Проверка ошибок при использовании виртуальных функций
В некоторых объектно-ориентированных
языках, которые поддерживают позднее
связывание, проверка ошибочных сообщений
осуществляется на этапе выполнения
программы. С++, посредством виртуальных
функций, поддерживает и статический
контроль сообщений, и позднее связывание.
class P {
public:
P(void){}
virtual void hello(void) {}
};
class C: public P {
public:
C(void) {}
virtual void hello(void) { cout << “Hello world”; }
};
void main() {
P *p; C c;
p=&c;
p->hello(“Hello”); // ошибка
}
Компилятор выдаст ошибку на строке
p->hello(“hello”). Компилятор может определить,
что виртуальная функция hello не имеет
параметров, даже если сообщение
связывается с методом hello класса C во
время выполнения программы. Виртуальные
функции, определенные в родительском
или потомственных классе имеют одинаковые
списки параметров, так как позднее
связывание не оказывает влияния на
контроль типов параметров.
Техническая реализация виртуальных функций
Объект С++ представляет собой непрерывный
участок памяти. Указатель на такой
объект содержит начальный адрес этого
участка. Когда вызывается функция-член
(объекту посылается сообщение), этот
вызов транслируется в обычный вызов
функции с дополнительным аргументом,
который содержит указатель на объект.
Например,
ClassName *object;
object->message(10);
преобразуется в
ClassName_message(object,10);
При создании объектов производных
классов их поля сцепляются с полями
родительских классов. Эту функцию
выполняет компилятор.
Виртуальные функции реализованы с
использованием таблиц функций. Рассмотрим
следующие классы.
class P {
int value;
public:
virtual int method1(float r):
virtual void method2(void);
virtual float method3(char *s);
};
class C1:public P {
public:
void method2(void);
};
class C2: public C1 {
public:
float method3(char *s);
};
Таблица виртуальных функций, virtualTabl,
содержит функции-члены каждого класса
в полиморфическом кластере. Указатель
на эту таблицу имеют все объекты классов
и подклассов полиморфического кластера.
Типичный объект, приведенных выше
классов, выглядит, примерно, так:
int value;
virtual_table->P::method1
C1::method2
C2::method3
Компилятор преобразует вызов виртуальной
функции в косвенный вызов через
virtualTable. Например,
С2 *с;
c->method3(“Hello”);
преобразуется в
(*(c->virtual_table[2]))(c,”Hello”);
Абстрактные базовые классы
Базовый класс иерархии типа обычно
содержит ряд виртуальных функций,
которые обеспечивают динамическую
типизацию. Часто в базовом классе эти
виртуальные функции фиктивны и имеют
пустое тело. Определенное значение им
придают в порожденных классах. В С++ для
этой цели применяется чистая виртуальная
функция. Чистая виртуальная функция
— виртуальная функция-член, тело которой
обычно не определено. Запись этого
объявления внутри класса следующая:
virtual прототип функции = 0;
Чистая виртуальная функция используется
для того, чтобы “отложить” решение о
реализации функции. В ООП терминологии
это называется отсроченным методом.
Класс, имеющий, по крайней мере, одну
чистую виртуальную функцию — абстрактный
класс. Для иерархии типа полезно иметь
базовый абстрактный класс. Он содержит
общий базовые свойства порожденных
классов, но сам по себе не может
использоваться для объявления объектов.
Напротив, он используется для объявления
указателей, которые могут обращаться
к объектам подтипа, порожденным от
абстрактного класса.
Объясним эту концепцию при помощи
разработки примитивной формы экологического
моделирования. В нашем примере будем
иметь различные формы взаимодействия
жизни с использованием абстрактного
базового класса living. Создадим fox
(лису) как типичного хищника, и rabbit
(кролика ) как его жертву. Rabbit есть grass
(траву).
const int N = 40, STATES=4 ; // размер квадратной
площади
enum state { EMPTY, GRASS, RABBIT, FOX };
class living;
typedef living *world[N][N]; // world будет
моделью
class living { // что живет в мире
protected:
int row, column; // местоположение
void sums(world, int sm[]); // sm[#states]
используется next
public:
living(int r,int c):row(r),column(c) {}
virtual state who()=0; // идентификация
состояний
virtual living* next(world w)=0; // расчет
next
};
void living::sums(world w,int sm[]) {
sm[EMPTY]=sm[GRASS]=sm[RABBIT]=sm[FOX]=0;
for(int i=-1; i <= 1; i++)
for(int j=-1; j <= 1; j++) sm[w[row+i][column+j]->who()]++;
}
// текущий класс
— только хищники
class fox: public living {
protected:
int age; // используется для принятия решения
о смерти
public:
fox(int r,int c,int a=0):living(r,c),age(a) {}
state who() { return FOX; } // отложенный
метод для
FOX
living* next(world w); // отложенный
метод для
FOX
};
// текущий класс
— только жертвы
class rabbit: public living {
protected:
int age; // используется для принятия решения
о смерти
public:
rabbit(int r,int c,int a=0):living(r,c),age(a) {}
state who() { return RABBIT; } // отложенный
метод для
RABBIT
living* next(world w); // отложенный
метод для
RABBIT
};
// текущий класс
— только растения
class grass: public living {
public:
grass(int r,int c):living(r,c) {}
state who() { return GRASS; } // отложенный
метод для
GRASS
living* next(world w); // отложенный
метод для
GRASS
};
// жизнь
отсутствует
class empty: public living {
public:
empty(int r,int c):living(r,c) {}
state who() { return EMPTY; } // отложенный
метод для
EMPTY
living* next(world w); // отложенный
метод для
EMPTY
};
Обратите внимание на то, что проект
позволяет развивать и другие формы
хищника, жертвы и растительной жизни,
используя следующий уровень наследования.
