При выборочном наблюдении регистрируется
только часть единиц генеральной
совокупности. Но эта часть по объему
должна быть такова, чтобы получаемые
сведения оказались репрезентативными,
т. е. достаточно верно отражали содержание
и закономерности изучаемого явления
в целом. Под репрезентативностью
понимается свойство выборочной
совокупности воспроизводить характеристики
генеральной совокупности.
Разность между данными генеральной и
выборочной совокупностей называют
ошибкой репрезентативности, или ошибкой
выборки. Например, генеральная
совокупность правонарушителей составляет
500 человек. Удельный вес лиц, воспитанных
в неполной семье, среди них равен
30%. При выборочном наблюдении было
изучено 50 человек, среди которых удельный
вес таких лиц оказался 25%. Ошибка выборки
равна: 30% — 25% = 5% (0,5). Аналогичным
образом выводится ошибка репрезентативности
и для количественного признака.
Предположим, что средняя арифметическая
величина возраста преступников в
генеральной совокупности была равна
28,3 года. В выборочной совокупности она
составила 26,5 года. Ошибка равна: 28,3
— 26,5 = 1,8 года.
Ошибки бывают тенденциозными, или
систематическими, и случайными. Первые
— результат неправильного или
преднамеренного отбора исследователем
тех или иных показателей, вторые —
результат случайностей неполного
отбора.
Тенденциозные ошибки возникают тогда,
когда исследователь неправильно
сформировал выборку, не знал научных
правил отбора единиц совокупности,
сознательно отобрал наиболее показательные
единицы. Например, исследуя правосознание
граждан, анкетер в целях экономии
времени воспользовался аудиторией
студентов-юристов и опросил их. Полученные
данные, естественно, отражали правовые
взгляды лишь этих респондентов и не
соответствовали взглядам всех граждан.
Выводы, сделанные на основе тенденциозных
выборок, будут ошибочными. Они могут
причинить вред делу.
Истории известны многие курьезы,
связанные с пренебрежением правилами
выборочного наблюдения. Один из них
произошел в США в 1936 г. при прогнозировании
исхода президентских выборов. Журнал
«Литерари Дайджест», используя телефонные
книги, опросил свыше 2 млн человек. По
итогам опроса президентом должен быть
избран Ландон. Социологи Геллап и другие
опросили только 4 тыс. жителей и пришли
к однозначному выводу: победит
Рузвельт. Их прогноз оправдался. В чем
причина таких расхождений? Первая
выборка отражала мнение лишь состоятельных
консервативных слоев населения, которые
имели телефоны, вторая — всех слоев
населения. Она оказалась более
представительной, хотя была в 500 раз
меньше первой. Роковую роль сыграли
тенденциозные ошибки.
Научно-практическая задача выборочного
наблюдения сводится не только к тому,
чтобы при малых затратах сил и средств
максимально приблизить данные выборки
к данным всей генеральной совокупности,
но и к тому, чтобы точно измерить, в каких
пределах результаты выборки отличаются
от данных генеральной совокупности.
Здесь и встает вопрос о характере ошибок.
Тенденциозные (систематические) ошибки
нельзя измерить. Они могут быть самыми
разными по величине и содержанию.
Тенденциозные ошибки тем меньше, чем
выше квалификация исследователя,
чем лучше он знаком с объектом изучения
и возможными источниками систематических
ошибок.
Измерить можно лишь случайные ошибки,
т. е. ошибки, обусловленные неполнотой
изучения реально существующей
совокупности. Случайные ошибки —
непреднамеренные неточности статистического
наблюдения, которые могут быть направлены
как в сторону преувеличения показателей
признака, так и в сторону их
преуменьшения. При относительно большом
изучении случайные ошибки взаимопогашаются
(вспомним третий этап эксперимента по
извлечению пронумерованных карточек,
когда было сделано 30 выборок по 40
извлечений каждая), в результате чего
данные выборочной совокупности становятся
близкими к данным генеральной.
Оставшиеся различия можно относительно
точно измерить на основе теории
вероятностей, закона больших чисел
и закономерностей распределения
случайных величин.
Для того чтобы избежать тенденциозных
ошибок, необходимо строго соблюдать
правила случайного отбора единиц
выборочной совокупности. Случайные
ошибки в выборочном наблюдении
объективны. Их нельзя избежать, но можно
уменьшить путем увеличения объема
выборки и точно вычислить.
Необходимость в точном расчете ошибки
выборки возникает тогда, когда
произведенное выборочное наблюдение
надо оценить с точки зрения его
репрезентативности и достоверности.
Формула для вычисления ошибки выборки
в общем виде выглядит так:
где W — ошибка выборки; а — средний
квадрат отклонения (дисперсия); о —
среднее квадратическое отклонение; п
— число единиц выборки.
Исходя из этой формулы, ошибка
репрезентативности прямо пропорциональна
дисперсии или среднему квадратическо-му
отклонению и обратно пропорциональна
числу единиц выборки. Ошибка выборки
будет тем меньше, чем меньше дисперсия
(колеблемость признака) и чем больше
численность выборки. Объем выборочной
совокупности, как правило, всегда
известен, если исследование уже
произведено. Остается вычислить
дисперсию, порядок расчета которой мы
излагали в предыдущем параграфе.
Подставляя значение дисперсии в формулу
ошибки выборки для качественного и
количественного признака получаем:
w =w =I/
Эти формулы позволяют рассчитывать
ошибку выборки на основе исходных
показателей. Рассчитаем ее по данным
предыдущих примеров. Дисперсия
качественного признака — состояния
опьянения, удельный вес которого в
структуре изучаемых преступлений
составлял 35%, оказалась равной 0,23.
Численность выборки определим в 100
единиц (уголовных дел, статкарт,
приговоров). В этом случае
W = ,/0,0023 = 0,048, или 4,8
Это означает, что при правильной случайной
выборке в 100 единиц удельный вес лиц,
совершивших преступления в состоянии
опьянения, будет колебаться относительно
удельного веса данного признака в
генеральной совокупности в пределах ±
4,8%, т. е. 35% ± 4,8% или от 30,2 до 39,8%. Если мы
увеличим выборку вчетверо, т. е. до 400
единиц, то ошибка выборки уменьшится
вдвое и будет составлять ± 2,4%. При
максимальной дисперсии качественного
признака (0,25) и 100 единицах выборки ошибка
выборки будет равняться 0,05, или ± 5%, а
при 400 единицах выборки — 0,025, или ± 2,5%.
