Opening an application to visualize charts through the hub, the visualization may fail and the error «Out of calculation memory» will be printed.

Environment:
- Qlik Sense Enterprise on Windows, all versions
Resolution
The issue is often related to having an app that is too large or requires a re-design or general optimization. A poorly designed application can lead to memory leaks.
Application optimization
Review the application and optimize as needed to prevent performance problems for the engine service.
Verify resource availability
Verify that the servers hosting the Qlik Sense engine service have sufficient resources (CPU / Memory) to proceed with the calculation. It is highly recommended to have at least 16 cores and 64 GB of memory.
Modify the Hypercube memory limit
You can otherwise change the timeout.
- Open the Qlik Sense Management Console. Default: https://<QPS server name>/qmc.
- Open Engines for each node
- Select the Engine to modify and click Modify
- Open the Advanced menu in menu to the right
- Modify the Hypercube memory limits (bytes). This is by default set to 0, which allows the engine to apply a global heuristic ensuring that we do not run more than 1 big calculation in parallel. Setting this value to -1 will disable the limit.
- Restart the Qlik Sense Engine and Qlik Sense Service Dispatcher on all nodes after the setting was changed.
Cause:
The «Hypercube memory limits» limits how much memory a hypercube evaluation can allocate during a request. If multiple hypercubes are calculated during the request, the limit is applied to each hypercube calculation separately.
If it sets to 0, the engine applies a global heuristic which basically ensures that it doesn’t run more than 1 «big» calculation in parallel.
If you set this value to -1 then you will disable the limit and allow the Engine to keep trying to load the application.
The negative value disables the limit, but it wouldn’t exceed the limit set under the Max memory usage (%) or Memory usage mode.
Related Content:
Qlik Sense: «Calculation timed out» while loading a chart into an application
прошу помощи,
у меня нет опыта, поэтому мои вопросы могут показаться неадекватными.
Сценарий -1:
1. есть данные которые нужно визулизировать анализировать и все такое, допустим объем данных 3 гигабайта
2. допустим что для обработки данных объемом 3 гигабайта в оперативной памяти, нужно 8 гигабайт оперативки
3. Потом вдруг понадобилось обработать объем данных 5 гигабайт
Вопрос, как поведет себя qlik sense? он не сможет обрабатывать 5 гигабайт? сможет обрабатывать но начнут притормаживания? qlik sense будет использовать что-то типа файла подкачки на диске?
Сценарий-2:
1. Есть БД под управлением Oracle, в этой БД содержится сотни милионов записей фактов, каждая запись имеет дату.
2. пользователь который не имеет технической квалификации по работе с системой, должен выбирать в протсом интерфейсе период данных за которое он хочет анализировать данные
вопрос — в qlik sense есть возможность натсроить интерфейс/права так чтобы учитывалась период данных при загрузке данных из БД в Qlik
заранее спасибо!
Opening an application to visualize charts through the hub, the visualization may fail and the error «Out of calculation memory» will be printed.
Environment:
- Qlik Sense Enterprise on Windows, all versions
Resolution
The issue is often related to having an app that is too large or requires a re-design or general optimization. A poorly designed application can lead to memory leaks.
Application optimization
Review the application and optimize as needed to prevent performance problems for the engine service.
Verify resource availability
Verify that the servers hosting the Qlik Sense engine service have sufficient resources (CPU / Memory) to proceed with the calculation. It is highly recommended to have at least 16 cores and 64 GB of memory.
Modify the Hypercube memory limit
You can otherwise change the timeout.
- Open the Qlik Sense Management Console. Default: https://<QPS server name>/qmc.
- Open Engines for each node
- Select the Engine to modify and click Modify
- Open the Advanced menu in menu to the right
- Modify the Hypercube memory limits (bytes). This is by default set to 0, which allows the engine to apply a global heuristic ensuring that we do not run more than 1 big calculation in parallel. Setting this value to -1 will disable the limit.
- Restart the Qlik Sense Engine and Qlik Sense Service Dispatcher on all nodes after the setting was changed.
