From Wikipedia, the free encyclopedia
In statistics, sampling errors are incurred when the statistical characteristics of a population are estimated from a subset, or sample, of that population. It can produce biased results. Since the sample does not include all members of the population, statistics of the sample (often known as estimators), such as means and quartiles, generally differ from the statistics of the entire population (known as parameters). The difference between the sample statistic and population parameter is considered the sampling error.[1] For example, if one measures the height of a thousand individuals from a population of one million, the average height of the thousand is typically not the same as the average height of all one million people in the country.
Since sampling is almost always done to estimate population parameters that are unknown, by definition exact measurement of the sampling errors will not be possible; however they can often be estimated, either by general methods such as bootstrapping, or by specific methods incorporating some assumptions (or guesses) regarding the true population distribution and parameters thereof.
Description[edit]
Sampling Error[edit]
The sampling error is the error caused by observing a sample instead of the whole population.[1] The sampling error is the difference between a sample statistic used to estimate a population parameter and the actual but unknown value of the parameter.[2]
Effective Sampling[edit]
In statistics, a truly random sample means selecting individuals from a population with an equivalent probability; in other words, picking individuals from a group without bias. Failing to do this correctly will result in a sampling bias, which can dramatically increase the sample error in a systematic way. For example, attempting to measure the average height of the entire human population of the Earth, but measuring a sample only from one country, could result in a large over- or under-estimation. In reality, obtaining an unbiased sample can be difficult as many parameters (in this example, country, age, gender, and so on) may strongly bias the estimator and it must be ensured that none of these factors play a part in the selection process.
Even in a perfectly non-biased sample, the sample error will still exist due to the remaining statistical component; consider that measuring only two or three individuals and taking the average would produce a wildly varying result each time. The likely size of the sampling error can generally be reduced by taking a larger sample.[3]
Sample Size Determination[edit]
The cost of increasing a sample size may be prohibitive in reality. Since the sample error can often be estimated beforehand as a function of the sample size, various methods of sample size determination are used to weigh the predicted accuracy of an estimator against the predicted cost of taking a larger sample.
Bootstrapping and Standard Error[edit]
As discussed, a sample statistic, such as an average or percentage, will generally be subject to sample-to-sample variation.[1] By comparing many samples, or splitting a larger sample up into smaller ones (potentially with overlap), the spread of the resulting sample statistics can be used to estimate the standard error on the sample.
In Genetics[edit]
The term «sampling error» has also been used in a related but fundamentally different sense in the field of genetics; for example in the bottleneck effect or founder effect, when natural disasters or migrations dramatically reduce the size of a population, resulting in a smaller population that may or may not fairly represent the original one. This is a source of genetic drift, as certain alleles become more or less common), and has been referred to as «sampling error»,[4] despite not being an «error» in the statistical sense.
See also[edit]
- Margin of error
- Propagation of uncertainty
- Ratio estimator
- Sampling (statistics)
References[edit]
- ^ a b c Sarndal, Swenson, and Wretman (1992), Model Assisted Survey Sampling, Springer-Verlag, ISBN 0-387-40620-4
- ^ Burns, N.; Grove, S. K. (2009). The Practice of Nursing Research: Appraisal, Synthesis, and Generation of Evidence (6th ed.). St. Louis, MO: Saunders Elsevier. ISBN 978-1-4557-0736-2.
- ^ Scheuren, Fritz (2005). «What is a Margin of Error?». What is a Survey? (PDF). Washington, D.C.: American Statistical Association. Archived from the original (PDF) on 2013-03-12. Retrieved 2008-01-08.
- ^ Campbell, Neil A.; Reece, Jane B. (2002). Biology. Benjamin Cummings. pp. 450–451. ISBN 0-536-68045-0.
Определение ошибок выборки
Разность между показателями выборочной
и генеральной совокупностей называется
ошибкой выборки:
![]()
—
генеральное среднее;
![]()
—
выборочное среднее;
![]()
—
генеральная дисперсия;
![]()
—
выборочная дисперсия;
Ошибки выборки подразделяют на ошибки
регистрации и ошибки репрезентативности.
Ошибки регистрации возникают из-за
неправильных или неточных сведений.
Источником таких ошибок могут быть
непонимание вопроса, невнимательность
регистратора, пропуск или повторный
счет некоторых единиц совокупности.
Среди ошибок регистрации выделяют
систематические, т.е. обусловленные
причинами, действующими в каком-то одном
направлении и искажающие результаты
работы (округление цифр, тяготение к
полным десяткам и сотням и т.д.), и
случайные, проявляющиеся в различных
