From Wikipedia, the free encyclopedia
In statistics, the mean squared error (MSE)[1] or mean squared deviation (MSD) of an estimator (of a procedure for estimating an unobserved quantity) measures the average of the squares of the errors—that is, the average squared difference between the estimated values and the actual value. MSE is a risk function, corresponding to the expected value of the squared error loss.[2] The fact that MSE is almost always strictly positive (and not zero) is because of randomness or because the estimator does not account for information that could produce a more accurate estimate.[3] In machine learning, specifically empirical risk minimization, MSE may refer to the empirical risk (the average loss on an observed data set), as an estimate of the true MSE (the true risk: the average loss on the actual population distribution).
The MSE is a measure of the quality of an estimator. As it is derived from the square of Euclidean distance, it is always a positive value that decreases as the error approaches zero.
The MSE is the second moment (about the origin) of the error, and thus incorporates both the variance of the estimator (how widely spread the estimates are from one data sample to another) and its bias (how far off the average estimated value is from the true value).[citation needed] For an unbiased estimator, the MSE is the variance of the estimator. Like the variance, MSE has the same units of measurement as the square of the quantity being estimated. In an analogy to standard deviation, taking the square root of MSE yields the root-mean-square error or root-mean-square deviation (RMSE or RMSD), which has the same units as the quantity being estimated; for an unbiased estimator, the RMSE is the square root of the variance, known as the standard error.
Definition and basic properties[edit]
The MSE either assesses the quality of a predictor (i.e., a function mapping arbitrary inputs to a sample of values of some random variable), or of an estimator (i.e., a mathematical function mapping a sample of data to an estimate of a parameter of the population from which the data is sampled). The definition of an MSE differs according to whether one is describing a predictor or an estimator.
Predictor[edit]
If a vector of  predictions is generated from a sample of data points on all variables, and
predictions is generated from a sample of data points on all variables, and  is the vector of observed values of the variable being predicted, with
is the vector of observed values of the variable being predicted, with  being the predicted values (e.g. as from a least-squares fit), then the within-sample MSE of the predictor is computed as
being the predicted values (e.g. as from a least-squares fit), then the within-sample MSE of the predictor is computed as

In other words, the MSE is the mean  of the squares of the errors
of the squares of the errors  . This is an easily computable quantity for a particular sample (and hence is sample-dependent).
. This is an easily computable quantity for a particular sample (and hence is sample-dependent).
In matrix notation,

where  is
is  and
and  is a
is a  column vector.
column vector.
The MSE can also be computed on q data points that were not used in estimating the model, either because they were held back for this purpose, or because these data have been newly obtained. Within this process, known as cross-validation, the MSE is often called the test MSE,[4] and is computed as

Estimator[edit]
The MSE of an estimator  with respect to an unknown parameter
with respect to an unknown parameter  is defined as[1]
is defined as[1]
![{\displaystyle \operatorname {MSE} ({\hat {\theta }})=\operatorname {E} _{\theta }\left[({\hat {\theta }}-\theta )^{2}\right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9a0e1b3bac58f9ba2d2f4ff8b85b2e35a8f4bf78)
This definition depends on the unknown parameter, but the MSE is a priori a property of an estimator. The MSE could be a function of unknown parameters, in which case any estimator of the MSE based on estimates of these parameters would be a function of the data (and thus a random variable). If the estimator is derived as a sample statistic and is used to estimate some population parameter, then the expectation is with respect to the sampling distribution of the sample statistic.
The MSE can be written as the sum of the variance of the estimator and the squared bias of the estimator, providing a useful way to calculate the MSE and implying that in the case of unbiased estimators, the MSE and variance are equivalent.[5]

Proof of variance and bias relationship[edit]
![{\displaystyle {\begin{aligned}\operatorname {MSE} ({\hat {\theta }})&=\operatorname {E} _{\theta }\left[({\hat {\theta }}-\theta )^{2}\right]\\&=\operatorname {E} _{\theta }\left[\left({\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]+\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)^{2}\right]\\&=\operatorname {E} _{\theta }\left[\left({\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]\right)^{2}+2\left({\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]\right)\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)+\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)^{2}\right]\\&=\operatorname {E} _{\theta }\left[\left({\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]\right)^{2}\right]+\operatorname {E} _{\theta }\left[2\left({\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]\right)\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)\right]+\operatorname {E} _{\theta }\left[\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)^{2}\right]\\&=\operatorname {E} _{\theta }\left[\left({\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]\right)^{2}\right]+2\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)\operatorname {E} _{\theta }\left[{\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]\right]+\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)^{2}&&\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta ={\text{const.}}\\&=\operatorname {E} _{\theta }\left[\left({\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]\right)^{2}\right]+2\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\operatorname {E} _{\theta }[{\hat {\theta }}]\right)+\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)^{2}&&\operatorname {E} _{\theta }[{\hat {\theta }}]={\text{const.}}\\&=\operatorname {E} _{\theta }\left[\left({\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]\right)^{2}\right]+\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)^{2}\\&=\operatorname {Var} _{\theta }({\hat {\theta }})+\operatorname {Bias} _{\theta }({\hat {\theta }},\theta )^{2}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2ac524a751828f971013e1297a33ca1cc4c38cd6)
An even shorter proof can be achieved using the well-known formula that for a random variable  ,
,  . By substituting with,
. By substituting with,  , we have
, we have
![{\displaystyle {\begin{aligned}\operatorname {MSE} ({\hat {\theta }})&=\mathbb {E} [({\hat {\theta }}-\theta )^{2}]\\&=\operatorname {Var} ({\hat {\theta }}-\theta )+(\mathbb {E} [{\hat {\theta }}-\theta ])^{2}\\&=\operatorname {Var} ({\hat {\theta }})+\operatorname {Bias} ^{2}({\hat {\theta }},\theta )\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a89b110dd50aaf64585bb22b53b45f92d39adbf9)
But in real modeling case, MSE could be described as the addition of model variance, model bias, and irreducible uncertainty (see Bias–variance tradeoff). According to the relationship, the MSE of the estimators could be simply used for the efficiency comparison, which includes the information of estimator variance and bias. This is called MSE criterion.
In regression[edit]
In regression analysis, plotting is a more natural way to view the overall trend of the whole data. The mean of the distance from each point to the predicted regression model can be calculated, and shown as the mean squared error. The squaring is critical to reduce the complexity with negative signs. To minimize MSE, the model could be more accurate, which would mean the model is closer to actual data. One example of a linear regression using this method is the least squares method—which evaluates appropriateness of linear regression model to model bivariate dataset,[6] but whose limitation is related to known distribution of the data.
The term mean squared error is sometimes used to refer to the unbiased estimate of error variance: the residual sum of squares divided by the number of degrees of freedom. This definition for a known, computed quantity differs from the above definition for the computed MSE of a predictor, in that a different denominator is used. The denominator is the sample size reduced by the number of model parameters estimated from the same data, (n−p) for p regressors or (n−p−1) if an intercept is used (see errors and residuals in statistics for more details).[7] Although the MSE (as defined in this article) is not an unbiased estimator of the error variance, it is consistent, given the consistency of the predictor.
In regression analysis, «mean squared error», often referred to as mean squared prediction error or «out-of-sample mean squared error», can also refer to the mean value of the squared deviations of the predictions from the true values, over an out-of-sample test space, generated by a model estimated over a particular sample space. This also is a known, computed quantity, and it varies by sample and by out-of-sample test space.
In the context of gradient descent algorithms, it is common to introduce a factor of  to the MSE for ease of computation after taking the derivative. So a value which is technically half the mean of squared errors may be called the MSE.
to the MSE for ease of computation after taking the derivative. So a value which is technically half the mean of squared errors may be called the MSE.
Examples[edit]
Mean[edit]
Suppose we have a random sample of size from a population,  . Suppose the sample units were chosen with replacement. That is, the units are selected one at a time, and previously selected units are still eligible for selection for all draws. The usual estimator for the
. Suppose the sample units were chosen with replacement. That is, the units are selected one at a time, and previously selected units are still eligible for selection for all draws. The usual estimator for the  is the sample average
is the sample average

which has an expected value equal to the true mean (so it is unbiased) and a mean squared error of
![{\displaystyle \operatorname {MSE} \left({\overline {X}}\right)=\operatorname {E} \left[\left({\overline {X}}-\mu \right)^{2}\right]=\left({\frac {\sigma }{\sqrt {n}}}\right)^{2}={\frac {\sigma ^{2}}{n}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b4647a2cc4c8f9a4c90b628faad2dcf80c4aae84)
where  is the population variance.
is the population variance.
For a Gaussian distribution, this is the best unbiased estimator (i.e., one with the lowest MSE among all unbiased estimators), but not, say, for a uniform distribution.
Variance[edit]
The usual estimator for the variance is the corrected sample variance:

This is unbiased (its expected value is ), hence also called the unbiased sample variance, and its MSE is[8]

where  is the fourth central moment of the distribution or population, and
is the fourth central moment of the distribution or population, and  is the excess kurtosis.
is the excess kurtosis.
However, one can use other estimators for which are proportional to  , and an appropriate choice can always give a lower mean squared error. If we define
, and an appropriate choice can always give a lower mean squared error. If we define

then we calculate:
![{\displaystyle {\begin{aligned}\operatorname {MSE} (S_{a}^{2})&=\operatorname {E} \left[\left({\frac {n-1}{a}}S_{n-1}^{2}-\sigma ^{2}\right)^{2}\right]\\&=\operatorname {E} \left[{\frac {(n-1)^{2}}{a^{2}}}S_{n-1}^{4}-2\left({\frac {n-1}{a}}S_{n-1}^{2}\right)\sigma ^{2}+\sigma ^{4}\right]\\&={\frac {(n-1)^{2}}{a^{2}}}\operatorname {E} \left[S_{n-1}^{4}\right]-2\left({\frac {n-1}{a}}\right)\operatorname {E} \left[S_{n-1}^{2}\right]\sigma ^{2}+\sigma ^{4}\\&={\frac {(n-1)^{2}}{a^{2}}}\operatorname {E} \left[S_{n-1}^{4}\right]-2\left({\frac {n-1}{a}}\right)\sigma ^{4}+\sigma ^{4}&&\operatorname {E} \left[S_{n-1}^{2}\right]=\sigma ^{2}\\&={\frac {(n-1)^{2}}{a^{2}}}\left({\frac {\gamma _{2}}{n}}+{\frac {n+1}{n-1}}\right)\sigma ^{4}-2\left({\frac {n-1}{a}}\right)\sigma ^{4}+\sigma ^{4}&&\operatorname {E} \left[S_{n-1}^{4}\right]=\operatorname {MSE} (S_{n-1}^{2})+\sigma ^{4}\\&={\frac {n-1}{na^{2}}}\left((n-1)\gamma _{2}+n^{2}+n\right)\sigma ^{4}-2\left({\frac {n-1}{a}}\right)\sigma ^{4}+\sigma ^{4}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cf22322412b8454c706d78671e5d94208675a6e0)
This is minimized when

