Чем сложнее устройство, чем из большего
числа элементов оно состоит, тем больше
должна быть вероятность отказов. Это
естественное умозаключение входит в
противоречие с нашей повседневной
действительностью. Скажем, стремительное
увеличение емкости накопителей информации
совсем не приводит к увеличению числа
сбоев. Напротив, нынешние терабайтные
жесткие диски много надежнее 2-мегабайтных,
которыми мы пользовались в начале 80-х
прошлого века. Еще удивительнее тот
факт, что при стремительном росте
скорости и объемов данных, передаваемых
по каналам связи, конечный пользователь
информации практически никогда не
замечает, чтобы в этих принятых данных
были ошибки.
Один нетривиальный пример того, как
увеличение сложности схемы может
повышать ее надежность, был приведен
в предыдущем параграфе. В данном параграфе
мы очень коротко опишем решение еще
одной задачи – защита от ошибок при
хранении либо передаче данных, записанных
в двоичной форме. Мы увидим, что для
надежной передачи информации к ней надо
добавить избыточные данные, которые
позволят обнаружить наличие ошибок, а
если ошибок не слишком много, то и
исправить их.
6.1. Постановка задачи.
Начнем
с примера. Рассмотрим систему связи, в
которой входом канала являются двоичные
сигналы, соответствующие символам
алфавита
![]() .
.
На выходе канала каждый сигнал
анализируется и выносится решение в
пользу одного из двоичных символов
выходного алфавита
![]() .
.
Будем считать, что
подлежащая передаче информация
представлена в двоичной форме и поэтому
элементарные сообщения представляют
собой также двоичные символы 0 либо 1.
Таким образом, мы можем непосредственно
использовать входные символы канала
для передачи сообщений источника.
Предположим, однако, что из-за шума в
канале связи при передаче сигналов
возможны ошибки. Как можно усовершенствовать
систему связи, с тем, чтобы устранить
ошибки или, по меньшей мере, уменьшить
их долю в принятой последовательности
сообщений?
Приведем примеры
кодов, исправляющих ошибки.
Пример
6.1.
Будем вместо сообщения 0 передавать
последовательность 000, а вместо 1 –
последовательность 111. Множество
передаваемых по каналу последовательностей
образует код, который в данном случае
имеет длину 3 и содержит 2 кодовых слова
(мощность кода равна 2). Считая, что
правильная передача символов более
вероятна, чем неправильная, легко
предложить разумную стратегию принятия
решений декодером. Если принятая из
канала последовательность «больше
похожа» на 000, чем на 111, декодер считает,
что передавалось сообщение 0, в противном
случае принимает решение в пользу
сообщения 1. Иначе говоря, если число
единиц меньше 2, решение принимается в
пользу 0, в противном случае – в пользу
1.
Число
несовпадающих позиций в двух
последовательностях
![]()
и
![]()
называют расстоянием
Хэмминга между
этими последовательностями. Описанный
в примере декодер является декодером,
принимающим решения по принципу минимума
расстояния Хэмминга.
Назовем
множество последовательностей
![]()
на выходе канала, декодируемых в пользу
некоторого кодового слова (точнее, в
пользу сообщения, соответствующего
этому слову), решающей
областью слова
(сообщения). Решающие области для данного
примера приведены в таблице 6.1.
Таблица
6.1.
Корректирующий
код из примера 6.1.
|
Сообщения |
Кодовые |
Решающие |
|
0 |
000 |
{000, |
|
1 |
111 |
{011, |
Нетрудно видеть,
что одиночная ошибка в канале связи при
использовании такого кода не опасна.
Декодер примет правильное решение. Про
такой код говорят, что он исправляет
все ошибки кратности 1. Заметим, что на
передачу одного бита информации данный
код затрачивает 3 двоичных сигнала.
Разумной характеристикой кода служит
его скорость, которая указывает количество
бит информации, переносимых одним
сигналом. Скорость кода в данном примере
равна
![]()
(бит/символ
канала). ■
Рассмотрим еще один,
немного более сложный, пример кода,
исправляющего одиночные ошибки.
Пример
6.2. Объединим
биты передаваемого сообщения в пары.
Множество «расширенных сообщений»
состоит теперь из 4 различных двоичных
комбинаций. Приведенный в таблице 6.2.
пример показывает одну из возможных
конструкций кода для этого множества
сообщений.
Таблица
6.2.
Код
для примера 6.2.
|
Сообщения |
Кодовые |
Решающие |
|
00 |
00000 |
{00000,00001,00010,00100,01000,10000,11000,10001} |
|
01 |
10110 |
{10110,10111,10100,10010,11110,00110,01110,00111} |
|
10 |
01011 |
{01011,01010,01001,01111,00011,11011,10011,11010} |
|
11 |
11101 |
{11101,11100,11111,11001,10101,01101,00101,01100} |
Непосредственной
проверкой можно убедиться в том, что
этот код также не боится однократных
ошибок, но его скорость несколько больше,
поскольку 5 сигналов будет затрачено
уже на передачу 2 двоичных сообщений.
Поэтому
![]()
(бит/символ
канала). ■
Понятно,
что рассмотренные коды не спасают
полностью от ошибок при передаче
сообщений. Код примера 6.1. не защищает
от двукратных ошибок. Код примера 6.2
исправляет некоторые комбинации
2-кратных ошибок (например, 11000, 10001), но
все остальные комбинации из 2 или большего
числа ошибок неминуемо приводят к выдаче
получателю неправильно восстановленных
сообщений.
Приведенные выше
примеры убеждают в том, что важными
характеристиками кода, защищающего
информацию от ошибок, являются его
скорость и помехоустойчивость. Последняя
характеристика может быть численно
измерена вероятностью выдачи получателю
ошибочного сообщения.
Для того, чтобы надежно передавать
данные, нужно исправлять много ошибок,
соответственно коды должны быть длинными.
Для того, чтобы скорость передачи
оставалась высокой, коды должны содержать
много кодовых слов. Например, по
сегодняшним меркам коды длины 1000 не
рассматривается как длинный. В то же
время, чтобы скорость была равна 1/2,
кодовое слово должно нести 500 бит
информации и, соответственно, код должен
содержать
![]()
кодовых слов. Очевидно, не может
существовать кодера, который хранил бы
список из такого числа слов и никакой
декодер не может искать переданное
слово, сравнивая принятую последовательность
