Время на прочтение
5 мин
Количество просмотров 68K
Если вы уже освоились с основами терминала, возможно, вы уже готовы к тому, чтобы комбинировать изученные команды. Иногда выполнения команд оболочки по одной вполне достаточно для решения некоей задачи, но в некоторых случаях вводить команду за командой слишком утомительно и нерационально. В подобной ситуации нам пригодятся некоторые особые символы, вроде угловых скобок.

Для оболочки, интерпретатора команд Linux, эти дополнительные символы — не пустая трата места на экране. Они — мощные команды, которые могут связывать воедино различные фрагменты информации, разделять то, что было до этого цельным, и делать ещё много всего. Одна из самых простых, и, в то же время, мощных и широко используемых возможностей оболочки — это перенаправление стандартных потоков ввода/вывода.
Три стандартных потока ввода/вывода
Для того, чтобы понять то, о чём мы будем тут говорить, важно знать, откуда берутся данные, которые можно перенаправлять, и куда они идут. В Linux существует три стандартных потока ввода/вывода данных.
Первый — это стандартный поток ввода (standard input). В системе это — поток №0 (так как в компьютерах счёт обычно начинается с нуля). Номера потоков ещё называют дескрипторами. Этот поток представляет собой некую информацию, передаваемую в терминал, в частности — инструкции, переданные в оболочку для выполнения. Обычно данные в этот поток попадают в ходе ввода их пользователем с клавиатуры.
Второй поток — это стандартный поток вывода (standard output), ему присвоен номер 1. Это поток данных, которые оболочка выводит после выполнения каких-то действий. Обычно эти данные попадают в то же окно терминала, где была введена команда, вызвавшая их появление.
И, наконец, третий поток — это стандартный поток ошибок (standard error), он имеет дескриптор 2. Этот поток похож на стандартный поток вывода, так как обычно то, что в него попадает, оказывается на экране терминала. Однако, он, по своей сути, отличается от стандартного вывода, как результат, этими потоками, при желании, можно управлять раздельно. Это полезно, например, в следующей ситуации. Есть команда, которая обрабатывает большой объём данных, выполняя сложную и подверженную ошибкам операцию. Нужно, чтобы полезные данные, которые генерирует эта команда, не смешивались с сообщениями об ошибках. Реализуется это благодаря раздельному перенаправлению потоков вывода и ошибок.
Как вы, вероятно, уже догадались, перенаправление ввода/вывода означает работу с вышеописанными потоками и перенаправление данных туда, куда нужно программисту. Делается это с использованием символов > и < в различных комбинациях, применение которых зависит от того, куда, в итоге, должны попасть перенаправляемые данные.
Перенаправление стандартного потока вывода
Предположим, вы хотите создать файл, в который будут записаны текущие дата и время. Дело упрощает то, что имеется команда, удачно названная date, которая возвращает то, что нам нужно. Обычно команды выводят данные в стандартный поток вывода. Для того, чтобы эти данные оказались в файле, нужно добавить символ > после команды, перед именем целевого файла. До и после > надо поставить пробел.
При использовании перенаправления любой файл, указанный после > будет перезаписан. Если в файле нет ничего ценного и его содержимое можно потерять, в нашей конструкции допустимо использовать уже существующий файл. Обычно же лучше использовать в подобном случае имя файла, которого пока не существует. Этот файл будет создан после выполнения команды. Назовём его date.txt. Расширение файла после точки обычно особой роли не играет, но расширения помогают поддерживать порядок. Итак, вот наша команда:
$ date > date.txt
Нельзя сказать, что сама по себе эта команда невероятно полезна, однако, основываясь на ней, мы уже можем сделать что-то более интересное. Скажем, вы хотите узнать, как меняются маршруты вашего трафика, идущего через интернет к некоей конечной точке, ежедневно записывая соответствующие данные. В решении этой задачи поможет команда traceroute, которая сообщает подробности о маршруте трафика между нашим компьютером и конечной точкой, задаваемой при вызове команды в виде URL. Данные включают в себя сведения обо всех маршрутизаторах, через которые проходит трафик.
Так как файл с датой у нас уже есть, будет вполне оправдано просто присоединить к этому файлу данные, полученные от traceroute. Для того, чтобы это сделать, надо использовать два символа >, поставленные один за другим. В результате новая команда, перенаправляющая вывод в файл, но не перезаписывающая его, а добавляющая новые данные после старых, будет выглядеть так:
$ traceroute google.com >> date.txt
Теперь нам осталось лишь изменить имя файла на что-нибудь более осмысленное, используя команду mv, которой, в качестве первого аргумента, передаётся исходное имя файла, а в качестве второго — новое:
$ mv date.txt trace1.txtПеренаправление стандартного потока ввода
Используя знак < вместо > мы можем перенаправить стандартный ввод, заменив его содержимым файла.
Предположим, имеется два файла: list1.txt и list2.txt, каждый из которых содержит неотсортированный список строк. В каждом из списков имеются уникальные для него элементы, но некоторые из элементов список совпадают. Мы можем найти строки, которые имеются и в первом, и во втором списках, применив команду comm, но прежде чем её использовать, списки надо отсортировать.
Существует команда sort, которая возвращает отсортированный список в терминал, не сохраняя отсортированные данные в файл, из которого они были взяты. Можно отправить отсортированную версию каждого списка в новый файл, используя команду >, а затем воспользоваться командой comm. Однако, такой подход потребует как минимум двух команд, хотя то же самое можно сделать в одной строке, не создавая при этом ненужных файлов.
Итак, мы можем воспользоваться командой < для перенаправления отсортированной версии каждого файла команде comm. Вот что у нас получилось:
$ comm <(sort list1.txt) <(sort list2.txt)
Круглые скобки тут имеют тот же смысл, что и в математике. Оболочка сначала обрабатывает команды в скобках, а затем всё остальное. В нашем примере сначала производится сортировка строк из файлов, а потом то, что получилось, передаётся команде comm, которая затем выводит результат сравнения списков.
Перенаправление стандартного потока ошибок
И, наконец, поговорим о перенаправлении стандартного потока ошибок. Это может понадобиться, например, для создания лог-файлов с ошибками или объединения в одном файле сообщений об ошибках и возвращённых некоей командой данных.
Например, что если надо провести поиск во всей системе сведений о беспроводных интерфейсах, которые доступны пользователям, у которых нет прав суперпользователя? Для того, чтобы это сделать, можно воспользоваться мощной командой find.
Обычно, когда обычный пользователь запускает команду find по всей системе, она выводит в терминал и полезные данные и ошибки. При этом, последних обычно больше, чем первых, что усложняет нахождение в выводе команды того, что нужно. Решить эту проблему довольно просто: достаточно перенаправить стандартный поток ошибок в файл, используя команду 2> (напомним, 2 — это дескриптор стандартного потока ошибок). В результате на экран попадёт только то, что команда отправляет в стандартный вывод:
$ find / -name wireless 2> denied.txtКак быть, если нужно сохранить результаты работы команды в отдельный файл, не смешивая эти данные со сведениями об ошибках? Так как потоки можно перенаправлять независимо друг от друга, в конец нашей конструкции можно добавить команду перенаправления стандартного потока вывода в файл:
$ find / -name wireless 2> denied.txt > found.txt
Обратите внимание на то, что первая угловая скобка идёт с номером — 2>, а вторая без него. Это так из-за того, что стандартный вывод имеет дескриптор 1, и команда > подразумевает перенаправление стандартного вывода, если номер дескриптора не указан.
И, наконец, если нужно, чтобы всё, что выведет команда, попало в один файл, можно перенаправить оба потока в одно и то же место, воспользовавшись командой &>:
$ find / -name wireless &> results.txtИтоги
Тут мы разобрали лишь основы механизма перенаправления потоков в интерпретаторе командной строки Linux, однако даже то немногое, что вы сегодня узнали, даёт вам практически неограниченные возможности. И, кстати, как и всё остальное, что касается работы в терминале, освоение перенаправления потоков требует практики. Поэтому рекомендуем вам приступить к собственным экспериментам с > и <.
Уважаемые читатели! Знаете ли вы интересные примеры использования перенаправления потоков в Linux, которые помогут новичкам лучше освоиться с этим приёмом работы в терминале?
Введение
Стандартные потоки ввода и вывода в Linux являются одним из наиболее распространенных средств для обмена информацией процессов, а перенаправление >, >> и | является одной из самых популярных конструкций командного интерпретатора.
В данной статье мы ознакомимся с возможностями перенаправления потоков ввода/вывода, используемых при работе файлами и командами.
Требования
- Linux-система, например, Ubuntu 20.04
Потоки
Стандартный ввод при работе пользователя в терминале передается через клавиатуру.
Стандартный вывод и стандартная ошибка отображаются на дисплее терминала пользователя в виде текста.
Ввод и вывод распределяется между тремя стандартными потоками:
- stdin — стандартный ввод (клавиатура),
- stdout — стандартный вывод (экран),
- stderr — стандартная ошибка (вывод ошибок на экран).
Потоки также пронумерованы:
- stdin — 0,
- stdout — 1,
- stderr — 2.
Из стандартного ввода команда может только считывать данные, а два других потока могут использоваться только для записи. Данные выводятся на экран и считываются с клавиатуры, так как стандартные потоки по умолчанию ассоциированы с терминалом пользователя. Потоки можно подключать к чему угодно: к файлам, программам и даже устройствам. В командном интерпретаторе bash такая операция называется перенаправлением:
- < file — использовать файл как источник данных для стандартного потока ввода.
- > file — направить стандартный поток вывода в файл. Если файл не существует, он будет создан, если существует — перезаписан сверху.
- 2> file — направить стандартный поток ошибок в файл. Если файл не существует, он будет создан, если существует — перезаписан сверху.
- >>file — направить стандартный поток вывода в файл. Если файл не существует, он будет создан, если существует — данные будут дописаны к нему в конец.
- 2>>file — направить стандартный поток ошибок в файл. Если файл не существует, он будет создан, если существует — данные будут дописаны к нему в конец.
