читать 2 мин
Стандартная ошибка среднего — это способ измерить, насколько разбросаны значения в наборе данных. Он рассчитывается как:
Стандартная ошибка = с / √n
куда:
- s : стандартное отклонение выборки
- n : размер выборки
Вы можете рассчитать стандартную ошибку среднего для любого набора данных в Excel, используя следующую формулу:
= СТАНДОТКЛОН (диапазон значений) / КОРЕНЬ ( СЧЁТ (диапазон значений))
В следующем примере показано, как использовать эту формулу.
Пример: Стандартная ошибка в Excel
Предположим, у нас есть следующий набор данных:
На следующем снимке экрана показано, как рассчитать стандартную ошибку среднего значения для этого набора данных:
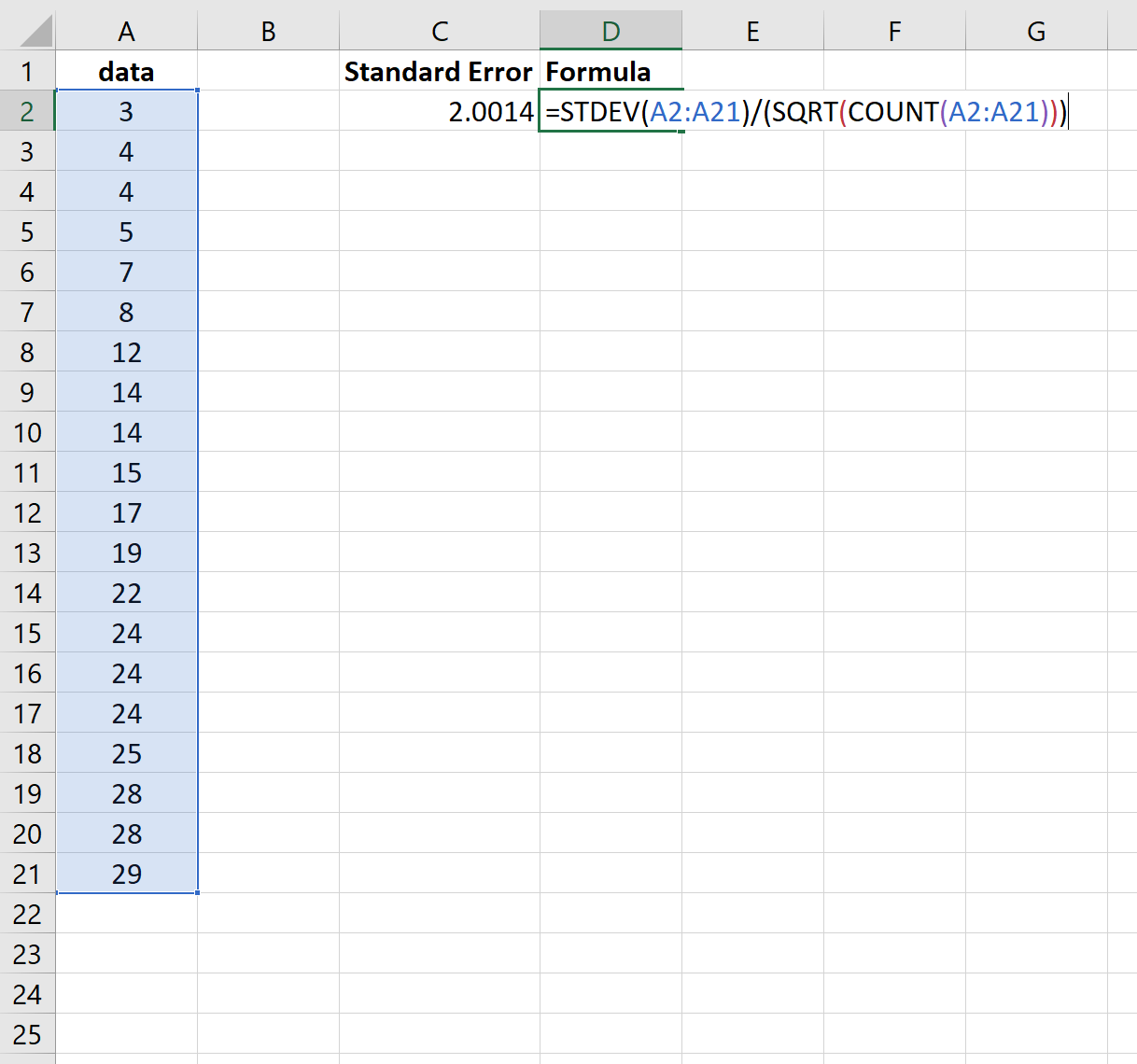
Стандартная ошибка оказывается равной 2,0014 .
Обратите внимание, что функция =СТАНДОТКЛОН() вычисляет выборочное среднее, что эквивалентно функции =СТАНДОТКЛОН.С() в Excel.
Таким образом, мы могли бы использовать следующую формулу для получения тех же результатов:
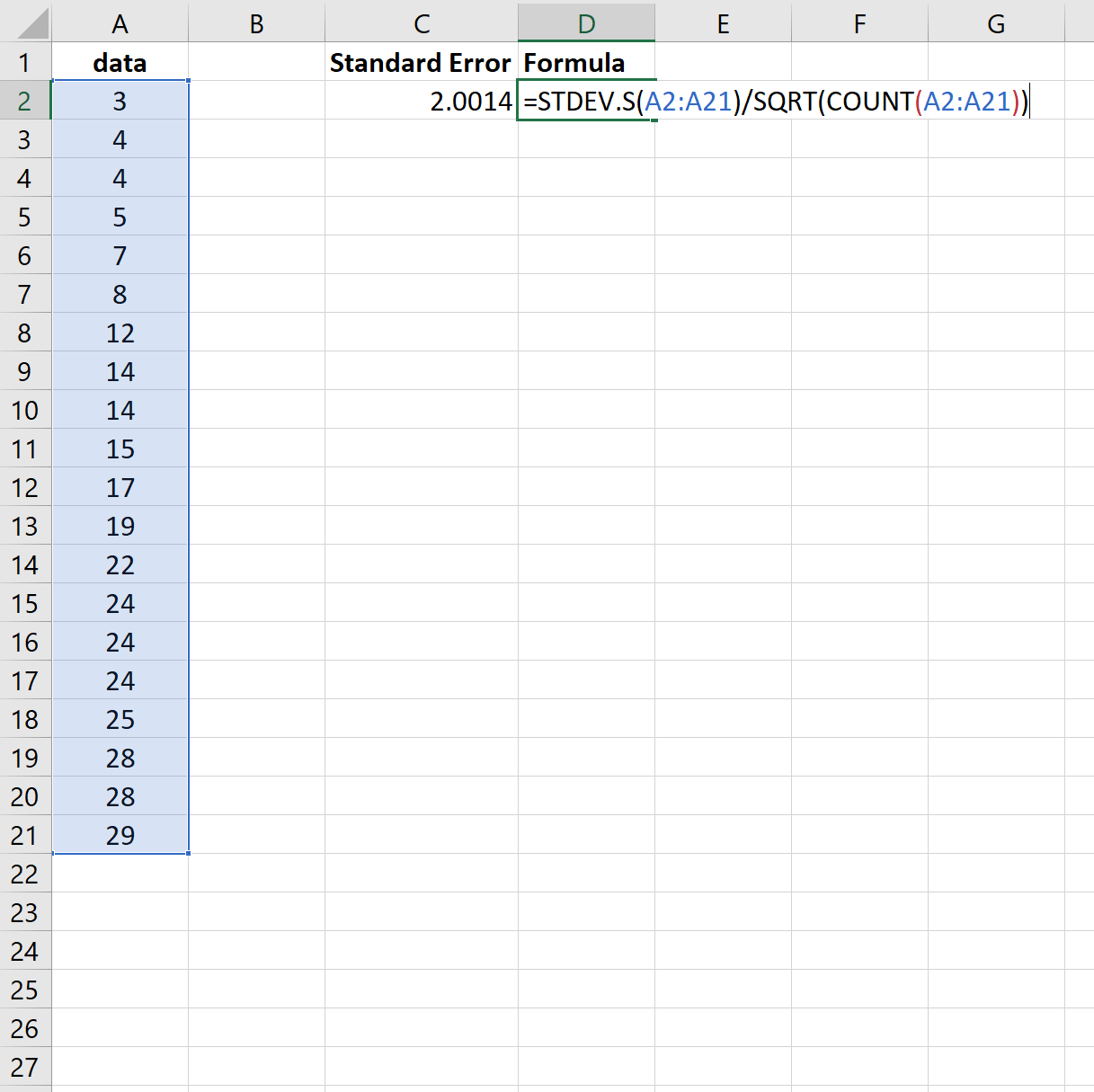
И снова стандартная ошибка оказывается равной 2,0014 .
