Оценка ошибки прогнозирования временного ряда
Работая с научными публикациями, сталкиваюсь с различными показателями ошибок прогнозирования временных рядов. Среди всех встречающихся оценок ошибки прогнозирования стоит отметить две, которые в настоящее время, являются самыми популярными: MAE и MAPE.
Пусть ошибка есть разность:
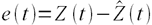 ,
,
где Z(t) – фактическое значение временного ряда, а  – прогнозное.
– прогнозное.
Тогда формулы для оценок ошибки прогнозирования временных рядов для N отчетов можно записать в следующем виде.
MAPE – средняя абсолютная ошибка в процентах
 .
.
Данная оценка применяется для временных рядов, фактические значения которых значительно больше 1. Например, оценки ошибки прогнозирования энергопотребления почти во всех статьях приводятся как значения MAPE.
Если же фактические значения временного ряда близки к 0, то в знаменателе окажется очень маленькое число, что сделает значение MAPE близким к бесконечности – это не совсем корректно. Например, фактическая цена РСВ = 0.01 руб/МВт.ч, a прогнозная = 10 руб/МВт.ч, тогда MAPE = (0.01 – 10)/0.01 = 999%, хотя в действительности мы не так уж сильно ошиблись, всего на 10 руб/МВт.ч. Для рядов, содержащих значения близкие к нулю, применяют следующую оценку ошибки прогноза.
MAE – средняя абсолютная ошибка
 .
.
Для оценки ошибки прогнозирования цен РСВ и индикатора БР корректнее использовать MAE.
После того, как получены значения для MAPE и/или MAE, то в работах обычно пишут: «Прогнозирование временного ряда энергопотребления с часовым разрешение проводилось на интервале с 01.01.2001 до 31.12.2001 (общее количество отсчетов N ~ 8500). Для данного прогноза значение MAPE = 1.5%». При этом, просматривая статьи, можно сложить общее впечатление об ошибки прогнозирования энергопотребления, для которого MAPE обычно колеблется от 1 до 5%; или ошибки прогнозирования цен на электроэнергию, для которого MAPE колеблется от 5 до 15% в зависимости от периода и рынка. Получив значение MAPE для собственного прогноза, вы можете оценить, насколько здорово у вас получается прогнозировать.
Кроме указанных иногда используют другие оценки ошибки, менее популярные, но также применимые. Подробнее об этих оценках ошибки прогноза читайте указанные статьи в Википедии.
MSE – среднеквадратичная ошибка
 .
.
RMSE – квадратный корень из среднеквадратичной ошибки
 .
.
ME – средняя ошибка
 .
.
SD – стандартное отклонение
 , где ME – есть средняя ошибка, определенная по формуле выше.
, где ME – есть средняя ошибка, определенная по формуле выше.
Связь точности и ошибки прогнозирования
Точность прогнозирования есть понятие прямо противоположное ошибке прогнозирования. Если ошибка прогнозирования велика, то точность мала и наоборот, если ошибка прогнозирования мала, то точность велика. По сути дела оценка ошибки прогноза MAPE есть обратная величина для точности прогнозирования — зависимость здесь простая.
Точность прогноза в % = 100% – MAPE
Величину точности оценивать не принято, говоря о прогнозировании всегда оценивают, то есть определяют значение именно ошибки прогноза, то есть величину MAPE и/или MAE. Однако нужно понимать, что если MAPE = 5%, то точность прогнозирования = 95%. Говоря о высокой точности, мы всегда говорим о низкой ошибки прогноза и в этой области недопонимания быть не должно. Вы практически не найдете материалов о прогнозировании, в которых приведены оценки именно точности прогноза, хотя с точки зрения здравого маркетинга корректней говорить именно о высокой точности. В рекламных статьях всегда будет написано о высокой точности.
При этом величина MAPE является количественной оценкой именно ошибки, и эта величина нам ясно говорит и о точности прогнозирования, исходя из приведенной выше простой формулы. Таким образом, оценивая ошибку, мы всегда оцениваем точность прогнозирования.
Стандартное
отклонение для оценки обозначается Se
и рассчитывается по формуле
среднеквадратичного отклонения:
![]() .
.
Величина стандартного
отклонения характеризует точность
прогноза.
Вариант
5. Возвращаясь к данным нашего примера,
рассчитаем значение Se:
![]()
Предположим,
необходимо оценить значение Y для
конкретного значения независимой
переменной, например, спрогнозировать
объем продаж при затратах на рекламу в
объеме 10 тыс. долл. Обычно при этом также
требуется оценить степень достоверности
результата, одним из показателей которого
является доверительный интервал для
Y.
Граница доверительного
интервала для Y при заданной величине
X рассчитывается следующим образом:

где
Хp
– выбранное значение независимой
переменной, на основе которого выполняется
прогноз. Обратите внимание: t – это
критическое значение текущего уровня
значимости. Например, для уровня
значимости, равного 0,025 (что соответствует
уровню доверительности двухстороннего
критерия, равному 95%) и числа степеней
свободы, равного 10, критическое значение
t равно 2, 228 (см. Приложение II). Как можно
увидеть, доверительный интервал – это
интервал, ограниченный с двух сторон
граничными значениями предсказания
(зависимой переменной).
Вариант
6. Для нашего примера расходов на рекламу
в размере 10 тыс. долл. интервал предсказания
зависимой переменной (объема продаж) с
уровнем доверительности в 95% находится
в пределах [10,5951; 21,8361]. Его границы
определяются следующим образом (обратите
внимание, что в Варианте 2 Y’=16,2156):

Из приведенного
расчета имеем: для заданных расходов
на рекламу в объеме 10 тыс. долл., объем
продаж изменяется в диапазоне от 10,5951
до 21,8361 тыс. долл. При этом:
10,5951=16,2156-5,6205 и 21,8361=16,2156+5,6205.
3. Стандартное отклонение для коэффициента регрессии Sb и t-статистика
Значения
стандартного отклонения для коэффициентов
регрессии Sb
и значение статистики тесно взаимосвязаны.
Sb
рассчитываются как
![]()
Или в сокращенной
форме:
![]()
Sb
задает интервал, в который попадают.
Все возможные значения коэффициента
регрессии. t-статистика
(или t-значение)
– мера статистической значимости
влияния независимой переменной Х на
зависимую переменную Y
определяется путем деления оценки
коэффициента b
на его стандартное отклонение Sb.
Полученное значение затем сравнивается
с табличным (см. табл. В Приложении II).
Таким
образом, t-статистика
показывает, насколько велики величина
стандартного отклонения для коэффициента
регрессии (насколько оно больше нуля).
Практика показывает, что любое t-значение,
не принадлежащее интервалу [-2;2], является
приемлемым. Чем выше t-значение,
тем выше достоверность коэффициента
(т.е. точнее прогноз на его основе). Низкое
t-значение
свидетельствует о низкой прогнозирующей
силе коэффициента регрессии.
Вариант
7. Sb
для нашего примера равно:
![]()
t-статистика
определяется:
![]()
Так
как t=3,94>2,
можно заключить,
что
коэффициент
b
является
статистически
значимым.
Как
отмечалось раньше,
табличное
критическое
значение (уровень отсечения)
для 10 степеней свободы равно
2,228
(см.
табл.
в
Приложении
11).
Обратите
внимание:
—
t-значения
играют большую
роль для коэффициентов
множественной регрессии
(множественная
модель описывается
с помощью
нескольких
коэффициентов
b);
—
R2
характеризует
общее согласие (всего
«леса»
невязок
на
диаграмме
разброса),
в
то время как
t-значение
характеризует
отдельную
независимую переменную
(отдельное
«дерево»
невязок).
В
общем случае
табличное
t-значение
для
заданных
числа
степеней свободы и уровня
значимости используется,
чтобы:
—
установить
диапазон
предсказания:
верхнюю
и нижнюю границы
для прогнозируемого
значения при заданном значении
независимой
переменной;
-установить
доверительные
интервалы
для
коэффициентов
регрессии;
—
определить
уровень
отсечения
для t-теста.
РЕГРЕССИОННЫЙ
АНАЛИЗ С ПРИМЕНЕНИЕМ ЭЛЕКТРОННЫХ ТАБЛИЦ
MS EXCEL
Электронные
таблицы,
такие
как Excel,
имеют
встроенную
процедуру
регрессионного
анализа,
легкую
в
применении.
Регрессионный
анализ
с помощью
MS Ехсеl
требует
выполнения
следующих
действий:
—
выберите
пункт
меню
«Сервис
— Надстройки»;
—
в
появившемся
окне отметьте
галочкой
надстройку
Analysis
ToolPak
–
VBA нажмите
кнопку
ОК.
Если
в списке Analysis
ToolPak
—
VВА
отсутствует,
выйдите
из MS Ехсеl
и добавьте эту надстройку,
воспользовавшись
программой
установки Мiсrosоft
Office.
Затем
запустите Ехсеl
снова
и повторите
эти действия.
Убедившись,
что
надстройка
Analysis
ToolPak
—
VВА
доступна,
запустите
инструмент
регрессионного
анализа,
выполнив
следующие
действия:
—
выберите
пункт меню «Сервис
—
Анализ»
данных;
—
в появившемся окне выберите
пункт
«Регрессия»
и
нажмите
кнопку
ОК.
На
рисунке 16.3
показано окно ввода данных для
регрессионного
анализа.

