Среднеквадратичная ошибка (Mean Squared Error) – Среднее арифметическое (Mean) квадратов разностей между предсказанными и реальными значениями Модели (Model) Машинного обучения (ML):

Рассчитывается с помощью формулы, которая будет пояснена в примере ниже:
$$MSE = \frac{1}{n} × \sum_{i=1}^n (y_i — \widetilde{y}_i)^2$$
$$MSE\space{}{–}\space{Среднеквадратическая}\space{ошибка,}$$
$$n\space{}{–}\space{количество}\space{наблюдений,}$$
$$y_i\space{}{–}\space{фактическая}\space{координата}\space{наблюдения,}$$
$$\widetilde{y}_i\space{}{–}\space{предсказанная}\space{координата}\space{наблюдения,}$$
MSE практически никогда не равен нулю, и происходит это из-за элемента случайности в данных или неучитывания Оценочной функцией (Estimator) всех факторов, которые могли бы улучшить предсказательную способность.
Пример. Исследуем линейную регрессию, изображенную на графике выше, и установим величину среднеквадратической Ошибки (Error). Фактические координаты точек-Наблюдений (Observation) выглядят следующим образом:

Мы имеем дело с Линейной регрессией (Linear Regression), потому уравнение, предсказывающее положение записей, можно представить с помощью формулы:
$$y = M * x + b$$
$$y\space{–}\space{значение}\space{координаты}\space{оси}\space{y,}$$
$$M\space{–}\space{уклон}\space{прямой}$$
$$x\space{–}\space{значение}\space{координаты}\space{оси}\space{x,}$$
$$b\space{–}\space{смещение}\space{прямой}\space{относительно}\space{начала}\space{координат}$$
Параметры M и b уравнения нам, к счастью, известны в данном обучающем примере, и потому уравнение выглядит следующим образом:
$$y = 0,5252 * x + 17,306$$
Зная координаты реальных записей и уравнение линейной регрессии, мы можем восстановить полные координаты предсказанных наблюдений, обозначенных серыми точками на графике выше. Простой подстановкой значения координаты x в уравнение мы рассчитаем значение координаты ỹ:

Рассчитаем квадрат разницы между Y и Ỹ:

Сумма таких квадратов равна 4 445. Осталось только разделить это число на количество наблюдений (9):
$$MSE = \frac{1}{9} × 4445 = 493$$
Само по себе число в такой ситуации становится показательным, когда Дата-сайентист (Data Scientist) предпринимает попытки улучшить предсказательную способность модели и сравнивает MSE каждой итерации, выбирая такое уравнение, что сгенерирует наименьшую погрешность в предсказаниях.
MSE и Scikit-learn
Среднеквадратическую ошибку можно вычислить с помощью SkLearn. Для начала импортируем функцию:
import sklearn
from sklearn.metrics import mean_squared_errorИнициализируем крошечные списки, содержащие реальные и предсказанные координаты y:
y_true = [5, 41, 70, 77, 134, 68, 138, 101, 131]
y_pred = [23, 35, 55, 90, 93, 103, 118, 121, 129]Инициируем функцию mean_squared_error(), которая рассчитает MSE тем же способом, что и формула выше:
mean_squared_error(y_true, y_pred)
Интересно, что конечный результат на 3 отличается от расчетов с помощью Apple Numbers:
496.0Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Автор оригинальной статьи: @mmoshikoo
Фото: @tobyelliott
Существует большое количество видов ошибок модели. В этом выпуске рассматривается один из самых простых видов – средняя абсолютная ошибка модели. Такая ошибка также может называться MAD (Mean Absolute Deviation, т.е. среднее абсолютное отклонение) или MAE (Mean Absolute Error, т.е. средняя абсолютная ошибка).
Внимание!
Уважаемый пользователь, нажав кнопку «Купить» или «Смотреть» Вы перейдете на сайт https://analytera.ispringmarket.ru, там Вы сможете оплатить и просмотреть выбранный материал.
Перед оплатой мы попросим Вас зарегистрироваться в системе (верхняя правая часть экрана, кнопка «Зарегистрироваться»). Это необходимо для создания Вашего личного аккаунта на нашей платформе. В дальнейшем аккаунт будет использоваться Вами для доступа ко всем материалам (бесплатным и оплаченным).
Во время регистрации просим указывать используемый Вами адрес электронной почты* (на него будут приходить оповещения и техническая информация).
*Важно!
Мы ни при каких обстоятельствах не будем передавать третьим лицам Ваши данные. Мы гарантируем конфиденциальность Вашей личной информации, предоставленной в результате регистрации. Адрес электронной почты, указанный Вами, будет использоваться только для сообщений системы и оповещении о новых материалах и событиях.

