Всякое статистическое
наблюдение ставит задачу получения
таких данных, которые точнее бы отражали
действительность. Отклонения, или
разности между исчисленными показателями
и действительными (истинными) величинами
исследуемых явлений нашли отражение в
показателях, называемых ошибками, или
погрешностями. В зависимости от характера
и степени влияния на конечные результаты
наблюдения, а также исходя из источников
и причин возникновения неточностей,
допускаемых в процессе статистического
наблюдения, обычно выделяют ошибки
регистрации и ошибки репрезентативности.
Ошибки регистрации
возникают вследствие неправильного
установления фактов в процессе наблюдения
или неправильной их записи. Они
подразделяются на случайные и
систематические и могут быть как при
сплошном, так и несплошном наблюдении.
Случайные
ошибки —
ошибки регистрации, которые могут быть
допущены как опрашиваемыми в их ответах,
так и регистраторами при заполнении
бланков.
Систематические
ошибки
могут быть преднамеренными, так и
непреднамеренными. Преднамеренные
ошибки получаются в результате того,
что опрашиваемый, зная действительное
положение дела, сознательно сообщает
неправильные данные. Непреднамеренные
ошибки вызываются различными случайными
причинами (небрежностью или невнимательностью
регистратора, неисправностью измерительных
приборов и т.д.).
Ошибки
репрезентативности
возникают в результате того, что состав
отобранной для обследования части
единиц совокупности недостаточно полно
отображает состав всей изучаемой
совокупности, хотя регистрация сведений
по каждой отобранной для обследования
единице была проведена точно. Ошибки
репрезентативности могут быть случайными
и систематическими.
Случайные
ошибки
возникают из-за того, что совокупность
отобранных единиц наблюдения неполно
воспроизводит всю совокупность в целом.
Систематические
ошибки
возникают вследствие нарушения принципов
случайного отбора единиц изучаемой
совокупности.
Для выявления и
устранения допущенных при регистрации
ошибок может применяться счётный и
логический контроль собранного материала.
Счётный контроль
заключается в проверке точности
арифметических расчётов, применявшихся
при составлении отчётности или заполнении
формуляров обследования.
Логический
контроль
заключается в проверке ответов на
вопросы программы наблюдения путём их
логического осмысления или путём
сравнения полученных данных с другими
источниками по этому же вопросу.
Указанные приемы
проверки статистических данных путем
счетного и логического контроля могут
быть использованы при проверке как
материалов специальных статистических
наблюдений, так и отчетности.
1.3. Сводка и группировка статистических данных
1.3.1. Сводка — второй этап статистического исследования
В результате первой
стадии статистического исследования
— статистического наблюдения — получают
сведения о каждой единице совокупности.
Задача второй стадии статистического
исследования состоит в том, чтобы
упорядочить и обобщить первичный
материал, свести его в группы и на этой
основе дать обобщающую характеристику
совокупности. Этот этап в статистике
называется сводкой.
Сводкой
в
статистике называется научно организованная
обработка
материалов наблюдения, включающая
контроль, систематизацию, составление
таблиц, получение итоговых и производных
показателей.
Целью
сводки служит получение обобщающих
статистических показателей,
отражающих сущность социально-экономических
явлений, а также установление статистических
закономерностей.
Статистическая
сводка осуществляется по программе,
составляемой одновременно с планом и
программой статистического наблюдения.
Программа сводки включает определения
групп и подгрупп, системы
показателей и видов таблиц.
По
технике и способу выполнения сводка
может быть ручной или механизированной.
Ручная
сводка применяется
для небольших массивов
данных и начинается с шифровки
статистических формуляров (карточек).
Затем они группируются с подсчетом их
числа и других показателей.
При механизированной
сводке большие
объемы статистических
данных сразу заносятся на машиночитаемые
носители информации
и полностью обрабатываются на ЭВМ.
Различают простую
сводку (подсчет только общих итогов) и
статистическую группировку, которая
сводится к расчленению совокупности
на группы по существенному для единиц
совокупности признаку. Группировка
позволяет получить такие результаты,
по которым можно выявить состав
совокупности, характерные черты и
свойства типичных явлений, обнаружить
закономерности и взаимосвязи.
Результаты сводки
могут быть представлены в виде
статистических рядов распределения.
Статистическим
рядом распределения
называют упорядоченное распределение
единиц совокупности на группы по
изучаемому признаку. В зависимости от
признака ряды могут быть вариационными
(количественными) и атрибутивными
(качественными).
Количественные
признаки —
это признаки, имеющие количественное
выражение у отдельных единиц совокупности,
например, заработная плата рабочих,
стоимость продукции промышленных
предприятий, возраст людей, урожайность
отдельных участков посевной площади и
т.д.
Атрибутивные
признаки —
это признаки, не имеющие количественной
меры. Например, пол (мужской, женский),
отрасль народного хозяйства, вид
продукции, профессия рабочего и т.д.
Вариационные
ряды могут
быть дискретными или интервальными.