Рисунок 16.3 – Окно
ввода данных для регрессионного анализа
Таблица
16.2
показывает
выходной
результат
регрессии,
содержащий
описанные
выше статистические
данные.
Примечание:
для
того чтобы получить
поточечный
график
(ХY график),
используйте
«Мастер
Диаграмм»
MS
Excel.
Получаем:
Y’
= 10,5386
+ 0,563197
Х (d
виде
Y’
=
а
+
bХ)
с R2=0,608373=60,84%.
Все
полученные
данные
ответствуют
данным,
рассчитанным
вручную.
Таблица 16.2 –
Результаты регрессионного анализа
в
электронных таблицах MS
Excel
|
Вывод |
||||||
|
Регрессионная |
||||||
|
Множественный |
0,7800 |
|||||
|
R-квадрат |
0,6084 |
|||||
|
Нормированный |
0,5692 |
|||||
|
Стандартная |
2,3436 |
|||||
|
Наблюдения |
12 |
|||||
|
Дисперсионный |
||||||
|
df |
SS |
MS |
F |
Значимость |
||
|
Регрессия |
1 |
85,3243 |
85,3243 |
15,5345 |
0,0028 |
|
|
Остаток |
10 |
54,9257 |
5,4926 |
|||
|
Итого |
11 |
140,2500 |
||||
|
Коэффи-циенты |
Стандарт-ная |
t-статистика |
Р- |
Нижние |
Верхние |
|
|
Свободный |
10,5836 |
2,1796 |
4,8558 |
0,0007 |
5,7272 |
15,4401 |
|
Линейный |
0,563197 |
0,1429 |
3,9414 |
0,0028 |
0,2448 |
0,8816 |
|
*Р |
Таблица
16.3 показывает выходной результат
регрессии, полученный с применением
популярного программного обеспечения
Minitab
для статистического анализа.
Таблица
16.3 – Результаты регрессионного анализа
Minitab
|
Анализ регрессии
Уравнение FO=10,6+0,563DLH |
|||||
|
Прогнозируемые |
Коэффициент |
Стандартное |
t-значение |
P |
|
|
Константа |
10,584 |
2,180 |
4,86 |
0,000 |
|
|
DLH |
0,5632 |
0,1429 |
3,94 |
0,003 |
|
|
s=2,344 |
R-квадрат=60,8% |
R-квадрат |
|||
|
Анализ |
|||||
|
Показатель |
DF |
SS |
MS |
F |
P |
|
Регрессия |
1 |
85,324 |
85,324 |
15,53 |
0,003 |
|
Отклонение |
10 |
54,926 |
5,493 |
||
|
Итого |
11 |
140,250 |
ВЫВОДЫ
C
помощью регрессионного анализа
устанавливается
зависимость
между
изменениями
независимых
переменных
и
значениями зависимой
переменной.
Регрессионный
анализ
— популярный
метод для прогнозирования
продаж.
В
этой
главе обсуждался
широко
распространенный
способ
оценки значений,
так
называемый
метод
наименьших
квадратов.
Метод
наименьших
квадратов
рассматривался
применительно
к
модели
простой
регрессии
Y
=
а
+ bх.
Обсуждались
различные
статистические
коэффициенты,
характеризующие
добротность
и надежность
уравнения
(согласие
модели)
и помогающие установить
доверительный
интервал.
Показано
применение
электронных
таблиц MS Ехсеl для
проведения
регрессионного
анализа
шаг за шагом.
С
помощью электронных
таблиц
можно не только составить
уравнение
регрессии,
но
и рассчитать статистические
коэффициенты.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #

Основной задачей при управлении запасами является определение объема пополнения, то есть, сколько необходимо заказать поставщику. При расчете этого объема используется несколько параметров — сколько будет продано в будущем, за какое время происходит пополнение, какие остатки у нас на складе и какое количество уже заказано у поставщика. То, насколько правильно мы определим эти параметры, будет влиять на то, будет ли достаточно товара на складе или его будет слишком много. Но наибольшее влияние на эффективность управления запасами влияет то, насколько точен будет прогноз. Многие считают, что это вообще основной вопрос в управлении запасами. Действительно, точность прогнозирования очень важный параметр. Поэтому важно понимать, как его оценивать. Это важно и для выявления причин дефицитов или неликвидов, и при выборе программных продуктов для прогнозирования продаж и управления запасами.
В данной статье я представила несколько формул для расчета точности прогноза и ошибки прогнозирования. Кроме этого, вы сможете скачать файлы с примерами расчетов этого показателя.
Статистические методы
Для оценки прогноза продаж используются статистические оценки Оценка ошибки прогнозирования временного ряда. Самый простой показатель – отклонение факта от прогноза в количественном выражении.
В практике рассчитывают ошибку прогнозирования по каждой отдельной позиции, а также рассчитывают среднюю ошибку прогнозирования. Следующие распространенные показатели ошибки относятся именно к показателям средних ошибок прогнозирования.
К ним относятся:
MAPE – средняя абсолютная ошибка в процентах

где Z(t) – фактическое значение временного ряда, а ![]() – прогнозное.
– прогнозное.
Данная оценка применяется для временных рядов, фактические значения которых значительно больше 1. Например, оценки ошибки прогнозирования энергопотребления почти во всех статьях приводятся как значения MAPE.
Если же фактические значения временного ряда близки к 0, то в знаменателе окажется очень маленькое число, что сделает значение MAPE близким к бесконечности – это не совсем корректно. Например, фактическая цена РСВ = 0.01 руб/МВт.ч, a прогнозная = 10 руб/МВт.ч, тогда MAPE = (0.01 – 10)/0.01 = 999%, хотя в действительности мы не так уж сильно ошиблись, всего на 10 руб/МВт.ч. Для рядов, содержащих значения близкие к нулю, применяют следующую оценку ошибки прогноза.
MAE – средняя абсолютная ошибка
 .
.
Для оценки ошибки прогнозирования цен РСВ и индикатора БР корректнее использовать MAE.
После того, как получены значения для MAPE и/или MAE, то в работах обычно пишут: «Прогнозирование временного ряда энергопотребления с часовым разрешение проводилось на интервале с 01.01.2001 до 31.12.2001 (общее количество отсчетов N ~ 8500). Для данного прогноза значение MAPE = 1.5%». При этом, просматривая статьи, можно сложить общее впечатление об ошибки прогнозирования энергопотребления, для которого MAPE обычно колеблется от 1 до 5%; или ошибки прогнозирования цен на электроэнергию, для которого MAPE колеблется от 5 до 15% в зависимости от периода и рынка. Получив значение MAPE для собственного прогноза, вы можете оценить, насколько здорово у вас получается прогнозировать.
Кроме указанных методов иногда используют другие оценки ошибки, менее популярные, но также применимые. Подробнее об этих оценках ошибки прогноза читайте указанные статьи в Википедии.
ME – средняя ошибка

