Задача
обнаружения
ошибки может быть решена довольно легко.
Достаточно просто передавать каждую
букву сообщения дважды. Например, при
необходимости передачи слова «гора»
можно передать «ггоорраа». При получении
искаженного сообщения, например,
«гготрраа»
с большой вероятностью (практически,
достоверно) можно догадаться, каким
было исходное слово. Конечно, возможно
такое искажение, которое делает
неоднозначным интерпретацию полученного
сообщения. Однако цель такого способа
кодирования состоит не в исправлении
ошибки, а в обнаружении факта искажения
и в повторной передаче подозрительной
на наличие ошибки части сообщения.
Недостаток данного способа обеспечения
надежности состоит в том, что относительная
избыточность сообщения оказывается
очень большой – очевидно,
![]() .
.
Так
как должен быть установлен только факт
наличия ошибки, можно предложить и
другой способ, позволяющий с высокой
вероятностью обнаружить ошибку в
сообщении. Суть этого способа заключается
в следующем. На входе в канал связи
производится подсчет числа единиц в
двоичной кодовой последовательности
– во входном сообщении. Если число
единиц оказывается нечетным, то в хвост
передаваемого сообщения добавляется
«1», а если нет, то «0». Таким образом, к
сообщению добавляют так называемый
контрольный бит
четности,
чтобы суммарное количество единиц
вместе с этим контрольным битом было
четным. На принимающем конце канала
связи производится аналогичный подсчет
числа единиц, и если контрольная сумма
единиц в принятой кодовой последовательности
оказывается нечетной, то делается вывод
о том, что при передаче произошло
искажение информации, в противном случае
принятая информация признается
правильной. Разумеется, этот способ
отнюдь не совершенен и применяется,
когда вероятность ошибки не очень
велика. При контроле на четность
единственный способ получить достоверную
информацию – это повторная передача
сообщения.
Избыточность
сообщения при контроле на четность
равна:
![]() . (14.2)
. (14.2)
На
первый взгляд кажется, что путем
увеличения
![]() можно сколь угодно приближать избыточность
можно сколь угодно приближать избыточность
сообщения к ее минимальному значению![]() ,
,
стремящемуся к единице. Однако с ростом![]() растет вероятность парной ошибки,
растет вероятность парной ошибки,
которая контрольным битом четности не
отслеживается, а также при обнаружении
ошибки потребуется заново передавать
много информации. Поэтому обычно![]() или
или![]() ,
,
следовательно,![]() или
или![]() соответственно.
соответственно.
3. Коды, исправляющие одиночную ошибку
По
аналогии с предыдущим пунктом можно
было бы предложить простой способ
установления факта наличия ошибки –
передавать каждый символ сообщения
трижды, например, «гггооорррааа» –
тогда при получении, например, сообщения
«гггооопррааа»
ясно, что ошибочной является буква «п»
и ее следует заменить на «р». Безусловно,
при этом предполагается, что вероятность
появления парной ошибки невелика. Такой
метод кодирования приводит к огромной
избыточности сообщения
![]() ,
,
что неприемлемо с экономической точки
зрения.
Прежде, чем обсуждать
метод кодирования, позволяющий
локализовать и исправить ошибку передачи,
произведем некоторые количественные
оценки. Как указывалось в предыдущей
лекции, наличие шумов в канале связи
ведет к частичной потере передаваемой
информации на величину возникающей
неопределенности. В случае передачи
одного бита исходного сообщения эта
неопределенность составляет
![]() , (14.3)
, (14.3)
где
p
– вероятность появления ошибки в
сообщении (искажения этого бита, то есть
его инверсии в случае двоичного
кодирования нулями и единицами). Для
восстановления информационного
содержания сообщения следует дополнительно
передать количество информации не менее
величины ее потерь, то есть вместо
передачи каждого 1 бита следует передавать
![]() бит. При этом избыточность сообщения
бит. При этом избыточность сообщения
составит как миимум
![]() . (14.4)
. (14.4)
Эта избыточность
является минимальной; в случае передачи
сообщения по каналу, характеризуемому
определенной вероятностью возникновения
ошибки, при избыточности, меньшей
минимальной, восстановление информации
оказывается невозможным.
Выражение
(14.4) указывает нижнюю границу избыточности,
необходимой для восстановления
информации. Однако поиск конкретного
способа осуществления кодирования, при
котором ошибка может быть локализована
(то есть определено, в каком конкретно
бите она находится) и устранена –
отдельная задача, которую мы теперь и
обсудим. Изложенный ниже метод кодирования
был предложен в 1948 году Р. Хеммингом;
построенные по этому методу коды получили
название «коды
Хемминга».
Основная
идея такого кодирования состоит в
добавлении к информационным битам
нескольких битов четности, каждый из
которых контролирует определенные
информационные биты. Если пронумеровать
все передаваемые биты (вместе с битами
четности) слева направо (напомним, что
информационные биты нумеруются справа
налево – от 0 до 7), то контрольными
(проверочными) оказываются биты, номера
которых равны степени 2, а остальные
биты являются информационными. Например,
для 8-битного информационного кода
«01101101» передаваемый код (код Хемминга)
будет 12-битным, так как к информационному
коду добавятся 4 контрольных бита –
1-й, 2-й, 4-й и 8-й (рис.
7):


|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
0 |
0 |
0 |
1 |
1 |
1 |
0 |
1 |
1 |
1 |
0 |
1 |
|
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |


Рис. 7. Построение
кода Хемминга
Принцип
выделения контролируемых битов такой:
для любого номера n
проверочного (контрольного) бита, начиная
с него, n
битов подряд оказываются проверяемыми
(контролируемыми), затем – группа из n
непроверяемых бит, и так далее –
происходит чередование групп. В число
контролируемых (проверяемых) битов
входит и сам контрольный (проверочный).
Состояние
контрольного (проверочного) бита
устанавливается при кодировании таким
образом, чтобы суммарное
количество единиц во
всех
контролируемых им битах было бы четным.
Таким образом, контрольный (проверочный)
бит может содержать как нуль, так и
единицу.
Номера контролируемых (прверяемых)
битов для каждого контрольного приведены
в табл. 22:
Табл. 22. Контрольные
и контролируемые биты
|
Контрольные |
Контролируемые |
|||||||||||
|
1 |
1 |
3 |
5 |
7 |
9 |
11 |
13 |
15 |
17 |
19 |
21 |
… |
|
2 |
2 |
3 |
6 |
7 |
10 |
11 |
14 |
15 |
18 |
19 |
22 |
… |
|
4 |
4 |
5 |
6 |
7 |
12 |
13 |
14 |
15 |
20 |
21 |
22 |
… |
|
8 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
24 |
25 |
26 |
… |
|
16 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
… |
|
32 |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 |
… |
Контрольный
бит (бит четности) признается неверным,
если сумма единиц в контролируемых им
битах (включая его самого) нечетна.
Если контрольный бит оказался неверным,
значит, в каком-то из контролируемых им
битов имеется ошибка.
Существует
общее свойство
кодов Хемминга: Ошибка
содержится в бите, номер которого
является суммой номеров неверных
контрольных битов, указавших на ее
наличие.
На основании
сказанного можно сформулировать простой
алгоритм проверки и исправления
передаваемой кодовой последовательности
в представлении Хемминга:
-
Произвести проверку
всех битов четности; -
Если все биты
четности верны, то перейти к пункту е); -
Вычислить сумму
номеров всех неверных битов четности; -
Инвертировать
(единицу заменить на нуль или наоборот)
содержимое бита, номер которого равен
сумме, найденной в пункте с); -
Исключить биты
четности.
Избыточность кодов Хемминга для различных
длин передаваемых кодовых последовательностей
приведена в табл. 23:
Табл. 23. Избыточность
кодов Хемминга для передаваемых кодовых
последовательностей различной длины
|
Число |
Число |
Избыточность, L |
|
8 |
4 |
1.50 |
|
16 |
5 |
1.31 |
|
32 |
6 |
1.06 |
Количество
контрольных битов определяется следующим
образом (см. таблицу выше):
![]() . (14.5)
. (14.5)
Из
сопоставления данных этой таблицы
видно, что выгоднее (с меньшей избыточностью)
передавать и хранить более длинные
последовательности битов. При этом
избыточность не должна оказаться меньше,
чем минимально допустимая
![]() для выбранного канала связи.
для выбранного канала связи.
Данный
способ кодирования требует увеличения
объема памяти компьютера приблизительно
на одну треть при 16-битной длине машинного
слова (см. таблицу), однако такой способ
позволяет автоматически исправлять
одиночные ошибки. Поэтому, оценивая
время наработки на отказ этого способа,
следует исходить из вероятности появления
парной ошибки внутри одной кодовой
последовательности (то есть сбои должны
произойти в двух битах одновременно).
Расчеты показывают, что для указанного
ранее количества (![]() )
)
двоичных ячеек в памяти объемом 1 Мбайт
среднее время до появления сбоя при
таком способе кодирования (код Хемминга)
составляет более 80 лет, что, безусловно,
можно считать вполне приемлемым с
практической точки зрения.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Data-link layer uses error control techniques to ensure that frames, i.e. bit streams of data, are transmitted from the source to the destination with a certain extent of accuracy.
Errors
When bits are transmitted over the computer network, they are subject to get corrupted due to interference and network problems. The corrupted bits leads to spurious data being received by the destination and are called errors.
Types of Errors
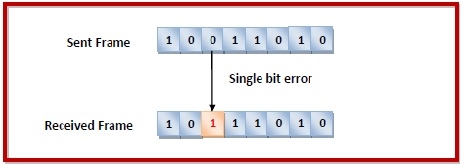
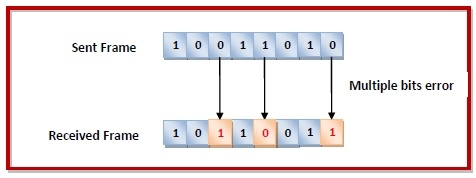
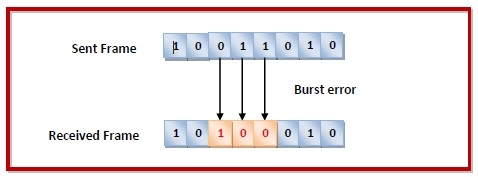
Errors can be of three types, namely single bit errors, multiple bit errors, and burst errors.
-
Single bit error − In the received frame, only one bit has been corrupted, i.e. either changed from 0 to 1 or from 1 to 0.

-
Multiple bits error − In the received frame, more than one bits are corrupted.

-
Burst error − In the received frame, more than one consecutive bits are corrupted.

Error Control
Error control can be done in two ways
-
Error detection − Error detection involves checking whether any error has occurred or not. The number of error bits and the type of error does not matter.
-
Error correction − Error correction involves ascertaining the exact number of bits that has been corrupted and the location of the corrupted bits.
For both error detection and error correction, the sender needs to send some additional bits along with the data bits. The receiver performs necessary checks based upon the additional redundant bits. If it finds that the data is free from errors, it removes the redundant bits before passing the message to the upper layers.
Error Detection Techniques
There are three main techniques for detecting errors in frames: Parity Check, Checksum, and Cyclic Redundancy Check (CRC).
Parity Check
The parity check is done by adding an extra bit, called parity bit to the data to make a number of 1s either even in case of even parity or odd in case of odd parity.
While creating a frame, the sender counts the number of 1s in it and adds the parity bit in the following way
-
In case of even parity: If a number of 1s is even then parity bit value is 0. If the number of 1s is odd then parity bit value is 1.
-
In case of odd parity: If a number of 1s is odd then parity bit value is 0. If a number of 1s is even then parity bit value is 1.
On receiving a frame, the receiver counts the number of 1s in it. In case of even parity check, if the count of 1s is even, the frame is accepted, otherwise, it is rejected. A similar rule is adopted for odd parity check.
The parity check is suitable for single bit error detection only.
Checksum
In this error detection scheme, the following procedure is applied
-
Data is divided into fixed sized frames or segments.
-
The sender adds the segments using 1’s complement arithmetic to get the sum. It then complements the sum to get the checksum and sends it along with the data frames.
-
The receiver adds the incoming segments along with the checksum using 1’s complement arithmetic to get the sum and then complements it.
-
If the result is zero, the received frames are accepted; otherwise, they are discarded.
Cyclic Redundancy Check (CRC)
Cyclic Redundancy Check (CRC) involves binary division of the data bits being sent by a predetermined divisor agreed upon by the communicating system. The divisor is generated using polynomials.
-
Here, the sender performs binary division of the data segment by the divisor. It then appends the remainder called CRC bits to the end of the data segment. This makes the resulting data unit exactly divisible by the divisor.
-
The receiver divides the incoming data unit by the divisor. If there is no remainder, the data unit is assumed to be correct and is accepted. Otherwise, it is understood that the data is corrupted and is therefore rejected.
Error Correction Techniques
Error correction techniques find out the exact number of bits that have been corrupted and as well as their locations. There are two principle ways
-
Backward Error Correction (Retransmission) − If the receiver detects an error in the incoming frame, it requests the sender to retransmit the frame. It is a relatively simple technique. But it can be efficiently used only where retransmitting is not expensive as in fiber optics and the time for retransmission is low relative to the requirements of the application.
-
Forward Error Correction − If the receiver detects some error in the incoming frame, it executes error-correcting code that generates the actual frame. This saves bandwidth required for retransmission. It is inevitable in real-time systems. However, if there are too many errors, the frames need to be retransmitted.
The four main error correction codes are
- Hamming Codes
- Binary Convolution Code
- Reed – Solomon Code
- Low-Density Parity-Check Code
- Related Articles
- Error control in Data Link Layer
- Hamming code for single error correction, double error detection
- What is the Error Control in the Data Link Layer?
- Framing in Data Link Layer
- Network Data Link Layer
- Design Issues in Data Link Layer
- Flow control in Data Link Layer
- Data Link Layer Design Issues
- The Data Link Layer Frame and Frame Fields
- General Data Link Layer Frame Structure
- What is Data Link Layer Switching?
- What is the data link layer?
- What is a Data Link Layer?
- Cisco Discovery Protocol(CDP) and Link Layer Dicovery Protocol(LLDP) in Data Link
- Feedback-based flow control in data link layer
Kickstart Your Career
Get certified by completing the course
Get Started

Контроль правильности передачи данных
Проверка
правильности передачи данных может
выполняться с использованием 3-х различных
подходов:
-
Обнаружение
ошибок. -
Контроль
ошибок (обнаружение + попытка исправления
путем запроса повторной передачи
данных). -
Исправление
ошибок (восстановление искаженных
данных без их повторной передачи).
Вместе с основной информацией по каналу
связи передаются дополнительные
контрольные данные, позволяющие
приемнику самому восстановить информацию
в случае ее искажения при передаче.
Простейшим
способом обнаружения ошибок при
асинхронной
последовательной передаче
является контроль
четности.
При
этом в состав кадра
вводится дополнительный служебный бит
— бит паритета (рис. 1).
|
|

Рис. 1.
Собственно
алгоритм обнаружения ошибок выглядит
следующим образом:
Действия
передатчика
-
Бит
паритета устанавливается в «0» -
Подсчитывается
количество единиц во всех информационных
битах -
Значение
бита паритета устанавливается таким,
чтобы полученная сумма плюс бит паритета
была четной
Действия
приемника
-
Подсчитывается
количество единиц во всех принятых
информационных битах полюс бит паритета. -
Если
полученная сумма является четной,
данные приняты без искажений, в противном
случае имела место ошибка.
Достоинством
данного метода является его простота.
Недостатком — то, что он может определить
состояние ошибки, только если искажению
подверглось нечетное количество бит.
При искажении, например, двух бит в
символе, данный метод не выявит ошибки.
Тем не менее, он получил очень широкое
распространение и реализован на
аппаратном уровне в большинстве
современных асинхронных приемопередатчиков.
Метод
контроля четности может быть использован
также и при параллельной передаче
данных, если это необходимо. В этом
случае необходимо использовать
дополнительную линию связи для передачи
бита паритета.
Пакетный метод передачи данных по последовательному каналу
При
пакетном методе передачи информация
передается порциями, каждая порция
называется пакетом
(рис. 1).
|
|

Рис. 1.
Пакет
состоит из отдельных символов,
а символ состоит из определенного числа
бит.
В начале пакета находятся стартовые
символы, которые имеют фиксированное
значение. Они определяют момент начала
передачи пакета и позволяют выполнить
синхронизацию приемника
с передатчиком
аналогично варианту асинхронной
передачи. Далее идут информационные
символы, в которых отсутствуют служебные
биты. Далее — контрольные символы,
содержащие информацию, позволяющую
проверить правильность передачи
информационных символов. Стоп-символы
имеют также фиксированное значение и
прием последнего стоп-символа определяет
момент окончания передачи пакета.
При
таком способе с одной стороны отсутствуют
служебные биты в каждом символе (т.е.
сохраняется высокая скорость передачи
данных), с другой стороны существует
возможность синхронизации передатчика
и приемника. Данный способ является
своеобразным «гибридом» синхронной
и асинхронной передачи.
Управление последовательным каналом при полудуплексной связи
При
полудуплексном
режиме
последовательной
передачи,
передача данных возможна в обоих
направлениях, но не одновременно. Это
означает, что на обоих концах линии
связи установлены и приемник,
и передатчик.
Но так как линия связи одна, она
используется поочередно то одной парой
«приемник-передатчик» (для передачи
в одном направлении), то другой парой
(рис. 1).
|
|
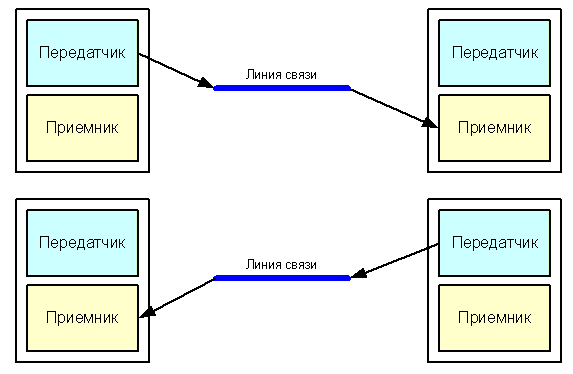
Рис. 1.
Следовательно,
необходима процедура согласования
между двумя парами «приемник-передатчик»
для определения права на занятие линии
связи и недопущения одновременного
занятия линии двумя передатчиками.
Для
решения этой задачи используются два
дополнительных управляющих сигнала:
RTS
(Request To Send — запрос на передачу данных)
и CTS
(Clear To Send — разрешение передачи данных).
Устройство, желающее начать передачу
данных, устанавливает активным сигнал
RTS.
Второе устройство, если оно освободило
линию и готово к приему, устанавливает
в ответ сигнал CTS.
Таким образом, в полудуплексном обмене
передача может начаться только при
получении активного сигнала CTS
от устройства, находящегося на другом
конце линии.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Способы обнаружения ошибок при передаче данных
8. МЕТОДЫ ПЕРЕДАЧИ ДАННЫХ КАНАЛЬНОГО УРОВНЯ
8.4. Методы обнаружения ошибок
Канальный уровень должен обнаруживать ошибки передачи данных, связанные с искажением бит в принятом кадре данных или с потерей кадра, и по возможности их корректировать.
Большая часть протоколов канального уровня выполняет только первую задачу — обнаружение ошибок, считая, что корректировать ошибки, то есть повторно передавать данные, содержавшие искаженную информацию, должны протоколы верхних уровней. Так работают такие популярные протоколы локальных сетей, как Ethernet , Token Ring , FDDI и другие. Однако существуют протоколы LLC2 или LAP-B самостоятельно решают задачу восстановления искаженных или потерянных кадров.
Однако наличие процедур восстановления данных требует от конечных узлов дополнительных вычислительных затрат, которые в условиях надежной работы сети являются избыточными.
Напротив, если в сети искажения и потери случаются часто, то желательно уже на канальном уровне использовать протокол с коррекцией ошибок, а не оставлять эту работу протоколам верхних уровней.
Поэтому нельзя считать, что один протокол лучше другого потому, что он восстанавливает ошибочные кадры, а другой протокол — нет. Каждый протокол должен работать в тех условиях, для которых он разработан.
Все методы обнаружения ошибок основаны на передаче в составе кадра данных служебной избыточной информации, по которой можно судить о достоверности принятых данных. Эту служебную информации принято называть контрольной суммой (или последовательностью контроля кадра — Frame Check Sequence , PCS). Контрольная сумма вычисляется как функция от основной информации. Принимающая сторона повторно вычисляет контрольную сумму кадра по известному алгоритму и в случае ее совпадения с контрольной суммой, вычисленной передающей стороной, делает вывод о корректости переданных данных.
Существует несколько распространенных алгоритмов вычисления контрольной суммы, отличающихся вычислительной сложностью и способностью обнаруживать ошибки в данных.
Контроль по паритету представляет собой наиболее простой метод контроля данных. В то же время это наименее мощный алгоритм контроля, так как с его помощью можно обнаружить только одиночные ошибки в проверяемых данных. Метод заключается в суммировании по модулю 2 всех бит контролируемой информации. Например, для данных 100101011 результатом контрольного суммирования будет значение 1. Результат суммирования также представляет собой один бит данных, который пересылается вместе с контролируемой информацией. При искажении при пересылке любого одного бита исходных данных (или контрольного разряда) результат суммирования будет отличаться от принятого контрольного разряда, что говорит об ошибке. Однако двойная ошибка, например 110101010, будет неверно принята за корректные данные. Поэтому контроль по паритету применяется к небольшим порциям данных, как правило, к каждому байту, что дает коэффициент избыточности для этого метода 1/8. Метод редко применяется в вычислительных сетях из-за его большой избыточности и невысоких диагностических способностей.
Вертикальный и горизонтальный контроль по паритету представляет собой модификацию описанного выше метода. Его отличие состоит в том, что исходные данные рассматриваются в виде матрицы, строки которой составляют байты данных. Контрольный разряд подсчитывается отдельно для каждой строки и для каждого столбца матрицы. Этот метод обнаруживает большую часть двойных ошибок, однако обладает еще большей избыточностью. На практике сейчас почти не применяется.
Циклический избыточный контроль ( Cyclic Redundancy Check , CRC) является в настоящее время наиболее популярным методом контроля в вычислительных сетях (и не только в сетях, например, этот метод широко применяется при записи данных на диски и дискеты). Метод основан на рассмотрении исходных данных в виде одного многоразрядного двоичного числа. Например, кадр стандарта Ethernet , состоящий из 1024 байт, будет рассматриваться как одно число, состоящее из 8192 бит . В качестве контрольной информации рассматривается остаток от деления этого числа на известный делитель R. Обычно в качестве делителя выбирается семнадцати- или тридцати трехразрядное число, чтобы остаток от деления имел длину 16 разрядов (2 байт) или 32 разряда (4 байт). При получении кадра данных снова вычисляется остаток от деления на тот же делитель R, но при этом к данным кадра добавляется и содержащаяся в нем контрольная сумма. Если остаток от деления на R равен нулю, то делается вывод об отсутствии ошибок в полученном кадре, в противном случае кадр считается искаженным.
Этот метод обладает более высокой вычислительной сложностью, но его диагностические возможности гораздо выше, чем у методов контроля по паритету. Метод CRC обнаруживает все одиночные ошибки, двойные ошибки и ошибки в нечетном числе бит. Метод обладает также невысокой степенью избыточности. Например, для кадра Ethernet размером в 1024 байт контрольная информация длиной в 4 байт составляет только 0,4 %.
Источник
Способы обнаружения и устранения ошибок при передачи данных в сетях.
Ошибки связаны с искажением бит в кадре или с потерей кадра. Методы обнаружения ошибок основаны на передаче в составе кадра избыточной информации (контрольных разрядов). Кр вычисляются в передатчике как функция от информационных разрядов(ир). Приемник повторно вычисляет кр по тому же алгоритму и при несовпадении с полученными кр фиксируется ошибка. Методы вычисления кр: контроль по паритету(обнаруживает одиночные и нечетное количество ошибок – контроль по четности, по нечетности), вертикальный и горизонтальный контроль по паритету (обнаруживается большая часть двойных ошибок, велика избыточность), контрольная сумма (передатчик дополняет сумму всех байт кадра до 0 или FF, приемник суммирует по модулю равному разрядности контрольного кода, включая кр, вероятность обнаружения ошибок 99,6%, уменьшается при увеличении разрядности кода), циклический контроль(исходные данные предоставляются многоразрядным двоичным числом в качестве кр берется остаток от деления этого числа на известный делитель, при приеме снова вычисляется остаток от деления на тот же делитель, но делятся данные кадры с полученным кр, если остаток = 0, то ошибки нет, если не =, то ошибка. Обнаруживаются одиночные, двойные и ошибки в нечетном числе бит.)
Методы исправления ошибок основаны на повторной передаче кадра данных. Отправитель нумерует посылаемые кадры и для каждого ожидает положительной квитанции (служебного кадра «ошибок нет»). При получении искаженного кадра приемник посылает отрицательную квитанцию, указывающую, что кадр надо передать повторно. При отправки каждого кадра передатчик запускает таймер, и если по его истечении не получена квитанция, то кадр (возможно квитанция) утерян и выполняется повторная передача. Методы исправления: метод с простоями (передатчик ожидает положительной квитанции и только после этого посылает следующий кадр, иначе повторяет передачу, +: надежность передачи, -: уменьшение производительности), метод скользящего окна (при отправке кадра источнику разрешается до получения квитанции на кадр передать еще некоторое количество кадров, если за это время квитанция так и не пришла, то передача приостанавливается и кадр передается снова, +: увеличивается скорость обмена, -: передатчик должен хранить в буфере все кадры на которые нет квитанций, надо отслеживать номер кадра на который пришла квитанция и номер кадра который можно передать до получения следующей квитанции).
IP адресация: классы сетей, деление на сети и подсети, маски подсетей.
В современных сетях для адресации узлов одновременно используются аппаратные, числовые и символьные адреса. Пользователи адресуют комп-ы с символьными адресами, которые автоматически заменяются в сообщениях передаваемых по сети на числовые адреса. После доставки в сеть назначения вместо числового адреса используется аппаратный адрес комп-а. типы адресов: лок адреса- используются для доставки сообщений в пределах подсети, IP адреса – используются для передачи пакетов между сетями, DNS-имя – символьные адреса с их помощью пользователи адресуют комп-ы.
4 класса IP-адресов: А(1 сеть 10.0.0.0), В(16 сетей 172.16.0.0-172.31.0.0), С(255 сетей 192.161.0.0-192.161.255.0).
Ограничение на IP-адреса узлов и сетей: 1) ни номер сети, ни номер узла не равны всем двоичным 0 или 1. 2)127.х.х.х – запрещен для узлов и сетей, т.к. используется для тестирования программ и взаимодействия процессов в пределах 1 комп-а 3)групповой адрес не содержит ни номера сети, ни номера узла.
Маска – содержит непрерывную последовательность двоичных единиц в тех разрядах, которые в IP адресе и непрерывную последовательность нулей в тех разрядах, которые соответствуют номеру узла.
+ : маска позволяет отказаться от класса адресов, маска используется в маршрутизаторе, маска позволяет администратору структурировать сеть, т.е. делить ее на подсети не требуя от поставщика услуг доп адреса, поставщики услуг могут объединять адресное пространство лс вводя прификсы, уменьшая объем маршрутизации.
Порядок назначения адресов — номера сетей назначаются: централизованно(поставщиками услуг), произвольно(если сеть работает автономно), номера узлов администратор назначает произвольно в пределах разрешенного диапазона адресов, для лок сетей зарезервированы адреса трех классов.
Сетевая технология Ethernet: физический и канальный уровни. Метод доступа CSMA/CD. Обработка коллизий. Топологии. Адресация. Формат кадров.
CSMA/CD реализуется сетевым адаптером аппаратно или микропрограммно, он используется в лс с логической общей шиной, включая радио сети. Сетевой адаптер прослушивает разделяемую среду, признаком ее незанятости является отсутствие несущей, т.е. основной гармоники сигнала. Частота несущей 5-10 МГц, при манчестерском кодировании, если среда не занята, сетевой адаптер передает кадр, который распространяется в обе стороны, после окончания передачи кадра все узлы выдерживают технологическую паузу. Если 2 и более станции передают кадр, возникает коллизия. Приемник обнаруживает коллизию по длине кадра меньше 64Б, а передатчик по несовпадению передаваемых и наблюдаемых сигналов. После этого сетевой адаптер прерывает передачу и усиливает коллизию, посылая jam-последовательность в 32 бита для оповещения других станций, затем сетевой адаптер делает случайную паузу. После 16 неудачных попыток кадр отбрасывается.
Формат кадра: сетевые адаптеры и их драйверы, мосты, коммутаторы, и маршрутизаторы работают со всеми форматами кадров. а) кадр 802.3/LLC: преамбула(необходима для синхронизации приемника и передатчика), SFD (начальный ограничитель кадра), DA (адрес назначения индивидуальный, широковещательный, групповой), SA (адрес источника), L(длина поля данных в байтах), FCS(контрольные разряды CRC). б) кадр Raw802.3/Novell 802.3 такой же как и предыдущий, но без вложенного LLC кадра. в) Ethernet DIX(II) = (б), но вместо поля L, поле Т (тип протокола верхнего уровня, вложившего свой пакет в поле данных кадра). г) Ethernet SWAP – расширение кадра (а), введением заголовка SWAP, который вложен в протокол LLC.
Топологии: шина, звезда с активным центром, двухстороннее соединение пары узлов без хаба, дерево.
Скорость – 10 Мб/с, мах диаметр сети 2500м, мах число станций в сети 1024
Стандарты Ethernet 10 Мб/с.
Толстый коксиал, диаметр 0,5, топология – шина, сегмент кабеля ограничивают терминаторы (заглушки), поглощающие сигналы и препятствующие возникновению отраженных сигналов, трансиверы – с их помощью станции подключаются к кабелю, функции трансивера – приемо-передача данных, определение коллизий по уровню постоянной составляющей, гальваническая развязка, контроль болтливости (если из-за неисправности повышается мах время передачи кадра, то трансивер отсоединяет кабель от передатчика). Повторитель побитно синхронно повторяет сигналы с одного сегмент в другой, улучшая их форму и мощность и синхронизируя их.
Правило «5-4-3» — мах конфигурация стандарта: 5- мах число сегментов, 4- мах число повторителей, 3- мах число нагруженных сегментов. Мах диаметр сети 2500м, мах число узлов 297.
Тонкий коксиал, BNST коннектор – это тройник, одна точка которого соединяется с СА, 2 других с точками разрыва.
Мах диаметр сети – 925м, мах число уровней – 87
Общий недостаток отсутствие оперативной информации о состоянии моноканала. Повреждение кабеля обнаруживается по неработоспособности сети, а поиск – кабельным тестером.
Топология – звезда с активным центром
Мах длина сегмента 100м, определяется полосой пропускания UTP позволяющей передавать данные в манчестерском коде со скоростью 10 Мб/с на 100м мах. Hub выполняет функции повторителя сигналов на всех отрезках подключенных к его портам, обнаруживает коллизию.
Правило 4 хабов. Мах число хабов между любыми двумя станциями равно 4. можно соединять в древовидную структуру. Петли, замкнутые контуры запрещены.
Мах диаметр сети 500м, мах число узлов 1024 достигается в двухуровневом соединении хабов.
Структура, топология как предыдущий.
Стандарты: FOIRL- мах длина сегмента 1000м мах диаметр сети 2500м, 10Base-FL- мах длина сегмента 2000м мах диаметр сети 2500м, 10Base-FB только для соединения «5 хабов», мах длина сегментов 2000м, мах диаметр сети 2740м.
Источник
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Ошибки в компьютерных сетях
12 минут чтения
Онлайн курс по Кибербезопасности
Изучи хакерский майндсет и научись защищать свою инфраструктуру! Самые важные и актуальные знания, которые помогут не только войти в ИБ, но и понять реальное положение дел в индустрии