Cause:
The «Hypercube memory limits» limits how much memory a hypercube evaluation can allocate during a request. If multiple hypercubes are calculated during the request, the limit is applied to each hypercube calculation separately.
If it sets to 0, the engine applies a global heuristic which basically ensures that it doesn’t run more than 1 «big» calculation in parallel.
If you set this value to -1 then you will disable the limit and allow the Engine to keep trying to load the application.
The negative value disables the limit, but it wouldn’t exceed the limit set under the Max memory usage (%) or Memory usage mode.
Related Content:
Qlik Sense: «Calculation timed out» while loading a chart into an application
Сегодня поговорим об устранение неполадок в Qlik Sense. Мы обсудим, как устранить проблемы, с которыми вы можете столкнуться в процессе работы в Qlik Sense. В этой статье мы увидим, как устранять проблемы, связанные с загрузкой данных, созданием визуализаций, обнаружением, экспортом, развертыванием и администрированием.
Итак, приступим к рассмотрению вопроса устранения неполадок в Qlik Sense.

Устранение неполадок в Qlik Sense – неприятные проблемы и их решения
i. Устранение неполадок при загрузке данных в Qlik Sense
Ниже обсуждаются проблемы и их предлагаемые решения для устранения неполадок Qlik Sense.
- Подключение к данным прерывается после перезапуска Сервера SQL?
Закройте приложение или все запущенные приложения и перезапустите хаб или Qlik Sense Desktop.
- Предупреждение о синтетическом ключе при загрузке данных?
Синтетические ключи генерируются, когда у двух таблиц есть более одного общего поля. Создание синтетического ключа считается плохим решением, поскольку оно указывает на неправильную структуру данных, которая может вызвать проблемы с обработкой данных и проведением анализа. Для решения этой проблемы нет идеального решения, кроме предотвращения появления более одного общего поля между таблицами.
- Предупреждение о циклической ссылке при загрузке данных?
Циклические ссылки или зацикливание происходят, когда мы соединяем одну таблицу с другой более чем одним способом. Это вызывает логически искаженную модель данных, которую мы можем исправить, переименовав общие поля и т. д.
- Невозможно выбрать данные из коннектора OLE DB?
Проверьте детали конфигурации подключения, оно должно быть правильно настроено, поэтому нужно проверить, правильно ли составлена строка подключения. Кроме того, вы можете проверить, правильно ли вы входите в систему.
- Неподдерживаемый набор символов, отличных от ANSI?
Иногда файлы данных, полученные с использованием соединения OLE DB, не поддерживают символы, которые не кодируются в ANSI. Чтобы решить эту проблему, вы должны получить файлы данных через подключение к папке, поскольку оно будет обрабатывать больше кодов символов.
- Когда коннектор не работает?
Коннектор не работает, т. е. не может установить соединение для передачи данных, потому что он установлен неправильно. Проверьте, правильно ли установлен коннектор. В случае развертывания с несколькими узлами коннектор должен быть установлен на всех узлах. И, в некоторых случаях, для работы Qlik Sense необходимо сделать его совместимым.
- Данные не загружаются даже после выполнения сценария данных?
Иногда, даже если сценарий выполняется без обнаружения ошибок, данные не загружаются. Чтобы решить эту проблему, активируйте параметр отладки и проверьте код на предмет отсутствия точек с запятой в конце операторов.
- Отображается ошибка неверного пути?
Путь к файлу может быть возвращен как недопустимый, если он не найден в системе или если имя превышает 171 символ, поскольку Qlik Sense поддерживает только имена файлов длиной до 171 символа.
- Если поле даты не распознается как поле даты?
Вы загружаете поле даты в таблицу, но система не распознает или не считывает поле даты? Откройте диспетчер данных, перейдите к параметру редактирования и отредактируйте эту таблицу. Измените тип поля на «Дата» или «Отметка времени» и укажите формат даты и времени.
- Таблицы не отображаются в диспетчере данных?
