Роботы Google бывают двух типов. Одни (поисковые) действуют автоматически и поддерживают стандарт исключений для роботов (REP).
Это означает, что перед сканированием сайта они скачивают и анализируют файл robots.txt, чтобы узнать, какие разделы сайта для них открыты. Другие контролируются пользователями (например, собирают контент для фидов) или обеспечивают их безопасность (например, выявляют вредоносное ПО). Они не следуют этому стандарту.
В этой статье рассказывается о том, как Google интерпретирует стандарт REP.
Что такое файл robots.txt
В файле robots.txt можно задать правила, которые запрещают поисковым роботам сканировать определенные разделы и страницы вашего сайта. Он создается в обычном текстовом формате и содержит набор инструкций. Так может выглядеть файл robots.txt на сайте example.com:
# This robots.txt file controls crawling of URLs under https://example.com. # All crawlers are disallowed to crawl files in the "includes" directory, such # as .css, .js, but Google needs them for rendering, so Googlebot is allowed # to crawl them. User-agent: * Disallow: /includes/ User-agent: Googlebot Allow: /includes/ Sitemap: https://example.com/sitemap.xml
Если вы только начинаете работать с файлами robots.txt, ознакомьтесь с общей информацией о них. Также мы подготовили для вас рекомендации по созданию файла и ответы на часто задаваемые вопросы.
Расположение файла и условия, при которых он действителен
Файл robots.txt должен находиться в каталоге верхнего уровня и передаваться по поддерживаемому протоколу. URL файла robots.txt (как и другие URL) должен указываться с учетом регистра. Google Поиск поддерживает протоколы HTTP, HTTPS и FTP. Для HTTP и HTTPS используется безусловный HTTP-запрос GET, а для FTP – стандартная команда RETR (RETRIEVE) и анонимный вход.
Правила, перечисленные в файле robots.txt, действительны только в отношении того хоста, где расположен файл, а также протокола и номера порта, по которым доступен этот файл.
Примеры действительных URL файла robots.txt
Примеры URL файла robots.txt и путей URL, для которых они действительны, приведены в таблице ниже.
В первом столбце указан URL файла robots.txt, а во втором – домены, к которым может или не может относиться этот файл.
| Примеры URL файла robots.txt | |
|---|---|
https://example.com/robots.txt |
Вот общий пример. Такой файл не действует в отношении других субдоменов, протоколов и номеров портов. При этом он действителен для всех файлов во всех подкаталогах, относящихся к тому же хосту, протоколу и номеру порта. Действителен для:
Не действителен для:
|
https://www.example.com/robots.txt |
Файл robots.txt в субдомене действителен только для этого субдомена. Действителен для: Недействителен для:
|
https://example.com/folder/robots.txt |
Недействительный файл robots.txt. Поисковые роботы не ищут файлы robots.txt в подкаталогах. |
https://www.exämple.com/robots.txt |
Эквивалентами IDN являются их варианты в кодировке Punycode. Ознакомьтесь также с документом RFC 3492. Действителен для:
Недействителен для: |
ftp://example.com/robots.txt |
Действителен для: Недействителен для: |
https://212.96.82.21/robots.txt |
Если файл robots.txt относится к хосту, имя которого совпадает с IP-адресом, он действителен только при обращении к сайту по этому IP-адресу. Инструкции в нем не распространяются автоматически на все сайты, размещенные по этому IP-адресу (хотя файл robots.txt может быть для них общим, и тогда он будет доступен также по общему имени хоста). Действителен для: Недействителен для: |
https://example.com:443/robots.txt |
Если URL указан со стандартным портом ( Действителен для:
Недействителен для: |
https://example.com:8181/robots.txt |
Файлы robots.txt, размещенные не по стандартным номерам портов, действительны только для контента, который доступен по этим номерам портов. Действителен для: Недействителен для: |
Обработка ошибок и коды статуса HTTP
От того, какой код статуса HTTP вернет сервер при обращении к файлу robots.txt, зависит, как дальше будут действовать поисковые роботы Google. О том, как робот Googlebot обрабатывает файлы robots.txt для разных кодов статуса HTTP, рассказано в таблице ниже.
| Обработка ошибок и коды статуса HTTP | |
|---|---|
2xx (success) |
Получив один из кодов статуса HTTP, которые сигнализируют об успешном выполнении, робот Google начинает обрабатывать файл robots.txt, предоставленный сервером. |
3xx (redirection) |
Google выполняет не менее пяти переходов в цепочке переадресаций согласно RFC 1945. Затем поисковый робот прерывает операцию и интерпретирует ситуацию как ошибку Google не обрабатывает логические перенаправления в файлах robots.txt (фреймы, JavaScript или метатеги refresh). |
4xx (client errors) |
Поисковые роботы Google воспринимают все ошибки |
5xx (server errors) |
Поскольку сервер не может дать определенный ответ на запрос файла robots.txt, Google временно интерпретирует ошибки сервера Если вам необходимо временно остановить сканирование, рекомендуем передавать код статуса HTTP
Если нам удается определить, что сайт настроен неправильно и в ответ на запросы отсутствующих страниц возвращает ошибку |
| Другие ошибки | Если файл robots.txt невозможно получить из-за проблем с DNS или сетью (слишком долгого ожидания, недопустимых ответов, разрыва соединения, ошибки поблочной передачи данных по HTTP), это приравнивается к ошибке сервера. |
Кеширование
Содержание файла robots.txt обычно хранится в кеше не более суток, но может быть доступно и дольше в тех случаях, когда обновить кешированную версию невозможно (например, из-за слишком долгого ожидания или ошибок 5xx). Сохраненный в кеше ответ может передаваться другим поисковым роботам.
Google может увеличить или уменьшить срок действия кеша с учетом соответствующих HTTP-заголовков.
Формат файла
В файле robots.txt должен быть обычный текст в кодировке UTF-8. В качестве разделителей строк следует использовать символы CR, CR/LF и LF.
Добавляемая в начало файла robots.txt метка порядка байтов Unicode BOM игнорируется, как и недопустимые строки. Например, если вместо правил robots.txt Google получит HTML-контент, система попытается проанализировать контент и извлечь правила. Все остальное будет проигнорировано.
Если для файла robots.txt используется не UTF-8, а другая кодировка, Google может проигнорировать символы, не относящиеся к UTF-8. В результате правила из файла robots.txt не будут работать.
В настоящее время максимальный размер файла robots.txt, установленный Google, составляет 500 кибибайт. Контент сверх этого лимита игнорируется. Чтобы не превысить его, применяйте более общие правила. Например, поместите все материалы, которые не нужно сканировать, в один каталог.
Синтаксис
Каждая действительная строка в файле robots.txt состоит из имени поля, двоеточия и значения. Использовать пробелы не обязательно, но рекомендуется для удобства чтения. Пробелы в начале и конце строки игнорируются. Чтобы добавить комментарии, начинайте их с символа #. Весь текст после символа # и до конца строки будет игнорироваться. Стандартный формат: <field>:<value><#optional-comment>.
Google поддерживает следующие поля:
user-agent: агент пользователя робота, для которого применяется правило.allow: путь URL, который можно сканировать.disallow: путь URL, который запрещено сканировать.sitemap: полный URL файла Sitemap.
Поля allow и disallow также называются правилами. Они всегда задаются в формате rule: [path], где значение [path] указывать необязательно. По умолчанию роботы могут сканировать весь контент. Они игнорируют правила без [path].
Значения [path] указываются относительно корневого каталога сайта, на котором находится файл robots.txt (используются те же протокол, порт, хост и домен).
Значение пути должно начинаться с символа /, обозначающего корневой каталог. Регистр учитывается. Подробнее о соответствии значения пути конкретным URL…
user-agent
Строка user-agent определяет, для какого робота применяется правило. Полный список поисковых роботов Google и строк для различных агентов пользователя, которые можно добавить в файл robots.txt, вы можете найти здесь.
Значение строки user-agent обрабатывается без учета регистра.
disallow
Правило disallow определяет, какие пути не должны сканироваться поисковыми роботами, заданными строкой user-agent, с которой сгруппирована директива disallow.
Роботы игнорируют правило без указания пути.
Google не может индексировать контент страниц, сканирование которых запрещено, однако может индексировать URL и показывать его в результатах поиска без фрагмента. Подробнее о том, как запретить индексирование…
Значение правила disallow обрабатывается с учетом регистра.
Синтаксис:
disallow: [path]
allow
Правило allow определяет пути, которые могут сканироваться поисковыми роботами. Если путь не указан, оно игнорируется.
Значение правила allow обрабатывается с учетом регистра.
Синтаксис:
allow: [path]
sitemap
Google, Bing и другие крупные поисковые системы поддерживают поле sitemap из файла robots.txt. Дополнительную информацию вы можете найти на сайте sitemaps.org.
Значение поля sitemap обрабатывается с учетом регистра.
Синтаксис:
sitemap: [absoluteURL]
Строка [absoluteURL] указывает на расположение файла Sitemap или файла индекса Sitemap.
URL должен быть полным, с указанием протокола и хоста. Нет необходимости кодировать URL. Хост URL не обязательно должен быть таким же, как и у файла robots.txt. Вы можете добавить несколько полей sitemap. Эти поля не связаны с каким-либо конкретным агентом пользователя. Если их сканирование не запрещено, они доступны для всех поисковых роботов.
Пример:
user-agent: otherbot disallow: /kale sitemap: https://example.com/sitemap.xml sitemap: https://cdn.example.org/other-sitemap.xml sitemap: https://ja.example.org/テスト-サイトマップ.xml
Группировка строк и правил
Вы можете группировать правила, которые применяются для разных агентов пользователя. Просто повторите строки user-agent для каждого поискового робота.
Пример:
user-agent: a disallow: /c user-agent: b disallow: /d user-agent: e user-agent: f disallow: /g user-agent: h
В этом примере есть четыре группы правил:
- первая – для агента пользователя «a»;
- вторая – для агента пользователя «b»;
- третья – одновременно для агентов пользователей «e» и «f»;
- четвертая – для агента пользователя «h».
Техническое описание группы вы можете найти в разделе 2.1 этого документа.
Приоритет агентов пользователей
Для отдельного поискового робота действительна только одна группа. Он должен найти ту, в которой наиболее конкретно указан агент пользователя из числа подходящих. Другие группы игнорируются. Весь неподходящий текст игнорируется. Например, значения googlebot/1.2 и googlebot* эквивалентны значению googlebot. Порядок групп в файле robots.txt не важен.
Если агенту пользователя соответствует несколько групп, то все относящиеся к нему правила из всех групп объединяются в одну. Группы, относящиеся к определенным агентам пользователя, не объединяются с общими группами, которые помечены значком *.
Примеры
Сопоставление полей user-agent
user-agent: googlebot-news (group 1) user-agent: * (group 2) user-agent: googlebot (group 3)
Поисковые роботы выберут нужные группы следующим образом:
| Выбор групп различными роботами | |
|---|---|
| Googlebot-News |
googlebot-news выбирает группу 1, поскольку это наиболее конкретная группа.
|
| Googlebot (веб-поиск) | googlebot выбирает группу 3. |
| Google StoreBot |
Storebot-Google выбирает группу 2, поскольку конкретной группы Storebot-Google нет.
|
| Googlebot-News (при сканировании изображений) |
При сканировании изображений googlebot-news выбирает группу 1.googlebot-news не сканирует изображения для Google Картинок, поэтому выбирает только группу 1.
|
| Otherbot (веб-поиск) | Остальные поисковые роботы Google выбирают группу 2. |
| Otherbot (для новостей) |
Другие поисковые роботы Google, которые сканируют новости, но не являются роботами googlebot-news, выбирают группу 2. Даже если имеется запись для схожего робота, она недействительна без точного соответствия.
|
Группировка правил
Если в файле robots.txt есть несколько групп для определенного агента пользователя, выполняется внутреннее объединение этих групп. Пример:
user-agent: googlebot-news disallow: /fish user-agent: * disallow: /carrots user-agent: googlebot-news disallow: /shrimp
Поисковые роботы объединяют правила с учетом агента пользователя, как указано в примере кода ниже.
user-agent: googlebot-news disallow: /fish disallow: /shrimp user-agent: * disallow: /carrots
Парсер для файлов robots.txt игнорирует все правила, кроме следующих: allow, disallow, user-agent. В результате указанный фрагмент файла robots.txt обрабатывается как единая группа и правило disallow: / влияет как на user-agent a, так и на b:
user-agent: a sitemap: https://example.com/sitemap.xml user-agent: b disallow: /
При обработке правил в файле robots.txt поисковые роботы игнорируют строку sitemap.
Например, вот как роботы обработали бы приведенный выше фрагмент файла robots.txt:
user-agent: a user-agent: b disallow: /
Соответствие значения пути конкретным URL
Google использует значение пути в правилах allow и disallow, чтобы определить, должно ли правило применяться к определенному URL на сайте. Для этого правило сравнивается с компонентом пути в URL, данные по которому пытается получить поисковый робот.
Символы, не входящие в набор 7-битных символов ASCII, можно указать в виде экранированных значений в кодировке UTF-8 (см. RFC 3986).
Google, Bing и другие крупные поисковые системы поддерживают определенные подстановочные знаки для путей:
*обозначает 0 или более вхождений любого действительного символа.$обозначает конец URL.
В таблице ниже показано, как на обработку влияют разные подстановочные знаки.
| Примеры | |
|---|---|
/ |
Соответствует корневому каталогу и всем URL более низкого уровня. |
/* |
Аналогичен элементу /. Подстановочный знак игнорируется. |
/$ |
Соответствует только корневому каталогу. На всех URL более низкого уровня разрешено сканирование. |
/fish |
Соответствует всем путям, которые начинаются с Соответствует:
Не соответствует:
|
/fish* |
Аналогичен элементу Соответствует:
Не соответствует:
|
/fish/ |
Соответствует любым элементам в папке Соответствует:
Не соответствует:
|
/*.php |
Соответствует всем путям, которые содержат Соответствует:
Не соответствует:
|
/*.php$ |
Соответствует всем путям, которые заканчиваются на Соответствует:
Не соответствует:
|
/fish*.php |
Соответствует всем путям, которые содержат Соответствует:
Не соответствует: |
Порядок применения правил
Когда роботы соотносят правила из файла robots.txt с URL, они используют самое строгое правило (с более длинным значением пути). При наличии конфликтующих правил (в том числе с подстановочными знаками) выбирается то, которое предполагает наименьшие ограничения.
Ознакомьтесь с примерами ниже.
| Примеры | |
|---|---|
https://example.com/page |
allow: /p disallow: /
Применяемое правило: |
https://example.com/folder/page |
allow: /folder disallow: /folder
Применяемое правило: |
https://example.com/page.htm |
allow: /page disallow: /*.htm
Применяемое правило: |
https://example.com/page.php5 |
allow: /page disallow: /*.ph
Применяемое правило: |
https://example.com/ |
allow: /$ disallow: /
Применяемое правило: |
https://example.com/page.htm |
allow: /$ disallow: /
Применяемое правило: |

На сайте с 05.03.2006
Offline
115
Я как-то сталкивался с подобным у одного хостера. У них статичное и динамическое содержимое отдается разными серверами (так объясняли, по крайней мере), поэтому подобная бяка вылазила. Попробуйте в сапорт хостера написать для начала.

На сайте с 24.09.2015
Offline
58
Search deer:
Что не тааак??
Права на robots.txt проверяли? Если всё нормально то скорей всего проблемы у вашего хостинга. Пишите в тех. поддержку.
Качественный и комплексный, но очень дешёвый SEO-аудит сайтов. (/ru/forum/911703)
CTR-SEO.RU (http://ctr-seo.ru/) | Полный спектр услуг поисковой оптимизации.

На сайте с 27.06.2015
Offline
41
CTRLISTING, да, все проверял, и по 20 раз перезаливал. Вот написал в техподержку, джу ответа..

На сайте с 03.08.2009
Offline
804
если права на файл нормальные, то не исключено, что роботс должен генерироваться движком и есть запись в .htaccess, проверьте.
Зы а еще чудес не бывает. По крайней мере в начале декабря.
На сайте с 27.06.2015
Offline
41
Jaf4, а что за запись в .htaccess ??

На сайте с 30.11.2015
Offline
36
Search deer:
Что не тааак?? Такое чувство, что формат .txt не хочет поддерживать мой сайт.
Так залей под другим названием .txt файл и проверь
На сайте с 03.08.2009
Offline
804
Search deer:
Jaf4, а что за запись в .htaccess ??
??
ну открой, посмотри фрагменты с «robots», за одно посмотри, что написано про txt.
Мы тут угадывать должны, что-ли? 
DN
На сайте с 08.09.2015
Offline
41
может в .htaccess он обращается по другому адресу, проверь, у меня такое было на OpenCart.

