Отладка программы призвана выискивать «вредителей» кода и устранять их. За это отвечают отладчик и журналирование для вывода сведений о программе.
В предыдущей части мы рассмотрели исходный код и его составляющие.
После того, как вы начнете проверять фрагменты кода или попытаетесь решить связанные с ним проблемы, вы очень скоро поймете, что существуют моменты, когда программа крашится, прерывается и прекращает работу.

Это часто вызвано ошибками, известными как дефекты или исключительные ситуации во время выполнения. Акт обнаружения и удаления ошибок из нашего кода – это отладка программы. Вы лучше разберетесь в отладке на практике, используя ее как можно чаще. Мы не только отлаживаем собственный код, но и порой дебажим написанное другими программистами.
Для начала необходимо рассортировать общие ошибки, которые могут возникнуть в исходном коде.

Синтаксические ошибки
Эти эрроры не позволяют скомпилировать исходный код на компилируемых языках программирования. Они обнаруживаются во время компиляции или интерпретации исходного кода. Они также могут быть легко обнаружены статическими анализаторами (линтами). Подробнее о линтах мы узнаем немного позже.
Синтаксические ошибки в основном вызваны нарушением ожидаемой формы или структуры языка, на котором пишется программа. Как пример, это может быть отсутствующая закрывающая скобка в уравнении.
Семантические ошибки
Отладка программы может потребоваться и по причине семантических ошибок, также известных как логические. Они являются наиболее сложными из всех, потому что не могут быть легко обнаружены. Признак того, что существует семантическая ошибка, – это когда программа запускается, отрабатывает, но не дает желаемого результата.
Рассмотрим данный пример:
3 + 5 * 6
По порядку приоритета, называемому старшинством операции, с учетом математических правил мы ожидаем, что сначала будет оценена часть умножения, и окончательный результат будет равен 33. Если программист хотел, чтобы сначала происходило добавление двух чисел, следовало поступить иначе. Для этого используются круглые скобки, которые отвечают за смещение приоритетов в математической формуле. Исправленный пример должен выглядеть так:
(3 + 5) * 6
3 + 5, заключенные в скобки, дадут желаемый результат, а именно 48.
Ошибки в процессе выполнения
Как и семантические, ошибки во время выполнения никогда не обнаруживаются при компиляции. В отличие от семантических ошибок, эти прерывают программу и препятствуют ее дальнейшему выполнению. Они обычно вызваны неожиданным результатом некоторых вычислений в исходном коде.
Вот хороший пример:
input = 25 x = 0.8/(Math.sqrt(input) - 5)
Фрагмент кода выше будет скомпилирован успешно, но input 25 приведет к ZeroDivisionError. Это ошибка во время выполнения. Другим популярным примером является StackOverflowError или IndexOutofBoundError. Важно то, что вы идентифицируете эти ошибки и узнаете, как с ними бороться.
Существуют ошибки, связанные с тем, как ваш исходный код использует память и пространство на платформе или в среде, в которой он запущен. Они также являются ошибками во время выполнения. Такие ошибки, как OutOfMemoryErrorand и HeapError обычно вызваны тем, что ваш исходный код использует слишком много ресурсов. Хорошее знание алгоритмов поможет написать код, который лучше использует ресурсы. В этом и заключается отладка программы.
Процесс перезаписи кода для повышения производительности называется оптимизацией. Менее популярное наименование процесса – рефакторинг. Поскольку вы тратите больше времени на кодинг, то должны иметь это в виду.
Отладка программы
Вот несколько советов о том, как правильно выполнять отладку:
- Использовать Linters. Linters – это инструменты, которые помогают считывать исходный код, чтобы проверить, соответствует ли он ожидаемому стандарту на выбранном языке программирования. Существуют линты для многих языков.
- Превалирование IDE над простыми редакторами. Вы можете выбрать IDE, разработанную для языка, который изучаете. IDE – это интегрированные среды разработки. Они созданы для написания, отладки, компиляции и запуска кода. Jetbrains создают отличные IDE, такие как Webstorm и IntelliJ. Также есть NetBeans, Komodo, Qt, Android Studio, XCode (поставляется с Mac), etc.
- Чтение кода вслух. Это полезно, когда вы ищете семантическую ошибку. Читая свой код вслух, есть большая вероятность, что вы зачитаете и ошибку.
- Чтение логов. Когда компилятор отмечает Error, обязательно посмотрите, где он находится.
Двигаемся дальше
Поздравляем! Слово «ошибка» уже привычно для вас, равно как и «отладка программы». В качестве новичка вы можете изучать кодинг по книгам, онлайн-урокам или видео. И даже чужой код вам теперь не страшен 
В процессе кодинга измените что-нибудь, чтобы понять, как он работает. Но будьте уверены в том, что сами написали.
Викторина
- Какая ошибка допущена в фрагменте кода Python ниже?
items = [0,1,2,3,4,5] print items[8] //комментарий: элементы здесь представляют собой массив с шестью элементами. Например, чтобы получить 4-й элемент, вы будете использовать [3]. Мы начинаем отсчет с 0.
- Какая ошибка допущена в фрагменте кода Python ниже?
input = Hippo' if input == 'Hippo': print 'Hello, Hippo'
Ответы на вопросы
- Ошибка выполнения: ошибка индекса вне диапазона.
2. Синтаксическая ошибка: Отсутствует стартовая кавычка в первой строке.
14. Типы ошибок и методы отладки программ.
Причиной таких ошибок могут быть неправильно написанные ключевые слова, неверно примененные разделители или недопустимые комбинации операторов. Такие ошибки VisualBasicраспознает сразу после того, как курсор покидает только что написанную строку. Строка с синтаксической ошибкой выделяется красным цветом. После устранения ошибки выделение цветом снимается.