Ни одна среда передачи данных не может считаться совершенной. Если среда передачи является общей, как радиочастота (RF), существует возможность возникновения помех или даже столкновений дейтаграмм. Это когда несколько отправителей пытаются передать информацию одновременно. Результатом является искаженное сообщение, которое не может быть понято предполагаемым получателем. Даже специализированная среда, такая как подводный оптический кабель типа point-to-point (световолновой), может испытывать ошибки из—за деградации кабеля или точечных событий-даже, казалось бы, безумных событий, таких как солнечные вспышки, вызывающие излучение, которое, в свою очередь, мешает передаче данных по медному кабелю.
Существует два ключевых вопроса, на которые сетевой транспорт должен ответить в области ошибок:
- Как можно обнаружить ошибки при передаче данных?
- Что должна делать сеть с ошибками при передаче данных?
Далее рассматриваются некоторые из возможных ответов на эти вопросы.
Обнаружение ошибок
Первый шаг в работе с ошибками, независимо от того, вызваны ли они отказом носителя передачи, повреждением памяти в коммутационном устройстве вдоль пути или любой другой причиной, заключается в обнаружении ошибки. Проблема, конечно, в том, что когда получатель изучает данные, которые он получает, нет ничего, с чем можно было бы сравнить эти данные, чтобы обнаружить ошибку.
Проверка четности — это самый простой механизм обнаружения. Существуют два взаимодополняющих алгоритма проверки четности. При четной проверке четности к каждому блоку данных добавляется один дополнительный бит. Если сумма битов в блоке данных четная—то есть если в блоке данных имеется четное число битов 1, то дополнительный бит устанавливается равным 0. Это сохраняет четное состояние четности блока. Если сумма битов нечетна, то дополнительный бит устанавливается равным 1, что переводит весь блок в состояние четной четности. Нечетная четность использует ту же самую дополнительную битную стратегию, но она требует, чтобы блок имел нечетную четность (нечетное число 1 бит). В качестве примера вычислите четную и нечетную четность для этих четырех октетов данных:
Простой подсчет цифр показывает, что в этих данных есть 14 «1» и 18 «0». Чтобы обеспечить обнаружение ошибок с помощью проверки четности, вы добавляете один бит к данным, либо делая общее число «1» в недавно увеличенном наборе битов четным для четной четности, либо нечетным для нечетной четности. Например, если вы хотите добавить четный бит четности в этом случае, дополнительный бит должен быть установлен в «0». Это происходит потому, что число «1» уже является четным числом. Установка дополнительного бита четности на «0» не добавит еще один «1» и, следовательно, не изменит, является ли общее число «1» четным или нечетным. Таким образом, для четной четности конечный набор битов равен:
С другой стороны, если вы хотите добавить один бит нечетной четности к этому набору битов, вам нужно будет сделать дополнительный бит четности «1», так что теперь есть 15 «1», а не 14. Для нечетной четности конечный набор битов равен:
Чтобы проверить, были ли данные повреждены или изменены при передаче, получатель может просто отметить, используется ли четная или нечетная четность, добавить число «1» и отбросить бит четности. Если число «1» не соответствует используемому виду четности (четное или нечетное), данные повреждены; в противном случае данные кажутся такими же, как и первоначально переданные.
Этот новый бит, конечно, передается вместе с оригинальными битами. Что произойдет, если сам бит четности каким-то образом поврежден? Это на самом деле нормально — предположим, что даже проверка четности на месте, и передатчик посылает
Приемник, однако, получает
Сам бит четности был изменен с 0 на 1. Приемник будет считать «1», определяя, что их 15. Поскольку даже проверка четности используется, полученные данные будут помечены как имеющие ошибку, даже если это не так. Проверка на четность потенциально слишком чувствительна к сбоям, но в случае обнаружения ошибок лучше ошибиться в начале.
Есть одна проблема с проверкой четности: она может обнаружить только один бит в передаваемом сигнале. Например, если даже четность используется, и передатчик отправляет
Приемник, однако, получает
Приемник подсчитает число «1» и обнаружит, что оно равно 12. Поскольку система использует четную четность, приемник будет считать данные правильными и обработает их в обычном режиме. Однако оба бита, выделенные жирным шрифтом, были повреждены. Если изменяется четное число битов в любой комбинации, проверка четности не может обнаружить изменение; только когда изменение включает нечетное число битов, проверка четности может обнаружить изменение данных.
Циклическая проверка избыточности (Cyclic Redundancy Check — CRC) может обнаруживать более широкий диапазон изменений в передаваемых данных, используя деление (а не сложение) в циклах по всему набору данных, по одной небольшой части за раз. Работа с примером — лучший способ понять, как рассчитывается CRC. Расчет CRC начинается с полинома, как показано на рисунке 1.
На рис. 1 трехчленный многочлен x3 + x2 + 1 расширен, чтобы включить все члены, включая члены, предшествующие 0 (и, следовательно, не влияют на результат вычисления независимо от значения x). Затем эти четыре коэффициента используются в качестве двоичного калькулятора, который будет использоваться для вычисления CRC.
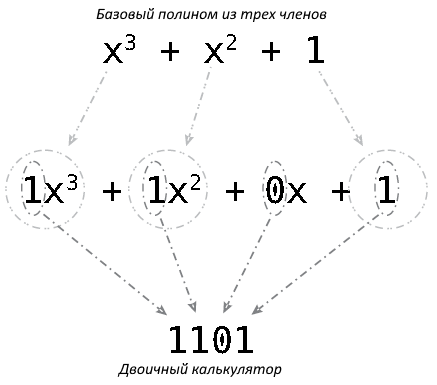
Чтобы выполнить CRC, начните с исходного двоичного набора данных и добавьте три дополнительных бита (поскольку исходный полином без коэффициентов имеет три члена; следовательно, это называется трехбитной проверкой CRC), как показано здесь:
Эти три бита необходимы для обеспечения того, чтобы все биты в исходных данных были включены в CRC; поскольку CRC перемещается слева направо по исходным данным, последние биты в исходных данных будут включены только в том случае, если эти заполняющие биты включены. Теперь начните с четырех битов слева (потому что четыре коэффициента представлены в виде четырех битов). Используйте операцию Exclusive OR (XOR) для сравнения крайних левых битов с битами CRC и сохраните результат, как показано здесь:
XOR’инг двух двоичных цифр приводит к 0, если эти две цифры совпадают, и 1, если они не совпадают. Контрольные биты, называемые делителем, перемещаются на один бит вправо (некоторые шаги здесь можно пропустить), и операция повторяется до тех пор, пока не будет достигнут конец числа:
CRC находится в последних трех битах, которые были первоначально добавлены в качестве заполнения; это «остаток» процесса разделения перемещения по исходным данным плюс исходное заполнение. Получателю несложно определить, были ли данные изменены, оставив биты CRC на месте (в данном случае 101) и используя исходный делитель поперек данных, как показано здесь:
Если данные не были изменены, то результат этой операции всегда должен быть равен 0. Если бит был изменен, результат не будет равен 0, как показано здесь:
Исправление ошибок
Однако обнаружение ошибки — это только половина проблемы. Как только ошибка обнаружена, что должна делать транспортная система? Есть, по существу, три варианта.
Транспортная система может просто выбросить данные. В этом случае транспорт фактически переносит ответственность за ошибки на протоколы более высокого уровня или, возможно, само приложение. Поскольку некоторым приложениям может потребоваться полный набор данных без ошибок (например, система передачи файлов или финансовая транзакция), у них, вероятно, будет какой-то способ обнаружить любые пропущенные данные и повторно передать их. Приложения, которые не заботятся о небольших объемах отсутствующих данных (например, о голосовом потоке), могут просто игнорировать отсутствующие данные, восстанавливая информацию в приемнике, насколько это возможно, с учетом отсутствующей информации.
Транспортная система может подать сигнал передатчику, что произошла ошибка, и позволить передатчику решить, что делать с этой информацией (как правило, данные при ошибке будут повторно переданы).
Транспортная система может выйти за рамки отбрасывания данных, включив достаточное количество информации в исходную передачу, определить, где находится ошибка, и попытаться исправить ее. Это называется Прямой коррекцией ошибок (Forward Error Correction — FEC). Коды Хэмминга, один из первых разработанных механизмов FEC, также является одним из самых простых для объяснения.
Код Хэмминга лучше всего объяснить на примере — для иллюстрации будет использована таблица 1.
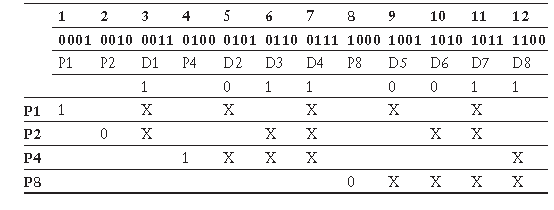
- Каждый бит в 12-битном пространстве, представляющий собой степень двух (1, 2, 4, 6, 8 и т. д.) и первый бит, устанавливается в качестве битов четности.
- 8-битное число, которое должно быть защищено с помощью FEC, 10110011, распределено по оставшимся битам в 12-битном пространстве.
- Каждый бит четности устанавливается равным 0, а затем четность вычисляется для каждого бита четности путем добавления числа «1» в позиции, где двоичный бит имеет тот же бит, что и бит четности. В частности:
- P1 имеет набор крайних правых битов в своем битовом номере; другие биты в числовом пространстве, которые также имеют набор крайних правых битов, включены в расчет четности (см. вторую строку таблицы, чтобы найти все позиции битов в номере с набором крайних правых битов). Они указаны в таблице с X в строке P1. Общее число «1»-нечетное число, 3, поэтому бит P1 устанавливается равным 1 (в этом примере используется четная четность).
- P2 имеет второй бит из правого набора; другие биты в числовом пространстве, которые имеют второй из правого набора битов, включены в расчет четности, как указано с помощью X в строке P2 таблицы. Общее число «1»-четное число, 4, поэтому бит P2 установлен в 0.
- P4 имеет третий бит из правого набора, поэтому другие биты, которые имеют третий бит из правого набора, имеют свои номера позиций, как указано с помощью X в строке P3. В отмеченных столбцах есть нечетное число «1», поэтому бит четности P4 установлен на 1.
Чтобы определить, изменилась ли какая-либо информация, получатель может проверить биты четности таким же образом, как их вычислял отправитель; общее число 1s в любом наборе должно быть четным числом, включая бит четности. Если один из битов данных был перевернут, приемник никогда не должен найти ни одной ошибки четности, потому что каждая из битовых позиций в данных покрыта несколькими битами четности. Чтобы определить, какой бит данных является неправильным, приемник добавляет позиции битов четности, которые находятся в ошибке; результатом является положение бита, которое было перевернуто. Например, если бит в позиции 9, который является пятым битом данных, перевернут, то биты четности P1 и P8 будут ошибочными. В этом случае 8 + 1 = 9, так что бит в позиции 9 находится в ошибке, и его переворачивание исправит данные. Если один бит четности находится в ошибке—например, P1 или P8—то это тот бит четности, который был перевернут, и сами данные верны.
В то время как код Хэмминга гениален, есть много битовых шаблонов-перевертышей, которые он не может обнаружить. Более современный код, такой как Reed-Solomon, может обнаруживать и исправлять более широкий диапазон условий ошибки, добавляя меньше дополнительной информации в поток данных.
Существует большое количество различных видов CRC и кодов исправления ошибок, используемых во всем мире связи. Проверки CRC классифицируются по количеству битов, используемых в проверке (количество битов заполнения или, точнее, длины полинома), а в некоторых случаях — по конкретному применению. Например, универсальная последовательная шина использует 5-битный CRC (CRC-5-USB); Глобальная система мобильной связи (GSM), широко используемый стандарт сотовой связи, использует CRC-3-GSM; Мультидоступ с кодовым разделением каналов (CDMA), другой широко используемый стандарт сотовой связи, использует CRC-6-CDMA2000A, CRC-6-CDMA2000B и CRC-30; и некоторые автомобильные сети (CAN), используемые для соединения различных компонентов в автомобиле, используют CRC-17-CAN и CRC-21-CAN. Некоторые из этих различных функций CRC являются не единственной функцией, а скорее классом или семейством функций со многими различными кодами и опциями внутри них.
Полный курс по Сетевым Технологиям
В курсе тебя ждет концентрат ТОП 15 навыков, которые обязан знать ведущий инженер или senior Network Operation Engineer
Источник
Канальный уровень должен обнаруживать ошибки передачи данных, связанные с
искажением бит в принятом кадре данных или с потерей кадра, и по возможности их
корректировать.
Большая часть протоколов канального уровня выполняет только первую задачу —
обнаружение ошибок, считая, что корректировать ошибки, то есть повторно
передавать данные, содержавшие искаженную информацию, должны протоколы верхних
уровней. Так работают такие популярные протоколы локальных сетей, как Ethernet,
Token Ring, FDDI и другие. Однако существуют протоколы канального уровня, например
LLC2 или LAP-B, которые самостоятельно решают задачу восстановления искаженных
или потерянных кадров.
Очевидно, что протоколы должны работать наиболее эффективно в типичных
условиях работы сети. Поэтому для сетей, в которых искажения и потери кадров являются
очень редкими событиями, разрабатываются протоколы типа Ethernet, в которых не
предусматриваются процедуры устранения ошибок. Действительно, наличие процедур
восстановления данных потребовало бы от конечных узлов дополнительных
вычислительных затрат, которые в условиях надежной работы сети являлись бы
избыточными.
Напротив, если в сети искажения и потери случаются часто, то желательно уже
на канальном уровне использовать протокол с коррекцией ошибок, а не оставлять
эту работу протоколам верхних уровней. Протоколы верхних уровней, например
транспортного или прикладного, работая с большими тайм-аутами, восстановят
потерянные данные с большой задержкой. В глобальных сетях первых поколений,
например сетях Х.25, которые работали через ненадежные каналы связи, протоколы
канального уровня всегда выполняли процедуры восстановления потерянных и
искаженных кадров.
Поэтому нельзя считать, что один протокол лучше другого потому, что он
восстанавливает ошибочные кадры, а другой протокол — нет. Каждый протокол должен
работать в тех условиях, для которых он разработан.
Методы обнаружения ошибок
Все методы обнаружения ошибок основаны на передаче в составе кадра данных
служебной избыточной информации, по которой можно судить с некоторой степенью
вероятности о достоверности принятых данных. Эту служебную информацию принято
называть контрольной суммой или (последовательностью
контроля кадра — Frame Check Sequence, FCS). Контрольная сумма вычисляется
как функция от основной информации, причем необязательно только путем суммирования.
Принимающая сторона повторно вычисляет контрольную сумму кадра по известному
алгоритму и в случае ее совпадения с контрольной суммой, вычисленной передающей
стороной, делает вывод о том, что данные были переданы через сеть корректно.
Существует несколько распространенных алгоритмов вычисления контрольной
суммы, отличающихся вычислительной сложностью и способностью обнаруживать
ошибки в данных.
Контроль по паритету представляет собой наиболее простой метод контроля данных. В то же
время это наименее мощный алгоритм контроля, так как с его помощью можно
обнаружить только одиночные ошибки в проверяемых данных. Метод заключается в
суммировании по модулю 2 всех бит контролируемой информации. Например, для
данных 100101011 результатом контрольного суммирования будет значение 1.
Результат суммирования также представляет собой один бит данных, который
пересылается вместе с контролируемой информацией. При искажении при пересылке
любого одного бита исходных данных (или контрольного разряда) результат суммирования
будет отличаться от принятого контрольного разряда, что говорит об ошибке.
Однако двойная ошибка, например 110101010, будет неверно принята за корректные
данные. Поэтому контроль по паритету применяется к небольшим порциям данных,
как правило, к каждому байту, что дает коэффициент избыточности для этого
метода 1/8. Метод редко применяется в вычислительных сетях из-за его большой
избыточности и невысоких диагностических способностей.
Вертикальный и горизонтальный контроль по паритету представляет собой модификацию
описанного выше метода. Его отличие состоит в том, что исходные данные
рассматриваются в виде матрицы, строки которой составляют байты данных.
Контрольный разряд подсчитывается отдельно для каждой строки и для каждого
столбца матрицы. Этот метод обнаруживает большую часть двойных ошибок, однако
обладает еще большей избыточностью. На практике сейчас также почти не
применяется.
Циклический избыточный контроль (Cyclic Redundancy Check, CRC) является в настоящее время наиболее
популярным методом контроля в вычислительных сетях (и не только в сетях,
например, этот метод широко применяется при записи данных на диски и дискеты).
Метод основан на рассмотрении исходных данных в виде одного многоразрядного
двоичного числа. Например, кадр стандарта Ethernet, состоящий из 1024 байт,
будет рассматриваться как одно число, состоящее из 8192 бит. В качестве
контрольной информации рассматривается остаток от деления этого числа на
известный делитель R. Обычно в качестве делителя выбирается семнадцати- или тридцати
трехразрядное число, чтобы остаток от деления имел длину 16 разрядов (2 байт)
или 32 разряда (4 байт). При получении кадра данных снова вычисляется остаток
от деления на тот же делитель R, но при этом к данным кадра добавляется и
содержащаяся в нем контрольная сумма. Если остаток от деления на R равен нулю1 (1 Существуетнесколько
модифицированная процедура вычисления остатка, приводящая к получению в случае
отсутствия ошибок известного ненулевого остатка, что является более надежным
показателем корректности.), то делается вывод об отсутствии ошибок в полученном
кадре, в противном случае кадр считается искаженным.
Этот метод обладает более высокой вычислительной сложностью, но его
диагностические возможности гораздо выше, чем у методов контроля по паритету.
Метод CRC обнаруживает все одиночные ошибки, двойные ошибки и ошибки в нечетном
числе бит. Метод обладает также невысокой степенью избыточности. Например, для
кадра Ethernet размером в 1024 байт контрольная информация длиной в 4 байт
составляет только 0,4 %.
Методы восстановления искаженных и потерянных кадров
Методы коррекции ошибок в вычислительных сетях основаны на повторной
передаче кадра данных в том случае, если кадр теряется и не доходит до адресата
или приемник обнаружил в нем искажение информации. Чтобы убедиться в
необходимости повторной передачи данных, отправитель нумерует отправляемые
кадры и для каждого кадра ожидает от приемника так называемой положительной
квитанции — служебного кадра, извещающего о том, что исходный кадр был
получен и данные в нем оказались корректными. Время этого ожидания ограничено —
при отправке каждого кадра передатчик запускает таймер, и, если по его
истечении положительная квитанция на получена, кадр считается утерянным.
Приемник в случае получения кадра с искаженными данными может отправить отрицательную
квитанцию — явное указание на то, что данный кадр нужно передать
повторно.
Существуют два подхода к организации процесса обмена квитанциями: с
простоями и с организацией «окна».
Метод с простоями (Idle Source) требует, чтобы источник, пославший кадр, ожидал получения квитанции
(положительной или отрицательной) от приемника и только после этого посылал
следующий кадр (или повторял искаженный). Если же квитанция не приходит в
течение тайм-аута, то кадр (или квитанция) считается утерянным и его передача
повторяется. На рис. 2.24, а видно, что в этом случае производительность обмена
данными существенно снижается, — хотя передатчик и мог бы послать следующий
кадр сразу же после отправки предыдущего, он обязан ждать прихода квитанции.
Снижение производительности этого метода коррекции особенно заметно на
низкоскоростных каналах связи, то есть в территориальных сетях.