Характеристики поведения каждой формы
жизни фиксируется в версии next().
Living* grass::next(world w) {
int sum[STATES];
sums(w,sum);
if(sum[GRASS] > sum[RABBIT) // есть
траву
return (new grass(row,column));
else
return (new empty(row,column));
}
Grass может быть съеден Rabbit. Если в
окрестности имеется больше grass, чем
rabbit, grass остается, иначе — grass будет
съедена.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #

- Введение
- 1 Некоторые ошибки переноса программ на 64-битные системы
- 1.1 Использование «магических» констант
- 1.2 Адресная арифметика
- 1.3 Совместное использование целочисленных типов и типов переменной размерности
- 1.4 Виртуальные и перегруженные функции
- 2 Требования к анализатору кода
- 3 Архитектура анализатора кода
- 3.1 Модуль лексического анализа
- 3.2. Модуль синтаксического анализа
- 3.3. Модуль семантического анализ
- 3.4 Система диагностики ошибок
- 4 Реализация анализатора кода
- 5 Результаты
- 6 Заключение
- Библиографический список
В статье рассмотрена задача разработки программного инструмента под названием статический анализатор. Разрабатываемый инструмент используется для диагностики потенциально опасных синтаксических конструкций языка Си++ с точки зрения переноса программного кода на 64-битные системы. Акцент сделан не на самих проблемах переноса, возникающих в программах, а на особенностях создания специализированного анализатора кода. Анализатор предназначен для работы с кодом программ на языках Си и Си++.
Введение
Одной из современных тенденций развития информационных технологий является перенос программного обеспечения на 64-разрядные процессоры. Старые 32-битные процессоры (и соответственно программы) имеют ряд ограничений, которые мешают производителям программных средств и сдерживают прогресс. Прежде всего, таким ограничением является размер максимально доступной оперативной памяти для программы (2 гигабайта). Хотя существуют некоторые приемы, которые позволяют в ряде случаях обойти это ограничение, в целом можно с уверенностью утверждать, что переход на 64-битные программные решения неизбежен.
Перенос программного обеспечения на новую архитектуру для большинства программ означает как минимум необходимость их перекомпиляции. Естественно, возможны варианты. Но в рамках данной статьи речь идет о языках Си и Си++, поэтому перекомпиляция неизбежна. К сожалению, эта перекомпиляция часто приводит к неожиданным и неприятным последствиям.
Изменение разрядности архитектуры (например, с 32 бит на 64) означает, прежде всего, изменение размеров базовых типов данных, а также соотношений между ними. В результате поведение программы после перекомпиляции для новой архитектуры может измениться. Практика показывает, что поведение не только может, но и реально меняется. Причем компилятор часто не выдает диагностических сообщений на те конструкции, которые являются потенциально опасными с точки зрения новой 64-битной архитектуры. Конечно же, наименее корректные участки кода будут обнаружены компилятором. Тем не менее, далеко не все потенциально опасные синтаксические конструкции можно найти с помощью традиционных программных инструментов. И именно здесь появляется место для нового анализатора кода. Но прежде чем говорить о новом инструменте, необходимо все-таки более подробно описать те ошибки, обнаружением которых должен будет заниматься наш анализатор.
1 Некоторые ошибки переноса программ на 64-битные системы
Подробный разбор и анализ всех потенциально опасных синтаксических конструкций языков программирования Си и Си++ выходит за рамки данной статьи. Читателей, интересующихся этой проблематикой, отсылаем к энциклопедической статье [1], где приведено достаточно полное исследование вопроса. Для целей проектирования анализатора кода необходимо все-таки привести здесь основные типы ошибок.
Прежде чем говорить о конкретных ошибках, напомним некоторые типы данных, используемые в языках Си и Си++. Они приведены в таблице 1.
|
Название типа |
Размер-ность типа в битах (32-битная система) |
Размер-ность типа в битах (64-битная система) |
Описание |
|---|---|---|---|
|
ptrdiff_t |
32 |
64 |
Знаковый целочисленный тип, образующийся при вычитании двух указателей. В основном используется для хранения размеров и индексов массивов. Иногда используется в качестве результата функции, возвращающей размер или -1 при возникновении ошибки. |
|
size_t |
32 |
64 |
Беззнаковый целочисленный тип. Результат оператора sizeof(). Часто служит для хранения размера или количества объектов. |
|
intptr_t, uintptr_t, SIZE_T, SSIZE_T, INT_PTR, DWORD_PTR и так далее |
32 |
64 |
Целочисленные типы, способные хранить в себе значение указателя. |
Таблица N1. Описание некоторых целочисленных типов.
Эти типы данных замечательны тем, что их размер изменяется в зависимости от архитектуры. На 64-битных системах размер равен 64 битам, а на 32-битных — 32 битам.
Введем понятие «memsize-тип»:
ОПРЕДЕЛЕНИЕ: Под memsize-типом мы будем понимать любой простой целочисленный тип, способный хранить в себе указатель и меняющий свою размерность при изменении разрядности платформы с 32-бит на 64-бита. Все типы, перечисленные в таблице 1, являются как раз memsize-типами.
Подавляющее большинство проблем, возникающих в коде программ (в контексте поддержки 64 бит), связано с неиспользованием или некорректным использованием memsize-типов.
