2.1. Средняя и предельная ошибки выборки. Построение доверительных границ для средней и доли
Средняя ошибка
выборки
показывает, насколько отклоняется в
среднем параметр выборочной
совокупности
от соответствующего параметра генеральной.
Если рассчитать среднюю из ошибок всех
возможных выборок определенного вида
заданного объема (n),
извлеченных из одной и той же генеральной
совокупности,
то получим их обобщающую характеристику
среднюю
ошибку выборки
().
В
теории выборочного наблюдения
выведены формулы для определения ,
которые индивидуальны для разных
способов отбора (повторного и
бесповторного), типов используемых
выборок и видов оцениваемых статистических
показателей.
Например, если
применяется повторная собственно
случайная выборка, то
определяется как:
![]()
при
оценивании среднего значения признака;
![]()
если
признак альтернативный, и оценивается
доля.
При бесповторном
собственно случайном отборе в формулы
вносится поправка
![]()
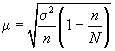
для
среднего значения признака;
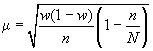
для
доли.
Вероятность
получения именно такой величины ошибки
всегда равна 0,683. На практике же
предпочитают получать данные с большей
вероятностью, но это приводит к возрастанию
величины ошибки выборки.
Предельная
ошибка выборки ()
равна t-кратному
числу средних ошибок выборки (в теории
выборки принято коэффициент t
называть
коэффициентом доверия):
t
.
Если ошибку выборки
увеличить в два раза (t
2), то получим гораздо большую вероятность
того, что она не превысит определенного
предела (в нашем случае
двойной средней ошибки)
0,954. Если взять t
3, то доверительная вероятность составит
0,997
практически достоверность.
Уровень предельной
ошибки выборки зависит от следующих
факторов:
степени вариации
единиц генеральной совокупности;
объема выборки;
выбранных схем
отбора (бесповторный отбор дает меньшую
величину ошибки);
уровня
доверительной вероятности.
Если объем выборки
больше 30, то значение t
определяется по таблице нормального
распределения, если меньше
по таблице распределения Стьюдента
(Приложение
1).
Приведем некоторые
значения коэффициента доверия из таблицы
нормального распределения.
![]()
Доверительный
интервал для среднего значения признака
и для доли в генеральной
совокупности
устанавливается следующим образом:
![]()
Итак, определение
границ генеральной средней и доли
состоит из следующих этапов:
нахождение в
выборке среднего значения признака
(или доли);
определение
в соответствии с выбранной схемой отбора
и вида выборки;
задание
доверительной вероятности Р
и определение коэффициента доверия t
по
соответствующей таблице;
вычисление
предельной ошибки выборки ;
построение
доверительного интервала для средней
(или доли).
Ошибки выборки
при различных видах отбора
1. Собственно
случайная и механическая выборка.
Средняя
ошибка собственно случайной и механической
выборки находятся по формулам,
представленным в табл. 11.1.
Таблица 1
Формулы для
расчета средней ошибки
собственно
случайной и механической выборки ()

где
2
дисперсия
признака в выборочной совокупности.
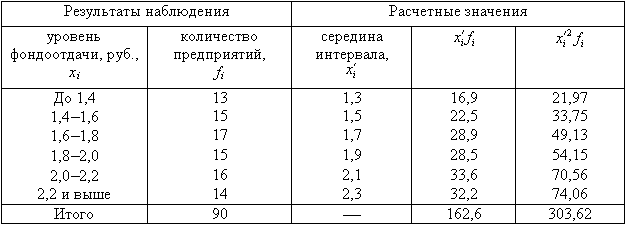
Пример 2. Для
изучения уровня фондоотдачи было
проведено выборочное обследование 90
предприятий из 225 методом случайной
повторной выборки, в результате которого
получены данные, представленные в
таблице.

В рассматриваемом
примере имеем 40%-ную выборку (90 : 225
0,4, или 40%). Определим ее предельную ошибку
и границы для среднего значения признака
в генеральной совокупности по шагам
алгоритма:
1. По результатам
выборочного обследования рассчитаем
среднее значение и дисперсию в выборочной
совокупности:
Выборочная средняя
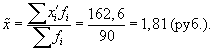
Выборочная
дисперсия изучаемого признака
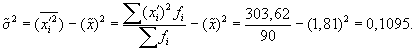
2. Определяем
среднюю ошибку повторной случайной
выборки
![]()
3. Зададим
вероятность, на уровне которой будем
говорить о величине предельной ошибки
выборки. Чаще всего она принимается
равной 0,999; 0,997; 0,954.
