If ECC works and corrects errors, some logs will contain that info.
A few soft errors per year can naturally occur, but if you really want to produce more of them, then probably rowhammerjs can help. It does not work on every architecture and with every memory settings however.
By AMD processors you can try to force enable ECC with the following code in Linux.
modprobe -v amd64_edac_mod ecc_enable_override=1
If it fails, then you can be certain that ECC is not supported. There are rumors that recent systems with Ryzen do not support this, and ofc. it is generally not recommended to force enable this feature.
Afaik. memtest86+ is good to, since it tries to check whether the ECC works, not just the meta data about whether it is turned on, which can’t be really trusted.
I did a little research in the topic. According to forums and articles here is a list of a few boards:
Motherboard ECC support
ASRock AB350 Pro4 1? (above 2.20 BIOS version)
ASRock Fatal1ty AB350 Gaming K4 0
ASRock X370 Killer SLI 1
Asrock X370 Taichi 1
Asus PRIME B350-PLUS 0?
Asus PRIME B350M-A 0?
Asus PRIME X370-PRO 1
Biostar B350GT5 0
Biostar X370GT3 0?
Gigabyte GA-AB350-Gaming 0
Gigabyte GA-AB350-Gaming 3 0
Gigabyte GA-AB350M-HD3 0
Gigabyte GA-AX370-Gaming K7 1
MSI B350 PC MATE 0?
MSI B350 TOMAHAWK 0?
MSI B350M GAMING PRO 0
MSI X370 KRAIT GAMING 0?
MSI X370 SLI PLUS 0?
By Biostar and MSI board there is no documentation about this in the manual, the other vendors tend to mention whether the board supports ECC in non-ECC mode. Most of the X370 boards support the feature. Afaik. Gigabyte don’t want to support the feature on its B350 boards. Not a clue about Asus by the same chipset. According to a forum in dutch the ASRock AB350 Pro4 supports the feature from 2.20b BIOS version, but it is not confirmed with tests.
4 things are needed to have a working ECC:
- memory controller that supports ECC (in the CPU nowadays)
- ECC memory
- some circuitry on the mobo to deliver the extra bits to the CPU (I am not a electrical engineer, so I don’t know the exact terms)
- a short mobo microcode to enable the feature
In some cases only the 4th is missing and latter BIOS updates can enable this feature.

- Test your ECC error detection and correction mechanisms.
- Inject single and double bit errors in real-time.
- Test machines with CPU, Motherboard and DDR4 RAM ECC support.
-
Suitable for use with
MemTest86 and BurnInTest.
Why test ECC Memory?
ECC (Error Correction Code) Memory is a type of RAM that automatically detects and corrects memory errors via an extra memory chip. Valued by those who store and manage critical data on workstations and servers, ECC RAM is supposed to have a much lower failure rate and thus, cause fewer crashes.
If you have installed ECC RAM, the PassMark ECC Tester allows you to know whether the error correcting capabilities are functioning as expected.


Test Error Detection and Correction
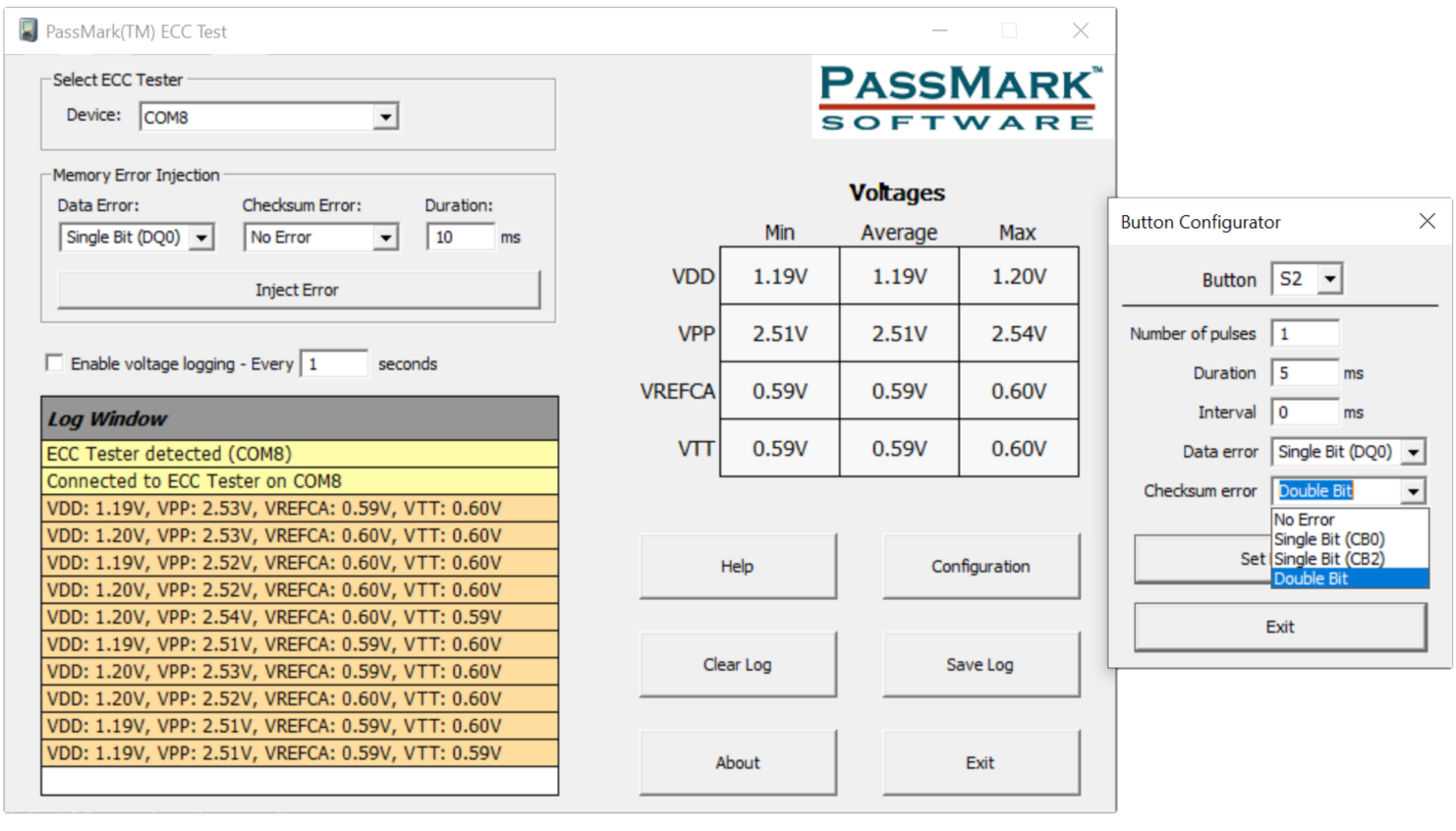
The PassMark ECC Tester is an DDR4 DIMM interposer, designed to inject single bit and double bit errors in real-time, to challenge and test the error detection and correction mechanism of machines that have CPU, motherboard and RAM sticks with ECC support.
The tester has 4 physical buttons, which can be programmed to inject single errors or a sequence of errors when pressed, as well as choose between disrupting the data or checksum line.
Direct Motherboard Compatability
Designed to house your ECC RAM inline on your motherboard, the ECC Tester acts as an interposer used to inject single and double bit errors. It is also connected to your system via USB, for tracking of results.
With the included USB Connector, users are able to change the ECC Testers setting, monitor voltages on the memory bus and allow MemTest86 and BurnInTest to control error injection.

ECCTest for Windows
Every Purchase of a PassMark ECC Tester includes access to ECCTest for Windows. Functionality includes:
Monitor the voltages on your RAM.
- Monitor the VTT, VREFCA, VPP, and VDD voltages on the RAM stick.
- Record and save a log of the voltages on the RAM stick while it is in use.
Customize the type of errors generated.
- Simple interface to program the type of error generated when a button on the ECC Tester is pressed.
- Customization options include creating single or periodic errors, as well as correctable or non-correctable errors.
Integrated Software Testing
Test error detection and correction directly within MemTest86 without the need for an operating system. Inject errors with the ECC Tester during your memory tests to see if the system correctly detects ECC errors.
Related software

MemTest86

BurnInTest
Related hardware

USB 3.0 Loopback Plugs

Audio Loopback Cable

Ответ на:
комментарий
от targitaj

Все платы для Ryzen запускаются с ECC памятью, но могут работать как с обычной.
dinn ★★★★★
()
- Показать ответ
- Ссылка
Ответ на:
комментарий
от dinn
Ответ на:
комментарий
от targitaj
Именно. Например MSI: «Supports ECC UDIMM memory (non-ECC mode)»
dinn ★★★★★
()
Последнее исправление: dinn
(всего
исправлений: 1)
- Показать ответ
- Ссылка
Ответ на:
комментарий
от targitaj

Просто игнорировать бит ЕСС, вроде даже в БИОСах такая опция есть(или была)
torvn77 ★★★★★
()
- Показать ответ
- Ссылка
Ответ на:
комментарий
от dinn
Так, ты говоришь про ситуацию «мат плата поддерживает модули с ECC, но работает с ними в non ECC режиме» и желаешь проверить на месте как именно у тебя будет работать ОЗУ?
targitaj ★★★★★
()
- Показать ответ
- Ссылка
Ответ на:
комментарий
от torvn77
вроде даже в БИОСах такая опция есть(или была)
Да, есть. При её использовании dmidecode не упоминает коррекцию ошибок.
dinn ★★★★★
()
- Ссылка
Ответ на:
комментарий
от targitaj
Скорее про ситуацию «есть поддержка, но никто не гарантирует что оно реально работает». Всегда найдутся опции, которые есть, но работают при строго определённых фазах луны.
dinn ★★★★★
()
- Ссылка
![]()
Чтобы проверить и исправить ошибку, нужен буфер, где это будет делаться. Буфер может быть на самой памяти, например в регистровой памяти. Или в контроллере памяти. Обычно все региcтровые dimm имеют ecc, и для их работы требуется поддержка контроллером памяти регистровых dimm. То есть, если регистровая память работает, то ecc тоже работает.
Можно сэкономить, сделать память с избыточным количеством бит на слово для ecc, но логику коррекции не делать, переложить на контроллер, заодно не нужен буфер в самой памяти. Небуферизированная память. И тут зависит от контроллера, будет он заниматься ecc, или можно выиграть минимум один такт и поднять произвоительность подсистемы памяти, буфер небесплатный и коррекция ошибок тоже.
anonymous
()
- Показать ответ
- Ссылка
Ответ на:
комментарий
от anonymous
![]()
прекращайте употреблять вещества. буферный регистр на линиях **адреса** у registered памяти никакого отношения к ЕСС не имеет в принципе.
NiTr0 ★★★★★
()
- Ссылка
Ответ на:
комментарий
от targitaj
А что ты вообще хочешь?
Может проще и надёжнее купить оверклокерскую память и использовать её в обычном режиме?
torvn77 ★★★★★
()
- Показать ответ
- Ссылка
![]()
смотреть dmesg.
# dmesg|grep -i edac
EDAC MC: Ver: 2.0.1 Jun 2 2015
EDAC amd64_edac: Ver: 3.4.0
EDAC amd64: ECC is enabled by BIOS.
EDAC amd64: F10h detected (node 0).
EDAC MC: DCT0 chip selects:
EDAC amd64: MC: 0: 1024MB 1: 1024MB
EDAC amd64: MC: 2: 1024MB 3: 1024MB
EDAC amd64: MC: 4: 0MB 5: 0MB
EDAC amd64: MC: 6: 0MB 7: 0MB
EDAC MC: DCT1 chip selects:
EDAC amd64: MC: 0: 1024MB 1: 1024MB
EDAC amd64: MC: 2: 1024MB 3: 1024MB
EDAC amd64: MC: 4: 0MB 5: 0MB
EDAC amd64: MC: 6: 0MB 7: 0MB
EDAC amd64: using x4 syndromes.
EDAC amd64: MCT channel count: 2
EDAC amd64: CS0: Unbuffered DDR2 RAM
EDAC amd64: CS1: Unbuffered DDR2 RAM
EDAC amd64: CS2: Unbuffered DDR2 RAM
EDAC amd64: CS3: Unbuffered DDR2 RAM
EDAC MC0: Giving out device to amd64_edac F10h: DEV 0000:00:18.2
ессно должен быть драйвер EDAC.
NiTr0 ★★★★★
()
- Показать ответ
- Ссылка
Ответ на:
комментарий
от torvn77
![]()
и как это избавит от ошибок из-за фонового радиационного излучения или «горячих» частиц в компаунде?
ну и да, у оверклоцкерской памяти тайминги выкручены на минимум, лишь бы как-то работало и игры не вылетали каждые полчаса. сталкивался с тем, что на ам2+ почти любая сохо память давала где-то 1 ошибку в сутки при прогоне мемтеста. некоторые — будучи в паре с другими на канале, некоторые — и самостоятельно тоже. воткнул в ту же плату ЕСС память — как отшептали, ни ошибок мемтеста, ни скорректированных/нескорректированных ошибок памяти.
NiTr0 ★★★★★
()
- Показать ответ
- Ссылка
Ответ на:
комментарий
от NiTr0
Если память оверклокерская то это значит что чип тестировали на работу при повышенных напряжениях и частотах и как следствие при повышенной температуре и по этому при эксплуатации в обычном режиме она очень надёжна, в том числе может проработать более 10 часов без ошибок.
Но это конечно надо брать хорошие и по этому дорогие модули.
torvn77 ★★★★★
()
- Показать ответы
- Ссылка
Ответ на:
комментарий
от torvn77

