Statistical Methods for Physical Science
William R. Leo, in Methods in Experimental Physics, 1994
1.4.1 Systematic Errors
Systematic errors concem the possible biases that may be present in an observation. A common example is the zeroing of a measuring instrument such as a balance or a voltmeter. Clearly, if this is not done properly, all measurements made with the instmment will be offset or biased by some constant amount. However, even if the greatest of care is taken, one can never be certain that the instrument is exactly at the zero point. Indeed, various physical factors such as the thickness of the scale lines, the lighting conditions under which the calibration is pefformed, and the sharpness of the calibrator’s eyesight will ultimately limit the process, so that one can say only that the instmment has been “zeroed” to within some range of values, say 0±δ. This uncertainty in the “zero value’ then introduces the possibility of a bias in all subsequent measurements made with this instmment; i.e., there will be a certain nonzero probability that the measurements are biased by a value as large as ±δ.
More generally, systematic errors arise whenever there is a comparison between two or more measurements. And indeed, some reflection will show that all measurements and observations involve comparisons of some sort. In the preceding case, for example, a measurement is referenced to the zero point (or some other calibration point) of the instmment. Similarly, in detecting the presence of a new particle, the signal must be compared to the background events that could simulate such a particle, etc. Part of the art of experimentation, in fact, is to ensure that systematic errors are sufficiently small for the measurement at hand, and indeed, in some experiments how well this uncertainty is controlled can be the key success factor.
One example of this is the measurement of parity violation in highenergy electron-nucleus scattering. This effect is due to the exchange of a Z0 boson between electron and nucleus and manifests itself as a tiny difference between the scattering cross sections for electrons that are longitudinally polarized parallel (dσR) and antiparallel (dσL) to their line of movement. This difference is expressed as the asymme try parameter, A=(dσR-dσL)/(dσR+dσL). which has an expected value of A≈9×10-5[9].
To perform the experiment, a longitudinally polarized electron beam is scattered off a suitable target, and the scattering rates are measured for beam polarization parallel and antiparallel. To be able to make a valid comparison of these two rates at the desired level, however, it is essential to maintain identical conditions for the two measurements. Indeed, a tiny change in any number of parameters, for example, the energy of the beam, could easily create an artificial difference between the two scattering rates, thereby masking any real effect. The major part of the effort in this experiment, therefore, is to identify the possible sources of systematic error, design the experiment so as to minimize or eliminate as many of these as possible and monitor those that remain!
Systematic errors are distinguished from random errors by two characteristics. First, in a series of measurements taken with the same instrument and calibration, all measurements will have the same systematic error. In contrast, the random errors in these same data will fluctuate from measurement to measurement in a completely independent fashion. Moreover, the random emrs may be decreased by making repeated measurements as shown by Eq. (1.32). The systematic errors, on the other hand, will remain constant no matter how many measurements are made and can be decreased only by changing the method of measurement. Systematic errors, therefore, cannot be treated using probability theory, and indeed there is no general procedure for this. One must usually resort to a case by case analysis, and as a general mle, systematic errors should be kept separate from the random errors.
A point of confusion, which sometimes occurs, especially when data are analyzed and treated in several different stages, is that a random error at one stage can become a systematic error at a later stage. In the first example, for instance, the uncertainty incurred when zeroing the voltmeter is a random error with respect to the zeroing process. The *experiment here is the positioning of the pointer exactly on the zero marking and one can easily imagine doing this process many times to obtain a distribution of “zero points” with a certain standard deviation. Once a zero calibration is made, however, subsequent measurements made with the instmment will all be referred to that particular zero point and its error. For these measurements, the zero-point error is a systematic error. Another similar example is the least-squares (see Chapter 9) fitted calibration curve. Assuming that the calibration is a straight line, the resulting slope and intercept values for this fit will contain random errors due to the calibration measurements. For all subsequent measurements referred to this calibration curve, however, these errors are not random but systematic.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/S0076695X08602513
Data Reduction and the Propagation of Errors
Robert G. Mortimer, in Mathematics for Physical Chemistry (Fourth Edition), 2013
16.1.1 The Combination of Random and Systematic Errors
Random and systematic errors combine in the same way as the errors in Eq. (16.4). If εr is the probable error due to random errors and εs is the probable error due to systematic errors, the total probable error is given by
(16.5)![]()
If you use the 95% confidence level for the random errors, you must use the same confidence level for systematic errors if you make an educated guess at the systematic error. Most people instinctively tend to estimate errors at about the 50% confidence level. To avoid this tendency, you might make a first guess at your systematic error and then double it.
Example 16.2
Assume that a length has been measured as 37.8 cm with an expected random error of 0.35 cm and a systematic error of 0.06 cm. Find the total expected error
εt=(0.35cm)2+(0.06cm)21/2=0.36cm≈0.4cm,l=37.8cm±0.4cm.
If one source of error is much larger than the other, the smaller error makes a much smaller contribution after the errors are squared. In the previous example, the systematic error is nearly negligible, especially since one significant digit is usually sufficient in an expected error.
Exercise 16.2
Assume that you estimate the total systematic error in a melting temperature measurement as 0.20 °C at the 95% confidence level and that the random error has been determined to be 0.06 °C at the same confidence level. Find the total expected error.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780124158092000161
Experimental Design and Sample Size Calculations
Andrew P. King, Robert J. Eckersley, in Statistics for Biomedical Engineers and Scientists, 2019
9.4.2 Blinding
Systematic errors can arise because either the participants or the researchers have particular knowledge about the experiment. Probably the best known example is the placebo effect, in which patients’ symptoms can improve simply because they believe that they have received some treatment even though, in reality, they have been given a treatment of no therapeutic value (e.g. a sugar pill). What is less well known, but nevertheless well established, is that the behavior of researchers can alter in a similar way. For example, a researcher who knows that a participant has received a specific treatment may monitor the participant much more carefully than a participant who he/she knows has received no treatment. Blinding is a method to reduce the chance of these effects causing a bias. There are three levels of blinding:
- 1.
-
Single-blind. The participant does not know if he/she is a member of the treatment or control group. This normally requires the control group to receive a placebo. Single-blinding can be easy to achieve in some types of experiments, for example, in drug trials the control group could receive sugar pills. However, it can be more difficult for other types of treatment. For example, in surgery there are ethical issues involved in patients having a placebo (or sham) operation.2
- 2.
-
Double-blind. Neither the participant nor the researcher who delivers the treatment knows whether the participant is in the treatment or control group.
- 3.
-
Triple-blind. Neither the participant, the researcher who delivers the treatment, nor the researcher who measures the response knows whether the participant is in the treatment or control group.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780081029398000189
Thermoluminescence Dating
L. Musílek, M. Kubelík, in Radiation in Art and Archeometry, 2000
8.2 Systematic errors
The uncertainties contributing to the systematic error originate from various sources. The first source of the systematic error is the calibration of the α source, the β source, the α counter, the potassium content measurement, the β measurement and the γ measurement. Assuming that each of these uncertainties is ±5 %, then, for the various versions of dosimetry, the error terms are:
(16a)(σ4)a2=25{fα2+(1−fα)2+(fα+fβ,Th,U+fγ,Th,U)2+(fβ,K+fγ,K)2},
(16b)(σ4)b2=25{fα2+(1−fα−fβ)2+(fα+fγ,Th,U)2+fγ,K2+fβ2},
(16c)(σ4)c2=25{fα2+(1−fα−fβ)2+(fα+fβ,Th,U)2+fβγ,K2+fγ2},
(16d)(σ4)d2=25{2fα2+fβ2+fγ2}.
