Ошибка оценки
Ошибка
оценки – это отклонение полученной
оценки от неизвестного значения
оцениваемой вероятностной характеристики
случайной величины.
Ошибка
оценки сама по себе является случайной
величиной. Она имеет нулевое математическое
ожидание (предполагается, что смещение
оценки отсутствует) и некоторую ненулевую
дисперсию n2,
величина которой зависит от объёма
выборки n.
Чем больше объём выборки n,
тем меньше дисперсия n2
и тем точнее оценка.
Обычно
для характеристики ошибки оценки
используется корень квадратный из
дисперсии оценки n2,
и эта величина n
носит название среднеквадратической
ошибки.
Поскольку
среднеквадратическая ошибка оценки n
заранее не известна, она также подлежит
оцениванию. Её оценка обозначается
добавлением «крышечки»:
![]() .
.
Выборочное среднее
Выборочное среднее
– это оценка неизвестного значения
математического ожидания случайной
величины по выборочным данным.
Вычисляется по
формуле среднего арифметического:
![]() =
=
(x1
+ x2
+ … + xn) / n = 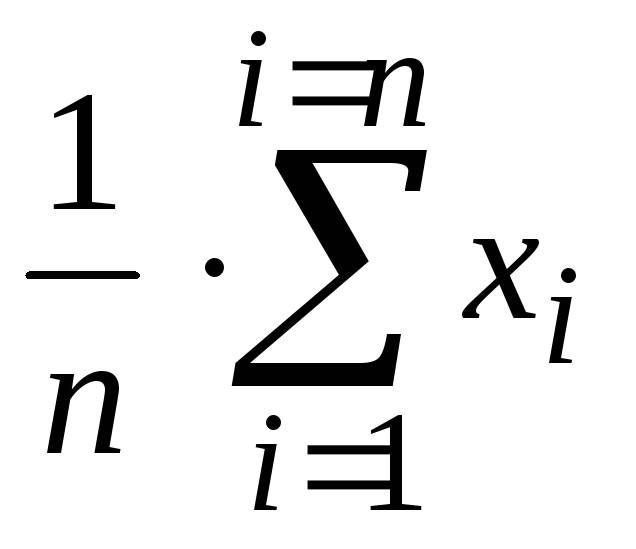 ,
,
гдеn
– объём выборки.
С ростом объёма
выборки возможное отклонение выборочного
среднего
![]()
от оцениваемого неизвестного
математического ожидания случайной
величины M(X)
уменьшается.
Выборочная дисперсия
Выборочная дисперсия
– это оценка неизвестного значения
дисперсии наблюдаемой в опыте случайной
величины.
Вычисляется по
формуле среднего арифметического, в
которой выборочные значения заменены
квадратами отклонений выборочных
значений от математического ожидания.
Как правило, математическое ожидание
генеральной совокупности неизвестно,
поэтому оно без большой ошибки заменяется
его оценкой, т.е. выборочным средним.
Таким образом,
выборочная дисперсия – это средний
квадрат отклонения выборочных значений
от выборочного среднего.
Формула для
вычисления выборочной дисперсии такова:
s2
= ( (x1
–
![]() )2
)2
+ (x2
–
![]() )2
)2
+ … + (xn
–
![]() )2
)2
) / n = 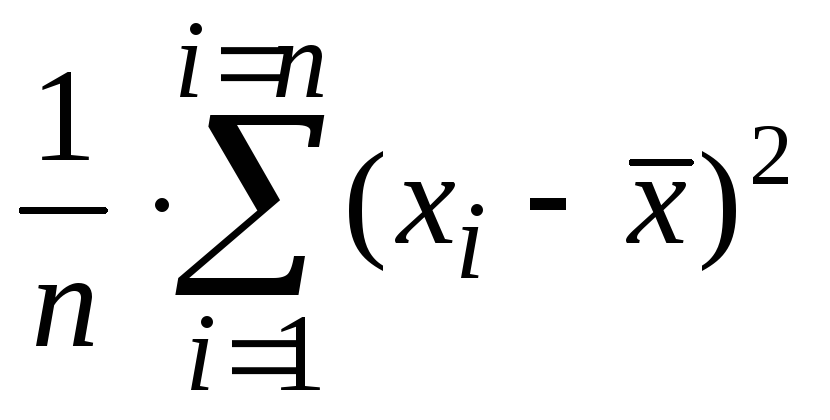 .
.
С ростом объёма
выборки n
возможное отклонение выборочной
дисперсии s2
от оцениваемой неизвестной дисперсии
случайной величины D(X)
уменьшается.
Выборочное среднеквадратическое отклонение
Выборочное
среднеквадратическое отклонение – это
оценка неизвестного значения
среднеквадратического отклонения
(стандартного отклонения) наблюдаемой
в опыте случайной величины.
Вычисляется как
квадратный корень из выборочной дисперсии
s2.
Буквенное
обозначение: s
.
С ростом объёма
выборки n
возможное отклонение выборочного
среднеквадратического отклонения s
от оцениваемого среднеквадратического
отклонения
случайной величины уменьшается.
Выборочная среднеквадратическая ошибка
Выборочная
среднеквадратическая ошибка – это
вычисленное по выборке отклонение
полученной оценки от неизвестного
значения оцениваемой вероятностной
характеристики случайной величины.
Вычисляется как
квадратный корень из выборочной дисперсии
оценки n2.
Буквенное
обозначение:
![]() .
.
С ростом объёма
выборки n
возможное значение выборочной
среднеквадратической ошибки
![]() уменьшается, изменяясь обратно
уменьшается, изменяясь обратно
пропорционально![]() .
.
Выборочный коэффициент корреляции
Выборочный
коэффициент корреляции – это оценка
неизвестного значения коэффициента
корреляции наблюдаемых случайных
величин X
и Y
по парам выборочных данных (x1, y1),
(x2, y2),
…, (xn, yn).
Буквенное обозначение: r .
Выборочный
коэффициент корреляции показывает
степень тесноты статистической связи
между отклонениями выборочных значений
двух наблюдаемых в опыте случайных
величин X
и Y
от своих математических ожиданий M(X)
и M(Y),
или, если они не известны, от выборочных
средних
![]()
и
![]() .
.
Формула
для выборочного коэффициента корреляции
такова:
r
=
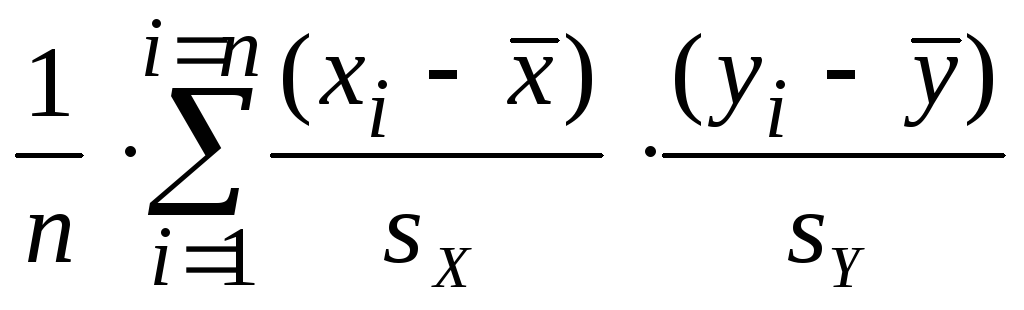 =
=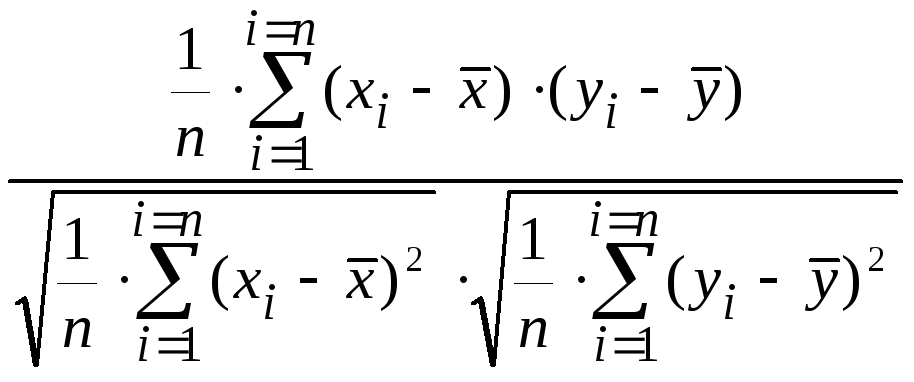 .
.