На сайте с 04.02.2008
Offline
272
А файл не пустой?
При некоторых условиях вебсервер может на пустой файл 404 отдавать.
На сайте с 27.06.2015
Offline
41
#10
Алексей Барыкин, нет, он заполнен.
———- Добавлено 04.12.2015 в 17:43 ———-
DenNickSeo, я вообще отключал файл .htaccess. Но ничего не менялось. Та же 404 ошибка
Роботы Google бывают двух типов. Одни (поисковые) действуют автоматически и поддерживают стандарт исключений для роботов (REP).
Это означает, что перед сканированием сайта они скачивают и анализируют файл robots.txt, чтобы узнать, какие разделы сайта для них открыты. Другие контролируются пользователями (например, собирают контент для фидов) или обеспечивают их безопасность (например, выявляют вредоносное ПО). Они не следуют этому стандарту.
В этой статье рассказывается о том, как Google интерпретирует стандарт REP. Ознакомиться с описанием самого стандарта можно здесь.
В файле robots.txt можно задать правила, которые запрещают поисковым роботам сканировать определенные разделы и страницы вашего сайта. Он создается в обычном текстовом формате и содержит набор инструкций. Так может выглядеть файл robots.txt на сайте example.com:
# This robots.txt file controls crawling of URLs under https://example.com. # All crawlers are disallowed to crawl files in the "includes" directory, such # as .css, .js, but Google needs them for rendering, so Googlebot is allowed # to crawl them. User-agent: * Disallow: /includes/ User-agent: Googlebot Allow: /includes/ Sitemap: https://example.com/sitemap.xml
Если вы только начинаете работать с файлами robots.txt, ознакомьтесь с общей информацией о них. Также мы подготовили для вас рекомендации по созданию файла и ответы на часто задаваемые вопросы.
Расположение файла и условия, при которых он действителен
Файл robots.txt должен находиться в каталоге верхнего уровня и передаваться по поддерживаемому протоколу. URL файла robots.txt (как и другие URL) должен указываться с учетом регистра. Google Поиск поддерживает протоколы HTTP, HTTPS и FTP. Для HTTP и HTTPS используется безусловный HTTP-запрос GET, а для FTP – стандартная команда RETR (RETRIEVE) и анонимный вход.
Правила, перечисленные в файле robots.txt, действительны только в отношении того хоста, где расположен файл, а также протокола и номера порта, по которым доступен этот файл.
Примеры действительных URL файла robots.txt
Примеры URL файла robots.txt и путей URL, для которых они действительны, приведены в таблице ниже.
В первом столбце указан URL файла robots.txt, а во втором – домены, к которым может или не может относиться этот файл.
| Примеры URL файла robots.txt | |
|---|---|
https://example.com/robots.txt |
Общий пример. Такой файл не действует в отношении других субдоменов, протоколов и номеров портов. При этом он действителен для всех файлов во всех подкаталогах, относящихся к тому же хосту, протоколу и номеру порта. Действителен для:
Недействителен для:
|
https://www.example.com/robots.txt |
Файл robots.txt в субдомене действителен только для этого субдомена. Действителен для: Недействителен для:
|
https://example.com/folder/robots.txt |
Недействительный файл robots.txt. Поисковые роботы не ищут файлы robots.txt в подкаталогах. |
https://www.exämple.com/robots.txt |
Эквивалентами IDN являются их варианты в кодировке Punycode. Ознакомьтесь также с документом RFC 3492. Действителен для:
Недействителен для: |
ftp://example.com/robots.txt |
Действителен для: Недействителен для: |
https://212.96.82.21/robots.txt |
Если robots.txt относится к хосту, имя которого совпадает с IP-адресом, то он действителен только при обращении к сайту по этому IP-адресу. Инструкции в нем не распространяются автоматически на все сайты, размещенные по этому IP-адресу (хотя файл robots.txt может быть для них общим, и тогда он будет доступен также по общему имени хоста). Действителен для: Недействителен для: |
https://example.com:443/robots.txt |
Если URL указан со стандартным портом ( Действителен для:
Недействителен для: |
https://example.com:8181/robots.txt |
Файлы robots.txt, размещенные не по стандартным номерам портов, действительны только для контента, который доступен по этим номерам портов. Действителен для: Недействителен для: |
Обработка ошибок и коды статуса HTTP
От того, какой код статуса HTTP вернет сервер при обращении к файлу robots.txt, зависит, как дальше будут действовать поисковые роботы Google. О том, как робот Googlebot обрабатывает файлы robots.txt для разных кодов статуса HTTP, рассказано в таблице ниже.
| Обработка ошибок и коды статуса HTTP | |
|---|---|
2xx (success) |
Получив один из кодов статуса HTTP, которые сигнализируют об успешном выполнении, робот Google начинает обрабатывать файл robots.txt, предоставленный сервером. |
3xx (redirection) |
Google выполняет пять переходов в цепочке переадресаций согласно RFC 1945. Затем поисковый робот прерывает операцию и интерпретирует ситуацию как ошибку Google не обрабатывает логические перенаправления в файлах robots.txt (фреймы, JavaScript или метатеги refresh). |
4xx (client errors) |
Поисковые роботы Google воспринимают все ошибки |
5xx (server errors) |
Поскольку сервер не может дать определенный ответ на запрос файла robots.txt, Google временно интерпретирует ошибки сервера Если вам необходимо временно остановить сканирование, рекомендуем передавать код статуса HTTP
Если нам удается определить, что сайт настроен неправильно и в ответ на запросы отсутствующих страниц возвращает ошибку |
| Другие ошибки | Если файл robots.txt невозможно получить из-за проблем с DNS или сетью (слишком долгого ожидания, недопустимых ответов, разрыва соединения, ошибки поблочной передачи данных по HTTP), это приравнивается к ошибке сервера. |
Кеширование
Содержание файла robots.txt обычно хранится в кеше не более суток, но может быть доступно и дольше в тех случаях, когда обновить кешированную версию невозможно (например, из-за истечения времени ожидания или ошибок 5xx). Сохраненный в кеше ответ может передаваться другим поисковым роботам.
Google может увеличить или уменьшить срок действия кеша в зависимости от значения атрибута max-age в HTTP-заголовке Cache-Control.
Формат файла
В файле robots.txt должен быть обычный текст в кодировке UTF-8. В качестве разделителей строк следует использовать символы CR, CR/LF и LF.
Добавляемая в начало файла robots.txt метка порядка байтов Unicode BOM игнорируется, как и недопустимые строки. Например, если вместо правил robots.txt Google получит HTML-контент, система попытается проанализировать контент и извлечь правила. Все остальное будет проигнорировано.
Если для файла robots.txt используется не UTF-8, а другая кодировка, то Google может проигнорировать символы, не относящиеся к UTF-8. В результате правила из файла robots.txt не будут работать.
В настоящее время максимальный размер файла, установленный Google, составляет 500 кибибайт (КиБ). Контент сверх этого лимита игнорируется. Чтобы не превысить его, применяйте более общие правила. Например, поместите все материалы, которые не нужно сканировать, в один каталог.
Синтаксис
Каждая действительная строка в файле robots.txt состоит из имени поля, двоеточия и значения. Использовать пробелы не обязательно, но рекомендуется для удобства чтения. Пробелы в начале и конце строки игнорируются. Чтобы добавить комментарии, начинайте их с символа #. Весь текст после символа # и до конца строки будет игнорироваться. Стандартный формат: <field>:<value><#optional-comment>.
Google поддерживает следующие поля:
user-agent: агент пользователя робота, для которого применяется правило.allow: путь URL, который можно сканировать.disallow: путь URL, который запрещено сканировать.sitemap: полный URL файла Sitemap.
Поля allow и disallow также называются правилами. Они всегда задаются в формате rule: [path], где значение [path] указывать необязательно. По умолчанию роботы могут сканировать весь контент. Они игнорируют правила без [path].
Значения [path] указываются относительно корневого каталога сайта, на котором находится файл robots.txt (используется тот же протокол, порт, хост и домен).
Значение пути должно начинаться с символа /, обозначающего корневой каталог. Регистр учитывается. Подробнее о соответствии значения пути конкретным URL…
user-agent
Строка user-agent определяет, для какого робота применяется правило. Полный список поисковых роботов Google и строк для различных агентов пользователя, которые можно добавить в файл robots.txt, вы можете найти здесь.
Значение строки user-agent обрабатывается без учета регистра.
disallow
Правило disallow определяет, какие пути не должны сканироваться поисковыми роботами, определенными строкой user-agent, с которой сгруппирована директива disallow.
Роботы игнорируют правило без указания пути.
Google не может индексировать контент страниц, сканирование которых запрещено, однако может индексировать URL и показывать его в результатах поиска без фрагмента. Подробнее о том, как блокировать индексирование…
Значение правила disallow обрабатывается с учетом регистра.
Синтаксис:
disallow: [path]
allow
Правило allow определяет пути, которые могут сканироваться поисковыми роботами. Если путь не указан, он игнорируется.
Значение правила allow обрабатывается с учетом регистра.
Синтаксис:
allow: [path]
sitemap
Google, Bing и другие крупные поисковые системы поддерживают поле sitemap из файла robots.txt. Дополнительную информацию вы можете найти на сайте sitemaps.org.
Значение поля sitemap обрабатывается с учетом регистра.
Синтаксис:
sitemap: [absoluteURL]
Строка [absoluteURL] указывает на расположение файла Sitemap или файла индекса Sitemap.
URL должен быть полным, с указанием протокола и хоста. Нет необходимости кодировать URL. Хост URL не обязательно должен быть таким же, как и у файла robots.txt. Вы можете добавить несколько полей sitemap. Эти поля не связаны с каким-либо конкретным агентом пользователя. Если их сканирование не запрещено, они доступны для всех поисковых роботов.
Пример:
user-agent: otherbot disallow: /kale sitemap: https://example.com/sitemap.xml sitemap: https://cdn.example.org/other-sitemap.xml sitemap: https://ja.example.org/テスト-サイトマップ.xml
Группировка строк и правил
Вы можете группировать правила, которые применяются для разных агентов пользователя. Просто повторите строки user-agent для каждого поискового робота.
Пример:
user-agent: a disallow: /c user-agent: b disallow: /d user-agent: e user-agent: f disallow: /g user-agent: h
В этом примере есть четыре группы правил:
- первая – для агента пользователя «a»;
- вторая – для агента пользователя «b»;
- третья – одновременно для агентов пользователей «e» и «f»;
- четвертая – для агента пользователя «h».
Техническое описание группы вы можете найти в разделе 2.1 этого документа.
Приоритет агентов пользователей
Для отдельного поискового робота действительна только одна группа. Он должен найти ту, в которой наиболее конкретно указан агент пользователя из числа подходящих. Другие группы игнорируются. Весь неподходящий текст игнорируется. Например, значения googlebot/1.2 и googlebot* эквивалентны значению googlebot. Порядок групп в файле robots.txt не важен.
Если агенту пользователя соответствует несколько групп, то все относящиеся к нему правила из всех групп объединяются в одну. Группы, относящиеся к определенным агентам пользователя, не объединяются с общими группами, которые помечены значком *.
Примеры
Сопоставление полей user-agent
user-agent: googlebot-news (group 1) user-agent: * (group 2) user-agent: googlebot (group 3)
Поисковые роботы выберут нужные группы следующим образом:
| Выбор групп различными роботами | |
|---|---|
| Googlebot-News |
googlebot-news выбирает группу 1, поскольку это наиболее конкретная группа.
|
| Googlebot (веб-поиск) | googlebot выбирает группу 3. |
| Google StoreBot |
Storebot-Google выбирает группу 2, поскольку конкретной группы Storebot-Google нет.
|
| Googlebot-News (при сканировании изображений) |
При сканировании изображений googlebot-news выбирает группу 1.googlebot-news не сканирует изображения для Google Картинок, поэтому выбирает только группу 1.
|
| Otherbot (веб-поиск) | Остальные поисковые роботы Google выбирают группу 2. |
| Otherbot (для новостей) |
Другие поисковые роботы Google, которые сканируют новости, но не являются роботами googlebot-news, выбирают группу 2. Даже если имеется запись для схожего робота, она недействительна без точного соответствия.
|
Группировка правил
Если в файле robots.txt есть несколько групп для определенного агента пользователя, выполняется внутреннее объединение этих групп. Пример:
user-agent: googlebot-news disallow: /fish user-agent: * disallow: /carrots user-agent: googlebot-news disallow: /shrimp
Поисковые роботы объединяют правила с учетом агента пользователя, как указано в примере кода ниже.
user-agent: googlebot-news disallow: /fish disallow: /shrimp user-agent: * disallow: /carrots
Парсер для файлов robots.txt игнорирует все правила, кроме следующих: allow, disallow, user-agent. В результате указанный фрагмент файла robots.txt обрабатывается как единая группа и правило disallow: /: влияет как на user-agent a, так и на b:
user-agent: a sitemap: https://example.com/sitemap.xml user-agent: b disallow: /
При обработке правил в файле robots.txt поисковые роботы игнорируют строку sitemap.
Например, вот как роботы обработали бы приведенный выше фрагмент файла robots.txt:
user-agent: a user-agent: b disallow: /
Соответствие значения пути конкретным URL
Google использует значение пути в правилах allow и disallow, чтобы определить, должно ли правило применяться к определенному URL на сайте. Для этого правило сравнивается с компонентом пути в URL, данные по которому пытается получить поисковый робот.
Символы, не входящие в набор 7-битных символов ASCII, можно указать в виде экранированных значений в кодировке UTF-8 (см. RFC 3986).
Google, Bing и другие крупные поисковые системы поддерживают определенные подстановочные знаки для путей:
*обозначает 0 или более вхождений любого действительного символа.$обозначает конец URL.
В таблице ниже показано, как на обработку влияют разные подстановочные знаки.
| Примеры | |
|---|---|
/ |
Соответствует корневому каталогу и всем URL более низкого уровня. |
/* |
Аналогичен элементу /. Подстановочный знак игнорируется. |
/$ |
Соответствует только корневому каталогу. На всех URL более низкого уровня разрешено сканирование. |
/fish |
Соответствует всем путям, которые начинаются с Соответствует:
Не соответствует:
|
/fish* |
Аналогичен элементу Соответствует:
Не соответствует:
|
/fish/ |
Соответствует любым элементам в папке Соответствует:
Не соответствует:
|
/*.php |
Соответствует всем путям, которые содержат Соответствует:
Не соответствует:
|
/*.php$ |
Соответствует всем путям, которые заканчиваются на Соответствует:
Не соответствует:
|
/fish*.php |
Соответствует всем путям, которые содержат Соответствует:
Не соответствует: |
Порядок применения правил
Когда роботы соотносят правила из файла robots.txt с URL, они используют самое строгое правило (с более длинным значением пути). При наличии конфликтующих правил (в том числе с подстановочными знаками) выбирается то, которое предполагает наименьшие ограничения.
Ознакомьтесь с примерами ниже.
| Примеры | |
|---|---|
https://example.com/page |
allow: /p disallow: /
Применяемое правило: |
https://example.com/folder/page |
allow: /folder disallow: /folder
Применяемое правило: |
https://example.com/page.htm |
allow: /page disallow: /*.htm
Применяемое правило: |
https://example.com/page.php5 |
allow: /page disallow: /*.ph
Применяемое правило: |
https://example.com/ |
allow: /$ disallow: /
Применяемое правило: |
https://example.com/page.htm |
allow: /$ disallow: /
Применяемое правило: |
Роботы Google бывают двух типов. Одни (поисковые) действуют автоматически и поддерживают стандарт исключений для роботов (REP).
Это означает, что перед сканированием сайта они скачивают и анализируют файл robots.txt, чтобы узнать, какие разделы сайта для них открыты. Другие контролируются пользователями (например, собирают контент для фидов) или обеспечивают их безопасность (например, выявляют вредоносное ПО). Они не следуют этому стандарту.
В этой статье рассказывается о том, как Google интерпретирует стандарт REP. Ознакомиться с описанием самого стандарта можно здесь.
Что такое файл robots.txt
В файле robots.txt можно задать правила, которые запрещают поисковым роботам сканировать определенные разделы и страницы вашего сайта. Он создается в обычном текстовом формате и содержит набор инструкций. Так может выглядеть файл robots.txt на сайте example.com:
# This robots.txt file controls crawling of URLs under https://example.com. # All crawlers are disallowed to crawl files in the "includes" directory, such # as .css, .js, but Google needs them for rendering, so Googlebot is allowed # to crawl them. User-agent: * Disallow: /includes/ User-agent: Googlebot Allow: /includes/ Sitemap: https://example.com/sitemap.xml
Если вы только начинаете работать с файлами robots.txt, ознакомьтесь с общей информацией о них. Также мы подготовили для вас рекомендации по созданию файла и ответы на часто задаваемые вопросы.
Расположение файла и условия, при которых он действителен
Файл robots.txt должен находиться в каталоге верхнего уровня и передаваться по поддерживаемому протоколу. URL файла robots.txt (как и другие URL) должен указываться с учетом регистра. Google Поиск поддерживает протоколы HTTP, HTTPS и FTP. Для HTTP и HTTPS используется безусловный HTTP-запрос GET, а для FTP – стандартная команда RETR (RETRIEVE) и анонимный вход.
Правила, перечисленные в файле robots.txt, действительны только в отношении того хоста, где расположен файл, а также протокола и номера порта, по которым доступен этот файл.
Примеры действительных URL файла robots.txt
Примеры URL файла robots.txt и путей URL, для которых они действительны, приведены в таблице ниже.
В первом столбце указан URL файла robots.txt, а во втором – домены, к которым может или не может относиться этот файл.
| Примеры URL файла robots.txt | |
|---|---|
http://example.com/robots.txt |
Общий пример. Такой файл не действует в отношении других субдоменов, протоколов и номеров портов. При этом он действителен для всех файлов во всех подкаталогах, относящихся к тому же хосту, протоколу и номеру порта. Действителен для:
Недействителен для:
|
https://www.example.com/robots.txt |
Файл robots.txt в субдомене действителен только для этого субдомена. Действителен для: Недействителен для:
|
https://example.com/folder/robots.txt |
Недействительный файл robots.txt. Поисковые роботы не ищут файлы robots.txt в подкаталогах. |
https://www.exämple.com/robots.txt |
Эквивалентами IDN являются их варианты в кодировке Punycode. Ознакомьтесь также с документом RFC 3492. Действителен для:
Недействителен для: |
ftp://example.com/robots.txt |
Действителен для: Недействителен для: |
https://212.96.82.21/robots.txt |
Если robots.txt относится к хосту, имя которого совпадает с IP-адресом, то он действителен только при обращении к сайту по этому IP-адресу. Инструкции в нем не распространяются автоматически на все сайты, размещенные по этому IP-адресу (хотя файл robots.txt может быть для них общим, и тогда он будет доступен также по общему имени хоста). Действителен для: Недействителен для: |
https://example.com:80/robots.txt |
Если URL указан со стандартным портом ( Действителен для:
Недействителен для: |
https://example.com:8181/robots.txt |
Файлы robots.txt, размещенные не по стандартным номерам портов, действительны только для контента, который доступен по этим номерам портов. Действителен для: Недействителен для: |
Обработка ошибок и коды статуса HTTP
От того, какой код статуса HTTP вернет сервер при обращении к файлу robots.txt, зависит, как дальше будут действовать поисковые роботы Google. О том, как робот Googlebot обрабатывает файлы robots.txt для разных кодов статуса HTTP, рассказано в таблице ниже.
| Обработка ошибок и коды статуса HTTP | |
|---|---|
2xx (success) |
Получив один из кодов статуса HTTP, которые сигнализируют об успешном выполнении, робот Google начинает обрабатывать файл robots.txt, предоставленный сервером. |
3xx (redirection) |
Google выполняет пять переходов в цепочке переадресаций согласно RFC 1945. Затем поисковый робот прерывает операцию и интерпретирует ситуацию как ошибку Google не обрабатывает логические перенаправления в файлах robots.txt (фреймы, JavaScript или метатеги refresh). |
4xx (client errors) |
Поисковые роботы Google воспринимают все ошибки |
5xx (server errors) |
Поскольку сервер не может дать определенный ответ на запрос файла robots.txt, Google временно интерпретирует ошибки сервера Если вам необходимо временно остановить сканирование, рекомендуем передавать код статуса HTTP
Если нам удается определить, что сайт настроен неправильно и в ответ на запросы отсутствующих страниц возвращает ошибку |
| Другие ошибки | Если файл robots.txt невозможно получить из-за проблем с DNS или сетью (слишком долгого ожидания, недопустимых ответов, разрыва соединения, ошибки поблочной передачи данных по HTTP), это приравнивается к ошибке сервера. |
Кеширование
Содержание файла robots.txt обычно хранится в кеше не более суток, но может быть доступно и дольше в тех случаях, когда обновить кешированную версию невозможно (например, из-за истечения времени ожидания или ошибок 5xx). Сохраненный в кеше ответ может передаваться другим поисковым роботам.
Google может увеличить или уменьшить срок действия кеша в зависимости от значения атрибута max-age в HTTP-заголовке Cache-Control.
Формат файла
В файле robots.txt должен быть обычный текст в кодировке UTF-8. В качестве разделителей строк следует использовать символы CR, CR/LF и LF.
Добавляемая в начало файла robots.txt метка порядка байтов Unicode BOM игнорируется, как и недопустимые строки. Например, если вместо правил robots.txt Google получит HTML-контент, система попытается проанализировать контент и извлечь правила. Все остальное будет проигнорировано.
Если для файла robots.txt используется не UTF-8, а другая кодировка, то Google может проигнорировать символы, не относящиеся к UTF-8. В результате правила из файла robots.txt не будут работать.
В настоящее время максимальный размер файла, установленный Google, составляет 500 кибибайт (КиБ). Контент сверх этого лимита игнорируется. Чтобы не превысить его, применяйте более общие правила. Например, поместите все материалы, которые не нужно сканировать, в один каталог.
Синтаксис
Каждая действительная строка в файле robots.txt состоит из имени поля, двоеточия и значения. Использовать пробелы не обязательно, но рекомендуется для удобства чтения. Пробелы в начале и конце строки игнорируются. Чтобы добавить комментарии, начинайте их с символа #. Весь текст после символа # и до конца строки будет игнорироваться. Стандартный формат: <field>:<value><#optional-comment>.
Google поддерживает следующие поля:
user-agent: агент пользователя робота, для которого применяется правило.allow: путь URL, который можно сканировать.disallow: путь URL, который запрещено сканировать.sitemap: полный URL файла Sitemap.
Поля allow и disallow также называются правилами или директивами. Они всегда задаются в формате rule: [path], где значение [path] указывать необязательно. По умолчанию роботы могут сканировать весь контент. Они игнорируют правила без [path].
Значения [path] указываются относительно корневого каталога сайта, на котором находится файл robots.txt (используется тот же протокол, порт, хост и домен).
Значение пути должно начинаться с символа /, обозначающего корневой каталог. Регистр учитывается. Подробнее о соответствии значения пути конкретным URL…
user-agent
Строка user-agent определяет, для какого робота применяется правило. Полный список поисковых роботов Google и строк для различных агентов пользователя, которые можно добавить в файл robots.txt, вы можете найти здесь.
Значение строки user-agent обрабатывается без учета регистра.
disallow
Правило disallow определяет, какие пути не должны сканироваться поисковыми роботами, определенными строкой user-agent, с которой сгруппирована директива disallow.
Роботы игнорируют правило без указания пути.
Google не может индексировать контент страниц, сканирование которых запрещено, однако может индексировать URL и показывать его в результатах поиска без фрагмента. Подробнее о том, как блокировать индексирование…
Значение правила disallow обрабатывается с учетом регистра.
Синтаксис:
disallow: [path]
allow
Правило allow определяет пути, которые могут сканироваться поисковыми роботами. Если путь не указан, он игнорируется.
Значение правила allow обрабатывается с учетом регистра.
Синтаксис:
allow: [path]
sitemap
Google, Bing и другие крупные поисковые системы поддерживают поле sitemap из файла robots.txt. Дополнительную информацию вы можете найти на сайте sitemaps.org.
Значение поля sitemap обрабатывается с учетом регистра.
Синтаксис:
sitemap: [absoluteURL]
Строка [absoluteURL] указывает на расположение файла Sitemap или файла индекса Sitemap.
URL должен быть полным, с указанием протокола и хоста. Нет необходимости кодировать URL. Хост URL не обязательно должен быть таким же, как и у файла robots.txt. Вы можете добавить несколько полей sitemap. Эти поля не связаны с каким-либо конкретным агентом пользователя. Если их сканирование не запрещено, они доступны для всех поисковых роботов.
Пример:
user-agent: otherbot disallow: /kale sitemap: https://example.com/sitemap.xml sitemap: https://cdn.example.org/other-sitemap.xml sitemap: https://ja.example.org/テスト-サイトマップ.xml
Группировка строк и правил
Вы можете группировать правила, которые применяются для разных агентов пользователя. Просто повторите строки user-agent для каждого поискового робота.
Пример:
user-agent: a disallow: /c user-agent: b disallow: /d user-agent: e user-agent: f disallow: /g user-agent: h
В этом примере есть четыре группы правил:
- первая – для агента пользователя «a»;
- вторая – для агента пользователя «b»;
- третья – одновременно для агентов пользователей «e» и «f»;
- четвертая – для агента пользователя «h».
Техническое описание группы вы можете найти в разделе 2.1 этого документа.
Приоритет агентов пользователей
Для отдельного поискового робота действительна только одна группа. Он должен найти ту, в которой наиболее конкретно указан агент пользователя из числа подходящих. Другие группы игнорируются. Весь неподходящий текст игнорируется. Например, значения googlebot/1.2 и googlebot* эквивалентны значению googlebot. Порядок групп в файле robots.txt не важен.
Если агенту пользователя соответствует несколько групп, то все относящиеся к нему правила из всех групп объединяются в одну. Группы, относящиеся к определенным агентам пользователя, не объединяются с общими группами, которые помечены значком *.
Примеры
Сопоставление полей user-agent
user-agent: googlebot-news (group 1) user-agent: * (group 2) user-agent: googlebot (group 3)
Поисковые роботы выберут нужные группы следующим образом:
| Выбор групп различными роботами | |
|---|---|
| Googlebot-News |
googlebot-news выбирает группу 1, поскольку это наиболее конкретная группа.
|
| Googlebot (веб-поиск) | googlebot выбирает группу 3. |
| Google StoreBot |
Storebot-Google выбирает группу 2, поскольку конкретной группы Storebot-Google нет.
|
| Googlebot-News (при сканировании изображений) |
При сканировании изображений googlebot-news выбирает группу 1.googlebot-news не сканирует изображения для Google Картинок, поэтому выбирает только группу 1.
|
| Otherbot (веб-поиск) | Остальные поисковые роботы Google выбирают группу 2. |
| Otherbot (для новостей) |
Другие поисковые роботы Google, которые сканируют новости, но не являются роботами googlebot-news, выбирают группу 2. Даже если имеется запись для схожего робота, она недействительна без точного соответствия.
|
Группировка правил
Если в файле robots.txt есть несколько групп для определенного агента пользователя, выполняется внутреннее объединение этих групп. Пример:
user-agent: googlebot-news disallow: /fish user-agent: * disallow: /carrots user-agent: googlebot-news disallow: /shrimp
Поисковые роботы объединяют правила с учетом агента пользователя, как указано в примере кода ниже.
user-agent: googlebot-news disallow: /fish disallow: /shrimp user-agent: * disallow: /carrots
Парсер для файлов robots.txt игнорирует все правила, кроме следующих: allow, disallow, user-agent. В результате указанный фрагмент файла robots.txt обрабатывается как единая группа и правило disallow: /: влияет как на user-agent a, так и на b:
user-agent: a sitemap: https://example.com/sitemap.xml user-agent: b disallow: /
При обработке правил в файле robots.txt поисковые роботы игнорируют строку sitemap.
Например, вот как роботы обработали бы приведенный выше фрагмент файла robots.txt:
user-agent: a user-agent: b disallow: /
Соответствие значения пути конкретным URL
Google использует значение пути в правилах allow и disallow, чтобы определить, должно ли правило применяться к определенному URL на сайте. Для этого правило сравнивается с компонентом пути в URL, данные по которому пытается получить поисковый робот.
Символы, не входящие в набор 7-битных символов ASCII, можно указать в виде экранированных значений в кодировке UTF-8 (см. RFC 3986).
Google, Bing и другие крупные поисковые системы поддерживают определенные подстановочные знаки для путей:
*обозначает 0 или более вхождений любого действительного символа.$обозначает конец URL.
| Примеры | |
|---|---|
/ |
Соответствует корневому каталогу и всем URL более низкого уровня. |
/* |
Аналогичен элементу /. Подстановочный знак игнорируется. |
/$ |
Соответствует только корневому каталогу. На всех URL более низкого уровня разрешено сканирование. |
/fish |
Соответствует всем путям, которые начинаются с Соответствует:
Не соответствует:
|
/fish* |
Аналогичен элементу Соответствует:
Не соответствует:
|
/fish/ |
Соответствует любым элементам в папке Соответствует:
Не соответствует:
|
/*.php |
Соответствует всем путям, которые содержат Соответствует:
Не соответствует:
|
/*.php$ |
Соответствует всем путям, которые заканчиваются на Соответствует:
Не соответствует:
|
/fish*.php |
Соответствует всем путям, которые содержат Соответствует:
Не соответствует: |
Порядок применения правил
Когда роботы соотносят правила из файла robots.txt с URL, они используют самое строгое правило (с более длинным значением пути). При наличии конфликтующих правил (в том числе с подстановочными знаками) выбирается то, которое предполагает наименьшие ограничения.
Ознакомьтесь с примерами ниже.
| Примеры | |
|---|---|
https://example.com/page |
allow: /p disallow: /
Применяемое правило: |
https://example.com/folder/page |
allow: /folder disallow: /folder
Применяемое правило: |
https://example.com/page.htm |
allow: /page disallow: /*.htm
Применяемое правило: |
https://example.com/page.php5 |
allow: /page disallow: /*.ph
Применяемое правило: |
https://example.com/ |
allow: /$ disallow: /
Применяемое правило: |
https://example.com/page.htm |
allow: /$ disallow: /
Применяемое правило: |

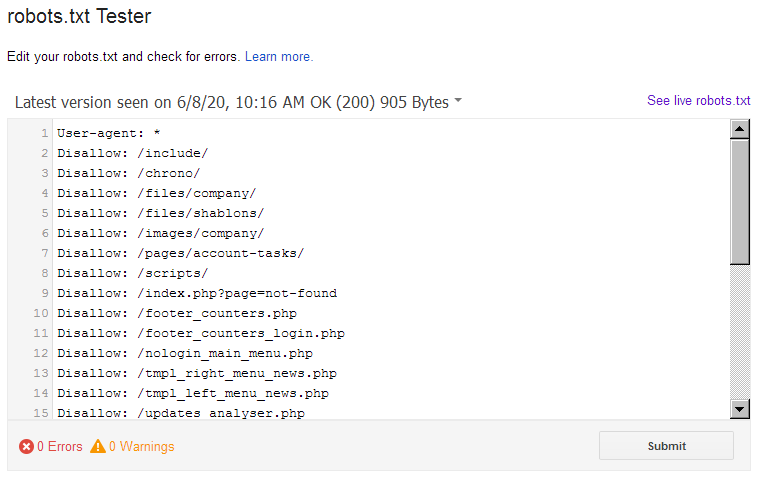
Примерно 60% пользователей сталкивается с тем, что новый сайт имеет проблемы с продвижением в поиске из-за неправильно настроенного файла robots.txt. Поэтому не всегда стоит сразу после запуска вкладывать все ресурсы в SEO-тексты, ссылки или внешнюю рекламу, так как некорректная настройка одного единственного файла на сайте способна привести к фатальным результатам и полной потере трафика и клиентов. Однако, всего этого можно избежать, правильно настроив индексацию сайта, и сделать это можно даже не будучи техническим специалистом или программистом.
Что такое файл robots.txt?
Robots.txt это обычный текстовый файл, содержащий руководство для ботов поисковых систем (Яндекс, Google, etc.) по сканированию и индексации вашего сайта. Таким образом, каждый поисковый бот (краулер) при обходе страниц сайта сначала скачивает актуальную версию robots.txt (обновляет его содержимое в своем кэше), а затем, переходя по ссылкам на сайте, заносит в свой индекс только те страницы, которые разрешены к индексации в настройках данного файла.
User-agent: *
Disallow: /*?*
Disallow: /data/
Disallow: /scripts/
Disallow: /plugins/
Sitemap: https://somesite.com/sitemap.xml
При этом у каждого краулера существует такое понятие, как «краулинговый бюджет», определяющее, сколько страниц можно просканировать единоразово (для разных сайтов это значение варьируется: обычно в зависимости от объема и значимости сайта). То есть, чем больше страниц на сайте и чем популярнее ресурс, тем объемнее и чаще будет идти его обход краулерами, и тем быстрее эти данные попадут в поисковую выдачу (например, на крупных новостных сайтах поисковые боты постоянно сканируют контент на предмет поиска новой информации (можно сказать что «живут»), за счет чего поисковая система может выдавать пользователем самые актуальные новости уже через несколько секунд после их публикации на сайте).
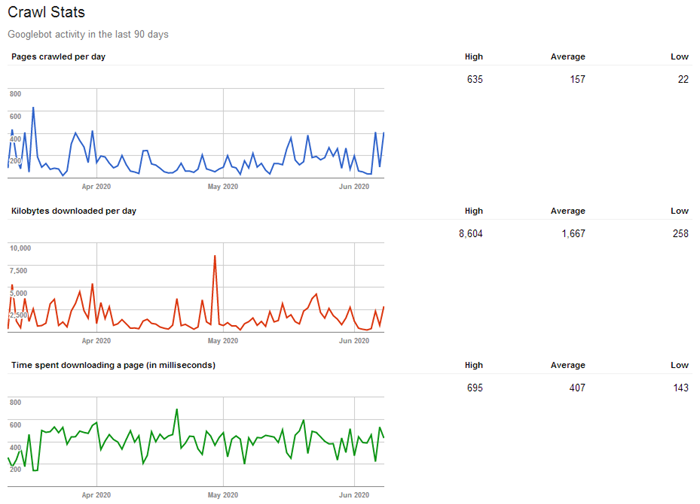
Таким образом, из-за ограниченности краулингового бюджета рекомендуется отдавать поисковым ботам в приоритете только ту информацию, которая должна обновляться или появляться в индексе поисковиков наиболее быстро (например, важные, полезные и актуальные страницы сайта), а все прочее устаревшее и не нужное можно смело скрывать, тем самым не распыляя краулинговый бюджет на не имеющий ценности контент.
Вывод: для оптимизации индексирования сайта стоит исключать из сканирования дубликаты страниц, результаты локального поиска по сайту, личный кабинет, корзину, сравнения, сортировки и фильтры, пользовательские профили, виш-листы и всё, что не имеет ценности для обычного пользователя.
Как найти и просмотреть содержимое robots.txt?
Файл размещается в корне домена по адресу somesite.com/robots.txt.
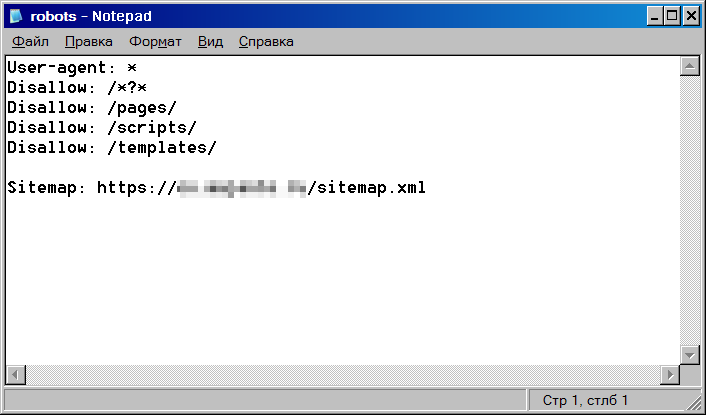
Данный метод прост и работает для всех веб-ресурсов, на которых размещен robots.txt. Доступ у файла открытый, поэтому каждый может просмотреть файлы других сайтов и узнать, как они настроены. Просто допишите «/robots.txt» в конец адресной строки интересующего домена, и вы получите один из двух вариантов:
- Откроется страница с содержимым robots.txt.
- Вы получите ошибку 404 (страница не найдена).
Вывод: если на вашем ресурсе по адресу /robots.txt вы получаете ошибку 404, то этот момент однозначно стоит исправить (создать, настроить и добавить файл на сервер).
Создание и редактирование robots.txt
- Если у вас еще нет файла, то нужно создать его с нуля. Откройте самый простой текстовый редактор (но не MS Word, т.к. нам нужен именно простой текстовый формат), к примеру, Блокнот (Windows) или TextEdit (Mac).
- Если файл уже существует, отыщите его в корневом каталоге вашего сайта (предварительно, подключившись к сайту по FTP-протоколу, для этого я рекомендую бесплатный Total Commander), скопируйте его на жесткий диск вашего компьютера и откройте через Блокнот.
Примечания:
- Если, например, сайт реализован на CMS WordPress, то по умолчанию, вы не сможете найти его в корне сайта, так как «из коробки» его наличие не предусмотрено. Поэтому для редактирования его придется создать заново.
- Регистр имени файла важен! Название robots.txt указывается исключительно строчными буквами. Также убедитесь, что вы написали корректное название, НЕ «Robots» или «robot» – это наиболее частые ошибки при создании файла.
Структура и синтаксис robots.txt
Существуют стандартные директивы разрешения или запрета индексации тех ли иных страниц и разделов сайта:
User-agent: * Disallow: /
В данном примере всем поисковым ботам не разрешается индексировать сайт (слеш через : и пробел от директивы Disallow указывает на корень сайта, а сама директива – на запрет чего-либо, указанного после двоеточия). Звездочка говорит о том, что данная секция открыта для всех User-agent (у каждой поисковой машины есть свой юзер-агент, которым она идентифицируется. Например, у Яндекса это Yandex, а у Гугла – Googlebot).
А, например, такая конструкция:
User-agent: Googlebot Disallow:
Говорит о том, что роботам Гугл разрешено индексировать весь сайт (для остальных поисковых систем директив в данном примере нет, поэтому если для них не прописаны какие-либо запрещающие правила, значит индексирование также разрешено).
Еще пример:
# директивы для Яндекса User-agent: Yandex Disallow: /profile/
Здесь роботам Яндекса запрещено индексировать личные профили пользователей (папка somesite.com/profile/), все остальное на сайте разрешено. А, например, роботу гугла разрешено индексировать вообще все на сайте.
Как вы уже могли догадаться, знак решетка «#» используется для написания комментариев.
Пример для запрета индексации конкретной страницы, входящей в блок типовых страниц:
User-agent: * Disallow: /profile/$
Данная директива запрещает индексацию раздела /profile/, однако разрешает индексацию всех его подразделов и отдельных страниц:
- /profile/logo.png
- /profile/users/
- /profile/all.html
Директива User-agent
Это обязательное поле, являющееся указанием поисковым ботам для какого поисковика настроены данные директивы. Звездочка (*) означает то, что директивы указаны для всех сканеров от всех поисковиков. Либо на ее месте может быть вписано конкретное имя поискового бота.
User-agent: * # определяем, для каких систем даются указания
Это будет работать до тех пор, пока в файле не встретятся инструкции для другого User-agent, если для него есть отдельные правила.
User-agent: Googlebot # указали, что директивы именно для ботов Гугла Disallow: / User-agent: Yandex # для Яндекса Disallow:
Директива Disallow
Как мы писали выше, это директива запрета индексации страниц и разделов на вашем сайте по указанным критериям.
User-agent: * Disallow: /profile/ #запрет индексирования профилей пользователей
Пример запрета индексации PDF и файлов MS Word и Excel:
User-agent: * Disallow: *.pdf Disallow: *.doc* Disallow: *.xls*
В данном случае, звездочка играет роль любой последовательности символов, то есть к индексации будут запрещены файлы формата: pdf, doc, xls, docx, xlsx.
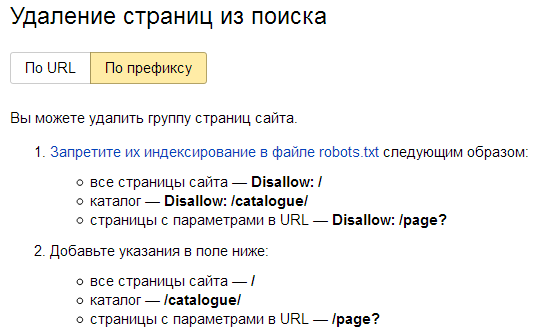
Примечание: для ускорения удаления из индекса недавно запрещенных к индексации страниц можно прибегнуть к помощи панели Яндекс Вебмастера: Удалить URL. Для группового удаления страниц и разделов нужно перейти в раздел «Инструменты» конкретного сайта и уже там выбрать режим «По префиксу».
Директивы Allow, Sitemap, Clean-param, Crawl-delay и другие
Дополнительные директивы предназначены для более тонкой настройки robots.txt.
Allow
Как противоположность Disallow, Allow дает указание на разрешение индексации отдельных элементов.
User-agent: Yandex Allow: / User-agent: * Disallow: /
Яндекс может проиндексировать сайт целиком, остальным поисковым системам сканирование запрещено.
Либо, к примеру, мы можем разрешить к индексации отдельные папки и файлы, запрещенные через Disallow.
User-agent: * Disallow: /upload/ Allow: /upload/iblock Allow: /upload/medialibrary
Sitemap.xml
Это файл для прямого указания краулерам списка актуальных страниц на сайте. Данная карта сайта предназначена только для поисковых роботов и оформлена специальным образом (XML-разметка). Файл sitemap.xml помогает поисковым ботам обнаружить страницы для дальнейшего индексирования и должен содержать только актуальные страницы с кодом ответа 200, без дублей, сортировок и пагинаций.
Стандартный путь размещения sitemap.xml – также в корневой папке сайта (хотя в принципе она может быть расположена в любой директории сайта, главное указать правильный путь к sitemap):
User-agent: Yandex Disallow: /comments/ Sitemap: https://smesite.com/sitemap.xml
Для крупных порталов карт сайта может быть даже несколько (Google допускает до 1000), но для большинства обычно хватает одного файла, если он удовлетворяет ограничениям:
- Не более 50 МБ (без сжатия) на один Sitemap.xml.
- Не более 50 000 URL на один Sitemap.xml.
Если ваш файл превышает указанный размер в 50 мегабайт, или же URL-адресов, содержащихся в нем, более 50 тысяч, то вам придется разбить список на несколько файлов Sitemap и использовать файл индекса для указания в нем всех частей общего Sitemap.
Пример:
User-agent: Yandex Allow: / Sitemap: https://project.com/my_sitemap_index.xml Sitemap: https://project.com/my_sitemap_1.xml Sitemap: https://project.com/my_sitemap_2.xml ... Sitemap: https://project.com/my_sitemap_X.xml
Примечание: параметр Sitemap – межсекционный, поэтому может быть указан в любом месте файла, однако обычно принято прописывать его в последней строке robots.txt.
Clean-param
Если на страницах есть динамические параметры, не влияющие на контент, то можно указать, что индексация сайта будет выполняться без учета этих параметров. Таким образом, поисковый робот не будет несколько раз загружать одну и ту же информацию, что повышает эффективность индексации.
К примеру, «Clean-param: highlight /forum/showthread.php» преобразует ссылку «/forum/showthread.php?t=30146&highlight=chart» в «/forum/showthread.php?t=30146» и таким образом не будет добавлять дубликат страницы форума с параметром подсветки найденного текста в ветке форума.
User-Agent: * Clean-param: p /forum/showthread.php Clean-param: highlight /forum/showthread.php
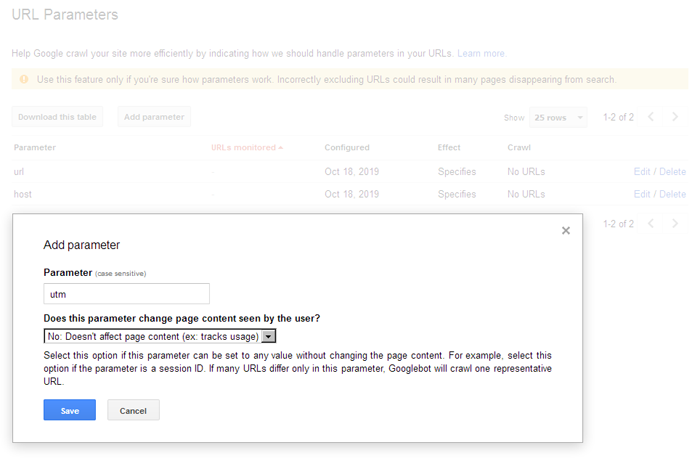
Clean-param используется исключительно для Яндекса, Гугл же использует настройки URL в Google Search Console. У гугла это осуществляется намного проще, простым добавлением параметров в интерфейсе вебмастера:
Crawl-delay
Данная инструкция относится к поисковой системе Яндекс и указывает правила по интенсивности его сканирования поисковым роботом. Это бывает полезно, если у вас слабый хостинг и роботы сильно нагружают сервер. В таком случае, вы можете указать им правило сканировать сайт реже, прописав интервалы между запросами к веб-сайту.
К примеру, Crawl-delay: 10 – это указание сканеру ожидать 10 секунд между каждым запросом. 0.5 – пол секунды.
User-Agent: * Crawl-delay: 10 # Crawl-delay: 0.5
Robots.txt для WordPress
Ниже выложен пример robots.txt для сайта на WordPress. Стандартно у Вордпресс есть три основных каталога:
- /wp-admin/
- /wp-includes/
- /wp-content/
Папка /wp-content/ содержит подпапку «uploads», где обычно размещены медиа-файлы, и этот основной каталог целиком блокировать не стоит:
User-agent: * Disallow: /wp-admin/ Disallow: /wp-includes/ Disallow: /wp-content/ Allow: /wp-content/uploads/
Данный пример блокирует выбранные служебные папки, но при этом позволяет сканировать подпапку «uploads» в «wp-content».
Настройка robots.txt для Google и Яндекс
Желательно настраивать директивы для каждой поисковой системы отдельно, как минимум, их стоит настроить для Яндекса и Гугл, а для остальных указать стандартные значения со звездочкой *.
User-agent: * User-agent: Yandex User-agent: Googlebot
Настройка robots.txt для Яндекса
В некоторых роботс иногда можно встретить устаревшую директиву Host, предназначенную для указания основной версии (зеркала) сайта. Данная директива устарела, поэтому ее можно не использовать (теперь поисковик определяет главное зеркало по 301-м редиректам):
User-agent: Yandex Disallow: /search Disallow: /profile Disallow: */feed Host: https://project.com # необязательно
Воспользуйтесь бесплатным инструментом Яндекса для автоматической проверки корректности настроек роботса.
Настройка robots.txt для Google
Принцип здесь тот же, что и у Яндекса, хоть и со своими нюансами. К примеру:
User-agent: Googlebot Disallow: /search Disallow: /profile Disallow: */feed Allow: *.css Allow: *.js
Важно: для Google мы добавляем возможность индексации CSS-таблиц и JS, которые важны именно для этой поисковой системы (поисковик умеет рендерить яваскрипт, соответственно может получить из него дополнительную информацию, имеющую пользу для сайта, либо просто для понимания, для чего служит тот или ной скрипт на сайте).
По ссылке в Google Webmaster Tools вы можете убедиться, правильно ли настроен ваш robots.txt для Гугла.
Запрет индексирования через Noindex и X-RobotsTag
В некоторых случаях, поисковая система Google может по своему усмотрению добавлять в индекс страницы, запрещенные к индексации через robots.txt (например, если на страницу стоит много внешних ссылок и размещена полезная информация).
Цитата из справки Google:

