Whenever we fit a linear regression model, the model takes on the following form:
Y = β0 + β1X + … + βiX +ϵ
where ϵ is an error term that is independent of X.
No matter how well X can be used to predict the values of Y, there will always be some random error in the model.
One way to measure the dispersion of this random error is by using the standard error of the regression model, which is a way to measure the standard deviation of the residuals ϵ.
This tutorial provides a step-by-step example of how to calculate the standard error of a regression model in Excel.
Step 1: Create the Data
For this example, we’ll create a dataset that contains the following variables for 12 different students:
- Exam Score
- Hours Spent Studying
- Current Grade

Step 2: Fit the Regression Model
Next, we’ll fit a multiple linear regression model using Exam Score as the response variable and Study Hours and Current Grade as the predictor variables.
To do so, click the Data tab along the top ribbon and then click Data Analysis:

If you don’t see this option available, you need to first load the Data Analysis ToolPak.
In the window that pops up, select Regression. In the new window that appears, fill in the following information:

Once you click OK, the output of the regression model will appear:

Step 3: Interpret the Standard Error of Regression
The standard error of the regression model is the number next to Standard Error:

The standard error of this particular regression model turns out to be 2.790029.
This number represents the average distance between the actual exam scores and the exam scores predicted by the model.
Note that some of the exam scores will be further than 2.79 units away from the predicted score while some will be closer. But, on average, the distance between the actual exam scores and the predicted scores is 2.790029.
Also note that a smaller standard error of regression indicates that a regression model fits a dataset more closely.
Thus, if we fit a new regression model to the dataset and ended up with a standard error of, say, 4.53, this new model would be worse at predicting exam scores than the previous model.
Additional Resources
Another common way to measure the precision of a regression model is to use R-squared. Check out this article for a nice explanation of the benefits of using the standard error of the regression to measure precision compared to R-squared.
Регрессия позволяет прогнозировать зависимую переменную на основании значений фактора. В
MS
EXCEL
имеется множество функций, которые возвращают не только наклон и сдвиг линии регрессии, характеризующей линейную взаимосвязь между факторами, но и регрессионную статистику. Здесь рассмотрим простую линейную регрессию, т.е. прогнозирование на основе одного фактора.
Disclaimer
: Данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Эта статья – о применении MS EXCEL для целей
Регрессионного анализа.
Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения
Регрессии
– плохая идея.
Статья про
Регрессионный анализ
получилась большая, поэтому ниже для удобства приведены ее разделы:
- Немного теории и основные понятия
- Предположения линейной регрессионной модели
- Задачи регрессионного анализа
- Оценка неизвестных параметров линейной модели (используя функции MS EXCEL)
- Оценка неизвестных параметров линейной модели (через статистики выборок)
- Оценка неизвестных параметров линейной модели (матричная форма)
- Построение линии регрессии
- Коэффициент детерминации
- Стандартная ошибка регрессии
- Стандартные ошибки и доверительные интервалы для наклона и сдвига
- Проверка значимости взаимосвязи переменных
- Доверительные интервалы для нового наблюдения Y и среднего значения
- Проверка адекватности линейной регрессионной модели
Примечание
: Если прогнозирование переменной осуществляется на основе нескольких факторов, то имеет место
множественная регрессия
.
Чтобы разобраться, чем может помочь MS EXCEL при проведении регрессионного анализа, напомним вкратце теорию, введем термины и обозначения, которые могут отличаться в зависимости от различных источников.
Примечание
: Для тех, кому некогда, незачем или просто не хочется разбираться в теоретических выкладках предлагается сразу перейти к вычислительной части —
оценке неизвестных параметров линейной модели
.
Немного теории и основные понятия
Пусть у нас есть массив данных, представляющий собой значения двух переменных Х и Y. Причем значения переменной Х мы можем произвольно задавать (контролировать) и использовать эту переменную для предсказания значений зависимой переменной Y. Таким образом, случайной величиной является только переменная Y.
Примером такой задачи может быть производственный процесс изготовления некого волокна, причем
прочность этого волокна
(Y) зависит только от
рабочей температуры процесса
в реакторе (Х), которая задается оператором.
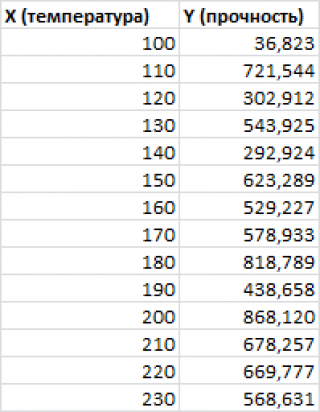
Построим
диаграмму рассеяния
(см.
файл примера лист Линейный
), созданию которой
посвящена отдельная статья
. Вообще, построение
диаграммы рассеяния
для целей
регрессионного анализа
де-факто является стандартом.
СОВЕТ
: Подробнее о построении различных типов диаграмм см. статьи
Основы построения диаграмм
и
Основные типы диаграмм
.
Приведенная выше
диаграмма рассеяния
свидетельствует о возможной
линейной взаимосвязи
между Y от Х: очевидно, что точки данных в основном располагаются вдоль прямой линии.
Примечание
: Наличие даже такой очевидной
линейной взаимосвязи
не может являться доказательством о наличии причинной взаимосвязи переменных. Наличие
причинной
взаимосвязи не может быть доказано на основании только анализа имеющихся измерений, а должно быть обосновано с помощью других исследований, например теоретических выкладок.
Примечание
: Как известно, уравнение прямой линии имеет вид
Y
=
m
*
X
+
k
, где коэффициент
m
отвечает за наклон линии (
slope
),
k
– за сдвиг линии по вертикали (
intercept
),
k
равно значению Y при Х=0.
Предположим, что мы можем зафиксировать переменную Х (
рабочую температуру процесса
) при некотором значении Х
i
и произвести несколько наблюдений переменной Y (
прочность нити
). Очевидно, что при одном и том же значении Хi мы получим различные значения Y. Это обусловлено влиянием других факторов на Y. Например, локальные колебания давления в реакторе, концентрации раствора, наличие ошибок измерения и др. Предполагается, что воздействие этих факторов имеет случайную природу и для каждого измерения имеются одинаковые условия проведения эксперимента (т.е. другие факторы не изменяются).
Полученные значения Y, при заданном Хi, будут колебаться вокруг некого
значения
. При увеличении количества измерений, среднее этих измерений, будет стремиться к
математическому ожиданию
случайной величины Y (при Х
i
) равному μy(i)=Е(Y
i
).
Подобные рассуждения можно привести для любого значения Хi.
Чтобы двинуться дальше, воспользуемся материалом из раздела
Проверка статистических гипотез
. В статье о
проверке гипотезы о среднем значении генеральной совокупности
в качестве
нулевой
гипотезы
предполагалось равенство неизвестного значения μ заданному μ0.
В нашем случае
простой линейной регрессии
в качестве
нулевой
гипотезы
предположим, что между переменными μy(i) и Хi существует линейная взаимосвязь μ
y(i)
=α* Х
i
+β. Уравнение μ
y(i)
=α* Х
i
+β можно переписать в обобщенном виде (для всех Х и μ
y
) как μ
y
=α* Х +β.
Для наглядности проведем прямую линию соединяющую все μy(i).
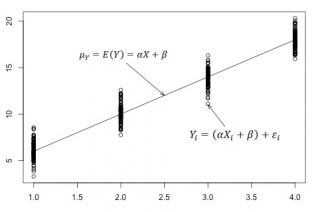
Данная линия называется
регрессионной линией генеральной совокупности
(population regression line), параметры которой (
наклон
a и
сдвиг β
) нам не известны (по аналогии с
гипотезой о среднем значении генеральной совокупности
, где нам было неизвестно истинное значение μ).
Теперь сделаем переход от нашего предположения, что μy=a* Х +
β
, к предсказанию значения случайной переменной Y в зависимости от значения контролируемой переменной Х. Для этого уравнение связи двух переменных запишем в виде Y=a*X+β+ε, где ε — случайная ошибка, которая отражает суммарный эффект влияния других факторов на Y (эти «другие» факторы не участвуют в нашей модели). Напомним, что т.к. переменная Х фиксирована, то ошибка ε определяется только свойствами переменной Y.
Уравнение Y=a*X+b+ε называют
линейной регрессионной моделью
. Часто Х еще называют
независимой переменной
(еще
предиктором
и
регрессором
, английский термин
predictor
,
regressor
), а Y –
зависимой
(или
объясняемой
,
response
variable
). Так как
регрессор
у нас один, то такая модель называется
простой линейной регрессионной моделью
(
simple
linear
regression
model
). α часто называют
коэффициентом регрессии.
Предположения линейной регрессионной модели перечислены в следующем разделе.
Предположения линейной регрессионной модели
Чтобы модель линейной регрессии Yi=a*Xi+β+ε
i
была адекватной — требуется:
-
Ошибки ε
i
должны быть независимыми переменными; -
При каждом значении Xi ошибки ε
i
должны быть иметь нормальное распределение (также предполагается равенство нулю математического ожидания, т.е. Е[ε
i
]=0); -
При каждом значении Xi ошибки ε
i
должны иметь равные дисперсии (обозначим ее σ
2
).
Примечание
: Последнее условие называется
гомоскедастичность
— стабильность, гомогенность дисперсии случайной ошибки e. Т.е.
дисперсия
ошибки σ
2
не должна зависеть от значения Xi.
Используя предположение о равенстве математического ожидания Е[ε
i
]=0 покажем, что μy(i)=Е[Yi]:
Е[Yi]= Е[a*Xi+β+ε
i
]= Е[a*Xi+β]+ Е[ε
i
]= a*Xi+β= μy(i), т.к. a, Xi и β постоянные значения.
Дисперсия
случайной переменной Y равна
дисперсии
ошибки ε, т.е. VAR(Y)= VAR(ε)=σ
2
. Это является следствием, что все значения переменной Х являются const, а VAR(ε)=VAR(ε
i
).
Задачи регрессионного анализа
Для проверки гипотезы о линейной взаимосвязи переменной Y от X делают выборку из генеральной совокупности (этой совокупности соответствует
регрессионная линия генеральной совокупности
, т.е. μy=a* Х +β). Выборка будет состоять из n точек, т.е. из n пар значений {X;Y}.
На основании этой выборки мы можем вычислить оценки наклона a и сдвига β, которые обозначим соответственно
a
и
b
. Также часто используются обозначения â и b̂.
Далее, используя эти оценки, мы также можем проверить гипотезу: имеется ли линейная связь между X и Y статистически значимой?
Таким образом:
Первая задача
регрессионного анализа
– оценка неизвестных параметров (
estimation
of
the
unknown
parameters
). Подробнее см. раздел
Оценки неизвестных параметров модели
.
Вторая задача
регрессионного анализа
–
Проверка адекватности модели
(
model
adequacy
checking
).
Примечание
: Оценки параметров модели обычно вычисляются
методом наименьших квадратов
(МНК),
которому посвящена отдельная статья
.
Оценка неизвестных параметров линейной модели (используя функции MS EXCEL)
Неизвестные параметры
простой линейной регрессионной модели
Y=a*X+β+ε оценим с помощью
метода наименьших квадратов
(в
статье про МНК подробно описано этот метод
).
Для вычисления параметров линейной модели методом МНК получены следующие выражения:
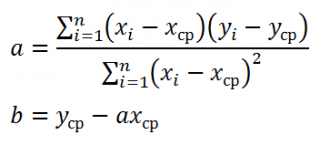
Таким образом, мы получим уравнение прямой линии Y=
a
*X+
b
, которая наилучшим образом аппроксимирует имеющиеся данные.
Примечание
: В статье про
метод наименьших квадратов
рассмотрены случаи аппроксимации
линейной
и
квадратичной функцией
, а также
степенной
,
логарифмической
и
экспоненциальной функцией
.
Оценку параметров в MS EXCEL можно выполнить различными способами:
-
с помощью функций
НАКЛОН()
и
ОТРЕЗОК()
; -
с помощью функции
ЛИНЕЙН()
; см. статьюФункция MS EXCEL ЛИНЕЙН()
-
формулами через статистики выборок
;
-
в матричной форме
;
-
с помощью
инструмента Регрессия надстройки Пакет Анализа
.
Сначала рассмотрим функции
НАКЛОН()
,
ОТРЕЗОК()
и
ЛИНЕЙН()
.
Пусть значения Х и Y находятся соответственно в диапазонах
C
23:
C
83
и
B
23:
B
83
(см.
файл примера
внизу статьи).
Примечание
: Значения двух переменных Х и Y можно сгенерировать, задав тренд и величину случайного разброса (см. статью
Генерация данных для линейной регрессии в MS EXCEL
).
В MS EXCEL наклон прямой линии
а
(
оценку
коэффициента регрессии
), можно найти по
методу МНК
с помощью функции
НАКЛОН()
, а сдвиг
b
(
оценку
постоянного члена
или
константы регрессии
), с помощью функции
ОТРЕЗОК()
. В английской версии это функции SLOPE и INTERCEPT соответственно.
Аналогичный результат можно получить с помощью функции
ЛИНЕЙН()
, английская версия LINEST (см.
статью об этой функции
).
Формула
=ЛИНЕЙН(C23:C83;B23:B83)
вернет наклон
а
. А формула =
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);2)
— сдвиг
b
. Здесь требуются пояснения.
Функция
ЛИНЕЙН()
имеет 4 аргумента и возвращает целый массив значений:
ЛИНЕЙН(известные_значения_y; [известные_значения_x]; [конст]; [статистика])
Если 4-й аргумент
статистика
имеет значение ЛОЖЬ или опущен, то функция
ЛИНЕЙН()
возвращает только оценки параметров модели:
a
и
b
.
Примечание
: Остальные значения, возвращаемые функцией
ЛИНЕЙН()
, нам потребуются при вычислении
стандартных ошибок
и для
проверки значимости регрессии
. В этом случае аргумент
статистика
должен иметь значение ИСТИНА.
Чтобы вывести сразу обе оценки:
- в одной строке необходимо выделить 2 ячейки,
-
ввести формулу в
Строке формул
-
нажать
CTRL
+
SHIFT
+
ENTER
(см. статью проформулы массива
).
Если в
Строке формул
выделить формулу =
ЛИНЕЙН(C23:C83;B23:B83)
и нажать
клавишу F9
, то мы увидим что-то типа {3,01279389265416;154,240057900613}. Это как раз значения
a
и
b
. Как видно, оба значения разделены точкой с запятой «;», что свидетельствует, что функция вернула значения «в нескольких ячейках одной строки».
Если требуется вывести параметры линии не в одной строке, а одном столбце (ячейки друг под другом), то используйте формулу =
ТРАНСП(ЛИНЕЙН(C23:C83;B23:B83))
. При этом выделять нужно 2 ячейки в одном столбце. Если теперь выделить новую формулу и нажать клавишу F9, то мы увидим что 2 значения разделены двоеточием «:», что означает, что значения выведены в столбец (функция
ТРАНСП()
транспонировала строку в столбец
).
Чтобы разобраться в этом подробнее необходимо ознакомиться с
формулами массива
.
Чтобы не связываться с вводом
формул массива
, можно
использовать функцию ИНДЕКС()
. Формула =
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);1)
или просто
ЛИНЕЙН(C23:C83;B23:B83)
вернет параметр, отвечающий за наклон линии, т.е.
а
. Формула
=ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);2)
вернет параметр
b
.
Оценка неизвестных параметров линейной модели (через статистики выборок)
Наклон линии, т.е. коэффициент
а
, можно также вычислить через
коэффициент корреляции
и
стандартные отклонения выборок
:
=
КОРРЕЛ(B23:B83;C23:C83) *(СТАНДОТКЛОН.В(C23:C83)/ СТАНДОТКЛОН.В(B23:B83))
Вышеуказанная формула математически эквивалентна отношению
ковариации
выборок Х и Y и
дисперсии
выборки Х:
=
КОВАРИАЦИЯ.В(B23:B83;C23:C83)/ДИСП.В(B23:B83)
И, наконец, запишем еще одну формулу для нахождения сдвига
b
. Воспользуемся тем фактом, что
линия регрессии
проходит через точку
средних значений
переменных Х и Y.
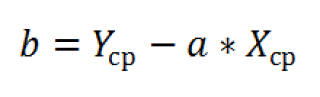
Вычислив
средние значения
и подставив в формулу ранее найденный наклон
а
, получим сдвиг
b
.
Оценка неизвестных параметров линейной модели (матричная форма)
Также параметры
линии регрессии
можно найти в матричной форме (см.
файл примера лист Матричная форма
).
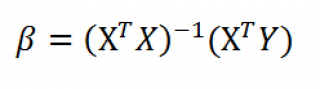
В формуле символом β обозначен столбец с искомыми параметрами модели: β0 (сдвиг
b
), β1 (наклон
a
).
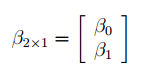
Матрица Х равна:
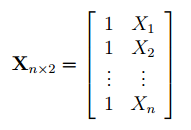
Матрица
Х
называется
регрессионной матрицей
или
матрицей плана
. Она состоит из 2-х столбцов и n строк, где n – количество точек данных. Первый столбец — столбец единиц, второй – значения переменной Х.
Матрица
Х
T
– это
транспонированная матрица
Х
. Она состоит соответственно из n столбцов и 2-х строк.
В формуле символом
Y
обозначен столбец значений переменной Y.
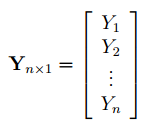
Чтобы
перемножить матрицы
используйте функцию
МУМНОЖ()
. Чтобы
найти обратную матрицу
используйте функцию
МОБР()
.
Пусть дан массив значений переменных Х и Y (n=10, т.е.10 точек).
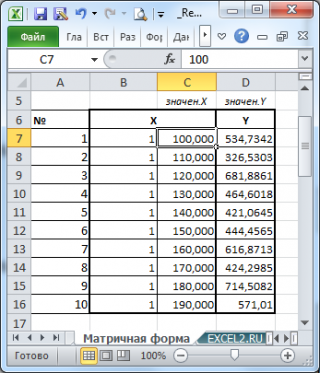
Слева от него достроим столбец с 1 для матрицы Х.
Записав формулу
=
МУМНОЖ(МОБР(МУМНОЖ(ТРАНСП(B7:C16);(B7:C16))); МУМНОЖ(ТРАНСП(B7:C16);(D7:D16)))
и введя ее как
формулу массива
в 2 ячейки, получим оценку параметров модели.
Красота применения матричной формы полностью раскрывается в случае
множественной регрессии
.
Построение линии регрессии
Для отображения
линии регрессии
построим сначала
диаграмму рассеяния
, на которой отобразим все точки (см.
начало статьи
).
Для построения прямой линии используйте вычисленные выше оценки параметров модели
a
и
b
(т.е. вычислите
у
по формуле
y
=
a
*
x
+
b
) или функцию
ТЕНДЕНЦИЯ()
.
Формула =
ТЕНДЕНЦИЯ($C$23:$C$83;$B$23:$B$83;B23)
возвращает расчетные (прогнозные) значения ŷi для заданного значения Хi из столбца
В2
.
Примечание
:
Линию регрессии
можно также построить с помощью функции
ПРЕДСКАЗ()
. Эта функция возвращает прогнозные значения ŷi, но, в отличие от функции
ТЕНДЕНЦИЯ()
работает только в случае одного регрессора. Функция
ТЕНДЕНЦИЯ()
может быть использована и в случае
множественной регрессии
(в этом случае 3-й аргумент функции должен быть ссылкой на диапазон, содержащий все значения Хi для выбранного наблюдения i).
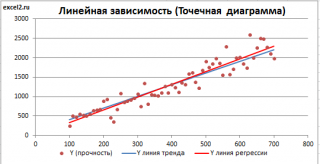
Как видно из диаграммы выше
линия тренда
и
линия регрессии
не обязательно совпадают: отклонения точек от
линии тренда
случайны, а МНК лишь подбирает линию наиболее точно аппроксимирующую случайные точки данных.
Линию регрессии
можно построить и с помощью встроенных средств диаграммы, т.е. с помощью инструмента
Линия тренда.
Для этого выделите диаграмму, в меню выберите
вкладку Макет
, в
группе Анализ
нажмите
Линия тренда
, затем
Линейное приближение.
В диалоговом окне установите галочку
Показывать уравнение на диаграмме
(подробнее см. в
статье про МНК
).
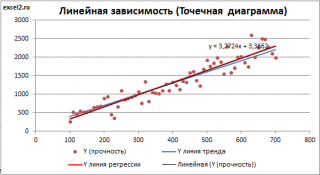
Построенная таким образом линия, разумеется, должна совпасть с ранее построенной нами
линией регрессии,
а параметры уравнения
a
и
b
должны совпасть с параметрами уравнения отображенными на диаграмме.
Примечание:
Для того, чтобы вычисленные параметры уравнения