С ростом объёма
выборки n
возможное отклонение выборочного
коэффициента корреляции r
от оцениваемого неизвестного коэффициента
корреляции
пары случайных величин уменьшается.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
From Wikipedia, the free encyclopedia
In statistics, the mean squared error (MSE)[1] or mean squared deviation (MSD) of an estimator (of a procedure for estimating an unobserved quantity) measures the average of the squares of the errors—that is, the average squared difference between the estimated values and the actual value. MSE is a risk function, corresponding to the expected value of the squared error loss.[2] The fact that MSE is almost always strictly positive (and not zero) is because of randomness or because the estimator does not account for information that could produce a more accurate estimate.[3] In machine learning, specifically empirical risk minimization, MSE may refer to the empirical risk (the average loss on an observed data set), as an estimate of the true MSE (the true risk: the average loss on the actual population distribution).
The MSE is a measure of the quality of an estimator. As it is derived from the square of Euclidean distance, it is always a positive value that decreases as the error approaches zero.
The MSE is the second moment (about the origin) of the error, and thus incorporates both the variance of the estimator (how widely spread the estimates are from one data sample to another) and its bias (how far off the average estimated value is from the true value).[citation needed] For an unbiased estimator, the MSE is the variance of the estimator. Like the variance, MSE has the same units of measurement as the square of the quantity being estimated. In an analogy to standard deviation, taking the square root of MSE yields the root-mean-square error or root-mean-square deviation (RMSE or RMSD), which has the same units as the quantity being estimated; for an unbiased estimator, the RMSE is the square root of the variance, known as the standard error.
Definition and basic properties[edit]
The MSE either assesses the quality of a predictor (i.e., a function mapping arbitrary inputs to a sample of values of some random variable), or of an estimator (i.e., a mathematical function mapping a sample of data to an estimate of a parameter of the population from which the data is sampled). The definition of an MSE differs according to whether one is describing a predictor or an estimator.
Predictor[edit]
If a vector of  predictions is generated from a sample of data points on all variables, and
predictions is generated from a sample of data points on all variables, and  is the vector of observed values of the variable being predicted, with
is the vector of observed values of the variable being predicted, with  being the predicted values (e.g. as from a least-squares fit), then the within-sample MSE of the predictor is computed as
being the predicted values (e.g. as from a least-squares fit), then the within-sample MSE of the predictor is computed as

In other words, the MSE is the mean  of the squares of the errors
of the squares of the errors  . This is an easily computable quantity for a particular sample (and hence is sample-dependent).
. This is an easily computable quantity for a particular sample (and hence is sample-dependent).
In matrix notation,

where  is
is  and
and  is a
is a  column vector.
column vector.
The MSE can also be computed on q data points that were not used in estimating the model, either because they were held back for this purpose, or because these data have been newly obtained. Within this process, known as cross-validation, the MSE is often called the test MSE,[4] and is computed as

Estimator[edit]
The MSE of an estimator  with respect to an unknown parameter
with respect to an unknown parameter  is defined as[1]
is defined as[1]
![{\displaystyle \operatorname {MSE} ({\hat {\theta }})=\operatorname {E} _{\theta }\left[({\hat {\theta }}-\theta )^{2}\right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9a0e1b3bac58f9ba2d2f4ff8b85b2e35a8f4bf78)
This definition depends on the unknown parameter, but the MSE is a priori a property of an estimator. The MSE could be a function of unknown parameters, in which case any estimator of the MSE based on estimates of these parameters would be a function of the data (and thus a random variable). If the estimator is derived as a sample statistic and is used to estimate some population parameter, then the expectation is with respect to the sampling distribution of the sample statistic.
The MSE can be written as the sum of the variance of the estimator and the squared bias of the estimator, providing a useful way to calculate the MSE and implying that in the case of unbiased estimators, the MSE and variance are equivalent.[5]

Proof of variance and bias relationship[edit]
![{\displaystyle {\begin{aligned}\operatorname {MSE} ({\hat {\theta }})&=\operatorname {E} _{\theta }\left[({\hat {\theta }}-\theta )^{2}\right]\\&=\operatorname {E} _{\theta }\left[\left({\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]+\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)^{2}\right]\\&=\operatorname {E} _{\theta }\left[\left({\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]\right)^{2}+2\left({\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]\right)\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)+\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)^{2}\right]\\&=\operatorname {E} _{\theta }\left[\left({\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]\right)^{2}\right]+\operatorname {E} _{\theta }\left[2\left({\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]\right)\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)\right]+\operatorname {E} _{\theta }\left[\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)^{2}\right]\\&=\operatorname {E} _{\theta }\left[\left({\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]\right)^{2}\right]+2\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)\operatorname {E} _{\theta }\left[{\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]\right]+\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)^{2}&&\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta ={\text{const.}}\\&=\operatorname {E} _{\theta }\left[\left({\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]\right)^{2}\right]+2\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\operatorname {E} _{\theta }[{\hat {\theta }}]\right)+\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)^{2}&&\operatorname {E} _{\theta }[{\hat {\theta }}]={\text{const.}}\\&=\operatorname {E} _{\theta }\left[\left({\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]\right)^{2}\right]+\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)^{2}\\&=\operatorname {Var} _{\theta }({\hat {\theta }})+\operatorname {Bias} _{\theta }({\hat {\theta }},\theta )^{2}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2ac524a751828f971013e1297a33ca1cc4c38cd6)
An even shorter proof can be achieved using the well-known formula that for a random variable  ,
,  . By substituting with,
. By substituting with,  , we have
, we have
![{\displaystyle {\begin{aligned}\operatorname {MSE} ({\hat {\theta }})&=\mathbb {E} [({\hat {\theta }}-\theta )^{2}]\\&=\operatorname {Var} ({\hat {\theta }}-\theta )+(\mathbb {E} [{\hat {\theta }}-\theta ])^{2}\\&=\operatorname {Var} ({\hat {\theta }})+\operatorname {Bias} ^{2}({\hat {\theta }},\theta )\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a89b110dd50aaf64585bb22b53b45f92d39adbf9)
But in real modeling case, MSE could be described as the addition of model variance, model bias, and irreducible uncertainty (see Bias–variance tradeoff). According to the relationship, the MSE of the estimators could be simply used for the efficiency comparison, which includes the information of estimator variance and bias. This is called MSE criterion.
In regression[edit]
In regression analysis, plotting is a more natural way to view the overall trend of the whole data. The mean of the distance from each point to the predicted regression model can be calculated, and shown as the mean squared error. The squaring is critical to reduce the complexity with negative signs. To minimize MSE, the model could be more accurate, which would mean the model is closer to actual data. One example of a linear regression using this method is the least squares method—which evaluates appropriateness of linear regression model to model bivariate dataset,[6] but whose limitation is related to known distribution of the data.
The term mean squared error is sometimes used to refer to the unbiased estimate of error variance: the residual sum of squares divided by the number of degrees of freedom. This definition for a known, computed quantity differs from the above definition for the computed MSE of a predictor, in that a different denominator is used. The denominator is the sample size reduced by the number of model parameters estimated from the same data, (n−p) for p regressors or (n−p−1) if an intercept is used (see errors and residuals in statistics for more details).[7] Although the MSE (as defined in this article) is not an unbiased estimator of the error variance, it is consistent, given the consistency of the predictor.
In regression analysis, «mean squared error», often referred to as mean squared prediction error or «out-of-sample mean squared error», can also refer to the mean value of the squared deviations of the predictions from the true values, over an out-of-sample test space, generated by a model estimated over a particular sample space. This also is a known, computed quantity, and it varies by sample and by out-of-sample test space.
In the context of gradient descent algorithms, it is common to introduce a factor of  to the MSE for ease of computation after taking the derivative. So a value which is technically half the mean of squared errors may be called the MSE.
to the MSE for ease of computation after taking the derivative. So a value which is technically half the mean of squared errors may be called the MSE.
Examples[edit]
Mean[edit]
Suppose we have a random sample of size from a population,  . Suppose the sample units were chosen with replacement. That is, the units are selected one at a time, and previously selected units are still eligible for selection for all draws. The usual estimator for the
. Suppose the sample units were chosen with replacement. That is, the units are selected one at a time, and previously selected units are still eligible for selection for all draws. The usual estimator for the  is the sample average
is the sample average

which has an expected value equal to the true mean (so it is unbiased) and a mean squared error of
![{\displaystyle \operatorname {MSE} \left({\overline {X}}\right)=\operatorname {E} \left[\left({\overline {X}}-\mu \right)^{2}\right]=\left({\frac {\sigma }{\sqrt {n}}}\right)^{2}={\frac {\sigma ^{2}}{n}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b4647a2cc4c8f9a4c90b628faad2dcf80c4aae84)
where  is the population variance.
is the population variance.
