Отладка программы призвана выискивать «вредителей» кода и устранять их. За это отвечают отладчик и журналирование для вывода сведений о программе.
В предыдущей части мы рассмотрели исходный код и его составляющие.
После того, как вы начнете проверять фрагменты кода или попытаетесь решить связанные с ним проблемы, вы очень скоро поймете, что существуют моменты, когда программа крашится, прерывается и прекращает работу.

Это часто вызвано ошибками, известными как дефекты или исключительные ситуации во время выполнения. Акт обнаружения и удаления ошибок из нашего кода – это отладка программы. Вы лучше разберетесь в отладке на практике, используя ее как можно чаще. Мы не только отлаживаем собственный код, но и порой дебажим написанное другими программистами.
Для начала необходимо рассортировать общие ошибки, которые могут возникнуть в исходном коде.

Синтаксические ошибки
Эти эрроры не позволяют скомпилировать исходный код на компилируемых языках программирования. Они обнаруживаются во время компиляции или интерпретации исходного кода. Они также могут быть легко обнаружены статическими анализаторами (линтами). Подробнее о линтах мы узнаем немного позже.
Синтаксические ошибки в основном вызваны нарушением ожидаемой формы или структуры языка, на котором пишется программа. Как пример, это может быть отсутствующая закрывающая скобка в уравнении.
Семантические ошибки
Отладка программы может потребоваться и по причине семантических ошибок, также известных как логические. Они являются наиболее сложными из всех, потому что не могут быть легко обнаружены. Признак того, что существует семантическая ошибка, – это когда программа запускается, отрабатывает, но не дает желаемого результата.
Рассмотрим данный пример:
3 + 5 * 6
По порядку приоритета, называемому старшинством операции, с учетом математических правил мы ожидаем, что сначала будет оценена часть умножения, и окончательный результат будет равен 33. Если программист хотел, чтобы сначала происходило добавление двух чисел, следовало поступить иначе. Для этого используются круглые скобки, которые отвечают за смещение приоритетов в математической формуле. Исправленный пример должен выглядеть так:
(3 + 5) * 6
3 + 5, заключенные в скобки, дадут желаемый результат, а именно 48.
Ошибки в процессе выполнения
Как и семантические, ошибки во время выполнения никогда не обнаруживаются при компиляции. В отличие от семантических ошибок, эти прерывают программу и препятствуют ее дальнейшему выполнению. Они обычно вызваны неожиданным результатом некоторых вычислений в исходном коде.
Вот хороший пример:
input = 25 x = 0.8/(Math.sqrt(input) - 5)
Фрагмент кода выше будет скомпилирован успешно, но input 25 приведет к ZeroDivisionError. Это ошибка во время выполнения. Другим популярным примером является StackOverflowError или IndexOutofBoundError. Важно то, что вы идентифицируете эти ошибки и узнаете, как с ними бороться.
Существуют ошибки, связанные с тем, как ваш исходный код использует память и пространство на платформе или в среде, в которой он запущен. Они также являются ошибками во время выполнения. Такие ошибки, как OutOfMemoryErrorand и HeapError обычно вызваны тем, что ваш исходный код использует слишком много ресурсов. Хорошее знание алгоритмов поможет написать код, который лучше использует ресурсы. В этом и заключается отладка программы.
Процесс перезаписи кода для повышения производительности называется оптимизацией. Менее популярное наименование процесса – рефакторинг. Поскольку вы тратите больше времени на кодинг, то должны иметь это в виду.
Отладка программы
Вот несколько советов о том, как правильно выполнять отладку:
- Использовать Linters. Linters – это инструменты, которые помогают считывать исходный код, чтобы проверить, соответствует ли он ожидаемому стандарту на выбранном языке программирования. Существуют линты для многих языков.
- Превалирование IDE над простыми редакторами. Вы можете выбрать IDE, разработанную для языка, который изучаете. IDE – это интегрированные среды разработки. Они созданы для написания, отладки, компиляции и запуска кода. Jetbrains создают отличные IDE, такие как Webstorm и IntelliJ. Также есть NetBeans, Komodo, Qt, Android Studio, XCode (поставляется с Mac), etc.
- Чтение кода вслух. Это полезно, когда вы ищете семантическую ошибку. Читая свой код вслух, есть большая вероятность, что вы зачитаете и ошибку.
- Чтение логов. Когда компилятор отмечает Error, обязательно посмотрите, где он находится.
Двигаемся дальше
Поздравляем! Слово «ошибка» уже привычно для вас, равно как и «отладка программы». В качестве новичка вы можете изучать кодинг по книгам, онлайн-урокам или видео. И даже чужой код вам теперь не страшен 
В процессе кодинга измените что-нибудь, чтобы понять, как он работает. Но будьте уверены в том, что сами написали.
Викторина
- Какая ошибка допущена в фрагменте кода Python ниже?
items = [0,1,2,3,4,5] print items[8] //комментарий: элементы здесь представляют собой массив с шестью элементами. Например, чтобы получить 4-й элемент, вы будете использовать [3]. Мы начинаем отсчет с 0.
- Какая ошибка допущена в фрагменте кода Python ниже?
input = Hippo' if input == 'Hippo': print 'Hello, Hippo'
Ответы на вопросы
- Ошибка выполнения: ошибка индекса вне диапазона.
2. Синтаксическая ошибка: Отсутствует стартовая кавычка в первой строке.
Добавлено 16 апреля 2021 в 20:18
В программном обеспечении распространены ошибки. Их легко сделать, а найти сложно. В этой главе мы рассмотрим темы, связанные с поиском и устранением ошибок в наших программах на C++, включая изучение того, как использовать интегрированный отладчик, который является частью нашей IDE.
Хотя инструменты и методы отладки не входят в стандарт C++, умение находить и устранять ошибки в программах, которые вы пишете, является чрезвычайно важной частью успешной работы программиста. Поэтому мы уделим немного времени рассмотрению этих тем, чтобы по мере усложнения программ, которые вы пишете, ваша способность диагностировать и устранять проблемы развивалась с той же скоростью.
Если у вас есть опыт отладки программ на другом компилируемом языке программирования, многое из этого будет вам знакомо.
Синтаксические и семантические ошибки
Программирование может быть сложной задачей, и C++ – довольно необычный язык. Сложите эти две вещи вместе и получите множество способов сделать ошибку. Ошибки обычно делятся на две категории: синтаксические ошибки и семантические ошибки (логические ошибки).
Синтаксическая ошибка возникает, когда вы пишете инструкцию, недопустимую в соответствии с грамматикой языка C++. Сюда входят такие ошибки, как отсутствие точек с запятой, использование необъявленных переменных, несоответствие круглых или фигурных скобок и т.д. Например, следующая программа содержит довольно много синтаксических ошибок:
#include <iostream>
int main()
{
std::cout < "Hi there"; << x; // недопустимый оператор (<), лишняя точка с запятой, необъявленная переменная (x)
return 0 // отсутствие точки с запятой в конце инструкции
}К счастью, компилятор обычно перехватывает синтаксические ошибки и генерирует предупреждения или ошибки, поэтому вы легко обнаружите и устраните проблему. Затем просто снова попробуйте скомпилировать программу, пока не избавитесь от всех ошибок.
После того, как ваша программа скомпилировалась правильно, может быть непросто добиться от нее желаемого результата. Семантическая ошибка возникает, когда оператор синтаксически правильный, но не выполняет то, что задумал программист.
Иногда это приводит к сбою программы, например, в случае деления на ноль:
#include <iostream>
int main()
{
int a { 10 };
int b { 0 };
std::cout << a << " / " << b << " = " << a / b; // деление на 0 не определено
return 0;
}Чаще всего они просто приводят к неправильному значению или поведению:
#include <iostream>
int main()
{
int x;
std::cout << x; // Использование неинициализированной переменной приводит к неопределенному результату
return 0;
}или же
#include <iostream>
int add(int x, int y)
{
return x - y; // функция должна складывать, но это не так
}
int main()
{
std::cout << add(5, 3); // должен выдать 8, но выдаст 2
return 0;
}или же
#include <iostream>
int main()
{
return 0; // функция завершается здесь
std::cout << "Hello, world!"; // поэтому это никогда не выполняется
}Современные компиляторы стали лучше обнаруживать определенные типы распространенных семантических ошибок (например, использование неинициализированной переменной). Однако в большинстве случаев компилятор не сможет отловить большинство из этих типов проблем, потому что компилятор предназначен для обеспечения соблюдения грамматики, а не намерений.
В приведенных выше примерах ошибки довольно легко обнаружить. Но в большинстве нетривиальных программ, взглянув на код, семантические ошибки найти нелегко. Здесь могут пригодиться методы отладки.
Теги
C++ / CppDebugLearnCppДля начинающихОбучениеОтладкаПрограммирование
Отладка программы призвана выискивать «вредителей» кода и устранять их. За это отвечают отладчик и журналирование для вывода сведений о программе.
В предыдущей части мы рассмотрели исходный код и его составляющие.
После того, как вы начнете проверять фрагменты кода или попытаетесь решить связанные с ним проблемы, вы очень скоро поймете, что существуют моменты, когда программа крашится, прерывается и прекращает работу.
Это часто вызвано ошибками, известными как дефекты или исключительные ситуации во время выполнения. Акт обнаружения и удаления ошибок из нашего кода – это отладка программы. Вы лучше разберетесь в отладке на практике, используя ее как можно чаще. Мы не только отлаживаем собственный код, но и порой дебажим написанное другими программистами.
Для начала необходимо рассортировать общие ошибки, которые могут возникнуть в исходном коде.
Синтаксические ошибки
Эти эрроры не позволяют скомпилировать исходный код на компилируемых языках программирования. Они обнаруживаются во время компиляции или интерпретации исходного кода. Они также могут быть легко обнаружены статическими анализаторами (линтами). Подробнее о линтах мы узнаем немного позже.
Синтаксические ошибки в основном вызваны нарушением ожидаемой формы или структуры языка, на котором пишется программа. Как пример, это может быть отсутствующая закрывающая скобка в уравнении.
Семантические ошибки
Отладка программы может потребоваться и по причине семантических ошибок, также известных как логические. Они являются наиболее сложными из всех, потому что не могут быть легко обнаружены. Признак того, что существует семантическая ошибка, – это когда программа запускается, отрабатывает, но не дает желаемого результата.
Рассмотрим данный пример:
3 + 5 * 6
По порядку приоритета, называемому старшинством операции, с учетом математических правил мы ожидаем, что сначала будет оценена часть умножения, и окончательный результат будет равен 33. Если программист хотел, чтобы сначала происходило добавление двух чисел, следовало поступить иначе. Для этого используются круглые скобки, которые отвечают за смещение приоритетов в математической формуле. Исправленный пример должен выглядеть так:
(3 + 5) * 6
3 + 5, заключенные в скобки, дадут желаемый результат, а именно 48.
Ошибки в процессе выполнения
Как и семантические, ошибки во время выполнения никогда не обнаруживаются при компиляции. В отличие от семантических ошибок, эти прерывают программу и препятствуют ее дальнейшему выполнению. Они обычно вызваны неожиданным результатом некоторых вычислений в исходном коде.
Вот хороший пример:
input = 25 x = 0.8/(Math.sqrt(input) - 5)
Фрагмент кода выше будет скомпилирован успешно, но input 25 приведет к ZeroDivisionError. Это ошибка во время выполнения. Другим популярным примером является StackOverflowError или IndexOutofBoundError. Важно то, что вы идентифицируете эти ошибки и узнаете, как с ними бороться.
Существуют ошибки, связанные с тем, как ваш исходный код использует память и пространство на платформе или в среде, в которой он запущен. Они также являются ошибками во время выполнения. Такие ошибки, как OutOfMemoryErrorand и HeapError обычно вызваны тем, что ваш исходный код использует слишком много ресурсов. Хорошее знание алгоритмов поможет написать код, который лучше использует ресурсы. В этом и заключается отладка программы.
Процесс перезаписи кода для повышения производительности называется оптимизацией. Менее популярное наименование процесса – рефакторинг. Поскольку вы тратите больше времени на кодинг, то должны иметь это в виду.
Отладка программы
Вот несколько советов о том, как правильно выполнять отладку:
- Использовать Linters. Linters – это инструменты, которые помогают считывать исходный код, чтобы проверить, соответствует ли он ожидаемому стандарту на выбранном языке программирования. Существуют линты для многих языков.
- Превалирование IDE над простыми редакторами. Вы можете выбрать IDE, разработанную для языка, который изучаете. IDE – это интегрированные среды разработки. Они созданы для написания, отладки, компиляции и запуска кода. Jetbrains создают отличные IDE, такие как Webstorm и IntelliJ. Также есть NetBeans, Komodo, Qt, Android Studio, XCode (поставляется с Mac), etc.
- Чтение кода вслух. Это полезно, когда вы ищете семантическую ошибку. Читая свой код вслух, есть большая вероятность, что вы зачитаете и ошибку.
- Чтение логов. Когда компилятор отмечает Error, обязательно посмотрите, где он находится.
Двигаемся дальше
Поздравляем! Слово «ошибка» уже привычно для вас, равно как и «отладка программы». В качестве новичка вы можете изучать кодинг по книгам, онлайн-урокам или видео. И даже чужой код вам теперь не страшен
В процессе кодинга измените что-нибудь, чтобы понять, как он работает. Но будьте уверены в том, что сами написали.
Викторина
- Какая ошибка допущена в фрагменте кода Python ниже?
items = [0,1,2,3,4,5] print items[8] //комментарий: элементы здесь представляют собой массив с шестью элементами. Например, чтобы получить 4-й элемент, вы будете использовать [3]. Мы начинаем отсчет с 0.
- Какая ошибка допущена в фрагменте кода Python ниже?
input = Hippo' if input == 'Hippo': print 'Hello, Hippo'
Ответы на вопросы
- Ошибка выполнения: ошибка индекса вне диапазона.
2. Синтаксическая ошибка: Отсутствует стартовая кавычка в первой строке.
Семантические ошибки в программировании
Ранее я рассказывал о видах ошибок в программировании. И там я упомянул об ошибках, которые я назвал логическими. Но вообще такие ошибки часто называют семантическими. И это самые труднонаходимые ошибки, которые доставляют программистам больше всего неприятностей. Поэтому я решил рассказать о них отдельно.
Семантика — это раздел лингвистики (науки о языках), который изучает смысловое значение частей языка (слов, предложений и т.п.).
Поскольку языки программирования — это тоже языки, то и правила и термины лингвистики точно также применимы и к языкам программирования. А семантика в языке программирования означает то же самое, что и в человеческом языке, например, в русском.
Семантика определяет смысл программы, а семантические ошибки связаны с нарушением смысла программы. То есть семантические ошибки нарушают логику программы (поэтому я и назвал их ранее логическими).
С точки зрения синтаксиса программа может быть безупречной. И даже во время выполнения в ней может не быть никаких ошибок. Но при этом она может быть бессмысленна с точки зрения решаемой задачи.
Например, вам надо было написать программу, которая вычисляет площадь круга. А вы “немного” ошиблись, и ваша программа вычисляет площадь прямоугольника.
При этом:
- Программа компилируется без ошибок
- Программа запускается, работает и завершается без ошибок
- Программа получает данные, обрабатывает их и выдаёт результат
Но, что самое страшное — пользователь думает, что результат правильный!!!
То есть программа безупречна во всём. Кроме одного — она решает не ту задачу, которую нужно решить пользователю. Поэтому с точки зрения пользователя она бессмысленна.
А с точки зрения программиста она содержит семантическую ошибку.
Такая программа делает не то, что вы от неё хотели, а то, что вы ей сказали. Вы ей сказали вычислять площадь прямоугольника, и она делает это. И это не её вина, а ваша. Вы дали неправильное указание.
Кстати, плохие руководители в жизни ведут себя точно также — дают сотрудникам неправильные или неоднозначные распоряжения, а потом удивляются, что работа выполнена неправильно. И обвиняют в этом, конечно, сотрудников.
Находить семантические ошибки бывает очень трудно. Особенно в чужих программах. Я это знаю не понаслышке. Иногда на это уходит несколько дней или даже недель. Иногда вообще хочется плюнуть на это и написать новую программу.
Так что старайтесь ещё до того, как начнёте писать код, тщательно продумать алгоритмы и прочие способы решения задачи, чтобы потом не было мучительно больно при поиске таких ошибок, которые не видит компилятор, и мучительно стыдно перед заказчиком.
А на сегодня всё. Подключайтесь к каналу в Телеграм или к другим моим группам, чтобы ничего не пропустить.
|
|
Основы программирования Каждый профессионал когда-то был чайником. Наверняка вам знакомо состояние, когда “не знаешь как начать думать, чтобы до такого додуматься”. Наверняка вы сталкивались с ситуацией, когда вы просто не знаете, с чего начать. Эта книга ориентирована как раз на таких людей, кто хотел бы стать программистом, но совершенно не знает, как начать этот путь. Подробнее… |

Dyslexia (Acquired) and Agraphia
M. Coltheart, in International Encyclopedia of the Social & Behavioral Sciences, 2001
1.6 Deep Dyslexia
This acquired dyslexia is reviewed in detail by Coltheart et al. (1980). Its cardinal symptom is the semantic error in reading aloud. When single isolated words are presented for reading aloud with no time pressure, the deep dyslexic will often produce as a response a word that is related in meaning, but in no other way, to the word he or she is looking at: dinner→‘food,’ uncle→‘cousin,’ and close→‘shut’ are examples of the semantic errors made by the deep dyslexic GR (Coltheart et al. 1980). Visual errors such as quarrel→‘squirrel’ or angle→‘angel,’ and morphological errors such as running→‘runner’ or unreal→‘real,’ are also seen. Concrete (highly-imageable) words such as tulip or green are much more likely to be successfully read than abstract (difficult-to-image) words such as idea or usual. Function words such as and, the, or or are very poorly read. Nonwords such as vib or ap cannot be read aloud at all.
As noted above, Marshall and Newcombe (1973) proposed that different forms of acquired dyslexia might be interpretable as consequences of specific different patterns of breakdown within a multicomponent model of the normal skilled reading system. That kind of interpretation has also been offered for deep dyslexia, by Morton and Patterson (1980). However, this way of approaching the explanation of deep dyslexia was rejected by Coltheart (1980) and Saffran et al. (1980), who proposed that deep dyslexic reading was not accomplished by an impaired version of the normal skilled reading system, located in the left hemisphere of the brain, but relied instead on reading mechanisms located in the intact right hemisphere.
Subsequent research has strongly favored the right-hemisphere interpretation of deep dyslexia. Patterson et al. (1987) report the case of an adolescent girl who developed a left-hemisphere pathology that necessitated removal of her left hemisphere. Before the onset of the brain disorder, she was apparently a normal reader for her age; after the removal of her left hemisphere, she was a deep dyslexic. Michel et al. (1996) report the case of a 23-year-old man who as a result of neurosurgery was left with a lesion of the posterior half of the corpus callosum. They studied his ability to read tachistoscopically displayed words presented to the left or right visual hemifields. With right hemifield (left hemisphere) presentation, his reading was normal. With left hemifield (right hemisphere) presentation, his reading showed all the symptoms of deep dyslexia. In a brain imaging study, Weekes et al. (1997) found that brain activation associated with visual word recognition was greater in the right than the left hemisphere for a deep dyslexic, but not for a surface dyslexic, nor for two normal readers.
It seems clear, then, that deep dyslexia is unlike all the other patterns of acquired dyslexia discussed here, in that deep dyslexics do not read via some damaged version of the normal (left-hemisphere) reading system, whereas patients with other forms of acquired dyslexia do.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B0080430767035816
The Development Process
Heinz Züllighoven, in Object-Oriented Construction Handbook, 2005
DISCUSSION
Advantages of pair programming
Pair programming has several advantages:
- •
-
It can improve the quality of the source code, because two people work together. There is a greater chance that concepts and programming conventions will be maintained. Formal and semantic errors are usually discovered right away.
- •
-
When pairs change systematically, knowledge about the overall system is dispersed throughout the team. The departure or unavailability of a developer thus has no serious effect on project progress.
- •
-
The developers frequently question design decisions. Any blocked thinking or dead ends are avoided in development.
Pair programming for team training
In addition to these advantages, which mainly apply to homogeneous pairs, pair programming can also be used for team training. For example, an experienced programmer works with the new team member in pairs. Two things are important when using pair programming for team training:
- •
-
New team members should have good basic programming knowledge; this is particularly important for retraining in a new technology. Without minimum qualification and experience, the gap between experienced and novice team members is too great, with the result that the inexperienced person does not understand the work at hand and is usually too timid to ask questions.
- •
-
Experienced programmers should keep an eye on the training task assigned to them. It should be made clear that this task does not focus on development work.
Training in pairs is efficient, but it requires a high degree of patience and discipline from the experienced programmer. We have successfully used this approach in projects and found that the technical and domain knowledge of new team members was quickly brought up to the level of the other members.
Pair programming develops its full potential when used in conjunction with refactoring (see Section 12.3.5), design by contract (see Section 2.3), test classes (see Section 12.4.2), continuous integration, and collective ownership. Continuous integration simply means that sources that have been changed are integrated as quickly as possible. Integration should take place several times a day during the construction phase.
Collective ownership means that each developer may basically change all documents and source texts of a project at any time. The overall project knowledge required for this can be disseminated effectively in pair programming.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9781558606876500128
Multiobjective Optimization for Software Refactoring and Evolution
Ali Ouni, … Houari Sahraoui, in Advances in Computers, 2014
5.1 Approach Overview
Our approach aims at exploring a huge search space to find refactoring solutions, i.e., sequence of refactoring operations, to correct bad smells. In fact, the search space is determined not only by the number of possible refactoring combinations but also by the order in which they are applied. Thus, a heuristic-based optimization method is used to generate refactoring solutions. We have four objectives to optimize: (1) maximize quality improvement (bad-smells correction), (2) minimize the number of semantic errors by preserving the way how code elements are semantically grouped and connected together, (3) minimize code changes needed to apply refactoring, and (4) maximize the consistency with development change history. To this end, we consider the refactoring as a multiobjective optimization problem instead of a single-objective one using the NSGA-II [50].
Our approach takes as inputs a source code of the program to be refactored, a list of possible refactorings that can be applied, a set of bad-smells detection rules [21,24], our technique for approximating code changes needed to apply refactorings, a set of semantic measures, and a history of applied refactorings to previous versions of the system. Our approach generates as output the optimal sequence of refactorings, selected from an exhaustive list of possible refactorings, that improve the software quality by minimizing as much as possible the number of design defects, minimize code change needed to apply refactorings, preserve semantic coherence, and maximize the consistency with development change history.
In the following, we describe the formal formulation of our four objectives to optimize.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128001615000049
Infrastructure and technology
Krish Krishnan, in Building Big Data Applications, 2020
Execution—how does Hive process queries?
A HiveQL statement is submitted via the CLI, the web UI, or an external client using the Thrift, ODBC, or JDBC API. The driver first passes the query to the compiler where it goes through parse, type check, and semantic analysis using the metadata stored in the metastore. The compiler generates a logical plan that is then optimized through a simple rule–based optimizer. Finally an optimized plan in the form of a DAG of mapreduce tasks and HDFS tasks is generated. The execution engine then executes these tasks in the order of their dependencies, using Hadoop.
We can further analyze this workflow of processing as follows:
- •
-
Hive client triggers a query
- •
-
Compiler receives the query and connects to metastore
- •
-
Compiler receives the query and initiates the first phase of compilation
- •
-
Parser—Converts the query into parse tree representation. Hive uses ANTLR to generate the abstract syntax tree (AST)
- •
-
Semantic Analyzer—In this stage the compiler builds a logical plan based on the information that is provided by the metastore on the input and output tables. Additionally the complier also checks type compatibilities in expressions and flags compile time semantic errors at this stage. The best step is the transformation of an AST to intermediate representation that is called the query block (QB) tree. Nested queries are converted into parent–child relationships in a QB tree during this stage
- •
-
Logical Plan Generator—In this stage the compiler writes the logical plan from the semantic analyzer into a logical tree of operations
- •
-
Optimization—This is the most involved phase of the complier as the entire series of DAG optimizations are implemented in this phase. There are several customizations than can be done to the complier if desired. The primary operations done at this stage are as follows:
- —
-
Logical optimization—Perform multiple passes over logical plan and rewrites in several ways
- —
-
Column pruning—This optimization step ensures that only the columns that are needed in the query processing are actually projected out of the row
- —
-
Predicate pushdown—Predicates are pushed down to the scan if possible so that rows can be filtered early in the processing
- —
-
Partition pruning—Predicates on partitioned columns are used to prune out files of partitions that do not satisfy the predicate
- —
-
Join optimization
- —
-
Grouping and regrouping
- —
-
Repartitioning
- —
-
Physical plan generator converts logical plan into physical.
- —
-
Physical plan generation creates the final DAG workflow of MapReduce
- •
-
Execution engine gets the compiler outputs to execute on the Hadoop platform.
- —
-
All the tasks are executed in the order of their dependencies. Each task is only executed if all of its prerequisites have been executed.
- —
-
A map/reduce task first serializes its part of the plan into a plan.xml file.
- —
-
This file is then added to the job cache for the task and instances of ExecMapper and ExecReducers are spawned using Hadoop.
- —
-
Each of these classes deserializes the plan.xml and executes the relevant part of the task.
- —
-
The final results are stored in a temporary location and at the completion of the entire query, the results are moved to the table if inserts or partitions, or returned to the calling program at a temporary location
The comparison between how Hive executes versus a traditional RDBMS shows that due to the schema on read design, the data placement, partitioning, joining, and storage can be decided at the execution time rather than planning cycles.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128157466000028
Data Types
Michael L. Scott, in Programming Language Pragmatics (Third Edition), 2009
Coercion
Example 7.27
Coercion in Ada
Whenever a language allows a value of one type to be used in a context that expects another, the language implementation must perform an automatic, implicit conversion to the expected type. This conversion is called a type coercion. Like the explicit conversions discussed above, a coercion may require run-time code to perform a dynamic semantic check, or to convert between low-level representations. Ada coercions sometimes need the former, though never the latter:
d : weekday; — as in Example 7.3
k : workday; — as in Example 7.9
type calendar_column is new weekday;
c : calendar_column;
…
k := d; — run-time check required
d := k; — no check required; every workday is a weekday
c := d; — static semantic error;
— weekdays and calendar_columns are not compatible
To perform this third assignment in Ada we would have to use an explicit conversion:
c := calendar_column(d);
Example 7.28
Coercion in C
As we noted in Section 3.5.3, coercions are a controversial subject in language design. Because they allow types to be mixed without an explicit indication of intent on the part of the programmer, they represent a significant weakening of type security. C, which has a relatively weak type system, performs quite a bit of coercion. It allows values of most numeric types to be intermixed in expressions, and will coerce types back and forth “as necessary.” Here are some examples:
short int s;
unsigned long int l;
char c; /* may be signed or unsigned — implementation-dependent */
float f; /* usually IEEE single-precision */
double d; /* usually IEEE double-precision */
…
s = l; /* l’s low-order bits are interpreted as a signed number. */
l = s; /* s is sign-extended to the longer length, then
its bits are interpreted as an unsigned number. */
s = c; /* c is either sign-extended or zero-extended to s’s length;
the result is then interpreted as a signed number. */
f = l; /* l is converted to floating-point. Since f has fewer
significant bits, some precision may be lost. */
d = f; /* f is converted to the longer format; no precision lost. */
f = d; /* d is converted to the shorter format; precision may be lost.
If d’s value cannot be represented in single-precision, the
result is undefined, but NOT a dynamic semantic error. */
Fortran 90 allows arrays and records to be intermixed if their types have the same shape. Two arrays have the same shape if they have the same number of dimensions, each dimension has the same size (i.e., the same number of elements), and the individual elements have the same shape. (In some other languages, the actual bounds of each dimension must be the same for the shapes to be considered the same.) Two records have the same shape if they have the same number of fields, and corresponding fields, in order, have the same shape. Field names do not matter, nor do the actual high and low bounds of array dimensions.
Ada’s compatibility rules for arrays are roughly equivalent to those of Fortran 90. C provides no operations that take an entire array as an operand. C does, however, allow arrays and pointers to be intermixed in many cases; we will discuss this unusual form of type compatibility further in Section 7.7.1. Neither Ada nor C allows records (structures) to be intermixed unless their types are name equivalent.
In general, modern compiled languages display a trend toward static typing and away from type coercion. Some language designers have argued, however, that coercions are a natural way in which to support abstraction and program extensibility, by making it easier to use new types in conjunction with existing ones. This ease-of-programming argument is particularly important for scripting languages (Chapter 13). Among more traditional languages, C++ provides an extremely rich, programmer-extensible set of coercion rules. When defining a new type (a class in C++), the programmer can define coercion operations to convert values of the new type to and from existing types. These rules interact in complicated ways with the rules for resolving overloading (Section 3.5.2); they add significant flexibility to the language, but are one of the most difficult C++ features to understand and use correctly.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123745149000173
Programming Language Syntax
Michael L. Scott, in Programming Language Pragmatics (Third Edition), 2009
2.3.4 Syntax Errors
Example 2.42
A Syntax Error in C
Suppose we are parsing a C program and see the following code fragment in a context where a statement is expected:
A = B : C + D;
We will detect a syntax error immediately after the B, when the colon appears from the scanner. At this point the simplest thing to do is just to print an error message and halt. This naive approach is generally not acceptable, however: it would mean that every run of the compiler reveals no more than one syntax error. Since most programs, at least at first, contain numerous such errors, we really need to find as many as possible now (we’d also like to continue looking for semantic errors). To do so, we must modify the state of the parser and/or the input stream so that the upcoming token(s) are acceptable. We shall probably want to turn off code generation, disabling the back end of the compiler: since the input is not a valid program, the code will not be of use, and there’s no point in spending time creating it.
In general, the term syntax error recovery is applied to any technique that allows the compiler, in the face of a syntax error, to continue looking for other errors later in the program. High-quality syntax error recovery is essential in any production-quality compiler. The better the recovery technique, the more likely the compiler will be to recognize additional errors (especially nearby errors) correctly, and the less likely it will be to become confused and announce spurious cascading errors later in the program.
 In More Depth
In More Depth
On the PLP CD we explore several possible approaches to syntax error recovery. In panic mode, the compiler writer defines a small set of “safe symbols” that delimit clean points in the input. Semicolons, which typically end a statement, are a good choice in many languages. When an error occurs, the compiler deletes input tokens until it finds a safe symbol, and then “backs the parser out” (e.g., returns from recursive descent subroutines) until it finds a context in which that symbol might appear. Phrase-level recovery improves on this technique by employing different sets of “safe” symbols in different productions of the grammar (right parentheses when in an expression; semicolons when in a declaration). Context-specific look-ahead obtains additional improvements by differentiating among the various contexts in which a given production might appear in a syntax tree. To respond gracefully to certain common programming errors, the compiler writer may augment the grammar with error productions that capture language-specific idioms that are incorrect but are often written by mistake.
Niklaus Wirth published an elegant implementation of phrase-level and context-specific recovery for recursive descent parsers in 1976 [Wir76, Sec. 5.9]. Exceptions (to be discussed further in Section 8.5) provide a simpler alternative if supported by the language in which the compiler is written. For table-driven top-down parsers, Fischer, Milton, and Quiring published an algorithm in 1980 that automatically implements a well-defined notion of locally least-cost syntax repair. Locally least-cost repair is also possible in bottom-up parsers, but it is significantly more difficult. Most bottom-up parsers rely on more straightforward phrase-level recovery; a typical example can be found in Yacc/bison.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123745149000112
Introduction
Michael L. Scott, in Programming Language Pragmatics (Third Edition), 2009
1.8 Exercises
- 1.1
-
Errors in a computer program can be classified according to when they are detected and, if they are detected at compile time, what part of the compiler detects them. Using your favorite imperative language, give an example of each of the following.
- (a)
-
A lexical error, detected by the scanner
- (b)
-
A syntax error, detected by the parser
- (c)
-
A static semantic error, detected by semantic analysis
- (d)
-
A dynamic semantic error, detected by code generated by the compiler
- (e)
-
An error that the compiler can neither catch nor easily generate code to catch (this should be a violation of the language definition, not just a program bug)
- 1.2
-
Consider again the Pascal tool set distributed by Niklaus Wirth (Example 1.15). After successfully building a machine language version of the Pascal compiler, one could in principle discard the P-code interpreter and the P-code version of the compiler. Why might one choose not to do so?
- 1.3
-
Imperative languages like Fortran and C are typically compiled, while scripting languages, in which many issues cannot be settled until run time, are typically interpreted. Is interpretation simply what one “has to do” when compilation is infeasible, or are there actually some advantages to interpreting a language, even when a compiler is available?
- 1.4
-
The gcd program of Example 1.20 might also be written
int main() {
int i = getint(), j = getint();
while (i != j) {
if (i > j) i = i % j;
else j = j % i;
}
putint(i);
}
Does this program compute the same result? If not, can you fix it? Under what circumstances would you expect one or the other to be faster?
- 1.5
-
In your local implementation of C, what is the limit on the size of integers? What happens in the event of arithmetic overflow? What are the implications of size limits on the portability of programs from one machine/compiler to another? How do the answers to these questions differ for Java? For Ada? For Pascal? For Scheme? (You may need to find a manual.)
- 1.6
-
The Unix make utility allows the programmer to specify dependences among the separately compiled pieces of a program. If file A depends on file B and file B is modified, make deduces that A must be recompiled, in case any of the changes to B would affect the code produced for A. How accurate is this sort of dependence management? Under what circumstances will it lead to unnecessary work? Under what circumstances will it fail to recompile something that needs to be recompiled?
- 1.7
-
Why is it difficult to tell whether a program is correct? How do you go about finding bugs in your code? What kinds of bugs are revealed by testing? What kinds of bugs are not? (For more formal notions of program correctness, see the bibliographic notes at the end of Chapter 4.)
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123745149000100
Names, Scopes, and Bindings
Michael L. Scott, in Programming Language Pragmatics (Third Edition), 2009
3.3.3 Declaration Order
In our discussion so far we have glossed over an important subtlety: suppose an object x is declared somewhere within block B. Does the scope of x include the portion of B before the declaration, and if so can x actually be used in that portion of the code? Put another way, can an expression E refer to any name declared in the current scope, or only to names that are declared before E in the scope?
Several early languages, including Algol 60 and Lisp, required that all declarations appear at the beginning of their scope. One might at first think that this rule would avoid the questions in the preceding paragraph, but it does not, because declarations may refer to one another.7
Example 3.7
A “Gotcha” in Declare-Before-Use
In an apparent attempt to simplify the implementation of the compiler, Pascal modified the requirement to say that names must be declared before they are used (with special-case mechanisms to accommodate recursive types and subroutines). At the same time, however, Pascal retained the notion that the scope of a declaration is the entire surrounding block. These two rules can interact in surprising ways:
- 1.
-
const N = 10;
- 2.
-
…
- 3.
-
procedure foo;
- 4.
-
const
- 5.
-
M = N; (* static semantic error! *)
- 6.
-
…
- 7.
-
N = 20; (* local constant declaration; hides the outer N *)
Pascal says that the second declaration of N covers all of foo, so the semantic analyzer should complain on line 5 that N is being used before its declaration. The error has the potential to be highly confusing, particularly if the programmer meant to use the outer N:
const N = 10;
…
procedure foo;
const
M = N; (* static semantic error! *)
var
A : array [1..M] of integer;
N : real; (* hiding declaration *)
Here the pair of messages “N used before declaration” and “N is not a constant” are almost certainly not helpful.
In order to determine the validity of any declaration that appears to use a name from a surrounding scope, a Pascal compiler must scan the remainder of the scope’s declarations to see if the name is hidden. To avoid this complication, most Pascal successors (and some dialects of Pascal itself) specify that the scope of an identifier is not the entire block in which it is declared (excluding holes), but rather the portion of that block from the declaration to the end (again excluding holes). If our program fragment had been written in Ada, for example, or in C, C++, or Java, no semantic errors would be reported. The declaration of M would refer to the first (outer) declaration of N.
Design & Implementation
Mutual Recursion
Some Algol 60 compilers were known to process the declarations of a scope in program order. This strategy had the unfortunate effect of implicitly outlawing mutually recursive subroutines and types, something the language designers clearly did not intend [Atk73].
Example 3.8
Whole-Block Scope in C#
C++ and Java further relax the rules by dispensing with the define-before-use requirement in many cases. In both languages, members of a class (including those that are not defined until later in the program text) are visible inside all of the class’s methods. In Java, classes themselves can be declared in any order. Interestingly, while C# echos Java in requiring declaration before use for local variables (but not for classes and members), it returns to the Pascal notion of whole-block scope. Thus the following is invalid in C#.
class A
const int N = 10;
void foo()
const int M = N; // uses inner N before it is declared
const int N = 20;
Example 3.9
“Local if written” in Python
Perhaps the simplest approach to declaration order, from a conceptual point of view, is that of Modula-3, which says that the scope of a declaration is the entire block in which it appears (minus any holes created by nested declarations), and that the order of declarations doesn’t matter. The principal objection to this approach is that programmers may find it counterintuitive to use a local variable before it is declared. Python takes the “whole block” scope rule one step further by dispensing with variable declarations altogether. In their place it adopts the unusual convention that the local variables of subroutine S are precisely those variables that are written by some statement in the (static) body of S. If S is nested inside of T, and the name x appears on the left-hand side of assignment statements in both S and T, then the x‘s are distinct: there is one in S and one in T. Non-local variables are read-only unless explicitly imported (using Python’s global statement). We will consider these conventions in more detail in Section 13.4.1, as part of a general discussion of scoping in scripting languages.
Example 3.10
Declaration Order in Scheme
In the interest of flexibility, modern Lisp dialects tend to provide several options for declaration order. In Scheme, for example, the letrec and let* constructs define scopes with, respectively, whole-block and declaration-to-end-of-block semantics. The most frequently used construct, let, provides yet another option:
(let ((A 1)) ; outer scope, with A defined to be 1
(let ((A 2) ; inner scope, with A defined to be 2
(B A)) ; and B defined to be A
B)) ; return the value of B
Here the nested declarations of A and B don’t until after the end of the declaration list. Thus when B is defined, the redefinition of A has not yet taken effect. B is defined to be the outer A, and the code as a whole returns 1.
Declarations and Definitions
Example 3.11
Declarations vs Definitions in C
Recursive types and subroutines introduce a problem for languages that require names to be declared before they can be used: how can two declarations each appear before the other? C and C++ handle the problem by distinguishing between the declaration of an object and its definition. A declaration introduces a name and indicates its scope, but may omit certain implementation details. A definition describes the object in sufficient detail for the compiler to determine its implementation. If a declaration is not complete enough to be a definition, then a separate definition must appear somewhere else in the scope. In C we can write
struct manager; /* declaration only */
struct employee {
struct manager *boss;
struct employee *next_employee;
…
};
struct manager { /* definition */
struct employee *first_employee;
…
};
and
void list_tail(follow_set fs); /* declaration only */
void list(follow_set fs)
{
switch (input_token) {
case id : match(id); list_tail(fs);
…
}
void list_tail(follow_set fs) /* definition */
{
switch (input_token) {
case comma : match(comma); list(fs);
…
}
The initial declaration of manager needed only to introduce a name: since pointers are all the same size, the compiler could determine the implementation of employee without knowing any manager details. The initial declaration of list_tail, however, must include the return type and parameter list, so the compiler can tell that the call in list is correct.