Рис. 2.24. Методы восстановления искаженных и
потерянных кадров
Второй метод называется методом «скользящего окна» (sliding
window). В этом методе для повышения коэффициента использования линии
источнику разрешается передать некоторое количество кадров в непрерывном
режиме, то есть в максимально возможном для источника темпе, без получения на
эти кадры положительных ответных квитанций. (Далее, где это не искажает
существо рассматриваемого вопроса, положительные квитанции для краткости будут
называться просто «квитанциями».) Количество кадров, которые разрешается
передавать таким образом, называется размером окна. Рисунок 2.24, б
иллюстрирует данный метод для окна размером в W кадров.
В начальный момент, когда еще не послано ни одного кадра, окно определяет
диапазон кадров с номерами от 1 до W включительно. Источник начинает передавать
кадры и получать в ответ квитанции. Для простоты предположим, что квитанции
поступают в той же последовательности, что и кадры, которым они соответствуют.
В момент t1 при получении первой квитанции К1 окно сдвигается
на одну позицию, определяя новый диапазон от 2 до (W+1).
Процессы отправки кадров и получения квитанций идут достаточно независимо
друг от друга. Рассмотрим произвольный момент времени tn, когда источник
получил квитанцию на кадр с номером n. Окно сдвинулось вправо и определило
диапазон разрешенных к передаче кадров от (n+1) до (W+n). Все множество кадров,
выходящих из источника, можно разделить на перечисленные ниже группы (рис.
2.24, б).
- Кадры с номерами от 1 доп. уже были отправлены и квитанции на них
получены, то есть они находятся за пределами окна слева. - Кадры, начиная с номера (п+1) и кончая номером
(W+n), находятся в пределах окна и
потому могут быть отправлены не дожидаясь прихода какой-либо квитанции.
Этот диапазон может быть разделен еще на два поддиапазона: - кадры с номерами от (n+1) до
т, которые уже отправлены, но квитанции на них еще не получены; - кадры с номерами от m до
(W+n), которые пока не отправлены, хотя запрета на это нет. - Все кадры с номерами, большими или равными
(W+n+1), находятся за пределами окна
справа и поэтому пока не могут быть отправлены.
Перемещение окна вдоль последовательности номеров кадров показано на рис.
2.24, в. Здесь t0 — исходный момент, t1 и tn —
моменты прихода квитанций на первый и n-й кадр соответственно. Каждый раз,
когда приходит квитанция, окно сдвигается влево, но его размер при этом не
меняется и остается равным W. Заметим, что хотя в данном примере размер окна в
процессе передачи остается постоянным, в реальных протоколах (например, TCP)
можно встретить варианты данного алгоритма с изменяющимся размером окна.
Итак, при отправке кадра с номером n источнику разрешается передать еще W-1
кадров до получения квитанции на кадр n, так что в сеть последним уйдет кадр с
номером (W+n-1). Если же за это время квитанция на кадр n так и не пришла, то
процесс передачи приостанавливается, и по истечении некоторого тайм-аута кадр n
(или квитанция на него) считается утерянным, и он передается снова.
Если же поток квитанций поступает более-менее регулярно, в пределах допуска
в W кадров, то скорость обмена достигает максимально возможной величины для
данного канала и принятого протокола.
Метод скользящего окна более сложен в реализации, чем метод с простоями,
так как передатчик должен хранить в буфере все кадры, на которые пока не
получены положительные квитанции. Кроме того, требуется отслеживать несколько
параметров алгоритма: размер окна W, номер кадра, на который получена
квитанция, номер кадра, который еще можно передать до получения новой
квитанции.
Приемник может не посылать квитанции на каждый принятый корректный кадр.
Если несколько кадров пришли почти одновременно, то приемник может послать
квитанцию только на последний кадр. При этом подразумевается, что все
предыдущие кадры также дошли благополучно.
Некоторые методы используют отрицательные квитанции. Отрицательные
квитанции бывают двух типов — групповые и избирательные. Групповая квитанция
содержит номер кадра, начиная с которого нужно повторить передачу всех кадров,
отправленных передатчиком в сеть. Избирательная отрицательная квитанция требует
повторной передачи только одного кадра.
Метод скользящего окна реализован во многих протоколах: LLC2, LAP-B, X.25,
TCP, Novell NCP Burst Mode.
Метод с простоями является частным случаем метода скользящего окна, когда
размер окна равен единице.
Метод скользящего окна имеет два параметра, которые могут заметно влиять на
эффективность передачи данных между передатчиком и приемником, — размер окна и
величина тайм-аута ожидания квитанции. В надежных сетях, когда кадры искажаются
и теряются редко, для повышения скорости обмена данными размер окна нужно
увеличивать, так как при этом передатчик будет посылать кадры с меньшими
паузами. В ненадежных сетях размер окна следует уменьшать, так как при частых
потерях и искажениях кадров резко возрастает объем вторично передаваемых через
сеть кадров, а значит, пропускная способность сети будет расходоваться во
многом вхолостую — полезная пропускная способность сети будет падать.
Выбор тайм-аута зависит не от надежности сети, а от задержек передачи
кадров сетью.
Во многих реализациях метода скользящего окна величина окна и тайм-аут
выбираются адаптивно, в зависимости от текущего состояния сети.
Data-link layer uses error control techniques to ensure that frames, i.e. bit streams of data, are transmitted from the source to the destination with a certain extent of accuracy.
Errors
When bits are transmitted over the computer network, they are subject to get corrupted due to interference and network problems. The corrupted bits leads to spurious data being received by the destination and are called errors.
Types of Errors
Errors can be of three types, namely single bit errors, multiple bit errors, and burst errors.
-
Single bit error − In the received frame, only one bit has been corrupted, i.e. either changed from 0 to 1 or from 1 to 0.
-
Multiple bits error − In the received frame, more than one bits are corrupted.
-
Burst error − In the received frame, more than one consecutive bits are corrupted.
Error Control
Error control can be done in two ways
-
Error detection − Error detection involves checking whether any error has occurred or not. The number of error bits and the type of error does not matter.
-
Error correction − Error correction involves ascertaining the exact number of bits that has been corrupted and the location of the corrupted bits.
For both error detection and error correction, the sender needs to send some additional bits along with the data bits. The receiver performs necessary checks based upon the additional redundant bits. If it finds that the data is free from errors, it removes the redundant bits before passing the message to the upper layers.
Error Detection Techniques
There are three main techniques for detecting errors in frames: Parity Check, Checksum and Cyclic Redundancy Check (CRC).
Parity Check
The parity check is done by adding an extra bit, called parity bit to the data to make a number of 1s either even in case of even parity or odd in case of odd parity.
While creating a frame, the sender counts the number of 1s in it and adds the parity bit in the following way
-
In case of even parity: If a number of 1s is even then parity bit value is 0. If the number of 1s is odd then parity bit value is 1.
-
In case of odd parity: If a number of 1s is odd then parity bit value is 0. If a number of 1s is even then parity bit value is 1.
On receiving a frame, the receiver counts the number of 1s in it. In case of even parity check, if the count of 1s is even, the frame is accepted, otherwise, it is rejected. A similar rule is adopted for odd parity check.
The parity check is suitable for single bit error detection only.
Checksum
In this error detection scheme, the following procedure is applied
-
Data is divided into fixed sized frames or segments.
-
The sender adds the segments using 1’s complement arithmetic to get the sum. It then complements the sum to get the checksum and sends it along with the data frames.
-
The receiver adds the incoming segments along with the checksum using 1’s complement arithmetic to get the sum and then complements it.
-
If the result is zero, the received frames are accepted; otherwise, they are discarded.
Cyclic Redundancy Check (CRC)
Cyclic Redundancy Check (CRC) involves binary division of the data bits being sent by a predetermined divisor agreed upon by the communicating system. The divisor is generated using polynomials.
-
Here, the sender performs binary division of the data segment by the divisor. It then appends the remainder called CRC bits to the end of the data segment. This makes the resulting data unit exactly divisible by the divisor.
-
The receiver divides the incoming data unit by the divisor. If there is no remainder, the data unit is assumed to be correct and is accepted. Otherwise, it is understood that the data is corrupted and is therefore rejected.
Error Correction Techniques
Error correction techniques find out the exact number of bits that have been corrupted and as well as their locations. There are two principle ways
-
Backward Error Correction (Retransmission) − If the receiver detects an error in the incoming frame, it requests the sender to retransmit the frame. It is a relatively simple technique. But it can be efficiently used only where retransmitting is not expensive as in fiber optics and the time for retransmission is low relative to the requirements of the application.
-
Forward Error Correction − If the receiver detects some error in the incoming frame, it executes error-correcting code that generates the actual frame. This saves bandwidth required for retransmission. It is inevitable in real-time systems. However, if there are too many errors, the frames need to be retransmitted.
The four main error correction codes are
- Hamming Codes
- Binary Convolution Code
- Reed – Solomon Code
- Low-Density Parity-Check Code
Data-link layer uses error control techniques to ensure that frames, i.e. bit streams of data, are transmitted from the source to the destination with a certain extent of accuracy.
Errors
When bits are transmitted over the computer network, they are subject to get corrupted due to interference and network problems. The corrupted bits leads to spurious data being received by the destination and are called errors.
Types of Errors
Errors can be of three types, namely single bit errors, multiple bit errors, and burst errors.
-
Single bit error − In the received frame, only one bit has been corrupted, i.e. either changed from 0 to 1 or from 1 to 0.
-
Multiple bits error − In the received frame, more than one bits are corrupted.
-
Burst error − In the received frame, more than one consecutive bits are corrupted.
Error Control
Error control can be done in two ways
-
Error detection − Error detection involves checking whether any error has occurred or not. The number of error bits and the type of error does not matter.
-
Error correction − Error correction involves ascertaining the exact number of bits that has been corrupted and the location of the corrupted bits.
For both error detection and error correction, the sender needs to send some additional bits along with the data bits. The receiver performs necessary checks based upon the additional redundant bits. If it finds that the data is free from errors, it removes the redundant bits before passing the message to the upper layers.
Error Detection Techniques
There are three main techniques for detecting errors in frames: Parity Check, Checksum and Cyclic Redundancy Check (CRC).
Parity Check
The parity check is done by adding an extra bit, called parity bit to the data to make a number of 1s either even in case of even parity or odd in case of odd parity.
While creating a frame, the sender counts the number of 1s in it and adds the parity bit in the following way
-
In case of even parity: If a number of 1s is even then parity bit value is 0. If the number of 1s is odd then parity bit value is 1.
-
In case of odd parity: If a number of 1s is odd then parity bit value is 0. If a number of 1s is even then parity bit value is 1.
On receiving a frame, the receiver counts the number of 1s in it. In case of even parity check, if the count of 1s is even, the frame is accepted, otherwise, it is rejected. A similar rule is adopted for odd parity check.
The parity check is suitable for single bit error detection only.
Checksum
In this error detection scheme, the following procedure is applied
-
Data is divided into fixed sized frames or segments.
-
The sender adds the segments using 1’s complement arithmetic to get the sum. It then complements the sum to get the checksum and sends it along with the data frames.
-
The receiver adds the incoming segments along with the checksum using 1’s complement arithmetic to get the sum and then complements it.
-
If the result is zero, the received frames are accepted; otherwise, they are discarded.
Cyclic Redundancy Check (CRC)
Cyclic Redundancy Check (CRC) involves binary division of the data bits being sent by a predetermined divisor agreed upon by the communicating system. The divisor is generated using polynomials.
-
Here, the sender performs binary division of the data segment by the divisor. It then appends the remainder called CRC bits to the end of the data segment. This makes the resulting data unit exactly divisible by the divisor.
-
The receiver divides the incoming data unit by the divisor. If there is no remainder, the data unit is assumed to be correct and is accepted. Otherwise, it is understood that the data is corrupted and is therefore rejected.
Error Correction Techniques
Error correction techniques find out the exact number of bits that have been corrupted and as well as their locations. There are two principle ways
-
Backward Error Correction (Retransmission) − If the receiver detects an error in the incoming frame, it requests the sender to retransmit the frame. It is a relatively simple technique. But it can be efficiently used only where retransmitting is not expensive as in fiber optics and the time for retransmission is low relative to the requirements of the application.
-
Forward Error Correction − If the receiver detects some error in the incoming frame, it executes error-correcting code that generates the actual frame. This saves bandwidth required for retransmission. It is inevitable in real-time systems. However, if there are too many errors, the frames need to be retransmitted.
The four main error correction codes are
- Hamming Codes
- Binary Convolution Code
- Reed – Solomon Code
- Low-Density Parity-Check Code
 Корректирующие (или помехоустойчивые) коды — это коды, которые могут обнаружить и, если повезёт, исправить ошибки, возникшие при передаче данных. Даже если вы ничего не слышали о них, то наверняка встречали аббревиатуру CRC в списке файлов в ZIP-архиве или даже надпись ECC на планке памяти. А кто-то, может быть, задумывался, как так получается, что если поцарапать DVD-диск, то данные всё равно считываются без ошибок. Конечно, если царапина не в сантиметр толщиной и не разрезала диск пополам.
Корректирующие (или помехоустойчивые) коды — это коды, которые могут обнаружить и, если повезёт, исправить ошибки, возникшие при передаче данных. Даже если вы ничего не слышали о них, то наверняка встречали аббревиатуру CRC в списке файлов в ZIP-архиве или даже надпись ECC на планке памяти. А кто-то, может быть, задумывался, как так получается, что если поцарапать DVD-диск, то данные всё равно считываются без ошибок. Конечно, если царапина не в сантиметр толщиной и не разрезала диск пополам.
Как нетрудно догадаться, ко всему этому причастны корректирующие коды. Собственно, ECC так и расшифровывается — «error-correcting code», то есть «код, исправляющий ошибки». А CRC — это один из алгоритмов, обнаруживающих ошибки в данных. Исправить он их не может, но часто это и не требуется.
Давайте же разберёмся, что это такое.
Для понимания статьи не нужны никакие специальные знания. Достаточно лишь понимать, что такое вектор и матрица, как они перемножаются и как с их помощью записать систему линейных уравнений.
Внимание! Много текста и мало картинок. Я постарался всё объяснить, но без карандаша и бумаги текст может показаться немного запутанным.
Каналы с ошибкой
Разберёмся сперва, откуда вообще берутся ошибки, которые мы собираемся исправлять. Перед нами стоит следующая задача. Нужно передать несколько блоков данных, каждый из которых кодируется цепочкой двоичных цифр. Получившаяся последовательность нулей и единиц передаётся через канал связи. Но так сложилось, что реальные каналы связи часто подвержены ошибкам. Вообще говоря, ошибки могут быть разных видов — может появиться лишняя цифра или какая-то пропасть. Но мы будем рассматривать только ситуации, когда в канале возможны лишь замены нуля на единицу и наоборот. Причём опять же для простоты будем считать такие замены равновероятными.
Ошибка — это маловероятное событие (а иначе зачем нам такой канал вообще, где одни ошибки?), а значит, вероятность двух ошибок меньше, а трёх уже совсем мала. Мы можем выбрать для себя некоторую приемлемую величину вероятности, очертив границу «это уж точно невозможно». Это позволит нам сказать, что в канале возможно не более, чем  ошибок. Это будет характеристикой канала связи.
ошибок. Это будет характеристикой канала связи.
Для простоты введём следующие обозначения. Пусть данные, которые мы хотим передавать, — это двоичные последовательности фиксированной длины. Чтобы не запутаться в нулях и единицах, будем иногда обозначать их заглавными латинскими буквами ( ,
,  ,
,  , …). Что именно передавать, в общем-то неважно, просто с буквами в первое время будет проще работать.
, …). Что именно передавать, в общем-то неважно, просто с буквами в первое время будет проще работать.
Кодирование и декодирование будем обозначать прямой стрелкой ( ), а передачу по каналу связи — волнистой стрелкой (
), а передачу по каналу связи — волнистой стрелкой ( ). Ошибки при передаче будем подчёркивать.
). Ошибки при передаче будем подчёркивать.
Например, пусть мы хотим передавать только сообщения  и
и  . В простейшем случае их можно закодировать нулём и единицей (сюрприз!):
. В простейшем случае их можно закодировать нулём и единицей (сюрприз!):

Передача по каналу, в котором возникла ошибка будет записана так:

Цепочки нулей и единиц, которыми мы кодируем буквы, будем называть кодовыми словами. В данном простом случае кодовые слова — это  и
и  .
.
Код с утроением
Давайте попробуем построить какой-то корректирующий код. Что мы обычно делаем, когда кто-то нас не расслышал? Повторяем дважды:

Правда, это нам не очень поможет. В самом деле, рассмотрим канал с одной возможной ошибкой:

Какие выводы мы можем сделать, когда получили  ? Понятно, что раз у нас не две одинаковые цифры, то была ошибка, но вот в каком разряде? Может, в первом, и была передана буква . А может, во втором, и была передана .
? Понятно, что раз у нас не две одинаковые цифры, то была ошибка, но вот в каком разряде? Может, в первом, и была передана буква . А может, во втором, и была передана .
То есть, получившийся код обнаруживает, но не исправляет ошибки. Ну, тоже неплохо, в общем-то. Но мы пойдём дальше и будем теперь утраивать цифры.

Проверим в деле:

Получили  . Тут у нас есть две возможности: либо это и было две ошибки (в крайних цифрах), либо это и была одна ошибка. Вообще, вероятность одной ошибки выше вероятности двух ошибок, так что самым правдоподобным будет предположение о том, что передавалась именно буква . Хотя правдоподобное — не значит истинное, поэтому рядом и стоит вопросительный знак.
. Тут у нас есть две возможности: либо это и было две ошибки (в крайних цифрах), либо это и была одна ошибка. Вообще, вероятность одной ошибки выше вероятности двух ошибок, так что самым правдоподобным будет предположение о том, что передавалась именно буква . Хотя правдоподобное — не значит истинное, поэтому рядом и стоит вопросительный знак.
Если в канале связи возможна максимум одна ошибка, то первое предположение о двух ошибках становится невозможным и остаётся только один вариант — передавалась буква .
Про такой код говорят, что он исправляет одну ошибку. Две он тоже обнаружит, но исправит уже неверно.
Это, конечно, самый простой код. Кодировать легко, да и декодировать тоже. Ноликов больше — значит передавался ноль, единичек — значит единица.
Если немного подумать, то можно предложить код исправляющий две ошибки. Это будет код, в котором мы повторяем одиночный бит 5 раз.
Расстояния между кодами
Рассмотрим поподробнее код с утроением. Итак, мы получили работающий код, который исправляет одиночную ошибку. Но за всё хорошее надо платить: он кодирует один бит тремя. Не очень-то и эффективно.
И вообще, почему этот код работает? Почему нужно именно утраивать для устранения одной ошибки? Наверняка это всё неспроста.
Давайте подумаем, как этот код работает. Интуитивно всё понятно. Нолики и единички — это две непохожие последовательности. Так как они достаточно длинные, то одиночная ошибка не сильно портит их вид.
Пусть мы передавали  , а получили
, а получили  . Видно, что эта цепочка больше похожа на исходные , чем на
. Видно, что эта цепочка больше похожа на исходные , чем на  . А так как других кодовых слов у нас нет, то и выбор очевиден.
. А так как других кодовых слов у нас нет, то и выбор очевиден.
Но что значит «больше похоже»? А всё просто! Чем больше символов у двух цепочек совпадает, тем больше их схожесть. Если почти все символы отличаются, то цепочки «далеки» друг от друга.
Можно ввести некоторую величину  , равную количеству различающихся цифр в соответствующих разрядах цепочек
, равную количеству различающихся цифр в соответствующих разрядах цепочек  и
и  . Эту величину называют расстоянием Хэмминга. Чем больше это расстояние, тем меньше похожи две цепочки.
. Эту величину называют расстоянием Хэмминга. Чем больше это расстояние, тем меньше похожи две цепочки.
Например,  , так как все цифры в соответствующих позициях равны, а вот
, так как все цифры в соответствующих позициях равны, а вот  .
.
Расстояние Хэмминга называют расстоянием неспроста. Ведь в самом деле, что такое расстояние? Это какая-то характеристика, указывающая на близость двух точек, и для которой верны утверждения:
- Расстояние между точками неотрицательно и равно нулю только, если точки совпадают.
- Расстояние в обе стороны одинаково.
- Путь через третью точку не короче, чем прямой путь.
Достаточно разумные требования.
Математически это можно записать так (нам это не пригодится, просто ради интереса посмотрим):

- .


 .
.Предлагаю читателю самому убедиться, что для расстояния Хэмминга эти свойства выполняются.
Окрестности
Таким образом, разные цепочки мы считаем точками в каком-то воображаемом пространстве, и теперь мы умеем находить расстояния между ними. Правда, если попытаться сколько нибудь длинные цепочки расставить на листе бумаги так, чтобы расстояния Хэмминга совпадали с расстояниями на плоскости, мы можем потерпеть неудачу. Но не нужно переживать. Всё же это особое пространство со своими законами. А слова вроде «расстояния» лишь помогают нам рассуждать.
Пойдём дальше. Раз мы заговорили о расстоянии, то можно ввести такое понятие как окрестность. Как известно, окрестность какой-то точки — это шар определённого радиуса с центром в ней. Шар? Какие ещё шары! Мы же о кодах говорим.
Но всё просто. Ведь что такое шар? Это множество всех точек, которые находятся от данной не дальше, чем некоторое расстояние, называемое радиусом. Точки у нас есть, расстояние у нас есть, теперь есть и шары.
Так, скажем, окрестность кодового слова радиуса 1 — это все коды, находящиеся на расстоянии не больше, чем 1 от него, то есть отличающиеся не больше, чем в одном разряде. То есть это коды:

Да, вот так странно выглядят шары в пространстве кодов.
А теперь посмотрите. Это же все возможные коды, которые мы получим в канале в одной ошибкой, если отправим ! Это следует прямо из определения окрестности. Ведь каждая ошибка заставляет цепочку измениться только в одном разряде, а значит удаляет её на расстояние 1 от исходного сообщения.
Аналогично, если в канале возможны две ошибки, то отправив некоторое сообщение  , мы получим один из кодов, который принадлежит окрестности радиусом 2.
, мы получим один из кодов, который принадлежит окрестности радиусом 2.
Тогда всю нашу систему декодирования можно построить так. Мы получаем какую-то цепочку нулей и единиц (точку в нашей новой терминологии) и смотрим, в окрестность какого кодового слова она попадает.
Сколько ошибок может исправить код?
Чтобы код мог исправлять больше ошибок, окрестности должны быть как можно шире. С другой стороны, они не должны пересекаться. Иначе если точка попадёт в область пересечения, непонятно будет, к какой окрестности её отнести.
В коде с удвоением между кодовыми словами  и
и  расстояние равно 2 (оба разряда различаются). А значит, если мы построим вокруг них шары радиуса 1, то они будут касаться. Это значит, точка касания будет принадлежать обоим шарам и непонятно будет, к какому из них её отнести.
расстояние равно 2 (оба разряда различаются). А значит, если мы построим вокруг них шары радиуса 1, то они будут касаться. Это значит, точка касания будет принадлежать обоим шарам и непонятно будет, к какому из них её отнести.
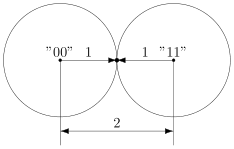
Именно это мы и получали. Мы видели, что есть ошибка, но не могли её исправить.
Что интересно, точек касания в нашем странном пространстве у шаров две — это коды и  . Расстояния от них до центров равны единице. Конечно же, в обычно геометрии такое невозможно, поэтому рисунки — это просто условность для более удобного рассуждения.
. Расстояния от них до центров равны единице. Конечно же, в обычно геометрии такое невозможно, поэтому рисунки — это просто условность для более удобного рассуждения.
В случае кода с утроением, между шарами будет зазор.

Минимальный зазор между шарами равен 1, так как у нас расстояния всегда целые (ну не могут же две цепочки отличаться в полутора разрядах).
В общем случае получаем следующее.
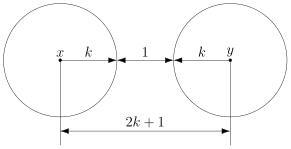
Этот очевидный результат на самом деле очень важен. Он означает, что код с минимальным кодовым расстоянием  будет успешно работать в канале с ошибками, если выполняется соотношение
будет успешно работать в канале с ошибками, если выполняется соотношение

Полученное равенство позволяет легко определить, сколько ошибок будет исправлять тот или иной код. А сколько код ошибок может обнаружить? Рассуждения такие же. Код обнаруживает ошибок, если в результате не получится другое кодовое слово. То есть, кодовые слова не должны находиться в окрестностях радиуса других кодовых слов. Математически это записывается так:

Рассмотрим пример. Пусть мы кодируем 4 буквы следующим образом.

Чтобы найти минимальное расстояние между различными кодовыми словами, построим таблицу попарных расстояний.
| A | B | C | D | |
|---|---|---|---|---|
| A | — | 3 | 3 | 4 |
| B | 3 | — | 4 | 3 |
| C | 3 | 4 | — | 3 |
| D | 4 | 3 | 3 | — |
Минимальное расстояние  , а значит
, а значит  , откуда получаем, что такой код может исправить до
, откуда получаем, что такой код может исправить до  ошибок. Обнаруживает же он две ошибки.
ошибок. Обнаруживает же он две ошибки.
Рассмотрим пример:

Чтобы декодировать полученное сообщение, посмотрим, к какому символу оно ближе всего.

Минимальное расстояние получилось для символа , значит вероятнее всего передавался именно он:

Итак, этот код исправляет одну ошибку, как и код с утроением. Но он более эффективен, так как в отличие от кода с утроением здесь кодируется уже 4 символа.
Таким образом, основная проблема при построении такого рода кодов — так расположить кодовые слова, чтобы они были как можно дальше друг от друга, и их было побольше.
Для декодирования можно было бы использовать таблицу, в которой указывались бы все возможные принимаемые сообщения, и кодовые слова, которым они соответствуют. Но такая таблица получилась бы очень большой. Даже для нашего маленького кода, который выдаёт 5 двоичных цифр, получилось бы  варианта возможных принимаемых сообщений. Для более сложных кодов таблица будет значительно больше.
варианта возможных принимаемых сообщений. Для более сложных кодов таблица будет значительно больше.
Попробуем придумать способ коррекции сообщения без таблиц. Мы всегда сможем найти полезное применение освободившейся памяти.
Интерлюдия: поле GF(2)
Для изложения дальнейшего материала нам потребуются матрицы. А при умножении матриц, как известно мы складываем и перемножаем числа. И тут есть проблема. Если с умножением всё более-менее хорошо, то как быть со сложением? Из-за того, что мы работаем только с одиночными двоичными цифрами, непонятно, как сложить 1 и 1, чтобы снова получилась одна двоичная цифра. Значит вместо классического сложения нужно использовать какое-то другое.
Введём операцию сложения как сложение по модулю 2 (хорошо известный программистам XOR):

Умножение будем выполнять как обычно. Эти операции на самом деле введены не абы как, а чтобы получилась система, которая в математике называется полем. Поле — это просто множество (в нашем случае из 0 и 1), на котором так определены сложение и умножение, чтобы основные алгебраические законы сохранялись. Например, чтобы основные идеи, касающиеся матриц и систем уравнений по-прежнему были верны. А вычитание и деление мы можем ввести как обратные операции.
Множество из двух элементов  с операциями, введёнными так, как мы это сделали, называется полем Галуа GF(2). GF — это Galois field, а 2 — количество элементов.
с операциями, введёнными так, как мы это сделали, называется полем Галуа GF(2). GF — это Galois field, а 2 — количество элементов.
У сложения есть несколько очень полезных свойств, которыми мы будем пользоваться в дальнейшем.

Это свойство прямо следует из определения.

А в этом можно убедиться, прибавив  к обеим частям равенства. Это свойство, в частности означает, что мы можем переносить в уравнении слагаемые в другую сторону без смены знака.
к обеим частям равенства. Это свойство, в частности означает, что мы можем переносить в уравнении слагаемые в другую сторону без смены знака.
Проверяем корректность
Вернёмся к коду с утроением.
Для начала просто решим задачу проверки, были ли вообще ошибки при передаче. Как видно, из самого кода, принятое сообщение будет кодовым словом только тогда, когда все три цифры равны между собой.
Пусть мы приняли вектор-строку из трёх цифр. (Стрелочки над векторами рисовать не будем, так как у нас почти всё — это вектора или матрицы.)

Математически равенство всех трёх цифр можно записать как систему:

Или, если воспользоваться свойствами сложения в GF(2), получаем

Или

В матричном виде эта система будет иметь вид

где

Транспонирование здесь нужно потому, что — это вектор-строка, а не вектор-столбец. Иначе мы не могли бы умножать его справа на матрицу.
Будем называть матрицу  проверочной матрицей. Если полученное сообщение — это корректное кодовое слово (то есть, ошибки при передаче не было), то произведение проверочной матрицы на это сообщение будет равно нулевому вектору.
проверочной матрицей. Если полученное сообщение — это корректное кодовое слово (то есть, ошибки при передаче не было), то произведение проверочной матрицы на это сообщение будет равно нулевому вектору.
Умножение на матрицу — это гораздо более эффективно, чем поиск в таблице, но у нас на самом деле есть ещё одна таблица — это таблица кодирования. Попробуем от неё избавиться.
Кодирование
Итак, у нас есть система для проверки
Её решения — это кодовые слова. Собственно, мы систему и строили на основе кодовых слов. Попробуем теперь решить обратную задачу. По системе (или, что то же самое, по матрице ) найдём кодовые слова.
Правда, для нашей системы мы уже знаем ответ, поэтому, чтобы было интересно, возьмём другую матрицу:

Соответствующая система имеет вид:

Чтобы найти кодовые слова соответствующего кода нужно её решить.
В силу линейности сумма двух решений системы тоже будет решением системы. Это легко доказать. Если  и
и  — решения системы, то для их суммы верно
— решения системы, то для их суммы верно

что означает, что она тоже — решение.
Поэтому если мы найдём все линейно независимые решения, то с их помощью можно получить вообще все решения системы. Для этого просто нужно найти их всевозможные суммы.
Выразим сперва все зависимые слагаемые. Их столько же, сколько и уравнений. Выражать надо так, чтобы справа были только независимые. Проще всего выразить  .
.
Если бы нам не так повезло с системой, то нужно было бы складывая уравнения между собой получить такую систему, чтобы какие-то три переменные встречались по одному разу. Ну, или воспользоваться методом Гаусса. Для GF(2) он тоже работает.
Итак, получаем:

Чтобы получить все линейно независимые решения, приравниваем каждую из зависимых переменных к единице по очереди.