- &>file или >&file — направить стандартный поток вывода и стандартный поток ошибок в файл. Другая форма записи: >file 2>&1.
Стандартный ввод
Стандартный входной поток обычно переносит данные от пользователя к программе. Программы, которые предполагают стандартный ввод, обычно получают входные данные от устройства типа клавиатура. Стандартный ввод прекращается по достижении EOF (конец файла), который указывает на то, что данных для чтения больше нет.
EOF вводится нажатием сочетания клавиш Ctrl+D.
Рассмотрим работу со стандартным выводом на примере команды cat (от CONCATENATE, в переводе «связать» или «объединить что-то»).
Cat обычно используется для объединения содержимого двух файлов.
Cat отправляет полученные входные данные на дисплей терминала в качестве стандартного вывода и останавливается после того как получает EOF.
Пример
catВ открывшейся строке введите, например, 1 и нажмите клавишу Enter. На дисплей выводится 1. Введите a и нажмите клавишу Enter. На дисплей выводится a.
Дисплей терминала выглядит следующим образом:
test@111:~/stream$ cat
1
1
a
aДля завершения ввода данных следует нажать сочетание клавиш Ctrl + D.
Стандартный вывод
Стандартный вывод записывает данные, сгенерированные программой. Когда стандартный выходной поток не перенаправляется в какой-либо файл, он выводит текст на дисплей терминала.
При использовании без каких-либо дополнительных опций, команда echo выводит на экран любой аргумент, который передается ему в командной строке:
echo ПримерАргументом является то, что получено программой, в результате на дисплей терминала будет выведено:
ПримерПри выполнении echo без каких-либо аргументов, возвращается пустая строка.
Пример
Команда объединяет три файла: file1, file2 и file3 в один файл bigfile:
cat file1 file1 file1 > bigfileКоманда cat по очереди выводит содержимое файлов, перечисленных в качестве параметров на стандартный поток вывода. Стандартный поток вывода перенаправлен в файл bigfile.
Стандартная ошибка
Стандартная ошибка записывает ошибки, возникающие в ходе исполнения программы. Как и в случае стандартного вывода, по умолчанию этот поток выводится на терминал дисплея.
Пример
Рассмотрим пример стандартной ошибки с помощью команды ls, которая выводит список содержимого каталогов.
При запуске без аргументов ls выводит содержимое в пределах текущего каталога.
Введем команду ls с каталогом % в качестве аргумента:
ls %В результате должно выводиться содержимое соответствующей папки. Но так как каталога % не существует, на дисплей терминала будет выведен следующий текст стандартной ошибки:
ls: cannot access %: No such file or directoryПеренаправление потока
Linux включает в себя команды перенаправления для каждого потока.
Команды со знаками > или < означают перезапись существующего содержимого файла:
- > — стандартный вывод,
- < — стандартный ввод,
- 2> — стандартная ошибка.
Команды со знаками >> или << не перезаписывают существующее содержимое файла, а присоединяют данные к нему:
- >> — стандартный вывод,
- << — стандартный ввод,
- 2>> — стандартная ошибка.
Пример
В приведенном примере команда cat используется для записи в файл file1, который создается в результате цикла:
cat > file1
a
b
cДля завершения цикла нажмите сочетание клавиш Ctrl + D.
Если файла file1 не существует, то в текущем каталоге создается новый файл с таким именем.
Для просмотра содержимого файла file1 введите команду:
cat file1В результате на дисплей терминала должно быть выведено следующее:
a
b
cДля перезаписи содержимого файла введите следующее:
cat > file1
1
2
3Для завершения цикла нажмите сочетание клавиш Ctrl + D.
В результате на дисплей терминала должно быть выведено следующее:
1
2
3Предыдущего текста в текущем файле больше не существует, так как содержимое файла было переписано командой >.
Для добавления нового текста к уже существующему в файле с помощью двойных скобок >> выполните команду:
cat >> file1
a
b
cДля завершения цикла нажмите сочетание клавиш Ctrl + D.
Откройте file1 снова и в результате на дисплее монитора должно быть отражено следующее:
1
2
3
a
b
cКаналы
Каналы используются для перенаправления потока из одной программы в другую. Стандартный вывод данных после выполнения одной команды перенаправляется в другую через канал. Данные первой программы, которые получает вторая программа, не будут отображаться. На дисплей терминала будут выведены только отфильтрованные данные, возвращаемые второй командой.
Пример
Введите команду:
ls | lessВ результате каждый файл текущего каталога будет размещен на новой строке:
file1
file2
t1
t2Перенаправлять данные с помощью каналов можно как из одной команды в другую, так и из одного файла к другому, а перенаправление с помощью > и >> возможно только для перенаправления данных в файлах.
Пример
Для сохранения имен файлов, содержащих строку «LOG», используется следующая команда:
dir /catalog | find "LOG" > loglistВывод команды dir отсылается в команду-фильтр find. Имена файлов, содержащие строку «LOG», хранятся в файле loglist в виде списка (например, Config.log, Logdat.svd и Mylog.bat).
При использовании нескольких фильтров в одной команде рекомендуется разделять их с помощью знака канала |.
Фильтры
Фильтры представляют собой стандартные команды Linux, которые могут быть использованы без каналов:
- find — возвращает файлы с именами, которые соответствуют передаваемому аргументу.
- grep — возвращает только строки, содержащие (или не содержащие) заданное регулярное выражение.
- tee — перенаправляет стандартный ввод как стандартный вывод и один или несколько файлов.
- tr — находит и заменяет одну строку другой.
- wc — подсчитывает символы, линии и слова.
Как правило, все нижеприведенные команды работают как фильтры, если у них нет аргументов (опции могут быть):
- cat — считывает данные со стандартного потока ввода и передает их на стандартный поток вывода. Без опций работает как простой повторитель. С опциями может фильтровать пустые строки, нумеровать строки и делать другую подобную работу.
- head — показывает первые 10 строк (или другое заданное количество), считанных со стандартного потока ввода.
- tail — показывает последние 10 строк (или другое заданное количество), считанные со стандартного потока ввода. Важный частный случай tail -f, который в режиме слежения показывает концовку файла. Это используется, в частности, для просмотра файлов журнальных сообщений.
- cut — вырезает столбец (по символам или полям) из потока ввода и передает на поток вывода. В качестве разделителей полей могут использоваться любые символы.
- sort — сортирует данные в соответствии с какими-либо критериями, например, арифметически по второму столбцу.
- uniq — удаляет повторяющиеся строки. Или (с ключом -с) не просто удалить, а написать сколько таких строк было. Учитываются только подряд идущие одинаковые строки, поэтому часто данные сортируются перед тем как отправить их на вход программе.
- bc — вычисляет каждую отдельную строку потока и записывает вместо нее результат вычисления.
- hexdump — показывает шестнадцатеричное представление данных, поступающих на стандартный поток ввода.
- strings — выделяет и показывает в стандартном потоке (или файле) то, что напоминает строки. Всё что не похоже на строковые последовательности, игнорируется. Команда полезна в сочетании с grep для поиска интересующих строковых последовательностей в бинарных файлах.
- sed — обрабатывает текст в соответствии с заданным скриптом. Наиболее часто используется для замены текста в потоке: sed s/было/стало/g.
- awk — обрабатывает текст в соответствии с заданным скриптом. Как правило, используется для обработки текстовых таблиц, например, вывод ps aux и т.д.
- sh -s — текст, который передается на стандартный поток ввода sh -s. может интерпретироваться как последовательность команд shell. На выход передается результат их исполнения.
- ssh — средство удаленного доступа ssh, может работать как фильтр, который подхватывает данные, переданные ему на стандартный поток ввода, затем передает их на удаленный хост и подает на вход процессу программы, имя которой было передано ему в качестве аргумента. Результат выполнения программы (то есть то, что она выдала на стандартный поток вывода) передается со стандартного вывода ssh.
Если в качестве аргумента передается файл, команда-фильтр считывает данные из этого файла, а не со стандартного потока ввода (есть исключения, например, команда tr, обрабатывающая данные, поступающие исключительно через стандартный поток ввода).
Пример
Команда tee, как правило, используется для просмотра выводимого содержимого при одновременном сохранении его в файл.
wc ~/stream | tee file2Пример
Допускается перенаправление нескольких потоков в один файл:
ls -z >> file3 2>&1В результате сообщение о неверной опции «z» в команде ls будет записано в файл t2, поскольку stderr перенаправлен в файл.
Для просмотра содержимого файла file3 введите команду cat:
cat file3В результате на дисплее терминала отобразиться следующее:
ls: invalid option -- 'z'
Try 'ls --help' for more information.Заключение
Мы рассмотрели возможности работы с перенаправлениями потоков >, >> и |, использование которых позволяет лучше работать с bash-скриптами.
 После того, как вы освоили базовые принципы работы с Linux, позволяющие более-менее уверенно чувствовать себя в среде этой операционной системы, следует начать углублять свои знания, переходя к более глубоким и фундаментальным принципам, на которых основаны многие приемы работы в ОС. Одним из важнейших является понятие потоков, которые позволяют передавать данные от одной программы к другой, а также конвейера, позволяющего выстраивать целые цепочки из программ, каждая из которых будет работать с результатом действий предыдущей. Все это очень широко используется и понимание того, как это работает важно для любого Linux-администратора.
После того, как вы освоили базовые принципы работы с Linux, позволяющие более-менее уверенно чувствовать себя в среде этой операционной системы, следует начать углублять свои знания, переходя к более глубоким и фундаментальным принципам, на которых основаны многие приемы работы в ОС. Одним из важнейших является понятие потоков, которые позволяют передавать данные от одной программы к другой, а также конвейера, позволяющего выстраивать целые цепочки из программ, каждая из которых будет работать с результатом действий предыдущей. Все это очень широко используется и понимание того, как это работает важно для любого Linux-администратора.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Прежде всего определимся с терминами. Мы часто говорим: «консоль», «терминал», «командная строка» — не сильно задумываясь о смысле этих слов и подразумевая под этим в большинстве своем CLI — интерфейс командной строки. Во многих случаях такое упрощение допустимо и широко используется в профессиональной среде. Но в данном случае точный смысл этих терминов имеет значение для правильного понимания происходящих процессов.