Если память оверклокерская то это значит
Что на неё налепили ненужные, но красивые радиаторы и продали лохам в 3 раза дороже.
()
- Показать ответы
- Ссылка
Ответ на:
комментарий
от K22
Ну запусти обычную память в том же режиме что и оверклокерскую, потом напиши тут режим и результат.
torvn77 ★★★★★
()
Последнее исправление: torvn77
(всего
исправлений: 1)
- Показать ответ
- Ссылка
Ответ на:
комментарий
от torvn77
![]()
это значит
Нет, это не значит.
хорошие и по этому дорогие
Купи кирпич, хороший, тк за 1000$.
anonymous
()
- Ссылка
Ответ на:
комментарий
от torvn77
![]()
Нет, запусти ты, а потом балаболь не от балды, а уже со знанием вопроса.
anonymous
()
- Показать ответ
- Ссылка
Ответ на:
комментарий
от anonymous
Я пользовался разной памятью, в том числе и выкручивая тайминги по принципу уменьшим тут и если компьютер работает то и ладно и для меня разница между качественной оверклокерской памятью и обычной просто факт.
Что такого сложного понять простую вещь: чипы при изготовлении получаются с некоторым разбросом характеристик, их сортируют, самые лучшие продают как оверклокерские, остальные помещают в товарную группу «обычные» и продают тебе, в том числе как и ECC Registered.
torvn77 ★★★★★
()
Последнее исправление: torvn77
(всего
исправлений: 1)
- Показать ответы
- Ссылка
Ответ на:
комментарий
от torvn77
![]()
Я пользовался разной памятью
А нужно было одинаковой: обычной на одних чипах и школоклокерской на таких же чипах. При достаточной выборке разницы не найдёшь 100%, кроме может совсем уж топовых набров на 4000+мгц.
anonymous
()
- Показать ответ
- Ссылка
Ответ на:
комментарий
от anonymous
кроме может совсем уж топовых набров на 4000+мгц.
Эта оговорка объясняет разницу наших мнений.
Хотя надо признаться моя последняя оверклокерская память была ddr2, на ddr3 я купил «временно» обычную и как-то мне её хватает, а память не глючит…
Хотя она всё равно с радиаторами.
В общем что сейчас за оверклокерская память я на самом деле не знаю, думаю что так-же, хочешь много плати за ТОПающего по потолку соседа.
torvn77 ★★★★★
()
Последнее исправление: torvn77
(всего
исправлений: 2)
- Показать ответ
- Ссылка
Ответ на:
комментарий
от torvn77
![]()
Нужно выбирать быстрые чипы, иначе купишь говно хуже обычной памяти, зато школоклокерское с заводским разгоном, на котором она не стартует.
anonymous
()
- Показать ответ
- Ссылка
Ответ на:
комментарий
от anonymous
Быстрые по какому признаку, не только частота, но и тайминги или ещё какой признак?
torvn77 ★★★★★
()
- Показать ответ
- Ссылка
Ответ на:
комментарий
от torvn77
![]()
Именно по этим признакам, и это зависит от типа чипов (например samsung b-die). Там не единственный в мире чип, который отбирают, а есть страрые или просто плохие типы чипов и наоборот.
anonymous
()
- Ссылка
Ответ на:
комментарий
от torvn77
![]()
Если память оверклокерская то это значит что чип тестировали на работу при повышенных напряжениях и частотах и как следствие при повышенной температуре и по этому при эксплуатации в обычном режиме она очень надёжна
бред. в оверклоцкерскую память берут, к примеру, 3200CL18 и дальше тупо поднимают частоту и урезают тайминги. и «в обычном режиме» у нее тоже тайминги зарезаны. а как чип CL18 будет работать на CL16 — думаю, саи догадываетесь 
в том числе может проработать более 10 часов без ошибок.
охтыжнифигасебе… аж целых 10 часов без ошибок… вот это «надежность», да… а на 11-й час сбойнул битик — и в таблице БД, чей кеш хранился в сбойнувшей ячейке в ожидании записи на диск, вместо данных — мусор. зато ж память оверклоцкерская, с ргб подсветкой и массивными нахрен не нужными радиаторами
NiTr0 ★★★★★
()
- Ссылка
Ответ на:
комментарий
от torvn77
![]()
Я пользовался разной памятью, в том числе и выкручивая тайминги по принципу уменьшим тут и если компьютер работает то и ладно
дадада, помнится я лет 15+ назад тоже гнал память по принципу «работает компьютер то и ладно», подумаешь тест мемтеста падал — ну и хрен с ним, игры-то не вылетали, ну мож какой-то полигон хрензнаеткуда улетит изредка…
Что такого сложного понять простую вещь: чипы при изготовлении получаются с некоторым разбросом характеристик, их сортируют, самые лучшие продают как оверклокерские
никто никого никуда не сортирует. берутся те же самые чипы, выкручиваются тайминги на минимум (во всех режимах), задираются частоты, лептся радиаторы и ргб подсветка и напариваются «счастливым владельцам».
NiTr0 ★★★★★
()
- Ссылка
Ответ на:
комментарий
от targitaj

некоторые модули (см. Samsung) могут работать в «обычном» режиме.
но это всё серая зона, инфы по подобному функуционалу мало, ибо большинству ЦА это просто не нужно
- Ссылка
Ответ на:
комментарий
от torvn77

в том числе может проработать более 10 часов без ошибок
Какие страшные вещи вы рассказываете. Если у меня на компе вот так память будет лагать, то будет мне беда-печаль из-за попортившихся данных.
peregrine ★★★★★
()
- Показать ответы
- Ссылка
Ответ на:
комментарий
от peregrine
![]()
Мне тут недавно рассказывали что сотни ошибок битой памяти в день это обычное дело и у любой памяти будет так. Я, признаться, прифигел, поскольку привык, что исправная память не будет сыпать ошибками, как ты с ней ни извращайся.
anonymous
()
- Показать ответы
- Ссылка
Ответ на:
комментарий
от peregrine
Какие страшные вещи вы рассказываете.
Что вы все цепляетесь к словам?
Я просто больше 10 часов не проверял, а так у меня компьютер по несколько дней работает, пока я не перегружу его по какой либо своей надобности.
torvn77 ★★★★★
()
Последнее исправление: torvn77
(всего
исправлений: 1)
- Показать ответ
- Ссылка
Ответ на:
комментарий
от torvn77
![]()
пока я не перегружу его по какой либо своей надобности
Например, почистить от набившихся тараканов?
anonymous
()
- Ссылка
Ответ на:
комментарий
от K22

Что на неё налепили ненужные, но красивые радиаторы
Если DDR4 запитывать 1,4 вольтами и ставить конские частоты, радиаторы становятся нужными.
Meyer ★★★★★
()
- Показать ответ
- Ссылка
Ответ на:
комментарий
от Meyer
![]()
Если DDR4 запитывать 1,4 вольтами
Если ты превышаешь нормальное напряжение (1.2 В), то ты ССЗБ.
anonymous
()
- Показать ответы
- Ссылка
Ответ на:
комментарий
от torvn77
![]()
может проработать более 10 часов без ошибок
И как это у меня комп неделями работает без проблем?
Deleted
()
- Ссылка

А можно выключить ECC сделать даун вольт на памяти (плата это позволяет?) до значений чтоб память сыпала ошибками и проверить что будет после включения ECC?
Aber ★★★★★
()
- Ссылка
Ответ на:
комментарий
от anonymous
Если ты превышаешь нормальное напряжение (1.2 В), то ты ССЗБ.
На стандартном напряжении мои плашки не работали, когда я выставлял частоту в 3733MHz.
Meyer ★★★★★
()
- Ссылка
Ответ на:
комментарий
от anonymous
Если ты превышаешь нормальное напряжение (1.2 В), то ты ССЗБ.
Плюс 10% вполне безопасно, когда делают ic закладывают некоторые приделы работы, тут конечно чуть больше, но думаю не критично. А вообще я помню во времена ddr2 брал оверклокерские модули TEAM и там уже дефолтно были повышенные вольты записаны в профилях.
Прямо сейчас нашел первый попавшийся модуль памяти TEAM:
Frequency 2666 3000
Voltage 1.2V 1.35V
Aber ★★★★★
()
Последнее исправление: Aber
(всего
исправлений: 1)
- Ссылка


