-
Исследование и проверка модели
Средства
вычислительной техники, которые в
настоящее время широко используются
либо для вычислений при аналитическом
моделировании, либо для реализации
имитационной модели системы, могут лишь
помочь с точки зрения эффективности
реализации сложной модели, но не позволяют
подтвердить правильность той или иной
модели. Проверку на синтаксические
ошибки программа проходит в процессе
компиляции или трансляции. Логические
же ошибки и ошибки формирования самой
математической модели выявляют на
следующем этапе — этапе проверки модели
с использованием готовой (откомпилированной)
моделирующей программы и набора тестовых
данных, полученных на реальной установке.
Проверка
достоверности программы выполняется
в следующей последовательности [161,163]:
а) проверка отдельных частей программы
при решении различных тестовых задач;
б) объединение всех частей программы и
проверка ее в целом;
в) оценка средств моделирования
(затраченных ресурсов).
Для
программы в целом и её отдельных частей
выполняют проверку:
• полноты учета основных факторов и
ограничений, влияющих на работу системы;
• соответствия исходных данных модели
реальным;
• наличия в модели всех данных,
необходимых для накопления ответных
величин;
• правильности преобразования исходных
данных в конечные результаты (например,
при условиях, приводящих к известному
аналитическому решению);
• осмысленности результатов при
нормальных условиях (поступательный
ход модельного времени, отсутствие
переполнения буферов и счетчиков) и в
предельных случаях (пробные прогоны в
условиях перегрузки системы).
Для
программы в целом выполняют проверку
адекватности, устойчивости, чувствительности
и точности модели.
Проверку
адекватности (соответствия)
математической модели исследуемому
процессу необходимо проводить по той
причине, что любая модель является лишь
приближенным отражением реального
процесса вследствие допущений, всегда
принимаемых при составлении математической
модели. На этом этапе устанавливается,
насколько принятые допущения правомерны,
и тем самым определяется, применима ли
полученная модель для исследования
процесса.
Для
проверки адекватности модели осуществляется
воспроизведение, или имитация, объекта
на ЭВМ с помощью программы в соответствии
с задачами исследования. После этого
определяется степень близости машинных
результатов и поведения исследуемого
объекта. При этом существенно не
«абсолютное качество» машинных
результатов, а степень сходства с
объектом исследования. Так, при
моделировании автоколебаний важно не
то, чтобы результаты моделирования в
точности совпадали с реально наблюдаемыми
колебаниями, а чтобы они имели аналогичную
форму и аналогичный характер протекания.
Модель должна обладать только существенными
признаками объекта моделирования.
Если
в ходе моделирования существенное место
занимает реальный физический эксперимент,
то здесь весьма важна и надежность
используемых инструментальных средств,
поскольку сбои и отказы программно-технических
средств могут приводить к искаженным
значениям выходных данных, отображающих
протекание процесса. И в этом смысле
при проведении физических экспериментов
необходимы специальная аппаратура,
специально разработанное математическое
и информационное обеспечение, которые
позволяют реализовать диагностику
средств моделирования, чтобы отсеять
те ошибки в выходной информации, которые
вызваны неисправностями функционирующей
аппаратуры. В ходе машинного эксперимента
могут иметь место и ошибочные действия
самого исследователя. В этих условиях
серьезные задачи стоят в области
эргономического обеспечения процесса
моделирования.
Успешный
результат сравнения (оценки) исследуемого
объекта с моделью свидетельствует о
достаточной степени изученности объекта,
о правильности принципов, положенных
в основу моделирования, и о том, что
алгоритм, моделирующий объект, не
содержит ошибок, т. е. о том, что созданная
модель работоспособна. Такая модель
может быть использована для дальнейших
более глубоких исследований объекта в
различных новых условиях, в которых
реальный объект еще не изучался.
Чаще,
однако, первые результаты моделирования
не удовлетворяют предъявленным
требованиям. Это означает, что, по крайней
мере, в одной из перечисленных выше
позиций (изученность объекта, исходные
принципы, алгоритм) имеются дефекты.
Это требует проведения дополнительных
исследований, корректировки математической
модели. Для этого используются результаты
измерений на самом объекте или на его
физической модели, воспроизводящей в
небольших масштабах основные физические
закономерности объекта моделирования.
После соответствующего изменения
машинной программы снова повторяются
третий и четвертый этапы. Процедура
повторяется до получения надежных
результатов.
При
решении всех задач проектирования с
использованием математического
моделирования важным вопросом также
является получение необходимой точности.
Недостаточная точность моделируемых
данных может привести к ложным выводам
или выбору неправильного варианта
технологического процесса (либо
параметра, что менее опасно). В случае
моделирования на ЭВМ инструментальную
точность ограничивают два существенных
фактора: надежность ЭВМ (или, точнее,
вероятность случайного сбоя в процессе
счета) и вычислительная точность,
связанная с ограниченностью представления
чисел в памяти ЭВМ и неизбежными ошибками
округления. При отсутствии двойного
счета ошибки вследствие случайного
сбоя ЭВМ входят непосредственно в
результаты моделирования и вносят
трудно устранимую дополнительную
погрешность, которая может быть
значительной, особенно при малых
вероятностях исследуемых событий.
Случайные сбои при решении ряда задач
могут быть обнаружены визуальным
контролем с помощью графических дисплеев,
сопряженных с ЭВМ, на которой выполняется
моделирование.
Представление
процессов реальных непрерывных систем
при моделировании в виде временного
ряда сопряжено с дополнительной потерей
точности. Поэтому представление состояний
модели и входных сигналов не может быть
выбрано произвольно, а зависит от
требуемой точности результатов,
характеристик этих сигналов и особенностей
моделируемой системы и должно быть
специально рассчитано.
На
точность и устойчивость результатов
моделирования, а также на его вычислительную
эффективность оказывает значительное
влияние, например, выбранный метод
решения системы обыкновенных
дифференциальных уравнений, описывающих
исследуемый процесс [161,163].
Анализ
чувствительности— это расчет
векторов градиентов выходных параметров.
Наиболее просто анализ чувствительности
реализуется путем численного
дифференцирования. Пусть анализ
проводится в некоторой точкеХномпространства аргументов, в которой
предварительно проведен одновариантный
анализ и найдены значения выходных
параметровYj
ном. ВыделяетсяN параметров-аргументовXi,
влияние которых на выходные параметры
подлежит оценить, поочередно каждый из
них получает приращениеΔXi,
выполняется моделирование, фиксируются
значения выходных параметровYjи подсчитываются значения абсолютных:
![]()
и
относительных коэффициентов
чувствительности:
![]() .
.
Такой
метод численного дифференцирования
называют методом
приращений. Для анализа
чувствительности, согласно методу
приращений, требуется выполнитьN+1 раз одновариантный анализ. Результат
его применения — получение матриц
абсолютной и относительной чувствительности,
элементами которых являются коэффициентыAji
иBji[162].
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
From Wikipedia, the free encyclopedia
Verification and validation of computer simulation models is conducted during the development of a simulation model with the ultimate goal of producing an accurate and credible model.[1][2] «Simulation models are increasingly being used to solve problems and to aid in decision-making. The developers and users of these models, the decision makers using information obtained from the results of these models, and the individuals affected by decisions based on such models are all rightly concerned with whether a model and its results are «correct».[3] This concern is addressed through verification and validation of the simulation model.
Simulation models are approximate imitations of real-world systems and they never exactly imitate the real-world system. Due to that, a model should be verified and validated to the degree needed for the model’s intended purpose or application.[3]
The verification and validation of a simulation model starts after functional specifications have been documented and initial model development has been completed.[4] Verification and validation is an iterative process that takes place throughout the development of a model.[1][4]
Verification[edit]
In the context of computer simulation, verification of a model is the process of confirming that it is correctly implemented with respect to the conceptual model (it matches specifications and assumptions deemed acceptable for the given purpose of application).[1][4]
During verification the model is tested to find and fix errors in the implementation of the model.[4]
Various processes and techniques are used to assure the model matches specifications and assumptions with respect to the model concept.
The objective of model verification is to ensure that the implementation of the model is correct.
There are many techniques that can be utilized to verify a model.
These include, but are not limited to, having the model checked by an expert, making logic flow diagrams that include each logically possible action, examining the model output for reasonableness under a variety of settings of the input parameters, and using an interactive debugger.[1]
Many software engineering techniques used for software verification are applicable to simulation model verification.[1]
Validation[edit]
Validation checks the accuracy of the model’s representation of the real system. Model validation is defined to mean «substantiation that a computerized model within its domain of applicability possesses a satisfactory range of accuracy consistent with the intended application of the model».[3] A model should be built for a specific purpose or set of objectives and its validity determined for that purpose.[3]
There are many approaches that can be used to validate a computer model. The approaches range from subjective reviews to objective statistical tests. One approach that is commonly used is to have the model builders determine validity of the model through a series of tests.[3]
Naylor and Finger [1967] formulated a three-step approach to model validation that has been widely followed:[1]
Step 1. Build a model that has high face validity.
Step 2. Validate model assumptions.
Step 3. Compare the model input-output transformations to corresponding input-output transformations for the real system.[5]
Face validity[edit]
A model that has face validity appears to be a reasonable imitation of a real-world system to people who are knowledgeable of the real world system.[4] Face validity is tested by having users and people knowledgeable with the system examine model output for reasonableness and in the process identify deficiencies.[1] An added advantage of having the users involved in validation is that the model’s credibility to the users and the user’s confidence in the model increases.[1][4] Sensitivity to model inputs can also be used to judge face validity.[1] For example, if a simulation of a fast food restaurant drive through was run twice with customer arrival rates of 20 per hour and 40 per hour then model outputs such as average wait time or maximum number of customers waiting would be expected to increase with the arrival rate.
Validation of model assumptions[edit]
Assumptions made about a model generally fall into two categories: structural assumptions about how system works and data assumptions. Also we can consider the simplification assumptions that are those that we use to simplify the reality.[6]
Structural assumptions[edit]
Assumptions made about how the system operates and how it is physically arranged are structural assumptions. For example, the number of servers in a fast food drive through lane and if there is more than one how are they utilized? Do the servers work in parallel where a customer completes a transaction by visiting a single server or does one server take orders and handle payment while the other prepares and serves the order. Many structural problems in the model come from poor or incorrect assumptions.[4] If possible the workings of the actual system should be closely observed to understand how it operates.[4] The systems structure and operation should also be verified with users of the actual system.[1]
Data assumptions[edit]
There must be a sufficient amount of appropriate data available to build a conceptual model and validate a model. Lack of appropriate data is often the reason attempts to validate a model fail.[3] Data should be verified to come from a reliable source. A typical error is assuming an inappropriate statistical distribution for the data.[1] The assumed statistical model should be tested using goodness of fit tests and other techniques.[1][3] Examples of goodness of fit tests are the Kolmogorov–Smirnov test and the chi-square test. Any outliers in the data should be checked.[3]
Simplification assumptions[edit]
Are those assumptions that we know that are not true, but are needed to simplify the problem we want to solve.[6] The use of this assumptions must be restricted to assure that the model is correct enough to serve as an answer for the problem we want to solve.
Validating input-output transformations[edit]
The model is viewed as an input-output transformation for these tests. The validation test consists of comparing outputs from the system under consideration to model outputs for the same set of input conditions. Data recorded while observing the system must be available in order to perform this test.[3] The model output that is of primary interest should be used as the measure of performance.[1] For example, if system under consideration is a fast food drive through where input to model is customer arrival time and the output measure of performance is average customer time in line, then the actual arrival time and time spent in line for customers at the drive through would be recorded. The model would be run with the actual arrival times and the model average time in line would be compared with the actual average time spent in line using one or more tests.
Hypothesis testing[edit]
Statistical hypothesis testing using the t-test can be used as a basis to accept the model as valid or reject it as invalid.
The hypothesis to be tested is
- H0 the model measure of performance = the system measure of performance
versus
- H1 the model measure of performance ≠ the system measure of performance.
The test is conducted for a given sample size and level of significance or α. To perform the test a number n statistically independent runs of the model are conducted and an average or expected value, E(Y), for the variable of interest is produced. Then the test statistic, t0 is computed for the given α, n, E(Y) and the observed value for the system μ0
 and the critical value for α and n-1 the degrees of freedom
and the critical value for α and n-1 the degrees of freedom

- is calculated.

If

reject H0, the model needs adjustment.
There are two types of error that can occur using hypothesis testing, rejecting a valid model called type I error or «model builders risk» and accepting an invalid model called Type II error, β, or «model user’s risk».[3] The level of significance or α is equal the probability of type I error.[3] If α is small then rejecting the null hypothesis is a strong conclusion.[1] For example, if α = 0.05 and the null hypothesis is rejected there is only a 0.05 probability of rejecting a model that is valid. Decreasing the probability of a type II error is very important.[1][3] The probability of correctly detecting an invalid model is 1 — β. The probability of a type II error is dependent of the sample size and the actual difference between the sample value and the observed value. Increasing the sample size decreases the risk of a type II error.
Model accuracy as a range[edit]
A statistical technique where the amount of model accuracy is specified as a range has recently been developed. The technique uses hypothesis testing to accept a model if the difference between a model’s variable of interest and a system’s variable of interest is within a specified range of accuracy.[7] A requirement is that both the system data and model data be approximately Normally Independent and Identically Distributed (NIID). The t-test statistic is used in this technique. If the mean of the model is μm and the mean of system is μs then the difference between the model and the system is D = μm — μs. The hypothesis to be tested is if D is within the acceptable range of accuracy. Let L = the lower limit for accuracy and U = upper limit for accuracy. Then
- H0 L ≤ D ≤ U
versus
- H1 D < L or D > U
is to be tested.
The operating characteristic (OC) curve is the probability that the null hypothesis is accepted when it is true. The OC curve characterizes the probabilities of both type I and II errors. Risk curves for model builder’s risk and model user’s can be developed from the OC curves. Comparing curves with fixed sample size tradeoffs between model builder’s risk and model user’s risk can be seen easily in the risk curves.[7] If model builder’s risk, model user’s risk, and the upper and lower limits for the range of accuracy are all specified then the sample size needed can be calculated.[7]
Confidence intervals[edit]
Confidence intervals can be used to evaluate if a model is «close enough»[1] to a system for some variable of interest. The difference between the known model value, μ0, and the system value, μ, is checked to see if it is less than a value small enough that the model is valid with respect that variable of interest. The value is denoted by the symbol ε. To perform the test a number, n, statistically independent runs of the model are conducted and a mean or expected value, E(Y) or μ for simulation output variable of interest Y, with a standard deviation S is produced. A confidence level is selected, 100(1-α). An interval, [a,b], is constructed by
- ,

where
is the critical value from the t-distribution for the given level of significance and n-1 degrees of freedom.
- If |a-μ0| > ε and |b-μ0| > ε then the model needs to be calibrated since in both cases the difference is larger than acceptable.
- If |a-μ0| < ε and |b-μ0| < ε then the model is acceptable as in both cases the error is close enough.
- If |a-μ0| < ε and |b-μ0| > ε or vice versa then additional runs of the model are needed to shrink the interval.
Graphical comparisons[edit]
If statistical assumptions cannot be satisfied or there is insufficient data for the system a graphical comparisons of model outputs to system outputs can be used to make a subjective decisions, however other objective tests are preferable.[3]
ASME Standards[edit]
Documents and standards involving verification and validation of computational modeling and simulation are developed by the American Society of Mechanical Engineers (ASME) Verification and Validation (V&V) Committee. ASME V&V 10 provides guidance in assessing and increasing the credibility of computational solid mechanics models through the processes of verification, validation, and uncertainty quantification.[8] ASME V&V 10.1 provides a detailed example to illustrate the concepts described in ASME V&V 10.[9] ASME V&V 20 provides a detailed methodology for validating computational simulations as applied to fluid dynamics and heat transfer.[10] ASME V&V 40 provides a framework for establishing model credibility requirements for computational modeling, and presents examples specific in the medical device industry. [11]
See also[edit]
- Verification and validation
- Software verification and validation
References[edit]
- ^ a b c d e f g h i j k l m n o p Banks, Jerry; Carson, John S.; Nelson, Barry L.; Nicol, David M. Discrete-Event System Simulation Fifth Edition, Upper Saddle River, Pearson Education, Inc. 2010 ISBN 0136062121
- ^ Schlesinger, S.; et al. (1979). «Terminology for model credibility». Simulation. 32 (3): 103–104. doi:10.1177/003754977903200304.
- ^ a b c d e f g h i j k l m Sargent, Robert G. «VERIFICATION AND VALIDATION OF SIMULATION MODELS». Proceedings of the 2011 Winter Simulation Conference.
- ^ a b c d e f g h Carson, John, «MODEL VERIFICATION AND VALIDATION». Proceedings of the 2002 Winter Simulation Conference.
- ^ NAYLOR, T. H., AND J. M. FINGER [1967], «Verification of Computer Simulation Models», Management Science, Vol. 2, pp. B92– B101., cited in Banks, Jerry; Carson, John S.; Nelson, Barry L.; Nicol, David M. Discrete-Event System Simulation Fifth Edition, Upper Saddle River, Pearson Education, Inc. 2010 p. 396. ISBN 0136062121
- ^ a b 1. Fonseca, P. Simulation hypotheses. In Proceedings of SIMUL 2011; 2011; pp. 114–119. https://www.researchgate.net/publication/262187532_Simulation_hypotheses_A_proposed_taxonomy_for_the_hypotheses_used_in_a_simulation_model
- ^ a b c Sargent, R. G. 2010. «A New Statistical Procedure for Validation of Simulation and Stochastic Models.» Technical Report SYR-EECS-2010-06, Department of Electrical Engineering and Computer Science, Syracuse University, Syracuse, New York.
- ^ “V&V 10 – 2006 Guide for Verification and Validation in Computational Solid Mechanics”. Standards. ASME. Retrieved 2 September 2018.
- ^ “V&V 10.1 – 2012 An Illustration of the Concepts of Verification and Validation in Computational Solid Mechanics”. Standards. ASME. Retrieved 2 September 2018.
- ^ “V&V 20 – 2009 Standard for Verification and Validation in Computational Fluid Dynamics and Heat Transfer”. Standards. ASME. Retrieved 2 September 2018.
- ^ “V&V 40 Industry Day”. Verification and Validation Symposium. ASME. Retrieved 2 September 2018.
From Wikipedia, the free encyclopedia
Verification and validation of computer simulation models is conducted during the development of a simulation model with the ultimate goal of producing an accurate and credible model.[1][2] «Simulation models are increasingly being used to solve problems and to aid in decision-making. The developers and users of these models, the decision makers using information obtained from the results of these models, and the individuals affected by decisions based on such models are all rightly concerned with whether a model and its results are «correct».[3] This concern is addressed through verification and validation of the simulation model.
Simulation models are approximate imitations of real-world systems and they never exactly imitate the real-world system. Due to that, a model should be verified and validated to the degree needed for the model’s intended purpose or application.[3]
The verification and validation of a simulation model starts after functional specifications have been documented and initial model development has been completed.[4] Verification and validation is an iterative process that takes place throughout the development of a model.[1][4]
Verification[edit]
In the context of computer simulation, verification of a model is the process of confirming that it is correctly implemented with respect to the conceptual model (it matches specifications and assumptions deemed acceptable for the given purpose of application).[1][4]
During verification the model is tested to find and fix errors in the implementation of the model.[4]
Various processes and techniques are used to assure the model matches specifications and assumptions with respect to the model concept.
The objective of model verification is to ensure that the implementation of the model is correct.
There are many techniques that can be utilized to verify a model.
These include, but are not limited to, having the model checked by an expert, making logic flow diagrams that include each logically possible action, examining the model output for reasonableness under a variety of settings of the input parameters, and using an interactive debugger.[1]
Many software engineering techniques used for software verification are applicable to simulation model verification.[1]
Validation[edit]
Validation checks the accuracy of the model’s representation of the real system. Model validation is defined to mean «substantiation that a computerized model within its domain of applicability possesses a satisfactory range of accuracy consistent with the intended application of the model».[3] A model should be built for a specific purpose or set of objectives and its validity determined for that purpose.[3]
There are many approaches that can be used to validate a computer model. The approaches range from subjective reviews to objective statistical tests. One approach that is commonly used is to have the model builders determine validity of the model through a series of tests.[3]
Naylor and Finger [1967] formulated a three-step approach to model validation that has been widely followed:[1]
Step 1. Build a model that has high face validity.
Step 2. Validate model assumptions.
Step 3. Compare the model input-output transformations to corresponding input-output transformations for the real system.[5]
Face validity[edit]
A model that has face validity appears to be a reasonable imitation of a real-world system to people who are knowledgeable of the real world system.[4] Face validity is tested by having users and people knowledgeable with the system examine model output for reasonableness and in the process identify deficiencies.[1] An added advantage of having the users involved in validation is that the model’s credibility to the users and the user’s confidence in the model increases.[1][4] Sensitivity to model inputs can also be used to judge face validity.[1] For example, if a simulation of a fast food restaurant drive through was run twice with customer arrival rates of 20 per hour and 40 per hour then model outputs such as average wait time or maximum number of customers waiting would be expected to increase with the arrival rate.
Validation of model assumptions[edit]
Assumptions made about a model generally fall into two categories: structural assumptions about how system works and data assumptions. Also we can consider the simplification assumptions that are those that we use to simplify the reality.[6]
Structural assumptions[edit]
Assumptions made about how the system operates and how it is physically arranged are structural assumptions. For example, the number of servers in a fast food drive through lane and if there is more than one how are they utilized? Do the servers work in parallel where a customer completes a transaction by visiting a single server or does one server take orders and handle payment while the other prepares and serves the order. Many structural problems in the model come from poor or incorrect assumptions.[4] If possible the workings of the actual system should be closely observed to understand how it operates.[4] The systems structure and operation should also be verified with users of the actual system.[1]
Data assumptions[edit]
There must be a sufficient amount of appropriate data available to build a conceptual model and validate a model. Lack of appropriate data is often the reason attempts to validate a model fail.[3] Data should be verified to come from a reliable source. A typical error is assuming an inappropriate statistical distribution for the data.[1] The assumed statistical model should be tested using goodness of fit tests and other techniques.[1][3] Examples of goodness of fit tests are the Kolmogorov–Smirnov test and the chi-square test. Any outliers in the data should be checked.[3]
Simplification assumptions[edit]
Are those assumptions that we know that are not true, but are needed to simplify the problem we want to solve.[6] The use of this assumptions must be restricted to assure that the model is correct enough to serve as an answer for the problem we want to solve.
Validating input-output transformations[edit]
The model is viewed as an input-output transformation for these tests. The validation test consists of comparing outputs from the system under consideration to model outputs for the same set of input conditions. Data recorded while observing the system must be available in order to perform this test.[3] The model output that is of primary interest should be used as the measure of performance.[1] For example, if system under consideration is a fast food drive through where input to model is customer arrival time and the output measure of performance is average customer time in line, then the actual arrival time and time spent in line for customers at the drive through would be recorded. The model would be run with the actual arrival times and the model average time in line would be compared with the actual average time spent in line using one or more tests.
Hypothesis testing[edit]
Statistical hypothesis testing using the t-test can be used as a basis to accept the model as valid or reject it as invalid.
The hypothesis to be tested is
- H0 the model measure of performance = the system measure of performance
versus
- H1 the model measure of performance ≠ the system measure of performance.
The test is conducted for a given sample size and level of significance or α. To perform the test a number n statistically independent runs of the model are conducted and an average or expected value, E(Y), for the variable of interest is produced. Then the test statistic, t0 is computed for the given α, n, E(Y) and the observed value for the system μ0
- and the critical value for α and n-1 the degrees of freedom
- is calculated.
If
reject H0, the model needs adjustment.
There are two types of error that can occur using hypothesis testing, rejecting a valid model called type I error or «model builders risk» and accepting an invalid model called Type II error, β, or «model user’s risk».[3] The level of significance or α is equal the probability of type I error.[3] If α is small then rejecting the null hypothesis is a strong conclusion.[1] For example, if α = 0.05 and the null hypothesis is rejected there is only a 0.05 probability of rejecting a model that is valid. Decreasing the probability of a type II error is very important.[1][3] The probability of correctly detecting an invalid model is 1 — β. The probability of a type II error is dependent of the sample size and the actual difference between the sample value and the observed value. Increasing the sample size decreases the risk of a type II error.
Model accuracy as a range[edit]
A statistical technique where the amount of model accuracy is specified as a range has recently been developed. The technique uses hypothesis testing to accept a model if the difference between a model’s variable of interest and a system’s variable of interest is within a specified range of accuracy.[7] A requirement is that both the system data and model data be approximately Normally Independent and Identically Distributed (NIID). The t-test statistic is used in this technique. If the mean of the model is μm and the mean of system is μs then the difference between the model and the system is D = μm — μs. The hypothesis to be tested is if D is within the acceptable range of accuracy. Let L = the lower limit for accuracy and U = upper limit for accuracy. Then
- H0 L ≤ D ≤ U
versus
- H1 D < L or D > U
is to be tested.
The operating characteristic (OC) curve is the probability that the null hypothesis is accepted when it is true. The OC curve characterizes the probabilities of both type I and II errors. Risk curves for model builder’s risk and model user’s can be developed from the OC curves. Comparing curves with fixed sample size tradeoffs between model builder’s risk and model user’s risk can be seen easily in the risk curves.[7] If model builder’s risk, model user’s risk, and the upper and lower limits for the range of accuracy are all specified then the sample size needed can be calculated.[7]
Confidence intervals[edit]
Confidence intervals can be used to evaluate if a model is «close enough»[1] to a system for some variable of interest. The difference between the known model value, μ0, and the system value, μ, is checked to see if it is less than a value small enough that the model is valid with respect that variable of interest. The value is denoted by the symbol ε. To perform the test a number, n, statistically independent runs of the model are conducted and a mean or expected value, E(Y) or μ for simulation output variable of interest Y, with a standard deviation S is produced. A confidence level is selected, 100(1-α). An interval, [a,b], is constructed by
- ,
where
is the critical value from the t-distribution for the given level of significance and n-1 degrees of freedom.
- If |a-μ0| > ε and |b-μ0| > ε then the model needs to be calibrated since in both cases the difference is larger than acceptable.
- If |a-μ0| < ε and |b-μ0| < ε then the model is acceptable as in both cases the error is close enough.
