МИНОБРНАУКИ
РОССИИ
Борисоглебский
филиал
федерального
государственного бюджетного образовательного учреждения
высшего
образования
«Воронежский
государственный университет»
Факультет
физико-математического и естественно – научного образования
Кафедра
прикладной математики, информатики,
Физики
и методики их преподавания
Отчёт
по научно-исследовательской практике
«Сканирование
и распознавание изображений»
Выполнила:
студентка 5 курса 2 группы
заочного отделения
Белева С.С
Проверил: Тараканов А.Ф.
Борисоглебск
— 2015
Содержание
Введение
Сканер. Характеристики
сканера
Сканирование
Распознавание текстов и
изображений
Применение сканирования
Заключение
Список используемых
источников
Введение
Одним из основных способов ввода
информации в вычислительные системы является сканирование. Именно сканер стал
тем устройством, с помощью которого в компьютер попадает огромное количество
информации.
С помощью современной
аппаратуры сканирования с высоким разрешением исходного документа довольно
просто формируется графический файл специального формата. Такой файл после
соответствующей обработки может быть преобразован в любой из форматов, которые
применяются в информационных технологиях. Это форматы представления текстов и
графических видов информации — фотографий, слайдов, рисунков и т.п.
Преобразование документа в
электронный вид делится на два этапа: получение графического образа документа и
перевод графического образа в текстовый формат. Графический образ документа
является результатом сканирования. Перевод графического образа документа в
текстовый формат может быть произведен вручную или посредством автоматического
распознавания.
Говоря о сканировании,
вспомним, что же такое сканер? А так же рассмотрим основные характеристики сканеров.
Сканер.
Характеристики сканера
Скамнер (англ. scanner) —
устройство, выполняющее преобразование расположенного на плоском носителе (чаще
всего бумаге) изображения в цифровой формат.
В 1857
году флорентийский аббат Джованни
Казелли (итал. GiovanniCaselli) изобрёл прибор для
передачи изображения на расстояние, названный
впоследствии пантелеграф. Передаваемая картинка наносилась на барабан токопроводящими
чернилами и считывалась с помощью иглы.
В 1902 году, немецким
физиком Артуром Корном (нем. ArthurKorn)
была запатентована технология фотоэлектрического сканирования,
получившая впоследствии название телефакс. Передаваемое изображение
закреплялось на прозрачном вращающемся барабане, луч света от лампы,
перемещающейся вдоль оси барабана, проходил сквозь оригинал и через
расположенные на оси барабана призму и объектив попадал
населеновый фотоприёмник. Эта технология до сих пор применяется в
барабанных сканерах.
В дальнейшем, с
развитием полупроводников, усовершенствовался фотоприёмник, был изобретен
планшетный способ сканирования, но сам принцип оцифровки изображения остаётся
почти неизменным.
Основные характеристики
сканеров.
Оптическое разрешение.
Является основной характеристикой сканера. Сканер снимает изображение не
целиком, а по строчкам. По вертикали планшетного сканера движется полоска
светочувствительных элементов и снимает по точкам изображение строку за
строкой. Чем больше светочувствительных элементов у сканера, тем больше точек он
может снять с каждой горизонтальной полосы изображения. Это и называется
оптическим разрешением. Оно определяется количеством светочувствительных
элементов (фотодатчиков), приходящихся на дюйм горизонтали сканируемого
изображения. Обычно его считают по количеству точек на дюйм — dpi
(dotsperinch). Нормальный уровень разрешение не менее 600 dpi, увеличивать его
еще дальше — значит, применять дорогую оптику, дорогие светочувствительные
элементы, и увеличивать время сканирования. Для обработки слайдов необходимо
более высокое разрешение 1200 dpi.
Разрешение по X. Этот
параметр показывает количество пикселей у фоточувствительной линейки, из
которых формируется изображение. Разрешение является одной из основных
характеристик сканера. Большинство моделей имеет оптическое разрешение сканера
600 или 1200 dpi (точек на дюйм). Его достаточно для получения качественной
копии. Для профессиональной работы с изображением необходимо более высокое
разрешение.
Разрешение по Y. Этот
параметр определяется величиной хода шагового двигателя и точностью работы
механики. Механическое разрешение сканера значительно выше оптического
разрешения фотолинейки. Именно оптическое разрешение линейки фотоэлементов
будет определять общее качество отсканированного изображения.
Скорость сканирования.
Скорость сканирования зависит от разрешения при сканировании и от размера
оригинала. Обычно производители указывают этот параметр для формата А4.
Скорость сканирования может измеряться количеством страниц в минуту или
временем, необходимым для сканирования одной страницы. Иногда измеряется в
количестве сканируемых линий в секунду.
Глубина цвета. Как правило,
производители указывают два значения для глубины цвета — внутреннюю глубину и
внешнюю. Внутренняя глубина — это разрядность АЦП (аналого-цифрового
преобразователя) сканера, она указывает на то, сколько цветов сканер способен
различить в принципе. Внешняя глубина — это количество цветов, которое сканер
может передать компьютеру. Большинство моделей используют для цветопередачи 24
бита (по 8 на каждый цвет). Для стандартных задач в офисе и дома этого вполне
достаточно. Но если вы собираетесь использовать сканер, для серьезной работы с
графикой, попробуйте найти модель с большим числом разрядов.
Максимальная оптическая
плотность. Максимальная оптическая плотность у сканера — это оптическая
плотность оригинала, которую сканер отличает от ‘полной темноты’. Чем больше
это значение, тем больше чувствительность сканера и, тем выше качество
сканирования темных изображений.
Тип источника света.
Ксеноновые лампы отличаются малым временем прогрева, долгим сроком службы и
небольшими размерами. Флуоресцентные лампы с холодным катодом дешевы в
производстве и имеют долгий срок службы. Светодиоды (LED) обладают малыми
размерами, низким энергопотреблением и не требуют времени для прогрева. Но по
качеству цветопередачи LED-сканеры уступают сканерам с флуоресцентными и
ксеноновыми лампами.
Тип датчика сканера. В
сканерах МФУ обычно используется один из двух типов датчиков: контактный (CIS)
или ПЗС (CCD). CIS представляет собой линейку фотоэлементов, которая равна
ширине сканируемой поверхности. Во время сканирования она перемещается под
стеклом и строка за строкой передает информацию об изображении на оригинале в
виде электрического сигнала. Для освещения обычно используются светодиоды,
которые расположены в непосредственной близости от фотолинейки на той же
подвижной платформе. Сканеры на базе CIS имеют простую конструкцию, тонкий
корпус и небольшой вес, они обычно дешевле сканеров на базе CCD. Основной
недостаток CIS состоит в малой глубине резкости.
Виды сканеров.
планшетные — наиболее
распространённый вид сканеров, поскольку обеспечивает максимальное удобство для
пользователя — высокое качество и приемлемую скорость сканирования.
