-
Значение и применение ошибки средней арифметической величины и относительного показателя.
Определение
ошибок репрезентативности: Возникает
в тех случаях, когда требуется по частям
охарактеризовать явление в целом.
Генеральная совокупность может быть
охарактеризована по выборочной только
с определенными погрешностями,
измеряемыми ошибкой репрезентативности.
По величине ошибки репрезентативности
определяют, на сколько результаты,
полученные при выборочном наблюдении,
отличаются от результатов, которые
могли бы быть получены при проведении
сплошного исследования.
-
Средняя ошибка
средней арифметической, при числе
наблюдений
п
30: тм
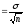 ,
,
при п
30; тм
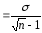
где: т
– ошибка репрезентативности средней
арифметической величины;
п – число
наблюдений;
σ- среднее
квадратическое отклонение.
Из формул видно,
что средняя ошибка средней арифметической
прямо пропорциональна степени
разнообразия признака и обратно
пропорциональна корню квадратному из
числа наблюдений, следовательно, для
уменьшения этой ошибки нужно увеличить
число наблюдений.
В) Ошибка относительных
показателей при числе наблюдений
п 30:
тр
 ,
,
при п
30 тр
 где
где
– mp –
ошибка относительных показателей
P
– показатель, выраженный в %, ‰ и.т.д.
g
– (100-Р) при Р=%; (1000-Р) при Р=‰
n
– число наблюдений.
-
Метод стандартизации, его значение и применение.
Условие для
применения метода стандартизации:
Метод стандартизации
применяется при сравнении интенсивных
показателей, рассчитанных для
совокупностей, отличающихся по своему
составу.
Сущность метода
стандартизации состоит в том, что он
позволяет устранить возможное внешнее
различие в составе совокупностей по
какому-либо признаку на величину
сравниваемых интенсивных показателей.
Это достигается путём условного
уравнивания составов этих совокупностей
по данному признаку.
Характеристика
стандартизированных показателей:
—- — это условные
величины, не дающие представление об
истинном размере явления, а указывающие
лишь на то, какова была бы величина
сравниваемых интенсивных показателей,
если бы они были бы вписаны для однородных
по своему составу совокупностей.
Назначение метода
стандартизации:
Метод стандартизации
применяется для того, чтобы установить,
повлияла ли неоднородность составов
совокупностей по какому-либо признаку
на различия сравниваемых интенсивных
показателей
Этапы расчёта
стандартизированных показателей:
I
этап. Расчёт интенсивных показателей
в отдельных группах, по признаку различия
и по совокупности в целом
II
этап. Определение стандарта, то есть
одинакового для сравниваемых совокупностей
численного состава по данному признаку.
Как правило за стандарт принимается
сумма или полу сумма численностей
соответствующих групп.
III
этап. Вычисление ожидаемых абсолютных
величин в группах стандарта на основе
групповых интенсивных показателей,
получение итоговых чисел по сравниваемым
совокупностям путём суммирования
ожидаемых величин
IV
этап. Вычисление стандартизированных
показателей для сравнивания совокупностей
V
этап. Сопоставление соотношений
стандартизированных и интенсивных
показателей. Формулировка вывода.
МЕДИЦИНСКАЯ
СТАТИСТИКА
Под статистикой
понимают:
+А. Самостоятельную
общественную науку, изучающую
количественную сторону массовых
общественных явлений в неразрывной
связи с их качественной стороной;
-Б. Научную дисциплину
по сбору, обработке и хранению информации,
характеризующую количественные
закономерности общественных явлений;
-В. Научную
дисциплину, объединяющую математические
методы, применяемые при сборе, обработке
и анализе информации.
Статистический
метод в медицине и здравоохранении
применяется для:
+А. Изучения
общественного здоровья и факторов, его
определяющих;
+Б. Изучения
состояния и деятельности органов и
учреждений здравоохранения;
+В. Планирования
научных исследований, обработки и
анализа полученных результатов.
1-ый этап проведения
статистического исследования включает:
-А. Сбор материала;
+Б. Составление
плана и программы исследований;
-В. Статистическая
обработка данных;
-Д. Анализ и выводы.
План статистического
исследования включает:
+А. Определение
места проведения исследования;
-Б. Выбор единицы
наблюдения;
+В. Установление
сроков проведения исследования;
-Г. Составление
макетов статистических таблиц.
На каком этапе
статистического исследования создаются
макеты статистических таблиц:
+А. При составлении
программы исследования;
-Б. На этапе сбора
материала;
-В. На этапе
статистической обработки материалов;
-Г. При проведении
анализа результатов.
Основными методами
формирования выборочной совокупности
являются все, кроме:
-А. Типологического;
-Б. Механического;
+В. Целевого;
-Г. Случайного.
Количественная
репрезентативность выборочной
совокупности обеспечивается за счет:
-А. 10-ти процентной
выборки из генеральной совокупности;
-Б. 50-ти процентной
выборки;
+В. Выборки,
включающей достаточное число наблюдений
(рассчитывается по специальным формулам).
К какому виду
статистического наблюдения относится
регистрация рождаемости и смертности:
-А. Единовременное;
+Б. Сплошной;
+В. Текущее;
-Г. Выборочный.
Какие из ниже
перечисленных способов наблюдения при
сборе информации о состоянии здоровья
населения являются более объективными:
-А. Опрос;
-Б. Анкетирование;
+В. Выкопировка
данных из медицинской документации.
К единовременному
наблюдению относится:
-А. Регистрация
рождений;
+Б. Перепись
населения;
-В. Регистрация
браков;
-Г. Регистрация
заболеваний;
+Д. Регистрация
численности и состава больных в стационаре
на определенную дату.
Текущим наблюдением
является:
+А. Регистрация
случаев смерти;
-Б. Перепись
населения;
+В. Регистрация
случаев рождений;
+Г. Регистрация
случаев обращения в поликлинику.
Для экспертной
оценки качества и эффективности
медицинской помощи в женской консультации
отобрана каждая десятая «Индивидуальная
карта беременной и родильницы».
Выборка является:
+А. Механической;
-Б. Гнездовой
(серийный отбор).
Программа
статистического исследования включает:
+А. Составление
программы сбора материала;
+Б. Составление
программы анализа;
-В. Определение
объекта исследования;
-Г. Определение
исполнителей исследования.
Выбор единицы
наблюдения зависит от:
-А. Программы
исследования;
-Б. Плана исследования;
+В. От цели и задач
исследования.
Из перечисленных
видов статистических таблиц наиболее
информативной является:
-А. Простая таблица;
-Б. Групповая
таблица;
+В. Комбинационная
таблица.
Единица наблюдения
— это:
+А. Первичный
элемент статистической совокупности,
являющийся носителем учетных признаков,
подлежащих регистрации;
-Б. Каждый признак
явления, подлежащего регистрации.
Два участковых
врача составили возрастную группировку
обслуживаемого контингента населения.
Какой из врачей сделал это правильно:
+А. До 20 лет, 20 — 39
лет, 40 — 59 лет, 60 лет и старше;
-Б. До 20 лет, 20 — 40
лет, 40 — 60 лет, старше 60 лет.
Типологические
группировки могут включать следующие
признаки:
+А. Пол;
-Б. Рост;
-В. Массу тела;
+Г. Диагноз;
+Д. Профессию.
Заболеваемость
вирусным гепатитом А в районе N.
в текущем году составила 6,0 на 10 000
населения. Указанный показатель является:
-А. Экстенсивным;
+Б. Интенсивным;
-В. Показателем
соотношения;
-Г. Показателем
наглядности.
Какие показатели
позволяют демонстрировать изменения
явления во времени или по территории
без раскрытия истинных размеров этого
явления:
-А. Экстенсивные;
-Б. Интенсивные;
-В. Соотношения;
+Г. Наглядности.
Обеспеченность
врачами населения города N
составляет 36,0 на 10 000 населения. Этот
показатель является:
-А. Экстенсивным;
-Б. Интенсивным;
+В. Показателем
соотношения;
-Г. Показателем
наглядности.