Дискретный ряд
распределения
— это ряд, в котором варианты выражены
целым числом.
Примером может
служить распределение рабочих по
тарифным разрядам:
|
Тарифный разряд |
Число рабочих, |
|
1-й |
10 |
|
2-й |
20 |
|
3-й |
40 |
|
4-й |
60 |
|
5-й |
50 |
|
6-й |
20 |
|
200 |
Интервальный
ряд распределения
— это ряд, в котором значения признака
заданы в виде интервала. Например,
распределение рабочих по разрядам можно
представить в виде интервального ряда.
|
Тарифный разряд |
Число рабочих, |
|
1-2-й |
30 |
|
3-4-й |
100 |
|
5-6-й |
70 |
|
200 |
Статистические
ряды распределения позволяют
систематизировать и обобщать статистический
материал. Однако они не дают всесторонней
характеристики выделенных групп. Чтобы
решить ряд конкретных задач, выявить
особенности в развитии явления, обнаружить
тенденции, установить зависимости,
необходимо произвести группировку
статистических данных.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
2.4. Точность статистического наблюдения
Под точностью статистического наблюдения понимают степень соответствия значения наблюдаемого показателя, вычисленного по материалам обследования, его действительной величине. Расхождение, или разница, между ними называется ошибкой статистического наблюдения.
Различают две группы ошибок:
- ошибки регистрации;
- ошибки репрезентативности.
Ошибки регистрации присущи любому статистическому наблюдению, как сплошному, так и несплошному. Они делятся на случайные ошибки регистрации и систематические ошибки регистрации.
Случайными ошибками регистрации называют ошибки, возникающие вследствие действия случайных факторов. К ним можно отнести различного рода непреднамеренные описки: например, вместо возраста человека «15 лет» указано «5 лет», у Ивановой Марии Петровны в графе пол отмечен «Мужской» и т. п. Такие ошибки легко выявляются методом логического анализа, например, если человеку 8 лет, но имеется высшее образование, а в графе «Семейное положение» указано «Состоит в браке», то, естественно, следует исправить возраст. Если объем исследуемой совокупности велик или велика доля отбора при выборочном наблюдении, случайные ошибки регистрации имеют тенденцию взаимопогашаться вследствие действия закона больших чисел, поскольку ошибки, как правило, разнонаправлены и искажают статистический показатель как в большую, так и в меньшую сторону. При небольшом объеме наблюдения требуется тщательная выверка его результатов — логический анализ данных.
Систематические ошибки регистрации чаще всего имеют однонаправленные искажения: они либо увеличивают, либо уменьшают статистический показатель, и, что характерно, подобная ситуация повторяется от обследования к обследованию. Так, по результатам переписей (практически всех!) число замужних женщин превышает число женатых мужчин — мужчинам приятнее ощущать себя неженатыми, а для женщины как бы «стыдно» быть не замужем. Другой пример, когда человек округляет свой возраст — вместо 32 лет говорит 30, вместо 79-80 и т. п. (это явление широко известно и даже получило свое название — «аккумуляция возрастов»). Систематические ошибки регистрации могут возникать и из-за неточностей измерительных приборов, если сбор информации проводят путем непосредственного наблюдения.
Ошибки репрезентативности присущи только несплошному обследованию. Они также делятся на случайные и систематические ошибки.
Случайные ошибки репрезентативности возникают из-за того, что обследованию подвергается не вся совокупность в целом, а только ее часть, и, следовательно, при несплошном наблюдении они присутствуют всегда. В теории статистики разработаны специальные методы для оценки величин таких ошибок, на их основе для наблюдаемых показателей строят доверительные интервалы, т.д. эти ошибки вычисляются и находятся как бы «под контролем».
Хуже обстоит дело, если наряду со случайными ошибками имеются и ошибки систематические.
Систематические ошибки репрезентативности возникают, если при несплошном наблюдении кардинально нарушаются технологии отбора единиц из генеральной совокупности объектов, но чаще — если в ходе обследования не удается получить информацию обо всех отобранных для наблюдения единицах, например, вследствие отказа отвечать на вопросы анкеты, или если человека не удалось застать дома и т. п.
Ошибки статистического наблюдения для наглядности можно изобразить в виде схемы (рис. 2.1).
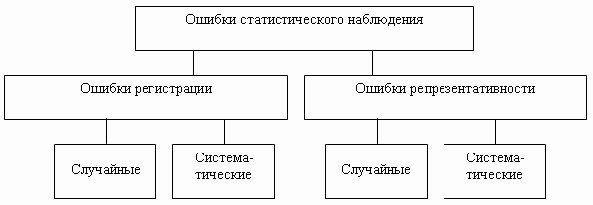
Рис.
2.1.