VisualBasicимеет средства, позволяющие не только обнаружить синтаксическую ошибку, но и избежать ее в процессе написания кода. К таким средствам относятся
– механизм контекстной подсказки (после написании ключевого слова появляется окно, в котором отображается полный синтаксис вводимого оператора или список аргументов используемой процедуры);
– автоматическое отображение списка элементов (например, после имени элемента управления появляется список всех свойств и методов, из которого можно выбрать требуемое);
– дополнение слова (при вводе нескольких начальных символов, достаточных для распознавания ключевого слова, недостающие символы автоматически добавляются).
2. Ошибки в структуре программы.
Ошибки такого рода появляется в результате неправильного написания многострочного оператора (например, в операторе цикла Forнет последней строки со словомNext или в уловном оператореIfнетEnd If).
Такие ошибки VisualBasicраспознает не в процессе ввода символов, а на этапе компиляции. Сообщение об ошибке выводится в специальном окне и начинается оно словамиCompileerror(«ошибка компиляции») и содержит указание на ошибку (например,BlockIfwithoutEndIf– «блокIfбезEndIf»).
3. Ошибки, возникающие во время выполнения программы.
Это ошибки, возникающие во время работы программы (например, при выполнении деления на ноль или при попытки чтения из несуществующего на диске файла). В таких случаях выводится сообщение в специальном окне, в котором указывается причина прерывания программы и номер ошибки. На этом окне есть четыре кнопки «Continue», «End», «Debug» и «Help».
В качестве примера на рис.33 показано окно с сообщением об ошибке деления на ноль.
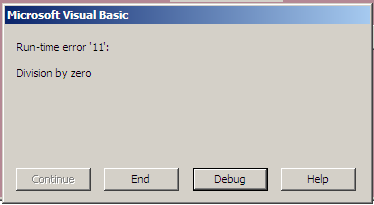
Рис.33. Вид окна с сообщением об ошибке на этапе выполнения
Из рисунка видно, что надпись на кнопке «Continue» бледнее остальных. Это означает, что при такой ошибке дальнейшее продолжение программы невозможно. Контур кнопки «Debug» выделен жирной линией, это означает, что для перехода в режим отладки эту кнопку можно «нажать» не только с помощью манипулятора «мышь», но и путем нажатия кнопки «Enter» клавиатуры. Нажатие кнопки «End» приведет к завершению программы, а кнопки «Help» – к появлению окна справки с информацией о типе ошибки и возможности ее устранения.
При переходе в режим отладки открывается окно с текстом программы, в которой выделена строка с командой, выполнение которой привело к прерыванию. При этом появляется возможность определить значения переменных на момент выполнения прерывания. Для этого достаточно подвести курсор к имени переменной, в появившемся окошке появится либо ее значение, либо слово «Empty» («пустая»), если на момент выполнения команды переменная не получила никакого значения.
На этапе разработки программы можно предусмотреть перехват возможных ошибок. Это делается с помощью специальной процедуры – обработчика ошибок.
Для перехвата возможной ошибки в исполняемой процедуре используется оператор On Error. В нем указывается метка, которая должна находиться в той же процедуре и помечать тот фрагмент кода, куда будет осуществлен переход при возникновении ошибки выполнения. Обычно этот фрагмент находится в конце процедуры, а перед меткой помещается операторExit, благодаря которому процедура завершается, если ошибка не возникла.
Обработка ошибки начинается с установления типа ошибки. Для этого используется объект Err, свойство которогоNumber содержит код последней возникшей ошибки.
После обработки ошибки программа должна продолжить свое исполнение. Для того, чтобы программа продолжала выполняться в строке, в которой возникла ошибка, в обработчике указывается оператор Resume. Если нужно продолжить программу не с этой, а со следующей строки, используется операторResume Next.
В качестве примера рассмотрим процедуру, которая запускается при нажатии кнопки со знаком «/» в проекте «Простой калькулятор» (Лекция №№). При этом число, введенное в текстовое окноText1делится на число, введенное в окноText2, результат заносится в окноText3. Возможная ошибка – деление на ноль. Обработка ошибки может выглядеть следующим образом.
Private Sub Command3_Click()
On Error GoTo ошибка
Z= Val (InputBox(“Введите число, не равное нулю”))
Если в программе возможно появление нескольких ошибок, их можно обработать, предварительно определив их код и в зависимости от кода применить тот или иной метод. В табл.11 приведены описания основных ошибок этапа выполнения программы.
Таблица 11. Коды основных ошибок
9.4 С ИНТАКСИЧЕСКИЕ ОШИБКИ
Это можно проиллюстрировать следующим примером. while x > y ; begin < something >end .
248 Никакого сообщения об ошибке при встрече «;» на данной стадии син- таксический анализатор не выдаст. Последствия ее могут появиться на более поздней фазе анализа. · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · Сообщив о синтаксической ошибке, анализатор в большинстве случаев постарается продолжить разбор. Для этого ему понадобится исключить ка- кие-либо символы, включить какие-либо символы или изменить их. Суще- ствует ряд стратегий исправления ошибок. Практически все они хорошо сра- батывают в одних случаях и плохо – в других. «Хорошая» стратегия заклю- чается в том, чтобы обнаружить как можно больше синтаксических ошибок и генерировать как можно меньше сообщений в связи с каждой синтаксиче- ской ошибкой. Обычно наилучшими методами являются методы, зависимые от языка, т.е. от знания исходного языка и от того, как он употребляется.
