Поскольку
выборка охватывает , как правило,
весьма незначительную часть генеральной
совокупности, то следует предполагать,
что будут иметь место различия между
оценкой и характеристикой генеральной
совокупности, которую эта оценка
отображает. Эти различия получили
название ошибок отображения или ошибок
репрезентативности. Ошибки
репрезентативности подразделяются
на два типа : систематические и случайные.
Систематические
ошибки —
это постоянное завышение или занижение
значения оценки по сравнению с
характеристикой генеральной совокупности
. Причиной появления систематической
ошибки является несоблюдение принципа
равновероятности попадания каждой
единицы генеральной совокупности в
выборку , то есть выборка формируется
из преимущественно «худших» ( или «
лучших») представителей генеральной
совокупности. Соблюдение принципа
равновозможности попадания каждой
единицы в выборку позволяет полностью
исключить этот тип ошибок .
Случайные
ошибки –
это меняющиеся
от выборки к выборке по знаку и величине
различия между оценкой и оцениваемой
характеристикой генеральной совокупности
. Причина возникновения случайных
ошибок- игра случая при формировании
выборки, составляющей лишь часть
генеральной совокупности. Этот тип
ошибок органически присущ выборочному
методу. Исключить их полностью нельзя,
задача состоит в том , чтобы предсказать
их возможную величину и свести их к
минимуму. Порядок связанных в связи
с этим действий вытекает из рассмотрения
трех видов случайных ошибок : конкретной
, средней и предельной.
2.2 Конкретная, средняя и предельная ошибки выборки
2.2.1
Конкретная
ошибка – это ошибка одной проведенной
выборки. Если средняя по этой выборке
(
![]() ) является оценкой для генеральной
) является оценкой для генеральной
средней (![]() 0
0
) и, если
предположить, что эта генеральная
средняя нам известна , то разница
![]() =
=![]()
![]() —
—![]() 0
0
и будет
конкретной ошибкой этой выборки. Если
из этой генеральной совокупности
выборку повторим многократно, то каждый
раз получим новую величину конкретной
ошибки :
![]() …,
…,
и так далее.
Относительно этих конкретных ошибок
можно сказать следующее: некоторые из
них будут совпадать между собой по
величине и знаку, то есть имеет место
распределение ошибок, часть из них
будет равна 0, наблюдается совпадение
оценки и параметра генеральной
совокупности;
2.2.2
Средняя ошибка
– это средняя квадратическая из всех
возможных по воле случая конкретных
ошибок оценки :
 ,
,
где![]() — величина меняющихся конкретных
— величина меняющихся конкретных
ошибок;![]() частота
частота
( вероятность ) встречаемости той или
иной конкретной ошибки. Средняя
ошибка выборки показывает насколько
в среднем можно ошибиться , если на
основе оценки делается суждение о
параметре генеральной совокупности.
Приведенная формула раскрывает
содержание средней ошибки, но она не
может быть использована для практических
расчетов, хотя бы потому, что предполагает
знание параметра генеральной совокупности
, что само по себе исключает необходимость
выборки.
Практические
расчеты средней ошибки оценки
основываются на той предпосылке, что
она ( средняя ошибка ) по сути является
средним квадратическим отклонением
всех возможных значений оценки. Эта
предпосылка позволяет получить алгоритмы
расчета средней ошибки, опирающиеся
на данные одной единственной выборки.
В частности средняя ошибка выборочной
средней может быть установлена на
основе следующих рассуждений. Имеется
выборка (
![]() ,
,![]()
![]() …
…![]() ) состоящая из
) состоящая из![]() единиц. По выборке в качестве оценки
единиц. По выборке в качестве оценки
генеральной средней определена
выборочная средняя . Каждое значение
. Каждое значение![]() (
(![]() ,
,![]()
![]() …
…![]() ) , стоящее под знаком суммы, следует
) , стоящее под знаком суммы, следует
рассматривать как независимую случайную
величину, поскольку при бесконечном
повторении выборки первая, вторая и
т.д. единицы могут принимать любые
значения из присутствующих в генеральной
совокупности. Следовательно Поскольку , как известно, дисперсия
Поскольку , как известно, дисперсия
суммы независимых случайных величин
равна сумме дисперсий , то![]()
 .
.
Отсюда следует, что средняя ошибка для
выборочной средней будет равная![]() и находится она в обратной зависимости
и находится она в обратной зависимости
от численности выборки ( через корень
квадратный из нее ) и в прямой от среднего
квадратического отклонения признака
в генеральной совокупности. Это логично,
поскольку выборочная средняя является
состоятельной оценкой для генеральной
средней и по мере увеличения численности
выборки приближается по своему значению
к оцениваемому параметру генеральной
совокупности. Прямая зависимость
средней ошибки от колеблемости признака
обусловлена тем, что чем больше
изменчивость признака в генеральной
совокупности, тем сложнее на основе
выборки построить адекватную модель
генеральной совокупности. На практике
среднее квадратическое отклонение
признака по генеральной совокупности
заменяется его оценкой по выборке, и
тогда формула для расчета средней
ошибки выборочной средней приобретает
вид:![]() ,
,
при этом учитывая смещенность
выборочной дисперсии ,
,
выборочное среднее квадратическое
отклонение рассчитывается по формуле![]()
 =
= . Так как символомn
. Так как символомn
обозначена численность выборки. ,то
в знаменателе при расчете среднего
квадратического отклонения должна
использоваться не численность выборки
( n
), а так называемое число степеней
свободы (n-1).
Под числом степеней свободы понимается
число единиц в совокупности, которые
могут свободно варьировать ( изменяться
), если по совокупности определена
какая-либо характеристика. В нашем
случае , поскольку по выборке определена
ее средняя, свободно варьировать могут
![]() единицы.
единицы.
В
таблице 2.2 приведены формулы для
расчета средних ошибок различных
выборочных оценок . Как видно из этой
таблицы, величина средней ошибки по
всем оценкам находится в обратной связи
с численностью выборки и в прямой с
колеблемостью. Это можно сказать и
относительно средней ошибки выборочной
доли ( частости ). Под корнем стоит
дисперсия альтернативного признака,
установленная по выборке (
![]() )
)
Приведенные
в таблице 2.2 формулы относятся к так
называемому случайному , повторному
отбору единиц в выборку. При других
способах отбора , о которых речь пойдет
ниже, формулы будут несколько
видоизменяться.
Таблица
2.2
Формулы для
расчета средних ошибок выборочных
оценок
|
Выборочные |
Формулы |
|
Выборочная |
|
|
Выборочная |
|
|
Выборочное |
|
|
Выборочная |
|
2.2.3
Предельная ошибка выборки
Знание оценки и ее средней ошибки в
ряде случаев совершенно недостаточно
. Например , при использовании гормонов
при кормлении животных знать только
средний размер неразложившихся их
вредных остатков и среднюю ошибку,
значит подвергать потребителей продукции
серьезной опасности. Здесь настоятельно
напрашивается необходимость определения
максимальной ( предельной
ошибки ).
При использовании выборочного метода
предельная ошибка устанавливается не
в виде конкретной величины , а виде
равных границ
(
интервалов) в ту и другую сторону от
значения оценки.
Определение
границ предельной ошибки основывается
на особенностях распределения конкретных
ошибок . Для так называемых больших
выборок, численность которых более 30
единиц (
![]() )
)
, конкретные ошибки распределяются в
соответствии с нормальным законом
распределения; при малых выборках (![]() ) конкретные ошибки распределяются
) конкретные ошибки распределяются
в соответствии с законом распределения
Госсета
(
Стьюдента ). Применительно к конкретным
ошибкам выборочной средней функция
нормального распределения имеет
вид:
 ,
,
где![]() — плотность вероятности появления тех
— плотность вероятности появления тех
или иных значений![]() ,
,
при условии, что![]()
 ,
,
где![]() выборочные средние;
выборочные средние;![]() —
—
генеральная средняя,![]()
![]() — средняя ошибка для выборочной
— средняя ошибка для выборочной
средней. Поскольку средняя ошибка
(![]() )
)
является величиной постоянной, то в
соответствии с нормальным законом
распределяются конкретные ошибки ,
,
выраженные в долях средней ошибки, или
так называемых нормированных отклонениях
.
Взяв
интеграл функции нормального
распределения, можно установить
вероятность того , что ошибка будет
заключена в некотором интервале
изменения t
и вероятность того, что ошибка выйдет
за пределы этого интервала ( обратное
событие ). Например , вероятность того,
что ошибка не превысит половину средней
ошибки ( в ту и другую сторону от
генеральной средней ) составляет
0,3829, что ошибка будет заключена в
пределах одной средней ошибки — 0,6827,
2-х средних ошибок -0,9545 и так далее.
Взаимосвязь
между уровнем вероятности и интервалом
изменения t
( а в конечном счете интервалом
изменения ошибки ) позволяет подойти
к определению интервала ( или границ )
предельной ошибки, увязав его величину
с вероятностью осуществления..
Вероятность осуществления -это
вероятность того, что ошибка будет
находится в некотором интервале.
Вероятность осуществления будет
«доверительной» в том случае, если
противоположное событие ( ошибка будет
находится вне интервала ) имеет такую
вероятность появления, которой можно
пренебречь. Поэтому доверительный
уровень вероятности устанавливают,
как правило, не ниже 0,90 (вероятность
противоположного события равна 0,10 ).
Чем больше негативных последствий
имеет появление ошибок вне установленного
интервала, тем выше должен быть
доверительный уровень вероятности (
0,95; 0,99 ; 0,999 и так далее ).
Выбрав
доверительный уровень вероятности
по таблице интеграла вероятности
нормального распределения, следует
найти соответствующее значение t,
а затем используя выражение
 =
=![]()
![]() определить интервал предельной ошибки
определить интервал предельной ошибки![]() .
.
Смысл полученной величины в следующем
– с принятым доверительным уровнем
вероятности предельная ошибка выборочной
средней не превысит величину![]() .
.
Для
установления границ предельной ошибки
на основе больших выборок для других
оценок ( дисперсии, среднего квадратического
отклонения, доли и так далее ) используется
выше рассмотренный подход, с учетом
того, что для определения средней
ошибки для каждой оценки используется
свой алгоритм.
Что
касается малых выборок (![]() ) то, как уже говорилось, распределение
) то, как уже говорилось, распределение
ошибок оценок соответствует в этом
случае распределениюt
— Стьюдента. Особенность этого
распределения состоит в том, что в
качестве параметра в нем , наряду с
ошибкой, присутствует численность
выборки ,вернее не численность выборки,
а число степеней свободы
![]() При увеличении численности выборки
При увеличении численности выборки
распределениеt-Стьюдента
приближается к нормальному, а при
![]() эти распределения практически совпадают.
эти распределения практически совпадают.
Сопоставляя значения величиныt-Стьюдента
и t
— нормального распределения при одной
и той же доверительной вероятности
можно сказать , что величина t-Стьюдента
всегда больше t
— нормального распределения, причем,
различия возрастают с уменьшением
численности выборки и с повышением
доверительного уровня вероятности.
Следовательно, при использовании малых
выборок имеют место по сравнению с
выборками большими , более широкие
границы предельной ошибки, причем , эти
границы расширяются с уменьшением
численности выборки и повышением
доверительного уровня вероятности.
Вопросы для
повторения
6-1.Какова
природа конкретной, средней и предельной
ошибок ?
6-2.Как
соблюсти принцип равновероятности
каждой единицы попасть в выборку при
выборочном устном опросе студентов ?
6-3 Каков источник
систематической ошибки ?
6-4.Какова
вероятность появления ошибки в 2.5 раза
превышающей среднюю?
