Готовая программа не всегда работает как надо. Бывает, возникают баги, предупреждения, исключения. В итоге программа зависает, дает сбой или вылетает. Но это не конец света. Любую ошибку в коде можно исправить, если знать, почему она возникла.
Программная ошибка: что это и почему возникает
Программная ошибка — это дефект в коде. Из-за него программа сбоит или выдает неверные результаты. Некоторые ошибки серьезные — например, блокируют логин и пароль, из-за чего пользователь не может попасть в личный кабинет. А другие незаметны. Некоторое время программа работает как будто бы исправно — и только потом начинает глючить.
Ошибка в программировании — это зачастую ошибки разработчиков, которые находят тестировщики. Запускают разные тесты и отладку, чтобы определить источники проблемы.
Научитесь находить ошибки в приложениях и на сайтах до того, как ими начнут пользоваться клиенты. Для этого освойте профессию «Инженер по тестированию». Изучать язык программирования необязательно. Тестировщик работает с готовыми сайтами, приложениями, сервисами, а не с кодом. В программе от Skypro: четыре проекта для портфолио, практика с обратной связью, все основные инструменты тестировщика.
Ошибки часто называют багами, но подразумевают под ними разное, например:
❗ Ворнинги, или предупреждения. Возникают, когда программа начинает вести себя не так, как задумывалось. Не являются критичными ошибками. Программа с ворнингами работает, но с аномалиями.
❗ Исключения. Это не ошибки, а особые ситуации, которые нужно обработать.
❗ Синтаксические ошибки. Это ошибка в программе, связанная с написанием кода. Пример: программист забыл поставить точку или неверно написал название оператора. Если не исправить, код программы не запустится, а останется просто текстом.
Классификация багов
У багов есть два атрибута — серьезности (Severity) и приоритета (Priority). Серьезность касается технической стороны, а приоритет — организационной.
🚨 По серьезности. Атрибут показывает, как сильно ошибка влияет на общую функциональность программы. Чем выше значение атрибута, тем хуже.
По серьезности баги классифицируют так:
- Blocker — блокирующий баг. Программа запускается, но спустя время баг останавливает ее выполнение. Чтобы снова пользоваться программой, блокирующую ошибку в коде устраняют.
- Critical — критический баг. Нарушает функциональность программы. Появляется в разных частях кода, из-за этого основные функции не выполняются.
- Major — существенный баг. Не нарушает, но затрудняет работу основного функционала программы либо не дает функциям выполняться так, как задумано.
- Minor — незначительный баг. Слабо влияет на функционал программы, но может нарушать работу некоторых дополнительных функций.
- Trivial — тривиальный баг. На работу программы не влияет, но ухудшает общее впечатление. Например, на экране появляются посторонние символы или всё рябит.
🚦 По приоритету. Атрибут показывает, как быстро баг необходимо исправить, пока он не нанес программе приличный ущерб. Бывает таким:
- Top — наивысший. Такой баг — суперсерьезный, потому что может обвалить всю программу. Его устраняют в первую очередь.
- High — высокий. Может затруднить работу программы или ее функций, устраняют как можно скорее.
- Normal — обычный. Баг программу не ломает, просто где-то что-то будет работать не совсем верно. Устраняют в штатном порядке.
- Low — низкий. Баг не влияет на программу. Исправляют, только если у команды есть на это время.
Типы ошибок в программе
🧨 Логические. Приводят к тому, что программа зависает, работает не так, как надо, или выдает неожиданные результаты — например, не записывает файл, а стирает.
Логические ошибки коварны: их трудно обнаружить. Программа выглядит так, будто в ней всё правильно, но при этом работает некорректно. Чтобы победить логические ошибки, специалист должен хорошо ориентироваться в коде программы.
🧨 Синтаксические. Это опечатки в названиях операторов, пропущенные запятые или кавычки. Безобидные ошибки: их обнаруживают и подсвечивают в коде компиляторы, а программисту остается исправить.
🧨 Взаимодействия. Это ошибка в участке кода, который отвечает за взаимодействие с аппаратным или программным окружением. Такая ошибка возникает, например, если неправильно использовать веб-протоколы. Исправляется элементарно: разработчик переписывает нужный кусок кода.
🧨 Компиляционные. Любая программа — это текст. Чтобы он заработал как программа, используют компилятор. Он преобразует программный код в машинный, но одновременно может вызывать ошибки.
Компиляционные баги появляются, если что-то не так с компилятором или в коде есть синтаксические ошибки. Компилятор будто ругается: «Не понимаю, что тут написано. Не знаю, как обработать».
🧨 Ошибки среды выполнения. Возникают, когда программа скомпилирована и уже выглядит как файл — жми и работай. Юзер запускает файл, а программа тормозит и виснет. Причина — нехватка ресурсов, например памяти или буфера.
Такой баг — ошибка разработчика. Он не предвидел реальные условия развертывания программы. Теперь ему надо вернуться в исходный код и поправить фрагмент.
🧨 Арифметические. Бывает, в коде есть числовые переменные и математические формулы. Если где-то проблема — не указаны константы или округление сработало не так, возникает баг. Надо лезть в код и проверять математику.
Инженер-тестировщик: новая работа через 9 месяцев
Получится, даже если у вас нет опыта в IT
Получить
программу

Что такое исключения в программах
Это механизм, который помогает программе обрабатывать нестандартную ситуацию и при этом не вылетать. Идеально, если программист предусмотрел все возможные ситуации. Но так бывает редко, поэтому лучше использовать специальный обработчик. Он обработает исключения так, что программа продолжит работать.
Как это происходит:
- Когда программист кодит, то продумывает, в какой части программы может вылезти ошибка.
- В этой части пишет специальный фрагмент, который предупредит компьютер, что ошибка — вполне ожидаемое явление и резко обрывать программу не нужно.
- Когда юзер запустит программу и появится ошибка, компьютер увидит заранее подготовленное предупреждение программиста. Продолжит выполнять алгоритм так, словно никакого бага и не было.
Исключения бывают программными и аппаратными:
- Аппаратные создает процессор. К ним относят деление на ноль, выход за границы массива, обращение к невыделенной памяти.
- Программные создает операционка и приложения. Возникают, когда программа их инициирует: аномальная ситуация возникла — программа создала исключение.
Как контролировать баги в программе
🔧 Следите за компилятором. Когда компилятор преобразует текст программы в машинный код, то подсвечивает в нём сомнительные участки, которые способны вызывать баги. Некоторые предупреждения не обозначают баг как таковой, а только говорят: «Тут что-то подозрительное». Всё подозрительное надо изучать и прорабатывать, чтобы не было проблемы в будущем.
🔧 Используйте отладчик. Это программа, которая без участия айтишника проверяет, исправно ли работает алгоритм. В случае чего сообщает об ошибках. Например, отладчик используют для построчного выполнения программы. Вместе с тем проверяют значения переменных: фактические сравнивают с ожидаемыми. Если что-то не сходится, ищут баги и исправляют.
🔧 Проводите юнит-тесты. Это когда разработчик или тестировщик описывает ситуации для каждого компонента и указывает, к какому результату должна привести программа. Потом запускает проверку. Если результат не совпадает с ожидаемым, появляется предупреждение. Дальше программисты находят и устраняют проблему.
Ключевое: что такое ошибки в программировании
- Ошибка в программировании — это дефект кода, баг, который может вызывать в программе сбои и неожиданное поведение.
- По серьезности баги делятся на блокирующие, критические, существенные, незначительные, тривиальные. По приоритету — на наивысший, высокий, обычный, низкий.
- Ошибки в коде могут быть разными, например связанные с логикой программы. Или с математическими вычислениями — логические. Еще бывают синтаксические, ошибки взаимодействия, компиляционные и ошибки среды выполнения.
- Некоторые ошибки помогают ловить обработчики исключений.
- Чтобы находить ошибки в коде, тестировщики используют компиляторы, отладчики и пишут юнит-тесты.

Существует две фундаментальные стратегии: обработка исправимых ошибок (исключения, коды возврата по ошибке, функции-обработчики) и неисправимых (assert(), abort()). В каких случаях какую стратегию лучше использовать?
Виды ошибок
Ошибки возникают по разным причинам: пользователь ввёл странные данные, ОС не может дать вам обработчика файла или код разыменовывает (dereferences) nullptr. Каждая из описанных ошибок требует к себе отдельного подхода. По причинам ошибки делятся на три основные категории:
- Пользовательские ошибки: здесь под пользователем подразумевается человек, сидящий перед компьютером и действительно «использующий» программу, а не какой-то программист, дёргающий ваш API. Такие ошибки возникают тогда, когда пользователь делает что-то неправильно.
- Системные ошибки появляются, когда ОС не может выполнить ваш запрос. Иными словами, причина системных ошибок — сбой вызова системного API. Некоторые возникают потому, что программист передал системному вызову плохие параметры, так что это скорее программистская ошибка, а не системная.
- Программистские ошибки случаются, когда программист не учитывает предварительные условия API или языка программирования. Если API требует, чтобы вы не вызывали
foo()с0в качестве первого параметра, а вы это сделали, — виноват программист. Если пользователь ввёл0, который был переданfoo(), а программист не написал проверку вводимых данных, то это опять же его вина.
Каждая из описанных категорий ошибок требует особого подхода к их обработке.
Пользовательские ошибки
Сделаю очень громкое заявление: такие ошибки — на самом деле не ошибки.
Все пользователи не соблюдают инструкции. Программист, имеющий дело с данными, которые вводят люди, должен ожидать, что вводить будут именно плохие данные. Поэтому первым делом нужно проверять их на валидность, сообщать пользователю об обнаруженных ошибках и просить ввести заново.
Поэтому не имеет смысла применять к пользовательским ошибкам какие-либо стратегии обработки. Вводимые данные нужно как можно скорее проверять, чтобы ошибок не возникало.
Конечно, такое не всегда возможно. Иногда проверять вводимые данные слишком дорого, иногда это не позволяет сделать архитектура кода или разделение ответственности. Но в таких случаях ошибки должны обрабатываться однозначно как исправимые. Иначе, допустим, ваша офисная программа будет падать из-за того, что вы нажали backspace в пустом документе, или ваша игра станет вылетать при попытке выстрелить из разряженного оружия.
Если в качестве стратегии обработки исправимых ошибок вы предпочитаете исключения, то будьте осторожны: исключения предназначены только для исключительных ситуаций, к которым не относится большинство случаев ввода пользователями неверных данных. По сути, это даже норма, по мнению многих приложений. Используйте исключения только тогда, когда пользовательские ошибки обнаруживаются в глубине стека вызовов, вероятно, внешнего кода, когда они возникают редко или проявляются очень жёстко. В противном случае лучше сообщать об ошибках с помощью кодов возврата.
Системные ошибки
Обычно системные ошибки нельзя предсказать. Более того, они недетерминистские и могут возникать в программах, которые до этого работали без нареканий. В отличие от пользовательских ошибок, зависящих исключительно от вводимых данных, системные ошибки — настоящие ошибки.
Но как их обрабатывать, как исправимые или неисправимые?
Это зависит от обстоятельств.
Многие считают, что ошибка нехватки памяти — неисправимая. Зачастую не хватает памяти даже для обработки этой ошибки! И тогда приходится просто сразу же прерывать выполнение.
Но падение программы из-за того, что ОС не может выделить сокет, — это не слишком дружелюбное поведение. Так что лучше бросить исключение и позволить catch аккуратно закрыть программу.
Но бросание исключения — не всегда правильный выбор.
Кто-то даже скажет, что он всегда неправильный.
Если вы хотите повторить операцию после её сбоя, то обёртывание функции в try-catch в цикле — медленное решение. Правильный выбор — возврат кода ошибки и цикличное исполнение, пока не будет возвращено правильное значение.
Если вы создаёте вызов API только для себя, то просто выберите подходящий для своей ситуации путь и следуйте ему. Но если вы пишете библиотеку, то не знаете, чего хотят пользователи. Дальше мы разберём подходящую стратегию для этого случая. Для потенциально неисправимых ошибок подойдёт «обработчик ошибок», а при других ошибках необходимо предоставить два варианта развития событий.
Обратите внимание, что не следует использовать подтверждения (assertions), включающиеся только в режиме отладки. Ведь системные ошибки могут возникать и в релизной сборке!
Программистские ошибки
Это худший вид ошибок. Для их обработки я стараюсь сделать так, чтобы мои ошибки были связаны только с вызовами функций, то есть с плохими параметрами. Прочие типы программистских ошибок могут быть пойманы только в runtime, с помощью отладочных макросов (assertion macros), раскиданных по коду.
При работе с плохими параметрами есть две стратегии: дать им определённое или неопределённое поведение.
Если исходное требование для функции — запрет на передачу ей плохих параметров, то, если их передать, это считается неопределённым поведением и должно проверяться не самой функцией, а оператором вызова (caller). Функция должна делать только отладочное подтверждение (debug assertion).
С другой стороны, если отсутствие плохих параметров не является частью исходных требований, а документация определяет, что функция будет бросать bad_parameter_exception при передаче ей плохого параметра, то передача — это хорошо определённое поведение (бросание исключения или любая другая стратегия обработки исправимых ошибок), и функция всегда должна это проверять.
В качестве примера рассмотрим получающие функции (accessor functions) std::vector<T>operator[] говорится, что индекс должен быть в пределах валидного диапазона, при этом at() сообщает нам, что функция кинет исключение, если индекс не попадает в диапазон. Более того, большинство реализаций стандартных библиотек обеспечивают режим отладки, в котором проверяется индекс operator[], но технически это неопределённое поведение, оно не обязано проверяться.
Примечание: необязательно бросать исключение, чтобы получилось определённое поведение. Пока это не упомянуто в исходных условиях для функции, это считается определённым. Всё, что прописано в исходных условиях, не должно проверяться функцией, это неопределённое поведение.
Когда нужно проверять только с помощью отладочных подтверждений, а когда — постоянно?
К сожалению, однозначного рецепта нет, решение зависит от конкретной ситуации. У меня есть лишь одно проверенное правило, которому я следую при разработке API. Оно основано на наблюдении, что проверять исходные условия должен вызывающий, а не вызываемый. А значит, условие должно быть «проверяемым» для вызывающего. Также условие «проверяемое», если можно легко выполнить операцию, при которой значение параметра всегда будет правильным. Если для параметра это возможно, то это получается исходное условие, а значит, проверяется только посредством отладочного подтверждения (а если слишком дорого, то вообще не проверяется).
Но конечное решение зависит от многих других факторов, так что очень трудно дать какой-то общий совет. По умолчанию я стараюсь свести к неопределённому поведению и использованию только подтверждений. Иногда бывает целесообразно обеспечить оба варианта, как это делает стандартная библиотека с operator[] и at().
Хотя в ряде случаев это может быть ошибкой.
Об иерархии std::exception
Если в качестве стратегии обработки исправимых ошибок вы выбрали исключения, то рекомендуется создать новый класс и наследовать его от одного из классов исключений стандартной библиотеки.
Я предлагаю наследовать только от одного из этих четырёх классов:
std::bad_alloc: для сбоев выделения памяти.std::runtime_error: для общих runtime-ошибок.std::system_error(производное отstd::runtime_error): для системных ошибок с кодами ошибок.std::logic_error: для программистских ошибок с определённым поведением.
Обратите внимание, что в стандартной библиотеке разделяются логические (то есть программистские) и runtime-ошибки. Runtime-ошибки — более широкое определение, чем «системные». Оно описывает «ошибки, обнаруживаемые только при выполнении программы». Такая формулировка не слишком информативна. Лично я использую её для плохих параметров, которые не являются исключительно программистскими ошибками, а могут возникнуть и по вине пользователей. Но это можно определить лишь глубоко в стеке вызовов. Например, плохое форматирование комментариев в standardese приводит к исключению при парсинге, проистекающему из std::runtime_error. Позднее оно ловится на соответствующем уровне и фиксируется в логе. Но я не стал бы использовать этот класс иначе, как и std::logic_error.
Подведём итоги
Есть два пути обработки ошибок:
- как исправимые: используются исключения или возвращаемые значения (в зависимости от ситуации/религии);
- как неисправимые: ошибки журналируются, а программа прерывается.
Подтверждения — это особый вид стратегии обработки неисправимых ошибок, только в режиме отладки.
Есть три основных источника ошибок, каждый требует особого подхода:
- Пользовательские ошибки не должны обрабатываться как ошибки на верхних уровнях программы. Всё, что вводит пользователь, должно проверяться соответствующим образом. Это может обрабатываться как ошибки только на нижних уровнях, которые не взаимодействуют с пользователями напрямую. Применяется стратегия обработки исправимых ошибок.
- Системные ошибки могут обрабатываться в рамках любой из двух стратегий, в зависимости от типа и тяжести. Библиотеки должны работать как можно гибче.
- Программистские ошибки, то есть плохие параметры, могут быть запрещены исходными условиями. В этом случае функция должна использовать только проверку с помощью отладочных подтверждений. Если же речь идёт о полностью определённом поведении, то функции следует предписанным образом сообщать об ошибке. Я стараюсь по умолчанию следовать сценарию с неопределённым поведением и определяю для функции проверку параметров лишь тогда, когда это слишком трудно сделать на стороне вызывающего.
Гибкие методики обработки ошибок в C++
Иногда что-то не работает. Пользователи вводят данные в недопустимом формате, файл не обнаруживается, сетевое соединение сбоит, в системе кончается память. Всё это ошибки, и их надо обрабатывать.
Это относительно легко сделать в высокоуровневых функциях. Вы точно знаете, почему что-то пошло не так, и можете обработать это соответствующим образом. Но в случае с низкоуровневыми функциями всё не так просто. Они не знают, что пошло не так, они знают лишь о самом факте сбоя и должны сообщить об этом тому, кто их вызвал.
В C++ есть два основных подхода: коды возврата ошибок и исключения. Сегодня широко распространено использование исключений. Но некоторые не могут / думают, что не могут / не хотят их использовать — по разным причинам.
Я не буду принимать чью-либо сторону. Вместо этого я опишу методики, которые удовлетворят сторонников обоих подходов. Особенно методики пригодятся разработчикам библиотек.
Проблема
Я работаю над проектом foonathan/memory. Это решение предоставляет различные классы выделения памяти (allocator classes), так что в качестве примера рассмотрим структуру функции выделения.
Для простоты возьмём malloc(). Она возвращает указатель на выделяемую память. Если выделить память не получается, то возвращается nullptr, то есть NULL, то есть ошибочное значение.
У этого решения есть недостатки: вам нужно проверять каждый вызов malloc(). Если вы забудете это сделать, то выделите несуществующую память. Кроме того, по своей натуре коды ошибок транзитивны: если вызвать функцию, которая может вернуть код ошибки, и вы не можете его проигнорировать или обработать, то вы тоже должны вернуть код ошибки.
Это приводит нас к ситуации, когда чередуются нормальные и ошибочные ветви кода. Исключения в таком случае выглядят более подходящим решением. Благодаря им вы сможете обрабатывать ошибки только тогда, когда вам это нужно, а в противном случае — достаточно тихо передать их обратно вызывающему.
Это можно расценить как недостаток.
Но в подобных ситуациях исключения имеют также очень большое преимущество: функция выделения памяти либо возвращает валидную память, либо вообще ничего не возвращает. Это функция «всё или ничего», возвращаемое значение всегда будет валидным. Это полезное следствие согласно принципу Скотта Майера «Make interfaces hard to use incorrectly and easy to use correctly».
Учитывая вышесказанное, можно утверждать, что вам следует использовать исключения в качестве механизма обработки ошибок. Этого мнения придерживается большинство разработчиков на С++, включая и меня. Но проект, которым я занимаюсь, — это библиотека, предоставляющая средства выделения памяти, и предназначена она для приложений, работающих в реальном времени. Для большинства разработчиков подобных приложений (особенно для игроделов) само использование исключений — исключение.
Каламбур детектед.
Чтобы уважить эту группу разработчиков, моей библиотеке лучше обойтись без исключений. Но мне и многим другим они нравятся за элегантность и простоту обработки ошибок, так что ради других разработчиков моей библиотеке лучше использовать исключения.
Так что же делать?
Идеальное решение: возможность включать и отключать исключения по желанию. Но, учитывая природу исключений, нельзя просто менять их местами с кодами ошибок, поскольку у нас не будет внутреннего кода проверки на ошибки — весь внутренний код опирается на предположение о прозрачности исключений. И даже если бы внутри можно было использовать коды ошибок и преобразовывать их в исключения, это лишило бы нас большинства преимуществ последних.
К счастью, я могу определить, что вы делаете, когда обнаруживаете ошибку нехватки памяти: чаще всего вы журналируете это событие и прерываете программу, поскольку она не может корректно работать без памяти. В таких ситуациях исключения — просто способ передачи контроля другой части кода, которая журналирует и прерывает программу. Но есть старый и эффективный способ передачи контроля: указатель функции (function pointer), то есть функция-обработчик (handler function).
Если у вас включены исключения, то вы просто их бросаете. В противном случае вызываете функцию-обработчика и затем прерываете программу. Это предотвратит бесполезную работу функции-обработчика, та позволит программе продолжить выполняться в обычном режиме. Если не прервать, то произойдёт нарушение обязательного постусловия функции: всегда возвращать валидный указатель. Ведь на выполнении этого условия может быть построена работа другого кода, да и вообще это нормальное поведение.
Я называю такой подход обработкой исключений и придерживаюсь его при работе с памятью.
Решение 1: обработчик исключений
Если вам нужно обработать ошибку в условиях, когда наиболее распространённым поведением будет «журналировать и прервать», то можно использовать обработчика исключений. Это такая функция-обработчик, которая вызывается вместо бросания объекта-исключения. Её довольно легко реализовать даже в уже существующем коде. Для этого нужно поместить управление обработкой в класс исключений и обернуть в макрос выражение throw.
Сначала дополним класс и добавим функции для настройки и, возможно, запрашивания функции-обработчика. Я предлагаю делать это так же, как стандартная библиотека обрабатывает std::new_handler:
class my_fatal_error
{
public:
// тип обработчика, он должен брать те же параметры, что и конструктор,
// чтобы у них была одинаковая информация
using handler = void(*)( ... );
// меняет функцию-обработчика
handler set_handler(handler h);
// возвращает текущего обработчика
handler get_handler();
... // нормальное исключение
};Поскольку это входит в область видимости класса исключений, вам не нужно именовать каким-то особым образом. Отлично, нам же легче.
Если исключения включены, то для удаления обработчика можно использовать условное компилирование (conditional compilation). Если хотите, то также напишите обычный подмешанный класс (mixin class), дающий требуемую функциональность.
Конструктор исключений элегантен: он вызывает текущую функцию-обработчика, передавая ей требуемые аргументы из своих параметров. А затем комбинирует с последующим макросом throw:
If```cpp #if EXCEPTIONS #define THROW(Ex) throw (Ex) #else #define THROW(Ex) (Ex), std::abort() #endif> Такой макрос throw также предоставляется [foonathan/compatiblity](https://github.com/foonathan/compatibility).
Можно использовать его и так:
```cpp
THROW(my_fatal_error(...))
Если у вас включена поддержка исключений, то будет создан и брошен объект-исключение, всё как обычно. Но если поддержка выключена, то объект-исключение всё равно будет создан, и — это важно — только после этого произойдёт вызов std::abort(). А поскольку конструктор вызывает функцию-обработчика, то он и работает, как требуется: вы получаете точку настройки для журналирования ошибки. Благодаря же вызову std::abort() после конструктора пользователь не может нарушить постусловие.
Когда я работаю с памятью, то при включённых исключениях у меня также включён и обработчик, который вызывается при бросании исключения.
Так что при этой методике вам ещё будет доступна определённая степень кастомизации, даже если вы отключите исключения. Конечно, замена неполноценная, мы только журналируем и прерываем работу программы, без дальнейшего продолжения. Но в ряде случаев, в том числе при исчерпании памяти, это вполне пригодное решение.
А если я хочу продолжить работу после бросания исключения?
Методика с обработчиком исключений не позволяет этого сделать в связи с постусловием кода. Как же тогда продолжить работу?
Ответ прост — никак. По крайней мере, это нельзя сделать так же просто, как в других случаях. Нельзя просто так вернуть код ошибки вместо исключения, если функция на это не рассчитана.
Есть только одно решение: сделать две функции. Одна возвращает код ошибки, а вторая бросает исключения. Клиенты, которым нужны исключения, будут использовать второй вариант, остальные — первый.
Извините, что говорю такие очевидные вещи, но ради полноты изложения я должен был об этом сказать.
Для примера снова возьмём функцию выделения памяти. В этом случае я использую такие функции:
void* try_malloc(..., int &error_code) noexcept;
void* malloc(...);
При сбое выделения памяти первая версия возвращает nullptr и устанавливает error_code в коде ошибки. Вторая версия не возвращает nullptr, зато бросает исключение. Обратите внимание, что в рамках первой версии очень легко реализовать вторую:
void* malloc(...)
{
auto error_code = 0;
auto res = try_malloc(..., error_code);
if (!res)
throw malloc_error(error_code);
return res;
}Не делайте этого в обратной последовательности, иначе вам придётся ловить исключение, а это дорого. Также это не даст нам скомпилировать код без включённой поддержки исключений. Если сделаете, как показано, то можете просто стереть другую перегрузку (overload) с помощью условного компилирования.
Но даже если у вас включена поддержка исключений, клиенту всё равно может понадобиться вторая версия. Например, когда нужно выделить наибольший возможный объём памяти, как в нашем примере. Будет проще и быстрее вызывать в цикле и проверять по условию, чем ловить исключение.
Решение 2: предоставить две перегрузки
Если недостаточно обработчика исключений, то нужно предоставить две перегрузки. Одна использует код возврата, а вторая бросает исключение.
Если рассматриваемая функция не имеет возвращаемого значения, то можете её использовать для кода ошибки. В противном случае вам придётся возвращать недопустимое значение для сигнализирования об ошибке — как nullptr в вышеприведённом примере, — а также установить выходной параметр для кода ошибки, если хотите предоставить вызывающему дополнительную информацию.
Пожалуйста, не используйте глобальную переменную errno или что-то типа GetLastError()!
Если возвращаемое значение не содержит недопустимое значение для обозначения сбоя, то по мере возможности используйте std::optional или что-то похожее.
Перегрузка исключения (exception overload) может — и должна — быть реализована в рамках версии с кодом ошибки, как это показано выше. Если компилируете без исключений, сотрите перегрузку с помощью условного компилирования.
std::system_error
Подобная система идеально подходит для работы с кодами ошибок в С++ 11.
Она возвращает непортируемый (non-portable) код ошибки std::error_code, то есть возвращаемый функцией операционной системы. С помощью сложной системы библиотечных средств и категорий ошибок вы можете добавить собственные коды ошибок, или портируемые std::error_condition. Для начала почитайте об этом здесь. Если нужно, то можете использовать в функции кода ошибки std::error_code. А для функции исключения есть подходящий класс исключения: std::system_error. Он берёт std::error_code и применяется для передачи этих ошибок в виде исключений.
Эту или подобную систему должны использовать все низкоуровневые функции, являющиеся закрытыми обёртками ОС-функций. Это хорошая — хотя и сложная — альтернатива службе кодов ошибок, предоставляемой операционной системой.
Да, и мне ещё нужно добавить подобное в функции виртуальной памяти. На сегодняшний день они не предоставляют коды ошибок.
std::expected
Выше упоминалось о проблеме, когда у вас нет возвращаемого значения, содержащего недопустимое значение, которое можно использовать для сигнализирования об ошибке. Более того, выходной параметр — не лучший способ получения кода ошибки.
А глобальные переменные вообще не вариант!
В № 4109 предложено решение: std::expected. Это шаблон класса, который также хранит возвращаемое значение или код ошибки. В вышеприведённом примере он мог бы использоваться так:
std::expected<void*, std::error_code> try_malloc(...);
В случае успеха std::expected будет хранить не-null указатель памяти, а при сбое — std::error_code. Сейчас эта методика работает при любых возвращаемых значениях. Комбинация std::expected и функции исключения определённо допускает любые варианты использования.
Заключение
Если вы создаёте библиотеки, то иногда приходится обеспечивать максимальную гибкость использования. Под этим подразумевается и разнообразие средств обработки ошибок: иногда требуются коды возврата, иногда — исключения.
Одна из возможных стратегий — улаживание этих противоречий с помощью обработчика исключений. Просто удостоверьтесь, что когда нужно, то вызывается callback, а не бросается исключение. Это замена для критических ошибок, которая в любом случае будет журналироваться перед прерыванием работы программы. Как таковой этот способ не универсален, вы не можете переключаться в одной программе между двумя версиями. Это лишь обходное решение при отключённой поддержке исключений.
Более гибкий подход — просто предоставить две перегрузки, одну с исключениями, а вторую без. Это даст пользователям максимальную свободу, они смогут выбирать ту версию, что лучше подходит в их ситуации. Недостаток этого подхода: вам придётся больше потрудиться при создании библиотеки.
Существует три
основных типа ошибок в программах:
— ошибки этапа
компиляции (или синтаксические ошибки);
— ошибки этапа
выполнения или семантические ошибки);
— логические
ошибки.
Cинтаксические
ошибки происходят из-за нарушений
правил синтаксиса
языка программирования.
Когда компилятор обнаруживает
синтаксическую
ошибку, то отмечает
место (позицию или строку) ошибки и
выводт сообщение
об ошибке.
Наиболее
распространенными синтаксическими
ошибками являются:
— ошибки набора
(опечатки);
— пропущенные
точки с запятой;
— ссылки на
неописанные переменные;
— передача
неверного числа (или типа) параметров
процедуры или
функции;
— присваивание
переменной значений неверного типа.
После исправления
cинтаксической ошибки компиляцию можно
выполнить
заново. После
устранения всех синтаксических ошибок
и успешной компиля-
ции программа готова
к выполнению и поиску ошибок этапа
выполнения и ло-
гических ошибок.
Семантические
ошибки происходят, когда программа
компилируется, но
при выполнении
операторов что-то происходит неверно.
Например, программа
пытается открыть
для ввода несуществующий файл или
выполнить деление на
ноль. При обнаружении
семантических ошибок выполнение
программы заверша-
ется и выводится
сообщение об ошибке. Например, в системе
Turbo Pascal
выводится сообщение
следующего вида:
Run-time error ## at seg:ofs
По номеру
ошибки (##) можно установить причину ее
возникновения.
Логические ошибки
— это ошибки проектирования и реализации
програм-
мы. Логические
ошибки приводят к некорректному или
непредвиденному зна-
чению переменных,
неправильному виду графических
изображений или невы-
полнению кода, когда
это ожидается. Эти ошибки часто трудно
отслежива-
ются, поскольку ни
компилятор, ни исполняющая система не
обнаруживают их
автоматически, как
синтаксические и семантические ошибки.
