МЕДИЦИНСКАЯ
СТАТИСТИКА
Под статистикой
понимают:
+А. Самостоятельную
общественную науку, изучающую
количественную сторону массовых
общественных явлений в неразрывной
связи с их качественной стороной;
-Б. Научную дисциплину
по сбору, обработке и хранению информации,
характеризующую количественные
закономерности общественных явлений;
-В. Научную
дисциплину, объединяющую математические
методы, применяемые при сборе, обработке
и анализе информации.
Статистический
метод в медицине и здравоохранении
применяется для:
+А. Изучения
общественного здоровья и факторов, его
определяющих;
+Б. Изучения
состояния и деятельности органов и
учреждений здравоохранения;
+В. Планирования
научных исследований, обработки и
анализа полученных результатов.
1-ый этап проведения
статистического исследования включает:
-А. Сбор материала;
+Б. Составление
плана и программы исследований;
-В. Статистическая
обработка данных;
-Д. Анализ и выводы.
План статистического
исследования включает:
+А. Определение
места проведения исследования;
-Б. Выбор единицы
наблюдения;
+В. Установление
сроков проведения исследования;
-Г. Составление
макетов статистических таблиц.
На каком этапе
статистического исследования создаются
макеты статистических таблиц:
+А. При составлении
программы исследования;
-Б. На этапе сбора
материала;
-В. На этапе
статистической обработки материалов;
-Г. При проведении
анализа результатов.
Основными методами
формирования выборочной совокупности
являются все, кроме:
-А. Типологического;
-Б. Механического;
+В. Целевого;
-Г. Случайного.
Количественная
репрезентативность выборочной
совокупности обеспечивается за счет:
-А. 10-ти процентной
выборки из генеральной совокупности;
-Б. 50-ти процентной
выборки;
+В. Выборки,
включающей достаточное число наблюдений
(рассчитывается по специальным формулам).
К какому виду
статистического наблюдения относится
регистрация рождаемости и смертности:
-А. Единовременное;
+Б. Сплошной;
+В. Текущее;
-Г. Выборочный.
Какие из ниже
перечисленных способов наблюдения при
сборе информации о состоянии здоровья
населения являются более объективными:
-А. Опрос;
-Б. Анкетирование;
+В. Выкопировка
данных из медицинской документации.
К единовременному
наблюдению относится:
-А. Регистрация
рождений;
+Б. Перепись
населения;
-В. Регистрация
браков;
-Г. Регистрация
заболеваний;
+Д. Регистрация
численности и состава больных в стационаре
на определенную дату.
Текущим наблюдением
является:
+А. Регистрация
случаев смерти;
-Б. Перепись
населения;
+В. Регистрация
случаев рождений;
+Г. Регистрация
случаев обращения в поликлинику.
Для экспертной
оценки качества и эффективности
медицинской помощи в женской консультации
отобрана каждая десятая «Индивидуальная
карта беременной и родильницы».
Выборка является:
+А. Механической;
-Б. Гнездовой
(серийный отбор).
Программа
статистического исследования включает:
+А. Составление
программы сбора материала;
+Б. Составление
программы анализа;
-В. Определение
объекта исследования;
-Г. Определение
исполнителей исследования.
Выбор единицы
наблюдения зависит от:
-А. Программы
исследования;
-Б. Плана исследования;
+В. От цели и задач
исследования.
Из перечисленных
видов статистических таблиц наиболее
информативной является:
-А. Простая таблица;
-Б. Групповая
таблица;
+В. Комбинационная
таблица.
Единица наблюдения
— это:
+А. Первичный
элемент статистической совокупности,
являющийся носителем учетных признаков,
подлежащих регистрации;
-Б. Каждый признак
явления, подлежащего регистрации.
Два участковых
врача составили возрастную группировку
обслуживаемого контингента населения.
Какой из врачей сделал это правильно:
+А. До 20 лет, 20 — 39
лет, 40 — 59 лет, 60 лет и старше;
-Б. До 20 лет, 20 — 40
лет, 40 — 60 лет, старше 60 лет.
Типологические
группировки могут включать следующие
признаки:
+А. Пол;
-Б. Рост;
-В. Массу тела;
+Г. Диагноз;
+Д. Профессию.
Заболеваемость
вирусным гепатитом А в районе N.
в текущем году составила 6,0 на 10 000
населения. Указанный показатель является:
-А. Экстенсивным;
+Б. Интенсивным;
-В. Показателем
соотношения;
-Г. Показателем
наглядности.
Какие показатели
позволяют демонстрировать изменения
явления во времени или по территории
без раскрытия истинных размеров этого
явления:
-А. Экстенсивные;
-Б. Интенсивные;
-В. Соотношения;
+Г. Наглядности.
Обеспеченность
врачами населения города N
составляет 36,0 на 10 000 населения. Этот
показатель является:
-А. Экстенсивным;
-Б. Интенсивным;
+В. Показателем
соотношения;
-Г. Показателем
наглядности.
Экстенсивные
показатели могут быть представлены
следующими видами диаграмм:
-А. Линейными;
+Б. Секторными;
-В. Столбиковыми;
+Г. Внутристолбиковыми;
-Д. Картограммами.
Интенсивные
показатели могут быть представлены
следующими видами диаграмм:
+А. Столбиковыми;
-Б. Секторными;
+В. Линейными;
+Г. Картограммами.
К экстенсивным
показателям относятся:
-А. Показатели
рождаемости;
+Б. Распределение
числа врачей по специальностям;
-В. Показатели
младенческой смертности;
+Г. Распределение
умерших по причинам смерти.
К интенсивным
показателям относятся все, кроме:
-А. Показателя
смертности;
+Б. Структуры
заболеваний по нозологическим формам;
+В. Обеспеченности
населения врачами;
-Г. Показателя
заболеваемости.
Вариационный
ряд — это:
-А. Ряд чисел,
отражающих частоту (повторяемость)
цифровых значений изучаемого признака;
-Б. Ряд цифровых
значений различных признаков;
+В. Ряд числовых
измерений признака, расположенных в
ранговом порядке и характеризующихся
определенной частотой.
Средняя
арифметическая — это:
-А. Варианта с
наибольшей частотой;
-Б. Варианта,
находящаяся в середине ряда;
+В. Обобщающая
величина, характеризующая размер
варьирующего признака в совокупности.
Что показывает
среднеквадратическое отклонение:
-А. Разность между
наибольшей и наименьшей вариантой ряда;
+Б. Степень
колеблемости вариационного ряда;
-В. Обобщающую
характеристику размера изучаемого
признака.
Для чего применяется
коэффициент вариации:
-А. Для определения
отклонения вариант от среднего результата;
+Б. Для сравнения
степени колеблемости вариационных
рядов с разноименными признаками;
-В. Для определения
ошибки репрезентативности.
При нормальном
распределении признака в пределах М±2σ
будет находиться:
-А. 68 % вариаций;
+Б. 95 % вариаций;
-В. 99 % вариаций.
Средняя ошибка
средней арифметической величины (ошибка
репрезентативности) — это:
-А. Средняя разность
между средней арифметической и вариантами
ряда;
+Б.
Величина, на которую полученная средняя
величина выборочной совокупности
отличается от среднего результата
генеральной cовокупности;
-В. Величина, на
которую в среднем отличается каждая
варианта от средней арифметической.
Средняя ошибка
средней арифметической величины прямо
пропорциональна:
-А. Числу наблюдений;
-Б. Частоте изучаемого
признака в вариационном ряду;
+В. Показателю
разнообразия изучаемого признака.
Средняя ошибка
средней арифметической величины обратно
пропорциональна:
+А. Числу наблюдений;
-Б. Показателю
разнообразия изучаемого признака;
-В. Частоте изучаемого
признака.
Размер ошибки
средней арифметической величины
зависит от:
-А. Типа вариационного
ряда;
+Б. Числа наблюдений;
-В. Способа расчета
средней;
+Г. Разнообразия
изучаемого признака.
Разность
между сравниваемыми величинами (средними,
относительными) при большом числе
наблюдений (n30)
считается существенной (достоверной),
если:
-А. t равно 1,0;
-Б. t больше 1,0 и
меньше 2,0;
+В. t больше или
равно 2,0.
С увеличением
объема выборки ошибка репрезентативности:
-А. Увеличивается;
+Б. Уменьшается;
-В. Остается
постоянной.
Малой выборкой
считается та совокупность, в которой:
-А. число наблюдений
меньше или равно 100;
+Б. число наблюдений
меньше или равно 30;
-В. число наблюдений
меньше или равно 40.
Доверительный
интервал — это:
-А. Интервал, в
пределах которого находятся не менее
68 % вариант, близких к средней величине
данного вариационного ряда;
+Б. Пределы возможных
колебаний средней величины (показателя)
в генеральной совокупности;
-В. Разница между
максимальной и минимальной вариантами
вариационного ряда.
Минимально
достаточной для медицинских статистических
исследований является вероятность
безошибочного прогноза:
-А. 68 %;
-Б. 90 %;
+В. 95 %;
-Г. 99 %.
При
оценке достоверности разности полученных
результатов исследования разность
является существенной (достоверной),
если при n
30
величина t
равна:
-А. 1,0;
-Б. 1,5;
+В. 2,0;
+Г. 3 и более.
Величина ошибки
репрезентативности средней величины
прямо пропорциональна:
-А.
Числу наблюдений (n);
+Б. Величине
среднеквадратического отклонения
(сигме).
Какой
степени вероятности соответствует
доверительный интервал M2
m (n
30):
-А. 68,3 %;
+Б. 95,5 %;
-В. 99,7 %.
Оценка достоверности
полученного значения критерия Стьюдента
(t) для малых выборок производится:
-А. По специальной
формуле;
-Б. По принципу:
если t = 2, то P = 95%;
+В. По таблице.
Чему
равно значение критерия Стьюдента (t)
при степени вероятности безошибочного
прогноза P=95,5 %, (n 30):
-А.
t
= 1,0
+Б.
t
= 2,0
-В. t = 3 и более.
При проведении
корреляционного анализа необходимо
учитывать следующие параметры:
-А. Направление
связи между признаками, её силу и ошибку
репрезентативности;
-Б. Направление
связи между признаками, её силу, ошибку
репрезентативности и величину коэффициента
вариации;
+В. Направление
связи между признаками, её силу, ошибку
репрезентативности и величину критерия
достоверности.
При следующих
условиях применяется только коэффициент
ранговой корреляции:
+А. Когда нужны
лишь ориентировочные данные о наличии
связи;
+Б. Когда ряды
распределения имеют только атрибутивные
признаки;
-В. Когда ряды
распределения взаимосвязанных признаков
имеют количественное выражение;
+Г. Когда ряды
распределения взаимосвязанных признаков
имеют открытые варианты;
+Д. Когда ряды
распределения имеют как количественное
выражение, так и атрибутивные признаки.
Коэффициент
корреляции по методу квадратов применяется
только при следующих условиях:
-А. Когда нужны
лишь ориентировочные данные о наличии
связи;
+Б. Когда ряды
распределения величины взаимосвязанных
признаков имеют только закрытые варианты;
+В. Когда ряды
распределения взаимосвязанных признаков
имеют количественное выражение;
+Г. Когда нужны
точные данные о наличии связи;
-Д. Когда ряды
распределения имеют как количественное
выражение, так и атрибутивные признаки.
Между какими из
ниже перечисленных признаков может
устанавливаться корреляционная связь:
+А. Ростом и массой
тела у детей;
+Б. Содержанием
кислорода в клетках крови и уровнем
осмотического давления;
-В. Уровнем
систолического и диастолического
давления;
+Г. Частотой случаев
хронических заболеваний и возрастом.
Коэффициент
корреляции между уровнем шума и снижением
слуха с учетом стажа у рабочих
механосборочного цеха равен
rxy + 0,91. Установленная
связь:
-А. Обратная и
слабая;
-Б. Обратная и
сильная;
-В. Прямая и слабая;
+Г. Прямая и сильная.
Для оценки
достоверности полученного значения
коэффициента корреляции используют:
+А. Таблицы
стандартных коэффициентов корреляции
для разных степеней вероятности;
+Б. Ошибку
коэффициентов корреляции;
-В. Оценку
достоверности разности результатов
статистического исследования.
Укажите первый
этап вычисления стандартизованных
показателей прямым методом:
-А. Выбор стандарта;
-Б. Расчет «ожидаемых
чисел»;
+В. Расчет общих и
погрупповых интенсивных показателей;
-Г. Сравнение общих
интенсивных и стандартизованных
показателей;
-Д. Расчет общих
стандартизованных показателей.
Какие статистические
методы позволяют оценивать достоверность
результатов, полученных при выборочных
исследованиях:
-А. Корреляция;
+Б. Определение
доверительных границ;
-В. Стандартизация;
+Г. Оценка
достоверности разности результатов.
Для установления
силы и характера связи между признаками
нужно найти:
-А. Среднеквадратическое
отклонение;
+Б. Коэффициент
корреляции;
-В. Критерий
достоверности;
-Г. Стандартизованные
показатели.
При сравнении
интенсивных показателей, полученных
на однородных по своему составу
совокупностях, необходимо применять:
-А. Метод корреляции;
-Б. Метод
стандартизации;
+В. Оценку
достоверности разности полученных
показателей.
Оценка достоверности
различий в результатах исследования
проводится с помощью:
-А. Коэффициента
корреляции (rxy);
-Б. Коэффициента
вариации (Cv);
+В. Критерия
Стьюдента (t).
Что такое
динамический ряд:
-А. Ряд числовых
измерений определенного признака,
отличающихся друг от друга по своей
величине, расположенных в ранговом
порядке;
+Б. Ряд, состоящий
из однородных сопоставимых величин,
характеризующих изменения какого-либо
явления во времени;
-В. Ряд величин,
характеризующих результаты исследований
в разных регионах.
Уровни динамического
ряда могут быть представлены:
+А. Абсолютными
величинами;
+Б. Средними
величинами;
+В. Относительными
величинами.
Способы вырвнивания
динамического ряда:
+А. Укрупнение
интервалов;
+Б. Вычисление
групповой средней;
-В. Вычисление
коэффициента вариации;
+Г. Вычисление
скользящей средней;
+Д. Использование
метода наименьших квадратов.
Основными
показателями динамического ряда являются
все, кроме:
-А. Темпа роста;
-Б. Абсолютного
прироста;
-В. Темпа прироста;
+Г. Сигмального
отклонения;
-Д. Среднего темпа
прироста.
В какую таблицу
может быть сведена информация,
представленная в виде следующих признаков
«подлежащее и взаимосвязанные между
собой сказуемые»:
-А. Групповая;
+Б. Комбинационная;
-В. Простая;
-Г. Смешанная.
Укажите признаки,
соответствующие типологическому виду
группировки:
+А. Пол: мужской,
женский;
+Б. Диагноз: ИБС,
стенокардия, инфаркт миокарда;
-В. Длительность
заболевания: 1-5 лет, 6-10 лет, более 10 лет;
-Г. Возраст: до 20
лет, 21-30 лет, 31-40 лет, старше 40 лет.
Укажите признаки
атрибутивного характера:
+А. Заболевание
+Б. Исход заболевания
-В. Длительность
заболевания
-Г. Дозы лекарства
+Д. Группа инвалидности
Динамический
ряд – это:
-А. Значения
количественного признака (варианты),
расположенные в определенном порядке
и отличающиеся друг от друга по своему
значению;
+Б. Ряд, состоящий
из однородных сопоставимых значений
признака, характеризующих изменение
какого-либо явления (процесса) во
времени;
-В. Атрибутивные
значения признака, характеризующие
качественное состояние явления в
динамике.
Динамический
ряд может быть представлен:
+А. Абсолютными
величинами;
+Б. Средними
величинами;
+В. Относительными
величинами.
Для сравнения
нескольких динамических рядов с разными
исходными уровнями необходимо рассчитывать
показатель динамического ряда:
61
Третье
свойство статистической совокупности
– разнообразие
признаков.
Четвертое
свойство статистической совокупности
— репрезентативность признаков
Студент
должен знать:
-
определение
второго свойства статистической
совокупности – средний уровень признака; -
виды
средних величин – статистические
критерии второго свойства статистической
совокупности; -
определение
вариационного ряда, виды вариационных
рядов; -
основные
статистические характеристики
вариационного ряда: варианты, частота,
число наблюдений; -
методика
вычисления средних величин при большом
числе наблюдений; -
методика
вычисления средних величин при малом
числе наблюдений; -
сущность
третьего свойства статистической
совокупности – разнообразие признака; -
статистические
критерии разнообразия признака
статистической совокупности (лимит,
амплитуда, среднее квадратическое
отклонение, коэффициент вариации),
особенности их использования; -
методика
вычисления среднего квадратического
отклонения при большом и малом числе
наблюдения; -
сущность
четвертого свойства
статистической совокупности –
репрезентативность (достоверность)
признаков; -
статистические
критерии, характеризующие репрезентативность
(достоверность) признака (ошибки средних
и относительных величин, доверительных
границ средних и относительных величин,
достоверности разности средних и
относительных величин); -
особенности
вычисления ошибок средних величин при
большом и малом числе наблюдений; -
особенности
вычисления ошибки относительных
величин; -
методика
определения доверительных границ
средних и относительных величин; -
методика
определения достоверности разности
средних и относительных величин; -
практическое
значение средних величин и оценки их
достоверности.
Студент
должен уметь:
-
строить
простой и сгруппированный вариационные
ряды; -
вычислять
среднюю величину (М), среднее квадратическое
отклонение (σ), ошибку средней величины
(m)
при большом и малом числе наблюдений; -
определять
доверительные границы для средней
величины при большом и малом числе
наблюдений, для относительных величин; -
определять
достоверность разности средних и
относительных величин.
План занятия
-
Сущность
второго свойства статистической
совокупности и его статистические
критерии; -
Характеристики
вариационного ряда. -
Виды
средних величин и методика их вычисления
при большом и
малом числе наблюдений.
Свойства средней величины. -
Сущность
разнообразия признака статистической
совокупности и статистические критерии.
Методика расчета среднего квадратического
отклонения при большом и малом числе
наблюдений. -
Сущность
четвертого свойства статистической
совокупности и статистические критерии
характеризующие его. -
Определение
ошибки репрезентативности средних
величин при
большом и малом числе наблюдений.
Особенности вычисления ошибки
относительных величин. -
Методика
определения доверительных границ
средних и относительных величин при
большом и малом числе наблюдений. -
Методика
определения достоверности разности
средних и относительных величин. -
Использование
средних величин в практической
деятельности врача.
Блок
информации:
Второе
свойство – средний уровень признака
используется для количественной
характеристики статистической
совокупности.
К
статистическим критериям, характеризующим
второе свойство статистической
совокупности, относят средние
величины.
Для
вычисления средних величин используются
вариационные ряды.
Вариационный
ряд, виды вариационных рядов.
Вариационный
ряд – это
ряд вариант одного и того же признака,
расположенных в определенном порядке
(по степени возрастания или убывания).
Вариационные
ряды бывают:
-
простые
и взвешенные; -
несгруппированные
и сгруппированные (интервальные); -
четные
(число вариант четное) и нечетные (число
вариант нечетное).
Простой
вариационный ряд представляет собой
ряд вариант, в котором каждая варианта
встречается с частотой, равной единице.
Взвешенный
вариационный
ряд представляет собой ряд вариант, в
котором каждая варианта встречается с
различной частотой.
Простой
и взвешенный вариационные ряды могут
быть представлены несгруппированными
и сгруппированными вариантами.
Несгруппированный
вариационный
ряд содержит отдельные варианты с
соответствующими им частотами.
Сгруппированный
(интервальный)
вариационный ряд имеет в своем составе
варианты, объединенные в пределах
определенного интервала, соответственно
с частотой их встречаемости.
Требования
к составлению сгруппированного
вариационного ряда
-
определенный
порядок расположения вариант -
непрерывность
вариационного ряда -
сгруппированный
вариационный ряд
Характеристики
вариационного ряда
Полученные
при исследовании числовые измерения
одного и того же признака называются
вариантами
(V
– vario).
Число
раз, которое встречается одна и та же
варианта в вариационном ряду называется
частотой (p
– pars).
Сумма
всех частот вариационного ряда определяет
число
наблюдений (n
= Σр).
Виды
средних величин и методика их вычисления
при большом
и малом числе наблюдений.
Свойства средней величины.
Виды
средних величин
-
мода;
-
медиана;
-
средняя
арифметическая;
Мода
(Мо) – средняя
величина, которая соответствует варианте,
встречающейся в вариационном ряду с
наибольшей частотой.
Медиана
(Ме) – средняя
величина, соответствующая варианте,
которая делит вариационный ряд пополам.
В нечетном
вариационном ряду находится в середине,
в четном
вариационном
ряду вычисляется как полусумма двух
средних вариант.
Средняя
величина
(средняя арифметическая, средняя
взвешенная) (М)
– обобщенная характеристика среднего
уровня изучаемого признака однородной
статистической совокупности в конкретных
условиях места и времени.
В
отличие от моды и медианы средняя
арифметическая учитывает все значения
вариант вариационного ряда.
Свойства
средней величины.
-
в
строго симметричном вариационном ряду
средняя величина занимает срединное
положение, поэтому средняя, мода и
медиана имеют одну и ту же величину (М
= Мо = Ме). -
средняя
величина имеет абстрактный характер
и является обобщающей величиной,
определяющей
закономерность всей совокупности. -
произведение
средней на число наблюдений всегда
равняется сумме произведений каждой
варианты на соответствующую ей частоту
встречаемости в вариационном ряду. -
алгебраическая
сумма отклонений всех вариант