со всеми словами такого списка. Как же
устроены реальные кодеры и декодеры?
Решение задачи состоит в том, что в
памяти хранится лишь небольшое число
слов, а остальные слова получаются из
них с помощью простых арифметических
операций. Чтоб двигаться дальше,
понадобится несколько определений и
понятий из линейной алгебры над конечными
множествами чисел.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Время на прочтение
5 мин
Количество просмотров 123K
Это продолженеие статьи о помехоустойчивом кодировании, которая очень долго лежала в черновиках. В прошлой части нет ничего интересного с практической точки зрения — лишь общие сведения о том, зачем это нужно, где применяется и т.п. В данной части будут рассматриваться некоторые (самые простые) коды для обнаружения и/или исправления ошибок. Итак, поехали.
Попытался все описать как можно легче для человека, который никогда не занимался кодированием информации, и без каких-либо особых математических формул.
Когда мы передаем сообщение от источника к приемнику, при передаче данных может произойти ошибка (помехи, неисправность оборудования и пр.). Чтобы обнаружить и исправить ошибку, применяют помехоустойчивое кодирование, т.е. кодируют сообщение таким образом, чтобы принимающая сторона знала, произошла ошибка или нет, и при могла исправить ошибки в случае их возникновения.
По сути, кодирование — это добавление к исходной информации дополнительной, проверочной, информации. Для кодирования на передающей стороне используются кодер, а на принимающей стороне — используют декодер для получения исходного сообщения.
Избыточность кода — это количество проверочной информации в сообщении. Рассчитывается она по формуле:
k/(i+k), где
k — количество проверочных бит,
i — количество информационных бит.
Например, мы передаем 3 бита и к ним добавляем 1 проверочный бит — избыточность составит 1/(3+1) = 1/4 (25%).
Код с проверкой на четность
Проверка четности – очень простой метод для обнаружения ошибок в передаваемом пакете данных. С помощью данного кода мы не можем восстановить данные, но можем обнаружить только лишь одиночную ошибку.
В каждом пакет данных есть один бит четности, или, так называемый, паритетный бит. Этот бит устанавливается во время записи (или отправки) данных, и затем рассчитывается и сравнивается во время чтения (получения) данных. Он равен сумме по модулю 2 всех бит данных в пакете. То есть число единиц в пакете всегда будет четно . Изменение этого бита (например с 0 на 1) сообщает о возникшей ошибке.
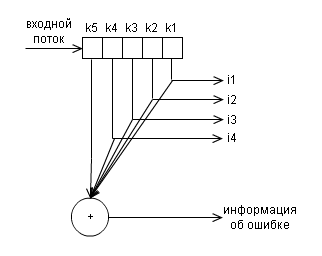
Ниже показана структурная схемы кодера для данного кода
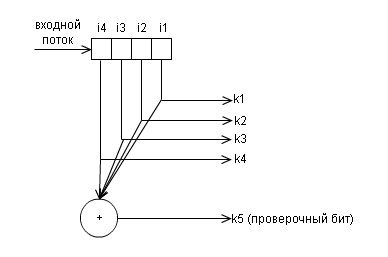
и и декодера
Пример:
Начальные данные: 1111
Данные после кодирования: 11110 ( 1 + 1 + 1 + 1 = 0 (mod 2) )
Принятые данные: 10110 (изменился второй бит)
Как мы видим, количество единиц в принятом пакете нечетно, следовательно, при передаче произошла ошибка.
Как говорилось ранее, этот метод служит только для определения одиночной ошибки. В случае изменения состояния двух битов, возможна ситуация, когда вычисление контрольного бита совпадет с записанным. В этом случае система не определит ошибку, а это не есть хорошо. К примеру:
Начальные данные: 1111
Данные после кодирования: 11110 ( 1 + 1 + 1 + 1 = 0 (mod 2) )
Принятые данные: 10010 (изменились 2 и 3 биты)
В принятых данных число единиц четно, и, следовательно, декодер не обнаружит ошибку.
Так как около 90% всех нерегулярных ошибок происходит именно с одиночным разрядом, проверки четности бывает достаточно для большинства ситуаций.
Код Хэмминга
Как говорилось в предыдущей части, очень много для помехоустойчивого кодирования сделал Ричард Хэмминг. В частности, он разработал код, который обеспечивает обнаружение и исправление одиночных ошибок при минимально возможном числе дополнительных проверочных бит. Для каждого числа проверочных символов используется специальная маркировка вида (k, i), где k — количество символов в сообщении, i — количество информационных символов в сообщении. Например, существуют коды (7, 4), (15, 11), (31, 26). Каждый проверочный символ в коде Хэмминга представляет сумму по модулю 2 некоторой подпоследовательности данных. Рассмотрим сразу на примере, когда количество информационных бит i в блоке равно 4 — это код (7,4), количество проверочных символов равно 3. Классически, эти символы располагаются на позициях, равных степеням двойки в порядке возрастания:
первый проверочный бит на 20 = 1;
второй проверочный бит на 21 = 2;
третий проверочный бит на 22 = 4;
но можно и разместить их в конце передаваемого блока данных (но тогда формула для их расчета будет другая).
Теперь рассчитаем эти проверочные символы:
r1 = i1 + i2 + i4
r2 = i1 + i3 + i4
r3 = i2 + i3 + i4
Итак, в закодированном сообщении у нас получится следующее:
r1 r2 i1 r3 i2 i3 i4
В принципе, работа этого алгоритма разобрана очень детально в статье Код Хэмминга. Пример работы алгоритма, так что особо подробно описывать в этой статье не вижу смысла. Вместо этого приведу структурную схему кодера:
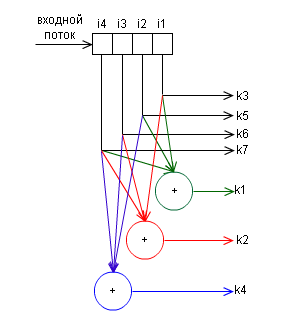
и декодера
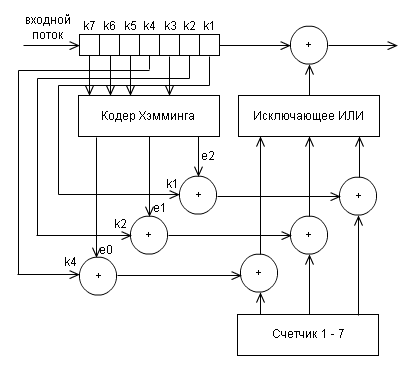
(может быть, довольно запутано, но лучше начертить не получилось)
e0,e1,e2 опрделяются как функции, зависящие от принятых декодером бит k1 — k7:
e0 = k1 + k3 + k5 + k7 mod 2
e1 = k2 + k3 + k6 + k7 mod 2
e2 = k4 + k5 + k6 + k7 mod 2
Набор этих значений e2e1e0 есть двоичная запись позиции, где произошла ошибка при передаче данных. Декодер эти значения вычисляет, и если они все не равны 0 (то есть не получится 000), то исправляет ошибку.
Коды-произведения
В канале связи кроме одиночных ошибок, вызванных шумами, часто встречаются пакетные ошибки, вызванные импульсными помехами, замираниями или выпадениями (при цифровой видеозаписи). При этом пораженными оказываются сотни, а то и тысячи бит информации подряд. Ясно, что ни один помехоустойчивый код не сможет справиться с такой ошибкой. Для возможности борьбы с такими ошибками используются коды-произведения. Принцип действия такого кода изображён на рисунке:

Передаваемая информация кодируется дважды: во внешнем и внутреннем кодерах. Между ними устанавливается буфер, работа которого показана на рисунке:
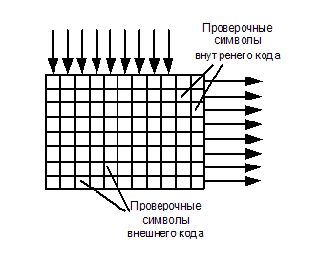
Информационные слова проходят через первый помехоустойчивый кодер, называемый внешним, т.к. он и соответствующий ему декодер находятся по краям системы помехоустойчивого кодирования. Здесь к ним добавляются проверочные символы, а они, в свою очередь, заносятся в буфер по столбцам, а выводятся построчно. Этот процесс называется перемешиванием или перемежением.
При выводе строк из буфера к ним добавляются проверочные символы внутреннего кода. В таком порядке информация передается по каналу связи или записывается куда-нибудь. Условимся, что и внутренний, и внешний коды – коды Хэмминга, с тремя проверочными символами, то есть и тот, и другой могут исправить по одной ошибке в кодовом слове (количество «кубиков» на рисунке не критично — это просто схема). На приемном конце расположен точно такой же массив памяти (буфер), в который информация заносится построчно, а выводится по столбцам. При возникновении пакетной ошибки (крестики на рисунке в третьей и четвертой строках), она малыми порциями распределяется в кодовых словах внешнего кода и может быть исправлена.
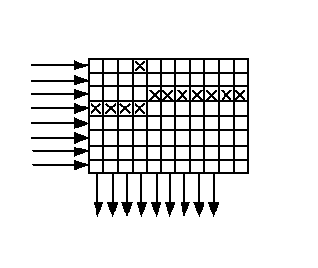
Назначение внешнего кода понятно – исправление пакетных ошибок. Зачем же нужен внутренний код? На рисунке, кроме пакетной, показана одиночная ошибка (четвертый столбец, верхняя строка). В кодовом слове, расположенном в четвертом столбце — две ошибки, и они не могут быть исправлены, т.к. внешний код рассчитан на исправление одной ошибки. Для выхода из этой ситуации как раз и нужен внутренний код, который исправит эту одиночную ошибку. Принимаемые данные сначала проходят внутренний декодер, где исправляются одиночные ошибки, затем записываются в буфер построчно, выводятся по столбцам и подаются на внешний декодер, где происходит исправление пакетной ошибки.
Использование кодов-произведений многократно увеличивает мощность помехоустойчивого кода при добавлении незначительной избыточности.
P.S.: Плотно занимался этой темой 3 года назад, когда писал дипломный проект, возможно что-то упустил. Все исправления, замечания, пожелания — пожалуйста через личные сообщения
Принципы помехоустойчивого кодирования
Помехоустойчивым (корректирующим) кодированием называется кодирование при котором осуществляется обнаружение либо обнаружение и исправление ошибок в принятых кодовых комбинациях.
Возможность помехоустойчивого кодирования осуществляется на основании теоремы, сформулированной Шенноном, согласно ей:
если производительность источника (Hи’(A)) меньше пропускной способности канала связи (Ск), то существует по крайней мере одна процедура кодирования и декодирования при которой вероятность ошибочного декодирования сколь угодно мала, если же производительность источника больше пропускной способности канала, то такой процедуры не существует.
Основным принципом помехоустойчивого кодирования является использование избыточных кодов, причем если для кодирования сообщения используется простой код, то в него специально вводят избыточность. Необходимость избыточности объясняется тем, что в простых кодах все кодовые комбинации являются разрешенными, поэтому при ошибке в любом из разрядов приведет к появлению другой разрешенной комбинации, и обнаружить ошибку будет не возможно. В избыточных кодах для передачи сообщений используется лишь часть кодовых комбинаций (разрешенные комбинации). Прием запрещенной кодовой комбинации означает ошибку. Причем, в процессе приема закодированного сообщения возможны три случая (рисунок 3).

