Comments
![]()
GirZ0n
added a commit
that referenced
this issue
Aug 4, 2021
![]()
![]()
GirZ0n
linked a pull request
Aug 4, 2021
that will
close
this issue
nbirillo
pushed a commit
that referenced
this issue
Aug 9, 2021
![]()
vyahhi
added a commit
that referenced
this issue
Aug 13, 2021
* wps-light support (#17) Add wps-light support * New flake8 plugins support (#18) Added support for flake8-broken-line, flake8-string-format, flake8-commas (they are WPS dependencies). Added support for cohesion. * Radon support (#19) Added new inspector: Radon. Added maintainability index. * Requirements upgrade (#21) Updated versions of dependencies Added django dictionary support Fixed tests * xlsx-run-tool (#24) Added xlsx_tool_run.py – script to run the tool on multiple code samples stored in xlsx file * Update version to 1.2.0 * Rename output_format to format * Fix double quotes * Fix small issues * Fix small issues * Fix double quotes * Fix double quotes * Inspectors fix (#39) * Add origin class for maintainability index * Add WPS518 to ignore due to collision with C0200 by Pylint * New category (#38) * Added a new category INFO, in order not to take into account some issues in the evaluation. * Fixed trailing commas * Delete create_directory function * Fix GitHub actions (#44) * Use the same environment as in the production dockerfile * Fix Dockerfiles * Install some dependencies for TeamCity * Update build * Add checks from teamcity * Update build * Fix indentation * Fix PR comments * Delete init files from resources * Add init in multi file project * Fix flake8 tests * Main upd bugs fix (#74) * Delete evaluation part * Fix bugs with detekt, pmd and flake8 * Issues fix (#80) * Fixed issue #70 * Fixed issue #72: now only spellcheck checks brackets * Fixed issue #73 * Fixed issue #77 * Fixed issue #78 * Fixed issue #71 * Fixed issue #79 * Fixed issue #81 * Added case 36: unpacking * Added case 37: wildcard import * Ignoring WPS347 and F405 * Added cases 36 (unpacking) and 37 (wildcard_import). Also removed W0622 (redefining_builtin) * Removed W0622 (redefining_builtin) * Issue #87 fix (#90) * Fixed issue #87 * Added test * Fixed issues #91 and #92 (#97) * Delete xlsx * Remove openpyxl * Issues fix (#104) * Fixed #100 * Fixed #102 * Added some more new words * Added toplevel * Update flake8 whitelist * Recovered accidentally deleted words Co-authored-by: Vlasov Ilya <55441714+GirZ0n@users.noreply.github.com> Co-authored-by: Daria Diatlova <dari.diatlova@gmail.com> Co-authored-by: Nikolay Vyahhi <Nikolay.Vyahhi@stepik.org> Co-authored-by: Ilya Vlasov <ilyavlasov2011@gmail.com>
nbirillo
added a commit
that referenced
this issue
Aug 26, 2021
* Fix GitHub actions (#46) * Update requirements and dockerfile * Use Dockerfile in Github Action * Ignore a part of flake8 issues * Ignore flake8 inspections * Separate docker file into two: for prod and for dev * Delete ` * Fix test_range_of_lines * Fix pylint and flake8 tests * Fix pylint tests * Check styles by flake8 * Fix C408 issue * Move production Dockerfile * Fix Dockefile for production * Set up Eslint in the DockerFile for production * Delete one case from flake8 tests * Add pathlib into whitelist * Delete Path from setup.py * Ignore pathlib * Don't count INFO issues * Fix flake8 tests * Small fix * Delete pathlib from the whitelist * Update docker (#54) * Use one docker file for prod and dev * Change base docker image * Fix requirements-test: delete duplicates, setup versions * Try to fix dockerfile * Fix run in subprocess function * Fix Dockerfile * Try to fix Dockerfile * Fix docker image (#58) * Change eslint installing * Update build.yaml * Introduce base docker image and auto-detect eslint path Co-authored-by: Andrey Balandin <andrvb@gmail.com> Closes #43, closes #45. * Add whitelist for flake8-spellcheck (#68) * Add whitelist for flake8-spellcheck * Add a test for spellcheck and ignore unnecessary rule * Fix flake8 config * Bump version 1.1.0 -> 1.1.1 * Add Python inspections and a script for tool evaluation (#26) * wps-light support (#17) Add wps-light support * New flake8 plugins support (#18) Added support for flake8-broken-line, flake8-string-format, flake8-commas (they are WPS dependencies). Added support for cohesion. * Radon support (#19) Added new inspector: Radon. Added maintainability index. * Requirements upgrade (#21) Updated versions of dependencies Added django dictionary support Fixed tests * xlsx-run-tool (#24) Added xlsx_tool_run.py – script to run the tool on multiple code samples stored in xlsx file * Update version to 1.2.0 * Rename output_format to format * Fix double quotes * Fix small issues * Fix small issues * Fix double quotes * Fix double quotes * Inspectors fix (#39) * Add origin class for maintainability index * Add WPS518 to ignore due to collision with C0200 by Pylint * New category (#38) * Added a new category INFO, in order not to take into account some issues in the evaluation. * Fixed trailing commas * Delete create_directory function * Fix GitHub actions (#44) * Use the same environment as in the production dockerfile * Fix Dockerfiles * Install some dependencies for TeamCity * Update build * Add checks from teamcity * Update build * Fix indentation * Fix PR comments * Delete init files from resources * Add init in multi file project * Fix flake8 tests * Main upd bugs fix (#74) * Delete evaluation part * Fix bugs with detekt, pmd and flake8 * Issues fix (#80) * Fixed issue #70 * Fixed issue #72: now only spellcheck checks brackets * Fixed issue #73 * Fixed issue #77 * Fixed issue #78 * Fixed issue #71 * Fixed issue #79 * Fixed issue #81 * Added case 36: unpacking * Added case 37: wildcard import * Ignoring WPS347 and F405 * Added cases 36 (unpacking) and 37 (wildcard_import). Also removed W0622 (redefining_builtin) * Removed W0622 (redefining_builtin) * Issue #87 fix (#90) * Fixed issue #87 * Added test * Fixed issues #91 and #92 (#97) * Delete xlsx * Remove openpyxl * Issues fix (#104) * Fixed #100 * Fixed #102 * Added some more new words * Added toplevel * Update flake8 whitelist * Recovered accidentally deleted words Co-authored-by: Vlasov Ilya <55441714+GirZ0n@users.noreply.github.com> Co-authored-by: Daria Diatlova <dari.diatlova@gmail.com> Co-authored-by: Nikolay Vyahhi <Nikolay.Vyahhi@stepik.org> Co-authored-by: Ilya Vlasov <ilyavlasov2011@gmail.com> * Fixed typo * Sort whitelists (Github Actions) * Fixed tests * Fixed requirements * Added numpy * Removed numpy * Fixed test Co-authored-by: Nastya Birillo <anastasia.i.birillo@gmail.com> Co-authored-by: Nikolay Vyahhi <Nikolay.Vyahhi@stepik.org> Co-authored-by: Daria Diatlova <dari.diatlova@gmail.com> Co-authored-by: GirZ0n <GirZ0n@users.noreply.github.com>
nbirillo
added a commit
that referenced
this issue
Aug 26, 2021