Обратимся к примеру с количественными
признаками —к 100 осужденным к разным
срокам лишения свободы. Дисперсия
количественного признака равнялась
2,29 года. Рассчитаем ошибку выборки:
w = V0.0229 = ± 0,048 года.
При увеличении выборки вчетверо, т. е.
до 400 единиц, ошибка выборки уменьшится
вдвое и составит ±0,075 года.
Приведенные примеры наглядно показывают,
что при правильном отборе выборочной
совокупности даже при небольшом объеме
в 100 единиц ошибка репрезентативности
может быть признана вполне допустимой,
а при выборке в 400 единиц — тем более.
При максимальной дисперсии качественного
признака и выборке в 100 единиц ошибка
выборки, например, не превышала ± 5%.
Эти величины постоянные, что и используется
в заранее рассчитанных таблицах.
Дисперсия и ошибка выборки количественных
признаков выражаются не в относительных
числах (процентах, долях), как у качественных
показателей, а в именованных числах, т.
е. в годах, рублях, классах, часах и т. д.
Они могут иметь самые разные содержательные
и численные значения. Их нельзя рассчитать
заранее безотносительно к конкретному
признаку, и поэтому готовых таблиц
ошибок выборки для количественных
признаков нет.
Все предшествующие формулы и расчеты
ошибки репрезентативности имеют
значение для повторной выборки. При ней
каждая отобранная из генеральной
совокупности единица (например, статкарта
на преступление) вновь возвращается в
массив. Поэтому не исключена возможность
ее повторного отбора. Наряду с таким
отбором есть отбор бесповторный. При
нем каждая отобранная единица
исключается из числа единиц генеральной
совокупности, а поэтому может попасть
в выборку лишь один раз. В связи с этим
ошибка выборки для качественных и
количественных признаков вычисляется
соответственно по разным формулам:
где и — число выборочной совокупности;
N — число генеральной совокупности.
Проанализируем эти формулы на конкретном
примере. Предположим, что в одном из
городов бесповторным способом был
произведен опрос 300 граждан о знании
ими УК РФ. Удельный вес лиц, которые не
знали ничего о кодексе, составил 20%.
Общая численность взрослого населения
города составила 15 тыс. человек. Необходимо
установить репрезентативность
произведенного изучения. В данном
случае W =0,2(1-0,2)
30015000J= Г’V 300(1 — 0,02) = ±0,022
Однократная ошибка выборки составила
± 0,022, или ± 2,2%, а двукратная — ± 4,4%. Если
опрос граждан производился при строгом
соблюдении процедуры, то удельный вес
тех из них, которые не знают ничего об
УК, в структуре всех граждан может
колебаться в пределах 20 ± 4,4% или от 15,6
до 24,4%. Возможные отклонения существенны,
но для практических целей результаты
могут быть признаны вполне
удовлетворительными.
Анализ формул ошибки бесповторной
выборки показывает, что дополнительный
множитель (1— n/N) не может быть больше
единицы, следовательно, он лишь уменьшает
величину ошибки выборки. В данном случае
этот множитель составил 0,98 и уменьшил
все подкоренное выражение на 0,00001, а
ошибку выборки — на 0,1%. В других
случаях это уменьшение может быть
большим. Таким образом, наличие
данного множителя позволяет более
точно вычислить ошибку бесповторной
выборки, причем в сторону ее минимизации.
Поэтому, если исследователю неизвестна
численность генеральной совокупности,
а он произвел бесповторную выборку, то
можно рассчитать ошибку репрезентативности
по формуле повторной выборки. Незначительной
неточностью, связанной с завышением
расчетной ошибки, можно пренебречь,
поскольку социально-правовые исследования
не требуют особой точности.
При рассмотрении закономерностей
нормального распределения (рис. 6)
говорилось о правиле трех сигм. Вспомним,
что если площадь выборки заключена в
пределах Зс, то она составит 99,7% (0,997)
всей площади, ограниченной кривой
распределения, если в пределах 2о —
95,4% (0,954), если в пределах 1о -68,3% (0,683). Эта
закономерность используется для расчета
коэффициента доверия (t).
Не вникая в математическую сторону
этого вопроса, скажем, что вероятность
отклонения изучаемого признака, как
качественного, так и количественного,
в пределах однократной ошибки
репрезентативности, т. е. при /= 1, равна
0,683. Это означает, что из 1000 изучаемых
единиц 683 будут находиться в пределах
однократной ошибки выборки, а остальные
317 единиц — за ее пределами. При
коэффициенте доверия, равном 2 (/=2),
вероятность отклонения изучаемого
признака будет находиться в пределах
двукратной ошибки репрезентативности
и равняться 0,954, те. из 1000 изучаемых
единиц 954 будут находиться в пределах
двукратной ошибки. При коэффициенте
доверия, равном 3 (/=3), из 1000 изучаемых
единиц 997 будут находиться в пределах
трехкратной ошибки.
Символ t именуют коэффициентом кратности
ошибки репрезентативности, или
коэффициентом доверия. Его увеличение
повышает репрезентативность выборки,
но не само по себе, а через увеличение
выборочной совокупности. Если, например,
при проведении криминологического
или социально-правового изучения есть
необходимость в том, чтобы ошибка
репрезентативности не превышала ± 4,8%,
как было в нашем примере, а коэффициент
доверия был равен не 1, а 3, т. е. t— 3, то
численность выборочной совокупности
придется увеличить в 6 раз, или до 600
единиц. При t=2 численность выборки должна
быть увеличена в 4 раза, т. е. до 400 единиц.
Выше говорилось, что если уменьшить
ошибку выборки в 2 раза, то выборочную
совокупность следует увеличить в 4 раза.
Поставим задачу по-иному. Если нас
удовлетворяет величина ошибки выборки,
но необходимо повысить коэффициент
доверия до 1=2, чтобы в 954 случаях из 1000
величина единиц изучения не отклонялась
от заданной ошибки, также надо увеличить
объем выборочной совокупности в 4
раза. Ошибка сохраняется та же, а
коэффициент доверия повышается. При
криминологических, социально-правовых
исследованиях и при изучении в
практических оперативных целях может
быть допустима точность с коэффициентом
доверия /= 1. При решении важных научных
или практических вопросов желательно,
чтобы ошибка репрезентативности
принималась с коэффициентом доверия t
= 2. Изучение с коэффициентом доверия /
= 3 в юридической статистике практически
нигде не требуется.
Предельная ошибка выборки обозначается
греческой буквой А (дельта). Она равна
произведению однократной ошибки выборки
на соответствующий коэффициент доверия
Д = W’t. Заменив W соответствущими формулами
для повторной выборки, получим:
Для бссповторной выборки эти формулы
будут иметь следующий вид:
Избежать сложных математических расчетов
при определении пределов ошибки
репрезентативности качественных
характеристик при заданном числе
наблюдений помогают специальные
таблицы, рассчитанные математиками
(табл. 5).
