Расхождения
между величиной какого-либо показателя,
найденного посредством статистического
наблюдения, и действительными его
размерами называются ошибками
наблюдения.В зависимости от
причин возникновения различают ошибки
регистрации и ошибки репрезентативности.
Ошибки
регистрациивозникают в результате
неправильного установления фактов или
ошибочной записи в процессе наблюдения
или опроса. Они бывают случайными или
систематическими. Случайные ошибки
регистрации могут быть допущены как
опрашиваемыми в их ответах, так и
регистраторами. Систематические ошибки
могут быть и преднамеренными, и
непреднамеренными. Преднамеренные –
сознательные, тенденциозные искажения
действительного положения дела.
Непреднамеренные вызываются различными
случайными причинами (небрежность,
невнимательность).
Ошибки
репрезентативности(представительности)
возникают в результате неполного
обследования и в случае, если обследуемая
совокупность недостаточно полно
воспроизводит генеральную совокупность.
Они могут быть случайными и систематическими.
Случайные ошибки репрезентативности
– это отклонения, возникающие при
несплошном наблюдении из-за того, что
совокупность отобранных единиц наблюдения
(выборка) неполно воспроизводит всю
совокупность в целом. Систематические
ошибки репрезентативности – это
отклонения, возникающие вследствие
нарушения принципов случайного отбора
единиц. Ошибки репрезентативности
органически присущи выборочному
наблюдению и возникают в силу того, что
выборочная совокупность не полностью
воспроизводит генеральную. Избежать
ошибок репрезентативности нельзя,
однако, пользуясь методами теории
вероятностей, основанными на использовании
предельных теорем закона больших чисел,
эти ошибки можно свести к минимальным
значениям, границы которых устанавливаются
с достаточно большой точностью.
Ошибки
выборки –разность между
характеристиками выборочной и генеральной
совокупности. Для среднего значения
ошибка будет определяться по формуле
![]()
(7.1)
где
![]()
Величина
![]() называетсяпредельной ошибкойвыборки.
называетсяпредельной ошибкойвыборки.
Предельная
ошибка выборки – величина случайная.
Исследованию закономерностей случайных
ошибок выборки посвящены предельные
теоремы закона больших чисел. Наиболее
полно эти закономерности раскрыты в
теоремах П. Л. Чебышева и А. М. Ляпунова.
Теорему П.
Л. Чебышева применительно к
рассматриваемому методу можно
сформулировать следующим образом: при
достаточно большом числе независимых
наблюдений можно с вероятностью, близкой
к единице (т. е. почти с достоверностью),
утверждать, что отклонение выборочной
средней от генеральной будет сколько
угодно малым. В теореме П. Л. Чебышева
доказано, что величина ошибки не должна
превышать![]() .
.
В свою очередь величина![]() ,
,
выражающая среднее квадратическое
отклонение выборочной средней от
генеральной средней, зависит от
колеблемости признака в генеральной
совокупности![]() и числа отобранных единицn. Эта
и числа отобранных единицn. Эта
зависимость выражается формулой
![]() ,
,
(7.2)
где
![]() зависит также от способа производства
зависит также от способа производства
выборки.
Величину
![]() =
=![]() называютсредней ошибкой выборки. В
называютсредней ошибкой выборки. В
этом выражении![]() – генеральная дисперсия,n– объем
– генеральная дисперсия,n– объем
выборочной совокупности.
Рассмотрим, как
влияет на величину средней ошибки число
отбираемых единиц n. Логически
нетрудно убедиться, что при отборе
большого числа единиц расхождения между
средними будут меньше, т. е. существует
обратная связь между средней ошибкой
выборки и числом отобранных единиц. При
этом здесь образуется не просто обратная
математическая зависимость, а такая
зависимость, которая показывает, что
квадрат расхождения между средними
обратно пропорционален числу отобранных
единиц.
Увеличение
колеблемости признака влечет за собой
увеличение среднего квадратического
отклонения, а следовательно, и ошибки.
Если предположить, что все единицы будут
иметь одинаковую величину признака, то
среднее квадратическое отклонение
станет равно нулю и ошибка выборки
также исчезнет. Тогда нет необходимости
применять выборку. Однако следует иметь
в виду, что величина колеблемости
признака в генеральной совокупности
неизвестна, поскольку неизвестны размеры
единиц в ней. Можно рассчитать лишь
колеблемость признака в выборочной
совокупности. Соотношение между
дисперсиями генеральной и выборочной
совокупности выражается формулой
![]()
Поскольку
величина
![]() при достаточно большихnблизка к
при достаточно большихnблизка к
единице, можно приближенно считать, что
выборочная дисперсия равна генеральной
дисперсии, т. е.![]()
Следовательно,
средняя ошибка выборки показывает,
какие возможны отклонения характеристик
выборочной совокупности от соответствующих
характеристик генеральной совокупности.
Однако о величине этой ошибки можно
судить с определенной вероятностью. На
величину вероятности указывает множитель
![]()
Теорема А.
М. Ляпунова. А. М. Ляпунов доказал,
что распределение выборочных средних
(следовательно, и их отклонений от
генеральной средней) при достаточно
большом числе независимых наблюдений
приближенно нормально при условии, что
генеральная совокупность обладает
конечной средней и ограниченной
дисперсией.
Математически
теорему Ляпуноваможно записать
так:
 (7.3)
(7.3)
где
![]() ,
,
(7.4)
где ![]() – математическая постоянная;
– математическая постоянная;
![]() –предельная ошибка выборки,которая дает возможность выяснить, в
–предельная ошибка выборки,которая дает возможность выяснить, в
каких пределах находится величина
генеральной средней.
Значения этого
интеграла для различных значений
коэффициента доверия tвычислены и
приводятся в специальных математических
таблицах. В частности, при:

Поскольку tуказывает на вероятность расхождения![]() ,
,
т. е. на вероятность того, на какую
величину генеральная средняя будет
отличаться от выборочной средней, то
это может быть прочитано так: с вероятностью
0,683 можно утверждать, что разность между
выборочной и генеральной средними не
превышает одной величины средней ошибки
выборки. Другими словами, в 68,3 % случаев
ошибка репрезентативности не выйдет
за пределы![]() С вероятностью 0,954 можно утверждать,
С вероятностью 0,954 можно утверждать,
что ошибка репрезентативности не
превышает![]() (т. е. в 95 % случаев). С вероятностью
(т. е. в 95 % случаев). С вероятностью
0,997, т. е. довольно близкой к единице,
можно ожидать, что разность между
выборочной и генеральной средней не
превзойдет трехкратной средней ошибки
выборки и т. д.
Логически связь
здесь выглядит довольно ясно: чем больше
пределы, в которых допускается
возможная ошибка, тем с большей
вероятностью судят о ее величине.
Зная выборочную
среднюю величину признака
![]() и предельную ошибку выборки
и предельную ошибку выборки![]() ,
,
можно определить границы (пределы),
в которых заключена генеральная
средняя
![]() (7.5)
(7.5)
1.
Собственно-случайная выборка–
этот способ ориентирован на выборку
единиц из генеральной совокупности без
всякого расчленения на части или группы.
При этом для соблюдения основного
принципа выборки – равной возможности
всем единицам генеральной совокупности
быть отобранным – используются схема
случайного извлечения единиц путем
жеребьевки (лотереи) или таблицы случайных
чисел. Возможен повторный и бесповторный
отбор единиц
Средняя ошибка
собственно-случайной выборки
представляет собой среднеквадратическое
отклонение возможных значений выборочной
средней от генеральной средней. Средние
ошибки выборки при собственно-случайном
методе отбора представлены в табл. 7.2.
Таблица 7.2
|
Средняя ошибка |
При отборе |
|
|
повторном |
бесповторном |
|
|
Для средней |
|
|
|
Для доли |
|
|

В таблице
использованы следующие обозначения:
![]() – дисперсия выборочной совокупности;
– дисперсия выборочной совокупности;
![]() – численность выборки;
– численность выборки;
![]() – численность генеральной совокупности;
– численность генеральной совокупности;
![]() – выборочная доля единиц, обладающих
– выборочная доля единиц, обладающих
изучаемым признаком;
![]() – число единиц, обладающих изучаемым
– число единиц, обладающих изучаемым
признаком;
![]() – численность выборки.
– численность выборки.
Для увеличения
точности вместо множителя
![]() следует
следует
брать множитель
![]() ,
,
но при большой численностиNразличие
между этими выражениями практического
значения не имеет.
Предельная
ошибка собственно-случайной выборки
![]() рассчитывается по формуле
рассчитывается по формуле
![]() ,
,
(7.6)
где t
– коэффициент доверия зависит от
значения вероятности.
Пример.При
обследовании ста образцов изделий,
отобранных из партии в случайном порядке,
20 оказалось нестандартными. С вероятностью
0,954 определите пределы, в которых
находится доля нестандартной продукции
в партии.
Решение.
Вычислим генеральную долю (Р):
![]() .
.
Доля нестандартной
продукции:
 .
.
Предельная
ошибка выборочной доли с вероятностью
0,954 рассчитывается по формуле (7.6) с
применением формулы табл. 7.2 для доли:

![]()
С вероятностью
0,954 можно утверждать, что доля нестандартной
продукции в партии товара находится в
пределах 12 % ≤ P≤ 28 %.
В практике
проектирования выборочного наблюдения
возникает потребность определения
численности выборки, которая необходима
для обеспечения определенной точности
расчета генеральных средних. Предельная
ошибка выборки и ее вероятность при
этом являются заданными. Из формулы
![]() и формул средних ошибок выборки
и формул средних ошибок выборки
устанавливается необходимая численность
выборки. Формулы для определения
численности выборки (n) зависят от
способа отбора. Расчет численности
выборки для собственно-случайной выборки
приведен в табл. 7.3.
Таблица 7.3
|
Предполагаемый |
Формулы |
|
|
для средней |
для доли |
|
|
Повторный |
|
|
|
Бесповторный |
|
|



2.
Механическая выборка– при этом
методе исходят из учета некоторых
особенностей расположения объектов в
генеральной совокупности, их упорядоченности
(по списку, номеру, алфавиту). Механическая
выборка осуществляется путем отбора
отдельных объектов генеральной
совокупности через определенный интервал
(каждый 10-й или 20-й). Интервал рассчитывается
по отношению![]() ,
,
гдеn– численность выборки,N–
численность генеральной совокупности.
Так, если из совокупности в 500 000 единиц
предполагается получить 2 %-ную выборку,
т. е. отобрать 10 000
единиц, то пропорция отбора составит![]() Отбор
Отбор
единиц осуществляется в соответствии
с установленной пропорцией через равные
интервалы. Если расположение объектов
в генеральной совокупности носит
случайный характер, то механическая
выборка по содержанию аналогична
случайному отбору. При механическом
отборе применяется только бесповторная
выборка [1, 5–10].
Средняя ошибка
и численность выборки при механическом
отборе подсчитывается по формулам
собственно-случайной выборки (см.
табл. 7.2 и 7.3).
3.
Типическая выборка, при котрой
генеральная совокупность делится по
некоторым существенным признакам на
типические группы; отбор единиц
производится из типических групп. При
этом способе отбора генеральная
совокупность расчленяется на однородные
в некотором отношении группы, которые
имеют свои характеристики, и вопрос
сводится к определению объема выборок
из каждой группы. Может бытьравномерная
выборка– при этом способе из каждой
типической группы отбирается одинаковое
число единиц![]() Такой подход оправдан лишь при равенстве
Такой подход оправдан лишь при равенстве
численностей исходных типических групп.
При типическом отборе, непропорциональном
объему групп, общее число отбираемых
единиц делится на число типических
групп, полученная величина дает
численность отбора из каждой типической
группы.
Более совершенной
формой отбора является пропорциональная
выборка. Пропорциональной называется
такая схема формирования выборочной
совокупности, когда численность выборок,
взятых из каждой типической группы в
генеральной совокупности, пропорциональна
численностям, дисперсиям (или комбинированно
и численностям, и дисперсиям). Условно
определяем численность выборки в 100
единиц и отбираем единицы из групп:
– пропорционально
численности их генеральной совокупности
(табл. 7.4). В таблице
обозначено:
Ni– численность типической группы;
dj
– доля (Ni/N);
N– численность
генеральной совокупности;
ni– численность выборки из типической
группы вычисляется:
![]() , (7.7)
, (7.7)
n – численность выборки из генеральной
совокупности.
Таблица
7.4
-
Группы
Ni
dj
ni
1
300
0,3
30
2
500
0,5
50
3
200
0,2
20
1000
1,0
100
–
пропорционально среднему квадратическому
отклонению(табл. 7.5).
здесь
i– среднее
квадратическое отклонение типических
групп;
ni
– численность выборки из типической
группы вычисляется по формуле

(7.8)
Таблица
7.5
-
Ni
i

ni
300
5
0,25
25
500
7
0,35
35
200
8
0,40
40
1000
20
1,0
100
–
комбинированно (табл. 7.6).
Численность
выборки вычисляется по формуле
![]() . (7.9)
. (7.9)
Таблица 7.6
-

i
iNi


300
5
1500
0,23
23
500
7
2100
0,53
53
200
8
1600
0.24
24
1000
20
6600
1,0
100
При проведении
типической выборки непосредственный
отбор из каждой группы проводится
методом случайного отбора.
Средние ошибки
выборки рассчитываются по формулам
табл. 7.7 в зависимости от способа отбора
из типических групп.
Таблица 7.7
|
Способ |
Повторный |
Бесповторный |
||
|
для |
для |
для |
для |
|
|
Непропорциональный |
|
|
|
|
|
Пропорциональный объему групп |
|
|
|
|
|
Пропорциональный |
|
|
|
|





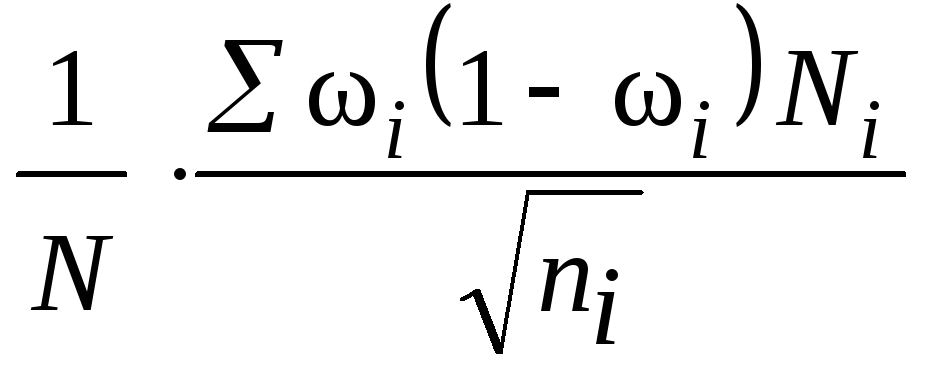


здесь
![]() – средняя из внутригрупповых дисперсий
– средняя из внутригрупповых дисперсий
типических групп;
![]() – доля единиц, обладающих изучаемым
– доля единиц, обладающих изучаемым
признаком;
![]() – средняя из внутригрупповых дисперсий
– средняя из внутригрупповых дисперсий
для доли;
![]() – среднее квадратическое отклонение
– среднее квадратическое отклонение
в выборке изi-й типической группы;
![]() – объем выборки из типической группы;
– объем выборки из типической группы;
![]() – общий объем выборки;
– общий объем выборки;
![]() –
–
объем типической группы;
![]() – объем генеральной совокупности.
– объем генеральной совокупности.
Численность
выборки из каждой типической группы
должна быть пропорциональна среднему
квадратическому отклонению в этой
группе
![]() .Расчет численности
.Расчет численности
![]() производится по формулам, приведенным
производится по формулам, приведенным
в табл. 7.8.
Таблица 7.8
|
Повторный |
Бесповторный |
|
|
Для определения |
|
|
|
Для определения |
|
|
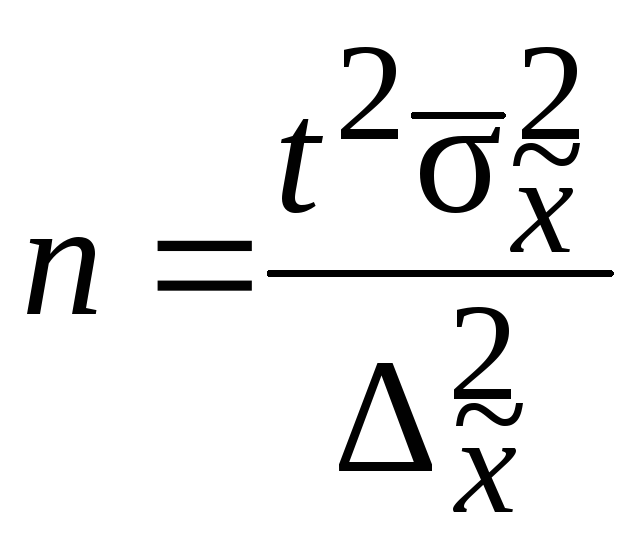

