при численном решении алгебраических уравнений — суммарное влияние округлений, сделанных на отдельных шагах вычислительного процесса, на точность полученного решения линейной алгебраич. системы. Наиболее распространенным способом априорной оценки суммарного влияния ошибок округления в численных методах линейной алгебры является схема т. н. обратного анализа. В применении к решению системы линейных алгебраич. уравнений

схема обратного анализа заключается в следующем. Вычисленное прямым методом Мрешение хуи не удовлетворяет (1), но может быть представлено как точное решение возмущенной системы

Качество прямого метода оценивается по наилучшей априорной оценке, к-рую можно дать для норм матрицы  и вектора
и вектора  . Такие «наилучшие»
. Такие «наилучшие» и
и  наз. соответственно матрицей и вектором эквивалентного возмущения для метода М.
наз. соответственно матрицей и вектором эквивалентного возмущения для метода М.
Если оценки для 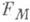 и
и 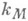 имеются, то теоретически ошибка приближенного решения
имеются, то теоретически ошибка приближенного решения  может быть оценена неравенством
может быть оценена неравенством
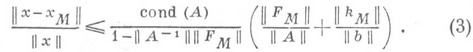
Здесь  — число обусловленности матрицы А, а матричная норма в (3) предполагается подчиненной векторной норме
— число обусловленности матрицы А, а матричная норма в (3) предполагается подчиненной векторной норме 
В действительности оценка для 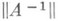 редко бывает известна, и основной смысл (2) состоит в возможности сравнения качества различных методов. Ниже приводится вид нек-рых типичных оценок для матрицы
редко бывает известна, и основной смысл (2) состоит в возможности сравнения качества различных методов. Ниже приводится вид нек-рых типичных оценок для матрицы  Для методов с ортогональными преобразованиями и арифметики с плавающей запятой (в системе (1) Аи bсчитаются действительными)
Для методов с ортогональными преобразованиями и арифметики с плавающей запятой (в системе (1) Аи bсчитаются действительными)

В этой оценке  — относительная точность арифметич. операций в ЭВМ,
— относительная точность арифметич. операций в ЭВМ,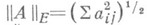 — евклидова матричная норма, f(n) — функция вида
— евклидова матричная норма, f(n) — функция вида 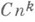 , где п- порядок системы. Точные значения константы Си показателя kопределяются такими деталями вычислительного процесса, как способ округления, использование операции накопления скалярных произведений и т. д. Наиболее часто k=1 или 3/2.
, где п- порядок системы. Точные значения константы Си показателя kопределяются такими деталями вычислительного процесса, как способ округления, использование операции накопления скалярных произведений и т. д. Наиболее часто k=1 или 3/2.
В случае методов типа Гаусса в правую часть оценки (4) входит еще множитель  , отражающий возможность роста элементов матрицы Ана промежуточных шагах метода по сравнению с первоначальным уровнем (такой рост отсутствует в ортогональных методах). Чтобы уменьшить значение
, отражающий возможность роста элементов матрицы Ана промежуточных шагах метода по сравнению с первоначальным уровнем (такой рост отсутствует в ортогональных методах). Чтобы уменьшить значение 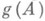 , применяют различные способы выбора ведущего элемента, препятствующие возрастанию элементов матрицы.
, применяют различные способы выбора ведущего элемента, препятствующие возрастанию элементов матрицы.
Для квадратного корня метода, к-рый применяется обычно в случае положительно определенной матрицы А, получена наиболее сильная оценка
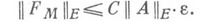
Существуют прямые методы (Жордана, окаймления, сопряженных градиентов), для к-рых непосредственное применение схемы обратного анализа не приводит к эффективным оценкам. В этих случаях при исследовании Н. п. применяются и иные соображения (см. [6] — [9]).
Лит.:[1] Givens W., «TJ. S. Atomic Energy Commiss. Repts. Ser. OR NL», 1954, № 1574; [2] Wilkinson J. H., Rounding errors in algebraic processes, L., 1963; [3] Уилкинсон Д ж. <Х., Алгебраическая проблема собственных значений, пер. с англ., М., 1970; [4] Воеводин В. В., Ошибки округления и устойчивость в прямых методах линейной алгебры, М., 1969; [5] его же, Вычислительные основы линейной алгебры, М., 1977; [6] Peters G., Wilkinsоn J. H., «Communs Assoc. Comput. Math.», 1975, v. 18, № 1, p. 20-24; [7] Вrоуden C. G., «J. Inst. Math, and Appl.», 1974, v. 14, № 2, p. 131-40; [8] Reid J. К., в кн.: Large Sparse Sets of Linear Equations, L.- N. Y., 1971, p. 231 — 254; [9] Икрамов Х. Д., «Ж. вычисл. матем. и матем. физики», 1978, т. 18, № 3, с. 531-45.
X. Д. Икрамов.
Н. п. округления или погрешности метода возникает при решении задач, где решение является результатом большого числа последовательно выполняемых арифметич. операций.
Значительная часть таких задач связана с решением алгебраич. задач, линейных или нелинейных (см. выше). В свою очередь среди алгебраич. задач наиболее распространены задачи, возникающие при аппроксимации дифференциальных уравнений. Этим задачам свойственны нек-рые специфич. особенности.
Н. п. метода решения задачи происходит по тем же или по более простым законам, что и Н. п. вычислительной погрешности; Н. ,п. метода исследуется при оценке метода решения задачи.
При исследовании накопления вычислительной погрешности различают два подхода. В первом случае считают, что вычислительные погрешности на каждом шаге вносятся самым неблагоприятным образом и получают мажорантную оценку погрешности. Во втором случае считают, что эти погрешности случайны с определенным законом распределения.
Характер Н. п. зависит от решаемой задачи, метода решения и ряда других факторов, на первый взгляд могущих показаться несущественными; сюда относятся форма записи чисел в ЭВМ (с фиксированной запятой или с плавающей запятой), порядок выполнения арифметич. операций и т. д. Напр., в задаче вычисления суммы Nчисел 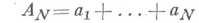
существенен порядок выполнения операций. Пусть вычисления производятся на машине с плавающей запятой с tдвоичными разрядами и все числа лежат в пределах 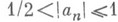 . При непосредственном вычислении
. При непосредственном вычислении 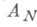 с помощью рекуррентной формулы
с помощью рекуррентной формулы 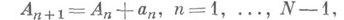 мажорантная оценка погрешности имеет порядок 2-tN. Можно поступить иначе (см. [1]). При вычислении попарных сумм
мажорантная оценка погрешности имеет порядок 2-tN. Можно поступить иначе (см. [1]). При вычислении попарных сумм 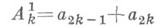 (если N=2l+1 нечетно) полагают
(если N=2l+1 нечетно) полагают  . Далее вычисляются их попарные суммы
. Далее вычисляются их попарные суммы  и т. д. При
и т. д. При 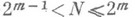 после тшагов образования попарных сумм по формулам
после тшагов образования попарных сумм по формулам

получают 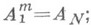 мажорантная оценка погрешности порядка
мажорантная оценка погрешности порядка 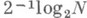
В типичных задачах величины а т вычисляются по формулам, в частности рекуррентным, или поступают последовательно в оперативную память ЭВМ; в этих случаях применение описанного приема приводит к увеличению загрузки памяти ЭВМ. Однако можно организовать последовательность вычислений так, что загрузка оперативной памяти не будет превосходить -log2N ячеек.
При численном решении дифференциальных уравнений возможны следующие случаи. При стремлении шага сетки hк нулю погрешность растет как 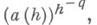 где
где 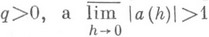 . Такие методы решения задач относят к классу неустойчивых. Их применение носит эпизодич. характер.
. Такие методы решения задач относят к классу неустойчивых. Их применение носит эпизодич. характер.
Для устойчивых методов характерен рост погрешности как  Оценка погрешности таких методов обычно производится следующим образом. Строится уравнение относительно возмущения, вносимого или округлением, или погрешностями метода и затем исследуется решение этого уравнения (см. [2], [3]).
Оценка погрешности таких методов обычно производится следующим образом. Строится уравнение относительно возмущения, вносимого или округлением, или погрешностями метода и затем исследуется решение этого уравнения (см. [2], [3]).
В более сложных случаях применяется метод эквивалентных возмущений (см. [1], [4]), развитый в отношении задачи исследования накопления вычислительной погрешности при решении дифференциальных уравнений (см. [3], [5], [6]). Вычисления по нек-рой расчетной схеме с округлениями рассматриваются как вычисления без округлений, но для уравнения с возмущенными коэффициентами. Сравнивая решение исходного сеточного уравнения с решением уравнения с возмущенными коэффициентами получают оценку погрешности.
Уделяется существенное внимание выбору метода по возможности с меньшими значениями qи A(h). При фиксированном методе решения задачи расчетные формулы обычно удается преобразовать к виду, где  (см. [3], [5]). Это особенно существенно в случае обыкновенных дифференциальных уравнений, где число шагов в отдельных случаях оказывается очень большим.
(см. [3], [5]). Это особенно существенно в случае обыкновенных дифференциальных уравнений, где число шагов в отдельных случаях оказывается очень большим.
Величина (h)может сильно расти с ростом промежутка интегрирования. Поэтому стараются применять методы по возможности с меньшим значением A(h). В случае задачи Коши ошибка округления на каждом конкретном шаге по отношению к последующим шагам может рассматриваться как ошибка в начальном условии. Поэтому нижняя грань (h)зависит от характеристики расхождения близких решений дифференциального уравнения, определяемого уравнением в вариациях.
В случае численного решения обыкновенного дифференциального уравнения 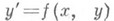 уравнение в вариациях имеет вид
уравнение в вариациях имеет вид
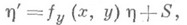
и потому при решении задачи на отрезке ( х 0 , X )нельзя рассчитывать на константу A(h)в мажорантной оценке вычислительной погрешности существенно лучшую, чем
Поэтому при решении этой задачи наиболее употребительны однощаговые методы типа Рунге — Кутта или методы типа Адамса (см. [3], [7]), где Н. п. в основном определяется решением уравнения в вариациях.