Добавил:
Upload
Опубликованный материал нарушает ваши авторские права? Сообщите нам.
Вуз:
Предмет:
Файл:
Лр№1Корреляционный анализ.doc
Скачиваний:
25
Добавлен:
16.08.2019
Размер:
928.77 Кб
Скачать
-
Стандартную (среднюю квадратическую) ошибку модели.
![]()
(9),
где
— фактические значения результативного
признака, полученные по данным наблюдений;
![]()
— рассчитанные значения результативного
признака;
n — объем выборки;
m – число параметров
в уравнении регрессии.
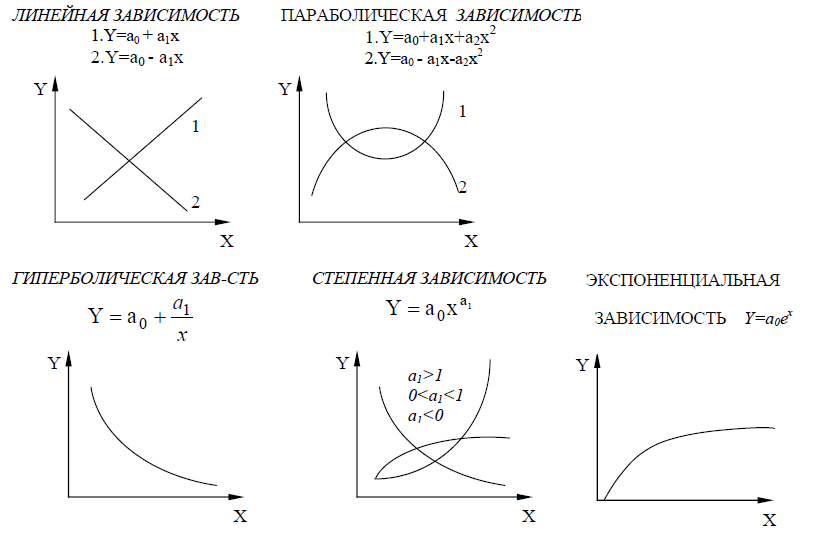
Рис.
7 Виды зависимостей линии регрессии
Задание 3. Построение модели линейной регрессии
Условие
задачи: По
20 туристическим фирмам были установлены
затраты на рекламную кампанию и количество
туристов, воспользовавшихся после ее
проведения услугами каждой фирмы.
Необходимо построить модель линейной
регрессии, учитывая, что переменные
подчинены нормальному закону распределения.
3.1 Расчет параметров уравнения линейной регрессии с использованием функции линейн
Откройте
новую книгу MS
Excel
и создайте таблицу согласно рис. 15,
сохраните в своей папке под именем
Регрессионный_Анализ.xls.
(Данные можно также скопировать из файла
по заданию №1).
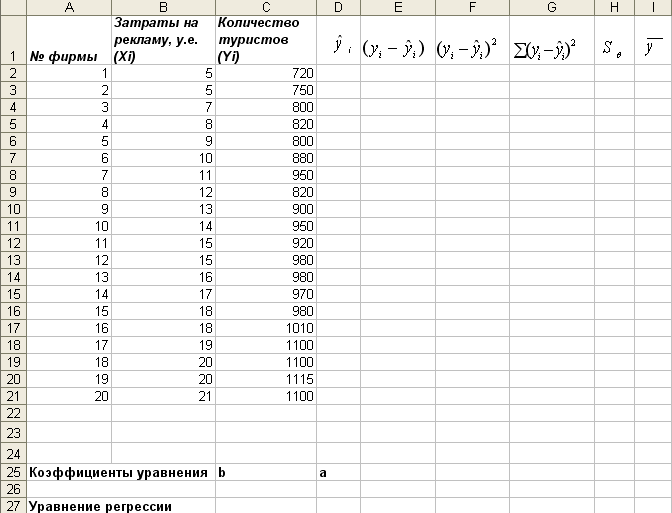
Рис.8.
Данные для задачи №3.
-
Для
получения коэффициентов а
и b
линейного уравнения регрессии
y=b*x+
a,
описывающего зависимость количества
привлеченных туристов от затрат на
рекламу воспользуемся статистической
функцией ЛИНЕЙН.
Для этого выделите две ячейки C26:D26
и выполните вставку функции ЛИНЕЙН
с аргументами
согласно рис.9. Здесь Известные_значения_y
– диапазон значений Количество
туристов,
Известные_значения_x
– диапазон значений Затраты
на рекламу.
Нажмите комбинацию клавиш
SHIFT+CTRL+ENTER.
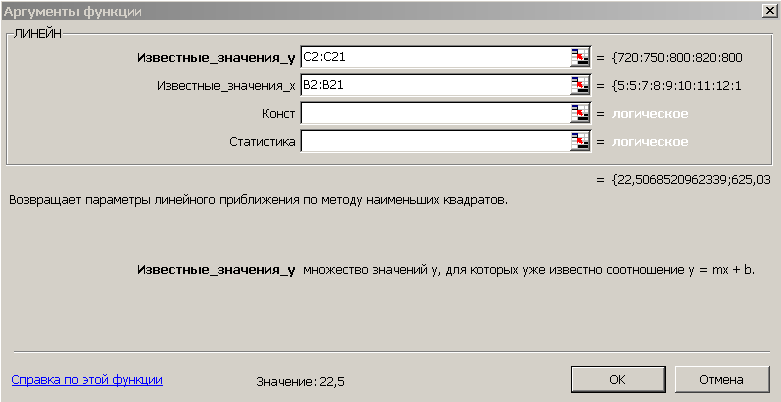
Рис.
9. Аргументы функции ЛИНЕЙН.
-
В
ячейку C27
введите уравнение регрессии y=b*x+
a,
(вместо b
и a
подставьте
полученные коэффициенты линейной
регрессии).