Для 100% скрытия нежелаемых страниц от индексации, используйте мета-тег NOINDEX.
Noindex – это мета-тег, который сообщает поисковой системе о запрете индексации страницы. В отличие от роботса, он является более надежным, поэтому для скрытия конфиденциальной информации лучше использовать именно его:
- <meta name=»robots» content=»noindex»>
Чтобы скрыть страницу только от Google, укажите:
- <meta name=»googlebot» content=»noindex»>
X-Robots-Tag
Тег x-robots позволяет вам управлять индексированием страницы в заголовке HTTP-ответа страницы. Данный тег похож на тег meta robots и также не позволяет роботам сканировать определенные виды контента, например, изображения, но уже на этапе обращения к файлу, не скачивая его, и, таким образом, не затрачивая ценный краулинговый ресурс.
Для настройки X-Robots-Tag необходимо иметь минимальные навыки программирования и доступ к файлам .php или .htaccess вашего сайта. Директивы тега meta robots также применимы к тегу x-robots.
<?
header("X-Robots-Tag: noindex, nofollow");
?>
Примечание: X-Robots-Tag эффективнее, если вы хотите запретить сканирование изображений и медиа-файлов. Применимо к контенту лучше выбирать запрет через мета-теги. Noindex и X-Robots Tag это директивы, которым поисковые роботы четко следуют, это не рекомендации как robots.txt, которые по определению можно не соблюдать.
Как быстро составить роботс для нового сайта с нуля?
Очень просто – скачать у конкурента! )

Просто зайдите на любой интересующий сайт и допишите в адресную строку /robots.txt, — так вы увидите, как это реализовано у конкурентов. При этом не стоит бездумно копировать их содержимое на свой сайт, ведь корректно настроенные директивы чужого сайта могут негативно подействовать на индексацию вашего веб-ресурса, поэтому желательно хотя бы немного разбираться в принципах работы роботс.тхт, чтобы не закрыть доступ к важным разделам.
И главное: после внесения изменений проверяйте robots.txt на валидность (соответствие правилам). Тогда вам точно не нужно будет опасаться за корректность индексации вашего сайта.
Другие примеры настройки Robots.txt
User-agent: Googlebot Disallow: /*?* # закрываем от индексации все страницы с параметрами Disallow: /users/*/photo/ # закрываем от индексации адреса типа "/users/big/photo/", "/users/small/photo/" Disallow: /promo* # закрываем от индексации адреса типа "/promo-1", "/promo-site/" Disallow: /templates/ #закрываем шаблоны сайта Disallow: /*?print= # версии для печати Disallow: /*&print=
Запрещаем сканировать сервисам аналитики Majestic, Ahrefs, Yahoo!
User-agent: MJ12bot Disallow: / User-agent: AhrefsBot Disallow: / User-agent: Slurp Disallow: /
Настройки robots для Opencart:
User-agent: * Disallow: /*route=account/ Disallow: /*route=affiliate/ Disallow: /*route=checkout/ Disallow: /*route=product/search Disallow: /index.php?route=product/product*&manufacturer_id= Disallow: /admin Disallow: /catalog Disallow: /download Disallow: /registration Disallow: /system Disallow: /*?sort= Disallow: /*&sort= Disallow: /*?order= Disallow: /*&order= Disallow: /*?limit= Disallow: /*&limit= Disallow: /*?filter_name= Disallow: /*&filter_name= Disallow: /*?filter_sub_category= Disallow: /*&filter_sub_category= Disallow: /*?filter_description= Disallow: /*&filter_description= Disallow: /*?tracking= Disallow: /*&tracking= Allow: /catalog/view/theme/default/stylesheet/stylesheet.css Allow: /catalog/view/theme/default/css/main.css Allow: /catalog/view/javascript/font-awesome/css/font-awesome.min.css Allow: /catalog/view/javascript/jquery/owl-carousel/owl.carousel.css Allow: /catalog/view/javascript/jquery/owl-carousel/owl.carousel.min.js
1. Введение
Технические аспекты созданного сайта играют не менее важную роль для продвижения сайта в поисковых системах, чем его наполнение. Одним из наиболее важных технических аспектов является индексирование сайта, т. е. определение областей сайта (файлов и директорий), которые могут или не могут быть проиндексированы роботами поисковых систем. Для этих целей используется robots.txt – это специальный файл, который содержит команды для роботов поисковиков. Правильный файл robots.txt для Яндекса и Google поможет избежать многих неприятных последствий, связанных с индексацией сайта.
2. Понятие файла robots.txt и требования, предъявляемые к нему
Файл /robots.txt предназначен для указания всем поисковым роботам (spiders) индексировать информационные сервера так, как определено в этом файле, т.е. только те директории и файлы сервера, которые не описаны в /robots.txt. Этот файл должен содержать 0 или более записей, которые связаны с тем или иным роботом (что определяется значением поля agent_id) и указывают для каждого робота или для всех сразу, что именно им не надо индексировать.
Синтаксис файла позволяет задавать запретные области индексирования, как для всех, так и для определенных, роботов.
К файлу robots.txt предъявляются специальные требования, не выполнение которых может привести к неправильному считыванию роботом поисковой системы или вообще к недееспособности данного файла.
Основные требования:
- все буквы в названии файла должны быть прописными, т. е. должны иметь нижний регистр:
- robots.txt – правильно,
- Robots.txt или ROBOTS.TXT – неправильно;
- файл robots.txt должен создаваться в текстовом формате Unix. При копировании данного файла на сайт ftp-клиент должен быть настроен на текстовый режим обмена файлами;
- файл robots.txt должен быть размещен в корневом каталоге сайта.
3. Содержимое файла robots.txt
Файл robots.txt включает в себя две записи: «User-agent» и «Disallow». Названия данных записей не чувствительны к регистру букв.
Некоторые поисковые системы поддерживают еще и дополнительные записи. Так, например, поисковая система «Yandex» использует запись «Host» для определения основного зеркала сайта (основное зеркало сайта – это сайт, находящийся в индексе поисковых систем).
Каждая запись имеет свое предназначение и может встречаться несколько раз, в зависимости от количества закрываемых от индексации страниц или (и) директорий и количества роботов, к которым Вы обращаетесь.
Предполагается следующий формат строк файла robots.txt:
имя_записи[необязательные
пробелы]:[необязательные
пробелы]значение[необязательные пробелы]
Чтобы файл robots.txt считался верным, необходимо, чтобы, как минимум, одна директива «Disallow» присутствовала после каждой записи «User-agent».
Полностью пустой файл robots.txt эквивалентен его отсутствию, что предполагает разрешение на индексирование всего сайта.
Запись «User-agent»
Запись «User-agent» должна содержать название поискового робота. В данной записи можно указать каждому конкретному роботу, какие страницы сайта индексировать, а какие нет.
Пример записи «User-agent», где обращение происходит ко всем поисковым системам без исключений и используется символ «*»:
User-agent: *
Пример записи «User-agent», где обращение происходит только к роботу поисковой системы Rambler:
User-agent: StackRambler
Робот каждой поисковой системы имеет свое название. Существует два основных способа узнать его (название):
на сайтах многих поисковых систем присутствует специализированный§ раздел «помощь веб-мастеру», в котором часто указывается название поискового робота;
при просмотре логов веб-сервера, а именно при просмотре обращений к§ файлу robots.txt, можно увидеть множество имен, в которых присутствуют названия поисковых систем или их часть. Поэтому Вам остается лишь выбрать нужное имя и вписать его в файл robots.txt.
Запись «Disallow»
Запись «Disallow» должна содержать предписания, которые указывают поисковому роботу из записи «User-agent», какие файлы или (и) каталоги индексировать запрещено.
Рассмотрим различные примеры записи «Disallow».
Пример записи в robots.txt (разрешить все для индексации):
Disallow:
Пример (сайт полностью запрещен к индексации. Для этого используется символ «/»):Disallow: /
Пример (для индексирования запрещен файл «page.htm», находящийся в корневом каталоге и файл «page2.htm», располагающийся в директории «dir»):
Disallow: /page.htm
Disallow: /dir/page2.htm
Пример (для индексирования запрещены директории «cgi-bin» и «forum» и, следовательно, все содержимое данной директории):
Disallow: /cgi-bin/
Disallow: /forum/
Возможно закрытие от индексирования ряда документов и (или) директорий, начинающихся с одних и тех же символов, используя только одну запись «Disallow». Для этого необходимо прописать начальные одинаковые символы без закрывающей наклонной черты.
Пример (для индексирования запрещены директория «dir», а так же все файлы и директории, начинающиеся буквами «dir», т. е. файлы: «dir.htm», «direct.htm», директории: «dir», «directory1», «directory2» и т. д.):
Запись «Allow»
Опция «Allow» используется для обозначения исключений из неиндексируемых директорий и страниц, которые заданы записью «Disallow».
Например, есть запись следующего вида:
Disallow: /forum/
Но при этом нужно, чтобы в директории /forum/ индексировалась страница page1. Тогда в файле robots.txt потребуются следующие строки:
Disallow: /forum/
Allow: /forum/page1
Запись «Sitemap»
Эта запись указывает на расположение карты сайта в формате xml, которая используется поисковыми роботами. Эта запись указывает путь к данному файлу.
Пример:
Sitemap: http://site.ru/sitemap.xml
Запись «Host»
Запись «host» используется поисковой системой «Yandex». Она необходима для определения основного зеркала сайта, т. е. если сайт имеет зеркала (зеркало – это частичная или полная копия сайта. Наличие дубликатов ресурса бывает необходимо владельцам высокопосещаемых сайтов для повышения надежности и доступности их сервиса), то с помощью директивы «Host» можно выбрать то имя, под которым Вы хотите быть проиндексированы. В противном случае «Yandex» выберет главное зеркало самостоятельно, а остальные имена будут запрещены к индексации.
В целях совместимости с поисковыми роботами, которые при обработке файла robots.txt не воспринимают директиву Host, необходимо добавлять запись «Host» непосредственно после записей Disallow.
Пример: www.site.ru – основное зеркало:
Host: www.site.ru
Запись «Crawl-delay»
Эту запись воспринимает Яндекс. Она является командой для робота делать промежутки заданного времени (в секундах) между индексацией страниц. Иногда это бывает нужно для защиты сайта от перегрузок.
Так, запись следующего вида обозначает, что роботу Яндекса нужно переходить с одной страницы на другую не раньше чем через 3 секунды:
Crawl-delay: 3
Комментарии
Любая строка в robots.txt, начинающаяся с символа «#», считается комментарием. Разрешено использовать комментарии в конце строк с директивами, но некоторые роботы могут неправильно распознать данную строку.
Пример (комментарий находится на одной строке вместе с директивой):
Disallow: /cgi-bin/ #комментарий
Желательно размещать комментарий на отдельной строке. Пробел в начале строки разрешается, но не рекомендуется.
4. Примеры файлов robots.txt
Пример (комментарий находится на отдельной строке):
Disallow: /cgi-bin/#комментарий
Пример файла robots.txt, разрешающего всем роботам индексирование всего сайта:
User-agent: *
Disallow:
Host: www.site.ru
Пример файла robots.txt, запрещающего всем роботам индексирование сайта:
User-agent: *
Disallow: /
Host: www.site.ru
Пример файла robots.txt, запрещающего всем роботам индексирование директории «abc», а так же всех директорий и файлов, начинающихся с символов «abc».
User-agent: *
Disallow: /abc
Host: www.site.ru
Пример файла robots.txt, запрещающего индексирование страницы «page.htm», находящейся в корневом каталоге сайта, поисковым роботом «googlebot»:
User-agent: googlebot
Disallow: /page.htm
Host: www.site.ru
Пример файла robots.txt, запрещающего индексирование:
– роботу «googlebot» – страницы «page1.htm», находящейся в директории «directory»;
– роботу «Yandex» – все директории и страницы, начинающиеся символами «dir» (/dir/, /direct/, dir.htm, direction.htm, и т. д.) и находящиеся в корневом каталоге сайта.
User-agent: googlebot
Disallow: /directory/page1.htm
User-agent: Yandex
Disallow: /dir
Host: www.site.ru
5. Ошибки, связанные с файлом robots.txt
Одна из самых распространенных ошибок – перевернутый синтаксис.
Неправильно:
User-agent: /
Disallow: Yandex
Правильно:
User-agent: Yandex
Disallow: /
Неправильно:
User-agent: *
Disallow: /dir/ /cgi-bin/ /forum/
Правильно:
User-agent: *
Disallow: /dir/
Disallow: /cgi-bin/
Disallow: /forum/
Если при обработке ошибки 404 (документ не найден), веб-сервер выдает специальную страницу, и при этом файл robots.txt отсутствует, то возможна ситуация, когда поисковому роботу при запросе файла robots.txt выдается та самая специальная страница, никак не являющаяся файлом управления индексирования.
Ошибка, связанная с неправильным использованием регистра в файле robots.txt. Например, если необходимо закрыть директорию «cgi-bin», то в записе «Disallow» нельзя писать название директории в верхнем регистре «cgi-bin».
Неправильно:
User-agent: *
Disallow: /CGI-BIN/
Правильно:
User-agent: *
Disallow: /cgi-bin/
Ошибка, связанная с отсутствием открывающей наклонной черты при закрытии директории от индексирования.
Неправильно:
User-agent: *
Disallow: dir
User-agent: *
Disallow: page.HTML
Правильно:
User-agent: *
Disallow: /dir
User-agent: *
Disallow: /page.HTML
Чтобы избежать наиболее распространенных ошибок, файл robots.txt можно проверить средствами Яндекс.Вебмастера или Инструментами для вебмастеров Google. Проверка осуществляется после загрузки файла.
6. Заключение
Таким образом, наличие файла robots.txt, а так же его составление, может повлиять на продвижение сайта в поисковых системах. Не зная синтаксиса файла robots.txt, можно запретить к индексированию возможные продвигаемые страницы, а так же весь сайт. И, наоборот, грамотное составление данного файла может очень помочь в продвижении ресурса, например, можно закрыть от индексирования документы, которые мешают продвижению нужных страниц.
Очень полезная вещь! Что это? Какие-то таинственные заклинания?

Да, это волшебство поможет резко снизить нагрузку на сервере от всяких сумасшедших роботов.
Суть проблемы ошибки 404 в WordPress.
Все ошибки 404 (нет запрошенной страницы) WordPress обрабатывает самостоятельно. Это здорово придумано, можно делать свою красивую страницу 404 — и будет счастье.
Но в интернете развелось очень много желающих сломать Ваш сайт и постоянно роботы (сетевые боты) делают проверки вида:
- domen,ru/pass.php
- domen,ru/login.php
- domen,ru/administrator.php
и прочая ахинея
Обратите на временной интервал подборщиков:
- 6:44
- 6:46
- 6:48
- 6:49
- 6:50
- 6:51
и на каждое такое обращение WP генерирует страницу 404…
Можно поискать плагин, который пишет ошибки не в базу, а в файл на сервере (пока не нашел, напишу сам). При наличии файла на сервере — можно подключить fail2ban (и скормить ему этот файл) и блочить тупых ботов по IP после трех-пяти ошибок 404.
Плюс часть «умных» утащили с Вашего сервера картинки себе на сайт методом «copypaste» — т.е. картинки на чужом сайта по-прежнему загружаются с Вашего сервера (и дополнительно его используют).
И после того, как Вы переделали свою исходную статью и картинки к ней (часть удалили, например) — Ваш WordPress начнет генерировать ошибку 404 на каждую отсутствующую картинку! Причем по одной странице 404 на каждую картинку!
Жесть какая, да? Нам нужно оставить генерацию 404 средствами WordPress только для отсутствующих страниц.
Возвращаем управление Error 404 серверу Apache
В WopdPress принудительно сделана передача себе обработки 404. Нужно изменить файл .htaccess, что бы движок обрабатывал только отсутствующие страницы (а не файлы).
Вот собственно код для модуля mod_rewrite.c (поделились добрые люди)