a
и
b
совпадали с параметрами уравнения на диаграмме, необходимо, чтобы тип у диаграммы был
Точечная, а не График
, т.к. тип диаграммы
График
не использует значения Х, а вместо значений Х используется последовательность 1; 2; 3; … Именно эти значения и берутся при расчете параметров
линии тренда
. Убедиться в этом можно если построить диаграмму
График
(см.
файл примера
), а значения
Хнач
и
Хшаг
установить равным 1. Только в этом случае параметры уравнения на диаграмме совпадут с
a
и
b
.
Коэффициент детерминации R
2
Коэффициент детерминации
R
2
показывает насколько полезна построенная нами
линейная регрессионная модель
.
Предположим, что у нас есть n значений переменной Y и мы хотим предсказать значение yi, но без использования значений переменной Х (т.е. без построения
регрессионной модели
). Очевидно, что лучшей оценкой для yi будет
среднее значение
ȳ. Соответственно, ошибка предсказания будет равна (yi — ȳ).
Примечание
: Далее будет использована терминология и обозначения
дисперсионного анализа
.
После построения
регрессионной модели
для предсказания значения yi мы будем использовать значение ŷi=a*xi+b. Ошибка предсказания теперь будет равна (yi — ŷi).
Теперь с помощью диаграммы сравним ошибки предсказания полученные без построения модели и с помощью модели.
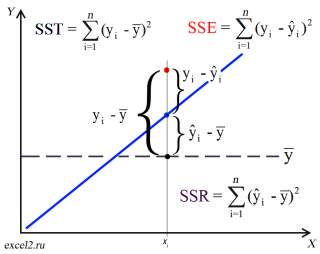
Очевидно, что используя
регрессионную модель
мы уменьшили первоначальную (полную) ошибку (yi — ȳ) на значение (ŷi — ȳ) до величины (yi — ŷi).
(yi — ŷi) – это оставшаяся, необъясненная ошибка.
Очевидно, что все три ошибки связаны выражением:
(yi — ȳ)= (ŷi — ȳ) + (yi — ŷi)
Можно показать, что в общем виде справедливо следующее выражение:
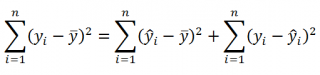
Доказательство:
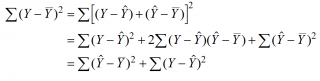
или в других, общепринятых в зарубежной литературе, обозначениях:
SST
=
SSR
+
SSE
Что означает:
Total Sum of Squares
=
Regression Sum of Squares
+
Error Sum of Squares
Примечание
: SS — Sum of Squares — Сумма Квадратов.
Как видно из формулы величины SST, SSR, SSE имеют размерность
дисперсии
(вариации) и соответственно описывают разброс (изменчивость):
Общую изменчивость
(Total variation),
Изменчивость объясненную моделью
(Explained variation) и
Необъясненную изменчивость
(Unexplained variation).
По определению
коэффициент детерминации
R
2
равен:
R
2
=
Изменчивость объясненная моделью / Общая изменчивость.
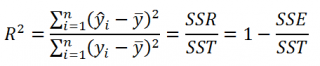
Этот показатель равен квадрату
коэффициента корреляции
и в MS EXCEL его можно вычислить с помощью функции
КВПИРСОН()
или
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3)
R
2
принимает значения от 0 до 1 (1 соответствует идеальной линейной зависимости Y от Х). Однако, на практике малые значения R2 вовсе не обязательно указывают, что переменную Х нельзя использовать для прогнозирования переменной Y. Малые значения R2 могут указывать на нелинейность связи или на то, что поведение переменной Y объясняется не только Х, но и другими факторами.
Стандартная ошибка регрессии
Стандартная ошибка регрессии
(
Standard Error of a regression
) показывает насколько велика ошибка предсказания значений переменной Y на основании значений Х. Отдельные значения Yi мы можем предсказывать лишь с точностью +/- несколько значений (обычно 2-3, в зависимости от формы распределения ошибки ε).
Теперь вспомним уравнение
линейной регрессионной модели
Y=a*X+β+ε. Ошибка ε имеет случайную природу, т.е. является случайной величиной и поэтому имеет свою функцию распределения со
средним значением
μ и
дисперсией
σ
2
.
Оценив значение
дисперсии
σ
2
и вычислив из нее квадратный корень – получим
Стандартную ошибку регрессии.
Чем точки наблюдений на диаграмме
рассеяния
ближе находятся к прямой линии, тем меньше
Стандартная ошибка.
Примечание
:
Вспомним
, что при построении модели предполагается, что
среднее значение
ошибки ε равно 0, т.е. E[ε]=0.
Оценим
дисперсию σ
2
. Помимо вычисления
Стандартной ошибки регрессии
эта оценка нам потребуется в дальнейшем еще и при построении
доверительных интервалов
для оценки параметров регрессии
a
и
b
.
Для оценки
дисперсии
ошибки ε используем
остатки регрессии
— разности между имеющимися значениями
yi
и значениями, предсказанными регрессионной моделью ŷ. Чем лучше регрессионная модель согласуется с данными (точки располагается близко к прямой линии), тем меньше величина остатков.
Для оценки
дисперсии σ
2
используют следующую формулу:
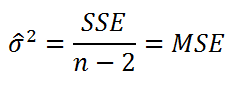
где SSE – сумма квадратов значений ошибок модели ε
i
=yi — ŷi (
Sum of Squared Errors
).
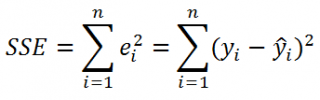
SSE часто обозначают и как SSres – сумма квадратов остатков (
Sum
of
Squared
residuals
).
Оценка
дисперсии
s
2
также имеет общепринятое обозначение MSE (Mean Square of Errors), т.е. среднее квадратов
ошибок
или MSRES (Mean Square of Residuals), т.е. среднее квадратов
остатков
. Хотя правильнее говорить сумме квадратов остатков, т.к. ошибка чаще ассоциируется с ошибкой модели ε, которая является непрерывной случайной величиной. Но, здесь мы будем использовать термины SSE и MSE, предполагая, что речь идет об остатках.
Примечание
: Напомним, что когда
мы использовали МНК
для нахождения параметров модели, то критерием оптимизации была минимизация именно SSE (SSres). Это выражение представляет собой сумму квадратов расстояний между наблюденными значениями yi и предсказанными моделью значениями ŷi, которые лежат на
линии регрессии.
Математическое ожидание
случайной величины MSE равно
дисперсии ошибки
ε, т.е.
σ
2
.
Чтобы понять почему SSE выбрана в качестве основы для оценки
дисперсии
ошибки ε, вспомним, что
σ
2
является также
дисперсией
случайной величины Y (относительно
среднего значения
μy, при заданном значении Хi). А т.к. оценкой μy является значение ŷi =
a
* Хi +
b
(значение
уравнения регрессии
при Х= Хi), то логично использовать именно SSE в качестве основы для оценки
дисперсии
σ
2
. Затем SSE усредняется на количество точек данных n за вычетом числа 2. Величина n-2 – это количество
степеней свободы
(
df
–
degrees
of
freedom
), т.е. число параметров системы, которые могут изменяться независимо (вспомним, что у нас в этом примере есть n независимых наблюдений переменной Y). В случае
простой линейной регрессии
число степеней свободы
равно n-2, т.к. при построении
линии регрессии
было оценено 2 параметра модели (на это было «потрачено» 2
степени свободы
).
Итак, как сказано было выше, квадратный корень из s
2
имеет специальное название
Стандартная ошибка регрессии
(
Standard Error of a regression
) и обозначается SEy. SEy показывает насколько велика ошибка предсказания. Отдельные значения Y мы можем предсказывать с точностью +/- несколько значений SEy (см.
этот раздел
). Если ошибки предсказания ε имеют
нормальное распределение
, то примерно 2/3 всех предсказанных значений будут на расстоянии не больше SEy от
линии регрессии
. SEy имеет размерность переменной Y и откладывается по вертикали. Часто на
диаграмме рассеяния
строят
границы предсказания
соответствующие +/- 2 SEy (т.е. 95% точек данных будут располагаться в пределах этих границ).
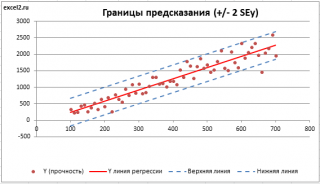
В MS EXCEL
стандартную ошибку
SEy можно вычислить непосредственно по формуле:
=
КОРЕНЬ(СУММКВРАЗН(C23:C83; ТЕНДЕНЦИЯ(C23:C83;B23:B83;B23:B83)) /( СЧЁТ(B23:B83) -2))
или с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3;2)
Примечание
: Подробнее о функции
ЛИНЕЙН()
см.
эту статью
.
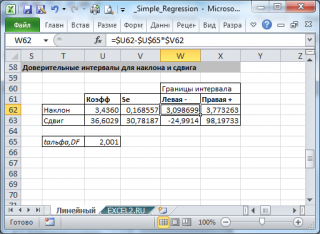
Стандартные ошибки и доверительные интервалы для наклона и сдвига
В разделе
Оценка неизвестных параметров линейной модели
мы получили точечные оценки наклона
а
и сдвига
b
. Так как эти оценки получены на основе случайных величин (значений переменных Х и Y), то эти оценки сами являются случайными величинами и соответственно имеют функцию распределения со
средним значением
и
дисперсией
. Но, чтобы перейти от
точечных оценок
к
интервальным
, необходимо вычислить соответствующие
стандартные ошибки
(т.е.
стандартные отклонения
).
Стандартная ошибка коэффициента регрессии
a
вычисляется на основании
стандартной ошибки регрессии
по следующей формуле:
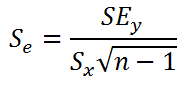
где Sx – стандартное отклонение величины х, вычисляемое по формуле:
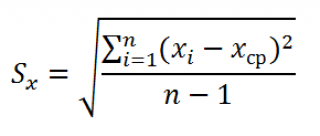
где Sey –
стандартная ошибка регрессии,
т.е. ошибка предсказания значения переменой Y
(
см. выше
).
В MS EXCEL
стандартную ошибку коэффициента регрессии
Se можно вычислить впрямую по вышеуказанной формуле:
=
КОРЕНЬ(СУММКВРАЗН(C23:C83; ТЕНДЕНЦИЯ(C23:C83;B23:B83;B23:B83)) /( СЧЁТ(B23:B83) -2))/ СТАНДОТКЛОН.В(B23:B83) /КОРЕНЬ(СЧЁТ(B23:B83) -1)
или с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);2;1)
Формулы приведены в
файле примера на листе Линейный
в разделе
Регрессионная статистика
.
Примечание
: Подробнее о функции
ЛИНЕЙН()
см.
эту статью
.
При построении
двухстороннего доверительного интервала
для
коэффициента регрессии
его границы определяются следующим образом:
![]()
где —
квантиль распределения Стьюдента
с n-2 степенями свободы. Величина
а
с «крышкой» является другим обозначением
наклона
а
.
Например для
уровня значимости
альфа=0,05, можно вычислить с помощью формулы
=СТЬЮДЕНТ.ОБР.2Х(0,05;n-2)
Вышеуказанная формула следует из того факта, что если ошибки регрессии распределены нормально и независимо, то выборочное распределение случайной величины
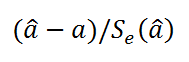
является
t-распределением Стьюдента
с n-2 степенью свободы (то же справедливо и для наклона
b
).
Примечание
: Подробнее о построении
доверительных интервалов
в MS EXCEL можно прочитать в этой статье
Доверительные интервалы в MS EXCEL
.
В результате получим, что найденный
доверительный интервал
с вероятностью 95% (1-0,05) накроет истинное значение
коэффициента регрессии.
Здесь мы считаем, что
коэффициент регрессии
a
имеет
распределение Стьюдента
с n-2
степенями свободы
(n – количество наблюдений, т.е. пар Х и Y).
Примечание
: Подробнее о построении
доверительных интервалов
с использованием t-распределения см. статью про построение
доверительных интервалов
для среднего
.
Стандартная ошибка сдвига
b
вычисляется по следующей формуле:
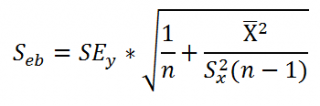
В MS EXCEL
стандартную ошибку сдвига
Seb можно вычислить с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);2;2)
При построении
двухстороннего доверительного интервала
для
сдвига
его границы определяются аналогичным образом как для
наклона
:
b
+/- t*Seb.
Проверка значимости взаимосвязи переменных
Когда мы строим модель Y=αX+β+ε мы предполагаем, что между Y и X существует линейная взаимосвязь. Однако, как это иногда бывает в статистике, можно вычислять параметры связи даже тогда, когда в действительности она не существует, и обусловлена лишь случайностью.
Единственный вариант, когда Y не зависит X (в рамках модели Y=αX+β+ε), возможен, когда
коэффициент регрессии
a
равен 0.
Чтобы убедиться, что вычисленная нами оценка
наклона
прямой линии не обусловлена лишь случайностью (не случайно отлична от 0), используют
проверку гипотез
. В качестве
нулевой гипотезы
Н
0
принимают, что связи нет, т.е. a=0. В качестве альтернативной гипотезы
Н
1
принимают, что a <>0.
Ниже на рисунках показаны 2 ситуации, когда
нулевую гипотезу
Н
0
не удается отвергнуть.
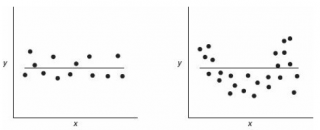
На левой картинке отсутствует любая зависимость между переменными, на правой – связь между ними нелинейная, но при этом
коэффициент линейной корреляции
равен 0.
Ниже — 2 ситуации, когда
нулевая гипотеза
Н
0
отвергается.
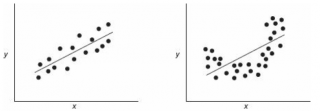
На левой картинке очевидна линейная зависимость, на правой — зависимость нелинейная, но коэффициент корреляции не равен 0 (метод МНК вычисляет показатели наклона и сдвига просто на основании значений выборки).
Для проверки гипотезы нам потребуется:
-
Установить
уровень значимости
, пусть альфа=0,05;
-
Рассчитать с помощью функции
ЛИНЕЙН()
стандартное отклонение
Se для
коэффициента регрессии
(см.предыдущий раздел
);
-
Рассчитать число степеней свободы: DF=n-2 или по формуле =
ИНДЕКС(ЛИНЕЙН(C24:C84;B24:B84;;ИСТИНА);4;2)
-
Вычислить значение тестовой статистики t
0
=a/S
e
, которая имеетраспределение Стьюдента
с
числом степеней свободы
DF=n-2; -
Сравнить значение
тестовой статистики
|t0| с пороговым значением t
альфа
,n-2. Если значение
тестовой статистики
больше порогового значения, то
нулевая гипотеза
отвергается (
наклон
не может быть объяснен лишь случайностью при заданном уровне альфа) либо -
вычислить
p-значение
и сравнить его с
уровнем значимости
.
В
файле примера
приведен пример проверки гипотезы:
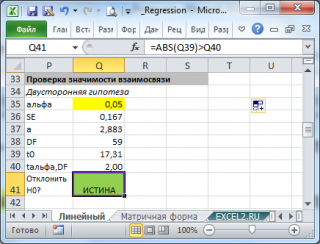
Изменяя
наклон
тренда k (ячейка
В8
) можно убедиться, что при малых углах тренда (например, 0,05) тест часто показывает, что связь между переменными случайна. При больших углах (k>1), тест практически всегда подтверждает значимость линейной связи между переменными.
Примечание
: Проверка значимости взаимосвязи эквивалентна
проверке статистической значимости коэффициента корреляции
. В
файле примера
показана эквивалентность обоих подходов. Также проверку значимости можно провести с помощью
процедуры F-тест
.
Доверительные интервалы для нового наблюдения Y и среднего значения
Вычислив параметры
простой линейной регрессионной модели
Y=aX+β+ε мы получили точечную оценку значения нового наблюдения Y при заданном значении Хi, а именно: Ŷ=
a
* Хi +
b
Ŷ также является точечной оценкой для
среднего значения
Yi при заданном Хi. Но, при построении
доверительных интервалов
используются различные
стандартные ошибки
.
Стандартная ошибка
нового наблюдения Y при заданном Хi учитывает 2 источника неопределенности:
-
неопределенность связанную со случайностью оценок параметров модели
a
и
b
; - случайность ошибки модели ε.
Учет этих неопределенностей приводит к
стандартной ошибке
S(Y|Xi), которая рассчитывается с учетом известного значения Xi.
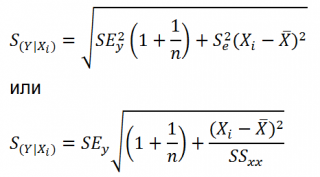
где SS
xx
– сумма квадратов отклонений от
среднего
значений переменной Х:
![]()
Примечание
: Se –
стандартная ошибка коэффициента регрессии
(
наклона
а
).
В
MS EXCEL 2010
нет функции, которая бы рассчитывала эту
стандартную ошибку
, поэтому ее необходимо рассчитывать по вышеуказанным формулам.
Доверительный интервал
или
Интервал предсказания для нового наблюдения
(Prediction Interval for a New Observation) построим по схеме показанной в разделе
Проверка значимости взаимосвязи переменных
(см.
файл примера лист Интервалы
). Т.к. границы интервала зависят от значения Хi (точнее от расстояния Хi до среднего значения Х
ср
), то интервал будет постепенно расширяться при удалении от Х
ср
.
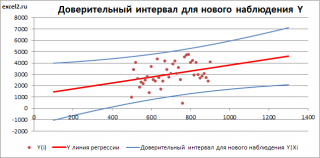
Границы
доверительного интервала
для
нового наблюдения
рассчитываются по формуле:
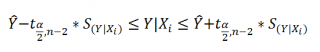
Аналогичным образом построим
доверительный интервал
для
среднего значения
Y при заданном Хi (Confidence Interval for the Mean of Y). В этом случае
доверительный интервал
будет уже, т.к.
средние значения
имеют меньшую изменчивость по сравнению с отдельными наблюдениями (
средние значения,
в рамках нашей линейной модели Y=aX+β+ε, не включают ошибку ε).
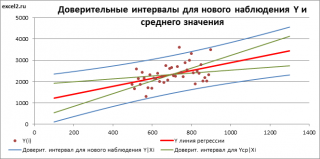
Стандартная ошибка
S(Yср|Xi) вычисляется по практически аналогичным формулам как и
стандартная ошибка
для нового наблюдения:
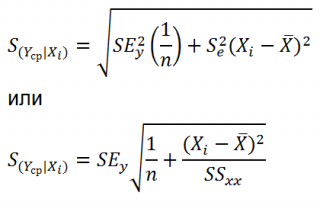
Как видно из формул,
стандартная ошибка
S(Yср|Xi) меньше
стандартной ошибки
S(Y|Xi) для индивидуального значения
.
Границы
доверительного интервала
для
среднего значения
рассчитываются по формуле:
![]()
Проверка адекватности линейной регрессионной модели
Модель адекватна, когда все предположения, лежащие в ее основе, выполнены (см. раздел
Предположения линейной регрессионной модели
).
Проверка адекватности модели в основном основана на исследовании остатков модели (model residuals), т.е. значений ei=yi – ŷi для каждого Хi. В рамках
простой линейной модели
n остатков имеют только n-2 связанных с ними
степеней свободы
. Следовательно, хотя, остатки не являются независимыми величинами, но при достаточно большом n это не оказывает какого-либо влияния на проверку адекватности модели.
Чтобы проверить предположение о
нормальности распределения
ошибок строят
график проверки на нормальность
(Normal probability Plot).
В
файле примера на листе Адекватность
построен
график проверки на нормальность
. В случае
нормального распределения
значения остатков должны быть близки к прямой линии.
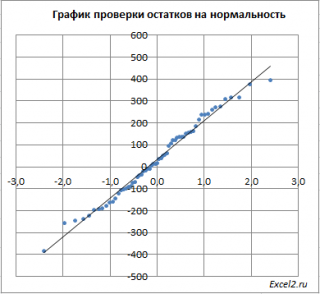
Так как значения переменной Y мы
генерировали с помощью тренда
, вокруг которого значения имели нормальный разброс, то ожидать сюрпризов не приходится – значения остатков располагаются вблизи прямой.
Также при проверке модели на адекватность часто строят график зависимости остатков от предсказанных значений Y. Если точки не демонстрируют характерных, так называемых «паттернов» (шаблонов) типа вор
о
нок или другого неравномерного распределения, в зависимости от значений Y, то у нас нет очевидных доказательств неадекватности модели.
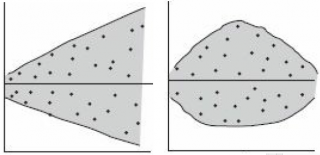
В нашем случае точки располагаются примерно равномерно.
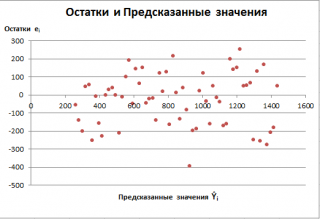
Часто при проверке адекватности модели вместо остатков используют нормированные остатки. Как показано в разделе
Стандартная ошибка регрессии
оценкой
стандартного отклонения ошибок
является величина SEy равная квадратному корню из величины MSE. Поэтому логично нормирование остатков проводить именно на эту величину.
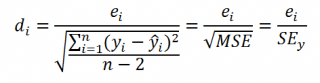
SEy можно вычислить с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3;2)
Иногда нормирование остатков производится на величину
стандартного отклонения
остатков (это мы увидим в статье об инструменте
Регрессия
, доступного в
надстройке MS EXCEL Пакет анализа
), т.е. по формуле:
Вышеуказанное равенство приблизительное, т.к. среднее значение остатков близко, но не обязательно точно равно 0.
C помощью инструмента
анализа данных Регрессия
можно получить
результаты регрессионной статистики,
дисперсионного анализа, доверительных
интервалов, остатки и графики подбора
линии регрессии.
Если в меню сервис
еще нет команды Анализ
данных, то
необходимо сделать следующее. В главном
меню последовательно выбираем
Сервис→Надстройки
и устанавливаем
«флажок» в строке Пакет
анализа (рис.
2.2):