Стандартные потоки
Начнем с основного понятия — терминал. Он уходит корнями в далекое (по компьютерным меркам) прошлое и обозначает собой оконечное устройство, предназначенное для взаимодействия оператора и компьютера, к одному компьютеру может быть присоединено несколько терминалов, каждый из которых работает самостоятельно и независимо от других. Смысл современного терминала, а приложение для работы с командной строкой называется в Linux именно так, не изменился и сегодня, хотя, если быть точными, его название — эмулятор терминала.
Данное приложение все также эмулирует оконечное устройство, предназначенное для взаимодействия пользователя с компьютером. Точно также мы можем запустить сразу несколько терминалов, каждый из которых будет работать независимо. Кроме того, следует понимать, что терминал может быть запущен как локально, так и удаленно, способ подключения к компьютеру может быть разным, но свойства терминала от этого не изменяются.
Работая с терминалом нам нужно каким-то образом передавать ему команды и получать результаты. Для этого предназначена консоль — совокупность устройств ввода-вывода обеспечивающих взаимодействие пользователя и компьютера. В качестве консоли на современных ПК выступают клавиатура и монитор, но это только один из возможных вариантов, например, в самых первых моделях терминалов в качестве консоли использовался телетайп. Консоль всегда подключена к текущему рабочему месту, в то время как терминал может быть запущен и удаленно.
Но в нашей схеме все еще чего-то не хватает. При помощи консоли мы вводим определенные команды и передаем их в терминал, а дальше? Терминал — это всего лишь оконечное устройство для взаимодействия с компьютером, но не сам компьютер, выполнять команды или производить какие-либо другие вычисления он не способен. Поэтому на сцену выходит третий компонент — командный интерпретатор. Это специальная программа, обеспечивающая базовое взаимодействие пользователя и ОС, а также дающая возможность запускать другие программы. В большинстве Linux-дистрибутивов командным интерпретатором по умолчанию является bash.
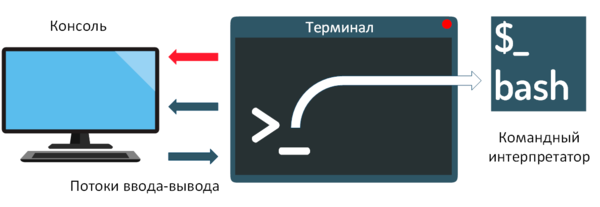 Теперь все становится на свои места. Для каждого сеанса взаимодействия пользователя и компьютера создается отдельный терминал, внутри терминала работает специальная программа — командный интерпретатор. При помощи консоли пользователь передает командному интерпретатору или запущенной с его помощью программе входящие данные и получает назад результат их работы. Осталось разобраться каким именно образом это происходит.
Теперь все становится на свои места. Для каждого сеанса взаимодействия пользователя и компьютера создается отдельный терминал, внутри терминала работает специальная программа — командный интерпретатор. При помощи консоли пользователь передает командному интерпретатору или запущенной с его помощью программе входящие данные и получает назад результат их работы. Осталось разобраться каким именно образом это происходит.
Для взаимодействия запускаемых в терминале программ и пользователя используются стандартные потоки ввода-вывода, имеющие зарезервированный номер (дескриптор) зарезервированный на уровне операционной системы. Всего существует три стандартных потока:
- stdin (standard input, 0) — стандартный ввод, по умолчанию нацелен на устройство ввода текущей консоли (клавиатура)
- stdout (standard output, 1) — стандартный вывод, по умолчанию нацелен на устройство вывода текущей консоли (экран)
- stderr (standard error, 2) — стандартный вывод ошибок, специальный поток для вывода сообщения об ошибках, также направлен на текущее устройство вывода (экран)
Как мы помним, в основе философии Linux лежит понятие — все есть файл. Стандартные потоки не исключение, с точки зрения любой программы — это специальные файлы, которые открываются либо на чтение (поток ввода), либо на запись (поток вывода). Это вызывает очевидный вопрос, а можно ли вместо консоли использовать файлы? Да, можно и здесь мы вплотную подошли к понятию перенаправления потоков.
Перенаправление потоков
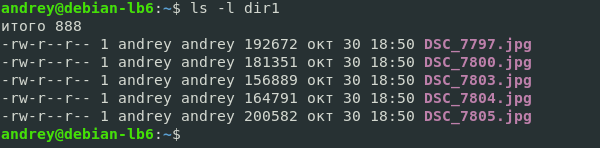
Начнем с наиболее простого и понятного — потока вывода. В него программа отправляет результат своей работы, и он отображается на подключенном к консоли устройстве вывода, в современных системах это экран. Допустим мы хотим получить список файлов в директории, для этого мы набираем на устройстве ввода консоли команду:
ls -l dir1Которая через стандартный поток ввода будет доставлена командному интерпретатору, тот запустит указанную программу и передаст ей требуемые аргументы, а результат вернет через стандартный поток вывода на устройство отображения информации.
 Но что, если мы хотим сохранить результат работы команды в файл? Нет ничего проще, воспользуемся перенаправлением, для этого следует использовать знак >.
Но что, если мы хотим сохранить результат работы команды в файл? Нет ничего проще, воспользуемся перенаправлением, для этого следует использовать знак >.
ls -l dir1 > resultНа экран теперь не будет выведено ничего, но весь вывод команды окажется в файле result, который мы можем прочитать следующим образом:
cat result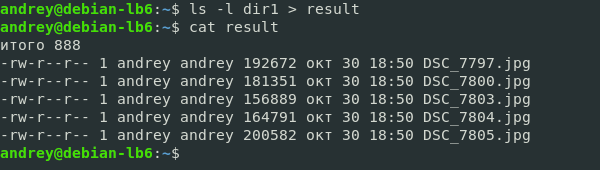 При таком перенаправлении вывода файл-приемник каждый раз будет создаваться заново, т.е. будет перезаписан. Это очень важный момент, сразу и навсегда запомните > — всегда перезаписывает файл!
При таком перенаправлении вывода файл-приемник каждый раз будет создаваться заново, т.е. будет перезаписан. Это очень важный момент, сразу и навсегда запомните > — всегда перезаписывает файл!

Можно ли этого избежать? Можно, для того, чтобы перенаправленный поток был дописан в конец уже существующего файла используйте для перенаправления знак >>.
Немного изменим последовательность команд:
ls -l dir1 > result
ls -l dir2 >> result
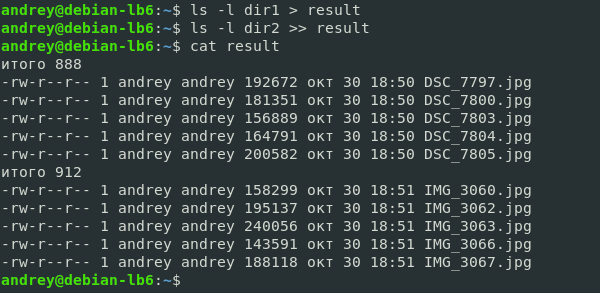
Теперь в файл попал вывод сразу двух команд, при этом, обратите внимание, первой командой мы перезаписали файл, а второй добавили в него содержимое из стандартного потока вывода.
Пойдем дальше. Как видим в выводе кроме списка файлов присутствуют строки «итого», нам они не нужны, и мы хотим от них избавиться. В этом нам поможет утилита grep, которая позволяет отфильтровать строки согласно некому выражению. Например, можно сделать так:
ls -l dir1 > result
ls -l dir2 >> result
grep rw result > result2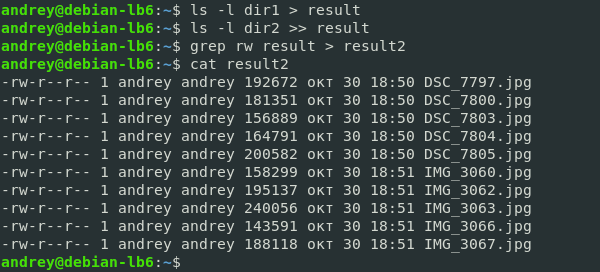 В целом результат достигнут, но ценой трех команд и наличием одного промежуточного файла. Можно ли сделать проще?
В целом результат достигнут, но ценой трех команд и наличием одного промежуточного файла. Можно ли сделать проще?
До этого мы перенаправляли поток вывода, но тоже самое можно сделать и с потоком ввода, используя для этого знак <. Например, мы можем сделать так:
grep rw < resultНо это ничего не изменит, поэтому мы пойдем другим путем и перенаправим на ввод одной команды вывод другой:
grep rw <(ls -l dir1) <(ls -l dir2)На первый взгляд выглядит несколько сложно, но обратимся к man по grep:
grep [OPTIONS] PATTERN [FILE][FILE...]В качестве паттерна мы используем rw, который есть в каждой интересующей нас строке, а в качестве файлов отдаем стандартный файл потока ввода, содержимого которого является результатом работы команды, указанной в скобках. А можно направить результат этой команды в файл? Конечно, можно:
grep rw <(ls -l dir1) <(ls -l dir2) > result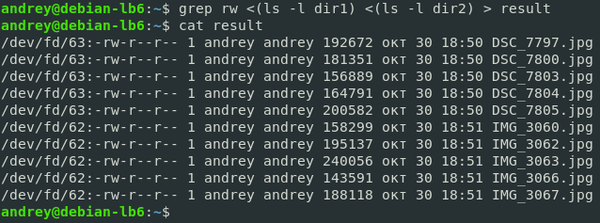 В последней команде мы перенаправили не только потоки ввода, но и поток вывода, при этом нужно понимать, что все перенаправления относятся к первой команде, иначе можно подумать, что в result будет выведен результат работы ls -l dir2, однако это неверно.