* Fix GitHub actions (#46) * Update requirements and dockerfile * Use Dockerfile in Github Action * Ignore a part of flake8 issues * Ignore flake8 inspections * Separate docker file into two: for prod and for dev * Delete ` * Fix test_range_of_lines * Fix pylint and flake8 tests * Fix pylint tests * Check styles by flake8 * Fix C408 issue * Move production Dockerfile * Fix Dockefile for production * Set up Eslint in the DockerFile for production * Delete one case from flake8 tests * Add pathlib into whitelist * Delete Path from setup.py * Ignore pathlib * Don't count INFO issues * Fix flake8 tests * Small fix * Delete pathlib from the whitelist * Update docker (#54) * Use one docker file for prod and dev * Change base docker image * Fix requirements-test: delete duplicates, setup versions * Try to fix dockerfile * Fix run in subprocess function * Fix Dockerfile * Try to fix Dockerfile * Fix docker image (#58) * Change eslint installing * Update build.yaml * Introduce base docker image and auto-detect eslint path Co-authored-by: Andrey Balandin <andrvb@gmail.com> Closes #43, closes #45. * Add whitelist for flake8-spellcheck (#68) * Add whitelist for flake8-spellcheck * Add a test for spellcheck and ignore unnecessary rule * Fix flake8 config * Bump version 1.1.0 -> 1.1.1 * Add Python inspections and a script for tool evaluation (#26) * wps-light support (#17) Add wps-light support * New flake8 plugins support (#18) Added support for flake8-broken-line, flake8-string-format, flake8-commas (they are WPS dependencies). Added support for cohesion. * Radon support (#19) Added new inspector: Radon. Added maintainability index. * Requirements upgrade (#21) Updated versions of dependencies Added django dictionary support Fixed tests * xlsx-run-tool (#24) Added xlsx_tool_run.py – script to run the tool on multiple code samples stored in xlsx file * Update version to 1.2.0 * Rename output_format to format * Fix double quotes * Fix small issues * Fix small issues * Fix double quotes * Fix double quotes * Inspectors fix (#39) * Add origin class for maintainability index * Add WPS518 to ignore due to collision with C0200 by Pylint * New category (#38) * Added a new category INFO, in order not to take into account some issues in the evaluation. * Fixed trailing commas * Delete create_directory function * Fix GitHub actions (#44) * Use the same environment as in the production dockerfile * Fix Dockerfiles * Install some dependencies for TeamCity * Update build * Add checks from teamcity * Update build * Fix indentation * Fix PR comments * Delete init files from resources * Add init in multi file project * Fix flake8 tests * Main upd bugs fix (#74) * Delete evaluation part * Fix bugs with detekt, pmd and flake8 * Issues fix (#80) * Fixed issue #70 * Fixed issue #72: now only spellcheck checks brackets * Fixed issue #73 * Fixed issue #77 * Fixed issue #78 * Fixed issue #71 * Fixed issue #79 * Fixed issue #81 * Added case 36: unpacking * Added case 37: wildcard import * Ignoring WPS347 and F405 * Added cases 36 (unpacking) and 37 (wildcard_import). Also removed W0622 (redefining_builtin) * Removed W0622 (redefining_builtin) * Issue #87 fix (#90) * Fixed issue #87 * Added test * Fixed issues #91 and #92 (#97) * Delete xlsx * Remove openpyxl * Issues fix (#104) * Fixed #100 * Fixed #102 * Added some more new words * Added toplevel * Update flake8 whitelist * Recovered accidentally deleted words Co-authored-by: Vlasov Ilya <55441714+GirZ0n@users.noreply.github.com> Co-authored-by: Daria Diatlova <dari.diatlova@gmail.com> Co-authored-by: Nikolay Vyahhi <Nikolay.Vyahhi@stepik.org> Co-authored-by: Ilya Vlasov <ilyavlasov2011@gmail.com> Co-authored-by: Nikolay Vyahhi <Nikolay.Vyahhi@stepik.org> Co-authored-by: Vlasov Ilya <55441714+GirZ0n@users.noreply.github.com> Co-authored-by: Daria Diatlova <dari.diatlova@gmail.com> Co-authored-by: Ilya Vlasov <ilyavlasov2011@gmail.com>
vyahhi
added a commit
that referenced
this issue
Sep 22, 2021
* wps-light support (#17) Add wps-light support * New flake8 plugins support (#18) Added support for flake8-broken-line, flake8-string-format, flake8-commas (they are WPS dependencies). Added support for cohesion. * Radon support (#19) Added new inspector: Radon. Added maintainability index. * Requirements upgrade (#21) Updated versions of dependencies Added django dictionary support Fixed tests * xlsx-run-tool (#24) Added xlsx_tool_run.py – script to run the tool on multiple code samples stored in xlsx file * Penalty system (#25) Add penalty system * Penalty coefficients update (#28) * Updated penalty coefficients; * Added new tests; * Fixed bug with _get_issue_class_to_influence, which caused the dictionary to get issues that should not be penalized. * Fixed two cases in test_categorize. There were two identical issues in the list of previously made issues. * Update version to 1.2.0 * Evaluation/code quality (#29) * Refactor the tool for evaluation: add multithreading, add a possibility to handle CSV arguments * Add script to filter solutions by language and drop duplicates * Add script to distribute grades from unique solutions to all solutions * Add script to find diffs between two graded dataframes * Add tests and descriptions * Rename output_format to format * Fix double quotes * Fix small issues * Fix small issues * Fix double quotes * Fix double quotes * Inspectors fix (#39) * Add origin class for maintainability index * Add WPS518 to ignore due to collision with C0200 by Pylint * New category (#38) * Added a new category INFO, in order not to take into account some issues in the evaluation. * Dataset labeling utility (#31) Added a utility for dataset marking * resolved merge conflicts * Fixed trailing commas * Delete create_directory function * Delete create_directory function * Update version * Graph plotter (#41) Added a script for plots * updated whitelist to resolve merge conflicts * Qodana simulation model (#40) * Add small dataset preparation block, train, and evaluation module to train and run Roberta-model for solving a multilabel classification task * Qodana stat (#42) Add a script to convert the data received by the Qodana into the format of the Hyperstyle tool for analysis and statistics gathering. * Delete Path from setup.py * Change exit code * Update whitelist * Inspector statistics (#48) * Calculate statistics for inspectors for four main categories of issues * Fix GitHub actions (#44) * Use the same environment as in the production dockerfile * Fix Dockerfiles * Install some dependencies for TeamCity * Update version in Github Actions * Reorganize dependencies and update dockerfile * History script (#47) * Add script that allows you to generate history based on issues from previous solutions * Fixed incorrect file name (#51) * Corrected the name of the dataset labeling script in the README * Distributed the issue categories (#53) * Distributed the issue categories * Qodana imitation model resources (#55) * Add Qodana imitation model resources * Small Github Actions config update (#56) * Update build.yml * Whitelist for flake8-spellcheck (#57) * Added whitelist * PMD update (#59) * Updated PMD to v6.36.0 * Small fix * Undo f4ab486 * Checkstyle update (#60) * Checkstyle update * Categorization update (#61) * Updated categorization for PMD and Checkstyle * New tests and documentation (#63) * Added tests for functions parsing PMD and Checkstyle output. * Documented methods related to PMD and Checkstyle. * Merge main into develop (#65) * Merge main into develop (#65) * Script for getting raw issues (#66) * Added Encoder and Decoder for 'raw' issues * Added test for RawIssueEncoder and RawIssueDecoder * Added __init__.py * Added get_raw_issues.py * Added __init__.py * Added to_safe_path flag * Fixed flake8 issue * Added test for get_raw_issues.py * Small fix * Fixed get_output_path test data * get_language -> get_language_version * Added ISSUE_TYPE_TO_CLASS and MEASURABLE_ISSUE_TYPE_TO_MEASURE_NAME * Fixed PR issue * Added LanguageVersion.JS * Added LanguageVersion.JS and LanguageVersion.JAVA_15 * Fixed a bug due to which all cyclomatic complexity issues were ignored * Added bad cyclomatic complexity test * Fixed test * Added LineLenIssue * Removed unnecessary time column * Update JS tests * Added README * Small fixes in README * Small fix * Fixed --allow-info-issues description * Fixed test * Fixed test * Fixed PR issue Co-authored-by: Anastasiia.Birillo <nbirillo@mail.ru> * Evaluation for the paper (#69) * Add evaluation for the paper: student dynamics and statistics abut the tool and the tutor tool * Fix flake8 * Rename statistics * statistics -> issues_statistics * Fixed flake8 * Undo some renaming Co-authored-by: Ilya Vlasov <ilyavlasov2011@gmail.com> * Script for extracting statistics from raw issues (#76) * Fixed get_output_path test data * Moved __get_total_lines to file_system.py * Added get_total_code_lines_from_file and get_total_code_lines_from_code * Added get_raw_issues_statistics * Renamed main_stats -> freq_stats and other_stats -> ratio_stats * Small fix * Added new data folders * Added tests * Removed duplicates * Removed unnecessary line * Now the script returns only one dataframe * Fixed tests * Added new tests * Added logger and small code refactoring * Added some more logging * Fixed test * Fixed test * Fixed help message * Update README.md * statistics -> issues_statistics * Fixed flake8 * Added from_value function * Added comment * Added get_ratio * Small refactoring: added get_ratio * Fixed PR issues * Small fixes * Added isnull * typo fix * Fixed tests * Added --log-output and fixed null checks * Added filemode * typo fix * Fixed tests * Fixed tests * Survey analysis (#84) * Add scripts for surveys statistics gathering * Fix flake8 * Issues fix (#88) * Fixed issue #73 * Fixed #75 * Small fix * Small fix * Sorted the whitelist.txt * Sorted whitelist.txt * Fixed tests * Fixed flake8 * Fixed get_raw_issues script (#86) * Fixed get_output_path test data * Moved __get_total_lines to file_system.py * Added get_total_code_lines_from_file and get_total_code_lines_from_code * Added get_raw_issues_statistics * Renamed main_stats -> freq_stats and other_stats -> ratio_stats * Small fix * Added new data folders * Added tests * Removed duplicates * Removed unnecessary line * Now the script returns only one dataframe * Fixed tests * Added new tests * Added logger and small code refactoring * Added some more logging * Fixed test * Fixed test * Fixed help message * Update README.md * Added more logging * statistics -> issues_statistics * Fixed flake8 * Added from_value function * Added comment * Added get_ratio * Small refactoring: added get_ratio * Fixed PR issues * Small fixes * Added isnull * typo fix * Fixed tests * Added --log-output and fixed null checks * Added filemode * typo fix * Fixed tests * Fixed tests * Code refactoring and bug fixing: - Added checks for columns 'code' and 'lang' for null - Now if flake8, pylint or WPS terminates with an error, this is logged - When creating a log file, all parent folders are created if necessary - Now the new log file overwrites the old one * Fixed test * Added new test * Replaced None with np.nan * Fixed test * Removed unnecessary space * Corrected dict errors and added types for Dict (#98) * Develop Branch Commit * Added Types for Dict * Added Any to typing * User dynamics (#95) * Add scripts for surveys statistics gathering * Fix flake8 * Add dynamics handlers * Fix flake8 * Sort whitelist * Fix evaluation run tool script * Use to_drop_nan arg * Fix tests * Fix PR#95 comments * Fix tests * `print_review.py` refactoring (#96) * Code refactoring: 1) Renamed ReviewResult -> GeneralReviewResult. 2) Added ReviewResult from which GeneralReviewResult and FileReviewResult are now inherited. 3) Put common code when printing GeneralReviewResult in different formats in the convert_review_result_to_json_dict function. 4) Also prepared the code for further addition of difficulty levels. 5) Fixed the test: now the json schema is checked more strictly. * get_influence_json_dict -> get_influence_on_penalty_json_dict * Fixed the old test and added a new one * typo fix * Renamed file * Fixed quotes * Added a new test and refactored the old one * Added typing * Update README.md * Undo Update README.md * Fixed PR issues * User dynamics visualization (#101) * Add scripts for surveys statistics gathering * Fix flake8 * Add dynamics handlers * Fix flake8 * Sort whitelist * Fix evaluation run tool script * Use to_drop_nan arg * Fix tests * Fix PR#95 comments * Fix tests * Add visualization * Fix flake8 * Fix plots * Fix plots * Delete print * Raw issues statisitcs plotter (#99) * Moved to plotters/ * Added line plot and histogram * Updated whitelist * Added plotters * Added script * Added the ability to draw horizontal lines when plotting box plot * Added boxplot * Fixed flake8 issues * Update README.md * create_line_plot -> create_line_chart * Added examples and fixed small errors * Fixed imports * Added sys.path * Difficulty levels (#103) * Code refactoring: 1) Renamed ReviewResult -> GeneralReviewResult. 2) Added ReviewResult from which GeneralReviewResult and FileReviewResult are now inherited. 3) Put common code when printing GeneralReviewResult in different formats in the convert_review_result_to_json_dict function. 4) Also prepared the code for further addition of difficulty levels. 5) Fixed the test: now the json schema is checked more strictly. * get_influence_json_dict -> get_influence_on_penalty_json_dict * Fixed the old test and added a new one * typo fix * Renamed file * Fixed quotes * Added a new test and refactored the old one * Added typing * Added group_issues_by_difficulty * Added --group-by-difficulty flag * Added IssueDifficulty * Added support for difficulty levels * Small fix * Fixed tests * Added IssueDifficulty * Added difficulty * Fixed tests * Fixed tests * Replaced literals with constants and added group_by_difficulty * Small fix * Fixed test and added a new one * Update README.md * Undo Update README.md * Fixed PR issues * Added tests * Added history * Added new tests and updated old ones * Update README.md * Fixed flake8 * Small fixes * Small fix * Small fix * Fixed flake8 * Small fix * Small fix * Added logger * Fixed todo message * Update traces and count percentage (#105) * Update traces and count percentage * Fix spellcheck * Issues fix (#107) * Update build.yml 1) actions/checkout@v1 -> actions/checkout@v2. 