- If |a-μ0| < ε and |b-μ0| > ε or vice versa then additional runs of the model are needed to shrink the interval.
Graphical comparisons[edit]
If statistical assumptions cannot be satisfied or there is insufficient data for the system a graphical comparisons of model outputs to system outputs can be used to make a subjective decisions, however other objective tests are preferable.[3]
ASME Standards[edit]
Documents and standards involving verification and validation of computational modeling and simulation are developed by the American Society of Mechanical Engineers (ASME) Verification and Validation (V&V) Committee. ASME V&V 10 provides guidance in assessing and increasing the credibility of computational solid mechanics models through the processes of verification, validation, and uncertainty quantification.[8] ASME V&V 10.1 provides a detailed example to illustrate the concepts described in ASME V&V 10.[9] ASME V&V 20 provides a detailed methodology for validating computational simulations as applied to fluid dynamics and heat transfer.[10] ASME V&V 40 provides a framework for establishing model credibility requirements for computational modeling, and presents examples specific in the medical device industry. [11]
See also[edit]
- Verification and validation
- Software verification and validation
References[edit]
- ^ a b c d e f g h i j k l m n o p Banks, Jerry; Carson, John S.; Nelson, Barry L.; Nicol, David M. Discrete-Event System Simulation Fifth Edition, Upper Saddle River, Pearson Education, Inc. 2010 ISBN 0136062121
- ^ Schlesinger, S.; et al. (1979). «Terminology for model credibility». Simulation. 32 (3): 103–104. doi:10.1177/003754977903200304.
- ^ a b c d e f g h i j k l m Sargent, Robert G. «VERIFICATION AND VALIDATION OF SIMULATION MODELS». Proceedings of the 2011 Winter Simulation Conference.
- ^ a b c d e f g h Carson, John, «MODEL VERIFICATION AND VALIDATION». Proceedings of the 2002 Winter Simulation Conference.
- ^ NAYLOR, T. H., AND J. M. FINGER [1967], «Verification of Computer Simulation Models», Management Science, Vol. 2, pp. B92– B101., cited in Banks, Jerry; Carson, John S.; Nelson, Barry L.; Nicol, David M. Discrete-Event System Simulation Fifth Edition, Upper Saddle River, Pearson Education, Inc. 2010 p. 396. ISBN 0136062121
- ^ a b 1. Fonseca, P. Simulation hypotheses. In Proceedings of SIMUL 2011; 2011; pp. 114–119. https://www.researchgate.net/publication/262187532_Simulation_hypotheses_A_proposed_taxonomy_for_the_hypotheses_used_in_a_simulation_model
- ^ a b c Sargent, R. G. 2010. «A New Statistical Procedure for Validation of Simulation and Stochastic Models.» Technical Report SYR-EECS-2010-06, Department of Electrical Engineering and Computer Science, Syracuse University, Syracuse, New York.
- ^ “V&V 10 – 2006 Guide for Verification and Validation in Computational Solid Mechanics”. Standards. ASME. Retrieved 2 September 2018.
- ^ “V&V 10.1 – 2012 An Illustration of the Concepts of Verification and Validation in Computational Solid Mechanics”. Standards. ASME. Retrieved 2 September 2018.
- ^ “V&V 20 – 2009 Standard for Verification and Validation in Computational Fluid Dynamics and Heat Transfer”. Standards. ASME. Retrieved 2 September 2018.
- ^ “V&V 40 Industry Day”. Verification and Validation Symposium. ASME. Retrieved 2 September 2018.
Проверка и проверка компьютерных имитационных моделей — Verification and validation of computer simulation models
Верификация и валидация компьютерных имитационных моделей проводится во время разработки имитационной модели с конечной целью создания точной и достоверной модели. «Имитационные модели все чаще используются для решения проблем и помощи в принятии решений. Разработчики и пользователи этих моделей, лица, принимающие решения, использующие информацию, полученную на основе результатов этих моделей, и лица, на которых влияют решения, основанные на таких моделях, являются все справедливо озабочены тем, являются ли модель и ее результаты «правильными». Эта проблема решается путем проверки и валидации имитационной модели.
Имитационные модели являются приблизительными имитациями реальных систем, и они никогда в точности не имитируют в реальной системе. В связи с этим модель должна быть проверена и подтверждена в степени, необходимой для предполагаемого назначения или применения модели.
Верификация и валидация имитационной модели начинается после того, как функциональные спецификации задокументированы и начальная разработка модели завершена. Верификация и валидация — это итеративный процесс, который происходит на протяжении всей разработки модели.
Содержание
- 1 Ver ification
- 2 Проверка достоверности
- 2.1 Подтверждение достоверности
- 2.2 Проверка допущений модели
- 2.2.1 Структурные допущения
- 2.2.2 Допущения данных
- 2.2.3 Допущения упрощения
- 2.3 Проверка входных данных -выводные преобразования
- 2.3.1 Проверка гипотез
- 2.3.1.1 Точность модели в виде диапазона
- 2.3.2 Доверительные интервалы
- 2.3.3 Графические сравнения
- 2.3.1 Проверка гипотез
- 3 Стандарты ASME
- 4 См. также
- 5 Ссылки
Верификация
В контексте компьютерного моделирования верификация модели — это процесс подтверждения того, что она правильно реализована по отношению к концептуальной модели (это соответствует спецификациям и предположениям, которые считаются приемлемыми для данной цели приложения). Во время верификации модель тестируется для поиска и исправления ошибок в реализации модели. Для обеспечения соответствия модели спецификациям и предположениям в отношении концепции модели используются различные процессы и методы. Цель проверки модели — убедиться, что реализация модели верна.
Есть много методов, которые можно использовать для проверки модели. К ним относятся, помимо прочего, проверка модели экспертом, создание логических блок-схем, включающих каждое логически возможное действие, проверка выходных данных модели на разумность при различных настройках входных параметров и использование интерактивного отладчика. Многие методы разработки программного обеспечения, используемые для верификации программного обеспечения, применимы к верификации имитационной модели.
Валидация
Валидация проверяет точность представления модели реальной системы. Валидация модели определяется как «подтверждение того, что компьютеризированная модель в пределах ее области применимости обладает удовлетворительным диапазоном точности, совместимым с предполагаемым применением модели». Модель должна быть построена для конкретной цели или набора задач, а ее достоверность должна определяться для этой цели.
Существует множество подходов, которые можно использовать для проверки компьютерной модели. Подходы варьируются от субъективных обзоров до объективных статистических тестов. Один из наиболее часто используемых подходов состоит в том, чтобы разработчики моделей определяли достоверность модели с помощью серии тестов.
Нейлор и Фингер [1967] сформулировали трехэтапный подход к валидации модели, который получил широкое распространение:
Шаг 1. Постройте модель с высокой достоверностью.
Шаг 2. Подтвердите допущения модели.
Шаг 3. Сравните преобразования ввода-вывода модели с соответствующими преобразованиями ввода-вывода для реальной системы.
Face validity
Модель, имеющая face validity представляется разумной имитацией системы реального мира для людей, знакомых с системой реального мира. Подтверждение подлинности проверяется тем, что пользователи и люди, знакомые с системой, проверяют выходные данные модели на предмет разумности и в процессе выявляют недостатки. Дополнительным преимуществом вовлечения пользователей в проверку является то, что доверие к модели для пользователей и доверие пользователя к модели возрастают. Чувствительность к входным данным модели также может использоваться для оценки достоверности лица. Например, если моделирование проезда в ресторан быстрого питания было выполнено дважды с темпами прибытия клиентов 20 в час и 40 в час, тогда ожидается, что выходные данные модели, такие как среднее время ожидания или максимальное количество ожидающих клиентов, увеличатся с прибытием. показатель.
Проверка допущений модели
Допущения, сделанные в отношении модели, обычно делятся на две категории: структурные допущения о том, как работает система, и допущения данных. Также мы можем рассмотреть упрощающие предположения, которые мы используем для упрощения реальности.
Структурные предположения
Предположения, сделанные о том, как работает система и как она устроена физически, являются структурными предположениями. Например, количество серверов в фаст-фуде проезжает по переулку, и если их больше одного, как они используются? Работают ли серверы параллельно, когда клиент завершает транзакцию, посещая один сервер, или один сервер принимает заказы и обрабатывает платежи, в то время как другой готовит и обслуживает заказ. Многие структурные проблемы в модели возникают из-за неверных или неверных предположений. Если возможно, необходимо внимательно наблюдать за работой реальной системы, чтобы понять, как она работает. Структура и работа системы также должны быть проверены пользователями реальной системы.
Допущения данных
Должен быть достаточный объем соответствующих данных, доступных для построения концептуальной модели и проверки модели. Отсутствие соответствующих данных часто является причиной неудачных попыток проверки модели. Данные должны быть проверены и получены из надежного источника. Типичная ошибка — это предположение о несоответствующем статистическом распределении данных. Предполагаемая статистическая модель должна быть протестирована с использованием критериев согласия и других методов. Примерами критериев согласия являются тест Колмогорова – Смирнова и критерий хи-квадрат. Следует проверять любые выбросы в данных.
Допущения упрощения
Это те предположения, которые, как мы знаем, не верны, но необходимы для упрощения проблемы, которую мы хотим решить. Использование этих предположений должно быть ограничено, чтобы гарантировать, что модель достаточно верна, чтобы служить ответом на проблему, которую мы хотим решить.
Проверка преобразований ввода-вывода
Модель рассматривается как преобразование ввода-вывода для этих тестов. Проверочный тест состоит из сравнения выходных данных рассматриваемой системы с выходными данными модели для того же набора входных условий. Данные, записанные во время наблюдения за системой, должны быть доступны для выполнения этого теста. Выходные данные модели, представляющие основной интерес, следует использовать в качестве меры производительности. Например, если рассматриваемая система представляет собой поездку в ресторан быстрого питания, где входными данными для модели является время прибытия клиента, а выходным показателем эффективности является среднее время ожидания клиента в очереди, тогда фактическое время прибытия и время, проведенное в очереди для клиентов в проезде. будет записан. Модель будет запускаться с фактическим временем прибытия, и среднее время нахождения в очереди будет сравниваться с фактическим средним временем, проведенным в очереди с использованием одного или нескольких тестов.
Проверка гипотез
Статистическая проверка гипотез с использованием t-критерия может использоваться в качестве основы для признания модели действительной или отклонения ее как недействительной.
Гипотеза, подлежащая проверке:
- H0модельный показатель производительности = системный показатель производительности
по сравнению с
- H1модельным показателем производительности ≠ системный показатель производительности.
Тест проводится для данного размера выборки и уровня значимости или α. Для выполнения теста проводится n статистически независимых прогонов модели и вычисляется среднее или ожидаемое значение E (Y) для интересующей переменной. Затем тестовая статистика t 0 вычисляется для заданных α, n, E (Y) и наблюдаемого значения для системы μ
- t 0 = (E (Y) — u 0) / (S / n) { displaystyle t_ {0} = {(E (Y) -u_ {0})} / {(S / { sqrt {n}})}}и критическое значения для α и n-1 вычисляются степени свободы
- ta / 2, n — 1 { displaystyle t_ {a / 2, n-1}}.
Если
- | t 0 |>ta / 2, n — 1 { displaystyle left vert t_ {0} right vert>t_ {a / 2, n-1}}
отклонить H 65>0, модель нуждается в корректировке.
Существует два типа ошибок, которые могут возникнуть при проверке гипотез: отклонение действительной модели, называемое ошибкой типа I, или «риск создателей модели» и принятие неверной модели называется ошибкой типа II, β или «риск пользователя модели». Уровень значимости или α равен вероятности ошибки типа I. Если α мало, то отклонение нулевой гипотезы является сильным выводом. Например, если α = 0,05 а нулевая гипотеза отклоняется, вероятность отклонения действительной модели составляет всего 0,05. Уменьшение вероятности ошибки типа II очень важно. Вероятность правильного обнаружения недействительной модели составляет 1 — β. Вероятность типа Ошибка II зависит от размера выборки и фактическая разница между значением выборки и наблюдаемым значением. Увеличение размера выборки снижает риск ошибки типа II.
Точность модели как диапазон
Недавно был разработан статистический метод, при котором степень точности модели задается как диапазон. Этот метод использует проверку гипотез для принятия модели, если разница между интересующей переменной модели и интересующей системной переменной находится в пределах указанного диапазона точности. Требование состоит в том, чтобы и системные данные, и данные модели были приблизительно Обычно Независимыми и идентично распределенными (NIID). В этом методе используется статистика t-критерия. Если среднее значение модели — μ, а среднее значение системы — μ, то разница между моделью и системой составляет D = μ — μ. Гипотеза, подлежащая проверке, заключается в том, находится ли D в приемлемом диапазоне точности. Пусть L = нижний предел точности и U = верхний предел точности. Затем необходимо проверить
- H0L ≤ D ≤ U
по сравнению с
- H1D < L or D>U
.
Кривая рабочей характеристики (ОС) — это вероятность того, что нулевая гипотеза будет принята, когда она верна. Кривая OC характеризует вероятность ошибок как I, так и II типа. Кривые риска для риска создателя модели и пользователя модели могут быть построены на основе кривых OC. Сравнение кривых с фиксированным размером выборки между риском разработчика модели и риском пользователя модели можно легко увидеть на кривых риска. Если заданы риски разработчика модели, риск пользователя модели, а также верхний и нижний пределы диапазона точности, то можно рассчитать необходимый размер выборки.
Доверительные интервалы
Доверительные интервалы могут быть используется для оценки того, «достаточно ли близка» модель к системе для некоторой интересующей переменной. Проверяется разница между известным модельным значением μ 0 и системным значением μ, чтобы увидеть, меньше ли оно значения, достаточно малого для того, чтобы модель была действительной в отношении этой интересующей переменной. Значение обозначается символом ε. Для выполнения теста проводится ряд n статистически независимых прогонов модели и создается среднее или ожидаемое значение E (Y) или μ для представляющей интерес выходной переменной Y моделирования со стандартным отклонением S. Выбран уровень достоверности 100 (1-α). Интервал [a, b] строится следующим образом:
- a = E (Y) — ta / 2, n — 1 S / nandb = E (Y) + ta / 2, n — 1 S / n { displaystyle a = E (Y) -t_ {a / 2, n-1} S / { sqrt {n}} qquad и qquad b = E (Y) + t_ {a / 2, n-1} S / { sqrt {n}}},
где
- ta / 2, n — 1 { displaystyle t_ {a / 2, n-1}}
— критическое значение из t-распределения для заданный уровень значимости и n-1 степеней свободы.
- Если | a-μ 0 |>ε и | b-μ 0 |>ε, то модель необходимо откалибровать, поскольку в обоих случаях разница больше допустимой.
- If | a-μ 0| < ε and |b-μ0| < ε then the model is acceptable as in both cases the error is close enough.
- If | a-μ 0| < ε and |b-μ0|>ε или наоборот, тогда необходимы дополнительные прогоны модели для сокращения интервала.
Графические сравнения
Если статистические допущения не могут быть выполнены или данных для системы недостаточно a графическое сравнение выходных данных модели с выходными данными системы может использоваться для принятия субъективных решений, однако другие объективные тесты предпочтительнее.
Стандарты ASME
Документы и стандарты, включающие проверку и валидацию компьютерного моделирования и моделирования разработаны Комитетом по верификации и валидации (VV) Американского общества инженеров-механиков (ASME). ASME VV 10 предоставляет руководство по оценке и повышению достоверности расчетных моделей механики твердого тела посредством процессов верификации, валидации и количественной оценки неопределенности. ASME VV 10.1 предоставляет подробный пример для иллюстрации концепций, описанных в ASME VV 10. ASME VV 20 предоставляет подробную методологию для проверки компьютерного моделирования применительно к гидродинамике и теплопередаче. ASME VV 40 обеспечивает основу для установления требований к достоверности модели для вычислительного моделирования и представляет примеры, характерные для индустрии медицинских устройств.
См. Также
- Проверка и проверка
- Проверка и проверка программного обеспечения
Ссылки
Как мы можем удостовериться, правильно ли работает средство моделирования? Одним из подходов является метод искусственного решения. Этот процесс включает допущение некого решения, получение исходных условий и других вспомогательных условий согласующихся с первоначальным предположением, решение задачи с этими условиями в качестве входных параметров для пакета моделирования и сравнение полученных результатов с предполагаемым решением. Метод прост в использовании и достаточно универсален. Например, исследователи из Национальной лаборатории Сандия использовали его в некоторых собственных программных разработках.
Проверка и подтверждение
Перед использованием инструмента численного моделирования для прогнозирования результатов предварительно неизвестных ситуаций, мы хотим создать критерий проверки его надежности. Мы можем сделать это либо проверкой того, что пакет для моделирования точно воспроизводит имеющиеся аналитические решения, либо тем, что его результаты согласуются с экспериментальными данными. Это приводит нас к двум тесно взаимосвязанным предметам обсуждения проверке (верификации) и подтверждению (валидации). Давайте проясним, что означают два эти термина в контексте численного моделирования.
Для численного моделирования физической проблемы, мы предпринимаем два шага:
- Построение математической модели физической системы. Это то место, где учитываются все факторы, которые оказывают влияние на наблюдаемое поведение и формулируются основные управляющие уравнения. Результатом зачастую является система неявных связей между входными и выходными величинами. Они часто записываются в виде системы дифференциальных уравнений в частных производных с начальными и граничными условиями, которая в совокупности называется как начально-краевая задача (initial boundary value problem — IBVP).
- Решение математической модели для получения выражений для выходных величин в виде явных функций от входных значений параметров. Однако, такая замкнутая форма решения недоступна для большинства задач, представляющих практический интерес. В таком случае, мы применяем численные методы для получения приближенных решений, часто с помощью вычислительной техники для решения больших систем, в общем случае, нелинейных алгебраических уравнений и неравенств.
Существует две ситуации, при которых могут появиться ошибки. Во-первых, они могут возникнуть в самой математической модели. Потенциальные ошибки вносятся при упущении важного фактора или при допущении нефизичного соотношения между переменными. Подтверждение (валидация) состоит в том, чтобы получить уверенность, что такие ошибки не вносятся при построении математической модели. Проверка (верификация), с другой стороны, заключается в том, чтобы удостовериться, что математическая модель решается достаточно точно. В этом случае, мы должны гарантировать, что численный алгоритм является сходящимся и его компьютерная реализация является корректной, так что численное решение будет точным.
Проще говоря, во время подтверждения, мы спрашиваем, корректно ли мы задали математическую модель для описания физической системы, в то время как при проверке, мы исследуем, получим ли мы точное численное решение математической модели. ")
Сравнение между процессами подтверждения и проверки.
Теперь, давайте углубимся в проблему проверки численного решения начально-краевых задач (IBVP-задач).
Различные подходы к процедуре проверки
Как мы можем удостовериться, обеспечивает ли инструмент моделирования достаточно точное решение IBVP-задачи? Одна из возможностей заключается в том, чтобы выбрать задачу, имеющую точное аналитическое решение и использовать точное решение в качестве критерия правильности. Метод разделения переменных, например, можно использовать для получения решения простой IBVP-задачи. Применимость этого подхода ограничивается тем, что большинство задач, представляющих практический интерес, не имеют точного решения, что и является основанием для использования компьютерного моделирования. Тем не менее, этот подход является полезным при проверке работоспособности алгоритмов и программ.
Другим подходом является сравнение результатов моделирования с экспериментальными данными. Вообще, это является сочетанием подтверждения и проверки в одном шаге, который иногда называется пригодность (квалификация). Возможно, но маловероятно, что экспериментальные данные случайно совпадут с неправильным решением в результате комбинации некорректной математической модели и неверного алгоритма или ошибке в программном коде. За исключением таких редких случаев, хорошее соответствие численного решения и экспериментальных результатов подтверждает справедливость математической модели и точность процедуры решения.
Библиотеки Приложений в среде COMSOL Multiphysics содержат множество проверочных моделей (verification models), которые используют один или оба этих подхода. Они сгруппированы по областям физики.
Данные модели доступны в Библиотеках Приложений среды COMSOL Multiphysics.
Что делать, если нам потребуется проверить наши результаты при отсутствии точных математических решений и экспериментальных данных? Мы можем обратиться к методу искусственного решения.
Реализация метода искусственного решения
Целью решения начально-краевой задачи (IBVP-задачи) является нахождения явного выражения для решения в терминах независимых переменных, как правило, пространства и времени, с учетом заданных параметров задачи, таких как свойства материала, а также граничные, начальные и исходные условия. Общая форма исходных условий подразумевает описание всех сил, действующих на тело, таких как гравитация в задачах строительной механики и аэро- и гидродинамики, силы сопротивления в задачах массопереноса и источников тепла в задачах термодинамики.
В методе искусственного решения (Method of Manufactured Solutions — MMS), мы решаем задачу от противного , т.е. начинаем с предполагаемого явного выражения для решения. Затем, мы подставляем решение в дифференциальные уравнения и получаем согласованный набор исходных, начальных и граничных условий. Обычно, это включает в себя оценку ряда производных. Вскоре мы увидим, как макрос на языке символической алгебры среды COMSOL Multiphysics может помочь в этом процессе. Аналогичным образом, мы вычисляем предполагаемое решение в момент времени t = 0 и на границах для получения начальных и граничных условий.
Далее идет этап проверки. С учетом только что полученных исходных и вспомогательных условий, мы применяем инструмент моделирования для получения численного решения IBVP-задачи и сравниваем его с изначально предполагавшимся решением, с которого мы “стартовали”.
Продемонстрируем эти шаги на простом примере.
Проверка одномерной задачи теплопроводности
Рассмотрим 1D задачу теплопроводности в стержне длиной L
A_crho C_p frac{partial T}{partial t} + frac{partial}{partial x}(-A_ckfrac{partial T}{partial x}) = A_cQ, t in (0,t_f), x in (0,L)
с начальным условием
T(x,0) = f(x)
и температурным режимом, поддерживаемым на обоих концах по закону, задаваемым функциями
T(0,t) = g_1(t), quad T(L,t) = g_2(t).
Константами A_c, rho, C_p и k являются площадь поперечного сечения, плотность материала, теплоемкость и коэффициент теплопроводности, соответственно. Источник тепла задается как Q.
Наша цель заключается в проверке решения этой задачи методом искусственного решения. Во-первых, предположим явный вид решения. В качестве такого решения давайте выберем следующее распределение температуры
u(x,t) = 500 K + frac{x}{L}(frac{x}{L}-1)frac{t}{tau} K,
где tau есть характерное время, которое для данного примера выберем равным одному часу. Введем новую переменную u для предполагаемой температуры, чтобы отличить ее от расчетной температуры T.
Далее, найдем исходное условие согласующееся с предполагаемым решением. Мы можем вручную вычислить частные производные по координате и времени и подставить их в дифференциальное уравнение для получения Q. Кроме того, поскольку среда COMSOL Multiphysics способна выполнять символические преобразования, то мы будем пользоваться этой встроенной опцией вместо вычисления вручную исходного условия.
В случае однородных материала и свойств поперечного сечения, мы можем объявить A_c, rho, C_p и k как параметры. В общем неоднородном случае для этого потребуются переменные величины, как это проделано для зависящих от времени граничных условий. Обратите внимание на использование оператора d(), одного из встроенных операторов дифференцирования в среду COMSOL Multiphysics, как показано на скриншоте ниже.
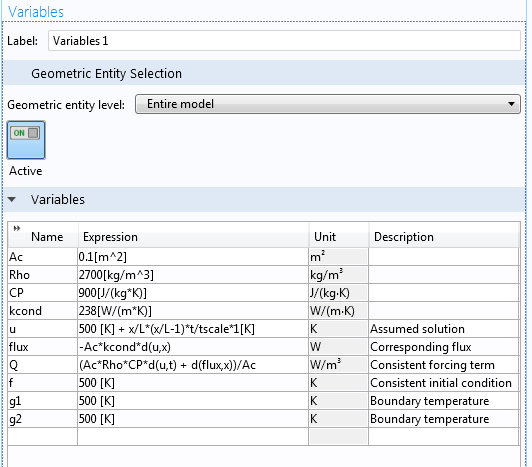
Макрос на языке символической алгебры среды COMSOL Multiphysics может автоматизировать оценку частных производных.
Мы выполняем эти символические вычисления с той оговоркой, что мы доверяем символической алгебре. Иначе, любые ошибки наблюдаемые позднее проистекали бы из символических вычислений, а не численного решения. Разумеется, мы можем построить график вычисляемого вручную выражения для Q рядом с результатом символических вычислений, показанных выше, для проверки макроса.
Далее, мы вычисляем начальные и граничные условия. Начальное условие – это предполагаемое решение, вычисленное в момент времени t = 0.
f(x) = u(x,0) = 500 K.
Значения температуры на концах стержня есть g_1(t) = g_2(t) = 500 K.
Далее, получим численное решение задачи, используя исходные, а также начальные и граничные условия, которые мы только что вычислили. В этом примере, будем использовать физический интерфейс Теплопередача в твердых телах.
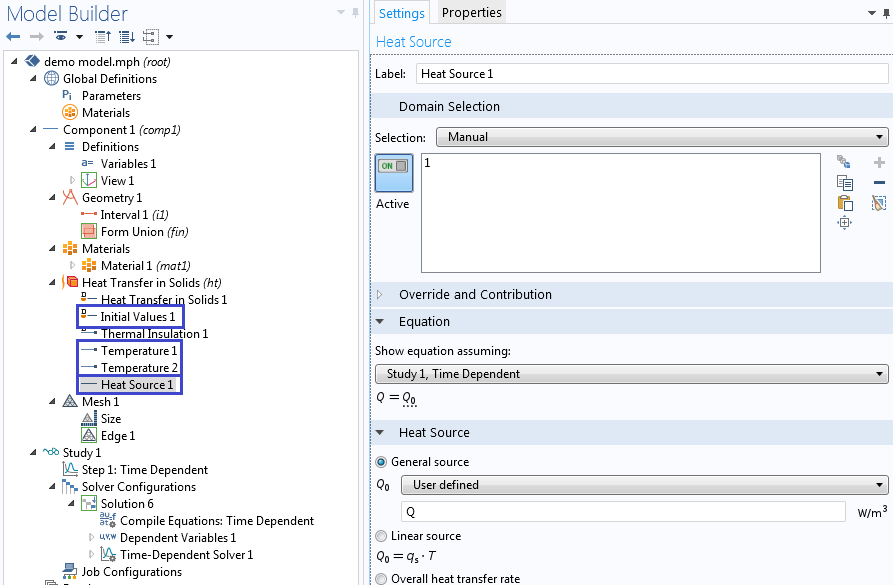
Добавление начальных значений, граничных условий и внешних источников, получаемых исходя из предполагаемого решения.