-
Рассчитайте
стандартную (среднюю квадратическую)
ошибку модели по формуле (7). Для этого:
-
В
диапазоне ячеек D2:D21
рассчитайте значения результативного
признакапутем подстановки значений независимого
признака-регрессора Х в уравнение
линейной регрессии. -
В
диапазоне ячеек E2:E21
рассчитайте отклонения фактических
значений результативного признака от
рассчитанных значений

. -
В
диапазоне ячеек F2:F21
рассчитайте квадраты отклонений

. -
В
ячейке G2 рассчитайте
сумму квадратов отклонений

. -
В
ячейке Н2 рассчитайте стандартную
ошибку модели

по формуле 9.
-
Проанализируйте
величину ошибки. Для этого рассчитайте
среднее значение

фактического результативного признака
в ячейке I2 и
найденное значение подставьте в формулу

.

-
Сделайте
вывод об адекватности линейной модели.
3.2 Нахождение уравнения линейной регрессии графическим методом
-
Для
получения уравнения регрессии построим
корреляционное
поле
переменных X
(затраты на рекламу) и Y
(количество туристов). -
Выделите
диапазон ячеек В2:С21,
запустите мастера диаграмм и выберите
тип диаграммы – Точечная.
Задайте для
диаграммы имя – Корреляционное
поле, ось Х
– Затраты
на рекламу,
ось Y
– Количество
туристов.
На последнем шаге мастера укажите место
расположения – отдельный
лист. -
Добавьте
линию тренда
на точечный график. Для этого необходимо
выделить диаграмму и выполнить команду
меню Диаграмма
/Добавить линию тренда, либо
выполнить данную команду из контекстного
меню, щелкнув по любой точке графика.
Линия тренда
– графическое
представление направления изменения
ряда данных -
Выберите
тип тренда Линейный,
который
используется для аппроксимации данных
по методу наименьших квадратов в
соответствии с уравнением y=b*x+
a. -
На
вкладке Параметры
установите флажки Показать
уравнение на диаграмме
и Поместить
на диаграмму
величину
достоверности аппроксимации