6-5.Какие
различия в знаках ( + , — ) имеют
систематические и случайные ошибки?
6-6.Каковы основные
пути уменьшения средней и предельной
ошибки ?
6-7.При какой
выборочной доле имеет место ее наибольшая
ошибка ?
6-8.При какой доле
признака имеет место ее наименьшая
ошибка 7
6-9.При
каких выборках ( больших или малых )
при прочих равных условиях имеет место
большая предельная ошибка ?
Резюме по
модульной единице 2
Использование
выборочного метода неизбежно сопряжено
с появлением ошибок. Случайный характер
этих ошибок, нормальный или t
— Стьюдента закон их распределения
позволяет определить их средний и
предельный размер и видеть пути их
снижения
Модульная
единица 3 Типовые задачи решаемые на
основе выборочного метода
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Когда исследователи рассматривают вопросы, представляющие интерес для аналитиков или портфельных менеджеров, они могут исключить из анализа определенные акции, облигации, портфели, или периоды времени, по разным причинам — возможно, из-за недоступности данных.
Когда недоступность данных приводит к исключению из анализа определенных активов, мы называем эту проблему систематической ошибкой или смещением выборки (англ. ‘sample selection bias’ или ‘sampling bias’).
Например, вы можете сделать выборку из базы данных, которая отслеживает только компании, существующие в настоящее время. Например, многие базы данных взаимных фондов предоставляют историческую информацию только о тех фондах, которые существуют в настоящее время.
Базы данных, в которых хранятся балансовые отчеты и отчеты о прибылях и убытках страдают от той же систематической ошибки, что и базы данных фондов: в них нет фондов или компаний, которые прекратили деятельность.
Исследование, которое использует подобные базы данных, подвержено разновидности систематической ошибки выборки, известной как систематическая ошибка выжившего (англ. ‘survivorship bias’).
Исследователи Димсон, Марш и Стонтон (Dimson, Marsh, and Staunton, 2002) подняли вопрос о систематической ошибке выжившего в международных финансовых индексах:
Известной проблемой является влияние выживания рынков на долгосрочную оценку доходности. Рынки могут испытывать не только разочаровывающие результаты, но и полную потерю стоимости за счет конфискации, гиперинфляции, национализации и кризисов.
При оценке результатов рынков, которые выживают в течение длительных интервалов времени, мы сделали выводы о том, чем обусловлено выживание. Тем не менее, как отметили в исследовании Браун, Готцман и Росс (Brown, Goetzmann, и Ross) в 1995 г. и Готцман и Джорион (Goetzmann and Jorion) в 1999 г., человек не способен заранее определить, какие рынки выживут, а какие нет. (стр. 41)
Систематическая ошибка выжившего иногда появляется, когда мы используем совместно цены акций и данные бухгалтерского учета.
Например, многие исследования в области финансов использовали соотношение рыночной стоимости компании к бухгалтерской стоимости компании на одну акцию (т.е. коэффициент котировки акций, англ. P/B, от ‘price-to-book ratio’ или ‘market-to-book ratio’) и обнаружили, что коэффициент P/B обратно пропорционален доходности компании (см. Fama and French 1992, 1993).
Коэффициент P/B также используется для многих популярных индексов стоимости и роста.
Если база данных, которую мы используем для сбора данных бухгалтерского учета, исключает обанкротившиеся компании, это может привести к систематической ошибке выжившего.
Котхари, Шанкен и Слоун (Kothari, Shanken, and Sloan) в 1995 г. исследовали именно этот вопрос, и оспорили то, что акциям обанкротившихся компаний свойственна самая низкая доходность и коэффициент P/B.
Если мы исключаем из выборки акции обанкротившихся компаний, то акции с низким P/B, которые включены в выборку, будут иметь в среднем более высокую доходность, по сравнению со средней доходностью при включении в выборку всех акций с низким P/B. Котхари, Шанкен и Слоун предположили, что эта систематическая ошибка привела к выводу об обратной связи между средней доходностью и P/B.
См. Fama and French (1996, стр. 80) о интеллектуальном анализе данных и систематической ошибке выжившего в их тестах.
Единственный совет, который мы можем предложить в этой ситуации, — это быть в курсе каких-либо смещений, потенциально присущих в выборке. Очевидно, что смещения выборки могут затуманить результаты любого исследования.
Выборка также может быть смещена из-за удаления (или делистинга) акций компании.
Делистинг (англ. ‘delisting’), т.е. исключение акций компании из котировального списка биржи, может происходить по разным причинам: слияние, банкротство, ликвидация, или переход на другую биржу.
Например, Центр исследований котировок ценных бумаг (CRSP, от англ. Center for Research in Security Prices) в Университете Чикаго является основным поставщиком данных о доходности, используемых в научных исследованиях. Когда происходит делистинг, CRSP пытается собрать данные о доходности исключенной компании, но во многих случаях он не может сделать этого из-за связанных с делистингом трудностях. CRSP вынужден просто указать значение доходности исключенной компании как отсутствующее.
Исследование, опубликованное в Финансовом журнале (см. The Journal of Finance) Шумвеем и Вортером (Shumway and Warther) в 1999 году, задокументировало смещение данных доходности NASDAQ в CRSP, вызванное делистингом.
Авторы показали, что делистинг, связанный с плохой работой компании (например, банкротством) исключается из данных чаще, чем делистинг, связанный с хорошей или нейтральной эффективностью компании (например, слиянием или перемещением на другой рынок). Кроме того, делистинг чаще происходит с небольшими компаниями.
Систематическая ошибка выборки встречается даже на рынках, где качество и согласованность данных весьма высоки. Новые классы активов, такие как хедж-фонды могут представлять еще большие проблемы смещения выборки.
Хедж-фонды (англ. ‘hedge funds’) представляют собой гетерогенную группу инвестиционных инструментов, как правило, организованных таким образом, чтобы быть свободными от регулирующего контроля. В целом, хедж-фонды не обязаны публично раскрывать свою эффективность (в отличие, скажем, от взаимных фондов). Хедж-фонды сами решают, нужно ли им включаться в какую-либо базу данных хедж-фондов.
Хедж фонды с плохой репутацией явно не желают, чтобы их результаты публиковались в базе данных, создавая проблему смещения самовыборки (англ. ‘self-selection bias’) в базах данных хедж-фондов.
Кроме того, как отметили Фанг и Хсие (Fung and Hsieh) в исследовании 2002 г., поскольку только хедж-фонды с хорошими показателями добровольно попадают в базу данных, в целом, историческая эффективность отрасли хедж-фондов имеет тенденцию казаться лучше, чем она есть на самом деле.
Кроме того, многие базы данных хедж-фондов исключают фонды, которые выходят из бизнеса, создавая в базе данных систематическую ошибку выжившего. Даже если база данных не удаляет несуществующие хедж-фонды, в попытке устранить ошибку выжившего, остается проблема хедж-фондов, которые перестают отчитываться об эффективности из-за плохих результатов.
См. Fung and Hsieh (2002) и Horst and Verbeek (2007) для более подробной информации о проблемах интерпретации эффективности хедж-фондов.
Обратите внимание, что систематическая ошибка также возможна, когда успешные фонды перестают отчитываться об эффективности, поскольку они больше не нуждаются в новых потоках денежных средств.
Систематическая ошибка опережения.
Процесс тестирования также подвержен систематической ошибке опережения (англ. ‘look-ahead bias’), если он использует информацию, которая не была доступна на момент тестирования.
Например, тесты правил биржевой торговли, которые используют ставки доходности фондового рынка и данные бухгалтерских балансов должны учитывать систематическую ошибку опережения.
В таких тестах, балансовая стоимость компании на акцию обычно используются для расчета коэффициента P/B.
Хотя рыночная цена акции доступна для всех участников рынка на заданный момент времени, балансовая стоимость на акцию на конец финансового года может стать общедоступной только в будущем — когда-то в следующем квартале.
Систематическая ошибка временного периода.
Тесты также подвержены систематической ошибке или смещению временного периода (англ. ‘time-period bias’), если они основаны на временном периоде, для которого результаты тестирования будут специфичными (т.е., характерными только для данного периода).
Ряды коротких временных периодов, скорее всего, дадут результаты, специфичные для определенного периода, которые могут не отражать более длительный период.
Ряды длительных временных периодов могут дать более точную картину истинной эффективности инвестиций. Недостаток длительных периодов заключается в потенциальных структурных изменениях, происходящих в течение периода, что приведет к двум различным распределениям доходности.
В этой ситуации, распределение, отражающее условия до изменений, будет отличаться от распределения, которые описывают условия после изменений.
Пример (7) систематических ошибок в инвестиционных исследованиях.
Финансовый аналитик рассматривает эмпирические данные об исторической доходности акций США.
Она выясняет, что недооцененные акции (то есть, акции с низким P/B) превзошли по эффективности растущие акции (то есть, акции с высоким P/B) в некоторых последних периодах времени.
После изучения американского рынка, аналитик задается вопросом, могут ли недооцененные акции быть привлекательными в Великобритании. Она исследует эффективность недооцененных и растущих акций на британском рынке за 14-летний период с января 2000 года по декабрь 2013 года.
Для проведения этого исследования, аналитик делает следующее:
- Получает текущий состав компаний Индекса всех акций FTSE (Financial Times Stock Exchange All Share Index), который является взвешенным индексом рыночной капитализации;
- Исключает несколько компаний, у которых финансовый год не заканчивается в декабре;
- Использует балансовую и рыночную стоимость компаний на конец года, чтобы ранжировать остальные пространство компаний по коэффициенту P/B на конец года;
- На основе этих рейтингов, она делит пространство ценных бумаг на 10 портфелей, каждый из которых содержит одинаковое количество акций;
- Вычисляет равновзвешенную доходность каждого портфеля и доходность FTSE All Share Index за 12 месяцев после даты расчета каждого рейтинга; а также
- Вычитает доходность FTSE из доходности каждого портфеля, чтобы получить избыточную доходность для каждого портфеля.
Опишите и обсудите каждую из следующих систематических ошибок, которым подвержен план исследований аналитика:
- систематическую ошибку выжившего;
- систематическую ошибку опережения; а также
- систематическую ошибку временного периода.
Систематическая ошибка выжившего.
План тестирования подвержен систематической ошибке выжившего, если он не принимает в расчет обанкротившиеся компании, слившиеся компании, а также компании, иным образом покинувшие базу.
В этом примере, аналитик использовала текущий список акций FTSE, а не фактический список акций на начало каждого года. В той степени, в которой расчет доходности не учитывает компании, исключенные из индекса, эффективность портфелей с наименьшим P/B подвершена систематической ошибке выжившего и, соответственно, может быть завышена.
В какой-то момент периода тестирования, эти ныне не существующие компании, были исключены из тестирования. У них, вероятно, были низкие цены на акции (и низкий P/ B) и плохая доходность.
Систематическая ошибка опережения.
План тестирования подвержен систематической ошибке опережения, если он использует информацию, недоступную на момент тестирования.
В этом примере, аналитик провела тест, сделав допущение о том, что необходимая бухгалтерская информация была доступна в конце финансового года.
Например, аналитик предположила, что балансовая стоимость на акцию за 2 000 финансовый года был известна на 31 декабря 2000 года. Поскольку эта информация, как правило, не публикуется в течение нескольких месяцев после завершения финансового года, тест, возможно, содержал систематическую ошибку опережения.
Эта ошибка может привести к стратегии, которая окажется успешной, но при этом потребуется идеальная способность прогнозировать бухгалтерские результаты.
Систематическая ошибка временного периода.
План тестирования подвержен систематической ошибке временного периода, если он основан на периоде, для которого результаты будут специфичны.