Как интерпретировать стандартную ошибку среднего
Стандартная ошибка среднего — это просто мера того, насколько разбросаны значения вокруг среднего. При интерпретации стандартной ошибки среднего следует помнить о двух вещах:
1. Чем больше стандартная ошибка среднего, тем более разбросаны значения вокруг среднего в наборе данных.
Чтобы проиллюстрировать это, рассмотрим, изменим ли мы последнее значение в предыдущем наборе данных на гораздо большее число:
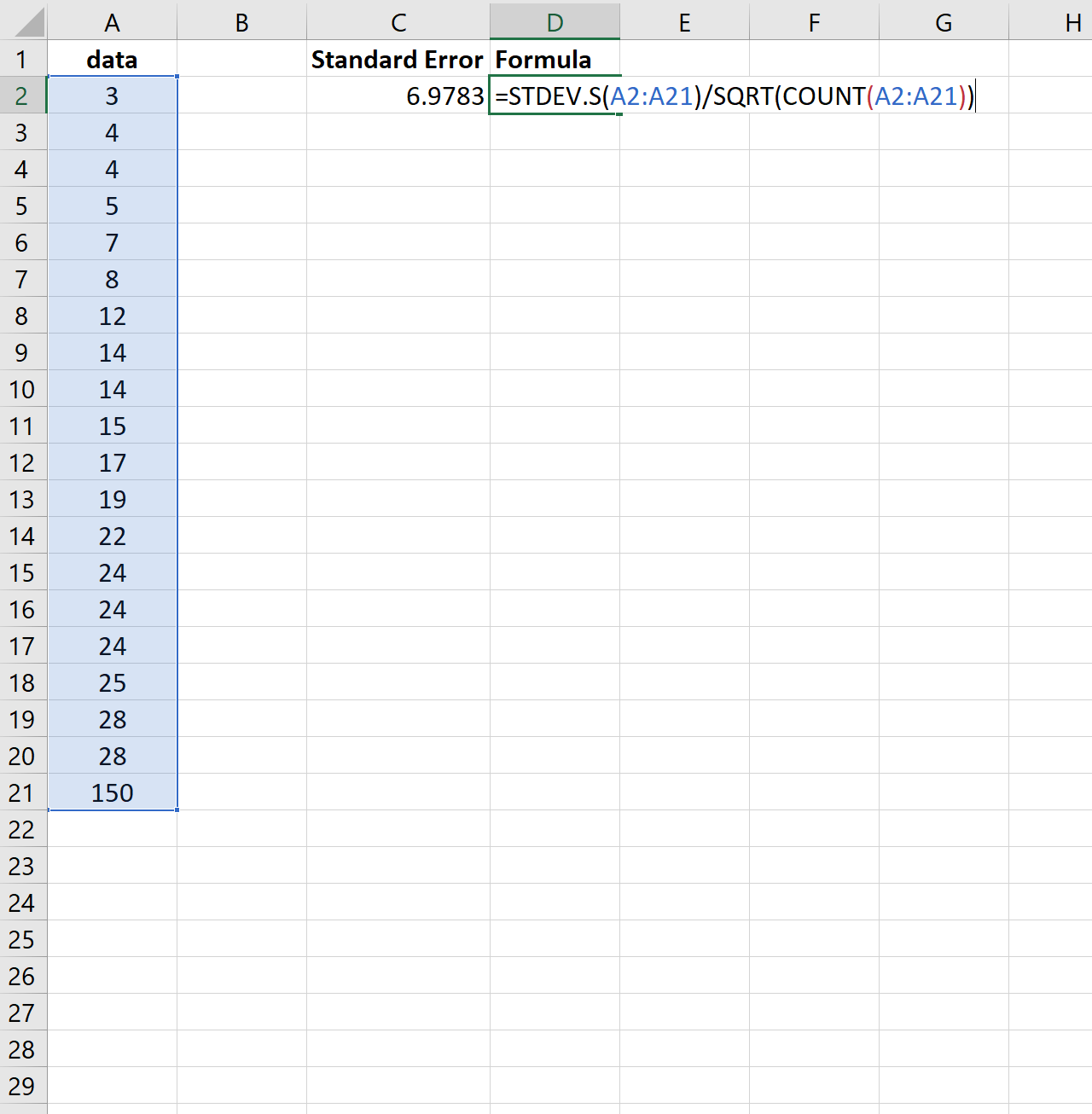
Обратите внимание на скачок стандартной ошибки с 2,0014 до 6,9783.Это указывает на то, что значения в этом наборе данных более разбросаны вокруг среднего значения по сравнению с предыдущим набором данных.
2. По мере увеличения размера выборки стандартная ошибка среднего имеет тенденцию к уменьшению.
Чтобы проиллюстрировать это, рассмотрим стандартную ошибку среднего для следующих двух наборов данных:
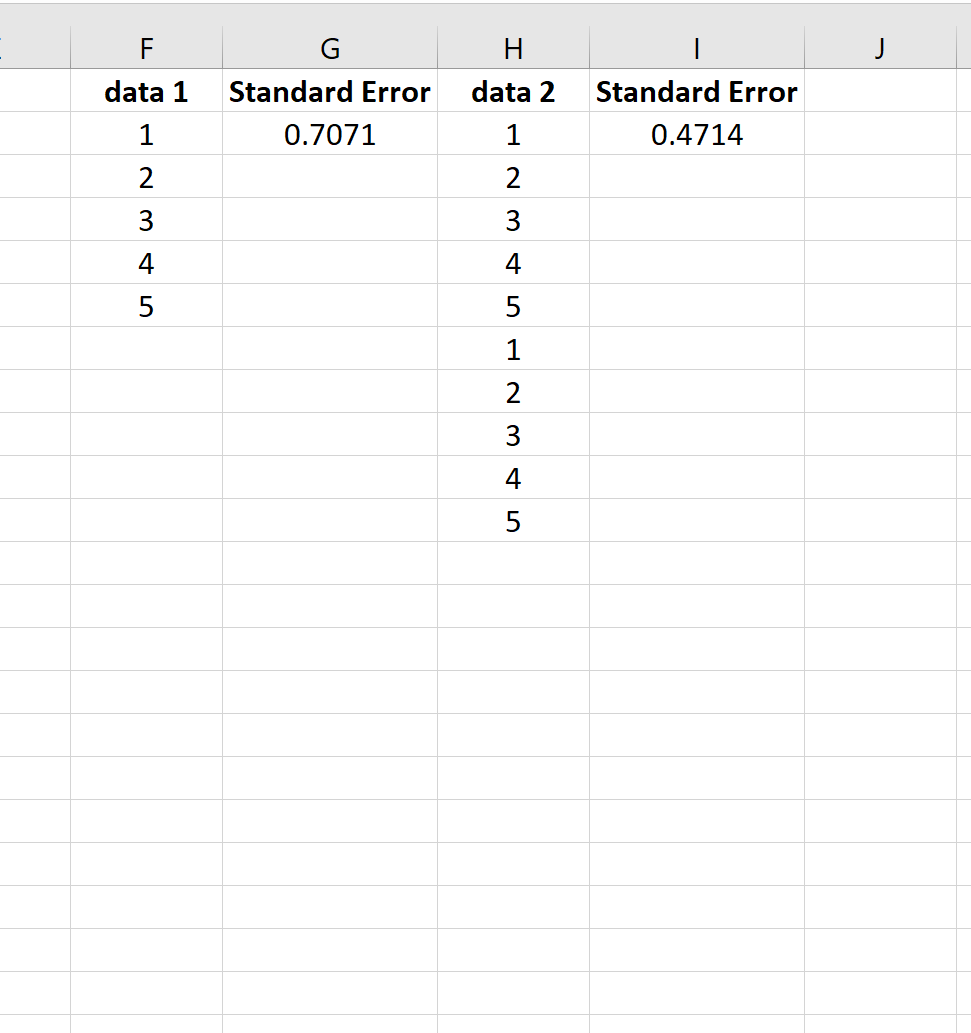
Второй набор данных — это просто первый набор данных, повторенный дважды. Таким образом, два набора данных имеют одинаковое среднее значение, но второй набор данных имеет больший размер выборки, поэтому стандартная ошибка меньше.