Рисунок 3 — Случаи приема закодированного сообщения
Прием сообщения без ошибок является оптимальным, но возможен только если канал связи идеальный. В этом случае помехоустойчивое декодирование не нужно.
В реальном канале из-за воздействия помех происходят ошибки в принимаемых кодовых комбинациях. Если принимаемая кодовая комбинация в результате воздействия помех перешла (трансформировалась) из одной разрешенной комбинации в другую, то определить ошибку не возможно, даже при использовании помехоустойчивого кодирования.
Если же передаваемая разрешенная кодовая комбинация, в результате воздействия помех, трансформируется в запрещенную комбинация, то в этом случае существует возможность обнаружить ошибку и исправить ее.
Помехоустойчивое кодирование может осуществляться двумя способами: с обнаружением ошибок либо с исправлением ошибок. Возможность кода обнаруживать или исправлять ошибки определяется кодовым расстоянием.
Если осуществляется кодирование с обнаружением ошибок, то кодовое расстояние должно быть хотя бы на единицу больше чем кратность обнаруживаемых ошибок, т. е.
d0? qо ош + 1.
Если данное условие не выполняется, то одни из ошибок обнаруживаются, а другие нет.
Если осуществляется кодирование с исправлением ошибок, то кодовое расстояние должно быть хотя бы на единицу больше удвоенного значения кратности исправляемых ошибок, т. е.
d0? 2qи ош + 1.
Если данное условие не выполняется, то одни из ошибок исправляются, а другие нет.
Следует отметить, что если код способен исправить одну ошибку (qи ош = 1), что соответствует кодовому расстоянию 3 (d0 = 1?2+1 = 3), то обнаружить он может две ошибки, т. к.
qо ош = d0 – 1 = 2.
Декодирование помехоустойчивых кодов
Декодирование — это процесс перехода от вторичного отображения сообщения к первичному алфавиту.
Декодирование помехоустойчивых кодов может осуществляться тремя способами: сравнения, синдромным и мажоритарным.
Способ сравнения основан на том, что, принятая кодовая комбинация сравнивается со всеми разрешенными комбинациями, которые заранее известны на приеме. Если принятая комбинация не совпадает ни с одной из разрешенных, выносится решение о принятии запрещенной комбинации. Недостатком данного способа является громоздкость и необходимость большого времени для декодирования в случае применения многоразрядных кодов. Данный способ используется в кодах с обнаружением ошибок.
Синдромный способ основан на вычислении определенным образом контрольного числа — синдрома ошибки (С). Если синдром ошибки равен нулю, то кодовая комбинация принята верно, если синдром не равен нулю, то комбинация принята не верно. Данный способ может быть использован в кодах с исправлением ошибок, в этом случае синдром указывает не только на наличие ошибки в кодовой комбинации, но и на место положение этой ошибки в кодовой комбинации. Для двоичного кода знание местоположения ошибки достаточно для ее исправления. Это объясняется тем, что любой символ кодовой комбинации может принимать всего два значения и если символ ошибочный, то его необходимо инвертировать. Следовательно, синдрома ошибки достаточно для исправления ошибок, если d0? 2qи ош + 1.
Мажоритарное декодирование основано на том, что каждый информационный символ кодовой комбинации определяется нескольким линейными выражениями через другие символы кодовой комбинации. Если принята комбинация без ошибок, то все соотношения остаются и все выражения дают одинаковые результаты (единицу или ноль). При ошибке в одном из разрядов эти соотношения нарушаются, в результате чего одни линейные выражения равны нулю, а другие единице. Решение о принятом символе определяется по большинству: если в результате вычислений выражений больше нулей, то принимается решение о принятии нуля, если больше единиц, то принимается решение о приеме единицы. Если, при декодировании, результаты вычисления выражений дают одинаковое число единиц и нулей, то при определении принятого символа приоритет имеет принятый символ, значение которого в данный момент определяется.
Классификация корректирующих кодов
Классификация корректирующих кодов представлена схемой (рисунок 4)
Блочные — это коды, в которых передаваемое сообщение разбивается на блоки и каждому блоку соответствует своя кодовая комбинация (например, в телеграфии каждой букве соответствует своя кодовая комбинация).