Для наших данных
определим предельную ошибку выборки,
например, с вероятностью 0,954. По таблице
значений вероятности функции нормального
распределения (см. выдержку из нее,
приведенную в Приложении 1) находим
величину коэффициента доверия t,
соответствующего вероятности 0,954. При
вероятности 0,954 коэффициент t
равен 2.
4. Предельная
ошибка выборки с вероятностью 0,954 равна
![]()
5. Найдем доверительные
границы для среднего значения уровня
фондоотдачи в генеральной совокупности
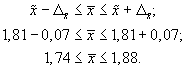
Таким образом, в
954 случаях из 1000 среднее значение
фондоотдачи будет не выше 1,88 руб. и не
ниже 1,74 руб.
Выше была
использована повторная схема случайного
отбора. Посмотрим, изменятся ли результаты
обследования, если предположить, что
отбор осуществлялся по схеме бесповторного
отбора. В этом случае расчет средней
ошибки проводится по формуле
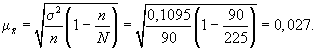
Тогда при вероятности
равной 0,954 величина предельной ошибки
выборки составит:
![]()
Доверительные
границы для среднего значения признака
при бесповторном случайном отборе будут
иметь следующие значения:
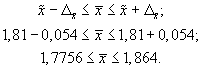
Сравнив результаты
двух схем отбора, можно сделать вывод
о том, что применение бесповторной
случайной выборки дает более точные
результаты по сравнению с применением
повторного отбора при одной и той же
доверительной вероятности. При этом,
чем больше объем выборки, тем существеннее
сужаются границы значений средней при
переходе от одной схемы отбора к другой.
По данным примера
определим, в каких границах находится
доля предприятий с уровнем фондоотдачи,
не превышающим значения 2,0 руб., в
генеральной совокупности:
1) рассчитаем
выборочную долю.
Количество
предприятий в выборке с уровнем
фондоотдачи, не превышающим значения
2,0 руб., составляет 60 единиц. Тогда
m
60, n
90, w
m/n
60 : 90
0,667;
2) рассчитаем
дисперсию доли в выборочной совокупности
w2
w(1
w)
0,667(1
0,667)
0,222;
3) средняя ошибка
выборки при использовании повторной
схемы отбора составит
![]()
Если предположить,
что была использована бесповторная
схема отбора, то средняя ошибка выборки
с учетом поправки на конечность
совокупности составит
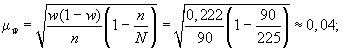
4) зададим
доверительную вероятность и определим
предельную ошибку выборки.
При значении
вероятности Р
0,997 по таблице нормального распределения
получаем значение для коэффициента
доверия t
3 (см. выдержку из нее, приведенную в
Приложении 1):
![]()
5) установим границы
для генеральной доли с вероятностью
0,997:

Таким образом, с
вероятностью 0,997 можно утверждать, что
в генеральной совокупности доля
предприятий с уровнем фондоотдачи, не
превышающим значения 2,0 руб., не меньше,
чем 54,7%, и не больше 78,7%.
2. Типическая
выборка. При
типической выборке генеральная
совокупность объектов разбита на k
групп, тогда
N1
N2
…
Ni
…
Nk
N.
Объем извлекаемых
из каждой типической группы единиц
зависит от принятого способа отбора;
их общее количество образует необходимый
объем выборки
n1
n2
…
ni
…
nk
n.
Существуют
следующие два способа организации
отбора внутри типической группы:
пропорциональной объему типических
групп и пропорциональной степени
колеблемости значений признака у единиц
наблюдения в группах. Рассмотрим первый
из них, как наиболее часто используемый.
Отбор, пропорциональный
объему типических групп, предполагает,
что в каждой из них будет отобрано
следующее число единиц совокупности:
![]()
где ni
количество извлекаемых единиц для
выборки из i-й
типической группы;
n
общий объем выборки;
Ni
количество единиц генеральной
совокупности, составивших i-ю
типическую группу;
N
общее количество единиц генеральной
совокупности.
Отбор единиц
внутри групп происходит в виде случайной
или механической выборки.
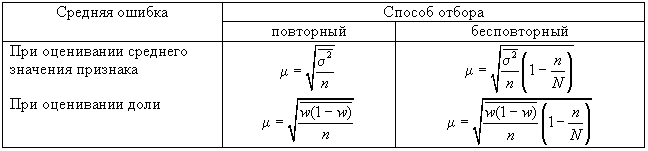
Формулы для
оценивания средней ошибки выборки для
среднего и доли представлены в табл.
11.2.