Посмотрите тут:
cat /sys/devices/system/edac/mc/mc0/ue_count
для других платформ (каких?) можно установить mcelog и следить за его логами.
Если что новое найдёте — пополняйте wiki
LeNiN ★★
()
- Ссылка
Ответ на:
комментарий
от anonymous
У меня самый большой аптайм моего компа (не сервера) порядка 5 месяцев. Если там сотни ошибок памяти в день были бы, то 15k ошибок должны были бы как-то себя показать. Правда память у меня таки ECC, работающая как ECC память. Сервер на работе крутился с аптаймом в 1.5 года и ~1 ТБ оперативки для кеширования БД. Правда я ХЗ как там оно было внутри устроено и что за железо/виртуализация. Ничего не сбоило, если рукопопы, вроде меня, туда багованный код не заливали.
peregrine ★★★★★
()
- Ссылка
Ответ на:
комментарий
от anonymous
![]()
Почему тогда только у оперативки а не у процессора (который сам состоит из кардинально боольшего числа транзисторов работающих в кардинально более сложных условиях) и вообще всех остальных чипов? И как оно все тогда работает?
anonymous
()
- Показать ответ
- Ссылка
Ответ на:
комментарий
от torvn77
![]()
может проработать более 10 часов без ошибок
надо брать хорошие и по этому дорогие модули
А если брать обыкновеннейшую память вроде https://mobilespecs.net/memory/AMD/AMD_R738G1869U2-US.html, то
—► uptime -p
up 5 weeks, 2 days, 14 hours, 10 minutesи более — настолько в порядке вещей, что речь про «10 часов без ошибок» как про что-то выдающееся вызывает недоумение.
dexpl ★★★★★
()
- Показать ответ
- Ссылка
Ответ на:
комментарий
от dexpl
То что я тестировал только 10 часов не значит что память на 11 часу даст ощибку, это значит что я тестировал память 10 часов.
torvn77 ★★★★★
()
- Ссылка
Ответ на:
комментарий
от anonymous
![]()
открою секрет: у процов есть ЕСС в кешах. да-да, при том что там SRAM, а не DRAM, и при том что размер кешей — единицы мегабайт, а не десятки гигабайт.
NiTr0 ★★★★★
()
- Показать ответ
- Ссылка
Ответ на:
комментарий
от NiTr0
![]()
Я в курсе. В остальном проце ecc нет.
anonymous
()
- Ссылка
Ответ на:
комментарий
от peregrine
Хехе. Проведи простой эксперимент. Возьми попереливай пару раз туда-сюда терабайт торрентов и потом проведи перехеширование. Ох, был у меня день с открытием… Кароч, данные бьются постоянно и непрерывно. Сквозное ECC по всем линиям связи — это тупо must have.
targitaj ★★★★★
()
- Показать ответы
- Ссылка
Ответ на:
комментарий
от targitaj
![]()
Забавно, далаю так и ни разу не видел, чтобы былось. Не терабайты правда, сотни гигов.
anonymous
()
- Показать ответ
- Ссылка
Ответ на:
комментарий
от anonymous
Да, от железа зависит, это факт. У некоторых десятки ошибок в день по ОЗУ бывает. А я тогда перелил 500 гиг туда-сюда и получил каждый 10-тый файл с 99% готовности. Это было неожиданно, мягко говоря. Вот тогда я на самом деле понял зачем надо сквозные ECC по всем коммуникациям.
targitaj ★★★★★
()
Последнее исправление: targitaj
(всего
исправлений: 2)
- Показать ответ
- Ссылка
Ответ на:
комментарий
от NiTr0
смотреть dmesg.
Вот тут начинается веселье:
edac-util: Error: No memory controller data foundlsmod | grep -i edac
edac_mce_amd 32768 0dinn ★★★★★
()
Последнее исправление: dinn
(всего
исправлений: 1)
- Показать ответ
- Ссылка
Вы не можете добавлять комментарии в эту тему. Тема перемещена в архив.
Оглавление
- Вступление
- Коррекция ошибок
- Финансовая сторона
- Тестовый стенд
- Методика тестирования
- Результаты тестирования
- Тест памяти
- 3DMark
- 7Zip
- Cinebench
- CrystalMark
- Fritz
- LinX
- wPrime
- AIDA64 Extreme
- Заключение
Вступление
На сегодняшний день на просторах Рунета можно встретить открытые темы на форумах с вопросами – стоит ли брать рабочую станцию с ECC-памятью или можно обойтись обычной? В данных ветках можно прочесть множество противоречивых утверждений, и часть из них говорит о том, что коррекция ошибок сильно замедляет память, а следовательно и ЦП. Но мало кто это проверял на деле на современных процессорах.
Сегодня мы разберемся в этом вопросе и сравним производительность серверного процессора с обоими типами памяти. Но для начала небольшой экскурс.
Коррекция ошибок
Для чего необходима коррекция? И почему в работе памяти возникают ошибки? Перед ответом на эти вопросы следует разделить ошибки на два типа:
- Аппаратные ошибки;
- Случайные ошибки.
Причиной появления аппаратных ошибок является дефектная микросхема DRAM, а случайные ошибки возникают под воздействием излучения, альфа-частиц, элементарных частиц и прочего. Соответственно, первые в принципе неисправимы – если чип дефектный, то поможет только его замена; а вот вторые могут быть исправлены.
Почему же так необходима коррекция ошибок в рабочих станциях и серверах? Однобитовая ошибка в 64-битном слове меняет содержимое ячейки памяти, а в конечном итоге на жесткий диск может быть записано другое число, другие данные, при этом компьютер не зафиксирует эту подмену. А изменение бита в оперативной памяти может вызвать сбой программы, что для рабочей станции и сервера недопустимо.
рекомендации
3060 дешевле 30тр в Ситилинке
3070 Gigabyte Gaming за 50 тр с началом
<b>13900K</b> в Регарде по СТАРОМУ курсу 62
3070 Gainward Phantom дешевле 50 тр
10 видов <b>4070 Ti</b> в Ситилинке — все до 100 тр
13700K дешевле 40 тр в Регарде
MSI 3050 за 25 тр в Ситилинке
13600K дешевле 30 тр в Регарде
4080 почти за 100тр — дешевле чем по курсу 60
12900K за 40тр с началом в Ситилинке
RTX 4090 за 140 тр в Регарде
Компьютеры от 10 тр в Ситилинке
3060 Ti Gigabyte дешевле 40 тр в Регарде
3070 дешевле 50 тр в Ситилинке
-7% на 4080 Gigabyte Gaming
Для обнаружения изменения битов памяти можно использовать метод подсчета контрольной суммы, но он позволяет лишь обнаруживать ошибки без их исправления.
В свое время было предложено много различных способов решения данной проблемы, но на сегодняшний день наибольшее распространение получил метод коррекции ошибок или ECC (Error-Correcting Code). Данный метод позволяет автоматически исправлять однобитовые ошибки в 64-битном слове – SEC (Single Error Correction) и детектировать двухбитовые – DED (Double Error Detection).
Физическая реализация ECC заключается в размещении дополнительной микросхемы памяти на модуле ОЗУ – соответственно, при одностороннем дизайне модуля памяти вместо восьми чипов располагается девять, а при двустороннем вместо шестнадцати – восемнадцать. Таким образом, ширина модуля становится не 64 бита, а 72 бита.
Метод коррекции ошибок работает следующим образом: при записи 64 бит данных в ячейку памяти происходит подсчет контрольной суммы, составляющей 8 бит. Когда процессор обращается к этим данным и производит считывание, проводится повторный подсчет контрольной суммы и сравнение с исходной. Если суммы не совпадают – произошла ошибка. Если она однобитовая, то неправильный бит исправляется автоматически, если двухбитовая – детектируется и сообщается ОС.
Финансовая сторона
Прежде чем приступить к тестированию, необходимо затронуть финансовый вопрос.
Стоимость обычного модуля памяти DDR3-1600 с напряжением 1.35 В и объемом 8 Гбайт составляет около 3600 рублей, а с коррекцией ошибок – 4800 рублей. На первый взгляд ECC-память выходит на 30-35% дороже, что, в целом, не позволяет их сравнивать в силу существенно большей стоимости последней. Но почему же тогда такой вопрос возникает при сборке рабочей станции? Все просто – необходимо смотреть на данный вопрос шире, а именно – смотреть на общую стоимость рабочей станции.
Ценник однопроцессорной станции на базе четырехъядерного восьмипоточного Xeon (настольные процессоры серий i5 и i7 не поддерживают ECC-память) с 32 Гбайтами памяти, материнской платы с чипсетом C222/С224/С226 (десктопные наборы логики Z87/Z97 и другие также не поддерживают память с коррекцией ошибок) будет превышать 70 000 рублей (при условии, что устанавливаются серверные SSD с повышенным ресурсом). А если включить в эту стоимость и дискретную видеокарту, и прочие сопутствующие компоненты, например, ИБП, то ценник из пятизначного превратится в шестиизначный, перевалив планку в 100 000 рублей.
Покупка 32 Гбайт памяти с коррекцией ошибок потребует дополнительных 4-6 тысяч рублей, что по отношению к общей стоимости рабочей станции не превышает 5%, то есть не является критичным. Также переход от десктопного к серверному железу предоставит и другие преимущества, например: интегрированные графические карты P4600 в процессорах Intel Xeon E3-1200 третьего поколения получили оптимизированные драйверы, которые должны повышать производительность в профессиональных приложениях, например, в CAD; поддержка технологии Intel VT-d, которая позволяет пробрасывать устройства в виртуальную среду, например, видеокарты; прочие серверные технологии – Intel AMT или IPMI, WatchDog и другие, которые также могут оказаться полезными.
Таким образом, хоть и сама ECC-память стоит заметно дороже обычной, в общей стоимости рабочей станции данная статья затрат является несущественной, и переплата не превышает 5%.
Тестовый стенд
Для данного обзора использовалась следующая конфигурация:
- Материнская плата: Supermicro X10SAE (Intel C226, LGA 1150);
- Процессор: Xeon E3-1245V3 (Turbo Boost – off, EIST – off, HT – on);
- Оперативная память:
- 2x Kingston DDR3-1600 ECC 8 Гбайт (KVR16LE11/8 CL11, 1.35 В);
- 2x Kingston DDR3-1600 8 Гбайт (KVR16LN11/8 CL11, 1.35 В);
- ОС: Windows 8.1 Pro 64-bit.
Методика тестирования
В рамках тестирования были произведены замеры производительности как при одноканальном режиме работы ИКП, так и при двухканальном. Суммарный объем ОЗУ составил 8 (один модуль) и 16 Гбайт (два модуля) соответственно.
Программное обеспечение:
- 3DMark 2006 1.2;
- 7Zip 9.20;
- AIDA64 Extreme 5.20.3400;
- Cinebench R15;
- CrystalMark 2004R3;
- Fritz 4.20;
- LinX 0.6.5;
- wPrime 2.10.
Результаты тестирования
Тест памяти
Перед тем, как приступить к тестированию, проведем замер пропускной способности памяти и латентности.

При изучении результатов можно заключить, что производительность ECC- и non-ECC- памяти находится на одном и том же уровне в рамках погрешности.

Если в предыдущем тесте от замера к замеру выигрывал то один, то другой тип памяти, то при замере латентности ECC-память постоянно показывает большие задержки. Но разница несущественна – всего лишь 1 нс.
Таким образом, замер ПС и латентности памяти не показал особых различий между ECC- и non-ECC-памятью. Посмотрим, повторится ли это в последующих тестах.
3DMark
Тестовый пакет 3DMark содержит подтесты как для процессора, так и для графической карты. Здесь и кроется самое интересное – давно известно, что встроенному видеоядру не хватает существующей ПСП в 25.6 Гбайт/с, поэтому именно в графических подтестах можно выявить негативное влияние коррекции ошибок, если оно вообще есть,…

… но разницы нет – что ECC, что non-ECC. Ни процессор, ни интегрированное ядро никак не реагируют на замену обычной памяти на DDR с коррекцией ошибок – результаты одинаковы в рамках погрешности. Среднеарифметическая разница составила 0.02% в пользу ECC-памяти для одноканального режима и 1.6% для двухканального режима.
При этом нельзя сказать, что встроенная видеокарта P4600 не зависит от скорости ОЗУ – при одноканальном доступе общий результат почти на 30% ниже, чем при двухканальном. Другими словами, скорость ОЗУ критична для графического ядра, но сами по себе «ECC-версии» не влияют ни на скорость ОЗУ, ни на видеокарту.
7Zip
Архиваторы, как известно, чувствительны к памяти, поэтому, возможно, здесь получится зафиксировать влияние типа памяти на производительность.

Ситуация с архивацией неоднозначная: с одной стороны – в одноканальном режиме (как при распаковке, так и при сжатии) ECC-память уверенно оказывается медленнее на 2%; с другой – в двухканальном режиме при сжатии ECC-память уверенно быстрее, а при распаковке – медленнее, а среднее арифметическое – быстрее на 0.65%.
Скорее всего, причина в следующем – пропускной способности памяти при одноканальном доступе процессору явно недостаточно, и поэтому чуть большая латентность ECC-памяти сказывается на производительности; а при двухканальном доступе ПСП полностью покрывает нужды CPU и поэтому чуть большая латентность памяти с коррекцией ошибок не сказывается на производительности. В любом случае зафиксировать существенного влияния на скорость архивации не получилось.
Cinebench
Тестовый пакет Cinebench содержит подтест как процессора, так и видеокарты.