Для ряда методов главный член погрешности метода накапливается по подобному закону, в то время как вычислительная погрешность накапливается существенно быстрее (см. [3]). Область практич. применимости таких методов оказывается существенно уже.
Накопление вычислительной погрешности существенно зависит от метода, применяемого для решения сеточной задачи. Напр., при решении сеточных краевых задач, соответствующих обыкновенным дифференциальным уравнениям, методами стрельбы и прогонки Н. п. имеет характер A(h)h-q, где qодно и то же. Значения A(h)у этих методов могут отличаться настолько, что в определенной ситуации один из методов становится неприменимым. При решении методом пристрелки сеточной краевой задачи для уравнения Лапласа Н. п. имеет характер с 1/h, с>1, а в случае метода прогонки Ah-q. При вероятностном подходе к исследованию Н. п. в одних случаях априорно предполагают какой-то закон распределения погрешности (см. [2]), в других случаях вводят меру на пространстве рассматриваемых задач и, исходя из этой меры, получают закон распределения погрешностей округления (см. [8], [9]).
При умеренной точности решения задачи мажорантные и вероятностные подходы к оценке накопления вычислительной погрешности обычно дают качественно одинаковые результаты: или в обоих случаях Н. п. происходит в допустимых пределах, или в обоих случаях Н. п. превосходит такие пределы.
Лит.:[1] Воеводин В. В., Вычислительные основы линейной алгебры, М., 1977; [2] Шура-Бура М. Р., «Прикл. матем. и механ.», 1952, т. 16, № 5, с. 575-88; [3] Бахвалов Н. С, Численные методы, 2 изд., М., 1975; [4] Уилкинсон Дж. X., Алгебраическая проблема собственных значений, пер. с англ., М.. 1970; [5] Бахвалов Н. С, в кн.: Вычислительные методы и программирование, в. 1, М., 1962, с, 69-79; [6] Годунов С. К., Рябенький В. С, Разностные схемы, 2 изд., М., 1977; [7] Бахвалов Н. С, «Докл. АН СССР», 1955, т. 104, № 5, с. 683-86; [8] его же, «Ж. вычислит, матем. и матем. физики», 1964; т. 4, № 3, с. 399- 404; [9] Лапшин Е. А., там же, 1971, т. 11, № 6, с.1425-36.
Н. С. Бахвалов.
Математическая энциклопедия. — М.: Советская энциклопедия.
.
1977—1985.
Закон накопления случайных ошибоккосвенных измерений выглядит следующим
образом:
![]() ;
;
![]() .
.
Закон накопления возможных предельных
абсолютных систематических ошибок
косвенных измерений представляется
следующими зависимостями:
![]() ;
;
![]() .
.
Закон накопления возможных предельных
относительных систематических ошибоккосвенных измерений имеет следующий
вид:
![]() ;
;
![]() .
.
В случаях, когда искомая величина (y)рассчитывается как функция результатов
нескольких независимых прямых измерений
вида
![]() ,
,
закон накопления предельных относительных
систематических ошибок косвенных
измерений принимает более простой вид:
![]() ;
;
![]() .
.
Ошибки и погрешности измерений определяют
их точность, воспроизводимость, сходимость
и правильность.
Чем меньше величина погрешности
измерения, тем выше его точность.
Воспроизводимостьисходимостьрезультатов измерений улучшаются при
уменьшении случайных ошибок измерений.
Правильностьрезультата измерений
увеличивается с уменьшением остаточных
систематических ошибок измерений.
Более подробно с теорией ошибок измерений
и их особенностями познакомьтесь в
[6,9]. Я же
обращу Ваше внимание на то, что современные
формы представления конечных результатов
измерений обязательно требуют приведения
ошибок или погрешностей измерения
(вторичных данных). Погрешности и ошибки
измерений должны представлятьсячислами,
которые содержат не болеедвух значащих
цифр.
4.2. Формы представления конечных результатов измерений
Для представления количественных
результатов измерений (при неизвестных
параметрах генеральной совокупности)
можно использовать следующие формы.
-
При одном единичном значении результата
измерений
(n = 1):
y = y1y,пр..
2. При наличии нескольких единичных
результатов измерений
(n 2) и отсутствии сведений о функции их
распределения:
a) y = y; Sy; n ; y,пр.(может дополнительно еще приводиться
значение вероятности Р, если расчет
y,пр.носил вероятностный характер;
б) y=y
Пy; Sy; n ; P.
3. При наличии нескольких единичных
результатов измерений
(n 2) и знании функции их распределения:
а) y =yПy; P (при симметричной погрешности);
б) y =y; Пyот Пy,
ндо Пy,
в; P (для несимметричной погрешности,
где Пy,
н— нижняя граница общей абсолютной
погрешности, а Пy,
в— верхняя граница общей абсолютной
погрешности).
При окончательном представлении
фактического результата измерения
число значащих цифриразрядовпосле десятичной запятой должно быть
скорректировано исходя из точности
математических вычислений и погрешности
измерения. Приведу пример обработки
первичных данных измерения с целью
получения и представления конечного
результата измерения.
П ример.
ример.
При трехкратном взвешивании образца
на аналитических весах (класс точности
0,01 ) были получены следующие единичные
результаты измерения его массы
(mi
): 1,2356; 1,2345;
1,2348 г. Результаты метрологической
поверки весов свидетельствуют об их
постоянной абсолютной систематической
ошибке m
= — 0,0003 г (для примененной гирьки из
разновесов массой 1 г систематическая
ошибка была равной нулю). Тогда ряд
исправленных единичных результатов
измерения массы образца (mi)
будет иметь вид: 1,2359; 1,2348; 1,2351 г.
Первоначально проведем поиск грубых
ошибок измерения (промахов). Так как для
данной выборки n < 8 (n = 3), то согласно
[6, с. 82-84] для обнаружения промахов
используем Q-критерий. Единичные
результаты измерений представим в виде
нового ряда с возрастающими величинами
массы образца: 1,2348; 1,2351; 1,2359 г. Проверим
на промахи крайние члены этого нового
ряда, которые кажутся сомнительными:
1. mn (проверяемый результат)
= 1,2359 г ; mn-1 (результат
соседний с проверяемым) = 1,2351 г ; R (размах)
= 1,2359 — 1,2348 = 0,0011 г ;
![]() .
.
Из данных табл.1 [6, с.82] выбираем табличное
значение Q-критерия (QТ)
для n = 3 и Р = 0,95 (принимаем наиболее часто
задаваемое значение вероятности в химии
и химической технологии). Так как
QТ > QР
(0,94 > 0,73), то проверяемый результат
(1,2359 г) не является грубой ошибкой
измерения.
2. mn = 1,2348 г ; mn-1
= 1,2351 г ;
![]() .
.
И этот проверяемый результат (1,2348 г)
не является промахом, так как QТ
> QР (0,94 > 0,27).
Учитывая то, что для непредставительных
выборок (n < 10) не рекомендуется проверять
их подчинение законам распределения,
сделаем допущение о соответствии
единичных результатов измерения массы
образца нормальному закону распределения.
Так как истинный закон распределения
результатов измерений неизвестен, то
для представления конечных результатов
измерения выберем форму 2б(с. 42). Выполним
следующие расчеты, применяя правила
математических действий и округления
с приближенными и случайными числами:
 г ;
г ;

![]() (г)2;
(г)2;![]() г ;
г ;
Пm,пр.=m,пр.+
![]() Sm
Sm
;![]() 10-4г ;
10-4г ;![]() =
=
4,3 (из таблицы квантилей распределения
Стьюдента при n = 3 для Р = 0,95);
m,пр.
=
![]() =
=
Еm
m (делаем допущение, что систематическая
ошибка весов намного превосходит прочие
систематические ошибки и ими можно
пренебречь);
Еm
= 0,0110-2
(исходя из обозначения класса точности
весов).
Поскольку
 ,
,
то систематическими ошибками можно
пренебречь. Тогда:
Пm,пр.
4,33,291410-4
= 1,41530210-3
110-3
г (так как в ошибках оставляют не более
двух первых разрядов цифр).
Таким образом, по форме 2б результат
измерения массы образца будет выглядеть
следующим образом:
m = 1,235
0,001 г ; Sm
= 310-4
г ; n = 3 ; P = 0,95.
В заключениеданной лекции еще раз
отмечу, что большинство научных,
технических, технологических, экологических
и других проблем и задач невозможно
решить без проведения измерений, знания
и практических навыков в области
метрологии (науки об измерениях), которые
определяют уровень профессиональной
культуры специалиста с высшим образованием.
Так как любые результаты измерений
являются случайными величинами (из-за
невозможности исключения ошибок
измерения), то подход к ним должен
основываться на методах математической
статистики и теории вероятности.
Спецификой измерений в химии и химической
технологии (и особенно при выполнении
лабораторных работ) можно считать малое
число, а иногда и отсутствие параллельных
(повторных, кратных) измерений, что
затрудняет оценку погрешностей,
проведение анализа и выбор формы
представления конечных результатов
измерений.
Соседние файлы в папке 100_v9_Глухих В.В.
- #
- #
- #
- #
- #
- #
- #
- #
Отладка программы — один их самых сложных этапов разработки программного обеспечения, требующий глубокого знания:
•специфики управления используемыми техническими средствами,
•операционной системы,
•среды и языка программирования,
•реализуемых процессов,
•природы и специфики различных ошибок,
•методик отладки и соответствующих программных средств.
Отладка — это процесс локализации и исправления ошибок, обнаруженных при тестировании программного обеспечения. Локализацией называют процесс определения оператора программы, выполнение которого вызвало нарушение нормального вычислительного процесса. Доя исправления ошибки необходимо определить ее причину, т. е. определить оператор или фрагмент, содержащие ошибку. Причины ошибок могут быть как очевидны, так и очень глубоко скрыты.