For a Gaussian distribution, where  , this means that the MSE is minimized when dividing the sum by
, this means that the MSE is minimized when dividing the sum by  . The minimum excess kurtosis is
. The minimum excess kurtosis is  ,[a] which is achieved by a Bernoulli distribution with p = 1/2 (a coin flip), and the MSE is minimized for
,[a] which is achieved by a Bernoulli distribution with p = 1/2 (a coin flip), and the MSE is minimized for  Hence regardless of the kurtosis, we get a «better» estimate (in the sense of having a lower MSE) by scaling down the unbiased estimator a little bit; this is a simple example of a shrinkage estimator: one «shrinks» the estimator towards zero (scales down the unbiased estimator).
Hence regardless of the kurtosis, we get a «better» estimate (in the sense of having a lower MSE) by scaling down the unbiased estimator a little bit; this is a simple example of a shrinkage estimator: one «shrinks» the estimator towards zero (scales down the unbiased estimator).
Further, while the corrected sample variance is the best unbiased estimator (minimum mean squared error among unbiased estimators) of variance for Gaussian distributions, if the distribution is not Gaussian, then even among unbiased estimators, the best unbiased estimator of the variance may not be 
Gaussian distribution[edit]
The following table gives several estimators of the true parameters of the population, μ and σ2, for the Gaussian case.[9]
| True value | Estimator | Mean squared error |
|---|---|---|
 |
= the unbiased estimator of the population mean,  |

|
 |
= the unbiased estimator of the population variance,  |

|
|
= the biased estimator of the population variance,  |

|
|
= the biased estimator of the population variance,  |

|
Interpretation[edit]
An MSE of zero, meaning that the estimator predicts observations of the parameter with perfect accuracy, is ideal (but typically not possible).
Values of MSE may be used for comparative purposes. Two or more statistical models may be compared using their MSEs—as a measure of how well they explain a given set of observations: An unbiased estimator (estimated from a statistical model) with the smallest variance among all unbiased estimators is the best unbiased estimator or MVUE (Minimum-Variance Unbiased Estimator).
Both analysis of variance and linear regression techniques estimate the MSE as part of the analysis and use the estimated MSE to determine the statistical significance of the factors or predictors under study. The goal of experimental design is to construct experiments in such a way that when the observations are analyzed, the MSE is close to zero relative to the magnitude of at least one of the estimated treatment effects.
In one-way analysis of variance, MSE can be calculated by the division of the sum of squared errors and the degree of freedom. Also, the f-value is the ratio of the mean squared treatment and the MSE.
MSE is also used in several stepwise regression techniques as part of the determination as to how many predictors from a candidate set to include in a model for a given set of observations.
Applications[edit]
- Minimizing MSE is a key criterion in selecting estimators: see minimum mean-square error. Among unbiased estimators, minimizing the MSE is equivalent to minimizing the variance, and the estimator that does this is the minimum variance unbiased estimator. However, a biased estimator may have lower MSE; see estimator bias.
- In statistical modelling the MSE can represent the difference between the actual observations and the observation values predicted by the model. In this context, it is used to determine the extent to which the model fits the data as well as whether removing some explanatory variables is possible without significantly harming the model’s predictive ability.
- In forecasting and prediction, the Brier score is a measure of forecast skill based on MSE.
Loss function[edit]
Squared error loss is one of the most widely used loss functions in statistics[citation needed], though its widespread use stems more from mathematical convenience than considerations of actual loss in applications. Carl Friedrich Gauss, who introduced the use of mean squared error, was aware of its arbitrariness and was in agreement with objections to it on these grounds.[3] The mathematical benefits of mean squared error are particularly evident in its use at analyzing the performance of linear regression, as it allows one to partition the variation in a dataset into variation explained by the model and variation explained by randomness.
Criticism[edit]
The use of mean squared error without question has been criticized by the decision theorist James Berger. Mean squared error is the negative of the expected value of one specific utility function, the quadratic utility function, which may not be the appropriate utility function to use under a given set of circumstances. There are, however, some scenarios where mean squared error can serve as a good approximation to a loss function occurring naturally in an application.[10]
Like variance, mean squared error has the disadvantage of heavily weighting outliers.[11] This is a result of the squaring of each term, which effectively weights large errors more heavily than small ones. This property, undesirable in many applications, has led researchers to use alternatives such as the mean absolute error, or those based on the median.
See also[edit]
- Bias–variance tradeoff
- Hodges’ estimator
- James–Stein estimator
- Mean percentage error
- Mean square quantization error
- Mean square weighted deviation
- Mean squared displacement
- Mean squared prediction error
- Minimum mean square error
- Minimum mean squared error estimator
- Overfitting
- Peak signal-to-noise ratio
Notes[edit]
- ^ This can be proved by Jensen’s inequality as follows. The fourth central moment is an upper bound for the square of variance, so that the least value for their ratio is one, therefore, the least value for the excess kurtosis is −2, achieved, for instance, by a Bernoulli with p=1/2.
References[edit]
- ^ a b «Mean Squared Error (MSE)». www.probabilitycourse.com. Retrieved 2020-09-12.
- ^ Bickel, Peter J.; Doksum, Kjell A. (2015). Mathematical Statistics: Basic Ideas and Selected Topics. Vol. I (Second ed.). p. 20.
If we use quadratic loss, our risk function is called the mean squared error (MSE) …
- ^ a b Lehmann, E. L.; Casella, George (1998). Theory of Point Estimation (2nd ed.). New York: Springer. ISBN 978-0-387-98502-2. MR 1639875.
- ^ Gareth, James; Witten, Daniela; Hastie, Trevor; Tibshirani, Rob (2021). An Introduction to Statistical Learning: with Applications in R. Springer. ISBN 978-1071614174.
- ^ Wackerly, Dennis; Mendenhall, William; Scheaffer, Richard L. (2008). Mathematical Statistics with Applications (7 ed.). Belmont, CA, USA: Thomson Higher Education. ISBN 978-0-495-38508-0.
- ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ Steel, R.G.D, and Torrie, J. H., Principles and Procedures of Statistics with Special Reference to the Biological Sciences., McGraw Hill, 1960, page 288.
- ^ Mood, A.; Graybill, F.; Boes, D. (1974). Introduction to the Theory of Statistics (3rd ed.). McGraw-Hill. p. 229.
- ^ DeGroot, Morris H. (1980). Probability and Statistics (2nd ed.). Addison-Wesley.
- ^ Berger, James O. (1985). «2.4.2 Certain Standard Loss Functions». Statistical Decision Theory and Bayesian Analysis (2nd ed.). New York: Springer-Verlag. p. 60. ISBN 978-0-387-96098-2. MR 0804611.
- ^ Bermejo, Sergio; Cabestany, Joan (2001). «Oriented principal component analysis for large margin classifiers». Neural Networks. 14 (10): 1447–1461. doi:10.1016/S0893-6080(01)00106-X. PMID 11771723.
Теорема 1. Вероятность того, что
отклонение выборочной доли от генеральной
доли не превосходит числа
(по абсолютной величине), равна
![]()
, где
![]()
.
Последняя формула называется формулой
доверительной вероятности при оценке
доли признака.
Определение 1. Средней
квадратической ошибкой выборки при
оценке генеральной доли признака
называется среднее квадратическое
отклонение выборочной доли w
собственно-случайной выборки (для
бесповторной выборки обозначается
w).
Следствие 1. При заданной
доверительной вероятности
предельная ошибка выборки равна t-кратной
величине средней квадратической ошибки,
т.е.
![]()
.
Следствие 2. Доверительный
интервал для генеральной доли может
быть найден по формуле
![]()
.
Используя формулы дисперсий
и
![]()
при оценке генеральной доли признака
соответственно при повторной и
бесповторной собственно-случайной
выборке, можно получить формулы средних
квадратических ошибок:
|
|
|

Заметим, что генеральная доля p
неизвестна, но при достаточно большом
объеме выборки практически достоверно,
что pw.
Более того, если даже выборочная доля
w неизвестна, то в
качестве pq можно взять
его максимально возможное значение
0,25.
Теорема 2. Вероятность того, что
отклонение выборочной средней от
генеральной средней не превосходит
числа
(по абсолютной величине), равна
![]()
,
где
![]()
.
Последняя формула называется формулой
доверительной вероятности для средней.
Доказательство теоремы основано на
теореме Ляпунова и свойстве 2 случайной
величины, распределенной по нормальному
закону распределения.
Определение 2. Средней
квадратической ошибкой выборки при
оценке генеральной средней называется
среднее квадратическое отклонение
выборочной доли
![]()
собственно-случайной выборки (для
бесповторной выборки обозначается
![]()
).
Следствие 3. При заданной
доверительной вероятности
предельная ошибка выборки равна t-кратной
величине средней квадратической ошибки,
т.е.
![]()
.
Следствие 4. Доверительный
интервал для генеральной средней может
быть найден по формуле
![]()
.
Используя формулы дисперсий
и
![]()
при оценке генеральной средней
соответственно при повторной и
бесповторной собственно-случайной
выборке, можно получить формулы средних
квадратических ошибок:
|
|
|
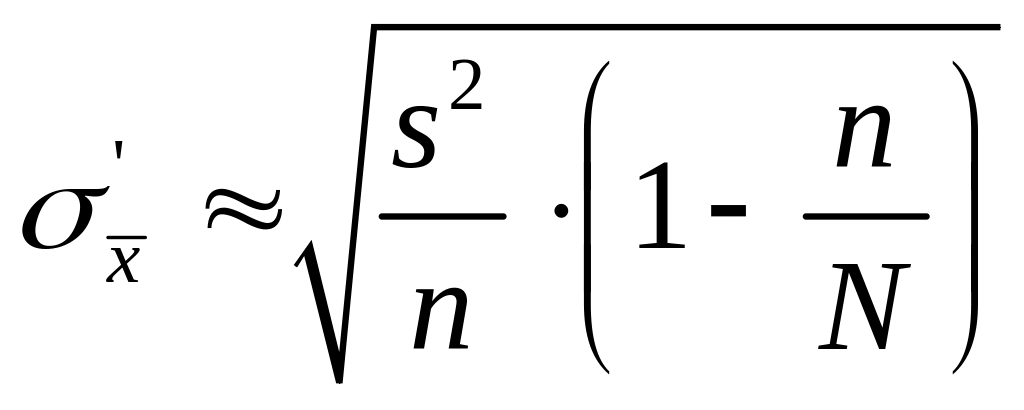
Заметим, что дисперсия 2
неизвестна, но при достаточно большом
объеме выборки практически достоверно,
что s22.
5. Определение необходимого объема повторной и бесповторной выборок
Для определения объема выборки n
необходимо знать надежность (доверительную
вероятность) оценки
и точность (предельную ошибку выборки)
.
Например, при оценке генеральной средней
для повторной выборки:
(t)=,
где
.
При заданной доверительной вероятности
предельная ошибка
выборки равна t-кратной
величине средней квадратической ошибки,
т.е.
(п.40, следствие 1).
Формула дисперсии
при оценке генеральной средней при
повторной собственно-случайной выборке
(п.36, теорема 1).
Следовательно,
![]()
.
Отсюда
![]()
.
Итак, для определения объема выборки
необходимо знать дисперсию генеральной
совокупности 2
, которая неизвестна. Обычно, с целью
определения 2
, проводят выборочное наблюдение (или
используют данные предыдущего аналогичного
исследования) и полагают, что s22.
Аналогично находятся другие формулы
для определения объема выборки по
известным надежности и точности:
![]()
– при оценке генеральной средней для
бесповторной выборки;
![]()
– при оценке генеральной доли для
повторной выборки;
![]()
– при оценке генеральной доли для
бесповторной выборки.
При оценке генеральной доли полагают
w
p.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Рассмотрим подробно перечисленные выше способы формирования выборочной совокупности и возникающие при этом ошибки репрезентативности.
Собственно-случайная выборка основывается на отборе единиц из генеральной совокупности наугад без каких-либо элементов системности. Технически собственно-случайный отбор проводят методом жеребьевки (например, розыгрыши лотерей) или по таблице случайных чисел.
Собственно-случайный отбор «в чистом виде» в практике выборочного наблюдения применяется редко, но он является исходным среди других видов отбора, в нем реализуются основные принципы выборочного наблюдения. Рассмотрим некоторые вопросы теории выборочного метода и формулы ошибок для простой случайной выборки.
Ошибка выборочного наблюдения — это разность между величиной параметра в генеральной совокупности, и его величиной, вычисленной по результатам выборочного наблюдения. Для средней количественного признака ошибка выборки определяется
Показатель называется предельной ошибкой выборки.
Выборочная средняя является случайной величиной, которая может принимать различные значения в зависимости от того, какие единицы попали в выборку. Следовательно, ошибки выборки также являются случайными величинами и могут принимать различные значения. Поэтому определяют среднюю из возможных ошибок — среднюю ошибку выборки, которая зависит от:
- 1) объема выборки: чем больше численность, тем меньше величина средней ошибки;
- 2) степени изменения изучаемого признака: чем меньше вариация признака, а, следовательно, и дисперсия, тем меньше средняя ошибка выборки.
При случайном повторном отборе средняя ошибка рассчитывается
Практически генеральная дисперсия точно не известна, но в теории вероятности доказано, что
![]()
Так как величина при достаточно больших n близка к 1, можно считать, что. Тогда средняя ошибка выборки может быть рассчитана:
Но в случаях малой выборки (при n30) коэффициент необходимо учитывать, и среднюю ошибку малой выборки рассчитывать по формуле

При случайной бесповторной выборке приведенные формулы корректируются на величину. Тогда средняя ошибка бесповторной выборки:


Т.к. всегда меньше, то множитель () всегда меньше 1. Это значит, что средняя ошибка при бесповторном отборе всегда меньше, чем при повторном.
Механическая выборка применяется, когда генеральная совокупность каким-либо способом упорядочена (например, списки избирателей по алфавиту, телефонные номера, номера домов, квартир). Отбор единиц осуществляется через определенный интервал, который равен обратному значению процента выборки. Так при 2% выборке отбирается каждая 50 единица =1/0,02 , при 5% каждая 1/0,05=20 единица генеральной совокупности.
Начало отсчета выбирается разными способами: случайным образом, из середины интервала, со сменой начала отсчета. Главное при этом — избежать систематической ошибки. Например, при 5% выборке, если первой единицей выбрана 13-я, то следующие 33, 53, 73 и т.д.
По точности механический отбор близок к собственно-случайной выборке. Поэтому для определения средней ошибки механической выборки используют формулы собственно-случайного отбора.
При типическом отборе обследуемая совокупность предварительно разбивается на однородные, однотипные группы. Например, при обследовании предприятий это могут быть отрасли, подотрасли, при изучении населения — районы, социальные или возрастные группы. Затем осуществляется независимый выбор из каждой группы механическим или собственно-случайным способом.
Типическая выборка дает более точные результаты по сравнению с другими способами. Типизация генеральной совокупности обеспечивает представительство в выборке каждой типологической группы, что позволяет исключить влияние межгрупповой дисперсии на среднюю ошибку выборки. Следовательно, при нахождении ошибки типической выборки согласно правилу сложения дисперсий () необходимо учесть лишь среднюю из групповых дисперсий. Тогда средняя ошибка выборки:
при повторном отборе
при бесповторном отборе
где — средняя из внутригрупповых дисперсий в выборке.
Серийный (или гнездовой) отбор применяется в случае, когда генеральная совокупность разбита на серии или группы до начала выборочного обследования. Этими сериями могут быть упаковки готовой продукции, студенческие группы, бригады. Серии для обследования выбираются механическим или собственно-случайным способом, а внутри серии производится сплошное обследование единиц. Поэтому средняя ошибка выборки зависит только от межгрупповой (межсерийной) дисперсии, которая вычисляется по формуле:
![]()
где r — число отобранных серий;
Средняя і-той серии.
Средняя ошибка серийной выборки рассчитывается:
при повторном отборе
при бесповторном отборе
где R — общее число серий.
Комбинированный отбор представляет собой сочетание рассмотренных способов отбора.
Средняя ошибка выборки при любом способе отбора зависит главным образом от абсолютной численности выборки и в меньшей степени — от процента выборки. Предположим, что проводится 225 наблюдений в первом случае из генеральной совокупности в 4500 единиц и во втором — в 225000 единиц. Дисперсии в обоих случаях равны 25. Тогда в первом случае при 5 %-ном отборе ошибка выборки составит:
![]()
Во втором случае при 0,1 %-ном отборе она будет равна:
![]()
Таким образом, при уменьшении процента выборки в 50 раз, ошибка выборки увеличилась незначительно, так как численность выборки не изменилась.
Предположим, что численность выборки увеличили до 625 наблюдений. В этом случае ошибка выборки равна:
![]()
Увеличение выборки в 2,8 раза при одной и той же численности генеральной совокупности снижает размеры ошибки выборки более чем в 1,6 раза.

Зачем эта презентация? Во-первых, «средняя квадратическая / стандартная ошибка выборки» – длинное и сложное название, которое часто обрубают в задачах до «средней» или «стандартной» ошибки. То, что это одно и то же, в свое время было для меня настоящим открытием. Эта пресловутая ошибка бывает разная и записывается всегда по-разному, что здорово путает. Оказывается, эта штука много где попадается, но постоянно меняет обличья. Из-за этого мы зубрим целую кучу формул, когда можно обойтись однойдвумя.


Как ее обозначают? Как только не измывались над несчастной! Это варианты написания стандартной ошибки для средней в лекциях и учебниках. Над ошибкой доли издевались точно так же, или вообще забыли о ее существовании и записывали сразу формулой, что здорово путает несчастных студентов. Здесь я обозначу ее через «ε» , потому что это, хвала Богам, редкая буква, и ее не перепутать ни с моментом, ни с выборочным СКО.

Собственно, формула (корень из дисперсии на число элементов в выборке или СКО разделить на корень из объема выборки) Это основная формула, фундамент, основа основ. Достаточно выучить только её, а дальше просто поработать головой! Как? Читай дальше!

Разновидности и откуда они взялись 1. Для доли. У доли дисперсия считается необычно. Если долю изучаемого признака взять за p, а долю «всего остального» — за q, то дисперсия равна p*q или p*(1 p). Отсюда взялась формула:

Разновидности и откуда они взялись (2) 2. Где взять генеральное СКО? σ – это, вообще-то, генеральное СКО, которое вам в задаче фиг дадут. Есть выход – выборочная дисперсия S 2 , которая, как всем известно, смещена. Поэтому оцениваем генеральную так: (чтобы и не думала смещаться), и подставляем. А можно сразу так: Но есть такая фишка. Если n>30, разница между S и σ крайне мала ©, поэтому можно схитрить и написать проще:

Разновидности и откуда они взялись (3) «Откуда взялись еще какие-то скобки и энки? ? ? » Есть 2 метода формирования выборки, помним? – повторный и бесповторный. Так вот, все предыдущие формулы годятся для повторной выборки или когда выборка n по отношению к генеральной совокупности N настолько мала, что отношением n/N можно пренебречь. В случае, когда прям принципиально, что выборка бесповторная, или когда в задаче открытым текстом говорится, сколько единиц в генеральной совокупности, обязательно использовать.
Понятие и расчет ошибки выборки.
Задачей выборочного наблюдения является дача верных представлений о сводных показателях всей совокупности на основе некоторой их части, подвергнутой наблюдению. Возможное отклонение выборочной доли и выборочной средней от доли и средней в генеральной совокупности называется ошибкойвыборки
или ошибкойрепрезентативности.
Чем больше величина этой ошибки, тем больше показатели выборочного наблюдения отличаются от показателей генеральной совокупности.
Различаются:
Ошибки выборки;
Ошибки регистрации.
Ошибки регистрации
возникают при неправильном установлении факта в процессе наблюдения. Они свойственны как сплошному наблюдению, так и выборочному, но в выборочном их меньше.
По природе ошибки бывают:
Тенденциозные – преднамеренные, т.е. были отобраны либо лучшие, либо худшие единицы совокупности. При этом наблюдения теряют смысл;
Случайные – основной организационный принцип выборочного наблюдения состоит в том, чтобы не допустить преднамеренного отбора, т.е. обеспечить строгое соблюдение принципа случайного отбора.
Общим правилом случайного отбора
является: у отдельных единиц генеральной совокупности должны быть совершенно одинаковые условия и возможности упасть в число единиц, входящих в выборку. Это характеризует независимость результата выборки от воли наблюдателя. Воля же наблюдателя порождает тенденциозные ошибки. Ошибка выборки при случайном отборе носит случайный характер. Она характеризует размеры отклонений генеральных характеристик от выборочных.
В связи с тем, что признаки в изучаемой совокупности варьируют, то состав единиц, попавших в выборку, может не совпадать с составом единиц всей совокупности. Это означает, что Р
и не совпадают с W
и . Возможное расхождение между этими характеристиками определяется ошибкой выборки, которая определяется по формуле:
где — генеральная дисперсия.
где — выборочная дисперсия.
Отсюда видно, где генеральная дисперсия отличается от выборочной дисперсии в раз.
Существует повторный и бесповторный отбор. Сущность повторного отбора состоит в том, что каждая, попавшая в выборку единица, после наблюдения возвращается в генеральную совокупность и может быть исследована повторно. При повторном отборе средняя ошибка выборки рассчитывается:
Для показателя доли альтернативного признака дисперсия выборки определяется по формуле:
![]()
На практике повторный отбор применяется редко. При бесповторном отборе, численность генеральной совокупности N
в ходе выборки сокращается, формула средней ошибки выборки для количественного признака имеет вид:
 , тогда
, тогда
Одно из возможных значений, в которых может находиться доля изучаемого признака равно:

где — ошибка выборки альтернативного признака.
Пример
.
При выборочном обследовании 10 % изделий партии готовой продукции по методу без повторного отбора получены следующие данные о содержании влаг в образцах.
Определить средний % влажности, дисперсию, среднее квадратическое отклонение, с вероятностью 0,954 возможные пределы, в которых ожидается ср. % влажности всей готовой продукции, с вероятность 0,987 возможные пределы удельного веса стандартной продукции при условии, что к нестандартной партии относятся изделия с влажностью до 13 и выше 19 %.
![]()

Лишь с определенной вероятностью можно утверждать, что генеральная доля от выборочной доли и генеральная средняя от выборочной средней, отклоняются в t
раз.
В статистике эти отклонения называются предельнымиошибкамивыборки
и обозначаются .
Вероятность суждений можно повысить или понизить в t
раз. При вероятности 0,683 , при 0,954 , при 0,987 , тогда показатели генеральной совокупности по показателям выборки определяются.
Между показателями выборочной совокупности и искомыми показателями (параметрами) генеральной совокупности, как правило, существуют некоторые разногласия, которые называют ошибками выборки.
Общая ошибка выборочной характеристики состоит из ошибок двух родов: ошибки регистрации и ошибки репрезентативности.
Ошибки регистрации свойственны любому статистическому наблюдению и появление их может быть вызвано невнимательностью регистратора, неточностью подсчетов, несовершенством измерительных приборов и т.д.
Ошибки репрезентативности присущи только выборочному наблюдению и обусловлены самой его природой поскольку как бы тщательно и правильно не проводился отбор единиц средние и относительные показатели выборочной совокупности всегда будут в какой-то степени отличаться от соответствующих показателей генеральной совокупности.
Различают систематические и случайные ошибки репрезентативности. Систематические ошибки репрезентативности — это неточности, которые возникают вследствие несоблюдения условий отбора единиц в выборочную совокупность, не предоставление равной возможности каждой единице генеральной совокупности попасть в выборку. Случайные ошибки репрезентативности — это погрешности, которые возникают вследствие того, что выборочная совокупность точно не воспроизводит характеристики генеральной совокупности (среднее, долю, дисперсию и др.) в силу несплошного характера обследования.
При соблюдении принципа случайного отбора размер ошибки выборки прежде всего зависит от численности выборки. Чем больше численность выборки при прочих равных условиях, тем меньше величина ошибки выборки. При большой численности выборки отчетливее проявляется действие закона больших чисел, согласно которому: с вероятностью, сколь угодно близкой к единице, можно утверждать, что при достаточно большом объеме выборки и ограниченной дисперсии выборочные характеристики (средняя доля) будут сколь угодно мало отличаться от соответствующих генеральных характеристик.
Размеры ошибки выборки также непосредственно связаны со степенью варьирования изучаемого признака, а степень варьирования, как отмечалось выше, в статистике характеризуется размером дисперсии (рассеяния): чем меньше дисперсия, тем меньше ошибка выборки, тем более надежные статистические выводы. Поэтому на практике дисперсию отождествляют с ошибкой выборки.
Поскольку параметр генеральной совокупности есть искомая величина и он неизвестен, нужно ориентироваться не на конкретную ошибку, а среднюю из всех возможных выборок.
Если из генеральной совокупности отобрать несколько выборочных совокупностей, то каждая из полученных выборок даст разное значение конкретной ошибки.
Средняя квадратическая величина /и
исчисленная из всех возможных значений конкретных ошибок (;) составит:
где *и — выборочные средние; х — генеральная средняя;)] — численность выборок по величине є1 = ~си — х.
Среднее квадратическое отклонение выборочных средних от генеральной средней называют средней ошибкой выборки.
Зависимость величины ошибки выборки от ее численности и от степени варьирования признака находит выражение в формуле средней ошибки выборки /и.
Квадрат средней ошибки (дисперсия выборочных средних) прямо пропорционален дисперсии
Сто и обратно пропорционален численности выборки п:
где — дисперсия признака в генеральной совокупности.
Отсюда среднюю ошибку в общем виде определяют по формуле:
Итак, определив по выборке среднее квадратичное отклонение, можно установить значение средней ошибки выборки, величина которой, как следует из формулы, тем больше, чем больше вариация случайной величины и тем меньше, чем больше численность выборки.
Поэтому по мере роста объема выборки размер средней ошибки уменьшается. Если, например, нужно уменьшить среднюю ошибку выборки в два раза, то численность выборки следует увеличить в четыре раза, если надо уменьшить ошибку выборки в три раза, то объем выборки следует увеличить в девять раз и т. д.
В практических расчетах применяются две формулы средней ошибки выборки для средней и для доли.
При выборочном изучении средних показателей формула средней ошибки такая:
При изучении относительных показателей (частных признаков) формула средней ошибки имеет вид:
где
г
— доля признака в генеральной совокупности.
Применение приведенных формул средней ошибки предполагает, что известны генеральная дисперсия и генеральная доля. Однако в действительности эти показатели неизвестны и вычислить их невозможно из-за отсутствия данных относительно генеральной совокупности. Поэтому возникает потребность замены генеральной дисперсии и генеральной доли другими, близкими к ним, величинами.
В математической статистике доказано, что такими величинами могут быть выборочная дисперсия(ст) и выборочная доля (со).
С учетом сказанного формулы средней ошибки могут быть записаны так:
![]()
Эти формулы дают возможность определить среднюю ошибку при повторной выборке. Применения простой случайной повторной выборки в практике является ограниченным. Прежде всего практически нецелесообразно, а иногда невозможно повторное обследование тех же единиц. Применение бесповторного отбора вместо повторного диктуется также требованием повышения степени точности и надежности выборки. Поэтому на практике чаще используют способ бесповторного случайного отбора. По этому способу отбора единица совокупности, отобранная в выборку, в дальнейшем отборе не участвует. Единицы отбирают из генеральной совокупности, уменьшенной на количество ранее отобранных единиц. Поэтому в связи с изменением численности генеральной совокупности после каждого отбора и вероятности отбора для единиц, что остались, в формулы средней ошибки выборки вводится поправочный множитель
где N — численность генеральной совокупности; п
— численность выборки. При достаточно большом значении N можно единицей в знаменателе пренебречь. Тогда
![]()
Следовательно, формулы средней ошибки выборки для бесповторного отбора для средней и для доли соответственно имеют вид:
Поскольку п
всегда меньше М, то дополнительный множитель всегда меньше единицы. Следовательно, абсолютное значение ошибки выборки при бесповторном отборе всегда будет меньше, чем при повторном.
Если численность выборки достаточно велика, то величина 1 ^ близка к единице, а потому ею можно пренебречь. Тогда среднюю ошибку случайного бесповторного отбора определяют по формуле собственно-случайной повторной выборки.
Рассчитаем для нашего примера среднюю ошибку для урожайности и доли участков с урожайностью 25 ц/га и более.
Средняя ошибка выборки
а) средней урожайности ячменя