направлениях, уравновешивающих друг
друга и лишь изредка дающих заметный
суммарный итог.
Ошибки репрезентативности также могут
быть систематическими и случайными.
Изучение и измерение случайных ошибок
репрезентативности является основной
задачей выборочного метода.
При случайном и механическом отборах
средняя ошибка выборки для средней
величины определяется по формуле:
![]()
—
при повторном отборе;
![]()
—
при бесповторном отборе,
![]()
—
объем выборки,
![]()
—
объем генеральной совокупности.
На практике значение генеральных
параметров, как правило, не известно.
Поэтому их заменяют исправленными
выборочными характеристиками:
![]()
При
![]()
Формулы для расчета средней ошибки
выборочной доли имеют следующий вид:
![]()
—
при повтор. отборе;
![]()
—
при бесповторном отборе;
![]()
—
дисперсия доли;
Это так называемые средние или стандартные
ошибки.
Предельная ошибка выборки
![]()
представляет
собой t-кратную среднюю
ошибку.
![]()
Здесь t – коэффициент
доверия, который определяется по таблице
значений интегральной функции Лапласа
при заданной доверительной вероятности.
|
|
0,683 |
0,954 |
0,997 |
|
t |
1 |
2 |
3 |
Зная предельную ошибку можно определить
доверительные интервалы, в которых
находятся значения генеральных
параметров.
![]()
Пример:
Для определения среднего срока пользования
краткосрочным кредитом в банке была
произведена 5% механическая выборка, в
которую попали 200 счетов. По результатам
выборки установлено, что средний срок
пользования кредитом составляет 60 дней
при среднеквадратичном отклонении 20
дней.
В 8 счетах срок пользования кредитом
превышал 6 месяцев. Необходимо с
вероятностью 0,99 определить пределы, в
которых находится срок пользования
краткосрочным кредитом банка и доля
краткосрочных кредитов со сроком
пользования более полугода.
Решение:
Среднюю ошибку выборки определяют по
формуле для бесповторного отбора.
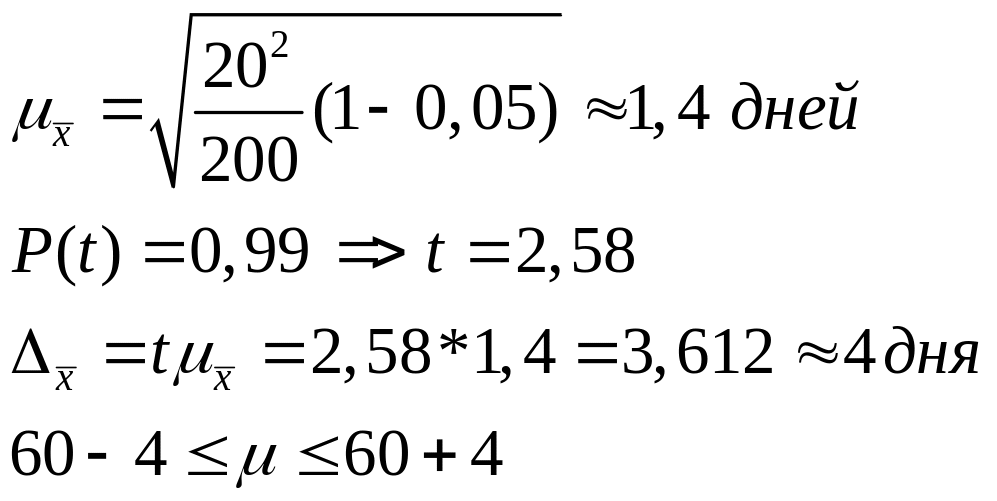
Т.е. с вероятностью 0,99 можно утверждать,
что средний срок пользования краткосрочным
кредитом составляет от 56 до 64 дней.
По итогам выборки определим долю кредитов
со сроком пользования более полугода.
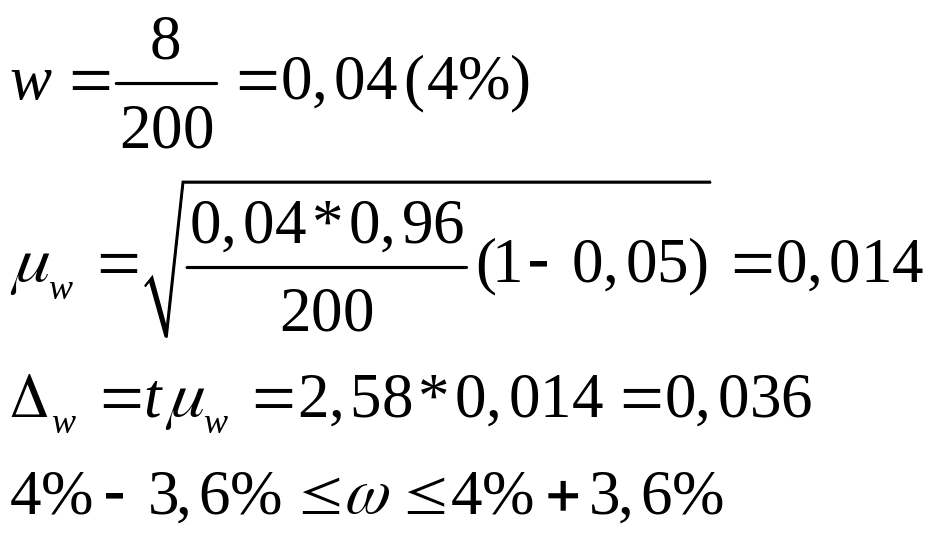
С вероятностью 0,99 можно гарантировать,
что доля кредитов банка со сроком
использования более полугода оставляет
![]()
общего числа кредитов.
Определение
оптимальной численности выборки
На
практике обычно расчет объема выборки
производят по формуле для повторного
отбора:
![]()
Если
полученный объем выборки превышает 5%
численности генеральной совокупности,
то расчеты корректируют на бесповторность:
![]()
В
данных формулах присутствуют значения
генеральной дисперсии, которые как
правило неизвестны. Для ее оценки можно
использовать:
1.
Выборочную дисперсию по данным прошлых
или пробных обследований.
2.
Дисперсию найденную из соотношения для
среднего квадратичного отклонения:
![]()
(если
все х >0 и х
min
0)
3.
Дисперсию, вычисленную из соотношения
для нормального распределения
![]()
4.
Дисперсию, определенную из соотношения
для асимметричного распределения
![]()
В
качестве оценки генеральной дисперсии
доли используют максимально возможную
дисперсию альтернативного признака:
![]()
Пример:
Определить численность выборки по
следующим данным. Для определения
средней цены говядины на 5000 рынках
города предполагается провести выборочную
регистрацию цен. Известно, что цены на
говядину колеблются от 40 до 70 руб/кг.
Сколько торговых точек необходимо
обследовать, чтобы с вероятностью 0,954
ошибка выборки при определении средней
цены не превышала 2 руб. за 1 кг.
Решение:
Предположим, что распределение цен
соответствует нормальному закону. Тогда
![]()
P(t)
= 0,954. Следовательно t
= 2.
![]()
![]()
Поскольку
доля отбора не превышает 5%, то к формуле
бемповторного отбора можно не переходить.
Т.е. для того, чтобы с вероятностью 0, 954
гарантировать, что ошибка при определении
функцией цены говядины не превысит 2
руб/кг необходимо исследовать 25 торговых
точек на рынках города.
Определение:
Относительная ошибка выборки– это
отношение предельной ошибки выборки к
среднему значению признака, выраженного
в %.
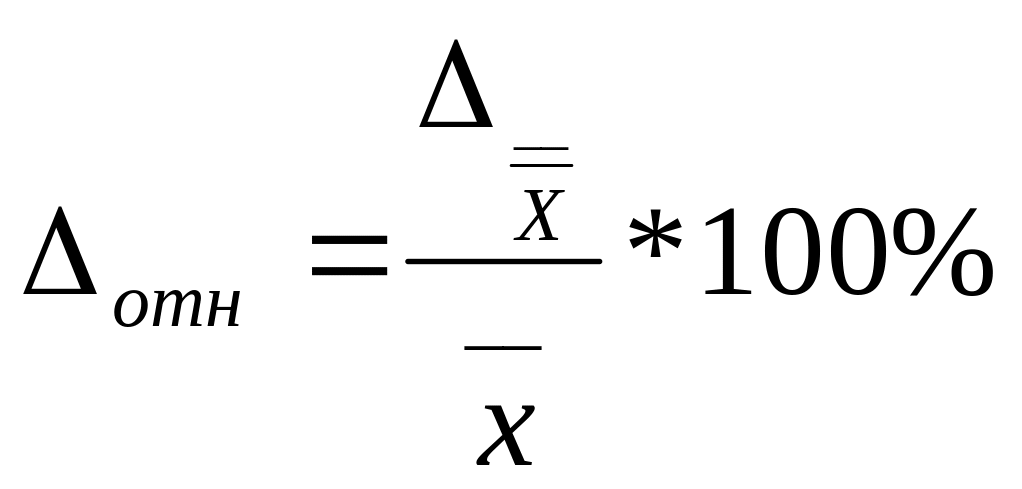
Расчёт
объема выборки при заданном уровне
относительной ошибки выборки осуществляется
по формулам:
![]()
![]()
![]()
—
коэффициент вариации
Пример:
В городе зарегистрировано 30000 безработных.
Для определения средней продолжительности
безработицы организуется выборочное
обследование. По данным прошлых лет
известно, что коэффициент вариации
объема продолжительности безработицы
составляет 40%. Какое число безработных
необходимо охватить выборочным
наблюдением, чтобы с вероятностью 0,997
утверждать, что полученным предельная
ошибка выборки не превышает 5% средней
продолжительности безработицы.
Решение:
P(t)
= 0,997. Следовательно t
= 3.
![]()
Объем выборки всегда округляют в большую
сторону.
Ответ: 566.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
3. Ошибки выборки
Каждая единица при выборочном наблюдении должна иметь равную с другими возможность быть отобранной – это является основой собственнослучайной выборки.
Собственнослучайная выборка – это отбор единиц из всей генеральной совокупности посредством жеребьевки или другим подобным способом.
Принципом случайности является то, что на включение или исключение объекта из выборки не может повлиять любой фактор, кроме случая.
Доля выборки – это отношение числа единиц выборочной совокупности к числу единиц генеральной совокупности:

Собственнослучайный отбор в чистом виде является исходным среди всех других видов отбора, в нем заключаются и реализуются основные принципы выборочного статистического наблюдения.
Два основных вида обобщающих показателей, которые используют в выборочном методе – это средняя величина количественного признака и относительная величина альтернативного признака.
Выборочная доля (w), или частность, определяется отношением числа единиц, обладающих изучаемым признаком m, к общему числу единиц выборочной совокупности (n):
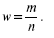
Для характеристики надежности выборочных показателей различают среднюю и предельную ошибки выборки.
Ошибка выборки, ее еще называют ошибкой репрезентативности, представляет собой разность соответствующих выборочных и генеральных характеристик:
1) для средней количественного признака:
?х =|х – х|;
2) для доли (альтернативного признака):
?w =|х – p|.
Только выборочным наблюдениям присуща ошибка выборки
Выборочная средняя и выборочная доля – это случайные величины, принимающие различные значения в зависимости от единиц изучаемой статистической совокупности, которые попали в выборку. Соответственно ошибки выборки – тоже случайные величины и также могут принимать различные значения. Поэтому определяют среднюю из возможных ошибок – среднюю ошибку выборки.
Средняя ошибка выборки определяется объемом выборки: чем больше численность при прочих равных условиях, тем меньше величина средней ошибки выборки. Охватывая выборочным обследованием все большее количество единиц генеральной совокупности, все более точно характеризуем всю генеральную совокупность.
Средняя ошибка выборки зависит от степени варьирования изучаемого признака, в свою очередь степень варьирования характеризуется дисперсией ?2 или w(l – w) – для альтернативного признака. Чем меньше вариация признака и дисперсия, тем меньше средняя ошибка выборки, и наоборот.
При случайном повторном отборе средние ошибки теоретически рассчитывают по следующим формулам:
1) для средней количественного признака:

где ?2 – средняя величина дисперсии количественного признака.
2) для доли (альтернативного признака):
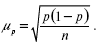
Так как дисперсия признака в генеральной совокупности ?2 точно неизвестна, на практике пользуются значением дисперсии S2 , рассчитанным для выборочной совокупности на основании закона больших чисел, согласно которому выборочная совокупность при достаточно большом объеме выборки достаточно точно воспроизводит характеристики генеральной совокупности.
Формулы средней ошибки выборки при случайном повторном отборе следующие. Для средней величины количественного признака: генеральная дисперсия выражается через выборную следующим соотношением:

где S2 – значение дисперсии.
Механическая выборка – это отбор единиц в выборочную совокупность из генеральной, которая разбита по нейтральному признаку на равные группы; производится так, что из каждой такой группы в выборку отбирается лишь одна единица.
При механическом отборе единицы изучаемой статистической совокупности предварительно располагают в определенном порядке, после чего отбирают заданное число единиц механически через определенный интервал. При этом размер интервала в генеральной совокупности равен обратному значению доли выборки.
При достаточно большой совокупности механический отбор по точности результатов близок к собственнослучайному Поэтому для определения средней ошибки механической выборки используют формулы собственнослучайной бесповторной выборки.
Для отбора единиц из неоднородной совокупности применяется так называемая типическая выборка, используется, когда все единицы генеральной совокупности можно разбить на несколько качественно однородных, однотипных групп по признакам, от которых зависят изучаемые показатели.
Затем из каждой типической группы собственнослучайной или механической выборкой производится индивидуальный отбор единиц в выборочную совокупность.
Типическая выборка обычно применяется при изучении сложных статистических совокупностей.
Типическая выборка дает более точные результаты. Типизация генеральной совокупности обеспечивает репрезентативность такой выборки, представительство в ней каждой типологической группы, что позволяет исключить влияние межгрупповой дисперсии на среднюю ошибку выборки. Поэтому при определении средней ошибки типической выборки в качестве показателя вариации выступает средняя из внутригрупповых дисперсий.
Серийная выборка предполагает случайный отбор из генеральной совокупности равновеликих групп для того, чтобы в таких группах подвергать наблюдению все без исключения единицы.
Поскольку внутри групп (серий) обследуются все без исключения единицы, средняя ошибка выборки (при отборе равновеликих серий) зависит только от межгрупповой (межсерийной) дисперсии.
Данный текст является ознакомительным фрагментом.
Читайте также
Ошибки резидента
Ошибки резидента
Относиться к ошибкам можно по-разному: можно бояться их совершить и переживать из-за каждой из них, можно радоваться своим ошибкам и кризисам, как указателям на пути к успеху и личным победам. Неизменно в ошибках только одно – за них приходится платить.
Формирование выборки
Формирование выборки
Процедура выборки является неотъемлемым этапом проекта внутреннего аудита. Она подробно описана в различных источниках, посвященных теме аудита. Однако во многом такие описания носят академичный характер. Предлагаю заострить внимание на тех
Ошибки в инвестициях – это ошибки инвесторов
Ошибки в инвестициях – это ошибки инвесторов
Сейчас я больше, чем когда бы то ни было, убежден в том, что все ошибки в инвестициях на самом деле ошибки инвесторов.Инвестиции не совершают ошибок. В отличие от инвесторов.Инвестирование – это выбор. Именно об этой
29. Определение необходимой численности выборки
29. Определение необходимой численности выборки
Одним из научных принципов в теории выбороч–ного метода является обеспечение достаточного чи–сла отобранных единиц.Уменьшение стандартной ошибки выборки всег–да связано с увеличением объема выборки. Расчет
30. Способы отбора и виды выборки. Собственно случайная выборка
30. Способы отбора и виды выборки. Собственно случайная выборка
В теории выборочного метода разработаны раз–личные способы отбора и виды выборки, обеспечи–вающие репрезентативность. Под способом отбора понимают порядок отбора единиц из генеральной со–вокупности.
31. Механическая и типическая выборки
31. Механическая и типическая выборки
При чисто механической выборке вся ге–неральная совокупность единиц должна быть прежде всего представлена в виде списка единиц отбора, со–ставленного в каком-то нейтральном по отношению к изучаемому признаку порядке. Затем список
32. Серийная и комбинированная выборки
32. Серийная и комбинированная выборки
Серийная (гнездовая) выборка – это такой вид формирования выборочной совокупности, когда в случайном порядке отбираются не единицы, подле–жащие обследованию, а группы единиц (серии, гнез–да). Внутри отобранных серий (гнезд)
33. Многоступенчатая, многофазная и взаимопроникающая выборки.
33. Многоступенчатая, многофазная и взаимопроникающая выборки.
Особенность многоступенчатой выборки со–стоит в том, что выборочная совокупность формиру–ется постепенно, по ступеням отбора. На первой ступени с помощью заранее определенного спосо–ба и вида отбора
3. Определение необходимой численности выборки
3. Определение необходимой численности выборки
Одним из научных принципов в теории выборочного метода является обеспечение достаточного числа отобранных единиц. Теоретически необходимость соблюдения этого принципа представлена в доказательствах предельных теорем
4. Способы отбора и виды выборки
4. Способы отбора и виды выборки
В теории выборочного метода разработаны различные способы отбора и виды выборки, обеспечивающие репрезентативность. Под способом отбора понимают порядок отбора единиц из генеральной совокупности. Различают два способа отбора: повторный
36. Ошибки выборки
36. Ошибки выборки
Собственнослучайная выборка – это отбор единиц из всей генеральной совокупности посредством жеребьевки или другим подобным способом. Принципом случайности является то, что на включение или исключение объекта из выборки не может повлиять любой фактор,
Лексические ошибки
Лексические ошибки
1. Неправильное использование слов и терминовОсновная масса ошибок в деловых письмах относится к лексическим. Недостаточная грамотность приводит не только к курьезной бессмыслице, но и абсурду.Отдельные термины и профессиональные жаргонные слова
5 Наши ошибки
5
Наши ошибки
Мы настаиваем: выбранный курс рыночных реформ был верным. И они вовсе не потерпели неудачу, они только еще раз споткнулись. Но ошибки и упущения были. Это и наши ошибки, и ошибки руководства страны, которые мы не сумели предотвратить. Ошибки — во многом
Важность размера выборки
Важность размера выборки
Как я уже говорил, люди склонны уделять слишком много внимания редким случаям возникновения какого-то феномена, несмотря на то что со статистической точки зрения из нескольких случаев невозможно извлечь много информации. Это – основная причина
Репрезентативные выборки
Репрезентативные выборки
Репрезентативность наших тестов для целей предсказания будущего определяется двумя факторами:– Количество рынков: тесты, проводимые на различных рынках, будут, скорее всего, включать рынки с разной степенью волатильности типов
Размер выборки
Размер выборки
Концепция размера выборки проста: для того чтобы делать статистически достоверные заключения, нужно иметь достаточно большую выборку. Чем меньше выборка, тем грубее выводы, которые можно сделать; чем выборка больше, тем выводы качественнее. Нет никакого
11.2. Оценка результатов выборочного наблюдения
11.2.1. Средняя и предельная ошибки выборки. Построение доверительных границ для средней и доли
Средняя ошибка выборки показывает, насколько отклоняется в среднем параметр выборочной совокупности от соответствующего параметра генеральной. Если рассчитать среднюю из ошибок всех возможных выборок определенного вида заданного объема (n), извлеченных из одной и той же генеральной совокупности, то получим их обобщающую характеристику — среднюю ошибку выборки ( ).
).
В теории выборочного наблюдения выведены формулы для определения , которые индивидуальны для разных способов отбора (повторного и бесповторного), типов используемых выборок и видов оцениваемых статистических показателей.
Например, если применяется повторная собственно случайная выборка, то определяется как:
 — при оценивании среднего значения признака;
— при оценивании среднего значения признака;
 — если признак альтернативный, и оценивается доля.
— если признак альтернативный, и оценивается доля.
При бесповторном собственно случайном отборе в формулы вносится поправка (1 — n/N):
 — для среднего значения признака;
— для среднего значения признака;
 — для доли.
— для доли.
Вероятность получения именно такой величины ошибки всегда равна 0,683. На практике же предпочитают получать данные с большей вероятностью, но это приводит к возрастанию величины ошибки выборки.
Предельная ошибка выборки ( ) равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
) равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
 .
.
Если ошибку выборки увеличить в два раза (t = 2), то получим гораздо большую вероятность того, что она не превысит определенного предела (в нашем случае — двойной средней ошибки) — 0,954. Если взять t = 3, то доверительная вероятность составит 0,997 — практически достоверность.
Уровень предельной ошибки выборки зависит от следующих факторов:
- степени вариации единиц генеральной совокупности;
- объема выборки;
- выбранных схем отбора (бесповторный отбор дает меньшую величину ошибки);
- уровня доверительной вероятности.
Если объем выборки больше 30, то значение t определяется по таблице нормального распределения, если меньше — по таблице распределения Стьюдента.
Приведем некоторые значения коэффициента доверия из таблицы нормального распределения.
| Значение доверительной вероятности P | 0,683 | 0,954 | 0,997 |
|---|---|---|---|
| Значение коэффициента доверия t | 1,0 | 2,0 | 3,0 |
Доверительный интервал для среднего значения признака и для доли в генеральной совокупности устанавливается следующим образом:

Итак, определение границ генеральной средней и доли состоит из следующих этапов:
Ошибки выборки при различных видах отбора
- Собственно случайная и механическая выборка. Средняя ошибка собственно случайной и механической выборки находятся по формулам, представленным в табл. 11.3.
 |
|
где |
Пример 11.2. Для изучения уровня фондоотдачи было проведено выборочное обследование 90 предприятий из 225 методом случайной повторной выборки, в результате которого получены данные, представленные в таблице.
| Уровень фондоотдачи, руб. | До 1,4 | 1,4-1,6 | 1,6-1,8 | 1,8-2,0 | 2,0-2,2 | 2,2 и выше | Итого |
|---|---|---|---|---|---|---|---|
| Количество предприятий | 13 | 15 | 17 | 15 | 16 | 14 | 90 |
В рассматриваемом примере имеем 40%-ную выборку (90 : 225 = 0,4, или 40%). Определим ее предельную ошибку и границы для среднего значения признака в генеральной совокупности по шагам алгоритма:
- По результатам выборочного обследования рассчитаем среднее значение и дисперсию в выборочной совокупности:
| Результаты наблюдения | Расчетные значения | |||
|---|---|---|---|---|
| уровень фондоотдачи, руб., xi | количество предприятий, fi | середина интервала, xi\xb4 | xi\xb4fi | xi\xb42fi |
| До 1,4 | 13 | 1,3 | 16,9 | 21,97 |
| 1,4-1,6 | 15 | 1,5 | 22,5 | 33,75 |
| 1,6-1,8 | 17 | 1,7 | 28,9 | 49,13 |
| 1,8-2,0 | 15 | 1,9 | 28,5 | 54,15 |
| 2,0-2,2 | 16 | 2,1 | 33,6 | 70,56 |
| 2,2 и выше | 14 | 2,3 | 32,2 | 74,06 |
| Итого | 90 | — | 162,6 | 303,62 |
Выборочная средняя

Выборочная дисперсия изучаемого признака

- Определяем среднюю ошибку повторной случайной выборки

- Зададим вероятность, на уровне которой будем говорить о величине предельной ошибки выборки. Чаще всего она принимается равной 0,999; 0,997; 0,954.

Для наших данных определим предельную ошибку выборки, например, с вероятностью 0,954. По таблице значений вероятности функции нормального распределения (см. выдержку из нее, приведенную в Приложении 1) находим величину коэффициента доверия t, соответствующего вероятности 0,954. При вероятности 0,954 коэффициент t равен 2.
- Предельная ошибка выборки с вероятностью 0,954 равна
- Найдем доверительные границы для среднего значения уровня фондоотдачи в генеральной совокупности


Таким образом, в 954 случаях из 1000 среднее значение фондоотдачи будет не выше 1,88 руб. и не ниже 1,74 руб.
Выше была использована повторная схема случайного отбора. Посмотрим, изменятся ли результаты обследования, если предположить, что отбор осуществлялся по схеме бесповторного отбора. В этом случае расчет средней ошибки проводится по формуле

Тогда при вероятности равной 0,954 величина предельной ошибки выборки составит:

Доверительные границы для среднего значения признака при бесповторном случайном отборе будут иметь следующие значения:

Сравнив результаты двух схем отбора, можно сделать вывод о том, что применение бесповторной случайной выборки дает более точные результаты по сравнению с применением повторного отбора при одной и той же доверительной вероятности. При этом, чем больше объем выборки, тем существеннее сужаются границы значений средней при переходе от одной схемы отбора к другой.
По данным примера определим, в каких границах находится доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., в генеральной совокупности:
- рассчитаем выборочную долю.
Количество предприятий в выборке с уровнем фондоотдачи, не превышающим значения 2,0 руб., составляет 60 единиц. Тогда
m = 60, n = 90, w = m/n = 60 : 90 = 0,667;
- рассчитаем дисперсию доли в выборочной совокупности
 ;
;
- средняя ошибка выборки при использовании повторной схемы отбора составит

Если предположить, что была использована бесповторная схема отбора, то средняя ошибка выборки с учетом поправки на конечность совокупности составит

- зададим доверительную вероятность и определим предельную ошибку выборки.
При значении вероятности Р = 0,997 по таблице нормального распределения получаем значение для коэффициента доверия t = 3 (см. выдержку из нее, приведенную в Приложении 1):

- установим границы для генеральной доли с вероятностью 0,997:

Таким образом, с вероятностью 0,997 можно утверждать, что в генеральной совокупности доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., не меньше, чем 54,7%, и не больше 78,7%.
- Типическая выборка. При типической выборке генеральная совокупность объектов разбита на k групп, тогда
N1 + N2 + … + Ni + … + Nk = N.
Объем извлекаемых из каждой типической группы единиц зависит от принятого способа отбора; их общее количество образует необходимый объем выборки
n1 + n2 + … + ni + … + nk = n.
Существуют следующие два способа организации отбора внутри типической группы: пропорциональной объему типических групп и пропорциональной степени колеблемости значений признака у единиц наблюдения в группах. Рассмотрим первый из них, как наиболее часто используемый.
Отбор, пропорциональный объему типических групп, предполагает, что в каждой из них будет отобрано следующее число единиц совокупности:
n = ni · Ni/N
где ni — количество извлекаемых единиц для выборки из i-й типической группы;
n — общий объем выборки;
Ni — количество единиц генеральной совокупности, составивших i-ю типическую группу;
N — общее количество единиц генеральной совокупности.
Отбор единиц внутри групп происходит в виде случайной или механической выборки.
Формулы для оценивания средней ошибки выборки для среднего и доли представлены в табл. 11.6.

|
 ) при использовании типического отбора, пропорционального объему типических групп
) при использовании типического отбора, пропорционального объему типических группЗдесь  — средняя из групповых дисперсий типических групп.
— средняя из групповых дисперсий типических групп.
Пример 11.3. В одном из московских вузов проведено выборочное обследование студентов с целью определения показателя средней посещаемости вузовской библиотеки одним студентом за семестр. Для этого была использована 5%-ная бесповторная типическая выборка, типические группы которой соответствуют номеру курса. При отборе, пропорциональном объему типических групп, получены следующие данные:
| Номер курса | Всего студентов, чел., Ni | Обследовано в результате выборочного наблюдения, чел., ni | Среднее число посещений библиотеки одним студентом за семестр, xi | Внутригрупповая выборочная дисперсия, 
|
|---|---|---|---|---|
| 1 | 650 | 33 | 11 | 6 |
| 2 | 610 | 31 | 8 | 15 |
| 3 | 580 | 29 | 5 | 18 |
| 4 | 360 | 18 | 6 | 24 |
| 5 | 350 | 17 | 10 | 12 |
| Итого | 2 550 | 128 | 8 | — |
Число студентов, которое необходимо обследовать на каждом курсе, рассчитаем следующим образом:
- общий объем выборочной совокупности:
n = 2550/130*5 =128 (чел.);
- количество единиц, отобранных из каждой типической группы:

аналогично для других групп:
n2 = 31 (чел.);
n3 = 29 (чел.);
n4 = 18 (чел.);
n5 = 17 (чел.).
Проведем необходимые расчеты.
- Выборочная средняя, исходя из значений средних типических групп, составит:
- Средняя из внутригрупповых дисперсий
- Средняя ошибка выборки:
С вероятностью 0,954 находим предельную ошибку выборки:
- Доверительные границы для среднего значения признака в генеральной совокупности:





Таким образом, с вероятностью 0,954 можно утверждать, что один студент за семестр посещает вузовскую библиотеку в среднем от семи до девяти раз.
- Малая выборка. В связи с небольшим объемом выборочной совокупности те формулы для определения ошибок выборки, которые использовались нами ранее при «больших» выборках, становятся неподходящими и требуют корректировки.
Среднюю ошибку малой выборки определяют по формуле

Предельная ошибка малой выборки:

Распределение значений выборочных средних всегда имеет нормальный закон распределения (или приближается к нему) при п > 100, независимо от характера распределения генеральной совокупности. Однако в случае малых выборок действует иной закон распределения — распределение Стьюдента. В этом случае коэффициент доверия находится по таблице t-распределения Стьюдента в зависимости от величины доверительной вероятности Р и объема выборки п. В Приложении 1 приводится фрагмент таблицы t-распределения Стьюдента, представленной в виде зависимости доверительной вероятности от объема выборки и коэффициента доверия t.
Пример 11.4. Предположим, что выборочное обследование восьми студентов академии показало, что на подготовку к контрольной работе по статистике они затратили следующее количество часов: 8,5; 8,0; 7,8; 9,0; 7,2; 6,2; 8,4; 6,6.
Оценим выборочные средние затраты времени и построим доверительный интервал для среднего значения признака в генеральной совокупности, приняв доверительную вероятность равной 0,95.
- Среднее значение признака в выборке равно
- Значение среднего квадратического отклонения составляет
- Средняя ошибка выборки:
- Значение коэффициента доверия t = 2,365 для п = 8 и Р = 0,95 .
- Предельная ошибка выборки:
- Доверительный интервал для среднего значения признака в генеральной совокупности:





То есть с вероятностью 0,95 можно утверждать, что затраты времени студента на подготовку к контрольной работе находятся в пределах от 6,9 до 8,5 ч.
11.2.2. Определение численности выборочной совокупности
Перед непосредственным проведением выборочного наблюдения всегда решается вопрос, сколько единиц исследуемой совокупности необходимо отобрать для обследования. Формулы для определения численности выборки выводят из формул предельных ошибок выборки в соответствии со следующими исходными положениями (табл. 11.7):
- вид предполагаемой выборки;
- способ отбора (повторный или бесповторный);
- выбор оцениваемого параметра (среднего значения признака или доли).
Кроме того, следует заранее определиться со значением доверительной вероятности, устраивающей потребителя информации, и с размером допустимой предельной ошибки выборки.
 |
Примечание: при использовании приведенных в таблице формул рекомендуется получаемую численность выборки округлять в большую сторону для обеспечения некоторого запаса в точности.
Пример 11.5. Рассчитаем, сколько из 507 промышленных предприятий следует проверить налоговой инспекции, чтобы с вероятностью 0,997 определить долю предприятий с нарушениями в уплате налогов. По данным прошлого аналогичного обследования величина среднего квадратического отклонения составила 0,15; размер ошибки выборки предполагается получить не выше, чем 0,05.
При использовании повторного случайного отбора следует проверить

При бесповторном случайном отборе потребуется проверить

Как видим, использование бесповторного отбора позволяет проводить обследование гораздо меньшего числа объектов.
Пример 11.6. Планируется провести обследование заработной платы на предприятиях отрасли методом случайного бесповторного отбора. Какова должна быть численность выборочной совокупности, если на момент обследования в отрасли число занятых составляло 100 000 чел.? Предельная ошибка выборки не должна превышать 100 руб. с вероятностью 0,954. По результатам предыдущих обследований заработной платы в отрасли известно, что среднее квадратическое отклонение составляет 500 руб.