![]()
Загрузить PDF
![]()
Загрузить PDF
В этой статье мы расскажем вам, как в Excel вычислить стандартную ошибку среднего. Для этого стандартное отклонение (σ) нужно разделить на квадратный корень (√) из размера выборки (N).
-

1
Запустите Excel. Нажмите на значок в виде белой буквы «Х» на зеленом фоне.
-
2
Откройте или создайте таблицу Excel. Чтобы открыть готовую таблицу с данными, нажмите «Открыть» на левой панели. Чтобы создать таблицу, нажмите «Создать» и введите данные.
-
3
Вычислите стандартное отклонение. Чтобы сделать это, нужно выполнить несколько действий, но в Excel можно просто ввести следующую формулу: =СТАНДОТКЛОН.В(''диапазон ячеек'').
- Например, если данные находятся в ячейках с A1 по A20, в пустой ячейке введите =СТАНДОТКЛОН.В(A1:A20), чтобы вычислить стандартное отклонение.
-
4
Введите формулу для вычисления стандартной ошибки среднего в пустой ячейке. Формула выглядит так:=СТАНДОТКЛОН.В(''диапазон ячеек'')/КОРЕНЬ(СЧЁТ("диапазон ячеек")).
- Например, если данные находятся в ячейках с A1 по A20, в пустой ячейке введите формулу =СТАНДОТКЛОН.В(A1:A20)/КОРЕНЬ(СЧЁТ(A1:A20)). Так вы вычислите стандартную ошибку среднего.
Реклама




Об этой статье
Эту страницу просматривали 35 211 раз.
Была ли эта статья полезной?
Here are a couple of ways to calculate standard error quickly
by Sagar Naresh
Sagar is a web developer and technology journalist. Currently associated with WindowsReport and SamMobile. When not writing, he is either at the gym sweating it out or playing… read more
Updated on
- Standard error lets you understand the variation between the population mean and the sample mean.
- You can use the general formula method to calculate the standard error.
- Else, you may check out the second method which is quite easy to calculate the standard error.
If you are working with a large dataset, knowing its standard deviation is handy as it will let you know the variability in the given dataset. You get to see the degree of asymmetry in your dataset and how much the data deviates from its mean value.
You can also calculate standard error in MS Excel. Here, we will guide you on how to calculate standard error in Excel quickly. Let us get right into it.
Why is calculating standard error important in Excel?
The standard deviation allows you to understand the variation in your sample. There are two varieties of standard deviation:
- The standard deviation of a sample: In this, you get to calculate the standard error of a certain dataset or a selected sample of data. For example, you have a chart of the marks of all students in a class. Then you can use the standard deviation of a sample to know the deviation in the marks.
- The standard deviation of a population: In this, you calculate the standard error of all entries in a table. In the above example, you can use the standard deviation of a population to know the deviation for all students.
On the other hand, a standard error lets you know the variability across the samples of the population. Using standard error you understand how a sample’s mean is accurate in terms of the true population mean.
So, to understand standard error remember that a standard error is the standard deviation from the population mean. It can be calculated by dividing the standard deviation of a sample by the square root of the sample size.
So, here’s how to find standard error in Excel using two simple methods we propose below.
How to calculate standard error or deviation in MS Excel quickly?
1. Use the formula
- Create a sample data or open your workbook.
- Click on a cell where you would like your standard error to appear.

- Click on the formula bar next to the fx symbol.
- Type the below formula in the formula bar:
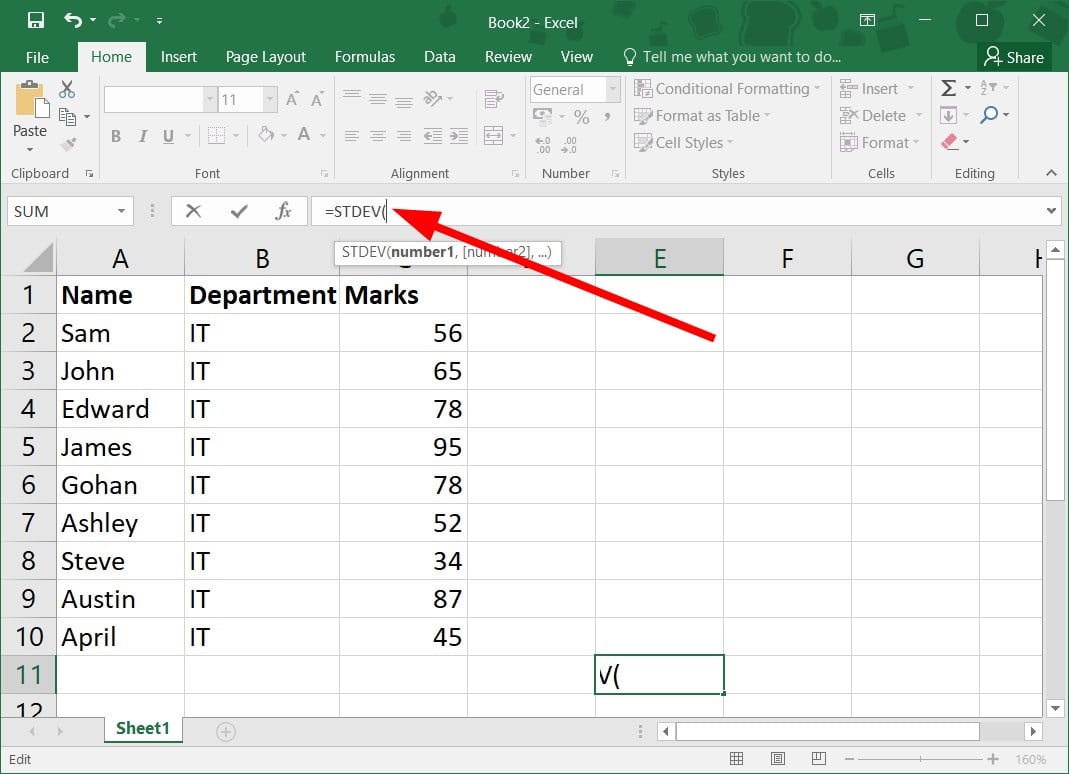
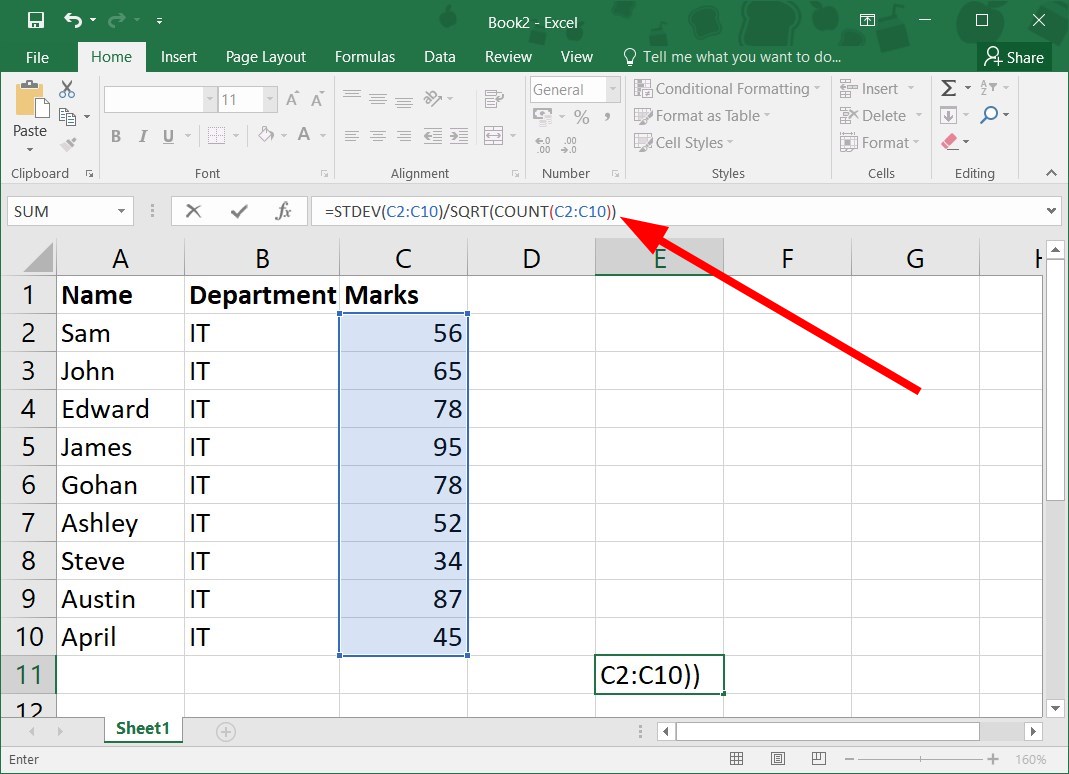
=STDEV( - Drag and select the range of cells in your sample data. For example, in our case, it would become
=STDEV(C2:C10 - Close the bracket for the formula:
=STDEV(C2:C10) - Add / symbol to the STDEV formula.