.
Щелкните
по кнопке ОК.
— это число
от 0 до 1, которое отражает близость
линии тренда к фактическим данным.
Линия тренда наиболее соответствует
действительности, когда значениеблизко к 1.
-
Сравните
уравнение регрессии, полученное
графическим методом (рис. 10), с уравнением,
рассчитанным с помощью функции ЛИНЕЙН.
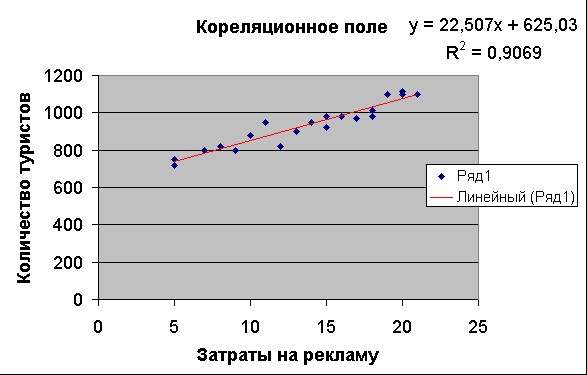
Рис.10.
Модель линейной регрессии.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Оценка точности модели кривой роста, выбор наилучшей кривой роста
Точность модели характеризуется разностью между фактическими и расчетными значениями исследуемого показателя Y. Мерой точности является стандартная ошибка модели
.
Точность модели удобнее оценивать с помощью средней относительной ошибки аппроксимации
,
которая показывает, на сколько процентов в среднем модельные значения отличаются от фактических yt. Если
, то считается, что модель имеет достаточно высокую точность, при
точность модели хорошая, при
— удовлетворительная, а при
— неудовлетворительная.
Если одновременно исследуются несколько моделей, то лучшей считается модель, имеющая наименьшую Sмод или Еотн.
Продолжение примера 9. Проверить точность модели.
Решение. Стандартная ошибка линейной модели может быть определена с помощью функции Excel «СТОШYX»: млн. руб.
Средняя относительная ошибка аппроксимации
%.
Предсказанные моделью значения спроса на кредитные ресурсы отличаются от фактических в среднем на 4,54 млн руб., или на 6,5 %. Модель имеет хорошую точность.
читать 2 мин
Регрессионный анализ — это метод, который мы можем использовать для понимания взаимосвязи между одной или несколькими переменными-предикторами и переменной отклика .