Таблица 5 Предел ошибки при заданном
числе наблюдений и t = 2, %
|
Удельный |
Число |
|||||||||
|
100 |
200 |
300 |
400 |
500 |
600 |
700 |
800 |
900 |
1000 |
|
|
5 |
4,4 6,0 7,2 8,0 |
3,1 4,3 5,1 5,7 |
2,8 3,5 4,1 4,6 |
2,5 3,0 3,6 4,0 |
1,9 2,7 3,2 3,6 3,9 |
1,8 2,5 2,9 3,3 |
1,6 2,3 2,7 3,0 |
1,5 2,1 2,5 2,8 3,1 3,2 |
1,4 2,0 2,4 2,7 |
1,4 1,9 2,3 2,5 |
|
40 |
Используя эту далеко не полную таблицу,
определим предельную ошибку
репрезентативности по уже известным
данным о лицах, совершивших преступления
в состоянии опьянения. Вспомним эти
данные: удельный вес указанных лиц
составлял 35%, объем выборочной совокупности
100 и 400 единиц. Ошибка репрезентативности,
рассчитанная по формулам, оказалась
равной соответственно ± 4,8 и ± 2,4%. Если
наши расчеты были верными, то они
совпадут с данными табл. 5.
Находим в графе 1 таблицы значение
показателя, равное 35% (оно подчеркнуто).
На этой же строке в графе 2, соответствующей
100 наблюдениям, находим ошибку
репрезентативности ± 9,6%, а в графе 5,
соответствующей 400 наблюдениям, — ошибку
репрезентативности ± 4,8%. Сопоставим
расчетные ошибки с табличными.
Последние оказались вдвое больше тех,
которые были получены путем расчета.
Однако никакой ошибки здесь нет. Пределы
ошибок, указанные в табл. 5, рассчитаны
при коэффициенте доверия, равном 2
(/=2), а мы рассчитывали без учета
коэффициента доверия (т. е. при /= 1).
Если использовать формулы расчета
предельных ошибок с /= 2, то получим те
же самые данные, которые указаны в табл.
5.
д = tW = 2 • 4,8 = ±9,6%;
Д = tW = 2 • 2,4 = ±4,8%.
Коэффициент доверия, равный 2, означающий,
что в 954 случаях из 1000 единицы изучения
не будут выходить за пределы заданной
ошибки репрезентативности, практически
надежен. Поэтому таблицы предельных
ошибок рассчитаны применительно к нему.
1. Выборочный метод в статистических исследованиях используется
для:
а) экономии
времени и снижения затрат на проведение статистического исследования;
б) повышения точности прогноза;
в) анализа факторов взаимосвязи.
2.Выборочный метод в торговле используется:
а) при анализе ритмичности оптовых поставок;
б) при
прогнозировании товарооборота;
в) при разрушающих методах контроля качества товаров.
3.Необходимая численность выборочной совокупности определяется:
а) колеблемостью
признака;
б) условиями формирования выборочной совокупности;
4. Выборочная совокупность отличается от генеральной:
а) разными единицами измерения наблюдаемых объектов;
б) разным
объемом единиц непосредственного наблюдения;
в) разным числом зарегистрированных наблюдений.
5.Средняя ошибка выборки:
а) прямо
пропорциональна рассеяности данных;
б) обратно пропорциональна разбросу варьирующего признака;
в) никак не зависит от колеблемости данных;
6.Ошибка репрезентативности обусловлена:
а) самим
методом выборочного исследования;
б) большой погрешностью зарегистрированных данных.
7. По виду различают:
а)единичный отбор
б)комбинированный
в)множественный
8. Повторный отбор отличается от бесповторного тем, что:
а) отбор повторяется, если в процессе выборки произошел сбой;
б) отобранная
однажды единица наблюдения возвращается в генеральную совокупность;
в) повторяется несколько раз расчет средней ошибки выборки.
9. Малая
выборка — это выборка объемом:
а) 4-5 единиц изучаемой совокупности;
б) до 50 единиц изучаемой совокупности;
в) до 30
единиц изучаемой совокупности.
10. Средняя величина количественного признака – это обобщающая
характеристика варьирующего признака у:
а) всей совокупности
б) у
отдельных единиц совокупности
в)у одной единицы
11.Средняя ошибка выборки представляет из себя расхождение между
средними:
а)выборочной совокупности
б)генеральными совокупностями
в)выборочной
и генеральной
12.К начальной цене относят:
а)цену
б)себестоимость
в)зп рабочих
13.В зависимости от базы сравнения различиают:
а)базисные
с постоянной базой
б)единичные с постоянной базой
в)арифмитические с переменной базой
14. ![]() Это формула для нахождения:
Это формула для нахождения:
а)средней
ошибки в выборочной доле
б)средней ошибки для общей выборки
в)средней ошибки дисперсии
15.Для вычисления расхождений между характеристиками выборочной и
генеральной совокупности необходимо:
а)
значение генеральной дисперсии
б)средней ошибки выборки
в)выборочной средней
16.Выборка всгда связана:
а)количеством выборки
б)объемом
выборки
в)временем выборки
17.начальные показатели рассчитываются,как:
а)отношения
уровня явления к базовому году
б)отношение базового года к уровню явления
в)отношение базового к текущему году
18. 5%
изготовленных изделий – брак, тогда 95% изделий годных. Дисперсия доли брака
равна:
а)475
б)0,475
в)0,0475
19.
 Формула для нахождения:
Формула для нахождения:
а)индекса цен
б)агрегат
индекса с товарооборота
в)индекс
Пааше
20.Выборочная доля представляет собой отношение числа единиц :
а)
обладающих данным признаком ( m ) к общему числу единиц
выборочной совокупности ( n )
б) общего числа единиц выборочной совокупности ( n )
к числу обладающих данным признаком ( m )
в)нет верного ответа
97 вопросов
Выполним любые типы работ
- Дипломные работы
- Курсовые работы
- Рефераты
- Контрольные работы
- Отчет по практике
- Эссе
1. Статистика как наука изучает:
а) единичные явления;
б) массовые явления;
в) периодические события.
2. Термин «статистика» происходит от слова:
а) статика;
б) статный;
в) статус.
3. Статистика зародилась и оформилась как самостоятельная учебная дисциплина:
а) до новой эры, в Китае и Древнем Риме;
б) в 17-18 веках, в Европе;
в) в 20 веке, в России.