Обычно системы
программирования
включает в себя средства отладки,
помогающие найти ло-
гические ошибки.
3.4.2. Цели и задачи отладки и тестирования.
Многие программисты
путают отладку программ с тестированием,
пред-
назначенным для
проверки их работоспособности. Отладка
имеет место тог-
да, когда программа
со всей очевидностью работает неправильно.
Поэтому
отладка начинается
всегда в предположении отказа программы.
Если же ока-
зывается, что
программа работает верно, то она
тестируется. Часто случа-
ется так, что после
прогона тестов программа вновь должна
быть подверг-
нута отладке. Таким
образом, тестирование устанавливает
факт наличия
ошибки, а отладка
выявляет ее причину, и эти два этапа
разработки прог-
раммы перекрываются.
3.4.3. Основные возможности интегрированного отладчика системы
программирования
Turbo Pascal.
Основной смысл
использования встроенного отладчика
состоит в управ-
ляемом выполнении
программы. Отслеживая выполнение
каждой инструкции,
можно легко определить,
какая часть программы вызывает проблемы.
В от-
ладчике предусмотрено
шесть основных механизмов управления
выполнением
программы, которые
позволяют:
— выполнять
инструкции по шагам(Run|Step Over или F8);
— трассировать
инструкции (Run|Trace Into или F7);
— выполнять
программы до позиции курсора (Run|Go to
Cursor или F4);
— выполнять
программу до заданной точки (Toggle
Breakpoint или
Ctrl+F8);
— находить
определенную точку (Search|Find Procedure…);
— выполнять сброс
программы (Run¦Reset Program или Ctrl+F2).
Выполнение
программы по шагам (команда Step Over меню
выполнения
Run) и трассировка
программы (команда Trace Into меню выполнения
Run)
дают возможность
построчного выполнения программы.
Единственное отличие
выполнения по шагам
и трассировки состоит в том, как они
работают с вы-
зовами процедур и
функций. Выполнение по шагам вызова
процедуры или
функции интерпретирует
вызов как простой оператор и после
завершения
подпрограммы
возвращает управление на следующую
строку. Трассировка
подпрограммы
загружает код этой подпрограммы и
продолжает ее построчное
выполнение.
Выполнение
программы до заданной точки (команда
Toggle Breakpoint
локального меню
редактора) — более гибкий механизм
отладки, чем исполь-
зование метода
выполнения до позиции курсора (команда
Go to Cursor меню
выполнения Run),
поскольку в программе можно установить
несколько точек
останова.
Интегрированная
среда разработки программы предусматривает
несколь-
ко способов поиска
в программе заданного места. Простейший
способ пре-
доставляет команда
Search|Find Procedure…, которая запрашивает
имя
процедуры или
функции, затем находит соответствующую
строку в файле, где
определяется эта
подпрограмма. Этот подход полезно
использовать при ре-
дактировании, но
его можно комбинировать с возможностью
выполнения прог-
раммы до определенной
точки, чтобы пройти программу до той
части кода,
которую надо отладить.
Чтобы сбрасить
все ранее задействованные отладочные
средства и
прекратитьт отладку
программы необходимо выполнить команду
Run|Program
reset или нажать клавиши
Ctrl+F2.
При выполнении
программы по шагам можно наблюдать ее
вывод несколь-
кими способами:
— переключение
в случае необходимости экранов
(Debug|User screen
или Alt+F5);
— открытие окна
вывода (Debug¦Output);
— использование
второго монитора;
Выполнение
программы по шагам или ее трассировка
могут помочь найти
ошибки в алгоритме
программы, но обычно желательно также
знать, что про-
исходит на каждом
шаге со значениями отдельных переменных.
Например, при
выполнении по шагам
цикла for полезно знать значение переменной
цикла.
Встроенный отладчик
имеет два инструментальных средства
для проверки со-
держимого переменных
программы:
— окно Watches
(Просмотр);
— диалоговое окно
Evaluate and Modify (Вычисление и модификация).
Чтобы открыть
окно Watches, необходимо выполнить
команду
Debug|Watch. Чтобы добавить
в окно Watches переменную, необходимо выпол-
нить
команду
Debug¦Watch¦Add Watch… или
нажать клавиши Ctrl+F7. Если
окно Watches является
активным окном, то можно добавить
выражение
просмотра, нажав
клавишу Ins. Отладчик открывает диалоговое
окно Add
Watch, запрашивающее
тип просматриваемого выражения. По
умолчанию выра-
жением считается
слово в позиции курсора в текущем окне
редактирования.
Просматриваемые
выражения, которые отслеживались ранее,
сохраняются в
списке протокола.
Последнее добавленное или модифицированное
просматри-
ваемое выражение
является текущим просматриваемым
выражением, которое
указывается выводимым
слева от него символом жирной левой
точки. Если
окно Watches активно,
можно удалить текущее выражение, нажав
клавишу Del
или Ctrl+Y. Чтобы
удалить все просматриваемые выражения,
необходимо вы-
полнить команду
Clear All локального меню активного окна
Watches. Чтобы
отредактировать
просматриваемое выражение, нужно
выполнить команду
Modify… или нажать
клавишу Enter локального меню активного
окна
Watches. Отладчик
открывает диалоговое окно Edit Watch,
аналогичное то-
му, которое
используется для добавления просматриваемого
выражения, ко-
торое позволяет
отредактировать текущее выражение.
Чтобы вычислить
выражение, необходимо выполнить
команду
Debug¦Evaluate/Modify…
или
нажать
клавиши
Ctrl+F4. Отладчик
открывает
диалоговое окно
Evaluate and Modify. По умолчанию слово в позиции
курсо-
ра в текущем окне
редактирования выводится подсвеченным
в поле
Expression. Можно
отредактировать это выражение, набрать
другое выраже-
ние или выбрать
вычисленное ранее выражение из списка
протокола.
Даже если не
установлены точки останова, можно выйти
в отладчик при
выполнении программы,
нажав клавиши Ctrl+Break. Отладчик находит
позицию
в исходном коде, где
прервалась программа. Затем, как и в
случае обычной
точки останова,
можно выполнить программу по шагам,
трассировать ее,
отследить или
вычислить выражения.
Иногда в ходе
отладки полезно узнать, как вы попали
в данную часть
кода. Окно Call Stack
показывает последовательность вызовов
процедур или
функций, которые
привели к текущему состоянию (глубиной
до 128 уровней).
Для вывода окна Call
Stack необходимо выполнить команду
Debug¦Call Stack
или нажать клавиши
Ctrl+F3.
13
Соседние файлы в папке 13_3xN
- #
- #
- #



Мы поможем в написании ваших работ!
ЗНАЕТЕ ЛИ ВЫ?
ОСКОЛЬСКИЙ ПОЛИТЕХНИЧЕСКИЙ КОЛЛЕДЖ
| Утверждены: решением Учёного совета СТИ НИТУ «МИСиС» от «22» июня 2020 г. протокол № 23 |
ПМ.03 Ревьюирование программных продуктов
УП 03. Учебная практика
Методические указания
для студентов очной формы обучения
По выполнению практических работ
(в редакции 2020 г.)
Наименование специальности: 09.02.07 Информационные системы и программирование
Год набора: 2018
Квалификация выпускника: специалист по информационным системам
Срок освоения: 3 года 10 месяцев
Методические указания составлены в соответствии с рабочей программой ПМ.03 Ревьюирование программных продуктов специальности 09.02.07 Информационные системы и программирование
Разработчик:
Артюхина Д.Д. – преподаватель ОПК СТИ НИТУ «МИСиС»
Рекомендованы:
П(Ц)К специальностей 09.02.04, 09.02.07
 протокол № 09 от «20» мая 2020 г.
протокол № 09 от «20» мая 2020 г.
Председатель П(Ц)К ____________ Назарова О.И.
Согласованы:
на заседании НМС ОПК
 протокол № 05 от «03» июня 2020 г.
протокол № 05 от «03» июня 2020 г.
Председатель НМС ___________ Дерикот О.В.
Содержание
Введение. 4
Практическая работа №1. 7
Ревьюирование части информационной системы для определённого рабочего места 7
Практическая работа №2. 11
Тестирование информационной системы различными способами. 11
Практическая работа №3. 14
Описание выявленных ошибок и способов их устранения. Разработка инструкции по устранению выявленных ошибок информационной системы. 14
Практическая работа №4. 17
Оценка качества и надежности системы по результатам ее исследования. 17
Практическая работа №5. 21
Проведение работ по оптимизации программного кода. 21
Практическая работа №6. 24
Формирование отчетной документации по результатам работ. 24
Список использованных источников. 28
Введение
ПМ.03 Ревьюирование программных продуктов является частью программы подготовки специалиста среднего звена в соответствии с ФГОС СПО по специальности 09.02.07 Информационные системы и программирование.
Актуальность изучаемого профессионального модуля ПМ.03 Ревьюирование программных продуктов заключается в формировании у студентов общих и профессиональных компетенций, владение которыми позволят осуществлять исследование созданного программного кода с использованием специализированных программных средств.
В результате освоения профессионального модуля обучающийся должен уметь:
— работать с проектной документацией, разработанной с использованием графических языков спецификаций;
— выполнять оптимизацию программного кода с использованием специализированных программных средств;
— использовать методы и технологии тестирования и ревьюирования кода и проектной документации;
— применять стандартные метрики по прогнозированию затрат, сроков и качества;
— распознавать задачу и/или проблему в профессиональном и/или социальном контексте;
— владеть актуальными методами работы в профессиональной и смежных сферах;
— определять задачи для поиска информации; определять необходимые источники информации;
— определять и выстраивать траектории профессионального развития и самообразования;
— взаимодействовать с коллегами, руководством, клиентами в ходе профессиональной деятельности;
— грамотно излагать свои мысли и оформлять документы по профессиональной тематике на государственном языке, проявлять толерантность в рабочем коллективе;
— описывать значимость своей специальности;
— определять направления ресурсосбережения в рамках профессиональной деятельности по специальности;
— применять рациональные приемы двигательных функций в профессиональной деятельности;
— применять средства информационных технологий для решения профессиональных задач;
— строить простые высказывания о себе и о своей профессиональной деятельности.
В результате освоения профессионального модуля обучающийся должен знать:
— задачи планирования и контроля развития проекта;
— принципы построения системы деятельностей программного проекта;
— современные стандарты качества программного продукта и процессов его обеспечения;
— основные источники информации и ресурсы для решения задач и проблем в профессиональном и/или социальном контексте;
— алгоритмы выполнения работ в профессиональной и смежных областях; методы работы в профессиональной и смежных сферах;
— номенклатура информационных источников, применяемых в профессиональной деятельности;
— возможные траектории профессионального развития и самообразования;
— основы проектной деятельности;
— правила оформления документов и построения устных сообщений;
— значимость профессиональной деятельности по специальности;
— основные ресурсы, задействованные в профессиональной деятельности;
— условия профессиональной деятельности и зоны риска физического здоровья для
— специальности;
— порядок применения программного обеспечения в профессиональной деятельности;
— лексический минимум, относящийся к описанию предметов, средств и процессов профессиональной деятельности.
Методические указания по выполнению практических работ по ПМ.03 Ревьюирование программных продуктов УП 03 Учебная практика предназначены для обучающихся 3 курса специальности 09.02.07 Информационные системы и программирование.
Практические работы проводятся с целью получения практического опыта в области:
— в измерении характеристик программного проекта;
— использовании основных методологий процессов разработки программного обеспечения;
— оптимизации программного кода с использованием специализированных программных средств.
Выполнение обучающимися практических работ направлено на формирование элементов общих компетенций:
ОК 01. Выбирать способы решения задач профессиональной деятельности, применительно к различным контекстам
ОК 02. Осуществлять поиск, анализ и интерпретацию информации, необходимой для выполнения задач профессиональной деятельности.
ОК 03. Планировать и реализовывать собственное профессиональное и личностное развитие.
ОК 04. Работать в коллективе и команде, эффективно взаимодействовать с коллегами, руководством, клиентами.
ОК 05. Осуществлять устную и письменную коммуникацию на государственном языке с учетом особенностей социального и культурного контекста.
ОК 06. Проявлять гражданско-патриотическую позицию, демонстрировать осознанное поведение на основе традиционных общечеловеческих ценностей
ОК 07. Содействовать сохранению окружающей среды, ресурсосбережению, эффективно действовать в чрезвычайных ситуациях.
ОК 08. Использовать средства физической культуры для сохранения и укрепления здоровья в процессе профессиональной деятельности и поддержания необходимого уровня физической подготовленности
ОК 09. Использовать информационные технологии в профессиональной деятельности.
ОК 10. Пользоваться профессиональной документацией на государственном и иностранном языке
Выполнение обучающимися практических работ направлено на формирование элементов профессиональных компетенций:
ПК 3.1 Осуществлять ревьюирование программного кода в соответствии с технической документацией
ПК 3.2 Выполнять измерение характеристик компонент программного продукта для определения соответствия заданным критериям
ПК 3.3 Производить исследование созданного программного кода с использованием специализированных программных средств, с целью выявления ошибок и отклонения от алгоритма
ПК 3.4 Проводить сравнительный анализ программных продуктов и средств разработки, с целью выявления наилучшего решения согласно критериям, определенным техническим заданием.
Практическая работа №1
Задание:
1. Изучить теоретическую часть.
2. Выполнить задание, следуя указаниям.
3. Ответить на контрольные вопросы (в устной форме).
4. Предъявить преподавателю результаты работы программы и исходные коды.
5. Оформить отчет в соответствии с ходом работы (тема, цель, условие задачи, программный код, результаты тестирования программы, выводы).
Теоретические сведения:
Не во всех случаях возможна разработка автоматических или хотя бы четко формализованных ручных тестов для проверки функциональности программной системы. В некоторых случаях выполнение программного кода, подвергаемого тестированию, невозможно в условиях, создаваемых тестовым окружением (например, во встроенных системах, если программный код предназначен для обработки исключительных ситуаций, создаваемых только при установке системы на реальное оборудование). В других случаях верифицируется не программный код, а проектная документация на систему, которую нельзя «выполнить» или создать для нее отдельные тестовые примеры. И в тех и в других случаях обычно прибегают к методу экспертных исследований программного кода или документации на корректность или непротиворечивость.
Такие экспертные исследования обычно называют инспекциями или просмотрами. Существует два типа инспекций – неформальные и формальные.
Формальная инспекция является четко управляемым процессом, структура которого обычно четко определяется соответствующим стандартом проекта. Таким образом, все формальные инспекции имеют одинаковую структуру и одинаковые выходные документы, которые затем используются при разработке.
Факт начала формальной инспекции четко фиксируется в общей базе данных проекта. Также фиксируются документы, подвергаемые инспекции, списки замечаний, отслеживаются внесенные по замечаниям изменения. Этим формальная инспекция похожа на автоматизированное тестирование – списки замечаний имеют много общего с отчетами о выполнении тестовых примеров.
В ходе формальной инспекции группой специалистов осуществляется независимая проверка соответствия инспектируемых документов исходным документам. Независимость проверки обеспечивается тем, что она осуществляется инспекторами, не участвовавшими в разработке инспектируемого документа. Входами процесса формальной инспекции являются инспектируемые документы и исходные документы, а выходами – материалы инспекции, включающие список обнаруженных несоответствий и решение об изменении статуса инспектируемых документов. рис. 1 иллюстрирует место формальной инспекции в процессе разработки программных систем.

Рис.1. Место формальной инспекции в процессе разработки программных систем
Выполнение работы:
Задание. Следуя указаниям, создайте программу, которая запрашивает у нового сотрудника имя, фамилию и дату рождения. Вы будете хранить эту информацию в свойствах нового класса с именем Person, и создадите метод класса, который будет вычислять текущий возраст нового сотрудника. Этот проект научит вас создавать собственные классы, экземпляры классов (объекты) а также как использовать эти классы в процедурах событий вашей программы.
Добавление в ваш проект нового класса
Класс, определенный пользователем, позволяет определить в программе ваши собственные объекты, которые имеют свойства, методы и события, точно так же, как объекты, создаваемые на формах Windows с помощью элементов управления из Области элементов. Чтобы добавить в ваш проект новый класс, щелкните в меню Проект (Project) на команде Добавить класс (AddClass), а затем определите этот класс с помощью кода программы и нескольких новых ключевых слов VisualBasic.
Создание свойств
1. Под объявлением переменных введите следующий оператор программы и нажмите клавишу (Enter):
Этот оператор создает свойство вашего класса с именем FirstName, которое имеет тип String. Когда вы нажмете (Enter), VisualStudio немедленно создаст структуру кода для остальных элементов объявления свойства. Требуемыми элементами являются: блок Get, который определяет, что программисты увидят, когда будут проверять свойство FirstName, блок Set, который определяет, что произойдет, когда свойство FirstName будет установлено или изменено, и оператор EndProperty, который отмечает конец процедуры свойства.
2. Заполните структуру процедуры свойства так, чтобы она выглядела, как показано ниже.
Ключевое слово Return указывает, что при обращении к свойству FirstName будет возвращена строковая переменная Name1. При установке значения свойства блок Set присваивает переменной Name1 строковое значение. Обратите особое внимание на переменную Value, используемую в процедурах свойств для обозначения значения, которое присваивается свойству класса при его установке. Хотя этот синтаксис может выглядеть странно, просто поверьте мне — именно так создаются свойства в элементах управления, хотя более сложные свойства будут иметь здесь дополнительную программную логику, которая будет проверять значения и производить вычисления.
3. Под оператором EndProperty введите для свойства LastName вашего класса вторую процедуру свойства. Она должна выглядеть так, как показано ниже.
Эта процедура свойства аналогична первой, за исключением того, что она использует вторую строковую переменную (Name2), которую вы объявили в верхней части кода класса. Вы закончили определять два свойства вашего класса. Теперь перейдем к методу с именем Age, который будет определять текущий возраст нового сотрудника на основе даты рождения.
Создание метода
· Под процедурой свойства LastName введите следующее определение функции:
Чтобы создать метод класса, который выполняет некое действие, добавьте в ваш класс процедуру Sub. Хотя многие методы не требуют для выполнения своей работы аргументов, метод Age, определенный мной, требует для своих вычислений аргумент Birthday типа Date. Это метод использует для вычитания даты рождения нового сотрудника из текущей системной даты метод Subtract, и возвращает значение, выраженное в днях, деленных на 365.25 — примерную длину одного года в днях. Функция Int преобразует это значение в целое, и это число с помощью оператора Return возвращается в вызывающую процедуру — как и в случае с обычной функцией.
Определение класса закончено! Вернитесь к форме Form1 и используйте новый класс в процедуре события.
Совет. Хотя в данном примере это и не делалось, в реальном проекте полезно добавить в модуль класса логику для проверки типов данных. Это делается для того, чтобы неправильное использование свойств или методов, не приводило к возникновению ошибок времени исполнения, из-за которых выполнение программы может прерваться.
Практическая работа №2
Задание:
1. Определить предметную область и сферу применения программного продукта.
2. Определить целевую аудиторию.
3. Построить описательную модель пользователя (профиль). При необходимости — выделить группы пользователей.
4. Сформировать множество сценариев поведения пользователей на основании составленной модели.
5. Выделить функциональные блоки приложения и схему навигации между ними (структуру диалога).
6. Провести тестирование интерфейса пользователя.
Теоретические сведения:
Тео Мандел в своей работе выделяет четыре этапа разработки пользовательского интерфейса, а именно:
· Сбор и анализ информации от пользователей;
· Разработка пользовательского интерфейса;
· Построение пользовательского интерфейса;
· Подтверждение качества пользовательского интерфейса.
Первый шаг – определение профиля пользователя. Профиль пользователя отвечает на вопрос: «Что представляет наш пользователь?». Он позволяет нам составить представление о возрасте, образовании, предпочтениях пользователей.
Второй шаг – анализ стоящих перед пользователями задач.
Анализ стоящих перед пользователями задач – это определение того, чего хотят пользователи и каким образом они собираются решать свои задачи.
Концептуальное проектирование есть определение общей структуры и взаимодействия продукта. По определению Алана Купера, концептуальные принципы проектирования «помогают определить сущность продукта и его место в более широком контексте использования, который требуется пользователям».
Концептуальное проектирование включает:
· Определение типа интерфейса будущего приложения (монопольный, временный, фоновый);
· Организацию инфраструктуры взаимодействия;
Согласно определению Алана Купера, тип интерфейса определяет поведенческую сущность продукта, то есть то, как он предъявляет себя пользователю. Тип интерфейса – это способ описать то, как много внимания пользователь будет уделять взаимодействию c продуктом, и каким образом продукт будет реагировать на это внимание.
Следует отметить зависимость типа интерфейса от используемой технической платформы: персонального компьютера, Интернет, информационный киоск, мобильное устройство, бытовая техника.
Применительно к программам, которые разрабатываются для современных персональных компьютеров, в литературе также используется термин «настольное приложение».
Интерфейс настольных приложений можно отнести к одному из трёх типов: монопольный, временный и фоновый.
К приложениям монопольного типа относятся программы, которые полностью завладевают вниманием пользователя на длительные периоды времени. Для продуктов с монопольным интерфейсом характерна длительная работа в течение длительных отрезков времени. В процессе работа пользователя монопольный продукт является его основным инструментом и преобладает над остальными.
Приложение временного типа приходит и уходит, предлагая одну функцию и ограниченный набор связанных с этой функцией элементов управления. Приложение этого типа вызывается при необходимости, делает свою работу и быстро исчезает, позволяя пользователю продолжить прерванную (как правило, в окне монопольного приложения) деятельность. Типичный пример сценария работы с временным приложением – вызов Проводника Windows для поиска и открытия другого файла в то время, когда пользователь уже редактирует один файл в MS Word.
Фоновыми называют приложения, которые в нормальном «рабочем» состоянии не взаимодействуют с пользователем. Такие программы выполняют задачи, которые в целом важны, но не требуют вмешательства пользователя. Примеры: драйвер принтера, подключение к сети.
Инфраструктура взаимодействия включает варианты поведения приложения. Создание инфраструктуры взаимодействия предполагает выполнение шести шагов:
Шаг 1. Определение форм-фактора, типа приложения и способов управления.
Шаг 2. Определение функциональных и информационных элементов.
Шаг 3. Определение функциональных групп и иерархических связей между ними.
Шаг 4. Макетирование общей инфраструктуры взаимодействия.
Шаг 5. Создание ключевых сценариев.
Шаг 6. Выполнение проверочных сценариев для верификации решений.
Форм-фактор – это зависимость вида пользовательского интерфейса от используемой технической платформы.
Функциональные и информационные элементы – это зримые представления функций и данных, доступные пользователю посредством интерфейса. Это конкретные проявления функциональных и информационных потребностей, выявленных на стадии выработки требований.
Информационные элементы – это, как правило, фундаментальные объекты интерактивных продуктов.
Функциональные элементы – это операции, которые могут выполняться над информационными объектами и представляющими эти объекты элементами интерфейса. В большинстве случаев функциональные элементы представляют собой инструменты, работающие с информационными элементами, а также контейнеры, содержащие информационные элементы.
Макетирование общей инфраструктуры взаимодействия Аланом Купером охарактеризовано как «фаза прямоугольников», поскольку эскизы будущего интерфейса начинаются с разделения каждого представления на прямоугольные области, соответствующие панелям, элементам управления и другим высокоуровневым контейнерам. При этом каждому прямоугольнику даётся своё название и показывается, каким образом одна группа элементов может влиять на другие. Содержательно этот шаг предназначен для исследования различных вариантов представления информации и функциональности в интерфейсе, при этом затраты на внесение изменений должны быть минимальны.
Известны два вида макетов: с жёсткой компоновкой и без компоновки.
При этом макет с жёсткой компоновкой:
· содержит взаимное расположение элементов и визуальную информацию о приоритетах;
· ограничивает работу графического дизайнера.
Для макета без компоновки характерно то, что он:
· не содержит графического представления элементов;
· содержит текстовое описание элементов и их приоритетов;
· не ограничивает работу графического дизайнера.
Сценарий определяется Аланом Купером как средство описания идеального для пользователя взаимодействия. Истоки этого понятия восходят к публикациям сообщества HCI (Human-Computer Interaction – взаимодействие человека и компьютера), где оно увязывалось с указанием на метод решения задач проектирования через конкретизацию, которая понималась как использование специально составленного рассказа, чтобы одновременно конструировать и иллюстрировать проектные решения. Применение сценарного подхода к проектированию, как показано в книге Кэрролла «Making Use» (Carroll, 2000), сосредоточено на описании того, как пользователи решают задачи. Такое описание включает характеристику обстановки рабочей среды, а также агентов, или действующих лиц, которые являются абстрактными представителями пользователей.
Сценарии, основанные на персонажах, есть краткие описания одного или более персонажей, применяющих программный продукт для достижения конкретных целей. Сценарии позволяют начинать проектирование с рассказа, описывающего идеальный с точки зрения персонажа опыт, при этом фокусируя внимание на людях, их образе мысли и поведении.
Процесс выработки требований с использованием персонажей и сценариев состоит из следующих пяти шагов:
Шаг 1. Постановка задач и определение образа продукта.
Шаг 2. Мозговой штурм.
Шаг 3. Выявление ожиданий персонажей.
Шаг 4. Разработка контекстных сценариев.
Шаг 5. Выявление требований.
Ключевой сценарий описывает взаимодействие персонажа с системой в терминах лексикона инфраструктуры взаимодействия. Он отражает магистральные пути внутри интерфейса, используемые персонажем чаще всего (например, ежедневно). Ключевые сценарии сосредоточены на задачах. Например, в случае приложения для работы с электронной почтой ключевые действия – это просмотр и создание новых сообщений, а не настройка нового почтового сервера.
Ключевые сценарии, как правило, являются результатом развития контекстных сценариев, но целенаправленно описывают взаимодействие персонажа с различными функциональными и информационными элементами, составляющими общую инфраструктуру взаимодействия.
Контекстные сценарии сосредоточены на целях, же ключевые сценарии больше сосредоточены на задачах, намеки на которые или описания которых содержатся в контекстных сценариях.
Выполнение работы:
В качестве основы для выполнения данной лабораторной работы предлагается использовать одно из ранее разработанных ими приложений.
Предметная область и сфера применения. Правильное определение этих аспектов является основой для разработки UI в частности и всего приложения в целом. Определение целевой аудитории, направлен на выделение из общей массы группы (или групп) потенциальных пользователей разрабатываемой программы. Естественно, что цели, задачи, способности и возможности групп пользователей будут существенно различаться.
Модель пользователя, или профиль, формируется в результате анализа целевых групп. Она отражает наиболее общие черты, характерные для представителей группы и может представлять следующую информацию о пользователе:
· Социальные и демографические характеристики (возраст, пол, основной язык, род занятий, потребности, привычки и т.п.).
· Уровень компьютерной грамотности.
· Цель и задачи, решаемые пользователем.
· Окружение (рабочее место, конфигурация оборудования, используемая операционная система и т.п.)
· Требования, специфичные для конкретной целевой группы.
После выделения одного или нескольких основных профилей пользователей и определения задач, стоящих перед ними, переходят к следующему этапу проектирования. Он связан с составлением пользовательских сценариев. Сценарий — это описание действий, выполняемых пользователем в рамках решения конкретной задачи на пути достижения его цели. Очевидно, что достигнуть некоторой цели можно, решая ряд задач. Каждую их них пользователь может решать несколькими способами, следовательно, должно быть сформировано несколько сценариев. Чем больше их будет, тем ниже вероятность того, что некоторые ключевые объекты и операции будут упущены.
Требования к отчету: Текст должен быть написан шрифтом Times New Roman, 12. Интервал между строками и абзацами – 1,5. Отступ слева 1,5. Ориентация текста – по ширине страницы. Скриншоты необходимо подписать. Название практической работы, цель работы, ход работы, вывод, ответы на контрольные вопросы, должны быть выделены жирным шрифтом, так же как в методичке.
Контрольные вопросы:
1. Что такое интерфейс?
2. Какие типы пользовательских интерфейсов существуют?
3. Перечислите этапы разработки пользовательских интерфейсов?
4. К какому типу интерфейсов будет относиться интерфейс, разработанный в данной лабораторной работе?
5. Какие модели интерфейсов существуют?
6. Какая модель интерфейса будет использована в данной работе?
7. Что такое диалог?
8. Какие типы диалогов существуют?
9. Какие формы диалога Вы знаете?
10. Какой тип диалога и какая форма диалога будет использована в данной работе?
Практическая работа №3
Задание:
1) Ознакомиться с лекционным материалом по теме «Тестирование, отладка и ПО»
2) Провести функциональное тестирование разработанного программного обеспечения
Теоретические сведения:
Процесс тестирования состоит из трёх этапов:
1. Проектирование тестов.
2. Исполнение тестов.
3. Анализ полученных результатов.
На первом этапе решается вопрос о выборе некоторого подмножества множества тестов, которое сможет найти наибольшее количество ошибок за наименьший промежуток времени. На этапе исполнения тестов проводят, запуск тестов и отлавливают ошибки в тестируемом программном продукте.
Виды тестов
Функциональные тесты составляются на уровне спецификации, до решения задачи. Будущий алгоритм рассматривается как «черный ящик» — функция с неизвестной (или не рассматриваемой) структурой, преобразующая входы в выходы. Суть функциональных тестов: каким бы способом ни решалась задача, при заданных входных значениях должны получиться соответствующие выходные значения.
Структурные тесты составляются для проверки логики решения, или логики работы уже готового алгоритма. Логика определяется последовательностью операций, их условным выполнением или повторением (т.е. композицией базовых конструкций). Совокупность структурных тестов должна обеспечить проверку каждой из таких конструкций.
Чаще всего совокупность тщательно составленных функциональных тестов покрывает множество структурных тестов.
Приведенные понятия различаются тем, что первое рассматривает программу только с точки зрения входов и выходов, тогда как второе относится к ее структуре; но оба понятия не касаются процесса организации тестирования.
Общая последовательность разработки тестов
Наиболее рациональная процедура заключается в том, что сначала разрабатываются функциональные тесты, а затем – структурные.
Функциональное тестирование (тестирование «черного ящика»)
При функциональном тестировании выявляются следующие категории ошибок:
· некорректность или отсутствие функций;
· ошибки интерфейса;
· ошибки в структурах данных;
· ошибки машинных характеристик (нехватка памяти и др.);
· ошибки инициализации и завершения.
Техника тестирования ориентирована:
· на сокращение необходимого количества тестовых вариантов;
· на выявление классов ошибок, а не отдельных ошибок.