Диспетчер Данных не показывает таблицы и их данные, даже если они загружены в скрипт? Перейдите в диспетчер данных и нажмите кнопку «Загрузить данные». Это перезагрузит таблицу, завершит профилирование и подготовку данных, а затем отобразит таблицы в приложении.
- Недостаточно места на диске?
У вас может закончиться дисковое пространство, когда все кэши данных в файлах QVD будут загружены. Чтобы решить эту проблему, удалите папку, содержащую все файлы QVD из источника, C:Users<username>DocumentsQlikSenseAppsDataPrepAppCache.
ii. Устранение неполадок при создании визуализаций
- Не можете найти свои поля на панели ресурсов?
Возможно такая ситуация возникает потому, что вы работаете в опубликованном приложении, в котором издатель не должен иметь доступа к полям.
- Отображается сообщение об ошибке «Данные содержат недопустимую геометрию, которую нельзя отобразить на карте. Проверьте свои данные на наличие ошибок и попробуйте еще раз»?
Геометрические данные (возможно, из файла KML), которые вы используете, не должны иметь неправильный формат или содержать ошибочные и неподдерживаемые данные. Проверьте формат и ошибки, исправьте их и перезагрузите файлы.
- Отображается сообщение об ошибке «Не удалось найти следующие местоположения: <местоположения>. Просмотрите значения в своих данных и попробуйте еще раз»?
Местоположения, предоставленные пользователями для использования на картах, иногда не обнаруживаются и не отображаются, вероятно, потому, что они написаны неправильно или данное местоположение не найдено в базе данных местоположений Qlik Sense. Чтобы решить эту проблему, проверьте наличие ошибок в написании или добавьте координаты местоположения вручную, если его нет в базе данных QS.
- Отображается сообщение об ошибке «Следующие местоположения дали более одного результата: < местоположения >. Установите настраиваемую область, чтобы уточнить, какие местоположения отображать»?
Введенное вами местоположение похоже на другие местоположения и возвращает несколько результатов? Вы можете указать дополнительные сведения об этом конкретном месте, чтобы отделить его от других. Мы называем это установкой области для местоположения. Установите для параметра «Область действия» значение «Пользовательский» и добавьте дополнительные сведения, такие как город, штат, страна и т. д.
iii. Устранение неполадок в обнаружении в Qlik Sense
- Не дает результатов при поиске?
Возможно, это связано с тем, что выборки, значения которых вы ищете, заблокированы. Разблокируйте выбор, а затем выполните поиск.
- Отображается сообщение об ошибке «Неполная визуализация»?
Визуализации не отображаются должным образом, если у вас нет доступа к некоторым полям данных. Попросите администратора приложения предоставить вам доступ к полям с ограниченными данными.
iv. Устранение неполадок при экспорте в Qlik Sense
- Данные не экспортируются полностью?
Возможно, вы превысили ограничение на размер файла. Создайте файл поддерживаемого размера и затем экспортируйте его.
- Не удается экспортировать визуализацию как изображение?
Возможно такая ситуация возникла потому, что размер визуализации слишком велик для экспорта. Допустимый размер – 2000 на 2000 пикселей. Если размер вашего изображения превышает этот, измените размер изображения и попробуйте экспортировать его снова.
- Наличие пробелов вместо символов определенного языка?
Иногда символы таких языков, как японский, корейский, упрощенный китайский или традиционный китайский, не поддерживаются в шрифтах историй. Итак, если вы хотите отображать эти шрифты на разных языках, вам необходимо загрузить шрифты, а затем экспортировать PDF-файлы.
- Таблица просмотра данных возвращается к визуализации после экспорта?
Это связано с тем, что просмотр данных не поддерживает экспорт. Вы можете выбрать параметр «Экспорт данных», чтобы вместо этого экспортировать данные из каждой визуализации.
- В таблице после экспорта не отображается поле «Итого»?