2) Added git. 3) Added automatic sorting of whitelists. * Update whitelist.txt * Sort whitelists (Github Actions) Co-authored-by: GirZ0n <GirZ0n@users.noreply.github.com> * Raw issues statistics plotter fix (#108) * Added Extension.HTML * Added COLORWAY * Added new words * Added create_box_trace and create_scatter_trace * Added --group-stats and colorway * Added the ability to show several languages on one graph at once * Sort whitelists (Github Actions) * Small code refactoring * Small code refactoring * Update README.md * Small fixes * Updated examples Co-authored-by: GirZ0n <GirZ0n@users.noreply.github.com> * Visualization of raw issues statistics for the paper (#110) * Added Extension.HTML * Added COLORWAY * Added new words * Added create_box_trace and create_scatter_trace * Added --group-stats and colorway * Added the ability to show several languages on one graph at once * Sort whitelists (Github Actions) * Small code refactoring * Small code refactoring * Update README.md * Small fixes * Updated examples * Added script * Small code refactoring * Added README and examples * Removed width * Changed width * Changed width * Fixed PR issues Co-authored-by: GirZ0n <GirZ0n@users.noreply.github.com> * Delete evaluation part (#113) * Delete evaluation * Update build * Fix tests * Rename: review -> hyperstyle * Add tests * Delete functions * Merged `main` into `develop` (#114) * Fix GitHub actions (#46) * Update requirements and dockerfile * Use Dockerfile in Github Action * Ignore a part of flake8 issues * Ignore flake8 inspections * Separate docker file into two: for prod and for dev * Delete ` * Fix test_range_of_lines * Fix pylint and flake8 tests * Fix pylint tests * Check styles by flake8 * Fix C408 issue * Move production Dockerfile * Fix Dockefile for production * Set up Eslint in the DockerFile for production * Delete one case from flake8 tests * Add pathlib into whitelist * Delete Path from setup.py * Ignore pathlib * Don't count INFO issues * Fix flake8 tests * Small fix * Delete pathlib from the whitelist * Update docker (#54) * Use one docker file for prod and dev * Change base docker image * Fix requirements-test: delete duplicates, setup versions * Try to fix dockerfile * Fix run in subprocess function * Fix Dockerfile * Try to fix Dockerfile * Fix docker image (#58) * Change eslint installing * Update build.yaml * Introduce base docker image and auto-detect eslint path Co-authored-by: Andrey Balandin <andrvb@gmail.com> Closes #43, closes #45. * Add whitelist for flake8-spellcheck (#68) * Add whitelist for flake8-spellcheck * Add a test for spellcheck and ignore unnecessary rule * Fix flake8 config * Bump version 1.1.0 -> 1.1.1 * Add Python inspections and a script for tool evaluation (#26) * wps-light support (#17) Add wps-light support * New flake8 plugins support (#18) Added support for flake8-broken-line, flake8-string-format, flake8-commas (they are WPS dependencies). Added support for cohesion. * Radon support (#19) Added new inspector: Radon. Added maintainability index. * Requirements upgrade (#21) Updated versions of dependencies Added django dictionary support Fixed tests * xlsx-run-tool (#24) Added xlsx_tool_run.py – script to run the tool on multiple code samples stored in xlsx file * Update version to 1.2.0 * Rename output_format to format * Fix double quotes * Fix small issues * Fix small issues * Fix double quotes * Fix double quotes * Inspectors fix (#39) * Add origin class for maintainability index * Add WPS518 to ignore due to collision with C0200 by Pylint * New category (#38) * Added a new category INFO, in order not to take into account some issues in the evaluation. * Fixed trailing commas * Delete create_directory function * Fix GitHub actions (#44) * Use the same environment as in the production dockerfile * Fix Dockerfiles * Install some dependencies for TeamCity * Update build * Add checks from teamcity * Update build * Fix indentation * Fix PR comments * Delete init files from resources * Add init in multi file project * Fix flake8 tests * Main upd bugs fix (#74) * Delete evaluation part * Fix bugs with detekt, pmd and flake8 * Issues fix (#80) * Fixed issue #70 * Fixed issue #72: now only spellcheck checks brackets * Fixed issue #73 * Fixed issue #77 * Fixed issue #78 * Fixed issue #71 * Fixed issue #79 * Fixed issue #81 * Added case 36: unpacking * Added case 37: wildcard import * Ignoring WPS347 and F405 * Added cases 36 (unpacking) and 37 (wildcard_import). Also removed W0622 (redefining_builtin) * Removed W0622 (redefining_builtin) * Issue #87 fix (#90) * Fixed issue #87 * Added test * Fixed issues #91 and #92 (#97) * Delete xlsx * Remove openpyxl * Issues fix (#104) * Fixed #100 * Fixed #102 * Added some more new words * Added toplevel * Update flake8 whitelist * Recovered accidentally deleted words Co-authored-by: Vlasov Ilya <55441714+GirZ0n@users.noreply.github.com> Co-authored-by: Daria Diatlova <dari.diatlova@gmail.com> Co-authored-by: Nikolay Vyahhi <Nikolay.Vyahhi@stepik.org> Co-authored-by: Ilya Vlasov <ilyavlasov2011@gmail.com> * Fixed typo * Sort whitelists (Github Actions) * Fixed tests * Fixed requirements * Added numpy * Removed numpy * Fixed test Co-authored-by: Nastya Birillo <anastasia.i.birillo@gmail.com> Co-authored-by: Nikolay Vyahhi <Nikolay.Vyahhi@stepik.org> Co-authored-by: Daria Diatlova <dari.diatlova@gmail.com> Co-authored-by: GirZ0n <GirZ0n@users.noreply.github.com> * Issues fix (#117) * Fixed #109 * Fixed #112 * Fixed #116 * Updated `README` (#119) * Added output examples with --group-by-difficulty * typo fix * Delete analysis part (#120) * Pylint categorization update (#121) * Added some new words * Added W0511 * Added WPS428 * Added many exceptions * Sort whitelists (Github Actions) * Comments fix Co-authored-by: GirZ0n <GirZ0n@users.noreply.github.com> * Detekt update (#123) * Updated detekt * Added new words * Sort whitelists (Github Actions) Co-authored-by: GirZ0n <GirZ0n@users.noreply.github.com> * Issue fix (#127) * Fixed #122 * Sort whitelists (Github Actions) Co-authored-by: GirZ0n <GirZ0n@users.noreply.github.com> * Delete evaluation resources * Delete Intellij and spotbugs inspectors (#131) * Delete intellij inspector * Delete spotbugs inspector * Fix teamcity build * Delete detekt sources (#132) * Delete intellij inspector * Delete spoibugs inspector * Download Detekt in Dockerfile * Install curl and unzip * Fix Dockerfile * Try to delete detekt sources * Check env variables * Try to get env variable * Use my docker image * Small code refactoring and also download detekt-jar file * Use my docker image * Use my docker image * Delete springlint inspector (#133) * Delete intellij inspector * Delete spoibugs inspector * Download Detekt in Dockerfile * Install curl and unzip * Fix Dockerfile * Try to delete detekt sources * Check env variables * Try to get env variable * Use my docker image * Small code refactoring and also download detekt-jar file * Use my docker image * Use my docker image * Delete springlint inspector * Delete checkstyle sources (#134) * Delete checkstyle sources * Fix curl command * Delete pmd sources (#135) * Delete PMD sources * Fix flake8 and echo env variables * Fix pmd tests * Delete ses evaluation resources * Add a guideline about tool installation (#137) Co-authored-by: Vlasov Ilya <55441714+GirZ0n@users.noreply.github.com> Co-authored-by: Daria Diatlova <dari.diatlova@gmail.com> Co-authored-by: Nikolay Vyahhi <Nikolay.Vyahhi@stepik.org> Co-authored-by: Ilya Vlasov <ilyavlasov2011@gmail.com> Co-authored-by: Nihal Shetty <80703906+nihalshetty-boop@users.noreply.github.com> Co-authored-by: GirZ0n <GirZ0n@users.noreply.github.com>
Обработка ошибок увеличивает отказоустойчивость кода, защищая его от потенциальных сбоев, которые могут привести к преждевременному завершению работы.