Рисунок 4 — Классификация корректирующих кодов
Непрерывные — коды, в которых сообщение не разбивается на блоки, а проверочные символы располагаются между информационными.
Неразделимые — это коды, в кодовых комбинациях которых нельзя выделить проверочные разряды.
Разделимые — это коды, в кодовых комбинациях которых можно указать положение проверочных разрядов, т. е. кодовые комбинации можно разделить на информационную и проверочную части.
Систематические (линейные) — это коды, в которых проверочные символы определяются как линейные комбинации информационных символов, в таких кодах суммирование по модулю два двух разрешенных кодовых комбинаций также дает разрешенную комбинацию. В несистематических кодах эти условия не выполняются.
Код с постоянным весом
Данный код относится к классу блочных не разделимых кодов. В нем все разрешенные кодовые комбинации имеют одинаковый вес. Примером кода с постоянным весом является Международный телеграфный код МТК-3. В этом коде все разрешенные кодовые комбинации имеют вес равный трем, разрядность же комбинаций n=7. Таким образом, из 128 комбинаций (N0 = 27 = 128) разрешенными являются Nа = 35 (именно столько комбинаций из всех имеют W=3). При декодировании кодовых комбинаций осуществляется вычисление веса кодовой комбинации и если W?3, то выносится решение об ошибке. Например, из принятых комбинаций 0110010, 1010010, 1000111 ошибочной является третья, т. к. W=4. Данный код способен обнаруживать все ошибки нечетной кратности и часть ошибок четной кратности. Не обнаруживаются только ошибки смещения, при которых вес комбинации не изменяется, например, передавалась комбинация 1001001, а принята 1010001 (вес комбинации не изменился W=3). Код МТК-3 способен только обнаруживать ошибки и не способен их исправлять. При обнаружении ошибки кодовая комбинация не используется для дальнейшей обработки, а на передающую сторону отправляется запрос о повторной передаче данной комбинации. Поэтому данный код используется в системах передачи информации с обратной связью.
Код с четным числом единиц
Данный код относится к классу блочных, разделимых, систематических кодов. В нем все разрешенные кодовые комбинации имеют четное число единиц. Это достигается введением в кодовую комбинацию одного проверочного символа, который равен единице если количество единиц в информационной комбинации нечетное и нулю ? если четное. Например:
При декодировании осуществляется поразрядное суммирование по модулю два всех элементов принятой кодовой комбинации и если результат равен единице, то принята комбинация с ошибкой, если результат равен нулю принята разрешенная комбинация. Например:
101101 = 1 + 0 + 1 + 1 + 0 + 1 = 0 — разрешенная комбинация
101111 = 1 + 0 + 1 + 1 + 1 + 1 = 1 — запрещенная комбинация.
Данный код способен обнаруживать как однократные ошибки, так и любые ошибки нечетной кратности, но не способен их исправлять. Данный код также используется в системах передачи информации с обратной связью.
Код Хэмминга
Код Хэмминга относится к классу блочных, разделимых, систематических кодов. Кодовое расстояние данного кода d0=3 или d0=4.
Блочные систематические коды характеризуются разрядностью кодовой комбинации n и количеством информационных разрядов в этой комбинации k остальные разряды являются проверочными (r):
r = n — k.
Данные коды обозначаются как (n,k).
Рассмотрим код Хэмминга (7,4). В данном коде каждая комбинация имеет 7 разрядов, из которых 4 являются информационными,
При кодировании формируется кодовая комбинация вида:
а1 а2 а3 а4 b1 b2 b
где аi — информационные символы;
bi — проверочные символы.
В данном коде проверочные элементы bi находятся через линейные комбинации информационных символов ai, причем, для каждого проверочного символа определяется свое правило. Для определения правил запишем таблицу синдромов кода (С) (таблица 3), в которой записываются все возможные синдромы, причем, синдромы имеющие в своем составе одну единицу соответствуют ошибкам в проверочных символах:
- синдром 100 соответствует ошибке в проверочном символе b1;
- синдром 010 соответствует ошибке в проверочном символе b2;
- синдром 001 соответствует ошибке в проверочном символе b3.
Синдромы с числом единиц больше 2 соответствуют ошибкам в информационных символах. Синдромы для различных элементов кодовой комбинации аi и bi должны быть различными.
Таблица 3 — Синдромы кода Хэмминга (7;4)
| Число | Элементы синдрома | Элементы кодовой | ||
| синдрома | С1 | С2 | С3 | комбинации |
| 1 | 0 | 0 | 1 | b3 |
| 2 | 0 | 1 | 0 | b2 |
| 3 | 0 | 1 | 1 | a1 |
| 4 | 1 | 0 | 0 | b1 |
| 5 | 1 | 0 | 1 | a2 |
| 6 | 1 | 1 | 0 | a3 |
| 7 | 1 | 1 | 1 | a4 |
Определим правило формирования элемента b3. Как следует из таблицы, ошибке в данном символе соответствует единица в младшем разряде синдрома С4. Поэтому, из таблицы, необходимо отобрать те элементы аi у которых, при возникновении ошибки, появляется единица в младшем разряде. Наличие единиц в младшем разряде, кроме b3,соответствует элементам a1, a2 и a4. Просуммировав эти информационные элементы получим правило формирования проверочного символа:
b3 = a1 + a2 + a4
Аналогично определяем правила для b2 и b1:
b2 = a1 + a3 + a4
b1 = a2 + a3 + a4
Пример 3, необходимо сформировать кодовую комбинацию кода Хэмминга (7,4) соответствующую информационным символам 1101.
В соответствии с проверочной матрицей определяем bi:
b1 = 1 + 0 + 1 = 0; b2 = 1 + 0 + 1=1; b3 = 1 + 1 + 1 = 1.
Добавляем проверочные символы к информационным и получаем кодовую комбинацию:
Biр = 1101001.
![]()
В теории циклических кодов все преобразования кодовых комбинаций производятся в виде математических операций над полиномами (степенными функциями). Поэтому двоичные комбинации преобразуют в полиномы согласно выражения:
Аi(х) = аn-1xn-1 + аn-2xn-2 +…+ а0x0
где an-1, … коэффициенты полинома принимающие значения 0 или 1. Например, комбинации 1001011 соответствует полином
Аi(х) = 1?x6 + 0?x5 + 0?x4 + 1?x3 + 0?x2 + 1?x+1?x0 ? x6 + x3 + x+1.
При формировании кодовых комбинаций над полиномами производят операции сложения, вычитания, умножения и деления. Операции умножения и деления производят по арифметическим правилам, сложение заменяется суммированием по модулю два, а вычитание заменяется суммированием.
Разрешенные кодовые комбинации циклических кодов обладают тем свойством, что все они делятся без остатка на образующий или порождающий полином G(х). Порождающий полином вычисляется с применением ЭВМ. В приложении приведена таблица синдромов.
Этапы формирования разрешенной кодовой комбинации разделимого циклического кода Biр(х).
1. Информационная кодовая комбинация Ai преобразуется из двоичной формы в полиномиальную (Ai(x)).
2. Полином Ai(x) умножается на хr,
Ai(x)?xr
где r количество проверочных разрядов:
r = n — k.
3. Вычисляется остаток от деления R(x) полученного произведения на порождающий полином:
R(x) = Ai(x)?xr/G(x).
4. Остаток от деления (проверочные разряды) прибавляется к информационным разрядам:
Biр(x) = Ai(x)?xr + R(x).
5. Кодовая комбинация Bip(x) преобразуется из полиномиальной формы в двоичную (Bip).
Пример 4. Необходимо сформировать кодовую комбинацию циклического кода (7,4) с порождающим полиномом G(x)=х3+х+1, соответствующую информационной комбинации 0110.
1. Преобразуем комбинацию в полиномиальную форму:
Ai = 0110 ? х2 + х = Ai(x).
2. Находим количество проверочных символов и умножаем полученный полином на xr:
r = n – k = 7 – 4 =3
Ai(x)?xr = (х2 + х)? x3 = х5 + х4
3. Определяем остаток от деления Ai(x)?xr на порождающий полином, деление осуществляется до тех пор пока наивысшая степень делимого не станет меньше наивысшей степени делителя:
R(x) = Ai(x)?xr/G(x)