Вцелом сложность отладки обусловлена следующими причинами:
•требует от программиста глубоких знаний специфики управления используемыми техническими средствами, операционной системы, среды и языка программирования, реализуемых процессов, природы и специфики различных ошибок, методик отладки и соответствующих программных средств;
•психологически дискомфортна, так как необходимо искать собственные ошибки и, как правило, в условиях ограниченного времени;
•возможно взаимовлияние ошибок в разных частях программы, например, за счет затирания области памяти одного модуля другим из-за ошибок адресации;
•отсутствуют четко сформулированные методики отладки.
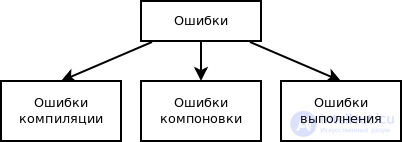
Всоответствии с этапом обработки, на котором проявляются ошибки, различают (рис. 10.1):
синтаксические ошибки — ошибки, фиксируемые компилятором (транслятором, интерпретатором) при выполнении синтаксического и частично семантического анализа программы; ошибки компоновки — ошибки, обнаруженные компоновщиком (редактором связей) при объединении модулей программы;
ошибки выполнения — ошибки, обнаруженные операционной системой, аппаратными средствами или пользователем при выполнении программы.
Синтаксические ошибки. Синтаксические ошибки относят к группе самых простых, так как синтаксис языка, как правило, строго формализован, и ошибки сопровождаются развернутым комментарием с указанием ее местоположения. Определение причин таких ошибок, как правило, труда не составляет, и даже при нечетком знании правил языка за несколько прогонов удается удалить все ошибки данного типа.
Следует иметь в виду, что чем лучше формализованы правила синтаксиса языка, тем больше ошибок из общего количества может обнаружить компилятор и, соответственно, меньше ошибок будет обнаруживаться на следующих этапах. В связи с этим говорят о языках программирования с защищенным синтаксисом и с незащищенным синтаксисом. К первым, безусловно, можно отнести Pascal, имеющий очень простой и четко определенный синтаксис, хорошо проверяемый при компиляции программы, ко вторым — Си со всеми его модификациями. Чего стоит хотя бы возможность выполнения присваивания в условном операторе в Си, например:
if (c = n) x = 0; /* в данном случае не проверятся равенство с и n, а выполняется присваивание с значения n, после чего результат операции сравнивается с нулем, если программист хотел выполнить не присваивание, а сравнение, то эта ошибка будет обнаружена только на этапе выполнения при получении результатов, отличающихся от ожидаемых */
Ошибки компоновки. Ошибки компоновки, как следует из названия, связаны с проблемами,
обнаруженными при разрешении внешних ссылок. Например, предусмотрено обращение к подпрограмме другого модуля, а при объединении модулей данная подпрограмма не найдена или не стыкуются списки параметров. В большинстве случаев ошибки такого рода также удается быстро локализовать и устранить.
Ошибки выполнения. К самой непредсказуемой группе относятся ошибки выполнения. Прежде всего они могут иметь разную природу, и соответственно по-разному проявляться. Часть ошибок обнаруживается и документируется операционной системой. Выделяют четыре способа проявления таких ошибок:
• появление сообщения об ошибке, зафиксированной схемами контроля выполнения машинных команд, например, переполнении разрядной сетки, ситуации «деление на ноль», нарушении адресации и т. п.;
•появление сообщения об ошибке, обнаруженной операционной системой, например, нарушении защиты памяти, попытке записи на устройства, защищенные от записи, отсутствии файла с заданным именем и т. п.;
•«зависание» компьютера, как простое, когда удается завершить программу без перезагрузки операционной системы, так и «тяжелое», когда для продолжения работы необходима перезагрузка;
•несовпадение полученных результатов с ожидаемыми.
Примечание. Отметим, что, если ошибки этапа выполнения обнаруживает пользователь, то в двух первых случаях, получив соответствующее сообщение, пользователь в зависимости от своего характера, степени необходимости и опыта работы за компьютером, либо попробует понять, что произошло, ища свою вину, либо обратится за помощью, либо постарается никогда больше не иметь дела с этим продуктом. При «зависании» компьютера пользователь может даже не сразу понять, что происходит что-то не то, хотя его печальный опыт и заставляет волноваться каждый раз, когда компьютер не выдает быстрой реакции на введенную команду, что также целесообразно иметь в виду. Также опасны могут быть ситуации, при которых пользователь получает неправильные результаты и использует их в своей работе.
Причины ошибок выполнения очень разнообразны, а потому и локализация может оказаться крайне сложной. Все возможные причины ошибок можно разделить на следующие группы:
•неверное определение исходных данных,
•логические ошибки,
•накопление погрешностей результатов вычислений (рис. 10.2).
Н е в е р н о е о п р е д е л е н и е и с х о д н ы х д а н н ы х происходит, если возникают любые ошибки при выполнении операций ввода-вывода: ошибки передачи, ошибки преобразования, ошибки перезаписи и ошибки данных. Причем использование специальных технических средств и программирование с защитой от ошибок (см.§ 2.7) позволяет обнаружить и предотвратить только часть этих ошибок, о чем безусловно не следует забывать.
Л о г и ч е с к и е о ш и б к и имеют разную природу. Так они могут следовать из ошибок, допущенных при проектировании, например, при выборе методов, разработке алгоритмов или определении структуры классов, а могут быть непосредственно внесены при кодировании модуля.
Кпоследней группе относят:
ошибки некорректного использования переменных, например, неудачный выбор типов данных, использование переменных до их инициализации, использование индексов, выходящих за границы определения массивов, нарушения соответствия типов данных при использовании явного или неявного переопределения типа данных, расположенных в памяти при использовании нетипизированных переменных, открытых массивов, объединений, динамической памяти, адресной арифметики и т. п.;
ошибки вычислений, например, некорректные вычисления над неарифметическими переменными, некорректное использование целочисленной арифметики, некорректное преобразование типов данных в процессе вычислений, ошибки, связанные с незнанием приоритетов выполнения операций для арифметических и логических выражений, и т. п.;
ошибки межмодульного интерфейса, например, игнорирование системных соглашений, нарушение типов и последовательности при передачи параметров, несоблюдение единства единиц измерения формальных и фактических параметров, нарушение области действия локальных и глобальных переменных;
другие ошибки кодирования, например, неправильная реализация логики программы при кодировании, игнорирование особенностей или ограничений конкретного языка программирования.
На к о п л е н и е п о г р е ш н о с т е й результатов числовых вычислений возникает, например, при некорректном отбрасывании дробных цифр чисел, некорректном использовании приближенных методов вычислений, игнорировании ограничения разрядной сетки представления вещественных чисел в ЭВМ и т. п.
Все указанные выше причины возникновения ошибок следует иметь в виду в процессе отладки. Кроме того, сложность отладки увеличивается также вследствие влияния следующих факторов:
опосредованного проявления ошибок;
возможности взаимовлияния ошибок;
возможности получения внешне одинаковых проявлений разных ошибок;
отсутствия повторяемости проявлений некоторых ошибок от запуска к запуску – так называемые стохастические ошибки;
возможности устранения внешних проявлений ошибок в исследуемой ситуации при внесении некоторых изменений в программу, например, при включении в программу диагностических фрагментов может аннулироваться или измениться внешнее проявление ошибок;
написания отдельных частей программы разными программистами.
Методы отладки программного обеспечения
Отладка программы в любом случае предполагает обдумывание и логическое осмысление всей имеющейся информации об ошибке. Большинство ошибок можно обнаружить по косвенным признакам посредством тщательного анализа текстов программ и результатов тестирования без получения дополнительной информации. При этом используют различные методы:
ручного тестирования;
индукции;
дедукции;
обратного прослеживания.
Метод ручного тестирования. Это — самый простой и естественный способ данной группы. При обнаружении ошибки необходимо выполнить тестируемую программу вручную, используя тестовый набор, при работе с которым была обнаружена ошибка.
Метод очень эффективен, но не применим для больших программ, программ со сложными вычислениями и в тех случаях, когда ошибка связана с неверным представлением программиста о выполнении некоторых операций.
Данный метод часто используют как составную часть других методов отладки.
Метод индукции. Метод основан на тщательном анализе симптомов ошибки, которые могут проявляться как неверные результаты вычислений или как сообщение об ошибке. Если компьютер просто «зависает», то фрагмент проявления ошибки вычисляют, исходя из последних полученных результатов и действий пользователя. Полученную таким образом информацию организуют и тщательно изучают, просматривая соответствующий фрагмент программы. В результате этих действий выдвигают гипотезы об ошибках, каждую из которых проверяют. Если гипотеза верна, то детализируют информацию об ошибке, иначе — выдвигают другую гипотезу. Последовательность выполнения отладки методом индукции показана на рис. 10.3 в виде схемы алгоритма.
Самый ответственный этап — выявление симптомов ошибки. Организуя данные об ошибке, целесообразно записать все, что известно о ее проявлениях, причем фиксируют, как ситуации, в которых фрагмент с ошибкой выполняется нормально, так и ситуации, в которых ошибка проявляется. Если в результате изучения данных никаких гипотез не появляется, то необходима дополнительная информация об ошибке. Дополнительную информацию можно получить, например, в результате выполнения схожих тестов.
В процессе доказательства пытаются выяснить, все ли проявления ошибки объясняет данная гипотеза, если не все, то либо гипотеза не верна, либо ошибок несколько.
Метод дедукции. По методу дедукции вначале формируют множество причин, которые могли бы вызвать данное проявление ошибки. Затем анализируя причины, исключают те, которые противоречат имеющимся данным. Если все причины исключены, то следует выполнить дополнительное тестирование исследуемого фрагмента. В противном случае наиболее вероятную гипотезу пытаются доказать. Если гипотеза объясняет полученные признаки ошибки, то ошибка найдена, иначе — проверяют следующую причину (рис. 10.4).
Метод обратного прослеживания. Для небольших программ эффективно применение метода обратного прослеживания. Начинают с точки вывода неправильного результата. Для этой точки строится гипотеза о значениях основных переменных, которые могли бы привести к получению имеющегося результата. Далее, исходя из этой гипотезы, делают предложения о значениях переменных в предыдущей точке. Процесс продолжают, пока не обнаружат причину ошибки.