# BEGIN WordPress <IfModule mod_rewrite.c> RewriteEngine On RewriteBase / RewriteRule ^index.php$ - [L] RewriteCond %{REQUEST_FILENAME} !-f RewriteCond %{REQUEST_URI} .(php|s?html?|css|js|jpe?g|png|gif|ico|txt|pdf)(/??.*)?$ RewriteRule . - [R=404,L] RewriteCond %{REQUEST_FILENAME} !-f RewriteCond %{REQUEST_FILENAME} !-d RewriteRule . /index.php [L] </IfModule> # END WordPress
Синим цветом — от WordPress, красным — в центре добавлены изменения:
- запрос файла
- проверка расширения
- действие -> 404
Этот код полностью переключит всю обработку 404 на Apache для соответствующих расширений файлов.
Обратите внимание на регулярное выражение s?html? — это означает целый набор расширений файлов:
- shtml
- shtm
- html
- htm
Знак вопрос в регулярном выражении разрешает повторение предыдущего символа 0 или 1 раз. Конструкция jpe?g работает аналогично — это или jpg или jpeg
Если Вам надо оставить обработку файлов .html на WordPress, а все остальные варианты htm отдать Apache — можно сделать так
s?htm|shtml — т.е. отдаем Apache три варианта (вертикальная черта означает «или»)
- shtm
- htm
- shtml
Можно еще добавить расширений файлов, которые любят роботы-подборщики
- yml — Yandex Market Language — для загрузки прайс-листов в Маркет
- swp — файл обмена виртуальной памяти
- bak — архивные файлы чего-либо
- xml — разметка xml
- env — настройка переменных среды Unix
- sql — дамп базы данных MySql
- dat — файл хранения необработанных данных
- new — не знаю почему, но роботы пробуют
- zip, gzip,rar — файлы архивов
- log — файлы логов
- suspected — расширение, которое присваивает антивирус хостера для зараженных файлов (index.php -> index.php.suspected)
- 7z — файл архива
- gz — файл архива
- tar — файл архива
И еще для особо продвинутых (любопытных) ботов надо запретить:
- тильду на конце расширения файла — т.е. вот такой вариант domen.ru/abcd.php~ (тильда в некоторых ОС используется как временно сохраненная версия)
- и слеш в конце — т.е. вот такой вариант тоже не должен обрабатываться 404 в WP — domen.ru/abcd.php/
Добавляем после скобки с расширениями файлов еще скобку (/?~?) — принцип тот же (символ на конце может быть а может и не быть) — это и /? и ~?
Лишний бэкслеш нужен для экранирования обычного слеша — т.к. он является системным символом.
Исключаем robots.txt из обработки Apahce
ВАЖНО: использование txt в списке расширений отключит генерацию виртуального файла robots.txt средствами WordPress (при отсутствии физического файла robots.txt на сервере). Просто запрос domen.ru/robots.txt не дойдет до сервера PHP.
Для исключение файла /robots.txt из обработки ошибки 404 средствами Apache — его надо добавить в условие (исключить ТОЛЬКО robots.txt)
RewriteCond %{REQUEST_URI} !^/robots.txt$
- символ ! означает отрицание
- символ ^ означает, что проверяется совпадение с начала строки
- символ означает, что следующий символ является просто символом, а не управляющим символом (наша точка перед txt) — в данном случае не критично (в regex точка означает одиночное совпадение с любым символом, в т.ч. и с точкой)
- символ $ означает (без доллара никуда…), что мы не только слева проверяем наличие robots.txt, но и справа. Символы txt справа — они последние в проверке. Без $ мы заодно исключим варианты для обработки Apache (а оно нам надо?)
- robots.txt~
- robots.txt/
- и так далее
Итоговая конструкция (которая в середине файла .htaccess) будет иметь вид
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_URI} !^/robots.txt$
RewriteCond %{REQUEST_URI} .(php|asp|suspected|log|xml|s?htm|shtml|css|js|yml|swp|bak|env|new|sql|dat|zip|gzip|rar|7z|tar|gz|jpe?g|svg|png|gif|ico|txt|pdf)(/?~?)$
RewriteRule . - [R=404,L]
Решение этого вопроса на WordPress (вариант и для Nginx)
How do I skip wordpress’s 404 handling and redirect all 404 errors for static files to 404.html?
https://wordpress.stackexchange.com/questions/24587/how-do-i-skip-wordpresss-404-handling-and-redirect-all-404-errors-for-static-fi
Вносим корректировки в .htaccess
ВАЖНО: ручная корректировка файла .htaccess не поможет, WordPress контролирует его содержимое и периодически возвращает свои исходные настройки в блоке, выделенному тэгами
# BEGIN WordPress
# Директивы (строки) между `BEGIN WordPress` и `END WordPress`
# созданы автоматически и подлежат изменению только через фильтры WordPress.
# Сделанные вручную изменения между этими маркерами будут перезаписаны.
# END WordPress
Используйте плагин, которые умеет его редактировать и перехватывает управление WP, например
Плагин All in One SEO Pack
Вот его раздела «Редактор файлов»
Или через использование хуков и функций WordPress
Вот в этой статье подробно написано, как это сделать
Вред от страницы 404 в WordPress или не загружаем страницу 404, если это файл
ВАЖНО: разработчики WordPress периодически что-то изменяют — обратите внимание на появление в WoprdPress 5.6 новой инструкции
RewriteRule .* — [E=HTTP_AUTHORIZATION:%{HTTP:Authorization}]
Поэтому можно вообще сделать отдельным блоком до модуля Вордпресса
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteBase /
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteCond %{REQUEST_URI} !^/robots.txt$
RewriteCond %{REQUEST_URI} .(php|asp|suspected|log|xml|s?htm|shtml|css|js|yml|swp|bak|env|new|sql|dat|zip|gzip|rar|7z|tar|gz|jpe?g|svg|png|gif|ico|txt|pdf)(/?~?)$
RewriteRule . - [R=404]
</IfModule>
# BEGIN WordPress
# Директивы (строки) между `BEGIN WordPress` и `END WordPress`
# созданы автоматически и подлежат изменению только через фильтры WordPress.
# Сделанные вручную изменения между этими маркерами будут перезаписаны.
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteRule .* - [E=HTTP_AUTHORIZATION:%{HTTP:Authorization}]
RewriteBase /
RewriteRule ^index.php$ - [L]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /index.php [L]
</IfModule>
# END WordPress
Обязательно в нашем правиле RewriteRule убираем флаг L (который Last — т.е. последнее перенаправление). Иначе часть инструкций ниже от WP работать не будет.
И конструкцию <IfModule mod_rewrite.c></IfModule> тоже крайне желательно использовать — она дает серверу исполнять инструкции внутри, если уставлен mod_rewrite.c для Apache. У 99% хостеров он установлен по умолчанию — но на всякий случай пусть будет.
Результат обработки 404 со стороны Apache
ВАЖНО: весь этот список файлов (по их расширениям) не блокируется Apache — мы просто ему возвращаем управление ошибкой 404 при отсутствии какого-либо файла с этим расширением. Если файл есть или расширение не запрещенное (в данном случае html разрешено) — Apache пропускает url в обработку WordPress.
Раз
Два
Три
Красота же
Нагрузка на сервер PHP падает на 50% — теперь ему не нужно обрабатывать 404 в ответ на тупые подборы…
Оставим только медиа для APACHE
Вроде всё хорошо, и Апач быстрый — но b «мамкиных» хакеров много.
Вот такое безобразие может быть
https://site.ru/site.php71 https://site.ru/site.php72 https://site.ru/site.php73 https://site.ru/site.php74 https://site.ru/site.php75
Причем скрипт подборщика делает это 60 раз в минуту (и в user agent = python) — т.е. APACHE занят полностью и никто к Вам на сайт из живых людей не зайдет.
Имеет смысл оставить 404 ошибку через APACHE только для медиафайлов — а всё остальное пропускать в WordPress. Делать лог и баннить
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteBase /
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteCond %{REQUEST_URI} !^/robots.txt$
RewriteCond %{REQUEST_URI} .(jpe?g|svg|png|gif|ico)(/?~?)$
#media only
RewriteRule . - [R=404]
</IfModule>
# BEGIN WordPress
# Директивы (строки) между `BEGIN WordPress` и `END WordPress`
# созданы автоматически и подлежат изменению только через фильтры WordPress.
# Сделанные вручную изменения между этими маркерами будут перезаписаны.
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteRule .* - [E=HTTP_AUTHORIZATION:%{HTTP:Authorization}]
RewriteBase /
RewriteRule ^index.php$ - [L]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /index.php [L]
</IfModule>
# END WordPress
Далее php-скриптом формируем лог ошибок 404 на сервере и отдаем в блокировку fail2ban.
В результате IP такого вредителя блокируется на уровне сервера (NetFilter) на 1 неделю — 1 месяц.
В принципе обработку 404 ошибки в логе можно оставить и в APACHE, но не удобно:
- это не ошибка вебсервера — это отсутствие URL
- все ответы сервера 200…400…500 пишутся в лог доступа, а в не лог ошибок
- если сайтов несколько — будут отдельные логи для каждого сайта
Плюс достаточно сложная логика обработки статуса 404:
- это могут быть боты поисковых систем — их не надо блокировать
- это могут быть ошибки реальных пользователей
- вообще кто угодно и что угодно может набрать в строке браузера
Проще всю логику сделать на PHP, чем на регулярных выражениях при настройке fail2ban.
 16.08.2022
16.08.2022
Публикация 6 месяцев назад
Длинная ссылка URL выходит за пределы блока Вот, например, ссылка на сайт MS
https://docs.microsoft.com/ru-ru/microsoftteams/platform/concepts/build-and-test/deep-links?tabs=teamsjs-v2
При просмотре на широком экране все в порядке.
В мобильной версии сайта ссылка выходит за пределы блока и браузер рисует лишнее место справа. Вроде немного ссылка за пределы блока вышла — но получается так. И самое плохое — наша кнопка «Обратная связь» оказалась за пределами экрана мобильной версии.
Особенно такая беда в бесплатных темах WordPress.
Как это исправить?
Нам нужен CSS для указания переноса строк
Таблицы каскадных стилей управляют выводом браузера на экран.
Кратко о…
(Читать полностью…)
 31.05.2022
31.05.2022
Публикация 8 месяцев назад
Есть такой плагин для архивирования сайта All-in-One WP Migration Читаем статью
Плагины для архивирования и переноса сайта
Было так: тестовый вариант до 64 Мб
бесплатный вариант (расширение Basic) до 500 Мб
выше 500 Мб сайт — платный вариант А стало так: бесплатный вариант до 100 МБ
платный вариант — сайты более 100 Мб Ссылка на расширение к плагину
https://import.wp-migration.com/en Чувствуете, что одной колонки не хватает?
Остался вариант только «премиум». Причем при создании архива Вам плагин ничего не сообщает, что правила игры изменились. Плагин дает возможность создать архив для любого объема сайта.
В результате архив у Вас есть — а…
(Читать полностью…)
 22.02.2022
22.02.2022
Публикация 11 месяцев назад
Как добавить свои столбцы в административной панели WordPress Нужно в простом варианте сделать несколько вещей: создать саму колонку и его название (через add_filter)
заполнить его данными (через add_action)
при необходимости включить возможность сортировки колонки (через add_filter) Создаем колонку
// создаем новую колонку для записей
add_filter( ‘manage_’.’post’.’_posts_columns’, ‘tsl_manage_pages_columns’, 4 );
function tsl_manage_pages_columns( $columns ){
$columns = array( ‘views’ => ‘Визиты’ );
return $columns;
}
Итого в массиве $columns появится новый элемент (обычно в самом конце)
Заполняем…
(Читать полностью…)
 20.11.2021
20.11.2021
Публикация 1 год назад
Это же просто. Возвращается текущая дата и текущее локальное время сервера (с правильно установленной таймзоной).
Вот каждый может проверить
https://wpavonis.ru/server.php
Но если запустить этот же код из среды WordPress — мы получим другие результаты
UTC
2021-11-20 07:42:01
Что это за фокус?
Почему время по Гринвичу и таймзона другая? WordPress живет в прошлом?
ДА! Как говорится — «это не баг, а фича».
При запуске ядро WP устанавливает таймзону на UTC. Сделано это специально.
Вот тут подробнее.
current_time
ВАЖНО: Функция учитывает время сервера установленное в date.timezone setting и переписывает его в момент инициализации системы,…
(Читать полностью…)
 20.04.2021
20.04.2021
Публикация 2 года назад
Вышла версия 1.9 плагина tsl-plugin-out-list-posts Страница плагина находится здесь
Плагин вывода анонсов постов в конце контента
Плагин добавляет в конце текста анонсы дочерних или одноуровневых страниц для текущего контента. Логика вывода: список дочерних страниц
при отсутствии дочерних страниц — выводятся страницы одного уровня
при наличии и дочерних страниц и страниц одного уровня — выводятся дочерние страницы
на верхнем уровне при отсутствии дочерних страниц ничего не выводится
По умолчанию выводятся первые 700 знаков текста и миниатюра.
Для примера дерево страниц. Верхняя страница Средняя страница 1
Средняя страница 2
Средняя страница…
(Читать полностью…)
 13.02.2021
13.02.2021
Публикация 2 года назад
После установки WordPress в папке сайта создаются несколько информационных файлов Это собственно файлы: license.txt
readme.html Их можно просмотреть через прямой доступ в строке URL. Ранее в файлах добрый WP указывал установленную версию, чем облегчал работу хакеров. Теперь убрали, но нельзя гарантировать, что в будущих обновлениях снова не добавят.
Поэтому лучше закрыть.
Совет «Удалить после установки!» не подходит — т.к. при обновлении эти файлы будут восстановлены.
Файл license.txt
Описание лицензии GPL и указание на CMS WP Файл readme.html
Общее описание WordPress Файл wp-config-sample.php
Это, собственно, не информационный файл. Это образец для создания…
(Читать полностью…)
 05.02.2021
05.02.2021
Публикация 2 года назад
В версии WP 5.6 страница с результатами поиска изменилась и стала попадать в индекс поисковых машин Что это такое?
А это теперь WordPress оптимизировал URL выдачи результатов внутреннего поиска в виде domen.ru/search/term
Ранее было domen.ru/? s = term
И побежали радостные китайские боты заводить в поиск всякую чепуху.
Если в этот момент на страницу заходит поисковый робот: он её проверяет
получает ответ от сервера 200 ОК (даже при отрицательных результатах поиска!)
ой
и радостно сохраняет в индексе Вот так это выглядит в строке URL
Для запрета поисковым роботам индексации необходимо добавить в файл robots.txt инструкцию
Disallow: /search
Это запрет на индекс…
(Читать полностью…)
 26.01.2021
26.01.2021
Публикация 2 года назад
Можно увидеть в файле .htaccess новую строку Это добавлена возможность создавать пароли приложений: на сайте должно быть включено шифрование SSL (протокол HTTPS)
для API WP
для защиты мобильного входа в админку xml-rpc.php (через сервер WordPress) Подробнее можно прочитать в статье
Пароли приложений (авторизация)
Сделано на основе плагина Application Passwords
Пароли можно установить в управлении учетной записью пользователя Смысл в том, что Вы указываете мобильное приложение на своем смартфоне (которое, например, WordPress), создаете для него пароль = и Вы можете входить в мобильную версию админки (только с данного устройства) без основного пароля…
(Читать полностью…)
Robots.txt — это текстовый файл, в котором прописаны указания (директивы) по индексации страниц сайта. С помощью данного файла можно указывать поисковым роботам, какие страницы или разделы на веб-ресурсе нужно сканировать и заносить в индекс (базу данных поисковой системы), а какие — нет.
Файл robots.txt располагается в корневом каталоге сайта и доступен по адресу: domain.com/robots.txt.
Почему robots.txt важен для продвижения?
Этот файл дает поисковым системам важные указания, которые напрямую будут влиять на результативность продвижения сайта. Использование robots.txt может помочь:
- предотвращению сканирования дублированного контента и бесполезных для пользователей страниц (результаты внутреннего поиска, технические страницы и др.);
- сохранению конфиденциальности разделов веб-сайта (например, можно закрыть системную информацию CMS);
- избежать перегрузки сервера;
- эффективно расходовать краулинговый бюджет на обход полезных страниц.
С другой стороны, если robots.txt содержит ошибки, то поисковые системы будут неправильно индексировать сайт, и в результатах поиска окажется не та информация, которая нужна.
Можно случайно запретить индексирование важных для продвижения страниц, и они не попадут в результаты поиска.
Ниже приведены ссылки на инструкции по использованию файла robots.txt:
- от Яндекса;
- от Google.
Содержание отчета

- Кнопка «обновить» — при нажатии на неё данные о наличии ошибок в файле robots.txt обновятся.
- Содержимое строк файла robots.txt.
- При наличии в какой-либо директиве ошибки Labrika дает её описание.
Ошибки robots.txt, которые определяет Labrika
Сервис находит следующие виды ошибок:
Директива должна отделятся от правила символом «:».
Каждая действительная строка в файле robots.txt должна состоять из имени поля, двоеточия и значения. Использовать пробелы не обязательно, но рекомендуется для удобства чтения. Для добавления комментария применяется символ решётки «#», который ставится перед его началом. Весь текст после символа «#» и до конца строки робот поисковой системы будет игнорировать.
Стандартный формат:
<field>:<value><#optional-comment>
Пример ошибки:
User-agent Googlebot
Пропущен символ “:”.
Правильный вариант:
User-agent: Googlebot
Пустая директива и пустое правило.
Недопустимо делать пустую строку в директиве User-agent. Это основная директива, которая указывает, для какого поискового робота прописаны дальнейшие правила индексации.
Пример ошибки:
User-agent:
Не указан пользовательский агент.
Правильный вариант:
User-agent: название бота
Например:
User-agent: Googlebot
Каждое правило должно содержать не менее одной директивы «Allow» или «Disallow». Disallow закрывает раздел или страницу от индексации, Allow открывает страницы сайта для индексации (например, разрешает сканирование подкаталога или страницы в закрытом для обработки каталоге). Эти директивы задаются в формате: directive: [path], где значение [path] (путь к странице или разделу) указывать не обязательно. Однако роботы игнорируют директивы Allow и Disallow без указания пути. В этом случае они могут сканировать весь контент. Пустая директива Disallow: равнозначна директиве Allow: /, то есть «не запрещать ничего».
Пример ошибки в директиве Sitemap:
Sitemap:
Не указан путь к карте сайта.
Правильный вариант:
Sitemap: https://www.site.ru/sitemap.xml
Перед правилом нет директивы User-agent
Правило должно всегда стоять после директивы User-agent. Размещение правила перед первым именем пользовательского агента означает, что никакие сканеры не будут ему следовать.
Пример ошибки:
Disallow: /category User-agent: Googlebot
Правильный вариант:
User-agent: Googlebot Disallow: /category
Найдено несколько правил вида «User-agent: *»
Запись вида User-agent: * означает, что правило задается для всех поисковых роботов.
Например:
User-agent: * Disallow: /
запрещает всем поисковым роботам индексирование всего сайта.
Должна быть только одна директива User-agent для одного робота и только одна директива вида User-agent: * для всех роботов. Если в файле robots.txt несколько раз указан один и тот же пользовательский агент с разными списками правил, то поисковым роботам будет сложно определить, какие из этих правил нужно учитывать. В результате возникает большая неопределенность в действиях роботов.
Пример ошибки:
User-agent: * Disallow: /category User-agent: * Disallow: /*.pdf.
Правильный вариант:
User-agent: * Disallow: /category Disallow: /*.pdf.
Неизвестная директива
Обнаружена директива, которая не поддерживается поисковой системой (например, не описана в правилах использования robots.txt Яндекса).
Причины этого могут быть следующие:
- была прописана несуществующая директива;
- допущены ошибки синтаксиса, использованы запрещенные символы и теги;
- эта директива может использоваться роботами других поисковых систем.
Пример ошибки:
Disalow: /catalog
Директивы «Disalow» не существует, допущена ошибка в написании слова.
Правильный вариант:
Disallow: /catalog
Количество правил в файле robots.txt превышает максимально допустимое
Поисковые роботы будут корректно обрабатывать файл robots.txt, если его размер не превышает 500 КБ. Допустимое количество правил в файле — 2048. Контент сверх этого лимита игнорируется. Чтобы не превышать его, вместо исключения каждой отдельной страницы применяйте более общие директивы.
Например, если вам нужно заблокировать сканирование файлов PDF, не запрещайте каждый отдельный файл. Вместо этого запретите все URL-адреса, содержащие .pdf, с помощью директивы:
Disallow: /*.pdf
Правило превышает допустимую длину
Правило не должно содержать более 1024 символов.
Некорректный формат правила
В файле robots.txt должен быть обычный текст в кодировке UTF-8. Поисковые системы могут проигнорировать символы, не относящиеся к UTF-8. В таком случае правила из файла robots.txt не будут работать.
Чтобы поисковые роботы корректно обрабатывали инструкции в файле robots.txt, все правила должны быть написаны согласно стандарту исключений для роботов (REP), который поддерживают Google, Яндекс и большинство известных поисковых машин.
Использование кириллицы и других национальных языков
Использование кириллицы запрещено в файле robots.txt. Согласно утверждённой стандартом системе доменных имен название домена может состоять только из ограниченного набора ASCII-символов (буквы латинского алфавита, цифры от 0 до 9 и дефис). Если домен содержит символы, не относящиеся к ASCII (в том числе буквы национальных алфавитов), его нужно преобразовать с помощью Punycode в допустимый набор символов.
Пример ошибки:
User-agent: Yandex Sitemap: сайт.рф/sitemap.xml
Правильный вариант:
User-agent: Yandex Sitemap: https://xn--80aswg.xn--p1ai/sitemap.xml
Возможно, был использован недопустимый символ
Допускается использование спецсимволов «*» и «$». Они применяются для указания шаблонов адресов при объявлении директив, чтобы не прописывать большой перечень конечных URL для блокировки. Например:
Disallow: /*.php$
запрещает индексировать любые php файлы.
- Звездочка «*» обозначает любую последовательность и любое количество символов.
- Знак доллара «$» означает конец адреса и ограничивает действие знака «*».
Например, если /*.php соответствует всем путям, которые содержат .php., то /*.php$ соответствует только тем путям, которые заканчиваются на .php.
Символ «$» прописан в середине значения
Знак «$» можно использовать только один раз и только в конце правила. Он показывает, что стоящий перед ним символ должен быть последним.
Пример ошибки:
Allow: /file$html
Правильный вариант:
Allow: /file.html$
Правило начинается не с символа «/» и не с символа «*».
Правило может начинаться только с символов «/» и «*».
Значение пути указывается относительно корневого каталога сайта, на котором находится файл robots.txt, и должно начинаться с символа слэш «/», обозначающего корневой каталог.
Пример ошибки:
Disallow: products
Правильным вариантом будет:
Disallow: /products
или
Disallow: *products
в зависимости от того, что вы хотите исключить из индексации.
Некорректный формат URL файла Sitemap
Sitemap — это карта сайта для поисковых роботов, которая содержит рекомендации того, какие страницы необходимо обходить в первую очередь и с какой частотой. Наличие карты сайта помогает роботам быстрее индексировать нужные страницы.
В качестве URL файла Sitemap должен быть указан полный адрес, который содержит обозначение протокола (http:// или https://), имя сайта, путь к файлу, а также имя файла.
Пример ошибки:
Sitemap: /sitemap.xml
Правильный вариант:
Sitemap: https://www.site.ru/sitemap.xml
Некорректное имя главного зеркала сайта
Директива Host указывала роботу Яндекса главное зеркало сайта, если к веб-ресурсу был доступ по нескольким доменам. Остальные поисковые роботы её не воспринимали.
Директива Host могла содержать только протокол (необязательный) и домен сайта. Прописывался протокол https, если он использовался. Указывалась только одна директива Host. Если их было несколько, робот учитывал первую.
Пример ошибки:
User-agent: Yandex Host: http://www.example.com/catalog Host: https://example.com
Правильный вариант:
User-agent: Yandex Host: https://example.com
Некорректный формат директивы «Crawl-delay»
Директива Crawl-delay задает роботу минимальный период времени между окончанием загрузки одной страницы и началом загрузки следующей.
Использовать директиву Crawl-delay следует в тех случаях, когда сервер сильно загружен и не успевает обрабатывать запросы поискового робота. Чем больше устанавливаемый интервал, тем меньше будет количество загрузок в течение одной сессии.
При указании интервала можно использовать как целые значения, так и дробные. В качестве разделителя применяется точка. Единица измерения – секунды:
К ошибкам относят:
- несколько директив Crawl-delay;
- некорректный формат директивы Crawl-delay.
Пример ошибки:
Crawl-delay: 0,5 second
Правильный вариант:
Crawl-delay: 0.5
С 22 февраля 2018 года Яндекс перестал учитывать директиву Crawl-delay. Чтобы задать скорость, с которой роботы будут загружать страницы сайта, используйте раздел «Скорость обхода сайта» в Яндекс.Вебмастере.
Google также не поддерживает эту директиву. Для Google-бота установить частоту обращений можно в панели вебмастера Search Console. Однако роботы Bing и Yahoo соблюдает директиву Crawl-delay.
Некорректный формат директивы «Clean-param»
Директива используется только для робота Яндекса. Google и другие роботы не поддерживают Clean-param.
Директива указывает, что URL страниц содержат GET-параметры, которые не влияют на содержимое, и поэтому их не нужно учитывать при индексировании. Робот Яндекса, следуя инструкциям Clean-param, не будет обходить страницы с динамическими параметрами, которые полностью дублируют контент основных страниц.
Labrika определяет некорректный формат директивы Clean-param, например:
В именах GET-параметров встречается два или более знака амперсанд «&» подряд:
Clean-param: sort&&session /category
Правильный вариант:
Clean-param: sort&session /category
Правило должно соответствовать виду «p0[&p1&p2&..&pn] [path]». В первом поле через символ «&» перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых применяется правило. Параметры отделяются от префикса пути пробелом.
Имена GET-параметров должны содержать только буквы латинского алфавита, цифры, нижнее подчеркивание и дефис.
Префикс PATH URL для директивы Clean-param может включать только буквы латинского алфавита, цифры и некоторые символы: «.», «-«, «/», «*», «_».
Ошибкой считается и превышение допустимой длины правила — 500 символов.
Строка содержит BOM (Byte Order Mark) — символ U+FEFF
BOM (Byte Order Mark — маркер последовательности байтов) — символ вида U+FEFF, который находится в самом начале текста. Этот Юникод-символ используется для определения последовательности байтов при считывании информации.
При создании и редактировании файла с помощью стандартных программ редакторы могут автоматически присвоить ему кодировку UTF-8 с BOM меткой.
BOM – это невидимый символ. У него нет графического выражения, поэтому большинство редакторов его не показывает. Но при копировании этот символ может переноситься в новый документ.
При использовании маркера последовательности байтов в файлах .html сбиваются настройки дизайна, сдвигаются блоки, могут появляться нечитаемые наборы символов, поэтому рекомендуется удалять маркер из веб-скриптов и CSS-файлов.
Как избавиться от BOM меток?
Избавиться от ВОМ довольно сложно. Один из простых способов это сделать — открыть файл в редакторе, который может изменять кодировку документа, и пересохранить его с кодировкой UTF-8 без BOM.
Например, вы можете бесплатно скачать редактор Notepad++, открыть в нём файл с ВОМ меткой и выбрать во вкладке меню «Кодировки» пункт «Кодировать в UTF-8 (без BOM)».
Страница 404 призвана сообщать пользователю, что заданный им url (адрес страницы) не существует.
Такие неправильные урлы еще можно назвать «битыми ссылками».
Многие сайты делают свои страницы 404 для удобства своих пользователей. Часто это красивые и интересные страницы, которые вызывают у пользователя улыбку вместо разочарования от того, что адрес страницы неправильный.
При создании страницы 404 есть важная техническая составляющая, которая сильно влияет на ранжирование сайтов в поисковых системах, если все не настроено правильно.
Если вы озадачились созданием страницы 404, то вам нужно учитывать три момента:
1) Переадресация со всех неправильно введенных url на страницу 404 в .htaccess.
2) Правильный ответ сервера после переадресации (http-код страницы должен быть 404, а не 200).
3) Закрытие страницы 404 от индексации в robots.txt
Сразу отмечу, что все вышеизложенное написано для самописных сайтов, преимущественно на php. Для wordpress существуют плагины по настройке того же самого. Но в этой статье мы рассмотрим, как все выглядит в реальности. %)
ЕСЛИ КРАТКО, то нужно сделать следующее:
I. В файле .htaccess добавить строку:
—————
ErrorDocument 404 http://mysite.com/404.php
—————
Это перенаправит все неправильные (битые) ссылки на страницу — 404.php. Детали ниже в статье.
II. В файле 404.php в самом начале php-кода пишите:
—————
—————
Это даст правильный ответ о статусе страницы. Не 200, не 302, а 404 — потому что страницы, на которую якобы хотел перейти пользователь — не существует. Как это проверить — читайте ниже.
III. В файле rodots.txt делаете следующую запись:
—————
User-agent: *
Disallow:
Disallow: /404.php
—————-
Это закрывает страницу 404.php от индексации поисковыми системами. В этом пункте будьте аккуратны. Детали читайте ниже.
Дальше каждый пункт расписан в деталях! Если вам достаточно короткого описания… то благодарности принимаются в виде комментариев и лайков.