=STDEV(C2:C10)/ - Apply the SQRT formula to the STDEV formula.
=STDEV(C2:C10)/SQRT( - Use the COUNT function with the STDEV formula.
=STDEV(C2:C10)/SQRT(COUNT( - Drag the range of cells that are part of your sample data. Close the SQRT bracket:
=STDEV(C2:C10)/SQRT(COUNT(C2:C10)) - Press Enter to get the standard error.
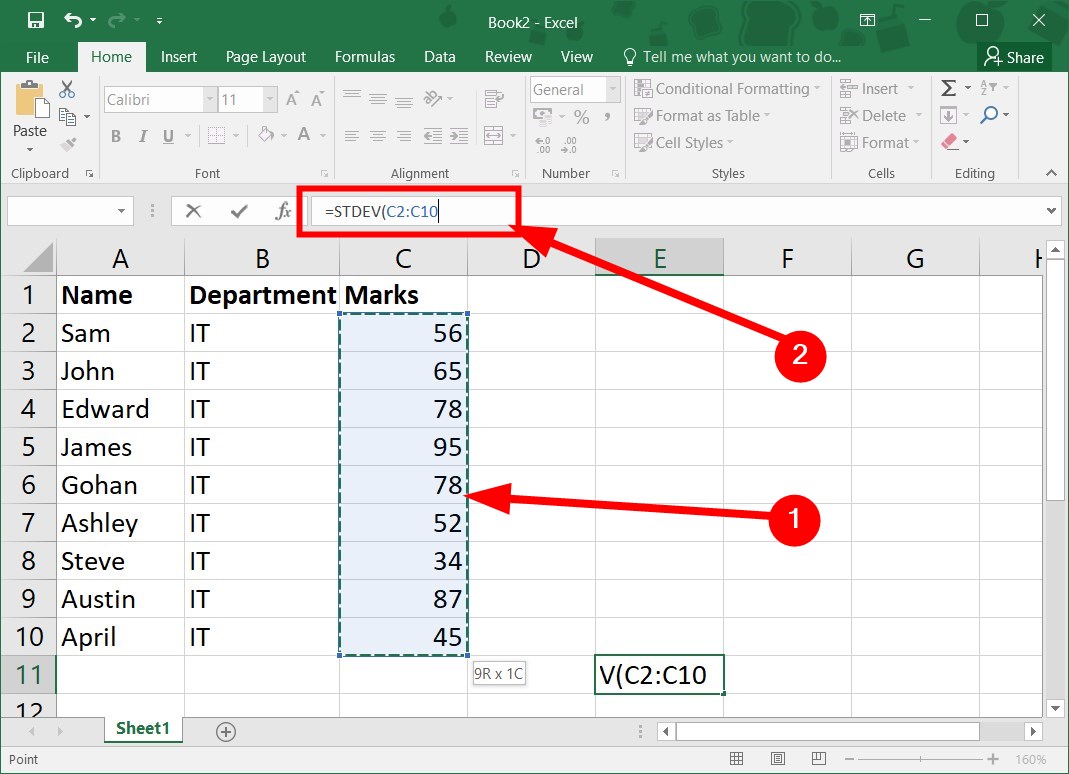
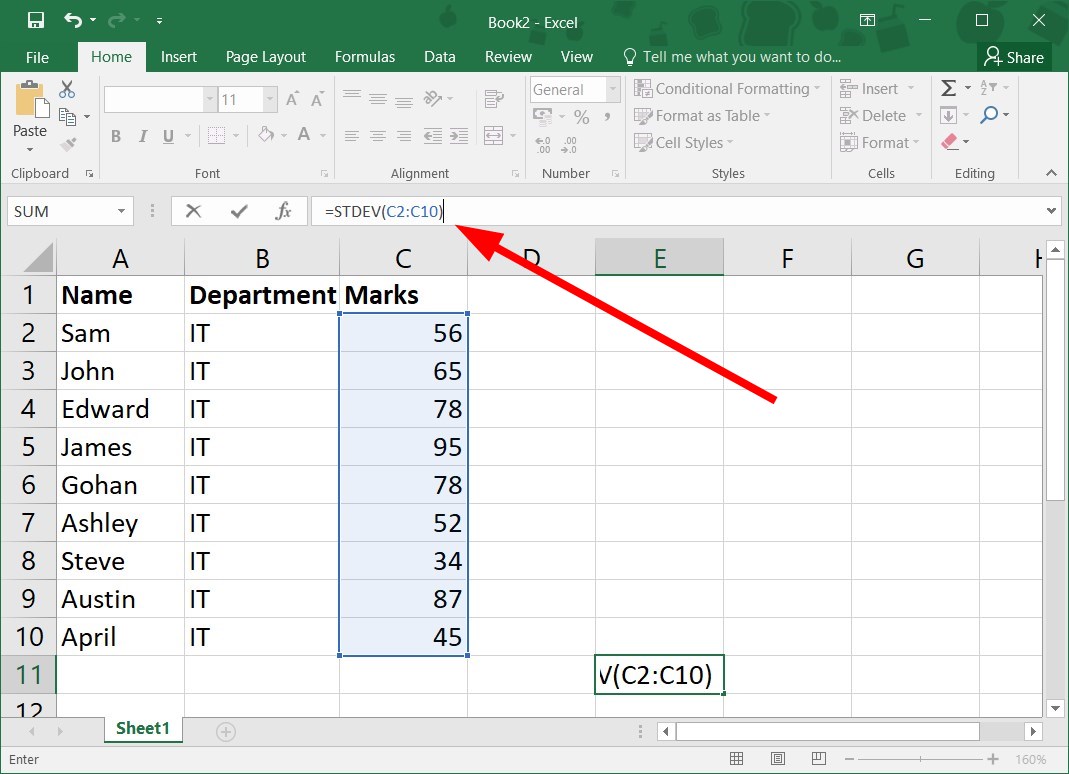
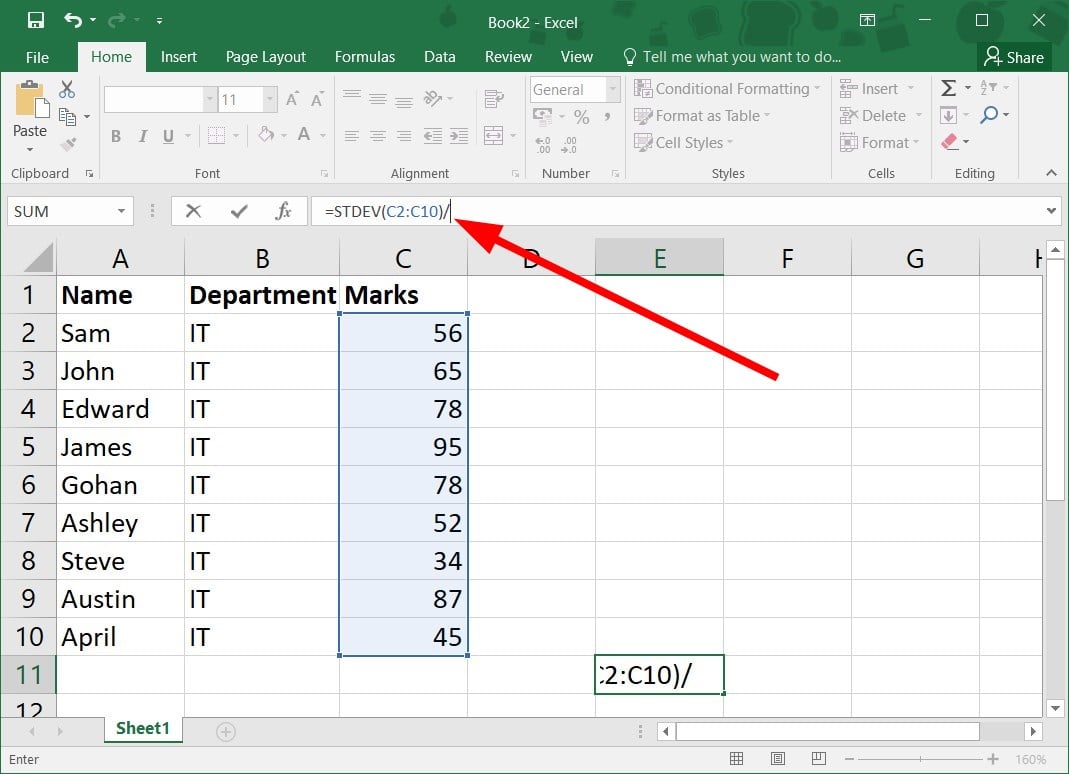