Экстенсивные
показатели могут быть представлены
следующими видами диаграмм:
-А. Линейными;
+Б. Секторными;
-В. Столбиковыми;
+Г. Внутристолбиковыми;
-Д. Картограммами.
Интенсивные
показатели могут быть представлены
следующими видами диаграмм:
+А. Столбиковыми;
-Б. Секторными;
+В. Линейными;
+Г. Картограммами.
К экстенсивным
показателям относятся:
-А. Показатели
рождаемости;
+Б. Распределение
числа врачей по специальностям;
-В. Показатели
младенческой смертности;
+Г. Распределение
умерших по причинам смерти.
К интенсивным
показателям относятся все, кроме:
-А. Показателя
смертности;
+Б. Структуры
заболеваний по нозологическим формам;
+В. Обеспеченности
населения врачами;
-Г. Показателя
заболеваемости.
Вариационный
ряд — это:
-А. Ряд чисел,
отражающих частоту (повторяемость)
цифровых значений изучаемого признака;
-Б. Ряд цифровых
значений различных признаков;
+В. Ряд числовых
измерений признака, расположенных в
ранговом порядке и характеризующихся
определенной частотой.
Средняя
арифметическая — это:
-А. Варианта с
наибольшей частотой;
-Б. Варианта,
находящаяся в середине ряда;
+В. Обобщающая
величина, характеризующая размер
варьирующего признака в совокупности.
Что показывает
среднеквадратическое отклонение:
-А. Разность между
наибольшей и наименьшей вариантой ряда;
+Б. Степень
колеблемости вариационного ряда;
-В. Обобщающую
характеристику размера изучаемого
признака.
Для чего применяется
коэффициент вариации:
-А. Для определения
отклонения вариант от среднего результата;
+Б. Для сравнения
степени колеблемости вариационных
рядов с разноименными признаками;
-В. Для определения
ошибки репрезентативности.
При нормальном
распределении признака в пределах М±2σ
будет находиться:
-А. 68 % вариаций;
+Б. 95 % вариаций;
-В. 99 % вариаций.
Средняя ошибка
средней арифметической величины (ошибка
репрезентативности) — это:
-А. Средняя разность
между средней арифметической и вариантами
ряда;
+Б.
Величина, на которую полученная средняя
величина выборочной совокупности
отличается от среднего результата
генеральной cовокупности;
-В. Величина, на
которую в среднем отличается каждая
варианта от средней арифметической.
Средняя ошибка
средней арифметической величины прямо
пропорциональна:
-А. Числу наблюдений;
-Б. Частоте изучаемого
признака в вариационном ряду;
+В. Показателю
разнообразия изучаемого признака.
Средняя ошибка
средней арифметической величины обратно
пропорциональна:
+А. Числу наблюдений;
-Б. Показателю
разнообразия изучаемого признака;
-В. Частоте изучаемого
признака.
Размер ошибки
средней арифметической величины
зависит от:
-А. Типа вариационного
ряда;
+Б. Числа наблюдений;
-В. Способа расчета
средней;
+Г. Разнообразия
изучаемого признака.
Разность
между сравниваемыми величинами (средними,
относительными) при большом числе
наблюдений (n30)
считается существенной (достоверной),
если:
-А. t равно 1,0;
-Б. t больше 1,0 и
меньше 2,0;
+В. t больше или
равно 2,0.
С увеличением
объема выборки ошибка репрезентативности:
-А. Увеличивается;
+Б. Уменьшается;
-В. Остается
постоянной.
Малой выборкой
считается та совокупность, в которой:
-А. число наблюдений
меньше или равно 100;
+Б. число наблюдений
меньше или равно 30;
-В. число наблюдений
меньше или равно 40.
Доверительный
интервал — это:
-А. Интервал, в
пределах которого находятся не менее
68 % вариант, близких к средней величине
данного вариационного ряда;
+Б. Пределы возможных
колебаний средней величины (показателя)
в генеральной совокупности;
-В. Разница между
максимальной и минимальной вариантами
вариационного ряда.
Минимально
достаточной для медицинских статистических
исследований является вероятность
безошибочного прогноза:
-А. 68 %;
-Б. 90 %;
+В. 95 %;
-Г. 99 %.
При
оценке достоверности разности полученных
результатов исследования разность
является существенной (достоверной),
если при n
30
величина t
равна:
-А. 1,0;
-Б. 1,5;
+В. 2,0;
+Г. 3 и более.
Величина ошибки
репрезентативности средней величины
прямо пропорциональна:
-А.
Числу наблюдений (n);
+Б. Величине
среднеквадратического отклонения
(сигме).
Какой
степени вероятности соответствует
доверительный интервал M2
m (n
30):
-А. 68,3 %;
+Б. 95,5 %;
-В. 99,7 %.
Оценка достоверности
полученного значения критерия Стьюдента
(t) для малых выборок производится:
-А. По специальной
формуле;
-Б. По принципу:
если t = 2, то P = 95%;
+В. По таблице.
Чему
равно значение критерия Стьюдента (t)
при степени вероятности безошибочного
прогноза P=95,5 %, (n 30):
-А.
t
= 1,0
+Б.
t
= 2,0
-В. t = 3 и более.
При проведении
корреляционного анализа необходимо
учитывать следующие параметры:
-А. Направление
связи между признаками, её силу и ошибку
репрезентативности;
-Б. Направление
связи между признаками, её силу, ошибку
репрезентативности и величину коэффициента
вариации;
+В. Направление
связи между признаками, её силу, ошибку
репрезентативности и величину критерия
достоверности.
При следующих
условиях применяется только коэффициент
ранговой корреляции:
+А. Когда нужны
лишь ориентировочные данные о наличии
связи;
+Б. Когда ряды
распределения имеют только атрибутивные
признаки;
-В. Когда ряды
распределения взаимосвязанных признаков
имеют количественное выражение;
+Г. Когда ряды
распределения взаимосвязанных признаков
имеют открытые варианты;
+Д. Когда ряды
распределения имеют как количественное
выражение, так и атрибутивные признаки.
Коэффициент
корреляции по методу квадратов применяется
только при следующих условиях:
-А. Когда нужны
лишь ориентировочные данные о наличии
связи;
+Б. Когда ряды
распределения величины взаимосвязанных
признаков имеют только закрытые варианты;
+В. Когда ряды
распределения взаимосвязанных признаков
имеют количественное выражение;
+Г. Когда нужны
точные данные о наличии связи;
-Д. Когда ряды
распределения имеют как количественное
выражение, так и атрибутивные признаки.
Между какими из
ниже перечисленных признаков может
устанавливаться корреляционная связь:
+А. Ростом и массой
тела у детей;
+Б. Содержанием
кислорода в клетках крови и уровнем
осмотического давления;
-В. Уровнем
систолического и диастолического
давления;
+Г. Частотой случаев
хронических заболеваний и возрастом.
Коэффициент
корреляции между уровнем шума и снижением
слуха с учетом стажа у рабочих
механосборочного цеха равен
rxy + 0,91. Установленная
связь:
-А. Обратная и
слабая;
-Б. Обратная и
сильная;
-В. Прямая и слабая;
+Г. Прямая и сильная.
Для оценки
достоверности полученного значения
коэффициента корреляции используют:
+А. Таблицы
стандартных коэффициентов корреляции
для разных степеней вероятности;
+Б. Ошибку
коэффициентов корреляции;
-В. Оценку
достоверности разности результатов
статистического исследования.
Укажите первый
этап вычисления стандартизованных
показателей прямым методом:
-А. Выбор стандарта;
-Б. Расчет «ожидаемых
чисел»;
+В. Расчет общих и
погрупповых интенсивных показателей;
-Г. Сравнение общих
интенсивных и стандартизованных
показателей;
-Д. Расчет общих
стандартизованных показателей.