Рис. 2.2
Далее следуем по
следующему плану.
1. Если исходные
данные уже внесены, то выбираем
Сервис→Анализ
данных→Регрессия.
2. Заполняем
диалоговое окно ввода данных и параметров
вывода (рис. 2.3):
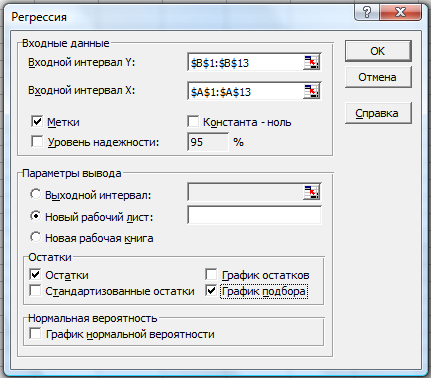
Рис. 2.3
Здесь:
Входной интервал
Y – диапазон,
содержащий данные результативного
признака;
Входной интервал
X – диапазон,
содержащий данные признака-фактора;
Метки –
«флажок», который указывает, содержи
ли первая строка названия столбцов;
Константа – ноль
– «флажок»,
указывающий на наличие или отсутствие
свободного члена в уравнении;
Выходной интервал
– достаточно
указать левую верхнюю ячейку будущего
диапазона;
Новый рабочий
лист – можно
указать произвольное имя нового листа
(или не указывать, тогда результаты
выводятся на вновь созданный лист).
Получаем следующие
результаты для рассмотренного выше
примера:

Рис. 2.4
Откуда выписываем,
округляя до 4 знаков после запятой и
переходя
к нашим обозначениям:
Уравнение регрессии:
![]()
Коэффициент
корреляции:
![]()
Коэффициент
детерминации:
![]()
Фактическое
значение F
-критерия
Фишера:
F =10,8280
Остаточная дисперсия
на одну степень свободы:
![]()
Корень квадратный
из остаточной дисперсии (стандартная
ошибка):
![]()
Стандартные ошибки
для параметров регрессии:
ma
= 24,2116, mb
= 0,2797.
Фактические
значения t
-критерия
Стьюдента:
ta
= 3,1793,
tb
= 3,2906.
Доверительные
интервалы:

Как видим, найдены
все рассмотренные выше параметры и
характеристики уравнения регрессии,
за исключением средней ошибки аппроксимации
(значение t
-критерия
Стьюдента для коэффициента корреляции
совпадает с tb
). Результаты
«ручного счета» от машинного отличаются
незначительно (отличия связаны с ошибками
округления).
3.Множественная регрессия и корреляция
3.1.Теоретическая справка
Множественная
регрессия – это
уравнение связи с несколькими независимыми
переменными:
![]()
где y
– зависимая
переменная (результативный признак);
![]() –независимые переменные (признаки-факторы).
–независимые переменные (признаки-факторы).
Для построения
уравнения множественной регрессии чаще
используются следующие функции:
-линейная
–
![]()
-степенная
–
![]()
-экспонента
–
![]()
-гипербола
–

Можно использовать
и другие функции, приводимые к линейному
виду.
Для оценки параметров
уравнения множественной регрессий
применяют метод
наименьших квадратов (МНК).
Для линейных уравнений
![]() (3.1)
(3.1)
строится следующая
система нормальных уравнений, решение
которой позволяет получить оценки
параметров регрессии:
 (3.2)
(3.2)
Для двухфакторной
модели данная система будет иметь вид:
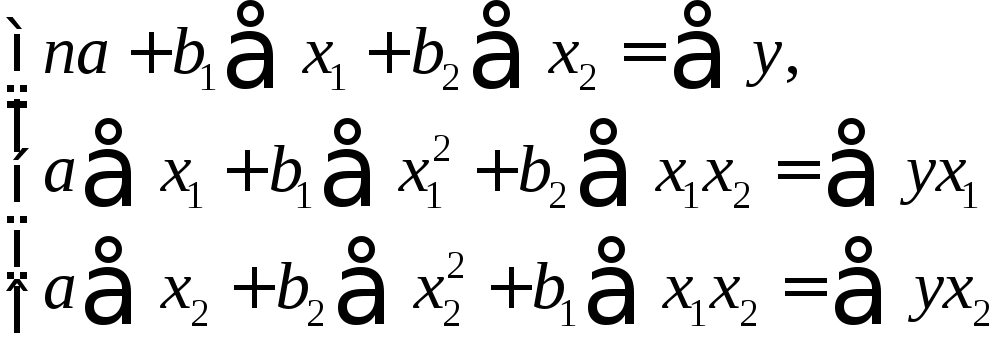 (3.3)
(3.3)
Так же можно
воспользоваться готовыми формулами,
которые являются следствием из этой
системы:
 (3.4)
(3.4)
В линейной
множественной регрессии параметры при
x называются
коэффициентами
«чистой» регрессии.
Они характеризуют среднее изменение
результата с изменением соответствующего
фактора на единицу при неизмененном
значении других факторов, закрепленных
на среднем уровне.
Метод наименьших
квадратов применим и к уравнению
множественной регрессии в стандартизированном
масштабе:
![]() (3.5)
(3.5)
где
![]() –стандартизированные
–стандартизированные
переменные:
 для которых среднее значение равно
для которых среднее значение равно
нулю:![]() ,
,
а среднее квадратическое отклонение
равно единице:![]() ;
;![]() —стандартизированные
—стандартизированные
коэффициенты регрессии.
В силу того, что
все переменные заданы как центрированные
и нормированные, стандартизованные
коэффициенты регрессии
![]() можно сравнивать между собой. Сравнивая
можно сравнивать между собой. Сравнивая
их друг с другом, можно ранжировать
факторы по силе их воздействия на
результат. В этом основное достоинство
стандартизованных коэффициентов
регрессии в отличие от коэффициентов
«чистой» регрессии, которые несравнимы
между собой.
Применяя МНК к
уравнению множественной регрессии в
стандартизированном масштабе, получим
систему нормальных уравнений вида
 (3.6)
(3.6)
где
![]()
– коэффициенты
парной и межфакторной корреляции.
Коэффициенты
«чистой» регрессии bi
связаны со
стандартизованными коэффициентами
регрессии
![]() следующим образом:
следующим образом:

(3.7)
Поэтому можно
переходить от уравнения регрессии в
стандартизованном масштабе (3.5) к
уравнению регрессии в натуральном
масштабе переменных (3.1), при этом параметр
a определяется
как
![]()
Рассмотренный
смысл стандартизованных коэффициентов
регрессии позволяет их использовать
при отсеве факторов – из модели
исключаются факторы с наименьшим
значением![]() .
.
Средние
коэффициенты эластичности для
линейной регрессии рассчитываются по
формуле
 (3.8)
(3.8)
которые показывают
на сколько процентов в среднем изменится
результат, при изменении соответствующего
фактора на 1%. Средние показатели
эластичности можно сравнивать друг с
другом и соответственно ранжировать
факторы по силе их воздействия на
результат.
Тесноту совместного
влияния факторов на результат оценивает
индекс
множественной корреляции:
 (3.9)
(3.9)
Значение индекса
множественной корреляции лежит в
пределах от 0 до 1 и должно быть больше
или равно максимальному парному индексу
корреляции:
![]()
При линейной
зависимости коэффициент
множественной корреляции можно
определить через матрицы парных
коэффициентов корреляции:
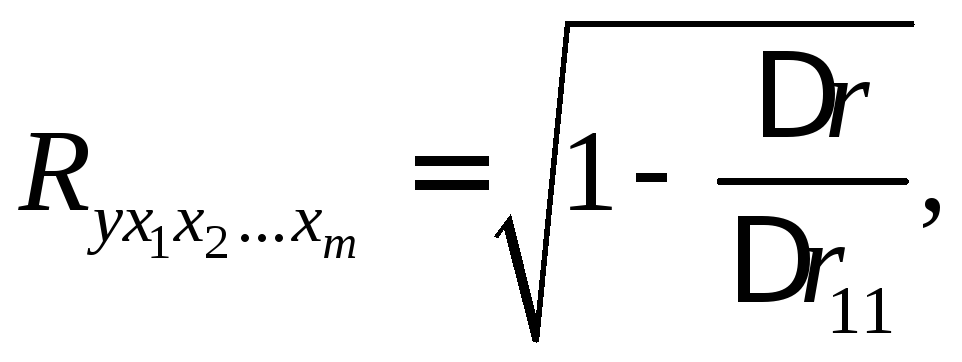
где

– определитель
матрицы парных коэффициентов корреляции;

– определитель
матрицы межфакторной корреляции.
Так же при линейной
зависимости признаков формула коэффициента
множественной корреляции может быть
также представлена следующим выражением:
![]() (3.11)
(3.11)
где
![]() – стандартизованные коэффициенты
– стандартизованные коэффициенты
регрессии;
![]() –
–
парные коэффициенты корреляции результата
с каждым фактором.
Качество построенной
модели в целом оценивает коэффициент
(индекс) детерминации. Коэффициент
множественной детерминации рассчитывается
как квадрат индекса множественной
корреляции
![]()
Для того чтобы не
допустить преувеличения тесноты связи,
применяется скорректированный
индекс множественной детерминации,
который содержит поправку на число
степеней свободы и рассчитывается по
формуле
 (3.12)
(3.12)
где n
– число
наблюдений, m
– число
факторов. При небольшом числе наблюдений
нескорректированная величина коэффициента
множественной детерминации R2
имеет тенденцию
переоценивать долю вариации результативного
признака, связанную с влиянием факторов,
включенных в регрессионную модель.
Частные коэффициенты
(или индексы) корреляции, измеряющие
влияние на y
фактора xi
, при
элиминировании (исключении влияния)
других факторов, можно определить по
формуле
 (3.13)
(3.13)
или по рекуррентной
формуле:
 (3.14)
(3.14)
Рассчитанные по
рекуррентной формуле частные коэффициенты
корреляции изменяются в пределах от –1
до +1, а по формулам через множественные
коэффициенты детерминации – от 0 до 1.
Сравнение их друг с другом позволяет
ранжировать факторы по тесноте их связи
с результатом. Частные коэффициенты
корреляции дают меру тесноты связи
каждого фактора с результатом в чистом
виде.
При двух факторах
формулы (3.12) и (3.13) примут вид:

Значимость уравнения
множественной регрессии в целом
оценивается с помощью F
-критерия
Фишера:
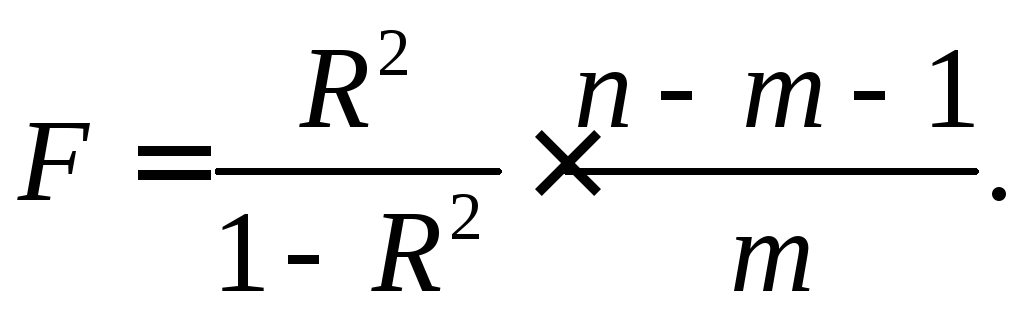 (3.15)
(3.15)
Частный F -критерий
оценивает
статистическую значимость присутствия
каждого из факторов в уравнении. В общем
виде для фактора x
частный F
-критерий
определится как
 (3.16)
(3.16)
Фактическое
значение F
-критерия
Фишера сравнивается с табличным значением
![]()
при уровне
значимости
![]() и степенях
и степенях
свободы
![]()
и
![]() .
.
При этом, если фактическое значение
![]() —
—
критерия больше табличного, то
дополнительное включение фактора xi
в модель
статистически оправданно и коэффициент
чистой регрессии bi
при факторе
xi
статистически значим. Если же фактическое
значение
![]() меньше
меньше
табличного, то дополнительное включение
в модель фактора xi
не увеличивает существенно долю
объясненной вариации признака y
, следовательно,
нецелесообразно его
включение в модель;
коэффициент регрессии при данном факторе
в этом случае статистически незначим.
Оценка
значимости коэффициентов чистой
регрессии проводится по t
-критерию
Стьюдента. В этом случае, как и в парной
регрессии, для каждого фактора используется
формула

(3.17)
Для уравнения
множественной регрессии (3.1) средняя
квадратическая ошибка коэффициента
регрессии может быть определена по
формуле:
 (3.18)
(3.18)
где
![]()
– коэффициент
детерминации для зависимости фактора
xi
со всеми
другими факторами уравнения множественной
регрессии. Для
двухфакторной
модели (m =
2 ) имеем:
 (3.19),
(3.19),
(3.20)
Существует связь
между t
-критерием
Стьюдента и частным F
— критерием
Фишера:
![]() (3.21)
(3.21)
Уравнения
множественной регрессии могут включать
в качестве независимых переменных
качественные признаки (например,
профессия, пол, образование, климатические
условия, отдельные регионы и т.д.). Чтобы
ввести такие переменные в регрессионную
модель, их необходимо упорядочить и
присвоить им те или иные значения, т.е.
качественные переменные преобразовать
в количественные.
Такого вида
сконструированные переменные принято
в эконометрике называть фиктивными
переменными. Например,
включать в модель фактор «пол» в виде
фиктивной переменной можно в следующем
виде:
 (3.22)
(3.22)
Коэффициент
регрессии при фиктивной переменной
интерпретируется как среднее изменение
зависимой переменной при переходе от
одной категории (женский пол) к другой
(мужской пол) при неизменных значениях
остальных параметров.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Регрессионный анализ в Microsoft Excel – наиболее полное руководств по использованию MS Excel для решения задач регрессионного анализа в области бизнес-аналитики. Конрад Карлберг доступно объясняет теоретические вопросы, знание которых поможет вам избежать многих ошибок как при самостоятельном проведении регрессионного анализа, так и при оценке результатов анализа, выполненного другими людьми. Весь материал, от простых корреляций и t-тестов до множественного ковариационного анализа, основан на реальных примерах и сопровождается подробным описанием соответствующих пошаговых процедур.
В книге обсуждаются особенности и противоречия, связанные с функциями Excel для работы с регрессией, рассматриваются последствия использования каждой их опции и каждого аргумента и объясняется, как надежно применять регрессионные методы в самых разных областях, от медицинских исследований до финансового анализа.
Ранее я опубликовал Левин. Статистика для менеджеров с использованием Microsoft Excel.
Конрад Карлберг. Регрессионный анализ в Microsoft Excel. – М.: Диалектика, 2017. – 400 с.