Но ни первый, ни вторая никак не отреагировали на ECC-память.
Зато налицо явная зависимость видеокарты от ПСП – при одноканальном доступе результат в OpenGL оказался на 25% ниже, чем при двухканальном. Вспоминая результаты 3DMark и смотря на нынешние, можно заключить, что производительность интегрированной видеокарты хоть и зависит от ПСП, но ECC-память не оказывает на нее негативного влияния.
Андрей Борзенко
Для обеспечения приемлемой производительности современным серверам требуются огромные объемы памяти. Одна из причин в том, что быстродействие используемых в серверах микропроцессоров Intel увеличилось по сравнению с началом 1990-х гг. в 20 раз, а быстродействие дисков за то же время возросло всего лишь в 5 раз. Известно также, что по мере дальнейшего увеличения быстродействия микропроцессоров элементы памяти становятся узким местом компьютерных систем. Если частоты микропроцессоров давно превысили частоты системной шины, то шина памяти до самого последнего времени работала синхронно с последней.
Однако использование быстродействующих и дорогих кристаллов памяти для серверов не всегда эффективно с точки зрения баланса стоимости и быстродействия. Для обеспечения удовлетворительной общей производительности систем обычно применяется недорогая память большого объема. Именно это позволяет сгладить разрыв между быстрыми микропроцессорами и медленными дисками. При такой высокой потребности в памяти на серверах заказчики нуждаются в оборудовании более дешевом, но обеспечивающем повышенную надежность.
Себестоимость памяти обычно снижают за счет максимального повышения разрядности микросхем. Плотная упаковка (т. е. повышение разрядности) микросхем памяти позволила резко снизить соотношение цена/емкость. Такие микросхемы передают и получают четыре или восемь разрядов данных в каждой операции доступа.
Напомним, что для микросхем памяти емкость традиционно измеряется в битах, а вот емкость модулей — в байтах (1 Мбайт = 8х1 Мбит). Обозначение 1 Мх4 означает, что данная микросхема может адресовать 1 Мбит ячеек, в каждой из которых может храниться 4 бита информации. Говорят также, что емкость такой микросхемы 4 Мбит. Как правило, емкость микросхем памяти растет с инкрементом четыре. Дело в том, что добавление одной адресной линии увеличивает количество строк (и столбцов) в матрице памяти вдвое, всего же ее размер возрастает вчетверо. Каждый кристалл памяти содержит ячейки, в которых может храниться от одного до шестнадцати разрядов данных. Например, 16-мегабитный кристалл можно сконфигурировать как 4 Mбит x 4, 2 Mбит x 8 или 1 Mбит x 16, но во всех случаях его общая емкость равна 16 Mбит. Число разрядов на ячейку показывает, сколько бит передается одновременно при обращении к ней.
От проверки четности до ECC
Ошибки памяти можно подразделить на аппаратные и случайные. Аппаратные ошибки обычно обусловлены дефектами кремниевого кристалла или монтажных соединений микросхем DRAM и со временем не исчезают. Случайные ошибки (или «мягкие») обычно вызываются заряженными частицами или излучением; они непостоянны и со временем пропадают. Ранее основной причиной случайных ошибок были альфа-частицы, но более строгий контроль качества материала, из которого делаются корпуса микросхем DRAM, позволил производителям практически ликвидировать эту причину сбоев. В настоящее время основной источник случайных ошибок в микросхемах DRAM — электрические возмущения, вызванные космическими лучами — потоками высокоэнергетических элементарных частиц, приходящими из космоса.
В начале 1990-х гг. в большинстве серверов, оборудованных микропроцессорами
Intel, применялся метод проверки четности памяти. Он позволяет обнаруживать
ошибки, но не исправлять их. Метод контроля по четности широко применялся еще
в первых моделях компьютеров для оценки достоверности хранимой в оперативной
памяти информации. Состоит он в следующем. При записи байта информации в запоминающее
устройство определяется дополнительный контрольный разряд, который вычисляется
обычно путем логического сложения всех информационных разрядов (как показано
в таблице). Обычно контрольный разряд равен единице, если число единиц в байте
было четным, и нулю, если число единиц в группе было нечетным.
Получение контрольного разряда
| Байт информации | Количество единичных разрядов | Значение бита четности | Количество единиц, включая бит четности |
| 00000000 | 0 | 1 | 1 |
| 10110011 | 5 | 0 | 5 |
| 00100100 | 2 | 1 | 3 |
| 11111111 | 8 | 1 | 9 |
Таким образом, при чтении ранее записанного байта, вновь получив контрольный
разряд и сравнив его с уже имеющимся, можно оценить достоверность получаемой
информации. Если значения хранимого и полученного разрядов совпадают, то данные
считаются истинными; в противном случае генерируется сообщение об ошибке четности,
которое приводит к остановке компьютера. При возникновении ошибки в самом разряде
четности работа системы нарушается и все данные в памяти безвозвратно теряются.
Представьте себе, что в памяти сервера находится 32 или даже 64 Mбайт данных,
еще не сохраненных на диске. В случае ошибки четности вся эта немалая информация
пропадает безвозвратно. А ведь все серверы размещают данные в памяти до того,
как сохранить их на диске.
Данный метод контроля имел определенный смысл, пока микросхемы памяти были недостаточно надежными. К тому же, если на каждые восемь информационных разрядов приходится один бит четности, то стоимость модуля тем самым увеличивается более чем на 10%. Значительные технологические успехи в производстве микросхем динамической памяти привели к существенному росту их надежности. Так, у современных микросхем памяти среднее время наработки на отказ определяется годами, а то и десятками лет. Примерно с середины 90-х гг. изготовители модулей памяти стали постепенно отказываться от схемы контроля по четности. Например, популярный набор микросхем Intel Triton (430FX) вообще не поддерживал проверку на четность. Некоторые системные платы для компьютеров хотя и допускали использование SIMM-модулей с контролем четности, но саму проверку могли и не поддерживать. Однако для построения серверов, работающих с критически важной информацией, такой подход был, разумеется, неприемлем.
В предыдущие годы высокая частота ошибок четности памяти вынудила отрасль перейти на новый стандарт и обеспечить поддержку ECC (Error Checking and Correcting — обнаружение и исправление ошибок). Обычно эту особенность называют SEC/DED (Single Error Correction/Double Error Detection — коррекция единичных и обнаружение двойных ошибок). Механизм SEC/DED не позволяет обнаруживать ошибки более чем в двух разрядах. В этом случае целостность информации нарушается. В архитектуре такого типа ошибки в нескольких разрядах неустранимы и приводят к отказу системы, а сбои единичных разрядов исправляются автоматически, незаметно («прозрачно») для операционной системы и прикладных программ.
Теперь для наиболее ответственных приложений, где цена ошибки очень высока, используются уже не обычные модули с проверкой на четность, а модули с коррекцией ошибок ECC. При обычной проверке на четность невозможно обнаружить, например, возникновение двух ошибок одновременно. Действительно, если в байте информации 00100100 со значением бита четности 1 изменятся значения двух разрядов — 01100000, то бит четности все равно будет равен 1.
Идея, лежащая в основе метода ECC, довольно проста — каждый разряд памяти входит более чем в одну контрольную сумму. Это увеличивает число контрольных разрядов, но дает возможность восстанавливать значение сбойного бита по несовпадающим контрольным суммам. Итак, ECC использует один разряд четности на байт информации для нахождения одиночных ошибок, а для исправления требуется 7 бит для 32- и 8 бит для 64-разрядной памяти. При этом легко обнаруживаются двойные ошибки, как та, что описана выше. Следовательно, для ECC можно использовать обычные модули с контролем четности, если это допускает контроллер памяти. Основной недостаток при такой схеме использования ECC — снижение общей производительности системы, на которую возлагаются дополнительные вычисления.
Другой способ реализации ECC — размещение логики контроля не в контроллере памяти на системной плате, а на самом модуле. Это позволяет избежать снижения производительности, но стоимость таких модулей выше, чем обычных. Поскольку ошибки в большем числе разрядов случались чрезвычайно редко, метод ECC позволил существенно повысить надежность систем. Сегодня технология ECC стала стандартом и применяется практически во всех серверах.
Разрядность данных различна для разных микросхем DRAM. Используемые в настоящее время DIMM-модули (Dual In-line Memory Module) со 168 и 184 контактными выводами (рис. 1) оснащаются микросхемами DRAM с разрядностью данных х4 (4 разряда данных), x8 или x16. Для поддержки 72 разрядов (64 разряда данных и 8 разрядов для кодов исправления ошибок) требуются микросхемы DRAM с более высокой разрядностью, так как на модуле DIMM просто недостаточно места, чтобы решить эту задачу, установив DRAM-микросхемы с меньшей плотностью.
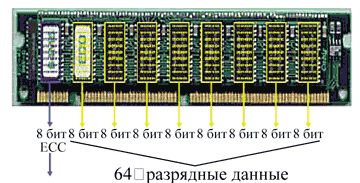 |
Рис. 1. Модуль памяти DIMM ECC.
|
Недостатки ECC
Безвозвратная потеря данных случается, когда на микросхеме в DIMM-модуле происходит ошибка в нескольких разрядах, — этот сбой механизм ECC устранить не в состоянии. Представьте себе, что за один цикл микросхема обменивается восемью разрядами данных. При возникновении ошибки, не подлежащей исправлению средствами механизма ECC, все восемь разрядов данных теряются, что, в свою очередь, вызывает аварийную остановку сервера. Потеря данных по причине ошибок памяти возможна как в 4-разрядных, так и в 8-разрядных микросхемах: ведь механизм ECC защищает от сбоев только единичных разрядов. По мере уплотнения DRAM-устройств доля многоразрядных ошибок увеличивается. Кроме того, объемы памяти на современных серверах все время растут (устанавливаются большие количества модулей или модули с большим объемом памяти), и вероятность неустранимых ошибок DRAM-памяти — как случайных, так и постоянных, — увеличивается. Таким образом, память стандарта SEC/DED, которая еще недавно обеспечивала вполне удовлетворительные характеристики, теперь не удовлетворяет требованиям высокой надежности, доступности и удобства в эксплуатации (RAS — Reliability, Availability and Serviceability), предъявляемым к современным серверам. Это, в частности, касается серверов масштаба предприятия, стандартные объемы памяти которых ныне превышают несколько гигабайт. Кроме того, следует отметить, что требования к объемам памяти существенно возросли после выпуска 64-разрядных компьютерных систем семейства Itanium.
На современных высокопроизводительных файловых серверах с микропроцессорами Intel такие ошибки в микросхемах памяти могут вызвать разрушение системы и безвозвратную потерю нескольких гигабайт критических данных. В большинстве файл-серверных приложений восстановление данных после такого аварийного отказа практически невозможно. Сбои в памяти также способны привести к существенным простоям приложений серверов баз данных, в которых информация защищается от потери путем записи всех транзакций на диск. Дело в том, что механизму восстановления обычно требуется масса времени на воссоздание базы данных на основании записей журнала транзакций, которые не успели попасть в базу данных. Иногда на это уходит несколько часов работы сервера, на протяжении которых он не способен обслуживать текущие бизнес-операции.
Новый механизм исправления ошибок
Одной из составных частей инициативы X-Architecture корпорации IBM (http://www.ibm.com/ru)
стала технология исправления ошибок Chipkill. Она обеспечивает защиту серверов
от отказов отдельных микросхем и многоразрядных ошибок в модулях памяти. Эта
технология, перенесенная IBM с больших систем, существенно сокращает среднее
время простоя серверов и обеспечивает более надежную платформу для клиент-серверных
вычислений на базе микропроцессоров Intel. Она призвана повысить надежность
систем, доступность и удобство в эксплуатации — ключевые характеристики серверов
масштаба предприятия, обслуживающих критически важные приложения. Архитектура
Chipkill позволяет системе безболезненно воспринимать ошибки, которые в обычных
условиях приводят к неустранимым сбоям, тем самым обеспечивая сохранность данных
и высокую доступность системы.
В системах высокой доступности, таких как серверы масштаба предприятия IBM S/390, проблема многоразрядных ошибок памяти DRAM отсутствует благодаря особой архитектуре оперативной памяти. Подсистема памяти сконструирована так, что отказ отдельной микросхемы, независимо от ее разрядности, не затронет более одного разряда в каком-либо из нескольких слов ECC. Например, в 4-разрядной микросхеме DRAM отдельные биты из всей четверки попадают в разные слова ECC, т. е. в разные адресные пространства памяти. Поэтому даже в случае полного отказа микросхемы количество ошибочных разрядов в словах ECC не превысит единицу, а такую ошибку механизм ECC устраняет автоматически. Данная архитектура обеспечивает отказоустойчивость всей подсистемы памяти.
Продуманная конструкция мэйнфреймов защищает их от сбоев микросхем памяти. В каждом модуле памяти разрядность микросхем равна числу разрядов, защищенных механизмом ECC. Нынешние серверы на базе микропроцессоров Intel такого механизма не поддерживают — ведь рынок требует дешевой памяти, вынуждая проектировщиков создавать очень плотные микросхемы памяти, поддерживающие отраслевой стандарт (иными словами, исключительно ECC).
Chipkill — это механизм, позволяющий памяти противостоять многоразрядным ошибкам на отдельных микросхемах DRAM, в том числе сбою всех разрядов данных. В механизме Chipkill есть два основных метода исправления ошибок, причем они могут применяться совместно. Эти методы базируются на определенном наборе микросхем и особой аппаратной архитектуре системы — их поддержку невозможно обеспечить простым обновлением ПО.
В первом методе каждый бит данных модуля памяти размещается в отдельном «слове ECC». (Слово ECC — это набор разрядов данных и контрольных разрядов, в котором обнаружение и исправление ошибок обеспечивается алгоритмом ECC.) Допустим, что разрядность системы памяти составляет 32 байт (или 256 разрядов). Биты ECC добавляются так, чтобы общая ширина блока (и контрольные, и биты данных) составляла 288 разрядов. Четыре слова ECC, каждое из которых состоит из 64 разрядов данных и 8 контрольных разрядов ECC, поддерживают механизм SEC/DED. Эти четыре слова ECC распределяются по DRAM-модулям. Например, если DIMM содержит модули х4 DRAM, четыре бита каждого устройства распределяются по разным словам ECC (рис. 2). Сбой всех четырех битов — это всего лишь четыре единичные ошибки в четырех словах ECC, и они устраняются автоматически. В этом примере механизм Chipkill поддерживается только на DIMM-модулях, состоящих из микросхем х4 DRAM.
 |
Рис. 2. Один из механизмов Chipkill.
|
Второй метод заключается в предоставлении механизму ECC большего числа разрядов для хранения контрольных кодов, чтобы обеспечить исправление не одного, а нескольких разрядов. При этом используются соответствующие математические алгоритмы устранения многоразрядных ошибок при определенном количестве контрольных битов ECC и битов данных. Например, 144-разрядное слово ECC, состоящее из 128 разрядов данных и 16 битов ECC, позволяет исправлять ошибки, охватывающие до 4 разрядов данных. (Для исправления сбоя четырех бит необходимо, чтобы они были смежными, а не располагались случайно.) Соотношение разрядов ECC и разрядов данных такое же, как и в предыдущем примере (16/128 и 8/64), однако более длинное слово ECC позволяет применить более эффективный алгоритм обнаружения и исправления ошибок.
Совместное использование этих двух методов обеспечивает коррекцию по механизму Chipkill на DIMM-модулях с микросхемами х8 DRAM. Два 144-разрядных слова ECC распределяются так, чтобы на каждом DRAM в первом и втором словах ECC исправлялись по 4 разряда. Этот метод обеспечивает поддержку механизма Chipkill при использовании DIMM-модулей, состоящих как из микросхем х4 DRAM, так и из х8 DRAM.
На серверах Netfinity (на смену которым пришли машины eServer xSeries) инженеры IBM решили эту проблему, разместив избыточный массив недорогих микросхем DRAM (Redundant Array of Inexpensive DRAM, RAID) непосредственно на DIMM-модулях. При каждом доступе к памяти RAID-микросхема вычисляет контрольный код ECC для всего набора микросхем и сохраняет результат в резервной памяти на защищаемом DIMM-модуле. В случае отказа одной микросхемы DIMM-модуля сохраненная на RAID-массиве информация применяется для восстановления потерянных данных, обеспечивая бесперебойную работу всего сервера Netfinity. Такая RAID-технология напоминает RAID-механизмы, применяемые для защиты данных в дисковых массивах, и называется Chipkill DRAM.
Специалисты компании IBM разработали заказную специализированную микросхему для Chipkill, которая называется ECC ASIC (Application-Specific Integrated Circuit) и выполняет исправление ошибок без замедления доступа к высокопроизводительной EDO-памяти со временем доступа 50 нс. Таким образом, при установке DIMM-модулей IBM Chipkill на серверы Netfinity, оборудованные процессором Intel Xeon, модификация плат памяти не нужна, а новые модули не вызывают снижения производительности
Результаты исследований показали, что на серверах, оборудованных 32 Мбайт памяти с проверкой четности, частота сбоев памяти за 3 года составила 7 отказов на 100 серверов. На серверах, оборудованных 1 Гбайт памяти с поддержкой ECC, частота сбоев за 3 года равна 9 отказам на 100 серверов. А вот на серверах, оборудованных 4 Гбайт памяти с поддержкой Chipkill, за 3 года число сбоев не превысило 6 отказов на 10 тыс. серверов. Кроме того, оказалось, что частота отказов по причине ошибок памяти на серверах с 1 Гбайт ECC-памяти выше, чем на серверах с 32 Мбайт памяти с проверкой четности. Причина здесь в том, что при том огромном числе DRAM-микросхем емкостью 64 Мбит, которое нужно, чтобы составить 1 Гбайт памяти, вероятность отказа отдельных микросхем существенно выше, чем вероятность возникновения единичных ошибок четности в 32 Мбайт памяти с проверкой четности. Технология IBM Chipkill Memory позволила снизить число отказов серверов Netfinity по причине сбоев подсистемы памяти до невероятно низкого уровня.
Обнаружение и оповещение
Поскольку основная задача механизма Chipkill — исправление ошибок памяти, в нем применяются такие же способы обнаружения и оповещения, что и в ECC. Обнаружение и оповещение Chipkill никак не сказывается на производительности оборудования или ПО — издержки те же, что и для стандартных механизмов ECC. Вкратце остановимся на том, как может выполняться обнаружение постоянных и случайных ошибок и оповещение о них в серверных архитектурах с применением обоих механизмов — ECC и Chipkill.
Обнаружение и исправление ошибок памяти выполняется в системном наборе микросхем. Код исправления ошибок (ECC) генерируется при записи и проверяется при чтении во всех системных операциях с памятью «прозрачно» для прикладных программ. Обнаруженная ошибка автоматически исправляется до передачи данных получателю. При этом событие ошибки регистрируется оборудованием, а системная BIOS уведомляется об исправлении ошибки и о месте, где она произошла. Набор микросхем также ведет учет исправленных ошибок, что позволяет BIOS выявлять DIMM-модули, в которых ошибки возникают и исправляются постоянно. Получив уведомление, система BIOS опрашивает регистры набора микросхем, чтобы определить, где произошла ошибка памяти (порядок такого опроса сильно зависит от конструкции конкретной системы, поэтому он и выполняется на уровне BIOS). Обнаружив модуль DIMM, вызвавший ошибку, BIOS регистрирует эту информацию в системном журнале, который является, например, частью встроенной системы управления сервером (Embedded Server Management). DIMM-модули легко заменить в процессе эксплуатации, для них требуется лишь предсказательное оповещение об ошибках и замене, поэтому нет необходимости локализовать ошибки с точностью до отдельной микросхемы на плате DIMM-модуля. Получая за сравнительно короткое время повторяющиеся сообщения об исправленных ошибках от одного и того же DIMM-модуля, BIOS отключает соответствующий механизм оповещения и регистрирует этот факт в журнале системы управления сервером. Это избавляет систему от дополнительной нагрузки, обусловленной обработкой всех ошибок памяти, поскольку постоянная ошибка DRAM иногда генерирует миллионы сообщений об исправлениях в минуту.
Программное обеспечение управления системой, поставляемое в составе многих серверов, анализирует системный журнал при каждом внесении записи системой BIOS. Ошибки единичных разрядов инициируют уведомления одного из трех возможных уровней: warning («предупреждение»), critical («критическая»), nonrecoverable («неустранимая»). По-настоящему случайная ошибка вряд ли инициирует уведомление в стеке программы управления системой. Однако в случае постоянных неполадок в работе DIMM-модуля инициируется уведомление программе управления системой, после чего та назначает службе технической поддержки задание на замену неисправного DIMM-модуля. Постоянная ошибка, вызвавшая отключение механизма регистрации исправлений, в любом случае инициирует уведомление. Постоянные ошибки в одном разряде или ошибки, устраняемые средствами Chipkill, не вызывают отказа системы; тем не менее они увеличивают вероятность того, что очередная случайная ошибка приведет к критическому, неустранимому сбою. Поэтому администраторы системы должны внимательно следить за уведомлениями о дефектных DIMM-модулях и своевременно назначать службе технической поддержки задания на их замену.
С Марса на Землю
Интересно, что, по некоторым данным, изначально технология Chipkill разрабатывалась IBM для марсианского вездехода Rover (рис. 3), где сбои памяти были, мягко говоря, нежелательны. Агентство NASA применило-таки эту технологию в исследовательском зонде Pathfinder. Надо отдать должное специалистам NASA, которые осознали важность такого параметра, как надежность памяти. Им, видимо, совсем не хотелось потратить миллиарды долларов на отправку Pathfinder на Марс и только потом обнаружить, что все мероприятие терпит крах по причине отказа одной микросхемы памяти.
 |
Рис. 3. Модуль памяти для марсианского вездехода.
|
Технология Chipkill поддерживается в новом универсальном наборе микросхем IBM Summit, который подходит как для 64-разрядных микропроцессоров семейства Itanium, так и для 32-разрядных Xeon. Каждый чипсет будет поддерживать до четырех процессоров, позволяя им разделять такие ресурсы, как шины ввода-вывода и шины памяти. Четыре набора могут связываться воедино, что даст серверам на базе Summit возможность поддерживать до 16 полностью автономных микропроцессоров. Например, в четырехпроцессорном сервере можно будет выделить три кристалла под Windows NT, а один — под Linux, а если все процессоры работают в одной среде, можно будет проводить их «горячую» замену.
В заключение следует отметить, что, по мнению ряда экспертов, те же рыночные силы, которые ранее вынудили перейти от проверки четности к технологии ECC на Intel-серверах с 32 Мбайт памяти, в ближайшее время заставят в обязательном порядке устанавливать память Chipkill на новых серверах Intel-архитектуры, оборудованных многими гигабайтами памяти и 64-разрядными микропроцессорами семейства Itanium. В исторической перспективе это и неудивительно, ведь именно такое магистральное направление намечалось технологиями IBM для больших систем. Если допустить, что мэйнфреймы были предшественниками распределенной, ориентированной на сеть модели клиент-серверных вычислений, то представляется очевидным, что присущая мэйнфреймам надежность и отказоустойчивость скоро потребуется и в серверах, оборудованных микропроцессорами Intel.