Due to the observed discrepancy between the calculated (from radioactive analysis) and measured (by TLD) γ dose rates, which is estimated to ±10 %, an additional error term needs to be added:
The second source of the systematic error arises from the uncertainty of the ratio between the uranium and thorium series. The measurement by α counting gives no information about this ratio, and converting the α count-rates to dose rates depends on it, as the energy of β and γ radiation emitted per α particle differs between both series. For the uncertainty in this ratio ±50 % is assumed and it is used for various options of dosimetry:
(18a)(σ6)a2=15fβ,Th,U2+10fγ,Th,U2,
Another problem is given by the fact, that both uranium and thorium series contain one of the isotopes of radon as a member. Possible escape of this gas can influence the dose rate and can be evaluated by the measurement in a gas cell, where only particles from escaped radon are detected by a scintillator. This technique is described in [37]. However, the estimate of the escape measured in the laboratory does not necessarily correspond to the real escape rate at the sampling location. Assuming that the uncertainty of the value gs, which expresses the lost α counts for the conditions of the sample, is ±25 %, then we obtain the error term:
(19)(σ7)2=(gs/4αB)2(fα+fβ,Th,U)2+(gw/2α′)2fγ,Th,U2,
where αB is the α count rate corrected for radon escape and the second term refers to radon escape in the soil, α’ being the corrected α count rate from the soil and gw the lost counts for the soil sample (having the same wetness as in the ground).
The last important source of the systematic error is given by the uncertainty δF of the fractional water uptake F. The value of δF must be estimated from the knowledge about the conditions (rainfall, drainage, etc.) on site. This error can be approximated by:
(20)σ8=(δF/F){W(1,5fα+1,25fβ)+W′(1,15fγ)}.
W and W’ is the saturation wetness of the sample and the soil, respectively, expressed as the ratio of the saturation weight minus the dry weight and the dry weight in percent.
The overall systematic error is a combination of the contributions discussed above, i.e.:
(21)σs2=σ42+σ52+σ62+σ72+σ82,
and the overall error for the sample is given by the combination of random and systematic errors as:
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780444504876500523
Total Survey Error
Tom W. Smith, in Encyclopedia of Social Measurement, 2005
Bias, or Systematic Error
Turning to bias, or systematic error, there is also a sampling component. First, the sample frame (i.e., the list or enumeration of elements in the population) may either omit or double count units. For example, the U.S. Census both misses people (especially African-Americans and immigrants) and counts others twice (especially people with more than one residence), and samples based on the census reflect these limitations. Second, certain housing units, such as new dwellings, secondary units (e.g., basement apartments in what appears to be a single-family dwelling), and remote dwellings, tend to be missed in the field. Likewise, within housing units, certain individuals, such as boarders, tend to be underrepresented and some respondent selection methods fail to work in an unbiased manner (e.g., the last/next birthday method overrepresents those who answer the sample-screening questions). Third, various statistical sampling errors occur. Routinely, the power of samples is overestimated because design effects are not taken into consideration. Also, systematic sampling can turn out to be correlated with various attributes of the target population. For example, in one study, both the experimental form and respondent selection were linked by systematic sampling in such a way that older household members were disproportionately assigned to one experimental version of the questionnaire, thus failing to randomize respondents to both experimental forms.
Nonsampling error comes from both nonobservational and observational errors. The first type of nonobservational error is coverage error, in which a distinct segment of the target population is not included in sample. For example, in the United States, preelection random-digit-dialing (RDD) polls want to generalize to the voting population, but systematically exclude all voters not living in households with telephones. Likewise, samples of businesses often underrepresent smaller firms. The second type of nonobservational error consists of nonresponse (units are included in the sample, but are not successfully interviewed). Nonresponse has three main causes: refusal to participate, failure to contact because people are away from home (e.g., working or on vacation), and all other reasons (such as illness and mental and/or physical handicaps).
Observational error includes collection, processing, and analysis errors. As with variable error, collection error is related to mode, instrument, interviewer, and respondent. Mode affects population coverage. Underrepresentation of the deaf and poor occurs in telephone surveys, and of the blind and illiterate, in mail surveys. Mode also affects the volume and quality of information gathered. Open-ended questions get shorter, less complete answers on telephone surveys, compared to in-person interviews. Bias also is associated with the instrument. Content, or the range of information covered, obviously determines what is collected. One example of content error is when questions presenting only one side of an issue are included, such as is commonly done in what is known as advocacy polling. A second example is specification error, in which one or more essential variable is omitted so that models cannot be adequately constructed and are therefore misspecified.
Various problematic aspects of question wordings can distort questions. These include questions that are too long and complex, are double-barreled, include double negatives, use loaded terms, and contain words that are not widely understood. For example, the following item on the Holocaust is both complex and uses a double negative: “As you know, the term ‘holocaust’ usually refers to the killing of millions of Jews in Nazi death camps during World War II. Does it seem possible or does it seem impossible to you that the Nazi extermination of the Jews never happened?” After being presented with this statement in a national U.S. RDD poll in 1992, 22% of respondents said it was possible that the Holocaust never happened, 65% said that it was impossible that it never happened, and 12% were unsure. Subsequent research, however, demonstrated that many people had been confused by the wording and that Holocaust doubters were actually about 2% of the population, not 22%. Error from question wording also occurs when terms are not understood in a consistent manner.
The response scales offered also create problems. Some formats, such as magnitude measurement scaling, are difficult to follow, leaving many, especially the least educated, unable to express an opinion. Even widely used and simple scales can cause error. The 10-point scalometer has no clear midpoint and many people wrongly select point 5 on the 1–10 scale in a failed attempt to place themselves in the middle. Context, or the order of items in a survey, also influences responses in a number of quite different ways. Prior questions may activate certain topics and make them more accessible (and thus more influential) when later questions are asked. Or they may create a contrast effect under which the prior content is excluded from later consideration under a nonrepetition rule. A norm of evenhandedness may be created that makes people answer later questions in a manner consistent with earlier questions. For example, during the Cold War, Americans, after being asked if American reporters should be allowed to report the news in Russia, were much more likely to say that Russian reporters should be allowed to cover stories in the United States, compared to when the questions about Russian reporters were asked first. Even survey introductions can influence the data quality of the subsequent questions.
Although social science scholars hope that interviewers merely collect information, in actuality, interviewers also affect what information is reported. First, the mere presence of an interviewer usually magnifies social desirability effects, so that there is more underreporting of sensitive behaviors to interviewers than when self- completion is used. Second, basic characteristics of interviewers influence responses. For example, Whites express more support for racial equality and integration when interviewed by Blacks than when interviewed by Whites. Third, interviewers may have points of view that they convey to respondents, leading interviewers to interpret responses, especially to open-ended questions, in light of their beliefs.
Much collection error originates from respondents. Some problems are cognitive. Even given the best of intentions, people are fallible sources. Reports of past behaviors may be distorted due to forgetting the incidents or misdating them. Minor events will often be forgotten, and major events will frequently be recalled as occurring more recently than was actually the case. Of course, respondents do not always have the best of intentions. People tend to underreport behaviors that reflect badly on themselves (e.g., drug use and criminal records) and to overreport positive behaviors (e.g., voting and giving to charities).