Всевозможные суммы этих независимых решений (а именно они и будут кодовыми векторами) можно получить так:

где  равны либо нулю или единице. Так как таких коэффициентов два, то всего возможно
равны либо нулю или единице. Так как таких коэффициентов два, то всего возможно  сочетания.
сочетания.
Но посмотрите! Формула, которую мы только что получили — это же снова умножение матрицы на вектор.

Строчки здесь — линейно независимые решения, которые мы получили. Матрица  называется порождающей. Теперь вместо того, чтобы сами составлять таблицу кодирования, мы можем получать кодовые слова простым умножением на матрицу:
называется порождающей. Теперь вместо того, чтобы сами составлять таблицу кодирования, мы можем получать кодовые слова простым умножением на матрицу:

Найдём кодовые слова для этого кода. (Не забываем, что длина исходных сообщений должна быть равна 2 — это количество найденных решений.)

Итак, у нас есть готовый код, обнаруживающий ошибки. Проверим его в деле. Пусть мы хотим отправить 01 и у нас произошла ошибка при передаче. Обнаружит ли её код?

А раз в результате не нулевой вектор, значит код заподозрил неладное. Провести его не удалось. Ура, код работает!
Для кода с утроением, кстати, порождающая матрица выглядит очень просто:

Подобные коды, которые можно порождать и проверять матрицей называются линейными (бывают и нелинейные), и они очень широко применяются на практике. Реализовать их довольно легко, так как тут требуется только умножение на константную матрицу.
Ошибка по синдрому
Ну хорошо, мы построили код обнаруживающий ошибки. Но мы же хотим их исправлять!
Для начала введём такое понятие, как вектор ошибки. Это вектор, на который отличается принятое сообщение от кодового слова. Пусть мы получили сообщение , а было отправлено кодовое слово  . Тогда вектор ошибки по определению
. Тогда вектор ошибки по определению

Но в странном мире GF(2), где сложение и вычитание одинаковы, будут верны и соотношения:

В силу особенностей сложения, как читатель сам может легко убедиться, в векторе ошибки на позициях, где произошла ошибка будет единица, а на остальных ноль.
Как мы уже говорили раньше, если мы получили сообщение с ошибкой, то  . Но ведь векторов, не равных нулю много! Быть может то, какой именно ненулевой вектор мы получили, подскажет нам характер ошибки?
. Но ведь векторов, не равных нулю много! Быть может то, какой именно ненулевой вектор мы получили, подскажет нам характер ошибки?
Назовём результат умножения на проверочную матрицу синдромом:

И заметим следующее

Это означает, что для ошибки синдром будет таким же, как и для полученного сообщения.
Разложим все возможные сообщения, которые мы можем получить из канала связи, по кучкам в зависимости от синдрома. Тогда из последнего соотношения следует, что в каждой кучке будут вектора с одной и той же ошибкой. Причём вектор этой ошибки тоже будет в кучке. Вот только как его узнать?
А очень просто! Помните, мы говорили, что у нескольких ошибок вероятность ниже, чем у одной ошибки? Руководствуясь этим соображением, наиболее правдоподобным будет считать вектором ошибки тот вектор, у которого меньше всего единиц. Будем называть его лидером.
Давайте посмотрим, какие синдромы дают всевозможные 5-элементные векторы. Сразу сгруппируем их и подчеркнём лидеров — векторы с наименьшим числом единиц.
 |
|
|---|---|
|
 |
|
 |
|
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
 |
В принципе, для корректирования ошибки достаточно было бы хранить таблицу соответствия синдрома лидеру.
Обратите внимание, что в некоторых строчках два лидера. Это значит для для данного синдрома два паттерна ошибки равновероятны. Иными словами, код обнаружил две ошибки, но исправить их не может.
Лидеры для всех возможных одиночных ошибок находятся в отдельных строках, а значит код может исправить любую одиночную ошибку. Ну, что же… Попробуем в этом убедиться.

Вектор ошибки равен  , а значит ошибка в третьем разряде. Как мы и загадали.
, а значит ошибка в третьем разряде. Как мы и загадали.
Ура, всё работает!
Что же дальше?
Чтобы попрактиковаться, попробуйте повторить рассуждения для разных проверочных матриц. Например, для кода с утроением.
Логическим продолжением изложенного был бы рассказ о циклических кодах — чрезвычайно интересном подклассе линейных кодов, обладающим замечательными свойствами. Но тогда, боюсь, статья уж очень бы разрослась.
Если вас заинтересовали подробности, то можете почитать замечательную книжку Аршинова и Садовского «Коды и математика». Там изложено гораздо больше, чем представлено в этой статье. Если интересует математика кодирования — то поищите «Теория и практика кодов, контролирующих ошибки» Блейхута. А вообще, материалов по этой теме довольно много.
Надеюсь, когда снова будет свободное время, напишу продолжение, в котором расскажу про циклические коды и покажу пример программы для кодирования и декодирования. Если, конечно, почтенной публике это интересно.
Когда
информация передается между различными
частями компьютера, или с Земли на Луну
и обратно, или просто оставляется на
запоминающем устройстве, существует
вероятность того, что полученный двоичный
код не тождественней исходному коду.
Частицы пыли или жира на магнитном
носителе или сбой схемы могут привести
к неправильной записи или к неправильному
чтению данных. Кроме того, фоновое
излучение некоторых устройств может
привести к изменению кода, хранящегося
в оперативной памяти машины.
Для
решения таких проблем было разработано
большое количество методов кодирования,
позволяющих обнаружить и даже исправить
ошибки. Сегодня эти методы включены во
внутренние составляющие вычислительных
машин и не видны пользователю. Тем не
менее их наличие является важным и
составляет значительную часть научных
исследований. Поэтому мы рассмотрим
некоторые из этих методов, обеспечивающих
надежность современного компьютерного
оборудования.
Контрольный
разряд четности. Простой метод обнаружения
ошибок основывается на том принципе,
что если известно, что обрабатываемый
двоичный код должен содержать нечетное
число единиц, а полученный код содержит
четное число единиц, то произошла ошибка.
Для того чтобы использовать этот принцип,
нам нужна система, в которой каждый код
содержит нечетное число единиц. Этого
легко достичь, добавив дополнительный
разряд, контрольный разряд соответствия
(parity bit), на место старшего разряда.
(Следовательно, каждый 8-битовый код
ASCII станет 9-битовым, а 16-битовой
дополнительный код станет 17-битовым.)
В каждом случае мы присваиваем этому
разряду значение 1 или 0, так чтобы весь
код содержал нечетное число единиц.
Например, ASCII-код буквы А становится
101000001 (контрольный разряд четности 1), а
код буквы F становится 001000110 (контрольный
разряд четности 0) (рис. 1.28). Хотя 8-битовый
код А содержит четное число единиц, а
8-битовый код F — нечетное, 9-битовый код
этих символов содержит нечетное
количество единиц. Теперь, когда мы
модифицировав нашу систему кодирования,
код с четным числом единиц будет означать,
что произошла ошибка и что обрабатываемый
двоичный код — неправильный.

Рисунок
1 — ASCII-коды букв А и F, измененные для
проверки на нечетность
Система
контроля, описанная выше, называется
контролем нечетности (odd parity), так как
мы построили нашу систему таким образом,
что каждый код содержит нечетное число
единиц. Существует также метод-антипод
— контроль четности (even parity). Б таких
системах каждый двоичный код содержит
четное число единиц, и, следовательно,
об ошибке говорит появление кода с
нечетным числом единиц.
Сегодня
использование контрольных разрядов
четности в оперативной памяти компьютера
довольно распространено. Хотя мы
говорили, что ячейка памяти машин состоит
из восьми битов, на самом деле она состоит
из девяти битов, один из которых
используется в качестве контрольного
бита. Каждый раз, когда 8-битовый код
передается в запоминающую схему, схема
добавляет контрольный бит соответствия
и сохраняет получающийся 9-битовый код.
Если код уже был получен, схема проверяет
его на четность. Если в нем нет ошибки,
память убирает контрольный бит и
возвращает 8-битовый код. В противном
случае память возвращает восемь
информационных битов с предупреждением
о том, что возвращенный код может не
совпадать с исходным кодом, помещенным
в память.
Длинные
двоичные коды часто сопровождает набор
контрольных битов четности, которые
образуют контрольный байт. Каждый разряд
в байте соответствует определенной
последовательности битов, находящейся
в коде. Например, один контрольный бит
может соответствовать каждому восьмому
биту кода, начиная с первого, а другой
может соответствовать каждому восьмому
биту, начиная со второго. В этом случае
больше вероятность обнаружить скопление
ошибок в какой-либо области исходного
кода, поскольку они будут находиться в
области действия нескольких контрольных
битов четности. Разновидностью
контрольного байта являются такие схемы
для обнаружения ошибок, как контрольная
сумма и циклический избыточный код.
Коды
с исправлением ошибок. Хотя использование
контрольного разряда четности и позволяет
обнаружить ошибку, но не дает возможности
исправить ее. Многие удивляются тому,
что коды с исправлением ошибок построены
таким образом, что с их помощью можно
не только найти ошибку, но и исправить
ее. Интуиция подсказывает нам, что мы
не сможем исправить ошибку в полученном
сообщении, не зная информацию, которая
в нем содержится. Однако простой
корректирующий код представлен на рис.
2.
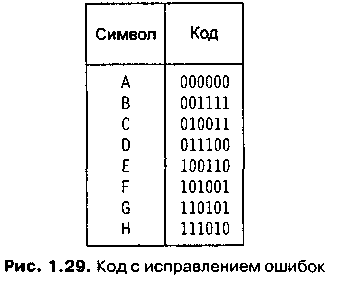
Рисунок
2 – Коды с исправлением ошибок
Для
того чтобы понять, как работает этот
код, определим сначала расстояние
Хемминга (Hamming distance) между двумя кодами
как число различающихся разрядов. Это
расстояние названо в честь Р. В. Хемминга
(R. W. Hamming), который первым стал исследовать
коды с исправлением ошибок, поняв
ненадежность релейных машин в 40-х годах
XX века. Например, расстояние Хемминга
между кодами символов А и В равно четырем
(см. рис. 1.29), а расстояние Хемминга между
В и С равно трем. Важное свойство этой
системы кодирования состоит в том, что
расстояние Хемминга между любыми двумя
кодами больше или равно трем. Поэтому
если один бит в коде будет изменен,
ошибку можно будет обнаружить, так как
результат не будет допустимым кодом.
(Для того чтобы код выглядел, как другой
допустимый код, мы должны изменить по
меньшей мере три бита.)
Кроме
того, если появится ошибка в коде (см.
рис. 1.29), мы сможем понять, как выглядел
исходный код. Расстояние Хемминга между
измененным кодом и исходным будет равно
единице, а между ним и другими допустимыми
кодами — по меньшей мере двум. Для того
чтобы расшифровать сообщение, мы просто
сравниваем каждый полученный код с
кодами в системе до тех пор, пока не
найдем код, находящийся на расстоянии,
равном единице, от исходного кода. Это
и будет правильный символ. Например,
предположим, что мы получили код 010100.
Если мы сравним его с другими кодами,
то получим таблицу расстояний (рис. 3).
Следовательно, мы можем сделать вывод,
что был послан символ D, так как между
его кодом и полученным кодом наименьшее
расстояние.

Рисунок
3 – Расшифровка кодов 010100 с использованием
кодов из рисунка 2
Вы
увидите, что использование этой системы
(коды на рис. 2) позволяет обнаружить до
двух ошибок в одном коде и исправить
одну. Если мы создадим систему, в которой
расстояние Хемминга между любыми двумя
кодами будет равно самое меньшее пяти,
мы сможем обнаружить до четырех ошибок
в одном коде и исправить две. Конечно,
создание эффективной системы кодов с
большими расстояниями Хемминга
представляет собой непростую задачу.
В действительности, она является частью
раздела математики, который называется
алгебраической теорией кодов и входит
в линейную алгебру и теорию матриц.
Методы
исправления ошибок широко применяются
для того, чтобы повысить надежность
компьютерного оборудования. Например,
они часто используются ii дисководах
для магнитных дисков большой емкости,
чтобы уменьшить вероятность того, что
изъян на магнитной поверхности диска
разрушит данные. Кроме того, главное
различие между форматом первоначальных
компакт-дисков, которые использовались
для звукозаписей, и более поздним
форматом, который используется для
хранения данных в компьютере, состоит
в степени исправления ошибок. Формат
CD-DA включает в себя возможности исправления
ошибок, которые сводят частоту появления
ошибок к одной ошибке на два компакт-диска.
Этого достаточно для звукозаписи, но
компании, использующие компакт-диски
для поставки программного обеспечения
покупателям, сказали бы, что наличие
дефектов в 50 процентах дисков — слишком
много. Поэтому в компакт-дисках для
хранения данных применяются дополнительные
возможности исправления ошибок,
сокращающие вероятность появления
ошибки до одной ошибки на 20 000 дисков.
Соседние файлы в папке Комплект Информатика
- #
- #
- #
- #
- #
- #
- #
- #
Лекция 5
Проверка правильности передачи данных
- Причины возникновения ошибок
- Классификация методов защиты от ошибок
- Групповые методы
- мажоритарный
- блок с количественной характеристикой
- Помехоустойчивое кодирование
- Системы передачи с обратной связью
- решающая
- информационная
- Групповые методы
Проблема обеспечения безошибочности (достоверности) передачи информации в
сетях имеет очень большое значение. Если при передаче обычной телеграммы в
тексте возникает ошибка или при разговоре по телефону слышен треск, то в
большинстве случаев ошибки и искажения легко обнаруживаются по смыслу. Но при
передаче данных одна ошибка (искажение одного бита) на тысячу переданных
сигналов может серьезно отразиться на качестве информации.
Существует множество методов обеспечения достоверности передачи информации
(методов защиты от ошибок), отличающихся по используемым для их реализации
средствам, по затратам времени на их применение на передающем и приемном
пунктах, по затратам дополнительного времени на передачу фиксированного объема
данных (оно обусловлено изменением объема трафика пользователя при реализации
данного метода), по степени обеспечения достоверности передачи информации.
Практическое воплощение методов состоит из двух частей — программной и
аппаратной. Соотношение между ними может быть самым различным, вплоть до почти
полного отсутствия одной из частей. Чем больше удельный вес аппаратных средств
по сравнению с программными, тем при прочих равных условиях сложнее
оборудование, реализующее метод, и меньше затрат времени на его реализацию, и
наоборот.
![]()
Причины возникновения ошибок
Выделяют две основные причины возникновения ошибок при передаче информации в
сетях:
- сбои в какой-то части оборудования сети или возникновение
неблагоприятных объективных событий в сети (например, коллизий при
использовании метода случайного доступа в сеть). Как правило, система
передачи данных готова к такого рода проявлениям и устраняет их с помощью
предусмотренных планом средств; - помехи, вызванные внешними источниками и атмосферными явлениями. Помехи
— это электрические возмущения, возникающие в самой аппаратуре или
попадающие в нее извне. Наиболее распространенными являются флуктуационные
(случайные) помехи. Они представляют собой последовательность импульсов,
имеющих случайную амплитуду и следующих друг за другом через различные
промежутки времени. Примерами таких помех могут быть атмосферные и
индустриальные помехи, которые обычно проявляются в виде одиночных импульсов
малой длительности и большой амплитуды. Возможны и сосредоточенные помехи в
виде синусоидальных колебаний. К ним относятся сигналы от посторонних
радиостанций, излучения генераторов высокой частоты. Встречаются и смешанные
помехи. В приемнике помехи могут настолько ослабить информационный сигнал,
что он либо вообще не будет обнаружен, либо будет искажен так, что «единица»
может перейти в «нуль», и наоборот.
Трудности борьбы с помехами заключаются в беспорядочности, нерегулярности и в
структурном сходстве помех с информационными сигналами. Поэтому защита
информации от ошибок и вредного влияния помех имеет большое практическое
значение и является одной из серьезных проблем современной теории и техники
связи.
![]()
Классификация методов защиты от ошибок
Среди многочисленных методов защиты от ошибок выделяются три группы методов:
групповые методы, помехоустойчивое кодирование и методы защиты от ошибок в
системах передачи с обратной связью.
Групповые методы
Из групповых методов получили широкое применение мажоритарный метод,
реализующий принцип Вердана, и метод передач информационными блоками с
количественной характеристикой блока.
- Мажоритарный метод
- Суть этого метода, давно и широко используемого в телеграфии,
состоит в следующем. Каждое сообщение ограниченной длины передается
несколько раз, чаще всего три раза. Принимаемые сообщения запоминаются,
а потом производится их поразрядное сравнение. Суждение о правильности
передачи выносится по совпадению большинства из принятой информации
методом «два из трех». Например, кодовая комбинация 01101 при
трехразовой передаче была частично искажена помехами, поэтому приемник
принял такие комбинации: 10101, 01110, 01001. В результате проверки по
отдельности каждой позиции правильной считается комбинация 01101.- Передача блоками с количественной характеристикой
- Этот метод также не требует перекодирования информации. Он
предполагает передачу данных блоками с количественной характеристикой
блока. Такими характеристиками могут быть: число единиц или нулей в
блоке, контрольная сумма передаваемых символов в блоке, остаток от
деления контрольной суммы на постоянную величину и др. На приемном
пункте эта характеристика вновь подсчитывается и сравнивается с
переданной по каналу связи. Если характеристики совпадают, считается,
что блок не содержит ошибок. В противном случае на передающую сторону
поступает сигнал с требованием повторной передачи блока. В современных
телекоммуникационных вычислительных сетях такой метод получил самое
широкое распространение.
![]()
Помехоустойчивое (избыточное) кодирование
Этот метод предполагает разработку и использование корректирующих
(помехоустойчивых) кодов. Он применяется не только в телекоммуникационных сетях,
но и в ЭВМ для защиты от ошибок при передаче информации между устройствами
машины. Помехоустойчивое кодирование позволяет получить более высокие
качественные показатели работы систем связи. Его основное назначение заключается
в обеспечении малой вероятности искажений передаваемой информации, несмотря на
присутствие помех или сбоев в работе сети.
Существует довольно большое количество различных помехоустойчивых кодов,
отличающихся друг от друга по ряду показателей и прежде всего по своим
корректирующим возможностям.
К числу наиболее важных показателей корректирующих кодов относятся:
- значность кода n, или длина
кодовой комбинации, включающей информационные символы (m)
и проверочные, или контрольные, символы (К):
n = m
+ K
(Значения
контрольных символов при кодировании определяются путем контроля на четность
количества единиц в информационных разрядах кодовой комбинации. Значение
контрольного символа равно 0, если количество единиц будет четным, и равно 1
при нечетном количестве единиц); - избыточность кода Кизб,
выражаемая отношением числа контрольных символов в кодовой комбинации к
значности кода: Кизб = К/
n;
- корректирующая способность кода Ккс, представляющая
собой отношение числа кодовых комбинаций L,
в которых ошибки были обнаружены и исправлены, к общему числу переданных
кодовых комбинаций M в фиксированном объеме
информации: Ккс =
L/ M
Выбор корректирующего кода для его использования в данной компьютерной сети
зависит от требований по достоверности передачи информации. Для правильного
выбора кода необходимы статистические данные о закономерностях появления ошибок,
их характере, численности и распределении во времени. Например, корректирующий
код, обнаруживающий и исправляющий одиночные ошибки, эффективен лишь при
условии, что ошибки статистически независимы, а вероятность их появления не
превышает некоторой величины. Он оказывается непригодным, если ошибки появляются
группами. При выборе кода надо стремиться, чтобы он имел меньшую избыточность.
Чем больше коэффициент Кизб, тем менее эффективно используется
пропускная способность канала связи и больше затрачивается времени на передачу
информации, но зато выше помехоустойчивость системы.
В телекоммуникационных вычислительных сетях корректирующие коды в основном
применяются для обнаружения ошибок, исправление которых осуществляется путем
повторной передачи искаженной информации. С этой целью в сетях используются
системы передачи с обратной связью (наличие между абонентами дуплексной связи
облегчает применение таких систем).
![]()
Системы передачи с обратной связью
Системы передачи с обратной связью делятся на системы с решающей обратной
связью и системы с информационной обратной связью.
- Системы с решающей обратной связью
- Особенностью систем с решающей обратной связью (систем с
перезапросом) является то, что решение о необходимости повторной передачи
информации (сообщения, пакета) принимает приемник. Здесь обязательно применяется
помехоустойчивое кодирование, с помощью которого на приемной станции
осуществляется проверка принимаемой информации. При обнаружении ошибки на
передающую сторону по каналу обратной связи посылается сигнал перезапроса, по
которому информация передается повторно. Канал обратной связи используется также
для посылки сигнала подтверждения правильности приема, автоматически
определяющего начало следующей передачи.- Системы с информационной обратной связью
- В системах с информационной обратной связью передача информации
осуществляется без помехоустойчивого кодирования. Приемник, приняв информацию по
прямому каналу и зафиксировав ее в своей памяти, передает ее в полном объеме по
каналу обратной связи передатчику, где переданная и возвра0щенная информация
сравниваются. При совпадении передатчик посылает приемнику сигнал подтверждения,
в противном случае происходит повторная передача всей информации. Таким образом,
здесь решение о необходимости повторной передачи принимает передатчик.
Обе рассмотренные системы обеспечивают практически одинаковую достоверность,
однако в системах с решающей обратной связью пропускная способность каналов
используется эффективнее, поэтому они получили большее распространение.
![]()
Сайт управляется системой uCoz
Обнаружение ошибок в технике связи — действие, направленное на контроль целостности данных при записи/воспроизведении информации или при её передаче по линиям связи. Исправление ошибок (коррекция ошибок) — процедура восстановления информации после чтения её из устройства хранения или канала связи.
Для обнаружения ошибок используют коды обнаружения ошибок, для исправления — корректирующие коды (коды, исправляющие ошибки, коды с коррекцией ошибок, помехоустойчивые коды).
Способы борьбы с ошибками
В процессе хранения данных и передачи информации по сетям связи неизбежно возникают ошибки. Контроль целостности данных и исправление ошибок — важные задачи на многих уровнях работы с информацией (в частности, физическом, канальном, транспортном уровнях модели OSI).
В системах связи возможны несколько стратегий борьбы с ошибками:
- обнаружение ошибок в блоках данных и автоматический запрос повторной передачи повреждённых блоков — этот подход применяется в основном на канальном и транспортном уровнях;
- обнаружение ошибок в блоках данных и отбрасывание повреждённых блоков — такой подход иногда применяется в системах потокового мультимедиа, где важна задержка передачи и нет времени на повторную передачу;
- исправление ошибок (forward error correction) применяется на физическом уровне.
Коды обнаружения и исправления ошибок
Корректирующие коды — коды, служащие для обнаружения или исправления ошибок, возникающих при передаче информации под влиянием помех, а также при её хранении.
Для этого при записи (передаче) в полезные данные добавляют специальным образом структурированную избыточную информацию (контрольное число), а при чтении (приёме) её используют для того, чтобы обнаружить или исправить ошибки. Естественно, что число ошибок, которое можно исправить, ограничено и зависит от конкретного применяемого кода.
С кодами, исправляющими ошибки, тесно связаны коды обнаружения ошибок. В отличие от первых, последние могут только установить факт наличия ошибки в переданных данных, но не исправить её.
В действительности, используемые коды обнаружения ошибок принадлежат к тем же классам кодов, что и коды, исправляющие ошибки. Фактически, любой код, исправляющий ошибки, может быть также использован для обнаружения ошибок (при этом он будет способен обнаружить большее число ошибок, чем был способен исправить).
По способу работы с данными коды, исправляющие ошибки делятся на блоковые, делящие информацию на фрагменты постоянной длины и обрабатывающие каждый из них в отдельности, и свёрточные, работающие с данными как с непрерывным потоком.
Блоковые коды
Пусть кодируемая информация делится на фрагменты длиной 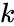 бит, которые преобразуются в кодовые слова длиной
бит, которые преобразуются в кодовые слова длиной 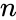 бит. Тогда соответствующий блоковый код обычно обозначают
бит. Тогда соответствующий блоковый код обычно обозначают  . При этом число
. При этом число 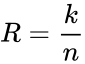 называется скоростью кода.
называется скоростью кода.
Если исходные бит код оставляет неизменными, и добавляет 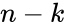 проверочных, такой код называется систематическим, иначе несистематическим.
проверочных, такой код называется систематическим, иначе несистематическим.
Задать блоковый код можно по-разному, в том числе таблицей, где каждой совокупности из информационных бит сопоставляется бит кодового слова. Однако, хороший код должен удовлетворять, как минимум, следующим критериям:
- способность исправлять как можно большее число ошибок,
- как можно меньшая избыточность,
- простота кодирования и декодирования.
Нетрудно видеть, что приведённые требования противоречат друг другу. Именно поэтому существует большое количество кодов, каждый из которых пригоден для своего круга задач.
Практически все используемые коды являются линейными. Это связано с тем, что нелинейные коды значительно сложнее исследовать, и для них трудно обеспечить приемлемую лёгкость кодирования и декодирования.
Линейные коды общего вида
Линейный блоковый код — такой код, что множество его кодовых слов образует -мерное линейное подпространство (назовём его 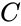 ) в -мерном линейном пространстве, изоморфное пространству -битных векторов.
) в -мерном линейном пространстве, изоморфное пространству -битных векторов.
Это значит, что операция кодирования соответствует умножению исходного -битного вектора на невырожденную матрицу  , называемую порождающей матрицей.
, называемую порождающей матрицей.
Пусть  — ортогональное подпространство по отношению к , а
— ортогональное подпространство по отношению к , а  — матрица, задающая базис этого подпространства. Тогда для любого вектора
— матрица, задающая базис этого подпространства. Тогда для любого вектора  справедливо:
справедливо:

Минимальное расстояние и корректирующая способность
-
Основная статья: Расстояние Хемминга
Расстоянием Хемминга (метрикой Хемминга) между двумя кодовыми словами  и
и 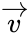 называется количество отличных бит на соответствующих позициях,
называется количество отличных бит на соответствующих позициях,  , что равно числу «единиц» в векторе
, что равно числу «единиц» в векторе  .
.
Минимальное расстояние Хемминга  является важной характеристикой линейного блокового кода. Она показывает насколько «далеко» расположены коды друг от друга. Она определяет другую, не менее важную характеристику — корректирующую способность:
является важной характеристикой линейного блокового кода. Она показывает насколько «далеко» расположены коды друг от друга. Она определяет другую, не менее важную характеристику — корректирующую способность:
- , округляем «вниз», так чтобы .
 , округляем «вниз», так чтобы
, округляем «вниз», так чтобы  .
.Корректирующая способность определяет, сколько ошибок передачи кода (типа  ) можно гарантированно исправить. То есть вокруг каждого кода
) можно гарантированно исправить. То есть вокруг каждого кода 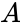 имеем
имеем 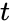 -окрестность
-окрестность 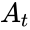 , которая состоит из всех возможных вариантов передачи кода с числом ошибок () не более . Никакие две окрестности двух любых кодов не пересекаются друг с другом, так как расстояние между кодами (то есть центрами этих окрестностей) всегда больше двух их радиусов
, которая состоит из всех возможных вариантов передачи кода с числом ошибок () не более . Никакие две окрестности двух любых кодов не пересекаются друг с другом, так как расстояние между кодами (то есть центрами этих окрестностей) всегда больше двух их радиусов  .
.
Таким образом получив искажённый код из декодер принимает решение, что был исходный код , исправляя тем самым не более ошибок.
Поясним на примере. Предположим, что есть два кодовых слова и  , расстояние Хемминга между ними равно 3. Если было передано слово , и канал внёс ошибку в одном бите, она может быть исправлена, так как даже в этом случае принятое слово ближе к кодовому слову , чем к любому другому, и в частности к . Но если каналом были внесены ошибки в двух битах (в которых отличалось от ) то результат ошибочной передачи окажется ближе к , чем , и декодер примет решение что передавалось слово .
, расстояние Хемминга между ними равно 3. Если было передано слово , и канал внёс ошибку в одном бите, она может быть исправлена, так как даже в этом случае принятое слово ближе к кодовому слову , чем к любому другому, и в частности к . Но если каналом были внесены ошибки в двух битах (в которых отличалось от ) то результат ошибочной передачи окажется ближе к , чем , и декодер примет решение что передавалось слово .
Коды Хемминга
Коды Хемминга — простейшие линейные коды с минимальным расстоянием 3, то есть способные исправить одну ошибку. Код Хемминга может быть представлен в таком виде, что синдром
- , где — принятый вектор, будет равен номеру позиции, в которой произошла ошибка. Это свойство позволяет сделать декодирование очень простым.
 , где
, где 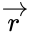 — принятый вектор, будет равен номеру позиции, в которой произошла ошибка. Это свойство позволяет сделать декодирование очень простым.
— принятый вектор, будет равен номеру позиции, в которой произошла ошибка. Это свойство позволяет сделать декодирование очень простым.Общий метод декодирования линейных кодов
Любой код (в том числе нелинейный) можно декодировать с помощью обычной таблицы, где каждому значению принятого слова  соответствует наиболее вероятное переданное слово
соответствует наиболее вероятное переданное слово  . Однако, данный метод требует применения огромных таблиц уже для кодовых слов сравнительно небольшой длины.
. Однако, данный метод требует применения огромных таблиц уже для кодовых слов сравнительно небольшой длины.
Для линейных кодов этот метод можно существенно упростить. При этом для каждого принятого вектора вычисляется синдром  . Поскольку
. Поскольку  , где
, где  — кодовое слово, а
— кодовое слово, а  — вектор ошибки, то
— вектор ошибки, то  . Затем с помощью таблицы по синдрому определяется вектор ошибки, с помощью которого определяется переданное кодовое слово. При этом таблица получается гораздо меньше, чем при использовании предыдущего метода.
. Затем с помощью таблицы по синдрому определяется вектор ошибки, с помощью которого определяется переданное кодовое слово. При этом таблица получается гораздо меньше, чем при использовании предыдущего метода.
Линейные циклические коды
Несмотря на то, что декодирование линейных кодов уже значительно проще декодирования большинства нелинейных, для большинства кодов этот процесс всё ещё достаточно сложен. Циклические коды, кроме более простого декодирования, обладают и другими важными свойствами.
Циклическим кодом является линейный код, обладающий следующим свойством: если является кодовым словом, то его циклическая перестановка также является кодовым словом.
Слова циклического кода удобно представлять в виде многочленов. Например, кодовое слово  представляется в виде полинома
представляется в виде полинома  . При этом циклический сдвиг кодового слова эквивалентен умножению многочлена на
. При этом циклический сдвиг кодового слова эквивалентен умножению многочлена на  по модулю
по модулю  .
.
В дальнейшем, если не указано иное, мы будем считать, что циклический код является двоичным, то есть  могут принимать значения 0 или 1.
могут принимать значения 0 или 1.
Порождающий (генераторный) полином
Можно показать, что все кодовые слова конкретного циклического кода кратны определённому порождающему полиному 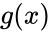 . Порождающий полином является делителем .
. Порождающий полином является делителем .
С помощью порождающего полинома осуществляется кодирование циклическим кодом. В частности:
Коды CRC
Коды CRC (cyclic redundancy check — циклическая избыточная проверка) являются систематическими кодами, предназначенными не для исправления ошибок, а для их обнаружения. Они используют способ систематического кодирования, изложенный выше: «контрольная сумма» вычисляется путем деления 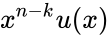 на . Ввиду того, что исправление ошибок не требуется, проверка правильности передачи может производиться точно так же.
на . Ввиду того, что исправление ошибок не требуется, проверка правильности передачи может производиться точно так же.
Таким образом, вид полинома задаёт конкретный код CRC. Примеры наиболее популярных полиномов:
| название кода | степень | полином |
|---|---|---|
| CRC-12 | 12 | 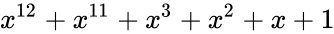 |
| CRC-16 | 16 | 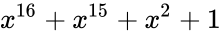 |
| CRC-CCITT | 16 |  |
| CRC-32 | 32 |  |
Коды БЧХ
Коды Боуза — Чоудхури — Хоквингема (БЧХ) являются подклассом циклических кодов. Их отличительное свойство — возможность построения кода БЧХ с минимальным расстоянием не меньше заданного. Это важно, потому что, вообще говоря, определение минимального расстояния кода есть очень сложная задача.
Математически полинома на множители в поле Галуа.
Коды коррекции ошибок Рида — Соломона
Коды Рида — Соломона — недвоичные циклические коды, позволяющие исправлять ошибки в блоках данных. Элементами кодового вектора являются не биты, а группы битов (блоки). Очень распространены коды Рида-Соломона, работающие с байтами (октетами).
Математически коды Рида — Соломона являются кодами БЧХ.
Преимущества и недостатки блоковых кодов
Хотя блоковые коды, как правило, хорошо справляются с редкими, но большими пачками ошибок, их эффективность при частых, но небольших ошибках (например, в канале с АБГШ), менее высока.
Свёрточные коды
Файл:ECC NASA standard coder.png
Свёрточный кодер ( )
)
Свёрточные коды, в отличие от блоковых, не делят информацию на фрагменты и работают с ней как со сплошным потоком данных.
Свёрточные коды, как правило, порождаются дискретной линейной инвариантной во времени системой. Поэтому, в отличие от большинства блоковых кодов, свёрточное кодирование — очень простая операция, чего нельзя сказать о декодировании.
Кодирование свёрточным кодом производится с помощью регистра сдвига, отводы от которого суммируются по модулю два. Таких сумм может быть две (чаще всего) или больше.
Декодирование свёрточных кодов, как правило, производится по алгоритму Витерби, который пытается восстановить переданную последовательность согласно критерию максимального правдоподобия.
Преимущества и недостатки свёрточных кодов
Свёрточные коды эффективно работают в канале с белым шумом, но плохо справляются с пакетами ошибок. Более того, если декодер ошибается, на его выходе всегда возникает пакет ошибок.
Каскадное кодирование. Итеративное декодирование
Преимущества разных способов кодирования можно объединить, применив каскадное кодирование. При этом информация сначала кодируется одним кодом, а затем другим, в результате получается код-произведение.
Например, популярной является следующая конструкция: данные кодируются кодом Рида-Соломона, затем перемежаются (при этом символы, расположенные близко, помещаются далеко друг от друга) и кодируются свёрточным кодом. На приёмнике сначала декодируется свёрточный код, затем осуществляется обратное перемежение (при этом пачки ошибок на выходе свёрточного декодера попадают в разные кодовые слова кода Рида — Соломона), и затем осуществляется декодирование кода Рида — Соломона.
Некоторые коды-произведения специально сконструированы для итеративного декодирования, при котором декодирование осуществляется в несколько проходов, каждый из которых использует информацию от предыдущего. Это позволяет добиться большой эффективности, однако, декодирование требует больших ресурсов. К таким кодам относят турбо-коды и LDPC-коды (коды Галлагера).
Оценка эффективности кодов
Эффективность кодов определяется количеством ошибок, которые тот может исправить, количеством избыточной информации, добавление которой требуется, а также сложностью реализации кодирования и декодирования (как аппаратной, так и в виде программы для ЭВМ).
Граница Хемминга и совершенные коды
-
Основная статья: Граница Хэмминга
Пусть имеется двоичный блоковый 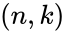 код с корректирующей способностью . Тогда справедливо неравенство (называемое границей Хемминга):
код с корректирующей способностью . Тогда справедливо неравенство (называемое границей Хемминга):

Коды, удовлетворяющие этой границе с равенством, называются совершенными. К совершенным кодам относятся, например, коды Хемминга. Часто применяемые на практике коды с большой корректирующей способностью (такие, как коды Рида — Соломона) не являются совершенными.
Энергетический выигрыш
При передаче информации по каналу связи вероятность ошибки зависит от отношения сигнал/шум на входе демодулятора, таким образом при постоянном уровне шума решающее значение имеет мощность передатчика. В системах спутниковой и мобильной, а также других типов связи остро стоит вопрос экономии энергии. Кроме того, в определённых системах связи (например, телефонной) неограниченно повышать мощность сигнала не дают технические ограничения.
Поскольку помехоустойчивое кодирование позволяет исправлять ошибки, при его применении мощность передатчика можно снизить, оставляя скорость передачи информации неизменной. Энергетический выигрыш определяется как разница отношений с/ш при наличии и отсутствии кодирования.
Применение кодов, исправляющих ошибки
Коды, исправляющие ошибки, применяются:
- в системах цифровой связи, в том числе: спутниковой, радиорелейной, сотовой, передаче данных по телефонным каналам.
- в системах хранения информации, в том числе магнитных и оптических.
Коды, обнаруживающие ошибки, применяются в сетевых протоколах различных уровней.
Автоматический запрос повторной передачи
Системы с автоматическим запросом повторной передачи (ARQ — Automatic Repeat reQuest) основаны на технологии обнаружения ошибок. Распространены следующие методы автоматического запроса:
Запрос ARQ с остановками (stop-and-wait ARQ)
Идея этого метода заключается в том, что передатчик ожидает от приемника подтверждения успешного приема предыдущего блока данных перед тем как начать передачу следующего. В случае, если блок данных был принят с ошибкой, приемник передает отрицательное подтверждение (negative acknowledgement, NAK), и передатчик повторяет передачу блока. Данный метод подходит для полудуплексного канала связи. Его недостатком является низкая скорость из-за высоких накладных расходов на ожидание.
Непрерывный запрос ARQ с возвратом (continuous ARQ with pullback)
Для этого метода необходим полнодуплексный канал. Передача данных от передатчика к приемнику производится одновременно. В случае ошибки передача возобновляется, начиная с ошибочного блока (то есть, передается ошибочный блок и все последующие).
Непрерывный запрос ARQ с выборочным повторением (continuous ARQ with selective repeat)
При этом подходе осуществляется передача только ошибочно принятых блоков данных.
См. также
- Цифровая связь
- Линейный код
- Циклический код
- Код Боуза — Чоудхури — Хоквингема
- Код Рида — Соломона
- LDPC
- Свёрточный код
- Турбо-код
Литература
- Мак-Вильямс Ф. Дж., Слоэн Н. Дж. А. Теория кодов, исправляющих ошибки. М.: Радио и связь, 1979.
- Блейхут Р. Теория и практика кодов, контролирующих ошибки. М.: Мир, 1986.
- Морелос-Сарагоса Р. Искусство помехоустойчивого кодирования. Методы, алгоритмы, применение. М.: Техносфера, 2005. — ISBN 5-94836-035-0
Ссылки
Имеется викиучебник по теме:
Обнаружение и исправление ошибок
- Помехоустойчивое кодирование (11 ноября 2001). — реферат по проблеме кодирования сообщений с исправлением ошибок. Проверено 25 декабря 2006.
Эта страница использует содержимое раздела Википедии на русском языке. Оригинальная статья находится по адресу: Обнаружение и исправление ошибок. Список первоначальных авторов статьи можно посмотреть в истории правок. Эта статья так же, как и статья, размещённая в Википедии, доступна на условиях CC-BY-SA .
Проверка правильности передачи данных
Проблема обеспечения безошибочности (достоверности) передачи информации в сетях имеет очень большое значение. Если при передаче обычной телеграммы в тексте возникает ошибка или при разговоре по телефону слышен треск, то в большинстве случаев ошибки и искажения легко обнаруживаются по смыслу. Но при передаче данных одна ошибка (искажение одного бита) на тысячу переданных сигналов может серьезно отразиться на качестве информации.
Существует множество методов обеспечения достоверности передачи информации (методов защиты от ошибок), отличающихся по используемым для их реализации средствам, по затратам времени на их применение на передающем и приемном пунктах, по затратам дополнительного времени на передачу фиксированного объема данных (оно обусловлено изменением объема трафика пользователя при реализации данного метода), по степени обеспечения достоверности передачи информации. Практическое воплощение методов состоит из двух частей — программной и аппаратной. Соотношение между ними может быть самым различным, вплоть до почти полного отсутствия одной из частей. Чем больше удельный вес аппаратных средств по сравнению с программными, тем при прочих равных условиях сложнее оборудование, реализующее метод, и меньше затрат времени на его реализацию, и наоборот.