Скачать заметку в формате Word или pdf, примеры в формате Excel
Купить книгу в Ozon или Лабиринте
Глава 1. Оценка изменчивости данных
В распоряжении статистиков имеется множество показателей вариации (изменчивости). Один из них – сумма квадратов отклонений индивидуальных значений от среднего. В Excel для него используется функция КВАДРОТКЛ(). Но чаще используется дисперсия. Дисперсия — это среднее квадратов отклонений. Дисперсия нечувствительна к количеству значений в исследуемом наборе данных (в то время как сумма квадратов отклонений растет с числом измерений).
Программа Excel предлагает две функции, возвращающие дисперсию: ДИСП.Г() и ДИСП.В():
- Используйте функцию ДИСП.Г(), если подлежащие обработке значения образуют генеральную совокупность. Т.е., значения, содержащиеся в диапазоне, являются единственными значениями, которые вас интересуют.
- Используйте функцию ДИСП.В(), если подлежащие обработке значения образуют выборку из совокупности большего объема. Предполагается, что имеются дополнительные значения, дисперсию которых вы также можете оценить.
См. также СТАНДОТКЛОН.В и СТАНДОТКЛОН.Г: в чем различие?
Если такая величина, как среднее значение или коэффициент корреляции, рассчитывается на основе генеральной совокупности, то она называется параметром. Аналогичная величина, рассчитываемая на основе выборки, называется статистикой. Отсчитывая отклонения от среднего значения в данном наборе, вы получите сумму квадратов отклонений меньшей величины, чем если бы отсчитывали их от любого другого значения. Аналогичное утверждение справедливо и для дисперсии.
Чем больше объем выборки, тем точнее рассчитанное значение статистики. Но не существует ни одной выборки с объемом меньше объема генеральной совокупности, относительно которой вы могли бы быть уверены в том, что значение статистики совпадает со значением параметра.
Допустим, у вас есть набор из 100 значений роста, среднее которых отличается от среднего по генеральной совокупности, каким бы малым ни было это различие. Рассчитав дисперсию для выборки, вы получите некоторое ее значение, скажем, 4. Это значение меньше любого другого, которое можно получить, рассчитывая отклонение каждого из 100 значений роста относительно любого значения, отличного от среднего по выборке, в там числе и относительно истинного среднего по генеральной совокупности. Поэтому вычисленная дисперсия будет отличаться, причем в меньшую сторону, от дисперсии, которую вы получили бы, если бы каким-то образом узнали и использовали не выборочное среднее, а параметр генеральной совокупности.
Средняя сумма квадратов, определенная для выборки, дает нижнюю оценку дисперсии генеральной совокупности. Вычисленную таким способом дисперсию называют смещенной оценкой. Оказывается, чтобы исключить смещение и получить несмещенную оценку, достаточно разделить сумму квадратов отклонений не на n, где n — размер выборки, а на n – 1.
Величина n – 1 называется количеством (числом) степеней свободы. Существуют разные способы расчета этой величины, хотя все они включают либо вычитание некоторого числа из размера выборки, либо подсчет количества категорий, в которые попадают наблюдения.
Суть различия между функциями ДИСП.Г() и ДИСП.В() состоит в следующем:
- В функции ДИСП.Г() сумма квадратов делится на количество наблюдений и, следовательно, представляет смещенную оценку дисперсии, истинное среднее.
- В функции ДИСП.В() сумма квадратов делится на количество наблюдений минус 1, т.е. на количество степеней свободы, что дает более точную, несмещенную оценку дисперсии генеральной совокупности, из которой была извлечена данная выборка.
Стандартное отклонение (англ. standard deviation, SD) – есть квадратный корень из дисперсии:
![]()
Возведение отклонений в квадрат переводит шкалу измерений в другую метрику, являющуюся квадратом исходной: метры — в квадратные метры, доллары — в квадратные доллары и т.д. Стандартное отклонение — это корень квадратный из дисперсии, и поэтому оно возвращает нас к исходным единицам измерения. Что удобнее.
Часто приходится рассчитывать стандартное отклонение после того, как данных были подвергнуты некоторым манипуляциям. И хотя в этих случаях результаты несомненно являются стандартными отклонениями, их принято называть стандартными ошибками. Существует несколько разновидностей стандартных ошибок, в том числе стандартная ошибка измерения, стандартная ошибка пропорции, стандартная ошибка среднего.
Предположим, вы собрали данные о росте 25 случайно выбранных взрослых мужчин в каждом из 50 штатов. Далее вы вычисляете средний рост взрослых мужчин в каждом штате. Полученные 50 средних значений в свою очередь можно считать наблюдениями. Исходя из этого, вы могли бы рассчитать их стандартное отклонение, которое и является стандартной ошибкой среднего. Рис. 1. позволяет сравнить распределение 1250 исходных индивидуальных значений (данные о росте 25 мужчин по каждому из 50 штатов) с распределением средних значений 50 штатов. Формула для оценки стандартной ошибки среднего (т.е. стандартного отклонения средних значений, а не индивидуальных наблюдений):
![]()
где ![]() – стандартная ошибка среднего; s – стандартное отклонение исходных наблюдений; n – количество наблюдений в выборке.
– стандартная ошибка среднего; s – стандартное отклонение исходных наблюдений; n – количество наблюдений в выборке.
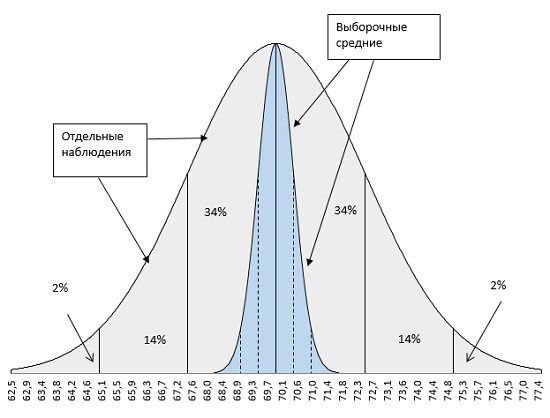
Рис. 1. Вариация средних значений от штата к штату значительно меньше вариации индивидуальных результатов наблюдений
В статистике существует соглашение относительно использования греческих и латинских букв для обозначения статистических величин. Греческими буквами принято обозначать параметры генеральной совокупности, латинскими — выборочные статистики. Следовательно, если речь идет о стандартном отклонении генеральной совокупности, мы записываем его как σ; если же рассматривается стандартное отклонение выборки, то используем обозначение s. Что касается символов для обозначения средних, то они согласуются между собой не столь удачно. Среднее по генеральной совокупности обозначается греческой буквой μ. Однако для представления выборочного среднего традиционно используется символ X̅.
z-оценка выражает положение наблюдения в распределении в единицах стандартного отклонения. Например, z = 1,5 означает, что наблюдение отстоит от среднего на 1,5 стандартного отклонения в сторону больших значений. Термин z-оценка используют для индивидуальных оценок, т.е. для измерений, приписываемых отдельным элементам выборки. В отношении таких статистик (например, среднее значение по штату) используют термин z-значение:
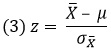
где X̅ – среднее значение выборки, μ – среднее значение генеральной совокупности, ![]() – стандартная ошибка средних набора выборок:
– стандартная ошибка средних набора выборок:
![]()
где σ – стандартная ошибка генеральной совокупности (индивидуальных измерений), n – размер выборки.
Предположим, вы работаете инструктором в гольф-клубе. Вы имели возможность в течение длительного времени измерять дальность ударов и знаете, что ее среднее значение составляет 205 ярдов, а стандартное отклонение — 36 ярдов. Вам предложили новую клюшку, утверждая, что она увеличит дальность удара на 10 ярдов. Вы просите каждого из последующих 81 посетителей клуба выполнить пробный удар новой клюшкой и записываете его дальность удара. Оказалось, что средняя дальность удара новой клюшкой составляет 215 ярдов. Какова вероятность того, что разница в 10 ярдов (215 – 205) обусловлена исключительно ошибкой выборки? Или по-другому: какова вероятность того, что при более масштабном тестировании новая клюшка не продемонстрирует увеличение дальности удара по сравнению с имеющимся долговременным средним показателем 205 ярдов?
Мы можем проверить это, сформировав z-значение. Стандартная ошибка среднего:
![]()
Тогда z-значение:
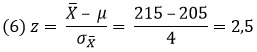
Нам нужно найти вероятность того, что среднее по выборке будет отстоять от среднего по генеральной совокупности на 2,5σ. Если вероятность будет маленькой, значит отличия обусловлены не случайностью, а качеством новой клюшки. В Excel для определения вероятности z-значения нет готовой функции. Однако можно использовать формулу =1-НОРМ.СТ.РАСП(z-значение;ИСТИНА), где функция НОРМ.СТ.РАСП() возвращает площадь под нормальной кривой слева от z-значения (рис. 2).
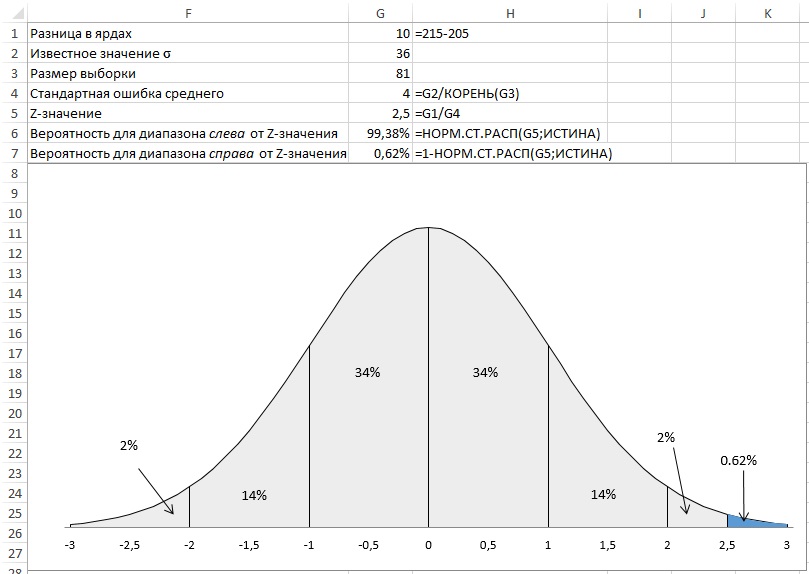
Рис. 2. Функция НОРМ.СТ.РАСП() возвращает площадь под кривой слева от z-значения; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
Второй аргумент функции НОРМ.СТ.РАСП() может принимать два значения: ИСТИНА – функция возвращает площадь области под кривой слева от точки, заданной первым аргументом; ЛОЖЬ – функция возвращает высоту кривой в точке, заданной первым аргументом.
Если среднее значение (μ) и стандартное отклонение (σ) генеральной совокупности не известны, используется t-значение (подробнее см. t-статистика Стьюдента в Excel). Структуры z- и t-значения отличаются тем, что для нахождения t-значения используется стандартное отклонение s, полученное на основе выборочных результатов, а не известное значение параметра генеральной совокупности σ. Нормальная кривая имеет единственную форму, а форма распределения t-значений варьирует в зависимости от количества степеней свободы df (от англ. degrees of freedom) выборки, которую оно представляет. Количество степеней свободы выборки равно n – 1, где n — размер выборки (рис. 3).

Рис. 3. Форма t-распределений, возникающих в тех случаях, когда параметр σ неизвестен, отличается от формы нормального распределения
В Excel есть две функции для t-распределения также называемого распределением Стьюдента: СТЬЮДЕНТ.РАСП() возвращает величину площади под кривой слева от заданного t-значения, а СТЬЮДЕНТ.РАСП.ПХ() – справа.
Глава 2. Корреляция
Корреляция — это мера зависимости между элементами набора упорядоченных пар. Корреляция характеризуется коэффициентам корреляции Пирсона – r. Коэффициент может принимать значения в интервале от –1,0 до +1,0.
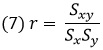
где Sx и Sy – стандартные отклонения переменных Х и Y, Sxy – ковариация:
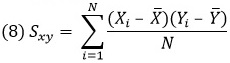
В этой формуле ковариация делится на стандартные отклонения переменных Х и Y, тем самым удаляя из ковариации эффекты масштабирования, связанные с единицами измерения. В Excel используется функция КОРРЕЛ(). В названии этой функции отсутствуют уточняющие элементы Г и В, которые используются в названиях таких функций, как СТАНДОТКЛОН(), ДИСП() или КОВАРИАЦИЯ(). Хотя коэффициенте корреляции по выборке предоставляемая смещенную оценку, однако причина смещения иная, нежели в случае дисперсии или стандартного отклонения.
В зависимости от величины генерального коэффициента корреляции (часто обозначаемого греческой буквой ρ), коэффициент корреляции r дает смещенную оценку, причем эффект смещения усиливается с уменьшением размера выборок. Тем не менее мы не пытаемся корректировать это смещение аналогично тому, как, например, делали это при вычислении стандартного отклонения, когда подставляли в соответствующую формулу не количество наблюдений, а количество степеней свободы. В действительности количество наблюдений, используемое для вычисления ковариации, не оказывает никакого влияния на величину.
Стандартный коэффициент корреляции предназначен для использования с переменными, связанными между собой линейным соотношением. Наличие нелинейности и/или ошибок в данных (выбросы) приводят к неверному расчету коэффициента корреляции. Для диагностики проблем с данными рекомендуется строить точечные диаграммы. Это единственный тип диаграмм в Excel, в котором и горизонтальная, и вертикальная оси трактуются как оси значений. Линейная же диаграмма один из столбцов определяет, как ось категорий, что искажает картину данных (рис. 4).
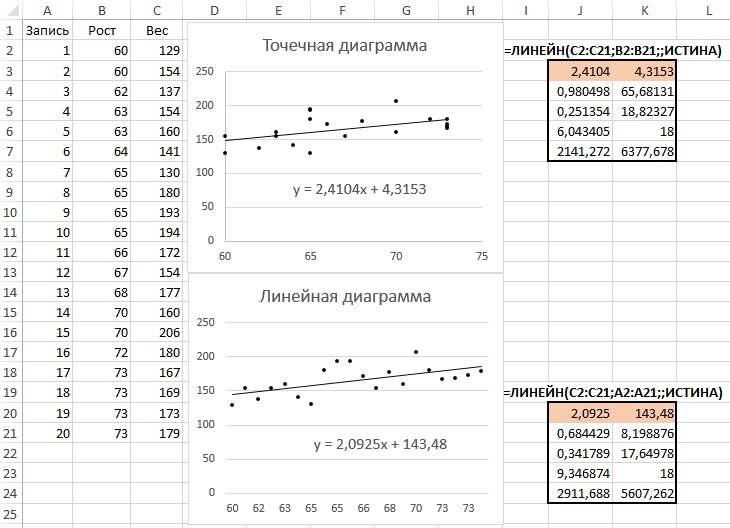
Рис. 4. Линии регрессии кажутся одинаковыми, однако сравните между собой их уравнения
Наблюдения, использованные для построения линейной диаграммы, располагаются вдоль горизонтальной оси эквидистантно. Надписи делений вдоль этой оси — это и есть всего лишь надписи, а не числовые значения.
Несмотря на то что корреляция часто означает наличие причинно-следственной связи, она не может служить доказательством того, что так оно и есть. Статистика не используется для демонстрации того, истинна или ложна теория. Для исключения конкурирующих объяснений результатов наблюдений ставят плановые эксперименты. Статистика же привлекается для обобщения информации, собранной в ходе таких экспериментов, и количественной оценки вероятности того, что принимаемое решение может быть неверным при имеющейся доказательной базе.
Глава 3. Простая регрессия
Если две переменные связаны между собой, так что значение коэффициента корреляции превышает, скажем, 0,5, то в этом случае можно прогнозировать (с некоторой точностью) неизвестное значение одной переменной по известному значению другой. Для получения прогнозных значений цены, исходя из данных, приведенных на рис. 5, можно использовать любой из нескольких возможных способов, но почти наверняка вы не будете использовать тот, который представлен на рис. 5. И все же вам стоит с ним ознакомиться, поскольку ни один другой способ не позволяет так же отчетливо продемонстрировать связь между корреляцией и прогнозированием, как этот. На рис. 5 в диапазоне В2:С12 представлена случайная выборка из десяти домов и приведены данные о площади каждого дома (в квадратных футах) и его продажной цене.
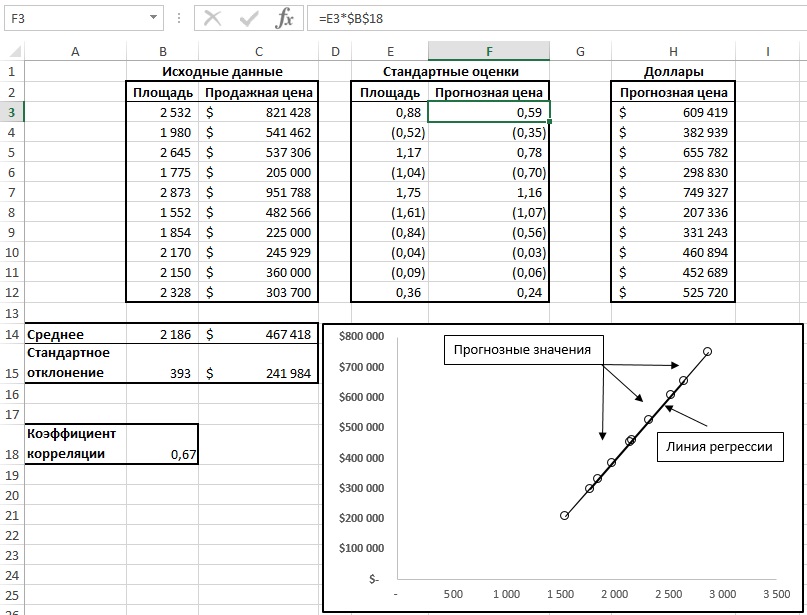
Рис. 5. Прогнозные значения продажной цены образуют прямую линию
Найдите средние значения, стандартные отклонения и коэффициент корреляции (диапазон А14:С18). Рассчитайте z-оценки площади (Е2:Е12). Например, ячейка ЕЗ содержит формулу: =(В3-$В$14)/$В$15. Вычислите z-оценки прогнозной цены (F2:F12). Например, ячейка F3 содержит формулу: =ЕЗ*$В$18. Переведите z-оценки в цены в долларах (Н2:Н12). В ячейке НЗ формула: =F3*$C$15+$C$14.
Обратите внимание: прогнозное значение всегда стремится сместиться в сторону среднего, равного 0. Чем ближе к нулю коэффициент корреляции, тем ближе к нулю прогнозная z-оценка. В нашем примере коэффициент корреляции между площадью и продажной ценой равен 0,67, и прогнозная цена равна 1,0*0,67, т.е. 0,67. Этому соответствует превышение значения над средним значением, равное двум третям стандартного отклонения. Если бы коэффициент корреляции был равен 0,5, то прогнозная цена составила бы 1,0*0,5, т.е. 0,5. Этому соответствует превышение значения над средним значением, равное лишь половине стандартного отклонения. Всякий раз, когда значение коэффициента корреляции отличается от идеального, т.е. больше -1,0 и меньше 1,0, оценка прогнозируемой переменной должна быть ближе к своему среднему значению, чем оценка предикторной (независимой) переменной к своему. Это явление называется регрессией к среднему, или просто регрессией.
В Excel есть несколько функций для определения коэффициентов уравнения линии регрессии (в Excel она называется линией тренда) у = kx + b. Для определения k служит функция
=НАКЛОН(известные_значения_у; известные_значения_х)
Здесь у – прогнозируемая переменная, а х – независимая переменная. Вы должны строго следовать этому порядку переменных. Наклон линии регрессии, коэффициент корреляции, стандартные отклонения переменных и ковариация тесно связаны между собой (рис. 6). Функция ОТРЕЗОК() возвращает значение, отсекаемое линией регрессии на вертикальной оси:
=ОТРЕЗОК(известные_значения_у; известные_значения_х)
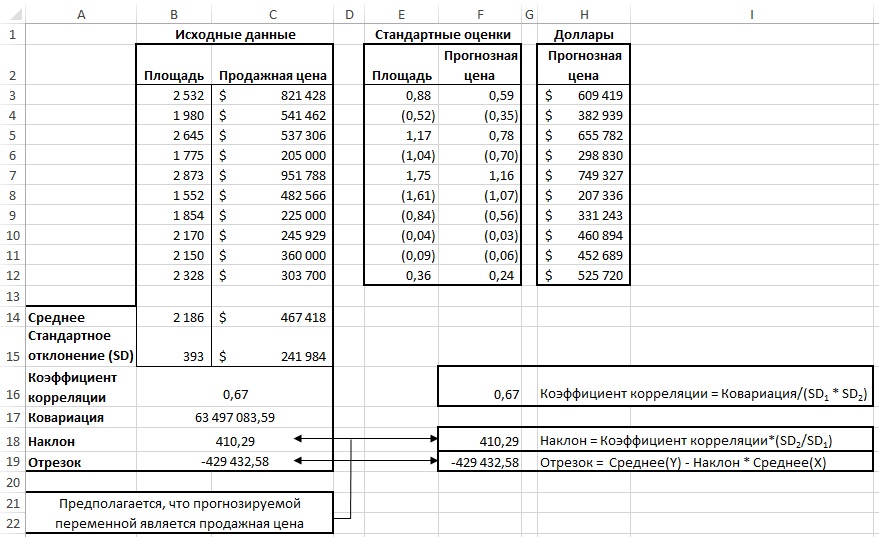
Рис. 6. Соотношение между стандартными отклонениями преобразует ковариацию в коэффициент корреляции и наклон линии регрессии
Обратите внимание, что количество значений х и у, предоставляемых функциям НАКЛОН() и ОТРЕЗОК() в качестве аргументов, должно быть одинаковым.
В регрессионном анализе используется еще один важный показатель – R2 (R-квадрат), или коэффициент детерминации. Он определяет, какой вклад в общую изменчивость данных вносит выявленная с помощью регрессии зависимость между х и у. В Excel для него есть функция КВПИРСОН(), которая принимает точно те же аргументы, что и функция КОРРЕЛ().
О двух переменных с ненулевым коэффициентом корреляции между ними говорят, что они объясняют дисперсию или имеют объясненную дисперсию. Обычно объясненная дисперсия выражается в процентах. Так R2 = 0,81 означает, что 81% дисперсии (разброса) двух переменных является объясненной. Остальные 19% обусловлены случайными флуктуациями.
В Excel имеется функция ТЕНДЕНЦИЯ, которая упрощает вычисления. Функция ТЕНДЕНЦИЯ():
- принимает предоставляемые вами известные значения х и известные значения у;
- вычисляет наклон линии регрессии и константу (отрезок);
- возвращает прогнозные значения у, определяемые на основании применения уравнения регрессии к известным значениям х (рис. 7).
Функция ТЕНДЕНЦИЯ() является функцией массива (если вы ранее не сталкивались с такими функциями, рекомендую Excel. Введение в формулы массива).
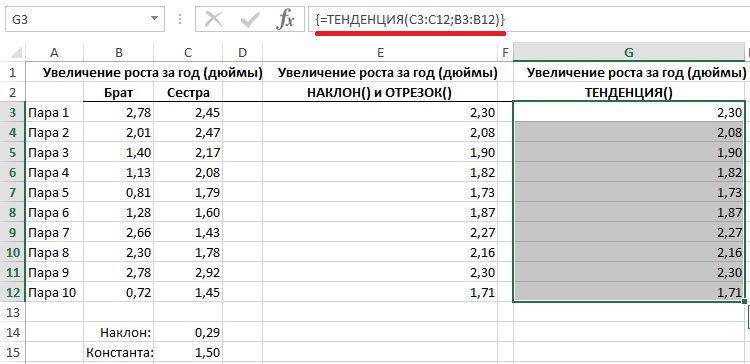
Рис. 7. Использование функции ТЕНДЕНЦИЯ() позволяет ускорить и упростить вычисления по сравнению с использованием пары функций НАКЛОН() и ОТРЕЗОК()
Чтобы ввести функцию ТЕНДЕНЦИЯ() в виде формулы массива в ячейки G3:G12, выделите диапазон G3:G12, введите формулу ТЕНДЕНЦИЯ (СЗ:С12;ВЗ:В12), нажмите и удерживайте клавиши <Ctrl+Shift> и только после этого нажмите клавишу <Enter>. Обратите внимание, что формула заключена в фигурные скобки: { и }. Так Excel сообщает вам о том, что данная формула воспринята именно как формула массива. Не вводите сами скобки: если вы попытаетесь ввести их самостоятельно в составе формулы, Excel воспримет ваш ввод как обычную текстовую строку.
У функции ТЕНДЕНЦИЯ() есть еще два аргумента: новые_значения_х и конст. Первый позволяет построить прогноз на будущее, а второй может заставить линию регрессии пройти через начало координат (значение ИСТИНА говорит Excel использовать расчетную константу, значение ЛОЖЬ – константу = 0). Excel позволяет нарисовать регрессионную прямую на графике так, чтобы она проходила через начало координат. Начните с построения точечной диаграммы, после чего щелкните правой кнопкой мыши на одном из маркеров ряда данных. Выберите в открывшемся контекстном меню пункт Добавить линию тренда; выберите вариант Линейная; при необходимости прокрутите панель вниз, установите флажок Настроить пересечение; убедитесь, что в связанном с ним текстовом поле задано значение 0,0.
Если у вас есть три переменных, и вы хотите определить корреляцию между двумя из них, исключив влияние третьей, можно использовать частную корреляцию. Предположим, вас интересует связь между процентной долей жителей города, закончивших колледж, и количеством книг в городских библиотеках. Вы собрали данные по 50 городам, но… Проблема в том, что оба этих параметра могут зависеть от благосостояния жителей того или иного города. Разумеется, очень трудно подобрать другие 50 городов, характеризующихся в точности одинаковым уровнем благосостояния жителей.
Применяя статистические методы для исключения влияния, оказываемого фактором благосостояния как на финансовую поддержку библиотек, так и на доступность обучения в колледже, вы могли бы получить более точную количественную оценку степени зависимости между интересующими вас переменными, а именно: количеством книг и количеством выпускников. Такая условная корреляция между двумя переменными, когда значения других переменных фиксированы, и называется частной корреляцией. Один из способов ее расчета заключается в использовании уравнения:
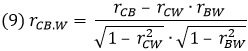
Где rCB.W — коэффициент корреляции между переменными Колледж (College) и Книги (Books) при исключенном влиянии (фиксированном значении) переменной Благосостояние (Wealth); rCB — коэффициент корреляции между переменными Колледж и Книги; rCW — коэффициент корреляции между переменными Колледж и Благосостояние; rBW — коэффициент корреляции между переменными Книги и Благосостояние.
С другой стороны, частную корреляцию можно рассчитать на основе анализа остатков, т.е. разностей между прогнозными значениями и связанными с ними результатами фактических наблюдений (оба метода представлены на рис. 8).
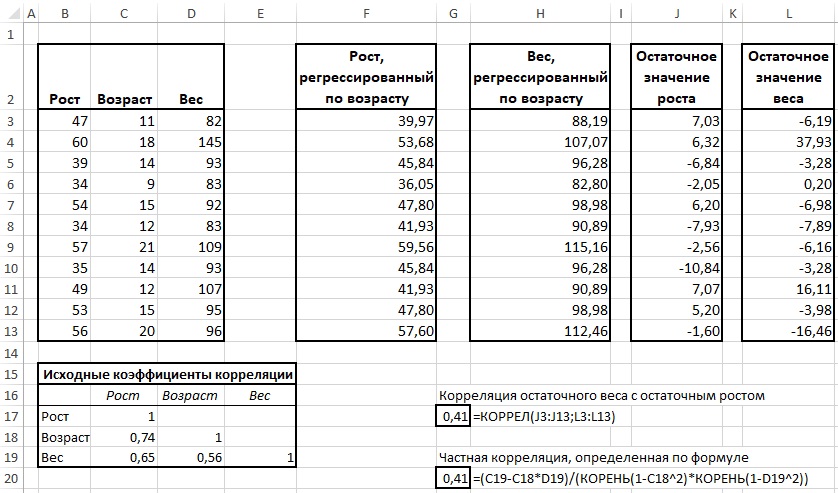
Рис. 8. Частная корреляция, как корреляция остатков
Для упрощения подсчета матрицы коэффициентов корреляции (В16:Е19) используйте пакет анализа Excel (меню Данные –> Анализ –> Анализ данных). По умолчанию этот пакет в Excel не активен. Для его установки пройдите по меню Файл –> Параметры –> Надстройки. Внизу открывшегося окна Параметры Excel найдите поле Управление, выберите Надстройки Excel, кликните Перейти. Поставьте галочку напротив надстройки Пакет анализа. Кликните Анализ данных, выберите опцию Корреляция. В качестве входного интервала укажите $B$2:$D$13, поставьте галочку Метки в первой строке, в качестве выходного интервала укажите $B$16:$E$19.
Еще одна возможность – определить получастную корреляцию. Например, вы исследуете влияние роста и возраста на вес. Таким образом, у вас две предикторные переменные – рост и возраст, и одна прогнозируемая переменная – вес. Вы хотите исключить влияние одной предикторной переменной на другую, но не на прогнозную переменную:
![]()
где Н – Рост (Height), W– Вес (Weight), А – Возраст (Age); в индексе получастного коэффициента корреляции используются круглые скобки, с помощью которых указывается, влияние какой переменной устраняется и из какой именно переменной. В данном случае обозначение W(Н.А) указывает на то, что влияние переменной Возраст удаляется из переменной Рост, но не из переменной Вес.
Может создаться впечатление, что обсуждаемый вопрос не имеет существенного значения. Ведь важнее всего то, насколько точно работает общее уравнение регрессии, тогда как проблема относительных вкладов отдельных переменных в суммарную объясненную дисперсию представляется второстепенной. Однако это далеко не так. Как только вы начинаете задумываться над тем, стоит ли вообще использовать какую-то переменную в уравнении множественной регрессии, проблема становится важной. Она может влиять на оценку правильности выбора модели для анализа.
Глава 4. Функция ЛИНЕЙН()
Функция ЛИНЕЙН() возвращает 10 статистик регрессионного анализа. Функция ЛИНЕЙН() является функцией массива. Для ее ввода выделите диапазон, содержащий пять строк и два столбца, напечатайте формулу, и нажмите <Ctrl+Shift+Enter> (рис. 9):
=ЛИНЕЙН(B2:B21;A2:A21;ИСТИНА;ИСТИНА)