Представляет собой планшет, внутри которого под прозрачным стеклом расположен
механизм сканирования;
ручные — в них отсутствует
двигатель, следовательно, объект приходится сканировать пользователю вручную,
единственным его плюсом является дешевизна и мобильность, при этом он имеет
массу недостатков — низкое разрешение, малую скорость работы, узкая полоса
сканирования, возможны перекосы изображения, поскольку пользователю будет
трудно перемещать сканер с постоянной скоростью;
листопротяжные — лист бумаги
вставляется в щель и протягивается по направляющим роликам внутри сканера мимо
лампы. Имеет меньшие размеры, по сравнению с планшетным, однако может
сканировать только отдельные листы, что ограничивает его применение в основном
офисами компаний. Многие модели имеют устройство автоматической подачи, что
позволяет быстро сканировать большое количество документов;
планетарные сканеры —
применяются для сканирования книг или легко повреждающихся документов. При
сканировании нет контакта со сканируемым объектом (как в планшетных сканерах).
Подробности на английском языке;
книжные сканеры —
предназначены для сканирования брошюрованных документов. Сканирование
производится лицевой стороной вверх — таким образом, Ваши действия по
сканированию неотличимы от перелистывания страниц при обычном чтении. Это
предотвращает их повреждение и позволяет пользователю видеть документ в
процессе сканирования;
слайд-сканеры — как ясно из
названия, служат для сканирования плёночных слайдов, выпускаются как
самостоятельные устройства, так и в виде дополнительных модулей к обычным
сканерам;
сканеры штрих-кода —
небольшие, компактные модели для сканирования штрих-кодов товара в магазинах.
Принцип действия
Сканируемый объект кладется
на стекло планшета сканируемой поверхностью вниз. Под стеклом располагается
подвижная лампа, движение которой регулируется шаговым двигателем. Свет,
отраженный от объекта, через систему зеркал попадает на чувствительную матрицу,
далее на АЦП и передается в компьютер. За каждый шаг двигателя сканируется
полоска объекта, которые потом объединяются программным обеспечением в общее
изображение.
Изображение всегда
сканируется в формат RAW — а затем конвертируется в обычный графический формат
с применением текущих настроек яркости, контрастности, и т. д. Эта конвертация
осуществляется либо в самом сканере, либо в компьютере — в зависимости от
модели конкретного сканера. На параметры и качество RAW-данных влияют такие
аппаратные настройки сканера, как время экспозиции матрицы, уровни калибровки
белого и чёрного, и т.п.
Сканирование
Для пользователей
компьютеров единственным путём просмотра электронных файлов является
сканирование изображения. Во время этого процесса сканер преобразовывает текст,
графику листа и плёнку в цифровой образ, процесс преобразования может быть
аналоговым и цифровым.
Процесс сканирования
изображения является лёгким и доступным и чаще всего работают со сканером, при
использовании он является наиболее эффективным и разнообразным. Его широко
используют для коммерческих целей, но любителям также нравится сканировать
изображения, особенно если они увлекаются фотографиями. Также часто его
используют в художественном творчестве, это заодно и весело, и полезно.
Обучающая программа по
сканированию всегда доступна, как и для рисунка, так и для документов. Не для
пользователей компьютеров единственным путём просмотра электронных файлов
является сканирование изображения. Во время этого процесса сканер
преобразовывает текст, графику листа и плёнку в цифровой образ, процесс
преобразования может быть аналоговым и цифровым.
Для сканирования изображения
нужно следовать нескольким основным шагам, для любого типа сканера или
программного обеспечения метод сканирования фотографий на планшетном сканере
один и тот же. Когда лампа светит на фотографию, оптические ячейки сканера
фиксируют цвета, отражающиеся с точек изображения. Такими цветами являются
красный, зелёный и синий. (КЗС).
Пиксель или элемент рисунка
передаётся к каждой точке и измеряется в пикселях из расчёта на дюйм, это
является разрешением образа. Три числа представляют каждый пиксель на образе, и
эти числа показывают яркость красного, зелёного и синего компонента цвета.
Итак, есть разные форматы изображения, и каждый формат хранит информацию о
пикселях и цветах в разных вариантах.имеет значения, что вы хотите перенести в
компьютер: текст или рисунок, вы должны знать, как работать со сканером. Обычно
программное обеспечение объясняет все шаги детально, и сканировать изображения
вы можете практически как цветным, так и чёрно- белым.
Пиксель или элемент рисунка
передаётся к каждой точке и измеряется в пикселях из расчёта на дюйм, это
является разрешением образа. Три числа представляют каждый пиксель на образе, и
эти числа показывают яркость красного, зелёного и синего компонента цвета.
Итак, есть разные форматы изображения, и каждый формат хранит информацию о
пикселях и цветах в разных вариантах.
Сканирование документов —
процесс создания электронного изображения бумажного документа, напоминает его
фотографирование. На этапе сканирования производится получение изображения при
помощи сканера и сохранение их в виде, удобном для последующей обработки.
Процесс сканирования
осуществляется автоматически и требует от пользователя только вспомогательных
операций, таких как смена сканируемой страницы.
Сканирование, как единый
сквозной процесс, распадается на две независимых ветви. По одному направлению
идёт ввод в вычислительные системы текстовых массивов информации, по другому —
графических.
Задача сканирования текстов,
при необходимом качественном разрешении, на 90% состоит в распознавании. А для
этого разработано математическое обеспечение, которое позволяет эффективно
построить технологию получения качественных электронных документов.
Чтобы реализовать
автоматический или автоматизированный перевод бумажных документов в электронный
вид, необходимо выполнить сканирование бумажных документов и распознать их
содержимое с помощью специальных программ, называемых системами оптического
распознавания символов.
Распознавание
текстов и изображений
Процесс распознавания
изображений является сложной многоэтапной процедурой. Многоэтапность
(иерархичность) обусловлена тем, что различные задачи обработки на самом деле
тесно связаны и качество решения одной из них влияет на выбор метода решения
остальных. Так выбор метода распознавания зависит от конкретных условий
предъявления входных изображений, в том числе характера фона, других
изображений, помеховой обстановки и связан с выбором методов предобработки,
сегментации, фильтрации.
Распознавание — чаще всего
конечный этап обработки, лежащий в основе процессов интерпретации и понимания.
Входными для распознавания являются изображения, выделенные в результате
сегментации и, частично, отреставрированные. Они отличаются от эталонных
геометрическими и яркостными искажениями, а также сохранившимися шумами.
На этом шаге происходит
идентификация документа и выделение его объектов (полей, пометок, штрихкодов и
прочего), удаляются помехи, которые мешают распознаванию (например, разграфка).
Далее происходит распознавание полей документа. Затем проводится оценка достоверности
результатов распознавания, после чего производится обобщенный лингвистический
анализ поля.
После распознавания может
следовать специальная обработка его результатов на основании априорной
лингвистической и структурной информации о поле. После этого принимается
решение о достоверности результатов распознавания. В системе реализована схема,
признающая поле недостоверным в случае наличия в нем хотя бы одного
недостоверного символа. После этого происходит сохранение результатов
распознавания во внутренний формат системы и выполняется контроль логической
непротиворечивости данных.
Кроме всего этот этап
выполняет дополнительные функции: автоматическое определение угла поворота
страницы и его автоматическая коррекция.
Процесс распознавания
полностью автоматический, не требует наличия оператора, при этом возможно
распараллеливание распознавания в рамках локальной сети.
При необходимости, после
распознавания документ передается на верификацию. Если же необходимости в
верификации нет, распознанные данные могут экспортироваться во внешние
информационные системы и базы данных.
