
14,07 |
18,48 |
24,32 |
|
8 |
15,51 |
20,09 |
26,12 |
|
9 |
16,92 |
21,67 |
27,88 |
|
10 |
18,31 |
23,21 |
29,59 |
Например,
из 100 испытуемых до
начала эксперимента 30 человек показали
результаты
ниже средних, 50 –
средние
и 20 –
выше средних.
После проведения формирующего эксперимента
результаты
распределились следующим образом: 20
человек
показали результаты ниже среднего, 40 –
средние и 40
–
выше среднего уровня.
Можно ли, опираясь
на эти данные, утверждать, что формирующий
эксперимент, направленный на увеличение
показателей (например, уровней самооценки)
удался?
Для
ответа на данный вопрос воспользуемся
формулой.
В данном примере переменная Pk
принимает
значение
30 %, 50 %, 20 %, a
Vk
–
20
%, 40 %, 40 %. Подставив
эти значения в формулу, получим
![]()
Воспользуемся
теперь таблицей «Граничные
(критические)
значения х2-критерия»,
где для заданного числа степеней
свободы (S–1=3–1=2)
можно определить степень
значимости различий показателей до и
после эксперимента. Полученное нами
значение 25,33 больше соответствующего
табличного значения
(13,82) при вероятности допустимой ошибки
меньше
0,1 % (0,001). Следовательно, эксперимент
удался, и мы можем
это утверждать, допуская ошибку, не
превышающую
0,1 %.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Обновлено: 22.09.2023
В группу параметрических критериев методов математической статистики входят методы для вычисления описательных статистик, построения графиков на нормальность распределения, проверка гипотез о принадлежности двух выборок одной совокупности. Эти методы основываются на предположении о том, что распределение выборок подчиняется нормальному (гауссовому) закону распределения. Среди параметрических критериев статистики нами будут рассмотрены критерий Стьюдента и Фишера.
Чтобы определить, имеем ли мы дело с нормальным распределением, можно применять следующие методы:
1) в пределах осей можно нарисовать полигон частоты (эмпирическую функцию распределения) и кривую нормального распределения на основе данных исследования. Исследуя формы кривой нормального распределения и графика эмпирической функции распределения, можно выяснить те параметры, которыми последняя кривая отличается от первой;
2) вычисляется среднее, медиана и мода и на основе этого определяется отклонение от нормального распределения. Если мода, медиана и среднее арифметическое друг от друга значительно не отличаются, мы имеем дело с нормальным распределением. Если медиана значительно отличается от среднего, то мы имеем дело с асимметричной выборкой.
3) эксцесс кривой распределения должен быть равен 0. Кривые с положительным эксцессом значительно вертикальнее кривой нормального распределения. Кривые с отрицательным эксцессом являются более покатистыми по сравнению с кривой нормального распределения;
4) после определения среднего значения распределения частоты и стандартного oтклонения находят следующие четыре интервала распределения сравнивают их с действительными данными ряда:
а) — к интервалу должно относиться около 25% частоты совокупности,
б) — к интервалу должно относиться около 50% частоты совокупности,
в) — к интервалу должно относиться около 75% частоты совокупности,
г) — к интервалу должно относиться около 100% частоты совокупности.
При использовании критерия можно выделить два случая. В первом случае его применяют для проверки гипотезы о равенстве генеральных средних двух независимых, несвязанных выборок (так называемый двухвыборочный t-критерий). В этом случае есть контрольная группа и экспериментальная (опытная) группа, количество испытуемых в группах может быть различно.
Во втором случае, когда одна и та же группа объектов порождает числовой материал для проверки гипотез о средних, используется так называемый парный t-критерий. Выборки при этом называют зависимыми, связанными.
Статистика критерия для случая несвязанных, независимых выборок равна:
где , — средние арифметические в экспериментальной и контрольной группах,
— стандартная ошибка разности средних арифметических. Находится из формулы:
где n 1 и n 2 соответственно величины первой и второй выборки.
Если n 1= n 2, то стандартная ошибка разности средних арифметических будет считаться по формуле:
где n величина выборки.
Подсчет числа степеней свободы осуществляется по формуле:
При численном равенстве выборок k = 2 n — 2.
Далее необходимо сравнить полученное значение t эмп с теоретическим значением t—распределения Стьюдента (см. приложение к учебникам статистики). Если t эмп t крит, то гипотеза H 0 принимается, в противном случае нулевая гипотеза отвергается и принимается альтернативная гипотеза.
Рассмотрим пример использования t -критерия Стьюдента для несвязных и неравных по численности выборок.
Пример 1 . В двух группах учащихся — экспериментальной и контрольной — получены следующие результаты по учебному предмету (тестовые баллы; см. табл. 1). [1]
Таблица 1. Результаты эксперимента
Первая группа (экспериментальная) N 1=11 человек
Вторая группа (контрольная)
12 14 13 16 11 9 13 15 15 18 14
13 9 11 10 7 6 8 10 11
Общее количество членов выборки: n 1=11, n 2=9.
Расчет средних арифметических: Хср=13,636; Y ср=9,444
Стандартное отклонение: s x=2,460; s y =2,186
По формуле (2) рассчитываем стандартную ошибку разности арифметических средних:
Считаем статистику критерия:
Сравниваем полученное в эксперименте значение t с табличным значением с учетом степеней свободы, равных по формуле (4) числу испытуемых минус два (18).
Табличное значение tкрит равняется 2,1 при допущении возможности риска сделать ошибочное суждение в пяти случаях из ста (уровень значимости=5 % или 0,05).
Если полученное в эксперименте эмпирическое значение t превышает табличное, то есть основания принять альтернативную гипотезу (H1) о том, что учащиеся экспериментальной группы показывают в среднем более высокий уровень знаний. В эксперименте t=3,981, табличное t=2,10, 3,981>2,10, откуда следует вывод о преимуществе экспериментального обучения.
Здесь могут возникнуть такие вопросы:
1. Что если полученное в опыте значение t окажется меньше табличного? Тогда надо принять нулевую гипотезу.
2. Доказано ли преимущество экспериментального метода? Не столько доказано, сколько показано, потому что с самого начала допускается риск ошибиться в пяти случаях из ста (р=0,05). Наш эксперимент мог быть одним из этих пяти случаев. Но 95% возможных случаев говорит в пользу альтернативной гипотезы, а это достаточно убедительный аргумент в статистическом доказательстве.
3. Что если в контрольной группе результаты окажутся выше, чем в экспериментальной? Поменяем, например, местами, сделав средней арифметической экспериментальной группы, a — контрольной:
Отсюда следует вывод, что новый метод пока не проявил себя с хорошей стороны по разным, возможно, причинам. Поскольку абсолютное значение 3,9811>2,1, принимается вторая альтернативная гипотеза (Н2) о преимуществе традиционного метода.
В случае связанных выборок с равным числом измерений в каждой можно использовать более простую формулу t-критерия Стьюдента.
Вычисление значения t осуществляется по формуле:
где — разности между соответствующими значениями переменной X и переменной У, а d — среднее этих разностей;
Sd вычисляется по следующей формуле:
Число степеней свободы k определяется по формуле k= n -1. Рассмотрим пример использования t -критерия Стьюдента для связных и, очевидно, равных по численности выборок.
Если t эмп t крит, то нулевая гипотеза принимается, в противном случае принимается альтернативная.