В последней команде мы перенаправили не только потоки ввода, но и поток вывода, при этом нужно понимать, что все перенаправления относятся к первой команде, иначе можно подумать, что в result будет выведен результат работы ls -l dir2, однако это неверно.
Немного особняком стоит стандартный поток вывода ошибок, допустим мы хотим получить список файлов несуществующей директории с перенаправлением вывода в файл, но сообщение об ошибке мы все равно получим на экран.
 Почему так? Да потому что вывод ошибок производится в отдельный поток, который мы никуда не перенаправляли. Если мы хотим подавить вывод сообщений об ошибках на экран, то можно использовать конструкцию:
Почему так? Да потому что вывод ошибок производится в отдельный поток, который мы никуда не перенаправляли. Если мы хотим подавить вывод сообщений об ошибках на экран, то можно использовать конструкцию:
ls -l dir3 > result 2>/dev/nullВ данном примере весь вывод стандартного потока ошибок будет перенаправлен в пустое устройство /dev/null.
Но можно пойти и другим путем, перенаправив поток ошибок в стандартный поток вывода:
ls -l dir3 > result 2>&1 В этом случае мы перенаправили поток вывода об ошибках в стандартный поток вывода и сообщение об ошибке не было выведено на экран, а было записано в файл, куда мы перенаправили стандартный поток вывода.
В этом случае мы перенаправили поток вывода об ошибках в стандартный поток вывода и сообщение об ошибке не было выведено на экран, а было записано в файл, куда мы перенаправили стандартный поток вывода.
Конвейер
В предыдущих примерах мы научились перенаправлять стандартные потоки ввода-вывода и даже частично коснулись вопроса о направлении вывода одной команды на вход другой. А почему бы и нет? Потоки стандартные, это позволяет использовать вывод одной команды как ввод другой. Это еще один очень важный механизм, позволяющий раскрыть всю мощь Linux в реализации очень сложных сценариев достаточно простым способом.
Для того, чтобы перенаправить вывод одной программы на вход другой используйте знак |, на жаргоне «труба».
Самый простой пример:
dpkg -l | grep gnomeПервая команда выведет список всех установленных пакетов, вторая отфильтрует только те, в наименовании которых есть строка «gnome».
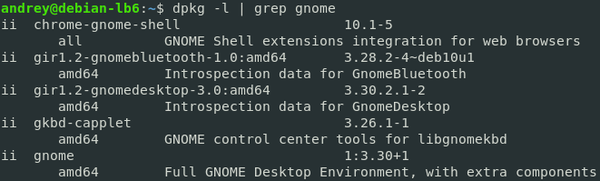 Длинна конвейера ограничена лишь нашей фантазией и здравым смыслом, никаких ограничений со стороны системы в этом нет. Но также в Linuх нет и единственно верных путей, каждую задачу можно решить самыми различными способами. Возвращаясь к получению списка файлов двух директорий мы можем сделать так:
Длинна конвейера ограничена лишь нашей фантазией и здравым смыслом, никаких ограничений со стороны системы в этом нет. Но также в Linuх нет и единственно верных путей, каждую задачу можно решить самыми различными способами. Возвращаясь к получению списка файлов двух директорий мы можем сделать так:
cat <(ls -l dir1) <(ls -l dir2) | grep rw > result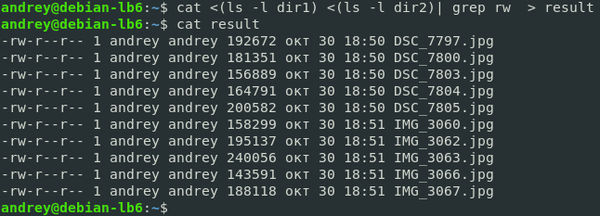 Какой из этих способов лучше? Любой, Linux ни в чем не ограничивает пользователей и предоставляет им много путей для решения одной и той же задачи.
Какой из этих способов лучше? Любой, Linux ни в чем не ограничивает пользователей и предоставляет им много путей для решения одной и той же задачи.
Еще один важный момент, если вы повышаете права с помощью команды sudo, то данное повышение прав через конвейер не распространяется. Например, если мы решим выполнить:
sudo command1 | command2То первая команда будет выполнена с правами суперпользователя, а вторая с правами запустившего терминал пользователя.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Одна из самых интересных и полезных тем для системных администраторов и новых пользователей, которые только начинают разбираться в работе с терминалом — это перенаправление потоков ввода вывода Linux. Эта особенность терминала позволяет перенаправлять вывод команд в файл, или содержимое файла на ввод команды, объединять команды вместе, и образовать конвейеры команд.