Хотя тестирование охватывает период более 10 лет, этот период может оказаться слишком коротким для тестирования аномалии.
В идеале, аналитик должна протестировать рыночные аномалии в течение нескольких бизнес-циклов, чтобы гарантировать, что результаты не являются специфичными для рассматриваемого периода.
Эта систематическая ошибка может способствовать предлагаемой стратегии, если выбрать временной период, благоприятный для стратегии.
Как мы уже знаем, репрезентативность — свойство выборочной совокупности представлять характеристику генеральной. Если совпадения нет, говорят об ошибке репрезентативности — мере отклонения статистической структуры выборки от структуры соответствующей генеральной совокупности. Предположим, что средний ежемесячный семейный доход пенсионеров в генеральной совокупности составляет 2 тыс. руб., а в выборочной — 6 тыс. руб. Это означает, что социолог опрашивал только зажиточную часть пенсионеров, а в его исследование вкралась ошибка репрезентативности. Иными словами, ошибкой репрезентативности называется расхождение между двумя совокупностями — генеральной, на которую направлен теоретический интерес социолога и представление о свойствах которой он хочет получить в конечном итоге, и выборочной, на которую направлен практический интерес социолога, которая выступает одновременно как объект обследования и средство получения информации о генеральной совокупности.
Наряду с термином «ошибка репрезентативности» в отечественной литературе можно встретить другой — «ошибка выборки». Иногда они употребляются как синонимы, а иногда «ошибка выборки» используется вместо «ошибки репрезентативности» как количественно более точное понятие.
Ошибка выборки — отклонение средних характеристик выборочной совокупности от средних характеристик генеральной совокупности.
На практике ошибка выборки определяется путем сравнения известных характеристик генеральной совокупности с выборочными средними. В социологии при обследованиях взрослого населения чаще всего используют данные переписей населения, текущего статистического учета, результаты предшествующих опросов. В качестве контрольных параметров обычно применяются социально-демографические признаки. Сравнение средних генеральной и выборочной совокупностей, на основе этого определение ошибки выборки и ее уменьшение называется контролированием репрезентативности. Поскольку сравнение своих и чужих данных можно сделать по завершении исследования, такой способ контроля называется апостериорным, т.е. осуществляемым после опыта.
В опросах Института Дж. Гэллапа репрезентативность контролируется по имеющимся в национальных переписях данным о распределении населения по полу, возрасту, образованию, доходу, профессии, расовой принадлежности, месту проживания, величине населенного пункта. Всероссийский центр изучения общественного мнения (ВЦИОМ) использует для подобных целей такие показатели, как пол, возраст, образование, тип поселения, семейное положение, сфера занятости, должностной статус респондента, которые заимствуются в Государственном комитете по статистике РФ. В том и другом случае генеральная совокупность известна. Ошибку выборки невозможно установить, если неизвестны значения переменной в выборочной и генеральной совокупностях.
Специалисты ВЦИОМ обеспечивают при анализе данных тщательный ремонт выборки, чтобы минимизировать отклонения, возникшие на этапе полевых работ. Особенно сильные смещения наблюдаются по параметрам пола и возраста. Объясняется это тем, что женщины и люди с высшим образованием больше времени проводят дома и легче идут на контакт с интервьюером, т.е. являются легко достижимой группой по сравнению с мужчинами и людьми «необразованными»35.
Ошибка выборки обусловливается двумя факторами: методом формирования выборки и размером выборки.
Ошибки выборки подразделяются на два типа — случайные и систематические. Случайная ошибка — это вероятность того, что выборочная средняя выйдет (или не выйдет) за пределы заданного интервала. К случайным ошибкам относят статистические погрешности, присущие самому выборочному методу. Они уменьшаются при возрастании объема выборочной совокупности.
Второй тип ошибок выборки — систематические ошибки. Если социолог решил узнать мнение всех жителей города о проводимой местными органами власти социальной политике, а опросил только тех, у кого есть телефон, то возникает предумышленное смещение выборки в пользу зажиточных слоев, т.е. систематическая ошибка.
Таким образом, систематические ошибки — результат деятельности самого исследователя. Они наиболее опасны, поскольку приводят к довольно значительным смещениям результатов исследования. Систематические ошибки считаются страшнее случайных еще и потому, что они не поддаются контролю и измерению.
Они возникают, когда, например:
- выборка не соответствует задачам исследования (социолог решил изучить только работающих пенсионеров, а опросил всех подряд);
- налицо незнание характера генеральной совокупности (социолог думал, что 70% всех пенсионеров не работает, а оказалось, что не работает только 10%);
- отбираются только «выигрышные» элементы генеральной совокупности (например, только обеспеченные пенсионеры).
Внимание! В отличие от случайных ошибок систематические ошибки при возрастании объема выборки не уменьшаются.
Обобщив все случаи, когда происходят систематические ошибки, методисты составили их реестр. Они полагают, что источником неконтролируемых перекосов в распределении выборочных наблюдений могут быть следующие факторы:
- нарушены методические и методологические правила проведения социологического исследования;
- выбраны неадекватные способы формирования выборочной совокупности, методы сбора и расчета данных;
- произошла замена требуемых единиц наблюдения другими, более доступными;
- отмечен неполный охват выборочной совокупности (недополучение анкет, неполное их заполнение, труднодоступность единиц наблюдения).
Намеренные ошибки социолог допускает редко. Чаще ошибки возникают из-за того, что социологу плохо известна структура генеральной совокупности: распределение людей по возрасту, профессии, доходам и т.д.
Систематические ошибки легче предупредить (по сравнению со случайными), но их очень трудно устранить. Предупреждать систематические ошибки, точно предвидя их источники, лучше всего заранее — в самом начале исследования.
Вот некоторые способы избежать ошибок выборки:
- каждая единица генеральной совокупности должна иметь равную вероятность попасть в выборку;
- отбор желательно производить из однородных совокупностей;
- надо знать характеристики генеральной совокупности;
- при составлении выборочной совокупности надо учитывать случайные и систематические ошибки.
Если выборочная совокупность (или просто выборка) составлена правильно, то социолог получает надежные результаты, харастеризующие всю генеральную совокупность. Если она составлена неправильно, то ошибка, возникшая на этапе составления выборки, на каждом следующем этапе проведения социологического исследования приумножается и достигает в конечном счете такой величины, которая перевешивает ценность проведенного исследования. Говорят, что от такого исследования больше вреда, нежели пользы.
Подобные ошибки могут произойти только с выборочной совокупностыо. Чтобы избежать или уменьшить вероятность ошибки, самый простой способ — увеличивать размеры выборки (в идеале до объема генеральной: когда обе совокупности совпадут, ошибка выборки вообще исчезнет). Экономически такой метод невозможен. Остается другой путь — совершенствовать математические методы составления выборки. Они то и применяются на практике. Таков первый канал проникновения в социологию математики. Второй канал — математическая обработка данных.
Особенно важной проблема ошибок становится в маркетинговых исследованиях, где используются не очень большие выборки. Обычно они составляют несколько сотен, реже — тысячу респондентов. Здесь исходным пунктом расчета выборки выступает вопрос об определении размеров выборочной совокупности. Численность выборочной совокупности зависит от двух факторов:
- стоимости сбора информации,
- стремления к определенной степени статистической достоверности результатов, которую надеется получить исследователь.
Конечно, даже не искушенные в статистике и социологии люди интуитивно понимают, что чем больше размеры выборки, т.е. чем ближе они к размерам генеральной совокупности в целом, тем более надежны и достоверны полученные данные. Однако выше мы уже говорили о практической невозможности сплошных опросов в тех случаях, когда они проводятся на объектах, численность которых превышает десятки, сотни тысяч и даже миллионы. Понятно, что стоимость сбора информации (включающая оплату тиражирования инструментария, труда анкетеров, полевых менеджеров и операторов по компьютерному вводу) зависит от той суммы, которую готов выделить заказчик, и слабо зависит от исследователей. Что же касается второго фактора, то мы остановимся на нем чуть подробнее.
Итак, чем больше величина выборки, тем меньше возможная ошибка. Хотя необходимо отметить, что при желании увеличить точность вдвое вам придется увеличить выборку не в два, а в четыре раза. Например, чтобы сделать в два раза более точной оценку данных, полученных путем опроса 400 человек, вам потребуется опросить не 800, а 1600 человек. Впрочем, вряд ли маркетинговое исследование испытывает нужду в стопроцентной точности. Если пивовару необходимо узнать, какая часть потребителей пива предпочитает именно его марку, а не сорт его конкурента, — 60% или 40%, то на его планы никак не повлияет разница между 57%, 60 или 63%.
Ошибка выборки может зависеть не только от ее величины, но и от степени различий между отдельными единицами внутри генеральной совокупности, которую мы исследуем. Например, если нам нужно узнать, какое количество пива потребляется, то мы обнаружим, что внутри нашей генеральной совокупности нормы потребления у различных людей существенно различаются (гетерогенная генеральная совокупность). В другом случае мы будем изучать потребление хлеба и установим, что у разных людей оно различается гораздо менее существенно {гомогенная генеральная совокупность). Чем больше различия (или гетерогенность) внутри генеральной совокупности, тем больше величина возможной ошибки выборки. Указанная закономерность лишь подтверждает то, что нам подсказывает простой здравый смысл. Таким образом, как справедливо утверждает В. Ядов, «численность (объем) выборки зависит от уровня однородности или разнородности изучаемых объектов. Чем более они однородны, тем меньшая численность может обеспечить статистически достоверные выводы».
Определение объема выборки зависит также от уровня доверительного интервала допустимой статистической ошибки. Здесь имеются в виду так называемые случайные ошибки, которые связаны с природой любых статистических погрешностей. В.И. Паниотто приводит следующие расчеты репрезентативной выборки с допущением 5%-ной ошибки:
Это означает,что если вы, опросив, предположим, 400 человек в районном городе, где численность взрослого платежеспособного населения составляет 100 тыс. человек, выявили, что 33% опрошенных покупателей предпочитают продукцию местного мясокомбината, то с 95%-ной вероятностью можете утверждать, что постоянными покупателями этой продукции являются 33+5% (т.е. от 28 до 38%) жителей этого города.
Можно также воспользоваться расчетами института Гэллапа для оценки соотношения размеров выборки и ошибки выборки.
Как мы уже знаем, репрезентативность — свойство выборочной совокупности представлять характеристику генеральной. Если совпадения нет, говорят об ошибке репрезентативности — мере отклонения статистической структуры выборки от структуры соответствующей генеральной совокупности. Предположим, что средний ежемесячный семейный доход пенсионеров в генеральной совокупности составляет 2 тыс. руб., а в выборочной — 6 тыс. руб. Это означает, что социолог опрашивал только зажиточную часть пенсионеров, а в его исследование вкралась ошибка репрезентативности. Иными словами, ошибкой репрезентативности называется расхождение между двумя совокупностями — генеральной, на которую направлен теоретический интерес социолога и представление о свойствах которой он хочет получить в конечном итоге, и выборочной, на которую направлен практический интерес социолога, которая выступает одновременно как объект обследования и средство получения информации о генеральной совокупности.
Наряду с термином «ошибка репрезентативности» в отечественной литературе можно встретить другой — «ошибка выборки». Иногда они употребляются как синонимы, а иногда «ошибка выборки» используется вместо «ошибки репрезентативности» как количественно более точное понятие.
Ошибка выборки — отклонение средних характеристик выборочной совокупности от средних характеристик генеральной совокупности.