Systematic error occurs during the processing of data. One source of error relates to the different ways in which data may be coded. A study of social change in Detroit initially found large changes in respondents’ answers to the same open-ended question asked and coded several decades apart. However, when the original open-ended responses from the earlier survey were recoded by the same coders who coded the latter survey, the differences virtually disappeared, indicating that the change had been in coding protocols and execution, not in the attitudes of Detroiters. Although data-entry errors are more often random, they can seriously bias results. For example, at one point in time, no residents of Hartford, Connecticut were being called for jury duty; it was discovered that the new database of residents had been formatted such that the “d” in “Hartford” fell in a field indicating that the listee was dead. Errors can also occur when data are transferred. Examples include incorrect recoding, misnamed variables, and misspecified data field locations. Sometimes loss can occur without any error being introduced. For example, 20 vocabulary items were asked on a Gallup survey in the 1950s and a summary scale was created. The summary scale data still survive, but the 20 individual variables have been lost. Later surveys included 10 of the vocabulary items, but they cannot be compared to the 20-item summary scale.
Wrong or incomplete documentation can lead to error. For example, documentation on the 1967 Political Participation Study (PPS) indicated that one of the group memberships asked about was “church-affiliated groups.” Therefore, when the group membership battery was later used in the General Social Surveys (GSSs), religious groups were one of the 16 groups presented to respondents. However, it was later discovered that church-affiliated groups had not been explicitly asked about on the earlier survey, but that the designation had been pulled out of an “other-specify” item. Because the GSS explicitly asked about religious groups, it got many more mentions than had appeared in the PPS; this was merely an artifact of different data collection procedures that resulted from unclear documentation.
Most discussions of total survey error stop at the data-processing stage. But data do not speak for themselves. Data “speak” when they are analyzed, and the analysis is reported by researchers. Considerable error is often introduced at this final stage. Models may be misspecified, not only by leaving crucial variables out of the survey, but also by omitting such variables from the analysis, even when they are collected. All sorts of statistical and computational errors occur during analysis. For example, in one analysis of a model explaining levels of gun violence, a 1 percentage point increase from a base incidence level of about 1% was misdescribed as a 1% increase, rather than as a 100% increase. Even when a quantitative analysis is done impeccably, distortion can occur in the write-up. Common problems include the use of jargon, unclear writing, the overemphasis and exaggeration of results, inaccurate descriptions, and incomplete documentation. Although each of the many sources of total survey error can be discussed individually, they constantly interact with one another in complex ways. For example, poorly trained interviewers are more likely to make mistakes with complex questionnaires, the race of the interviewer can interact with the race of respondents to create response effects, long, burdensome questionnaires are more likely to create fatigue among elderly respondents, and response scales using full rankings are harder to do over the phone than in person. In fact, no stage of a survey is really separate from the other stages, and most survey error results from, or is shaped by, interactions between the various components of a survey.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B0123693985001262
Part 1
D. DELAUNAY, in Advances in Wind Engineering, 1988
Observations errors
To test the effects of possible systematic errors of observation on ΔP, R, and T, the values of the parameters of observed cyclones have been increased, in succession, by 10% for ΔP and T and 20% for R. Similarly, it may be feared that all the cyclones which have crossed the area in question were not listed. Simulation was therefore carried out with an average value of NC increased by 10%. It appears that these modifications result in an increase of the values of V50 and V1000 not exceeding 1.5 m/s, except for ΔP, for which a systematic over-evaluation of 10% leads to an increase of V50 and V1000 between 2 and 2.5 m/s.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B978044487156550014X
Model Evaluation and Enhancement
Robert Nisbet Ph.D., … Ken Yale D.D.S., J.D., in Handbook of Statistical Analysis and Data Mining Applications (Second Edition), 2018
Evaluation of Models According to Random Error
We can express the total of the random error and systematic error mathematically, but it is very difficult to distinguish between them in practice. For example, the general form of a regression model is
(11.2)Y=a+b1X1+b2X2+b3X3+⋯+bnXn+Error
where a is the slope intercept, X-values are the predictor variables, and b-values are the coefficients associated with each X-value.
If the signal in the data set is faint, the error term will be relatively large. If the signal in the data is strong, the error will be relatively small. Unfortunately, the error term in Eq. (11.1) is a combination of random error and model error. Most model performance metrics do not distinguish between random error and model error. But there are some techniques that can be used to measure model error to some extent and correct for it. We will begin by discussing model performance metrics, which express the total combined error. Later in the chapter, we will present some common techniques for assessing model error and show some ways to correct for it (partially).
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780124166325000116
Quantum Entanglement and Information Processing
J.A. Jones, in Les Houches, 2004
4.2 Composite rotations
The use of composite rotations to reduce the effects of systematic errors in conventional NMR experiments relies on the fact that any state of a single isolated qubit can be mapped to a point on the Bloch sphere, and any unitary operation on a single isolated qubit corresponds to a rotation on the Bloch sphere. The result of applying any series of rotations (a composite rotation) is itself a rotation, and so there are many apparently equivalent ways of performing a desired rotation. These different methods may, however, show different sensitivity to errors: composite rotations can be designed to be much less error prone than simple rotations!
A rotation can go wrong in two basic ways: the rotation angle can be wrong or the rotation axis can be wrong. In an NMR experiment (viewed in the rotating frame) ideal RF pulses cause rotation of a spin through an angle θ = ω1 t around an axis in the xy-plane. So called pulse length errors occur when the pulse power ω1 is incorrect, so that the flip angle θ is systematically wrong by some fraction. This can be due to experimenter carelessness, but more usually arises from the inhomogeneity in the RF field over a macroscopic sample. The second type of error, off-resonance effects (Fig. 6), occur when the excitation frequency doesn
S⌣t match the transition frequency, so that the Hamiltonian is the sum of RF and off-resonance terms. This results in rotations around a tilted axis, and the rotation angle is also increased.

Fig. 6. Effect of applying an off-resonance 180° pulse to a spin with initial state Iz; the spin rotates around a tilted axis. Trajectories are shown for small, medium and large off-resonance effects.
The first composite rotation [47] was designed to compensate for pulse length errors in an inversion pulse, that is a pulse which takes the state Iz to − Iz. This can be achieved by, for example, a simple 180° pulse, but this is quite sensitive to pulse length errors. The composite rotation 90°x180°y90°x has the same effect in the absence of errors, but will also partly compensate for pulse length errors. This is shown in Fig. 7 which plots the inversion efficiency of the simple and composite 180° pulses as a function of the fractional pulse length error g. (The inversion efficiency of an inversion pulse measures the component of the final spin state along −Iz after the pulse is applied to an initial state of Iz.)

Fig. 7. The inversion efficiency of a simple 180° pulse (dashed line) and of the composite pulse 90°x 180°y 90°x. (solid line) as a function of the fractional pulse length error g. The way in which the composite pulse works can be understood by examining trajectories on the Bloch sphere, which are shown on the right for three values of g.