На завершающем этапе, мы сравним численное решение с предполагаемым решением. Графики ниже показывают температуру по истечении одного дня. Первое решение получено с использованием линейных элементов, в то время как второе решение получается при использовании квадратичных элементов. Для данного типа задач, по умолчанию среда COMSOL Multiphysics выбирает квадратичные элементы.
")
")
Решение, вычисленное при использовании искусственного решения с линейными элементами (слева) и квадратичными элементами (справа).
Проверка различных частей кода
Метод MMS предоставляет нам необходимую гибкость для проверки различных частей кода. Ради простоты, в приведенном выше примере, мы умышленно оставили многие части IBVP-задачи непроверенными. На практике, каждый элемент в уравнении должен быть проверен в наиболее общем виде. Например, для проверки того, насколько точно программа обрабатывает области с неоднородным поперечным сечением, мы должны определить пространственно-переменную область до получения исходных условий. То же можно сказать и в отношении других коэффициентов уравнения, например для свойств материала.
Аналогичная проверка должна производиться для всех граничных и начальных условий. Если, к примеру, мы хотим на левом конце стержня задать поток тепла взамен температуры, мы сначала оцениваем поток, соответствующий искусственному решению, т. е. -ncdot(-A_ck nabla u) где n есть единичная внешняя нормаль. Для предполагаемого решения в данном примере, направленный внутрь поток на левом конце становится равным frac{A_ck}{L}frac{t}{tau}*1K.
В среде COMSOL Multiphysics для теплопередачи в твердых телах граничными условиями по умолчанию являются условия тепловой изоляции. Что делать, если мы захотим проверить обработку тепловой изоляции на левом краю? Нам нужно будет придумать такое новое искусственное решение, в котором производная обращается в ноль на левом конце. Например, мы можем использовать
u(x,t) = 500 K + (frac{x}{L})^2frac{t}{tau} K.
Обратите внимание, что во время проверки, мы проверяем только, корректно ли решаются уравнения. Мы не затрагиваем вопроса о том, соответствует ли решение физической ситуации.
Важно помнить, что как только мы выдумываем новое искусственное решение, мы должны пересчитать исходные, начальные и граничные условия в соответствии предполагаемым решением. Разумеется, при использовании средств символических вычислений в среде COMSOL Multiphysics, мы освобождены от утомительных вычислений!
Скорость сходимости
Как было показано на графиках выше, решения, получаемые с помощью линейного и квадратичного элемента сходятся по мере уменьшения размера сетки разбиения. Это качественное поведение сходимости придает нам некоторую уверенность в численном решении. Мы можем продолжить тщательное рассмотрение численного метода, изучая его скорость сходимости, которая предоставит нам количественный критерий проверки численной процедуры.
Например, для стационарной модификаци изадачи, стандартная оценка конечного- элементной погрешности для погрешности измеряемой в норме Соболева
m-порядка, есть
||u-u_h||_m leq C h^{p+1-m}||u||_{p+1},
где u и u_h являются точным и конечно-элементным решениями, h является максимальным размером элемента, p -порядок полиномиальной аппроксимации (функция формы). Для m = 0, это дает оценку погрешности
||e|| = ||u-u_h|| = (int_{Omega}(u-u_h)^2dOmega)^{frac{1}{2}} leq C h^{p+1}||u||_{p+1},
где C – константа независимая от сетки разбиения.
Возвращаясь к методу искусственного решения, это означает, что решение с линейным элементом (p = 1) должно показывать сходимость второго порядка при измельчении сетки. Если мы построим график нормы ошибки по отношению к размеру сетки в логарифмическом масштабе, тангенс угла наклона должен асимптотически приближаться к 2. Если этого не происходит, то мы должны будем проверить код или точность и регулярность входных параметров, таких как материальные и геометрические свойства. Как показано на рисунках ниже, численное решение сходится с теоретически ожидаемой скоростью.
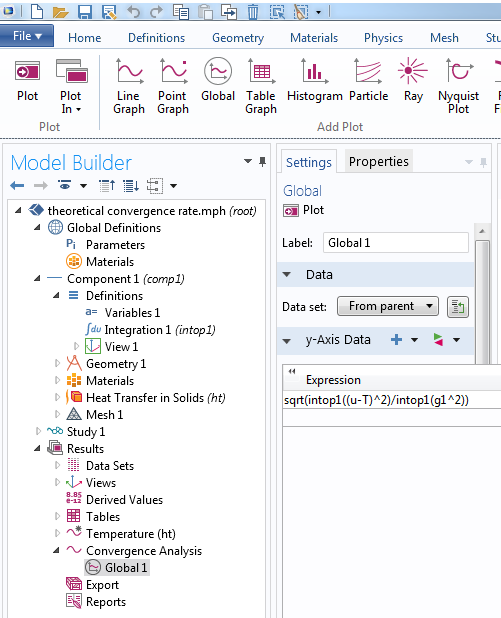
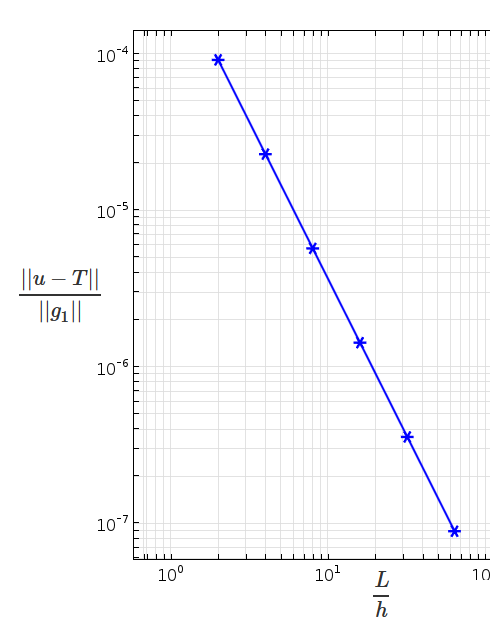
Слева: Использование операторов интегрирования для определения норм. Оператор intop1 определяется для интегрирования по области. Справа: График ошибки в зависимости от размера сетки, построенный в логарифмических осях, показывает второй порядок сходимости в норме L_2 (m = 0) для линейных элементов, что согласуется с теоретической оценкой.
Несмотря на то, что мы всегда должны проверять сходимость, теоретическая скорость сходимости может быть проверена только для тех проблем, для которых, как выше, доступна априорная оценка погрешности. Когда у вас имеются такие задачи, помните, что метод искусственного решения поможет вам удостовериться в том, что ваш код показывает правильное асимптотическое поведение.
Нелинейный задачи и взаимосвязанные междисциплинарные задачи
В случае существенной нелинейности, коэффициенты в уравнении зависят от решения. В задачах теплопроводности, например, коэффициент теплопроводности может зависеть от температуры. В таких случаях коэффициенты должны быть получены из предполагаемого решения.
Взаимосвязанные (мультифизические) задачи имеют несколько управляющих уравнений. Решения предполагаются сразу для всех взаимосвязанных полей, и исходные условия должны быть расчитаны для каждого управляющего уравнения.
Единственность
Обратите внимание, что логика метода искусственного решения сохраняется, только если управляющая система уравнений имеет единственное решение при условиях (исходные, граничные и начальные условия), подразумеваемых предполагаемым решением. Например, в стационарной задаче теплопроводности, доказательство единственности требует положительного значения теплопроводности. В то время, как это довольно просто проверяется в случае изотропной однородной среды, в случае температурной зависимости коэффициента теплопроводности или анизотропии большее внимание должно быть уделено при конструировании решения, чтобы не нарушить такие предположения.
При использовании метода искусственного решения, решение существует по определению. Кроме того, доказательства единственности существуют для гораздо большего класса задач, чем те, для которых у нас имеются точные аналитические решения. Таким образом, метод предоставляет нам большее пространство для маневра, чем поиск точного решения, начиная с исходных, начальных и граничных условий.
Попробуйте Самостоятельно
Встроенная функциональность в виде символических вычислений в среде COMSOL Multiphysics позволяет легко реализовать метод MMS для проверки кода программ, а также для образовательных целей. Несмотря на то, что мы всесторонне тестируем коды наших программ, мы приветствуем любые замечания со стороны наших пользователей. В данном топике был представлен универсальный инструмент, который вы можете использовать для проверки различных физических интерфейсов. Вы также можете проверить свои собственные реализации при использовании моделирования на основе пользовательских уравнений или Построителя интерфейсов для новой физики (Physics Builder) в среде COMSOL Multiphysics. Если у вас есть какие-либо вопросы по данной методике , пожалуйста, не стесняйтесь написать нам!
Информационные ресурсы
- Для всестороннего обсуждения метода искусственного решения, включая его сильные и слабые стороны, посмотрите данный Отчет из Национальной лаборатории Сэндиа (Sandia). В Отчете подробно излагается система “слепых” тестов, в которых один автор заложил ряд ошибок в код программы незаметно от второго автора, который выискивает заложенные “мины” с использованием метода, описанного в этом топике.
- Для расширенной дискуссии по проверке и подтверждению в контексте научных вычислений, ознакомьтесь с
- W. J. Oberkampf and C. J. Roy, Проверка и подтверждение в научных расчетах (Verification and Validation in Scientific Computing), Cambridge University Press, 2010
- Оценка стандартной погрешности в методе конечных элементов имеется в таких книгах, как
- Thomas J. R. Hughes, Метод конечных элементов: Линейный статический и динамический конечно-элементный анализ (The Finite Element Method: Linear Static and Dynamic Finite Element Analysis), Dover Publications, 2000
- B. Daya Reddy, Вводный функциональный анализ: с приложениями к краевым задачам и конечным элементам (Introductory Functional Analysis: With Applications to Boundary Value Problems and Finite Elements), Springer-Verlag, 1997
Такого
процесса, как «испытание» правильности
модели, не существует. Вместо этого
экспериментатор в ходе разработки
должен провести серию проверок, с тем,
чтобы укрепить свое доверие к модели.
Для этого могут быть использованы
проверки трех видов. Применяя первую
из них, мы должны убедиться, что модель
верна, так сказать, в первом приближении.
Например, следует поставить такой
вопрос: не будет ли модель давать
абсурдные ответы, если ее параметры
будут принимать предельные значения?
Мы должны также убедиться в том, что
результаты, которые мы получаем,
по-видимому, имеют смысл. Последнее
может быть выполнено для моделей
существующих систем методом, предложенным
Тьюрингом [31]. Он состоит в том, что людей,
непосредственно связанных с работой
реальной системы, просят сравнить
результаты, полученные имитирующим
устройством, с данными, получаемыми на
выходе реальной системы. Для того чтобы
такая проверка была несколько более
строгой в научном отношении, мы можем
предложить экспертам указать на различия
между несколькими выборками имитированных
данных и аналогичными выборками,
полученными в реальной системе.
Второй
метод оценки адекватности модели состоит
в проверке исходных предположений,
третий — в проверке преобразований
информации от входа к выходу. Последние
два метода могут привести к необходимости
использовать статистические выборки
для оценки средних значений и дисперсий,
дисперсионный анализ, регрессионный
анализ, факторный анализ, спектральный
анализ, автокорреляцию, метод проверки
с помощью критерия «хи-квадрат» и
непараметрические проверки. Поскольку
каждый из этих статистических методов
основан на некоторых допущениях, то при
использовании каждого из них возникают
вопросы, связанные с оценкой адекватности.
Некоторые статистические испытания
требуют меньшего количества допущений,
чем другие, но, в общем, эффективность
проверки убывает по мере того, как
исходные ограничения ослабляются.
Оценку
имитационной модели можно производить
тремя способами:
1)
верификацией, используя которую
экспериментатор хочет убедиться, что
модель ведет себя так, как было задумано;
2)
оценкой адекватности — проверкой
соответствия между поведением модели
и поведением реальной системы;
3)
проблемным анализом — формулированием
статистически значимых выводов на
основе данных, полученных путем машинного
моделирования.
5.2. Языки имитационного моделирования
Каждое
исследование включает сбор данных, под
которым обычно понимают получение
каких-то численных характеристик. Но
это только одна сторона сбора данных.
Системного аналитика должны интересовать
входные и выходные данные изучаемой
системы, а также информация о различных
компонентах системы, взаимозависимостях
и соотношениях между ними. Поэтому он
заинтересован в сборе как количественных,
так и качественных данных; он должен
решить, какие из них необходимы, насколько
они соответствуют поставленной задаче
и как собрать всю эту информацию. Учебники
обычно сообщают студенту нужную для
решения задачи информацию без ссылок
на то, как она была собрана и оценена.
Но когда такой студент впервые сталкивается
с реальной задачей и при этом сам должен
определить, какие данные ему нужны и
как их отобрать, то с подобной задачей
он справиться не может.
Создавая
стохастическую имитационную модель,
всегда приходится решать, следует ли в
модели использовать имеющиеся эмпирические
данные непосредственно или целесообразно
использовать теоретико-вероятностные
или частотные распределения. Этот выбор
имеет фундаментальное значение по трем
причинам. Во-первых, использование
необработанных эмпирических данных
означает, что, как бы вы ни старались,
вы можете имитировать только прошлое.
Использование данных за один год
отобразит работу системы за этот год и
не обязательно скажет нам что-либо об
ожидаемых особенностях работы системы
в будущем. При этом возможными будут
считаться только те события, которые
уже происходили. Одно дело предполагать,
что данное распределение в своей основной
форме будет неизменным во времени, и
совсем иное дело считать, что характерные
особенности данного года будут всегда
повторяться. Во-вторых, в общем случае
применение теоретических частотных
или вероятностных распределений с
учетом требований к машинному времени
и памяти более эффективно, чем использование
табличных данных для получения случайных
вариационных рядов, необходимых в работе
с моделью. В-третьих, крайне желательно
и даже, пожалуй, обязательно, чтобы
аналитик-разработчик модели определил
ее чувствительность к изменению вида
используемых вероятностных распределений
и значений параметров. Иными словами,
крайне важны испытания модели на
чувствительность конечных результатов
к изменению исходных данных. Таким
образом, решения относительно пригодности
данных для использования, их достоверности,
формы представления, степени соответствия
теоретическим распределениям и прошлым
результатам функционирования системы
— все это в сильной степени влияет на
успех эксперимента по имитационному
моделированию и не является плодом
чисто теоретических умозаключений.
В
конечном счете, перед разработчиком
модели возникает проблема ее описания
на языке, приемлемом для используемой
ЭВМ. Быстрый переход к машинному
моделированию привел к развитию большого
числа специализированных языков
программирования, предназначенных для
этой цели. На практике, однако, каждый
из большинства предложенных языков
ориентирован только на ограниченный
набор машин. Имитационные модели обычно
имеют очень сложную логическую структуру,
характеризующуюся множеством взаимосвязей
между элементами системы, причем многие
из этих взаимосвязей претерпевают в
ходе выполнения программы динамические
изменения. Эта ситуация побудила
исследователей разработать языки
программирования для облегчения проблемы
трансляции. Поэтому языки имитационного
моделирования типа GPSS,
Симскрипт, Симула, Динамо и им подобные
являются языками более высокого уровня,
чем универсальные языки типа Фортран,
Алгол и Бэйсик. Требуемая модель может
быть описана с помощью любого универсального
языка, тем не менее какой-либо из
специальных языков имитационного
моделирования может обладать теми или
иными преимуществами при определенных
характеристиках модели. Основные отличия
языков имитационного моделирования
друг от друга определяются:
1)
способом организации учета времени
происходящих действий;
2)
правилами присвоения имен структурным
элементам;
3)
способом проверки условий, при которые
реализуются действия;
4)
видом статистических испытаний, которые
возможны при наличии данных;
5)
степенью трудности изменения структуры
модели.
Хотя некоторые из
специальных языков имитационного
моделирования обладают очень нужными
и полезными свойствами, выбор того пли
иного языка, как это ни печально, чаще
всего определяется типом имеющейся
машины и теми языками, которые известны
исследователю. И если существует выбор,
то правильность его, по-видимому, зависит
от того, в какой степени исследователь
владеет методами имитационного
моделирования. В некоторых случаях
простой язык, который легко понять и
изучить, может оказаться более ценным,
чем любой из более «богатых» языков,
пользоваться которым труднее вследствие
присущих ему особенностей.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
-
Исследование и проверка модели
Средства
вычислительной техники, которые в
настоящее время широко используются
либо для вычислений при аналитическом
моделировании, либо для реализации
имитационной модели системы, могут лишь
помочь с точки зрения эффективности
реализации сложной модели, но не позволяют
подтвердить правильность той или иной
модели. Проверку на синтаксические
ошибки программа проходит в процессе
компиляции или трансляции. Логические
же ошибки и ошибки формирования самой
математической модели выявляют на
следующем этапе — этапе проверки модели
с использованием готовой (откомпилированной)
моделирующей программы и набора тестовых
данных, полученных на реальной установке.
Проверка
достоверности программы выполняется
в следующей последовательности [161,163]:
а) проверка отдельных частей программы
при решении различных тестовых задач;
б) объединение всех частей программы и
проверка ее в целом;
в) оценка средств моделирования
(затраченных ресурсов).
Для
программы в целом и её отдельных частей
выполняют проверку:
• полноты учета основных факторов и
ограничений, влияющих на работу системы;
• соответствия исходных данных модели
реальным;
• наличия в модели всех данных,
необходимых для накопления ответных
величин;
• правильности преобразования исходных
данных в конечные результаты (например,
при условиях, приводящих к известному
аналитическому решению);
• осмысленности результатов при
нормальных условиях (поступательный
ход модельного времени, отсутствие
переполнения буферов и счетчиков) и в
предельных случаях (пробные прогоны в
условиях перегрузки системы).
Для
программы в целом выполняют проверку
адекватности, устойчивости, чувствительности
и точности модели.
Проверку
адекватности (соответствия)
математической модели исследуемому
процессу необходимо проводить по той
причине, что любая модель является лишь
приближенным отражением реального
процесса вследствие допущений, всегда
принимаемых при составлении математической
модели. На этом этапе устанавливается,
насколько принятые допущения правомерны,
и тем самым определяется, применима ли
полученная модель для исследования
процесса.
Для
проверки адекватности модели осуществляется
воспроизведение, или имитация, объекта
на ЭВМ с помощью программы в соответствии
с задачами исследования. После этого
определяется степень близости машинных
результатов и поведения исследуемого
объекта. При этом существенно не
«абсолютное качество» машинных
результатов, а степень сходства с
объектом исследования. Так, при
моделировании автоколебаний важно не
то, чтобы результаты моделирования в
точности совпадали с реально наблюдаемыми
колебаниями, а чтобы они имели аналогичную
форму и аналогичный характер протекания.
Модель должна обладать только существенными
признаками объекта моделирования.
Если
в ходе моделирования существенное место
занимает реальный физический эксперимент,
то здесь весьма важна и надежность
используемых инструментальных средств,
поскольку сбои и отказы программно-технических
средств могут приводить к искаженным
значениям выходных данных, отображающих
протекание процесса. И в этом смысле
при проведении физических экспериментов
необходимы специальная аппаратура,
специально разработанное математическое
и информационное обеспечение, которые
позволяют реализовать диагностику
средств моделирования, чтобы отсеять
те ошибки в выходной информации, которые
вызваны неисправностями функционирующей
аппаратуры. В ходе машинного эксперимента
могут иметь место и ошибочные действия
самого исследователя. В этих условиях
серьезные задачи стоят в области
эргономического обеспечения процесса
моделирования.
Успешный
результат сравнения (оценки) исследуемого
объекта с моделью свидетельствует о
достаточной степени изученности объекта,
о правильности принципов, положенных
в основу моделирования, и о том, что
алгоритм, моделирующий объект, не
содержит ошибок, т. е. о том, что созданная
модель работоспособна. Такая модель
может быть использована для дальнейших
более глубоких исследований объекта в
различных новых условиях, в которых
реальный объект еще не изучался.
Чаще,
однако, первые результаты моделирования
не удовлетворяют предъявленным
требованиям. Это означает, что, по крайней
мере, в одной из перечисленных выше
позиций (изученность объекта, исходные
принципы, алгоритм) имеются дефекты.
Это требует проведения дополнительных
исследований, корректировки математической
модели. Для этого используются результаты
измерений на самом объекте или на его
физической модели, воспроизводящей в
небольших масштабах основные физические
закономерности объекта моделирования.
После соответствующего изменения
машинной программы снова повторяются
третий и четвертый этапы. Процедура
повторяется до получения надежных
результатов.
При
решении всех задач проектирования с
использованием математического
моделирования важным вопросом также
является получение необходимой точности.
Недостаточная точность моделируемых
данных может привести к ложным выводам
или выбору неправильного варианта
технологического процесса (либо
параметра, что менее опасно). В случае
моделирования на ЭВМ инструментальную
точность ограничивают два существенных
фактора: надежность ЭВМ (или, точнее,
вероятность случайного сбоя в процессе
счета) и вычислительная точность,
связанная с ограниченностью представления
чисел в памяти ЭВМ и неизбежными ошибками
округления. При отсутствии двойного
счета ошибки вследствие случайного
сбоя ЭВМ входят непосредственно в
результаты моделирования и вносят
трудно устранимую дополнительную
погрешность, которая может быть
значительной, особенно при малых
вероятностях исследуемых событий.
Случайные сбои при решении ряда задач
могут быть обнаружены визуальным
контролем с помощью графических дисплеев,
сопряженных с ЭВМ, на которой выполняется
моделирование.
Представление
процессов реальных непрерывных систем
при моделировании в виде временного
ряда сопряжено с дополнительной потерей
точности. Поэтому представление состояний
модели и входных сигналов не может быть
выбрано произвольно, а зависит от
требуемой точности результатов,
характеристик этих сигналов и особенностей
моделируемой системы и должно быть
специально рассчитано.
На
точность и устойчивость результатов
моделирования, а также на его вычислительную
эффективность оказывает значительное
влияние, например, выбранный метод
решения системы обыкновенных
дифференциальных уравнений, описывающих
исследуемый процесс [161,163].
Анализ
чувствительности— это расчет
векторов градиентов выходных параметров.
Наиболее просто анализ чувствительности
реализуется путем численного
дифференцирования. Пусть анализ
проводится в некоторой точкеХномпространства аргументов, в которой
предварительно проведен одновариантный
анализ и найдены значения выходных
параметровYj
ном. ВыделяетсяN параметров-аргументовXi,
влияние которых на выходные параметры
подлежит оценить, поочередно каждый из
них получает приращениеΔXi,
выполняется моделирование, фиксируются
значения выходных параметровYjи подсчитываются значения абсолютных:
![]()
и
относительных коэффициентов
чувствительности:
![]() .
.
Такой
метод численного дифференцирования
называют методом
приращений. Для анализа
чувствительности, согласно методу
приращений, требуется выполнитьN+1 раз одновариантный анализ. Результат
его применения — получение матриц
абсолютной и относительной чувствительности,
элементами которых являются коэффициентыAji
иBji[162].
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
From Wikipedia, the free encyclopedia
Verification and validation of computer simulation models is conducted during the development of a simulation model with the ultimate goal of producing an accurate and credible model.[1][2] «Simulation models are increasingly being used to solve problems and to aid in decision-making. The developers and users of these models, the decision makers using information obtained from the results of these models, and the individuals affected by decisions based on such models are all rightly concerned with whether a model and its results are «correct».[3] This concern is addressed through verification and validation of the simulation model.
Simulation models are approximate imitations of real-world systems and they never exactly imitate the real-world system. Due to that, a model should be verified and validated to the degree needed for the model’s intended purpose or application.[3]
The verification and validation of a simulation model starts after functional specifications have been documented and initial model development has been completed.[4] Verification and validation is an iterative process that takes place throughout the development of a model.[1][4]
Verification[edit]
In the context of computer simulation, verification of a model is the process of confirming that it is correctly implemented with respect to the conceptual model (it matches specifications and assumptions deemed acceptable for the given purpose of application).[1][4]
During verification the model is tested to find and fix errors in the implementation of the model.[4]
Various processes and techniques are used to assure the model matches specifications and assumptions with respect to the model concept.
The objective of model verification is to ensure that the implementation of the model is correct.
There are many techniques that can be utilized to verify a model.
These include, but are not limited to, having the model checked by an expert, making logic flow diagrams that include each logically possible action, examining the model output for reasonableness under a variety of settings of the input parameters, and using an interactive debugger.[1]
Many software engineering techniques used for software verification are applicable to simulation model verification.[1]
Validation[edit]
Validation checks the accuracy of the model’s representation of the real system. Model validation is defined to mean «substantiation that a computerized model within its domain of applicability possesses a satisfactory range of accuracy consistent with the intended application of the model».[3] A model should be built for a specific purpose or set of objectives and its validity determined for that purpose.[3]
There are many approaches that can be used to validate a computer model. The approaches range from subjective reviews to objective statistical tests. One approach that is commonly used is to have the model builders determine validity of the model through a series of tests.[3]
Naylor and Finger [1967] formulated a three-step approach to model validation that has been widely followed:[1]
Step 1. Build a model that has high face validity.
Step 2. Validate model assumptions.
Step 3. Compare the model input-output transformations to corresponding input-output transformations for the real system.[5]
Face validity[edit]
A model that has face validity appears to be a reasonable imitation of a real-world system to people who are knowledgeable of the real world system.[4] Face validity is tested by having users and people knowledgeable with the system examine model output for reasonableness and in the process identify deficiencies.[1] An added advantage of having the users involved in validation is that the model’s credibility to the users and the user’s confidence in the model increases.[1][4] Sensitivity to model inputs can also be used to judge face validity.[1] For example, if a simulation of a fast food restaurant drive through was run twice with customer arrival rates of 20 per hour and 40 per hour then model outputs such as average wait time or maximum number of customers waiting would be expected to increase with the arrival rate.