Итак, приступим к описанию потенциальных ошибок.
1.1 Использование «магических» констант
Наличие «магических» констант (то есть непонятно каким образом рассчитанных значений) в программах само по себе является нежелательным. Однако в контексте переноса программ на 64-битные системы у «магических» чисел появляется еще один очень важный недостаток. Они могут привести к некорректной работе программ. Речь идет о тех «магических» числах, которые ориентированы на какую-то конкретную особенность архитектуры. Например, на то, что размер указателя составляет 32 бита (4 байта).
Рассмотрим простой пример.
size_t values[ARRAY_SIZE];
memset(values, ARRAY_SIZE * 4, 0);На 32-битной системе данный код был вполне корректен, однако размер типа size_t на 64-битной системе увеличился до 8 байт. К сожалению, в коде использовался фиксированный размер (4 байта). В результате чего массив будет заполнен нулями не полностью.
Есть и другие варианты некорректного применения подобных констант.
1.2 Адресная арифметика
Рассмотрим типовой пример ошибки в адресной арифметике
unsigned short a16, b16, c16;
char *pointer;
...
pointer += a16 * b16 * c16;Данный пример корректно работает с указателями, если значение выражения «a16 * b16 * c16» не превышает UINT_MAX (4Gb). Такой код мог всегда корректно работать на 32-битной платформе, так как программа никогда не выделяла массивов больших размеров. На 64-битной архитектуре размер массива превысил UINT_MAX элементов. Допустим, мы хотим сдвинуть значение указателя на 6.000.000.000 байт, и поэтому переменные a16, b16 и c16 имеют значения 3000, 2000 и 1000 соответственно. При вычислении выражения «a16 * b16 * c16» все переменные, согласно правилам языка Си++, будут приведены к типу int, а уже затем будет произведено их умножение. В ходе выполнения умножения произойдет переполнение. Некорректный результат выражения будет расширен до типа ptrdiff_t и произойдет некорректное вычисление указателя.
Но подобные ошибки возникают не только на больших данных, но и на обычных массивах. Рассмотрим интересный код для работы с массивом, содержащим всего 5 элементов. Пример работоспособен в 32-битном варианте и не работоспособен в 64-битном:
int A = -2;
unsigned B = 1;
int array[5] = { 1, 2, 3, 4, 5 };
int *ptr = array + 3;
ptr = ptr + (A + B); //Invalid pointer value on 64-bit platform
printf("%i\n", *ptr); //Access violation on 64-bit platformДавайте проследим, как происходит вычисление выражения «ptr + (A + B)»:
- Согласно правилам языка Си++ переменная A типа int приводится к типу unsigned.
- Происходит сложение A и B. В результате мы получаем значение 0xFFFFFFFF типа unsigned.
Затем происходит вычисление выражения «ptr + 0xFFFFFFFFu», но результат будет зависеть от размера указателя на данной архитектуре. Если сложение будет происходить в 32-битной программе, то данное выражение будет эквивалентно «ptr — 1» и мы успешно распечатаем число 3.
В 64-битной программе к указателю честным образом прибавится значение 0xFFFFFFFFu, в результате чего указатель окажется далеко за пределами массива. И при доступе к элементу по данному указателю нас ждут неприятности.
1.3 Совместное использование целочисленных типов и типов переменной размерности
Смешанное использование memsize- и не memsize-типов в выражениях может приводить к некорректным результатам на 64-битных системах и быть связано с изменением диапазона входных значений. Рассмотрим ряд примеров:
size_t Count = BigValue;
for (unsigned Index = 0; Index != Count; ++Index)
{ ... }Это пример вечного цикла, если Count > UINT_MAX. Предположим, что на 32-битных системах этот код работал с диапазоном менее UINT_MAX итераций. Но 64-битный вариант программы может обрабатывать больше данных и ему может потребоваться большее количество итераций. Поскольку значения переменной Index лежат в диапазоне [0..UINT_MAX], то условие «Index != Count» никогда не выполнится, что и приводит к бесконечному циклу.
1.4 Виртуальные и перегруженные функции
Если у Вас в программе имеются большие иерархии наследования классов с виртуальными функциями, то существует вероятность использования по невнимательности аргументов различных типов, которые фактически совпадают на 32-битной системе. Например, в базовом классе Вы используете в качестве аргумента виртуальной функции тип size_t, а в наследнике — тип unsigned. Соответственно, на 64-битной системе этот код будет некорректен.
Такая ошибка не обязательно кроется в сложных иерархиях наследования, и вот один из примеров:
class CWinApp {
...
virtual void WinHelp(DWORD_PTR dwData, UINT nCmd);
};
class CSampleApp : public CWinApp {
...
virtual void WinHelp(DWORD dwData, UINT nCmd);
};Неприятности проявят себя при компиляции данного кода под 64-битную платформу. Получатся две функции с одинаковыми именами, но с различными параметрами, в результате чего перестанет вызываться пользовательский код.
Похожие проблемы возможны и при использовании перегруженных функций.
Как уже говорилось, это далеко не полный список потенциальных проблем (см. [1]), тем не менее, он позволяет сформулировать требования к анализатору кода.
2 Требования к анализатору кода
На основе списка потенциально-опасных конструкций, диагностирование которых необходимо, можно сформулировать следующие требования:
- Анализатор должен позволять осуществлять лексический разбор кода программы. Это необходимо для анализа использования потенциально опасных числовых констант.