Виды ошибок статистического наблюдения
Для повышения точности наблюдения необходимо:
- правильно разработать формуляр статистического наблюдения: вопросы должны быть четкими, однозначными, не допускающими двойного толкования;
- иметь хорошо обученный персонал для проведения обследования;
- строго придерживаться выбранной технологии обследования (если проводится несплошное наблюдение) и помнить, что если не удается опросить какую-то конкретную единицу, отобранную для наблюдения, замена ее на другую единицу может привести к возникновению систематической ошибки репрезентативности;
- провести логический анализ данных, основанный на логических взаимосвязях показателей, после сбора всей совокупности анкет или формуляров;
- целесообразно провести и арифметический контроль данных, т.д. заново пересчитать расчетные величины, если какие-либо показатели получаются в результате определенных арифметических действий;
- предпринять определенные меры по восстановлению данных при наличии незаполненных анкет или формуляров либо при получении результатов обследования сделать поправку на неответы респондентов.
Ошибки в статистике
Ошибки в статистике (сплошных и выборочных) могут возникнуть ошибки двух видов: репрезентативности и регистрации.
Ошибки репрезентативности характерны только для выборочного наблюдения и возникают в результате того, что выборочная совокупность не полностью воспроизводит генеральную. Они определяются как расхождение между значениями показателей, полученных по выборке, и значениями показателей этих же величин, которые были бы получены при проведенном сплошном наблюдении с одинаковой степенью точности.
Ошибки регистрации могут иметь случайный, систематический и непреднамеренный характер.
Случайные ошибки часто уравновешивают друг друга, так как они не имеют преимущественного направления в сторону преувеличения (преуменьшении) значения изучаемого показателя. Данные ошибки имеют объективный характер и возникают в следствии случайных различий между единицами, попавшими в выборку, и единицами генеральной совокупности. В результате и структуры этих совокупностей чаще всего не совпадают. Научным обоснованием случайных ошибок являются теория вероятностей и ее предельные теоремы.
Систематические ошибки направлены в одну сторону в результате предумышленного нарушения правил отбора. Их можно избежать при правильной организации и проведении наблюдения.
Ошибка выборки в статистике
Ошибка выборки или ошибка репрезентативности определяется как разница между значением показателя, который был получен по выборке, и генеральным параметром. Она характерна только для выборочных наблюдений. Чем больше значение этой ошибки, тем в большей степени выборочные показатели отличаются от соответствующих им генеральных показателей.
Ошибку выборки часто определяют по формулам:
1. Для среднего количественного признака:

где первое — среднее значение признака в генеральной совокупности или генеральная средняя;
второе — выборочная средняя.
2. Для доли (альтернативного признака):

где w — выборочная доля;
р — генеральная доля, или доля единиц, обладающих данным значением признака в общем числе единиц генеральной совокупности.
Ошибки выборки возникают вследствие двух причин из-за нарушения принципа случайности как основного принципа выборки (систематические ошибки) и в результате случайного отбора (случайные ошибки). Выборки являются случайными величинами и могут принимать разные значения.
Источник: Балинова B.C. Статистика в вопросах и ответах: Учеб. пособие. — М.: ТК. Велби, Изд-во Проспект, 2004. — 344 с.
Всякое статистическое
наблюдение ставит задачу получения
таких данных, которые точнее бы отражали
действительность. Отклонения, или
разности между исчисленными показателями
и действительными (истинными) величинами
исследуемых явлений нашли отражение в
показателях, называемых ошибками, или
погрешностями. В зависимости от характера
и степени влияния на конечные результаты
наблюдения, а также исходя из источников
и причин возникновения неточностей,
допускаемых в процессе статистического
наблюдения, обычно выделяют ошибки
регистрации и ошибки репрезентативности.
Ошибки регистрации
возникают вследствие неправильного
установления фактов в процессе наблюдения
или неправильной их записи. Они
подразделяются на случайные и
систематические и могут быть как при
сплошном, так и несплошном наблюдении.
Случайные
ошибки —
ошибки регистрации, которые могут быть
допущены как опрашиваемыми в их ответах,
так и регистраторами при заполнении
бланков.
Систематические
ошибки
могут быть преднамеренными, так и
непреднамеренными. Преднамеренные
ошибки получаются в результате того,
что опрашиваемый, зная действительное
положение дела, сознательно сообщает
неправильные данные. Непреднамеренные
ошибки вызываются различными случайными
причинами (небрежностью или невнимательностью
регистратора, неисправностью измерительных
приборов и т.д.).
Ошибки
репрезентативности
возникают в результате того, что состав
отобранной для обследования части
единиц совокупности недостаточно полно
отображает состав всей изучаемой
совокупности, хотя регистрация сведений
по каждой отобранной для обследования
единице была проведена точно. Ошибки
репрезентативности могут быть случайными
и систематическими.
Случайные
ошибки
возникают из-за того, что совокупность
отобранных единиц наблюдения неполно
воспроизводит всю совокупность в целом.
Систематические
ошибки
возникают вследствие нарушения принципов
случайного отбора единиц изучаемой
совокупности.
Для выявления и
устранения допущенных при регистрации
ошибок может применяться счётный и
логический контроль собранного материала.
Счётный контроль
заключается в проверке точности
арифметических расчётов, применявшихся
при составлении отчётности или заполнении
формуляров обследования.