Nested Blocks
In many languages, including Algol 60, C89, and Ada, local variables can be declared not only at the beginning of any subroutine, but also at the top of any begin…end ({…}) block. Other languages, including Algol 68, C99, and all of C’s descendants, are even more flexible, allowing declarations wherever a statement may appear. In most languages a nested declaration hides any outer declaration with the same name (Java and C# make it a static semantic error if the outer declaration is local to the current subroutine).
Example 3.12
Inner Declarations in C
Variables declared in nested blocks can be very useful, as for example in the following C code:
{
int temp = a;
a = b;
b = temp;
}
Keeping the declaration of temp lexically adjacent to the code that uses it makes the program easier to read, and eliminates any possibility that this code will interfere with another variable named temp.
No run-time work is needed to allocate or deallocate space for variables declared in nested blocks; their space can be included in the total space for local variables allocated in the subroutine prologue and deallocated in the epilogue. Exercise 3.9 considers how to minimize the total space required.
Design & Implementation
Redeclarations
Some languages, particularly those that are intended for interactive use, permit the programmer to redeclare an object: to create a new binding for a given name in a given scope. Interactive programmers commonly use redeclarations to fix bugs. In most interactive languages, the new meaning of the name replaces the old in all contexts. In ML, however, the old meaning of the name may remain accessible to functions that were elaborated before the name was redeclared. This design choice in ML can sometimes be counterintuitive. It probably reflects the fact that ML is usually compiled, bit by bit on the fly, rather than interpreted. A language like Scheme, which is lexically scoped but usually interpreted, stores the binding for a name in a known location. A program accesses the meaning of the name indirectly through that location: if the meaning of the name changes, all accesses to the name will use the new meaning. In ML, previously elaborated functions have already been compiled into a form (often machine code) that accesses the meaning of the name directly.
 Check Your Understanding
Check Your Understanding
- 12.
-
What do we mean by the scope of a name-to-object binding?
- 13.
-
Describe the difference between static and dynamic scoping.
- 14.
-
What is elaboration?
- 15.
-
What is a referencing environment?
- 16.
-
Explain the closest nested scope rule.
- 17.
-
What is the purpose of a scope resolution operator?
- 18.
-
What is a static chain? What is it used for?
- 19.
-
What are forward references? Why are they prohibited or restricted in many programming languages?
- 20.
-
Explain the difference between a declaration and a definition. Why is the distinction important?
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123745149000124
Named Entity Resolution in Social Media
Paul A. Watters, in Automating Open Source Intelligence, 2016
Discussion
In this chapter, I have sketched out two different algorithmic approaches that could be used undertake named entity resolution. The first takes a dynamical systems view of the machine translation process and how it can account for translations that either succeed or fail, and provides a metaphor for how dynamical system states can be related to single-pass translations using the iterative semantic processing paradigm. In the three examples presented in this chapter, I have demonstrated how dynamical system states correspond to the different kinds of translation errors of semantic material in the context of direct translations systems (e.g., word sense disambiguation of polysemous words). In terms of the absolute preservation of meaning across sentences, the aim of the translation system is to form a point attractor in a “translation space,” although we have also seen that for practical purposes, limit cycles are also acceptable. Unacceptable translations defined by the iterative method are those that rapidly lose information about their initial semantic conditions, perhaps by a translation system equivalent to the period-doubling route to chaos.
What is important about describing machine translation systems using this methodology is that it is possible to use these states as benchmarks for the performance of translation systems. Thus, when translation systems are modified to correct characteristic semantic errors, it is possible to directly assess the performance improvement by using the two statistical measures we have introduced in this chapter, the iterative information loss index, ILOSS, and the cumulative information losses, ITOTAL. An attempt to reduce errors at any particular translation stage can be monitored by examining ILOSS at that particular iteration – for example, some direct translation systems have excellent source→target dictionaries, but poor target→source dictionaries. Improvement of the latter can be tracked at iteration 2 (and indeed, all even-numbered iterations thereafter), with a reduction in ITOTAL after all translations being the main indicator of overall performance.
Obviously, computing these statistics from single sentences is misleading in the sense that they are drawn from larger discourse, and should always be considered with respect to their literary or linguistic origins. Discourse longer than single sentences or phrases is needed for measures of entropy or of information loss to become statistically reliable. In addition, the computation of numerical exponents to quantify the rate of information loss in terms of the system’s entropy (e.g., Lyapunov exponent) needs to be developed and applied to both single sentences and large corpora.
From a neural network perspective, the dynamics of resolving named entities has similarities to resolving the senses of polysemous terms, especially by taking advantage of local context through semantic priming. From the simple examples shown here, it should be obvious how similar contextual information could be used to resolve the identities of individual names on social media. A key question remains as to how such context can be readily gathered using an automated process: for semantic priming of polysemous terms, parameter estimates must be supplied to the model a priori, yet fully automated OSINT systems would not necessarily have trusted access (Tran, Watters, & Hitchens, 2005) to this kind of data. Future research is needed to determine the extent to which names can be automatically resolved, versus a set of candidate choices should be presented to a knowledgeable analyst.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128029169000026
Fundamental Concepts
Peter J. Ashenden, in The Designer’s Guide to VHDL (Third Edition), 2008
1.4.5 Analysis, Elaboration and Execution
One of the main reasons for writing a model of a system is to enable us to simulate it. This involves three stages: analysis, elaboration and execution. Analysis and elaboration are also required in preparation for other uses of the model, such as logic synthesis.
In the first stage, analysis, the VHDL description of a system is checked for various kinds of errors. Like most programming languages, VHDL has rigidly defined syntax and semantics. The syntax is the set of grammatical rules that govern how a model is written. The rules of semantics govern the meaning of a program. For example, it makes sense to perform an addition operation on two numbers but not on two processes.
During the analysis phase, the VHDL description is examined, and syntactic and static semantic errors are located. The whole model of a system need not be analyzed at once. Instead, it is possible to analyze design units, such as entity and architecture body declarations, separately. If the analyzer finds no errors in a design unit, it creates an intermediate representation of the unit and stores it in a library. The exact mechanism varies between VHDL tools.
The second stage in simulating a model, elaboration, is the act of working through the design hierarchy and creating all of the objects defined in declarations. The ultimate product of design elaboration is a collection of signals and processes, with each process possibly containing variables. A model must be reducible to a collection of signals and processes in order to simulate it.
We can see how elaboration achieves this reduction by starting at the top level of a model, namely, an entity, and choosing an architecture of the entity to simulate. The architecture comprises signals, processes and component instances. Each component instance is a copy of an entity and an architecture that also comprises signals, processes and component instances. Instances of those signals and processes are created, corresponding to the component instance, and then the elaboration operation is repeated for the subcomponent instances. Ultimately, a component instance is reached that is a copy of an entity with a purely behavioral architecture, containing only processes. This corresponds to a primitive component for the level of design being simulated. Figure 1.7 shows how elaboration proceeds for the structural architecture body of the reg4 entity from Example 1.3. As each instance of a process is created, its variables are created and given initial values. We can think of each process instance as corresponding to one instance of a component.

Figure 1.7. The elaboration of the reg4 entity using the structural architecture body. Each instance of the d_ff and and2 entities is replaced with the contents of the corresponding basic architecture. These each consist of a process with its variables and statements.
The third stage of simulation is the execution of the model. The passage of time is simulated in discrete steps, depending on when events occur. Hence the term discrete event simulation is used. At some simulation time, a process may be stimulated by changing the value on a signal to which it is sensitive. The process is resumed and may schedule new values to be given to signals at some later simulated time. This is called scheduling a transaction on that signal. If the new value is different from the previous value on the signal, an event occurs, and other processes sensitive to the signal may be resumed.
The simulation starts with an initialization phase, followed by repetitive execution of a simulation cycle. During the initialization phase, each signal is given an initial value, depending on its type. The simulation time is set to zero, then each process instance is activated and its sequential statements executed. Usually, a process will include a signal assignment statement to schedule a transaction on a signal at some later simulation time. Execution of a process continues until it reaches a wait statement, which causes the process to be suspended.
During the simulation cycle, the simulation time is first advanced to the next time at which a transaction on a signal has been scheduled. Second, all the transactions scheduled for that time are performed. This may cause some events to occur on some signals. Third, all processes that are sensitive to those events are resumed and are allowed to continue until they reach a wait statement and suspend. Again, the processes usually execute signal assignments to schedule further transactions on signals. When all the processes have suspended again, the simulation cycle is repeated. When the simulation gets to the stage where there are no further transactions scheduled, it stops, since the simulation is then complete.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780120887859000010
Dyslexia (Acquired) and Agraphia
M. Coltheart, in International Encyclopedia of the Social & Behavioral Sciences, 2001
1.6 Deep Dyslexia
This acquired dyslexia is reviewed in detail by Coltheart et al. (1980). Its cardinal symptom is the semantic error in reading aloud. When single isolated words are presented for reading aloud with no time pressure, the deep dyslexic will often produce as a response a word that is related in meaning, but in no other way, to the word he or she is looking at: dinner→‘food,’ uncle→‘cousin,’ and close→‘shut’ are examples of the semantic errors made by the deep dyslexic GR (Coltheart et al. 1980). Visual errors such as quarrel→‘squirrel’ or angle→‘angel,’ and morphological errors such as running→‘runner’ or unreal→‘real,’ are also seen. Concrete (highly-imageable) words such as tulip or green are much more likely to be successfully read than abstract (difficult-to-image) words such as idea or usual. Function words such as and, the, or or are very poorly read. Nonwords such as vib or ap cannot be read aloud at all.
As noted above, Marshall and Newcombe (1973) proposed that different forms of acquired dyslexia might be interpretable as consequences of specific different patterns of breakdown within a multicomponent model of the normal skilled reading system. That kind of interpretation has also been offered for deep dyslexia, by Morton and Patterson (1980). However, this way of approaching the explanation of deep dyslexia was rejected by Coltheart (1980) and Saffran et al. (1980), who proposed that deep dyslexic reading was not accomplished by an impaired version of the normal skilled reading system, located in the left hemisphere of the brain, but relied instead on reading mechanisms located in the intact right hemisphere.
Subsequent research has strongly favored the right-hemisphere interpretation of deep dyslexia. Patterson et al. (1987) report the case of an adolescent girl who developed a left-hemisphere pathology that necessitated removal of her left hemisphere. Before the onset of the brain disorder, she was apparently a normal reader for her age; after the removal of her left hemisphere, she was a deep dyslexic. Michel et al. (1996) report the case of a 23-year-old man who as a result of neurosurgery was left with a lesion of the posterior half of the corpus callosum. They studied his ability to read tachistoscopically displayed words presented to the left or right visual hemifields. With right hemifield (left hemisphere) presentation, his reading was normal. With left hemifield (right hemisphere) presentation, his reading showed all the symptoms of deep dyslexia. In a brain imaging study, Weekes et al. (1997) found that brain activation associated with visual word recognition was greater in the right than the left hemisphere for a deep dyslexic, but not for a surface dyslexic, nor for two normal readers.
It seems clear, then, that deep dyslexia is unlike all the other patterns of acquired dyslexia discussed here, in that deep dyslexics do not read via some damaged version of the normal (left-hemisphere) reading system, whereas patients with other forms of acquired dyslexia do.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B0080430767035816
The Development Process
Heinz Züllighoven, in Object-Oriented Construction Handbook, 2005
DISCUSSION
Advantages of pair programming
Pair programming has several advantages:
- •
-
It can improve the quality of the source code, because two people work together. There is a greater chance that concepts and programming conventions will be maintained. Formal and semantic errors are usually discovered right away.
- •
-
When pairs change systematically, knowledge about the overall system is dispersed throughout the team. The departure or unavailability of a developer thus has no serious effect on project progress.
- •
-
The developers frequently question design decisions. Any blocked thinking or dead ends are avoided in development.
Pair programming for team training
In addition to these advantages, which mainly apply to homogeneous pairs, pair programming can also be used for team training. For example, an experienced programmer works with the new team member in pairs. Two things are important when using pair programming for team training:
- •
-
New team members should have good basic programming knowledge; this is particularly important for retraining in a new technology. Without minimum qualification and experience, the gap between experienced and novice team members is too great, with the result that the inexperienced person does not understand the work at hand and is usually too timid to ask questions.
- •
-
Experienced programmers should keep an eye on the training task assigned to them. It should be made clear that this task does not focus on development work.
Training in pairs is efficient, but it requires a high degree of patience and discipline from the experienced programmer. We have successfully used this approach in projects and found that the technical and domain knowledge of new team members was quickly brought up to the level of the other members.
Pair programming develops its full potential when used in conjunction with refactoring (see Section 12.3.5), design by contract (see Section 2.3), test classes (see Section 12.4.2), continuous integration, and collective ownership. Continuous integration simply means that sources that have been changed are integrated as quickly as possible. Integration should take place several times a day during the construction phase.
Collective ownership means that each developer may basically change all documents and source texts of a project at any time. The overall project knowledge required for this can be disseminated effectively in pair programming.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9781558606876500128
Multiobjective Optimization for Software Refactoring and Evolution
Ali Ouni, … Houari Sahraoui, in Advances in Computers, 2014
5.1 Approach Overview
Our approach aims at exploring a huge search space to find refactoring solutions, i.e., sequence of refactoring operations, to correct bad smells. In fact, the search space is determined not only by the number of possible refactoring combinations but also by the order in which they are applied. Thus, a heuristic-based optimization method is used to generate refactoring solutions. We have four objectives to optimize: (1) maximize quality improvement (bad-smells correction), (2) minimize the number of semantic errors by preserving the way how code elements are semantically grouped and connected together, (3) minimize code changes needed to apply refactoring, and (4) maximize the consistency with development change history. To this end, we consider the refactoring as a multiobjective optimization problem instead of a single-objective one using the NSGA-II [50].
Our approach takes as inputs a source code of the program to be refactored, a list of possible refactorings that can be applied, a set of bad-smells detection rules [21,24], our technique for approximating code changes needed to apply refactorings, a set of semantic measures, and a history of applied refactorings to previous versions of the system. Our approach generates as output the optimal sequence of refactorings, selected from an exhaustive list of possible refactorings, that improve the software quality by minimizing as much as possible the number of design defects, minimize code change needed to apply refactorings, preserve semantic coherence, and maximize the consistency with development change history.
In the following, we describe the formal formulation of our four objectives to optimize.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128001615000049
Infrastructure and technology
Krish Krishnan, in Building Big Data Applications, 2020
Execution—how does Hive process queries?
A HiveQL statement is submitted via the CLI, the web UI, or an external client using the Thrift, ODBC, or JDBC API. The driver first passes the query to the compiler where it goes through parse, type check, and semantic analysis using the metadata stored in the metastore. The compiler generates a logical plan that is then optimized through a simple rule–based optimizer. Finally an optimized plan in the form of a DAG of mapreduce tasks and HDFS tasks is generated. The execution engine then executes these tasks in the order of their dependencies, using Hadoop.
We can further analyze this workflow of processing as follows:
- •
-
Hive client triggers a query
- •
-
Compiler receives the query and connects to metastore
- •
-
Compiler receives the query and initiates the first phase of compilation
- •
-
Parser—Converts the query into parse tree representation. Hive uses ANTLR to generate the abstract syntax tree (AST)
- •
-
Semantic Analyzer—In this stage the compiler builds a logical plan based on the information that is provided by the metastore on the input and output tables. Additionally the complier also checks type compatibilities in expressions and flags compile time semantic errors at this stage. The best step is the transformation of an AST to intermediate representation that is called the query block (QB) tree. Nested queries are converted into parent–child relationships in a QB tree during this stage
- •
-
Logical Plan Generator—In this stage the compiler writes the logical plan from the semantic analyzer into a logical tree of operations
- •
-
Optimization—This is the most involved phase of the complier as the entire series of DAG optimizations are implemented in this phase. There are several customizations than can be done to the complier if desired. The primary operations done at this stage are as follows:
- —
-
Logical optimization—Perform multiple passes over logical plan and rewrites in several ways
- —
-
Column pruning—This optimization step ensures that only the columns that are needed in the query processing are actually projected out of the row
- —
-
Predicate pushdown—Predicates are pushed down to the scan if possible so that rows can be filtered early in the processing
- —
-
Partition pruning—Predicates on partitioned columns are used to prune out files of partitions that do not satisfy the predicate
- —
-
Join optimization
- —
-
Grouping and regrouping
- —
-
Repartitioning
- —
-
Physical plan generator converts logical plan into physical.
- —
-
Physical plan generation creates the final DAG workflow of MapReduce
- •
-
Execution engine gets the compiler outputs to execute on the Hadoop platform.
- —
-
All the tasks are executed in the order of their dependencies. Each task is only executed if all of its prerequisites have been executed.
- —
-
A map/reduce task first serializes its part of the plan into a plan.xml file.
- —
-
This file is then added to the job cache for the task and instances of ExecMapper and ExecReducers are spawned using Hadoop.
- —
-
Each of these classes deserializes the plan.xml and executes the relevant part of the task.
- —
-
The final results are stored in a temporary location and at the completion of the entire query, the results are moved to the table if inserts or partitions, or returned to the calling program at a temporary location
The comparison between how Hive executes versus a traditional RDBMS shows that due to the schema on read design, the data placement, partitioning, joining, and storage can be decided at the execution time rather than planning cycles.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128157466000028
Data Types
Michael L. Scott, in Programming Language Pragmatics (Third Edition), 2009
Coercion
Example 7.27
Coercion in Ada
Whenever a language allows a value of one type to be used in a context that expects another, the language implementation must perform an automatic, implicit conversion to the expected type. This conversion is called a type coercion. Like the explicit conversions discussed above, a coercion may require run-time code to perform a dynamic semantic check, or to convert between low-level representations. Ada coercions sometimes need the former, though never the latter:
d : weekday; — as in Example 7.3
k : workday; — as in Example 7.9
type calendar_column is new weekday;
c : calendar_column;
…
k := d; — run-time check required
d := k; — no check required; every workday is a weekday
c := d; — static semantic error;
— weekdays and calendar_columns are not compatible
To perform this third assignment in Ada we would have to use an explicit conversion:
c := calendar_column(d);
Example 7.28
Coercion in C
As we noted in Section 3.5.3, coercions are a controversial subject in language design. Because they allow types to be mixed without an explicit indication of intent on the part of the programmer, they represent a significant weakening of type security. C, which has a relatively weak type system, performs quite a bit of coercion. It allows values of most numeric types to be intermixed in expressions, and will coerce types back and forth “as necessary.” Here are some examples:
short int s;
unsigned long int l;
char c; /* may be signed or unsigned — implementation-dependent */
float f; /* usually IEEE single-precision */
double d; /* usually IEEE double-precision */
…
s = l; /* l’s low-order bits are interpreted as a signed number. */
l = s; /* s is sign-extended to the longer length, then
its bits are interpreted as an unsigned number. */
s = c; /* c is either sign-extended or zero-extended to s’s length;
the result is then interpreted as a signed number. */
f = l; /* l is converted to floating-point. Since f has fewer
significant bits, some precision may be lost. */
d = f; /* f is converted to the longer format; no precision lost. */
f = d; /* d is converted to the shorter format; precision may be lost.
If d’s value cannot be represented in single-precision, the
result is undefined, but NOT a dynamic semantic error. */
Fortran 90 allows arrays and records to be intermixed if their types have the same shape. Two arrays have the same shape if they have the same number of dimensions, each dimension has the same size (i.e., the same number of elements), and the individual elements have the same shape. (In some other languages, the actual bounds of each dimension must be the same for the shapes to be considered the same.) Two records have the same shape if they have the same number of fields, and corresponding fields, in order, have the same shape. Field names do not matter, nor do the actual high and low bounds of array dimensions.
Ada’s compatibility rules for arrays are roughly equivalent to those of Fortran 90. C provides no operations that take an entire array as an operand. C does, however, allow arrays and pointers to be intermixed in many cases; we will discuss this unusual form of type compatibility further in Section 7.7.1. Neither Ada nor C allows records (structures) to be intermixed unless their types are name equivalent.
In general, modern compiled languages display a trend toward static typing and away from type coercion. Some language designers have argued, however, that coercions are a natural way in which to support abstraction and program extensibility, by making it easier to use new types in conjunction with existing ones. This ease-of-programming argument is particularly important for scripting languages (Chapter 13). Among more traditional languages, C++ provides an extremely rich, programmer-extensible set of coercion rules. When defining a new type (a class in C++), the programmer can define coercion operations to convert values of the new type to and from existing types. These rules interact in complicated ways with the rules for resolving overloading (Section 3.5.2); they add significant flexibility to the language, but are one of the most difficult C++ features to understand and use correctly.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123745149000173
Programming Language Syntax
Michael L. Scott, in Programming Language Pragmatics (Third Edition), 2009
2.3.4 Syntax Errors
Example 2.42
A Syntax Error in C
Suppose we are parsing a C program and see the following code fragment in a context where a statement is expected:
A = B : C + D;
We will detect a syntax error immediately after the B, when the colon appears from the scanner. At this point the simplest thing to do is just to print an error message and halt. This naive approach is generally not acceptable, however: it would mean that every run of the compiler reveals no more than one syntax error. Since most programs, at least at first, contain numerous such errors, we really need to find as many as possible now (we’d also like to continue looking for semantic errors). To do so, we must modify the state of the parser and/or the input stream so that the upcoming token(s) are acceptable. We shall probably want to turn off code generation, disabling the back end of the compiler: since the input is not a valid program, the code will not be of use, and there’s no point in spending time creating it.
In general, the term syntax error recovery is applied to any technique that allows the compiler, in the face of a syntax error, to continue looking for other errors later in the program. High-quality syntax error recovery is essential in any production-quality compiler. The better the recovery technique, the more likely the compiler will be to recognize additional errors (especially nearby errors) correctly, and the less likely it will be to become confused and announce spurious cascading errors later in the program.
In More Depth
On the PLP CD we explore several possible approaches to syntax error recovery. In panic mode, the compiler writer defines a small set of “safe symbols” that delimit clean points in the input. Semicolons, which typically end a statement, are a good choice in many languages. When an error occurs, the compiler deletes input tokens until it finds a safe symbol, and then “backs the parser out” (e.g., returns from recursive descent subroutines) until it finds a context in which that symbol might appear. Phrase-level recovery improves on this technique by employing different sets of “safe” symbols in different productions of the grammar (right parentheses when in an expression; semicolons when in a declaration). Context-specific look-ahead obtains additional improvements by differentiating among the various contexts in which a given production might appear in a syntax tree. To respond gracefully to certain common programming errors, the compiler writer may augment the grammar with error productions that capture language-specific idioms that are incorrect but are often written by mistake.
Niklaus Wirth published an elegant implementation of phrase-level and context-specific recovery for recursive descent parsers in 1976 [Wir76, Sec. 5.9]. Exceptions (to be discussed further in Section 8.5) provide a simpler alternative if supported by the language in which the compiler is written. For table-driven top-down parsers, Fischer, Milton, and Quiring published an algorithm in 1980 that automatically implements a well-defined notion of locally least-cost syntax repair. Locally least-cost repair is also possible in bottom-up parsers, but it is significantly more difficult. Most bottom-up parsers rely on more straightforward phrase-level recovery; a typical example can be found in Yacc/bison.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123745149000112
Introduction
Michael L. Scott, in Programming Language Pragmatics (Third Edition), 2009
1.8 Exercises
- 1.1
-
Errors in a computer program can be classified according to when they are detected and, if they are detected at compile time, what part of the compiler detects them. Using your favorite imperative language, give an example of each of the following.
- (a)
-
A lexical error, detected by the scanner
- (b)
-
A syntax error, detected by the parser
- (c)
-
A static semantic error, detected by semantic analysis
- (d)
-
A dynamic semantic error, detected by code generated by the compiler
- (e)
-
An error that the compiler can neither catch nor easily generate code to catch (this should be a violation of the language definition, not just a program bug)
- 1.2
-
Consider again the Pascal tool set distributed by Niklaus Wirth (Example 1.15). After successfully building a machine language version of the Pascal compiler, one could in principle discard the P-code interpreter and the P-code version of the compiler. Why might one choose not to do so?
- 1.3
-
Imperative languages like Fortran and C are typically compiled, while scripting languages, in which many issues cannot be settled until run time, are typically interpreted. Is interpretation simply what one “has to do” when compilation is infeasible, or are there actually some advantages to interpreting a language, even when a compiler is available?
- 1.4
-
The gcd program of Example 1.20 might also be written
int main() {
int i = getint(), j = getint();
while (i != j) {
if (i > j) i = i % j;
else j = j % i;
}
putint(i);
}
Does this program compute the same result? If not, can you fix it? Under what circumstances would you expect one or the other to be faster?
- 1.5
-
In your local implementation of C, what is the limit on the size of integers? What happens in the event of arithmetic overflow? What are the implications of size limits on the portability of programs from one machine/compiler to another? How do the answers to these questions differ for Java? For Ada? For Pascal? For Scheme? (You may need to find a manual.)
- 1.6
-
The Unix make utility allows the programmer to specify dependences among the separately compiled pieces of a program. If file A depends on file B and file B is modified, make deduces that A must be recompiled, in case any of the changes to B would affect the code produced for A. How accurate is this sort of dependence management? Under what circumstances will it lead to unnecessary work? Under what circumstances will it fail to recompile something that needs to be recompiled?
- 1.7
-
Why is it difficult to tell whether a program is correct? How do you go about finding bugs in your code? What kinds of bugs are revealed by testing? What kinds of bugs are not? (For more formal notions of program correctness, see the bibliographic notes at the end of Chapter 4.)
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123745149000100
Names, Scopes, and Bindings
Michael L. Scott, in Programming Language Pragmatics (Third Edition), 2009
3.3.3 Declaration Order
In our discussion so far we have glossed over an important subtlety: suppose an object x is declared somewhere within block B. Does the scope of x include the portion of B before the declaration, and if so can x actually be used in that portion of the code? Put another way, can an expression E refer to any name declared in the current scope, or only to names that are declared before E in the scope?
Several early languages, including Algol 60 and Lisp, required that all declarations appear at the beginning of their scope. One might at first think that this rule would avoid the questions in the preceding paragraph, but it does not, because declarations may refer to one another.7
Example 3.7
A “Gotcha” in Declare-Before-Use
In an apparent attempt to simplify the implementation of the compiler, Pascal modified the requirement to say that names must be declared before they are used (with special-case mechanisms to accommodate recursive types and subroutines). At the same time, however, Pascal retained the notion that the scope of a declaration is the entire surrounding block. These two rules can interact in surprising ways:
- 1.
-
const N = 10;
- 2.
-
…
- 3.
-
procedure foo;
- 4.
-
const
- 5.
-
M = N; (* static semantic error! *)
- 6.
-
…
- 7.
-
N = 20; (* local constant declaration; hides the outer N *)
Pascal says that the second declaration of N covers all of foo, so the semantic analyzer should complain on line 5 that N is being used before its declaration. The error has the potential to be highly confusing, particularly if the programmer meant to use the outer N:
const N = 10;
…
procedure foo;
const
M = N; (* static semantic error! *)
var
A : array [1..M] of integer;
N : real; (* hiding declaration *)
Here the pair of messages “N used before declaration” and “N is not a constant” are almost certainly not helpful.
In order to determine the validity of any declaration that appears to use a name from a surrounding scope, a Pascal compiler must scan the remainder of the scope’s declarations to see if the name is hidden. To avoid this complication, most Pascal successors (and some dialects of Pascal itself) specify that the scope of an identifier is not the entire block in which it is declared (excluding holes), but rather the portion of that block from the declaration to the end (again excluding holes). If our program fragment had been written in Ada, for example, or in C, C++, or Java, no semantic errors would be reported. The declaration of M would refer to the first (outer) declaration of N.
Design & Implementation
Mutual Recursion
Some Algol 60 compilers were known to process the declarations of a scope in program order. This strategy had the unfortunate effect of implicitly outlawing mutually recursive subroutines and types, something the language designers clearly did not intend [Atk73].
Example 3.8
Whole-Block Scope in C#
C++ and Java further relax the rules by dispensing with the define-before-use requirement in many cases. In both languages, members of a class (including those that are not defined until later in the program text) are visible inside all of the class’s methods. In Java, classes themselves can be declared in any order. Interestingly, while C# echos Java in requiring declaration before use for local variables (but not for classes and members), it returns to the Pascal notion of whole-block scope. Thus the following is invalid in C#.
class A
const int N = 10;
void foo()
const int M = N; // uses inner N before it is declared
const int N = 20;
Example 3.9
“Local if written” in Python
Perhaps the simplest approach to declaration order, from a conceptual point of view, is that of Modula-3, which says that the scope of a declaration is the entire block in which it appears (minus any holes created by nested declarations), and that the order of declarations doesn’t matter. The principal objection to this approach is that programmers may find it counterintuitive to use a local variable before it is declared. Python takes the “whole block” scope rule one step further by dispensing with variable declarations altogether. In their place it adopts the unusual convention that the local variables of subroutine S are precisely those variables that are written by some statement in the (static) body of S. If S is nested inside of T, and the name x appears on the left-hand side of assignment statements in both S and T, then the x‘s are distinct: there is one in S and one in T. Non-local variables are read-only unless explicitly imported (using Python’s global statement). We will consider these conventions in more detail in Section 13.4.1, as part of a general discussion of scoping in scripting languages.
Example 3.10
Declaration Order in Scheme
In the interest of flexibility, modern Lisp dialects tend to provide several options for declaration order. In Scheme, for example, the letrec and let* constructs define scopes with, respectively, whole-block and declaration-to-end-of-block semantics. The most frequently used construct, let, provides yet another option:
(let ((A 1)) ; outer scope, with A defined to be 1
(let ((A 2) ; inner scope, with A defined to be 2
(B A)) ; and B defined to be A
B)) ; return the value of B
Here the nested declarations of A and B don’t until after the end of the declaration list. Thus when B is defined, the redefinition of A has not yet taken effect. B is defined to be the outer A, and the code as a whole returns 1.
Declarations and Definitions
Example 3.11
Declarations vs Definitions in C
Recursive types and subroutines introduce a problem for languages that require names to be declared before they can be used: how can two declarations each appear before the other? C and C++ handle the problem by distinguishing between the declaration of an object and its definition. A declaration introduces a name and indicates its scope, but may omit certain implementation details. A definition describes the object in sufficient detail for the compiler to determine its implementation. If a declaration is not complete enough to be a definition, then a separate definition must appear somewhere else in the scope. In C we can write
struct manager; /* declaration only */
struct employee {
struct manager *boss;
struct employee *next_employee;
…
};
struct manager { /* definition */
struct employee *first_employee;
…
};
and
void list_tail(follow_set fs); /* declaration only */
void list(follow_set fs)
{
switch (input_token) {
case id : match(id); list_tail(fs);
…
}
void list_tail(follow_set fs) /* definition */
{
switch (input_token) {
case comma : match(comma); list(fs);
…
}
The initial declaration of manager needed only to introduce a name: since pointers are all the same size, the compiler could determine the implementation of employee without knowing any manager details. The initial declaration of list_tail, however, must include the return type and parameter list, so the compiler can tell that the call in list is correct.
Nested Blocks
In many languages, including Algol 60, C89, and Ada, local variables can be declared not only at the beginning of any subroutine, but also at the top of any begin…end ({…}) block. Other languages, including Algol 68, C99, and all of C’s descendants, are even more flexible, allowing declarations wherever a statement may appear. In most languages a nested declaration hides any outer declaration with the same name (Java and C# make it a static semantic error if the outer declaration is local to the current subroutine).
Example 3.12
Inner Declarations in C
Variables declared in nested blocks can be very useful, as for example in the following C code:
{
int temp = a;
a = b;
b = temp;
}
Keeping the declaration of temp lexically adjacent to the code that uses it makes the program easier to read, and eliminates any possibility that this code will interfere with another variable named temp.
No run-time work is needed to allocate or deallocate space for variables declared in nested blocks; their space can be included in the total space for local variables allocated in the subroutine prologue and deallocated in the epilogue. Exercise 3.9 considers how to minimize the total space required.
Design & Implementation
Redeclarations
Some languages, particularly those that are intended for interactive use, permit the programmer to redeclare an object: to create a new binding for a given name in a given scope. Interactive programmers commonly use redeclarations to fix bugs. In most interactive languages, the new meaning of the name replaces the old in all contexts. In ML, however, the old meaning of the name may remain accessible to functions that were elaborated before the name was redeclared. This design choice in ML can sometimes be counterintuitive. It probably reflects the fact that ML is usually compiled, bit by bit on the fly, rather than interpreted. A language like Scheme, which is lexically scoped but usually interpreted, stores the binding for a name in a known location. A program accesses the meaning of the name indirectly through that location: if the meaning of the name changes, all accesses to the name will use the new meaning. In ML, previously elaborated functions have already been compiled into a form (often machine code) that accesses the meaning of the name directly.
Check Your Understanding
- 12.
-
What do we mean by the scope of a name-to-object binding?
- 13.
-
Describe the difference between static and dynamic scoping.
- 14.
-
What is elaboration?
- 15.
-
What is a referencing environment?
- 16.
-
Explain the closest nested scope rule.
- 17.
-
What is the purpose of a scope resolution operator?
- 18.
-
What is a static chain? What is it used for?
- 19.
-
What are forward references? Why are they prohibited or restricted in many programming languages?
- 20.
-
Explain the difference between a declaration and a definition. Why is the distinction important?
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123745149000124
Named Entity Resolution in Social Media
Paul A. Watters, in Automating Open Source Intelligence, 2016
Discussion
In this chapter, I have sketched out two different algorithmic approaches that could be used undertake named entity resolution. The first takes a dynamical systems view of the machine translation process and how it can account for translations that either succeed or fail, and provides a metaphor for how dynamical system states can be related to single-pass translations using the iterative semantic processing paradigm. In the three examples presented in this chapter, I have demonstrated how dynamical system states correspond to the different kinds of translation errors of semantic material in the context of direct translations systems (e.g., word sense disambiguation of polysemous words). In terms of the absolute preservation of meaning across sentences, the aim of the translation system is to form a point attractor in a “translation space,” although we have also seen that for practical purposes, limit cycles are also acceptable. Unacceptable translations defined by the iterative method are those that rapidly lose information about their initial semantic conditions, perhaps by a translation system equivalent to the period-doubling route to chaos.
What is important about describing machine translation systems using this methodology is that it is possible to use these states as benchmarks for the performance of translation systems. Thus, when translation systems are modified to correct characteristic semantic errors, it is possible to directly assess the performance improvement by using the two statistical measures we have introduced in this chapter, the iterative information loss index, ILOSS, and the cumulative information losses, ITOTAL. An attempt to reduce errors at any particular translation stage can be monitored by examining ILOSS at that particular iteration – for example, some direct translation systems have excellent source→target dictionaries, but poor target→source dictionaries. Improvement of the latter can be tracked at iteration 2 (and indeed, all even-numbered iterations thereafter), with a reduction in ITOTAL after all translations being the main indicator of overall performance.
Obviously, computing these statistics from single sentences is misleading in the sense that they are drawn from larger discourse, and should always be considered with respect to their literary or linguistic origins. Discourse longer than single sentences or phrases is needed for measures of entropy or of information loss to become statistically reliable. In addition, the computation of numerical exponents to quantify the rate of information loss in terms of the system’s entropy (e.g., Lyapunov exponent) needs to be developed and applied to both single sentences and large corpora.
From a neural network perspective, the dynamics of resolving named entities has similarities to resolving the senses of polysemous terms, especially by taking advantage of local context through semantic priming. From the simple examples shown here, it should be obvious how similar contextual information could be used to resolve the identities of individual names on social media. A key question remains as to how such context can be readily gathered using an automated process: for semantic priming of polysemous terms, parameter estimates must be supplied to the model a priori, yet fully automated OSINT systems would not necessarily have trusted access (Tran, Watters, & Hitchens, 2005) to this kind of data. Future research is needed to determine the extent to which names can be automatically resolved, versus a set of candidate choices should be presented to a knowledgeable analyst.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128029169000026
Fundamental Concepts
Peter J. Ashenden, in The Designer’s Guide to VHDL (Third Edition), 2008
1.4.5 Analysis, Elaboration and Execution
One of the main reasons for writing a model of a system is to enable us to simulate it. This involves three stages: analysis, elaboration and execution. Analysis and elaboration are also required in preparation for other uses of the model, such as logic synthesis.
In the first stage, analysis, the VHDL description of a system is checked for various kinds of errors. Like most programming languages, VHDL has rigidly defined syntax and semantics. The syntax is the set of grammatical rules that govern how a model is written. The rules of semantics govern the meaning of a program. For example, it makes sense to perform an addition operation on two numbers but not on two processes.
During the analysis phase, the VHDL description is examined, and syntactic and static semantic errors are located. The whole model of a system need not be analyzed at once. Instead, it is possible to analyze design units, such as entity and architecture body declarations, separately. If the analyzer finds no errors in a design unit, it creates an intermediate representation of the unit and stores it in a library. The exact mechanism varies between VHDL tools.
The second stage in simulating a model, elaboration, is the act of working through the design hierarchy and creating all of the objects defined in declarations. The ultimate product of design elaboration is a collection of signals and processes, with each process possibly containing variables. A model must be reducible to a collection of signals and processes in order to simulate it.
We can see how elaboration achieves this reduction by starting at the top level of a model, namely, an entity, and choosing an architecture of the entity to simulate. The architecture comprises signals, processes and component instances. Each component instance is a copy of an entity and an architecture that also comprises signals, processes and component instances. Instances of those signals and processes are created, corresponding to the component instance, and then the elaboration operation is repeated for the subcomponent instances. Ultimately, a component instance is reached that is a copy of an entity with a purely behavioral architecture, containing only processes. This corresponds to a primitive component for the level of design being simulated. Figure 1.7 shows how elaboration proceeds for the structural architecture body of the reg4 entity from Example 1.3. As each instance of a process is created, its variables are created and given initial values. We can think of each process instance as corresponding to one instance of a component.
Figure 1.7. The elaboration of the reg4 entity using the structural architecture body. Each instance of the d_ff and and2 entities is replaced with the contents of the corresponding basic architecture. These each consist of a process with its variables and statements.
The third stage of simulation is the execution of the model. The passage of time is simulated in discrete steps, depending on when events occur. Hence the term discrete event simulation is used. At some simulation time, a process may be stimulated by changing the value on a signal to which it is sensitive. The process is resumed and may schedule new values to be given to signals at some later simulated time. This is called scheduling a transaction on that signal. If the new value is different from the previous value on the signal, an event occurs, and other processes sensitive to the signal may be resumed.