9.4.1 М ЕТОДЫ ИСПРАВЛЕНИЯ СИНТАКСИЧЕСКИХ ОШИБОК
Режим переполоха . Один из наиболее распространенных методов ис- правления синтаксических ошибок носит название « режим переполоха ». При появлении недопустимого символа весь последующий исходный текст, вплоть до соответствующего ограничителя (например, «;» или end ), игнорируется. Ограничитель заканчивает какую-то конструкцию языка, и элементы удаляются из стека разбора до тех пор, пока не встретится адрес возврата. Этот элемент тоже удаляется из стека, а разбор продолжается, начиная с адреса в таблице разбора, содержащего следующий входной сим- вол. Такой метод довольно легко реализуется, но имеет серьезный недоста- ток: длинные последовательности кода, соответствующие игнорируемым символам, не анализируются. Исключение символов . Метод исключения символов также легко реа- лизуется и не требует изменения степени разбора. Когда считывается недо- пустимый символ, и он сам, и все последующие символы исключаются из
249 исходной строки до тех пор, пока не встретится допустимый символ. Хотя при таком методе могут исключаться длинные последовательности, в от- дельных случаях он весьма эффективен.
| · · · · · · · · · · · · · · · · · · · · · · · · | Пример · · · · · · · · · · · · · · · · · · · · · · · |
Например, в записи c := d +3; end , где символ «;» является недопустимым, исправление ошибки – идеальное. · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · Однако исключение скобок обычно разрушает блочную структуру и приводит к дальнейшим синтаксическим ошибкам. Включение символов . Некоторые синтаксические анализаторы имеют наготове множество действительных символов продолжения. В некоторых случаях оправдано исправление программ путем включения символов – под- становки одного из таких символов перед недопустимым символом, который вызвал ошибку.
| · · · · · · · · · · · · · · · · · · · · · · · · | Пример · · · · · · · · · · · · · · · · · · · · · · · |
Например, последовательность end begin никогда не будет допустимой. Однако включение «;» между end begin позво- лит анализатору продолжить работу. · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · Конечно, в таких ситуациях может иметь место неправильная подста- новка, даже если анализатор продолжит работу. Правила для ошибок . Один из способов исправления некоторых ти- пов синтаксических ошибок заключается в расширении синтаксиса языка за
250 счет включения в него программ, содержащих типичные ошибки. Это не зна- чит, что ошибки пройдут незамеченными, так как в грамматику могут быть включены сообщения о них. Но анализатор не будет считать такой вход не- допустимым и не потребует никаких исправлений.
| · · · · · · · · · · · · · · · · · · · · · · · · | Пример · · · · · · · · · · · · · · · · · · · · · · · |
Так, можно обращаться, например, с ошибками типа «;» перед end или пропуск «;». · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · Дополнительные правила, включенные в грамматику, обычно называ- ются правилами для ошибок . Они неизбежно приводят к увеличению грамма- тики, и поэтому включать их следует только для наиболее часто встречаю- щихся ошибок программирования. При этом надо следить за тем, чтобы при включении этих правил грамматика не стала неоднозначной.
9.4.2 П РЕДУПРЕЖДЕНИЯ
· · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · Наряду с сообщениями о синтаксических ошибках, анали- затор может выдавать предупреждения , когда ему встрети- лась допустимая, но маловероятная последовательность симво- лов. · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · ·
| · · · · · · · · · · · · · · · · · · · · · · · · | Пример · · · · · · · · · · · · · · · · · · · · · · · |
Пример маловероятной последовательности символов: ; do · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · ·
При подготовке материала использовались источники:
https://studfile.net/preview/6154379/page:15/
https://studfile.net/preview/16875961/page:45/
From Wikipedia, the free encyclopedia
In computer science, a syntax error is an error in the syntax of a sequence of characters or tokens that is intended to be written in a particular programming language.
For compiled languages, syntax errors are detected at compile-time. A program will not compile until all syntax errors are corrected. For interpreted languages, however, a syntax error may be detected during program execution, and an interpreter’s error messages might not differentiate syntax errors from errors of other kinds.
There is some disagreement as to just what errors are «syntax errors». For example, some would say that the use of an uninitialized variable’s value in Java code is a syntax error, but many others would disagree[1][2] and would classify this as a (static) semantic error.
In 8-bit home computers that used BASIC interpreter as their primary user interface, the SYNTAX ERROR error message became somewhat notorious, as this was the response to any command or user input the interpreter could not parse.
A syntax error can occur or take place, when an invalid equation is being typed on a calculator. This can be caused, for instance, by opening brackets without closing them, or less commonly, entering several decimal points in one number.
In Java the following is a syntactically correct statement:
-
System.out.println("Hello World");
while the following is not:
-
System.out.println(Hello World);
The second example would theoretically print the variable Hello World instead of the words «Hello World». However, a variable in Java cannot have a space in between, so the syntactically correct line would be System.out.println(Hello_World).
A compiler will flag a syntax error when given source code that does not meet the requirements of the language’s grammar.
Type errors (such as an attempt to apply the ++ increment operator to a boolean variable in Java) and undeclared variable errors are sometimes considered to be syntax errors when they are detected at compile-time. However, it is common to classify such errors as (static) semantic errors instead.[2][3][4]
Syntax errors on calculators[edit]

A syntax error is one of several types of errors on calculators (most commonly found on scientific calculators and graphing calculators), representing that the equation that has been input has incorrect syntax of numbers, operations and so on. It can result in various ways, including but not limited to:
- An open bracket without closing parenthesis (unless missing closing parenthesis is at very end of equation)
- Using minus sign instead of negative symbol (or vice versa), which are distinct on most scientific calculators. Note that while some scientific calculators allow a minus sign to stand in for a negative symbol, the reverse is less common.
See also[edit]
- Tag soup
References[edit]
- ^ Issue of syntax or semantics?
- ^ a b Semantic Errors in Java
- ^ Aho, Alfred V.; Monica S. Lam; Ravi Sethi; Jeffrey D. Ullman (2007). Compilers: Principles, Techniques, and Tools (2nd ed.). Addison Wesley. ISBN 978-0-321-48681-3. Section 4.1.3: Syntax Error Handling, pp.194–195.