Пример 2. Изучался уровень ориентации учащихся на художественно-эстетические ценности. С целью активизации формирования этой ориентации в экспериментальной группе проводились беседы, выставки детских рисунков, были организованы посещения музеев и картинных галерей, проведены встречи с музыкантами, художниками и др. Закономерно встает вопрос: какова эффективность проведенной работы? С целью проверки эффективности этой работы до начала эксперимента и после давался тест. Из методических соображений в таблице 2 приводятся результаты небольшого числа испытуемых. [2]
Таблица 2. Результаты эксперимента
Вспомогательные расчеты
до начала эксперимента (Х)
эксперимента (У)
Вначале произведем расчет по формуле:
Затем применим формулу (6), получим:
И, наконец, следует применить формулу (5). Получим:
Число степеней свободы: k =10-1=9 и по таблице Приложения 1 находим tкрит =2.262, экспериментальное t=6,678, откуда следует возможность принятия альтернативной гипотезы (H1) о достоверных различиях средних арифметических, т. е. делается вывод об эффективности экспериментального воздействия.
В терминах статистических гипотез полученный результат будет звучать так: на 5% уровне гипотеза Н0 отклоняется и принимается гипотеза Н1 .
Критерий Фишера позволяет сравнивать величины выборочных дисперсий двух независимых выборок. Для вычисления Fэмп нужно найти отношение дисперсий двух выборок, причем так, чтобы большая по величине дисперсия находилась бы в числителе, а меньшая – в знаменателе. Формула вычисления критерия Фишера такова:
где — дисперсии первой и второй выборки соответственно.
Так как, согласно условию критерия, величина числителя должна быть больше или равна величине знаменателя, то значение Fэмп всегда будет больше или равно единице.
Число степеней свободы определяется также просто:
k 1=nl — 1 для первой выборки (т.е. для той выборки, величина дисперсии которой больше) и k 2= n 2 — 1 для второй выборки.
В Приложении 1 критические значения критерия Фишера находятся по величинам k 1 (верхняя строчка таблицы) и k 2 (левый столбец таблицы).
Если t эмп> t крит, то нулевая гипотеза принимается, в противном случае принимается альтернативная.
Пример 3. В двух третьих классах проводилось тестирование умственного развития по тесту ТУРМШ десяти учащихся. [3] Полученные значения величин средних достоверно не различались, однако психолога интересует вопрос — есть ли различия в степени однородности показателей умственного развития между классами.
Решение. Для критерия Фишера необходимо сравнить дисперсии тестовых оценок в обоих классах. Результаты тестирования представлены в таблице:
Рассчитав дисперсии для переменных X и Y, получаем:
Тогда по формуле (8) для расчета по F критерию Фишера находим:
По таблице из Приложения 1 для F критерия при степенях свободы в обоих случаях равных k =10 — 1 = 9 находим F крит=3,18 ( c следователь может утверждать, что по степени однородности такого показателя, как умственное развитие, имеется различие между выборками из двух классов.
Сравнивая на глазок (по процентным соотношениям) результаты до и после какого-либо воздействия, исследователь приходит к заключению, что если наблюдаются различия, то имеет место различие в сравниваемых выборках. Подобный подход категорически неприемлем, так как для процентов нельзя определить уровень достоверности в различиях. Проценты, взятые сами по себе, не дают возможности делать статистически достоверные выводы. Чтобы доказать эффективность какого-либо воздействия, необходимо выявить статистически значимую тенденцию в смещении (сдвиге) показателей. Для решения подобных задач исследователь может использовать ряд критериев различия. Ниже будет рассмотрены непараметрические критерии: критерий знаков и критерий хи-квадрат.
Критерий предназначен для сравнения состояния некоторого свойства у членов двух зависимых выборок на основе измерений, сделанных по шкале не ниже ранговой.
Имеется две серии наблюдений над случайными переменными X и У, полученные при рассмотрении двух зависимых выборок. На их основе составлено N пар вида (х i , у i ), где х i , у i — результаты двукратного измерения одного и того же свойства у одного и того же объекта.
В педагогических исследованиях объектами изучения могут служить учащиеся, учителя, администрация школ. При этом х i , у i могут быть, например, балловыми оценками, выставленными учителем за двукратное выполнение одной и той же или различных работ одной и той же группой учащихся до и после применения некоторого педагогическою средства.
Нулевая гипотеза формулируются следующим образом: в состоянии изучаемого свойства нет значимых различий при первичном и вторичном измерениях. Альтернативная гипотеза: законы распределения величин X и У различны, т. е. состояния изучаемого свойства существенно различны в одной и той же совокупности при первичном и вторичном измерениях этого свойства.
Статистика критерия (Т) определяется следующим образом:
Нулевая гипотеза принимается на уровне значимости 0,05, если наблюдаемое значение T n — ta , где значение n — ta определяется из статистических таблиц для критерия знаков Приложения 2.
Пример 4. Учащиеся выполняли контрольную работу, направленную на проверку усвоения некоторого понятия. Пятнадцати учащимся затем предложили электронное пособие, составленное с целью формирования данного понятия у учащихся с низким уровнем обучаемости. После изучения пособия учащиеся снова выполняли ту же контрольного работу, которая оценивалась по пятибалльной системе.
Результаты двукратного выполнения работы представляют измерения по шкале порядка (пятибалльная шкала). В этих условиях возможно применение знакового критерия для выявления тенденции изменения состояния знаний учащихся после изучения пособия, так как выполняются все допущения этого критерия.
Результаты двукратного выполнения работы (в баллах) 15 учащимися запишем в форме таблицы (см. табл. 1). [4]
Сегодня мы говорим о t-критерии. Т-критерий наиболее популярный статистический тест в биомедицинских исследованиях. Также его называют парный Т-критерий Стьюдента, t-test, two-sample unpaired t-test. Однако, при использовании этого статистического инструмента допускается достаточно много ошибок. Сегодня в этой статье мы постараемся разобраться, как избежать ошибок применения t-критерия Стьюдента, как интерпретировать его результаты и как рассчитывать t-критерий самостоятельно. Об этом обо всем читайте далее.
При описании любого статистического критерия, будь то t-критерий Стьюдента, либо какой-либо еще, нужно вспомнить о том, как же вообще используются статистические критерии. Для того, чтобы понять, как используется любой критерий, нужно перейти к нескольким достаточно логичным для понимания этапам:
Этапы статистического вывода (statistic inference)
- Первый из них – это вопрос, который мы хотим изучить с помощью статистических методов. То есть первый этап: что изучаем? И какие у нас есть предположения относительно результата? Этот этап называется этап статистических гипотез.
- Второй этап – нужно определиться с тем, какие у нас есть в реальности данные для того, чтобы ответить на первый вопрос. Этот этап – тип данных.
- Третий этап состоит в том, чтобы выбрать корректный для применения в данной ситуации статистический критерий.
- Четвертый этап это логичный этап применения интерпретации любой формулы, какие результаты мы получили.
- Пятый этап это создание, синтез выводов относительно первого, второго, третьего, четвертого, пятого этапа, то есть что же получили и что же это в реальности значит.
Предлагаю долго не ходить вокруг да около и посмотреть применение t-критерия Стьюдента на реальном примере.