Validation of model assumptions[edit]
Assumptions made about a model generally fall into two categories: structural assumptions about how system works and data assumptions. Also we can consider the simplification assumptions that are those that we use to simplify the reality.[6]
Structural assumptions[edit]
Assumptions made about how the system operates and how it is physically arranged are structural assumptions. For example, the number of servers in a fast food drive through lane and if there is more than one how are they utilized? Do the servers work in parallel where a customer completes a transaction by visiting a single server or does one server take orders and handle payment while the other prepares and serves the order. Many structural problems in the model come from poor or incorrect assumptions.[4] If possible the workings of the actual system should be closely observed to understand how it operates.[4] The systems structure and operation should also be verified with users of the actual system.[1]
Data assumptions[edit]
There must be a sufficient amount of appropriate data available to build a conceptual model and validate a model. Lack of appropriate data is often the reason attempts to validate a model fail.[3] Data should be verified to come from a reliable source. A typical error is assuming an inappropriate statistical distribution for the data.[1] The assumed statistical model should be tested using goodness of fit tests and other techniques.[1][3] Examples of goodness of fit tests are the Kolmogorov–Smirnov test and the chi-square test. Any outliers in the data should be checked.[3]
Simplification assumptions[edit]
Are those assumptions that we know that are not true, but are needed to simplify the problem we want to solve.[6] The use of this assumptions must be restricted to assure that the model is correct enough to serve as an answer for the problem we want to solve.
Validating input-output transformations[edit]
The model is viewed as an input-output transformation for these tests. The validation test consists of comparing outputs from the system under consideration to model outputs for the same set of input conditions. Data recorded while observing the system must be available in order to perform this test.[3] The model output that is of primary interest should be used as the measure of performance.[1] For example, if system under consideration is a fast food drive through where input to model is customer arrival time and the output measure of performance is average customer time in line, then the actual arrival time and time spent in line for customers at the drive through would be recorded. The model would be run with the actual arrival times and the model average time in line would be compared with the actual average time spent in line using one or more tests.
Hypothesis testing[edit]
Statistical hypothesis testing using the t-test can be used as a basis to accept the model as valid or reject it as invalid.
The hypothesis to be tested is
- H0 the model measure of performance = the system measure of performance
versus
- H1 the model measure of performance ≠ the system measure of performance.
The test is conducted for a given sample size and level of significance or α. To perform the test a number n statistically independent runs of the model are conducted and an average or expected value, E(Y), for the variable of interest is produced. Then the test statistic, t0 is computed for the given α, n, E(Y) and the observed value for the system μ0
- and the critical value for α and n-1 the degrees of freedom
- is calculated.
If
reject H0, the model needs adjustment.
There are two types of error that can occur using hypothesis testing, rejecting a valid model called type I error or «model builders risk» and accepting an invalid model called Type II error, β, or «model user’s risk».[3] The level of significance or α is equal the probability of type I error.[3] If α is small then rejecting the null hypothesis is a strong conclusion.[1] For example, if α = 0.05 and the null hypothesis is rejected there is only a 0.05 probability of rejecting a model that is valid. Decreasing the probability of a type II error is very important.[1][3] The probability of correctly detecting an invalid model is 1 — β. The probability of a type II error is dependent of the sample size and the actual difference between the sample value and the observed value. Increasing the sample size decreases the risk of a type II error.
Model accuracy as a range[edit]
A statistical technique where the amount of model accuracy is specified as a range has recently been developed. The technique uses hypothesis testing to accept a model if the difference between a model’s variable of interest and a system’s variable of interest is within a specified range of accuracy.[7] A requirement is that both the system data and model data be approximately Normally Independent and Identically Distributed (NIID). The t-test statistic is used in this technique. If the mean of the model is μm and the mean of system is μs then the difference between the model and the system is D = μm — μs. The hypothesis to be tested is if D is within the acceptable range of accuracy. Let L = the lower limit for accuracy and U = upper limit for accuracy. Then
- H0 L ≤ D ≤ U
versus
- H1 D < L or D > U
is to be tested.
The operating characteristic (OC) curve is the probability that the null hypothesis is accepted when it is true. The OC curve characterizes the probabilities of both type I and II errors. Risk curves for model builder’s risk and model user’s can be developed from the OC curves. Comparing curves with fixed sample size tradeoffs between model builder’s risk and model user’s risk can be seen easily in the risk curves.[7] If model builder’s risk, model user’s risk, and the upper and lower limits for the range of accuracy are all specified then the sample size needed can be calculated.[7]
Confidence intervals[edit]
Confidence intervals can be used to evaluate if a model is «close enough»[1] to a system for some variable of interest. The difference between the known model value, μ0, and the system value, μ, is checked to see if it is less than a value small enough that the model is valid with respect that variable of interest. The value is denoted by the symbol ε. To perform the test a number, n, statistically independent runs of the model are conducted and a mean or expected value, E(Y) or μ for simulation output variable of interest Y, with a standard deviation S is produced. A confidence level is selected, 100(1-α). An interval, [a,b], is constructed by
- ,
where
is the critical value from the t-distribution for the given level of significance and n-1 degrees of freedom.
- If |a-μ0| > ε and |b-μ0| > ε then the model needs to be calibrated since in both cases the difference is larger than acceptable.
- If |a-μ0| < ε and |b-μ0| < ε then the model is acceptable as in both cases the error is close enough.
- If |a-μ0| < ε and |b-μ0| > ε or vice versa then additional runs of the model are needed to shrink the interval.
Graphical comparisons[edit]
If statistical assumptions cannot be satisfied or there is insufficient data for the system a graphical comparisons of model outputs to system outputs can be used to make a subjective decisions, however other objective tests are preferable.[3]
ASME Standards[edit]
Documents and standards involving verification and validation of computational modeling and simulation are developed by the American Society of Mechanical Engineers (ASME) Verification and Validation (V&V) Committee. ASME V&V 10 provides guidance in assessing and increasing the credibility of computational solid mechanics models through the processes of verification, validation, and uncertainty quantification.[8] ASME V&V 10.1 provides a detailed example to illustrate the concepts described in ASME V&V 10.[9] ASME V&V 20 provides a detailed methodology for validating computational simulations as applied to fluid dynamics and heat transfer.[10] ASME V&V 40 provides a framework for establishing model credibility requirements for computational modeling, and presents examples specific in the medical device industry. [11]
See also[edit]
- Verification and validation
- Software verification and validation
References[edit]
- ^ a b c d e f g h i j k l m n o p Banks, Jerry; Carson, John S.; Nelson, Barry L.; Nicol, David M. Discrete-Event System Simulation Fifth Edition, Upper Saddle River, Pearson Education, Inc. 2010 ISBN 0136062121
- ^ Schlesinger, S.; et al. (1979). «Terminology for model credibility». Simulation. 32 (3): 103–104. doi:10.1177/003754977903200304.
- ^ a b c d e f g h i j k l m Sargent, Robert G. «VERIFICATION AND VALIDATION OF SIMULATION MODELS». Proceedings of the 2011 Winter Simulation Conference.
- ^ a b c d e f g h Carson, John, «MODEL VERIFICATION AND VALIDATION». Proceedings of the 2002 Winter Simulation Conference.
- ^ NAYLOR, T. H., AND J. M. FINGER [1967], «Verification of Computer Simulation Models», Management Science, Vol. 2, pp. B92– B101., cited in Banks, Jerry; Carson, John S.; Nelson, Barry L.; Nicol, David M. Discrete-Event System Simulation Fifth Edition, Upper Saddle River, Pearson Education, Inc. 2010 p. 396. ISBN 0136062121
- ^ a b 1. Fonseca, P. Simulation hypotheses. In Proceedings of SIMUL 2011; 2011; pp. 114–119. https://www.researchgate.net/publication/262187532_Simulation_hypotheses_A_proposed_taxonomy_for_the_hypotheses_used_in_a_simulation_model
- ^ a b c Sargent, R. G. 2010. «A New Statistical Procedure for Validation of Simulation and Stochastic Models.» Technical Report SYR-EECS-2010-06, Department of Electrical Engineering and Computer Science, Syracuse University, Syracuse, New York.
- ^ “V&V 10 – 2006 Guide for Verification and Validation in Computational Solid Mechanics”. Standards. ASME. Retrieved 2 September 2018.
- ^ “V&V 10.1 – 2012 An Illustration of the Concepts of Verification and Validation in Computational Solid Mechanics”. Standards. ASME. Retrieved 2 September 2018.
- ^ “V&V 20 – 2009 Standard for Verification and Validation in Computational Fluid Dynamics and Heat Transfer”. Standards. ASME. Retrieved 2 September 2018.
- ^ “V&V 40 Industry Day”. Verification and Validation Symposium. ASME. Retrieved 2 September 2018.
From Wikipedia, the free encyclopedia
Verification and validation of computer simulation models is conducted during the development of a simulation model with the ultimate goal of producing an accurate and credible model.[1][2] «Simulation models are increasingly being used to solve problems and to aid in decision-making. The developers and users of these models, the decision makers using information obtained from the results of these models, and the individuals affected by decisions based on such models are all rightly concerned with whether a model and its results are «correct».[3] This concern is addressed through verification and validation of the simulation model.
Simulation models are approximate imitations of real-world systems and they never exactly imitate the real-world system. Due to that, a model should be verified and validated to the degree needed for the model’s intended purpose or application.[3]
The verification and validation of a simulation model starts after functional specifications have been documented and initial model development has been completed.[4] Verification and validation is an iterative process that takes place throughout the development of a model.[1][4]
Verification[edit]
In the context of computer simulation, verification of a model is the process of confirming that it is correctly implemented with respect to the conceptual model (it matches specifications and assumptions deemed acceptable for the given purpose of application).[1][4]
During verification the model is tested to find and fix errors in the implementation of the model.[4]
Various processes and techniques are used to assure the model matches specifications and assumptions with respect to the model concept.
The objective of model verification is to ensure that the implementation of the model is correct.
There are many techniques that can be utilized to verify a model.
These include, but are not limited to, having the model checked by an expert, making logic flow diagrams that include each logically possible action, examining the model output for reasonableness under a variety of settings of the input parameters, and using an interactive debugger.[1]
Many software engineering techniques used for software verification are applicable to simulation model verification.[1]
Validation[edit]
Validation checks the accuracy of the model’s representation of the real system. Model validation is defined to mean «substantiation that a computerized model within its domain of applicability possesses a satisfactory range of accuracy consistent with the intended application of the model».[3] A model should be built for a specific purpose or set of objectives and its validity determined for that purpose.[3]
There are many approaches that can be used to validate a computer model. The approaches range from subjective reviews to objective statistical tests. One approach that is commonly used is to have the model builders determine validity of the model through a series of tests.[3]
Naylor and Finger [1967] formulated a three-step approach to model validation that has been widely followed:[1]
Step 1. Build a model that has high face validity.
Step 2. Validate model assumptions.
Step 3. Compare the model input-output transformations to corresponding input-output transformations for the real system.[5]
Face validity[edit]
A model that has face validity appears to be a reasonable imitation of a real-world system to people who are knowledgeable of the real world system.[4] Face validity is tested by having users and people knowledgeable with the system examine model output for reasonableness and in the process identify deficiencies.[1] An added advantage of having the users involved in validation is that the model’s credibility to the users and the user’s confidence in the model increases.[1][4] Sensitivity to model inputs can also be used to judge face validity.[1] For example, if a simulation of a fast food restaurant drive through was run twice with customer arrival rates of 20 per hour and 40 per hour then model outputs such as average wait time or maximum number of customers waiting would be expected to increase with the arrival rate.
Validation of model assumptions[edit]
Assumptions made about a model generally fall into two categories: structural assumptions about how system works and data assumptions. Also we can consider the simplification assumptions that are those that we use to simplify the reality.[6]
Structural assumptions[edit]
Assumptions made about how the system operates and how it is physically arranged are structural assumptions. For example, the number of servers in a fast food drive through lane and if there is more than one how are they utilized? Do the servers work in parallel where a customer completes a transaction by visiting a single server or does one server take orders and handle payment while the other prepares and serves the order. Many structural problems in the model come from poor or incorrect assumptions.[4] If possible the workings of the actual system should be closely observed to understand how it operates.[4] The systems structure and operation should also be verified with users of the actual system.[1]
Data assumptions[edit]
There must be a sufficient amount of appropriate data available to build a conceptual model and validate a model. Lack of appropriate data is often the reason attempts to validate a model fail.[3] Data should be verified to come from a reliable source. A typical error is assuming an inappropriate statistical distribution for the data.[1] The assumed statistical model should be tested using goodness of fit tests and other techniques.[1][3] Examples of goodness of fit tests are the Kolmogorov–Smirnov test and the chi-square test. Any outliers in the data should be checked.[3]
Simplification assumptions[edit]
Are those assumptions that we know that are not true, but are needed to simplify the problem we want to solve.[6] The use of this assumptions must be restricted to assure that the model is correct enough to serve as an answer for the problem we want to solve.
Validating input-output transformations[edit]
The model is viewed as an input-output transformation for these tests. The validation test consists of comparing outputs from the system under consideration to model outputs for the same set of input conditions. Data recorded while observing the system must be available in order to perform this test.[3] The model output that is of primary interest should be used as the measure of performance.[1] For example, if system under consideration is a fast food drive through where input to model is customer arrival time and the output measure of performance is average customer time in line, then the actual arrival time and time spent in line for customers at the drive through would be recorded. The model would be run with the actual arrival times and the model average time in line would be compared with the actual average time spent in line using one or more tests.
Hypothesis testing[edit]
Statistical hypothesis testing using the t-test can be used as a basis to accept the model as valid or reject it as invalid.
The hypothesis to be tested is
- H0 the model measure of performance = the system measure of performance
versus
- H1 the model measure of performance ≠ the system measure of performance.
The test is conducted for a given sample size and level of significance or α. To perform the test a number n statistically independent runs of the model are conducted and an average or expected value, E(Y), for the variable of interest is produced. Then the test statistic, t0 is computed for the given α, n, E(Y) and the observed value for the system μ0
- and the critical value for α and n-1 the degrees of freedom
- is calculated.
If
reject H0, the model needs adjustment.
There are two types of error that can occur using hypothesis testing, rejecting a valid model called type I error or «model builders risk» and accepting an invalid model called Type II error, β, or «model user’s risk».[3] The level of significance or α is equal the probability of type I error.[3] If α is small then rejecting the null hypothesis is a strong conclusion.[1] For example, if α = 0.05 and the null hypothesis is rejected there is only a 0.05 probability of rejecting a model that is valid. Decreasing the probability of a type II error is very important.[1][3] The probability of correctly detecting an invalid model is 1 — β. The probability of a type II error is dependent of the sample size and the actual difference between the sample value and the observed value. Increasing the sample size decreases the risk of a type II error.
Model accuracy as a range[edit]
A statistical technique where the amount of model accuracy is specified as a range has recently been developed. The technique uses hypothesis testing to accept a model if the difference between a model’s variable of interest and a system’s variable of interest is within a specified range of accuracy.[7] A requirement is that both the system data and model data be approximately Normally Independent and Identically Distributed (NIID). The t-test statistic is used in this technique. If the mean of the model is μm and the mean of system is μs then the difference between the model and the system is D = μm — μs. The hypothesis to be tested is if D is within the acceptable range of accuracy. Let L = the lower limit for accuracy and U = upper limit for accuracy. Then
- H0 L ≤ D ≤ U
versus
- H1 D < L or D > U
is to be tested.
The operating characteristic (OC) curve is the probability that the null hypothesis is accepted when it is true. The OC curve characterizes the probabilities of both type I and II errors. Risk curves for model builder’s risk and model user’s can be developed from the OC curves. Comparing curves with fixed sample size tradeoffs between model builder’s risk and model user’s risk can be seen easily in the risk curves.[7] If model builder’s risk, model user’s risk, and the upper and lower limits for the range of accuracy are all specified then the sample size needed can be calculated.[7]
Confidence intervals[edit]
Confidence intervals can be used to evaluate if a model is «close enough»[1] to a system for some variable of interest. The difference between the known model value, μ0, and the system value, μ, is checked to see if it is less than a value small enough that the model is valid with respect that variable of interest. The value is denoted by the symbol ε. To perform the test a number, n, statistically independent runs of the model are conducted and a mean or expected value, E(Y) or μ for simulation output variable of interest Y, with a standard deviation S is produced. A confidence level is selected, 100(1-α). An interval, [a,b], is constructed by
- ,
where
is the critical value from the t-distribution for the given level of significance and n-1 degrees of freedom.
- If |a-μ0| > ε and |b-μ0| > ε then the model needs to be calibrated since in both cases the difference is larger than acceptable.
- If |a-μ0| < ε and |b-μ0| < ε then the model is acceptable as in both cases the error is close enough.
- If |a-μ0| < ε and |b-μ0| > ε or vice versa then additional runs of the model are needed to shrink the interval.
Graphical comparisons[edit]
If statistical assumptions cannot be satisfied or there is insufficient data for the system a graphical comparisons of model outputs to system outputs can be used to make a subjective decisions, however other objective tests are preferable.[3]
ASME Standards[edit]
Documents and standards involving verification and validation of computational modeling and simulation are developed by the American Society of Mechanical Engineers (ASME) Verification and Validation (V&V) Committee. ASME V&V 10 provides guidance in assessing and increasing the credibility of computational solid mechanics models through the processes of verification, validation, and uncertainty quantification.[8] ASME V&V 10.1 provides a detailed example to illustrate the concepts described in ASME V&V 10.[9] ASME V&V 20 provides a detailed methodology for validating computational simulations as applied to fluid dynamics and heat transfer.[10] ASME V&V 40 provides a framework for establishing model credibility requirements for computational modeling, and presents examples specific in the medical device industry. [11]
See also[edit]
- Verification and validation
- Software verification and validation
References[edit]
- ^ a b c d e f g h i j k l m n o p Banks, Jerry; Carson, John S.; Nelson, Barry L.; Nicol, David M. Discrete-Event System Simulation Fifth Edition, Upper Saddle River, Pearson Education, Inc. 2010 ISBN 0136062121
- ^ Schlesinger, S.; et al. (1979). «Terminology for model credibility». Simulation. 32 (3): 103–104. doi:10.1177/003754977903200304.
- ^ a b c d e f g h i j k l m Sargent, Robert G. «VERIFICATION AND VALIDATION OF SIMULATION MODELS». Proceedings of the 2011 Winter Simulation Conference.
- ^ a b c d e f g h Carson, John, «MODEL VERIFICATION AND VALIDATION». Proceedings of the 2002 Winter Simulation Conference.
- ^ NAYLOR, T. H., AND J. M. FINGER [1967], «Verification of Computer Simulation Models», Management Science, Vol. 2, pp. B92– B101., cited in Banks, Jerry; Carson, John S.; Nelson, Barry L.; Nicol, David M. Discrete-Event System Simulation Fifth Edition, Upper Saddle River, Pearson Education, Inc. 2010 p. 396. ISBN 0136062121
- ^ a b 1. Fonseca, P. Simulation hypotheses. In Proceedings of SIMUL 2011; 2011; pp. 114–119. https://www.researchgate.net/publication/262187532_Simulation_hypotheses_A_proposed_taxonomy_for_the_hypotheses_used_in_a_simulation_model
- ^ a b c Sargent, R. G. 2010. «A New Statistical Procedure for Validation of Simulation and Stochastic Models.» Technical Report SYR-EECS-2010-06, Department of Electrical Engineering and Computer Science, Syracuse University, Syracuse, New York.
- ^ “V&V 10 – 2006 Guide for Verification and Validation in Computational Solid Mechanics”. Standards. ASME. Retrieved 2 September 2018.
- ^ “V&V 10.1 – 2012 An Illustration of the Concepts of Verification and Validation in Computational Solid Mechanics”. Standards. ASME. Retrieved 2 September 2018.
- ^ “V&V 20 – 2009 Standard for Verification and Validation in Computational Fluid Dynamics and Heat Transfer”. Standards. ASME. Retrieved 2 September 2018.
- ^ “V&V 40 Industry Day”. Verification and Validation Symposium. ASME. Retrieved 2 September 2018.
Проверка и проверка компьютерных имитационных моделей — Verification and validation of computer simulation models
Верификация и валидация компьютерных имитационных моделей проводится во время разработки имитационной модели с конечной целью создания точной и достоверной модели. «Имитационные модели все чаще используются для решения проблем и помощи в принятии решений. Разработчики и пользователи этих моделей, лица, принимающие решения, использующие информацию, полученную на основе результатов этих моделей, и лица, на которых влияют решения, основанные на таких моделях, являются все справедливо озабочены тем, являются ли модель и ее результаты «правильными». Эта проблема решается путем проверки и валидации имитационной модели.
Имитационные модели являются приблизительными имитациями реальных систем, и они никогда в точности не имитируют в реальной системе. В связи с этим модель должна быть проверена и подтверждена в степени, необходимой для предполагаемого назначения или применения модели.
Верификация и валидация имитационной модели начинается после того, как функциональные спецификации задокументированы и начальная разработка модели завершена. Верификация и валидация — это итеративный процесс, который происходит на протяжении всей разработки модели.
Содержание
- 1 Ver ification
- 2 Проверка достоверности
- 2.1 Подтверждение достоверности
- 2.2 Проверка допущений модели
- 2.2.1 Структурные допущения
- 2.2.2 Допущения данных
- 2.2.3 Допущения упрощения
- 2.3 Проверка входных данных -выводные преобразования
- 2.3.1 Проверка гипотез
- 2.3.1.1 Точность модели в виде диапазона
- 2.3.2 Доверительные интервалы
- 2.3.3 Графические сравнения
- 2.3.1 Проверка гипотез
- 3 Стандарты ASME
- 4 См. также
- 5 Ссылки
Верификация
В контексте компьютерного моделирования верификация модели — это процесс подтверждения того, что она правильно реализована по отношению к концептуальной модели (это соответствует спецификациям и предположениям, которые считаются приемлемыми для данной цели приложения). Во время верификации модель тестируется для поиска и исправления ошибок в реализации модели. Для обеспечения соответствия модели спецификациям и предположениям в отношении концепции модели используются различные процессы и методы. Цель проверки модели — убедиться, что реализация модели верна.
Есть много методов, которые можно использовать для проверки модели. К ним относятся, помимо прочего, проверка модели экспертом, создание логических блок-схем, включающих каждое логически возможное действие, проверка выходных данных модели на разумность при различных настройках входных параметров и использование интерактивного отладчика. Многие методы разработки программного обеспечения, используемые для верификации программного обеспечения, применимы к верификации имитационной модели.
Валидация
Валидация проверяет точность представления модели реальной системы. Валидация модели определяется как «подтверждение того, что компьютеризированная модель в пределах ее области применимости обладает удовлетворительным диапазоном точности, совместимым с предполагаемым применением модели». Модель должна быть построена для конкретной цели или набора задач, а ее достоверность должна определяться для этой цели.
Существует множество подходов, которые можно использовать для проверки компьютерной модели. Подходы варьируются от субъективных обзоров до объективных статистических тестов. Один из наиболее часто используемых подходов состоит в том, чтобы разработчики моделей определяли достоверность модели с помощью серии тестов.
Нейлор и Фингер [1967] сформулировали трехэтапный подход к валидации модели, который получил широкое распространение:
Шаг 1. Постройте модель с высокой достоверностью.
Шаг 2. Подтвердите допущения модели.
Шаг 3. Сравните преобразования ввода-вывода модели с соответствующими преобразованиями ввода-вывода для реальной системы.
Face validity
Модель, имеющая face validity представляется разумной имитацией системы реального мира для людей, знакомых с системой реального мира. Подтверждение подлинности проверяется тем, что пользователи и люди, знакомые с системой, проверяют выходные данные модели на предмет разумности и в процессе выявляют недостатки. Дополнительным преимуществом вовлечения пользователей в проверку является то, что доверие к модели для пользователей и доверие пользователя к модели возрастают. Чувствительность к входным данным модели также может использоваться для оценки достоверности лица. Например, если моделирование проезда в ресторан быстрого питания было выполнено дважды с темпами прибытия клиентов 20 в час и 40 в час, тогда ожидается, что выходные данные модели, такие как среднее время ожидания или максимальное количество ожидающих клиентов, увеличатся с прибытием. показатель.
Проверка допущений модели
Допущения, сделанные в отношении модели, обычно делятся на две категории: структурные допущения о том, как работает система, и допущения данных. Также мы можем рассмотреть упрощающие предположения, которые мы используем для упрощения реальности.
Структурные предположения
Предположения, сделанные о том, как работает система и как она устроена физически, являются структурными предположениями. Например, количество серверов в фаст-фуде проезжает по переулку, и если их больше одного, как они используются? Работают ли серверы параллельно, когда клиент завершает транзакцию, посещая один сервер, или один сервер принимает заказы и обрабатывает платежи, в то время как другой готовит и обслуживает заказ. Многие структурные проблемы в модели возникают из-за неверных или неверных предположений. Если возможно, необходимо внимательно наблюдать за работой реальной системы, чтобы понять, как она работает. Структура и работа системы также должны быть проверены пользователями реальной системы.
Допущения данных
Должен быть достаточный объем соответствующих данных, доступных для построения концептуальной модели и проверки модели. Отсутствие соответствующих данных часто является причиной неудачных попыток проверки модели. Данные должны быть проверены и получены из надежного источника. Типичная ошибка — это предположение о несоответствующем статистическом распределении данных. Предполагаемая статистическая модель должна быть протестирована с использованием критериев согласия и других методов. Примерами критериев согласия являются тест Колмогорова – Смирнова и критерий хи-квадрат. Следует проверять любые выбросы в данных.
Допущения упрощения
Это те предположения, которые, как мы знаем, не верны, но необходимы для упрощения проблемы, которую мы хотим решить. Использование этих предположений должно быть ограничено, чтобы гарантировать, что модель достаточно верна, чтобы служить ответом на проблему, которую мы хотим решить.
Проверка преобразований ввода-вывода
Модель рассматривается как преобразование ввода-вывода для этих тестов. Проверочный тест состоит из сравнения выходных данных рассматриваемой системы с выходными данными модели для того же набора входных условий. Данные, записанные во время наблюдения за системой, должны быть доступны для выполнения этого теста. Выходные данные модели, представляющие основной интерес, следует использовать в качестве меры производительности. Например, если рассматриваемая система представляет собой поездку в ресторан быстрого питания, где входными данными для модели является время прибытия клиента, а выходным показателем эффективности является среднее время ожидания клиента в очереди, тогда фактическое время прибытия и время, проведенное в очереди для клиентов в проезде. будет записан. Модель будет запускаться с фактическим временем прибытия, и среднее время нахождения в очереди будет сравниваться с фактическим средним временем, проведенным в очереди с использованием одного или нескольких тестов.