- ^ Louden, Kenneth C. (1997). Compiler Construction: Principles and Practice. Brooks/Cole. ISBN 981-243-694-4. Exercise 1.3, pp.27–28.
Синтаксическая ошибка (программирование)
-
В информатике, синтаксическая ошибка относится к ошибке в синтаксисе последовательности символов или токенов, которая записана на определенном языке программирования.В компилируемых языках программирования синтаксические ошибки выявляются строго во время компиляции. Программа не будет компилироваться, пока все синтаксические ошибки не будут исправлены. Для интерпретируемых языков программирования, однако, не все синтаксические ошибки могут быть обнаружены во время выполнения и они не обязательно могут быть синтаксическими, но и логическими; во многих программах такие ошибки не обнаруживаются никогда.
В 8-разрядных домашних компьютерах, которые использовали интерпретатор языка Бейсик в качестве основного пользовательского интерфейса, сообщение СИНТАКСИЧЕСКАЯ ОШИБКА было малопонятным, так как это была реакция на любой ввод пользователя, который интерпретатор не мог разобрать.
Синтаксическая ошибка может возникать при некорректном вводе уравнения в калькулятор. Это может быть вызвано, например, путём открытия скобок без их закрытия, или, реже, вводом нескольких десятичных разделителей подряд.
Компилятор ставит флаг в строке, где совершена синтаксическая ошибка.
В Java синтаксически правильная постановка:
System.out.println(«Hello World»);А эта нет:
System.out.println(Hello World);В C++ синтаксически правильная постановка:
std::cout<<«Hello, World»;А эта нет:
std::cout<
Источник: Википедия
Связанные понятия
Синтаксис языка программирования — набор правил, описывающий комбинации символов алфавита, считающиеся правильно структурированной программой (документом) или её фрагментом. Синтаксису языка противопоставляется его семантика. Синтаксис языка описывает «чистый» язык, в то же время семантика приписывает значения (действия) различным синтаксическим конструкциям.
Псевдоко́д — компактный (зачастую неформальный) язык описания алгоритмов, использующий ключевые слова императивных языков программирования, но опускающий несущественные подробности и специфический синтаксис. Псевдокод обычно опускает детали, несущественные для понимания алгоритма человеком. Такими несущественными деталями могут быть описания переменных, системно-зависимый код и подпрограммы. Главная цель использования псевдокода — обеспечить понимание алгоритма человеком, сделать описание более воспринимаемым…
Синтаксический сахар (англ. syntactic sugar) в языке программирования — это синтаксические возможности, применение которых не влияет на поведение программы, но делает использование языка более удобным для человека.
Синтакси́ческий ана́лиз (или разбор, жарг. па́рсинг ← англ. parsing) в лингвистике и информатике — процесс сопоставления линейной последовательности лексем (слов, токенов) естественного или формального языка с его формальной грамматикой. Результатом обычно является дерево разбора (синтаксическое дерево). Обычно применяется совместно с лексическим анализом.
Упоминания в литературе
Как бы внимательно вы ни набирали текст, все равно возникают ошибки. При проверке работы грамматические ошибки не способствуют ее высокой оценке. В результате применения инструментов проверки правописания в редакторе Word можно будет избежать опечаток, а также многих синтаксических ошибок, которые часто возникают, если работать с текстом непосредственно в электронном виде. Правильные настройки проверки правописания и пунктуации приведут к тому, что слова, которые были набраны с ошибками, будут подчеркнуты красной волнистой линией, предложения с пунктуационными ошибками – зеленой волнистой линией.
Как бы внимательно вы ни набирали текст, все равно возникают ошибки. При проверке работы ошибки не способствуют ее высокой оценке. При помощи инструментов проверки правописания в редакторе Word можно будет избежать опечаток, а также многих синтаксических ошибок, которые часто возникают, если работать с текстом непосредственно в электронном виде. Правильные настройки проверки правописания и пунктуации приведут к тому, что слова с ошибками будут подчеркнуты красной волнистой линией, предложения с пунктуационными ошибками – зеленой волнистой линией.
Проверку синтаксиса HTML-документов невозможно выполнить с помощью обычных браузеров, так как они предназначены только для просмотра HTML-страниц. Если в документе имеются синтаксические ошибки, браузер пытается, игнорируя их, каким-либо образом показать страницу на экране. Однако решается такая задача каждый раз по-новому – в зависимости от типа браузера и даже от его версии. Если ошибок на странице слишком много, она может быть не отображена в окне браузера или отображена лишь частично. Программные и сетевые средства проверки HTML-документов позволяют предупредить такое поведение браузеров, выявляя допущенные при разработке страниц ошибки. Отметим, что сделать это довольно просто. Выявив ошибки до размещения HTML-документов в Internet, вы заметите, что страницы будут загружаться быстрее, а проблем станет значительно меньше.
Связанные понятия (продолжение)
Многопроходный компилятор (англ. Multi-pass compiler) — тип компилятора, который обрабатывает исходный код или абстрактное синтаксическое дерево программы несколько раз (в отличие от однопроходного компилятора, который проходит программу только один раз). Между проходами генерируется промежуточный код, который принимается следующим проходом в качестве входа. Таким образом, многопроходный компилятор обрабатывает код по частям, проход за проходом, а последний проход выдает финальный результат программы…
Конкатенативный язык программирования — это язык программирования, основанный на том, что конкатенация двух фрагментов кода выражает их композицию. В таком языке широко используется неявное указание аргументов функций (см. бесточечное программирование), новые функции определяются как композиция функций, а вместо аппликации применяется конкатенация. Этому подходу противопоставляется аппликативное программирование.