Причины возникновения ошибок
Выделяют две основные причины возникновения ошибок при передаче информации в сетях:
- сбои в какой-то части оборудования сети или возникновение неблагоприятных объективных событий в сети (например, коллизий при использовании метода случайного доступа в сеть). Как правило, система передачи данных готова к такого рода проявлениям и устраняет их с помощью предусмотренных планом средств;
- помехи, вызванные внешними источниками и атмосферными явлениями. Помехи — это электрические возмущения, возникающие в самой аппаратуре или попадающие в нее извне. Наиболее распространенными являются флуктуационные (случайные) помехи. Они представляют собой последовательность импульсов, имеющих случайную амплитуду и следующих друг за другом через различные промежутки времени. Примерами таких помех могут быть атмосферные и индустриальные помехи, которые обычно проявляются в виде одиночных импульсов малой длительности и большой амплитуды. Возможны и сосредоточенные помехи в виде синусоидальных колебаний. К ним относятся сигналы от посторонних радиостанций, излучения генераторов высокой частоты. Встречаются и смешанные помехи. В приемнике помехи могут настолько ослабить информационный сигнал, что он либо вообще не будет обнаружен, либо будет искажен так, что «единица» может перейти в «нуль», и наоборот.
Трудности борьбы с помехами заключаются в беспорядочности, нерегулярности и в структурном сходстве помех с информационными сигналами. Поэтому защита информации от ошибок и вредного влияния помех имеет большое практическое значение и является одной из серьезных проблем современной теории и техники связи.
Классификация методов защиты от ошибок
Среди многочисленных методов защиты от ошибок выделяются три группы методов: групповые методы, помехоустойчивое кодирование и методы защиты от ошибок в системах передачи с обратной связью.
Групповые методы
Из групповых методов получили широкое применение мажоритарный метод, реализующий принцип Вердана, и метод передач информационными блоками с количественной характеристикой блока.
Мажоритарный метод Суть этого метода, давно и широко используемого в телеграфии, состоит в следующем. Каждое сообщение ограниченной длины передается несколько раз, чаще всего три раза. Принимаемые сообщения запоминаются, а потом производится их поразрядное сравнение. Суждение о правильности передачи выносится по совпадению большинства из принятой информации методом «два из трех». Например, кодовая комбинация 01101 при трехразовой передаче была частично искажена помехами, поэтому приемник принял такие комбинации: 10101, 01110, 01001. В результате проверки по отдельности каждой позиции правильной считается комбинация 01101.
Передача блоками с количественной характеристикой Этот метод также не требует перекодирования информации. Он предполагает передачу данных блоками с количественной характеристикой блока. Такими характеристиками могут быть: число единиц или нулей в блоке, контрольная сумма передаваемых символов в блоке, остаток от деления контрольной суммы на постоянную величину и др. На приемном пункте эта характеристика вновь подсчитывается и сравнивается с переданной по каналу связи. Если характеристики совпадают, считается, что блок не содержит ошибок. В противном случае на передающую сторону поступает сигнал с требованием повторной передачи блока. В современных телекоммуникационных вычислительных сетях такой метод получил самое широкое распространение.
Помехоустойчивое (избыточное) кодирование
Этот метод предполагает разработку и использование корректирующих (помехоустойчивых) кодов. Он применяется не только в телекоммуникационных сетях, но и в ЭВМ для защиты от ошибок при передаче информации между устройствами машины. Помехоустойчивое кодирование позволяет получить более высокие качественные показатели работы систем связи. Его основное назначение заключается в обеспечении малой вероятности искажений передаваемой информации, несмотря на присутствие помех или сбоев в работе сети.
Существует довольно большое количество различных помехоустойчивых кодов, отличающихся друг от друга по ряду показателей и прежде всего по своим корректирующим возможностям.
К числу наиболее важных показателей корректирующих кодов относятся:
- значность кода n , или длина кодовой комбинации, включающей информационные символы ( m) и проверочные, или контрольные, символы (К): n = m + K
(Значения контрольных символов при кодировании определяются путем контроля на четность количества единиц в информационных разрядах кодовой комбинации. Значение контрольного символа равно 0, если количество единиц будет четным, и равно 1 при нечетном количестве единиц); - избыточность кода Кизб, выражаемая отношением числа контрольных символов в кодовой комбинации к значности кода: Кизб = К/ n ;
- корректирующая способность кода Ккс, представляющая собой отношение числа кодовых комбинаций L , в которых ошибки были обнаружены и исправлены, к общему числу переданных кодовых комбинаций M в фиксированном объеме информации: Ккс = L / M
Выбор корректирующего кода для его использования в данной компьютерной сети зависит от требований по достоверности передачи информации. Для правильного выбора кода необходимы статистические данные о закономерностях появления ошибок, их характере, численности и распределении во времени. Например, корректирующий код, обнаруживающий и исправляющий одиночные ошибки, эффективен лишь при условии, что ошибки статистически независимы, а вероятность их появления не превышает некоторой величины. Он оказывается непригодным, если ошибки появляются группами. При выборе кода надо стремиться, чтобы он имел меньшую избыточность. Чем больше коэффициент Кизб, тем менее эффективно используется пропускная способность канала связи и больше затрачивается времени на передачу информации, но зато выше помехоустойчивость системы.
В телекоммуникационных вычислительных сетях корректирующие коды в основном применяются для обнаружения ошибок, исправление которых осуществляется путем повторной передачи искаженной информации. С этой целью в сетях используются системы передачи с обратной связью (наличие между абонентами дуплексной связи облегчает применение таких систем).
Системы передачи с обратной связью
Системы передачи с обратной связью делятся на системы с решающей обратной связью и системы с информационной обратной связью.
Системы с решающей обратной связью Особенностью систем с решающей обратной связью (систем с перезапросом) является то, что решение о необходимости повторной передачи информации (сообщения, пакета) принимает приемник. Здесь обязательно применяется помехоустойчивое кодирование, с помощью которого на приемной станции осуществляется проверка принимаемой информации. При обнаружении ошибки на передающую сторону по каналу обратной связи посылается сигнал перезапроса, по которому информация передается повторно. Канал обратной связи используется также для посылки сигнала подтверждения правильности приема, автоматически определяющего начало следующей передачи.
Системы с информационной обратной связью В системах с информационной обратной связью передача информации осуществляется без помехоустойчивого кодирования. Приемник, приняв информацию по прямому каналу и зафиксировав ее в своей памяти, передает ее в полном объеме по каналу обратной связи передатчику, где переданная и возвра0щенная информация сравниваются. При совпадении передатчик посылает приемнику сигнал подтверждения, в противном случае происходит повторная передача всей информации. Таким образом, здесь решение о необходимости повторной передачи принимает передатчик.
Обе рассмотренные системы обеспечивают практически одинаковую достоверность, однако в системах с решающей обратной связью пропускная способность каналов используется эффективнее, поэтому они получили большее распространение.
Источник
Способы контроля правильности передачи данных
Управление правильностью (помехозащищенностью) передачи информации выполняется с помощью помехоустойчивого кодирования. Различают коды, обнаруживающие ошибки, и корректирующие коды, которые дополнительно к обнаружению еще и исправляют ошибки. Помехозащищенность достигается с помощью введения избыточности. Устранение ошибок с помощью корректирующих кодов (такое управление называют Forward Error Control) реализуют в симплексных каналах связи. В дуплексных каналах достаточно применения кодов, обнаруживающих ошибки (Feedback or Backward Error Control), так как сигнализация об ошибке вызывает повторную передачу от источника. Это основные методы, используемые в информационных сетях.
Простейшими способами обнаружения ошибок являются контрольное суммирование, проверка на нечетность. Однако они недостаточно надежны, особенно при появлении пачек ошибок. Поэтому в качестве надежных обнаруживающих кодов применяют циклические коды. Примером корректирующего кода является код Хемминга.
В коде Хемминга вводится понятие кодового расстояния d (расстояния между двумя кодами), равного числу разрядов с неодинаковыми значениями. Возможности исправления ошибок связаны с минимальным кодовым расстоянием dmin. Исправляются ошибки кратности r = ent(dmin–1)/2 и обнаруживаются ошибки кратности dmin–1 (здесь ent означает “целая часть”). Так, при контроле на нечетность dmin=2 и обнаруживаются одиночные ошибки. В коде Хемминга dmin=3. Дополнительно к информационным разрядам вводится L=log2K избыточных контролирующих разрядов, где К – число информационных разрядов, L округляется до ближайшего большего целого значения. L-разрядный контролирующий код есть инвертированный результат поразрядного сложения (т.е. сложения по модулю 2) номеров тех информационных разрядов, значения которых равны 1.
Пример 1. Пусть имеем основной код 100110, т.е. К = 6. Следовательно, L = 3 и дополнительный код равен
010 # 011 # 110= 111,
где # – символ операции поразрядного сложения, и после инвертирования имеем 000. Теперь вместе с основным кодом будет передан и дополнительный. На приемном конце вновь рассчитывается дополнительный код и сравнивается с переданным. Фиксируется код сравнения (поразрядная операция отрицания равнозначности), и если он отличен от нуля, то его значение есть номер ошибочно принятого разряда основного кода. Так, если принят код 100010, то рассчитанный в приемнике дополнительный код равен инверсии от 010 # 110 = 100, т.е. 011, что означает ошибку в третьем разряде.
Пример 2. Основной код 1100000, дополнительный код 110 (результат инверсии кода 110 # 111 =001). Пусть принятый код 1101000, его дополнительный код 010, код сравнения 100, т.е. ошибка в четвертом разряде.
К числу эффективных кодов, обнаруживающих одиночные, кратные ошибки и пачки ошибок, относятся циклические коды (CRC – Cyclic Redundance Code). Они высоконадежны и могут применяться при блочной синхронизации, при которой выделение, например, бита нечетности было бы затруднительно.
Один из вариантов циклического кодирования заключается в умножении исходного кода на образующий полином g(Х), a декодирование – в делении на g(Х). Если остаток от деления не равен нулю, то произошла ошибка. Сигнал об ошибке поступает на передатчик, что вызывает повторную передачу.
Образующий полином есть двоичное представление одного из простых множителей, на которые раскладывается число Xn–1, где Xnобозначает единицу в n-м разряде, n равно числу разрядов кодовой группы. Так, если n=10 и Х=2, то Xn–1=1023=11·93, и если g(X) = 11 или в двоичном коде 1011, то примеры циклических кодов Ai·g(X) чисел Aiв кодовой группе при этом образующем полиноме можно видеть в табл. 2.2.
Основной вариант циклического кода, широко применяемый на практике, отличается от предыдущего тем, что операция деления на образующий полином заменяется следующим алгоритмом: 1) к исходному кодируемому числу А справа приписывается К нулей, где К – число битов в образующем полиноме, уменьшенное на единицу; 2) над полученным числом А(2К) выполняется операция О, отличающаяся от деления тем, что на каждом шаге операции вместо вычитания выполняется поразрядная операция “исключающее ИЛИ”; 3) полученный остаток В и есть CRC – избыточный K-разрядный код, который заменяет в закодированном числе С приписанные справа К нулей, т.е.
На приемном конце над кодом С выполняется операция О. Если остаток не равен нулю, то при передаче произошла ошибка и нужна повторная передача кода А.
Пример 3. Пусть А = 1001 1101, образующий полином 11001.
Так как К = 4, то А(2К)=100111010000. Выполнение операции О расчета циклического кода показано на рис. 2.7.
Рис. 2.7. Пример получения циклического кода
Положительными свойствами циклических кодов являются малая вероятность необнаружения ошибки и сравнительно небольшое число избыточных разрядов.
Общепринятое обозначение образующих полиномов дает следующий пример:
g(X) = Xl6 + Х l2 + Х5+ 1,
что эквивалентно коду 1 0001 0000 0010 0001.
Наличие в сообщениях избыточности позволяет ставить вопрос о сжатии данных, т.е. о передаче того же количества информации с помощью последовательностей символов меньшей длины. Для этого используются специальные алгоритмы сжатия, уменьшающие избыточность. Эффект сжатия оценивают коэффициентом сжатия:
где n – число минимально необходимых символов для передачи сообщения (практически это число символов на выходе эталонного алгоритма сжатия); q – число символов в сообщении, сжатом данным алгоритмом. Так, при двоичном кодировании n равно энтропии источника информации. Часто степень сжатия оценивают отношением длин кодов на входе и выходе алгоритма сжатия.
Наряду с методами сжатия, не уменьшающими количество информации в сообщении, применяются методы сжатия, основанные на потере малосущественной информации.
Сжатие данных осуществляется либо на прикладном уровне с помощью программ сжатия, называемых архиваторами, либо с помощью устройств защиты от ошибок (УЗО) непосредственно в составе модемов.
Очевидный способ сжатия числовой информации, представленной в коде ASCII, заключается в использовании сокращенного кода с четырьмя битами на символ вместо восьми, так как передается набор, включающий только 10 цифр, символы “точка”, “запятая” и “пробел”.
Среди простых алгоритмов сжатия наиболее известны алгоритмы RLE (Run Length Encoding). В них вместо передачи цепочки из одинаковых символов передаются символ и значение длины цепочки. Метод эффективен при передаче растровых изображений, но малополезен при передаче текста.
К методам сжатия относят также методы разностного кодирования, поскольку разности амплитуд отсчетов представляются меньшим числом разрядов, чем сами амплитуды. Разностное кодирование реализовано в методах дельта-модуляции и ее разновидностях.
Предсказывающие (предиктивные) методы основаны на экстраполяции значений амплитуд отсчетов, и если выполнено условие
то отсчет должен быть передан, иначе он является избыточным; здесь Аrи Ар– амплитуды реального и предсказанного отсчетов; d – допуск (допустимая погрешность представления амплитуд).
Иллюстрация предсказывающего метода с линейной экстраполяцией представлена на рис. 2.8. Здесь точками показаны предсказываемые значения сигнала. Если точка выходит за пределы “коридора” (допуска d), показанного пунктирными линиями, то происходит передача отсчета. На рис. 2.8 передаваемые отсчеты отмечены темными кружками в моменты времени t1, t2, t4, t7. Если передачи отсчета нет, то на приемном конце принимается экстраполированное значение.
Рис. 2.8. Предиктивное кодирование
Методы MPEG (Moving Pictures Experts Group) используют предсказывающее кодирование изображений (для сжатия данных о движущихся объектах вместе со звуком). Так, если передавать только изменившиеся во времени пиксели изображения, то достигается сжатие в несколько десятков раз. Методы MPEG становятся мировыми стандартами для цифрового телевидения.
Для сжатия данных об изображениях можно использовать также методы типа JPEG (Joint Photographic Expert Group), основанные на потере малосущественной информации (не различимые для глаза оттенки кодируются одинаково, коды могут стать короче). В этих методах передаваемая последовательность пикселей делится на блоки, в каждом блоке производится преобразование Фурье, устраняются высокие частоты, передаются коэффициенты разложения для оставшихся частот, по ним в приемнике изображение восстанавливается.
Другой принцип воплощен в фрактальном кодировании, при котором изображение, представленное совокупностью линий, описывается уравнениями этих линий.
Более универсален широко известный метод Хаффмена, относящийся к статистическим методам сжатия. Идея метода, – часто повторяющиеся символы нужно кодировать более короткими цепочками битов, чем цепочки редких символов. Недостаток метода заключается в необходимости знать вероятности символов. Если заранее они не известны, то требуются два прохода: на одном в передатчике подсчитываются вероятности, на другом эти вероятности и сжатый поток символов передаются к приемнику. Однако двухпроходность не всегда возможна.
Этот недостаток устраняется в однопроходных алгоритмах адаптивного сжатия, в которых схема кодирования есть схема приспособления к текущим особенностям передаваемого потока символов. Поскольку схема кодирования известна как кодеру, так и декодеру, сжатое сообщение будет восстановлено на приемном конце.
Обобщением этого способа является алгоритм, основанный на словаре сжатия данных. В нем происходит выделение и запоминание в словаре повторяющихся цепочек символов, которые кодируются цепочками меньшей длины.
Интересен алгоритм “стопка книг”, в котором код символа равен его порядковому номеру в списке. Появление символа в кодируемом потоке вызывает его перемещение в начало списка. Очевидно, что часто встречающиеся символы будут тяготеть к малым номерам, а они кодируются более короткими цепочками 1 и 0.
Кроме упомянутых алгоритмов сжатия существует ряд других алгоритмов, например LZ-алгоритмы (алгоритмы Лемпеля–Зива). В LZ-алгоритме используется следующая идея: если в тексте сообщения появляется последовательность из двух ранее уже встречавшихся символов, то эта последовательность объявляется новым символом, для нее назначается код, который при определенных условиях может быть значительно короче исходной последовательности. В дальнейшем в сжатом сообщении вместо исходной последовательности записывается назначенный код. При декодировании повторяются аналогичные действия и поэтому становятся известными последовательности символов для каждого кода.
Статьи к прочтению:
- Способы организации и их особенности
- Способы организации высокопроизводительных процессоров. ассоциативные процессоры. конвейерные процессоры. матричные процессоры
Телекоммуникация Часть 6: Способы контроля
Похожие статьи:
Информация в локальных сетях, правило, пересдается отдельным и порциями, кусками, называемыми в различных источниках пакетами кадрами пли блоками….
Процессы передачи или приема информации в вычислительных сетях могут быть привязаны к определенным временным отметкам, т.е. один из процессов может…
Источник
Кодирование и защита от ошибок
Существует три наиболее распространенных орудия борьбы с ошибками в процессе передачи данных:
- коды обнаружения ошибок;
- коды с коррекцией ошибок, называемые также схемами прямой коррекции ошибок (Forward Error Correction — FEC);
- протоколы с автоматическим запросом повторной передачи (Automatic Repeat Request — ARQ).
Код обнаружения ошибок позволяет довольно легко установить наличие ошибки. Как правило, подобные коды используются совместно с определенными протоколами канального или транспортного уровней, имеющими схему ARQ. В схеме ARQ приемник попросту отклоняет блок данных, в котором была обнаружена ошибка, после чего передатчик передает этот блок повторно. Коды с прямой коррекцией ошибок позволяют не только обнаружить ошибки, но и исправить их, не прибегая к повторной передаче. Схемы FEC часто используются в беспроводной передаче, где повторная передача крайне неэффективна, а уровень ошибок довольно высок.
1) Методы обнаружения ошибок
Методы обнаружения ошибок основаны на передаче в составе блока данных избыточной служебной информации, по которой можно судить с некоторой степенью вероятности о достоверности принятых данных.
Избыточную служебную информацию принято называть контрольной суммой, или контрольной последовательностью кадра (Frame Check Sequence, FCS). Контрольная сумма вычисляется как функция от основной информации, причем не обязательно путем суммирования. Принимающая сторона повторно вычисляет контрольную сумму кадра по известному алгоритму и в случае ее совпадения с контрольной суммой, вычисленной передающей стороной, делает вывод о том, что данные были переданы через сеть корректно. Рассмотрим несколько распространенных алгоритмов вычисления контрольной суммы, отличающихся вычислительной сложностью и способностью обнаруживать ошибки в данных.
Контроль по паритету представляет собой наиболее простой метод контроля данных. В то же время это наименее мощный алгоритм контроля, так как с его помощью можно обнаружить только одиночные ошибки в проверяемых данных. Метод заключается в суммировании по модулю 2 всех битов контролируемой информации. Нетрудно заметить, что для информации, состоящей из нечетного числа единиц, контрольная сумма всегда равна 1, а при четном числе единиц — 0. Например, для данных 100101011 результатом контрольного суммирования будет значение 1. Результат суммирования также представляет собой один дополнительный бит данных, который пересылается вместе с контролируемой информацией. При искажении в процессе пересылки любого бита исходных данных (или контрольного разряда) результат суммирования будет отличаться от принятого контрольного разряда, что говорит об ошибке.
Однако двойная ошибка, например 110101010, будет неверно принята за корректные данные. Поэтому контроль по паритету применяется к небольшим порциям данных, как правило, к каждому байту, что дает коэффициент избыточности для этого метода 1/8. Метод редко применяется в компьютерных сетях из-за значительной избыточности и невысоких диагностических способностей.
Вертикальный и горизонтальный контроль по паритету представляет собой модификацию описанного выше метода. Его отличие состоит в том, что исходные данные рассматриваются в виде матрицы, строки которой составляют байты данных. Контрольный разряд подсчитывается отдельно для каждой строки и для каждого столбца матрицы. Этот метод обнаруживает значительную часть двойных ошибок, однако обладает еще большей избыточностью. Он сейчас также почти не применяется при передаче информации по сети.
Циклический избыточный контроль (Cyclic Redundancy Check — CRC) является в настоящее время наиболее популярным методом контроля в вычислительных сетях (и не только в сетях; в частности, этот метод широко применяется при записи данных на гибкие и жесткие диски). Метод основан на рассмотрении исходных данных в виде одного многоразрядного двоичного числа. Например, кадр стандарта Ethernet, состоящий из 1024 байт, будет рассматриваться как одно число, состоящее из 8192 бит. Контрольной информацией считается остаток от деления этого числа на известный делитель R. Обычно в качестве делителя выбирается семнадцати- или тридцатитрехразрядное число, чтобы остаток от деления имел длину 16 разрядов (2 байт) или 32 разряда (4 байт). При получении кадра данных снова вычисляется остаток от деления на тот же делитель R, но при этом к данным кадра добавляется и содержащаяся в нем контрольная сумма.
Если остаток от деления на R равен нулю, то делается вывод об отсутствии ошибок в полученном кадре, в противном случае кадр считается искаженным.
Этот метод обладает более высокой вычислительной сложностью, но его диагностические возможности гораздо шире, чем у методов контроля по паритету. Метод CRC обнаруживает все одиночные ошибки, двойные ошибки и ошибки в нечетном числе битов. Метод также обладает невысокой степенью избыточности. Например, для кадра Ethernet размером 1024 байта контрольная информация длиной 4 байта составляет только 0,4 %.
2) Методы коррекции ошибок
Техника кодирования, которая позволяет приемнику не только понять, что присланные данные содержат ошибки, но и исправить их, называется прямой коррекцией ошибок (Forward Error Correction — FEC). Коды, обеспечивающие прямую коррекцию ошибок, требуют введения большей избыточности в передаваемые данные, чем коды, которые только обнаруживают ошибки.
При применении любого избыточного кода не все комбинации кодов являются разрешенными. Например, контроль по паритету делает разрешенными только половину кодов. Если мы контролируем три информационных бита, то разрешенными 4-битными кодами с дополнением до нечетного количества единиц будут:
000 1, 001 0, 010 0, 011 1, 100 0, 101 1, 110 1, 111 0, то есть всего 8 кодов из 16 возможных.
Для того чтобы оценить количество дополнительных битов, необходимых для исправления ошибок, нужно знать так называемое расстояние Хемминга между разрешенными комбинациями кода. Расстоянием Хемминга называется минимальное число битовых разрядов, в которых отличается любая пара разрешенных кодов. Для схем контроля по паритету расстояние Хемминга равно 2.
Можно доказать, что если мы сконструировали избыточный код с расстоянием Хемминга, равным n, такой код будет в состоянии распознавать (n-1) -кратные ошибки и исправлять (n-1)/2 -кратные ошибки. Так как коды с контролем по паритету имеют расстояние Хемминга, равное 2, они могут только обнаруживать однократные ошибки и не могут исправлять ошибки.
Коды Хемминга эффективно обнаруживают и исправляют изолированные ошибки, то есть отдельные искаженные биты, которые разделены большим количеством корректных битов. Однако при появлении длинной последовательности искаженных битов (пульсации ошибок) коды Хемминга не работают.
Наиболее часто в современных системах связи применяется тип кодирования, реализуемый сверхточным кодирующим устройством (Сonvolutional coder), потому что такое кодирование несложно реализовать аппаратно с использованием линий задержки (delay) и сумматоров. В отличие от рассмотренного выше кода, который относится к блочным кодам без памяти, сверточный код относится к кодам с конечной памятью (Finite memory code); это означает, что выходная последовательность кодера является функцией не только текущего входного сигнала, но также нескольких из числа последних предшествующих битов. Длина кодового ограничения (Constraint length of a code) показывает, как много выходных элементов выходит из системы в пересчете на один входной. Коды часто характеризуются их эффективной степенью (или коэффициентом) кодирования (Code rate). Вам может встретиться сверточный код с коэффициентом кодирования 1/2.
Этот коэффициент указывает, что на каждый входной бит приходится два выходных. При сравнении кодов обращайте внимание на то, что, хотя коды с более высокой эффективной степенью кодирования позволяют передавать данные с более высокой скоростью, они, соответственно, более чувствительны к шуму.
В беспроводных системах с блочными кодами широко используется метод чередования блоков. Преимущество чередования состоит в том, что приемник распределяет пакет ошибок, исказивший некоторую последовательность битов, по большому числу блоков, благодаря чему становится возможным исправление ошибок. Чередование выполняется с помощью чтения и записи данных в различном порядке. Если во время передачи пакет помех воздействует на некоторую последовательность битов, то все эти биты оказываются разнесенными по различным блокам. Следовательно, от любой контрольной последовательности требуется возможность исправить лишь небольшую часть от общего количества инвертированных битов.
3) Методы автоматического запроса повторной передачи
В простейшем случае защита от ошибок заключается только в их обнаружении. Система должна предупредить передатчик об обнаружении ошибки и необходимости повторной передачи. Такие процедуры защиты от ошибок известны как методы автоматического запроса повторной передачи (Automatic Repeat Request — ARQ). В беспроводных локальных сетях применяется процедура «запрос ARQ с остановками» (stop-and-wait ARQ).
В этом случае источник, пославший кадр, ожидает получения подтверждения (Acknowledgement — ACK), или, как еще его называют, квитанции, от приемника и только после этого посылает следующий кадр. Если же подтверждение не приходит в течение тайм-аута, то кадр (или подтверждение) считается утерянным и его передача повторяется. На
рис.
1.13 видно, что в этом случае производительность обмена данными ниже потенциально возможной; хотя передатчик и мог бы послать следующий кадр сразу же после отправки предыдущего, он обязан ждать прихода подтверждения.
Контроль правильности передачи данных
Проверка
правильности передачи данных может
выполняться с использованием 3-х различных
подходов:
-
Обнаружение
ошибок. -
Контроль
ошибок (обнаружение + попытка исправления
путем запроса повторной передачи
данных). -
Исправление
ошибок (восстановление искаженных
данных без их повторной передачи).
Вместе с основной информацией по каналу
связи передаются дополнительные
контрольные данные, позволяющие
приемнику самому восстановить информацию
в случае ее искажения при передаче.
Простейшим
способом обнаружения ошибок при
асинхронной
последовательной передаче
является контроль
четности.
При
этом в состав кадра
вводится дополнительный служебный бит
— бит паритета (рис. 1).
|
|
Рис. 1.
Собственно
алгоритм обнаружения ошибок выглядит
следующим образом:
Действия
передатчика
-
Бит
паритета устанавливается в «0» -
Подсчитывается
количество единиц во всех информационных
битах -
Значение
бита паритета устанавливается таким,
чтобы полученная сумма плюс бит паритета
была четной
Действия
приемника
-
Подсчитывается
количество единиц во всех принятых
информационных битах полюс бит паритета. -
Если
полученная сумма является четной,
данные приняты без искажений, в противном
случае имела место ошибка.
Достоинством
данного метода является его простота.
Недостатком — то, что он может определить
состояние ошибки, только если искажению
подверглось нечетное количество бит.
При искажении, например, двух бит в
символе, данный метод не выявит ошибки.
Тем не менее, он получил очень широкое
распространение и реализован на
аппаратном уровне в большинстве
современных асинхронных приемопередатчиков.
Метод
контроля четности может быть использован
также и при параллельной передаче
данных, если это необходимо. В этом
случае необходимо использовать
дополнительную линию связи для передачи
бита паритета.
Пакетный метод передачи данных по последовательному каналу
При
пакетном методе передачи информация
передается порциями, каждая порция
называется пакетом
(рис. 1).
|
|
Рис. 1.
Пакет
состоит из отдельных символов,
а символ состоит из определенного числа
бит.
В начале пакета находятся стартовые
символы, которые имеют фиксированное
значение. Они определяют момент начала
передачи пакета и позволяют выполнить
синхронизацию приемника
с передатчиком
аналогично варианту асинхронной
передачи. Далее идут информационные
символы, в которых отсутствуют служебные
биты. Далее — контрольные символы,
содержащие информацию, позволяющую
проверить правильность передачи
информационных символов. Стоп-символы
имеют также фиксированное значение и
прием последнего стоп-символа определяет
момент окончания передачи пакета.
При
таком способе с одной стороны отсутствуют
служебные биты в каждом символе (т.е.
сохраняется высокая скорость передачи
данных), с другой стороны существует
возможность синхронизации передатчика
и приемника. Данный способ является
своеобразным «гибридом» синхронной
и асинхронной передачи.
Управление последовательным каналом при полудуплексной связи
При
полудуплексном
режиме
последовательной
передачи,
передача данных возможна в обоих
направлениях, но не одновременно. Это
означает, что на обоих концах линии
связи установлены и приемник,
и передатчик.
Но так как линия связи одна, она
используется поочередно то одной парой
«приемник-передатчик» (для передачи
в одном направлении), то другой парой
(рис. 1).
|
|
Рис. 1.
Следовательно,
необходима процедура согласования
между двумя парами «приемник-передатчик»
для определения права на занятие линии
связи и недопущения одновременного
занятия линии двумя передатчиками.
Для
решения этой задачи используются два
дополнительных управляющих сигнала:
RTS
(Request To Send — запрос на передачу данных)
и CTS
(Clear To Send — разрешение передачи данных).
Устройство, желающее начать передачу
данных, устанавливает активным сигнал
RTS.
Второе устройство, если оно освободило
линию и готово к приему, устанавливает
в ответ сигнал CTS.
Таким образом, в полудуплексном обмене
передача может начаться только при
получении активного сигнала CTS
от устройства, находящегося на другом
конце линии.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Канальный уровень должен обнаруживать ошибки передачи данных, связанные с
искажением бит в принятом кадре данных или с потерей кадра, и по возможности их
корректировать.
Большая часть протоколов канального уровня выполняет только первую задачу —
обнаружение ошибок, считая, что корректировать ошибки, то есть повторно
передавать данные, содержавшие искаженную информацию, должны протоколы верхних
уровней. Так работают такие популярные протоколы локальных сетей, как Ethernet,
Token Ring, FDDI и другие. Однако существуют протоколы канального уровня, например
LLC2 или LAP-B, которые самостоятельно решают задачу восстановления искаженных
или потерянных кадров.
Очевидно, что протоколы должны работать наиболее эффективно в типичных
условиях работы сети. Поэтому для сетей, в которых искажения и потери кадров являются
очень редкими событиями, разрабатываются протоколы типа Ethernet, в которых не
предусматриваются процедуры устранения ошибок. Действительно, наличие процедур
восстановления данных потребовало бы от конечных узлов дополнительных
вычислительных затрат, которые в условиях надежной работы сети являлись бы
избыточными.
Напротив, если в сети искажения и потери случаются часто, то желательно уже
на канальном уровне использовать протокол с коррекцией ошибок, а не оставлять
эту работу протоколам верхних уровней. Протоколы верхних уровней, например
транспортного или прикладного, работая с большими тайм-аутами, восстановят
потерянные данные с большой задержкой. В глобальных сетях первых поколений,
например сетях Х.25, которые работали через ненадежные каналы связи, протоколы
канального уровня всегда выполняли процедуры восстановления потерянных и
искаженных кадров.
Поэтому нельзя считать, что один протокол лучше другого потому, что он
восстанавливает ошибочные кадры, а другой протокол — нет. Каждый протокол должен
работать в тех условиях, для которых он разработан.
Методы обнаружения ошибок
Все методы обнаружения ошибок основаны на передаче в составе кадра данных
служебной избыточной информации, по которой можно судить с некоторой степенью
вероятности о достоверности принятых данных. Эту служебную информацию принято
называть контрольной суммой или (последовательностью
контроля кадра — Frame Check Sequence, FCS). Контрольная сумма вычисляется
как функция от основной информации, причем необязательно только путем суммирования.
Принимающая сторона повторно вычисляет контрольную сумму кадра по известному
алгоритму и в случае ее совпадения с контрольной суммой, вычисленной передающей
стороной, делает вывод о том, что данные были переданы через сеть корректно.
Существует несколько распространенных алгоритмов вычисления контрольной
суммы, отличающихся вычислительной сложностью и способностью обнаруживать
ошибки в данных.
Контроль по паритету представляет собой наиболее простой метод контроля данных. В то же
время это наименее мощный алгоритм контроля, так как с его помощью можно
обнаружить только одиночные ошибки в проверяемых данных. Метод заключается в
суммировании по модулю 2 всех бит контролируемой информации. Например, для
данных 100101011 результатом контрольного суммирования будет значение 1.
Результат суммирования также представляет собой один бит данных, который
пересылается вместе с контролируемой информацией. При искажении при пересылке
любого одного бита исходных данных (или контрольного разряда) результат суммирования
будет отличаться от принятого контрольного разряда, что говорит об ошибке.
Однако двойная ошибка, например 110101010, будет неверно принята за корректные
данные. Поэтому контроль по паритету применяется к небольшим порциям данных,
как правило, к каждому байту, что дает коэффициент избыточности для этого
метода 1/8. Метод редко применяется в вычислительных сетях из-за его большой
избыточности и невысоких диагностических способностей.
Вертикальный и горизонтальный контроль по паритету представляет собой модификацию
описанного выше метода. Его отличие состоит в том, что исходные данные
рассматриваются в виде матрицы, строки которой составляют байты данных.
Контрольный разряд подсчитывается отдельно для каждой строки и для каждого
столбца матрицы. Этот метод обнаруживает большую часть двойных ошибок, однако
обладает еще большей избыточностью. На практике сейчас также почти не
применяется.
Циклический избыточный контроль (Cyclic Redundancy Check, CRC) является в настоящее время наиболее
популярным методом контроля в вычислительных сетях (и не только в сетях,
например, этот метод широко применяется при записи данных на диски и дискеты).
Метод основан на рассмотрении исходных данных в виде одного многоразрядного
двоичного числа. Например, кадр стандарта Ethernet, состоящий из 1024 байт,
будет рассматриваться как одно число, состоящее из 8192 бит. В качестве
контрольной информации рассматривается остаток от деления этого числа на
известный делитель R. Обычно в качестве делителя выбирается семнадцати- или тридцати
трехразрядное число, чтобы остаток от деления имел длину 16 разрядов (2 байт)
или 32 разряда (4 байт). При получении кадра данных снова вычисляется остаток
от деления на тот же делитель R, но при этом к данным кадра добавляется и
содержащаяся в нем контрольная сумма. Если остаток от деления на R равен нулю1 (1 Существуетнесколько
модифицированная процедура вычисления остатка, приводящая к получению в случае
отсутствия ошибок известного ненулевого остатка, что является более надежным
показателем корректности.), то делается вывод об отсутствии ошибок в полученном
кадре, в противном случае кадр считается искаженным.
Этот метод обладает более высокой вычислительной сложностью, но его
диагностические возможности гораздо выше, чем у методов контроля по паритету.
Метод CRC обнаруживает все одиночные ошибки, двойные ошибки и ошибки в нечетном
числе бит. Метод обладает также невысокой степенью избыточности. Например, для
кадра Ethernet размером в 1024 байт контрольная информация длиной в 4 байт
составляет только 0,4 %.
Методы восстановления искаженных и потерянных кадров
Методы коррекции ошибок в вычислительных сетях основаны на повторной
передаче кадра данных в том случае, если кадр теряется и не доходит до адресата
или приемник обнаружил в нем искажение информации. Чтобы убедиться в
необходимости повторной передачи данных, отправитель нумерует отправляемые
кадры и для каждого кадра ожидает от приемника так называемой положительной
квитанции — служебного кадра, извещающего о том, что исходный кадр был
получен и данные в нем оказались корректными. Время этого ожидания ограничено —
при отправке каждого кадра передатчик запускает таймер, и, если по его
истечении положительная квитанция на получена, кадр считается утерянным.
Приемник в случае получения кадра с искаженными данными может отправить отрицательную
квитанцию — явное указание на то, что данный кадр нужно передать
повторно.
Существуют два подхода к организации процесса обмена квитанциями: с
простоями и с организацией «окна».
Метод с простоями (Idle Source) требует, чтобы источник, пославший кадр, ожидал получения квитанции
(положительной или отрицательной) от приемника и только после этого посылал
следующий кадр (или повторял искаженный). Если же квитанция не приходит в
течение тайм-аута, то кадр (или квитанция) считается утерянным и его передача
повторяется. На рис. 2.24, а видно, что в этом случае производительность обмена
данными существенно снижается, — хотя передатчик и мог бы послать следующий
кадр сразу же после отправки предыдущего, он обязан ждать прихода квитанции.
Снижение производительности этого метода коррекции особенно заметно на
низкоскоростных каналах связи, то есть в территориальных сетях.
Рис. 2.24. Методы восстановления искаженных и
потерянных кадров
Второй метод называется методом «скользящего окна» (sliding
window). В этом методе для повышения коэффициента использования линии
источнику разрешается передать некоторое количество кадров в непрерывном
режиме, то есть в максимально возможном для источника темпе, без получения на
эти кадры положительных ответных квитанций. (Далее, где это не искажает
существо рассматриваемого вопроса, положительные квитанции для краткости будут
называться просто «квитанциями».) Количество кадров, которые разрешается
передавать таким образом, называется размером окна. Рисунок 2.24, б
иллюстрирует данный метод для окна размером в W кадров.
В начальный момент, когда еще не послано ни одного кадра, окно определяет
диапазон кадров с номерами от 1 до W включительно. Источник начинает передавать
кадры и получать в ответ квитанции. Для простоты предположим, что квитанции
поступают в той же последовательности, что и кадры, которым они соответствуют.
В момент t1 при получении первой квитанции К1 окно сдвигается
на одну позицию, определяя новый диапазон от 2 до (W+1).
Процессы отправки кадров и получения квитанций идут достаточно независимо
друг от друга. Рассмотрим произвольный момент времени tn, когда источник
получил квитанцию на кадр с номером n. Окно сдвинулось вправо и определило
диапазон разрешенных к передаче кадров от (n+1) до (W+n). Все множество кадров,
выходящих из источника, можно разделить на перечисленные ниже группы (рис.
2.24, б).
- Кадры с номерами от 1 доп. уже были отправлены и квитанции на них
получены, то есть они находятся за пределами окна слева. - Кадры, начиная с номера (п+1) и кончая номером
(W+n), находятся в пределах окна и
потому могут быть отправлены не дожидаясь прихода какой-либо квитанции.
Этот диапазон может быть разделен еще на два поддиапазона: - кадры с номерами от (n+1) до
т, которые уже отправлены, но квитанции на них еще не получены; - кадры с номерами от m до
(W+n), которые пока не отправлены, хотя запрета на это нет. - Все кадры с номерами, большими или равными
(W+n+1), находятся за пределами окна
справа и поэтому пока не могут быть отправлены.
Перемещение окна вдоль последовательности номеров кадров показано на рис.
2.24, в. Здесь t0 — исходный момент, t1 и tn —
моменты прихода квитанций на первый и n-й кадр соответственно. Каждый раз,
когда приходит квитанция, окно сдвигается влево, но его размер при этом не
меняется и остается равным W. Заметим, что хотя в данном примере размер окна в
процессе передачи остается постоянным, в реальных протоколах (например, TCP)
можно встретить варианты данного алгоритма с изменяющимся размером окна.
Итак, при отправке кадра с номером n источнику разрешается передать еще W-1
кадров до получения квитанции на кадр n, так что в сеть последним уйдет кадр с
номером (W+n-1). Если же за это время квитанция на кадр n так и не пришла, то
процесс передачи приостанавливается, и по истечении некоторого тайм-аута кадр n
(или квитанция на него) считается утерянным, и он передается снова.
Если же поток квитанций поступает более-менее регулярно, в пределах допуска
в W кадров, то скорость обмена достигает максимально возможной величины для
данного канала и принятого протокола.
Метод скользящего окна более сложен в реализации, чем метод с простоями,
так как передатчик должен хранить в буфере все кадры, на которые пока не
получены положительные квитанции. Кроме того, требуется отслеживать несколько
параметров алгоритма: размер окна W, номер кадра, на который получена
квитанция, номер кадра, который еще можно передать до получения новой
квитанции.
Приемник может не посылать квитанции на каждый принятый корректный кадр.
Если несколько кадров пришли почти одновременно, то приемник может послать
квитанцию только на последний кадр. При этом подразумевается, что все
предыдущие кадры также дошли благополучно.
Некоторые методы используют отрицательные квитанции. Отрицательные
квитанции бывают двух типов — групповые и избирательные. Групповая квитанция
содержит номер кадра, начиная с которого нужно повторить передачу всех кадров,
отправленных передатчиком в сеть. Избирательная отрицательная квитанция требует
повторной передачи только одного кадра.
Метод скользящего окна реализован во многих протоколах: LLC2, LAP-B, X.25,
TCP, Novell NCP Burst Mode.
Метод с простоями является частным случаем метода скользящего окна, когда
размер окна равен единице.
Метод скользящего окна имеет два параметра, которые могут заметно влиять на
эффективность передачи данных между передатчиком и приемником, — размер окна и
величина тайм-аута ожидания квитанции. В надежных сетях, когда кадры искажаются
и теряются редко, для повышения скорости обмена данными размер окна нужно
увеличивать, так как при этом передатчик будет посылать кадры с меньшими
паузами. В ненадежных сетях размер окна следует уменьшать, так как при частых
потерях и искажениях кадров резко возрастает объем вторично передаваемых через
сеть кадров, а значит, пропускная способность сети будет расходоваться во
многом вхолостую — полезная пропускная способность сети будет падать.
Выбор тайм-аута зависит не от надежности сети, а от задержек передачи
кадров сетью.
Во многих реализациях метода скользящего окна величина окна и тайм-аут
выбираются адаптивно, в зависимости от текущего состояния сети.
Data-link layer uses error control techniques to ensure that frames, i.e. bit streams of data, are transmitted from the source to the destination with a certain extent of accuracy.
Errors
When bits are transmitted over the computer network, they are subject to get corrupted due to interference and network problems. The corrupted bits leads to spurious data being received by the destination and are called errors.
Types of Errors
Errors can be of three types, namely single bit errors, multiple bit errors, and burst errors.
-
Single bit error − In the received frame, only one bit has been corrupted, i.e. either changed from 0 to 1 or from 1 to 0.
-
Multiple bits error − In the received frame, more than one bits are corrupted.
-
Burst error − In the received frame, more than one consecutive bits are corrupted.
Error Control
Error control can be done in two ways
-
Error detection − Error detection involves checking whether any error has occurred or not. The number of error bits and the type of error does not matter.
-
Error correction − Error correction involves ascertaining the exact number of bits that has been corrupted and the location of the corrupted bits.
For both error detection and error correction, the sender needs to send some additional bits along with the data bits. The receiver performs necessary checks based upon the additional redundant bits. If it finds that the data is free from errors, it removes the redundant bits before passing the message to the upper layers.
Error Detection Techniques
There are three main techniques for detecting errors in frames: Parity Check, Checksum and Cyclic Redundancy Check (CRC).
Parity Check
The parity check is done by adding an extra bit, called parity bit to the data to make a number of 1s either even in case of even parity or odd in case of odd parity.
While creating a frame, the sender counts the number of 1s in it and adds the parity bit in the following way
-
In case of even parity: If a number of 1s is even then parity bit value is 0. If the number of 1s is odd then parity bit value is 1.
-
In case of odd parity: If a number of 1s is odd then parity bit value is 0. If a number of 1s is even then parity bit value is 1.
On receiving a frame, the receiver counts the number of 1s in it. In case of even parity check, if the count of 1s is even, the frame is accepted, otherwise, it is rejected. A similar rule is adopted for odd parity check.
The parity check is suitable for single bit error detection only.
Checksum
In this error detection scheme, the following procedure is applied
-
Data is divided into fixed sized frames or segments.
-
The sender adds the segments using 1’s complement arithmetic to get the sum. It then complements the sum to get the checksum and sends it along with the data frames.
-
The receiver adds the incoming segments along with the checksum using 1’s complement arithmetic to get the sum and then complements it.
-
If the result is zero, the received frames are accepted; otherwise, they are discarded.
Cyclic Redundancy Check (CRC)
Cyclic Redundancy Check (CRC) involves binary division of the data bits being sent by a predetermined divisor agreed upon by the communicating system. The divisor is generated using polynomials.
-
Here, the sender performs binary division of the data segment by the divisor. It then appends the remainder called CRC bits to the end of the data segment. This makes the resulting data unit exactly divisible by the divisor.
-
The receiver divides the incoming data unit by the divisor. If there is no remainder, the data unit is assumed to be correct and is accepted. Otherwise, it is understood that the data is corrupted and is therefore rejected.
Error Correction Techniques
Error correction techniques find out the exact number of bits that have been corrupted and as well as their locations. There are two principle ways
-
Backward Error Correction (Retransmission) − If the receiver detects an error in the incoming frame, it requests the sender to retransmit the frame. It is a relatively simple technique. But it can be efficiently used only where retransmitting is not expensive as in fiber optics and the time for retransmission is low relative to the requirements of the application.
-
Forward Error Correction − If the receiver detects some error in the incoming frame, it executes error-correcting code that generates the actual frame. This saves bandwidth required for retransmission. It is inevitable in real-time systems. However, if there are too many errors, the frames need to be retransmitted.
The four main error correction codes are
- Hamming Codes
- Binary Convolution Code
- Reed – Solomon Code
- Low-Density Parity-Check Code
Методы, обеспечивающие надежную доставку цифровых данных по ненадежным каналам связи  Устранение ошибок передачи, вызванных атмосферой Земли ( слева), ученые Годдарда применили исправление ошибок Рида – Соломона (справа), которое обычно используется в компакт-дисках и DVD. Типичные ошибки включают отсутствие пикселей (белые) и ложные сигналы (черные). Белая полоса указывает на короткий период, когда передача была приостановлена.
Устранение ошибок передачи, вызванных атмосферой Земли ( слева), ученые Годдарда применили исправление ошибок Рида – Соломона (справа), которое обычно используется в компакт-дисках и DVD. Типичные ошибки включают отсутствие пикселей (белые) и ложные сигналы (черные). Белая полоса указывает на короткий период, когда передача была приостановлена.
В теории информации и теории кодирования с приложениями в информатике и телекоммуникациях, обнаружение и исправление ошибок или контроль ошибок — это методы, которые обеспечивают надежную доставку цифровых данных по ненадежным каналам связи. Многие каналы связи подвержены канальному шуму, и поэтому во время передачи от источника к приемнику могут возникать ошибки. Методы обнаружения ошибок позволяют обнаруживать такие ошибки, а исправление ошибок во многих случаях позволяет восстановить исходные данные.
Содержание
- 1 Определения
- 2 История
- 3 Введение
- 4 Типы исправления ошибок
- 4.1 Автоматический повторный запрос (ARQ)
- 4.2 Прямое исправление ошибок
- 4.3 Гибридные схемы
- 5 Схемы обнаружения ошибок
- 5.1 Кодирование на минимальном расстоянии
- 5.2 Коды повторения
- 5.3 Бит четности
- 5.4 Контрольная сумма
- 5.5 Циклическая проверка избыточности
- 5.6 Криптографическая хеш-функция
- 5.7 Ошибка код исправления
- 6 Приложения
- 6.1 Интернет
- 6.2 Связь в дальнем космосе
- 6.3 Спутниковое вещание
- 6.4 Хранение данных
- 6.5 Память с исправлением ошибок
- 7 См. также
- 8 Ссылки
- 9 Дополнительная литература
- 10 Внешние ссылки
Определения
Обнаружение ошибок — это обнаружение ошибок, вызванных шумом или другими помехами во время передачи от передатчика к приемнику. Исправление ошибок — это обнаружение ошибок и восстановление исходных безошибочных данных.
История
Современная разработка кодов исправления ошибок приписывается Ричарду Хэммингу в 1947 году. Описание кода Хэмминга появилось в Математической теории коммуникации Клода Шеннона и было быстро обобщено Марселем Дж. Э. Голэем.
Введение
Все схемы обнаружения и исправления ошибок добавляют некоторые избыточность (т. е. некоторые дополнительные данные) сообщения, которые получатели могут использовать для проверки согласованности доставленного сообщения и для восстановления данных, которые были определены как поврежденные. Схемы обнаружения и исправления ошибок могут быть систематическими или несистематическими. В систематической схеме передатчик отправляет исходные данные и присоединяет фиксированное количество контрольных битов (или данных четности), которые выводятся из битов данных некоторым детерминированным алгоритмом. Если требуется только обнаружение ошибок, приемник может просто применить тот же алгоритм к полученным битам данных и сравнить свой вывод с полученными контрольными битами; если значения не совпадают, в какой-то момент во время передачи произошла ошибка. В системе, которая использует несистематический код, исходное сообщение преобразуется в закодированное сообщение, несущее ту же информацию и имеющее по крайней мере такое же количество битов, как и исходное сообщение.
Хорошие характеристики контроля ошибок требуют, чтобы схема была выбрана на основе характеристик канала связи. Распространенные модели каналов включают в себя модели без памяти, в которых ошибки возникают случайно и с определенной вероятностью, и динамические модели, в которых ошибки возникают в основном в пакетах . Следовательно, коды обнаружения и исправления ошибок можно в целом различать между обнаружением / исправлением случайных ошибок и обнаружением / исправлением пакетов ошибок. Некоторые коды также могут подходить для сочетания случайных ошибок и пакетных ошибок.
Если характеристики канала не могут быть определены или сильно изменяются, схема обнаружения ошибок может быть объединена с системой для повторных передач ошибочных данных. Это известно как автоматический запрос на повторение (ARQ) и наиболее широко используется в Интернете. Альтернативный подход для контроля ошибок — это гибридный автоматический запрос на повторение (HARQ), который представляет собой комбинацию ARQ и кодирования с исправлением ошибок.
Типы исправления ошибок
Существует три основных типа исправления ошибок.
Автоматический повторный запрос (ARQ)
Автоматический повторный запрос (ARQ) — это метод контроля ошибок для передачи данных, который использует коды обнаружения ошибок, сообщения подтверждения и / или отрицательного подтверждения и тайм-ауты для обеспечения надежной передачи данных. Подтверждение — это сообщение, отправленное получателем, чтобы указать, что он правильно получил кадр данных.
Обычно, когда передатчик не получает подтверждения до истечения тайм-аута (т. Е. В течение разумного периода времени после отправки фрейм данных), он повторно передает фрейм до тех пор, пока он либо не будет правильно принят, либо пока ошибка не останется сверх заранее определенного количества повторных передач.
Три типа протоколов ARQ: Stop-and-wait ARQ, Go-Back-N ARQ и Selective Repeat ARQ.
ARQ is подходит, если канал связи имеет переменную или неизвестную пропускную способность, например, в случае с Интернетом. Однако ARQ требует наличия обратного канала, что приводит к возможному увеличению задержки из-за повторных передач и требует обслуживания буферов и таймеров для повторных передач, что в случае перегрузка сети может вызвать нагрузку на сервер и общую пропускную способность сети.
Например, ARQ используется на коротковолновых радиоканалах в форме ARQ-E, или в сочетании с мультиплексированием как ARQ-M.
Прямое исправление ошибок
Прямое исправление ошибок (FEC) — это процесс добавления избыточных данных, таких как исправление ошибок code (ECC) в сообщение, чтобы оно могло быть восстановлено получателем, даже если в процессе передачи или при хранении был внесен ряд ошибок (в зависимости от возможностей используемого кода). Так как получатель не должен запрашивать у отправителя повторную передачу данных, обратный канал не требуется при прямом исправлении ошибок, и поэтому он подходит для симплексной связи, например вещание. Коды с исправлением ошибок часто используются в нижнем уровне связи, а также для надежного хранения на таких носителях, как CD, DVD, жесткие диски и RAM.
Коды с исправлением ошибок обычно различают между сверточными кодами и блочными кодами. :
- Сверточные коды обрабатываются побитно. Они особенно подходят для аппаратной реализации, а декодер Витерби обеспечивает оптимальное декодирование.
- Блочные коды обрабатываются на поблочной основе. Ранними примерами блочных кодов являются коды повторения, коды Хэмминга и многомерные коды контроля четности. За ними последовал ряд эффективных кодов, из которых коды Рида – Соломона являются наиболее известными из-за их широкого распространения в настоящее время. Турбокоды и коды с низкой плотностью проверки четности (LDPC) — это относительно новые конструкции, которые могут обеспечить почти оптимальную эффективность.
Теорема Шеннона — важная теорема при прямом исправлении ошибок и описывает максимальную информационную скорость, на которой возможна надежная связь по каналу, имеющему определенную вероятность ошибки или отношение сигнал / шум (SNR). Этот строгий верхний предел выражается в единицах пропускной способности канала . Более конкретно, в теореме говорится, что существуют такие коды, что с увеличением длины кодирования вероятность ошибки на дискретном канале без памяти может быть сделана сколь угодно малой при условии, что кодовая скорость меньше чем емкость канала. Кодовая скорость определяется как доля k / n из k исходных символов и n кодированных символов.
Фактическая максимальная разрешенная кодовая скорость зависит от используемого кода исправления ошибок и может быть ниже. Это связано с тем, что доказательство Шеннона носило только экзистенциальный характер и не показало, как создавать коды, которые одновременно являются оптимальными и имеют эффективные алгоритмы кодирования и декодирования.
Гибридные схемы
Гибридный ARQ — это комбинация ARQ и прямого исправления ошибок. Существует два основных подхода:
- Сообщения всегда передаются с данными четности FEC (и избыточностью для обнаружения ошибок). Получатель декодирует сообщение, используя информацию о четности, и запрашивает повторную передачу с использованием ARQ только в том случае, если данных четности было недостаточно для успешного декодирования (идентифицировано посредством неудачной проверки целостности).
- Сообщения передаются без данных четности (только с информация об обнаружении ошибок). Если приемник обнаруживает ошибку, он запрашивает информацию FEC от передатчика с помощью ARQ и использует ее для восстановления исходного сообщения.
Последний подход особенно привлекателен для канала стирания при использовании код бесскоростного стирания.
.
Схемы обнаружения ошибок
Обнаружение ошибок чаще всего реализуется с использованием подходящей хэш-функции (или, в частности, контрольной суммы, циклической проверка избыточности или другой алгоритм). Хеш-функция добавляет к сообщению тег фиксированной длины, который позволяет получателям проверять доставленное сообщение, повторно вычисляя тег и сравнивая его с предоставленным.
Существует огромное количество различных конструкций хеш-функций. Однако некоторые из них имеют особенно широкое распространение из-за их простоты или их пригодности для обнаружения определенных видов ошибок (например, производительности циклического контроля избыточности при обнаружении пакетных ошибок ).
Кодирование с минимальным расстоянием
Код с исправлением случайных ошибок на основе кодирования с минимальным расстоянием может обеспечить строгую гарантию количества обнаруживаемых ошибок, но может не защитить против атаки прообразом.
Коды повторения
A код повторения — это схема кодирования, которая повторяет биты по каналу для достижения безошибочной связи. Учитывая поток данных, которые необходимо передать, данные делятся на блоки битов. Каждый блок передается определенное количество раз. Например, чтобы отправить битовую комбинацию «1011», четырехбитовый блок можно повторить три раза, таким образом получая «1011 1011 1011». Если этот двенадцатибитовый шаблон был получен как «1010 1011 1011» — где первый блок не похож на два других, — произошла ошибка.
Код повторения очень неэффективен и может быть подвержен проблемам, если ошибка возникает в одном и том же месте для каждой группы (например, «1010 1010 1010» в предыдущем примере будет определено как правильное). Преимущество кодов повторения состоит в том, что они чрезвычайно просты и фактически используются в некоторых передачах номеров станций.
Бит четности
Бит четности — это бит, который добавляется к группе исходные биты, чтобы гарантировать, что количество установленных битов (т. е. битов со значением 1) в результате будет четным или нечетным. Это очень простая схема, которую можно использовать для обнаружения одного или любого другого нечетного числа (т. Е. Трех, пяти и т. Д.) Ошибок в выводе. Четное количество перевернутых битов сделает бит четности правильным, даже если данные ошибочны.
Расширениями и вариантами механизма битов четности являются проверки с продольным избыточным кодом, проверки с поперечным избыточным кодом и аналогичные методы группирования битов.
Контрольная сумма
Контрольная сумма сообщения — это модульная арифметическая сумма кодовых слов сообщения фиксированной длины слова (например, байтовых значений). Сумма может быть инвертирована посредством операции дополнения до единиц перед передачей для обнаружения непреднамеренных сообщений с нулевым значением.
Схемы контрольных сумм включают биты четности, контрольные цифры и проверки продольным избыточным кодом. Некоторые схемы контрольных сумм, такие как алгоритм Дамма, алгоритм Луна и алгоритм Верхоффа, специально разработаны для обнаружения ошибок, обычно вносимых людьми при записи или запоминание идентификационных номеров.
Проверка циклическим избыточным кодом
Проверка циклическим избыточным кодом (CRC) — это незащищенная хэш-функция, предназначенная для обнаружения случайных изменений цифровых данных в компьютерных сетях. Он не подходит для обнаружения злонамеренно внесенных ошибок. Он характеризуется указанием порождающего полинома, который используется в качестве делителя в полиномиальном делении над конечным полем, принимая входные данные в качестве дивиденд. остаток становится результатом.
CRC имеет свойства, которые делают его хорошо подходящим для обнаружения пакетных ошибок. CRC особенно легко реализовать на оборудовании и поэтому обычно используются в компьютерных сетях и устройствах хранения, таких как жесткие диски.
. Бит четности может рассматриваться как 1-битный частный случай. CRC.
Криптографическая хеш-функция
Выходные данные криптографической хеш-функции, также известные как дайджест сообщения, могут обеспечить надежную гарантию целостности данных, независимо от того, происходят ли изменения данных случайно (например, из-за ошибок передачи) или злонамеренно. Любая модификация данных, скорее всего, будет обнаружена по несоответствию хеш-значения. Кроме того, с учетом некоторого хэш-значения, как правило, невозможно найти некоторые входные данные (кроме заданных), которые дадут такое же хеш-значение. Если злоумышленник может изменить не только сообщение, но и значение хеш-функции, то для дополнительной безопасности можно использовать хэш-код с ключом или код аутентификации сообщения (MAC). Не зная ключа, злоумышленник не может легко или удобно вычислить правильное ключевое значение хеш-функции для измененного сообщения.
Код исправления ошибок
Для обнаружения ошибок можно использовать любой код исправления ошибок. Код с минимальным расстоянием Хэмминга, d, может обнаруживать до d — 1 ошибок в кодовом слове. Использование кодов с коррекцией ошибок на основе минимального расстояния для обнаружения ошибок может быть подходящим, если требуется строгое ограничение на минимальное количество обнаруживаемых ошибок.
Коды с минимальным расстоянием Хэмминга d = 2 являются вырожденными случаями кодов с исправлением ошибок и могут использоваться для обнаружения одиночных ошибок. Бит четности является примером кода обнаружения одиночной ошибки.
Приложения
Приложения, которым требуется низкая задержка (например, телефонные разговоры), не могут использовать автоматический запрос на повторение (ARQ); они должны использовать прямое исправление ошибок (FEC). К тому времени, когда система ARQ обнаружит ошибку и повторно передаст ее, повторно отправленные данные прибудут слишком поздно, чтобы их можно было использовать.
Приложения, в которых передатчик сразу же забывает информацию, как только она отправляется (например, большинство телекамер), не могут использовать ARQ; они должны использовать FEC, потому что при возникновении ошибки исходные данные больше не доступны.
Приложения, использующие ARQ, должны иметь канал возврата ; приложения, не имеющие обратного канала, не могут использовать ARQ.
Приложения, требующие чрезвычайно низкого уровня ошибок (например, цифровые денежные переводы), должны использовать ARQ из-за возможности неисправимых ошибок с помощью FEC.
Надежность и инженерная проверка также используют теорию кодов исправления ошибок.
Интернет
В типичном стеке TCP / IP ошибка управление осуществляется на нескольких уровнях:
- Каждый кадр Ethernet использует CRC-32 обнаружение ошибок. Фреймы с обнаруженными ошибками отбрасываются оборудованием приемника.
- Заголовок IPv4 содержит контрольную сумму , защищающую содержимое заголовка. Пакеты с неверными контрольными суммами отбрасываются в сети или на приемнике.
- Контрольная сумма не указана в заголовке IPv6, чтобы минимизировать затраты на обработку в сетевой маршрутизации и поскольку предполагается, что текущая технология канального уровня обеспечивает достаточное обнаружение ошибок (см. также RFC 3819 ).
- UDP, имеет дополнительную контрольную сумму, покрывающую полезную нагрузку и информацию об адресации в заголовки UDP и IP. Пакеты с неверными контрольными суммами отбрасываются сетевым стеком . Контрольная сумма не является обязательной для IPv4 и требуется для IPv6. Если не указано, предполагается, что уровень канала передачи данных обеспечивает желаемый уровень защиты от ошибок.
- TCP обеспечивает контрольную сумму для защиты полезной нагрузки и адресной информации в заголовках TCP и IP. Пакеты с неверными контрольными суммами отбрасываются сетевым стеком и в конечном итоге повторно передаются с использованием ARQ либо явно (например, как через тройное подтверждение ) или неявно из-за тайм-аута .
Телекоммуникации в дальнем космосе
Разработка кодов исправления ошибок была тесно связана с историей полетов в дальний космос из-за сильного ослабления мощности сигнала на межпланетных расстояниях и ограниченной мощности на борту космических зондов. В то время как ранние миссии отправляли свои данные в незашифрованном виде, начиная с 1968 года, цифровая коррекция ошибок была реализована в форме (субоптимально декодированных) сверточных кодов и кодов Рида – Маллера. Код Рида-Мюллера хорошо подходил к шуму, которому подвергался космический корабль (примерно соответствуя кривой ), и был реализован для космического корабля Mariner и использовался в миссиях между 1969 и 1977 годами.
Миссии «Вояджер-1 » и «Вояджер-2 «, начатые в 1977 году, были разработаны для доставки цветных изображений и научной информации с Юпитера и Сатурна. Это привело к повышенным требованиям к кодированию, и, таким образом, космический аппарат поддерживался (оптимально Витерби-декодированный ) сверточными кодами, которые могли быть сцеплены с внешним Голеем (24,12, код. Корабль «Вояджер-2» дополнительно поддерживал реализацию кода Рида-Соломона. Конкатенированный код Рида – Соломона – Витерби (RSV) позволил произвести очень мощную коррекцию ошибок и позволил космическому кораблю совершить длительное путешествие к Урану и Нептуну. После модернизации системы ECC в 1989 году оба корабля использовали кодирование V2 RSV.
Консультативный комитет по космическим информационным системам в настоящее время рекомендует использовать коды исправления ошибок, как минимум, аналогичные RSV-коду Voyager 2. Составные коды все больше теряют популярность в космических миссиях и заменяются более мощными кодами, такими как Турбо-коды или LDPC-коды.
Различные виды выполняемых космических и орбитальных миссий. предполагают, что попытки найти универсальную систему исправления ошибок будут постоянной проблемой. Для полетов вблизи Земли характер шума в канале связи отличается от того, который испытывает космический корабль в межпланетной миссии. Кроме того, по мере того как космический корабль удаляется от Земли, проблема коррекции шума становится все более сложной.
Спутниковое вещание
Спрос на пропускную способность спутникового транспондера продолжает расти, чему способствует желание предоставлять телевидение (включая новые каналы и телевидение высокой четкости ) и данные IP. Доступность транспондеров и ограничения полосы пропускания ограничили этот рост. Емкость транспондера определяется выбранной схемой модуляции и долей мощности, потребляемой FEC.
Хранение данных
Коды обнаружения и исправления ошибок часто используются для повышения надежности носителей данных. «Дорожка четности» присутствовала на первом устройстве хранения данных на магнитной ленте в 1951 году. «Оптимальный прямоугольный код», используемый в записи с групповым кодированием, не только обнаруживает, но и корректирует однобитовые записи. ошибки. Некоторые форматы файлов, особенно архивные форматы, включают контрольную сумму (чаще всего CRC32 ) для обнаружения повреждений и усечения и могут использовать избыточность и / или четность files для восстановления поврежденных данных. Коды Рида-Соломона используются в компакт-дисках для исправления ошибок, вызванных царапинами.
Современные жесткие диски используют коды CRC для обнаружения и коды Рида – Соломона для исправления незначительных ошибок при чтении секторов, а также для восстановления данных из секторов, которые «испортились», и сохранения этих данных в резервных секторах. Системы RAID используют различные методы исправления ошибок для исправления ошибок, когда жесткий диск полностью выходит из строя. Файловые системы, такие как ZFS или Btrfs, а также некоторые реализации RAID, поддерживают очистку данных и восстановление обновлений, что позволяет удалять поврежденные блоки. обнаружены и (надеюсь) восстановлены, прежде чем они будут использованы. Восстановленные данные могут быть перезаписаны точно в том же физическом месте, чтобы освободить блоки в другом месте на том же оборудовании, или данные могут быть перезаписаны на заменяющее оборудование.
Память с исправлением ошибок
Память DRAM может обеспечить более надежную защиту от программных ошибок, полагаясь на коды исправления ошибок. Такая память с исправлением ошибок, известная как память с защитой ECC или EDAC, особенно желательна для критически важных приложений, таких как научные вычисления, финансы, медицина и т. Д., А также для приложений дальнего космоса из-за повышенное излучение в космосе.
Контроллеры памяти с исправлением ошибок традиционно используют коды Хэмминга, хотя некоторые используют тройную модульную избыточность.
Чередование позволяет распределить эффект одного космического луча, потенциально нарушающего множество физически соседние биты в нескольких словах путем связывания соседних битов с разными словами. До тех пор, пока нарушение единичного события (SEU) не превышает пороговое значение ошибки (например, одиночная ошибка) в любом конкретном слове между доступами, оно может быть исправлено (например, путем исправления однобитовой ошибки code), и может сохраняться иллюзия безошибочной системы памяти.
Помимо оборудования, обеспечивающего функции, необходимые для работы памяти ECC, операционные системы обычно содержат соответствующие средства отчетности, которые используются для предоставления уведомлений при прозрачном восстановлении программных ошибок. Увеличение количества программных ошибок может указывать на то, что модуль DIMM нуждается в замене, и такая обратная связь не была бы легко доступна без соответствующих возможностей отчетности. Одним из примеров является подсистема EDAC ядра Linux (ранее известная как Bluesmoke), которая собирает данные из компонентов компьютерной системы, поддерживающих проверку ошибок; Помимо сбора и отправки отчетов о событиях, связанных с памятью ECC, он также поддерживает другие ошибки контрольного суммирования, в том числе обнаруженные на шине PCI.
Некоторые системы также поддерживают очистку памяти.
См. также
Ссылки
Дополнительная литература
- Шу Линь; Дэниел Дж. Костелло младший (1983). Кодирование с контролем ошибок: основы и приложения. Прентис Холл. ISBN 0-13-283796-X.
Внешние ссылки
Error control in data link layer is the process of detecting and correcting data frames that have been corrupted or lost during transmission.
In case of lost or corrupted frames, the receiver does not receive the correct data-frame and sender is ignorant about the loss. Data link layer follows a technique to detect transit errors and take necessary actions, which is retransmission of frames whenever error is detected or frame is lost. The process is called Automatic Repeat Request (ARQ).
Phases in Error Control
The error control mechanism in data link layer involves the following phases −
-
Detection of Error − Transmission error, if any, is detected by either the sender or the receiver.
-
Acknowledgment − acknowledgment may be positive or negative.
-
Positive ACK − On receiving a correct frame, the receiver sends a positive acknowledge.
-
Negative ACK − On receiving a damaged frame or a duplicate frame, the receiver sends a negative acknowledgment back to the sender.
-
-
Retransmission − The sender maintains a clock and sets a timeout period. If an acknowledgment of a data-frame previously transmitted does not arrive before the timeout, or a negative acknowledgment is received, the sender retransmits the frame.
Error Control Techniques
There are three main techniques for error control −