Рис. 9. Функция ЛИНЕЙН(): а) выделите диапазон D2:E6, б) введите формулу, как показано в строке формул, в) нажмите <Ctrl+Shift+Enter>
Функция ЛИНЕЙН() возвращает:
- коэффициент регрессии (или наклон, ячейка D2);
- отрезок (или константа, ячейка Е3);
- стандартные ошибки коэффициента регрессии и константы (диапазон D3:E3);
- коэффициент детерминации R2 для регрессии (ячейка D4);
- стандартная ошибка оценки (ячейка Е4);
- F-критерий для полной регрессии (ячейка D5);
- количество степеней свободы для остаточной суммы квадратов (ячейка Е5);
- регрессионная сумма квадратов (ячейка D6);
- остаточная сумма квадратов (ячейка Е6).
Рассмотрим каждую из этих статистик и их взаимодействие.
Стандартная ошибка в нашем случае – это стандартное отклонение, вычисляемое для ошибок выборки. Т.е., это ситуация, когда генеральная совокупность имеет одну статистику, а выборка – другую. Разделив коэффициент регрессии на стандартную ошибку, вы получите значение 2,092/0,818 = 2,559. Иными словами, коэффициент регрессии, равный 2,092, отстоит от нуля на две с половиной стандартные ошибки.
Если коэффициент регрессии равен нулю, то наилучшей оценкой прогнозируемой переменной является ее среднее значение. Две с половиной стандартные ошибки — это довольно большая величина, и вы с уверенностью можете полагать, что коэффициент регрессии для генеральной совокупности имеет ненулевое значение.
Можно определить вероятность получения выборочного коэффициента регрессии 2,092, если его фактическое значение в генеральной совокупности равно 0,0 с помощью функции
=СТЬЮДЕНТ.РАСП.ПХ(t-критерий = 2,559; количество степеней свободы =18)
В общем количество степеней свободы = n – k – 1, где n — количество наблюдений, а k — количество предикторных переменных.
Эта формула возвращает значение 0,00987 или, округленно, 1%. Оно сообщает нам следующее: если коэффициент регрессии для генеральной совокупности равен 0%, то вероятность получения выборки из 20 человек, для которой расчетное значение коэффициента регрессии равно 2,092, составляет скромный 1%.
F-критерий (ячейка D5 на рис. 9) выполняет те же функции по отношению к полной регрессии, что и t-критерий по отношению к коэффициенту простой парной регрессии. F-критерий используется для проверки того, действительно ли коэффициент детерминации R2 для регрессии имеет достаточно большую величину, позволяющую отбросить гипотезу о том, что в генеральной совокупности он имеет значение 0,0, которое указывает на отсутствие дисперсии, объясняемой предикторной и прогнозируемой переменной. При наличии только одной предикторной переменной F-критерий в точности равен квадрату t-критерия.
До сих пор мы рассматривали интервальные переменные. Если же у вас переменные, которые могут принимать несколько значений, представляющих собой простые имена, например, Мужчина и Женщина или Пресмыкающееся, Земноводное и Рыба, представьте их в виде числового кода. Такие переменные называются номинальными.
Статистика R2 дает количественную оценку доли объясненной дисперсии.
Стандартная ошибка оценки. На рис. 4.9 представлены прогнозные значения переменной Вес, полученные на основании ее связи с переменной Рост. В диапазоне Е2:Е21 содержатся значения остатков для переменной Вес. Точнее эти остатки называть ошибками — отсюда и следует термин стандартная ошибка оценки.
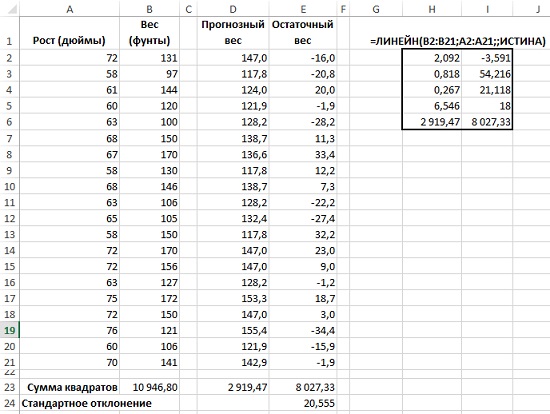
Рис. 10. Как R2, так и стандартная ошибка оценки выражают точность прогнозов, получаемых с помощью регрессии
Чем меньше стандартная ошибка оценки, тем точнее уравнение регрессии и тем более близкого совпадения любого прогноза, полученного с помощью уравнения, с фактическим наблюдением вы ожидаете. Стандартная ошибка оценки предоставляет способ количественной оценки этих ожиданий. Вес 95% людей, обладающих неким ростом, будет находиться в диапазоне:
(рост * 2,092 – 3,591) ± 2,092*21,118
F-статистика – это отношение межгрупповой дисперсии к внутригрупповой дисперсии. Это название было введено статистиком Джорджем Снедекором в честь сэра Рональда Фишера, разработавшего в начале XX столетия дисперсионный анализ (ANOVA, Analysis of Variance).
Коэффициент детерминации R2 выражает долю общей суммы квадратов, связанную с регрессией. Величина (1 – R2) выражает долю общей суммы квадратов, связанную с остатками — ошибками прогнозирования. F-критерий можно получить с использованием функции ЛИНЕЙН (ячейка F5 на рис. 11), с использованием сумм квадратов (диапазон G10:J11), с использованием долей дисперсии (диапазон G14:J15). Формулы можно изучить в прилагаемом файле Excel.

Рис. 11. Расчет F-критерия
При использовании номинальных переменных используется фиктивное кодирование (рис. 12). Для кодирования значений удобно использовать значения 0 и 1. Вероятность F рассчитывается с помощью функции:
=F.РАСП.ПХ(К2;I2;I3)
Здесь функция F.РАСП.ПХ() возвращает вероятность получения F-критерия, подчиняющегося центральному F-распределению (рис. 13) для двух наборов данных с количествами степеней свободы, приведенными в ячейках I2 и I3, значение которого совпадает со значением, приведенным в ячейке К2.
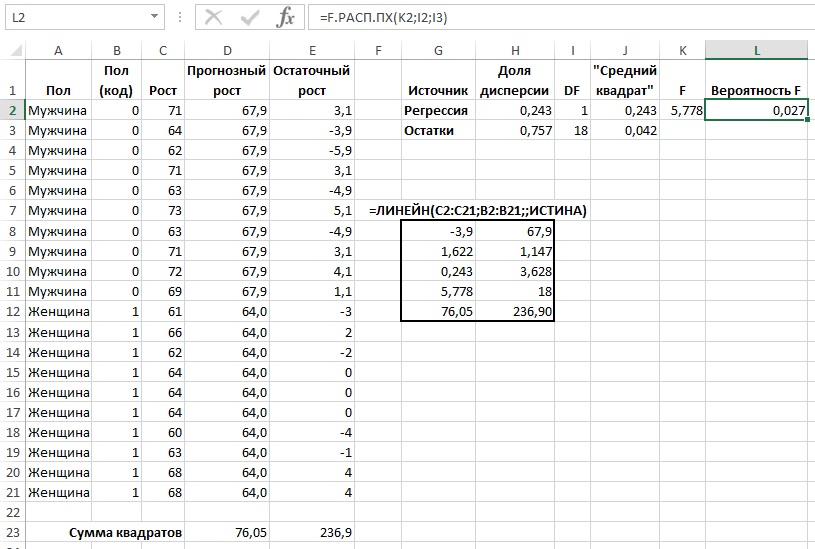
Рис. 12. Регрессионный анализ с использованием фиктивных переменных
Рис. 13. Центральное F-распределение при λ = 0
Глава 5. Множественная регрессия
Переходя от простой парной регрессии с одной предикторной переменной к множественной регрессии, вы добавляете одну или несколько предикторных переменных. Сохраняйте значения предикторных переменных в смежных столбцах, например, в столбцах А и В в случае двух предикторов или А, В и С в случае трех предикторов. Прежде чем вводить формулу, включающую функцию ЛИНЕЙН(), выберите пять строк и столько столбцов, сколько имеется предикторных переменных, плюс еще один для константы. В случае регрессии с двумя предикторными переменными можно использовать следующую структуру:
=ЛИНЕЙН(А2: А41; В2: С41;;ИСТИНА)
Точно так же в случае трех переменных:
=ЛИНЕЙН(А2:А61;В2:D61;;ИСТИНА)
Предположим, вы хотите изучить возможное влияние возраста и диеты на содержание ЛПНП — липопротеинов низкой плотности, которые считаются ответственными за образование атеросклеротических бляшек, служащих причиной атеротромбоза (рис. 14).
Рис. 14. Множественная регрессия
R2 множественной регрессии (отражаемый в ячейке F13), больше, чем R2 любой простой регрессии (Е4, Н4). В множественной регрессии одновременно используются несколько предикторных переменных. При этом R2 почти всегда увеличивается.
Для любого простого линейного уравнения регрессии с одной предикторной переменной между прогнозными значениями и значениями предикторной переменной всегда будет наблюдаться идеальная корреляция, поскольку в таком уравнении значения предиктора умножаются на одну константу и к каждому произведению прибавляется другая константа. Этот эффект не сохраняется во множественной регрессии.
Отображение результатов, возвращаемых функцией ЛИНЕЙН() для множественной регрессии (рис. 15). Коэффициенты регрессии выводятся в составе результатов, возвращаемых функцией ЛИНЕЙН() в порядке обратном расположению переменных (G–H–I соответствует С–В–А).