Новый адрес страницы: Технология Chipkill для оперативной памяти
Память
- Информация о материале
- Категория: Память
- Опубликовано: 09.08.2016, 08:24
- Автор: ServersTech.ru
![]()
В Сети часто можно увидеть на тематических форумах вопросы, касающиеся памяти с коррекцией ошибок, а именно – ее влияние на производительность системы. Сегодняшнее тестирование ответит на этот вопрос.
Перед прочтением данного материала рекомендуем ознакомится с материалами по микроархитектуре Core и платформе LGA1151.
Теория
Перед тестированием расскажем об ошибках памяти.
Ошибки, возникающие в памяти, можно разделить на два типа – аппаратные и случайные. Причиной появления первых являются дефектные микросхемы DRAM. Вторые же возникают по причине воздействия электромагнитных помех, излучения, альфа- и элементарных частиц и т.д. Соответственно, исправить аппаратные ошибки можно только путем замены микросхем DRAM, а случайные – с помощью специальных технологий, например, ECC (Error-Correcting Code). Коррекция ошибок ECC в своем арсенале имеет два метода: SEC (Single Error Correction) и DED (Double Error Detection). Первый исправляет однобитовые ошибки в 64-битном слове, а второй детектирует двухбитовые ошибки.
Аппаратная реализация ECC заключается в размещении дополнительных чипов памяти, которые необходимы для записи 8-битных контрольных сумм. Таким образом, модуль памяти с коррекцией ошибок при одностороннем дизайне будет иметь 9 чипов памяти вместо 8 (как у стандартного модуля), а при двустороннем — 18 вместо 16. Вместе с этим увеличивается и ширина модуля с 64 до 72 бит.
При считывании данных из памяти происходит повторный подсчет контрольной суммы, которая сравнивается с исходной. Если ошибка в одном бите — она исправляется, если в двух — детектируется.
Практика
В теории всё хорошо – память с коррекцией ошибок повышает надежность системы, что очень важно при построении сервера или рабочей станции. А на практике существует еще и финансовая сторона данного вопроса. Если серверу память с коррекцией ошибок обязательна, то рабочая станция вполне может обойтись без ECC (многие готовые рабочие станции разных производителей оснащаются обычной ОЗУ). Насколько же дороже память с коррекцией ошибок?
Типичный модуль DDR4-2133 с объемом 8 ГБ стоит порядка 39 долларов, а модуль с ECC – 48 долларов (на момент написания материала). Разница в стоимости составляет около 23%, что весьма значительно на первый взгляд. Но если посмотреть на общую стоимость рабочей станции, то эта разница не превысит и 5% от нее. Таким образом, приобретение памяти с ECC лишь незначительно увеличивает стоимость рабочей станции. Остается лишь вопрос – а как влияет память с ECC на производительность процессора.
Для того, чтобы ответить на этот вопрос редакция ServersTech.ru взяла для тестирования модули памяти Samsung DDR4-2133 ECC и Kingston DDR4-2133 с одинаковыми таймингами 15-15-15-36 и объемом 8 ГБ.


На модулях памяти Samsung M391A1G43DB0-CPB с коррекцией ошибок распаяно по 9 чипов с каждой стороны.


В то время как на обычных модулях памяти Kingston KVR21N15D8/8 распаяно по 8 чипов с каждой стороны.
Тестовый стенд: Intel Xeon E3-1275v5, Supermicro X11SAE-F, Samsung DDR4-2133 ECC 8GB, Kingston DDR4-2133 non-ECC 8GB
Детализация
— Процессор: Xeon E3-1275v5 (HT on; TB off);
— Материнская плата: Supermicro X11SAE-F;
— Оперативная память: 2x Samsung DDR4-2133 ECC 8GB (M391A1G43DB0-CPB), 2x Kingston DDR4-2133 non-ECC 8GB (KVR21N15D8/8);
— ОС: Windows Server 2012R2.
Методика тестирования
— 3DMark06 1.21;
— 7zip 15.14;
— AIDA64 5.60;
— Cinebench R15;
— Fritz 4.2;
— Geekbench 3.4.1;
— LuxMark v3.1;
— MaxxMEMI 1.99;
— PassMark v8;
— RealBench v2.43;
— SiSoftware Sandra 2016;
— SVPmark v3.0.3b;
— TrueCrypt 7.1a;
— WinRAR 5.30;
— wPrime 2.10;
— x264 v5.0.1;
— x265 v0.1.4;
— Kraken;
— Octane;
— Octane 2.0;
— Peacekeeper;
— SunSpider;
— WebXPRT.
AIDA64
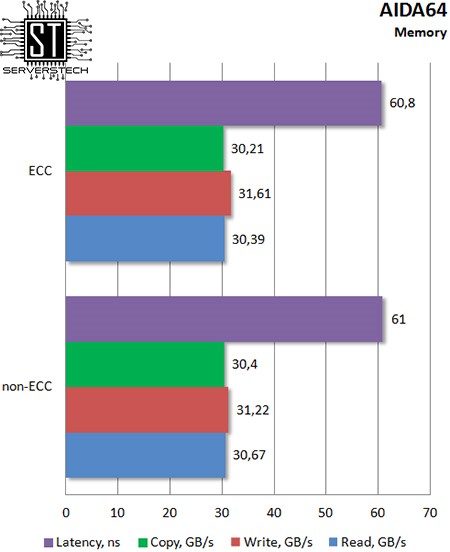
В тесте памяти результаты на удивление одинаковые (в пределах погрешности теста).
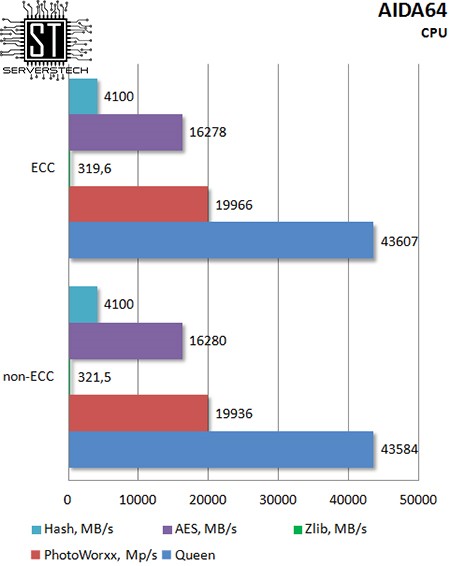
Для целочисленной арифметики не имеет значения используемый тип памяти – коррекция ошибок не оказывает существенного влияния на конечный результат.
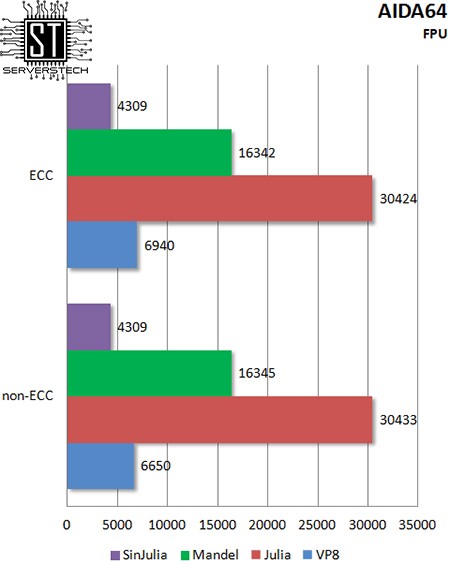
Арифметика с плавающей точкой также оказалась невосприимчивой к типу памяти.
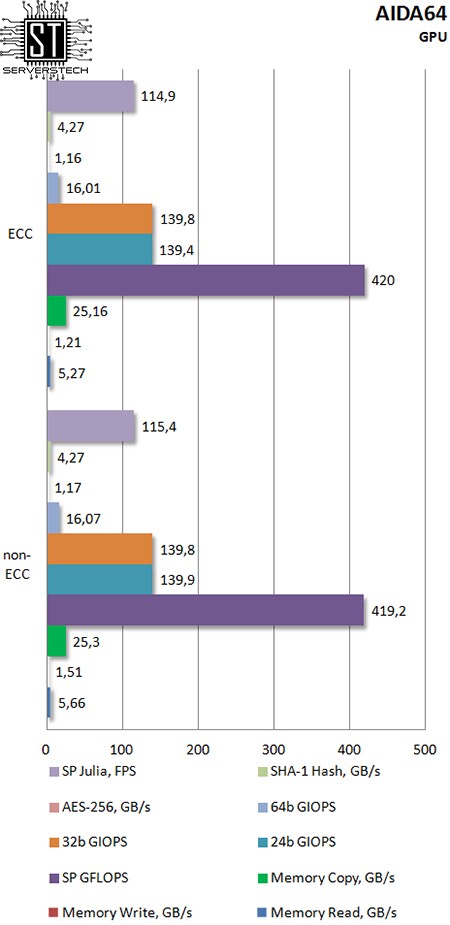
Даже наиболее требовательная к скорости памяти интегрированная графика не показала значительной разницы между ECC и non-ECC памятью.
SiSoftware Sandra
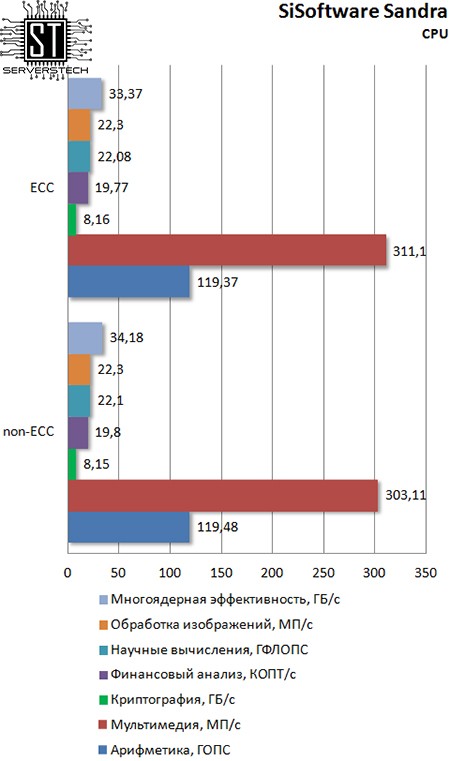
Данный тестовый пакет также не заметил смену типа памяти, показав практически одинаковые результаты для обоих участников.
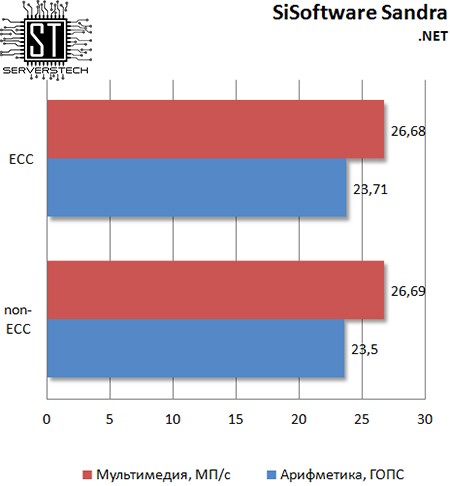
Абстрагированный от «железа» фрейморк также не заметил разницы между тестируемыми.
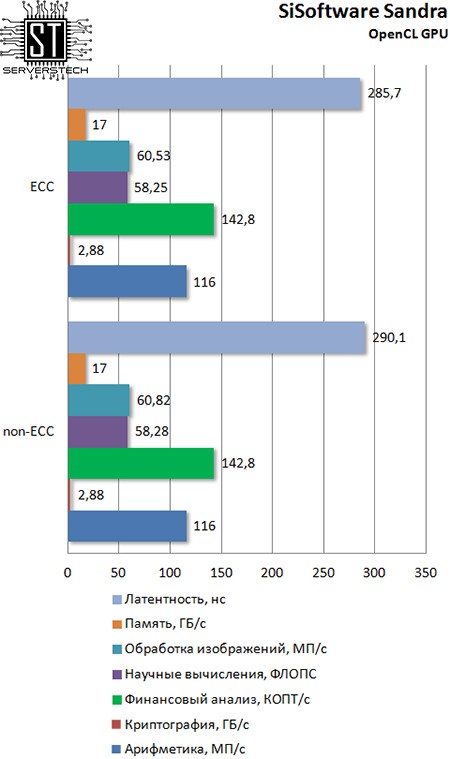
Требовательная к скорости памяти интегрированная графическая карта не видит разницу между ECC и non-ECC.
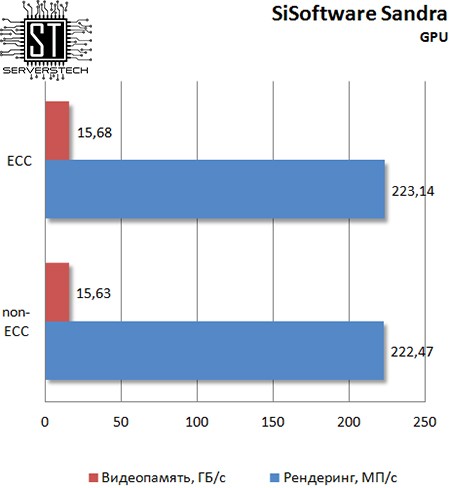
На скорость рендеринга тип памяти также не влияет.
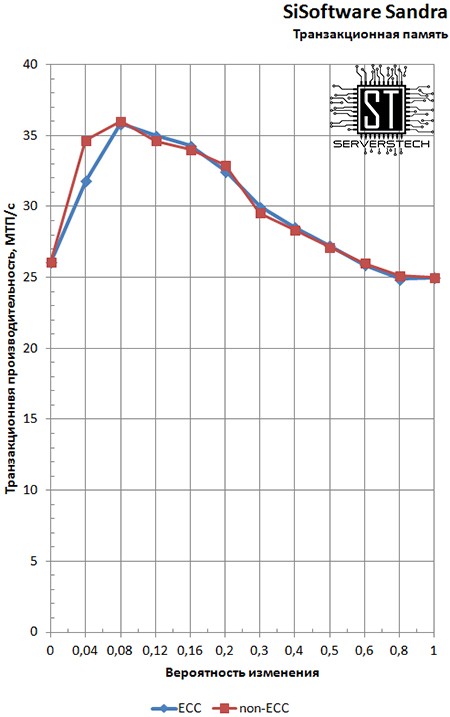
В тесте транзакционной памяти в области низкой вероятности изменений ECC-память всё же проигрывает обычной, показывая небольшой провал.
MaxxMEMI