Прежде чем переходить к обсуждению того, почему обработка исключений так важна, и рассматривать встроенные в Python исключения, важно понять, что есть тонкая грань между понятиями ошибки и исключения.
Ошибку нельзя обработать, а исключения Python обрабатываются при выполнении программы. Ошибка может быть синтаксической, но существует и много видов исключений, которые возникают при выполнении и не останавливают программу сразу же. Ошибка может указывать на критические проблемы, которые приложение и не должно перехватывать, а исключения — состояния, которые стоит попробовать перехватить. Ошибки — вид непроверяемых и невозвратимых ошибок, таких как OutOfMemoryError, которые не стоит пытаться обработать.
Обработка исключений делает код более отказоустойчивым и помогает предотвращать потенциальные проблемы, которые могут привести к преждевременной остановке выполнения. Представьте код, который готов к развертыванию, но все равно прекращает работу из-за исключения. Клиент такой не примет, поэтому стоит заранее обработать конкретные исключения, чтобы избежать неразберихи.
Ошибки могут быть разных видов:
- Синтаксические
- Недостаточно памяти
- Ошибки рекурсии
- Исключения
Разберем их по очереди.
Синтаксические ошибки (SyntaxError)
Синтаксические ошибки часто называют ошибками разбора. Они возникают, когда интерпретатор обнаруживает синтаксическую проблему в коде.
Рассмотрим на примере.
a = 8
b = 10
c = a b
File "", line 3
c = a b
^
SyntaxError: invalid syntax
Стрелка вверху указывает на место, где интерпретатор получил ошибку при попытке исполнения. Знак перед стрелкой указывает на причину проблемы. Для устранения таких фундаментальных ошибок Python будет делать большую часть работы за программиста, выводя название файла и номер строки, где была обнаружена ошибка.
Недостаточно памяти (OutofMemoryError)
Ошибки памяти чаще всего связаны с оперативной памятью компьютера и относятся к структуре данных под названием “Куча” (heap). Если есть крупные объекты (или) ссылки на подобные, то с большой долей вероятности возникнет ошибка OutofMemory. Она может появиться по нескольким причинам:
- Использование 32-битной архитектуры Python (максимальный объем выделенной памяти невысокий, между 2 и 4 ГБ);
- Загрузка файла большого размера;
- Запуск модели машинного обучения/глубокого обучения и много другое;
Обработать ошибку памяти можно с помощью обработки исключений — резервного исключения. Оно используется, когда у интерпретатора заканчивается память и он должен немедленно остановить текущее исполнение. В редких случаях Python вызывает OutofMemoryError, позволяя скрипту каким-то образом перехватить самого себя, остановить ошибку памяти и восстановиться.
Но поскольку Python использует архитектуру управления памятью из языка C (функция malloc()), не факт, что все процессы восстановятся — в некоторых случаях MemoryError приведет к остановке. Следовательно, обрабатывать такие ошибки не рекомендуется, и это не считается хорошей практикой.
Ошибка рекурсии (RecursionError)
Эта ошибка связана со стеком и происходит при вызове функций. Как и предполагает название, ошибка рекурсии возникает, когда внутри друг друга исполняется много методов (один из которых — с бесконечной рекурсией), но это ограничено размером стека.
Все локальные переменные и методы размещаются в стеке. Для каждого вызова метода создается стековый кадр (фрейм), внутрь которого помещаются данные переменной или результат вызова метода. Когда исполнение метода завершается, его элемент удаляется.
Чтобы воспроизвести эту ошибку, определим функцию recursion, которая будет рекурсивной — вызывать сама себя в бесконечном цикле. В результате появится ошибка StackOverflow или ошибка рекурсии, потому что стековый кадр будет заполняться данными метода из каждого вызова, но они не будут освобождаться.
def recursion():
return recursion()
recursion()
---------------------------------------------------------------------------
RecursionError Traceback (most recent call last)
in
----> 1 recursion()
in recursion()
1 def recursion():
----> 2 return recursion()
... last 1 frames repeated, from the frame below ...
in recursion()
1 def recursion():
----> 2 return recursion()
RecursionError: maximum recursion depth exceeded
Ошибка отступа (IndentationError)
Эта ошибка похожа по духу на синтаксическую и является ее подвидом. Тем не менее она возникает только в случае проблем с отступами.
Пример:
for i in range(10):
print('Привет Мир!')
File "", line 2
print('Привет Мир!')
^
IndentationError: expected an indented block
Исключения
Даже если синтаксис в инструкции или само выражение верны, они все равно могут вызывать ошибки при исполнении. Исключения Python — это ошибки, обнаруживаемые при исполнении, но не являющиеся критическими. Скоро вы узнаете, как справляться с ними в программах Python. Объект исключения создается при вызове исключения Python. Если скрипт не обрабатывает исключение явно, программа будет остановлена принудительно.
Программы обычно не обрабатывают исключения, что приводит к подобным сообщениям об ошибке:
Ошибка типа (TypeError)
a = 2
b = 'PythonRu'
a + b
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
in
1 a = 2
2 b = 'PythonRu'
----> 3 a + b
TypeError: unsupported operand type(s) for +: 'int' and 'str'
Ошибка деления на ноль (ZeroDivisionError)
10 / 0
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
in
----> 1 10 / 0
ZeroDivisionError: division by zero
Есть разные типы исключений в Python и их тип выводится в сообщении: вверху примеры TypeError и ZeroDivisionError. Обе строки в сообщениях об ошибке представляют собой имена встроенных исключений Python.
Оставшаяся часть строки с ошибкой предлагает подробности о причине ошибки на основе ее типа.