Возможно, это из-за того, что после экспорта сохраняются только исходные поля, поэтому вам придется заново создать вычисленное поле «Итого».
v. Устранение неполадок Qlik Sense при развертывании
Чтобы устранить проблемы, связанные с развертыванием, вы должны выполнить процедуру, чтобы правильно обнаружить проблему. Вы можете решить проблему самостоятельно, используя файлы журнала, или обратиться за профессиональной помощью. Чтобы обнаружить проблему, попробуйте выяснить, что это за проблема. Это проблема конфигурации, проблема компонента или глобальная проблема? Есть ли сообщения об ошибках? Система вела себя ненормально? В каком компоненте возникла проблема?
Найдя ответы на эти вопросы, найдите файл журнала, соответствующий компоненту (движку, хранилищу, прокси и планировщику), в котором возникает проблема. Затем сравните детали обычного файла журнала с деталями файла журнала, в котором были записаны данные во время ошибки или неисправности. Так вы сможете определить проблему и исправить ее.
vi. Устранение неполадок при администрировании
Для устранения неполадок при выполнении задач администрирования используются файлы журналов, в которых хранится информация, связанная с производительностью системы, для всех типов операций, выполняемых в Qlik Sense. В файлах журнала хранится журнал операций безопасности, загрузки данных, балансировки нагрузки, распределения и т.д. Все возникающие проблемы и предлагаемые для них методы устранения неполадок обычно делятся на разделы вариантов использования. Таких разделов три,
- Процедура: записывает процедуру или операцию, выполняемую Qlik Sense.
- Успех: в этом разделе перечислены все имена файлов журналов, в которые записываются подробные сведения о процедурах.
- Ошибки: этот раздел содержит список всех возможных ошибок, связанных с различными процедурами.




прошу помощи,
у меня нет опыта, поэтому мои вопросы могут показаться неадекватными.
Сценарий -1:
1. есть данные которые нужно визулизировать анализировать и все такое, допустим объем данных 3 гигабайта
2. допустим что для обработки данных объемом 3 гигабайта в оперативной памяти, нужно 8 гигабайт оперативки
3. Потом вдруг понадобилось обработать объем данных 5 гигабайт
Вопрос, как поведет себя qlik sense? он не сможет обрабатывать 5 гигабайт? сможет обрабатывать но начнут притормаживания? qlik sense будет использовать что-то типа файла подкачки на диске?
Сценарий-2:
1. Есть БД под управлением Oracle, в этой БД содержится сотни милионов записей фактов, каждая запись имеет дату.
2. пользователь который не имеет технической квалификации по работе с системой, должен выбирать в протсом интерфейсе период данных за которое он хочет анализировать данные
вопрос — в qlik sense есть возможность натсроить интерфейс/права так чтобы учитывалась период данных при загрузке данных из БД в Qlik
заранее спасибо!
Есть много обсуждений о том, как расходуется память на сервере QlikView. При этом, если вы используете параметр WorkingSetLimit в QMC, вы увидите что в системе идет регулярное кэширование данных. Так, при создании новый диаграммы, исходя из новой выборки пользователя, сначала сервер QlikView будет пытаться выполнить процедуру кэширования. Так, серверу QlikView требуется меньше и меньше процессорного времени на выполнение операции, но в течение дня память будет потребляться этими процессами.
А возьмем ситуацию, что на том же сервере вы запускаете Publisher / ServerReload, а также кто-то там ведет разработку.
Итак, вы можете создать такое своеобразное пасхальное яйцо через файл settings.ini сервера QlikView..
ClearCacheTimesPerDay=1
Так, кэш QlikView будет обнуляться в полночь, что означает, что все кэшированные вычисления удаляются, а сервер QlikView освободит эту часть памяти обратно в операционную систему.
Так, вы можете настроить периодичность обнуления кэша.
| ClearCacheTimesPerDay=1 | Einmal am Tag um Mitternacht 00:00 |
| ClearCacheTimesPerDay=2 | 00:00 und 12:00 |
| ClearCacheTimesPerDay=3 | 00:00 08:00 16:00 |
| … | usw. |
| ClearCacheTimesPerDay=24 | jede Stunde |
Тестирование
Мы протестировали сервер Win2016 с оперативной памятью 8 ГБ. Рабочий набор сервера ограничен 50%, поэтому серверный процесс QlikView должен кэшировать до 4 ГБ данных.
 |
Скрипт
Скрипт для тестирования работы приложения Qlik:
|
load ‘A’&rowno() as row, rand() as value autogenerate(1000000) |
В макете есть простая таблица. Если вы выберете некоторые значения, а затем щелкните правой кнопкой мыши «Select excluded», вы заполните кеш-память сервера несколькими десятками мегабайт с каждым новым выбором.
 |
Конфигурация и тестирование
- Служба QlikView Server остановлена. Внесены изменения в файл Settings.ini, служба запущена вновь

- Так у нас выглядит планировщик заданий.