Верификация документа:
исправление ошибок заполнения и распознавания, подтверждение результатов
распознавания «сомнительных» полей, просмотр полей, не прошедших логический
контроль, и принятие решения о дальнейшей судьбе таких документов. На этом
этапе оператор производит визуальный контроль результатов распознавания и
принимает решение о дальнейшем маршруте документа. Процесс реализован в
двухоконном редакторе форм. В одном окне показано изображение бумажного
документа, в другом — электронная форма, содержащая распознанные данные.
Процесс верификации
документа идет по следующей схеме. Оператору предъявляется изображение и
электронная форма с распознанными данными. При этом поля, не прошедшие контроль
достоверности и логической непротиворечивости, подсвечены цветом для
привлечения внимания оператора. Оператор, перемещая фокус между полями
электронной формы, видит диагностику ошибок и либо исправляет ошибку, либо,
если ошибку нельзя исправить, принимает решение передать документ на этап
обработки «плохих» документов. При передвижении по полям модуль автоматически
подсвечивает рамку поля на изображении.
Для повышения эффективности
работы оператора предусмотрены два режима: проход только по полям, не прошедшим
контроль, и режим пропуска незаполненных полей. Кроме этого, если прикреплен
словарь, содержащий допустимые значения для поля, то имеется возможность
указать в описании поля необходимость предъявления словаря оператору и
разрешить оператору вставлять в поле значения из словаря.
После окончания верификации
документа оператору предлагается либо отложить его, либо передать на этап
экспорта данных.
Возможно распараллеливание
процесса верификации в рамках локальной сети. В крупных проектах массового
ввода могут быть одновременно задействованы десятки операторов, выполняющих
функцию верификации потока документов.
После верификации, данные
могут экспортироваться во внешние информационные системы и базы данных.
Точность распознавания
Ключевым параметром систем
распознавания, характеризующим их практическую ценность, является точность
распознавания, то есть процент правильно распознанных символов.
OpticalCharacterRecognition
— системы могут достигать наилучшей точности распознавания — свыше 99,9% для
чистых изображений, составленных из обычных шрифтов. На первый взгляд такая
точность распознавания кажется идеальной, но уровень ошибок все же удручает,
потому что, если имеется приблизительно 1500 символов на странице, то даже при
коэффициенте успешного распознавания 99,9 % получается одна или две ошибки на
страницу. В таких случаях на помощь приходит метод проверки по словарю. То
есть, если какого-то слова нет в словаре системы, то она по специальным
правилам пытается найти похожее. Но это все равно не позволяет исправлять 100 %
ошибок, что требует человеческого контроля результатов.
Точность распознавания
падает за счет ошибок распознавания. Повышению точности распознавания
способствует устранение указанных ниже причин ошибок.
Причины ошибок при распознавании
Встречающиеся в реальной
жизни тексты обычно далеки от совершенства, и процент ошибок распознавания для
«нечистых» текстов часто недопустимо велик. Грязные изображения —
здесь наиболее очевидная проблема, потому что даже небольшие пятна могут затенять
определяющие части символа или преобразовывать один в другой. Еще одной
проблемой является неаккуратное сканирование, связанное с «человеческим
фактором», так как оператор, сидящий за сканером, просто не в состоянии
разглаживать каждую сканируемую страницу и точно выравнивать ее по краям
сканера.
Если документ был
ксерокопирован, нередко возникают разрывы и слияния символов. Любой из этих
эффектов может заставлять систему ошибаться, потому что некоторые из OCR-систем
полагают, что непрерывная область изображения должна быть одиночным символом.
Страница, расположенная с
нарушением границ или перекосом, создает немного искаженные символьные
изображения, которые могут быть перепутаны OCR.
Более трудоёмкой является
задача сканирования цветных изображений. Она обычно заключается в наиболее
полном считывании информации с оригинала, т. е. его тонового и цветового
диапазона, а также разрешения. При этом желательно по необходимости
скорректировать недостатки оригинала с точки зрения последующего использования
изображения. Например, компенсировать нежелательный цветовой сдвиг, тоновый
дисбаланс или подавить полиграфический растр оригинала.
В настоящее время для
решения этих задач многие фирмы производят соответствующее оборудование и
разрабатывают математическое обеспечение. Однако именно в наличии большого
количества возможностей и способов организовать технологический процесс
сканирования и кроется главная опасность. Выбор определённого устройства и
программ позволяет удовлетворительно и без перенастроек работать только со
сравнительно небольшим диапазоном типов документов.
Применение сканирования
Применение сканеров имеет
широкий диапазон и находится в постоянном развитии. Сканирование интенсивно
используются в специализированных информационных технологиях. По сканированию
текста наиболее полно наработан опыт в создании электронных библиотек
Интернета. По второму направлению — цветной графики, давно работают в области
полиграфии
Успешность применения
сканеров зависит не только от их собственных качеств, но и от правильного их
использования. Каждая из областей применения имеет свой собственный акцент и
делает ударение на различные характеристики системы.
Настольные издательские
системы (вы вводите в издаваемую статью рисунки, диаграммы, фотографии). В
данном случае сканеры должны быть как минимум цветными, обладать высокой
разрешающей способностью, широким диапазоном оптических плотностей, с числом
передаваемых цветов 16 777 216 (24 бита на точку — 8 бит на каждый цвет RGB) и
т.д.
Системы обработки документов
(пакет оптического распознавания символов вместе со сканером научат ваш
компьютер «читать» текст, экономия времени, которое тратится на ввод
с клавиатуры). Сканеры, применяемые для этих целей не должны быть цветными,
т.к. для сканирования текста необходимо регистрировать только два уровня —
белый и черный (глубина точки 1 бит), высоких разрешающих способностей здесь
тоже не требуется, а значит, стоимость сканера сильно снижается.
САПР (сканер + программа
векторизации облегчает процесс ввода чертежей для дальнейшего их использования
в пакетах автоматического проектирования). Нет необходимости применять здесь
цветной сканер, но разрешающая способность должна быть достаточно высокой,
чтобы косые линии не выглядели как ступеньки лестницы.
Системы компьютерной
анимации. Здесь почти всю область применения занимают проекционные сканеры,
обеспечивающие хорошее качество вводимых изображений и возможность ввода
проекций трехмерных тел.
Системы для передачи
информации (факс — модем + сканер = факс машина).
Заключение
Качество сканированного
изображения определяется многими факторами. Такие как — тип сканируемого
оригинала, технические возможности сканера, квалификация оператора сканера,
размер оригинала, от которого зависит необходимая кратность увеличения, разрешение
при сканировании, а также особенности любой обработки, примененной к
изображению в ходе сканирования. Сканируете ли вы оригиналы самостоятельно,
пользуетесь ли услугами сервисного бюро или агентства допечатной обработки, для
успеха проектов в области печати нелишне детально представлять себе процесс
получения сканированных изображений. Кроме того, если вы хотите, чтобы
сканированные изображения имели высокое качество, до стадии сканирования
необходимо в максимально возможной степени узнать о возможностях вывода
изображения и специфике печати — размере выводимого изображения, а также
параметрах печатного станка — пространственной частоте растра, типе бумаги,
типе печатного станка, ограничениях на тоновый диапазон, а также ожидаемом
увеличении размера растровой точки. Согласование характеристик сканирования и
этих факторов гарантирует, что каждое сканированное вами изображение будет
качественным.