Теперь рассмотрим встроенные исключения Python.
Встроенные исключения
BaseException
+-- SystemExit
+-- KeyboardInterrupt
+-- GeneratorExit
+-- Exception
+-- StopIteration
+-- StopAsyncIteration
+-- ArithmeticError
| +-- FloatingPointError
| +-- OverflowError
| +-- ZeroDivisionError
+-- AssertionError
+-- AttributeError
+-- BufferError
+-- EOFError
+-- ImportError
| +-- ModuleNotFoundError
+-- LookupError
| +-- IndexError
| +-- KeyError
+-- MemoryError
+-- NameError
| +-- UnboundLocalError
+-- OSError
| +-- BlockingIOError
| +-- ChildProcessError
| +-- ConnectionError
| | +-- BrokenPipeError
| | +-- ConnectionAbortedError
| | +-- ConnectionRefusedError
| | +-- ConnectionResetError
| +-- FileExistsError
| +-- FileNotFoundError
| +-- InterruptedError
| +-- IsADirectoryError
| +-- NotADirectoryError
| +-- PermissionError
| +-- ProcessLookupError
| +-- TimeoutError
+-- ReferenceError
+-- RuntimeError
| +-- NotImplementedError
| +-- RecursionError
+-- SyntaxError
| +-- IndentationError
| +-- TabError
+-- SystemError
+-- TypeError
+-- ValueError
| +-- UnicodeError
| +-- UnicodeDecodeError
| +-- UnicodeEncodeError
| +-- UnicodeTranslateError
+-- Warning
+-- DeprecationWarning
+-- PendingDeprecationWarning
+-- RuntimeWarning
+-- SyntaxWarning
+-- UserWarning
+-- FutureWarning
+-- ImportWarning
+-- UnicodeWarning
+-- BytesWarning
+-- ResourceWarning
Прежде чем переходить к разбору встроенных исключений быстро вспомним 4 основных компонента обработки исключения, как показано на этой схеме.
Try: он запускает блок кода, в котором ожидается ошибка.Except: здесь определяется тип исключения, который ожидается в блокеtry(встроенный или созданный).Else: если исключений нет, тогда исполняется этот блок (его можно воспринимать как средство для запуска кода в том случае, если ожидается, что часть кода приведет к исключению).Finally: вне зависимости от того, будет ли исключение или нет, этот блок кода исполняется всегда.
В следующем разделе руководства больше узнаете об общих типах исключений и научитесь обрабатывать их с помощью инструмента обработки исключения.
Ошибка прерывания с клавиатуры (KeyboardInterrupt)
Исключение KeyboardInterrupt вызывается при попытке остановить программу с помощью сочетания Ctrl + C или Ctrl + Z в командной строке или ядре в Jupyter Notebook. Иногда это происходит неумышленно и подобная обработка поможет избежать подобных ситуаций.
В примере ниже если запустить ячейку и прервать ядро, программа вызовет исключение KeyboardInterrupt. Теперь обработаем исключение KeyboardInterrupt.
try:
inp = input()
print('Нажмите Ctrl+C и прервите Kernel:')
except KeyboardInterrupt:
print('Исключение KeyboardInterrupt')
else:
print('Исключений не произошло')
Исключение KeyboardInterrupt
Стандартные ошибки (StandardError)
Рассмотрим некоторые базовые ошибки в программировании.
Арифметические ошибки (ArithmeticError)
- Ошибка деления на ноль (Zero Division);
- Ошибка переполнения (OverFlow);
- Ошибка плавающей точки (Floating Point);
Все перечисленные выше исключения относятся к классу Arithmetic и вызываются при ошибках в арифметических операциях.
Деление на ноль (ZeroDivisionError)
Когда делитель (второй аргумент операции деления) или знаменатель равны нулю, тогда результатом будет ошибка деления на ноль.
try:
a = 100 / 0
print(a)
except ZeroDivisionError:
print("Исключение ZeroDivisionError." )
else:
print("Успех, нет ошибок!")
Исключение ZeroDivisionError.
Переполнение (OverflowError)
Ошибка переполнение вызывается, когда результат операции выходил за пределы диапазона. Она характерна для целых чисел вне диапазона.
try:
import math
print(math.exp(1000))
except OverflowError:
print("Исключение OverFlow.")
else:
print("Успех, нет ошибок!")
Исключение OverFlow.
Ошибка утверждения (AssertionError)
Когда инструкция утверждения не верна, вызывается ошибка утверждения.
Рассмотрим пример. Предположим, есть две переменные: a и b. Их нужно сравнить. Чтобы проверить, равны ли они, необходимо использовать ключевое слово assert, что приведет к вызову исключения Assertion в том случае, если выражение будет ложным.
try:
a = 100
b = "PythonRu"
assert a == b
except AssertionError:
print("Исключение AssertionError.")
else:
print("Успех, нет ошибок!")
Исключение AssertionError.
Ошибка атрибута (AttributeError)
При попытке сослаться на несуществующий атрибут программа вернет ошибку атрибута. В следующем примере можно увидеть, что у объекта класса Attributes нет атрибута с именем attribute.
class Attributes(obj):
a = 2
print(a)
try:
obj = Attributes()
print(obj.attribute)
except AttributeError:
print("Исключение AttributeError.")
2
Исключение AttributeError.
Ошибка импорта (ModuleNotFoundError)
Ошибка импорта вызывается при попытке импортировать несуществующий (или неспособный загрузиться) модуль в стандартном пути или даже при допущенной ошибке в имени.
import nibabel
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
in
----> 1 import nibabel
ModuleNotFoundError: No module named 'nibabel'
Ошибка поиска (LookupError)
LockupError выступает базовым классом для исключений, которые происходят, когда key или index используются для связывания или последовательность списка/словаря неверна или не существует.
Здесь есть два вида исключений:
- Ошибка индекса (
IndexError); - Ошибка ключа (
KeyError);
Ошибка ключа
Если ключа, к которому нужно получить доступ, не оказывается в словаре, вызывается исключение KeyError.
try:
a = {1:'a', 2:'b', 3:'c'}
print(a[4])
except LookupError:
print("Исключение KeyError.")
else:
print("Успех, нет ошибок!")
Исключение KeyError.
Ошибка индекса
Если пытаться получить доступ к индексу (последовательности) списка, которого не существует в этом списке или находится вне его диапазона, будет вызвана ошибка индекса (IndexError: list index out of range python).
try:
a = ['a', 'b', 'c']
print(a[4])
except LookupError:
print("Исключение IndexError, индекс списка вне диапазона.")
else:
print("Успех, нет ошибок!")
Исключение IndexError, индекс списка вне диапазона.
Ошибка памяти (MemoryError)
Как уже упоминалось, ошибка памяти вызывается, когда операции не хватает памяти для выполнения.
Ошибка имени (NameError)
Ошибка имени возникает, когда локальное или глобальное имя не находится.
В следующем примере переменная ans не определена. Результатом будет ошибка NameError.
try:
print(ans)
except NameError:
print("NameError: переменная 'ans' не определена")
else:
print("Успех, нет ошибок!")