Средняя урожайность ячменя в генеральной совокупности х -Г^
= 25,1 ± 0,12 ц/га, то есть находится в пределах от 24,98 до 25,22 ц/га.
Доля участков с урожайностью 25 ц/га и более в генеральной совокупности р
Т-^Г = 0,80 ± 0,07, т.е. находится в пределах от 73 до 87%.
Средняя ошибка выборки показывает возможные отклонения характеристик выборочной совокупности от характеристик генеральной совокупности. Вместе с тем при проведении выборочного наблюдения перед исследователями часто стоит задача расчета не только средней ошибки, но и определение предельной возможной ошибки выборки. Зная среднюю ошибку, можно определить границы, за которые не выйдет величина ошибки выборки. Однако утверждать, что эти отклонения не превысят заданной величины, можно не с абсолютной достоверностью, а лишь с определенной степенью вероятности. Уровень вероятности, что принимается при определении возможных пределов, в которых содержатся значения параметров генеральной совокупности, называется
доверительным уровнем вероятности.
Доверительная вероятность
— это довольно высокая и, такая, что практически считается осуществленной в каждом конкретном случае, вероятность, что гарантирует получение надежных статистических выводов. Обозначим ее через Г
а вероятность превысить этот уровень — а.
Итак,
а
=1 — Р
Вероятность
а
называют уровнем значимости
(существенности), который характеризует относительное число ошибочных выводов в общем числе выводов и определяется как разница между единицей и доверительной вероятностью, что принимается.
Уровень доверительной вероятности устанавливает исследователь исходя из степени ответственности и характера задач, которые решаются. В статистических исследованиях в экономике чаще всего принимается уровень доверительной вероятности
Г
= 0,95; Р = 0,99 (соответственно уровень значимости
а = 0,05;
а = 0,01) реже
Г = 0,999. Например, доверительная вероятность
Г = 0,99 означает, что ошибка оценки в 99 случаях из 100 не превысит установленной величины и только в одном случае из 100 может достичь вычисленного значения, или превысить его.
Ошибка выборки, исчисленная с заданной степенью надежной вероятности, называется
предельной ошибкой выборки Ер.
Рассмотрим, как устанавливается величина возможной предельной ошибки выборки. Величина
ер связана с нормированным отклонением и, которое определяется как отношение предельной ошибки выборки
ер к средней ошибки
и:
Для удобства расчетов отклонения случайной величины от ее среднего значения обычно выражают в единицах среднего квадратического отклонения. Выражение
называют
нормированным отклонением. в В статистической литературе
и называют
коэффициентом доверия, или коэффициентом кратности средней ошибки выборки.
Так, нормированное отклонение выборочной средней можно определить по формуле:

и _є_р_
Из выражения
1 можно найти возможную предельную ошибку выборки
ер = и/л.
Подставив вместо
г. в ее значение, приведем формулы предельных ошибок выборки для средней и для доли при бесповторном случайном отборе:
Следовательно, предельная ошибка выборки зависит от величины средней ошибки и нормированного отклонения и равна ± кратному числу средних ошибок выборки.
Средняя и предельная ошибки выборки — именованные величины и выражаются в тех же единицах, что и средняя арифметическая и среднее квадратическое
отклонения.
Нормированное отклонение функционально связано с вероятностью. Для нахождения значений
и
составлены специальные таблицы (доб.2), по которым можно найти значение
и
при заданном уровне доверительной вероятности и значения вероятности при известном и.
Приведем значения
и и соответствующие им вероятности для выборок с численностью
п >
30, что чаще всего используется в практических расчетах:
Следовательно, при
и = 1 вероятность отклонения выборочных характеристик от генеральных на величину однократной средней ошибки выборки равна 0,6827. Это означает, что в среднем с каждой 1000 выборок 683 дадут обобщенные характеристики, которые будут отличаться от генеральных обобщенных характеристик не более, чем на величину однократной средней ошибки. При и = 2 вероятность равна 0,9545. в Это означает, что с каждого
1000 выборок 954 дадут обобщенные характеристики, которые будут отличаться от генеральных обобщенных характеристик не более чем на двукратную среднюю ошибку выборки и т.д.
Однако в связи с тем, что, как правило, проводится только одна выборка, то мы говорим, что, например, с вероятностью
0,9545 можно гарантировать, что размеры предельной ошибки не превысят двукратную среднюю ошибку выборки.
Математически доказано, что отношение ошибки выборки к средней ошибки, как правило, не превышает
± 3д при достаточно большой численности п, несмотря на то, что ошибка выборки может приобретать любые значения. Другими словами можно сказать, что при достаточно высокой вероятности суждения (Р = 0,9973) предельная ошибка выборки, как правило, не превышает трех средних ошибок выборки. Поэтому величину Ер = 3д можно принять за предел возможной ошибки выборки.
Определим для нашего примера предельную ошибку выборки для средней урожайности и доли участков с урожайностью
25 ц/га и более. Доверительный уровень вероятности примем равным Р = 0,9545. в По таблице (прил
.2) найдем значения и = 2. Средние ошибки выборки для урожайности и доли участков с урожайностью 25 ц/га и больше были найдены ранее и соответственно составляли: Ц~
= ±0,12 ц/га;
МР = ± 0,07.
Предельная ошибка средней урожайности ячменя:
Итак, разница между выборочной средней урожайностью и генеральной средней будет не больше 0,24 ц/га. Пределы средней урожайности в генеральной совокупности: х = х ±есть~ = 25,1 + 0,24, то есть от 24,86 до 25,34 ц/га.
Предельная ошибка доли участков с урожайностью 25 ц/га и более:
![]()
Следовательно, предельная ошибка в определении доли участков с урожайностью 25 ц/га и больше не превысит 14%, то есть удельный вес участков с указанной урожайностью в генеральной совокупности находится в пределах: г
= а> ± ер = 0,80 ± 0,14, то есть от 66 до 94%.
Ошибки систематические и случайные
Модульная единица 2 Ошибки выборки
Поскольку выборка охватывает, как правило, весьма незначительную часть генеральной совокупности, то следует предполагать, что будут иметь место различия между оценкой и характеристикой генеральной совокупности, которую эта оценка отображает. Эти различия получили название ошибок отображения или ошибок репрезентативности. Ошибки репрезентативности подразделяются на два типа: систематические и случайные.
Систематические ошибки
— это постоянное завышение или занижение значения оценки по сравнению с характеристикой генеральной совокупности. Причиной появления систематической ошибки является несоблюдение принципа равновероятности попадания каждой единицы генеральной совокупности в выборку, то есть выборка формируется из преимущественно «худших» (или « лучших») представителей генеральной совокупности. Соблюдение принципа равновозможности попадания каждой единицы в выборку позволяет полностью исключить этот тип ошибок.
Случайные ошибки –
это меняющиеся от выборки к выборке по знаку и величине различия между оценкой и оцениваемой характеристикой генеральной совокупности. Причина возникновения случайных ошибок- игра случая при формировании выборки, составляющей лишь часть генеральной совокупности. Этот тип ошибок органически присущ выборочному методу. Исключить их полностью нельзя, задача состоит в том, чтобы предсказать их возможную величину и свести их к минимуму. Порядок связанных в связи с этим действий вытекает из рассмотрения трех видов случайных ошибок: конкретной, средней и предельной.
2.2.1 Конкретная
ошибка – это ошибка одной проведенной выборки. Если средняя по этой выборке () является оценкой для генеральной средней (0) и, если предположить, что эта генеральная средняя нам известна, то разница = -0 и будет конкретной ошибкой этой выборки. Если из этой генеральной совокупности выборку повторим многократно, то каждый раз получим новую величину конкретной ошибки: …, и так далее. Относительно этих конкретных ошибок можно сказать следующее: некоторые из них будут совпадать между собой по величине и знаку, то есть имеет место распределение ошибок, часть из них будет равна 0, наблюдается совпадение оценки и параметра генеральной совокупности;
2.2.2 Средняя ошибка
– это средняя квадратическая из всех возможных по воле случая конкретных ошибок оценки: , где — величина меняющихся конкретных ошибок; частота (вероятность) встречаемости той или иной конкретной ошибки. Средняя ошибка выборки показывает насколько в среднем можно ошибиться, если на основе оценки делается суждение о параметре генеральной совокупности. Приведенная формула раскрывает содержание средней ошибки, но она не может быть использована для практических расчетов, хотя бы потому, что предполагает знание параметра генеральной совокупности, что само по себе исключает необходимость выборки.
Практические расчеты средней ошибки оценки основываются на той предпосылке, что она (средняя ошибка) по сути является средним квадратическим отклонением всех возможных значений оценки. Эта предпосылка позволяет получить алгоритмы расчета средней ошибки, опирающиеся на данные одной единственной выборки. В частности средняя ошибка выборочной средней может быть установлена на основе следующих рассуждений. Имеется выборка (,… ) состоящая из единиц. По выборке в качестве оценки генеральной средней определена выборочная средняя . Каждое значение(,… ) , стоящее под знаком суммы, следует рассматривать как независимую случайную величину, поскольку при бесконечном повторении выборки первая, вторая и т.д. единицы могут принимать любые значения из присутствующих в генеральной совокупности. Следовательно ![]() Поскольку, как известно, дисперсия суммы независимых случайных величин равна сумме дисперсий, то
Поскольку, как известно, дисперсия суммы независимых случайных величин равна сумме дисперсий, то ![]() . Отсюда следует, что средняя ошибка для выборочной средней будет равная и находится она в обратной зависимости от численности выборки (через корень квадратный из нее) и в прямой от среднего квадратического отклонения признака в генеральной совокупности. Это логично, поскольку выборочная средняя является состоятельной оценкой для генеральной средней и по мере увеличения численности выборки приближается по своему значению к оцениваемому параметру генеральной совокупности. Прямая зависимость средней ошибки от колеблемости признака обусловлена тем, что чем больше изменчивость признака в генеральной совокупности, тем сложнее на основе выборки построить адекватную модель генеральной совокупности. На практике среднее квадратическое отклонение признака по генеральной совокупности заменяется его оценкой по выборке, и тогда формула для расчета средней ошибки выборочной средней приобретает вид:, при этом учитывая смещенность выборочной дисперсии , выборочное среднее квадратическое отклонение рассчитывается по формуле = . Так как символом n обозначена численность выборки. ,то в знаменателе при расчете среднего квадратического отклонения должна использоваться не численность выборки (n), а так называемое число степеней свободы (n-1). Под числом степеней свободы понимается число единиц в совокупности, которые могут свободно варьировать (изменяться), если по совокупности определена какая-либо характеристика. В нашем случае, поскольку по выборке определена ее средняя, свободно варьировать могут единицы.
. Отсюда следует, что средняя ошибка для выборочной средней будет равная и находится она в обратной зависимости от численности выборки (через корень квадратный из нее) и в прямой от среднего квадратического отклонения признака в генеральной совокупности. Это логично, поскольку выборочная средняя является состоятельной оценкой для генеральной средней и по мере увеличения численности выборки приближается по своему значению к оцениваемому параметру генеральной совокупности. Прямая зависимость средней ошибки от колеблемости признака обусловлена тем, что чем больше изменчивость признака в генеральной совокупности, тем сложнее на основе выборки построить адекватную модель генеральной совокупности. На практике среднее квадратическое отклонение признака по генеральной совокупности заменяется его оценкой по выборке, и тогда формула для расчета средней ошибки выборочной средней приобретает вид:, при этом учитывая смещенность выборочной дисперсии , выборочное среднее квадратическое отклонение рассчитывается по формуле = . Так как символом n обозначена численность выборки. ,то в знаменателе при расчете среднего квадратического отклонения должна использоваться не численность выборки (n), а так называемое число степеней свободы (n-1). Под числом степеней свободы понимается число единиц в совокупности, которые могут свободно варьировать (изменяться), если по совокупности определена какая-либо характеристика. В нашем случае, поскольку по выборке определена ее средняя, свободно варьировать могут единицы.
В таблице 2.2 приведены формулы для расчета средних ошибок различных выборочных оценок. Как видно из этой таблицы, величина средней ошибки по всем оценкам находится в обратной связи с численностью выборки и в прямой с колеблемостью. Это можно сказать и относительно средней ошибки выборочной доли (частости). Под корнем стоит дисперсия альтернативного признака, установленная по выборке ()
Приведенные в таблице 2.2 формулы относятся к так называемому случайному, повторному отбору единиц в выборку. При других способах отбора, о которых речь пойдет ниже, формулы будут несколько видоизменяться.
Таблица 2.2
Формулы для расчета средних ошибок выборочных оценок
2.2.3 Предельная ошибка выборки
Знание оценки и ее средней ошибки в ряде случаев совершенно недостаточно. Например, при использовании гормонов при кормлении животных знать только средний размер неразложившихся их вредных остатков и среднюю ошибку, значит подвергать потребителей продукции серьезной опасности. Здесь настоятельно напрашивается необходимость определения максимальной (предельной ошибки
). При использовании выборочного метода предельная ошибка устанавливается не в виде конкретной величины, а виде равных границ
(интервалов) в ту и другую сторону от значения оценки.
Определение границ предельной ошибки основывается на особенностях распределения конкретных ошибок. Для так называемых больших выборок, численность которых более 30 единиц () , конкретные ошибки распределяются в соответствии с нормальным законом распределения; при малых выборках () конкретные ошибки распределяются в соответствии с законом распределения Госсета
(Стьюдента). Применительно к конкретным ошибкам выборочной средней функция нормального распределения имеет вид:  , где — плотность вероятности появления тех или иных значений , при условии, что , где выборочные средние; — генеральная средняя, — средняя ошибка для выборочной средней. Поскольку средняя ошибка () является величиной постоянной, то в соответствии с нормальным законом распределяются конкретные ошибки , выраженные в долях средней ошибки, или так называемых нормированных отклонениях.
, где — плотность вероятности появления тех или иных значений , при условии, что , где выборочные средние; — генеральная средняя, — средняя ошибка для выборочной средней. Поскольку средняя ошибка () является величиной постоянной, то в соответствии с нормальным законом распределяются конкретные ошибки , выраженные в долях средней ошибки, или так называемых нормированных отклонениях.
Взяв интеграл функции нормального распределения, можно установить вероятность того, что ошибка будет заключена в некотором интервале изменения t и вероятность того, что ошибка выйдет за пределы этого интервала (обратное событие). Например, вероятность того, что ошибка не превысит половину средней ошибки (в ту и другую сторону от генеральной средней) составляет 0,3829, что ошибка будет заключена в пределах одной средней ошибки — 0,6827, 2-х средних ошибок -0,9545 и так далее.
Взаимосвязь между уровнем вероятности и интервалом изменения t (а в конечном счете интервалом изменения ошибки) позволяет подойти к определению интервала (или границ) предельной ошибки, увязав его величину с вероятностью осуществления.. Вероятность осуществления -это вероятность того, что ошибка будет находится в некотором интервале. Вероятность осуществления будет «доверительной» в том случае, если противоположное событие (ошибка будет находится вне интервала) имеет такую вероятность появления, которой можно пренебречь. Поэтому доверительный уровень вероятности устанавливают, как правило, не ниже 0,90 (вероятность противоположного события равна 0,10). Чем больше негативных последствий имеет появление ошибок вне установленного интервала, тем выше должен быть доверительный уровень вероятности (0,95; 0,99 ; 0,999 и так далее).
Выбрав доверительный уровень вероятности по таблице интеграла вероятности нормального распределения, следует найти соответствующее значение t, а затем используя выражение =определить интервал предельной ошибки . Смысл полученной величины в следующем – с принятым доверительным уровнем вероятности предельная ошибка выборочной средней не превысит величину .
Для установления границ предельной ошибки на основе больших выборок для других оценок (дисперсии, среднего квадратического отклонения, доли и так далее) используется выше рассмотренный подход, с учетом того, что для определения средней ошибки для каждой оценки используется свой алгоритм.
Что касается малых выборок () то, как уже говорилось, распределение ошибок оценок соответствует в этом случае распределению t — Стьюдента. Особенность этого распределения состоит в том, что в качестве параметра в нем, наряду с ошибкой, присутствует численность выборки,вернее не численность выборки, а число степеней свободы При увеличении численности выборки распределение t-Стьюдента приближается к нормальному, а при эти распределения практически совпадают. Сопоставляя значения величины t-Стьюдента и t — нормального распределения при одной и той же доверительной вероятности можно сказать, что величина t-Стьюдента всегда больше t — нормального распределения, причем, различия возрастают с уменьшением численности выборки и с повышением доверительного уровня вероятности. Следовательно, при использовании малых выборок имеют место по сравнению с выборками большими, более широкие границы предельной ошибки, причем, эти границы расширяются с уменьшением численности выборки и повышением доверительного уровня вероятности.
Средняя ошибка выборки показывает, насколько отклоняется в среднем параметр выборочной совокупности от соответствующего параметра генеральной. Если рассчитать среднюю из ошибок всех возможных выборок определенного вида заданного объема (n
), извлеченных из одной и той же генеральной совокупности, то получим их обобщающую характеристику — среднюю ошибку выборки ()
.
В теории выборочного наблюдения выведены формулы для определения , которые индивидуальны для разных способов отбора (повторного и бесповторного), типов используемых выборок и видов оцениваемых статистических показателей.
Например, если применяется повторная собственно случайная выборка, то определяется как:
При оценивании среднего значения признака;
Если признак альтернативный, и оценивается доля.
При бесповторном собственно случайном отборе в формулы вносится поправка (1 — n/N):
 — для среднего значения признака;
— для среднего значения признака;
 — для доли.
— для доли.
Вероятность получения именно такой величины ошибки всегда равна 0,683. На практике же предпочитают получать данные с большей вероятностью, но это приводит к возрастанию величины ошибки выборки.
Предельная ошибка выборки () равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
Если ошибку выборки увеличить в два раза (t = 2), то получим гораздо большую вероятность того, что она не превысит определенного предела (в нашем случае — двойной средней ошибки) — 0,954. Если взять t = 3, то доверительная вероятность составит 0,997 — практически достоверность.
Уровень предельной ошибки выборки зависит от следующих факторов:
- степени вариации единиц генеральной совокупности;
- объема выборки;
- выбранных схем отбора (бесповторный отбор дает меньшую величину ошибки);
- уровня доверительной вероятности.
Если объем выборки больше 30, то значение t определяется по таблице нормального распределения, если меньше — по таблице распределения Стьюдента.
Приведем некоторые значения коэффициента доверия из таблицы нормального распределения.
Доверительный интервал для среднего значения признака и для доли в генеральной совокупности устанавливается следующим образом:
![]()
Итак, определение границ генеральной средней и доли состоит из следующих этапов:
Ошибки выборки при различных видах отбора
- Собственно случайная и механическая выборка. Средняя ошибка собственно случайной и механической выборки находятся по формулам, представленным в табл. 11.3.
Пример 11.2. Для изучения уровня фондоотдачи было проведено выборочное обследование 90 предприятий из 225 методом случайной повторной выборки, в результате которого получены данные, представленные в таблице.
В рассматриваемом примере имеем 40%-ную выборку (90: 225 = 0,4, или 40%). Определим ее предельную ошибку и границы для среднего значения признака в генеральной совокупности по шагам алгоритма:
- По результатам выборочного обследования рассчитаем среднее значение и дисперсию в выборочной совокупности:
| Результаты наблюдения | Расчетные значения | |||
|---|---|---|---|---|
| уровень фондоотдачи, руб., x i | количество предприятий, f i | середина интервала, x i \xb4 | x i \xb4 f i | x i \xb4 2 f i |
| До 1,4 | 13 | 1,3 | 16,9 | 21,97 |
| 1,4-1,6 | 15 | 1,5 | 22,5 | 33,75 |
| 1,6-1,8 | 17 | 1,7 | 28,9 | 49,13 |
| 1,8-2,0 | 15 | 1,9 | 28,5 | 54,15 |
| 2,0-2,2 | 16 | 2,1 | 33,6 | 70,56 |
| 2,2 и выше | 14 | 2,3 | 32,2 | 74,06 |
| Итого | 90 | — | 162,6 | 303,62 |
Таблица
11.5.
Выборочная средняя

Выборочная дисперсия изучаемого признака
![]()
Для наших данных определим предельную ошибку выборки, например, с вероятностью 0,954. По таблице значений вероятности функции нормального распределения (см. выдержку из нее, приведенную в Приложении 1) находим величину коэффициента доверия t, соответствующего вероятности 0,954. При вероятности 0,954 коэффициент t равен 2.
Таким образом, в 954 случаях из 1000 среднее значение фондоотдачи будет не выше 1,88 руб. и не ниже 1,74 руб.
Выше была использована повторная схема случайного отбора. Посмотрим, изменятся ли результаты обследования, если предположить, что отбор осуществлялся по схеме бесповторного отбора. В этом случае расчет средней ошибки проводится по формуле
Тогда при вероятности равной 0,954 величина предельной ошибки выборки составит:
Доверительные границы для среднего значения признака при бесповторном случайном отборе будут иметь следующие значения:

Сравнив результаты двух схем отбора, можно сделать вывод о том, что применение бесповторной случайной выборки дает более точные результаты по сравнению с применением повторного отбора при одной и той же доверительной вероятности. При этом, чем больше объем выборки, тем существеннее сужаются границы значений средней при переходе от одной схемы отбора к другой.
По данным примера определим, в каких границах находится доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., в генеральной совокупности:
- рассчитаем выборочную долю.
Количество предприятий в выборке с уровнем фондоотдачи, не превышающим значения 2,0 руб., составляет 60 единиц. Тогда
m = 60, n = 90, w = m/n = 60: 90 = 0,667;
- рассчитаем дисперсию доли в выборочной совокупности
- средняя ошибка выборки при использовании повторной схемы отбора составит
![]()
Если предположить, что была использована бесповторная схема отбора, то средняя ошибка выборки с учетом поправки на конечность совокупности составит
- зададим доверительную вероятность и определим предельную ошибку выборки.
При значении вероятности Р = 0,997 по таблице нормального распределения получаем значение для коэффициента доверия t = 3 (см. выдержку из нее, приведенную в Приложении 1):