Переадресация (редирект) неправильных url на страницу 404
Первое, что вы делаете – создаете саму страницу 404, чтобы было куда людей посылать %).
Перенаправление url настраивается в файле .htaccess
Просто вписываете строчку:
ErrorDocument 404 http://mysite.com/404.php
Где «mysite.com» – ваш домен, а http://mysite.com/404.php — путь к реальной странице. Если ваш сайт на html, то строка будет выглядеть как:
ErrorDocument 404 http://mysite.com/404.html
Проверка очень проста. После заливки на хостинг файла .htaccess с вышеуказанной строкой, делаете проверку, вводя заведомо не существующий урл (битая ссылка), например: http://mysite.com/$%$%
Если переадресация на созданную вами страницу произошла, значит все работает.
Итак, полностью файл .htaccess, где настроена ТОЛЬКО переадресация на 404 будет выглядеть так:
____________________________
RewriteEngine on
ErrorDocument 404 http://mysite.com/404.html
____________________________
Правильный ответ сервера (http-код страницы)
Очень важно, чтобы при перенаправлении был правильный ответ сервера, а именно – 404 Not Found.
Тут следует объяснить отдельно.
Любому url при запросе назначается статус (http-код страницы).
• Для всех существующих страниц, это: HTTP/1.1 200 OK
• Для страниц перенаправленных: HTTP/1.1 302 Found
• Если страницы не существует, это должен быть HTTP/1.1 404 Not Found
То есть, какой бы урл не был введен, ему присваивается статус, определенный код ответа сервера.
Проверить ответ сервера можно:
1. Консоль браузера, закладка Network. Нажмите F12 для Chrome. Или Ctrl + Shift + I — подходит и для Chrome и для Opera.
2. На такой ресурсе как bertal.ru
3. SEARCH CONCOLE GOOGLE – Сканирование/Посмотреть как GOOGLE бот.
Когда у вас не было перенаправления через .htaccess на страницу 404, то на любой несуществующий url, введенный пользователем, а также на битые ссылки был ответ «HTTP/1.1 404 Not Found»
Итак, после краткой теоретической части, вернемся к нашим
баранам
настройкам.
После того, как вы настроили перенаправление на свою авторскую страницу 404 через .htaccess, как описано выше, то вводя битую ссылку (неверный url, который заведомо не существует), типа http://mysite.com/$%$%, ответ сервера будет:
— сначала HTTP/1.1 302 Found (перенаправление),
— а затем HTTP/1.1 200 OK (страница существует).
Проверьте через bertal.ru.
Чем это грозит? Это будет означать, что гугл в свою базу данных (индекс) может внести все битые ссылки, как существующие страницы с содержанием страницы 404. По сути — дубли страниц. А это невероятно вредно для поисковой оптимизации (SEO).
В этом случае нужно сделать две вещи:
1) Настроить правильный ответ сервера на странице 404.
2) Закрыть от индексирования страницу 404. Это делается через файл robots.txt
Настраиваем ответ сервера HTTP/1.1 404 Not Found для несуществующих страниц
Ответ сервера настраивается благодаря функции php в самом начале страницы 404.php:
Пишите ее вначале файла 404.php.
В результате мы должны получить ответ на битую ссылку:
Пример страницы 404.php. Вот как это выглядит +/-:
Естественно, что у вас скорее всего сайт полностью на php и динамический, то просто вставляете строку с ответом сервера в начало — перед всеми переменными и подключенными шаблонами.
Закрыть страницу 404 от индексирования
Закрыть страницу от индексирования можно в файле rodots.txt. Будьте внимательны с этим инструментом, ведь через этот файл ваш сайт, по сути, общается с поисковыми роботами!
Полный текст файла rodots.txt, где ТОЛЬКО закрыта индексация 404 страницы, выглядит так:
____________________________
User-agent: *
Disallow:
Disallow: /404.php
____________________________
Первая строка User-agent: * сообщает, что правило для всех поисковых систем.
Вторая строка Disallow: сообщает что весь сайт открыт для индексации.
Третья строка Disallow: /404.php закрывает индексацию для страницы /404.php, которая находится в корневой папке.
Замечания по коду: «/404.php» означает путь к странице. Если на вашем сайте страница 404.php (или 404.html соответственно) находится в какой-то папке, то путь будет выглядеть:
/holder/404.php
где «holder» — название папки.
Вот, собственно и все по странице 404. Проверьте работу страницы, перенаправления битых ссылок, и ответы серверов.
Повторюсь: Все вышеизложенное для самописных сайтов. Если вы используете wordpress, то можете поискать приличный плагин для настройки ошибки 404.
Благодарности принимаются в виде комментариев
Читать также:
Быстро создать свой сайт на WordPress
Сколько стоит создать сайт
Как залить сайт на хостинг
Зарегистрировать торговую марку самостоятельно
Самое ценное на сайте
Сайт бесплатно – это миф!
Продвижение сайта
Резервная копия сайта (бэкап)
Страница 404 призвана сообщать пользователю, что заданный им url (адрес страницы) не существует.
Такие неправильные урлы еще можно назвать «битыми ссылками».
Многие сайты делают свои страницы 404 для удобства своих пользователей. Часто это красивые и интересные страницы, которые вызывают у пользователя улыбку вместо разочарования от того, что адрес страницы неправильный.
При создании страницы 404 есть важная техническая составляющая, которая сильно влияет на ранжирование сайтов в поисковых системах, если все не настроено правильно.
Если вы озадачились созданием страницы 404, то вам нужно учитывать три момента:
1) Переадресация со всех неправильно введенных url на страницу 404 в .htaccess.
2) Правильный ответ сервера после переадресации (http-код страницы должен быть 404, а не 200).
3) Закрытие страницы 404 от индексации в robots.txt
Сразу отмечу, что все вышеизложенное написано для самописных сайтов, преимущественно на php. Для wordpress существуют плагины по настройке того же самого. Но в этой статье мы рассмотрим, как все выглядит в реальности. %)
ЕСЛИ КРАТКО, то нужно сделать следующее:
I. В файле .htaccess добавить строку:
—————
ErrorDocument 404 http://mysite.com/404.php
—————
Это перенаправит все неправильные (битые) ссылки на страницу — 404.php. Детали ниже в статье.
II. В файле 404.php в самом начале php-кода пишите:
—————
—————
Это даст правильный ответ о статусе страницы. Не 200, не 302, а 404 — потому что страницы, на которую якобы хотел перейти пользователь — не существует. Как это проверить — читайте ниже.
III. В файле rodots.txt делаете следующую запись:
—————
User-agent: *
Disallow:
Disallow: /404.php
—————-
Это закрывает страницу 404.php от индексации поисковыми системами. В этом пункте будьте аккуратны. Детали читайте ниже.
Дальше каждый пункт расписан в деталях! Если вам достаточно короткого описания… то благодарности принимаются в виде комментариев и лайков.
Переадресация (редирект) неправильных url на страницу 404
Первое, что вы делаете – создаете саму страницу 404, чтобы было куда людей посылать %).
Перенаправление url настраивается в файле .htaccess
Просто вписываете строчку:
ErrorDocument 404 http://mysite.com/404.php
Где «mysite.com» – ваш домен, а http://mysite.com/404.php — путь к реальной странице. Если ваш сайт на html, то строка будет выглядеть как:
ErrorDocument 404 http://mysite.com/404.html
Проверка очень проста. После заливки на хостинг файла .htaccess с вышеуказанной строкой, делаете проверку, вводя заведомо не существующий урл (битая ссылка), например: http://mysite.com/$%$%
Если переадресация на созданную вами страницу произошла, значит все работает.
Итак, полностью файл .htaccess, где настроена ТОЛЬКО переадресация на 404 будет выглядеть так:
____________________________
RewriteEngine on
ErrorDocument 404 http://mysite.com/404.html
____________________________
Правильный ответ сервера (http-код страницы)
Очень важно, чтобы при перенаправлении был правильный ответ сервера, а именно – 404 Not Found.
Тут следует объяснить отдельно.
Любому url при запросе назначается статус (http-код страницы).
• Для всех существующих страниц, это: HTTP/1.1 200 OK
• Для страниц перенаправленных: HTTP/1.1 302 Found
• Если страницы не существует, это должен быть HTTP/1.1 404 Not Found
То есть, какой бы урл не был введен, ему присваивается статус, определенный код ответа сервера.
Проверить ответ сервера можно:
1. Консоль браузера, закладка Network. Нажмите F12 для Chrome. Или Ctrl + Shift + I — подходит и для Chrome и для Opera.
2. На такой ресурсе как bertal.ru
3. SEARCH CONCOLE GOOGLE – Сканирование/Посмотреть как GOOGLE бот.
Когда у вас не было перенаправления через .htaccess на страницу 404, то на любой несуществующий url, введенный пользователем, а также на битые ссылки был ответ «HTTP/1.1 404 Not Found»
Итак, после краткой теоретической части, вернемся к нашим
баранам
настройкам.
После того, как вы настроили перенаправление на свою авторскую страницу 404 через .htaccess, как описано выше, то вводя битую ссылку (неверный url, который заведомо не существует), типа http://mysite.com/$%$%, ответ сервера будет:
— сначала HTTP/1.1 302 Found (перенаправление),
— а затем HTTP/1.1 200 OK (страница существует).
Проверьте через bertal.ru.
Чем это грозит? Это будет означать, что гугл в свою базу данных (индекс) может внести все битые ссылки, как существующие страницы с содержанием страницы 404. По сути — дубли страниц. А это невероятно вредно для поисковой оптимизации (SEO).
В этом случае нужно сделать две вещи:
1) Настроить правильный ответ сервера на странице 404.
2) Закрыть от индексирования страницу 404. Это делается через файл robots.txt
Настраиваем ответ сервера HTTP/1.1 404 Not Found для несуществующих страниц
Ответ сервера настраивается благодаря функции php в самом начале страницы 404.php:
Пишите ее вначале файла 404.php.
В результате мы должны получить ответ на битую ссылку:
Пример страницы 404.php. Вот как это выглядит +/-:
Естественно, что у вас скорее всего сайт полностью на php и динамический, то просто вставляете строку с ответом сервера в начало — перед всеми переменными и подключенными шаблонами.
Закрыть страницу 404 от индексирования
Закрыть страницу от индексирования можно в файле rodots.txt. Будьте внимательны с этим инструментом, ведь через этот файл ваш сайт, по сути, общается с поисковыми роботами!
Полный текст файла rodots.txt, где ТОЛЬКО закрыта индексация 404 страницы, выглядит так:
____________________________
User-agent: *
Disallow:
Disallow: /404.php
____________________________
Первая строка User-agent: * сообщает, что правило для всех поисковых систем.
Вторая строка Disallow: сообщает что весь сайт открыт для индексации.
Третья строка Disallow: /404.php закрывает индексацию для страницы /404.php, которая находится в корневой папке.
Замечания по коду: «/404.php» означает путь к странице. Если на вашем сайте страница 404.php (или 404.html соответственно) находится в какой-то папке, то путь будет выглядеть:
/holder/404.php
где «holder» — название папки.
Вот, собственно и все по странице 404. Проверьте работу страницы, перенаправления битых ссылок, и ответы серверов.
Повторюсь: Все вышеизложенное для самописных сайтов. Если вы используете wordpress, то можете поискать приличный плагин для настройки ошибки 404.
Благодарности принимаются в виде комментариев 
Читать также:
Быстро создать свой сайт на WordPress
Сколько стоит создать сайт
Как залить сайт на хостинг
Зарегистрировать торговую марку самостоятельно
Самое ценное на сайте
Сайт бесплатно – это миф!
Продвижение сайта
Резервная копия сайта (бэкап)
Подробный SEO-гайд по Отчёту об индексировании Google Search Console. Разберёмся, как проверить индексацию сайта с его помощью, как «читать» статусы URL, какие ошибки можно обнаружить и как их исправить.
Перевод с сайта onely.com.
В Отчёте вы можете получить данные о сканировании и индексации всех URL-адресов, которые Google смог обнаружить на вашем сайте. Он поможет отследить, добавлен ли сайт в индекс, и проинформирует о технических проблемах со сканированием и индексацией.
Но перед тем, как говорить об Отчёте, вспомним все этапы индексации страницы в Google.
Как проходит индексация в Google
Чтобы страница ранжировалась в поиске и показывалась пользователям, она должна быть обнаружена, просканирована и проиндексирована.
Обнаружение
Перед тем, как просканировать страницу, Google должен её обнаружить. Он может сделать это несколькими способами.
Наиболее распространённые — с помощью внутренних или внешних ссылок или через карту сайта (файл Sitemap.xml).
Сканирование
Суть сканирования состоит и том, что поисковые системы изучают страницу и анализируют её содержимое.
Главный аспект в этом вопросе — краулинговый бюджет, который представляет собой лимит времени и ресурсов, который поисковая система готова «потратить» на сканирование вашего сайта.
Что такое «краулинговый бюджет, как его проверить и оптимизировать
Индексация
В процессе индексации Google оценивает качество страницы и добавляет её в индекс — базу данных, где собраны все страницы, о которых «знает» Google.
В этот этап включается и рендеринг, который помогает Google видеть макет и содержимое страницы. Собранная информация даёт поисковой системе понимание, как показывать страницу в результатах поиска.
Даже если Google нашёл и просканировал страницу, это не означает, что она обязательно будет проиндексирована.
Но главное, что вы должны понять и запомнить: нет необходимости в том, чтобы абсолютно все страницы вашего сайты были проиндексированы. Вместо этого убедитесь, что в индекс включены все важные и полезные для пользователей страницы с качественным контентом.
Некоторые страницы могут содержать контент низкого качества или быть дублями. Если поисковые системы их увидят, это может негативно отразится на всём сайте.
Поэтому важно в процессе создания стратегии индексации решить, какие страницы должны и не должны быть проиндексированы.
Ранжирование
Только проиндексированные страницы могут появиться в результатах поиска и ранжироваться.
Google определяет, как ранжировать страницу, основываясь на множестве факторов, таких как количество и качество ссылок, скорость страницы, удобство мобильной версии, релевантность контента и др.
Теперь перейдём к Отчёту.
Как пользоваться Отчётом об индексировании в Google Search Console
Чтобы просмотреть Отчёт, авторизуйтесь в своём аккаунте Google Search Console. Затем в меню слева выберите «Покрытие» в секции «Индекс»:
Перед вами Отчёт. Отметив галочками любой из статусов или все сразу, вы сможете выбрать то, что хотите визуализировать на графике:
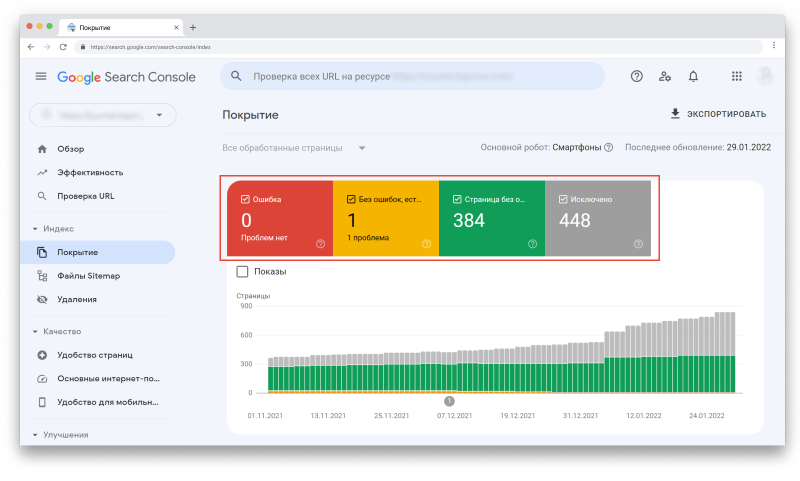
Вы увидите четыре статуса URL-адресов:
- Ошибка — критическая проблема сканирования или индексации.
- Без ошибок, есть предупреждения — URL-адреса проиндексированы, но содержат некоторые некритичные ошибки.
- Страница без ошибок — страницы проиндексированы корректно.
- Исключено — страницы, которые не были проиндексированы из-за проблем (это самый важный раздел, на котором нужно сфокусироваться).
Фильтры «Все обработанные страницы» vs «Все отправленные страницы»
В верхнем углу вы можете отфильтровать, какие страницы хотите видеть:
«Все обработанные страницы» показываются по умолчанию. В этот фильтр включены все URL-адреса, которые Google смог обнаружить любым способом.
Фильтр «Все отправленные страницы» включает только URL-адреса, добавленные с помощью файла Sitemap.
В чём разница?
Первый обычно включает в себя больше URL-адресов и многие из них попадают в секцию «Исключено». Это происходит потому, что карта сайта включает только индексируемые URL, в то время как сайты обычно содержат множество страниц, которые не должны быть проиндексированы.
Как пример — URL с параметрами на сайтах eCommerce. Googlebot может найти их разными способами, но не в карте сайта.
Так что когда открываете Отчёт, убедитесь, что смотрите нужные данные.
Проверка статусов URL
Чтобы увидеть подробную информацию о проблемах, обнаруженных для каждого статуса, посмотрите «Сведения» под графиком:

Тут показан статус, тип проблемы и количество затронутых страниц. Обратите внимание на столбец «Проверка» — после исправления ошибки, вы можете попросить Google проверить URL повторно.
Например, если кликнуть на первую строку со статусом «Предупреждение», то вверху появится кнопка «Проверить исправление»:
Вы также можете увидеть динамику каждого статуса: увеличилось, уменьшилось или осталось на том же уровне количество URL-адресов в этом статусе.
Если в «Сведениях» кликнуть на любой статус, вы увидите количество адресов, связанных с ним. Кроме того, вы сможете посмотреть, когда каждая страница была просканирована (но помните, что эта информация может быть неактуальна из-за задержек в обновлении отчётов).
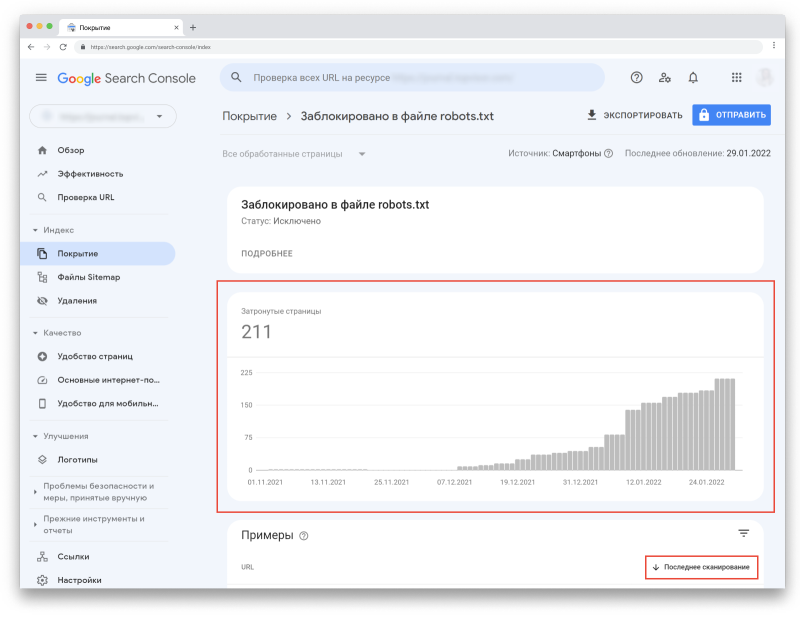
Что учесть при использовании отчёта
- Всегда проверяйте, смотрите ли вы отчёт по всем обработанным или по всем отправленным страницам. Разница может быть очень существенной.
- Отчёт может показывать изменения с задержкой. После публикации контента подождите несколько дней, пока страницы просканируются и проиндексируются.
- Google пришлёт уведомления на электронную почту, если увидит какие-то критичные проблемы с сайтом.
- Стремитесь к индексации канонической версии страницы, которую вы хотите показывать пользователям и поисковым ботам.
- В процессе развития сайта, на нём будет появляться больше контента, так что ожидайте увеличения количества проиндексированных страниц в Отчёте.
Как часто смотреть Отчёт
Обычно достаточно делать это раз в месяц.
Но если вы внесли значимые изменения на сайте, например, изменили макет страницы, структуру URL или сделали перенос сайта, мониторьте Отчёт чаще, чтобы вовремя поймать негативное влияние изменений.
Рекомендую делать это хотя бы раз в неделю и обращать особое внимание на статус «Исключено».
Дополнительно: инструмент проверки URL
В Search Console есть ещё один инструмент, который даст ценную информацию о сканировании и индексации страниц вашего сайта — Инструмент проверки URL.
Он находится в самом верху страницы в GSC:
Просто вставьте URL, который вы хотите проверить, в эту строку и увидите данные по нему. Например:

Инструментом можно пользоваться для того, чтобы:
- проверить статус индексирования URL, и обнаружить возможные проблемы;
- узнать, индексируется ли URL;
- просмотреть проиндексированную версию URL;
- запросить индексацию, например, если страница изменилась;
- посмотреть загруженные ресурсы, например, такие как JavaScript;
- посмотреть, какие улучшения доступны для URL, например, реализация структурированных данных или удобство для мобильных.
Если в Отчёте об индексировании обнаружены какие-то проблемы со страницами, используйте Инструмент, чтобы тщательнее проверить их и понять, что именно нужно исправить.
Статус «Ошибка»
Под этим статусом собраны URL, которые не были проиндексированы из-за ошибок.
Если вы видите проблему с пометкой «Отправлено», то это может касаться только URL, которые были отправлены через карту сайту. Убедитесь, что в карте сайте содержатся только те страницы, которые вы действительно хотите проиндексировать.
Ошибка сервера (5xx)
Эта проблема говорит об ошибке сервера со статусом 5xx, например, 502 Bad Gateway или 503 Service Unavailable.
Советую регулярно проверять этот раздел и следить, нет ли у Googlebot проблем с индексацией страниц из-за ошибки сервера.
Что делать. Нужно связаться с вашим хостинг-провайдером, чтобы исправить эту проблему или проверить, не вызваны ли эти ошибки недавними обновлениями и изменениями на сайте.
Как исправить ошибки сервера — рекомендации Google
Ошибка переадресации
Редиректы перенаправляют поисковых ботов и пользователей со старого URL на новый. Обычно они применяются, если старый адрес изменился или страницы больше не существует.
Ошибки переадресации могут указывать на такие проблемы:
- цепочка редиректов слишком длинная;
- обнаружен циклический редирект — страницы переадресуют друг на друга;
- редирект настроен на страницу, URL которой превышает максимальную длину;
- в цепочке редиректов найден пустой или ошибочный URL.
Что делать. Проверьте и исправьте редиректы каждой затронутой страницы.
Доступ к отправленному URL заблокирован в файле robots.txt
Эти страницы есть в файле Sitemap, но заблокированы в файле robots.txt.
Robots.txt — это файл, который содержит инструкции для поисковых роботов о том, как сканировать ваш сайт. Чтобы URL был проиндексирован, Google нужно для начала его просканировать.
Что делать. Если вы видите такую ошибку, перейдите в файл robots.txt и проверьте настройку директив. Убедитесь, что страницы не закрыты через noindex.
Страница, связанная с отправленным URL, содержит тег noindex
По аналогии с предыдущей ошибкой, эта страница была отправлена на индексацию, но она содержит директиву noindex в метатеге или в заголовке ответа HTTP.
Что делать. Если страница должна быть проиндексирована, уберите noindex.
Отправленный URL возвращает ложную ошибку 404
Ложная ошибка 404 означает, что страница возвращает статус 200 OK, но её содержимое может указывать на ошибку. Например, страница пустая или содержит слишком мало контента.
Что делать. Проверьте страницы с ошибками и посмотрите, есть ли возможность изменить контент или настроить редирект.
Отправленный URL возвращает ошибку 401 (неавторизованный запрос)
Ошибка 401 Unauthorized означает, что запрос не может быть обработан, потому что необходимо залогиниться под правильными user ID и паролем.
Что делать. Googlebot не может индексировать страницы, скрытые за логинами. Или уберите необходимость авторизации или подтвердите авторизацию Googlebot, чтобы он мог получить доступ к странице.
Отправленный URL не найден (ошибка 404)
Ошибка 404 говорит о том, что запрашиваемая страница не найдена, потому что была изменена или удалена. Такие страницы есть на каждом сайте и наличие их в малом количестве обычно ни на что не влияет. Но если пользователи будут находить такие страницы, это может отразиться негативно.
Что делать. Если вы увидели эту проблему в отчёте, перейдите на затронутые страницы и проверьте, можете ли вы исправить ошибку. Например, настроить 301-й редирект на рабочую страницу.
Дополнительно убедитесь, что файл Sitemap не содержит URL, которые возвращают какой-либо другой код состояния HTTP кроме 200 OK.
При отправке URL произошла ошибка 403
Код состояния 403 Forbidden означает, что сервер понимает запрос, но отказывается авторизовывать его.
Что делать. Можно либо предоставить доступ анонимным пользователям, чтобы робот Googlebot мог получить доступ к URL, либо, если это невозможно, удалить URL из карты сайта.
URL заблокирован из-за ошибки 4xx (ошибка клиента)
Страница может быть непроиндексирована из-за других ошибок 4xx, которые не описаны выше.
Что делать. Чтобы понять, о какой именно ошибке речь, используйте Инструмент проверки URL. Если устранить ошибку невозможно, уберите URL из карты сайта.
Статус «Без ошибок, есть предупреждения»
URL без ошибок, но с предупреждениями, были проиндексированы, но могут требовать вашего внимания. Тут обычно случается две проблемы.
Проиндексировано, несмотря на блокировку в файле robots.txt
Обычно эти страницы не должны быть проиндексированы, но скорее всего Google нашёл ссылки, указывающие на них, и посчитал их важными.
Что делать. Проверьте эти страницы. Если они всё же должны быть проиндексированы, то обновите файл robots.txt, чтобы Google получил к ним доступ. Если не должны — поищите ссылки, которые на них указывают. Если вы хотите, чтобы URL были просканированы, но не проиндексированы, добавьте директиву noindex.
Страница проиндексирована без контента
URL проиндексированы, но Google не смог прочитать их контент. Это может быть из-за таких проблем:
- Клоакинг — маскировка контента, когда Googlebot и пользователи видят разный контент.
- Страница пустая.
- Google не может отобразить страницу.
- Страница в формате, который Google не может проиндексировать.
Зайдите на эти страницы сами и проверьте, виден ли на них контент. Также проверьте их через Инструмент проверки URL и посмотрите, как их видит Googlebot. После того, как устраните ошибки, или если не обнаружите каких-либо проблем, вы можете запросить у Google повторное индексирование.
Статус «Страница без ошибок»
Здесь показываются страницы, которые корректно проиндексированы. Но на эту часть Отчёта всё равно нужно обращать внимание, чтобы сюда не попали страницы, которые не должны были оказаться в индексе. Тут тоже есть два статуса.
Страница была отправлена в Google и проиндексирована
Это значит, что страницы отправлена через Sitemap и Google её проиндексировал.
Страница проиндексирована, но её нет в файле Sitemap
Это значит, что страница проиндексирована даже несмотря на то, что её нет в Sitemap. Посмотрите, как Google нашёл эту страницу, через Инструмент проверки URL.
Чаще всего страницы в этом статусе — это страницы пагинации, что нормально, учитывая, что их и не должно быть в Sitemap. Посмотрите список этих URL, вдруг какие-то из них стоит добавить в карту сайта.
Статус «Исключено»
В этом статусе находятся страницы, которые не были проиндексированы. В большинстве случаев это вызвано теми же проблемами, которые мы обсуждали выше. Единственное различие в том, что Google не считает, что исключение этих страниц вызвано какой-либо ошибкой.
Вы можете обнаружить, что многие URL здесь исключены по разумным причинам. Но регулярный просмотр Отчёта поможет убедиться, что не исключены важные страницы.
Индексирование страницы запрещено тегом noindex
Что делать. Тут то же самое — если страница и не должна быть проиндексирована, то всё в порядке. Если должна — удалите noindex.
Индексирование страницы запрещено с помощью инструмента удаления страниц
У Google есть Инструмент удаления страниц. Как правило с его помощью Google удаляет страницы из индекса не навсегда. Через 90 дней они снова могут быть проиндексированы.
Что делать. Если вы хотите заблокировать страницу насовсем, вы можете удалить её, настроит редирект, внедрить авторизацию или закрыть от индексации с помощью тега noindex.
Заблокировано в файле robots.txt
У Google есть Инструмент проверки файла robots.txt, где вы можете в этом убедиться.
Что делать. Если эти страницы и не должны быть в индексе, то всё в порядке. Если должны — обновите файл robots.txt.
Помните, что блокировка в robots.txt — не стопроцентный вариант закрыть страницу от индексации. Google может проиндексировать её, например, если найдёт ссылку на другой странице. Чтобы страница точно не была проиндексирована, используйте директиву noindex.
Подробнее о блокировке индексирования при помощи директивы noindex
Страница не проиндексирована вследствие ошибки 401 (неавторизованный запрос)
Обычно это происходит на страницах, защищённых паролем.
Что делать. Если они и не должны быть проиндексированы, то ничего делать не нужно. Если вы не хотите, чтобы Google обнаруживал эти страницы, уберите существующие внутренние и внешние ссылки на них.
Страница просканирована, но пока не проиндексирована
Это значит, что страница «ждёт» решения. Для этого может быть несколько причин. Например, с URL нет проблем и вскоре он будет проиндексирован.
Но чаще всего Google не будет торопиться с индексацией, если контент недостаточно качественный или выглядит похожим на остальные страницы сайта.
В этом случае он поставит её в очередь с низким приоритетом и сфокусируется на индексации более важных страниц. Google говорит, что отправлять такие страницы на переиндексацию не нужно.
Что делать. Для начала убедитесь, что это не ошибка. Проверьте, действительно ли URL не проиндексирован, в Инструменте проверки URL или через инструмент «Индексация» в Анализе сайта в Топвизоре. Они показывают более свежие данные, чем Отчёт.
Как исправить ошибку, когда страница просканирована, но не проиндексирована (на английском)
Обнаружена, не проиндексирована
Это значит, что Google увидел страницу, например, в карте сайта, но ещё не просканировал её. В скором времени страница может быть просканирована.
Иногда эта проблема возникает из-за проблем с краулинговым бюджетом. Google может посчитать сайт некачественным, потому что ему не хватает производительности или на нём слишком мало контента.
Что такое краулинговый бюджет и как его оптимизировать
Возможно, Google не нашёл каких-либо ссылок на эту страницу или нашёл страницы с большим ссылочным весом и посчитал их более приоритетными для сканирования.
Если на сайте есть более качественные и важные страницы, Google может игнорировать менее важные страницы месяцами или даже никогда их не просканировать.
Вариант страницы с тегом canonical
Эти URL — дубли канонической страницы, отмеченные правильным тегом, который указывает на основную страницу.
Что делать. Ничего, вы всё сделали правильно.
Страница является копией, канонический вариант не выбран пользователем
Это значит, что Google не считает эти страницы каноническими. Посмотрите через Инструмент проверки URL какую страницу он считает канонической.
Что делать. Выберите страницу, которая по вашему мнению является канонической, и разметьте дубли с помощью rel=”canonical”.
Страница является копией, канонические версии страницы, выбранные Google и пользователем, не совпадают
Вы выбрали каноническую страницу, но Google решил по-другому. Возможно, страница, которую вы выбрали, не имеет столько внутреннего ссылочного веса, как неканоническая.
Что делать. В этом случае может помочь объединение URL повторяющихся страниц.
Как правильно настроить внутренние ссылки на сайте
Не найдено (404)
URL нет в Sitemap, но Google всё равно его обнаружил. Возможно, это произошло с помощью ссылки на другом сайте или ранее страница существовала и была удалена.
Что делать. Если вы и не хотели, чтобы Google индексировал страницу, то ничего делать не нужно. Другой вариант — поставить 301-й редирект на работающую страницу.
Страница с переадресацией
Эта страница редиректит на другую страницу, поэтому не была проиндексирована. Обычно, такие страницы не требуют внимания.
Что делать. Эти страницы и не должны быть проиндексированы, так что делать ничего не нужно.
Для постоянного редиректа убедитесь, что вы настроили перенаправление на ближайшую альтернативную страницу, а не на Главную. Редирект страницы с 404 ошибкой на Главную может определять её как soft 404.
@JohnMu what does Google do when a site redirects all its 404s to the homepage? Seeing more and more sites do this and it’s such an anti-pattern.
— Joost de Valk (@jdevalk) January 7, 2019
Yeah, it’s not a great practice (confuses users), and we mostly treat them as 404s anyway (they’re soft-404s), so there’s no upside. It’s not critically broken/bad, but additional complexity for no good reason — make a better 404 page instead.
— ? John ? (@JohnMu) January 8, 2019
Ложная ошибка 404
Обычно это страницы, на которых пользователь видит сообщение «не найдено», но которые не сопровождаются кодом ошибки 404.
Что делать. Для исправления проблемы вы можете:
- Добавить или улучшить контент таких страниц.
- Настроить 301-й редирект на ближайшую альтернативную страницу.
- Настроить сервер, чтобы он возвращал правильный код ошибки 404 или 410.
Страница является копией, отправленный URL не выбран в качестве канонического
Эти страницы есть в Sitemap, но для них не выбрана каноническая страница. Google считает их дублями и канонизировал их другими страницами, которые определил самостоятельно.
Что делать. Выберите и добавьте канонические страницы для этих URL.
Страница заблокирована из-за ошибки 403 (доступ запрещён)
Что делать. Если Google не может получить доступ к URL, лучше закрыть их от индексации с помощью метатега noindex или файла robots.txt.
URL заблокирован из-за ошибки 4xx (ошибка клиента)
Сервер столкнулся с ошибкой 4xx, которая не описана выше.
Гайд по ошибкам 4xx и способы их устранения (на английском)
Попробуйте исправить ошибки или оставьте страницы как есть.
Ключевые выводы
- Проверяя данные в Отчёте помните, что не все страницы сайта должны быть просканированы и проиндексированы.
- Закрыть от индексации некоторые страницы может быть так же важно, как и следить за тем, чтобы нужные страницы сайта индексировались корректно.
- Отчёт об индексировании показывает как критичные ошибки, так и неважные, которые не обязательно требуют действий с вашей стороны.
- Регулярно проверяйте Отчёт, но только для того, чтобы убедиться, что всё идёт по плану. Исправляйте только те ошибки, которые не соответствуют вашей стратегии индексации.