Проверка гипотез
Статистическая проверка гипотез с использованием t-критерия может использоваться в качестве основы для признания модели действительной или отклонения ее как недействительной.
Гипотеза, подлежащая проверке:
- H0модельный показатель производительности = системный показатель производительности
по сравнению с
- H1модельным показателем производительности ≠ системный показатель производительности.
Тест проводится для данного размера выборки и уровня значимости или α. Для выполнения теста проводится n статистически независимых прогонов модели и вычисляется среднее или ожидаемое значение E (Y) для интересующей переменной. Затем тестовая статистика t 0 вычисляется для заданных α, n, E (Y) и наблюдаемого значения для системы μ
- t 0 = (E (Y) — u 0) / (S / n) { displaystyle t_ {0} = {(E (Y) -u_ {0})} / {(S / { sqrt {n}})}}и критическое значения для α и n-1 вычисляются степени свободы
- ta / 2, n — 1 { displaystyle t_ {a / 2, n-1}}.
Если
- | t 0 |>ta / 2, n — 1 { displaystyle left vert t_ {0} right vert>t_ {a / 2, n-1}}
отклонить H 65>0, модель нуждается в корректировке.
Существует два типа ошибок, которые могут возникнуть при проверке гипотез: отклонение действительной модели, называемое ошибкой типа I, или «риск создателей модели» и принятие неверной модели называется ошибкой типа II, β или «риск пользователя модели». Уровень значимости или α равен вероятности ошибки типа I. Если α мало, то отклонение нулевой гипотезы является сильным выводом. Например, если α = 0,05 а нулевая гипотеза отклоняется, вероятность отклонения действительной модели составляет всего 0,05. Уменьшение вероятности ошибки типа II очень важно. Вероятность правильного обнаружения недействительной модели составляет 1 — β. Вероятность типа Ошибка II зависит от размера выборки и фактическая разница между значением выборки и наблюдаемым значением. Увеличение размера выборки снижает риск ошибки типа II.
Точность модели как диапазон
Недавно был разработан статистический метод, при котором степень точности модели задается как диапазон. Этот метод использует проверку гипотез для принятия модели, если разница между интересующей переменной модели и интересующей системной переменной находится в пределах указанного диапазона точности. Требование состоит в том, чтобы и системные данные, и данные модели были приблизительно Обычно Независимыми и идентично распределенными (NIID). В этом методе используется статистика t-критерия. Если среднее значение модели — μ, а среднее значение системы — μ, то разница между моделью и системой составляет D = μ — μ. Гипотеза, подлежащая проверке, заключается в том, находится ли D в приемлемом диапазоне точности. Пусть L = нижний предел точности и U = верхний предел точности. Затем необходимо проверить
- H0L ≤ D ≤ U
по сравнению с
- H1D < L or D>U
.
Кривая рабочей характеристики (ОС) — это вероятность того, что нулевая гипотеза будет принята, когда она верна. Кривая OC характеризует вероятность ошибок как I, так и II типа. Кривые риска для риска создателя модели и пользователя модели могут быть построены на основе кривых OC. Сравнение кривых с фиксированным размером выборки между риском разработчика модели и риском пользователя модели можно легко увидеть на кривых риска. Если заданы риски разработчика модели, риск пользователя модели, а также верхний и нижний пределы диапазона точности, то можно рассчитать необходимый размер выборки.
Доверительные интервалы
Доверительные интервалы могут быть используется для оценки того, «достаточно ли близка» модель к системе для некоторой интересующей переменной. Проверяется разница между известным модельным значением μ 0 и системным значением μ, чтобы увидеть, меньше ли оно значения, достаточно малого для того, чтобы модель была действительной в отношении этой интересующей переменной. Значение обозначается символом ε. Для выполнения теста проводится ряд n статистически независимых прогонов модели и создается среднее или ожидаемое значение E (Y) или μ для представляющей интерес выходной переменной Y моделирования со стандартным отклонением S. Выбран уровень достоверности 100 (1-α). Интервал [a, b] строится следующим образом:
- a = E (Y) — ta / 2, n — 1 S / nandb = E (Y) + ta / 2, n — 1 S / n { displaystyle a = E (Y) -t_ {a / 2, n-1} S / { sqrt {n}} qquad и qquad b = E (Y) + t_ {a / 2, n-1} S / { sqrt {n}}},
где
- ta / 2, n — 1 { displaystyle t_ {a / 2, n-1}}
— критическое значение из t-распределения для заданный уровень значимости и n-1 степеней свободы.
- Если | a-μ 0 |>ε и | b-μ 0 |>ε, то модель необходимо откалибровать, поскольку в обоих случаях разница больше допустимой.
- If | a-μ 0| < ε and |b-μ0| < ε then the model is acceptable as in both cases the error is close enough.
- If | a-μ 0| < ε and |b-μ0|>ε или наоборот, тогда необходимы дополнительные прогоны модели для сокращения интервала.
Графические сравнения
Если статистические допущения не могут быть выполнены или данных для системы недостаточно a графическое сравнение выходных данных модели с выходными данными системы может использоваться для принятия субъективных решений, однако другие объективные тесты предпочтительнее.
Стандарты ASME
Документы и стандарты, включающие проверку и валидацию компьютерного моделирования и моделирования разработаны Комитетом по верификации и валидации (VV) Американского общества инженеров-механиков (ASME). ASME VV 10 предоставляет руководство по оценке и повышению достоверности расчетных моделей механики твердого тела посредством процессов верификации, валидации и количественной оценки неопределенности. ASME VV 10.1 предоставляет подробный пример для иллюстрации концепций, описанных в ASME VV 10. ASME VV 20 предоставляет подробную методологию для проверки компьютерного моделирования применительно к гидродинамике и теплопередаче. ASME VV 40 обеспечивает основу для установления требований к достоверности модели для вычислительного моделирования и представляет примеры, характерные для индустрии медицинских устройств.
См. Также
- Проверка и проверка
- Проверка и проверка программного обеспечения
Ссылки
Как мы можем удостовериться, правильно ли работает средство моделирования? Одним из подходов является метод искусственного решения. Этот процесс включает допущение некого решения, получение исходных условий и других вспомогательных условий согласующихся с первоначальным предположением, решение задачи с этими условиями в качестве входных параметров для пакета моделирования и сравнение полученных результатов с предполагаемым решением. Метод прост в использовании и достаточно универсален. Например, исследователи из Национальной лаборатории Сандия использовали его в некоторых собственных программных разработках.
Проверка и подтверждение
Перед использованием инструмента численного моделирования для прогнозирования результатов предварительно неизвестных ситуаций, мы хотим создать критерий проверки его надежности. Мы можем сделать это либо проверкой того, что пакет для моделирования точно воспроизводит имеющиеся аналитические решения, либо тем, что его результаты согласуются с экспериментальными данными. Это приводит нас к двум тесно взаимосвязанным предметам обсуждения проверке (верификации) и подтверждению (валидации). Давайте проясним, что означают два эти термина в контексте численного моделирования.
Для численного моделирования физической проблемы, мы предпринимаем два шага:
- Построение математической модели физической системы. Это то место, где учитываются все факторы, которые оказывают влияние на наблюдаемое поведение и формулируются основные управляющие уравнения. Результатом зачастую является система неявных связей между входными и выходными величинами. Они часто записываются в виде системы дифференциальных уравнений в частных производных с начальными и граничными условиями, которая в совокупности называется как начально-краевая задача (initial boundary value problem — IBVP).
- Решение математической модели для получения выражений для выходных величин в виде явных функций от входных значений параметров. Однако, такая замкнутая форма решения недоступна для большинства задач, представляющих практический интерес. В таком случае, мы применяем численные методы для получения приближенных решений, часто с помощью вычислительной техники для решения больших систем, в общем случае, нелинейных алгебраических уравнений и неравенств.
Существует две ситуации, при которых могут появиться ошибки. Во-первых, они могут возникнуть в самой математической модели. Потенциальные ошибки вносятся при упущении важного фактора или при допущении нефизичного соотношения между переменными. Подтверждение (валидация) состоит в том, чтобы получить уверенность, что такие ошибки не вносятся при построении математической модели. Проверка (верификация), с другой стороны, заключается в том, чтобы удостовериться, что математическая модель решается достаточно точно. В этом случае, мы должны гарантировать, что численный алгоритм является сходящимся и его компьютерная реализация является корректной, так что численное решение будет точным.
Проще говоря, во время подтверждения, мы спрашиваем, корректно ли мы задали математическую модель для описания физической системы, в то время как при проверке, мы исследуем, получим ли мы точное численное решение математической модели.
Сравнение между процессами подтверждения и проверки.
Теперь, давайте углубимся в проблему проверки численного решения начально-краевых задач (IBVP-задач).
Различные подходы к процедуре проверки
Как мы можем удостовериться, обеспечивает ли инструмент моделирования достаточно точное решение IBVP-задачи? Одна из возможностей заключается в том, чтобы выбрать задачу, имеющую точное аналитическое решение и использовать точное решение в качестве критерия правильности. Метод разделения переменных, например, можно использовать для получения решения простой IBVP-задачи. Применимость этого подхода ограничивается тем, что большинство задач, представляющих практический интерес, не имеют точного решения, что и является основанием для использования компьютерного моделирования. Тем не менее, этот подход является полезным при проверке работоспособности алгоритмов и программ.
Другим подходом является сравнение результатов моделирования с экспериментальными данными. Вообще, это является сочетанием подтверждения и проверки в одном шаге, который иногда называется пригодность (квалификация). Возможно, но маловероятно, что экспериментальные данные случайно совпадут с неправильным решением в результате комбинации некорректной математической модели и неверного алгоритма или ошибке в программном коде. За исключением таких редких случаев, хорошее соответствие численного решения и экспериментальных результатов подтверждает справедливость математической модели и точность процедуры решения.
Библиотеки Приложений в среде COMSOL Multiphysics содержат множество проверочных моделей (verification models), которые используют один или оба этих подхода. Они сгруппированы по областям физики.
Данные модели доступны в Библиотеках Приложений среды COMSOL Multiphysics.
Что делать, если нам потребуется проверить наши результаты при отсутствии точных математических решений и экспериментальных данных? Мы можем обратиться к методу искусственного решения.
Реализация метода искусственного решения
Целью решения начально-краевой задачи (IBVP-задачи) является нахождения явного выражения для решения в терминах независимых переменных, как правило, пространства и времени, с учетом заданных параметров задачи, таких как свойства материала, а также граничные, начальные и исходные условия. Общая форма исходных условий подразумевает описание всех сил, действующих на тело, таких как гравитация в задачах строительной механики и аэро- и гидродинамики, силы сопротивления в задачах массопереноса и источников тепла в задачах термодинамики.
В методе искусственного решения (Method of Manufactured Solutions — MMS), мы решаем задачу от противного , т.е. начинаем с предполагаемого явного выражения для решения. Затем, мы подставляем решение в дифференциальные уравнения и получаем согласованный набор исходных, начальных и граничных условий. Обычно, это включает в себя оценку ряда производных. Вскоре мы увидим, как макрос на языке символической алгебры среды COMSOL Multiphysics может помочь в этом процессе. Аналогичным образом, мы вычисляем предполагаемое решение в момент времени t = 0 и на границах для получения начальных и граничных условий.
Далее идет этап проверки. С учетом только что полученных исходных и вспомогательных условий, мы применяем инструмент моделирования для получения численного решения IBVP-задачи и сравниваем его с изначально предполагавшимся решением, с которого мы “стартовали”.
Продемонстрируем эти шаги на простом примере.
Проверка одномерной задачи теплопроводности
Рассмотрим 1D задачу теплопроводности в стержне длиной L
A_crho C_p frac{partial T}{partial t} + frac{partial}{partial x}(-A_ckfrac{partial T}{partial x}) = A_cQ, t in (0,t_f), x in (0,L)
с начальным условием
T(x,0) = f(x)
и температурным режимом, поддерживаемым на обоих концах по закону, задаваемым функциями
T(0,t) = g_1(t), quad T(L,t) = g_2(t).
Константами A_c, rho, C_p и k являются площадь поперечного сечения, плотность материала, теплоемкость и коэффициент теплопроводности, соответственно. Источник тепла задается как Q.
Наша цель заключается в проверке решения этой задачи методом искусственного решения. Во-первых, предположим явный вид решения. В качестве такого решения давайте выберем следующее распределение температуры
u(x,t) = 500 K + frac{x}{L}(frac{x}{L}-1)frac{t}{tau} K,
где tau есть характерное время, которое для данного примера выберем равным одному часу. Введем новую переменную u для предполагаемой температуры, чтобы отличить ее от расчетной температуры T.
Далее, найдем исходное условие согласующееся с предполагаемым решением. Мы можем вручную вычислить частные производные по координате и времени и подставить их в дифференциальное уравнение для получения Q. Кроме того, поскольку среда COMSOL Multiphysics способна выполнять символические преобразования, то мы будем пользоваться этой встроенной опцией вместо вычисления вручную исходного условия.
В случае однородных материала и свойств поперечного сечения, мы можем объявить A_c, rho, C_p и k как параметры. В общем неоднородном случае для этого потребуются переменные величины, как это проделано для зависящих от времени граничных условий. Обратите внимание на использование оператора d(), одного из встроенных операторов дифференцирования в среду COMSOL Multiphysics, как показано на скриншоте ниже.
Макрос на языке символической алгебры среды COMSOL Multiphysics может автоматизировать оценку частных производных.
Мы выполняем эти символические вычисления с той оговоркой, что мы доверяем символической алгебре. Иначе, любые ошибки наблюдаемые позднее проистекали бы из символических вычислений, а не численного решения. Разумеется, мы можем построить график вычисляемого вручную выражения для Q рядом с результатом символических вычислений, показанных выше, для проверки макроса.
Далее, мы вычисляем начальные и граничные условия. Начальное условие – это предполагаемое решение, вычисленное в момент времени t = 0.
f(x) = u(x,0) = 500 K.
Значения температуры на концах стержня есть g_1(t) = g_2(t) = 500 K.
Далее, получим численное решение задачи, используя исходные, а также начальные и граничные условия, которые мы только что вычислили. В этом примере, будем использовать физический интерфейс Теплопередача в твердых телах.
Добавление начальных значений, граничных условий и внешних источников, получаемых исходя из предполагаемого решения.
На завершающем этапе, мы сравним численное решение с предполагаемым решением. Графики ниже показывают температуру по истечении одного дня. Первое решение получено с использованием линейных элементов, в то время как второе решение получается при использовании квадратичных элементов. Для данного типа задач, по умолчанию среда COMSOL Multiphysics выбирает квадратичные элементы.
Решение, вычисленное при использовании искусственного решения с линейными элементами (слева) и квадратичными элементами (справа).
Проверка различных частей кода
Метод MMS предоставляет нам необходимую гибкость для проверки различных частей кода. Ради простоты, в приведенном выше примере, мы умышленно оставили многие части IBVP-задачи непроверенными. На практике, каждый элемент в уравнении должен быть проверен в наиболее общем виде. Например, для проверки того, насколько точно программа обрабатывает области с неоднородным поперечным сечением, мы должны определить пространственно-переменную область до получения исходных условий. То же можно сказать и в отношении других коэффициентов уравнения, например для свойств материала.
Аналогичная проверка должна производиться для всех граничных и начальных условий. Если, к примеру, мы хотим на левом конце стержня задать поток тепла взамен температуры, мы сначала оцениваем поток, соответствующий искусственному решению, т. е. -ncdot(-A_ck nabla u) где n есть единичная внешняя нормаль. Для предполагаемого решения в данном примере, направленный внутрь поток на левом конце становится равным frac{A_ck}{L}frac{t}{tau}*1K.
В среде COMSOL Multiphysics для теплопередачи в твердых телах граничными условиями по умолчанию являются условия тепловой изоляции. Что делать, если мы захотим проверить обработку тепловой изоляции на левом краю? Нам нужно будет придумать такое новое искусственное решение, в котором производная обращается в ноль на левом конце. Например, мы можем использовать
u(x,t) = 500 K + (frac{x}{L})^2frac{t}{tau} K.
Обратите внимание, что во время проверки, мы проверяем только, корректно ли решаются уравнения. Мы не затрагиваем вопроса о том, соответствует ли решение физической ситуации.
Важно помнить, что как только мы выдумываем новое искусственное решение, мы должны пересчитать исходные, начальные и граничные условия в соответствии предполагаемым решением. Разумеется, при использовании средств символических вычислений в среде COMSOL Multiphysics, мы освобождены от утомительных вычислений!
Скорость сходимости
Как было показано на графиках выше, решения, получаемые с помощью линейного и квадратичного элемента сходятся по мере уменьшения размера сетки разбиения. Это качественное поведение сходимости придает нам некоторую уверенность в численном решении. Мы можем продолжить тщательное рассмотрение численного метода, изучая его скорость сходимости, которая предоставит нам количественный критерий проверки численной процедуры.
Например, для стационарной модификаци изадачи, стандартная оценка конечного- элементной погрешности для погрешности измеряемой в норме Соболева
m-порядка, есть
||u-u_h||_m leq C h^{p+1-m}||u||_{p+1},
где u и u_h являются точным и конечно-элементным решениями, h является максимальным размером элемента, p -порядок полиномиальной аппроксимации (функция формы). Для m = 0, это дает оценку погрешности
||e|| = ||u-u_h|| = (int_{Omega}(u-u_h)^2dOmega)^{frac{1}{2}} leq C h^{p+1}||u||_{p+1},
где C – константа независимая от сетки разбиения.
Возвращаясь к методу искусственного решения, это означает, что решение с линейным элементом (p = 1) должно показывать сходимость второго порядка при измельчении сетки. Если мы построим график нормы ошибки по отношению к размеру сетки в логарифмическом масштабе, тангенс угла наклона должен асимптотически приближаться к 2. Если этого не происходит, то мы должны будем проверить код или точность и регулярность входных параметров, таких как материальные и геометрические свойства. Как показано на рисунках ниже, численное решение сходится с теоретически ожидаемой скоростью.
Слева: Использование операторов интегрирования для определения норм. Оператор intop1 определяется для интегрирования по области. Справа: График ошибки в зависимости от размера сетки, построенный в логарифмических осях, показывает второй порядок сходимости в норме L_2 (m = 0) для линейных элементов, что согласуется с теоретической оценкой.
Несмотря на то, что мы всегда должны проверять сходимость, теоретическая скорость сходимости может быть проверена только для тех проблем, для которых, как выше, доступна априорная оценка погрешности. Когда у вас имеются такие задачи, помните, что метод искусственного решения поможет вам удостовериться в том, что ваш код показывает правильное асимптотическое поведение.
Нелинейный задачи и взаимосвязанные междисциплинарные задачи
В случае существенной нелинейности, коэффициенты в уравнении зависят от решения. В задачах теплопроводности, например, коэффициент теплопроводности может зависеть от температуры. В таких случаях коэффициенты должны быть получены из предполагаемого решения.
Взаимосвязанные (мультифизические) задачи имеют несколько управляющих уравнений. Решения предполагаются сразу для всех взаимосвязанных полей, и исходные условия должны быть расчитаны для каждого управляющего уравнения.
Единственность
Обратите внимание, что логика метода искусственного решения сохраняется, только если управляющая система уравнений имеет единственное решение при условиях (исходные, граничные и начальные условия), подразумеваемых предполагаемым решением. Например, в стационарной задаче теплопроводности, доказательство единственности требует положительного значения теплопроводности. В то время, как это довольно просто проверяется в случае изотропной однородной среды, в случае температурной зависимости коэффициента теплопроводности или анизотропии большее внимание должно быть уделено при конструировании решения, чтобы не нарушить такие предположения.
При использовании метода искусственного решения, решение существует по определению. Кроме того, доказательства единственности существуют для гораздо большего класса задач, чем те, для которых у нас имеются точные аналитические решения. Таким образом, метод предоставляет нам большее пространство для маневра, чем поиск точного решения, начиная с исходных, начальных и граничных условий.
Попробуйте Самостоятельно
Встроенная функциональность в виде символических вычислений в среде COMSOL Multiphysics позволяет легко реализовать метод MMS для проверки кода программ, а также для образовательных целей. Несмотря на то, что мы всесторонне тестируем коды наших программ, мы приветствуем любые замечания со стороны наших пользователей. В данном топике был представлен универсальный инструмент, который вы можете использовать для проверки различных физических интерфейсов. Вы также можете проверить свои собственные реализации при использовании моделирования на основе пользовательских уравнений или Построителя интерфейсов для новой физики (Physics Builder) в среде COMSOL Multiphysics. Если у вас есть какие-либо вопросы по данной методике , пожалуйста, не стесняйтесь написать нам!
Информационные ресурсы
- Для всестороннего обсуждения метода искусственного решения, включая его сильные и слабые стороны, посмотрите данный Отчет из Национальной лаборатории Сэндиа (Sandia). В Отчете подробно излагается система “слепых” тестов, в которых один автор заложил ряд ошибок в код программы незаметно от второго автора, который выискивает заложенные “мины” с использованием метода, описанного в этом топике.
- Для расширенной дискуссии по проверке и подтверждению в контексте научных вычислений, ознакомьтесь с
- W. J. Oberkampf and C. J. Roy, Проверка и подтверждение в научных расчетах (Verification and Validation in Scientific Computing), Cambridge University Press, 2010
- Оценка стандартной погрешности в методе конечных элементов имеется в таких книгах, как
- Thomas J. R. Hughes, Метод конечных элементов: Линейный статический и динамический конечно-элементный анализ (The Finite Element Method: Linear Static and Dynamic Finite Element Analysis), Dover Publications, 2000
- B. Daya Reddy, Вводный функциональный анализ: с приложениями к краевым задачам и конечным элементам (Introductory Functional Analysis: With Applications to Boundary Value Problems and Finite Elements), Springer-Verlag, 1997
From Wikipedia, the free encyclopedia
Verification and validation of computer simulation models is conducted during the development of a simulation model with the ultimate goal of producing an accurate and credible model.[1][2] «Simulation models are increasingly being used to solve problems and to aid in decision-making. The developers and users of these models, the decision makers using information obtained from the results of these models, and the individuals affected by decisions based on such models are all rightly concerned with whether a model and its results are «correct».[3] This concern is addressed through verification and validation of the simulation model.
Simulation models are approximate imitations of real-world systems and they never exactly imitate the real-world system. Due to that, a model should be verified and validated to the degree needed for the model’s intended purpose or application.[3]
The verification and validation of a simulation model starts after functional specifications have been documented and initial model development has been completed.[4] Verification and validation is an iterative process that takes place throughout the development of a model.[1][4]
Verification[edit]
In the context of computer simulation, verification of a model is the process of confirming that it is correctly implemented with respect to the conceptual model (it matches specifications and assumptions deemed acceptable for the given purpose of application).[1][4]
During verification the model is tested to find and fix errors in the implementation of the model.[4]
Various processes and techniques are used to assure the model matches specifications and assumptions with respect to the model concept.
The objective of model verification is to ensure that the implementation of the model is correct.
There are many techniques that can be utilized to verify a model.
These include, but are not limited to, having the model checked by an expert, making logic flow diagrams that include each logically possible action, examining the model output for reasonableness under a variety of settings of the input parameters, and using an interactive debugger.[1]
Many software engineering techniques used for software verification are applicable to simulation model verification.[1]
Validation[edit]
Validation checks the accuracy of the model’s representation of the real system. Model validation is defined to mean «substantiation that a computerized model within its domain of applicability possesses a satisfactory range of accuracy consistent with the intended application of the model».[3] A model should be built for a specific purpose or set of objectives and its validity determined for that purpose.[3]
There are many approaches that can be used to validate a computer model. The approaches range from subjective reviews to objective statistical tests. One approach that is commonly used is to have the model builders determine validity of the model through a series of tests.[3]
Naylor and Finger [1967] formulated a three-step approach to model validation that has been widely followed:[1]
Step 1. Build a model that has high face validity.
Step 2. Validate model assumptions.
Step 3. Compare the model input-output transformations to corresponding input-output transformations for the real system.[5]
Face validity[edit]
A model that has face validity appears to be a reasonable imitation of a real-world system to people who are knowledgeable of the real world system.[4] Face validity is tested by having users and people knowledgeable with the system examine model output for reasonableness and in the process identify deficiencies.[1] An added advantage of having the users involved in validation is that the model’s credibility to the users and the user’s confidence in the model increases.[1][4] Sensitivity to model inputs can also be used to judge face validity.[1] For example, if a simulation of a fast food restaurant drive through was run twice with customer arrival rates of 20 per hour and 40 per hour then model outputs such as average wait time or maximum number of customers waiting would be expected to increase with the arrival rate.
Validation of model assumptions[edit]
Assumptions made about a model generally fall into two categories: structural assumptions about how system works and data assumptions. Also we can consider the simplification assumptions that are those that we use to simplify the reality.[6]
Structural assumptions[edit]
Assumptions made about how the system operates and how it is physically arranged are structural assumptions. For example, the number of servers in a fast food drive through lane and if there is more than one how are they utilized? Do the servers work in parallel where a customer completes a transaction by visiting a single server or does one server take orders and handle payment while the other prepares and serves the order. Many structural problems in the model come from poor or incorrect assumptions.[4] If possible the workings of the actual system should be closely observed to understand how it operates.[4] The systems structure and operation should also be verified with users of the actual system.[1]
Data assumptions[edit]
There must be a sufficient amount of appropriate data available to build a conceptual model and validate a model. Lack of appropriate data is often the reason attempts to validate a model fail.[3] Data should be verified to come from a reliable source. A typical error is assuming an inappropriate statistical distribution for the data.[1] The assumed statistical model should be tested using goodness of fit tests and other techniques.[1][3] Examples of goodness of fit tests are the Kolmogorov–Smirnov test and the chi-square test. Any outliers in the data should be checked.[3]
Simplification assumptions[edit]
Are those assumptions that we know that are not true, but are needed to simplify the problem we want to solve.[6] The use of this assumptions must be restricted to assure that the model is correct enough to serve as an answer for the problem we want to solve.
Validating input-output transformations[edit]
The model is viewed as an input-output transformation for these tests. The validation test consists of comparing outputs from the system under consideration to model outputs for the same set of input conditions. Data recorded while observing the system must be available in order to perform this test.[3] The model output that is of primary interest should be used as the measure of performance.[1] For example, if system under consideration is a fast food drive through where input to model is customer arrival time and the output measure of performance is average customer time in line, then the actual arrival time and time spent in line for customers at the drive through would be recorded. The model would be run with the actual arrival times and the model average time in line would be compared with the actual average time spent in line using one or more tests.