Видео-версия статьи
Пример использования т-критерия Стьюдента
А пример будет достаточно простой: мне интересно, стали ли люди выше за последние 100 лет. Для этого нужно подобрать некоторые данные. Я обнаружил интересную информацию в достаточно известной статье The Guardian (Tall story’s men and women have grown taller over last century, Study Shows (The Guardian, July 2016), которая сравнивает средний возраст человека в разных странах в 1914 году и в аналогичных странах в 2014 году.
Там приведены данные практически по всем государствам. Однако, я взял лишь 5 стран для простоты вычислений: это Россия, Германия, Китай, США и ЮАР, соответственно 1914 год и 2014 год.
Общее количество наблюдений – 5 в 1914 году в группе 1914 года и общее значение также 5 в 2014 году. Будем думать опять же для простоты, что эти данные сопоставимы, и с ними можно работать.
Дальше нужно выбрать критерии – критерии, по которым мы будем давать ответ. Равны ли средние по росту в 1914 году x̅1914 и в 2014 году x̅2014. Я считаю, что нет. Поэтому моя гипотеза это то, что они не равны (x̅1914≠x̅2014). Соответственно альтернативная гипотеза моему предположению, так называемая нулевая гипотеза (нулевая гипотеза консервативна, обратная вашей, часто говорит об отсутствии статистически значимых связей/зависимостей) будет говорить о том, что они между собой на самом деле равны (x̅1914=x̅2014), то есть о том, что все эти находки случайны, и я, по сути, не прав.
Теперь нужно дать какой-то аргументированный ответ. Даем его с помощью статистического критерия. Соответственно теперь наступает самое важное: как выбрать статистический критерий? Я думаю, это будет темой отдельной статьи. Для корректности использования t-критерия Стьюдента лишь скажу, что нужно, чтобы:
Условия применения статистического критерия т-теста (критерия Стьюдента)
— данные распределялись по закону нормального распределения;
— данные были количественными;
— и это две независимые между собой выборки (независимые это значит, что в этих группах разные люди, а никак, например, до и после применения препарата у одной группы, люди должны быть разными, тогда группы являются несвязанными, либо независимыми), этот аспект стоит учитывать для выбора вида т-критерия Стьюдента, так как для парных выборок существует свой парный т-критерий (paired t-test).
В итоге Мы определились с тем, что это будет t-критерий Стьюдента.
Формула t-критерия Стьюдента достаточно простая. Она гласит о том, что в числителе у нас разница средних, в знаменателе у нас корень квадратный суммы ошибок репрезентативности по этим группам:
Ошибки репрезентативности были подробно объяснены мною в статье по доверительным интервалам. Поэтому я рекомендую вам ознакомиться с ней, чтобы лучше разобраться, что такое ошибки репрезентативности, что такое выборка, как она соотносится с генеральной совокупностью.
Для того, чтобы не тратить время, я в принципе все уже рассчитал по каждой из групп: средняя (x̅) ,стандартное отклонение (SD) и ошибка репрезентативности (m r ).
Давайте остановимся на том, что же значат эти значения:
— средняя (x̅) это среднеарифметическое по 5 наблюдениям в каждой группе;
— если совсем упрощать значение стандартного отклонения (SD), то можно сказать, что оно представляет собой обобщенную среднюю отклонения каждого значения от среднего (стандартное отклонение показывает, насколько широко значения рассеяны (разбросаны) относительно средней). И дальше мы находим нечто среднее отклонений каждого варианта в группе от среднего;
— и ошибка репрезентативности она тоже находится достаточно просто: это как раз наше отклонение от средней некоторое стандартизованное, поэтому стандартное отклонение на размер выборки (mr=).
Итак, продолжаем. В ходе подстановки каждого значения в нашу формулу, мы находим, что t-критерий Стьюдента равен 3,78. Однако, я думаю, пока тем, кто не знаком со статистическими критериями, это мало о чем говорит.
Итак, как нам перейти от нашей t к р вероятности? Это сделать достаточно просто, стоит лишь воспользоваться табличными значениями t для определенных степеней свободы. Теперь вопрос: как найти эти степени свободы? Но это сделать достаточно просто. Для того, чтобы обнаружить степени свободы для наших групп, нужно лишь сложить количество наблюдений 5 и 5 в нашем случае и вычесть 2. В нашем случае степень свободы равна 8.
Итак, t=3,78, степень свободы равна 8. Переходим в табличное значение и получаем р вероятность – вероятность равна 0,005. То есть вероятность того, что мы ошибаемся при констатации факта различия роста ранее и сейчас, крайне мала – это 0,005 %, не 5 %, а 0,005 %. То есть мы можем говорить с высокой долей достоверности того, что наш рост сейчас в XXI веке и 100 лет назад отличаются.
Вот то, что касается расчета t-критерия Стьюдента и его интерпретации.
На этом наш разговор о t-критерии Стьюдента закончен. Спасибо, что ознакомились с этой статьей. Я очень надеюсь на вашу обратную связь. Пожалуйста, подписывайтесь на наш сайте, ставьте лайки, предлагайте свои темы для следующих выпусков. Спасибо большое за поддержку. С вами был Кирилл Мильчаков. Пока, до новых встреч!
Если Вам понравилась статья и оказалась полезной, Вы можете поделиться ею с коллегами и друзьями в социальных сетях:
Проверка статистической гипотезы позволяет сделать строгий вывод о характеристиках генеральной совокупности на основе выборочных данных. Гипотезы бывают разные. Одна из них – это гипотеза о средней (математическом ожидании). Суть ее в том, чтобы на основе только имеющейся выборки сделать корректное заключение о том, где может или не может находится генеральная средняя (точную правду мы никогда не узнаем, но можем сузить круг поиска).
Распределение Стьюдента
Общий подход в проверке гипотез описан здесь, поэтому сразу к делу. Предположим для начала, что выборка извлечена из нормальной совокупности случайных величин X с генеральной средней μ и дисперсией σ 2 . Средняя арифметическая из этой выборки, очевидно, сама является случайной величиной. Если извлечь много таких выборок и посчитать по ним средние, то они также будут иметь нормальное распределение с математическим ожиданием μ и дисперсией
Тогда случайная величина
имеет стандартное нормальное распределение со всеми вытекающими отсюда последствиями. Например, с вероятностью 95% ее значение не выйдет за пределы ±1,96.
Однако такой подход будет корректным, если известна генеральная дисперсия. В реальности, как правило, она не известна. Вместо нее берут оценку – несмещенную выборочную дисперсию:
Возникает вопрос: будет ли генеральная средняя c вероятностью 95% находиться в пределах ±1,96sx̅. Другими словами, являются ли распределения случайных величин
Впервые этот вопрос был поставлен (и решен) одним химиком, который трудился на пивной фабрике Гиннесса в г. Дублин (Ирландия). Химика звали Уильям Сили Госсет и он брал пробы пива для проведения химического анализа. В какой-то момент, видимо, Уильяма стали терзать смутные сомнения на счет распределения средних. Оно получалось немного более размазанным, чем должно быть у нормального распределения.
Посмотрим, что же мог увидеть У. Госсет. Сгенерируем 20 тысяч нормальных выборок из 6-ти наблюдений со средней (X̅) 50 и среднеквадратичным отклонением (σ) 10. Затем нормируем выборочные средние, используя генеральную дисперсию:
Получившиеся 20 тысяч средних сгруппируем в интервалы длинной 0,1 и подсчитаем частоты. Изобразим на диаграмме фактическое (Norm) и теоретическое (ENorm) распределение частот выборочных средних.