Следовательно, для решения поставленной задачи необходимо включить в выборку не менее 100 человек.
Как мы уже знаем, репрезентативность — свойство выборочной совокупности представлять характеристику генеральной. Если совпадения нет, говорят об ошибке репрезентативности — мере отклонения статистической структуры выборки от структуры соответствующей генеральной совокупности. Предположим, что средний ежемесячный семейный доход пенсионеров в генеральной совокупности составляет 2 тыс. руб., а в выборочной — 6 тыс. руб. Это означает, что социолог опрашивал только зажиточную часть пенсионеров, а в его исследование вкралась ошибка репрезентативности. Иными словами, ошибкой репрезентативности называется расхождение между двумя совокупностями — генеральной, на которую направлен теоретический интерес социолога и представление о свойствах которой он хочет получить в конечном итоге, и выборочной, на которую направлен практический интерес социолога, которая выступает одновременно как объект обследования и средство получения информации о генеральной совокупности.
Наряду с термином «ошибка репрезентативности» в отечественной литературе можно встретить другой — «ошибка выборки». Иногда они употребляются как синонимы, а иногда «ошибка выборки» используется вместо «ошибки репрезентативности» как количественно более точное понятие.
Ошибка выборки — отклонение средних характеристик выборочной совокупности от средних характеристик генеральной совокупности.
На практике ошибка выборки определяется путем сравнения известных характеристик генеральной совокупности с выборочными средними. В социологии при обследованиях взрослого населения чаще всего используют данные переписей населения, текущего статистического учета, результаты предшествующих опросов. В качестве контрольных параметров обычно применяются социально-демографические признаки. Сравнение средних генеральной и выборочной совокупностей, на основе этого определение ошибки выборки и ее уменьшение называется контролированием репрезентативности. Поскольку сравнение своих и чужих данных можно сделать по завершении исследования, такой способ контроля называется апостериорным, т.е. осуществляемым после опыта.
В опросах Института Дж. Гэллапа репрезентативность контролируется по имеющимся в национальных переписях данным о распределении населения по полу, возрасту, образованию, доходу, профессии, расовой принадлежности, месту проживания, величине населенного пункта. Всероссийский центр изучения общественного мнения (ВЦИОМ) использует для подобных целей такие показатели, как пол, возраст, образование, тип поселения, семейное положение, сфера занятости, должностной статус респондента, которые заимствуются в Государственном комитете по статистике РФ. В том и другом случае генеральная совокупность известна. Ошибку выборки невозможно установить, если неизвестны значения переменной в выборочной и генеральной совокупностях.
Специалисты ВЦИОМ обеспечивают при анализе данных тщательный ремонт выборки, чтобы минимизировать отклонения, возникшие на этапе полевых работ. Особенно сильные смещения наблюдаются по параметрам пола и возраста. Объясняется это тем, что женщины и люди с высшим образованием больше времени проводят дома и легче идут на контакт с интервьюером, т.е. являются легко достижимой группой по сравнению с мужчинами и людьми «необразованными»35.
Ошибка выборки обусловливается двумя факторами: методом формирования выборки и размером выборки.
Ошибки выборки подразделяются на два типа — случайные и систематические. Случайная ошибка — это вероятность того, что выборочная средняя выйдет (или не выйдет) за пределы заданного интервала. К случайным ошибкам относят статистические погрешности, присущие самому выборочному методу. Они уменьшаются при возрастании объема выборочной совокупности.
Второй тип ошибок выборки — систематические ошибки. Если социолог решил узнать мнение всех жителей города о проводимой местными органами власти социальной политике, а опросил только тех, у кого есть телефон, то возникает предумышленное смещение выборки в пользу зажиточных слоев, т.е. систематическая ошибка.
Таким образом, систематические ошибки — результат деятельности самого исследователя. Они наиболее опасны, поскольку приводят к довольно значительным смещениям результатов исследования. Систематические ошибки считаются страшнее случайных еще и потому, что они не поддаются контролю и измерению.
Они возникают, когда, например:
- выборка не соответствует задачам исследования (социолог решил изучить только работающих пенсионеров, а опросил всех подряд);
- налицо незнание характера генеральной совокупности (социолог думал, что 70% всех пенсионеров не работает, а оказалось, что не работает только 10%);
- отбираются только «выигрышные» элементы генеральной совокупности (например, только обеспеченные пенсионеры).
Внимание! В отличие от случайных ошибок систематические ошибки при возрастании объема выборки не уменьшаются.
Обобщив все случаи, когда происходят систематические ошибки, методисты составили их реестр. Они полагают, что источником неконтролируемых перекосов в распределении выборочных наблюдений могут быть следующие факторы:
- нарушены методические и методологические правила проведения социологического исследования;
- выбраны неадекватные способы формирования выборочной совокупности, методы сбора и расчета данных;
- произошла замена требуемых единиц наблюдения другими, более доступными;
- отмечен неполный охват выборочной совокупности (недополучение анкет, неполное их заполнение, труднодоступность единиц наблюдения).
Намеренные ошибки социолог допускает редко. Чаще ошибки возникают из-за того, что социологу плохо известна структура генеральной совокупности: распределение людей по возрасту, профессии, доходам и т.д.
Систематические ошибки легче предупредить (по сравнению со случайными), но их очень трудно устранить. Предупреждать систематические ошибки, точно предвидя их источники, лучше всего заранее — в самом начале исследования.
Вот некоторые способы избежать ошибок выборки:
- каждая единица генеральной совокупности должна иметь равную вероятность попасть в выборку;
- отбор желательно производить из однородных совокупностей;
- надо знать характеристики генеральной совокупности;
- при составлении выборочной совокупности надо учитывать случайные и систематические ошибки.
Если выборочная совокупность (или просто выборка) составлена правильно, то социолог получает надежные результаты, харастеризующие всю генеральную совокупность. Если она составлена неправильно, то ошибка, возникшая на этапе составления выборки, на каждом следующем этапе проведения социологического исследования приумножается и достигает в конечном счете такой величины, которая перевешивает ценность проведенного исследования. Говорят, что от такого исследования больше вреда, нежели пользы.
Подобные ошибки могут произойти только с выборочной совокупностыо. Чтобы избежать или уменьшить вероятность ошибки, самый простой способ — увеличивать размеры выборки (в идеале до объема генеральной: когда обе совокупности совпадут, ошибка выборки вообще исчезнет). Экономически такой метод невозможен. Остается другой путь — совершенствовать математические методы составления выборки. Они то и применяются на практике. Таков первый канал проникновения в социологию математики. Второй канал — математическая обработка данных.
Особенно важной проблема ошибок становится в маркетинговых исследованиях, где используются не очень большие выборки. Обычно они составляют несколько сотен, реже — тысячу респондентов. Здесь исходным пунктом расчета выборки выступает вопрос об определении размеров выборочной совокупности. Численность выборочной совокупности зависит от двух факторов:
- стоимости сбора информации,
- стремления к определенной степени статистической достоверности результатов, которую надеется получить исследователь.
Конечно, даже не искушенные в статистике и социологии люди интуитивно понимают, что чем больше размеры выборки, т.е. чем ближе они к размерам генеральной совокупности в целом, тем более надежны и достоверны полученные данные. Однако выше мы уже говорили о практической невозможности сплошных опросов в тех случаях, когда они проводятся на объектах, численность которых превышает десятки, сотни тысяч и даже миллионы. Понятно, что стоимость сбора информации (включающая оплату тиражирования инструментария, труда анкетеров, полевых менеджеров и операторов по компьютерному вводу) зависит от той суммы, которую готов выделить заказчик, и слабо зависит от исследователей. Что же касается второго фактора, то мы остановимся на нем чуть подробнее.
Итак, чем больше величина выборки, тем меньше возможная ошибка. Хотя необходимо отметить, что при желании увеличить точность вдвое вам придется увеличить выборку не в два, а в четыре раза. Например, чтобы сделать в два раза более точной оценку данных, полученных путем опроса 400 человек, вам потребуется опросить не 800, а 1600 человек. Впрочем, вряд ли маркетинговое исследование испытывает нужду в стопроцентной точности. Если пивовару необходимо узнать, какая часть потребителей пива предпочитает именно его марку, а не сорт его конкурента, — 60% или 40%, то на его планы никак не повлияет разница между 57%, 60 или 63%.
Ошибка выборки может зависеть не только от ее величины, но и от степени различий между отдельными единицами внутри генеральной совокупности, которую мы исследуем. Например, если нам нужно узнать, какое количество пива потребляется, то мы обнаружим, что внутри нашей генеральной совокупности нормы потребления у различных людей существенно различаются (гетерогенная генеральная совокупность). В другом случае мы будем изучать потребление хлеба и установим, что у разных людей оно различается гораздо менее существенно {гомогенная генеральная совокупность). Чем больше различия (или гетерогенность) внутри генеральной совокупности, тем больше величина возможной ошибки выборки. Указанная закономерность лишь подтверждает то, что нам подсказывает простой здравый смысл. Таким образом, как справедливо утверждает В. Ядов, «численность (объем) выборки зависит от уровня однородности или разнородности изучаемых объектов. Чем более они однородны, тем меньшая численность может обеспечить статистически достоверные выводы».
Определение объема выборки зависит также от уровня доверительного интервала допустимой статистической ошибки. Здесь имеются в виду так называемые случайные ошибки, которые связаны с природой любых статистических погрешностей. В.И. Паниотто приводит следующие расчеты репрезентативной выборки с допущением 5%-ной ошибки:
Это означает,что если вы, опросив, предположим, 400 человек в районном городе, где численность взрослого платежеспособного населения составляет 100 тыс. человек, выявили, что 33% опрошенных покупателей предпочитают продукцию местного мясокомбината, то с 95%-ной вероятностью можете утверждать, что постоянными покупателями этой продукции являются 33+5% (т.е. от 28 до 38%) жителей этого города.
Можно также воспользоваться расчетами института Гэллапа для оценки соотношения размеров выборки и ошибки выборки.