Отладка, или debugging, — это поиск (локализация), анализ и устранение ошибок в программном обеспечении, которые были найдены во время тестирования.
Виды ошибок
Ошибки компиляции
Это простые ошибки, которые в компилируемых языках программирования выявляет компилятор (программа, которая преобразует текст на языке программирования в набор машинных кодов). Если компилятор показывает несколько ошибок, отладку кода начинают с исправления самой первой, так как она может быть причиной других.
В интерпретируемых языках (например Python) текст программы команда за командой переводится в машинный код и сразу исполняется. К моменту обнаружения ошибки часть программы уже может исполниться.
Ошибки компоновки
Ошибки связаны с разрешением внешних ссылок. Выявляет компоновщик (редактор связей) при объединении модулей программы. Простой пример — ситуация, когда требуется обращение к подпрограмме другого модуля, но при компоновке она не найдена. Ошибки также просто найти и устранить.
Ошибки выполнения (RUNTIME Error)
Ошибки, которые обнаруживают операционная система, аппаратные средства или пользователи при выполнении программы. Они считаются непредсказуемыми и проявляются после успешной компиляции и компоновки. Можно выделить четыре вида проявления таких ошибок:
- сообщение об ошибке, которую зафиксировали схемы контроля машинных команд. Это может быть переполнение разрядной сетки (когда старшие разряды результата операции не помещаются в выделенной области памяти), «деление на ноль», нарушение адресации и другие;
- сообщение об ошибке, которую зафиксировала операционная система. Она же, как правило, и документирует ошибку. Это нарушение защиты памяти, отсутствие файла с заданным именем, попытка записи на устройство, защищенное от записи;
- прекращение работы компьютера или зависание. Это и простые ошибки, которые не требуют перезагрузки компьютера, и более сложные, когда нужно выключать ПК;
- получение результатов, которые отличаются от ожидаемых. Программа работает стабильно, но выдает некорректный результат, который пользователь воспринимает за истину.
Ошибки выполнения можно разделить на три большие группы.
Ошибки определения данных или неверное определение исходных данных. Они могут появиться во время выполнения операций ввода-вывода.
К ним относятся:
- ошибки преобразования;
- ошибки данных;
- ошибки перезаписи.
Как правило, использование специальных технических средств для отладки (API-логгеров, логов операционной системы, профилировщиков и пр.) и программирование с защитой от ошибок помогает обнаружить и решить лишь часть из них.
Логические ошибки. Они могут возникать из ошибок, которые были допущены при выборе методов, разработке алгоритмов, определении структуры данных, кодировании модуля.
В эту группу входят:
- ошибки некорректного использования переменных. Сюда относятся неправильный выбор типов данных, использование индексов, выходящих за пределы определения массивов, использование переменных до присвоения переменной начального значения, нарушения соответствия типов данных;
- ошибки вычислений. Это некорректная работа с переменными, неправильное преобразование типов данных в процессе вычислений;
- ошибки взаимодействия модулей или межмодульного интерфейса. Это нарушение типов и последовательности при передаче параметров, области действия локальных и глобальных переменных, несоблюдение единства единиц измерения формальных и фактических параметров;
- неправильная реализация логики при программировании.
Ошибки накопления погрешностей. Могут возникать при неправильном округлении, игнорировании ограничений разрядной сетки, использовании приближенных методов вычислений и т.д.
Методы отладки программного обеспечения
Метод ручного тестирования
Отладка программы заключается в тестировании вручную с помощью тестового набора, при работе с которым была допущена ошибка. Несмотря на эффективность, метод не получится использовать для больших программ или программ со сложными вычислениями. Ручное тестирование применяется как составная часть других методов отладки.
Метод индукции
В основе отладки системы — тщательный анализ проявлений ошибки. Это могут быть сообщения об ошибке или неверные результаты вычислений. Например, если во время выполнения программы завис компьютер, то, чтобы найти фрагмент проявления ошибки, нужно проанализировать последние действия пользователя. На этапе отладки программы строятся гипотезы, каждая из них проверяется. Если гипотеза подтвердилась, информация об ошибке детализируется, если нет — выдвигаются новые.
Вот как выглядит процесс:
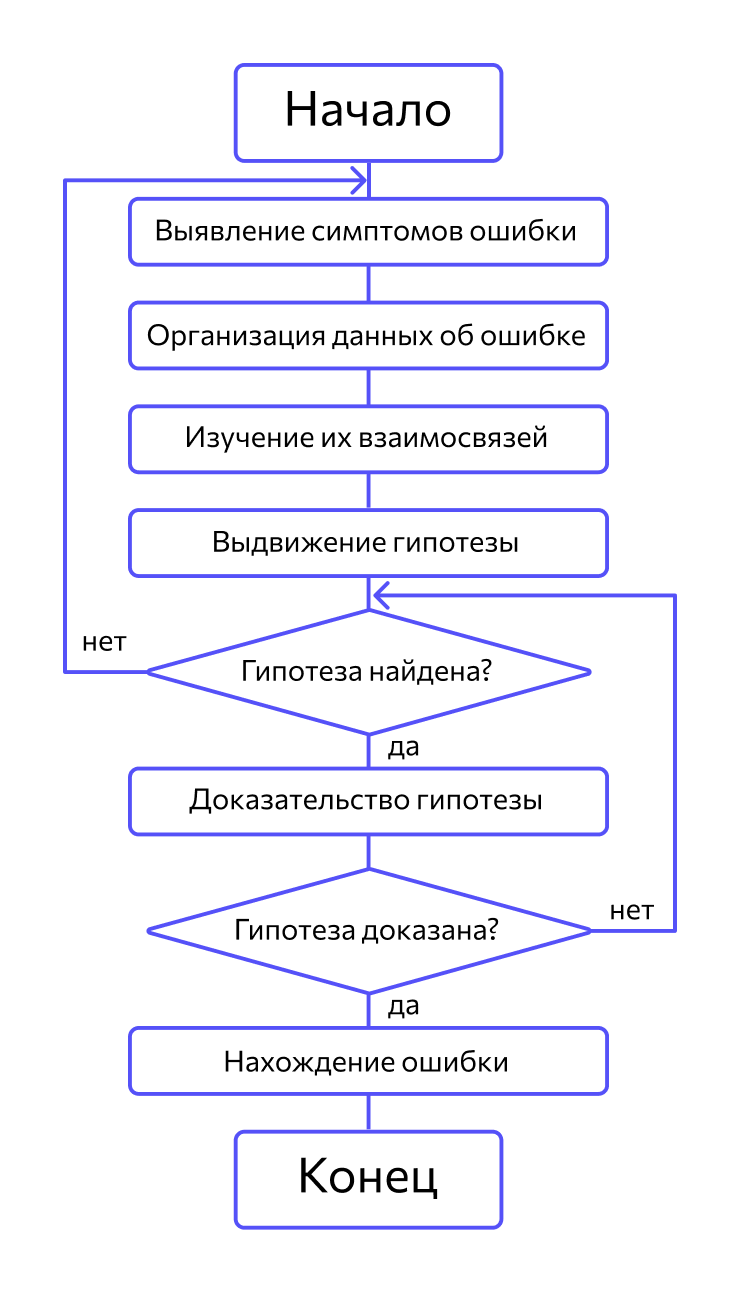
Важно, чтобы выдвинутая гипотеза объясняла все проявления ошибки. Если объясняется только их часть, то либо гипотеза неверна, либо ошибок несколько.
Метод дедукции
Сначала специалисты предлагают множество причин, по которым могла возникнуть ошибка. Затем анализируют их, исключают противоречащие имеющимся данным. Если все причины были исключены, проводят дополнительное тестирование. В обратном случае наиболее вероятную причину пытаются доказать.
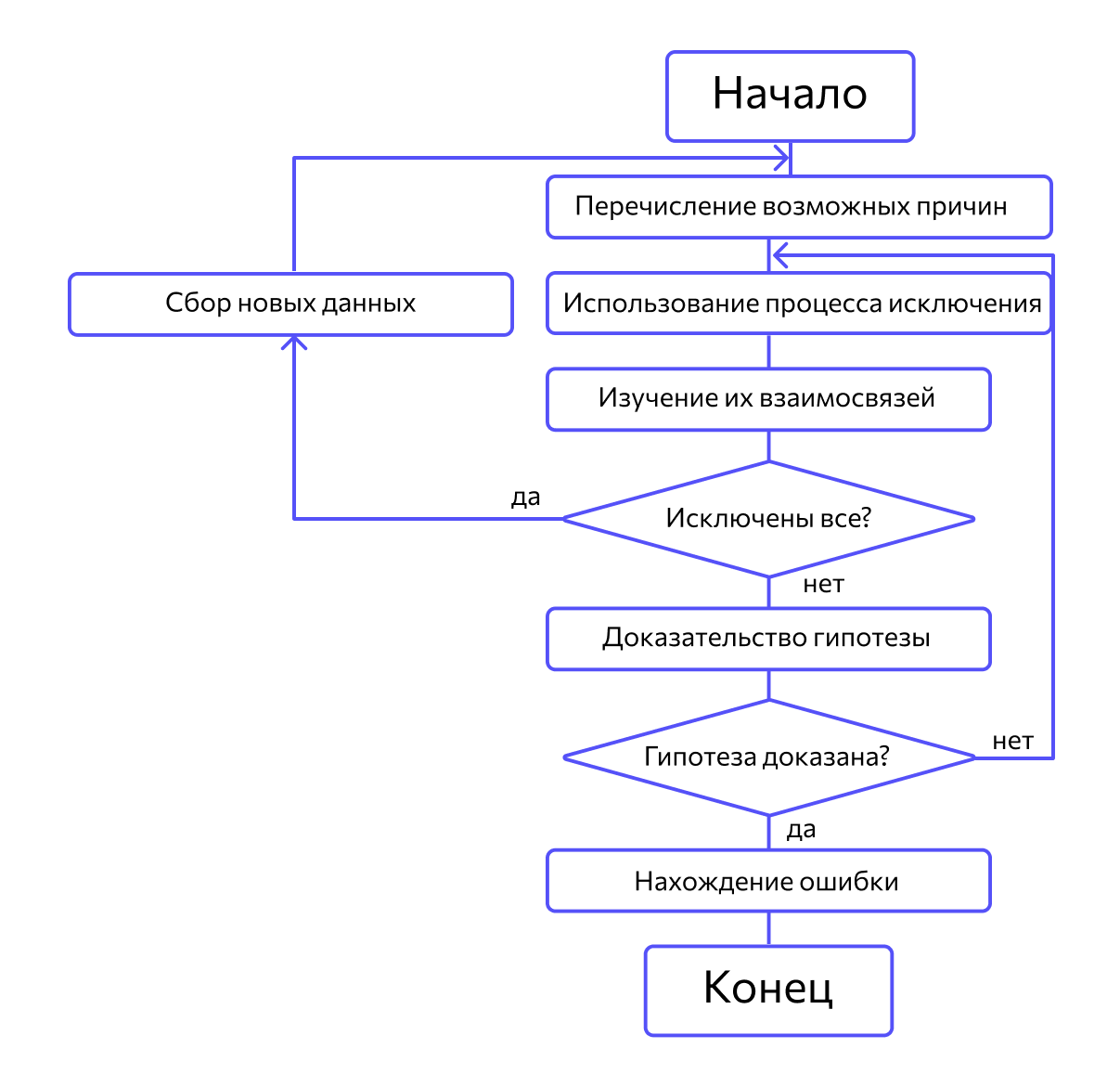
Метод обратного прослеживания
Эффективен для небольших программ. Начинается с точки вывода неправильного результата. Для точки выдвигается гипотеза о значениях основных переменных, которые могли привести к ошибке. Далее на основании этой гипотезы строятся предположения о значениях переменных в предыдущей точке. Процесс продолжается до момента, пока не найдут ошибку.