- После обнуления кэша, по итогам тестирования мы видим такую картину: в 10:00 вы можете увидеть крутой фланг в Performance Monitor. Таким образом, память освобождается! Размер серверного процесса QlikView упал до 192 мегабайт в диспетчере задач. Установка сбросила кеш 1,98 ГБ! Оставшиеся 192 МБ — это данные в нашем тестовом приложении, а также небольшие накладные расходы на серверный процесс QlikView.


Настройка ClearCacheTimesPerDay работает более аккуратно, чем чистая остановка / начало службы QlikViewServer (в которой все онлайн-пользователи вылетают из текущего сеанса QlikView). Тем не менее, это может быть очень полезно для тестового сервера.
Источник
Business Intelligence, QlikView
If you have worked with QlikView and encountered the error message “Allocated Memory Exceeded”, there could be numerous reasons for this message. You may have a quite a quest in store for yourself to figure out what the issue is. But there’s quick and easy thing to check that may just be the reason for your plight.
If you have been writing expressions, one of the primary culplits for generating this memory error is a simple syntax error with your expression.
Here’s just such a scenerio: You have created a fantastic pie chart and wish to add some intelligence to the chart.
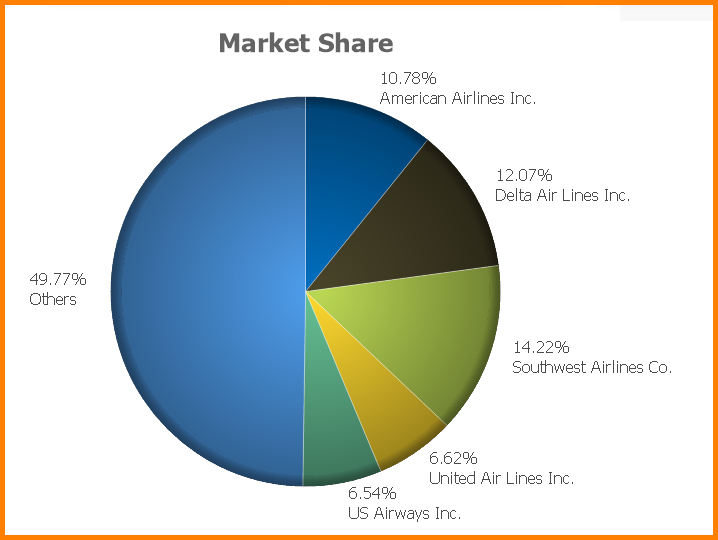
So you right-click on the chart and select Properties…
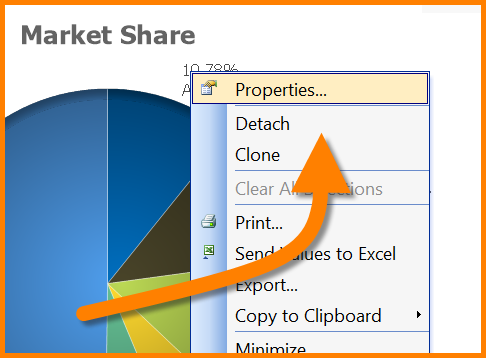
You then select the Expressions tab to write a bit of scripting magic.