For a Gaussian distribution, this is the best unbiased estimator (i.e., one with the lowest MSE among all unbiased estimators), but not, say, for a uniform distribution.
Variance[edit]
The usual estimator for the variance is the corrected sample variance:

This is unbiased (its expected value is ), hence also called the unbiased sample variance, and its MSE is[8]

where  is the fourth central moment of the distribution or population, and
is the fourth central moment of the distribution or population, and  is the excess kurtosis.
is the excess kurtosis.
However, one can use other estimators for which are proportional to  , and an appropriate choice can always give a lower mean squared error. If we define
, and an appropriate choice can always give a lower mean squared error. If we define

then we calculate:
![{\displaystyle {\begin{aligned}\operatorname {MSE} (S_{a}^{2})&=\operatorname {E} \left[\left({\frac {n-1}{a}}S_{n-1}^{2}-\sigma ^{2}\right)^{2}\right]\\&=\operatorname {E} \left[{\frac {(n-1)^{2}}{a^{2}}}S_{n-1}^{4}-2\left({\frac {n-1}{a}}S_{n-1}^{2}\right)\sigma ^{2}+\sigma ^{4}\right]\\&={\frac {(n-1)^{2}}{a^{2}}}\operatorname {E} \left[S_{n-1}^{4}\right]-2\left({\frac {n-1}{a}}\right)\operatorname {E} \left[S_{n-1}^{2}\right]\sigma ^{2}+\sigma ^{4}\\&={\frac {(n-1)^{2}}{a^{2}}}\operatorname {E} \left[S_{n-1}^{4}\right]-2\left({\frac {n-1}{a}}\right)\sigma ^{4}+\sigma ^{4}&&\operatorname {E} \left[S_{n-1}^{2}\right]=\sigma ^{2}\\&={\frac {(n-1)^{2}}{a^{2}}}\left({\frac {\gamma _{2}}{n}}+{\frac {n+1}{n-1}}\right)\sigma ^{4}-2\left({\frac {n-1}{a}}\right)\sigma ^{4}+\sigma ^{4}&&\operatorname {E} \left[S_{n-1}^{4}\right]=\operatorname {MSE} (S_{n-1}^{2})+\sigma ^{4}\\&={\frac {n-1}{na^{2}}}\left((n-1)\gamma _{2}+n^{2}+n\right)\sigma ^{4}-2\left({\frac {n-1}{a}}\right)\sigma ^{4}+\sigma ^{4}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cf22322412b8454c706d78671e5d94208675a6e0)
This is minimized when

For a Gaussian distribution, where  , this means that the MSE is minimized when dividing the sum by
, this means that the MSE is minimized when dividing the sum by  . The minimum excess kurtosis is
. The minimum excess kurtosis is  ,[a] which is achieved by a Bernoulli distribution with p = 1/2 (a coin flip), and the MSE is minimized for
,[a] which is achieved by a Bernoulli distribution with p = 1/2 (a coin flip), and the MSE is minimized for  Hence regardless of the kurtosis, we get a «better» estimate (in the sense of having a lower MSE) by scaling down the unbiased estimator a little bit; this is a simple example of a shrinkage estimator: one «shrinks» the estimator towards zero (scales down the unbiased estimator).
Hence regardless of the kurtosis, we get a «better» estimate (in the sense of having a lower MSE) by scaling down the unbiased estimator a little bit; this is a simple example of a shrinkage estimator: one «shrinks» the estimator towards zero (scales down the unbiased estimator).
Further, while the corrected sample variance is the best unbiased estimator (minimum mean squared error among unbiased estimators) of variance for Gaussian distributions, if the distribution is not Gaussian, then even among unbiased estimators, the best unbiased estimator of the variance may not be 
Gaussian distribution[edit]
The following table gives several estimators of the true parameters of the population, μ and σ2, for the Gaussian case.[9]
| True value | Estimator | Mean squared error |
|---|---|---|
 |
= the unbiased estimator of the population mean,  |

|
 |
= the unbiased estimator of the population variance,  |

|
|
= the biased estimator of the population variance,  |

|
|
= the biased estimator of the population variance,  |

|
Interpretation[edit]
An MSE of zero, meaning that the estimator predicts observations of the parameter with perfect accuracy, is ideal (but typically not possible).
Values of MSE may be used for comparative purposes. Two or more statistical models may be compared using their MSEs—as a measure of how well they explain a given set of observations: An unbiased estimator (estimated from a statistical model) with the smallest variance among all unbiased estimators is the best unbiased estimator or MVUE (Minimum-Variance Unbiased Estimator).
Both analysis of variance and linear regression techniques estimate the MSE as part of the analysis and use the estimated MSE to determine the statistical significance of the factors or predictors under study. The goal of experimental design is to construct experiments in such a way that when the observations are analyzed, the MSE is close to zero relative to the magnitude of at least one of the estimated treatment effects.
In one-way analysis of variance, MSE can be calculated by the division of the sum of squared errors and the degree of freedom. Also, the f-value is the ratio of the mean squared treatment and the MSE.
MSE is also used in several stepwise regression techniques as part of the determination as to how many predictors from a candidate set to include in a model for a given set of observations.
Applications[edit]
- Minimizing MSE is a key criterion in selecting estimators: see minimum mean-square error. Among unbiased estimators, minimizing the MSE is equivalent to minimizing the variance, and the estimator that does this is the minimum variance unbiased estimator. However, a biased estimator may have lower MSE; see estimator bias.
- In statistical modelling the MSE can represent the difference between the actual observations and the observation values predicted by the model. In this context, it is used to determine the extent to which the model fits the data as well as whether removing some explanatory variables is possible without significantly harming the model’s predictive ability.
- In forecasting and prediction, the Brier score is a measure of forecast skill based on MSE.
Loss function[edit]
Squared error loss is one of the most widely used loss functions in statistics[citation needed], though its widespread use stems more from mathematical convenience than considerations of actual loss in applications. Carl Friedrich Gauss, who introduced the use of mean squared error, was aware of its arbitrariness and was in agreement with objections to it on these grounds.[3] The mathematical benefits of mean squared error are particularly evident in its use at analyzing the performance of linear regression, as it allows one to partition the variation in a dataset into variation explained by the model and variation explained by randomness.
Criticism[edit]
The use of mean squared error without question has been criticized by the decision theorist James Berger. Mean squared error is the negative of the expected value of one specific utility function, the quadratic utility function, which may not be the appropriate utility function to use under a given set of circumstances. There are, however, some scenarios where mean squared error can serve as a good approximation to a loss function occurring naturally in an application.[10]
Like variance, mean squared error has the disadvantage of heavily weighting outliers.[11] This is a result of the squaring of each term, which effectively weights large errors more heavily than small ones. This property, undesirable in many applications, has led researchers to use alternatives such as the mean absolute error, or those based on the median.
See also[edit]
- Bias–variance tradeoff
- Hodges’ estimator
- James–Stein estimator
- Mean percentage error
- Mean square quantization error
- Mean square weighted deviation
- Mean squared displacement
- Mean squared prediction error
- Minimum mean square error
- Minimum mean squared error estimator
- Overfitting
- Peak signal-to-noise ratio
Notes[edit]
- ^ This can be proved by Jensen’s inequality as follows. The fourth central moment is an upper bound for the square of variance, so that the least value for their ratio is one, therefore, the least value for the excess kurtosis is −2, achieved, for instance, by a Bernoulli with p=1/2.
References[edit]
- ^ a b «Mean Squared Error (MSE)». www.probabilitycourse.com. Retrieved 2020-09-12.
- ^ Bickel, Peter J.; Doksum, Kjell A. (2015). Mathematical Statistics: Basic Ideas and Selected Topics. Vol. I (Second ed.). p. 20.
If we use quadratic loss, our risk function is called the mean squared error (MSE) …
- ^ a b Lehmann, E. L.; Casella, George (1998). Theory of Point Estimation (2nd ed.). New York: Springer. ISBN 978-0-387-98502-2. MR 1639875.
- ^ Gareth, James; Witten, Daniela; Hastie, Trevor; Tibshirani, Rob (2021). An Introduction to Statistical Learning: with Applications in R. Springer. ISBN 978-1071614174.
- ^ Wackerly, Dennis; Mendenhall, William; Scheaffer, Richard L. (2008). Mathematical Statistics with Applications (7 ed.). Belmont, CA, USA: Thomson Higher Education. ISBN 978-0-495-38508-0.
- ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ Steel, R.G.D, and Torrie, J. H., Principles and Procedures of Statistics with Special Reference to the Biological Sciences., McGraw Hill, 1960, page 288.