Логический
контроль
заключается в проверке ответов на
вопросы программы наблюдения путём их
логического осмысления или путём
сравнения полученных данных с другими
источниками по этому же вопросу.
Указанные приемы
проверки статистических данных путем
счетного и логического контроля могут
быть использованы при проверке как
материалов специальных статистических
наблюдений, так и отчетности.
1.3. Сводка и группировка статистических данных
1.3.1. Сводка — второй этап статистического исследования
В результате первой
стадии статистического исследования
— статистического наблюдения — получают
сведения о каждой единице совокупности.
Задача второй стадии статистического
исследования состоит в том, чтобы
упорядочить и обобщить первичный
материал, свести его в группы и на этой
основе дать обобщающую характеристику
совокупности. Этот этап в статистике
называется сводкой.
Сводкой
в
статистике называется научно организованная
обработка
материалов наблюдения, включающая
контроль, систематизацию, составление
таблиц, получение итоговых и производных
показателей.
Целью
сводки служит получение обобщающих
статистических показателей,
отражающих сущность социально-экономических
явлений, а также установление статистических
закономерностей.
Статистическая
сводка осуществляется по программе,
составляемой одновременно с планом и
программой статистического наблюдения.
Программа сводки включает определения
групп и подгрупп, системы
показателей и видов таблиц.
По
технике и способу выполнения сводка
может быть ручной или механизированной.
Ручная
сводка применяется
для небольших массивов
данных и начинается с шифровки
статистических формуляров (карточек).
Затем они группируются с подсчетом их
числа и других показателей.
При механизированной
сводке большие
объемы статистических
данных сразу заносятся на машиночитаемые
носители информации
и полностью обрабатываются на ЭВМ.
Различают простую
сводку (подсчет только общих итогов) и
статистическую группировку, которая
сводится к расчленению совокупности
на группы по существенному для единиц
совокупности признаку. Группировка
позволяет получить такие результаты,
по которым можно выявить состав
совокупности, характерные черты и
свойства типичных явлений, обнаружить
закономерности и взаимосвязи.
Результаты сводки
могут быть представлены в виде
статистических рядов распределения.
Статистическим
рядом распределения
называют упорядоченное распределение
единиц совокупности на группы по
изучаемому признаку. В зависимости от
признака ряды могут быть вариационными
(количественными) и атрибутивными
(качественными).
Количественные
признаки —
это признаки, имеющие количественное
выражение у отдельных единиц совокупности,
например, заработная плата рабочих,
стоимость продукции промышленных
предприятий, возраст людей, урожайность
отдельных участков посевной площади и
т.д.
Атрибутивные
признаки —
это признаки, не имеющие количественной
меры. Например, пол (мужской, женский),
отрасль народного хозяйства, вид
продукции, профессия рабочего и т.д.
Вариационные
ряды могут
быть дискретными или интервальными.
Дискретный ряд
распределения
— это ряд, в котором варианты выражены
целым числом.
Примером может
служить распределение рабочих по
тарифным разрядам:
|
Тарифный разряд |
Число рабочих, |
|
1-й |
10 |
|
2-й |
20 |
|
3-й |
40 |
|
4-й |
60 |
|
5-й |
50 |
|
6-й |
20 |
|
200 |
Интервальный
ряд распределения
— это ряд, в котором значения признака
заданы в виде интервала. Например,
распределение рабочих по разрядам можно
представить в виде интервального ряда.
|
Тарифный разряд |
Число рабочих, |
|
1-2-й |
30 |
|
3-4-й |
100 |
|
5-6-й |
70 |
|
200 |
Статистические
ряды распределения позволяют
систематизировать и обобщать статистический
материал. Однако они не дают всесторонней
характеристики выделенных групп. Чтобы
решить ряд конкретных задач, выявить
особенности в развитии явления, обнаружить
тенденции, установить зависимости,
необходимо произвести группировку
статистических данных.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
2.4. Точность статистического наблюдения
Под точностью статистического наблюдения понимают степень соответствия значения наблюдаемого показателя, вычисленного по материалам обследования, его действительной величине. Расхождение, или разница, между ними называется ошибкой статистического наблюдения.
Различают две группы ошибок:
- ошибки регистрации;
- ошибки репрезентативности.
Ошибки регистрации присущи любому статистическому наблюдению, как сплошному, так и несплошному. Они делятся на случайные ошибки регистрации и систематические ошибки регистрации.
Случайными ошибками регистрации называют ошибки, возникающие вследствие действия случайных факторов. К ним можно отнести различного рода непреднамеренные описки: например, вместо возраста человека «15 лет» указано «5 лет», у Ивановой Марии Петровны в графе пол отмечен «Мужской» и т. п. Такие ошибки легко выявляются методом логического анализа, например, если человеку 8 лет, но имеется высшее образование, а в графе «Семейное положение» указано «Состоит в браке», то, естественно, следует исправить возраст. Если объем исследуемой совокупности велик или велика доля отбора при выборочном наблюдении, случайные ошибки регистрации имеют тенденцию взаимопогашаться вследствие действия закона больших чисел, поскольку ошибки, как правило, разнонаправлены и искажают статистический показатель как в большую, так и в меньшую сторону. При небольшом объеме наблюдения требуется тщательная выверка его результатов — логический анализ данных.