Список используемых
источников
1. http://www.microbs.ru/hardware_pc/scan.shtml
2.
http://cognitiveforms.ru/technologies/
3.
http://www.novojonov.ru/content/printable.aspx?key=soft-electronic-archive&file=08-scan-ocr
4.
http://www.awella.ru/newsscanirovanie.php.htm
5. В.П. Леонтьев «Новейшая
энциклопедия персонального компьютера 2003». — М.: «ОЛМА-ПРЕСС», 2003. — 920с.
В июле Николя Паперно из Университета Торонто и его коллеги опубликовали исследование, в котором представлен способ обмануть модели машинного обучения, работающие с языком, при помощи незаметных для человека манипуляций с входным текстом. Команда Паперно продемонстрировала, что даже крошечные элементы, вроде единичных знаков, обозначающих пустое пространство, могут повлиять на понимание текста моделью. Ошибки отражаются и на пользователях — например, из-за одного-единственного знака алгоритм сгенерировал указание отправить деньги на неправильный банковский счет.
Внесение изменений во входные данные с целью обмануть алгоритм и вынудить его совершить ошибку называется конфронтационной атакой. Об уязвимости алгоритмов перед такого рода атаками стало известно в 2013 году, когда исследователям удалось обмануть глубокую нейросеть, модель машинного обучения с многочисленными слоями искусственных нейронов.
На данный момент не существует надежных способов устранить эту уязвимость. Но есть свет в конце тоннеля. Например, глубокую нейросеть можно обучить на примере конфронтационных изображений. К сожалению, этот метод, получивший название конфронтационного машинного обучения, помогает преодолеть уязвимость только в случае с изображениями, которые модель уже видела. Кроме того, он снижает эффективность модели при распознавании не-конфронтационных изображений, а также требует значительной вычислительной мощности.
Вот почему некоторые ученые обратили внимание на тот факт, что человеческий глаз почти невозможно обмануть конфронтационной атакой.

«Эволюция на протяжении миллионов лет совершенствовала живые организмы и нашла довольно неожиданные и изобретательные решения. Мы должны изучить эти решения и попытаться сымитировать их», — говорит Бенджамин Эванс, специалист по вычислительной нейробиологии из Бристольского университета.
Акцент на центральном углублении
Самое очевидное различие между зрительным восприятием людей и нейросетей состоит в том, что люди воспринимают мир при помощи глаз. Мы наиболее отчетливо видим объекты, находящиеся в центре нашего поля зрения, так как посередине заднего полюса наших глазных яблок расположена область с наибольшей концентрацией чувствительных к свету фоторецепторов, называемая центральным углублением.
«Нам кажется, что мы видим все вокруг одинаково хорошо, но это не так», — говорит Томазо Поджо, специалист по вычислительной нейробиологии из Массачусетского технологического института и директор Центра изучения мозга, сознания и компьютеров.
Компьютеры «видят», анализируя последовательность чисел, обозначающих цвет и яркость каждого пикселя в изображении. Это означает, что острота зрения компьютера одинакова в любой точке поля зрения (или, точнее, последовательности чисел).
Поджо и его коллеги решили проверить, может ли обработка изображений, имитирующая человеческое зрение, снизить вредоносное воздействие шума и обеспечить устойчивость к конфронтационным атакам. Исследователи обучили несколько глубоких нейросетей на примере изображений, отредактированных таким образом, чтобы высокое разрешение было только посередине. А поскольку наши глаза поочередно фиксируются на разных фрагментах изображения, исследователи создали много вариантов каждого изображения с высоким разрешением в разных частях.
Это исследование, результаты которого были опубликованы в прошлом году, показало, что модели, обученные на отредактированных таким образом изображениях, более устойчивы к конфронтационным атакам и не теряют в точности. Однако этот метод все же показал более низкую эффективность, чем метод конфронтационного машинного обучения. Двое исследователей из лаборатории Поджо, Артуро Дедза и Анджей Банбурски, продолжают исследования в данном направлении с применением более сложных отредактированных изображений, делая акцент на периферийном зрении.

Имитация зрительных нейронов
Соприкосновение света с клетками сетчатки — это всего лишь первый этап восприятия визуальной информации. Пройдя через глазные яблоки, электрические сигналы по аксонам передаются в центр обработки зрительной информации, расположенный в затылочной доле. Открытие иерархической организации нейронов, отвечающих за разные признаки изображений, в 1980 году вдохновило специалиста в области информатики Кунихико Фукусиму на создание первой сверточной нейронной сети — модели, которая по сей день используется при распознавании изображений.
Сверточные нейронные сети содержат фильтры, которые сканируют изображения на предмет определенных признаков, например линий и контуров объектов. Однако процесс обработки изображений в зрительной коре мозга все же намного сложнее. Некоторые ученые считают, что более точная имитация этого процесса позволит машинам видеть как мы — и, как следствие, повысить сопротивляемость к конфронтационным атакам.
Лаборатории Джеймса ДиКарло при МТИ и Джеффри Бауэрса при Бристольском университете как раз испытывают специальный фильтр, имитирующий обработку зрительной информации нейронами первичной зрительной коры. Лаборатория ДиКарло также снабдила свою модель генератором шума, имитирующим нейронный шум. Это дополнение позволило сделать машинное зрение более похожим на человеческое и избежать типичного для ИИ излишнего акцента на текстурах.
Когда исследователи из лаборатории ДиКарло испытали свою усовершенствованную сверточную нейронную сеть с помощью конфронтационных атак, то обнаружили, что модификации обеспечили ей четырехкратное увеличение точности по сравнению с обычными сверточными нейросетями. Она также показала лучшие результаты, чем метод конфронтационного машинного обучения, но только применительно к изображениям, не использовавшимся в процессе обучения. Исследователи обнаружили, что все элементы сверточной нейросети взаимодействовали друг с другом в противостоянии атакам, однако решающее значение имел случайный шум.
В статье, опубликованной в ноябре, описывается совместное исследование лаборатории ДиКарло и других команд, посвященное эффекту нейронного шума. Исследователи снабдили генератором случайного шума нейросеть, имитирующую слуховую систему человека. По их утверждениям, данная модель также успешно противостоит конфронтационным атакам в виде звуков речи.
«Однако мы по-прежнему не знаем, почему шум взаимодействует с остальными элементами», — говорит один из авторов статьи Джоел Дапелло.
Спящие машины
Активность мозга в период, когда наши глаза закрыты, а зрительная кора перестает обрабатывать информацию об окружающем мире, имеет не менее важное значение для сопротивления атакам.
Специалист по вычислительной нейробиологии Максим Баженов из Калифорнийского университета в Сан-Диего вот уже более двадцати лет изучает активность мозга во время сна. А недавно ему пришло в голову, что сон может помочь преодолеть многочисленные проблемы в области ИИ, в том числе проблему уязвимости к конфронтационным атакам.
Идея проста. Сон играет ключевую роль в консолидации памяти, то есть в превращении нового опыта в долгосрочные воспоминания. Баженов и некоторые другие исследователи считают, что сон также помогает в формировании обобщенных знаний о мире. Если они правы, то имитация сна поможет нейросетям приобрести более надежные знания об изображениях, на которых они обучаются, и тем самым повысить сопротивляемость к небольшим количествам шума.
«Во время сна мозг получает возможность отключить поток входящей информации и заняться внутренними представлениями, — говорит Баженов. — Быть может, во сне нуждаются не только живые организмы, но и машины».