Как выполняется отладка в современных IDE
Ранние отладчики, например gdb, представляли собой отдельные программы с интерфейсами командной строки. Более поздние, например первые версии Turbo Debugger, были автономными, но имели собственный графический интерфейс для облегчения работы. Сейчас большинство IDE имеют встроенный отладчик. Он использует такой же интерфейс, как и редактор кода, поэтому можно выполнять отладку в той же среде, которая используется для написания кода.
Отладчик позволяет разработчику контролировать выполнение и проверять (или изменять) состояние программ. Например, можно использовать отладчик для построчного выполнения программы, проверяя по ходу значения переменных. Сравнение фактических и ожидаемых значений переменных или наблюдение за ходом выполнения кода может помочь в отслеживании логических (семантических) ошибок.
Пошаговое выполнение — это набор связанных функций отладчика, позволяющих поэтапно выполнять код.
Шаг с заходом (step into)
Команда выполняет очередную инструкцию, а потом приостанавливает процесс, чтобы с помощью отладчика было можно проверить состояние программы. Если в выполняемом операторе есть вызов функции, step into заставляет программу переходить в начало вызываемой функции, где она приостанавливается.
Шаг с обходом (step over)
Команда также выполняет очередную инструкцию. Однако когда step into будет входить в вызовы функций и выполнять их строка за строкой, step over выполнит всю функцию, не останавливаясь, и вернет управление после ее выполнения. Команда step over позволяет пропустить функции, если разработчик уверен, что они уже исправлены, или не заинтересован в их отладке в данный момент.
Шаг с выходом (step out)
В отличие от step into и step over, step out выполняет не следующую строку кода, а весь оставшийся код функции, исполняемой в настоящее время. После возврата из функции он возвращает управление разработчику. Эта команда полезна, когда специалист случайно вошел в функцию, которую не нужно отлаживать.
Как правило, при пошаговом выполнении можно идти только вперед. Поэтому легко перешагнуть место, которое нужно проверить. Если это произошло, необходимо перезапустить отладку.
У некоторых отладчиков (таких как GDB 7.0, Visual Studio Enterprise Edition 15.5 и более поздних версий) есть возможность вернуться на шаг назад. Это полезно, если пропущена цель либо нужно повторно проверить выполненную инструкцию.
Привет, Вы узнаете про виды ошибок программного обеспечения, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
виды ошибок программного обеспечения, принципы отладки, ошибки в программировании , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance..
1. Отладка программы
Отладка, как мы уже говорили, бывает двух видов:
Синтаксическая отладка. Синтаксические ошибки выявляет компилятор, поэтому исправлять их достаточно легко.
Семантическая (смысловая) отладка. Ее время наступает тогда, когда синтаксических ошибок не осталось, но результаты программа выдает неверные. Здесь компилятор сам ничего выявить не сможет, хотя в среде программирования обычно существуют вспомогательные средства отладки, о которых мы еще поговорим.
Отладка — это процесс локализации и исправления ошибок в программе.
Как бы тщательно мы ни писали, отладка почти всегда занимает больше времени, чем программирование.
2. Локализация ошибок в программировании
Локализация — это нахождение места ошибки в программе.
В процессе поиска ошибки мы обычно выполняем одни и те же действия:
- прогоняем программу и получаем результаты;
- сверяем результаты с эталонными и анализируем несоответствие;
- выявляем наличие ошибки, выдвигаем гипотезу о ее характере и месте в программе;
- проверяем текст программы, исправляем ошибку, если мы нашли ее правильно.
Способы обнаружения ошибки:
- Аналитический — имея достаточное представление о структуре программы, просматриваем ее текст вручную, без прогона.
- Экспериментальный — прогоняем программу, используя отладочную печать и средства трассировки, и анализируем результаты ее работы.
Оба способа по-своему удобны и обычно используются совместно.
3.
принципы отладки кода в програмировании
Принципы локализации ошибок:
- Большинство ошибок обнаруживается вообще без запуска программы — просто внимательным просматриванием текста.
- Если отладка зашла в тупик и обнаружить ошибку не удается, лучше отложить программу. Когда глаз «замылен», эффективность работы упорно стремится к нулю.
- Чрезвычайно удобные вспомогательные средства — это отладочные механизмы среды разработки: трассировка, промежуточный контроль значений. Можно использовать даже дамп памяти, но такие радикальные действия нужны крайне редко.
- Экспериментирования типа «а что будет, если изменить плюс на минус» — нужно избегать всеми силами. Обычно это не дает результатов, а только больше запутывает процесс отладки, да еще и добавляет новые ошибки.
Принципы исправления ошибок еще больше похожи на законы Мерфи:
- Там, где найдена одна ошибка, возможно, есть и другие.
- Вероятность, что ошибка найдена правильно, никогда не равна ста процентам.
- Наша задача — найти саму ошибку, а не ее симптом.
Это утверждение хочется пояснить. Если программа упорно выдает результат 0,1 вместо эталонного нуля, простым округлением вопрос не решить. Если результат получается отрицательным вместо эталонного положительного, бесполезно брать его по модулю — мы получим вместо решения задачи ерунду с подгонкой.
Исправляя одну ошибку, очень легко внести в программу еще парочку. «Наведенные» ошибки — настоящий бич отладки.
Исправление ошибок зачастую вынуждает нас возвращаться на этап составления программы. Это неприятно, но порой неизбежно.
4. Методы отладки программного кода
Силовые методы
- — Использование дампа (распечатки) памяти.Это интересно с познавательной точки зрения: можно досконально разобраться в машинных процессах. Иногда такой подход даже необходим — например, когда речь идет о выделении и высвобождении памяти под динамические переменные с использованием недокументированных возможностей языка. Однако, в большинстве случаев мы получаем огромное количество низкоуровневой информации, разбираться с которой — не пожелаешь и врагу, а результативность поиска — исчезающе низка.
- — Использование отладочной печати в тексте программы — произвольно и в большом количестве.Получать информацию о выполнении каждого оператора тоже небезынтересно. Но здесь мы снова сталкиваемся со слишком большими объемами информации. Кроме того, мы здорово захламляем программу добавочными операторами, получая малочитабельный текст, да еще рискуем внести десяток новых ошибок.
- — Использование автоматических средств отладки — трассировки с отслеживанием промежуточных значений переменых.Пожалуй, это самый распространенный способ отладки. Не нужно только забывать, что это только один из способов, и применять всегда и везде только его — часто невыгодно.
Сложности возникают, когда приходится отслеживать слишком большие структуры данных или огромное их число. Еще проблематичнее трассировать проект, где выполнение каждой подпрограммы приводит к вызову пары десятков других. Но для небольших программ трассировки вполне достаточно.
С точки зрения «правильного» программирования силовые методы плохи тем, что не поощряют анализ задачи.
Суммируя свойства силовых методов, получаем практические советы:
— использовать трассировку и отслеживание значений переменных для небольших проектов, отдельных подпрограмм;
— использовать отладочную печать в небольших количества и «по делу»;
— оставить дамп памяти на самый крайний случай.
Метод индукции — анализ программы от частного к общему.
Просматриваем симптомы ошибки и определяем данные, которые имеют к ней хоть какое-то отношение. Затем, используя тесты, исключаем маловероятные гипотезы, пока не остается одна, которую мы пытаемся уточнить и доказать.
Метод дедукции — от общего к частному.
Выдвигаем гипотезу, которая может объяснить ошибку, пусть и не полностью. Затем при помощи тестов эта гипотеза проверяется и доказывается.
Обратное движение по алгоритму.
Отладка начинается там, где впервые встретился неправильный результат. Затем работа программы прослеживается (мысленно или при помощи тестов) в обратном порядке, пока не будет обнаружено место возможной ошибки.
Метод тестирования.