4. Прибавляем остаток от деления к информационным разрядам и переводим в двоичную систему счисления:
Biр(x) = Ai(x)?xr+ R(x) = х5 + х4 + 1? 0110001.
5. Преобразуем кодовую комбинацию из полиномиальной формы в двоичную:
Biр(x) = х5 + х4 + 1 ? 0110001 = Biр
Как видно из комбинации четыре старших разряда соответствуют информационной комбинации, а три младших — проверочные.
Формирование разрешенной кодовой комбинации неразделимого циклического кода.
Формирование данных комбинаций осуществляется умножением информационной комбинации на порождающий полином:
Biр(x) = Ai(x)?G(x).
Причем умножение можно производить в двоичной форме.
Пример 5, необходимо сформировать кодовую комбинацию неразделимого циклического кода используя данные примера 2, т. е. G(x) = х3+х+1, Ai(x) = 0110, код (7,4).
1. Переводим комбинацию из двоичной формы в полиномиальную:
Ai = 0110? х2+х = Ai(x)
2. Осуществляем деление Ai(x)?G(x)

3. Переводим кодовую комбинацию из полиномиальной форы в двоичную:
Bip(x) = х5+х4+х3+х ? 0111010 = Bip
В этой комбинации невозможно выделить информационную и проверочную части.
Матричное представление систематических кодов
Систематические коды, рассмотренные выше (код Хэмминга и разделимый циклический код) удобно представить в виде матриц. Рассмотрим, как это осуществляется.
Поскольку систематические коды обладают тем свойством, что сумма двух разрешенных комбинаций по модулю два дают также разрешенную комбинацию, то для формирования комбинаций таких кодов используют производящую матрицу Gn,k. С помощью производящей матрицы можно получить любую кодовую комбинацию кода путем суммирования по модулю два строк матрицы в различных комбинациях. Для получения данной матрицы в нее заносятся исходные комбинации, которые полностью определяют систематический код. Исходные комбинации определяются исходя из условий:
1) все исходные комбинации должны быть различны;
2) нулевая комбинация не должна входить в число исходных комбинаций;
3) каждая исходная комбинация должна иметь вес не менее кодового расстояния, т. е. W?d0;
4) между любыми двумя исходными комбинациями расстояние Хэмминга должно быть не меньше кодового расстояния, т. е. dij?d0.
Производящая матрица имеет вид:

Производящая подматрица имеет k строк и n столбцов. Она образована двумя подматрицами: информационной (включает элементы аij) и проверочной (включает элементы bij). Информационная матрица имеет размеры k?k, а проверочная — r?k.
В качестве информационной подматрицы удобно брать единичную матрицу Ekk:

Проверочная подматрица Gr,k строится путем подбора различных r-разрядных комбинаций, удовлетворяющих следующим правилам:
1) в каждой строке подматрицы количество единиц должно быть не менее d0-1;
2) сумма по модулю два двух любых строк должна иметь не менее d0-2 единицы;
Полученная таким образом подматрица Gr,k приписывается справа к подматрице Ekk, в результате чего получается производящая матрица Gn,k. Затем, используя производящую матрицу, можно получить любую комбинацию кода путем суммирования двух и более строк по модулю два в различных комбинациях.
Пример 6. Необходимо построить производящую матрицу кода Хэмминга способного исправлять 1 ошибку и имеющего n=7. Закодировать с помощью полученной матрицы комбинацию Ai=1101.
Определяем кодовое расстояние:
d0=2qи ош+1= 2?1+1=3.
Для кодов с d0=3 количество проверочных разрядов определяется по формуле:
r=log2(n+1)= log28=3.
Определяем разрядность информационной части:
k = n — r = 7 — 4 =3.
Запишем все возможные комбинации проверочной подматрицы: 000, 001, 010, 011, 100, 101, 110, 111. Выберем из этих комбинаций те, что удовлетворяют правилам:
1) в каждой строке не менее d0-1, этому условию соответствуют комбинации 011, 101, 110, 111;
2) сумма двух любых комбинаций по модулю два содержит единиц не менее d0-2:

3) записываем проверочную подматрицу:

4) приписываем полученную подматрицу к единичной и получаем производящую матрицу:

Если произвести определение d0 для исходных комбинаций полученной матрицы (определив расстояние Хэмминга для всех пар комбинаций), то оно окажется равным 3.
Для кодирования заданной комбинации Ai, необходимо просуммировать те строки матрицы G, которые в информационной части имеют единицу на том месте, на котором они находятся в комбинации Аi. Для заданной комбинации 1101 единичными разрядами являются а1, а2, а4. В матрице G единицы на этих местах имеют строки: первая, вторая и четвертая. Просуммировав их получаем разрешенную комбинацию заданного кода.

Сравнивая полученную кодовую комбинацию Bip с комбинацией полученной примере 3, для которой также использована комбинация Ai=1101, видим что они одинаковы.
Для кода Хэмминга выше были определены правила формирования проверочных символов bk:

Эти правила можно отобразить в виде проверочной матрицы Нn,k. Она состоит из n столбцов (соответствует разрядности кодовой комбинации) и r столбцов (соответствует количеству проверочных разрядов кодовой комбинации). В правой части матрицы указываются синдромы, соответствующие ошибкам в проверочных символах, в левой части записываются элементы информационной части комбинации, причем, те элементы, которые участвуют в образовании определенного элемента bi равны единицы, а те которые не участвуют — нулю.