На практике ошибка выборки определяется путем сравнения известных характеристик генеральной совокупности с выборочными средними. В социологии при обследованиях взрослого населения чаще всего используют данные переписей населения, текущего статистического учета, результаты предшествующих опросов. В качестве контрольных параметров обычно применяются социально-демографические признаки. Сравнение средних генеральной и выборочной совокупностей, на основе этого определение ошибки выборки и ее уменьшение называется контролированием репрезентативности. Поскольку сравнение своих и чужих данных можно сделать по завершении исследования, такой способ контроля называется апостериорным, т.е. осуществляемым после опыта.
В опросах Института Дж. Гэллапа репрезентативность контролируется по имеющимся в национальных переписях данным о распределении населения по полу, возрасту, образованию, доходу, профессии, расовой принадлежности, месту проживания, величине населенного пункта. Всероссийский центр изучения общественного мнения (ВЦИОМ) использует для подобных целей такие показатели, как пол, возраст, образование, тип поселения, семейное положение, сфера занятости, должностной статус респондента, которые заимствуются в Государственном комитете по статистике РФ. В том и другом случае генеральная совокупность известна. Ошибку выборки невозможно установить, если неизвестны значения переменной в выборочной и генеральной совокупностях.
Специалисты ВЦИОМ обеспечивают при анализе данных тщательный ремонт выборки, чтобы минимизировать отклонения, возникшие на этапе полевых работ. Особенно сильные смещения наблюдаются по параметрам пола и возраста. Объясняется это тем, что женщины и люди с высшим образованием больше времени проводят дома и легче идут на контакт с интервьюером, т.е. являются легко достижимой группой по сравнению с мужчинами и людьми «необразованными»35.
Ошибка выборки обусловливается двумя факторами: методом формирования выборки и размером выборки.
Ошибки выборки подразделяются на два типа — случайные и систематические. Случайная ошибка — это вероятность того, что выборочная средняя выйдет (или не выйдет) за пределы заданного интервала. К случайным ошибкам относят статистические погрешности, присущие самому выборочному методу. Они уменьшаются при возрастании объема выборочной совокупности.
Второй тип ошибок выборки — систематические ошибки. Если социолог решил узнать мнение всех жителей города о проводимой местными органами власти социальной политике, а опросил только тех, у кого есть телефон, то возникает предумышленное смещение выборки в пользу зажиточных слоев, т.е. систематическая ошибка.
Таким образом, систематические ошибки — результат деятельности самого исследователя. Они наиболее опасны, поскольку приводят к довольно значительным смещениям результатов исследования. Систематические ошибки считаются страшнее случайных еще и потому, что они не поддаются контролю и измерению.
Они возникают, когда, например:
- выборка не соответствует задачам исследования (социолог решил изучить только работающих пенсионеров, а опросил всех подряд);
- налицо незнание характера генеральной совокупности (социолог думал, что 70% всех пенсионеров не работает, а оказалось, что не работает только 10%);
- отбираются только «выигрышные» элементы генеральной совокупности (например, только обеспеченные пенсионеры).
Внимание! В отличие от случайных ошибок систематические ошибки при возрастании объема выборки не уменьшаются.
Обобщив все случаи, когда происходят систематические ошибки, методисты составили их реестр. Они полагают, что источником неконтролируемых перекосов в распределении выборочных наблюдений могут быть следующие факторы:
- нарушены методические и методологические правила проведения социологического исследования;
- выбраны неадекватные способы формирования выборочной совокупности, методы сбора и расчета данных;
- произошла замена требуемых единиц наблюдения другими, более доступными;
- отмечен неполный охват выборочной совокупности (недополучение анкет, неполное их заполнение, труднодоступность единиц наблюдения).
Намеренные ошибки социолог допускает редко. Чаще ошибки возникают из-за того, что социологу плохо известна структура генеральной совокупности: распределение людей по возрасту, профессии, доходам и т.д.
Систематические ошибки легче предупредить (по сравнению со случайными), но их очень трудно устранить. Предупреждать систематические ошибки, точно предвидя их источники, лучше всего заранее — в самом начале исследования.
Вот некоторые способы избежать ошибок выборки:
- каждая единица генеральной совокупности должна иметь равную вероятность попасть в выборку;
- отбор желательно производить из однородных совокупностей;
- надо знать характеристики генеральной совокупности;
- при составлении выборочной совокупности надо учитывать случайные и систематические ошибки.
Если выборочная совокупность (или просто выборка) составлена правильно, то социолог получает надежные результаты, харастеризующие всю генеральную совокупность. Если она составлена неправильно, то ошибка, возникшая на этапе составления выборки, на каждом следующем этапе проведения социологического исследования приумножается и достигает в конечном счете такой величины, которая перевешивает ценность проведенного исследования. Говорят, что от такого исследования больше вреда, нежели пользы.
Подобные ошибки могут произойти только с выборочной совокупностыо. Чтобы избежать или уменьшить вероятность ошибки, самый простой способ — увеличивать размеры выборки (в идеале до объема генеральной: когда обе совокупности совпадут, ошибка выборки вообще исчезнет). Экономически такой метод невозможен. Остается другой путь — совершенствовать математические методы составления выборки. Они то и применяются на практике. Таков первый канал проникновения в социологию математики. Второй канал — математическая обработка данных.
Особенно важной проблема ошибок становится в маркетинговых исследованиях, где используются не очень большие выборки. Обычно они составляют несколько сотен, реже — тысячу респондентов. Здесь исходным пунктом расчета выборки выступает вопрос об определении размеров выборочной совокупности. Численность выборочной совокупности зависит от двух факторов:
- стоимости сбора информации,
- стремления к определенной степени статистической достоверности результатов, которую надеется получить исследователь.
Конечно, даже не искушенные в статистике и социологии люди интуитивно понимают, что чем больше размеры выборки, т.е. чем ближе они к размерам генеральной совокупности в целом, тем более надежны и достоверны полученные данные. Однако выше мы уже говорили о практической невозможности сплошных опросов в тех случаях, когда они проводятся на объектах, численность которых превышает десятки, сотни тысяч и даже миллионы. Понятно, что стоимость сбора информации (включающая оплату тиражирования инструментария, труда анкетеров, полевых менеджеров и операторов по компьютерному вводу) зависит от той суммы, которую готов выделить заказчик, и слабо зависит от исследователей. Что же касается второго фактора, то мы остановимся на нем чуть подробнее.
Итак, чем больше величина выборки, тем меньше возможная ошибка. Хотя необходимо отметить, что при желании увеличить точность вдвое вам придется увеличить выборку не в два, а в четыре раза. Например, чтобы сделать в два раза более точной оценку данных, полученных путем опроса 400 человек, вам потребуется опросить не 800, а 1600 человек. Впрочем, вряд ли маркетинговое исследование испытывает нужду в стопроцентной точности. Если пивовару необходимо узнать, какая часть потребителей пива предпочитает именно его марку, а не сорт его конкурента, — 60% или 40%, то на его планы никак не повлияет разница между 57%, 60 или 63%.
Ошибка выборки может зависеть не только от ее величины, но и от степени различий между отдельными единицами внутри генеральной совокупности, которую мы исследуем. Например, если нам нужно узнать, какое количество пива потребляется, то мы обнаружим, что внутри нашей генеральной совокупности нормы потребления у различных людей существенно различаются (гетерогенная генеральная совокупность). В другом случае мы будем изучать потребление хлеба и установим, что у разных людей оно различается гораздо менее существенно {гомогенная генеральная совокупность). Чем больше различия (или гетерогенность) внутри генеральной совокупности, тем больше величина возможной ошибки выборки. Указанная закономерность лишь подтверждает то, что нам подсказывает простой здравый смысл. Таким образом, как справедливо утверждает В. Ядов, «численность (объем) выборки зависит от уровня однородности или разнородности изучаемых объектов. Чем более они однородны, тем меньшая численность может обеспечить статистически достоверные выводы».
Определение объема выборки зависит также от уровня доверительного интервала допустимой статистической ошибки. Здесь имеются в виду так называемые случайные ошибки, которые связаны с природой любых статистических погрешностей. В.И. Паниотто приводит следующие расчеты репрезентативной выборки с допущением 5%-ной ошибки:
Это означает,что если вы, опросив, предположим, 400 человек в районном городе, где численность взрослого платежеспособного населения составляет 100 тыс. человек, выявили, что 33% опрошенных покупателей предпочитают продукцию местного мясокомбината, то с 95%-ной вероятностью можете утверждать, что постоянными покупателями этой продукции являются 33+5% (т.е. от 28 до 38%) жителей этого города.
Можно также воспользоваться расчетами института Гэллапа для оценки соотношения размеров выборки и ошибки выборки.
Поскольку
выборка охватывает , как правило,
весьма незначительную часть генеральной
совокупности, то следует предполагать,
что будут иметь место различия между
оценкой и характеристикой генеральной
совокупности, которую эта оценка
отображает. Эти различия получили
название ошибок отображения или ошибок
репрезентативности. Ошибки
репрезентативности подразделяются
на два типа : систематические и случайные.
Систематические
ошибки —
это постоянное завышение или занижение
значения оценки по сравнению с
характеристикой генеральной совокупности
. Причиной появления систематической
ошибки является несоблюдение принципа
равновероятности попадания каждой
единицы генеральной совокупности в
выборку , то есть выборка формируется
из преимущественно «худших» ( или «
лучших») представителей генеральной
совокупности. Соблюдение принципа
равновозможности попадания каждой
единицы в выборку позволяет полностью
исключить этот тип ошибок .
Случайные
ошибки –
это меняющиеся
от выборки к выборке по знаку и величине
различия между оценкой и оцениваемой
характеристикой генеральной совокупности
. Причина возникновения случайных
ошибок- игра случая при формировании
выборки, составляющей лишь часть
генеральной совокупности. Этот тип
ошибок органически присущ выборочному
методу. Исключить их полностью нельзя,
задача состоит в том , чтобы предсказать
их возможную величину и свести их к
минимуму. Порядок связанных в связи
с этим действий вытекает из рассмотрения
трех видов случайных ошибок : конкретной
, средней и предельной.
2.2 Конкретная, средняя и предельная ошибки выборки
2.2.1
Конкретная
ошибка – это ошибка одной проведенной
выборки. Если средняя по этой выборке
(
![]() ) является оценкой для генеральной
) является оценкой для генеральной
средней (![]() 0
0
) и, если
предположить, что эта генеральная
средняя нам известна , то разница
![]() =
=![]()
![]() —
—![]() 0
0
и будет
конкретной ошибкой этой выборки. Если
из этой генеральной совокупности
выборку повторим многократно, то каждый
раз получим новую величину конкретной
ошибки :
![]() …,
…,
и так далее.
Относительно этих конкретных ошибок
можно сказать следующее: некоторые из
них будут совпадать между собой по
величине и знаку, то есть имеет место
распределение ошибок, часть из них
будет равна 0, наблюдается совпадение
оценки и параметра генеральной
совокупности;
2.2.2
Средняя ошибка
– это средняя квадратическая из всех
возможных по воле случая конкретных
ошибок оценки :
,
где![]() — величина меняющихся конкретных
— величина меняющихся конкретных
ошибок;![]() частота
частота
( вероятность ) встречаемости той или
иной конкретной ошибки. Средняя
ошибка выборки показывает насколько
в среднем можно ошибиться , если на
основе оценки делается суждение о
параметре генеральной совокупности.
Приведенная формула раскрывает
содержание средней ошибки, но она не
может быть использована для практических
расчетов, хотя бы потому, что предполагает
знание параметра генеральной совокупности
, что само по себе исключает необходимость
выборки.
Практические
расчеты средней ошибки оценки
основываются на той предпосылке, что
она ( средняя ошибка ) по сути является
средним квадратическим отклонением
всех возможных значений оценки. Эта
предпосылка позволяет получить алгоритмы
расчета средней ошибки, опирающиеся
на данные одной единственной выборки.