В статье, опубликованной в 2020 году, описывается эксперимент, в ходе которого исследователи из лаборатории Баженова перевели нейросеть в режим сна после обучения по распознаванию изображений. В режиме сна связи между нейронами обновлялись не согласно методу обратного распространения ошибки, а произвольным способом, имитируя процесс, происходящий, согласно теории Хебба, в мозгу спящего человека.
Оказалось, что после сна обмануть нейросеть можно было лишь увеличив количество шума. Однако в случае с некоторыми атаками метод конфронтационного машинного обучения все равно оказался более эффективным.

Неопределенное будущее
Несмотря на примеры успешного применения биологических подходов в противодействии конфронтационным атакам, надежными их пока назвать нельзя. Быть может, очень скоро какой-нибудь другой исследователь опровергнет их эффективность. Подобное нередко случается в области конфронтационного машинного обучения.
Кроме того, не все считают биологические решения верным направлением.
«Нам не хватает знаний для создания биологических систем, имеющих гарантированную неуязвимость перед подобными атаками», — говорит Зико Колтер, специалист в области информатики из Университета Карнеги — Меллона. Колтер внес весомый вклад в разработку небиологических методов противодействия конфронтационным атакам.
Колтер считает, что самым эффективным методом будет обучение нейросетей при помощи огромных объемов данных, то есть предоставление машинам такого же количества информации о мире, каким владеем мы, — пусть они и видят мир иначе.
Современные технологии позволяют нам использовать голосовые помощники, переводчики, автозаполнение поисковых запросов и многие другие удобные функции. Однако, все эти инструменты сталкиваются с проблемой распознавания русской речи. Гугл, наиболее популярный и удобный поисковик, не всегда справляется со своей задачей.
Среди главных причин того, почему Гугл ошибается при распознавании некоторых русских слов и выражений, можно назвать орфографические и грамматические ошибки, диалектные и социолектные особенности речи, а также характеристики произношения определенных слов, которые накладываются на особенности акустической обработки и распознавания звуковой информации.
Стоит отметить, что Гугл использует искусственный интеллект и машинное обучение, чтобы улучшить точность распознавания русской речи, но это все еще является сложной задачей. Возможно, в будущем технологии распознавания речи будут совершенствоваться, а пока рекомендуется обращать большее внимание на правильное произношение и грамматику при общении с голосовыми помощниками и использовании поисковиков.
Почему Гугл ошибается при распознавании подслушанных русских слов?
Несовершенство алгоритмов. Первая и, возможно, наиболее важная причина, почему Гугл ошибается при распознавании подслушанных русских слов, заключается в несовершенстве алгоритмов. В настоящее время никакой алгоритм не может справиться со всеми типами обработки речи и распознавания речевых данных на высоком уровне точности. Конечно, Гугл периодически обновляет алгоритмы распознавания речи, но все же могут возникать ошибки.
Сложности диалектов. Некоторые слова на русском языке в разных регионах звучат по-разному из-за различных диалектов, акцентов и т. д. Гугл не всегда может правильно распознать эти особенности и перевести слова на язык компьютера.
Шум и плохие условия записи. Другая причина ошибки при распознавании подслушанных русских слов заключается в шуме и плохих условиях записи. Если слово произносится слишком быстро, на фоне других звуков, то Гугл может помешаться и выдать неправильный результат. Кроме того, плохое качество записи может также вызвать ошибки в распознавании речевых данных.
Недостаточность данных. Наконец, еще одна причина ошибок при распознавании подслушанных русских слов заключается в недостаточности данных. Чем больше данных у Гугла для распознавания конкретных слов и фраз, тем точнее будет результат. Если Гугл не обладает достаточным количеством данных для определенных слов или фраз на русском языке, то распознавание может быть неточным.
Проблемы русской речи
Небрежное произношение
Одной из основных проблем русской речи является небрежное произношение слов. Нередко, люди не уделяют достаточного внимания составляющим слов, их интонации, дикции и темпу речи. Это приводит к тому, что распознавание русских слов машинами, такими как Гугл, оказывается затруднительным из-за того, что заданный запрос звучит нечетко, либо акустическая картина слишком запутана.
Множество диалектов
В России, как и в большинстве многоязычных стран, существует множество диалектов, что делает проблемным понимание русской речи, особенно если в контексте появляются неадекватные словосочетания, местные названия, или даже лексика-арго. Каждый диалект имеет свои особенности, свои произношения, термины и даже грамматические особенности, что затрудняет автоматическое распознание слов и полноценное понимание речи.
Отсутствие орфоэпической культуры
Отсутствие орфоэпической культуры является одной из основных причин неверного распознавания слов. Нередко, люди произносят слова по-разному, с различными ударениями, что может привести к недопониманию слова. Некоторые слова имеют множество возможных произношений, но машинное распознавание XML-документов нередко приводит к проблемам, даже если слово было произнесено правильно, но не с тем ударением при оформлении запроса — он может быть неправильно идентифицирован.
Нестандартная лексика
Нестандартные слова и фразы, которые не входят в общий словарный запас, также могут вызывать проблемы при распознавании русской речи. Это может быть связано с использованием сокращений, аббревиатур, иностранных и сленговых слов и фраз. Все это создает наиважнейшие трудности для машинной обработки речи, поскольку в таком случае необходимо проводить подробный анализ не только входного сигнала, но и вариантов возможного значения, что неминуемо затрудняет работу с алгоритмом.
Непонимание контекста
Одной из причин ошибок при распознавании русских слов Гуглом является непонимание контекста. Приложение не всегда способно правильно определить, в каком контексте используется слово, и, следовательно, не может точно распознать его.
Например, слово «лыжи» может быть воспринято как множественное число от слова «лыжа» или как форма глагола «лыжить». Или слово «банка» может означать банку для консервирования, банку как учреждение, или банку как форма глагола. Без контекста приложение не может точно определить, какой именно вариант использован в данном случае.
Другой пример — при использовании сокращений или аббревиатур. Например, «США» может быть воспринято как «Соединенные Штаты Америки», «Северная Служба Автомобильных дорог», или в другом контексте как что-то еще. Это приводит к возникновению ошибок при распознавании текста.
Для правильного распознавания текста, приложению необходим достаточный контекст, который позволит сделать точный вывод о том, какое слово использовано и в каком значении. Также важно учитывать локальные особенности русского языка, чтобы увеличить точность распознавания.
Роль многозначности в ошибке распознавания русских слов в Гугле
Одной из причин ошибок в распознавании русских слов в Гугле является многозначность слов. Когда мы говорим или пишем слово, оно может иметь несколько значений в зависимости от контекста использования.
Например, слово «конь» может означать животное, а также часть игрового набора для детей. Если Гугл не учитывает контекст, то может неверно распознать слово и дать неправильный перевод. Это особенно актуально при распознавании разговорной речи, где контекст может быть неоднозначным.
Кроме того, русский язык славится своей богатой и разнообразной грамматикой, что также может приводить к многозначности слов. Например, глагол «замок» может означать как закрыть на ключ, так и крепость или дворец. Также существуют слова с одинаковым написанием, но разным произношением и значением (например, «газета» и «газета»).
Чтобы уменьшить количество ошибок в распознавании русских слов, Гугл использует алгоритмы машинного обучения, которые учитывают контекст и ассоциативные связи между словами. Однако, к сожалению, это не всегда помогает избежать ошибок в распознавании.