Эта статья о логической ошибке в программировании. Об ошибках, связанных с нарушением логической правильности рассуждений, см. Логическая ошибка.В программировании логической ошибкой называется баг, который приводит к некорректной работе программы, но не к краху программы.
Подробнее: Логическая ошибка (программирование)
Компилятор компиляторов — программа, воспринимающая синтаксическое или семантическое описание языка программирования и генерирующая компилятор для этого языка.
Интерпретируемый язык программирования — язык программирования, исходный код на котором выполняется методом интерпретации. Классифицируя языки программирования по способу исполнения, к группе интерпретируемых относят языки, в которых операторы программы друг за другом отдельно транслируются и сразу выполняются (интерпретируются) с помощью специальной программы-интерпретатора (что противопоставляется компилируемым языкам, в которых все операторы программы заранее оттранслированы в объектный код…
Язы́к ассе́мблера (англ. assembly language) — машинно-ориентированный язык программирования низкого уровня. Его команды прямо соответствуют отдельным командам машины или их последовательностям, также он может предоставлять дополнительные возможности облегчения программирования, такие как макрокоманды, выражения, средства обеспечения модульности программ. Может рассматриваться как автокод (см. ниже), расширенный конструкциями языков программирования высокого уровня. Является существенно платформо-зависимым…
В информатике лексический анализ («токенизация», от англ. tokenizing) — процесс аналитического разбора входной последовательности символов на распознанные группы — лексемы, с целью получения на выходе идентифицированных последовательностей, называемых «токенами» (подобно группировке букв в словах). В простых случаях понятия «лексема» и «токен» идентичны, но более сложные токенизаторы дополнительно классифицируют лексемы по различным типам («идентификатор, оператор», «часть речи» и т. п.). Лексический…
Количество строк кода (англ. Source Lines of Code — SLOC) — это метрика программного обеспечения, используемая для измерения его объёма с помощью подсчёта количества строк в тексте исходного кода. Как правило, этот показатель используется для прогноза трудозатрат на разработку конкретной программы на конкретном языке программирования, либо для оценки производительности труда уже после того, как программа написана.
Интерпретатор (англ. interpreter ıntə:’prıtə, от лат. interpretator — толкователь) — программа (разновидность транслятора), выполняющая интерпретацию.
Интерпретатор (англ. Interpreter) — поведенческий шаблон проектирования, решающий часто встречающуюся, но подверженную изменениям, задачу. Также известен как Little (Small) Language…
Трансля́тор — программа или техническое средство, выполняющее трансляцию программы.
Компилируемый язык программирования — язык программирования, исходный код которого преобразуется компилятором в машинный код и записывается в файл с особым заголовком и/или расширением для последующей идентификации этого файла, как исполняемого операционной системой (в отличие от интерпретируемых языков программирования, чьи программы выполняются программой-интерпретатором).
Стековый язык программирования (англ. stack-oriented programming language) — это язык программирования, в котором для передачи параметров используется машинная модель стека. Этому описанию соответствует несколько языков, в первую очередь Forth и PostScript, а также многие ассемблерные языки (использующие эту модель на низком уровне — Java, C#). При использовании стека в качестве основного канала передачи параметров между словами элементы языка естественным образом образуют фразы (последовательное…
Си (англ. C) — компилируемый статически типизированный язык программирования общего назначения, разработанный в 1969—1973 годах сотрудником Bell Labs Деннисом Ритчи как развитие языка Би. Первоначально был разработан для реализации операционной системы UNIX, но впоследствии был перенесён на множество других платформ. Согласно дизайну языка, его конструкции близко сопоставляются типичным машинным инструкциям, благодаря чему он нашёл применение в проектах, для которых был свойственен язык ассемблера…
Неопределённое поведение (англ. undefined behaviour, в ряде источников непредсказуемое поведение) — свойство некоторых языков программирования (наиболее заметно в Си), программных библиотек и аппаратного обеспечения в определённых маргинальных ситуациях выдавать результат, зависящий от реализации компилятора (библиотеки, микросхемы) и случайных факторов наподобие состояния памяти или сработавшего прерывания. Другими словами, спецификация не определяет поведение языка (библиотеки, микросхемы) в любых…
Правило одного определения (One Definition Rule, ODR) — один из основных принципов языка программирования C++. Назначение ODR состоит в том, чтобы в программе не могло появиться два или более конфликтующих между собой определения одной и той же сущности (типа данных, переменной, функции, объекта, шаблона). Если это правило соблюдено, программа ведёт себя так, как будто в ней существует только одно, общее определение любой сущности. Нарушение ODR, если оно не будет обнаружено при компиляции и сборке…
Гомоикони́чность (гомоиконность, англ. homoiconicity, англ. homoiconic, от греч. ὁμός — равный, одинаковый + ср.-греч. εἰκόνα — «о́браз», «изображение») — свойство некоторых языков программирования, в которых структура программы похожа на его синтаксис, и поэтому внутреннее представление программы можно определить прочитав текстовую разметку. Если язык гомоиконичен, это означает, что текст программы имеет такую же структуру, как её абстрактное синтаксическое дерево (то есть AST и синтаксис являются…
В программировании, ассемблерной вставкой называют возможность компилятора встраивать низкоуровневый код, написанный на ассемблере, в программу, написанную на языке высокого уровня, например, Си или Ada. Использование ассемблерных вставок может преследовать следующие цели…
Подробнее: Ассемблерная вставка
Язык программирования Си поддерживает множество функций стандартных библиотек для файлового ввода и вывода. Эти функции составляют основу заголовочного файла стандартной библиотеки языка Си
.