- Анализатор должен позволять осуществлять синтаксический разбор кода программы. Только на уровне лексического анализа невозможно выполнить все необходимые проверки. Стоит отметить сложность синтаксиса языков Си и, особенно, Си++. Из этого следует необходимость именно полноценного синтаксического анализа, а не, например, поиска на основе регулярных выражений.
- Важной составляющей частью анализатора является анализ типов. Сложность типов в целевых языках такова, что подсистема вычисления типов является достаточно трудоемкой. Тем не менее, обойтись без нее нельзя.
Необходимо отметить, что конкретная архитектура реализации перечисленного функционала роли не играет, однако эта реализация должна быть полноценной.
В литературе по разработке компиляторов [2] сказано, что традиционный компилятор имеет следующие фазы своей работы:
![]()
Рисунок 1 — Фазы работы традиционного компилятора
Обратим внимание, что это «логические» фазы работы. В реальном компиляторе какие-то этапы объединены, какие-то выполняются параллельно с другими. Так, например, достаточно часто фазы синтаксического и семантического анализа объединены.
Для анализатора кода ни генерация кода, ни его оптимизация не требуются. То есть необходимо разработать часть компилятора, которая отвечает за лексический, синтаксический и семантический анализ.
3 Архитектура анализатора кода
Исходя из рассмотренных требований к разрабатываемой системе, можно предложить следующую структуру анализатора кода:
- Модуль лексического анализа. Математическим аппаратом данного модуля являются конечные автоматы. В качестве результата лексического анализа получается набор лексем.
- Модуль синтаксического анализа. Математический аппарат — грамматики; в результате работы получается дерево разбора кода.
- Модуль семантического (контекстного) анализа. Математическим аппаратом также являются грамматики, но особого вида: либо специальным образом «расширенные» грамматики, либо так называемые атрибутные грамматики [3]. Результатом является дерево разбора кода с проставленной дополнительной информацией о типах (либо атрибутированное дерево разбора кода).
- Система диагностики ошибок. Это та часть анализатора кода, которая непосредственно отвечает за обнаружение потенциально опасных конструкций с точки зрения переноса кода на 64-битные системы.
Перечисленные модули являются стандартными [4] для традиционных компиляторов (рисунок 2), точнее для той части компилятора, которая называется компилятор переднего плана (front-end compiler).

Рисунок 2 — Схема компилятора переднего плана
Другая же часть традиционного компилятора (back-end compiler) отвечает за оптимизацию и кодогенерацию и в данной работе не представляет интереса.
Таким образом, разрабатываемый анализатор кода должен иметь в своем составе компилятор переднего плана для того, чтобы обеспечить необходимый уровень анализа кода.
3.1 Модуль лексического анализа
Лексический анализатор представляет собой конечный автомат, описывающий правила лексического разбора конкретного языка программирования.
Описание лексического анализатора может быть не только в виде конечного автомата, но и в виде регулярного выражения. И тот, и другой варианты описания равнозначны, так как легко переводятся друг в друга. На рисунке 3 приведена часть конечного автомата, описывающего анализатор языка Си.

Рисунок 3 — Конечный автомат, описывающий часть лексического анализатора (рисунок из [3])
Как уже говорилось, на данном этапе возможен лишь анализ одного типа потенциально опасных конструкций — использование «магических» констант. Все другие виды анализа будут выполняться на следующих этапах.
3.2. Модуль синтаксического анализа
Модуль синтаксического анализа работает с аппаратом грамматик для того, чтобы по набору лексем, полученных на предыдущем этапе, построить дерево разбора кода (английский термин — abstract syntax tree). Точнее можно сформулировать задачу синтаксического анализа так. Является ли код программы выводимым из грамматики заданного языка? В результате проверки выводимости получается дерево разбора кода, но суть именно в определении принадлежности кода конкретному языку программирования.
В результате разбора кода строится дерево кода. Пример такого дерева для фрагмента кода приведен на рисунке 5.
int main()
{
int a = 2;
int b = a + 3;
printf("%d", b);
}
Рисунок 5 — Пример дерева кода
Важно отметить, что для каких-то простых языков программирования в результате построения дерева кода структура программы становится полностью известной. Однако для сложного языка вроде Си++ необходим дополнительный этап, когда построенное дерево будет дополняться, например, информацией о типах данных.
3.3. Модуль семантического анализ
В модуле семантического анализа наибольший интерес представляет подсистема вычисления типов. Дело в том, что типы данных в Си++ представляют собой довольно сложный и очень сильно расширяемый набор сущностей. Помимо базовых типов, характерных для любых языков программирования (целое, символ и т.п.), в Си++ есть понятие указателей на функции, шаблонов, классов и так далее.
Столь сложная подсистема типов не позволяет выполнить полный анализ программы на стадии синтаксического анализа. Поэтому на вход модуля семантического анализа подается дерево разбора кода, которое затем дополняется информацией уже обо всех типах данных.
Здесь же происходит и операция вычисления типов. Язык Си++ позволяет кодировать достаточно сложные выражения, при этом определить их тип зачастую не просто. На рисунке 6 показан пример кода, для которого необходимо вычисление типов при передаче аргументов в функцию.
void call_func(double x);
int main()
{
int a = 2;
float b = 3.0;
call_func(a+b);
}В данном случае необходимо вычислить тип результата выражения (a+b), и добавить информацию о типе в дерево (рисунок 7).

Рисунок 5 — Пример дерева кода, дополненного информацией о типах
После завершения работы модуля семантического анализа вся возможная информация о программе становится доступной для дальнейшей обработки.