Точки (наблюдаемые частоты) практически совпадают с линией (теоретическими частотами). Оно и понятно, ведь данные взяты из одной и то же генеральной совокупности, а отличия – это лишь ошибки выборки.
Проведем новый эксперимент. Нормируем средние, используя выборочную дисперсию.
Снова подсчитаем частоты и нанесем их на диаграмму в виде точек, оставив для сравнения линию стандартного нормального распределения. Обозначим эмпирическое частоты средних, скажем, через букву t.

У Госсета-Стьюдента не было последней версии MS Excel, но именно этот эффект он и заметил. Почему так получается? Объяснение заключается в том, что случайная величина
зависит не только от ошибки выборки (числителя), но и от стандартной ошибки средней (знаменателя), которая также является случайной величиной.
Давайте немного разберемся, какое распределение должно быть у такой случайной величины. Вначале придется кое-что вспомнить (или узнать) из математической статистики. Есть такая теорема Фишера, которая гласит, что в выборке из нормального распределения:
1. средняя X̅ и выборочная дисперсия s 2 являются независимыми величинами;
2. соотношение выборочной и генеральной дисперсии, умноженное на количество степеней свободы, имеет распределение χ 2 (хи-квадрат) с таким же количеством степеней свободы, т.е.
где k – количество степеней свободы (на английском degrees of freedom (d.f.))
Вернемся к распределению средней. Разделим числитель и знаменатель выражения
Числитель – это стандартная нормальная случайная величина (обозначим ξ (кси)). Знаменатель выразим из теоремы Фишера.
Тогда исходное выражение примет вид
Это и есть t-критерий Стьюдента в общем виде (стьюдентово отношение). Вывести функцию его распределения можно уже непосредственно, т.к. распределения обеих случайных величин в данном выражении известны. Оставим это удовольствие математикам.
Функция t-распределения Стьюдента имеет довольно сложную для понимания формулу, поэтому не имеет смысла ее разбирать. Вероятности и квантили t-критерия приведены в специальных таблицах распределения Стьюдента и забиты в функции разных ПО вроде Excel.
Итак, вооружившись новыми знаниями, вы сможете понять официальное определение распределения Стьюдента.
Случайной величиной, подчиняющейся распределению Стьюдента с k степенями свободы, называется отношение независимых случайных величин
где ξ распределена по стандартному нормальному закону, а χ 2 k подчиняется распределению χ 2 c k степенями свободы.
Таким образом, формула критерия Стьюдента для средней арифметической
есть частный случай стьюдентова отношения
Из формулы и определения следует, что распределение т-критерия Стьюдента зависит лишь от количества степеней свободы.
При k > 30 t-критерий практически не отличается от стандартного нормального распределения.
В отличие от хи-квадрат, t-критерий может быть одно- и двусторонним. Обычно пользуются двусторонним, предполагая, что отклонение может происходить в обе стороны от средней. Но если условие задачи допускает отклонение только в одну сторону, то разумно применять односторонний критерий. От этого немного увеличивается мощность критерия.
Условия применения t-критерия Стьюдента
Несмотря на то, что открытие Стьюдента в свое время совершило переворот в статистике, t-критерий все же довольно сильно ограничен в возможностях применения, т.к. сам по себе происходит из предположения о нормальном распределении исходных данных. Если данные не являются нормальными (что обычно и бывает), то и t-критерий уже не будет иметь распределения Стьюдента. Однако в силу действия центральной предельной теоремы средняя даже у ненормальных данных быстро приобретает колоколообразную форму распределения.
Рассмотрим, для примера, данные, имеющие выраженный скос вправо, как у распределения хи-квадрат с 5-ю степенями свободы.