Подробнее: Файловый ввод-вывод в языке Си
Транспайлер — тип компилятора, который использует исходный код программы, написанной на одном языке программирования, в качестве исходных данных и производит эквивалентный исходный код на другом языке программирования. Транспайлер переводит между языками программирования, которые работают примерно на одном и том же уровне абстракции, в то время как традиционный компилятор переводит с более высокого уровня языка программирования на язык более низкого уровня. Например, транспайлер может выполнить перевод…
Низкоуровневый язык программирования (язык программирования низкого уровня) — язык программирования, близкий к программированию непосредственно в машинных кодах используемого реального или виртуального (например, байт-код, Microsoft .NET) процессора. Для обозначения машинных команд обычно применяется мнемоническое обозначение. Это позволяет запоминать команды не в виде последовательности двоичных нулей и единиц, а в виде осмысленных сокращений слов человеческого языка (обычно английских).
Вариативный макрос — возможность препроцессором Си при помощи специального макроса объявлять поддержку различного числа аргументов.
Обфуска́ция (от лат. obfuscare — затенять, затемнять; и англ. obfuscate — делать неочевидным, запутанным, сбивать с толку) или запутывание кода — приведение исходного текста или исполняемого кода программы к виду, сохраняющему её функциональность, но затрудняющему анализ, понимание алгоритмов работы и модификацию при декомпиляции.
Каламбур типизации является прямым нарушением типобезопасности. Традиционно возможность построить каламбур типизации связывается со слабой типизацией, но и некоторые сильно типизированные языки или их реализации предоставляют такие возможности (как правило, используя в связанных с ними идентификаторах слова unsafe или unchecked). Сторонники типобезопасности утверждают, что «необходимость» каламбуров типизации является мифом.
Код операции, операционный код, опкод — часть машинного языка, называемая инструкцией и определяющая операцию, которая должна быть выполнена.
Абстрактное синтаксическое дерево (АСД) — в информатике конечное помеченное ориентированное дерево, в котором внутренние вершины сопоставлены (помечены) с операторами языка программирования, а листья — с соответствующими операндами. Таким образом, листья являются пустыми операторами и представляют только переменные и константы.
Коммента́рии — пояснения к исходному тексту программы, находящиеся непосредственно внутри комментируемого кода. Синтаксис комментариев определяется языком программирования. С точки зрения компилятора или интерпретатора, комментарии — часть текста программы, не влияющая на её семантику. Комментарии не оказывают никакого влияния на результат компиляции программы или её интерпретацию. Помимо исходных текстов программ, комментарии также применяются в языках разметки и языках описания.
Расширенная форма Бэкуса — Наура (расширенная Бэкус — Наурова форма (РБНФ)) (англ. Extended Backus–Naur Form (EBNF)) — формальная система определения синтаксиса, в которой одни синтаксические категории последовательно определяются через другие. Используется для описания контекстно-свободных формальных грамматик. Предложена Никлаусом Виртом. Является расширенной переработкой форм Бэкуса — Наура, отличается от БНФ более «ёмкими» конструкциями, позволяющими при той же выразительной способности упростить…
Сема́нтика в программировании — дисциплина, изучающая формализации значений конструкций языков программирования посредством построения их формальных математических моделей. В качестве инструментов построения таких моделей могут использоваться различные средства, например, математическая логика, λ-исчисление, теория множеств, теория категорий, теория моделей, универсальная алгебра. Формализация семантики языка программирования может использоваться как для описания языка, определения свойств языка…
Пара́метр в программировании — принятый функцией аргумент. Термин «аргумент» подразумевает, что конкретно и какой конкретной функции было передано, а параметр — в каком качестве функция применила это принятое. То есть вызывающий код передает аргумент в параметр, который определен в члене спецификации функции.
Нисходящий синтаксический анализ (англ. top-down parsing) — это один из методов определения принадлежности входной строки к некоторому формальному языку, описанному LL(k) контекстно-свободной грамматикой. Это класс алгоритмов грамматического анализа, где правила формальной грамматики раскрываются, начиная со стартового символа, до получения требуемой последовательности токенов.
Макропроце́ссор (также макрогенера́тор) — программа, выполняющая преобразование входного текста в выходной при помощи задаваемых ей правил замены последовательностей символов, называемых правилами макроподстановки.
Шебанг (англ. shebang, sha-bang, hashbang, pound-bang, or hash-pling) — в программировании последовательность из двух символов: решётки и восклицательного знака («#!») в начале файла скрипта.
Дизассе́мблер (от англ. disassembler ) — транслятор, преобразующий машинный код, объектный файл или библиотечные модули в текст программы на языке ассемблера.
Пролог (англ. Prolog) — язык и система логического программирования, основанные на языке предикатов математической логики дизъюнктов Хорна, представляющей собой подмножество логики предикатов первого порядка.
Программи́рование ме́тодом копи́рования-вста́вки, C&P-программирование или копипаста в программировании — процесс создания программного кода с часто повторяющимися частями, произведёнными операциями копировать-вставить (англ. copy-paste). Обычно этот термин используется в уничижительном понимании для обозначения недостаточных навыков компьютерного программирования или отсутствия выразительной среды разработки, в которой, как правило, можно использовать подключаемые библиотеки.
Грамотное программирование (ГП; англ. Literate Programming) — концепция, методология программирования и документирования, в которой программа состоит из прозы на естественном языке вперемежку с макроподстановками и кодом на языках программирования. Термин и саму концепцию предложил Дональд Кнут в 1981 году при разработке системы компьютерной вёрстки TeX.
Вариативный шаблон или шаблон с переменным числом аргументов в программировании — шаблон с заранее неизвестным числом аргументов, которые формируют один или несколько так называемых пакетов параметров.
Перебор по словарю (англ. dictionary attack) — атака на систему защиты, использующая метод полного перебора (англ. brute-force) предполагаемых паролей, используемых для аутентификации, осуществляемого путём последовательного пересмотра всех слов (паролей в чистом виде или их зашифрованных образов) определённого вида и длины из словаря с целью последующего взлома системы и получения доступа к секретной информации.