В этой статье мы рассмотрим как выполняется перенаправление потоков ввода вывода в Linux, какие операторы для этого используются, а также где все это можно применять.
Как работает перенаправление ввода вывода
Все команды, которые мы выполняем, возвращают нам три вида данных:
- Результат выполнения команды, обычно текстовые данные, которые запросил пользователь;
- Сообщения об ошибках — информируют о процессе выполнения команды и возникших непредвиденных обстоятельствах;
- Код возврата — число, которое позволяет оценить правильно ли отработала программа.
В Linux все субстанции считаются файлами, в том числе и потоки ввода вывода linux — файлы. В каждом дистрибутиве есть три основных файла потоков, которые могут использовать программы, они определяются оболочкой и идентифицируются по номеру дескриптора файла:
- STDIN или 0 — этот файл связан с клавиатурой и большинство команд получают данные для работы отсюда;
- STDOUT или 1 — это стандартный вывод, сюда программа отправляет все результаты своей работы. Он связан с экраном, или если быть точным, то с терминалом, в котором выполняется программа;
- STDERR или 2 — все сообщения об ошибках выводятся в этот файл.
Перенаправление ввода / вывода позволяет заменить один из этих файлов на свой. Например, вы можете заставить программу читать данные из файла в файловой системе, а не клавиатуры, также можете выводить ошибки в файл, а не на экран и т д. Все это делается с помощью символов «<« и «>».
Перенаправить вывод в файл
Все очень просто. Вы можете перенаправить вывод в файл с помощью символа >. Например, сохраним вывод команды top:
top -bn 5 > top.log
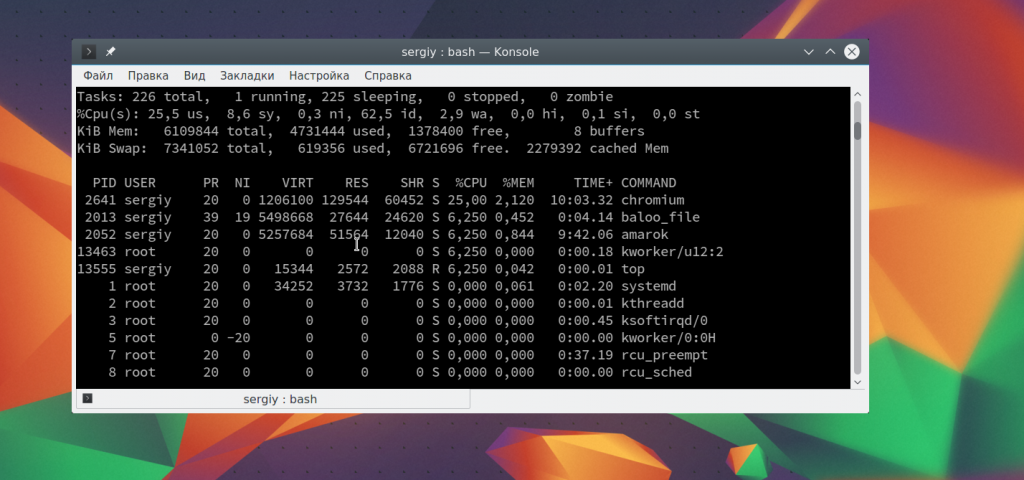
Опция -b заставляет программу работать в не интерактивном пакетном режиме, а n — повторяет операцию пять раз, чтобы получить информацию обо всех процессах. Теперь смотрим что получилось с помощью cat:
cat top.log
Символ «>» перезаписывает информацию из файла, если там уже что-то есть. Для добавления данных в конец используйте «>>». Например, перенаправить вывод в файл linux еще для top:
top -bn 5 >> top.log
По умолчанию для перенаправления используется дескриптор файла стандартного вывода. Но вы можете указать это явно. Эта команда даст тот же результат:
top -bn 5 1>top.log
Перенаправить ошибки в файл
Чтобы перенаправить вывод ошибок в файл вам нужно явно указать дескриптор файла, который собираетесь перенаправлять. Для ошибок — это номер 2. Например, при попытке получения доступа к каталогу суперпользователя ls выдаст ошибку:
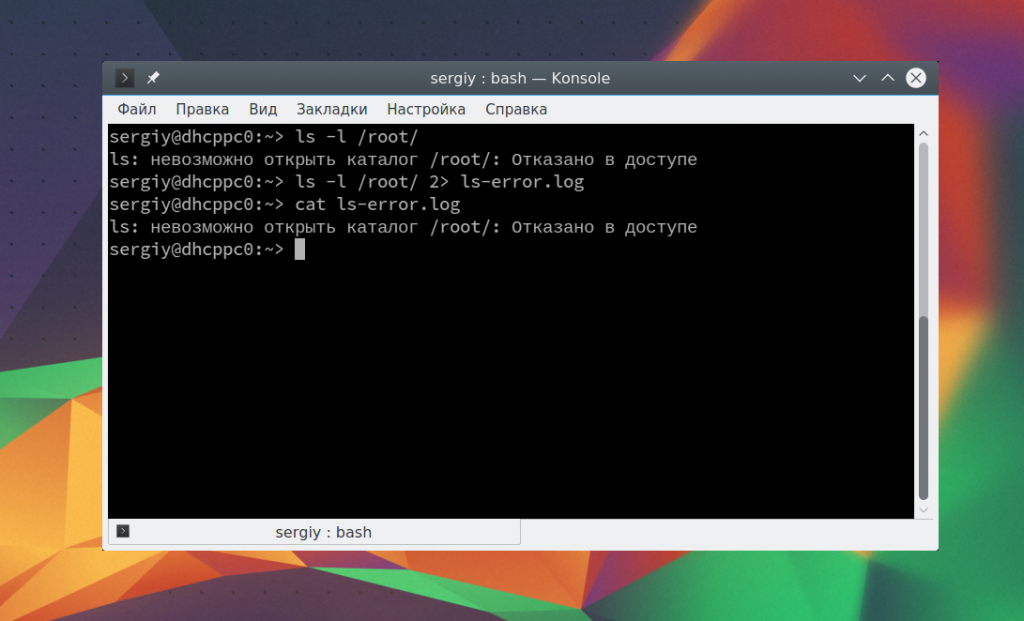
ls -l /root/
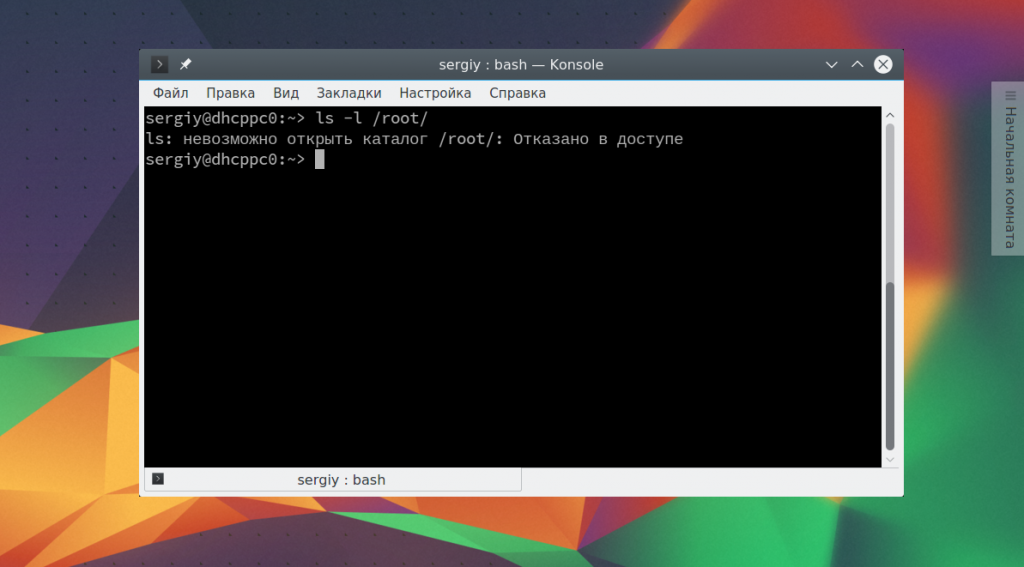
Вы можете перенаправить стандартный поток ошибок в файл так:
ls -l /root/ 2> ls-error.log
$ cat ls-error.log
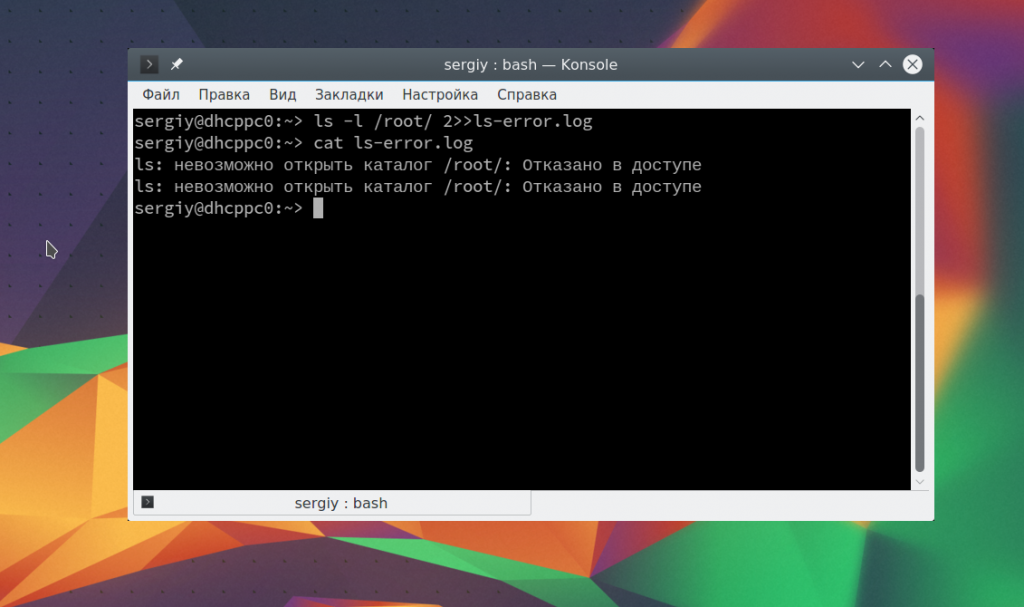
Чтобы добавить данные в конец файла используйте тот же символ:
ls -l /root/ 2>>ls-error.log
Перенаправить стандартный вывод и ошибки в файл
Вы также можете перенаправить весь вывод, ошибки и стандартный поток вывода в один файл. Для этого есть два способа. Первый из них, более старый, состоит в том, чтобы передать оба дескриптора:
ls -l /root/ >ls-error.log 2>&1
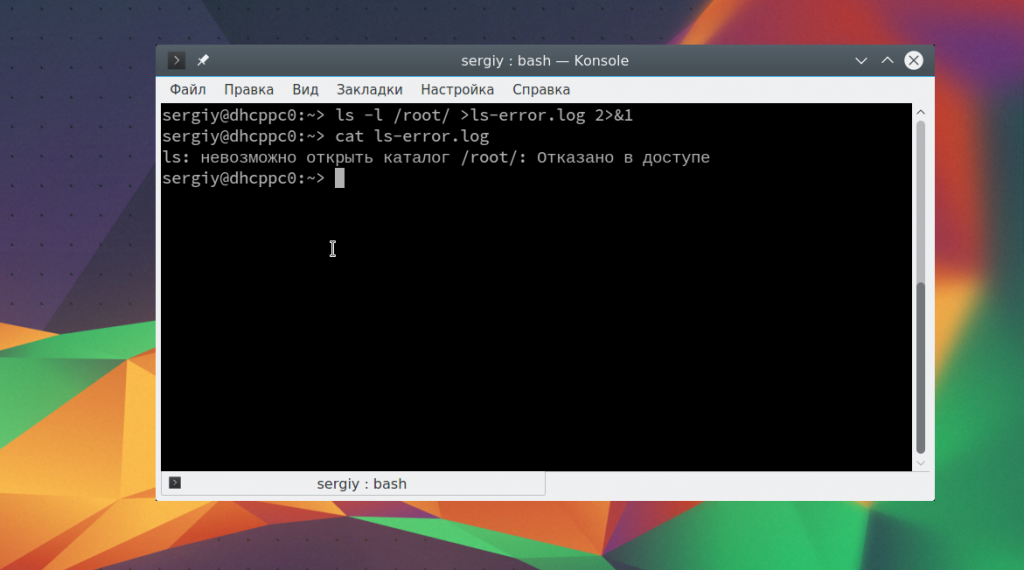
Сначала будет отправлен вывод команды ls в файл ls-error.log c помощью первого символа перенаправления. Дальше в тот же самый файл будут направлены все ошибки. Второй метод проще:
ls -l /root/ &> ls-error.log
Также можно использовать добавление вместо перезаписи:
ls -l /root/ &>> ls-error.log
Стандартный ввод из файла
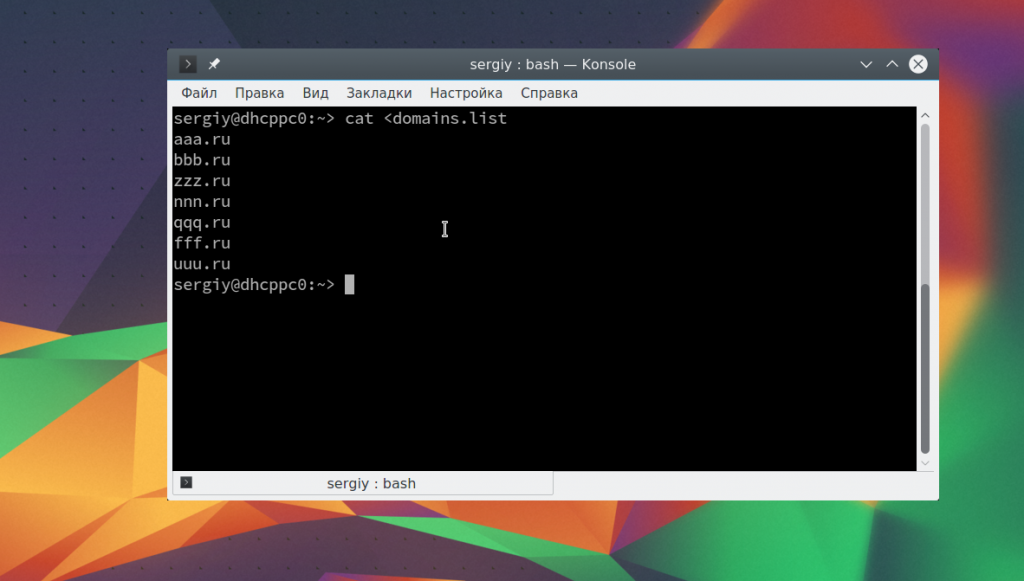
Большинство программ, кроме сервисов, получают данные для своей работы через стандартный ввод. По умолчанию стандартный ввод ожидает данных от клавиатуры. Но вы можете заставить программу читать данные из файла с помощью оператора «<«:
cat <domains.list
Вы также можете сразу же перенаправить вывод тоже в файл. Например, пересортируем список:
sort <domains.list >sort.output
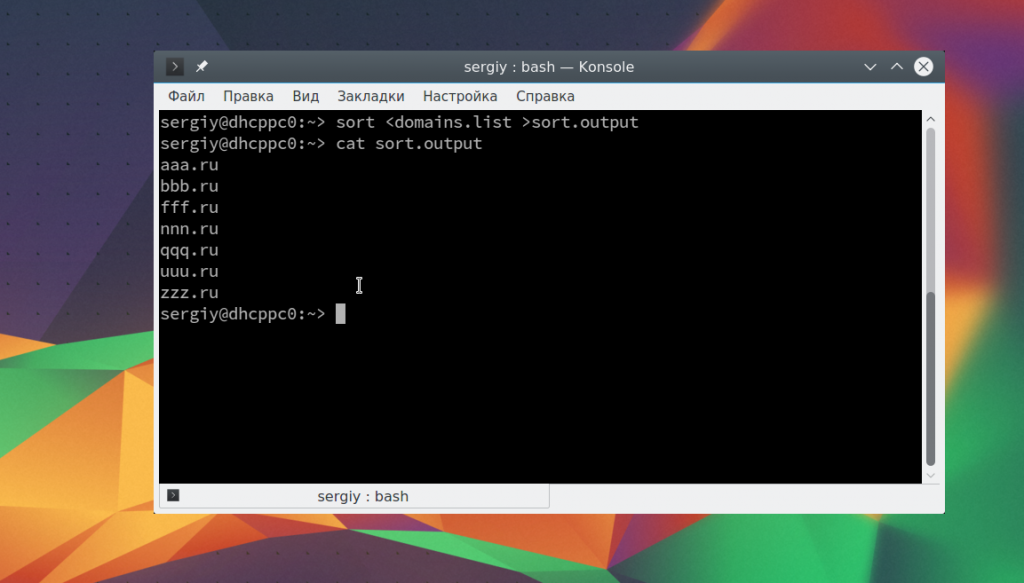
Таким образом, мы в одной команде перенаправляем ввод вывод linux.