3.4 Система диагностики ошибок
Говоря об обработке ошибок, разработчики компиляторов имеют в виду особенности поведения компилятора при обнаружении некорректных кодов программ. В этом смысле ошибки можно разделить на несколько типов [2]:
- лексические — неверно записанные идентификаторы, ключевые слова или операторы;
- синтаксические — например, арифметические выражения с несбалансированными скобками;
- семантические — такие как операторы, применяемые с несовместимыми с ними операндами.
Все эти типы ошибок означают, что вместо корректной с точки зрения языка программирования программы на вход компилятору подали некорректную программу. И задача компилятора состоит в том, чтобы, во-первых, диагностировать ошибку, а, во-вторых, по возможности продолжить работу по трансляции или остановиться.
Совсем другой подход к ошибкам возникает, если мы говорим о статическом анализе исходных кодов программ с целью выявления потенциально опасных синтаксических конструкций. Основное отличие заключается в том, что на вход синтаксического анализатора кода подается лексически, синтаксически и семантически абсолютно корректный программный код. Поэтому реализовывать систему диагностики некорректных конструкций в статическом анализаторе так же, как и систему диагностики ошибок в традиционном компиляторе, к сожалению, нельзя.
4 Реализация анализатора кода
Реализация анализатора кода состоит из реализации двух частей:
- компилятора переднего плана (front end compiler);
- подсистемы диагностики потенциально опасных конструкций.
Для реализации компилятора переднего плана будем использовать существующую открытую библиотеку анализа Си++ кода OpenC++ [6], точнее ее модификацию VivaCore [7]. Это рукописный синтаксический анализатор кода, в котором осуществляется анализ методом рекурсивного спуска (рекурсивный нисходящий анализ) с возвратом. Выбор рукописного анализатора обусловлен сложностью языка Си++ и отсутствием готовых описанных грамматик этого языка для использования средств автоматического создания анализаторов кода типа YACC и Bison.
Для реализации подсистемы поиска потенциально опасных конструкций, как уже было сказано в разделе 3.4, использовать традиционную для компиляторов систему диагностики ошибок нельзя. Используем для этого несколько приемов по модификации базовой грамматики языка Си++.
Прежде всего, необходимо поправить описание базовых типов языка Си++. В разделе 1 было введено понятие memsize-типов, то есть типов переменной размерности (таблица 1). Все данные типы в программах будем обрабатывать как один специальный тип (memsize). Другими словами, все реальные типы данных, важные с точки зрения переноса кода на 64-битные системы, в коде программ (например, ptrdiff_t, size_t, void* и др.) будут обрабатываться как один тип.
Далее необходимо внести расширение в понятие грамматики, добавив в ее правила вывода символы-действия [5]. Тогда процедура рекурсивного спуска, которая выполняет синтаксический анализ, также будет выполнять некоторые дополнительные действия по проверке семантики. Именно эти дополнительные действия и составляют суть статического анализатора кода.
Например, фрагмент грамматики для проверки корректности использования виртуальных функций (из раздела 1.4) может выглядеть так:
<ЗАГОЛОВОК_ВИРТУАЛЬНОЙ_ФУНКЦИИ> > <virtual> <ЗАГОЛОВОК_ФУНКЦИИ> CheckVirtual()
Здесь CheckVirtual() — это тот самый символ-действие. Действие CheckVirtual() будет вызвано, как только процедура рекурсивного спуска обнаружит объявление виртуальной функции в анализируемом коде. А уже внутри процедуры CheckVirtual() будет осуществляться проверка корректности аргументов в объявлении виртуальной функции.
Проверки всех потенциально опасных конструкций в языках Си и Си++, о которых говорится в [1], оформлены в аналогичные символы-действия. Сами эти символы-действия добавлены в грамматику языка, точнее в синтаксический анализатор, который вызывает символы-действия при разборе кода программы.
5 Результаты
Рассмотренная в работе архитектура и структура анализатора кода легли в основу коммерческого программного продукта Viva64 [8]. Viva64 — это статический анализатор кода программ, написанных на языках Си и Си++. Он предназначен для обнаружения в исходном коде программ потенциально опасных синтаксических конструкций с точки зрения переноса кода на 64-битные систем.
6 Заключение
Статический анализатор — это программа, состоящая из двух частей:
- компилятора переднего плана (front end compiler);
- подсистемы диагностики потенциально опасных синтаксических конструкций.
Компилятор переднего плана является традиционным компонентом обычного компилятора, поэтому принципы его построения и разработки достаточно хорошо изучены.
Подсистема диагностики потенциально опасных синтаксических конструкций является тем элементом статического анализатора кода, который и делает анализаторы уникальными, отличающимися по кругу решаемых задач. Так, в рамках данной работы рассматривалась задача переноса кода программ на 64-битные системы. Именно свод знаний о 64-битном программном обеспечении лег в основу подсистемы диагностики.
Объединение компилятора переднего плана из проекта VivaCore [7] и свода знаний о 64-битном программном обеспечении [1] позволило разработать программный продукт Viva64 [8].
Библиографический список
- Карпов А. 20 ловушек переноса Си++ — кода на 64-битную платформу // RSDN Magazine #1-2007.
- Ахо А., Сети Р., Ульман Д.. Компиляторы: принципы, технологии и инструменты. : Пер. с англ. — М.: Издательский дом «Вильямс», 2003. — 768 с.: ил. — Парал. тит. англ.
- Серебряков В.А., Галочкин М.П.. Основы конструирования компиляторов. М.: Едиториал УРСС, 2001. — 224 с.
