И снова здравствуйте. Перевод следующей статьи подготовлен специально для студентов курса «Администратор Linux». Поехали!

Что такое S.M.A.R.T.?
S.M.A.R.T. (расшифровывается как Self-Monitoring, Analysis, and Reporting Technology) – это технология, вшитая в накопители, такие как жесткие диски или SSD. Ее основная задача – это мониторинг состояния.
На деле, S.M.A.R.T. контролирует несколько параметров во время обычной работы с диском. Он мониторит такие параметры как количество ошибок чтения, время запуска диска и даже состояние окружающей среды. Помимо этого, S.M.A.R.T. также может проводить тесты с использованием накопителя.
В идеале, S.M.A.R.T. позволит прогнозировать предсказуемые отказы, такие как отказы, вызванные механическим износом или ухудшением состояния поверхности диска, а также непредсказуемые отказы, вызванные каким-либо неожиданным дефектом. Поскольку обычно диски не выходят из строя внезапно, S.M.A.R.T. помогает операционной системе или системному администратору идентифицировать те диски, которые скоро выйдут из строя, чтобы их можно было заменить и избежать потери данных.
Что не относится к S.M.A.R.T.?
Все это, конечно, круто. Однако S.M.A.R.T. – это не хрустальный шар. Он не может спрогнозировать отказ со стопроцентной вероятностью и не может гарантировать, что накопитель не выйдет из строя без предупреждения. В лучшем случае S.M.A.R.T. стоит использовать для оценки вероятности поломки.
Учитывая статистический характер прогнозирования отказов, технология S.M.A.R.T. особенно интересует компании, использующие большое количество устройств для хранения данных. Чтобы выяснить, насколько точно S.M.A.R.T. может прогнозировать отказы и сообщать о необходимости замены дисков в центрах обработки данных или серверных мейнфреймах, даже проводились специальные исследования.
В 2016 году Microsoft и университет штата Пенсильвания провели исследование, связанное с SSD.
Согласно этому исследованию, некоторые атрибуты S.M.A.R.T. считаются хорошими индикаторами неизбежности отказа. В особенности в статье упоминаются:
Счетчик переназначенных (Realloc) секторов:
Несмотря на то, что основополагающие технологии радикально отличаются, этот показатель остается востребованным как в мире SSD, так и в мире жестких дисков. Стоит отметить, что из-за особенностей алгоритмов балансировки износа, используемых в SSD, когда несколько секторов выходят из строя, то с большой вероятностью можно предположить, что скоро выйдут из строя еще больше.
Ошибки в цикле Program/Erase (P/E):
Это признак проблем с основным оборудованием флеш-памяти, связанных с тем, что диск не может удалить данные из блока или сохранить их там. Дело в том, что процесс производства несовершенен, поэтому появление таких ошибок вполне можно ожидать. Однако флеш-память имеет ограниченное число циклов записи/удаления. По этой причине внезапное увеличение числа событий может сигнализировать о том, что диск достигает своего предела, и вполне ожидаемо, что другие ячейки памяти также начнут выходить из строя.
CRC и неисправимые ошибки («Data Error ”):
События такого типа могут быть вызваны ошибками хранения, либо проблемами с внутренним каналом связи накопителя. Этот индикатор учитывает как исправленные ошибки (без проблем сообщенные хост-системе), так и неисправленные ошибки (из-за которых происходит блокировка диска, сообщившего хост-системе о невозможности чтения). Другими словами, исправляемые ошибки невидимы для операционной системы, тем не менее они влияют на производительность накопителя, увеличивая вероятность переназначения сектора.
SATA downshift count:
Из-за временных помех, проблем с каналом связи между накопителем и хостом или из-за внутренних проблем с накопителем, интерфейс SATA может переключиться на более низкую скорость передачи сигналов. Снижение скорости соединения ниже номинального уровня оказывает очевидное влияние на производительность диска. Таким образом, этот показатель является наиболее значимым, в особенности, когда он коррелирует с наличием одного или нескольких предыдущих показателей.
Согласно исследованию, 62% вышедших из строя SSD показали наличие как минимум одного из вышеприведенных симптомов. С другой стороны можно сказать, что 38% изученных накопителей сломались без индикации этих симптомов. В исследованиях не упоминалось, были ли какие-то еще сообщения об отказах от S. M. A. R. T. по другим «симптомам». По этой причине нельзя напрямую сопоставить эти значения с отказом без предупреждения в 36% случаев из статьи от Google.
В исследовании Microsoft и университета штата Пенсильвания не раскрывались модели исследуемых дисков, однако, по словам авторов, большинство дисков поступают от одного и того же поставщика в течение уже нескольких поколений.
В ходе исследования также были отмечены значительные различия в надёжности между различными моделями. Например, «худшая» изученная модель показывает двадцатипроцентную частоту отказов через 9 месяцев после первой ошибки переназначения и до 36-ти процентов отказов в течение 9 месяцев после первого появления ошибок данных. «Худшей» моделью было названо более старое поколение дисков, рассматриваемых в статье.
С другой стороны, с теми же симптомами, что приведены выше, накопители нового поколения отказали в 3% и 20% в соответствии с теми же ошибками. Трудно сказать, можно ли объяснить эти цифры улучшением конструкции накопителя и производственного процесса, или здесь роль играет эффект устаревания накопителя.
Самое интересное, что упоминается в статье (я уже писал об этом ранее), так это то, что увеличение количества зарегистрированных ошибок может случить тревожным индикатором:
«Существует большая вероятность появления симптомов, предшествующих отказу SSD, которые активно себя проявляют и быстро прогрессируют, сильно сокращая время жизни накопителя до нескольких месяцев.»
Другими словами, одна случайная ошибка, о которой сообщил S.M.A.R.T., определенно не должна рассматриваться как сигнал о неизбежном отказе. Однако, когда исправный SSD начинает сообщать о все большем количестве ошибок, следует ждать краткосрочного или среднесрочного сбоя.
Но как узнать, в каком состоянии сейчас ваш SSD? Для удовлетворения своего любопытства, либо из желания начать внимательно следить за своими накопителями, вы можете использовать инструмент мониторинга smartctl.
Использование smartctl для мониторинга состояния вашего SSD в Linux
Чтобы следить за S.M.A.R.T статусом вашего диска, я предлагаю использовать инструмент smartctl, который является частью пакета smartmontool (по крайней мере на Debian/Ubuntu).
sudo apt install smartmontoolssmartctl – это инструмент командной строки, но это особенно помогает в случаях, когда вам нужно автоматизировать сбор данных, например, с ваших серверов.
Первый шаг в использовании smartctl – это проверка того, есть ли на вашем диске S.M.A.R.T. и поддерживается ли он инструментом:
sh$ sudo smartctl -i /dev/sdb
smartctl 6.6 2016-05-31 r4324 [x86_64-linux-4.9.0-6-amd64] (local build)
Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate Momentus 7200.4
Device Model: ST9500420AS
Serial Number: 5VJAS7FL
LU WWN Device Id: 5 000c50 02fa0b800
Firmware Version: D005SDM1
User Capacity: 500,107,862,016 bytes [500 GB]
Sector Size: 512 bytes logical/physical
Rotation Rate: 7200 rpm
Device is: In smartctl database [for details use: -P show]
ATA Version is: ATA8-ACS T13/1699-D revision 4
SATA Version is: SATA 2.6, 3.0 Gb/s
Local Time is: Mon Mar 12 15:54:43 2018 CET
SMART support is: Available - device has SMART capability.
SMART support is: EnabledКак видите, мой внутренний жесткий диск ноутбука действительно поддерживает S.M.A.R.T. и он включен. Итак, как теперь получить S.M.A.R.T статус? Есть ли какие-то зафиксированные ошибки?