Использование тоннелей
Можно работать не только с файлами, но и перенаправлять вывод одной команды в качестве ввода другой. Это очень полезно для выполнения сложных операций. Например, выведем пять недавно измененных файлов:
ls -lt | head -n 5
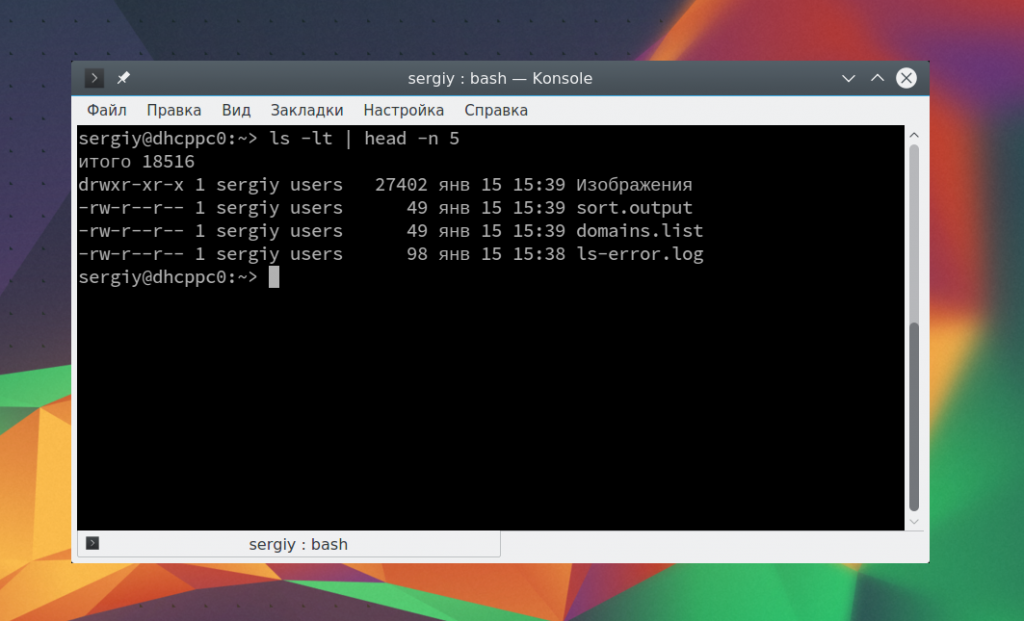
С помощью утилиты xargs вы можете комбинировать команды таким образом, чтобы стандартный ввод передавался в параметры. Например, скопируем один файл в несколько папок:
echo test/ tmp/ | xargs -n 1 cp -v testfile.sh
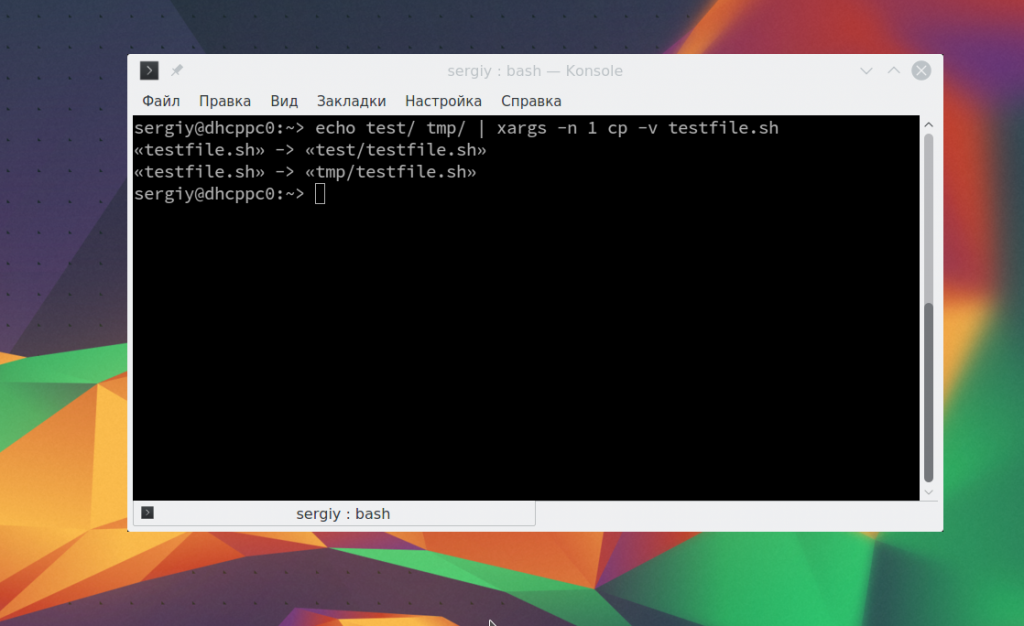
Здесь параметр -n 1 задает, что для одной команды нужно подставлять только один параметр, а опция -v в cp позволяет выводить подробную информацию о перемещениях. Еще одна, полезная в таких случаях команда — это tee. Она читает данные из стандартного ввода и записывает в стандартный вывод или файлы. Например:
echo "Тест работы tee" | tee file1
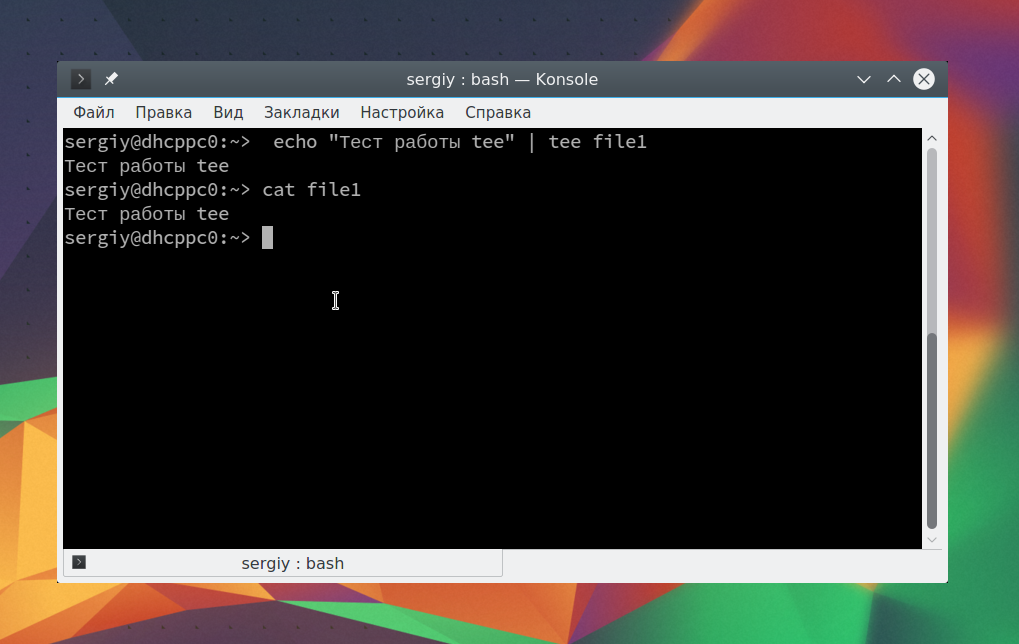
В сочетании с другими командами все это может использоваться для создания сложных инструкций из нескольких команд.
Выводы
В этой статье мы рассмотрели основы перенаправления потоков ввода вывода Linux. Теперь вы знаете как перенаправить вывод в файл linux или вывод из файла. Это очень просто и удобно. Если у вас остались вопросы, спрашивайте в комментариях!
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.
Материал из Xgu.ru
Перейти к: навигация, поиск
- Короткий URL: stdin
Стандартные потоки ввода и вывода в UNIX/Linux наряду с файлами
являются одним из наиболее распространённых средств
для обмена информацией процессов с внешним миром,
а перенаправления >, >> и |,
одной из самых популярных конструкций командного интерпретатора.
На этой странице рассматриваются как базовые вопросы использования потоков ввода/вывода,
так и тонкости и хитрости, например, почему не работает echo text | read ver
и многие другие.