Встречается еще другое название этого показателя — Bias (англ. – смещение) демонстрирует величину отклонения, а также — в какую сторону прогноз продаж отклоняется от фактической потребности. Этот индикатор показывает, был ли прогноз оптимистичным или пессимистичным. То есть, отрицательное значение Bias говорит о том, что прогноз был завышен (реальная потребность оказалась ниже), и, наоборот, положительное значение о том, что прогноз был занижен. Цифровое значение показателя определяет величину отклонения (смещения).
MSE – среднеквадратичная ошибка
 .
.
RMSE – квадратный корень из среднеквадратичной ошибки
![]() .
.
.
SD – стандартное отклонение

где ME – есть средняя ошибка, определенная по формуле выше.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме ниже. Скачать пример расчета в Excel >>>
Связь точности и ошибки прогнозирования
В начале этого обсуждения разберемся с определениями.
Ошибка прогноза — апостериорная величина отклонения прогноза от действительного состояния объекта. Если говорить о прогнозе продаж, то это показатель отклонения фактических продаж от прогноза.
Точность прогнозирования есть понятие прямо противоположное ошибке прогнозирования. Если ошибка прогнозирования велика, то точность мала и наоборот, если ошибка прогнозирования мала, то точность велика. По сути дела оценка ошибки прогноза MAPE есть обратная величина для точности прогнозирования — зависимость здесь простая.
Точность прогноза в % = 100% – MAPE, встречается еще название этого показателя Forecast Accuracy. Вы практически не найдете материалов о прогнозировании, в которых приведены оценки именно точности прогноза, хотя с точки зрения здравого маркетинга корректней говорить именно о высокой точности. В рекламных статьях всегда будет написано о высокой точности. Показатель точности прогноза выражается в процентах:
- Если точность прогноза равна 100%, то выбранная модель описывает фактические значения на 100%, т.е. очень точно. Нужно сразу оговориться, что такого показателя никогда не будет, основное свойство прогноза в том, что он всегда ошибочен.
- Если 0% или отрицательное число, то совсем не описывает, и данной модели доверять не стоит.
Выбрать подходящую модель прогноза можно с помощью расчета показателя точность прогноза. Модель прогноза, у которой показатель точность прогноза будет ближе к 100%, с большей вероятностью сделает более точный прогноз. Такую модель можно назвать оптимальной для выбранного временного ряда. Говоря о высокой точности, мы говорим о низкой ошибки прогноза и в этой области недопонимания быть не должно. Не имеет значения, что именно вы будете отслеживать, но важно, чтобы вы сравнивали модели прогнозирования или целевые показатели по одному показателю – ошибка прогноза или точность прогнозирования.
Ранее я использовала оценку MAPE, до тех пор пока не встретила формулу, которую рекомендует Валерий Разгуляев.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме. Скачать пример расчета в Excel >>>
Оценка ошибки прогноза – формула Валерия Разгуляева (сайт http://upravlenie-zapasami.ru/)
Одной из самых используемых формул оценки ошибки прогнозирования является следующая формула:

где: P – это прогноз, а S – факт за тот же месяц. Однако у этой формулы есть серьезное ограничение — как оценить ошибку, если факт равен нулю? Возможный ответ, что в таком случае D = 100% – который означает, что мы полностью ошиблись. Однако простой пример показывает, что такой ответ — не верен:
|
вариант |
прогноз |
факт |
ошибка прогноза |
|
№1 |
4 |
0 |
100% |
|
№2 |
4 |
1 |
300% |
|
№3 |
1 |
4 |
75% |
Оказывается, что в варианте развития событий №2, когда мы лучше угадали спрос, чем в варианте №1, ошибка по данной формуле оказалась – больше. То есть ошиблась уже сама формула. Есть и другая проблема, если мы посмотрим на варианты №2 и №3, то увидим, что имеем дело с зеркальной ситуацией в прогнозе и факте, а ошибка при этом отличается – в разы!.. То есть при такой оценке ошибки прогноза нам лучше его заведомо делать менее точным, занижая показатель – тогда ошибка будет меньше!.. Хотя понятно, что чем точнее будет прогноз – тем лучше будет и закупка. Поэтому для расчёта ошибки Валерий Разгуляев рекомендует использовать следующую формулу:

В таком случае для тех же примеров ошибка рассчитается иначе:
|
вариант |
прогноз |
факт |
ошибка прогноза |
|
№1 |
4 |
0 |
100% |
|
№2 |
4 |
1 |
75% |
|
№3 |
1 |
4 |
75% |
Как мы видим, в варианте №1 ошибка становится равной 100%, причём это уже – не наше предположение, а чистый расчёт, который можно доверить машине. Зеркальные же варианты №2 и №3 – имеют и одинаковую ошибку, причём эта ошибка меньше ошибки самого плохого варианта №1. Единственная ситуация, когда данная формула не сможет дать однозначный ответ – это равенство знаменателя нулю. Но максимум из прогноза и факта равен нулю, только когда они оба равны нулю. В таком случае получается, что мы спрогнозировали отсутствие спроса, и его, действительно, не было – то есть ошибка тоже равна нулю – мы сделали совершенно точное предсказание.
Визуальный метод – графический
Визуальный метод состоит в том, что мы на график выводим значение прогнозной модели и факта продаж по тем моделям, которые хотим сравнить. Далее сравниваем визуально, насколько прогнозная модель близка к фактическим продажам. Давайте рассмотрим на примере. В таблице представлены две прогнозные модели, а также фактические продажи по этому товару за тот же период. Для наглядности мы также рассчитали ошибку прогнозирования по обеим моделям.

По графикам очевидно, что модель 2 описывает лучше продажи этого товара. Оценка ошибки прогнозирования тоже это показывает – 65% и 31% ошибка прогнозирования по модели 1 и модели 2 соответственно.