Выдача отчета «о всей S.M.A.R.T. информации о диске» — это опция -a:
sh$ sudo smartctl -i -a /dev/sdb
smartctl 6.6 2016-05-31 r4324 [x86_64-linux-4.9.0-6-amd64] (local build)
Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate Momentus 7200.4
Device Model: ST9500420AS
Serial Number: 5VJAS7FL
LU WWN Device Id: 5 000c50 02fa0b800
Firmware Version: D005SDM1
User Capacity: 500,107,862,016 bytes [500 GB]
Sector Size: 512 bytes logical/physical
Rotation Rate: 7200 rpm
Device is: In smartctl database [for details use: -P show]
ATA Version is: ATA8-ACS T13/1699-D revision 4
SATA Version is: SATA 2.6, 3.0 Gb/s
Local Time is: Mon Mar 12 15:56:58 2018 CET
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
See vendor-specific Attribute list for marginal Attributes.
General SMART Values:
Offline data collection status: (0x82) Offline data collection activity
was completed without error.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: ( 0) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 110) minutes.
Conveyance self-test routine
recommended polling time: ( 3) minutes.
SCT capabilities: (0x103f) SCT Status supported.
SCT Error Recovery Control supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 10
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000f 111 099 006 Pre-fail Always - 29694249
3 Spin_Up_Time 0x0003 100 098 085 Pre-fail Always - 0
4 Start_Stop_Count 0x0032 095 095 020 Old_age Always - 5413
5 Reallocated_Sector_Ct 0x0033 100 100 036 Pre-fail Always - 3
7 Seek_Error_Rate 0x000f 071 060 030 Pre-fail Always - 51710773327
9 Power_On_Hours 0x0032 070 070 000 Old_age Always - 26423
10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0
12 Power_Cycle_Count 0x0032 096 037 020 Old_age Always - 4836
184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0
187 Reported_Uncorrect 0x0032 072 072 000 Old_age Always - 28
188 Command_Timeout 0x0032 100 096 000 Old_age Always - 4295033738
189 High_Fly_Writes 0x003a 100 100 000 Old_age Always - 0
190 Airflow_Temperature_Cel 0x0022 056 042 045 Old_age Always In_the_past 44 (Min/Max 21/44 #22)
191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 184
192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 104
193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 395415
194 Temperature_Celsius 0x0022 044 058 000 Old_age Always - 44 (0 13 0 0 0)
195 Hardware_ECC_Recovered 0x001a 050 045 000 Old_age Always - 29694249
197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 1
198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 1
199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0
240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 25131 (246 202 0)
241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 3028413736
242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 1613088055
254 Free_Fall_Sensor 0x0032 100 100 000 Old_age Always - 0
SMART Error Log Version: 1
ATA Error Count: 3
CR = Command Register [HEX]
FR = Features Register [HEX]
SC = Sector Count Register [HEX]
SN = Sector Number Register [HEX]
CL = Cylinder Low Register [HEX]
CH = Cylinder High Register [HEX]
DH = Device/Head Register [HEX]
DC = Device Command Register [HEX]
ER = Error register [HEX]
ST = Status register [HEX]
Powered_Up_Time is measured from power on, and printed as
DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes,
SS=sec, and sss=millisec. It "wraps" after 49.710 days.
Error 3 occurred at disk power-on lifetime: 21171 hours (882 days + 3 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 00 08 ff ff ff 4f 00 00:45:12.580 READ FPDMA QUEUED
60 00 08 ff ff ff 4f 00 00:45:12.580 READ FPDMA QUEUED
60 00 08 ff ff ff 4f 00 00:45:12.579 READ FPDMA QUEUED
60 00 08 ff ff ff 4f 00 00:45:12.571 READ FPDMA QUEUED
60 00 20 ff ff ff 4f 00 00:45:12.543 READ FPDMA QUEUED
Error 2 occurred at disk power-on lifetime: 21171 hours (882 days + 3 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 00 00 ff ff ff 4f 00 00:45:09.456 READ FPDMA QUEUED
60 00 00 ff ff ff 4f 00 00:45:09.451 READ FPDMA QUEUED
61 00 08 ff ff ff 4f 00 00:45:09.450 WRITE FPDMA QUEUED
60 00 00 ff ff ff 4f 00 00:45:08.878 READ FPDMA QUEUED
60 00 00 ff ff ff 4f 00 00:45:08.856 READ FPDMA QUEUED
Error 1 occurred at disk power-on lifetime: 21131 hours (880 days + 11 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 00 00 ff ff ff 4f 00 05:52:18.809 READ FPDMA QUEUED
61 00 00 7e fb 31 45 00 05:52:18.806 WRITE FPDMA QUEUED
60 00 00 ff ff ff 4f 00 05:52:18.571 READ FPDMA QUEUED
ea 00 00 00 00 00 a0 00 05:52:18.529 FLUSH CACHE EXT
61 00 08 ff ff ff 4f 00 05:52:18.527 WRITE FPDMA QUEUED
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed without error 00% 10904 -
# 2 Short offline Completed without error 00% 12 -
# 3 Short offline Completed without error 00% 0 -
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.Понимание выходных данных команд smartctl
На выходе получается много информации, которую не всегда легко понять. Наиболее интересной, вероятно, является та часть, которая помечена как “Vendor Specific SMART Attributes with Thresholds”. Она сообщает различные статистические данные, собранные S.M.A.R.T. устройством, и позволяет сравнить эти значения (текущие или худшие за все время) с некоторым порогом, определенным поставщиком.
Например, вот мои отчеты о переназначенных секторах на диске:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
5 Reallocated_Sector_Ct 0x0033 100 100 036 Pre-fail Always - 3Вы можете заметить атрибут «Pre-fail». Он означает, что значение является аномальным. Таким образом, если значение превышает пороговое, велика вероятность сбоя. Другая категория »Old_age» используется для атрибутов, отвечающих значениям «нормального износа».
Последнее поле (здесь со значением «3») соответствует исходному значению атрибута, которое сообщает диск. Обычно это число имеет физическое значение. Здесь это фактическое количество переназначенных секторов. Для других атрибутов это может быть температура в градусах Цельсия, время в часах или минутах или количество раз, когда для диска было выполнено определенное условие.
В дополнение к исходному значению, диск с поддержкой S.M.A.R.T. должен сообщать «нормализованные значения» (значения полей, самые худшие и пороговые). Эти значения нормируются в диапазоне 1-254 (0-255 для пороговых значений). Прошивка диска выполняет эту нормализацию с помощью некоторого внутреннего алгоритма. Кроме того, разные производители могут нормализовать один и тот же атрибут по-разному. Большинство значений представлены в процентах, причем чем выше, тем лучше, но так бывает не всегда. Когда параметр ниже или равен пороговому значению, указанному производителем, диск считается неисправным в терминах этого атрибута. Помня о всех указаниях из первой части статьи, когда атрибут, показывающий ранее значение “pre-fail” все-таки дал сбой, наиболее вероятно, что скоро диск выйдет из строя.
В качестве второго примера возьмем “seek error rate”:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
7 Seek_Error_Rate 0x000f 071 060 030 Pre-fail Always - 51710773327На самом деле (и это основная проблема отчетности S.M.A.R.T.), точное значение полей каждого атрибута понимает только поставщик. В моем случае Seagate использует логарифмическую шкалу для нормализации значения. Таким образом, «71» означает примерно одну ошибку на 10 миллионов запросов (10 в степени 7,1). Забавно, что самым худшим показателем за все время была одна ошибка на 1 миллион запросов (10 в 6-й степени).
Если я правильно понимаю, то это значит, что головки моего диска сейчас расположены точнее, чем раньше. Я не следил за этим диском внимательно, поэтому анализирую полученные данные весьма субъективно. Возможно накопитель просто надо было немного «обкатать» с тех пор как он был введен в эксплуатацию? Или может быть это следствие механического износа деталей и, следовательно, теперь имеет место меньшая сила трения? В любом случае, какова бы ни была причина, это значение является скорее показателем производительности, чем ранним предупреждением об ошибке. Так что меня оно не сильно беспокоит.