Composite pulses of this kind are very widely used within conventional NMR, and many different pulses have been developed [48], but most of them are not directly applicable to quantum computing [50]. This is because conventional NMR pulse sequences are designed to perform specific motions on the Bloch sphere (such as inversion), in which case the initial and final spin states are known, while for quantum computing it is necessary to use general rotations, which are accurate whatever the initial state of the system. Perhaps surprisingly composite pules are known which have the desired property, of performing accurate rotations whatever the initial spin state.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/S0924809903800343
Probability, Statistics, and Experimental Errors
Robert G. Mortimer, in Mathematics for Physical Chemistry (Fourth Edition), 2013
Abstract
Every measured quantity is subject to experimental error. The two types of experimental error are systematic errors and random errors. Systematic errors must usually be estimated by educated guesswork. Random errors are assumed to be a sample from a population of many imaginary replicas of the experiment. Such a population is assumed to be governed by probability theory. Mathematical statistics is used to infer the properties of a population from a sample. Random errors can be treated statistically if the measurement can be repeated a number of times. The mean of a set of repeated measurements is a better estimate of the correct value of a variable than is a single measurement.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B978012415809200015X
The B → D*ℓν Form Factor at Zero Recoil and the Determination of |Vcb|
J.N. Simone, … S.M. Ryan, in Proceedings of the 31st International Conference on High Energy Physics Ichep 2002, 2003
2 DOUBLE RATIO METHOD
We consider three double ratios of hadronic matrix elements for which the bulk of statistical and systematic errors are expected to cancel. From these ratios we extract three zero recoil form factors:
(3)〈D|v0|B〉 〈B|v0|D〉〈D|v0|D〉 〈B|v0|B〉⇒ | h+(1)|2
(4)〈D∗|v0|B∗〉 〈B∗|v0|D∗〉〈D∗|v0|D∗〉 〈B∗|v0|B∗〉⇒ | h1(1)|2
(5)〈D∗|A1|B〉 〈B∗|A1|D〉〈D∗|A1|D〉 〈B∗|A1|B〉⇒ | HA1(1)|2
Form factor h+ is one of two form factors contributing to B → Dℓν decays[8]. Note that the third ratio yields HA1 and not hA1.
Form factors h+, h1 and HA1 depend, respectively, upon parameters ℓP, ℓV and ℓA and have quark mass dependence:
(6)1−|hX(1)|Δ2=ℓx−ℓx[3](12mc+12mb)+…
where Δ=(12mc−12mb). The bare charm and bottom quark masses are inputs in lattice QCD. We compute double ratios for a range of “charm” and “bottom” quark masses. After matching the lattice theory to HQET, we determine all the ℓx as well as the order 1/mQ3 coefficients ℓx[3] by studying the mass dependence of the form factors. These long-distance coefficients are combined as in Equation 2 to give our determination of hA1(1).
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780444513434501484
Для
выявления ошибок и их численной оценки
(особенно при разработке новых
аналитических методик) количественный
анализ повторяют несколько раз, т.е.
проводят параллельные
определения. Под
параллельными определениями понимают
получение нескольких результатов
единичных определений для одной и той
же пробы в одинаковых условиях.
Пусть
μ
— истинное
значение определяемой величины; Х1,
Х2,
…, Хi,
…, …, Хn
— измеренные
(единичные) значения определяемой
величины — результаты единичных
определений; п- общее
число единичных определений.
Под
единичным определением понимают
однократное проведение всей
последовательности операций,
предусмотренных методикой анализа.
Результат единичного определения- это
значение содержания определяемого
компонента, найденное при единичном
определении.
Иногда
(часто) вместо истинного значения
определяемой величины μ
используют действительное
значение содержания а
(или просто
действительное
значение а),
под которым
подразумевают экспериментально
полученное или расчетное значение
определяемого содержания, настолько
близкое к истинному, что для данной цели
может быть использовано вместо него.
Тогда величина

есть
среднее
арифметическое (среднее) из
результатов единичных определений.
Считается, что х–
— наиболее вероятное значение определяемой
величины, более вероятное, чем каждое
отдельное значение Хi.
Под
правильностью
результата
анализа понимают качество анализа,
отражающее близость к нулю разности
между средним арифметическим и истинным
μ
(или действительным а)
значением определяемой величины:

Другими
словами, правильность результата анализа
отражает близость полученного среднего
значения х–
к истинному (или действительному)
значению определяемой величины.
Воспроизводимость
результата
анализа характеризует степень близости
результатов единичных определений Хi,
друг к другу.
Правильность
и воспроизводимость результата анализа
зависят от различного типа ошибок.
1.4.2. Классификация ошибок количественного анализа.
Ошибки
количественного анализа условно
подразделяют
на систематические,
случайные и грубые.
Грубые
ошибки,
обусловленные
несоблюдением методики анализа, очевидны.
Они устраняются при повторном проведении
анализа с соблюдением всех требуемых
условий, предусмотренных методикой
анализа.
а)
Систематическая ошибка
Различают:
систематическую
ошибку и
процентную
систематическую ошибку.
Систематическая
ошибка результата
анализа Δ0
— это статистически значимая разность
между средним х–
и действительным а
(или истинным
μ)
значениями содержания компонента:

Систематическая
ошибка результата анализа может быть
больше нуля, меньше нуля или равна нулю.
Процентная
систематическая ошибка (относительная
величина систематической ошибки) —
это систематическая ошибка, выраженная
в процентах от действительного значения
а
(или истинного
значения μ)
определяемой величины:
δ
= (х–
– а)∙100%
/ а
или δ = (х–
– μ)•100% / μ (1.3)
Для
относительной величины систематической
ошибки вместо символа 5 используют
также обозначение Δ0
%.
Систематическая
ошибка характеризует правильность
результатов анализа; поэтому правильность
анализа можно определить так же, как
качество анализа, отражающее близость
к нулю систематической ошибки.
Систематические
ошибки обусловлены либо постоянно
действующими причинами (и поэтому они
повторяются при многократном проведении
анализа), либо изменяются по постоянно
действующему закону, который можно
учесть.
Так,
например, процентная систематическая
ошибка (Δс/с)•100% фотометрических
определений (с
— концентрация,
Δс — систематическая ошибка определения
концентрации фотометрическим методом)
минимальна в интервале изменений
оптической плотности А
от А
≈ 0,2 до А
≈ 0,8 и
составляет (Δс/с)•100% < 0,4%.
Источники
систематических ошибок. Невозможно
с исчерпывающей полнотой перечислить
все источники систематических ошибок.
Основными являются следующие.
Методические
— обусловлены
особенностями методики анализа. Например,
аналитическая реакция прошла не до
конца; имеются потери осадка вследствие
его частичной растворимости в растворе
или при его промывании; наблюдается
соосаждение примесей с осадком, вследствие
чего масса осадка возрастает, и т.д.
Инструментальные
— обусловлены
несовершенством используемых приборов
и оборудования. Так, например,
систематическая ошибка взвешивания на
лабораторных аналитических весах
составляет ±0,0002 г. Систематическая
ошибка в титриметрических методах
анализа вносится вследствие неточности
калибровки бюреток, пипеток, мерных
колб, цилиндров, мензурок и т.д.
Индивидуальные
— обусловлены
субъективными качествами аналитика.
Так, например, дальтонизм может влиять
на определение конечной точки титрования
при визуальной фиксации изменения
окраски индикатора.
В
конечном итоге правильность результатов
анализа определяется наличием или
отсутствием именно систематических
ошибок.
Существуют способы
выявления систематических ошибок.
а)
Использование стандартных, образцов.
Общий состав
стандартного образца должен быть близким
к составу анализируемой пробы, а
содержание определяемого компонента
в стандартном образце должно быть точно
известно.
Анализ
стандартного образца — наиболее надежный
способ выявления наличия или отсутствия
систематической ошибки и оценки
правильности результата анализа.
б) Анализ
исследуемого объекта другими методами.
Исследуемый
объект анализируют методом или методами,
которые не дают систематической ошибки
(метрологически аттестованы), и сравнивают
результаты анализа с данными, полученными
при анализе того же объекта с использованием
оцениваемой методики или не аттестованного
оборудования. Сравнение позволяет
охарактеризовать правильность оцениваемой
методики анализа.
в)
Метод добавок или метод удвоения —
используют при отсутствии стандартных
образцов и метрологически аттестованной
методики (метода) анализа.