Давайте рассмотрим процесс локализации ошибки на конкретном примере. Пусть дана небольшая программа, которая выдает значение максимального из трех введенных пользователем чисел.
var
a, b, c: real;
begin
writeln('Программа находит значение максимального из трех введенных чисел');
write('Введите первое число '); readln(a);
write('Введите второе число '); readln(b);
write('Введите третье число '); readln(c);
if (a>b)and(a>c) then
writeln('Наибольшим оказалось первое число ',a:8:2)
else if (b>a)and(a>c) then
writeln('Наибольшим оказалось второе число ',b:8:2)
else
writeln('Наибольшим оказалось третье число ',b:8:2);
end.
Обе выделенные ошибки можно обнаружить невооруженным глазом: первая явно допущена по невнимательности, вторая — из-за того, что скопированную строку не исправили.
Тестовые наборы данных должны учитывать все варианты решения, поэтому выберем следующие наборы чисел:
Данные Ожидаемый результат
a=10; b=-4; c=1 max=a=10
a=-2; b=8; c=4 max=b=8
a=90; b=0; c=90.4 max=c=90.4
В результате выполнения программы мы, однако, получим следующие результаты:
Для a=10; b=-4; c=1:
Наибольшим оказалось первое число 10.00
Для a=-2; b=8; c=4: < pre class=»list»>Наибольшим оказалось третье число 8.00Для a=90; b=0; c=90.4:
Наибольшим оказалось третье число 0.00
Вывод во втором и третьем случаях явно неверен. Будем разбираться.
1. Трассировка и промежуточная наблюдение за переменными
Добавляем промежуточную печать или наблюдение за переменными:
- — вывод a, b, c после ввода (проверяем, правильно ли получили данные)
- — вывод значения каждого из условий (проверяем, правильно ли записали условия)
Листинг программы существенно увеличился и стал вот таким:
var
a, b, c: real;
begin
writeln(‘Программа находит значение максимального из трех введенных чисел’);
write(‘Введите первое число ‘); readln(a);
writeln(‘Вы ввели число ‘,a:8:2); {отл.печать}
write(‘Введите второе число ‘); readln(b);
writeln(‘Вы ввели число ‘,b:8:2); {отл.печать}
write(‘Введите третье число ‘); readln(c);
writeln(‘Вы ввели число ‘,c:8:2); {отл.печать}
writeln(‘a>b=’,a>b,’, a>c=’,a>c,’, (a>b)and(a>c)=’,(a>b)and(a>c)); {отл.печать}
if (a>b)and(a>c) then
writeln(‘Наибольшим оказалось первое число ‘,a:8:2)
else begin
writeln(‘b>a=’,b>a,’, b>c=’,b>c,’, (b>a)and(b>c)=’,(b>a)and(b>c)); {отл.печать}
if (b>a)and(a>c) then
writeln(‘Наибольшим оказалось второе число ‘,b:8:2)
else
writeln(‘Наибольшим оказалось третье число ‘,b:8:2);
end;
end.
В принципе, еще при наборе у нас неплохой шанс отловить ошибку в условии: подобные кусочки кода обычно не перебиваются, а копируются, и если дать себе труд слегка при этом задуматься, ошибку найти легко.
Но давайте считать, что глаз «замылен» совершенно, и найти ошибку не удалось.
Вывод для второго случая получается следующим:
Программа находит значение максимального из трех введенных чисел
Введите первое число -2
Вы ввели число -2.00
Введите второе число 8
Вы ввели число 8.00
Введите третье число 4
Вы ввели число 4.00
a>b=FALSE, a>c=FALSE, (a>b)and(a>c)=FALSE
b>a=TRUE, b>c=TRUE, (b>a)and(b>c)=TRUE
Наибольшим оказалось третье число 8.00
Со вводом все в порядке. Об этом говорит сайт https://intellect.icu . Впрочем, в этом сомнений и так было немного. А вот что касается второй группы операторов печати, то картина вышла интересная: в результате выводится верное число (8.00), но неправильное слово («третье», а не «второе»).
Вероятно, проблемы в выводе результатов. Тщательно проверяем текст и обнаруживаем, что действительно в последнем случае выводится не c, а b. Однако к решению текущей проблемы это не относится: исправив ошибку, мы получаем для чисел -2.0, 8.0, 4.0 следующий результат.
Наибольшим оказалось третье число 4.00
Теперь ошибка локализована до расчетного блока и, после некоторых усилий, мы ее находим и исправляем.
2. Метод индукции в выявлении ошибок в пограммировании
Судя по результатам, ошибка возникает, когда максимальное число — второе или третье (если максимальное — первое, то определяется оно правильно, для доказательства можно програть еще два-три теста).
Просматриваем все, относящееся к переменным b и с. Со вводом никаких проблем не замечено, а что касается вывода — то мы быстро натыкаемся на замену b на с. Исправляем.
Как видно, невыявленные ошибки в программе остаются. Просматриваем расчетный блок: все, что относится к максимальному b (максимум с получается «в противном случае»), и обнаруживаем пресловутую проблему «a>c» вместо «b>c». Программа отлажена.
3. Метод дедукции использемый при выявлении ошибок
Неверные результаты в нашем случае могут получиться из-за ошибки в:
- — вводе данных;
- — расчетном блоке;
- — собственно выводе.
Для доказательства мы можем пользоваться отладочной печатью, трассировкой или просто набором тестов. В любом случае мы выявляем одну ошибку в расчете и одну в выводе.
4. Обратное движение по алгоритму
Зная, что ошибка возникает при выводе результатов, рассматриваем код, начиная с операторов вывода. Сразу же находим лишнюю b в операторе writeln.
Далее, смотрим по конкретной ветке условного оператора, откуда взялся результат. Для значений -2.0, 8.0, 4.0 расчет идет по ветке с условием if (b>a)and(a>c) then… где мы тут же обнаруживаем искомую ошибку.
5. Тестирование
В нашей задаче для самого полного набора данных нужно выбрать такие переменные, что
a > b > c
a > c > b
b > a > c
b > c > a
c > a > b
c > b > a
Анализируя получившиеся в каждом из этих случаев результаты, мы приходим к тому, что проблемы возникают при b>c>a и с — максимальном. Зная эти подробности, мы можем заострить внимание на конкретных участках программы.
Конечно, в реальной работе мы не расписываем так занудно каждый шаг, не прибегаем исключительно к одной методике, да и вообще частенько не задумываемся, каким образом искать ляпы. Теперь, когда мы разобрались со всеми подходами, каждый волен выбрать те из них, которые кажутся самыми удобными.
5. Средства отладки программного кода
Помимо методик, хорошо бы иметь представление о средствах, которые помогают нам выявлять ошибки. Это:
1) Аварийная печать — вывод сообщений о ненормальном завершении отдельных блоков и всей программы в целом.
2) Печать в узлах программы — вывод промежуточных значений параметров в местах, выбранных программистом. Обычно, это критичные участки алгоритма (например, значение, от которого зависит дальнейший ход выполнения) или составные части сложных формул (отдельно просчитать и вывести числитель и знаменатель большой дроби).
3) Непосредственное слежение:
- — арифметическое (за тем, чему равны, когда и как изменяются выбранные переменные),
- — логическое (когда и как выполняется выбранная последовательность операторов),
- — контроль выхода индексов за допустимые пределы,
- — отслеживание обращений к переменным,
- — отслеживание обращений к подпрограммам,
- — проверка значений индексов элементов массивов и т.д.
Нынешние среды разработки часто предлагают нам реагировать на возникающую проблему в диалоговом режиме. При этом можно:
- — просмотреть текущие значения переменных, состояние памяти, участок алгоритма, где произошел сбой;
- — прервать выполнение программы;
- — внести в программу изменения и повторно запустить ее (в компиляторных средах для этого потребуется перекомпилировать код, в интерпретаторных выполнение можно продолжить прямо с измененного оператора).