Способы функционального тестирования
Разбиение на классы эквивалентности
Это самый популярный способ. Его суть заключается в разделении области входных данных программы на классы эквивалентности и разработке для каждого класса одного тестового варианта.
Класс эквивалентности – набор данных с общими свойствами, в силу чего при обработке любого набора данных этого класса задействуется один и тот же набор операторов.
Классы эквивалентности определяются по спецификации программы. Тесты строятся в соответствии с классами эквивалентности, а именно: выбирается вариант исходных данных некоторого класса и определяются соответствующие выходные данные.
Самыми общими классами эквивалентности являются классы допустимых и недопустимых (аномальных) исходных данных. Описание класса строится как комбинация условий, описывающих каждое входное данное.
Условия допустимости или недопустимости данных задают возможные значения данных и могут описывать:
· некоторое конкретное значение; определяется один допустимый и два недопустимых класса эквивалентности: заданное значение, множество значений меньше заданного, множество значений больше заданного;
· диапазон значений; определяется один допустимый и два недопустимых класса эквивалентности: множество значений в границах диапазона; множество значений, выходящих за левую границу диапазона; множество значений, выходящих за правую границу диапазона;
· множество конкретных значений; определяется один допустимый и один недопустимый класс эквивалентности: заданное множество и множество значений, в него не входящих.
Такие классы можно описать языком логики, например, языком исчисления предикатов. Описания более сложных условий и соответствующих классов (например, элементы массива должны находиться в некотором диапазоне и при этом массив не должен содержать нулевых элементов) могут быть построены на основании приведенных выше условий.
В примере, приводимом в вопросе 2 темы 3, при построении тестов неформально использовался описанный метод. В методических целях были выделены только основные класс тестов. Кроме того, исходя из условия задачи, были выделены классы эквивалентности внутри класса правильных данных.
Анализ граничных значений
Этот способ построения тестов дополняет предыдущий. Также он предполагает анализ значений, лежащих на границе допустимых и недопустимых данных. Построение таких тестов часто диктуется интуицией.
Основные правила построения тестов:
· если условие правильности данных задает диапазон, то строятся тесты для левой и правой границы диапазона; для значений чуть левее левой и чуть правее правой границы;
· если условие правильности данных задает дискретное множество значений, то строятся тесты для минимального и максимального значений; для значений чуть меньше минимума и чуть больше максимума;
· если используются структуры данных с переменными границами (массивы), то строятся тесты для минимального и максимального значения границ.
· Диаграммы причин-следствий
· Взаимосвязь классов эквивалентности и соответствующих им действий описывается формально в виде графа на основе автоматного подхода. Граф преобразуется в таблицу решений, столбцы которой в свою очередь преобразуются в тестовые варианты.
Выполнение работы:
1) Разработать тестовые наборы для функционального тестирования.
2) Провести тестирование программы и представить результаты в виде таблицы.
3) Выработать рекомендации для корректировки тестируемой программы.
4) Представить отчет по лабораторной работе для защиты.
Требования к отчету: Текст должен быть написан шрифтом Times New Roman, 12. Интервал между строками и абзацами – 1,5. Отступ слева 1,5. Ориентация текста – по ширине страницы. Скриншоты необходимо подписать. Название практической работы, цель работы, ход работы, вывод, ответы на контрольные вопросы, должны быть выделены жирным шрифтом, так же как в методичке.
Контрольные вопросы:
1. Что такое тестирование ПС?
2. Чем тестирование отличается от отладки ПС?
3. Для чего проводится функциональное тестирование?
4. Каковы правила тестирования программы «как черного ящика»?
5. Как проводится тестирования программы по принципу «белого ящика»?
6. Как осуществляется сборка программы при модульно тестировании?
Практическая работа №4
Практическая работа №5
Задание:
Разработать тестовые модулей проекта для тестирования отдельных модулей, провести оптимизацию программы по выбранному параметру.
Теоретические сведения:
Оптимизация – преобразование программы, сохраняющее ее семантику (конструкции языка программирования), но уменьшающие ее размер и время выполнения.
Виды оптимизация программы:
· глобальная (всей программы);
· локальная (нескольких соседних операторов, образующих линейный участок);
· квазилокальная (фрагментов программы фиксированной структуры, например, циклов).
Способы оптимизации:
1. Разгрузка участков повторяемости: вынесение вычислений из многократно проходимых исполняемых участков программы на участки программы, редко проходимые. Таким образом, это преобразование тела цикла или рекурсивных процедур.
2. Упрощение действий: улучшение программы за счет замены групп вычислений на группу вычислений, дающих тот же результат с точки зрения всей программы, но имеющих меньшую сложность.
а) упрощение действий происходит при замене сложных операций в выражениях более простыми: x / 0.4 -> x*0.25;
б) преобразование по объединению или расчленению циклов, по перестановке заголовков циклов, по удалению избыточных выражений (замене их на переменную).
3. Реализация действия: действия над константами заменяются на константы; ликвидация константных распознавателей -замена условного оператора на одну из его ветвей, если его выбирающее условие-выражение имеет постоянное значение; удаление из программы ненужных пересылок вида:
Y=F(W), X=Y на X=F(W)
4. Чистка программы (удаление ненужных конструкций): недостижимых операторов, существенных операторов, неиспользуемых переменных, видов, операций.
5. Сокращение размера программы: вынесение одинаковых конструкций в начальную или конечную точку программы; поиск в программе похожих объектов и формирование их в виде процедуры.
6. Экономия памяти -уменьшение объема памяти, отводимые под информационные объекты программы (например, параметры процедуры).
Выполнение работы:
Поможем в ✍️ написании учебной работы
Учебное заведение: ТОГБПОУ
Населённый пункт: г.Уварово
Наименование материала: Комплект контрольно-оценочных средств
Тема: Комплект контрольно-оценочных средств по профессиональному модулю ПМ 3 Ревьюирование программных продуктов
Тамбовское областное государственное бюджетное
профессиональное образовательное учреждение
«Уваровский химико-технологический колледж»
РАССМОТРЕНО ОДОБРЕНО:
Предметно-цикловой комиссией
_информационных технологий_
Протокол №_______________
от «__»_______________ 2019г.
Председатель ПЦК____________
УТВЕРЖДАЮ:
Директор ТОГБПОУ УХТК
____________Н.А.Ермакова
«__»_______________ 2019г.
Комплект контрольно-оценочных средств по профессиональному модулю
ПМ 3 Ревьюирование программных продуктов
основной профессиональной образовательной программы (ОПОП) по
направлению подготовки (специальности)
по специальности СПО
09.02.07 «Информационные системы и программирование»
(код, название)
1
СОДЕРЖАНИЕ
1 ПАСПОРТ КОНТРОЛЬНО-ИЗМЕРИТЕЛЬНЫХ МАТЕРИАЛОВ ……………………….3
2 КОМПЛЕКТ МАТЕРАЛОВ ДЛЯ ТЕКУЩЕЙ АТТЕСТАЦИИ ……………………………..5
3КОМПЛЕКТ МАТЕРАЛОВ ДЛЯ ПРОМЕЖУТОЧНОЙ АТТЕСТАЦИИ ………….10
2
1 ПАСПОРТ КОНТРОЛЬНО-ИЗМЕРИТЕЛЬНЫХ МАТЕРИАЛОВ
Контрольно-
измерительные
материалы
предназначены
для
проверки
результатов
освоения
профессионального модуля ПМ.03 Ревьюирование программных продуктов программы
подготовки специалистов среднего звена по специальности 09.02.07 Информационные
системы и программирование. Контрольно-измерительные материалы позволяют оценивать
освоение умений и усвоение знаний по междисциплинарному курсу.
1.1 Контроль и оценка результатов освоения
Результаты обучения (освоенные умения,
усвоенные знания)
Формы и методы контроля и оценки
результатов обучения
В результате изучения профессионального
модуля обучающийся должен уметь:
работать с проектной документацией,
разработанной с использованием
графических языков спецификаций;
• выполнять оптимизацию программного
кода с использованием специализированных
программных средств;
• использовать методы и технологии
тестирования и ревьюирования кода и
проектной документации;
• применять стандартные метрики по
прогнозированию затрат, сроков и качества
Тестирование
Практическое задание
Дифференцированный зачет
В результате изучения профессионального
модуля обучающийся должен
Знать:
• задачи планирования и контроля развития
проекта;
• принципы построения системы
деятельностей программного проекта;
• современные стандарты качества
программного продукта и процессов его
обеспечения
Тестирование
Практическое задание
Дифференцированный зачет
1.2 Организация промежуточного контроля
Промежуточный контроль освоения междисциплинарного курса осуществляется в форме
дифференцированного зачёта.
Дифференцированный зачет проводится в виде устного ответа на теоретические вопросы
и выполнения практического задания на компьютере
1.3. Освоение профессиональных и общих компетенций
Наименование результата обучения
Средства проверки
ПК 3.1 Осуществлять ревьюирование
программного кода в соответствии с
технической документацией
Вопросы для текущего контроля
Тесты
Практическое задание
ПК.3.2 Выполнять измерение
характеристик компонент программного
продукта для определения соответствия
заданным критериям
Вопросы для текущего контроля
Тесты
Практическое задание
ПК.3.3 Производить исследование
Вопросы для текущего контроля
3
созданного программного кода с
использованием специализированных
программных средств с целью выявления
ошибок и отклонения от алгоритма
Тесты
Практическое задание
ПК.3.4 Проводить сравнительный анализ
программных продуктов и средств
разработки, с целью выявления наилучшего
решения согласно критериям,
определенным техническим заданием
Вопросы для текущего контроля
Тесты
Практическое задание
ОК 1 Выбирать способы решения задач
профессиональной деятельности,
применительно к различным контекстам
Вопросы для текущего контроля
Тесты
Практическое задание
ОК 2 Осуществлять поиск, анализ и
интерпретацию информации, необходимой
для выполнения задач профессиональной
деятельности
Вопросы для текущего контроля
Тесты
Практическое задание
ОК 3 Планировать и реализовывать
собственное профессиональное и
личностное развитие
Вопросы для текущего контроля
Тесты
Практическое задание
ОК 4 Работать в коллективе и команде,
эффективно взаимодействовать с
коллегами, руководством, клиентами
Вопросы для текущего контроля
Тесты
Практическое задание
ОК 5 Осуществлять устную и письменную
коммуникацию на государственном языке с
учетом особенностей социального и
культурного контекста.
Вопросы для текущего контроля
Тесты
Практическое задание
ОК 6 Проявлять гражданско-
патриотическую позицию, демонстрировать
осознанное поведение на основе
традиционных общечеловеческих
ценностей
Вопросы для текущего контроля
Тесты
Практическое задание
ОК 7 Содействовать сохранению
окружающей среды, ресурсосбережению,
эффективно действовать в чрезвычайных
ситуациях
Вопросы для текущего контроля
Тесты
Практическое задание
ОК 8 Использовать средства физической
культуры для сохранения и укрепления
здоровья в процессе профессиональной
деятельности и поддержания необходимого
уровня физической подготовленности
Вопросы для текущего контроля
Тесты
Практическое задание
ОК 9 Использовать информационные
технологии в профессиональной
деятельности
Вопросы для текущего контроля
Тесты
Практическое задание
ОК 10 Пользоваться профессиональной
документацией на государственном и
иностранном языке
Вопросы для текущего контроля
Тесты
Практическое задание
ОК 11 Планировать предпринимательскую
деятельность в профессиональной сфере
Вопросы для текущего контроля
Тесты
Практическое задание
4
2
КОМПЛЕКТ МАТЕРИАЛОВ ДЛЯ ТЕКУЩЕЙ АТТЕСТАЦИИ
Информационная модель – это
Процесс построения информационных
моделей с помощью формальных языков
называют
имитационное моделирование применяют
в случаях
метод построения информационных систем
Многокомпонентная система
Автоматизированная система
моделирования (АСМ)
В основе Объектно-ориентированого
подхода лежат понятия
жизненный цикл Объектно-
ориентированого подхода
проектирование
Для чего нужно моделирование
программного обеспечения
Информационная модель – это
Для создания описательных текстовых
информационных моделей обычно
используют
Модели, построенные с использованием
математических понятий и формул,
называют
метод построения информационных систем
Метод “снизу-вверх”
Каскадная модель ИС
Автоматизированная система
моделирования (АСМ) Функциональное
наполнение
жизненный цикл Объектно-
ориентированого подхода
Программирование, тестирование и
сборка системы
Для чего нужно моделирование
программного обеспечения
Информационная модель – это
Основное отличие формальных языков от
естественных состоит
Концептуально-методологическое
моделирование представляет собой
метод построения информационных систем
Метод “сверху-вниз”
Поэтапная (итерационная) модель ИС с
промежуточным контролем
Автоматизированная система
моделирования (АСМ) Системное
наполнение
жизненный цикл Объектно-
ориентированого подхода анализ
5
Для чего нужно моделирование
программного обеспечения
Информационная модель – это
Модели, построенные с использованием
математических понятий и формул,
называют
метод построения информационных систем
Принципы “дуализма” и
многокомпонентности
Концептуально-методологическое
моделирование представляет собой
имитационное моделирование применяют
в случаях
Автоматизированная система
моделирования (АСМ) Язык заданий (ЯЗ)
Преимущества Объектно-
ориентированого подхода Повторное
использование
Для чего нужно моделирование
программного обеспечения
Информационная модель – это
Концептуально-методологическое
моделирование представляет собой
метод построения информационных систем
Принципы “дуализма” и
многокомпонентности
метод построения информационных систем
Многокомпонентная система
Автоматизированная система
моделирования (АСМ) Язык заданий (ЯЗ)
Преимущества Объектно-
ориентированого подхода
Распараллеливание работ
жизненный цикл Объектно-
ориентированого подхода
Программирование, тестирование и
сборка системы
Для чего нужно моделирование
программного обеспечения
Информационная модель – это
С помощью формальных языков строят
информационные модели определённого
типа
Концептуальное
моделирование представляет собой
Каскадная модель ИС
В основе Объектно-ориентированого
подхода лежат понятия
Преимущества Объектно-
ориентированого подхода Повторное
6
использование
жизненный цикл Объектно-
ориентированого подхода анализ
Для чего нужно моделирование
программного обеспечения
Информационная модель – это
Наряду с естественными языками (русский,
английский и т.д.) разработаны и
используются формальные языки:
Процесс построения информационных
моделей с помощью формальных языков
называют
имитационное моделирование на ЭВМ
метод построения информационных систем
Метод “сверху-вниз”
Поэтапная (итерационная) модель ИС с
промежуточным контролем
Преимущества Объектно-
ориентированого подхода Повторное
использование
Для чего нужно моделирование
программного обеспечения
Информационная модель – это
Модели, построенные с использованием
математических понятий и формул,
называют
Концептуальное
моделирование представляет собой
имитационное моделирование применяют
в случаях
метод построения информационных систем
Многокомпонентная система
Автоматизированная система
моделирования (АСМ)
Преимущества Объектно-
ориентированого подхода
Распараллеливание работ
Для чего нужно моделирование
программного обеспечения
Ролевой состав коллектива разработчиков,
взаимодействие между ролями в различных
технологических процессах
Заказчик (заявитель).
Менеджер проекта
Менеджер программы
Разработчик.
Специалист по тестированию
Специалист по контролю качества.
Специалист по сертификации.
7
Специалист по внедрению и
сопровождению
Специалист по безопасности
Инструктор
Технический писатель
цели верификации
Задачи процесса верификации
Основная идея в тестировании системы, как
черного ящика состоит в том, что
С точки зрения программного кода черный
ящик может представлять собой
При тестировании системы, как
стеклянного ящика, тестировщик имеет
доступ
Тестирование моделей позволяет
тестировщику
Анализ программного кода (инспекции)
производится в случае когда
Тестовое окружение может использоваться
для
Целью тестирования тестового окружения
является
Тестовые вопросы.
1.Модель может быть построена для любого
Вариант1= объекта, явления или процесса
Вариант2= объекта или процесса
Вариант3= объекта или явления
Вариант4= объекта
2.Процесс замены реального объекта (процесса, явления) моделью, отражающей его
существенные признаки, называется
Вариант1= реализацией
Вариант2= упрощением
Вариант3= микромоделированием
Вариант4= моделированием
3.Формализация в процессе моделирования это
Вариант1= процесс замещения оригинала его аналога
Вариант2= комплексирование с уже имеющимися реальными системами
Вариант3= проектирование и настройка модели
Вариант4= постановка различных задач и решение их на модели
4.Процесс моделирования это
Вариант1= постановка различных задач и решение их на модели
Вариант2= проектирование и настройка модели
Вариант3= комплексирование с уже имеющимися реальными системами
Вариант4= процесс замещения оригинала его аналога
5.Процесс интерпретации результатов моделирования это
Вариант1= постановка различных задач и решение их на модели
Вариант2= проектирование и настройка модели
Вариант3= комплексирование с уже имеющимися реальными системами
Вариант4= процесс замещения оригинала его аналога
8
6.Принцип моделирования ПО – правильно выбранная модель позволит проникнуть в
суть задачи, неправильная модель заведет в тупик
Вариант1= возможность рассматривать систему на разных уровнях детализации
Вариант2= модели могут создаваться и изучаться по отдельности, но остаются
взаимосвязанными
Вариант3= выбор модели оказывает влияние на решение проблем
Вариант4= необходимо объединить все независимые представления системы в единое целое
7.Принцип моделирования ПО– каждая модель может быть представлена с различной
степенью точности
Вариант1= модели могут создаваться и изучаться по отдельности, но остаются
взаимосвязанными
Вариант2= возможность рассматривать систему на разных уровнях детализации
Вариант3= необходимо объединить все независимые представления системы в единое целое
Вариант4= выбор модели оказывает влияние на решение проблем
8.Принцип моделирования ПО — лучшие модели те, что ближе к реальности
Вариант1= выбор модели оказывает влияние на решение проблем
Вариант2= модели могут создаваться и изучаться по отдельности, но остаются
взаимосвязанными
Вариант3= возможность рассматривать систему на разных уровнях детализации
Вариант4= необходимо объединить все независимые представления системы в единое целое
9.Принцип моделирования ПО – нельзя ограничиваться созданием только одной модели
Вариант1= необходимо объединить все независимые представления системы в единое целое
Вариант2= возможность рассматривать систему на разных уровнях детализации
Вариант3= выбор модели оказывает влияние на решение проблем
Вариант4= модели могут создаваться и изучаться по отдельности, но остаются
взаимосвязанными
10.Алгоритмический подход моделирования при разработке ПО
Вариант1= основным строительным блоком является процедура или функция
Вариант2= основным строительным блоком является объект или класс
11.Объектно-ориентированный подход моделирования при разработке ПО
Вариант1= основным строительным блоком является процедура или функция
Вариант2= основным строительным блоком является объект или класс
12.Свойство объектов и классов при объектно-ориентированном моделировании ПО
инкапсуляция — это
Вариант1= скрытие объектом внутренней информации от внешнего мира
Вариант2= возможность создавать из классов новые классы по принципу «от общего к
частному»
13.Свойство объектов и классов при объектно-ориентированном моделировании ПО –
наследование это
Вариант1= скрытие объектом внутренней информации от внешнего мира
Вариант2= возможность создавать из классов новые классы по принципу «от общего к
частному»
14.Преимущество методологии объектно-ориентированного программирования —
повторное использование
Вариант1= когда изменение носит характер уточнения, детализации, вводятся новые классы,
наследующие поведение ранее созданных
Вариант2= при наличии развитых библиотек классов проектирование и программирование
новых приложений будет в основном сводиться к сборке системы из готовых фрагментов.
Вариант3= программирование и тестирование отдельных компонент системы возможно до
завершения проектирования целевой программной системы
15.Преимущество методологии объектно-ориентированного программирования —
упрощение внесения изменений
9
Вариант1= при наличии развитых библиотек классов проектирование и программирование
новых приложений будет в основном сводиться к сборке системы из готовых фрагментов
Вариант2= когда изменение носит характер уточнения, детализации, вводятся новые классы,
наследующие поведение ранее созданных
Вариант3= программирование и тестирование отдельных компонент системы возможно до
завершения проектирования целевой программной системы
16.Преимущество методологии объектно-ориентированного программирования —
распараллеливание работ
Вариант1= когда изменение носит характер уточнения, детализации, вводятся новые классы,
наследующие поведение ранее созданных
Вариант2= программирование и тестирование отдельных компонент системы возможно до
завершения проектирования целевой программной системы
Вариант3= при наличии развитых библиотек классов проектирование и программирование
новых приложений будет в основном сводиться к сборке системы из готовых фрагментов
Вариант3= при наличии развитых библиотек классов проектирование и программирование
новых приложений будет в основном сводиться к сборке системы из готовых фрагментов
17.Ролевой состав коллектива разработчиков. Заказчик (заявитель).
Вариант1= принимает технические решения, которые могут быть реализованы и
использованы, создает продукт, удовлетворяющий спецификациям
Вариант2= ограничен в своем взаимодействии и общается только с менеджерами проекта и
специалистом по сертификации или внедрению.
Вариант3= приводит документацию на программную систему в соответствие требованиям
сертифицирующего органа
Вариант4= Участвует в анализе особенностей площадки заказчика, на которой планируется
проводить внедрение разрабатываемой системы
18.Ролевой состав коллектива разработчиков. Менеджер проекта.
Вариант1= обеспечивает коммуникационный канал между заказчиком и проектной группой
Вариант2= принимает технические решения, которые могут быть реализованы и
использованы, создает продукт, удовлетворяющий спецификациям
Вариант3= ограничен в своем взаимодействии и общается только с менеджерами проекта и
специалистом по сертификации или внедрению
Вариант4= приводит документацию на программную систему в соответствие требованиям
сертифицирующего органа
19.Ролевой состав коллектива разработчиков. Менеджер программы
Вариант1= принимает технические решения, которые могут быть реализованы и
использованы, создает продукт, удовлетворяющий спецификациям
Вариант2= ограничен в своем взаимодействии и общается только с менеджерами проекта и
специалистом по сертификации или внедрению
Вариант3= управляет коммуникациями и взаимоотношениями в проектной группе, является
координатором
Вариант4= приводит документацию на программную систему в соответствие требованиям
сертифицирующего органа
20.Ролевой состав коллектива разработчиков. Разработчик.
Вариант1= принимает технические решения, которые могут быть реализованы и
использованы, создает продукт, удовлетворяющий спецификациям
Вариант2= ограничен в своем взаимодействии и общается только с менеджерами проекта и
специалистом по сертификации или внедрению
Вариант3= Участвует в анализе особенностей площадки заказчика, на которой планируется
проводить внедрение разрабатываемой системы
Вариант4= несет обязанности по подготовке документации к разработанному
21. Ролевой состав коллектива разработчиков. Специалист по тестированию.
Вариант1= несет обязанности по подготовке документации к разработанному продукту
10
Вариант2= Участвует в анализе особенностей площадки заказчика, на которой планируется
проводить внедрение разрабатываемой системы
Вариант3= ограничен в своем взаимодействии и общается только с менеджерами проекта и
специалистом по сертификации или внедрению
Вариант4= определяет стратегию тестирования, тест-требования и тест-планы для каждой из
фаз проекта
22.Ролевой состав коллектива разработчиков. Специалист по контролю качества.
Вариант1= осуществляет взаимодействие с разработчиком, менеджером программы и
специалистами по безопасности и сертификации
Вариант2= участвует в анализе особенностей площадки заказчика, на которой планируется
проводить внедрение разрабатываемой системы
Вариант3= несет обязанности по подготовке документации к разработанному продукту
Вариант4= приводит документацию на программную систему в соответствие требованиям
сертифицирующего органа
23.Ролевой состав коллектива разработчиков. Специалист по сертификации.
Вариант1= Участвует в анализе особенностей площадки заказчика, на которой планируется
проводить внедрение разрабатываемой системы
Вариант2= несет обязанности по подготовке документации к разработанному продукту
Вариант3= обеспечивает коммуникационный канал между заказчиком и проектной группой
Вариант4= приводит документацию на программную систему в соответствие требованиям
сертифицирующего органа
24.Ролевой состав коллектива разработчиков. Специалист по внедрению и
сопровождению.
Вариант1= несет обязанности по подготовке документации к разработанному продукту
Вариант2= участвует в анализе особенностей площадки заказчика, на которой планируется
проводить внедрение разрабатываемой системы
Вариант3= приводит документацию на программную систему в соответствие требованиям
сертифицирующего органа
Вариант4= обеспечивает коммуникационный канал между заказчиком и проектной группой
25.Ролевой состав коллектива разработчиков. Специалист по безопасности.
Вариант1= ответственен за весь спектр вопросов безопасности создаваемого продукта
Вариант2= участвует в анализе особенностей площадки заказчика, на которой планируется
проводить внедрение разрабатываемой системы
Вариант3= несет обязанности по подготовке документации к разработанному продукту
Вариант4= приводит документацию на программную систему в соответствие требованиям
сертифицирующего органа
26.Ролевой состав коллектива разработчиков. Инструктор.
Вариант1= отвечает за снижение затрат на дальнейшее сопровождение продукта, обеспечение
максимальной эффективности работы пользователя
Вариант2= Участвует в анализе особенностей площадки заказчика, на которой планируется
проводить внедрение разрабатываемой системы
Вариант3= приводит документацию на программную систему в соответствие требованиям
сертифицирующего органа
Вариант4= обеспечивает коммуникационный канал между заказчиком и проектной группой
27.Ролевой состав коллектива разработчиков. Технический писатель.
Вариант1= участвует в анализе особенностей площадки заказчика, на которой планируется
проводить внедрение разрабатываемой системы
Вариант2= обеспечивает коммуникационный канал между заказчиком и проектной группой
Вариант3= управляет коммуникациями и взаимоотношениями в проектной группе, является
координатором
Вариант4= несет обязанности по подготовке документации к разработанному продукту
28.Тестирование программного обеспечения
Вариант1= проверка соответствия системы ожиданиям заказчика
11
Вариант2= включает в себя инспекции, тестирование кода, анализ результатов тестирования,
формирование и анализ отчетов о проблемах
Вариант3= управляемое выполнение программы с целью обнаружения несоответствий ее
поведения и требований
29.Верификация программного обеспечения
Вариант1= включает в себя инспекции, тестирование кода, анализ результатов тестирования,
формирование и анализ отчетов о проблемах
Вариант2= управляемое выполнение программы с целью обнаружения несоответствий ее
поведения и требований
Вариант3= проверка соответствия системы ожиданиям заказчика
Вариант4=
30.Валидация программной системы
Вариант1= проверка соответствия системы ожиданиям заказчика
Вариант2= управляемое выполнение программы с целью обнаружения несоответствий ее
поведения и требований
Вариант3= включает в себя инспекции, тестирование кода, анализ результатов тестирования,
формирование и анализ отчетов о проблемах
31.Модульному тестированию подвергаются
Вариант1= система целиком
Вариант2= небольшие модули
Вариант3= тестируется вся программа в целом
32.Интеграционное тестирование
Вариант1= когда выполняется сборка отдельных модулей в более крупные конфигурации
Вариант2= тестируются небольшие модули
Вариант3= тестируется система в целом
33. Системное тестирование
Вариант1= тестируется конфигурация сборки отдельных модулей в более крупные
Вариант2= тестируются небольшие модули
Вариант3= тестируется система в целом
34.Целью тестов для нормальных ситуаций является
Вариант1= демонстрация способности программного обеспечения адекватно реагировать на
ненормальные входы и условия
Вариант2= демонстрация способности программного обеспечения давать отклик на
нормальные входы и условия в соответствии с требованиями.
35.Целью тестов для ненормальных ситуаций является
Вариант1= демонстрация способности программного обеспечения давать отклик на
нормальные входы и условия в соответствии с требованиями
Вариант2= демонстрация способности программного обеспечения адекватно реагировать на
ненормальные входы и условия
36.Сертификация ПО
Вариант1= процесс установления того, что разработка ПО проводилась в соответствии с
определенными требованиями
Вариант2= процесс установления и официального признания того, что разработка ПО
проводилась в соответствии с определенными требованиями
Вариант3= процесс официального признания того, что разработка ПО проводилась в
соответствии с определенными требованиями
37.Если сертификация направлена на получение сертификата соответствия
Вариант1= то результатом сертификации является признание соответствия процессов
разработки определенным критериям, а функциональности системы определенным
требованиям.
Вариант2= то результатом является признание соответствия процессов разработки
определенным критериям, гарантирующим соответствующий уровень качества выпускаемой
продукции
12
38.Если сертификация направлена на получение сертификата качества
Вариант1= то результатом является признание соответствия процессов разработки
определенным критериям, гарантирующим соответствующий уровень качества выпускаемой
продукции
Вариант2= то результатом сертификации является признание соответствия процессов
разработки определенным критериям, а функциональности системы определенным
требованиям
39.Тестирование программного кода это процесс
Вариант1= выполнения программного кода, направленный на исправление существующих в
нем дефектов
Вариант2= выполнения программного кода, направленный на выявление существующих в нем
дефектов
40.Под дефектом программного кода понимается
Вариант1= участок программного кода, выполнение которого при определенных условиях
приводит к ожидаемому поведению системы
Вариант2= участок программного кода, выполнение которого при определенных условиях
приводит к неожиданному поведению системы
41.В задачи тестирования
Вариант1= не входит выявление конкретных дефектных участков программного кода
Вариант2= входит выявление конкретных дефектных участков программного кода
Вариант3= входит исправление дефектов
Вариант4= не входит выявление конкретных дефектных участков программного кода, но
входит исправление дефектов
42.Цель применения процедуры тестирования программного кода
Вариант1= оптимизация количества дефектов в конечном продукте
Вариант2= минимизация количества дефектов в конечном продукте.
Вариант3= декомпозиция количества дефектов в конечном продукте
43. Метод функциональной декомпозиции состоит в том, что
Вариант1= система разбивается на отдельные модули– выполняется модульное тестирование,
затем выполняется интеграционное тестирование и после этого выполняется системное
тестирование.
Вариант2= система разбивается на отдельные модули– выполняется модульное тестирование,
затем выполняется системное тестирование.
Вариант3= система разбивается на отдельные модули– выполняется модульное тестирование,
затем выполняется интеграционное тестирование
Вариант4= система разбивается на отдельные модули– выполняется модульное тестирование,
затем выполняется системное тестирование и после этого выполняется интеграционное
тестирование.
44.Робастность системы
Вариант1= управляемое выполнение программы с целью обнаружения несоответствий ее
поведения и требований
Вариант2= включает в себя инспекции, тестирование кода, анализ результатов тестирования,
формирование и анализ отчетов о проблемах
Вариант3= проверка соответствия системы ожиданиям заказчика
Вариант4= это степень ее чувствительности к факторам, не учтенным на этапах ее
проектирования
45.Разбиение на классы эквивалентности
Вариант1= способ увеличения необходимого числа тестовых примеров.