Теперь создадим 20 тысяч выборок и будет наблюдать, как меняется распределение средних в зависимости от их объема.
Отличие довольно заметно в малых выборках до 15-20-ти наблюдений. Но дальше оно стремительно исчезает. Таким образом, ненормальность распределения – это, конечно, нехорошо, но некритично.

Картина получается нерадостная. Фактические частоты средних сильно отличаются от теоретических. Использование t-распределения в такой ситуации становится весьма рискованной затеей.
Итак, в не очень малых выборках (от 15-ти наблюдений) t-критерий относительно устойчив к ненормальному распределению исходных данных. А вот выбросы в данных сильно искажают распределение t-критерия, что, в свою очередь, может привести к ошибкам статистического вывода, поэтому от аномальных наблюдений следует избавиться. Часто из выборки удаляют все значения, выходящие за пределы ±2 стандартных отклонения от средней.
Пример проверки гипотезы о математическом ожидании с помощью t- критерия Стьюдента в MS Excel
В Excel есть несколько функций, связанных с t-распределением. Рассмотрим их.
СТЬЮДЕНТ.РАСП.2Х – двухсторонне распределение. В качестве аргумента подается абсолютное значение (по модулю) t-критерия и количество степеней свободы. На выходе получаем вероятность получить такое или еще больше значение t-критерия (по модулю), т.е. фактический уровень значимости (p-value).
СТЬЮДЕНТ.РАСП.ПХ – правостороннее t-распределение. Так, 1-СТЬЮДЕНТ.РАСП(2;5;1) = СТЬЮДЕНТ.РАСП.ПХ(2;5) = 0,05097. Если t-критерий положительный, то полученная вероятность – это p-value.
СТЬЮДЕНТ.ОБР – используется для расчета левостороннего обратного значения t-распределения. В качестве аргумента подается вероятность и количество степеней свободы. На выходе получаем соответствующее этой вероятности значение t-критерия. Отсчет вероятности идет слева. Поэтому для левого хвоста нужен сам уровень значимости α, а для правого 1 — α.
СТЬЮДЕНТ.ОБР.2Х – обратное значение для двухстороннего распределения Стьюдента, т.е. значение t-критерия (по модулю). Также на вход подается уровень значимости α. Только на этот раз отсчет ведется с двух сторон одновременно, поэтому вероятность распределяется на два хвоста. Так, СТЬЮДЕНТ.ОБР(1-0,025;5) = СТЬЮДЕНТ.ОБР.2Х(0,05;5) = 2,57058
СТЬЮДЕНТ.ТЕСТ – функция для проверки гипотезы о равенстве математических ожиданий в двух выборках. Заменяет кучу расчетов, т.к. достаточно указать лишь два диапазона с данными и еще пару параметров. На выходе получим p-value.
ДОВЕРИТ.СТЬЮДЕНТ – расчет доверительного интервала средней с учетом t-распределения.
Рассмотрим такой учебный пример. На предприятии фасуют цемент в мешки по 50кг. В силу случайности в отдельно взятом мешке допускается некоторое отклонение от ожидаемой массы, но генеральная средняя должна оставаться 50кг. В отделе контроля качества случайным образом взвесили 9 мешков и получили следующие результаты: средняя масса (X̅) составила 50,3кг, среднеквадратичное отклонение (s) – 0,5кг.
Согласуется ли полученный результат с нулевой гипотезой о том, что генеральная средняя равна 50кг? Другими словами, можно ли получить такой результат по чистой случайности, если оборудование работает исправно и выдает среднее наполнение 50 кг? Если гипотеза не будет отклонена, то полученное различие вписывается в диапазон случайных колебаний, если же гипотеза будет отклонена, то, скорее всего, в настройках аппарата, заполняющего мешки, произошел сбой. Требуется его проверка и настройка.
Краткое условие в обще принятых обозначениях выглядит так.
Есть основания предположить, что распределение заполняемости мешков подчиняются нормальному распределению (или не сильно от него отличается). Значит, для проверки гипотезы о математическом ожидании можно использовать t-критерий Стьюдента. Случайные отклонения могут происходить в любую сторону, значит нужен двусторонний t-критерий.
Вначале применим допотопные средства: ручной расчет t-критерия и сравнение его с критическим табличным значением. Расчетный t-критерий:
Теперь определим, выходит ли полученное число за критический уровень при уровне значимости α = 0,05. Воспользуемся таблицей для критерия Стьюдента (есть в любом учебнике по статистике).