Стандартная библиотека языка программирования — набор модулей, классов, объектов, констант, глобальных переменных, шаблонов, макросов, функций и процедур, доступных для вызова из любой программы, написанной на этом языке и присутствующих во всех реализациях языка.
Спецификация (стандарт, определение) языка программирования — это предмет документации, который определяет язык программирования, чтобы пользователи и разработчики языка могли согласовывать, что означают программы на данном языке. Спецификации обычно являются подробными и формальными и в основном используются разработчиками языка, в то время как пользователи обращаются к ним в случае двусмысленности: например, спецификация языка C++ часто цитируется пользователями из-за сложности. Сопутствующая документация…
Метод Даффа (англ. Duff’s device) в программировании — это оптимизированная реализация последовательного копирования, использующая ту же технику, что применяется для размотки циклов. Первое описание сделано в ноябре 1983 года Томом Даффом (англ. Tom Duff), который в то время работал на Lucasfilm. Пожалуй, это самое необычное использование того факта, что в языке Си инструкции внутри блока switch выполняются «насквозь» через все метки case.
Польская нотация (запись), также известна как префиксная нотация (запись), это форма записи логических, арифметических и алгебраических выражений. Характерная черта такой записи — оператор располагается слева от операндов. Если оператор имеет фиксированную арность, то в такой записи будут отсутствовать круглые скобки и она может быть интерпретирована без неоднозначности. Польский логик Ян Лукасевич изобрел эту запись примерно в 1920, чтобы упростить пропозициональную логику.
Обра́тная по́льская запись (англ. Reverse Polish notation, RPN) — форма записи математических и логических выражений, в которой операнды расположены перед знаками операций. Также именуется как обратная польская запись, обратная бесскобочная запись, постфиксная нотация, бесскобочная символика Лукасевича, польская инверсная запись, ПОЛИЗ.
Ошибки в программировании – дело обычное, хоть и неприятное. В данной статье будет рассказано о том, какими бывают ошибки (баги), а также что собой представляют исключения.
Определение
Ошибка в программировании (или так называемый баг) – это ситуация у разработчиков, при которой определенный код вследствие обработки выдает неверный результат. Причин данному явлению множество: неисправность компилятора, сбои интерфейса, неточности и нарушения в программном коде.
Баги обнаруживаются чаще всего в момент отладки или бета-тестирования. Реже – после итогового релиза готовой программы. Вот несколько вариантов багов:
- Появляется сообщение об ошибке, но приложение продолжает функционировать.
- ПО вылетает или зависает. Никаких предупреждений или предпосылок этому не было. Процедура осуществляется неожиданно для пользователя. Возможен вариант, при котором контент перезапускается самостоятельно и непредсказуемо.
- Одно из событий, описанных ранее, сопровождается отправкой отчетов разработчикам.
Ошибки в программах могут привести соответствующее приложение в негодность, а также к непредсказуемым алгоритмам функционирования. Желательно обнаруживать баги на этапе ранней разработки или тестирования. Лишь в этом случае программист сможет оперативно и относительно недорого внести необходимые изменения в код для отладки ПО.
История происхождения термина
Баг – слово, которое используется разработчиками в качестве сленга. Оно произошло от слова «bug» – «жук». Точно неизвестно, откуда в программировании и IT возник соответствующий термин. Существуют две теории:
- 9 сентября 1945 года ученые из Гарварда тестировали очередную вычислительную машину. Она называлась Mark II Aiken Relay Calculator. Устройство начало работать с ошибками. Когда его разобрали, то ученые заметили мотылька, застрявшего между реле. Тогда некая Грейс Хоппер назвала произошедший сбой упомянутым термином.
- Слово «баг» появилось задолго до появления Mark II. Термин использовался Томасом Эдисоном и указывал на мелкие недочеты и трудности. Во время Второй Мировой войны «bugs» называли проблемы с радарной электроникой.
Второй вариант кажется более реалистичным. Это факт, который подтвержден документально. Со временем научились различать различные типы багов в IT. Далее они будут рассмотрены более подробно.
Как классифицируют
Ошибки работы программ разделяются по разным факторам. Классификация у рядовых пользователей и разработчиков различается. То, что для первых – «просто программа вылетела» или «глючит», для вторых – огромная головная боль. Но существует и общепринятая классификация ошибок. Пример – по критичности:
- Серьезные неполадки. Это нарушения работоспособности приложения, которые могут приводить к непредвиденным крупным изменениям.
- Незначительные ошибки в программах. Чаще всего не оказывают серьезного воздействия на функциональность ПО.
- Showstopper. Критические проблемы в приложении или аппаратном обеспечении. Приводят к выходу программы из строя почти всегда. Для примера можно взять любое клиент-серверное приложение, в котором не получается авторизоваться через логин и пароль.
Последний вариант требует особого внимания со стороны программистов. Их стараются обнаружить и устранить в первую очередь. Критические ошибки могут отложить релиз исходной программы на неопределенный срок.
Также существуют различные виды сбоев в плане частоты проявления: постоянные и «разовые». Вторые встречаются редко, чаще – при определенных настройках и действиях со стороны пользователя. Первые появляются независимо от используемой платформы и выполненных клиентом манипуляций.
Иногда может получиться так, что ошибка возникает только на устройстве конкретного пользователя. В данном случае устранение неполадки требует индивидуального подхода. Иногда – полной замены компьютера. Связано это с тем, что никто не будет редактировать исходный код, когда он «глючит» только у одного пользователя.
Виды
Существуют различные типы ошибок в программах в зависимости от типовых условий использования приложений. Пример – сбои, которые возникают при возрастании нагрузки на оперативную память или центральный процессор устройства. Есть баги граничных условий, сбоя идентификаторов, несовместимости с архитектурой процессора (наиболее распространенная проблема на мобильных устройствах).