Какие статистические
методы позволяют оценивать достоверность
результатов, полученных при выборочных
исследованиях:
-А. Корреляция;
+Б. Определение
доверительных границ;
-В. Стандартизация;
+Г. Оценка
достоверности разности результатов.
Для установления
силы и характера связи между признаками
нужно найти:
-А. Среднеквадратическое
отклонение;
+Б. Коэффициент
корреляции;
-В. Критерий
достоверности;
-Г. Стандартизованные
показатели.
При сравнении
интенсивных показателей, полученных
на однородных по своему составу
совокупностях, необходимо применять:
-А. Метод корреляции;
-Б. Метод
стандартизации;
+В. Оценку
достоверности разности полученных
показателей.
Оценка достоверности
различий в результатах исследования
проводится с помощью:
-А. Коэффициента
корреляции (rxy);
-Б. Коэффициента
вариации (Cv);
+В. Критерия
Стьюдента (t).
Что такое
динамический ряд:
-А. Ряд числовых
измерений определенного признака,
отличающихся друг от друга по своей
величине, расположенных в ранговом
порядке;
+Б. Ряд, состоящий
из однородных сопоставимых величин,
характеризующих изменения какого-либо
явления во времени;
-В. Ряд величин,
характеризующих результаты исследований
в разных регионах.
Уровни динамического
ряда могут быть представлены:
+А. Абсолютными
величинами;
+Б. Средними
величинами;
+В. Относительными
величинами.
Способы вырвнивания
динамического ряда:
+А. Укрупнение
интервалов;
+Б. Вычисление
групповой средней;
-В. Вычисление
коэффициента вариации;
+Г. Вычисление
скользящей средней;
+Д. Использование
метода наименьших квадратов.
Основными
показателями динамического ряда являются
все, кроме:
-А. Темпа роста;
-Б. Абсолютного
прироста;
-В. Темпа прироста;
+Г. Сигмального
отклонения;
-Д. Среднего темпа
прироста.
В какую таблицу
может быть сведена информация,
представленная в виде следующих признаков
«подлежащее и взаимосвязанные между
собой сказуемые»:
-А. Групповая;
+Б. Комбинационная;
-В. Простая;
-Г. Смешанная.
Укажите признаки,
соответствующие типологическому виду
группировки:
+А. Пол: мужской,
женский;
+Б. Диагноз: ИБС,
стенокардия, инфаркт миокарда;
-В. Длительность
заболевания: 1-5 лет, 6-10 лет, более 10 лет;
-Г. Возраст: до 20
лет, 21-30 лет, 31-40 лет, старше 40 лет.
Укажите признаки
атрибутивного характера:
+А. Заболевание
+Б. Исход заболевания
-В. Длительность
заболевания
-Г. Дозы лекарства
+Д. Группа инвалидности
Динамический
ряд – это:
-А. Значения
количественного признака (варианты),
расположенные в определенном порядке
и отличающиеся друг от друга по своему
значению;
+Б. Ряд, состоящий
из однородных сопоставимых значений
признака, характеризующих изменение
какого-либо явления (процесса) во
времени;
-В. Атрибутивные
значения признака, характеризующие
качественное состояние явления в
динамике.
Динамический
ряд может быть представлен:
+А. Абсолютными
величинами;
+Б. Средними
величинами;
+В. Относительными
величинами.
Для сравнения
нескольких динамических рядов с разными
исходными уровнями необходимо рассчитывать
показатель динамического ряда:
МЕДИЦИНСКАЯ
СТАТИСТИКА
Под статистикой
понимают:
+А. Самостоятельную
общественную науку, изучающую
количественную сторону массовых
общественных явлений в неразрывной
связи с их качественной стороной;
-Б. Научную дисциплину
по сбору, обработке и хранению информации,
характеризующую количественные
закономерности общественных явлений;
-В. Научную
дисциплину, объединяющую математические
методы, применяемые при сборе, обработке
и анализе информации.
Статистический
метод в медицине и здравоохранении
применяется для:
+А. Изучения
общественного здоровья и факторов, его
определяющих;
+Б. Изучения
состояния и деятельности органов и
учреждений здравоохранения;
+В. Планирования
научных исследований, обработки и
анализа полученных результатов.
1-ый этап проведения
статистического исследования включает:
-А. Сбор материала;
+Б. Составление
плана и программы исследований;
-В. Статистическая
обработка данных;
-Д. Анализ и выводы.
План статистического
исследования включает:
+А. Определение
места проведения исследования;
-Б. Выбор единицы
наблюдения;
+В. Установление
сроков проведения исследования;
-Г. Составление
макетов статистических таблиц.
На каком этапе
статистического исследования создаются
макеты статистических таблиц:
+А. При составлении
программы исследования;
-Б. На этапе сбора
материала;
-В. На этапе
статистической обработки материалов;
-Г. При проведении
анализа результатов.
Основными методами
формирования выборочной совокупности
являются все, кроме:
-А. Типологического;
-Б. Механического;
+В. Целевого;
-Г. Случайного.
Количественная
репрезентативность выборочной
совокупности обеспечивается за счет:
-А. 10-ти процентной
выборки из генеральной совокупности;
-Б. 50-ти процентной
выборки;
+В. Выборки,
включающей достаточное число наблюдений
(рассчитывается по специальным формулам).
К какому виду
статистического наблюдения относится
регистрация рождаемости и смертности:
-А. Единовременное;
+Б. Сплошной;
+В. Текущее;
-Г. Выборочный.
Какие из ниже
перечисленных способов наблюдения при
сборе информации о состоянии здоровья
населения являются более объективными:
-А. Опрос;
-Б. Анкетирование;
+В. Выкопировка
данных из медицинской документации.
К единовременному
наблюдению относится:
-А. Регистрация
рождений;
+Б. Перепись
населения;
-В. Регистрация
браков;
-Г. Регистрация
заболеваний;
+Д. Регистрация
численности и состава больных в стационаре
на определенную дату.
Текущим наблюдением
является:
+А. Регистрация
случаев смерти;
-Б. Перепись
населения;
+В. Регистрация
случаев рождений;
+Г. Регистрация
случаев обращения в поликлинику.
Для экспертной
оценки качества и эффективности
медицинской помощи в женской консультации
отобрана каждая десятая «Индивидуальная
карта беременной и родильницы».
Выборка является:
+А. Механической;
-Б. Гнездовой
(серийный отбор).
Программа
статистического исследования включает:
+А. Составление
программы сбора материала;
+Б. Составление
программы анализа;
-В. Определение
объекта исследования;
-Г. Определение
исполнителей исследования.
Выбор единицы
наблюдения зависит от:
-А. Программы
исследования;
-Б. Плана исследования;
+В. От цели и задач
исследования.
Из перечисленных
видов статистических таблиц наиболее
информативной является:
-А. Простая таблица;
-Б. Групповая
таблица;
+В. Комбинационная
таблица.
Единица наблюдения
— это:
+А. Первичный
элемент статистической совокупности,
являющийся носителем учетных признаков,
подлежащих регистрации;
-Б. Каждый признак
явления, подлежащего регистрации.
Два участковых
врача составили возрастную группировку
обслуживаемого контингента населения.
Какой из врачей сделал это правильно:
+А. До 20 лет, 20 — 39
лет, 40 — 59 лет, 60 лет и старше;
-Б. До 20 лет, 20 — 40
лет, 40 — 60 лет, старше 60 лет.
Типологические
группировки могут включать следующие
признаки:
+А. Пол;
-Б. Рост;
-В. Массу тела;
+Г. Диагноз;
+Д. Профессию.
Заболеваемость
вирусным гепатитом А в районе N.
в текущем году составила 6,0 на 10 000
населения. Указанный показатель является:
-А. Экстенсивным;
+Б. Интенсивным;
-В. Показателем
соотношения;
-Г. Показателем
наглядности.
Какие показатели
позволяют демонстрировать изменения
явления во времени или по территории
без раскрытия истинных размеров этого
явления:
-А. Экстенсивные;
-Б. Интенсивные;
-В. Соотношения;
+Г. Наглядности.