Вариант2= способ уменьшения необходимого числа тестовых примеров.
46.Если различные входные значения приводят к одним и тем же реакциям системы
Вариант1= то невозможно объединение таких значений в классы эквивалентности
Вариант2= то возможно объединение таких значений в классы эквивалентности
47.Разбиение на классы эквивалентности особенно полезно
13
Вариант1= когда на вход системы может быть подано большое количество различных
значений
Вариант2= когда на вход системы может быть подано малое количество различных значений
Вариант3= когда на вход системы не может быть подано большое количество различных
значений
48.Тест-план представляет собой
Вариант1= документ, в котором перечислены часть тестовых примеров, необходимых для
тестирования системы
Вариант2= документ, в котором перечислены все тестовые примеры, необходимые для
тестирования системы
49.В каждом тестовом примере обязательно перечислены
Вариант1= все входные значения а также сценарий, описывающий последовательность
действий, которые необходимо выполнить тестовому окружению для выполнения тестового
примера
Вариант2= все входные значения и ожидаемые выходные значения, а также сценарий,
описывающий последовательность действий, которые необходимо выполнить тестовому
окружению для выполнения тестового примера
Вариант3= все входные значения и ожидаемые выходные значения
50.Тест считается пройденным
Вариант1= если ожидаемые и реальные выходные значения совпадают
Вариант2= если ожидаемые и реальные выходные значения не совпадают
Вариант3= если система выдала выходные значения, которые не ожидались
51.Одна из оценок качества системы тестов — это ее полнота, т.е.
Вариант1= величина той части функциональности системы, которая не проверяется тестовыми
примерами
Вариант2= величина той части функциональности системы, которая проверяется тестовыми
примерами
52.Покрытие требований позволяет оценить
Вариант1= полноту по отношению к программной реализации системы
Вариант2= степень полноты системы тестов по отношению к функциональности системы
Вариант3= каждая компонента логического условия в результате выполнения тестовых
примеров должна принимать все возможные значения
53.Уровни покрытия. По строкам программного кода (Statement Coverage)
Вариант1= в результате выполнения тестов каждый оператор был выполнен хотя бы один раз
Вариант2= для обеспечения полного покрытия необходимо, чтобы как логическое условие,
так и каждая его компонента приняла все возможные значения
Вариант3= каждая компонента логического условия в результате выполнения тестовых
примеров должна принимать все возможные значения
Вариант4= метод учитывающий структуру компонент условий и значения, которые они
принимают при выполнении тестовых примеров
54.Уровни покрытия. По веткам условных операторов (Decision Coverage)
Вариант1= метод учитывающий структуру компонент условий и значения, которые они
принимают при выполнении тестовых примеров
Вариант2= каждая точка входа и выхода в программе и во всех ее функциях должна быть
выполнена по крайней мере один раз и все логические выражения в программе должны
принять каждое из возможных значений хотя бы один раз
Вариант3= должны быть проверены все возможные наборы значений компонент логических
условий
Вариант4= в результате выполнения тестов каждый оператор был выполнен хотя бы один раз
55.Уровни покрытия. По компонентам логических условий
Вариант1= в результате выполнения тестов каждый оператор был выполнен хотя бы один раз
Вариант2= метод учитывающий структуру компонент условий и значения, которые они
принимают при выполнении тестовых примеров
14
Вариант3= должны быть проверены все возможные наборы значений компонент логических
условий
Вариант4= каждая компонента логического условия в результате выполнения тестовых
примеров должна принимать все возможные значения
56.Уровни покрытия. Покрытие по условиям (Condition Coverage)
Вариант1= каждая компонента логического условия в результате выполнения тестовых
примеров должна принимать все возможные значения
Вариант2= в результате выполнения тестов каждый оператор был выполнен хотя бы один раз
Вариант3= должны быть проверены все возможные наборы значений компонент логических
условий
Вариант4= для обеспечения полного покрытия необходимо, чтобы как логическое условие,
так и каждая его компонента приняла все возможные значения
57.Уровни покрытия. Покрытие по веткам/условиям (Condition/Decision Coverage)
Вариант1= для обеспечения полного покрытия необходимо, чтобы как логическое условие,
так и каждая его компонента приняла все возможные значения
Вариант2= должны быть проверены все возможные наборы значений компонент логических
условий
Вариант3= метод учитывающий структуру компонент условий и значения, которые они
принимают при выполнении тестовых примеров
Вариант4= в результате выполнения тестов каждый оператор был выполнен хотя бы один раз
58.Уровни покрытия. Покрытие по всем условиям (Multiple Condition Coverage)
Вариант1= в результате выполнения тестов каждый оператор был выполнен хотя бы один раз
Вариант2= должны быть проверены все возможные наборы значений компонент логических
условий
Вариант3= для обеспечения полного покрытия необходимо, чтобы как логическое условие,
так и каждая его компонента приняла все возможные значения
Вариант4= метод учитывающий структуру компонент условий и значения, которые они
принимают при выполнении тестовых примеров
Критерии оценки:
85% и более правильных ответов — оценка «отлично»
от 70 до 85% правильных ответов — оценка «хорошо»
от 50 до 70% правильных ответов — оценка «удовлетворительно»
до 50% правильных ответов — оценка «неудовлетворительно»
КОМПЛЕКТ МАТЕРИАЛОВ ДЛЯ ПРОМЕЖУТОЧНОЙ АТТЕСТАЦИИ
Теоретические вопросы
1.
Модель. Моделирование. Информационная модель.
2.
Классификация методов моделирования.
3.
Концептуальное моделирование
4.
Имитационное моделирование
5.
Методы построения информационных систем. Метод “снизу-вверх”
6.
Методы построения информационных систем. Метод “сверху-вниз”
7.
Методы построения информационных систем. Принципы “дуализма” и
многокомпонентности
8.
Методы построения информационных систем. Каскадная модель.
9.
Методы построения информационных систем. Спиральная модель.
10. Автоматизированная система моделирования (АСМ)
11. Объектно-ориентированный подход проектирования ИС.
12. Цели и задачи моделирования ПО.
15
13. Модели при визуальном моделировании ПО
14. Граф модели и диаграммы
15. Ролевой состав коллектива разработчиков. Заказчик (заявитель).
16. Ролевой состав коллектива разработчиков. Менеджер проекта
17. Ролевой состав коллектива разработчиков. Менеджер программы
18. Ролевой состав коллектива разработчиков. Разработчик
19. Ролевой состав коллектива разработчиков. Специалист по тестированию
20. Ролевой состав коллектива разработчиков. Специалист по контролю качества
21. Ролевой состав коллектива разработчиков. Специалист по сертификации
22. Ролевой состав коллектива разработчиков. Специалист по внедрению и
сопровождению
23. Ролевой состав коллектива разработчиков. Специалист по безопасности
24. Ролевой состав коллектива разработчиков. Инструктор
25. Ролевой состав коллектива разработчиков. Технический писатель
26. Тестирование программного обеспечения
27. Верификация программного обеспечения
28. Валидация программной системы
29. Модульное тестирование
30. Интеграционное тестирование
31. Системное тестирование
32. Верификация сертифицируемого программного обеспечения
33. Задачи и цели тестирования программного кода
34. Методы тестирования. Черный ящик.
35. Методы тестирования. Стеклянный (белый) ящик
36. Методы тестирования. Тестирование моделей
37. Методы тестирования. Анализ программного кода (инспекции)
38. Тестовое окружение. Драйверы и заглушки
39. Тестовое окружение. Тестовые классы
40. Тестовое окружение. Генераторы сигналов (событийно-управляемый код)
41. Типы тестовых примеров. Допустимые данные.
42. Типы тестовых примеров. Граничные данные
43. Типы тестовых примеров. Отсутствие данных
44. Типы тестовых примеров. Повторный ввод данных
45. Типы тестовых примеров. Неверные данные
46. Типы тестовых примеров. Реинициализация системы
47. Типы тестовых примеров. Устойчивость системы.
48. Типы тестовых примеров. Нештатные состояния среды выполнения
49. Типы тестовых примеров. Граничные условия.
50. Тестовые примеры. Проверка робастности (выхода за границы диапазона)
51. Тестовые примеры Классы эквивалентности.
52. Тестовые примеры. Тестирование операций сравнения чисел
53. Типовая структура тест-плана
54. Оценка качества тестируемого кода – статистика выполнения тестов.
55. Покрытие программного кода. Понятие покрытия
56. Покрытие программного кода. Уровни покрытия. По строкам программного кода
(Statement Coverage)
57. Покрытие программного кода. Уровни покрытия. По веткам условных операторов
(Decision Coverage)
58. Покрытие программного кода. Уровни покрытия. Покрытие по условиям (Condition
Coverage)
59. Покрытие программного кода. Уровни покрытия. Покрытие по веткам/условиям
(Condition/Decision Coverage)
16
60. Покрытие программного кода. Уровни покрытия. Покрытие по всем условиям (Multiple
Condition Coverage)
61. Покрытие программного кода. Анализ покрытия.
62. Задачи и цели обеспечения повторяемости тестирования.
63. Предусловия для выполнения теста, настройка тестового окружения, оптимизация
последовательностей тестовых примеров.
64. Зависимость между тестовыми примерами, настройки по умолчанию для тестовых
примеров и их групп
Перечень теоретических вопросов к дифференцированному зачету (экзамену)
1. Цели, задачи, этапы и объекты моделирования и ревьюирования.
2. Графические языки спецификаций.
3. Основные элементы языка UML.
4. Цели, корректность и направления анализа программных продуктов.
5. Методики оценки программных продуктов.
6. Цели, задачи и методы исследования программного кода.
7. Механизмы и контроль внесения изменений в код.
8. Обратное проектирование.
9. Анализ потоков данных. Диаграмма потоков данных.
10.Валидация кода на стороне сервера и разработчика.
11. Совместимость и использование инструментов ревьюирования в различных системах
контроля версий.
12.Особенности ревьюирования в Linux. Настройки доступа.
13.Типовые инструменты и методы анализа программных проектов.
14.Измерительные методы оценки программ: назначение, условия применения.
15.Корректность программ. Эталоны и методы проверки корректности.
16.Метрики, направления применения метрик. Метрики сложности. Метрики стилистики.
17.Исследование программного кода на предмет ошибок и отклонения от алгоритма.
18.Основные понятия управления проектами. Специфика управления проектами в сфере IT.
19.Методологии анализа и управления информационных систем.
20.Общая характеристика проектов внедрения ИТ-решений.
21.Определение ЖЦ продукта ИТ-проекта. Обзор моделей жизненного цикла. Обоснование и
приоретизация проекта.
22.Устав проекта.
23.Границы проекта.
24.Реестр заинтересованных лиц.
25.Матрица ожиданий и требований. Балансировка требований.
26.Содержание проекта.
27.Обзор ПО для управления проектами.
28.Иерархическая структура работ. Методы формирования списка работ.
29.Планирование ресурсов. Виды ресурсов.
30.Методы определения продолжительности проекта.
31.Планирование стоимости проекта. Методы расчета стоимости проекта.
32.Расписание проекта. Сетевой анализ расписания проекта.
33.Распределение ответственности. Матрица ответственности. Закрепление функций и
полномочий в проекте.
34.Календарно-ресурсный план.
35.План обеспечения проекта персоналом.
36.Планирование коммуникаций в проекте.
37.План управления качеством.
38.Риски, виды рисков проекта. Реестр рисков.
39.Качественный анализ рисков.
17
40.Количественный анализ рисков.
41.Планирование реагирования на риски.
42.Управление исполнением проекта. Отслеживание выполнения работ. Управление
требованиями.
43.Выявление потребностей пользователей. Мотивирование и развитие команды. 44.Закрытие
проекта.
Перечень практических заданий к дифференцированному зачету (экзамену)
1. По заданным условиям составить календарно-ресурсный план.
2. Определить заинтересованных лиц проекта.
3. Составить матрицу ответственности.
4. Определить список необходимых для выполнения проекта трудовых и материальных
ресурсов. Определить рабочее время для сотрудников, работающих по особому графику,
учесть отбытие сотрудников в отпуска и командировки. Выполнить назначения ресурсов,
определить типы задач.
5. В рамках предполагаемого времени проведения проекта определить календарь рабочего
времени, учитывая праздничные дни РФ, сокращенное рабочее время предпраздничных дней
и переносы рабочих дней.
6. Определить состав работ: фазы, задачи, вехи; приблизительные длительности задач, типы
связей, ограничения. В ходе планирования следует учитывать, что дата начала проекта
известна, но лишь приблизительно и впоследствии может быть изменена. Определить
приблизительные сроки выполнения всего проекта.
7. Определить ставки трудовых ресурсов и порядок оплаты работ, определить стоимость
материальных ресурсов, учесть штрафы за выполнение работ не в срок. Учесть оклады
штатных сотрудников и премии по окончании работ. Определить итоговую стоимость
проекта. Ввести информацию о бюджете, сравнить с оценочными данными.
8. Выровнять загрузку тех сотрудников, кто не согласился работать сверхурочно. Учесть в
стоимости проекта сверхурочную занятость сотрудников. Изменить план проекта в связи с
переносами сроков окончания проекта. Оптимизировать стоимость проекта в связи с
уменьшением бюджета.
9. Рассчитать длительность и вероятность завершения в заданный срок проекта, заданного
сетевым графиком и имеющего известные параметры работ.
10.Управление стоимостью проекта. NASA заказало самарскому СНТК Кузнецова
изготовление двигателей для ракеты-носителя «Атлантис». Оценить значения показателей CV,
SV, CPI, SPI на момент окончания проекта по методу освоенного объема. Известны плановые
и фактические показатели проекта.
11. Рассчитать показатели NPV, PI и РР проекта длительностью 6 лет, если известны ставка
дисконтирования, инвестиции, расходы и доходы. Рассчитать длительность проекта.
12.Определить вероятность завершения проекта в заданный срок.
13.Исследовать влияние неопределенности длительности работ на вероятность завершения
проекта в заданный срок. Проект по разработке программного обеспечения для
моделирования нагрузок в силовых конструкциях самолетов. Известны параметры работ,
сетевой график и желаемый срок завершения проекта.
Деловая игра
по междисциплинарному курсу 03.01 «Моделирование и анализ программного
обеспечения»
Тема: «Ревьюирование предложенного программного кода на соответствие требованиям
технического задания на проект».
Концепция игры. Участники игры получают от преподавателя персональный программный
код и техническое задание на проект. Каждый обучающийся должен самостоятельно
построить модель программного кода, определить его характеристики, провести анализ
18
программного кода и его соответствие техническому заданию, а также предложить
оптимизацию данного кода и доказать ее целесообразность. Результаты выполнения
представляются остальным участникам игры и оцениваются ими. Победители определяются
по максимальному объему выполненных анализа и оптимизации.
Роли:
• тестировщик — производит анализ и оптимизацию программного кода;
• эксперты — оценивают анализ и проведенную оптимизацию.
Ожидаемый результат:
понимание правильного написания программного кода для
дальнейшего тестирования и обнаружения несоответствия техническому заданию.
Критерии оценки:
Оценка 5 «отлично»: участник справился с ролью без недочетов и ошибок.
Оценка 4 «хорошо»: участник справился с ролью с некоторыми недочетами, не повлиявшими
на конечный результат.
Оценка 3 «удовлетворительно»: участник справился с ролью с ошибками, повлиявшими на
конечный результат.
Оценка 2 «неудовлетворительно»: участник не справился с ролью.
Деловая игра
по междисциплинарному курсу 03.02 «Управление проектами»
Тема: «Зависимость финансового результата от качества сделанной работы».
Концепция игры. Участники игры используют проект, над которым работали во время
предыдущих
практических
занятий.
Каждый
обучающийся
должен
самостоятельно
определить методы анализа и оптимизации проекта и реализовать их на практике.
Результаты выполнения представляются разработчиком проекта и оцениваются остальными
участниками игры, выступающими в роли инвесторов. Победители определяются по
максимальному объему сделанных инвестиций.
Роли:
• разработчик проекта — производит анализ и оптимизацию проекта;
• инвестор — оценивает проект и делает инвестиции, в случае положительной оценки.
Ожидаемый результат:
понимание зависимости финансового результата от качества
сделанной работы.
Критерии оценки:
Оценка 5 «отлично» — более 75% инвесторов сделали вложения в проект.
Оценка 4 «хорошо» — от 50 до 75% инвесторов сделали вложения в проект.
Оценка 3 «удовлетворительно» — от 25 до 50% инвесторов сделали вложения в проект.
Оценка 2 «неудовлетворительно» — менее 25% инвесторов сделали вложения в проект.
Деловая игра
по междисциплинарному курсу 03.02 «Управление проектами»
Тема:
«Анализ рисков. Необходимость учета эстетического фактора при применении
информационной».
Концепция игры. Участники игры используют проект, над которым работали во время
предыдущих
практических
занятий.
Каждый
обучающийся
должен
самостоятельно
проанализировать риски проекта, выбрать стратегию их смягчения, планы сдерживания и
реакции на риски.
Результаты выполнения представляются разработчиком проекта и оцениваются остальными
участниками игры, выступающими в роли инвесторов. Победители определяются по
максимальному объему сделанных инвестиций.
Роли:
19
• разработчик проекта — производит анализ рисков и оптимизацию проекта, с учетом
проведенного анализа;
• инвестор — оценивает проект и делает инвестиции, в случае положительной оценки.
Ожидаемый результат:
понимание зависимости финансового результата от качества
сделанной работы.
Критерии оценки:
Оценка 5 «отлично» — более 75% инвесторов сделали вложения в проект.
Оценка 4 «хорошо» — от 50 до 75% инвесторов сделали вложения в проект.
Оценка 3 «удовлетворительно» — от 25 до 50% инвесторов сделали вложения в проект.
Оценка 2 «неудовлетворительно» — менее 25% инвесторов сделали вложения в проект.
Деловая игра
по междисциплинарному курсу 03.02 «Управление проектами»
Тема: «Создание физического дизайна. Зависимость результата от командных условий».
Концепция игры.
Участники игры делятся на две проектные команды и распределяют между собой роли (см.
ниже). Каждая команда получает от преподавателя проект. В ходе игры, участники за
отведенное время должны справиться со своими ролями, подготовить общую картину
решения и продемонстрировать результаты. При демонстрации результата, вторая команда
выступает в роли пользователя и оценивает работу каждого участника другой команды.
Роли:
•
менеджер
решения:
управление
ожиданиями
пользователей
и
создание
плана
взаимодействия, подготовка к развертыванию решения;
•
менеджер
программы:
управление
процессом
физического
дизайна
и
создание
функциональной спецификации;
• разработчик: представление проектных моделей, планов, календарных графиков и смет
разработки;
• специалист по удобству использования: оценка физического дизайна на предмет
удовлетворения требований пользователей и разработка плана справочной системы;
• тестировщик: оценка и проверка функционального наполнения и целостности физического
дизайна на основании СИС;
• менеджер по выпуску: оценка влияния инфраструктуры на физический дизайн. Ожидаемый
результат: понимание важности подбора команды и ответственного отношения к делу каждого
из ее участников.
Критерии оценки:
Оценка 5 «отлично»: участник справился с ролью без недочетов и ошибок.
Оценка 4 «хорошо»: участник справился с ролью с некоторыми недочетами, не повлиявшими
на конечный результат.
Оценка 3 «удовлетворительно»: участник справился с ролью с ошибками, повлиявшими на
конечный результат.
Оценка 2 «неудовлетворительно»: участник не справился с ролью.
20
Существует три
основных типа ошибок в программах:
— ошибки этапа
компиляции (или синтаксические ошибки);
— ошибки этапа
выполнения или семантические ошибки);
— логические
ошибки.
Cинтаксические
ошибки происходят из-за нарушений
правил синтаксиса
языка программирования.
Когда компилятор обнаруживает
синтаксическую
ошибку, то отмечает
место (позицию или строку) ошибки и
выводт сообщение
об ошибке.
Наиболее
распространенными синтаксическими
ошибками являются:
— ошибки набора
(опечатки);
— пропущенные
точки с запятой;
— ссылки на
неописанные переменные;
— передача
неверного числа (или типа) параметров
процедуры или
функции;
— присваивание
переменной значений неверного типа.
После исправления
cинтаксической ошибки компиляцию можно
выполнить
заново. После
устранения всех синтаксических ошибок
и успешной компиля-
ции программа готова
к выполнению и поиску ошибок этапа
выполнения и ло-
гических ошибок.
Семантические
ошибки происходят, когда программа
компилируется, но
при выполнении
операторов что-то происходит неверно.
Например, программа
пытается открыть
для ввода несуществующий файл или
выполнить деление на
ноль. При обнаружении
семантических ошибок выполнение
программы заверша-
ется и выводится
сообщение об ошибке. Например, в системе
Turbo Pascal
выводится сообщение
следующего вида:
Run-time error ## at seg:ofs
По номеру
ошибки (##) можно установить причину ее
возникновения.
Логические ошибки
— это ошибки проектирования и реализации
програм-
мы. Логические
ошибки приводят к некорректному или
непредвиденному зна-
чению переменных,
неправильному виду графических
изображений или невы-
полнению кода, когда
это ожидается. Эти ошибки часто трудно
отслежива-
ются, поскольку ни
компилятор, ни исполняющая система не
обнаруживают их
автоматически, как
синтаксические и семантические ошибки.
Обычно системы
программирования
включает в себя средства отладки,
помогающие найти ло-
гические ошибки.
3.4.2. Цели и задачи отладки и тестирования.
Многие программисты
путают отладку программ с тестированием,
пред-
назначенным для
проверки их работоспособности. Отладка
имеет место тог-
да, когда программа
со всей очевидностью работает неправильно.
Поэтому
отладка начинается
всегда в предположении отказа программы.
Если же ока-
зывается, что
программа работает верно, то она
тестируется. Часто случа-
ется так, что после
прогона тестов программа вновь должна
быть подверг-
нута отладке. Таким
образом, тестирование устанавливает
факт наличия
ошибки, а отладка
выявляет ее причину, и эти два этапа
разработки прог-
раммы перекрываются.
3.4.3. Основные возможности интегрированного отладчика системы
программирования
Turbo Pascal.
Основной смысл
использования встроенного отладчика
состоит в управ-
ляемом выполнении
программы. Отслеживая выполнение
каждой инструкции,
можно легко определить,
какая часть программы вызывает проблемы.
В от-
ладчике предусмотрено
шесть основных механизмов управления
выполнением
программы, которые
позволяют:
— выполнять
инструкции по шагам(Run|Step Over или F8);
— трассировать
инструкции (Run|Trace Into или F7);
— выполнять
программы до позиции курсора (Run|Go to
Cursor или F4);
— выполнять
программу до заданной точки (Toggle
Breakpoint или
Ctrl+F8);
— находить
определенную точку (Search|Find Procedure…);
— выполнять сброс
программы (Run¦Reset Program или Ctrl+F2).
Выполнение
программы по шагам (команда Step Over меню
выполнения
Run) и трассировка
программы (команда Trace Into меню выполнения
Run)
дают возможность
построчного выполнения программы.
Единственное отличие
выполнения по шагам
и трассировки состоит в том, как они
работают с вы-
зовами процедур и
функций. Выполнение по шагам вызова
процедуры или
функции интерпретирует
вызов как простой оператор и после
завершения
подпрограммы
возвращает управление на следующую
строку. Трассировка
подпрограммы
загружает код этой подпрограммы и
продолжает ее построчное
выполнение.
Выполнение
программы до заданной точки (команда
Toggle Breakpoint
локального меню
редактора) — более гибкий механизм
отладки, чем исполь-
зование метода
выполнения до позиции курсора (команда
Go to Cursor меню
выполнения Run),
поскольку в программе можно установить
несколько точек
останова.
Интегрированная
среда разработки программы предусматривает
несколь-
ко способов поиска
в программе заданного места. Простейший
способ пре-
доставляет команда
Search|Find Procedure…, которая запрашивает
имя
процедуры или
функции, затем находит соответствующую
строку в файле, где
определяется эта
подпрограмма. Этот подход полезно
использовать при ре-
дактировании, но
его можно комбинировать с возможностью
выполнения прог-
раммы до определенной
точки, чтобы пройти программу до той
части кода,
которую надо отладить.
Чтобы сбрасить
все ранее задействованные отладочные
средства и
прекратитьт отладку
программы необходимо выполнить команду
Run|Program
reset или нажать клавиши
Ctrl+F2.
При выполнении
программы по шагам можно наблюдать ее
вывод несколь-
кими способами:
— переключение
в случае необходимости экранов
(Debug|User screen
или Alt+F5);
— открытие окна
вывода (Debug¦Output);
— использование
второго монитора;
Выполнение
программы по шагам или ее трассировка
могут помочь найти
ошибки в алгоритме
программы, но обычно желательно также
знать, что про-
исходит на каждом
шаге со значениями отдельных переменных.
Например, при
выполнении по шагам
цикла for полезно знать значение переменной
цикла.
Встроенный отладчик
имеет два инструментальных средства
для проверки со-
держимого переменных
программы:
— окно Watches
(Просмотр);
— диалоговое окно
Evaluate and Modify (Вычисление и модификация).
Чтобы открыть
окно Watches, необходимо выполнить
команду
Debug|Watch. Чтобы добавить
в окно Watches переменную, необходимо выпол-
нить
команду
Debug¦Watch¦Add Watch… или
нажать клавиши Ctrl+F7. Если
окно Watches является
активным окном, то можно добавить
выражение
просмотра, нажав
клавишу Ins. Отладчик открывает диалоговое
окно Add
Watch, запрашивающее
тип просматриваемого выражения. По
умолчанию выра-
жением считается
слово в позиции курсора в текущем окне
редактирования.
Просматриваемые
выражения, которые отслеживались ранее,
сохраняются в
списке протокола.
Последнее добавленное или модифицированное
просматри-
ваемое выражение
является текущим просматриваемым
выражением, которое
указывается выводимым
слева от него символом жирной левой
точки. Если
окно Watches активно,
можно удалить текущее выражение, нажав
клавишу Del
или Ctrl+Y. Чтобы
удалить все просматриваемые выражения,
необходимо вы-
полнить команду
Clear All локального меню активного окна
Watches. Чтобы
отредактировать
просматриваемое выражение, нужно
выполнить команду
Modify… или нажать
клавишу Enter локального меню активного
окна
Watches. Отладчик
открывает диалоговое окно Edit Watch,
аналогичное то-
му, которое
используется для добавления просматриваемого
выражения, ко-
торое позволяет
отредактировать текущее выражение.
Чтобы вычислить
выражение, необходимо выполнить
команду
Debug¦Evaluate/Modify…
или
нажать
клавиши
Ctrl+F4. Отладчик
открывает
диалоговое окно
Evaluate and Modify. По умолчанию слово в позиции
курсо-
ра в текущем окне
редактирования выводится подсвеченным
в поле
Expression. Можно
отредактировать это выражение, набрать
другое выраже-
ние или выбрать
вычисленное ранее выражение из списка
протокола.
Даже если не
установлены точки останова, можно выйти
в отладчик при
выполнении программы,
нажав клавиши Ctrl+Break. Отладчик находит
позицию
в исходном коде, где
прервалась программа. Затем, как и в
случае обычной
точки останова,
можно выполнить программу по шагам,
трассировать ее,
отследить или
вычислить выражения.
Иногда в ходе
отладки полезно узнать, как вы попали
в данную часть
кода. Окно Call Stack
показывает последовательность вызовов
процедур или
функций, которые
привели к текущему состоянию (глубиной
до 128 уровней).
Для вывода окна Call
Stack необходимо выполнить команду
Debug¦Call Stack
или нажать клавиши
Ctrl+F3.
13
Соседние файлы в папке 13_3xN
- #
- #
- #
Ошибки в программировании – дело обычное, хоть и неприятное. В данной статье будет рассказано о том, какими бывают ошибки (баги), а также что собой представляют исключения.
Определение
Ошибка в программировании (или так называемый баг) – это ситуация у разработчиков, при которой определенный код вследствие обработки выдает неверный результат. Причин данному явлению множество: неисправность компилятора, сбои интерфейса, неточности и нарушения в программном коде.
Баги обнаруживаются чаще всего в момент отладки или бета-тестирования. Реже – после итогового релиза готовой программы. Вот несколько вариантов багов:
- Появляется сообщение об ошибке, но приложение продолжает функционировать.
- ПО вылетает или зависает. Никаких предупреждений или предпосылок этому не было. Процедура осуществляется неожиданно для пользователя. Возможен вариант, при котором контент перезапускается самостоятельно и непредсказуемо.
- Одно из событий, описанных ранее, сопровождается отправкой отчетов разработчикам.
Ошибки в программах могут привести соответствующее приложение в негодность, а также к непредсказуемым алгоритмам функционирования. Желательно обнаруживать баги на этапе ранней разработки или тестирования. Лишь в этом случае программист сможет оперативно и относительно недорого внести необходимые изменения в код для отладки ПО.
История происхождения термина
Баг – слово, которое используется разработчиками в качестве сленга. Оно произошло от слова «bug» – «жук». Точно неизвестно, откуда в программировании и IT возник соответствующий термин. Существуют две теории:
- 9 сентября 1945 года ученые из Гарварда тестировали очередную вычислительную машину. Она называлась Mark II Aiken Relay Calculator. Устройство начало работать с ошибками. Когда его разобрали, то ученые заметили мотылька, застрявшего между реле. Тогда некая Грейс Хоппер назвала произошедший сбой упомянутым термином.
- Слово «баг» появилось задолго до появления Mark II. Термин использовался Томасом Эдисоном и указывал на мелкие недочеты и трудности. Во время Второй Мировой войны «bugs» называли проблемы с радарной электроникой.
Второй вариант кажется более реалистичным. Это факт, который подтвержден документально. Со временем научились различать различные типы багов в IT. Далее они будут рассмотрены более подробно.
Как классифицируют
Ошибки работы программ разделяются по разным факторам. Классификация у рядовых пользователей и разработчиков различается. То, что для первых – «просто программа вылетела» или «глючит», для вторых – огромная головная боль. Но существует и общепринятая классификация ошибок. Пример – по критичности:
- Серьезные неполадки. Это нарушения работоспособности приложения, которые могут приводить к непредвиденным крупным изменениям.
- Незначительные ошибки в программах. Чаще всего не оказывают серьезного воздействия на функциональность ПО.
- Showstopper. Критические проблемы в приложении или аппаратном обеспечении. Приводят к выходу программы из строя почти всегда. Для примера можно взять любое клиент-серверное приложение, в котором не получается авторизоваться через логин и пароль.