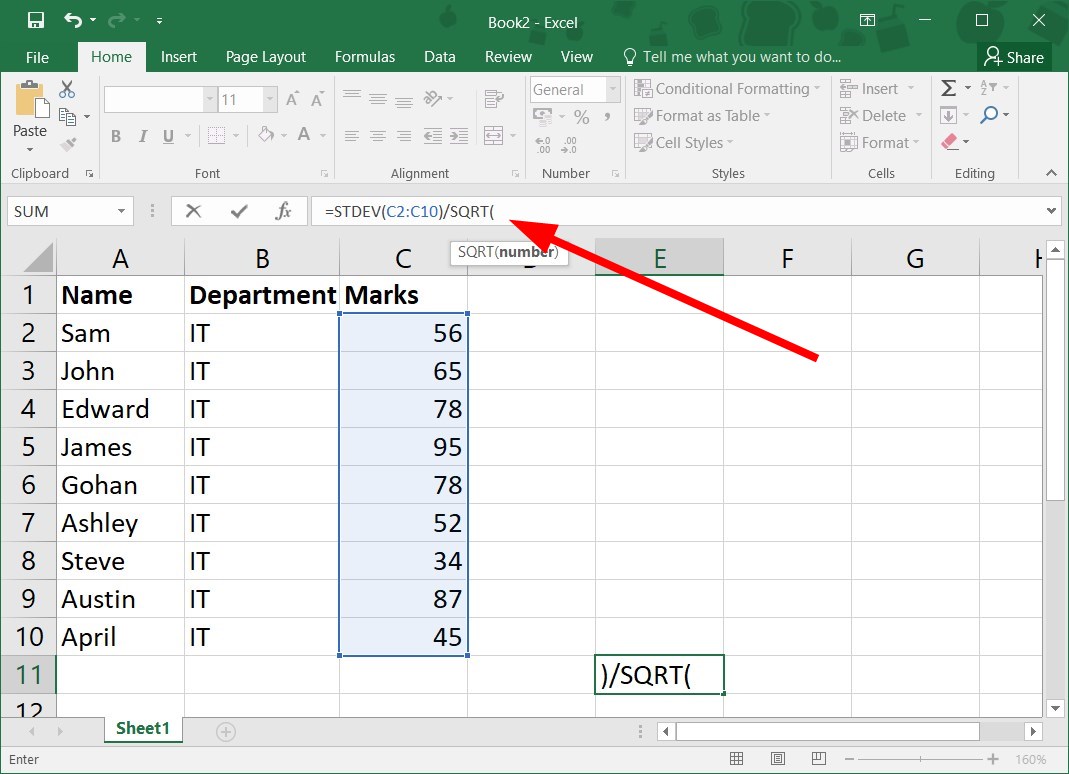
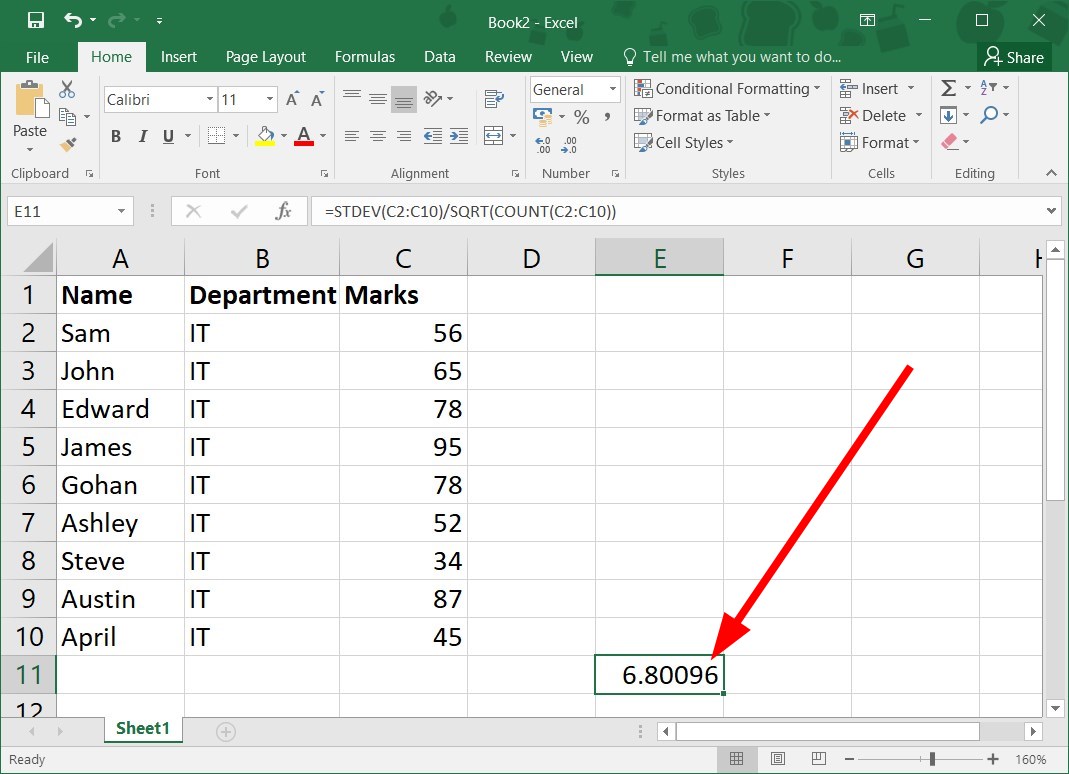
This is the quickest way to calculate standard error in Excel formula, so make sure you try it.
- Fix: Keyboard Shortcuts are Not Working in Excel
- Excel Keeps Crashing: 5 Simple Ways to Fix
2. Use Data Analysis ToolPak
- Open your workbook.
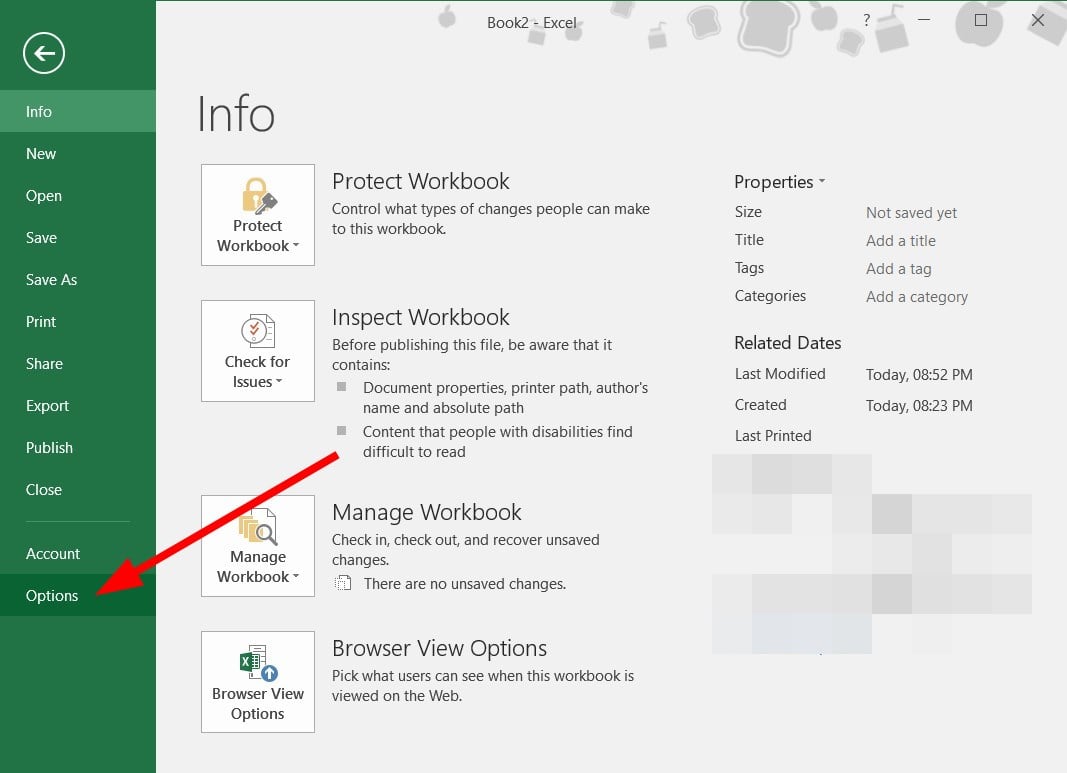
- Click on File and select Options from the left side pane.