Обеспеченность
врачами населения города N
составляет 36,0 на 10 000 населения. Этот
показатель является:
-А. Экстенсивным;
-Б. Интенсивным;
+В. Показателем
соотношения;
-Г. Показателем
наглядности.
Экстенсивные
показатели могут быть представлены
следующими видами диаграмм:
-А. Линейными;
+Б. Секторными;
-В. Столбиковыми;
+Г. Внутристолбиковыми;
-Д. Картограммами.
Интенсивные
показатели могут быть представлены
следующими видами диаграмм:
+А. Столбиковыми;
-Б. Секторными;
+В. Линейными;
+Г. Картограммами.
К экстенсивным
показателям относятся:
-А. Показатели
рождаемости;
+Б. Распределение
числа врачей по специальностям;
-В. Показатели
младенческой смертности;
+Г. Распределение
умерших по причинам смерти.
К интенсивным
показателям относятся все, кроме:
-А. Показателя
смертности;
+Б. Структуры
заболеваний по нозологическим формам;
+В. Обеспеченности
населения врачами;
-Г. Показателя
заболеваемости.
Вариационный
ряд — это:
-А. Ряд чисел,
отражающих частоту (повторяемость)
цифровых значений изучаемого признака;
-Б. Ряд цифровых
значений различных признаков;
+В. Ряд числовых
измерений признака, расположенных в
ранговом порядке и характеризующихся
определенной частотой.
Средняя
арифметическая — это:
-А. Варианта с
наибольшей частотой;
-Б. Варианта,
находящаяся в середине ряда;
+В. Обобщающая
величина, характеризующая размер
варьирующего признака в совокупности.
Что показывает
среднеквадратическое отклонение:
-А. Разность между
наибольшей и наименьшей вариантой ряда;
+Б. Степень
колеблемости вариационного ряда;
-В. Обобщающую
характеристику размера изучаемого
признака.
Для чего применяется
коэффициент вариации:
-А. Для определения
отклонения вариант от среднего результата;
+Б. Для сравнения
степени колеблемости вариационных
рядов с разноименными признаками;
-В. Для определения
ошибки репрезентативности.
При нормальном
распределении признака в пределах М±2σ
будет находиться:
-А. 68 % вариаций;
+Б. 95 % вариаций;
-В. 99 % вариаций.
Средняя ошибка
средней арифметической величины (ошибка
репрезентативности) — это:
-А. Средняя разность
между средней арифметической и вариантами
ряда;
+Б.
Величина, на которую полученная средняя
величина выборочной совокупности
отличается от среднего результата
генеральной cовокупности;
-В. Величина, на
которую в среднем отличается каждая
варианта от средней арифметической.
Средняя ошибка
средней арифметической величины прямо
пропорциональна:
-А. Числу наблюдений;
-Б. Частоте изучаемого
признака в вариационном ряду;
+В. Показателю
разнообразия изучаемого признака.
Средняя ошибка
средней арифметической величины обратно
пропорциональна:
+А. Числу наблюдений;
-Б. Показателю
разнообразия изучаемого признака;
-В. Частоте изучаемого
признака.
Размер ошибки
средней арифметической величины
зависит от:
-А. Типа вариационного
ряда;
+Б. Числа наблюдений;
-В. Способа расчета
средней;
+Г. Разнообразия
изучаемого признака.
Разность
между сравниваемыми величинами (средними,
относительными) при большом числе
наблюдений (n30)
считается существенной (достоверной),
если:
-А. t равно 1,0;
-Б. t больше 1,0 и
меньше 2,0;
+В. t больше или
равно 2,0.
С увеличением
объема выборки ошибка репрезентативности:
-А. Увеличивается;
+Б. Уменьшается;
-В. Остается
постоянной.
Малой выборкой
считается та совокупность, в которой:
-А. число наблюдений
меньше или равно 100;
+Б. число наблюдений
меньше или равно 30;
-В. число наблюдений
меньше или равно 40.
Доверительный
интервал — это:
-А. Интервал, в
пределах которого находятся не менее
68 % вариант, близких к средней величине
данного вариационного ряда;
+Б. Пределы возможных
колебаний средней величины (показателя)
в генеральной совокупности;
-В. Разница между
максимальной и минимальной вариантами
вариационного ряда.
Минимально
достаточной для медицинских статистических
исследований является вероятность
безошибочного прогноза:
-А. 68 %;
-Б. 90 %;
+В. 95 %;
-Г. 99 %.
При
оценке достоверности разности полученных
результатов исследования разность
является существенной (достоверной),
если при n
30
величина t
равна:
-А. 1,0;
-Б. 1,5;
+В. 2,0;
+Г. 3 и более.
Величина ошибки
репрезентативности средней величины
прямо пропорциональна:
-А.
Числу наблюдений (n);
+Б. Величине
среднеквадратического отклонения
(сигме).
Какой
степени вероятности соответствует
доверительный интервал M2
m (n
30):
-А. 68,3 %;
+Б. 95,5 %;
-В. 99,7 %.
Оценка достоверности
полученного значения критерия Стьюдента
(t) для малых выборок производится:
-А. По специальной
формуле;
-Б. По принципу:
если t = 2, то P = 95%;
+В. По таблице.
Чему
равно значение критерия Стьюдента (t)
при степени вероятности безошибочного
прогноза P=95,5 %, (n 30):
-А.
t
= 1,0
+Б.
t
= 2,0
-В. t = 3 и более.
При проведении
корреляционного анализа необходимо
учитывать следующие параметры:
-А. Направление
связи между признаками, её силу и ошибку
репрезентативности;
-Б. Направление
связи между признаками, её силу, ошибку
репрезентативности и величину коэффициента
вариации;
+В. Направление
связи между признаками, её силу, ошибку
репрезентативности и величину критерия
достоверности.
При следующих
условиях применяется только коэффициент
ранговой корреляции:
+А. Когда нужны
лишь ориентировочные данные о наличии
связи;
+Б. Когда ряды
распределения имеют только атрибутивные
признаки;
-В. Когда ряды
распределения взаимосвязанных признаков
имеют количественное выражение;
+Г. Когда ряды
распределения взаимосвязанных признаков
имеют открытые варианты;
+Д. Когда ряды
распределения имеют как количественное
выражение, так и атрибутивные признаки.
Коэффициент
корреляции по методу квадратов применяется
только при следующих условиях:
-А. Когда нужны
лишь ориентировочные данные о наличии
связи;
+Б. Когда ряды
распределения величины взаимосвязанных
признаков имеют только закрытые варианты;
+В. Когда ряды
распределения взаимосвязанных признаков
имеют количественное выражение;
+Г. Когда нужны
точные данные о наличии связи;
-Д. Когда ряды
распределения имеют как количественное
выражение, так и атрибутивные признаки.
Между какими из
ниже перечисленных признаков может
устанавливаться корреляционная связь:
+А. Ростом и массой
тела у детей;
+Б. Содержанием
кислорода в клетках крови и уровнем
осмотического давления;
-В. Уровнем
систолического и диастолического
давления;
+Г. Частотой случаев
хронических заболеваний и возрастом.
Коэффициент
корреляции между уровнем шума и снижением
слуха с учетом стажа у рабочих
механосборочного цеха равен
rxy + 0,91. Установленная
связь:
-А. Обратная и
слабая;
-Б. Обратная и
сильная;
-В. Прямая и слабая;
+Г. Прямая и сильная.
Для оценки
достоверности полученного значения
коэффициента корреляции используют:
+А. Таблицы
стандартных коэффициентов корреляции
для разных степеней вероятности;
+Б. Ошибку
коэффициентов корреляции;
-В. Оценку
достоверности разности результатов
статистического исследования.
Укажите первый
этап вычисления стандартизованных
показателей прямым методом:
-А. Выбор стандарта;
-Б. Расчет «ожидаемых
чисел»;
+В. Расчет общих и
погрупповых интенсивных показателей;
-Г. Сравнение общих
интенсивных и стандартизованных
показателей;
-Д. Расчет общих
стандартизованных показателей.