Последний вариант требует особого внимания со стороны программистов. Их стараются обнаружить и устранить в первую очередь. Критические ошибки могут отложить релиз исходной программы на неопределенный срок.
Также существуют различные виды сбоев в плане частоты проявления: постоянные и «разовые». Вторые встречаются редко, чаще – при определенных настройках и действиях со стороны пользователя. Первые появляются независимо от используемой платформы и выполненных клиентом манипуляций.
Иногда может получиться так, что ошибка возникает только на устройстве конкретного пользователя. В данном случае устранение неполадки требует индивидуального подхода. Иногда – полной замены компьютера. Связано это с тем, что никто не будет редактировать исходный код, когда он «глючит» только у одного пользователя.
Виды
Существуют различные типы ошибок в программах в зависимости от типовых условий использования приложений. Пример – сбои, которые возникают при возрастании нагрузки на оперативную память или центральный процессор устройства. Есть баги граничных условий, сбоя идентификаторов, несовместимости с архитектурой процессора (наиболее распространенная проблема на мобильных устройствах).
Разработчики выделяют следующие типы ошибок по уровню сложности:
- «Борбаг» – «стабильная» неполадка. Она легко обнаруживается на этапе разработки и компилирования. Иногда – во время тестирования наработкой исходной программы.
- «Гейзенбаг» – баги с поддержкой изменения свойств, включая зависимость от среды, в которой было запущено приложение. Сюда относят периодические неполадки в программах. Они могут исчезать на некоторое время, но через какой-то промежуток вновь дают о себе знать.
- «Мандельбаг» – непредвиденные ошибки. Обладают энтропийным поведением. Предсказать, к чему они приведут, практически невозможно.
- «Шрединбаг» – критические неполадки. Приводят к тому, что злоумышленники могут взломать программу. Данный тип ошибок обнаружить достаточно трудно, потому что они никак себя не проявляют.
Также есть классификация «по критичности». Тут всего два варианта – warning («варнинги») и критические весомые сбои. Первые сопровождаются характерными сообщениями и отчетами для разработчиков. Они не представляют серьезной опасности для работоспособности приложения. При компилировании такие сбои легко исправляются. В отдельных случаях компилятор справляется с этой задачей самостоятельно. А вот критические весомые сбои говорят сами за себя. Они приводят к серьезным нарушениям ПО. Исправляются обычно путем проработки логики и значительных изменений программного кода.
Типы багов
Ошибки в программах бывают:
- логическими;
- синтаксическими;
- взаимодействия;
- компиляционные;
- ресурсные;
- арифметические;
- среды выполнения.
Это – основная классификация сбоев в приложениях и операционных системах. Логические, синтаксические и «среды выполнения» встречаются в разработке чаще остальных. На них будет сделан основной акцент.
Ошибки синтаксиса
Синтаксические баги распространены среди новичков. Они относятся к категории «самых безобидных». С данной категорией ошибок способны справиться компиляторы тех или иных языков. Соответствующие инструменты показывают, где допущена неточность. Остается лишь понять, как исправить ее.
Синтаксические ошибки – ошибки синтаксиса, правил языка. Вот пример в Паскале:

Код написан неверно. Согласно действующим синтаксическим нормам, в Pascal в первой строчке нужно в конце поставить точку с запятой.
Логические
Тут стоит выделить обычные и арифметические типы. Вторые возникают, когда программе при работе необходимо вычислить много переменных, но на каком-то этапе расчетов возникают неполадки или нечто непредвиденное. Пример – получение в результатах «бесконечности».
Логические сбои обычного типа – самые сложные и неприятные. Их тяжелее всего обнаружить и исправить. С точки зрения языка программа может быть написана идеально, но работать неправильно. Подобное явление – следствие логической ошибки. Компиляторы их не обнаруживают.

Выше – пример логической ошибки в программе. Тут:
- Происходит сравнение значения i с 15.
- На экран выводится сообщение, если I = 15.
- В заданном цикле i не будет равно 15. Связано это с диапазоном значений – от 1 до 10.
Может показаться, что ошибка безобидная. В приведенном примере так и есть, но в более крупных программах такое явление приводит к серьезным последствиям.
Время выполнения
Run-time сбои – это ошибка времени выполнения программы. Встречается даже когда исходный код лишен логических и синтаксических ошибок. Связаны такие неполадки с ходом выполнения программного продукта. Пример – в процессе функционирования ПО был удален файл, считываемый программой. Если игнорировать подобные неполадки, можно столкнуться с аварийным завершением работы контента.
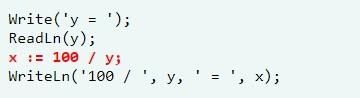
Самый распространенный пример в данной категории – это неожиданное деление на ноль. Предложенный фрагмент кода с точки зрения синтаксиса и логики написан грамотно. Но, если клиент наберет 0, произойдет сбой системы.
Компиляционный тип
Встречается при разработке на языках высокого уровня. Во время преобразований в машинный тип «что-то идет не так». Причиной служат синтаксические ошибки или сбои непосредственно в компиляторе.
Наличие подобных неполадок делает бета-тестирование невозможным. Компиляционные ошибки устраняются при разработке-отладке.
Ресурсные
Ресурсный тип ошибок – это сбои вроде «переполнение буфера» или «нехватка памяти». Тесно связаны с «железом» устройства. Могут быть вызваны действиями пользователя. Пример – запуск «свежих» игр на стареньких компьютерах.
Исправить ситуацию помогают основательные работы над исходным кодом. А именно – полное переписывание программы или «проблемного» фрагмента.
Взаимодействие
Подразумевается взаимодействие с аппаратным или программным окружением. Пример – ошибка при использовании веб-протоколов. Это приведет к тому, что облачный сервис не будет нормально функционировать. При постоянном возникновении соответствующей неполадки остается один путь – полностью переписывать «проблемный» участок кода, ответственный за соответствующий баг.
Исключения и как избежать багов
Исключение – событие, при возникновении которых начинается «неправильное» поведение программы. Механизм, необходимый для стабилизации обработки неполадок независимо от типа ПО, платформ и иных условий. Помогают разрабатывать единые концепции ответа на баги со стороны операционной системы или контента.
Исключения бывают:
- Программными. Они генерируются приложением или ОС.
- Аппаратными. Создаются процессором. Пример – обращение к невыделенной памяти.
Исключения нужны для охвата критических багов. Избежать неполадок помогут отладчики на этапе разработки. А еще – своевременное поэтапное тестирование программы.
P. S. Большой выбор курсов по тестированию есть и в Otus. Присутствуют варианты как для продвинутых, так и для начинающих пользователей.
Готовая программа не всегда работает как надо. Бывает, возникают баги, предупреждения, исключения. В итоге программа зависает, дает сбой или вылетает. Но это не конец света. Любую ошибку в коде можно исправить, если знать, почему она возникла.
Программная ошибка: что это и почему возникает
Программная ошибка — это дефект в коде. Из-за него программа сбоит или выдает неверные результаты. Некоторые ошибки серьезные — например, блокируют логин и пароль, из-за чего пользователь не может попасть в личный кабинет. А другие незаметны. Некоторое время программа работает как будто бы исправно — и только потом начинает глючить.
Ошибка в программировании — это зачастую ошибки разработчиков, которые находят тестировщики. Запускают разные тесты и отладку, чтобы определить источники проблемы.
Научитесь находить ошибки в приложениях и на сайтах до того, как ими начнут пользоваться клиенты. Для этого освойте профессию «Инженер по тестированию». Изучать язык программирования необязательно. Тестировщик работает с готовыми сайтами, приложениями, сервисами, а не с кодом. В программе от Skypro: четыре проекта для портфолио, практика с обратной связью, все основные инструменты тестировщика.
Ошибки часто называют багами, но подразумевают под ними разное, например:
❗ Ворнинги, или предупреждения. Возникают, когда программа начинает вести себя не так, как задумывалось. Не являются критичными ошибками. Программа с ворнингами работает, но с аномалиями.
❗ Исключения. Это не ошибки, а особые ситуации, которые нужно обработать.
❗ Синтаксические ошибки. Это ошибка в программе, связанная с написанием кода. Пример: программист забыл поставить точку или неверно написал название оператора. Если не исправить, код программы не запустится, а останется просто текстом.
Классификация багов
У багов есть два атрибута — серьезности (Severity) и приоритета (Priority). Серьезность касается технической стороны, а приоритет — организационной.
🚨 По серьезности. Атрибут показывает, как сильно ошибка влияет на общую функциональность программы. Чем выше значение атрибута, тем хуже.
По серьезности баги классифицируют так:
- Blocker — блокирующий баг. Программа запускается, но спустя время баг останавливает ее выполнение. Чтобы снова пользоваться программой, блокирующую ошибку в коде устраняют.
- Critical — критический баг. Нарушает функциональность программы. Появляется в разных частях кода, из-за этого основные функции не выполняются.
- Major — существенный баг. Не нарушает, но затрудняет работу основного функционала программы либо не дает функциям выполняться так, как задумано.
- Minor — незначительный баг. Слабо влияет на функционал программы, но может нарушать работу некоторых дополнительных функций.
- Trivial — тривиальный баг. На работу программы не влияет, но ухудшает общее впечатление. Например, на экране появляются посторонние символы или всё рябит.
🚦 По приоритету. Атрибут показывает, как быстро баг необходимо исправить, пока он не нанес программе приличный ущерб. Бывает таким:
- Top — наивысший. Такой баг — суперсерьезный, потому что может обвалить всю программу. Его устраняют в первую очередь.
- High — высокий. Может затруднить работу программы или ее функций, устраняют как можно скорее.
- Normal — обычный. Баг программу не ломает, просто где-то что-то будет работать не совсем верно. Устраняют в штатном порядке.
- Low — низкий. Баг не влияет на программу. Исправляют, только если у команды есть на это время.
Типы ошибок в программе
🧨 Логические. Приводят к тому, что программа зависает, работает не так, как надо, или выдает неожиданные результаты — например, не записывает файл, а стирает.
Логические ошибки коварны: их трудно обнаружить. Программа выглядит так, будто в ней всё правильно, но при этом работает некорректно. Чтобы победить логические ошибки, специалист должен хорошо ориентироваться в коде программы.
🧨 Синтаксические. Это опечатки в названиях операторов, пропущенные запятые или кавычки. Безобидные ошибки: их обнаруживают и подсвечивают в коде компиляторы, а программисту остается исправить.
🧨 Взаимодействия. Это ошибка в участке кода, который отвечает за взаимодействие с аппаратным или программным окружением. Такая ошибка возникает, например, если неправильно использовать веб-протоколы. Исправляется элементарно: разработчик переписывает нужный кусок кода.
🧨 Компиляционные. Любая программа — это текст. Чтобы он заработал как программа, используют компилятор. Он преобразует программный код в машинный, но одновременно может вызывать ошибки.
Компиляционные баги появляются, если что-то не так с компилятором или в коде есть синтаксические ошибки. Компилятор будто ругается: «Не понимаю, что тут написано. Не знаю, как обработать».
🧨 Ошибки среды выполнения. Возникают, когда программа скомпилирована и уже выглядит как файл — жми и работай. Юзер запускает файл, а программа тормозит и виснет. Причина — нехватка ресурсов, например памяти или буфера.
Такой баг — ошибка разработчика. Он не предвидел реальные условия развертывания программы. Теперь ему надо вернуться в исходный код и поправить фрагмент.
🧨 Арифметические. Бывает, в коде есть числовые переменные и математические формулы. Если где-то проблема — не указаны константы или округление сработало не так, возникает баг. Надо лезть в код и проверять математику.
Что такое исключения в программах
Это механизм, который помогает программе обрабатывать нестандартную ситуацию и при этом не вылетать. Идеально, если программист предусмотрел все возможные ситуации. Но так бывает редко, поэтому лучше использовать специальный обработчик. Он обработает исключения так, что программа продолжит работать.
Как это происходит:
- Когда программист кодит, то продумывает, в какой части программы может вылезти ошибка.
- В этой части пишет специальный фрагмент, который предупредит компьютер, что ошибка — вполне ожидаемое явление и резко обрывать программу не нужно.
- Когда юзер запустит программу и появится ошибка, компьютер увидит заранее подготовленное предупреждение программиста. Продолжит выполнять алгоритм так, словно никакого бага и не было.
Исключения бывают программными и аппаратными:
- Аппаратные создает процессор. К ним относят деление на ноль, выход за границы массива, обращение к невыделенной памяти.
- Программные создает операционка и приложения. Возникают, когда программа их инициирует: аномальная ситуация возникла — программа создала исключение.
Как контролировать баги в программе
🔧 Следите за компилятором. Когда компилятор преобразует текст программы в машинный код, то подсвечивает в нём сомнительные участки, которые способны вызывать баги. Некоторые предупреждения не обозначают баг как таковой, а только говорят: «Тут что-то подозрительное». Всё подозрительное надо изучать и прорабатывать, чтобы не было проблемы в будущем.
🔧 Используйте отладчик. Это программа, которая без участия айтишника проверяет, исправно ли работает алгоритм. В случае чего сообщает об ошибках. Например, отладчик используют для построчного выполнения программы. Вместе с тем проверяют значения переменных: фактические сравнивают с ожидаемыми. Если что-то не сходится, ищут баги и исправляют.
🔧 Проводите юнит-тесты. Это когда разработчик или тестировщик описывает ситуации для каждого компонента и указывает, к какому результату должна привести программа. Потом запускает проверку. Если результат не совпадает с ожидаемым, появляется предупреждение. Дальше программисты находят и устраняют проблему.
Ключевое: что такое ошибки в программировании
- Ошибка в программировании — это дефект кода, баг, который может вызывать в программе сбои и неожиданное поведение.
- По серьезности баги делятся на блокирующие, критические, существенные, незначительные, тривиальные. По приоритету — на наивысший, высокий, обычный, низкий.
- Ошибки в коде могут быть разными, например связанные с логикой программы. Или с математическими вычислениями — логические. Еще бывают синтаксические, ошибки взаимодействия, компиляционные и ошибки среды выполнения.
- Некоторые ошибки помогают ловить обработчики исключений.
- Чтобы находить ошибки в коде, тестировщики используют компиляторы, отладчики и пишут юнит-тесты.
#Руководства
- 30 июн 2020
-

14
Что такое баги, ворнинги и исключения в программировании
Разбираемся, какие бывают типы ошибок в программировании и как с ними справляться.
vlada_maestro / shutterstock

Пишет о программировании, в свободное время создаёт игры. Мечтает открыть свою студию и выпускать ламповые RPG.
Многим известно слово баг (англ. bug — жук), которым называют ошибки в программах. Однако баг — это не совсем ошибка, а скорее неожиданный результат работы. Также есть и другие термины: ворнинг, исключение, утечка.
В этой статье мы на примере C++ разберём, что же значат все эти слова и как эти проблемы влияют на эффективность программы.
Словом «ошибка» (англ. error) можно описать любую проблему, но чаще всего под ним подразумевают синтаксическую ошибку — некорректно написанный код, который даже не скомпилируется:
//В конце команды забыли поставить точку с запятой (;) int a = 5
Компилятор тут же скажет, что в коде ошибка и скорее всего не хватает запятой или точки с запятой.
Также существуют ворнинги (англ. warning — предупреждение). Они не являются ошибками, поэтому программа всё равно будет собрана. Вот пример:
int main() { //Мы создаём две переменные, которые просто занимают память и никак не используются int a, b; }
Мы можем попросить компилятор показать нам все предупреждения с помощью флага -Wall:
Предупреждения не являются чем-то критичным, но могут иметь негативные последствия. Например, ваша программа будет использовать больше памяти, чем должна. Так как C++ нужен в том числе и для разработки высоконагруженных систем, этого допускать нельзя.

После восклицательного знака в треугольнике — количество предупреждений
Третий вид ошибок — ошибки сегментации (англ. segmentation fault, сокр. segfault, жарг. сегфолт). Они возникают, если программа пытается записать что-то в ячейку, недоступную для записи. Например:
//Создаём константный массив символов const char * s = "Hello World"; //Если мы попытаемся перезаписать значение константы, компилятор выдаст ошибку //Но с помощью указателей мы можем обойти её, поэтому программа успешно скомпилируется //Однако во время работы она будет выдавать ошибку сегментации * (char *) s = 'H';
Вот результат работы такого кода:
Мы выяснили, что баг — это не совсем ошибка, а скорее неожиданное поведение программы или результат такого поведения. Баги могут быть чем-то забавным или неприятным. Например, как в играх:
Но они могут привести и к более серьёзным последствиям. Если неправильно спроектировать работу многопоточного приложения, то потоки будут постоянно опережать друг друга. Например, сообщение об ошибке из одного потока может опоздать на миллисекунду, из-за чего второй поток подумает, что никакой ошибки не было, и продолжит работу.
Если ваш код приводит в действие какое-нибудь потенциально опасное устройство, то ценой такой ошибки может быть чья-нибудь жизнь. Такое случилось с кодом для аппарата лучевой терапии Therac-25 — как минимум два человека умерло и ещё больше пострадали из-за превышения дозы радиации.
Также во время работы программы могут возникать ситуации, которые мешают корректной работе программы. Например, если вы просите пользователя ввести число, а он вводит строку.
Конвертировать введённое значение не всегда возможно, поэтому функция, которая занимается преобразованием, «выбрасывает» исключение (англ. exception). Это специальное сообщение говорит о том, что что-то идёт не так.
Если разработчик не описывает логику работы программы при вы выбрасывании исключения, то программа аварийно закрывается. Подробнее мы рассказали об этом в статье про ввод и конвертацию в C++.
Одно из самых известных исключений — переполнение стека (англ. stack overflow). В честь него даже назвали сайт, на котором программисты ищут помощь в решении своих проблем.
int main() { //Бесконечная рекурсия - одна из причин переполнения стека вызовов main(); }
Компилятор C++ при этом может выдать ошибку сегментации, а не сообщение о переполнении стека:
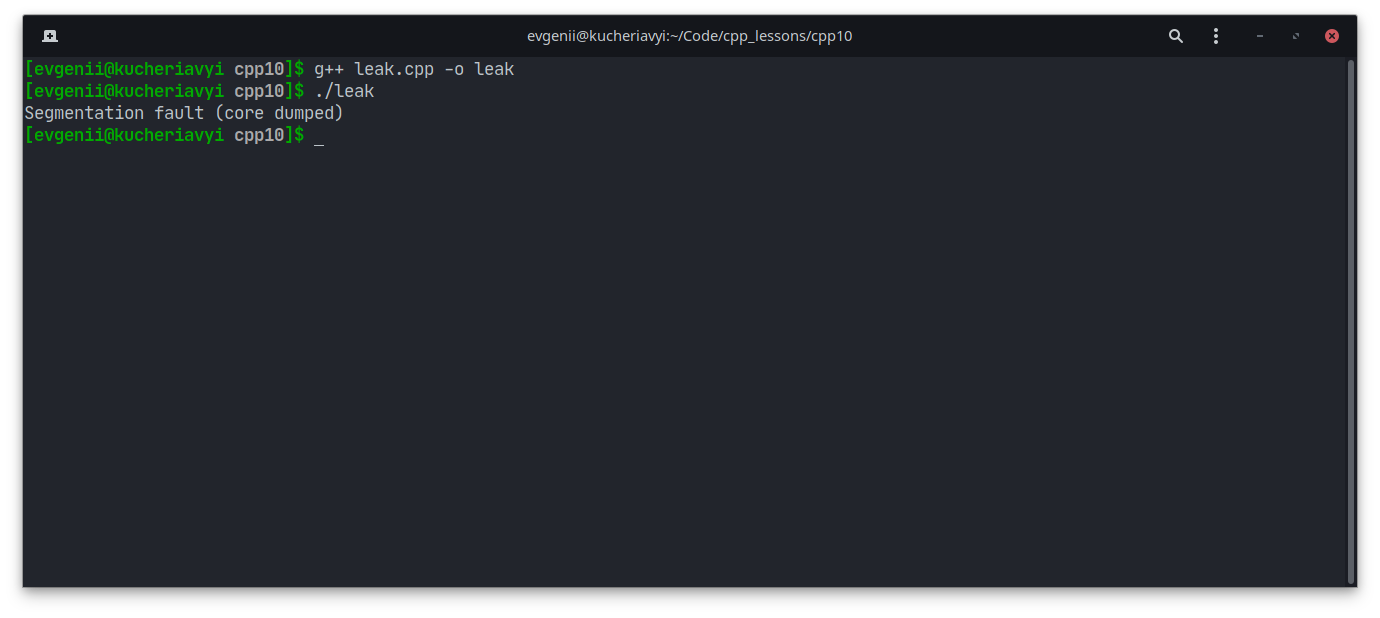
Вот аналогичный код на языке C#:
class Program { static void Main(string[] args) { Main(args); } }
Однако сообщение в этот раз более конкретное:
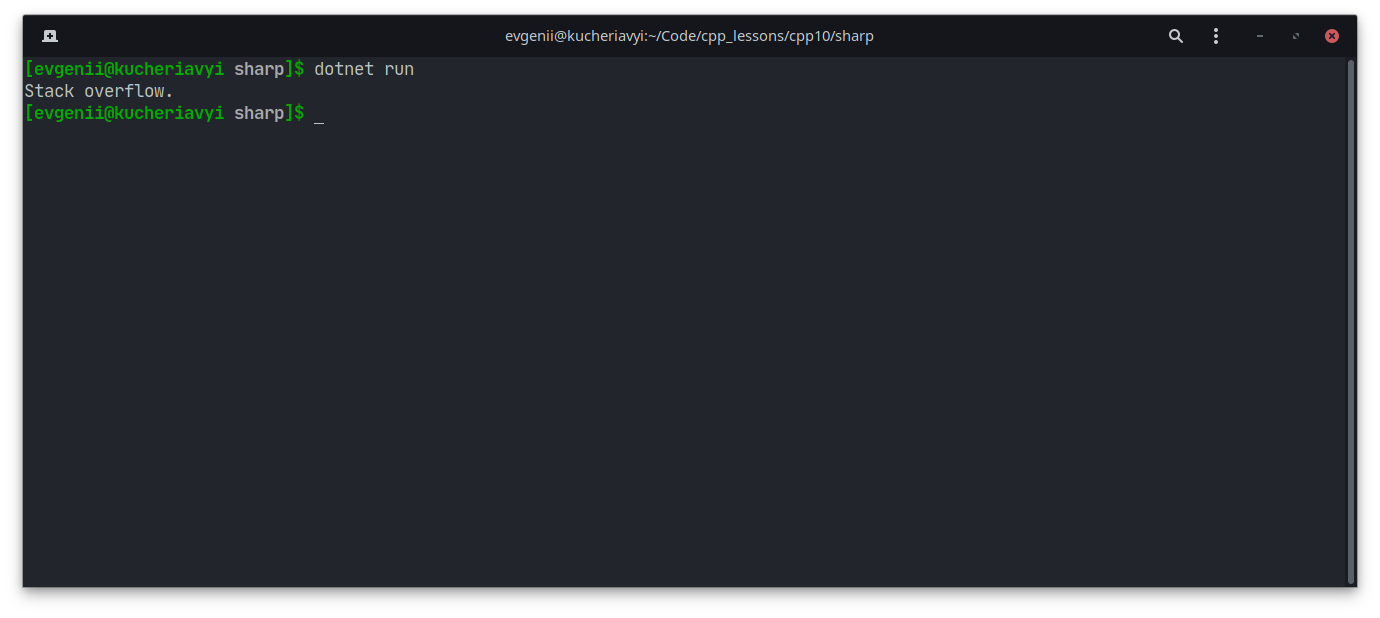
В обоих случаях программа завершается, потому что не может дальше корректно работать.
Похожая ситуация — переполнение буфера (англ. buffer overflow). Она происходит, когда записываемое значение больше выделенной области в памяти.
//Пробуем записать в переменную типа int значение, которое превышает лимит //Константа INT_MAX находится в библиотеке climits int a = INT_MAX + 1;
Обратите внимание, что мы получили предупреждение об арифметическом переполнении (англ. integer overflow):
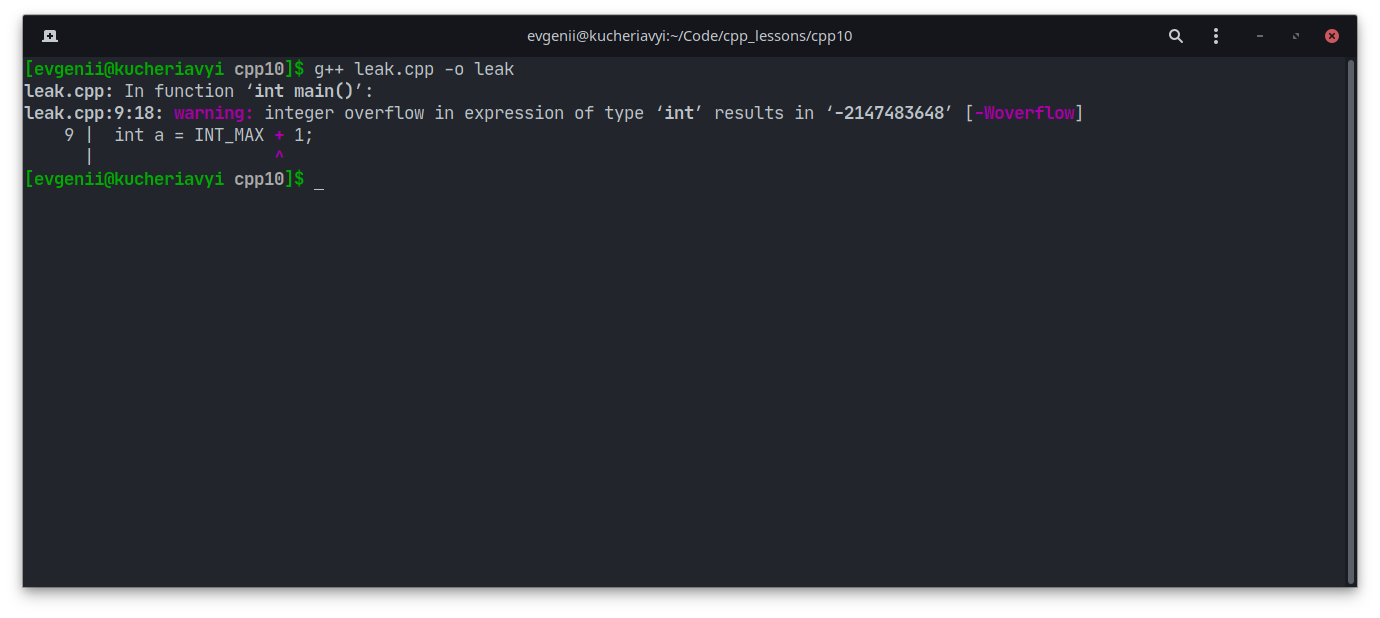
Тем не менее программа скомпилировалась. Если же такая ситуация возникнет во время вычислений, то мы можем не получить предупреждения.
Арифметическое переполнение стало причиной одной из самых дорогих аварий, произошедших из-за ошибки в коде. В 1996 году ракета-носитель «Ариан-5» взорвалась на 40-й секунде полёта — потери оценивают в 360–500 миллионов долларов.
К сожалению, вручную всё это заметить и исправить не получится. Однако существуют различные инструменты и технологии, которые могут помочь.
Один из таких инструментов — отладчик. Он помогает контролировать ход работы программы, чтобы отслеживать разные показатели.
Второй, более эффективный метод — unit-тесты. Они представляют из себя набор описанных ситуаций для каждого компонента программы с указанием ожидаемого поведения.
Например, у вас есть функция sum (int a, int b), которая возвращает сумму двух чисел. Вы можете написать unit-тесты, чтобы проверять следующие ситуации:
| Входные данные | Ожидаемый результат |
|---|---|
| 5, 10 | 15 |
| 99, 99 | 198 |
| 8, -9 | -1 |
| -1, -1 | -2 |
| fff, 8 | IllegalArgumentException |
Если какой-то из этих тестов не пройден, вы узнаете об этом и сможете всё исправить. Это намного быстрее, чем проверять всё вручную.
Ошибок существует слишком много. При этом самые опасные тяжелее обнаружить, что только усугубляет ситуацию.

Научитесь: Профессия Разработчик на C++
Узнать больше
Существует три
основных типа ошибок в программах:
— ошибки этапа
компиляции (или синтаксические ошибки);
— ошибки этапа
выполнения или семантические ошибки);
— логические
ошибки.
Cинтаксические
ошибки происходят из-за нарушений
правил синтаксиса
языка программирования.
Когда компилятор обнаруживает
синтаксическую
ошибку, то отмечает
место (позицию или строку) ошибки и
выводт сообщение
об ошибке.
Наиболее
распространенными синтаксическими
ошибками являются:
— ошибки набора
(опечатки);
— пропущенные
точки с запятой;
— ссылки на
неописанные переменные;
— передача
неверного числа (или типа) параметров
процедуры или
функции;
— присваивание
переменной значений неверного типа.
После исправления
cинтаксической ошибки компиляцию можно
выполнить
заново. После
устранения всех синтаксических ошибок
и успешной компиля-
ции программа готова
к выполнению и поиску ошибок этапа
выполнения и ло-
гических ошибок.
Семантические
ошибки происходят, когда программа
компилируется, но
при выполнении
операторов что-то происходит неверно.
Например, программа
пытается открыть
для ввода несуществующий файл или
выполнить деление на
ноль. При обнаружении
семантических ошибок выполнение
программы заверша-
ется и выводится
сообщение об ошибке. Например, в системе
Turbo Pascal
выводится сообщение
следующего вида:
Run-time error ## at seg:ofs
По номеру
ошибки (##) можно установить причину ее
возникновения.
Логические ошибки
— это ошибки проектирования и реализации
програм-
мы. Логические
ошибки приводят к некорректному или
непредвиденному зна-
чению переменных,
неправильному виду графических
изображений или невы-
полнению кода, когда
это ожидается. Эти ошибки часто трудно
отслежива-
ются, поскольку ни
компилятор, ни исполняющая система не
обнаруживают их
автоматически, как
синтаксические и семантические ошибки.
Обычно системы
программирования
включает в себя средства отладки,
помогающие найти ло-
гические ошибки.
3.4.2. Цели и задачи отладки и тестирования.
Многие программисты
путают отладку программ с тестированием,
пред-
назначенным для
проверки их работоспособности. Отладка
имеет место тог-
да, когда программа
со всей очевидностью работает неправильно.
Поэтому
отладка начинается
всегда в предположении отказа программы.
Если же ока-
зывается, что
программа работает верно, то она
тестируется. Часто случа-
ется так, что после
прогона тестов программа вновь должна
быть подверг-
нута отладке. Таким
образом, тестирование устанавливает
факт наличия
ошибки, а отладка
выявляет ее причину, и эти два этапа
разработки прог-
раммы перекрываются.