вариационного ряда от средней равна
нулю. -
если
к каждой варианте вариационного ряда
прибавить или отнять одно и то же число,
то на такое же число увеличится или
уменьшится средняя арифметическая
величина. -
если
каждую варианту вариационного ряда
разделить или умножить на одно и то же
число, то во столько же раз уменьшится
или увеличится средняя арифметическая
величина.
Методика
расчета средних величин при большом и
малом числе наблюдений рассмотрена в
образцах выполнения практических
заданий.
Третье
свойство
(разнообразия
признака) характеризует
распределение
вариант количественных признаков
в однородной статистической
совокупности.
К
статистическим критериям, характеризующим
третье свойство статистической
совокупности, относят:
-
лимит
(lim)
определяется крайними значениями
вариант в вариационном ряду –
Lim
= Vmax
: Vmin; -
амплитуда
(Am)
равна разности между крайними значениями
вариант в вариационном ряду – (Am
= Vmax
–Vmin); -
среднее
квадратическое отклонение
(δ) дает наиболее полную характеристику
разнообразия признака в статистической
совокупности, так как учитывает все
значения вариант;
Методика
вычисления среднего квадратического
отклонения при большом числе наблюдений
рассмотрена в образце выполнения
практического задания.
-
коэффициент
вариации
(Cv)
является относительной мерой разнообразия
признака в статистической совокупности
–
 ,
,
где
δ
– среднее квадратическое отклонение
М
– средняя арифметическая взвешенная
Величина
коэффициента вариации больше 20%
свидетельствует о высокой степени
разнообразия признака, при величине
коэффициента вариации от 10 до 20% –
степень разнообразия средняя, величина
коэффициента вариации менее 10%
свидетельствует о низкой степени
разнообразия признака.
Среднее
квадратическое отклонение и
коэффициент вариации
являются обобщающими характеристиками
статистической совокупности.
Роль
среднего
квадратического отклонения
состоит в том, что по величине δ
можно:
-
определить
структуру вариационного ряда; -
охарактеризовать
степень однородности вариационного
ряда; -
судить
о типичности средней (арифметической
или взвешенной) величины; -
оценить
отдельные признаки у каждого индивидуума; -
оценить
достоверность (репрезентативность)
результатов исследования.
Четвертое
свойство
статистической совокупности характеризует
репрезентативность
выборки, которая может быть достигнута
специальными методами отбора выборочной
совокупности.
Репрезентативность
(достоверность) выборочной совокупности
означает представительность в ней всех
учитываемых признаков характерных для
генеральной совокупности, что гарантирует
высокую вероятность соответствия
закономерностей, полученных при
исследовании выборочной совокупности
существующим в генеральной совокупности.
Статистические
критерии,
характеризующие репрезентативность
статистической совокупности:
-
ошибки
средних и относительных величин; -
доверительные
границы средних и относительных величин; -
достоверность
различий средних и относительных
величин по критерию t.
Определение
ошибки репрезентативности.
Величина
ошибки прямо
пропорциональна степени разнообразия
признака и
обратно
пропорциональна числу наблюдений
в статистической совокупности.
Следовательно, чем менее разнообразен
признак и больше число наблюдений в
статистической совокупности, тем меньше
величина ошибки
и более
достоверен результат
исследования.
Вычисление
ошибки репрезентативности для средних
величин при большом числе (n
≥ 30) наблюдений
осуществляется по формуле:
![]() ,
,
где
mМ
– ошибка средней величины
n
– число наблюдений
δ
– среднее квадратическое отклонение
Вычисление
ошибки репрезентативности для средних
величин при малом числе наблюдений (n
< 30) осуществляется
по формуле:
![]() ,
,
где
mМ
–ошибка средней величины
n
– число наблюдений
δ
– среднее квадратическое отклонение
Вычисление
ошибки репрезентативности для
относительных величин осуществляется
по формуле:
![]() ,
,
где
m%
–ошибка относительной величины,
p
– относительный показатель, выраженный
в процентах (%),
q
– величина равная 100-p.
Методика
среднего квадратического отклонения
и ошибок при малом числе наблюдений
рассмотрена в
образцах выполнения практических
заданий.
Методика
определения доверительных границ
средней величины.
Доверительные
границы – интервал колеблемости средней
величины (или относительной величины),
выход за пределы которого имеет
незначительную вероятность.
Доверительные
границы для средних
величин
определяют по формуле:
![]() ,
,
где
М
ген
– средняя генеральной совокупности
М
выб
– средняя выборочной совокупности
m
– ошибка средней величины
t
– доверительный коэффициент
Доверительные
границы для относительных
величин
определяют по формуле:
![]() ,
,
где
Р
ген
– средняя генеральной совокупности
Р
выб
– средняя выборочной совокупности
m
– ошибка показателя (относительной
величины)
t
– доверительный коэффициент
Величина
доверительного
коэффициента
(t)
определяется величиной доверительной
вероятности,
с которой необходимо получить конечный
результат, и числом
наблюдений.
В медико-статистических
исследованиях обычно используют
доверительную вероятность, равную 95%
или-99% (или 0,95-0,99), которым соответствует
определенная величина критерия t.
При
большом числе наблюдений (n
≥ 30) и доверительной вероятности Р=95%
величина доверительного коэффициента
соответствует t
= 2, при доверительной вероятности Р=99%
величина доверительного коэффициента
соответствует t
= 3.
При
малом числе наблюдений (n
< 30) величина t
несколько больше указанных выше значений
и ее необходимо определять по таблице
Стьюдента.
Использование
средних величин и доверительных границ
в практической деятельности врача.
Средние
величины и доверительный интервал лежат
в основе определения достоверных границ
средних величин, которые широко
используются в процессе профессиональной
деятельности врача для оценки данных
физиологических и лабораторных
исследований.
И снова о погрешностях
Окончание. См. № 15/07
Д.А.ИВАШКИНА,
лицей г. Троицка, Московская обл.
aivashkin@mail.ru
И снова о погрешностях
4. Учёт случайных погрешностей при
прямых измерениях
Если, проведя одно и то же измерение
несколько раз, вы видите, что результат остаётся
одним и тем же, то случайные погрешности
эксперимента малы, их не следует учитывать. Но
если при повторении измерения получаются разные
значения, то следует взять среднее значение из
серии измерений:
![]()
где n – число измерений. Как
узнать, какова погрешность результата? Логично, и
ученики сами обычно предлагают это, определить
среднее отклонение результата от среднего
значения. Полученная величина носит название средней
арифметической ошибки: ![]() Она показывает, на сколько в
Она показывает, на сколько в
среднем каждое измеренное значение отклоняется
от среднего значения. Но эта величина слабо
зависит от количества проведённых измерений. В
чём же тогда смысл многократных измерений?
Для среднеквадратичной погрешности,
которая определяется немного сложнее:
![]()
есть простое правило: средняя
квадратичная погрешность среднего
арифметического равна средней квадратичной
погрешности отдельного результата, делённой на
корень квадратный из числа измерений: ![]() Из формулы ясно,
Из формулы ясно,
что с увеличением числа измерений случайная
погрешность среднего значения уменьшается.
Поэтому необходимо проводить столько измерений,
чтобы случайная погрешность стала меньше
значения систематической погрешности данного
измерения.
К сожалению, в лабораторных работах и
при любых других экспериментах в школе провести
достаточное количество измерений невозможно в
силу нехватки времени. Как поступать, может
решить сам учитель. На мой взгляд, для нахождения
средней арифметической погрешности среднего
значения можно использовать формулу,
аналогичную формуле для средней квадратичной
ошибки: ![]()
Хотя эта формула и неверна, она
помогает понять смысл проведения большого числа
измерений. Использоваться же она будет всего в
нескольких работах, и, следовательно, нет нужды
специально обучать нахождению погрешности
среднего значения. Зато, получив в этих работах
случайную погрешность меньше погрешности
систематической, ученик запомнит, что каждое
измерение следует производить несколько раз при
малейшем подозрении, что в данном эксперименте
имеется случайная погрешность. Как правило, уже
при пяти измерениях достигается необходимая
малость случайной погрешности по сравнению с
систематической.
5. Определение погрешности
результата косвенных измерений
К определению погрешности результата
косвенных измерений учащиеся готовы, на мой
взгляд, уже к 8-му классу. В зависимости от уровня
класса впервые метод границ [1, 12] можно
применить или в работе по сравнению количеств
теплоты при смешивании воды, или при нахождении
сопротивления проводника. Поясню на примерах.
-
Допустим, при нагревании холодной
воды в процессе смешивания мы имеем следующие
результаты измерений:
– температура холодной воды t1
= (16,0 ± 1,5) °С;
– температура смеси t = (43,0 ± 1,5) °С;
– объём холодной воды V1 = (80
± 2) мл = (80 ± 2) • 10–6 м3.
Получаем количество теплоты,
полученное холодной водой:
Q = 4190 Дж/(кг • °С) • 1000 кг/м3
• 80 • 10–6 м3 ![]() (43 – 16) °С = 9050,4 Дж.
(43 – 16) °С = 9050,4 Дж.
(1)
Возникает вопрос: а какова погрешность
полученного значения? Другими словами, на
сколько мы можем ошибиться, если точные значения
не равны измеренным, а лежат где-то в интервале,
даваемом погрешностью? Например, начальная
температура воды может быть равна 16,5 °С, 17,0 °С и
т.д. Тогда вычисленное количество теплоты будет
меньше. Логично посмотреть, на сколько мы можем
ошибиться по максимуму. Максимальное количество
теплоты получится, если взять для всех
сомножителей максимальные значения, т.е. верхние
границы интервалов значений с погрешностью, для
уменьшаемого взять верхнюю границу значения, а
для вычитаемого – нижнюю:
Qв = 4190 Дж/(кг • °С) • 1000
кг/м3 • 82 • 10–6 м3 ![]() (44,5 – 14,5)°С = 10 307,4 Дж.
(44,5 – 14,5)°С = 10 307,4 Дж.
Аналогично вычисляем нижнюю границу
значения количества теплоты:
Qн = 4190 Дж/(кг • °С) • 1000
кг/м3 • 78 • 10–6 м3 ![]() (41,5 – 17,5) °С = 7843,68
(41,5 – 17,5) °С = 7843,68
Дж.
В данных пределах и лежит искомое
значение. Чтобы сравнивать методом интервалов
это значение с количеством теплоты, отданным
горячей водой, надо округлить значения верхней и
нижней границ. Лучше это сделать, оценив
абсолютную погрешность найденного значения
количества теплоты.
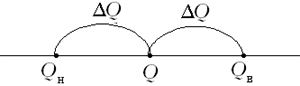
Рис. 2
Из рис. 2 видно, что
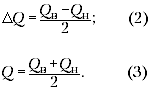
Найденное выше значение (1) близко к (3),
поэтому его не стоит находить ещё раз. А вот для
погрешности найдём с помощью (2):
![]() (две
(две
значащие цифры, т.к. первая «1»). Поэтому
количество теплоты, полученное холодной водой,
можно округлить: Qполуч = 9000 Дж ±
1200 Дж (т.е. между 7800 Дж и 10 200 Дж). Если количество
теплоты, отданное горячей водой, лежит между 8500
Дж и 11 500 Дж (Qотдан = 10 000 Дж ± 1500 Дж), то
можно видеть, что эти количества теплоты
совпадают в пределах погрешности эксперимента
(рис. 3).
Рис.3
-
Определение сопротивления резистора.
Пусть измеренные значения напряжения и силы тока
следующие:
– U = 2,60 В ± 0,15 В (инструментальная
погрешность 0,15 В; погрешность отсчёта может быть
взята равной 0,05 В, т.е. в 3 раза меньше
инструментальной, поэтому ею можно пренебречь);
– I = 1,2 А ± 0,1 А (инструментальная
погрешность 0,05 А, погрешность отсчёта 0,05 А).
Тогда для сопротивления получаем:
![]()
Но на самом резисторе написано: «2 ± 0,1 ![]() ». Получается, что
». Получается, что
мы неверно определили сопротивление? Рассчитаем
погрешность нашего определения значения
сопротивления:
Uв = 2,75 В; Uн = 2,45 В; Iв
= 1,3 А, Iн = 1,1 А;
![]()
Полученное экспериментально значение
сопротивления R = (2,2 ± 0,3) Ом совпадает в
пределах погрешности со значением R = (2,0 ± 0,1)
Ом, указанным на резисторе.
С помощью метода границ можно вывести
и формулы для погрешности при обобщении темы
«Определение погрешности косвенных измерений»,
но уже в 9-м классе.
Определение погрешности разности. Пусть
А = В – С. Рассчитаем погрешность А в
общем виде:
Ав = Вв – Сн
= (В + ![]() В)
В)
– (С – ![]() С)
С)
= (В – С) + (![]() В
В
+ ![]() С);
С);
Ан = Вн – Св
= (В – ![]() В)
В)
– (С + ![]() С)
С)
= (В – С) – (![]() В
В
+ ![]() С);
С);
![]()
Полученное очень важно: в некоторых
работах в формулах для вычисления результата
встречается разность двух близких по значению
величин, что приводит к большой относительной
погрешности результата.
-
В cтарой работе «Определение модуля
Юнга резины» [11] удлинение резинового жгута
находилось как разность его результирующей и
начальной длин. Если условия опыта таковы, что
эта разность мала, например, составляет 1,5 см, то
относительная погрешность определения разности (погрешность
(погрешность
отсчёта взята гораздо меньше инструментальной
погрешности). Ясно, что такое измерение
использовать для определения модуля Юнга
нежелательно, – может получиться погрешность
больше 100%. Лучше увеличить нагрузку на жгут.
Аналогичная проблема возникает в работе
«Измерение ЭДС и внутреннего сопротивления
источника» [2] (одно сопротивление должно быть в
несколько раз больше другого) и др.
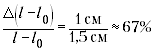 (погрешность
(погрешностьОпределение погрешности частного
двух величин. Пусть ![]() Рассчитаем погрешность в общем виде:
Рассчитаем погрешность в общем виде:
![]()
Такую формулу трудно запоминать.
Поэтому найдём относительную погрешность
величины А:
![]()
Итак, относительная погрешность
частного равна сумме относительных погрешностей
величин, входящих в него. Такая же формула
получается и для относительной погрешности
произведения.
Важным я считаю не сам процесс расчёта
погрешности. Эти формулы дают мощный инструмент
для оценки обоснованности проведения
эксперимента. При их использовании легко
объяснить, при измерении какой из величин
следует увеличить точность, чтобы получить
лучший результат.
Рассмотрим формулу для нахождения
модуля Юнга: 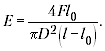
Если воспользоваться для расчёта погрешности
результата методом границ, то неясным останется,
какая из величин в формуле вносит наибольшую
погрешность.
Для нахождения относительной
погрешности результата лучше воспользоваться
формулой:
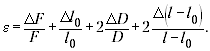
При подстановке значений оказывается,
что слагаемое 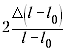
даёт максимальный вклад в сумму, а остальные
слагаемые в несколько раз меньше, так что ими
можно пренебречь. Если l – l0 будет
невелико, то значение относительной погрешности
окажется очень большим, порой выше 100%. Какой
вывод сделают в таком случае ученики?
Такая ситуация – пример того, как
применение упрощённого способа вычисления
погрешностей может привести к большим ошибкам.
Конечно же, этот эксперимент совершенно
обоснован, с помощью него можно найти модуль
Юнга. Только следует выбрать те измерения, где l
– l0 достаточно велико, и не забыть
пренебречь малыми слагаемыми при расчёте
погрешности.
6. Определение коэффициента
прямой пропорциональности
В лабораторных работах нередко
встречается ситуация, когда необходимо по
графику определить коэффициент
пропорциональности в зависимости одной величины
от другой. И здесь в учебниках встречаются две
ситуации.
В работе «Определение модуля Юнга» [13]
после нахождения модуля Юнга для измерений с
тремя различными нагрузками учащимся
предлагается найти среднее арифметическое трёх
полученных значений. Такой подход ошибочен, т.к.
каждое значение получено с различными
систематическими погрешностями, т.е. с разной
степенью точности. Нельзя суммировать эти
значения «с одинаковым весом». При подобных
вычислениях в теории ошибок находится сумма этих
значений с разными коэффициентами.
Далее, в работе «Измерение жёсткости
пружины» [7] в аналогичной ситуации совершенно
справедливо отмечено, что, поскольку жёсткость
пружины в каждом из опытов получена при разных
условиях, среднее арифметическое этих значений
находить нельзя. И предлагается найти среднее
значение коэффициента жёсткости по графику как
коэффициент пропорциональности. Однако,
поскольку учащиеся не могут найти погрешность
найденного таким образом коэффициента
пропорциональности, предлагается взять в
качестве этой погрешности погрешность
наихудшего результата. Я считаю, что такой подход
не оправдан. Зачем брать погрешность самого
ненадёжного результата, если сам способ
нахождения коэффициента жёсткости из графика
применяется для того, чтобы определить этот
коэффициент наиболее точно? Думаю, авторы просто
не хотели заострять внимание на этом вопросе.
На мой взгляд, для определения
коэффициента пропорциональности по графику
можно предложить несколько вариантов.
Вариант 1. Самый простой, а потому
пригодный для младших классов. Отмечаем на
графике экспериментальные значения с указанием
погрешности. Обращаем внимание учащихся на то,
что если бы мы не нанесли погрешности на графики,
то провести прямую было бы затруднительно. В 7-м
классе достаточно просто отметить тот факт, что
зависимость между двумя величинами прямо
пропорциональна. Но если всё-таки необходимо
найти значение коэффициента пропорциональности,
можно обойтись без расчёта погрешности, отметив
только, что этот способ (многократные измерения
при различных условиях и построение графика)
используется именно для того, чтобы уменьшить
погрешность результата.
Вариант 2. Чертим прямую, находим
экспериментальную точку, которая лежит ближе
всего к прямой, и именно эту точку и считаем самой
точной. Остаётся вычислить результат для неё по
обычным формулам, рассчитав также и погрешность.
Вариант 3. Самый логичный. Пробуем
провести через точки вместе с их погрешностями
две прямые: с наибольшим и с наименьшим наклоном.
Значения коэффициентов для них и будут верхней и
нижней границами для результата. Зная границы,
рассчитываем среднее значение коэффициента и
погрешность. Данная погрешность неявно будет
содержать в себе как систематическую
погрешность экспериментально измеренных
величин, так и случайную погрешность определения
среднего, но уже с учётом точности каждого
результата. Этот вариант годится для
использования в экспериментах, когда
коэффициент должен быть оценён достаточно точно.
Но он достаточно сложен, поэтому не стоит его
использовать во всех случаях.
Вариант 4. Использование
встроенных программ в калькуляторах или готовых
компьютерных программ для вычисления
коэффициентов по методу наименьших квадратов.
Этот способ пригоден для практикума в старших
классах и/или в классах физматпрофиля. К
сожалению, в такие программы, как правило,
встроен метод наименьших квадратов, не
учитывающий погрешностей экспериментальных
точек. Применение имеет смысл в случаях, когда
погрешности всех точек практически одинаковы
или когда доминирующей является случайная
погрешность. Она и будет учтена.
Какой из этих вариантов выбрать, может
решать сам учитель. К счастью, таких работ
довольно мало. Продемонстрируем все эти варианты
на примере.
-
Возьмём данные эксперимента по
зависимости пути от времени равномерного
движения (машинка из конструктора с
электрическим приводом):
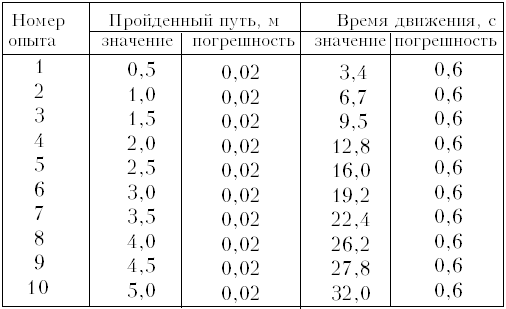
Действуя так, как описано в варианте 1,
строим график (рис. 4).
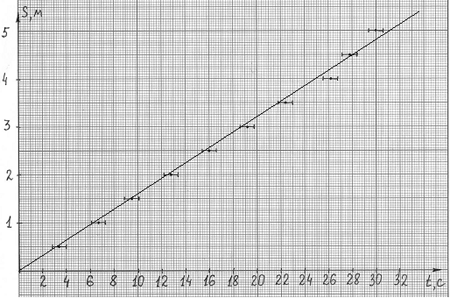
Рис. 4
Так как точек на графике много, можно с
уверенностью утверждать, что 8-я и 10-я точки
являются «выбросами», т.е. измерены небрежно.
Учитывая погрешность эксперимента, можно
провести прямую практически единственным
способом: соответствующая скорость 0,16 м/с. Если
воспользоваться методом наименьших квадратов
(например, встроенной функцией ЛИНЕЙН в
программе MicrosoftExcel), то для коэффициента мы
получим значение 0,158 ± 0,002 м/с (вариант 4).
Для варианта 2 подходит 3-я точка.
Скорость, вычисленная по данным для этой точки,
0,158 м/с. Рассчитаем погрешность: ![]() Так как относительная
Так как относительная
погрешность пути мала по сравнению с
относительной погрешностью времени,
пренебрегаем ею. Абсолютная погрешность
результата: ![]() 0,063
0,063
• 0,158 = 0,010 м/с. То есть скорость, вычисленная в
варианте 2: (0,158 ± 0,010) м/с.
Из приведённого примера видно, что
значения коэффициента пропорциональности
получаются очень близкими. В этом примере
погрешности отдельных измерений были достаточно
малы, а точек, наоборот, было много. Рассмотрим
пример, когда погрешности, напротив, велики, а
количество опытов в силу объективных причин
мало.
-
Найдём плотности пластмассы путём
измерения массы и объёмов тел.
В случае варианта 1 прямую проводим
так, чтобы количество точек над и под прямой было
одинаково (рис. 5), т.е. в данном случае – одна
сверху, одна снизу (прямая 1). Плотность в
этом случае равна 1,23 г/см3.