Помимо вышеприведенного и трех крайне подозрительных ошибок, записанных около шести месяцев назад, этот диск находится в удивительно хорошем состоянии (по данным S.M.A.R.T.) для стокового диска ноутбука, проработавшего более 1100 дней (26423 часа).
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
9 Power_On_Hours 0x0032 070 070 000 Old_age Always - 26423Из любопытства я провел этот же тест на гораздо более новом ноутбуке, оснащенном SSD:
sh$ sudo smartctl -i /dev/sdb
smartctl 6.5 2016-01-24 r4214 [x86_64-linux-4.10.0-32-generic] (local build)
Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Device Model: TOSHIBA THNSNK256GVN8
Serial Number: 17FS131LTNLV
LU WWN Device Id: 5 00080d 9109b2ceb
Firmware Version: K8XA4103
User Capacity: 256 060 514 304 bytes [256 GB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: Solid State Device
Form Factor: M.2
Device is: Not in smartctl database [for details use: -P showall]
ATA Version is: ACS-3 (minor revision not indicated)
SATA Version is: SATA 3.2, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Tue Mar 13 01:03:23 2018 CET
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
Первое, что бросается в глаза, так это то, что несмотря на наличие S.M.A.R.T., устройства нет в базе данных smartctl. Но это не помешает инструменту собирать данные с SSD, однако он не сможет сообщить точные значения различных атрибутов, специфичных для поставщика:
sh$ sudo smartctl -a /dev/sdb
smartctl 6.5 2016-01-24 r4214 [x86_64-linux-4.10.0-32-generic] (local build)
Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x00) Offline data collection activity
was never started.
Auto Offline Data Collection: Disabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: ( 120) seconds.
Offline data collection
capabilities: (0x5b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
No Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 11) minutes.
SCT capabilities: (0x003d) SCT Status supported.
SCT Error Recovery Control supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000a 100 100 000 Old_age Always - 0
2 Throughput_Performance 0x0005 100 100 050 Pre-fail Offline - 0
3 Spin_Up_Time 0x0007 100 100 050 Pre-fail Always - 0
5 Reallocated_Sector_Ct 0x0013 100 100 050 Pre-fail Always - 0
7 Unknown_SSD_Attribute 0x000b 100 100 050 Pre-fail Always - 0
8 Unknown_SSD_Attribute 0x0005 100 100 050 Pre-fail Offline - 0
9 Power_On_Hours 0x0012 100 100 000 Old_age Always - 171
10 Unknown_SSD_Attribute 0x0013 100 100 050 Pre-fail Always - 0
12 Power_Cycle_Count 0x0012 100 100 000 Old_age Always - 105
166 Unknown_Attribute 0x0012 100 100 000 Old_age Always - 0
167 Unknown_Attribute 0x0022 100 100 000 Old_age Always - 0
168 Unknown_Attribute 0x0012 100 100 000 Old_age Always - 0
169 Unknown_Attribute 0x0013 100 100 010 Pre-fail Always - 100
170 Unknown_Attribute 0x0013 100 100 010 Pre-fail Always - 0
173 Unknown_Attribute 0x0012 200 200 000 Old_age Always - 0
175 Program_Fail_Count_Chip 0x0013 100 100 010 Pre-fail Always - 0
192 Power-Off_Retract_Count 0x0012 100 100 000 Old_age Always - 18
194 Temperature_Celsius 0x0023 063 032 020 Pre-fail Always - 37 (Min/Max 11/68)
197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 0
240 Unknown_SSD_Attribute 0x0013 100 100 050 Pre-fail Always - 0
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
No self-tests have been logged. [To run self-tests, use: smartctl -t]
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.
Выше вы видите выходные данные абсолютно нового SSD. Данные понятны даже в случае отсутствия нормализации или метаинформации для данных конкретного поставщика, как в моем случае с “Unknown_SSD_Attribute.” Я могу только надеяться, что в последующих версиях smartctl в базе данных появятся данные об этой модели диска, и я смогу лучше определять потенциальные проблемы.
Проверьте свой SSD в Linux с помощью smartctl
До сих пор мы рассматривали данные, собранные во время нормальной работы накопителя. Однако протокол S.M.A.R.T. также поддерживает несколько команд для автономного тестирования для запуска диагностики по требованию.
Автономное тестирование может проводиться во время обычных операций с диском, если не было указано иное. Поскольку тест и запросы ввода-вывода хоста будут конкурировать, производительность диска упадет на время теста. Спецификация S.M.A.R.T. определяет несколько видов автономного тестирования:
Короткое автономное тестирование (-t short)
Такой тест проверит электрическую и механическую, производительность, а также производительность чтения диска. Короткое автономное тестирование обычно занимает всего несколько минут (обычно от 2 до 10).
Расширенное автономное тестирование (-t long)
Этот тест занимает почти в два раза больше времени. Как правило, это просто более детальная версия короткого автономного тестирования. Кроме того, этот тест будет сканировать всю поверхность диска на наличие ошибок данных без ограничения по времени. Продолжительность теста будет пропорциональна размеру диска.
Транспортировочное автономное тестирование (-t conveyance)
Этот тестовый набор предложен в качестве сравнительно быстрого способа проверки на возможные повреждения, возникшие во время транспортировки устройства.
Вот примеры, взятые с тех же дисков, что были выше. Я предлагаю вам угадать, где какой:
sh$ sudo smartctl -t short /dev/sdb
smartctl 6.5 2016-01-24 r4214 [x86_64-linux-4.10.0-32-generic] (local build)
Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF OFFLINE IMMEDIATE AND SELF-TEST SECTION ===
Sending command: "Execute SMART Short self-test routine immediately in off-line mode".
Drive command "Execute SMART Short self-test routine immediately in off-line mode" successful.
Testing has begun.
Please wait 2 minutes for test to complete.
Test will complete after Mon Mar 12 18:06:17 2018
Use smartctl -X to abort test.Сейчас производится проверка. Давайте дождемся завершения, чтобы посмотреть результат:
sh$ sudo sh -c 'sleep 120 && smartctl -l selftest /dev/sdb'
smartctl 6.5 2016-01-24 r4214 [x86_64-linux-4.10.0-32-generic] (local build)
Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF READ SMART DATA SECTION ===
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed without error 00% 171 -Проведем тот же тест на другом диске:
sh$ sudo smartctl -t short /dev/sdb
smartctl 6.6 2016-05-31 r4324 [x86_64-linux-4.9.0-6-amd64] (local build)
Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF OFFLINE IMMEDIATE AND SELF-TEST SECTION ===
Sending command: "Execute SMART Short self-test routine immediately in off-line mode".
Drive command "Execute SMART Short self-test routine immediately in off-line mode" successful.
Testing has begun.
Please wait 2 minutes for test to complete.
Test will complete after Mon Mar 12 21:59:39 2018
Use smartctl -X to abort test.И еще раз, отправим в сон на две минуты и посмотрим результат:
sh$ sudo sh -c 'sleep 120 && smartctl -l selftest /dev/sdb'
smartctl 6.6 2016-05-31 r4324 [x86_64-linux-4.9.0-6-amd64] (local build)
Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF READ SMART DATA SECTION ===
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed without error 00% 26429 -
# 2 Short offline Completed without error 00% 10904 -
# 3 Short offline Completed without error 00% 12 -
# 4 Short offline Completed without error 00% 0 -Интересно, что в этом случае мы видим, что производители диска и компьютера, похоже, уже тестировали диск (на времени жизни в 0 часов и 12 часов). Я сам определенно был гораздо менее озабочен состоянием диска, чем они. Итак, поскольку я уже показал быстрые тесты, то и расширенный тоже запущу, чтобы посмотреть как это происходит.
sh$ sudo smartctl -t long /dev/sdb
smartctl 6.6 2016-05-31 r4324 [x86_64-linux-4.9.0-6-amd64] (local build)
Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF OFFLINE IMMEDIATE AND SELF-TEST SECTION ===
Sending command: "Execute SMART Extended self-test routine immediately in off-line mode".