Таким образом, с вероятностью 0,997 можно утверждать, что в генеральной совокупности доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., не меньше, чем 54,7%, и не больше 78,7%.
- Типическая выборка. При типической выборке генеральная совокупность объектов разбита на k групп, тогда
N 1 + N 2 + … + N i + … + N k = N.
Объем извлекаемых из каждой типической группы единиц зависит от принятого способа отбора; их общее количество образует необходимый объем выборки
n 1 + n 2 + … + n i + … + n k = n.
Существуют следующие два способа организации отбора внутри типической группы: пропорциональной объему типических групп и пропорциональной степени колеблемости значений признака у единиц наблюдения в группах. Рассмотрим первый из них, как наиболее часто используемый.
Отбор, пропорциональный объему типических групп, предполагает, что в каждой из них будет отобрано следующее число единиц совокупности:
n = n i · N i /N
где n i — количество извлекаемых единиц для выборки из i-й типической группы;
n — общий объем выборки;
N i — количество единиц генеральной совокупности, составивших i-ю типическую группу;
N — общее количество единиц генеральной совокупности.
Отбор единиц внутри групп происходит в виде случайной или механической выборки.
Формулы для оценивания средней ошибки выборки для среднего и доли представлены в табл. 11.6.
Здесь — средняя из групповых дисперсий типических групп.
Пример 11.3. В одном из московских вузов проведено выборочное обследование студентов с целью определения показателя средней посещаемости вузовской библиотеки одним студентом за семестр. Для этого была использована 5%-ная бесповторная типическая выборка, типические группы которой соответствуют номеру курса. При отборе, пропорциональном объему типических групп, получены следующие данные:
| Номер курса | Всего студентов, чел., N i | Обследовано в результате выборочного наблюдения, чел., n i | Среднее число посещений библиотеки одним студентом за семестр, x i | Внутригрупповая выборочная дисперсия, |
|---|---|---|---|---|
| 1 | 650 | 33 | 11 | 6 |
| 2 | 610 | 31 | 8 | 15 |
| 3 | 580 | 29 | 5 | 18 |
| 4 | 360 | 18 | 6 | 24 |
| 5 | 350 | 17 | 10 | 12 |
| Итого | 2 550 | 128 | 8 | — |
Таблица
11.7.
Число студентов, которое необходимо обследовать на каждом курсе, рассчитаем следующим образом:
![]()
аналогично для других групп:
![]()
Распределение значений выборочных средних всегда имеет нормальный закон распределения (или приближается к нему) при п > 100, независимо от характера распределения генеральной совокупности. Однако в случае малых выборок действует иной закон распределения — распределение Стьюдента. В этом случае коэффициент доверия находится по таблице t-распределения Стьюдента в зависимости от величины доверительной вероятности Р и объема выборки п. В Приложении 1 приводится фрагмент таблицы t-распределения Стьюдента, представленной в виде зависимости доверительной вероятности от объема выборки и коэффициента доверия t.
Пример 11.4. Предположим, что выборочное обследование восьми студентов академии показало, что на подготовку к контрольной работе по статистике они затратили следующее количество часов: 8,5; 8,0; 7,8; 9,0; 7,2; 6,2; 8,4; 6,6.
Пример 11.5. Рассчитаем, сколько из 507 промышленных предприятий следует проверить налоговой инспекции, чтобы с вероятностью 0,997 определить долю предприятий с нарушениями в уплате налогов. По данным прошлого аналогичного обследования величина среднего квадратического отклонения составила 0,15; размер ошибки выборки предполагается получить не выше, чем 0,05.
При использовании повторного случайного отбора следует проверить
При бесповторном случайном отборе потребуется проверить
Как видим, использование бесповторного отбора позволяет проводить обследование гораздо меньшего числа объектов.
Пример 11.6. Планируется провести обследование заработной платы на предприятиях отрасли методом случайного бесповторного отбора. Какова должна быть численность выборочной совокупности, если на момент обследования в отрасли число занятых составляло 100 000 чел.? Предельная ошибка выборки не должна превышать 100 руб. с вероятностью 0,954. По результатам предыдущих обследований заработной платы в отрасли известно, что среднее квадратическое отклонение составляет 500 руб.
Следовательно, для решения поставленной задачи необходимо включить в выборку не менее 100 человек.
При выборочном наблюдении должна быть обеспечена слу-чайность
отбора единиц. Каждая единица должна иметь равную с другими возможность быть отобранной. Именно на этом основывается собственно-случайная выборка.
К собственно-случайной выборке
относится отбор единиц из всей генеральной совокупности (без предварительного рас-членения ее на какие-либо группы) посредством жеребьевки (преимущественно) или какого-либо иного подобного спосо-ба, например, с помощью таблицы случайных чисел. Случай-ный отбор
— это отбор не беспорядочный. Принцип случай-ности предполагает, что на включение или исключение объ-екта из выборки не может повлиять какой-либо фактор, кро-ме случая. Примером собственно-случайного
отбора могут служить тиражи выигрышей: из общего количества выпущен-ных билетов наугад отбирается определенная часть номеров, на которые приходятся выигрыши. Причем всем номерам обеспечивается равная возможность попадания в выборку. При этом количество отобранных в выборочную совокупность единиц обычно определяется исходя из принятой доли выборки.
Доля выборки
есть отношение числа единиц выборочной со-вокупности к числу единиц генеральной совокупности:
Так, при 5%-ной выборке из партии деталей в 1000 ед. объ-ём выборки п
составляет 50 ед., а при 10%-ной выборке — 100 ед. и т.д. При правильной научной организации выборки ошибки репрезентативности можно свести к минимальным значениям, в результате — выборочное наблюдение становится достаточно точным.
Собственно-случайный отбор «в чистом виде» применяет-ся в практике выборочного наблюдения редко, но он является исходным среди всех других видов отбора, в нем заключаются и реализуются основные принципы выборочного наблюдения.
Рассмотрим некоторые вопросы теории выборочного метода и формулы ошибок для простой случайной выборки.
Применяя выборочный метод в статистике, обычно используют два основных вида обобщающих показателей: среднюю величину ко-личественного признака
и относительную величину альтернативного признака
(долю или удельный вес единиц в статистической совокупности, которые отличаются от всех других единиц этой сово-купности только наличием изучаемого признака).
Выборочная доля
(w),
или частость, определяется отношением числа единиц, обладающих изучаемым признаком т,
к общему числу единиц выборочной совокупности п:
Например, если из 100 деталей выборки (n
=100), 95 деталей оказались стандартными (т
=95), то выборочная доля
w
=95/100=0,95 .
Для характеристики надежности выборочных показателей различают среднюю
и предельную ошибки выборки.
Ошибка выборки
? или, иначе говоря, ошибка репрезента-тивности представляет собой разность соответствующих выбо-рочных и генеральных характеристик:
*
*
Ошибка выборки свойственна только выборочным наблюде-ниям. Чем больше значение этой ошибки, тем в большей степе-ни выборочные показатели отличаются от соответствующих генеральных показателей.
Выборочная средняя и выборочная доля по своей сути яв-ляются случайными величинами,
которые могут принимать раз-личные значения в зависимости от того, какие единицы сово-купности попали в выборку. Следовательно, ошибки выборки также являются случайными величинами и могут принимать различные значения. Поэтому определяют среднюю из возмож-ных ошибок — среднюю ошибку выборки.
От чего зависит средняя ошибка выборки?
При соблюдении принципа случайного отбора средняя ошибка выборки определя-ется прежде всего объемом выборки:
чем больше численность при прочих равных условиях, тем меньше величина средней ошибки выборки. Охватывая выборочным обследованием все большее количество единиц генеральной совокупности, всё более точно характеризуем всю генеральную совокупность.
Средняя ошибка выборки также зависит от степени варьи-рования
изучаемого признака. Степень варьирования, как из-вестно, характеризуется дисперсией? 2 или w(1-w)
—
для альтернативного признака. Чем меньше вариация признака, а следовательно, и дисперсия, тем меньше средняя ошибка вы-борки, и наоборот. При нулевой дисперсии (признак не варь-ирует) средняя ошибка выборки равна нулю, т. е. любая еди-ница генеральной совокупности будет совершенно точно ха-рактеризовать всю совокупность по этому признаку.
Зависимость средней ошибки выборки от ее объема и степе-ни варьирования признака отражена в формулах, с помощью которых можно рассчитать среднюю ошибку выборки в условиях выборочного наблюдения, когда генеральные характеристики (х,p)
неизвестны, и следовательно, не представляется возмож-ным нахождение реальной ошибки выборки непосредственно по формулам (форм. 1), (форм. 2).
Ш При случайном повторном отборе
средние ошибки
теоретически рассчитывают по следующим формулам:
* для средней количественного признака
* для доли (альтернативного признака)
![]()
Поскольку практически дисперсия признака в генеральной совокупности? 2 точно неизвестна, на практике пользуются значением дисперсии S 2 , рассчитанным для выборочной сово-купности на основании закона больших чисел, согласно кото-рому выборочная совокупность при достаточно большом объеме выборки достаточно точно воспроизводит характеристики гене-ральной совокупности.
Таким образом, расчетные формулы
средней
ошиб-ки выборки
при случайном повторном отборе будут следующие:
* для средней количественного признака
* для доли (альтернативного признака)
![]()
Однако дисперсия выборочной совокупности не равна диспер-сии генеральной совокупности, и следовательно, средние ошибки выборки, рассчитанные по формулам (форм. 5) и (форм. 6), будут прибли-женными. Но в теории вероятностей доказано, что генеральная дисперсия выражается через выборную следующим соотношением:
Так как п/
(n
-1) при достаточно больших п —
величина, близкая к единице, то можно принять, что, а следова-тельно, в практических расчетах средних ошибок выборки мож-но использовать формулы (форм. 5) и (форм. 6). И только в случаях ма-лой выборки (когда объем выборки не превышает 30) необхо-димо учитывать коэффициент п
/(n
-1) и исчислять среднюю ошибку малой выборки
по формуле:
Ш X При случайном бесповторном отборе
в приведенные выше формулы расчета средних ошибок выборки необходимо подко-ренное выражение умножить на 1-(n/N), поскольку в процес-се бесповторной выборки сокращается численность единиц генеральной совокупности. Следовательно, для бесповторной вы-борки расчетные формулы
средней ошибки выборки
примут такой вид:
* для средней количественного признака
![]()
* для доли (альтернативного признака)
![]()
. (форм. 10)
Так как п
всегда меньше N
, то дополнительный множи-тель 1-(n/N
)
всегда будет меньше единицы. Отсюда следу-ет, что средняя ошибка при бесповторном отборе всегда будет меньше, чем при повторном. В то же время при сравнительно небольшом проценте выборки этот множитель близок к еди-нице (например, при 5%-ной выборке он равен 0,95; при 2%-ной — 0,98 и т.д.). Поэтому иногда на практике пользуются для определения средней ошибки выборки формулами (форм. 5) и (форм. 6) без указанного множителя, хотя выборку и организуют как бесповторную. Это имеет место в тех случаях, когда число единиц генеральной совокупности N неизвестно или безгра-нично, или когда п
очень мало по сравнению с N
, и по су-ществу, введение дополнительного множителя, близкого по значению к единице, практически не повлияет на значение средней ошибки выборки.
Механическая выборка
состоит в том, что отбор единиц в выборочную совокупность из генеральной, разбитой по ней-тральному признаку на равные интервалы (группы), произво-дится таким образом, что из каждой такой группы в выборку отбирается лишь одна единица. Чтобы избежать систематиче-ской ошибки, отбираться должна единица, которая находится в середине каждой группы.
При организации механического отбора единицы совокуп-ности предварительно располагают (обычно в списке) в опре-деленном порядке (например, по алфавиту, местоположению, в порядке возрастания или убывания значений какого-либо по-казателя, не связанного с изучаемым свойством, и т.д.), после чего отбирают заданное число единиц механически, через оп-ределенный интервал. При этом размер интервала в генеральной совокупности равен обратному значению доли выборки. Так, при 2%-ной выборке отбирается и проверяется каждая 50-я единица (1: 0,02), при 5%-ной выборке — каждая 20-я едини-ца (1: 0,05), например, сходящая со станка деталь.
При достаточно большой совокупности механический отбор по точности результатов близок к собственно-случайному. По-этому для определения средней ошибки механической выборки используют формулы собственно-случайной бесповторной вы-борки (форм. 9), (форм. 10).
Для отбора единиц из неоднородной совокупности применя-ется, так называемая типическая выборка
,
которая используется в тех случаях, когда все единицы генеральной совокупности можно разбить на несколько качественно однородных, однотипных групп по признакам, влияющим на изучаемые показатели.
При обследовании предприятий такими группами могут быть, например, отрасль и подотрасль, формы собственности. Затем из каждой типической группы собственно-случайной или механической выборкой производится индивидуальный отбор единиц в выборочную совокупность.
Типическая выборка обычно применяется при изучении слож-ных статистических совокупностей. Например, при выборочном обследовании семейных бюджетов рабочих и служащих в отдель-ных отраслях экономики, производительности труда рабочих пред-приятия, представленных отдельными группами по квалификации.
Типическая выборка дает более точные результаты по сравнению с другими способами отбора единиц в выбороч-ную совокупность. Типизация генеральной совокупности обеспечивает репрезентативность такой выборки, представи-тельство в ней каждой типологической группы, что позволяет исключить влияние межгрупповой дисперсии на среднюю ошибку выборки.
При определении средней ошибки типической выборки
в ка-честве показателя вариации выступает средняя из внутригрупповых дисперсий.
Среднюю ошибку выборки
находят по формулам:
* для средней количественного признака
(повторный отбор); (форм. 11)