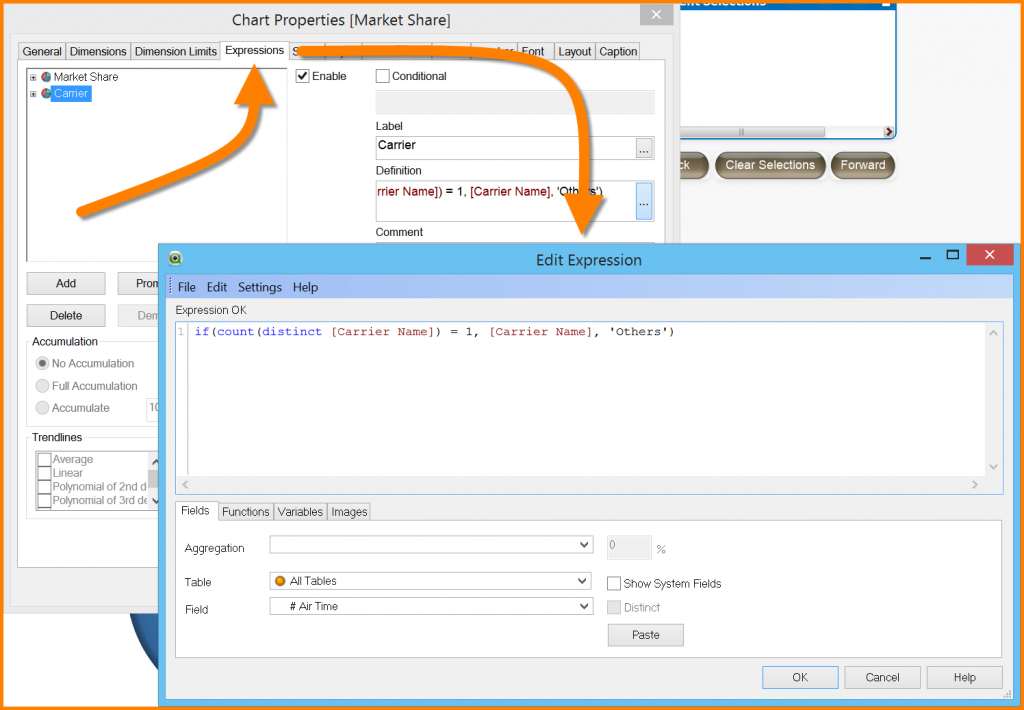
If you examine this script closely, there is a missing closing parenthesis in the expression.
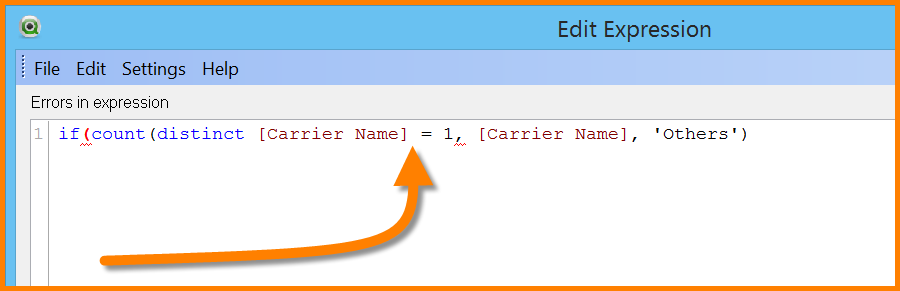
The mere fact that you missed this closing parenthesis is enough to generate the “Allocated Memory Exceeded” message. Adding the closing parenthesis will correct this error and send you on your merry way.
Хотя Qlik Sense позволяет решать задачи аналитики разными способами, есть ряд рекомендованных подходов для обеспечения наилучшей производительности ваших приложений. Неприменение этих подходов не сделает вашу аналитику нерабочей, но может привести к проблемам при масштабировании, связанным с ростом кол-ва пользователей и объема данных, а также сложности моделей.
Рекомендации по росту производительности затрагивают 3 уровня:
- Скорость загрузки данных;
- Ресурсоемкость приложений (объем потребления оператиной памяти);
- Скорость работы визуального слоя приложений.
Начнем же.