- ^ Mood, A.; Graybill, F.; Boes, D. (1974). Introduction to the Theory of Statistics (3rd ed.). McGraw-Hill. p. 229.
- ^ DeGroot, Morris H. (1980). Probability and Statistics (2nd ed.). Addison-Wesley.
- ^ Berger, James O. (1985). «2.4.2 Certain Standard Loss Functions». Statistical Decision Theory and Bayesian Analysis (2nd ed.). New York: Springer-Verlag. p. 60. ISBN 978-0-387-96098-2. MR 0804611.
- ^ Bermejo, Sergio; Cabestany, Joan (2001). «Oriented principal component analysis for large margin classifiers». Neural Networks. 14 (10): 1447–1461. doi:10.1016/S0893-6080(01)00106-X. PMID 11771723.
Среднеквадратическая ошибка, как вы ее написали для OLS, что-то скрывает:
∑in(yi−y^i)2n−2=∑in[yi−(β^0+β^xxi)]2n−2
Обратите внимание, что числитель суммирует функции как y , так и x , поэтому вы теряете степень свободы для каждой переменной, следовательно, n−2 . В формуле для выборочной дисперсии числитель является функцией одной переменной, поэтому вы теряете только одну степень свободы в знаменателе.
Однако вы заметили, что это концептуально схожие величины. Дисперсионная дисперсия измеряет разброс данных вокруг среднего значения выборки (в квадратах), в то время как MSE измеряет вертикальный разброс данных вокруг линии регрессии выборки (в квадратах вертикальных единиц).
Результат любого измерения не определён однозначно и имеет случайную составляющую.
Поэтому адекватным языком для описания погрешностей является язык вероятностей.
Тот факт, что значение некоторой величины «случайно», не означает, что
она может принимать совершенно произвольные значения. Ясно, что частоты, с которыми
возникает те или иные значения, различны. Вероятностные законы, которым
подчиняются случайные величины, называют распределениями.
2.1 Случайная величина
Случайной будем называть величину, значение которой не может быть достоверно определено экспериментатором. Чаще всего подразумевается, что случайная величина будет изменяться при многократном повторении одного и того же эксперимента. При интерпретации результатов измерений в физических экспериментах, обычно случайными также считаются величины, значение которых является фиксированным, но не известно экспериментатору. Например смещение нуля шкалы прибора. Для формализации работы со случайными величинами используют понятие вероятности. Численное значение вероятности того, что какая-то величина примет то или иное значение определяется либо как относительная частота наблюдения того или иного значения при повторении опыта большое количество раз, либо как оценка на основе данных других экспериментов.
Замечание.
Хотя понятия вероятности и случайной величины являются основополагающими, в литературе нет единства в их определении. Обсуждение формальных тонкостей или построение строгой теории лежит за пределами данного пособия. Поэтому на начальном этапе лучше использовать «интуитивное» понимание этих сущностей. Заинтересованным читателям рекомендуем обратиться к специальной литературе: [5].
Рассмотрим случайную физическую величину x, которая при измерениях может
принимать непрерывный набор значений. Пусть
P[x0,x0+δx] — вероятность того, что результат окажется вблизи
некоторой точки x0 в пределах интервала δx: x∈[x0,x0+δx].
Устремим интервал
δx к нулю. Нетрудно понять, что вероятность попасть в этот интервал
также будет стремиться к нулю. Однако отношение
w(x0)=P[x0,x0+δx]δx будет оставаться конечным.
Функцию w(x) называют плотностью распределения вероятности или кратко
распределением непрерывной случайной величины x.
Замечание. В математической литературе распределением часто называют не функцию
w(x), а её интеграл W(x)=∫w(x)𝑑x. Такую функцию в физике принято
называть интегральным или кумулятивным распределением. В англоязычной литературе
для этих функций принято использовать сокращения:
pdf (probability distribution function) и
cdf (cumulative distribution function)
соответственно.
Гистограммы.
Проиллюстрируем наглядно понятие плотности распределения. Результат
большого числа измерений случайной величины удобно представить с помощью
специального типа графика — гистограммы.
Для этого область значений x, размещённую на оси абсцисс, разобьём на
равные малые интервалы — «корзины» или «бины» (англ. bins)
некоторого размера h. По оси ординат будем откладывать долю измерений w,
результаты которых попадают в соответствующую корзину. А именно,
пусть k — номер корзины; nk — число измерений, попавших
в диапазон x∈[kh,(k+1)h]. Тогда на графике изобразим «столбик»
шириной h и высотой wk=nk/n.
В результате получим картину, подобную изображённой на рис. 2.1.
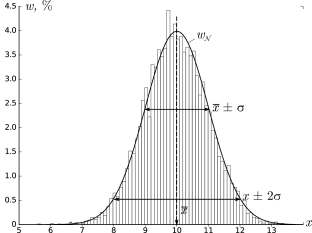
σ=1,0, h=0,1, n=104)
Высоты построенных столбиков будут приближённо соответствовать значению
плотности распределения w(x) вблизи соответствующей точки x.
Если устремить число измерений к бесконечности (n→∞), а ширину корзин
к нулю (h→0), то огибающая гистограммы будет стремиться к некоторой
непрерывной функции w(x).
Самые высокие столбики гистограммы будут группироваться вблизи максимума
функции w(x) — это наиболее вероятное значение случайной величины.
Если отклонения в положительную и отрицательную стороны равновероятны,
то гистограмма будет симметрична — в таком случае среднее значение ⟨x⟩
также будет лежать вблизи этого максимума. Ширина гистограммы будет характеризовать разброс
значений случайной величины — по порядку величины
она, как правило, близка к среднеквадратичному отклонению sx.
Свойства распределений.
Из определения функции w(x) следует, что вероятность получить в результате
эксперимента величину x в диапазоне от a до b
можно найти, вычислив интеграл:
| Px∈[a,b]=∫abw(x)𝑑x. | (2.1) |
Согласно определению вероятности, сумма вероятностей для всех возможных случаев
всегда равна единице. Поэтому интеграл распределения w(x) по всей области
значений x (то есть суммарная площадь под графиком w(x)) равен единице:
Это соотношение называют условием нормировки.
Среднее и дисперсия.
Вычислим среднее по построенной гистограмме. Если размер корзин
h достаточно мал, все измерения в пределах одной корзины можно считать примерно
одинаковыми. Тогда среднее арифметическое всех результатов можно вычислить как
Переходя к пределу, получим следующее определение среднего значения
случайной величины:
где интегрирование ведётся по всей области значений x.
В теории вероятностей x¯ также называют математическим ожиданием
распределения.
Величину
| σ2=(x-x¯)2¯=∫(x-x¯)2w𝑑x | (2.3) |
называют дисперсией распределения. Значение σ есть
срекднеквадратичное отклонение в пределе n→∞. Оно имеет ту
же размерность, что и сама величина x и характеризует разброс распределения.
Именно эту величину, как правило, приводят как характеристику погрешности
измерения x.
Доверительный интервал.
Обозначим как P|Δx|<δ вероятность
того, что отклонение от среднего Δx=x-x¯ составит величину,
не превосходящую по модулю значение δ:
| P|Δx|<δ=∫x¯-δx¯+δw(x)𝑑x. | (2.4) |
Эту величину называют доверительной вероятностью для
доверительного интервала |x-x¯|≤δ.
2.2 Нормальное распределение
Одним из наиболее примечательных результатов теории вероятностей является
так называемая центральная предельная теорема. Она утверждает,
что сумма большого количества независимых случайных слагаемых, каждое
из которых вносит в эту сумму относительно малый вклад, подчиняется
универсальному закону, не зависимо от того, каким вероятностным законам
подчиняются её составляющие, — так называемому нормальному
распределению (или распределению Гаусса).
Доказательство теоремы довольно громоздко и мы его не приводим (его можно найти
в любом учебнике по теории вероятностей). Остановимся
кратко на том, что такое нормальное распределение и его основных свойствах.
Плотность нормального распределения выражается следующей формулой:
| w𝒩(x)=12πσe-(x-x¯)22σ2. | (2.5) |
Здесь x¯ и σ
— параметры нормального распределения: x¯ равно
среднему значению x, a σ —
среднеквадратичному отклонению, вычисленным в пределе n→∞.
Как видно из рис. 2.1, распределение представляет собой
симметричный
«колокол», положение вершины которого
соответствует x¯ (ввиду симметрии оно же
совпадает с наиболее вероятным значением — максимумом
функции w𝒩(x)).