Рис. 5
В случае варианта 2 пригодна 2-я точка.
Для неё значение плотности (1,2 ± 0,2) г/см3.
Вариант 3: проведём прямые 2 и 3.
Для прямой 2 коэффициент пропорциональности
1,09 г/см3 является нижней границей
искомого значения плотности, а для прямой 3
(1,27 г/см3) – верхней. Полусумма этих
значений есть значение плотности (1,18 г/см3),
а полуразность – значение погрешности (0,09 г/см3).
Вариант 4 в данном случае менее
пригоден, т.к. не учитывает больших значений
погрешностей при измерении объёма с помощью
мерного цилиндра, но и в этом варианте плотность
(1,18 ± 0,05) г/см3.
Следует заметить, что в двух последних
примерах на графиках были обозначены только
погрешности вдоль горизонтальной оси, т.к.
погрешности значений второй переменной были
очень малы.
Послесловие
Научиться обрабатывать результаты
экспериментов учащиеся могут, лишь обрабатывая
результаты экспериментов. Это означает, что
помимо стандартного набора лабораторных работ
необходимо проводить много фронтальных и
демонстрационных экспериментов с обработкой
результатов. Это большая работа, и я хочу
пожелать успехов всем учителям, кто вступит на
этот путь или уже стоит на нём.
Литература
1. Анофрикова С.В., Стефанова Г.П.
Практическая методика преподавания физики.
Часть первая. – Астрахань: Издательство
Астраханского ГПИ, 1995.
2. Физика: Под ред. А.А.Пинского: Учебник
для 10 кл. школ и классов с угл. изучением физики. –
М.: Просвещение, 2002.
3. Попова О.Н. Обучение учащихся
выявлению устойчивых связей и отношений между
физическими величинами: Методическое пособие
для учителей физики. – Элиста: Элистинский лицей,
1998.
4. Анофрикова С.В. Азбука
учительской деятельности, иллюстрированная
примерами деятельности учителя физики. Ч. 1.
Разработка уроков. – М.: МПГУ, 2001.
5. Пёрышкин А.В. Физика-8. – М.:
Дрофа, 2004.
6. Громов С.В., Родина Н.А. Физика-8.
– М.: Просвещение, 2000.
7. Кикоин И.К., Кикоин А.К. Физика-10.
Механика. – М.: Просвещение, 2001.
8. Фронтальные лабораторные занятия по
физике в 7–11 классах общеобразовательных
учреждений. Книга для учителя: Под ред. В.А.Бурова,
Г.Г.Никифорова. – М.: Просвещение, Учебная
литература, 1996.
9. Зайдель А.Н. Элементарные оценки
ошибок измерений. – Л.: Наука, 1967.
10. Хорозов С.А. Работа над
ошибками: В кн. «Энциклопедия для детей», т. 16
«Физика», ч. 1 «Биография физики. Путешествие в
глубь материи. Механистическая картина мира». –
М.: Аванта+, 2000.
11. Мякишев Г.Я., Буховцев Б.Б., Сотский
Н.Н. Физика-10. – М.: Просвещение, 2004.
12. Кирик Л.А. Физика-9: Методические
материалы. – М.: Илекса, 2003.
13. Шахмаев Н.М., Шахмаев С.Н., Шодиев
Д.Ш. Физика-10. – М.: Просвещение, 1994.
МЕДИЦИНСКАЯ
СТАТИСТИКА
Под статистикой
понимают:
+А. Самостоятельную
общественную науку, изучающую
количественную сторону массовых
общественных явлений в неразрывной
связи с их качественной стороной;
-Б. Научную дисциплину
по сбору, обработке и хранению информации,
характеризующую количественные
закономерности общественных явлений;
-В. Научную
дисциплину, объединяющую математические
методы, применяемые при сборе, обработке
и анализе информации.
Статистический
метод в медицине и здравоохранении
применяется для:
+А. Изучения
общественного здоровья и факторов, его
определяющих;
+Б. Изучения
состояния и деятельности органов и
учреждений здравоохранения;
+В. Планирования
научных исследований, обработки и
анализа полученных результатов.
1-ый этап проведения
статистического исследования включает:
-А. Сбор материала;
+Б. Составление
плана и программы исследований;
-В. Статистическая
обработка данных;
-Д. Анализ и выводы.
План статистического
исследования включает:
+А. Определение
места проведения исследования;
-Б. Выбор единицы
наблюдения;
+В. Установление
сроков проведения исследования;
-Г. Составление
макетов статистических таблиц.
На каком этапе
статистического исследования создаются
макеты статистических таблиц:
+А. При составлении
программы исследования;
-Б. На этапе сбора
материала;
-В. На этапе
статистической обработки материалов;
-Г. При проведении
анализа результатов.
Основными методами
формирования выборочной совокупности
являются все, кроме:
-А. Типологического;
-Б. Механического;
+В. Целевого;
-Г. Случайного.
Количественная
репрезентативность выборочной
совокупности обеспечивается за счет:
-А. 10-ти процентной
выборки из генеральной совокупности;
-Б. 50-ти процентной
выборки;
+В. Выборки,
включающей достаточное число наблюдений
(рассчитывается по специальным формулам).
К какому виду
статистического наблюдения относится
регистрация рождаемости и смертности:
-А. Единовременное;
+Б. Сплошной;
+В. Текущее;
-Г. Выборочный.
Какие из ниже
перечисленных способов наблюдения при
сборе информации о состоянии здоровья
населения являются более объективными:
-А. Опрос;
-Б. Анкетирование;
+В. Выкопировка
данных из медицинской документации.
К единовременному
наблюдению относится:
-А. Регистрация
рождений;
+Б. Перепись
населения;
-В. Регистрация
браков;
-Г. Регистрация
заболеваний;
+Д. Регистрация
численности и состава больных в стационаре
на определенную дату.
Текущим наблюдением
является:
+А. Регистрация
случаев смерти;
-Б. Перепись
населения;
+В. Регистрация
случаев рождений;
+Г. Регистрация
случаев обращения в поликлинику.
Для экспертной
оценки качества и эффективности
медицинской помощи в женской консультации
отобрана каждая десятая «Индивидуальная
карта беременной и родильницы».
Выборка является:
+А. Механической;
-Б. Гнездовой
(серийный отбор).
Программа
статистического исследования включает:
+А. Составление
программы сбора материала;
+Б. Составление
программы анализа;
-В. Определение
объекта исследования;
-Г. Определение
исполнителей исследования.
Выбор единицы
наблюдения зависит от:
-А. Программы
исследования;
-Б. Плана исследования;
+В. От цели и задач
исследования.
Из перечисленных
видов статистических таблиц наиболее
информативной является:
-А. Простая таблица;
-Б. Групповая
таблица;
+В. Комбинационная
таблица.
Единица наблюдения
— это:
+А. Первичный
элемент статистической совокупности,
являющийся носителем учетных признаков,
подлежащих регистрации;
-Б. Каждый признак
явления, подлежащего регистрации.
Два участковых
врача составили возрастную группировку
обслуживаемого контингента населения.
Какой из врачей сделал это правильно:
+А. До 20 лет, 20 — 39
лет, 40 — 59 лет, 60 лет и старше;
-Б. До 20 лет, 20 — 40
лет, 40 — 60 лет, старше 60 лет.
Типологические
группировки могут включать следующие
признаки:
+А. Пол;
-Б. Рост;
-В. Массу тела;
+Г. Диагноз;
+Д. Профессию.
Заболеваемость
вирусным гепатитом А в районе N.
в текущем году составила 6,0 на 10 000
населения. Указанный показатель является:
-А. Экстенсивным;
+Б. Интенсивным;
-В. Показателем
соотношения;
-Г. Показателем
наглядности.
Какие показатели
позволяют демонстрировать изменения
явления во времени или по территории
без раскрытия истинных размеров этого
явления:
-А. Экстенсивные;
-Б. Интенсивные;
-В. Соотношения;
+Г. Наглядности.
Обеспеченность
врачами населения города N
составляет 36,0 на 10 000 населения. Этот
показатель является:
-А. Экстенсивным;
-Б. Интенсивным;
+В. Показателем
соотношения;
-Г. Показателем
наглядности.
Экстенсивные
показатели могут быть представлены
следующими видами диаграмм:
-А. Линейными;
+Б. Секторными;
-В. Столбиковыми;
+Г. Внутристолбиковыми;
-Д. Картограммами.
Интенсивные
показатели могут быть представлены
следующими видами диаграмм:
+А. Столбиковыми;
-Б. Секторными;
+В. Линейными;
+Г. Картограммами.
К экстенсивным
показателям относятся:
-А. Показатели
рождаемости;
+Б. Распределение
числа врачей по специальностям;
-В. Показатели
младенческой смертности;
+Г. Распределение
умерших по причинам смерти.
К интенсивным
показателям относятся все, кроме:
-А. Показателя
смертности;
+Б. Структуры
заболеваний по нозологическим формам;
+В. Обеспеченности
населения врачами;
-Г. Показателя
заболеваемости.
Вариационный
ряд — это:
-А. Ряд чисел,
отражающих частоту (повторяемость)
цифровых значений изучаемого признака;
-Б. Ряд цифровых
значений различных признаков;
+В. Ряд числовых
измерений признака, расположенных в
ранговом порядке и характеризующихся
определенной частотой.
Средняя
арифметическая — это:
-А. Варианта с
наибольшей частотой;
-Б. Варианта,
находящаяся в середине ряда;
+В. Обобщающая
величина, характеризующая размер
варьирующего признака в совокупности.
Что показывает
среднеквадратическое отклонение:
-А. Разность между
наибольшей и наименьшей вариантой ряда;
+Б. Степень
колеблемости вариационного ряда;
-В. Обобщающую
характеристику размера изучаемого
признака.
Для чего применяется
коэффициент вариации:
-А. Для определения
отклонения вариант от среднего результата;
+Б. Для сравнения
степени колеблемости вариационных
рядов с разноименными признаками;
-В. Для определения
ошибки репрезентативности.
При нормальном
распределении признака в пределах М±2σ
будет находиться:
-А. 68 % вариаций;
+Б. 95 % вариаций;
-В. 99 % вариаций.
Средняя ошибка
средней арифметической величины (ошибка
репрезентативности) — это:
-А. Средняя разность
между средней арифметической и вариантами
ряда;
+Б.
Величина, на которую полученная средняя
величина выборочной совокупности
отличается от среднего результата
генеральной cовокупности;
-В. Величина, на
которую в среднем отличается каждая
варианта от средней арифметической.
Средняя ошибка
средней арифметической величины прямо
пропорциональна:
-А. Числу наблюдений;
-Б. Частоте изучаемого
признака в вариационном ряду;
+В. Показателю
разнообразия изучаемого признака.
Средняя ошибка
средней арифметической величины обратно
пропорциональна:
+А. Числу наблюдений;
-Б. Показателю
разнообразия изучаемого признака;
-В. Частоте изучаемого
признака.
Размер ошибки
средней арифметической величины
зависит от:
-А. Типа вариационного
ряда;
+Б. Числа наблюдений;
-В. Способа расчета
средней;
+Г. Разнообразия
изучаемого признака.
Разность
между сравниваемыми величинами (средними,
относительными) при большом числе
наблюдений (n30)
считается существенной (достоверной),
если:
-А. t равно 1,0;
-Б. t больше 1,0 и
меньше 2,0;
+В. t больше или
равно 2,0.
С увеличением
объема выборки ошибка репрезентативности:
-А. Увеличивается;
+Б. Уменьшается;
-В. Остается
постоянной.
Малой выборкой
считается та совокупность, в которой:
-А. число наблюдений
меньше или равно 100;
+Б. число наблюдений
меньше или равно 30;
-В. число наблюдений
меньше или равно 40.
Доверительный
интервал — это:
-А. Интервал, в
пределах которого находятся не менее
68 % вариант, близких к средней величине
данного вариационного ряда;
+Б. Пределы возможных
колебаний средней величины (показателя)
в генеральной совокупности;
-В. Разница между
максимальной и минимальной вариантами
вариационного ряда.
Минимально
достаточной для медицинских статистических
исследований является вероятность
безошибочного прогноза:
-А. 68 %;
-Б. 90 %;
+В. 95 %;
-Г. 99 %.
При
оценке достоверности разности полученных
результатов исследования разность
является существенной (достоверной),
если при n
30
величина t
равна:
-А. 1,0;
-Б. 1,5;
+В. 2,0;
+Г. 3 и более.
Величина ошибки
репрезентативности средней величины
прямо пропорциональна:
-А.
Числу наблюдений (n);
+Б. Величине
среднеквадратического отклонения
(сигме).
Какой
степени вероятности соответствует
доверительный интервал M2
m (n
30):
-А. 68,3 %;
+Б. 95,5 %;
-В. 99,7 %.
Оценка достоверности
полученного значения критерия Стьюдента
(t) для малых выборок производится:
-А. По специальной
формуле;
-Б. По принципу:
если t = 2, то P = 95%;
+В. По таблице.
Чему
равно значение критерия Стьюдента (t)
при степени вероятности безошибочного
прогноза P=95,5 %, (n 30):
-А.
t
= 1,0
+Б.
t
= 2,0
-В. t = 3 и более.
При проведении
корреляционного анализа необходимо
учитывать следующие параметры:
-А. Направление
связи между признаками, её силу и ошибку
репрезентативности;
-Б. Направление
связи между признаками, её силу, ошибку
репрезентативности и величину коэффициента
вариации;
+В. Направление
связи между признаками, её силу, ошибку
репрезентативности и величину критерия
достоверности.
При следующих
условиях применяется только коэффициент
ранговой корреляции:
+А. Когда нужны
лишь ориентировочные данные о наличии
связи;
+Б. Когда ряды
распределения имеют только атрибутивные
признаки;
-В. Когда ряды
распределения взаимосвязанных признаков
имеют количественное выражение;
+Г. Когда ряды
распределения взаимосвязанных признаков
имеют открытые варианты;
+Д. Когда ряды
распределения имеют как количественное
выражение, так и атрибутивные признаки.
Коэффициент
корреляции по методу квадратов применяется
только при следующих условиях:
-А. Когда нужны
лишь ориентировочные данные о наличии
связи;
+Б. Когда ряды
распределения величины взаимосвязанных
признаков имеют только закрытые варианты;
+В. Когда ряды
распределения взаимосвязанных признаков
имеют количественное выражение;
+Г. Когда нужны
точные данные о наличии связи;
-Д. Когда ряды
распределения имеют как количественное
выражение, так и атрибутивные признаки.
Между какими из
ниже перечисленных признаков может
устанавливаться корреляционная связь:
+А. Ростом и массой
тела у детей;
+Б. Содержанием
кислорода в клетках крови и уровнем
осмотического давления;
-В. Уровнем
систолического и диастолического
давления;
+Г. Частотой случаев
хронических заболеваний и возрастом.
Коэффициент
корреляции между уровнем шума и снижением
слуха с учетом стажа у рабочих
механосборочного цеха равен
rxy + 0,91. Установленная
связь:
-А. Обратная и
слабая;
-Б. Обратная и
сильная;
-В. Прямая и слабая;
+Г. Прямая и сильная.
Для оценки
достоверности полученного значения
коэффициента корреляции используют:
+А. Таблицы
стандартных коэффициентов корреляции
для разных степеней вероятности;
+Б. Ошибку
коэффициентов корреляции;
-В. Оценку
достоверности разности результатов
статистического исследования.
Укажите первый
этап вычисления стандартизованных
показателей прямым методом:
-А. Выбор стандарта;
-Б. Расчет «ожидаемых
чисел»;
+В. Расчет общих и
погрупповых интенсивных показателей;
-Г. Сравнение общих
интенсивных и стандартизованных
показателей;
-Д. Расчет общих
стандартизованных показателей.
Какие статистические
методы позволяют оценивать достоверность
результатов, полученных при выборочных
исследованиях:
-А. Корреляция;
+Б. Определение
доверительных границ;
-В. Стандартизация;
+Г. Оценка
достоверности разности результатов.
Для установления
силы и характера связи между признаками
нужно найти:
-А. Среднеквадратическое
отклонение;
+Б. Коэффициент
корреляции;
-В. Критерий
достоверности;
-Г. Стандартизованные
показатели.
При сравнении
интенсивных показателей, полученных
на однородных по своему составу
совокупностях, необходимо применять:
-А. Метод корреляции;
-Б. Метод
стандартизации;
+В. Оценку
достоверности разности полученных
показателей.
Оценка достоверности
различий в результатах исследования
проводится с помощью:
-А. Коэффициента
корреляции (rxy);
-Б. Коэффициента
вариации (Cv);
+В. Критерия
Стьюдента (t).
Что такое
динамический ряд:
-А. Ряд числовых
измерений определенного признака,
отличающихся друг от друга по своей
величине, расположенных в ранговом
порядке;
+Б. Ряд, состоящий
из однородных сопоставимых величин,
характеризующих изменения какого-либо
явления во времени;
-В. Ряд величин,
характеризующих результаты исследований
в разных регионах.
Уровни динамического
ряда могут быть представлены:
+А. Абсолютными
величинами;
+Б. Средними
величинами;
+В. Относительными
величинами.
Способы вырвнивания
динамического ряда:
+А. Укрупнение
интервалов;
+Б. Вычисление
групповой средней;
-В. Вычисление
коэффициента вариации;
+Г. Вычисление
скользящей средней;
+Д. Использование
метода наименьших квадратов.
Основными
показателями динамического ряда являются
все, кроме:
-А. Темпа роста;
-Б. Абсолютного
прироста;
-В. Темпа прироста;
+Г. Сигмального
отклонения;
-Д. Среднего темпа
прироста.
В какую таблицу
может быть сведена информация,
представленная в виде следующих признаков
«подлежащее и взаимосвязанные между
собой сказуемые»:
-А. Групповая;
+Б. Комбинационная;
-В. Простая;
-Г. Смешанная.
Укажите признаки,
соответствующие типологическому виду
группировки:
+А. Пол: мужской,
женский;
+Б. Диагноз: ИБС,
стенокардия, инфаркт миокарда;
-В. Длительность
заболевания: 1-5 лет, 6-10 лет, более 10 лет;
-Г. Возраст: до 20
лет, 21-30 лет, 31-40 лет, старше 40 лет.
Укажите признаки
атрибутивного характера:
+А. Заболевание
+Б. Исход заболевания
-В. Длительность
заболевания
-Г. Дозы лекарства
+Д. Группа инвалидности
Динамический
ряд – это:
-А. Значения
количественного признака (варианты),
расположенные в определенном порядке
и отличающиеся друг от друга по своему
значению;
+Б. Ряд, состоящий
из однородных сопоставимых значений
признака, характеризующих изменение
какого-либо явления (процесса) во
времени;
-В. Атрибутивные
значения признака, характеризующие
качественное состояние явления в
динамике.
Динамический
ряд может быть представлен:
+А. Абсолютными
величинами;
+Б. Средними
величинами;
+В. Относительными
величинами.
Для сравнения
нескольких динамических рядов с разными
исходными уровнями необходимо рассчитывать
показатель динамического ряда:

Концепция репрезентативности часто встречается в статистических отчетах и при подготовке выступлений и отчетов. Пожалуй, без него сложно представить какое-либо представление информации для ознакомления.
Содержание
- 1 Репрезентативность — что это?
- 2 Другие определения
- 3 Репрезентативная выборка
- 4 Вероятностная выборка
- 5 Вероятностные выборки
- 6 Выборка потребителей
- 7 Размер выборки
- 8 Понятие ошибки репрезентативности
- 9 Виды ошибок
- 10 Преднамеренные и непреднамеренные ошибки репрезентативности
- 11 Валидность, надежность, репрезентативность. Расчет ошибок
- 12 Репрезентативные системы
Репрезентативность — что это?

Репрезентативность отражает степень, в которой выбранные объекты или части соответствуют содержанию и значению набора данных, из которого они были выбраны.
Другие определения
Репрезентативность можно понимать в разных контекстах. Но по своему смыслу репрезентативность — это соответствие характеристик и свойств выбранных единиц генеральной совокупности, которые точно отражают характеристики всей генеральной базы данных в целом.
Кроме того, репрезентативность информации определяется как способность данных выборки представлять параметры и свойства совокупности, которые важны с точки зрения проводимых исследований.
Репрезентативная выборка
Принцип выборки заключается в выборе наиболее важных свойств, которые точно отражают общую совокупность данных. Для этого используются различные методы, позволяющие получить точные результаты и общее представление о генеральной совокупности, используя только выборочные материалы, описывающие качество всех данных.
Таким образом, нет необходимости изучать весь материал, но достаточно учесть выборочную репрезентативность. Что это? Это набор отдельных данных, чтобы получить представление об общей массе информации.
В зависимости от метода они делятся на вероятностные и маловероятные. Вероятностный — это выборка, которая создается путем вычисления наиболее важных и интересных данных, которые в будущем будут репрезентативными для генеральной совокупности. Это осознанный выбор или случайная выборка, однако оправданная своим содержанием.
Маловероятно — это одна из разновидностей случайной выборки, составленной по принципу обычной лотереи. В этом случае мнение лица, взявшего такую пробу, не принимается во внимание. Используется только слепая жребий.
Вероятностная выборка
Вероятностные выборки также можно разделить на несколько типов:
- Один из самых простых и понятных принципов — нерепрезентативная выборка. Например, этот метод часто используется при проведении социальных опросов. При этом участники опроса не выбираются из общей массы по каким-либо конкретным критериям, а информация берется от первых 50 человек, принявших участие.
- Выборка вероятностей — это еще одна разновидность выборки невероятности, которая часто используется для исследования больших наборов данных. Для этого используется множество условий и правил. Выбираются объекты, которые должны им соответствовать. То есть на примере социального опроса можно предположить, что будет опрошено 100 человек, но при составлении статистического отчета будет учитываться только мнение определенного количества людей, которые будут соответствовать установленным требованиям.
- Преднамеренные выборки отличаются тем, что они имеют ряд требований и условий для отбора, но все же полагаются на совпадения, не преследуя цели получения хорошей статистики.

Вероятностные выборки
Для вероятностных выборок рассчитывается ряд параметров, которым будут соответствовать объекты в выборке, и среди них различными способами могут быть выбраны именно те факты и данные, которые будут представлены как репрезентативность данных выборки. Эти методы расчета требуемых данных могут быть:
- Простая случайная выборка. Он заключается в том, что среди выделенного сегмента методом полностью случайной лотереи выбирается необходимый объем данных, который будет репрезентативной выборкой.
- Систематическая и случайная выборка позволяет составить систему расчета необходимых данных на основе случайно выбранного сегмента. Итак, если первое случайное число, указывающее порядковый номер данных, выбранных из общей совокупности, равно 5, следующими данными для выбора могут быть, например, 15, 25, 35 и так далее. Этот пример ясно объясняет, что даже случайный выбор может быть основан на систематических вычислениях требуемых входных данных.
Выборка потребителей
Осмысленная выборка — это способ взглянуть на каждый отдельный сегмент, и на основе его оценки составляется генеральная совокупность, отражающая характеристики и свойства всей базы данных. Таким образом, собирается больше данных, отвечающих требованиям репрезентативной выборки. Легко выбрать набор параметров, которые не будут включены в общее количество, без потери качества выбранных данных, представляющих генеральную совокупность. Таким образом определяется репрезентативность результатов исследования.
Размер выборки
Не последняя проблема, которую необходимо решить, — это размер выборки для репрезентативной репрезентативности населения. Размер выборки не всегда зависит от количества источников в генеральной совокупности. Однако репрезентативность выборки напрямую зависит от того, на сколько сегментов в конечном итоге следует разделить результат. Чем больше таких сегментов, тем больше данных включается в итоговую выборку. Если результаты требуют общих обозначений и не требуют конкретики, то в результате выборка становится меньше, поскольку, не вдаваясь в детали, информация представлена более поверхностно, а значит, ее прочтение будет общим.