Drive command "Execute SMART Extended self-test routine immediately in off-line mode" successful.
Testing has begun.
Please wait 110 minutes for test to complete.
Test will complete after Tue Mar 13 00:09:08 2018
Use smartctl -X to abort test.Судя по всему на этот раз ждать придется гораздо дольше, чем при проведении короткого теста. Так что давайте посмотрим:
sh$ sudo bash -c 'sleep $((110*60)) && smartctl -l selftest /dev/sdb'
[sudo] password for sylvain:
smartctl 6.6 2016-05-31 r4324 [x86_64-linux-4.9.0-6-amd64] (local build)
Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF READ SMART DATA SECTION ===
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Extended offline Completed: read failure 20% 26430 810665229
# 2 Short offline Completed without error 00% 26429 -
# 3 Short offline Completed without error 00% 10904 -
# 4 Short offline Completed without error 00% 12 -
# 5 Short offline Completed without error 00% 0 -
В последнем тесте обратите внимание на различие в результатах, полученных с помощью короткого и расширенного теста, даже если они были выполнены один за другим. Ну, возможно, этот диск не в таком уж и хорошем состоянии! Отмечу, что тест остановился после первой ошибки чтения. Поэтому, если вы хотите получить исчерпывающую информацию обо всех ошибках чтения, вам придется продолжать тест после каждой ошибки. Я призываю вас взглянуть на одну очень хорошо написанную страницу руководства smartctl(8) для получения дополнительной информации о параметрах -t select, N-max и -t select, чтобы уметь делать так:
sh$ sudo smartctl -t select,810665230-max /dev/sdb
smartctl 6.6 2016-05-31 r4324 [x86_64-linux-4.9.0-6-amd64] (local build)
Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF OFFLINE IMMEDIATE AND SELF-TEST SECTION ===
Sending command: "Execute SMART Selective self-test routine immediately in off-line mode".
SPAN STARTING_LBA ENDING_LBA
0 810665230 976773167
Drive command "Execute SMART Selective self-test routine immediately in off-line mode" successful.
Testing has begun.smartctl 6.6 2016-05-31 r4324 [x86_64-linux-4.9.0-6-amd64] (local build)
Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF READ SMART DATA SECTION ===
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Selective offline Completed without error 00% 26432 -
# 2 Extended offline Completed: read failure 20% 26430 810665229
# 3 Short offline Completed without error 00% 26429 -
# 4 Short offline Completed without error 00% 10904 -
# 5 Short offline Completed without error 00% 12 -
# 6 Short offline Completed without error 00% 0 -Заключение
Определенно, S.M.A.R.T. – это именно та технология, которую стоит добавить в свой инструментарий для мониторинга работоспособности дисков ваших серверов. Вам также стоит взглянуть на S.M.A.R.T. Disk Monitoring Daemon smartd(8), который может помочь вам автоматизировать мониторинг с помощью отчетов системного журнала.
Учитывая статистическую природу прогнозирования сбоев, я не уверен, что агрессивный S.M.A.R.T. мониторинг будет сильно полезен на персональных компьютерах. Помните, что каким бы ни был накопитель, однажды он все равно выйдет из строя – и, как мы видели ранее, в одной трети случаев он сделает это без предупреждения. Поэтому ничто не обеспечит целостность ваших данных лучше, чем RAID технология и резервные копии!
До встречи на курсе, друзья!
For Kingston drives on Debian-based computers
Similar to this answer execute
# apt-get install smartmontools
However when I execute the command to show the drive info, it looks like SMART was disabled:
# smartctl -a /dev/sda
smartctl 6.2 2013-07-26 r3841 [x86_64-linux-3.13.0-45-generic] (local build)
[ ... ]
SMART support is: Available - device has SMART capability.
SMART support is: Disabled
You need to enable that by executing the following as root:
# smartctl -s on -a /dev/sda
You can then execute a self-test by doing either a short test (which took me about 1 minute):
# smartctl -t short -a /dev/sda
or a more thorough test (which took me about 1.5 hours):
# smartctl -t long -a /dev/sda
Note, in most circumstances you do not need to unmount the drive to execute these tests. If you do, see man smartctl.
Now, when you execute smartctl -a /dev/sda you should then see a self-assessment test result. This is probably all you really need to concern yourself with:
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
If you like details, you will also see a table like this:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x0032 095 095 050 Old_age Always - 0/178007034
5 Retired_Block_Count 0x0033 100 100 003 Pre-fail Always - 0
9 Power_On_Hours_and_Msec 0x0032 092 092 000 Old_age Always - 7626h+46m+45.580s
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 8
171 Program_Fail_Count 0x000a 100 100 000 Old_age Always - 0
172 Erase_Fail_Count 0x0032 100 100 000 Old_age Always - 0
174 Unexpect_Power_Loss_Ct 0x0030 000 000 000 Old_age Offline - 4
177 Wear_Range_Delta 0x0000 000 000 000 Old_age Offline - 1
181 Program_Fail_Count 0x000a 100 100 000 Old_age Always - 0
182 Erase_Fail_Count 0x0032 100 100 000 Old_age Always - 0
187 Reported_Uncorrect 0x0012 100 100 000 Old_age Always - 0
189 Airflow_Temperature_Cel 0x0000 030 035 000 Old_age Offline - 30 (Min/Max 24/35)
194 Temperature_Celsius 0x0022 030 035 000 Old_age Always - 30 (Min/Max 24/35)
195 ECC_Uncorr_Error_Count 0x001c 120 120 000 Old_age Offline - 0/178007034
196 Reallocated_Event_Count 0x0033 100 100 003 Pre-fail Always - 0
201 Unc_Soft_Read_Err_Rate 0x001c 120 120 000 Old_age Offline - 0/178007034
204 Soft_ECC_Correct_Rate 0x001c 120 120 000 Old_age Offline - 0/178007034
230 Life_Curve_Status 0x0013 100 100 000 Pre-fail Always - 100
231 SSD_Life_Left 0x0013 100 100 010 Pre-fail Always - 0
233 SandForce_Internal 0x0032 000 000 000 Old_age Always - 3498
234 SandForce_Internal 0x0032 000 000 000 Old_age Always - 2885
241 Lifetime_Writes_GiB 0x0032 000 000 000 Old_age Always - 2885
242 Lifetime_Reads_GiB 0x0032 000 000 000 Old_age Always - 868
If you are looking for what all of these values mean, see the Kingston documentation.
SMART (Self-Monitoring, Analysis, and Reporting Technology) is a feature enabled in all modern hard disk drives and SSDs to monitor/test reliability. It checks different drive attributes to detect the possibility of drive failure. There are different tools available in Linux and Windows to perform the SMART tests.
In this tutorial, we will learn how to test SSD/HDD health in Linux from CLI and GUI
Two methods explained here are:
- Using Smartctl
- Using Gnome Disks
Test SSD Health using Smartctl
Smartctl is a command-line utility tool that can be used to check S.M.A.R.T-enabled HDD or SSD status in the Linux system.
Smartctl utility tool comes with the package smartmontools. The Smartmontools is available by default in all Linux distributions including Ubuntu, RHEL and Centos and Fedora.
To install smartmontools in Linux:
Ubuntu
sudo apt install smartmontools Start the service using the following command.
sudo /etc/init.d/smartmontools startRHEL and CentOS
sudo yum install smartmontoolsFedora
sudo dnf install smartmontoolsSmartd service will start automatically after the successful installation.