The simulation starts with an initialization phase, followed by repetitive execution of a simulation cycle. During the initialization phase, each signal is given an initial value, depending on its type. The simulation time is set to zero, then each process instance is activated and its sequential statements executed. Usually, a process will include a signal assignment statement to schedule a transaction on a signal at some later simulation time. Execution of a process continues until it reaches a wait statement, which causes the process to be suspended.
During the simulation cycle, the simulation time is first advanced to the next time at which a transaction on a signal has been scheduled. Second, all the transactions scheduled for that time are performed. This may cause some events to occur on some signals. Third, all processes that are sensitive to those events are resumed and are allowed to continue until they reach a wait statement and suspend. Again, the processes usually execute signal assignments to schedule further transactions on signals. When all the processes have suspended again, the simulation cycle is repeated. When the simulation gets to the stage where there are no further transactions scheduled, it stops, since the simulation is then complete.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780120887859000010
Типы ошибок в программном обеспечении
Существуют три
типа ошибок программирования:
–
синтаксические
ошибки,
–
ошибки
выполнения,
–
семантические
ошибки.
В
любом языке программирования каждое
предложение (оператор) строится по
определенным правилам. Когда
в программе встречается предложение,
которое нарушает эти правила, то говорят
о наличии синтаксической ошибки.
Синтаксическая ошибка легко обнаруживается
компиляторами и интерпретаторами
языка и легко исправляется.
Второй
тип ошибок
обычно возникает во время выполнения
программы (их принято называть
исключительными ситуациями). Такие
ошибки имеют другую причину. Если в
программе возникает исключение, то это
означает, что случилось непредвиденное:
например, программе передали
некорректное значение или программа
попыталась разделить какое-то значение
на ноль, что недопустимо с точки зрения
математики. Если операционная система
присылает запрос на немедленное
завершение программы, то также
возникает исключение. Ошибки выполнения
легко обнаруживаются, однако устранение
их причин может оказаться нетривиальной
задачей.
Семантические
(смысловые) ошибки
– это
применение операторов, которые не
дают нужного эффекта (например, (a–b)
вместо (a+b)),
ошибка в структуре алгоритма, в логической
взаимосвязи его частей, в применении
алгоритма к тем данным, к которым он
неприменим и т.д. Правила семантики
не формализуемы. Поэтому поиск и
устранение семантической ошибки и
составляет основу отладки.
3.1.2. Причины появления ошибок в программном обеспечении
Прежде всего
необходимо понять первопричины ошибок
программного обеспечения и связать
их с процессом создания программных
комплексов. В данном учебном пособии
считается, что создание программного
обеспечения можно описать как ряд
процессов перевода, начинающихся с
постановки задачи и заканчивающихся
большим набором подробных инструкций,
управляющих ЭВМ при решении этой задачи.
Создание программного обеспечения
в этом случае – просто совокупность
процессов трансляции, т.е. перевода
исходной задачи в различные промежуточные
решения, пока наконец не будет получен
подробный набор машинных команд [1].
Когда не удается полно и точно перевести
некоторое представление задачи или
решения в другое, более детальное, тогда
и возникают ошибки в программном
обеспечении.
Для того чтобы
подробнее исследовать проблему ошибок
в программном обеспечении (ПО),
рассмотрим различные типы процессов
перевода при его создании.
Создание ПО
начинается с формирования требований
пользователя, т.е. с разработки описания
решаемой задачи. Такое описание имеет
вид перечня требований пользователя.
В некоторых случаях пользователь
составляет этот перечень сам. В других
случаях это делает разработчик ПО в
беседе с пользователем, либо исследуя
его потребности, либо самостоятельно
оценивая эти потребности в будущем,
либо комбинируя перечисленные методы.
В данном учебном пособии будем считать,
что на данном этапе ошибки не вносятся.
1. Первый процесс
– перевод требований пользователя в
цели программы. Хотя на этом шаге
объем перевода невелик, здесь требуется
явно выделить и оценить довольно много
компромиссных решений, которые будут
рассмотрены в дальнейшем. Ошибки на
этом шаге возникают, когда неверно
интерпретируются требования, не удается
выявить все требующие компромиссных
решений проблемы или приняты неправильные
решения, а также в случае, когда не
сформулированы цели, необходимые, но
не поставленные явно в требованиях
пользователя.
2. Второй процесс
связан с преобразованием целей программы
в ее внешние спецификации, т.е. точное
описание поведения всей системы с точки
зрения пользователя. По объему перевода
это самый сложный шаг в разработке ПО,
поэтому он больше всего подвержен
ошибкам – они бывают и наиболее
серьезными и наиболее многочисленными.
3. Далее следуют
несколько последовательных процессов
перевода – от внешнего описания готового
продукта до получения детального
проекта, описывающего множество
составляющих программу предложений,
выполнение которых должно обеспечить
поведение системы, соответствующее
внешним спецификациям. Сюда включаются
такие процессы, как перевод внешнего
описания в структуру компонент программы
(например, модулей) и перевод каждой из
этих компонент в описание процедурных
шагов (например, в блок-схемы). Поскольку
нам приходится иметь дело со все большими
объемами информации, шансы внесения
ошибок становятся чрезвычайно высокими.
4. Последний процесс
– перевод описания логики программы в
предложения языка программирования.
Хотя на этом шаге часто делается много
ошибок, они обычно незначительные, легко
обнаруживаются и корректируются.
Кроме процессов
перевода имеются и другие источники
ошибок, которые будут кратко рассмотрены
ниже. Однако в данном учебном пособии
мы сосредоточимся на ошибках, возникающих
в четырех вышеназванных процессах
перевода.
В результате работы
над программным проектом возникают как
само ПО, так и документы, описывающие
правила пользования им. Последние обычно
имеют вид печатных руководств или
встроенной в программу помощи и носят
название публикаций. Эти руководства
обычно получаются переводом внешних
спецификаций в материалы, ориентированные
на конкретные группы пользователей.
Публикации
определенным образом влияют на надежность
программного обеспечения. Если при
их подготовке возникает ошибка, то они
не будут точно описывать поведение
программы. Если прочитав руководство,
пользователь начнет работать с программой
и обнаружит, что она ведет себя не так,
как он ожидал, то решит, что это ошибка
в программе, т.е. придет к неправильному
заключению.
Другие источники
ошибок – это неправильное понимание
спецификаций используемой в системе
аппаратуры, базового ПО (операционной
системы), синтаксиса и семантики языка
программирования.
И наконец, при
непосредственном взаимодействии
пользователя с ПО, если слабо разработан
диалог человек – машина (отсутствие
«дружественного интерфейса»),
вероятность ошибки пользователя
увеличивается. Ошибки пользователя же
ставят систему в новые, непредвиденные
обстоятельства, увеличивая таким
образом шансы проявления оставшихся в
программе ошибок.
Эта модель описывает
происхождение большинства ошибок в ПО.
Нередко считается, что ошибки в программе
– это те ошибки, которые делает
программист, когда пишет программу на
языке программирования. Здесь и
проявляется важность модели, поскольку
она более полно описывает причины,
лежащие в основе ненадежности. Благодаря
ей нам стал известен перечень
подлежащих решению задач, способствующих
созданию надежного ПО.
Соседние файлы в папке Надежность
- #
- #
- #
- #
- #
- #
Тестирование и отладка программ
При разработке программ наиболее трудоемким является этап отладки и тестирования программ. Цель тестирования, т.е. испытания программы, заключается в выявлении имеющихся в программе ошибок. Цель отладки состоит в выявлении и устранении причин ошибок.
Отладку программы начинают с составления плана тестирования. Такой план должен представлять себе любой программист. Составление плана опирается на понятие об источниках и характере ошибок. Основными источниками ошибок являются недостаточно глубокая проработка математической модели или алгоритма решения задачи; нарушение соответствия между схемой алгоритма или записью его на алгоритмическом языке и программой, записанной на языке программирования; неверное представление исходных данных на программном бланке; невнимательность при наборе программы и исходных данных на клавиатуре устройства ввода.
Нарушение соответствия между детально разработанной записью алгоритма в процессе кодирования программы относится к ошибкам, проходящим вследствие невнимательности программиста. Отключение внимания приводит и ко всем остальным ошибкам, возникающим в процессе подготовки исходных данных и ввода программы в ЭВМ. Ошибки, возникающие вследствие невнимательности, могут иметь непредсказуемые последствия, так как наряду с потерей меток и описаний массивов, дублированием меток, нарушением баланса скобок возможны и такие ошибки, как потеря операторов, замена букв в обозначениях переменных, отсутствие определений начальных значений переменных, нарушение адресации в массивах, сдвиг исходных данных относительно полей значений, определенных спецификациями формата.
Учитывая разнообразие источников ошибок, при составлении плана тестирования классифицируют ошибки на два типа: 1 – синтаксические; 2 – семантические (смысловые).
Синтаксические ошибки – это ошибки в записи конструкций языка программирования (чисел, переменных, функций, выражений, операторов, меток, подпрограмм).
Семантические ошибки – это ошибки, связанные с неправильным содержанием действий и использованием недопустимых значений величин.
Обнаружение большинства синтаксических ошибок автоматизировано в основных системах программирования. Поиск же семантических ошибок гораздо менее формализован; часть их проявляется при исполнении программы в нарушениях процесса автоматических вычислений и индицируется либо выдачей диагностических сообщений рабочей программы, либо отсутствием печати результатов из-за бесконечного повторения одной и той же части программы (зацикливания), либо появлением непредусмотренной формы или содержания печати результатов.
В план тестирования обычно входят следующие этапы:
- Сравнение программы со схемой алгоритма.
- Визуальный контроль программы на экране дисплея или визуальное изучение распечатки программы и сравнение ее с оригиналом на программном бланке. Первые два этапа тестирования способны устранить больше количество ошибок, как синтаксических (что не так важно), так и семантических (что очень важно, так как позволяет исключить их трудоемкий поиск в процессе дальнейшей отладки).
- Трансляция программы на машинных язык. На этом этапе выявляются синтаксические ошибки. Компиляторы с языков Си, Паскаль выдают диагностическое сообщение о синтаксических ошибках в листинге программы (листингом называется выходной документ транслятора, сопровождающий оттранслированную программу на машинном языке – объектный модуль).
- Редактирование внешних связей и компоновка программы. На этапе редактирования внешних связей программных модуле программа-редактор внешних связей, или компоновщик задач, обнаруживает такие синтаксические ошибки, как несоответствие числа параметров в описании подпрограммы и обращении к ней, вызов несуществующей стандартной программы. например, 51 H вместо 51 N, различные длины общего блока памяти в вызывающем и вызываемом модуле и ряд других ошибок.
- Выполнение программы. После устранения обнаруженных транслятором и редактором внешних связей (компоновщиком задач) синтаксических ошибок переходят к следующему этапу – выполнению программы на ЭВМ на машинном языке: программа загружается в оперативную память, в соответствие с программой вводятся исходные данные и начинается счет. Проявление ошибки в процессе вода исходных данных или в процессе счета приводит к прерыванию счета и выдаче диагностического сообщения рабочей программы. Проявление ошибки дает повод для выполнения отладочных действий; отсутствие же сообщений об ошибках не означает их отсутствия в программе. План тестирования включает при этом проверку правильности полученных результатов для каких-либо допустимых значений исходных данных.
- Тестирование программы. Если программа выполняется успешно, желательно завершить ее испытания тестированием при задании исходных данных, принимающих предельные для программы значения. а также выходящие за допустимые пределы значения на входе.
Контрольные примеры (тесты) – это специально подобранные задачи, результаты которых заранее известны или могут быть определены без существенных затрат.
Наиболее простые способы получения тестов:
- Подбор исходных данных, для которых несложно определить результата вычислений вручную или расчетом на калькуляторе.
- Использование результатов, полученных на других ЭВМ или по другим программам.
- Использование знаний о физической природе процесса, параметры которого определяются, о требуемых и возможных свойствах рассчитываемой конструкции. Хотя точное решение задачи заранее известно, суждение о порядке величин позволяет с большой вероятностью оценить достоверность результатов.
Было решено сделать небольшой скачок до интересной темы: Отладка, которая понадобится начинающим и не очень.
Ошибки ПО распространены. Их легко сделать, и их трудно найти. В этой главе мы рассмотрим темы, связанные с поиском и удалением ошибок в наших программах на языке C++, в том числе научимся использовать встроенный отладчик, который является частью нашей IDE.
Хотя инструменты и методы отладки не являются частью стандарта C++, умение находить и удалять ошибки в программах, которые вы пишете, является чрезвычайно важной частью успешного программиста. Поэтому мы потратим немного времени на освещение таких тем, чтобы по мере усложнения программ, которые вы пишете, ваша способность диагностировать и устранять проблемы развивалась с той же скоростью.
Если у вас есть опыт отладки программ на другом скомпилированном языке программирования, многое из этого будет Вам знакомо.
Синтаксические и семантические ошибки
Программирование может быть сложным, а C++ — это несколько причудливый язык. Сложите эти два понятия вместе, и вы обнаружите множество способов совершать ошибки. Ошибки обычно делятся на две категории: синтаксические ошибки и семантические ошибки (логические ошибки).
Синтаксическая ошибка возникает, когда вы пишете стейтмент, который не является допустимым в соответствии с грамматикой языка C++. Это включает в себя такие ошибки, как пропущенные точки с запятой, использование необъявленных переменных, несоответствующие скобки или фигурные скобки и т. д. Например, следующая программа содержит довольно много синтаксических ошибок:
#include <iostream>
int main()
{
std::cout < "Hi there"; < < x; // недопустимый оператор (<), лишняя точка с запятой, необъявленная переменная (x)
return 0 // отсутствует точка с запятой в конце стейтмента
}К счастью, компилятор обычно ловит синтаксические ошибки и генерирует предупреждения или ошибки, поэтому вы легко определяете и устраняете проблему. Тогда это просто вопрос времени, пока вы не избавитесь от всех ошибок.
Как только ваша программа компилируется правильно, заставить ее действительно выдавать желаемый результат(ы) может быть непросто. Семантическая ошибка возникает, когда стейтмент синтаксически корректен, но не выполняет то, что задумал программист.
Иногда это приведет к сбою вашей программы, например, в случае деления на ноль:
#include <iostream>
int main()
{
int a = 10;
int b = 0;
std::cout << a << " / " << b << " = " << a / b; // деление на 0 не определено
return 0;
}Чаще всего они просто производят неправильное значение или поведение:
#include <iostream>
int main()
{
int x;
std::cout << x; // Использование неинициализированной переменной приводит к неопределенному результату
return 0;
}или
#include <iostream>
int add(int x, int y)
{
return x - y; // предполагается, что функция добавляет, но это не так
}
int main()
{
std::cout < < add(5, 3); // должно произвести 8, но производит 2
return 0;
}или
#include <iostream>
int main()
{
return 0; // функция возвращается здесь
std:: cout << "Hello, world!"; // так что это никогда не выполнится
}Современные компиляторы стали лучше выявлять некоторые типы распространенных семантических ошибок (например, использование неинициализированной переменной). Однако в большинстве случаев компилятор не сможет поймать большинство из этих типов проблем, потому что компилятор предназначен для обеспечения соблюдения грамматики, а не намерения.
В приведенном выше примере ошибки довольно легко обнаружить. Но в большинстве нетривиальных программ семантические ошибки не так-то просто обнаружить, изучив код. Именно здесь могут пригодиться методы отладки.
Оригинальная статья —
Добавлено 30 мая 2021 в 17:27
В уроке «3.1 – Синтаксические и семантические ошибки» мы рассмотрели синтаксические ошибки, которые возникают, когда вы пишете код, который не соответствует грамматике языка C++. Компилятор уведомит вас об ошибках этого типа, поэтому их легко обнаружить и обычно легко исправить.
Мы также рассмотрели семантические ошибки, которые возникают, когда вы пишете код, который выполняет не то, что вы планировали. Как правило, компилятор не обнаруживает семантических ошибок (хотя в некоторых случаях умные компиляторы могут генерировать предупреждения).
Семантические ошибки могут вызывать большинство из симптомов неопределенного поведения, например, приводить к тому, что программа выдает неправильные результаты, быть причиной неустойчивого поведения, искажать данные программы, вызывать сбой программы – или они могут вообще никак не влиять.
При написании программ семантические ошибки практически неизбежны. Некоторые из них вы, вероятно, заметите, просто используя программу: например, если вы писали игру лабиринт, а ваш персонаж может проходить сквозь стены. Тестирование вашей программы (7.12 – Введение в тестирование кода) также может помочь выявить семантические ошибки.
Но есть еще одна вещь, которая может помочь – это знание того, какой тип семантических ошибок наиболее распространен, чтобы вы могли потратить немного больше времени на то, чтобы убедиться, что в этих случаях всё правильно.
В этом уроке мы рассмотрим ряд наиболее распространенных типов семантических ошибок, возникающих в C++ (большинство из которых так или иначе связаны с управлением порядком выполнения программы).
Условные логические ошибки
Один из наиболее распространенных типов семантических ошибок – это условная логическая ошибка. Условная логическая ошибка возникает, когда программист неправильно пишет логику условного оператора или условия цикла. Вот простой пример:
#include <iostream>
int main()
{
std::cout << "Enter an integer: ";
int x{};
std::cin >> x;
if (x >= 5) // упс, мы использовали operator>= вместо operator>
std::cout << x << " is greater than 5";
return 0;
}А вот результат запуска программы, при котором была обнаружена эта условная логическая ошибка:
Enter an integer: 5
5 is greater than 5Когда пользователь вводит 5, условное выражение x >= 5 принимает значение true, поэтому выполняется соответствующая инструкция.
Вот еще один пример для цикла for:
#include <iostream>
int main()
{
std::cout << "Enter an integer: ";
int x{};
std::cin >> x;
// упс, мы использовали operator> вместо operator<
for (unsigned int count{ 1 }; count > x; ++count)
{
std::cout << count << ' ';
}
return 0;
}Эта программа должна напечатать все числа от 1 до числа, введенного пользователем. Но вот что она на самом деле делает:
Enter an integer: 5Она ничего не напечатала. Это происходит потому, что при входе в цикл for условие count > x равно false, поэтому цикл вообще не повторяется.
Бесконечные циклы
В уроке «7.7 – Введение в циклы и инструкции while» мы рассмотрели бесконечные циклы и показали этот пример:
#include <iostream>
int main()
{
int count{ 1 };
while (count <= 10) // это условие никогда не будет ложным
{
std::cout << count << ' '; // поэтому эта строка выполняется многократно
}
return 0; // эта строка никогда не будет выполнена
}В этом случае мы забыли увеличить count, поэтому условие цикла никогда не будет ложным, и цикл продолжит печатать:
1 1 1 1 1 1 1 1 1 1пока пользователь не закроет программу.
Вот еще один пример, который преподаватели любят задавать в тестах. Что не так со следующим кодом?
#include <iostream>
int main()
{
for (unsigned int count{ 5 }; count >= 0; --count)
{
if (count == 0)
std::cout << "blastoff! ";
else
std::cout << count << ' ';
}
return 0;
}Эта программа должна напечатать «5 4 3 2 1 blastoff!«, что она и делает, но не останавливается на достигнутом. На самом деле она печатает:
5 4 3 2 1 blastoff! 4294967295 4294967294 4294967293 4294967292 4294967291а затем просто продолжает печатать уменьшающиеся числа. Программа никогда не завершится, потому что условие count >= 0 никогда не может быть ложным, если count является целым числом без знака.
Ошибки на единицу
Ошибки «на единицу» возникают, когда цикл повторяется на один раз больше или на один раз меньше, чем это необходимо. Вот пример, который мы рассмотрели в уроке «7.9 – Инструкции for»:
#include <iostream>
int main()
{
for (unsigned int count{ 1 }; count < 5; ++count)
{
std::cout << count << ' ';
}
return 0;
}Этот код должен печатать «1 2 3 4 5«, но он печатает только «1 2 3 4«, потому что был использован неправильный оператор отношения.
Неправильный приоритет операторов
Следующая программа из урока «5.7 – Логические операторы» допускает ошибку приоритета операторов:
#include <iostream>
int main()
{
int x{ 5 };
int y{ 7 };
if (!x > y)
std::cout << x << " is not greater than " << y << 'n';
else
std::cout << x << " is greater than " << y << 'n';
return 0;
}Поскольку логическое НЕ имеет более высокий приоритет, чем operator>, условное выражение вычисляется так, как если бы оно было написано (!x) > y, что не соответствует замыслу программиста.
В результате эта программа печатает:
5 is greater than 7Это также может произойти при смешивании в одном выражении логического ИЛИ и логического И (логическое И имеет больший приоритет, чем логическое ИЛИ). Используйте явные скобки, чтобы избежать подобных ошибок.
Проблемы точности с типами с плавающей запятой
Следующая переменная с плавающей запятой не имеет достаточной точности для хранения всего числа:
#include <iostream>
int main()
{
float f{ 0.123456789f };
std::cout << f;
}Как следствие, эта программа напечатает:
0.123457В уроке «5.6 – Операторы отношения и сравнение чисел с плавающей запятой» мы говорили о том, что использование operator== и operator!= может вызывать проблемы с числами с плавающей запятой из-за небольших ошибок округления (а также о том, что с этим делать). Вот пример:
#include <iostream>
int main()
{
// сумма должна быть равна 1.0
double d{ 0.1 + 0.1 + 0.1 + 0.1 + 0.1 + 0.1 + 0.1 + 0.1 + 0.1 + 0.1 };
if (d == 1.0)
std::cout << "equal";
else
std::cout << "not equal";
}Эта программа напечатает:
not equalЧем больше вы выполняете арифметических действий с числом с плавающей запятой, тем больше в нем накапливаются небольшие ошибки округления.
Целочисленное деление
В следующем примере мы хотим выполнить деление с плавающей запятой, но поскольку оба операнда принадлежат целочисленному типу, вместо этого мы выполняем целочисленное деление:
#include <iostream>
int main()
{
int x{ 5 };
int y{ 3 };
std::cout << x << " divided by " << y << " is: " << x / y; // целочисленное деление
return 0;
}Этот код напечатает:
5 divided by 3 is: 1В уроке «5.2 – Арифметические операторы» мы показали, что мы можем использовать static_cast для преобразования одного из целочисленных операндов в значение с плавающей запятой, чтобы выполнять деление с плавающей запятой.
Случайные пустые инструкции
В уроке «7.3 – Распространенные проблемы при работе с операторами if» мы рассмотрели пустые инструкции, которые ничего не делают.
В приведенной ниже программе мы хотим взорвать мир, только если у нас есть разрешение пользователя:
#include <iostream>
void blowUpWorld()
{
std::cout << "Kaboom!n";
}
int main()
{
std::cout << "Should we blow up the world again? (y/n): ";
char c{};
std::cin >> c;
if (c=='y'); // здесь случайная пустая инструкция
blowUpWorld(); // поэтому это всегда будет выполняться, так как это не часть оператора if
return 0;
}Однако из-за случайной пустой инструкции вызов функции blowUpWorld() выполняется всегда, поэтому мы взрываем независимо от ввода:
Should we blow up the world again? (y/n): n
Kaboom!Неиспользование составной инструкции, когда она требуется
Еще один вариант приведенной выше программы, которая всегда взрывает мир:
#include <iostream>
void blowUpWorld()
{
std::cout << "Kaboom!n";
}
int main()
{
std::cout << "Should we blow up the world again? (y/n): ";
char c{};
std::cin >> c;
if (c=='y')
std::cout << "Okay, here we go...n";
blowUpWorld(); // упс, всегда будет выполняться. Должно быть внутри составной инструкции.
return 0;
}Эта программа печатает:
Should we blow up the world again? (y/n): n
Kaboom!Висячий else (рассмотренный в уроке «7.3 – Распространенные проблемы при работе с операторами if») также попадает в эту категорию.
Что еще?
Приведенные выше примеры представляют собой хороший образец наиболее распространенных типов семантических ошибок, которые склонны совершать на C++ начинающие программисты, но их гораздо больше. Читатели, если у вас есть дополнительные примеры, которые, по вашему мнению, являются распространенными ошибками, напишите об этом в комментариях.
Теги
C++ / CppLearnCppДля начинающихОбучениеПрограммирование
Отладка программы – это процесс поиска и устранения ошибок. Часть ошибок формального характера, связанных с нарушением правил записи конструкций языка или отсутствием необходимых описаний, обнаруживает транслятор, производя синтаксический анализ текста программы. Транслятор выявляет ошибки и сообщает о них, указывая их тип и место в программе. Такие ошибки называются ошибками времени трансляции или синтаксическими ошибками.
Ошибочные ситуации могут возникнуть и при выполнении программы, например, деление на нуль или извлечение корня квадратного из отрицательного числа. Такие ошибки называются ошибками времени выполнения.
Программа, не имеющая ошибок трансляции и выполнения, может и не дать верных результатов из-за логических ошибок в алгоритме, т. е. алгоритмических или семантических ошибок. Ошибки подобного рода могут возникнуть на любом этапе разработки программы: постановки задачи, разработке математической модели или алгоритма. Необходим действенный контроль над процессом вычислений, позволяющий предотвращать или своевременно обнаруживать ошибки подобного рода. Для этого используются как качественный анализ задачи, основанный на различного рода интуитивных соображениях и правдоподобных рассуждениях, так и контрольный просчет или тестирование программы.
Тестирование программы – это выполнение программы на наборах исходных данных (тестах), для которых известны результаты, полученные другим методом. Система тестов подбирается таким образом, чтобы
а) проверить все возможные режимы работы программы;
б) по возможности, локализовать ошибку.
При тестировании программы простой и действенный метод дополнительного контроля над ходом её выполнения – получение контрольных точек, т. е. контрольный вывод промежуточных результатов.
Для проверки правильности работы программы иногда полезно также выполнить проверку выполнения условий задачи (например, для алгебраического уравнения найденные корни подставляются в исходное уравнение и проверяются расхождения левой и правой частей).
33. ВИДЫ ОШИБОК В ПРОГРАММАХ
Об ошибках в программе сигнализируют некорректная работоспособность программы либо ее полное невыполнение. В наше время для обозначения ошибки в программе используют термин «Баг» (с англ. Bug-жук).
Есть несколько типов ошибок:
1) Логическая ошибка. Это, пожалуй, наиболее серьезная из всех ошибок. Когда написанная программа на любом языке компилирует и работает правильно, но выдает неправильный вывод, недостаток заключается в логике основного программирования. Это ошибка, которая была унаследована от недостатка в базовом алгоритме. Сама логика, на которой базируется вся программа, является ущербной. Чтобы найти решение такой ошибки нужно фундаментальное изменение алгоритма. Вам нужно начать копать в алгоритмическом уровне, чтобы сузить область поиска такой ошибки. (пример: задача программы вывести сумму двух чисел а и b.
varc,a,b:integer;
Begin
readln(a,b);
c:=a-b; {нужнобылонаписатьc:=a+b;}
writeln(c);
readln;
end.
2) Синтаксическая ошибка.Каждый компьютерный язык, такой как C, Java, Perl и Python имеет специфический синтаксис, в котором будет написан код. Когда программист не придерживаться «грамматики» спецификациями компьютерного языка, возникнет ошибка синтаксиса. Такого рода ошибки легко устраняются на этапе компиляции.
begin
writln(‘helloworld!’); {вместоwritElnнаписаноwritln, чтоприведеткошибке}
readln;
end.
3) Ошибка компиляции.Компиляция это процесс, в котором программа, написанная на языке высокого уровня, преобразуется в машиночитаемую форму. Многие виды ошибок могут происходить на этом этапе, в том числе и синтаксические ошибки. Иногда, синтаксис исходного кода может быть безупречным, но ошибка компиляции все же может произойти. Это может быть связано с проблемами в самом компиляторе. Эти ошибки исправляются на стадии разработки.
vara,b:real;
begin
b:=7.5;
с:=b*3; {ошибка компиляции, мы присваиваем значениие несуществующей переменой}
writeln(a);
readln;
end.
4) Ошибки среды выполнения (RunTime).Программный код успешно скомпилирован, и исполняемый файл был создан. Вы можете вздохнуть с облегчением и запустить программу, чтобы проверить ее работу. Ошибки при выполнении программы могут возникнуть в результате аварии или нехватки ресурсов носителя. Разработчик должен был предвидеть реальные условия развертывания программы. Это можно исправить, вернувшись к стадии кодирования.

vara:array[1..5] of integer;
begin
a[0]:=5; {ошибка в том, что мы вышли за предел массива}
writeln(a[0]);
readln;
end;
5) Арифметическая ошибка.Многие программы используют числовые переменные, и алгоритм может включать несколько математических вычислений. Арифметические ошибки возникают, когда компьютер не может справиться с проблемами, такими как «Деление на ноль», или ведущие к бесконечному результату. Это снова логическая ошибка, которая может быть исправлена только путем изменения алгоритма.
vara:real;
begin
a:=10/0; {ошибка, делениена 0}
writeln(a);
readln
end.
6) Ошибки ресурса. Ошибка ресурса возникает, когда значение переменной переполняет максимально допустимое значение. Переполнение буфера, использование неинициализированной переменной, нарушение прав доступа и переполнение стека — примеры некоторых распространенных ошибок.
vara:integer;
begin
a:=32768; {ошибка, максимальное значение переменной типа integer равно 32767}
end.
7) Ошибка взаимодействия. Они могут возникнуть в связи с несоответствием программного обеспечения с аппаратным интерфейсом или интерфейсом прикладного программирования. В случае веб-приложений, ошибка интерфейса может быть результатом неправильного использования веб-протоколов
Синтаксические ошибки – это ошибки в записи конструкций языка программирования (чисел, переменных, функций, выражений, операторов, меток, подпрограмм).
Семантические ошибки – это ошибки, связанные с неправильным содержанием действий и использованием недопустимых значений величин.
Обнаружение большинства синтаксических ошибок автоматизировано в основных системах программирования. Поиск же семантических ошибок гораздо менее формализован; часть их проявляется при исполнении программы в нарушениях процесса автоматических вычислений и индицируется либо выдачей диагностических сообщений рабочей программы, либо отсутствием печати результатов из-за бесконечного повторения одной и той же части программы (зацикливания), либо появлением непредусмотренной формы или содержания печати результатов. Семантически ошибки можно выявить, пользуясь отладчиком, встроенным в компилятор.
Поможем в ✍️ написании учебной работы
Компилятор анализирует и преобразует исходный текст в объектный код (промежуточное состояние программы в относительных адресах и с неразрешенными внешними ссылками) с использованием всей логической структуры программы. Затем программа, представленная в объектном коде, обрабатывается служебной программой – компоновщиком, который осуществляет подключение внешних подпрограмм/разрешение внешних ссылок и выполняет дальнейший перевод программы пользователя в коды машины (в абсолютный/загрузочный код – с абсолютной адресацией машинных команд).
Интерпретатор сразу производит анализ, перевод (в машинный код) и выполнение программы строка за строкой.
Отладка программы– это процесс поиска и устранения ошибок.
Виды ошибок: синтаксические ошибки, ошибки времени выполнения, логических ошибок в алгоритме, т. е. алгоритмических или семантических ошибок.
Тестирование программы– это выполнение программы на наборах исходных данных (тестах), для которых известны результаты, полученные другим методом. Система тестов подбирается таким образом, чтобы проверить все возможные режимы работы программы и локализовать ошибку.
При тестировании программы простой и действенный метод дополнительного контроля над ходом её выполнения – получение контрольных точек, т. е. контрольный вывод промежуточных результатов.
В ходе отладки программа должна быть проверена в двух измерениях: в пространстве и во времени. Первое представляет собой контроль содержимого памяти в конкретные моменты работы программы, отслеживание текущих значений всех или выбранных групп переменных, проверку на соответствие их значений декларированным диапазонам (типам). Второе – это отслеживание хода выполнения алгоритма для проверки правильности заданной последовательности операций и передач управления при различных значениях параметров. Самым распространенным и полезным приемом отладки, позволяющим объединить обе формы контроля, являются отчеты о трассировке. Трассировка программы – это регистрация логического пути выполнения программы – последовательности выполнения ее операторов/блоков с контрольной выдачей информации о результатах каждого шага – обо всех изменениях значений рабочих переменных и параметров связи. Сам принцип трассировки – слишком общий. На практике реализуют трассировку программы в том или ином объеме, используя различные способы и средства отладки.
Самый простой способ отладки – это расстановка в тексте программы отладочных печатей промежуточных результатов вычислений,позволяющих проследить логический и арифметический следы программы, т. е. каким образом она выполнялась и что она вычисляла.Отладочные печати ставятся в узловых/ключевых точках программы, позволяющих контролировать ошибки ввода (эхо-печать введенных данных), результаты вычислительных операций и логику работы программы или отдельных ее частей. Отладочные операторы оформляются в отдельные строки, выделяются особым образом (например, сдвигом влево или вправо) и в зависимости от цели контроля могут содержать вывод значений контролируемых переменных, проверку условий или идентифицирующее сообщение (комментарий) о прохождении заданной точки программы, о начале или завершении работы определенного участка/блока. Средства для отладки могут быть вставлены в программу еще при ее разработке. В ходе отладки количество и место расположения отладочных операторов меняется, но их лучше не удалять, а превращать в комментарии. Такой способ отладки весьма трудоемок и может сам служить источником ошибок.
Процесс отладки значительно облегчается, если использовать для этого системные средства отладки – специальные программы-отладчики, имеющиеся в программном обеспечении компьютера.
Встроенный отладчик среды Delphi или Турбо Паскаля (Debugger) позволяет контролировать ход выполнения программы – выполнять трассировку программы без изменения самой программы с помощью следующих действий:
• выполнения программы построчно/по шагам;
• остановки выполнения программы в заданной точке останова;
• перезапуска программы, не закончив ее выполнение;
• назначения и модификации значений любых переменных и параметров программы, а также получения некоторых дополнительных сведений о программе, например списка активных процедур.
Эти возможности позволяют, отследив выполнение каждого оператора/операции, определить местоположение ошибки и понять ее причину. (Далее рассмотрим все эти управляющие средства.)
Автономный отладчик (TurboDebugger – файл td.exe) предоставляет большие возможности: позволяет осуществить трассировку программы/блока на уровне ассемблерных и машинных инструкций, просмотреть содержимое/дамп памяти и пр., что требует особого режима компиляции исходного текста. Использование дополнительных возможностей автономного отладчика целесообразно при отладке и тестировании больших по объему и сложных программ и при наличии у программиста достаточно высокого уровня квалификации. (В данном пособии автономные средства отладки не рассматриваются.)
28.Виды ошибок в программах
В зависимости от этапа разработки ПО, на котором выявляется ошибка выделяют:
► Ошибка периода компиляции — это синтаксические ошибки
► предупреждения (warnings) компилятора
► ошибки времени исполнения, смысловые ошибки — они могут проявляться только при особых, заранее неизвестн
Отладка программы – это деятельность, направленная на обнаружение и исправление ошибок в программе. Обнаружить ошибки, связанные с нарушением правил записи программы на языке программирования (синтаксические и семантические ошибки), помогает используемая система программирования. Пользователь получает сообщение об ошибке, исправляет ее и снова повторяет попытку исполнить программу.
Тестирование программы – это процесс выполнения программы с целью обнаружения ошибки в программе на некотором наборе данных, для которого заранее известен результат применения или известны правила поведения этих программ. Указанный набор данных называется тестовым, или просто тестом. Прохождение теста – необходимое условие подтверждения правильности программы. На тестах проверяется правильность реализации программой запланированного алгоритма. Таким образом, отладку можно представить в виде многократного повторения трех процессов: тестирования, в результате которого может быть констатировано наличие в ПС ошибки, поиска места ошибки в программах и документации ПС и редактирования программ и документации с целью устранения обнаруженной ошибки.
Успех отладки в значительной степени предопределяет рациональная организация тестирования. При отладке отыскиваются и устраняются в основном те ошибки, наличие которых в программе устанавливается при тестировании. Тестирование не может доказать правильность программы, в лучшем случае оно может продемонстрировать наличие в нем ошибки. Другими словами, нельзя гарантировать, что тестированием программы на соответствующих наборах тестов можно установить наличие каждой имеющейся в программе ошибки. Поэтому возникают две задачи. Первая: подготовить такой набор тестов и применить к ним программу, чтобы обнаружить в нем по возможности большее число ошибок. Однако чем дольше продолжается процесс тестирования (и отладки в целом), тем выше становится стоимость программы. Отсюда вторая задача: определить момент окончания отладки программы (или отдельной ее компоненты). Признаком возможности окончания отладки является полнота охвата тестами, к которым применена программа, множества различных ситуаций, возникающих при выполнении программы, и относительно редкое проявление ошибок в программе на последнем отрезке процесса тестирования. Последнее определяется в соответствии с требуемой степенью надежности программы, указанной в спецификации ее качества.
Для оптимизации набора тестов, т.е. для подготовки такого набора тестов, который позволял бы при заданном их числе (или при заданном интервале времени, отведенном на тестирование) обнаруживать большее число ошибок, необходимо, во-первых, заранее планировать этот набор и, во-вторых, использовать рациональную стратегию планирования тестов.
Таким образом, тестирование и отладка включают в себя синтаксическую отладку; отладку семантики и логической структуры программы; тестовые расчеты и анализ результатов тестирования. Затем идет совершенствование программы.
Документирование программы.При разработке ПС создается большой объем разнообразной документации. Продуманная документация программных разработок облегчает совместную работу над проектом больших групп программистов, позволяет подключать новых людей, избегать дублирования многих действий. В итоге повышается производительность труда программистов и увеличивается надежность кода. Кроме того, документация необходима для управления разработкой ПС и для передачи пользователям информации, необходимой для применения и сопровождения ПС. На создание этой документации приходится большая доля стоимости ПС.
Всю документацию можно разбить на две группы:
– документы управления разработкой ПС;
– документы, входящие в состав ПС.
Документы управления разработкой ПС протоколируют процессы разработки и сопровождения ПС, обеспечивая связи внутри коллектива разработчиков и между коллективом разработчиков и менеджерами – лицами, управляющими разработкой.
Пользовательская документация ПС объясняет пользователям, как они должны действовать, чтобы применить данное ПС.
Она необходима, если ПС предполагает какое-либо взаимодействие с пользователями. К такой документации относятся документы, которыми руководствуется пользователь при инсталляции ПС, при применении ПС для решения своих задач и при управлении ПС (например, когда данное ПС взаимодействует с другими системами). Эти документы частично затрагивают вопросы сопровождения ПС, но не касаются вопросов, связанных с модификацией программ.
Контрольные вопросы
1. Что такое система программирования?
2. Что относится к технологии OLE?
3. Что относится к технологии Microsoft .NET?
4. Что такое модульное программирование?
5. Назовите основные принципы объектно-ориентрованного программирования.
6. Что относится к процедурному программированию?
7. Как происходит отладка и тестирование программ?