Недостатком данного метода является то, что небольшую разницу между моделями сложно выявить — разницу в несколько процентов сложно оценить по диаграмме. Однако эти несколько процентов могут существенно улучшить качество прогнозирования и планирования пополнения запасов в целом.
Использование формул ошибки прогнозирования на практике
Практический аспект оценки ошибки прогнозирования я вывела отдельным пунктом. Это связано с тем, что все статистические методы расчета показателя ошибки прогнозирования рассчитывают то, насколько мы ошиблись в прогнозе в количественных показателях. Давайте теперь обсудим, насколько такой показатель будет полезен в вопросах управления запасами. Дело в том, что основная цель управления запасами — обеспечить продажи, спрос наших клиентов. И, в конечном счете, максимизировать доход и прибыль компании. А эти показатели оцениваются как раз в стоимостном выражении. Таким образом, нам важно при оценке ошибки прогнозирования понимать какой вклад каждая позиция внесла в объем продаж в стоимостном выражении. Когда мы оцениваем ошибку прогнозирования в количественном выражении мы предполагаем, что каждый товар имеет одинаковый вес в общем объеме продаж, но на самом деле это не так – есть очень дорогие товары, есть товары, которые продаются в большом количестве, наша группа А, а есть не очень дорогие товары, есть товары которые вносят небольшой вклад в объем продаж. Другими словами большая ошибка прогнозирования по товарам группы А будет нам «стоить» дороже, чем низкая ошибка прогнозирования по товарам группы С, например. Для того, чтобы наша оценка ошибки прогнозирования была корректной, релевантной целям управления запасами, нам необходимо оценивать ошибку прогнозирования по всем товарам или по отдельной группе не по средними показателями, а средневзвешенными с учетом прогноза и факта в стоимостном выражении.
Пример расчета такой оценки Вы сможете увидеть в файле Excel.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме. Скачать пример расчета в Excel >>>
При этом нужно помнить, что для оценки ошибки прогнозирования по отдельным позициям мы рассчитываем по количеству, но вот если нам важно понять в целом ошибку прогнозирования по компании, например, для оценки модели, которую используем, то нам нужно рассчитывать не среднюю оценку по всем товарам, а средневзвешенную с учетом стоимостной оценки. Оценку можно брать по ценам себестоимости или ценам продажи, это не играет большой роли, главное, эти же цены (тип цен) использовать при всех расчетах.
Для чего используется ошибка прогнозирования
В первую очередь, оценка ошибки прогнозирования нам необходима для оценки того, насколько мы ошибаемся при планировании продаж, а значит при планировании поставок товаров. Если мы все время прогнозируем продажи значительно больше, чем потом фактически продаем, то вероятнее всего у нас будет излишки товаров, и это невыгодно компании. В случае, когда мы ошибаемся в обратную сторону – прогнозируем продажи меньше чем фактические продажи, с большой вероятностью у нас будут дефициты и компания не дополучит прибыль. В этом случае ошибка прогнозирования служит индикатором качества планирования и качества управления запасами.
Индикатором того, что повышение эффективности возможно за счет улучшения качества прогнозирования. За счет чего можно улучшить качество прогнозирования мы не будем здесь рассматривать, но одним из вариантов является поиск другой модели прогнозирования, изменения параметров расчета, но вот насколько новая модель будет лучше, как раз поможет показатель ошибки прогнозирования или точности прогноза. Сравнение этих показателей по нескольким моделям поможет определить ту модель, которая дает лучше результат.
В идеальном случае, мы можем так подбирать модель для каждой отдельной позиции. В этом случае мы будем рассчитывать прогноз по разным товарам по разным моделям, по тем, которые дают наилучший вариант именно для конкретного товара.
Также этот показатель можно использовать при выборе автоматизированного инструмента для прогнозирования спроса и управления запасами. Вы можете сделать тестовые расчеты прогноза в предлагаемой программе и сравнить ошибку прогнозирования полученного прогноза с той, которая есть у вашей существующей модели. Если у предлагаемого инструмента ошибка прогнозирования меньше. Значит, этот инструмент можно рассматривать для применения в компании. Кроме этого, показатель точности прогноза или ошибки прогнозирования можно использовать как KPI сотрудников, которые отвечают за подготовку прогноза продаж или менеджеров по закупкам, в том случае, если они рассчитывают прогноз будущих продаж при расчете заказа.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме. Скачать пример расчета в Excel >>>
Если вы хотите повысить эффективность управления запасами и увеличить оборачиваемость товарных запасов, предлагаю изучить мастер-класс «Как увеличить оборачиваемость товарных запасов».
Источник: сайт http://uppravuk.net/
Имея
прямую регрессии, необходимо оценить
насколько сильно точки исходных данных
отклоняются от прямой регрессии. Можно
выполнить оценку разброса, аналогичную
стандартному отклонению выборки. Этот
показатель, называемый стандартной
ошибкой оценки, демонстрирует величину
отклонения точек исходных данных от
прямой регрессии в направлении оси Y.
Стандартная ошибка оценки (![]() )
)
вычисляется по следующей формуле.
![]()
Стандартная
ошибка оценки измеряет степень отличия
реальных значений Y от оцененной величины.
Для сравнительно больших выборок следует
ожидать, что около 67% разностей по модулю
не будет превышать
![]()
и около 95% модулей разностей будет не
больше 2![]() .
.
Стандартная
ошибка оценки подобна стандартному
отклонению. Ее можно использовать для
оценки стандартного отклонения
совокупности. Фактически
![]()
оценивает стандартное отклонение
![]()
слагаемого ошибки
![]()
в статистической модели простой линейной
регрессии. Другими словами,
![]()
оценивает общее стандартное отклонение
![]()
нормального распределения значений Y,
имеющих математические ожидания
![]()
для каждого X.
Малая
стандартная ошибка оценки, полученная
при регрессионном анализе, свидетельствует,
что все точки данных находятся очень
близко к прямой регрессии. Если стандартная
ошибка оценки велика, точки данных могут
значительно удаляться от прямой.
2.3 Прогнозирование величины y
Регрессионную
прямую можно использовать для оценки
величины переменной Y
при данных значениях переменной X. Чтобы
получить точечный прогноз, или предсказание
для данного значения X, просто вычисляется
значение найденной функции регрессии
в точке X.
Конечно
реальные значения величины Y,
соответствующие рассматриваемым
значениям величины X, к сожалению, не
лежат в точности на регрессионной
прямой. Фактически они разбросаны
относительно прямой в соответствии с
величиной
![]() .
.
Более того, выборочная регрессионная
прямая является оценкой регрессионной
прямой генеральной совокупности,
основанной на выборке из определенных
пар данных. Другая случайная выборка
даст иную выборочную прямую регрессии;
это аналогично ситуации, когда различные
выборки из одной и той же генеральной
совокупности дают различные значения
выборочного среднего.
Есть
два источника неопределенности в
точечном прогнозе, использующем уравнение
регрессии.
-
Неопределенность,
обусловленная отклонением точек данных
от выборочной прямой регрессии. -
Неопределенность,
обусловленная отклонением выборочной
прямой регрессии от регрессионной
прямой генеральной совокупности.
Интервальный
прогноз значений переменной Y
можно построить так, что при этом будут
учтены оба источника неопределенности.
Стандартная
ошибка прогноза
![]()
дает меру вариативности предсказанного
значения Y
около истинной величины Y
для данного значения X.
Стандартная ошибка прогноза равна:

Стандартная
ошибка прогноза зависит от значения X,
для которого прогнозируется величина
Y.
![]()
минимально, когда
![]() ,
,
поскольку тогда числитель в третьем
слагаемом под корнем в уравнении будет
0. При прочих неизменных величинах
большему отличию соответствует большее
значение стандартной ошибки прогноза.
Если
статистическая модель простой линейной
регрессии соответствует действительности,
границы интервала прогноза величины Y
равны:
![]()
где
![]()
— квантиль распределения Стьюдента с
n-2 степенями свободы (![]() ).
).
Если выборка велика (![]() ),
),
этот квантиль можно заменить соответствующим
квантилем нормального распределения.
Например, для большой выборки 95%-ный
интервал прогноза задается следующими
значениями:
![]()
Завершим
раздел обзором предположений, положенных
в основу статистической модели линейной
регрессии.
-
Для
заданного значения X генеральная
совокупность значений Y имеет нормальное
распределение относительно регрессионной
прямой совокупности. На практике
приемлемые результаты получаются
и
тогда, когда значения Y имеют
нормальное распределение лишь
приблизительно. -
Разброс
генеральной совокупности точек данных
относительно регрессионной прямой
совокупности остается постоянным всюду
вдоль этой прямой. Иными словами, при
возрастании значений X в точках данных
дисперсия генеральной совокупности
не увеличивается и не уменьшается.
Нарушение этого предположения называется
гетероскедастичностью. -
Слагаемые
ошибок

независимы между собой. Это предположение
определяет случайность выборки точек
Х-Y.
Если точки данных X-Y
записывались в течение некоторого
времени, данное предположение часто
нарушается. Вместо независимых данных,
такие последовательные наблюдения
будут давать серийно коррелированные
значения. -
В
генеральной совокупности существует
линейная зависимость между X и Y.
По аналогии с простой линейной регрессией
может рассматриваться и нелинейная
зависимость между X и У. Некоторые такие
случаи будут обсуждаться ниже.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Когда мы подгоняем регрессионную модель к набору данных, нас часто интересует, насколько хорошо регрессионная модель «подходит» к набору данных. Две метрики, обычно используемые для измерения согласия, включают R -квадрат (R2) и стандартную ошибку регрессии , часто обозначаемую как S.
В этом руководстве объясняется, как интерпретировать стандартную ошибку регрессии (S), а также почему она может предоставить более полезную информацию, чем R 2 .
Стандартная ошибка по сравнению с R-квадратом в регрессии
Предположим, у нас есть простой набор данных, который показывает, сколько часов 12 студентов занимались в день в течение месяца, предшествующего важному экзамену, а также их баллы за экзамен:

Если мы подгоним простую модель линейной регрессии к этому набору данных в Excel, мы получим следующий результат:

R-квадрат — это доля дисперсии переменной отклика, которая может быть объяснена предикторной переменной. При этом 65,76% дисперсии экзаменационных баллов можно объяснить количеством часов, потраченных на учебу.
Стандартная ошибка регрессии — это среднее расстояние, на которое наблюдаемые значения отклоняются от линии регрессии. В этом случае наблюдаемые значения отклоняются от линии регрессии в среднем на 4,89 единицы.
Если мы нанесем фактические точки данных вместе с линией регрессии, мы сможем увидеть это более четко:

Обратите внимание, что некоторые наблюдения попадают очень близко к линии регрессии, в то время как другие не так близки. Но в среднем наблюдаемые значения отклоняются от линии регрессии на 4,19 единицы .
Стандартная ошибка регрессии особенно полезна, поскольку ее можно использовать для оценки точности прогнозов. Примерно 95% наблюдений должны находиться в пределах +/- двух стандартных ошибок регрессии, что является быстрым приближением к 95% интервалу прогнозирования.
Если мы заинтересованы в прогнозировании с использованием модели регрессии, стандартная ошибка регрессии может быть более полезной метрикой, чем R-квадрат, потому что она дает нам представление о том, насколько точными будут наши прогнозы в единицах измерения.
Чтобы проиллюстрировать, почему стандартная ошибка регрессии может быть более полезной метрикой для оценки «соответствия» модели, рассмотрим другой пример набора данных, который показывает, сколько часов 12 студентов занимались в день в течение месяца, предшествующего важному экзамену, а также их экзаменационная оценка:

Обратите внимание, что это точно такой же набор данных, как и раньше, за исключением того, что все значения s сокращены вдвое.Таким образом, студенты из этого набора данных учились ровно в два раза дольше, чем студенты из предыдущего набора данных, и получили ровно половину экзаменационного балла.
Если мы подгоним простую модель линейной регрессии к этому набору данных в Excel, мы получим следующий результат:

Обратите внимание, что R-квадрат 65,76% точно такой же, как и в предыдущем примере.
Однако стандартная ошибка регрессии составляет 2,095 , что ровно вдвое меньше стандартной ошибки регрессии в предыдущем примере.
Если мы нанесем фактические точки данных вместе с линией регрессии, мы сможем увидеть это более четко:

Обратите внимание на то, что наблюдения располагаются гораздо плотнее вокруг линии регрессии. В среднем наблюдаемые значения отклоняются от линии регрессии на 2,095 единицы .
Таким образом, несмотря на то, что обе модели регрессии имеют R-квадрат 65,76% , мы знаем, что вторая модель будет давать более точные прогнозы, поскольку она имеет более низкую стандартную ошибку регрессии.
Преимущества использования стандартной ошибки
Стандартную ошибку регрессии (S) часто бывает полезнее знать, чем R-квадрат модели, потому что она дает нам фактические единицы измерения. Если мы заинтересованы в использовании регрессионной модели для получения прогнозов, S может очень легко сказать нам, достаточно ли точна модель для прогнозирования.
Например, предположим, что мы хотим создать 95-процентный интервал прогнозирования, в котором мы можем прогнозировать результаты экзаменов с точностью до 6 баллов от фактической оценки.
Наша первая модель имеет R-квадрат 65,76%, но это ничего не говорит нам о том, насколько точным будет наш интервал прогнозирования. К счастью, мы также знаем, что у первой модели показатель S равен 4,19. Это означает, что 95-процентный интервал прогнозирования будет иметь ширину примерно 2*4,19 = +/- 8,38 единиц, что слишком велико для нашего интервала прогнозирования.
Наша вторая модель также имеет R-квадрат 65,76%, но опять же это ничего не говорит нам о том, насколько точным будет наш интервал прогнозирования. Однако мы знаем, что вторая модель имеет S 2,095. Это означает, что 95-процентный интервал прогнозирования будет иметь ширину примерно 2*2,095= +/- 4,19 единиц, что меньше 6 и, следовательно, будет достаточно точным для использования для создания интервалов прогнозирования.
Дальнейшее чтение
Введение в простую линейную регрессию
Что такое хорошее значение R-квадрата?
Очень наивный способ оценки модели — рассматривать значение R-Squared. Предположим, что если я получу 95% R-Squared, этого будет достаточно? В этом блоге давайте попробуем понять способы оценки вашей регрессионной модели.

Метрики оценки;
- Среднее / Медиана прогноза
- Стандартное отклонение прогноза
- Диапазон предсказания
- Коэффициент детерминации (R2)
- Относительное стандартное отклонение / коэффициент вариации (RSD)
- Относительная квадратная ошибка (RSE)
- Средняя абсолютная ошибка (MAE)
- Относительная абсолютная ошибка (RAE)
- Среднеквадратичная ошибка (MSE)
- Среднеквадратичная ошибка прогноза (RMSE / RMSEP)
- Нормализованная среднеквадратическая ошибка (Норма RMSEP)
- Относительная среднеквадратическая ошибка (RRMSEP)
Давайте рассмотрим пример прогнозирования концентрации активных фармацевтических ингредиентов (API) в таблетке. Используя единицы поглощения из NIR-спектроскопии, мы прогнозируем уровень API в таблетке. Концентрация API в таблетке может составлять 0,0, 0,1, 0,3, 0,5, 1,0, 1,5, 2,0, 2,5, 3,0. Мы применяем PLS (частичный наименьший квадрат) и SVR (регрессор вектора поддержки) для прогнозирования уровня API.
ПРИМЕЧАНИЕ: метрики можно использовать для сравнения нескольких моделей или одной модели с разными моделями.
Среднее / Медиана прогноза
Мы можем понять смещение прогнозов между двумя моделями, используя среднее арифметическое предсказанных значений.
Например, среднее значение прогнозируемых значений 0,5 API рассчитывается путем деления суммы прогнозируемых значений для 0,5 API на общее количество выборок, имеющих 0,5 API.
np.mean(predictedArray)
На рисунке 1 мы можем понять, как PLS и SVR работали относительно среднего. SVR предсказал API 0.0 намного лучше, чем PLS, тогда как PLS предсказал API 3.0 лучше, чем SVR. Мы можем выбирать модели исходя из интересов уровня API.
Недостаток: на среднее значение влияют выбросы. Используйте «Медиана», если у вас есть выбросы в прогнозируемых значениях

Стандартное отклонение прогноза
Стандартное отклонение (SD) — это мера степени вариации или разброса набора значений. Низкое стандартное отклонение указывает на то, что значения имеют тенденцию быть близкими к среднему (также называемому ожидаемым значением) набора. Напротив, высокое стандартное отклонение указывает на то, что значения разбросаны в более широком диапазоне. Стандартное отклонение предсказанных значений помогает понять разброс значений в различных моделях.

np.std(predictedArray)
На рисунке 2 разброс предсказанных значений меньше в SVR по сравнению с PLS. Таким образом, SVR работает лучше, если мы учитываем показатели SD.

Диапазон предсказания
Диапазон прогноза — это максимальное и минимальное значение в прогнозируемых значениях. Равный диапазон помогает нам понять разницу между моделями.
Коэффициент детерминации (R2)
R-квадрат (R2) — это статистическая мера, которая представляет собой долю дисперсии для зависимой переменной, которая объясняется независимой переменной или переменными в регрессионной модели. В то время как корреляция объясняет силу взаимосвязи между независимой и зависимой переменной, R-квадрат объясняет, в какой степени дисперсия одной переменной объясняет дисперсию второй переменной. Таким образом, если R2 модели составляет 0,50, то примерно половина наблюдаемой вариации может быть объяснена входными данными модели.


from sklearn.metrics import r2_score r2_score(Actual, Predicted)
Недостаток: R2 не учитывает переоснащение. Подробнее.
Относительное стандартное отклонение (RSD) / коэффициент вариации (CV)
Есть пословица, что яблоки не следует сравнивать с апельсинами или, другими словами, не сравнивать два предмета или группу предметов, которые практически не сравниваются. Но недостаток сопоставимости можно преодолеть, если эти два предмета или группы каким-то образом стандартизировать или привести к одной и той же шкале. Например, при сравнении дисперсий двух групп, которые в целом сильно различаются, таких как дисперсия в размере синего тунца и синего кита, коэффициент вариации (CV) является методом выбора: CV просто представляет собой дисперсию каждая группа стандартизирована по среднему значению группы
Коэффициент вариации (CV), также известный как относительное стандартное отклонение (RSD), является стандартизированной мерой дисперсии распределения вероятностей или частотного распределения. Это помогает нам понять, как распределяются данные в двух разных тестах.
Стандартное отклонение — наиболее распространенная мера изменчивости для одного набора данных. Но зачем нам еще один показатель, например коэффициент вариации? Что ж, сравнивать стандартные отклонения двух разных наборов данных бессмысленно, а сравнивать коэффициенты вариации — нет.

