From Wikipedia, the free encyclopedia
The mean absolute percentage error (MAPE), also known as mean absolute percentage deviation (MAPD), is a measure of prediction accuracy of a forecasting method in statistics. It usually expresses the accuracy as a ratio defined by the formula:

where At is the actual value and Ft is the forecast value. Their difference is divided by the actual value At. The absolute value of this ratio is summed for every forecasted point in time and divided by the number of fitted points n.
MAPE in regression problems[edit]
Mean absolute percentage error is commonly used as a loss function for regression problems and in model evaluation, because of its very intuitive interpretation in terms of relative error.
Definition[edit]
Consider a standard regression setting in which the data are fully described by a random pair  with values in
with values in  , and n i.i.d. copies
, and n i.i.d. copies  of
of  . Regression models aim at finding a good model for the pair, that is a measurable function g from
. Regression models aim at finding a good model for the pair, that is a measurable function g from  to
to  such that
such that  is close to Y.
is close to Y.
In the classical regression setting, the closeness of to Y is measured via the L2 risk, also called the mean squared error (MSE). In the MAPE regression context,[1] the closeness of to Y is measured via the MAPE, and the aim of MAPE regressions is to find a model  such that:
such that:
![{\displaystyle g_{\mathrm {MAPE} }(x)=\arg \min _{g\in {\mathcal {G}}}\mathbb {E} {\Biggl [}\left|{\frac {g(X)-Y}{Y}}\right||X=x{\Biggr ]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5d1d5361807456edf90eb56a90450ac09d5964a2)
where  is the class of models considered (e.g. linear models).
is the class of models considered (e.g. linear models).
In practice
In practice  can be estimated by the empirical risk minimization strategy, leading to
can be estimated by the empirical risk minimization strategy, leading to

From a practical point of view, the use of the MAPE as a quality function for regression model is equivalent to doing weighted mean absolute error (MAE) regression, also known as quantile regression. This property is trivial since

As a consequence, the use of the MAPE is very easy in practice, for example using existing libraries for quantile regression allowing weights.
Consistency[edit]
The use of the MAPE as a loss function for regression analysis is feasible both on a practical point of view and on a theoretical one, since the existence of an optimal model and the consistency of the empirical risk minimization can be proved.[1]
WMAPE[edit]
WMAPE (sometimes spelled wMAPE) stands for weighted mean absolute percentage error.[2] It is a measure used to evaluate the performance of regression or forecasting models. It is a variant of MAPE in which the mean absolute percent errors is treated as a weighted arithmetic mean. Most commonly the absolute percent errors are weighted by the actuals (e.g. in case of sales forecasting, errors are weighted by sales volume).[3]. Effectively, this overcomes the ‘infinite error’ issue.[4]
Its formula is:[4]

Where  is the weight,
is the weight,  is a vector of the actual data and
is a vector of the actual data and  is the forecast or prediction.
is the forecast or prediction.
However, this effectively simplifies to a much simpler formula:

Confusingly, sometimes when people refer to wMAPE they are talking about a different model in which the numerator and denominator of the wMAPE formula above are weighted again by another set of custom weights . Perhaps it would be more accurate to call this the double weighted MAPE (wwMAPE). Its formula is:

Issues[edit]
Although the concept of MAPE sounds very simple and convincing, it has major drawbacks in practical application,[5] and there are many studies on shortcomings and misleading results from MAPE.[6][7]
To overcome these issues with MAPE, there are some other measures proposed in literature:
- Mean Absolute Scaled Error (MASE)
- Symmetric Mean Absolute Percentage Error (sMAPE)
- Mean Directional Accuracy (MDA)
- Mean Arctangent Absolute Percentage Error (MAAPE): MAAPE can be considered a slope as an angle, while MAPE is a slope as a ratio.[7]
See also[edit]
- Least absolute deviations
- Mean absolute error
- Mean percentage error
- Symmetric mean absolute percentage error
External links[edit]
- Mean Absolute Percentage Error for Regression Models
- Mean Absolute Percentage Error (MAPE)
- Errors on percentage errors — variants of MAPE
- Mean Arctangent Absolute Percentage Error (MAAPE)
References[edit]
- ^ a b de Myttenaere, B Golden, B Le Grand, F Rossi (2015). «Mean absolute percentage error for regression models», Neurocomputing 2016 arXiv:1605.02541
- ^ Forecast Accuracy: MAPE, WAPE, WMAPE https://www.baeldung.com/cs/mape-vs-wape-vs-wmape%7Ctitle=Understanding Forecast Accuracy: MAPE, WAPE, WMAPE. ;
- ^ Weighted Mean Absolute Percentage Error https://ibf.org/knowledge/glossary/weighted-mean-absolute-percentage-error-wmape-299%7Ctitle=WMAPE: Weighted Mean Absolute Percentage Error. ;
- ^ a b «Statistical Forecast Errors».
- ^ a b Tofallis (2015). «A Better Measure of Relative Prediction Accuracy for Model Selection and Model Estimation», Journal of the Operational Research Society, 66(8):1352-1362. archived preprint
- ^ Hyndman, Rob J., and Anne B. Koehler (2006). «Another look at measures of forecast accuracy.» International Journal of Forecasting, 22(4):679-688 doi:10.1016/j.ijforecast.2006.03.001.
- ^ a b Kim, Sungil and Heeyoung Kim (2016). «A new metric of absolute percentage error for intermittent demand forecasts.» International Journal of Forecasting, 32(3):669-679 doi:10.1016/j.ijforecast.2015.12.003.
- ^ Kim, Sungil; Kim, Heeyoung (1 July 2016). «A new metric of absolute percentage error for intermittent demand forecasts». International Journal of Forecasting. 32 (3): 669–679. doi:10.1016/j.ijforecast.2015.12.003.
- ^ Makridakis, Spyros (1993) «Accuracy measures: theoretical and practical concerns.» International Journal of Forecasting, 9(4):527-529 doi:10.1016/0169-2070(93)90079-3
читать 2 мин
Одной из наиболее распространенных метрик, используемых для измерения точности прогнозирования модели, является средняя абсолютная ошибка в процентах , часто обозначаемая аббревиатурой MAPE .
Он рассчитывается как:
MAPE = (1/n) * Σ(|факт – прогноз| / |факт|) * 100
куда:
- Σ — символ, означающий «сумма».
- n – размер выборки
- фактический – фактическое значение данных
- прогноз – прогнозируемое значение данных
MAPE обычно используется, потому что его легко интерпретировать. Например , значение MAPE, равное 14 %, означает, что средняя разница между прогнозируемым значением и фактическим значением составляет 14 %.
В следующем примере показано, как рассчитать и интерпретировать значение MAPE для данной модели.
Пример: интерпретация значения MAPE для данной модели
Предположим, сеть продуктовых магазинов строит модель для прогнозирования будущих продаж. На следующей диаграмме показаны фактические продажи и прогнозируемые продажи по модели за 12 последовательных периодов продаж:

Мы можем использовать следующую формулу для расчета абсолютной процентной ошибки каждого прогноза:
- Абсолютная ошибка в процентах = |фактический-прогноз| / |фактическое| * 100

Затем мы можем вычислить среднее значение абсолютных процентных ошибок:

MAPE для этой модели оказывается равным 5,12% .
Это говорит нам о том, что средняя абсолютная процентная ошибка между продажами, предсказанными моделью, и фактическими продажами составляет 5,12% .
Чтобы определить, является ли это хорошим значением для MAPE , необходимо использовать отраслевые стандарты.
Если стандартная модель в продовольственной отрасли дает значение MAPE, равное 2%, то это значение 5,12% можно считать высоким.
И наоборот, если большинство моделей прогнозирования в продуктовой промышленности дают значения MAPE от 10% до 15%, то значение MAPE, равное 5,12%, можно считать низким, и эта модель может считаться отличной для прогнозирования будущих продаж.
Сравнение значений MAPE для разных моделей
MAPE особенно полезен для сравнения соответствия различных моделей.
Например, предположим, что сеть продуктовых магазинов хочет построить модель для прогнозирования будущих продаж и найти наилучшую из возможных моделей.
Предположим, они соответствуют трем различным моделям и находят соответствующие им значения MAPE:
- MAPE модели 1: 14,5%
- MAPE модели 2: 16,7%
- MAPE модели 3: 9,8%
Модель 3 имеет самое низкое значение MAPE, что говорит нам о том, что она способна прогнозировать будущие продажи наиболее точно среди трех потенциальных моделей.
Дополнительные ресурсы
Как рассчитать MAPE в Excel
Как рассчитать MAPE в R
Как рассчитать MAPE в Python
Калькулятор MAPE
 MAPE – средняя абсолютная ошибка в процентах используется:
MAPE – средняя абсолютная ошибка в процентах используется:
- Для оценки точности прогноза;
- Показывает на сколько велики ошибки в сравнении со значениями ряда;
- Хороша для сравнения 1-й модели для разных рядов;
- Используется для сравнения разных моделей для одного ряда;
- Оценки экономического эффекта, за счет повышения точности прогноза.
В данной статье мы рассмотрим, как рассчитать MAPE в Excel и как ее использовать.
Формула расчета MAPE:
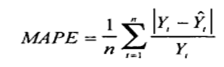
Где:
- Yt – фактический объем продаж за анализируемый период;
- Ŷt — значение прогнозной модели за аналазируемый период;
- n — количество периодов.
Для того, чтобы рассчитать среднюю абсолютную ошибку мы:
- Рассчитываем значение модели прогноза — Ŷt;
- Рассчитываем ошибку прогноза;
- Берем ошибку по модулю;
- Определяем абсолютную ошибку;
- Рассчитываем среднюю абсолютную ошибку в процентах — MAPE.
1. Рассчитаем значение модели прогноза — Ŷt
Возьмем модель с трендом и сезонностью. Рассчитаем значение модели для каждого периода, когда нам известны фактические продажи. Для этого сложившийся тренд за анализируемый период умножим на коэффициент сезонности для соответствующего месяца.
Получили значения прогнозной модели для каждого периода времени:
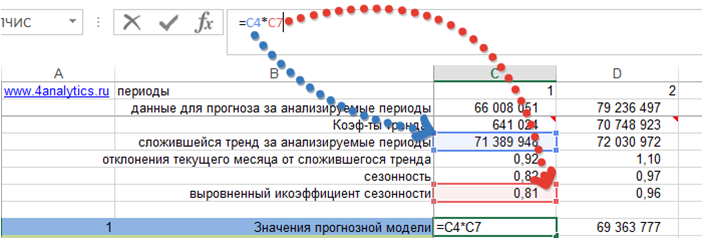
Подробнее о расчете прогноза с помощью тренда и сезонности читайте в статье «Расчет прогноза с помощью тренда и сезонности».
2. Рассчитаем значения ошибки прогноза.
В формуле расчета MAPE – это:
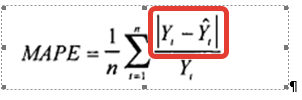
e — Ошибка прогноза — это разность между значениями временного ряда (фактом продаж) и моделью прогноза:
e= Yt — Ŷt
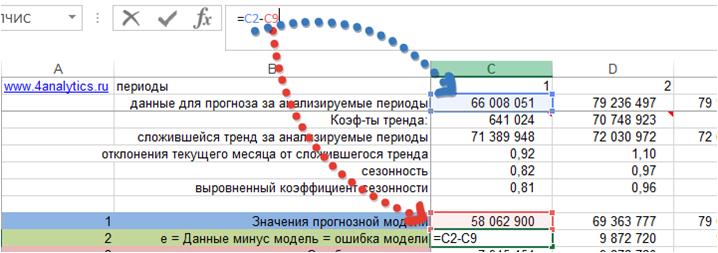
Получили значение ошибки прогноза для каждого момента времени за анализируемый период.
3. Рассчитаем ошибку по модулю.
Для этого воспользуемся функцией Excel =ABC()
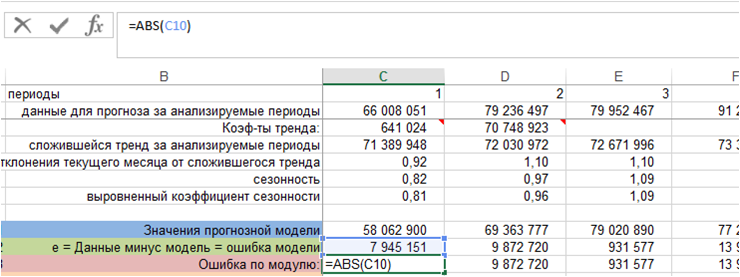
4. Определяем абсолютную ошибку.
Для каждого периода ошибку по модулю делим на фактические значения ряда, т.е. на фактический объем продаж:
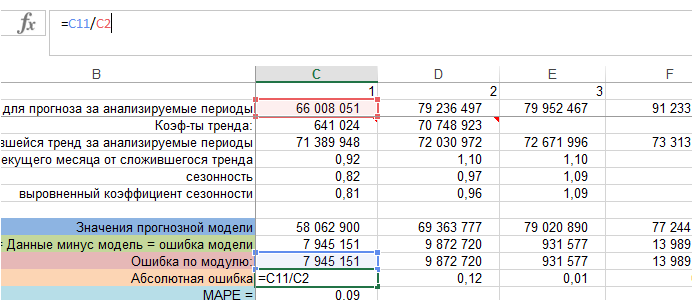
Получили абсолютную ошибку для каждого периода фактических продаж. В формуле MAPE — это:

5. Рассчитаем MAPE – среднюю абсолютную ошибку.
Для этого рассчитаем среднее значение абсолютной ошибки за все периоды:
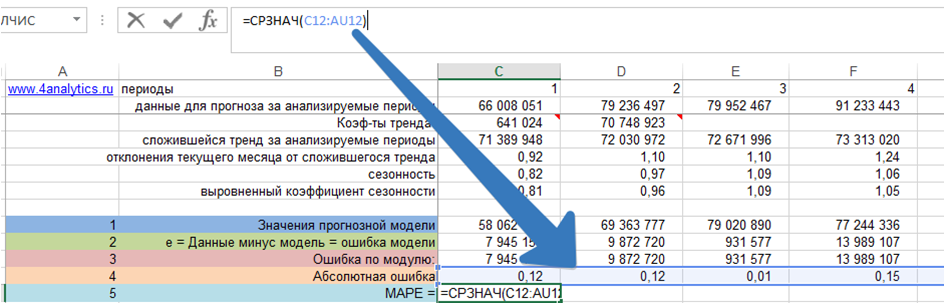
Скачать файл с примером расчета MAPE – средней абсолютной ошибки.
Как рассчитать показатель точность прогноза?
Показатель точность прогноза = 1 –MAPE:

С помощью MAPE вы можете сравнивать различные модели между собой, можете оценивать, как и на сколько модель делает точные прогнозы для разных временных рядов.
А также, что самое главное, можете оценить экономический эффект для компании за счет повышения точности прогноза.
Об этом подробнее можете почитать в нашей статье на сайте http://novoforecast.com/novo-forecast/instruktsiya/item/rost-tochnosti-prognoza-rost-pribyli.html
Если есть вопросы, пожалуйста, пишите в комментариях!
Forecast4AC PRO рассчитает MAPE для каждого временного ряда!
Точных вам прогнозов!
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:

- Novo Forecast Lite — автоматический расчет прогноза в Excel.
- 4analytics — ABC-XYZ-анализ и анализ выбросов в Excel.
- Qlik Sense Desktop и QlikView Personal Edition — BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
- Novo Forecast PRO — прогнозирование в Excel для больших массивов данных.
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.
Зарегистрируйтесь и скачайте решения
Статья полезная? Поделитесь с друзьями
Ошибка прогнозирования: виды, формулы, примеры

Ошибка прогнозирования — это такая величина, которая показывает, как сильно прогнозное значение отклонилось от фактического. Она используется для расчета точности прогнозирования, что в свою очередь помогает нам оценивать как точно и корректно мы сформировали прогноз. В данной статье я расскажу про основные процентные «ошибки прогнозирования» с кратким описанием и формулой для расчета. А в конце статьи я приведу общий пример расчётов в Excel. Напомню, что в своих расчетах я в основном использую ошибку WAPE или MAD-Mean Ratio, о которой подробно я рассказал в статье про точность прогнозирования, здесь она также будет упомянута.
В каждой формуле буквой Ф обозначено фактическое значение, а буквой П — прогнозное. Каждая ошибка прогнозирования (кроме последней!), может использоваться для нахождения общей точности прогнозирования некоторого списка позиций, по типу того, что изображен ниже (либо для любого другого подобной детализации):
Алгоритм для нахождения любой из ошибок прогнозирования для такого списка примерно одинаковый: сначала находим ошибку прогнозирования по одной позиции, а затем рассчитываем общую. Итак, основные ошибки прогнозирования!
MPE — Mean Percent Error
MPE — средняя процентная ошибка прогнозирования. Основная проблема данной ошибки заключается в том, что в нестабильном числовом ряду с большими выбросами любое незначительное колебание факта или прогноза может значительно поменять показатель ошибки и, как следствие, точности прогнозирования. Помимо этого, ошибка является несимметричной: одинаковые отклонения в плюс и в минус по-разному влияют на показатель ошибки.

- Для каждой позиции рассчитывается ошибка прогноза (из факта вычитается прогноз) — Error
- Для каждой позиции рассчитывается процентная ошибка прогноза (ошибка прогноза делится на фактический показатель) — Percent Error
- Находится среднее арифметическое всех процентных ошибок прогноза (процентные ошибки суммируются и делятся на количество) — Mean Percent Error
MAPE — Mean Absolute Percent Error
MAPE — средняя абсолютная процентная ошибка прогнозирования. Основная проблема данной ошибки такая же, как и у MPE — нестабильность.

- Для каждой позиции рассчитывается абсолютная ошибка прогноза (прогноз вычитается из факта по модулю) — Absolute Error
- Для каждой позиции рассчитывается абсолютная процентная ошибка прогноза (абсолютная ошибка прогноза делится на фактический показатель) — Absolute Percent Error
- Находится среднее арифметическое всех абсолютных процентных ошибок прогноза (абсолютные процентные ошибки суммируются и делятся на количество) — Mean Absolute Percent Error
Вместо среднего арифметического всех абсолютных процентных ошибок прогноза можно использовать медиану числового ряда (MdAPE — Median Absolute Percent Error), она наиболее устойчива к выбросам.
WMAPE / MAD-Mean Ratio / WAPE — Weighted Absolute Percent Error
WAPE — взвешенная абсолютная процентная ошибка прогнозирования. Одна из «лучших ошибок» для расчета точности прогнозирования. Часто называется как MAD-Mean Ratio, то есть отношение MAD (Mean Absolute Deviation — среднее абсолютное отклонение/ошибка) к Mean (среднее арифметическое). После упрощения дроби получается искомая формула WAPE, которая очень проста в понимании:

- Для каждой позиции рассчитывается абсолютная ошибка прогноза (прогноз вычитается из факта, по модулю) — Absolute Error
- Находится сумма всех фактов по всем позициям (общий фактический объем)
- Сумма всех абсолютных ошибок делится на сумму всех фактов — WAPE
Данная ошибка прогнозирования является симметричной и наименее чувствительна к искажениям числового ряда.
Рекомендуется к использованию при расчете точности прогнозирования. Более подробно читать здесь.
RMSE (as %) / nRMSE — Root Mean Square Error
RMSE — среднеквадратичная ошибка прогнозирования. Примерно такая же проблема, как и в MPE и MAPE: так как каждое отклонение возводится в квадрат, любое небольшое отклонение может значительно повлиять на показатель ошибки. Стоит отметить, что существует также ошибка MSE, из которой RMSE как раз и получается путем извлечения корня. Но так как MSE дает расчетные единицы измерения в квадрате, то использовать данную ошибку будет немного неправильно.

- Для каждой позиции рассчитывается квадрат отклонений (разница между фактом и прогнозом, возведенная в квадрат) — Square Error
- Затем рассчитывается среднее арифметическое (сумма квадратов отклонений, деленное на количество) — MSE — Mean Square Error
- Извлекаем корень из полученного результат — RMSE
- Для перевода в процентную или в «нормализованную» среднеквадратичную ошибку необходимо:
- Разделить на разницу между максимальным и минимальным значением показателей
- Разделить на разницу между третьим и первым квартилем значений показателей
- Разделить на среднее арифметическое значений показателей (наиболее часто встречающийся вариант)
MASE — Mean Absolute Scaled Error
MASE — средняя абсолютная масштабированная ошибка прогнозирования. Согласно Википедии, является очень хорошим вариантом для расчета точности, так как сама ошибка не зависит от масштабов данных и является симметричной: то есть положительные и отрицательные отклонения от факта рассматриваются в равной степени.
Важно! Если предыдущие ошибки прогнозирования мы могли использовать для нахождения точности прогнозирования некого списка номенклатур, где каждой из которых соответствует фактическое и прогнозное значение (как было в примере в начале статьи), то данная ошибка для этого не предназначена: MASE используется для расчета точности прогнозирования одной единственной позиции, основываясь на предыдущих показателях факта и прогноза, и чем больше этих показателей, тем более точно мы сможем рассчитать показатель точности. Вероятно, из-за этого ошибка не получила широкого распространения.
Здесь данная формула представлена исключительно для ознакомления и не рекомендуется к использованию.
Суть формулы заключается в нахождении среднего арифметического всех масштабированных ошибок, что при упрощении даст нам следующую конечную формулу:

Также, хочу отметить, что существует ошибка RMMSE (Root Mean Square Scaled Error — Среднеквадратичная масштабированная ошибка), которая примерно похожа на MASE, с теми же преимуществами и недостатками.
Это основные ошибки прогнозирования, которые могут использоваться для расчета точности прогнозирования. Но не все! Их очень много и, возможно, чуть позже я добавлю еще немного информации о некоторых из них. А примеры расчетов уже описанных ошибок прогнозирования будут выложены через некоторое время, пока что я подготавливаю пример, ожидайте.
Об авторе

HeinzBr
Автор статей и создатель сайта SHTEM.RU
Методы оценки качества прогноза
Время на прочтение
3 мин
Количество просмотров 30K
Часто при составлении любого прогноза — забывают про способы оценки его результатов. Потому как часто бывает, прогноз есть, а сравнение его с фактом отсутствует. Еще больше ошибок случается, когда существуют две (или больше) модели и не всегда очевидно — какая из них лучше, точнее. Как правило одной цифрой (R2) сложно обойтись. Как если бы вам сказали — этот парень ходит в синей футболке. И вам сразу все стало про него ясно )
В статьях о методах прогнозирования при оценке полученной модели я постоянно использовал такие аббревиатуры или обозначения.
- R2
- MSE
- MAPE
- MAD
- Bias
Попробую объяснить, что я имел в виду.
Остатки
Итак, по порядку. Основная величина, через которую оценивается точность прогноза это остатки (иногда: ошибки, error, e). В общем виде это разность между спрогнозированными значениями и исходными данными (либо фактическими значениями). Естественно, что чем больше остатки тем сильнее мы ошиблись. Для вычисления сравнительных коэффициентов остатки преобразуют: либо берут по модулю, либо возводят в квадрат (см. таблицу, колонки 4,5,6). В сыром виде почти не используют, так как сумма отрицательных и положительных остатков может свести суммарную ошибку в ноль. А это глупо, сами понимаете.
Суровые MSE и R2
Когда нам требуется подогнать кривую под наши данные, то точность этой подгонки будет оцениваться программой по среднеквадратической ошибке (mean squared error, MSE). Рассчитывается по незамысловатой формуле
![]()
где n-количество наблюдений.
Соотвественно, программа, рассчитывая кривую подгонки, стремится минимизировать этот коэффициент. Квадраты остатков в числителе взяты именно по той причине, чтобы плюсы и минусы не взаимоуничтожились. Физического смысла MSE не имеет, но чем ближе к нулю, тем модель лучше.
Вторая абстрактная величина это R2 — коэффициент детерминации. Характеризует степень сходства исходных данных и предсказанных. В отличии от MSE не зависит от единиц измерения данных, поэтому поддается сравнению. Рассчитывается коэффициент по следующей формуле:
![]()
где Var(Y) — дисперсия исходных данных.
Безусловно коэффициент детерминации — важный критерий выбора модели. И если модель плохо коррелирует с исходными данными, она вряд ли будет иметь высокую предсказательную силу.

MAPE и MAD для сравнения моделей
Статистические методы оценки моделей вроде MSE и R2, к сожалению, трудно интерпретировать, поэтому светлые головы придумали облегченные, но удобные для сравнения коэффициенты.
Среднее абсолютное отклонение (mean absolute deviation, MAD) определяется как частное от суммы остатков по модулю к числу наблюдений. То есть, средний остаток по модулю. Удобно? Вроде да, а вроде и не очень. В моем примере MAD=43. Выраженный в абсолютных единицах MAD показывает насколько единиц в среднем будет ошибаться прогноз.
MAPE призван придать модели еще более наглядный смысл. Расшифровывается выражение как средняя абсолютная ошибка в процентах (mean percentage absolute error, MAPE).
![]()
где Y — значение исходного ряда.
Выражается MAPE в процентах, и в моем случае означает, что в модель может ошибаться в среднем на 16%. Что, согласитесь, вполне допустимо.
Наконец, последняя абсолютно синтетическая величина — это Bias, или просто смещение. Дело в том, что в реальном мире отклонения в одну сторону зачастую гораздо болезненнее, чем в другую. К примеру, при условно неограниченных складских помещениях, важнее учитывать скачки реального спроса вверх от спрогнозированных значений. Поэтому случаи, где остатки положительные относятся к общему числу наблюдений. В моем случае 44% спрогнозированных значений оказались ниже исходных. И можно пожертвовать другими критериями оценки, чтобы минимизировать этот Bias.
Можете попробовать это сами в ![]() Excel и
Excel и ![]() Numbers
Numbers
Интересно узнать — какие методы оценки качества прогнозирования вы используете в своей работе?
Подробности на блоге