Рис. 15. Коэффициенты и их стандартные ошибки отображаются в обратном порядке их следования на рабочем листе
Принципы и процедуры, используемые в регрессионном анализе с одной предикторной переменной, легко адаптируются для учета нескольких предикторных переменных. Оказывается, что многое в этой адаптации зависит от устранения влияния предикторных переменных друг на друга. Последнее связано с частной и получастной корреляциями (рис. 16).
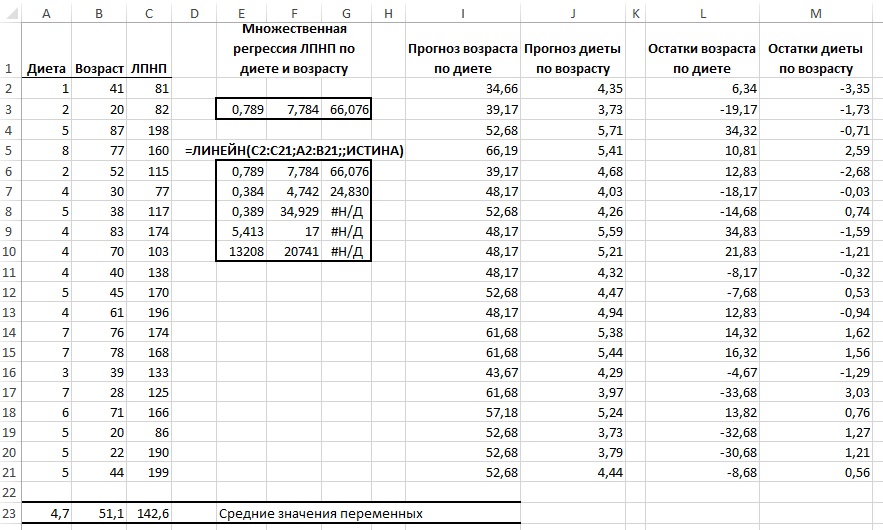
Рис. 16. Множественная регрессия может быть выражена через парную регрессию остатков (формулы см. в Excel-файле)
В Excel, имеются функции, предоставляющие информацию о t- и F-распределениях. Функции, имена которых включают часть РАСП, такие как СТЬЮДЕНТ.РАСП() и F.РАСП(), принимают t- или F-критерий в качестве аргумента и возвращают вероятность наблюдения указанного значения. Функции, имена которых включают часть ОБР, такие как СТЬЮДЕНТ.ОБР() и F.ОБР(), принимают значение вероятности в качестве аргумента и возвращают значение критерия, соответствующее указанной вероятности.
Поскольку мы ищем критические значения t-распределения, которые отсекают края его хвостовых областей, мы передаем 5% в качестве аргумента одной из функций СТЬЮДЕНТ.ОБР(), которая возвращает значение, соответствующее этой вероятности (рис. 17, 18).
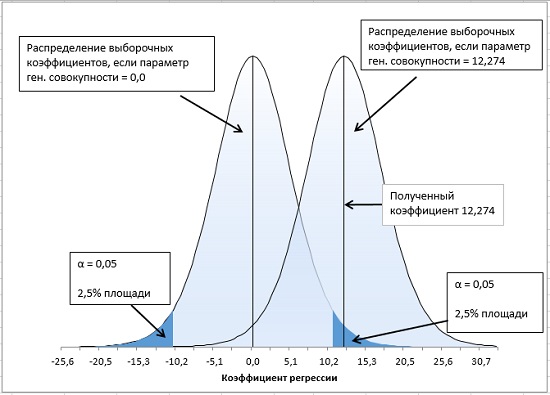
Рис. 17. Двусторонний t-тест
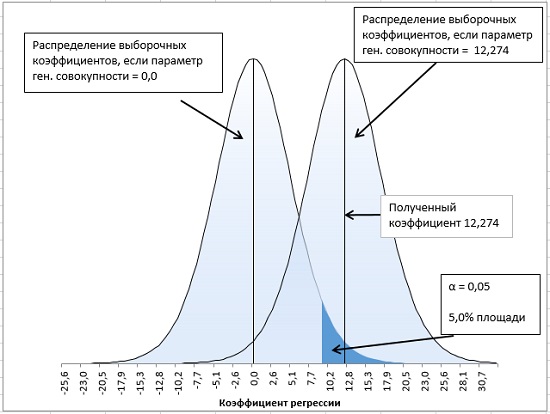
Рис. 18. Односторонний t-тест
Устанавливая правило принятия решений в случае однохвостовой альфа-области, вы увеличиваете статистическую мощность теста. Если, приступая к эксперименту, вы уверены в том, что у вас есть все основания ожидать получения положительного (или отрицательного) коэффициента регрессии, то вам следует выполнить однохвостовой тест. В этом случае вероятность того, что вы принимаете правильное решение, отвергая гипотезу о нулевом коэффициенте регрессии в генеральной совокупности, будет выше.
Статистики предпочитают использовать термин направленный тест вместо термина однохвостовой тест и термин ненаправленный тест вместо термина двуххвостовой тест. Термины направленный и ненаправленный предпочтительнее, поскольку делают акцент на типе гипотезы, а не на природе хвостов распределения.
Подход к оценке влияния предикторов, основанный на сравнении моделей. На рис. 19 представлены результаты регрессионного анализа, в котором тестируется вклад переменной Диета в уравнение регрессии.
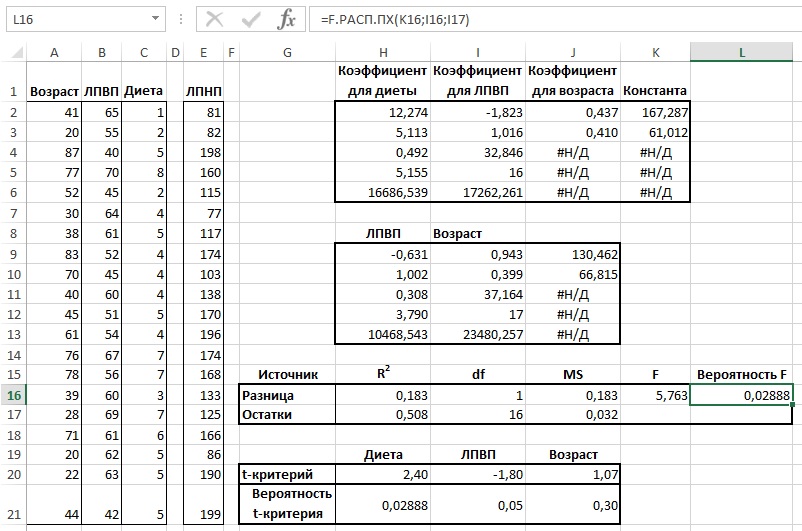
Рис. 19. Сравнение двух моделей путем проверки различий в их результатах
Результаты функции ЛИНЕЙН() (диапазон Н2:К6) имеют отношение к тому, что я называю полной моделью, в которой выполняется регрессия переменной ЛПНП по переменным Диета, Возраст и ЛПВП. В диапазоне Н9:J1З представлены расчеты без учета предикторной переменной Диета. Я называю это ограниченной моделью. В полной модели 49,2% дисперсии зависимой переменной ЛПНП объясняется предикторными переменными. В ограниченной модели лишь 30,8% ЛПНП объясняется переменными Возраст и ЛПВП. Потеря R2, обусловленная исключением переменной Диета из модели, составляет 0,183. В диапазоне G15:L17 сделаны расчеты, которые показывают, что лишь с вероятностью 0,0288 влияние переменной Диета является случайным. В остальных 97,1% Диета оказывает влияние на ЛПНП.
Глава 6. Допущения и предостережения в отношении регрессионного анализа
Термин «допущение» не определен достаточно строго, а способ его использования предполагает, что если допущение не соблюдается, то результаты всего анализа являются по меньшей мере сомнительными или, возможно, не имеющими силы. На самом деле это не так, хотя, безусловно, существуют случаи, когда нарушение допущения в корне меняет картину. Основные допущения: а) остатки переменной Y нормально распределены в любой точке X вдоль линии регрессии; б) значения Y находятся в линейной зависимости от значений X; в) дисперсия остатков примерно одинакова в каждой точке Х; г) между остатками отсутствует зависимость.
Если допущения не играют существенной роли, статистики говорят о робастности анализа по отношению к нарушению допущения. В частности, когда вы используете регрессию для тестирования различий между групповыми средними, допущение о том, что значения Y — а значит, и остатки — нормально распределены, не играет существенной роли: тесты робастны по отношению к нарушению допущения о нормальности. При этом важно анализировать данные с помощью диаграмм. Например, включенных в надстройку Анализ данных инструмент Регрессия.
Если данные не соответствуют допущениям линейной регрессии, в вашем распоряжении имеются другие подходы, отличные от линейного. Один из них – логистическая регрессия (рис. 20). Вблизи верхнего и нижнего предельных значений предикторной переменной линейная регрессия приводит к нереалистичным прогнозам.
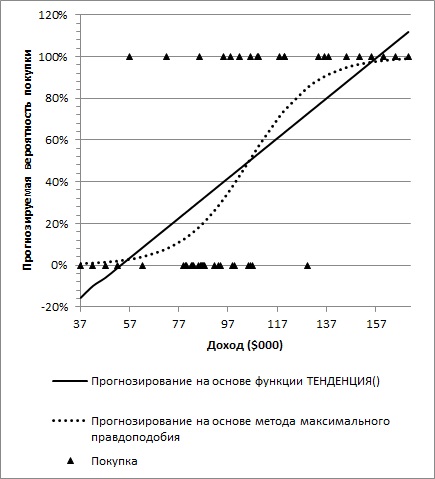
Рис. 20. Логистическая регрессия
На рис. 20 отображены результаты двух методов анализа данных, направленного на исследование связи между ежегодным доходом и вероятностью покупки дома. Очевидно, вероятность совершения покупки будет увеличиваться с увеличением дохода. Диаграммы упрощают выявление различий между результатами, прогнозирующими вероятность покупки дома посредством линейной регрессии, и результатами, которые вы могли бы получить, используя другой подход.
В основе линейного (а в данном контексте — и криволинейного) регрессионного анализа лежат корреляции. Фундамент логистической регрессии образуют шансы и отношения шансов. Несмотря на использование слова регрессия в названиях обоих методов, между этими подходами имеются значительные различия. В частности, логистическая регрессия не обязательно дает прямую регрессионную линию, как в случае линейной регрессии. Это свойство логистической регрессии означает, что ее линия максимального правдоподобия, которой на рис. 20 соответствует S-образная точечная кривая, меняет свой наклон при перемещении вдоль континуума значений X (в данном случае — дохода). Поэтому линия логистической регрессии никогда не доходит до отрицательных значений вероятности покупки в области нижней границы шкалы дохода и до значений вероятности свыше 100% в области верхней границы шкалы (см. также Использование модели Раша в пересчете баллов ЕГЭ).
На языке статистиков отбрасывание нулевой гипотезы, когда в действительности она является истинной, называется ошибкой I рода.
В надстройке Анализ данных предлагается удобный инструмент для генерации случайных чисел, предоставляющий пользователю возможность задать желаемую форму распределения (например, Нормальное, Биномиальное или Пуассона), а также среднее значение и стандартное отклонение.
Различия между функциями семейства СТЬЮДЕНТ.РАСП(). Начиная с версии Excel 2010 доступны три разные формы функции, возвращающей долю распределения слева и/или справа от заданного значения t-критерия. Функция СТЬЮДЕНТ.РАСП() возвращает долю площади под кривой распределения слева от указанного вами значения t-критерия. Предположим, у вас имеется 36 наблюдений, и поэтому количество степеней свободы для анализа равно 34, а значение t-критерия = 1,69. В этом случае формула
=СТЬЮДЕНТ.РАСП(+1,69;34;ИСТИНА)
возвращает значение 0,05, или 5% (рис. 21). Третий аргумент функции СТЬЮДЕНТ.РАСП() может иметь значение ИСТИНА или ЛОЖЬ. Если он задан равным ИСТИНА, функция возвращает кумулятивную площадь под кривой слева от заданного t-критерия, выраженную в виде доли. Если же он равен ЛОЖЬ, функция возвращает относительную высоту кривой в точке, соответствующей t-критерию. Другие версии функции СТЬЮДЕНТ.РАСП() — СТЬЮДЕНТ.РАСП.ПХ() и СТЬЮДЕНТ.РАСП.2Х() — принимают в качестве аргументов только значение t-критерия и количество степеней свободы и не требуют задания третьего аргумента.
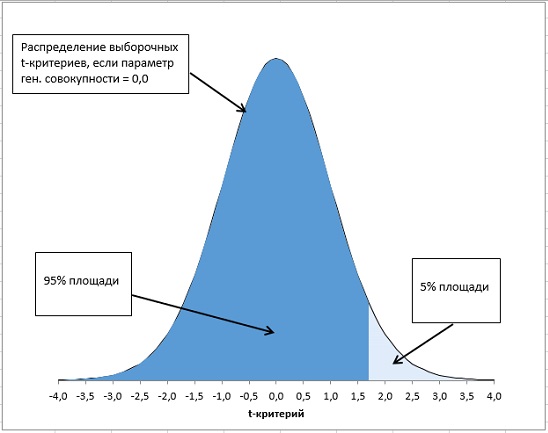
Рис. 21. Более темная затененная область в левом хвосте распределения соответствует доле площади под кривой слева от большого положительного значения t-критерия
Чтобы определить площадь справа от t-критерия используйте одну из формул:
=1 — СТЬЮДЕНТ.РАСП (1, 69;34;ИСТИНА)
=СТЬЮДЕНТ.РАСП.ПХ(1,69;34)
Вся площадь под кривой должна составлять 100%, поэтому вычитание из 1 доли площади слева от значения t-критерия, которую возвращает функция, дает долю площади, располагающейся справа от значения t-критерия. Возможно, вам покажется более предпочтительным вариант непосредственного получения интересующей вас доли площади с помощью функции СТЬЮДЕНТ.РАСП.ПХ(), где ПХ означает правый хвост распределения (рис. 22).
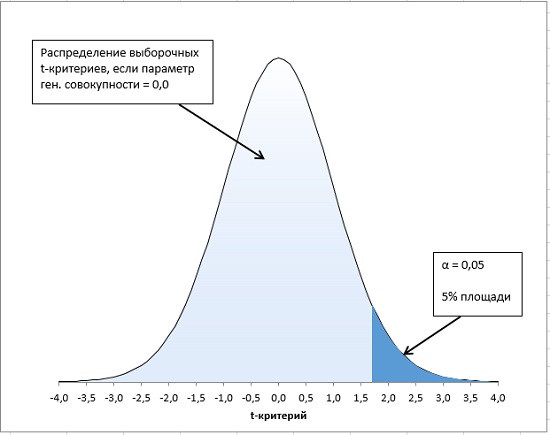
Рис. 22. 5%-ная альфа область для направленного теста
Использование функций СТЬЮДЕНТ.РАСП() или СТЬЮДЕНТ.РАСП.ПХ () подразумевает, что вы выбрали направленную рабочую гипотезу. Направленная рабочая гипотеза в сочетании с установкой значения альфа на уровне 5% означает, что вы помещаете все 5% в правый хвост распределениями. Вы должны будете отвергнуть нулевую гипотезу лишь в том случае, если вероятность полученного вами значения t-критерия составит 5% и менее. Направленные гипотезы обычно приводят к более чувствительным статистическим тестам (эту большую чувствительность также называют большей статистической мощностью).
При ненаправленном тесте значение альфа остается на том же уровне 5%, но распределение будет иным. Поскольку вы должны допускать два исхода вероятность ложноположительного результата должна быть распределена между двумя хвостами распределения. Общепринято распределять эту вероятность поровну (рис. 23).
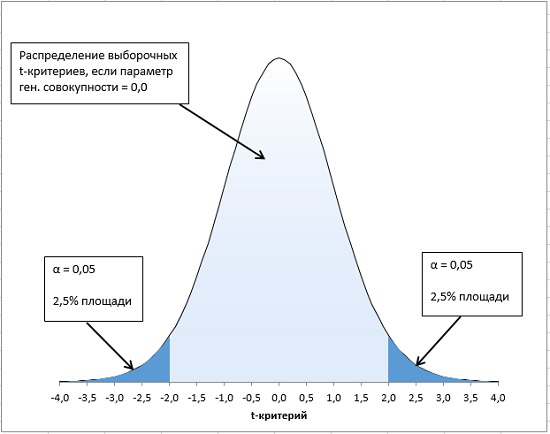
Рис. 23. Ненаправленный тест
Используя то же самое полученное значение t-критерия и то же количество степеней свободы, что и в предыдущем примере, воспользуйтесь формулой
=СТЬЮДЕНТ.РАСП.2Х(1,69;34)
Без каких-либо особых на то причин функция СТЬЮДЕНТ.РАСП.2Х() возвращает код ошибки #ЧИСЛО!, если в качестве первого аргумента ей предоставляется отрицательное значение t-критерия.
Если выборки содержат разное число данных, воспользуйтесь двухвыборочным t-тестом с различными дисперсиями, включенным в пакет Анализ данных.
Глава 7. Использование регрессии для тестирования различий между групповыми средними
Переменные, которые ранее фигурировали под названием прогнозируемых переменных, в этой главе будут называться результативными переменными, а вместо термина предикторные переменные будет использоваться термин факторные переменные.
Простейшим из подходов к кодированию номинальной переменной является фиктивное кодирование (рис. 24).
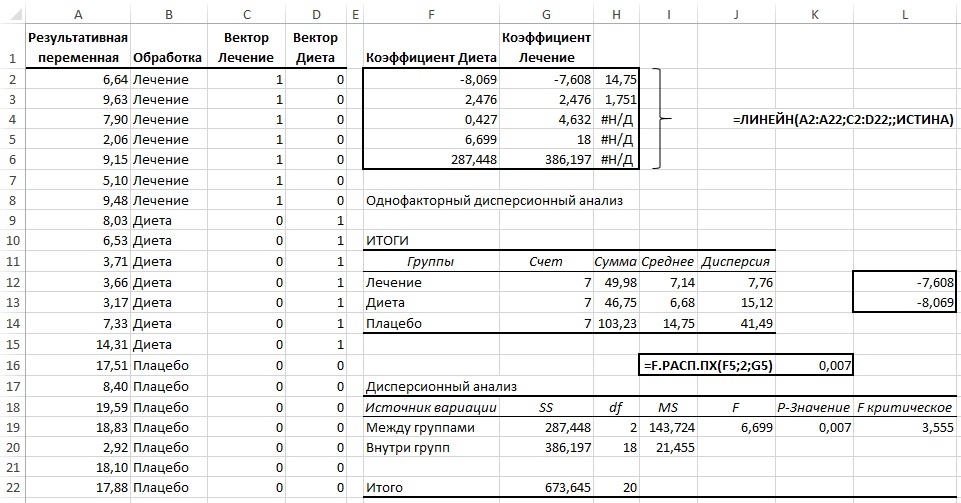
Рис. 24. Регрессионный анализ на основе фиктивного кодирования
При использовании фиктивного кодирования любого рода следует придерживаться правил:
- Количество столбцов, резервируемых для новых данных, должно быть равным количеству уровней фактора минус
- Каждый вектор представляет один уровень фактора.
- Субъекты одного из уровней, которым часто является контрольная группа, получают код 0 во всех векторах.
Формула в ячейках F2:H6 =ЛИНЕЙН(A2:A22;C2:D22;;ИСТИНА) возвращает регрессионные статистики. Для сравнения на рис. 24 отображены результаты традиционного дисперсионного анализа, возвращаемого инструментом Однофакторный дисперсионный анализ надстройки Анализ данных.
Кодирование эффектов. В другом типе кодирования, получившем название кодирование эффектов, среднее каждой группы сравнивается со средним групповых средних. Этот аспект кодирования эффектов обусловлен использованием значения -1 вместо 0 в качестве кода для группы, которая получает один и тот же код во всех кодовых векторах (рис. 25).
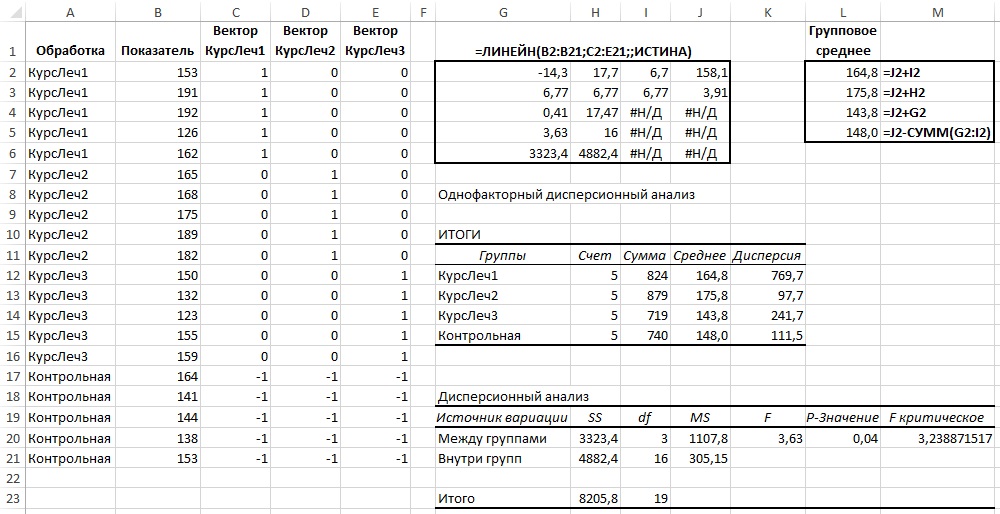
Рис. 25. Кодирование эффектов
Когда используется фиктивное кодирование, значение константы, возвращаемое функцией ЛИНЕЙН(), совпадает со средним группы, которой во всех векторах назначены нулевые коды (обычно это контрольная группа). В случае кодирования эффектов константа равна общему среднему (ячейка J2).
Общая линейная модель — полезный способ концептуализации компонентов значения результирующей переменной:
Yij = μ + αj + εij
Использование в этой формуле греческих букв вместо латинских подчеркивает тот факт, что она относится к генеральной совокупности, из которой извлекаются выборки, но ее можно переписать в виде, указывающем на то, что она относится к выборкам, извлекаемым изданной генеральной совокупности:
Yij = Y̅ + aj + eij
Идея состоит в том, что каждое наблюдение Yij можно рассматривать как сумму следующих трех компонентов: общее среднее, μ; эффект обработки j, аj; величина eij, которая представляет отклонение индивидуального количественного показателя Yij от комбинированного значения общего среднего и эффекта j-й обработки (рис. 26). Целью уравнения регрессии является минимизация суммы квадратов остатков.
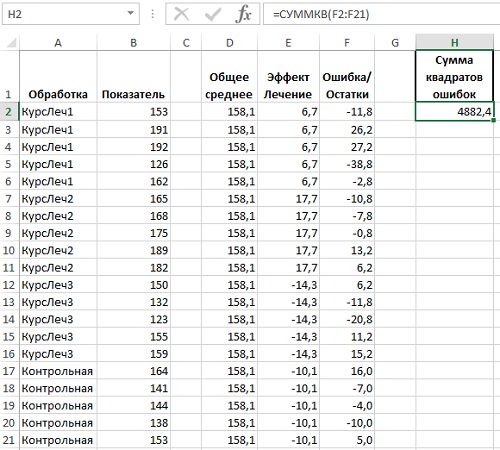
Рис. 26. Наблюдения, разложенные на компоненты общей линейной модели
Факторный анализ. Если исследуется связь между результативной переменной и одновременно двумя или более факторами, то в этом случае говорят об использовании факторного анализа. Добавление одного или нескольких факторов в однофакторный дисперсионный анализ может увеличивать статистическую мощность. В однофакторном дисперсионном анализе вариация результативной переменной, которая не может быть приписана фактору, включается в остаточный средний квадрат. Но вполне может быть так, что эта вариация с вязана с другим фактором. Тогда эта вариация может быть удалена из среднеквадратической ошибки, уменьшение которой приводит к увеличению значений F-критерия, а значит, к увеличению статистической мощности теста. Надстройка Анализ данных включает инструмент, обеспечивающий обработку двух факторов одновременно (рис. 27).
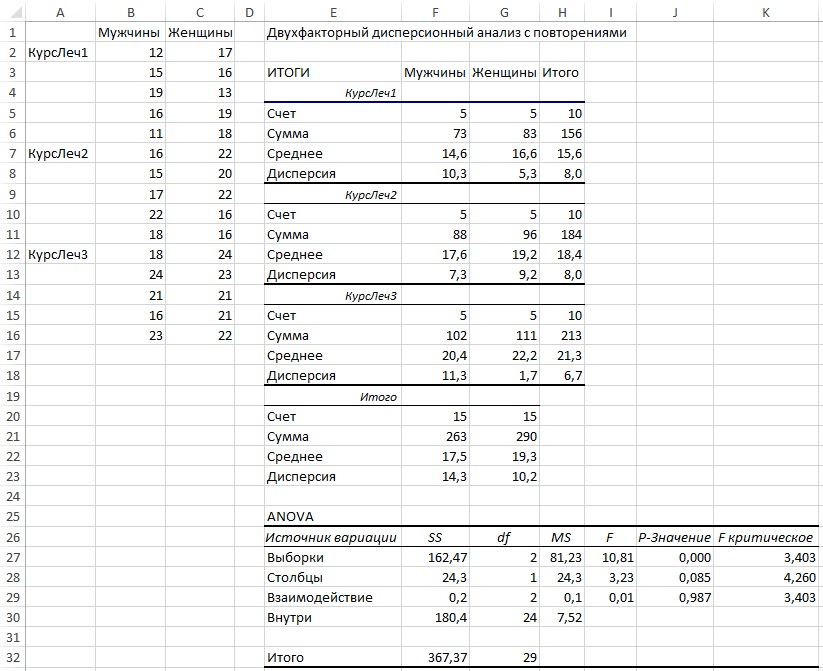
Рис. 27. Инструмент Двухфакторный дисперсионный анализ с повторениями Пакета анализа
Использованный на этом рисунке инструмент дисперсионного анализа, полезен тем, что он возвращает среднее и дисперсию результативной переменной, а также значение счетчика для каждой группы, включенной в план. В таблице Дисперсионный анализ отображаются два параметра, отсутствующие в выходной информации однофакторной версии инструмента дисперсионного анализа. Обратите внимание на источники вариации Выборка и Столбцы в строках 27 и 28. Источник вариации Столбцы относится к полу. Источник вариации Выборка относится к любой переменной, значения которой занимают различные строки. На рис. 27 значения для группы КурсЛеч1 находятся в строках 2-6, группы КурсЛеч2 — в строках 7-11, а группы КурсЛечЗ — в строках 12-16.
Главный момент заключается в том, что оба фактора, Пол (подпись Столбцы в ячейке Е28) и Лечение (подпись Выборка в ячейке Е27), включены в таблицу Дисперсионный анализ как источники вариации. Средние для мужчин отличаются от средних для женщин, и это создает источник вариации. Средние для трех видов лечения также различаются — вот вам еще один источник вариации. Существует также третий источник — Взаимодействие, который относится к объединенному эффекту переменных Пол и Лечение.
Глава 8. Ковариационный анализ
Ковариационный анализ, или ANCOVA (Analysis of Covariation) уменьшает смещения и увеличивает статистическую мощность. Напомню, что одним из способов оценки надежности регрессионного уравнения являются F-тесты:
F = MSRegression/MSResidual
где MS (Mean Square) — средний квадрат, а индексы Regression и Residual указывают на регрессионную и остаточную компоненты соответственно. Расчет MSResidual выполняется по формуле:
MSResidual = SSResidual / dfResidual
где SS (Sum of Squares) — сумма квадратов, a df – количество степеней свободы. Когда вы добавляете ковариацию в уравнение регрессии, некоторая доля общей суммы квадратов включается не в SSResiduaI, а в SSRegression. Это приводит к уменьшению SSResidual, а значит, и MSResidual. Чем меньше MSResidual, тем больше F-критерий и тем вероятнее, что вы отвергнете нулевую гипотезу об отсутствии различий между средними. В результате вы перераспределяете изменчивость результативной переменной. В ANOVA, когда ковариация не учитывается, изменчивость переходит в ошибку. Но в ANCOVA часть изменчивости, ранее относившаяся к ошибке, назначается ковариате и становится частью SSRegression.
Рассмотрим пример, в котором один и тот же набор данных анализируется сначала с помощью ANOVA, а затем с помощью ANCOVA (рис. 28).
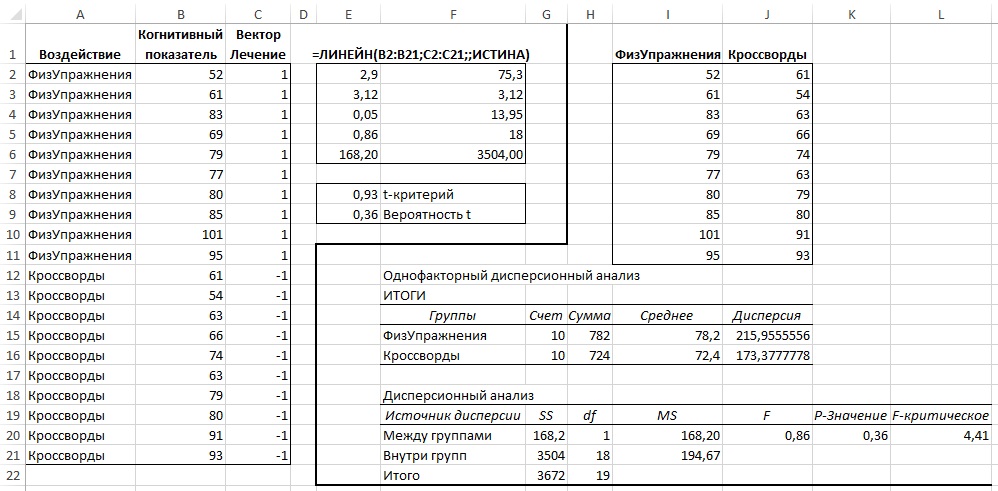
Рис. 28. Анализ ANOVA указывает на то, что результаты, полученные с помощью уравнения регрессии, ненадежны
В исследовании сравниваются относительные эффекты физических упражнений, развивающих мышечную силу, и когнитивных упражнений (разгадывание кроссвордов), активизирующих мозговую деятельность. Субъекты были случайным образом распределены по двум группам, чтобы в начале эксперимента обе группы находились в одинаковых условиях. По прошествии трех месяцев были измерены когнитивные характеристики субъектов. Результаты этих измерений приведены в столбце В.
В диапазоне А2:С21 размещены исходные данные, передаваемые функции ЛИНЕЙН() для выполнения анализа с использованием кодирования эффектов. Результаты работы функции ЛИНЕЙН() приведены в диапазоне E2:F6, где в ячейке Е2 отображается коэффициент регрессии, связанный с вектором воздействия. В ячейке Е8 содержится t-критерий = 0,93, а в ячейке Е9 тестируется надежность этого t-критерия. Содержащееся в ячейке Е9 значение говорит о том, что вероятность встретить различие между групповыми средними, наблюдаемое в данном эксперименте, составляет 36%, если в генеральной совокупности групповые средние равны. Лишь немногие признают этот результат статистически значимым.
На рис. 29 показано, что произойдет при добавлении ковариаты в анализ. В данном случае я добавил в набор данных возраст каждого субъекта. Коэффициент детерминации R2 для уравнения регрессии, в котором используется ковариата, равен 0,80 (ячейка F4). Значение R2 в диапазоне F15:G19, в котором я воспроизвел результаты ANOVA, полученные без использования ковариаты, равно всего лишь 0,05 (ячейка F17). Следовательно, уравнение регрессии, включающее ковариату, предсказывает значения переменной Когнитивный показатель намного точнее, чем с использованием только вектора Воздействие. Для ANCOVA вероятность случайного получения значения F-критерия, отображаемого в ячейке F5, равна менее чем 0,01%.
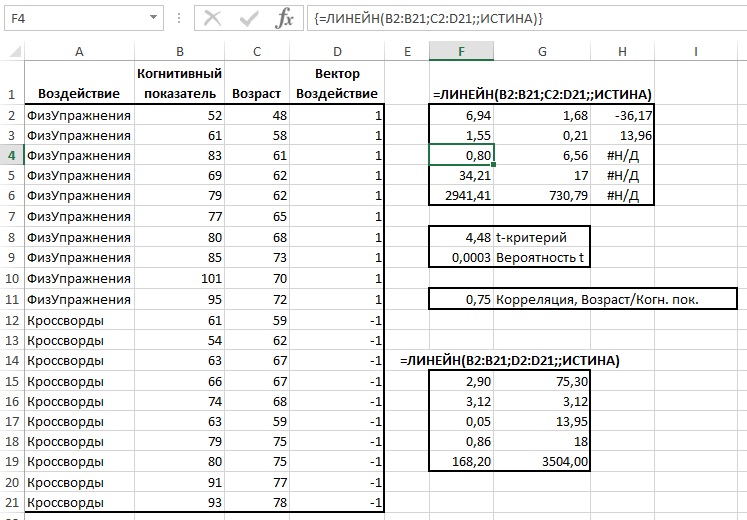
Рис. 29. ANCOVA возвращает совершенно иную картину
Поэтому далее остановимся на изучении алгоритма решения уравнений регрессии с применением соответствующих вычислительных программ. При этом работу с уравнениями регрессии в компьютерных программах можно разделить на три этапа.
На первом, подготовительном этапе необходимо определиться с набором факторов, которые необходимо включить в уравнение регрессии, а также с его аналитической формой, что в ряде случаев требует предварительной обработки данных. Например, в случае выбора степенного уравнения регрессии вместо исходных данных нужно взять их логарифмы.
Второй этап состоит из собственно решения уравнения регрессии и нахождения его параметров.
На третьем этапе проводится оценка и тестирования общего качества уравнения регрессии, проверка статистической значимости каждого из коэффициентов регрессии, определяются их доверительные интервалы, а также принимается окончательное решение об адекватности или неадекватности полученного уравнения регрессии.
Как известно, одним из наиболее распространенных способов определения тренда в динамике курса валюты является построение его зависимости от фактора времени T. Так, если в качестве зависимой переменной Y мы возьмем ежемесячный курс доллара, а в качестве независимой переменной T – время (в данном случае порядковые номера месяцев, начиная с июня 1992 г.=1), то у нас получится следующее уравнение парной линейной регрессии:
Y расч. =a + bT (2.2);
где a – свободный член уравнения регрессии; b – линейной коэффициент регрессии, показывающий, как изменение величины независимой переменной (фактора) T в среднем способствует изменению зависимой переменной (результативного признака) Y; Y расч. – расчетное значение результативного признака, вычисляемое по формуле (2.2).
Минимизируем сумму квадратов отклонений (остатков) Y факт. от Y расч.,то есть от фактических значений курса доллара от его расчетных значений. В результате формулу МНК (2.1.1) для линейной регрессии можно в данном случае представить в виде формулы (2.3):
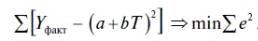
Уравнение (2.3) в принципе можно решить самостоятельно, если найти его параметры согласно формулам (2.1.4) и (2.1.5), но в целях ускорения этого процесса мы будем его решать с помощью Пакета анализа Excel. Кстати, желающие лучше усвоить суть МНК могут сначала самостоятельно в «ручном режиме» решить данное уравнение регрессии, а затем сверить свои результаты с теми, что мы получим в Excel.
Для того чтобы подготовить исходные данные к решению данного уравнения регрессии разместим в Excel два столбца исходных данных. В первом столбце, который озаглавим Time, поместим порядковые номера месяцев, начиная с июня 1992 г. (с номером =1) и кончая апрелем 2010 г. (с номером =215). Во втором столбце, который озаглавим USDOLLAR, поместим данные по курсу доллара на конец месяца, начиная с июня 1992 г. и заканчивая апрелем 2010 г. (последние данные, имевшиеся на тот момент, когда писались эти строки). Таким образом столбец Time представляет собой независимую переменную, которая в формуле (5) обозначена символом T, а столбец USDOLLAR является зависимой переменной Yфакт. Далее переходим к решению уравнения регрессии в Пакете анализа Excel, о том, как это делается, можно прочитать ниже – в алгоритме действий № 3.
Алгоритм действий № 3 «Как решить уравнение регрессии в Excel»
Шаг 1. Ввод в уравнение исходных данных
Делается это следующим образом: сначала в Microsoft Excel 2007 г. в верхней панели инструментов выбирается опция Данные (в Microsoft Excel 1997-2003 гг. нужно выбрать опцию Сервис), потом в появившемся окне Анализ данных – опция Регрессия. После чего появляется новое окно – Регрессия (см. рис. 2.1), в котором в графе Входной интервал y выделяем (с помощью мышки) столбец данных USDOLLAR (ячейки $C$1:$C$216). Здесь же в графе Входной интервал Х» выделяем столбец данных Time(ячейки $B$1:$B$216), то есть независимую переменную T из нашего уравнения регрессии (5).
Шаг 2. Дополнительные опции
Если бы мы хотели получить уравнение регрессии без свободного члена, который в формуле (2.2) обозначен символом a, то тогда нам следовало бы выбрать еще и опцию КОНСТАНТА-НОЛЬ. Однако в данном случае в использовании этой опции нет необходимости.
Опцию Остатки следует выбирать тогда, когда есть необходимость, чтобы в выходных данных содержалась информация об отклонении расчетных y от их фактических значений. При этом остатки находятся по следующей формуле (2.4):
Остатки = Yрасч.– Yфакт. (7); где Yрасч. – расчетные, Yфакт. – фактические значения результативного признака.
Опцию МЕТКИ применяют для того, чтобы переменные, включенные в уравнение регрессии, в выводе итогов были обозначены в виде заголовков соответствующих столбцов.
По умолчанию оценка в Excel параметров уравнения регрессии делается с 95% уровнем надежности. Однако в случае необходимости в опции Уровень надежности можно поставить цифру 99, что означает задание для программы оценить коэффициенты регрессии с 99% уровнем надежности. В результате в выводе итогов мы получим данные, характеризующие как в целом уравнение регрессии, так и верхние и нижние интервальные оценки коэффициентов данного уравнения с 95% и 99 % уровнями надежности. При 95% уровне надежности существует риск, что в 5 % случаях оценки коэффициентов уравнения регрессии могут оказаться неточными, а при 99% уровне надежности этот риск равен 1%.
Шаг 3. Вывод итогов
На заключительном этапе выбираем в параметрах вывода (окно РЕГРЕСССИЯ) опцию выходной интервал, в которой указываем соответствующую ячейку Excel ($H$2), далее щелкаем по надписи ОК и получаем ВЫВОД ИТОГОВ (см. рис 2.1, где можно увидеть все заданные нами параметры уравнения регрессии). В случае необходимости вывод итогов можно получить на отдельном листе (см. опцию НОВЫЙ РАБОЧИЙ ЛИСТ) или в новой книге Excel (см. опцию НОВАЯ РАБОЧАЯ КНИГА).
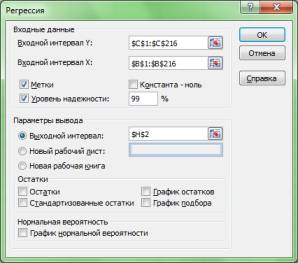
Рис. 2.1. Диалоговое окно РЕГРЕССИЯ для вывода итогов при решении в Excel уравнения регрессии
Результаты решения уравнения регрессии, которые в программе Excel выдаются в виде единой таблицы под заголовком ВЫВОД ИТОГОВ, у нас представлены в виде трех блоков (см. табл. 2.2-2.4). Так, в табл. 2.2 сгенерированы результаты по регрессионной статистике, в табл. 2.3 дается дисперсионный анализ, а в табл. 2.4 оценивается статистическая значимость коэффициентов регрессии .
Параметры, представленные в табл. 2.2, оценивают уровень аппроксимации фактических данных, полученный с помощью данного уравнения регрессии. Так, параметр Множественный R обозначает множественный коэффициент корреляции R, который характеризует тесноту связи между результативным признаком Y и факторами переменными X1, X2…Xn. Данный коэффициент изменяется в пределах от 0 до 1, причем, чем ближе к 1, тем теснее корреляционная связь между переменными, включенными в уравнение регрессии. Множественный коэффициент корреляции равен квадратному корню, извлеченному из коэффициента детерминации R2, который у нас также приводится в регрессионной статистике. Множественный коэффициент R также находят по формуле (2.5):