Систематические ошибки регистрации чаще всего имеют однонаправленные искажения: они либо увеличивают, либо уменьшают статистический показатель, и, что характерно, подобная ситуация повторяется от обследования к обследованию. Так, по результатам переписей (практически всех!) число замужних женщин превышает число женатых мужчин — мужчинам приятнее ощущать себя неженатыми, а для женщины как бы «стыдно» быть не замужем. Другой пример, когда человек округляет свой возраст — вместо 32 лет говорит 30, вместо 79-80 и т. п. (это явление широко известно и даже получило свое название — «аккумуляция возрастов»). Систематические ошибки регистрации могут возникать и из-за неточностей измерительных приборов, если сбор информации проводят путем непосредственного наблюдения.
Ошибки репрезентативности присущи только несплошному обследованию. Они также делятся на случайные и систематические ошибки.
Случайные ошибки репрезентативности возникают из-за того, что обследованию подвергается не вся совокупность в целом, а только ее часть, и, следовательно, при несплошном наблюдении они присутствуют всегда. В теории статистики разработаны специальные методы для оценки величин таких ошибок, на их основе для наблюдаемых показателей строят доверительные интервалы, т.д. эти ошибки вычисляются и находятся как бы «под контролем».
Хуже обстоит дело, если наряду со случайными ошибками имеются и ошибки систематические.
Систематические ошибки репрезентативности возникают, если при несплошном наблюдении кардинально нарушаются технологии отбора единиц из генеральной совокупности объектов, но чаще — если в ходе обследования не удается получить информацию обо всех отобранных для наблюдения единицах, например, вследствие отказа отвечать на вопросы анкеты, или если человека не удалось застать дома и т. п.
Ошибки статистического наблюдения для наглядности можно изобразить в виде схемы (рис. 2.1).
Рис.
2.1.
Виды ошибок статистического наблюдения
Для повышения точности наблюдения необходимо:
- правильно разработать формуляр статистического наблюдения: вопросы должны быть четкими, однозначными, не допускающими двойного толкования;
- иметь хорошо обученный персонал для проведения обследования;
- строго придерживаться выбранной технологии обследования (если проводится несплошное наблюдение) и помнить, что если не удается опросить какую-то конкретную единицу, отобранную для наблюдения, замена ее на другую единицу может привести к возникновению систематической ошибки репрезентативности;
- провести логический анализ данных, основанный на логических взаимосвязях показателей, после сбора всей совокупности анкет или формуляров;
- целесообразно провести и арифметический контроль данных, т.д. заново пересчитать расчетные величины, если какие-либо показатели получаются в результате определенных арифметических действий;
- предпринять определенные меры по восстановлению данных при наличии незаполненных анкет или формуляров либо при получении результатов обследования сделать поправку на неответы респондентов.
Ошибки в статистике
Ошибки в статистике (сплошных и выборочных) могут возникнуть ошибки двух видов: репрезентативности и регистрации.
Ошибки репрезентативности характерны только для выборочного наблюдения и возникают в результате того, что выборочная совокупность не полностью воспроизводит генеральную. Они определяются как расхождение между значениями показателей, полученных по выборке, и значениями показателей этих же величин, которые были бы получены при проведенном сплошном наблюдении с одинаковой степенью точности.
Ошибки регистрации могут иметь случайный, систематический и непреднамеренный характер.
Случайные ошибки часто уравновешивают друг друга, так как они не имеют преимущественного направления в сторону преувеличения (преуменьшении) значения изучаемого показателя. Данные ошибки имеют объективный характер и возникают в следствии случайных различий между единицами, попавшими в выборку, и единицами генеральной совокупности. В результате и структуры этих совокупностей чаще всего не совпадают. Научным обоснованием случайных ошибок являются теория вероятностей и ее предельные теоремы.
Систематические ошибки направлены в одну сторону в результате предумышленного нарушения правил отбора. Их можно избежать при правильной организации и проведении наблюдения.
Ошибка выборки в статистике
Ошибка выборки или ошибка репрезентативности определяется как разница между значением показателя, который был получен по выборке, и генеральным параметром. Она характерна только для выборочных наблюдений. Чем больше значение этой ошибки, тем в большей степени выборочные показатели отличаются от соответствующих им генеральных показателей.
Ошибку выборки часто определяют по формулам:
1. Для среднего количественного признака:

где первое — среднее значение признака в генеральной совокупности или генеральная средняя;
второе — выборочная средняя.
2. Для доли (альтернативного признака):

где w — выборочная доля;
р — генеральная доля, или доля единиц, обладающих данным значением признака в общем числе единиц генеральной совокупности.