from scipy.stats import variation variation(data)
Например, если мы рассмотрим два разных данных;
Данные 1: Среднее1 = 120000: SD1 = 2000
Данные 2: Среднее2 = 900000: SD2 = 10000
Давайте рассчитаем CV для обоих наборов данных
CV1 = SD1 / Среднее1 = 1,6%
CV2 = SD2 / Среднее2 = 1,1%
Мы можем заключить, что данные 1 более распространены, чем данные 2.
Относительная квадратная ошибка (RSE)
Относительная квадратная ошибка (RSE) относится к тому, что было бы, если бы использовался простой предиктор. В частности, этот простой предсказатель представляет собой просто среднее значение фактических значений. Таким образом, относительная ошибка в квадрате берет общую ошибку в квадрате и нормализует ее путем деления на общую ошибку в квадрате простого предсказателя. Его можно сравнивать между моделями, ошибки которых измеряются в разных единицах.
Математически относительная квадратная ошибка Ei отдельной модели i вычисляется по формуле:

где P (ij) — это значение, предсказанное отдельной моделью i для записи j (из n записей); Tj — это целевое значение для записи j, а Tbar задается формулой:

Для идеального соответствия числитель равен 0 и Ei = 0. Таким образом, индекс Ei находится в диапазоне от 0 до бесконечности, где 0 соответствует идеалу.
Средняя абсолютная ошибка (MAE)
В статистике средняя абсолютная ошибка (MAE) — это мера ошибок между парными наблюдениями, выражающими одно и то же явление. Примеры Y по сравнению с X включают сравнения прогнозируемого и наблюдаемого, последующего времени и начального времени, а также один метод измерения по сравнению с альтернативным методом измерения. Он имеет ту же единицу, что и исходные данные, и его можно сравнивать только между моделями, ошибки которых измеряются в тех же единицах. Обычно он по величине похож на RMSE, но немного меньше. MAE рассчитывается как:

from sklearn.metrics import mean_absolute_error mean_absolute_error(actual, predicted)
Таким образом, это среднее арифметическое абсолютных ошибок, где yi — прогноз, а xi — фактическое значение. Обратите внимание, что альтернативные составы могут включать относительные частоты в качестве весовых коэффициентов. Средняя абсолютная ошибка использует ту же шкалу, что и измеряемые данные. Это известно как мера точности, зависящая от масштаба, и поэтому не может использоваться для сравнения серий с использованием разных шкал.
Примечание. Как видите, все статистические данные сравнивают истинные значения со своими оценками, но делают это немного по-другому. Все они говорят вам, насколько далеко ваши оценочные значения от истинного значения. Иногда используются квадратные корни, а иногда и абсолютные значения — это связано с тем, что при использовании квадратных корней экстремальные значения имеют большее влияние на результат (см. Зачем возводить разницу в квадрат вместо того, чтобы брать абсолютное значение в стандартном отклонении? Или в Mathoverflow. »).
В MAE и RMSE вы просто смотрите на «среднюю разницу» между этими двумя значениями. Таким образом, вы интерпретируете их в сравнении со шкалой вашей переменной (т.е. MSE в 1 балл представляет собой разницу в 1 балл между прогнозируемым и фактическим).
В RAE и Relative RSE эти различия делятся на изменение фактических значений, поэтому они имеют шкалу от 0 до 1, и если вы умножите это значение на 100, вы получите сходство по шкале от 0 до 100 (т. е. в процентах). .
Значения ∑ (MeanofActual — фактический) ² или ∑ | MeanofActual — фактический | сказать вам, насколько фактическое значение отличается от своего среднего значения — чтобы вы могли понять, насколько фактическое значение отличается от самого себя (сравните с дисперсией). Из-за этого меры названы относительными — они дают вам результаты, относящиеся к фактическому масштабу.
Относительная абсолютная ошибка (RAE)
Относительная абсолютная ошибка (RAE) — это способ измерения производительности прогнозной модели. RAE не следует путать с относительной погрешностью, которая является общей мерой точности или точности для таких инструментов, как часы, линейки или весы. Он выражается в виде отношения, сравнивающего среднюю ошибку (невязку) с ошибками, произведенными тривиальной или наивной моделью. Хорошая модель прогнозирования даст коэффициент, близкий к нулю; Плохая модель (хуже, чем наивная модель) даст отношение больше единицы.
Он очень похож на относительную квадратичную ошибку в том смысле, что он также относится к простому предиктору, который представляет собой просто среднее значение фактических значений. Однако в этом случае ошибка — это просто полная абсолютная ошибка, а не общая ошибка в квадрате. Таким образом, относительная абсолютная ошибка берет полную абсолютную ошибку и нормализует ее путем деления на полную абсолютную ошибку простого предсказателя.
Математически относительная абсолютная ошибка Ei отдельной модели i оценивается по уравнению:

где P (ij) — это значение, предсказанное отдельной моделью i для записи j (из n записей); Tj — это целевое значение для записи j, а Tbar задается формулой:

Для идеального соответствия числитель равен 0 и Ei = 0. Таким образом, индекс Ei находится в диапазоне от 0 до бесконечности, где 0 соответствует идеалу.
Среднеквадратичная ошибка (MSE)
Среднеквадратичная ошибка (MSE) или среднеквадратическое отклонение (MSD) оценщика (процедуры оценки ненаблюдаемой величины) измеряет среднее квадратов ошибок, то есть среднеквадратичную разницу между оцененными значениями и фактическими значениями. ценить. MSE — это функция риска, соответствующая ожидаемому значению квадрата потери ошибок. Тот факт, что MSE почти всегда строго положительна (а не равна нулю), объясняется случайностью или тем, что оценщик не учитывает информацию, которая могла бы дать более точную оценку.
MSE оценивает качество предсказателя (т. Е. Функция, отображающая произвольные входные данные в выборку значений некоторой случайной переменной) или оценщика (т. Е. Математическая функция, отображающая выборку данных в оценку параметра совокупности из которого берутся данные). Определение MSE различается в зависимости от того, описывается ли предсказатель или оценщик.
MSE — это мера качества оценки — она всегда неотрицательна, а значения, близкие к нулю, лучше.

from sklearn.metrics import mean_squared_error
mean_squared_error(actual, predicted)Давайте проанализируем, что на самом деле означает это уравнение.
- В математике символ, который выглядит как странный E, называется суммированием (греческая сигма). Это сумма последовательности чисел от i = 1 до n. Представим это как массив точек, в котором мы перебираем все точки, от первой (i = 1) до последней (i = n).
- Для каждой точки мы берем координату y точки и координату y’. Мы вычитаем значение координаты y из значения координаты y и вычисляем квадрат результата.
- Третья часть — взять сумму всех значений (y-y ’) ² и разделить ее на n, что даст среднее значение.
Наша цель — минимизировать это среднее, чтобы получить лучшую линию, проходящую через все точки. «Для дополнительной информации».
Среднеквадратичная ошибка прогноза (RMSE / RMSEP)
В статистическом моделировании и, в частности, регрессионном анализе, обычным способом измерения качества соответствия модели является RMSE (также называемое среднеквадратичным отклонением), определяемое выражением

from sklearn.metrics import mean_squared_error
mse = mean_squared_error(actual, predicted)
rmse = sqrt(mse)где yi — i-е наблюдение y, а ŷ — прогнозируемое значение y для данной модели. Если предсказанные ответы очень близки к истинным ответам, RMSE будет небольшим. Если предсказанные и истинные ответы существенно различаются — по крайней мере, для некоторых наблюдений — RMSE будет большим. Нулевое значение указывает на полное соответствие данным. Поскольку RMSE измеряется в той же шкале, с теми же единицами измерения, что и y, можно ожидать, что 68% значений y будут в пределах 1 RMSE — при условии, что данные распределены нормально.
ПРИМЕЧАНИЕ: RMSE касается отклонений от истинного значения, тогда как S касается отклонений от среднего.
Таким образом, вычисление MSE помогает сравнивать разные модели, основанные на одних и тех же наблюдениях y. Но что, если
- кто-то хочет сравнить соответствие модели для разных переменных отклика?
- переменная ответа y изменяется в некоторых моделях, например стандартизированный или преобразованный в sqrt или логарифм?
- И влияет ли разделение данных на обучающий и тестовый набор данных (после модификации) и вычисление RMSE на основе тестовых данных на точки 1. и 2.?
Первые два пункта являются типичными проблемами при сравнении эффективности экологических индикаторов, а последний, так называемый подход с использованием набора проверки, довольно распространен в статистике и машинном обучении. Одним из способов преодоления этих препятствий является вычисление нормализованного RMSE.
Нормализованная среднеквадратическая ошибка (Норма RMSEP)
Нормализация RMSE облегчает сравнение наборов данных или моделей с разными масштабами. Однако в литературе вы найдете различные методы нормализации RMSE:
Вы можете нормализовать