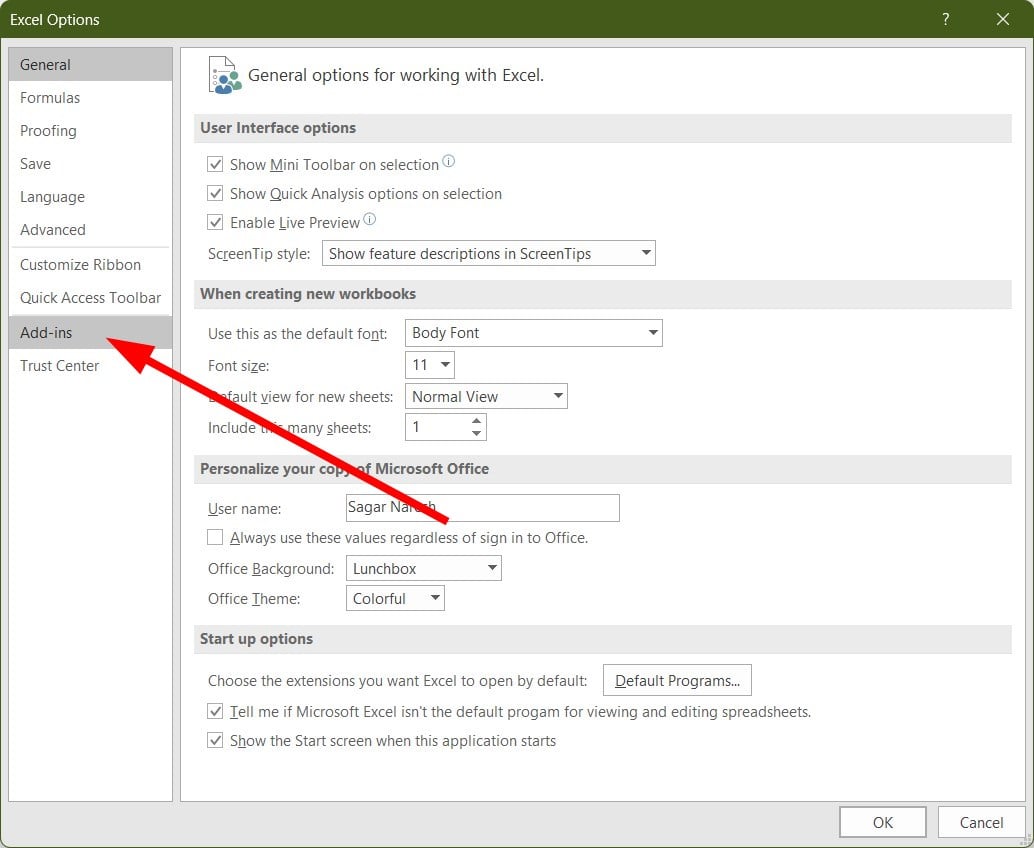
- Select Add-ins in the Options window.

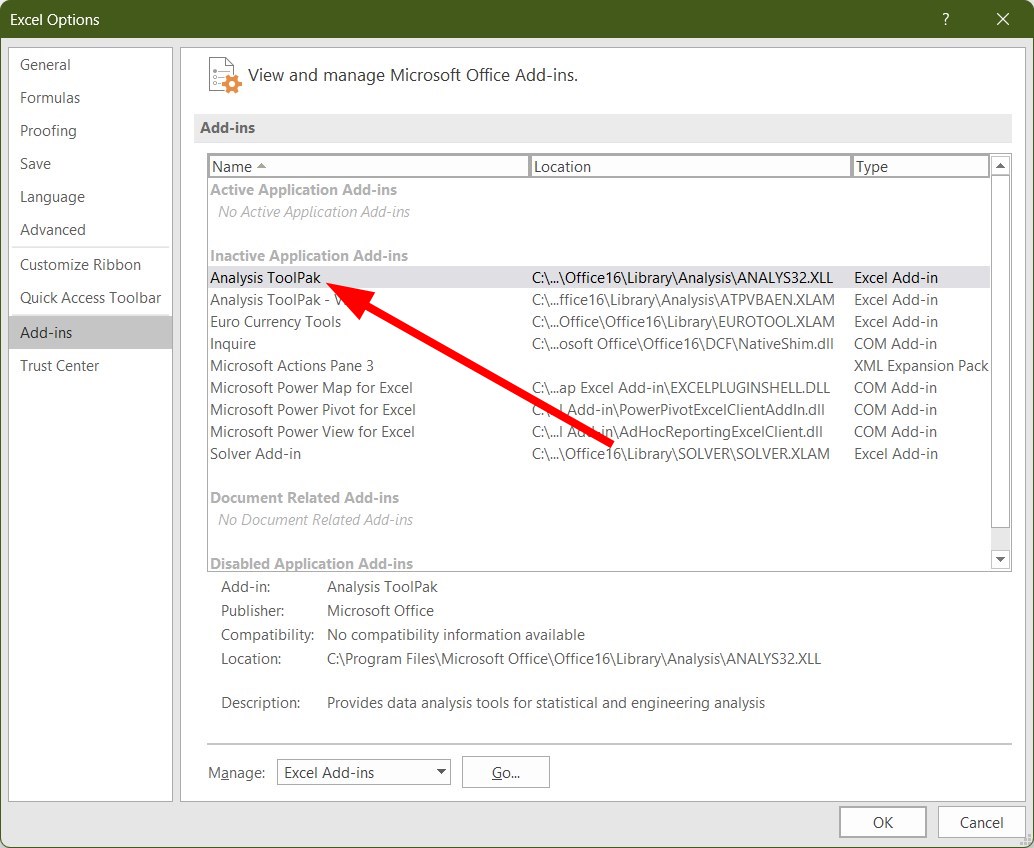
- Select Analysis ToolPaK.
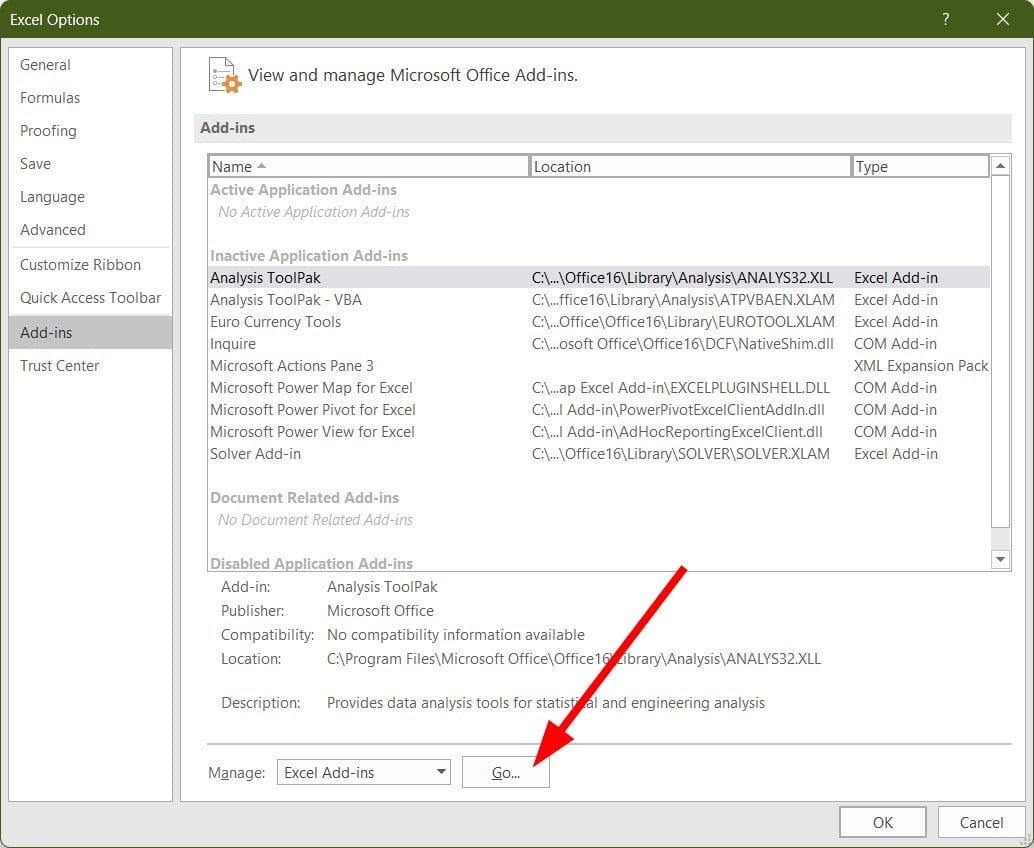
- Click the Go button at the bottom.