(бесповоротный отбор); (форм. 12)
* для доли (альтернативного признака)
![]()
(повторный отбор); (форм.13)
![]()
(бесповторный отбор), (форм. 14)
где — средняя из внутригрупповых дисперсий по вы-борочной совокупности;
Средняя из внутригрупповых дисперсий доли (альтернативного признака) по выборочной совокупности.
Серийная выборка
предполагает случайный отбор из генераль-ной совокупности не отдельных единиц, а их равновеликих групп (гнезд, серий) с тем, чтобы в таких группах подвергать наблюде-нию все без исключения единицы.
Применение серийной выборки обусловлено тем, что многие товары для их транспортировки, хранения и продажи упаковываются в пачки, ящики и т.п. Поэтому при контроле качества упакованного товара рациональнее проверить не-сколько упаковок (серий), чем из всех упаковок отбирать необходимое количество товара.
Поскольку внутри групп (серий) обследуются все без исключе-ния единицы, средняя ошибка выборки (при отборе равновеликих серий) зависит только от межгрупповой (межсерийной) дисперсии.
Ш Среднюю ошибку выборки для средней количественного признака
при серийном отборе находят по формулам:
(повторный отбор); (форм.15)
![]()
(бесповторный отбор), (форм. 16)
где r —
число отобранных серий; R —
общее число серий.
Межгрупповую дисперсию серийной выборки вычисляют сле-дующим образом:

где — средняя i
— й серии; — общая средняя по всей выбо-рочной совокупности.
Ш Средняя ошибка выборки для доли (альтернативного при-знака)
при серийном отборе:
(повторный отбор); (форм. 17)
![]()
(бесповторный отбор). (форм. 18)
Межгрупповую
(межсерийную) дисперсию доли серийной вы-борки
определяют по формуле:

, (форм. 19)
где — доля признака в i
-й серии; — общая доля признака во всей выборочной совокупности.
В практике статистических обследований помимо рассмот-ренных ранее способов отбора применяется их комбинация (комбинированный отбор).
Понятие и расчет ошибки выборки.
Задачей выборочного наблюдения является дача верных представлений о сводных показателях всей совокупности на основе некоторой их части, подвергнутой наблюдению. Возможное отклонение выборочной доли и выборочной средней от доли и средней в генеральной совокупности называется ошибкойвыборки
или ошибкойрепрезентативности.
Чем больше величина этой ошибки, тем больше показатели выборочного наблюдения отличаются от показателей генеральной совокупности.
Различаются:
Ошибки выборки;
Ошибки регистрации.
Ошибки регистрации
возникают при неправильном установлении факта в процессе наблюдения. Они свойственны как сплошному наблюдению, так и выборочному, но в выборочном их меньше.
По природе ошибки бывают:
Тенденциозные – преднамеренные, т.е. были отобраны либо лучшие, либо худшие единицы совокупности. При этом наблюдения теряют смысл;
Случайные – основной организационный принцип выборочного наблюдения состоит в том, чтобы не допустить преднамеренного отбора, т.е. обеспечить строгое соблюдение принципа случайного отбора.
Общим правилом случайного отбора
является: у отдельных единиц генеральной совокупности должны быть совершенно одинаковые условия и возможности упасть в число единиц, входящих в выборку. Это характеризует независимость результата выборки от воли наблюдателя. Воля же наблюдателя порождает тенденциозные ошибки. Ошибка выборки при случайном отборе носит случайный характер. Она характеризует размеры отклонений генеральных характеристик от выборочных.
В связи с тем, что признаки в изучаемой совокупности варьируют, то состав единиц, попавших в выборку, может не совпадать с составом единиц всей совокупности. Это означает, что Р
и не совпадают с W
и . Возможное расхождение между этими характеристиками определяется ошибкой выборки, которая определяется по формуле:
где — генеральная дисперсия.
где — выборочная дисперсия.
Отсюда видно, где генеральная дисперсия отличается от выборочной дисперсии в раз.
Существует повторный и бесповторный отбор. Сущность повторного отбора состоит в том, что каждая, попавшая в выборку единица, после наблюдения возвращается в генеральную совокупность и может быть исследована повторно. При повторном отборе средняя ошибка выборки рассчитывается:
Для показателя доли альтернативного признака дисперсия выборки определяется по формуле:
![]()
На практике повторный отбор применяется редко. При бесповторном отборе, численность генеральной совокупности N
в ходе выборки сокращается, формула средней ошибки выборки для количественного признака имеет вид:
, тогда
Одно из возможных значений, в которых может находиться доля изучаемого признака равно:

где — ошибка выборки альтернативного признака.
Пример
.
При выборочном обследовании 10 % изделий партии готовой продукции по методу без повторного отбора получены следующие данные о содержании влаг в образцах.
Определить средний % влажности, дисперсию, среднее квадратическое отклонение, с вероятностью 0,954 возможные пределы, в которых ожидается ср. % влажности всей готовой продукции, с вероятность 0,987 возможные пределы удельного веса стандартной продукции при условии, что к нестандартной партии относятся изделия с влажностью до 13 и выше 19 %.
![]()
Лишь с определенной вероятностью можно утверждать, что генеральная доля от выборочной доли и генеральная средняя от выборочной средней, отклоняются в t
раз.
В статистике эти отклонения называются предельнымиошибкамивыборки
и обозначаются .
Вероятность суждений можно повысить или понизить в t
раз. При вероятности 0,683 , при 0,954 , при 0,987 , тогда показатели генеральной совокупности по показателям выборки определяются.
Выборочное наблюдение
Понятие выборочного наблюдения
Выборочный метод используется, когда применение сплошного наблюдения физически невозможно из-за огромного массива данных или экономически нецелесообразно. Физическая невозможность имеет место, например, при изучении пассажиропотоков, рыночных цен, семейных бюджетов. Экономическая нецелесообразность имеет место при оценке качества товаров, связанной с их уничтожением. Например, дегустация, испытание кирпичей на прочность и т.п. Выборочное наблюдение используется также для проверки результатов сплошного.
Статистические единицы, отобранные для наблюдения, составляют выборочную
совокупность или выборку,
а весьих массив — генеральную
совокупность (ГС). При этом число единиц в выборке обозначают п,
во всей ГС – N.
Отношение n/N
называется относительный размер или доля выборки
.
Качество результатов выборочного наблюдения зависит от репрезентативности
выборки, т.е. от того, насколько она представительна в ГС. Для обеспечения репрезентативности выборки необходимо соблюдать принцип случайности отбора единиц, который предполагает, что на включение единицы ГС в выборку не может повлиять какой-либо иной фактор кроме случая..
Способы формирования выборки
1. Собственно случайный
отбор: все единицы ГС нумеруются, а выпавшие в результате жеребьевки номера соответствуют единицам, попавшим в выборку, причем число номеров равно запланированному объему выборки. На практике вместо жеребьевки используют генераторы случайных чисел. Данный способ отбора может быть повторным
(когда каждая единица, отобранная в выборку, после проведения наблюдения возвращается в ГС и может быть вновь подвергнута обследованию) и бесповторным
(когда обследованные единицы в ГС не возвращаются и не могут быть обследованы повторно). При повторном отборе вероятность попадания в выборку для каждой единицы ГС остается неизменной, а при бесповторном отборе она меняется (увеличивается), но для оставшихся в ГС после отбора из нее нескольких единиц, вероятность попадания в выборку одинакова.
2. Механический
отбор: отбираются единицы генеральной совокупности с постоянным шагом N/п
. Так, если она генеральная совокупность содержит 100 тыс.ед., а требуется выбрать 1 тыс.ед., то в выборку попадет каждая сотая единица.
3. Стратифицированный
(расслоенным) отбор осуществляется из неоднородной генеральной совокупности, когда ее предварительно разбивают на однородные группы, после чего производят отбор единиц из каждой группы в выборочную совокупность случайный или механическим способом пропорционально их численности в генеральной совокупности.
4. Серийный
(гнездовой)отбор: случайным или механическим способом выбирают не отдельные единицы, а определенные серии (гнезда), внутри которых производится сплошное наблюдение.
Средняя ошибка выборки
После завершения отбора необходимого числа единиц в выборку и регистрации предусмотренных программой наблюдения изучаемых признаков этих единиц, переходят к расчету обобщающих показателей. К ним относят среднюю величину изучаемого признака и долю единиц, обладающих каким-либо значением этого признака. Однако, если ГС произвести несколько выборок, определив при этом их обобщающие характеристики, то можно установить, что их значения будут различными, кроме того, они будут отличаться и от реального их значения в ГС, если такое определить с помощью сплошного наблюдения. Другими словами, обобщающие характеристики, рассчитанные по данным выборки, будут отличаться от их реальных значений в ГС, поэтому введем следующие условные обозначения (табл. 8).
Таблица 8. Условные обозначения
Разность между значением обобщающих характеристик выборочной и генеральной совокупностей называется ошибкой выборки,
которая подразделяется на ошибку регистрации
и ошибку репрезентативности
. Первая возникает из-за неправильных или неточных сведений по причинам непонимания существа вопроса, невнимательности регистратора при заполнении анкет, формуляров и т.п. Она достаточно легко обнаруживается и устраняется. Вторая возникает из-за несоблюдения принципа случайности отбора единиц в выборку. Ее сложнее обнаружить и устранить, она гораздо больше первой и потому ее измерение является основной задачей выборочного наблюдения.
Для измерения ошибки выборки определяется ее средняя ошибка по формуле (39) для повторного отбора и по формуле (40) – для бесповторного:
=
;(39) =  . (40)
. (40)
Из формул (39) и (40) видно, что средняя ошибка меньше у бесповторной выборки, что и обусловливает ее более широкое применение.
Теория статистики: конспект лекций Бурханова Инесса Викторовна
3. Ошибки выборки
3. Ошибки выборки
Каждая единица при выборочном наблюдении должна иметь равную с другими возможность быть отобранной – это является основой собственнослучайной выборки.
Собственнослучайная выборка
– это отбор единиц из всей генеральной совокупности посредством жеребьевки или другим подобным способом.
Принципом случайности является то, что на включение или исключение объекта из выборки не может повлиять любой фактор, кроме случая.
Доля выборки
– это отношение числа единиц выборочной совокупности к числу единиц генеральной совокупности:
Собственнослучайный отбор в чистом виде является исходным среди всех других видов отбора, в нем заключаются и реализуются основные принципы выборочного статистического наблюдения.
Два основных вида обобщающих показателей, которые используют в выборочном методе – это средняя величина количественного признака и относительная величина альтернативного признака.
Выборочная доля (w), или частность, определяется отношением числа единиц, обладающих изучаемым признаком m,
к общему числу единиц выборочной совокупности (n):
Для характеристики надежности выборочных показателей различают среднюю и предельную ошибки выборки.
Ошибка выборки, ее еще называют ошибкой репрезентативности, представляет собой разность соответствующих выборочных и генеральных характеристик:
?х =|х – х|;
?w =|х – p|.
Только выборочным наблюдениям присуща ошибка выборки
Выборочная средняя и выборочная доля
– это случайные величины, принимающие различные значения в зависимости от единиц изучаемой статистической совокупности, которые попали в выборку. Соответственно ошибки выборки – тоже случайные величины и также могут принимать различные значения. Поэтому определяют среднюю из возможных ошибок – среднюю ошибку выборки.
Средняя ошибка выборки определяется объемом выборки: чем больше численность при прочих равных условиях, тем меньше величина средней ошибки выборки. Охватывая выборочным обследованием все большее количество единиц генеральной совокупности, все более точно характеризуем всю генеральную совокупность.
Средняя ошибка выборки зависит от степени варьирования изучаемого признака, в свою очередь степень варьирования характеризуется дисперсией? 2 или w(l – w)
– для альтернативного признака. Чем меньше вариация признака и дисперсия, тем меньше средняя ошибка выборки, и наоборот.
При случайном повторном отборе средние ошибки теоретически рассчитывают по следующим формулам:
1) для средней количественного признака:
где? 2 – средняя величина дисперсии количественного признака.
2) для доли (альтернативного признака):
Так как дисперсия признака в генеральной совокупности? 2 точно неизвестна, на практике пользуются значением дисперсии S 2 , рассчитанным для выборочной совокупности на основании закона больших чисел, согласно которому выборочная совокупность при достаточно большом объеме выборки достаточно точно воспроизводит характеристики генеральной совокупности.
Формулы средней ошибки выборки при случайном повторном отборе следующие. Для средней величины количественного признака: генеральная дисперсия выражается через выборную следующим соотношением:
![]()
где S 2 – значение дисперсии.
Механическая выборка
– это отбор единиц в выборочную совокупность из генеральной, которая разбита по нейтральному признаку на равные группы; производится так, что из каждой такой группы в выборку отбирается лишь одна единица.
При механическом отборе единицы изучаемой статистической совокупности предварительно располагают в определенном порядке, после чего отбирают заданное число единиц механически через определенный интервал. При этом размер интервала в генеральной совокупности равен обратному значению доли выборки.
При достаточно большой совокупности механический отбор по точности результатов близок к собственнослучайному Поэтому для определения средней ошибки механической выборки используют формулы собственнослучайной бесповторной выборки.
Для отбора единиц из неоднородной совокупности применяется так называемая типическая выборка, используется, когда все единицы генеральной совокупности можно разбить на несколько качественно однородных, однотипных групп по признакам, от которых зависят изучаемые показатели.
Затем из каждой типической группы собственнослучайной или механической выборкой производится индивидуальный отбор единиц в выборочную совокупность.
Типическая выборка обычно применяется при изучении сложных статистических совокупностей.
Типическая выборка дает более точные результаты. Типизация генеральной совокупности обеспечивает репрезентативность такой выборки, представительство в ней каждой типологической группы, что позволяет исключить влияние межгрупповой дисперсии на среднюю ошибку выборки. Поэтому при определении средней ошибки типической выборки в качестве показателя вариации выступает средняя из внутригрупповых дисперсий.
Серийная выборка предполагает случайный отбор из генеральной совокупности равновеликих групп для того, чтобы в таких группах подвергать наблюдению все без исключения единицы.
Поскольку внутри групп (серий) обследуются все без исключения единицы, средняя ошибка выборки (при отборе равновеликих серий) зависит только от межгрупповой (межсерийной) дисперсии.
Из книги
Личный бюджет. Деньги под контролем
автора
Макаров Сергей Владимирович
Ошибки резидента
Относиться к ошибкам можно по-разному: можно бояться их совершить и переживать из-за каждой из них, можно радоваться своим ошибкам и кризисам, как указателям на пути к успеху и личным победам. Неизменно в ошибках только одно – за них приходится платить.
Из книги
Настольная книга по внутреннему аудиту. Риски и бизнес-процессы
автора
Крышкин Олег
Формирование выборки
Процедура выборки является неотъемлемым этапом проекта внутреннего аудита. Она подробно описана в различных источниках, посвященных теме аудита. Однако во многом такие описания носят академичный характер. Предлагаю заострить внимание на тех
Из книги
Психология инвестиций [Как перестать делать глупости со своими деньгами]
автора
Ричардс Карл
Ошибки в инвестициях – это ошибки инвесторов
Сейчас я больше, чем когда бы то ни было, убежден в том, что все ошибки в инвестициях на самом деле ошибки инвесторов.Инвестиции не совершают ошибок. В отличие от инвесторов.Инвестирование – это выбор. Именно об этой
автора
Щербина Лидия Владимировна
29. Определение необходимой численности выборки
Одним из научных принципов в теории выбороч–ного метода является обеспечение достаточного чи–сла отобранных единиц.Уменьшение стандартной ошибки выборки всег–да связано с увеличением объема выборки. Расчет
Из книги
Общая теория статистики
автора
Щербина Лидия Владимировна
30. Способы отбора и виды выборки. Собственно случайная выборка
В теории выборочного метода разработаны раз–личные способы отбора и виды выборки, обеспечи–вающие репрезентативность. Под способом отбора понимают порядок отбора единиц из генеральной со–вокупности.
Из книги
Общая теория статистики
автора
Щербина Лидия Владимировна
31. Механическая и типическая выборки
При чисто механической выборке вся ге–неральная совокупность единиц должна быть прежде всего представлена в виде списка единиц отбора, со–ставленного в каком-то нейтральном по отношению к изучаемому признаку порядке. Затем список
Из книги
Общая теория статистики
автора
Щербина Лидия Владимировна
32. Серийная и комбинированная выборки
Серийная (гнездовая) выборка – это такой вид формирования выборочной совокупности, когда в случайном порядке отбираются не единицы, подле–жащие обследованию, а группы единиц (серии, гнез–да). Внутри отобранных серий (гнезд)
Из книги
Общая теория статистики
автора
Щербина Лидия Владимировна
33. Многоступенчатая, многофазная и взаимопроникающая выборки.
Особенность многоступенчатой выборки со–стоит в том, что выборочная совокупность формиру–ется постепенно, по ступеням отбора. На первой ступени с помощью заранее определенного спосо–ба и вида отбора
автора
Коник Нина Владимировна
3. Определение необходимой численности выборки
Одним из научных принципов в теории выборочного метода является обеспечение достаточного числа отобранных единиц. Теоретически необходимость соблюдения этого принципа представлена в доказательствах предельных теорем
Из книги
Общая теория статистики: конспект лекции
автора
Коник Нина Владимировна
4. Способы отбора и виды выборки
В теории выборочного метода разработаны различные способы отбора и виды выборки, обеспечивающие репрезентативность. Под способом отбора понимают порядок отбора единиц из генеральной совокупности. Различают два способа отбора: повторный
Из книги
Теория статистики
автора
Бурханова Инесса Викторовна
36. Ошибки выборки
Собственнослучайная выборка – это отбор единиц из всей генеральной совокупности посредством жеребьевки или другим подобным способом. Принципом случайности является то, что на включение или исключение объекта из выборки не может повлиять любой фактор,
Из книги
Деловая переписка: учебное пособие
автора
Кирсанова Мария Владимировна
Лексические ошибки
1. Неправильное использование слов и терминовОсновная масса ошибок в деловых письмах относится к лексическим. Недостаточная грамотность приводит не только к курьезной бессмыслице, но и абсурду.Отдельные термины и профессиональные жаргонные слова
Из книги
Новая эпоха — старые тревоги: Политическая экономия
автора
Ясин Евгений Григорьевич
5
Наши ошибки
Мы настаиваем: выбранный курс рыночных реформ был верным. И они вовсе не потерпели неудачу, они только еще раз споткнулись. Но ошибки и упущения были. Это и наши ошибки, и ошибки руководства страны, которые мы не сумели предотвратить. Ошибки — во многом
автора
Куртис Фейс
Важность размера выборки
Как я уже говорил, люди склонны уделять слишком много внимания редким случаям возникновения какого-то феномена, несмотря на то что со статистической точки зрения из нескольких случаев невозможно извлечь много информации. Это – основная причина
Из книги
Путь Черепах. Из дилетантов в легендарные трейдеры
автора
Куртис Фейс
Репрезентативные выборки
Репрезентативность наших тестов для целей предсказания будущего определяется двумя факторами:– Количество рынков: тесты, проводимые на различных рынках, будут, скорее всего, включать рынки с разной степенью волатильности типов
Из книги
Путь Черепах. Из дилетантов в легендарные трейдеры
автора
Куртис Фейс
Размер выборки
Концепция размера выборки проста: для того чтобы делать статистически достоверные заключения, нужно иметь достаточно большую выборку. Чем меньше выборка, тем грубее выводы, которые можно сделать; чем выборка больше, тем выводы качественнее. Нет никакого
1.1. Ошибки
выборочного наблюдения
Средняя
ошибка выборки показывает, как генеральная средняя отклоняется в среднем от выборочной средней в ту или другую сторону. Формула
расчета средней ошибки выборки определяется видом исследуемого признака единиц
совокупности (количественный или альтернативный) и
способом отбора (бесповторный или повторный).
·
Если отбор повторный, а признак количественный
средняя ошибка выборки определяется по формуле
![]() , где
, где ![]() — дисперсия признака в выборочной совокупности
— дисперсия признака в выборочной совокупности
n- число единиц
в выборке
·
Если отбор бесповторный, а признак
количественный
 , где N—
, где N—
число единиц в генеральной совокупности
·
Если отбор повторный, а признак альтернативный
 , где w-выборочная
, где w-выборочная
доля
·
Если отбор бесповторный, а признак
альтернативный

Предельная ошибка выборки— показывающая с определенной степенью вероятности
отклонения средней от выборочной средней.
Предельная ошибка выборки
![]() , где параметр t зависит
, где параметр t зависит
от вероятности
Некоторые значения параметра t приведены
в таблице:
|
Вероятность, p |
0.95 |
0.954 |
0.9876 |
0.9907 |
0.9973 |
0.9999 |
|
Параметр t |
1.96 |
2.0 |
2.5 |
2.6 |
3.0 |
4.0 |
·
Если отбор повторный, а признак количественный
средняя ошибка выборки определяется по формуле
![]() , где
, где ![]() — дисперсия признака в выборочной совокупности
— дисперсия признака в выборочной совокупности
n- число единиц
в выборке
·
Если отбор бесповторный, а признак
количественный
 , где N—
, где N—
число единиц в генеральной совокупности
·
Если отбор повторный, а признак альтернативный
 , где w-выборочная
, где w-выборочная
доля
·
Если отбор бесповторный, а признак
альтернативный

Доверительный интервал для генеральной средней
![]()
Доверительный интервал для
генеральной доли
![]()
Пример расчета доверительного
интервала:
При выборочном обследовании 5% продукции по методу случайного
бесповторного отбора получены данные о содержании сахара в образцах:
|
Сахарность, % |
Число |
|
16-17 17-18 18-19 19-20 20-21 |
10 158 154 50 28 |
|
На основании этих данных вычислите:
1. Средний процент сахаристости.
2. Дисперсию и среднее квадратическое
отклонение.
3. С вероятностью 0.954 возможные пределы среднего значения
сахаристости продукции для всей партии.
4. С вероятностью 0.997 возможный процент продукции высшего
сорта по всей партии, если известно, что из 400 проб, попавших в выборку , 80
ед. отнесены к продукции высшего сорта.
Решение.
1.
Средний процент сахаристости найдем по формуле средней взвешенной
![]() , где xi–
, где xi–
середина i-го интервала
![]() =18,32 %
=18,32 %
2.
Дисперсия
![]()
![]()
![]() =336,49
=336,49
D(X)=336.49–
18.322=0.8676
Среднее квадратическое отклонение
![]() =0,93%
=0,93%
5. Предельная ошибка для
среднего процента сахаристости
![]()
для вероятности 0,954 параметр t=2.0
![]()
Доверительный интервал для среднего значения процента
сахаристости
![]()
![]()
![]()
С вероятностью 0,954 можно утверждать, что в генеральной
совокупности средний процент сахаристости лежит в пределах от 18,23% до 18,41%.
5. Доля продукции высшего сорта в выборочной совокупности
![]()
Предельная ошибка для
доли продукции высшего сорта
![]()
для вероятности 0,997 параметр t=3.0
![]()
Доверительный интервал для доли продукции высшего сорта
![]()
![]()
![]()
С вероятностью 0,997 можно утверждать, что в генеральной
совокупности доля продукции высшего сорта лежит в пределах от 14,0% до 26,0%.