3.4.3. Основные возможности интегрированного отладчика системы
программирования
Turbo Pascal.
Основной смысл
использования встроенного отладчика
состоит в управ-
ляемом выполнении
программы. Отслеживая выполнение
каждой инструкции,
можно легко определить,
какая часть программы вызывает проблемы.
В от-
ладчике предусмотрено
шесть основных механизмов управления
выполнением
программы, которые
позволяют:
— выполнять
инструкции по шагам(Run|Step Over или F8);
— трассировать
инструкции (Run|Trace Into или F7);
— выполнять
программы до позиции курсора (Run|Go to
Cursor или F4);
— выполнять
программу до заданной точки (Toggle
Breakpoint или
Ctrl+F8);
— находить
определенную точку (Search|Find Procedure…);
— выполнять сброс
программы (Run¦Reset Program или Ctrl+F2).
Выполнение
программы по шагам (команда Step Over меню
выполнения
Run) и трассировка
программы (команда Trace Into меню выполнения
Run)
дают возможность
построчного выполнения программы.
Единственное отличие
выполнения по шагам
и трассировки состоит в том, как они
работают с вы-
зовами процедур и
функций. Выполнение по шагам вызова
процедуры или
функции интерпретирует
вызов как простой оператор и после
завершения
подпрограммы
возвращает управление на следующую
строку. Трассировка
подпрограммы
загружает код этой подпрограммы и
продолжает ее построчное
выполнение.
Выполнение
программы до заданной точки (команда
Toggle Breakpoint
локального меню
редактора) — более гибкий механизм
отладки, чем исполь-
зование метода
выполнения до позиции курсора (команда
Go to Cursor меню
выполнения Run),
поскольку в программе можно установить
несколько точек
останова.
Интегрированная
среда разработки программы предусматривает
несколь-
ко способов поиска
в программе заданного места. Простейший
способ пре-
доставляет команда
Search|Find Procedure…, которая запрашивает
имя
процедуры или
функции, затем находит соответствующую
строку в файле, где
определяется эта
подпрограмма. Этот подход полезно
использовать при ре-
дактировании, но
его можно комбинировать с возможностью
выполнения прог-
раммы до определенной
точки, чтобы пройти программу до той
части кода,
которую надо отладить.
Чтобы сбрасить
все ранее задействованные отладочные
средства и
прекратитьт отладку
программы необходимо выполнить команду
Run|Program
reset или нажать клавиши
Ctrl+F2.
При выполнении
программы по шагам можно наблюдать ее
вывод несколь-
кими способами:
— переключение
в случае необходимости экранов
(Debug|User screen
или Alt+F5);
— открытие окна
вывода (Debug¦Output);
— использование
второго монитора;
Выполнение
программы по шагам или ее трассировка
могут помочь найти
ошибки в алгоритме
программы, но обычно желательно также
знать, что про-
исходит на каждом
шаге со значениями отдельных переменных.
Например, при
выполнении по шагам
цикла for полезно знать значение переменной
цикла.
Встроенный отладчик
имеет два инструментальных средства
для проверки со-
держимого переменных
программы:
— окно Watches
(Просмотр);
— диалоговое окно
Evaluate and Modify (Вычисление и модификация).
Чтобы открыть
окно Watches, необходимо выполнить
команду
Debug|Watch. Чтобы добавить
в окно Watches переменную, необходимо выпол-
нить
команду
Debug¦Watch¦Add Watch… или
нажать клавиши Ctrl+F7. Если
окно Watches является
активным окном, то можно добавить
выражение
просмотра, нажав
клавишу Ins. Отладчик открывает диалоговое
окно Add
Watch, запрашивающее
тип просматриваемого выражения. По
умолчанию выра-
жением считается
слово в позиции курсора в текущем окне
редактирования.
Просматриваемые
выражения, которые отслеживались ранее,
сохраняются в
списке протокола.
Последнее добавленное или модифицированное
просматри-
ваемое выражение
является текущим просматриваемым
выражением, которое
указывается выводимым
слева от него символом жирной левой
точки. Если
окно Watches активно,
можно удалить текущее выражение, нажав
клавишу Del
или Ctrl+Y. Чтобы
удалить все просматриваемые выражения,
необходимо вы-
полнить команду
Clear All локального меню активного окна
Watches. Чтобы
отредактировать
просматриваемое выражение, нужно
выполнить команду
Modify… или нажать
клавишу Enter локального меню активного
окна
Watches. Отладчик
открывает диалоговое окно Edit Watch,
аналогичное то-
му, которое
используется для добавления просматриваемого
выражения, ко-
торое позволяет
отредактировать текущее выражение.
Чтобы вычислить
выражение, необходимо выполнить
команду
Debug¦Evaluate/Modify…
или
нажать
клавиши
Ctrl+F4. Отладчик
открывает
диалоговое окно
Evaluate and Modify. По умолчанию слово в позиции
курсо-
ра в текущем окне
редактирования выводится подсвеченным
в поле
Expression. Можно
отредактировать это выражение, набрать
другое выраже-
ние или выбрать
вычисленное ранее выражение из списка
протокола.
Даже если не
установлены точки останова, можно выйти
в отладчик при
выполнении программы,
нажав клавиши Ctrl+Break. Отладчик находит
позицию
в исходном коде, где
прервалась программа. Затем, как и в
случае обычной
точки останова,
можно выполнить программу по шагам,
трассировать ее,
отследить или
вычислить выражения.
Иногда в ходе
отладки полезно узнать, как вы попали
в данную часть
кода. Окно Call Stack
показывает последовательность вызовов
процедур или
функций, которые
привели к текущему состоянию (глубиной
до 128 уровней).
Для вывода окна Call
Stack необходимо выполнить команду
Debug¦Call Stack
или нажать клавиши
Ctrl+F3.
13
Соседние файлы в папке 13_3xN
- #
- #
- #
Ошибки в программировании – дело обычное, хоть и неприятное. В данной статье будет рассказано о том, какими бывают ошибки (баги), а также что собой представляют исключения.
Определение
Ошибка в программировании (или так называемый баг) – это ситуация у разработчиков, при которой определенный код вследствие обработки выдает неверный результат. Причин данному явлению множество: неисправность компилятора, сбои интерфейса, неточности и нарушения в программном коде.
Баги обнаруживаются чаще всего в момент отладки или бета-тестирования. Реже – после итогового релиза готовой программы. Вот несколько вариантов багов:
- Появляется сообщение об ошибке, но приложение продолжает функционировать.
- ПО вылетает или зависает. Никаких предупреждений или предпосылок этому не было. Процедура осуществляется неожиданно для пользователя. Возможен вариант, при котором контент перезапускается самостоятельно и непредсказуемо.
- Одно из событий, описанных ранее, сопровождается отправкой отчетов разработчикам.
Ошибки в программах могут привести соответствующее приложение в негодность, а также к непредсказуемым алгоритмам функционирования. Желательно обнаруживать баги на этапе ранней разработки или тестирования. Лишь в этом случае программист сможет оперативно и относительно недорого внести необходимые изменения в код для отладки ПО.
История происхождения термина
Баг – слово, которое используется разработчиками в качестве сленга. Оно произошло от слова «bug» – «жук». Точно неизвестно, откуда в программировании и IT возник соответствующий термин. Существуют две теории:
- 9 сентября 1945 года ученые из Гарварда тестировали очередную вычислительную машину. Она называлась Mark II Aiken Relay Calculator. Устройство начало работать с ошибками. Когда его разобрали, то ученые заметили мотылька, застрявшего между реле. Тогда некая Грейс Хоппер назвала произошедший сбой упомянутым термином.
- Слово «баг» появилось задолго до появления Mark II. Термин использовался Томасом Эдисоном и указывал на мелкие недочеты и трудности. Во время Второй Мировой войны «bugs» называли проблемы с радарной электроникой.
Второй вариант кажется более реалистичным. Это факт, который подтвержден документально. Со временем научились различать различные типы багов в IT. Далее они будут рассмотрены более подробно.
Как классифицируют
Ошибки работы программ разделяются по разным факторам. Классификация у рядовых пользователей и разработчиков различается. То, что для первых – «просто программа вылетела» или «глючит», для вторых – огромная головная боль. Но существует и общепринятая классификация ошибок. Пример – по критичности:
- Серьезные неполадки. Это нарушения работоспособности приложения, которые могут приводить к непредвиденным крупным изменениям.
- Незначительные ошибки в программах. Чаще всего не оказывают серьезного воздействия на функциональность ПО.
- Showstopper. Критические проблемы в приложении или аппаратном обеспечении. Приводят к выходу программы из строя почти всегда. Для примера можно взять любое клиент-серверное приложение, в котором не получается авторизоваться через логин и пароль.
Последний вариант требует особого внимания со стороны программистов. Их стараются обнаружить и устранить в первую очередь. Критические ошибки могут отложить релиз исходной программы на неопределенный срок.
Также существуют различные виды сбоев в плане частоты проявления: постоянные и «разовые». Вторые встречаются редко, чаще – при определенных настройках и действиях со стороны пользователя. Первые появляются независимо от используемой платформы и выполненных клиентом манипуляций.
Иногда может получиться так, что ошибка возникает только на устройстве конкретного пользователя. В данном случае устранение неполадки требует индивидуального подхода. Иногда – полной замены компьютера. Связано это с тем, что никто не будет редактировать исходный код, когда он «глючит» только у одного пользователя.
Виды
Существуют различные типы ошибок в программах в зависимости от типовых условий использования приложений. Пример – сбои, которые возникают при возрастании нагрузки на оперативную память или центральный процессор устройства. Есть баги граничных условий, сбоя идентификаторов, несовместимости с архитектурой процессора (наиболее распространенная проблема на мобильных устройствах).
Разработчики выделяют следующие типы ошибок по уровню сложности:
- «Борбаг» – «стабильная» неполадка. Она легко обнаруживается на этапе разработки и компилирования. Иногда – во время тестирования наработкой исходной программы.
- «Гейзенбаг» – баги с поддержкой изменения свойств, включая зависимость от среды, в которой было запущено приложение. Сюда относят периодические неполадки в программах. Они могут исчезать на некоторое время, но через какой-то промежуток вновь дают о себе знать.
- «Мандельбаг» – непредвиденные ошибки. Обладают энтропийным поведением. Предсказать, к чему они приведут, практически невозможно.
- «Шрединбаг» – критические неполадки. Приводят к тому, что злоумышленники могут взломать программу. Данный тип ошибок обнаружить достаточно трудно, потому что они никак себя не проявляют.
Также есть классификация «по критичности». Тут всего два варианта – warning («варнинги») и критические весомые сбои. Первые сопровождаются характерными сообщениями и отчетами для разработчиков. Они не представляют серьезной опасности для работоспособности приложения. При компилировании такие сбои легко исправляются. В отдельных случаях компилятор справляется с этой задачей самостоятельно. А вот критические весомые сбои говорят сами за себя. Они приводят к серьезным нарушениям ПО. Исправляются обычно путем проработки логики и значительных изменений программного кода.
Типы багов
Ошибки в программах бывают:
- логическими;
- синтаксическими;
- взаимодействия;
- компиляционные;
- ресурсные;
- арифметические;
- среды выполнения.
Это – основная классификация сбоев в приложениях и операционных системах. Логические, синтаксические и «среды выполнения» встречаются в разработке чаще остальных. На них будет сделан основной акцент.
Ошибки синтаксиса
Синтаксические баги распространены среди новичков. Они относятся к категории «самых безобидных». С данной категорией ошибок способны справиться компиляторы тех или иных языков. Соответствующие инструменты показывают, где допущена неточность. Остается лишь понять, как исправить ее.
Синтаксические ошибки – ошибки синтаксиса, правил языка. Вот пример в Паскале:
Код написан неверно. Согласно действующим синтаксическим нормам, в Pascal в первой строчке нужно в конце поставить точку с запятой.
Логические
Тут стоит выделить обычные и арифметические типы. Вторые возникают, когда программе при работе необходимо вычислить много переменных, но на каком-то этапе расчетов возникают неполадки или нечто непредвиденное. Пример – получение в результатах «бесконечности».
Логические сбои обычного типа – самые сложные и неприятные. Их тяжелее всего обнаружить и исправить. С точки зрения языка программа может быть написана идеально, но работать неправильно. Подобное явление – следствие логической ошибки. Компиляторы их не обнаруживают.
Выше – пример логической ошибки в программе. Тут:
- Происходит сравнение значения i с 15.
- На экран выводится сообщение, если I = 15.
- В заданном цикле i не будет равно 15. Связано это с диапазоном значений – от 1 до 10.
Может показаться, что ошибка безобидная. В приведенном примере так и есть, но в более крупных программах такое явление приводит к серьезным последствиям.
Время выполнения
Run-time сбои – это ошибка времени выполнения программы. Встречается даже когда исходный код лишен логических и синтаксических ошибок. Связаны такие неполадки с ходом выполнения программного продукта. Пример – в процессе функционирования ПО был удален файл, считываемый программой. Если игнорировать подобные неполадки, можно столкнуться с аварийным завершением работы контента.
Самый распространенный пример в данной категории – это неожиданное деление на ноль. Предложенный фрагмент кода с точки зрения синтаксиса и логики написан грамотно. Но, если клиент наберет 0, произойдет сбой системы.
Компиляционный тип
Встречается при разработке на языках высокого уровня. Во время преобразований в машинный тип «что-то идет не так». Причиной служат синтаксические ошибки или сбои непосредственно в компиляторе.
Наличие подобных неполадок делает бета-тестирование невозможным. Компиляционные ошибки устраняются при разработке-отладке.
Ресурсные
Ресурсный тип ошибок – это сбои вроде «переполнение буфера» или «нехватка памяти». Тесно связаны с «железом» устройства. Могут быть вызваны действиями пользователя. Пример – запуск «свежих» игр на стареньких компьютерах.
Исправить ситуацию помогают основательные работы над исходным кодом. А именно – полное переписывание программы или «проблемного» фрагмента.
Взаимодействие
Подразумевается взаимодействие с аппаратным или программным окружением. Пример – ошибка при использовании веб-протоколов. Это приведет к тому, что облачный сервис не будет нормально функционировать. При постоянном возникновении соответствующей неполадки остается один путь – полностью переписывать «проблемный» участок кода, ответственный за соответствующий баг.
Исключения и как избежать багов
Исключение – событие, при возникновении которых начинается «неправильное» поведение программы. Механизм, необходимый для стабилизации обработки неполадок независимо от типа ПО, платформ и иных условий. Помогают разрабатывать единые концепции ответа на баги со стороны операционной системы или контента.
Исключения бывают:
- Программными. Они генерируются приложением или ОС.
- Аппаратными. Создаются процессором. Пример – обращение к невыделенной памяти.
Исключения нужны для охвата критических багов. Избежать неполадок помогут отладчики на этапе разработки. А еще – своевременное поэтапное тестирование программы.
P. S. Большой выбор курсов по тестированию есть и в Otus. Присутствуют варианты как для продвинутых, так и для начинающих пользователей.
#Руководства
- 30 июн 2020
-
14
Что такое баги, ворнинги и исключения в программировании
Разбираемся, какие бывают типы ошибок в программировании и как с ними справляться.
vlada_maestro / shutterstock
Пишет о программировании, в свободное время создаёт игры. Мечтает открыть свою студию и выпускать ламповые RPG.
Многим известно слово баг (англ. bug — жук), которым называют ошибки в программах. Однако баг — это не совсем ошибка, а скорее неожиданный результат работы. Также есть и другие термины: ворнинг, исключение, утечка.
В этой статье мы на примере C++ разберём, что же значат все эти слова и как эти проблемы влияют на эффективность программы.
Словом «ошибка» (англ. error) можно описать любую проблему, но чаще всего под ним подразумевают синтаксическую ошибку — некорректно написанный код, который даже не скомпилируется:
//В конце команды забыли поставить точку с запятой (;) int a = 5
Компилятор тут же скажет, что в коде ошибка и скорее всего не хватает запятой или точки с запятой.
Также существуют ворнинги (англ. warning — предупреждение). Они не являются ошибками, поэтому программа всё равно будет собрана. Вот пример:
int main() { //Мы создаём две переменные, которые просто занимают память и никак не используются int a, b; }
Мы можем попросить компилятор показать нам все предупреждения с помощью флага -Wall:
Предупреждения не являются чем-то критичным, но могут иметь негативные последствия. Например, ваша программа будет использовать больше памяти, чем должна. Так как C++ нужен в том числе и для разработки высоконагруженных систем, этого допускать нельзя.
После восклицательного знака в треугольнике — количество предупреждений
Третий вид ошибок — ошибки сегментации (англ. segmentation fault, сокр. segfault, жарг. сегфолт). Они возникают, если программа пытается записать что-то в ячейку, недоступную для записи. Например:
//Создаём константный массив символов const char * s = "Hello World"; //Если мы попытаемся перезаписать значение константы, компилятор выдаст ошибку //Но с помощью указателей мы можем обойти её, поэтому программа успешно скомпилируется //Однако во время работы она будет выдавать ошибку сегментации * (char *) s = 'H';
Вот результат работы такого кода:
Мы выяснили, что баг — это не совсем ошибка, а скорее неожиданное поведение программы или результат такого поведения. Баги могут быть чем-то забавным или неприятным. Например, как в играх:
Но они могут привести и к более серьёзным последствиям. Если неправильно спроектировать работу многопоточного приложения, то потоки будут постоянно опережать друг друга. Например, сообщение об ошибке из одного потока может опоздать на миллисекунду, из-за чего второй поток подумает, что никакой ошибки не было, и продолжит работу.
Если ваш код приводит в действие какое-нибудь потенциально опасное устройство, то ценой такой ошибки может быть чья-нибудь жизнь. Такое случилось с кодом для аппарата лучевой терапии Therac-25 — как минимум два человека умерло и ещё больше пострадали из-за превышения дозы радиации.
Также во время работы программы могут возникать ситуации, которые мешают корректной работе программы. Например, если вы просите пользователя ввести число, а он вводит строку.
Конвертировать введённое значение не всегда возможно, поэтому функция, которая занимается преобразованием, «выбрасывает» исключение (англ. exception). Это специальное сообщение говорит о том, что что-то идёт не так.
Если разработчик не описывает логику работы программы при вы выбрасывании исключения, то программа аварийно закрывается. Подробнее мы рассказали об этом в статье про ввод и конвертацию в C++.
Одно из самых известных исключений — переполнение стека (англ. stack overflow). В честь него даже назвали сайт, на котором программисты ищут помощь в решении своих проблем.
int main() { //Бесконечная рекурсия - одна из причин переполнения стека вызовов main(); }
Компилятор C++ при этом может выдать ошибку сегментации, а не сообщение о переполнении стека:
Вот аналогичный код на языке C#:
class Program { static void Main(string[] args) { Main(args); } }
Однако сообщение в этот раз более конкретное:
В обоих случаях программа завершается, потому что не может дальше корректно работать.
Похожая ситуация — переполнение буфера (англ. buffer overflow). Она происходит, когда записываемое значение больше выделенной области в памяти.
//Пробуем записать в переменную типа int значение, которое превышает лимит //Константа INT_MAX находится в библиотеке climits int a = INT_MAX + 1;
Обратите внимание, что мы получили предупреждение об арифметическом переполнении (англ. integer overflow):
Тем не менее программа скомпилировалась. Если же такая ситуация возникнет во время вычислений, то мы можем не получить предупреждения.
Арифметическое переполнение стало причиной одной из самых дорогих аварий, произошедших из-за ошибки в коде. В 1996 году ракета-носитель «Ариан-5» взорвалась на 40-й секунде полёта — потери оценивают в 360–500 миллионов долларов.
К сожалению, вручную всё это заметить и исправить не получится. Однако существуют различные инструменты и технологии, которые могут помочь.
Один из таких инструментов — отладчик. Он помогает контролировать ход работы программы, чтобы отслеживать разные показатели.
Второй, более эффективный метод — unit-тесты. Они представляют из себя набор описанных ситуаций для каждого компонента программы с указанием ожидаемого поведения.
Например, у вас есть функция sum (int a, int b), которая возвращает сумму двух чисел. Вы можете написать unit-тесты, чтобы проверять следующие ситуации:
| Входные данные | Ожидаемый результат |
|---|---|
| 5, 10 | 15 |
| 99, 99 | 198 |
| 8, -9 | -1 |
| -1, -1 | -2 |
| fff, 8 | IllegalArgumentException |
Если какой-то из этих тестов не пройден, вы узнаете об этом и сможете всё исправить. Это намного быстрее, чем проверять всё вручную.
Ошибок существует слишком много. При этом самые опасные тяжелее обнаружить, что только усугубляет ситуацию.

Учись бесплатно:
вебинары по программированию, маркетингу и дизайну.
Участвовать

Школа дронов для всех
Учим программировать беспилотники и управлять ими.
Узнать больше
Ошибки в программах – дело обыденное. Приложения зависают, вылетают, перестают запускаться. В простейшем случае пользователь решает проблему переустановкой ПО или чисткой от «мусора». Разработчикам же нужно четко понимать, что такое баг, как исправить его и каким образом получить своевременную обратную связь от пользователей.
Что такое баг?
Термин «баг» (в переводе «жук») у программистов обозначает ситуацию, когда определенный код выдает неверный результат. Причины возникновения разные: ошибки в исходном коде, интерфейсе программы или некорректной работе компилятора. Обнаруживают их на этапе отладки или уже на стадии бета-тестирования, выпуска продукта на рынок.
Варианты ошибок:
- Появилось сообщение об ошибке, программа продолжает работу.
- Приложение зависает или вылетает без каких-либо предупреждений.
- Происходит одно из событий с одновременной отправкой отчета разработчику.
Сложнее всего работать с компьютерными играми, в которых чаще используют термин «краш» (crash). Он означает критическую проблему при запуске или использовании программы. Когда говорят о багах, то чаще имеют в виду сбои графики, например, если игрок «проваливается в текстуры».
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Классификация багов
Точка зрения пользователей часто не совпадает с мнением программистов. Так, для первых всего лишь произошел сбой, «приложение перестало работать». Кодеру же предстоит головная боль с определением источника проблемы. Ведь ошибка в программе, вероятно, проявляется лишь на конкретном железе или при сочетании с другим софтом (часто с антивирусами).
Баги делят на категории в зависимости от их критичности:
- незначительные ошибки,
- серьезные ошибки,
- showstopper.
Последние указывают на критическую программную или аппаратную проблему, из-за которой ПО теряет свою функциональность практически на 100%. Например, не удается авторизоваться через логин-пароль или перестала работать кнопка «Далее». Поэтому таким ошибкам отдают приоритет.
Также есть деление ошибок по частоте проявления. Проще всего исправлять постоянные, возникающие при одних и тех же обстоятельствах, независимо от платформы, аппаратной части компьютера или каких-то действий пользователя. Сложность возрастает при периодических сбоях, когда причиной вполне может оказаться глючная оперативная память или ошибки накопителей.
Есть вариант, когда проблема возникает только на машине конкретного клиента. Здесь приходится либо заказывать индивидуальную «работу над ошибками», либо менять компьютер. Потому что ПО для массового пользователя никто не будет редактировать из-за «одного». Только если наберется некая критическая масса одинаковых случаев.
Разновидности ошибок
Программисту еще важно деление на разные типы ошибок приложений исходя из типовых условий их эксплуатации. Например, возникающие при повышении нагрузки на процессор, в интерфейсе, в модуле обработки входящих данных. Существуют баги граничных условий, сбоя идентификаторов, банальной несовместимости с архитектурой процессора (чаще в мобильных устройствах).
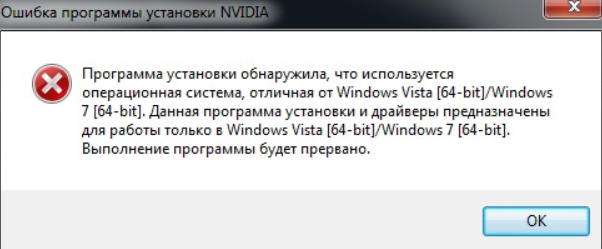
Кодеры делят ошибки по сложности:
- Борбаг (Bohr Bug) – «стабильная» ошибка, легко выявляемая еще на этапе отладки или при бета-тестировании, когда речь еще не идет о выпуске стабильной версии.
- Гейзенбаг (Heisenbug) – периодически проявляющиеся, иногда надолго исчезающие баги с меняющимися свойствами, включая зависимость от программной среды, «железа».
- Мандельбаг (Mandelbug) – ошибка с энтропийным поведением, почти с непредсказуемым результатом.
- Шрединбаг (Schroedinbug) – критические баги, чаще приводящие к появлению возможности взлома, хотя внешне никак себя не проявляют.
Последняя категория ошибок – одна из основных причин регулярного обновления операционных систем Windows. Вроде бы пользователя все устраивает, а разработчик раз за разом выпускает новые пакеты исправлений. Наиболее известный баг, попортивший нервы многим кодерам, это «ошибка 2000 года» (Y2K Error). Про нее успешно забыли, но уроки извлекли.
Программисты различают и те ошибки, что мешают скомпилировать программу, и ворнинги. Вторая категория представляет собой лишь предупреждение о найденных «косяках» в коде, но они не мешают ни сборке ПО, ни последующей эксплуатации. Например, речь идет об отсутствии точки или точки запятой в синтаксисе, когда компилятор способен сам решить проблему.

Логические
Наиболее серьезная из ошибок. Такие баги приводят к изменению функционирования программы вопреки техническому заданию. К чему это приведет, никто не знает – могут записаться на диске «не те данные», некорректно измениться важные документы или предоставиться доступ к коммерческой информации без авторизации. Исправить их получится только при знании изначальной логики.
Синтаксические
Ошибки синтаксиса существуют на уровне конкретного языка программирования: C, Java, Python, Perl и т.д. Что на одной платформе работает максимум с ворнингами, для другой будет серьезной проблемой. Такие баги легко исправить на этапе компиляции, потому что инструмент не позволит «пройти дальше» некорректного участка кода.
Компиляционные
Ситуация происходит, когда код, написанный на языке высокого уровня, преобразуют в «простой», машиночитаемый. Причиной может служить как серьезная ошибка в синтаксисе, так и сбои в самом компиляторе. Такие баги устраняют на этапе разработки-отладки программ, потому что выпустить их даже для бета-тестирования не получится.
Среды выполнения
Так называемые ошибки Run-Time. Проявляются в скомпилированных программах, при запуске. Например, из-за нехватки ресурсов на машине, в результате аварийной ситуации (поломка памяти, носителя, устройств ввода-вывода). Такое происходит, если разработчик не учел реальных условий работы; придется вернуться к стадии проработки логики.
Арифметические
Одна из разновидностей логических ошибок. Происходят, когда программа при работе вычисляет массу переменных, но на каком-то этапе происходит непредвиденное. Например, деление на ноль или же приложение получает «бесконечный» результат. Изменить ситуацию получится только на уровне кода, внедренного в него алгоритма.
Ресурсные
Преимущественно к этой категории относят ошибки типа «переполнение буфера». Программист не учел необходимость очистки памяти перед размещением новых данных. Или интерфейс разработан без учета типовых разрешений экранов, и его элементы постоянно «съезжают», нарушается логика срабатывания кнопок и т.д. Исправить получится только переписыванием части кода.
Взаимодействия
Речь идет о взаимодействии с аппаратным или программным окружением. В случае с приложением для облачного ресурса программист мог допустить ошибку при использовании веб-протоколов. При постоянном появлении ошибки остается только переписывать участок кода, ответственный за появление бага, иначе программа останется неработоспособной.
Что такое исключение
Снизить риски появления непредвиденных ошибок позволяет внедрение в программу исключений. Это события, при возникновении которых начинается «неправильное» поведение. Такой механизм позволяет систематизировать обработку багов независимо от типа приложения, платформы и иных условий. И разработать единую систему реагирования, например, со стороны операционки.
Существуют программные и аппаратные исключения. Первые генерируются самой программой и ОС, под которой она запущена. К аппаратным относятся те, что создаются процессором. Например, деление на 0, переполнение буфера, обращение к невыделенной памяти. Исключениями кодеры охватывают наиболее серьезные, критические баги.
Как избежать ошибок?
Существует два эффективных способа избежать проблем еще на стадии разработки. Первый – это отладка при помощи специальных программ. Они отображают результаты выполнения в цифрах, которые объективно показывают кодеру, правильно ли был обработан следующий участок кода или нужно искать закравшуюся ошибку.
Второй способ представляет собой привлечение специальных людей, тестировщиков. Они помогут разобраться с работоспособностью интерфейса в различных ситуациях, на разных платформах. Это происходит максимально приближенно к реальным условиям. Поэтому любой серьезный продукт проходит такую стадию обязательно.
Выводы
Баги – сопутствующий фактор любой разработки. Большую их часть пользователь не видит, потому что устраняются они еще в «лаборатории», на этапе альфа-тестирования. В бета-версии попадают уже незначительные ошибки, например, связанные с конкретными «узкими» условиями эксплуатации. Редкие проблемы помогают решать краш-репорты – отчеты, отсылаемые производителю самой программой.
Дефекты программного обеспечения можно обнаружить на каждом этапе разработки и тестирования продукта. Чтобы гарантировать исправление наиболее серьезных дефектов программного обеспечения, тестировщикам важно иметь хорошее представление о различных типах дефектов, которые могут возникнуть.

В этой статье мы обсудим самые распространенные типы ПО дефекты и способы их выявления.
Что такое дефект?
Дефект программного обеспечения — это ошибка, изъян, сбой или неисправность в компьютерной программе, из-за которой она выдает неправильный или неожиданный результат или ведет себя непреднамеренным образом. Программная ошибка возникает, когда фактические результаты не совпадают с ожидаемыми. Разработчики и программисты иногда допускают ошибки, которые создают ошибки, называемые дефектами. Большинство ошибок возникает из-за ошибок, которые допускают разработчики или программисты.
Обязательно прочтите: Разница между дефектом, ошибкой, ошибкой и сбоем
Типы программных ошибок при тестировании программного обеспечения
Существует множество различных типов дефектов программного обеспечения, и тестировщикам важно знать наиболее распространенные из них, чтобы они могут эффективно тестировать их.
Ошибки программного обеспечения подразделяются на три типа:
- Дефекты программного обеспечения по своей природе
- Дефекты программного обеспечения по их приоритету
- Дефекты программного обеспечения по их серьезности
Обычно мы можем видеть приоритет и серьезность классификаторов в большинстве инструментов отслеживания ошибок. Если мы настроим классификатор в соответствии с характером ошибки, а также приоритетом и серьезностью, это поможет легко управлять распределением обязанностей по исправлению ошибок соответствующим командам.