4. Статистика изучает явления и процессы посредством изучения:
а) определенной информации;
б) статистических показателей;
в) признаков различных явлений.
5. Статистическая совокупность – это:
а) множество изучаемых разнородных объектов;
б) множество единиц изучаемого явления;
в) группа зафиксированных случайных событий.
6. Основными задачами статистики на современном этапе являются:
а) исследование преобразований экономических и социальных процессов в обществе; б) анализ и прогнозирование тенденций развития экономики; в) регламентация и планирование хозяйственных процессов;
а) а, в
б) а, б
в) б, в
7. Статистический показатель дает оценку свойства изучаемого явления:
а) количественную;
б) качественную;
в) количественную и качественную.
8. Основные стадии экономико-статистического исследования включают: а) сбор первичных данных, б) статистическая сводка и группировка данных, в) контроль и управление объектами статистического изучения, г) анализ статистических данных
а) а, б, в
б) а, в, г
в) а ,б, г
г) б, в, г
9. Закон больших чисел утверждает, что:
а) чем больше единиц охвачено статистическим наблюдением,тем лучше проявляется общая закономерность;
б) чем больше единиц охвачено статистическим наблюдением, тем хуже проявляется общая закономерность;
в) чем меньше единиц охвачено статистическим наблюдением, тем лучше проявляется общая закономерность.
10. Современная организация статистики включает: а) в России — Росстат РФ и его территориальные органы, б) в СНГ — Статистический комитет СНГ, в) в ООН — Статистическая комиссия и статистическое бюро, г) научные исследования в области теории и методологии статистики
а) а, б, г
б) а, б, в
в) а, в, г
1. Статистическое наблюдение – это:
а) научная организация регистрации информации;
б) оценка и регистрация признаков изучаемой совокупности;
в) работа по сбору массовых первичных данных;
г) обширная программа статистических исследований.
2. Назовите основные организационные формы статистического наблюдения:
а) перепись и отчетность;
в) разовое наблюдение;
г) опрос.
3. Перечень показателей (вопросов) статистического наблюдения, цель, метод, вид, единица наблюдения, объект, период статистического наблюдения излагаются:
а) в инструкции по проведению статистического наблюдения;
б) в формуляре статистического наблюдения;
в) в программе статистического наблюдения.
4. Назовите виды статистического наблюдения по степени охвата единиц совокупности:
а) анкета;
б) непосредственное;
в) сплошное;
г) текущее.
5. Назовите виды статистического наблюдения по времени регистрации:
а) текущее, б) единовременное; в) выборочное; г) периодическое; д) сплошное
а) а, в, д
б) а, б, г
в) б, г, д
6. Назовите основные виды ошибок регистрации: а) случайные; б) систематические; в) ошибки репрезентативности; г) расчетные
а) а
б) а, б
в) а, б, в,
г) а, б, в, г
7. Несплошное статистическое наблюдение имеет виды: а) выборочное;
б) монографическое; в) метод основного массива; г) ведомственная отчетность
а) а, б, в
б) а, б, г
в) б, в, г
8. Организационный план статистического наблюдения регламентирует: а) время и сроки наблюдения; б) подготовительные мероприятия;
в) прием, сдачу и оформление результатов наблюдения; г) методы обработки данных
а) а, б, г
б) а, б, в
9. Является ли статистическим наблюдением наблюдения покупателя за качеством товаров или изменением цен на городских рынках?
а) да
б) нет
10. Ошибка репрезентативности относится к:
а) сплошному наблюдению;
б) не сплошному выборочному наблюдению.
1. Статистическая сводка — это:
а) систематизация и подсчет итогов зарегистрированных фактов и данных;
б) форма представления и развития изучаемых явлений;
в) анализ и прогноз зарегистрированных данных.
2. Статистическая группировка — это:
а) объединение данных в группы по времени регистрации;
б) расчленение изучаемой совокупности на группы по существенным признакам;
в) образование групп зарегистрированной информации по мере ее поступления.
3. Статистические группировки могут быть: а) типологическими; б) структурными; в) аналитическими; г) комбинированными
а) а
б) а, б
в) а, б, в
г) а, б, в, г
4. Группировочные признаки, которыми одни единицы совокупности обладают, а другие — нет, классифицируются как:
а) факторные;
б) атрибутивные;
в) альтернативные.
5. К каким группировочным признакам относятся: образование сотрудников, профессия бухгалтера, семейное положение:
а) к атрибутивным;
б) к количественны.
6. Ряд распределения — это:
а) упорядоченное расположение единиц изучаемой совокупности по группам;
б) ряд значений показателя, расположенных по каким-то правилам.
7. К каким группировочным признакам относятся: сумма издержек обращения, объем продаж, стоимость основных фондов
а) к дискретным;
б) к непрерывным.
8. Какие виды статистических таблиц встречаются:
а) простые и комбинационные;
б) линейные и нелинейные.
1. Статистический показатель — это
а) размер изучаемого явления в натуральных единицах измерения
б) количественная характеристика свойств в единстве с их качественной определенностью
в) результат измерения свойств изучаемого объекта
2. Статистические показатели могут характеризовать:
а) объемы изучаемых процессов
б) уровни развития изучаемых явлений
в) соотношение между элементами явлений
г) а, б, в
3. По способу выражения абсолютные статистические показатели подразделяются на: а) суммарные; б) индивидуальные; в) относительные; г) средние; д) структурные
а) а, д
б) б, в
в) в, г
г) а, б
4. В каких единицах выражаются абсолютные статистические показатели?
а) в коэффициентах
б) в натуральных
в) в трудовых
5. В каких единицах будет выражаться относительный показатель, если база сравнения принимается за единицу?
а) в процентах
б) в натуральных
в) в коэффициентах
6. Относительные показатели динамики с переменной базой сравнения подразделяются на:
а) цепные
б) базисные
7. Сумма всех удельных весов показателя структуры
а) строго равна 1
б) больше или равна 1
в) меньше или равна 1
8. Относительные показатели по своему познавательному значению подразделяются на показатели: а) выполнения и сравнения, б) структуры и динамики, в) интенсивности и координации, г) прогнозирования и экстраполяции
а) а, б, г
б) б, в, г
в) а, б, в
9. Статистические показатели по сущности изучаемых явлений могут быть:
а) качественными
б) объёмными
в) а, б
10. Статистические показатели в зависимости от характера изучаемых явлений могут быть:
а) интервальными
б) моментными
в) а, б
1. Исчисление средних величин — это
а) способ изучения структуры однородных элементов совокупности
б) прием обобщения индивидуальных значений показателя
в) метод анализа факторов
2. Требуется вычислить средний стаж деятельности работников фирмы: 6,5,4,6,3,1,4,5,4,5. Какую формулу Вы примените?