- Зуев Е.А. Принципы и методы создания компилятора переднего плана Стандарта Си++. Диссертация на соискание ученой степени кандидата физико-математических наук. Москва, 1999.
- Формальные грамматики и языки. Элементы теории трансляции / Волкова И. А., Руденко Т. В. ; Моск. гос. ун-т им. М. В. Ломоносова, Фак. вычисл. математики и кибернетики, 62 с. 21 см, 2-е изд., перераб. и доп. М. Диалог-МГУ 1999.
- OpenC++ (C++ frontend library). http://opencxx.sourceforge.net/.
- VivaCore Library. http://www.viva64.com/ru/vivacore-library/.
- Viva64 Tool. http://www.viva64.com/ru/viva64-tool/.
Присылаем лучшие статьи раз в месяц
Время на прочтение
6 мин
Количество просмотров 10K
В разных языках программирования поведение виртуальных функций отличается, когда речь заходит о конструкторах и деструкторах. Неправильное использование виртуальных функций – это классическая ошибка при разработке на языке С++, которую мы разберём в этой статье.
Теория
Предполагаю, что читатель уже знаком с виртуальными функциями в языке C++, поэтому сразу перейду к сути. Когда в конструкторе вызывается виртуальная функция, она работает только в пределах базовых или создаваемого в данный момент классов. Конструкторы в классах-наследниках ещё не вызывались, и поэтому реализованные в них виртуальные функции не будут вызваны.
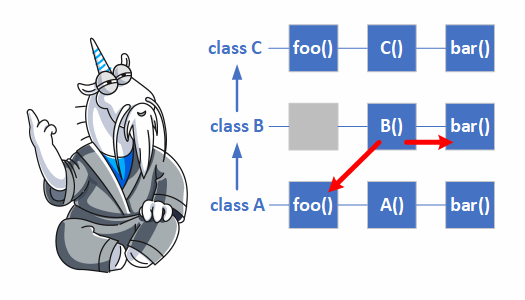
Для начала поясню это рисунком.
Пояснения:
- От класса A наследуется класс B;
- От класса B наследуется класс C;
- Функции foo и bar являются виртуальными;
- У функции foo нет реализации в классе B.
Создадим объект класса C и рассмотрим, что произойдёт, если мы вызовем эти две функции в конструкторе класса B.
- Функция foo. Класс C ещё не создан, а в классе B нет функции foo. Поэтому будет вызвана реализация функции из класса A.
- Функция bar. Класс C ещё не создан. Поэтому вызывается функция, относящаяся к текущему классу B.
Теперь продемонстрирую то же самое кодом.
#include <iostream>
class A
{
public:
A() { std::cout << "A()\n"; };
virtual void foo() { std::cout << "A::foo()\n"; };
virtual void bar() { std::cout << "A::bar()\n"; };
};
class B : public A
{
public:
B() {
std::cout << "B()\n";
foo();
bar();
};
void bar() { std::cout << "B::bar()\n"; };
};
class C : public B
{
public:
C() { std::cout << "C()\n"; };
void foo() { std::cout << "C::foo()\n"; };
void bar() { std::cout << "C::bar()\n"; };
};
int main()
{
C x;
return 0;
}Если скомпилировать и запустить этот код, то он распечатает:
A()
B()
A::foo()
B::bar()
C()При вызове виртуальных методов в деструкторах всё работает точно так же.
Казалось бы, в чём проблема? Всё это описано в книжках по программированию на языке С++.
Проблема в том, что про это легко забыть! И считать, что функции foo и bar будут вызваны из крайнего наследника, т.е. из класса C.
Вопрос «Почему код работает неожиданным образом?» вновь и вновь поднимается на форумах. Пример: Calling virtual functions inside constructors.
Думаю, теперь понятно, почему в подобном коде легко допустить ошибку. Особенно легко запутаться, если довелось программировать на других языках, где поведение отличается. Рассмотрим следующую программу на языке C#:
class Program
{
class Base
{
public Base()
{
Test();
}
protected virtual void Test()
{
Console.WriteLine("From base");
}
}
class Derived : Base
{
protected override void Test()
{
Console.WriteLine("From derived");
}
}
static void Main(string[] args)
{
var obj = new Derived();
}
}Если её запустить, то будет распечатано:
From derivedСоответствующая визуальная схема:
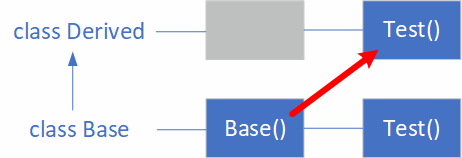
Вызывается функция в наследнике из конструктора базового класса!
При вызове виртуального метода из конструктора учитывается тип времени выполнения создаваемого экземпляра. Исходя из этого типа и происходит виртуальный вызов. Несмотря на то, что вызов метода происходит в конструкторе базового типа, фактический тип создаваемого экземпляра – Derived, что и определяет выбор метода. Подробнее про виртуальные методы можно почитать в спецификации.
Стоит отметить, что такое поведение тоже может быть чревато ошибками. Например, проблемы могут возникнуть, если виртуальный метод работает с членами производного типа, которые ещё не были проинициализированы в его конструкторе.
Рассмотрим пример:
class Base
{
public Base()
{
Test();
}
protected virtual void Test() { }
}
class Derived : Base
{
public String MyStr { get; set; }
public Derived(String myStr)
{
MyStr = myStr;
}
protected override void Test()
=> Console.WriteLine($"Length of {nameof(MyStr)}: {MyStr.Length}");
}При попытке создания экземпляра типа Derived возникнет исключение типа NullReferenceException, даже если в качестве аргумента в конструктор передаётся значение, отличное от null: new Derived(«Hello there»).