Hypothesis testing[edit]
Statistical hypothesis testing using the t-test can be used as a basis to accept the model as valid or reject it as invalid.
The hypothesis to be tested is
- H0 the model measure of performance = the system measure of performance
versus
- H1 the model measure of performance ≠ the system measure of performance.
The test is conducted for a given sample size and level of significance or α. To perform the test a number n statistically independent runs of the model are conducted and an average or expected value, E(Y), for the variable of interest is produced. Then the test statistic, t0 is computed for the given α, n, E(Y) and the observed value for the system μ0
- and the critical value for α and n-1 the degrees of freedom
- is calculated.
If
reject H0, the model needs adjustment.
There are two types of error that can occur using hypothesis testing, rejecting a valid model called type I error or «model builders risk» and accepting an invalid model called Type II error, β, or «model user’s risk».[3] The level of significance or α is equal the probability of type I error.[3] If α is small then rejecting the null hypothesis is a strong conclusion.[1] For example, if α = 0.05 and the null hypothesis is rejected there is only a 0.05 probability of rejecting a model that is valid. Decreasing the probability of a type II error is very important.[1][3] The probability of correctly detecting an invalid model is 1 — β. The probability of a type II error is dependent of the sample size and the actual difference between the sample value and the observed value. Increasing the sample size decreases the risk of a type II error.
Model accuracy as a range[edit]
A statistical technique where the amount of model accuracy is specified as a range has recently been developed. The technique uses hypothesis testing to accept a model if the difference between a model’s variable of interest and a system’s variable of interest is within a specified range of accuracy.[7] A requirement is that both the system data and model data be approximately Normally Independent and Identically Distributed (NIID). The t-test statistic is used in this technique. If the mean of the model is μm and the mean of system is μs then the difference between the model and the system is D = μm — μs. The hypothesis to be tested is if D is within the acceptable range of accuracy. Let L = the lower limit for accuracy and U = upper limit for accuracy. Then
- H0 L ≤ D ≤ U
versus
- H1 D < L or D > U
is to be tested.
The operating characteristic (OC) curve is the probability that the null hypothesis is accepted when it is true. The OC curve characterizes the probabilities of both type I and II errors. Risk curves for model builder’s risk and model user’s can be developed from the OC curves. Comparing curves with fixed sample size tradeoffs between model builder’s risk and model user’s risk can be seen easily in the risk curves.[7] If model builder’s risk, model user’s risk, and the upper and lower limits for the range of accuracy are all specified then the sample size needed can be calculated.[7]
Confidence intervals[edit]
Confidence intervals can be used to evaluate if a model is «close enough»[1] to a system for some variable of interest. The difference between the known model value, μ0, and the system value, μ, is checked to see if it is less than a value small enough that the model is valid with respect that variable of interest. The value is denoted by the symbol ε. To perform the test a number, n, statistically independent runs of the model are conducted and a mean or expected value, E(Y) or μ for simulation output variable of interest Y, with a standard deviation S is produced. A confidence level is selected, 100(1-α). An interval, [a,b], is constructed by
- ,
where
is the critical value from the t-distribution for the given level of significance and n-1 degrees of freedom.
- If |a-μ0| > ε and |b-μ0| > ε then the model needs to be calibrated since in both cases the difference is larger than acceptable.
- If |a-μ0| < ε and |b-μ0| < ε then the model is acceptable as in both cases the error is close enough.
- If |a-μ0| < ε and |b-μ0| > ε or vice versa then additional runs of the model are needed to shrink the interval.
Graphical comparisons[edit]
If statistical assumptions cannot be satisfied or there is insufficient data for the system a graphical comparisons of model outputs to system outputs can be used to make a subjective decisions, however other objective tests are preferable.[3]
ASME Standards[edit]
Documents and standards involving verification and validation of computational modeling and simulation are developed by the American Society of Mechanical Engineers (ASME) Verification and Validation (V&V) Committee. ASME V&V 10 provides guidance in assessing and increasing the credibility of computational solid mechanics models through the processes of verification, validation, and uncertainty quantification.[8] ASME V&V 10.1 provides a detailed example to illustrate the concepts described in ASME V&V 10.[9] ASME V&V 20 provides a detailed methodology for validating computational simulations as applied to fluid dynamics and heat transfer.[10] ASME V&V 40 provides a framework for establishing model credibility requirements for computational modeling, and presents examples specific in the medical device industry. [11]
See also[edit]
- Verification and validation
- Software verification and validation
References[edit]
- ^ a b c d e f g h i j k l m n o p Banks, Jerry; Carson, John S.; Nelson, Barry L.; Nicol, David M. Discrete-Event System Simulation Fifth Edition, Upper Saddle River, Pearson Education, Inc. 2010 ISBN 0136062121
- ^ Schlesinger, S.; et al. (1979). «Terminology for model credibility». Simulation. 32 (3): 103–104. doi:10.1177/003754977903200304.
- ^ a b c d e f g h i j k l m Sargent, Robert G. «VERIFICATION AND VALIDATION OF SIMULATION MODELS». Proceedings of the 2011 Winter Simulation Conference.
- ^ a b c d e f g h Carson, John, «MODEL VERIFICATION AND VALIDATION». Proceedings of the 2002 Winter Simulation Conference.
- ^ NAYLOR, T. H., AND J. M. FINGER [1967], «Verification of Computer Simulation Models», Management Science, Vol. 2, pp. B92– B101., cited in Banks, Jerry; Carson, John S.; Nelson, Barry L.; Nicol, David M. Discrete-Event System Simulation Fifth Edition, Upper Saddle River, Pearson Education, Inc. 2010 p. 396. ISBN 0136062121
- ^ a b 1. Fonseca, P. Simulation hypotheses. In Proceedings of SIMUL 2011; 2011; pp. 114–119. https://www.researchgate.net/publication/262187532_Simulation_hypotheses_A_proposed_taxonomy_for_the_hypotheses_used_in_a_simulation_model
- ^ a b c Sargent, R. G. 2010. «A New Statistical Procedure for Validation of Simulation and Stochastic Models.» Technical Report SYR-EECS-2010-06, Department of Electrical Engineering and Computer Science, Syracuse University, Syracuse, New York.
- ^ “V&V 10 – 2006 Guide for Verification and Validation in Computational Solid Mechanics”. Standards. ASME. Retrieved 2 September 2018.
- ^ “V&V 10.1 – 2012 An Illustration of the Concepts of Verification and Validation in Computational Solid Mechanics”. Standards. ASME. Retrieved 2 September 2018.
- ^ “V&V 20 – 2009 Standard for Verification and Validation in Computational Fluid Dynamics and Heat Transfer”. Standards. ASME. Retrieved 2 September 2018.
- ^ “V&V 40 Industry Day”. Verification and Validation Symposium. ASME. Retrieved 2 September 2018.
Оценка адекватности модели. Исследование модели
Оценка качества имитационной модели
Оценка качества модели является завершающим этапом ее разработки и преследует две
цели:
1) проверить соответствие модели ее предназначению (целям исследования);
2 ) оценить достоверность и статистические характеристики результатов, получаемых при
проведении модельных экспериментов.
При аналитическом
основными факторами:
моделировании достоверность результатов определяется двумя
1 ) корректным выбором математического аппарата, используемого для описания
исследуемой системы;
2) методической ошибкой, присущей данному математическому методу.
При имитационном
дополнительных факторов, основными из которых являются:
моделировании на достоверность результатов влияет целый ряд
• моделирование случайных факторов, основанное на использовании датчиков СЧ,
которые могут вносить «искажения» в поведение модели;
• наличие нестационарного режима работы модели;
• использование нескольких разнотипных математических методов в рамках одной
модели;
• зависимость результатов моделирования от плана эксперимента;
• необходимость синхронизации работы отдельных компонентов модели;
• наличие модели рабочей нагрузки, качество которой зависит, в свою очередь, от тех же
факторов.
Пригодность имитационной модели для решения задач исследования характеризуется
тем, в какой степени она обладает так называемыми целевыми свойствами. Основными из
них являются:
• адекватность;
• устойчивость; • чувствительность.
Оценка адекватности модели. В общем случае под адекватностью понимают степень
соответствия модели тому реальному явлению или объекту, для описания которого она
строится. Адекватность модели определяется степенью ее соответствия не столько
реальному объекту, сколько целям исследования.
Один из способов обоснования адекватности разработанной модели использование
методов математической статистики. Суть этих методов заключается в проверке
выдвинутой гипотезы (в данном случае об адекватности модели) на основе некоторых
статистических критериев.
Процедура оценки основана на сравнении измерений на реальной системе и результатов
экспериментов на модели и может проводиться различными способами. Наиболее
распространенные из них:
• по средним значениям откликов модели и системы;
• по дисперсиям отклонений откликов модели от среднего
значения откликов системы;
• по максимальному значению относительных отклонений откликов модели от откликов
системы.
Оценка устойчивости модели. Устойчивость модели это ее способность сохранять
адекватность при исследовании эффективности системы на всем возможном диапазоне
рабочей нагрузки, а также при внесении изменений в конфигурацию системы. Разработчик
вынужден прибегать к методам «для данного случая», частичным тестам и здравому
смыслу. Часто бывает полезна апостериорная проверка. Она состоит в сравнении
результатов моделирования и результатов измерений на системе после внесения в нее
изменений. Если результаты моделирования приемлемы, уверенность в устойчивости
модели возрастает.
Чем ближе структура модели структуре системы и чем выше степень детализации, тем
устойчивее модель. Устойчивость результатов моделирования может быть также оценена
методами математической статистики [2].
Оценка чувствительности модели. Достаточно часто возникает задача оценивания
чувствительности модели к изменению параметров рабочей нагрузки и внутренних
параметров самой системы. Такую оценку проводят по каждому параметру
что обычно диапазон возможных изменений параметра известен. Одна из наиболее
простых и распространенных процедур оценивания состоит в следующем.
в отдельности. Основана она на том,
1) вычисляется величина относительного среднего приращения параметра
:
2) проводится пара модельных экспериментов при значениях
средних фиксированных значениях остальных параметров. Определяются значения
,
и
отклика модели
и
;
3) вычисляются ее относительное приращение наблюдаемой переменной
:
В результате для
характеризующую чувствительность модели по этому параметру.
го параметра модели имеют пару значений
,
Аналогично формируются пары для остальных параметров модели, которые образуют
множество
.
Данные, полученные при оценке чувствительности модели, могут быть использованы, в
частности, при планировании экспериментов: большее внимание должно уделяться тем
параметрам, по которым модель является более чувствительной.
Калибровка модели. Если в результате проведенной оценки качества модели оказалось,
что ее целевые свойства не удовлетворяют разработчика, необходимо выполнить ее
калибровку, т. е. коррекцию с целью приведения в соответствие предъявляемым
требованиям.
Как правило, процесс калибровки носит итеративный характер и состоит из трех
основных этапов [2]:
1) глобальные изменения модели (например, введение новых процессов, изменение типов
событий и т. д.); 2) локальные изменения (в частности, изменение некоторых законов распределения
моделируемыхслучайных
величин);
3) изменение специальных параметров, называемых калибровочными.
Целесообразно объединить оценку целевых свойств имитационной модели и ее калибров
ку в единый процесс.
Процедура калибровки состоит из трех шагов, каждый из которых является итеративным
(рис. 1.11).
Шаг 1. Сравнение выходных распределений.
Цель — оценка адекватности ИМ. Критерии сравнения могут быть различны. В частности,
может использоваться величина разности между средними
значениями откликов модели и
системы. Устранение различий на этом шаге основано на внесении глобальных изменений.
Шаг 2. Балансировка модели.
Основная задача — оценка устойчивости и чувствительности модели. По его результатам,
как правило, производятся локальные изменения (но возможны и глобальные).
Шаг 3. Оптимизация модели.
Цель этого этапа — обеспечение требуемой точности результатов. Здесь возможны три
основных направления работ: дополнительная проверка качества датчиков
случайных
чисел; снижение влияния переходного режима; применение специальных методов
понижения дисперсии.
Оценка адекватности модели является основной задачей машинного
моделирования. [1]
Оценка адекватности модели включает решение двух вопросов: 1 адекватна ли модель
объекту. [2] Для оценки адекватности модели реальному объекту следует сравнить результаты,
полученные на ЭВМ с экспериментальными, еальную машину можно сравнить с
идеализированной. [3]
Для оценки адекватности модели реальному объекту следует сравнить результаты,
полученные на ЭВМ, с экспериментальными. [4]
Второй метод оценки адекватности модели состоит в проверке исходных
предположений, и третий в проверке преобразований информации от входа к выходу.
Последние два метода могут привести к необходимости использовать статистические
выборки для оценки средних значений и дисперсий, дисперсионный анализ,
регрессионный анализ, факторный анализ, спектральный анализ, автокорреляцию, метод
проверки с помощью критерия хиквадрат и непараметрические проверки. Поскольку
каждый из этих статистических методов основан на некоторых допущениях, то при
использовании каждого из них возникают вопросы, связанные с оценкой адекватности.
Некоторые статистические испытания требуют меньшего количества допущений, чем
другие, но в общем эффективность проверки убывает по мере того, как исходные
ограничения ослабляются. [5]
В любом случае оценка адекватности модели реальному объекту оценивается по
близости результатов расчетов экспериментальным данным. Методы оценки адекватности
можно разделить на субъективные и объективные, в последнем случае оценка адвоатнооти
приводится независимо от исследователя. [6]
Линейная регрессия для данных.
ИРКУТ1 и ИРКУТ2.
Важным элементом анализа является оценка адекватности модели. [7]
Таким образом, вопрос оценки адекватности модели имеет две стороны: приобретение
уверенности в том, что модель ведет себя таким же образом, как и реальная система;
установление того, что выводы, полученные из экспериментов с моделью, справедливы и корректны. Оба эти момента в совокупности сводятся к обычной задаче нахождения
равновесия между стоимостью каждого действия, связанного с оценкой адекватности
модели, ценностью получаемой все в больших количествах информации и последствиями
ошибочных заключений. [8]
На заключительном четвертом этапе прогнозирования производится оценка
адекватности модели реальным процессам и достоверности получаемой прогнозной
информации. При этом могут использоваться различные методы. [9]
Кроме / критерия, для оценки адекватности модели необходимо знать величину
множественного коэффициента корреляции. [10]
Решение задачи идентификации необходимо, следовательно, и для оценки адекватности
модели. [11]
Задача моделирования сводится к нахождению регрессии bj, Ц и оценке адекватности
модели в соответствии с определенными правилами. [12]
Ниже будут рассмотрены вопросы построения моделей, связанные с идентификацией
и оценкой адекватности модели при наличии экспериментальных данных. [13]
При статистическом анализе полученных результатов эксперимента обычно проводится
оценка дисперсии воспроизводимости, определяется значимость коэффициентов
регрессии и дается оценка адекватности модели. [14]
Степень детализации математических моделей процессов полимеризации существенно
определяется объемом и качественным составом эмпирической информации,
используемой для идентификации и оценки адекватности модели. [1]
После вычисления коэффициентов регрессии переходят к статистическому анализу
уравнения регрессии, который состоит из трех основных этапов: 1) оценка дисперсии
воспроизводимости ( или оценка ошибки опыта), 2) оценка значимости коэффициентов
уравнения регрессии и 3) оценка адекватности модели. [2]
Уравнения связи представляют собой систему алгебраических линейных и нелинейных
уравнений, которая включает уравнения материальнотепловых балансов процесса,
физикохимические и экспериментально полученные зависимости. Оценка адекватности
модели и объекта производится путем сравнения основных рассчитанных выходных
величин со значением, измеряемым непосредственно на объекте. В случае неадекватности
модели происходит корректировка модели. [3] Для оценки адекватности модели использованы данные дополнительных экспериментов
при сопоставлении по значениям степени конверсии и молекулярной массы. По F
критерию доказана адекватность такой модели. [4]
Таким образом, вопрос оценки адекватности модели имеет две стороны: приобретение
уверенности в том, что модель ведет себя таким же образом, как и реальная система;
установление того, что выводы, полученные из экспериментов с моделью, справедливы и
корректны. Оба эти момента в совокупности сводятся к обычной задаче нахождения
равновесия между стоимостью каждого действия, связанного с оценкой адекватности
модели, ценностью получаемой все в больших количествах информации и последствиями
ошибочных заключений. [5]
Поскольку имитационный эксперимент предлагается начинать с формулировки
проблемы, а не с изучения моделируемого процесса, то основное внимание уделяется
проблеме планирования эксперимента, оценке адекватности модели, методам
статистической обработки результатов эксперимента. [6]
В пособии изложены ключевые понятия и математические модели элементов
измерительного процесса; подробно рассмотрены методы и алгоритмы расчета
характеристик погрешности в статическом и динамическом режима измерения. Большое
внимание уделено многократным измерениям как эффективному способу обеспечения
единства измерений относительно погрешности результата измерения; приводятся
оптимальные алгоритмы обработки многократных измерении постоянных и переменных
величин, а также алгоритмы оценки адекватности моделей этих величин и качества
изделий с использованием алгоритмических шкал нглменований и порядка. [7]
Изложены ключевые понятия и математические модели элементов измерительного
процесса; подробно рассмотрены методы и алгоритмы расчета характеристик
погрешности в статическом и динамическом режимах измерения. Большое внимание
уделено многократным измерениям, как эффективному способу обеспечения единства
измерений относительно погрешности результата измерения; приводятся оптимальные
алгоритмы обработки многократных измерений постоянных и переменных величин, а
также алгоритмыоценки адекватности моделей этих величин и качества изделий с
использованием алгоритмических шкал наименований и порядка. [8]
Коррекция математической модели процесса ректификации проводится на основе
экспериментальных данных о моделируемом процессе. В качестве таких данных чаще
всего используются значения концентраций компонентов разделяемой смеси по высоте
колонного аппарата в паровой и жидкой фазах, значения температур на ступенях
разделения, а также составы продуктов разделения. При этом под оценкой адекватности модели объекта моделирования понимается сравнение расчетных и экспериментальных
данных, по результатам которого и проводится коррекция математических моделей
Следует отметить, что получение достаточно полного объема экспериментальных данных
во многих случаях представляется сложной задачей и может служить источником
ошибок, если не принять соответствующих мер по проверке их корректности. [9]
Коррекция математической модели процесса ректификации проводится на основе
экспериментальных данных о моделируемом процессе. В качестве таких данных чаще
всего используются значения концентраций компонентов разделяемой смеси по высоте
колонного аппарата в паровой и жидкой фазах, значения температур на ступенях
разделения, а также составы продуктов разделения. При этом под оценкой адекватности
модели объекта моделирования понимается сравнение расчетных и экспериментальных
данных, по результатам которого и проводится коррекция математических моделей.
Получение достаточно полного объема экспериментальных данных во многих случаях
представляется сложной задачей и может служить источником ошибок, если не принять
соответствующих мер по проверке их корректности. [10]
Свойство плана, задающееся разностью между числом точек спектра плана и числом
оцениваемых параметров, называется насыщенностью плана. План, в котором число точек
спектра плана совпадает с числом оцениваемых параметров, называется насыщенным
планом. Если применять насыщенные планы, то для регрессионного анализа ( оценка
адекватности модели, дисперсии и доверительного интервала коэффициентов
регрессии) необходимо проведение дублирующих опытов. [11]
Зависимость функции интенсивности от
безразмерного времени для систем с
застойной зоной и байпаси.
Так, например, в простейшем: случае, когда математическая модель процесса
разрабатывается при изучении влияния условий разделения на характеристики конечных
продуктов, наибольшие значения весовых коэффициентов принимаются для переменных,
которые представляют в модели эти характеристики. Естественно, что чем больше измеряемых переменных может быть включено в выражение (VII.26), тем точнее оценка
адекватности модели реальному процессу. [12]
Так, например, в простейшем случае, когда математическая модель процесса
разрабатывается при изучении влияния условий разделения на характеристики конечных
продуктов, наибольшие значения весовых коэффициентов принимаются для переменных,
которые представляют в модели эти характеристики. Естественно, что чем больше
измеряемых переменных может быть включено в выражение ( 11 72), тем точнее
производится оценка адекватности модели реальному процессу. [13]
Так, например, в простейшем случае, когда математическая модель процесса
разрабатывается при изучении влияния условий разделения на характеристики конечных
продуктов, наибольшие значения весовых коэффициентов принимаются для переменных,
которые представляют в модели эти характеристики. Естественно, что чем больше
измеряемых переменных может быть включено в выражение ( 11 72), тем точнее
производится оценка адекватности модели реальному процессу. [14]
Так, например, в простейшем случае, когда математическая модель процесса
разрабатывается при изучении влияния условий разделения на характеристики конечных
продуктов, наибольшие значения весовых коэффициентов принимаются для переменных,
которые представляют в модели эти характеристики. Естественно, что чем больше
измеряемых переменных может быть включено в выражение ( 11 43), тем точнее
производится оценка адекватности модели реальному процессу. [1]
Так, например, в простейшем случае, когда математическая модель процесса
разрабатывается при изучении влияния условий разделения на характеристики конечных
продуктов, наибольшие значения весовых коэффициентов принимаются для переменных,
которые представляют в модели эти характеристики. Естественно, что чем больше
измеряемых переменных может быть включено в выражение ( 11 81), тем точнее
производится оценка адекватности модели реальному процессу. [2]
Так, например, в простейшем случае, когда математическая модель процесса
разрабатывается при изучении влияния условий разделения на характеристики конечных
продуктов, наибольшие значения весовых коэффициентов принимаются для переменных,
которые представляют в модели эти характеристики. Естественно, что чем больше
измеряемых переменных может быть включено в выражение ( 11 72), тем точнее
производится оценка адекватности модели реальному процессу. [3]
К третьей группе относятся модели, построенные с учетом упругости, сжимаемости
жидкости, инерционности нескольких масс, зазоров. Они позволяют добиться хорошего совпадения с экспериментом по силовым параметрам переходных процессов, ускорениям,
мощностям, моментам во всем диапазоне нагрузок. Показатели качества, по которым
имеется статистический материал для многих типов поворотных устройств К, ЛГ0, Кк,
ам, Ая [32], служат не только для оценки адекватности модели, но и для выделения
допустимой области изменения ее параметров. [4]
Оценка адекватности модели является основной задачей машинного моделирования.
Исследование системы на неадекватной модели вообще теряет смысл. Оценка
адекватности модели является непременным этапом моделирования. Этап, включающий
такую оценку, сам по себе может представлять большую и сложную задачу. [5]
Полная математическая модель включает в себя связь между основными переменными
технологического процесса в стационарном и нестационарном режимах, технологические,
экономические и прочие ограничения на процесс; для сложных систем в нее часто
включают критерий оптимальной работы. Последний может быть простым, если
экстремум находится изменением одной переменной, и сложным, если он находится из
условий, заданных также и на ряд других величин. Однако любое математическое
описание является лишь приближением к реальному процессу. Поэтому при его
использовании возникает задача оценки адекватности модели и необходимости ее
коррекции. [6]
Любая модель является лишь приближенным отражением реального процесса. В
зависимости от степени изученности конкретного процесса возможно создание модели, с
большей или меньшей степенью точности воспроизводящей поведение моделируемого
объекта. Поскольку при разработке математических моделей приходится так или иначе
использовать приближенные данные о возможных величинах некоторых параметров
уравнений модели, возникает задача оценки адекватности модели и при необходимости
ее коррекции. [7]
Другой метод проверки адекватности основан на контрольных задачах, использующих
данные реальной системы. Он применим в тех случаях, когда мы располагаем реальными
входными и выходными данными, связанными функциональным соответствием.
Бесспорно, такой способ проверки адекватности является самым лучшим, хотя и более
сложным. Сложность и трудоемкость этого способа проверки модели объясняется
необходимостью получения характеристик реальной системы. Оценка адекватности
модели на реальных данных лучше всего убеждает разработчика в плодотворности его
усилий и дает представление о качестве модели. [8]
Оценка созданной модели прежде всего предполагает проверку модели на некоторых
специфических этапах разработки методом сравнения с ее предыдущим состоянием. Логическая блоксхема при этом сравнивается с принципиальной структурой модели.
Программная блоксхема проверяется на адекватность с логической блоксхемой. Далее
проверяется соответствие между программой и программной блоксхемой. После
сопоставления программы с программной блоксхемой весьма полезно для оценки
адекватности моделиприменить метод контрольных задач. Контрольные задачи, или
контрольные варианты, могут быть подготовлены независимо от реализации модели и
затем использованы для проверки модели в целом. Совпадение результатов
моделирования и контрольных вариантов при одинаковых входных данных
свидетельствует об адекватности и корректности модели в отношении задач данного
типа. [9]
Моделирование систем
4.1. Основные понятия моделирования
Модель объект или описание объекта, системы для замещения (при определенных
условиях предложениях, гипотезах) одной системы (т.е. оригинала) другой системы для
изучения оригинала или воспроизведения его каких либо свойств. Модель результат
отображения одной структуры на другую. Отображая физическую систему (объект) на
математическую систему (например, математический аппарат уравнений) получим
физико математическую модель системы или математическую модель физической
системы. В частности, физиологическая система система кровообращения человека,
подчиняется некоторым законам термодинамики и описав эту систему на физическом
(термодинамическом) языке получим физическую, термодинамическую модель
физиологической системы. Если записать эти законы на математическом языке,
например, выписать соответствующие термодинамические уравнения, то получим
математическую модель системы кровообращения. Эту модель можно назвать
физиолого физико математической моделью или физико математической моделью.
Модели, если отвлечься от областей, сфер их применения, бывают трех типов:
познавательные, прагматические и инструментальные.
Познавательная модель форма организации и представления знаний, средство
соединение новых и старых знаний. Познавательная модель, как правило, подгоняется
под реальность и является теоретической моделью.
Прагматическая модель средство организации практических действий, рабочего
представления целей системы для ее управления. Реальность в них подгоняется под
некоторую прагматическую модель. Это, как правило, прикладные модели.
Инструментальная модель является средством построения, исследования и/или использования прагматических и/или познавательных моделей.
Познавательные отражают существующие, а прагматические хоть и не
существующие, но желаемые и, возможно, исполнимые отношения и связи.
По уровню, «глубине» моделирования модели бывают эмпирические на основе
эмпирических фактов, зависимостей, теоретические на основе математических
описаний и смешанные, полуэмпирические использующие эмпирические зависимости
и математические описания.