а) средняя арифметическая
б) средняя арифметическая взвешенная
в) средняя гармоническая
3. Средняя геометрическая — это:
а) корень из произведения индивидуальных показателей
б) произведение корней из индивидуальных показателей
4. По какой формуле производится вычисление средней величины в интервальном ряду?
а) средняя арифметическая взвешенная
б) средняя гармоническая взвешенная
5. Могут ли взвешенные и невзвешенные средние, рассчитанные по одним и тем же данным, совпадать?
а) да
б) нет
6. Как изменяется средняя арифметическая, если все веса уменьшить в А раз?
а) уменьшатся
б) увеличится
в) не изменится
7. Как изменится средняя арифметическая, если все значения определенного признака увеличить на число А?
а) уменьшится
б) увеличится
в) не изменится
8. Значения признака, повторяющиеся с наибольшей частотой, называется
а) модой
б) медианой
9. Средняя хронологическая исчисляется
а) в моментных рядах динамики с равными интервалами
б) в интервальных рядах динамики с равными интервалами
в) в интервальных рядах динамики с неравными интервалами
10. Медиана в ряду распределения с четным числом членов ряда равна
а) полусумме двух крайних членов
б) полусумме двух срединных членов
1. Что понимается в статистике под термином «вариация показателя»?
а) изменение величины показателя
б) изменение названия показателя
в) изменение размерности показателя
2. Укажите показатели вариации
а) мода и медиана
б) сигма и дисперсия
в) темп роста и прироста
3. Показатель дисперсии — это:
а) квадрат среднего отклонения
б) средний квадрат отклонений
в) отклонение среднего квадрата
4. Коэффициент вариации измеряет колеблемость признака
а) в относительном выражении
б) в абсолютном выражении
5. Среднеквадратическое отклонение характеризует
а) взаимосвязь данных
б) разброс данных
в) динамику данных
6. Размах вариации исчисляется как
а) разность между максимальным и минимальным значением показателя
б) разность между первым и последним членом ряда распределения
7. Показатели вариации могут быть
а) простыми и взвешенными
б) абсолютными и относительными
в) а) и б)
8. Закон сложения дисперсий характеризует
а) разброс сгруппированных данных
б) разброс неупорядоченных данных
9. Средне квадратическое отклонение исчисляется как
а) корень квадратный из медианы
б) корень квадратный из коэффициента вариации
в) корень квадратный из дисперсии
10. Кривая закона распределения характеризует
а) разброс данных в зависимости от уровня показателя
б) разброс данных в зависимости от времени
1. Выборочный метод в статистических исследованиях используется для:
а) экономии времени и снижения затрат на проведение статистического исследования;
б) повышения точности прогноза;
в) анализа факторов взаимосвязи.
2. Выборочный метод в торговле используется:
а) при анализе ритмичности оптовых поставок;
б) при прогнозировании товарооборота;
в) при разрушающих методах контроля качества товаров.
3. Ошибка репрезентативности обусловлена:
а) самим методом выборочного исследования;
б) большой погрешностью зарегистрированных данных.
4. Коэффициент доверия в выборочном методе может принимать значения:
а) 1, 2, 3;
б) 4, 5, 6;
в) 7, 8, 9.
5. Выборка может быть: а) случайная, б) механическая, в) типическая, серийная, д) техническая
а) а, б, в, г,
б) а, б, в, д
в) б, в, г, д
6. Необходимая численность выборочной совокупности определяется:
а) колеблемостью признака;
б) условиями формирования выборочной совокупности;
7. Выборочная совокупность отличается от генеральной:
а) разными единицами измерения наблюдаемых объектов;
б) разным объемом единиц непосредственного наблюдения;
в) разным числом зарегистрированных наблюдений.
8. Средняя ошибка выборки:
а) прямо пропорциональна рассеяности данных;
б) обратно пропорциональна разбросу варьирующего признака;
в) никак не зависит от колеблемости данных;
9. Повторный отбор отличается от бесповторного тем, что:
а) отбор повторяется, если в процессе выборки произошел сбой;
б) отобранная однажды единица наблюдения возвращается в генеральную совокупность;
в) повторяется несколько раз расчет средней ошибки выборки.
10. Малая выборка — это выборка объемом:
а) 4-5 единиц изучаемой совокупности;
б) до 50 единиц изучаемой совокупности;
в) до 30 единиц изучаемой совокупности.
1. Ряд динамики характеризует: а) структуру совокупности по какому-то признаку; б) изменение характеристик совокупности во времени; в) определенное значение признака в совокупности; г) величину показателя на определенную дату или за определенный период
а) а, б
б) б, г
в) б, в
2. Ряд динамики может состоять: а) из абсолютных суммарных величин; б) из относительных и средних величин;
а) а
б) б
в) а, б
3. Ряд динамики, характеризующий уровень развития социально-экономического явления на определенные даты времени, называется:
а) интервальным;
б) моментным.
4. Средний уровень интервального ряда динамики определяется как:
а) средняя арифметическая;
б) средняя хронологическая.
5. Средний уровень моментного ряда динамики исчисляется как: а) средняя арифметическая взвешенная при равных интервалах между датами; б) при неравных интервалах между датами как средняя хронологическая, в) при равных интервалах между датами как средняя хронологическая;
а) а
б) б
в) б, в
6. Абсолютный прирост исчисляется как: а) отношение уровней ряда; б) разность уровней ряда. Темп роста исчисляется как: в) отношение уровней ряда; г) разность уровней ряда;
а) а, в
б) б, в
в) а, г
7. Для выявления основной тенденции развития используется: а) метод укрупнения интервалов; б) метод скользящей средней; в) метод аналитического выравнивания; г) метод наименьших квадратов;
а) а, г
б) б, г
в) а, б, г
г) а, б, в
8. Трендом ряда динамики называется:
а) основная тенденция;
б) устойчивый темп роста.
9. Прогнозирование в статистике ‑ это:
а) предсказание предполагаемого события в будущем;
б) оценка возможной меры изучаемого явления в будущем.
10. К наиболее простым методам прогнозирования относят:
а) индексный метод;
б) метод скользящей средней;
в) метод на основе среднего абсолютного прироста.
1. Статистический индекс — это:
а) критерий сравнения относительных величин;
б) сравнительная характеристика двух абсолютных величин;
в) относительная величина сравнения двух показателей.
2. Индексы позволяют соизмерить социально-экономические явления:
а) в пространстве;
б) во времени;
в) в пространстве и во времени.