Понятие ошибки репрезентативности
Репрезентативная систематическая ошибка — это конкретное несоответствие между характеристиками населения и данными выборки. При проведении выборочного исследования невозможно получить абсолютно точные данные, как при полном изучении генеральных популяций и выборки, представленной только частью информации и параметров, в то время как более детальное изучение возможно только при изучении всей совокупности численность населения. Поэтому некоторые ошибки и ошибки неизбежны.
Виды ошибок
При составлении репрезентативной выборки возникают некоторые ошибки:
- Случайный.
- Стандарт.
- Не намеренно.
- Систематический.
- Предел.
- Умышленное.
Причиной появления случайных ошибок может быть прерывистый характер исследования генеральной совокупности. Обычно ошибка случайной репрезентативности незначительна по величине и характеру.
Между тем систематические ошибки возникают, когда нарушаются правила отбора данных из генеральной совокупности.
Средняя ошибка — это разница между средним значением выборки и основной совокупностью. Это не зависит от количества единиц в выборке. Он обратно пропорционален размеру выборки. Таким образом, чем больше объем, тем меньше среднее значение ошибки.
Предельная ошибка — это наибольшая возможная разница между средним значением выполненной выборки и всей генеральной совокупностью. Эта ошибка характеризуется как максимум возможных ошибок в данных условиях их возникновения.
Преднамеренные и непреднамеренные ошибки репрезентативности
Ошибки искажения данных могут быть преднамеренными или непреднамеренными.
Итак, причины появления преднамеренных ошибок — это подход к отбору данных с использованием метода выявления трендов. Непреднамеренные ошибки возникают и на этапе подготовки выборочного наблюдения, формирования репрезентативной выборки. Чтобы избежать таких ошибок, необходимо создать хорошую основу выборки для списков единиц выборки. Он должен полностью соответствовать целям выборки, быть надежным и охватывать все аспекты исследования.
Валидность, надежность, репрезентативность. Расчет ошибок

Расчет ошибки репрезентативности (Mm) среднего арифметического (M).
Стандартное отклонение: размер выборки (> 30).
Репрезентативная ошибка (Мр) и относительная величина (Р): размер выборки (n> 30).
В случае, если необходимо изучить совокупность, где размер выборки невелик и менее 30 единиц, количество наблюдений уменьшится на одну единицу.
Величина ошибки прямо пропорциональна размеру выборки. Репрезентативность информации и расчет степени возможности составления точного прогноза отражает определенное значение предельной погрешности.
Репрезентативные системы
В процессе оценки представления информации используется не только репрезентативная выборка, но и лицо, получающее информацию, также использует репрезентативные системы. Таким образом, мозг обрабатывает определенный объем информации, создавая репрезентативную выборку всего потока информации, чтобы качественно и быстро оценить предоставленные данные и понять суть проблемы. Ответьте на вопрос: «Представление — что это?» — В масштабе человеческого сознания это довольно просто. Для этого мозг использует все подчиненные органы чувств, в зависимости от типа информации, которую необходимо изолировать от общего потока. Поэтому проводится различие между:
- Система визуального представления, в которой задействованы органы зрительного восприятия глаза. Людей, которые часто используют эту систему, называют визуалами. С помощью этой системы человек обрабатывает информацию, поступающую в виде изображений.
- Система кинестетической репрезентации — это обработка потока информации путем ее восприятия через обонятельные и тактильные каналы.
- Система слухового представления. Основной используемый орган — слух. Информация, предоставленная в виде аудио- или голосового файла, обрабатывается именно этой системой. Людей, которые лучше всего воспринимают информацию на слух, называют аудиалами.

- Система цифрового представления используется вместе с другими как средство получения информации извне. Это субъективно-логическое восприятие и понимание полученных данных.

Так что же такое репрезентативность? Простая выборка из набора или целостная процедура обработки информации? Мы можем однозначно сказать, что репрезентативность во многом определяет наше восприятие потоков данных, помогая выделить самые тяжелые и наиболее важные из них.
Обратная связь
Ошибка репрезентативности прямо пропорциональна колеблемости ря- да (сигме) и обратно пропорциональна числу наблюдений.
Следовательно, чем больше число наблюдений, (т.е. чем ближе по числу на- блюдений выборочная совокупность к генеральной), тем меньше ошибка репре- зентативности.
Интервал, в котором с заданным уровнем вероятности колеблется истинное значение средней величины или показателя, называется доверительным интер- валом, а его границы — доверительными границами. Они используются для оп- ределения размеров средней или показателя в генеральной совокупности.
Доверительные границы средней арифметической и показателя в генеральной совокупности равны:
М± tm
P± tm, где t — доверительный коэффициент
Доверительный коэффициент ( t )— это число, показывающее, во сколько раз надо увеличить ошибку средней величины или показателя, чтобы при данном числе наблюдений с желаемой степенью вероятности утверждать, что они не выйдут за полученные таким образом пределы.
C увеличением t степень вероятности возрастает.
Т. к. известно, что полученная средняя или показатель при повторных наблю- дениях, даже при одинаковых условиях, в силу случайных колебаний будут отли- чаться от предыдущего результата, теорией статистики установлена степень ве- роятности, с которой можно ожидать, что колебания эти не выйдут за определен- ные пределы. Так, колебания средней в интервале М ± 1m гарантируют ее точность с вероятностью 68,3% (такая степень вероятности не удовлетворяет
исследователей), в интервале М ± 2m — 95,5% (достаточная степень вероятности)
и в интервале М ± 3m — 99,7% (большая степень вероятности).
М± 1 m® 68,3 % М± 2 m® 95,5 % М± 3 m® 99,7 %
Для медико-биологических исследований принята степень вероятности
95% ( t = 2 ), что соответствует доверительному интервалу М ± 2 m.
Это означает, что практически с полной достоверностью (в 95%) можно утверждать, что полученный средний результат (М) отклоняется от ис- тинного значения не больше, чем на удвоенную (М ± 2 m) ошибку.
Конечный результат любого медико-статистического исследования выражает- ся средней арифметической и ее параметрами:
ОЦЕНКА ДОСТОВЕРНОСТИ ОТНОСИТЕЛЬНЫХ ВЕЛИЧИН (ПОКАЗАТЕЛЕЙ)
Средняя ошибка показателя также служит для определения пределов его слу- чайных колебаний, т.е. дает представление, в каких пределах может находиться показатель в различных выборках в зависимости от случайных причин. С увели- чением численности выборки ошибка уменьшается.
Мерой достоверности показателя является его средняя ошибка ( m ), ко- торая показывает, на сколько результат, полученный при выборочном исследова- нии, отличается от результата, который был бы получен при изучении всей гене- ральной совокупности.
Средняя ошибка показателя определяется по формуле:
mp =
, где mp — ошибка показателя
р — показатель
q — величина, обратная показателю (100-р, 1000-р и т.д. в зависимости от того, на какое основание рассчитан показатель)
n — число наблюдений
ПРИМЕР: Из стационара выбыло 289 больных, умерло 12.
Показатель летальности: 12 ´100
р = 289 = 4,1%
4,1 ´ (100-4,1)4,1 ´ 95,9
m p= ±Ö 289 = ±Ö 289 = ± 1.16%
Возможные пределы колебаний показателя равняются 4,1% ± 1,16% (Р±mp).
ОЦЕНКА ДОСТОВЕРНОСТИ РАЗНОСТИ СРЕДНИХ И ОТНОСИТЕЛЬНЫХ ВЕЛИЧИН
В научных исследованиях и клинической практике с целью сравнения двух средних величин или показателей (например, для выявления преимуществ одного метода лечения перед другим, сопоставления результатов исследования в кон- трольной и экспериментальной группах, сравнения показателей здоровья двух групп населения и т.п.) возникает необходимость не только определить их раз- ность, но и оценить ее достоверность.
Разность между двумя средними или относительными величинами (показате-
лями), каждая из которых имеет свою ошибку, также имеет свою ошибку.
Средняя ошибка разности ( mразн )вычисляется по формуле:
mразн =± Ö m12 + m22 ,где m1 и m2 — средние ошибки сравниваемых
величин
Т.о., ошибка разности равняется корню квадратному из суммы квадратов ошибок сравниваемых величин.
Мерой достоверности разности двух величин является критерий досто- верности ( критерий Стьюдента — t ):
для средних величин M1 —M2
для относительных величин P1 —P2
где t — критерий достоверности
M1 и M2 — сравниваемые средние р1 и р2 — сравниваемые показатели m12 и m22 — их ошибки
Для медико-биологических исследований принято считать, что если критерий достоверности t ³ 2, то различие двух величин (средних или отно- сительных) следует считать существенным, достоверным, доказанным с ве- роятностью в 95%. Если t < 2 , то различие величин не доказано.
ПРИМЕР. Требуется определить достоверность разности показателей (средний бал успе- ваемости) студентов медицинского института. На лечебном факультете средний балл составил 3,86 ± 0,04 , на педиатрическом — 4,03 ± 0,04.
M1 — M2 4,03 — 3,86 0,17
t = ± Ö m12 + m22 = Ö 0,042 + 0,042 = Ö 0,0032 = 3,0
Таким образом, в данном случае различие между средними величинами следует считать статистически достоверным.
СПЕЦИАЛЬНЫЕ СТАТИСТИЧЕСКИЕ МЕТОДИКИ
МЕТОД СТАНДАРТИЗАЦИИ
Общие показатели интенсивности, полученные на 4 этапе статистического исследования при статистическом анализе, не всегда правильно выявляют зако- номерности изучаемых явлений, так как на их уровень может влиять различие состава сравниваемых совокупностей , в отношении которых эти показатели рас- считаны . При сравнении показателей, характеризующих то или иное явление (за- болеваемость, рождаемость, летальность и т .д) их различия могут определяться не только разным уровнем распространенности этих явлений, но и неоднородно- стью состава сравниваемых совокупностей . Эта неоднородность может быть обусловлена различным возрастным, половым, профессиональным или другим составом совокупностей.
Так, например , при изучении заболеваемости в двух изучаемых коллектива, необходимо учитывать их возрастно-половую структуру.
Статистический метод, при котором можно устранить влияние на результаты исследования различий сравниваемых совокупностей , неоднородных по своему составу, называется методом стандартизации.
Сущность этого метода заключается в том, что сравниваемые явления ис- кусственно ставятся в одинаковые условия относительно группового рас- пределения среды, т.е. совокупности, которые характеризуют анализируе- мые показатели, условно считают одинаковыми.
Результатом проведения этого метода является вычисление стандартизован- ных показателей. Эти показатели, при сопоставлении их с обычными интенсив- ными показателями, позволяют сделать вывод, связаны ли различия в интенсив- ных показателях с неоднородностью составов сравниваемых совокупностей.
Стандартизованные показатели являются условными и не отражают истинных размеров изучаемого явления. Они применяются только для сравне- ния и анализа данной ситуации вследствие того, что рассчитаны они при искусст- венно созданных условиях и не отражают действительного размера явлений.
Существует три метода расчета стандартизованных показателей: прямой, косвенный и обратный косвенному.
При проведении медицинских исследований обычно пользуются прямым методом стандартизации, который состоит из трех этапов.
1. Вычисление погрупповых показателей,т.е. ”истинных”или обычных относительных величин, характеризующих изучаемое явление в двух сравнивае- мых совокупностях. В зависимости от характера исследования это могут быть показатели заболеваемости, инфицированности, травматизма, смертности, и т.д., рассчитанные по группам (по диагнозам, тяжести заболевания, полу, возрасту, месту жительства и т.д.)
2. Вычисление стандарта, т.е. нового искусственного распределения среды в определенном масштабе. За масштаб стандарта берется основание (коэффи- циент), на который рассчитывались показатели на первом этапе: 100,1000,10000 и т.д.
©2015- 2023 pdnr.ru Все права принадлежат авторам размещенных материалов.
Подборка по базе: Исправьте ошибки в построении сложных предложений.docx, тест 1 теория и методика основы физического воспитания.docx, Найдите и исправьте ошибки в словоупотреблении.docx, тест 1 теория и методика основы физического воспитания.docx, № Правильно ли сформулированы следующие вопросы. Найдите ошибки., Памятка для родителей Как помочь ребенку победить ошибки 1.doc, Конспект урока по алгебре в 9 классе на тему _Абсолютная и относ, математика — Какие ошибки допускают младшие школьники при делени, Речевые ошибки.docx, Инструкция по устранению ошибки со входом в phpMyAdmin (1).docx
Ч а с т ь I
ОБРАБОТКА РЕЗУЛЬТАТОВ ИЗМЕРЕНИЙ
1. КРАТКИЕ СВЕДЕНИЯ ИЗ ТЕОРИИ ОШИБОК
Абсолютная и относительная ошибки
Никакую физическую величину невозможно измерить абсолютно точно: как бы тщательно ни был поставлен опыт, измеренное значение величины х будет отличаться от ее истинного значения Х. Разница между этими значениями представляет собой абсолютную ошибку (или абсолютную погрешность*) измерения х:
х = х – Х. (1)
Абсолютная погрешность является размерной величиной: она выражается в тех же единицах, что и сама измеряемая величина (например, абсолютная погрешность измерения длины выражается в метрах, силы тока – в амперах и т.д.). Как следует из выражения (1), х может быть как положительной, так и отрицательной величиной.
Хотя величина х показывает, насколько измеренное значение отличается от истинного, одной лишь абсолютной ошибкой нельзя полностью характеризовать точность проделанного измерения. Пусть, например, известно, что абсолютная погрешность измерения расстояния равна 1 м. Если измерялось расстояние между географическими пунктами (порядка нескольких километров), то точность такого измерения следует признать весьма высокой; если же измерялись размеры помещения (не превышающие десятка метров), то измерение является грубым. Для характеристики точности существует понятие относительной ошибки (или относительной погрешности) Е, представляющей собой отношение модуля абсолютной ошибки к измеряемой величине:
![]() . (2)
. (2)
Очевидно, что относительная погрешность – величина безразмерная, чаще всего ее выражают в процентах.
При определении ошибок измерений важно иметь в виду следующее. Выражения (1) и (2) содержат истинное значение измеряемой величины Х, которое точно знать невозможно: поэтому значения х и Е в принципе не могут быть рассчитаны точно. Можно лишь оценить эти значения, т.е. найти их приближенно с той или иной степенью достоверности. Поэтому все расчеты, связанные с определением погрешностей, должны носить приближенный (оценочный) характер.
Случайная и приборная погрешности
Разнообразные ошибки, возникающие при измерениях, можно классифицировать как по их происхождению, так и по характеру их проявления.
По происхождению ошибки делятся на инструментальные и методические.
Инструментальные погрешности обусловлены несовершенством применяемых измерительных приборов и приспособлений. Эти погрешности могут быть уменьшены за счет применения более точных приборов. Так, размер детали можно измерить линейкой или штанген-циркулем. Очевидно, что во втором случае ошибка измерения меньше, чем в первом.
Методические погрешности возникают из-за того, что реальные физические процессы всегда в той или иной степени отличаются от их теоретических моделей. Например, формула для периода колебаний математического маятника в точности верна лишь при бесконечно малой амплитуде колебаний; формула Стокса, определяющая силу трения при движении шарика в вязкой жидкости, справедлива только в случае идеально сферической формы и т.д. Обнаружить и учесть методическую погрешность можно путем измерения той же величины совершенно иным независимым методом.
По характеру проявления ошибки бывают систематические и случайные.
Систематическая погрешность может быть обусловлена как приборами, так и методикой измерения. Она имеет две характерные особенности. Во-первых, систематическая погрешность всегда либо положительна, либо отрицательна и не меняет своего знака от опыта к опыту. Во-вторых, систематическую погрешность нельзя уменьшить за счет увеличения числа измерений. Например, если при отсутствии внешних воздействий стрелка измерительного прибора показывает величину х0 , отличную от нуля, то во всех дальнейших измерениях будет присутствовать систематическая ошибка, равная х0 .
Случайная ошибка также может быть как инструментальной, так и методической. Причину ее появления установить трудно, а чаще всего – невозможно (это могут быть различные помехи, случайные толчки, вибрации, неверно взятый отсчет по прибору и т.д.). Случайная погрешность бывает и положительной и отрицательной, причем непредсказуемо изменяет свой знак от опыта к опыту. Значение ее можно уменьшить путем увеличения числа измерений.
Детальный анализ погрешностей измерения представляет собой сложную задачу, для решения которой не существует единого рецепта. Поэтому в каждом конкретном случае этот анализ проводят по-разному. Однако, в первом приближении, если исключена систематическая ошибка, то остальные можно условно свести к следующим двум видам: приборная и случайная.
Приборной погрешностью в дальнейшем будем называть случайную ошибку, обусловленную измерительными приборами и приспособлениями, а случайной – ошибку, причина появления которой неизвестна. Приборную погрешность измерения величины х будем обозначать как х, случайную – как s x.
Оценка случайной погрешности. Доверительный интервал
Методика оценки случайной погрешности основана на положениях теории вероятностей и математической статистики. Оценить случайную ошибку можно только в том случае, когда проведено неоднократное измерение одной и той же величины.
Пусть в результате проделанных измерений получено п значений величины х: х1 , х2 , …, хп . Обозначим через ![]() среднеарифметическое значение
среднеарифметическое значение
![]() . (3)
. (3)
В теории вероятностей доказано, что при увеличении числа измерений п среднеарифметическое значение измеряемой величины приближается к истинному:
![]()
При небольшом числе измерений (п 10) среднее значение может существенно отличаться от истинного. Для того, чтобы знать, насколько точно значение ![]() характеризует измеряемую величину, необходимо определить так называемый доверительный интервал полученного результата.
характеризует измеряемую величину, необходимо определить так называемый доверительный интервал полученного результата.
Поскольку абсолютно точное измерение невозможно, то вероятность правильности утверждения «величина х имеет значение, в точности равное ![]() » равна нулю. Вероятность же утверждения «величина х имеет какое-либо значение» равна единице (100%). Таким образом, вероятность правильности любого промежуточного утверждения лежит в пределах от 0 до 1. Цель измерения – найти такой интервал, в котором с наперед заданной вероятностью (0 < < 1) находится истинное значение измеряемой величины. Этот интервал называется доверительным интервалом, а неразрывно связанная с ним величина – доверительной вероятностью (или коэффициентом надежности). За середину интервала принимается среднее значение, рассчитанное по формуле (3). Половина ширины доверительного интервала представляет собой случайную погрешность s x (рис. 1).
» равна нулю. Вероятность же утверждения «величина х имеет какое-либо значение» равна единице (100%). Таким образом, вероятность правильности любого промежуточного утверждения лежит в пределах от 0 до 1. Цель измерения – найти такой интервал, в котором с наперед заданной вероятностью (0 < < 1) находится истинное значение измеряемой величины. Этот интервал называется доверительным интервалом, а неразрывно связанная с ним величина – доверительной вероятностью (или коэффициентом надежности). За середину интервала принимается среднее значение, рассчитанное по формуле (3). Половина ширины доверительного интервала представляет собой случайную погрешность s x (рис. 1).