Даже в непосредственном тесте памяти результаты оказались одинаковыми – как по пропускной способности, так и по латентности.

Cinebench R15
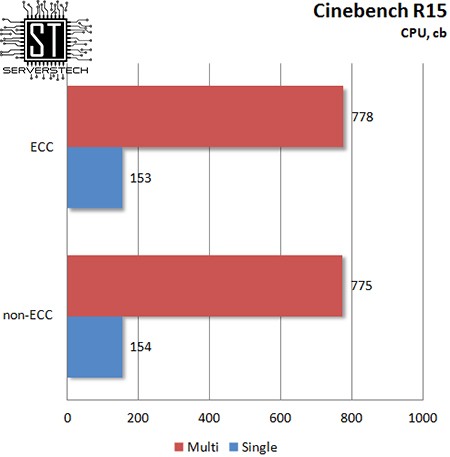
В процессорном подтесте результаты обоих типов памяти оказались максимально схожими.
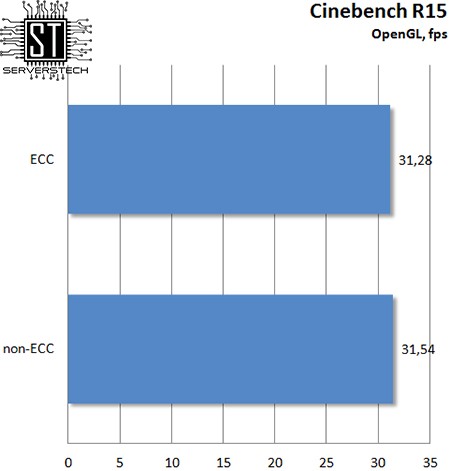
Да и на производительности интегрированного графического ядра смена типа памяти не сказалась.
Fritz

Данный бенчмарк также не показал существенной разницы между разными типами памяти.
LuxMark
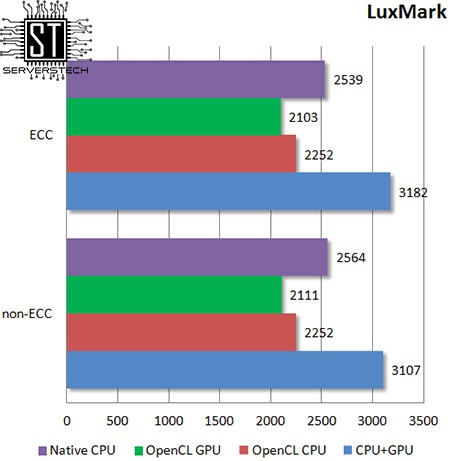
Данный бенчмарк позволяет производить расчеты как на процессоре, так и на видеокарте, но ни на то, ни на другое существенного влияния использование памяти с коррекцией ошибок не оказывает.
RealBench

Пожалуй, лишь в подтесте Image Editing присутствует более-менее существенная разница – 2% в пользу обычной памяти.
SVPmark
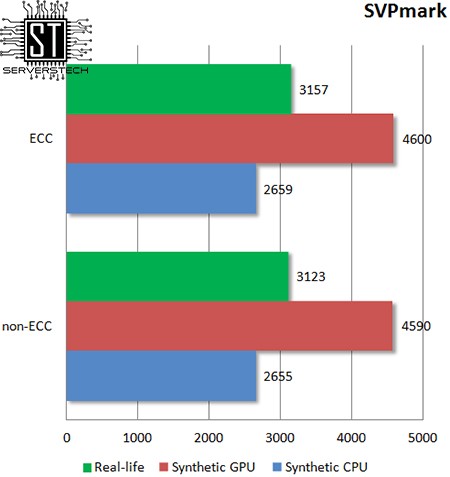
Данный бенчмарк также не заметил смену типа памяти.
Geekbench
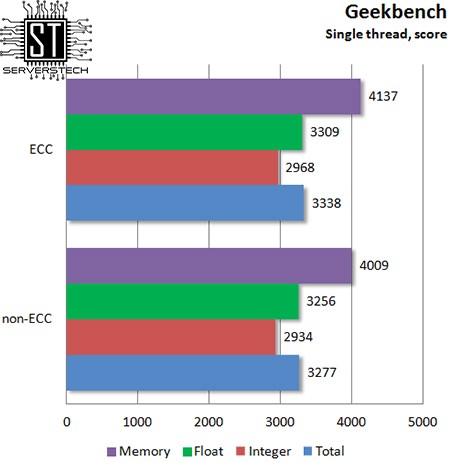
В общем зачете ЕСС-память сумела вырваться вперед, но учитывая определенную погрешность теста, можно смело заключить, что между ECC и non-ECC разницы нет.
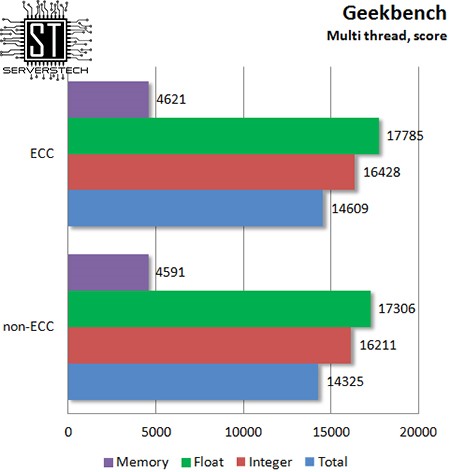
Многопоточный режим картину не меняет – разницы в производительности нет.
PassMark
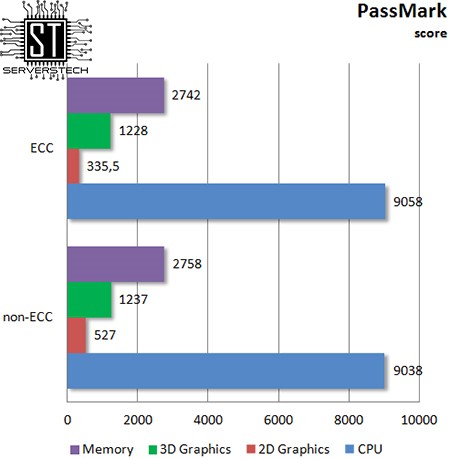
Существенной разницы в производительности между различными типами памяти нет (следует отметить, что результат в 2D зависит целиком от работоспособности драйвера, который на момент тестирования не хотел стабильно работать).
3DMark06
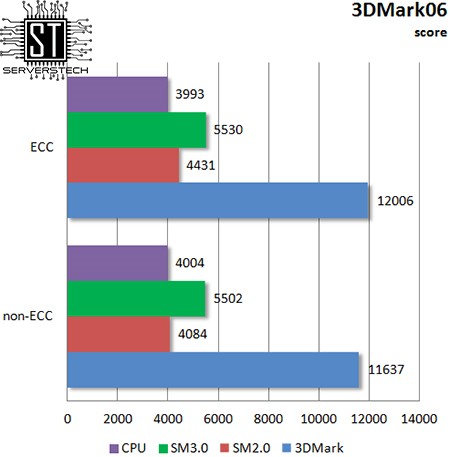
Смотря на результаты, можно заключить, что коррекция ошибок не сказывается на производительности графического ядра, которое в большей мере, чем процессор, зависит от скорости памяти.
wPrime
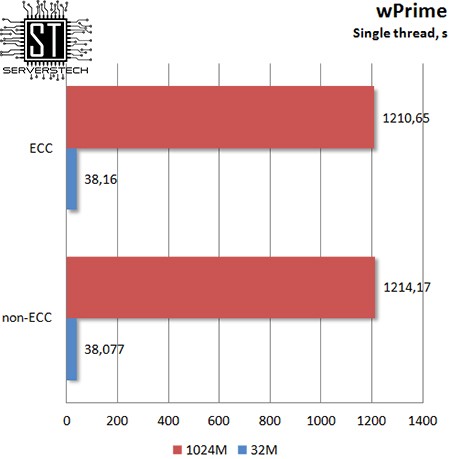
Даже весьма требовательный к скорости памяти wPrime не заметил разницу между обычной и памятью с коррекцией ошибок.