If not started, start smartd service:
sudo systemctl start smartdTo test overall-health of the drive, type:
sudo smartctl -d ata -H /dev/sdaWhere,
d — Specifies the type of device.
ata — the device type is ATA, use scsi for SCSI device type.
H — Check the device to report its SMART health status.

The result PASSED indicates that the disk drive is good. If the device reports failing health status, this means either that the device has already failed or could fail very soon.
If it indicates failing use -a option to get more information.
sudo smartctl -a /dev/sda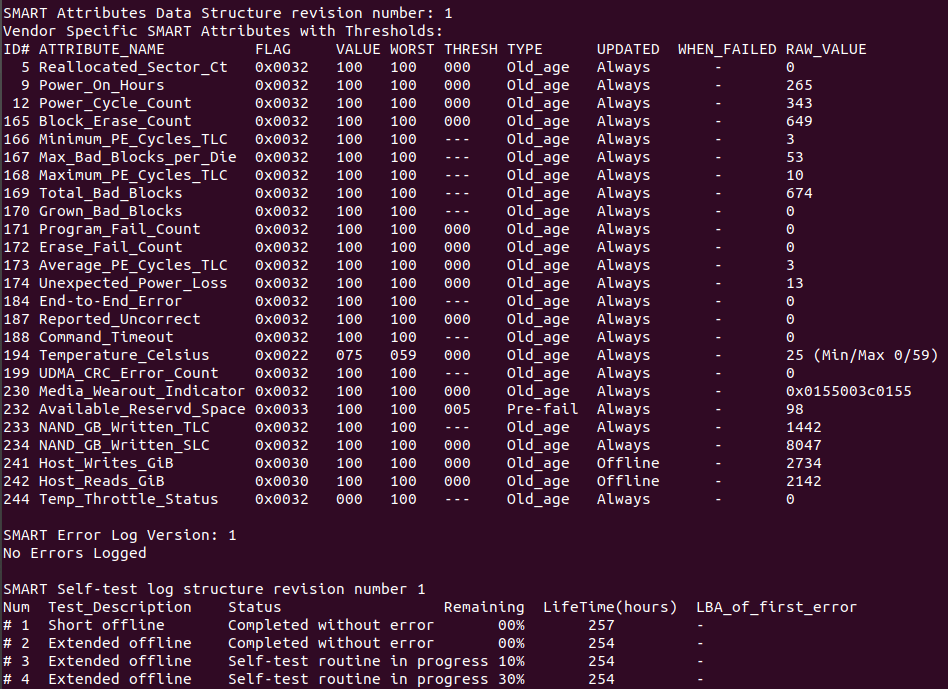
You can monitor the following attributes:
[ID 5] Reallocated Sectors Count — Numbers of sectors reallocated due to read errors.
[ID 187] Reported Uncorrect — Number of uncorrectable errors while accessing read/write to sector.
[ID 230] Media Wearout Indicator — Current state of drive operation based upon the Life Curve.
100 is the BEST value and 0 is the WORST.
Check SMART Attribute Details for more information.
To initiate the extended test (long) using the following command:
sudo smartctl -t long /dev/sda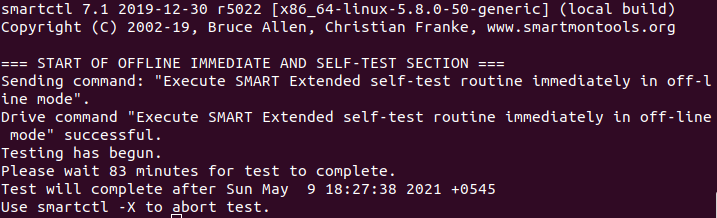
To perform a self test, run:
sudo smartctl -t short /dev/sda
To find drive’s self test result, use the following command.
sudo smartctl -l selftest /dev/sda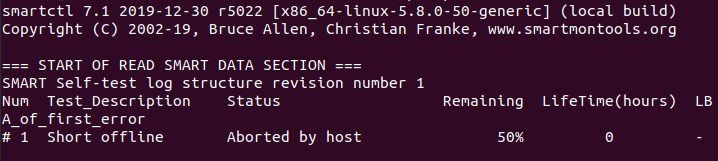
To evaluate estimate time to perform test, run the following command.
sudo smartctl -c /dev/sda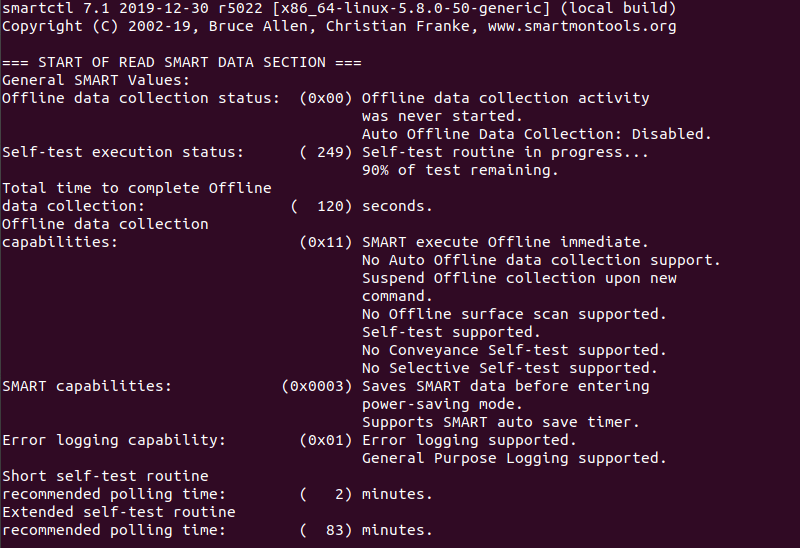
You can print error logs of the disk by using the command:
sudo smartctl -l error /dev/sda
Test SSD/HDD Health using Gnome Disks
With GNOME disks utility you can get a quick review of your SSD drives, format your drives, create a disk image, run standard tests against SSD drives, and restore a disk image.
Install Gnome Disks
In Ubuntu 20.04, the GNOME Disks application comes with the GNOME disk tool installed. If you are unable to find the tool, use the following command to install it.
sudo apt-get install gnome-disk-utilityGNOME Disk is now installed, now you can go to your desktop menu navigate to the application, and launch. From the application, you can overview all your attached drives. You can also use the following command to launch the GNOME Disk application.
sudo gnome-disks 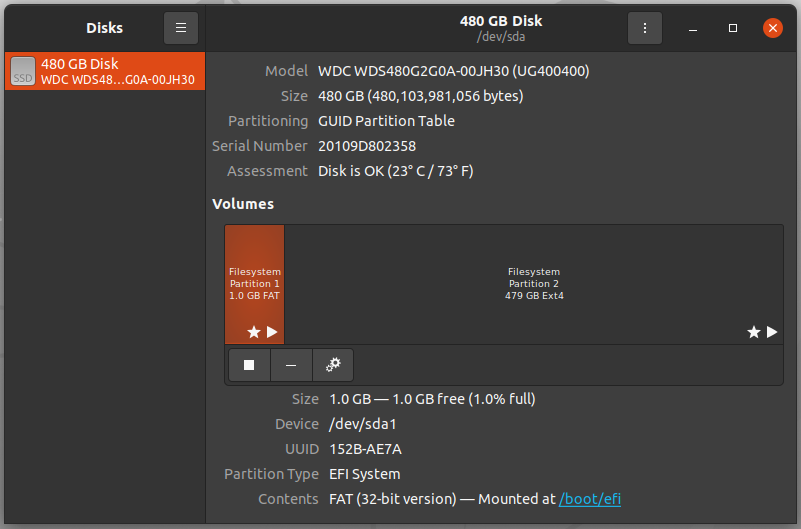
Now the test can be performed on the drives. To do so, launch the GNOME disks and select the disk which you want to test. You can find the quick assessment of the drives such as size, partitioning, Serial number, temp, and health. Click on the gear icon and select SMART Data & Self-tests.