#1. Дефекты программного обеспечения по своей природе
Ошибки в программном обеспечении имеют широкий спектр природы, каждая из которых имеет свой собственный набор симптомов. Несмотря на то, что таких багов много, сталкиваться с ними можно не часто. Вот наиболее распространенные ошибки программного обеспечения, классифицированные по характеру, с которыми вы, скорее всего, столкнетесь при тестировании программного обеспечения.
#1. Функциональные ошибки
Как следует из названия, функциональные ошибки — это те, которые вызывают сбои в работе программного обеспечения. Хорошим примером этого может служить кнопка, при нажатии на которую должно открываться новое окно, но вместо этого ничего не происходит.
Функциональные ошибки можно исправить, выполнив функциональное тестирование.
#2. Ошибки на уровне модуля
Ошибки на уровне модуля — это дефекты, связанные с функциональностью отдельного программного модуля. Программный модуль — это наименьшая тестируемая часть приложения. Примеры программных модулей включают классы, методы и процедуры. Ошибки на уровне подразделения могут существенно повлиять на общее качество программного обеспечения.
Ошибки на уровне модуля можно исправить, выполнив модульное тестирование.
#3. Ошибки уровня интеграции
Ошибки уровня интеграции — это дефекты, возникающие при объединении двух или более программных модулей. Эти дефекты может быть трудно найти и исправить, потому что они часто требуют координации между несколькими командами. Однако они могут оказать существенное влияние на общее качество программного обеспечения.
Ошибки интеграции можно исправить, выполнив интеграционное тестирование.
#4. Дефекты юзабилити
Ошибки юзабилити — это дефекты, влияющие на работу пользователя с программным обеспечением и затрудняющие его использование. Дефект юзабилити — это дефект пользовательского опыта программного обеспечения, который затрудняет его использование. Ошибки юзабилити — это такие ошибки, как если веб-сайт сложен для доступа или обойти, или процесс регистрации сложен для прохождения.
Во время тестирования удобства использования тестировщики программного обеспечения проверяют приложения на соответствие требованиям пользователей и Руководству по доступности веб-контента (WCAG) для выявления таких проблем. Однако они могут оказать существенное влияние на общее качество программного обеспечения.
Ошибки, связанные с удобством использования, можно исправить, выполнив тестирование удобства использования.
#5. Дефекты производительности
Ошибки производительности — это дефекты, влияющие на производительность программного обеспечения. Это может включать в себя такие вещи, как скорость программного обеспечения, объем используемой памяти или количество потребляемых ресурсов. Ошибки уровня производительности сложно отследить и исправить, поскольку они могут быть вызваны рядом различных факторов.
Ошибки юзабилити можно исправить, выполнив тестирование производительности.
#6. Дефекты безопасности
Ошибки безопасности — это тип дефекта программного обеспечения, который может иметь серьезные последствия, если его не устранить. Эти дефекты могут позволить злоумышленникам получить доступ к конфиденциальным данным или системам или даже позволить им получить контроль над уязвимым программным обеспечением. Таким образом, очень важно, чтобы ошибкам уровня безопасности уделялось первоочередное внимание и устранялись как можно скорее.
Ошибки безопасности можно исправить, выполнив тестирование безопасности.
#7. Дефекты совместимости
Дефекты совместимости — это те ошибки, которые возникают, когда приложение несовместимо с оборудованием, на котором оно работает, или с другим программным обеспечением, с которым оно должно взаимодействовать. Несовместимость программного и аппаратного обеспечения может привести к сбоям, потере данных и другому непредсказуемому поведению. Тестировщики должны знать о проблемах совместимости и проводить соответствующие тесты. Программное приложение, имеющее проблемы с совместимостью, не работает последовательно на различных видах оборудования, операционных системах, веб-браузерах и устройствах при подключении к определенным программам или работе в определенных сетевых условиях.
Ошибки совместимости можно исправить, выполнение тестирования совместимости.
#8. Синтаксические ошибки
Синтаксические ошибки являются самым основным типом дефекта. Они возникают, когда код нарушает правила языка программирования. Например, использование неправильной пунктуации или забывание закрыть скобку может привести к синтаксической ошибке. Синтаксические ошибки обычно мешают запуску кода, поэтому их относительно легко обнаружить и исправить.
#9. Логические ошибки
Логические ошибки — это дефекты, из-за которых программа выдает неправильные результаты. Эти ошибки может быть трудно найти и исправить, потому что они часто не приводят к каким-либо видимым ошибкам. Логические ошибки могут возникать в любом типе программного обеспечения, но они особенно распространены в приложениях, требующих сложных вычислений или принятия решений.
Общие симптомы логических ошибок включают:
- Неверные результаты или выходные данные
- Неожиданное поведение
- Сбой или зависание программного обеспечения
Чтобы найти и исправить логические ошибки, тестировщикам необходимо иметь четкое представление о коде программы и о том, как она должна работать. Часто лучший способ найти такие ошибки — использовать инструменты отладки или пошаговое выполнение, чтобы отслеживать выполнение программы и видеть, где что-то идет не так.
#2. Дефекты программного обеспечения по степени серьезности
Уровень серьезности присваивается дефекту по его влиянию. В результате серьезность проблемы отражает степень ее влияния на функциональность или работу программного продукта. Дефекты серьезности классифицируются как критические, серьезные, средние и незначительные в зависимости от степени серьезности.
#1. Критические дефекты
Критический дефект — это программная ошибка, имеющая серьезные или катастрофические последствия для работы приложения. Критические дефекты могут привести к сбою, зависанию или некорректной работе приложения. Они также могут привести к потере данных или уязвимостям в системе безопасности. Разработчики и тестировщики часто придают первостепенное значение критическим дефектам, поскольку их необходимо исправить как можно скорее.
#2. Серьезные дефекты
Серьезный дефект — это программная ошибка, существенно влияющая на работу приложения. Серьезные дефекты могут привести к замедлению работы приложения или другому неожиданному поведению. Они также могут привести к потере данных или уязвимостям в системе безопасности. Разработчики и тестировщики часто придают первостепенное значение серьезным дефектам, поскольку их необходимо исправить как можно скорее.
#3. Незначительные дефекты
Незначительный дефект — это программная ошибка, которая оказывает небольшое или незначительное влияние на работу приложения. Незначительные дефекты могут привести к тому, что приложение будет работать немного медленнее или демонстрировать другое неожиданное поведение. Разработчики и тестировщики часто не придают незначительным дефектам приоритет, потому что их можно исправить позже.
#4. Тривиальные дефекты
Тривиальный дефект – это программная ошибка, не влияющая на работу приложения. Тривиальные дефекты могут привести к тому, что приложение отобразит сообщение об ошибке или проявит другое неожиданное поведение. Разработчики и тестировщики часто присваивают тривиальным дефектам самый низкий приоритет, потому что они могут быть исправлены позже.
#3. Дефекты программного обеспечения по приоритету
#1. Дефекты с низким приоритетом
Дефекты с низким приоритетом, как правило, не оказывают серьезного влияния на работу программного обеспечения и могут быть отложены для исправления в следующей версии или выпуске. В эту категорию попадают косметические ошибки, такие как орфографические ошибки, неправильное выравнивание и т. д.
#2. Дефекты со средним приоритетом
Дефекты со средним приоритетом — это ошибки, которые могут быть исправлены после предстоящего выпуска или в следующем выпуске. Приложение, возвращающее ожидаемый результат, которое, однако, неправильно форматируется в конкретном браузере, является примером дефекта со средним приоритетом.
#3. Дефекты с высоким приоритетом
Как следует из названия, дефекты с высоким приоритетом — это те, которые сильно влияют на функционирование программного обеспечения. В большинстве случаев эти дефекты необходимо исправлять немедленно, так как они могут привести к серьезным нарушениям нормального рабочего процесса. Дефекты с высоким приоритетом обычно классифицируются как непреодолимые, так как они могут помешать пользователю продолжить выполнение поставленной задачи.
Некоторые распространенные примеры дефектов с высоким приоритетом включают:
- Дефекты, из-за которых приложение не работает. сбой
- Дефекты, препятствующие выполнению задачи пользователем
- Дефекты, приводящие к потере или повреждению данных
- Дефекты, раскрывающие конфиденциальную информацию неавторизованным пользователям
- Дефекты, делающие возможным несанкционированный доступ к системе
- Дефекты, приводящие к потере функциональности
- Дефекты, приводящие к неправильным результатам или неточным данным
- Дефекты, вызывающие проблемы с производительностью, такие как чрезмерное использование памяти или медленное время отклика
#4. Срочные дефекты
Срочные дефекты — это дефекты, которые необходимо устранить в течение 24 часов после сообщения о них. В эту категорию попадают дефекты со статусом критической серьезности. Однако дефекты с низким уровнем серьезности также могут быть классифицированы как высокоприоритетные. Например, опечатка в названии компании на домашней странице приложения не оказывает технического влияния на программное обеспечение, но оказывает существенное влияние на бизнес, поэтому считается срочной.
#4. Дополнительные дефекты
#1. Отсутствующие дефекты
Отсутствующие дефекты возникают из-за требований, которые не были включены в продукт. Они также считаются несоответствиями спецификации проекта и обычно негативно сказываются на пользовательском опыте или качестве программного обеспечения.
#2. Неправильные дефекты
Неправильные дефекты — это те дефекты, которые удовлетворяют требованиям, но не должным образом. Это означает, что хотя функциональность достигается в соответствии с требованиями, но не соответствует ожиданиям пользователя.
#3. Дефекты регрессии
Дефект регрессии возникает, когда изменение кода вызывает непреднамеренное воздействие на независимую часть программного обеспечения.
Часто задаваемые вопросы — Типы программных ошибок< /h2>
Почему так важна правильная классификация дефектов?
Правильная классификация дефектов важна, поскольку она помогает эффективно использовать ресурсы и управлять ими, правильно приоритизировать дефекты и поддерживать качество программного продукта.
Команды тестирования программного обеспечения в различных организациях используют различные инструменты отслеживания дефектов, такие как Jira, для отслеживания дефектов и управления ими. Несмотря на то, что в этих инструментах есть несколько вариантов классификации дефектов по умолчанию, они не всегда могут наилучшим образом соответствовать конкретным потребностям организации.
Следовательно, важно сначала определить и понять типы дефектов программного обеспечения, которые наиболее важны для организации, а затем соответствующим образом настроить инструмент управления дефектами.
Правильная классификация дефектов также гарантирует, что команда разработчиков сможет сосредоточиться на критических дефектах и исправить их до того, как они повлияют на конечных пользователей.
Кроме того, это также помогает определить потенциальные области улучшения в процессе разработки программного обеспечения, что может помочь предотвратить появление подобных дефектов в будущих выпусках.
Таким образом, отслеживание и устранение дефектов программного обеспечения может показаться утомительной и трудоемкой задачей. , правильное выполнение может существенно повлиять на качество конечного продукта.
Как найти лежащие в основе ошибки программного обеспечения?
Определение основной причины программной ошибки может быть сложной задачей даже для опытных разработчиков. Чтобы найти лежащие в основе программные ошибки, тестировщики должны применять систематический подход. В этот процесс входят различные этапы:
1) Репликация. Первым этапом является воспроизведение ошибки. Это включает в себя попытку воспроизвести тот же набор шагов, в котором возникла ошибка. Это поможет проверить, является ли ошибка реальной или нет.
2) Изоляция. После того, как ошибка воспроизведена, следующим шагом будет попытка ее изоляции. Это включает в себя выяснение того, что именно вызывает ошибку. Для этого тестировщики должны задать себе несколько вопросов, например:
– Какие входные данные вызывают ошибку?
– При каких различных условиях возникает ошибка?
– Каковы различные способы проявления ошибки?
3) Анализ: после Изолируя ошибку, следующим шагом будет ее анализ. Это включает в себя понимание того, почему возникает ошибка. Тестировщики должны задать себе несколько вопросов, таких как:
– Какова основная причина ошибки?
– Какими способами можно исправить ошибку?
– Какое исправление было бы наиболее эффективным? эффективно?
4) Отчет. После анализа ошибки следующим шагом является сообщение о ней. Это включает в себя создание отчета об ошибке, который включает всю соответствующую информацию об ошибке. Отчет должен быть четким и кратким, чтобы разработчики могли его легко понять.
5) Проверка. После сообщения об ошибке следующим шагом является проверка того, была ли она исправлена. Это включает в себя повторное тестирование программного обеспечения, чтобы убедиться, что ошибка все еще существует. Если ошибка исправлена, то тестер может подтвердить это и закрыть отчет об ошибке. Если ошибка все еще существует, тестировщик может повторно открыть отчет об ошибке.
Заключение
В индустрии программного обеспечения дефекты — неизбежная реальность. Однако благодаря тщательному анализу и пониманию их характера, серьезности и приоритета дефектами можно управлять, чтобы свести к минимуму их влияние на конечный продукт.
Задавая правильные вопросы и применяя правильные методы, тестировщики могут помочь обеспечить чтобы дефекты обнаруживались и исправлялись как можно раньше в процессе разработки.
TAG: qa
- Подробности
- июля 04, 2014
- Просмотров: 133097

Существуют различные типы программных ошибок, которые могут возникать на этапе разработки программы программного обеспечения и каждый программист должен знать о них.
В этой статье вы найдете описание самых распространенных ошибок программирования, cкоторыми может столкнуться каждый разработчик.
Если вы абсолютный новичок в области программирования то эта статья непременно будет вам интересна: Основы программирования для начинающих.
Ошибки программирования, более известные как «Баги» на жаргоне, бич любого разработчика программного обеспечения. Поскольку машины все чаще используются в автоматическом режиме, с бортовыми встраиваемыми системами или компьютерами, контролирующими их функционирование, программная ошибка может иметь серьезные последствия. Были случаи, когда космические челноки и самолеты, разбивались из-за ошибки в программном обеспечении во встраиваемом компьютерном оборудовании. Одна лазейка, оставленная в коде операционной системы, может обеспечить точку входа для хакеров, которые могут использовать эту уязвимость. К этим, ошибкам нужно относиться очень серьезно, так как мы все больше и больше полагаемся на компьютеры.
Основные виды ошибок в программировании
Компьютерное программирование это огромное поле с сотнями языков, которые используют миллионы приложений. Это программирование операционной системы, прикладное программирование, встроенное кодирование системы, веб-разработка, приложения для мобильных платформ, развитие программ, развернутых в интернете, научные вычисления. В таблице представлены основные виды ошибок.
|
Тип ошибок программирования |
Описание |
|
Логическая ошибка |
Это, пожалуй, наиболее серьезная из всех ошибок. Когда написанная программа на любом языке компилирует и работает правильно, но выдает неправильный вывод, недостаток заключается в логике основного программирования. Это ошибка, которая была унаследована от недостатка в базовом алгоритме. Сама логика, на которой базируется вся программа, является ущербной. Чтобы найти решение такой ошибки нужно фундаментальное изменение алгоритма. Вам нужно начать копать в алгоритмическом уровне, чтобы сузить область поиска такой ошибки. |
|
Синтаксическая ошибка |
Каждый компьютерный язык, такой как C, Java, Perl и Python имеет специфический синтаксис, в котором будет написан код. Когда программист не придерживаться «грамматики» спецификациями компьютерного языка, возникнет ошибка синтаксиса. Такого рода ошибки легко устраняются на этапе компиляции. |
|
Ошибка компиляции |
Компиляция это процесс, в котором программа, написанная на языке высокого уровня, преобразуется в машиночитаемую форму. Многие виды ошибок могут происходить на этом этапе, в том числе и синтаксические ошибки. Иногда, синтаксис исходного кода может быть безупречным, но ошибка компиляции все же может произойти. Это может быть связано с проблемами в самом компиляторе. Эти ошибки исправляются на стадии разработки. |
|
Ошибки среды выполнения (RunTime) |
Программный код успешно скомпилирован, и исполняемый файл был создан. Вы можете вздохнуть с облегчением и запустить программу, чтобы проверить ее работу. Ошибки при выполнении программы могут возникнуть в результате аварии или нехватки ресурсов носителя. Разработчик должен был предвидеть реальные условия развертывания программы. Это можно исправить, вернувшись к стадии кодирования. |
|
Арифметическая ошибка |
Многие программы используют числовые переменные, и алгоритм может включать несколько математических вычислений. Арифметические ошибки возникают, когда компьютер не может справиться с проблемами, такими как «Деление на ноль», или ведущие к бесконечному результату. Это снова логическая ошибка, которая может быть исправлена только путем изменения алгоритма. |
|
Ошибки ресурса |
Ошибка ресурса возникает, когда значение переменной переполняет максимально допустимое значение. Переполнение буфера, использование неинициализированной переменной, нарушение прав доступа и переполнение стека — примеры некоторых распространенных ошибок. |
|
Ошибка взаимодействия |
Они могут возникнуть в связи с несоответствием программного обеспечения с аппаратным интерфейсом или интерфейсом прикладного программирования. В случае веб-приложений, ошибка интерфейса может быть результатом неправильного использования веб-протокола. |
Интенсивное тестирование и фаза отладки неотъемлемая часть цикла разработки программного обеспечения, которое может помочь пресечь эти ошибки в зародыше, прежде чем произойдет полномасштабное развертывание программного обеспечения. Много ошибок можно избежать с помощью предварительного планирования во время стадии кодирования. Большинство ошибок можно исправить в процессе разработки программного обеспечения через практику и строгие процедуры отладки. Ошибки являются частью обучения, и их никогда нельзя полностью избежать, Тем не менее, у вас могут появляться новые ошибки, но повторять старые вы не должны!
Читайте также

Improve Article
Save Article
Improve Article
Save Article
Defects are defined as the deviation of the actual and expected result of system or software application. Defects can also be defined as any deviation or irregularity from the specifications mentioned in the product functional specification document. Defects are caused by the developer in development phase of software. When a developer or programmer during the development phase makes some mistake then that turns into bugs that are called defects. It is basically caused by the developers’ mistakes.
Defect in a software product represents the inability and inefficiency of the software to meet the specified requirements and criteria and subsequently prevent the software application to perform the expected and desired working.
Types of Defects:
Following are some of the basic types of defects in the software development:
- Arithmetic Defects:
It include the defects made by the developer in some arithmetic expression or mistake in finding solution of such arithmetic expression. This type of defects are basically made by the programmer due to access work or less knowledge. Code congestion may also lead to the arithmetic defects as programmer is unable to properly watch the written code. - Logical Defects:
Logical defects are mistakes done regarding the implementation of the code. When the programmer doesn’t understand the problem clearly or thinks in a wrong way then such types of defects happen. Also while implementing the code if the programmer doesn’t take care of the corner cases then logical defects happen. It is basically related to the core of the software. - Syntax Defects:
Syntax defects means mistake in the writing style of the code. It also focuses on the small mistake made by developer while writing the code. Often the developers do the syntax defects as there might be some small symbols escaped. For example, while writing a code in C++ there is possibility that a semicolon(;) is escaped. - Multithreading Defects:
Multithreading means running or executing the multiple tasks at the same time. Hence in multithreading process there is possibility of the complex debugging. In multithreading processes sometimes there is condition of the deadlock and the starvation is created that may lead to system’s failure. - Interface Defects:
Interface defects means the defects in the interaction of the software and the users. The system may suffer different kinds of the interface testing in the forms of the complicated interface, unclear interface or the platform based interface. - Performance Defects:
Performance defects are the defects when the system or the software application is unable to meet the desired and the expected results. When the system or the software application doesn’t fulfill the users’s requirements then that is the performance defects. It also includes the response of the system with the varying load on the system.
Refer for – differences between defect, bug and failure
Improve Article
Save Article
Improve Article
Save Article
Defects are defined as the deviation of the actual and expected result of system or software application. Defects can also be defined as any deviation or irregularity from the specifications mentioned in the product functional specification document. Defects are caused by the developer in development phase of software. When a developer or programmer during the development phase makes some mistake then that turns into bugs that are called defects. It is basically caused by the developers’ mistakes.
Defect in a software product represents the inability and inefficiency of the software to meet the specified requirements and criteria and subsequently prevent the software application to perform the expected and desired working.
Types of Defects:
Following are some of the basic types of defects in the software development:
- Arithmetic Defects:
It include the defects made by the developer in some arithmetic expression or mistake in finding solution of such arithmetic expression. This type of defects are basically made by the programmer due to access work or less knowledge. Code congestion may also lead to the arithmetic defects as programmer is unable to properly watch the written code. - Logical Defects:
Logical defects are mistakes done regarding the implementation of the code. When the programmer doesn’t understand the problem clearly or thinks in a wrong way then such types of defects happen. Also while implementing the code if the programmer doesn’t take care of the corner cases then logical defects happen. It is basically related to the core of the software. - Syntax Defects:
Syntax defects means mistake in the writing style of the code. It also focuses on the small mistake made by developer while writing the code. Often the developers do the syntax defects as there might be some small symbols escaped. For example, while writing a code in C++ there is possibility that a semicolon(;) is escaped. - Multithreading Defects:
Multithreading means running or executing the multiple tasks at the same time. Hence in multithreading process there is possibility of the complex debugging. In multithreading processes sometimes there is condition of the deadlock and the starvation is created that may lead to system’s failure. - Interface Defects:
Interface defects means the defects in the interaction of the software and the users. The system may suffer different kinds of the interface testing in the forms of the complicated interface, unclear interface or the platform based interface. - Performance Defects:
Performance defects are the defects when the system or the software application is unable to meet the desired and the expected results. When the system or the software application doesn’t fulfill the users’s requirements then that is the performance defects. It also includes the response of the system with the varying load on the system.
Refer for – differences between defect, bug and failure
Ошибки в программах – дело обыденное. Приложения зависают, вылетают, перестают запускаться. В простейшем случае пользователь решает проблему переустановкой ПО или чисткой от «мусора». Разработчикам же нужно четко понимать, что такое баг, как исправить его и каким образом получить своевременную обратную связь от пользователей.
Что такое баг?
Термин «баг» (в переводе «жук») у программистов обозначает ситуацию, когда определенный код выдает неверный результат. Причины возникновения разные: ошибки в исходном коде, интерфейсе программы или некорректной работе компилятора. Обнаруживают их на этапе отладки или уже на стадии бета-тестирования, выпуска продукта на рынок.
Варианты ошибок:
- Появилось сообщение об ошибке, программа продолжает работу.
- Приложение зависает или вылетает без каких-либо предупреждений.
- Происходит одно из событий с одновременной отправкой отчета разработчику.
Сложнее всего работать с компьютерными играми, в которых чаще используют термин «краш» (crash). Он означает критическую проблему при запуске или использовании программы. Когда говорят о багах, то чаще имеют в виду сбои графики, например, если игрок «проваливается в текстуры».
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Классификация багов
Точка зрения пользователей часто не совпадает с мнением программистов. Так, для первых всего лишь произошел сбой, «приложение перестало работать». Кодеру же предстоит головная боль с определением источника проблемы. Ведь ошибка в программе, вероятно, проявляется лишь на конкретном железе или при сочетании с другим софтом (часто с антивирусами).
Баги делят на категории в зависимости от их критичности:
- незначительные ошибки,
- серьезные ошибки,
- showstopper.
Последние указывают на критическую программную или аппаратную проблему, из-за которой ПО теряет свою функциональность практически на 100%. Например, не удается авторизоваться через логин-пароль или перестала работать кнопка «Далее». Поэтому таким ошибкам отдают приоритет.
Также есть деление ошибок по частоте проявления. Проще всего исправлять постоянные, возникающие при одних и тех же обстоятельствах, независимо от платформы, аппаратной части компьютера или каких-то действий пользователя. Сложность возрастает при периодических сбоях, когда причиной вполне может оказаться глючная оперативная память или ошибки накопителей.
Есть вариант, когда проблема возникает только на машине конкретного клиента. Здесь приходится либо заказывать индивидуальную «работу над ошибками», либо менять компьютер. Потому что ПО для массового пользователя никто не будет редактировать из-за «одного». Только если наберется некая критическая масса одинаковых случаев.
Разновидности ошибок
Программисту еще важно деление на разные типы ошибок приложений исходя из типовых условий их эксплуатации. Например, возникающие при повышении нагрузки на процессор, в интерфейсе, в модуле обработки входящих данных. Существуют баги граничных условий, сбоя идентификаторов, банальной несовместимости с архитектурой процессора (чаще в мобильных устройствах).
Кодеры делят ошибки по сложности:
- Борбаг (Bohr Bug) – «стабильная» ошибка, легко выявляемая еще на этапе отладки или при бета-тестировании, когда речь еще не идет о выпуске стабильной версии.
- Гейзенбаг (Heisenbug) – периодически проявляющиеся, иногда надолго исчезающие баги с меняющимися свойствами, включая зависимость от программной среды, «железа».
- Мандельбаг (Mandelbug) – ошибка с энтропийным поведением, почти с непредсказуемым результатом.
- Шрединбаг (Schroedinbug) – критические баги, чаще приводящие к появлению возможности взлома, хотя внешне никак себя не проявляют.
Последняя категория ошибок – одна из основных причин регулярного обновления операционных систем Windows. Вроде бы пользователя все устраивает, а разработчик раз за разом выпускает новые пакеты исправлений. Наиболее известный баг, попортивший нервы многим кодерам, это «ошибка 2000 года» (Y2K Error). Про нее успешно забыли, но уроки извлекли.
Программисты различают и те ошибки, что мешают скомпилировать программу, и ворнинги. Вторая категория представляет собой лишь предупреждение о найденных «косяках» в коде, но они не мешают ни сборке ПО, ни последующей эксплуатации. Например, речь идет об отсутствии точки или точки запятой в синтаксисе, когда компилятор способен сам решить проблему.
Логические
Наиболее серьезная из ошибок. Такие баги приводят к изменению функционирования программы вопреки техническому заданию. К чему это приведет, никто не знает – могут записаться на диске «не те данные», некорректно измениться важные документы или предоставиться доступ к коммерческой информации без авторизации. Исправить их получится только при знании изначальной логики.
Синтаксические
Ошибки синтаксиса существуют на уровне конкретного языка программирования: C, Java, Python, Perl и т.д. Что на одной платформе работает максимум с ворнингами, для другой будет серьезной проблемой. Такие баги легко исправить на этапе компиляции, потому что инструмент не позволит «пройти дальше» некорректного участка кода.
Компиляционные
Ситуация происходит, когда код, написанный на языке высокого уровня, преобразуют в «простой», машиночитаемый. Причиной может служить как серьезная ошибка в синтаксисе, так и сбои в самом компиляторе. Такие баги устраняют на этапе разработки-отладки программ, потому что выпустить их даже для бета-тестирования не получится.
Среды выполнения
Так называемые ошибки Run-Time. Проявляются в скомпилированных программах, при запуске. Например, из-за нехватки ресурсов на машине, в результате аварийной ситуации (поломка памяти, носителя, устройств ввода-вывода). Такое происходит, если разработчик не учел реальных условий работы; придется вернуться к стадии проработки логики.
Арифметические
Одна из разновидностей логических ошибок. Происходят, когда программа при работе вычисляет массу переменных, но на каком-то этапе происходит непредвиденное. Например, деление на ноль или же приложение получает «бесконечный» результат. Изменить ситуацию получится только на уровне кода, внедренного в него алгоритма.
Ресурсные
Преимущественно к этой категории относят ошибки типа «переполнение буфера». Программист не учел необходимость очистки памяти перед размещением новых данных. Или интерфейс разработан без учета типовых разрешений экранов, и его элементы постоянно «съезжают», нарушается логика срабатывания кнопок и т.д. Исправить получится только переписыванием части кода.
Взаимодействия
Речь идет о взаимодействии с аппаратным или программным окружением. В случае с приложением для облачного ресурса программист мог допустить ошибку при использовании веб-протоколов. При постоянном появлении ошибки остается только переписывать участок кода, ответственный за появление бага, иначе программа останется неработоспособной.
Что такое исключение
Снизить риски появления непредвиденных ошибок позволяет внедрение в программу исключений. Это события, при возникновении которых начинается «неправильное» поведение. Такой механизм позволяет систематизировать обработку багов независимо от типа приложения, платформы и иных условий. И разработать единую систему реагирования, например, со стороны операционки.
Существуют программные и аппаратные исключения. Первые генерируются самой программой и ОС, под которой она запущена. К аппаратным относятся те, что создаются процессором. Например, деление на 0, переполнение буфера, обращение к невыделенной памяти. Исключениями кодеры охватывают наиболее серьезные, критические баги.
Как избежать ошибок?
Существует два эффективных способа избежать проблем еще на стадии разработки. Первый – это отладка при помощи специальных программ. Они отображают результаты выполнения в цифрах, которые объективно показывают кодеру, правильно ли был обработан следующий участок кода или нужно искать закравшуюся ошибку.
Второй способ представляет собой привлечение специальных людей, тестировщиков. Они помогут разобраться с работоспособностью интерфейса в различных ситуациях, на разных платформах. Это происходит максимально приближенно к реальным условиям. Поэтому любой серьезный продукт проходит такую стадию обязательно.
Выводы
Баги – сопутствующий фактор любой разработки. Большую их часть пользователь не видит, потому что устраняются они еще в «лаборатории», на этапе альфа-тестирования. В бета-версии попадают уже незначительные ошибки, например, связанные с конкретными «узкими» условиями эксплуатации. Редкие проблемы помогают решать краш-репорты – отчеты, отсылаемые производителю самой программой.
Привет, Вы узнаете про виды ошибок программного обеспечения, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
виды ошибок программного обеспечения, принципы отладки , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance..
1. Отладка программы
Отладка, как мы уже говорили, бывает двух видов:
Синтаксическая отладка. Синтаксические ошибки выявляет компилятор, поэтому исправлять их достаточно легко.
Семантическая (смысловая) отладка. Ее время наступает тогда, когда синтаксических ошибок не осталось, но результаты программа выдает неверные. Здесь компилятор сам ничего выявить не сможет, хотя в среде программирования обычно существуют вспомогательные средства отладки, о которых мы еще поговорим.
Отладка — это процесс локализации и исправления ошибок в программе.
Как бы тщательно мы ни писали, отладка почти всегда занимает больше времени, чем программирование.
2. Локализация ошибок
Локализация — это нахождение места ошибки в программе.
В процессе поиска ошибки мы обычно выполняем одни и те же действия:
- прогоняем программу и получаем результаты;
- сверяем результаты с эталонными и анализируем несоответствие;
- выявляем наличие ошибки, выдвигаем гипотезу о ее характере и месте в программе;
- проверяем текст программы, исправляем ошибку, если мы нашли ее правильно.
Способы обнаружения ошибки:
- Аналитический — имея достаточное представление о структуре программы, просматриваем ее текст вручную, без прогона.