где Y факт. – фактическое, а Y расч. – расчетное (предсказанное по уравнению регрессии) значение результативного признака.
Зная величину коэффициента корреляции R, можно дать качественную оценку силы связи между зависимой и независимыми переменными, включенными в данное уравнение. С целью классификации силы связи обычно используют шкалу Чеддока (см. табл. 2.1).
Таблица 2.1. Шкала Чеддока для классификации силы связи
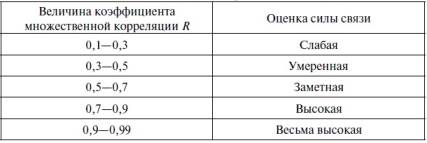
В случае между переменными существует функциональная связь, то R=1, а если корреляционная связь отсутствует, то R=0. Поскольку в таблице 2.2 множественный коэффициент корреляции R равен 0,8456, то согласно таблице Чеддока, связь между переменными, включенными в уравнение регрессии можно считать высокой. Следует также заметить, что если коэффициент множественной корреляции меньше 0,7, то это означает, что величина коэффициента детерминации R2 (о нем мы расскажем ниже) будет меньше 50%, а потому регрессионные модели с таким коэффициентом детерминации не имеют большого практического значения.
Однако самым важным является другой параметр регрессионной статистики – R-квадрат (его мы выделили жирным шрифтом), обозначающий коэффициент детерминации R2. Коэффициент детерминации R2 характеризует долю дисперсии результативного признака Y, объясняемую уравнением регрессии, в общей дисперсии результативного признака. Коэффициент детерминации R2 находится по формуле (2.6):
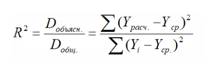
где Y i – фактическое, а Y расч. – расчетное (по уравнению регрессии) значение результативного признака (зависимой переменной), D объясн. – объясненная дисперсия, а D общ. – общая дисперсия результативного признака Y.
Коэффициент детерминации R2, как и множественный коэффициент корреляции R, изменяется в пределах от 0 до 1. Если R2 равен 1, то доля объясненной дисперсии составляет 100%, а, следовательно, связь между зависимой переменной Y и независимой переменными X 1, X 2…X t носит функциональный характер. В том случае, когда R2равен 0, то какая-либо связь между переменными в данном уравнении регрессии отсутствует.
Величина коэффициента детерминации R2 является одним из важнейших критериев при оценке качества уравнения регрессии. Так, при выборе из нескольких уравнений регрессии предпочтение (при прочих равных условиях) отдается тому, у которого коэффициент детерминации R2 ближе к 1. И это вполне понятно: чем выше коэффициент детерминации у данного уравнения регрессии, тем выше у него уровень аппроксимации и соответственно ниже доля необъясненной дисперсии. В нашем случае коэффициент детерминации R2 = 0,7151, а потому можно сделать вывод, что в период с июня 1992 года по апрель 2010 г. 71,51% ежемесячных колебаний курса доллара (зависимая переменная Y), согласно данному уравнению регрессии, объяснялись изменением порядкового номера месяца (независимая переменная Т).
Другой параметр регрессионной статистики – Нормированный R-квадрат. Дело в том, что при добавлении в уравнении регрессии дополнительных факторов (независимых переменных) величина коэффициента детерминации R2 соответственно растет. Поэтому для того чтобы сделать сравнения коэффициентов детерминации между уравнениями регрессии с разным числом факторов более сопоставимыми, используется нормированный R2, величина которого корректируется в сторону уменьшения при добавлении в уравнение дополнительных факторов. Пакете анализа EXcel нормированный R2 вычисляют по формуле (2.7):
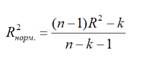
где n – количество наблюдений; k – количество переменных в уравнении регрессии.
В нашем случае расчет по этой формуле будет следующим:
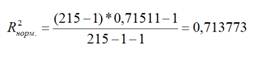
Еще один параметр регрессионной статистики Стандартная ошибка или остаточное стандартное отклонение, которое можно найти по формуле (2.8):
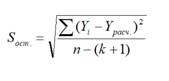
где n – количество наблюдений; k – количество переменных в уравнении регрессии.
Наблюдения – этот параметр регрессионной статистике показывает число наблюдений n, которых у нас в данном случае 215 (то есть равен числу месяцев с июня 1992 г. по апрель 2010 г., по которым у нас есть данные)
Таблица 2.2. Регрессионная статистика