8. Какие виды документации используют при разработке программ?
9. Что такое парадигма программирования?
10. Что такое объекты, классы?
…
Читайте также:
©2015-2022 poisk-ru.ru
Все права принадлежать их авторам. Данный сайт не претендует на авторства, а предоставляет бесплатное использование.
Дата создания страницы: 2017-04-03
Нарушение авторских прав и Нарушение персональных данных
Поиск по сайту:

Мы поможем в написании ваших работ!
Семантическая
отладка — это процесс нахождения и
исправления ошибок, связанных с
неправильным указанием логических
страниц данных.
Существует
3 способа отладки программы:
Пошаговая
отладка программ с заходом в подпрограммы;
Пошаговая
отладка программ с выполнением
подпрограммы как одного оператора;
Выполнение
программы до точки остановки.
Пошаговая
отладка программ заключается в том,
что выполняется один оператор программы
и, затем контролируются те переменные,
на которые должен был воздействовать
данный оператор.
Если
в программе имеются уже отлаженные
подпрограммы, то подпрограмму можно
рассматривать, как один оператор
программы и воспользоваться вторым
способом отладки программ.
Если
в программе существует достаточно
большой участок программы, уже отлаженный
ранее, то его можно выполнить, не
контролируя переменные, на которые он
воздействует. Использование точек
остановки позволяет пропускать уже
отлаженную часть программы. Точка
остановки устанавливается в местах,
где необходимо проверить содержимое
переменных или просто проконтролировать,
передаётся ли управление данному
оператору.
Тестирование
— это динамический контроль программы,
т.е. проверка правильности программы
при ее выполнении на компьютере.
Каждому
программисту известно, сколько времени
и сил уходит на отладку и тестирование
программ. На этот этап приходится около
50% общей стоимости разработки программного
обеспечения. Но не каждый из разработчиков
программных средств может верно,
определить цель тестирования. Нередко
можно услышать, что тестирование — это
процесс выполнения программы с целью
обнаружения в ней ошибок. Но эта цель
недостижима: ни какое самое тщательное
тестирование не дает гарантии, что
программа не содержит ошибок. Другое
определение: это процесс выполнения
программы с целью обнаружения в ней
ошибок. Отсюда ясно, что “удачным”
тестом является такой, на котором
выполнение программы завершилось с
ошибкой. Напротив, “неудачным” можно
назвать тест, не позволивший выявить
ошибку в программе. Определение также
указывает на объективную трудность
тестирования: это деструктивный ( т.е.
обратный созидательному ) процесс.
Поскольку программирование — процесс
конструктивный, ясно, что большинству
разработчиков программных средств
сложно “переключиться” при тестировании
созданной ими продукции. Основные
принципы организации тестирования:
необходимой
частью каждого теста должно являться
описание ожидаемых результатов работы
программы, чтобы можно было быстро
выяснить наличие или отсутствие ошибки
в ней;
следует
по возможности избегать тестирования
программы ее автором, т.к. кроме уже
указанной объективной сложности
тестирования для программистов здесь
присутствует и тот фактор, что обнаружение
недостатков в своей деятельности
противоречит человеческой психологии
(однако отладка программы эффективнее
всего выполняется именно автором
программы);
по
тем же соображениям организация —
разработчик программного обеспечения
не должна “единолично ” его тестировать
(должны существовать организации,
специализирующиеся на тестировании
программных средств);
должны
являться правилом доскональное изучение
результатов каждого теста, чтобы не
пропустить малозаметную на поверхностный
взгляд ошибку в программе;
необходимо
тщательно подбирать тест не только для
правильных (предусмотренных ) входных
данных, но и для неправильных
(непредусмотренных);
при
анализе результатов каждого теста
необходимо проверять, не делает ли
программа того, что она не должна делать;
следует
сохранять использованные тесты (для
повышения эффективности повторного
тестирования программы после ее
модификации или установки у заказчика);
тестирования
не должно планироваться исходя из
предположения, что в программе не будут
обнаружены ошибки (в частности, следует
выделять для тестирования достаточные
временные и материальные ресурсы);
следует
учитывать так называемый “принцип
скопления ошибок” : вероятность наличия
не обнаруженных ошибок в некоторой
части программы прямо пропорциональна
числу ошибок, уже обнаруженных в этой
части;
следует
всегда помнить, что тестирование —
творческий процесс, а не относиться к
нему как к рутинному занятию.
Существует
два основных вида тестирования:
функциональное и структурное. При
функциональном тестировании программа
рассматривается как “черный ящик”
(то есть ее текст не используется).
Происходит проверка соответствия
поведения программы ее внешней
спецификации. Возможно ли при этом
полное тестирование программы? Очевидно,
что критерием полноты тестирования в
этом случае являлся бы перебор всех
возможных значений входных данных, что
невыполнимо.
Поскольку
исчерпывающее функциональное тестирование
невозможно, речь может идти о разработки
методов, позволяющих подбирать тесты
не “вслепую”, а с большой вероятностью
обнаружения ошибок в программе. При
структурном тестировании программа
рассматривается как “белый ящик”
(т.е. ее текст открыт для пользования).
Происходит проверка логики программы.
Полным тестированием в этом случае
будет такое, которое приведет к перебору
всех возможных путей на графе передач
управления программы (ее управляющем
графе). Даже для средних по сложности
программ числом таких путей может
достигать десятков тысяч.
Таким
образом, ни структурное, ни функциональное
тестирование не может быть исчерпывающим.
Рассмотрим подробнее основные этапы
тестирования программных комплексов.
В тестирование многомодульных программных
комплексов можно выделить четыре этапа:
тестирование
отдельных модулей;
совместное
тестирование модулей;
тестирование
функций программного комплекса (т.е.
поиск различий между разработанной
программой и ее внешней спецификацией
);
тестирование
всего комплекса в целом (т.е. поиск
несоответствия созданного программного
продукта, сформулированным ранее целям
проектирования, отраженным обычно в
техническом задании).
На
первых двух этапах используются, прежде
всего, методы структурного тестирования,
т.к. на последующих этапах тестирования
эти методы использовать сложнее из-за
больших размеров проверяемого
программного обеспечения; последующие
этапы тестирования ориентированы на
обнаружение ошибок различного типа,
которые не обязательно связаны с логикой
программы.
12.
Данные в языке Си: константы и переменные.
Скалярные типы данных. Модификаторы
типов.






13.
Данные числовых типов в языке Си:
объявление, характеристика, допустимые
операции, приведение типов. Пример
использования.
14.
Операции языка Си. Приоритет операций.
Оператор и операция присваивания в
языке операции, приведение типов. Пример
использования.



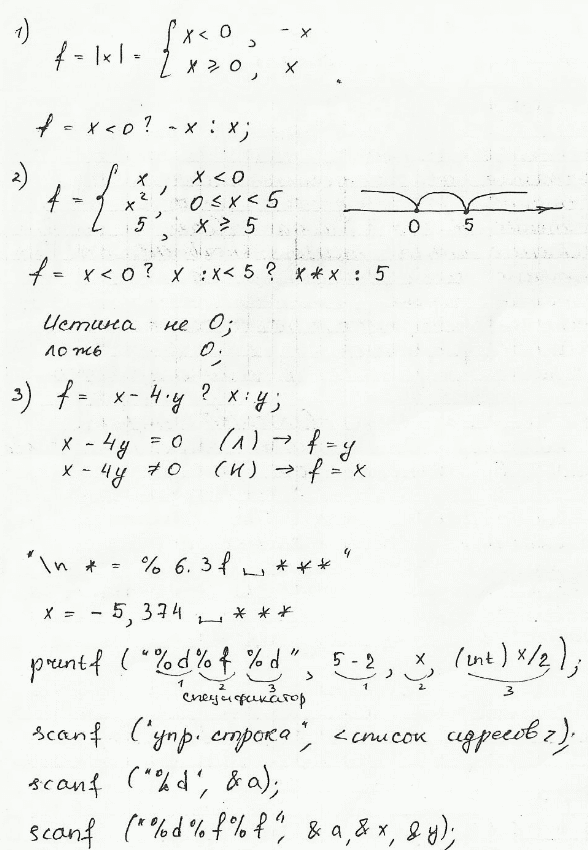
Оператор
присваивания может присутствовать в
любом выражении языка С[1].
Этим С отличается от большинства других
языков программирования (Pascal, BASIC и
FORTRAN), в которых присваивание возможно
только в отдельном операторе. Общая
форма оператора присваивания:
имя_переменной=выражение;
Выражение
может быть просто константой или сколь
угодно сложным выражением. В отличие
от Pascal или Modula-2, в которых для присваивания
используется знак «:=», в языке С
оператором присваивания служит
единственный знак присваивания
«=». Адресатом(получателем),
т.е. левой частью оператора присваивания
должен быть объект, способный получить
значение, например, переменная.
В
книгах по С и в сообщениях компилятора
часто встречаются термины lvalue[2] (left
side value)
и rvalue[3] (right
side value).
Попросту говоря, lvalue —
это объект. Если этот объект может
стоять в левой части присваивания, то
он называется такжемодифицируемым (modifiable) lvalue.
Подытожим сказанное: lvalue —
это объект в левой части оператора
присваивания, получающий значение,
чаще всего этим объектом является
переменная. Термин rvalue означает
значение выражения в правой части
оператора присваивания.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Отладка программы призвана выискивать «вредителей» кода и устранять их. За это отвечают отладчик и журналирование для вывода сведений о программе.
В предыдущей части мы рассмотрели исходный код и его составляющие.
После того, как вы начнете проверять фрагменты кода или попытаетесь решить связанные с ним проблемы, вы очень скоро поймете, что существуют моменты, когда программа крашится, прерывается и прекращает работу.
Это часто вызвано ошибками, известными как дефекты или исключительные ситуации во время выполнения. Акт обнаружения и удаления ошибок из нашего кода – это отладка программы. Вы лучше разберетесь в отладке на практике, используя ее как можно чаще. Мы не только отлаживаем собственный код, но и порой дебажим написанное другими программистами.
Для начала необходимо рассортировать общие ошибки, которые могут возникнуть в исходном коде.
Синтаксические ошибки
Эти эрроры не позволяют скомпилировать исходный код на компилируемых языках программирования. Они обнаруживаются во время компиляции или интерпретации исходного кода. Они также могут быть легко обнаружены статическими анализаторами (линтами). Подробнее о линтах мы узнаем немного позже.
Синтаксические ошибки в основном вызваны нарушением ожидаемой формы или структуры языка, на котором пишется программа. Как пример, это может быть отсутствующая закрывающая скобка в уравнении.
Семантические ошибки
Отладка программы может потребоваться и по причине семантических ошибок, также известных как логические. Они являются наиболее сложными из всех, потому что не могут быть легко обнаружены. Признак того, что существует семантическая ошибка, – это когда программа запускается, отрабатывает, но не дает желаемого результата.
Рассмотрим данный пример:
3 + 5 * 6
По порядку приоритета, называемому старшинством операции, с учетом математических правил мы ожидаем, что сначала будет оценена часть умножения, и окончательный результат будет равен 33. Если программист хотел, чтобы сначала происходило добавление двух чисел, следовало поступить иначе. Для этого используются круглые скобки, которые отвечают за смещение приоритетов в математической формуле. Исправленный пример должен выглядеть так:
(3 + 5) * 6
3 + 5, заключенные в скобки, дадут желаемый результат, а именно 48.
Ошибки в процессе выполнения
Как и семантические, ошибки во время выполнения никогда не обнаруживаются при компиляции. В отличие от семантических ошибок, эти прерывают программу и препятствуют ее дальнейшему выполнению. Они обычно вызваны неожиданным результатом некоторых вычислений в исходном коде.
Вот хороший пример:
input = 25 x = 0.8/(Math.sqrt(input) - 5)
Фрагмент кода выше будет скомпилирован успешно, но input 25 приведет к ZeroDivisionError. Это ошибка во время выполнения. Другим популярным примером является StackOverflowError или IndexOutofBoundError. Важно то, что вы идентифицируете эти ошибки и узнаете, как с ними бороться.
Существуют ошибки, связанные с тем, как ваш исходный код использует память и пространство на платформе или в среде, в которой он запущен. Они также являются ошибками во время выполнения. Такие ошибки, как OutOfMemoryErrorand и HeapError обычно вызваны тем, что ваш исходный код использует слишком много ресурсов. Хорошее знание алгоритмов поможет написать код, который лучше использует ресурсы. В этом и заключается отладка программы.
Процесс перезаписи кода для повышения производительности называется оптимизацией. Менее популярное наименование процесса – рефакторинг. Поскольку вы тратите больше времени на кодинг, то должны иметь это в виду.
Отладка программы
Вот несколько советов о том, как правильно выполнять отладку:
- Использовать Linters. Linters – это инструменты, которые помогают считывать исходный код, чтобы проверить, соответствует ли он ожидаемому стандарту на выбранном языке программирования. Существуют линты для многих языков.
- Превалирование IDE над простыми редакторами. Вы можете выбрать IDE, разработанную для языка, который изучаете. IDE – это интегрированные среды разработки. Они созданы для написания, отладки, компиляции и запуска кода. Jetbrains создают отличные IDE, такие как Webstorm и IntelliJ. Также есть NetBeans, Komodo, Qt, Android Studio, XCode (поставляется с Mac), etc.
- Чтение кода вслух. Это полезно, когда вы ищете семантическую ошибку. Читая свой код вслух, есть большая вероятность, что вы зачитаете и ошибку.
- Чтение логов. Когда компилятор отмечает Error, обязательно посмотрите, где он находится.
Двигаемся дальше
Поздравляем! Слово «ошибка» уже привычно для вас, равно как и «отладка программы». В качестве новичка вы можете изучать кодинг по книгам, онлайн-урокам или видео. И даже чужой код вам теперь не страшен
В процессе кодинга измените что-нибудь, чтобы понять, как он работает. Но будьте уверены в том, что сами написали.
Викторина
- Какая ошибка допущена в фрагменте кода Python ниже?
items = [0,1,2,3,4,5] print items[8] //комментарий: элементы здесь представляют собой массив с шестью элементами. Например, чтобы получить 4-й элемент, вы будете использовать [3]. Мы начинаем отсчет с 0.
- Какая ошибка допущена в фрагменте кода Python ниже?
input = Hippo' if input == 'Hippo': print 'Hello, Hippo'
Ответы на вопросы
- Ошибка выполнения: ошибка индекса вне диапазона.
2. Синтаксическая ошибка: Отсутствует стартовая кавычка в первой строке.
Классификация ошибок. Последовательность, способы и средства их обнаружения. Методика поиска семантических ошибок.
Способы
и средства получения информации о ходе
вычислительного процесса
1
Аварийная печать
2
Печать в узлах
3
Слежение
4
Прокрутка
5
Контроль индексов
Методика
поиска семантических ошибок
Локализация
: установление сущности ошибки->
установление фрагментов программы с
ошибкой (печать в узлах)-> установление
конкретного места.
1.Прослеживание
по схеме алгоритма
2.Обратное
отслеживание идентификаторов
3.Ручная
прокрутка программы
Экономическая
информационная система. Определение,
задачи, характеристики, этапы развития.
Развитие эис
В
50-е годы на
ЭВМ в основном решались отдельные
экономические задачи, связанные с
необходимостью переработки больших
информационных массивов, например,
такие, как начисление заработной платы,
составление статистических отчетов и
т.д., или задачи, выполняющие оптимизационные
расчеты, например, решение транспортной
задачи.
В
60-е годы
возникает
идея комплексной автоматизации управления
предприятиями и интеграции информационного
обеспечения на основе баз данных.
Реальностью автоматизированные системы
управления стали в 70-е годы на базе ЭВМ
3-го поколения, которые позволили
создавать вычислительные системы с
распределенной терминальной сетью.
Однако недостаточное быстродействие
и надежность вычислительных машин,
отсутствие гибких средств реализации
информационных потребностей пользователей
не смогли превратить ЭИС в инструмент
коренного повышения эффективности
управления предприятиями.
80-годы
отмечены внедрением персональных ЭВМ
в практику работы управленческих
работников, созданием широкого набора
автоматизированных рабочих мест (АРМов)
на базе языков 4-го поколения (4GL),
позволяющих с помощью генераторов
запросов, отчетов, экранных форм, диалога
быстро разрабатывать удобные для
пользователей приложения. Однако
рассредоточение ЭИС в виде АРМов,
локальная («островная») автоматизация
не способствовали интеграции управленческих
функций и, как следствие, существенному
повышению эффективности управления
предприятием.
Для
90-х годов
характерно развитие телекоммуникационных
средств, которое привело к созданию
гибких локальных и глобальных
вычислительных сетей, предопределивших
возможность разработки и внедрения
корпоративных ЭИС (КЭИС). КЭИС объединяют
возможности систем комплексной
автоматизации управления 70-х годов и
локальной автоматизации 80 — годов.
Наличие гибких средств связывания
управленческих работников в процессе
хозяйственной деятельности, возможность
коллективной работы, как непосредственных
исполнителей хозяйственных операций,
так и менеджеров, принимающих управленческие
решения, позволяют во многом пересмотреть
принципы управления предприятиями или
проводить кардинальный реинжиниринг
бизнес-процессов.
Понятие эис
Методологическую
основу проектирования ЭИС составляет
системный подход, в соответствии с
которым любая система представляет
собой совокупность взаимосвязанных
объектов (элементов), функционирующих
совместно для достижения общей цели.
Для системы характерно изменение
состояний объектов, которые с течением
времени происходят в результате
взаимодействия объектов в различных
процессах и с внешней средой. В результате
такого поведения системы важно соблюдение
следующих принципов:
• эмерджентности,
то есть целостности системы на основе
общей структуры, когда поведение
отдельных объектов рассматривается с
позиции функционирования всей системы;
• гомеостазиса,
то есть обеспечения устойчивого
функционирования системы и достижения
общей цели;
• адаптивности
к изменениям внешней среды и управляемости
посредством воздействия на элементы
системы;
• обучаемости
путем изменения структуры системы в
соответствии с изменением целей системы.
С
позиций кибернетики процесс управления
системой, как направленное воздействие
на элементы системы для достижения
цели, можно представить в виде
информационного процесса, связывающего
внешнюю среду, объект и систему управления.
При этом внешняя среда и объект управления
информируют систему управления о своем
состоянии, система управления анализирует
эту информацию, вырабатывает управляющее
воздействие на объект управления,
отвечает на возмущения внешней среды
и при необходимости модифицирует цель
и структуру всей системы.
Структура
экономической информационной системы.
Классификация экономических информационных
систем.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
The third type of error is the semantic error, also called a logic error. If there is a semantic error
in your program, it will run successfully in the sense that the computer will
not generate any error messages. However, your program will not do the right thing. It will do
something else. Specifically, it will do what you told it to do, not what you wanted it to do.
The following program has a semantic error. Execute it to see what goes wrong:
This program runs and produces a result. However, the result is not what the programmer intended. It contains
a semantic error. The error is that the program performs concatenation instead of addition, because the programmer
failed to write the code necessary to convert the inputs to integers.
With semantic errors, the problem is that the program you wrote is not the program you wanted to
write. The meaning of the program (its semantics) is wrong. The computer is
faithfully carrying out the instructions you wrote, and its results
are correct, given the instructions that you provided. However, because your instructions
have a flaw in their design, the program does not behave as desired.
Identifying semantic errors can be tricky because no error message appears to make it obvious that the results are
incorrect. The only way you can detect semantic errors is if you know in advance what the program should do for a given set
of input. Then, you run the program with that input data and compare the output of the program with what you expect. If
there is a discrepancy between the actual output and the expected output, you can conclude that there is either 1) a
semantic error or 2) an error in your expected results.
Once you’ve determined that you have a semantic error, locating it can be tricky because you must work
backward by looking at the output of the program and trying to figure out what it is doing.
3.7.1. Test Cases¶
To detect a semantic error in your program, you need the help of something called a test case.
Test Case
A test case is a set of input values for the program, together with the output that you expect the program should produce when it is run with those particular
inputs.
Here is an example of a test case for the program above:
Test Case --------- Input: 2, 3 Expected Output: 5
If you give this test case to someone and ask them to test the program, they can type in the inputs, observe the output,
check it against the expected output, and determine whether a semantic error exists based on whether the actual output
matches the expected output or not. The tester doesn’t even have to know what the program is supposed to do. For this reason,
software companies often have separate quality assurance departments whose responsibility is to check that the programs written
by the programmers perform as expected. The testers don’t have to be programmers; they just have to be able to operate the
program and compare its results with the test cases they’re given.
In this case, the program is so simple that we don’t need to write down a test case at all; we can compute the expected output
in our heads with very little effort. More complicated programs require effort to create the test case (since you shouldn’t use
the program to compute the expected output; you have to do it with a calculator or by hand), but the effort pays off when
the test case helps you to identify a semantic error that you didn’t know existed.
Semantic errors are the most dangerous of the three types of errors, because in some cases they are not noticed by either
the programmers or the users who use the program. Syntax errors cannot go undetected (the program won’t run at all if
they exist), and runtime errors are usually also obvious and typically detected by developers before a program is
released for use (although it is possible for a runtime error to occur for some inputs and not for
others, so these can sometimes remain undetected for a while). However, programs often go for years with undetected
semantic errors; no one realizes that the program has been producing incorrect results. They just assume that because the
results seem reasonable, they are correct. Sometimes, these errors are relatively harmless. But if they involve
financial transactions or medical equipment, the results can be harmful or even deadly. For this reason, creating test
cases is an important part of the work that programmers perform in order to help them produce programs that work
correctly.
Check your understanding
- Attempting to divide by 0.
- A semantic error is an error in logic. In this case the program does not produce the correct output because the problem is not solved correctly. This would be considered a run-time error.
- Forgetting a semi-colon at the end of a statement where one is required.
- A semantic error is an error in logic. In this case the program does not produce the correct output because the code can not be processed by the compiler or interpreter. This would be considered a syntax error.
- Forgetting to divide by 100 when printing a percentage amount.
- This will produce the wrong answer because the programmer implemented the solution incorrectly. This is a semantic error.
Which of the following is a semantic error?
- The programmer.
- You must fully understand the problem so the you can tell if your program properly solves it.
- The compiler / interpreter.
- The compiler and / or interpreter will only do what you instruct it to do. It does not understand what the problem is that you want to solve.
- The computer.
- The computer does not understand your problem. It just executes the instructions that it is given.
- The teacher / instructor.
- Your teacher and instructor may be able to find most of your semantic errors, but only because they have experience solving problems. However it is your responsibility to understand the problem so you can develop a correct solution.
Who or what typically finds semantic errors?
You have attempted of activities on this page
Время на прочтение
32 мин
Количество просмотров 3.6K
В предыдущей статье мы закончили на том, что мы написали лексический и синтаксический анализаторы для нашего учебного языка. В данной статье мы продолжим начатое и рассмотрим следующую стадию анализа исходного кода программы — семантический анализ.
Семантический анализ
Основная задача семантического анализа заключается в проверки того, что программа корректна с точки зрения языка, например:
-
Все переменные в программе объявлены;
-
Все выражения совершаются над корректными типами;
-
Если в программе используется безусловный/условный переход, то метка, на которую совершается переход должна существовать;
-
Функция возвращает значение корректного типа.
Замечание. Нужно понимать, что семантический анализ не может выловить все ошибки в программе, а только те их типы, которые были заложены разработчиком компилятора или описаны в спецификации языка. Например в языке C++ компилятор не сможет обнаружить все ошибки работы с памятью, даже если разработчик компилятора внес специальную обработку для выявления ошибок такого типа. Но в Rust ошибки такого типа исключаются на уровне самого языка.
Все семантические правила обычно описываются в спецификации конкретного языка и описывают критерии нахождения не корректных программ на данном языке.
Область видимости (Scope)
Область видимости — это часть программы, в пределах которой идентификатор, объявленный как имя некоторой программной сущности (обычно — переменной, типа данных или функции), остаётся связанным с этой сущностью, то есть позволяет посредством себя обратиться к ней.
Часто в спецификации языка описаны правила, для формирования областей видимости, например может быть глобальная область видимости, область видимости класса, область видимости функции и др. Обычно области видимости образуют иерархию и для поиска сущности, на которую ссылается идентификатор в конкретном месте программы, может понадобиться поиск этого идентификатора во всех уровнях этой иерархии.
В simple есть следующие виды областей видимости:
-
Модуль (все объявления объявленные на самом верхнем уровне файла);
-
Класс/Структура (более подробно будут рассмотрены в последующих частях серии);
-
Функция;
-
Блок в функции.
Так же в simple объявления не могут перекрывать другие объявление доступные в данной области видимости (за исключением перегрузки функций (рассмотри в последующих частях серии)). В simple, любые переменная объявленная в функции может быть использована в любом месте после ее объявления, любое имя объявленное в модуле может быть использовано в любом месте в этом модуле (т. е. разрешено использовать имя класса до его объявления, если оно находится в этом же модуле).
Более подробно про области видимости можно почитать в [1].
Для работы с областью видимости будем использовать следующий класс:
struct Scope {
Scope(DiagnosticsEngine &D) ;
Scope(Scope* enclosed) ;
Scope(ModuleDeclAST* thisModule) ;
// Поиск идентификатора во всех доступных в данной точке областях видимости
SymbolAST* find(Name* id);
// Поиск идентификатора — члена класса или структуры
SymbolAST* findMember(Name* id, int flags = 0);
// Создать новую область видимости
Scope* push();
// Создать новую область видимости на основе объявления
Scope* push(ScopeSymbol* sym);
// Закрыть текущую область видимости (возвращает родительский Scope)
Scope* pop();
// Воссоздать список областей видимости для иерархии классов
static Scope* recreateScope(Scope* scope, SymbolAST* sym);
// Очистка списка областей видимости и оставить только область видимости
// самого модуля
static void clearAllButModule(Scope* scope);
// Вывод сообщения об ошибке
template <typename... Args>
void report(SMLoc Loc, unsigned DiagID, Args &&...Arguments) {
Diag.report(Loc, DiagID, std::forward<Args>(Arguments)...);
}
Scope* Enclosed; ///< родительский Scope
ModuleDeclAST* ThisModule; ///< родительский модуль
/// символ для текущей области видимости (например функция или класс)
SymbolAST* CurScope;
/// функция к которой принадлежит область видимости
FuncDeclAST* EnclosedFunc;
StmtAST* BreakLoc; ///< цикл для инструкции break
StmtAST* ContinueLoc; ///< цикл для инструкции continue
LandingPadAST* LandingPad; ///< нужно для генерации кода (см. описание ниже)
DiagnosticsEngine &Diag; ///< модуль диагностики
};Ниже приведу реализацию данного класса:
Hidden text
SymbolAST* Scope::find(Name* id) {
Scope* s = this;
// Если идентификатор не указан, то это глобальная область
// видимости
if (!id) {
return ThisModule;
}
// Циклический поиск объявления во всех доступных из данной точки
// областях видимости
for ( ; s; s = s->Enclosed) {
if (s->CurScope) {
SymbolAST* sym = s->CurScope->find(id);
if (sym) {
return sym;
}
}
}
return nullptr;
}
SymbolAST* Scope::findMember(Name* id, int flags) {
if (CurScope) {
return CurScope->find(id, flags);
}
return nullptr;
}
Scope* Scope::push() {
Scope* s = new Scope(this);
return s;
}
Scope* Scope::push(ScopeSymbol* sym) {
Scope* s = push();
s->CurScope = sym;
return s;
}
Scope* Scope::pop() {
Scope* res = Enclosed;
delete this;
return res;
}
Scope* Scope::recreateScope(Scope* scope, SymbolAST* sym) {
Scope* p = scope;
// Поиск области видимости самого верхнего уровня (модуля)
while (p->Enclosed) {
p = p->Enclosed;
}
// Создаем список все родительских объявлений
SymbolList symList;
SymbolAST* tmp = sym;
while (tmp->Parent) {
symList.push_back(tmp);
tmp = tmp->Parent;
}
// Воссоздаем все области видимости в обратном порядке объявленных
// сущностей. Нужно для поиска в имени в иерархии классов
for (SymbolList::reverse_iterator it = symList.rbegin(),
end = symList.rend(); it != end; ++it) {
p = p->push((ScopeSymbol*)*it);
}
// Возвращаем созданный Scope
return p;
}
void Scope::clearAllButModule(Scope* scope) {
Scope* p = scope;
while (p->Enclosed) {
p = p->pop();
}
}Проверка типов
Суть проверки типов заключается в том, что бы проверить, что все операции выполняемые в программе производятся с операндами корректных типов.
Проверка типов бывает:
-
Статическая (данная проверка происходит на этапе компиляции программы);
-
Динамическая (данная проверка происходит на этапе выполнения программы).
Более подробно можно почитать в [2].
В simple у нас будет статическая проверка и все типы будут определяться во время анализа исходного кода программы. В последующих частях мы добавим классы с поддержкой виртуальных функций, при вызове которых результирующая функция будет разрешаться во время выполнения программы.
Семантический анализ типов
Для начала рассмотрим какие именно функции члены иерархии типов будут отвечать за семантический анализ этих ветвей AST:
struct TypeAST {
...
/// Производит семантический анализ для типа
virtual TypeAST* semantic(Scope* scope) = 0;
/// Проверка на то, что данный тип может быть преобразован в "newType"
virtual bool implicitConvertTo(TypeAST* newType) = 0;
/// Проверка на то, что данный тип совпадает с "otherType"
bool equal(TypeAST* otherType);
/// Сгенерировать и поместить в буфер декорированную строку для
/// данного типа (реализуется в потомках)
virtual void toMangleBuffer(llvm::raw_ostream& output) = 0;
/// Сгенерировать декорированную строку для данного типа
void calcMangle();
llvm::StringRef MangleName; ///< декорированная строка с именем данного типа
};Если посмотреть на приведенный выше код, то можно увидеть, что функция semantic возвращает TypeAST*, это нужно для того, что бы при необходимости можно было бы вернуть новый тип в замен старого. Например в simple можно объявить переменную с типом A и на момент построения дерева мы не можем сказать, какой именно тип будет иметь данная переменная, поэтому во время парсинга будет создан экземпляр типа QualifiedTypeAST, который во время семантического анализа будет заменен типом StructTypeAST или ClassTypeAST (все эти типы будут рассмотрены в последующих частях серии).
Так же можно увидеть, что существуют функции для создания декорированного имени, данная функция генерирует уникальное имя типа в системе и если два объекта производные от TypeAST имеют одинаковое декорированное имя, то эти типы совпадают. Так же декорация имен нужна для создания уникальных имен функций, например функция
fn check(s: string, a: float, b: float)после декорации будет иметь следующие имя
_P5checkPKcffБолее подробнее про декорирование имен (Name mangling) можно посмотреть тут [3].
Теперь мы можем рассмотреть реализацию семантического анализа для иерархии типов:
Hidden text
// Хранит множество всех уникальных декорированных строк
StringSet< > TypeAST::TypesTable;
void TypeAST::calcMangle() {
// Ничего не делаем, если декорированное имя для типа уже задано
if (!MangleName.empty()) {
return;
}
// Для большинства типов 128 байт будет достаточно
llvm::SmallString< 128 > s;
llvm::raw_svector_ostream output(s);
// Пишем декорированное имя в буфер и добавляем в множество имен,
// т. к. StringRef требует выделенный блок памяти со строкой
toMangleBuffer(output);
TypesTable.insert(output.str());
// Устанавливаем внутреннее состояние MangleName на основе записи
// созданной в множестве имен
StringSet< >::iterator pos = TypesTable.find(s);
assert(pos != TypesTable.end());
MangleName = pos->getKeyData();
}
bool TypeAST::equal(TypeAST* otherType) {
// Два типа эквивалентны, если их "MangleName" совпадают, для
// сложных типов это может быть гораздо быстрее, чем сравнивать
// их структуру
assert(!MangleName.empty() && !otherType->MangleName.empty());
return MangleName == otherType->MangleName;
}
TypeAST* BuiltinTypeAST::semantic(Scope* scope) {
// Для базовых типов для проверки семантики достаточно произвести
// декорирование имени типа
calcMangle();
return this;
}
bool BuiltinTypeAST::implicitConvertTo(TypeAST* newType) {
// Список разрешенных преобразований
static bool convertResults[TI_Float + 1][TI_Float + 1] = {
// void bool int float
{ false, false, false, false }, // void
{ false, true, true, true }, // bool
{ false, true, true, true }, // int
{ false, true, true, true }, // float
};
// Только базовые типы могут быть преобразованы друг в друга
if (newType->TypeKind > TI_Float) {
return false;
}
return convertResults[TypeKind][newType->TypeKind];
}
void BuiltinTypeAST::toMangleBuffer(llvm::raw_ostream& output) {
switch (TypeKind) {
case TI_Void : output << "v"; break;
case TI_Bool : output << "b"; break;
case TI_Int : output << "i"; break;
case TI_Float : output << "f"; break;
default: assert(0 && "Should never happen"); break;
}
}
TypeAST* FuncTypeAST::semantic(Scope* scope) {
if (!ReturnType) {
// Если у функции не был задан тип возвращаемого значения, то
// установить как "void"
ReturnType = BuiltinTypeAST::get(TypeAST::TI_Void);
}
// Произвести семантический анализ для типа возвращаемого
// значения
ReturnType = ReturnType->semantic(scope);
// Произвести семантический анализ для всех параметров
for (ParameterList::iterator it = Params.begin(),
end = Params.end(); it != end; ++it) {
(*it)->Param = (*it)->Param->semantic(scope);
}
calcMangle();
return this;
}
bool FuncTypeAST::implicitConvertTo(TypeAST* newType) {
return false;
}
void FuncTypeAST::toMangleBuffer(llvm::raw_ostream& output) {
// Добавляем "v", если функция возвращает "void"
if (Params.empty()) {
output << "v";
return;
}
ParameterList::iterator it = Params.begin(), end = Params.end();
// Произвести декорацию имен для всех параметров
for ( ; it != end; ++it) {
(*it)->Param->toMangleBuffer(output);
}
}На данной стадии у нас есть только несколько базовых типов и семантический анализ для иерархии типов достаточно прост, мы просто генерируем декорированные имена для каждого типа. Но в последующих статьях с добавлением более сложных типов семантический анализ усложнится и список преобразований между типами будет так же расширен.
Семантический анализ выражений
Для начала рассмотрим какие именно функции члены иерархии выражений будут отвечать за семантический анализ этих ветвей AST:
struct ExprAST {
...
/// Проверка, что это целочисленная константа
bool isIntConst() { return ExprKind == EI_Int; }
/// Проверка, что это константное выражение
bool isConst() {
return ExprKind == EI_Int || ExprKind == EI_Float;
}
/// Проверяем, что константное выражение имеет истинное значение
virtual bool isTrue();
/// Проверка на то, что данное выражение может быть использовано
/// в качестве значения с левой стороны от "="
virtual bool isLValue();
/// Произвести семантический анализ выражения
virtual ExprAST *semantic(Scope *scope) = 0;
/// Сделать копию ветви дерева
virtual ExprAST *clone() = 0;
TypeAST *ExprType; ///< тип выражения
};Так же, как и у типов, ExprAST после семантического анализа может быть изменено (например можно сделать оптимизацию и произвести вычисление константных выражений, но в нашем случае мы будем использовать это для замены некоторых выражений их аналогами, что бы упростить генерацию кода).