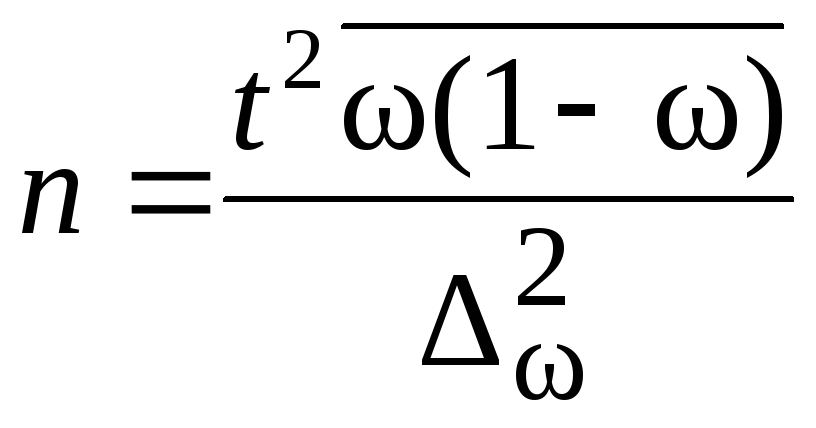

4. Серийная
выборка– удобена в тех случаях,
когда единицы совокупности объединены
в небольшие группы или серии. При серийной
выборке генеральную совокупность делят
на одинаковые по объему группы – серии.
В выборочную совокупность отбираются
серии. Сущность серийной выборки
заключается в случайном или механическом
отборе серий, внутри которых производится
сплошное обследование единиц. Средняя
ошибка серийной выборки с равновеликими
сериями зависит от величины только
межгрупповой дисперсии. Средние ошибки
сведены в табл. 7.9.
Таблица 7.9
|
Способ |
Формулы |
|
|
для |
для |
|
|
Повторный |
|
|
|
Бесповторный |
|
|


Здесь
R– число серий в генеральной
совокупности;
r – число
отобранных серий;
![]() – межсерийная (межгрупповая) дисперсия
– межсерийная (межгрупповая) дисперсия
средних;
![]() – межсерийная (межгрупповая) дисперсия
– межсерийная (межгрупповая) дисперсия
доли.
При серийном
отборе необходимую численность отбираемых
серий определяют так же, как и при
собственно-случайном методе отбора.
Расчет численности
серийной выборки производится по
формулам, приведенным в табл. 7.10.
Таблица 7.10
|
Повторный |
Бесповторный |
|
|
Для |
|
|
|
Для |
|
|
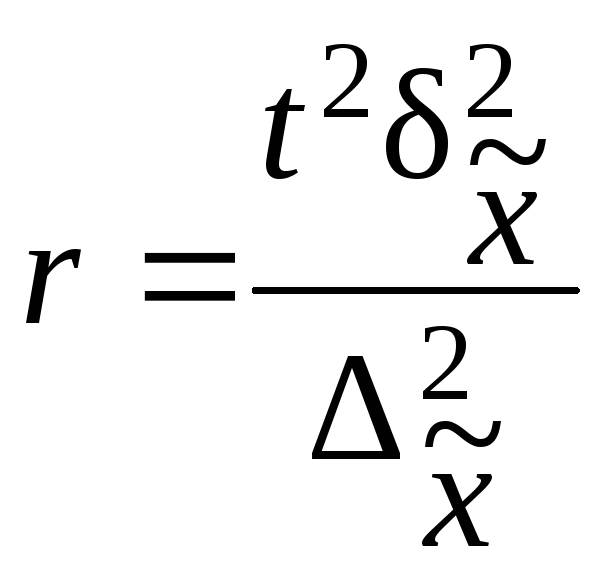

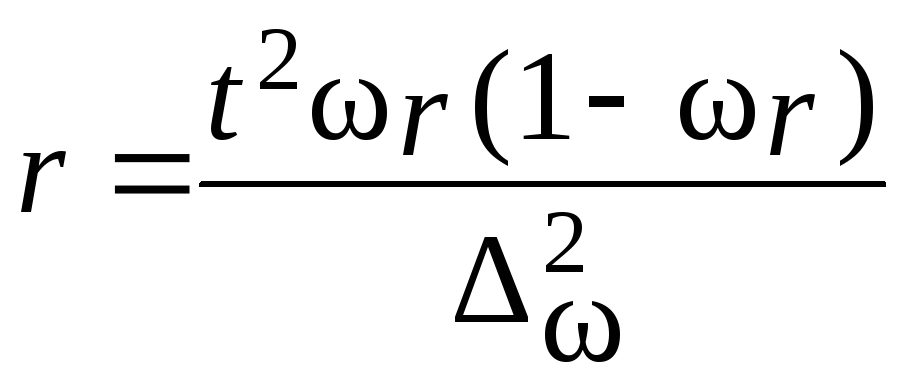

Пример.В
механическом цехе завода в десяти
бригадах работает 100 рабочих. В целях
изучения квалификации рабочих была
произведена 20 %-ная серийная бесповторная
выборка, в которую вошли две бригады.
Получено следующее распределение
обследованных рабочих по разрядам:
|
Рабочие |
Разряды рабочих |
Разряды рабочих |
Рабочие |
Разряды |
Разряды |
|
1 2 3 4 5 |
2 4 5 2 5 |
3 6 1 5 3 |
6 7 8 9 10 |
6 5 8 4 5 |
4 2 1 3 2 |
Необходимо
определить с вероятностью 0,997 пределы,
в которых находится средний разряд
рабочих механического цеха.
Решение.
Определим выборочные средние по
бригадам и общую среднюю как среднюю
взвешенную из групповых средних:

Определим
межсерийную дисперсию по формулам
(5.25):
![]()
Рассчитаем
среднюю ошибку выборки по формуле табл.
7.9:
![]()
Вычислим
предельную ошибку выборки с вероятностью
0,997:
![]()
С вероятностью
0,997 можно утверждать, что средний разряд
рабочих механического цеха находится
в пределах
![]()
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Как мы уже знаем, репрезентативность — свойство выборочной совокупности представлять характеристику генеральной. Если совпадения нет, говорят об ошибке репрезентативности — мере отклонения статистической структуры выборки от структуры соответствующей генеральной совокупности. Предположим, что средний ежемесячный семейный доход пенсионеров в генеральной совокупности составляет 2 тыс. руб., а в выборочной — 6 тыс. руб. Это означает, что социолог опрашивал только зажиточную часть пенсионеров, а в его исследование вкралась ошибка репрезентативности. Иными словами, ошибкой репрезентативности называется расхождение между двумя совокупностями — генеральной, на которую направлен теоретический интерес социолога и представление о свойствах которой он хочет получить в конечном итоге, и выборочной, на которую направлен практический интерес социолога, которая выступает одновременно как объект обследования и средство получения информации о генеральной совокупности.
Наряду с термином «ошибка репрезентативности» в отечественной литературе можно встретить другой — «ошибка выборки». Иногда они употребляются как синонимы, а иногда «ошибка выборки» используется вместо «ошибки репрезентативности» как количественно более точное понятие.
Ошибка выборки — отклонение средних характеристик выборочной совокупности от средних характеристик генеральной совокупности.
На практике ошибка выборки определяется путем сравнения известных характеристик генеральной совокупности с выборочными средними. В социологии при обследованиях взрослого населения чаще всего используют данные переписей населения, текущего статистического учета, результаты предшествующих опросов. В качестве контрольных параметров обычно применяются социально-демографические признаки. Сравнение средних генеральной и выборочной совокупностей, на основе этого определение ошибки выборки и ее уменьшение называется контролированием репрезентативности. Поскольку сравнение своих и чужих данных можно сделать по завершении исследования, такой способ контроля называется апостериорным, т.е. осуществляемым после опыта.
В опросах Института Дж. Гэллапа репрезентативность контролируется по имеющимся в национальных переписях данным о распределении населения по полу, возрасту, образованию, доходу, профессии, расовой принадлежности, месту проживания, величине населенного пункта. Всероссийский центр изучения общественного мнения (ВЦИОМ) использует для подобных целей такие показатели, как пол, возраст, образование, тип поселения, семейное положение, сфера занятости, должностной статус респондента, которые заимствуются в Государственном комитете по статистике РФ. В том и другом случае генеральная совокупность известна. Ошибку выборки невозможно установить, если неизвестны значения переменной в выборочной и генеральной совокупностях.
Специалисты ВЦИОМ обеспечивают при анализе данных тщательный ремонт выборки, чтобы минимизировать отклонения, возникшие на этапе полевых работ. Особенно сильные смещения наблюдаются по параметрам пола и возраста. Объясняется это тем, что женщины и люди с высшим образованием больше времени проводят дома и легче идут на контакт с интервьюером, т.е. являются легко достижимой группой по сравнению с мужчинами и людьми «необразованными»35.
Ошибка выборки обусловливается двумя факторами: методом формирования выборки и размером выборки.
Ошибки выборки подразделяются на два типа — случайные и систематические. Случайная ошибка — это вероятность того, что выборочная средняя выйдет (или не выйдет) за пределы заданного интервала. К случайным ошибкам относят статистические погрешности, присущие самому выборочному методу. Они уменьшаются при возрастании объема выборочной совокупности.
Второй тип ошибок выборки — систематические ошибки. Если социолог решил узнать мнение всех жителей города о проводимой местными органами власти социальной политике, а опросил только тех, у кого есть телефон, то возникает предумышленное смещение выборки в пользу зажиточных слоев, т.е. систематическая ошибка.
Таким образом, систематические ошибки — результат деятельности самого исследователя. Они наиболее опасны, поскольку приводят к довольно значительным смещениям результатов исследования. Систематические ошибки считаются страшнее случайных еще и потому, что они не поддаются контролю и измерению.
Они возникают, когда, например:
- выборка не соответствует задачам исследования (социолог решил изучить только работающих пенсионеров, а опросил всех подряд);
- налицо незнание характера генеральной совокупности (социолог думал, что 70% всех пенсионеров не работает, а оказалось, что не работает только 10%);
- отбираются только «выигрышные» элементы генеральной совокупности (например, только обеспеченные пенсионеры).
Внимание! В отличие от случайных ошибок систематические ошибки при возрастании объема выборки не уменьшаются.
Обобщив все случаи, когда происходят систематические ошибки, методисты составили их реестр. Они полагают, что источником неконтролируемых перекосов в распределении выборочных наблюдений могут быть следующие факторы:
- нарушены методические и методологические правила проведения социологического исследования;
- выбраны неадекватные способы формирования выборочной совокупности, методы сбора и расчета данных;
- произошла замена требуемых единиц наблюдения другими, более доступными;
- отмечен неполный охват выборочной совокупности (недополучение анкет, неполное их заполнение, труднодоступность единиц наблюдения).
Намеренные ошибки социолог допускает редко. Чаще ошибки возникают из-за того, что социологу плохо известна структура генеральной совокупности: распределение людей по возрасту, профессии, доходам и т.д.
Систематические ошибки легче предупредить (по сравнению со случайными), но их очень трудно устранить. Предупреждать систематические ошибки, точно предвидя их источники, лучше всего заранее — в самом начале исследования.
Вот некоторые способы избежать ошибок выборки:
- каждая единица генеральной совокупности должна иметь равную вероятность попасть в выборку;
- отбор желательно производить из однородных совокупностей;
- надо знать характеристики генеральной совокупности;
- при составлении выборочной совокупности надо учитывать случайные и систематические ошибки.
Если выборочная совокупность (или просто выборка) составлена правильно, то социолог получает надежные результаты, харастеризующие всю генеральную совокупность. Если она составлена неправильно, то ошибка, возникшая на этапе составления выборки, на каждом следующем этапе проведения социологического исследования приумножается и достигает в конечном счете такой величины, которая перевешивает ценность проведенного исследования. Говорят, что от такого исследования больше вреда, нежели пользы.
Подобные ошибки могут произойти только с выборочной совокупностыо. Чтобы избежать или уменьшить вероятность ошибки, самый простой способ — увеличивать размеры выборки (в идеале до объема генеральной: когда обе совокупности совпадут, ошибка выборки вообще исчезнет). Экономически такой метод невозможен. Остается другой путь — совершенствовать математические методы составления выборки. Они то и применяются на практике. Таков первый канал проникновения в социологию математики. Второй канал — математическая обработка данных.
Особенно важной проблема ошибок становится в маркетинговых исследованиях, где используются не очень большие выборки. Обычно они составляют несколько сотен, реже — тысячу респондентов. Здесь исходным пунктом расчета выборки выступает вопрос об определении размеров выборочной совокупности. Численность выборочной совокупности зависит от двух факторов:
- стоимости сбора информации,
- стремления к определенной степени статистической достоверности результатов, которую надеется получить исследователь.
Конечно, даже не искушенные в статистике и социологии люди интуитивно понимают, что чем больше размеры выборки, т.е. чем ближе они к размерам генеральной совокупности в целом, тем более надежны и достоверны полученные данные. Однако выше мы уже говорили о практической невозможности сплошных опросов в тех случаях, когда они проводятся на объектах, численность которых превышает десятки, сотни тысяч и даже миллионы. Понятно, что стоимость сбора информации (включающая оплату тиражирования инструментария, труда анкетеров, полевых менеджеров и операторов по компьютерному вводу) зависит от той суммы, которую готов выделить заказчик, и слабо зависит от исследователей. Что же касается второго фактора, то мы остановимся на нем чуть подробнее.
Итак, чем больше величина выборки, тем меньше возможная ошибка. Хотя необходимо отметить, что при желании увеличить точность вдвое вам придется увеличить выборку не в два, а в четыре раза. Например, чтобы сделать в два раза более точной оценку данных, полученных путем опроса 400 человек, вам потребуется опросить не 800, а 1600 человек. Впрочем, вряд ли маркетинговое исследование испытывает нужду в стопроцентной точности. Если пивовару необходимо узнать, какая часть потребителей пива предпочитает именно его марку, а не сорт его конкурента, — 60% или 40%, то на его планы никак не повлияет разница между 57%, 60 или 63%.
Ошибка выборки может зависеть не только от ее величины, но и от степени различий между отдельными единицами внутри генеральной совокупности, которую мы исследуем. Например, если нам нужно узнать, какое количество пива потребляется, то мы обнаружим, что внутри нашей генеральной совокупности нормы потребления у различных людей существенно различаются (гетерогенная генеральная совокупность). В другом случае мы будем изучать потребление хлеба и установим, что у разных людей оно различается гораздо менее существенно {гомогенная генеральная совокупность). Чем больше различия (или гетерогенность) внутри генеральной совокупности, тем больше величина возможной ошибки выборки. Указанная закономерность лишь подтверждает то, что нам подсказывает простой здравый смысл. Таким образом, как справедливо утверждает В. Ядов, «численность (объем) выборки зависит от уровня однородности или разнородности изучаемых объектов. Чем более они однородны, тем меньшая численность может обеспечить статистически достоверные выводы».
Определение объема выборки зависит также от уровня доверительного интервала допустимой статистической ошибки. Здесь имеются в виду так называемые случайные ошибки, которые связаны с природой любых статистических погрешностей. В.И. Паниотто приводит следующие расчеты репрезентативной выборки с допущением 5%-ной ошибки:
Это означает,что если вы, опросив, предположим, 400 человек в районном городе, где численность взрослого платежеспособного населения составляет 100 тыс. человек, выявили, что 33% опрошенных покупателей предпочитают продукцию местного мясокомбината, то с 95%-ной вероятностью можете утверждать, что постоянными покупателями этой продукции являются 33+5% (т.е. от 28 до 38%) жителей этого города.
Можно также воспользоваться расчетами института Гэллапа для оценки соотношения размеров выборки и ошибки выборки.

Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!

Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:

где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).

Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
ШПАРГАЛКА (скопируйте ссылку или текст)
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:

Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)

где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.

Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).

Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.

Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.