Математическая модель М описывающая ситему S (x1,x2,…,xn; R), имеет
вид: М=(z1,z2,…,zм; Q), где zяÎZ, i=1,2,…,n, Q, R множества отношений над X
множеством входных, выходных сигналов и состояний системы и Z множеством
описаний, представлений элементов и подмножеств X, соответственно.
Основные требования к модели: наглядность построения; обозримость основных его
свойств и отношений; доступность ее для исследования или воспроизведения; простота
исследования, воспроизведения; сохранение информации, содержавшиеся в оригинале (с
точностью рассматриваемых при построении модели гипотез) и получение новой
информации.
Проблема моделирования состоит из трех задач:
построение модели (эта задача менее формализуема и конструктивна, в том
смысле, что нет алгоритма для построения моделей);
исследование модели (эта задача более формализуема, имеются методы
исследования различных классов моделей);
использование модели (конструктивная и конкретизируемая задача).
Модель М называется статической, если среди xя нет временного параметра t.
Статическая модель в каждый момент времени дает лишь «фотографию» сиcтемы, ее
срез.
Модель динамическая, если среди xi есть временной параметр, т.е. она отображает
систему (процессы в системе) во времени.
Модель дискретная, если она описывает поведение системы только в дискретные
моменты времени.
Модель непрерывная, если она описывает поведение системы для всех моментов времени из некоторого промежутка времени.
Модель имитационная, если она предназначена для испытания или изучения,
проигрывания возможных путей развития и поведения объекта путем варьирования
некоторых или всех параметров xя модели М.
Модель детерминированная, если каждому входному набору параметров
соответствует вполне определенный и однозначно определяемый набор выходных
параметров; в противном случае модель недетерминированная, стохастическая
(вероятностная).
Можно говорить о различных режимах использования моделей об имитационном
режиме, о стохастическом режиме и т. д.
Модель включает в себя: объект О, субъект (не обязательный) А, задачу Z,
ресурсы B, среду моделирования С: М=.
Свойства любой модели таковы:
конечность: модель отображает оригинал лишь в конечном числе его отношений
и, кроме того, ресурсы моделирования конечны;
упрощенность: модель отображает только существенные стороны объекта;
приблизительность: действительность отображается моделью грубо или
приблизительно;
адекватность: модель успешно описывает моделируемую систему;
информативность: модель должна содержать достаточную информацию о
системе в рамках гипотез, принятых при построении модели.
Жизненный цикл моделируемой системы:
1. Сбор информации об объекте, выдвижение гипотез, предмодельный анализ;
2. Проектирование структуры и состава моделей (подмоделей);
3. Построение спецификаций модели, разработка и отладка отдельных подмоделей,
сборка модели в целом, идентификация (если это нужно) параметров моделей;
4. Исследование модели выбор метода исследования и разработка алгоритма
(программы) моделирования; 5. Исследование адекватности, устойчивости, чувствительности модели;
6. Оценка средств моделирования (затраченных ресурсов);
7. Интерпретация, анализ результатов моделирования и установление некоторых
причинно следственных связей в исследуемой системе;
8. Генерация отчетов и проектных (народно хозяйственных) решений;
9. Уточнение, модификация модели, если это необходимо, и возврат к исследуемой
системе с новыми знаниями, полученными с помощью моделирования.
Основными операциями над используемыми моделями являются:
1. Линеаризация. Пусть М=М(X,Y,A), где X множество входов, Y выходов, А
состояний системы. Схематически можно это изобразить:
X ® В ® Y
Если X, Y, линейные пространства (множества), а j, y линейные операторы, то система
(модель) называется линейной. Другие системы (модели) нелинейные. Нелинейные
системы трудно поддаются исследованию, поэтому их часто линеаризуют сводят к
линейным какимто образом.
2. Идентификация. Пусть М=М(X,Y,A), A={aя }, я=(i1,ai2,…,aik) вектор состояния
объекта (системы). Если вектор ai зависит от некоторых неизвестных параметров,
то задача идентификации (модели, параметров модели) состоит в определении по
некоторым дополнительным условиям, например, экспериментальным данным,
характеризующим состояние системы в некоторых случаях. Идентификация
решение задачи построения по результатам наблюдений математических моделей,
описывающих адекватно поведение реальной системы.
3. Агрегирование. Операция состоит в преобразовании (сведении) модели к модели
(моделям) меньшей размерности (X, Y, A).
4. Декомпозиция. Операция состоит в разделении системы (модели) на подсистемы
(подмодели) с сохранением структур и принадлежности одних элементов и
подсистем другим.
5. Сборка. Операция состоит в преобразовании системы, модели, реализующей
поставленную цель из заданных или определяемых подмоделей (структурно
связанных и устойчивых). 6. Макетирование. Эта операция состоит в апробации, исследовании структурной
связности, сложности, устойчивости с помощью макетов или подмоделей
упрощенного вида, у которых функциональная часть упрощена (хотя вход и выход
подмоделей сохранены).
7. Экспертиза, экспертное оценивание. Операция или процедура использования
опыта, знаний, интуиции, интеллекта экспертов для исследования или
моделирования плохо структурируемых, плохо формализуемых подсистем
исследуемой системы.
8. Вычислительный эксперимент. Это эксперимент, осуществляемый с помощью
модели на ЭВМ с целью распределения, прогноза тех или иных состояний
системы, реакции на те или иные входные сигналы. Прибором эксперимента здесь
является компьютер (и модель!).
Модели и моделирование применяются по следующим основным и важным
направлениям.
1. Обучение (как моделям, моделированию, так и самих моделей).
2. Познание и разработка теории исследуемых систем с помощью каких то
моделей, моделирования, результатов моделирования.
3. Прогнозирование (выходных данных, ситуаций, состояний системы).
4. Управление (системой в целом, отдельными подсиситемами системы, выработка
управленческих решений и стратегий).
5. Автоматизация (системы или отдельных подсистем системы).
В базовой четверке информатики: «модель алгоритм компьютер технология» при
компьютерном моделировании главную роль играют уже алгоритм (программа),
компьютер и технология (точнее, инструментальные системы для компьютера,
компьютерные технологии).
Например, при имитационном моделировании (при отсутствии строгого и формально
записанного алгоритма) главную роль играют технология и средства моделирования;
аналогично и в когнитивной графике.
Основные функции компьютера при моделировании систем:
выполнять роль вспомогательного средства для решения задач, решаемых
обычными вычислительными средствами, алгоритмами, технологиями; выполнять роль средства постановки и решения новых задач, не решаемых
традиционными средствами, алгоритмами, технологиями;
выполнять роль средства конструирования компьютерных обучающе
моделирующих сред;
выполнять роль средства моделирования для получения новых знаний;
выполнять роль «обучения» новых моделей (самообучающиеся модели).
Компьютерное моделирование основа представления знаний в ЭВМ (построения
различных баз знаний). Компьютерное моделирование для рождения новой информации
использует любую информацию, которую можно актуализировать с помощью ЭВМ.
Разновидностью компьютерного моделирования является вычислительный
эксперимент.
Компьютерное моделирование, вычислительный эксперимент становится новым
инструментом, методом научного познания, новой технологией также изза
возрастающей необходимости перехода от исследования линейных математических
моделей систем .
Компьютерное моделирование, от постановки задачи до получения результатов,
проходит следующие этапы.
1. Постановка задачи.
a. Формулировка задачи.
b. Определение цели моделирования и их приоритетов.
c. Сбор информации о системе, объекте моделирования.
d. Описание данных (их структуры, диапазона, источника и т. д.).
2. Предмодельный анализ.
a. Анализ существующих аналогов и подсистем.
b. Анализ технических средств моделирования (ЭВМ, периферия).
c. Анализ программного обеспечения(языки программирования, пакеты
программ, инструментальные среды).
d. Анализ математического обеспечения(модели, методы, алгоритмы). 3. Анализ задачи (модели).
a. Разработка структур данных.
b. Разработка входных и выходных спецификаций, форм представления
данных.
c. Проектирование структуры и состава модели (подмоделей).
4. Исследование модели.
a. Выбор методов исследования подмоделей.
b. Выбор, адаптация или разработка алгоритмов, их псевдокодов.
c. Сборка модели в целом из подмоделей.
d. Идентификация модели, если в этом есть необходимость.
e. Формулировка используемых критериев адекватности, устойчивости и
чувствительности модели.
5. Программирование (проектирование программы).
a. Выбор метода тестирования и тестов (контрольных примеров).
b. Кодирование на языке программирования(написание команд).
c. Комментирование программы.
6. Тестирование и отладка.
a. Синтаксическая отладка.
b. Семантическая отладка (отладка логической структуры).
c. Тестовые расчеты, анализ результатов тестирования.
d. Оптимизация программы.
7. Оценка моделирования.
a. Оценка средств моделирования.
b. Оценка адекватности моделирования.
c. Оценка чувствительности модели. d. Оценка устойчивости модели.
8. Документирование.
a. Описание задачи, целей.
b. Описание модели, метода, алгоритма.
c. Описание среды реализации.
d. Описание возможностей и ограничений.
e. Описание входных и выходных форматов, спецификаций.
f. Описание тестирования.
g. Описание инструкций пользователю.
9. Сопровождение.
a. Анализ использования, периодичности использования, количества
пользователей, типа использования (диалог, автономно и др.), анализ
отказов во время использования модели.
b. Обслуживание модели, алгоритма, программы и их эксплуатация.
c. Расширение возможностей: включение новых функций или изменение
режимов моделирования, в том числе и под модифицированную среду.
d. Нахождение, исправление скрытых ошибок в программе, если таковые
найдутся.
10.Использование модели.
Лабораторная работа №6
4.2. Модели и моделирование систем
Математическое и компьютерное моделирование.
Данный период характерен необходимостью моделирования различных социально
экономических процессов и систем и принятия решений на основе результатов
моделирования, ибо такие системы и процессы достаточно сложны, многогранны, динамичны, подвержены случайным воздействиям. Достаточно интенсивно
моделируются сейчас такие социальноэкономические процессы, как демографические
(например, эволюция и цикличность), социальные (например, поведение социальных
групп, социальных последствий тех или иных решений), экономические (например,
рыночные отношения, налоговые сборы, риски), гуманитарные (например, воздействие
на человека информационного потока) и др. Приведём пример математического
моделирования некоторой системы (полный жизненный цикл моделирования).Решение
поставленной задачи разобьем на этапы, в соответствии с этапами жизненного цикла
моделирования, объединяя для удобства некоторые этапы для удобства и краткости
изложения.
Этап 1. Содержательная постановка задачи
Современное производство характеризуется тем, что некоторая часть производимой
продукции (в стоимостном выражении) возвращается в виде инвестиций (т.е. части
конечной продукции, используемой для создания основных фондов производства) в
производство. При этом время возврата, ввода в оборот новых фондов может быть
различной для различного рода производства. Необходимо промоделировать данную эту
ситуацию и выявить динамику изменения величины основных фондов производства
(капитала).
Сложность и многообразие, слабая структурированность и плохая формализуемость
основных экономических механизмов, определяющих работу предприятий не позволяют
преобразовать процедуры принятия решений в экономической системе в полностью
эффективные математические модели и алгоритмы прогнозирования. Поэтому часто
эффективно использование простых, но гибких и надёжных процедур принятия
решения.
Рассмотрим одну такую простую модель. Эта модель будет полезна для прогноза
событий и связанных с ними социальноэкономических процессов.
Этап 2. Формулировка гипотез, построение, исследование модели
Структура производства и сбыта часто зависит от изменений в окружающей среде
(социальноэкономических условий).
Динамика изменения величины капитала определяется, в основном, в нашей модели,
простыми процессами производства и описывается так называемыми обобщенными
коэффициентами амортизации (расхода фондов) и потока инвестиций (часть конечного
продукта, используемого в единицу времени для создания основных фондов). Эти коэффициенты относительные величины (за единицу времени). Необходимо
разработать и исследовать модель динамики основных фондов. Считаем при этом
допустимость определённых гипотез, определяющих рассматриваемую систему
производства.
Пусть x(t) величина основных фондов (капитала) в момент времени t, где 0 £ t £ N.
Через промежуток времени Dt она будет равна x(t+Dt).
Абсолютный прирост равен
Относительный прирост будет равен
Примем следующие гипотезы:
1. социальноэкономические условия производства достаточно хорошие и
способствуют росту производства, а поток инвестиций задается в виде известной
функции y(t);
2. коэффициент амортизации фондов считается неизменным и равным m и при
достаточно малом Dt изменение основных фондов прямо пропорционально
текущей величине капитала, т.е.
Считая Dt ® 0, а также учитывая определение производной, получим из предыдущего
соотношения следующее математическое выражение закона изменения величины
капитала математическую модель (уравнение) динамики капитала (такие уравнения
называются дифференциальными):
где х(0) начальное значение капитала в момент времени t=0.
Эта величина х0 везде в дальнейшем будет считаться заданной. Эта простейшая
модель динамики величины капитала.
Эта простейшая модель не отражает того факта, что социально экономические
ресурсы производства таковы, что между выделением инвестиций и их введением и
использованием в выпуске новой продукции проходит некоторое время лаг. Учитывая это можно записать модель (1) в виде:
Данной непрерывной, дифференциальной, динамической модели можно поставить в
соответствие простую дискретную модель:
где n предельное значение момента времени при моделировании. Эта дискретная
модель получается из непрерывной при Dt=1, а также заменой производной x'(t) на
относительное приращение Dt (замена, как это следует из определения производной,
справедлива при малых Dt).
Этап 3. Построение алгоритма и программы моделирования
Рассмотрим для простоты режим моделирования когда m, c, y известны и
постоянны, а также рассмотрим наиболее простой алгоритм моделирования в
укрупнённых шагах.
1. Ввод входных данных для моделирования:
с=х(0) начальный капитал;
n конечное время моделирования;
m коэффициент амортизации;
s единица измерения времени;
y инвестиции.
2. Вычисление xi от i=1 до i=n по рекуррентной формуле (2).
3. Поиск стационарного состояния такого момента времени j, 0<=j<=n, начиная с
которого все хj, хj+1,…,хn постоянны или изменяются на малую допустимую
величину e>0.
4. Выдача результатов моделирования и, по желанию пользователя, графика.
Приведём программу на Паскале для имитационного моделирования (компактность
программы «принесена в жертву» структурированности).
PROGRAM MODFOND; {Исходные данные находятся в файле in.dat текущего
каталога} {Результаты записываются в файл out.dat текущего каталога} Uses Crt,
Graph, Textwin; Type Vector = Array[0..2000] of Real; Mas = Array[0..2000] of LongInt; Var Time,Lag,t,dv,mv,i,yi,p : Integer; tmax,tmin : LongInt;
a,b,m,X0,maxx,minx,aa,bb,cc,sx,tk : Real; x : Vector; ax,ay
: Mas; ch : Char; f1,f2 : Text;
{} Procedure InputKeyboard;
{ Ввод с клавиатуры } Begin OpenWindow(10,5,70,20,’ Ввод данных ‘,14,4); ClrScr;
WriteLn; WriteLn(‘Введите время Т прогнозирования системы:’); Repeat Writeln(‘Для
удобства построения графика введите Т не меньше 2’); Write(‘Т =’); ReadLn(Time);
until Time>=2; WriteLn(‘Введите лаг:’); Repeat Write(‘Лаг должен быть строго меньше
Т ‘); ReadLn(Lag); until Lagmaxx then begin maxx:=x[t]; tmax:=t; end else if x[t]
Этап 4. Проведение вычислительных экспериментов
Эксперимент 1. Поток инвестиций постоянный и в каждый момент времени равен
111. В начальный момент капитал 1000 руб. Коэффициент амортизации 0.0025.
Построить модель динамики (посуточно) и найти величину основных фондов через 50
суток, если лаг равен 10 суток.
Эксперимент 2. Основные фонды в момент времени t=0 была равны 50000. Через
какое время общая их сумма превысит 1200000 руб., если поток инвестиций постоянный
и равен 200, а m=0.02, T=5?
Этап 5. Модификация (развитие) модели
Для модели динамики фондов с переменным законом потока инвестиций:
а) построить гипотезы, модель и алгоритм моделирования;
б) сформулировать планы вычислительных, компьютерных экспериментов по модели;
в) реализовать алгоритм и планы экспериментов на ЭВМ.
Компьютерное моделирование и вычислительные эксперименты
Рассмотрим следующую модель течения эпидемии. Пусть существует группа
из n контактирующих индивидуумов, в которой в момент
времени t имеется x восприимчивых индивидуумов, y источников инфекции и z
удаленных (изолированных или выздоровевших и ставших невосприимчивыми к
инфекции) индивидуумов. Таким образом, имеем: x+y+z=n.
Определим исходные параметры системы: b — частота контактов между членами
группы; g — частота случаев удаления; m — скорость пополнения восприимчивых
индивидуумов извне (она же и есть скорость гибели индивидуумов, удаленных из
популяции); y* — критическое значение, при котором начинается эпидемия. После какой — либо одной вспышки эпидемии, в результате которой плотность
восприимчивых индивидуумов упадет ниже критического значения y*, наступает период
относительного затишья, длящийся до тех пор, пока снова не будет достигнуто
критическое значение y* и не возникнет новая вспышка. За время Dt группа
восприимчивых индивидуумов, с одной стороны, уменьшается на b xy Dt за счет
заражения части из них, а с другой — увеличивается на n Dt.
При t=0 заданы x(0)=x0, y(0)=y0, z(0)=z0 число восприимчивых, инфекционных и
удаленных индивидуумов соответственно.
Рассматривается промежуток времени t (0 £ t £ T). При малых Dt=1 (например,
минута) получим соотношения (дискретную модель):
Приведём результаты проведённых вычислительных экспериментов. Первые два случая демонстрируют периодичность эпидемии. В последнем примере
имеет место случай стационарного состояния, т.е. после некоторого момента
времени t количества индивидуумов в группах x, y, z остаются постоянными.
Программу компьютерного моделирования и вычислительные эксперименты реализовали студентки математического факультета КБГУ Буздова Асият и Мильман
Евгения.
Компьютерное моделирование.
Рассмотрим проблему расчета влажности почвы с учетом накапливаемой биомассы и
прогнозирования урожайности сельхозкультур по заданной (экологически
обоснованной) влагообеспеченности корнеобитаемого слоя почвы. Разработать
соответствующую компьютерную моделирующую среду, которая позволяет решать
задачи прогноза влажности корнеобитаемого слоя почвы и урожайности (биомассы)
сельхозкультур на заданный момент времени с развитыми интерфейсными средствами,
рассчитанными на неподготовленного пользователяагронома, эколога и др. Опишем
одну такую программную среду, реализованную реально в среде Delphi 2.0 Windows 95
автором и студентами КБГУ Кирьязевой С.К. и Кирьязевым Д.А. для расчета
влажности почвы и определения урожайности сельхозкультур. Общение с пользователем
осуществляется с помощью диалогового окна “Расчет влажности и урожайности”,
содержащего 5 страниц: “Эксперимент”, “С/х культура”, “Регион”, “Рабочая” и
“Результат”.
Страница “С/х культура” для ввода входной информации по культуре.
Страница “Регион” для ввода информации по региону эксперимента. Страница “Эксперимент” выглядит следующим образом.
Данная страница предназначена для ввода названия эксперимента, выбора названия
культуры из списка имеющихся (которые были введены на странице “С/х культура”),
региона проведения эксперимента из списка регионов, введенных на странице “Регион”,
ввода даты посева культуры и даты снятия урожая, для ввода данных по величинам,
зависящим от вида культуры, типа почв (по фазам вегетации). Предусмотрена возможность выбора: вычислять ли значения коэффициентов e и l или же рассматривать
их как постоянные величины? После заполнения страницы “Эксперимент”, можно
произвести расчет влажности почвы и прогноз урожайности культуры. Для этого
достаточно лишь нажать кнопку “Произвести расчет” на странице “Эксперимент”.
После этого автоматически раскрывается страница “Результат” с таблицей
рассчитанных величин и выводится график зависимости влажности почвы от времени (1
синим цветом), накопления биомассы растений от времени при вычисленной влажности
(2 зеленым цветом) и оптимального развития растений по экспериментальным данным
за прошлый год (3 красным цветом).
Страница “Рабочая” для визуального анализа расчётных величин. Были проведены вычислительные эксперименты для двух сельхозкультур кукурузы
и ярового ячменя с использованием общедоступных данных (это также можно отнести к
достоинствам системы). Данные по температуре воздуха, величине осадков, уровню
грунтовых вод и относительной влажности воздуха представлены с интервалом в 1015
суток за весь период вегетационного цикла растения. Программа отображает результаты
расчета в таблице и на графике. График оптимального развития рассматриваемой
культуры имеет “ступенчатый” характер ввиду того, что экспериментально полученные
значения за прошлый год вводятся по фазам вегетации, а для межфазных периодов
программно рассчитываются по соответствующим математическим моделям.
Результаты экспериментов приведены ниже.
Эксперимент 1
С/х культура: Кукуруза «Луч300»;
Fmax = 20 Дж/(м2сут.); s = 0,6; m = 108; а = 0,8;
Время проведения посева с 01.04. по 20.04.
Тип почвы: Черноземные почвы. Пороговая величина уровня грунтовых вод: Нр = 24;
Влажность устойчивого завядания: Wmin = 180 мм.
где Р величина осадков (мм); Н уровень грунтовых вод (м3/га);
А относительная влажность воздуха (%); Т температура воздуха;
k коэффициент испаряемости на 1оС.
С/х культура: Кукуруза «Луч300». Тип почвы: Черноземные почвы. Дата посева:
02.04.97. Дата снятия: 10.07.97. e = 0,0370; l = 0,0002. Результаты расчетов в виде
графиков, таблица расчётов не выводится.
Экспертная система.
Спроектируем одну гипотетическую базу знаний и экспертную систему. Структура
базы знаний и экспертной системы изображена ниже. Экспертная система может рассуждать (имитировать рассуждения) и настраиваться
на предметную область.
Рассматривается база знаний и экспертная система “Социально экономико
экологическая система”, которая построена (Казиевым В. М. и студентом КБГУ
Тебуевым М. Д.) с использованием аппарата нечётких множеств и логики и позволяет
оценивать (качественно) социально экономико экологическое состояние некоторой
среды по задаваемым пользователям (экспертом) количественным оценкам тех или иных
параметров среды (выбираемых из базы знаний системы). Для каждого входного
фактора в диалоговом режиме задаются относительные (от 0 до 1) оценки влияния этого
фактора (вес фактора). После анализа этих данных (этой экологической обстановки)
система принимает на основе базы знаний решение о состоянии социально
экологической среды, используя удельную количественную оценку (от 0 до 1) и
десятибалльную качественную систему оценок. Функции и работу системы
характеризует нижеприведённый сценарий и протокол диалога с этой системой.
Экспертная система
(23.02.1998 Понедельник, 11: 23: 37)
Входные данные:
1. Контроль над эрозией: 0.6
2. Сооружения для отдыха: 0.1
3. Ирригация: 0.9
4. Сжигание отходов: 1.0
5. Строительство мостов и дорог: 0.6 6. Искусственные каналы: 0.5
7. Плотины: 0.3
8. Туннели и подземные сооружения: 0.9
9. Взрывные и буровые работы: 0.45667
10.Открытая разработка: 0.567
11.Вырубка лесов: 0.345
12.Охота и рыболовство: 0.234
13.Растениеводство: 0.678
14.Скотоводство: 0.648
15.Химическая промышленность: 0.2456
16.Лесопосадки: 0.54846
17.Удобрения: 0.6
18.Регулирование диких животных: IGNORE (игнорирование фактора)
19.Автомобильное движение: 0.6
20.Трубопроводы: 0.0
21.Хранилища отходов: 0.0
22.Использование ядохимикатов: 0.2
23.Течи и разливы: 0.0
Принятие решения о социальноэкономикоэкологической обстановке:
1. Состояние почвы: 0.55177 (слабое положительное)
2. Состояние поверхностных вод: 0.52969 (слабое положительное)
3. Качественный состав вод: 0.62299 (некоторое положительное)
4. Качественный состав воздуха: 0.61298 (некоторое положительное)
5. Температура воздуха: 0.48449 (слабое отрицательное)
6. Эрозия: 0.59051 (слабое положительное) 7. Деревья и кустарники: 0.54160 (слабое положительное)
8. Травы: 0.59051 (слабое положительное)
9. Сельхозкультуры: 0.51698 (слабое положительное)
10.Микрофлора: 0.48702 (слабое отрицательное)
11.Животные суши: 0.59804 (слабое положительное)
12.Рыбы и моллюски: 0.51525 (слабое положительное)
13.Насекомые: 0.56000 (слабое положительное)
14.Заболачивание территории: 0.50000 (слабое положительное)
15.Курорты на суше: 0.52729 (слабое положительное)
16.Парки и заповедники: 0.54668 (слабое положительное)
17.Здоровье и безопасность: 0.62870 (некоторое положительное)
18.Занятость людей: 0.51196 (слабое положительное)
19.Плотность населения: 0.55539 (слабое положительное)
20.Соленость воды: 0.48750 (слабое отрицательное)
21.Солончаки: 0.57000 (слабое положительное)
22.Заросли: 0.62935 (некоторое положительное)
23.Оползни: 0.70588 (выраженное положительное)
Пакеты прикладных программ (ППП).
ППП комплекс программ, имеющих следующие особенности (отличающие его от
«большого программного комплекса»):
наличие управляющей всеми программами ППП программы (монитора);
наличие языка запросов (оформления и расшифровки заданий для ППП);
ориентация ППП на достаточно широкий класс однотипных задач;
расширяемость, модифицируем ость функций (программ) ППП;
наличие средств для работы с базами данных, операционными системами. Пример интегрированного ППП простой и универсальный пакет статистического
анализа данных SPSS. Интерфейс пользователя с SPSS для Windows реализуется с
помощью простых меню и диалоговых окон т.е. как и предыдущая разработка, SPSS
свободна от использования специально изучаемого командного языка пакета. Имеется
редактор Data Editor для визуального контроля вводимых данных, функционально
аналогичный, например, Excel. По столбцам отображаются варьируемые переменные, а
по строкам наборы их вариации, причем с каждой из переменных можно ознакомиться,
вызвав её имя. Ввод данных аналогичен вводу данных, например, в Excel. В диалоговых
окнах можно определять и сложных выражений арифметического или логического типа,
используемых далее в расчётах.