При исполнении тела конструктора типа Base будет вызвана реализация метода Test из типа Derived. Этот метод обращается к свойству MyStr, которое в текущий момент проинициализировано значением по умолчанию (null), а не параметром, переданным в конструктор (myStr).
С теорией разобрались. Теперь расскажу, почему я вообще решил написать эту статью.
Как появилась статья
Всё началось с вопроса «Scan-Build for clang-13 not showing errors» на сайте StackOverflow. Хотя вернее будет сказать, что всё началось с обсуждения статьи «О том, как мы с сочувствием смотрим на вопрос на StackOverflow, но молчим».
Можете не переходить по ссылкам. Я сейчас кратко перескажу суть истории.
Человек спросил, как с помощью статического анализа искать ошибки двух видов. Первая ошибка касается переменных типа bool, и сейчас нам не интересна. Вторая часть вопроса как раз касалась поиска вызовов виртуальных функций в конструкторе и деструкторе.
Если удалить всё, не относящееся к теме, то задача состоит в выявлении вызовов виртуальных функций в этом коде:
class M {
public:
virtual int GetAge(){ return 0; }
};
class P : public M {
public:
virtual int GetAge() { return 1; }
P() { GetAge(); } // maybe warn
~P() { GetAge(); } // maybe warn
};И вдруг выяснилось, что не все понимают, чем опасен такой код и почему статические анализаторы кода предупреждают о вызове виртуальных методов в конструкторах/деструкторах.

К публикации на сайте habr появились комментарии (RU) следующего вида:
Сокращенный комментарий N1. Так что компилятор прав, ошибки нет. Ошибка только в логике программиста, его пример кода всегда будет возвращать единицу в первом случае. И он мог бы даже использовать inline для того, чтобы ускорить работу и кода конструктора, и деструктора. Но компилятору это все равно не имеет значение, либо результат функции нигде не используется, функция не задействует никакие внешние аргументы — компилятор просто выкинет пример в качестве оптимизации. И это логичный правильный поступок. Как итог, ошибки просто нет.
Сокращенный комментарий N2. Про виртуальные функции вообще вашего юмора не понял. [цитата из книги про виртуальные функции]. Автор подчеркивает, что ключевое слово virtual используется только один раз. Далее в книге разъясняется, что оно наследуется. А теперь студенты ответьте мне на вопрос: «Где вы увидели проблему вызова виртуальной функции в конструкторе и деструкторе класса? Ответ дать по отдельности для каждого случая». Подразумевая, что вы оба, как неприлежные студенты, не разбираетесь в вопросе, когда вызываются конструктор и деструктор класса. И в добавок совершенно упустили тему «В каком порядке определяются объекты родительских классов при определение предка, и в каком порядке они уничтожаются».
Возможно, прочитав эти комментарии вы недоумеваете, как всё это относится к рассмотренной ранее теме. Правильно, что недоумеваете. Ответ: никак не относится.
Тот, кто оставлял комментарии, просто не догадывается, от какой проблемы хочет защититься человек, задавший вопрос на StackOverflow.
Да, стоит признать, что вопрос можно было бы сформулировать лучше. Собственно, как таковой проблемы в приведённом коде действительно нет. Пока нет. Она появится в дальнейшем, когда у классов появятся новые наследники, реализующие функцию GetAge, которые что-то делают. Если бы в примере присутствовал ещё один класс, наследующий P, то вопрос стал бы более полным.
Однако любой, кто хорошо знает язык C++, сразу понимает, какая проблема обсуждается и почему человек хочет искать вызовы функций.
Запрет на вызов виртуальных функций в конструкторах/деструкторах нашёл своё отражение и в стандартах кодирования. Например в SEI CERT C++ Coding Standard есть правило: OOP50-CPP. Do not invoke virtual functions from constructors or destructors. Это диагностическое правило реализуют многие анализаторы кода, такие как Parasoft C/C++test, Polyspace Bug Finder, PRQA QA-C++, SonarQube C/C++ Plugin. В их число входит и разрабатываемый нашей командой PVS-Studio (диагностика V1053).
А если ошибки нет?
Мы не рассмотрели ситуацию, что никакой ошибки нет. Другими словами, всё работает ровно так, как задумывалось. В этом случае можно явно указать, какие функции мы планируем вызывать:
B() {
std::cout << "B()\n";
A::foo();
B::bar();
};Такой код будет однозначно правильно понят вашими коллегами. Статические анализаторы в свою очередь тоже всё поймут и промолчат.
Заключение
Цените статический анализ кода. Он поможет выявить потенциальные проблемы в коде, причём такие, о которых вы и ваши коллеги могут даже не догадываться. Несколько примеров:
- V718. The ‘Foo’ function should not be called from ‘DllMain’ function.
- V1032. Pointer is cast to a more strictly aligned pointer type.
- V1036. Potentially unsafe double-checked locking.
Работа виртуальных функций, конечно, не такое тайное знание, как примеры по ссылкам :). Однако, как показывают комментарии и вопросы на StackOverflow, эта тема заслуживает внимания и контроля. Было бы всё очевидно – не было бы этой статьи. Хорошо, что анализаторы кода способны подстраховать программиста в его работе.
Спасибо за внимание, и приходите попробовать анализатор PVS-Studio.