При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p — ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p — ∆; p + ∆) = (20% — 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:

(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s — выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:

где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ — ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ — ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет
Лекции по дисциплине Геодезия (стр. 3 )
 |
Из за большого объема этот материал размещен на нескольких страницах: 1 2 3 4 5 6 7 |

Такая наука, как геодезия тесно связана с измерениями, которые сопровождаются неизбежными ошибками. Если обозначим:
У – истинное значение измеряемой величины;
у – результат измерений;
 — истинная ошибка.
— истинная ошибка.
то истинная ошибка  может быть вычислена по формуле:
может быть вычислена по формуле:
 (15)
(15)
2 Виды ошибок измерений
По источникам и характеру ошибки делятся на грубые, систематические и случайные.
Грубые ошибки являются, как правило, следствие промахов, просчетов в измерениях, неисправностями инструментов и приборов, резким ухудшением внешних условий и пр. Они обнаруживаются при несоблюдении допусков и контролей и исключаются повторными измерениями.
Систематические – те, которые знаком или величиной однообразно повторяются в многократных измерениях. Их источниками являются неисправности в применяемых инструментах, неточная установка инструментов, личные физиологические особенности наблюдателя, влияние внешних факторов и т. п.
Примеры систематических ошибок:
— ошибка в измеренном значении длины линии на местности из-за отклонения мерной ленты от створа;
— ошибка в определении длины мерного прибора (ошибка компарирования).Эта ошибка постоянна и действует пропорционально измеренному расстоянию;
— систематическая ошибка нанесения шрихов лимба теодолита.
Влияние систематических ошибок сводят к допустимому минимуму путем тщательной поверки инструментов, применения соответствующей методики измерений, а также путем введения поправок в результаты измерений.
Некоторые рекомендации по уменьшению влияния систематических ошибок измерения:
— устанавливают закон появления систематической ошибки, после чего ошибку устраняют введением поправки в результаты измерений. Например, эталонирование мерного прибора и введение потом поправок за длину и температуру;
— применяют соответствующую методику измерений, чтобы систематические ошибки меняли знак. Например:
1) отсчитывание по диаметрально противоположным штрихам лимба, что приводит к исключению влияния эксцентриситета алидады;
2) перестановка лимба между приёмами на угол 180˚/n, где n-число приёмов ( при этом ослабевает влияние систематических ошибок штрихов лимба);
— используют определённую методику обработки результатов измерений. Например, углы и координаты вытянутого теодолитного хода уравнивают раздельно. Это ведёт к ослаблению влияния систематических ошибок угловых и линейных измерений.
Таким образом, будем считать, что результаты измерений содержат только слуайные ошибки, т. е. такие, размер и характер влияния которых на каждый отдельный результат измерения остается неизвестным.
3 Свойства случайных ошибок
Величину и знак случайных погрешностей  установить нельзя.
установить нельзя.
Примеры случайных ошибок:
— ошибки отсчитывания по угломерному кругу;
— часть ошибки визирования, обусловленную колебаниями изображения;
— случайные ошибки нанесения штрихов лимба;
— влияние вибрации сигнала;
— ошибка отсчитывания по нивелирной рейке;
— ошибка за округление чисел при вычислениях.
Если результаты измерений содержат только случайные ошибки (грубые и систематические исключают), то

Чем ближе результат измерений к истинному значению, тем он точнее. Чем меньше ошибки, тем выше точность.
4 Обработка рядя равноточных измерений.
По точности результаты измерений разделяют на равноточные и неравноточные.
Под равноточными понимают однородные результаты, полученные при измерениях одним и тем же инструментом, одинаковым числом приемов, одним и тем же или равноценными методами и в одинаковых условиях.
5 Критерии оценки точности результатов измерений.
В геодезии необходиом уметь оценивать точность результатов измерений. Основным критерием точности в геодезии является средняя квадратическая ошибка  (СКО). Ее математическое выражение:
(СКО). Ее математическое выражение:
 , (16)
, (16)
то есть квадрат СКО равен математическому ожиданию квадрата истинной ошибки.
Для оценки точности отдельного измерения применяется формула Гаусса:
 или
или  (17)
(17)
 — случайная ошибка, тоже истинная, но
— случайная ошибка, тоже истинная, но
θ- истинная ошибка в более широком смысле. Она может состоять из случайной и систематической частей.
СПРАВКА: (1777 – 1855гг) – немецкий математик. Автор работ по астрономии. геодезии. физике. Разработал математические основы высшей геодезии, вычисляя погрешности при измерениях, разработал метод наименьших квадратов.
Кроме основной характеристики m, характеризующей влияние случайных ошибок на результаты измерений. иногда применяют дополнительную характеристику – среднюю ошибку
 ,
,
но СКО имеет ряд преимуществ по сравнению со средней квадратической погрешностью:
— на величину СКО сильнее влияют большие по абсолютной величине ошибки;
— СКО – устойчивая характеристика, даже при небольшом числе измерений даёт надёжные результаты.
Если  — среднее арифметическое или арифметическая средина, то СКО арифметической средины М находится по формуле
— среднее арифметическое или арифметическая средина, то СКО арифметической средины М находится по формуле

где n – число измерений;
m – СКО одного измерения.
Для решения практических задач используется предельная ошибка ∆пред. Для серии ошибок в качестве ∆пред принимается утроенная СКО.
Это допуск, предел, больше которого не должно быть ошибки.
На практике во многих работах для повышения требований к точности измерений за предельную ошибку принимают удвоенную СКО.
Все приведённые выше ошибки называются абсолютными ошибками. Кроме абсолютных бывают относительные ошибки fотн, которыми называют отношение абсолютной ошибки к среднему значению измеряемой величины. Относительная ошибка выражается дробью, числитель которой равен 1, а знаменатель – отношение среднего значения измеряемой величины к абсолютной ошибке.
Приведенная выше формула Гаусса 17 применима для случаев, когда известны истинные значения измеряемых величин (или истинные ошибки). Эти случаи в практике редки. Известны они могут быть например, при моделировании, или за истинные значения принимают результаты измерений более высокой точности.
6 Арифметическая средина и ее средняя квадратичная ошибка
Как правило, истинные значения измеряемых величин неизвестны, но из измерений можно получить наиболее надежный результат – арифметическую средину  по формуле:
по формуле:
 (18)
(18)
 =
= 
Вычислив уклонение отдельных измерений от арифметической средины
 , (19)
, (19)
можно СКО одного измерения определить по формуле Бесселя:
 (20)
(20)
Справка: (1784 – 1846гг) – немецкий астроном. член Берлинской АН. Он один из первых определил расстояние до звёзд. Реформировал методы учёта инструментальных и других ошибок, что повысило точность астрономических измерений.
7Средние квадратичные ошибки функций измеренных величин.
Формулы Гаусса и Бесселя определяют СКО непосредственно измеренных величин. Если определяемая величина является функцией других непосредственно измеряемых величин, то СКО функции может быть найдена по формуле:

где  — СКО функции;
— СКО функции;
 — функция многих независимых аргументов
— функция многих независимых аргументов  ;
;
 — частные производные от функции по каждой переменной (результату измерений);
— частные производные от функции по каждой переменной (результату измерений);
 — СКО каждого результата измерений.
— СКО каждого результата измерений.
8 Неравноточные измерения.
9 Понятие о весе.
На практике часто производятся неравноточные измерения, которые выполнены в различных условиях, приборами различной точности, различным числом приемов и т. д. В этом случае уже нельзя ограничиваться простым арифметическим средним, а необходимо учитывать степень надежности каждого результата измерений. Надежность результата, выраженная числом, называется его весом. Чем надежнее результат, тем больше его вес. Следовательно, вес связан с точностью результата измерения, которая характеризуется СКО. Поэтому вес результата измерения принимают обратно пропорциональным квадрату СКО, то есть:
 , (22)
, (22)
где  — некоторая постоянная величина, коэффициент пропорциональности;
— некоторая постоянная величина, коэффициент пропорциональности;
 — СКО
— СКО  измерения.
измерения.
Таким образом, вес – относительная характеристика точности измерений. Использование веса вместо СКО облегчает. упрощает формулы математической обработки в случае неравноточных измерений. Необходим вес и потому, что более точные измерения в большей степени должны влиять на окончательный результат. (Для облегчения задачи отыскивания весов обычно вес какого-либо результата принимают за единицу и относительно его вычисляют веса остальных неизвестных.)
Если вес результат какого-либо измерения принять равным единице, а СКО измерения его обозначить через  , то общее выражение веса примет вид:
, то общее выражение веса примет вид:
 , (23)
, (23)
где — ср. кв. ош-ка единицы веса.
В практике геодезических работ в качестве весов принимают:
— при обработке результатов угловых измерений одним и тем же прибором – величины, пропорциональные количеству измерений каждого угла; для суммы углов в ходе, имеющем ni вершин,

— при обработке линейных измерений одним и тем же мерным прибором вес вычисляется по формуле

где si – длина линии;
— при обработке превышений из геометрического нивелирования — величины, обратно пропорциональные длине ходов или числу станций;
— при тригонометрическом нивелировании вес вычисляется по формуле

где si – расстояние между пунктами.
Принципы уравнивания геодезических сетей
1 Уравнивание геодезических сетей по МНК коррелатным способом.
2 Средняя квадратичная ошибка единицы веса
Геодезические измерения характерны тем, что их всегда больше, чем необходимо для определения искомых величин. Необходимыми называют такие измерения, которые позволяют однократно, бесконтрольно найти определяемые величины. Избыточными измерениями называются те, которые выполняют сверх необходимых. Например, для решения треугольника измеряют три угла, тогда как было бы достаточно измерить два угла.
Избыточные измерения позволяют:
— проконтролировать результаты измерений;
— в среднем повысит точность определяемых величин;
— выполнить оценку точности этих величин.
Число избыточных измерений  определяется по формуле
определяется по формуле  , (24)
, (24)
где  — число всех измерений в сети;
— число всех измерений в сети;
 — число необходимых измерений.
— число необходимых измерений.
Геодезические измерения ведутся в создаваемых на местности геодезических построениях, истинные элементы которых, в том числе и измеряемые, связаны между собой Математическими зависимостями.
Каждое избыточное измерение приводит к появлению математического соотношения с другими измеренными величинами. Неизбежные ошибки в измерениях приводят к появлению невязок в этих соотношениях. Для устранения невязок необходимо уравнивание результатов измерений.
Уравнивание – это математическая обработка результатов измерений, позволяющая:
— найти наиболее надежные (вероятнейшие) значения неизвестных с оценкой точности полученных результатов;
— исключить все математические противоречия в зависимостях, существующих между измеряемыми величинами.
ВЫВОД: сама задача уравнивания может быть поставлена только при наличии в сети избыточных измерений.
Целью уравнивания является:
— нахождение таких поправок к результатам измерений, которые не только компенсировали бы невязки, но и наилучшим образом приблизили уравненные значения измеренных величин к их истинным значениям;
— повышение точности всех измеренных величин;
— выполнение оценки точности по материалам уравнивания.
Может быть найдено множество систем поправок (множество вариантов), ликвидирующих невязки, но только одна система поправок позволяет найти вероятнейшие (т. е. наиболее приближённые к истинным) значения определяемых величин (и их функций).
Такая система поправок находится под условиями 25 и 26:
 — для равноточных измерений,
— для равноточных измерений,
(условие Лежандра) (25)
 -для неравноточных измерений)
-для неравноточных измерений)
(условие Гаусса) (26)
Первое условие – сумма квадратов поправок в непосредственные измерения должна быть минимальной.
Второе условие – сумма произведений квадратов поправок на веса соответствующих результатов измерений должна быть минимальной.
Уравнивание под условиями 25 и 26 называют уравниванием по методу наименьших квадратов (МНК), а условия (25) и (26) – принципом наименьших квадратов.
Уравнивание по МНК – строгое. Другие способы нахождения поправок – приближённое уравнивание.
Для решения задачи уравнивания по МНК применяются два основных способа:
— коррелатный, основанный на способе Лагранжа с неопределенными множителями для нахождения условного экстремума;
— параметрический – способ абсолютного экстремума, при котором все измеренные величины представляют в виде функций некоторых независимых неизвестных параметров.
Существуют также комбинированные способы уравнивания – коррелатный с дополнительными неизвестными и параметрический с избыточными параметрами.
1 Уравнивание геодезических сетей по МНК коррелатным способом
Пусть выполнено измерений их которых — необходимых.
— результаты измерений;
 — истинные значения измеренных величин;
— истинные значения измеренных величин;
 — установленная система весов результатов измерений;
— установленная система весов результатов измерений;
 — обратные веса.
— обратные веса.
Связь между ними может быть выражена следующими соотношениями:
 , (27)
, (27)
где 
 — случайные ошибки;
— случайные ошибки;
 . (28)
. (28)
Число избыточных измерений , где  .
.
Каждое избыточное измерение приводит к математическому соотношению между истинными значениями измеренных величин, т. е. в геодезической сети возникает условий:
 , (29)
, (29)
где 
( т. е. здесь r функций:  ).
).
Эта исходная система условных уравнений связи включает только независимые уравнения, число которых равно 
 Вследствие неизбежных ошибок в измерениях, эти же функции, но от измеренных величин примут вид:
Вследствие неизбежных ошибок в измерениях, эти же функции, но от измеренных величин примут вид:
где  — невязки.
— невязки.
Это выражение называется системой условных уравнений связи от измеренных значений.
 (31)
(31)
Отдельные ошибки неизвестны, но их совокупность (сумма) в каждом условии может быть вычислена.
Необходимо найти такие поправки к результатам измерений, которые ликвидируют невязки, то есть должно выполняться равенство:
 , (32)
, (32)
где  поправки к результатам измерений;
поправки к результатам измерений;


Уравненные результаты измерений находят по формуле:
 (33)
(33)
Тогда система условных уравнений связи от уравненных значений примет вид:
 (34)
(34)
где 
В правой части опять нули, т. к. невязки компенсировались поправками.
 Систему (34) приводят к линейному виду, раскладывая каждое уравнение в ряд Тейлора, и пренебрегая при этом малыми (нелинейными) членами разложения:
Систему (34) приводят к линейному виду, раскладывая каждое уравнение в ряд Тейлора, и пренебрегая при этом малыми (нелинейными) членами разложения:
 Первое слагаемое согласно формуле (30) является невязкой , поэтому выражение (35) примет вид:
Первое слагаемое согласно формуле (30) является невязкой , поэтому выражение (35) примет вид:
Обозначим частные производные от первой функции буквой  , от второй —
, от второй — , от третьей —
, от третьей — и т. д. То есть:
и т. д. То есть:

 ,
,  ,…,
,…, ;
;
 ,
,  ,…,
,…,  (37)
(37)
 ,
,  ,…,
,…,
 С учетом (37) система (36) примет вид:
С учетом (37) система (36) примет вид:

 (38)
(38)

Это система условных уравнений поправок. В ней:
— невязки;
 — коэффициенты при поправках;
— коэффициенты при поправках;
 — неизвестные поправки, которые надо найти, решив систему (38).
— неизвестные поправки, которые надо найти, решив систему (38).
Так как в системе (38) число уравнений меньше числа неизвестных поправок  , то такая система имеет множество решений, т. е. не решается однозначно. Чтобы из множества вариантов выбрать один, наилучший, необходимо поставить дополнительное условие. Это условие:
, то такая система имеет множество решений, т. е. не решается однозначно. Чтобы из множества вариантов выбрать один, наилучший, необходимо поставить дополнительное условие. Это условие:
 (39)
(39)
является принципом наименьших квадратов.
Вывод нормальных уравнений коррелат представляется в матричной форме. Система (38) условных уравнений поправок

решается под условием (39) МНК
 ,
,

 где
где 


 — матрица коэффициентов при поправках условных уравнений поправок;
— матрица коэффициентов при поправках условных уравнений поправок;
 — вектор поправок;
— вектор поправок;
 — трансформированный вектор поправок;
— трансформированный вектор поправок;
 — вектор свободных членов;
— вектор свободных членов;





 — матрица весов результатов измерений;
— матрица весов результатов измерений;
Используя метод Лагранжа с неопределенными множителями, называемыми в геодезии коррелатами, представленными в виде вектора коррелат  (40)
(40)
составляют функцию Лагранжа  (41)
(41)
чтобы найти min, находят производную от этой функции  (42)
(42)
 , (43)
, (43)
 (44)
(44)
где 


 — трансформированная матрица коэффициентов при поправках;
— трансформированная матрица коэффициентов при поправках;
 — вектор коррелат.
— вектор коррелат.
Полагая, что  , как симметричная матрица, получим коррелатное уравнение поправок, выражающее поправки в виде функций коррелат
, как симметричная матрица, получим коррелатное уравнение поправок, выражающее поправки в виде функций коррелат
 (45)
(45)



 — матрица обратных весов результатов измерений;
— матрица обратных весов результатов измерений;
— обратный вес результата измерений;
 — единичная матрица – т. е. уравнение (45) можно представить в виде
— единичная матрица – т. е. уравнение (45) можно представить в виде
 (46)
(46)
Выражение (46) является коррелатным уравнением поправок.
Подставив (46) в (38), получают систему нормальных уравнений коррелат:
 (47)
(47)

 ,
,

 где
где 


 — матрица коэффициентов нормальных уравнений.
— матрица коэффициентов нормальных уравнений.
Коэффициенты, стоящие на главной диагонали, называются квадратичными, они всегда положительны, остальные – неквадратичные.
 (48)
(48)
В системе нормальных уравнений коррелат (48)  — неизвестные коррелаты. Их число r, как и число уравнений, поэтому система (48) решается однозначно.
— неизвестные коррелаты. Их число r, как и число уравнений, поэтому система (48) решается однозначно.
Способы решения могут быть различны:
— по схеме Гаусса;
— методом исключения, когда из последнего уравнения выражается последнее неизвестное, подставляется в предыдущее уравнение и т. д.;
— на ЭВМ, по готовым программам.
Из решения нормальных уравнений находят коррелаты , а по ним поправки:
 (49)
(49)
Выражение (49) называется коррелатным уравнением поправок.
Контролем вычисления поправок является равенство:
 (50)
(50)
После этого вычисляют уравненные значения результатов измерений
 , (
, ( ) (51)
) (51)
и делают контроль уравнивания путем подстановки уравненных измерений в условные уравнения связи
 (52)
(52)
2 Средняя квадратическая ошибка единицы веса
Оценка точности по результатам уравнивания, то есть по поправкам, может быть выполнена по формуле:
 , (53)
, (53)
где — средняя квадратическая ошибка единицы веса, то есть ошибка измерения с весом  .
.
Чтобы оценить какой-либо элемент сети (отметку, координату, угол и т. д.) необходимо составить функцию, то есть математически выразить этот элемент.
 (54)
(54)
где — средняя квадратическая ошибка функции;
 — вес функции.
— вес функции.
1 Уравнивание одиночного нивелирного хода коррелатным способом
Рассмотрим нивелирный ход