3. В индексном методе анализа несуммарность цен на разнородные товары преодолевается:
а) переходом от абсолютных единиц измерения цен к относительной форме;
б) переходом к стоимостной форме измерения товарной массы.
4. Можно ли утверждать, что индивидуальные индексы по методологии исчисления адекватны темпам роста:
а) можно;
б) нельзя.
5. Сводные индексы позволяют получить обобщающую оценку изменения:
а) по товарной группе;
б) одного товара за несколько периодов.
6. Может ли в отдельных случаях средний гармонический индекс рассчитываться по средней гармонической невзвешенной:
а) может;
б) не может.
7. Индексы переменного состава рассчитываются:
а) по товарной группе;
б) по одному товару.
8. Может ли индекс переменного состава превышать индекс фиксированного состава:
а) может;
б) не может.
9. Первая индексная мультипликативная модель товарооборота – это:
а) произведение индекса цен на индекс физического объема товарооборота;
б) произведение индекса товарооборота в сопоставимых ценах на индекс средней цены постоянного состава;
в) а, б.
10. Вторая факторная индексная мультипликативная модель анализа – это:
а) произведение индекса постоянного состава на индекс структурных сдвигов;
б) частное от деления индекса переменного состава на индекс структурных сдвигов;
в) а, б.
1. Статистическая связь — это:
а) когда зависимость между факторным и результирующим
показателями неизвестна;
б) когда каждому факторному соответствует свой результирующий показатель;
в) когда каждому факторному соответствует несколько разных значений результирующего показателя.
2. Термин корреляция в статистике понимают как:
а) связь, зависимость;
б) отношение, соотношение;
в) функцию, уравнение.
3. По направлению связь классифицируется как:
а) линейная;
б) прямая;
в) обратная.
4. Анализ взаимосвязи в статистике исследует:
а) тесноту связи;
б) форму связи;
в) а, б
5. При каком значении коэффициента корреляции связь можно считать умеренной?
а) r = 0,43;
б) r = 0,71.
6. Термин регрессия в статистике понимают как: а) функцию связи, зависимости; б) направление развития явления вспять; в) функцию анализа случайных событий во времени; г) уравнение линии связи
а) а, б
б) в, г
в) а, г
7. Для определения тесноты связи двух альтернативных показателей применяют:
а) коэффициенты ассоциации и контингенции;
б) коэффициент Спирмена.
8. Дайте классификацию связей по аналитическому выражению:
а) обратная;
б) сильная;
в) прямая;
г) линейная.
9. Какой коэффициент корреляции характеризует связь между YиX:
а) линейный;
б) частный;
в) множественный.
10. При каком значении линейного коэффициента корреляции связь между YиXможно признать более существенной:
а) ryx = 0,25;
б) ryx = 0,14;
в) ryx = — 0,57.
2. Виды отбора.
3. Ошибки выборки, определение объема выборочной совокупности.
4. Способы распространения выборочных характеристик.
1. Понятие выборочного наблюдения, репрезентативность выборочного наблюдения.
1. Выборочное наблюдение несложное наблюдение, при котором обследуется не вся совокупность, а лишь часть, отобранная по определенным правилам выборки и обеспечивающая получение данных, характеризующих всю совокупность в целом.
При проведении выборочного наблюдения нельзя получить абсолютно точные данные, как при сплошном, т. к. обследованию подвергается не вся совокупность, а ее часть. Поэтому при проведении выборочного наблюдения неизбежна некоторая свойственная ему погрешность, ошибка.
Ошибки, свойственные выборочному наблюдению, называются ошибками репрезентативности, т. е. представительства. Они характеризуют размер расхождения между данными выборочного наблюдения и всей совокупности.
Ошибки репрезентативности делятся на случайные и систематические.
Случайные ошибки возникают вследствие того, что выборочная совокупность недостаточно точно воспроизводит совокупность, вследствие несплошного характера наблюдения. Случайные ошибки м. б. доведены до незначительных размеров, а главное размеры и пределы их можно определить с достаточной точностью на основании закона больших чисел и теории вероятности.
Систематические ошибки возникают в результате нарушения принципа случайности отбора единиц совокупности для наблюдения.
Вся совокупность единиц, из которой производится отбор, называется генеральной совокупностью и обозначается буквой N. Часть генеральной совокупности, попавшая в выборку, называется выборочной совокупностью и обозначается n.
Обобщающие показатели генеральной совокупности средняя, дисперсия, доля называются генеральными и соответственно обозначаются ![]() доля отнесения М единиц, обладающих определенным признаком, ко всей численности генеральной совокупности, т. е. М/N.
доля отнесения М единиц, обладающих определенным признаком, ко всей численности генеральной совокупности, т. е. М/N.
Обобщающие характеристики в выборочной совокупности называются выборочными и обозначаются соответственно x*, ![]() частость отношение числа единиц, обладающих данным признаком, в выборочной совокупности n, т. е.
частость отношение числа единиц, обладающих данным признаком, в выборочной совокупности n, т. е. ![]()
![]()
Теория выборочного метода дает возможность определить случайные ошибки обобщающих характеристик в выборочной совокупности.
Ошибка репрезентативности разность между выборочной средней и генеральной средней при достаточно большом числе наблюдений будет сколько угодно малой, т. е.
![]()
где ![]() абсолютная величина расхождения между генеральной средней и выборочной средней, составляющая ошибку репрезентативности.
абсолютная величина расхождения между генеральной средней и выборочной средней, составляющая ошибку репрезентативности.
![]() — среднее квадратическое отклонение вариантов выборочной средней от генеральной средней (средняя ошибка выборки). Она зависит от колеблемости признака в генеральной совокупности
— среднее квадратическое отклонение вариантов выборочной средней от генеральной средней (средняя ошибка выборки). Она зависит от колеблемости признака в генеральной совокупности ![]() и числа отобранных единиц n:
и числа отобранных единиц n: ![]() . Величина m зависит также от способа образования выборочной совокупности, т. к. между
. Величина m зависит также от способа образования выборочной совокупности, т. к. между ![]() средней ошибкой выборки и n числом отбираемых единиц существует обратно пропорциональная связь. Отсюда вытекает следующее правило: если надо уменьшить ошибку выборки, например, в 3 раза, необходимо увеличить объем выборки в девять раз.
средней ошибкой выборки и n числом отбираемых единиц существует обратно пропорциональная связь. Отсюда вытекает следующее правило: если надо уменьшить ошибку выборки, например, в 3 раза, необходимо увеличить объем выборки в девять раз.