ETL (подготовка данных)
QVD-слой. Создайте приложения подготовки данных, которые загружают данные из источников, очищают их, и сохраняют в QVD-файлы для дальнейшего использования аналитическими приложениями. Ваши скрипты станут проще, а преобразование данных не будет происходить повторно — вы сразу будете брать готовые данные.
Используйте инкрементальное обновление данных. Не перезагружайте данные из источника полностью, берите только измененные/новые данные. Остальное подтягивайте из QVD-файлов. Справка
Создайте агрегированные QVD-файлы. Не обязательно сразу давать пользователю аналитику на исходных данных. Если исходные таблицы очень большие (миллионы записей), стоит сделать их агрегированные варианты. Вместо реестра отгрузок — суммы отгрузок в разрезе Месяца, Клиента, Товара, Магазина. Кол-во строк данных сильно сократится, приложение будет работать быстрее и потреблять меньше ресурсов. При необходимости, доступ к базовыми данным можно дать с помощью функционала ODAG или Dynamic Views.
Уменьшайте уникальность данных. Чем меньше в поле уникальных записей, тем меньше ресурсов будет пореблять его обработка и визуализации. Если в исходной базе есть поле Timestamp (Дата+время), потенциально оно содержит очень много уникальных значений. Его можно разбить на 2 поля: Дата — не более 366 уникальных значений за год, и Время. Поле Время нужно округлить до необходимого уровня детализации. Если аналитика глубже часа не нужна — округляем до часа.
Упрощайте данные. Операции над числами выполняются быстрее чем операции над текстом. Более короткие значения потребляют меньше памяти. Если в ваших данных есть поля вроде GUID документа со значениями типа 0a0d25f-f415-11e5-64adfbbb-6645c, спросите себя: “реально ли для аналитики необходимо наличие именно таких значений в этом поле”? Если нет, то можно обработать поле функцией autonumber вне оператора load.
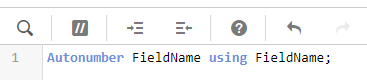
Это преобразует все уникальные значения поля в последовательные числа. Связь элементов по полю сохранится, но значения будут потреблять меньше памяти. Если нужно сохранить уникальность номера независимо от порядка загрузки — используйте функцию hash. На выходе будут конечно не числа, но уже более короткие значения чем GUID. Конечно, нужно исопльзовать это только если вам не требуется использовать оригинальные значения в аналитических целях.
Создавайте флаги для подсчетов. Суммирование (sum) работает быстрее чем подсчет (count). Заметно на больших объемах данных. Вместо подсчета уникальных элементов (count (distinct Deal_ID)) можно создать в таблице поле со значением 1, и выполнять суммирование по нему (sum(DealCountFlag))
Попробуйте перенести часть обработки данных на запрос к БД. Особенно если это касается агрегирования или сложного объединения таблиц. Однако помните, что тогда на БД будет повышенная нагрузка. Лучше комбинировать этот подход с инкрементальной загрузкой.
Excel — самый медленный формат для загрузки данных. Если есть необходимость грузить большие объемы данных из таблиц, пусть они будут в CSV.
Используйте подход preceding load для последовательного преобразования таблиц где это возможно, вместо resident. Это позволит вам ссылаться на имена рассчетных полей, не инициируя перезагрузку данных из таблицы. Кроме того, читабельность вашего кода возрастет.
Скрипт и построение модели
Стремитесь свести модели данных к топологии Звезда (все таблицы объединены через центральную таблицу связей). Чем меньше в модели переходов между таблицами, тем быстрее работает отрисовка визуализаций.
На больших объемах данных, выносите в центральную таблицу связей также поля, по которым считаются меры. Когда переходов между таблицами нет, вычисления работают еще быстрее.
Учитывайте, что нету единой правльной топологии, т.к. существуют сценарии связи данных, которые нельзя реализовать в конкатенированных фактах, т.к. это приведет к дублированию данных (например, связи один-ко-многим).
Удаляйте временные таблицы как только они стали не нужны, а не тяните их до конца скрипта для массового уничтожения.