В частности средняя ошибка выборочной
средней может быть установлена на
основе следующих рассуждений. Имеется
выборка (
![]() ,
,![]()
![]() …
…![]() ) состоящая из
) состоящая из![]() единиц. По выборке в качестве оценки
единиц. По выборке в качестве оценки
генеральной средней определена
выборочная средняя. Каждое значение![]() (
(![]() ,
,![]()
![]() …
…![]() ) , стоящее под знаком суммы, следует
) , стоящее под знаком суммы, следует
рассматривать как независимую случайную
величину, поскольку при бесконечном
повторении выборки первая, вторая и
т.д. единицы могут принимать любые
значения из присутствующих в генеральной
совокупности. СледовательноПоскольку , как известно, дисперсия
суммы независимых случайных величин
равна сумме дисперсий , то![]() .
.
Отсюда следует, что средняя ошибка для
выборочной средней будет равная![]() и находится она в обратной зависимости
и находится она в обратной зависимости
от численности выборки ( через корень
квадратный из нее ) и в прямой от среднего
квадратического отклонения признака
в генеральной совокупности. Это логично,
поскольку выборочная средняя является
состоятельной оценкой для генеральной
средней и по мере увеличения численности
выборки приближается по своему значению
к оцениваемому параметру генеральной
совокупности. Прямая зависимость
средней ошибки от колеблемости признака
обусловлена тем, что чем больше
изменчивость признака в генеральной
совокупности, тем сложнее на основе
выборки построить адекватную модель
генеральной совокупности. На практике
среднее квадратическое отклонение
признака по генеральной совокупности
заменяется его оценкой по выборке, и
тогда формула для расчета средней
ошибки выборочной средней приобретает
вид:![]() ,
,
при этом учитывая смещенность
выборочной дисперсии,
выборочное среднее квадратическое
отклонение рассчитывается по формуле![]() =. Так как символомn
=. Так как символомn
обозначена численность выборки. ,то
в знаменателе при расчете среднего
квадратического отклонения должна
использоваться не численность выборки
( n
), а так называемое число степеней
свободы (n-1).
Под числом степеней свободы понимается
число единиц в совокупности, которые
могут свободно варьировать ( изменяться
), если по совокупности определена
какая-либо характеристика. В нашем
случае , поскольку по выборке определена
ее средняя, свободно варьировать могут
![]() единицы.
единицы.
В
таблице 2.2 приведены формулы для
расчета средних ошибок различных
выборочных оценок . Как видно из этой
таблицы, величина средней ошибки по
всем оценкам находится в обратной связи
с численностью выборки и в прямой с
колеблемостью. Это можно сказать и
относительно средней ошибки выборочной
доли ( частости ). Под корнем стоит
дисперсия альтернативного признака,
установленная по выборке (
![]() )
)
Приведенные
в таблице 2.2 формулы относятся к так
называемому случайному , повторному
отбору единиц в выборку. При других
способах отбора , о которых речь пойдет
ниже, формулы будут несколько
видоизменяться.
Таблица
2.2
Формулы для
расчета средних ошибок выборочных
оценок
|
Выборочные |
Формулы |
|
Выборочная |
|
|
Выборочная |
|
|
Выборочное |
|
|
Выборочная |
|
2.2.3
Предельная ошибка выборки
Знание оценки и ее средней ошибки в
ряде случаев совершенно недостаточно
. Например , при использовании гормонов
при кормлении животных знать только
средний размер неразложившихся их
вредных остатков и среднюю ошибку,
значит подвергать потребителей продукции
серьезной опасности. Здесь настоятельно
напрашивается необходимость определения
максимальной ( предельной
ошибки ).
При использовании выборочного метода
предельная ошибка устанавливается не
в виде конкретной величины , а виде
равных границ
(
интервалов) в ту и другую сторону от
значения оценки.
Определение
границ предельной ошибки основывается
на особенностях распределения конкретных
ошибок . Для так называемых больших
выборок, численность которых более 30
единиц (
![]() )
)
, конкретные ошибки распределяются в
соответствии с нормальным законом
распределения; при малых выборках (![]() ) конкретные ошибки распределяются
) конкретные ошибки распределяются
в соответствии с законом распределения
Госсета
(
Стьюдента ). Применительно к конкретным
ошибкам выборочной средней функция
нормального распределения имеет
вид:
,
где![]() — плотность вероятности появления тех
— плотность вероятности появления тех
или иных значений![]() ,
,
при условии, что![]() ,
,
где![]() выборочные средние;
выборочные средние;![]() —
—
генеральная средняя,![]()
![]() — средняя ошибка для выборочной
— средняя ошибка для выборочной
средней. Поскольку средняя ошибка
(![]() )
)
является величиной постоянной, то в
соответствии с нормальным законом
распределяются конкретные ошибки,
выраженные в долях средней ошибки, или
так называемых нормированных отклонениях
.
Взяв
интеграл функции нормального
распределения, можно установить
вероятность того , что ошибка будет
заключена в некотором интервале
изменения t
и вероятность того, что ошибка выйдет
за пределы этого интервала ( обратное
событие ). Например , вероятность того,
что ошибка не превысит половину средней
ошибки ( в ту и другую сторону от
генеральной средней ) составляет
0,3829, что ошибка будет заключена в
пределах одной средней ошибки — 0,6827,
2-х средних ошибок -0,9545 и так далее.
Взаимосвязь
между уровнем вероятности и интервалом
изменения t
( а в конечном счете интервалом
изменения ошибки ) позволяет подойти
к определению интервала ( или границ )
предельной ошибки, увязав его величину
с вероятностью осуществления..
Вероятность осуществления -это
вероятность того, что ошибка будет
находится в некотором интервале.
Вероятность осуществления будет
«доверительной» в том случае, если
противоположное событие ( ошибка будет
находится вне интервала ) имеет такую
вероятность появления, которой можно
пренебречь. Поэтому доверительный
уровень вероятности устанавливают,
как правило, не ниже 0,90 (вероятность
противоположного события равна 0,10 ).
Чем больше негативных последствий
имеет появление ошибок вне установленного
интервала, тем выше должен быть
доверительный уровень вероятности (
0,95; 0,99 ; 0,999 и так далее ).
Выбрав
доверительный уровень вероятности
по таблице интеграла вероятности
нормального распределения, следует
найти соответствующее значение t,
а затем используя выражение
=![]()
![]() определить интервал предельной ошибки
определить интервал предельной ошибки![]() .
.
Смысл полученной величины в следующем
– с принятым доверительным уровнем
вероятности предельная ошибка выборочной
средней не превысит величину![]() .
.
Для
установления границ предельной ошибки
на основе больших выборок для других
оценок ( дисперсии, среднего квадратического
отклонения, доли и так далее ) используется
выше рассмотренный подход, с учетом
того, что для определения средней
ошибки для каждой оценки используется
свой алгоритм.
Что
касается малых выборок (![]() ) то, как уже говорилось, распределение
) то, как уже говорилось, распределение
ошибок оценок соответствует в этом
случае распределениюt
— Стьюдента. Особенность этого
распределения состоит в том, что в
качестве параметра в нем , наряду с
ошибкой, присутствует численность
выборки ,вернее не численность выборки,
а число степеней свободы
![]() При увеличении численности выборки
При увеличении численности выборки
распределениеt-Стьюдента
приближается к нормальному, а при
![]() эти распределения практически совпадают.
эти распределения практически совпадают.
Сопоставляя значения величиныt-Стьюдента
и t
— нормального распределения при одной
и той же доверительной вероятности
можно сказать , что величина t-Стьюдента
всегда больше t
— нормального распределения, причем,
различия возрастают с уменьшением
численности выборки и с повышением
доверительного уровня вероятности.
Следовательно, при использовании малых
выборок имеют место по сравнению с
выборками большими , более широкие
границы предельной ошибки, причем , эти
границы расширяются с уменьшением
численности выборки и повышением
доверительного уровня вероятности.
Вопросы для
повторения
6-1.Какова
природа конкретной, средней и предельной
ошибок ?
6-2.Как
соблюсти принцип равновероятности
каждой единицы попасть в выборку при
выборочном устном опросе студентов ?
6-3 Каков источник
систематической ошибки ?
6-4.Какова
вероятность появления ошибки в 2.5 раза
превышающей среднюю?
6-5.Какие
различия в знаках ( + , — ) имеют
систематические и случайные ошибки?
6-6.Каковы основные
пути уменьшения средней и предельной
ошибки ?
6-7.При какой
выборочной доле имеет место ее наибольшая
ошибка ?
6-8.При какой доле
признака имеет место ее наименьшая
ошибка 7
6-9.При
каких выборках ( больших или малых )
при прочих равных условиях имеет место
большая предельная ошибка ?
Резюме по
модульной единице 2
Использование
выборочного метода неизбежно сопряжено
с появлением ошибок. Случайный характер
этих ошибок, нормальный или t
— Стьюдента закон их распределения
позволяет определить их средний и
предельный размер и видеть пути их
снижения
Модульная
единица 3 Типовые задачи решаемые на
основе выборочного метода
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Когда исследователи рассматривают вопросы, представляющие интерес для аналитиков или портфельных менеджеров, они могут исключить из анализа определенные акции, облигации, портфели, или периоды времени, по разным причинам — возможно, из-за недоступности данных.
Когда недоступность данных приводит к исключению из анализа определенных активов, мы называем эту проблему систематической ошибкой или смещением выборки (англ. ‘sample selection bias’ или ‘sampling bias’).
Например, вы можете сделать выборку из базы данных, которая отслеживает только компании, существующие в настоящее время. Например, многие базы данных взаимных фондов предоставляют историческую информацию только о тех фондах, которые существуют в настоящее время.
Базы данных, в которых хранятся балансовые отчеты и отчеты о прибылях и убытках страдают от той же систематической ошибки, что и базы данных фондов: в них нет фондов или компаний, которые прекратили деятельность.
Исследование, которое использует подобные базы данных, подвержено разновидности систематической ошибки выборки, известной как систематическая ошибка выжившего (англ. ‘survivorship bias’).
Исследователи Димсон, Марш и Стонтон (Dimson, Marsh, and Staunton, 2002) подняли вопрос о систематической ошибке выжившего в международных финансовых индексах:
Известной проблемой является влияние выживания рынков на долгосрочную оценку доходности. Рынки могут испытывать не только разочаровывающие результаты, но и полную потерю стоимости за счет конфискации, гиперинфляции, национализации и кризисов.
При оценке результатов рынков, которые выживают в течение длительных интервалов времени, мы сделали выводы о том, чем обусловлено выживание. Тем не менее, как отметили в исследовании Браун, Готцман и Росс (Brown, Goetzmann, и Ross) в 1995 г. и Готцман и Джорион (Goetzmann and Jorion) в 1999 г., человек не способен заранее определить, какие рынки выживут, а какие нет. (стр. 41)
Систематическая ошибка выжившего иногда появляется, когда мы используем совместно цены акций и данные бухгалтерского учета.
Например, многие исследования в области финансов использовали соотношение рыночной стоимости компании к бухгалтерской стоимости компании на одну акцию (т.е. коэффициент котировки акций, англ. P/B, от ‘price-to-book ratio’ или ‘market-to-book ratio’) и обнаружили, что коэффициент P/B обратно пропорционален доходности компании (см. Fama and French 1992, 1993).
Коэффициент P/B также используется для многих популярных индексов стоимости и роста.
Если база данных, которую мы используем для сбора данных бухгалтерского учета, исключает обанкротившиеся компании, это может привести к систематической ошибке выжившего.