Ошибки выборки возникают вследствие двух причин из-за нарушения принципа случайности как основного принципа выборки (систематические ошибки) и в результате случайного отбора (случайные ошибки). Выборки являются случайными величинами и могут принимать разные значения.
Источник: Балинова B.C. Статистика в вопросах и ответах: Учеб. пособие. — М.: ТК. Велби, Изд-во Проспект, 2004. — 344 с.
6. Достоверность статистических данных и
ошибки статистического наблюдения
Важнейшим требованием
предъявляемым к статистическим данным является их достоверность. Под достоверностью
данных наблюдения понимается степень приближения, соответствия
данных тому, что есть на самом деле. Расхождение межу фактическим значением и
результатом наблюдения называют погрешностью (ошибкой) наблюдения.
Ошибки наблюдения
разнообразны по происхождению и своему содержанию. В зависимости от
причин возникновения различают следующие виды ошибок:
• методические ошибки;
• ошибки регистрации;
• ошибки
репрезентативности (представительности).
Методические ошибки возникают
в результате использования несовершенных методик, неправильных теоретических
концепций, лежащих в основе исследования.
Ошибки регистрации возникают при
получении данных об отдельных единицах совокупности вследствие неправильного
установления фактов в процессе наблюдения или неправильной их записи. Они
подразделяются на:
-объективные (непреднамеренные)
причиной появления которых является неправильное восприятие наблюдаемых фактов,
неисправность измерительных приборов и неправильная регистрация. Такие ошибки
являются результатом добросовестного заблуждения регистратора;
— субъективные (преднамеренные)
ошибки, возникающие по причине сознательного искажения фактов. К ним относятся
всевозможные преднамеренные ошибки и приписки, при которых опрашиваемый
преднамеренно сообщает неправильные сведения; регистратор преднамеренно
воздействует на респондента с целью получения нужного ответа; регистратор
преднамеренно искажает в формулярах результаты наблюдения.
Ошибки репрезентативности
(представительности) характерны только для несплошного наблюдения.
Они возникают в результате того, что состав отобранной для обследования части
единиц совокупности (выборки) не полностью отражает состав и свойства всей
изучаемой совокупности, несмотря на то, что регистрация сведений по каждой
отобранной единице была проведена точно.
По форме проявления (по
влиянию на результат) ошибки делятся на:
• систематически;
• случайные.
Систематические ошибки возникают
по какой-то определенной причине и вызывают одностороннее искажение значений
признака у наблюдаемых единиц (увеличение или уменьшение). Они очень опасны,
так как величина показателя, рассчитанная в целом по всей совокупности будет
включать накопленную ошибку.
Случайные ошибки являются
результатом действия различных случайных факторов. Они не имеют какой-либо
направленности. В больших совокупностях в результате действия закона больших
чисел эти ошибки взаимно погашаются и не оказывают существенного влияния на
точность наблюдения.
Оба вида ошибок в любом
исследовании выступают совместно и составляют совокупную ошибку наблюдения Δ:
Δ=σ+ε;
где σ — систематическая
ошибка наблюдения,
ε — случайная ошибка
наблюдения.
Для выявления и
исправления ошибок, данные наблюдения необходимо тщательно контролировать.
Процедура контроля сводится к следующему:
• Проверка материалов
наблюдения на полноту и правильность оформления. Проверяется полнота охвата
статистических единиц наблюдения, правильность заполнения каждого формуляра.
• Арифметический
(счетный) контроль. Этот вид контроля основан на использовании
количественных связей между показателями, которые могут быть проверены
арифметическими действиями. Такие связи обычно отражаются в заголовках граф или
строк формуляров. Например, графа x = графа y — графа z и т.д. Арифметический
контроль используется для проверки итоговых данных, с его помощью устанавливается
наличие ошибки.
• Логический контроль основан
на использовании логической взаимосвязи показателей, установлении логического
соответствия между ними. Он не выявляет ошибки наблюдения, а лишь ставит под
сомнение правильность полученных данных. Логический контроль заключается в
проверке ответов на вопросы программы наблюдения путем их логического
осмысления или сравнения полученных данных с другими источниками по данному
вопросу. Классическим примером логического контроля является соответствие данных
при переписи населения о возрасте, образовании и семейном положении. Для
проверки данных наблюдения обычно составляется схема контроля, в которую
включаются различные виды контроля. При обнаружении ошибок нельзя
самостоятельно их исправлять. Для этого необходимо получить дополнительную
информацию путем повторного наблюдения. Данные наблюдения считаются принятыми,
если они прошли контроль, и в них внесены все необходимые исправления.
Проверкой собранных данных заканчивается начальная стадия статистического
исследования. После этого можно переходить ко второй стадии исследования
обработке данных наблюдения. Обработка заключается в классификации и
систематизации полученного статистического материала, осуществляемых через
сводку и группировку.
О сводке и группировке мы
поговорим с Вами в следующей лекции.