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Andrey Karpov. Virtual function calls in constructors and destructors (C++).
Недавно мой коллега столкнулся с проблемой, когда использовалась старая версия файла заголовка для библиотеки. В результате код, сгенерированный для вызова виртуальная функция в C ++ ссылается на неправильное смещение в таблице поиска виртуальных функций для класса ( виртуальные таблицы).
К сожалению, эта ошибка не была обнаружена во время компиляции.
Все обычные функции связаны с использованием их искаженных имен, что гарантирует компоновщику правильную функцию (включая правильный вариант перегрузки). Аналогично, можно представить, что объектный файл или библиотека могут содержать символическую информацию о функциях в виртуальные таблицы для класса C ++.
Есть ли способ позволить компилятору C ++ (скажем, g++ или Visual Studio) проверка типа вызовов виртуальной функции во время связывания?
Вот простой тестовый пример. Представьте себе этот простой заголовочный файл и связанную с ним реализацию:
Base.hpp:
#ifndef BASE_HPP
#define BASE_HPP
namespace Test
{
class Base
{
public:
virtual int f() const = 0;
virtual int g() const = 0;
virtual int h() const = 0;
};
class BaseFactory
{
public:
static const Base* createBase();
};
}
#endif
Derived.cpp:
#include "Base.hpp"
#include <iostream>
using namespace std;
namespace Test
{
class Derived : public Base
{
public:
virtual int f() const
{
cout << "Derived::f()" << endl;
return 1;
}
virtual int g() const
{
cout << "Derived::g()" << endl;
return 2;
}
virtual int h() const
{
cout << "Derived::h()" << endl;
return 3;
}
};
const Base* BaseFactory::createBase()
{
return new Derived();
}
}
Теперь представьте, что программа использует неправильную / старую версию файла заголовка, в которой отсутствует виртуальная функция в середине:
BaseWrong.hpp
#ifndef BASEWRONG_HPP
#define BASEWRONG_HPP
namespace Test
{
class Base
{
public:
virtual int f() const = 0;
// Missing: virtual int g() const = 0;
virtual int h() const = 0;
};
class BaseFactory
{
public:
static const Base* createBase();
};
}
#endif
Итак, у нас есть основная программа:
main.cpp
// Including the _wrong_ version of the header!
#include "BaseWrong.hpp"
#include <iostream>
using namespace std;
int main()
{
const Test::Base* base = Test::BaseFactory::createBase();
const int fres = base->f();
cout << "f() returned: " << fres << endl;
const int hres = base->h();
cout << "h() returned: " << hres << endl;
return 0;
}
Когда мы собираем «библиотеку», используя правильный заголовок, а затем скомпилировать и связать основную программу, используя неправильно заголовок …
$ g++ -c Derived.cpp
$ g++ Main.cpp Derived.o -o Main
… тогда виртуальный вызов h() использует неправильный индекс в виртуальные таблицы так что вызов на самом деле идет g():
$ ./Main
Derived::f()
f() returned: 1
Derived::g()
h() returned: 2
В этом небольшом примере функции g() а также h() имеют одну и ту же сигнатуру, поэтому «единственной» ошибкой является то, что вызывается неправильная функция (которая сама по себе плохая и может остаться незамеченной), но если сигнатуры отличаются, это может привести (и было замечено) к повреждению стека — например, при вызове функции в DLL в Windows, где используется соглашение о вызовах Pascal (вызывающая сторона выдвигает аргументы, а вызываемая сторона выдает их перед возвратом).
6
Решение
Краткий ответ на ваш вопрос — нет. Основная проблема заключается в том, что смещения для вызываемых функций вычисляются во время компиляции; поэтому, если ваш код вызывающего абонента был скомпилирован с (неправильным) заголовочным файлом, который включал «virtual int g () const», то ваш main.o будет иметь все ссылки на h (), смещенные присутствием g (). Но ваша библиотека скомпилирована с правильным заголовочным файлом, поэтому функции g () нет, поэтому смещение h () в Derived.o будет отличаться от main.o
Это не вопрос проверки типов вызовов виртуальных функций — это «ограничение», основанное на том факте, что компилятор C ++ выполняет вычисление смещения функции во время компиляции, а не во время выполнения.
Вы можете обойти эту проблему, используя dl_open вместо прямых вызовов функций и динамически связывая вашу библиотеку вместо статического связывания.
0
Другие решения
Других решений пока нет …
In the list of cppcheck rules there is
<error id=»virtualCallInConstructor» severity=»style» msg=»Virtual
function ‘f’ is called from constructor » at line
- Dynamic binding is not used.» verbose=»Virtual function ‘f’ is called from constructor » at line 1.
Dynamic binding is not used.»/>
I’ve written a call to a virtual functions in several classes in my solution and run cppcheck o them, but it didn’t show this error.
I’ve used GUI and also run cppcheck from command line with —enable=style and —enable=all
How can I make cppcheck to show this issue?
I’m using latest cppcheck
Another dummy code I’ve run cppcheck on
class A
{
public:
A() { }
virtual void fin() = 0;
};
class B : public A
{
public:
B() { fin(); }
void fin() { std::cout << "l"; }
};
class C : public B
{
public:
C() {}
void fin() { std::cout << "c"; }
};
UPDATE: I’ve checked cppcheck 1.8 and it shows me this errors. What’s happened to the 2.5 that it didn’t show them despite in the set of rules of 2.5 it is stated that it should find such?
asked Jul 6, 2021 at 17:34
![]()
NameName
374 bronze badges
3