Котхари, Шанкен и Слоун (Kothari, Shanken, and Sloan) в 1995 г. исследовали именно этот вопрос, и оспорили то, что акциям обанкротившихся компаний свойственна самая низкая доходность и коэффициент P/B.
Если мы исключаем из выборки акции обанкротившихся компаний, то акции с низким P/B, которые включены в выборку, будут иметь в среднем более высокую доходность, по сравнению со средней доходностью при включении в выборку всех акций с низким P/B. Котхари, Шанкен и Слоун предположили, что эта систематическая ошибка привела к выводу об обратной связи между средней доходностью и P/B.
См. Fama and French (1996, стр. 80) о интеллектуальном анализе данных и систематической ошибке выжившего в их тестах.
Единственный совет, который мы можем предложить в этой ситуации, — это быть в курсе каких-либо смещений, потенциально присущих в выборке. Очевидно, что смещения выборки могут затуманить результаты любого исследования.
Выборка также может быть смещена из-за удаления (или делистинга) акций компании.
Делистинг (англ. ‘delisting’), т.е. исключение акций компании из котировального списка биржи, может происходить по разным причинам: слияние, банкротство, ликвидация, или переход на другую биржу.
Например, Центр исследований котировок ценных бумаг (CRSP, от англ. Center for Research in Security Prices) в Университете Чикаго является основным поставщиком данных о доходности, используемых в научных исследованиях. Когда происходит делистинг, CRSP пытается собрать данные о доходности исключенной компании, но во многих случаях он не может сделать этого из-за связанных с делистингом трудностях. CRSP вынужден просто указать значение доходности исключенной компании как отсутствующее.
Исследование, опубликованное в Финансовом журнале (см. The Journal of Finance) Шумвеем и Вортером (Shumway and Warther) в 1999 году, задокументировало смещение данных доходности NASDAQ в CRSP, вызванное делистингом.
Авторы показали, что делистинг, связанный с плохой работой компании (например, банкротством) исключается из данных чаще, чем делистинг, связанный с хорошей или нейтральной эффективностью компании (например, слиянием или перемещением на другой рынок). Кроме того, делистинг чаще происходит с небольшими компаниями.
Систематическая ошибка выборки встречается даже на рынках, где качество и согласованность данных весьма высоки. Новые классы активов, такие как хедж-фонды могут представлять еще большие проблемы смещения выборки.
Хедж-фонды (англ. ‘hedge funds’) представляют собой гетерогенную группу инвестиционных инструментов, как правило, организованных таким образом, чтобы быть свободными от регулирующего контроля. В целом, хедж-фонды не обязаны публично раскрывать свою эффективность (в отличие, скажем, от взаимных фондов). Хедж-фонды сами решают, нужно ли им включаться в какую-либо базу данных хедж-фондов.
Хедж фонды с плохой репутацией явно не желают, чтобы их результаты публиковались в базе данных, создавая проблему смещения самовыборки (англ. ‘self-selection bias’) в базах данных хедж-фондов.
Кроме того, как отметили Фанг и Хсие (Fung and Hsieh) в исследовании 2002 г., поскольку только хедж-фонды с хорошими показателями добровольно попадают в базу данных, в целом, историческая эффективность отрасли хедж-фондов имеет тенденцию казаться лучше, чем она есть на самом деле.
Кроме того, многие базы данных хедж-фондов исключают фонды, которые выходят из бизнеса, создавая в базе данных систематическую ошибку выжившего. Даже если база данных не удаляет несуществующие хедж-фонды, в попытке устранить ошибку выжившего, остается проблема хедж-фондов, которые перестают отчитываться об эффективности из-за плохих результатов.
См. Fung and Hsieh (2002) и Horst and Verbeek (2007) для более подробной информации о проблемах интерпретации эффективности хедж-фондов.
Обратите внимание, что систематическая ошибка также возможна, когда успешные фонды перестают отчитываться об эффективности, поскольку они больше не нуждаются в новых потоках денежных средств.
Систематическая ошибка опережения.
Процесс тестирования также подвержен систематической ошибке опережения (англ. ‘look-ahead bias’), если он использует информацию, которая не была доступна на момент тестирования.
Например, тесты правил биржевой торговли, которые используют ставки доходности фондового рынка и данные бухгалтерских балансов должны учитывать систематическую ошибку опережения.
В таких тестах, балансовая стоимость компании на акцию обычно используются для расчета коэффициента P/B.
Хотя рыночная цена акции доступна для всех участников рынка на заданный момент времени, балансовая стоимость на акцию на конец финансового года может стать общедоступной только в будущем — когда-то в следующем квартале.
Систематическая ошибка временного периода.
Тесты также подвержены систематической ошибке или смещению временного периода (англ. ‘time-period bias’), если они основаны на временном периоде, для которого результаты тестирования будут специфичными (т.е., характерными только для данного периода).
Ряды коротких временных периодов, скорее всего, дадут результаты, специфичные для определенного периода, которые могут не отражать более длительный период.
Ряды длительных временных периодов могут дать более точную картину истинной эффективности инвестиций. Недостаток длительных периодов заключается в потенциальных структурных изменениях, происходящих в течение периода, что приведет к двум различным распределениям доходности.
В этой ситуации, распределение, отражающее условия до изменений, будет отличаться от распределения, которые описывают условия после изменений.
Пример (7) систематических ошибок в инвестиционных исследованиях.
Финансовый аналитик рассматривает эмпирические данные об исторической доходности акций США.
Она выясняет, что недооцененные акции (то есть, акции с низким P/B) превзошли по эффективности растущие акции (то есть, акции с высоким P/B) в некоторых последних периодах времени.
После изучения американского рынка, аналитик задается вопросом, могут ли недооцененные акции быть привлекательными в Великобритании. Она исследует эффективность недооцененных и растущих акций на британском рынке за 14-летний период с января 2000 года по декабрь 2013 года.
Для проведения этого исследования, аналитик делает следующее:
- Получает текущий состав компаний Индекса всех акций FTSE (Financial Times Stock Exchange All Share Index), который является взвешенным индексом рыночной капитализации;
- Исключает несколько компаний, у которых финансовый год не заканчивается в декабре;
- Использует балансовую и рыночную стоимость компаний на конец года, чтобы ранжировать остальные пространство компаний по коэффициенту P/B на конец года;
- На основе этих рейтингов, она делит пространство ценных бумаг на 10 портфелей, каждый из которых содержит одинаковое количество акций;
- Вычисляет равновзвешенную доходность каждого портфеля и доходность FTSE All Share Index за 12 месяцев после даты расчета каждого рейтинга; а также
- Вычитает доходность FTSE из доходности каждого портфеля, чтобы получить избыточную доходность для каждого портфеля.
Опишите и обсудите каждую из следующих систематических ошибок, которым подвержен план исследований аналитика:
- систематическую ошибку выжившего;
- систематическую ошибку опережения; а также
- систематическую ошибку временного периода.
Систематическая ошибка выжившего.
План тестирования подвержен систематической ошибке выжившего, если он не принимает в расчет обанкротившиеся компании, слившиеся компании, а также компании, иным образом покинувшие базу.
В этом примере, аналитик использовала текущий список акций FTSE, а не фактический список акций на начало каждого года. В той степени, в которой расчет доходности не учитывает компании, исключенные из индекса, эффективность портфелей с наименьшим P/B подвершена систематической ошибке выжившего и, соответственно, может быть завышена.
В какой-то момент периода тестирования, эти ныне не существующие компании, были исключены из тестирования. У них, вероятно, были низкие цены на акции (и низкий P/ B) и плохая доходность.
Систематическая ошибка опережения.
План тестирования подвержен систематической ошибке опережения, если он использует информацию, недоступную на момент тестирования.
В этом примере, аналитик провела тест, сделав допущение о том, что необходимая бухгалтерская информация была доступна в конце финансового года.
Например, аналитик предположила, что балансовая стоимость на акцию за 2 000 финансовый года был известна на 31 декабря 2000 года. Поскольку эта информация, как правило, не публикуется в течение нескольких месяцев после завершения финансового года, тест, возможно, содержал систематическую ошибку опережения.
Эта ошибка может привести к стратегии, которая окажется успешной, но при этом потребуется идеальная способность прогнозировать бухгалтерские результаты.
Систематическая ошибка временного периода.
План тестирования подвержен систематической ошибке временного периода, если он основан на периоде, для которого результаты будут специфичны.
Хотя тестирование охватывает период более 10 лет, этот период может оказаться слишком коротким для тестирования аномалии.
В идеале, аналитик должна протестировать рыночные аномалии в течение нескольких бизнес-циклов, чтобы гарантировать, что результаты не являются специфичными для рассматриваемого периода.
Эта систематическая ошибка может способствовать предлагаемой стратегии, если выбрать временной период, благоприятный для стратегии.
Систематическая ошибка , связанная с отсутствием ответов, — это систематическая ошибка, возникающая, когда люди, принявшие участие в опросе, значительно отличаются от людей, которые не ответили на опрос.
Систематическая ошибка, связанная с отсутствием ответов, может возникать по нескольким причинам:
- Опрос плохо разработан и приводит к отсутствию ответов. Например, слишком длинные опросы без стимулов могут привести к тому, что большой процент людей не заполнит опрос.
- Определенные люди с большей вероятностью ответят на конкретный опрос. Например, люди, которые часто занимаются скалолазанием, с большей вероятностью ответят на опрос о потенциальном новом скалодроме, чем люди, которые не занимаются скалолазанием.
- Опрос не охватил всех членов населения. Например, опрос, разосланный в новом телефонном приложении, может охватывать только молодых людей, у которых есть это приложение, что приводит к неответам со стороны пожилых людей.
- В опросе задаются неудобные вопросы о личной информации, на которые многие люди не хотят отвечать.
Систематическая ошибка, связанная с отсутствием ответов, может возникать по всем этим причинам.
Почему систематическая ошибка неответа является проблемой?
Систематическая ошибка, связанная с отсутствием ответов, представляет собой проблему по двум основным причинам:
1. Систематическая ошибка, связанная с отсутствием ответов, приводит к тому, что выборка не репрезентативна для населения в целом. Весь смысл сбора данных для выборки заключается в том, что это быстрее и дешевле, чем сбор данных для всей совокупности, и дает возможность экстраполировать результаты выборки на большую совокупность.
Однако для того, чтобы экстраполировать результаты, выборка должна быть репрезентативной для нашей популяции в целом. В идеале мы хотели бы, чтобы наша выборка была «мини» версией генеральной совокупности.
К сожалению, систематическая ошибка, связанная с отсутствием ответа, может привести к тому, что люди в нашей выборке будут значительно отличаться от людей в большей совокупности.
Например, предположим, что город рассматривает возможность строительства нового центра скалолазания. Чтобы оценить, насколько горожане будут заинтересованы в использовании такого типа объектов, городские власти рассылают короткий опрос через новое приложение для смартфонов.
Из-за метода, использованного для проведения опроса, и из-за содержания опроса (вопросы о скалолазании) в основном отвечают молодые люди, у которых есть приложение и которые интересуются скалолазанием.
Таким образом, когда приходят результаты опроса, оказывается, что подавляющее большинство горожан заинтересовано в строительстве этого нового объекта. К сожалению, результаты опроса не являются репрезентативными для большей части населения.
Наглядное изображение ниже иллюстрирует эту проблему: предположим, что зеленые кружки представляют людей, которые заинтересованы в использовании объекта, а красные кружки представляют людей, которые не заинтересованы в использовании объекта:

Обратите внимание, что выборка не является репрезентативной для большей части населения. Результаты опроса показали, что большинство людей в восторге от нового скалолазного комплекса. К сожалению, если городские власти предположили, что эта выборка репрезентативна для населения, они могут решить построить объект, а затем быстро понять, что им будет пользоваться гораздо меньше людей, чем они думали.