Всякое статистическое
наблюдение ставит задачу получения
таких данных, которые точнее бы отражали
действительность. Отклонения, или
разности между исчисленными показателями
и действительными (истинными) величинами
исследуемых явлений нашли отражение в
показателях, называемых ошибками, или
погрешностями. В зависимости от характера
и степени влияния на конечные результаты
наблюдения, а также исходя из источников
и причин возникновения неточностей,
допускаемых в процессе статистического
наблюдения, обычно выделяют ошибки
регистрации и ошибки репрезентативности.
Ошибки регистрации
возникают вследствие неправильного
установления фактов в процессе наблюдения
или неправильной их записи. Они
подразделяются на случайные и
систематические и могут быть как при
сплошном, так и несплошном наблюдении.
Случайные
ошибки —
ошибки регистрации, которые могут быть
допущены как опрашиваемыми в их ответах,
так и регистраторами при заполнении
бланков.
Систематические
ошибки
могут быть преднамеренными, так и
непреднамеренными. Преднамеренные
ошибки получаются в результате того,
что опрашиваемый, зная действительное
положение дела, сознательно сообщает
неправильные данные. Непреднамеренные
ошибки вызываются различными случайными
причинами (небрежностью или невнимательностью
регистратора, неисправностью измерительных
приборов и т.д.).
Ошибки
репрезентативности
возникают в результате того, что состав
отобранной для обследования части
единиц совокупности недостаточно полно
отображает состав всей изучаемой
совокупности, хотя регистрация сведений
по каждой отобранной для обследования
единице была проведена точно. Ошибки
репрезентативности могут быть случайными
и систематическими.
Случайные
ошибки
возникают из-за того, что совокупность
отобранных единиц наблюдения неполно
воспроизводит всю совокупность в целом.
Систематические
ошибки
возникают вследствие нарушения принципов
случайного отбора единиц изучаемой
совокупности.
Для выявления и
устранения допущенных при регистрации
ошибок может применяться счётный и
логический контроль собранного материала.
Счётный контроль
заключается в проверке точности
арифметических расчётов, применявшихся
при составлении отчётности или заполнении
формуляров обследования.
Логический
контроль
заключается в проверке ответов на
вопросы программы наблюдения путём их
логического осмысления или путём
сравнения полученных данных с другими
источниками по этому же вопросу.
Указанные приемы
проверки статистических данных путем
счетного и логического контроля могут
быть использованы при проверке как
материалов специальных статистических
наблюдений, так и отчетности.
1.3. Сводка и группировка статистических данных
1.3.1. Сводка — второй этап статистического исследования
В результате первой
стадии статистического исследования
— статистического наблюдения — получают
сведения о каждой единице совокупности.
Задача второй стадии статистического
исследования состоит в том, чтобы
упорядочить и обобщить первичный
материал, свести его в группы и на этой
основе дать обобщающую характеристику
совокупности. Этот этап в статистике
называется сводкой.
Сводкой
в
статистике называется научно организованная
обработка
материалов наблюдения, включающая
контроль, систематизацию, составление
таблиц, получение итоговых и производных
показателей.
Целью
сводки служит получение обобщающих
статистических показателей,
отражающих сущность социально-экономических
явлений, а также установление статистических
закономерностей.
Статистическая
сводка осуществляется по программе,
составляемой одновременно с планом и
программой статистического наблюдения.
Программа сводки включает определения
групп и подгрупп, системы
показателей и видов таблиц.
По
технике и способу выполнения сводка
может быть ручной или механизированной.
Ручная
сводка применяется
для небольших массивов
данных и начинается с шифровки
статистических формуляров (карточек).
Затем они группируются с подсчетом их
числа и других показателей.
При механизированной
сводке большие
объемы статистических
данных сразу заносятся на машиночитаемые
носители информации
и полностью обрабатываются на ЭВМ.
Различают простую
сводку (подсчет только общих итогов) и
статистическую группировку, которая
сводится к расчленению совокупности
на группы по существенному для единиц
совокупности признаку. Группировка
позволяет получить такие результаты,
по которым можно выявить состав
совокупности, характерные черты и
свойства типичных явлений, обнаружить
закономерности и взаимосвязи.
Результаты сводки
могут быть представлены в виде
статистических рядов распределения.
Статистическим
рядом распределения
называют упорядоченное распределение
единиц совокупности на группы по
изучаемому признаку. В зависимости от
признака ряды могут быть вариационными
(количественными) и атрибутивными
(качественными).
Количественные
признаки —
это признаки, имеющие количественное
выражение у отдельных единиц совокупности,
например, заработная плата рабочих,
стоимость продукции промышленных
предприятий, возраст людей, урожайность
отдельных участков посевной площади и
т.д.
Атрибутивные
признаки —
это признаки, не имеющие количественной
меры. Например, пол (мужской, женский),
отрасль народного хозяйства, вид
продукции, профессия рабочего и т.д.
Вариационные
ряды могут
быть дискретными или интервальными.
Дискретный ряд
распределения
— это ряд, в котором варианты выражены
целым числом.