- Check the box for Analysis ToolPak and hit OK.

- Click on the Data tab.

- The Data Analysis Toolpak will be added to your Excel toolbar.
- Click on the Data Analysis button.
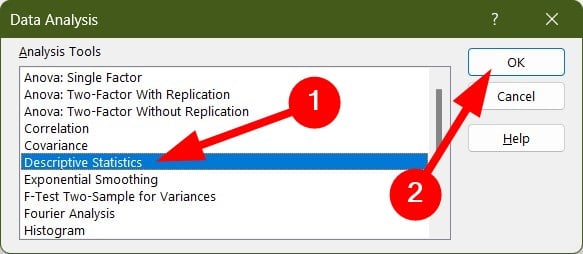
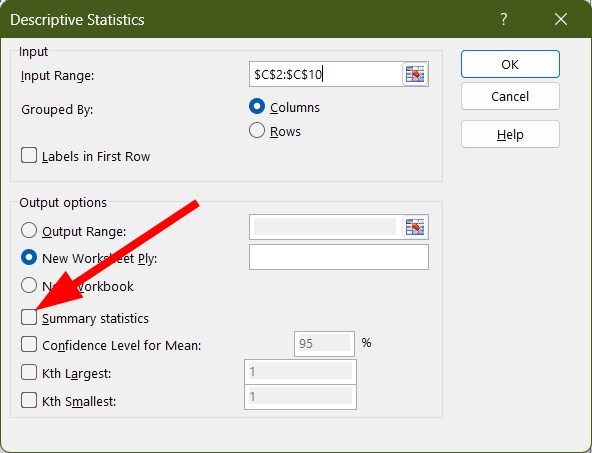
- Select Descriptive Statistics and click OK.

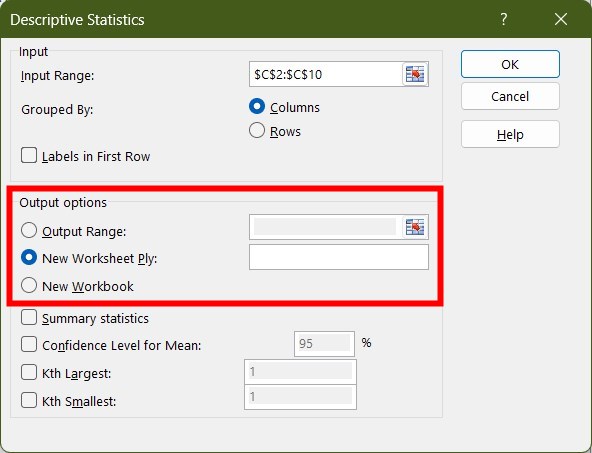
- Select the range of cells from your sample.
- If your data has column headers then choose Labels in first row option.
- Under Output options, select New Worksheet to get the result in a new worksheet in the same workbook, or select New Workbook to get the result in a fresh workbook.

- Check the Summary statistics option, then click OK.
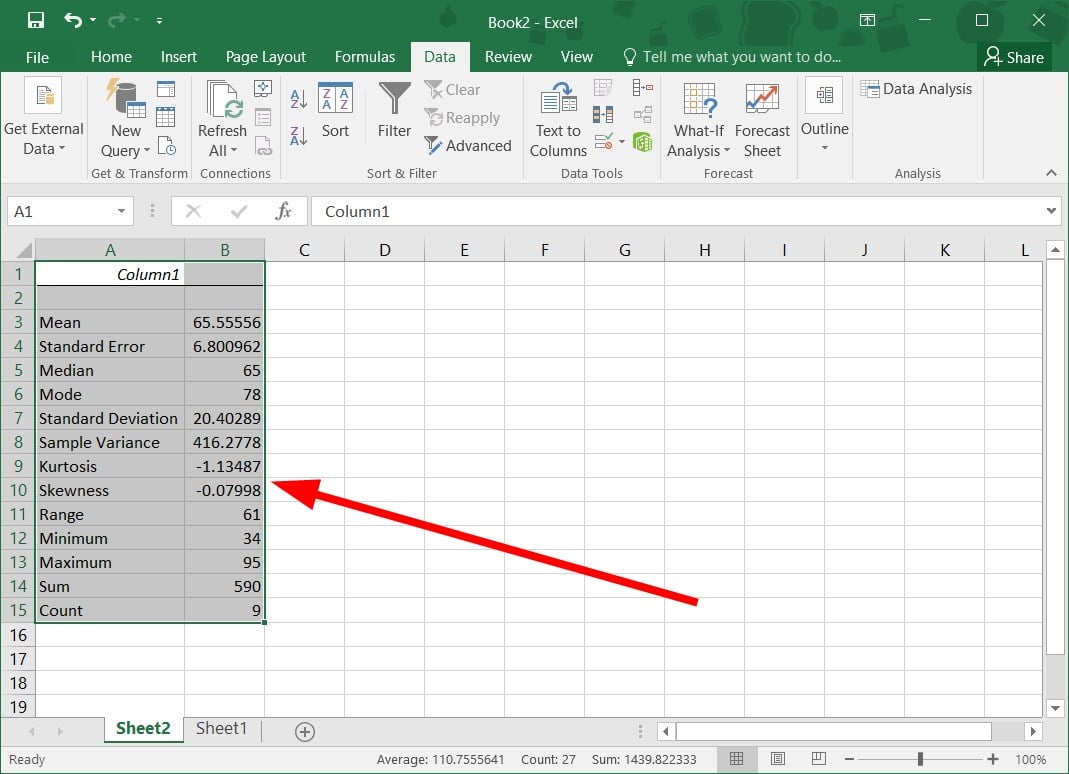
- You will get the result and you will see the Standard Error.



That is it from us in this guide on how you can calculate standard error in MS Excel quickly.
If you are having issues opening or running MS Excel then we would suggest you check out our dedicated guide to resolving it in no time.
You can also refer to our guide, which will help you with how you can fix the problem if the Excel toolbar is missing. We also have a guide that you can check out and learn how you can open multiple Excel files at once.
If you wish to learn how you can import data from PDF to MS Excel then you can check out our dedicated guide on it. For users having trouble inserting cells in MS Excel, they can check out our guide, which lists some of the most effective solutions to resolve the problem.
Let us know in the comments below which one of the above two solutions you use to calculate standard error in Excel.
![]()
Представление результатов исследования
В научных публикациях важно представление результатов исследования. Очень часто окончательный результат приводится в следующем виде: M±m, где M – среднее арифметическое, m –ошибка среднего арифметического. Например, 163,7±0,9 см.
Прежде чем разбираться в правилах представления результатов исследования, давайте точно усвоим, что же такое ошибка среднего арифметического.
Ошибка среднего арифметического
Среднее арифметическое, вычисленное на основе выборочных данных (выборочное среднее), как правило, не совпадает с генеральным средним (средним арифметическим генеральной совокупности). Экспериментально проверить это утверждение невозможно, потому что нам неизвестно генеральное среднее. Но если из одной и той же генеральной совокупности брать повторные выборки и вычислять среднее арифметическое, то окажется, что для разных выборок среднее арифметическое будет разным.
Чтобы оценить, насколько выборочное среднее арифметическое отличается от генерального среднего, вычисляется ошибка среднего арифметического или ошибка репрезентативности.
Ошибка среднего арифметического обозначается как m или ![]()
Ошибка среднего арифметического рассчитывается по формуле:

где: S — стандартное отклонение, n – объем выборки; Например, если стандартное отклонение равно S=5 см, объем выборки n=36 человек, то ошибка среднего арифметического равна: m=5/6 = 0,833.
Ошибка среднего арифметического показывает, какая ошибка в среднем допускается, если использовать вместо генерального среднего выборочное среднее.
Так как при небольшом объеме выборки истинное значение генерального среднего не может быть определено сколь угодно точно, поэтому при вычислении выборочного среднего арифметического нет смысла оставлять большое число значащих цифр.