Анализируют
образец, используя оцениваемую методику.
Затем удваивают массу анализируемой
пробы или увеличивают (уменьшают) массу
в иное число раз, снова находят содержание
определяемого компонента в уже новой
пробе и сравнивают результаты анализов.
Должна выполняться определенная
закономерность (например, пропорциональность).
б)
Случайные ошибки.
Случайные
ошибки показывают отличие результатов
параллельных определений друг от друга
и фактически характеризуют воспроизводимость
анализа. Причины
случайных ошибок однозначно указать
невозможно. При многократном повторении
анализа они или не воспроизводятся, или
имеют разные численные значения и даже
разные знаки.
Случайные
ошибки можно оценить методами
математической статистики, если
выявлены и устранены систематические
ошибки (или систематические ошибки
меньше случайных).
ЭТАПЫ
КОЛИЧЕСТВЕННОГО ХИМИЧЕСКОГО АНАЛИЗА
Наука
об измерениях, методах и средствах
обеспечения их единства
и способах достижения требуемой точности
называется метрологией.
Количественный
химический анализ, целью которого
является
определение содержания веществ в разных
объектах, может
рассматриваться как измерительная
процедура, характеризующаяся
рядом специфических особенностей.
Количественный
химический анализ, прежде всего, является
многостадийным процессом, включающим
ряд этапов и стадий. При выполнении
химического анализа с помощью любого
метода можно выделить следующие
основные этапы:
— постановка
аналитической задачи;
— выбор метода
анализа;
— выполнение
анализа;
— оценка качества
анализа;
— принятие решений
по результатам анализа.
При
постановке аналитической задачи
необходимо дать характеристику объекта
анализа, указать химическую формулу
определяемого
компонента, возможный интервал его
содержаний, требуемую
точность и продолжительность анализа.
Выбор
метода анализа определяется поставленной
аналитической
задачей и техническими возможностями
аналитической лаборатории.
Этап,
связанный непосредственно с проведением
химического
анализа, наиболее трудоемок и включает
ряд стадий, представленных на рис. 5.2.

Методика
анализа включает
подробное описание последовательности
и условий проведения всех стадий анализа.
Точное следование
методике анализа позволяет выполнить
анализ с минимальными
погрешностями на каждой стадии и получить
правильный
результат анализа.
Первая
стадия химического анализа — отбор
средней
(представительной)
пробы. Это
небольшая часть анализируемого объекта,
средний
состав и свойства которой должны быть
идентичны во всех
отношениях среднему составу и свойствам
объекта анализа. Содержание
определяемого компонента в анализируемой
пробе должно
отражать среднее содержание этого
компонента во всем исследуемом
объекте, т. е. анализируемая проба должна
быть представительной.
Погрешность в отборе пробы часто
определяет общую
погрешность химического анализа. Не
оценив погрешность на
этой стадии, нельзя говорить о правильности
определения компонента
в анализируемом объекте.
Подготовка
пробы к анализу включает ряд сложных
операций, например, такие как высушивание
пробы, разложение (вскрытие)
пробы,
устранение влияния мешающих компонентов.
В зависимости
от цели анализа, природы объекта и
выбранного метода могут быть использованы
разные модификации и комбинации этих
операций.
В правильном проведении химического
анализа роль подготовки
пробы настолько велика, что химик-аналитик
должен каждый
раз оценивать необходимость включения
операций пробоподготовки
в методику анализа, их влияние на общую
погрешность анализа.
После
отбора и подготовки пробы наступают
стадии химического
анализа, на которых определяют количество
компонента. С
этой целью измеряют аналитический
сигнал. В
большинстве методов им является среднее
из измерений физической величины на
заключительной стадии анализа,
функционально связанной с содержанием
определяемого компонента. Это
может быть сила тока, ЭДС системы,
оптическая плотность, интенсивность
излучения и т.д. В отдельных методах
анализа возможно непосредственное
определение содержания. Например, в
гравиметрическом методе иногда прямо
измеряют массу определяемого компонента.
При
определении количества компонента
измеряют величину аналитического
сигнала. Затем рассчитывают содержание
компонента с использованием функциональной
зависимости аналитического
сигнала от содержания: у =
f(с),
которая устанавливается расчетным или
опытным путем и может быть представлена
в виде формулы, таблицы или графика.
Содержание может быть выражено абсолютным
количеством определяемого компонента
в молях, в единицах массы или через
соответствующие концентрации.
При
измерении аналитического сигнала
учитывают наличие полезного аналитического
сигнала, являющегося функцией содержания
определяемого компонента, и аналитического
сигнала фона, обусловленного
примесями определяемого компонента и
мешающими компонентами в растворах,
растворителях и матрице образца, а также
«шумами» в
измерительных приборах, усилителях
и другой аппаратуре. Эти шумы не имеют
отношения к определяемому компоненту,
но накладываются на его собственный
аналитический сигнал. Задача аналитика
состоит в том, чтобы максимально снизить
величину аналитического сигнала фона
и, главное, сделать минимальными его
колебания.
Обычно
аналитический сигнал фона учитывают в
контрольном
(холостом) опыте, когда
через все стадии химического анализа
проводится проба, не содержащая
определяемого компонента. Полезным при
этом будет аналитический сигнал, равный
разности измеренного сигнала и
аналитического сигнала фона.
На
основании существующей зависимости
между аналитическим сигналом и содержанием
находят концентрацию определяемого
компонента. Обычно при этом используют
методы
градуированного графика, стандартов
или
добавок. Описанные
в литературе другие способы определения
содержания компонента, как правило,
являются модификацией этих трех методов.
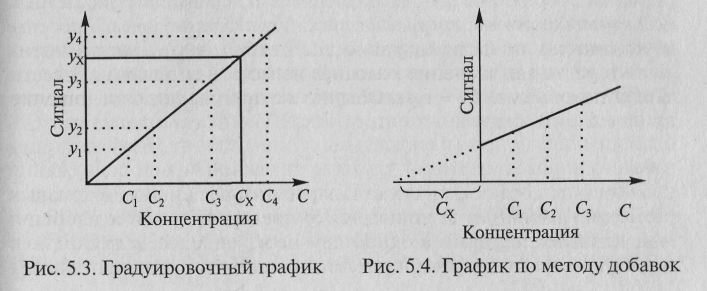
Наиболее
распространен метод
градуировочного графика: в
координатах (аналитический сигнал –
содержание компонента) строят график
с использованием образцов сравнения с
разными и точно известными уровнями
содержания компонента (концентрация
С).
Затем, измерив
величину аналитического сигнала в
пробе, находят содержание определяемого
компонента по градуировочному графику
(рис. 5.3).
В
методе
стандартов измеряют
аналитический сигнал в образце
сравнения (стандартном образце) с
известным содержанием компонента и в
анализируемой пробе: Уст
= sСст
и ух
= sСХ,
где s-коэффициент
пропорциональности.
Если
определенное в идентичных условиях
значение s
заранее известно, то можно провести
расчет по формуле Сх
= Ух/S.
Обычно же используют соотношение Уст/УХ
= Сст/СХ,
откуда
![]()
Иногда
работают с двумя стандартными образцами,
в которых содержание компонента
отличается от предполагаемого содержания
в анализируемой пробе в одном случае в
меньшую, в другом — в большую сторону.
Этот вариант метода стандартов называют
методом
ограничивающих растворов.
Содержание определяемого компонента
рассчитывают по формуле

Если
при определении малых количеств
компонента нужно учесть
влияние матрицы образца на величину
аналитического сигнала,
то часто используют
методы добавок — расчетный
или графический.