Рассмотрим более подробно сам семантический анализ для выражений:
Hidden text
bool ExprAST::isTrue() {
return false;
}
bool ExprAST::isLValue() {
return false;
}
bool IntExprAST::isTrue() {
return Val != 0;
}
ExprAST* IntExprAST::semantic(Scope* ) {
return this;
}
ExprAST* IntExprAST::clone() {
return new IntExprAST(Loc, Val);
}
bool FloatExprAST::isTrue() {
return Val != 0.0;
}
ExprAST* FloatExprAST::semantic(Scope* ) {
return this;
}
ExprAST* FloatExprAST::clone() {
return new FloatExprAST(Loc, Val);
}
bool IdExprAST::isLValue() {
return true;
}
ExprAST* IdExprAST::semantic(Scope* scope) {
// Если "ThisSym" задан, то семантический анализ над данным
// выражением уже был ранее завершен
if (!ThisSym) {
// Ищем объявление в текущей области видимости
ThisSym = scope->find(Val);
if (!Val) {
return this;
}
if (!ThisSym) {
// Объявление не найдено, возвращаем ошибку
scope->report(Loc, diag::ERR_SemaUndefinedIdentifier,
Val->Id);
return nullptr;
}
// Устанавливаем тип данного выражения в соответствии с типом
// объявленной переменной
ExprType = ThisSym->getType();
}
return this;
}
ExprAST* IdExprAST::clone() {
return new IdExprAST(Loc, Val);
}
ExprAST* CastExprAST::semantic(Scope* scope) {
if (SemaDone) {
return this;
}
// Проверяем, что тип был корректно задан и что это не "void"
assert(ExprType != nullptr && "Type for cast not set");
if (ExprType->isVoid()) {
scope->report(Loc, diag::ERR_SemaCastToVoid);
return nullptr;
}
// Производим семантический анализ выражения для преобразования
Val = Val->semantic(scope);
// Проверяем, что тип исходного выражения корректный
if (!Val->ExprType || Val->ExprType->isVoid()) {
scope->report(Loc, diag::ERR_SemaCastToVoid);
return nullptr;
}
// Запрещаем преобразования функций
if (isa<FuncTypeAST>(ExprType)
|| isa<FuncTypeAST>(Val->ExprType)) {
scope->report(Loc, diag::ERR_SemaFunctionInCast);
return nullptr;
}
// Проверяем, что типы совместимы
if (!Val->ExprType->implicitConvertTo(ExprType)) {
scope->report(Loc, diag::ERR_SemaInvalidCast);
return nullptr;
}
SemaDone = true;
return this;
}
ExprAST* CastExprAST::clone() {
return new CastExprAST(Loc, Val->clone(), ExprType);
}Т.к. все выражения с одним операндом могут быть переписаны в виде эквивалентного выражения с двумя операндами, то для упрощения кодогенерации при семантическом анализе мы проверяем корректность операнда и возвращаем эквивалентный аналог:
Hidden text
ExprAST* UnaryExprAST::semantic(Scope* scope) {
// Проверяем, что операнд был корректно задан
if (!Val) {
assert(0 && "Invalid expression value");
return nullptr;
}
// Производим семантический анализ для операнда
Val = Val->semantic(scope);
// Проверяем корректность типа операнда, т. к. он может быть
// "void"
if (!Val->ExprType || Val->ExprType->isVoid()) {
scope->report(Loc, diag::ERR_SemaOperandIsVoid);
return nullptr;
}
// Исключаем операции над булевыми значениями
if (Val->ExprType->isBool() && (Op == tok::Plus
|| Op == tok::Minus)) {
scope->report(Loc, diag::ERR_SemaInvalidBoolForUnaryOperands);
return nullptr;
}
// Список замен:
// +Val to Val
// -Val to 0 - Val
// ~intVal to intVal ^ -1
// ++id to id = id + 1
// --id to id = id - 1
// !Val to Val == 0
ExprAST* result = this;
// Проверяем тип оператора, для необходимой замены
switch (Op) {
// "+" - noop
case tok::Plus: result = Val; break;
case tok::Minus:
// Преобразовываем в 0 - Val с учетом типа Val
if (Val->ExprType->isFloat()) {
result = new BinaryExprAST(Val->Loc, tok::Minus,
new FloatExprAST(Val->Loc, 0),
Val);
} else {
result = new BinaryExprAST(Val->Loc, tok::Minus,
new IntExprAST(Val->Loc, 0),
Val);
}
break;
case tok::Tilda:
// ~ можно применять только к целочисленным выражениям
if (!Val->ExprType->isInt()) {
scope->report(Loc,
diag::ERR_SemaInvalidOperandForComplemet);
return nullptr;
} else {
// Преобразуем в Val ^ -1
result = new BinaryExprAST(Val->Loc, tok::BitXor, Val,
new IntExprAST(Val->Loc, -1));
break;
}
case tok::PlusPlus:
case tok::MinusMinus: {
// "++" и "--" можно вызывать только для IdExprAST в
// качестве операнда и только для целочисленного типа
if (!Val->ExprType->isInt() || !Val->isLValue()) {
scope->report(Loc,
diag::ERR_SemaInvalidPostfixPrefixOperand);
return nullptr;
}
// Необходимо заменить "++" id или "--" id на id = id + 1
// или id = id + -1
ExprAST* val = Val;
ExprAST* valCopy = Val->clone();
result = new BinaryExprAST(Val->Loc, tok::Assign,
val,
new BinaryExprAST(Val->Loc, tok::Plus,
valCopy,
new IntExprAST(Val->Loc,
(Op == tok::PlusPlus) ? 1 : -1)));
}
break;
case tok::Not:
// Заменяем на Val == 0
result = new BinaryExprAST(Val->Loc, tok::Equal, Val,
new IntExprAST(Val->Loc,
0));
break;
default:
// Никогда не должно произойти
assert(0 && "Invalid unary expression");
return nullptr;
}
if (result != this) {
// Т.к. старое выражение было заменено, очищаем память и
// производим семантический анализ нового выражения
Val = nullptr;
delete this;
return result->semantic(scope);
}
return result;
}
ExprAST* UnaryExprAST::clone() {
return new UnaryExprAST(Loc, Op, Val->clone());
}Рассмотрим семантический анализ выражений с двумя операндами:
Hidden text
ExprAST* BinaryExprAST::semantic(Scope* scope) {
// Семантический анализ уже был произведен ранее
if (ExprType) {
return this;
}
// Производим семантический анализ операнда с левой стороны
LeftExpr = LeftExpr->semantic(scope);
// Проверяем на "++" или "--", т. к. эти операции имеют только
// один операнд
if (Op == tok::PlusPlus || Op == tok::MinusMinus) {
// "++" и "--" можно вызывать только для IdExprAST в качестве
// операнда и только для целочисленного типа
if (!LeftExpr->isLValue() || !LeftExpr->ExprType->isInt()) {
scope->report(Loc,
diag::ERR_SemaInvalidPostfixPrefixOperand);
return nullptr;
}
// Устанавливаем результирующий тип выражения
ExprType = LeftExpr->ExprType;
return this;
}
// Производим семантический анализ операнда с правой стороны
RightExpr = RightExpr->semantic(scope);
// Проверяем, что оба операнда имеют корректные типы
if (!LeftExpr->ExprType || !RightExpr->ExprType) {
scope->report(Loc,
diag::ERR_SemaUntypedBinaryExpressionOperands);
return nullptr;
}
// "," имеет специальную обработку и тип выражения совпадает с
// типом операнда с правой стороны
if (Op == tok::Comma) {
ExprType = RightExpr->ExprType;
return this;
}
// Исключаем операции, если хотя бы один операнд имеет тип "void"
if (LeftExpr->ExprType->isVoid()
|| RightExpr->ExprType->isVoid()) {
scope->report(Loc, diag::ERR_SemaOperandIsVoid);
return nullptr;
}
// Проверка на операторы сравнения, т. к. их результат всегда
// будет иметь тип "bool"
switch (Op) {
case tok::Less:
case tok::Greater:
case tok::LessEqual:
case tok::GreaterEqual:
case tok::Equal:
case tok::NotEqual:
// Если левый операнд "bool", то сначала конвертируем его в
// "int"
if (LeftExpr->ExprType->isBool()) {
LeftExpr = new CastExprAST(LeftExpr->Loc, LeftExpr,
BuiltinTypeAST::get(TypeAST::TI_Int));
LeftExpr = LeftExpr->semantic(scope);
}
// Операнды для "<", "<=", ">", ">=", "==" и "!=" всегда
// должны иметь одинаковые типы, если они отличаются, то
// нужно сделать преобразование
if (!LeftExpr->ExprType->equal(RightExpr->ExprType)) {
RightExpr = new CastExprAST(RightExpr->Loc, RightExpr,
LeftExpr->ExprType);
RightExpr = RightExpr->semantic(scope);
}
// Результирующий тип выражения — "bool"
ExprType = BuiltinTypeAST::get(TypeAST::TI_Bool);
return this;
case tok::LogOr:
case tok::LogAnd:
// Для логических операций оба операнда должны
// конвертироваться в "bool"
if (!LeftExpr->ExprType->implicitConvertTo(
BuiltinTypeAST::get(TypeAST::TI_Bool))
|| !RightExpr->ExprType->implicitConvertTo(
BuiltinTypeAST::get(TypeAST::TI_Bool))) {
scope->report(Loc, diag::ERR_SemaCantConvertToBoolean);
return nullptr;
}
// Результирующий тип выражения — "bool"
ExprType = BuiltinTypeAST::get(TypeAST::TI_Bool);
return this;
default:
// Остальные варианты обрабатываем ниже
break;
}
// Если левый операнд "bool", то сначала конвертируем его в "int"
if (LeftExpr->ExprType == BuiltinTypeAST::get(TypeAST::TI_Bool)) {
LeftExpr = new CastExprAST(LeftExpr->Loc, LeftExpr,
BuiltinTypeAST::get(TypeAST::TI_Int));
LeftExpr = LeftExpr->semantic(scope);
}
// Результирующий тип выражения будет совпадать с типом левого
// операнда
ExprType = LeftExpr->ExprType;
// Для "=" тоже есть специальная обработка
if (Op == tok::Assign) {
// Если типы левого и правого операнда отличаются, то нужно
// сделать преобразование
if (!LeftExpr->ExprType->equal(RightExpr->ExprType)) {
RightExpr = new CastExprAST(RightExpr->Loc, RightExpr,
LeftExpr->ExprType);
RightExpr = RightExpr->semantic(scope);
}
// Проверяем, что операнд с левой стороны является адресом
if (!LeftExpr->isLValue()) {
scope->report(Loc, diag::ERR_SemaMissingLValueInAssignment);
return nullptr;
}
// Выражение корректно, завершаем анализ
return this;
}
// Если операнды имеют различные типы, то нужно произвести
// преобразования
if (!LeftExpr->ExprType->equal(RightExpr->ExprType)) {
// Если операнд с правой стороны имеет тип "float", то
// результат операции тоже будет "float"
if (RightExpr->ExprType->isFloat()) {
ExprType = RightExpr->ExprType;
LeftExpr = new CastExprAST(LeftExpr->Loc, LeftExpr,
RightExpr->ExprType);
LeftExpr = LeftExpr->semantic(scope);
} else {
// Преобразуем операнд с правой стороны к типу операнда с
// левой стороны
RightExpr = new CastExprAST(RightExpr->Loc, RightExpr,
LeftExpr->ExprType);
RightExpr = RightExpr->semantic(scope);
}
}
// "int" и "float" имеют отличный набор допустимых бинарных
// операций
if (ExprType == BuiltinTypeAST::get(TypeAST::TI_Int)) {
// Проверяем допустимые операции над "int"
switch (Op) {
case tok::Plus:
case tok::Minus:
case tok::Mul:
case tok::Div:
case tok::Mod:
case tok::BitOr:
case tok::BitAnd:
case tok::BitXor:
case tok::LShift:
case tok::RShift:
return this;
default:
// Никогда не должны сюда попасть, если только нет ошибки
// в парсере
assert(0 && "Invalid integral binary operator");
return nullptr;
}
} else {
// Проверяем допустимые операции над "float"
switch (Op) {
case tok::Plus:
case tok::Minus:
case tok::Mul:
case tok::Div:
case tok::Mod:
case tok::Less:
return this;
default:
// Сообщаем об ошибке, т. к. данная операция не допустима
scope->report(Loc,
diag::ERR_SemaInvalidBinaryExpressionForFloatingPoint);
return nullptr;
}
}
}
ExprAST* BinaryExprAST::clone() {
return new BinaryExprAST(Loc, Op, LeftExpr->clone(),
RightExpr ? RightExpr->clone() : nullptr);
}Семантический анализ тернарного оператор:
Hidden text
bool CondExprAST::isLValue() {
return IfExpr->isLValue() && ElseExpr->isLValue();
}
ExprAST* CondExprAST::semantic(Scope* scope) {
if (SemaDone) {
return this;
}
// Производим семантический анализ условия и всех операндов
Cond = Cond->semantic(scope);
IfExpr = IfExpr->semantic(scope);
ElseExpr = ElseExpr->semantic(scope);
// Проверяем, что условие не является "void"
if (Cond->ExprType == nullptr || Cond->ExprType->isVoid()) {
scope->report(Loc, diag::ERR_SemaConditionIsVoid);
return nullptr;
}
// Проверяем, что условие может быть преобразовано в "bool"
if (!Cond->ExprType->implicitConvertTo(
BuiltinTypeAST::get(TypeAST::TI_Bool))) {
scope->report(Loc, diag::ERR_SemaCantConvertToBoolean);
return nullptr;
}
// Результирующий тип совпадает с тем, что задан в ветке с
// выражением, если условие истинно
ExprType = IfExpr->ExprType;
// Если обе части имеют одинаковые типы, то больше семантический
// анализ завершен
if (IfExpr->ExprType->equal(ElseExpr->ExprType))
SemaDone = true;
return this;
}
// Исключаем вариант, когда один из операндов имеет тип "void",
// но разрешаем если оба операнда имеют тип "void"
if (!IfExpr->ExprType || !ElseExpr->ExprType ||
IfExpr->ExprType->isVoid() || ElseExpr->ExprType->isVoid()) {
scope->report(Loc, diag::ERR_SemaOperandIsVoid);
return nullptr;
}
// Приводим типы к единому
ElseExpr = new CastExprAST(ElseExpr->Loc, ElseExpr, ExprType);
ElseExpr = ElseExpr->semantic(scope);
SemaDone = true;
return this;
}
ExprAST* CondExprAST::clone() {
return new CondExprAST(Loc, Cond->clone(), IfExpr->clone(),
ElseExpr->clone());
}Семантический анализ вызова функции:
Hidden text
static SymbolAST* resolveFunctionCall(Scope *scope, SymbolAST* func,
CallExprAST* args) {
// Проверяем, что это функция
if (isa<FuncDeclAST>(func)) {
FuncDeclAST* fnc = static_cast< FuncDeclAST* >(func);
FuncTypeAST* type = static_cast< FuncTypeAST* >(fnc->ThisType);
// Количество аргументов должно совпадать с количеством
// параметров у функции
if (args->Args.size() != type->Params.size()) {
scope->report(args->Loc,
diag::ERR_SemaInvalidNumberOfArgumentsInCall);
return nullptr;
}
ExprList::iterator arg = args->Args.begin();
ParameterList::iterator it = type->Params.begin();
// Проверяем все аргументы
for (ParameterList::iterator end = type->Params.end();
it != end; ++it, ++arg) {
// Проверяем, что аргумент может быть использован для вызова
// и диагностируем об ошибке, если нет
if (!(*arg)->ExprType->implicitConvertTo((*it)->Param)) {
scope->report(args->Loc,
diag::ERR_SemaInvalidTypesOfArgumentsInCall);
return nullptr;
}
}
// Вызов функции может быть произведен с данными аргументами
return func;
}
return nullptr;
}
ExprAST* CallExprAST::semantic(Scope* scope) {
if (ExprType) {
return this;
}
// Производим семантический анализ выражения до "("
Callee = Callee->semantic(scope);
// Мы можем использовать только IdExprAST в качестве выражения
// для вызова
if (isa<IdExprAST>(Callee)) {
SymbolAST* sym = ((IdExprAST*)Callee)->ThisSym;
// Идентификатор может ссылаться только на функцию
if (isa<FuncDeclAST>(sym)) {
TypeAST* returnType = nullptr;
// Производим семантический анализ для всех аргументов
// функции
for (ExprList::iterator arg = Args.begin(), end = Args.end();
arg != end; ++arg) {
*arg = (*arg)->semantic(scope);
}
// Ищем функцию для вызова
if (SymbolAST* newSym = resolveFunctionCall(scope, sym,
this)) {
FuncDeclAST* fnc = static_cast< FuncDeclAST* >(newSym);
FuncTypeAST* type = static_cast< FuncTypeAST* >(
fnc->ThisType);
ExprList::iterator arg = Args.begin();
ParameterList::iterator it = type->Params.begin();
// Производим сопоставление аргументов и параметров
for (ParameterList::iterator end = type->Params.end();
it != end; ++it, ++arg) {
// Если тип аргумента отличается от типа параметра,
// производим преобразование типа
if (!(*arg)->ExprType->equal((*it)->Param)) {
ExprAST* oldArg = (*arg);
*arg = new CastExprAST(oldArg->Loc, oldArg->clone(),
(*it)->Param);
*arg = (*arg)->semantic(scope);
delete oldArg;
}
}
// Определяем тип возвращаемого значения и устанавливаем
// тип для результата вызова функции
if (!returnType) {
ExprType = ((FuncDeclAST*)newSym)->ReturnType;
} else {
ExprType = returnType;
}
// Устанавливаем объявление функции для вызова для
// дальнейшей работы
CallFunc = newSym;
return this;
}
}
}
// Диагностируем ошибку
scope->report(Loc, diag::ERR_SemaInvalidArgumentsForCall);
return nullptr;
}
ExprAST* CallExprAST::clone() {
ExprList exprs;
ExprList::iterator it = Args.begin();
ExprList::iterator end = Args.end();
for ( ; it != end; ++it) {
exprs.push_back((*it)->clone());
}
return new CallExprAST(Loc, Callee->clone(), exprs);
}Семантический анализ инструкций
Для начала рассмотрим какие именно функции члены иерархии инструкций будут отвечать за семантический анализ этих ветвей AST:
struct StmtAST {
...
/// Проверяет есть ли выход из функции в данной ветви дерева
virtual bool hasReturn();
/// Проверяет есть ли инструкция выхода из цикла или возврат из функции в
/// данной ветви дерева
virtual bool hasJump();
/// Произвести семантический анализ для инструкции
StmtAST* semantic(Scope* scope);
/// Произвести семантический анализ для инструкции (должна быть реализована
// в потомках, вызывается только через "semantic"
virtual StmtAST* doSemantic(Scope* scope);
int SemaState; ///< стадия семантического анализа для текущей инструкции
}; Так же, как и у типов и выражений, StmtAST после семантического анализа может быть изменено (например одна инструкция может быть реализована через другую).
Один из важных классов для работы семантического анализа (и генерации кода) является LandingPadAST (более подробное описание зачем он нужен рассмотрим в следующей части серии, на данный момент приведу только те члены класса, которые нужны для семантического анализа):
struct LandingPadAST {
LandingPadAST* Prev; ///< родительский LandingPadAST
StmtAST* OwnerBlock; ///< блок к которому относится данный LandingPadAST
int Breaks; ///< количество инструкций выхода из цикла в ветви дерева
/// количество инструкций возврата из функции в ветви дерева
int Returns;
/// количество инструкций перехода к следующей итерации цикла в ветви дерева
int Continues;
bool IsLoop; ///< LandingPadAST находится частью цикла
};Рассмотрим более подробно сам семантический анализ для инструкций:
Hidden text
bool StmtAST::hasReturn() {
return false;
}
bool StmtAST::hasJump() {
return false;
}
StmtAST* StmtAST::semantic(Scope* scope) {
// Защита от повторного вызова
if (SemaState > 0) {
return this;
}
++SemaState;
return doSemantic(scope);
}
StmtAST* StmtAST::doSemantic(Scope* ) {
assert(0 && "StmtAST::semantic should never be reached");
return this;
}
StmtAST* ExprStmtAST::doSemantic(Scope* scope) {
if (Expr) {
// Проверка семантики выражения
Expr = Expr->semantic(scope);
// После окончания семантического анализа хранимого выражения
// у него должен быть задан тип
if (!Expr->ExprType) {
scope->report(Loc, diag::ERR_SemaNoTypeForExpression);
return nullptr;
}
}
return this;
}
bool BlockStmtAST::hasReturn() {
return HasReturn;
}
bool BlockStmtAST::hasJump() {
return HasJump;
}
StmtAST* BlockStmtAST::doSemantic(Scope* scope) {
// Для блока мы должны создать новую область видимости
ThisBlock = new ScopeSymbol(Loc, SymbolAST::SI_Block, nullptr);
Scope* s = scope->push((ScopeSymbol*)ThisBlock);
// Создать LandingPadAST для данного блока
LandingPad = new LandingPadAST(s->LandingPad);
LandingPad->OwnerBlock = this;
s->LandingPad = LandingPad;
ExprList args;
// Проверяем все ветви дерева принадлежащие данному блоку
for (StmtList::iterator it = Body.begin(), end = Body.end();
it != end; ++it) {
// Если в предыдущей инструкции был "break", "continue" или
// "return", то диагностируем об ошибке (предотвращаем
// появление кода, который не может быть достижимым
if (HasJump) {
scope->report(Loc, diag::ERR_SemaDeadCode);
return nullptr;
}
// Проверяем семантику вложенной инструкции
*it = (*it)->semantic(s);
// Проверяем, что это "break", "continue" или "return"
if ((*it)->isJump()) {
HasJump = true;
// Проверяем, что это "return"
if ((*it)->hasReturn()) {
HasReturn = true;
}
} else {
// Это обычная инструкция, но все равно проверяем, наличие
// "break", "continue" или "return" в дочерних ветках
// инструкции
HasJump = (*it)->hasJump();
HasReturn = (*it)->hasReturn();
}
}
// Удаляем область видимости
s->pop();
return this;
}
StmtAST* DeclStmtAST::doSemantic(Scope* scope) {
// Производим семантический анализ для всех объявлений
for (SymbolList::iterator it = Decls.begin(), end = Decls.end();
it != end; ++it) {
(*it)->semantic(scope);
(*it)->semantic2(scope);
(*it)->semantic3(scope);
(*it)->semantic4(scope);
(*it)->semantic5(scope);
}
return this;
}
bool BreakStmtAST::hasJump() {
return true;
}
StmtAST* BreakStmtAST::doSemantic(Scope* scope) {
// Проверяем, что мы находимся в цикле, т. к. "break" может быть
// только в цикле
if (!scope->BreakLoc) {
scope->report(Loc, diag::ERR_SemaInvalidJumpStatement);
return nullptr;
}
// Запоминаем местоположение точки, куда нужно перевести
// управление для выхода из цикла
BreakLoc = scope->LandingPad;
++BreakLoc->Breaks;
return this;
}
// ContinueStmtAST implementation
bool ContinueStmtAST::hasJump() {
return true;
}
StmtAST* ContinueStmtAST::doSemantic(Scope* scope) {
// Проверяем, что мы находимся в цикле, т. к. "continue" может
// быть только в цикле
if (!scope->ContinueLoc) {
scope->report(Loc, diag::ERR_SemaInvalidJumpStatement);
return nullptr;
}
// Запоминаем местоположение точки, куда нужно перевести
// управление для перехода к следующей итерации цикла
ContinueLoc = scope->LandingPad;
++ContinueLoc->Continues;
return this;
}
bool ReturnStmtAST::hasReturn() {
return true;
}
bool ReturnStmtAST::hasJump() {
return true;
}
StmtAST* ReturnStmtAST::doSemantic(Scope* scope) {
assert(scope→LandingPad);
// Сохраняем местоположения точки, куда нужно перевести
// управление для выхода из функции
ReturnLoc = scope->LandingPad;
++ReturnLoc->Returns;
// Проверка наличия возвращаемого значения
if (Expr) {
// Если тип возвращаемого значения функции "void", то
// сигнализируем об ошибке
if (!scope->EnclosedFunc->ReturnType
|| scope->EnclosedFunc->ReturnType->isVoid()) {
scope->report(Loc, diag::ERR_SemaReturnValueInVoidFunction);
return nullptr;
}
// Производим семантический анализ возвращаемого значения
Expr = Expr->semantic(scope);
// Если тип возвращаемого значения не совпадает с типом
// возвращаемого значения самой функции, то мы должны
// произвести преобразование типов
if (!scope->EnclosedFunc->ReturnType->equal(Expr->ExprType)) {
Expr = new CastExprAST(Loc, Expr,
scope->EnclosedFunc->ReturnType);
Expr = Expr->semantic(scope);
}
return this;
}
// У нас нет выражения для возврата. Проверяем, что тип
// возвращаемого значения самой функции "void" и сигнализируем
// об ошибке, если он отличен от "void"
if (scope->EnclosedFunc->ReturnType
&& !scope->EnclosedFunc->ReturnType->isVoid()) {
scope->report(Loc, diag::ERR_SemaReturnVoidFromFunction);
return nullptr;
}
return this;
}
bool WhileStmtAST::hasReturn() {
// Всегда возвращаем "false", т. к. может быть 0 итераций
return false;
}
StmtAST* WhileStmtAST::doSemantic(Scope* scope) {
// Производим семантический анализ условия цикла
Cond = Cond->semantic(scope);
// Условие цикла должно иметь не "void" тип
if (!Cond->ExprType || Cond->ExprType->isVoid()) {
scope->report(Loc, diag::ERR_SemaConditionIsVoid);
return nullptr;
}
// Проверяем, что условие цикла может быть преобразовано в "bool"
if (!Cond->ExprType->implicitConvertTo(
BuiltinTypeAST::get(TypeAST::TI_Bool))) {
scope->report(Loc, diag::ERR_SemaCantConvertToBoolean);
return nullptr;
}
// Делаем копии для точек возврата из цикла и перехода к
// следующей итерации
StmtAST* oldBreak = scope->BreakLoc;
StmtAST* oldContinue = scope->ContinueLoc;
// Устанавливаем данный цикл в качестве точек возврата из цикла
// и перехода к следующей итерации
scope->BreakLoc = this;
scope->ContinueLoc = this;
// Создаем новую LandingPadAST для всех вложенных инструкций
LandingPad = new LandingPadAST(scope->LandingPad);
LandingPad->IsLoop = true;
scope->LandingPad = LandingPad;
// Производим семантический анализ тела цикла
Body = Body->semantic(scope);
// Восстанавливаем предыдущие значения для точек возврата
scope->BreakLoc = oldBreak;
scope->ContinueLoc = oldContinue;
scope->LandingPad = LandingPad->Prev;
if (PostExpr) {
// Производим семантический анализ для "PostExpr", который был
// создан в процессе конвертации цикла "for" в цикл "while"
PostExpr = PostExpr->semantic(scope);
}
return this;
}
StmtAST* ForStmtAST::doSemantic(Scope* scope) {
// Заменяем цикл "for" эквивалентным аналогом цикла "while", что
// бы упростить генерацию кода, но предварительно проверив
// семантику
// {
// init
// while (cond) {
// body
// continueZone: post
// }
// }
StmtAST* init = nullptr;
// Если в цикле задано выражение для инициализации или объявлены
// переменные цикла, то нужно создать на их основе
// соответствующие инструкции
if (InitExpr) {
init = new ExprStmtAST(Loc, InitExpr);
} else if (!InitDecls.empty()) {
init = new DeclStmtAST(Loc, InitDecls);
}
if (Cond) {
// У нас есть условие выхода из цикла
StmtList stmts;
// Если у нас есть блок инициализации цикла, то добавляем его
// к телу новой конструкции
if (init) {
stmts.push_back(init);
}
// Создаем новый цикл "while" на основе данного цикла "for" и
// добавляем его к списку инструкций в блоке
WhileStmtAST* newLoop = new WhileStmtAST(Loc, Cond, Body);
newLoop->PostExpr = Post;
stmts.push_back(newLoop);
// Очищаем и удаляем данную ветку
InitExpr = nullptr;
InitDecls.clear();
Cond = nullptr;
Post = nullptr;
Body = nullptr;
delete this;
// Создаем новы блочный элемент для нового цикла и производим
// его семантический анализ
StmtAST* res = new BlockStmtAST(Loc, stmts);
return res->semantic(scope);
} else {
// У нас нет условия выхода из цикла
StmtList stmts;
// Если у нас есть блок инициализации цикла, то добавляем его
// к телу новой конструкции
if (init) {
stmts.push_back(init);
}
// Создаем новый цикл "while" на основе данного цикла "for" и
// добавляем его к списку инструкций в блоке
WhileStmtAST* newLoop = new WhileStmtAST(Loc,
new IntExprAST(Loc, 1),
Body);
newLoop->PostExpr = Post;
stmts.push_back(newLoop);
// Очищаем и удаляем данную ветку
InitExpr = nullptr;
InitDecls.clear();
Cond = nullptr;
Post = nullptr;
Body = nullptr;
delete this;
// Создаем новы блочный элемент для нового цикла и производим
// его семантический анализ
StmtAST* res = new BlockStmtAST(Loc, stmts);
return res->semantic(scope);
}
}
bool IfStmtAST::hasReturn() {
if (!ElseBody) {
return false;
}
// Возвращаем "true" только если обе ветки имеют инструкции
// возврата из функции
return ThenBody->hasReturn() && ElseBody->hasReturn();
}
bool IfStmtAST::hasJump() {
if (!ElseBody) {
return false;
}
// Возвращаем "true" только если обе ветки имеют инструкции
// возврата из функции или выхода из цикла
return ThenBody->hasJump() && ElseBody->hasJump();
}
StmtAST* IfStmtAST::doSemantic(Scope* scope) {
// Производим семантический анализ условия
Cond = Cond->semantic(scope);
// Запрещаем условия с типом "void"
if (!Cond->ExprType
|| Cond->ExprType == BuiltinTypeAST::get(TypeAST::TI_Void)) {
scope->report(Loc, diag::ERR_SemaConditionIsVoid);
return nullptr;
}
// Проверяем, что условие может быть преобразовано в "bool"
if (!Cond->ExprType->implicitConvertTo(
BuiltinTypeAST::get(TypeAST::TI_Bool))) {
scope->report(Loc, diag::ERR_SemaCantConvertToBoolean);
return nullptr;
}
// Создаем новый LandingPadAST
LandingPad = new LandingPadAST(scope->LandingPad);
scope->LandingPad = LandingPad;
// Производим семантический анализ ветки, если условие истинно
ThenBody = ThenBody->semantic(scope);
// Производим семантический анализ ветки, если условие ложно,
// если она есть
if (ElseBody) {
ElseBody = ElseBody->semantic(scope);
}
// Восстанавливаем старый LandingPadAST
scope->LandingPad = LandingPad->Prev;
return this;
}Семантический анализ для объявлений
Для начала рассмотрим какие именно функции члены иерархии объявлений будут отвечать за семантический анализ этих ветвей AST:
struct SymbolAST {
/// Получить тип объявления
virtual TypeAST *getType();
/// Произвести 1 фазу семантического анализа
void semantic(Scope *scope);
/// Произвести 2 фазу семантического анализа
void semantic2(Scope *scope);
/// Произвести 3 фазу семантического анализа
void semantic3(Scope *scope);
/// Произвести 4 фазу семантического анализа
void semantic4(Scope *scope);
/// Произвести 5 фазу семантического анализа
void semantic5(Scope *scope);
/// Произвести 1 фазу семантического анализа (должна быть переопределена в
/// потомках, вызывается только через "semantic")
virtual void doSemantic(Scope *scope);
/// Произвести 2 фазу семантического анализа (может быть переопределена в
/// потомках, вызывается только через "semantic2")
virtual void doSemantic2(Scope *scope);
/// Произвести 3 фазу семантического анализа (может быть переопределена в
/// потомках, вызывается только через "semantic3")
virtual void doSemantic3(Scope *scope);
/// Произвести 4 фазу семантического анализа (может быть переопределена в
/// потомках, вызывается только через "semantic4")
virtual void doSemantic4(Scope *scope);
/// Произвести 5 фазу семантического анализа (может быть переопределена в
/// потомках, вызывается только через "semantic5")
virtual void doSemantic5(Scope *scope);
/// Поиск дочернего объявления ("flags" — 1 если не нужен поиск в
/// родительских классах)
virtual SymbolAST *find(Name *id, int flags = 0);
/// область видимости, в которой было объявлено данное объявление
SymbolAST *Parent;
int SemaState; ///< текущая стадия семантического анализа
}; Из-за правил поиска идентификаторов в simple, весь семантический анализ был разбит на 5 фаз:
-
Создание списка всех объявлений в области видимости;
-
Разрешение типов базовых классов;
-
Разрешение типов для имен переменных и функций членов структур и классов;
-
Построение таблиц виртуальных функций, конструкторов и деструкторов;
-
Анализ функций и их тел.
Разбивка семантики на несколько фаз позволяет упростить грамматику языка, т. к. не нужно вводить дополнительные конструкции для объявления и определения (т. е. введение имени в программу (что бы оно могло быть использовано) и описание ее реализации (т. е. для классов это описание всех его функций и переменных членов, а для функций ее тело). Например в C++ можно сперва объявить класс (написать «class A;»), что позволяет использовать имя этого класса в других объявлениях (например в качестве параметра функции), а потом в другой части исходного кода произвести определение — описать все функции и переменные члены класса. При разбивке семантического анализа на части, такие разграничения объявления и определения на разные сущности просто не нужны, т. к. даже циклические зависимости могут быть спокойно разрешены, т. к. в каждой фазе происходят действия, которые позволят продолжить анализ на следующих стадиях.
Ниже рассмотрим сам семантический анализ для объявлений:
Hidden text
TypeAST* SymbolAST::getType() {
assert(0 && "SymbolAST::getType should never be reached");
return nullptr;
}
void SymbolAST::semantic(Scope* scope) {
// Пропускаем семантический анализ для этой фазы, если она уже
// была завершена
if (SemaState > 0) {
return;
}
// Произвести семантический анализ и переход к следующей стадии
doSemantic(scope);
++SemaState;
}
void SymbolAST::semantic2(Scope* scope) {
// Пропускаем семантический анализ для этой фазы, если она уже
// была завершена
assert(SemaState >= 1);
if (SemaState > 1) {
return;
}
// Произвести семантический анализ и переход к следующей стадии
doSemantic2(scope);
++SemaState;
}
void SymbolAST::semantic3(Scope* scope) {
// Пропускаем семантический анализ для этой фазы, если она уже
// была завершена
assert(SemaState >= 2);
if (SemaState > 2) {
return;
}
// Произвести семантический анализ и переход к следующей стадии
doSemantic3(scope);
++SemaState;
}
void SymbolAST::semantic4(Scope* scope) {
// Пропускаем семантический анализ для этой фазы, если она уже
// была завершена
assert(SemaState >= 3);
if (SemaState > 3) {
return;
}
// Произвести семантический анализ и переход к следующей стадии
doSemantic4(scope);
++SemaState;
}
void SymbolAST::semantic5(Scope* scope) {
// Пропускаем семантический анализ для этой фазы, если она уже
// была завершена
assert(SemaState >= 4);
if (SemaState > 4) {
return;
}
// Произвести семантический анализ и переход к следующей стадии
doSemantic5(scope);
++SemaState;
}
void SymbolAST::doSemantic(Scope* ) {
// Данная функция обязательна для реализации в дочерних классах
assert(0 && "SymbolAST::semantic should never be reached");
}
void SymbolAST::doSemantic2(Scope* ) {
// По умолчанию игнорируем данную фазу
}
void SymbolAST::doSemantic3(Scope* ) {
// По умолчанию игнорируем данную фазу
}
void SymbolAST::doSemantic4(Scope* ) {
// По умолчанию игнорируем данную фазу
}
void SymbolAST::doSemantic5(Scope* ) {
// По умолчанию игнорируем данную фазу
}
SymbolAST* SymbolAST::find(Name* id, int flags) {
// В базовой реализации только проверяем имя самой сущности
if (id == Id) {
return this;
}
return nullptr;
}
TypeAST* VarDeclAST::getType() {
return ThisType;
}
void VarDeclAST::doSemantic(Scope* scope) {
// Исключаем повторные объявления переменных
if (scope->find(Id)) {
scope->report(Loc, diag::ERR_SemaIdentifierRedefinition);
return;
}
// Добавляем переменную в список объявленных переменных в текущей
// области видимости
((ScopeSymbol*)scope->CurScope)->Decls[Id] = this;
Parent = scope->CurScope;
// Так же добавляем переменную к списку объявленных переменных в
// функции, если она была объявлена в функции (нужны для
// генерации кода)
if (scope->EnclosedFunc) {
scope->EnclosedFunc->FuncVars.push_back(this);
}
// Производим семантический анализ для типа переменной
ThisType = ThisType->semantic(scope);
}
void VarDeclAST::doSemantic3(Scope* scope) {
// Проверяем наличие инициализатора
if (Val) {
// Производим семантический анализ инициализирующего выражения
Val = Val->semantic(scope);
// Запрещаем использования выражений с типов "void" в
// инициализации
if (!Val->ExprType || Val->ExprType->isVoid()) {
scope->report(Loc, diag::ERR_SemaVoidInitializer);
return;
}
// Если типы не совпадают, то добавляем преобразование
if (!Val->ExprType->equal(ThisType)) {
Val = new CastExprAST(Loc, Val, ThisType);
Val = Val->semantic(scope);
}
}
}
ScopeSymbol::~ScopeSymbol() {
}
SymbolAST* ScopeSymbol::find(Name* id, int /*flags*/) {
// Производим поиск в объявленных в данном блоке объявлениях
SymbolMap::iterator it = Decls.find(id);
if (it == Decls.end()) {
return nullptr;
}
return it->second;
}
TypeAST* ParameterSymbolAST::getType() {
return Param->Param;
}
void ParameterSymbolAST::doSemantic(Scope* ) {
}
SymbolAST* ParameterSymbolAST::find(Name* id, int ) {
if (id == Param->Id) {
return this;
}
return nullptr;
}
TypeAST* FuncDeclAST::getType() {
return ThisType;
}
void FuncDeclAST::doSemantic(Scope* scope) {
// Производим семантический анализ для прототипа функции
ThisType = ThisType->semantic(scope);
Parent = scope->CurScope;
// Настраиваем тип возвращаемого значения
ReturnType = ((FuncTypeAST*)ThisType)->ReturnType;
// Отдельная проверка для функции "main"
if (Id->Length == 4 && memcmp(Id->Id, "main", 4) == 0) {
FuncTypeAST* thisType = (FuncTypeAST*)ThisType;
// Должна не иметь параметров
if (thisType->Params.size()) {
scope->report(Loc, diag::ERR_SemaMainParameters);
return;
}
// Должна возвращать "float"
if (ReturnType != BuiltinTypeAST::get(TypeAST::TI_Float)) {
scope->report(Loc, diag::ERR_SemaMainReturnType);
return;
}
}
// Проверяем, что идентификатор еще не был объявлен ранее
if (SymbolAST* fncOverload = scope->findMember(Id, 1)) {
scope->report(Loc, diag::ERR_SemaFunctionRedefined, Id->Id);
return;
}
// Добавляем функцию к списку объявлений
((ScopeSymbol*)Parent)->Decls[Id] = this;
}
void FuncDeclAST::doSemantic5(Scope* scope) {
FuncTypeAST* func = (FuncTypeAST*)ThisType;
// Проверяем наличие тела функции (если его нет, то это прототип)
if (Body) {
// Создаем новую область видимости и устанавливаем текущую
// функции в данной области видимости
Scope* s = scope->push(this);
s->EnclosedFunc = this;
// Производим проверку всех параметров функции
for (ParameterList::iterator it = func->Params.begin(),
end = func->Params.end(); it != end; ++it) {
ParameterAST* p = *it;
// Особая обработка для именованных параметров
if (p->Id) {
// Запрещаем переопределение
if (find(p->Id)) {
scope->report(Loc, diag::ERR_SemaIdentifierRedefinition);
return;
}
// Для каждого параметра в прототипе, создаем отдельную
// переменную в самой функции
SymbolAST* newSym = new ParameterSymbolAST(p);
Decls[p->Id] = newSym;
FuncVars.push_back(newSym);
}
}
// Устанавливаем новый LandingPadAST
LandingPadAST* oldLandingPad = s->LandingPad;
LandingPad = new LandingPadAST();
s->LandingPad = LandingPad;
// Производим семантический анализ тела функции
Body = Body->semantic(s);
// Восстанавливаем старый LandingPadAST
s->LandingPad = oldLandingPad;
// Проверяем, что функция с типов возвращаемого значения
// отличным от "void" вернуло значение
if (!ReturnType->isVoid() && !Body->hasReturn()) {
scope->report(Loc,
diag::ERR_SemaMissingReturnValueInFunction);
return;
}
// Удаляем область видимости для данной функции
s->pop();
}
}
// Функции, которые будут доступны из simple
extern "C" void lle_X_printDouble(double val) {
outs() << val;
}
extern "C" void lle_X_printLine() {
outs() << "n";
}
/// Добавить прототип функции и связать ее с функцией C++
FuncDeclAST* addDynamicFunc(const char* protoString,
const char* newName,
ModuleDeclAST* modDecl,
void* fncPtr) {
// Разбор прототипа функции
FuncDeclAST* func = (FuncDeclAST*)parseFuncProto(protoString);
// Добавляем функцию и указываем, что ее компиляция уже была
// произведена
func->CodeValue = Function::Create(
(FunctionType*)func->ThisType->getType(),
Function::ExternalLinkage,
Twine(newName),
getSLContext().TheModule
);
func->Compiled = true;
modDecl->Members.insert(modDecl->Members.begin(), func);
// Делаем функцию доступной из LLVM
ExitOnError ExitOnErr;
ExitOnErr(getJIT().addSymbol(newName, fncPtr));
return func;
}
void initRuntimeFuncs(ModuleDeclAST* modDecl) {
addDynamicFunc("fn print(_: float)", "lle_X_printDouble",
modDecl, (void*)lle_X_printDouble);
addDynamicFunc("fn printLn()", "lle_X_printLine",
modDecl, (void*)lle_X_printLine);
}
void ModuleDeclAST::semantic() {
Scope s(this);
// Инициализация runtime функций
initRuntimeFuncs(this);
// Производим семантический анализ всех базовых типов
for (int i = TypeAST::TI_Void; i <= TypeAST::TI_Float; ++i) {
BuiltinTypeAST::get(i)->semantic(&s);
}
// Производим семантический анализ для всех объявлений
// (кроме функций)
for (SymbolList::iterator it = Members.begin(),
end = Members.end(); it != end; ++it) {
if (!isa<FuncDeclAST>(*it))
(*it)->semantic(&s);
}
// Производим семантический анализ всех функций
for (SymbolList::iterator it = Members.begin(),
end = Members.end(); it != end; ++it) {
if (isa<FuncDeclAST>(*it))
(*it)->semantic(&s);
}
// Запускаем 2-ю фазу семантического анализа для всех объявлений
for (SymbolList::iterator it = Members.begin(),
end = Members.end(); it != end; ++it) {
(*it)->semantic2(&s);
}
// Запускаем 3-ю фазу семантического анализа для всех объявлений
for (SymbolList::iterator it = Members.begin(),
end = Members.end(); it != end; ++it) {
(*it)->semantic3(&s);
}
// Запускаем 4-ю фазу семантического анализа для всех объявлений
for (SymbolList::iterator it = Members.begin(),
end = Members.end(); it != end; ++it) {
(*it)->semantic4(&s);
}
// Запускаем 5-ю фазу семантического анализа для всех объявлений
for (SymbolList::iterator it = Members.begin(),
end = Members.end(); it != end; ++it) {
(*it)->semantic5(&s);
}
}Заключение
В данной части мы рассмотрели семантический анализ программы на языке simple, произвели проверку ее корректности и подготовили наше промежуточное представление к заключительной части — генерации кода.