Опишем расчёты с использованием ППП по анализу систем и динамики
задолженности, например, множественный регрессионный анализ; результаты одного
такого анализа с помощью авторского ППП приведены ниже.
Смысл переменных: х(1) коэффициент абсолютной ликвидности; х(2)
коэффициент текущей ликвидности; х(3) дебиторская задолженность; х(4)
кредиторская задолженность; х(5) превышение кредиторской задолженности над
дебиторской; х(6) коэффициент финансовой зависимости; х(7) коэффициент
соотношения привлечённых и собственных средств; х(8) кредиторская задолженность
перед бюджетом; х(9) кредиторская задолженность по социальному страхованию и
внебюджетным платежам; х(10) коэффициент собираемости налоговых
платежей; х(11) коэффициент собираемости налога на добавленную стоимость.
Были проведены различные вычислительные эксперименты, например, если: х(1)
коэффициент абсолютной ликвидности, х(2) текущей ликвидности, х(6) финансовой
зависимости, х(7) коэффициент привлечения собственных средств, а y = х(10)
коэффициент собираемости налогов, то находится зависимость коэффициента
собираемости налогов от коэффициентов абсолютной ликвидности, текущей
ликвидности, финансовой зависимости и привлечения собственных средств, т.е.
зависимость вида
Типы экспериментов определяются экономическими соображениями, например, с
целью выявления факторов, наиболее влияющих на собираемость налогов (на
коэффициент собираемости налогов).
БАКСАНСКИЙ РАЙОН КБР
(205 предприятия(й)) Регрессионная модель вида Y = a(0) + a(1)*x(1) + … + a(7)*x(7)
Таблица 1.
Таблица коэффициентов модели Примечание: «+» коэффициент значим, «»
коэффициент не значим.
Коэффициент множественной корреляции значим и равен: 0.98.
Таблица 2.
Таблица корреляции y и x(i), i=1,2,…,7
Таблица 3.
Таблица адекватности модели Рис. 27. Фрагменты результатов вычислительных экспериментов.
В результате анализа проведенных экспериментов по каждому району, городу
найдена регрессионная зависимость с очень высокой степенью адекватности;
коэффициент множественной корреляции равен 0.99 1.0, а относительная погрешность
в среднем порядка 5 8 процентов (для таких зависимостей такая погрешность
считается очень низкой).
При этом:
использованная программа работает качественно, например, имевшиеся в
исходных данных сильные колебания параметров (колебания от 7814.612 до 0)
моделью «ухвачены» и отражены;
вычисленные доверительные интервалы коэффициентов зависимостей можно
использовать для определения наилучших и наихудших прогнозных значений
функции отклика;
погрешности коэффициентов можно использовать для коррекции влияния тех или
иных параметров в рамках рассматриваемой модели (найденной зависимости), а
полученные зависимости можно использовать для краткосрочного прогноза. Вопросы для самоконтроля
1. Какая модель называется статической (динамической, дискретной, непрерывной,
имитационной, детерминированной)? Приведите пример каждой модели.
2. Перечислите три задачи моделирования и примеры по каждой задаче из различных
областей.
3. Перечислите свойства моделей. Как эти свойства взаимосвязаны? Приведите
примеры, убедительно показывающие необходимость каждого из этих свойств.
4. Перечислите основные этапы жизненного цикла моделирования.
5. Что такое оценка адекватности модели? Оцените адекватность какой либо
модели.
6. Что такое вычислительный или компьютерный эксперимент?
7. Перечислите основные направления применения моделей и приведите примеры по
каждому из них.
8. В чем особенности компьютерного моделирования по сравнению с
математическим моделированием?
9. Перечислите этапы (задачи этапов) компьютерного моделирования.
10.Приведите примеры актуальности использования новых технологий.
11.Приведите различные примеры использования новой информационной технологии
в различных областях знания, в познании.
12.Приведите примеры, показывающие роль новых информационных технологий в
развитии общества, в социальной сфере, в развитии инфраструктуры общества.
Независимо от вида и способа построения экономико-математической
модели вопрос о возможности ее применения в целях анализа и
прогнозирования экономического явления может быть решен только
после установления адекватности, т.е. соответствия модели
исследуемому процессу или объекту. Так как полного соответствия
модели реальному процессу или объекту быть не может, адекватность
— в какой-то мере условное понятие. При моделировании имеется в виду адекватность не вообще, а по тем свойствам модели, которые
считаются существенными для исследования.
, конкретного временного ряда yt, считается адекватной, если
Трендовая модель
правильно отражает систематические компоненты временного ряда. Это требование
(t = 1, 2, …,п)
эквивалентно требованию, чтобы остаточная компонента
удовлетворяла свойствам случайной компоненты временного ряда, указанным в
параграфе 4.1: случайность колебаний уровней остаточной последовательности,
соответствие распределения случайной компоненты нормальному закону распределения,
равенство математического ожидания случайной компоненты нулю, независимость
значений уровней случайной компоненты. Рассмотрим, каким образом осуществляется
проверка этих свойств остаточной последовательности.
Проверка случайности колебаний уровней остаточной последовательности означает
проверку гипотезы о правильности выбора вида тренда. Для исследования случайности
отклонений от тренда мы располагаем набором разностей
Характер этих отклонений изучается с помощью ряда непараметрических критериев.
Одним из таких критериев является критерий серий, основанный на медиане выборки.
Ряд из величин е, располагают в порядке возрастания их значений и находят
медиану εт полученного вариационного ряда, т.е. срединное значение при нечетном п, или
среднюю арифметическую из двух срединных значений, при п четном. Возвращаясь к
исходной последовательности εt и сравнивая значения этой последовательности
с εт, будем ставить знак «плюс», если значение εt превосходит медиану, и знак «минус»,
если оно меньше медианы; в случае равенства сравниваемых величин соответствующее
значение εt опускается. Таким образом, получается последовательность, состоящая из
плюсов и минусов, общее число которых не превосходит п. Последовательность подряд
идущих плюсов или минусов называетсясерией. Для того чтобы последовательность е,
была случайной выборкой, протяженность самой длинной серии не должна быть слишком
большой, а общее число серий слишком малым.
.ν
Обозначим протяженность самой длинной серии через Кmax, а общее число серий через
Выборка признается случайной, если выполняются следующие неравенства для 5%ного
уровня значимости: (5.8)
где квадратные скобки означают целую часть числа.
Если хотя бы одно из этих неравенств нарушается, то гипотеза о случайном характере
отклонений уровней временного ряда от тренда отвергается и, следовательно, трендовая
модель признается неадекватной.
Другим критерием для данной проверки может служить критерий пиков (поворотных
точек). Уровень последовательности εt считается максимумом, если он больше двух
рядом стоящих уровней, т.е. εt1 < εt > εt+1, и минимумом, если он меньше обоих соседних
уровней, т.е. εt1 > εt < εt+1. В обоих случаях εt считается поворотной точкой; общее число
поворотных точек для остаточной последовательности εt обозначим через р. В случайной
выборке математическое ожидание числа точек поворота р и дисперсия σ2
р выражаются
формулами:
Критерием случайности с 5%ным уровнем значимости, т.е. с доверительной
вероятностью 95%, является выполнение неравенства
(5.9)
где квадратные скобки означают целую часть числа. Если это неравенство не
выполняется, трендовая модель считается неадекватной.
Проверка соответствия распределения остаточной последовательности нормальному
закону распределения может быть произведена лишь приближенно с помощью
исследования показателей асимметрии (γ1) и эксцесса (γ2), так как временные ряды,
как правило, не очень велики. При нормальном распределении показатели асимметрии и
эксцесса некоторой генеральной совокупности равны нулю. Мы предполагаем, что
отклонения от тренда представляют собой выборку из генеральной совокупности,
поэтому можно определить только выборочные характеристики асимметрии и эксцесса и
их ошибки: (5.10)
выборочная характеристика асимметрии;
В этих формулах
характеристика эксцесса;
одновременно выполняются следующие неравенства:
выборочная
и
соответствующие среднеквадратические ошибки. Если
то гипотеза о нормальном характере распределения остаточной последовательности
принимается.
Если выполняется хотя бы одно из неравенств
то гипотеза о нормальном характере распределения отвергается, трендовая модель
признается неадекватной. Другие случаи требуют дополнительной проверки с помощью
более сложных критериев.
Кроме рассмотренного метода известен ряд других методов проверки нормальности
закона распределения случайной величины: метод Вестергарда, RSкритерий и т.д.
Рассмотрим наиболее простой из них, основанный на RSкритерии. Этот критерий
численно равен отношению размаха вариации случайной величины R к стандартному
отклонению S.
, а
В нашем случае
. Вычисленное значение критерия сравнивается
с табличными (критическими) нижней и верхней границами данного отношения, и если это
значение не попадает в интервал между критическими границами, то с заданным уровнем
значимости гипотеза о нормальности распределения отвергается; в противном случае эта
гипотеза принимается. Для иллюстрации приведем несколько пар значений критических
границ RSкритерия для уровня значимости а = 0,05: при п = 10 нижняя граница равна
2,67, а верхняя равна 3,685; при п = 20 эти числа составляют соответственно 3,18 и 4,49;
при п = 30 они равны 3,47 и 4,89. Проверка равенства математического ожидания остаточной последовательности
нулю, если она распределена по нормальному закону, осуществляется на основе i
критерия Стыодента. Расчетное значение этого критерия задается формулой
(5.11)
где
среднее арифметическое значение уровней остаточной последовательности εt;
Sε стандартное (среднеквадратическое) отклонение для этой последовательности.
Если расчетное значение t меньше табличного значения tα статистики Стьюдента с
заданным уровнем значимости
нулю математического ожидания остаточной последовательности принимается; в
противном случае эта гипотеза отвергается и модель считается неадекватной.
α
и числом степеней свободы
п 1, то гипотеза о равенстве
Следует отметить, что проверку данного свойства на основе tкритерия имеет смысл
проводить лишь в том случае, когда это свойство не очевидно из самого значения
величины
.
Проверка независимости значений уровней остаточной последовательности, т.е. проверка
отсутствия существенной автокорреляции в остаточной последовательности может
осуществляться по ряду критериев, наиболее распространенным из которых является d
критерий Дарбина Уотсона. Расчетное значение этого критерия определяется по
формуле
(5.12)
Заметим, что расчетное значение критерия Дарбина Уотсона в интервале от 2 до 4
свидетельствует об отрицательной связи; в этом случае его надо преобразовать по
формуле d’ = 4 d и в дальнейшем использовать значение d’.
Расчетное значение критерия d (или d’) сравнивается с верхним d2 и
нижним dt критическими значениями статистики Дарбина Уотсона, фрагмент табличных
значений которых для различного числа уровней ряда п и числа определяемых
параметров модели k представлен для наглядности в табл. 5.2 (уровень значимости 5%).
Таблица 5.2
п k = 1
k = 2
k = 3 d1
d2
d1
d2
d1
d2
15 1,08 1,36 0,95 1,54 0.82 1,75
20 1,20 1,41 1,10 1,54 1.00 1,68
30 1,35 1,49 1,28 1,57 1,21 1,65
Если расчетное значение критерия d больше верхнего табличного значения d2, то гипотеза
о независимости уровней остаточной последовательности, т.е. об отсутствии в ней
автокорреляции, принимается. Если значение d меньше нижнего табличного значения d1,
то эта гипотеза отвергается и модель неадекватна. Если значение d находится между
значениямиd1 и d2, включая сами эти значения, то считается, что нет достаточных
оснований сделать тот или иной вывод и необходимы дальнейшие исследования,
например, по большему числу наблюдений. В этом случае можно использовать
также первый коэффициент автокорреляции:
Если расчетное значение этого коэффициента по модулю меньше табличного
(критического) значения r1кр, то гипотеза об отсутствии автокорреляции принимается; в
противном случае эта гипотеза отвергается. В частности, при п = 10 можно принять r1кр =
0,36.
Вывод об адекватности трендовой модели делается, если все указанные выше четыре
проверки свойств остаточной последовательности дают положительный результат. Для
адекватных моделей имеет смысл ставить задачу оценки их точности. Точность модели
характеризуется величиной отклонения выхода модели от реального значения
моделируемой переменной (экономического показателя). Для показателя,
представленного временным рядом, точность определяется как разность между значением
фактического уровня временного ряда и его оценкой, полученной расчетным путем с
использованием модели, при этом в качестве статистических показателей точности
применяются следующие: среднее квадратическое отклонение
(5.13)
средняя относительная ошибка аппроксимации (5.14)
коэффициент сходимости
(5.15)
коэффициент детерминации
(5.16)
и другие показатели; в приведенных формулах п количество уровней ряда, k число
определяемых параметров модели,
арифметическое значение уровней ряда.
оценка уровней ряда по модели,
среднее
На основании указанных показателей можно сделать выбор из нескольких адекватных
трендовых моделей экономической динамики наиболее точной, хотя может встретиться
случай, когда по некоторому показателю более точна одна модель, а по другому другая.
Данные показатели точности моделей рассчитываются на основе всех уровней временного
ряда и поэтому отражают лишь точность аппроксимации. Для оценки прогнозных свойств
модели целесообразно использовать так называемый ретроспективный прогноз подход,
основанный на выделении участка из ряда последних уровней исходного временного ряда
в количестве, допустим, п2 уровней в качестве проверочного, а саму трендовую модель в
этом случае следует строить по первым точкам, количество которых будет
равно п1 = п п2. Тогда для расчета показателей точности модели по ретроспективному
прогнозу применяются те же формулы, но суммирование в них будет вестись не по всем
наблюдениям, а лишь по последним п2 наблюдениям. Например, формула для среднего
квадратического отклонения будет иметь вид
где
значения уровней ряда по модели, построенной для первых и, уровней.
Оценивание прогнозных свойств модели на ретроспективном участке весьма полезно,
особенно при сопоставлении различных моделей прогнозирования из числа адекватных.
Однако надо помнить, что оценки ретропрогноза лишь приближенная мера точности
прогноза и модели в целом, так как прогноз на период упреждения делается по модели,
построенной по всем уровням ряда. Пример 5.1. Для временного ряда, представленного в первых двух графах табл. 5.3,
построена трендовая модель в виде полинома первой степени (линейная модель):
Требуется оценить адекватность и точность построенной модели.
Решение. Прежде всего, сформируем остаточную последовательность (ряд остатков), для
чего из фактических значений уровней ряда вычтем соответствующие расчетные значения
по модели: остаточная последовательность приведена в графе 4 табл. 5.3.
Проверку случайности уровней ряда остатков проведем на основе критерия пиков
(поворотных точек). Точки пиков отмечены в графе 5 табл. 5.3; их количество равно
шести (р = 6). Правая часть неравенства (5.9) равняется в данном случае двум, т.е. это
неравенство выполняется. Следовательно, можно сделать вывод, что свойство
случайности ряда остатков подтверждается.
Результаты предыдущей проверки дают возможность провести проверку соответствия
остаточной последовательности нормальному закону распределения. Воспользуемся RS
критерием. В нашем случае размах вариации R = εmax εmin = 2,7 (2,1) = 4,8, а среднее
квадратическое отклонение
Таблица 5.3
t Фактическое yt Расчетное
Отклонение
εt
Точки пиков
1 2
1 85
2 81
3 78
4 72
5 69
6 70
3
84,4
81,0
77,6
74,1
70,7
67,3
4
0,6
0,0
0,4
2,1
1,7
2,7
5
1
1
1
0
1
6
7
0,36
8
0,00 0,6 0,36
0,16 0,4
0,16
4,41 2,5 6,25
2,89 0,4
0,16
9
0,71
0,00
0,49
2,69
2,46
7,29 4,4
19,36
3,86 7 64
8 61
9 56
45 636
63,8
60,4
57,0
636,3
0,2
0,6
1,0
0,3
1
1
6
0,04 2,5 6,25
0,36 0,4
0,16
1,00 1,6 2,56
0,31
0,98
1,79
16,51
35,26
13,29
Следовательно, критерий RS = 4,8 : 1,44 = 3,33, и это значение попадает в интервал между
нижней и верхней границами табличных значений данного критерия (эти границы для п =
10 и уровня значимости
сделать вывод, что свойство нормальности распределения выполняется.
= 0,05 составляют соответственно 2,7 и 3,7). Это позволяет
α
Переходя к проверке равенства (близости) нулю математического ожидания ряда
остатков, заметим, что по результатам вычислений в табл. 5.3 это математическое
ожидание равно (0,3) : 9 = 0,03 и, следовательно, можно подтвердить выполнение
данного свойства, не прибегая к статистике Стьюдента.
Для проверки независимости уровней ряда остатков (отсутствия автокорреляции)
вычислим значение критерия Дарбина Уотсона.
Расчеты по формуле (5.12), представленные в графах 6, 7, 8 табл. 5.3, дают следующее
значение этого критерия: d = 35,26 : 15,51 = 2,27. Эта величина превышает 2, что
свидетельствует об отрицательной автокорреляции (при наличии последней), поэтому
критерий Дарбина Уотсона необходимо преобразовать: d’ = А d = А 2,27 = 1,73.
Данное значение сравниваем с двумя критическими табличными значениями критерия,
которые для линейной модели в нашем случае можно принять равными d1 = 1,08
и d2 = 1,36. Так как расчетное значение попадает в интервал от (d2 до 2, то делается вывод
о независимости уровней остаточной последовательности.
Из сказанного выше следует, что остаточная последовательность удовлетворяет всем
свойствам случайной компоненты временного ряда, следовательно, построенная линейная
модель является адекватной.
Для характеристики точности модели воспользуемся показателем средней относительной
ошибки аппроксимации, который рассчитывается по формуле (5.14):
= 13,29 : 9 =
1,48 (%).Полученное значение средней относительной ошибки говорит о достаточно
высоком уровне точности построенной модели (ошибка менее 5% свидетельствует об
удовлетворительном уровне точности; ошибка в 10 и более процентов считается очень
большой). 7.4.1. Этапы имитационного моделирования
Как уже отмечалось, имитационное моделирование применяют для
исследования сложных экономических систем. Естественно, что и имитационные
модели оказываются достаточно сложными как с точки зрения заложенного в них
математического аппарата, так и в плане машинной реализации. При
этом сложность любой модели определяется двумя факторами:
• сложностью исследуемого объектаоригинала;
• точностью, предъявляемой к результатам расчетов.
Использование машинного эксперимента как средства решения сложных прикладных
проблем, несмотря на присущие каждой конкретной задаче специфику, имеетряд общих
черт (этапов). На рис. 7.24 представлены этапы применения математической
(имитационной) модели (по взглядам академика А. А. Самарского).
Каждому из показанных на рис. 7.24 этапов присущи собственные приемы, методы,
технологии. В данном учебнике вопросы построения (разработки) математической
модели, алгоритмизации и программирования (за исключением выбора языка) не
рассматриваются. Отметим лишь, что все эти этапы носят ярко выраженный творческий
характер и требуют от разработчика модели особой подготовки. После того как имитационная модель реализована на ЭВМ, исследователь должен
выполнить последовательность следующих этапов (их часто называют
технологическими):
• испытание модели;
• исследование свойств модели;
• планирование имитационного эксперимента;
• эксплуатация модели (проведение расчетов).
Кратко охарактеризуем первые два этапа (изложение методов математической теории
планирования эксперимента и организации проведения модельных расчетов и обработки
их результатов выходят за рамки настоящего учебника).
Испытание имитационной модели
Испытание имитационной модели включает работы по четырем направлениям:
– задание исходной информации;
– верификацию имитационной модели;
– проверку адекватности модели;
– калибровку имитационной модели.
Задание исходной информации
Процедура задания исходной информации полностью определяется типом
моделируемой системы:
• если моделируется функционирующая (существующая) система, проводят измерение
характеристик ее функционирования и затем используют эти данные в качестве
исходных при моделировании;
• если моделируется проектируемая система, проводят измерения на прототипах;
• если прототипов нет, используют экспертные оценки параметров и переменных
модели, формализующих характеристики реальной системы.
Каждому из этих вариантов присущи собственные особенности и сложности. Так,
проведение измерений на существующих и проектируемых системах требует
применения качественных измерительных средств, а проведение экспертного оценивания исходных данных представляет собой комплекс достаточно сложных
процедурполучения, обработки и интерпретации экспертной информации.
Верификация имитационной модели
Верификация имитационной модели состоит в доказательстве утверждений
соответствия алгоритма ее функционирования цели моделирования путем
формальных и неформальных исследований реализованной программы модели.
Неформальные исследования представляют собой ряд процедур, входящих
в автономную и комплексную отладку.
Формальные методы включают:
– использование специальных процессоров»читателей» программ;
– замену стохастических элементов модели детерминированными;
– тест на так называемую непрерывность моделирования и др.
Проверка адекватности модели
Количественную оценку адекватности модели объекту исследования проводят для
случая, когда можно определить значения отклика системы в ходе натурных
испытаний.
Наиболее распространены три способа проверки:
– по средним значениям откликов модели и системы;
– по дисперсиям отклонений откликов;
– по максимальному значению абсолютных отклонений откликов.
Если возможность измерения отклика реальной системы отсутствует, оценку
адекватности модели проводят на основе субъективного
суждения соответствующегодолжностного лица о возможности использования
результатов, полученных с использованием этой модели при выполнении им служебных
обязанностей (в частности – при обосновании решений).
Калибровка имитационной модели
К калибровке имитационной модели приступают в случае, когда модель оказывается
неадекватной реальной системе. За счет калибровки иногда удается уменьшить неточности описания отдельных подсистем (элементов) реальной системы и тем
самым повысить достоверность получаемых модельных результатов.
В модели при калибровке возможны изменения трех типов:
– глобальные структурные изменения;
– локальные структурные изменения;
– изменение так называемых калибровочных параметров в результате реализации
достаточно сложной итерационной процедуры, включающей многократное построение
регрессионных зависимостей и статистическую оценку значимости улучшения модели на
очередном шаге.
При необходимости проведения некоторых локальных и особенно глобальных
структурных изменений приходится возвращаться к содержательному
описаниюмоделируемой системы и искать дополнительную информацию о ней.
Исследование свойств имитационной модели
После испытаний имитационной модели переходят к изучению ее свойств. При этом
наиболее важны четыре процедуры:
• оценка погрешности имитации;
• определение длительности переходного режима в имитационной модели;
• оценка устойчивости результатов имитации;
• исследование чувствительности имитационной модели.
Оценка погрешности имитации, связанной с использованием в модели
генераторов ПСЧ
Исследование качества генераторов ПСЧ проводится известными методами теории
вероятностей и математической статистики (см. п. 3.3.1). Важнейшим показателем
качества любого генератора ПСЧ является период последовательности ПСЧ (при
требуемых статистических свойствах). В большинстве случаев о качестве генератора ПСЧ
судят по оценкам математических ожиданий и дисперсий отклонений компонент
функции отклика. Как уже отмечалось, для подавляющего числа практических задач
стандартные (встроенные) генераторы дают вполне пригодные последовательности ПСЧ.
Определение длительности переходного режима Обычно имитационные модели применяются для изучения системы в типичных для нее
и повторяющихся условиях. В большинстве стохастических моделей требуется
некоторое время T0 для достижения моделью установившегося состояния.
Под статистическим равновесием или установившимся состоянием модели понимают
такое состояние, в котором противодействующие влияния сбалансированы и
компенсируют друг друга. Иными словами: модель находится в равновесии, если ее
отклик не выходит за предельные значения.
Существуют три способа уменьшения влияния начального периода на динамику
моделирования сложной системы:
– использование длинных прогонов, позволяющих получать результаты после заведомого
выхода модели на установившийся режим;
– исключение из рассмотрения начального периода прогона;
– выбор таких начальных условий, которые ближе всего к типичным.
Каждый из этих способов не свободен от недостатков: «длинные прогоны» приводят
к большим затратам машинного времени; при исключении из рассмотрения начального
периода теряется часть информации; выбор типичных начальных условий,
обеспечивающих быструю сходимость, как правило, затруднен отсутствием
достаточного объема исходных данных (особенно для принципиально новых систем).
Для отделения переходного режима от стационарного у исследователя должна
быть возможность наблюдения за моментом входа контролируемого параметра в
стационарный режим. Часто используют такой метод: строят графики изменения
контролируемого параметра в модельном времени и на нем выявляют переходный режим.
На рис. 7.25 представлен график изменения kго контролируемого параметра
модели gk в зависимости от модельного времени t0.
На рисунке видно, что, начиная со времени tперех, этот параметр «вошел» в установившийся
режим со средним значением g(cid:22) k.
Если построить подобные графики для всех (или большинства
существенных) контролируемых параметров модели, определить для каждого из них
длительность переходного режима и выбрать из них наибольшую, в большинстве случаев
можно считать, что после этого времени все интересующие исследователя
параметрынаходятся в установившемся режиме. На практике встречаются случаи, когда переходные режимы исследуются
специально. Понятно, что при этом используют короткие прогоны, исключают из
рассмотрения установившиеся режимы и стремятся найти начальные условия
моделирования, приводящие к наибольшей длительности переходных процессов. Иногда
для увеличения точности результатов проводят замедление изменения системного
времени.
Оценка устойчивости результатов имитации
Под устойчивостью результатов имитации понимают степень их
нечувствительности к изменению входных условий. Универсальной процедуры оценки
устойчивостинет. Практически часто находят дисперсию отклика модели Y по
нескольким компонентам и проверяют, увеличивается ли она с ростом интервала
моделирования. Еслиувеличения дисперсии отклика не наблюдается, результаты
имитации считают устойчивыми.
Важная практическая рекомендация: чем ближе структура модели к структуре
реальной системы и чем выше степень детализации учитываемых в модели факторов,
тем шире область устойчивости (пригодности) результатов имитации.
Исследование чувствительности модели
Работы на этом этапе имеют два направления: – установление диапазона изменения отклика, модели при варьировании каждого
параметра;
– проверка зависимости отклика модели от изменения параметров внешней среды.
В зависимости от диапазона изменения откликов Y при изменении каждой компоненты
вектора параметров X определяется стратегия планирования экспериментов на модели.
Если при значительной амплитуде изменения некоторой компоненты вектора
параметров модели отклик меняется незначительно, то точность представления ее в
модели не играет существенной роли.
Проверка зависимости отклика модели Y от изменений параметров внешней среды
основана на расчете соответствующих частных производных и их анализе.