NameError: переменная 'ans' не определена
Ошибка выполнения (Runtime Error)
Ошибка «NotImplementedError»
Ошибка выполнения служит базовым классом для ошибки NotImplemented. Абстрактные методы определенного пользователем класса вызывают это исключение, когда производные методы перезаписывают оригинальный.
class BaseClass(object):
"""Опередляем класс"""
def __init__(self):
super(BaseClass, self).__init__()
def do_something(self):
# функция ничего не делает
raise NotImplementedError(self.__class__.__name__ + '.do_something')
class SubClass(BaseClass):
"""Реализует функцию"""
def do_something(self):
# действительно что-то делает
print(self.__class__.__name__ + ' что-то делает!')
SubClass().do_something()
BaseClass().do_something()
SubClass что-то делает!
---------------------------------------------------------------------------
NotImplementedError Traceback (most recent call last)
in
14
15 SubClass().do_something()
---> 16 BaseClass().do_something()
in do_something(self)
5 def do_something(self):
6 # функция ничего не делает
----> 7 raise NotImplementedError(self.__class__.__name__ + '.do_something')
8
9 class SubClass(BaseClass):
NotImplementedError: BaseClass.do_something
Ошибка типа (TypeError)
Ошибка типа вызывается при попытке объединить два несовместимых операнда или объекта.
В примере ниже целое число пытаются добавить к строке, что приводит к ошибке типа.
try:
a = 5
b = "PythonRu"
c = a + b
except TypeError:
print('Исключение TypeError')
else:
print('Успех, нет ошибок!')
Исключение TypeError
Ошибка значения (ValueError)
Ошибка значения вызывается, когда встроенная операция или функция получают аргумент с корректным типом, но недопустимым значением.
В этом примере встроенная операция float получат аргумент, представляющий собой последовательность символов (значение), что является недопустимым значением для типа: число с плавающей точкой.
try:
print(float('PythonRu'))
except ValueError:
print('ValueError: не удалось преобразовать строку в float: 'PythonRu'')
else:
print('Успех, нет ошибок!')
ValueError: не удалось преобразовать строку в float: 'PythonRu'
Пользовательские исключения в Python
В Python есть много встроенных исключений для использования в программе. Но иногда нужно создавать собственные со своими сообщениями для конкретных целей.
Это можно сделать, создав новый класс, который будет наследовать из класса Exception в Python.
class UnAcceptedValueError(Exception):
def __init__(self, data):
self.data = data
def __str__(self):
return repr(self.data)
Total_Marks = int(input("Введите общее количество баллов: "))
try:
Num_of_Sections = int(input("Введите количество разделов: "))
if(Num_of_Sections < 1):
raise UnAcceptedValueError("Количество секций не может быть меньше 1")
except UnAcceptedValueError as e:
print("Полученная ошибка:", e.data)
Введите общее количество баллов: 10
Введите количество разделов: 0
Полученная ошибка: Количество секций не может быть меньше 1
В предыдущем примере если ввести что-либо меньше 1, будет вызвано исключение. Многие стандартные исключения имеют собственные исключения, которые вызываются при возникновении проблем в работе их функций.
Недостатки обработки исключений в Python
У использования исключений есть свои побочные эффекты, как, например, то, что программы с блоками try-except работают медленнее, а количество кода возрастает.
Дальше пример, где модуль Python timeit используется для проверки времени исполнения 2 разных инструкций. В stmt1 для обработки ZeroDivisionError используется try-except, а в stmt2 — if. Затем они выполняются 10000 раз с переменной a=0. Суть в том, чтобы показать разницу во времени исполнения инструкций. Так, stmt1 с обработкой исключений занимает больше времени чем stmt2, который просто проверяет значение и не делает ничего, если условие не выполнено.
Поэтому стоит ограничить использование обработки исключений в Python и применять его в редких случаях. Например, когда вы не уверены, что будет вводом: целое или число с плавающей точкой, или не уверены, существует ли файл, который нужно открыть.
import timeit
setup="a=0"
stmt1 = '''
try:
b=10/a
except ZeroDivisionError:
pass'''
stmt2 = '''
if a!=0:
b=10/a'''
print("time=",timeit.timeit(stmt1,setup,number=10000))
print("time=",timeit.timeit(stmt2,setup,number=10000))
time= 0.003897680000136461
time= 0.0002797570000439009
Выводы!
Как вы могли увидеть, обработка исключений помогает прервать типичный поток программы с помощью специального механизма, который делает код более отказоустойчивым.
Обработка исключений — один из основных факторов, который делает код готовым к развертыванию. Это простая концепция, построенная всего на 4 блоках: try выискивает исключения, а except их обрабатывает.
Очень важно поупражняться в их использовании, чтобы сделать свой код более отказоустойчивым.
import cmath
def sqrt():
try:
num = int(input("Enter the number : "))
if num >= 0:
main(num)
else:
complex_num(num)
except:
print("OOPS..!!Something went wrong, try again")
sqrt()
return
def main(num):
square_root = num**(1/2)
print("The square Root of ", num, " is ", square_root)
return
def complex_num(num):
ans = cmath.sqrt(num)
print("The Square root if ", num, " is ", ans)
return
sqrt()
Предыдущие исправят проблемы PEP8. После вашего импорта вам нужно иметь 2 новые строки перед началом кода. Кроме того, между каждым def foo() вам также должно быть 2.
В вашем случае у вас было 0 после импорта, и у вас была 1 новая линия между каждой функцией. Часть PEP8 вам нужно иметь новую строку после окончания вашего кода. К сожалению, я не знаю, как это показать, когда я вставляю код здесь.
Обратите внимание на именование, это часть PEP8. Я изменил complex на complex_num, чтобы предотвратить путаницу со встроенным complex.
В конце концов, они только предупреждают, их можно игнорировать при необходимости.
I need to clean the misspelling words in a query like «eat an appple», «eat an bannnna». I have tried the autocorrect function but it only works for single words.
from autocorrect import spell
spell("appple")
it returns the correct word «apple». However, for the whole sentence, it does not work.
I wonder if there is any easier way to automatically correct the misspelling words in a sentence without writing a loop.