При значительном отклонении x от среднего величина
w𝒩(x)
очень быстро убывает. Это означает, что вероятность встретить отклонения,
существенно большие, чем σ, оказывается пренебрежимо
мала. Ширина «колокола» по порядку величины
равна σ — она характеризует «разброс»
экспериментальных данных относительно среднего значения.
Замечание. Точки x=x¯±σ являются точками
перегиба графика w(x) (в них вторая производная по x
обращается в нуль, w′′=0), а их положение по высоте составляет
w(x¯±σ)/w(x¯)=e-1/2≈0,61
от высоты вершины.
Универсальный характер центральной предельной теоремы позволяет широко
применять на практике нормальное (гауссово) распределение для обработки
результатов измерений, поскольку часто случайные погрешности складываются из
множества случайных независимых факторов. Заметим, что на практике
для приближённой оценки параметров нормального распределения
случайной величины используются выборочные значения среднего
и дисперсии: x¯≈⟨x⟩, sx≈σx.
Вычислим некоторые доверительные вероятности (2.4) для нормально Замечание. Значение интеграла вида ∫e-x2/2𝑑x Вероятность того, что результат отдельного измерения x окажется Вероятность отклонения в пределах x¯±2σ: а в пределах x¯±3σ: Иными словами, при большом числе измерений нормально распределённой Пример. В сообщениях об открытии бозона Хиггса на Большом адронном коллайдере Полученные значения доверительных вероятностей используются при означает, что измеренное значение лежит в диапазоне (доверительном Замечание. Хотя нормальный закон распределения встречается на практике довольно Теперь мы можем дать количественный критерий для сравнения двух измеренных Пусть x1 и x2 (x1≠x2) измерены с Допустим, одна из величин известна с существенно большей точностью: Пусть погрешности измерений сравнимы по порядку величины: Замечание. Изложенные здесь соображения применимы, только если x¯ и x-x0σ2=2w(x)σ1=1
x-x0σ2=2w(x)σ1=1Доверительные вероятности.
распределённых случайных величин.
(его называют интегралом ошибок) в элементарных функциях не выражается,
но легко находится численно.
в пределах x¯±σ оказывается равна
P|Δx|<σ=∫x¯-σx¯+σw𝒩𝑑x≈0,68.
величины можно ожидать, что лишь треть измерений выпадут за пределы интервала
[x¯-σ,x¯+σ]. При этом около 5%
измерений выпадут за пределы [x¯-2σ;x¯+2σ],
и лишь 0,27% окажутся за пределами
[x¯-3σ;x¯+3σ].
говорилось о том, что исследователи ждали подтверждение результатов
с точностью «5 сигма». Используя нормальное распределение (2.5)
нетрудно посчитать, что они использовали доверительную вероятность
P≈1-5,7⋅10-7=0,99999943. Такую точность можно назвать фантастической.
стандартной записи результатов измерений. В физических измерениях
(в частности, в учебной лаборатории), как правило, используется P=0,68,
то есть, запись
интервале) x∈[x¯-δx;x¯+δx] с
вероятностью 68%. Таким образом погрешность ±δx считается
равной одному среднеквадратичному отклонению: δx=σ.
В технических измерениях чаще используется P=0,95, то есть под
абсолютной погрешностью имеется в виду удвоенное среднеквадратичное
отклонение, δx=2σ. Во избежание разночтений доверительную
вероятность следует указывать отдельно.
часто, стоит помнить, что он реализуется далеко не всегда.
Полученные выше соотношения для вероятностей попадания значений в
доверительные интервалы можно использовать в качестве простейшего
признака нормальности распределения: в частности, если количество попадающих
в интервал ±σ результатов существенно отличается от 2/3 — это повод
для более детального исследования закона распределения ошибок.Сравнение результатов измерений.
величин или двух результатов измерения одной и той же величины.
погрешностями σ1 и σ2 соответственно.
Ясно, что если различие результатов |x2-x1| невелико,
его можно объяснить просто случайными отклонениями.
Если же теория предсказывает, что вероятность обнаружить такое отклонение
слишком мала, различие результатов следует признать значимым.
Предварительно необходимо договориться о соответствующем граничном значении
вероятности. Универсального значения здесь быть не может,
поэтому приходится полагаться на субъективный выбор исследователя. Часто
в качестве «разумной» границы выбирают вероятность 5%,
что, как видно из изложенного выше, для нормального распределения
соответствует отклонению более, чем на 2σ.
σ2≪σ1 (например, x1 — результат, полученный
студентом в лаборатории, x2 — справочное значение).
Поскольку σ2 мало, x2 можно принять за «истинное»:
x2≈x¯. Предполагая, что погрешность измерения
x1 подчиняется нормальному закону с и дисперсией σ12,
можно утверждать, что
различие считают будет значимы, если
σ1∼σ2. В теории вероятностей показывается, что
линейная комбинация нормально распределённых величин также имеет нормальное
распределение с дисперсией σ2=σ12+σ22
(см. также правила сложения погрешностей (2.7)). Тогда
для проверки гипотезы о том, что x1 и x2 являются измерениями
одной и той же величины, нужно вычислить, является ли значимым отклонение
|x1-x2| от нуля при σ=σ12+σ22.
Пример. Два студента получили следующие значения для теплоты испарения
некоторой жидкости: x1=40,3±0,2 кДж/моль и
x2=41,0±0,3 кДж/моль, где погрешность соответствует
одному стандартному отклонению. Можно ли утверждать, что они исследовали
одну и ту же жидкость?
Имеем наблюдаемую разность |x1-x2|=0,7 кДж/моль,
среднеквадратичное отклонение для разности
σ=0,22+0,32=0,36 кДж/моль.
Их отношение |x2-x1|σ≈2. Из
свойств нормального распределения находим вероятность того, что измерялась
одна и та же величина, а различия в ответах возникли из-за случайных
ошибок: P≈5%. Ответ на вопрос, «достаточно»
ли мала или велика эта вероятность, остаётся на усмотрение исследователя.
его стандартное отклонение σ получены на основании достаточно
большой выборки n≫1 (или заданы точно). При небольшом числе измерений
(n≲10) выборочные средние ⟨x⟩ и среднеквадратичное отклонение
sx сами имеют довольно большую ошибку, а
их распределение будет описываться не нормальным законом, а так
называемым t-распределением Стъюдента. В частности, в зависимости от
значения n интервал ⟨x⟩±sx будет соответствовать несколько
меньшей доверительной вероятности, чем P=0,68. Особенно резко различия
проявляются при высоких уровнях доверительных вероятностей P→1.
2.3 Независимые величины
Величины x и y называют независимыми если результат измерения одной
из них никак не влияет на результат измерения другой. Для таких величин вероятность того, что x окажется в некоторой области X, и одновременно y — в области Y,
равна произведению соответствующих вероятностей:
Обозначим отклонения величин от их средних как Δx=x-x¯ и
Δy=y-y¯.
Средние значения этих отклонений равны, очевидно, нулю: Δx¯=x¯-x¯=0,
Δy¯=0. Из независимости величин x и y следует,
что среднее значение от произведения Δx⋅Δy¯
равно произведению средних Δx¯⋅Δy¯
и, следовательно, равно нулю:
| Δx⋅Δy¯=Δx¯⋅Δy¯=0. | (2.6) |
Пусть измеряемая величина z=x+y складывается из двух независимых
случайных слагаемых x и y, для которых известны средние
x¯ и y¯, и их среднеквадратичные погрешности
σx и σy. Непосредственно из определения (1.1)
следует, что среднее суммы равно сумме средних:
Найдём дисперсию σz2. В силу независимости имеем
| Δz2¯=Δx2¯+Δy2¯+2Δx⋅Δy¯≈Δx2¯+Δy2¯, |
то есть:
Таким образом, при сложении независимых величин их погрешности
складываются среднеквадратичным образом.
Подчеркнём, что для справедливости соотношения (2.7)
величины x и y не обязаны быть нормально распределёнными —
достаточно существования конечных значений их дисперсий. Однако можно
показать, что если x и y распределены нормально, нормальным
будет и распределение их суммы.
Замечание. Требование независимости
слагаемых является принципиальным. Например, положим y=x. Тогда
z=2x. Здесь y и x, очевидно, зависят друг от друга. Используя
(2.7), находим σ2x=2σx,
что, конечно, неверно — непосредственно из определения
следует, что σ2x=2σx.
Отдельно стоит обсудить математическую структуру формулы (2.7).
Если одна из погрешностей много больше другой, например,
σx≫σy,
то меньшей погрешностью можно пренебречь, σx+y≈σx.
С другой стороны, если два источника погрешностей имеют один порядок
σx∼σy, то и σx+y∼σx∼σy.