При
определении содержания расчетным
методом берут
две аликвоты
раствора анализируемой пробы. В одну
из них вводят добавку
определяемого компонента известного
содержания. В обеих
пробах измеряют аналитический сигнал
— ух
и
ух+доб—
Неизвестную
концентрацию определяемого компонента
рассчитывают
по формуле
![]()
где
Vдоб
и Сдоб
— объем и концентрация добавленного
раствора определяемого компонента; V
— аликвота
анализируемой пробы.
При
определении содержания компонента
графическим
методом
берут
п
аликвот
анализируемой пробы: 1, 2, 3, …, п.
Во
2-ю, …, п-ю
аликвоты
вводят известные, возрастающие, количества
определяемого
компонента. Во всех аликвотах измеряют
аналитический сигнал
и строят график в координатах аналитический
сигнал -содержание
определяемого компонента, приняв за
условный нуль содержание
определяемого компонента в аликвоте
без добавки (аликвота 1). Экстраполяция
полученной прямой до пересечения с
осью абсцисс дает отрезок слева от
условного нуля координат, величина
которого в выбранном масштабе и единицах
измерения соответствует
Сх
определяемого компонента (рис. 5.4).
Метод
стандартов и метод добавок применимы
для линейной градуировочной функции.
Метод градуировочного графика допускает
использование как линейной, так и
нелинейной функций аналитический
сигнал—содержание. В последнем случае
требуется большее число экспериментальных
данных, и результат определения содержания
компонента бывает, как правило, менее
точным.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Какими причинами вызываются систематические и случайные ошибки анализа, грубые ошибки [c.193]
К систематическим ошибкам И типа относятся инструментальная, реактивная, методическая ошибки (включая индикаторную), эталонная ошибка и некоторые другие. Инструментальная ошибка. Каждый прибор, используемый для измерения, вносит в результаты измерения погрешности, часть из кото рых имеет характер случайных, а часть — систематических ошибок. Поскольку случайные ошибки рассматриваются и учитываются в совокупности, имеет смысл попытаться вычленить систематическую составляющую инструментальной ошибки химического анализа. Систематический характер носят ошибки калибровки приборов. Так, например, истинный объем мерной посуды (бюреток, пипеток, мерных колб) никогда в точности не соответствует номиналу, указанному на заводском клейме или в паспорте. Разница между истинным значением и номиналом тем меньше, чем выше класс точности измерительного прибора и обычно не превышает цены наименьшего деления на измерительной шкале. В частности, каждый конкретный экземпляр мерной посуды содержит свою персональную систематическую ошибку, завышающую или занижающую измеряемый объем в сравнении с номиналом. Для того чтобы оценить величину этой ошибки, следует провести калибровку посуды — найти достаточно точный вес точно отмеренного объема чистой жидкости (например, дистиллированной воды), а затем вычислить объем, используя точное справочное значение плотности жидкости при заданной температуре рн< [c.25]
По своему характеру ошибки анализа подразделяются на 1) систематические ошибки 2) случайные ошибки 3) промахи. [c.48]
Вследствие своеобразия вида концентрата и возможной неполноты выделения некоторых примесей эталоны проводят через операцию отгонки. Эталонирование метода испарения облегчается тем, что в образцах допустимо присутствие посторонних, в том числе летучих, компонентов в концентрации до 0,1% и тем, что способ приготовления эталонов (составление механических смесей, введение из раствора, сокристаллизация) не играет роли, если температура испарения превосходит упомянутую выше температуру разрыхления кристаллической решетки основы. Разумеется, требование близости химического состава примесей в эталонах и пробах остается в силе. Вопрос о том, в каком виде нужно вводить примеси в эталоны, чтобы избежать систематической ошибки анализа, следует решать экспериментально. Например, установлено, что определение 1п и Оа в элементарном кремнии возможно по эталонным механическим смесям, содержащим окислы элементов, а определение В и 2п — по эталонам, содержащим элементарный бор и металлический цинк [292]. [c.247]
Общая ошибка анализа складывается из систематической и случайной ошибок определения. Систематическая ошибка зависит от постоянных причин и повторяется при повторных измерениях она связана с постоян ными методическими ошибками анализа, например, с загрязнениями применяемых реактивов, с потерями осадка вследствие его некоторой растворимости и т. п. Все это может быть учтено при анализе. Величина систематической ошибки характеризует правильность метода. Случайные ошибки анализа вызваны неопределенными причинами и изменяются при повторных измерениях (или при повторных анализах) в ту или другую сторону. Если повторить измерение несколько раз, и вгл-числить среднее арифметическое значение из полученных данных, то средний результат будет точнее, чем отдельные измерения. Отклонение отдельных результатов измерений от среднего значения измеряемой величины характеризует воспроизводимость ( точность ) метода. [c.15]
Целый ряд аналитических методов известен своей склонностью к более или менее положительным или отрицательным систематическим ошибкам. Примером этому может служить гравиметрическое определение кремниевой кислоты, при котором постоянно занижаются истинные значения. Однако это занижение можно выявить, только если, например, потери, возникшие из-за растворимости осадка, выше, чем колебания из-за случайной ошибки анализа. Вообще систематические ошибки можно обнаружить только в том случае, когда смещение измеряемых величин больше, чем случайная ошибка применяемого метода анализа. [c.27]
Если нужно сравнить результаты внутри одной большой серии измерений (иногда это называют относительным измерением), то достаточно знать появляющуюся случайную ошибку. Содержит ли метод анализа систематическую ошибку в таком случае менее важно. Нужно только быть уверенным, что эта возможная систематическая ошибка не менялась в ходе исследования. Напротив, при абсолютных определениях (например, содержания вредных примесей в некотором продаваемом продукте) надо знать не только случайную ошибку, но и то, что к ней не примешалась систематическая ошибка. Правильность результатов анализа, как правило, считается доказанной только тогда, когда два [c.27]
Все рассмотренные критерии позволяют либо признать наличие систематической ошибки, либо прийти к заключению, что в рамках существующей случайной ошибки наличие систематической ошибки признать нельзя Но то, что ошибку не удалось обнаружить, вовсе не означат, что она отсутствует Такая интерпретация, например основанная на < <С t(P = 0,95,/), — следующий шаг Предполагается, что метод анализа ведет к правильным значениям анализа Понятие правильность (см гл 1) поэтому всегда надо рассматривать вместе с результатами анализа Существует соответственно результату проверки качественное решение да/нет, которое нельзя выразить в числах Только в случае неустранимой систематической ошибки допустимы точные указания вида, величины и знака ошибочного решения , например, в смысле максимальной погрешности измерения [8] [c.182]
При систематическом наблюдении за изменением количества смол при хранении одного и того же образца бензина можно заметить периодическое снижение его вслед за небольшим повышением, после чего вновь наблюдается плавное и постепенное нарастание. Такие участки минимумов на кривых смолообразования могут повторяться (рис.  , колебания при этом невелики (от 8 до 12 л1з/100 мл), но выходят за пределы ошибки анализа. Обычно спад этих волн отмечается зимой, а подъем — весной и летом, что можно связать с изменением температуры бензина. [c.79]
, колебания при этом невелики (от 8 до 12 л1з/100 мл), но выходят за пределы ошибки анализа. Обычно спад этих волн отмечается зимой, а подъем — весной и летом, что можно связать с изменением температуры бензина. [c.79]
Увеличение числа независимых измерений и усреднение их результатов является универсальным способом повышения точности количественного анализа и снижения предела обнаружения тогда, когда случайная ошибка больше систематической (см. 1.2). [c.54]