Многопоточный режим кардинально не меняет картину – результаты максимально схожи.
Encoder
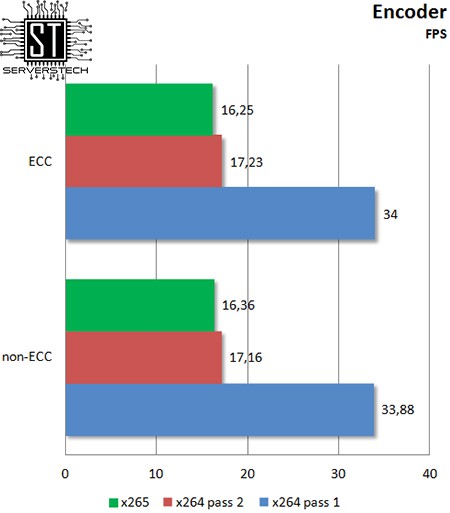
На скорость работы с видео смена типа памяти также не оказывает никакого влияния.
TrueCrypt
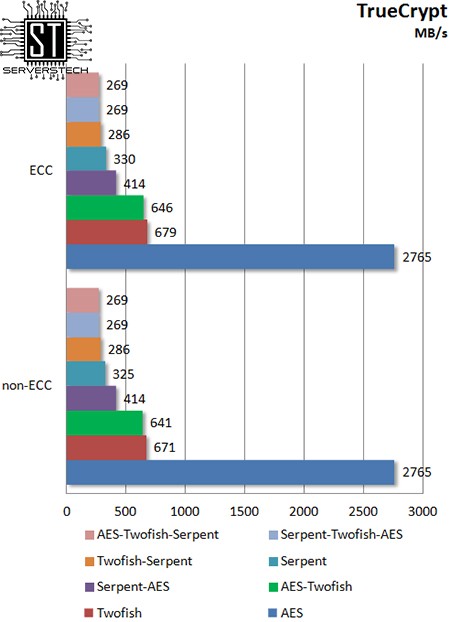
Скорость шифрования также не зависит от типа памяти.
7zip
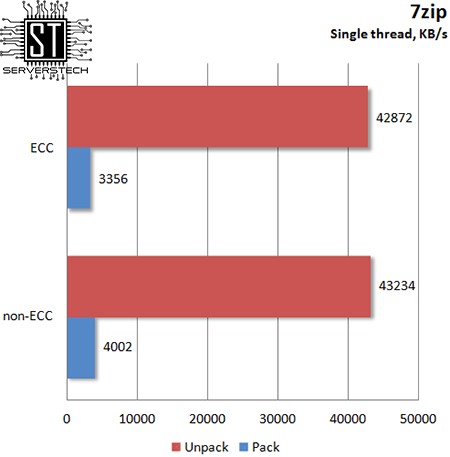
В однопоточном режиме 7zip «заметил» разницу между разными типами памяти, отдав предпочтение обычной ОЗУ, показавшей на 16% большую скорость сжатия.
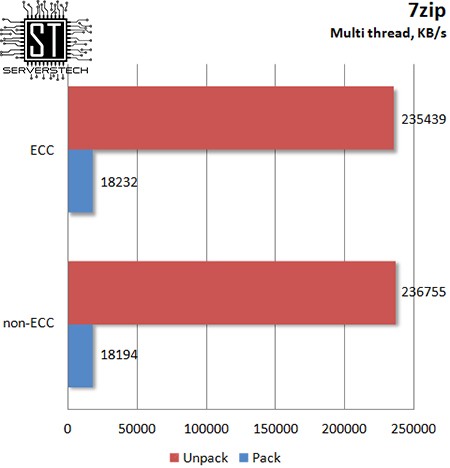
В многопоточном режиме 7zip не почувствовал особой разницы между ECC и non-ECC – разница в результатах в пределах +/- 1%.
WinRAR
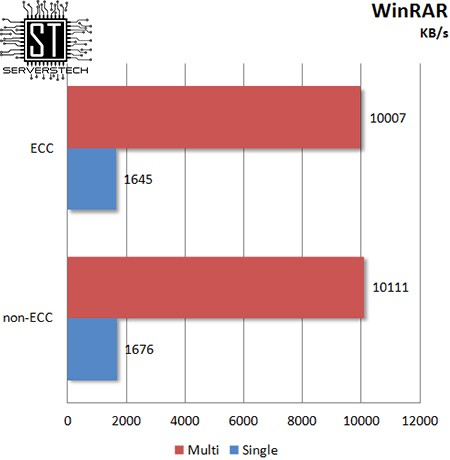
В отличие от 7zip, WinRAR остается безразличным к типу памяти.
Browser benchmark
Все бенчмарки проводились в Firefox 45.
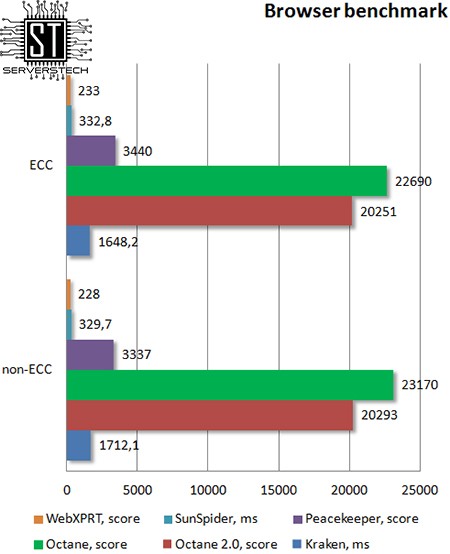
Браузерные тесты также оказались безразличны к типу памяти.
Заключение
Подводя итоги, можно сказать, что коррекция ошибок никак не сказывается на производительности как процессора, так и интегрированной графической карты — по крайней мере это применимо к процессорам Интел. Но рассматривая данный вопрос, необходимо учитывать трехуровневый кэш, его высокую скорость и достаточно большой объем — всё это снижает зависимость от скорости ОЗУ, уравнивая ECC-память с обычной.
Таким образом, приобретение ECC-памяти вместо обычной не скажется на производительности процессора, а разница в их стоимости не превысит и 5% от общей стоимости сервера или рабочей станции.

ECC Technical Details
- What is ECC memory?
- How does ECC work?
- What are the different ECC schemes?
- What’s new in DDR5 ECC RAM?
- Is ECC memory neccessary?
- What system requirements are needed to enable ECC protection?
- Do I need to change BIOS settings?
- How do I know when ECC errors are detected?
- How does MemTest86 report ECC errors?
- How does Windows report ECC errors?
- How does Linux report ECC errors?
- What is ECC injection?
- Can I use MemTest86 inject ECC errors?
- How do I know if my system supports ECC injection?
- Why are ECC errors not being reported on my AMD Ryzen system?
- Why am I consistently seeing Correctable ECC / EDAC errors on my system?
What is ECC memory?
Error correction code (ECC) is a mechanism used to detect and correct errors in memory data due to
environmental interference and physical defects. ECC memory is used in high-reliability applications
that cannot tolerate failure due to corrupted data such as medical equipment, aircraft control systems, or bank database servers.
Most memory errors are single (1-bit) errors caused by soft errors (eg. cosmic rays, alpha rays, electromagnetic interference) but some can be due to hardware faults (eg. row hammer fault).
Soft errors are more prevalent for systems that operate at higher altitudes, such as commercial aircrafts. It is said that at an altitude of approximately 10km, bit error inducing cosmic rays are 300 times higher.
Such single bit errors can be corrected by ECC memory systems. Multi-bit errors, may also be detected and/or corrected, depending on the number of symbols in error.
Symptoms of memory errors include corruption of data, system crash, and/or security vulnerabilities giving unprivileged code access to the kernel.
Memory errors are known to be one of the most common hardware causes of machine crashes in large scale data centers.
How does ECC work?
ECC is implemented by generating and storing an encrypted, parity-like code used to not only identify the bit in error but correct it as well.
This implementation-dependent ECC code is generated and stored on writes, and verified on reads.
The most common implementations use Hamming codes for single-bit correction and double-bit detection (SECDED).
Hamming codes define parity bits which cover a pre-defined set of data bits. Typically, an 8-bit hamming code is used to protect 64-bit data.
The ECC verification step, using a parity-check matrix, generates a value called a syndrome.
If the syndrome is zero, no error occurred. Otherwise, it is used to index a lookup table called the syndrome table to identifying the bits in error (if correctable), or otherwise determine if the error is uncorrectable.
An example of a syndrome table for the Hamming (7,4) code (4 data bits dn, 3 parity-check bits pn) encoded as p1p2d1p3d2d3d4 is as follows:
| Syndrome | Error Vector |
| 000 | 0000000 |
| 100 | 1000000 |
| 010 | 0100000 |
| 110 | 0010000 |
| 001 | 0001000 |
| 101 | 0000100 |
| 011 | 0000010 |
| 111 | 0000001 |
For example, if the ECC verification step calculates the syndrome to be 111, the above syndrome table can be used to lookup the error vector to be 0000001.
The error vector identifies d4 as the bit in error for the 7-bit message.
The sequences for read and write accesses are summarized below.
Memory write sequence
- CPU sends write data to the memory controller (on the same chipset, for newer CPUs)
- Memory controller generates ECC code based on the write data
- Memory controller sends write data and ECC code across the memory channel
- Write data and ECC code are stored in the memory DRAM chips
Memory read sequence
- CPU issues read request to the memory controller (on the same chipset, for newer CPUs)
- Memory controller reads data and ECC code from the memory
- Memory controller generates ECC code based on read data
- Memory controller verifies generated and stored ECC match. If not, use ECC SECDED mechanism to correct single-bit errors and detect double-bit errors.
Full end-to-end ECC memory system involves the CPU, memory controller, and DRAM modules during memory access.
Consequently, these components require additional circuitry to support ECC functionality.
For example, ECC RAM contains an additional DRAM chip to store the ECC codes as shown in the following diagram.