Рисунок 9 — Нивелирный ход
 — исходные пункты;
— исходные пункты;
 — отметки исходных пунктов;
— отметки исходных пунктов;
 — измеренные превышения;
— измеренные превышения;
 — длины секций;
— длины секций;
 — определяемые пункты, отметки которых необходимо найти.
— определяемые пункты, отметки которых необходимо найти.
Уравнивание нивелирного хода начинается с подсчета числа избыточных измерений по формуле
 (55)
(55)
В ходе, представленном на рисунке 9, число измеренных превышений  . Число необходимых измерений
. Число необходимых измерений  — по числу определяемых пунктов. Поэтому
— по числу определяемых пунктов. Поэтому  .
.
Контроль вычисления производится по формуле  , (56)
, (56)
где  — число замкнутых полигонов;
— число замкнутых полигонов;
 — число исходных пунктов.
— число исходных пунктов.
Таким образом, в нивелирном ходе возникает только одно условие и соответственно одно условное уравнение связи:
 (57)
(57)
где  — невязка.
— невязка.
Так как  , то, согласно общей теории уравнивания, составляется одно нормальное уравнение коррелат
, то, согласно общей теории уравнивания, составляется одно нормальное уравнение коррелат
 , (58)
, (58)
где  — обратные веса;
— обратные веса;
при  , обратные веса
, обратные веса  ;
;
— коэффициенты при поправках условного уравнения поправок
 (59)
(59)
Коэффициенты находятся как частные производные от функции  по результатам измерений
по результатам измерений  , т. е.
, т. е.  ,
,  ,…,
,…,  .
.
Коррелатный способ уравнивания
Коррелатный способ основан на использовании функциональной связи между собой элементов геодезических построений Xi (i = 1, n). Эти уравнения связи называются условными уравнениями:
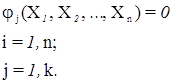
При коррелатном способе уравнивания вначале составляется система условных уравнений AV + W = 0,
где А – матрица коэффициентов системы условных уравнений;
V – вектор поправок в измеренные значения элементов сети;
W – вектор невязок условных уравнений.
При этом коэффициенты aij условных уравнений поправок определяются по формуле:
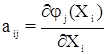
а невязки уравнений – по формуле:
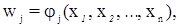
где xi (i = 1, n) – измеренные значения элементов геодезических построений.
При известной весовой матрице Р вначале вычисляют обратную весовую матрицу Q = P -1 , а затем от системы условных уравнений переходят к системе нормальных уравнений:
Определив коррелаты К = — (AQA T ) W, вычисляют поправки V = QA T K и уравненные значения измеренных элементов сети x* = x + v,
где х* – вектор уравненных значений;
х – вектор измеренных значений элементов геодезических построений.
Дата добавления: 2016-06-02 ; просмотров: 1885 ; ЗАКАЗАТЬ НАПИСАНИЕ РАБОТЫ
Примеры коррелатного способа уравнивания
В этом разделе приводятся примеры уравнивания некоторых геодезических построений. В примерах рассматривается алгоритм решения задачи уравнивания для разных вариантов геодезических построений со сравнительно небольшим числом измеренных величин, как это часто имеет место, например, в практике геодезических и маркшейдерских работ на земной поверхности при создании опорных сетей либо в горных выработках при обработке результатов измерений в системах полигонометрических ходов. Уравнивание систем нивелирных ходов обычно производится при точных и высокоточных измерениях, например, при наблюдениях за деформациями горных выработок и наземных сооружений, что тоже имеет место и в практике геодезических и маркшейдерских работ.
В примерах рассмотрены сравнительно простые схемы геодезических построений, однако принцип расчётов и в сложных системах точно такой же, как и в простых.
137.1. Уравнивание углов в полигоне
В полигоне, состоящем из четырёх вершин (рис. 14.7), неравноточно измерены горизонтальные углы: А = β1 , В = β2 , С = β3 , D = β4 (табл. 14.4).
Выполнить уравнивание углов без учёта измерения длин сторон.
Предварительно найдем веса pi и обратные веса qi, приняв  м (см. табл. 14.4) без учёта величин измеренных углов, считая их практически примерно одинаковыми (значения весов определяются по условию возможной погрешности в направлениях из-за центрирования теодолита; для веса угла применяется правило сложения обратных весов направлений):
м (см. табл. 14.4) без учёта величин измеренных углов, считая их практически примерно одинаковыми (значения весов определяются по условию возможной погрешности в направлениях из-за центрирования теодолита; для веса угла применяется правило сложения обратных весов направлений):
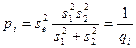 , (14.91)
, (14.91)
где s1 и s2 – стороны, образующие данный угол.
Шаг 1. Общее число измеренных величин n = 4, число необходимых измерений k = 3, число избыточных измерений r = 1.
Шаг 2. Составим условное уравнение (условие сумм углов полигона).
Всего одно уравнение, поскольку r = 1.
Шаг 3. Приводим условное уравнение к линейному виду, для чего продифференцируем его и найдем частные производные функции по аргументам βi . Очевидно, что
Составим матрицу коэффициентов aij со строкой обратных весов qi (таблица 14.5).

Рис. 14.7. Уравнивание углов в полигоне.
| Обозначение | Значение угла | Вес pi | Обратный вес qi |
| β1 | 80 0 16′ 44,3″ | 0,221 | 4,520 |
| β2 | 91 0 45′ 00,7″ | 0,459 | 2,181 |
| β3 | 69 0 25′ 56,8″ | 0,473 | 2,113 |
| β4 | 118 0 32′ 25,2″ | 0,225 | 4,452 |
Матрица коэффициентов, весов и обратных весов
| i→ j↓ | ||||
| + 1 | + 1 | + 1 | + 1 | |
| рi | 0,221 | 0,459 | 0,473 | 0,225 |
| qi | 4,520 | 2,181 | 2,113 | 4,452 |
Свободный член уравнения
Шаг 4. Найдём коэффициенты bjj нормальных уравнений (в данном случае – уравнений коррелат):
 , (14.92)
, (14.92)
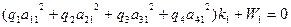 . (14.93)
. (14.93)
Для приведенного примера, с учётом значений aij и qi , 13,266 k1 + 7 = 0, откуда k1 = — 0,528.
Шаг 5. Составляем условное уравнение поправок
 (14.94)
(14.94)
и формулы для вычисления поправок (с вычислением их значений):

Контроль по формуле (14.94): условие выполнено! (проверьте сами). Отступление при округлениях значений поправок на 0,1″ является допустимым.
Вспомните загадку, которая прозвучала в начале этой главы. А если забыли, то возвратитесь к этому началу. Вот оно, что «под конец тонко» — это и есть хвостик решения всей задачи уравнивания: маленькие поправочки в измеренные величины. Ну а что тут было зелено, да посерёдке толсто – это уж понятно из решения данной задачи. Правда, приведенная задача – одна из самых простых. Дальше будет корнеплод посложнее. Но, всему своё время. А сейчас – закончим решение приведенной задачи.
Шаг 6. Вычисляем уравненные значения углов:
β1 ‘ = 80° 16′ 44,3″ – 2,4″ = 80° 16′ 41,9″; β2 ‘ = 91° 45′ 00,7″ – 1,1″ = 91° 44′ 59,6″;
β3 ‘ = 69° 25′ 56,8″ – 1,2″ = 69° 25′ 55,6″; β4 ‘ = 118° 32′ 25,2″ – 2,4″ = 181° 32′ 22,8″.
Контроль: подстановка уравненных значений углов в уравнение (14.91) – условие выполнено! (проверьте это условие).
Очевидно, что при равноточных измерениях углов для них были бы получены одинаковые поправки, т.е. невязка была бы распределена поровну во все углы.
137.2. Уравнивание системы нивелирных ходов с несколькими узловыми точками
На местности пройдена система нивелирных ходов с четырьмя узловыми точками 1, 2, 3 и 4 (рис. 14.8). В результате измерений образовано 9 секций, превышения в которых по указанному направлению приведены непосредственно на схеме. Указаны также высоты исходных реперов Р10, Р20 и Р30. В табл. 14.6 приведены длины ходов в секциях и значения весов и обратных весов превышений в секциях, вычисленные по формулам:

Рис. 14.8. Схема нивелирных ходов с четырьмя узловыми точками.
| № секции | Превышение h, мм | Длина хода s в секции, км | Вес p пре-вышения | Обратный вес q пре-вышения |
| +3586 | 0,84 | 2,38 | 0,42 | |
| +2841 | 1,36 | 1,47 | 0,68 | |
| -752 | 2,15 | 0,93 | 1,08 | |
| -1243 | 0,78 | 2,56 | 0,39 | |
| +509 | 2,63 | 0,76 | 1,32 | |
| +5338 | 2,05 | 0,98 | 1,03 | |
| -5863 | 3,02 | 0,66 | 1,51 | |
| +4639 | 3,44 | 0,58 | 1,72 | |
| -3024 | 2,38 | 0,84 | 1,19 |
 , (14.95)
, (14.95)
где 
Требуется определить уравненные значения высот узловых точек.
Шаг 1. Общее число измерений n = 9, число необходимых измерений k = 4, число избыточных измерений r = 5.
Шаг 2. Составим r = 5 условных уравнений:
Шаг 3. Приведём условные уравнения к линейному виду, продифференцировав их по аргументам hi. Получим коэффициенты aij условных уравнений поправок:
Составим матрицу коэффициентов aij со строкой обратных весов qi (табл. 14.7).
Матрица коэффициентов и обратных весов
| → i j↓ | |||||||||
| +1 | -1 | +1 | |||||||
| -1 | +1 | +1 | |||||||
| +1 | +1 | +1 | |||||||
| +1 | +1 | -1 | |||||||
| +1 | +1 | +1 | |||||||
| qi | 0,42 | 0,68 | 1,08 | 0,39 | 1,32 | 1,03 | 1,51 | 1,72 | 1,19 |
Вычислим свободные члены (в мм), подставив в уравнения (14.96) измеренные значения hi в секциях:
Шаг 4. Найдём по формулам (14.88) коэффициенты bjj нормальных уравнений коррелат:
 (14.97)
(14.97)
После подстановки значений aij и qi в уравнения (14.97) получим исходные нормальные уравнения коррелат:
Из решения системы уравнений (14.98) одним из способов получим:
Контроль вычисления коррелат выполняем подстановкой их значений в исходные уравнения (14.98):
1. 2,18 (-2,137) – 1,08 (-11,552) + 0,42 (-1,945) – 7 = + 0,001;
2. -1,08(-2,137) + 2,79(-11,552) + 1,32(+9,606) + 0,39(-1,945) + 18 = -0,001;
3. 1,32(-11,552) + 3,86(+9,606) + 1,51(-3,882) – 16 = — 0,031;
4. 1,51(+9,606) + 4,42(-3,882) + 1,72(-1,945) + 6 = +0,001;
5. 0,42(-2,137) + 0,39(-11,552) + 1,72(-3,882) + 2,53(-1,945) + 17 = -0,001.
Сравнительно большее невыполнение условия мы видим в уравнении 3. Это вызвано погрешностями округлений. При вычислении с большими значащими цифрами этого не наблюдалось бы. При этом результаты вычислений принимаем удовлетворительными, поскольку поправки в измеренные значения превышений для данных условий будут в дальнейшем округляться до 1 мм, а вычисления проведены с большим запасом точности.
Шаг 5. Составляем условные уравнения поправок vi, пользуясь формулами (14.86) и табл. 14.7:

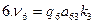

 (14.99)
(14.99)



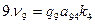

1. v1 = 0,42 ∙1∙ (-2,137) + 0,42∙1∙ (-1,945) = — 1,714 = — 2 мм;
2. v2 = 0,68 ∙ (-1) ∙ (-2,137) = + 1,453 = + 1 мм;
3. v3 = 1,08 ∙ 1 ∙ (2,137) + 1,08 ∙ (-1) ∙ (-11,552) = +10,168 = + 10 мм;
4. v4 = 0,39 ∙ 1 ∙ (-11,552) + 0,39 ∙1 ∙ (-1,945) = — 5,264 = — 5 мм;
5. v5 = 1,32 ∙1∙ (-11,552) + 1,32 ∙ 1 ∙ (+9,606) = — 2,569 = — 3 мм;
6. v6 = 1,03 ∙1 ∙ (+9,606) = + 9,894 = + 10 мм;
7. v7 = 1,51 ∙ 1 ∙ (+9,606) + 1,51 ∙1 ∙ (-3,882) = + 8,643 = + 9 мм;
8. v8 = 1,72 ∙ 1 ∙ (-3,882) + 1,72 ∙ 1 ∙ (-1,945) = — 10,022 = — 10 мм;
9. v9 = 1,19 ∙ (-1) ∙ (-3,882) = + 4,620 = + 5 мм.
Контроль вычисления поправок можно выполнить по формулам (14.96), подставив в них вместо превышений значения поправок (суммы поправок должны быть равны значениям соответствующих невязок с обратным знаком):
Шаг 6. Вычисляем уравненные значения превышений в секциях и контролируем уравнивание по выполнению условия (14.96):
h6 ‘= + 5338 + 10 = + 5348 мм;
Подстановка в уравнения (14.96) подтверждает выполнение указанного условия.
Вычисляем уравненные значения высот узловых точек 1, 2 , 3 и 4:
Контроль вычислений здесь можно выполнить вторичным получением высот искомых точек по другим направлениям. Должны получиться те же результаты. Например, H1 = HP30 – h8‘ – h4‘ = 85,301 – 4,629 + 1,248 = 81,920 м.
137.3. Уравнивание системы полигонометрических ходов с двумя узловыми точками
Уравнивание таких систем полигонометрических ходов аналогично уравниванию как одиночного полигонометрического хода, так и системы полигонометрических ходов с одной узловой точкой. В такой системе (рис. 14.9) образуется три независимых полигонометрических хода [(1), (2), (3)], в которых возникает по три условия: три условия дирекционных углов и шесть условий координат, т.е. получается девять условных уравнений.

Рис. 14.9. Система полигонометрических ходов с двумя узловыми точками.
В табл. 14.8, 14.9 и 14.10 приведены необходимые исходные данные для решения задачи уравнивания, заключающейся в определении уравненных значений координат точек 1, 2, 3, M, N, а также уравненного значения дирекционного угла узловой линии MN. (В данном примере узловые точки M и N образуют и узловую линию).
Часто между узловыми точками прокладывают полигонометрический ход в две и более линии. Тогда понятие узловой линии не будет иметь места. Ею может быть любая линия с началом в какой-либо узловой точке).
Горизонтальные углы измерены равноточно с погрешностью mβ = 2,0″. Расстояния измерены светодальномером с погрешностью, примерно одинаковой для всех линий (ms = 18 мм = 1,8 см). В соответствии с указанной точностью измерения расстояний и углов веса углов принимаем равными единице (pβ = 1; qβ = 1), а веса расстояний –
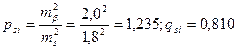
Координаты исходных пунктов
| Координаты, м | B | C | F | G |
| Х | 7183,652 | 8137,565 | 6124,924 | 7894,521 |
| Y | 4380,124 | 6463,782 | 4718,048 | 7173,596 |
Исходные дирекционные углы
| αАВ | 71º 08′ 14,3″ | α BA | 251º 08′ 14,3″ |
| α CD | 118º 19′ 14,7″ | α DC | 298º 19′ 14,7″ |
| α EF | 324º 21′ 18,0″ | α FE | 144º 21′ 18,0″ |
| α GH | 159º 58′ 14,2″ | α HG | 339º 58′ 14,2″ |
Измеренные горизонтальные углы и расстояния
| Обозначение угла | Значение угла | Обозначение расстояния | Значение расстояния, м |
| β 1 | 226º 15′ 25″ | s 1 | 475,885 |
| β 2 | 201º 36′ 36″ | s 2 | 693,027 |
| β 3 | 85º 02′ 31″ | s 3 | 857,338 |
| β 4 | 170º 15′ 07″ | s 4 | 401,239 |
| β 5 | 172º 53′ 18″ | s 5 | 841,215 |
| β 6 | 271º 07′ 58″ | s 6 | 625,329 |
| β 7 | 280º 34′ 07″ | s 7 | 573,421 |
| β 8 | 84º 46′ 52″ | s 8 | 989,716 |
| β 9 | 337º 03′ 44″ | ||
| β 10 | 178º 54 26″ | ||
| β 11 | 78º 21 28″ |
Выполним предварительные вычисления в полигонометрических ходах (1), (2) и (3), т.е. определим координаты точек ходов, используя только измеренные величины (табл. 14.11).
Шаг 1. Общее число измерений n = 19 (11 углов и 8 расстояний), число необходимых измерений k = 10, число избыточных измерений r = 9.
| №№ точек | Гориз.углы β | Дирекц.углы α | Рассто-яния s , м | Приращения координат, м | Координаты, м | №№ точек |
| Δх | Δу | Х | Y | |||
| A | Ход (1) | |||||
| 71°08’14,3″ | ||||||
| B | 226°15’25» | 7183,652 | 4380,124 | B | ||
| 117°23’39,3″ | 475,885 | -218,960 | +422,520 | |||
| 201°36’36» | 6964,692 | 4802,644 | ||||
| 139°00’15,3″ | 693,027 | -523,068 | +454,628 | |||
| M | 280°34’07» | 6441,624 | 5257,272 | M | ||
| 239°34’22,3″ | 625,329 | -316,693 | -539,205 | |||
| F | 84°46’52» | 6124,931 6124,924 +0,7 см | 4718,067 4718,048 +1,9 см | F o FИСХ | ||
| 144°21’14,3″ 144°21’18,0″ -3,7″ | ||||||
| E | ||||||
| Ход (2) | ||||||
| A | ||||||
| 71°08’14,3″ | ||||||
| B | 226°15’25» | 7183,652 | 4380,124 | B | ||
| 117°23’39,3″ | 475,885 | -218,960 | +422,520 | |||
| 201°36’36» | 6964,692 | 4802,644 | 1 | |||
| 139°00’15,3″ | 693,027 | -523,068 | +454,628 | |||
| M | 85°02’31» | 6441,624 | 5257,272 | M | ||
| 44°02’46,3″ | 857,338 | +616,237 | +596,054 | |||
| N | 170°15’07» | 7057,861 | 5853,326 | N | ||
| 34°17’53,3″ | 401,239 | +331,470 | +226,098 | |||
| 172°53’18» | 7389,331 | 6079,424 | ||||
| 27°11’11,3″ | 841,215 | +748,281 | +384,341 | |||
| C | 271°07’58» | 8137,612 8137,565 | 6463,765 6463,782 | C o СИСХ | ||
| 118°19’09,3″ 118°19’14,7″ -5,4″ | ||||||
| D | +4,7 см | -1,7 см | ||||
| Ход (3) | ||||||
| H | ||||||
| 339°58’14,2″ | ||||||
| G | 78°21’28» | 7894,521 | 7173,596 | G | ||
| 238°19’42,2″ | 573,421 | -301,075 | -488,022 | |||
| 178°54’26» | 7593,446 | 6685,574 | ||||
| 237°14’08,2″ | 989,716 | -535,620 | -832,255 | |||
| N | 337°03’44» | 7057,826 | 5853,320 | N | ||
| 34°17’52,2″ | 401,239 | +331,471 | +226,096 | |||
| 172°53’18» | 7389,297 | 6079,415 | ||||
| 27°11’10,2″ | 841,215 | +748,283 | +384,337 | |||
| C | 271°07’58» | 8137,580 8137,565 | 6463,752 6463,782 | C o СИСХ | ||
| 118°19’08,2″ 118°19’14,7″ -6,5″ | ||||||
| D | +1,5 см | -3,0 см |
Шаг 2. Составление условных уравнений.
Для трёх независимых ходов, будем иметь три условных уравнения для дирекционных углов и шесть условных уравнений для координат ( три – для абсцисс, три – для ординат).
1. 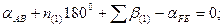
2. 
3. 
4. 
5.  (14.100)
(14.100)
6. 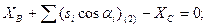
7. 
8. 
9. 
В уравнениях (14.100) индексы (1), (2) и (3) относятся к соответствующим ходам (см. табл. 14.11), например, n(1) = 4, n(2) = 6, n(3) = 5.
Приведём условные уравнения к линейному виду по правилам, изложенным выше. В полученные выражения введём знак гауссовых сумм.
1. 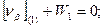
2. 
3. 
4. 
5. 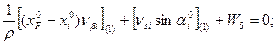 (14.101)
(14.101)
6. 
7. 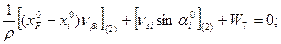
8. 
9. 
В уравнениях (14.101) значения координат берут в километрах, а значение ρ = 206265″ уменьшают на 100000.
Вычислим значения невязок в уравнениях (14.101) с учётом данных измерений и предварительных вычислений:
где Ti o – результат вычисления исходной величины Ti(исх).
W1 = 144º 21′ 14,3″ – 144º 21′ 18,0″ = — 3,7″ ;
W2 = 118º 19′ 09,3″ – 118º 19′ 14,7″ = — 5,4″ ;
W3 = 118º 19′ 08,2″ – 118º 19′ 14,7″ = — 6,5″ ;
W4 = 6124,931 – 6124,924 = +0,007 м = + 0,7 см;
W5 = 4718,067 – 4718,048 = + 0,019 м = + 1,9 см;
W6 = 8137,612 – 8137,565 = + 0,047м = + 4,7 см;
W7 = 6463,765 – 6463,782 = — 0,017 м = — 1,7 см;
W8 = 8137,580 – 8137,565 = + 0,015 м = + 1,5 см;
W9 = 6463,752 – 6463,782 = — 0,030 м = — 3.0 см .
По данным табл. 14.11 составим табл. 14.12 значений синусов и косинусов дирекционных углов и разностей абсцисс и ординат. Получим окончательные условные уравнения поправок:
Значения синусов и косинусов дирекционных углов, значения разностей координат
| №№ точек | Sin αi | Cos αi | (хn 0 -xi 0 ), км | (yn 0 -yi 0 ), км |
| Ход 1 | ||||
| В | (В-1) 0,8879 | -0,4601 | -1,0587 | 0,3379 |
| (1-М) 0,6560 | -0,7548 | -0,8398 | -0,0846 | |
| М | (M-F) -0,8623 | -0,5064 | -0,3167 | -0,5392 |
| F | ||||
| Ход 2 | ||||
| В | (В-1) 0,8879 | -0,4601 | 0,9540 | 2,0836 |
| (1-М) 0,6560 | -0,7548 | 1,1729 | 1,6611 | |
| М | (M-N) 0,6952 | 0,7188 | 1,6960 | 1,2065 |
| N | (N-2) 0,5635 | 0,8261 | 1,0798 | 0,6104 |
| (2-C) 0,4569 | 0,8895 | 0,7483 | 0,3843 | |
| C | ||||
| Ход 3 | ||||
| G | (G-3)-0,8511 | -0,5250 | 0,2431 | -0,7098 |
| (3-N)-0,8409 | -0,5412 | 0,5441 | -0,2218 | |
| N | (N-2)0,5635 | 0,8261 | 1,0798 | 0,6104 |
| (2-C)0,4569 | 0,8895 | 0,7483 | 0,3843 | |
| C |

Составим матрицу коэффициентов aij и обратных весов qi , необходимую для определения коэффициентов нормальных уравнений коррелат (табл. 14.13).
Матрица коэффициентов и обратных весов
| i→ j↓ | β1 | β2 | β3 | β4 | β5 | β6 | β7 | β8 | β9 |
| -0,1638 | 0,0410 | 0,2614 | |||||||
| -0,5133 | -0,4071 | -0,1535 | |||||||
| -1,0102 | -0,8053 | -0,5849 | -0,2959 | -0,1863 | |||||
| 0,4625 | 0,5686 | 0,8222 | 0,5235 | 0,3628 | |||||
| -0,1863 | -0,2959 | ||||||||
| 0,3628 | 0,5235 | ||||||||
| qi |
(продолжение табл. 14.13)
| β10 | β11 | s1 | s2 | s3 | s4 | s5 | s6 | s7 | s8 |
| -0,4601 | -0,7548 | -0,5064 | |||||||
| 0,8879 | 0,6560 | -0,8623 | |||||||
| -0,4601 | -0,7548 | 0,7188 | 0,8261 | 0,8895 | |||||
| 0,8879 | 0,6560 | 0,6952 | 0,5635 | 0,4569 | |||||
| 0,1076 | 0,3441 | 0,8261 | 0,8895 | -0,5250 | -0,5412 | ||||
| 0,2638 | 0,1178 | 0,5635 | 0,4569 | -0,8511 | -0,8409 | ||||
| 0,810 | 0,810 | 0,810 | 0,810 | 0,810 | 0,810 | 0,810 | 0,810 |
Шаг 4. Составление нормальных уравнений коррелат.
источники:
http://helpiks.org/8-23439.html
http://lektsii.org/3-97898.html
Онлайн-исследования стали неотъемлемой частью нашей жизни. Они позволяют собирать мнения и данные на различные темы, без необходимости долгих телефонных опросов или личных встреч. Сегодня, существует множество инструментов, которые помогают проводить и анализировать онлайн-опросы. Однако, несмотря на все преимущества, средняя ошибка выборки может быть одной из проблем в онлайн-исследованиях.
Средняя ошибка выборки – это ошибка, которая возникает при использовании выборки при опросе группы людей. При этом, ошибочная выборка может привести к неточным результатам и, как следствие, недостоверным выводам. В этой статье, мы рассмотрим, как избежать средней ошибки выборки в онлайн-исследованиях, чтобы получить более точные ответы и достоверные данные.
Существует несколько способов уменьшения средней ошибки выборки в онлайн-исследованиях, таких как увеличение размера выборки, использование случайной выборки и тд. Мы рассмотрим каждый из них и сделаем выводы о том, какой из способов является наиболее эффективным.
Содержание
- Ошибки в онлайн-исследованиях
- Неправильная выборка
- Неясная формулировка вопросов
- Недостаточное количество участников
- Заключение
- Что такое ошибка выборки?
- Почему возникает ошибка выборки в онлайн-исследованиях?
- 1. Неправильная выборка респондентов
- 2. Неслучайная выборка
- Как минимизировать среднюю ошибку выборки?
- 1. Определить точную целевую аудиторию
- 2. Увеличить размер выборки
- 3. Использовать специализированные сервисы
- Примеры использования практических методик уменьшения ошибки выборки в онлайн-исследованиях
- 1. Рандомизация выборки
- 2. Фильтрация выборки
- 3. Использование участников контрольной группы
- 4. Контроль размера выборки
- Выводы
- Онлайн-исследования могут быть полезны, но требуют внимания к деталям
- Работа средств автоматической обработки может повысить точность результатов
- Вопрос-ответ:
- Почему средняя ошибка выборки является проблемой в онлайн-исследованиях?
- Как уменьшить среднюю ошибку выборки в онлайн-исследованиях?
- Можно ли использовать онлайн-опросы для получения достоверных результатов?
- Как определить достоверность результатов онлайн-исследования?
- Как оценить размер выборки для онлайн-исследования?
- Как убедиться, что выборка является представительной в онлайн-исследованиях?
- Как учитывать отсутствующие данные в онлайн-исследованиях?
- Можно ли использовать онлайн-исследования для изучения сложных тем?
- Какие существуют проблемы при использовании онлайн-опросов для получения данных?
- Как влияет размер выборки на точность результатов онлайн-исследования?
- Как влияет уровень доверия на точность результатов онлайн-исследования?
- Как связаны выборка и ошибки выборки в онлайн-исследованиях?
- Как важно брать случайную выборку в онлайн-исследованиях?
- Как выбрать правильный метод анализа данных в онлайн-исследованиях?
- Что такое предварительное заполнение данных в онлайн-исследованиях?
Ошибки в онлайн-исследованиях
Неправильная выборка
Одной из основных ошибок, которую могут допустить при проведении онлайн-исследований, является неправильный выбор образца. Если выбранная выборка не будет представлять целевую аудиторию и будет состоять из людей, которые не знают ответа на заданный вопрос, то результаты исследования окажутся значительно искаженными.
Неясная формулировка вопросов
Другой распространенной ошибкой в онлайн-исследованиях является неясная формулировка вопросов. Важно, чтобы каждый вопрос был четким и понятным, не оставляя места для различных интерпретаций. Если вопросы сформулированы неясно, то результаты исследования будут искаженными, и скорее всего, непригодными к дальнейшему анализу.
Недостаточное количество участников
Третьей ошибкой, которую часто допускают при проведении онлайн-исследований, является недостаточное количество участников. Если участников слишком мало, то результаты исследования будут не репрезентативными и не будут отражать мнения всей целевой аудитории. Важно проводить исследование на достаточно большой выборке, чтобы результаты были более точными и достоверными.
Заключение
Ошибки в онлайн-исследованиях могут привести к некорректным результатам искажению представления людей о мнении аудитории. Важно правильно выбирать образец, формулировать вопросы четко и понятно, а также проводить исследование на достаточно большой выборке. Тогда результаты будут более точными и можно будет доверять выводам.
Что такое ошибка выборки?
Ошибка выборки – это расхождение между оценкой параметра генеральной совокупности и его реальным значением, которое возникает из-за несоответствия выборки генеральной совокупности.
В онлайн-исследованиях ошибки выборки являются проблемой, поскольку выборка респондентов обычно чрезвычайно маленькая по сравнению с генеральной совокупностью. В результате, вероятность получить ненадежные данные высока.
Как правило, ошибки выборки происходят из-за недостаточного размера выборки, ошибок при подборе или случайного искажения. Важно знать, что чем больше выборка, тем меньше вероятность получения ненадежных данных.
Отсутствие контроля за ошибками выборки может привести к неправильному принятию решений на основе ненадежной информации.
Ошибки выборки также могут возникнуть из-за неоднородности популяции, которую исследователь пытается изучить, технических ошибок или несовершенства методологии исследования.
Чтобы избежать ошибок выборки в онлайн-исследованиях, необходимо строго контролировать каждый процесс и убедиться, что выборка хорошо представляет генеральную совокупность. Оформление корректного опроса, правильный подбор выборки и анализ данных – все эти шаги являются важными элементами для стратегического планирования и развития бизнеса.
Почему возникает ошибка выборки в онлайн-исследованиях?
1. Неправильная выборка респондентов
В онлайн-исследованиях ошибки выборки могут возникать из-за неправильной выборки респондентов. Например, если выборка получается слишком маленькой, то результаты не будут репрезентативными. Если же выборка слишком большая, то это может привести к некоторым проблемам, например, низкой ответственности респондентов или эффекту «ширинки». Кроме того, слишком узкая выборка может привести к искажению результатов.
2. Неслучайная выборка
Еще одна причина ошибки выборки является неслучайная выборка. Это означает, что часть определенной группы респондентов была исключена или не участвовала в исследовании. Это может привести к ошибке выборки, так как результаты не будут репрезентативными для всей группы. Например, если исследование проводится по определенной группе профессионалов, а определенная часть этой группы не участвует в исследовании, то это может привести к ситуации, когда результаты не соответствуют действительности.
В целом, чтобы избежать ошибки выборки в онлайн-исследованиях, необходимо проводить исследования, учитывая все основные характеристики выборки, такие как ее размер, сложность и т.д. Кроме того, необходимо использовать правильные методы и инструменты для сбора данных, чтобы получить наиболее точные результаты.
Как минимизировать среднюю ошибку выборки?
1. Определить точную целевую аудиторию
Перед началом онлайн-исследования необходимо определить, какая аудитория будет выполнять опрос. Чем точнее вы определяете исследуемую аудиторию, тем меньше будет средняя ошибка выборки.
2. Увеличить размер выборки
Увеличение размера выборки помогает уменьшить среднюю ошибку выборки и повышает точность исследования. Чем больше число опрашиваемых людей, тем точнее будет результат.
3. Использовать специализированные сервисы
Существуют специализированные сервисы, которые могут помочь с минимизацией ошибки выборки при онлайн-исследованиях. Такие сервисы предоставляют данные о целевой аудитории, а также позволяют увеличить выборку, что помогает повысить точность полученных результатов.
Важно помнить, что минимизация ошибки выборки необходима для точности получаемых результатов при онлайн-исследованиях. Следуя этим советам, можно улучшить качество проводимых исследований и получить более точные результаты.
Примеры использования практических методик уменьшения ошибки выборки в онлайн-исследованиях
1. Рандомизация выборки
Принцип: Случайность — это ключ к репрезентативности выборки. Рандомизация (случайный выбор) позволяет увеличить вероятность получения репрезентативной выборки.
Как использовать: Существует множество онлайн-сервисов, которые предлагают случайную выборку участников опроса. Однако, необходимо учитывать, что рандомизация может быть невозможна при проведении опроса с целевой аудиторией.
2. Фильтрация выборки
Принцип: Ошибки могут возникать из-за неправильного выбора целевой аудитории. Как правило, не все участники охватываемой выборки могут быть подходящими для опроса.
Как использовать: Для избежания подобного рода ошибок, требуется использовать фильтрацию выборки. Например, опрос о политических предпочтениях может быть направлен только к взрослым гражданам определенной страны. При этом, опрос нельзя отправлять людям, не достигшим определенного возраста.
3. Использование участников контрольной группы
Принцип: Участники контрольной группы могут помочь увидеть эффективность исследования и количество возможных ошибок.
Как использовать: Используйте контрольную группу, чтобы оценить точность опроса. Например, если вы проводите опрос на сказочную тематику, создайте две группы участников: одну, которая знакома со всеми сказками, и вторую, где люди не знают сказок. Благодаря контрольной группе можно определить, какие вопросы имеют наибольшую степень ошибок, и сделать выводы о возможных вариантах улучшения опроса.
4. Контроль размера выборки
Принцип: Ошибки могут возникнуть, если размер выборки слишком мал. Чем менее масштабен опрос, тем меньше вероятность получения точных данных.
Как использовать: Исследуйте рынок и оцените количество людей, которые могут принять участие в опросе, перед тем, как определить размер выборки. Минимальное количество должно позволять получить достаточно точные результаты.
Выводы
Онлайн-исследования могут быть полезны, но требуют внимания к деталям
Из проведенного исследования можно сделать вывод, что использование онлайн-опросов для сбора данных может быть эффективным способом получения статистически значимых результатов. Однако, чтобы результаты были достоверными и точными, необходимо учитывать ряд факторов, который влияют на исходы.
- Необходимо составлять качественные и понятные вопросы, чтобы избежать неправильных ответов.
- Надо убедиться, что выборка соответствует реальной целевой аудитории и учитывает особенности этой группы.
- Не следует полагаться только на онлайн-исследования, необходимо оценивать результаты в сочетании с другими источниками информации.
Исходя из этого, можно заключить, что онлайн-исследования – это полезный инструмент для получения данных, но их использование должно быть осознанным и внимательным.
Работа средств автоматической обработки может повысить точность результатов
Разные инструменты автоматической обработки (например, программы для анализа данных, машинное обучение и др.) могут помочь повысить точность результатов. Однако использование таких средств также требует опыта и внимания.
Важно понимать, что автоматизированные методы сбора и обработки данных не могут заменить человеческий фактор полностью. Их использование дает возможность быстро получать результаты и анализировать большие объемы данных, но для обработки содержательной информации всегда требуется человеческий анализ и интерпретация.
Вопрос-ответ:
Почему средняя ошибка выборки является проблемой в онлайн-исследованиях?
Средняя ошибка выборки – это показатель, который указывает на то, насколько результаты исследования могут отличаться от реальных значений в генеральной совокупности. В онлайн-исследованиях выборка может быть непредставительной, поэтому средняя ошибка выборки может быть значительной, что снижает достоверность результатов.
Как уменьшить среднюю ошибку выборки в онлайн-исследованиях?
Существует несколько способов уменьшить среднюю ошибку выборки в онлайн-исследованиях. Во-первых, необходимо правильно определить генеральную совокупность исследования. Во-вторых, необходимо использовать случайную выборку, чтобы минимизировать искажения данных. В-третьих, можно использовать различные методы статистического анализа, например, множественную регрессию, чтобы учесть влияние различных факторов на результаты исследования.
Можно ли использовать онлайн-опросы для получения достоверных результатов?
Да, онлайн-опросы могут быть использованы для получения достоверных результатов, если выборка и генеральная совокупность правильно определены, а методы исследования и анализа данных используются правильно. Также важно учитывать, что онлайн-опросы могут быть предметом искажений из-за склонности определенных групп людей к ответам на определенные вопросы.
Как определить достоверность результатов онлайн-исследования?
Для определения достоверности результатов онлайн-исследования необходимо провести анализ данных, используя статистические методы. Например, можно провести тест Стьюдента для проверки значимости различий между выборками. Также можно использовать коэффициент корреляции Пирсона для определения связи между двумя переменными.
Как оценить размер выборки для онлайн-исследования?
Оценку размера выборки можно провести с помощью статистических калькуляторов, таких как калькулятор размера выборки Оттано. Однако, для точной оценки размера выборки необходимо учитывать множество факторов, таких как уровень доверия, вероятность ошибки, а также дисперсию в генеральной совокупности.
Как убедиться, что выборка является представительной в онлайн-исследованиях?
Для того, чтобы убедиться в том, что выборка является представительной, необходимо правильно определить генеральную совокупность исследования, а также использовать случайную выборку. Также возможно проведение тестов на непредставительность, например, тест Шапиро-Уилка или тест Колмогорова-Смирнова.
Как учитывать отсутствующие данные в онлайн-исследованиях?
Отсутствующие данные в онлайн-исследованиях могут быть учтены при помощи методов обработки данных, таких как предварительное заполнение, импутация или даже удаление пропущенных значений. Однако, необходимо помнить, что каждый метод имеет свои преимущества и недостатки, и выбор метода должен быть обоснован в соответствии с целями исследования.
Можно ли использовать онлайн-исследования для изучения сложных тем?
Да, онлайн-исследования могут быть использованы для изучения сложных тем, если вопросы формулируются понятно и ясно, а выборка и генеральная совокупность правильно определены. Также возможно использование дополнительных методов, например, интервью с экспертами или проведение фокус-групп, чтобы углубить понимание предметной области.
Какие существуют проблемы при использовании онлайн-опросов для получения данных?
Среди проблем, которые могут возникнуть при использовании онлайн-опросов, могут быть: браконьерство (т.е. ответы не от целевой аудитории), непредставительная выборка, отсутствие контроля за процессом опроса, отсутствие возможности задавать уточняющие вопросы и прочее.
Как влияет размер выборки на точность результатов онлайн-исследования?
Больший размер выборки увеличивает точность результатов онлайн-исследования, так как уменьшает вероятность случайных отклонений. Однако, необходимо учитывать, что большой размер выборки также увеличивает затраты на проведение исследования.
Как влияет уровень доверия на точность результатов онлайн-исследования?
Уровень доверия – это вероятность того, что реальное значение показателя находится в заданном диапазоне значений. Чем выше уровень доверия, тем больший диапазон значений необходимо учесть при проведении исследования, что может привести к увеличению средней ошибки выборки и, следовательно, к ухудшению точности результатов онлайн-исследования.
Как связаны выборка и ошибки выборки в онлайн-исследованиях?
Ошибки выборки в онлайн-исследованиях зависят от выборки, то есть от того, насколько представительна выборка в отношении генеральной совокупности. Чем больше выборка, тем меньше средняя ошибка выборки и тем более представительны данные.
Как важно брать случайную выборку в онлайн-исследованиях?
Важность использования случайной выборки в онлайн-исследованиях заключается в том, что она позволяет получить представительные данные, которые не будут искажены из-за предвзятости конкретных групп людей. Также случайная выборка уменьшает вероятность систематических ошибок, которые могут возникнуть при использовании непредставительной выборки.
Как выбрать правильный метод анализа данных в онлайн-исследованиях?
Выбор метода анализа данных в онлайн-исследованиях зависит от целей исследования, а также от факторов, которые могут влиять на результаты исследования. Например, для изучения взаимосвязи между двумя переменными может использоваться корреляционный анализ, а для определения влияния нескольких факторов на один показатель – множественная регрессия.
Что такое предварительное заполнение данных в онлайн-исследованиях?
Предварительное заполнение данных – это метод обработки данных, при котором пропущенные значения заменяются на конкретные числа, например, на среднее значение или на значение, которое наиболее часто встречается в выборке. Такой метод может быть использован, если пропущенных значений не очень много и если они распределены случайным образом.
Ошибки,
проявляющиеся в ходе сбора данных, могут
быть разделены на две группы
[Черчилль, с. 500]:
-
Ошибки
в выборке.
Они связаны
с несоответствие параметров изучаемой
выборки и генеральной совокупности.
Такие ошибки возникают на стадии
проектирования выборки и подробно
рассмотрены в главе 7. -
Систематические
ошибки.
В эту группу входят все
остальные ошибки, не являющиеся ошибками
выборки.
Они возникают в результате несовершенной
концепции или логики исследования,
неправильной интерпретацией ответов,
а также ошибок на стадии обработки,
анализа данных и представления
информации.
Систематические
ошибки делятся на два вида:
-
Случайные.
Такие ошибки приводят к отклонениям
от истинного значения на случайную
величину и в случайную сторону. -
Неслучайные.
Такие ошибки приводят к одностороннему
отклонению результата от истинного
значения.
Систематические
ошибки более опасны, чем ошибки в выборке:
их труднее измерить, кроме того, увеличение
выборки далеко не всегда позволяет их
сократить. Величина систематической
ошибки может в десять раз превысить
ошибку выборки и обратить результаты
исследований практически в ничто.
Систематические
ошибки могут быть сокращены.
Однако, инструментами
такого сокращения выступают
не увеличение численности выборки, а
специальные
методы.
Для того, чтобы их правильно применить,
необходимо определить основные источники
систематических ошибок.
Классификация
систематических ошибок по источникам
возникновения
представлена на
рис. 8.2.

Существует
два основных вида систематических
ошибок по источникам их возникновения
[Черчилль, с. 501 – 521]:
-
ошибка
ненаблюдения; -
ошибка
наблюдения.
Ошибка
ненаблюдения
связана с невозможностью получить
данные от части элементов исследуемой
совокупности.
Такая
ошибка может возникнуть по двум основным
причинам:
-
часть
объекта исследования не представлена
в выборке (ошибка
неохвата); -
часть
элементов выборки не представила данных
(ошибка
неполучения данных
из-за отсутствия на месте либо отказа
от интервью).
Ошибка
наблюдения
возникает при несоответствии данных
об элементах совокупности, представленных
в отчёте, истинным значениям.
Такое
несоответствие может возникнуть при
следующих
обстоятельствах:
-
предоставлении
элементами некорректных данных; -
неправильной
регистрации данных; -
ошибках
в обработке, анализе или представлении
итогов исследования.
Ошибки
неохвата
возникают вследствие недостаточно
тщательному анализу процедуры формирования
выборки.
При использовании
пропорциональных методов формирования
выборки на результаты опроса накладывают
отпечаток волевые решения полевых
сотрудников. Они склонны получать данные
от наиболее доступных им респондентов,
что приводит часто к выпадению из
исследования людей с очень низкими и
очень высокими доходами при поквартирном
обходе. При опросе по телефону могут
выпасть люди, не имеющие телефона. При
опросе в магазине выпадают те, кто редко
посещает магазины либо вообще в них не
ходит.
С ошибкой неохвата
связана ошибка
перебора,
которая возникает при попадании некоторых
элементов в выборку несколько раз.
Основная проблема
ошибки неохвата заключается в том, что
для её оценки необходимо иметь некие
независимые внешние показатели по
исследуемой совокупности, с которыми
можно сопоставить результаты проведённого
исследования
(например, результатов переписи или
другого надёжного исследования, не
утратившие своей актуальности). При
наличии таких независимых достоверных
данных, исследователь должен заранее
определить вид собираемых данных для
того, чтобы их можно было сопоставить
с независимым источником.
Основным методом
сокращения ошибок неохвата и ошибок
перебора является улучшение основы
выборки,
чтобы она охватывала все исследуемые
элементы и не допускала дублирования.
Например, для избежания ошибки перебора
каждому элементу может приписываться
весовой корректирующий коэффициент,
обратно пропорциональный вероятности
попадания указанного элемента в выборку.
Ошибка
неполучения данных
является вторым видом ошибок ненаблюдения.
Она возникает в том случае, если
исследователи не могут собрать данные
от элементов, входящих в состав выборки.
Это происходит по двум причинам:
отсутствие и отказ от интервью.
Для измерения
возможной величины этой ошибки в практике
маркетинговых исследований при опросах
применяется специальный показатель –
доля ответивших.
Доля
ответивших
– отношение количества полных интервью
к общему количеству приемлемых
респондентов в выборке.
Главным критерием
является чёткое определение требований
приемлемости применительно к исследуемой
совокупности.
Проблема
отсутствия может решаться несколькими
способами:
-
установление
предварительной договорённости о
времени контакта с респондентом
(эффективно для опроса промышленных
потребителей либо чиновников); -
повторные
попытки контакта.
Повторные попытки
контакта являются одним из самых
эффективных способов снижения ошибки
неполучения данных.
Исследователи пришли к выводу, что
исследование с небольшой выборкой, но
многократными повторными попытками
контакта предоставляют более точную
информацию, чем исследования с большой
выборкой и без повторных попыток контакта
при отсутствии респондента.
Эффективность
в решении проблемы отсутствия респондентов
разрешается путём профессиональной
подготовки полевых сотрудников
установлению контакта и процедуре
повторных попыток контакта.
Кроме
повторных попыток контактов, возможно
сократить данную ошибку, используя
статистические методы.
В таком случае у респондентов выясняют
с помощью специальных вопросов, как
часто они бывают на месте исследования
(например, дома), и, в зависимости от
этого, им присваивается весовой
коэффициент. Чем реже респондент бывает
на месте исследования, тем более высокий
весовой коэффициент он получает.
Отказ респондента
от общения может возникать по многим
причинам,
обусловленным особенностями респондентов,
организаций-исследователей, обстоятельств
контакта, темы исследований и
профессионализма интервьюера. Определённое
значение имеет метод сбора информации:
личная встреча приводит к наименьшему,
а почтовый опрос к наибольшему количеству
отказов.
Существует
три основных группы методов снижения
ошибок из-за отказа респондента от
общения:
-
Методы
повышения доли первичных ответов.
Для этого производится создание
благоприятных условий для интервью и
обучение полевого персонала. -
Повторные
попытки контакта.
Они приносят результат, если причиной
отказа респондента являются врéменные,
изменчивые условия: состояние здоровья,
настроение, усталость. В таком случае
при повторной попытке контакта респондент
может согласиться участвовать в
исследовании. -
Статистическая
коррекция результатов.
Они заключаются в придании определённых
весовых коэффициентов респондентам в
зависимости от степени сотрудничества
страты, к которой они принадлежат, с
исследователями.
Ошибки
наблюдения,
вторая группа систематических ошибок,
ещё более
сложны в оценке и контроле.
Ошибки наблюдения ещё менее заметны,
чем ошибки ненаблюдения.
Существует два
основных вида ошибок наблюдения:
-
ошибки
сбора; -
ошибки
регистрации.
Ошибки
сбора
заключаются
в предоставлении респондентом ложных
данных.
Причиной
может быть неполное соответствие трёх
групп характеристик интервьюера и
респондента
[Черчилль, 516 – 521]:
-
Личные
особенности
(возраст, образование, общественный
статус, этническая и религиозная
принадлежность, пол и другие). Чем
сильнее различаются по этим характеристикам
респондент и интервьюер, тем сильнее
недопонимание, возникающее между ними.
В этом отношении наиболее эффективным
способом снижения ошибки является
подбор личности интервьюера к каждой
группе респондентов. -
Психологические
особенности (восприятие,
позиция, намерения, мотивы). Каждый
интервьюер имеет свои психологические
особенности, которые могут повлиять
на результаты сбора данных, исказив
их. Для сокращения такой ошибки
разрабатываются детальные формальные
процедуры, которым интервьюер должен
неукоснительно следовать. -
Поведенческие
особенности.
Эти особенности интервьюера и респондента
влияют на возникновение ошибок в ходе
их взаимодействия. Ошибки возникают,
в основном, вследствие того, что
интервьюеры не придерживаются инструкций,
не могут правильно сформулировать и
уточнить вопрос, правильно записать
ответ. В некоторых случаях происходит
подтасовка данных интервьюерами.
Методом снижения ошибки в этом случае
является тщательный подбор и обучение
полевого персонала, а также последующий
контроль. Подробнее это было рассмотрено
в предыдущем параграфе.
Итак,
процедура сбора данных подвержена
влиянию множества ошибок, систематических
и ошибок выборки. Только
тщательные и действенные превентивные
меры позволяют на этом этапе обеспечить
достоверность полученных данных для
сохранения практической значимости
проекта маркетингового исследования.
Контрольные
вопросы к блоку А
-
Каковы
основные элементы процесса полевых
исследований? -
Какие
подходы существуют к осуществлению
полевых работ, в чём их преимущества и
недостатки? -
Каковы
структура полевых работ? -
Каковы
особенности отбора персонала для
полевых работ? -
Что
происходит на этапе подготовки полевого
персонала? -
Как
осуществляется контроль над работой
полевого персонала? -
Как
проверяются результаты полевых работ
и оценивается труд полевого персонала? -
Какие
ошибки возникают на этапе сбора данных? -
Что
такое ошибки в выборке и как они
возникают? -
Что
такое систематические ошибки? -
Какие
виды систематических ошибок существуют? -
Что
такое ошибка ненаблюдения и по каким
причинам она возникает? -
Что
такое ошибка наблюдения и каковы факторы
её возникновения? -
В
чём заключается ошибка неохвата и как
она может быть снижена? -
Что
такое ошибка перебора? -
Как
можно оценить ошибку неохвата? -
В
чём причина возникновения ошибки
неполучения данных? -
Для
чего используется показатель «доля
ответивших»? -
Как
разрешается проблема отсутствия
респондента на месте интервью? -
Какие
методы существуют для решения проблемы
отказа от ответа? -
Что
такое ошибка сбора, почему она возникает? -
Как
можно сократить ошибку сбора?
Блок
B
Полевые
исследования:
-
Подготовка
полевых работ
[Божук-Ковалик, с. 142 – 144; Голубков, с.
253 – 254; Малхотра, с. 500 – 507] -
Контроль
над полевыми работами
[Божук-Ковалик, с. 144 – 145; Малхотра, с.
507 – 511]
Ошибки
на этапе сбора данных:
-
Ошибки
ненаблюдения
[Малхотра, с. 454 – 462; Черчилль, с. 503 –
515]. -
Ошибки
наблюдения
[Голубков, с. 254 – 258; Черчилль, с. 515 –
521].
Контрольные
задания к блоку B
-
Составьте
инструкции для интервьюеров по проведению
полевых исследований по определённой
Вами теме среди студентов университета. -
Посетите
Интернет-сайты агентств по маркетинговым
исследованиям и составьте отчёт по
найденной информации о проведении
полевых работ. -
На
сайте Ассоциации маркетинговых
исследований США (http://www.mra—net.org)
найдите этический кодекс по маркетинговым
исследованиям, ознакомьтесь с разделом,
касающимся полевых работ. Попытайтесь
найти аналогичный документ российской
ассоциации. -
Определите
цели, задачи и методы проведения
какого-либо проекта маркетингового
исследования. Опишите детально все
возможные ошибки на этапе сбора данных
и способы их сокращения.
Блок
C
Подготовка и
проведение сбора данных.
Осуществите процедуру подготовки этапа
сбора данных: составьте программу,
определите требования к финансовым и
людским ресурсам. Определите источники
возможных ошибок ненаблюдения и
наблюдения. Выработайте мероприятия
для сокращения указанных ошибок.
Определите возможности для последующего
контроля величины указанных ошибок.
При получении соответствующего задания
от преподавателя, осуществите сбор
данных. Результаты осуществления этапа
подготовки полевых работ и сбора данных
отразите в отчёте о групповой работе.
Литература
для дальнейшего изучения
-
Божук
С.Г., Ковалик Л.Н.
Маркетинговые исследования. СПб.: Питер,
2003. -
Голубков
Е.П.
Маркетинговые исследования: теория,
методология и практика. 2-е изд. М.:
Финпресс, 2000. -
Малхотра
Н.К.
Маркетинговые исследования. Практическое
руководство, 3-е изд. М.: Вильямс, 2002. -
Черчилль
Г.А.
Маркетинговые исследования. СПб.: Питер,
2001.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
3. Ошибки выборки
Каждая единица при выборочном наблюдении должна иметь равную с другими возможность быть отобранной – это является основой собственнослучайной выборки.
Собственнослучайная выборка – это отбор единиц из всей генеральной совокупности посредством жеребьевки или другим подобным способом.
Принципом случайности является то, что на включение или исключение объекта из выборки не может повлиять любой фактор, кроме случая.
Доля выборки – это отношение числа единиц выборочной совокупности к числу единиц генеральной совокупности:

Собственнослучайный отбор в чистом виде является исходным среди всех других видов отбора, в нем заключаются и реализуются основные принципы выборочного статистического наблюдения.
Два основных вида обобщающих показателей, которые используют в выборочном методе – это средняя величина количественного признака и относительная величина альтернативного признака.
Выборочная доля (w), или частность, определяется отношением числа единиц, обладающих изучаемым признаком m, к общему числу единиц выборочной совокупности (n):
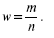
Для характеристики надежности выборочных показателей различают среднюю и предельную ошибки выборки.
Ошибка выборки, ее еще называют ошибкой репрезентативности, представляет собой разность соответствующих выборочных и генеральных характеристик:
1) для средней количественного признака:
?х =|х – х|;
2) для доли (альтернативного признака):
?w =|х – p|.
Только выборочным наблюдениям присуща ошибка выборки
Выборочная средняя и выборочная доля – это случайные величины, принимающие различные значения в зависимости от единиц изучаемой статистической совокупности, которые попали в выборку. Соответственно ошибки выборки – тоже случайные величины и также могут принимать различные значения. Поэтому определяют среднюю из возможных ошибок – среднюю ошибку выборки.
Средняя ошибка выборки определяется объемом выборки: чем больше численность при прочих равных условиях, тем меньше величина средней ошибки выборки. Охватывая выборочным обследованием все большее количество единиц генеральной совокупности, все более точно характеризуем всю генеральную совокупность.
Средняя ошибка выборки зависит от степени варьирования изучаемого признака, в свою очередь степень варьирования характеризуется дисперсией ?2 или w(l – w) – для альтернативного признака. Чем меньше вариация признака и дисперсия, тем меньше средняя ошибка выборки, и наоборот.
При случайном повторном отборе средние ошибки теоретически рассчитывают по следующим формулам:
1) для средней количественного признака:

где ?2 – средняя величина дисперсии количественного признака.
2) для доли (альтернативного признака):
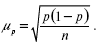
Так как дисперсия признака в генеральной совокупности ?2 точно неизвестна, на практике пользуются значением дисперсии S2 , рассчитанным для выборочной совокупности на основании закона больших чисел, согласно которому выборочная совокупность при достаточно большом объеме выборки достаточно точно воспроизводит характеристики генеральной совокупности.
Формулы средней ошибки выборки при случайном повторном отборе следующие. Для средней величины количественного признака: генеральная дисперсия выражается через выборную следующим соотношением:

где S2 – значение дисперсии.
Механическая выборка – это отбор единиц в выборочную совокупность из генеральной, которая разбита по нейтральному признаку на равные группы; производится так, что из каждой такой группы в выборку отбирается лишь одна единица.
При механическом отборе единицы изучаемой статистической совокупности предварительно располагают в определенном порядке, после чего отбирают заданное число единиц механически через определенный интервал. При этом размер интервала в генеральной совокупности равен обратному значению доли выборки.
При достаточно большой совокупности механический отбор по точности результатов близок к собственнослучайному Поэтому для определения средней ошибки механической выборки используют формулы собственнослучайной бесповторной выборки.
Для отбора единиц из неоднородной совокупности применяется так называемая типическая выборка, используется, когда все единицы генеральной совокупности можно разбить на несколько качественно однородных, однотипных групп по признакам, от которых зависят изучаемые показатели.
Затем из каждой типической группы собственнослучайной или механической выборкой производится индивидуальный отбор единиц в выборочную совокупность.
Типическая выборка обычно применяется при изучении сложных статистических совокупностей.
Типическая выборка дает более точные результаты. Типизация генеральной совокупности обеспечивает репрезентативность такой выборки, представительство в ней каждой типологической группы, что позволяет исключить влияние межгрупповой дисперсии на среднюю ошибку выборки. Поэтому при определении средней ошибки типической выборки в качестве показателя вариации выступает средняя из внутригрупповых дисперсий.
Серийная выборка предполагает случайный отбор из генеральной совокупности равновеликих групп для того, чтобы в таких группах подвергать наблюдению все без исключения единицы.
Поскольку внутри групп (серий) обследуются все без исключения единицы, средняя ошибка выборки (при отборе равновеликих серий) зависит только от межгрупповой (межсерийной) дисперсии.
Данный текст является ознакомительным фрагментом.
Читайте также
Ошибки резидента
Ошибки резидента
Относиться к ошибкам можно по-разному: можно бояться их совершить и переживать из-за каждой из них, можно радоваться своим ошибкам и кризисам, как указателям на пути к успеху и личным победам. Неизменно в ошибках только одно – за них приходится платить.
Формирование выборки
Формирование выборки
Процедура выборки является неотъемлемым этапом проекта внутреннего аудита. Она подробно описана в различных источниках, посвященных теме аудита. Однако во многом такие описания носят академичный характер. Предлагаю заострить внимание на тех
Ошибки в инвестициях – это ошибки инвесторов
Ошибки в инвестициях – это ошибки инвесторов
Сейчас я больше, чем когда бы то ни было, убежден в том, что все ошибки в инвестициях на самом деле ошибки инвесторов.Инвестиции не совершают ошибок. В отличие от инвесторов.Инвестирование – это выбор. Именно об этой
29. Определение необходимой численности выборки
29. Определение необходимой численности выборки
Одним из научных принципов в теории выбороч–ного метода является обеспечение достаточного чи–сла отобранных единиц.Уменьшение стандартной ошибки выборки всег–да связано с увеличением объема выборки. Расчет
30. Способы отбора и виды выборки. Собственно случайная выборка
30. Способы отбора и виды выборки. Собственно случайная выборка
В теории выборочного метода разработаны раз–личные способы отбора и виды выборки, обеспечи–вающие репрезентативность. Под способом отбора понимают порядок отбора единиц из генеральной со–вокупности.
31. Механическая и типическая выборки
31. Механическая и типическая выборки
При чисто механической выборке вся ге–неральная совокупность единиц должна быть прежде всего представлена в виде списка единиц отбора, со–ставленного в каком-то нейтральном по отношению к изучаемому признаку порядке. Затем список
32. Серийная и комбинированная выборки
32. Серийная и комбинированная выборки
Серийная (гнездовая) выборка – это такой вид формирования выборочной совокупности, когда в случайном порядке отбираются не единицы, подле–жащие обследованию, а группы единиц (серии, гнез–да). Внутри отобранных серий (гнезд)
33. Многоступенчатая, многофазная и взаимопроникающая выборки.
33. Многоступенчатая, многофазная и взаимопроникающая выборки.
Особенность многоступенчатой выборки со–стоит в том, что выборочная совокупность формиру–ется постепенно, по ступеням отбора. На первой ступени с помощью заранее определенного спосо–ба и вида отбора
3. Определение необходимой численности выборки
3. Определение необходимой численности выборки
Одним из научных принципов в теории выборочного метода является обеспечение достаточного числа отобранных единиц. Теоретически необходимость соблюдения этого принципа представлена в доказательствах предельных теорем
4. Способы отбора и виды выборки
4. Способы отбора и виды выборки
В теории выборочного метода разработаны различные способы отбора и виды выборки, обеспечивающие репрезентативность. Под способом отбора понимают порядок отбора единиц из генеральной совокупности. Различают два способа отбора: повторный
36. Ошибки выборки
36. Ошибки выборки
Собственнослучайная выборка – это отбор единиц из всей генеральной совокупности посредством жеребьевки или другим подобным способом. Принципом случайности является то, что на включение или исключение объекта из выборки не может повлиять любой фактор,
Лексические ошибки
Лексические ошибки
1. Неправильное использование слов и терминовОсновная масса ошибок в деловых письмах относится к лексическим. Недостаточная грамотность приводит не только к курьезной бессмыслице, но и абсурду.Отдельные термины и профессиональные жаргонные слова
5 Наши ошибки
5
Наши ошибки
Мы настаиваем: выбранный курс рыночных реформ был верным. И они вовсе не потерпели неудачу, они только еще раз споткнулись. Но ошибки и упущения были. Это и наши ошибки, и ошибки руководства страны, которые мы не сумели предотвратить. Ошибки — во многом
Важность размера выборки
Важность размера выборки
Как я уже говорил, люди склонны уделять слишком много внимания редким случаям возникновения какого-то феномена, несмотря на то что со статистической точки зрения из нескольких случаев невозможно извлечь много информации. Это – основная причина
Репрезентативные выборки
Репрезентативные выборки
Репрезентативность наших тестов для целей предсказания будущего определяется двумя факторами:– Количество рынков: тесты, проводимые на различных рынках, будут, скорее всего, включать рынки с разной степенью волатильности типов
Размер выборки
Размер выборки
Концепция размера выборки проста: для того чтобы делать статистически достоверные заключения, нужно иметь достаточно большую выборку. Чем меньше выборка, тем грубее выводы, которые можно сделать; чем выборка больше, тем выводы качественнее. Нет никакого
Содержание
- Ошибки статистического наблюдения и способы их устранения.
- Ошибки в наблюдении и способы их преодоления.
- 5. Ошибки статистического наблюдения
- Б) Способы предотвращения ошибок статистического наблюдения
- Ошибки статистического наблюдения и меры борьбы с ними
Ошибки статистического наблюдения и способы их устранения.
Всякое статистическое наблюдение ставит задачу получения таких данных, которые точнее бы отображали действительность Точность и достоверность собираемой статистической информации — важнейшая задача статистического наблюдения Отклонения или разности между исчисленными показателями и действительными (истинными) величинами исследуемых явлений нашли отражение в показателях, называемых ошибками или погрешностями.
В зависимости от характера и степени влияния на конечные результаты наблюдения, а также исходя из источников и причин возникновения неточностей, допускаемых в процессе статистического наблюдения, обычно выделяют ошибки регистрации и ошибки репрезентативности (представительности).
Ошибки регистрации возникают вследствие неправильного установления фактов в процессе наблюдения или неправильной их записи Они подразделяются на случайные и систематические и могут быть как при сплошном, так при несплошном наблюдении
Случайные ошибки — это, как правило, ошибки регистрации, которые могут быть допущены как опрашиваемыми в их ответах, так и регистраторами при заполнении бланков. Например, записывается цифра не в ту графу или вместо возраста 28 лет записывается 38 лет
Систематические ошибки могут быть преднамеренными и непреднамеренными Преднамеренные ошибки (сознательные, тенденциозные искажения) получаются в результате того, что опрашиваемый, зная действительное положение дела, сознательно сообщает неправильные данные Нередки случаи преднамеренного искажения в отчетах сведений об объеме выпущенной продукции, об остатках дефицитного сырья, материалов и т д. Непреднамеренные ошибки вызываются различными случайными причинами (например, небрежностью или невнимательностью регистратора, неисправностью измерительных приборов и т п )
Ошибки репрезентативности (представительности) свойственны несплошному наблюдению Они возникают в результате того, что состав отобранной для обследования части единиц совокупности недостаточно полно отображает состав всей изучаемой совокупности, хотя регистрация сведений по каждой отобранной для обследования единице была проведена точно Ошибки репрезентативности (так же, как и ошибки регистрации) могут быть случайными и систематическими.
Случайные ошибки репрезентативности — это отклонения, возникающие при несплошном наблюдении из-за того, что совокупность отобранных единиц наблюдения неполно воспроизводит всю совокупность в целом.
Систематические ошибки репрезентативности — это отклонения, возникающие вследствие нарушения принципов случайного отбора единиц изучаемой совокупности.
Для выявления и устранения допущенных при регистрации ошибок может применяться_счетный и логический контроль собранного материала.
Счетный контроль заключается в проверке точности арифметических расчетов, применявшихся при составлении отчетности или заполнении формуляров обследования.
Логический контроль заключается в проверке ответов на вопросы программы наблюдения путем их логического осмысления или путем сравнения полученных данных с другими источниками по этому же вопросу.
Примером логического сопоставления могут служить листы переписи населения. Например, в переписном листе двухлетний мальчик показан женатым, а девятилетний ребенок — грамотным. Ясно, что полученные ответы на вопросы неверны.
Источник
Ошибки в наблюдении и способы их преодоления.
Вероятность статистических данных — закон государственной статистики Обеспечивается она должным составлением программы и плана наблюдения, научной организацией сбора, обработки и анализа информации Как к тщательно не было организованное статистическое наблюдение, собранные материалы могут иметь разные по характеру и возникновением неточности: неполный охват единиц наблюдения, подлежащих рег ее; пропуски отдельных записей; ошибки отдельных записей и т.п. Если полноту охвата единиц наблюдения и пропуски отдельных показателей установить нетрудно, то найти допущенные погрешности единичных запись ей, так называемые ошибки наблюдения, дело не из легкиких.
Ошибки в процессе наблюдения приводят к снижению его точности
Точностью статистического наблюдения называют степень соответствия величины какого-либо показателя (признака), установленной с помощью наблюдения, действительной величине Она измеряется разницей или соотнонням этих величинын.
Разница между величиной какого-либо показателя, установленного путем наблюдения и настоящим его размером называютошибками статистического наблюдения Ошибки наблюдения разделяют на два вида: ошибки регистрации и ошибки репрезентативности
Ошибки регистрации возникают вследствие неправильного установления фактов или неправильного их записи в формуляр
Ошибки репрезентативности имеют место лишь при выборочном обследовании и возникают вследствие того, что выборочная совокупность недостаточно полно воспроизводит всю изучаемую совокупность Подробнее ошибки репрезентативности описаны в § 11.4.
Ошибки репрезентативности могут быть как при сплошном, так и при сплошные наблюдении Они могут быть преднамеренными и непреднамереннымиУмышленные ошибки являются следствием сознательного искажения действительности в сторону увеличения или уменьшения истинных размеров исследуемого признака
Непреднамеренные ошибки возникают независимо от желания лиц, сообщающих или регистрируют данные
Непреднамеренные ошибки регистрации могут иметь случайный или систематический характер
Случайные непреднамеренные ошибки регистрации — это ошибки, возникающие вследствие различных случайных причин: описка, оговорка и т др. Они приводят к отклонениям данных наблюдения от фактических размеров признаки с одинаковой вероятностью ю как в сторону увеличения, так и в сторону уменьшения данных При достаточно большом количестве единиц наблюдений случайные ошибки могут взаимно погашаться и не производить существенного влияния на результаты видеонаблюдениЭннння.
Систематические непреднамеренные ошибки регистрации возникают из определенных неслучайных причин и приводят к отклонениям данных наблюдения от фактических размеров признаки в сторону увеличения или уменьшения Причиной таких ошибок может быть несправнисво измерительных приборов, нечеткая формулировка вопросов, несовершенство статистического инструментария, склонность людей к округлению цифр и т иін.
Умышленные ошибки регистрации всегда имеют систематический характер
Логично завершается статистическое наблюдение приемом материалов исследования Когда материал статистического наблюдения получены полностью от всех единиц, подлежащих наблюдению, проверяют полноту (качество) заполнения бланков Если при приеме материала наблюдения выявлено незаполненные (или частично заполненные) бланки, значит при статистическом наблюдении пропущена единица сп выговор Поэтому ответственное лицо, принимая статистические формуляры (бланки) в первую очередь проверяет полноту их заполнения и в случае необходимости принимает меры для их исправленияня. .
Наряду с проверкой полноты заполнения бланков осуществляется контроль за достоверностью и правильностью ответов При приеме материалов наблюдения главное внимание уделяется правильности заполнения соответствующих бланков и проверке достоверности (точности) показательв.
Контроля за достоверностью статистических данных статистические органы уделяют особое внимание Такие функции (обязанности) государственная статистика выполняет в тесном контакте с органами контроля, прокуратуры и гром венных организациями.
С целью выявления и устранения допущенных при регистрации ошибок статистические органы осуществляют арифметический и логический контроль собранного материала
Арифметический контроль заключается в проверке точности арифметических подсчетов и расчетов: проверка итоговых показателей в документах, проверка правильности подсчетов процентов, средних величин и т др.
Логический контроль заключался в сопоставлении ответов на вопросы и выяснения их логической согласованности В процессе логического контроля могут быть установлены нереальные или малоправдоподибни ответа
Рассмотрим общие приемы логического контроля
1 Сопоставление ответов на различные взаимосвязанные вопросы в формулярах Например, запись в формуляре о том, что ребенок дошкольного возраста имеет среднее образование, является ошибочным
2 Сравнение записей в документе, проверяемого с аналогичными записями в других документах
3 Сопоставление отчетных показателей за смежные периоды
4 Применение метода балансовой согласованности показателей
часто используют такую ??балансовую равенство: наличие на начало периода плюс поступления минус выбытия равна наличии на конец отчетного периода
5 Проведение напрямую переписями контрольных проверок — сплошных или выборочных
Указанные приемы проверки статистических данных путем арифметического и логического контроля используют как при проверке материалов специально организованных статистических наблюдений, так и отчетности Можно утверждать, что арифметический контроль четко устанавливает наличие ошибки, а логический — в большинстве случаев лишь выявляет возможность ошибки При этом, если проведение арифметического контроля вы МАГАТЭ от статистика элементарной грамотности, то логический — может осуществляться только высококвалифицированными специалистамми.
Значительная вероятность статистических данных обусловлено действующей системой мер, направленных на уменьшение и избежание ошибок Среди них следует назвать следующие: качественный первичный учет, разработка научных рекомендаций ендаций по вопросам проверки достоверности данных; подбор квалифицированных кадров-статистиков, автоматизация статистических работ и т д.

Общие условия выбора системы дренажа: Система дренажа выбирается в зависимости от характера защищаемого.

Папиллярные узоры пальцев рук — маркер спортивных способностей: дерматоглифические признаки формируются на 3-5 месяце беременности, не изменяются в течение жизни.

Опора деревянной одностоечной и способы укрепление угловых опор: Опоры ВЛ — конструкции, предназначенные для поддерживания проводов на необходимой высоте над землей, водой.