Содержание
- 1 Потоки и файлы
- 2 Каналы
- 3 Программы фильтры
- 4 Переменные командного интерпретатора и потоки
- 5 Именованные каналы
- 6 Потоки ввода/вывода и терминал
- 7 Подстановка процесса
- 8 Перенаправление вывода скрипта
- 9 Поменять местами стандартный поток вывода и стандартный поток ошибок
- 10 Просмотр прогресса и скорости обработки данных в потоке
- 11 Дополнительная информация
[править] Потоки и файлы
Процесс взаимодействия с пользователем выполняется в терминах записи и чтения в файл. То есть вывод на экран представляется как запись в файл, а ввод — как чтение файла. Файл, из которого осуществляется чтение, называется стандартным потоком ввода, а в который осуществляется запись — стандартным потоком вывода.

Стандартные потоки — воображаемые файлы, позволяющие осуществлять взаимодействие с пользователем как чтение и запись в файл.
Кроме потоков ввода и вывода, существует еще и стандартный поток ошибок, на который выводятся все сообщения об ошибках и те информативные сообщения о ходе работы программы, которые не могут быть выведены в стандартный поток вывода.
Стандартные потоки привязаны к файловым дескрипторам с номерами 0, 1 и 2.
- Стандартный поток ввода (stdin) — 0;
- Стандартный поток вывода (stdout) — 1;
- Стандартный поток ошибок (stderr) — 2.
Вывод данных на экран и чтение их с клавиатуры происходит потому, что по умолчанию стандартные потоки ассоциированы с терминалом пользователя. Это не является обязательным — потоки можно подключать к чему угодно — к файлам, программам и даже устройствам. В командном интерпретаторе bash такая операция называется перенаправлением.
- < файл
- Использовать файл как источник данных для стандартного потока ввода.
- > файл
- Направить стандартный поток вывода в файл. Если файл не существует, он будет создан; если существует — перезаписан сверху.
- 2> файл
- Направить стандартный поток ошибок в файл. Если файл не существует, он будет создан; если существует — перезаписан сверху.
- >>файл
- Направить стандартный поток вывода в файл. Если файл не существует, он будет создан; если существует — данные будут дописаны к нему в конец.
- 2>>файл
- Направить стандартный поток ошибок в файл. Если файл не существует, он будет создан; если существует — данные будут дописаны к нему в конец.
- &>файл или >&файл
- Направить стандартный поток вывода и стандартный поток ошибок в файл. Другая форма записи: >файл 2>&1.
- >&-
- Закрыть поток вывода перед вызовом команды (спасибо [1]);
- 2>&-
- Закрыть поток ошибок перед вызовом команды (спасибо [2]);
- cat <<EOF
Весь текст между блоками EOF (в общем случае вместо EOF можно использовать любое слово) будет выведен на экран. Важно: перед последним EOF не должно быть пробелов! (heredoc синтаксис).
- EOF
- <<<string
- Аналогично, но только для одной строки (для bash версии 3 и выше)
Пример.
Эта команда объединяет три файла: header, body и footer в один файл letter:
%$ cat header body footer > letter
Команда cat по очереди выводит содержимое файлов, перечисленных в качестве параметров на стандартный поток вывода. Стандартный поток вывода перенаправлен в файл letter.
Здесь используется сразу перенаправление стандартного потока ввода и стандартного потока вывода:
%$ sort < unsortedlines > sortedlines
Программа sort сортирует данные, поступившие в стандартный поток ввода, и выводит их на стандартный поток вывода. Стандартный поток ввода подключен к файлу unsortedlines, а выход записывается в sortedlines.
Здесь перенаправлены потоки вывода и ошибок:
%$ find /home -name '*.rpm' >rpmlist 2> /dev/null
Программа find ищет в каталоге /home файлы с суффиксом .rpm. Список найденных файлов записывается в файл rpmlist. Все сообщения об ошибках удаляются. Удаление достигается при помощи перенаправления потока ошибок на устройство /dev/null — специальный файл, означающий ничто. Данные, отправленные туда, безвозвратно исчезают. Если же прочитать содержимое этого файла, он окажется пуст.
Для того чтобы лучше понять, что потоки работают как файлы,
рассмотрим такой пример:
%$ cat > /tmp/fff & [1] 28378 [1]+ Stopped cat > /tmp/fff %$ ls -l /proc/28378/fd/ total 0 lrwx------ 1 igor igor 64 2009-06-24 18:58 0 -> /dev/pts/1 l-wx------ 1 igor igor 64 2009-06-24 18:58 1 -> /tmp/fff lrwx------ 1 igor igor 64 2009-06-24 18:58 2 -> /dev/pts/1 l-wx------ 1 igor igor 64 2009-06-24 18:58 5 -> pipe:[13325] lr-x------ 1 igor igor 64 2009-06-24 18:58 7 -> pipe:[13329]
Программа cat запускается для записи данных в файл /tmp/fff.
Он запускается в фоне (&), и получает номер работы 1 ([1]).
Процесс этой программы имеет номер 28378.
Информация о процессе 28738 находится в каталоге /proc/28738
специальной псевдофайловой системы /proc.
В частности, в подкаталоге /proc/28738/fd/
находится список файловых дескрипторов для открытых процессом файлов.
Здесь видно, что стандартный поток ввода (0), и стандартный поток ошибок (2) процесса
подключены на терминал, а вот стандартный поток вывода (1) перенаправлен в файл.
Завершить работу программы cat можно командой kill %1.
Командный интерпретатор — это тоже процесс.
И у него есть стандартные потоки ввода и вывода.
Если интерпретатор работает в интерактивном режиме,
то они подключены на консоль (вывода на экран; чтение с клавиатуры).
Можно обратиться напрямую к этим потокам изнутри интерпретатора:
- /dev/stdin — стандартный поток ввода;
- /dev/stdout — стандартный поток вывода;
- /dev/stderr — стандартный поток ошибок.
Например, здесь видно, что потоки ссылаются в конечном итоге на файл-устройство
терминала, с которым работает интерпретатор:
%$ ls -l /dev/std* lrwxrwxrwx 1 root root 15 2009-06-17 23:54 /dev/stderr -> /proc/self/fd/2 lrwxrwxrwx 1 root root 15 2009-06-17 23:54 /dev/stdin -> /proc/self/fd/0 lrwxrwxrwx 1 root root 15 2009-06-17 23:54 /dev/stdout -> /proc/self/fd/1 %$ ls -l /proc/self/fd/[012] lrwx------ 1 igor igor 64 2009-06-24 18:16 /proc/self/fd/0 -> /dev/pts/1 lrwx------ 1 igor igor 64 2009-06-24 18:16 /proc/self/fd/1 -> /dev/pts/1 lrwx------ 1 igor igor 64 2009-06-24 18:16 /proc/self/fd/2 -> /dev/pts/1 %$ tty /dev/pts/1
[править] Каналы
Стандартные потоки можно перенаправлять не только в файлы, но и на вход других программ. Если поток вывода одной программы соединить с потоком ввода другой программы, получится конструкция, называемая каналом, конвейером или пайпом (от англ. pipe, труба).

В bash канал выглядит как последовательность команд, отделенных друг от друга символом |:
- команда1 | команда2 | команда3 …
Стандартный поток вывода команды1 подключается к стандартному потоку ввода команды2,
стандартный поток вывода команды2 в свою очередь подключается к потоку ввода команды3 и т.д.
В UNIX/Linux существует целый класс команд, предназначенных для преобразования потоков данных в каналах. Такие программы известны как фильтры. Программа-фильтр читает данные, поступающие со стандартного потока ввода (на вход), преобразовывает их требуемым образом и выводит на стандартный поток вывода (на выход). Существует множество хорошо известных фильтров, призванных решать определенные задачи, и являющихся незаменимым инструментом в руках пользователя ОС.
|
|
Каналы в ОС Linux являются одной из наиболее часто применяемых конструкций, а фильтры — наиболее часто применяемых программ. Большинство повседневных задач в Linux легко решаются при помощи конструкций построенных на основе нескольких фильтров. |
Программы, образующие канал, выполняются параллельно как независимые процессы.
Можно создавать ответвление в каналах. Команда tee позволяет сохранять данные, передающиеся в канале:
- tee [опции] файл
Программа tee копирует данные, поступающие на стандартный поток ввода, в указанные в качестве аргументов команды файлы, и передает данные на стандартный поток вывода.
Рассмотренный ниже пример: сортируется файл unsortedlines и результат записывается в sortedlines.
%$ cat unsortedlines | sort > sortedlines
Команда выполняет те же действия, но запись является более наглядной.
Вот пример посложнее. Вывести название и размер пользовательского каталога, занимающее наибольшее место на диске.
$ du -s /home/* | sort -nr | head -1
Программа du, при вызове ее с ключом -s, сообщает суммарный объем каждого каталога или файла, перечисленного в ее параметрах.
Ключ -n команды sort означает, что сортировка должна быть арифметической, т.е. строки должны рассматриваться как числа, а не как последовательности символов (Например, 12>5 в то время как строка ’12′<‘5’ т.к. сравнение строк производится посимвольно и ‘1’<‘5’). Ключ -r означает изменения порядка сортировки — с возрастающего на убывающий.
Команда head выводит несколько первых строк поступающего на ее вход потока, отбрасывая все остальные. Ключ -1 означает, что надо вывести только одну строку.
Таким образом, список пользовательских каталогов с их суммарным объемом арифметически сортируется по убыванию, и из полученного списка берется первая строка, т.е. строка с наибольшим числом, соответствующая самому объемному каталогу.
Использование команды tee:
$ sort text | tee sorted_text | head -n 1
Содержимое файла text сортируется, и результат сортировки записывается в файл sorted_text. Первая строка отсортированного текста выдается на экран.
[править] Программы фильтры
В UNIX/Linux существует целый класс команд, которые
принимают данные со стандартного потока ввода,
каким-то образом обрабатывают их,
и выдают результат на стандартный поток вывода.
Такие программы называются программами-фильтрами.