Во время работы над очередным сайтом на WordPress возникла необходимость генерировать robots.txt «на лету». К счастью, для этого WordPress располагает удобным функционалом — хуками robots_txt и do_robotstxt.
Так, например, можно создать виртуальные robots.txt
|
add_action( ‘do_robotstxt’, ‘make_robotstxt’ ); function make_robotstxt(){ $lines = [ ‘User-agent: *’, ‘Disallow: /wp-admin/’, ‘Disallow: /wp-login.php’, », ]; echo implode( «\r\n», $lines ); die; } |
А так можно внедриться в уже созданный в другом месте кода robots.txt
|
add_filter( ‘robots_txt’, ‘change_robotstxt’, —1 ); function change_robotstxt( $text ){ $text .= «Disallow: */page»; return $text; } |
Казалось бы, всё просто и понятно, однако вместо нужного содержимого robots.txt я получал 404 ошибку.
Судя по всему, wordpress даже не обрабатывал запрос при переходе на https://example.com/robots.txt
Оказалось, проблема была в конфиге nginx:
|
location = /robots.txt { allow all; access_log off; log_not_found off; } |
Nginx пытался найти в корне файл robots.txt (которго, не было) и отдавал ошибку 404.
Кстати, такой конфиг рекомендуется в официальной документации WordPress: https://wordpress.org/support/article/nginx/ Это довольно странно.
Исправить проблему достаточно просто. Меняем эту строку на следующую, и всё работает. Обращение к robots.txt обрабатывает WordPress.
|
location = /robots.txt { try_files $uri $uri/ /index.php?$args; access_log off; log_not_found off; } |
Можно поступить ещё проще, просто удалив или закомментировав строку
|
#location = /robots.txt { allow all; access_log off; log_not_found off; } |
Перезапускаем nginx и наслаждаемся.
-
Метки
nginx, wordpress
Роботы Google бывают двух типов. Одни (поисковые) действуют автоматически и поддерживают стандарт исключений для роботов (REP).
Это означает, что перед сканированием сайта они скачивают и анализируют файл robots.txt, чтобы узнать, какие разделы сайта для них открыты. Другие контролируются пользователями (например, собирают контент для фидов) или обеспечивают их безопасность (например, выявляют вредоносное ПО). Они не следуют этому стандарту.
В этой статье рассказывается о том, как Google интерпретирует стандарт REP. Ознакомиться с описанием самого стандарта можно здесь.
Что такое файл robots.txt
В файле robots.txt можно задать правила, которые запрещают поисковым роботам сканировать определенные разделы и страницы вашего сайта. Он создается в обычном текстовом формате и содержит набор инструкций. Так может выглядеть файл robots.txt на сайте example.com:
# This robots.txt file controls crawling of URLs under https://example.com. # All crawlers are disallowed to crawl files in the "includes" directory, such # as .css, .js, but Google needs them for rendering, so Googlebot is allowed # to crawl them. User-agent: * Disallow: /includes/ User-agent: Googlebot Allow: /includes/ Sitemap: https://example.com/sitemap.xml
Если вы только начинаете работать с файлами robots.txt, ознакомьтесь с общей информацией о них. Также мы подготовили для вас рекомендации по созданию файла и ответы на часто задаваемые вопросы.
Расположение файла и условия, при которых он действителен
Файл robots.txt должен находиться в каталоге верхнего уровня и передаваться по поддерживаемому протоколу. URL файла robots.txt (как и другие URL) должен указываться с учетом регистра. Google Поиск поддерживает протоколы HTTP, HTTPS и FTP. Для HTTP и HTTPS используется безусловный HTTP-запрос GET, а для FTP – стандартная команда RETR (RETRIEVE) и анонимный вход.
Правила, перечисленные в файле robots.txt, действительны только в отношении того хоста, где расположен файл, а также протокола и номера порта, по которым доступен этот файл.
Примеры действительных URL файла robots.txt
Примеры URL файла robots.txt и путей URL, для которых они действительны, приведены в таблице ниже.
В первом столбце указан URL файла robots.txt, а во втором – домены, к которым может или не может относиться этот файл.
| Примеры URL файла robots.txt | |
|---|---|
http://example.com/robots.txt |
Общий пример. Такой файл не действует в отношении других субдоменов, протоколов и номеров портов. При этом он действителен для всех файлов во всех подкаталогах, относящихся к тому же хосту, протоколу и номеру порта. Действителен для:
Недействителен для:
|
https://www.example.com/robots.txt |
Файл robots.txt в субдомене действителен только для этого субдомена. Действителен для: Недействителен для:
|
https://example.com/folder/robots.txt |
Недействительный файл robots.txt. Поисковые роботы не ищут файлы robots.txt в подкаталогах. |
https://www.exämple.com/robots.txt |
Эквивалентами IDN являются их варианты в кодировке Punycode. Ознакомьтесь также с документом RFC 3492. Действителен для:
Недействителен для: |
ftp://example.com/robots.txt |
Действителен для: Недействителен для: |
https://212.96.82.21/robots.txt |
Если robots.txt относится к хосту, имя которого совпадает с IP-адресом, то он действителен только при обращении к сайту по этому IP-адресу. Инструкции в нем не распространяются автоматически на все сайты, размещенные по этому IP-адресу (хотя файл robots.txt может быть для них общим, и тогда он будет доступен также по общему имени хоста). Действителен для: Недействителен для: |
https://example.com:80/robots.txt |
Если URL указан со стандартным портом ( Действителен для:
Недействителен для: |
https://example.com:8181/robots.txt |
Файлы robots.txt, размещенные не по стандартным номерам портов, действительны только для контента, который доступен по этим номерам портов. Действителен для: Недействителен для: |
Обработка ошибок и коды статуса HTTP
От того, какой код статуса HTTP вернет сервер при обращении к файлу robots.txt, зависит, как дальше будут действовать поисковые роботы Google. О том, как робот Googlebot обрабатывает файлы robots.txt для разных кодов статуса HTTP, рассказано в таблице ниже.
| Обработка ошибок и коды статуса HTTP | |
|---|---|
2xx (success) |
Получив один из кодов статуса HTTP, которые сигнализируют об успешном выполнении, робот Google начинает обрабатывать файл robots.txt, предоставленный сервером. |
3xx (redirection) |
Google выполняет пять переходов в цепочке переадресаций согласно RFC 1945. Затем поисковый робот прерывает операцию и интерпретирует ситуацию как ошибку Google не обрабатывает логические перенаправления в файлах robots.txt (фреймы, JavaScript или метатеги refresh). |
4xx (client errors) |
Поисковые роботы Google воспринимают все ошибки |
5xx (server errors) |
Поскольку сервер не может дать определенный ответ на запрос файла robots.txt, Google временно интерпретирует ошибки сервера Если вам необходимо временно остановить сканирование, рекомендуем передавать код статуса HTTP
Если нам удается определить, что сайт настроен неправильно и в ответ на запросы отсутствующих страниц возвращает ошибку |
| Другие ошибки | Если файл robots.txt невозможно получить из-за проблем с DNS или сетью (слишком долгого ожидания, недопустимых ответов, разрыва соединения, ошибки поблочной передачи данных по HTTP), это приравнивается к ошибке сервера. |
Кеширование
Содержание файла robots.txt обычно хранится в кеше не более суток, но может быть доступно и дольше в тех случаях, когда обновить кешированную версию невозможно (например, из-за истечения времени ожидания или ошибок 5xx). Сохраненный в кеше ответ может передаваться другим поисковым роботам.
Google может увеличить или уменьшить срок действия кеша в зависимости от значения атрибута max-age в HTTP-заголовке Cache-Control.
Формат файла
В файле robots.txt должен быть обычный текст в кодировке UTF-8. В качестве разделителей строк следует использовать символы CR, CR/LF и LF.
Добавляемая в начало файла robots.txt метка порядка байтов Unicode BOM игнорируется, как и недопустимые строки. Например, если вместо правил robots.txt Google получит HTML-контент, система попытается проанализировать контент и извлечь правила. Все остальное будет проигнорировано.
Если для файла robots.txt используется не UTF-8, а другая кодировка, то Google может проигнорировать символы, не относящиеся к UTF-8. В результате правила из файла robots.txt не будут работать.
В настоящее время максимальный размер файла, установленный Google, составляет 500 кибибайт (КиБ). Контент сверх этого лимита игнорируется. Чтобы не превысить его, применяйте более общие правила. Например, поместите все материалы, которые не нужно сканировать, в один каталог.
Синтаксис
Каждая действительная строка в файле robots.txt состоит из имени поля, двоеточия и значения. Использовать пробелы не обязательно, но рекомендуется для удобства чтения. Пробелы в начале и конце строки игнорируются. Чтобы добавить комментарии, начинайте их с символа #. Весь текст после символа # и до конца строки будет игнорироваться. Стандартный формат: <field>:<value><#optional-comment>.
Google поддерживает следующие поля:
user-agent: агент пользователя робота, для которого применяется правило.allow: путь URL, который можно сканировать.disallow: путь URL, который запрещено сканировать.sitemap: полный URL файла Sitemap.
Поля allow и disallow также называются правилами или директивами. Они всегда задаются в формате rule: [path], где значение [path] указывать необязательно. По умолчанию роботы могут сканировать весь контент. Они игнорируют правила без [path].
Значения [path] указываются относительно корневого каталога сайта, на котором находится файл robots.txt (используется тот же протокол, порт, хост и домен).
Значение пути должно начинаться с символа /, обозначающего корневой каталог. Регистр учитывается. Подробнее о соответствии значения пути конкретным URL…
user-agent
Строка user-agent определяет, для какого робота применяется правило. Полный список поисковых роботов Google и строк для различных агентов пользователя, которые можно добавить в файл robots.txt, вы можете найти здесь.
Значение строки user-agent обрабатывается без учета регистра.
disallow
Правило disallow определяет, какие пути не должны сканироваться поисковыми роботами, определенными строкой user-agent, с которой сгруппирована директива disallow.
Роботы игнорируют правило без указания пути.
Google не может индексировать контент страниц, сканирование которых запрещено, однако может индексировать URL и показывать его в результатах поиска без фрагмента. Подробнее о том, как блокировать индексирование…
Значение правила disallow обрабатывается с учетом регистра.
Синтаксис:
disallow: [path]
allow
Правило allow определяет пути, которые могут сканироваться поисковыми роботами. Если путь не указан, он игнорируется.
Значение правила allow обрабатывается с учетом регистра.
Синтаксис:
allow: [path]
sitemap
Google, Bing и другие крупные поисковые системы поддерживают поле sitemap из файла robots.txt. Дополнительную информацию вы можете найти на сайте sitemaps.org.
Значение поля sitemap обрабатывается с учетом регистра.
Синтаксис:
sitemap: [absoluteURL]
Строка [absoluteURL] указывает на расположение файла Sitemap или файла индекса Sitemap.
URL должен быть полным, с указанием протокола и хоста. Нет необходимости кодировать URL. Хост URL не обязательно должен быть таким же, как и у файла robots.txt. Вы можете добавить несколько полей sitemap. Эти поля не связаны с каким-либо конкретным агентом пользователя. Если их сканирование не запрещено, они доступны для всех поисковых роботов.
Пример:
user-agent: otherbot disallow: /kale sitemap: https://example.com/sitemap.xml sitemap: https://cdn.example.org/other-sitemap.xml sitemap: https://ja.example.org/テスト-サイトマップ.xml
Группировка строк и правил
Вы можете группировать правила, которые применяются для разных агентов пользователя. Просто повторите строки user-agent для каждого поискового робота.
Пример:
user-agent: a disallow: /c user-agent: b disallow: /d user-agent: e user-agent: f disallow: /g user-agent: h
В этом примере есть четыре группы правил:
- первая – для агента пользователя «a»;
- вторая – для агента пользователя «b»;
- третья – одновременно для агентов пользователей «e» и «f»;
- четвертая – для агента пользователя «h».
Техническое описание группы вы можете найти в разделе 2.1 этого документа.
Приоритет агентов пользователей
Для отдельного поискового робота действительна только одна группа. Он должен найти ту, в которой наиболее конкретно указан агент пользователя из числа подходящих. Другие группы игнорируются. Весь неподходящий текст игнорируется. Например, значения googlebot/1.2 и googlebot* эквивалентны значению googlebot. Порядок групп в файле robots.txt не важен.
Если агенту пользователя соответствует несколько групп, то все относящиеся к нему правила из всех групп объединяются в одну. Группы, относящиеся к определенным агентам пользователя, не объединяются с общими группами, которые помечены значком *.
Примеры
Сопоставление полей user-agent
user-agent: googlebot-news (group 1) user-agent: * (group 2) user-agent: googlebot (group 3)
Поисковые роботы выберут нужные группы следующим образом:
| Выбор групп различными роботами | |
|---|---|
| Googlebot-News |
googlebot-news выбирает группу 1, поскольку это наиболее конкретная группа.
|
| Googlebot (веб-поиск) | googlebot выбирает группу 3. |
| Google StoreBot |
Storebot-Google выбирает группу 2, поскольку конкретной группы Storebot-Google нет.
|
| Googlebot-News (при сканировании изображений) |
При сканировании изображений googlebot-news выбирает группу 1.googlebot-news не сканирует изображения для Google Картинок, поэтому выбирает только группу 1.
|
| Otherbot (веб-поиск) | Остальные поисковые роботы Google выбирают группу 2. |
| Otherbot (для новостей) |
Другие поисковые роботы Google, которые сканируют новости, но не являются роботами googlebot-news, выбирают группу 2. Даже если имеется запись для схожего робота, она недействительна без точного соответствия.
|
Группировка правил
Если в файле robots.txt есть несколько групп для определенного агента пользователя, выполняется внутреннее объединение этих групп. Пример:
user-agent: googlebot-news disallow: /fish user-agent: * disallow: /carrots user-agent: googlebot-news disallow: /shrimp
Поисковые роботы объединяют правила с учетом агента пользователя, как указано в примере кода ниже.
user-agent: googlebot-news disallow: /fish disallow: /shrimp user-agent: * disallow: /carrots
Парсер для файлов robots.txt игнорирует все правила, кроме следующих: allow, disallow, user-agent. В результате указанный фрагмент файла robots.txt обрабатывается как единая группа и правило disallow: /: влияет как на user-agent a, так и на b:
user-agent: a sitemap: https://example.com/sitemap.xml user-agent: b disallow: /
При обработке правил в файле robots.txt поисковые роботы игнорируют строку sitemap.
Например, вот как роботы обработали бы приведенный выше фрагмент файла robots.txt:
user-agent: a user-agent: b disallow: /
Соответствие значения пути конкретным URL
Google использует значение пути в правилах allow и disallow, чтобы определить, должно ли правило применяться к определенному URL на сайте. Для этого правило сравнивается с компонентом пути в URL, данные по которому пытается получить поисковый робот.
Символы, не входящие в набор 7-битных символов ASCII, можно указать в виде экранированных значений в кодировке UTF-8 (см. RFC 3986).
Google, Bing и другие крупные поисковые системы поддерживают определенные подстановочные знаки для путей:
*обозначает 0 или более вхождений любого действительного символа.$обозначает конец URL.
| Примеры | |
|---|---|
/ |
Соответствует корневому каталогу и всем URL более низкого уровня. |
/* |
Аналогичен элементу /. Подстановочный знак игнорируется. |
/$ |
Соответствует только корневому каталогу. На всех URL более низкого уровня разрешено сканирование. |
/fish |
Соответствует всем путям, которые начинаются с Соответствует:
Не соответствует:
|
/fish* |
Аналогичен элементу Соответствует:
Не соответствует:
|
/fish/ |
Соответствует любым элементам в папке Соответствует:
Не соответствует:
|
/*.php |
Соответствует всем путям, которые содержат Соответствует:
Не соответствует:
|
/*.php$ |
Соответствует всем путям, которые заканчиваются на Соответствует:
Не соответствует:
|
/fish*.php |
Соответствует всем путям, которые содержат Соответствует:
Не соответствует: |
Порядок применения правил
Когда роботы соотносят правила из файла robots.txt с URL, они используют самое строгое правило (с более длинным значением пути). При наличии конфликтующих правил (в том числе с подстановочными знаками) выбирается то, которое предполагает наименьшие ограничения.
Ознакомьтесь с примерами ниже.
| Примеры | |
|---|---|
https://example.com/page |
allow: /p disallow: /
Применяемое правило: |
https://example.com/folder/page |
allow: /folder disallow: /folder
Применяемое правило: |
https://example.com/page.htm |
allow: /page disallow: /*.htm
Применяемое правило: |
https://example.com/page.php5 |
allow: /page disallow: /*.ph
Применяемое правило: |
https://example.com/ |
allow: /$ disallow: /
Применяемое правило: |
https://example.com/page.htm |
allow: /$ disallow: /
Применяемое правило: |
Примерно 60% пользователей сталкивается с тем, что новый сайт имеет проблемы с продвижением в поиске из-за неправильно настроенного файла robots.txt. Поэтому не всегда стоит сразу после запуска вкладывать все ресурсы в SEO-тексты, ссылки или внешнюю рекламу, так как некорректная настройка одного единственного файла на сайте способна привести к фатальным результатам и полной потере трафика и клиентов. Однако, всего этого можно избежать, правильно настроив индексацию сайта, и сделать это можно даже не будучи техническим специалистом или программистом.
Что такое файл robots.txt?
Robots.txt это обычный текстовый файл, содержащий руководство для ботов поисковых систем (Яндекс, Google, etc.) по сканированию и индексации вашего сайта. Таким образом, каждый поисковый бот (краулер) при обходе страниц сайта сначала скачивает актуальную версию robots.txt (обновляет его содержимое в своем кэше), а затем, переходя по ссылкам на сайте, заносит в свой индекс только те страницы, которые разрешены к индексации в настройках данного файла.
User-agent: *
Disallow: /*?*
Disallow: /data/
Disallow: /scripts/
Disallow: /plugins/
Sitemap: https://somesite.com/sitemap.xml
При этом у каждого краулера существует такое понятие, как «краулинговый бюджет», определяющее, сколько страниц можно просканировать единоразово (для разных сайтов это значение варьируется: обычно в зависимости от объема и значимости сайта). То есть, чем больше страниц на сайте и чем популярнее ресурс, тем объемнее и чаще будет идти его обход краулерами, и тем быстрее эти данные попадут в поисковую выдачу (например, на крупных новостных сайтах поисковые боты постоянно сканируют контент на предмет поиска новой информации (можно сказать что «живут»), за счет чего поисковая система может выдавать пользователем самые актуальные новости уже через несколько секунд после их публикации на сайте).
Таким образом, из-за ограниченности краулингового бюджета рекомендуется отдавать поисковым ботам в приоритете только ту информацию, которая должна обновляться или появляться в индексе поисковиков наиболее быстро (например, важные, полезные и актуальные страницы сайта), а все прочее устаревшее и не нужное можно смело скрывать, тем самым не распыляя краулинговый бюджет на не имеющий ценности контент.
Вывод: для оптимизации индексирования сайта стоит исключать из сканирования дубликаты страниц, результаты локального поиска по сайту, личный кабинет, корзину, сравнения, сортировки и фильтры, пользовательские профили, виш-листы и всё, что не имеет ценности для обычного пользователя.
Как найти и просмотреть содержимое robots.txt?
Файл размещается в корне домена по адресу somesite.com/robots.txt.
Данный метод прост и работает для всех веб-ресурсов, на которых размещен robots.txt. Доступ у файла открытый, поэтому каждый может просмотреть файлы других сайтов и узнать, как они настроены. Просто допишите «/robots.txt» в конец адресной строки интересующего домена, и вы получите один из двух вариантов:
- Откроется страница с содержимым robots.txt.
- Вы получите ошибку 404 (страница не найдена).
Вывод: если на вашем ресурсе по адресу /robots.txt вы получаете ошибку 404, то этот момент однозначно стоит исправить (создать, настроить и добавить файл на сервер).
Создание и редактирование robots.txt
- Если у вас еще нет файла, то нужно создать его с нуля. Откройте самый простой текстовый редактор (но не MS Word, т.к. нам нужен именно простой текстовый формат), к примеру, Блокнот (Windows) или TextEdit (Mac).
- Если файл уже существует, отыщите его в корневом каталоге вашего сайта (предварительно, подключившись к сайту по FTP-протоколу, для этого я рекомендую бесплатный Total Commander), скопируйте его на жесткий диск вашего компьютера и откройте через Блокнот.
Примечания:
- Если, например, сайт реализован на CMS WordPress, то по умолчанию, вы не сможете найти его в корне сайта, так как «из коробки» его наличие не предусмотрено. Поэтому для редактирования его придется создать заново.
- Регистр имени файла важен! Название robots.txt указывается исключительно строчными буквами. Также убедитесь, что вы написали корректное название, НЕ «Robots» или «robot» – это наиболее частые ошибки при создании файла.
Структура и синтаксис robots.txt
Существуют стандартные директивы разрешения или запрета индексации тех ли иных страниц и разделов сайта:
User-agent: * Disallow: /
В данном примере всем поисковым ботам не разрешается индексировать сайт (слеш через : и пробел от директивы Disallow указывает на корень сайта, а сама директива – на запрет чего-либо, указанного после двоеточия). Звездочка говорит о том, что данная секция открыта для всех User-agent (у каждой поисковой машины есть свой юзер-агент, которым она идентифицируется. Например, у Яндекса это Yandex, а у Гугла – Googlebot).
А, например, такая конструкция:
User-agent: Googlebot Disallow:
Говорит о том, что роботам Гугл разрешено индексировать весь сайт (для остальных поисковых систем директив в данном примере нет, поэтому если для них не прописаны какие-либо запрещающие правила, значит индексирование также разрешено).
Еще пример:
# директивы для Яндекса User-agent: Yandex Disallow: /profile/
Здесь роботам Яндекса запрещено индексировать личные профили пользователей (папка somesite.com/profile/), все остальное на сайте разрешено. А, например, роботу гугла разрешено индексировать вообще все на сайте.
Как вы уже могли догадаться, знак решетка «#» используется для написания комментариев.
Пример для запрета индексации конкретной страницы, входящей в блок типовых страниц:
User-agent: * Disallow: /profile/$
Данная директива запрещает индексацию раздела /profile/, однако разрешает индексацию всех его подразделов и отдельных страниц:
- /profile/logo.png
- /profile/users/
- /profile/all.html
Директива User-agent
Это обязательное поле, являющееся указанием поисковым ботам для какого поисковика настроены данные директивы. Звездочка (*) означает то, что директивы указаны для всех сканеров от всех поисковиков. Либо на ее месте может быть вписано конкретное имя поискового бота.
User-agent: * # определяем, для каких систем даются указания
Это будет работать до тех пор, пока в файле не встретятся инструкции для другого User-agent, если для него есть отдельные правила.
User-agent: Googlebot # указали, что директивы именно для ботов Гугла Disallow: / User-agent: Yandex # для Яндекса Disallow:
Директива Disallow
Как мы писали выше, это директива запрета индексации страниц и разделов на вашем сайте по указанным критериям.
User-agent: * Disallow: /profile/ #запрет индексирования профилей пользователей
Пример запрета индексации PDF и файлов MS Word и Excel:
User-agent: * Disallow: *.pdf Disallow: *.doc* Disallow: *.xls*
В данном случае, звездочка играет роль любой последовательности символов, то есть к индексации будут запрещены файлы формата: pdf, doc, xls, docx, xlsx.
Примечание: для ускорения удаления из индекса недавно запрещенных к индексации страниц можно прибегнуть к помощи панели Яндекс Вебмастера: Удалить URL. Для группового удаления страниц и разделов нужно перейти в раздел «Инструменты» конкретного сайта и уже там выбрать режим «По префиксу».
Директивы Allow, Sitemap, Clean-param, Crawl-delay и другие
Дополнительные директивы предназначены для более тонкой настройки robots.txt.
Allow
Как противоположность Disallow, Allow дает указание на разрешение индексации отдельных элементов.
User-agent: Yandex Allow: / User-agent: * Disallow: /
Яндекс может проиндексировать сайт целиком, остальным поисковым системам сканирование запрещено.
Либо, к примеру, мы можем разрешить к индексации отдельные папки и файлы, запрещенные через Disallow.
User-agent: * Disallow: /upload/ Allow: /upload/iblock Allow: /upload/medialibrary
Sitemap.xml
Это файл для прямого указания краулерам списка актуальных страниц на сайте. Данная карта сайта предназначена только для поисковых роботов и оформлена специальным образом (XML-разметка). Файл sitemap.xml помогает поисковым ботам обнаружить страницы для дальнейшего индексирования и должен содержать только актуальные страницы с кодом ответа 200, без дублей, сортировок и пагинаций.
Стандартный путь размещения sitemap.xml – также в корневой папке сайта (хотя в принципе она может быть расположена в любой директории сайта, главное указать правильный путь к sitemap):
User-agent: Yandex Disallow: /comments/ Sitemap: https://smesite.com/sitemap.xml
Для крупных порталов карт сайта может быть даже несколько (Google допускает до 1000), но для большинства обычно хватает одного файла, если он удовлетворяет ограничениям:
- Не более 50 МБ (без сжатия) на один Sitemap.xml.
- Не более 50 000 URL на один Sitemap.xml.
Если ваш файл превышает указанный размер в 50 мегабайт, или же URL-адресов, содержащихся в нем, более 50 тысяч, то вам придется разбить список на несколько файлов Sitemap и использовать файл индекса для указания в нем всех частей общего Sitemap.
Пример:
User-agent: Yandex Allow: / Sitemap: https://project.com/my_sitemap_index.xml Sitemap: https://project.com/my_sitemap_1.xml Sitemap: https://project.com/my_sitemap_2.xml ... Sitemap: https://project.com/my_sitemap_X.xml
Примечание: параметр Sitemap – межсекционный, поэтому может быть указан в любом месте файла, однако обычно принято прописывать его в последней строке robots.txt.
Clean-param
Если на страницах есть динамические параметры, не влияющие на контент, то можно указать, что индексация сайта будет выполняться без учета этих параметров. Таким образом, поисковый робот не будет несколько раз загружать одну и ту же информацию, что повышает эффективность индексации.