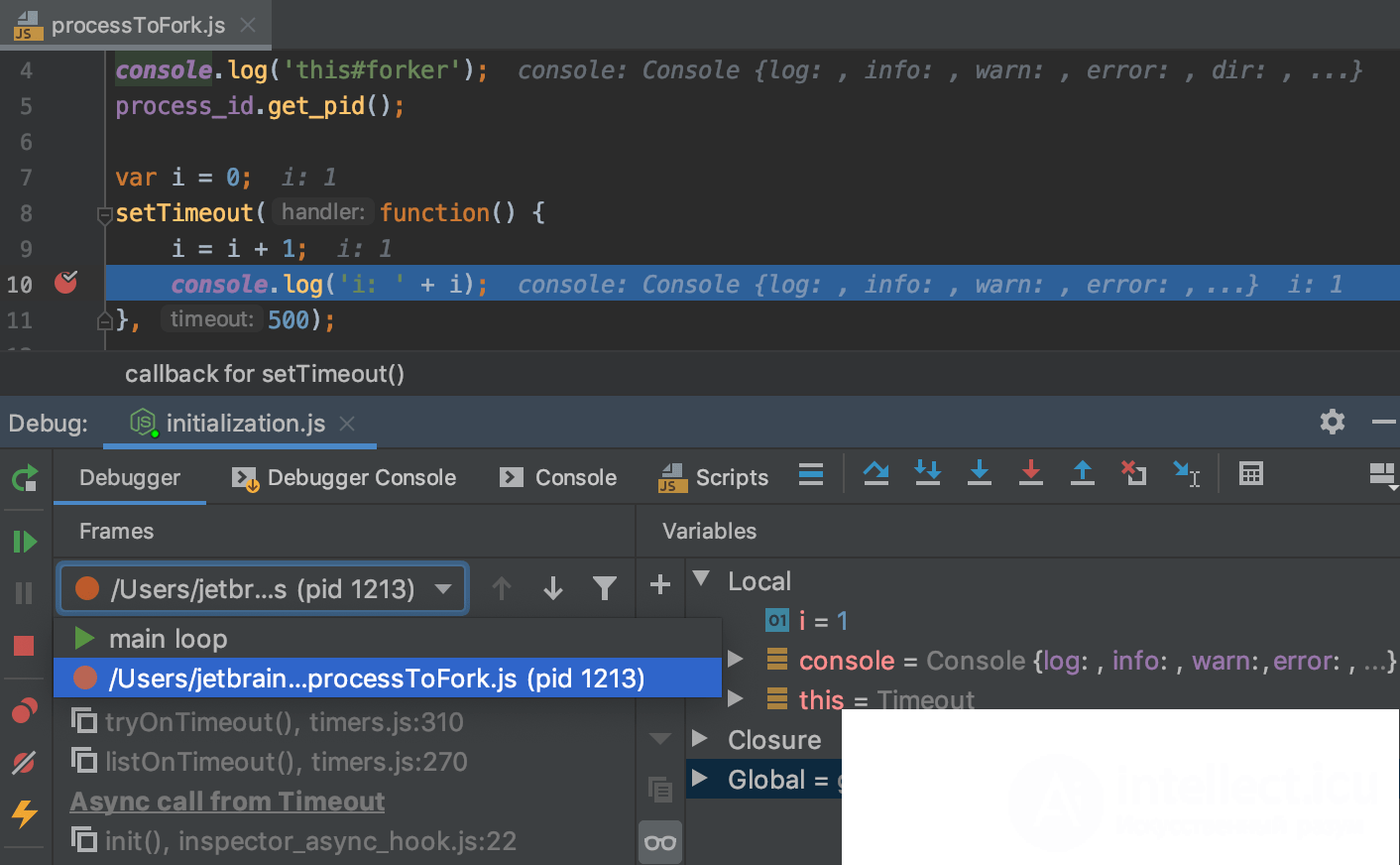 Рис Пример отладки приложения
Рис Пример отладки приложения
6. Классификация и виды ошибок в программировании
Ошибки в программах могут допускаться от самого начального этапа составления алгоритма решения задачи до окончательного оформления программы. Разновидностей ошибок достаточно много. Рассмотрим некоторые группы ошибок и соответствующие примеры:
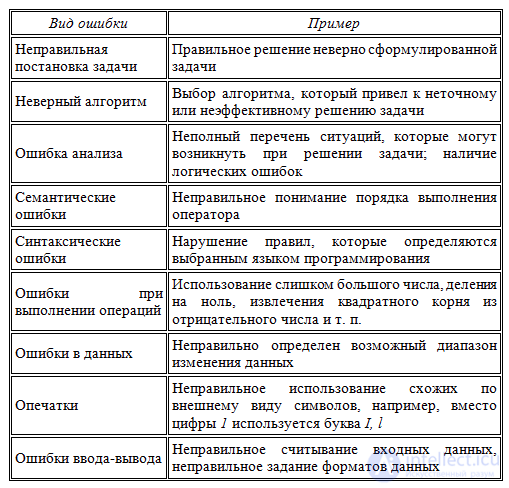
Если вы удручены тем, что насажали в текст программы глупых ошибок — не расстраивайтесь. Ошибки вообще не бывают умными, хотя и могут относиться к самым разным частям кода:
- — ошибки обращения к данным,
- — ошибки описания данных,
- — ошибки вычислений,
- — ошибки при сравнении,
- — ошибки в передаче управления,
- — ошибки ввода-вывода,
- — ошибки интерфейса,
- и т д
Классификация ошибок по этапу обработки программы
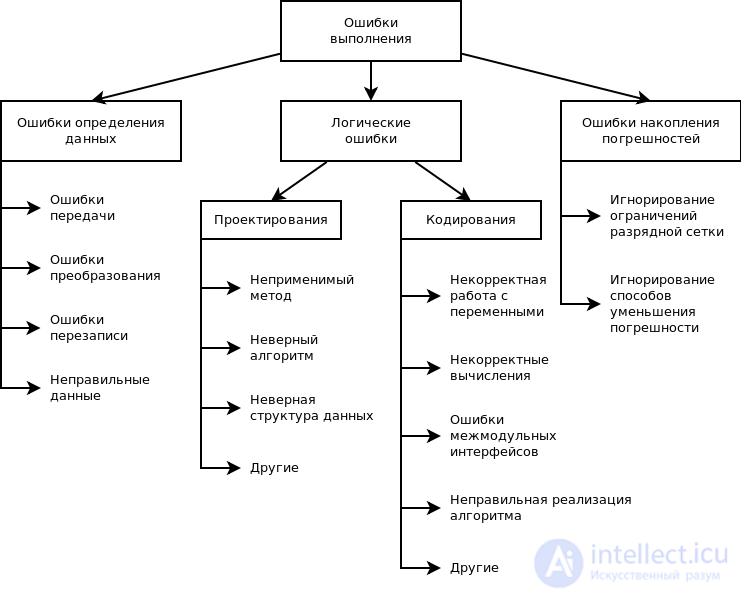
рис Классификация ошибок этапа выполнения по возможным причинам
Синтаксические ошибки
Синтаксические ошибки зачастую выявляют уже на этапе трансляции. К сожалению, многие ошибки других видов транслятор выявить не в силах, т.к. ему не известен задуманный или требуемый результат работы программы. Отсутствие сообщений транслятора о наличии синтаксических ошибок является необходимым условием правильности программы, но не может свидетельствовать о том, что она даст правильный результат.
Примеры синтаксических ошибок :
- отсутствие знака пунктуации;
- несоответствие количества открывающих и закрывающих скобок;
- неправильно сформированный оператор;
- неправильная запись имени переменной;
- ошибка в написании служебных слов;
- отсутствие условия окончания цикла;
- отсутствие описания массивов и т.п.
Ошибки, которые не обнаруживает транслятор
В случае правильного написания операторов в программе может присутствовать большое количество ошибок, которые транслятор не может обнаружить. Рассмотрим примеры таких ошибок:
Логические ошибки: после проверки заданного условия неправильно указана ветвь алгоритма; неполный перечень возможных условий при решении задачи; один или более блоков алгоритма в программе пропущен.
Ошибки в циклах: неправильно указано начало цикла; неправильно указаны условия окончания цикла; неправильно указано количество повторений цикла; использование бесконечного цикла.
Ошибки ввода-вывода; ошибки при работе с данными: неправильно задан тип данных; организовано считывание меньшего или большего объема данных, чем нужно; неправильно отредактированы данные.
Ошибки в использовании переменных: используются переменных, для которых не указаны начальные значения; ошибочно указана одна переменная вместо другой. Ошибки при работе с массивами: пропущено предварительное обнуление массивов; неправильное описание массивов; индексы массивов следуют в ошибочном порядке.
ошибки безопасности, умышленные и не умышленные уязвимости в системе, открытость к отказам в обслуживании. несанкционированном доступе. екхолы
Ошибки в арифметических операциях: неправильное использование типа переменной (например, для сохранения результата деления используется целочисленная переменная); неправильно определен порядок действий; выполняется деление на нуль; при расчете выполняется попытка извлечения квадратного корня из отрицательного числа; не учитываются значащие разряды числа.
ошибки в архитектуре приложения пприводящие к увеличени технического долга
Методы (пути) снижение ошибок в программировании
- использование тестиования
- использование более простых решений
- использование систем с наименьшим числом составлящих
- использование ранее использованных и проверенных компонентов
- использование более квалифицрованных специалистов
7. Советы отладчику
1) Проверяйте тщательнее: ошибка скорее всего находится не в том месте, в котором кажется.
2) Часто оказывается легче выделить те места программы, ошибок в которых нет, а затем уже искать в остальных.
3) Тщательнее следить за объявлениями констант, типов и переменных, входными данными.
4) При последовательной разработке приходится особенно аккуратно писать драйверы и заглушки — они сами могут быть источником ошибок.
5) Анализировать код, начиная с самых простых вариантов. Чаще всего встречаются ошибки:
— значения входных аргументов принимаются не в том порядке,
— переменная не проинициализирована,
— при повторном прохождении модуля, перемен ная повторно не инициализируется,
— вместо предполагаемого полного копирования структуры данных, копируется только верхний уровень (например, вместо создания новой динамической переменной и присваивания ей нужного значения, адрес тупо копируется из уже существующей переменной),
— скобки в сложном выражении расставлены неправильно.
6) При упорной длительной отладке глаз «замыливается». Хороший прием — обратиться за помощью к другому лицу, чтобы не повторять ошибочных рассуждений. Правда, частенько остается проблемой убедить это другое лицо помочь вам.
7) Ошибка, скорее всего окажется вашей и будет находиться в тексте программы. Гораздо реже она оказывается:
- в компиляторе,
- операционной системе,
- аппаратной части,
- электропроводке в здании и т.д.
Но если вы совершенно уверены, что в программе ошибок нет, просмотрите стандартные модули, к которым она обращается, выясните, не менялась ли версия среды разработки, в конце концов, просто перегрузите компьютер — некоторые проблемы (особенно в DOS-средах, запускаемых из-под Windows) возникают из-за некорректной работы с памятью.
 Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
9) Навязчивый поиск одной ошибки почти всегда непродуктивен. Не получается — отложите задачу, возьмитесь за написание следующего модуля, на худой конец займитесь документированием.
10) Старайтесь не жалеть времени, чтобы уясненить причину ошибки. Это поможет вам:
исправить программу,
обнаружить другие ошибки того же типа,
не делать их в дальнейшем.
11) Если вы уже знаете симптомы ошибки, иногда полезно не исправлять ее сразу, а на фоне известного поведения программы поискать другие ляпы.
12) Самые труднообнаруживаемые ошибки — наведенные, то есть те, что были внесены в код при исправлении других.
8. Тестирование
Тестирование — это выполнение программы для набора проверочных входных значений и сравнение полученных результатов с ожидаемыми.
Цель тестирования — проверка и доказательство правильности работы программы. В противном случае — выявление того, что в ней есть ошибки. Тестирование само не показывает местонахождение ошибки и не указывает на ее причины.
Принципы тестирования.
1) Тест — просчитанный вручную пример выполнения программы от исходных данных до ожидаемых результатов расчета. Эти результаты считаются эталонными.
Полномаршрутным будет такое тестирование, при котором каждый линейный участок программы будет пройден хотя бы при выполнении одного теста.
2) При прогоне программы по тестовым начальным данным, полученные результаты нужно сверить с эталонными и проанализировать разницу, если она есть.