Диалекты и иностранные слова
Диалекты
Главная проблема при распознавании русских слов заключается в большом количестве диалектов и различных произносительных особенностей. Некоторые слова в народной речи звучат совершенно иначе, чем принято в литературном языке. Это может вносить путаницу в обработку речи при использовании компьютерных систем.
Кроме того, взаимопонимание и узнаваемость слов между людьми зависит от региона и происхождения собеседников. К примеру, слова «самовар» и «чайник» в разных регионах России могут объединяться в одно понятие, или наоборот различаться в значении.
Иностранные слова
В последнее время все большую популярность получают иностранные слова в русском языке. Это может вызывать трудности в распознавании и узнаваемости, так как системы обработки речи не всегда могут распознать иностранные слова или правильно произнести их.
Кроме того, произношение иностранных слов зависит от языка и региональных особенностей, что еще больше усложняет автоматическую обработку речи. Например, слово «пицца» может быть произнесено совершенно по разному в зависимости от страны и языка.
Выводы и рекомендации
В результате исследования можно сделать несколько выводов. В первую очередь, Гугл не ошибается при распознавании русских слов. Эта технология работает по принципу машинного обучения, которое на основе большого количества данных составляет свой словарь.
Однако, возможно, появление ошибок связано с актуализацией словаря. Так как язык постоянно развивается и появляются новые слова, возможно, словарь Гугла не успевает обновляться в режиме реального времени.
Для того чтобы не столкнуться с ошибками при распознавании слов, рекомендуется использовать четкую и громкую речь. Также следует избегать диалектов и местных говоров, которые могут быть непонятны даже для носителей языка в другом регионе.
- Использовать стандартный русский язык
- Говорить четко и громко
- Избегать диалектов и местных говоров
В целом, технология распознавания речи является сложным процессом, который не идеален. Однако, развитие машинного обучения и совершенствование алгоритмов помогут улучшить эту технологию в будущем.
Проблемы снятия регулярных помех в формах с рукопечатным заполнением
Время на прочтение
9 мин
Количество просмотров 4.7K
Привет, Хабр)
Этой статьей мы начинаем серию публикаций о технологиях оптического распознавания (OCR, ICR) и понимания документов, разработанных специалистами компании Cognitive Technologies. Многие из этих решений более 10 лет успешно функционируют в разных организациях и помогают оптимизировать процессы обработки бланков Пенсионного фонда, анкет на получение загранпаспорта, платежных поручений Сбербанка РФ, результатов голосования акционеров Газпрома и десятки других документов.
Сегодня наш рассказ об одной из наиболее сложных и интересных с научной точки зрения проблем, которую приходится решать при распознавании деловых документов, это снятие помех или отделение полезной информации от «мусора».
Вначале необходимо определить, что речь идет о документах с рукопечатным заполнением, построенных по заранее известной форме.

Сетка ячеек

Отдельные клетки

Строка с засечками
Рисунок 1. Виды решеток знакомест
а)
б)
Рисунок 2.Пример заполненного поля в присутствии засечек (а) и после снятия регулярных помех (б)
В таких случаях расположение полей ввода данных в документе известно заранее и описано в
модели документа, которая включает описание статических элементов (линий разграфки, заголовки полей), состав элементов, их взаимное расположение, размеры и другие характеристики. Для бланков документов, подразумевающих заполнение от руки, поля ввода оформляются как специального вида решетка, в которой для каждой буквы отведена отдельная клетка (знакоместо).
Решетки знакомест бывают различного типа. На практике наиболее часто используются три основных типа решеток: в виде сетки ячеек, отдельных клеток и в виде строки с засечками (Рисунок 1). Все они имеют характерную прямоугольную структуру (состоят из горизонтальных и вертикальных линий).
На рисунке 2а приведен пример заполненного рукопечатного поля с решеткой типа «строка с засечками». С точки зрения распознающей системы, решетка знакомест по сути является структурированным шумом, наложенным на текстовые данные, порождающим большое количество ошибок распознавания. В частности, в отличие от некоррелированного шума типа «соль/перец», наложенные решетки делают полностью непригодными топологические методы распознавания символов. Таким образом, попытка удаления этих «искусственных» помех может привести к существенному росту качества распознавания.
Знания о точном расположении опорных элементов позволяют подавить их, почти не искажая при этом текста. Несмотря на то, что теоретически эта информация известна (заложена в модель документа), на практике она часто бывает неполной или неверной. В процессе печати, заполнения и последующей оцифровки бланков привносятся различного рода деформации (сдвиг, наклон, незначительные растяжения, связанные с протяжкой в принтере и/или сканере) и шумовые сигналы (пятна, тени от сгиба бумаги и другие). Поэтому эталонное описание решеток часто не соответствует их реализации: теряется свойство прямоугольной формы, нарушается периодичность между засечками и прочее (Рисунок 3).


Нарушение периодичности

Искажение прямолинейности
Рисунок 3. Примеры деформаций решеток знакомест
Из вышесказанного вытекают следующие проблемы, связанные с точной локализацией опорных элементов:
- • Искажение прямолинейности линий.
- • Нарушение периодичности в решетках знакомест.
- • Наличие посторонних статических элементов в непосредственной близости к полям ввода (Рис. 4).
- • Наличие элементов заполнения, морфологически похожих на отрезки прямых.
Первые две проблемы могут быть устранены путем применения алгоритма динамической трансформации временной оси (DTW, Dynamic time warping), который является классическим примером использования метода динамического программирования. Исключить из внимания линии разграфки можно с помощью дополнительных знаний о структуре решеток знакомест: наличии стыков горизонтальных и вертикальных соединительных линий. Такие структурные особенности легко детектируются с помощью морфологических фильтров типа «hit-or-miss».
Остановимся немного подробнее на алгоритме локализации опорных решеток, построенном на применении этих двух инструментов.
Методы предварительной идентификации документов позволяют определить приблизительные области полей заполнения, а также угол наклона документа в целом. К сожалению, из-за деформаций изображения это не гарантирует точной ориентации отдельных полей. Кроме того, на анкетах встречаются так называемые «надпечатки» – наносимые с помощью принтера вариативные части анкеты. По понятным причинам поля надпечатки могут иметь наклон, отличный от глобального наклона документа. Предлагаемый алгоритм локализации ожидает «на входе» прямо ориентированное изображение, поэтому первым шагом следует довернуть изображение поля, определив его угол наклона. Для этого используется алгоритм, опирающийся на быстрое преобразование Хафа. Далее, на основании знаний о числе и типе стыков с вертикальными составляющими решетки, определяется положение горизонтальных опорных линий. Следующим этапом находится расположение вертикальных опорных элементов. В заключение, с помощью метода динамического программирования корректируются расположение горизонтальных линий для каждой ячейки.
Отметим, что задачи определения ориентации изображения и снятия точно найденной решетки являются отдельными задачами и в этой статье не рассматриваются.
Теперь рассмотрим более подробно алгоритмы поиска и корректировки линий и стыков.
Поиск горизонтальных линий с известным шаблоном стыков
Итак, для того, чтобы выделять опорные горизонтальные линии решеток на фоне посторонних контрастных линий, предлагается опереться на информацию о сопряжении опорной линии с вертикальными элементами решетки. Будем описывать искомый объект простейшим регулярным выражением – строкой, содержащей смысловые символы и символ возможного повтора (‘*’). Назовем это описание шаблоном линии.