Установлено [1063], что при многократной съемке спектров предварительно очищенных обжигом спектральных особо чистых углей частота появления линий атмосферных металлических примесей в спектрах подчиняется биномиальному закону распределения [549]. Например, в условиях указанной выше лаборатории (Дрезден) вероятность того, что два или даже все три спектра из трех параллельных определений будут содержать линии магния и кремния, являющихся случайными воздушными загрязнениями, оказалась равной 1,6 (Мд) и 33,6% (51). Расчет показывает, что для всех элементов, содержание которых в лабораторной воздушной пыли (при концентрации частиц порядка 150 мкг/м ) приближается к 10%, систематическая ошибка анализа может достигать величины порядка 10″ % [1065]. [c.321]
Обычно ошибка анализа складывается из систематической ошибки выходных приборов и флуктуацией измеряемой величины. Данный -метод регистрации имеет выходным прибором самописец ЭПП-09 с чувствительностью 0,1%, которая и определяет предельную чувствительность измерения Т изотопных отношений Т получают из формулы (16), принимая ДКа=0,02 мв — удвоенная величина чувствительности (шкала 10 мв), так как измеряется разница между линиями стандарта и образца [c.49]
Во многих случаях случайные ошибки анализа не превышают 0,01%. Однако если сравнить результаты таких точных анализов, выполненных в разное время, то оказывается, что разница между величинами 6 может составлять 0,03—0,07% (табл. 8). Такие отличия результатов нельзя считать случайными они свидетельствуют о наличии систематической ошибки, присущей каждому отдельному анализу. Эта ошибка обусловлена изменением во времени вакуумных условий, состоянием электронной аппаратуры, и т. д. величина ее во многих случаях, как было проверено на масс-спектрометрах МС-2 и МИ-1305, составляет не менее 0,02—0,04% 56]. В координатах времени систематическая ошибка единичного анализа носит статистический характер, а поэтому ее можно рассчитать по тем же статистическим формулам эта ошибка суммируется со статистической ошибкой единичного замера. [c.50]
Для изучения правильности метода весьма полезен дисперсионный анализ результатов всех определений [549, 903], позволяющий выявить вклад ошибок различного происхождения и значимость этого вклада в общую ошибку метода. Таким путем можно установить и систематическую ошибку метода анализа. Удобный графический способ выявления и учета систематических погрешностей результатов количественных определений предложен в работе [156]. Полезные рекомендации по текущему контролю за систематической ошибкой анализа содержатся в работах [594, 675]. В тех случаях, когда случайная о и систематическая б ошибки сравнимы, в ка честве верхней границы суммарной ошибки метода обычно принимают (б Ч- 2а) [239]. В аналитической арбитражной службе [c.37]
На основании полученного результата можно сделать вывод, что в данном случае систематическая ошибка анализа, обусловленная увлечением хлорид-ионов в осадок, лежит в пределах погрешности весового метода. [c.209]
По своему характеру ошибки анализа подразделяются на а) систематические ошибки б) случайные ошибки в) промахи. [c.50]
Еще раз напомним, что величины S, вычисляемые описанным выше способом, характеризуют только влияние случайных, но не систематических сшибок анализа. Последний может оказаться совершенно неправильным, несмотря на хорошую точность, т е. на малую величину S, если при анализе были какие-либо систематические ошибки. Отсутствие систематических ошибок может быть установлено сопоставлением разницы между полученным при анализе средним арифметическим (AI) и истинным содержанием (Л) определяемого, элемента, т. е величины Д=М—А, с величиной вероятной случайной ошибки 2. Если Д<2, то систематические ошибки отсутствуют. Наоборот, если то имеют [c.60]
Систематические ошибки, которые можно заранее предвидеть, учесть и избежать. Эти ошибки могут систематически повторяться, и параллельные количественные определения дают близкие, во тем не менее неправильные результаты. Поэтому совпадение параллельных количественных определений не может еш,е служить неопровержимым доказательством того, что получены правильные результаты анализа. [c.37]
Требование полной идентичности эталонов и образцов естественно невыполнимо, поскольку предполагает априорное знание состава, подлежащего определению, однако максимально доступная близость состава — непременное требование, которое следует соблюдать для уменьшения эталонной ошибки. Широкий набор эталонов разнообразного состава — условие успешной работы химико-аналитической лаборатории. В заключение отметим, что наличие эталона, близко совпадающего по составу с анализируемым образцом, открывает возможность оценки общей и систематической ошибки анализа, а следовательно, правильности анализа в целом. [c.40]
Метод достаточно точен, но разница между взятым количеством F и найденным — значительна, вследствие систематической отрицательной ошибки анализа. Конец титрования отчетлив. [c.54]
Ошибки метода. Систематические ошибки часто возникают вследствие отклонения поведения реагентов или реакций, на которых основано определение, от идеального. Причинами таких отклонений могут быть малая скорость реакций, неполнота их протекания, неустойчивость каких-либо веществ, неспецифичность большинства реагентов и протекание побочных реакций, мешающих процессу определения. Например, в гравиметрическом анализе перед химиком стоит задача выделения определяемого элемента в виде возможно более чистого осадка. Если осадок не удается хорошо промыть, он будет загрязнен посторонними веществами и масса его будет завышена. С другой стороны, промывание, необходимое для удаления загрязнений, может привести к потере заметного количества осадка вследствие его растворимости в результате возникает систематическая отрицательная ошибка. В любом случае тщательность проведения операции сводится на нет систематической ошибкой, обусловленной методом анализа. [c.60]
Если точность анализа оказывается недостаточной, необходимо составить ясное представление, какого рода ошибки (случайные, систематические или промахи) являются в рассматриваемых условиях определяющими вследствие различной их природы различны и мероприятия по их устранению. [c.159]
Следует оговориться об отсчете времени секундомером, например, при измерении вязкостей. В этих случаях точность измерений в большей степени зависит от точности включения и выключения часового механизма, чем от точности отсчета положения стрелки. Между тем всякое наблюдение или измерение, как бы тщательно оно не производилось и как бы ни был опытен работник лаборатории, никогда не может быть абсолютно точным. Оно неизбежно сопровождается погрешностями или ошибками, которые в большей или меньшей степени искажают результат анализа, вследствие чего мы всегда получаем лишь приближенное значение искомой величины. Погрешности или ошибки бывают систематическими, случайными или промахами. [c.12]
Из ошибок, присущих любому методу анализа, особый интерес обычно представляют случайные ошибки и систематические ошибки, определяющие воспроизводимость (точность) метода анализа и его правильность. В трактовке понятий воспроизводимость и правильность анализа, а равно и в классификации ошибок нет полной ясности и определенности (Налимов, 1960 Дмитриев, 1968 Спиридонов, Лопаткин, 1970). Чтобы этого избежать, нам представляется целесообразным смысл упомянутых выше понятий определить путем рассмотрения математических моделей, которыми приходится пользоваться при изучении ошибок анализов. [c.264]
Как будет показано ниже, расчет неразделенных пиков в принципе возможен, однако связан с введением упрощающих предположений, ведущих к появлению систематических ошибок. В то же время расчет неразделенных пиков связан с усложнением измерений на хроматограмме, что увеличивает случайную ошибку анализа. Поэтому достаточное разделение пиков является основным условием количественного хроматографического анализа. Теоретически проблема разделения впервые исследована в работе [14]. Детально этот вопрос разработан в трех капитальных трудах по газовой хроматографии [15—17]. Применительно к анализу примесей оценка разделения рассмотрена в работе [12]. [c.24]