Какие статистические
методы позволяют оценивать достоверность
результатов, полученных при выборочных
исследованиях:
-А. Корреляция;
+Б. Определение
доверительных границ;
-В. Стандартизация;
+Г. Оценка
достоверности разности результатов.
Для установления
силы и характера связи между признаками
нужно найти:
-А. Среднеквадратическое
отклонение;
+Б. Коэффициент
корреляции;
-В. Критерий
достоверности;
-Г. Стандартизованные
показатели.
При сравнении
интенсивных показателей, полученных
на однородных по своему составу
совокупностях, необходимо применять:
-А. Метод корреляции;
-Б. Метод
стандартизации;
+В. Оценку
достоверности разности полученных
показателей.
Оценка достоверности
различий в результатах исследования
проводится с помощью:
-А. Коэффициента
корреляции (rxy);
-Б. Коэффициента
вариации (Cv);
+В. Критерия
Стьюдента (t).
Что такое
динамический ряд:
-А. Ряд числовых
измерений определенного признака,
отличающихся друг от друга по своей
величине, расположенных в ранговом
порядке;
+Б. Ряд, состоящий
из однородных сопоставимых величин,
характеризующих изменения какого-либо
явления во времени;
-В. Ряд величин,
характеризующих результаты исследований
в разных регионах.
Уровни динамического
ряда могут быть представлены:
+А. Абсолютными
величинами;
+Б. Средними
величинами;
+В. Относительными
величинами.
Способы вырвнивания
динамического ряда:
+А. Укрупнение
интервалов;
+Б. Вычисление
групповой средней;
-В. Вычисление
коэффициента вариации;
+Г. Вычисление
скользящей средней;
+Д. Использование
метода наименьших квадратов.
Основными
показателями динамического ряда являются
все, кроме:
-А. Темпа роста;
-Б. Абсолютного
прироста;
-В. Темпа прироста;
+Г. Сигмального
отклонения;
-Д. Среднего темпа
прироста.
В какую таблицу
может быть сведена информация,
представленная в виде следующих признаков
«подлежащее и взаимосвязанные между
собой сказуемые»:
-А. Групповая;
+Б. Комбинационная;
-В. Простая;
-Г. Смешанная.
Укажите признаки,
соответствующие типологическому виду
группировки:
+А. Пол: мужской,
женский;
+Б. Диагноз: ИБС,
стенокардия, инфаркт миокарда;
-В. Длительность
заболевания: 1-5 лет, 6-10 лет, более 10 лет;
-Г. Возраст: до 20
лет, 21-30 лет, 31-40 лет, старше 40 лет.
Укажите признаки
атрибутивного характера:
+А. Заболевание
+Б. Исход заболевания
-В. Длительность
заболевания
-Г. Дозы лекарства
+Д. Группа инвалидности
Динамический
ряд – это:
-А. Значения
количественного признака (варианты),
расположенные в определенном порядке
и отличающиеся друг от друга по своему
значению;
+Б. Ряд, состоящий
из однородных сопоставимых значений
признака, характеризующих изменение
какого-либо явления (процесса) во
времени;
-В. Атрибутивные
значения признака, характеризующие
качественное состояние явления в
динамике.
Динамический
ряд может быть представлен:
+А. Абсолютными
величинами;
+Б. Средними
величинами;
+В. Относительными
величинами.
Для сравнения
нескольких динамических рядов с разными
исходными уровнями необходимо рассчитывать
показатель динамического ряда:

Концепция репрезентативности часто встречается в статистических отчетах и при подготовке выступлений и отчетов. Пожалуй, без него сложно представить какое-либо представление информации для ознакомления.
Содержание
- 1 Репрезентативность — что это?
- 2 Другие определения
- 3 Репрезентативная выборка
- 4 Вероятностная выборка
- 5 Вероятностные выборки
- 6 Выборка потребителей
- 7 Размер выборки
- 8 Понятие ошибки репрезентативности
- 9 Виды ошибок
- 10 Преднамеренные и непреднамеренные ошибки репрезентативности
- 11 Валидность, надежность, репрезентативность. Расчет ошибок
- 12 Репрезентативные системы
Репрезентативность — что это?

Репрезентативность отражает степень, в которой выбранные объекты или части соответствуют содержанию и значению набора данных, из которого они были выбраны.
Другие определения
Репрезентативность можно понимать в разных контекстах. Но по своему смыслу репрезентативность — это соответствие характеристик и свойств выбранных единиц генеральной совокупности, которые точно отражают характеристики всей генеральной базы данных в целом.
Кроме того, репрезентативность информации определяется как способность данных выборки представлять параметры и свойства совокупности, которые важны с точки зрения проводимых исследований.
Репрезентативная выборка
Принцип выборки заключается в выборе наиболее важных свойств, которые точно отражают общую совокупность данных. Для этого используются различные методы, позволяющие получить точные результаты и общее представление о генеральной совокупности, используя только выборочные материалы, описывающие качество всех данных.
Таким образом, нет необходимости изучать весь материал, но достаточно учесть выборочную репрезентативность. Что это? Это набор отдельных данных, чтобы получить представление об общей массе информации.
В зависимости от метода они делятся на вероятностные и маловероятные. Вероятностный — это выборка, которая создается путем вычисления наиболее важных и интересных данных, которые в будущем будут репрезентативными для генеральной совокупности. Это осознанный выбор или случайная выборка, однако оправданная своим содержанием.
Маловероятно — это одна из разновидностей случайной выборки, составленной по принципу обычной лотереи. В этом случае мнение лица, взявшего такую пробу, не принимается во внимание. Используется только слепая жребий.
Вероятностная выборка
Вероятностные выборки также можно разделить на несколько типов:
- Один из самых простых и понятных принципов — нерепрезентативная выборка. Например, этот метод часто используется при проведении социальных опросов. При этом участники опроса не выбираются из общей массы по каким-либо конкретным критериям, а информация берется от первых 50 человек, принявших участие.
- Выборка вероятностей — это еще одна разновидность выборки невероятности, которая часто используется для исследования больших наборов данных. Для этого используется множество условий и правил. Выбираются объекты, которые должны им соответствовать. То есть на примере социального опроса можно предположить, что будет опрошено 100 человек, но при составлении статистического отчета будет учитываться только мнение определенного количества людей, которые будут соответствовать установленным требованиям.
- Преднамеренные выборки отличаются тем, что они имеют ряд требований и условий для отбора, но все же полагаются на совпадения, не преследуя цели получения хорошей статистики.

Вероятностные выборки
Для вероятностных выборок рассчитывается ряд параметров, которым будут соответствовать объекты в выборке, и среди них различными способами могут быть выбраны именно те факты и данные, которые будут представлены как репрезентативность данных выборки. Эти методы расчета требуемых данных могут быть:
- Простая случайная выборка. Он заключается в том, что среди выделенного сегмента методом полностью случайной лотереи выбирается необходимый объем данных, который будет репрезентативной выборкой.
- Систематическая и случайная выборка позволяет составить систему расчета необходимых данных на основе случайно выбранного сегмента. Итак, если первое случайное число, указывающее порядковый номер данных, выбранных из общей совокупности, равно 5, следующими данными для выбора могут быть, например, 15, 25, 35 и так далее. Этот пример ясно объясняет, что даже случайный выбор может быть основан на систематических вычислениях требуемых входных данных.
Выборка потребителей
Осмысленная выборка — это способ взглянуть на каждый отдельный сегмент, и на основе его оценки составляется генеральная совокупность, отражающая характеристики и свойства всей базы данных. Таким образом, собирается больше данных, отвечающих требованиям репрезентативной выборки. Легко выбрать набор параметров, которые не будут включены в общее количество, без потери качества выбранных данных, представляющих генеральную совокупность. Таким образом определяется репрезентативность результатов исследования.