Увеличение колеблемости признака в генеральной совокупности влечет за собой увеличение среднего квадратического отклонения, и следовательно и ошибки выборки.
Доказано, что соотношение между дисперсиями генеральной и выборочной совокупностей выражаются формулой:
![]() , т. к.
, т. к. ![]() при больших n приближается к 1, то
при больших n приближается к 1, то ![]()
Средняя ошибка выборки показывает, какие возможны отклонения характеристик выборочной совокупности от соответствующих характеристик генеральной совокупности. Однако о величине этой ошибки можно судить с определенной вероятностью, на величину которой указывает коэффициент доверия t.
Величина ![]() обозначается
обозначается ![]() называется предельной ошибкой выборки. Следовательно предельная ошибка выборки определяется формулой
называется предельной ошибкой выборки. Следовательно предельная ошибка выборки определяется формулой ![]() =
= ![]() . С увеличением t увеличивается вероятность нашего утверждения, но вместе с тем увеличивается и величина ошибки.
. С увеличением t увеличивается вероятность нашего утверждения, но вместе с тем увеличивается и величина ошибки.
2. Виды и схемы отбора.
Формирование выборочной совокупности из генеральной может осуществляться по-разному: в зависимости от вида и схемы отбора, и т. д. От их особенностей зависит размер ошибки и методы определения. Различаются 4 вида отбора:
1. собственно-случайный
2. механический
3. типический
4. серийный (гнездовой)
Собственно-случайный отбор включение единиц совокупности осуществляется наудачу. Наиболее распространенным способом отбора в случайной выборке является жеребьевка, при которой на каждую единицу заготавливают билет с порядковым номером. Затем в случайном порядке отбирают необходимое количество единиц совокупности. При этих условиях каждая из них имеет одинаковую вероятность попасть в выборку.
Механический отбор вся совокупность разбивается на равные по объему группы по случайному признаку. Затем из каждой группы случайно отбирается одна единица.
Типичный отбор совокупность расчленяется по существенному, типическому признаку на качественно однородные, однотипные группы. Затем из каждой группы случайным или механическим способом отбирается количество единиц, пропорциональное удельному весу группы во всей совокупности.
Типический отбор дает более точные результаты чем случайный или механический, потому что при нем в выборку в такой же пропорции как и в генеральной совокупности, попадают представители всех типических групп.
Серийный отбор (гнездовой) отбору подлежат не отдельные единицы совокупности, а целые группы, серии, гнезда, отобранные случайным или механическим способом. В каждой такой группе, серии проводится сплошное наблюдение, а результаты переносятся на всю совокупность.
Точность выборки зависит и от схемы отбора. Выборка м. б. проведена по схеме повторного или бесповторного отбора.
Повторный отбор каждая отобранная единица или серия возвращается во всю совокупность и может вновь попасть в выборку.
Бесповторный отбор каждая обследованная единица не возвращается в совокупность и не м. б. подвергнута повторному обследованию. Бесповторный отбор дает более точные результаты, т. к. при одном и том же объеме выборки наблюдение охватывает большее количество единиц изучаемой совокупности.
Обе схемы отбора могут применяться в сочетании с разными видами отбора, за исключением механического, который всегда бывает бесповторным.
3. Ошибки выборки, определение объема выборочной совокупности
Для суждения о праве распространения данных выборочного наблюдения на генеральную совокупность определяют величину ошибок между сводимыми показателями выборочной и генеральной совокупностей.
Обычно сопоставляют такие показатели:
1. Среднюю выборочной совокупности со средней генеральной совокупности, в результате чего получаем ошибку средней.
![]()
2. Частость выборочной совокупности с долей генеральной совокупности, что дает возможность определить ошибку частостей:
![]()
Разность между показателями выборочной и генеральной совокупностей называется ошибкой репрезентативности. Если эти показатели достаточно близки, то выборка считается репрезентативной.
Выборочная средняя и частость являются переменными величинами, т. е. могут принимать различные значения в зависимости от того, какие единицы совокупности попали в выборку. Следовательно, ошибки выборки также являются переменными величинами и также могут принимать различные значения в зависимости от единиц совокупности, попавшие в выборку. Вот почему определяется средняя из возможных ошибок, которая обозначается буквой ![]() . Величина
. Величина ![]() зависит от степени колеблемости значений признака в генеральной совокупности и от численности выборки n. Степень колеблемости в генеральной совокупности определяется средним квадратом отклонений или дисперсией
зависит от степени колеблемости значений признака в генеральной совокупности и от численности выборки n. Степень колеблемости в генеральной совокупности определяется средним квадратом отклонений или дисперсией ![]() . Из математических теорем и закона больших чисел следует, что при случайном отборе, проведенном по системе повторной выборки, между
. Из математических теорем и закона больших чисел следует, что при случайном отборе, проведенном по системе повторной выборки, между ![]() и п существует следующая зависимость:
и п существует следующая зависимость:
![]()
Ошибка выборочного наблюдения это разность между величиной параметра в генеральной совокупности и его величиной, вычисленной по результатам выборочного наблюдения
![]()
Чебышев доказал, что при достаточно большом числе независимых наблюдений можно с вероятностью, близкой к единице утверждать, что отклонение выборочной средней от генеральной будет сколь угодно малым.
![]() , величину
, величину ![]() называют средней ошибкой выборки.
называют средней ошибкой выборки.
Соотношение между дисперсиями генеральной и выборочной совокупности выражается формулой
![]()
Если выборочное наблюдение применяется для определения доли признака, то средняя ошибка доли исчисляется по формуле
![]() , т. к. дисперсия альтернативного признака
, т. к. дисперсия альтернативного признака ![]() , где p доля единиц совокупности, обладающих данным признаком, а q не обладающим данным признаком.
, где p доля единиц совокупности, обладающих данным признаком, а q не обладающим данным признаком.
В этих формулах ![]() и pq характеристики генеральной совокупности, которые при выборочном наблюдении неизвестны. На практике их заменяют аналогичными характеристиками выборочной совокупности, что вполне правомерно, т. к. основано на законе больших чисел, по которому выборочная совокупность при достаточно большом объеме выборки достаточно точно воспроизводит характеристики генеральной совокупности.
и pq характеристики генеральной совокупности, которые при выборочном наблюдении неизвестны. На практике их заменяют аналогичными характеристиками выборочной совокупности, что вполне правомерно, т. к. основано на законе больших чисел, по которому выборочная совокупность при достаточно большом объеме выборки достаточно точно воспроизводит характеристики генеральной совокупности.
При бесповторном отборе средняя ошибка выборки равна
![]() , а ошибка доли
, а ошибка доли ![]() , где N численность единиц генеральной совокупности.