В таблице 2.3 дается дисперсионный анализ, то есть анализ изменения результативного признака под воздействием включенных в уравнение регрессии факторов.
При этом столбцы данной таблицы имеют следующую интерпретацию.
Столбец df (degrees of freedom) сообщает число степеней свободы.
Причем, для строки Регрессия число степеней свободы равно количеству факторов kфакт., включенных в уравнение регрессии. В нашем случае dfрегр.=k =1.
Для строки Остаток число степеней свободы определяется число наблюдений и количеством факторов, включенных в уравнении регрессии. При этом dfост. находится по следующей формуле:
df ост. = n-(k +1) (2.9); где n – число наблюдений, k – количество факторов.
В нашем случае df ост. = 215-(1 +1)=213.
Для строки ИТОГО число степеней свободы находится по следующей формуле:
df итого = df регр. + df ост (2.10)
В нашем случае df итого = 1 +213=214
Столбец SS означает сумму квадратов отклонений.
Для строки РЕГРЕССИЯ данный столбец обозначает сумму квадратов отклонений рассчитанных (предсказанных) значений результативного признака от его среднего, рассчитанного по фактическим данным (2.11):
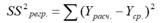
Для строки ОСТАТОК cтолбец SS обозначает сумму квадратов отклонений фактических данных от их расчетных значений (2.12):
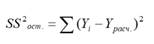
Для строки ИТОГО cтолбец SS обозначает сумму квадратов отклонений фактических данных от их среднего (2.13):
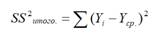
SS2итого можно также найти, сложив SS2регр. с SS2ост. =21779,45+8676,619=30456,07
Столбец MS означает дисперсию на одну степень свободы, которая находится по формуле (2.14):

Для строки РЕГРЕССИЯ – это факторная или объясненная дисперсия D факт.= MS факт.=21779,45/1=21779,45
Для строки ОСТАТОК – это остаточная дисперсия D ост.= MS ост.= 8676,619/213=40,7353
В столбце F дается фактический F-критерий Фишера, который находится путем сопоставления факторной и остаточной дисперсии на одну степень свободы. При этом F-критерий Фишера рассчитывается по формуле (2.15):
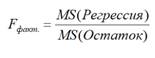
Если нулевая гипотеза (об отсутствии связи между переменными, включенными в уравнение регрессии) справедлива, то факторная и остаточная дисперсия не отличаются друг от друга. Поэтому для того чтобы уравнение регрессии было признано значимым, для нулевой гипотезы требуется опровержение, а для этого необходимо, чтобы факторная дисперсия превышала остаточную дисперсию в несколько раз. Статистиками разработаны соответствующие таблицы критических значений F-критерия при разных уровнях значимости нулевой гипотезы и различном числе степеней свободы. При этом следует иметь в виду, что табличное значение F-критерия – это максимальная величина отношения факторной дисперсии к остаточной дисперсии, которая может иметь место при случайном их расхождении для данного уровня вероятности наличия нулевой гипотезы. Если фактический (то есть рассчитанный для этого уравнения регрессии) F-критерий больше его табличного значения, то нулевая гипотеза об отсутствии связи между результативном признаком и факторами отклоняется. И в этом случае делается вывод о существенности этой связи.
5.В столбце значимость F показывается уровень значимости, который соответствует величине фактического F-критерия Фишера, вычисленного для данного уравнения регрессии. В нашем случае значимость F факт. практически равна нулю, то есть F факт. больше F табл. (значения F-критерия Фишера при уровне значимости 0,05 или 5% можно найти в любом учебнике по статистике) при 1% и 5 % уровне значимости. Отсюда можно сделать вывод, о статистической значимости уравнения регрессии, поскольку связь между включенными в него факторами в данном случае доказана.
В тех случаях, когда значимость F бывает больше, например, 0,01, но меньше 0,05, то тогда делается вывод, что F факт. меньше F табл. при 1% уровне значимости, но больше F табл при 5 % уровне значимости. Следовательно, в этой ситуации нулевая гипотеза об отсутствии связи между результативным признаком и факторами, включенными в уравнение регрессии, на 1% уровне значимости не отклоняется, но отклоняется на 5 % уровне значимости. Таким образом, в этом случае каждый исследователь должен сам решить, считать ли 5% уровень значимости F-критерия достаточным для того чтобы сделать вывод о статистической значимости данного уравнения регрессии. При этом следует иметь в виду, что если значимость F-критерия выше 0,05, то есть F факт. меньше F табл. при 5% уровне значимости, то в этой ситуации уравнение регрессии, как правило, считается статистически незначимым.
Таблица 2.3 «Дисперсионный анализ»
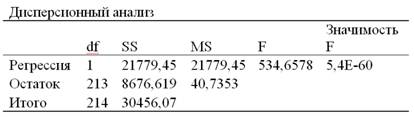
В таблице 2. 4 сгенерированы коэффициенты уравнения регрессии и оценки их статистической значимости.
1. При этом в столбце Коэффициенты представлены коэффициенты уравнения регрессии. На пересечении этого столбца со строкой Y-пересечение дан свободный член, который в формуле линейного уравнения регрессии (6) обозначен символом а =1,995805.
Во второй строке данного столбца, обозначенной как Time (независимая переменная – порядковый номер месяца), сгенерирован коэффициент уравнения регрессии, который в формуле (6) представлен символом b =0,162166.
Таким образом, данные, представленные в столбце Коэффициенты, дают нам возможность составить – путем подстановки соответствующих цифр в формулу (2.2) – следующее уравнение линейной парной регрессии:
y = 0,1622x + 1,9958;
где независимая переменная x означает порядковый номер месяца (июнь 1992 г. =1, а апрель 2010 г. = 215), а зависимая переменная y – ежемесячное значение курса доллара.
При этом экономическая интерпретация данного линейного уравнения следующая: в период с июня 1992 по апрель 2010 г. курс доллара к рублю ежемесячно рос со средней скоростью 16,22 коп. при исходном уровне временного ряда в размере одного рубля и 99,58 коп. В свою очередь, геометрическая интерпретация данного линейного уравнения следующая: свободный член уравнения =1,9958 показывает точку пересечения линии тренда с осью Y, а коэффициент уравнения 0,1622x равен углу наклона линии тренда к оси X.
Таблица 2.4. Коэффициенты уравнения регрессии и их статистическая значимость
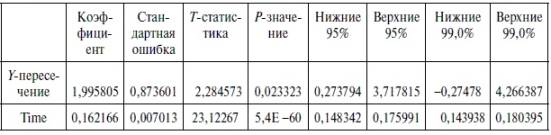
2. В столбце СТАНДАРТНАЯ ОШИБКА сгенерированы стандартные ошибки свободного члена и коэффициента регрессии, значения которых даны в предыдущем столбце табл. 4. При этом стандартная ошибка свободного члена уравнения регрессии находится по формуле (2.16):
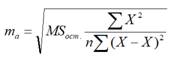
где MS ост.= D ост. – остаточная дисперсия на одну степень свободы. Для нашего случая стандартная ошибка свободного члена уравнения регрессии вычисляется следующим образом:

В свою очередь, стандартная ошибка коэффициента регрессии оценивается по формуле (2.17):
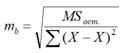
Для нашего случая стандартная ошибка коэффициента регрессии рассчитывается таким образом:

3. В столбце t-СТАТИСТИКА даны расчетные значения t-критерия. При этом для свободного члена t-статистика вычисляется по формуле (2.18):
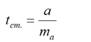
где a – коэффициент свободного члена уравнения.
В нашем случае t-статистика находится следующим образом:
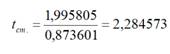
Для коэффициента регрессии t-статистика рассчитывается по формуле (2.19):
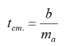
где b – коэффициент регрессии
В нашем случае t-статистика находится следующим образом:
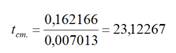
4. В столбце Р-ЗНАЧЕНИЕ сгенерированы уровни значимости, соответствующие вычисленным в предыдущем столбце значениям t-статистики.
В Excel Р-значение находится с помощью следующей функции:
СТЬЮДРАСП (Х=tст.;df=n-k-1;хвосты=2);
где в опции Х дается t-статистика, для которой нужно вычислить двустороннее распределение; в опции df – число степеней свободы; в опции хвосты – цифра 2 для двустороннего распределения.
В данном случае для свободного члена уравнения эта функция приобретает следующий вид: СТЬЮДРАСП (2,284573;215-1-1=213;2)= 0,023323
Следовательно, Р-значение коэффициента свободного члена уравнения показывает, что данный коэффициент значим лишь при 5% уровне значимости, но не значим при 1% уровне значимости.
Для коэффициента регрессии Р-значение в Excel находится следующим образом: СТЬЮДРАСП (23,12267;215-1-1=213;2)= 5,4E-60=0,0
Следовательно, Р-значение коэффициента регрессии показывает, что данный коэффициент значим не только при 5% уровне значимости, но и при 1% уровне значимости.
5. Столбцы Нижние 95% и Верхние 95% показывают соответственно нижние и верхние интервалы значений коэффициентов при 95 % уровне значимости. Для расчета доверительных интервалов сначала находится критическое значение t-критерия, которое в Excel находится с помощью функции СТЬЮДРАСПОБР (? =0,05 ;df=n-k-1); где в опции ? – величина риска, коэффициент регрессии (или свободный член) не окажутся в рамках установленных доверительных интервалов); в опции df – число степеней свободы.
Таким образом для 95% уровня надежности t-критерий = СТЬЮДРАСПОБР (? =0,05 ;df=215-1-1)= 1,9712
Далее для свободного члена уравнения находим:
Значение столбца Нижние 95%=Коэффициент – Стандартная ошибка* t-критерий=1,995805– (0,873601*1,9712)= 0,273794.
Значение столбца ВЕРХНИЕ 95%=Коэффициент + Стандартная ошибка* t-критерий=1,995805 + (0,873601*1,9712)= 3,717815.
Для коэффициента регрессии Time находим:
Значение столбца Нижние 95%=Коэффициент – Стандартная ошибка* t-критерий=0,162166– (0,007013*1,9712)= 0,148342.
Значение столбца ВЕРХНИЕ 95%=Коэффициент + Стандартная ошибка* t-критерий=0,162166+ (0,007013*1,9712)= 0,175991.
6. Столбцы Нижние 99% и Верхние 99% показывают соответственно нижние и верхние интервалы значений коэффициентов при 99 % уровне значимости. При этом значения столбца Нижние 99% и Верхние 99% находятся аналогичным образом, как и значения столбцов Нижние 95% и Верхние 95%.
Единственное отличие, это расчет t-критерия для 99% уровня надежности. При этом t-критерий = СТЬЮДРАСПОБР (? =0,01 ;df=215-1-1)= 3,3368. Найденный t-критерий используют при нахождении 99% доверительных интервалов для свободного члена и коэффициента регрессии. Правда, с коэффициентом свободного члена у нас возникает довольно серьезная проблема. Дело в том, что при 99% уровне надежности у коэффициента свободного члена при переходе от столбца Нижние 99% к столбцу Верхние 99% происходит смена знака от минуса к плюсу. Вполне очевидно, что в практических расчетах столь неоднозначно изменяющийся коэффициент уравнения (он может быть как положительным, так и отрицательным, также равным 0) невозможно использовать. Поэтому для 99 % уровня надежности коэффициент свободного члена уравнения считается статистически незначимым, в то время как для 95 % уровня надежности данный коэффициент считается статистически значимым, поскольку в последнем случае при переходе от столбца Нижние 95% к столбцу Верхние 95% смена знака происходит от минуса к плюсу
Алгоритм действий № 4 «Оценка статистической значимости уравнения регрессии и его коэффициентов»
Суммируя вышесказанное, приведем краткий алгоритм принятия решения о статистической значимости уравнения регрессии на основе ВЫВОДА ИТОГОВ в Excel.
Шаг 1. Принятие решения о значимости уравнения регрессии
1.1 Чем ближе R-квадрат к 1, тем лучше, что дает отличный критерий для выбора одного из нескольких уравнений регрессии.
Значимость F должна быть меньше 0,05 – при 95% уровне надежности; при 99% должна быть меньше 0,01 ? при 99% уровне надежности уровне.
Шаг 2. Принятие решения о значимости коэффициентов уравнения регрессии
P-Значение должно быть меньше 0,05 – при 95% уровне надежности; при 99% P-Значение должно быть меньше 0,01 ? при 99% уровне надежности уровне.
Коэффициенты регрессии и свободного члена при переходе от столбца Нижние и Верхние (при заданном уровне надежности) не должны менять свой знак. Если смена знака происходит, то коэффициенты данного уравнения признаются статистически незначимыми.
Исходя из этого краткого алгоритма, мы отметили жирным шрифтом в ВЫВОДЕ ИТОГОВ (см. табл. 2.5) именно те пункты, на которые следует обратить внимание. При этом те пункты, которые не являются статистически значимыми при данном уровне надежности, мы не только выделили жирным шрифтом, но еще и подчеркнули.
Таблица 2.5. ВЫВОД ИТОГОВ и принятие решения о статистической значимости уравнения регрессии и значимости его коэффициентов
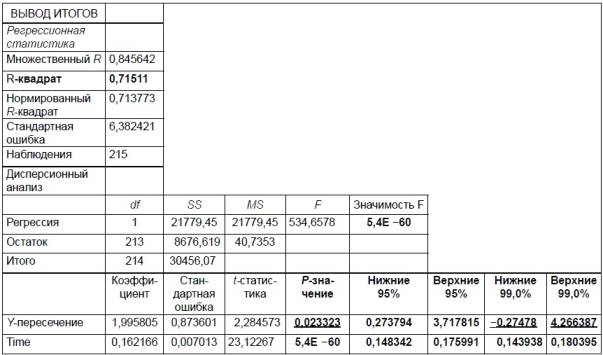
Таким образом, взяв за основу данные из таблицы 2.5 и действуя по алгоритму № 4, мы дадим ответы на все четыре пункта последнего:
1.1. Поскольку коэффициент детерминации R2 для данного уравнения регрессии оказался равен 0,71511, то отсюда можно сделать вывод, что оно в 71,51% случаях в состоянии объяснить ежемесячные колебания курса доллара.
1.2. Значимость F равна 5,4E-60 или =0, а, следовательно, уравнение регрессии статистически значимо как при 95% уровне надежности, так и при 99% уровне надежности.
2.1. P-Значение для коэффициента свободного члена уравнения равно 0,023323, а следовательно этот коэффициент статистически значим лишь при 95% уровне надежности, но не значим при 99% уровне надежности, поскольку он больше 0,01. P-Значение для коэффициента регрессии равно 0, а, следовательно, этот коэффициент статистически значим как при 95% уровне надежности, так и при 99% уровне надежности .
2.2. Коэффициент свободного члена (константа) уравнения при переходе от столбца Нижние 99,0% к столбцу Верхние 99,0% меняет знак с минуса на плюс, а потому статистически не значим при 99% уровне надежности. При 95% уровне надежности смены знаков не происходит, а потому свободный член уравнения при данном уровне надежности статистически значим. Коэффициент регрессии статистически значим как при 95%, так и при 99% уровне надежности, поскольку и в том и другом случае смены знака у данного коэффициента не происходит. Следовательно, на основании таблицы 5 можно сделать вывод, что в целом уравнение регрессии и все его коэффициенты статистически значимы при 95% уровне надежности.
Как мы уже говорили ранее, уравнение регрессии – в отличие от обычных уравнений, оценивающих функциональную, то есть жестко детерминированную связь между переменными – дает прогноз зависимой переменной с учетом воздействия случайного фактора. Поэтому фактические значения результативного признака практически всегда отличаются от его расчетных (теоретических) значений. При этом случайная компонента (остаток) находится следующим образом.
Сначала находится прогнозируемый курс доллара, например, на апрель 2010 г. С учетом того, что порядковый номер апреля 2010 равен 215 (при июне 1992 г. =1), предсказываемый на этот месяц курс доллара может быть найден следующим образом:
Y расч.=0,1622*215++ 1,9958=36,8616
e = Y факт. – Y расч.= -7,573
Следовательно, прогноз, сделанный по данному уравнению регрессии, в апреле 2010 г. оказался выше фактического курса доллара на 7 руб. 57,3 коп. Вполне очевидно, что это слишком большая величина отклонения, чтобы данное уравнение регрессии можно было бы использовать для прогноза валютного курса. В свою очередь, чем ближе теоретические значения подходят к фактическим данным, тем лучше качество прогностической модели. Поскольку разница между фактическим и предсказываемым значением курса доллара (yфакт. – yрасч.) может быть как величиной положительной, так и отрицательной, то ошибка аппроксимации (подгонки модели к фактическим данным) следует определять как в абсолютных цифрах по модулю, так и в процентах модулю.
При этом среднюю абсолютную ошибку по модулю находят по формуле (2.20):
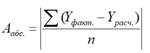
Для нашего уравнения регрессии средняя абсолютная ошибка по модулю по данной формуле была рассчитана таким образом:
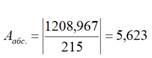
Иначе говоря, прогноз по данной статистической модели в среднем по каждому наблюдению отклонялся от фактического значения курса доллара на 5 руб. 62,3 коп. по модулю.
Среднюю относительную ошибку по модулю в процентах вычисляют по формуле (2.21):
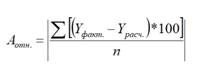
При этом средняя относительная ошибка по модулю в процентах находится в нашем случае таким образом:
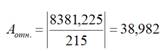
Следовательно, прогноз по данной статистической модели в среднем по каждому наблюдению отклонялся от фактического значения курса доллара на 38,98 %. В то время как о хорошем качестве уравнения регрессии можно говорить лишь в том случае, если средняя относительная ошибка по модулю составит не более 5-7%. (См. учебник «Эконометрика» под ред. И.И. Елисеевой. ? 2-е изд., пер. и доп. ? М,: Финансы и статистика, 2006, стр. 107).
Для того чтобы окончательно убедиться в непригодности для прогноза данного уравнения регрессии, построим таблицу 2.6, в которой дадим прогнозы и фактический курс доллара за период с января 2009 г. по апрель 2010 г.
Таблица 2.6. Прогноз, фактический курс доллара и остатки с января 2009 г. по апрель 2010 г.
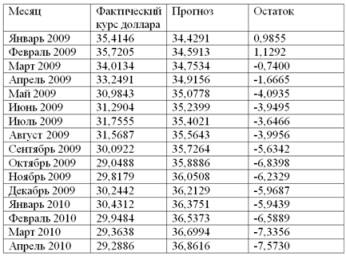
Судя по табл. 2.6, с января 2009 г. по апрелю 2010 г. отклонения от прогноза (остатки), сделанного по уравнению регрессии Y расч.=0,1622*215++ 1,9958, колебались в диапазоне от 98,5 коп. до 7 руб. 57,3 коп., что свидетельствует о невысокой точности данной прогностической модели. Более того, если построить график остатков по линейной прогностической модели, то легко обнаружить, что на нем наблюдается несколько локальных трендов (см. рис. 2.2). А это признак – как мы об этом уже говорили – нестационарности полученных остатков.
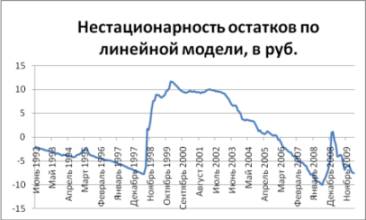
Рис. 2.2. Нестационарность остатков, полученных в линейной статистической модели
Источник: по данным Банка России
Данный текст является ознакомительным фрагментом.