Один из способов оценить, насколько хорошо регрессионная модель соответствует набору данных, — вычислить среднеквадратичную ошибку , которая представляет собой показатель, указывающий нам среднее расстояние между прогнозируемыми значениями из модели и фактическими значениями в наборе данных.
Чем ниже RMSE, тем лучше данная модель может «соответствовать» набору данных.
Формула для нахождения среднеквадратичной ошибки, часто обозначаемая аббревиатурой RMSE , выглядит следующим образом:
СКО = √ Σ(P i – O i ) 2 / n
куда:
- Σ — причудливый символ, означающий «сумма».
- P i — прогнозируемое значение для i -го наблюдения в наборе данных.
- O i — наблюдаемое значение для i -го наблюдения в наборе данных.
- n — размер выборки
В следующем примере показано, как интерпретировать RMSE для данной модели регрессии.
Пример: как интерпретировать RMSE для регрессионной модели
Предположим, мы хотим построить регрессионную модель, которая использует «учебные часы» для прогнозирования «экзаменационного балла» студентов на конкретном вступительном экзамене в колледж.
Мы собираем следующие данные для 15 студентов:
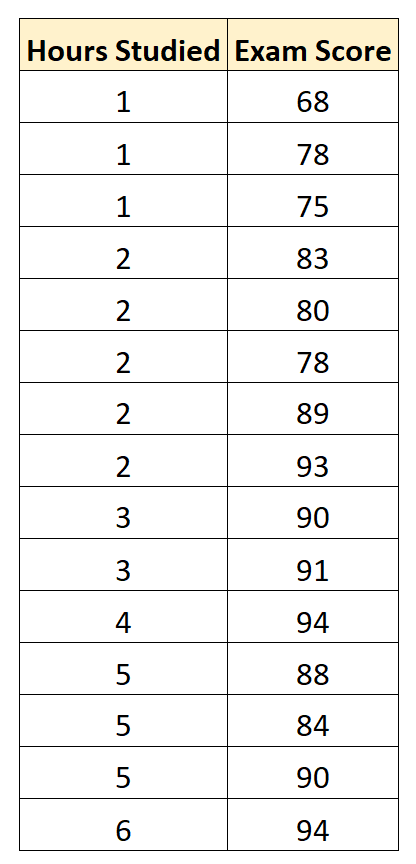
Затем мы используем статистическое программное обеспечение (например, Excel, SPSS, R, Python) и т. д., чтобы найти следующую подогнанную модель регрессии:
Экзаменационный балл = 75,95 + 3,08 * (часы обучения)
Затем мы можем использовать это уравнение, чтобы предсказать экзаменационную оценку каждого студента, исходя из того, сколько часов они учились:
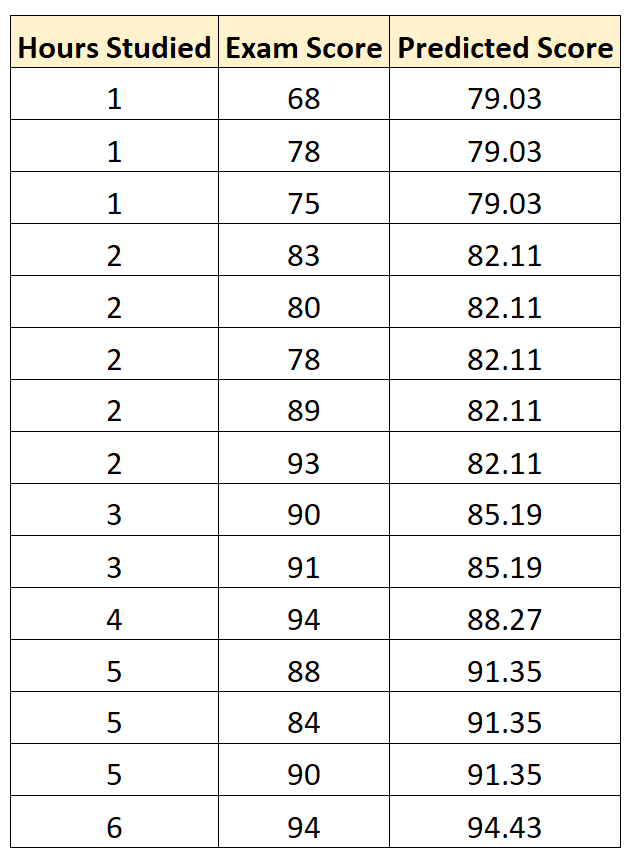
Затем мы можем вычислить квадрат разницы между каждой прогнозируемой оценкой экзамена и фактической оценкой экзамена. Затем мы можем извлечь квадратный корень из среднего значения этих разностей:
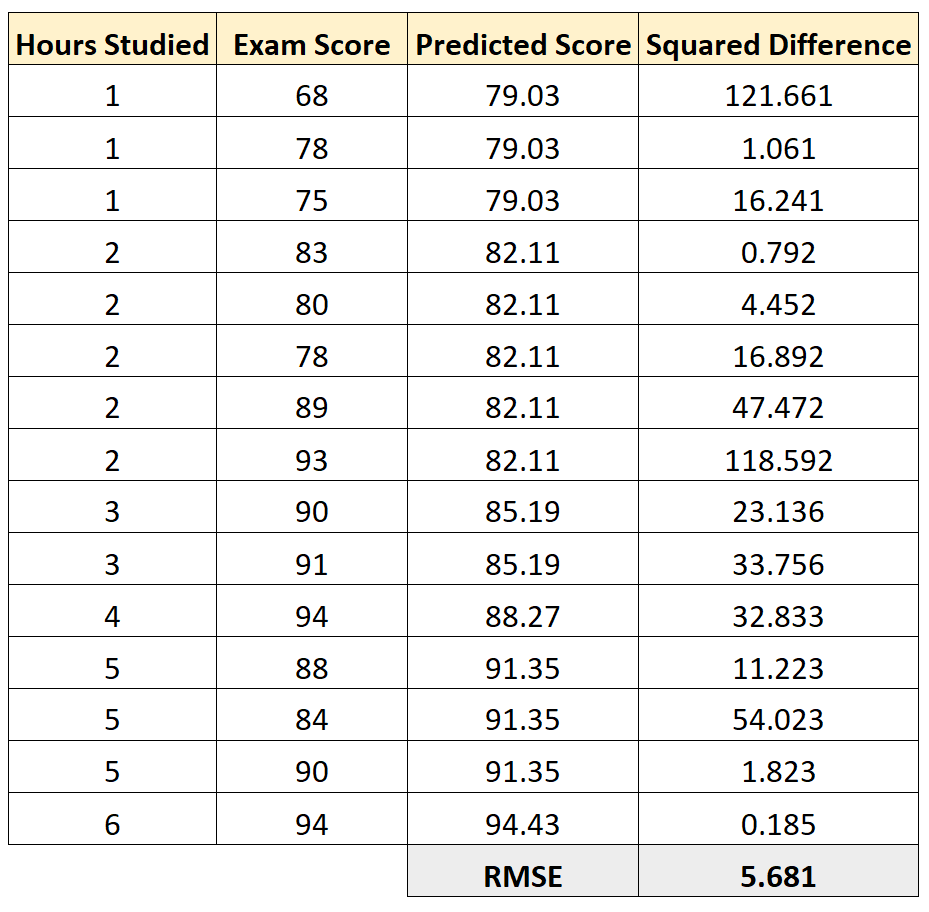
RMSE для этой регрессионной модели оказывается равным 5,681 .
Напомним, что остатки регрессионной модели представляют собой разницу между наблюдаемыми значениями данных и значениями, предсказанными моделью.
Остаток = (P i – O i )
куда
- P i — прогнозируемое значение для i -го наблюдения в наборе данных.
- O i — наблюдаемое значение для i -го наблюдения в наборе данных.
И помните, что RMSE регрессионной модели рассчитывается как:
СКО = √ Σ(P i – O i ) 2 / n
Это означает, что RMSE представляет собой квадратный корень из дисперсии остатков.
Это значение полезно знать, поскольку оно дает нам представление о среднем расстоянии между наблюдаемыми значениями данных и прогнозируемыми значениями данных.
Это отличается от R-квадрата модели, который сообщает нам долю дисперсии переменной отклика, которая может быть объяснена предикторной переменной (переменными) в модели.
Сравнение значений RMSE из разных моделей
RMSE особенно полезен для сравнения соответствия различных моделей регрессии.
Например, предположим, что мы хотим построить регрессионную модель, чтобы предсказать результаты экзаменов студентов, и мы хотим найти наилучшую возможную модель среди нескольких потенциальных моделей.
Предположим, мы подгоняем три разные модели регрессии и находим соответствующие им значения RMSE:
- RMSE модели 1: 14,5
- RMSE модели 2: 16,7
- RMSE модели 3: 9,8
Модель 3 имеет самый низкий RMSE, что говорит нам о том, что она способна лучше всего соответствовать набору данных из трех потенциальных моделей.
Дополнительные ресурсы
Калькулятор среднеквадратичной ошибки
Как рассчитать RMSE в Excel
Как рассчитать RMSE в R
Как рассчитать RMSE в Python