Если переменные отклика имеют несколько экстремальных значений, выбор межквартильного диапазона является хорошим вариантом, поскольку он менее чувствителен к выбросам.
RMSEP / стандартное отклонение называется относительной среднеквадратичной ошибкой (RRMSEP).
1 / RRMSEP также является показателем. Значение больше 2 считается хорошим.
Существуют также такие термины, как стандартная ошибка прогноза (SEP) и отношение стандартной ошибки прогноза к стандартному отклонению (RPD), которые в основном используются в хемометрике.
Я надеюсь, что этот блог помог вам понять различные метрики для оценки вашей регрессионной модели. Я использовал несколько источников, чтобы понять и написать эту статью. Спасибо за уделенное время.
Использованная литература:
Https://www.gepsoft.com/
https://www.investopedia.com/
https://en.wikipedia.org/wiki
https://scikit-learn.org/
https://www.saedsayad.com/
https://www.marinedatascience.co/blog/2019/01/07/ normalizing-the-rmse /
Очень наивный способ оценки модели — рассматривать значение R-Squared. Предположим, что если я получу 95% R-Squared, этого будет достаточно? В этом блоге давайте попробуем понять способы оценки вашей регрессионной модели.
Метрики оценки;
- Среднее / Медиана прогноза
- Стандартное отклонение прогноза
- Диапазон предсказания
- Коэффициент детерминации (R2)
- Относительное стандартное отклонение / коэффициент вариации (RSD)
- Относительная квадратная ошибка (RSE)
- Средняя абсолютная ошибка (MAE)
- Относительная абсолютная ошибка (RAE)
- Среднеквадратичная ошибка (MSE)
- Среднеквадратичная ошибка прогноза (RMSE / RMSEP)
- Нормализованная среднеквадратическая ошибка (Норма RMSEP)
- Относительная среднеквадратическая ошибка (RRMSEP)
Давайте рассмотрим пример прогнозирования концентрации активных фармацевтических ингредиентов (API) в таблетке. Используя единицы поглощения из NIR-спектроскопии, мы прогнозируем уровень API в таблетке. Концентрация API в таблетке может составлять 0,0, 0,1, 0,3, 0,5, 1,0, 1,5, 2,0, 2,5, 3,0. Мы применяем PLS (частичный наименьший квадрат) и SVR (регрессор вектора поддержки) для прогнозирования уровня API.
ПРИМЕЧАНИЕ: метрики можно использовать для сравнения нескольких моделей или одной модели с разными моделями.
Среднее / Медиана прогноза
Мы можем понять смещение прогнозов между двумя моделями, используя среднее арифметическое предсказанных значений.
Например, среднее значение прогнозируемых значений 0,5 API рассчитывается путем деления суммы прогнозируемых значений для 0,5 API на общее количество выборок, имеющих 0,5 API.
np.mean(predictedArray)
На рисунке 1 мы можем понять, как PLS и SVR работали относительно среднего. SVR предсказал API 0.0 намного лучше, чем PLS, тогда как PLS предсказал API 3.0 лучше, чем SVR. Мы можем выбирать модели исходя из интересов уровня API.
Недостаток: на среднее значение влияют выбросы. Используйте «Медиана», если у вас есть выбросы в прогнозируемых значениях
Стандартное отклонение прогноза
Стандартное отклонение (SD) — это мера степени вариации или разброса набора значений. Низкое стандартное отклонение указывает на то, что значения имеют тенденцию быть близкими к среднему (также называемому ожидаемым значением) набора. Напротив, высокое стандартное отклонение указывает на то, что значения разбросаны в более широком диапазоне. Стандартное отклонение предсказанных значений помогает понять разброс значений в различных моделях.
np.std(predictedArray)
На рисунке 2 разброс предсказанных значений меньше в SVR по сравнению с PLS. Таким образом, SVR работает лучше, если мы учитываем показатели SD.
Диапазон предсказания
Диапазон прогноза — это максимальное и минимальное значение в прогнозируемых значениях. Равный диапазон помогает нам понять разницу между моделями.
Коэффициент детерминации (R2)
R-квадрат (R2) — это статистическая мера, которая представляет собой долю дисперсии для зависимой переменной, которая объясняется независимой переменной или переменными в регрессионной модели. В то время как корреляция объясняет силу взаимосвязи между независимой и зависимой переменной, R-квадрат объясняет, в какой степени дисперсия одной переменной объясняет дисперсию второй переменной. Таким образом, если R2 модели составляет 0,50, то примерно половина наблюдаемой вариации может быть объяснена входными данными модели.
from sklearn.metrics import r2_score r2_score(Actual, Predicted)
Недостаток: R2 не учитывает переоснащение. Подробнее.
Относительное стандартное отклонение (RSD) / коэффициент вариации (CV)
Есть пословица, что яблоки не следует сравнивать с апельсинами или, другими словами, не сравнивать два предмета или группу предметов, которые практически не сравниваются. Но недостаток сопоставимости можно преодолеть, если эти два предмета или группы каким-то образом стандартизировать или привести к одной и той же шкале. Например, при сравнении дисперсий двух групп, которые в целом сильно различаются, таких как дисперсия в размере синего тунца и синего кита, коэффициент вариации (CV) является методом выбора: CV просто представляет собой дисперсию каждая группа стандартизирована по среднему значению группы
Коэффициент вариации (CV), также известный как относительное стандартное отклонение (RSD), является стандартизированной мерой дисперсии распределения вероятностей или частотного распределения. Это помогает нам понять, как распределяются данные в двух разных тестах.
Стандартное отклонение — наиболее распространенная мера изменчивости для одного набора данных. Но зачем нам еще один показатель, например коэффициент вариации? Что ж, сравнивать стандартные отклонения двух разных наборов данных бессмысленно, а сравнивать коэффициенты вариации — нет.
from scipy.stats import variation variation(data)
Например, если мы рассмотрим два разных данных;
Данные 1: Среднее1 = 120000: SD1 = 2000
Данные 2: Среднее2 = 900000: SD2 = 10000
Давайте рассчитаем CV для обоих наборов данных
CV1 = SD1 / Среднее1 = 1,6%
CV2 = SD2 / Среднее2 = 1,1%
Мы можем заключить, что данные 1 более распространены, чем данные 2.
Относительная квадратная ошибка (RSE)
Относительная квадратная ошибка (RSE) относится к тому, что было бы, если бы использовался простой предиктор. В частности, этот простой предсказатель представляет собой просто среднее значение фактических значений. Таким образом, относительная ошибка в квадрате берет общую ошибку в квадрате и нормализует ее путем деления на общую ошибку в квадрате простого предсказателя. Его можно сравнивать между моделями, ошибки которых измеряются в разных единицах.
Математически относительная квадратная ошибка Ei отдельной модели i вычисляется по формуле:
где P (ij) — это значение, предсказанное отдельной моделью i для записи j (из n записей); Tj — это целевое значение для записи j, а Tbar задается формулой:
Для идеального соответствия числитель равен 0 и Ei = 0. Таким образом, индекс Ei находится в диапазоне от 0 до бесконечности, где 0 соответствует идеалу.
Средняя абсолютная ошибка (MAE)
В статистике средняя абсолютная ошибка (MAE) — это мера ошибок между парными наблюдениями, выражающими одно и то же явление. Примеры Y по сравнению с X включают сравнения прогнозируемого и наблюдаемого, последующего времени и начального времени, а также один метод измерения по сравнению с альтернативным методом измерения. Он имеет ту же единицу, что и исходные данные, и его можно сравнивать только между моделями, ошибки которых измеряются в тех же единицах. Обычно он по величине похож на RMSE, но немного меньше. MAE рассчитывается как:
from sklearn.metrics import mean_absolute_error mean_absolute_error(actual, predicted)
Таким образом, это среднее арифметическое абсолютных ошибок, где yi — прогноз, а xi — фактическое значение. Обратите внимание, что альтернативные составы могут включать относительные частоты в качестве весовых коэффициентов. Средняя абсолютная ошибка использует ту же шкалу, что и измеряемые данные. Это известно как мера точности, зависящая от масштаба, и поэтому не может использоваться для сравнения серий с использованием разных шкал.