Рис.1
Очевидно, что ширина доверительного интервала (а следовательно, и ошибка s x) зависит от того, насколько сильно отличаются отдельные измерения величины хi от среднего значения ![]() . «Разброс» результатов измерений относительно среднего характеризуется среднеквадратичной ошибкой , которую находят по формуле
. «Разброс» результатов измерений относительно среднего характеризуется среднеквадратичной ошибкой , которую находят по формуле
![]() , (4)
, (4)
где ![]() .
.
Ширина искомого доверительного интервала прямо пропорциональна среднеквадратичной ошибке:
![]() . (5)
. (5)
Коэффициент пропорциональности tn, называется коэффициентом Стьюдента; он зависит от числа опытов п и доверительной вероятности .
На рис. 1, а, б наглядно показано, что при прочих равных условиях для увеличения вероятности попадания истинного значения в доверительный интервал необходимо увеличить ширину последнего (вероятность «накрывания» значения Х более широким интервалом выше). Следовательно, величина tn, должна быть тем больше, чем выше доверительная вероятность .
С увеличением количества опытов среднее значение приближается к истинному; поэтому при той же вероятности доверительный интервал можно взять более узким (см. рис. 1, а,в). Таким образом, с ростом п коэффициент Сьюдента должен уменьшаться. Таблица значений коэффи-циента Стьюдента в зависимости от п и дана в приложениях к настоящему пособию.
Следует отметить, что доверительная вероятность никак не связана с точностью результата измерений. Величиной задаются заранее, исходя из требований к их надежности. В большинстве технических экспериментов и в лабораторном практикуме значение принимается равным 0,95.
Расчет случайной погрешности измерения величины х проводится в следующем порядке:
1) вычисляется сумма измеренных значений, а затем – среднее значение величины ![]() по формуле (3);
по формуле (3);
2) для каждого i-го опыта рассчитываются разность между измеренным и средним значениями ![]() , а также квадрат этой разности (отклонения) ( хi)2 ;
, а также квадрат этой разности (отклонения) ( хi)2 ;
3) находится сумма квадратов отклонений, а затем – средне-квадратичная ошибка по формуле (4);
4) по заданной доверительной вероятности и числу проведенных опытов п из таблицы на с. 149 приложений выбирается соответствующее значение коэффициента Стьюдента tn, и определяется случайная погрешность s x по формуле (5).
Для удобства расчетов и проверки промежуточных результатов данные заносятся в таблицу, три последних столбца которой заполняются по образцу табл.1.
Таблица 1
Номер опыта |
… | х | х | ( х)2 |
| 1 | … | |||
| 2 | … | |||
| … | … | |||
| п | … | |||
| = | = |
В каждом конкретном случае величина х имеет определенный физический смысл и соответствующие единицы измерения. Это может быть, например, ускорение свободного падения g (м/с2), коэффициент вязкости жидкости (Пас) и т.д. Пропущенные столбцы табл. 1 могут содержать промежуточные измеряемые величины, необходимые для расчета соответствующих значений х.
Пример 1. Для определения ускорения а движения тела измерялось время t прохождения им пути S без начальной скорости. Используя известное соотношение ![]() , получим расчетную формулу
, получим расчетную формулу
![]() . (6)
. (6)
Результаты измерений пути S и времени t приведены во втором и третьем столбцах табл. 2. Проведя вычисления по формуле (6), заполним
четвертый столбец значениями ускорения ai и найдем их сумму, которую запишем под этим столбцом в ячейку « = ». Затем рассчитаем среднее значение ![]() по формуле (3)
по формуле (3)
![]() .
.
Таблица 2
| Номер опыта | S,
м |
t,
c |
а,
м/с2 |
а,
м/с2 |
(а)2,
(м/с2)2 |
| 1 | 5 | 2,20 | 2,07 | 0,04 | 0,0016 |
| 2 | 7 | 2,68 | 1,95 | -0,08 | 0,0064 |
| 3 | 9 | 2,91 | 2,13 | 0,10 | 0,0100 |
| 4 | 11 | 3,35 | 1,96 | -0,07 | 0,0049 |
| = | 8,11 | = | 0,0229 |
Вычитая из каждого значения ai среднее, найдем разности ai и занесем их в пятый столбец таблицы. Возводя эти разности в квадрат, заполним последний столбец. Затем рассчитаем сумму квадратов отклонений и запишем ее во вторую ячейку « = ». По формуле (4) определим среднеквадратичную погрешность:
![]() .
.
Задавшись величиной доверительной вероятности = 0,95, для числа опытов п = 4 из таблицы в приложениях (с. 149) выбираем значение коэффициента Стьюдента tn, = 3,18; с помощью формулы (5) оценим случайную погрешность измерения ускорения
s а = 3,180,0437 0,139 (м/с2) .
Способы определения приборных ошибок
Основными характеристиками измерительных приборов являются предел измерения и цена деления, а также – главным образом для электро-измерительных приборов – класс точности.
Предел измерения П – это максимальное значение величины, которое может быть измерено с помощью данной шкалы прибора. Если предел измерения не указан отдельно, то его определяют по оцифровке шкалы. Так, если рис. 2 изображает шкалу миллиамперметра, то его предел измерения равен 100 мА.
Р
ис.2

Цена деления Ц – значение измеряемой величины, соответствующее самому малому делению шкалы. Если шкала начинается с нуля, то
![]() ,
,
где N – общее количество делений (например, на рис. 2 N = 50). Если эта шкала принадлежит амперметру с пределом измерения 5 А, то цена деления равна 5/50 = 0,1 (А). Если шкала принадлежит термометру и проградуирована в С, то цена деления Ц = 100/50 = 2 (С). Многие электроизмерительные приборы имеют несколько пределов измерения. При переключении их с одного предела на другой изменяется и цена деления шкалы.
Класс точности К представляет собой отношение абсолютной приборной погрешности к пределу измерения шкалы, выраженное в процентах:
![]() . (7)
. (7)
Значение класса точности (без символа «%») указывается, как правило, на электроизмерительных приборах.
В зависимости от вида измерительного устройства абсолютная приборная погрешность определяется одним из нижеперечисленных способов.
1. Погрешность указана непосредственно на приборе. Так, на микрометре есть надпись «0,01 мм». Если с помощью этого прибора измеряется, например, диаметр шарика D (лабораторная работа 1.2), то погрешность его измерения D = 0,01 мм. Абсолютная ошибка указывается обычно на жидкостных (ртутных, спиртовых) термометрах, штангенциркулях и др.
2. На приборе указан класс точности. Согласно определению этой величины, из формулы (7) имеем
![]() . (8)
. (8)
Например, для вольтметра с классом точности 2,5 и пределом измерения 600 В абсолютная приборная ошибка измерения напряжения
![]() .
.
3. Если на приборе не указаны ни абсолютная погрешность, ни класс точности, то в зависимости от характера работы прибора возможны два способа определения величины х:
а) указатель значения измеряемой величины может занимать только определенные (дискретные) положения, соответствующие делениям шкалы (например, электронные часы, секундомеры, счетчики импульсов и т.п.). Такие приборы являются приборами дискретного действия, и их абсолютная погрешность равна цене деления шкалы: х = Ц. Так, при измерении промежутка времени t секундомером с ценой деления 0,2 с погрешность t = 0,2 с;

б) указатель значения измеряемой величины может занимать любое положение на шкале (линейки, рулетки, стрелочные весы, термометры и т.п.). В этом случае абсолютная приборная погрешность равна половине цены деления: х = Ц/2. Точность снимаемых показаний прибора не должна превышать его возможностей. Например, при показанном на рис. 3 положении стрелки прибора следует записать либо 62,5 либо 63,0 – в обоих случаях ошибка не превысит половины цены деления. Записи же типа 62,7 или 62,8 не имеют смысла.
Рис.3
4. Если какая-либо величина не измеряется в данном оыте, а была измерена независимо и известно лишь ее значение, то она является заданным параметром. Так, в работе 2.1 по определению коэффициента вязкости воздуха такими параметрами являются размеры капилляра, в опыте Юнга по интерференции света (работа 5.1) – расстояние между щелями и т.д. Погрешность заданного параметра принимается равной половине единицы последнего разряда числа, которым задано значение этого параметра. Например, если радиус капилляра r задан с точностью до сотых долей миллиметра, то его погрешность r = 0,005 мм.
Погрешности косвенных измерений
В большинстве физических экспериментов искомая величина и не измеряется непосредственно каким-либо одним прибором, а рассчитывается на основе измерения ряда промежуточных величин x, y, z,… Расчет проводится по определенной формуле, которую в общем виде можно записать как
и = и( x, y, z,…). (9)
В этом случае говорят, что величина и представляет собой результат косвенного измерения в отличие от x, y, z,…, являющихся результатами прямых измерений. Например, в работе 1.2 коэффициент вязкости жидкости рассчитывается по формуле
![]() , (10)
, (10)
где ш – плотность материала шарика; ж – плотность жидкости; g – ускорение свободного падения; D – диаметр шарика; t – время его падения в жидкости; l – расстояние между метками на сосуде. В данном случае результатами прямых измерений являются величины l, D и t, а коэффициент вязкости – результат косвенного измерения. Величины ш, ж и g представляют собой заданные параметры.
Абсолютная погрешность косвенного измерения и зависит от погрешностей прямых измерений x, y, z…и от вида функции (9). Как правило, величину и можно оценить по формуле вида
![]() , (11)
, (11)
где коэффициенты kx , ky , kz ,… определяются видом зависимостей величины и от x, y, z,… Приведенная ниже табл. 3 позволяет найти эти коэффициенты для наиболее распространенных элементарных функций (a, b, c, n – заданные константы).
Таблица 3
| и(х) | kx |
|
|
|
|
|
|
|
|
На практике зависимость (9) чаще всего имеет вид степенной функции
![]() ,
,
показатели степеней которой k, m, n,… – вещественные (положительные или отрицательные, целые или дробные) числа; С – постоянный коэффициент. В этом случае абсолютная приборная погрешность и оценивается по формуле
![]() , (12)
, (12)
где ![]() – среднее значение величины и;
– среднее значение величины и; ![]() – относительные приборные погрешности прямых измерений величин x, y, z,… Для подстановки в формулу (12) выбираются наиболее представительные, т.е. близкие к средним значения x, y, z,…
– относительные приборные погрешности прямых измерений величин x, y, z,… Для подстановки в формулу (12) выбираются наиболее представительные, т.е. близкие к средним значения x, y, z,…
При расчетах по формулам типа (12) необходимо помнить следующее.
1. Измеряемые величины и их абсолютные погрешности (например, х и х) должны быть выражены в одних и тех же единицах.
2. Расчеты не требуют высокой точности вычислений и должны иметь оценочный характер. Так, входящие в подкоренное выражение и возводимые в квадрат величины ( kEx , mEy , nEz ,…) обычно округляются с точностью до двух значащих цифр (напомним, что ноль является значащей цифрой только тогда, когда перед ним слева есть хотя бы одна цифра, отличная от нуля). Далее, если одна из этих величин (например, | kEx | ) по модулю превышает наибольшую из остальных ( | mEy | , | nEz | ,…) более чем в три раза, то можно, не прибегая к вычислениям по формуле (12), принять абсолютную ошибку равной ![]() . Если же одна из них более чем в три раза меньше наименьшей из остальных, то при расчете по формуле (12) ею можно пренебречь.
. Если же одна из них более чем в три раза меньше наименьшей из остальных, то при расчете по формуле (12) ею можно пренебречь.
Пример 2. Пусть при определении ускорения тела (см. пример 1) путь S измерялся рулеткой с ценой деления 1 мм, а время t – электронным секундомером. Тогда, в соответствии с изложенными в п.3, а, б (с. 13) правилами, погрешности прямых измерений будут равны
S = 0,5 мм = 0,0005 м;
t = 0,01 с.
Расчетную формулу (6) можно записать в виде степенной функции
a( S, t) = 2S 1t – 2 ;
тогда на основании (12) погрешность косвенного измерения ускорения а определится выражением
![]() .
.
В качестве наиболее представительных значений измеренных величин возьмем (см. табл. 2) S 8 м; t 3 с и оценим по модулю относительные приборные ошибки прямых измерений с учетом их весовых коэффициентов:
![]() ;
;
![]() .
.
Очевидно, что в данном случае величиной ES можно пренебречь и принять погрешность а равной
![]()
Пример 3. Вернемся к определению коэффициента вязкости жидкости (работа 1.2). Расчетную формулу (10) можно представить в виде
![]() ,
,
где ![]() . Тогда для оценки приборной погрешности , согласно (12), получим выражение
. Тогда для оценки приборной погрешности , согласно (12), получим выражение
![]() , (13)
, (13)
где ![]() .
.
Пусть расстояние между метками l измерено сантиметровой лентой с ценой деления 0,5 см, диаметр шарика – микрометром, время его падения – электронным секундомером. Тогда l = 0,25 см; D = 0,01 мм; t = 0,01 с. Предположим, что измеренные значения равны: l 80 cм; D 4 мм; t 10 с; ![]() Пас. Оценим величины, входящие в формулу (13):
Пас. Оценим величины, входящие в формулу (13):