Эти обстоятельства важны при планирования эксперимента: как правило,
величина, измеренная наименее точно, вносит наибольший вклад в погрешность
конечного результата. При этом, пока не устранены наиболее существенные
ошибки, бессмысленно гнаться за повышением точности измерения остальных
величин.
Пример. Пусть σy=σx/3,
тогда σz=σx1+19≈1,05σx,
то есть при различии двух погрешностей более, чем в 3 раза, поправка
к погрешности составляет менее 5%, и уже нет особого смысла в учёте
меньшей погрешности: σz≈σx. Это утверждение
касается сложения любых независимых источников погрешностей в эксперименте.
2.4 Погрешность среднего
Выборочное среднее арифметическое значение ⟨x⟩, найденное
по результатам n измерений, само является случайной величиной.
Действительно, если поставить серию одинаковых опытов по n измерений,
то в каждом опыте получится своё среднее значение, отличающееся от
предельного среднего x¯.
Вычислим среднеквадратичную погрешность среднего арифметического
σ⟨x⟩.
Рассмотрим вспомогательную сумму n слагаемых
Если {xi} есть набор независимых измерений
одной и той же физической величины, то мы можем, применяя результат
(2.7) предыдущего параграфа, записать
| σZ=σx12+σx22+…+σxn2=nσx, |
поскольку под корнем находится n одинаковых слагаемых. Отсюда с
учётом ⟨x⟩=Z/n получаем
Таким образом, погрешность среднего значения x по результатам
n независимых измерений оказывается в n раз меньше погрешности
отдельного измерения. Это один из важнейших результатов, позволяющий
уменьшать случайные погрешности эксперимента за счёт многократного
повторения измерений.
Подчеркнём отличия между σx и σ⟨x⟩:
величина σx — погрешность отдельного
измерения — является характеристикой разброса значений
в совокупности измерений {xi}, i=1..n. При
нормальном законе распределения примерно 68% измерений попадают в
интервал ⟨x⟩±σx;
величина σ⟨x⟩ — погрешность
среднего — характеризует точность, с которой определено
среднее значение измеряемой физической величины ⟨x⟩ относительно
предельного («истинного») среднего x¯;
при этом с доверительной вероятностью P=68% искомая величина x¯
лежит в интервале
⟨x⟩-σ⟨x⟩<x¯<⟨x⟩+σ⟨x⟩.
2.5 Результирующая погрешность опыта
Пусть для некоторого результата измерения известна оценка его максимальной
систематической погрешности Δсист и случайная
среднеквадратичная
погрешность σслуч. Какова «полная»
погрешность измерения?
Предположим для простоты, что измеряемая величина в принципе
может быть определена сколь угодно точно, так что можно говорить о
некотором её «истинном» значении xист
(иными словами, погрешность результата связана в основном именно с
процессом измерения). Назовём полной погрешностью измерения
среднеквадратичное значения отклонения от результата измерения от
«истинного»:
Отклонение x-xист можно представить как сумму случайного
отклонения от среднего δxслуч=x-x¯
и постоянной (но, вообще говоря, неизвестной) систематической составляющей
δxсист=x¯-xист=const:
Причём случайную составляющую можно считать независимой от систематической.
В таком случае из (2.7) находим:
| σполн2=⟨δxсист2⟩+⟨δxслуч2⟩≤Δсист2+σслуч2. | (2.9) |
Таким образом, для получения максимального значения полной
погрешности некоторого измерения нужно квадратично сложить максимальную
систематическую и случайную погрешности.
Если измерения проводятся многократно, то согласно (2.8)
случайная составляющая погрешности может быть уменьшена, а систематическая
составляющая при этом остаётся неизменной:
Отсюда следует важное практическое правило
(см. также обсуждение в п. 2.3): если случайная погрешность измерений
в 2–3 раза меньше предполагаемой систематической, то
нет смысла проводить многократные измерения в попытке уменьшить погрешность
всего эксперимента. В такой ситуации измерения достаточно повторить
2–3 раза — чтобы убедиться в повторяемости результата, исключить промахи
и проверить, что случайная ошибка действительно мала.
В противном случае повторение измерений может иметь смысл до
тех пор, пока погрешность среднего
σ⟨x⟩=σxn
не станет меньше систематической.
Замечание. Поскольку конкретная
величина систематической погрешности, как правило, не известна, её
можно в некотором смысле рассматривать наравне со случайной —
предположить, что её величина была определена по некоторому случайному
закону перед началом измерений (например, при изготовлении линейки
на заводе произошло некоторое случайное искажение шкалы). При такой
трактовке формулу (2.9) можно рассматривать просто
как частный случай формулы сложения погрешностей независимых величин
(2.7).
Подчеркнем, что вероятностный закон, которому подчиняется
систематическая ошибка, зачастую неизвестен. Поэтому неизвестно и
распределение итогового результата. Из этого, в частности, следует,
что мы не можем приписать интервалу x±Δсист какую-либо
определённую доверительную вероятность — она равна 0,68
только если систематическая ошибка имеет нормальное распределение.
Можно, конечно, предположить,
— и так часто делают — что, к примеру, ошибки
при изготовлении линеек на заводе имеют гауссов характер. Также часто
предполагают, что систематическая ошибка имеет равномерное
распределение (то есть «истинное» значение может с равной вероятностью
принять любое значение в пределах интервала ±Δсист).
Строго говоря, для этих предположений нет достаточных оснований.
Пример. В результате измерения диаметра проволоки микрометрическим винтом,
имеющим цену деления h=0,01 мм, получен следующий набор из n=8 значений:
Вычисляем среднее значение: ⟨d⟩≈386,3 мкм.
Среднеквадратичное отклонение:
σd≈9,2 мкм. Случайная погрешность среднего согласно
(2.8):
σ⟨d⟩=σd8≈3,2
мкм. Все результаты лежат в пределах ±2σd, поэтому нет
причин сомневаться в нормальности распределения. Максимальную погрешность
микрометра оценим как половину цены деления, Δ=h2=5 мкм.
Результирующая полная погрешность
σ≤Δ2+σd28≈6,0 мкм.
Видно, что σслуч≈Δсист и проводить дополнительные измерения
особого смысла нет. Окончательно результат измерений может быть представлен
в виде (см. также правила округления
результатов измерений в п. 4.3.2)
d=386±6мкм,εd=1,5%.
Заметим, что поскольку случайная погрешность и погрешность
прибора здесь имеют один порядок величины, наблюдаемый случайный разброс
данных может быть связан как с неоднородностью сечения проволоки,
так и с дефектами микрометра (например, с неровностями зажимов, люфтом
винта, сухим трением, деформацией проволоки под действием микрометра
и т. п.). Для ответа на вопрос, что именно вызвало разброс, требуются
дополнительные исследования, желательно с использованием более точных
приборов.
Пример. Измерение скорости
полёта пули было осуществлено с погрешностью δv=±1 м/c.
Результаты измерений для n=6 выстрелов представлены в таблице:
Усреднённый результат ⟨v⟩=162,0м/с,
среднеквадратичное отклонение σv=13,8м/c, случайная
ошибка для средней скорости
σv¯=σv/6=5,6м/с.
Поскольку разброс экспериментальных данных существенно превышает погрешность
каждого измерения, σv≫δv, он почти наверняка связан
с реальным различием скоростей пули в разных выстрелах, а не с ошибками
измерений. В качестве результата эксперимента представляют интерес
как среднее значение скоростей ⟨v⟩=162±6м/с
(ε≈4%), так и значение σv≈14м/с,
характеризующее разброс значений скоростей от выстрела к выстрелу.
Малая инструментальная погрешность в принципе позволяет более точно
измерить среднее и дисперсию, и исследовать закон распределения выстрелов
по скоростям более детально — для этого требуется набрать
бо́льшую статистику по выстрелам.
Пример. Измерение скорости
полёта пули было осуществлено с погрешностью δv=10 м/c. Результаты
измерений для n=6 выстрелов представлены в таблице:
Усреднённый результат ⟨v⟩=163,3м/с,
σv=12,1м/c, σ⟨v⟩=5м/с,
σполн≈11,2м/с. Инструментальная
погрешность каждого измерения превышает разброс данных, поэтому в
этом опыте затруднительно сделать вывод о различии скоростей от выстрела
к выстрелу. Результат измерений скорости пули:
⟨v⟩=163±11м/с,
ε≈7%. Проводить дополнительные выстрелы при такой
большой инструментальной погрешности особого смысла нет —
лучше поработать над точностью приборов и методикой измерений.
2.6 Обработка косвенных измерений
Косвенными называют измерения, полученные в результате расчётов,
использующих результаты прямых (то есть «непосредственных»)
измерений физических величин. Сформулируем основные правила пересчёта
погрешностей при косвенных измерениях.
2.6.1 Случай одной переменной
Пусть в эксперименте измеряется величина x, а её «наилучшее»
(в некотором смысле) значение равно x⋆ и оно известно с
погрешностью σx. После чего с помощью известной функции
вычисляется величина y=f(x).
В качестве «наилучшего» приближения для y используем значение функции
при «наилучшем» x:
Найдём величину погрешности σy. Обозначая отклонение измеряемой
величины как Δx=x-x⋆, и пользуясь определением производной,
при условии, что функция y(x) — гладкая
вблизи x≈x⋆, запишем
где f′≡dydx — производная фукнции f(x), взятая в точке
x⋆. Возведём полученное в квадрат, проведём усреднение
(σy2=⟨Δy2⟩,
σx2=⟨Δx2⟩), и затем снова извлечём
корень. В результате получим
Пример. Для степенной функции
y=Axn имеем σy=nAxn-1σx, откуда
σyy=nσxx,или εy=nεx,
то есть относительная погрешность степенной функции возрастает пропорционально
показателю степени n.
Пример. Для y=1/x имеем ε1/x=εx
— при обращении величины сохраняется её относительная
погрешность.
Упражнение. Найдите погрешность логарифма y=lnx, если известны x
и σx.
Упражнение. Найдите погрешность показательной функции y=ax,
если известны x и σx. Коэффициент a задан точно.
2.6.2 Случай многих переменных
Пусть величина u вычисляется по измеренным значениям нескольких
различных независимых физических величин x, y, …
на основе известного закона u=f(x,y,…). В качестве
наилучшего значения можно по-прежнему взять значение функции f
при наилучших значениях измеряемых параметров:
Для нахождения погрешности σu воспользуемся свойством,
известным из математического анализа, — малые приращения гладких
функции многих переменных складываются линейно, то есть справедлив
принцип суперпозиции малых приращений:
где символом fx′≡∂f∂x обозначена
частная производная функции f по переменной x —
то есть обычная производная f по x, взятая при условии, что
все остальные аргументы (кроме x) считаются постоянными параметрами.
Тогда пользуясь формулой для нахождения дисперсии суммы независимых
величин (2.7), получим соотношение, позволяющее вычислять
погрешности косвенных измерений для произвольной функции
u=f(x,y,…):
| σu2=fx′2σx2+fy′2σy2+… | (2.11) |
Это и есть искомая общая формула пересчёта погрешностей при косвенных
измерениях.
Отметим, что формулы (2.10) и (2.11) применимы
только если относительные отклонения всех величин малы
(εx,εy,…≪1),
а измерения проводятся вдали от особых точек функции f (производные
fx′, fy′ … не должны обращаться в бесконечность).
Также подчеркнём, что все полученные здесь формулы справедливы только
для независимых переменных x, y, …
Остановимся на некоторых важных частных случаях формулы
(2.11).
Пример. Для суммы (или разности) u=∑i=1naixi имеем
σu2=∑i=1nai2σxi2.
(2.12)
Пример. Найдём погрешность степенной функции:
u=xα⋅yβ⋅…. Тогда нетрудно получить,
что
σu2u2=α2σx2x2+β2σy2y2+…
или через относительные погрешности
εu2=α2εx2+β2εy2+…
(2.13)
Пример. Вычислим погрешность произведения и частного: u=xy или u=x/y.
Тогда в обоих случаях имеем
εu2=εx2+εy2,
(2.14)
то есть при умножении или делении относительные погрешности складываются
квадратично.
Пример. Рассмотрим несколько более сложный случай: нахождение угла по его тангенсу
u=arctgyx.
В таком случае, пользуясь тем, что (arctgz)′=11+z2,
где z=y/x, и используя производную сложной функции, находим
ux′=uz′zx′=-yx2+y2,
uy′=uz′zy′=xx2+y2, и наконец
σu2=y2σx2+x2σy2(x2+y2)2.
Упражнение. Найти погрешность вычисления гипотенузы z=x2+y2
прямоугольного треугольника по измеренным катетам x и y.
По итогам данного раздела можно дать следующие практические рекомендации.
-
•
Как правило, нет смысла увеличивать точность измерения какой-то одной
величины, если другие величины, используемые в расчётах, остаются
измеренными относительно грубо — всё равно итоговая погрешность
скорее всего будет определяться самым неточным измерением. Поэтому
все измерения имеет смысл проводить примерно с одной и той же
относительной погрешностью. -
•
При этом, как следует из (2.13), особое внимание
следует уделять измерению величин, возводимых при расчётах в степени
с большими показателями. А при сложных функциональных зависимостях
имеет смысл детально проанализировать структуру формулы
(2.11):
если вклад от некоторой величины в общую погрешность мал, нет смысла
гнаться за высокой точностью её измерения, и наоборот, точность некоторых
измерений может оказаться критически важной. -
•
Следует избегать измерения малых величин как разности двух близких
значений (например, толщины стенки цилиндра как разности внутреннего
и внешнего радиусов): если u=x-y, то абсолютная погрешность
σu=σx2+σy2
меняется мало, однако относительная погрешность
εu=σux-y
может оказаться неприемлемо большой, если x≈y.
Стандартное отклонение среднего результата, выборочную дисперсию среднего значения, доверительный интервал и точность определения используют для различных статистических расчетов. При оценке точности полученных результатов вычисляют стандартное отклонение среднего результата (среднюю квадратичную ошибку среднего арифметического) [c.195]
Статистические характеристики случайных величин. Важнейшими характеристиками случайных величин являются дисперсия, средняя квадратичная ошибка (стандартное отклонение), коэффициент вариации, среднее значение. Дисперсия (а — для генеральной совокупности и — для выборки) — характеризует степень разброса полученных результатов относительно среднего значения резуль- [c.6]
Например, при повторных взвешиваниях стеклянного фильтра были получены следующие результаты (в г) 10,2375 10,2374 10,2378 10,2375. Определить среднее арифметическое значение, дисперсию, среднюю квадратичную ошибку, среднюю квадратичную ошибку среднего арифметического, коэффициент нормирования отклонений, вероятное квадратичное отклонение среднего арифметического, истинную массу стеклянного фильтра и относительную ошибку взвешивания с надежностью а, равной 0,95. Для удобства вычислений запишем данные в виде таблицы [c.302]
При оценке точности полученных результатов вычисляют также выборочную дисперсию средней квадратичной ошибки [c.227]
Находим дисперсию, среднюю квадратичную ошибку и доверительный интервал найденной константы уравнения [c.103]
Среднее значение Дисперсия средне- квадратичная ошибка [c.289]
Среднюю квадратичную ошибку всегда указывают только по величине, и ее квадрат называют дисперсией. Стоящая в знаменателе уравнения (2.3.2) величина л — т соответствует числу контрольных определений ее называют числом степеней свободы /. Суммы квадратов разностей в уравнении (2.3.2) для каждой серии j рассчитывают по формуле [c.23]
При безошибочных измерениях влияние фиктивных переменных х , Хз, х , Xg должно было быть равным нулю. Однако вследствие случайной ошибки оно рассеивается в области нуля. Исходя из рассчитанных влияний кажущихся переменных W s, можно найти среднюю квадратичную ошибку s и дисперсию s . [c.38]
При определении алюминия в хроме [159] используют спектрограф средней дисперсии, спектры возбуждают в дуге переменного тока при 6а, задающем промежутке 0,8 мм и дуговом промежутке 3 лш. Второй электрод — медный стержень Диаметром 6—8 мм, заточенный на усеченный конус с площадкой 2 лш. Предварительный обжиг 10 сек., экспозиция 15 сек. Используют фотопластинки типа 1. Аналитическая пара линий А1 3082,16 — Сг 3077,83 А. Определяемые пределы 0 11—1,0% алюминия, средняя квадратичная ошибка метода 3%. [c.153]
Положительное значение корня квадратного из дисперсии называется средней квадратичной ошибкой отдельного определения или выборочным стандартным отклонением [c.267]
Выборочная дисперсия среднего значения и средняя квадратичная ошибка среднего арифметического. Для оценки воспроизводимости полученных результатов вычисляют также выборочную дисперсию среднего значения (среднего результата) [c.267]
При измерениях радиоактивности скорость счета исследуемого образца определяется как разность между суммарной скоростью счета препарата с фоном и скоростью счета фона (6—П). Поэтому важно знать, какое влияние оказывает фон на точность измерений радиоактивных препаратов. Если определена дисперсия суммарной скорости счета препарата с фоном и дисперсия фона, то абсолютное статистическое отклонение и средняя квадратичная ошибка [c.80]