- Экспериментальный — прогоняем программу, используя отладочную печать и средства трассировки, и анализируем результаты ее работы.
Оба способа по-своему удобны и обычно используются совместно.
3.
принципы отладки
Принципы локализации ошибок:
- Большинство ошибок обнаруживается вообще без запуска программы — просто внимательным просматриванием текста.
- Если отладка зашла в тупик и обнаружить ошибку не удается, лучше отложить программу. Когда глаз «замылен», эффективность работы упорно стремится к нулю.
- Чрезвычайно удобные вспомогательные средства — это отладочные механизмы среды разработки: трассировка, промежуточный контроль значений. Можно использовать даже дамп памяти, но такие радикальные действия нужны крайне редко.
- Экспериментирования типа «а что будет, если изменить плюс на минус» — нужно избегать всеми силами. Обычно это не дает результатов, а только больше запутывает процесс отладки, да еще и добавляет новые ошибки.
Принципы исправления ошибок еще больше похожи на законы Мерфи:
- Там, где найдена одна ошибка, возможно, есть и другие.
- Вероятность, что ошибка найдена правильно, никогда не равна ста процентам.
- Наша задача — найти саму ошибку, а не ее симптом.
Это утверждение хочется пояснить. Если программа упорно выдает результат 0,1 вместо эталонного нуля, простым округлением вопрос не решить. Если результат получается отрицательным вместо эталонного положительного, бесполезно брать его по модулю — мы получим вместо решения задачи ерунду с подгонкой.
Исправляя одну ошибку, очень легко внести в программу еще парочку. «Наведенные» ошибки — настоящий бич отладки.
Исправление ошибок зачастую вынуждает нас возвращаться на этап составления программы. Это неприятно, но порой неизбежно.
4. Методы отладки
Силовые методы
- — Использование дампа (распечатки) памяти.Это интересно с познавательной точки зрения: можно досконально разобраться в машинных процессах. Иногда такой подход даже необходим — например, когда речь идет о выделении и высвобождении памяти под динамические переменные с использованием недокументированных возможностей языка. Однако, в большинстве случаев мы получаем огромное количество низкоуровневой информации, разбираться с которой — не пожелаешь и врагу, а результативность поиска — исчезающе низка.
- — Использование отладочной печати в тексте программы — произвольно и в большом количестве.Получать информацию о выполнении каждого оператора тоже небезынтересно. Но здесь мы снова сталкиваемся со слишком большими объемами информации. Кроме того, мы здорово захламляем программу добавочными операторами, получая малочитабельный текст, да еще рискуем внести десяток новых ошибок.
- — Использование автоматических средств отладки — трассировки с отслеживанием промежуточных значений переменых.Пожалуй, это самый распространенный способ отладки. Не нужно только забывать, что это только один из способов, и применять всегда и везде только его — часто невыгодно.
Сложности возникают, когда приходится отслеживать слишком большие структуры данных или огромное их число. Еще проблематичнее трассировать проект, где выполнение каждой подпрограммы приводит к вызову пары десятков других. Но для небольших программ трассировки вполне достаточно.
С точки зрения «правильного» программирования силовые методы плохи тем, что не поощряют анализ задачи.
Суммируя свойства силовых методов, получаем практические советы:
— использовать трассировку и отслеживание значений переменных для небольших проектов, отдельных подпрограмм;
— использовать отладочную печать в небольших количества и «по делу»;
— оставить дамп памяти на самый крайний случай.
Метод индукции — анализ программы от частного к общему.
Просматриваем симптомы ошибки и определяем данные, которые имеют к ней хоть какое-то отношение. Затем, используя тесты, исключаем маловероятные гипотезы, пока не остается одна, которую мы пытаемся уточнить и доказать.
Метод дедукции — от общего к частному.
Выдвигаем гипотезу, которая может объяснить ошибку, пусть и не полностью. Затем при помощи тестов эта гипотеза проверяется и доказывается.
Обратное движение по алгоритму.
Отладка начинается там, где впервые встретился неправильный результат. Затем работа программы прослеживается (мысленно или при помощи тестов) в обратном порядке, пока не будет обнаружено место возможной ошибки.
Метод тестирования.
Давайте рассмотрим процесс локализации ошибки на конкретном примере. Пусть дана небольшая программа, которая выдает значение максимального из трех введенных пользователем чисел.
var
a, b, c: real;
begin
writeln('Программа находит значение максимального из трех введенных чисел');
write('Введите первое число '); readln(a);
write('Введите второе число '); readln(b);
write('Введите третье число '); readln(c);
if (a>b)and(a>c) then
writeln('Наибольшим оказалось первое число ',a:8:2)
else if (b>a)and(a>c) then
writeln('Наибольшим оказалось второе число ',b:8:2)
else
writeln('Наибольшим оказалось третье число ',b:8:2);
end.
Обе выделенные ошибки можно обнаружить невооруженным глазом: первая явно допущена по невнимательности, вторая — из-за того, что скопированную строку не исправили.
Тестовые наборы данных должны учитывать все варианты решения, поэтому выберем следующие наборы чисел:
Данные Ожидаемый результат
a=10; b=-4; c=1 max=a=10
a=-2; b=8; c=4 max=b=8
a=90; b=0; c=90.4 max=c=90.4
В результате выполнения программы мы, однако, получим следующие результаты:
Для a=10; b=-4; c=1:
Наибольшим оказалось первое число 10.00
Для a=-2; b=8; c=4: < pre class=»list»>Наибольшим оказалось третье число 8.00Для a=90; b=0; c=90.4:
Наибольшим оказалось третье число 0.00
Вывод во втором и третьем случаях явно неверен. Будем разбираться.
1. Трассировка и промежуточная наблюдение за переменными
Добавляем промежуточную печать или наблюдение за переменными:
- — вывод a, b, c после ввода (проверяем, правильно ли получили данные)
- — вывод значения каждого из условий (проверяем, правильно ли записали условия)
Листинг программы существенно увеличился и стал вот таким:
var
a, b, c: real;
begin
writeln(‘Программа находит значение максимального из трех введенных чисел’);
write(‘Введите первое число ‘); readln(a);
writeln(‘Вы ввели число ‘,a:8:2); {отл.печать}
write(‘Введите второе число ‘); readln(b);
writeln(‘Вы ввели число ‘,b:8:2); {отл.печать}
write(‘Введите третье число ‘); readln(c);
writeln(‘Вы ввели число ‘,c:8:2); {отл.печать}
writeln(‘a>b=’,a>b,’, a>c=’,a>c,’, (a>b)and(a>c)=’,(a>b)and(a>c)); {отл.печать}
if (a>b)and(a>c) then
writeln(‘Наибольшим оказалось первое число ‘,a:8:2)
else begin
writeln(‘b>a=’,b>a,’, b>c=’,b>c,’, (b>a)and(b>c)=’,(b>a)and(b>c)); {отл.печать}
if (b>a)and(a>c) then
writeln(‘Наибольшим оказалось второе число ‘,b:8:2)
else
writeln(‘Наибольшим оказалось третье число ‘,b:8:2);
end;
end.
В принципе, еще при наборе у нас неплохой шанс отловить ошибку в условии: подобные кусочки кода обычно не перебиваются, а копируются, и если дать себе труд слегка при этом задуматься, ошибку найти легко.
Но давайте считать, что глаз «замылен» совершенно, и найти ошибку не удалось.
Вывод для второго случая получается следующим:
Программа находит значение максимального из трех введенных чисел
Введите первое число -2
Вы ввели число -2.00
Введите второе число 8
Вы ввели число 8.00
Введите третье число 4
Вы ввели число 4.00
a>b=FALSE, a>c=FALSE, (a>b)and(a>c)=FALSE
b>a=TRUE, b>c=TRUE, (b>a)and(b>c)=TRUE
Наибольшим оказалось третье число 8.00
Со вводом все в порядке . Об этом говорит сайт https://intellect.icu . Впрочем, в этом сомнений и так было немного. А вот что касается второй группы операторов печати, то картина вышла интересная: в результате выводится верное число (8.00), но неправильное слово («третье», а не «второе»).
Вероятно, проблемы в выводе результатов. Тщательно проверяем текст и обнаруживаем, что действительно в последнем случае выводится не c, а b. Однако к решению текущей проблемы это не относится: исправив ошибку, мы получаем для чисел -2.0, 8.0, 4.0 следующий результат.
Наибольшим оказалось третье число 4.00
Теперь ошибка локализована до расчетного блока и, после некоторых усилий, мы ее находим и исправляем.
2. Метод индукции
Судя по результатам, ошибка возникает, когда максимальное число — второе или третье (если максимальное — первое, то определяется оно правильно, для доказательства можно програть еще два-три теста).
Просматриваем все, относящееся к переменным b и с. Со вводом никаких проблем не замечено, а что касается вывода — то мы быстро натыкаемся на замену b на с. Исправляем.
Как видно, невыявленные ошибки в программе остаются. Просматриваем расчетный блок: все, что относится к максимальному b (максимум с получается «в противном случае»), и обнаруживаем пресловутую проблему «a>c» вместо «b>c». Программа отлажена.
3. Метод дедукции
Неверные результаты в нашем случае могут получиться из-за ошибки в:
- — вводе данных;
- — расчетном блоке;
- — собственно выводе.
Для доказательства мы можем пользоваться отладочной печатью, трассировкой или просто набором тестов. В любом случае мы выявляем одну ошибку в расчете и одну в выводе.
4. Обратное движение по алгоритму
Зная, что ошибка возникает при выводе результатов, рассматриваем код, начиная с операторов вывода. Сразу же находим лишнюю b в операторе writeln.
Далее, смотрим по конкретной ветке условного оператора, откуда взялся результат. Для значений -2.0, 8.0, 4.0 расчет идет по ветке с условием if (b>a)and(a>c) then… где мы тут же обнаруживаем искомую ошибку.
5. Тестирование
В нашей задаче для самого полного набора данных нужно выбрать такие переменные, что
a > b > c
a > c > b
b > a > c
b > c > a
c > a > b
c > b > a
Анализируя получившиеся в каждом из этих случаев результаты, мы приходим к тому, что проблемы возникают при b>c>a и с — максимальном. Зная эти подробности, мы можем заострить внимание на конкретных участках программы.
Конечно, в реальной работе мы не расписываем так занудно каждый шаг, не прибегаем исключительно к одной методике, да и вообще частенько не задумываемся, каким образом искать ляпы. Теперь, когда мы разобрались со всеми подходами, каждый волен выбрать те из них, которые кажутся самыми удобными.
5. Средства отладки
Помимо методик, хорошо бы иметь представление о средствах, которые помогают нам выявлять ошибки. Это:
1) Аварийная печать — вывод сообщений о ненормальном завершении отдельных блоков и всей программы в целом.
2) Печать в узлах программы — вывод промежуточных значений параметров в местах, выбранных программистом. Обычно, это критичные участки алгоритма (например, значение, от которого зависит дальнейший ход выполнения) или составные части сложных формул (отдельно просчитать и вывести числитель и знаменатель большой дроби).
3) Непосредственное слежение:
- — арифметическое (за тем, чему равны, когда и как изменяются выбранные переменные),
- — логическое (когда и как выполняется выбранная последовательность операторов),
- — контроль выхода индексов за допустимые пределы,
- — отслеживание обращений к переменным,
- — отслеживание обращений к подпрограммам,
- — проверка значений индексов элементов массивов и т.д.
Нынешние среды разработки часто предлагают нам реагировать на возникающую проблему в диалоговом режиме. При этом можно:
- — просмотреть текущие значения переменных, состояние памяти, участок алгоритма, где произошел сбой;
- — прервать выполнение программы;
- — внести в программу изменения и повторно запустить ее (в компиляторных средах для этого потребуется перекомпилировать код, в интерпретаторных выполнение можно продолжить прямо с измененного оператора).
 Рис Пример отладки приложения
Рис Пример отладки приложения
6. Классификация ошибок
Ошибки в программах могут допускаться от самого начального этапа составления алгоритма решения задачи до окончательного оформления программы. Разновидностей ошибок достаточно много. Рассмотрим некоторые группы ошибок и соответствующие примеры:
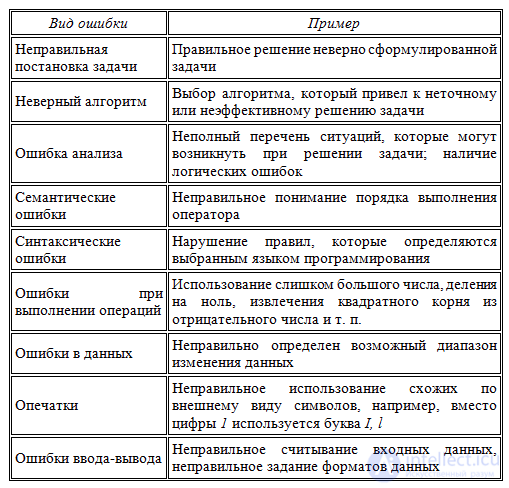
Если вы удручены тем, что насажали в текст программы глупых ошибок — не расстраивайтесь. Ошибки вообще не бывают умными, хотя и могут относиться к самым разным частям кода:
- — ошибки обращения к данным,
- — ошибки описания данных,
- — ошибки вычислений,
- — ошибки при сравнении,
- — ошибки в передаче управления,
- — ошибки ввода-вывода,
- — ошибки интерфейса,
- и т д
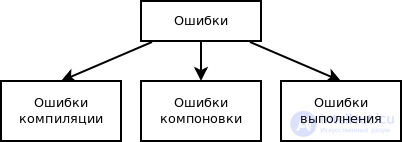
Классификация ошибок по этапу обработки программы
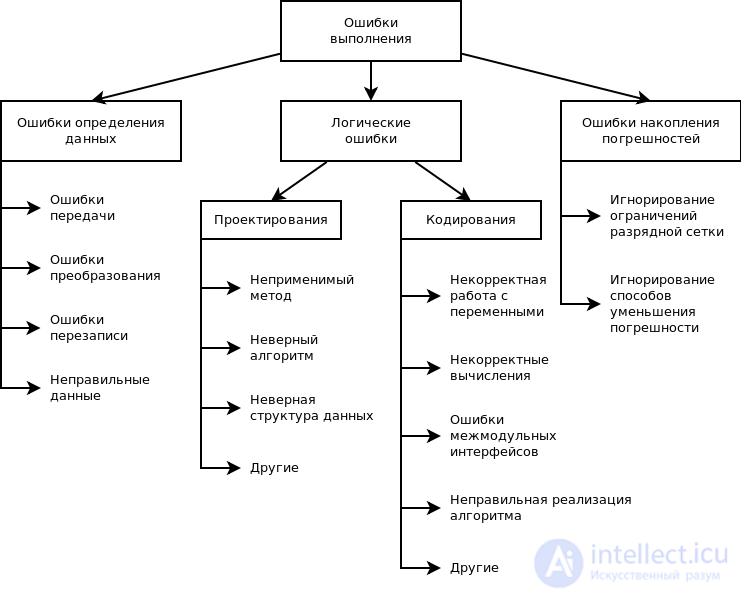
рис Классификация ошибок этапа выполнения по возможным причинам
Синтаксические ошибки
Синтаксические ошибки зачастую выявляют уже на этапе трансляции. К сожалению, многие ошибки других видов транслятор выявить не в силах, т.к. ему не известен задуманный или требуемый результат работы программы. Отсутствие сообщений транслятора о наличии синтаксических ошибок является необходимым условием правильности программы, но не может свидетельствовать о том, что она даст правильный результат.
Примеры синтаксических ошибок :
- отсутствие знака пунктуации;
- несоответствие количества открывающих и закрывающих скобок;
- неправильно сформированный оператор;
- неправильная запись имени переменной;
- ошибка в написании служебных слов;
- отсутствие условия окончания цикла;
- отсутствие описания массивов и т.п.
Ошибки, которые не обнаруживает транслятор
В случае правильного написания операторов в программе может присутствовать большое количество ошибок, которые транслятор не может обнаружить. Рассмотрим примеры таких ошибок:
Логические ошибки: после проверки заданного условия неправильно указана ветвь алгоритма; неполный перечень возможных условий при решении задачи; один или более блоков алгоритма в программе пропущен.
Ошибки в циклах: неправильно указано начало цикла; неправильно указаны условия окончания цикла; неправильно указано количество повторений цикла; использование бесконечного цикла.
Ошибки ввода-вывода; ошибки при работе с данными: неправильно задан тип данных; организовано считывание меньшего или большего объема данных, чем нужно; неправильно отредактированы данные.
Ошибки в использовании переменных: используются переменных, для которых не указаны начальные значения; ошибочно указана одна переменная вместо другой. Ошибки при работе с массивами: пропущено предварительное обнуление массивов; неправильное описание массивов; индексы массивов следуют в ошибочном порядке.
ошибки безопасности, умышленные и не умышленные уязвимости в системе, открытость к отказам в обслуживании. несанкционированном доступе. екхолы
Ошибки в арифметических операциях: неправильное использование типа переменной (например, для сохранения результата деления используется целочисленная переменная); неправильно определен порядок действий; выполняется деление на нуль; при расчете выполняется попытка извлечения квадратного корня из отрицательного числа; не учитываются значащие разряды числа.
ошибки в архитектуре приложения пприводящие к увеличени технического долга
Методы (пути) снижение ошибок в программировании
- использование тестиования
- использование более простых решений
- использование систем с наименьшим числом составлящих
- использование ранее использованных и проверенных компонентов
- использование более квалифицрованных специалистов
7. Советы отладчику
1) Проверяйте тщательнее: ошибка скорее всего находится не в том месте, в котором кажется.
2) Часто оказывается легче выделить те места программы, ошибок в которых нет, а затем уже искать в остальных.
3) Тщательнее следить за объявлениями констант, типов и переменных, входными данными.
4) При последовательной разработке приходится особенно аккуратно писать драйверы и заглушки — они сами могут быть источником ошибок.
5) Анализировать код, начиная с самых простых вариантов. Чаще всего встречаются ошибки:
— значения входных аргументов принимаются не в том порядке,
— переменная не проинициализирована,
— при повторном прохождении модуля, перемен ная повторно не инициализируется,
— вместо предполагаемого полного копирования структуры данных, копируется только верхний уровень (например, вместо создания новой динамической переменной и присваивания ей нужного значения, адрес тупо копируется из уже существующей переменной),
— скобки в сложном выражении расставлены неправильно.
6) При упорной длительной отладке глаз «замыливается». Хороший прием — обратиться за помощью к другому лицу, чтобы не повторять ошибочных рассуждений. Правда, частенько остается проблемой убедить это другое лицо помочь вам.
7) Ошибка, скорее всего окажется вашей и будет находиться в тексте программы. Гораздо реже она оказывается:
- в компиляторе,
- операционной системе,
- аппаратной части,
- электропроводке в здании и т.д.
Но если вы совершенно уверены, что в программе ошибок нет, просмотрите стандартные модули, к которым она обращается, выясните, не менялась ли версия среды разработки, в конце концов, просто перегрузите компьютер — некоторые проблемы (особенно в DOS-средах, запускаемых из-под Windows) возникают из-за некорректной работы с памятью.
Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
9) Навязчивый поиск одной ошибки почти всегда непродуктивен. Не получается — отложите задачу, возьмитесь за написание следующего модуля, на худой конец займитесь документированием.
10) Старайтесь не жалеть времени, чтобы уясненить причину ошибки. Это поможет вам:
исправить программу,
обнаружить другие ошибки того же типа,
не делать их в дальнейшем.
11) Если вы уже знаете симптомы ошибки, иногда полезно не исправлять ее сразу, а на фоне известного поведения программы поискать другие ляпы.
12) Самые труднообнаруживаемые ошибки — наведенные, то есть те, что были внесены в код при исправлении других.
8. Тестирование
Тестирование — это выполнение программы для набора проверочных входных значений и сравнение полученных результатов с ожидаемыми.
Цель тестирования — проверка и доказательство правильности работы программы. В противном случае — выявление того, что в ней есть ошибки. Тестирование само не показывает местонахождение ошибки и не указывает на ее причины.
Принципы тестирования.
1) Тест — просчитанный вручную пример выполнения программы от исходных данных до ожидаемых результатов расчета. Эти результаты считаются эталонными.
Полномаршрутным будет такое тестирование, при котором каждый линейный участок программы будет пройден хотя бы при выполнении одного теста.
2) При прогоне программы по тестовым начальным данным, полученные результаты нужно сверить с эталонными и проанализировать разницу, если она есть.
3) При разработке тестов нужно учитывать не только правильные, но и неверные исходные данные.
4) Мы должны проверить программу на нежелательные побочные эффекты при задании некоторых исходных данных (деление на ноль, попытка считывания из несуществующего файла и т.д.).
5) Тестирование нужно планировать: заранее выбрать, что мы контролируем и как это сделать лучше. Обычно тесты планируются на этапе алгоритмизации или выбора численного метода решения. Причем, составляя тесты, мы предполагаем, что ошибки в программе есть.
6) Чем больше ошибок в коде мы уже нашли, тем больше вероятность, что мы обнаружим еще не найденные.
Хорошим называют тест, который с большой вероятностью должен обнаруживать ошибки, а удачным — тот, который их обнаружил.
9. Проектирование тестов
Тесты просчитываются вручную, значит, они должны быть достаточно просты для этого.
Тесты должны проверять каждую ветку алгоритма. По возможности, конечно. Так что количество и сложность тестов зависит от сложности программы.
Тесты составляются до кодирования и отладки: во время разработки алгоритма или даже составления математической модели.
Обычно для экономии времени сначала пропускают более простые тесты, а затем более сложные.
Давайте рассмотрим задачу: нужно проверить, попадает ли введенное число в заданный пользователем диапазон.
program Example;
(******************************************************
* Задача: проверить, попадает ли введенное число в *
* заданный пользователем диапазон *
******************************************************)
var
min, max, A, tmp: real;
begin
writeln(‘Программа проверяет, попадают ли введенные пользователем’);
writeln(‘значения в заданный диапазон’);
writeln;
writeln(‘Введите нижнюю границу диапазона ‘); readln(min);
writeln(‘Введите верхнюю границу диапазона ‘); readln(max);
if min>max then begin
writeln(‘Вы перепутали диапазоны, и я их поменяю’);
tmp:=min;
min:=max;
max:=tmp;
end;
repeat
writeln(‘Введите число для проверки (0 — конец работы) ‘); readln(A);
if (A>=min)and(A<=max) then
writeln(‘Число ‘,A,’ попадает в диапазон [‘,min,’..’,max,’]’)
else
writeln(‘Число ‘,A,’ не попадает в диапазон [‘,min,’..’,max,’]’);
until A=0;
writeln;
end.
Если исходить из алгоритма программы, мы должны составить следующие тесты:
ввод границ диапазона
— min< max
— min>max
ввод числа
— A < min (A<>0)
— A > max (A<>0)
— min <= A <= max (A<>0)
— A=0
Как видите, программа очень мала, а тестов для проверки всех ветвей ее алгоритма, требуется довольно много.
10. Стратегии тестирования
1) Тестирование программы как «черного ящика».
Мы знаем только о том, что делает программа, но даже не задумываемся о ее внутренней структуре. Задаем набор входных данных, получаем результаты, сверяем с эталонными.
При этом обнаружить все ошибки мы можем только если составили тесты для всех возможных наборов данных. Естественно, это противоречит экономическим принципам, да и просто достаточно глупо.
«Черным ящиком» удобно тестировать небольшие подпрограммы.
2) Тестирование программы как «белого ящика».
Здесь перед составлением теста мы изучаем логику программы, ее внутреннюю структуру. Тестирование будет считаться удачным, если проверяет программу по всем направлениям. Однако, как мы уже говорили, это требует огромного количества тестов.
На практике мы, как всегда, совместно используем оба принципа.
3) Тестирование программ модульной структуры.
Мы снова возвращаемся к вопросу о структурном программировании. Если вы помните, программы строятся из модулей не в последнюю очередь для того, чтобы их легко было отлаживать и тестировать. Действительно, структурированную программу мы будем тестировать частями. При этом нам нужно:
строить набор тестов;
комбинировать модули для тестирования.
Такое комбинирование может строиться двумя способами:
Пошаговое тестирование — тестируем каждый модуль, присоединяя его к уже оттестированным. При этом можем соединять части программы сверху вниз (нисходящий способ) или снизу вверх (восходящий).
Монолитное тестирование — каждый модуль тестируется отдельно, а затем из них формируется готовая рабочая программа и тестируется уже целиком.
Чтобы протестировать отдельный модуль, нужен модуль-драйвер (всегда один) и модул и-заглушки (этих может быть несколько).
Модуль-драйвер содержит фиксированные исходные данные. Он вызывает тестируемый модуль и отображает (а возможно, и анализирует) результаты.
Модуль-заглушка нужен, если в тестируемом модуле есть вызовы других. Вместо этого вызова управление передается модулю-заглушке, и уже он имитирует необходимые действия.
К сожалению, мы опять сталкиваемся с тем, что драйверы и заглушки сами могут оказаться источником ошибок. Поэтому создаваться они должны с большой осторожностью.
См. также
- ошибки в приложениях , bugs , баг репорт , bug report ,
- Фича
- GIGO
- Патч
- тестирование
- цикломатическая сложность
- баг репорт
- качество программного обеспечения
К сожалению, в одной статье не просто дать все знания про виды ошибок программного обеспечения. Но я — старался.
Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое виды ошибок программного обеспечения, принципы отладки
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Качество и тестирование программного обеспечения. Quality Assurance.
Отладка программы призвана выискивать «вредителей» кода и устранять их. За это отвечают отладчик и журналирование для вывода сведений о программе.
В предыдущей части мы рассмотрели исходный код и его составляющие.
После того, как вы начнете проверять фрагменты кода или попытаетесь решить связанные с ним проблемы, вы очень скоро поймете, что существуют моменты, когда программа крашится, прерывается и прекращает работу.

Это часто вызвано ошибками, известными как дефекты или исключительные ситуации во время выполнения. Акт обнаружения и удаления ошибок из нашего кода – это отладка программы. Вы лучше разберетесь в отладке на практике, используя ее как можно чаще. Мы не только отлаживаем собственный код, но и порой дебажим написанное другими программистами.
Для начала необходимо рассортировать общие ошибки, которые могут возникнуть в исходном коде.

Синтаксические ошибки
Эти эрроры не позволяют скомпилировать исходный код на компилируемых языках программирования. Они обнаруживаются во время компиляции или интерпретации исходного кода. Они также могут быть легко обнаружены статическими анализаторами (линтами). Подробнее о линтах мы узнаем немного позже.
Синтаксические ошибки в основном вызваны нарушением ожидаемой формы или структуры языка, на котором пишется программа. Как пример, это может быть отсутствующая закрывающая скобка в уравнении.
Семантические ошибки
Отладка программы может потребоваться и по причине семантических ошибок, также известных как логические. Они являются наиболее сложными из всех, потому что не могут быть легко обнаружены. Признак того, что существует семантическая ошибка, – это когда программа запускается, отрабатывает, но не дает желаемого результата.
Рассмотрим данный пример:
3 + 5 * 6
По порядку приоритета, называемому старшинством операции, с учетом математических правил мы ожидаем, что сначала будет оценена часть умножения, и окончательный результат будет равен 33. Если программист хотел, чтобы сначала происходило добавление двух чисел, следовало поступить иначе. Для этого используются круглые скобки, которые отвечают за смещение приоритетов в математической формуле. Исправленный пример должен выглядеть так:
(3 + 5) * 6
3 + 5, заключенные в скобки, дадут желаемый результат, а именно 48.
Ошибки в процессе выполнения
Как и семантические, ошибки во время выполнения никогда не обнаруживаются при компиляции. В отличие от семантических ошибок, эти прерывают программу и препятствуют ее дальнейшему выполнению. Они обычно вызваны неожиданным результатом некоторых вычислений в исходном коде.
Вот хороший пример:
input = 25 x = 0.8/(Math.sqrt(input) - 5)
Фрагмент кода выше будет скомпилирован успешно, но input 25 приведет к ZeroDivisionError. Это ошибка во время выполнения. Другим популярным примером является StackOverflowError или IndexOutofBoundError. Важно то, что вы идентифицируете эти ошибки и узнаете, как с ними бороться.
Существуют ошибки, связанные с тем, как ваш исходный код использует память и пространство на платформе или в среде, в которой он запущен. Они также являются ошибками во время выполнения. Такие ошибки, как OutOfMemoryErrorand и HeapError обычно вызваны тем, что ваш исходный код использует слишком много ресурсов. Хорошее знание алгоритмов поможет написать код, который лучше использует ресурсы. В этом и заключается отладка программы.
Процесс перезаписи кода для повышения производительности называется оптимизацией. Менее популярное наименование процесса – рефакторинг. Поскольку вы тратите больше времени на кодинг, то должны иметь это в виду.
Отладка программы
Вот несколько советов о том, как правильно выполнять отладку:
- Использовать Linters. Linters – это инструменты, которые помогают считывать исходный код, чтобы проверить, соответствует ли он ожидаемому стандарту на выбранном языке программирования. Существуют линты для многих языков.
- Превалирование IDE над простыми редакторами. Вы можете выбрать IDE, разработанную для языка, который изучаете. IDE – это интегрированные среды разработки. Они созданы для написания, отладки, компиляции и запуска кода. Jetbrains создают отличные IDE, такие как Webstorm и IntelliJ. Также есть NetBeans, Komodo, Qt, Android Studio, XCode (поставляется с Mac), etc.
- Чтение кода вслух. Это полезно, когда вы ищете семантическую ошибку. Читая свой код вслух, есть большая вероятность, что вы зачитаете и ошибку.
- Чтение логов. Когда компилятор отмечает Error, обязательно посмотрите, где он находится.
Двигаемся дальше
Поздравляем! Слово «ошибка» уже привычно для вас, равно как и «отладка программы». В качестве новичка вы можете изучать кодинг по книгам, онлайн-урокам или видео. И даже чужой код вам теперь не страшен
В процессе кодинга измените что-нибудь, чтобы понять, как он работает. Но будьте уверены в том, что сами написали.
Викторина
- Какая ошибка допущена в фрагменте кода Python ниже?
items = [0,1,2,3,4,5] print items[8] //комментарий: элементы здесь представляют собой массив с шестью элементами. Например, чтобы получить 4-й элемент, вы будете использовать [3]. Мы начинаем отсчет с 0.
- Какая ошибка допущена в фрагменте кода Python ниже?
input = Hippo' if input == 'Hippo': print 'Hello, Hippo'
Ответы на вопросы
- Ошибка выполнения: ошибка индекса вне диапазона.
2. Синтаксическая ошибка: Отсутствует стартовая кавычка в первой строке.