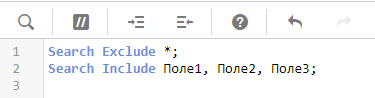
Используйте команду Search, чтобы в явном виде обозначить поля, для которых нужно делать индексацию интеллектуального поиска (вместо полного включения/выключения).
Не используйте DERIVED-поля на больших объемах данных. Т.к. эти поля на самом деле считаются на лету в визуальном слое (сюрприз).
Не ломайте Оптимизированную загрузку QVD-файлов. Иначе говоря — загружайте их без изменений, а ограничения по загрузке данных прописывайте только через where exist. Нужно внести изменения в данные QVD-файла — делайте это в приложении которое его формирует.
Обновляйте приложения через бинарную загрузку. У вас несколько одинаковых приложений (пользовательское и разработчика)? Создайте приложение с обычным скриптом, которое загружает данные. А в рабочие приложения загружайте данные из него с помощью Binary Load. И в них создавайте визуализации. Таким образом полноценная загрузка данных произойдет только один раз, а в 2 рабочих приложения данные попадут по ускоренной схеме. Что в итоге быстрее, чем обновлять 2 приложения через полную перезагрузку. Таким образом загружать данные в т.ч. из папки Qlik Share на сервере.
Используйте функцию FieldValue, если нужно получить список уникальных значений поля, а также минимальное или максимальное значение поля, если источник — таблица с очень большим кол-вом записей. Так вы изначально будете обращаться к только перечню уникальных значений поля, а не грузить 10 000 000 записей, а потом схлопывать до 100 уникальных. Вот такой скрипт вернет таблицу с уникальными значениями поля, и сделает это очень быстро:
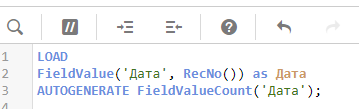
Используйте составные ключи в таблицах связи вместо первичных ключей, где это возможно. Допустим, у вас есть таблица отгрузок на 10 000 000 млн. строк, с данными за 2 года. Но если для связи с другими таблицами не нужен ее первичный ключ (ИД документа), то в таблице связей можно использовать составной ключ, содержащий комбинацию общих полей с другими таблицами и дат. Таким образом, вместо 10 000 000 первичных ключей в таблицу может попасть на порядки меньше записей на основе составного ключа, например 100 000.
Удаляйте из модели поля, которые не используются в визуальном слое. Загружать ВСЕ поля прозапас — нагружать память зря.
Визуальный слой
Используйте однотипное написание формул. sum(Sales) и Sum([Sales]) вернут одинаковый результат, но каждая формула будет вычисляться заново.
Скрывайте визуализации с большим объемом данных через функцию Ограничения вычислений. Требуйте от пользователя сначала задать фильтры, а не сразу рисуйте ему таблицу на 10 000 000 строк.
Если используете функцию AGGR, подумайте, можно ли вынести эти группировки данных в скрипт загрузки.
Не злоупотребляйте вычисляемыми измерениями. Лучше выносить формирование полей, особенно по сложным условиям, в скрипт загрузки.
Создавая динамические цвета в таблицах, по возможности ссылайтесь на уже существующие в ней данные через функцию column или указание наименований мер. Это позволит использовать уже готовые вычисления вместо повторного.
Создавая динамические формулы с переменными, конструируйте формулы так, чтобы они работали без if(). Например, нам нужно чтобы формула переключалась кнопкой между кол-вом продаж и суммой продаж. Вариант с if — создать переменную vMeasure, в которой могут быть значения 1 или 2, а в формулу написать “if($(vMeasure)=1,sum(Sales),count(distinct SaleID))”. Такую формулу сложно писать и масштабировать. Вместо этого, пишите формулы прямо в переменную. А в меру подставляйте имя переменной $(vMeasure). Так можно вогнать в одну меру бесконечное кол-во вариантов, ведь вам не надо править формулу меры каждый раз — только добавлять новый вариант значения переменной.
Вместо условий if, используйте функционал Set Analysis. Условия с if проверяют построчно весь гиперкуб (массив данных, используемый для отрисовки визуализации), а Set Analysis предварительно отбирает ограниченный массив, и по нему выполняет агрегацию.