![]()
cs95
381k97 gold badges706 silver badges748 bronze badges
asked Mar 14, 2018 at 19:36
![]()
2
«Without a loop»
>>> ' '.join(map(spell, 'i like appples'.split()))
'i like apples'
Unfortunately, you still need some mechanism of autocorrecting each word separately, for which a loop, or «looping» construct (such as map) cannot be avoided.
answered Mar 14, 2018 at 19:39
![]()
cs95cs95
381k97 gold badges706 silver badges748 bronze badges
Зарегистрируйтесь для доступа к 15+ бесплатным курсам по программированию с тренажером
Ошибки оформления — синтаксис и линтер
—
Основы Python
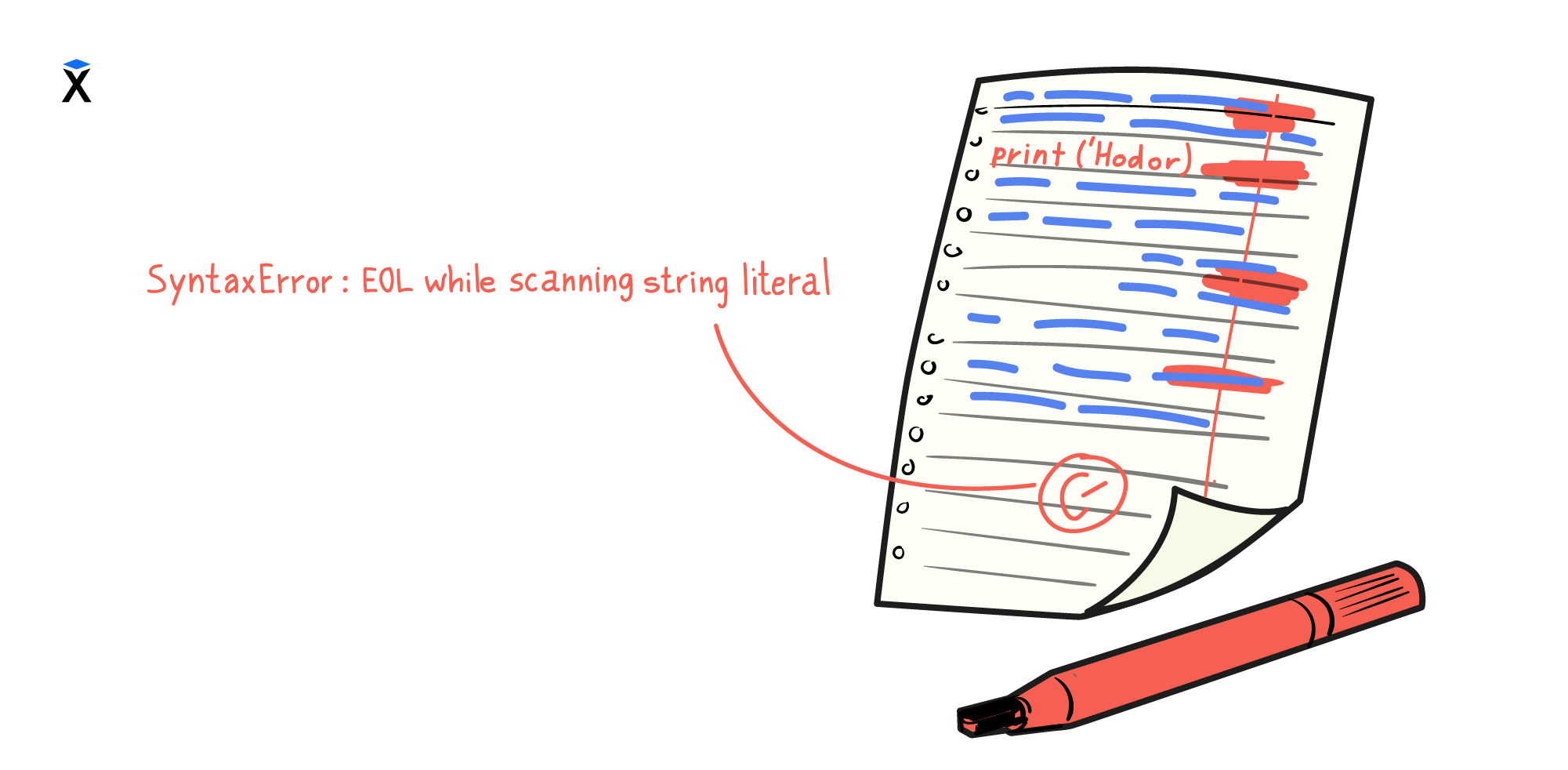
Если программа на Python написана синтаксически некорректно, то интерпретатор выводит на экран соответствующее сообщение. Также он указывает на файл и строчку, где произошла ошибка.
Синтаксическая ошибка возникает в том случае, когда код записали с нарушением грамматических правил. В естественных языках грамматика важна, но текст с ошибками обычно можно понять и прочитать. В программировании все строго. Мельчайшее нарушение — и программа даже не запустится. Примером может быть забытая ;, неправильно расставленные скобки и другие детали.
Вот пример кода с синтаксической ошибкой:
print('Hodor)
Если запустить код выше, то мы увидим следующее сообщение:
$ python index.py
File "index.py", line 1
print('Hodor)
^
SyntaxError: EOL while scanning string literal
С одной стороны, ошибки синтаксиса — самые простые, потому что они связаны с грамматическими правилами написания кода, а не со смыслом кода. Их легко исправить: нужно лишь найти нарушение в записи. С другой стороны, интерпретатор не всегда может четко указать на это нарушение. Поэтому бывает, что забытую скобку нужно поставить не туда, куда указывает сообщение об ошибке.
Ошибки линтера
Мы уже научились писать простые программы, и поэтому можно немного поговорить о том, как писать их правильно.
Код нужно оформлять определенным образом, чтобы он был понятным и простым в поддержке. Существуют специальные наборы правил, которые описывают различные аспекты написания кода — их называют стандартами кодирования. В Python стандарт один — PEP8. Он отвечает практически на все вопросы о том, как оформлять ту или иную часть кода. Этот документ содержит все правила, которых нужно придерживаться. Новичкам мы советуем завести привычку заглядывать в стандарт PEP8 и писать код по нему.
Сегодня не нужно помнить все правила из стандарта, потому что существуют специальные программы, которые проверяют код автоматически и сообщают о нарушениях. Такие программы называются линтерами. Они проверяют код на соответствие стандартам. В Python их достаточно много, и наиболее популярный из них — flake8.
Взгляните на пример:
result = 1+ 3
Линтер будет ругаться на нарушение правила: E225 missing whitespace around operator. По стандарту, все операторы всегда должны отделяться пробелами от операндов.
Выше мы увидели правило E225 — это одно из большого количества правил. Другие правила описывают отступы, названия, скобки, математические операции, длину строчек и множество иных аспектов. Каждое отдельное правило кажется неважным и мелким, но вместе они составляют основу хорошего кода. Список всех правил flake8 доступен в этой документации.
Вы уже знакомы с линтером, потому что в практических заданиях платформа Хекслета проверяет ваш код с помощью него. Скоро вы начнете использовать его и за пределами Хекслета, когда будете реализовывать учебные проекты. Вы настроите линтер, и он будет проверять код уже в реальной разработке и сообщать вам о нарушениях.
Дополнительные материалы
- Как читать вывод тестов в Python
![]()
Остались вопросы? Задайте их в разделе «Обсуждение»
Вам ответят команда поддержки Хекслета или другие студенты
Открыть доступ
Курсы программирования для новичков и опытных разработчиков. Начните обучение бесплатно
-
130 курсов, 2000+ часов теории -
1000 практических заданий в браузере -
360 000 студентов
Наши выпускники работают в компаниях:
Рекомендуемые программы
профессия
•
от 5 025 ₽ в месяц
Сбор, анализ и интерпретация данных
профессия
•
от 6 300 ₽ в месяц
Разработка веб-приложений на Django