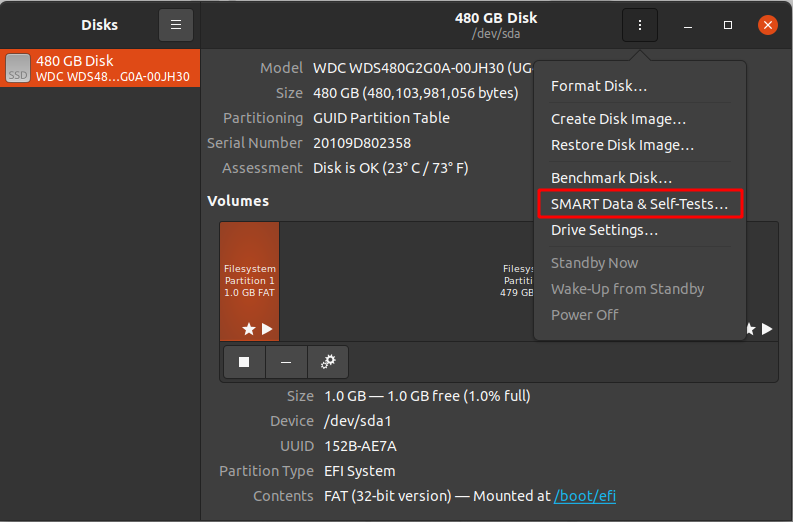
In the new window you can find the results of the last test. In the top right of the window, you can find that the SMART option is enabled. If SMART is disabled, it can be enabled by clicking on the slider. To start the new test click on the Start Self-test button.
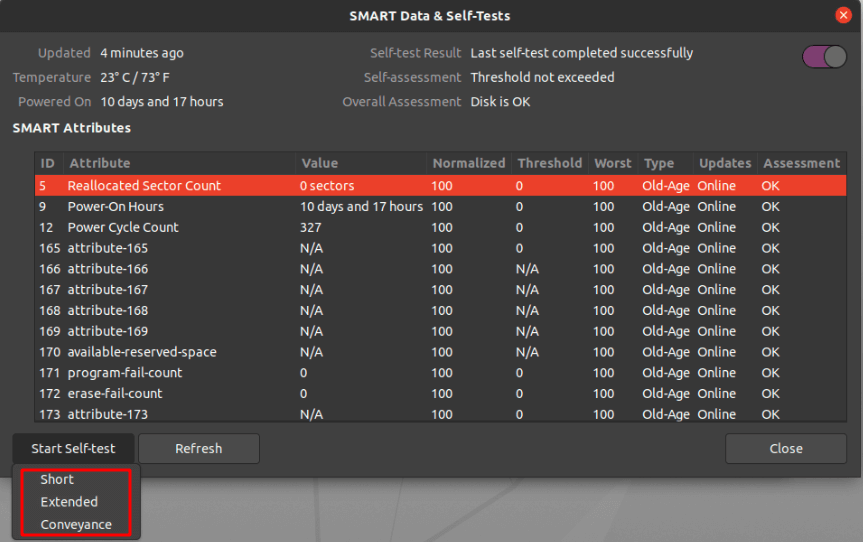
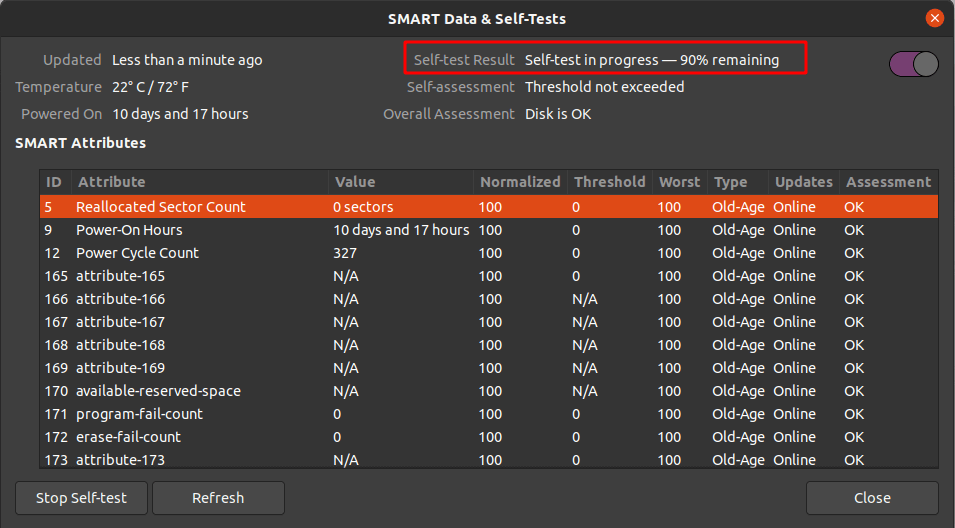
Once the Start Self-test button is clicked, a drop down menu will be appeared to select the type of the tests which are Short, Extended and Conveyance. Select the test type and provide your sudo password to continue the test. From the progress meter, percentage of the test complete can be seen.
Conclusion
In this tutorial, I have explained the basic concept of the S.M.A.R.T technology including its uses in the Linux system. Also, I have covered how to install the smartctl command-line utility tool in the Linux machine and how it can be used to monitor the health of hard drives. You have also got an idea about the GNOME Disks utility tool to monitor SSD drives. I hope this article will help you to monitor your SSD drives using smartctl and GNOME Disks utility.
12.08.2019

Сегодня в статье рассмотрим, как в Linux проверить ваш HDD,SSD или USB флешку на битые сектора – Бэд-блоки.
Бэд-блок (англ. bad block) — испорченный кластер (единица хранения данных) дискового носителя информации, куда нельзя записать информацию.
Проверка HDD на бэд-блоки программой badblocks.
-
1.
Проверка HDD на бэд-блоки программой badblocks. -
2.
Проверка HDD на бэд-блоки на Linux с помощью smartmontools -
3.
Проверка HDD на бэд-блоки на Linux с помощью GParted -
4.
Safecopy
Badblocks — стандартная утилита Linux для проверки на битые секторы. Она устанавливается по-умолчанию практически в любой дистрибутив и с ее помощью можно проверить как жесткий диск, так и внешний накопитель.
Но для начала воспользуемся ещё одной стандартной утилитой для просмотра подключенных накопители к нашей системе — fdisk.
sudo fdisk -l- -l – показать список разделов и выйти.
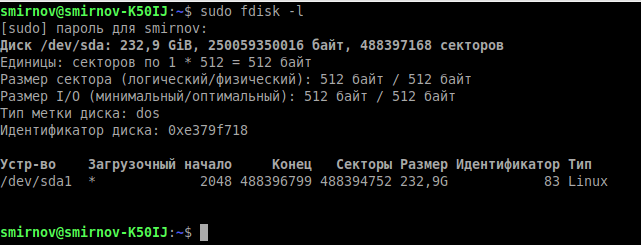
Теперь, когда мы знаем, какие разделы у нас есть, мы можем проверить их на битые секторы программой badblocks:
sudo badblocks -sv /dev/sda1 > ~/badblocks.txt- -v — вывод подробной информации о результатах проверки.
- -s — отображать в правильном порядке ход проверки блоков.
- /dev/sda1 — раздел, который мы хотим проверить на битые секторы.
- > ~/badblocks.txt — выводим результат выполнения команды в файл badblocks.txt расположенный в корневом каталоги пользователя.

Если же в результате были найдены битые секторы, то нам надо дать
указание операционной системе не записывать в них информацию в будущем.
Для этого нам понадобятся утилиты Linux для работы с файловыми
системами:
- e2fsck. Если мы будем исправлять раздел с файловыми система Linux ( ext2,ext3,ext4).