, где N численность единиц генеральной совокупности.
Множитель ![]() всегда меньше единицы, т. к. n < N. Поэтому величина средней ошибки выборки при бесповторном отборе меньше чем при повторном.
всегда меньше единицы, т. к. n < N. Поэтому величина средней ошибки выборки при бесповторном отборе меньше чем при повторном.
Для решения практических задач выборочного обследования средней ошибки выборки недостаточно, потому что при исчислении ошибки конкретной выборки фактическая ошибка м. б. больше или меньше средней ошибки выборки ![]() . Поэтому пользуются не средней, а предельной ошибкой выборки, т. е. пределами, за которые не выйдет фактическая ошибка выборки.
. Поэтому пользуются не средней, а предельной ошибкой выборки, т. е. пределами, за которые не выйдет фактическая ошибка выборки.
Предельная ошибка выборки зависит от того, с какой вероятностью должна гарантироваться ошибка выборки. Уровень вероятности определяется на основе теорем Чебышева и Ляпунова при помощи специального коэффициента t.
Если предельную ошибку выборки обозначить буквой ![]() , то
, то 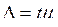 , где t коэффициент, зависящий от вероятности, с которой гарантируется ошибка выборки. Он называется еще коэффициентом доверия. Чтобы определить величину вероятности для различных значений t на практике пользуются готовой таблицей.
, где t коэффициент, зависящий от вероятности, с которой гарантируется ошибка выборки. Он называется еще коэффициентом доверия. Чтобы определить величину вероятности для различных значений t на практике пользуются готовой таблицей.
Систематизируем формулы для определения предельной ошибки средней и доли
|
Схема отбора |
Предельная ошибка выборки |
|
|
Для средней |
Для доли |
|
|
Повторный отбор Бесповторный отбор |
|
|
Из формул видно, что предельная ошибка выборки прямо пропорциональна коэффициенту t, дисперсии ![]() и обратно пропорциональна корню квадратному из численности выборки.
и обратно пропорциональна корню квадратному из численности выборки.
Дисперсия ![]() величина конкретная, свойственная данной совокупности. Обычно она неизвестна, а известна
величина конкретная, свойственная данной совокупности. Обычно она неизвестна, а известна ![]() *, которой и заменяют величину
*, которой и заменяют величину ![]() , потому что в силу действия закона больших чисел при достаточно большом объеме выборки n распределение признака x в выборочной совокупности близко воспроизводит распределение этого признака в генеральной совокупности.
, потому что в силу действия закона больших чисел при достаточно большом объеме выборки n распределение признака x в выборочной совокупности близко воспроизводит распределение этого признака в генеральной совокупности.
Ошибка выборки зависит и от ее объема n. Чем больше объем выборки, тем меньше предельная ошибка (при данных ![]() и t)
и t)
Рассмотренные формулы средней и предельной ошибки и доли применяются при случайном и механическом видах отбора.
При типическом отборе предельная ошибка выборки и доли определяется по формулам:
|
Схема отбора |
Предельная ошибка выборки |
|
|
Для средней |
Для доли |
|
|
Повторный отбор Бесповторный отбор |
|
|
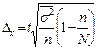
т. е. при типичном отборе надо брать средние из внутригрупповых дисперсий и доли, полученные по каждой типической группе.
Из этих формул видно, что при типическом отборе в отличие от случайного исключается влияние межгрупповой вариации на точность выборки, т. к. в выборку обязательно попадают представители всех групп в тех же пропорциях, что и в генеральной совокупности. Ошибка выборки при типичном отборе зависит только от средней из внутригрупповых дисперсий, а не от общей дисперсии, как при случайном отборе т. к.
![]() , откуда
, откуда 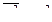
Следовательно ошибка выборки при типическом отборе всегда меньше ошибки выборки, проведенной случайным отбором.
При серийном отборе каждая серия рассматривается как единица совокупности, и мерой колеблемости будет межсерийная выборочная дисперсия, т. е. средний квадрат отклонений серийных средних от общей выборочной средней:
![]() , где
, где ![]() средняя по каждой серии, x* общая выборочная средняя, s число отобранных серий.
средняя по каждой серии, x* общая выборочная средняя, s число отобранных серий.
Предельная ошибка выборки и доли при серийном отборе с равновеликими сериями определяется по формулам, где S общее число серий в генеральной совокупности.
|
Схема отбора |
Предельная ошибка выборки |
|
|
Для средней |
Для доли |
|
|
Повторный отбор Бесповторный отбор |
|
|
Выборочное наблюдение, объем которого превышает 20 единиц, называется малой выборкой. Для определения средней и предельной ошибок при малой выборке пользуются теми же формулами, что и при большой, но только с некоторыми особенностями, так ![]() , а
, а 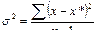 .
.
Кроме того, в случае малой выборки действует особый закон распределения величин t, и при определении вероятности учитывается не только коэффициент t, но и объем выборки n.
Необходимая численность выборки (n) определяется на основе формул предельной ошибки выборки.
Если выборка повторная, то при случайном и механическом отборах определяется по формуле
![]() , при бесповторном отборе
, при бесповторном отборе ![]()
4. Способы распространения выборочных характеристик.
Есть два способа распространения выборочных характеристик на всю совокупность прямой пересчет и способ коэффициентов
Способ прямого пересчета заключается в том, что средние или частости выборочной совокупности умножаются на числа единиц генеральной совокупности.
Когда выборочное обследование проводится в целях уточнения данных сплошного наблюдения, применяется способ коэффициентов. В этом случае данные сплошного наблюдения сопоставляют с данными выборочного наблюдения и устанавливают процент расхождения между ними, т. е. процент надоучета или переучета. Коэффициенты, полученные в результате такого сопоставления, используются для внесения поправок в данные сплошного учета.
Пример.
1) способ прямого пересчета
Для определения качества продукции проверено 500 изделий из 10000. В результате чего установлено, что средний % изделий 3-го сорта всей партии будет находиться в пределах 6,1-13,9%. Способом прямого пересчета определяем, что обще кол-во изделий 3-го сорта всей партии составит от 610 до 1390
10000*0,061= 610
10000*0,139 = 1390
2) способ коэффициентов
Пример
Необходимо определить численность выборки, которая позволила бы оценить долю брака в партии продукции с точностью до 2%, с вероятностью Р =0,954. Партия состоит из 10000 изделий
![]() ,
, ![]()
![]()
 , P =0,954, t =2
, P =0,954, t =2
![]() pq=0,25 (p=0,5; q=0,5)
pq=0,25 (p=0,5; q=0,5)