В качестве смысловых символов будем использовать символы типа стыка (например, ‘└’, ‘┴’, ‘┘’), а также символы наличия линии без стыков (‘─’) и отсутствия линии (‘○’). Например, нижние опорные линии всех полей, изображенных на Рис. 4, описываются паттерном «└ ─* ┴ ─* ┘», а полей с решеткой типа «отдельные клетки» – «└ ─* ┘ ○ * └ ─* ┘ ○ * └ ─* ┘ …».
Рассмотрим теперь метод оценивания пикселя изображения как центрального пикселя стыка линий. Фактически, нам необходимо оценить, насколько темным является центральный пиксель, а также пиксели, располагающиеся в тех направлениях, в которых мы ожидаем наличия линий. Кроме того, мы должны проверить, что в остальных направлениях пиксели достаточно светлые (иначе на крестообразный стык будут реагировать все детекторы), а, кроме того, светлыми должны быть диагонали (иначе детектор будет реагировать на углы черных прямоугольников). Будем рассматривать паттерн из 9 пикселей в узлах регулярной решетки с шагом L, соразмерным ожидаемой толщине линии. На рис. 5 изображена ожидаемая конфигурация для стыка «┴». Пиксель, для которого производятся вычисления, соответствует центру приведенной схемы.
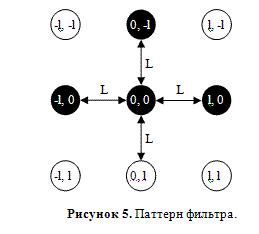
Построим теперь морфологический фильтр, соответствующий рассматриваемой конфигурации. По пикселям, помеченным на схеме белым, будем искать минимум, а по черным – максимум. Затем найдем разность полученных значений, и обнулим, если она меньше 0. Полученное значение W будем считать оценкой качества искомого стыка в данном пикселе:
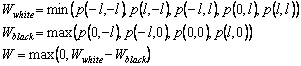
Аналогичным образом строятся детекторы всех остальных типов стыков, а также детектор прямой без стыков. Для детектора отсутствия линии способ построения немного отличается:
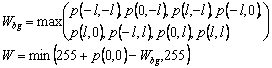
где Wbg несет смысл оценки яркости фона в присутствии возможных загрязнений в любом из пикселей паттерна.
Итак, применяя соответствующие морфологические фильтры к изображению поля, мы получаем в каждом пикселе набор оценок, говорящих, насколько данный пиксель похож на центральный пиксель стыка, линии или пробела (Рис. 5).
Теперь для каждой строки изображения поля определим, насколько она соответствует искомому паттерну, и среди всех строк выберем наилучшую. Вполне очевидно, что задача оценки одной строки – это задача динамического программирования. Действительно, создадим таблицу, каждый столбец которого соответствует смысловому символу шаблона либо символу, сопровождаемому звездочкой, а каждая строка – пикселю строки изображения. Каждый элемент таблицы заполним оценкой пикселя, задаваемого строкой, на соответствие стыку, задаваемому столбцом (Табл. 1). Нашей задачей будет найти путь с наибольшим весом в таблице от левого до правого края, при условии, что в столбцах без звездочки мы можем двигаться только на одну ячейку вправо вниз по диагонали, а в столбцах со звездочкой – так же или на одну ячейку вниз. При этом весом пути будет считаться сумма значений ячеек, по которым проходит путь. (В Табл. 1 оптимальный путь выделен голубым цветом.)
Решив эту задачу последовательно для каждой строки изображения, найдем координаты нижней и (если есть у данного вида решетки) верхней опорной линии решетки.

Таблица 1. Пример поиска оценивания соответствия шаблону методом динамического программирования.
Поиск вертикальных линий
Вертикальные линии решетки можно было бы искать с помощью частотного анализа горизонтальной проекции. Но из-за неидеальной системы подачи бумаги принтеров и протяжных сканеров в решетках знакомест часто нарушается периодичность между засечками (Рис. 6).
a) б)
б)
в) г)
г)
Рисунок 6. Результат детекции стыков ‘└’, ‘┴’ и ‘─’ (б, в, г) на изображении поля (а).
Кроме того, при экстренном увеличении числа ячеек поля на этапе разработки бланка (при внезапном знакомстве с фамилией «Гедиминайте-Бержанскайте-Клаусутайте») случается, что добавленные ячейки имеют нестандартный размер. Проблема усугубляется тем, что даже в случае идеальной геометрии решетки из-за символов, имеющих выраженные вертикальные штрихи, на проекции отображается много ложных пиков.
Последнюю проблему, впрочем, можно частично ослабить: так как на данном этапе детектирования решетки нам уже известно расположение горизонтальных линий, можно рассматривать не проекцию всего изображения на горизонтальную ось, а проекцию лишь части, которая находится выше нижней линии решетки, но ниже верхней линии или высоты засечек в случае решеток соответствующего типа. Тем самым обеспечивается, что пики, образованные высокими буквами, не будут превышать пики, образованные элементами решетки. Кроме того, разумно добавить в гистограмму вес «┴» и «┬» стыков, чтобы усилить истинные пики.
Зная предположительный период и возможную погрешность в расстоянии между вертикальными опорными элементами, можно быстро посчитать всевозможные варианты расположения таких элементов на заданном нам участке, и выбрать наилучший вариант. Эта задача хорошо решается методом динамического программирования, причем в данном случае для решения не потребуется таблица.
Будем двигаться вдоль гистограммы слева направо. На каждом шагу рассмотрим отрезок гистограммы, где x – наше текущее положение, p – ожидаемый период, а ∆ – максимальное отклонение. Найдём максимум среди значений гистограммы по указанному отрезку и прибавим к текущей ячейке, а в параллельном массиве сохраним индекс максимума. Тогда глобальный максимум полученной гистограммы будет соответствовать положению последней вертикальной линии, а соответствующий индекс будет указывать на предыдущий элемент списка найденных линий. Пройдя по списку, восстановим положения всех вертикальных опорных элементов.
Корректировка расположения горизонтальных линий
После нахождения вертикальных и горизонтальных линий решетка знакомест считается сформированной. Однако, для алгоритма снятия решётки требуется пиксельная точность, а при протягивании бумаги на этапе печати и сканирования изображение может подвергнуться веерной дисторсии (если лист будет поворачиваться по мере прохождения по тракту). Кроме того, алгоритм определения угла наклона изображения поля также может внести небольшие ошибки. Поставим задачу следующим образом: требуется найти последовательность смещений по вертикали элементов горизонтальной линии от ячейки к ячейке (Рис. 3), при условии, что каждое отдельное смещение не может быть больше, чем k пикселей (как правило, k=1).
Эта задача также решается методом динамического программирования.
Соберем вертикальную гистограмму размера, равного высоте поля (что превышает размер решетки), для каждой ячейки решетки и заполним этими гистограммами таблицу шириной, равной числу ячеек. Будем максимизировать путь от левой до правой границы таблицы, разрешая при смещении вправо сдвигаться вверх или вниз не более чем на k элементов. Найденный максимальный путь будет проходить по положениям элементов опорной горизонтальной линии.
С помощью этих двух инструментов и решалась задача точной локализации решеток знакомест. Разработанный подход к решению задачи сопоставления был программно реализован и в настоящий момент промышленно используется для потокового ввода анкет ОСАГО, заявлений на выдачу кредитов, а также анкет сетевого маркетинга.