Разработчики выделяют следующие типы ошибок по уровню сложности:
- «Борбаг» – «стабильная» неполадка. Она легко обнаруживается на этапе разработки и компилирования. Иногда – во время тестирования наработкой исходной программы.
- «Гейзенбаг» – баги с поддержкой изменения свойств, включая зависимость от среды, в которой было запущено приложение. Сюда относят периодические неполадки в программах. Они могут исчезать на некоторое время, но через какой-то промежуток вновь дают о себе знать.
- «Мандельбаг» – непредвиденные ошибки. Обладают энтропийным поведением. Предсказать, к чему они приведут, практически невозможно.
- «Шрединбаг» – критические неполадки. Приводят к тому, что злоумышленники могут взломать программу. Данный тип ошибок обнаружить достаточно трудно, потому что они никак себя не проявляют.
Также есть классификация «по критичности». Тут всего два варианта – warning («варнинги») и критические весомые сбои. Первые сопровождаются характерными сообщениями и отчетами для разработчиков. Они не представляют серьезной опасности для работоспособности приложения. При компилировании такие сбои легко исправляются. В отдельных случаях компилятор справляется с этой задачей самостоятельно. А вот критические весомые сбои говорят сами за себя. Они приводят к серьезным нарушениям ПО. Исправляются обычно путем проработки логики и значительных изменений программного кода.
Типы багов
Ошибки в программах бывают:
- логическими;
- синтаксическими;
- взаимодействия;
- компиляционные;
- ресурсные;
- арифметические;
- среды выполнения.
Это – основная классификация сбоев в приложениях и операционных системах. Логические, синтаксические и «среды выполнения» встречаются в разработке чаще остальных. На них будет сделан основной акцент.
Ошибки синтаксиса
Синтаксические баги распространены среди новичков. Они относятся к категории «самых безобидных». С данной категорией ошибок способны справиться компиляторы тех или иных языков. Соответствующие инструменты показывают, где допущена неточность. Остается лишь понять, как исправить ее.
Синтаксические ошибки – ошибки синтаксиса, правил языка. Вот пример в Паскале:

Код написан неверно. Согласно действующим синтаксическим нормам, в Pascal в первой строчке нужно в конце поставить точку с запятой.
Логические
Тут стоит выделить обычные и арифметические типы. Вторые возникают, когда программе при работе необходимо вычислить много переменных, но на каком-то этапе расчетов возникают неполадки или нечто непредвиденное. Пример – получение в результатах «бесконечности».
Логические сбои обычного типа – самые сложные и неприятные. Их тяжелее всего обнаружить и исправить. С точки зрения языка программа может быть написана идеально, но работать неправильно. Подобное явление – следствие логической ошибки. Компиляторы их не обнаруживают.

Выше – пример логической ошибки в программе. Тут:
- Происходит сравнение значения i с 15.
- На экран выводится сообщение, если I = 15.
- В заданном цикле i не будет равно 15. Связано это с диапазоном значений – от 1 до 10.
Может показаться, что ошибка безобидная. В приведенном примере так и есть, но в более крупных программах такое явление приводит к серьезным последствиям.
Время выполнения
Run-time сбои – это ошибка времени выполнения программы. Встречается даже когда исходный код лишен логических и синтаксических ошибок. Связаны такие неполадки с ходом выполнения программного продукта. Пример – в процессе функционирования ПО был удален файл, считываемый программой. Если игнорировать подобные неполадки, можно столкнуться с аварийным завершением работы контента.
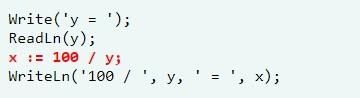
Самый распространенный пример в данной категории – это неожиданное деление на ноль. Предложенный фрагмент кода с точки зрения синтаксиса и логики написан грамотно. Но, если клиент наберет 0, произойдет сбой системы.
Компиляционный тип
Встречается при разработке на языках высокого уровня. Во время преобразований в машинный тип «что-то идет не так». Причиной служат синтаксические ошибки или сбои непосредственно в компиляторе.
Наличие подобных неполадок делает бета-тестирование невозможным. Компиляционные ошибки устраняются при разработке-отладке.
Ресурсные
Ресурсный тип ошибок – это сбои вроде «переполнение буфера» или «нехватка памяти». Тесно связаны с «железом» устройства. Могут быть вызваны действиями пользователя. Пример – запуск «свежих» игр на стареньких компьютерах.
Исправить ситуацию помогают основательные работы над исходным кодом. А именно – полное переписывание программы или «проблемного» фрагмента.
Взаимодействие
Подразумевается взаимодействие с аппаратным или программным окружением. Пример – ошибка при использовании веб-протоколов. Это приведет к тому, что облачный сервис не будет нормально функционировать. При постоянном возникновении соответствующей неполадки остается один путь – полностью переписывать «проблемный» участок кода, ответственный за соответствующий баг.
Исключения и как избежать багов
Исключение – событие, при возникновении которых начинается «неправильное» поведение программы. Механизм, необходимый для стабилизации обработки неполадок независимо от типа ПО, платформ и иных условий. Помогают разрабатывать единые концепции ответа на баги со стороны операционной системы или контента.
Исключения бывают:
- Программными. Они генерируются приложением или ОС.
- Аппаратными. Создаются процессором. Пример – обращение к невыделенной памяти.
Исключения нужны для охвата критических багов. Избежать неполадок помогут отладчики на этапе разработки. А еще – своевременное поэтапное тестирование программы.
P. S. Большой выбор курсов по тестированию есть и в Otus. Присутствуют варианты как для продвинутых, так и для начинающих пользователей.