Как правило, все эти программы работают как фильтры,
если у них нет аргументов (опции могут быть),
но как только им в качестве аргумента передаётся файл,
они считывают данные из этого файла, а не со стандартного потока ввода
(существуют и исключения, например, программа tr, которая обрабатывает данные
поступающие исключительно через стандартный поток ввода).

- cat
- Считывает данные со стандартного потока ввода и передаёт их на стандартный поток вывода. Без опций работает как простой повторитель. С опциями может фильтровать пустые строки, нумеровать строки и делать другую подобную работу.
- head
- Показывает первые 10 строк (или другое заданное количество), считанных со стандартного потока ввода.
- tail
- Показывает последние 10 строк (или другое заданное количество), считанные со стандартного потока ввода. Важный частный случай tail -f, который в режиме слежения показывает концовку файла. Это используется, в частности, для просмотра файлов журнальных сообщений.
- cut
- Вырезает столбец (по символам или полям) из потока ввода и передаёт на поток вывода. В качестве разделителей полей могут использоваться любые символы.
- sort
- Отсортировать данные в соответствии с какими-либо критериями, например, арифметически по второму столбцу.
- uniq
- Удалить повторяющиеся строки. Или (с ключом -с) не просто удалить, а написать сколько таких строк было. Учитываются только подряд идущие одинаковые строки, поэтому часто данные сортируются перед тем как отправить их на вход программе.
- tee
- Ответвить данные в файл. Используется для сохранения промежуточных данных, передающихся в потоке, в файл.
- bc
- Вычислить каждую отдельную строку потока и записать вместо неё результат вычисления.
- hexdump
- Показать шестнадцатеричное представление данных, поступающих на стандартный поток ввода.
- strings
- вычленить и показать в стандартном потоке (или файле) то, что напоминает строки. Всё что не похоже на строковые последовательности, игнорировать. Полезна в сочетании с grep для поиска интересующих строковых последовательностей в бинарных файлах.
- grep
- Отфильтровать поток, и показать только строки, содержащие (или не содержащие) заданное регулярное выражение.
- tr
- Посимвольная замена текста в потоке. Например, tr A-Z a-z меняет регистр символов с большого на маленький.
- sed
- Обработать текст в соответствии с заданным скриптом. Наиболее часто используется для замены текста в потоке: sed s/было/стало/g
- awk
- Обработать текст в соответствии с заданным скриптом. Как правило, используется для обработки текстовых таблиц, например таких как вывод ps aux и тому подобных, но не только.
- perl
- Обработать текст в соответствии с заданным скриптом. Возможности языка Perl выходят далеко за рамки однострочников для командной строки, но с однострочниками он справляется особенно виртуозно. В Perl существует оператор <> (diamond operator) и конструкция while(<>) { … }, которая предполагает обработку данных со стандартного потока ввода (или из файлов, если они переданы в качестве аргументов). При написании однострочников можно использовать ключи -n (равносильный оборачиванию кода в while(<>) { … }) или -p (равносильный while(<>) { … }).

- sh -s
- Текст, который передаётся на стандартный поток ввода sh -s может интерпретироваться как последовательность команд shell. На выход передаётся результат их исполнения.
- ssh
- Средство удалённого доступа ssh, может работать как фильтр. ssh подхватывает данные, переданные ему на стандартный поток ввода, передаёт их на удалённых хост и подаёт на вход процессу программы, имя которой было передано ему в качестве аргумента. Результат выполнения программы (то есть то, что она выдала на стандартный поток вывода) передаётся со стандартного вывода ssh.
[править] Переменные командного интерпретатора и потоки
Для того чтобы вывести содержимое переменной командного интерпретатора
на стандартный поток вывода, используется команда echo:
%$ echo $VAR
На стандартный поток ошибок данные можно передать с помощью перенаправления:
%$ echo $VAR > /dev/stderr
Содержимое переменной (или любой другой текст) поступят не на стандартный поток вывода,
а на стандартный поток ошибок.
Считать данные со стандартного потока ввода внутрь одной или нескольких переменных
можно при помощи команды read:
%$ read VAR
Строка из стандартного потока ввода считается внутрь переменной VAR.
Если указать несколько переменных,
то в первую попадёт первое слово; во вторую — второе слово; в последнюю — всё остальное.
%$ df -h | head -1
Filesystem Size Used Avail Use% Mounted on
%$ df -h | head -1 | { read VAR1 VAR2 VAR3; echo $VAR1; echo $VAR2; echo $VAR3 ; }
Filesystem
Size
Used Avail Use% Mounted on
|
|
Обратите внимание на конструкцию { read VAR; echo $VAR }. |
Если прочитать данные со стандартного потока ввода не удалось,
то команда read возвращает код завершения отличный от нуля.
Это позволяет использовать read, например, в такой конструкции:
%$ cat users | while read user
do
useradd $user
done
В этом примере read считывает строки из файла users,
и для каждой прочитанной строки вызывается команда useradd, которая добавляет пользователя в системе.
В результате: создаются учётные записи пользователей, имена которых перечислены в файле users.
|
|
Переменная user после выхода из цикла остаётся в том же виде, в каком она была до входа в цикл |
[править] Именованные каналы
Безымянный канал можно построить только между процессами,
которые порождены от одного процесса (и на практике они должны быть порождены одновременно, а не последовательно,
хотя теоретически это не обязательно).
Если же процессы имеют разных родителей,
то между ними обычный, безымянный канал построить не получится.

Например, в данном случае d и e, и f и g
легко могут быть соединены при помощи канала,
но e и f соединить с помощью канала не получится.
Для решения этой задачи используются именованные каналы fifo (first in, first out).
Они во всём повторяют обычные каналы (pipe), только имеют привязку к файловой системе.
Создать именованный канал можно командой mkfifo:
%$ mkfifo /tmp/fifo
Созданный канал можно использовать для соединения процессов
между собой.
Например, эти перенаправления будут работать одинаково:
%$ f | g
и
%$ f > /tmp/fifo & g < /tmp/fifo
(здесь f и g — процессы из вышеуказанной иерархии процессов).
Процессы f и g имеют общего предка. А вот для процессов e и g,
не связанных между собой, обычный канал использовать не получится,
только именованный:
%$ e > /tmp/fifo& %$ g < /tmp/fifo # в другом интерпретаторе
[править] Потоки ввода/вывода и терминал
Большинство программ, которые работают с потоками ввода и вывода,
работают с ними как с простыми файлами, и не рассчитывают на то,
что поток подключен к терминалу.
Но не все.
Если потоки ввода/вывода отключаются от терминала
и перенаправляются в файл, часть возможностей программы может пропасть.
Например, если командный интерпретатор отвязать от терминала,
то у него потеряется множество интерактивных возможностей:
%$ cat | sh -i | cat
Например, возможности прокручивать историю команд
у него теперь нет. Возможности по редактированию
теперь тоже сильно урезаны.
Фактически, редактирование команды теперь выполняется
уже с помощью программы cat, которая держит терминал,
а интерпретатору поступают уже полностью введённые команды.
Проверить, подключен ли наш стандартный поток
к терминалу, или он перенаправлен в файл,
можно при помощи test, ключ -t:
%$ test -t 0 && echo terminal terminal %$ cat | test -t 0 && echo terminal %$ cat | test -t 0 || echo file file
[править] Подстановка процесса
Есть хитрый трюк, который в чистом виде перенаправлением потока ввода/вывода не является,
но имеет к нему отношение — подстановка процесса.
Результат выполнения процесса можно представить в виде воображаемого файла
и передать его другому процессу.
Форма вызова:
команда1 <(команда2)
При таком вызове процессу команда1 передаётся файл (созданный налету канал или файл /dev/fd/…),
в котором находятся данные, которые выводит команда2.
Например, у вас есть два файла с различными словами по одному в строке.
Вы хотите определить, какие из них встречаются в одном файле,
но не встречаются во втором. И наоборот.
%$ cat f1 a b c b b %$ cat f2 a c c c %$ diff <(sort -u f1) <(sort -u f2) 2d1 < b
Получается, что в первом файле присутствует слово, которое отсутствует во втором (слово b).
Подробнее: [3]
[править] Перенаправление вывода скрипта
Потоки ввода/вывода скрипта, исполняющегося сейчас,
изнутри самого скрипта можно следующим образом:
exec > file exec 2>&1
Подробнее:
- How do I redirect the output of an entire shell script within the script itself?

[править] Поменять местами стандартный поток вывода и стандартный поток ошибок
$ cmd 3>&2 2>&1 1>&3
Подробнее:
- IO Redirection — Swapping stdout and stderr (Advanced)
[править] Просмотр прогресса и скорости обработки данных в потоке
Если пропустить данные, передающиеся в канале, через программу pv,
то будет видна скорость обработки,
время в течение которого работает канал
и, если известно сколько данных должно быть обработано,
приблизительное время окончания выполнения.
$ pv /tmp/shre.tar.gz | tar xz 62MB 0:00:18 [12,6MB/s] [==> ] 10% ETA 0:02:27
Подробнее: [4], [5].
[править] Дополнительная информация
- Monadic i/o and UNIX shell programming (англ.) — взгляд на каналы (pipelines) как на монады
- http://wiki.bash-hackers.org/howto/redirection_tutorial (англ.) — очень подробно на живых примерах разобраны различные виды перенаправлений
- How do I write stderr to a file while using “tee” with a pipe? — прекрасный пример использования подстановки процесса (process substitution); в этом примере таким образом перенаправляется поток ошибок
- http://mywiki.wooledge.org/BashGuide/InputAndOutput (англ.) — всевозможные манипуляции со стандартными потоками ввода и вывода
| |
|
|---|---|
| Основы | Потоки ввода/вывода • Командная строка |
| Пользовательское окружение | Оболочка интерпретатора • Приглашение командного интерпретатора • bash_completion • shopt |
| Скриптинг | Скриптинг • Интерпретатор • Shebang • Shell-скриптинг • shell-framework • expect • awk • sed |