В статье мы научились изменять изначальное представление программы его аналогом, что позволит упростить многие части генерации кода (например автоматическое создание преобразований типов, где они были необходимы, позволит не задумываться о преобразовании типов на стадии генерации кода, т. к. этим будет заниматься отдельный класс). Автоматическая генерация и модификация дерева может быть полезна при решении многих задач в проектировании своего языка. В последующих частях мы еще не раз будем использовать данный подход, например для генерации кода для вызова конструкторов и деструкторов для объектов класса, генерации конструкторов по умолчанию, а так же автоматический вызов конструкторов и деструкторов для родительских классов. В более сложных языках программирования данный подход может быть применен для генерации замыканий, итераторов и многих других высокоуровневых конструкциях.
Разбиение семантического анализа на фазы так же позволяет делать язык более выразительным и дает возможность убрать из него многие ограничения, которые при однопроходном варианте приходилось бы решать другими способами.
Полный исходный код доступен на gihub. В следующей статье мы закончим реализацию базовой версии языка simple и добавим генерацию кода для LLVM IR.
Полезные ссылки
-
https://en.wikipedia.org/wiki/Scope_(computer_science)
-
https://en.wikipedia.org/wiki/Type_system
-
https://en.wikipedia.org/wiki/Name_mangling
The third type of error is the semantic error, also called a logic error. If there is a semantic error
in your program, it will run successfully in the sense that the computer will
not generate any error messages. However, your program will not do the right thing. It will do
something else. Specifically, it will do what you told it to do, not what you wanted it to do.
The following program has a semantic error. Execute it to see what goes wrong:
This program runs and produces a result. However, the result is not what the programmer intended. It contains
a semantic error. The error is that the program performs concatenation instead of addition, because the programmer
failed to write the code necessary to convert the inputs to integers.
With semantic errors, the problem is that the program you wrote is not the program you wanted to
write. The meaning of the program (its semantics) is wrong. The computer is
faithfully carrying out the instructions you wrote, and its results
are correct, given the instructions that you provided. However, because your instructions
have a flaw in their design, the program does not behave as desired.
Identifying semantic errors can be tricky because no error message appears to make it obvious that the results are
incorrect. The only way you can detect semantic errors is if you know in advance what the program should do for a given set
of input. Then, you run the program with that input data and compare the output of the program with what you expect. If
there is a discrepancy between the actual output and the expected output, you can conclude that there is either 1) a
semantic error or 2) an error in your expected results.
Once you’ve determined that you have a semantic error, locating it can be tricky because you must work
backward by looking at the output of the program and trying to figure out what it is doing.
3.7.1. Test Cases¶
To detect a semantic error in your program, you need the help of something called a test case.
Test Case
A test case is a set of input values for the program, together with the output that you expect the program should produce when it is run with those particular
inputs.
Here is an example of a test case for the program above:
Test Case --------- Input: 2, 3 Expected Output: 5
If you give this test case to someone and ask them to test the program, they can type in the inputs, observe the output,
check it against the expected output, and determine whether a semantic error exists based on whether the actual output
matches the expected output or not. The tester doesn’t even have to know what the program is supposed to do. For this reason,
software companies often have separate quality assurance departments whose responsibility is to check that the programs written
by the programmers perform as expected. The testers don’t have to be programmers; they just have to be able to operate the
program and compare its results with the test cases they’re given.
In this case, the program is so simple that we don’t need to write down a test case at all; we can compute the expected output
in our heads with very little effort. More complicated programs require effort to create the test case (since you shouldn’t use
the program to compute the expected output; you have to do it with a calculator or by hand), but the effort pays off when
the test case helps you to identify a semantic error that you didn’t know existed.
Semantic errors are the most dangerous of the three types of errors, because in some cases they are not noticed by either
the programmers or the users who use the program. Syntax errors cannot go undetected (the program won’t run at all if
they exist), and runtime errors are usually also obvious and typically detected by developers before a program is
released for use (although it is possible for a runtime error to occur for some inputs and not for
others, so these can sometimes remain undetected for a while). However, programs often go for years with undetected
semantic errors; no one realizes that the program has been producing incorrect results. They just assume that because the
results seem reasonable, they are correct. Sometimes, these errors are relatively harmless. But if they involve
financial transactions or medical equipment, the results can be harmful or even deadly. For this reason, creating test
cases is an important part of the work that programmers perform in order to help them produce programs that work
correctly.
Check your understanding
- Attempting to divide by 0.
- A semantic error is an error in logic. In this case the program does not produce the correct output because the problem is not solved correctly. This would be considered a run-time error.
- Forgetting a right-parenthesis ) when invoking a function.
- A semantic error is an error in logic. In this case the program does not produce the correct output because the code can not be processed by the compiler or interpreter. This would be considered a syntax error.
- Forgetting to divide by 100 when printing a percentage amount.
- This will produce the wrong answer because the programmer implemented the solution incorrectly. This is a semantic error.
Which of the following is a semantic error?
- The programmer.
- You must fully understand the problem so that you can tell if your program properly solves it.
- The compiler / interpreter.
- The compiler and / or interpreter will only do what you instruct it to do. It does not understand what the problem is that you want to solve.
- The computer.
- The computer does not understand your problem. It just executes the instructions that it is given.
- The teacher / instructor.
- Your teacher and instructor may be able to find most of your semantic errors, but only because they have experience solving problems. However it is your responsibility to understand the problem so you can develop a correct solution.
Who or what typically finds semantic errors?
You have attempted of activities on this page
Отладка программы призвана выискивать «вредителей» кода и устранять их. За это отвечают отладчик и журналирование для вывода сведений о программе.
В предыдущей части мы рассмотрели исходный код и его составляющие.
После того, как вы начнете проверять фрагменты кода или попытаетесь решить связанные с ним проблемы, вы очень скоро поймете, что существуют моменты, когда программа крашится, прерывается и прекращает работу.
Это часто вызвано ошибками, известными как дефекты или исключительные ситуации во время выполнения. Акт обнаружения и удаления ошибок из нашего кода – это отладка программы. Вы лучше разберетесь в отладке на практике, используя ее как можно чаще. Мы не только отлаживаем собственный код, но и порой дебажим написанное другими программистами.
Для начала необходимо рассортировать общие ошибки, которые могут возникнуть в исходном коде.
Синтаксические ошибки
Эти эрроры не позволяют скомпилировать исходный код на компилируемых языках программирования. Они обнаруживаются во время компиляции или интерпретации исходного кода. Они также могут быть легко обнаружены статическими анализаторами (линтами). Подробнее о линтах мы узнаем немного позже.
Синтаксические ошибки в основном вызваны нарушением ожидаемой формы или структуры языка, на котором пишется программа. Как пример, это может быть отсутствующая закрывающая скобка в уравнении.
Семантические ошибки
Отладка программы может потребоваться и по причине семантических ошибок, также известных как логические. Они являются наиболее сложными из всех, потому что не могут быть легко обнаружены. Признак того, что существует семантическая ошибка, – это когда программа запускается, отрабатывает, но не дает желаемого результата.
Рассмотрим данный пример:
3 + 5 * 6
По порядку приоритета, называемому старшинством операции, с учетом математических правил мы ожидаем, что сначала будет оценена часть умножения, и окончательный результат будет равен 33. Если программист хотел, чтобы сначала происходило добавление двух чисел, следовало поступить иначе. Для этого используются круглые скобки, которые отвечают за смещение приоритетов в математической формуле. Исправленный пример должен выглядеть так:
(3 + 5) * 6
3 + 5, заключенные в скобки, дадут желаемый результат, а именно 48.
Ошибки в процессе выполнения
Как и семантические, ошибки во время выполнения никогда не обнаруживаются при компиляции. В отличие от семантических ошибок, эти прерывают программу и препятствуют ее дальнейшему выполнению. Они обычно вызваны неожиданным результатом некоторых вычислений в исходном коде.
Вот хороший пример:
input = 25 x = 0.8/(Math.sqrt(input) - 5)
Фрагмент кода выше будет скомпилирован успешно, но input 25 приведет к ZeroDivisionError. Это ошибка во время выполнения. Другим популярным примером является StackOverflowError или IndexOutofBoundError. Важно то, что вы идентифицируете эти ошибки и узнаете, как с ними бороться.
Существуют ошибки, связанные с тем, как ваш исходный код использует память и пространство на платформе или в среде, в которой он запущен. Они также являются ошибками во время выполнения. Такие ошибки, как OutOfMemoryErrorand и HeapError обычно вызваны тем, что ваш исходный код использует слишком много ресурсов. Хорошее знание алгоритмов поможет написать код, который лучше использует ресурсы. В этом и заключается отладка программы.
Процесс перезаписи кода для повышения производительности называется оптимизацией. Менее популярное наименование процесса – рефакторинг. Поскольку вы тратите больше времени на кодинг, то должны иметь это в виду.
Отладка программы
Вот несколько советов о том, как правильно выполнять отладку:
- Использовать Linters. Linters – это инструменты, которые помогают считывать исходный код, чтобы проверить, соответствует ли он ожидаемому стандарту на выбранном языке программирования. Существуют линты для многих языков.
- Превалирование IDE над простыми редакторами. Вы можете выбрать IDE, разработанную для языка, который изучаете. IDE – это интегрированные среды разработки. Они созданы для написания, отладки, компиляции и запуска кода. Jetbrains создают отличные IDE, такие как Webstorm и IntelliJ. Также есть NetBeans, Komodo, Qt, Android Studio, XCode (поставляется с Mac), etc.
- Чтение кода вслух. Это полезно, когда вы ищете семантическую ошибку. Читая свой код вслух, есть большая вероятность, что вы зачитаете и ошибку.
- Чтение логов. Когда компилятор отмечает Error, обязательно посмотрите, где он находится.
Двигаемся дальше
Поздравляем! Слово «ошибка» уже привычно для вас, равно как и «отладка программы». В качестве новичка вы можете изучать кодинг по книгам, онлайн-урокам или видео. И даже чужой код вам теперь не страшен 
В процессе кодинга измените что-нибудь, чтобы понять, как он работает. Но будьте уверены в том, что сами написали.
Викторина
- Какая ошибка допущена в фрагменте кода Python ниже?
items = [0,1,2,3,4,5] print items[8] //комментарий: элементы здесь представляют собой массив с шестью элементами. Например, чтобы получить 4-й элемент, вы будете использовать [3]. Мы начинаем отсчет с 0.
- Какая ошибка допущена в фрагменте кода Python ниже?
input = Hippo' if input == 'Hippo': print 'Hello, Hippo'
Ответы на вопросы
- Ошибка выполнения: ошибка индекса вне диапазона.
2. Синтаксическая ошибка: Отсутствует стартовая кавычка в первой строке.
Дебаг и поиск ошибок

Для опытных разработчиков информация статьи может быть очевидной и если вы себя таковым считаете, то лучше добавьте в комментариях полезных советов.
По опыту работы с начинающими разработчиками, я сталкиваюсь с тем, что поиск ошибок порой занимает слишком много времени. Не из-за того, что они глупее более опытных товарищей или не разбираются в процессах, а из-за отсутствия понимания с чего начать и на чём акцентировать внимание. В статье я собрал общие советы о том где обитают ошибки и как найти причину их возникновения. Примеры в статье даны на JavaScript и .NET, но они актуальны и для других платформ с поправкой на специфику.
Как обнаружить ошибку
Прочитай информацию об исключении
Если выполнение программы прерывается исключением, то это первое место откуда стоит начинать поиск.
В каждом языке есть свои способы уведомления об исключениях. Например в JavaScript для обработки ошибок связанных с Web Api существует DOMException. Для пользовательских сценариев есть базовый тип Error. В обоих случаях в них содержится информация о наименовании и описании ошибки.
Для .NET существует класс Exception и каждое исключение в приложении унаследовано от данного класса, который представляет ошибки происходящие во время выполнения программы. В свойстве Message читаем текст ошибки. Это даёт общее понимание происходящего. В свойстве Source смотрим в каком объекте произошла ошибка. В InnerException смотрим, нет ли внутреннего исключения и если было, то разворачиваем его и смотрим информацию уже в нём. В свойстве StackTrace хранится строковое представление информации о стеке вызова в момент появления ошибки.
Каким бы языком вы не пользовались, не поленитесь изучить каким образом язык предоставляет информацию об исключениях и что эта информация означает.
Всю полученную информацию читаем вдумчиво и внимательно. Любая деталь важна при поиске ошибки. Иногда начинающие разработчики не придают значения этому описанию. Например в .NET при возникновении ошибки NRE с описанием параметра, который разработчик задаёт выше по коду. Из-за этого думает, что параметр не может быть NRE, а значит ошибка в другом месте. На деле оказывается, что ошибки транслируют ту картину, которую видит среда выполнения и первым делом за гипотезу стоит взять утверждение, что этот параметр равен null. Поэтому разберитесь при каких условиях параметр стал null, даже если он определялся выше по коду.
Пример неявного переопределения параметров — использование интерцептора, который изменяет этот параметр в запросе и о котором вы не знаете.
Разверните стек
Когда выбрасывается исключение, помимо самого описания ошибки полезно изучить стек выполнения. Для .NET его можно посмотреть в свойстве исключения StackTrace. Для JavaScript аналогично смотрим в Error.prototype.stack (свойство не входит в стандарт) или можно вывести в консоль выполнив console.trace(). В стеке выводятся названия методов в том порядке в котором они вызывались. Если то место, где падает ошибка зависит от аргументов которые пришли из вызывающего метода, то если развернуть стек, мы проследим где эти аргументы формировались.
Загуглите текст ошибки
Очевидное правило, которым не все пользуются. Применимо к не типовым ошибкам, например связанным с конкретной библиотекой или со специфическим типом исключения. Поиск по тексту ошибки помогает найти аналогичные случаи, которые даже если не дадут конкретного решения, то помогут понять контекст её возникновения.
Прочитайте документацию
Если ошибка связана с использованием внешней библиотеки, убедитесь что понимаете как она работает и как правильно с ней взаимодействовать. Типичные ошибки, когда подключив новую библиотеку после прочтения Getting Started она не работает как ожидалось или выбрасывает исключение. Проблема может быть в том, что базовый шаблон подключения библиотеки не применим к текущему приложению и требуются дополнительные настройки или библиотека не совместима с текущим окружением. Разобраться в этом поможет прочтение документации.
Проведите исследовательское тестирование
Если используете библиотеку которая не работает как ожидалось, а нормальная документация отсутствует, то создайте тесты которые покроют интересующий функционал. В ассертах опишите ожидаемое поведение. Если тесты не проходят, то подбирая различные вариации входных данных выясните рабочую конфигурацию. Цель исследовательских тестов помочь разобраться без документации, какое ожидаемое поведение у изучаемой библиотеки в разных сценариях работы. Получив эти знания будет легче понять как правильно использовать библиотеку в проекте.
Бинарный поиск
В неочевидных случаях, если нет уверенности что проблема в вашем коде, а сообщение об ошибке не даёт понимания где проблема, комментируем блок кода в котором обнаружилась проблема. Убеждаемся что ошибка пропала. Аналогично бинарному алгоритму раскомментировали половину кода, проверили воспроизводимость ошибки. Если воспроизвелась, закомментировали половину выполняемого кода, повторили проверку и так далее пока не будет локализовано место появления ошибки.
Где обитают ошибки
Ошибки в своём коде
Самые распространенные ошибки. Мы писали код, ошиблись в формуле, забыли присвоить значение переменной или что-то не проинициализировали перед вызовом. Такие ошибки легко исправить и легко найти место возникновения если внимательно прочитать описание возникшей ошибки.
Ошибки в чужом коде
Если над проектом работает больше одного разработчика, чей код взаимодействует друг с другом, возможна ситуация, когда ошибка происходит в чужом коде. Может сложиться впечатление, что если программа раньше работала, а сломалась только после того, как вы добавили свой код, то проблема в этом коде. На деле может быть, что ваш код обращается к уже существующему чужому коду, но передаёт туда граничные значения данных, работу с которыми забыли протестировать и обработать такие случаи.
В зависимости от соглашений на проекте исправляйте такие ошибки как свои собственные, либо сообщайте о них автору и ждите внесения правок.
Ошибки в библиотеках
Ошибки могут падать во внешних библиотеках к которым нет доступа и в таком случае непонятно что делать. Такие ошибки можно разделить на два типа. Первый- это ошибки в коде библиотеки. Второй- это ошибки связанные с невалидными данными или окружением, которые приводят к внутреннему исключению.
Первый случай хотя и редкий, но не стоит о нём забывать. В этом случае можно откатиться на другую версию библиотеки и создать Issue с описанием проблемы. Если это open-source и нет времени ждать обновления, можно собрать свою версию исправив баг самостоятельно, с последующей заменой на официальную исправленную версию.
Во втором случае определите откуда из вашего кода пришли невалидные данные. Для этого смотрим стек выполнения и по цепочке прослеживаем место в котором библиотека вызывается из нашего кода. Далее с этого места начинаем анализ, как туда попали невалидные данные.
Ошибки не воспроизводимые локально
Ошибка воспроизводится на develop стенде или в production, но не воспроизводится локально. Такие ошибки сложнее отлавливать потому что не всегда есть возможность запустить дебаг на удалённой машине. Поэтому убеждаемся, что ваше окружение соответствует внешнему.
Проверьте версию приложения
На стенде и локально версии приложения должны совпадать. Возможно на стенде приложение развёрнуто из другой ветки.
Проверьте данные
Проблема может быть в невалидных данных, а локальная и тестовая база данных рассинхронизированы. В этом случае поиск ошибки воспроизводим локально подключившись к тестовой БД, либо сняв с неё актуальный дамп.
Проверьте соответствие окружений
Если проект на стенде развёрнут в контейнере, то в некоторых IDE (JB RIder) можно дебажить в контейнере. Если проект развёрнут не в контейнере, то воспроизводимость ошибки может зависеть от окружения. Хотя .Net Core мультиплатформенный фреймворк, не всё что работает под Windows так же работает под Linux. В этом случае либо найти рабочую машину с таким же окружением, либо воспроизвести окружение через контейнеры или виртуальную машину.
Коварные ошибки
Метод из подключенной библиотеки не хочет обрабатывать ваши аргументы или не имеет нужных аргументов. Такие ситуации возникают, когда в проекте подключены две разных библиотеки содержащие методы с одинаковым названием, а разработчик по привычке понадеялся, что IDE автоматически подключит правильный using. Такое часто бывает с библиотеками расширяющими функционал LINQ в .NET. Поэтому при автоматическом добавлении using, если всплывает окно с выбором из нескольких вариантов, будьте внимательны.
Похожая ситуация и с одинаково названными типами. Если сборка включает несколько проектов в которых присутствуют одинаково названные классы, то можно по ошибке обращаться не к тому который требуется. Чтобы избежать обоих случаев, убедитесь, что в месте возникновения ошибки идёт обращение к правильным типам и методам.
Дополнительные материалы
Алгоритм отладки
-
Повтори ошибку.
-
Опиши проблему.
-
Сформулируй гипотезу.
-
Проверь гипотезу — если гипотеза проверку не прошла то п.3.
-
Примени исправления.
-
Убедись что исправлено — если не исправлено, то п.3.
Подробнее ознакомиться с ним можно в докладе Сергея Щегриковича «Отладка как процесс».
Чем искать ошибки, лучше не допускать ошибки. Прочитайте статью «Качество вместо контроля качества», чтобы узнать как это делать.
Итого
-
При появлении ошибки в которой сложно разобраться сперва внимательно и вдумчиво читаем текст ошибки.
-
Смотрим стек выполнения и проверяем, не находится ли причина возникновения выше по стеку.
-
Если по прежнему непонятно, гуглим текст и ищем похожие случаи.
-
Если проблема при взаимодействии с внешней библиотекой, читаем документацию.
-
Если нет документации проводим исследовательское тестирование.
-
Если не удается локализовать причину ошибки, применяем метод Бинарного поиска.
Существует три
основных типа ошибок в программах:
— ошибки этапа
компиляции (или синтаксические ошибки);
— ошибки этапа
выполнения или семантические ошибки);
— логические
ошибки.
Cинтаксические
ошибки происходят из-за нарушений
правил синтаксиса
языка программирования.
Когда компилятор обнаруживает
синтаксическую
ошибку, то отмечает
место (позицию или строку) ошибки и
выводт сообщение
об ошибке.
Наиболее
распространенными синтаксическими
ошибками являются:
— ошибки набора
(опечатки);
— пропущенные
точки с запятой;
— ссылки на
неописанные переменные;
— передача
неверного числа (или типа) параметров
процедуры или
функции;
— присваивание
переменной значений неверного типа.
После исправления
cинтаксической ошибки компиляцию можно
выполнить
заново. После
устранения всех синтаксических ошибок
и успешной компиля-
ции программа готова
к выполнению и поиску ошибок этапа
выполнения и ло-
гических ошибок.
Семантические
ошибки происходят, когда программа
компилируется, но
при выполнении
операторов что-то происходит неверно.
Например, программа
пытается открыть
для ввода несуществующий файл или
выполнить деление на
ноль. При обнаружении
семантических ошибок выполнение
программы заверша-
ется и выводится
сообщение об ошибке. Например, в системе
Turbo Pascal
выводится сообщение
следующего вида:
Run-time error ## at seg:ofs
По номеру
ошибки (##) можно установить причину ее
возникновения.
Логические ошибки
— это ошибки проектирования и реализации
програм-
мы. Логические
ошибки приводят к некорректному или
непредвиденному зна-
чению переменных,
неправильному виду графических
изображений или невы-
полнению кода, когда
это ожидается. Эти ошибки часто трудно
отслежива-
ются, поскольку ни
компилятор, ни исполняющая система не
обнаруживают их
автоматически, как
синтаксические и семантические ошибки.
Обычно системы
программирования
включает в себя средства отладки,
помогающие найти ло-
гические ошибки.
3.4.2. Цели и задачи отладки и тестирования.
Многие программисты
путают отладку программ с тестированием,
пред-
назначенным для
проверки их работоспособности. Отладка
имеет место тог-
да, когда программа
со всей очевидностью работает неправильно.
Поэтому
отладка начинается
всегда в предположении отказа программы.
Если же ока-
зывается, что
программа работает верно, то она
тестируется. Часто случа-
ется так, что после
прогона тестов программа вновь должна
быть подверг-
нута отладке. Таким
образом, тестирование устанавливает
факт наличия
ошибки, а отладка
выявляет ее причину, и эти два этапа
разработки прог-
раммы перекрываются.
3.4.3. Основные возможности интегрированного отладчика системы
программирования
Turbo Pascal.
Основной смысл
использования встроенного отладчика
состоит в управ-
ляемом выполнении
программы. Отслеживая выполнение
каждой инструкции,
можно легко определить,
какая часть программы вызывает проблемы.
В от-
ладчике предусмотрено
шесть основных механизмов управления
выполнением
программы, которые
позволяют:
— выполнять
инструкции по шагам(Run|Step Over или F8);
— трассировать
инструкции (Run|Trace Into или F7);
— выполнять
программы до позиции курсора (Run|Go to
Cursor или F4);
— выполнять
программу до заданной точки (Toggle
Breakpoint или
Ctrl+F8);
— находить
определенную точку (Search|Find Procedure…);
— выполнять сброс
программы (Run¦Reset Program или Ctrl+F2).
Выполнение
программы по шагам (команда Step Over меню
выполнения
Run) и трассировка
программы (команда Trace Into меню выполнения
Run)
дают возможность
построчного выполнения программы.
Единственное отличие
выполнения по шагам
и трассировки состоит в том, как они
работают с вы-
зовами процедур и
функций. Выполнение по шагам вызова
процедуры или
функции интерпретирует
вызов как простой оператор и после
завершения
подпрограммы
возвращает управление на следующую
строку. Трассировка
подпрограммы
загружает код этой подпрограммы и
продолжает ее построчное
выполнение.
Выполнение
программы до заданной точки (команда
Toggle Breakpoint
локального меню
редактора) — более гибкий механизм
отладки, чем исполь-
зование метода
выполнения до позиции курсора (команда
Go to Cursor меню
выполнения Run),
поскольку в программе можно установить
несколько точек
останова.
Интегрированная
среда разработки программы предусматривает
несколь-
ко способов поиска
в программе заданного места. Простейший
способ пре-
доставляет команда
Search|Find Procedure…, которая запрашивает
имя
процедуры или
функции, затем находит соответствующую
строку в файле, где
определяется эта
подпрограмма. Этот подход полезно
использовать при ре-
дактировании, но
его можно комбинировать с возможностью
выполнения прог-
раммы до определенной
точки, чтобы пройти программу до той
части кода,
которую надо отладить.
Чтобы сбрасить
все ранее задействованные отладочные
средства и
прекратитьт отладку
программы необходимо выполнить команду
Run|Program
reset или нажать клавиши
Ctrl+F2.
При выполнении
программы по шагам можно наблюдать ее
вывод несколь-
кими способами:
— переключение
в случае необходимости экранов
(Debug|User screen
или Alt+F5);
— открытие окна
вывода (Debug¦Output);
— использование
второго монитора;
Выполнение
программы по шагам или ее трассировка
могут помочь найти
ошибки в алгоритме
программы, но обычно желательно также
знать, что про-
исходит на каждом
шаге со значениями отдельных переменных.
Например, при
выполнении по шагам
цикла for полезно знать значение переменной
цикла.
Встроенный отладчик
имеет два инструментальных средства
для проверки со-
держимого переменных
программы:
— окно Watches
(Просмотр);
— диалоговое окно
Evaluate and Modify (Вычисление и модификация).
Чтобы открыть
окно Watches, необходимо выполнить
команду
Debug|Watch. Чтобы добавить
в окно Watches переменную, необходимо выпол-
нить
команду
Debug¦Watch¦Add Watch… или
нажать клавиши Ctrl+F7. Если
окно Watches является
активным окном, то можно добавить
выражение
просмотра, нажав
клавишу Ins. Отладчик открывает диалоговое
окно Add
Watch, запрашивающее
тип просматриваемого выражения. По
умолчанию выра-
жением считается
слово в позиции курсора в текущем окне
редактирования.
Просматриваемые
выражения, которые отслеживались ранее,
сохраняются в
списке протокола.
Последнее добавленное или модифицированное
просматри-
ваемое выражение
является текущим просматриваемым
выражением, которое
указывается выводимым
слева от него символом жирной левой
точки. Если
окно Watches активно,
можно удалить текущее выражение, нажав
клавишу Del
или Ctrl+Y. Чтобы
удалить все просматриваемые выражения,
необходимо вы-
полнить команду
Clear All локального меню активного окна
Watches. Чтобы
отредактировать
просматриваемое выражение, нужно
выполнить команду
Modify… или нажать
клавишу Enter локального меню активного
окна
Watches. Отладчик
открывает диалоговое окно Edit Watch,
аналогичное то-
му, которое
используется для добавления просматриваемого
выражения, ко-
торое позволяет
отредактировать текущее выражение.
Чтобы вычислить
выражение, необходимо выполнить
команду
Debug¦Evaluate/Modify…
или
нажать
клавиши
Ctrl+F4. Отладчик
открывает
диалоговое окно
Evaluate and Modify. По умолчанию слово в позиции
курсо-
ра в текущем окне
редактирования выводится подсвеченным
в поле
Expression. Можно
отредактировать это выражение, набрать
другое выраже-
ние или выбрать
вычисленное ранее выражение из списка
протокола.
Даже если не
установлены точки останова, можно выйти
в отладчик при
выполнении программы,
нажав клавиши Ctrl+Break. Отладчик находит
позицию
в исходном коде, где
прервалась программа. Затем, как и в
случае обычной
точки останова,
можно выполнить программу по шагам,
трассировать ее,
отследить или
вычислить выражения.
Иногда в ходе
отладки полезно узнать, как вы попали
в данную часть
кода. Окно Call Stack
показывает последовательность вызовов
процедур или
функций, которые
привели к текущему состоянию (глубиной
до 128 уровней).
Для вывода окна Call
Stack необходимо выполнить команду
Debug¦Call Stack
или нажать клавиши
Ctrl+F3.
13
Соседние файлы в папке 13_3xN
- #
- #
- #
Добавлено 16 апреля 2021 в 20:18
В программном обеспечении распространены ошибки. Их легко сделать, а найти сложно. В этой главе мы рассмотрим темы, связанные с поиском и устранением ошибок в наших программах на C++, включая изучение того, как использовать интегрированный отладчик, который является частью нашей IDE.
Хотя инструменты и методы отладки не входят в стандарт C++, умение находить и устранять ошибки в программах, которые вы пишете, является чрезвычайно важной частью успешной работы программиста. Поэтому мы уделим немного времени рассмотрению этих тем, чтобы по мере усложнения программ, которые вы пишете, ваша способность диагностировать и устранять проблемы развивалась с той же скоростью.
Если у вас есть опыт отладки программ на другом компилируемом языке программирования, многое из этого будет вам знакомо.
Синтаксические и семантические ошибки
Программирование может быть сложной задачей, и C++ – довольно необычный язык. Сложите эти две вещи вместе и получите множество способов сделать ошибку. Ошибки обычно делятся на две категории: синтаксические ошибки и семантические ошибки (логические ошибки).
Синтаксическая ошибка возникает, когда вы пишете инструкцию, недопустимую в соответствии с грамматикой языка C++. Сюда входят такие ошибки, как отсутствие точек с запятой, использование необъявленных переменных, несоответствие круглых или фигурных скобок и т.д. Например, следующая программа содержит довольно много синтаксических ошибок:
#include <iostream>
int main()
{
std::cout < "Hi there"; << x; // недопустимый оператор (<), лишняя точка с запятой, необъявленная переменная (x)
return 0 // отсутствие точки с запятой в конце инструкции
}К счастью, компилятор обычно перехватывает синтаксические ошибки и генерирует предупреждения или ошибки, поэтому вы легко обнаружите и устраните проблему. Затем просто снова попробуйте скомпилировать программу, пока не избавитесь от всех ошибок.
После того, как ваша программа скомпилировалась правильно, может быть непросто добиться от нее желаемого результата. Семантическая ошибка возникает, когда оператор синтаксически правильный, но не выполняет то, что задумал программист.
Иногда это приводит к сбою программы, например, в случае деления на ноль:
#include <iostream>
int main()
{
int a { 10 };
int b { 0 };
std::cout << a << " / " << b << " = " << a / b; // деление на 0 не определено
return 0;
}Чаще всего они просто приводят к неправильному значению или поведению:
#include <iostream>
int main()
{
int x;
std::cout << x; // Использование неинициализированной переменной приводит к неопределенному результату
return 0;
}или же
#include <iostream>
int add(int x, int y)
{
return x - y; // функция должна складывать, но это не так
}
int main()
{
std::cout << add(5, 3); // должен выдать 8, но выдаст 2
return 0;
}или же
#include <iostream>
int main()
{
return 0; // функция завершается здесь
std::cout << "Hello, world!"; // поэтому это никогда не выполняется
}Современные компиляторы стали лучше обнаруживать определенные типы распространенных семантических ошибок (например, использование неинициализированной переменной). Однако в большинстве случаев компилятор не сможет отловить большинство из этих типов проблем, потому что компилятор предназначен для обеспечения соблюдения грамматики, а не намерений.
В приведенных выше примерах ошибки довольно легко обнаружить. Но в большинстве нетривиальных программ, взглянув на код, семантические ошибки найти нелегко. Здесь могут пригодиться методы отладки.
Теги
C++ / CppDebugLearnCppДля начинающихОбучениеОтладкаПрограммирование
Привет, Вы узнаете про виды ошибок программного обеспечения, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
виды ошибок программного обеспечения, принципы отладки , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance..
1. Отладка программы
Отладка, как мы уже говорили, бывает двух видов:
Синтаксическая отладка. Синтаксические ошибки выявляет компилятор, поэтому исправлять их достаточно легко.
Семантическая (смысловая) отладка. Ее время наступает тогда, когда синтаксических ошибок не осталось, но результаты программа выдает неверные. Здесь компилятор сам ничего выявить не сможет, хотя в среде программирования обычно существуют вспомогательные средства отладки, о которых мы еще поговорим.
Отладка — это процесс локализации и исправления ошибок в программе.
Как бы тщательно мы ни писали, отладка почти всегда занимает больше времени, чем программирование.
2. Локализация ошибок
Локализация — это нахождение места ошибки в программе.
В процессе поиска ошибки мы обычно выполняем одни и те же действия:
- прогоняем программу и получаем результаты;
- сверяем результаты с эталонными и анализируем несоответствие;
- выявляем наличие ошибки, выдвигаем гипотезу о ее характере и месте в программе;
- проверяем текст программы, исправляем ошибку, если мы нашли ее правильно.
Способы обнаружения ошибки:
- Аналитический — имея достаточное представление о структуре программы, просматриваем ее текст вручную, без прогона.
- Экспериментальный — прогоняем программу, используя отладочную печать и средства трассировки, и анализируем результаты ее работы.
Оба способа по-своему удобны и обычно используются совместно.
3.
принципы отладки
Принципы локализации ошибок:
- Большинство ошибок обнаруживается вообще без запуска программы — просто внимательным просматриванием текста.
- Если отладка зашла в тупик и обнаружить ошибку не удается, лучше отложить программу. Когда глаз «замылен», эффективность работы упорно стремится к нулю.
- Чрезвычайно удобные вспомогательные средства — это отладочные механизмы среды разработки: трассировка, промежуточный контроль значений. Можно использовать даже дамп памяти, но такие радикальные действия нужны крайне редко.
- Экспериментирования типа «а что будет, если изменить плюс на минус» — нужно избегать всеми силами. Обычно это не дает результатов, а только больше запутывает процесс отладки, да еще и добавляет новые ошибки.
Принципы исправления ошибок еще больше похожи на законы Мерфи:
- Там, где найдена одна ошибка, возможно, есть и другие.
- Вероятность, что ошибка найдена правильно, никогда не равна ста процентам.
- Наша задача — найти саму ошибку, а не ее симптом.
Это утверждение хочется пояснить. Если программа упорно выдает результат 0,1 вместо эталонного нуля, простым округлением вопрос не решить. Если результат получается отрицательным вместо эталонного положительного, бесполезно брать его по модулю — мы получим вместо решения задачи ерунду с подгонкой.
Исправляя одну ошибку, очень легко внести в программу еще парочку. «Наведенные» ошибки — настоящий бич отладки.
Исправление ошибок зачастую вынуждает нас возвращаться на этап составления программы. Это неприятно, но порой неизбежно.
4. Методы отладки
Силовые методы
- — Использование дампа (распечатки) памяти.Это интересно с познавательной точки зрения: можно досконально разобраться в машинных процессах. Иногда такой подход даже необходим — например, когда речь идет о выделении и высвобождении памяти под динамические переменные с использованием недокументированных возможностей языка. Однако, в большинстве случаев мы получаем огромное количество низкоуровневой информации, разбираться с которой — не пожелаешь и врагу, а результативность поиска — исчезающе низка.
- — Использование отладочной печати в тексте программы — произвольно и в большом количестве.Получать информацию о выполнении каждого оператора тоже небезынтересно. Но здесь мы снова сталкиваемся со слишком большими объемами информации. Кроме того, мы здорово захламляем программу добавочными операторами, получая малочитабельный текст, да еще рискуем внести десяток новых ошибок.
- — Использование автоматических средств отладки — трассировки с отслеживанием промежуточных значений переменых.Пожалуй, это самый распространенный способ отладки. Не нужно только забывать, что это только один из способов, и применять всегда и везде только его — часто невыгодно.
Сложности возникают, когда приходится отслеживать слишком большие структуры данных или огромное их число. Еще проблематичнее трассировать проект, где выполнение каждой подпрограммы приводит к вызову пары десятков других. Но для небольших программ трассировки вполне достаточно.
С точки зрения «правильного» программирования силовые методы плохи тем, что не поощряют анализ задачи.
Суммируя свойства силовых методов, получаем практические советы:
— использовать трассировку и отслеживание значений переменных для небольших проектов, отдельных подпрограмм;
— использовать отладочную печать в небольших количества и «по делу»;
— оставить дамп памяти на самый крайний случай.
Метод индукции — анализ программы от частного к общему.
Просматриваем симптомы ошибки и определяем данные, которые имеют к ней хоть какое-то отношение. Затем, используя тесты, исключаем маловероятные гипотезы, пока не остается одна, которую мы пытаемся уточнить и доказать.
Метод дедукции — от общего к частному.
Выдвигаем гипотезу, которая может объяснить ошибку, пусть и не полностью. Затем при помощи тестов эта гипотеза проверяется и доказывается.
Обратное движение по алгоритму.
Отладка начинается там, где впервые встретился неправильный результат. Затем работа программы прослеживается (мысленно или при помощи тестов) в обратном порядке, пока не будет обнаружено место возможной ошибки.
Метод тестирования.
Давайте рассмотрим процесс локализации ошибки на конкретном примере. Пусть дана небольшая программа, которая выдает значение максимального из трех введенных пользователем чисел.
var
a, b, c: real;
begin
writeln('Программа находит значение максимального из трех введенных чисел');
write('Введите первое число '); readln(a);
write('Введите второе число '); readln(b);
write('Введите третье число '); readln(c);
if (a>b)and(a>c) then
writeln('Наибольшим оказалось первое число ',a:8:2)
else if (b>a)and(a>c) then
writeln('Наибольшим оказалось второе число ',b:8:2)
else
writeln('Наибольшим оказалось третье число ',b:8:2);
end.