Пренебрегая величиной Еt , проведем расчет по формуле (13):
![]() .
.
Полная ошибка. Окончательный результат измерений
В результате оценки случайной и приборной ошибок измерения величины х получено два доверительных интервала, характеризуемые значениями s x и х. Результирующий доверительный интервал характеризуется полной абсолютной ошибкой , которая, в зависимости от соотношения между величинами s x и х, находится следующим образом.
Если одна из погрешностей более чем в три раза превышает другую (например, s x > 3х), то полная ошибка принимается равной этой большей величине (в приведенном примере s x). Если же величины s x и х близки между собой, то полная ошибка вычисляется как
![]() . (14)
. (14)
Запись окончательного результата измерений должна включать в себя следующие обязательные элементы.
1) Доверительный интервал вида
![]()
с указанием значения доверительной вероятности . Величины ![]() и выражаются в одних и тех же единицах измерения, которые выносятся за скобку.
и выражаются в одних и тех же единицах измерения, которые выносятся за скобку.
2) Значение полной относительной погрешности
![]() ,
,
выраженное в процентах и округленное до десятых долей.
Полная ошибка округляется до двух значащих цифр. Если полученное после округления число оканчивается цифрами 4, 5 или 6, то дальнейшее округление не производится; если же вторая значащая цифра 1, 2, 3, 7, 8 или 9, то значение округляется до одной значащей цифры (примеры: а) 0,2642 0,26; б) 3,177 3,2 3; в) 7,8310 – 7 810 – 7 и т.д.). После этого среднее значение ![]() округляется с той же точностью.
округляется с той же точностью.
Пример 4. В результате определения ускорения движения тела (примеры 1 и 2) получено среднее значение ускорения ![]() = 2,03 м/с2, случайная ошибка s а = 0,139 м/с2 с доверительной вероятностью = 0,95 и приборная ошибка а = 0,0136 м/с2. Так как а более чем в десять раз меньше s а, то ею можно пренебречь и принять округленную полную абсолютную погрешность равной s а 0,14 м/с2. Оценим относительную ошибку:
= 2,03 м/с2, случайная ошибка s а = 0,139 м/с2 с доверительной вероятностью = 0,95 и приборная ошибка а = 0,0136 м/с2. Так как а более чем в десять раз меньше s а, то ею можно пренебречь и принять округленную полную абсолютную погрешность равной s а 0,14 м/с2. Оценим относительную ошибку:
![]()
и запишем окончательный результат измерений:

![]()
![]()
Пример 5. Пусть при определении скорости звука и (лабораторная работа 4.2) получены следующие результаты: среднее значение ![]() = 343,3 м/с; случайная погрешность s и = 8,27 м/с при = 0,90; абсолютная приборная погрешность и = 1,52 м/с. Очевидно, что и в данном случае величиной и можно пренебречь по сравнению с s и, и расчет по формуле (14) не требуется. Полная ошибка после округления равна s и 8 м/с; округленное среднее значение
= 343,3 м/с; случайная погрешность s и = 8,27 м/с при = 0,90; абсолютная приборная погрешность и = 1,52 м/с. Очевидно, что и в данном случае величиной и можно пренебречь по сравнению с s и, и расчет по формуле (14) не требуется. Полная ошибка после округления равна s и 8 м/с; округленное среднее значение ![]() 343 м/с. Полная относительная погрешность
343 м/с. Полная относительная погрешность
![]() .
.
Окончательный результат измерений имеет вид

![]()
![]()
Пример 6. При определении длины волны лазерного излучения (работа 5.1) получено: ![]() при = 0,95; = 1,8610 — 5 мм. В данном случае значения приборной и случайной погрешностей близки между собой, поэтому полную ошибку найдем по формуле (14):
при = 0,95; = 1,8610 — 5 мм. В данном случае значения приборной и случайной погрешностей близки между собой, поэтому полную ошибку найдем по формуле (14):
![]() .
.
Округленное среднее будет равно ![]() мм. Оценим полную относительную ошибку
мм. Оценим полную относительную ошибку
![]()
и запишем окончательный результат:

![]()
Е = 4,4 %.
* Термины «ошибка» и «погрешность» применительно к измерениям имеют один и тот же смысл.
ДЕПАРТАМЕНТ ОБРАЗОВАНИЯ И НАУКИ ГОРОДА МОСКВЫ
Государственное бюджетное профессиональное образовательное учреждение города Москвы
«ЮРИДИЧЕСКИЙ КОЛЛЕДЖ»
(ГБПОУ Юридический колледж)
ПЛАН-КОНСПЕКТ учебного занятия
по ОП.11 Статистика
учебной дисциплине/междисциплинарному курсу
для обучающихся 2 курса
специальность 40.02.01 Право и организация социального обеспечения
(набор 2016 г.)
(углубленная подготовка)
дата проведения занятия по расписанию
Тема 3.1. Выборочное наблюдение
Занятие 15. ПЗ №8 Определение ошибки репрезентативности.
Определение объема выборочной совокупности
Цель занятия: отработать практические навыки по определению доверительных пределов и исчислению ошибок выборки
Задачи занятия:
Обучающая: Обеспечить усвоение обучающимися материала о понятиях: ошибки репрезентативности, выборка, выборочная совокупность;
Воспитательная: воспитывать навыки самостоятельной работы, чувство ответственности за порученный участок работы, дисциплину умственного труда, уверенность в своих силах, стремление к достижению результата;
Развивающая: создавать условия для развития самостоятельности мышления, способности высказывания собственной точки зрения, систематизировать необходимую информацию, анализировать, сравнивать и обобщать информацию, развивать монологическую речь.
Основная литература:
Глава 11. Выборочное наблюдение. (211-220) Статистика: учебник / И.В. Гладун. – 2-е издание, стер. – М.: КНОРУС, 2014. – 232 с. – СПО
Дополнительная литература:
Савюк Л.К. Правовая статистика: Учебник. — М.: Юрист, 2016
Интернет-ресурсы:
- Информационно-издательский центр «Статистика России» http://www.statbook.ru
- Электронный фонд правовой и технической документации http://docs.cntd.ru
- Информационно правовой портал http://www.garant.ru/
Междисциплинарные связи: Право социальное обеспечение
Внутридисциплинарные связи: Тема 2.1. Сводка и группировка статистических данных
1. Актуализация знаний по ранее пройденному материалу учебного курса
(ответить на вопросы (тестовые задания) и провести самооценку усвоенного материала)
Таблица 1.
|
Вопрос (тестовое задание) |
Ответ |
|
|
|
|
|
|
|
|
|
2. Изучаемые вопросы занятия
|
1. Определение ошибки репрезентативности. |
|
2. Определение объема выборочной совокупности. |
Вопрос 1. Определение ошибки репрезентативности
В статистике выделяют два основных метода исследования – сплошной и выборочный. При проведении выборочного исследования обязательным является соблюдение следующих требований: репрезентативность выборочной совокупности и достаточное число единиц наблюдений. При выборе единиц наблюдения возможны Ошибки смещения, т. е. такие события, появление которых не может быть точно предсказуемым. Эти ошибки являются объективными и закономерными. При определении степени точности выборочного исследования оценивается величина ошибки, которая может произойти в процессе выборки – Случайная ошибка репрезентативности (M) – Является фактической разностью между средними или относительными величинами, полученными при проведении выборочного исследования и аналогичными величинами, которые были бы получены при проведении исследования на генеральной совокупности.
Оценка достоверности результатов исследования предусматривает определение:
1. ошибки репрезентативности
2. доверительных границ средних (или относительных) величин в генеральной совокупности
3. достоверности разности средних (или относительных) величин (по критерию t)
Расчет ошибки репрезентативности (mм) средней арифметической величины (М):

 , где σ – среднее квадратическое отклонение; n – численность выборки (>30).
, где σ – среднее квадратическое отклонение; n – численность выборки (>30).
Расчет ошибки репрезентативности (mР) относительной величины (Р):
 , где Р – соответствующая относительная величина (рассчитанная, например, в %);
, где Р – соответствующая относительная величина (рассчитанная, например, в %);
Q =100 – Ρ% – величина, обратная Р; n – численность выборки (n>30)
В клинических и экспериментальных работах довольно часто приходится использовать Малую выборку, Когда число наблюдений меньше или равно 30. При малой выборке для расчета ошибок репрезентативности, как средних, так и относительных величин, Число наблюдений уменьшается на единицу, т. е.
 ;
;  .
.
Величина ошибки репрезентативности зависит от объема выборки: чем больше число наблюдений, тем меньше ошибка. Для оценки достоверности выборочного показателя принят следующий подход: показатель (или средняя величина) должен в 3 раза превышать свою ошибку, в этом случае он считается достоверным.
Знание величины ошибки недостаточно для того, чтобы быть уверенным в результатах выборочного исследования, так как конкретная ошибка выборочного исследования может быть значительно больше (или меньше) величины средней ошибки репрезентативности. Для определения точности, с которой исследователь желает получить результат, в статистике используется такое понятие, как вероятность безошибочного прогноза, которая является характеристикой надежности результатов выборочных медико-биологических статистических исследований. Обычно, при проведении медико-биологических статистических исследований используют вероятность безошибочного прогноза 95% или 99%. В наиболее ответственных случаях, когда необходимо сделать особенно важные выводы в теоретическом или практическом отношении, используют вероятность безошибочного прогноза 99,7%
Определенной степени вероятности безошибочного прогноза соответствует определенная величина Предельной ошибки случайной выборки (Δ – дельта), которая определяется по формуле:
Δ=t * m, где t – доверительный коэффициент, который при большой выборке при вероятности безошибочного прогноза 95% равен 2,6; при вероятности безошибочного прогноза 99% – 3,0; при вероятности безошибочного прогноза 99,7% – 3,3, а при малой выборке определяется по специальной таблице значений t Стьюдента.
Используя предельную ошибку выборки (Δ), можно определить Доверительные границы, в которых с определенной вероятностью безошибочного прогноза заключено действительное значение статистической величины, Характеризующей всю генеральную совокупность (средней или относительной).
Для определения доверительных границ используются следующие формулы:
- для средних величин:
 ,где Мген – доверительные границы средней величины в генеральной совокупности;
,где Мген – доверительные границы средней величины в генеральной совокупности;
Мвыб – средняя величина, Полученная при проведении исследования на выборочной совокупности; t – доверительный коэффициент, значение которого определяется степенью вероятности безошибочного прогноза, с которой исследователь желает получить результат; mM – ошибка репрезентативности средней величины.
2) для относительных величин:
 , где Рген – доверительные границы относительной величины в генеральной совокупности; Рвыб – относительная величина, полученная при проведении исследования на выборочной совокупности; t – доверительный коэффициент; mP – ошибка репрезентативности относительной величины.
, где Рген – доверительные границы относительной величины в генеральной совокупности; Рвыб – относительная величина, полученная при проведении исследования на выборочной совокупности; t – доверительный коэффициент; mP – ошибка репрезентативности относительной величины.
Доверительные границы показывают, в каких пределах может колебаться размер выборочного показателя в зависимости от причин случайного характера.
При малом числе наблюдений (n<30), для вычисления доверительных границ значение коэффициента t находят по специальной таблице Стьюдента. Значения t расположены в таблице на пересечении с избранной вероятностью безошибочного прогноза и строки, Указывающей на имеющееся число степеней свободы (n), Которое равно n-1.
на определение ошибок репрезентативности (m) и доверительных границ средней величины генеральной совокупности (Мген) при числе наблюдений больше 30
Условие задачи: при изучении комбинированного воздействия шума и низкочастотной вибрации на организм человека было установлено, что средняя частота пульса у 36 обследованных водителей сельскохозяйственных машин через 1 ч работы составила 80 ударов в 1 минуту; σ = ± 6 ударов в минуту.
Задание: определить ошибку репрезентативности (mM) и доверительные границы средней величины генеральной совокупности (Мген).
Решение.
- Вычисление средней ошибки средней арифметической (ошибки репрезентативности) (m): m = σ / √n = 6 / √36 = ±1 удар в минуту
- Вычисление доверительных границ средней величины генеральной совокупности (Мген). Для этого необходимо:
- а) задать степень вероятности безошибочного прогноза (Р = 95 %);
- б) определить величину критерия t. При заданной степени вероятности (Р=95%) и числе наблюдений меньше 30 величина критерия t, определяемого по таблице, равна 2 (t = 2). Тогда Мген = Мвыб ± tm = 80 ± 2×1 = 80 ± 2 удара в минуту.
Вывод. Установлено с вероятностью безошибочного прогноза Р = 95%, что средняя частота пульса в генеральной совокупности, т.е. у всех водителей сельскохозяйственных машин, через 1 ч работы в аналогичных условиях будет находиться в пределах от 78 до 82 ударов в минуту, т.е. средняя частота пульса менее 78 и более 82 ударов в минуту возможна не более, чем у 5% случаев генеральной совокупности.
на определение ошибок репрезентативности (m) и доверительных границ относительного показателя генеральной совокупности (Рген)
Условие задачи: при медицинском осмотре 164 детей 3 летнего возраста, проживающих в одном из районов городе Н., в 18% случаев обнаружено нарушение осанки функционального характера.
Задание: определить ошибку репрезентативности (mp) и доверительные границы относительного показателя генеральной совокупности (Рген).
Решение.
- Вычисление ошибки репрезентативности относительного показателя: m = √P x q / n = √18 x (100 — 18) / 164 = ± 3%
- Вычисление доверительных границ средней величины генеральной совокупности (Рген) производится следующим образом:
- необходимо задать степень вероятности безошибочного прогноза (Р=95%);
- при заданной степени вероятности и числе наблюдений больше 30, величина критерия t равна 2 (t = 2). Тогда Рген = Рвыб± tm = 18% ± 2 х 3 = 18% ± 6%.
Вывод. Установлено с вероятностью безошибочного прогноза Р=95%, что частота нарушения осанки функционального характера у детей 3 летнего возраста, проживающих в городе Н., будет находиться в пределах от 12 до 24% случаев.
на оценку достоверности разности средних величин
Условие задачи: при изучении комбинированного воздействия шума и низкочастотной вибрации на организм человека было установлено, что средняя частота пульса у водителей сельскохозяйственных машин через 1 ч после начала работы составила 80 ударов в минуту; m = ± 1 удар в мин. Средняя частота пульса у этой же группы водителей до начала работы равнялась 75 ударам в минуту; m = ± 1 удар в минуту.
Задание: оценить достоверность различий средних значений пульса у водителей сельскохозяйственных машин до и после 1 ч работы.
Решение.

Вывод. Значение критерия t = 3,5 соответствует вероятности безошибочного прогноза Р > 99,7%, следовательно можно утверждать, что различия в средних значениях пульса у водителей сельскохозяйственных машин до и после 1 ч работы не случайно, а достоверно, существенно, т.е. обусловлено влиянием воздействия шума и низкочастотной вибрации.
на оценку достоверности разности относительных показателей
Условие задачи: при медицинском осмотре детей 3 летнего возраста в 18% (m = ± 3%) случаях обнаружено нарушение осанки функционального характера. Частота аналогичных нарушений осанки при медосмотре детей 4-летнего возраста составила 24% (m = ± 2,64%).
Задание: оценить достоверность различий в частоте нарушения осанки у детей 2 возрастных групп.
Решение.