По столбцам идет вероятность правой части распределения, по строкам – число степеней свободы. Нас интересует двусторонний t-критерий с уровнем значимости 0,05, что равносильно t-значению для половины уровня значимости справа: 1 — 0,05/2 = 0,975. Количество степеней свободы – это объем выборки минус 1, т.е. 9 — 1 = 8. На пересечении находим табличное значение t-критерия – 2,306. Если бы мы использовали стандартное нормальное распределение, то критической точкой было бы значение 1,96, а тут она больше, т.к. t-распределение на небольших выборках имеет более приплюснутый вид.
Сравниваем фактическое (1,8) и табличное значение (2.306). Расчетный критерий оказался меньше табличного. Следовательно, имеющиеся данные не противоречат гипотезе H0 о том, что генеральная средняя равна 50 кг (но и не доказывают ее). Это все, что мы можем узнать, используя таблицы. Можно, конечно, еще p-value попробовать найти, но он будет приближенным. А, как правило, именно p-value используется для проверки гипотез. Поэтому далее переходим в Excel.
Готовой функции для расчета t-критерия в Excel нет. Но это и не страшно, ведь формула t-критерия Стьюдента довольно проста и ее можно легко соорудить прямо в ячейке Excel.

Получили те же 1,8. Найдем вначале критическое значение. Альфа берем 0,05, критерий двусторонний. Нужна функция обратного значения t-распределения для двухсторонней гипотезы СТЬЮДЕНТ.ОБР.2Х.

Полученное значение отсекает критическую область. Наблюдаемый t-критерий в нее не попадает, поэтому гипотеза не отклоняется.
Однако это тот же способ проверки гипотезы с помощью табличного значения. Более информативно будет рассчитать p-value, т.е. вероятность получить наблюдаемое или еще большее отклонение от средней 50кг, если эта гипотеза верна. Потребуется функция распределения Стьюдента для двухсторонней гипотезы СТЬЮДЕНТ.РАСП.2Х.

P-value равен 0,1096, что больше допустимого уровня значимости 0,05 – гипотезу не отклоняем. Но теперь можно судить о степени доказательства. P-value оказался довольно близок к тому уровню, когда гипотеза отклоняется, а это наводит на разные мысли. Например, что выборка оказалась слишком мала для обнаружения значимого отклонения.
Пусть через некоторое время отдел контроля снова решил проверить, как выдерживается стандарт заполняемости мешков. На этот раз для большей надежности было отобрано не 9, а 25 мешков. Интуитивно понятно, что разброс средней уменьшится, а, значит, и шансов найти сбой в системе становится больше.
Допустим, были получены те же значения средней и стандартного отклонения по выборке, что и в первый раз (50,3 и 0,5 соответственно). Рассчитаем t-критерий.
Критическое значение для 24-х степеней свободы и α = 0,05 составляет 2,064. На картинке ниже видно, что t-критерий попадает в область отклонения гипотезы.

Можно сделать вывод о том, что с доверительной вероятностью более 95% генеральная средняя отличается от 50кг. Для большей убедительности посмотрим на p-value (последняя строка в таблице). Вероятность получить среднюю с таким или еще большим отклонением от 50, если гипотеза верна, составляет 0,0062, или 0,62%, что при однократном измерении практически невозможно. В общем, гипотезу отклоняем, как маловероятную.
Расчет доверительного интервала для математического ожидания с помощью t-распределения Стьюдента в Excel
С проверкой гипотез тесно связан еще один статистический метод – расчет доверительных интервалов. Если в полученный интервал попадает значение, соответствующее нулевой гипотезе, то это равносильно тому, что нулевая гипотеза не отклоняется. В противном случае, гипотеза отклоняется с соответствующей доверительной вероятностью. В некоторых случаях аналитики вообще не проверяют гипотез в классическом виде, а рассчитывают только доверительные интервалы. Такой подход позволяет извлечь еще больше полезной информации.
Рассчитаем доверительные интервалы для средней при 9 и 25 наблюдениях. Для этого воспользуемся функцией Excel ДОВЕРИТ.СТЬЮДЕНТ. Здесь, как ни странно, все довольно просто. В аргументах функции нужно указать только уровень значимости α, стандартное отклонение по выборке и размер выборки. На выходе получим полуширину доверительного интервала, то есть значение которое нужно отложить по обе стороны от средней. Проведя расчеты и нарисовав наглядную диаграмму, получим следующее.