- fsck. Если мы будем исправлять файловую систему, отличную от ext.
Вводим следующие команды:
sudo e2fsck -l ~/badblocks.txt /dev/sda1Или, если у нас файловая система не ext:
sudo fsck -l ~/badblocks.txt /dev/sda1Если после ввода данных команд вы получаете что-то вроде этого:
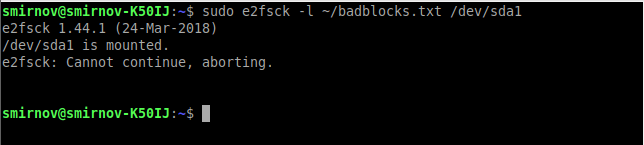
Значит данные операции надо выполнить в командной строке до загрузки операционной системы. Для этого выполним следующее:
sudo nano /etc/network/interfacesВ конце файла дописываем следующие строки:
pre-up e2fsck -l ~/badblocks.txt /dev/sda1Теперь перезагружаем ПК:
sudo rebootТеперь давайте рассмотрим более современный и надежный способ
проверить диск на битые секторы linux. Современные накопители ATA/SATA
,SCSI/SAS,SSD имеют встроенную систему самоконтроля S.M.A.R.T (Self-Monitoring, Analysis and Reporting Technology,
Технология самоконтроля, анализа и отчетности), которая производит
мониторинг параметров накопителя и поможет определить ухудшение
параметров работы накопителя на ранних стадиях. Для работы со S.M.A.R.T в
Linux есть утилита smartmontools.
Давайте сначала ее установим. Если ваш дистрибутив основан на Debian\Ubuntu, то вводите:
sudo apt install smartmontoolsЕсли же у Вас дистрибутив на основе RHEL\CentOS, то вводите:
sudo yum install smartmontoolsТеперь, когда мы установили smartmontools мы можем посмотреть страницу помощи, с помощью команды:
man smartctlили
smartctl -hДавайте перейдем к работе с утилитой. Вводим следующую команду с параметром -H,чтобы утилита показала нам информацию о состоянии накопителя:
sudo smartctl -H /dev/sda1
Как видим, проверка диска на битые секторы linux завершена и утилита говорит нам, что с накопителем все в порядке!
Ещё одна команда, если SMART поддерживается, то добавляем -s. Если он не поддерживается или уже включён, то этот аргумент можно убрать.
sudo smartctl -s on -a /dev/sdaДополнительно, можно указать следующие параметры -a или –all, чтобы получить еще больше информации о накопителе, или -x и –xall, чтобы просмотреть информацию в том числе и об остальных параметрах накопителя.
Проверка HDD на бэд-блоки на Linux с помощью GParted
GParted как раз для тех, кому текстовый интерфейс не по душе. Утилита выполняет большое количество задач, связанных с работой HDD на Ubuntu и всех Debian-подобных системах. В их число входит и проверка диска на ошибки.
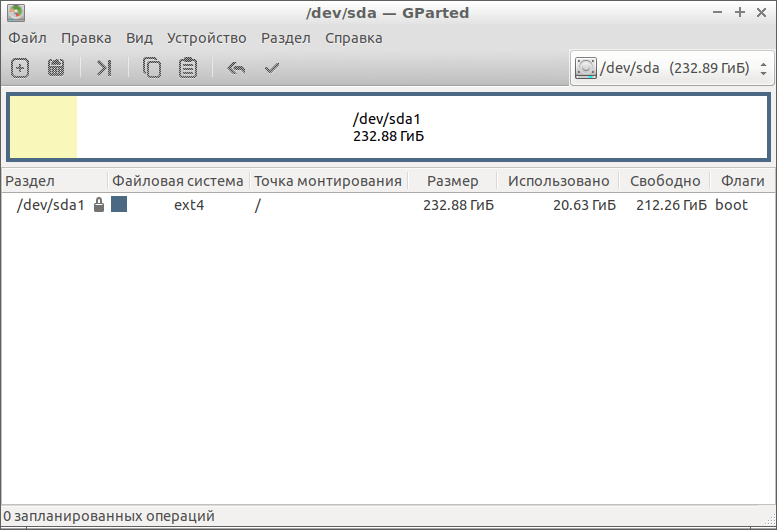
Для
начала нам нужно скачать и установить GParted. Вводим следующую
команду, чтобы выполнить загрузку из официальных репозиториев:
sudo apt install gparted- Открываем
приложение. На главном экране сразу же выводятся все носители. Если
какой-то из них помечен восклицательным знаком, значит, с ним уже что-то
не так. - Щёлкаем по тому диску, который хотим проверить.
- Жмём на кнопку «Разделы», расположенную сверху.
- Выбираем «Проверка на ошибки».
Программа отсканирует диск. В зависимости от его объёма процесс может занять продолжительное время. После сканирования Вы будете оповещены о его результатах.
Safecopy
Это уже та программа,
которую впору использовать на тонущем судне. Если мы осведомлены, что с
нашим диском что-то не так, и нацелены спасти как можно больше выживших
файлов, то Safecopy придёт на помощь. Её задача как раз заключается в
копировании данных с повреждённых носителей. Причём она извлекает файлы
даже из битых блоков.
Устанавливаем Safecopy:
sudo apt install safecopyПереносим
файлы из одной директории в другую. Выбрать можно любую другую. В
данном случае мы переносим данные с диска sda в папку home.
sudo safecopy /dev/sda /home/Если есть вопросы, то пишем в комментариях.
Также можете вступить в Телеграм канал, ВКонтакте или подписаться на Twitter. Ссылки в шапке страницы.
Заранее всем спасибо!!!
RSS
Добавление RSS-ленты на главную страницу этого сайта не поддерживается, так как это может привести к зацикливанию, замедляющему работу вашего сайта. Попробуйте использовать другой блок, например блок Последние записи, для отображения записей сайта.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
5
4
голоса
Рейтинг статьи
To protect the data on the SSD/HDD disks, especially with the limited lifespan, the experts recommend keeping a check on its health. The SSD/HDD is not immune to damage and corruption, which leads to data loss. To prevent it, users can test SSD/HDD health after identification of drives using various methods on Linux.
This guide elaborates on the approaches to test SSD/HDD health in Linux effectively.
- View List of Disks
- Method 1: Using Smartctl
- Method 2: Using nvme-cli
- Method 3: Using Disks Application (GUI)
How to View the List of Disks on Linux?
Many tools are available to view the list of disks on Linux, such as lsblk, df, fdisk, hwinfo, and many more, discussed here in detail. Let’s use the lsblk command to view a list of disks:
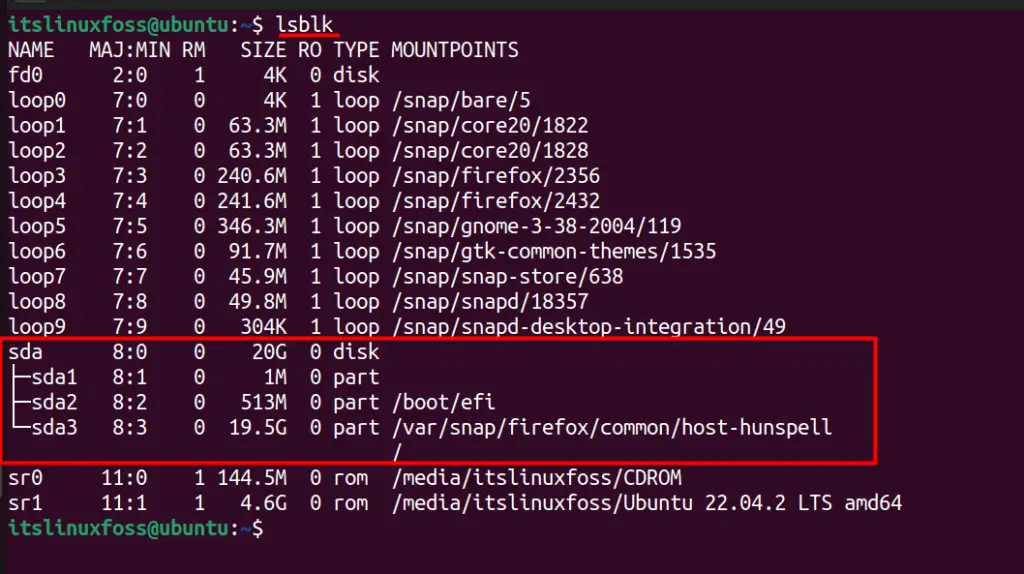
The output shows disk partitions “sda1”, “sda2” and “sda3” in the operating system and a system can have multiple hard drives.