2. Систематическая ошибка, связанная с отсутствием ответов, может привести к большей дисперсии оценок.Если размер выборки исследования окажется меньше, чем размер выборки, который исследователи планировали использовать, дисперсия оценок исследования может быть больше, чем планировалось.
Например, из проверки гипотез мы знаем, что чем больше размер нашей выборки, тем ниже дисперсия нашей оценки среднего значения или доли населения. Однако чем меньше размер нашей выборки, тем выше дисперсия наших оценок параметров популяции и тем сложнее найти статистически значимый результат.
Примеры систематической ошибки, связанной с неответом
Следующие примеры иллюстрируют несколько случаев, в которых может иметь место систематическая ошибка, связанная с отсутствием ответов.
Пример 1
Исследователи хотят знать, как ученые-компьютерщики воспринимают новую программу. Необходимо получить как можно больше данных из опроса, поэтому исследователи разрабатывают опрос, который занимает примерно один час. Когда они распространяют опрос, они обнаруживают, что многие специалисты по информатике либо вообще не отвечают, либо начинают отвечать, но в конце концов прекращают работу, не заполнив весь опрос.
Когда исследователи получают данные обратно, они обнаруживают, что респонденты считают программное обеспечение отличным и высококачественным. Однако, как только они внедряют новое программное обеспечение для всех компьютерных ученых, они обнаруживают, что получают в основном негативные отзывы.
Выяснилось, что люди, потратившие время на прохождение всего опроса, оказались в основном компьютерщиками начального уровня, не способными оценить недостатки программы.
Из-за этого респонденты опроса не отражали большую часть населения компьютерных наук в целом, и поэтому результаты опроса были ненадежными.
Пример 2
Исследователи хотят узнать о нормах потребления алкоголя в определенном колледже. Они решают установить будку на территории кампуса, где студенты могут остановиться и заполнить анкету относительно того, сколько и как часто они употребляют алкоголь. К сожалению, анкета не является анонимной, поэтому ее заполняют только те студенты, которые пьют очень мало или вообще не пьют.
Когда результаты возвращаются, выясняется, что употребление алкоголя среди студентов низкое и нечастое. К сожалению, респонденты опроса не отражают большее количество студентов в кампусе, и поэтому результаты ненадежны.
Пример 3
Одним из классических примеров систематической ошибки, связанной с отсутствием ответов, являются президентские выборы 1936 года. Популярное в то время издание провело опрос, который предсказывал, что Альф Лэндон с большим отрывом победит Франклина Д. Рузвельта. Однако, когда состоялись выборы, Франклин Д. Рузвельт фактически победил с большим перевесом.
Получается, что из 10 миллионов разосланных анкет ответили только 2,3 миллиона человек. Те 7,7 миллиона, которые не ответили, оказались существенно разными с точки зрения политических предпочтений.
Таким образом, результаты опроса не отражали население в целом, поэтому предсказание о победе Альфа Лэндона оказалось столь неверным.
Как предотвратить систематическую ошибку, связанную с неответом
Предвзятость, связанную с отсутствием ответов, можно предотвратить (или, по крайней мере, смягчить), предприняв следующие шаги:
- Сделайте опрос относительно коротким. Чем длиннее опрос, тем меньше вероятность того, что люди будут тратить время на ответы.
- Предлагайте поощрения за прохождение опроса. Стимулы обычно увеличивают скорость отклика.
- Убедитесь, что люди знают, что ответы на опрос будут конфиденциальными или анонимными. Как правило, это заставляет людей более охотно реагировать.
- Распространяйте опрос таким образом, чтобы он охватил большой процент населения, например, используйте традиционные формы распространения, а не новое приложение, которое есть у немногих.
Хотя не всегда возможно полностью устранить последствия систематической ошибки, связанной с отсутствием ответов, можно свести их к минимуму, используя продуманный план опроса и метод распределения.
Дополнительные ресурсы
Что такое предвзятость самоотбора?
Что такое предвзятость неполного охвата?
Что такое реферальная предвзятость?
В статистике смещение выборки — это смещение в при котором выборка собирается таким образом, что некоторые члены предполагаемой совокупности имеют более низкую или более высокую вероятность выборки, чем другие. Это приводит к смещенной выборке, неслучайной выборке из популяции (или факторов, не связанных с человеком), в которой не все люди или экземпляры были отобраны с одинаковой вероятностью. Если это не учитывать, результаты могут быть ошибочно отнесены к изучаемому явлению, а не к методу выборки.
. Медицинские источники иногда называют систематическую ошибку выборки систематической ошибкой установления . Систематическая ошибка установления имеет в основном то же определение, но все же иногда классифицируется как отдельный тип систематической ошибки.
Содержание
- 1 Отличие от систематической ошибки выбора
- 2 Типа
- 2.1 Выборка на основе симптомов
- 2.2 Усечение отбор в племенных исследованиях
- 2.3 Эффект пещерного человека
- 3 Проблемы из-за систематической ошибки выборки
- 4 Исторические примеры
- 5 Статистические поправки для смещенной выборки
- 6 См. также
- 7 Ссылки
Отличие от смещения выборки
Смещение выборки обычно классифицируется как подтип смещения выборки, иногда конкретно называемое смещение выборки, но некоторые классифицируют его как отдельный тип предвзятость. Различие, хотя и не общепризнанное, смещения выборки состоит в том, что оно подрывает внешнюю валидность теста (способность его результатов быть обобщенными для всей совокупности), в то время как смещение выборки в основном касается внутренней достоверности различий или сходств, обнаруженных в данном образце. В этом смысле ошибки, возникающие в процессе сбора выборки или когорты, вызывают смещение выборки, тогда как ошибки в любом последующем процессе вызывают смещение выборки.
Однако смещение выборки и смещение выборки часто используются как синонимы.
Типы
- Выбор из конкретной реальной области . Например, опрос старшеклассников для измерения употребления незаконных наркотиков подростками будет необъективной выборкой, поскольку он не включает учащихся, обучающихся на дому, или бросивших школу. Выборка также является смещенной, если одни члены недопредставлены или перепредставлены по сравнению с другими в генеральной совокупности. Например, интервью «человек с улицы», в ходе которого отбираются люди, проходящие мимо определенного места, будет иметь слишком большое количество здоровых людей, которые с большей вероятностью будут находиться вне дома, чем люди с хроническими заболеваниями. Это может быть крайним проявлением предвзятости выборки, поскольку некоторые члены совокупности полностью исключены из выборки (т. Е. Имеют нулевую вероятность быть выбранными).
- Самостоятельный выбор систематическая ошибка (см. также систематическая ошибка отсутствия ответов ), что возможно в тех случаях, когда изучаемая группа людей имеет какую-либо форму контроля над тем, участвовать ли в ней (как того требуют действующие стандарты этики исследования человека и субъекта для многие формы обучения в реальном времени и некоторые продольные формы обучения). Решение участников об участии может быть коррелировано с характеристиками, которые влияют на исследование, что делает участников нерепрезентативной выборкой. Например, люди, у которых есть твердое мнение или существенные знания, могут с большей охотой тратить время на ответы на вопросы опроса, чем те, у кого их нет. Другой пример — онлайн-опросы и опросы по телефону, которые являются необъективными выборками, поскольку респонденты выбираются самостоятельно. Те люди, которые имеют высокую мотивацию к ответу, обычно люди, которые придерживаются твердого мнения, перепредставлены, а люди, которые безразличны или апатичны, с меньшей вероятностью ответят. Это часто приводит к поляризации ответов, когда крайним точкам зрения придается непропорциональный вес в резюме. В результате такие опросы считаются ненаучными.
- Предварительный отбор участников испытаний или реклама волонтеров в определенных группах. Например, исследование, призванное «доказать», что курение не влияет на физическую форму, может набираться в местном фитнес-центре, но рекламироваться для курящих во время занятий по продвинутой аэробике и для некурящих во время сеансов похудания.
- Исключение систематическая ошибка возникает из-за исключения определенных групп из выборки, например исключение субъектов, которые недавно мигрировали в исследуемую область (это может происходить, когда новоприбывших нет в регистре, используемом для идентификации исходной популяции). Исключение субъектов, которые покидают исследуемую зону во время последующего наблюдения, скорее эквивалентно выбыванию или отсутствию ответа, систематической ошибке выбора в том смысле, что она скорее влияет на внутреннюю валидность исследования.
- систематическая ошибка здорового пользователя, когда исследуемая популяция, вероятно, более здорова, чем население в целом. Например, человек со слабым здоровьем вряд ли будет работать физическим трудом.
- Заблуждение Берксона, когда исследуемая популяция выбрана из больницы и поэтому менее здорова, чем население в целом. Это может привести к ложной отрицательной корреляции между заболеваниями: больной пациент без диабета с большей вероятностью болеет другим заболеванием, таким как холецистит, поскольку у него изначально должна была быть какая-то причина для госпитализации.
- Превышение соответствия, соответствие явному искажающему элементу, которое на самом деле является результатом воздействия. Контрольная группа становится более похожей на случаи в отношении воздействия, чем население в целом.
- Ошибка выживаемости, в которой отбираются только «выжившие» субъекты, игнорируя тех, которые выпали из поля зрения. Например, при использовании данных о текущих компаниях в качестве индикатора делового климата или экономики игнорируются предприятия, которые потерпели неудачу и больше не существуют.
- Смещение Мальмквиста, эффект в астрономии наблюдений, который приводит к предпочтительному обнаружению
Выборка на основе симптомов
Изучение медицинских состояний начинается с анекдотических сообщений. По своему характеру такие отчеты включают только те, которые направлены для диагностики и лечения. У ребенка, который не может учиться в школе, больше шансов получить диагноз дислексия, чем у ребенка, который борется, но проходит. Ребенок, обследованный на одно заболевание, с большей вероятностью будет проверен и диагностирован с другим заболеванием, что искажает статистику коморбидности. По мере того, как определенные диагнозы становятся связанными с проблемами поведения или умственной отсталостью, родители пытаются предотвратить стигматизацию своих детей с помощью этих диагнозов, что вносит дополнительную предвзятость. Исследования, тщательно отобранные из целых популяций, показывают, что многие состояния встречаются гораздо чаще и обычно намного мягче, чем считалось ранее.
Обрезать выборку в племенных исследованиях
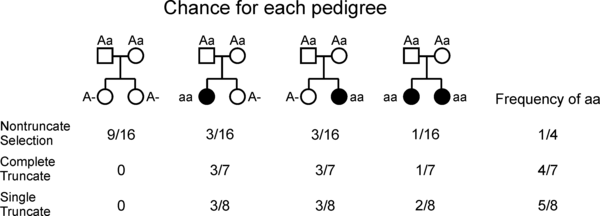 Простой пример родословной систематической ошибки выборки
Простой пример родословной систематической ошибки выборки
Генетики ограничены в том, как они могут получить данные из человеческих популяций. В качестве примера рассмотрим человеческую характеристику. Мы заинтересованы в том, чтобы определить, наследуется ли характеристика как простой менделевский признак. Согласно законам менделевского наследования, если родители в семье не имеют характеристики, но несут ее аллель, они являются носителями (например, невыразительная гетерозигота ). В этом случае у каждого из детей будет 25% шанс показать характеристику. Проблема возникает из-за того, что мы не можем сказать, в каких семьях есть оба родителя в качестве носителей (гетерозиготные), если в них нет ребенка, который проявляет эту характеристику. Описание следует из учебника Саттона.
На рисунке показаны родословные всех возможных семей с двумя детьми, когда родители являются носителями (Aa).