Примером может
служить распределение рабочих по
тарифным разрядам:
|
Тарифный разряд |
Число рабочих, |
|
1-й |
10 |
|
2-й |
20 |
|
3-й |
40 |
|
4-й |
60 |
|
5-й |
50 |
|
6-й |
20 |
|
200 |
Интервальный
ряд распределения
— это ряд, в котором значения признака
заданы в виде интервала. Например,
распределение рабочих по разрядам можно
представить в виде интервального ряда.
|
Тарифный разряд |
Число рабочих, |
|
1-2-й |
30 |
|
3-4-й |
100 |
|
5-6-й |
70 |
|
200 |
Статистические
ряды распределения позволяют
систематизировать и обобщать статистический
материал. Однако они не дают всесторонней
характеристики выделенных групп. Чтобы
решить ряд конкретных задач, выявить
особенности в развитии явления, обнаружить
тенденции, установить зависимости,
необходимо произвести группировку
статистических данных.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
2.4. Точность статистического наблюдения
Под точностью статистического наблюдения понимают степень соответствия значения наблюдаемого показателя, вычисленного по материалам обследования, его действительной величине. Расхождение, или разница, между ними называется ошибкой статистического наблюдения.
Различают две группы ошибок:
- ошибки регистрации;
- ошибки репрезентативности.
Ошибки регистрации присущи любому статистическому наблюдению, как сплошному, так и несплошному. Они делятся на случайные ошибки регистрации и систематические ошибки регистрации.
Случайными ошибками регистрации называют ошибки, возникающие вследствие действия случайных факторов. К ним можно отнести различного рода непреднамеренные описки: например, вместо возраста человека «15 лет» указано «5 лет», у Ивановой Марии Петровны в графе пол отмечен «Мужской» и т. п. Такие ошибки легко выявляются методом логического анализа, например, если человеку 8 лет, но имеется высшее образование, а в графе «Семейное положение» указано «Состоит в браке», то, естественно, следует исправить возраст. Если объем исследуемой совокупности велик или велика доля отбора при выборочном наблюдении, случайные ошибки регистрации имеют тенденцию взаимопогашаться вследствие действия закона больших чисел, поскольку ошибки, как правило, разнонаправлены и искажают статистический показатель как в большую, так и в меньшую сторону. При небольшом объеме наблюдения требуется тщательная выверка его результатов — логический анализ данных.
Систематические ошибки регистрации чаще всего имеют однонаправленные искажения: они либо увеличивают, либо уменьшают статистический показатель, и, что характерно, подобная ситуация повторяется от обследования к обследованию. Так, по результатам переписей (практически всех!) число замужних женщин превышает число женатых мужчин — мужчинам приятнее ощущать себя неженатыми, а для женщины как бы «стыдно» быть не замужем. Другой пример, когда человек округляет свой возраст — вместо 32 лет говорит 30, вместо 79-80 и т. п. (это явление широко известно и даже получило свое название — «аккумуляция возрастов»). Систематические ошибки регистрации могут возникать и из-за неточностей измерительных приборов, если сбор информации проводят путем непосредственного наблюдения.
Ошибки репрезентативности присущи только несплошному обследованию. Они также делятся на случайные и систематические ошибки.
Случайные ошибки репрезентативности возникают из-за того, что обследованию подвергается не вся совокупность в целом, а только ее часть, и, следовательно, при несплошном наблюдении они присутствуют всегда. В теории статистики разработаны специальные методы для оценки величин таких ошибок, на их основе для наблюдаемых показателей строят доверительные интервалы, т.д. эти ошибки вычисляются и находятся как бы «под контролем».
Хуже обстоит дело, если наряду со случайными ошибками имеются и ошибки систематические.
Систематические ошибки репрезентативности возникают, если при несплошном наблюдении кардинально нарушаются технологии отбора единиц из генеральной совокупности объектов, но чаще — если в ходе обследования не удается получить информацию обо всех отобранных для наблюдения единицах, например, вследствие отказа отвечать на вопросы анкеты, или если человека не удалось застать дома и т. п.
Ошибки статистического наблюдения для наглядности можно изобразить в виде схемы (рис. 2.1).
Рис.
2.1.
Виды ошибок статистического наблюдения
Для повышения точности наблюдения необходимо:
- правильно разработать формуляр статистического наблюдения: вопросы должны быть четкими, однозначными, не допускающими двойного толкования;
- иметь хорошо обученный персонал для проведения обследования;
- строго придерживаться выбранной технологии обследования (если проводится несплошное наблюдение) и помнить, что если не удается опросить какую-то конкретную единицу, отобранную для наблюдения, замена ее на другую единицу может привести к возникновению систематической ошибки репрезентативности;
- провести логический анализ данных, основанный на логических взаимосвязях показателей, после сбора всей совокупности анкет или формуляров;
- целесообразно провести и арифметический контроль данных, т.д. заново пересчитать расчетные величины, если какие-либо показатели получаются в результате определенных арифметических действий;
- предпринять определенные меры по восстановлению данных при наличии незаполненных анкет или формуляров либо при получении результатов обследования сделать поправку на неответы респондентов.