Примечание. Как видите, все статистические данные сравнивают истинные значения со своими оценками, но делают это немного по-другому. Все они говорят вам, насколько далеко ваши оценочные значения от истинного значения. Иногда используются квадратные корни, а иногда и абсолютные значения — это связано с тем, что при использовании квадратных корней экстремальные значения имеют большее влияние на результат (см. Зачем возводить разницу в квадрат вместо того, чтобы брать абсолютное значение в стандартном отклонении? Или в Mathoverflow. »).
В MAE и RMSE вы просто смотрите на «среднюю разницу» между этими двумя значениями. Таким образом, вы интерпретируете их в сравнении со шкалой вашей переменной (т.е. MSE в 1 балл представляет собой разницу в 1 балл между прогнозируемым и фактическим).
В RAE и Relative RSE эти различия делятся на изменение фактических значений, поэтому они имеют шкалу от 0 до 1, и если вы умножите это значение на 100, вы получите сходство по шкале от 0 до 100 (т. е. в процентах). .
Значения ∑ (MeanofActual — фактический) ² или ∑ | MeanofActual — фактический | сказать вам, насколько фактическое значение отличается от своего среднего значения — чтобы вы могли понять, насколько фактическое значение отличается от самого себя (сравните с дисперсией). Из-за этого меры названы относительными — они дают вам результаты, относящиеся к фактическому масштабу.
Относительная абсолютная ошибка (RAE)
Относительная абсолютная ошибка (RAE) — это способ измерения производительности прогнозной модели. RAE не следует путать с относительной погрешностью, которая является общей мерой точности или точности для таких инструментов, как часы, линейки или весы. Он выражается в виде отношения, сравнивающего среднюю ошибку (невязку) с ошибками, произведенными тривиальной или наивной моделью. Хорошая модель прогнозирования даст коэффициент, близкий к нулю; Плохая модель (хуже, чем наивная модель) даст отношение больше единицы.
Он очень похож на относительную квадратичную ошибку в том смысле, что он также относится к простому предиктору, который представляет собой просто среднее значение фактических значений. Однако в этом случае ошибка — это просто полная абсолютная ошибка, а не общая ошибка в квадрате. Таким образом, относительная абсолютная ошибка берет полную абсолютную ошибку и нормализует ее путем деления на полную абсолютную ошибку простого предсказателя.
Математически относительная абсолютная ошибка Ei отдельной модели i оценивается по уравнению:
где P (ij) — это значение, предсказанное отдельной моделью i для записи j (из n записей); Tj — это целевое значение для записи j, а Tbar задается формулой:
Для идеального соответствия числитель равен 0 и Ei = 0. Таким образом, индекс Ei находится в диапазоне от 0 до бесконечности, где 0 соответствует идеалу.
Среднеквадратичная ошибка (MSE)
Среднеквадратичная ошибка (MSE) или среднеквадратическое отклонение (MSD) оценщика (процедуры оценки ненаблюдаемой величины) измеряет среднее квадратов ошибок, то есть среднеквадратичную разницу между оцененными значениями и фактическими значениями. ценить. MSE — это функция риска, соответствующая ожидаемому значению квадрата потери ошибок. Тот факт, что MSE почти всегда строго положительна (а не равна нулю), объясняется случайностью или тем, что оценщик не учитывает информацию, которая могла бы дать более точную оценку.
MSE оценивает качество предсказателя (т. Е. Функция, отображающая произвольные входные данные в выборку значений некоторой случайной переменной) или оценщика (т. Е. Математическая функция, отображающая выборку данных в оценку параметра совокупности из которого берутся данные). Определение MSE различается в зависимости от того, описывается ли предсказатель или оценщик.
MSE — это мера качества оценки — она всегда неотрицательна, а значения, близкие к нулю, лучше.
from sklearn.metrics import mean_squared_error
mean_squared_error(actual, predicted)Давайте проанализируем, что на самом деле означает это уравнение.
- В математике символ, который выглядит как странный E, называется суммированием (греческая сигма). Это сумма последовательности чисел от i = 1 до n. Представим это как массив точек, в котором мы перебираем все точки, от первой (i = 1) до последней (i = n).
- Для каждой точки мы берем координату y точки и координату y’. Мы вычитаем значение координаты y из значения координаты y и вычисляем квадрат результата.
- Третья часть — взять сумму всех значений (y-y ’) ² и разделить ее на n, что даст среднее значение.
Наша цель — минимизировать это среднее, чтобы получить лучшую линию, проходящую через все точки. «Для дополнительной информации».
Среднеквадратичная ошибка прогноза (RMSE / RMSEP)
В статистическом моделировании и, в частности, регрессионном анализе, обычным способом измерения качества соответствия модели является RMSE (также называемое среднеквадратичным отклонением), определяемое выражением
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(actual, predicted)
rmse = sqrt(mse)где yi — i-е наблюдение y, а ŷ — прогнозируемое значение y для данной модели. Если предсказанные ответы очень близки к истинным ответам, RMSE будет небольшим. Если предсказанные и истинные ответы существенно различаются — по крайней мере, для некоторых наблюдений — RMSE будет большим. Нулевое значение указывает на полное соответствие данным. Поскольку RMSE измеряется в той же шкале, с теми же единицами измерения, что и y, можно ожидать, что 68% значений y будут в пределах 1 RMSE — при условии, что данные распределены нормально.
ПРИМЕЧАНИЕ: RMSE касается отклонений от истинного значения, тогда как S касается отклонений от среднего.
Таким образом, вычисление MSE помогает сравнивать разные модели, основанные на одних и тех же наблюдениях y. Но что, если
- кто-то хочет сравнить соответствие модели для разных переменных отклика?
- переменная ответа y изменяется в некоторых моделях, например стандартизированный или преобразованный в sqrt или логарифм?
- И влияет ли разделение данных на обучающий и тестовый набор данных (после модификации) и вычисление RMSE на основе тестовых данных на точки 1. и 2.?
Первые два пункта являются типичными проблемами при сравнении эффективности экологических индикаторов, а последний, так называемый подход с использованием набора проверки, довольно распространен в статистике и машинном обучении. Одним из способов преодоления этих препятствий является вычисление нормализованного RMSE.
Нормализованная среднеквадратическая ошибка (Норма RMSEP)
Нормализация RMSE облегчает сравнение наборов данных или моделей с разными масштабами. Однако в литературе вы найдете различные методы нормализации RMSE:
Вы можете нормализовать
Если переменные отклика имеют несколько экстремальных значений, выбор межквартильного диапазона является хорошим вариантом, поскольку он менее чувствителен к выбросам.
RMSEP / стандартное отклонение называется относительной среднеквадратичной ошибкой (RRMSEP).
1 / RRMSEP также является показателем. Значение больше 2 считается хорошим.
Существуют также такие термины, как стандартная ошибка прогноза (SEP) и отношение стандартной ошибки прогноза к стандартному отклонению (RPD), которые в основном используются в хемометрике.
Я надеюсь, что этот блог помог вам понять различные метрики для оценки вашей регрессионной модели. Я использовал несколько источников, чтобы понять и написать эту статью. Спасибо за уделенное время.
Использованная литература:
Https://www.gepsoft.com/
https://www.investopedia.com/
https://en.wikipedia.org/wiki
https://scikit-learn.org/
https://www.saedsayad.com/
https://www.marinedatascience.co/blog/2019/01/07/ normalizing-the-rmse /