Note: The above output is from Ubuntu installed on the Vmware Workstation, and the output on your end can be different.
Method 1: Using Smartctl on Linux
The Smartctl comes in the “smartmontools” package. It has a self-monitoring feature to monitor the system’s performance. The Smartctl tool supports ATA/SATA, SCSI/SAD, and NVME. It is not pre-installed in the Linux distro. It can be installed using these commands:
$ sudo apt install smartmontools #Ubuntu/Debian/LinuxMint $ sudo dnf install smartmontools #Fedora $ sudo yum install smartmontools # RHEL/CentOS
The above figure confirms that the installation of smartmontools has been done on Ubuntu.
To test the SSD/HDD for health, understand this command before executing it:
- smartctl is there to view the information on storage devices
- -t long specifies that a long self-test is to be performed to check the entire surface of the drive for any potential issues
- -a displays the current status and attributes of the disk
- /dev/sda is the name of the drive to check
$ sudo smartctl -t long -a /dev/sda
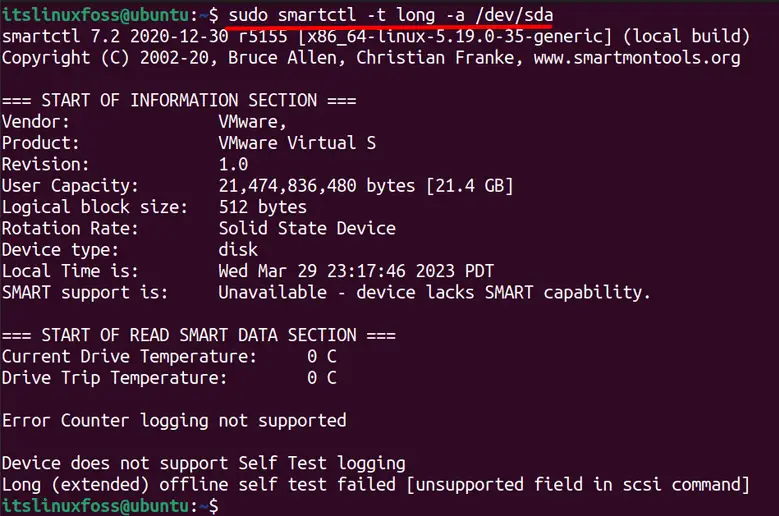
The current drive on the system does not support Self Test logging but this
Method 2: Using nvme-cli to Test SSD/HDD Health
Another popular tool named “nvme-cli” can be used to check SSD/HDD health. This is designed especially for the NVME type SSDs, as expected from the name. To install it, use these commands:
$ sudo apt install nvme-cli #Ubuntu/Debian $ sudo dnf install nvme-cli #Fedora $ sudo yum install nvme-cli #RHEL/CentOS
The above image confirms the installation of nvme-cli has been done on Ubuntu.
To test the SSD/HDD for health, use this command after understanding it:
- The watch utility is used to continuously monitor the SMART log
- -n 1 tells the watch command to monitor the SMART log every second
- nvme is used to manage the NVMe devices
- smart-log is used with the nvme command to view the SMART logs
- /dev/nvme0n1p is the drive being monitored
$ sudo watch -n 1 nvme smart-log /dev/nvme0n1p6
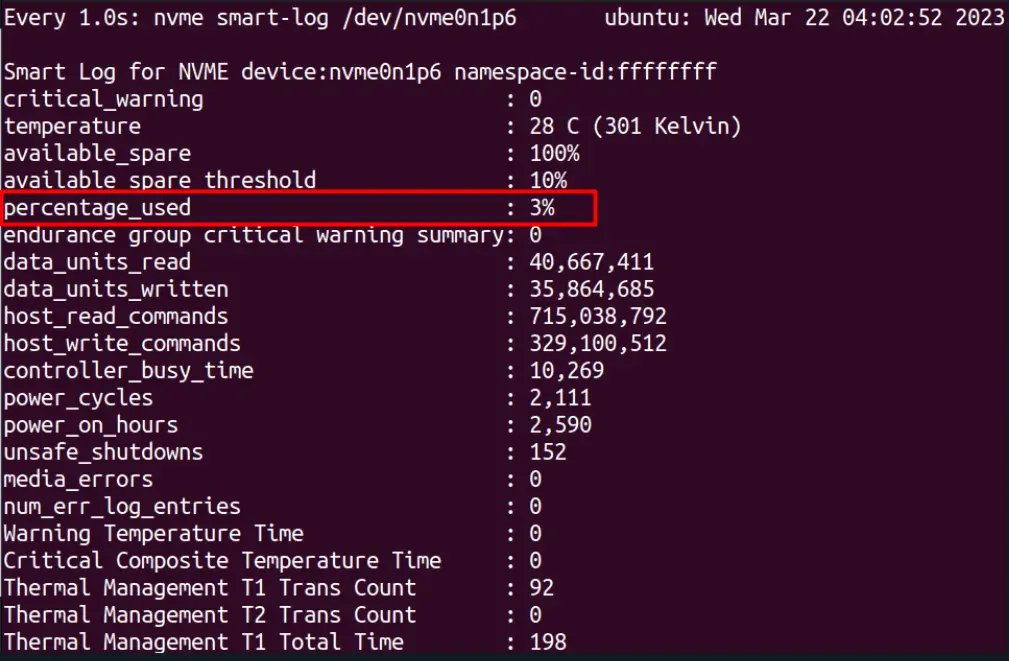
In the above figure, users can check the percentage_used, which is 3% (good health). While if it is over 50%, you should be worried and consider changing the drive. Additionally, users can visualize the “power_on_hours”, “unsafe_shutdowns”, and many more in the terminal.
Note: The above command is executed in dual-boot, and the drive used is NVME.
To check the temperature of the NVME, use the grep command to filter it like this:
$ sudo nvme smart-log /dev/nvme0n1p6 | grep "^temperature"

As seen in the above image, make sure that the temperature remains between 0 and 70 degrees Celsius. If the temperature exceeds this limit, it could cause serious damage to the drive, which ultimately leads to data loss.
Method 3: Using Disks Application (GUI)
To check the SSD/HDD health via the graphical interface, use the GNOME Disk Application by following these steps:
Step 1: Open Disk Application
To open the disk application, click on “Activities” from the top right corner of the screen and then type “Disks” in the search bar and open it:
After clicking on “Disks,” a new window opens up.
Step 2: Select Disk and do SMART Data & Self-Tests
From the new screen, select the drive you want to test (1). Next, choose disk (2). Now click on three dots and then pick the “SMART Data & Self-Tests” option: The disk on the current system does not support this feature, so the option is greyed out. So use the CLI methods discussed above when this option is unavailable.
Conclusion
Linux offers the “Smartctl” and “nvme-cli” command line tools to test the health of SSD/HDD. These tools are used to visualize the “percentage_used ”, “power_on_hours”, “unsafe_shutdowns”, and many more in the terminal. Users can also utilize the “Disks” application in GUI to test SSD/HDD’s health.
This guide explained the methods to test SSD/HDD health on Linux.