В данном случае обведенные пунктиром проверочные элементы образуют единичную матрицу. Проверочная матрица позволяет определить ошибочный разряд, поскольку каждый столбец данной матрицы представляет собой синдром соответствующего символа. При этом строки матрицы будут соответствовать разрядам синдрома Ck. Например, согласно приведенной проверочной матрице, синдром соответствующий ошибку в разряде а1 имеет вид 011, в разряде а2 — 101, в разряде а3 — 110, в разряде а4 — 111, в разряде b1 — 100, в разряде b2 — 010, в разряде b3 — 001. Также с помощью проверочной матрицы легко определить проверочные и символы и сформировать кодовую комбинацию. Например, необходимо сформировать кодовую комбинацию кода Хэмминга (7,4) соответствующую информационным символам 1101.
В соответствии с проверочной матрицей определяем bi:
b1 = 1 + 0 + 1 = 0; b2 = 1 + 0 + 1=0; b3 = 1 + 1 + 1 = 1.
Добавляем проверочные символы к информационным и получаем кодовую комбинацию:
Biр = 1101001.
Также проверочную матрицу можно построить и другим способом. Для этого сначала строится единичная матрица Еr. К которой слева приписывается подматрица Dk,r. Каждая строка этой подматрицы соответствует столбцу проверочных разрядов подматрицы Сr,k производящей матрицы Gn,k.

Такое преобразование строк матрицы в столбцы называется транспонированием.
В результате получаем

Декодирование циклических кодов
При декодировании таких кодов (разделимых и неразделимых) используется Синдромный способ. Вычисление синдрома осуществляется в три этапа:
1. принятая комбинация Bip’ преобразуется их двоичной формы в полиномиальную (Bip(x));
2. осуществляется деление Bip(x) на порождающий полином G(x) в результате чего определяется синдром ошибки C(x) (остаток от деления);
3. синдром ошибки преобразуется из полиномиальной формы в двоичную;
4. По проверочной матрице или таблице синдромов определяется ошибочный разряд;
5. Ошибочный разряд в Bip’(x) инвертируется;
6. Исправленная комбинация преобразуется из полиномиальной формы в двоичную Bip.
делением принятой кодовой комбинации Biр’(x) на порождающий полином G(x), который заранее известен на приеме. Остаток от деления и является синдромом ошибки С(х).
Мажоритарное декодирование циклических кодов
Мажоритарное декодирование может применятся только для декодирования систематических кодов (кода Хэмминга, циклического разделимого кода). Рассмотрим мажоритарное декодирование на примере циклического кода.
Доброго времени суток, в этом посте хотел разобрать пару примеров для помехоустойчивое кодирование.
Для чего это нужно?
Предположим у нас есть канал связи C, содержащий источник помех, а также S — множество отправляемых данных и S’ — множество принятых данных. Рассмотрим следующий пример:
Множество S = {1,0,0,1} мы отправляем данные по каналу связи C и получаем S’ = {1,0,0,0}. Что случилось? Почему данные отличаются? А все потому, что на канале связи была помеха. И из-за этого произошла ошибка типа «замещение разряда», т.е. 1 -> 0, 0 -> 1. Как видно из-за таких ошибок данные могут меняться, а это не допустимо.
Как бороться?
Я думаю, что вы уже догадались, что борьба с такими ошибками выполняется с помощью помехоустойчивых алгоритмов.
Рассмотрим не сложный пример:
У на есть 4 бита, которые мы хотим передать «1011». Как сделать так, чтобы у нас не пропал бит? Мы просто добавим проверочные биты, т.е. будем передавать «111 000 111 111». Мы просто взяли и добавили 2 проверочных бита, теперь когда будет осуществляться передачу данных, декодер будет знать что 2 лишнее бита проверочные и таким образом вероятность потери данных уменьшиться.
Недостатком этого алгоритма является то, что если ошибок будет больше чем две, данные потеряются, чтобы увеличить эффективность алгоритма можно добавить больше проверочных битов, но это уменьшает производительность.
Ошибки могут быть следующих типов:
Код Хемминга:
Код Хеммига это блочный код, позволяющий исправлять одиночные ошибки, разработанный в середине 1940-х годах Ричардом Хеммингом.
Рассмотрим классический пример:
Передавать будем следующее «1010», чтобы обнаружить ошибку в битах, нужно добавить 3 проверочных бита. Сгруппируем проверочные символы следующим образом:



Получаем:

знак  означает сложение по модулю 2.
означает сложение по модулю 2.
Теперь наши биты выглядят так: «1010011»
Получение кодового слова выглядит следующим образом:

 =
= 
здесь просто умножается наши 4 бита на столбики: 5,6 и 7, после каждого умножение на столбик складываем по модулю два, получаем аналогичный результат предыдущему.
Декодирование данных выглядит так:



Получаем:

 называется синдромом последовательности.
называется синдромом последовательности.
Получение синдрома выглядит так:

 =
= 
здесь умножается все кодовое слово из 7 бит на столбцы, получаем синдром:
 этот синдром указывает на то, что в кодовом слове нет ошибок.
этот синдром указывает на то, что в кодовом слове нет ошибок.
Исказим один бит специально, заменим 0 на 1 в 4-й позиции и получим «1011011».
Посчитаем:

Наш синдром «011», по таблице ниже можно узнать в какой позиции ошибка:
| Синдром | 001 | 010 | 011 | 100 | 101 | 110 | 111 |
| Ошибка в символе | r3 | r2 | i4 | r1 | i1 | i3 | i2 |
Из таблицы видно, что ошибка находиться в 4-й позиции.
На этом все, всего доброго.
Автор: web_loki
Источник
Предложите, как улучшить StudyLib
(Для жалоб на нарушения авторских прав, используйте
другую форму
)
Ваш е-мэйл
Заполните, если хотите получить ответ
Оцените наш проект
1
2
3
4
5