Правила записи результатов исследования
- В записи ошибки среднего арифметического оставляем две значащие цифры, если первые цифры в ошибке «1» или «2».
- В остальных случаях в записи ошибки среднего арифметического оставляем одну значащую цифру.
- В записи среднего арифметического положение последней значащей цифры должно соответствовать положению первой значащей цифры в записи ошибки среднего арифметического.
Представление результатов научных исследований
В своей статье «Осторожно, статистика!», опубликованной в 1989 году В.М. Зациорский указал, какие числовые характеристики должны быть представлены в публикации, чтобы она имела научную ценность. Он писал, что исследователь «…должен назвать: 1) среднюю величину (или другой так называемый показатель положения); 2) среднее квадратическое отклонение (или другой показатель рассеяния) и 3) число испытуемых. Без них его публикация научной ценности иметь не будет “с. 52
В научных публикациях в области физической культуры и спорта очень часто окончательный результат приводится в виде: (М±m) (табл.1).
Таблица 1 — Изменение механических свойств латеральной широкой мышцы бедра под воздействием физической нагрузки (n=34)
| Эффективный модуль
упругости (Е), кПа |
Эффективный модуль
вязкости (V), Па с |
|||
| Этап
эксперимента |
Рассл. | Напряж. | Рассл. | Напряж. |
| До ФН | 7,0±0,3 | 17,1±1,4 | 29,7±1,7 | 46±4 |
| После ФН | 7,7±0,3 | 18,7±1,4 | 30,9±2,0 | 53±6 |
Литература
- Высшая математика и математическая статистика: учебное пособие для вузов / Под общ. ред. Г. И. Попова. – М. Физическая культура, 2007.– 368 с.
- Гласс Дж., Стэнли Дж. Статистические методы в педагогике и психологии. М.: Прогресс. 1976.- 495 с.
- Зациорский В.М. Осторожно — статистика! // Теория и практика физической культуры, 1989.- №2.
- Катранов А.Г. Компьютерная обработка данных экспериментальных исследований: Учебное пособие/ А. Г. Катранов, А. В. Самсонова; СПб ГУФК им. П.Ф. Лесгафта. – СПб.: изд-во СПб ГУФК им. П.Ф. Лесгафта, 2005. – 131 с.
- Основы математической статистики: Учебное пособие для ин-тов физ. культ / Под ред. В.С. Иванова.– М.: Физкультура и спорт, 1990. 176 с.
Среднее арифметическое, как известно, используется для получения обобщающей характеристики некоторого набора данных. Если данные более-менее однородны и в них нет аномальных наблюдений (выбросов), то среднее хорошо обобщает данные, сведя к минимуму влияние случайных факторов (они взаимопогашаются при сложении).
Когда анализируемые данные представляют собой выборку (которая состоит из случайных значений), то среднее арифметическое часто (но не всегда) выступает в роли приближенной оценки математического ожидания. Почему приближенной? Потому что среднее арифметическое – это величина, которая зависит от набора случайных чисел, и, следовательно, сама является случайной величиной. При повторных экспериментах (даже в одних и тех же условиях) средние будут отличаться друг от друга.
Для того, чтобы на основе статистического анализа данных делать корректные выводы, необходимо оценить возможный разброс полученного результата. Для этого рассчитываются различные показатели вариации. Но то исходные данные. И как мы только что установили, среднее арифметическое также обладает разбросом, который необходимо оценить и учитывать в дальнейшем (в выводах, в выборе метода анализа и т.д.).
Интуитивно понятно, что разброс средней должен быть как-то связан с разбросом исходных данных. Основной характеристикой разброса средней выступает та же дисперсия.
Дисперсия выборочных данных – это средний квадрат отклонения от средней, и рассчитать ее по исходным данным не составляет труда, например, в Excel предусмотрены специальные функции. Однако, как же рассчитать дисперсию средней, если в распоряжении есть только одна выборка и одно среднее арифметическое?
Расчет дисперсии и стандартной ошибки средней арифметической
Чтобы получить дисперсию средней арифметической нет необходимости проводить множество экспериментов, достаточно иметь только одну выборку. Это легко доказать. Для начала вспомним, что средняя арифметическая (простая) рассчитывается по формуле:
![]()
где xi – значения переменной,
n – количество значений.
Теперь учтем два свойства дисперсии, согласно которым, 1) — постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат и 2) — дисперсия суммы независимых случайных величин равняется сумме соответствующих дисперсий. Предполагается, что каждое случайное значение xi обладает одинаковым разбросом, поэтому несложно вывести формулу дисперсии средней арифметической:
![]()
Используя более привычные обозначения, формулу записывают как:
![]()
где σ2 – это дисперсия, случайной величины, причем генеральная.
На практике же, генеральная дисперсия известна далеко не всегда, точнее совсем редко, поэтому в качестве оной используют выборочную дисперсию:
![]()
Стандартное отклонение средней арифметической называется стандартной ошибкой средней и рассчитывается, как квадратный корень из дисперсии.
Формула стандартной ошибки средней при использовании генеральной дисперсии
![]()
Формула стандартной ошибки средней при использовании выборочной дисперсии
![]()
Последняя формула на практике используется чаще всего, т.к. генеральная дисперсия обычно не известна. Чтобы не вводить новые обозначения, стандартную ошибку средней обычно записывают в виде соотношения стандартного отклонения выборки и корня объема выборки.
Назначение и свойство стандартной ошибки средней арифметической
Стандартная ошибка средней много, где используется. И очень полезно понимать ее свойства. Посмотрим еще раз на формулу стандартной ошибки средней:
![]()
Числитель – это стандартное отклонение выборки и здесь все понятно. Чем больше разброс данных, тем больше стандартная ошибка средней – прямо пропорциональная зависимость.
Посмотрим на знаменатель. Здесь находится квадратный корень из объема выборки. Соответственно, чем больше объем выборки, тем меньше стандартная ошибка средней. Для наглядности изобразим на одной диаграмме график нормально распределенной переменной со средней равной 10, сигмой – 3, и второй график – распределение средней арифметической этой же переменной, полученной по 16-ти наблюдениям (которое также будет нормальным).

Судя по формуле, разброс стандартной ошибки средней должен быть в 4 раза (корень из 16) меньше, чем разброс исходных данных, что и видно на рисунке выше. Чем больше наблюдений, тем меньше разброс средней.
Казалось бы, что для получения наиболее точной средней достаточно использовать максимально большую выборку и тогда стандартная ошибка средней будет стремиться к нулю, а сама средняя, соответственно, к математическому ожиданию. Однако квадратный корень объема выборки в знаменателе говорит о том, что связь между точностью выборочной средней и размером выборки не является линейной. Например, увеличение выборки с 20-ти до 50-ти наблюдений, то есть на 30 значений или в 2,5 раза, уменьшает стандартную ошибку средней только на 36%, а со 100-а до 130-ти наблюдений (на те же 30 значений), снижает разброс данных лишь на 12%.
Лучше всего изобразить эту мысль в виде графика зависимости стандартной ошибки средней от размера выборки. Пусть стандартное отклонение равно 10 (на форму графика это не влияет).

Видно, что примерно после 50-ти значений, уменьшение стандартной ошибки средней резко замедляется, после 100-а – наклон постепенно становится почти нулевым.
Таким образом, при достижении некоторого размера выборки ее дальнейшее увеличение уже почти не сказывается на точности средней. Этот факт имеет далеко идущие последствия. Например, при проведении выборочного обследования населения (опроса) чрезмерное увеличение выборки ведет к неоправданным затратам, т.к. точность почти не меняется. Именно поэтому количество опрошенных редко превышает 1,5 тысячи человек. Точность при таком размере выборки часто является достаточной, а дальнейшее увеличение выборки – нецелесообразным.
Подведем итог. Расчет дисперсии и стандартной ошибки средней имеет довольно простую формулу и обладает полезным свойством, связанным с тем, что относительно хорошая точность средней достигается уже при 100 наблюдениях (в этом случае стандартная ошибка средней становится в 10 раз меньше, чем стандартное отклонение выборки). Больше, конечно, лучше, но бесконечно увеличивать объем выборки не имеет практического смысла. Хотя, все зависит от поставленных задач и цены ошибки. В некоторых опросах участие принимают десятки тысяч людей.
Дисперсия и стандартная ошибка средней имеют большое практическое значение. Они используются в проверке гипотез и расчете доверительных интервалов.
Поделиться в социальных сетях: