Систематическая ошибка отбора
- Систематическая ошибка отбора — статистическое понятие, показывающее, что выводы, сделанные применительно к какой-либо группе, могут оказаться неточными вследствие неправильного отбора в эту группу.
Источник: Википедия
Связанные понятия
Шкала Ликерта, или (неверно) Лайкерта (англ. Likert scale (/ˈlɪkərt/ ), шкала суммарных оценок) — психометрическая шкала, которая часто используется в опросниках и анкетных исследованиях (разработана в 1932 году Ренсисом Ликертом). При работе со шкалой испытуемый оценивает степень своего согласия или несогласия с каждым суждением, от «полностью согласен» до «полностью не согласен». Сумма оценок каждого отдельного суждения позволяет выявить установку испытуемого по какому-либо вопросу. Предполагается…
Надёжностью называется один из критериев качества теста, его устойчивость по отношению к погрешностям измерения. Различают два вида надёжности — надёжность как устойчивость и надёжность как внутреннюю согласованность.
Подробнее: Надёжность психологического теста
Тест стандартными прогрессивными матрицами Равена (Рейвена) — тест, предназначенный для дифференцировки испытуемых по уровню их интеллектуального развития. Авторы теста Джон Рейвен и Л. Пенроуз. Предложен в 1936 году. Тест Равена известен как один из наиболее «чистых» измерений фактора общего интеллекта g, выделенного Ч.Э. Спирменом. Успешность выполнения теста SPM интерпретируется как показатель способности к научению на основе обобщения собственного опыта и создания схем, позволяющих обрабатывать…
Репрезентати́вность — соответствие характеристик выборки характеристикам популяции или генеральной совокупности в целом. Репрезентативность определяет, насколько возможно обобщать результаты исследования с привлечением определённой выборки на всю генеральную совокупность, из которой она была собрана.
Слепо́й ме́тод — процедура проведения исследования реакции людей на какое-либо воздействие, заключающаяся в том, что испытуемые не посвящаются в важные детали проводимого исследования. Метод применяется для исключения субъективных факторов, которые могут повлиять на результат эксперимента.
Нулевая гипотеза — принимаемое по умолчанию предположение о том, что не существует связи между двумя наблюдаемыми событиями, феноменами. Так, нулевая гипотеза считается верной до того момента, пока нельзя доказать обратное. Опровержение нулевой гипотезы, то есть приход к заключению о том, что связь между двумя событиями, феноменами существует, — главная задача современной науки. Статистика как наука даёт чёткие условия, при наступлении которых нулевая гипотеза может быть отвергнута.
Иллюзорная корреляция (англ. illusory correlation) — когнитивное искажение преувеличенно тесной связи между переменными, которая в реальности или не существует, или значительно меньше, чем предполагается. Типичным примером могут служить приписывание группе этнического меньшинства отрицательных качеств. Иллюзорная корреляция считается одним из способов формирования стереотипов.
Автокорреляция — статистическая взаимосвязь между последовательностями величин одного ряда, взятыми со сдвигом, например, для случайного процесса — со сдвигом по времени.
Долгосрочное иссле́дование (англ. Longitudinal study от longitude — долговременный) — научный метод, применяемый, в частности, в социологии и психологии, в котором изучается одна и та же группа объектов (в психологии — людей) в течение времени, за которое эти объекты успевают существенным образом поменять какие-либо свои значимые признаки. В самом широком смысле является синонимом панельного исследования, а в более узком смысле — выборочное панельное исследование любой возрастной или образовательной…
Исследование случай-контроль (ИСК) – это тип обсервационного наблюдения, в котором две исследуемые группы, различающиеся по полученному результату, сравниваются на основе предполагаемого влияющего фактора. Исследования с контрольной группой часто используются для определения факторов, которые могут повлиять на состояние здоровья, путем сравнения участников, у которых есть заболевание («случаи») и участников, у которых оно отсутствует («контроли»).
Доверительный интервал — термин, используемый в математической статистике при интервальной оценке статистических параметров, более предпочтительной при небольшом объёме выборки, чем точечная. Доверительным называют интервал, который покрывает неизвестный параметр с заданной надёжностью.
Генеральная совокупность (от лат. generis — общий, родовой) — совокупность всех объектов (единиц), относительно которых предполагается делать выводы при изучении конкретной задачи.
Эмпирические исследования – наблюдение и исследование конкретных явлений, эксперимент, а также обобщение, классификация и описание результатов исследования эксперимента, внедрение их в практическую деятельность человека.
Выявление аномалий (также обнаружение выбросов) — это опознавание во время интеллектуального анализа данных редких данных, событий или наблюдений, которые вызывают подозрения ввиду существенного отличия от большей части данных. Обычно аномальные данные превращаются в некоторый вид проблемы, такой как мошенничество в банке, структурный дефект, медицинские проблемы или ошибки в тексте. Аномалии также упоминаются как выбросы, необычности, шум, отклонения или исключения.
Робастность (англ. robustness, от robust — «крепкий», «сильный», «твёрдый», «устойчивый») — свойство статистического метода, характеризующее независимость влияния на результат исследования различного рода выбросов, устойчивости к помехам. Выбросоустойчивый (робастный) метод — метод, направленный на выявление выбросов, снижение их влияния или исключение их из выборки.
Системати́ческая оши́бка вы́жившего (англ. survivorship bias) — разновидность систематической ошибки отбора, когда по одной группе («выжившим») есть много данных, а по другой («погибшим») — практически нет, в результате чего исследователи пытаются искать общие черты среди «выживших» и упускают из вида, что не менее важная информация скрывается среди «погибших».
Фактор общего интеллекта (англ. general factor, g factor) является распространённым, но противоречивым конструктом, используемым в психологии (см. также психометрию) для выявления общего в различных тестах интеллекта. Словосочетание «теория g» имеет дело с гипотезой и полученными из неё результатами о биологической природе g, постоянством/податливостью, уместностью его применения в реальной жизни и другими исследованиями.
В когнитивной науке под когнити́вными искаже́ниями понимаются систематические ошибки в мышлении или шаблонные отклонения, которые возникают на основе дисфункциональных убеждений, внедрённых в когнитивные схемы, и легко обнаруживаются при анализе автоматических мыслей. Существование большинства когнитивных искажений было описано учёными, а многие были доказаны в психологических экспериментах.
Подробнее: Список когнитивных искажений
Эксперимент Ричарда Лазаруса — известный эксперимент в психологии, проведенный Ричардом Лазарусом и группой исследователей для изучения влияния когнитивной оценки ситуации угрозы на формирование стрессовой реакции. На основе результатов данного исследования Ричардом Лазарусом и его коллегами была разработана теория психологического стресса, которая стоит на одном уровне значимости для науки с концепцией стресса Ганса Селье.
Испыту́емый — участник эксперимента в психологии и других отраслях науки. В психолингвистике, этот термин — в отличие от информанта — предполагает, что собирается ещё и информация о носителе языка как языковой и речевой личности. Испытуемые могут быть специально отобраны для эксперимента, либо же являться имеющимися в наличии представителями изучаемой популяции.
Коэффициент инбридинга может быть вычислен для отдельной персоны и является мерой степени редукции предков в родословии конкретной личности.
Тест Айзенка — тест коэффициента интеллекта (IQ), разработанный английским психологом Гансом Айзенком. Известно восемь различных вариантов теста Айзенка на интеллект.
Статистический вывод (англ. statistical inference), также называемый индуктивной статистикой (англ. inferential statistics, inductive statistics) — обобщение информации из выборки для получения представления о свойствах генеральной совокупности.
Гетероскедастичность (англ. heteroscedasticity) — понятие, используемое в прикладной статистике (чаще всего — в эконометрике), означающее неоднородность наблюдений, выражающуюся в неодинаковой (непостоянной) дисперсии случайной ошибки регрессионной (эконометрической) модели. Гетероскедастичность противоположна гомоскедастичности, означающей однородность наблюдений, то есть постоянство дисперсии случайных ошибок модели.
Статистический критерий — строгое математическое правило, по которому принимается или отвергается та или иная статистическая гипотеза с известным уровнем значимости. Построение критерия представляет собой выбор подходящей функции от результатов наблюдений (ряда эмпирически полученных значений признака), которая служит для выявления меры расхождения между эмпирическими значениями и гипотетическими.
Дисперсионный анализ — метод в математической статистике, направленный на поиск зависимостей в экспериментальных данных путём исследования значимости различий в средних значениях. В отличие от t-критерия, позволяет сравнивать средние значения трёх и более групп. Разработан Р. Фишером для анализа результатов экспериментальных исследований. В литературе также встречается обозначение ANOVA (от англ. ANalysis Of VAriance).
В психологии фиксирование установки (эффект предшествования, прайминг) (англ. priming) — это явление имплицитной памяти, при котором обработка воздействия заданного стимула определяется предшествующим действием того же самого или подобного стимула. Реакция на действие данного стимула оказывает влияние на реакцию, возникающую в ответ на последующие стимулы. Действие предшествующего стимула может осознаваться человеком, но также фиксирование установки стимула происходит и при неосознаваемом воздействии…
Причинность по Грэнджеру (англ. Granger causality) — понятие, используемое в эконометрике (анализе временных рядов), формализующее понятие причинно-следственной связи между временными рядами. Причинность по Грэнджеру является необходимым, но не достаточным условием причинно-следственной связи.
Системати́ческий обзо́р — научное исследование ряда опубликованных отдельных однородных оригинальных исследований с целью их критического анализа и оценки. Систематический обзор проводится с использованием методологии, позволяющей исключить случайные и систематические ошибки, а также для обеспечения полного отчета о всех имеющихся исследований по данной теме, включая серую литературу с целью избежания предвзятости. В систематическом обзоре используются стандартизированные методы отбора и проверки…
Метод балльных оценок — один из методов одномерного шкалирования, используемых в психологии, процедура которого заключается в построении шкал на основе балльных оценок, получаемых из суждений испытуемых. Из всех методов психологических измерений, использующих оценочные суждения человека, шкалирование, основанное на балльных оценках, является наиболее популярным в виду своей простоты. Метод распространен как в прикладных, так и в академических разделах психологии, например, при психологической оценке…
Статистика — измеримая числовая функция от выборки, не зависящая от неизвестных параметров распределения элементов выборки.
Закон Парето (принцип Парето, принцип 80/20) — эмпирическое правило, названное в честь экономиста и социолога Вильфредо Парето, в наиболее общем виде формулируется как «20 % усилий дают 80 % результата, а остальные 80 % усилий — лишь 20 % результата». Может использоваться как базовая установка в анализе факторов эффективности какой-либо деятельности и оптимизации её результатов: правильно выбрав минимум самых важных действий, можно быстро получить значительную часть от планируемого полного результата…
Фа́кторный анализ — многомерный метод, применяемый для изучения взаимосвязей между значениями переменных. Предполагается, что известные переменные зависят от меньшего количества неизвестных переменных и случайной ошибки.
В математической статистике семплирование — обобщенное название методов манипулирования начальной выборкой при известной цели моделирования, которые позволяют выполнить структурно-параметрическую идентификацию наилучшей статистической модели стационарного эргодического случайного процесса.
Алекситимия (от др.-греч. ἀ- — приставка с отрицательным значением, λέξις — слово, θυμός — чувство, буквально «без слов для чувств») — затруднения в передаче, словесном описании своего состояния.
Приня́тие жела́емого за действи́тельное — формирование убеждений и принятие решений в соответствии с тем, что является приятным человеку, вместо апелляции к имеющимся доказательствам, рациональности или реальности.
Двоичная, бинарная или дихотомическая классификация — это задача классификации элементов заданного множества в две группы (предсказание, какой из групп принадлежит каждый элемент множества) на основе правила классификации. Контекст, в котором требуется решение, имеет ли объект некоторое качественное свойство, некоторые специфичные характеристики или некоторую типичную двоичную классификацию, включает…
Независимая переменная — в эксперименте переменная, которая намеренно манипулируется или выбирается экспериментатором с целью выяснить её влияние на зависимую переменную.
Метод анкети́рования — психологический вербально-коммуникативный метод, в котором в качестве средства для сбора сведений от респондента используется специально оформленный список вопросов — анкета. В социологии анкетирование — это метод опроса, используемый для составления статических (однократное анкетирование) или динамических (при многократном анкетировании) статистических представлений о состоянии общества, общественного мнения, состояния политической, социальной и прочей напряжённости с целью…
Выброс (англ. outlier), промах — в статистике результат измерения, выделяющийся из общей выборки.
Байесовская вероятность — это интерпретация понятия вероятности, используемая в байесовской теории. Вероятность определяется как степень уверенности в истинности суждения. Для определения степени уверенности в истинности суждения при получении новой информации в байесовской теории используется теорема Байеса.
Теория обнаружения сигнала (ТОС) — современный психофизический метод, учитывающий вероятностный характер обнаружения стимула, в котором наблюдатель рассматривается как активный субъект принятия решения в ситуации неопределённости. Теория обнаружения сигнала описывает сенсорный процесс как двухступенчатый: процесс отображения физической энергии стимула в интенсивность ощущения и процесс принятия решения субъектом.
Регрессия прошлой жизни (англ. past life regression, PLR) — техника использования гипноза для обнаружения того, что практикующие эту технику считают воспоминаниями людей о прошлых жизнях или реинкарнациях. Используется в парапсихологии в связи с попытками подтвердить гипотезу существования феномена реинкарнации.
Частотное распределение — метод статистического описания данных (измеренных значений, характерных значений). Математически распределение частот является функцией, которая в первую очередь определяет для каждого показателя идеальное значение, так как эта величина обычно уже измерена. Такое распределение можно представить в виде таблицы или графика, моделируя функциональные уравнения. В описательной статистике частота распределения имеет ряд математических функций, которые используются для выравнивания…
У́мственный во́зраст — понятие в психологии, предложено Альфредом Бине и Т. Симоном в 1908 году. За основу взят уровень умственного развития человека по сравнению с этим уровнем у людей такого же возраста. То есть возраст, в котором — по среднестатистическим данным, — люди могут решить испытательные задания такого же уровня сложности. Таким образом, основное назначение понятия «умственного возраста» в психологии — характеристика интеллектуального развития личности, в основе которой лежит сравнение…
Эмпирические данные (от др.-греч. εμπειρία «опыт») — данные, полученные через органы чувств, в частности, путём наблюдения или эксперимента. В философии после Канта полученное таким образом знание принято называть апостериорным. Оно противопоставляется априорному, доопытному знанию, доступному через чисто умозрительное мышление.
Групповáя поляризáция — психологический феномен расхождения по разным полюсам мнений участников дискуссии во время принятия группового решения. Величина разброса конечных вариантов напрямую зависит от первоначальных позиций участников. То есть, чем дальше от середины находились их мнения в начале дискуссии, тем сильней будет проявляться феномен. Важно разделять «поляризацию» и «экстремизацию». Поляризация — явление, при котором решение члена группы смещается к ранее выбранному им полюсу; при экстремизации…
Подробнее: Групповая поляризация
То́чечная оце́нка в математической статистике — это число, оцениваемое на основе наблюдений, предположительно близкое к оцениваемому параметру.
Рандомизированное контролируемое испытание (рандомизированное контролируемое исследование, РКИ) — тип научного (часто медицинского) эксперимента, при котором его участники случайным образом делятся на группы, в одной из которых проводится исследуемое вмешательство, а в другой (контрольной) применяются стандартные методики или плацебо.
Тест отноше́ния правдоподо́бия (англ. likelihood ratio test, LR) — статистический тест, используемый для проверки ограничений на параметры статистических моделей, оценённых на основе выборочных данных. Является одним из трёх базовых тестов проверки ограничений наряду с тестом множителей Лагранжа и тестом Вальда.
Когда исследователи рассматривают вопросы, представляющие интерес для аналитиков или портфельных менеджеров, они могут исключить из анализа определенные акции, облигации, портфели, или периоды времени, по разным причинам — возможно, из-за недоступности данных.
Когда недоступность данных приводит к исключению из анализа определенных активов, мы называем эту проблему систематической ошибкой или смещением выборки (англ. ‘sample selection bias’ или ‘sampling bias’).
Например, вы можете сделать выборку из базы данных, которая отслеживает только компании, существующие в настоящее время. Например, многие базы данных взаимных фондов предоставляют историческую информацию только о тех фондах, которые существуют в настоящее время.
Базы данных, в которых хранятся балансовые отчеты и отчеты о прибылях и убытках страдают от той же систематической ошибки, что и базы данных фондов: в них нет фондов или компаний, которые прекратили деятельность.
Исследование, которое использует подобные базы данных, подвержено разновидности систематической ошибки выборки, известной как систематическая ошибка выжившего (англ. ‘survivorship bias’).
Исследователи Димсон, Марш и Стонтон (Dimson, Marsh, and Staunton, 2002) подняли вопрос о систематической ошибке выжившего в международных финансовых индексах:
Известной проблемой является влияние выживания рынков на долгосрочную оценку доходности. Рынки могут испытывать не только разочаровывающие результаты, но и полную потерю стоимости за счет конфискации, гиперинфляции, национализации и кризисов.
При оценке результатов рынков, которые выживают в течение длительных интервалов времени, мы сделали выводы о том, чем обусловлено выживание. Тем не менее, как отметили в исследовании Браун, Готцман и Росс (Brown, Goetzmann, и Ross) в 1995 г. и Готцман и Джорион (Goetzmann and Jorion) в 1999 г., человек не способен заранее определить, какие рынки выживут, а какие нет. (стр. 41)
Систематическая ошибка выжившего иногда появляется, когда мы используем совместно цены акций и данные бухгалтерского учета.
Например, многие исследования в области финансов использовали соотношение рыночной стоимости компании к бухгалтерской стоимости компании на одну акцию (т.е. коэффициент котировки акций, англ. P/B, от ‘price-to-book ratio’ или ‘market-to-book ratio’) и обнаружили, что коэффициент P/B обратно пропорционален доходности компании (см. Fama and French 1992, 1993).
Коэффициент P/B также используется для многих популярных индексов стоимости и роста.
Если база данных, которую мы используем для сбора данных бухгалтерского учета, исключает обанкротившиеся компании, это может привести к систематической ошибке выжившего.
Котхари, Шанкен и Слоун (Kothari, Shanken, and Sloan) в 1995 г. исследовали именно этот вопрос, и оспорили то, что акциям обанкротившихся компаний свойственна самая низкая доходность и коэффициент P/B.
Если мы исключаем из выборки акции обанкротившихся компаний, то акции с низким P/B, которые включены в выборку, будут иметь в среднем более высокую доходность, по сравнению со средней доходностью при включении в выборку всех акций с низким P/B. Котхари, Шанкен и Слоун предположили, что эта систематическая ошибка привела к выводу об обратной связи между средней доходностью и P/B.
См. Fama and French (1996, стр. 80) о интеллектуальном анализе данных и систематической ошибке выжившего в их тестах.
Единственный совет, который мы можем предложить в этой ситуации, — это быть в курсе каких-либо смещений, потенциально присущих в выборке. Очевидно, что смещения выборки могут затуманить результаты любого исследования.
Выборка также может быть смещена из-за удаления (или делистинга) акций компании.
Делистинг (англ. ‘delisting’), т.е. исключение акций компании из котировального списка биржи, может происходить по разным причинам: слияние, банкротство, ликвидация, или переход на другую биржу.
Например, Центр исследований котировок ценных бумаг (CRSP, от англ. Center for Research in Security Prices) в Университете Чикаго является основным поставщиком данных о доходности, используемых в научных исследованиях. Когда происходит делистинг, CRSP пытается собрать данные о доходности исключенной компании, но во многих случаях он не может сделать этого из-за связанных с делистингом трудностях. CRSP вынужден просто указать значение доходности исключенной компании как отсутствующее.
Исследование, опубликованное в Финансовом журнале (см. The Journal of Finance) Шумвеем и Вортером (Shumway and Warther) в 1999 году, задокументировало смещение данных доходности NASDAQ в CRSP, вызванное делистингом.
Авторы показали, что делистинг, связанный с плохой работой компании (например, банкротством) исключается из данных чаще, чем делистинг, связанный с хорошей или нейтральной эффективностью компании (например, слиянием или перемещением на другой рынок). Кроме того, делистинг чаще происходит с небольшими компаниями.
Систематическая ошибка выборки встречается даже на рынках, где качество и согласованность данных весьма высоки. Новые классы активов, такие как хедж-фонды могут представлять еще большие проблемы смещения выборки.
Хедж-фонды (англ. ‘hedge funds’) представляют собой гетерогенную группу инвестиционных инструментов, как правило, организованных таким образом, чтобы быть свободными от регулирующего контроля. В целом, хедж-фонды не обязаны публично раскрывать свою эффективность (в отличие, скажем, от взаимных фондов). Хедж-фонды сами решают, нужно ли им включаться в какую-либо базу данных хедж-фондов.
Хедж фонды с плохой репутацией явно не желают, чтобы их результаты публиковались в базе данных, создавая проблему смещения самовыборки (англ. ‘self-selection bias’) в базах данных хедж-фондов.
Кроме того, как отметили Фанг и Хсие (Fung and Hsieh) в исследовании 2002 г., поскольку только хедж-фонды с хорошими показателями добровольно попадают в базу данных, в целом, историческая эффективность отрасли хедж-фондов имеет тенденцию казаться лучше, чем она есть на самом деле.
Кроме того, многие базы данных хедж-фондов исключают фонды, которые выходят из бизнеса, создавая в базе данных систематическую ошибку выжившего. Даже если база данных не удаляет несуществующие хедж-фонды, в попытке устранить ошибку выжившего, остается проблема хедж-фондов, которые перестают отчитываться об эффективности из-за плохих результатов.
См. Fung and Hsieh (2002) и Horst and Verbeek (2007) для более подробной информации о проблемах интерпретации эффективности хедж-фондов.
Обратите внимание, что систематическая ошибка также возможна, когда успешные фонды перестают отчитываться об эффективности, поскольку они больше не нуждаются в новых потоках денежных средств.
Систематическая ошибка опережения.
Процесс тестирования также подвержен систематической ошибке опережения (англ. ‘look-ahead bias’), если он использует информацию, которая не была доступна на момент тестирования.
Например, тесты правил биржевой торговли, которые используют ставки доходности фондового рынка и данные бухгалтерских балансов должны учитывать систематическую ошибку опережения.
В таких тестах, балансовая стоимость компании на акцию обычно используются для расчета коэффициента P/B.
Хотя рыночная цена акции доступна для всех участников рынка на заданный момент времени, балансовая стоимость на акцию на конец финансового года может стать общедоступной только в будущем — когда-то в следующем квартале.
Систематическая ошибка временного периода.
Тесты также подвержены систематической ошибке или смещению временного периода (англ. ‘time-period bias’), если они основаны на временном периоде, для которого результаты тестирования будут специфичными (т.е., характерными только для данного периода).
Ряды коротких временных периодов, скорее всего, дадут результаты, специфичные для определенного периода, которые могут не отражать более длительный период.
Ряды длительных временных периодов могут дать более точную картину истинной эффективности инвестиций. Недостаток длительных периодов заключается в потенциальных структурных изменениях, происходящих в течение периода, что приведет к двум различным распределениям доходности.
В этой ситуации, распределение, отражающее условия до изменений, будет отличаться от распределения, которые описывают условия после изменений.
Пример (7) систематических ошибок в инвестиционных исследованиях.
Финансовый аналитик рассматривает эмпирические данные об исторической доходности акций США.
Она выясняет, что недооцененные акции (то есть, акции с низким P/B) превзошли по эффективности растущие акции (то есть, акции с высоким P/B) в некоторых последних периодах времени.
После изучения американского рынка, аналитик задается вопросом, могут ли недооцененные акции быть привлекательными в Великобритании. Она исследует эффективность недооцененных и растущих акций на британском рынке за 14-летний период с января 2000 года по декабрь 2013 года.
Для проведения этого исследования, аналитик делает следующее:
- Получает текущий состав компаний Индекса всех акций FTSE (Financial Times Stock Exchange All Share Index), который является взвешенным индексом рыночной капитализации;
- Исключает несколько компаний, у которых финансовый год не заканчивается в декабре;
- Использует балансовую и рыночную стоимость компаний на конец года, чтобы ранжировать остальные пространство компаний по коэффициенту P/B на конец года;
- На основе этих рейтингов, она делит пространство ценных бумаг на 10 портфелей, каждый из которых содержит одинаковое количество акций;
- Вычисляет равновзвешенную доходность каждого портфеля и доходность FTSE All Share Index за 12 месяцев после даты расчета каждого рейтинга; а также
- Вычитает доходность FTSE из доходности каждого портфеля, чтобы получить избыточную доходность для каждого портфеля.
Опишите и обсудите каждую из следующих систематических ошибок, которым подвержен план исследований аналитика:
- систематическую ошибку выжившего;
- систематическую ошибку опережения; а также
- систематическую ошибку временного периода.
Систематическая ошибка выжившего.
План тестирования подвержен систематической ошибке выжившего, если он не принимает в расчет обанкротившиеся компании, слившиеся компании, а также компании, иным образом покинувшие базу.
В этом примере, аналитик использовала текущий список акций FTSE, а не фактический список акций на начало каждого года. В той степени, в которой расчет доходности не учитывает компании, исключенные из индекса, эффективность портфелей с наименьшим P/B подвершена систематической ошибке выжившего и, соответственно, может быть завышена.
В какой-то момент периода тестирования, эти ныне не существующие компании, были исключены из тестирования. У них, вероятно, были низкие цены на акции (и низкий P/ B) и плохая доходность.
Систематическая ошибка опережения.
План тестирования подвержен систематической ошибке опережения, если он использует информацию, недоступную на момент тестирования.
В этом примере, аналитик провела тест, сделав допущение о том, что необходимая бухгалтерская информация была доступна в конце финансового года.
Например, аналитик предположила, что балансовая стоимость на акцию за 2 000 финансовый года был известна на 31 декабря 2000 года. Поскольку эта информация, как правило, не публикуется в течение нескольких месяцев после завершения финансового года, тест, возможно, содержал систематическую ошибку опережения.
Эта ошибка может привести к стратегии, которая окажется успешной, но при этом потребуется идеальная способность прогнозировать бухгалтерские результаты.
Систематическая ошибка временного периода.
План тестирования подвержен систематической ошибке временного периода, если он основан на периоде, для которого результаты будут специфичны.
Хотя тестирование охватывает период более 10 лет, этот период может оказаться слишком коротким для тестирования аномалии.
В идеале, аналитик должна протестировать рыночные аномалии в течение нескольких бизнес-циклов, чтобы гарантировать, что результаты не являются специфичными для рассматриваемого периода.
Эта систематическая ошибка может способствовать предлагаемой стратегии, если выбрать временной период, благоприятный для стратегии.
Расхождения
между величиной какого-либо показателя,
найденного посредством статистического
наблюдения, и действительными его
размерами называются ошибками
наблюдения.В зависимости от
причин возникновения различают ошибки
регистрации и ошибки репрезентативности.
Ошибки
регистрациивозникают в результате
неправильного установления фактов или
ошибочной записи в процессе наблюдения
или опроса. Они бывают случайными или
систематическими. Случайные ошибки
регистрации могут быть допущены как
опрашиваемыми в их ответах, так и
регистраторами. Систематические ошибки
могут быть и преднамеренными, и
непреднамеренными. Преднамеренные –
сознательные, тенденциозные искажения
действительного положения дела.
Непреднамеренные вызываются различными
случайными причинами (небрежность,
невнимательность).
Ошибки
репрезентативности(представительности)
возникают в результате неполного
обследования и в случае, если обследуемая
совокупность недостаточно полно
воспроизводит генеральную совокупность.
Они могут быть случайными и систематическими.
Случайные ошибки репрезентативности
– это отклонения, возникающие при
несплошном наблюдении из-за того, что
совокупность отобранных единиц наблюдения
(выборка) неполно воспроизводит всю
совокупность в целом. Систематические
ошибки репрезентативности – это
отклонения, возникающие вследствие
нарушения принципов случайного отбора
единиц. Ошибки репрезентативности
органически присущи выборочному
наблюдению и возникают в силу того, что
выборочная совокупность не полностью
воспроизводит генеральную. Избежать
ошибок репрезентативности нельзя,
однако, пользуясь методами теории
вероятностей, основанными на использовании
предельных теорем закона больших чисел,
эти ошибки можно свести к минимальным
значениям, границы которых устанавливаются
с достаточно большой точностью.
Ошибки
выборки –разность между
характеристиками выборочной и генеральной
совокупности. Для среднего значения
ошибка будет определяться по формуле
![]()
(7.1)
где
![]()
Величина
![]() называетсяпредельной ошибкойвыборки.
называетсяпредельной ошибкойвыборки.
Предельная
ошибка выборки – величина случайная.
Исследованию закономерностей случайных
ошибок выборки посвящены предельные
теоремы закона больших чисел. Наиболее
полно эти закономерности раскрыты в
теоремах П. Л. Чебышева и А. М. Ляпунова.
Теорему П.
Л. Чебышева применительно к
рассматриваемому методу можно
сформулировать следующим образом: при
достаточно большом числе независимых
наблюдений можно с вероятностью, близкой
к единице (т. е. почти с достоверностью),
утверждать, что отклонение выборочной
средней от генеральной будет сколько
угодно малым. В теореме П. Л. Чебышева
доказано, что величина ошибки не должна
превышать![]() .
.
В свою очередь величина![]() ,
,
выражающая среднее квадратическое
отклонение выборочной средней от
генеральной средней, зависит от
колеблемости признака в генеральной
совокупности![]() и числа отобранных единицn. Эта
и числа отобранных единицn. Эта
зависимость выражается формулой
![]() ,
,
(7.2)
где
![]() зависит также от способа производства
зависит также от способа производства
выборки.
Величину
![]() =
=![]() называютсредней ошибкой выборки. В
называютсредней ошибкой выборки. В
этом выражении![]() – генеральная дисперсия,n– объем
– генеральная дисперсия,n– объем
выборочной совокупности.
Рассмотрим, как
влияет на величину средней ошибки число
отбираемых единиц n. Логически
нетрудно убедиться, что при отборе
большого числа единиц расхождения между
средними будут меньше, т. е. существует
обратная связь между средней ошибкой
выборки и числом отобранных единиц. При
этом здесь образуется не просто обратная
математическая зависимость, а такая
зависимость, которая показывает, что
квадрат расхождения между средними
обратно пропорционален числу отобранных
единиц.
Увеличение
колеблемости признака влечет за собой
увеличение среднего квадратического
отклонения, а следовательно, и ошибки.
Если предположить, что все единицы будут
иметь одинаковую величину признака, то
среднее квадратическое отклонение
станет равно нулю и ошибка выборки
также исчезнет. Тогда нет необходимости
применять выборку. Однако следует иметь
в виду, что величина колеблемости
признака в генеральной совокупности
неизвестна, поскольку неизвестны размеры
единиц в ней. Можно рассчитать лишь
колеблемость признака в выборочной
совокупности. Соотношение между
дисперсиями генеральной и выборочной
совокупности выражается формулой
![]()
Поскольку
величина
![]() при достаточно большихnблизка к
при достаточно большихnблизка к
единице, можно приближенно считать, что
выборочная дисперсия равна генеральной
дисперсии, т. е.![]()
Следовательно,
средняя ошибка выборки показывает,
какие возможны отклонения характеристик
выборочной совокупности от соответствующих
характеристик генеральной совокупности.
Однако о величине этой ошибки можно
судить с определенной вероятностью. На
величину вероятности указывает множитель
![]()
Теорема А.
М. Ляпунова. А. М. Ляпунов доказал,
что распределение выборочных средних
(следовательно, и их отклонений от
генеральной средней) при достаточно
большом числе независимых наблюдений
приближенно нормально при условии, что
генеральная совокупность обладает
конечной средней и ограниченной
дисперсией.
Математически
теорему Ляпуноваможно записать
так:
 (7.3)
(7.3)
где
![]() ,
,
(7.4)
где ![]() – математическая постоянная;
– математическая постоянная;
![]() –предельная ошибка выборки,которая дает возможность выяснить, в
–предельная ошибка выборки,которая дает возможность выяснить, в
каких пределах находится величина
генеральной средней.
Значения этого
интеграла для различных значений
коэффициента доверия tвычислены и
приводятся в специальных математических
таблицах. В частности, при:

Поскольку tуказывает на вероятность расхождения![]() ,
,
т. е. на вероятность того, на какую
величину генеральная средняя будет
отличаться от выборочной средней, то
это может быть прочитано так: с вероятностью
0,683 можно утверждать, что разность между
выборочной и генеральной средними не
превышает одной величины средней ошибки
выборки. Другими словами, в 68,3 % случаев
ошибка репрезентативности не выйдет
за пределы![]() С вероятностью 0,954 можно утверждать,
С вероятностью 0,954 можно утверждать,
что ошибка репрезентативности не
превышает![]() (т. е. в 95 % случаев). С вероятностью
(т. е. в 95 % случаев). С вероятностью
0,997, т. е. довольно близкой к единице,
можно ожидать, что разность между
выборочной и генеральной средней не
превзойдет трехкратной средней ошибки
выборки и т. д.
Логически связь
здесь выглядит довольно ясно: чем больше
пределы, в которых допускается
возможная ошибка, тем с большей
вероятностью судят о ее величине.
Зная выборочную
среднюю величину признака
![]() и предельную ошибку выборки
и предельную ошибку выборки![]() ,
,
можно определить границы (пределы),
в которых заключена генеральная
средняя
![]() (7.5)
(7.5)
1.
Собственно-случайная выборка–
этот способ ориентирован на выборку
единиц из генеральной совокупности без
всякого расчленения на части или группы.
При этом для соблюдения основного
принципа выборки – равной возможности
всем единицам генеральной совокупности
быть отобранным – используются схема
случайного извлечения единиц путем
жеребьевки (лотереи) или таблицы случайных
чисел. Возможен повторный и бесповторный
отбор единиц
Средняя ошибка
собственно-случайной выборки
представляет собой среднеквадратическое
отклонение возможных значений выборочной
средней от генеральной средней. Средние
ошибки выборки при собственно-случайном
методе отбора представлены в табл. 7.2.
Таблица 7.2
|
Средняя ошибка |
При отборе |
|
|
повторном |
бесповторном |
|
|
Для средней |
|
|
|
Для доли |
|
|

В таблице
использованы следующие обозначения:
![]() – дисперсия выборочной совокупности;
– дисперсия выборочной совокупности;
![]() – численность выборки;
– численность выборки;
![]() – численность генеральной совокупности;
– численность генеральной совокупности;
![]() – выборочная доля единиц, обладающих
– выборочная доля единиц, обладающих
изучаемым признаком;
![]() – число единиц, обладающих изучаемым
– число единиц, обладающих изучаемым
признаком;
![]() – численность выборки.
– численность выборки.
Для увеличения
точности вместо множителя
![]() следует
следует
брать множитель
![]() ,
,
но при большой численностиNразличие
между этими выражениями практического
значения не имеет.
Предельная
ошибка собственно-случайной выборки
![]() рассчитывается по формуле
рассчитывается по формуле
![]() ,
,
(7.6)
где t
– коэффициент доверия зависит от
значения вероятности.
Пример.При
обследовании ста образцов изделий,
отобранных из партии в случайном порядке,
20 оказалось нестандартными. С вероятностью
0,954 определите пределы, в которых
находится доля нестандартной продукции
в партии.
Решение.
Вычислим генеральную долю (Р):
![]() .
.
Доля нестандартной
продукции:
 .
.
Предельная
ошибка выборочной доли с вероятностью
0,954 рассчитывается по формуле (7.6) с
применением формулы табл. 7.2 для доли:

![]()
С вероятностью
0,954 можно утверждать, что доля нестандартной
продукции в партии товара находится в
пределах 12 % ≤ P≤ 28 %.
В практике
проектирования выборочного наблюдения
возникает потребность определения
численности выборки, которая необходима
для обеспечения определенной точности
расчета генеральных средних. Предельная
ошибка выборки и ее вероятность при
этом являются заданными. Из формулы
![]() и формул средних ошибок выборки
и формул средних ошибок выборки
устанавливается необходимая численность
выборки. Формулы для определения
численности выборки (n) зависят от
способа отбора. Расчет численности
выборки для собственно-случайной выборки
приведен в табл. 7.3.
Таблица 7.3
|
Предполагаемый |
Формулы |
|
|
для средней |
для доли |
|
|
Повторный |
|
|
|
Бесповторный |
|
|



2.
Механическая выборка– при этом
методе исходят из учета некоторых
особенностей расположения объектов в
генеральной совокупности, их упорядоченности
(по списку, номеру, алфавиту). Механическая
выборка осуществляется путем отбора
отдельных объектов генеральной
совокупности через определенный интервал
(каждый 10-й или 20-й). Интервал рассчитывается
по отношению![]() ,
,
гдеn– численность выборки,N–
численность генеральной совокупности.
Так, если из совокупности в 500 000 единиц
предполагается получить 2 %-ную выборку,
т. е. отобрать 10 000
единиц, то пропорция отбора составит![]() Отбор
Отбор
единиц осуществляется в соответствии
с установленной пропорцией через равные
интервалы. Если расположение объектов
в генеральной совокупности носит
случайный характер, то механическая
выборка по содержанию аналогична
случайному отбору. При механическом
отборе применяется только бесповторная
выборка [1, 5–10].
Средняя ошибка
и численность выборки при механическом
отборе подсчитывается по формулам
собственно-случайной выборки (см.
табл. 7.2 и 7.3).
3.
Типическая выборка, при котрой
генеральная совокупность делится по
некоторым существенным признакам на
типические группы; отбор единиц
производится из типических групп. При
этом способе отбора генеральная
совокупность расчленяется на однородные
в некотором отношении группы, которые
имеют свои характеристики, и вопрос
сводится к определению объема выборок
из каждой группы. Может бытьравномерная
выборка– при этом способе из каждой
типической группы отбирается одинаковое
число единиц![]() Такой подход оправдан лишь при равенстве
Такой подход оправдан лишь при равенстве
численностей исходных типических групп.
При типическом отборе, непропорциональном
объему групп, общее число отбираемых
единиц делится на число типических
групп, полученная величина дает
численность отбора из каждой типической
группы.
Более совершенной
формой отбора является пропорциональная
выборка. Пропорциональной называется
такая схема формирования выборочной
совокупности, когда численность выборок,
взятых из каждой типической группы в
генеральной совокупности, пропорциональна
численностям, дисперсиям (или комбинированно
и численностям, и дисперсиям). Условно
определяем численность выборки в 100
единиц и отбираем единицы из групп:
– пропорционально
численности их генеральной совокупности
(табл. 7.4). В таблице
обозначено:
Ni– численность типической группы;
dj
– доля (Ni/N);
N– численность
генеральной совокупности;
ni– численность выборки из типической
группы вычисляется:
![]() , (7.7)
, (7.7)
n – численность выборки из генеральной
совокупности.
Таблица
7.4
-
Группы
Ni
dj
ni
1
300
0,3
30
2
500
0,5
50
3
200
0,2
20
1000
1,0
100
–
пропорционально среднему квадратическому
отклонению(табл. 7.5).
здесь
i– среднее
квадратическое отклонение типических
групп;
ni
– численность выборки из типической
группы вычисляется по формуле

(7.8)
Таблица
7.5
-
Ni
i

ni
300
5
0,25
25
500
7
0,35
35
200
8
0,40
40
1000
20
1,0
100
–
комбинированно (табл. 7.6).
Численность
выборки вычисляется по формуле
![]() . (7.9)
. (7.9)
Таблица 7.6
-

i
iNi


300
5
1500
0,23
23
500
7
2100
0,53
53
200
8
1600
0.24
24
1000
20
6600
1,0
100
При проведении
типической выборки непосредственный
отбор из каждой группы проводится
методом случайного отбора.
Средние ошибки
выборки рассчитываются по формулам
табл. 7.7 в зависимости от способа отбора
из типических групп.
Таблица 7.7
|
Способ |
Повторный |
Бесповторный |
||
|
для |
для |
для |
для |
|
|
Непропорциональный |
|
|
|
|
|
Пропорциональный объему групп |
|
|
|
|
|
Пропорциональный |
|
|
|
|





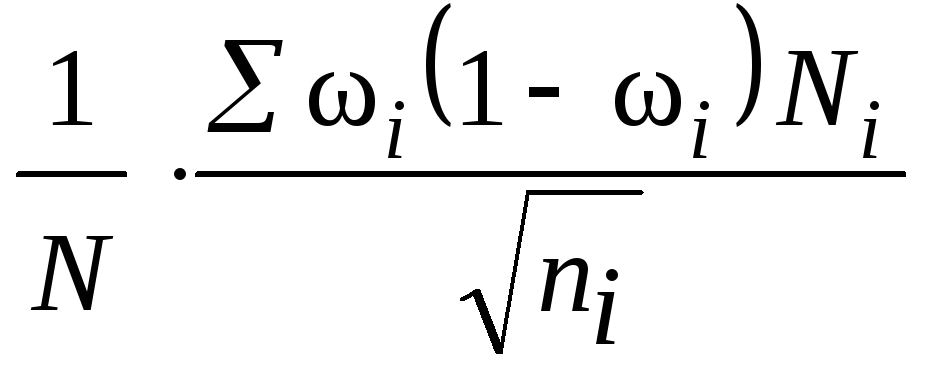


здесь
![]() – средняя из внутригрупповых дисперсий
– средняя из внутригрупповых дисперсий
типических групп;
![]() – доля единиц, обладающих изучаемым
– доля единиц, обладающих изучаемым
признаком;
![]() – средняя из внутригрупповых дисперсий
– средняя из внутригрупповых дисперсий
для доли;
![]() – среднее квадратическое отклонение
– среднее квадратическое отклонение
в выборке изi-й типической группы;
![]() – объем выборки из типической группы;
– объем выборки из типической группы;
![]() – общий объем выборки;
– общий объем выборки;
![]() –
–
объем типической группы;
![]() – объем генеральной совокупности.
– объем генеральной совокупности.
Численность
выборки из каждой типической группы
должна быть пропорциональна среднему
квадратическому отклонению в этой
группе
![]() .Расчет численности
.Расчет численности
![]() производится по формулам, приведенным
производится по формулам, приведенным
в табл. 7.8.
Таблица 7.8
|
Повторный |
Бесповторный |
|
|
Для определения |
|
|
|
Для определения |
|
|
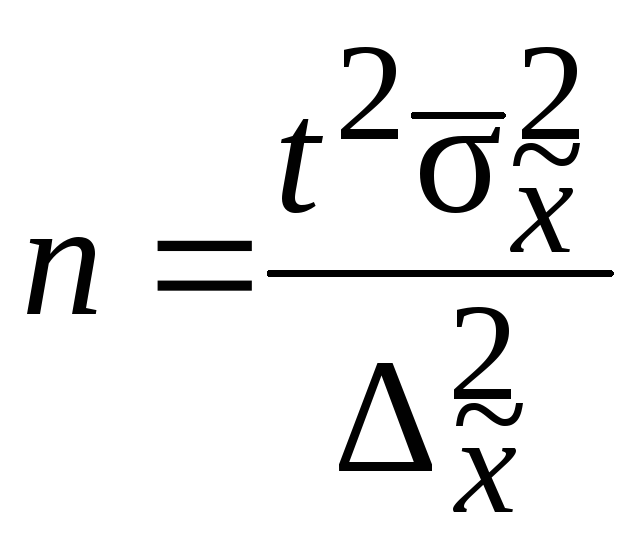

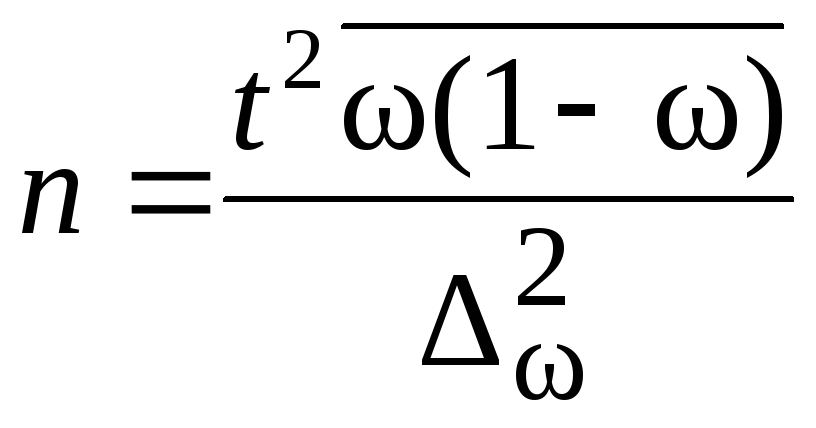

4. Серийная
выборка– удобена в тех случаях,
когда единицы совокупности объединены
в небольшие группы или серии. При серийной
выборке генеральную совокупность делят
на одинаковые по объему группы – серии.
В выборочную совокупность отбираются
серии. Сущность серийной выборки
заключается в случайном или механическом
отборе серий, внутри которых производится
сплошное обследование единиц. Средняя
ошибка серийной выборки с равновеликими
сериями зависит от величины только
межгрупповой дисперсии. Средние ошибки
сведены в табл. 7.9.
Таблица 7.9
|
Способ |
Формулы |
|
|
для |
для |
|
|
Повторный |
|
|
|
Бесповторный |
|
|


Здесь
R– число серий в генеральной
совокупности;
r – число
отобранных серий;
![]() – межсерийная (межгрупповая) дисперсия
– межсерийная (межгрупповая) дисперсия
средних;
![]() – межсерийная (межгрупповая) дисперсия
– межсерийная (межгрупповая) дисперсия
доли.
При серийном
отборе необходимую численность отбираемых
серий определяют так же, как и при
собственно-случайном методе отбора.
Расчет численности
серийной выборки производится по
формулам, приведенным в табл. 7.10.
Таблица 7.10
|
Повторный |
Бесповторный |
|
|
Для |
|
|
|
Для |
|
|
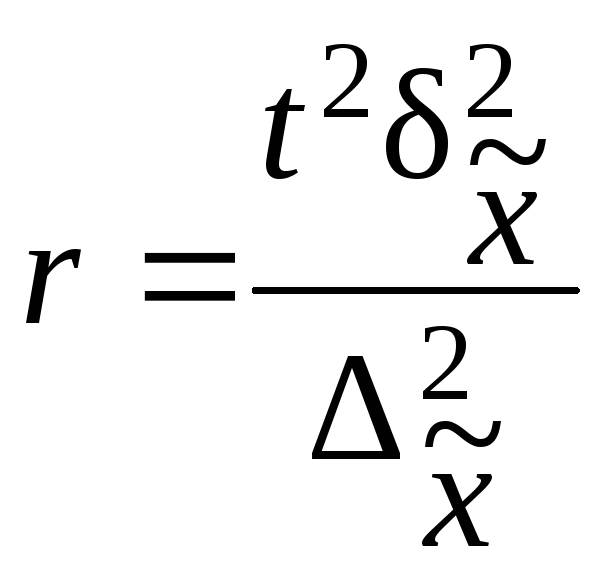

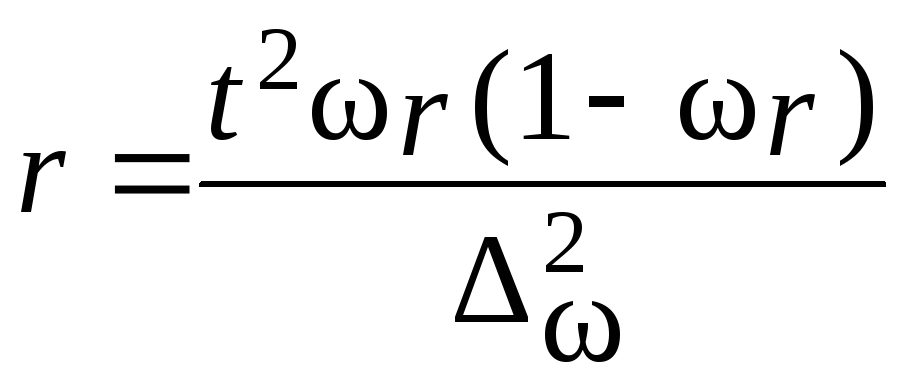

Пример.В
механическом цехе завода в десяти
бригадах работает 100 рабочих. В целях
изучения квалификации рабочих была
произведена 20 %-ная серийная бесповторная
выборка, в которую вошли две бригады.
Получено следующее распределение
обследованных рабочих по разрядам:
|
Рабочие |
Разряды рабочих |
Разряды рабочих |
Рабочие |
Разряды |
Разряды |
|
1 2 3 4 5 |
2 4 5 2 5 |
3 6 1 5 3 |
6 7 8 9 10 |
6 5 8 4 5 |
4 2 1 3 2 |
Необходимо
определить с вероятностью 0,997 пределы,
в которых находится средний разряд
рабочих механического цеха.
Решение.
Определим выборочные средние по
бригадам и общую среднюю как среднюю
взвешенную из групповых средних:

Определим
межсерийную дисперсию по формулам
(5.25):
![]()
Рассчитаем
среднюю ошибку выборки по формуле табл.
7.9:
![]()
Вычислим
предельную ошибку выборки с вероятностью
0,997:
![]()
С вероятностью
0,997 можно утверждать, что средний разряд
рабочих механического цеха находится
в пределах
![]()
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Существует интересный феномен — ошибка выжившего — так называется вид систематической ошибки отбора, когда по одной подгруппе («выжившим») имеется много информации, а по другой («погибшим») — почти ничего. Поэтому исследователи некой проблемы ищут общие показатели именно среди «выживших», но игнорируют тот факт, что не менее важные данные могут быть и у «погибших».
Рассмотрим на двух примерах:
1 пример:
Во время Второй мировой войны большинство американских бомбардировщиков возвращались на базу с пробоинами, сосредоточенными на крыльях, стабилизаторах и фюзеляже.
Из этого конструкторы сделали вывод: нужно укреплять именно эти места. И поддались ошибке выжившего!
А вот математик Абрахам Вальд сделал совершенно другой вывод. Он рассуждал так: «Мы видим дырки в обшивке. А чего не видим? Правильно, самолетов, у которых были пробоины в кабине, двигателях и топливных баках.
Получается, что крылатая машина с дырками в крыльях в состоянии вернуться на базу, а вот если у самолета повреждена кабина, то этого уже не произойдет — пилот-то погиб.
Так зачем укреплять крылья, если нужно защищать кабину?»
Кстати, уже после войны в лесах и болотах нашли немало подбитых самолетов — с повреждениями именно в двигателе, топливной системе и кабинах пилота. Они никуда улететь не смогли.
Получается, что если делать выводы только исходя из данных по «выжившим самолётам», то есть по той информации которая лежит на поверхности, игнорируя возможные скрытые данные, можно прийти к неправильным выводам.
2 пример:
В тот день, когда юный Бред Питт впервые приехал в Голливуд, вместе с ним туда отправились сотни таких же амбициозных парней. Возможно, они были опытнее, умнее и красивее, чем Питт, однако, именно ему удалось добиться успеха.
Вот именно в этой истории и кроется главный парадокс. Без сомнений Питт сделал все правильно, но едва ли только он один сможет рассказать, как добиться реального успеха. Помочь в объяснении этого помогут и те, у кого ничего не вышло, так как, проанализировав их решения, мы сможем понять, на каком из этапов они могли ошибиться.
Таким образом, пытаясь сделать вывод из информации, которая у вас «на руках», обязательно задумайтесь о данных, которыми вы возможно не владеете. И в противовес аргументам книг из серии «Как я быстро разбогател и добился успеха» найдутся тысячи случаев, когда эти же шаги не помогли.
А полезная информация о том, чего НЕ надо делать, чтобы обанкротиться/проиграть, возможно как раз таки есть у людей, которые через это прошли, но потерпели неудачу — у тех самых «погибших». Только они мануалов не пишут. Ведь кому нужны фолианты от неудачников.
Что думаете об этом феномене? Знаете ещё подобные примеры?

Систематическая ошибка отбора — статистическое понятие, показывающее, что выводы, сделанные применительно к какой либо выборке, могут оказаться неточными вследствие неслучайного неправильного отбора объектов в эту выборку. Типы систематических ошибок Пространство: – Выбор первой и последней точки в серии. К примеру, для того, чтобы максимизировать заявленный тренд, можно начать серию с года с необычно низкими показателями и закончить годом с самыми высокими показателями. – «Своевременное» окончание, то есть тогда, когда результаты укладываются в желаемую теорию. – Отделение части данных на основе знаний обо всей выборке и затем применение математического аппарата к этой части как к слепой (случайной) выборке (т. н. «районированная выборка» , или «ошибка меткого стрелка» ).
, заведомо меньшем, чем требуется для")
– Изучение процесса на интервале (во времени или пространстве), заведомо меньшем, чем требуется для полного представления о явлении. Данные: – Вычёркивание неких «плохих» данных в соответствии с придуманными правилами, хотя бы эти правила и шли вразрез с предварительно объявленными правилами для этой выборки. Участники: – Пристрастный предварительный отбор участников. К примеру, для доказательства, что курение никак не вредит результатам фитнес тренировок, можно разместить в местном фитнесцентре объявление для набора добровольцев, но курящих набирать в среди тренеров и опытных участников, а некурящих – среди начинающих или желающих сбросить вес.

– Выбрасывание из выборки участников, не дошедших до конца теста (т. н. «систематическая ошибка выжившего» ). Во время Второй мировой войны математику Абрахаму Вальду поручили найти варианты бронирования бомбардировщиков: не все они возвращались на базу, а на тех, что возвращались, оставалось множество пробоин от зениток и истребителей на крыльях и хвосте. Значило ли это, что в этих местах нужно было больше брони? Вальд ответил: нет, эти места достаточно защищены. Самолёт, которому попали в кабину или топливный бак, выходит из строя и не возвращается. Поэтому укреплять надо те места, которые наиболее «чистые» . «Слухи об уме и доброте дельфинов основаны на рассказах пловцов, которых они толкали к берегу, а не в открытое море» . Из старых зданий остаются только самые красивые и прочные — остальные подвергаются сносу, и на их месте строят новые. Классическое искусство — это то, что проверено временем, но плохими работами того времени большинство людей не интересуется.

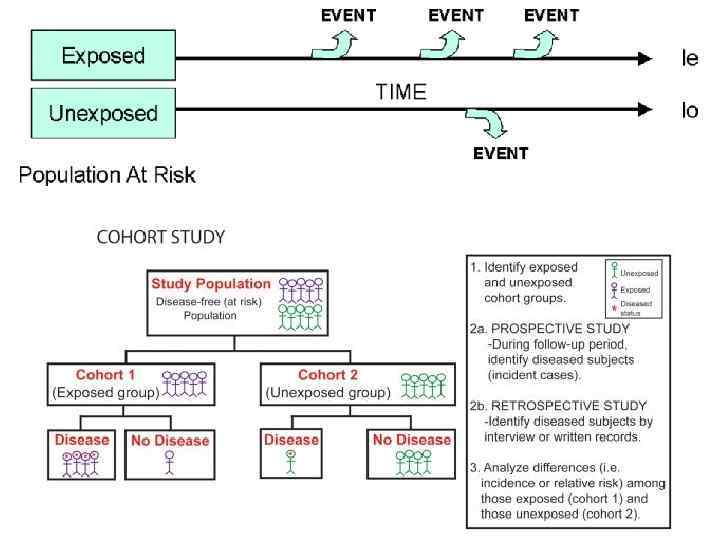
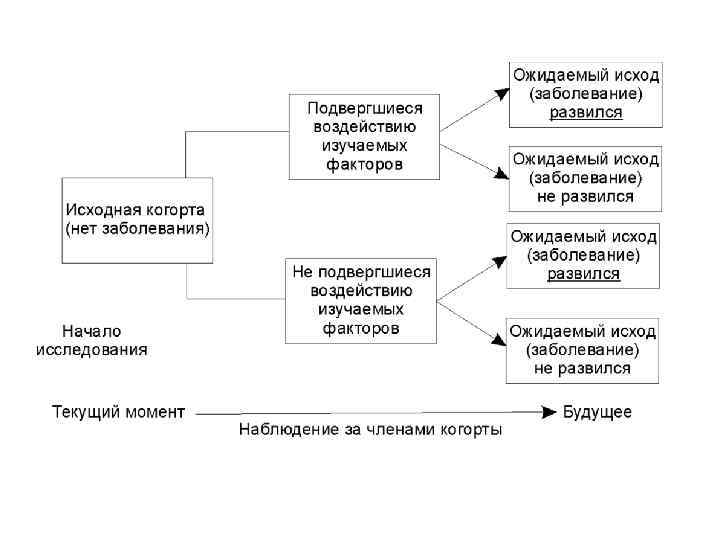
Когортные исследования

Данные исследования обладают большой доказательной силой и широко используются исследователями США и стран Западной Европы. Эти исследования основаны на наблюдении и не предполагают активного вмешательства исследователей в естественное течение изучаемого процесса; они также всегда являются «продольными» , и почти всегда – проспективными (бывают и ретроспективные когортные исследования). Основная цель когортных исследований – установить, влияет ли определенное воздействие (или несколько) на последующее развитие определенного исхода (например, клинически манифестного заболевания).

Кроме того, исследования подобного типа предпринимаются для точного описания типичного течения и характерных осложнений различных заболеваний, частоты встречаемости каких либо событий, интересующих ученых, изучения побочных эффектов и взаимодействия лекарственных препаратов, выявления факторов риска различных заболеваний и состояний и оценки степени их вклада в развитие изучаемого исхода и т. п. Это лучший вид клинических исследований для тех случаев, когда эксперимент невозможен.
 группами исследуемых")
Принцип когортных исследований – в продолжительном наблюдении за одной (реже – несколькими) группами исследуемых лиц ( «когортами» ). Срок наблюдения варьирует от нескольких месяцев до десятков лет и оговаривается заранее (хотя в дальнейшем может быть увеличен в соответствии с результатами промежуточных анализов полученных данных). Размер когорты обычно стараются сделать как можно большим; в идеале когорта совпадает по численности с исследуемой генеральной совокупностью. В случае, если исследуется широко распространенное заболевание или состояние, представляющее большую социальную значимость, и все случаи таких заболеваний тщательно регистрируются на государственном уровне, описанный выше идеальный вариант достижим; так, ученые ряда стран исследуют национальные когорты ВИЧ инфицированных или больных атеросклерозом. При согласованном объединении когорт нескольких стран образуются огромные интернациональные когорты; так поступают при организации международных мультицентровых исследований.

Когортное исследование отчасти похоже на исследование вида «случай-контроль» : – когорта формируется из лиц, имеющих риск развития какоголибо состояния, интересующего исследователей (например, ВИЧ-инфекции – у взрослых социально и сексуально активных лиц, ОНМК – у пациентов с артериальной гипертензией, обострения/хронизации – у пациентов с вирусными гепатитами, побочных эффектов АРТ – у получающих АРТ и т. п. ); – в дальнейшем в ходе наблюдения регистрируются случаи развития искомого состояния (т. н. «исходы» ). По завершении исследования когорта разделяется на группу, где действовал интересующий исследователей фактор ( «опытная группа» ), и группу, где указанный фактор не действовал ( «контрольная группа» ), после чего в указанных группах сравниваются показатели, характеризующие вероятность развития исхода.

– если в ходе когортного исследования стоит цель просто описать частоту развития некоего явления в определённой группе лиц, подвергающихся воздействию какого-либо фактора (например, рака лёгких либо ХОБЛ у курильщиков, ВИЧ-инфекции – у парентеральных наркоманов и т. п. ), то когорта формируется из лиц, находящихся под воздействием соответствующего фактора (например, из парентеральных наркоманов), а контрольная группа не нужна; – всё вышеперечисленное должно учитываться в критериях включения/исключения в исследование; – перед проведением когортного исследования желательно выполнение «пилотного» исследования с менее доказательным типом дизайна для получения начальной информации о структуре изучаемого явления – это необходимо для процедуры определения должного размера выборки (sample size calculation). Репрезентативность!!
 Коморбидность Сопутствующие заболевания (в настоящее время или")
Категории критериев включения/исключения (исходя из контекста исследования) Коморбидность Сопутствующие заболевания (в настоящее время или ранее), не изучаемые в исследовании. Могут быть критериями исключения. Лечение Медикаментозная терапия, проводимая ранее или в настоящее время, хирургические вмешательства, участие в другом исследовании. Форма или степень тяжести заболевания Клиническая форма и степень тяжести изучаемого заболевания Критерии, связанные с беременностью Беременность, лактация, методы контрацепции Персональные критерии Например: возраст, пол, национальность (раса)
 диагностических процедур, необходимых для включения в")
Диагностические процедуры Касается выполнения обследований (не их результата!) диагностических процедур, необходимых для включения в исследование (например, измерение кровяного давления, любые специфические лабораторные тесты и т. д. ) Прочее Например, такие специфические индивидуальные критерии, как исключение при беременности партнёра, либо включение в зависимости от места жительства, наличия информированного согласия, грамотности/способности изъясняться на государственном языке и т. д. Также могут использоваться в качестве дополнительных критериев исключения (например, ожидаемая низкая приверженность рекомендациям и т. п. )

Примером является Euro. SIDA, согласованно проводимая на 6 когортах ВИЧ инфицированных, проживающих во многих странах Евросоюза, включая Польшу и страны Балтии, а также в России, Белоруссии и на Украине; общий размер объединенной когорты – более 11. 200 больных. Другим примером мультицентрового когортного исследования является D: A: D (сбор данных о побочных эффектах АРТ). Объединенная когорта данного исследования включает 11 национальных когорт ВИЧ инфицированных лиц, проживающих в 21 европейской стране, а также в США и Австралии и наблюдающихся в 188 клиниках; суммарный размер данной когорты составляет 23. 468 больных. Если в когорту удалось (или планируется) включить всех зарегистрированных больных с изучаемой патологией, она называется регистром. Регистр может быть региональный, национальный и (для редких заболеваний) – международный; регистр больных с острым коронарным синдромом Global Registry of Acute Coronary Events (GRACE), его приблизительным аналогом в России является регистр ОКС РЕКОРД.

Чем больше размер когорты, тем точнее получаемые данные и тем ближе они приближаются к таковым в генеральной совокупности; при этом пропорционально возрастает стоимость исследования и сложность его организации. Большие мультицентровые когортные исследования по силам только большим интернациональным научным коллективам при поддержке влиятельных спонсоров, как правило – фармацевтических компаний. Когортные исследования бывают фиксированные (после достижения определенного размера когорты включение в исследование новых пациентов прекращается) и динамические (возможно пополнение когорты новыми участниками в ходе наблюдения).

Лица, включенные в когорту, находятся под наблюдением до проявления у них изучаемого исхода (outcome, endpoint). Исходом может быть, например, развитие какого либо заболевания либо его осложнения, выздоровление или смерть больного, неудача лечения, появление побочного эффекта терапии; такие исходы называют истинными, поскольку они отражают реальные клинически значимые события в жизни исследуемого лица. Кроме того, бывают суррогатные исходы – обычно достижение определенного уровня каким либо показателем, полученным при лабораторных либо инструментальных исследованиях (например, уровня CD 4+ лимфоцитов, вирус нагрузки плазмы крови, холестерина и т. п. ). Суррогатные исходы косвенно указывают на развитие тех или иных истинных исходов (например, неудачи лечения или обострения заболевания), но сами таковыми не являются. Два или более независимых события, последователь ного или одновременного наступления которых ждет исследователь, могут объединяться в т. н. составной (composite) исход (например,

При анализе результатов когортных исследований наиболее часто используется метод анализа времени до наступления исхода (также называется «анализ вероятности наступления изучаемого исхода в определенный период времени» или «анализ дожития» ). Корректные результаты могут быть получены только при анализе синхронизированной когорты, т. е. такой когорты, каждый из членов которой был включен в исследование в строго определенный и одинаковый для всех момент развития своего заболевания / состояния (наступление определенной стадии заболевания, первичное проявление симптомов заболевания или его обострение, госпитализация, начало лечения, оперативное вмешательство и т. п. Данное условия требует тщательной формулировки критериев включения участников в исследование; в дальнейшем эти критерии должны неукоснительно соблюдаться.

Пациенты, включенные в исследование в разное время, могут быть несопоставимы по ряду признаков. Например, в случае хронических инфекционных заболеваний (вирусные гепатиты В, С, ВИЧ инфекция и т. п. ) методы диагностики и лечения достаточно быстро улучшаются с течением времени; если сравнить больных, включенных в исследование 15 лет назад и в настоящий момент, то окажется, что у современных больных заболевание было выявлено на более ранней стадии, а прогноз существенно лучше, чем 15 лет назад, из за радикального улучшения терапевтических подходов. Систематическая ошибка данного рода, связанная с улучшением методов диагностики и лечения по ходу продолжительного исследования, называется «ошибка временного сдвига» (leadtime bias); примером такой ошибки является исследование выживаемости ВИЧ инфицированных больных, заболевание у которых было выявлено до и после 1985 г. , из которого ожидаемо следует, что у больных, выявленных до 1985 г. , выживаемость ниже.

Аналогично, при исследовании выживаемости ВИЧ инфицированных лиц на фоне ВААРТ, начатой при различных уровнях CD 4+ лимфоцитов (50 клеток/мм 3 и 350 клеток/мм 3, соответственно) оказалось, что при начале ВААРТ на фоне выраженной иммуносупрессии (50 клеток/мм 3) выживаемость больных существенно ниже по сравнению с исходно высоким уровнем CD 4+ лимфоцитов. При этом исследователи не учли, что процесс снижения уровня Тh лимфоцитов с 350 до 50 клеток/мкл занимает несколько (2 7) лет, которые стоило бы приплюсовать к выживаемости лиц с глубоким иммунодефицитом. Данный пример также подчеркивает необходимость синхронизации формируемой когорты по ключевым показателям, способным оказать критическое влияние на ожидаемый результат исследования.
. Данная ошибка возникает в")
Другой систематической ошибкой является т. н. ошибка выжившего (survivorship bias). Данная ошибка возникает в случае, если сравнивается выживаемость больных, получавших или не получавших определенную терапию, причем анализируемый метод лечения стал доступен для использования на определенном этапе уже проводимого когортного исследования. В этом случае для того, чтобы подвергнуться определенному лечению, больные должны были дожить до его введения в клиническую практику, а все больные, умершие до этого момента, не имели шанса получить указанную терапию. Соответственно, оказывается, что лечение получили больные, у которых прогноз заболевания исходно был наиболее благоприятным, и в результате эффективность оцениваемой терапии может быть существенно завышена.
 выборка лиц,")
В целом, для обеспечения корректности анализа выживаемости необходимо соблюдение следующих условий: 1) выборка лиц, вошедших в когорту, случайна и репрезентативна; 2) наблюдения независимы; 3) в период исследования не происходило изменений в методах диагностики, лечения и процедурах наблюдения (т. е. критерии включения не изменялись); 4) в период исследования для всех больных, входящих в когорту, вероятность наступления изучаемого исхода не изменялась; 5) случаи смерти, выбывания из исследования и включения новых больных в когорту происходили более или менее равномерно на всем периоде наблюдения.

Для оценки влияния каких либо факторов на развитие изучаемого исхода определяют следующие численные показатели: 1) Риск наступления исхода к моменту Х (risk of event by time t) – некоторое число в интервале между 0 и 1. 2) Шанс наступления исхода к моменту Х (odds of event by time t) – некоторое число между 0 и бесконечностью, приблизитель но равен риску, если частота исследуемого исхода невелика.
 Частота (наступления) исхода – incidence rate (также просто incidence или просто rate) Определение")
3) Частота (наступления) исхода – incidence rate (также просто incidence или просто rate) Определение частоты исхода предпочтительнее, чем оценка риска или шанса, поскольку при этом учитывается тот факт, что не все члены когорты находятся под наблюдением в течение одинакового временного интервала.

Если какой либо из наблюдаемых индивидуумов вышел из исследования до его завершения по любым причинам (кроме наступления ожидаемого исхода), считается, что время наблюдения в данном случае цензурировано моментом последнего планового осмотра данного лица. Такое наблюдение называется неполным, незавершенным или цензурированным. К неполным относятся также те наблюдения, в которых изучаемый исход не наступил на момент окончания исследования. Полным, завершенным или нецензурированным считается такое наблюдение, в котором изучаемый исход наступил до окончания исследования, и при этом точно известен интервал времени между включением больного в исследование и наступлением исхода.
 – это сумма времени, проведенного всеми")
Сумма человеко-лет под наблюдением (person years at risk) – это сумма времени, проведенного всеми участниками исследования под наблюдением в ожидании наступления изучаемого события.
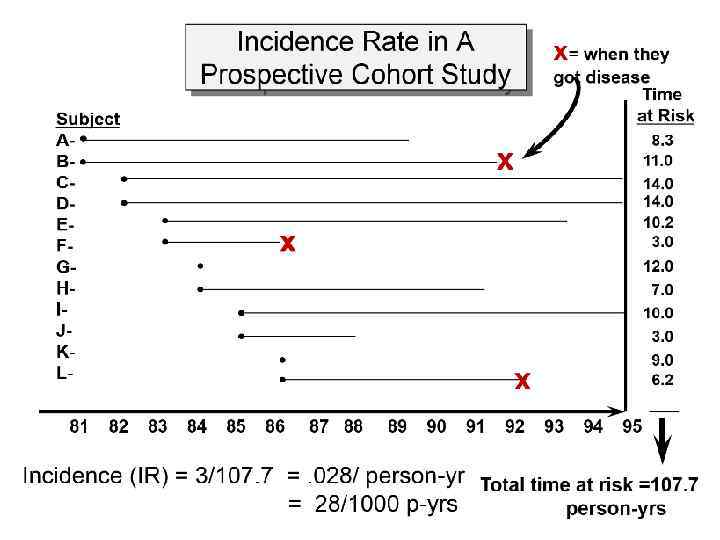

Частота исхода – величина постоянная для всего периода исследования, т. к. вычисляется на основании суммарных данных за весь период (так, для ситуации, изображенной на рисунке, частота исхода составляет 5 ÷ 34, 7 = 0, 14 на 1 человеко год). В то же время ясно, что вероятность появления ожидаемого исхода на разных временных отрезках неодинакова и с течением времени может закономерно изменяться (например, вероятность умереть возрастает пропорционально возрасту, начиная приблизительно с 40 лет). Вероятность развития интересующего нас исхода в данный момент времени характеризуется показателем, называемым «вероятность опасности исхода» (event hazard rate). Она вычисляется как отношение числа лиц с ожидаемым исходом, развившимся за интересующий нас отрезок времени (определенный день, неделю, месяц, год) к количеству человеко лет (месяцев, недель, дней), проведенных под наблюдением за это время всеми наличными участниками исследования.

Собственно сравнение частоты развития исхода в различных группах внутри когорты, выделенных по наличию или отсутствию воздействия факторов, влияние которых на исход изучается в данном исследовании, производится при помощи вычисления относительных характеристик – отношения рисков (risk ratio), отношения шансов (odds ratio) и отношения частот (rate ratio). Для всех указанных величин рассчитывается 95% доверительный интервал (95% CI).

Результатам когортных исследований о влиянии каких-либо факторов на частоту появления определенного события можно доверять, если: 1) выявленное влияние изучаемого фактора на регистрируемый исход велико (относительный риск, отношение частот, отношение шансов >2 или <0, 5); 2) аналогичные результаты получены более чем в двух независимых исследованиях; 3) систематические ошибки и явление «смешивания эффектов» при наборе когорт, наблюдении за участниками исследования и анализе результатов отсутствуют, либо систематические ошибки имеются, но в разных исследованиях они имеют различную направленность (т. е. неодинаковы).
. Вначале строится")
Оценка времени до наступления ожидаемого исхода также называется «анализ дожития» (методика Каплана-Мейера). Вначале строится таблица следующего вида:
")
Из таблицы видно, что число лиц под наблюдением без исхода (см. колонку № 2) уменьшается всякий раз после регистрации очередного исхода или выхода члена когорты из исследования (регистрации неполного, или цензурированного, наблюдения) на суммарное число лиц, покинувших исследование за рассматриваемый временной интервал (исходы + неполные наблюдения), причем указанное уменьшение регистрируется начиная со следующего за текущим временного интервала. Размер временного интервала выбирается произвольно, исходя из цели исследования. Обычно его продолжительность устанавливается равной промежутку времени между плановыми обследованиями членов когорты, причем собственно момент обследования разграничивает соседние интервалы. Именно поэтому лица, выбывшие из исследования по разным причинам, учитываются начиная с отрезка времени, следующего за тем, во время которого состоялся выход данных лиц из состава когорты

Все наблюдения, в которых ожидаемый исход не был зафиксирован к моменту окончания исследования, считаются цензурированными, что и отражено в последней ячейке колонки № 4 ( «количество неполных наблюдений…» ). Если участник исследования по каким либо причинам (кроме регистрации ожидаемого исхода) покинул когорту до окончания исследования, такое наблюдение считается цензурированным по времени последнего планового осмотра указанного лица (т. е. последним эпизодом наблюдения за данным членом когорты считается момент последнего планового осмотра, во время которого не было зафиксировано ожидаемого исхода).

После расчета вероятности отсутствия исхода вплоть до момента завершения исследования производится построение графика Каплана-Мейера, который отражает вероятность отсутствия изучаемого исхода у членов когорты с момента начала исследования до момента его окончания.

График Каплана Мейера представляет собой серию «ступенек» , где снижение кумулятивной вероятности отсутствия исхода происходит скачкообразно после регистрации очередного случая (случаев) ожидаемого исхода; регистрация цензурированных наблюдений не приводит к снижению вероятности отсутствия исхода, вследствие чего «ступенька» на графике не образуется, но сам факт регистрации неполного наблюдения отмечается на графике специальным значком. Данная особенность построения графиков Каплана Мейера напрямую вытекает из принципа организации когортных исследований, который подразумевает не непрерывный, а периодический учет изменений в состоянии членов когорты во время регулярных контрольных осмотров, вследствие чего изменение вероятности наличия либо отсутствия искомого состояния происходит не плавно, а скачками.

Изображенная на графике Каплана Мейера кривая называется кривой дожития. Две кривые дожития, полученные при анализе независимых групп, можно сравнивать, используя лог-ранговый тест (log rank test); если в результате вероятность нулевой гипотезы (р) оказывается равна или менее 0, 05, то кривые дожития отличаются друг от друга с вероятностью 95% и более. Кривую дожития можно представить и в альтернативном виде – как кривую вероятности появления ожидаемого исхода с течением времени.
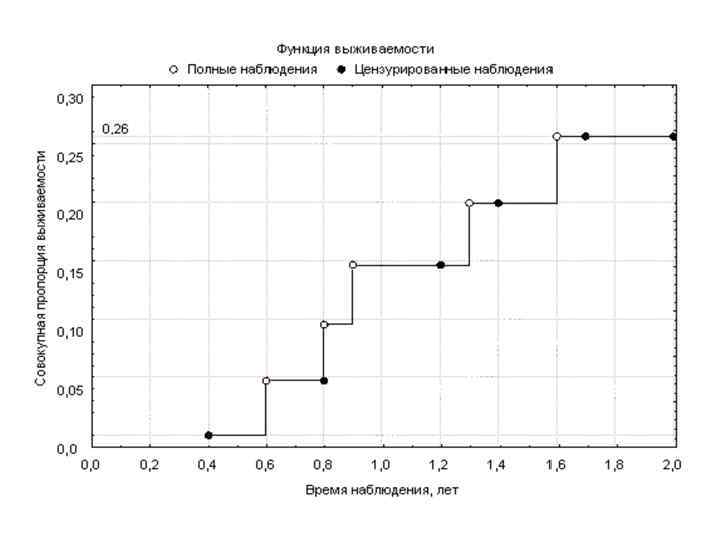
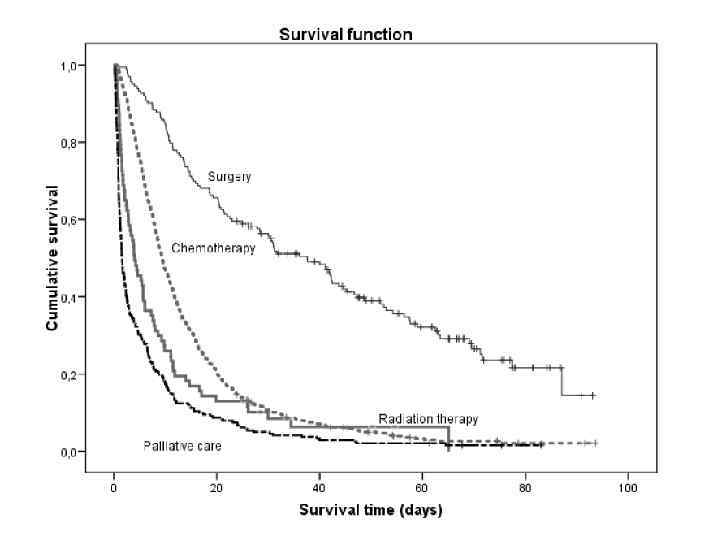

Следует обратить внимание на то, что вероятность развития исхода к моменту окончания исследования составляет примерно 26% (1 − 0, 742), при этом риск наступления исхода к тому же моменту, рассчитанный по приведенной ранее формуле и имеющий тот же смысл, равен 5 ÷ 22 = 22, 7%. Величина риска получилась заниженной, поскольку формула для его вычисления не предусматривает постепенное уменьшение размера когорты в ходе исследования (ввиду наступления исхода у части наблюдаемых лиц, а также вследствие выхода больных из состава когорты по другим причинам). Таким образом, применение методики Каплана-Мейера дает более точные результаты, чем просто расчет риска наступления события к интересующему моменту, ввиду чего данная методика является предпочтительной для обработки результатов когортных исследований.
 дожитие (доля")
Помимо построения графика Каплана Мейера, анализ дожития подразумевает определение следующих показателей: 1) дожитие (доля участников исследования, у которых искомый исход не наступил) для интересующего срока наблюдения; 2) стандартная ошибка кумулятивного дожития – рассчитывается при помощи соответствующей функции программы для статистического анализа (standard error of cumulative survival), в нашем примере – 0, 0996; 3) суммарное число членов когорты для интересующего срока наблюдения; 4) медиана времени дожития (median survival time) – период времени, в течение которого изучаемый исход наступит у 50% участников исследования. Указанная величина соответствует медиане времени до наступления исхода (median time to event) в случае выбора альтернативного представления графика Каплана Мейера. Кроме того, указываются 25 й и 75 й процентили кривой дожития (т. е. первый и третий квартили).

В нашем примере медиану времени дожития указать невозможно, поскольку на момент окончания наблюдения более половины членов когорты не имели изучаемого исхода. Тем не менее, можно указать первый квартиль (25 й процентиль) кривой дожития – он равен 1, 57 лет; к этому сроку изучаемое состояние разовьется у 25% испытуемых лиц.
. Указанное явление наблюдается")
Анализируя данные когортных исследований, необходимо помнить о возможности смешивания эффектов (confounding). Указанное явление наблюдается в случае, если некий фактор А, учет и анализ которого в исследовании не производился, влияет как на развитие изучаемого исхода И, так и на проявление одного или нескольких факторов (Б, В, Г), учитываемых в данном исследовании. Внешне это выглядит, как если бы факторы Б, В, Г влияли на развитие исхода И, хотя на самом деле они с ним непосредственно не связаны. Например, употребление парентеральных наркотиков увеличивает риск смерти; при этом может иметь место смешивание эффектов – наркоманы почти всегда заболевают хроническим вирусным гепатитом С (неучтенный фактор), который тоже увеличивает риск смерти. Факт наркомании как таковой может увеличивать риск смерти индивидуума, но наличие неучтенного фактора (ХВГС) приводит к завышению степени данного увеличения.

Возможность смешивания эффектов нельзя полностью учесть на этапе планирования исследования, поскольку невозможно учесть вообще все факторы, могущие представлять какую либо значимость. До некоторой степени возможное смешивание эффектов можно нейтрализовать на этапе анализа данных исследования посредством проведения стратификации. Например, мы анализируем сравнительную эффективность схем антиретровирусной терапии А и В. Каждой из схем было пролечено по 1000 ВИЧ инфицированных; отсутствие вирусологического ответа было отмечено у 300 человек, получавших схему А (30%), и у 450 человек, получавших схему В (45%), относительный риск неудачи лечения составил в данном случае 30÷ 45=0, 67. Можно ли вести речь о том, что схема лечения А достоверно более эффективна, чем терапевтическая схема В? На самом деле в обеих группах имеется неучтенный фактор – количество лиц, впервые получающих антиретровирусную терапию (т. е. «АРТ наивных» ). Известно, что у лиц, ранее получавших АРТ, эффективность последующих схем существенно снижается с каждой очередной сменой терапии. Ввиду этого, учет указанного фактора критически важен для анализа результатов данного исследования.
, а")
Оказывается, в группе, пролеченной по схеме А, АРТ наивных лиц было 800 (80%), а в группе, пролеченной по схеме В – 200 (20%), т. е. при формировании исследуемых групп рандомизация по этому признаку не проводилась. Для «подгонки» (adjustment) результатов статистических выкладок по данному фактору необходимо обратиться к базе данных исследования и выяснить частоту вирусологической неудачи лечения отдельно для АРТ наивных лиц и больных, получавших АРТ более одного раза, для каждой из двух анализируемых групп: В обеих группах пропорция лиц с вирусологической неудачей лечения одинакова как среди АРТ наивных лиц, так и среди ВИЧ инфицированных, ранее уже получавших АРТ; в обоих случаях относительный риск равен 1, 0. В итоге приходится признать, что на самом деле схемы лечения А и В обладают одинаковой эффективностью, а полученная в исследовании разница обусловлена только лишь ошибкой при формировании изучаемых групп, которые не были рандомизированы по фактору, оказывающему существенное влияние на результат интересующего нас вмешательства. Важно помнить, что при стратификации уменьшается размер сравниваемых групп, что ведет к существенному снижению статистической значимости исследования.

В качестве типичного примера когортного дизайна можно привести исследование, выполненное на когорте больных гемофилией Бесплатного Королевского Госпиталя (Royal Free Hospital). В гематологическом отделении вышеупомянутой больницы наблюдалось 111 ВИЧ инфицированных мужчин гемофиликов, заразившихся в период с 1979 по 1985 гг. , на предмет особенностей течения ВИЧ инфекции у данной категории больных. Продолжительность наблюдения составила 25 лет. Учитывались демографические факторы, клиническая симптоматика, лабораторные данные, а также информация об эффективности лечения. На момент окончания исследования в живых остались 39 его участников, в том числе 28 – под непосредственным наблюдением в составе когорты.

Другим примером «классического» когортного исследования является мультицентровое исследование когорты лиц со СПИДом. В течение двух вербовочных периодов (с апреля 1984 г. по март 1985 г. и с 1987 г. по 1991 г. ) было рекрутировано несколько сотен ВИЧ инфицированных гомосексуалистов, проживающих в 4 столичных областях США; в дальнейшем они проходили амбулаторное обследование каждые 6 месяцев. В процессе обследования собиралась демографическая информация (дата рождения, национальность), клинические данные (обследование на наличие признаков СПИДа при каждом осмотре, регистрация даты и причины смерти), лабораторные данные (подсчет уровня CD 4+ лимфоцитов и количества копий РНК ВИЧ в плазме крови), сведения о проводимой терапии (даты начала и прекращения назначения всех антиретровирусных препаратов), а также некоторые другие данные (дата первого положительного обследования на ВИЧ инфекцию, проводилась ли профилактика пневмоцистной пневмонии и т. п. ).

Еще одним образцом когортного дизайна является исследование частоты коинфекции ВИЧ и туберкулеза, проведенное в одном из госпиталей Нью Йорка. Первоначально 513 внутривенных наркоманов были обследованы на ВИЧ инфекцию; 215 из них оказались ВИЧ позитивными. Затем вся указанная когорта наблюдалась в течение 2 лет, при этом регистрировались любые признаки активного туберкулеза. Были получены следующие результаты: среди серопозитивных лиц (215) туберкулез развился у 8, среди серонегативных (298) – ни у одного из наблюдавшихся наркоманов, включенных в когорту. Риск развития туберкулеза в группе ВИЧ позитивных лиц был оценен как 0, 037 (в группе ВИЧ негатив ных лиц риск развития туберкулеза оказался равен нулю).

Когортный дизайн имеет следующие преимущества: 1. Можно оценить временную взаимосвязь между воздействием какого либо фактора и развитием исхода (например, заболевания), поскольку всегда известен порядок следования регистрируемых событий; 2. На основании анализа данных, полученных в когортных исследованиях, можно попытаться установить причинно следственные взаимосвязи между воздействиями и исходами (хотя рандомизированные контролируемые исследования в этом смысле предпочтительнее). Недостатки когортного дизайна следующие: 1. Если исследуемый исход относится к редким явлениям, то размер когорты должен быть очень большим, а период наблюдения за ней – весьма продолжительным, что приводит к удорожанию всего исследования;

2. Когортные исследования занимают много времени и требуют вложения значительно бóльших средств, чем ранее описанные типы дизайна, что накладывает определенные ограничения как на максимальные размеры когорт, так и на продолжительность исследования; это особенно актуально для стран с невысоким уровнем ассигнований на науку; 3. Высокая вероятность систематических ошибок (biases) при сборе и анализе данных из за «смешивания эффектов» (confounding) – ведь невозможно заранее знать, какие факторы являются существенными для развития интересующего исследователей исхода, и включить их регистрацию в план исследования; соответственно, оставшийся неучтенным фактор (факторы) может как обусловливать развитие изучаемого явления, так и взаимодействовать с регистрируемыми воздействиями, что приводит к эффектам, описанным выше;

4. Возможны проблемы с уменьшением статистической надежности исследования ввиду неизбежного уменьшения размера когорт в ходе исследования по неустановленным причинам (т. н. loss to follow up). Поскольку когортные исследования длятся годами и десятилетиями, члены когорты могут сменить место жительства, семейный статус, умереть, а также отказаться от наблюдения и выйти из исследования, не уточняя причин. При этом всякий раз желательно проверять, не связан ли выход конкретного лица из научного проекта с развитием интересующего исследователей исхода; особенно данное положение касается исследований т. н. «психотравмирующих» (scaring) заболеваний, в частности, ВИЧ инфекции, парентеральных гепатитов и заболеваний, передающихся половым путем (ЗППП).