Размер выборки
Не последняя проблема, которую необходимо решить, — это размер выборки для репрезентативной репрезентативности населения. Размер выборки не всегда зависит от количества источников в генеральной совокупности. Однако репрезентативность выборки напрямую зависит от того, на сколько сегментов в конечном итоге следует разделить результат. Чем больше таких сегментов, тем больше данных включается в итоговую выборку. Если результаты требуют общих обозначений и не требуют конкретики, то в результате выборка становится меньше, поскольку, не вдаваясь в детали, информация представлена более поверхностно, а значит, ее прочтение будет общим.

Понятие ошибки репрезентативности
Репрезентативная систематическая ошибка — это конкретное несоответствие между характеристиками населения и данными выборки. При проведении выборочного исследования невозможно получить абсолютно точные данные, как при полном изучении генеральных популяций и выборки, представленной только частью информации и параметров, в то время как более детальное изучение возможно только при изучении всей совокупности численность населения. Поэтому некоторые ошибки и ошибки неизбежны.
Виды ошибок
При составлении репрезентативной выборки возникают некоторые ошибки:
- Случайный.
- Стандарт.
- Не намеренно.
- Систематический.
- Предел.
- Умышленное.
Причиной появления случайных ошибок может быть прерывистый характер исследования генеральной совокупности. Обычно ошибка случайной репрезентативности незначительна по величине и характеру.
Между тем систематические ошибки возникают, когда нарушаются правила отбора данных из генеральной совокупности.
Средняя ошибка — это разница между средним значением выборки и основной совокупностью. Это не зависит от количества единиц в выборке. Он обратно пропорционален размеру выборки. Таким образом, чем больше объем, тем меньше среднее значение ошибки.
Предельная ошибка — это наибольшая возможная разница между средним значением выполненной выборки и всей генеральной совокупностью. Эта ошибка характеризуется как максимум возможных ошибок в данных условиях их возникновения.
Преднамеренные и непреднамеренные ошибки репрезентативности
Ошибки искажения данных могут быть преднамеренными или непреднамеренными.
Итак, причины появления преднамеренных ошибок — это подход к отбору данных с использованием метода выявления трендов. Непреднамеренные ошибки возникают и на этапе подготовки выборочного наблюдения, формирования репрезентативной выборки. Чтобы избежать таких ошибок, необходимо создать хорошую основу выборки для списков единиц выборки. Он должен полностью соответствовать целям выборки, быть надежным и охватывать все аспекты исследования.
Валидность, надежность, репрезентативность. Расчет ошибок

Расчет ошибки репрезентативности (Mm) среднего арифметического (M).
Стандартное отклонение: размер выборки (> 30).
Репрезентативная ошибка (Мр) и относительная величина (Р): размер выборки (n> 30).
В случае, если необходимо изучить совокупность, где размер выборки невелик и менее 30 единиц, количество наблюдений уменьшится на одну единицу.
Величина ошибки прямо пропорциональна размеру выборки. Репрезентативность информации и расчет степени возможности составления точного прогноза отражает определенное значение предельной погрешности.
Репрезентативные системы
В процессе оценки представления информации используется не только репрезентативная выборка, но и лицо, получающее информацию, также использует репрезентативные системы. Таким образом, мозг обрабатывает определенный объем информации, создавая репрезентативную выборку всего потока информации, чтобы качественно и быстро оценить предоставленные данные и понять суть проблемы. Ответьте на вопрос: «Представление — что это?» — В масштабе человеческого сознания это довольно просто. Для этого мозг использует все подчиненные органы чувств, в зависимости от типа информации, которую необходимо изолировать от общего потока. Поэтому проводится различие между:
- Система визуального представления, в которой задействованы органы зрительного восприятия глаза. Людей, которые часто используют эту систему, называют визуалами. С помощью этой системы человек обрабатывает информацию, поступающую в виде изображений.
- Система кинестетической репрезентации — это обработка потока информации путем ее восприятия через обонятельные и тактильные каналы.
- Система слухового представления. Основной используемый орган — слух. Информация, предоставленная в виде аудио- или голосового файла, обрабатывается именно этой системой. Людей, которые лучше всего воспринимают информацию на слух, называют аудиалами.

- Система цифрового представления используется вместе с другими как средство получения информации извне. Это субъективно-логическое восприятие и понимание полученных данных.

Так что же такое репрезентативность? Простая выборка из набора или целостная процедура обработки информации? Мы можем однозначно сказать, что репрезентативность во многом определяет наше восприятие потоков данных, помогая выделить самые тяжелые и наиболее важные из них.
Обратная связь
Ошибка репрезентативности прямо пропорциональна колеблемости ря- да (сигме) и обратно пропорциональна числу наблюдений.
Следовательно, чем больше число наблюдений, (т.е. чем ближе по числу на- блюдений выборочная совокупность к генеральной), тем меньше ошибка репре- зентативности.
Интервал, в котором с заданным уровнем вероятности колеблется истинное значение средней величины или показателя, называется доверительным интер- валом, а его границы — доверительными границами. Они используются для оп- ределения размеров средней или показателя в генеральной совокупности.
Доверительные границы средней арифметической и показателя в генеральной совокупности равны:
М± tm
P± tm, где t — доверительный коэффициент
Доверительный коэффициент ( t )— это число, показывающее, во сколько раз надо увеличить ошибку средней величины или показателя, чтобы при данном числе наблюдений с желаемой степенью вероятности утверждать, что они не выйдут за полученные таким образом пределы.
C увеличением t степень вероятности возрастает.
Т. к. известно, что полученная средняя или показатель при повторных наблю- дениях, даже при одинаковых условиях, в силу случайных колебаний будут отли- чаться от предыдущего результата, теорией статистики установлена степень ве- роятности, с которой можно ожидать, что колебания эти не выйдут за определен- ные пределы. Так, колебания средней в интервале М ± 1m гарантируют ее точность с вероятностью 68,3% (такая степень вероятности не удовлетворяет
исследователей), в интервале М ± 2m — 95,5% (достаточная степень вероятности)
и в интервале М ± 3m — 99,7% (большая степень вероятности).
М± 1 m® 68,3 % М± 2 m® 95,5 % М± 3 m® 99,7 %
Для медико-биологических исследований принята степень вероятности
95% ( t = 2 ), что соответствует доверительному интервалу М ± 2 m.
Это означает, что практически с полной достоверностью (в 95%) можно утверждать, что полученный средний результат (М) отклоняется от ис- тинного значения не больше, чем на удвоенную (М ± 2 m) ошибку.
Конечный результат любого медико-статистического исследования выражает- ся средней арифметической и ее параметрами:
ОЦЕНКА ДОСТОВЕРНОСТИ ОТНОСИТЕЛЬНЫХ ВЕЛИЧИН (ПОКАЗАТЕЛЕЙ)
Средняя ошибка показателя также служит для определения пределов его слу- чайных колебаний, т.е. дает представление, в каких пределах может находиться показатель в различных выборках в зависимости от случайных причин. С увели- чением численности выборки ошибка уменьшается.
Мерой достоверности показателя является его средняя ошибка ( m ), ко- торая показывает, на сколько результат, полученный при выборочном исследова- нии, отличается от результата, который был бы получен при изучении всей гене- ральной совокупности.
Средняя ошибка показателя определяется по формуле:
mp =
, где mp — ошибка показателя
р — показатель
q — величина, обратная показателю (100-р, 1000-р и т.д. в зависимости от того, на какое основание рассчитан показатель)
n — число наблюдений
ПРИМЕР: Из стационара выбыло 289 больных, умерло 12.
Показатель летальности: 12 ´100
р = 289 = 4,1%
4,1 ´ (100-4,1)4,1 ´ 95,9
m p= ±Ö 289 = ±Ö 289 = ± 1.16%
Возможные пределы колебаний показателя равняются 4,1% ± 1,16% (Р±mp).