Вывод. Значение критерия t=1,5 соответствует вероятности безошибочного прогноза Р<95%. Следовательно, различие в частоте нарушений осанки среди детей, сравниваемых возрастных групп случайно, недостоверно, несущественно, т.е. не обусловлено влиянием возраста детей.
|
Источники информации по 1 вопросу |
Автор и наименование |
Страницы (форма доступа для Интернет-ресурсов) |
|
Основная литература |
Глава 11. Выборочное наблюдение. Статистика: учебник / И.В. Гладун. – 2-е издание, стер. – М.: КНОРУС, 2014. – 232 с. – СПО |
стр. 211-220 |
|
Интернет ресурсы |
|
http://www.statbook.ru |
|
http://docs.cntd.ru |
|
|
http://www.garant.ru/ |
Контрольное задание по Вопросу 1
- Записать в тетрадь конспект (1-2 стр.)
Вопрос 2. Определение объема выборочной совокупности
Социологические исследования редко бывают сплошными, как, например, перепись населения. Обычно сплошное исследование проводится при небольшой генеральной совокупности.
Чаще всего исследования носят выборочный характер, при котором наиболее важным основанием является возможность распространения полученных результатов и выводов на всю генеральную совокупность. В таком случае сплошное исследование нецелесообразно. Обеспечение этой нецелесообразности — вопрос о репрезентативности выборки, т.е. достаточной количественной и качественной представительности генеральной совокупности в выборке.
Условиями соблюдения репрезентативности выборки являются:
1) равная возможность каждого члена генеральной совокупности попасть в выборку;
2) отбор необходимо проводить независимо от изучаемого признака (иначе в выборку могут попасть, например, только спортсмены);
3) отбор по возможности должен производиться из однородных совокупностей;
4) величина выборки должна быть достаточно большой.
Далее возникает вопрос: как определить достаточный объем выборки? Для этого необходимо иметь характеристики генеральной совокупности по важнейшим (с точки зрения исследования) признакам. К ним, например, можно отнести сведения о количестве желающих заниматься физической культурой и спортом, о числе занимающихся и т.д. Но, как правило, такие характеристики (или многие из них) не известны. Пилотажные исследования как раз и направлены на их выявление.
Приведем пример определения объема выборочной совокупности. В ходе подготовки к проведению конкретно-социологического исследования на основании теоретических посылок были выделены характеристики и признаки, подлежащие изучению. Например, желание заниматься физической культурой, спортом, величина потребности, участие в видах деятельности и др.
На основании результатов изучения этих признаков в пробном исследовании (30 и более респондентов) определяется объем выборки.
Предположим, что в пробном исследовании опрошено 147 студентов 4-х курсов в четырех вузах Республики Беларусь.
Для желания заниматься физической культурой получены следующие распределения:
1.«Нет, не хочу» — 5 человек;
2.«Скорее не хочу, чем хочу» — 3 человека;
3.«Безразлично» — 11 человек;
4.«Скорее хочу, чем не хочу» — 34 человека;
5.«Да, хочу» — 72 человека.
Для расчета объема выборки используются формулы:

t — 1,96 — распределение Стьюдента для вероятности 0,95 или 95% (т.е., если требуемая вероятность соответствия характеристик выборки и характеристик генеральной совокупности 95%, всегда = 1,96. Их соответствие на 95% — общепринятое требование в социологических исследованиях.
Для нашего распределения:

При условии, что выборка в пробном исследовании представляла бы собой модель генеральной совокупности, величина выборочной совокупности для изучения желания заниматься физической культурой должна быть не меньше 147 человек. Тогда с вероятностью 95% можно утверждать, что генеральное среднее лежит в пределах 4,39+0,155.
Поскольку модель выборки в пробном исследовании во вузам не представляет собой модели генеральной совокупности (опрос был в четырех вузах из 30), то увеличиваем полученное n (30/4) в 7,5 раза. Тогда необходимый объем выборки — 1102 респондента.
Качественная представительность полученной выборки оценивается сравнением существенных характеристик (либо связанных с существенными) генеральной совокупности и выборки. Для студенчества, например, такими характеристиками являются: соотношение по полу, охват учебными занятиями по физическому воспитанию, соотношение форм занятий и др.
Когда информация о признаках элементов генеральной совокупности отсутствует, исключается возможность определения объема выборочной совокупности при помощи формул. В этом случае можно опереться на многолетний опыт социологов — практиков, свидетельствующий о том, что для пробных опросов достаточна выборка объемом 100-250 человек. При массовых опросах, если величина генеральной совокупности 5000 человек, достаточный объем выборочной совокупности — не менее 500 человек, если же величина генеральной совокупности 5000 человек и более, то — 10% ее состава (но не более 2000-2500 человек). Это характеризует достаточно достоверные результаты исследования.
ПРИМЕР 1
При проверке импортирования груза на таможне методом случайной выборки было обработано 200 изделий. В результате был установлен средний вес изделия 30г., при СКО=4г с вероятностью 0,997. Определите пределы в которых находится средний вес изделий генеральной совокупности.
Решение.
В данном примере – случайный повторный отбор.
n=200
 =30г
=30г
 =4г — СКО
=4г — СКО
p=0,997, тогда t=3
Формула средней ошибки для случайного повторного отбора:

 =0,84 г
=0,84 г
 г
г
Определяем величину средней ошибки.

Ответ: пределы в которых находится средний вес изделий: г
г
ПРИМЕР 2
В городе проживает 250тыс. семей. Для определения среднего числа детей в семье была организована 2%-я бесповторная выборка семей. По ее результатам было получено следующее распространение семей по числу детей:
P=0,954. Найти пределы в которых будет находится среднее число детей в генеральной совокупности.
|
Число детей в семье, xi |
0 |
1 |
2 |
3 |
4 |
5 |
|
Кол-во детей в семье |
1000 |
2000 |
1200 |
400 |
200 |
200 |
Решение
2%-я выборка означает: n=250000*0,02= 5000 семей было исследовано.
Т.к. выборка бесповторная, используем следующую формулу для определения средней величины ошибки:

Найдем среднее число детей в выборочной совокупности:
 ребенка
ребенка
Определим дисперсию

 ребенка – средняя величина ошибки
ребенка – средняя величина ошибки
Т.к p = 0,954, то t = 2
 ребенка
ребенка
 ребенка
ребенка
Вывод: из-за слишком малой величины ошибки, среднее число детей в генеральной совокупности можно принять за 1,5 ребенка.
|
Источники информации по 2 вопросу |
Автор и наименование |
Страницы (форма доступа для Интернет-ресурсов) |
|
Основная литература |
Глава 11. Выборочное наблюдение. Статистика: учебник / И.В. Гладун. – 3-е издание, стер. – М.: КНОРУС, 2019. – 232 с. – СПО |
стр. 211-220 |
|
Интернет ресурсы |
|
http://www.statbook.ru |
|
http://docs.cntd.ru |
|
|
http://www.garant.ru/ |
Контрольное задание по Вопросу 2
- Записать в тетрадь конспект (1-2 стр.)
3. Подведение итогов учебного занятия
(ответить на вопросы (тестовые задания) и провести самооценку усвоенного материала)
Таблица 2.
|
Наименование изученного вопроса учебного занятия |
Контрольное задание по изученному вопросу |
Ответ |
|
Определение ошибки репрезентативности. |
ЗАДАНИЕ 1 Условие задачи: при медицинском осмотре 126 детей 6 летнего возраста, проживающих в одном из районов городе А., в 12% случаев обнаружено нарушение осанки функционального характера. Задание: определить ошибку репрезентативности (mp) и доверительные границы относительного показателя генеральной совокупности (Рген). |
|
|
Определение ошибки репрезентативности. |
ЗАДАНИЕ 2. Условие задачи: при медицинском осмотре детей 6 летнего возраста в 15% (m = ± 3%) случаях обнаружено нарушение осанки функционального характера. Частота аналогичных нарушений осанки при медосмотре детей 7-летнего возраста составила 24% (m = ± 2,64%). Задание: оценить достоверность различий в частоте нарушения осанки у детей 2 возрастных групп. |
|
|
Определение объема выборочной совокупности |
ЗАДАНИЕ 3. В городе проживает 300 тыс. семей. Для определения среднего числа детей в семье была организована 2%-я бесповторная выборка семей. По ее результатам было получено следующее распространение семей по числу детей: P=0,954. Найти пределы в которых будет находится среднее число детей в генеральной совокупности |
|
|
Определение объема выборочной совокупности |
Сформулируйте понятие генеральной совокупности |
|
|
Определение объема выборочной совокупности |
Перечислите способы отбора единиц для выборочного наблюдения |
- Домашнее задание на следующее занятие
- Выучить основные понятия. Глава 11. Выборочное наблюдение. Статистика: учебник / И.В. Гладун. – 2-е издание, стер. – М.: КНОРУС, 2014. – 232 с. – СПО (стр. 211-220)
- Выполнить задание 11.1. в тетради (стр. 224) учебник / И.В. Гладун. – 2-е издание, стер. – М.: КНОРУС, 2014. – 232 с. – СПО
Преподаватель Ю.В. Древаль
|
СОГЛАСОВАНО Протокол заседания ЦК дисциплин профессионального цикла специальности «Право и организация социального обеспечения» ГБПОУ Юридический колледж от ____________ 2017 г. № ___ |
Среднее арифметическое, как известно, используется для получения обобщающей характеристики некоторого набора данных. Если данные более-менее однородны и в них нет аномальных наблюдений (выбросов), то среднее хорошо обобщает данные, сведя к минимуму влияние случайных факторов (они взаимопогашаются при сложении).
Когда анализируемые данные представляют собой выборку (которая состоит из случайных значений), то среднее арифметическое часто (но не всегда) выступает в роли приближенной оценки математического ожидания. Почему приближенной? Потому что среднее арифметическое – это величина, которая зависит от набора случайных чисел, и, следовательно, сама является случайной величиной. При повторных экспериментах (даже в одних и тех же условиях) средние будут отличаться друг от друга.
Для того, чтобы на основе статистического анализа данных делать корректные выводы, необходимо оценить возможный разброс полученного результата. Для этого рассчитываются различные показатели вариации. Но то исходные данные. И как мы только что установили, среднее арифметическое также обладает разбросом, который необходимо оценить и учитывать в дальнейшем (в выводах, в выборе метода анализа и т.д.).
Интуитивно понятно, что разброс средней должен быть как-то связан с разбросом исходных данных. Основной характеристикой разброса средней выступает та же дисперсия.
Дисперсия выборочных данных – это средний квадрат отклонения от средней, и рассчитать ее по исходным данным не составляет труда, например, в Excel предусмотрены специальные функции. Однако, как же рассчитать дисперсию средней, если в распоряжении есть только одна выборка и одно среднее арифметическое?
Расчет дисперсии и стандартной ошибки средней арифметической
Чтобы получить дисперсию средней арифметической нет необходимости проводить множество экспериментов, достаточно иметь только одну выборку. Это легко доказать. Для начала вспомним, что средняя арифметическая (простая) рассчитывается по формуле:
![]()
где xi – значения переменной,
n – количество значений.
Теперь учтем два свойства дисперсии, согласно которым, 1) — постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат и 2) — дисперсия суммы независимых случайных величин равняется сумме соответствующих дисперсий. Предполагается, что каждое случайное значение xi обладает одинаковым разбросом, поэтому несложно вывести формулу дисперсии средней арифметической:
![]()
Используя более привычные обозначения, формулу записывают как:
![]()
где σ2 – это дисперсия, случайной величины, причем генеральная.
На практике же, генеральная дисперсия известна далеко не всегда, точнее совсем редко, поэтому в качестве оной используют выборочную дисперсию:
![]()
Стандартное отклонение средней арифметической называется стандартной ошибкой средней и рассчитывается, как квадратный корень из дисперсии.
Формула стандартной ошибки средней при использовании генеральной дисперсии
![]()
Формула стандартной ошибки средней при использовании выборочной дисперсии
![]()
Последняя формула на практике используется чаще всего, т.к. генеральная дисперсия обычно не известна. Чтобы не вводить новые обозначения, стандартную ошибку средней обычно записывают в виде соотношения стандартного отклонения выборки и корня объема выборки.
Назначение и свойство стандартной ошибки средней арифметической
Стандартная ошибка средней много, где используется. И очень полезно понимать ее свойства. Посмотрим еще раз на формулу стандартной ошибки средней:
![]()
Числитель – это стандартное отклонение выборки и здесь все понятно. Чем больше разброс данных, тем больше стандартная ошибка средней – прямо пропорциональная зависимость.
Посмотрим на знаменатель. Здесь находится квадратный корень из объема выборки. Соответственно, чем больше объем выборки, тем меньше стандартная ошибка средней. Для наглядности изобразим на одной диаграмме график нормально распределенной переменной со средней равной 10, сигмой – 3, и второй график – распределение средней арифметической этой же переменной, полученной по 16-ти наблюдениям (которое также будет нормальным).

Судя по формуле, разброс стандартной ошибки средней должен быть в 4 раза (корень из 16) меньше, чем разброс исходных данных, что и видно на рисунке выше. Чем больше наблюдений, тем меньше разброс средней.
Казалось бы, что для получения наиболее точной средней достаточно использовать максимально большую выборку и тогда стандартная ошибка средней будет стремиться к нулю, а сама средняя, соответственно, к математическому ожиданию. Однако квадратный корень объема выборки в знаменателе говорит о том, что связь между точностью выборочной средней и размером выборки не является линейной. Например, увеличение выборки с 20-ти до 50-ти наблюдений, то есть на 30 значений или в 2,5 раза, уменьшает стандартную ошибку средней только на 36%, а со 100-а до 130-ти наблюдений (на те же 30 значений), снижает разброс данных лишь на 12%.
Лучше всего изобразить эту мысль в виде графика зависимости стандартной ошибки средней от размера выборки. Пусть стандартное отклонение равно 10 (на форму графика это не влияет).

Видно, что примерно после 50-ти значений, уменьшение стандартной ошибки средней резко замедляется, после 100-а – наклон постепенно становится почти нулевым.
Таким образом, при достижении некоторого размера выборки ее дальнейшее увеличение уже почти не сказывается на точности средней. Этот факт имеет далеко идущие последствия. Например, при проведении выборочного обследования населения (опроса) чрезмерное увеличение выборки ведет к неоправданным затратам, т.к. точность почти не меняется. Именно поэтому количество опрошенных редко превышает 1,5 тысячи человек. Точность при таком размере выборки часто является достаточной, а дальнейшее увеличение выборки – нецелесообразным.
Подведем итог. Расчет дисперсии и стандартной ошибки средней имеет довольно простую формулу и обладает полезным свойством, связанным с тем, что относительно хорошая точность средней достигается уже при 100 наблюдениях (в этом случае стандартная ошибка средней становится в 10 раз меньше, чем стандартное отклонение выборки). Больше, конечно, лучше, но бесконечно увеличивать объем выборки не имеет практического смысла. Хотя, все зависит от поставленных задач и цены ошибки. В некоторых опросах участие принимают десятки тысяч людей.
Дисперсия и стандартная ошибка средней имеют большое практическое значение. Они используются в проверке гипотез и расчете доверительных интервалов.
Поделиться в социальных сетях:
Среднее квадратическое отклонение характеризует среднее отклонение всех вариант вариационного ряда от средней арифметической величины. Поскольку отклонения вариант от средней, имеют значения с «+» и «-», то при суммировании они взаимоуничтожаются. Чтобы избежать этого, отклонения возводятся во вторую степень, а затем, после определенных вычислений, производится обратное действие — извлечение корня квадратного. Поэтому среднее отклонение именуется квадратическим.
Среднее квадратическое отклонение определяют по формуле: 
(отклонение d — это разность между каждой вариантой и средней величиной, т. е. d = V—M; р –частота; количество вариант n (при числе наблюдений менее 30 сумма делится на n-1);
При вычислении среднеквад. отклонения по способу моментов используется следующая формула. Т.о. , формула вычисления сред. отклонения по способу моментов будет читаться как корень квадратный из разности момента второй степени и квадрата момента первой степени. Результаты вычисления сред. отклонения обычным способом и способом моментов идентичны. Однако, как указывалось выше, второй способ значительно убыстряет и упрощает расчеты. Итак, нахождение сред. отклонения позволяет судить о характере однородности исследуемой группы наблюдений. Если величина среднеквад. отклонения небольшая, то это свидетельствует о достаточно высокой однородности изучаемого явления. Среднюю арифметическую в таком случае следует признать вполне характерной для данного вариационного ряда. Однако слишком малая величина сигмы заставляет думать об искусственном подборе наблюдений. При очень большой сигме средняя арифметическая в меньшей степени характеризует вариационный ряд, что говорит о значительной вариабельности изучаемого признака или явления или о неоднородности исследуемой группы. Значение: Определение среднеквад. отклонения представляет немалую ценность для медицинской науки и практики. При диагностике отдельных заболеваний очень важно оценить на основании конкретных исследований, какие признаки проявляются у соответствующей группы больных относительно одинаково, с небольшими колебаниями, а для каких признаков характерны большие индивидуальные колебания. Очень широко используется это свойство при оценке физического развития отдельных групп населения, при выработке стандартов школьной меб.
Ошибка репрезентативности (сред. ошибка сред. арифметич.)
Чтобы определить степень точности выборочного наблюдения, необходимо оценить величину ошибки, которая может случайно произойти в процессе выборки. Такие ошибки носят название случайных ошибок репрезентативности т. Они фактически являются разностью между средними числами, полученными при выборочном статистическом наблюдении, и аналогичными величинами, которые были бы получены при сплошном исследовании того же объекта (т. е. при исследовании генеральной совокупности). Ошибки репрезентативности вытекают из самой сущности выборочного исследования. С помощью ошибок репрезентативности числовые характеристики выборочной совокупности распространяются на всю генеральную совокупность, то есть она характеризуется с учетом определенной погрешности. Величины ошибок репрезентативности определяются как объемом выборки, так и разнообразием признака. Чем больше число наблюдений, тем меньше ошибка, чем больше изменчив признак, тем больше величина статистической ошибки. На практике для определения средней ошибки выборки в статистических исследованиях пользуются следующей формулой:

(где m — ошибка репрезентативности; σ — среднее квадратическое отклонение;
n — число наблюдений в выборке (при числе наблюдений менее 30 в подкоренное выражение вносится значение п-1)).
Размер средней ошибки прямо пропорционален среднему квадратичному отклонению, т. е. вариабельности изучаемого признака, и обратно пропорционален корню квадратному из числа наблюдений