Таблица 2
Формулы для
расчета средней ошибки выборки ()
при использовании типического отбора,
пропорционального объему типических
групп
Здесь
![]()
средняя из групповых дисперсий типических
групп.
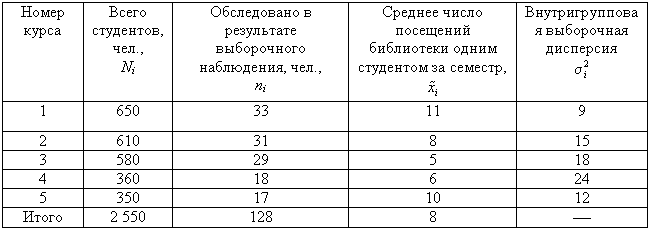
Пример 3. В
одном из московских вузов проведено
выборочное обследование студентов с
целью определения показателя средней
посещаемости вузовской библиотеки
одним студентом за семестр. Для этого
была использована 5%-ная бесповторная
типическая выборка, типические группы
которой соответствуют номеру курса.
При отборе, пропорциональном объему
типических групп, получены следующие
данные:
Число студентов,
которое необходимо обследовать на
каждом курсе, рассчитаем следующим
образом:
общий объем
выборочной совокупности:
![]()
количество
единиц, отобранных из каждой типической
группы:
![]()
аналогично для
других групп:
п2
31 (чел.);
п3
29 (чел.);
п4
18 (чел.);
п5
17 (чел.).
Проведем необходимые
расчеты.
1. Выборочная
средняя, исходя из значений средних
типических групп, составит:

2. Средняя из
внутригрупповых дисперсий
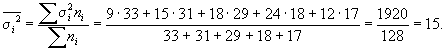
3. Средняя ошибка
выборки:
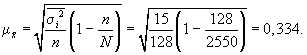
С вероятностью
0,954 находим предельную ошибку выборки:
![]()
4. Доверительные
границы для среднего значения признака
в генеральной совокупности:
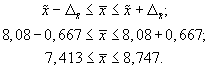
Таким образом, с
вероятностью 0,954 можно утверждать, что
один студент за семестр посещает
вузовскую библиотеку в среднем от семи
до девяти раз.
3.
Малая выборка. В
связи с небольшим объемом выборочной
совокупности
те формулы для определения ошибок
выборки,
которые использовались нами ранее при
«больших» выборках, становятся
неподходящими и требуют корректировки.
Среднюю ошибку
малой выборки
определяют по формуле
![]()
Предельная
ошибка малой выборки:
![]()
Распределение
значений выборочных средних всегда
имеет нормальный закон распределения
(или приближается к нему) при п
100, независимо от характера распределения
генеральной
совокупности.
Однако в случае малых выборок действует
иной закон распределения
распределение Стьюдента.
В этом случае коэффициент доверия
находится по таблице t-распределения
Стьюдента в зависимости от величины
доверительной вероятности Р
и объема выборки п.
В Приложении
1
приводится фрагмент таблицы t-распределения
Стьюдента, представленной в виде
зависимости доверительной вероятности
от объема выборки и коэффициента доверия
t.
Пример 4.
Предположим,
что выборочное обследование восьми
студентов академии показало, что на
подготовку к контрольной работе по
статистике они затратили следующее
количество часов: 8,5; 8,0; 7,8; 9,0; 7,2; 6,2; 8,4;
6,6.
Оценим выборочные
средние затраты времени и построим
доверительный интервал для среднего
значения признака в генеральной
совокупности, приняв доверительную
вероятность равной 0,95.
1. Среднее значение
признака в выборке равно
![]()
2. Значение среднего
квадратического отклонения составляет
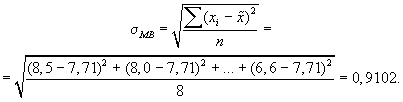
3. Средняя ошибка
выборки:
![]()
4. Значение
коэффициента доверия t
2,365 для п
8 и Р
0,95 (Приложение 1).
5. Предельная
ошибка выборки:
![]()
6. Доверительный
интервал для среднего значения признака
в генеральной совокупности:
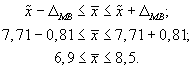
То есть с вероятностью
0,95 можно утверждать, что затраты времени
студента на подготовку к контрольной
работе находятся в пределах от 6,9 до 8,5
ч.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
При обследовании 500 образцов изделий, отобранных из партии готовой продукции предприятия в случайном порядке, 40 оказались нестандартными.
С вероятностью 0,954 определите пределы, в которых находится доля нестандартной продукции, выпускаемой заводом.