Как видно, при выборке в 9 наблюдений значение 50 попадает в доверительный интервал (гипотеза не отклоняется), а при 25-ти наблюдениях не попадает (гипотеза отклоняется). При этом в эксперименте с 25-ю мешками можно утверждать, что с вероятностью 97,5% генеральная средняя превышает 50,1 кг (нижняя граница доверительного интервала равна 50,094кг). А это довольно ценная информация.
Таким образом, мы решили одну и ту же задачу тремя способами:
1. Древним подходом, сравнивая расчетное и табличное значение t-критерия
2. Более современным, рассчитав p-value, добавив степень уверенности при отклонении гипотезы.
3. Еще более информативным, рассчитав доверительный интервал и получив минимальное значение генеральной средней.
Важно помнить, что t-критерий относится к параметрическим методам, т.к. основан на нормальном распределении (у него два параметра: среднее и дисперсия). Поэтому для его успешного применения важна хотя бы приблизительная нормальность исходных данных и отсутствие выбросов.
Напоследок предлагаю видеоролик о том, как рассчитать критерий Стьюдента и проверить гипотезу о генеральной средней в Excel.
Иногда просят объяснить, как делаются такие наглядные диаграммы с распределением. Ниже можно скачать файл, где проводились расчеты для этой статьи.

Наступила осень, а значит, настало время для запуска нового тематического проекта «Статистический анализ с R». В нем мы рассмотрим статистические методы с точки зрения их применения на практике: узнаем какие методы существуют, в каких случаях и каким образом их проводить в среде R. На мой взгляд, Критерий Стьюдента или t-тест (от англ. t-test) идеально подходит в качестве введения в мир статистического анализа. Тест Стьюдента достаточно прост и показателен, а также требует минимум базовых знаний в статистике, с которыми читатель может ознакомиться в ходе прочтения этой статьи.
Примечание_1: здесь и в других статьях Вы не увидите формул и математических объяснений, т.к. информация рассчитана на студентов естественных и гуманитарных специальностей, которые делают лишь первые шаги в стат. анализе.
Примечание_2: перед прочтением, я рекомендую ознакомиться с этой статьей, чтобы вспомнить базовые понятия описательной статистики, такие как медиана, стандартное отклонение, квантили и прочее.
Что такое t-тест и в каких случаях его стоит применять
В начале следует сказать, что в статистике зачастую действует принцип бритвы Оккамы, который гласит, что нет смысла проводить сложный статистический анализ, если можно применить более простой (не стоит резать хлеб бензопилой, если есть нож). Именно поэтому, несмотря на свою простоту, t-тест является серьезным инструментом, если знать что он из себя представляет и в каких случаях его стоит применять.

Любопытно, что создал этот метод Уильямом Госсет — химик, приглашенный работать на фабрику Guinness. Разработанный им тест служил изначально для оценки качества пива. Однако, химикам фабрики запрещалось независимо публиковать научные работы под своим именем. Поэтому в 1908 году Уильям опубликовал свою статью в журнале «Biometrika» под псевдонимом «Стьюдент». Позже, выдающийся математик и статистик Рональд Фишер доработал метод, который затем получил массовое распространение под названием Student’s t-test.
Критерий Стьюдента (t-тест) — это статистический метод, который позволяет сравнивать средние значения двух выборок и на основе результатов теста делать заключение о том, различаются ли они друг от друга статистически или нет. Если Вы хотите узнать, отличается ли средний уровень продолжительности жизни в Вашем регионе от среднего уровня по стране; сравнить урожайность картофеля в разных районах; или изменяется ли кровяное давление до и после употребления нового лекарства, то t-тест может быть Вам полезен. Почему может быть? Потому что для его проведения, необходимо, чтобы данные выборок имели распределение близкое к нормальному. Для этого существуют методы оценки, которые позволяют сказать, допустимо ли в данном случае полагать, что данные распределены нормально или нет. Поговорим об этом подробнее.
Нормальное распределение данных и методы его оценки qqplot и shapiro.test
Нормальное распределение данных характерно для количественных данных, на распределение которых влияет множество факторов, либо оно случайно. Нормальное распределение характеризуется несколькими особенностями:
- Оно всегда симметрично и имеет форму колокола.
- Значения среднего и медианы совпадают.
- В пределах одного стандартного отклонения в обе стороны лежат 68.2% всех данных, в пределах двух — 95,5%, в пределах трех — 99,7%

Давайте создадим случайную выборку с нормальным распределением на языке программирования R, где общее количество измерений = 100, среднее арифметическое = 5, а стандартное отклонение = 1. Затем отобразим его на графике в виде гистограммы:
Ваш график может слегка отличаться от моего, так как числа сгенерированы случайным образом. Как Вы видите, данные не идеально симметричны, но кажется сохраняют форму нормального распределения. Однако, мы воспользуемся более объективными методами определения нормальности данных.

Одним из наиболее простых тестов нормальности является график квантилей (qqplot). Суть теста проста: если данные имеют нормальное распределение, то они не должны сильно отклоняться от линии теоретических квантилей и выходить за пределы доверительных интервалов. Давайте проделаем этот тест в R.