Качество работы алгоритма оценивалось на наборе из 395 полисов ОСАГО, содержащих 12245 полей (Табл. 2). Для этого набора вручную были введены правильные значения всех полей, затем система распознавания была запущена в трех режимах: с выключенной подсистемой снятия решеток, с включенным «наивным» алгоритмом (опирающимся исключительно на анализ гистограмм) и с предложенным алгоритмом. Качество распознавания замерялось как процент правильно (без единой ошибки) распознанных полей. Ценой двухкратного замедления работы системы удалось поднять качество распознавания с 30% до 80%. Следует отметить, что системы распознавания документов с качеством распознавания ниже 70% как правило нерентабельны – заполнение оператором всех полей оказывается быстрее, чем исправление ошибок.
Как показал детальный просмотр обработанных изображений, предложенный алгоритм обеспечивает:
- Корректную работу с полями, захватывающими посторонние контрастные линии разграфки.
- Корректную обработку полей с переменной шириной ячеек.
- Корректную обработку решеток знакомест с нарушенной геометрией (включая веерные искажения).

Таблица 2
Подробнее информацию по этой теме можно прочитать в статье А.В. Куроптев, Д.П. Николаев, В.В. Постников. «Точная локализация опорных решеток полей заполнения в анкетах методами динамического программирования и морфологической фильтрации», опубликованной в Трудах института системного анализа Российской академии наук (ИСА РАН), 2013, Т. 63, №3, стр.
Microsoft Word — одно из самых популярных приложений для работы с текстовыми документами. Однако многие пользователи сталкиваются с ситуацией, когда программа не исправляет все ошибки, допускаемые в написании. Существует несколько причин, по которым это может происходить, а также ряд решений, которые помогут улучшить качество исправления.
Одной из возможных причин ошибок в исправлении Microsoft Word является ограничение программы на исправление только наиболее распространенных ошибок. В то время как Microsoft Word обладает мощной системой автоматического исправления, она не может учесть все возможные варианты ошибок и исключений. Это может привести к тому, что некоторые ошибки остаются незамеченными или остаются неисправленными.
Кроме того, ошибки в исправлении могут возникать из-за наличия специфических терминов, названий или аббревиатур, которые Microsoft Word просто не распознает. Приложение может ошибочно считать эти слова неправильными и предлагать заменить их на альтернативный вариант, что может привести к искажению смысла текста.
Чтобы улучшить качество исправления Microsoft Word, пользователи могут воспользоваться дополнительными инструментами проверки, такими как расширения или плагины. Дополнительные инструменты обеспечивают более точное и своевременное исправление ошибок, учитывая контекст и специфику текста. Они могут быть особенно полезны для профессиональных писателей, редакторов и академических работников, чьи тексты требуют высокой точности и грамматической правильности.
Несмотря на недостатки, Microsoft Word все равно остается одним из лучших инструментов для создания и редактирования текстовых документов. Он предлагает широкий набор функций и возможностей, позволяющих улучшить качество и эффективность работы с текстом. Вместе с тем, чтобы добиться наилучших результатов, рекомендуется сочетать использование Microsoft Word с другими инструментами и методами проверки текста, чтобы избежать ошибок и улучшить качество написания.
Проблемы с автоматической коррекцией
Microsoft Word предлагает удобный и быстрый способ исправления опечаток и грамматических ошибок. Однако, нередко возникают ситуации, когда автоматическая коррекция не срабатывает должным образом. Рассмотрим основные причины и возможные решения этих проблем.
1. Некорректные настройки автокоррекции. Проверьте, правильно ли настроена функция автокоррекции в Microsoft Word. Проверьте список автозаменяемых слов и фраз, добавленные вами собственные коррекции, а также исключения и исключительные правила.
2. Ошибки и опечатки в пользовательском словаре. Если слово, которое вы часто используете, почему-то не исправляется автоматически, возможно, оно определено в пользовательском словаре с неправильным написанием. Проверьте этот список и удалите нежелательные записи.
3. Особенности спеллчекера. Спеллчекер в Microsoft Word не всегда распознает все ошибки, особенно если они связаны с контекстом или использованием необычных слов. Если у вас возникли сомнения в правильности исправления, рекомендуется производить проверку написания в других редакторах или с помощью онлайн-инструментов.
4. Пользовательские предпочтения. Каждый человек имеет свои индивидуальные предпочтения в отношении автоматической коррекции. Возможно, вы не хотите, чтобы некоторые слова автоматически исправлялись, или наоборот, хотите изменить стандартное поведение программы. Настройте эти параметры с учетом ваших потребностей.
Важно помнить, что автоматическая коррекция – это всего лишь инструмент, и она не всегда сможет правильно исправить все ошибки. Постоянное внимание и проверка со стороны пользователя также являются неотъемлемой частью процесса создания качественного текста.
Ошибки при распознавании
Microsoft Word, как и любая другая программа, имеет свои ограничения в распознавании и исправлении ошибок. В некоторых случаях, программа может пропустить определенные ошибки или допустить некорректное исправление.
Одна из причин, по которой Microsoft Word может не распознать ошибку, является наличие слова или фразы, которые не входят в его словарь. Несмотря на большой словарный запас программы, всегда есть слова, аббревиатуры или специализированная терминология, которые неизвестны программе.
Еще одной причиной неправильного распознавания ошибок может быть наличие опечаток или некорректной раскладки клавиатуры. Если слово написано с опечатками или использована неверная раскладка клавиатуры, программа может искать его в словаре и не распознать его как ошибку.
Кроме того, Microsoft Word может неправильно исправлять ошибки из-за неполного контекста. Например, если фраза содержит несколько слов, и одно из них является ошибкой, но исправляется другое слово, программа может не заметить ошибку.
Если вы столкнулись с подобными проблемами, есть несколько способов решить их. Во-первых, вы можете добавить недостающие слова, аббревиатуры или термины в пользовательский словарь программы. Это позволит Word распознавать и исправлять эти слова и фразы.
Во-вторых, если вы заметили, что программа часто неправильно распознает ошибки из-за определенной раскладки клавиатуры, вы можете изменить настройки программы и добавить нужную раскладку клавиатуры. Это поможет программе правильно распознавать слова и исправлять ошибки.
Наконец, если вы часто сталкиваетесь с проблемами, связанными с неправильным исправлением ошибок, вы можете отключить функцию автоматического исправления ошибок или изменить настройки программы так, чтобы Word предлагал вам только рекомендации по исправлению ошибок, а не автоматическое исправление.
Помимо этих способов, вы также можете использовать другие программы или сервисы для проверки правописания и грамматики. Некоторые из них имеют более обширные словари и алгоритмы распознавания ошибок, что может помочь вам избежать некорректных исправлений или пропущенных ошибок.
| Причины ошибок при распознавании | Решения |
|---|---|
| Отсутствие слова в словаре программы | Добавить слово в пользовательский словарь |
| Опечатки или неправильная раскладка клавиатуры | Исправить опечатки или изменить настройки раскладки клавиатуры |
| Неполный контекст при проверке ошибок | Вручную исправить ошибку или переформулировать фразу |
| Отключение автоматического исправления ошибок | Изменить настройки программы или использовать другие сервисы проверки правописания и грамматики |