Решение:
Рассчитаем долю нестандартной продукции в выборочной совокупности:
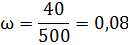
Средняя ошибка выборочной доли при повторном отборе рассчитывается по формуле:
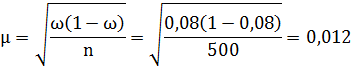
где n – численность выборки.
С вероятностью 0,954 рассчитаем предельную ошибку выборочной доли по формуле:
Δ = μ × t
где
t – коэффициент доверия.
Значение коэффициента доверия t определяется в зависимости от того, с какой доверительной вероятностью надо гарантировать результаты выборочного наблюдения и берётся из готовых таблиц.
При Р = 0,954, t = 2.
Δ = t * μ = 2 * 0,012 = 0,024
С вероятностью 0,954 можно утверждать, что доля нестандартной продукции в партии товара колеблется:
ω – Δ ˂ р ˂ ω + Δ
0,08 – 0,02 ˂ р ˂ 0,08+0,02
0,06 ˂ р ˂ 0,10
или
6% ˂ р ˂ 10%
Повторный и бесповторный отбор.
Ошибка выборки
Краткая теория
На основании выборочных данных дается оценка статистических
показателей по всей (генеральной) совокупности. Подобное возможно, если выборка
основывается на принципах случайности отбора и репрезентативности
(представительности) выборочных данных. Каждая единица генеральной совокупности
должна иметь равную возможность (вероятность) попасть в выборку.
При формировании выборочной совокупности используются следующие
способы отбора: а) собственно-случайный отбор; б) механическая выборка; в)
типический (районированный) отбор; г) многоступенчатая (комбинированная)
выборка; д) моментно-выборочное наблюдение.
Выборка может осуществляться по схеме повторного и бесповторного
отбора.
В первом случае единицы совокупности, попавшие в выборку, снова
возвращаются в генеральную, а во втором случае – единицы совокупности, попавшие
в выборку, в генеральную совокупность уже не возвращаются.
Выборка может осуществляться отдельными единицами или сериями
(гнездами).
Собственно-случайная выборка
Отбор в этом случае производится либо по жребию, либо по таблицам
случайных чисел.
На основании приемов классической выборки решаются следующие
задачи:
а) определяются границы среднего значения показателя по генеральной
совокупности;
б) определяются границы доли признака по генеральной совокупности.
Предельная ошибка средней при собственно-случайном отборе
исчисляется по формулам:
а) при повторном отборе:
б) при бесповторном отборе:
где
– численность выборочной совокупности;
– численность генеральной совокупности;
– дисперсия признака;
– критерий кратности ошибки: при
;
при
;
при
.
Значения
определяются
по таблице функции Лапласа.
Границы (пределы) среднего значения признака по генеральной
совокупности определяются следующим неравенством:
где
– среднее значение признака по выборочной
совокупности.
Предельная ошибка доли при собственно-случайном отборе определяется
по формулам:
а) при повторном отборе:
при бесповторном отборе:
где
– доля единиц совокупности с заданным
значением признака в обзей численности выборки,
– дисперсия доли признака.
Границы (пределы) доли признака по всей (генеральной) совокупности
определяются неравенством:
где
– доля признака по генеральной совокупности.
Типическая (районированная) выборка
Особенность этого вида
выборки заключается в том, что предварительно генеральная совокупность по
признаку типизации разбивается на частные группы (типы, районы), а затем в
пределах этих групп производится выборка.
Предельная ошибка средней
при типическом бесповторном отборе определяется по формуле:
где
– средняя из внутригрупповых дисперсий
по каждой типичной группе.
При пропорциональном отборе из групп генеральной совокупности
средняя из внутригрупповых дисперсий определяется по формуле:
где
– численности единиц совокупности групп по выборке.
Границы (пределы) средней по генеральной совокупности на основании
данных типической выборки определяются по тому же неравенству, что при
собственно-случайной выборке. Только предварительно необходимо вычислить общую
выборочную среднюю
из частных выборочных средних
.
Для случая пропорционального отбора это определяется по формуле:
При непропорциональном отборе средняя из внутригрупповых дисперсий вычисляется по
формуле:
где
– численность единиц групп по генеральной
совокупности.
Общая выборочная средняя в этом случае определяется по формуле:
Предельная ошибка доли
признака при типическом бесповторном отборе определяется формулой:
Средняя дисперсия доли
признака из групповых дисперсий доли
при
типической пропорциональной выборке вычисляется по формуле:
Средняя доля признака по
выборке из показателей групповых долей рассчитывается формуле:
Средняя дисперсия доли при
непропорциональном типическом отборе определяется следующим образом:
а средняя доля признака:
Формулы ошибок выборки при типическом повторном отборе будут те же,
то и для случая бесповторного отбора. Отличие заключается только в том, что в
них будет отсутствовать по корнем сомножитель
.