ОЦЕНКА ДОСТОВЕРНОСТИ РАЗНОСТИ СРЕДНИХ И ОТНОСИТЕЛЬНЫХ ВЕЛИЧИН
В научных исследованиях и клинической практике с целью сравнения двух средних величин или показателей (например, для выявления преимуществ одного метода лечения перед другим, сопоставления результатов исследования в кон- трольной и экспериментальной группах, сравнения показателей здоровья двух групп населения и т.п.) возникает необходимость не только определить их раз- ность, но и оценить ее достоверность.
Разность между двумя средними или относительными величинами (показате-
лями), каждая из которых имеет свою ошибку, также имеет свою ошибку.
Средняя ошибка разности ( mразн )вычисляется по формуле:
mразн =± Ö m12 + m22 ,где m1 и m2 — средние ошибки сравниваемых
величин
Т.о., ошибка разности равняется корню квадратному из суммы квадратов ошибок сравниваемых величин.
Мерой достоверности разности двух величин является критерий досто- верности ( критерий Стьюдента — t ):
для средних величин M1 —M2
для относительных величин P1 —P2
где t — критерий достоверности
M1 и M2 — сравниваемые средние р1 и р2 — сравниваемые показатели m12 и m22 — их ошибки
Для медико-биологических исследований принято считать, что если критерий достоверности t ³ 2, то различие двух величин (средних или отно- сительных) следует считать существенным, достоверным, доказанным с ве- роятностью в 95%. Если t < 2 , то различие величин не доказано.
ПРИМЕР. Требуется определить достоверность разности показателей (средний бал успе- ваемости) студентов медицинского института. На лечебном факультете средний балл составил 3,86 ± 0,04 , на педиатрическом — 4,03 ± 0,04.
M1 — M2 4,03 — 3,86 0,17
t = ± Ö m12 + m22 = Ö 0,042 + 0,042 = Ö 0,0032 = 3,0
Таким образом, в данном случае различие между средними величинами следует считать статистически достоверным.
СПЕЦИАЛЬНЫЕ СТАТИСТИЧЕСКИЕ МЕТОДИКИ
МЕТОД СТАНДАРТИЗАЦИИ
Общие показатели интенсивности, полученные на 4 этапе статистического исследования при статистическом анализе, не всегда правильно выявляют зако- номерности изучаемых явлений, так как на их уровень может влиять различие состава сравниваемых совокупностей , в отношении которых эти показатели рас- считаны . При сравнении показателей, характеризующих то или иное явление (за- болеваемость, рождаемость, летальность и т .д) их различия могут определяться не только разным уровнем распространенности этих явлений, но и неоднородно- стью состава сравниваемых совокупностей . Эта неоднородность может быть обусловлена различным возрастным, половым, профессиональным или другим составом совокупностей.
Так, например , при изучении заболеваемости в двух изучаемых коллектива, необходимо учитывать их возрастно-половую структуру.
Статистический метод, при котором можно устранить влияние на результаты исследования различий сравниваемых совокупностей , неоднородных по своему составу, называется методом стандартизации.
Сущность этого метода заключается в том, что сравниваемые явления ис- кусственно ставятся в одинаковые условия относительно группового рас- пределения среды, т.е. совокупности, которые характеризуют анализируе- мые показатели, условно считают одинаковыми.
Результатом проведения этого метода является вычисление стандартизован- ных показателей. Эти показатели, при сопоставлении их с обычными интенсив- ными показателями, позволяют сделать вывод, связаны ли различия в интенсив- ных показателях с неоднородностью составов сравниваемых совокупностей.
Стандартизованные показатели являются условными и не отражают истинных размеров изучаемого явления. Они применяются только для сравне- ния и анализа данной ситуации вследствие того, что рассчитаны они при искусст- венно созданных условиях и не отражают действительного размера явлений.
Существует три метода расчета стандартизованных показателей: прямой, косвенный и обратный косвенному.
При проведении медицинских исследований обычно пользуются прямым методом стандартизации, который состоит из трех этапов.
1. Вычисление погрупповых показателей,т.е. ”истинных”или обычных относительных величин, характеризующих изучаемое явление в двух сравнивае- мых совокупностях. В зависимости от характера исследования это могут быть показатели заболеваемости, инфицированности, травматизма, смертности, и т.д., рассчитанные по группам (по диагнозам, тяжести заболевания, полу, возрасту, месту жительства и т.д.)
2. Вычисление стандарта, т.е. нового искусственного распределения среды в определенном масштабе. За масштаб стандарта берется основание (коэффи- циент), на который рассчитывались показатели на первом этапе: 100,1000,10000 и т.д.
©2015- 2023 pdnr.ru Все права принадлежат авторам размещенных материалов.
Обратная связь
Ошибка репрезентативности прямо пропорциональна колеблемости ря- да (сигме) и обратно пропорциональна числу наблюдений.
Следовательно, чем больше число наблюдений, (т.е. чем ближе по числу на- блюдений выборочная совокупность к генеральной), тем меньше ошибка репре- зентативности.
Интервал, в котором с заданным уровнем вероятности колеблется истинное значение средней величины или показателя, называется доверительным интер- валом, а его границы — доверительными границами. Они используются для оп- ределения размеров средней или показателя в генеральной совокупности.
Доверительные границы средней арифметической и показателя в генеральной совокупности равны:
М± tm
P± tm, где t — доверительный коэффициент
Доверительный коэффициент ( t )— это число, показывающее, во сколько раз надо увеличить ошибку средней величины или показателя, чтобы при данном числе наблюдений с желаемой степенью вероятности утверждать, что они не выйдут за полученные таким образом пределы.
C увеличением t степень вероятности возрастает.
Т. к. известно, что полученная средняя или показатель при повторных наблю- дениях, даже при одинаковых условиях, в силу случайных колебаний будут отли- чаться от предыдущего результата, теорией статистики установлена степень ве- роятности, с которой можно ожидать, что колебания эти не выйдут за определен- ные пределы. Так, колебания средней в интервале М ± 1m гарантируют ее точность с вероятностью 68,3% (такая степень вероятности не удовлетворяет
исследователей), в интервале М ± 2m — 95,5% (достаточная степень вероятности)
и в интервале М ± 3m — 99,7% (большая степень вероятности).
М± 1 m® 68,3 % М± 2 m® 95,5 % М± 3 m® 99,7 %
Для медико-биологических исследований принята степень вероятности
95% ( t = 2 ), что соответствует доверительному интервалу М ± 2 m.
Это означает, что практически с полной достоверностью (в 95%) можно утверждать, что полученный средний результат (М) отклоняется от ис- тинного значения не больше, чем на удвоенную (М ± 2 m) ошибку.
Конечный результат любого медико-статистического исследования выражает- ся средней арифметической и ее параметрами:
ОЦЕНКА ДОСТОВЕРНОСТИ ОТНОСИТЕЛЬНЫХ ВЕЛИЧИН (ПОКАЗАТЕЛЕЙ)
Средняя ошибка показателя также служит для определения пределов его слу- чайных колебаний, т.е. дает представление, в каких пределах может находиться показатель в различных выборках в зависимости от случайных причин. С увели- чением численности выборки ошибка уменьшается.
Мерой достоверности показателя является его средняя ошибка ( m ), ко- торая показывает, на сколько результат, полученный при выборочном исследова- нии, отличается от результата, который был бы получен при изучении всей гене- ральной совокупности.
Средняя ошибка показателя определяется по формуле:
mp =
, где mp — ошибка показателя
р — показатель
q — величина, обратная показателю (100-р, 1000-р и т.д. в зависимости от того, на какое основание рассчитан показатель)
n — число наблюдений
ПРИМЕР: Из стационара выбыло 289 больных, умерло 12.
Показатель летальности: 12 ´100
р = 289 = 4,1%
4,1 ´ (100-4,1)4,1 ´ 95,9
m p= ±Ö 289 = ±Ö 289 = ± 1.16%
Возможные пределы колебаний показателя равняются 4,1% ± 1,16% (Р±mp).