-
Stop and Wait ARQ
This protocol involves the following transitions −
-
A timeout counter is maintained by the sender, which is started when a frame is sent.
-
If the sender receives acknowledgment of the sent frame within time, the sender is confirmed about successful delivery of the frame. It then transmits the next frame in queue.
-
If the sender does not receive the acknowledgment within time, the sender assumes that either the frame or its acknowledgment is lost in transit. It then retransmits the frame.
-
If the sender receives a negative acknowledgment, the sender retransmits the frame.
-
-
Go-Back-N ARQ
The working principle of this protocol is −
-
The sender has buffers called sending window.
-
The sender sends multiple frames based upon the sending-window size, without receiving the acknowledgment of the previous ones.
-
The receiver receives frames one by one. It keeps track of incoming frame’s sequence number and sends the corresponding acknowledgment frames.
-
After the sender has sent all the frames in window, it checks up to what sequence number it has received positive acknowledgment.
-
If the sender has received positive acknowledgment for all the frames, it sends next set of frames.
-
If sender receives NACK or has not receive any ACK for a particular frame, it retransmits all the frames after which it does not receive any positive ACK.
-
-
Selective Repeat ARQ
- Both the sender and the receiver have buffers called sending window and receiving window respectively.
-
The sender sends multiple frames based upon the sending-window size, without receiving the acknowledgment of the previous ones.
-
The receiver also receives multiple frames within the receiving window size.
-
The receiver keeps track of incoming frame’s sequence numbers, buffers the frames in memory.
-
It sends ACK for all successfully received frames and sends NACK for only frames which are missing or damaged.
-
The sender in this case, sends only packet for which NACK is received.
Лекция 5
Проверка правильности передачи данных
- Причины возникновения ошибок
- Классификация методов защиты от ошибок
- Групповые методы
- мажоритарный
- блок с количественной характеристикой
- Помехоустойчивое кодирование
- Системы передачи с обратной связью
- решающая
- информационная
- Групповые методы
Проблема обеспечения безошибочности (достоверности) передачи информации в
сетях имеет очень большое значение. Если при передаче обычной телеграммы в
тексте возникает ошибка или при разговоре по телефону слышен треск, то в
большинстве случаев ошибки и искажения легко обнаруживаются по смыслу. Но при
передаче данных одна ошибка (искажение одного бита) на тысячу переданных
сигналов может серьезно отразиться на качестве информации.
Существует множество методов обеспечения достоверности передачи информации
(методов защиты от ошибок), отличающихся по используемым для их реализации
средствам, по затратам времени на их применение на передающем и приемном
пунктах, по затратам дополнительного времени на передачу фиксированного объема
данных (оно обусловлено изменением объема трафика пользователя при реализации
данного метода), по степени обеспечения достоверности передачи информации.
Практическое воплощение методов состоит из двух частей — программной и
аппаратной. Соотношение между ними может быть самым различным, вплоть до почти
полного отсутствия одной из частей. Чем больше удельный вес аппаратных средств
по сравнению с программными, тем при прочих равных условиях сложнее
оборудование, реализующее метод, и меньше затрат времени на его реализацию, и
наоборот.
![]()
Причины возникновения ошибок
Выделяют две основные причины возникновения ошибок при передаче информации в
сетях:
- сбои в какой-то части оборудования сети или возникновение
неблагоприятных объективных событий в сети (например, коллизий при
использовании метода случайного доступа в сеть). Как правило, система
передачи данных готова к такого рода проявлениям и устраняет их с помощью
предусмотренных планом средств; - помехи, вызванные внешними источниками и атмосферными явлениями. Помехи
— это электрические возмущения, возникающие в самой аппаратуре или
попадающие в нее извне. Наиболее распространенными являются флуктуационные
(случайные) помехи. Они представляют собой последовательность импульсов,
имеющих случайную амплитуду и следующих друг за другом через различные
промежутки времени. Примерами таких помех могут быть атмосферные и
индустриальные помехи, которые обычно проявляются в виде одиночных импульсов
малой длительности и большой амплитуды. Возможны и сосредоточенные помехи в
виде синусоидальных колебаний. К ним относятся сигналы от посторонних
радиостанций, излучения генераторов высокой частоты. Встречаются и смешанные
помехи. В приемнике помехи могут настолько ослабить информационный сигнал,
что он либо вообще не будет обнаружен, либо будет искажен так, что «единица»
может перейти в «нуль», и наоборот.
Трудности борьбы с помехами заключаются в беспорядочности, нерегулярности и в
структурном сходстве помех с информационными сигналами. Поэтому защита
информации от ошибок и вредного влияния помех имеет большое практическое
значение и является одной из серьезных проблем современной теории и техники
связи.
![]()
Классификация методов защиты от ошибок
Среди многочисленных методов защиты от ошибок выделяются три группы методов:
групповые методы, помехоустойчивое кодирование и методы защиты от ошибок в
системах передачи с обратной связью.
Групповые методы
Из групповых методов получили широкое применение мажоритарный метод,
реализующий принцип Вердана, и метод передач информационными блоками с
количественной характеристикой блока.
- Мажоритарный метод
- Суть этого метода, давно и широко используемого в телеграфии,
состоит в следующем. Каждое сообщение ограниченной длины передается
несколько раз, чаще всего три раза. Принимаемые сообщения запоминаются,
а потом производится их поразрядное сравнение. Суждение о правильности
передачи выносится по совпадению большинства из принятой информации
методом «два из трех». Например, кодовая комбинация 01101 при
трехразовой передаче была частично искажена помехами, поэтому приемник
принял такие комбинации: 10101, 01110, 01001. В результате проверки по
отдельности каждой позиции правильной считается комбинация 01101.- Передача блоками с количественной характеристикой
- Этот метод также не требует перекодирования информации. Он
предполагает передачу данных блоками с количественной характеристикой
блока. Такими характеристиками могут быть: число единиц или нулей в
блоке, контрольная сумма передаваемых символов в блоке, остаток от
деления контрольной суммы на постоянную величину и др. На приемном
пункте эта характеристика вновь подсчитывается и сравнивается с
переданной по каналу связи. Если характеристики совпадают, считается,
что блок не содержит ошибок. В противном случае на передающую сторону
поступает сигнал с требованием повторной передачи блока. В современных
телекоммуникационных вычислительных сетях такой метод получил самое
широкое распространение.
![]()
Помехоустойчивое (избыточное) кодирование
Этот метод предполагает разработку и использование корректирующих
(помехоустойчивых) кодов. Он применяется не только в телекоммуникационных сетях,
но и в ЭВМ для защиты от ошибок при передаче информации между устройствами
машины. Помехоустойчивое кодирование позволяет получить более высокие
качественные показатели работы систем связи. Его основное назначение заключается
в обеспечении малой вероятности искажений передаваемой информации, несмотря на
присутствие помех или сбоев в работе сети.
Существует довольно большое количество различных помехоустойчивых кодов,
отличающихся друг от друга по ряду показателей и прежде всего по своим
корректирующим возможностям.
К числу наиболее важных показателей корректирующих кодов относятся:
- значность кода n, или длина
кодовой комбинации, включающей информационные символы (m)
и проверочные, или контрольные, символы (К):
n = m
+ K
(Значения
контрольных символов при кодировании определяются путем контроля на четность
количества единиц в информационных разрядах кодовой комбинации. Значение
контрольного символа равно 0, если количество единиц будет четным, и равно 1
при нечетном количестве единиц); - избыточность кода Кизб,
выражаемая отношением числа контрольных символов в кодовой комбинации к
значности кода: Кизб = К/
n;
- корректирующая способность кода Ккс, представляющая
собой отношение числа кодовых комбинаций L,
в которых ошибки были обнаружены и исправлены, к общему числу переданных
кодовых комбинаций M в фиксированном объеме
информации: Ккс =
L/ M
Выбор корректирующего кода для его использования в данной компьютерной сети
зависит от требований по достоверности передачи информации. Для правильного
выбора кода необходимы статистические данные о закономерностях появления ошибок,
их характере, численности и распределении во времени. Например, корректирующий
код, обнаруживающий и исправляющий одиночные ошибки, эффективен лишь при
условии, что ошибки статистически независимы, а вероятность их появления не
превышает некоторой величины. Он оказывается непригодным, если ошибки появляются
группами. При выборе кода надо стремиться, чтобы он имел меньшую избыточность.
Чем больше коэффициент Кизб, тем менее эффективно используется
пропускная способность канала связи и больше затрачивается времени на передачу
информации, но зато выше помехоустойчивость системы.
В телекоммуникационных вычислительных сетях корректирующие коды в основном
применяются для обнаружения ошибок, исправление которых осуществляется путем
повторной передачи искаженной информации. С этой целью в сетях используются
системы передачи с обратной связью (наличие между абонентами дуплексной связи
облегчает применение таких систем).
![]()
Системы передачи с обратной связью
Системы передачи с обратной связью делятся на системы с решающей обратной
связью и системы с информационной обратной связью.
- Системы с решающей обратной связью
- Особенностью систем с решающей обратной связью (систем с
перезапросом) является то, что решение о необходимости повторной передачи
информации (сообщения, пакета) принимает приемник. Здесь обязательно применяется
помехоустойчивое кодирование, с помощью которого на приемной станции
осуществляется проверка принимаемой информации. При обнаружении ошибки на
передающую сторону по каналу обратной связи посылается сигнал перезапроса, по
которому информация передается повторно. Канал обратной связи используется также
для посылки сигнала подтверждения правильности приема, автоматически
определяющего начало следующей передачи.- Системы с информационной обратной связью
- В системах с информационной обратной связью передача информации
осуществляется без помехоустойчивого кодирования. Приемник, приняв информацию по
прямому каналу и зафиксировав ее в своей памяти, передает ее в полном объеме по
каналу обратной связи передатчику, где переданная и возвра0щенная информация
сравниваются. При совпадении передатчик посылает приемнику сигнал подтверждения,
в противном случае происходит повторная передача всей информации. Таким образом,
здесь решение о необходимости повторной передачи принимает передатчик.
Обе рассмотренные системы обеспечивают практически одинаковую достоверность,
однако в системах с решающей обратной связью пропускная способность каналов
используется эффективнее, поэтому они получили большее распространение.
![]()
Сайт управляется системой uCoz
Обнаружение ошибок в технике связи — действие, направленное на контроль целостности данных при записи/воспроизведении информации или при её передаче по линиям связи. Исправление ошибок (коррекция ошибок) — процедура восстановления информации после чтения её из устройства хранения или канала связи.
Для обнаружения ошибок используют коды обнаружения ошибок, для исправления — корректирующие коды (коды, исправляющие ошибки, коды с коррекцией ошибок, помехоустойчивые коды).
Способы борьбы с ошибками[]
В процессе хранения данных и передачи информации по сетям связи неизбежно возникают ошибки. Контроль целостности данных и исправление ошибок — важные задачи на многих уровнях работы с информацией (в частности, физическом, канальном, транспортном уровнях модели OSI).
В системах связи возможны несколько стратегий борьбы с ошибками:
- обнаружение ошибок в блоках данных и автоматический запрос повторной передачи повреждённых блоков — этот подход применяется в основном на канальном и транспортном уровнях;
- обнаружение ошибок в блоках данных и отбрасывание повреждённых блоков — такой подход иногда применяется в системах потокового мультимедиа, где важна задержка передачи и нет времени на повторную передачу;
- исправление ошибок (forward error correction) применяется на физическом уровне.
Коды обнаружения и исправления ошибок[]
Корректирующие коды — коды, служащие для обнаружения или исправления ошибок, возникающих при передаче информации под влиянием помех, а также при её хранении.
Для этого при записи (передаче) в полезные данные добавляют специальным образом структурированную избыточную информацию (контрольное число), а при чтении (приёме) её используют для того, чтобы обнаружить или исправить ошибки. Естественно, что число ошибок, которое можно исправить, ограничено и зависит от конкретного применяемого кода.
С кодами, исправляющими ошибки, тесно связаны коды обнаружения ошибок. В отличие от первых, последние могут только установить факт наличия ошибки в переданных данных, но не исправить её.
В действительности, используемые коды обнаружения ошибок принадлежат к тем же классам кодов, что и коды, исправляющие ошибки. Фактически, любой код, исправляющий ошибки, может быть также использован для обнаружения ошибок (при этом он будет способен обнаружить большее число ошибок, чем был способен исправить).
По способу работы с данными коды, исправляющие ошибки делятся на блоковые, делящие информацию на фрагменты постоянной длины и обрабатывающие каждый из них в отдельности, и свёрточные, работающие с данными как с непрерывным потоком.
Блоковые коды[]
Пусть кодируемая информация делится на фрагменты длиной  бит, которые преобразуются в кодовые слова длиной
бит, которые преобразуются в кодовые слова длиной  бит. Тогда соответствующий блоковый код обычно обозначают
бит. Тогда соответствующий блоковый код обычно обозначают  . При этом число
. При этом число  называется скоростью кода.
называется скоростью кода.
Если исходные бит код оставляет неизменными, и добавляет  проверочных, такой код называется систематическим, иначе несистематическим.
проверочных, такой код называется систематическим, иначе несистематическим.
Задать блоковый код можно по-разному, в том числе таблицей, где каждой совокупности из информационных бит сопоставляется бит кодового слова. Однако, хороший код должен удовлетворять, как минимум, следующим критериям:
- способность исправлять как можно большее число ошибок,
- как можно меньшая избыточность,
- простота кодирования и декодирования.
Нетрудно видеть, что приведённые требования противоречат друг другу. Именно поэтому существует большое количество кодов, каждый из которых пригоден для своего круга задач.
Практически все используемые коды являются линейными. Это связано с тем, что нелинейные коды значительно сложнее исследовать, и для них трудно обеспечить приемлемую лёгкость кодирования и декодирования.
Линейные коды общего вида[]
Линейный блоковый код — такой код, что множество его кодовых слов образует -мерное линейное подпространство (назовём его  ) в -мерном линейном пространстве, изоморфное пространству -битных векторов.
) в -мерном линейном пространстве, изоморфное пространству -битных векторов.
Это значит, что операция кодирования соответствует умножению исходного -битного вектора на невырожденную матрицу  , называемую порождающей матрицей.
, называемую порождающей матрицей.
Пусть  — ортогональное подпространство по отношению к , а
— ортогональное подпространство по отношению к , а  — матрица, задающая базис этого подпространства. Тогда для любого вектора
— матрица, задающая базис этого подпространства. Тогда для любого вектора  справедливо:
справедливо:

Минимальное расстояние и корректирующая способность[]
-
Основная статья: Расстояние Хемминга
Расстоянием Хемминга (метрикой Хемминга) между двумя кодовыми словами  и
и  называется количество отличных бит на соответствующих позициях,
называется количество отличных бит на соответствующих позициях,  , что равно числу «единиц» в векторе
, что равно числу «единиц» в векторе  .
.
Минимальное расстояние Хемминга  является важной характеристикой линейного блокового кода. Она показывает насколько «далеко» расположены коды друг от друга. Она определяет другую, не менее важную характеристику — корректирующую способность:
является важной характеристикой линейного блокового кода. Она показывает насколько «далеко» расположены коды друг от друга. Она определяет другую, не менее важную характеристику — корректирующую способность:
- , округляем «вниз», так чтобы .


Корректирующая способность определяет, сколько ошибок передачи кода (типа  ) можно гарантированно исправить. То есть вокруг каждого кода
) можно гарантированно исправить. То есть вокруг каждого кода  имеем
имеем  -окрестность
-окрестность  , которая состоит из всех возможных вариантов передачи кода с числом ошибок () не более . Никакие две окрестности двух любых кодов не пересекаются друг с другом, так как расстояние между кодами (то есть центрами этих окрестностей) всегда больше двух их радиусов
, которая состоит из всех возможных вариантов передачи кода с числом ошибок () не более . Никакие две окрестности двух любых кодов не пересекаются друг с другом, так как расстояние между кодами (то есть центрами этих окрестностей) всегда больше двух их радиусов  .
.
Таким образом получив искажённый код из декодер принимает решение, что был исходный код , исправляя тем самым не более ошибок.
Поясним на примере. Предположим, что есть два кодовых слова и  , расстояние Хемминга между ними равно 3. Если было передано слово , и канал внёс ошибку в одном бите, она может быть исправлена, так как даже в этом случае принятое слово ближе к кодовому слову , чем к любому другому, и в частности к . Но если каналом были внесены ошибки в двух битах (в которых отличалось от ) то результат ошибочной передачи окажется ближе к , чем , и декодер примет решение что передавалось слово .
, расстояние Хемминга между ними равно 3. Если было передано слово , и канал внёс ошибку в одном бите, она может быть исправлена, так как даже в этом случае принятое слово ближе к кодовому слову , чем к любому другому, и в частности к . Но если каналом были внесены ошибки в двух битах (в которых отличалось от ) то результат ошибочной передачи окажется ближе к , чем , и декодер примет решение что передавалось слово .
Коды Хемминга[]
Коды Хемминга — простейшие линейные коды с минимальным расстоянием 3, то есть способные исправить одну ошибку. Код Хемминга может быть представлен в таком виде, что синдром
- , где — принятый вектор, будет равен номеру позиции, в которой произошла ошибка. Это свойство позволяет сделать декодирование очень простым.


Общий метод декодирования линейных кодов[]
Любой код (в том числе нелинейный) можно декодировать с помощью обычной таблицы, где каждому значению принятого слова  соответствует наиболее вероятное переданное слово
соответствует наиболее вероятное переданное слово  . Однако, данный метод требует применения огромных таблиц уже для кодовых слов сравнительно небольшой длины.
. Однако, данный метод требует применения огромных таблиц уже для кодовых слов сравнительно небольшой длины.
Для линейных кодов этот метод можно существенно упростить. При этом для каждого принятого вектора вычисляется синдром  . Поскольку
. Поскольку  , где
, где  — кодовое слово, а
— кодовое слово, а  — вектор ошибки, то
— вектор ошибки, то  . Затем с помощью таблицы по синдрому определяется вектор ошибки, с помощью которого определяется переданное кодовое слово. При этом таблица получается гораздо меньше, чем при использовании предыдущего метода.
. Затем с помощью таблицы по синдрому определяется вектор ошибки, с помощью которого определяется переданное кодовое слово. При этом таблица получается гораздо меньше, чем при использовании предыдущего метода.
Линейные циклические коды[]
Несмотря на то, что декодирование линейных кодов уже значительно проще декодирования большинства нелинейных, для большинства кодов этот процесс всё ещё достаточно сложен. Циклические коды, кроме более простого декодирования, обладают и другими важными свойствами.
Циклическим кодом является линейный код, обладающий следующим свойством: если является кодовым словом, то его циклическая перестановка также является кодовым словом.
Слова циклического кода удобно представлять в виде многочленов. Например, кодовое слово  представляется в виде полинома
представляется в виде полинома  . При этом циклический сдвиг кодового слова эквивалентен умножению многочлена на
. При этом циклический сдвиг кодового слова эквивалентен умножению многочлена на  по модулю
по модулю  .
.
В дальнейшем, если не указано иное, мы будем считать, что циклический код является двоичным, то есть  могут принимать значения 0 или 1.
могут принимать значения 0 или 1.
Порождающий (генераторный) полином[]
Можно показать, что все кодовые слова конкретного циклического кода кратны определённому порождающему полиному  . Порождающий полином является делителем .
. Порождающий полином является делителем .
С помощью порождающего полинома осуществляется кодирование циклическим кодом. В частности:
Коды CRC[]
Коды CRC (cyclic redundancy check — циклическая избыточная проверка) являются систематическими кодами, предназначенными не для исправления ошибок, а для их обнаружения. Они используют способ систематического кодирования, изложенный выше: «контрольная сумма» вычисляется путем деления  на . Ввиду того, что исправление ошибок не требуется, проверка правильности передачи может производиться точно так же.
на . Ввиду того, что исправление ошибок не требуется, проверка правильности передачи может производиться точно так же.
Таким образом, вид полинома задаёт конкретный код CRC. Примеры наиболее популярных полиномов:
| название кода | степень | полином |
|---|---|---|
| CRC-12 | 12 | 
|
| CRC-16 | 16 | 
|
| CRC-CCITT | 16 | 
|
| CRC-32 | 32 | 
|
Коды БЧХ[]
Коды Боуза — Чоудхури — Хоквингема (БЧХ) являются подклассом циклических кодов. Их отличительное свойство — возможность построения кода БЧХ с минимальным расстоянием не меньше заданного. Это важно, потому что, вообще говоря, определение минимального расстояния кода есть очень сложная задача.
Математически полинома на множители в поле Галуа.
Коды коррекции ошибок Рида — Соломона[]
Коды Рида — Соломона — недвоичные циклические коды, позволяющие исправлять ошибки в блоках данных. Элементами кодового вектора являются не биты, а группы битов (блоки). Очень распространены коды Рида-Соломона, работающие с байтами (октетами).
Математически коды Рида — Соломона являются кодами БЧХ.
Преимущества и недостатки блоковых кодов[]
Хотя блоковые коды, как правило, хорошо справляются с редкими, но большими пачками ошибок, их эффективность при частых, но небольших ошибках (например, в канале с АБГШ), менее высока.
Свёрточные коды[]
Файл:ECC NASA standard coder.png Свёрточный кодер ( )
)
Свёрточные коды, в отличие от блоковых, не делят информацию на фрагменты и работают с ней как со сплошным потоком данных.
Свёрточные коды, как правило, порождаются дискретной линейной инвариантной во времени системой. Поэтому, в отличие от большинства блоковых кодов, свёрточное кодирование — очень простая операция, чего нельзя сказать о декодировании.
Кодирование свёрточным кодом производится с помощью регистра сдвига, отводы от которого суммируются по модулю два. Таких сумм может быть две (чаще всего) или больше.
Декодирование свёрточных кодов, как правило, производится по алгоритму Витерби, который пытается восстановить переданную последовательность согласно критерию максимального правдоподобия.
Преимущества и недостатки свёрточных кодов[]
Свёрточные коды эффективно работают в канале с белым шумом, но плохо справляются с пакетами ошибок. Более того, если декодер ошибается, на его выходе всегда возникает пакет ошибок.
Каскадное кодирование. Итеративное декодирование[]
Преимущества разных способов кодирования можно объединить, применив каскадное кодирование. При этом информация сначала кодируется одним кодом, а затем другим, в результате получается код-произведение.
Например, популярной является следующая конструкция: данные кодируются кодом Рида-Соломона, затем перемежаются (при этом символы, расположенные близко, помещаются далеко друг от друга) и кодируются свёрточным кодом. На приёмнике сначала декодируется свёрточный код, затем осуществляется обратное перемежение (при этом пачки ошибок на выходе свёрточного декодера попадают в разные кодовые слова кода Рида — Соломона), и затем осуществляется декодирование кода Рида — Соломона.
Некоторые коды-произведения специально сконструированы для итеративного декодирования, при котором декодирование осуществляется в несколько проходов, каждый из которых использует информацию от предыдущего. Это позволяет добиться большой эффективности, однако, декодирование требует больших ресурсов. К таким кодам относят турбо-коды и LDPC-коды (коды Галлагера).
Оценка эффективности кодов[]
Эффективность кодов определяется количеством ошибок, которые тот может исправить, количеством избыточной информации, добавление которой требуется, а также сложностью реализации кодирования и декодирования (как аппаратной, так и в виде программы для ЭВМ).
Граница Хемминга и совершенные коды[]
-
Основная статья: Граница Хэмминга
Пусть имеется двоичный блоковый  код с корректирующей способностью . Тогда справедливо неравенство (называемое границей Хемминга):
код с корректирующей способностью . Тогда справедливо неравенство (называемое границей Хемминга):

Коды, удовлетворяющие этой границе с равенством, называются совершенными. К совершенным кодам относятся, например, коды Хемминга. Часто применяемые на практике коды с большой корректирующей способностью (такие, как коды Рида — Соломона) не являются совершенными.
Энергетический выигрыш[]
При передаче информации по каналу связи вероятность ошибки зависит от отношения сигнал/шум на входе демодулятора, таким образом при постоянном уровне шума решающее значение имеет мощность передатчика. В системах спутниковой и мобильной, а также других типов связи остро стоит вопрос экономии энергии. Кроме того, в определённых системах связи (например, телефонной) неограниченно повышать мощность сигнала не дают технические ограничения.
Поскольку помехоустойчивое кодирование позволяет исправлять ошибки, при его применении мощность передатчика можно снизить, оставляя скорость передачи информации неизменной. Энергетический выигрыш определяется как разница отношений с/ш при наличии и отсутствии кодирования.
Применение кодов, исправляющих ошибки[]
Коды, исправляющие ошибки, применяются:
- в системах цифровой связи, в том числе: спутниковой, радиорелейной, сотовой, передаче данных по телефонным каналам.
- в системах хранения информации, в том числе магнитных и оптических.
Коды, обнаруживающие ошибки, применяются в сетевых протоколах различных уровней.
Автоматический запрос повторной передачи[]
Системы с автоматическим запросом повторной передачи (ARQ — Automatic Repeat reQuest) основаны на технологии обнаружения ошибок. Распространены следующие методы автоматического запроса:
Запрос ARQ с остановками (stop-and-wait ARQ)[]
Идея этого метода заключается в том, что передатчик ожидает от приемника подтверждения успешного приема предыдущего блока данных перед тем как начать передачу следующего. В случае, если блок данных был принят с ошибкой, приемник передает отрицательное подтверждение (negative acknowledgement, NAK), и передатчик повторяет передачу блока. Данный метод подходит для полудуплексного канала связи. Его недостатком является низкая скорость из-за высоких накладных расходов на ожидание.
Непрерывный запрос ARQ с возвратом (continuous ARQ with pullback)[]
Для этого метода необходим полнодуплексный канал. Передача данных от передатчика к приемнику производится одновременно. В случае ошибки передача возобновляется, начиная с ошибочного блока (то есть, передается ошибочный блок и все последующие).
Непрерывный запрос ARQ с выборочным повторением (continuous ARQ with selective repeat)[]
При этом подходе осуществляется передача только ошибочно принятых блоков данных.
См. также[]
- Цифровая связь
- Линейный код
- Циклический код
- Код Боуза — Чоудхури — Хоквингема
- Код Рида — Соломона
- LDPC
- Свёрточный код
- Турбо-код
Литература[]
- Мак-Вильямс Ф. Дж., Слоэн Н. Дж. А. Теория кодов, исправляющих ошибки. М.: Радио и связь, 1979.
- Блейхут Р. Теория и практика кодов, контролирующих ошибки. М.: Мир, 1986.
- Морелос-Сарагоса Р. Искусство помехоустойчивого кодирования. Методы, алгоритмы, применение. М.: Техносфера, 2005. — ISBN 5-94836-035-0
Ссылки[]
Имеется викиучебник по теме:
Обнаружение и исправление ошибок
- Помехоустойчивое кодирование (11 ноября 2001). — реферат по проблеме кодирования сообщений с исправлением ошибок. Проверено 25 декабря 2006.
Эта страница использует содержимое раздела Википедии на русском языке. Оригинальная статья находится по адресу: Обнаружение и исправление ошибок. Список первоначальных авторов статьи можно посмотреть в истории правок. Эта статья так же, как и статья, размещённая в Википедии, доступна на условиях CC-BY-SA .