- Неусекать выделение . В идеальном мире мы должны иметь возможность обнаружить все такие семьи с геном, включая тех, которые являются просто носителями. В этой ситуации анализ будет свободен от предвзятости в установлении, а родословные будут находиться в рамках «неточного отбора». На практике большинство исследований выявляют и включают семьи в исследование на основании того, что они затронули людей.
- Отбор с усечением . Когда пораженные люди имеют равные шансы быть включенными в исследование, это называется усеченным отбором, означающим непреднамеренное исключение (усечение) семей, которые являются носителями гена. Поскольку отбор осуществляется на индивидуальном уровне, семьи с двумя или более затронутыми детьми будут иметь более высокую вероятность включения в исследование.
- Отбор полного усечения — это особый случай, когда каждая семья с пораженным ребенком имеет равные шансы быть отобранными для исследования.
Вероятность каждой из выбранных семей представлена на рисунке, а также дана частота выборки затронутых детей. В этом простом случае исследователь будет искать для характеристики частоту ⁄ 7 или ⁄ 8, в зависимости от используемого типа усеченного выделения.
Эффект пещерного человека
Пример смещения выбора называется «эффектом пещерного человека». Большая часть нашего понимания доисторических народов происходит из пещер, таких как наскальные рисунки, сделанные почти 40 000 лет назад. Если бы существовали современные картины на деревьях, шкурах животных или склонах холмов, их бы давно смыло. Точно так же следы кострищ, мусора, захоронений и т.д., скорее всего, останутся нетронутыми до современной эпохи в пещерах. Доисторические люди ассоциируются с пещерами, потому что именно там до сих пор существуют данные, не обязательно потому, что большинство из них прожили в пещерах большую часть своей жизни.
Проблемы из-за смещения выборки
Смещение выборки проблематично, потому что возможно, что статистика, вычисленная для выборки, систематически ошибочна. Систематическая ошибка выборки может привести к систематической переоценке или занижению соответствующего параметра в генеральной совокупности. Систематическая ошибка выборки возникает на практике, поскольку практически невозможно гарантировать абсолютную случайность выборки. Если степень искажения невелика, то выборку можно рассматривать как разумное приближение к случайной выборке. Кроме того, если выборка не отличается заметно по измеряемой величине, то смещенная выборка все же может быть разумной оценкой.
Слово предвзятость имеет сильный негативный оттенок. Действительно, предубеждения иногда возникают из-за умышленного введения в заблуждение или другого научного мошенничества. В статистическом использовании систематическая ошибка представляет собой просто математическое свойство, независимо от того, является ли оно преднамеренным или бессознательным, или вызвано несовершенством инструментов, используемых для наблюдения. Хотя некоторые люди могут намеренно использовать предвзятую выборку для получения вводящих в заблуждение результатов, чаще предвзятая выборка является просто отражением трудности получения действительно репрезентативной выборки или незнания предвзятости в их процессе измерения или анализа. Примером того, как может существовать игнорирование предвзятости, является широко распространенное использование отношения (также известного как кратное изменение ) в качестве меры различия в биологии. Поскольку легче достичь большого отношения с двумя маленькими числами с заданной разницей и относительно труднее достичь большого отношения с двумя большими числами с большей разницей, при сравнении относительно больших числовых измерений могут быть упущены большие существенные различия. Некоторые называют это «предвзятостью демаркации», потому что использование соотношения (деления) вместо разницы (вычитания) переводит результаты анализа из науки в псевдонауку (см. Проблема демаркации ).
В некоторых выборках используется предвзятый статистический план, который, тем не менее, позволяет оценивать параметры. Национальный центр статистики здравоохранения США, например, намеренно увеличивает выборку среди меньшинств во многих своих общенациональных опросах, чтобы получить достаточную точность для оценок внутри этих групп. Эти обследования требуют использования весов выборки (см. Ниже) для получения правильных оценок по всем этническим группам. При соблюдении определенных условий (главным образом, при правильном вычислении и использовании весов) эти выборки позволяют точно оценить параметры совокупности.
Исторические примеры
 Пример предвзятой выборки: по состоянию на июнь 2008 г. 55% используемых веб-браузеров (Internet Explorer ) не прошли тест Acid2. Из-за характера теста выборка состояла в основном из веб-разработчиков.
Пример предвзятой выборки: по состоянию на июнь 2008 г. 55% используемых веб-браузеров (Internet Explorer ) не прошли тест Acid2. Из-за характера теста выборка состояла в основном из веб-разработчиков.
Классический пример предвзятой выборки и вводящих в заблуждение результатов, полученных ею, произошел в 1936 году. На заре опроса общественного мнения американская Literary Журнал Digest собрал более двух миллионов почтовых опросов и предсказал, что республиканский кандидат в США президентские выборы, Альф Лэндон, с большим отрывом победят действующего президента Франклина Рузвельта. Результат был прямо противоположным. Обзор «Литературный дайджест» представляет собой выборку, собранную среди читателей журнала, дополненную записями зарегистрированных владельцев автомобилей и пользователей телефонов. Эта выборка включала чрезмерное представительство людей, которые были богатыми, которые как группа с большей вероятностью проголосовали бы за кандидата от республиканцев. Напротив, опрос только 50 тысяч граждан, выбранных организацией Джорджа Гэллапа, успешно предсказал результат, что привело к популярности опроса Гэллапа.
Другой классический пример произошел в Выборы президента 1948 года. В ночь выборов Chicago Tribune напечатала заголовок ДЬЮИ ПОБЕДАЕТ ТРУМЭНА, который оказался ошибочным. Утром ухмыляющийся избранный президент, Гарри С. Трумэн был сфотографирован с газетой с таким заголовком. Причина ошибки Tribune заключается в том, что их редактор доверял результатам. Опросные исследования были тогда в зачаточном состоянии, и лишь немногие ученые осознавали, что выборка пользователей телефонов не является репрезентативной для населения в целом. Телефоны еще не получили широкого распространения, а те, у кого они были, были зажиточными и имели стабильные адреса. (Во многих городах телефонный справочник Bell System содержал те же имена, что и Социальный регистр ). Кроме того, опрос Gallup, на котором Tribune основал свой заголовок, проводился более двух недель на момент публикации.
Более недавним примером является пандемия COVID-19, где есть вариации в смещении выборки в тестировании на COVID-19, как было показано, объясняются широкие различия как в коэффициентах летальности, так и в возрастном распределении случаев в разных странах.
Статистические поправки для смещенной выборки
Если из выборки исключаются целые сегменты генеральной совокупности, то корректировки, которые могут дать оценки, репрезентативные для всей генеральной совокупности, отсутствуют. Но если некоторые группы недопредставлены и степень недопредставленности может быть определена количественно, то веса выборки могут исправить смещение. Однако успех исправления ограничен выбранной моделью выбора. Если некоторые переменные отсутствуют, методы, используемые для исправления смещения, могут быть неточными.
Например, гипотетическая совокупность может включать 10 миллионов мужчин и 10 миллионов женщин. Предположим, что необъективная выборка из 100 пациентов включала 20 мужчин и 80 женщин. Исследователь может исправить этот дисбаланс, добавив гирю 2,5 для каждого мужчины и 0,625 для каждой женщины. Это приведет к корректировке любых оценок для достижения того же ожидаемого значения, что и для выборки, включающей ровно 50 мужчин и 50 женщин, если только мужчины и женщины не различаются по вероятности участия в опросе.
См. Также
 Портал математики
Портал математики
Ссылки
Two Types of Experimental Error
No matter how careful you are, there is always error in a measurement. Error is not a «mistake»—it’s part of the measuring process. In science, measurement error is called experimental error or observational error.
There are two broad classes of observational errors: random error and systematic error. Random error varies unpredictably from one measurement to another, while systematic error has the same value or proportion for every measurement. Random errors are unavoidable, but cluster around the true value. Systematic error can often be avoided by calibrating equipment, but if left uncorrected, can lead to measurements far from the true value.
Key Takeaways
- Random error causes one measurement to differ slightly from the next. It comes from unpredictable changes during an experiment.
- Systematic error always affects measurements the same amount or by the same proportion, provided that a reading is taken the same way each time. It is predictable.
- Random errors cannot be eliminated from an experiment, but most systematic errors can be reduced.
Random Error Example and Causes
If you take multiple measurements, the values cluster around the true value. Thus, random error primarily affects precision. Typically, random error affects the last significant digit of a measurement.
The main reasons for random error are limitations of instruments, environmental factors, and slight variations in procedure. For example:
- When weighing yourself on a scale, you position yourself slightly differently each time.
- When taking a volume reading in a flask, you may read the value from a different angle each time.
- Measuring the mass of a sample on an analytical balance may produce different values as air currents affect the balance or as water enters and leaves the specimen.
- Measuring your height is affected by minor posture changes.
- Measuring wind velocity depends on the height and time at which a measurement is taken. Multiple readings must be taken and averaged because gusts and changes in direction affect the value.
- Readings must be estimated when they fall between marks on a scale or when the thickness of a measurement marking is taken into account.
Because random error always occurs and cannot be predicted, it’s important to take multiple data points and average them to get a sense of the amount of variation and estimate the true value.
Systematic Error Example and Causes
Systematic error is predictable and either constant or else proportional to the measurement. Systematic errors primarily influence a measurement’s accuracy.
Typical causes of systematic error include observational error, imperfect instrument calibration, and environmental interference. For example:
- Forgetting to tare or zero a balance produces mass measurements that are always «off» by the same amount. An error caused by not setting an instrument to zero prior to its use is called an offset error.
- Not reading the meniscus at eye level for a volume measurement will always result in an inaccurate reading. The value will be consistently low or high, depending on whether the reading is taken from above or below the mark.
- Measuring length with a metal ruler will give a different result at a cold temperature than at a hot temperature, due to thermal expansion of the material.
- An improperly calibrated thermometer may give accurate readings within a certain temperature range, but become inaccurate at higher or lower temperatures.
- Measured distance is different using a new cloth measuring tape versus an older, stretched one. Proportional errors of this type are called scale factor errors.
- Drift occurs when successive readings become consistently lower or higher over time. Electronic equipment tends to be susceptible to drift. Many other instruments are affected by (usually positive) drift, as the device warms up.
Once its cause is identified, systematic error may be reduced to an extent. Systematic error can be minimized by routinely calibrating equipment, using controls in experiments, warming up instruments prior to taking readings, and comparing values against standards.
While random errors can be minimized by increasing sample size and averaging data, it’s harder to compensate for systematic error. The best way to avoid systematic error is to be familiar with the limitations of instruments and experienced with their correct use.
Key Takeaways: Random Error vs. Systematic Error
- The two main types of measurement error are random error and systematic error.
- Random error causes one measurement to differ slightly from the next. It comes from unpredictable changes during an experiment.
- Systematic error always affects measurements the same amount or by the same proportion, provided that a reading is taken the same way each time. It is predictable.
- Random errors cannot be eliminated from an experiment, but most systematic errors may be reduced.
Sources
- Bland, J. Martin, and Douglas G. Altman (1996). «Statistics Notes: Measurement Error.» BMJ 313.7059: 744.
- Cochran, W. G. (1968). «Errors of Measurement in Statistics». Technometrics. Taylor & Francis, Ltd. on behalf of American Statistical Association and American Society for Quality. 10: 637–666. doi:10.2307/1267450
- Dodge, Y. (2003). The Oxford Dictionary of Statistical Terms. OUP. ISBN 0-19-920613-9.
- Taylor, J. R. (1999). An Introduction to Error Analysis: The Study of Uncertainties in Physical Measurements. University Science Books. p. 94. ISBN 0-935702-75-X.