Организация стока поверхностных вод: Наибольшее количество влаги на земном шаре испаряется с поверхности морей и океанов (88‰).
Источник
5. Ошибки статистического наблюдения
В процессе исследования явлений может возникать отклонение исчисленных показателей от их действительной величины, то есть могут возникать ошибки статистического наблюдения.
По источникам происхождения ошибки наблюдения можно подразделить на следующие:
непреднамеренные, которые в свою очередь делятся на:
Преднамеренные(сознательные, злостные) получаются в результате того, что сознательно сообщаются неправильные данные. Например, сокрытие фирмами прибыли от налогообложения, искажение сведений об объеме выпускаемой продукции, приписки и т. д.
Законом предусматривается применение экономических и административных мер к предприятиям и лицам за злостные ошибки (иногда и уголовная ответственность).
Непреднамеренные случайныеошибки чаще связаны с невнимательностью регистратора, небрежностью в заполнении документов, неточностью измерительных приборов, ошибками в ответах опрашиваемых.
Непреднамеренные систематическиеошибки возникают при округлении признака в большую или меньшую сторону, при использовании ЭВМ.
Ошибки репрезентативности(представительности) свойственны несплошному наблюдению, они возникают вследствие неправильного выбора единиц для обследования, нарушен принцип случайного отбора, и выборочная совокупность не полно характеризует генеральную.
Б) Способы предотвращения ошибок статистического наблюдения
Чтобы предупредить возникновение ошибок или уменьшить их размеры необходимо:
обеспечивать правильный подбор и подготовку кадров;
вести широкую разъяснительную работу, применять меры взыскания за искажение фактов;
проводить систематический контроль.
Контроль может быть: счетным и логическим.
Счетный контроль заключается в проверке точности арифметических расчетов.
Логический контроль проводится путем сопоставления полученных данных с известными признаками, логическое осмысление, сопоставление с данными за прошлый период.
Например, о заработной плате работников предприятия можно судить по отчету, по труду и по отчету о себестоимости продукции. Сведения о заработной плате должны быть одинаковыми, сопоставимыми (приведите примеры).
Источник
Ошибки статистического наблюдения и меры борьбы с ними




![]()
![]()
Одним из наиболее важных требований, предъявляемых к результатам статистического наблюдения, является их точность, под которой понимается мера соответствия статистических значений, полученных посредством статистического наблюдения, действительным его значениям. При этом чем ближе значения, полученные в результате наблюдения к фактическим значениям показателей, тем выше точность статистического наблюдения.
Расхождение (разность) между величиной показателя, установленной на основе статистического наблюдения, и действительной его величиной принято называть абсолютной ошибкой статистического наблюдения. Так, как эти ошибки могут быть обусловлены различными причинами, их подразделяют на два вида: случайные; систематические.
Случайные ошибки возникают вследствие различных случайных обстоятельств при проведении статистического наблюдения и, как правило, при достаточно большом числе наблюдений, в силу действия закона больших чисел, взаимно более или менее уравновешиваются (взаимно погашаются). При этом чем больше число наблюдений, тем полнее это взаимопогашение. Примером случайной ошибки может быть неточность, возникшая при случайной перестановке знаков в цифре. Допустим, действительное поголовье коров в сельскохозяйственной организации составляет 1566 голов, а в статистическом отчёте регистратор по невнимательности или рассеянности записал 1656 голов.
Систематические ошибки могут возникать под действием определённых причин. В каждом отдельном случае они действуют в одном и том же направлении и приводят к серьёзным искажениям общих результатов статистического наблюдения. Систематические ошибки допускаются, например, лицами, производящими измерения, в результате их недостаточной квалификации или по небрежности. Такие ошибки несложно распознать, так как результаты наблюдений, содержащих их, могут существенно отличаться от других аналогичных значений. Например, среди значений урожайности зерновых культур по всем сельскохозяйственным организациям района оказалась в одном из хозяйств цифра 102 ц/га, в то время как во всех остальных колебаниях урожайности составляют от 29 до 55 ц/га.
Систематические ошибки регистрации могут быть следствием преднамеренного искажения фактов, например, приписки в отчётных и других официальных документах. Так, в целях очковтирательства некоторые руководители, специалисты могут пойти на ухищрения, приписав в статотчёте незасеянные или неубранные площади. В условиях переходного периода многие предприниматели пытаются скрыть в отчётных документах часть своих доходов, чтобы уйти от законного налогообложения.
В целях сокращения ошибок до минимума обычно проводится логический и арифметический (счётный) контроль результатов наблюдения.
Логический контроль основан на сопоставлении ответов на взаимосвязанные вопросы статистического формуляра с целью выявления логически несопоставимых ответов. При этом устанавливается, имеется ли логическая увязка между отдельными ответами. Например, выявляется, насколько логически увязаны между собой ответы на вопросы о возрасте и семейном положении человека. В сельскохозяйственном производстве может быть допущена логическая ошибка, заключающаяся в том, что площадь посева и валовой сбор зерновых культур включают в группу кормовых.
Арифметический контроль – это проверка правильности арифметических результатов, содержащихся в статистическом формуляре. Например, в статотчёте показано, что общее поголовье крупно рогатого скота в сельскохозяйственной организации составляет 2000 голов, а в том числе по всем половозрастным группам поголовье почему-то получается 2200 голов, т.е. допущена арифметическая ошибка либо при подсчёте общего поголовья (2000), либо по отдельным половозрастным группам. В этом случае применение приёма арифметического контроля позволит исправить ошибку статистического наблюдения.
Источник
Нейронные сети – это мощный инструмент машинного обучения, который позволяет анализировать и обрабатывать сложные данные. Однако, в процессе обучения нейронной сети возникает важный вопрос – как оценить её эффективность? Именно здесь в помощь приходит среднеквадратичная ошибка.
Среднеквадратичная ошибка (Mean Squared Error, MSE) – это метрика, позволяющая измерить разницу между средним предсказанных значений и фактическими значениями. Чем меньше значение MSE, тем более точно нейронная сеть справляется с задачей.
Причины возникновения среднеквадратичной ошибки могут быть различными. Одной из причин является недостаточное количество данных для обучения. Чем больше данных, тем точнее может быть модель. Еще одной причиной может быть неправильное представление данных или выбор признаков. Важно проводить тщательный анализ данных и подбирать подходящие признаки для решаемой задачи.
Для уменьшения среднеквадратичной ошибки нейронной сети можно применять различные методы. Один из них – это увеличение объема обучающих данных. Другим подходом может быть изменение архитектуры нейронной сети, например, добавление или удаление слоев. Также можно использовать регуляризацию, которая позволяет уменьшить переобучение.
Содержание
- Среднеквадратичная ошибка нейронной сети
- Определение и причины возникновения
- Значение среднеквадратичной ошибки в обучении нейронной сети
- Способы уменьшения среднеквадратичной ошибки
- Использование среднеквадратичной ошибки в практике
- Примеры применения среднеквадратичной ошибки
- Сравнение с другими метриками качества нейронной сети
Среднеквадратичная ошибка нейронной сети
Среднеквадратичная ошибка (Mean Squared Error, MSE) – одна из распространенных метрик, позволяющая оценивать качество работы нейронной сети. Это среднее значение квадратов отклонений прогнозируемого значения от истинного значения.
Среднеквадратичная ошибка широко применяется в задачах регрессии, где требуется предсказать непрерывное числовое значение. Чем меньше значение среднеквадратичной ошибки, тем точнее предсказания нейронной сети.
Основные причины среднеквадратичной ошибки в нейронных сетях:
- Неправильная выборка обучающих данных
- Недостаточное количество данных для обучения
- Проблемы с архитектурой нейронной сети
- Проблемы с выбранными гиперпараметрами
- Переобучение или недообучение модели
Существует ряд способов уменьшения среднеквадратичной ошибки нейронной сети:
- Увеличение объема обучающих данных
- Использование более сложной модели нейронной сети
- Тщательная настройка гиперпараметров
- Применение регуляризации для борьбы с переобучением
- Использование других алгоритмов оптимизации весов
В практике анализа данных и машинного обучения среднеквадратичная ошибка широко используется для оценки моделей и выбора наилучшей нейронной сети. Она позволяет сравнить различные модели и определить, какая из них предсказывает целевую переменную наиболее точно. Кроме того, среднеквадратичная ошибка часто используется в обучении моделей с учителем для определения оптимальных гиперпараметров и контроля процесса обучения.
Определение и причины возникновения
Среднеквадратическая ошибка (MSE) является одним из наиболее распространенных метрик оценки качества работы нейронных сетей. Она используется для измерения разницы между предсказанными значениями модели и реальными значениями.
Среднеквадратическая ошибка рассчитывается путем вычисления суммы квадратов разностей между предсказанными значениями и реальными значениями, а затем деления этой суммы на общее количество данных или образцов.
Существуют несколько причин, по которым среднеквадратическая ошибка может возникать:
- Недостаточные данные: Если у вас недостаточно данных для обучения нейронной сети, то ее способность делать точные предсказания будет ограничена. Из-за этого MSE может быть высокой.
- Переобучение: Если модель слишком хорошо запомнила тренировочные данные и не смогла обобщить свои знания на новые данные, то MSE будет высокой.
- Неправильный выбор архитектуры модели: Некоторые типы задач требуют определенных архитектур модели для достижения низкой MSE. Неправильный выбор архитектуры может привести к высокой ошибке.
- Неправильные входные данные: Если входные данные содержат ошибки или отклонения от ожидаемых значений, то MSE будет высокой. Например, если входные данные имеют выбросы или шум, модель может давать неправильные предсказания.
Понимание причин возникновения среднеквадратической ошибки позволяет искать способы ее уменьшения и повышения точности нейронной сети.
Значение среднеквадратичной ошибки в обучении нейронной сети
Среднеквадратичная ошибка (MSE) является одной из основных метрик для оценки качества работы нейронной сети. Она вычисляется путем суммирования квадратов разностей между предсказанными значениями и фактическими значениями целевой переменной.
Значение MSE показывает среднюю ошибку модели на обучающей выборке. Чем меньше значение MSE, тем лучше работает нейронная сеть. То есть, низкое значение MSE свидетельствует о том, что модель хорошо предсказывает значения целевой переменной.
Вычисление MSE происходит следующим образом:
- Для каждого объекта обучающей выборки вычисляются предсказанные значения с помощью нейронной сети.
- Для каждого объекта обучающей выборки вычисляется разница между предсказанным и фактическим значением целевой переменной.
- Разницы между предсказанными и фактическими значениями целевой переменной возводятся в квадрат.
- Полученные квадраты разниц складываются и делятся на количество объектов обучающей выборки.
Преимуществом использования MSE в обучении нейронных сетей является то, что она является дифференцируемой функцией. Это позволяет применять метод градиентного спуска для нахождения оптимальных параметров модели.
Для уменьшения значения MSE можно использовать различные методы оптимизации. Некоторые из них включают в себя изменение структуры сети, изменение гиперпараметров (например, скорость обучения) и применение регуляризации.
В практике обучения нейронных сетей значение MSE широко используется для оценки качества модели и сравнения различных моделей. Более низкое значение MSE указывает на лучшую предсказательную способность модели.
Способы уменьшения среднеквадратичной ошибки
Среднеквадратичная ошибка (MSE) является одним из наиболее распространенных критериев для оценки качества работы нейронных сетей. Чем меньше значение MSE, тем лучше работает нейронная сеть. Существуют различные способы, как можно уменьшить среднеквадратичную ошибку и повысить эффективность работы нейронной сети.
- Увеличение объема обучающей выборки. Увеличение размера обучающего набора данных может помочь уменьшить среднеквадратичную ошибку. Больший объем данных позволяет нейронной сети обучаться на более разнообразных примерах, что может улучшить ее способность к обобщению и снизить ошибку на новых данных.
- Нормализация входных данных. Предварительная нормализация входных данных может помочь сети более эффективно обучаться и уменьшить среднеквадратичную ошибку. Нормализация данных позволяет привести значения входных переменных к одному диапазону и избежать перекосов в данных, что может помочь нейронной сети более точно предсказывать результаты.
- Использование оптимизаторов. Оптимизаторы, такие как стохастический градиентный спуск (SGD) или алгоритм Адама (Adam), могут помочь уменьшить среднеквадратичную ошибку путем эффективной настройки весов и смещений нейронной сети. Оптимизаторы позволяют найти оптимальные значения параметров сети для минимизации ошибки.
- Изменение архитектуры нейронной сети. Изменение архитектуры нейронной сети может помочь уменьшить среднеквадратичную ошибку. Это может быть изменение количества слоев, количества нейронов в слоях, выбор других активационных функций или использование различных типов слоев, таких как сверточные или рекуррентные.
- Регуляризация. Регуляризация может быть полезным методом для уменьшения среднеквадратичной ошибки. Техники, такие как L1 или L2 регуляризация, позволяют добавить штрафы на веса нейронной сети, что способствует снижению переобучения и улучшению ее обобщающих способностей.
Выбор конкретных методов и комбинация их использования зависит от конкретной задачи и данных, на которых требуется обучить нейронную сеть. Минимизация среднеквадратичной ошибки является важным этапом обучения нейронной сети и позволяет достичь лучших результатов в практическом применении.
Использование среднеквадратичной ошибки в практике
Среднеквадратичная ошибка (Mean Squared Error, MSE) является одной из наиболее распространенных метрик для оценки качества работы нейронных сетей. Она позволяет измерить разницу между истинными значениями и значениями, предсказанными нейронной сетью.
Основное преимущество использования MSE заключается в том, что она оценивает как величину ошибки, так и ее направление. В отличие от других метрик, таких как абсолютное значение ошибки (MAE), MSE уделяет большее внимание большим отклонениям, что может быть полезным во многих задачах, например, при прогнозировании финансовых показателей.
Использование MSE позволяет сравнить различные модели нейронных сетей и выбрать наилучшую. Чем меньше значение MSE, тем ближе предсказания сети к истинным значениям, и тем лучше модель справляется с задачей.
Однако, следует отметить, что MSE имеет некоторые недостатки. В случае наличия выбросов в данных, ошибка может значительно возрастать и портить общую оценку качества модели. Например, если в выборке имеются выбросы, MSE может давать завышенную оценку ошибки, даже если модель хорошо предсказывает большую часть данных.
В практике использования MSE важно учитывать особенности задачи и данные, с которыми вы работаете. Например, для задач регрессии, MSE может быть полезен для оценки точности предсказаний. В то же время, для задач классификации, другие метрики, такие как точность (accuracy) или F1-мера могут быть более информативными и полезными.
Также, при использовании MSE можно задействовать различные методы уменьшения ошибки, такие как изменение архитектуры нейронной сети, проведение дополнительной предобработки данных или применение регуляризации. Все эти методы могут помочь улучшить качество модели и снизить значение MSE.
В заключение, использование среднеквадратичной ошибки в практике является важным инструментом для оценки качества работы нейронных сетей. Однако, следует помнить о ее недостатках и учитывать особенности конкретной задачи при выборе и использовании этой метрики.
Примеры применения среднеквадратичной ошибки
1. Обработка изображений
Среднеквадратичная ошибка (MSE) может использоваться для оптимизации нейронных сетей, работающих с изображениями. В этом случае MSE является мерой близости между исходным изображением и его восстановленной версией. Чем меньше значение MSE, тем более точно изображение восстанавливается.
2. Прогнозирование временных рядов
Среднеквадратичная ошибка может быть использована для оценки точности прогнозирования временных рядов нейронной сетью. Например, при прогнозировании цен на акции, MSE может быть использована для оценки разницы между прогнозируемыми и фактическими значениями цены.
3. Обучение с учителем
В обучении с учителем, где для каждого входного примера есть соответствующий целевой выход, среднеквадратичная ошибка может быть использована для оценки эффективности алгоритма обучения. Чем меньше значение MSE, тем лучше алгоритм справляется с задачей.
4. Оптимизация параметров
MSE может использоваться для оптимизации параметров нейронной сети. Например, при обучении нейронной сети с помощью градиентного спуска, MSE может быть использована в качестве функции потерь, которую необходимо минимизировать для нахождения оптимальных значений параметров.
5. Классификация
В задачах классификации MSE можно использовать для оценки ошибки нейронной сети на различных классах. Ошибка MSE может показать, насколько точно нейронная сеть предсказывает вероятности принадлежности объектов к определенным классам.
В целом, среднеквадратичная ошибка является важной метрикой в обучении и оптимизации нейронных сетей, позволяя оценить и сравнить эффективность различных моделей и алгоритмов.
Сравнение с другими метриками качества нейронной сети
При анализе работы нейронной сети и оценке ее качества необходимо использовать различные метрики, которые позволяют измерить, насколько точно модель предсказывает целевые значения. Одной из самых часто используемых метрик является среднеквадратичная ошибка (MSE), но она не является единственной и может быть сравнена с другими метриками.
Одной из альтернативных метрик является средняя абсолютная ошибка (MAE), которая измеряет среднее отклонение предсказанных значений от фактических. Отличие MAE от MSE заключается в том, что MAE не учитывает веса ошибок и даёт более равномерную оценку качества предсказаний.
Еще одной метрикой, используемой для оценки качества нейронных сетей, является коэффициент детерминации (R2). R2 варьируется от 0 до 1 и позволяет определить, насколько модель лучше, чем среднее значение целевой переменной. Чем ближе R2 к 1, тем лучше модель справляется с предсказанием.
Также в практике могут использоваться другие метрики, такие как F1-мера, точность (precision) и полнота (recall). Они часто используются при задачах классификации и оценке точности работы нейронной сети на разных классах.
| Метрика | Описание | Преимущества | Недостатки |
|---|---|---|---|
| Среднеквадратичная ошибка (MSE) | Измеряет среднеквадратичное отклонение предсказанных значений от фактических | — Учитывает веса ошибок — Чувствительна к выбросам |
— Взвешивает большие ошибки — Не интерпретируема |
| Средняя абсолютная ошибка (MAE) | Измеряет среднее отклонение предсказанных значений от фактических | — Равномерно учитывает ошибки — Интерпретируема |
— Не учитывает веса ошибок — Не чувствительна к выбросам |
| Коэффициент детерминации (R2) | Оценивает, насколько модель лучше, чем простое среднее значение целевой переменной | — Интерпретируема — Нормирована в диапазоне [0, 1] |
— Не учитывает веса ошибок — Не чувствительна к выбросам |
Каждая из вышеперечисленных метрик имеет свои преимущества и недостатки, и выбор метрики зависит от задачи и требований к оценке качества модели. Важно также помнить, что оценка качества модели не должна основываться только на одной метрике, поэтому полезно использовать несколько метрик одновременно для более полной оценки.