ОЦЕНКА ДОСТОВЕРНОСТИ РАЗНОСТИ СРЕДНИХ И ОТНОСИТЕЛЬНЫХ ВЕЛИЧИН
В научных исследованиях и клинической практике с целью сравнения двух средних величин или показателей (например, для выявления преимуществ одного метода лечения перед другим, сопоставления результатов исследования в кон- трольной и экспериментальной группах, сравнения показателей здоровья двух групп населения и т.п.) возникает необходимость не только определить их раз- ность, но и оценить ее достоверность.
Разность между двумя средними или относительными величинами (показате-
лями), каждая из которых имеет свою ошибку, также имеет свою ошибку.
Средняя ошибка разности ( mразн )вычисляется по формуле:
mразн =± Ö m12 + m22 ,где m1 и m2 — средние ошибки сравниваемых
величин
Т.о., ошибка разности равняется корню квадратному из суммы квадратов ошибок сравниваемых величин.
Мерой достоверности разности двух величин является критерий досто- верности ( критерий Стьюдента — t ):
для средних величин M1 —M2
для относительных величин P1 —P2
где t — критерий достоверности
M1 и M2 — сравниваемые средние р1 и р2 — сравниваемые показатели m12 и m22 — их ошибки
Для медико-биологических исследований принято считать, что если критерий достоверности t ³ 2, то различие двух величин (средних или отно- сительных) следует считать существенным, достоверным, доказанным с ве- роятностью в 95%. Если t < 2 , то различие величин не доказано.
ПРИМЕР. Требуется определить достоверность разности показателей (средний бал успе- ваемости) студентов медицинского института. На лечебном факультете средний балл составил 3,86 ± 0,04 , на педиатрическом — 4,03 ± 0,04.
M1 — M2 4,03 — 3,86 0,17
t = ± Ö m12 + m22 = Ö 0,042 + 0,042 = Ö 0,0032 = 3,0
Таким образом, в данном случае различие между средними величинами следует считать статистически достоверным.
СПЕЦИАЛЬНЫЕ СТАТИСТИЧЕСКИЕ МЕТОДИКИ
МЕТОД СТАНДАРТИЗАЦИИ
Общие показатели интенсивности, полученные на 4 этапе статистического исследования при статистическом анализе, не всегда правильно выявляют зако- номерности изучаемых явлений, так как на их уровень может влиять различие состава сравниваемых совокупностей , в отношении которых эти показатели рас- считаны . При сравнении показателей, характеризующих то или иное явление (за- болеваемость, рождаемость, летальность и т .д) их различия могут определяться не только разным уровнем распространенности этих явлений, но и неоднородно- стью состава сравниваемых совокупностей . Эта неоднородность может быть обусловлена различным возрастным, половым, профессиональным или другим составом совокупностей.
Так, например , при изучении заболеваемости в двух изучаемых коллектива, необходимо учитывать их возрастно-половую структуру.
Статистический метод, при котором можно устранить влияние на результаты исследования различий сравниваемых совокупностей , неоднородных по своему составу, называется методом стандартизации.
Сущность этого метода заключается в том, что сравниваемые явления ис- кусственно ставятся в одинаковые условия относительно группового рас- пределения среды, т.е. совокупности, которые характеризуют анализируе- мые показатели, условно считают одинаковыми.
Результатом проведения этого метода является вычисление стандартизован- ных показателей. Эти показатели, при сопоставлении их с обычными интенсив- ными показателями, позволяют сделать вывод, связаны ли различия в интенсив- ных показателях с неоднородностью составов сравниваемых совокупностей.
Стандартизованные показатели являются условными и не отражают истинных размеров изучаемого явления. Они применяются только для сравне- ния и анализа данной ситуации вследствие того, что рассчитаны они при искусст- венно созданных условиях и не отражают действительного размера явлений.
Существует три метода расчета стандартизованных показателей: прямой, косвенный и обратный косвенному.
При проведении медицинских исследований обычно пользуются прямым методом стандартизации, который состоит из трех этапов.
1. Вычисление погрупповых показателей,т.е. ”истинных”или обычных относительных величин, характеризующих изучаемое явление в двух сравнивае- мых совокупностях. В зависимости от характера исследования это могут быть показатели заболеваемости, инфицированности, травматизма, смертности, и т.д., рассчитанные по группам (по диагнозам, тяжести заболевания, полу, возрасту, месту жительства и т.д.)
2. Вычисление стандарта, т.е. нового искусственного распределения среды в определенном масштабе. За масштаб стандарта берется основание (коэффи- циент), на который рассчитывались показатели на первом этапе: 100,1000,10000 и т.д.
©2015- 2023 pdnr.ru Все права принадлежат авторам размещенных материалов.
Среднее квадратическое отклонение характеризует среднее отклонение всех вариант вариационного ряда от средней арифметической величины. Поскольку отклонения вариант от средней, имеют значения с «+» и «-», то при суммировании они взаимоуничтожаются. Чтобы избежать этого, отклонения возводятся во вторую степень, а затем, после определенных вычислений, производится обратное действие — извлечение корня квадратного. Поэтому среднее отклонение именуется квадратическим.
Среднее квадратическое отклонение определяют по формуле: 
(отклонение d — это разность между каждой вариантой и средней величиной, т. е. d = V—M; р –частота; количество вариант n (при числе наблюдений менее 30 сумма делится на n-1);
При вычислении среднеквад. отклонения по способу моментов используется следующая формула. Т.о. , формула вычисления сред. отклонения по способу моментов будет читаться как корень квадратный из разности момента второй степени и квадрата момента первой степени. Результаты вычисления сред. отклонения обычным способом и способом моментов идентичны. Однако, как указывалось выше, второй способ значительно убыстряет и упрощает расчеты. Итак, нахождение сред. отклонения позволяет судить о характере однородности исследуемой группы наблюдений. Если величина среднеквад. отклонения небольшая, то это свидетельствует о достаточно высокой однородности изучаемого явления. Среднюю арифметическую в таком случае следует признать вполне характерной для данного вариационного ряда. Однако слишком малая величина сигмы заставляет думать об искусственном подборе наблюдений. При очень большой сигме средняя арифметическая в меньшей степени характеризует вариационный ряд, что говорит о значительной вариабельности изучаемого признака или явления или о неоднородности исследуемой группы. Значение: Определение среднеквад. отклонения представляет немалую ценность для медицинской науки и практики. При диагностике отдельных заболеваний очень важно оценить на основании конкретных исследований, какие признаки проявляются у соответствующей группы больных относительно одинаково, с небольшими колебаниями, а для каких признаков характерны большие индивидуальные колебания. Очень широко используется это свойство при оценке физического развития отдельных групп населения, при выработке стандартов школьной меб.
Ошибка репрезентативности (сред. ошибка сред. арифметич.)
Чтобы определить степень точности выборочного наблюдения, необходимо оценить величину ошибки, которая может случайно произойти в процессе выборки. Такие ошибки носят название случайных ошибок репрезентативности т. Они фактически являются разностью между средними числами, полученными при выборочном статистическом наблюдении, и аналогичными величинами, которые были бы получены при сплошном исследовании того же объекта (т. е. при исследовании генеральной совокупности). Ошибки репрезентативности вытекают из самой сущности выборочного исследования. С помощью ошибок репрезентативности числовые характеристики выборочной совокупности распространяются на всю генеральную совокупность, то есть она характеризуется с учетом определенной погрешности. Величины ошибок репрезентативности определяются как объемом выборки, так и разнообразием признака. Чем больше число наблюдений, тем меньше ошибка, чем больше изменчив признак, тем больше величина статистической ошибки. На практике для определения средней ошибки выборки в статистических исследованиях пользуются следующей формулой:

(где m — ошибка репрезентативности; σ — среднее квадратическое отклонение;
n — число наблюдений в выборке (при числе наблюдений менее 30 в подкоренное выражение вносится значение п-1)).
Размер средней ошибки прямо пропорционален среднему квадратичному отклонению, т. е. вариабельности изучаемого признака, и обратно пропорционален корню квадратному из числа наблюдений