Обе выделенные ошибки можно обнаружить невооруженным глазом: первая явно допущена по невнимательности, вторая — из-за того, что скопированную строку не исправили.
Тестовые наборы данных должны учитывать все варианты решения, поэтому выберем следующие наборы чисел:
Данные Ожидаемый результат
a=10; b=-4; c=1 max=a=10
a=-2; b=8; c=4 max=b=8
a=90; b=0; c=90.4 max=c=90.4
В результате выполнения программы мы, однако, получим следующие результаты:
Для a=10; b=-4; c=1:
Наибольшим оказалось первое число 10.00
Для a=-2; b=8; c=4: < pre class=»list»>Наибольшим оказалось третье число 8.00Для a=90; b=0; c=90.4:
Наибольшим оказалось третье число 0.00
Вывод во втором и третьем случаях явно неверен. Будем разбираться.
1. Трассировка и промежуточная наблюдение за переменными
Добавляем промежуточную печать или наблюдение за переменными:
- — вывод a, b, c после ввода (проверяем, правильно ли получили данные)
- — вывод значения каждого из условий (проверяем, правильно ли записали условия)
Листинг программы существенно увеличился и стал вот таким:
var
a, b, c: real;
begin
writeln(‘Программа находит значение максимального из трех введенных чисел’);
write(‘Введите первое число ‘); readln(a);
writeln(‘Вы ввели число ‘,a:8:2); {отл.печать}
write(‘Введите второе число ‘); readln(b);
writeln(‘Вы ввели число ‘,b:8:2); {отл.печать}
write(‘Введите третье число ‘); readln(c);
writeln(‘Вы ввели число ‘,c:8:2); {отл.печать}
writeln(‘a>b=’,a>b,’, a>c=’,a>c,’, (a>b)and(a>c)=’,(a>b)and(a>c)); {отл.печать}
if (a>b)and(a>c) then
writeln(‘Наибольшим оказалось первое число ‘,a:8:2)
else begin
writeln(‘b>a=’,b>a,’, b>c=’,b>c,’, (b>a)and(b>c)=’,(b>a)and(b>c)); {отл.печать}
if (b>a)and(a>c) then
writeln(‘Наибольшим оказалось второе число ‘,b:8:2)
else
writeln(‘Наибольшим оказалось третье число ‘,b:8:2);
end;
end.
В принципе, еще при наборе у нас неплохой шанс отловить ошибку в условии: подобные кусочки кода обычно не перебиваются, а копируются, и если дать себе труд слегка при этом задуматься, ошибку найти легко.
Но давайте считать, что глаз «замылен» совершенно, и найти ошибку не удалось.
Вывод для второго случая получается следующим:
Программа находит значение максимального из трех введенных чисел
Введите первое число -2
Вы ввели число -2.00
Введите второе число 8
Вы ввели число 8.00
Введите третье число 4
Вы ввели число 4.00
a>b=FALSE, a>c=FALSE, (a>b)and(a>c)=FALSE
b>a=TRUE, b>c=TRUE, (b>a)and(b>c)=TRUE
Наибольшим оказалось третье число 8.00
Со вводом все в порядке . Об этом говорит сайт https://intellect.icu . Впрочем, в этом сомнений и так было немного. А вот что касается второй группы операторов печати, то картина вышла интересная: в результате выводится верное число (8.00), но неправильное слово («третье», а не «второе»).
Вероятно, проблемы в выводе результатов. Тщательно проверяем текст и обнаруживаем, что действительно в последнем случае выводится не c, а b. Однако к решению текущей проблемы это не относится: исправив ошибку, мы получаем для чисел -2.0, 8.0, 4.0 следующий результат.
Наибольшим оказалось третье число 4.00
Теперь ошибка локализована до расчетного блока и, после некоторых усилий, мы ее находим и исправляем.
2. Метод индукции
Судя по результатам, ошибка возникает, когда максимальное число — второе или третье (если максимальное — первое, то определяется оно правильно, для доказательства можно програть еще два-три теста).
Просматриваем все, относящееся к переменным b и с. Со вводом никаких проблем не замечено, а что касается вывода — то мы быстро натыкаемся на замену b на с. Исправляем.
Как видно, невыявленные ошибки в программе остаются. Просматриваем расчетный блок: все, что относится к максимальному b (максимум с получается «в противном случае»), и обнаруживаем пресловутую проблему «a>c» вместо «b>c». Программа отлажена.
3. Метод дедукции
Неверные результаты в нашем случае могут получиться из-за ошибки в:
- — вводе данных;
- — расчетном блоке;
- — собственно выводе.
Для доказательства мы можем пользоваться отладочной печатью, трассировкой или просто набором тестов. В любом случае мы выявляем одну ошибку в расчете и одну в выводе.
4. Обратное движение по алгоритму
Зная, что ошибка возникает при выводе результатов, рассматриваем код, начиная с операторов вывода. Сразу же находим лишнюю b в операторе writeln.
Далее, смотрим по конкретной ветке условного оператора, откуда взялся результат. Для значений -2.0, 8.0, 4.0 расчет идет по ветке с условием if (b>a)and(a>c) then… где мы тут же обнаруживаем искомую ошибку.
5. Тестирование
В нашей задаче для самого полного набора данных нужно выбрать такие переменные, что
a > b > c
a > c > b
b > a > c
b > c > a
c > a > b
c > b > a
Анализируя получившиеся в каждом из этих случаев результаты, мы приходим к тому, что проблемы возникают при b>c>a и с — максимальном. Зная эти подробности, мы можем заострить внимание на конкретных участках программы.
Конечно, в реальной работе мы не расписываем так занудно каждый шаг, не прибегаем исключительно к одной методике, да и вообще частенько не задумываемся, каким образом искать ляпы. Теперь, когда мы разобрались со всеми подходами, каждый волен выбрать те из них, которые кажутся самыми удобными.
5. Средства отладки
Помимо методик, хорошо бы иметь представление о средствах, которые помогают нам выявлять ошибки. Это:
1) Аварийная печать — вывод сообщений о ненормальном завершении отдельных блоков и всей программы в целом.
2) Печать в узлах программы — вывод промежуточных значений параметров в местах, выбранных программистом. Обычно, это критичные участки алгоритма (например, значение, от которого зависит дальнейший ход выполнения) или составные части сложных формул (отдельно просчитать и вывести числитель и знаменатель большой дроби).
3) Непосредственное слежение:
- — арифметическое (за тем, чему равны, когда и как изменяются выбранные переменные),
- — логическое (когда и как выполняется выбранная последовательность операторов),
- — контроль выхода индексов за допустимые пределы,
- — отслеживание обращений к переменным,
- — отслеживание обращений к подпрограммам,
- — проверка значений индексов элементов массивов и т.д.
Нынешние среды разработки часто предлагают нам реагировать на возникающую проблему в диалоговом режиме. При этом можно:
- — просмотреть текущие значения переменных, состояние памяти, участок алгоритма, где произошел сбой;
- — прервать выполнение программы;
- — внести в программу изменения и повторно запустить ее (в компиляторных средах для этого потребуется перекомпилировать код, в интерпретаторных выполнение можно продолжить прямо с измененного оператора).
 Рис Пример отладки приложения
Рис Пример отладки приложения
6. Классификация ошибок
Ошибки в программах могут допускаться от самого начального этапа составления алгоритма решения задачи до окончательного оформления программы. Разновидностей ошибок достаточно много. Рассмотрим некоторые группы ошибок и соответствующие примеры:
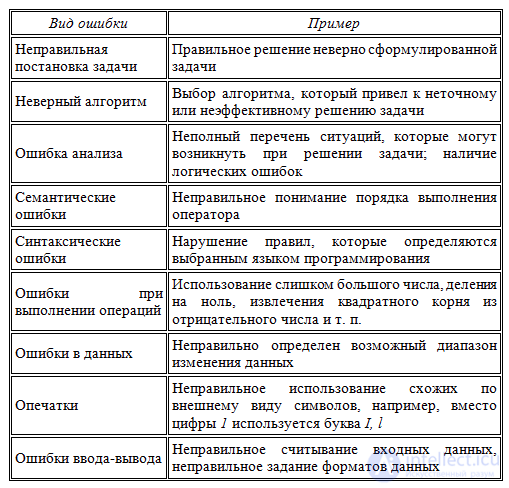
Если вы удручены тем, что насажали в текст программы глупых ошибок — не расстраивайтесь. Ошибки вообще не бывают умными, хотя и могут относиться к самым разным частям кода:
- — ошибки обращения к данным,
- — ошибки описания данных,
- — ошибки вычислений,
- — ошибки при сравнении,
- — ошибки в передаче управления,
- — ошибки ввода-вывода,
- — ошибки интерфейса,
- и т д
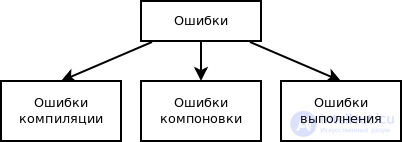
Классификация ошибок по этапу обработки программы
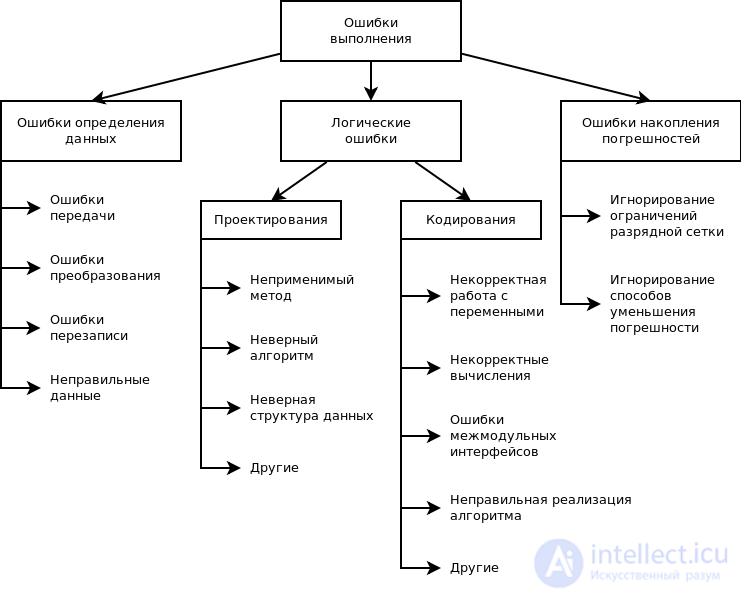
рис Классификация ошибок этапа выполнения по возможным причинам
Синтаксические ошибки
Синтаксические ошибки зачастую выявляют уже на этапе трансляции. К сожалению, многие ошибки других видов транслятор выявить не в силах, т.к. ему не известен задуманный или требуемый результат работы программы. Отсутствие сообщений транслятора о наличии синтаксических ошибок является необходимым условием правильности программы, но не может свидетельствовать о том, что она даст правильный результат.
Примеры синтаксических ошибок :
- отсутствие знака пунктуации;
- несоответствие количества открывающих и закрывающих скобок;
- неправильно сформированный оператор;
- неправильная запись имени переменной;
- ошибка в написании служебных слов;
- отсутствие условия окончания цикла;
- отсутствие описания массивов и т.п.
Ошибки, которые не обнаруживает транслятор
В случае правильного написания операторов в программе может присутствовать большое количество ошибок, которые транслятор не может обнаружить. Рассмотрим примеры таких ошибок:
Логические ошибки: после проверки заданного условия неправильно указана ветвь алгоритма; неполный перечень возможных условий при решении задачи; один или более блоков алгоритма в программе пропущен.
Ошибки в циклах: неправильно указано начало цикла; неправильно указаны условия окончания цикла; неправильно указано количество повторений цикла; использование бесконечного цикла.
Ошибки ввода-вывода; ошибки при работе с данными: неправильно задан тип данных; организовано считывание меньшего или большего объема данных, чем нужно; неправильно отредактированы данные.
Ошибки в использовании переменных: используются переменных, для которых не указаны начальные значения; ошибочно указана одна переменная вместо другой. Ошибки при работе с массивами: пропущено предварительное обнуление массивов; неправильное описание массивов; индексы массивов следуют в ошибочном порядке.
ошибки безопасности, умышленные и не умышленные уязвимости в системе, открытость к отказам в обслуживании. несанкционированном доступе. екхолы
Ошибки в арифметических операциях: неправильное использование типа переменной (например, для сохранения результата деления используется целочисленная переменная); неправильно определен порядок действий; выполняется деление на нуль; при расчете выполняется попытка извлечения квадратного корня из отрицательного числа; не учитываются значащие разряды числа.
ошибки в архитектуре приложения пприводящие к увеличени технического долга
Методы (пути) снижение ошибок в программировании
- использование тестиования
- использование более простых решений
- использование систем с наименьшим числом составлящих
- использование ранее использованных и проверенных компонентов
- использование более квалифицрованных специалистов
7. Советы отладчику
1) Проверяйте тщательнее: ошибка скорее всего находится не в том месте, в котором кажется.
2) Часто оказывается легче выделить те места программы, ошибок в которых нет, а затем уже искать в остальных.
3) Тщательнее следить за объявлениями констант, типов и переменных, входными данными.
4) При последовательной разработке приходится особенно аккуратно писать драйверы и заглушки — они сами могут быть источником ошибок.
5) Анализировать код, начиная с самых простых вариантов. Чаще всего встречаются ошибки:
— значения входных аргументов принимаются не в том порядке,
— переменная не проинициализирована,
— при повторном прохождении модуля, перемен ная повторно не инициализируется,
— вместо предполагаемого полного копирования структуры данных, копируется только верхний уровень (например, вместо создания новой динамической переменной и присваивания ей нужного значения, адрес тупо копируется из уже существующей переменной),
— скобки в сложном выражении расставлены неправильно.
6) При упорной длительной отладке глаз «замыливается». Хороший прием — обратиться за помощью к другому лицу, чтобы не повторять ошибочных рассуждений. Правда, частенько остается проблемой убедить это другое лицо помочь вам.
7) Ошибка, скорее всего окажется вашей и будет находиться в тексте программы. Гораздо реже она оказывается:
- в компиляторе,
- операционной системе,
- аппаратной части,
- электропроводке в здании и т.д.
Но если вы совершенно уверены, что в программе ошибок нет, просмотрите стандартные модули, к которым она обращается, выясните, не менялась ли версия среды разработки, в конце концов, просто перегрузите компьютер — некоторые проблемы (особенно в DOS-средах, запускаемых из-под Windows) возникают из-за некорректной работы с памятью.
 Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
9) Навязчивый поиск одной ошибки почти всегда непродуктивен. Не получается — отложите задачу, возьмитесь за написание следующего модуля, на худой конец займитесь документированием.
10) Старайтесь не жалеть времени, чтобы уясненить причину ошибки. Это поможет вам:
исправить программу,
обнаружить другие ошибки того же типа,
не делать их в дальнейшем.
11) Если вы уже знаете симптомы ошибки, иногда полезно не исправлять ее сразу, а на фоне известного поведения программы поискать другие ляпы.
12) Самые труднообнаруживаемые ошибки — наведенные, то есть те, что были внесены в код при исправлении других.
8. Тестирование
Тестирование — это выполнение программы для набора проверочных входных значений и сравнение полученных результатов с ожидаемыми.
Цель тестирования — проверка и доказательство правильности работы программы. В противном случае — выявление того, что в ней есть ошибки. Тестирование само не показывает местонахождение ошибки и не указывает на ее причины.
Принципы тестирования.
1) Тест — просчитанный вручную пример выполнения программы от исходных данных до ожидаемых результатов расчета. Эти результаты считаются эталонными.
Полномаршрутным будет такое тестирование, при котором каждый линейный участок программы будет пройден хотя бы при выполнении одного теста.
2) При прогоне программы по тестовым начальным данным, полученные результаты нужно сверить с эталонными и проанализировать разницу, если она есть.
3) При разработке тестов нужно учитывать не только правильные, но и неверные исходные данные.
4) Мы должны проверить программу на нежелательные побочные эффекты при задании некоторых исходных данных (деление на ноль, попытка считывания из несуществующего файла и т.д.).
5) Тестирование нужно планировать: заранее выбрать, что мы контролируем и как это сделать лучше. Обычно тесты планируются на этапе алгоритмизации или выбора численного метода решения. Причем, составляя тесты, мы предполагаем, что ошибки в программе есть.
6) Чем больше ошибок в коде мы уже нашли, тем больше вероятность, что мы обнаружим еще не найденные.
Хорошим называют тест, который с большой вероятностью должен обнаруживать ошибки, а удачным — тот, который их обнаружил.
9. Проектирование тестов
Тесты просчитываются вручную, значит, они должны быть достаточно просты для этого.
Тесты должны проверять каждую ветку алгоритма. По возможности, конечно. Так что количество и сложность тестов зависит от сложности программы.
Тесты составляются до кодирования и отладки: во время разработки алгоритма или даже составления математической модели.
Обычно для экономии времени сначала пропускают более простые тесты, а затем более сложные.
Давайте рассмотрим задачу: нужно проверить, попадает ли введенное число в заданный пользователем диапазон.
program Example;
(******************************************************
* Задача: проверить, попадает ли введенное число в *
* заданный пользователем диапазон *
******************************************************)
var
min, max, A, tmp: real;
begin
writeln(‘Программа проверяет, попадают ли введенные пользователем’);
writeln(‘значения в заданный диапазон’);
writeln;
writeln(‘Введите нижнюю границу диапазона ‘); readln(min);
writeln(‘Введите верхнюю границу диапазона ‘); readln(max);
if min>max then begin
writeln(‘Вы перепутали диапазоны, и я их поменяю’);
tmp:=min;
min:=max;
max:=tmp;
end;
repeat
writeln(‘Введите число для проверки (0 — конец работы) ‘); readln(A);
if (A>=min)and(A<=max) then
writeln(‘Число ‘,A,’ попадает в диапазон [‘,min,’..’,max,’]’)
else
writeln(‘Число ‘,A,’ не попадает в диапазон [‘,min,’..’,max,’]’);
until A=0;
writeln;
end.
Если исходить из алгоритма программы, мы должны составить следующие тесты:
ввод границ диапазона
— min< max
— min>max
ввод числа
— A < min (A<>0)
— A > max (A<>0)
— min <= A <= max (A<>0)
— A=0
Как видите, программа очень мала, а тестов для проверки всех ветвей ее алгоритма, требуется довольно много.
10. Стратегии тестирования
1) Тестирование программы как «черного ящика».
Мы знаем только о том, что делает программа, но даже не задумываемся о ее внутренней структуре. Задаем набор входных данных, получаем результаты, сверяем с эталонными.
При этом обнаружить все ошибки мы можем только если составили тесты для всех возможных наборов данных. Естественно, это противоречит экономическим принципам, да и просто достаточно глупо.
«Черным ящиком» удобно тестировать небольшие подпрограммы.
2) Тестирование программы как «белого ящика».
Здесь перед составлением теста мы изучаем логику программы, ее внутреннюю структуру. Тестирование будет считаться удачным, если проверяет программу по всем направлениям. Однако, как мы уже говорили, это требует огромного количества тестов.
На практике мы, как всегда, совместно используем оба принципа.
3) Тестирование программ модульной структуры.
Мы снова возвращаемся к вопросу о структурном программировании. Если вы помните, программы строятся из модулей не в последнюю очередь для того, чтобы их легко было отлаживать и тестировать. Действительно, структурированную программу мы будем тестировать частями. При этом нам нужно:
строить набор тестов;
комбинировать модули для тестирования.
Такое комбинирование может строиться двумя способами:
Пошаговое тестирование — тестируем каждый модуль, присоединяя его к уже оттестированным. При этом можем соединять части программы сверху вниз (нисходящий способ) или снизу вверх (восходящий).
Монолитное тестирование — каждый модуль тестируется отдельно, а затем из них формируется готовая рабочая программа и тестируется уже целиком.
Чтобы протестировать отдельный модуль, нужен модуль-драйвер (всегда один) и модул и-заглушки (этих может быть несколько).
Модуль-драйвер содержит фиксированные исходные данные. Он вызывает тестируемый модуль и отображает (а возможно, и анализирует) результаты.
Модуль-заглушка нужен, если в тестируемом модуле есть вызовы других. Вместо этого вызова управление передается модулю-заглушке, и уже он имитирует необходимые действия.
К сожалению, мы опять сталкиваемся с тем, что драйверы и заглушки сами могут оказаться источником ошибок. Поэтому создаваться они должны с большой осторожностью.
См. также
- ошибки в приложениях , bugs , баг репорт , bug report ,
- Фича
- GIGO
- Патч
- тестирование
- цикломатическая сложность
- баг репорт
- качество программного обеспечения
К сожалению, в одной статье не просто дать все знания про виды ошибок программного обеспечения. Но я — старался.
Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое виды ошибок программного обеспечения, принципы отладки
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Качество и тестирование программного обеспечения. Quality Assurance.
Отладка, или debugging, — это поиск (локализация), анализ и устранение ошибок в программном обеспечении, которые были найдены во время тестирования.
Это простые ошибки, которые в компилируемых языках программирования выявляет компилятор (программа, которая преобразует текст на языке программирования в набор машинных кодов). Если компилятор показывает несколько ошибок, отладку кода начинают с исправления самой первой, так как она может быть причиной других.
В интерпретируемых языках (например Python) текст программы команда за командой переводится в машинный код и сразу исполняется. К моменту обнаружения ошибки часть программы уже может исполниться.
Ошибки связаны с разрешением внешних ссылок. Выявляет компоновщик (редактор связей) при объединении модулей программы. Простой пример — ситуация, когда требуется обращение к подпрограмме другого модуля, но при компоновке она не найдена. Ошибки также просто найти и устранить.
Ошибки, которые обнаруживают операционная система, аппаратные средства или пользователи при выполнении программы. Они считаются непредсказуемыми и проявляются после успешной компиляции и компоновки. Можно выделить четыре вида проявления таких ошибок:
- сообщение об ошибке, которую зафиксировали схемы контроля машинных команд. Это может быть переполнение разрядной сетки (когда старшие разряды результата операции не помещаются в выделенной области памяти), «деление на ноль», нарушение адресации и другие;
- сообщение об ошибке, которую зафиксировала операционная система. Она же, как правило, и документирует ошибку. Это нарушение защиты памяти, отсутствие файла с заданным именем, попытка записи на устройство, защищенное от записи;
- прекращение работы компьютера или зависание. Это и простые ошибки, которые не требуют перезагрузки компьютера, и более сложные, когда нужно выключать ПК;
- получение результатов, которые отличаются от ожидаемых. Программа работает стабильно, но выдает некорректный результат, который пользователь воспринимает за истину.
Ошибки выполнения можно разделить на три большие группы.
Ошибки определения данных или неверное определение исходных данных. Они могут появиться во время выполнения операций ввода-вывода.
К ним относятся:
- ошибки преобразования;
- ошибки данных;
- ошибки перезаписи.
Как правило, использование специальных технических средств для отладки (API-логгеров, логов операционной системы, профилировщиков и пр.) и программирование с защитой от ошибок помогает обнаружить и решить лишь часть из них.
Логические ошибки. Они могут возникать из ошибок, которые были допущены при выборе методов, разработке алгоритмов, определении структуры данных, кодировании модуля.
В эту группу входят:
- ошибки некорректного использования переменных. Сюда относятся неправильный выбор типов данных, использование индексов, выходящих за пределы определения массивов, использование переменных до присвоения переменной начального значения, нарушения соответствия типов данных;
- ошибки вычислений. Это некорректная работа с переменными, неправильное преобразование типов данных в процессе вычислений;
- ошибки взаимодействия модулей или межмодульного интерфейса. Это нарушение типов и последовательности при передаче параметров, области действия локальных и глобальных переменных, несоблюдение единства единиц измерения формальных и фактических параметров;
- неправильная реализация логики при программировании.
Ошибки накопления погрешностей. Могут возникать при неправильном округлении, игнорировании ограничений разрядной сетки, использовании приближенных методов вычислений и т.д.
Отладка программы заключается в тестировании вручную с помощью тестового набора, при работе с которым была допущена ошибка. Несмотря на эффективность, метод не получится использовать для больших программ или программ со сложными вычислениями. Ручное тестирование применяется как составная часть других методов отладки.
В основе отладки системы — тщательный анализ проявлений ошибки. Это могут быть сообщения об ошибке или неверные результаты вычислений. Например, если во время выполнения программы завис компьютер, то, чтобы найти фрагмент проявления ошибки, нужно проанализировать последние действия пользователя. На этапе отладки программы строятся гипотезы, каждая из них проверяется. Если гипотеза подтвердилась, информация об ошибке детализируется, если нет — выдвигаются новые.
Вот как выглядит процесс:

Важно, чтобы выдвинутая гипотеза объясняла все проявления ошибки. Если объясняется только их часть, то либо гипотеза неверна, либо ошибок несколько.
Сначала специалисты предлагают множество причин, по которым могла возникнуть ошибка. Затем анализируют их, исключают противоречащие имеющимся данным. Если все причины были исключены, проводят дополнительное тестирование. В обратном случае наиболее вероятную причину пытаются доказать.

Эффективен для небольших программ. Начинается с точки вывода неправильного результата. Для точки выдвигается гипотеза о значениях основных переменных, которые могли привести к ошибке. Далее на основании этой гипотезы строятся предположения о значениях переменных в предыдущей точке. Процесс продолжается до момента, пока не найдут ошибку.
Ранние отладчики, например gdb, представляли собой отдельные программы с интерфейсами командной строки. Более поздние, например первые версии Turbo Debugger, были автономными, но имели собственный графический интерфейс для облегчения работы. Сейчас большинство IDE имеют встроенный отладчик. Он использует такой же интерфейс, как и редактор кода, поэтому можно выполнять отладку в той же среде, которая используется для написания кода.
Отладчик позволяет разработчику контролировать выполнение и проверять (или изменять) состояние программ. Например, можно использовать отладчик для построчного выполнения программы, проверяя по ходу значения переменных. Сравнение фактических и ожидаемых значений переменных или наблюдение за ходом выполнения кода может помочь в отслеживании логических (семантических) ошибок.
Пошаговое выполнение — это набор связанных функций отладчика, позволяющих поэтапно выполнять код.
Команда выполняет очередную инструкцию, а потом приостанавливает процесс, чтобы с помощью отладчика было можно проверить состояние программы. Если в выполняемом операторе есть вызов функции, step into заставляет программу переходить в начало вызываемой функции, где она приостанавливается.
Команда также выполняет очередную инструкцию. Однако когда step into будет входить в вызовы функций и выполнять их строка за строкой, step over выполнит всю функцию, не останавливаясь, и вернет управление после ее выполнения. Команда step over позволяет пропустить функции, если разработчик уверен, что они уже исправлены, или не заинтересован в их отладке в данный момент.
В отличие от step into и step over, step out выполняет не следующую строку кода, а весь оставшийся код функции, исполняемой в настоящее время. После возврата из функции он возвращает управление разработчику. Эта команда полезна, когда специалист случайно вошел в функцию, которую не нужно отлаживать.
Как правило, при пошаговом выполнении можно идти только вперед. Поэтому легко перешагнуть место, которое нужно проверить. Если это произошло, необходимо перезапустить отладку.
У некоторых отладчиков (таких как GDB 7.0, Visual Studio Enterprise Edition 15.5 и более поздних версий) есть возможность вернуться на шаг назад. Это полезно, если пропущена цель либо нужно повторно проверить выполненную инструкцию.
Аннотация: Лекция носит факультативный характер. Здесь мы рассматриваем виды допускаемых в программировании ошибок, способы тестирования и отладки программ, инструменты встроенного отладчика.
Цель лекции
Освоить работу с встроенным отладчиком, изучить категории ошибок, способы их обнаружения и устранения.
Тестирование и отладка программы
Чем больше опыта имеет программист, тем меньше ошибок в коде он совершает. Но, хотите верьте, хотите нет, даже самый опытный программист всё же допускает ошибки. И любая современная среда разработки программ должна иметь собственные инструменты для отладки приложений, а также для своевременного обнаружения и исправления возможных ошибок. Программные ошибки на программистском сленге называют багами (англ. bug — жук), а программы отладки кода — дебаггерами (англ. debugger — отладчик). Lazarus, как современная среда разработки приложений, имеет собственный встроенный отладчик, работу с которым мы разберем на этой лекции.
Ошибки, которые может допустить программист, условно делятся на три группы:
- Синтаксические
- Времени выполнения (run-time errors)
- Алгоритмические
Синтаксические ошибки
Синтаксические ошибки легче всего обнаружить и исправить — их обнаруживает компилятор, не давая скомпилировать и запустить программу. Причем компилятор устанавливает курсор на ошибку, или после неё, а в окне сообщений выводит соответствующее сообщение, например, такое:
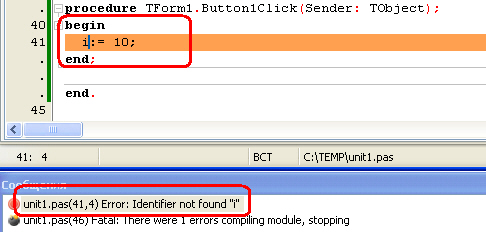
Рис.
27.1.
Найденная компилятором синтаксическая ошибка — нет объявления переменной i
Подобные ошибки могут возникнуть при неправильном написании директивы или имени функции (процедуры); при попытке обратиться к переменной или константе, которую не объявляли (
рис.
27.1); при попытке вызвать функцию (процедуру, переменную, константу) из модуля, который не был подключен в разделе uses; при других аналогичных недосмотрах программиста.
Как уже говорилось, компилятор при нахождении подобной ошибки приостанавливает процесс компиляции, выводит сообщение о найденной ошибке и устанавливает курсор на допущенную ошибку, или после неё. Программисту остается только внести исправления в код программы и выполнить повторную компиляцию.
Ошибки времени выполнения
Ошибки времени выполнения (run-time errors) тоже, как правило, легко устранимы. Они обычно проявляются уже при первых запусках программы, или во время тестирования. Если такую программу запустить из среды Lazarus, то она скомпилируется, но при попытке загрузки, или в момент совершения ошибки, приостановит свою работу, выведя на экран соответствующее сообщение. Например, такое:

Рис.
27.2.
Сообщение Lazarus об ошибке времени выполнения
В данном случае программа при загрузке должна была считать в память отсутствующий текстовый файл MyFile.txt. Поскольку программа вызвала ошибку, она не запустилась, но в среде Lazarus процесс отладки продолжается, о чем свидетельствует сообщение в скобках в заголовке главного меню, после названия проекта. Программисту в подобных случаях нужно сбросить отладчик командой меню «Запуск -> Сбросить отладчик«, после чего можно продолжить работу над проектом.
Ошибка времени выполнения может возникнуть не только при загрузке программы, но и во время её работы. Например, если бы попытка чтения несуществующего файла была сделана не при загрузке программы, а при нажатии на кнопку, то программа бы нормально запустилась и работала, пока пользователь не нажмет на эту кнопку.
Если программу запустить из самой Windows, при возникновении этой ошибки появится такое же сообщение. При этом если нажать «OK«, программа даже может запуститься, но корректно работать все равно не будет.
Ошибки времени выполнения бывают не только явными, но и неявными, при которых программа продолжает свою работу, не выводя никаких сообщений, а программист даже не догадывается о наличии ошибки. Примером неявной ошибки может служить так называемая утечка памяти. Утечка памяти возникает в случаях, когда программист забывает освободить выделенную под объект память. Например, мы объявляем переменную типа TStringList, и работаем с ней:
begin
MySL:= TStringList.Create;
MySL.Add('Новая строка');
end;
В данном примере программист допустил типичную для начинающих ошибку — не освободил класс TStringList. Это не приведет к сбою или аварийному завершению программы, но в итоге можно бесполезно израсходовать очень много памяти. Конечно, эта память будет освобождена после выгрузки программы (за этим следит операционная система), но утечка памяти во время выполнения программы тоже может привести к неприятным последствиям, потребляя все больше и больше ресурсов и излишне нагружая процессор. В подобных случаях после работы с объектом программисту нужно не забывать освобождать память:
begin
MySL:= TStringList.Create;
MySL.Add('Новая строка');
...; //работа с объектом
MySL.Free; //освободили объект
end;
Однако ошибки времени выполнения могут случиться и во время работы с объектом. Если есть такой риск, программист должен не забывать про возможность обработки исключительных ситуаций. В данном случае вышеприведенный код правильней будет оформить таким образом:
begin
try
MySL:= TStringList.Create;
MySL.Add('Новая строка');
...; //работа с объектом
finally
MySL.Free; //освободили объект, даже если была ошибка
end;
end;
Итак, во избежание ошибок времени выполнения программист должен не забывать делать проверку на правильность ввода пользователем допустимых значений, заключать опасный код в блоки try…finally…end или try…except…end, делать проверку на существование открываемого файла функцией FileExists и вообще соблюдать предусмотрительность во всех слабых местах программы. Не полагайтесь на пользователя, ведь недаром говорят, что если в программе можно допустить ошибку, пользователь эту возможность непременно найдет.
Алгоритмические ошибки
Если вы не допустили ни синтаксических ошибок, ни ошибок времени выполнения, программа скомпилировалась, запустилась и работает нормально, то это еще не означает, что в программе нет ошибок. Убедиться в этом можно только в процессе её тестирования.
Тестирование — процесс проверки работоспособности программы путем ввода в неё различных, даже намеренно ошибочных данных, и последующей контрольной проверке выводимого результата.
Если программа работает правильно с одними наборами исходных данных, и неправильно с другими, то это свидетельствует о наличии алгоритмической ошибки. Алгоритмические ошибки иногда называют логическими, обычно они связаны с неверной реализацией алгоритма программы: вместо «+» ошибочно поставили «-«, вместо «/» — «*», вместо деления значения на 0,01 разделили на 0,001 и т.п. Такие ошибки обычно не обнаруживаются во время компиляции, программа нормально запускается, работает, а при анализе выводимого результата выясняется, что он неверный. При этом компилятор не укажет программисту на ошибку — чтобы найти и устранить её, приходится анализировать код, пошагово «прокручивать» его выполнение, следя за результатом. Такой процесс называется отладкой.
Отладка — процесс поиска и устранения ошибок, чаще алгоритмических. Хотя отладчик позволяет справиться и с ошибками времени выполнения, которые не обнаруживаются явно.
Приготовьте отладчик! Пишем приложение с ошибками, затем учимся их находить и дебажить
https://gbcdn.mrgcdn.ru/uploads/post/2735/og_image/ce05da5c8c8f97a3bf7713b7cbaf3802.png

Иногда в приложении встречаются ошибки, которые нельзя увидеть даже после запуска. Например, код компилируется, проект запускается, но результат далёк от желаемого: приложение падает или вдруг появляется какая-то ошибка (баг). В таких случаях приходится «запасаться логами», «брать в руки отладчик» и искать ошибки.
Часто процесс поиска и исправления бага состоит из трёх шагов:
- Воспроизведение ошибки — вы понимаете, какие действия нужно сделать в приложении, чтобы повторить ошибку.
- Поиск места ошибки — определяете класс и метод, в котором ошибка происходит.
- Исправление ошибки.
Если приложение не падает и чтение логов ничего не даёт, то найти точное место ошибки в коде помогает дебаггер (отладчик) — инструмент среды разработки.
Чтобы посмотреть на логи и воспользоваться дебаггером, давайте напишем простое тестовое (и заведомо неправильное) приложение, которое даст нам все возможности для поиска ошибок.
Это будет приложение, которое сравнивает два числа. Если числа равны, то будет выводиться результат «Равно», и наоборот. Начнём с простых шагов:
- Открываем Android Studio.
- Создаём проект с шаблоном Empty Activity.
- Выбираем язык Java, так как его, как правило, знают больше людей, чем Kotlin.
Нам автоматически откроются две вкладки: activity_main.xml и MainActivity.java. Сначала нарисуем макет: просто замените всё, что есть в activity_main.xml, на код ниже:
<?xml version="1.0" encoding="utf-8"?> <androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:app="http://schemas.android.com/apk/res-auto" xmlns:tools="http://schemas.android.com/tools" android:layout_width="match_parent" android:layout_height="match_parent" tools:context=".MainActivity"> <EditText android:id="@+id/first_number_et" android:layout_width="wrap_content" android:layout_height="wrap_content" android:ems="10" android:gravity="center" app:layout_constraintLeft_toLeftOf="parent" app:layout_constraintRight_toRightOf="parent" app:layout_constraintTop_toTopOf="parent" /> <EditText android:id="@+id/second_number_et" android:layout_width="wrap_content" android:layout_height="wrap_content" android:ems="10" android:gravity="center" app:layout_constraintLeft_toLeftOf="parent" app:layout_constraintRight_toRightOf="parent" app:layout_constraintTop_toBottomOf="@+id/first_number_et" /> <Button android:id="@+id/button" android:layout_width="wrap_content" android:layout_height="wrap_content" android:text="Равно?" app:layout_constraintLeft_toLeftOf="parent" app:layout_constraintRight_toRightOf="parent" app:layout_constraintTop_toBottomOf="@+id/second_number_et" /> <TextView android:id="@+id/answer_tv" android:layout_width="wrap_content" android:layout_height="wrap_content" android:text="" android:textSize="32sp" app:layout_constraintLeft_toLeftOf="parent" app:layout_constraintRight_toRightOf="parent" app:layout_constraintTop_toBottomOf="@+id/button" /> </androidx.constraintlayout.widget.ConstraintLayout>
Можете запустить проект и посмотреть, что получилось:
Теперь оживим наше приложение. Скопируйте в MainActivity этот код:
public class MainActivity extends AppCompatActivity { @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); final Button button = (Button) findViewById(R.id.button); final EditText first = (EditText) findViewById(R.id.first_number_et); final EditText second = (EditText) findViewById(R.id.second_number_et); final TextView answer = (TextView) findViewById(R.id.answer_tv); button.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { Integer firstInt = Integer.parseInt(first.getText().toString()); Integer secondInt = Integer.parseInt(second.getText().toString()); if (firstInt == secondInt) { answer.setText("Равно"); } else { answer.setText("Равно"); } } }); } }
В этом коде всё просто:
- Находим поля ввода, поле с текстом и кнопку.
- Вешаем на кнопку слушатель нажатий.
- По нажатию на кнопку получаем числа из полей ввода и сравниваем их.
- В зависимости от результата выводим «Равно» или «Не равно».