Систематические ошибки — это повторяющиеся при выполнении нескольких параллельных анализов ошибки. К систематически повторяющимся ошибкам приводит прежде всего пользование неточными измерительными приборами (неправильно калиброванными измерительными сосудами, нестандартными гирями разновесов и т. д.), применение одного и того же реактива, загрязненного определяемым веществом. [c.300]
Содержание той или иной составной части анализируемого вещестна определяют не одним измерением, а в результате целого ряда операций и измерений Между тем выполнение их может быть связано с ошибками. Так возможны ошибки при отборе и обработке средней пробы, при взятии аналитической навески, при осаждении, а также при фильтровании, промывании и взвешивании осадка. Естественно, что все они скажутся на результате анализа. Как бы тщательно ни выполнялось определение, результат его всегда содержит некоторую ошибку, т. е. несколько отличается от действительного содержания определяемого компонента в веществе. Ошибки анализа подразделяют на систематические (постоянные) и случайные. [c.239]
Следовательно, выбор оптимальной величины Do можно считать законченным тогда, когда по результатам измерений можно определить наименьшую величину произведения GSt- Чем ближе значения С и Сд, тем меньше ошибка, вызываемая несоответствием кювет. Однако если при выполнении анализов систематически используются одни и те же кюветы и методика их обработки остается постоянной, то ошибкой Si/l можно пренебречь. Остальные две ошибки, содержащие стандартные отклонения а и Ь, могут быть определены, как уже было сказано, методом наименьших квадратов. Если при построении калибровочного графика использовать большую серию стандартных растворов , то все компоненты общей ошибки могут быть определены с большой точностью, и положение калибровочного графика будет достоверным. [c.33]
Как было отмечено ранее, ошибки анализа могут быть систематическими или случайными. Систематические ошибки влияют на точность определения, т. е. на отклонение среднего значения от истинного значения, тогда как случайные ошибки приводят как к положительным, так и к отрицательным отклонениям от среднего значения, по которым рассчитывается разброс. Ошибки последнего типа обычно распределяются нормально вокруг среднего значения. Кривые нормального распределения хорошо известны экспериментаторам и хорошо изучены их можно получить из гистограмм при неограниченном увеличении числа измерений и уменьшении интервалов разбиения. В силикатном анализе 5 [c.67]
В аналитической практике выделяют три разновидности погрешностей, которые могут искажать результаты анализов при проявлении причин различной природы случайные погрешности, систематические погрешности и промахи. Случайные погрешности обусловлены неявными факторами, меняющимися от опыта к опыту, и характеризуют понятие воспроизводимости метода (методики) анализа. Систематическая погрешность обусловлена причинами известной природы (или же причинами, которые могут быть выявлены при детальном рассмотрении методики). Ей соответствует понятие правильность метода анализа . Понятие точность объединяет воспроизводимость и правильность метода анализа. Разница между случайными и систематическими отклонениями ( ,) заключается в том, что первые могут принимать различные значения с различными знаками, и для выборки достаточно большого объема число положительных отклонений должно быть равно числу отрицательных, вторые постоянны как по значению, так и по знаку, хотя постоянство их по значению может быть абсолютным или относительным. Наконец, третий вид погрешности — промах — предст авляет собой отклонение, которое резко отличается по значению от других отклонений выборки и причиной которого является невнимательность или некомпетентность аналитика. Промахи и систематические ошибки, присутствующие в выборке результатов анализа, выявляются в результате ее статистической обработки. [c.84]
Трудно определить надежность экспериментальных рекомендаций. Однако для реакции 15 весьма информативным и эффективным является систематический численный анализ поведения системы при вариациях /г] . В низкотемпературной области стационарного процесса доля реакций с участием радикала НО2 необычно высока— 2и 25, 30 (0,75 — 0,80), причем большая часть этой величины обусловлена дхй. Таким образом, процесс оказался весьма чувствительным к вариациям /е 5. Двукратное пз .генение nts приводило к отклонениям НО2 = = НОгСО, выходящим за коридор ошпбок в эксперименте [51]. (Авторы [51] не приводят оценки возможной ошибки. Анализ [51 ] позволяет предположить, что ошибка определения НОз не должна превышать 10%.) Поэтому ошибка 100% есть нижняя оценка. Она дол/кна быть увеличена по крайней мере в 2—2,5 раза, поскольку в системе реакций Г — по, (/ = 10—19, 21, 25, 30) величина [c.282]
Численная оценка величины Ахс может быть проведена лишь с привлечением дополнительных экспериментов и с погрешносгью, лимитируемой случайными ошибками анализа. Кроме того, систематическая погрешность анализа не может быть оценена точно ёще и потому, что истинное содержание компонента Хист в пробе [c.31]
В методических указаниях приведены общие положения и понятия по проведению количественного газохроматографнческого аналнзаа с использованием различных приемов уменьшения случайной и систематической ошибки анализа. Рассмотреены методы внешнего стандарта, внутреннего стандарта, метод стандартной добавки, объединенный метод стандартной добавки и внутреннего стандарта. [c.2]
После выявления систематической погрешности она должна быть оценена и устранена. Заметим, что числовая оценка систематической погрешности может бьггь проведена лишь с погрешностью, лимитируемой случайными ошибками анализа. При оценке систематических ошибок можно условно выделить погрешности трех типов. [c.40]
Предположим, что имеется статистический ансамбль, состоящий из множества измерений одного стандартного образца (или спектрального эталона )), выполненных в одной лаборатории, в пределах небольшого отрезка времени. Если мы примем за центр рассеяния среднее арифметическое из результатов анализа, то случайную ошибку, полученную по отношению к этой величине, будем в дальнейшем называть внутрилабораторпой ошибкой воспроизводимости или просто ошибкой воспроизводимости. Очень часто совершенно необоснованно считают, что все случайные ошибки анализа ограничиваются одной ошибкой воспроизводимости. Если при достаточно большом количестве параллельных определений обнаруживается упорное расхождение между результатами анализа (центрами рассеяния) и паспортными данными стандартного образца (или спектрального эталона), то имеем постоянную ошибку, которую часто называют систематической ошибкой анализа. Обычно полагают, что она характеризует методическую ошибку анализа в целом, по крайней мере, для проб, близких но составу к данному стандартному образцу, хотя причины появления этой ошибки II законы, по которым действуют эти причины, обычно остаются неизвестными. Если исходить из данного выше определения систематической ошибки, то эту величину, постоянную для данного множества измерений, еще нельзя рассматривать как систематическую ошибку данного метода анализа. Грубое и метрологически не оправданное деление аналитических ошибок только на две категории—внутрилабораторные ошибки воспроизводимости и систематические ошибки—привело к тому, что объектом применения математической статистики в аналитической работе до сих нор часто оказываются только внутрилабораторные ошибки воспроизводимости, [c.20]
Это утверждение становится очевидным, если принять, что общая ошибка анализа Ах складывается из систематической (Д.хгсист) и случайной (Ал сл) в соответствии с законом сложения случайных ошибок Ахз = + (Дхсл) — Тогда при заданной величине ДХсист = б общая ошибка анализа в зависимости от соотношений ДХс л/Ал сист принимает следующие величины [c.23]
Отклонения от истинного содержания пробы вызываются систематической ошибкой. Метод анализа лишь тогда может дать правильные значения, когда он свободен от систематических ошибок. Случахшые ошибки делают неточным результат анализа, систематические ошибки делают неверным сам анализ. Итак, воспроизводимость или точность и правильность метода анализа следует рассматривать порознь. [c.11]