Серийная выборка
Серийная ошибка выборки
может применяться в двух вариантах:
а) объем серий различный
б) все серии имеют
одинаковое число единиц (равновеликие серии).
Наиболее распространенной
в практике статистических исследований является серийная выборка с
равновеликими сериями. Генеральная совокупность делится на одинаковые по объему
группы-серии
и
производится отбор не единиц совокупности, а серий
. Группы (серии) для обследования отбирают в
случайном порядке или путем механической выборки как повторным, так и
бесповторными способами. Внутри каждой отобранной серии осуществляется сплошное
наблюдение. Предельные ошибки выборки
при
серийном отборе исчисляются по формулам:
а) при повторном отборе
б) при бесповторном отборе
где
– число
серий в генеральной совокупности;
– число
отобранных серий;
– межсерийная дисперсия, исчисляемая для случая равновеликих
серий по формуле:
где
–
среднее значение признака в каждой из отобранных серий;
– межсерийная
средняя, исчисляемая для случая равновеликих серий по формуле:
Определение численности выборочной совокупности
При проектировании
выборочного наблюдения важно наряду с организационными вопросами решить одну из
основных постановочных задач: какова должна быть необходимая численность
выборки с тем, чтобы с заданной степенью точности (вероятности) заранее
установленная ошибка выборки не была бы превзойдена.
Примеры решения задач
Задача 1
На основании результатов проведенного на заводе 5%
выборочного наблюдения (отбор случайный, бесповторный) получен следующий ряд
распределения рабочих по заработной плате:
| Группы рабочих по размеру заработной платы, тыс.р. | до 200 | 200-240 | 240-280 | 280-320 | 320 и выше | Итого |
| Число рабочих | 33 | 35 | 47 | 45 | 40 | 200 |
На основании приведенных данных определите:
1) с вероятностью 0,954 (t=2) возможные пределы, в которых
ожидается средняя заработная плата рабочего в целом по заводу (по генеральной
совокупности);
2) с вероятностью 0,997 (t=3) предельную ошибку и границы доли
рабочих с заработной платой от 320 тыс.руб. и выше.
Решение
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Вычислим среднюю з/п: Для этого просуммируем произведения середин
интервалов и соответствующих частот, и полученную сумму разделим на сумму
частот.
2) Выборочная дисперсия:
Найдем доверительный интервал для средней. Предельная ошибка выборочной
средней считается по формуле:
где
—
аргумент функции Лапласа.
Искомые возможные пределы, в которых ожидается средняя заработная плата
рабочего в целом по заводу:
Найдем доверительный интервал для выборочной доли. Предельная ошибка
выборочной доли считается по формуле:
Доля рабочих с з/п от 320 тыс.р.:
Искомые границы доли рабочих с заработной платой от 320 тыс.руб. и выше:
Задача 2
В
городе 23560 семей. В порядке механической выборки предполагается определить
количество семей в городе с числом детей трое и более. Какова должна быть
численность выборки, чтобы с вероятностью 0,954 ошибка выборки не превышала
0,02 человека. На основе предыдущих обследований известно, что дисперсия равна
0,3.
Решение
Численность
выборки можно найти по формуле:
В нашем случае:
Вывод к задаче
Таким образом численность
выборки должна составить 2661 чел.
Задача 3
С
целью определения средней месячной заработной платы персонала фирмы было
проведено 25%-ное выборочное обследование с отбором
единиц пропорционально численности типических групп. Для отбора сотрудников
внутри каждого филиала использовался механический отбор. Результаты
обследования представлены в следующей таблице:
| Номер филиала |
Средняя месячная заработная плата, руб. |
Среднее квадратическое отклонение, руб. |
Число сотрудников, чел. |
| 1 | 870 | 40 | 30 |
| 2 | 1040 | 160 | 80 |
| 3 | 1260 | 190 | 140 |
| 4 | 1530 | 215 | 190 |
С
вероятностью 0,954 определите пределы средней месячной заработной платы всех
сотрудников гостиниц.
Решение
Предельная
ошибка выборочной средней:
Средняя
из внутригрупповых дисперсий:
Получаем:
Средняя
месячная заработная плата по всей совокупности филиалов:
Искомые
пределы средней месячной заработной платы:
Вывод к задаче
Таким
образом с вероятностью 0,954 средняя месячная заработная плата всех сотрудников
гостиниц находится в пределах от 1294,3 руб. до 1325,7 руб.