Дисперсия и средняя квадратичная ошибка [c.42]
Во всех случаях квадратный корень из дисперсии параметра дает среднюю квадратичную ошибку, а доверительный интервал параметра вычисляют по формулам [c.91]
Дисперсия и средняя квадратичная ошибка. Рассеяние случайной величины относительно среднего принято характеризовать дисперсией. Чем меньше точность измерений, тем больше дисперсия. Для п найденных значений x , случайной величины выборочная дисперсия определяется выражением [c.26]
Последняя колонка табл. 42 показывает, что 1) ошибки между подгруппами значительно превышают ошибки внутри подгруппы и отношение их дисперсий превышает 70 2) дисперсия внутри подгруппы сравн,има со значением N , представляющим собой квадрат средней квадратичной ошибки счета из уравнения (98). [c.300]
Результаты испытаний четвертой группы приведены в табл. 44. Найденные значения дисперсии показывают, что средняя квадратичная ошибка установки образца сравнима со средней квадратичной ошибкой счета. При таких условиях десяти- [c.302]
Средняя квадратичная ошибка (соответственно дисперсия 2) получается из уравнения 2 1 ( 1 — 1) Ч- 1 ( 2— 1) + + ( т -1) [c.94]
Для выбранного в конце концов математического описания находят далее среднюю квадратичную ошибку найденных параметров (различных констант, порядков реакции, энергий активации). Как доказывается в курсах математической статистики, величина дисперсии в единственной константе 0 равна обратному значению второй производной минимизируемой функции остаточной суммы квадратов по данному параметру [c.262]
Когда одновременно определяются два или более параметра уравнения, общее решение для средней квадратичной ошибки и дисперсии каждого из параметров сильно усложняется с ним можно познакомиться в специальной литературе. [c.262]
После нахождения дисперсии параметра приводят его численное значение с указанием средней квадратичной ошибки с учетом которой в величине параметра исключают излишние значащие цифры. Кроме того, нередко вычисляют доверительные интервалы найденных параметров [c.262]
При четырех параллельных опытах найдены следующие значения концентраций 0,264, 0,272, 0,267, 0,259 моль/л. Подсчитайте среднюю квадратичную ошибку и дисперсию воспроизводимости. [c.305]
Определите адекватность модели и среднюю квадратичную ошибку константы скорости для примера, приведенного на стр. 269, если дисперсия, воспроизводимости в абсолютной величине С по четырем параллельным опытам составила 0,00004. [c.305]
Выше рассматривались задача об установлении доверительных пределов для среднего результата. Подобную же задачу можно поставить и применительно к оценке другого примера — средней квадратичной ошибки (или ее квадрата — дисперсии). [c.32]
Для решения задач подобного типа пользуются так называемым дисперсионным анализом, т. е. приемом, имеющим целью разделить общую дисперсию (квадрат средней квадратичной ошибки) на составляющие, что позволяет оценить относительную величину каждой из них. [c.37]
Однако обычно в качестве показателя вариабельности применяются среднее квадратическое отклонение, дисперсия и коэффициент вари а ц и и. Среднее квадратическое отклонение, иногда называемое средней квадратичной ошибкой или стандартным отклонением, определяется по формуле [c.247]
Результаты расчетов сводят в таблицу по приводимой ниже форме. Обозначения в таблице следующие а — истинное содержание компонента п — число измерений X — средний результат — дисперсия 5 — стандартное отклонение отдельного результата (средняя квадратичная ошибка) — стандартное отклонение среднего результата (средняя квадратичная ошибка серии нзмере- [c.237]
Источником возбуждения служит дуга постоянного тока (400 в, 5,8 а), поджигаемая мощным высокочастотным разрядом. Брикеты устанавливают на угольный электрод (катод) диаметром 10 лш. Электрод имеет небольшое углубление для удерживания капли расплава окислов. В качестве постоянного электрода применяют медный пруток диаметром 6—8 мм, заточенный на усеченный конус с округленным концом. Используется спектрограф средней дисперсии, ширина щели 0,02—0,025 мм, экспозиция 60 сек. Более подробное описание методики см. в работе [212а]. Аналитическая пара линий А1 3082,16 — Си 3088,13 А, определяемые пределы 0,002—0,40% алюминия, средняя квадратичная ошибка метода составляет 5%. [c.155]
При анализе карбонатов кальция и магния, смитсонита и цинковых обманок используют горизонтальную дугу переменного тока (8а) между угольными электродами, наполненными Na l. Пробу смешивают с Naa Og и NaNOg и вводят в дугу на полосках бумаги. Аналитической парой линий служит d 3261,0 — Sb 3232,5 А. Метод применим в интервале концентраций 0,02— 0,05% d, средняя квадратичная ошибка 11—17% [359]. При совместном определении d и Zn в рудах и технологических продуктах на дифракционном спектрографе ДФС-13 (при дисперсии 1 А]мм) линия кадмия 3261,0 А полностью отделяется от линий железа даже при анализе железных руд. Для идентичности форм нахождения кадмия и цинка в пробах и эталонах последние готовят разбавлением пустой породой цинкового концентрата с известным содержанием обоих элементов. Эталоны и пробы разбавляют этой смесью в отношении 1 4 и набивают в угольные электроды. Спектры возбуждают в дуге постоянного тока (15а) и фотографируют на фотопластинках типа СП-3 или СП-2 в течение 30 сек. Ширина щели спектрографа 0,030— 0,035 мм. При анализе проб с содержанием кадмия >0,1% спектры фотографируют через трехступенчатый ослабитель. Определение производят по линиям d — 3261,0 (Jan) — Ge 3260,5 А (J p) градуировочные кривые строят в координатах lg (Jan/ p) — с учетом фона вблизи линий кадмия. Интервал определимых концентраций [c.167]
Статистический анализ результатов эксперимента и уравнения регрессии показал следующее. Дисперсия параметра оптимизации равна 5,4. Средняя квадратичная ошибка эксперимента ( 2,33%) вполне удовлетворительна. Наиболее значимыми коэффициентами регрессии оказались 64. >5. Ьв. Из этого следует, что выход 2-этилкарбаматбензимидазола больше всего зависит от концентрации цианамида кальция (Х ), диэтил карбоната (Х5) и температуры реакции на первой стадии (Хе). Значение этих трех факторов следует увеличивать, поскольку перед этими коэффициентами регрессии стоит знак плюс. Количество кислоты (Хз), наоборот, необходимо уменьшать. Время первой и второй стадий в данных интервалах варьирования незначительно влияет на этот процесс. Проверка адекватности линейной модели по критерию Фишера показала, что модель адекватна, поскольку / эксп=0,13 / табл = 3,8 5ад —0,7. [c.150]
Монолитные образцы металлического циркония Дуговой разряд между о разцом и графитовым проти-воэлектродом от генератора с электронным управлением Спектрограф С дифракционной решеткой (дисперсия 2,5 А мм) и большой кварцевый спектрограф Хильгера 2.10-3-2-Ю-Ш.Сг, 51, V 5.10-5-5-10- В, са 1-10-8-1.10-2 Со, Мп,Т1 1.10-3—2.10-2 Си, N1 1-10-2—1,5.10-1 Ре 1-10-2—1.10-1 НГ 5.10-4—2,5.10-8 Мд 2.10-3—1,5.10-2 Мо 2-10-3—3-10-2 РЬ 5-10-8-3,5-10-2 Средняя квадратичная ошибка метода от 2 до 10% для отдельных элементов [437] [c.207]
Для оценки точности или надежности результатов аналитических определений пользуются статистической обработкой результатов и вычисляют следующие величины среднее арифметическое дисперсию 5 , среднюю квадратичную ошибку 5, среднюю квадратичную ошибку среднего арифметического Зх, коэффициент нормирования отклонений /а, к и интервальное значение измеряемой величины или доверительный интервал Ия. [c.299]
Проверяют соотношение а 0,75ст. Если оно выполняется, то проделанных 25 измерений достаточно, чтобы утверждать, что средняя величина размера частиц дисперсии равна А с вероятностью 0,999 и абсолютной а, относительной е и средней квадратичной ошибкой а соответственно. [c.64]
Она является мерох разброса, используемой в аналитической химии почти всегда и характеризующей случайную ошибку метода анализа (но не единичные значения, ср. гл. 6). Средняя квадратичная ошибка является лучшим приближением для соответствующей величины сг в генеральной совокупности. Ее квадрат. 9 (соответственно а ) называют дисперсией. [c.29]