Как видно из графика, наши данные не имеют серьезных отклонений от теоретического нормального распределения. Но порой при помощи qqplot невозможно дать однозначный ответ. В этом случае следует использовать тест Шапиро-Уилка, который основан на нулевой гипотезе, что наши данные распределены нормально. Если же P-значение менее 0.05 (p-value
Провести тест Шапиро-Уилка в R не составит труда. Для этого нужно всего лишь вызвать функцию shapiro.test, и в скобках вставить имя ваших данных. В нашем случае p-value должен быть значительно больше 0.05, что не позволяет отвергнуть нулевую гипотезу о том, что наши данные распределены нормально.
Запускаем t-тест Стьюдента в среде R
Итак, если данные из выборок имеют нормальное распределение, можно смело приступать к сравнению средних этих выборок. Существует три основных типа t-теста, которые применяются в различных ситуациях. Рассмотрим каждый из них с использованием наглядных примеров.
Одновыборочный критерий Стьюдента (one-sample t-test)
Одновыборочный t-тест следует выбирать, если Вы сравниваете выборку с общеизвестным средним. Например, отличается ли средний возраст жителей Северо-Кавказского Федерального округа от общего по России. Существует мнение, что климат Кавказа и культурные особенности населяющих его народов способствуют продлению жизни. Для того, чтобы проверить эту гипотезу, мы возьмем данные РосСтата (таблицы среднего ожидаемого продолжительности жизни по регионам России) и применим одновыборочный критерий Стьюдента. Так как критерий Стьюдента основан на проверке статистических гипотез, то за нулевую гипотезу будем принимать то, что различий между средним ожидаемым уровнем продолжительности по России и республикам Северного Кавказа нет. Если различия существуют, то для того, чтобы считать их статистически значимыми p-value должно быть менее 0.05 (логика та же, что и в вышеописанном тесте Шапиро-Уилка).
Загрузим данные в R. Для этого, создадим вектор со средними значениями по республикам Кавказа (включая Адыгею). Затем, запустим одновыборочный t-тест, указав в параметре mu среднее значение ожидаемого возраста жизни по России равное 70.93.
Несмотря на то, что у нас всего 7 точек в выборке, в целом они проходят тесты нормальности и мы можем на них полагаться, так как эти данные уже были усреднены по региону.

Результаты t-теста говорят о том, что средняя ожидаемая продолжительность жизни у жителей Северного Кавказа (74.6 лет) действительно выше, чем в среднем по России (70.93 лет), а результаты теста являются статистически значимыми (p когда Вы сравниваете две независимые выборки . Допустим, мы хотим узнать, отличается ли урожайность картофеля на севере и на юге какого-либо региона. Для этого, мы собрали данные с 40 фермерских хозяйств: 20 из которых располагались на севере и сформировали выборку «North», а остальные 20 — на юге, сформировав выборку «South».
Загрузим данные в среду R. Кроме проверки нормальности данных, будет полезно построить «график с усами», на котором можно видеть медианы и разброс данных для обеих выборок.
Как видно из графика, медианы выборок не сильно отличаются друг от друга, однако разброс данных гораздо сильнее на севере. Проверим отличаются ли статистически средние значения при помощи функции t.test. Однако в этот раз на место параметра mu мы ставим имя второй выборки. Результаты теста, которые Вы видите на рисунке снизу, говорят о том, что средняя урожайность картофеля на севере статистически не отличается от урожайности на юге (p = 0.6339).

Двувыборочный для зависимых выборок ( dependent two-sample t-test )
Третий вид t-теста используется в том случае, если элементы выборок зависят друг от друга . Он идеально подходит для проверки повторяемости результатов эксперимента: если данные повтора статистически не отличаются от оригинала, то повторяемость данных высокая. Также двувыборочный критерий Стьюдента для зависимых выборок широко применяется в медицинских исследованиях при изучении эффекта лекарства на организм до и после приема.
Для того, чтобы запустить его в R, следует ввести все ту же функцию t.test . Однако, в скобках, после таблиц данных, следует ввести дополнительный аргумент paired = TRUE . Этот аргумент говорит о том, что Ваши данные зависят друг от друга. Например:
Также в функции t.test существует два дополнительных аргумента, которые могут улучшить качество результатов теста: var.equal и alternative . Если вы знаете, что вариация между выборками равна, вставьте аргумент var.equal = TRUE . Если же вы хотите проверить гипотезу о том, что разница между средними в выборках значительно меньше или больше 0, то введите аргумент alternative=»less» или alternative=»greater» (по умолчанию альтернативная гипотеза говорит о том, что выборки просто отличаются друг от друга: alternative=»two.sided» ).
Заключение
Статья получилась довольно длинной, зато теперь Вы знаете: что такое критерий Стьюдента и нормальное распределение; как при помощи функций qqplot и shapiro.test проверять нормальность данных в R; а также разобрали три типа t-тестов и провели их в среде R.
Тема для тех, кто только начинает знакомиться со статистическим анализом — непростая. Поэтому не стесняйтесь, задавайте вопросы, я с удовольствием на них отвечу. Гуру статистики, пожалуйста поправьте меня, если где-нибудь допустил ошибку. В общем, пишите Ваши комментарии, друзья!
t-критерий Стьюдента — общее название для класса методов статистической проверки гипотез ( статистических критериев ), основанных на распределении Стьюдента. Наиболее частые случаи применения t-критерия связаны с проверкой равенства средних значений в двух выборках .
Здравствуйте! Благодарю за подробное пояснение по теме t-критерия. Пытаюсь провести сравнительный анализ в своей магистерской диссертации по двум независимым выборкам. Шкал у меня несколько. В результате анализа с помощью программы SPSS какие-то значения по критерию равенства дисперсий Ливиня оказались меньше 0,05. Насколько я понимаю, использование t-критерия в этом случае будет неправомерным. Что посоветуете в этом случае?
Здравствуйте! Спасибо за Ваш комментарий. К сожалению, ни с SPSS, ни с критерием Ливиня мне не доводилось работать, поэтому помочь не в силах.
Добрый день, извините, что не по теме. Пишу дипломную работу и мне нужно оценить 2 уравнения методом максимального правдоподобия в R. Нигде не могу найти про это в интернете.Вы не знаете как это можно сделать?
Читайте также:
- Портретная живопись серова кратко
- Горбачев и его окружение кратко
- Проблема человека в социологии кратко
- Всеобщая история 18 век 8 класс кратко
- Итоги реформ китая во второй половине xx века кратко