К примеру, «Clean-param: highlight /forum/showthread.php» преобразует ссылку «/forum/showthread.php?t=30146&highlight=chart» в «/forum/showthread.php?t=30146» и таким образом не будет добавлять дубликат страницы форума с параметром подсветки найденного текста в ветке форума.
User-Agent: * Clean-param: p /forum/showthread.php Clean-param: highlight /forum/showthread.php
Clean-param используется исключительно для Яндекса, Гугл же использует настройки URL в Google Search Console. У гугла это осуществляется намного проще, простым добавлением параметров в интерфейсе вебмастера:
Crawl-delay
Данная инструкция относится к поисковой системе Яндекс и указывает правила по интенсивности его сканирования поисковым роботом. Это бывает полезно, если у вас слабый хостинг и роботы сильно нагружают сервер. В таком случае, вы можете указать им правило сканировать сайт реже, прописав интервалы между запросами к веб-сайту.
К примеру, Crawl-delay: 10 – это указание сканеру ожидать 10 секунд между каждым запросом. 0.5 – пол секунды.
User-Agent: * Crawl-delay: 10 # Crawl-delay: 0.5
Robots.txt для WordPress
Ниже выложен пример robots.txt для сайта на WordPress. Стандартно у Вордпресс есть три основных каталога:
- /wp-admin/
- /wp-includes/
- /wp-content/
Папка /wp-content/ содержит подпапку «uploads», где обычно размещены медиа-файлы, и этот основной каталог целиком блокировать не стоит:
User-agent: * Disallow: /wp-admin/ Disallow: /wp-includes/ Disallow: /wp-content/ Allow: /wp-content/uploads/
Данный пример блокирует выбранные служебные папки, но при этом позволяет сканировать подпапку «uploads» в «wp-content».
Настройка robots.txt для Google и Яндекс
Желательно настраивать директивы для каждой поисковой системы отдельно, как минимум, их стоит настроить для Яндекса и Гугл, а для остальных указать стандартные значения со звездочкой *.
User-agent: * User-agent: Yandex User-agent: Googlebot
Настройка robots.txt для Яндекса
В некоторых роботс иногда можно встретить устаревшую директиву Host, предназначенную для указания основной версии (зеркала) сайта. Данная директива устарела, поэтому ее можно не использовать (теперь поисковик определяет главное зеркало по 301-м редиректам):
User-agent: Yandex Disallow: /search Disallow: /profile Disallow: */feed Host: https://project.com # необязательно
Воспользуйтесь бесплатным инструментом Яндекса для автоматической проверки корректности настроек роботса.
Настройка robots.txt для Google
Принцип здесь тот же, что и у Яндекса, хоть и со своими нюансами. К примеру:
User-agent: Googlebot Disallow: /search Disallow: /profile Disallow: */feed Allow: *.css Allow: *.js
Важно: для Google мы добавляем возможность индексации CSS-таблиц и JS, которые важны именно для этой поисковой системы (поисковик умеет рендерить яваскрипт, соответственно может получить из него дополнительную информацию, имеющую пользу для сайта, либо просто для понимания, для чего служит тот или ной скрипт на сайте).
По ссылке в Google Webmaster Tools вы можете убедиться, правильно ли настроен ваш robots.txt для Гугла.
Запрет индексирования через Noindex и X-RobotsTag
В некоторых случаях, поисковая система Google может по своему усмотрению добавлять в индекс страницы, запрещенные к индексации через robots.txt (например, если на страницу стоит много внешних ссылок и размещена полезная информация).
Цитата из справки Google:
Для 100% скрытия нежелаемых страниц от индексации, используйте мета-тег NOINDEX.
Noindex – это мета-тег, который сообщает поисковой системе о запрете индексации страницы. В отличие от роботса, он является более надежным, поэтому для скрытия конфиденциальной информации лучше использовать именно его:
- <meta name=»robots» content=»noindex»>
Чтобы скрыть страницу только от Google, укажите:
- <meta name=»googlebot» content=»noindex»>
X-Robots-Tag
Тег x-robots позволяет вам управлять индексированием страницы в заголовке HTTP-ответа страницы. Данный тег похож на тег meta robots и также не позволяет роботам сканировать определенные виды контента, например, изображения, но уже на этапе обращения к файлу, не скачивая его, и, таким образом, не затрачивая ценный краулинговый ресурс.
Для настройки X-Robots-Tag необходимо иметь минимальные навыки программирования и доступ к файлам .php или .htaccess вашего сайта. Директивы тега meta robots также применимы к тегу x-robots.
<?
header("X-Robots-Tag: noindex, nofollow");
?>
Примечание: X-Robots-Tag эффективнее, если вы хотите запретить сканирование изображений и медиа-файлов. Применимо к контенту лучше выбирать запрет через мета-теги. Noindex и X-Robots Tag это директивы, которым поисковые роботы четко следуют, это не рекомендации как robots.txt, которые по определению можно не соблюдать.
Как быстро составить роботс для нового сайта с нуля?
Очень просто – скачать у конкурента! )
Просто зайдите на любой интересующий сайт и допишите в адресную строку /robots.txt, — так вы увидите, как это реализовано у конкурентов. При этом не стоит бездумно копировать их содержимое на свой сайт, ведь корректно настроенные директивы чужого сайта могут негативно подействовать на индексацию вашего веб-ресурса, поэтому желательно хотя бы немного разбираться в принципах работы роботс.тхт, чтобы не закрыть доступ к важным разделам.
И главное: после внесения изменений проверяйте robots.txt на валидность (соответствие правилам). Тогда вам точно не нужно будет опасаться за корректность индексации вашего сайта.
Другие примеры настройки Robots.txt
User-agent: Googlebot Disallow: /*?* # закрываем от индексации все страницы с параметрами Disallow: /users/*/photo/ # закрываем от индексации адреса типа "/users/big/photo/", "/users/small/photo/" Disallow: /promo* # закрываем от индексации адреса типа "/promo-1", "/promo-site/" Disallow: /templates/ #закрываем шаблоны сайта Disallow: /*?print= # версии для печати Disallow: /*&print=
Запрещаем сканировать сервисам аналитики Majestic, Ahrefs, Yahoo!
User-agent: MJ12bot Disallow: / User-agent: AhrefsBot Disallow: / User-agent: Slurp Disallow: /
Настройки robots для Opencart:
User-agent: * Disallow: /*route=account/ Disallow: /*route=affiliate/ Disallow: /*route=checkout/ Disallow: /*route=product/search Disallow: /index.php?route=product/product*&manufacturer_id= Disallow: /admin Disallow: /catalog Disallow: /download Disallow: /registration Disallow: /system Disallow: /*?sort= Disallow: /*&sort= Disallow: /*?order= Disallow: /*&order= Disallow: /*?limit= Disallow: /*&limit= Disallow: /*?filter_name= Disallow: /*&filter_name= Disallow: /*?filter_sub_category= Disallow: /*&filter_sub_category= Disallow: /*?filter_description= Disallow: /*&filter_description= Disallow: /*?tracking= Disallow: /*&tracking= Allow: /catalog/view/theme/default/stylesheet/stylesheet.css Allow: /catalog/view/theme/default/css/main.css Allow: /catalog/view/javascript/font-awesome/css/font-awesome.min.css Allow: /catalog/view/javascript/jquery/owl-carousel/owl.carousel.css Allow: /catalog/view/javascript/jquery/owl-carousel/owl.carousel.min.js
1. Введение
Технические аспекты созданного сайта играют не менее важную роль для продвижения сайта в поисковых системах, чем его наполнение. Одним из наиболее важных технических аспектов является индексирование сайта, т. е. определение областей сайта (файлов и директорий), которые могут или не могут быть проиндексированы роботами поисковых систем. Для этих целей используется robots.txt – это специальный файл, который содержит команды для роботов поисковиков. Правильный файл robots.txt для Яндекса и Google поможет избежать многих неприятных последствий, связанных с индексацией сайта.
2. Понятие файла robots.txt и требования, предъявляемые к нему
Файл /robots.txt предназначен для указания всем поисковым роботам (spiders) индексировать информационные сервера так, как определено в этом файле, т.е. только те директории и файлы сервера, которые не описаны в /robots.txt. Этот файл должен содержать 0 или более записей, которые связаны с тем или иным роботом (что определяется значением поля agent_id) и указывают для каждого робота или для всех сразу, что именно им не надо индексировать.
Синтаксис файла позволяет задавать запретные области индексирования, как для всех, так и для определенных, роботов.
К файлу robots.txt предъявляются специальные требования, не выполнение которых может привести к неправильному считыванию роботом поисковой системы или вообще к недееспособности данного файла.
Основные требования:
- все буквы в названии файла должны быть прописными, т. е. должны иметь нижний регистр:
- robots.txt – правильно,
- Robots.txt или ROBOTS.TXT – неправильно;
- файл robots.txt должен создаваться в текстовом формате Unix. При копировании данного файла на сайт ftp-клиент должен быть настроен на текстовый режим обмена файлами;
- файл robots.txt должен быть размещен в корневом каталоге сайта.
3. Содержимое файла robots.txt
Файл robots.txt включает в себя две записи: «User-agent» и «Disallow». Названия данных записей не чувствительны к регистру букв.
Некоторые поисковые системы поддерживают еще и дополнительные записи. Так, например, поисковая система «Yandex» использует запись «Host» для определения основного зеркала сайта (основное зеркало сайта – это сайт, находящийся в индексе поисковых систем).
Каждая запись имеет свое предназначение и может встречаться несколько раз, в зависимости от количества закрываемых от индексации страниц или (и) директорий и количества роботов, к которым Вы обращаетесь.
Предполагается следующий формат строк файла robots.txt:
имя_записи[необязательные
пробелы]:[необязательные
пробелы]значение[необязательные пробелы]
Чтобы файл robots.txt считался верным, необходимо, чтобы, как минимум, одна директива «Disallow» присутствовала после каждой записи «User-agent».
Полностью пустой файл robots.txt эквивалентен его отсутствию, что предполагает разрешение на индексирование всего сайта.
Запись «User-agent»
Запись «User-agent» должна содержать название поискового робота. В данной записи можно указать каждому конкретному роботу, какие страницы сайта индексировать, а какие нет.
Пример записи «User-agent», где обращение происходит ко всем поисковым системам без исключений и используется символ «*»:
User-agent: *
Пример записи «User-agent», где обращение происходит только к роботу поисковой системы Rambler:
User-agent: StackRambler
Робот каждой поисковой системы имеет свое название. Существует два основных способа узнать его (название):
на сайтах многих поисковых систем присутствует специализированный§ раздел «помощь веб-мастеру», в котором часто указывается название поискового робота;
при просмотре логов веб-сервера, а именно при просмотре обращений к§ файлу robots.txt, можно увидеть множество имен, в которых присутствуют названия поисковых систем или их часть. Поэтому Вам остается лишь выбрать нужное имя и вписать его в файл robots.txt.
Запись «Disallow»
Запись «Disallow» должна содержать предписания, которые указывают поисковому роботу из записи «User-agent», какие файлы или (и) каталоги индексировать запрещено.
Рассмотрим различные примеры записи «Disallow».
Пример записи в robots.txt (разрешить все для индексации):
Disallow:
Пример (сайт полностью запрещен к индексации. Для этого используется символ «/»):Disallow: /
Пример (для индексирования запрещен файл «page.htm», находящийся в корневом каталоге и файл «page2.htm», располагающийся в директории «dir»):
Disallow: /page.htm
Disallow: /dir/page2.htm
Пример (для индексирования запрещены директории «cgi-bin» и «forum» и, следовательно, все содержимое данной директории):
Disallow: /cgi-bin/
Disallow: /forum/
Возможно закрытие от индексирования ряда документов и (или) директорий, начинающихся с одних и тех же символов, используя только одну запись «Disallow». Для этого необходимо прописать начальные одинаковые символы без закрывающей наклонной черты.
Пример (для индексирования запрещены директория «dir», а так же все файлы и директории, начинающиеся буквами «dir», т. е. файлы: «dir.htm», «direct.htm», директории: «dir», «directory1», «directory2» и т. д.):
Запись «Allow»
Опция «Allow» используется для обозначения исключений из неиндексируемых директорий и страниц, которые заданы записью «Disallow».
Например, есть запись следующего вида:
Disallow: /forum/
Но при этом нужно, чтобы в директории /forum/ индексировалась страница page1. Тогда в файле robots.txt потребуются следующие строки:
Disallow: /forum/
Allow: /forum/page1
Запись «Sitemap»
Эта запись указывает на расположение карты сайта в формате xml, которая используется поисковыми роботами. Эта запись указывает путь к данному файлу.
Пример:
Sitemap: http://site.ru/sitemap.xml
Запись «Host»
Запись «host» используется поисковой системой «Yandex». Она необходима для определения основного зеркала сайта, т. е. если сайт имеет зеркала (зеркало – это частичная или полная копия сайта. Наличие дубликатов ресурса бывает необходимо владельцам высокопосещаемых сайтов для повышения надежности и доступности их сервиса), то с помощью директивы «Host» можно выбрать то имя, под которым Вы хотите быть проиндексированы. В противном случае «Yandex» выберет главное зеркало самостоятельно, а остальные имена будут запрещены к индексации.
В целях совместимости с поисковыми роботами, которые при обработке файла robots.txt не воспринимают директиву Host, необходимо добавлять запись «Host» непосредственно после записей Disallow.
Пример: www.site.ru – основное зеркало:
Host: www.site.ru
Запись «Crawl-delay»
Эту запись воспринимает Яндекс. Она является командой для робота делать промежутки заданного времени (в секундах) между индексацией страниц. Иногда это бывает нужно для защиты сайта от перегрузок.
Так, запись следующего вида обозначает, что роботу Яндекса нужно переходить с одной страницы на другую не раньше чем через 3 секунды:
Crawl-delay: 3
Комментарии
Любая строка в robots.txt, начинающаяся с символа «#», считается комментарием. Разрешено использовать комментарии в конце строк с директивами, но некоторые роботы могут неправильно распознать данную строку.
Пример (комментарий находится на одной строке вместе с директивой):
Disallow: /cgi-bin/ #комментарий
Желательно размещать комментарий на отдельной строке. Пробел в начале строки разрешается, но не рекомендуется.
4. Примеры файлов robots.txt
Пример (комментарий находится на отдельной строке):
Disallow: /cgi-bin/#комментарий
Пример файла robots.txt, разрешающего всем роботам индексирование всего сайта:
User-agent: *
Disallow:
Host: www.site.ru
Пример файла robots.txt, запрещающего всем роботам индексирование сайта:
User-agent: *
Disallow: /
Host: www.site.ru
Пример файла robots.txt, запрещающего всем роботам индексирование директории «abc», а так же всех директорий и файлов, начинающихся с символов «abc».
User-agent: *
Disallow: /abc
Host: www.site.ru
Пример файла robots.txt, запрещающего индексирование страницы «page.htm», находящейся в корневом каталоге сайта, поисковым роботом «googlebot»:
User-agent: googlebot
Disallow: /page.htm
Host: www.site.ru
Пример файла robots.txt, запрещающего индексирование:
– роботу «googlebot» – страницы «page1.htm», находящейся в директории «directory»;
– роботу «Yandex» – все директории и страницы, начинающиеся символами «dir» (/dir/, /direct/, dir.htm, direction.htm, и т. д.) и находящиеся в корневом каталоге сайта.
User-agent: googlebot
Disallow: /directory/page1.htm
User-agent: Yandex
Disallow: /dir
Host: www.site.ru
5. Ошибки, связанные с файлом robots.txt
Одна из самых распространенных ошибок – перевернутый синтаксис.
Неправильно:
User-agent: /
Disallow: Yandex
Правильно:
User-agent: Yandex
Disallow: /
Неправильно:
User-agent: *
Disallow: /dir/ /cgi-bin/ /forum/
Правильно:
User-agent: *
Disallow: /dir/
Disallow: /cgi-bin/
Disallow: /forum/
Если при обработке ошибки 404 (документ не найден), веб-сервер выдает специальную страницу, и при этом файл robots.txt отсутствует, то возможна ситуация, когда поисковому роботу при запросе файла robots.txt выдается та самая специальная страница, никак не являющаяся файлом управления индексирования.
Ошибка, связанная с неправильным использованием регистра в файле robots.txt. Например, если необходимо закрыть директорию «cgi-bin», то в записе «Disallow» нельзя писать название директории в верхнем регистре «cgi-bin».
Неправильно:
User-agent: *
Disallow: /CGI-BIN/
Правильно:
User-agent: *
Disallow: /cgi-bin/
Ошибка, связанная с отсутствием открывающей наклонной черты при закрытии директории от индексирования.
Неправильно:
User-agent: *
Disallow: dir
User-agent: *
Disallow: page.HTML
Правильно:
User-agent: *
Disallow: /dir
User-agent: *
Disallow: /page.HTML
Чтобы избежать наиболее распространенных ошибок, файл robots.txt можно проверить средствами Яндекс.Вебмастера или Инструментами для вебмастеров Google. Проверка осуществляется после загрузки файла.
6. Заключение
Таким образом, наличие файла robots.txt, а так же его составление, может повлиять на продвижение сайта в поисковых системах. Не зная синтаксиса файла robots.txt, можно запретить к индексированию возможные продвигаемые страницы, а так же весь сайт. И, наоборот, грамотное составление данного файла может очень помочь в продвижении ресурса, например, можно закрыть от индексирования документы, которые мешают продвижению нужных страниц.
Очень полезная вещь! Что это? Какие-то таинственные заклинания?
Да, это волшебство поможет резко снизить нагрузку на сервере от всяких сумасшедших роботов.
Суть проблемы ошибки 404 в WordPress.
Все ошибки 404 (нет запрошенной страницы) WordPress обрабатывает самостоятельно. Это здорово придумано, можно делать свою красивую страницу 404 — и будет счастье.
Но в интернете развелось очень много желающих сломать Ваш сайт и постоянно роботы (сетевые боты) делают проверки вида:
- domen,ru/pass.php
- domen,ru/login.php
- domen,ru/administrator.php
и прочая ахинея
Обратите на временной интервал подборщиков:
- 6:44
- 6:46
- 6:48
- 6:49
- 6:50
- 6:51
и на каждое такое обращение WP генерирует страницу 404…
Можно поискать плагин, который пишет ошибки не в базу, а в файл на сервере (пока не нашел, напишу сам). При наличии файла на сервере — можно подключить fail2ban (и скормить ему этот файл) и блочить тупых ботов по IP после трех-пяти ошибок 404.
Плюс часть «умных» утащили с Вашего сервера картинки себе на сайт методом «copypaste» — т.е. картинки на чужом сайта по-прежнему загружаются с Вашего сервера (и дополнительно его используют).
И после того, как Вы переделали свою исходную статью и картинки к ней (часть удалили, например) — Ваш WordPress начнет генерировать ошибку 404 на каждую отсутствующую картинку! Причем по одной странице 404 на каждую картинку!
Жесть какая, да? Нам нужно оставить генерацию 404 средствами WordPress только для отсутствующих страниц.
Возвращаем управление Error 404 серверу Apache
В WopdPress принудительно сделана передача себе обработки 404. Нужно изменить файл .htaccess, что бы движок обрабатывал только отсутствующие страницы (а не файлы).
Вот собственно код для модуля mod_rewrite.c (поделились добрые люди)
# BEGIN WordPress <IfModule mod_rewrite.c> RewriteEngine On RewriteBase / RewriteRule ^index.php$ - [L] RewriteCond %{REQUEST_FILENAME} !-f RewriteCond %{REQUEST_URI} .(php|s?html?|css|js|jpe?g|png|gif|ico|txt|pdf)(/??.*)?$ RewriteRule . - [R=404,L] RewriteCond %{REQUEST_FILENAME} !-f RewriteCond %{REQUEST_FILENAME} !-d RewriteRule . /index.php [L] </IfModule> # END WordPress
Синим цветом — от WordPress, красным — в центре добавлены изменения:
- запрос файла
- проверка расширения
- действие -> 404
Этот код полностью переключит всю обработку 404 на Apache для соответствующих расширений файлов.
Обратите внимание на регулярное выражение s?html? — это означает целый набор расширений файлов:
- shtml
- shtm
- html
- htm
Знак вопрос в регулярном выражении разрешает повторение предыдущего символа 0 или 1 раз. Конструкция jpe?g работает аналогично — это или jpg или jpeg
Если Вам надо оставить обработку файлов .html на WordPress, а все остальные варианты htm отдать Apache — можно сделать так
s?htm|shtml — т.е. отдаем Apache три варианта (вертикальная черта означает «или»)
- shtm
- htm
- shtml
Можно еще добавить расширений файлов, которые любят роботы-подборщики
- yml — Yandex Market Language — для загрузки прайс-листов в Маркет
- swp — файл обмена виртуальной памяти
- bak — архивные файлы чего-либо
- xml — разметка xml
- env — настройка переменных среды Unix
- sql — дамп базы данных MySql
- dat — файл хранения необработанных данных
- new — не знаю почему, но роботы пробуют
- zip, gzip,rar — файлы архивов
- log — файлы логов
- suspected — расширение, которое присваивает антивирус хостера для зараженных файлов (index.php -> index.php.suspected)
- 7z — файл архива
- gz — файл архива
- tar — файл архива
И еще для особо продвинутых (любопытных) ботов надо запретить:
- тильду на конце расширения файла — т.е. вот такой вариант domen.ru/abcd.php~ (тильда в некоторых ОС используется как временно сохраненная версия)
- и слеш в конце — т.е. вот такой вариант тоже не должен обрабатываться 404 в WP — domen.ru/abcd.php/
Добавляем после скобки с расширениями файлов еще скобку (/?~?) — принцип тот же (символ на конце может быть а может и не быть) — это и /? и ~?
Лишний бэкслеш нужен для экранирования обычного слеша — т.к. он является системным символом.
Исключаем robots.txt из обработки Apahce
ВАЖНО: использование txt в списке расширений отключит генерацию виртуального файла robots.txt средствами WordPress (при отсутствии физического файла robots.txt на сервере). Просто запрос domen.ru/robots.txt не дойдет до сервера PHP.
Для исключение файла /robots.txt из обработки ошибки 404 средствами Apache — его надо добавить в условие (исключить ТОЛЬКО robots.txt)
RewriteCond %{REQUEST_URI} !^/robots.txt$
- символ ! означает отрицание
- символ ^ означает, что проверяется совпадение с начала строки
- символ означает, что следующий символ является просто символом, а не управляющим символом (наша точка перед txt) — в данном случае не критично (в regex точка означает одиночное совпадение с любым символом, в т.ч. и с точкой)
- символ $ означает (без доллара никуда…), что мы не только слева проверяем наличие robots.txt, но и справа. Символы txt справа — они последние в проверке. Без $ мы заодно исключим варианты для обработки Apache (а оно нам надо?)
- robots.txt~
- robots.txt/
- и так далее
Итоговая конструкция (которая в середине файла .htaccess) будет иметь вид
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_URI} !^/robots.txt$
RewriteCond %{REQUEST_URI} .(php|asp|suspected|log|xml|s?htm|shtml|css|js|yml|swp|bak|env|new|sql|dat|zip|gzip|rar|7z|tar|gz|jpe?g|svg|png|gif|ico|txt|pdf)(/?~?)$
RewriteRule . - [R=404,L]
Решение этого вопроса на WordPress (вариант и для Nginx)
How do I skip wordpress’s 404 handling and redirect all 404 errors for static files to 404.html?
https://wordpress.stackexchange.com/questions/24587/how-do-i-skip-wordpresss-404-handling-and-redirect-all-404-errors-for-static-fi
Вносим корректировки в .htaccess
ВАЖНО: ручная корректировка файла .htaccess не поможет, WordPress контролирует его содержимое и периодически возвращает свои исходные настройки в блоке, выделенному тэгами
# BEGIN WordPress
# Директивы (строки) между `BEGIN WordPress` и `END WordPress`
# созданы автоматически и подлежат изменению только через фильтры WordPress.
# Сделанные вручную изменения между этими маркерами будут перезаписаны.
# END WordPress
Используйте плагин, которые умеет его редактировать и перехватывает управление WP, например
Плагин All in One SEO Pack
Вот его раздела «Редактор файлов»
Или через использование хуков и функций WordPress
Вот в этой статье подробно написано, как это сделать
Вред от страницы 404 в WordPress или не загружаем страницу 404, если это файл
ВАЖНО: разработчики WordPress периодически что-то изменяют — обратите внимание на появление в WoprdPress 5.6 новой инструкции
RewriteRule .* — [E=HTTP_AUTHORIZATION:%{HTTP:Authorization}]
Поэтому можно вообще сделать отдельным блоком до модуля Вордпресса
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteBase /
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteCond %{REQUEST_URI} !^/robots.txt$
RewriteCond %{REQUEST_URI} .(php|asp|suspected|log|xml|s?htm|shtml|css|js|yml|swp|bak|env|new|sql|dat|zip|gzip|rar|7z|tar|gz|jpe?g|svg|png|gif|ico|txt|pdf)(/?~?)$
RewriteRule . - [R=404]
</IfModule>
# BEGIN WordPress
# Директивы (строки) между `BEGIN WordPress` и `END WordPress`
# созданы автоматически и подлежат изменению только через фильтры WordPress.
# Сделанные вручную изменения между этими маркерами будут перезаписаны.
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteRule .* - [E=HTTP_AUTHORIZATION:%{HTTP:Authorization}]
RewriteBase /
RewriteRule ^index.php$ - [L]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /index.php [L]
</IfModule>
# END WordPress
Обязательно в нашем правиле RewriteRule убираем флаг L (который Last — т.е. последнее перенаправление). Иначе часть инструкций ниже от WP работать не будет.
И конструкцию <IfModule mod_rewrite.c></IfModule> тоже крайне желательно использовать — она дает серверу исполнять инструкции внутри, если уставлен mod_rewrite.c для Apache. У 99% хостеров он установлен по умолчанию — но на всякий случай пусть будет.
Результат обработки 404 со стороны Apache
ВАЖНО: весь этот список файлов (по их расширениям) не блокируется Apache — мы просто ему возвращаем управление ошибкой 404 при отсутствии какого-либо файла с этим расширением. Если файл есть или расширение не запрещенное (в данном случае html разрешено) — Apache пропускает url в обработку WordPress.
Раз
Два
Три
Красота же 
Нагрузка на сервер PHP падает на 50% — теперь ему не нужно обрабатывать 404 в ответ на тупые подборы…
Оставим только медиа для APACHE
Вроде всё хорошо, и Апач быстрый — но b «мамкиных» хакеров много.
Вот такое безобразие может быть
https://site.ru/site.php71 https://site.ru/site.php72 https://site.ru/site.php73 https://site.ru/site.php74 https://site.ru/site.php75
Причем скрипт подборщика делает это 60 раз в минуту (и в user agent = python) — т.е. APACHE занят полностью и никто к Вам на сайт из живых людей не зайдет.
Имеет смысл оставить 404 ошибку через APACHE только для медиафайлов — а всё остальное пропускать в WordPress. Делать лог и баннить
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteBase /
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteCond %{REQUEST_URI} !^/robots.txt$
RewriteCond %{REQUEST_URI} .(jpe?g|svg|png|gif|ico)(/?~?)$
#media only
RewriteRule . - [R=404]
</IfModule>
# BEGIN WordPress
# Директивы (строки) между `BEGIN WordPress` и `END WordPress`
# созданы автоматически и подлежат изменению только через фильтры WordPress.
# Сделанные вручную изменения между этими маркерами будут перезаписаны.
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteRule .* - [E=HTTP_AUTHORIZATION:%{HTTP:Authorization}]
RewriteBase /
RewriteRule ^index.php$ - [L]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /index.php [L]
</IfModule>
# END WordPress
Далее php-скриптом формируем лог ошибок 404 на сервере и отдаем в блокировку fail2ban.
В результате IP такого вредителя блокируется на уровне сервера (NetFilter) на 1 неделю — 1 месяц.
В принципе обработку 404 ошибки в логе можно оставить и в APACHE, но не удобно:
- это не ошибка вебсервера — это отсутствие URL
- все ответы сервера 200…400…500 пишутся в лог доступа, а в не лог ошибок
- если сайтов несколько — будут отдельные логи для каждого сайта
Плюс достаточно сложная логика обработки статуса 404:
- это могут быть боты поисковых систем — их не надо блокировать
- это могут быть ошибки реальных пользователей
- вообще кто угодно и что угодно может набрать в строке браузера
Проще всю логику сделать на PHP, чем на регулярных выражениях при настройке fail2ban.
16.08.2022
Публикация 6 месяцев назад
Длинная ссылка URL выходит за пределы блока Вот, например, ссылка на сайт MS
https://docs.microsoft.com/ru-ru/microsoftteams/platform/concepts/build-and-test/deep-links?tabs=teamsjs-v2
При просмотре на широком экране все в порядке.
В мобильной версии сайта ссылка выходит за пределы блока и браузер рисует лишнее место справа. Вроде немного ссылка за пределы блока вышла — но получается так. И самое плохое — наша кнопка «Обратная связь» оказалась за пределами экрана мобильной версии.
Особенно такая беда в бесплатных темах WordPress.
Как это исправить?
Нам нужен CSS для указания переноса строк
Таблицы каскадных стилей управляют выводом браузера на экран.
Кратко о…
(Читать полностью…)
31.05.2022
Публикация 8 месяцев назад
Есть такой плагин для архивирования сайта All-in-One WP Migration Читаем статью
Плагины для архивирования и переноса сайта
Было так: тестовый вариант до 64 Мб
бесплатный вариант (расширение Basic) до 500 Мб
выше 500 Мб сайт — платный вариант А стало так: бесплатный вариант до 100 МБ
платный вариант — сайты более 100 Мб Ссылка на расширение к плагину
https://import.wp-migration.com/en Чувствуете, что одной колонки не хватает?
Остался вариант только «премиум». Причем при создании архива Вам плагин ничего не сообщает, что правила игры изменились. Плагин дает возможность создать архив для любого объема сайта.
В результате архив у Вас есть — а…
(Читать полностью…)
22.02.2022
Публикация 11 месяцев назад
Как добавить свои столбцы в административной панели WordPress Нужно в простом варианте сделать несколько вещей: создать саму колонку и его название (через add_filter)
заполнить его данными (через add_action)
при необходимости включить возможность сортировки колонки (через add_filter) Создаем колонку
// создаем новую колонку для записей
add_filter( ‘manage_’.’post’.’_posts_columns’, ‘tsl_manage_pages_columns’, 4 );
function tsl_manage_pages_columns( $columns ){
$columns = array( ‘views’ => ‘Визиты’ );
return $columns;
}
Итого в массиве $columns появится новый элемент (обычно в самом конце)
Заполняем…
(Читать полностью…)
20.11.2021
Публикация 1 год назад
Это же просто. Возвращается текущая дата и текущее локальное время сервера (с правильно установленной таймзоной).
Вот каждый может проверить
https://wpavonis.ru/server.php
Но если запустить этот же код из среды WordPress — мы получим другие результаты
UTC
2021-11-20 07:42:01
Что это за фокус?
Почему время по Гринвичу и таймзона другая? WordPress живет в прошлом?
ДА! Как говорится — «это не баг, а фича».
При запуске ядро WP устанавливает таймзону на UTC. Сделано это специально.
Вот тут подробнее.
current_time
ВАЖНО: Функция учитывает время сервера установленное в date.timezone setting и переписывает его в момент инициализации системы,…
(Читать полностью…)
20.04.2021
Публикация 2 года назад
Вышла версия 1.9 плагина tsl-plugin-out-list-posts Страница плагина находится здесь
Плагин вывода анонсов постов в конце контента
Плагин добавляет в конце текста анонсы дочерних или одноуровневых страниц для текущего контента. Логика вывода: список дочерних страниц
при отсутствии дочерних страниц — выводятся страницы одного уровня
при наличии и дочерних страниц и страниц одного уровня — выводятся дочерние страницы
на верхнем уровне при отсутствии дочерних страниц ничего не выводится
По умолчанию выводятся первые 700 знаков текста и миниатюра.
Для примера дерево страниц. Верхняя страница Средняя страница 1
Средняя страница 2
Средняя страница…
(Читать полностью…)
13.02.2021
Публикация 2 года назад
После установки WordPress в папке сайта создаются несколько информационных файлов Это собственно файлы: license.txt
readme.html Их можно просмотреть через прямой доступ в строке URL. Ранее в файлах добрый WP указывал установленную версию, чем облегчал работу хакеров. Теперь убрали, но нельзя гарантировать, что в будущих обновлениях снова не добавят.
Поэтому лучше закрыть.
Совет «Удалить после установки!» не подходит — т.к. при обновлении эти файлы будут восстановлены.
Файл license.txt
Описание лицензии GPL и указание на CMS WP Файл readme.html
Общее описание WordPress Файл wp-config-sample.php
Это, собственно, не информационный файл. Это образец для создания…
(Читать полностью…)
05.02.2021
Публикация 2 года назад
В версии WP 5.6 страница с результатами поиска изменилась и стала попадать в индекс поисковых машин Что это такое?
А это теперь WordPress оптимизировал URL выдачи результатов внутреннего поиска в виде domen.ru/search/term
Ранее было domen.ru/? s = term
И побежали радостные китайские боты заводить в поиск всякую чепуху.
Если в этот момент на страницу заходит поисковый робот: он её проверяет
получает ответ от сервера 200 ОК (даже при отрицательных результатах поиска!)
ой
и радостно сохраняет в индексе Вот так это выглядит в строке URL
Для запрета поисковым роботам индексации необходимо добавить в файл robots.txt инструкцию
Disallow: /search
Это запрет на индекс…
(Читать полностью…)
26.01.2021
Публикация 2 года назад
Можно увидеть в файле .htaccess новую строку Это добавлена возможность создавать пароли приложений: на сайте должно быть включено шифрование SSL (протокол HTTPS)
для API WP
для защиты мобильного входа в админку xml-rpc.php (через сервер WordPress) Подробнее можно прочитать в статье
Пароли приложений (авторизация)
Сделано на основе плагина Application Passwords
Пароли можно установить в управлении учетной записью пользователя Смысл в том, что Вы указываете мобильное приложение на своем смартфоне (которое, например, WordPress), создаете для него пароль = и Вы можете входить в мобильную версию админки (только с данного устройства) без основного пароля…
(Читать полностью…)
Robots.txt — это текстовый файл, в котором прописаны указания (директивы) по индексации страниц сайта. С помощью данного файла можно указывать поисковым роботам, какие страницы или разделы на веб-ресурсе нужно сканировать и заносить в индекс (базу данных поисковой системы), а какие — нет.
Файл robots.txt располагается в корневом каталоге сайта и доступен по адресу: domain.com/robots.txt.
Почему robots.txt важен для продвижения?
Этот файл дает поисковым системам важные указания, которые напрямую будут влиять на результативность продвижения сайта. Использование robots.txt может помочь:
- предотвращению сканирования дублированного контента и бесполезных для пользователей страниц (результаты внутреннего поиска, технические страницы и др.);
- сохранению конфиденциальности разделов веб-сайта (например, можно закрыть системную информацию CMS);
- избежать перегрузки сервера;
- эффективно расходовать краулинговый бюджет на обход полезных страниц.
С другой стороны, если robots.txt содержит ошибки, то поисковые системы будут неправильно индексировать сайт, и в результатах поиска окажется не та информация, которая нужна.
Можно случайно запретить индексирование важных для продвижения страниц, и они не попадут в результаты поиска.
Ниже приведены ссылки на инструкции по использованию файла robots.txt:
- от Яндекса;
- от Google.
Содержание отчета
- Кнопка «обновить» — при нажатии на неё данные о наличии ошибок в файле robots.txt обновятся.
- Содержимое строк файла robots.txt.
- При наличии в какой-либо директиве ошибки Labrika дает её описание.
Ошибки robots.txt, которые определяет Labrika
Сервис находит следующие виды ошибок:
Директива должна отделятся от правила символом «:».
Каждая действительная строка в файле robots.txt должна состоять из имени поля, двоеточия и значения. Использовать пробелы не обязательно, но рекомендуется для удобства чтения. Для добавления комментария применяется символ решётки «#», который ставится перед его началом. Весь текст после символа «#» и до конца строки робот поисковой системы будет игнорировать.
Стандартный формат:
<field>:<value><#optional-comment>
Пример ошибки:
User-agent Googlebot
Пропущен символ “:”.
Правильный вариант:
User-agent: Googlebot
Пустая директива и пустое правило.
Недопустимо делать пустую строку в директиве User-agent. Это основная директива, которая указывает, для какого поискового робота прописаны дальнейшие правила индексации.
Пример ошибки:
User-agent:
Не указан пользовательский агент.
Правильный вариант:
User-agent: название бота
Например:
User-agent: Googlebot
Каждое правило должно содержать не менее одной директивы «Allow» или «Disallow». Disallow закрывает раздел или страницу от индексации, Allow открывает страницы сайта для индексации (например, разрешает сканирование подкаталога или страницы в закрытом для обработки каталоге). Эти директивы задаются в формате: directive: [path], где значение [path] (путь к странице или разделу) указывать не обязательно. Однако роботы игнорируют директивы Allow и Disallow без указания пути. В этом случае они могут сканировать весь контент. Пустая директива Disallow: равнозначна директиве Allow: /, то есть «не запрещать ничего».
Пример ошибки в директиве Sitemap:
Sitemap:
Не указан путь к карте сайта.
Правильный вариант:
Sitemap: https://www.site.ru/sitemap.xml
Перед правилом нет директивы User-agent
Правило должно всегда стоять после директивы User-agent. Размещение правила перед первым именем пользовательского агента означает, что никакие сканеры не будут ему следовать.
Пример ошибки:
Disallow: /category User-agent: Googlebot
Правильный вариант:
User-agent: Googlebot Disallow: /category
Найдено несколько правил вида «User-agent: *»
Запись вида User-agent: * означает, что правило задается для всех поисковых роботов.
Например:
User-agent: * Disallow: /
запрещает всем поисковым роботам индексирование всего сайта.
Должна быть только одна директива User-agent для одного робота и только одна директива вида User-agent: * для всех роботов. Если в файле robots.txt несколько раз указан один и тот же пользовательский агент с разными списками правил, то поисковым роботам будет сложно определить, какие из этих правил нужно учитывать. В результате возникает большая неопределенность в действиях роботов.
Пример ошибки:
User-agent: * Disallow: /category User-agent: * Disallow: /*.pdf.
Правильный вариант:
User-agent: * Disallow: /category Disallow: /*.pdf.
Неизвестная директива
Обнаружена директива, которая не поддерживается поисковой системой (например, не описана в правилах использования robots.txt Яндекса).
Причины этого могут быть следующие:
- была прописана несуществующая директива;
- допущены ошибки синтаксиса, использованы запрещенные символы и теги;
- эта директива может использоваться роботами других поисковых систем.
Пример ошибки:
Disalow: /catalog
Директивы «Disalow» не существует, допущена ошибка в написании слова.
Правильный вариант:
Disallow: /catalog
Количество правил в файле robots.txt превышает максимально допустимое
Поисковые роботы будут корректно обрабатывать файл robots.txt, если его размер не превышает 500 КБ. Допустимое количество правил в файле — 2048. Контент сверх этого лимита игнорируется. Чтобы не превышать его, вместо исключения каждой отдельной страницы применяйте более общие директивы.
Например, если вам нужно заблокировать сканирование файлов PDF, не запрещайте каждый отдельный файл. Вместо этого запретите все URL-адреса, содержащие .pdf, с помощью директивы:
Disallow: /*.pdf
Правило превышает допустимую длину
Правило не должно содержать более 1024 символов.
Некорректный формат правила
В файле robots.txt должен быть обычный текст в кодировке UTF-8. Поисковые системы могут проигнорировать символы, не относящиеся к UTF-8. В таком случае правила из файла robots.txt не будут работать.
Чтобы поисковые роботы корректно обрабатывали инструкции в файле robots.txt, все правила должны быть написаны согласно стандарту исключений для роботов (REP), который поддерживают Google, Яндекс и большинство известных поисковых машин.
Использование кириллицы и других национальных языков
Использование кириллицы запрещено в файле robots.txt. Согласно утверждённой стандартом системе доменных имен название домена может состоять только из ограниченного набора ASCII-символов (буквы латинского алфавита, цифры от 0 до 9 и дефис). Если домен содержит символы, не относящиеся к ASCII (в том числе буквы национальных алфавитов), его нужно преобразовать с помощью Punycode в допустимый набор символов.
Пример ошибки:
User-agent: Yandex Sitemap: сайт.рф/sitemap.xml
Правильный вариант:
User-agent: Yandex Sitemap: https://xn--80aswg.xn--p1ai/sitemap.xml
Возможно, был использован недопустимый символ
Допускается использование спецсимволов «*» и «$». Они применяются для указания шаблонов адресов при объявлении директив, чтобы не прописывать большой перечень конечных URL для блокировки. Например:
Disallow: /*.php$
запрещает индексировать любые php файлы.
- Звездочка «*» обозначает любую последовательность и любое количество символов.
- Знак доллара «$» означает конец адреса и ограничивает действие знака «*».
Например, если /*.php соответствует всем путям, которые содержат .php., то /*.php$ соответствует только тем путям, которые заканчиваются на .php.
Символ «$» прописан в середине значения
Знак «$» можно использовать только один раз и только в конце правила. Он показывает, что стоящий перед ним символ должен быть последним.
Пример ошибки:
Allow: /file$html
Правильный вариант:
Allow: /file.html$
Правило начинается не с символа «/» и не с символа «*».
Правило может начинаться только с символов «/» и «*».
Значение пути указывается относительно корневого каталога сайта, на котором находится файл robots.txt, и должно начинаться с символа слэш «/», обозначающего корневой каталог.
Пример ошибки:
Disallow: products
Правильным вариантом будет:
Disallow: /products
или
Disallow: *products
в зависимости от того, что вы хотите исключить из индексации.
Некорректный формат URL файла Sitemap
Sitemap — это карта сайта для поисковых роботов, которая содержит рекомендации того, какие страницы необходимо обходить в первую очередь и с какой частотой. Наличие карты сайта помогает роботам быстрее индексировать нужные страницы.
В качестве URL файла Sitemap должен быть указан полный адрес, который содержит обозначение протокола (http:// или https://), имя сайта, путь к файлу, а также имя файла.
Пример ошибки:
Sitemap: /sitemap.xml
Правильный вариант:
Sitemap: https://www.site.ru/sitemap.xml
Некорректное имя главного зеркала сайта
Директива Host указывала роботу Яндекса главное зеркало сайта, если к веб-ресурсу был доступ по нескольким доменам. Остальные поисковые роботы её не воспринимали.
Директива Host могла содержать только протокол (необязательный) и домен сайта. Прописывался протокол https, если он использовался. Указывалась только одна директива Host. Если их было несколько, робот учитывал первую.
Пример ошибки:
User-agent: Yandex Host: http://www.example.com/catalog Host: https://example.com
Правильный вариант:
User-agent: Yandex Host: https://example.com
Некорректный формат директивы «Crawl-delay»
Директива Crawl-delay задает роботу минимальный период времени между окончанием загрузки одной страницы и началом загрузки следующей.
Использовать директиву Crawl-delay следует в тех случаях, когда сервер сильно загружен и не успевает обрабатывать запросы поискового робота. Чем больше устанавливаемый интервал, тем меньше будет количество загрузок в течение одной сессии.
При указании интервала можно использовать как целые значения, так и дробные. В качестве разделителя применяется точка. Единица измерения – секунды:
К ошибкам относят:
- несколько директив Crawl-delay;
- некорректный формат директивы Crawl-delay.
Пример ошибки:
Crawl-delay: 0,5 second
Правильный вариант:
Crawl-delay: 0.5
С 22 февраля 2018 года Яндекс перестал учитывать директиву Crawl-delay. Чтобы задать скорость, с которой роботы будут загружать страницы сайта, используйте раздел «Скорость обхода сайта» в Яндекс.Вебмастере.
Google также не поддерживает эту директиву. Для Google-бота установить частоту обращений можно в панели вебмастера Search Console. Однако роботы Bing и Yahoo соблюдает директиву Crawl-delay.
Некорректный формат директивы «Clean-param»
Директива используется только для робота Яндекса. Google и другие роботы не поддерживают Clean-param.
Директива указывает, что URL страниц содержат GET-параметры, которые не влияют на содержимое, и поэтому их не нужно учитывать при индексировании. Робот Яндекса, следуя инструкциям Clean-param, не будет обходить страницы с динамическими параметрами, которые полностью дублируют контент основных страниц.
Labrika определяет некорректный формат директивы Clean-param, например:
В именах GET-параметров встречается два или более знака амперсанд «&» подряд:
Clean-param: sort&&session /category
Правильный вариант:
Clean-param: sort&session /category
Правило должно соответствовать виду «p0[&p1&p2&..&pn] [path]». В первом поле через символ «&» перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых применяется правило. Параметры отделяются от префикса пути пробелом.
Имена GET-параметров должны содержать только буквы латинского алфавита, цифры, нижнее подчеркивание и дефис.
Префикс PATH URL для директивы Clean-param может включать только буквы латинского алфавита, цифры и некоторые символы: «.», «-«, «/», «*», «_».
Ошибкой считается и превышение допустимой длины правила — 500 символов.
Строка содержит BOM (Byte Order Mark) — символ U+FEFF
BOM (Byte Order Mark — маркер последовательности байтов) — символ вида U+FEFF, который находится в самом начале текста. Этот Юникод-символ используется для определения последовательности байтов при считывании информации.
При создании и редактировании файла с помощью стандартных программ редакторы могут автоматически присвоить ему кодировку UTF-8 с BOM меткой.
BOM – это невидимый символ. У него нет графического выражения, поэтому большинство редакторов его не показывает. Но при копировании этот символ может переноситься в новый документ.
При использовании маркера последовательности байтов в файлах .html сбиваются настройки дизайна, сдвигаются блоки, могут появляться нечитаемые наборы символов, поэтому рекомендуется удалять маркер из веб-скриптов и CSS-файлов.
Как избавиться от BOM меток?
Избавиться от ВОМ довольно сложно. Один из простых способов это сделать — открыть файл в редакторе, который может изменять кодировку документа, и пересохранить его с кодировкой UTF-8 без BOM.
Например, вы можете бесплатно скачать редактор Notepad++, открыть в нём файл с ВОМ меткой и выбрать во вкладке меню «Кодировки» пункт «Кодировать в UTF-8 (без BOM)».
Страница 404 призвана сообщать пользователю, что заданный им url (адрес страницы) не существует.
Такие неправильные урлы еще можно назвать «битыми ссылками».
Многие сайты делают свои страницы 404 для удобства своих пользователей. Часто это красивые и интересные страницы, которые вызывают у пользователя улыбку вместо разочарования от того, что адрес страницы неправильный.
При создании страницы 404 есть важная техническая составляющая, которая сильно влияет на ранжирование сайтов в поисковых системах, если все не настроено правильно.
Если вы озадачились созданием страницы 404, то вам нужно учитывать три момента:
1) Переадресация со всех неправильно введенных url на страницу 404 в .htaccess.
2) Правильный ответ сервера после переадресации (http-код страницы должен быть 404, а не 200).
3) Закрытие страницы 404 от индексации в robots.txt
Сразу отмечу, что все вышеизложенное написано для самописных сайтов, преимущественно на php. Для wordpress существуют плагины по настройке того же самого. Но в этой статье мы рассмотрим, как все выглядит в реальности. %)
ЕСЛИ КРАТКО, то нужно сделать следующее:
I. В файле .htaccess добавить строку:
—————
ErrorDocument 404 http://mysite.com/404.php
—————
Это перенаправит все неправильные (битые) ссылки на страницу — 404.php. Детали ниже в статье.
II. В файле 404.php в самом начале php-кода пишите:
—————
—————
Это даст правильный ответ о статусе страницы. Не 200, не 302, а 404 — потому что страницы, на которую якобы хотел перейти пользователь — не существует. Как это проверить — читайте ниже.
III. В файле rodots.txt делаете следующую запись:
—————
User-agent: *
Disallow:
Disallow: /404.php
—————-
Это закрывает страницу 404.php от индексации поисковыми системами. В этом пункте будьте аккуратны. Детали читайте ниже.
Дальше каждый пункт расписан в деталях! Если вам достаточно короткого описания… то благодарности принимаются в виде комментариев и лайков.
Переадресация (редирект) неправильных url на страницу 404
Первое, что вы делаете – создаете саму страницу 404, чтобы было куда людей посылать %).
Перенаправление url настраивается в файле .htaccess
Просто вписываете строчку:
ErrorDocument 404 http://mysite.com/404.php
Где «mysite.com» – ваш домен, а http://mysite.com/404.php — путь к реальной странице. Если ваш сайт на html, то строка будет выглядеть как:
ErrorDocument 404 http://mysite.com/404.html
Проверка очень проста. После заливки на хостинг файла .htaccess с вышеуказанной строкой, делаете проверку, вводя заведомо не существующий урл (битая ссылка), например: http://mysite.com/$%$%
Если переадресация на созданную вами страницу произошла, значит все работает.
Итак, полностью файл .htaccess, где настроена ТОЛЬКО переадресация на 404 будет выглядеть так:
____________________________
RewriteEngine on
ErrorDocument 404 http://mysite.com/404.html
____________________________
Правильный ответ сервера (http-код страницы)
Очень важно, чтобы при перенаправлении был правильный ответ сервера, а именно – 404 Not Found.
Тут следует объяснить отдельно.
Любому url при запросе назначается статус (http-код страницы).
• Для всех существующих страниц, это: HTTP/1.1 200 OK
• Для страниц перенаправленных: HTTP/1.1 302 Found
• Если страницы не существует, это должен быть HTTP/1.1 404 Not Found
То есть, какой бы урл не был введен, ему присваивается статус, определенный код ответа сервера.
Проверить ответ сервера можно:
1. Консоль браузера, закладка Network. Нажмите F12 для Chrome. Или Ctrl + Shift + I — подходит и для Chrome и для Opera.
2. На такой ресурсе как bertal.ru
3. SEARCH CONCOLE GOOGLE – Сканирование/Посмотреть как GOOGLE бот.
Когда у вас не было перенаправления через .htaccess на страницу 404, то на любой несуществующий url, введенный пользователем, а также на битые ссылки был ответ «HTTP/1.1 404 Not Found»
Итак, после краткой теоретической части, вернемся к нашим
баранам
настройкам.
После того, как вы настроили перенаправление на свою авторскую страницу 404 через .htaccess, как описано выше, то вводя битую ссылку (неверный url, который заведомо не существует), типа http://mysite.com/$%$%, ответ сервера будет:
— сначала HTTP/1.1 302 Found (перенаправление),
— а затем HTTP/1.1 200 OK (страница существует).
Проверьте через bertal.ru.
Чем это грозит? Это будет означать, что гугл в свою базу данных (индекс) может внести все битые ссылки, как существующие страницы с содержанием страницы 404. По сути — дубли страниц. А это невероятно вредно для поисковой оптимизации (SEO).
В этом случае нужно сделать две вещи:
1) Настроить правильный ответ сервера на странице 404.
2) Закрыть от индексирования страницу 404. Это делается через файл robots.txt
Настраиваем ответ сервера HTTP/1.1 404 Not Found для несуществующих страниц
Ответ сервера настраивается благодаря функции php в самом начале страницы 404.php:
Пишите ее вначале файла 404.php.
В результате мы должны получить ответ на битую ссылку:
Пример страницы 404.php. Вот как это выглядит +/-:
Естественно, что у вас скорее всего сайт полностью на php и динамический, то просто вставляете строку с ответом сервера в начало — перед всеми переменными и подключенными шаблонами.
Закрыть страницу 404 от индексирования
Закрыть страницу от индексирования можно в файле rodots.txt. Будьте внимательны с этим инструментом, ведь через этот файл ваш сайт, по сути, общается с поисковыми роботами!
Полный текст файла rodots.txt, где ТОЛЬКО закрыта индексация 404 страницы, выглядит так:
____________________________
User-agent: *
Disallow:
Disallow: /404.php
____________________________
Первая строка User-agent: * сообщает, что правило для всех поисковых систем.
Вторая строка Disallow: сообщает что весь сайт открыт для индексации.
Третья строка Disallow: /404.php закрывает индексацию для страницы /404.php, которая находится в корневой папке.
Замечания по коду: «/404.php» означает путь к странице. Если на вашем сайте страница 404.php (или 404.html соответственно) находится в какой-то папке, то путь будет выглядеть:
/holder/404.php
где «holder» — название папки.
Вот, собственно и все по странице 404. Проверьте работу страницы, перенаправления битых ссылок, и ответы серверов.
Повторюсь: Все вышеизложенное для самописных сайтов. Если вы используете wordpress, то можете поискать приличный плагин для настройки ошибки 404.
Благодарности принимаются в виде комментариев
Читать также:
Быстро создать свой сайт на WordPress
Сколько стоит создать сайт
Как залить сайт на хостинг
Зарегистрировать торговую марку самостоятельно
Самое ценное на сайте
Сайт бесплатно – это миф!
Продвижение сайта
Резервная копия сайта (бэкап)