Запустим приложение и введём буквы вместо чисел:
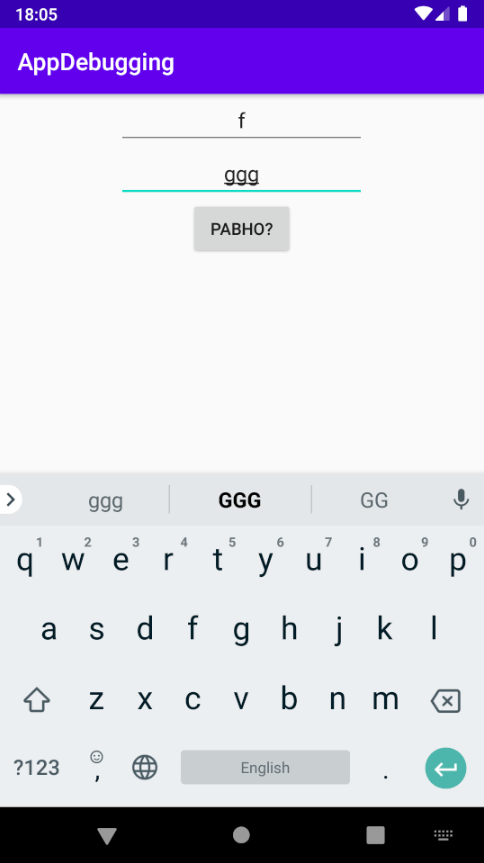
Нажмём на кнопку, и приложение упадёт! Время читать логи. Открываем внизу слева вкладку «6: Logcat» и видим:
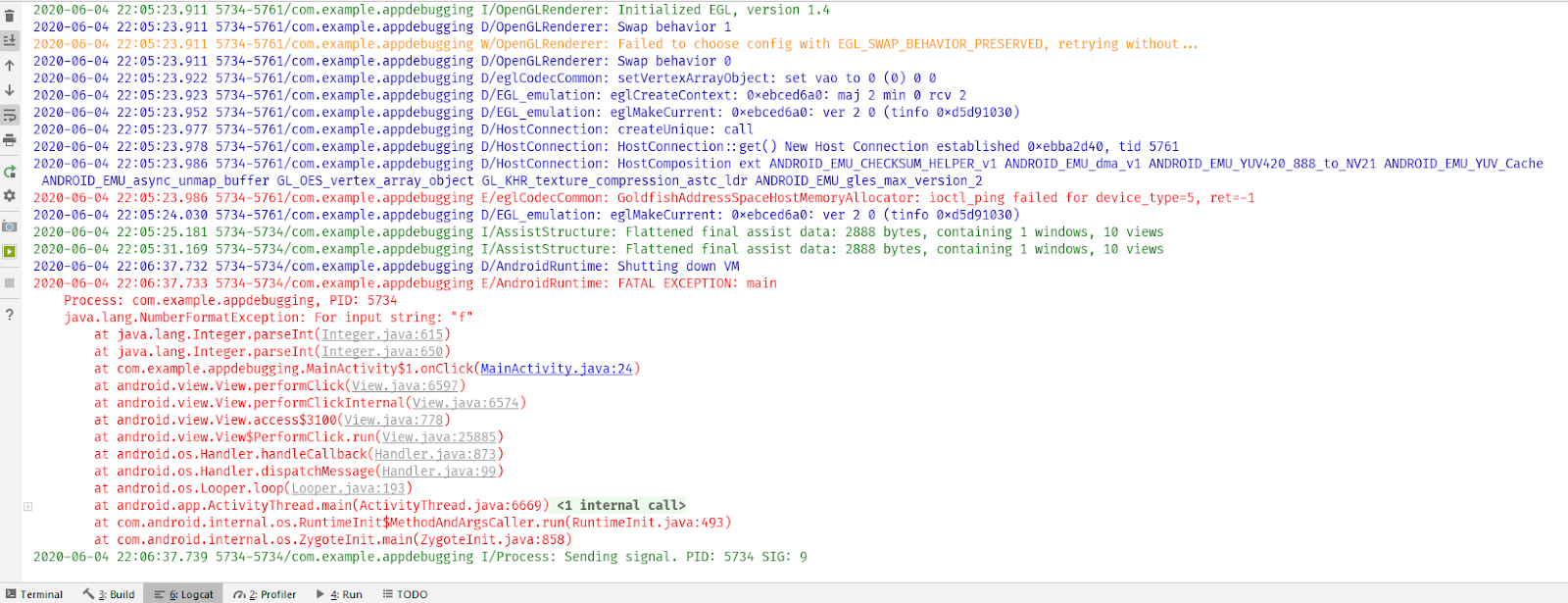
Читать логи просто: нужно найти красный текст и прочитать сообщение системы. В нашем случае это java.lang.NumberFormatException: For input string: «f». Указан тип ошибки NumberFormatException, который говорит, что возникла какая-то проблема с форматированием числа. И дополнение: For input string: «f». Введено “f”. Уже можно догадаться, что программа ждёт число, а мы передаём ей символ. Далее в красном тексте видно и ссылку на проблемную строку: at com.example.appdebugging.MainActivity$1.onClick(MainActivity.java:26). Проблема в методе onClick класса MainActivity, строка 24. Можно просто кликнуть по ссылке и перейти на указанную строку:
int firstInt = Integer.parseInt(first.getText().toString());
Конечно, метод parseInt может принимать только числовые значения, но никак не буквенные! Даже в его описании это сказано — и мы можем увидеть, какой тип ошибки этот метод выбрасывает (NumberFormatException).

Здесь мы привели один из примеров. Типов ошибок может быть огромное количество, все мы рассматривать не будем. Но все ошибки в Logcat’е указываются по похожему принципу:
- красный текст;
- тип ошибки — в нашем случае это NumberFormatException;
- пояснение — у нас это For input string: «f»;
- ссылка на строку, на которой произошла ошибка — здесь видим MainActivity.java:26.
Исправим эту ошибку и обезопасим себя от некорректного ввода. Добавим в наши поля ввода android:inputType=»number», а остальной код оставим без изменений:
... <EditText android:id="@+id/first_number_et" android:layout_width="wrap_content" android:layout_height="wrap_content" android:ems="10" android:gravity="center" android:inputType="number" app:layout_constraintLeft_toLeftOf="parent" app:layout_constraintRight_toRightOf="parent" app:layout_constraintTop_toTopOf="parent" /> <EditText android:id="@+id/second_number_et" android:layout_width="wrap_content" android:layout_height="wrap_content" android:ems="10" android:gravity="center" android:inputType="number" app:layout_constraintLeft_toLeftOf="parent" app:layout_constraintRight_toRightOf="parent" app:layout_constraintTop_toBottomOf="@+id/first_number_et" /> ...
Теперь можем вводить только числа. Проверим, как работает равенство: введём одинаковые числа в оба поля. Всё в порядке:
На равенство проверили. Введём разные числа:
Тоже равно. То есть приложение работает, ничего не падает, но результат не совсем тот, который требуется. Наверняка вы и без дебаггинга догадались, в чём ошибка, потому что приложение очень простое, всего несколько строк кода. Но такие же проблемы возникают в приложениях и на миллион строк. Поэтому пройдём по уже известным нам этапам дебаггинга:
- Воспроизведём ошибку: да, ошибка воспроизводится стабильно с любыми двумя разными числами.
- Подумаем, где может быть ошибка: наверняка там, где сравниваются числа. Туда и будем смотреть.
- Исправим ошибку: сначала найдём её с помощью дебаггера, а когда поймём, в чём проблема, — будем исправлять.
И здесь на помощь приходит отладчик. Для начала поставим точки останова сразу в трёх местах:
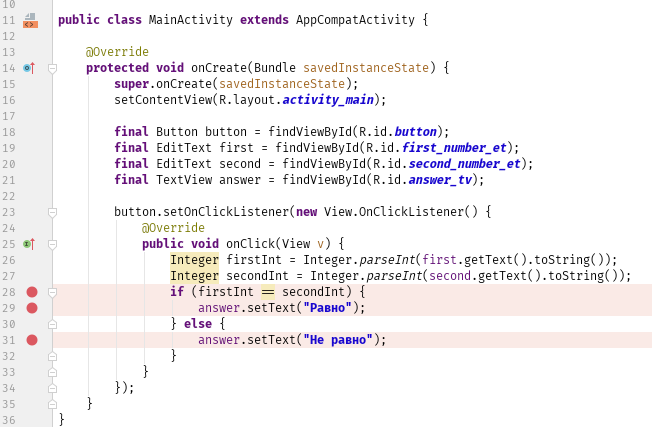
Чтобы поставить или снять точку останова, достаточно кликнуть левой кнопкой мыши справа от номера строки или поставить курсор на нужную строку, а затем нажать CTRL+F8. Почему мы хотим остановить программу именно там? Чтобы посмотреть, правильные ли числа сравниваются, а затем определить, в какую ветку в нашем ветвлении заходит программа дальше. Запускаем программу с помощью сочетания клавиш SHIFT+F9 или нажимаем на кнопку с жучком:
Появится дополнительное окно, в котором нужно выбрать ваш девайс и приложение:
Вы в режиме дебага. Обратите внимание на две вещи:
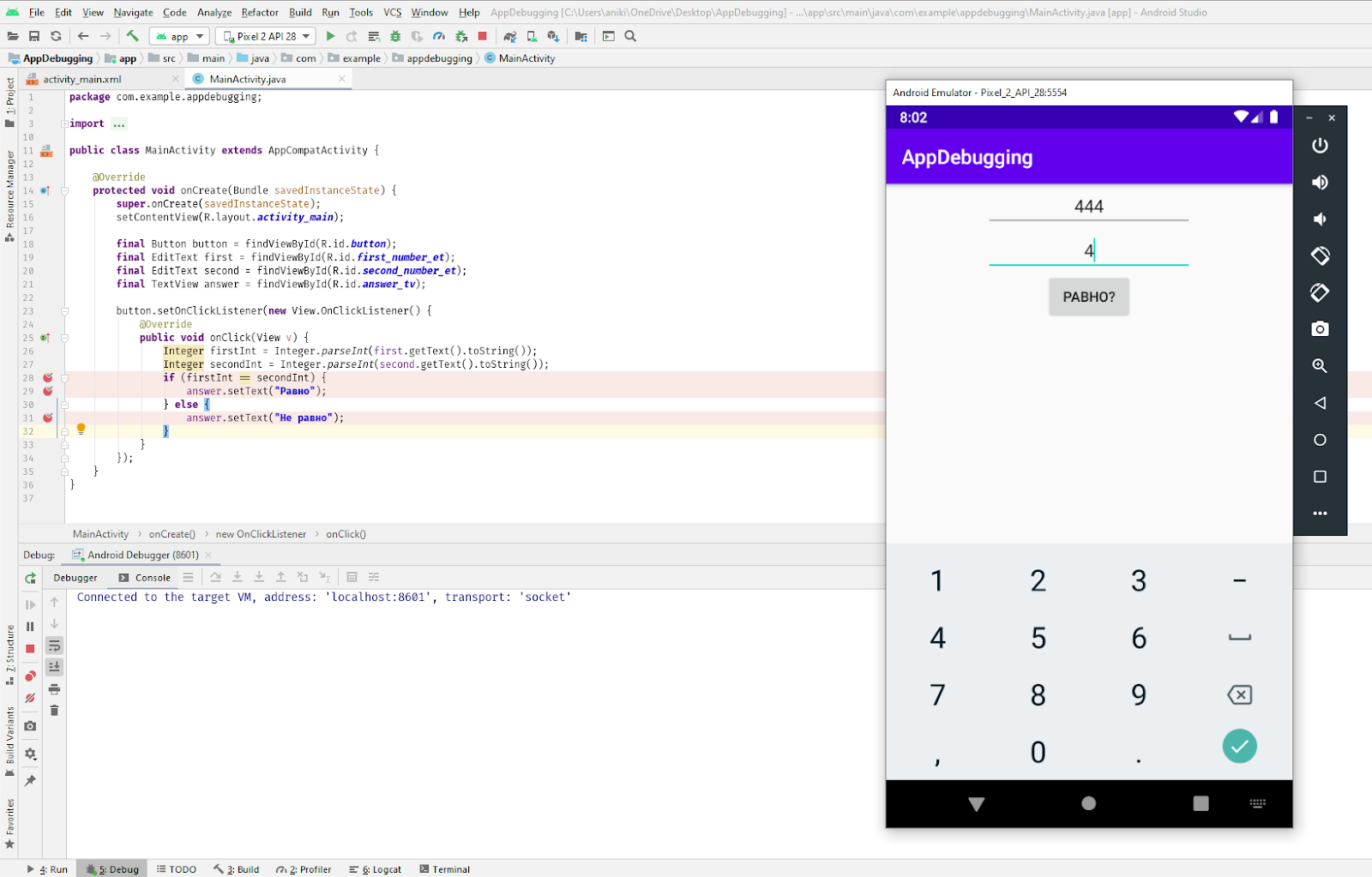
- Точки останова теперь помечены галочками. Это значит, что вы находитесь на экране, где стоят эти точки, и что дебаггер готов к работе.
- Открылось окно дебага внизу: вкладка «5: Debug». В нём будет отображаться необходимая вам информация.
Введём неравные числа и нажмём кнопку «РАВНО?». Программа остановилась на первой точке:
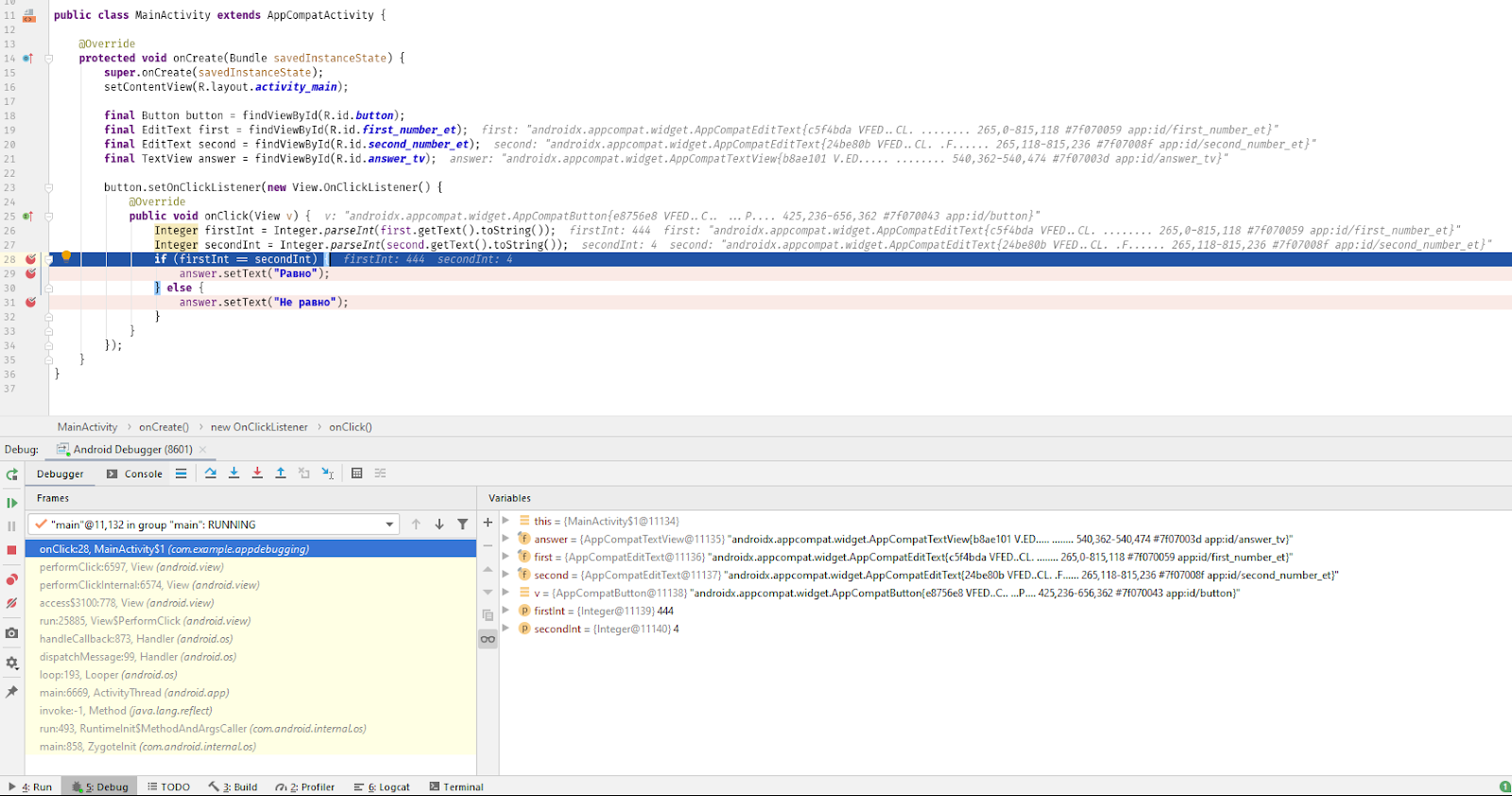
Давайте разбираться:
- Сразу подсвечивается синим строка, где программа остановлена: в окне кода на 28-й строке и в левом окне отладчика (там даже можно увидеть, какой метод вызван, — onClick).
- В правом, основном окне отладчика, всё гораздо интереснее. Здесь можно увидеть инстансы наших вью (answer, first, second), в конце которых серым текстом даже отображаются их id. Но интереснее всего посмотреть на firstInt и secondInt. Там записаны значения, которые мы сейчас будем сравнивать.
Как видим, значения именно такие, какие мы и ввели. Значит, проблема не в получении чисел из полей. Давайте двигаться дальше — нам нужно посмотреть, в правильную ли ветку мы заходим. Для этого можно нажать F8 (перейти на следующую строку выполнения кода). А если следующая точка останова далеко или в другом классе, можно нажать F9 — программа просто возобновит работу и остановится на следующей точке. В интерфейсе эти кнопки находятся здесь:
Остановить дебаггер, если он больше не нужен, можно через CTRL+F2 или кнопку «Стоп»:
В нашем случае неважно, какую кнопку нажимать (F9 или F8). Мы сразу переходим к следующей точке останова программы:
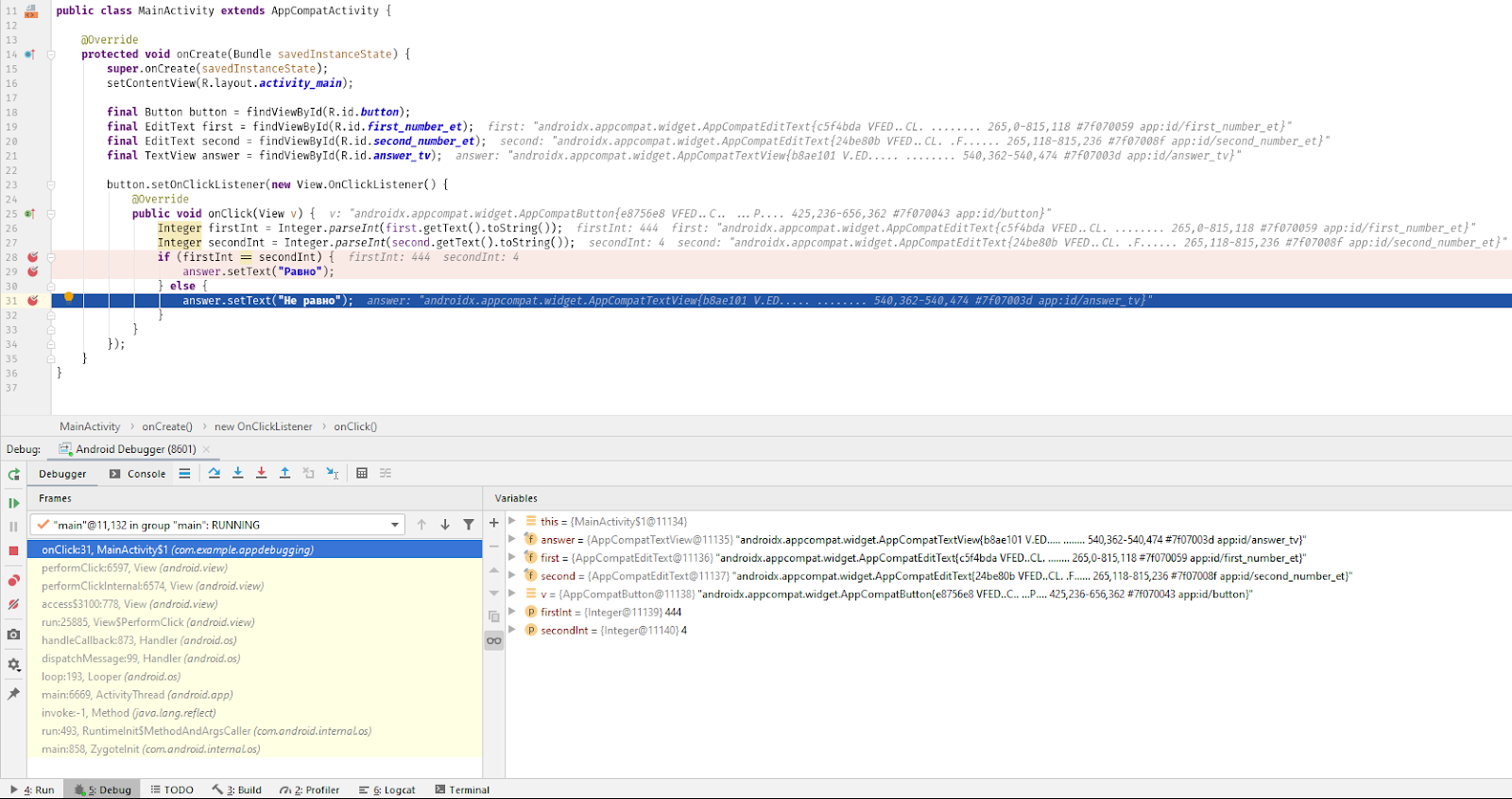
Ветка правильная, то есть логика программы верна, числа firstInt и secondInt не изменились. Зато мы сразу видим, что подпись некорректная! Вот в чём была ошибка. Исправим подпись и проверим программу ещё раз.
Мы уже починили два бага: падение приложения с помощью логов и некорректную логику (с помощью отладчика). Хеппи пас (happy path) пройден. То есть основная функциональность при корректных данных работает. Но нам надо проверить не только хеппи пас — пользователь может ввести что угодно. И программа может нормально работать в большинстве случаев, но вести себя странно в специфических состояниях. Давайте введём числа побольше и посмотрим, что будет:
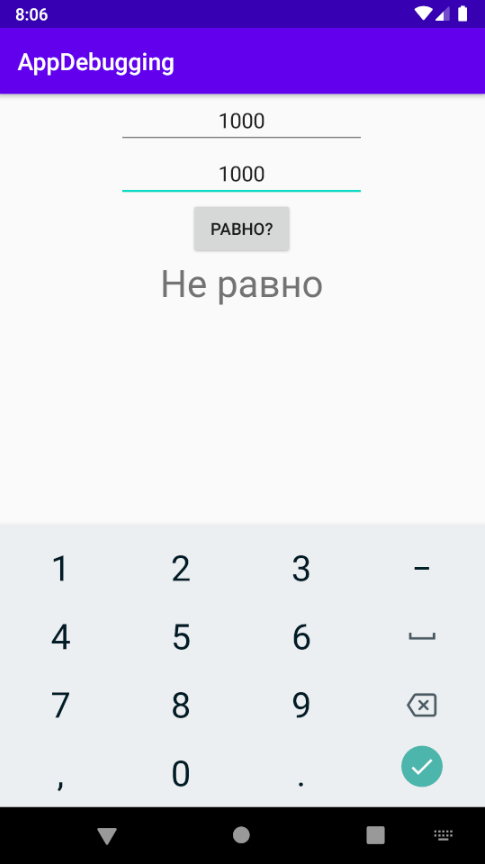
Не сработало — программа хочет сказать, что 1000 не равна 1000, но это абсурд. Запускаем приложение в режиме отладки. Точка останова уже есть. Смотрим в отладчик:
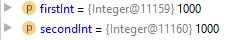
Числа одинаковые, что могло пойти не так? Обращаем внимание на тип переменной — Integer. Так вот в чём проблема! Это не примитивный тип данных, а ссылочный. Ссылочные типы нельзя сравнивать через ==, потому что будут сравниваться ссылки объектов, а не они сами. Но для Integer в Java есть нюанс: Integer может кешироваться до 127, и если мы вводим по единице в оба поля числа до 127, то фактически сравниваем просто int. А если вводим больше, то получаем два разных объекта. Адреса у объектов не совпадают, а именно так Java сравнивает их.
Есть два решения проблемы:
- Изменить тип Integer на примитив int.
- Сравнивать как объекты.
Не рекомендуется менять тип этих полей в реальном приложении: числа могут приходить извне, и тип лучше оставлять прежним. Изменим то, как мы сравниваем числа:
if (firstInt.equals(secondInt)) { answer.setText("Равно"); } else { answer.setText("Не равно"); }
Проверяем:
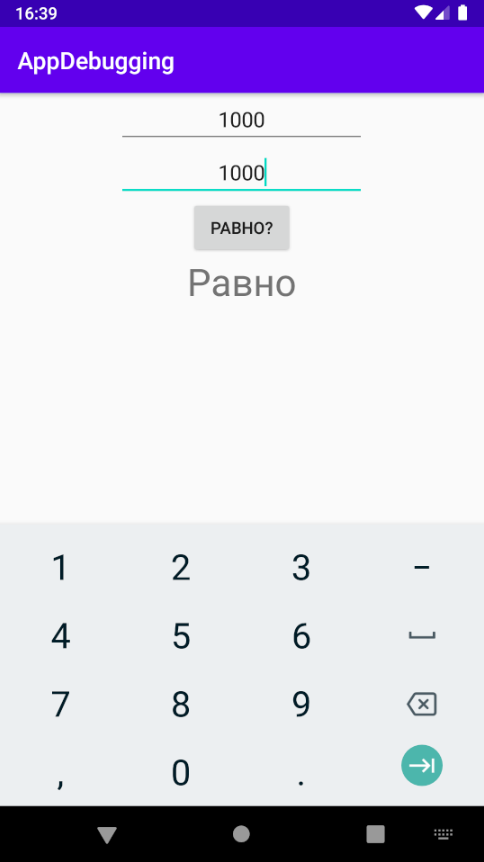
Всё работает. Наконец-то! Хотя… Давайте посмотрим, что будет, если пользователь ничего не введёт, но нажмёт на кнопку? Приложение опять упало… Смотрим в логи:
Опять NumberFormatException, при этом строка пустая. Давайте поставим точку останова на 26-й строке и заглянем с помощью отладчика глубже.
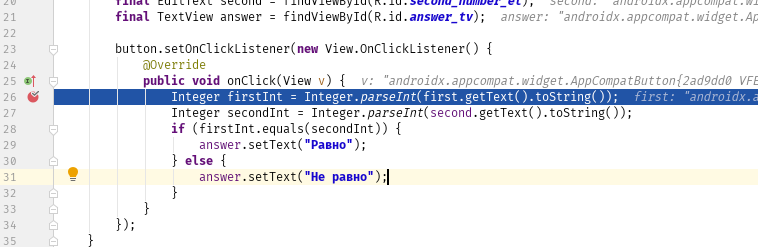
Нажмём F8 — и перейдём в глубины операционной системы:
Интересно! Давайте обернём код в try/catch и посмотрим ошибке в лицо. Если что, поправим приложение. Выделяем код внутри метода onClick() и нажимаем Ctrl+Alt+T:
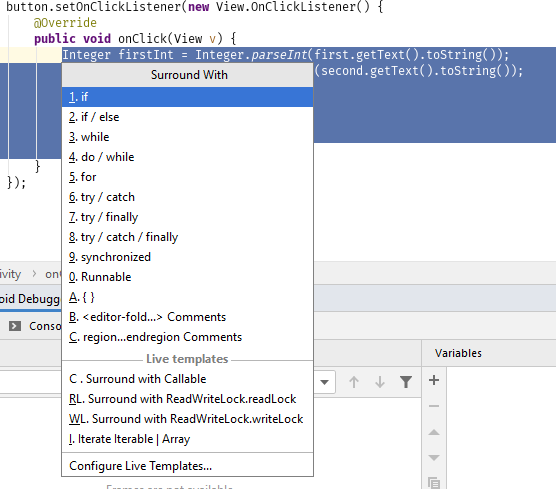
Выбираем try / catch, среда разработки сама допишет код. Поставим точку останова. Получим:
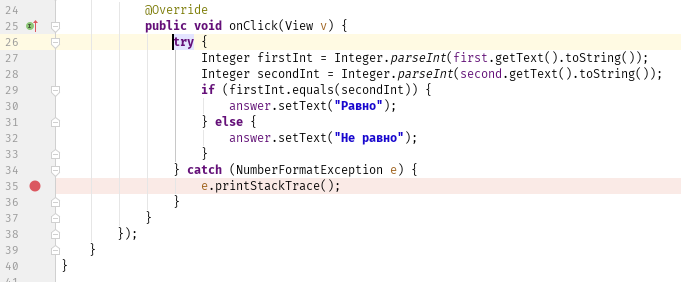
Запускаем приложение и ловим ошибку:
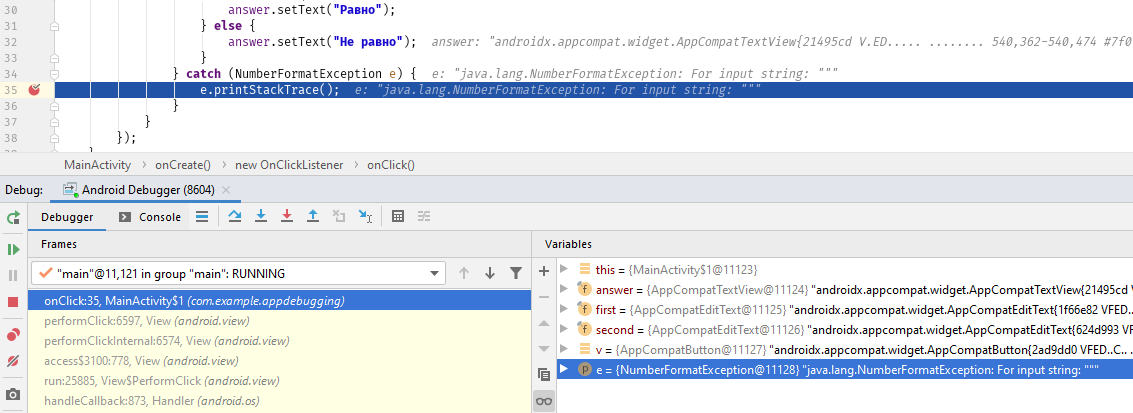
Действительно, как и в логах, — NumberFormatException. Метод parseInt выбрасывает исключение, если в него передать пустую строку. Как обрабатывать такую проблему — решать исключительно вам. Два самых простых способа:
- Проверять получаемые строки first.getText().toString() и second.getText().toString() на пустые значения. И если хоть одно значение пустое — говорить об этом пользователю и не вызывать метод parseInt.
- Или использовать уже готовую конструкцию try / catch:
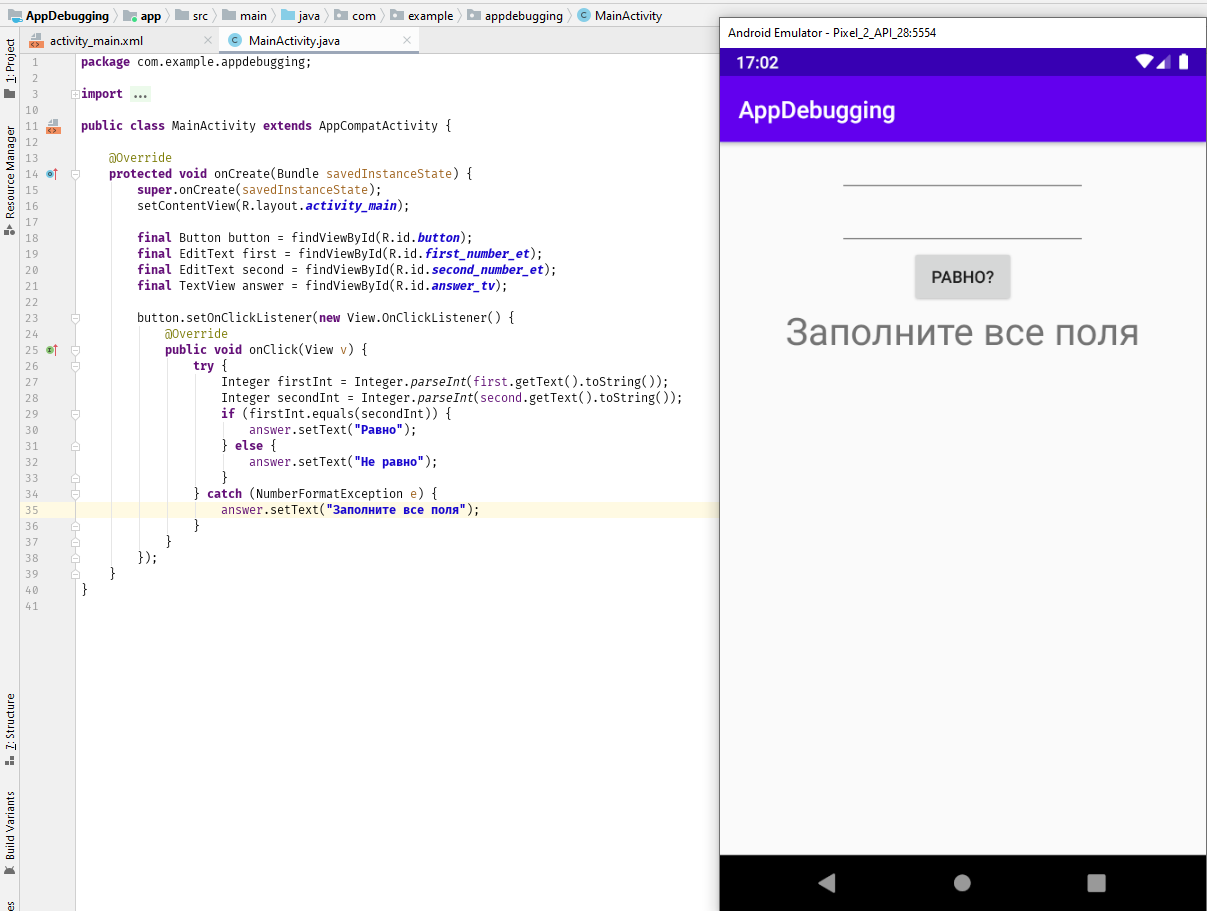
Теперь-то точно всё в порядке! Хотя профессиональным тестировщикам это приложение никто не отдавал: поищете ещё ошибки?
Тестирование и отладка программ
При разработке программ наиболее трудоемким является этап отладки и тестирования программ. Цель тестирования, т.е. испытания программы, заключается в выявлении имеющихся в программе ошибок. Цель отладки состоит в выявлении и устранении причин ошибок.
Отладку программы начинают с составления плана тестирования. Такой план должен представлять себе любой программист. Составление плана опирается на понятие об источниках и характере ошибок. Основными источниками ошибок являются недостаточно глубокая проработка математической модели или алгоритма решения задачи; нарушение соответствия между схемой алгоритма или записью его на алгоритмическом языке и программой, записанной на языке программирования; неверное представление исходных данных на программном бланке; невнимательность при наборе программы и исходных данных на клавиатуре устройства ввода.
Нарушение соответствия между детально разработанной записью алгоритма в процессе кодирования программы относится к ошибкам, проходящим вследствие невнимательности программиста. Отключение внимания приводит и ко всем остальным ошибкам, возникающим в процессе подготовки исходных данных и ввода программы в ЭВМ. Ошибки, возникающие вследствие невнимательности, могут иметь непредсказуемые последствия, так как наряду с потерей меток и описаний массивов, дублированием меток, нарушением баланса скобок возможны и такие ошибки, как потеря операторов, замена букв в обозначениях переменных, отсутствие определений начальных значений переменных, нарушение адресации в массивах, сдвиг исходных данных относительно полей значений, определенных спецификациями формата.
Учитывая разнообразие источников ошибок, при составлении плана тестирования классифицируют ошибки на два типа: 1 – синтаксические; 2 – семантические (смысловые).
Синтаксические ошибки – это ошибки в записи конструкций языка программирования (чисел, переменных, функций, выражений, операторов, меток, подпрограмм).
Семантические ошибки – это ошибки, связанные с неправильным содержанием действий и использованием недопустимых значений величин.
Обнаружение большинства синтаксических ошибок автоматизировано в основных системах программирования. Поиск же семантических ошибок гораздо менее формализован; часть их проявляется при исполнении программы в нарушениях процесса автоматических вычислений и индицируется либо выдачей диагностических сообщений рабочей программы, либо отсутствием печати результатов из-за бесконечного повторения одной и той же части программы (зацикливания), либо появлением непредусмотренной формы или содержания печати результатов.
В план тестирования обычно входят следующие этапы:
- Сравнение программы со схемой алгоритма.
- Визуальный контроль программы на экране дисплея или визуальное изучение распечатки программы и сравнение ее с оригиналом на программном бланке. Первые два этапа тестирования способны устранить больше количество ошибок, как синтаксических (что не так важно), так и семантических (что очень важно, так как позволяет исключить их трудоемкий поиск в процессе дальнейшей отладки).
- Трансляция программы на машинных язык. На этом этапе выявляются синтаксические ошибки. Компиляторы с языков Си, Паскаль выдают диагностическое сообщение о синтаксических ошибках в листинге программы (листингом называется выходной документ транслятора, сопровождающий оттранслированную программу на машинном языке – объектный модуль).
- Редактирование внешних связей и компоновка программы. На этапе редактирования внешних связей программных модуле программа-редактор внешних связей, или компоновщик задач, обнаруживает такие синтаксические ошибки, как несоответствие числа параметров в описании подпрограммы и обращении к ней, вызов несуществующей стандартной программы. например, 51 H вместо 51 N, различные длины общего блока памяти в вызывающем и вызываемом модуле и ряд других ошибок.
- Выполнение программы. После устранения обнаруженных транслятором и редактором внешних связей (компоновщиком задач) синтаксических ошибок переходят к следующему этапу – выполнению программы на ЭВМ на машинном языке: программа загружается в оперативную память, в соответствие с программой вводятся исходные данные и начинается счет. Проявление ошибки в процессе вода исходных данных или в процессе счета приводит к прерыванию счета и выдаче диагностического сообщения рабочей программы. Проявление ошибки дает повод для выполнения отладочных действий; отсутствие же сообщений об ошибках не означает их отсутствия в программе. План тестирования включает при этом проверку правильности полученных результатов для каких-либо допустимых значений исходных данных.
- Тестирование программы. Если программа выполняется успешно, желательно завершить ее испытания тестированием при задании исходных данных, принимающих предельные для программы значения. а также выходящие за допустимые пределы значения на входе.
Контрольные примеры (тесты) – это специально подобранные задачи, результаты которых заранее известны или могут быть определены без существенных затрат.
Наиболее простые способы получения тестов:
- Подбор исходных данных, для которых несложно определить результата вычислений вручную или расчетом на калькуляторе.
- Использование результатов, полученных на других ЭВМ или по другим программам.
- Использование знаний о физической природе процесса, параметры которого определяются, о требуемых и возможных свойствах рассчитываемой конструкции. Хотя точное решение задачи заранее известно, суждение о порядке величин позволяет с большой вероятностью оценить достоверность результатов.