In addition, the memory bus not only includes the Data DQ lines (eg. DQ0-63) but also the ECC Check Bits CB lines (eg. CB0-7).
More often than not, ECC RAM is also Registered RAM which places a register between the memory controller and DRAM banks.
This reduces the electrical load especially for systems that have a large amount of RAM installed, which is often the case for server-grade machines.
What are the different ECC schemes?
An ECC-enabled memory subsystem may use one or more of the following schemes:
- Side-band ECC (DDR4/DDR5)
- Inline ECC (LPDDR4/LPDDR5)
- On-die ECC (DDR5)
- Link ECC (LPDDR5)
Side-band ECC
Side-band ECC is the most typical scheme used in ECC memory systems today.
Side-band ECC requires supporting hardware including ECC logic in the memory controller, extra bits in the memory bus and separate DRAM chips in the memory module to store the ECC code.
During write operations, the memory controller generates and transmits the ECC code alongside the write data as «side-band» without introducing extra command overhead.
On read operations, the stored ECC code accompanies the read data as «side-band» which is then verified, and if necessary, corrected by the memory controller.
Inline ECC
Inline ECC is used for LPDDR memory systems that have stricter hardware constraints. This effectively removes the requirements of extra bits in the memory bus and separate DRAM chips for the ECC code needed for Side-band ECC.
In contrast to Side-band ECC rather than bundling the data and ECC code in a single command, Inline ECC issues separate read/write commands for both the data and ECC code.
In addition, the ECC code is stored in the same DRAM chips as the data. As a result, Inline ECC introduces extra command overhead during read/write operations.
On-die ECC
On-die ECC is a new scheme introduced for DDR5 memory which is completely self-contained in the DDR5 memory module.
On-die ECC, unlike the above schemes, does not provide end-to-end protection. The purpose of On-die ECC is to protect the integrity of data stored in the memory cells of DRAM arrays; it does not detect or prevent errors that occur during transmission between the memory controller and the memory module.
All ECC detection and correction is performed internally within DRAM memory cells; it is completely invisible to the CPU and memory controller.
To provide full end-to-end protection, On-die ECC would need to be used in conjuction with Side-band ECC.
Link ECC
Link ECC is another new scheme introduced for LPDDR5 memory to augment end-to-end protection for systems with hardware constraints.
Link ECC, by itself, does not provide end-to-end protection; it provides protection for errors that occur during transmission on the channel between the memory controller and the DRAM.
On write operations, the memory controller generates and sends the ECC code along with the write data to the DRAM module.
The DRAM module receives the write data, generates its own ECC code and verifies whether it matches with the ECC code sent by the memory controller.
If necessary, single-bit errors are corrected accordingly.
In constrast to the other schemes, Link ECC does not detect or prevent errors while being stored in DRAM cells.
To provide full end-to-end protection, Link ECC would need to be used in conjuction with Inline ECC to provide full end-to-end protection.
What’s new in DDR5 ECC RAM?
Previous generation ECC memory systems Side-band and Inline ECC schemes which provides end-to-end detection and correction for errors during transmission and storage in DRAM cells
DDR5 RAM introduces two additional schemes, On-die ECC (or On-chip) and Link ECC, to compensate for higher bit error rates (BER) due to increased speed and density of DDR5 RAM.
On-die ECC detects and corrects errors in the DRAM cells that may occur during, for example, a DRAM row refresh.
Due to increasing error rates as process technology reduces the size of memory cells, on-die ECC sustains the yield of «good»
memory cells.
On-die ECC is completely invisible to the system. Its implementation, encoding/decoding algorithms, and metadata are all fully contained within the DRAM device and provide no feedback about error detection and/or correction to the rest of the system
Similarily, Link-ECC detects and corrects transmission errors on the LPDDR5 link or channel. Compared to previous generations the likelihood of errors on the DQ line is much higher, due to significant changes in speed and power usage of LPDDR5 RAM.
Link-ECC offers protection for speed and power improvements.
Is ECC memory neccessary?
In general, there is a trade-off between the higher cost of ECC hardware and slight decrease in performance versus greater system reliability and availability.
Depending on the implementation, it is said that enabling ECC may consume additional power and lower memory performance by around 2–3 percent.
For home or personal use, the consequence of memory errors may not be significant enough to justify the additional cost.
However, for highly-sensitive, industrial-grade systems, the additional hardware costs become neglible compared to the socio-economical consequences of memory failures.
As a result, ECC memory should always be used in systems where memory failure has significant consequences (eg. medical equipment, aircraft control systems, bank payment system).
What system requirements are needed to enable ECC protection?
Due to additional circuitry required for ECC protection, specialized ECC hardware support is required by the CPU chipset, motherboard and DRAM module.
This includes the following:
- Server-grade CPU chipset with ECC support (Intel Xeon, AMD Ryzen)
- Motherboard supporting ECC operation
- ECC RAM
Consult the motherboard and/or CPU documentation for the specific model to verify whether the hardware supports ECC.
Use vendor-supplied list of certified ECC RAM, if provided.
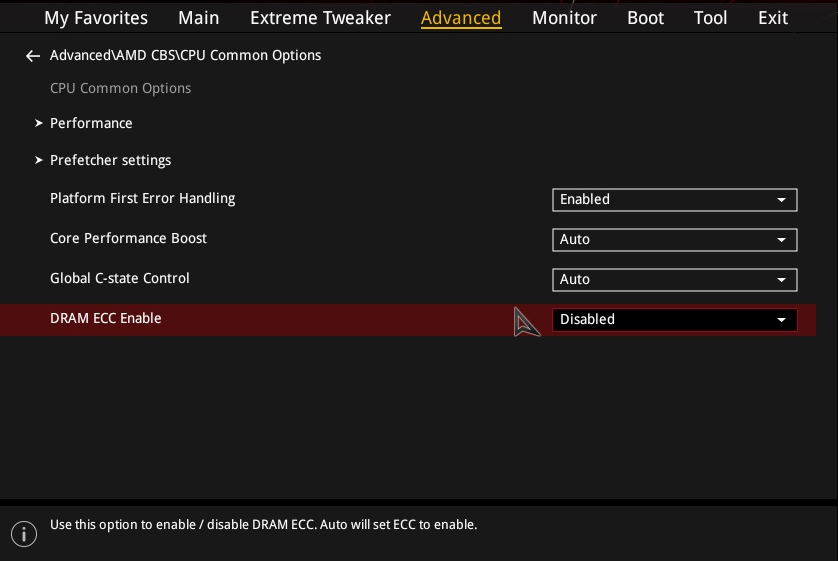
Do I need to change BIOS settings?
Most ECC-supported motherboards allow you to configure ECC settings from the BIOS setup.
The specific option depends on the motherboard vendor or model such as the following:
- DRAM ECC Enable (American Megatrends, ASUS, ASRock, MSI)
- ECC Mode (ASUS)
An example of such ECC setting is shown in the following screenshot.
How do I know when ECC errors are detected?
The mechanism for how ECC errors are logged and reported to the end-user depends on the BIOS and operating system.
In most cases, corrected ECC errors are written to system/event logs. Uncorrected ECC errors may result in kernel panic or blue screen.
How does MemTest86 report ECC errors?
MemTest86 directly polls ECC errors logged in the chipset/memory controller registers and displays it to the user on-screen.
In addition, ECC errors are written to the log and report file.
During testing, MemTest86 may report ECC errors detected by the memory controller if ECC is supported and enabled.
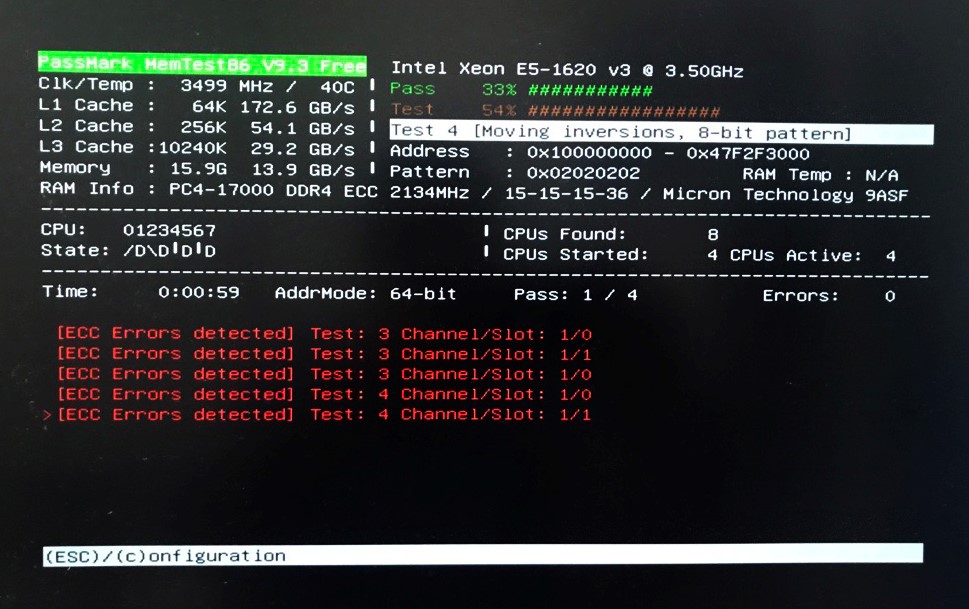
This is demonstrated in the following screenshot:
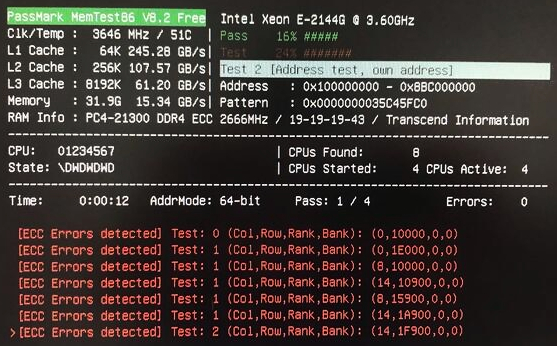
The degree of information available for the detected ECC error depends heavily on the CPU/memory controller chipset. This includes any of the following:
- Memory address
- DRAM address (column, row, rank, bank)
- Channel and DIMM slot number
The following examples illustrate possible outputs displayed on screen for detected ECC errors.
[ECC Error] Test: 1, Addr: 0x8F32540AC
The ECC error was detected in memory address 0x8F32540AC.
[ECC Error] Test: 1, (Ch,Sl,Rk,Bk,Rw,Cl): (1,0,2,0,17900,0)
The ECC error was detected in the DIMM module located in channel 1, slot 0 with the indicated rank address (0x2), and bank address (0x0), row address (0x17900), column address (0x0).
[ECC Error] Test: 1, Channel/Slot: 1/0
The ECC error was detected in the DIMM module located in channel 1, slot 0. No information regarding the memory address that triggered the ECC error is available.
*Note* The reported channel/slot of the ECC error is from the point of view of the memory controller and does not necessarily correspond to the expected physical slot on the motherboard.
Although this is true for most motherboards, there are boards that do not map to the expected physical slot. One particular motherboard is the Supermicro H12SSL-NT which follows the physical slot mapping below:
| Reported channel | Motherboard slot |
| 0 | A1 |
| 1 | B1 |
| 2 | D1 |
| 3 | C1 |
| 4 | H1 |
| 5 | G1 |
| 6 | E1 |
| 7 | F1 |
Credits to lunadesign for determining the mapping for Supermicro H12SSL-NT
Due to different memory controller architectures amongst different chipsets, there is no common ECC error framework; specific ECC polling code is required for each chipset.
In particular, this would involve polling one or more of the following hardware registers:
- Machine Check Architecture (MCA) registers for x86-based systems
- Integrated Memory Controller (IMC) PCI registers
- Sideband registers for Intel SoC chipsets
- System Management Network (SMN) registers for AMD Ryzen chipsets
Machine Check Architecture (MCA) is an x86-specific mechanism for CPUs to report generic hardware errors to higher-level software (eg. operating system).
This allows system software to handle hardware errors in a generic way, without needing to the internal details of chipset.
It defines a common set of model-specific registers (MSRs) that deterine the system response when hardware errors are detected. In the case of ECC errors,
an exception, Machine Check Exception (MCE), may be generated and the offending address, channel, and/or syndrome may be logged in the MSRs.
Some chipsets may also define a set of Integrated Memory Controller (IMC) PCI registers that record detected ECC errors such as the offending
DRAM address (rank, bank, row, column), channel and/or syndrome. These registers are accessed through standard PCI mechanism.
Unlike the Machine Check Architecture (MCA), the PCI registers are specific to each chipset and would required a separate chipset-specific implementation.
Some chipsets, such as Intel Atom SoCs, use an internal bus as an indirect method for accessing ECC registers.
Such registers are called Sideband registers which adds an additional layer of complexity on top of the previously described PCI registers.
Despite the extra layer, similar ECC error details are logged in these registers such as DRAM address (rank, bank, row, column), channel and/or syndrome.
For AMD Ryzen chipsets, an internal sideband bus called System Management Network (SMN) is used to access ECC registers.
Similar to Sideband registers in Intel SoCs, SMN registers are an indirect way to access ECC error details logged in these registers such as DRAM address (rank, bank, row, column), channel and/or syndrome.
How does Windows report ECC errors?
ECC errors detected in Windows appear in the Event Log as Microsoft Windows Hardware Error Architecture (WHEA) Warning Event.
Log Name: System Source: Microsoft-Windows-WHEA-Logger Date: 1/1/2021 12:00:00 AM Event ID: 19 Task Category: None Level: Warning Keywords: User: LOCAL SERVICE Computer: WIN10 Description: A corrected hardware error has occurred. Reported by component: Processor Core Error Source: Corrected Machine Check Error Type: Cache Hierarchy Error Processor APIC ID: 2
If ECC is enabled properly in the BIOS, end-users should be able to receive errors via WHEA without needing to configure anything in Windows.
How does Linux report ECC errors?
The Linux kernel supports reporting ECC errors for ECC memory via the EDAC (Error Detection And Correction) driver subsystem.
Depending on the Linux distribution, ECC errors may be reported by the following:
mcelog— collects and decodes MCA error events on x86 (deprecated)edac-utils— fills DIMM labels data and summarizes memory errors (deprecated)rasdaemon— monitor ECC memory and report both correctable and uncorrectable memory errors on recent Linux kernels
Installing rasdaemon
rasdaemon can be installed for most Linux distributions using the respective package manager:
apt-get install rasdaemon # Debian/Ubuntu
Enabling rasdaemon service
The rasdaemon service can be started using the systemd service manager systemctl
systemctl enable rasdaemon
systemctl start rasdaemon
Querying ECC error count & summary
# ras-mc-ctl --error-count
Label CE UE
mc#0csrow#2channel#0 0 0
mc#0csrow#2channel#1 0 0
mc#0csrow#3channel#1 0 0
mc#0csrow#3channel#0 0 0
# ras-mc-ctl --summary
Memory controller events summary:
Corrected on DIMM Label(s): 'mc#0csrow#2channel#1' location: 0:2:1:-1 errors: 3
Corrected on DIMM Label(s): 'mc#0csrow#3channel#0' location: 0:3:0:-1 errors: 3
Fatal on DIMM Label(s): 'mc#0csrow#3channel#0' location: 0:3:0:-1 errors: 1
What is ECC injection?
ECC injection is a debugging feature introduced in the memory controller to artificially insert memory errors to verify proper system behaviour.
This feature is meanted to be used by developers and system integrators, and not meant to be used in production by end-users.
Various ECC injection options are available depending on the vendor (eg. Intel, AMD) and chipset (eg. Xeon, Ryzen, Atom).
These options include the following:
- Read and/or write data path
- Address range
- Per chunk count
- Single or Multi-bit errors
- Single-shot or continuous
Can I use MemTest86 inject ECC errors?
MemTest86 Pro Edition supports ECC injection if the CPU/memory controller chipset supports error injection and the feature is not locked by BIOS.
See the current list of chipsets with ECC injection capability supported by MemTest86.
Once ECC injection is enabled in the main menu or configuration file, MemTest86 will attempt to inject single-bit ECC errors at the beginning of each test.
If ECC errors were successfully injected and detected by the system, the user shall see an [ECC Inject] message followed by an [ECC Errors Detected] message.
If [ECC Errors Detected] message does not appear, it is highly likely the ECC injection is locked or disabled by BIOS.
How do I know if my system supports ECC injection?
In general, ECC injection is not a feature that is normally accessible by end-users. Even if the chipset supports the ECC injection feature, details are often sparse and not described in publicly available datasheets.
Consult the datasheet for your CPU/memory controller chipset to determine whether the ECC injection feature is available and fully specified.
In particular, some Intel chipsets (Broadwell, Xeon Scalable) use Intel Trusted Execution Technology (Intel TXT) to lock ECC injection.
Intel TXT, using secure hardware modules, verifies the integrity of the BIOS, firmware, OS and hypervisor in order to guarantee a trusted operating environment.
As a result, this requires preventing access to specific memory controller registers from being compromised, including ECC injection registers.
Some chipsets that support ECC injection have a locking mechanism that once enabled in the BIOS, effectively disables the ECC injection capability.
For these cases, a BIOS option may be available to leave the feature unlocked. Otherwise, a custom BIOS is required for unlocking the feature.
Why are ECC errors not being reported on my AMD Ryzen system?
There is a possibility that a BIOS setting, Platform First Error Handling (PFEH), is preventing ECC errors from being reported to MemTest86.
An example of this setting is shown in the following screenshot.
If this setting is enabled, set to disabled and try running MemTest86 again.
Another explanation is the use of out-of-band (OOB) monitoring solutions such as Baseboard Management Controller (BMC) and Intelligent Platform Management Interface (IPMI),
which is used in server platforms (eg. Supermicro servers)
Why am I consistently seeing Correctable ECC / EDAC errors on my system?
There is likely a bug in your EDAC/BIOS. Your ECC RAM is OK, but was not initialized properly by the BIOS on boot.
In order to initialize ECC, memory has to be written before it can be used. Usually this is done by BIOS, but with some motherboards this step is skipped if «Quick Boot» is enabled.
Possible Solution: If your system allows for it, try disabling Quick Boot in the BIOS, some error messages should disappear. The boot process may taker 30-60 seconds longer, but the EDAC error messages disappear due to the RAM check by the BIOS when booting.
BIOS known to experience this issue: KONTRON AMI BIOS