3) При разработке тестов нужно учитывать не только правильные, но и неверные исходные данные.
4) Мы должны проверить программу на нежелательные побочные эффекты при задании некоторых исходных данных (деление на ноль, попытка считывания из несуществующего файла и т.д.).
5) Тестирование нужно планировать: заранее выбрать, что мы контролируем и как это сделать лучше. Обычно тесты планируются на этапе алгоритмизации или выбора численного метода решения. Причем, составляя тесты, мы предполагаем, что ошибки в программе есть.
6) Чем больше ошибок в коде мы уже нашли, тем больше вероятность, что мы обнаружим еще не найденные.
Хорошим называют тест, который с большой вероятностью должен обнаруживать ошибки, а удачным — тот, который их обнаружил.
9. Проектирование тестов
Тесты просчитываются вручную, значит, они должны быть достаточно просты для этого.
Тесты должны проверять каждую ветку алгоритма. По возможности, конечно. Так что количество и сложность тестов зависит от сложности программы.
Тесты составляются до кодирования и отладки: во время разработки алгоритма или даже составления математической модели.
Обычно для экономии времени сначала пропускают более простые тесты, а затем более сложные.
Давайте рассмотрим задачу: нужно проверить, попадает ли введенное число в заданный пользователем диапазон.
program Example;
(******************************************************
* Задача: проверить, попадает ли введенное число в *
* заданный пользователем диапазон *
******************************************************)
var
min, max, A, tmp: real;
begin
writeln(‘Программа проверяет, попадают ли введенные пользователем’);
writeln(‘значения в заданный диапазон’);
writeln;
writeln(‘Введите нижнюю границу диапазона ‘); readln(min);
writeln(‘Введите верхнюю границу диапазона ‘); readln(max);
if min>max then begin
writeln(‘Вы перепутали диапазоны, и я их поменяю’);
tmp:=min;
min:=max;
max:=tmp;
end;
repeat
writeln(‘Введите число для проверки (0 — конец работы) ‘); readln(A);
if (A>=min)and(A<=max) then
writeln(‘Число ‘,A,’ попадает в диапазон [‘,min,’..’,max,’]’)
else
writeln(‘Число ‘,A,’ не попадает в диапазон [‘,min,’..’,max,’]’);
until A=0;
writeln;
end.
Если исходить из алгоритма программы, мы должны составить следующие тесты:
ввод границ диапазона
— min< max
— min>max
ввод числа
— A < min (A<>0)
— A > max (A<>0)
— min <= A <= max (A<>0)
— A=0
Как видите, программа очень мала, а тестов для проверки всех ветвей ее алгоритма, требуется довольно много.
10. Стратегии тестирования
1) Тестирование программы как «черного ящика».
Мы знаем только о том, что делает программа, но даже не задумываемся о ее внутренней структуре. Задаем набор входных данных, получаем результаты, сверяем с эталонными.
При этом обнаружить все ошибки мы можем только если составили тесты для всех возможных наборов данных. Естественно, это противоречит экономическим принципам, да и просто достаточно глупо.
«Черным ящиком» удобно тестировать небольшие подпрограммы.
2) Тестирование программы как «белого ящика».
Здесь перед составлением теста мы изучаем логику программы, ее внутреннюю структуру. Тестирование будет считаться удачным, если проверяет программу по всем направлениям. Однако, как мы уже говорили, это требует огромного количества тестов.
На практике мы, как всегда, совместно используем оба принципа.
3) Тестирование программ модульной структуры.
Мы снова возвращаемся к вопросу о структурном программировании. Если вы помните, программы строятся из модулей не в последнюю очередь для того, чтобы их легко было отлаживать и тестировать. Действительно, структурированную программу мы будем тестировать частями. При этом нам нужно:
строить набор тестов;
комбинировать модули для тестирования.
Такое комбинирование может строиться двумя способами:
Пошаговое тестирование — тестируем каждый модуль, присоединяя его к уже оттестированным. При этом можем соединять части программы сверху вниз (нисходящий способ) или снизу вверх (восходящий).
Монолитное тестирование — каждый модуль тестируется отдельно, а затем из них формируется готовая рабочая программа и тестируется уже целиком.
Чтобы протестировать отдельный модуль, нужен модуль-драйвер (всегда один) и модул и-заглушки (этих может быть несколько).
Модуль-драйвер содержит фиксированные исходные данные. Он вызывает тестируемый модуль и отображает (а возможно, и анализирует) результаты.
Модуль-заглушка нужен, если в тестируемом модуле есть вызовы других. Вместо этого вызова управление передается модулю-заглушке, и уже он имитирует необходимые действия.
К сожалению, мы опять сталкиваемся с тем, что драйверы и заглушки сами могут оказаться источником ошибок. Поэтому создаваться они должны с большой осторожностью.
Вау!! 😲 Ты еще не читал? Это зря!
- ошибки в приложениях , bugs ,
- основы qa , тестовые артефакты ,
- метрики по обеспечению качества , метрики тестирования ,
- баг , ошибки в программировании ,
- причины появления ошибок , ошибки ,
- try-catch , исключения ,
- Фича
- GIGO
- Патч
- тестирование
- цикломатическая сложность
- баг репорт
- качество программного обеспечения
Выводы из данной статьи про виды ошибок программного обеспечения указывают на необходимость использования современных методов для оптимизации систем. Надеюсь, что теперь ты понял что такое виды ошибок программного обеспечения, принципы отладки, ошибки в программировании
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Качество и тестирование программного обеспечения. Quality Assurance.
Отладка программы — один их самых сложных этапов разработки программного обеспечения, требующий глубокого знания:
•специфики управления используемыми техническими средствами,
•операционной системы,
•среды и языка программирования,
•реализуемых процессов,
•природы и специфики различных ошибок,
•методик отладки и соответствующих программных средств.
Отладка — это процесс локализации и исправления ошибок, обнаруженных при тестировании программного обеспечения. Локализацией называют процесс определения оператора программы, выполнение которого вызвало нарушение нормального вычислительного процесса. Доя исправления ошибки необходимо определить ее причину, т. е. определить оператор или фрагмент, содержащие ошибку. Причины ошибок могут быть как очевидны, так и очень глубоко скрыты.
Вцелом сложность отладки обусловлена следующими причинами:
•требует от программиста глубоких знаний специфики управления используемыми техническими средствами, операционной системы, среды и языка программирования, реализуемых процессов, природы и специфики различных ошибок, методик отладки и соответствующих программных средств;
•психологически дискомфортна, так как необходимо искать собственные ошибки и, как правило, в условиях ограниченного времени;
•возможно взаимовлияние ошибок в разных частях программы, например, за счет затирания области памяти одного модуля другим из-за ошибок адресации;
•отсутствуют четко сформулированные методики отладки.
Всоответствии с этапом обработки, на котором проявляются ошибки, различают (рис. 10.1):
синтаксические ошибки — ошибки, фиксируемые компилятором (транслятором, интерпретатором) при выполнении синтаксического и частично семантического анализа программы; ошибки компоновки — ошибки, обнаруженные компоновщиком (редактором связей) при объединении модулей программы;
ошибки выполнения — ошибки, обнаруженные операционной системой, аппаратными средствами или пользователем при выполнении программы.
Синтаксические ошибки. Синтаксические ошибки относят к группе самых простых, так как синтаксис языка, как правило, строго формализован, и ошибки сопровождаются развернутым комментарием с указанием ее местоположения. Определение причин таких ошибок, как правило, труда не составляет, и даже при нечетком знании правил языка за несколько прогонов удается удалить все ошибки данного типа.
Следует иметь в виду, что чем лучше формализованы правила синтаксиса языка, тем больше ошибок из общего количества может обнаружить компилятор и, соответственно, меньше ошибок будет обнаруживаться на следующих этапах. В связи с этим говорят о языках программирования с защищенным синтаксисом и с незащищенным синтаксисом. К первым, безусловно, можно отнести Pascal, имеющий очень простой и четко определенный синтаксис, хорошо проверяемый при компиляции программы, ко вторым — Си со всеми его модификациями. Чего стоит хотя бы возможность выполнения присваивания в условном операторе в Си, например:
if (c = n) x = 0; /* в данном случае не проверятся равенство с и n, а выполняется присваивание с значения n, после чего результат операции сравнивается с нулем, если программист хотел выполнить не присваивание, а сравнение, то эта ошибка будет обнаружена только на этапе выполнения при получении результатов, отличающихся от ожидаемых */
Ошибки компоновки. Ошибки компоновки, как следует из названия, связаны с проблемами,
обнаруженными при разрешении внешних ссылок. Например, предусмотрено обращение к подпрограмме другого модуля, а при объединении модулей данная подпрограмма не найдена или не стыкуются списки параметров. В большинстве случаев ошибки такого рода также удается быстро локализовать и устранить.
Ошибки выполнения. К самой непредсказуемой группе относятся ошибки выполнения. Прежде всего они могут иметь разную природу, и соответственно по-разному проявляться. Часть ошибок обнаруживается и документируется операционной системой. Выделяют четыре способа проявления таких ошибок:
• появление сообщения об ошибке, зафиксированной схемами контроля выполнения машинных команд, например, переполнении разрядной сетки, ситуации «деление на ноль», нарушении адресации и т. п.;
•появление сообщения об ошибке, обнаруженной операционной системой, например, нарушении защиты памяти, попытке записи на устройства, защищенные от записи, отсутствии файла с заданным именем и т. п.;
•«зависание» компьютера, как простое, когда удается завершить программу без перезагрузки операционной системы, так и «тяжелое», когда для продолжения работы необходима перезагрузка;
•несовпадение полученных результатов с ожидаемыми.
Примечание. Отметим, что, если ошибки этапа выполнения обнаруживает пользователь, то в двух первых случаях, получив соответствующее сообщение, пользователь в зависимости от своего характера, степени необходимости и опыта работы за компьютером, либо попробует понять, что произошло, ища свою вину, либо обратится за помощью, либо постарается никогда больше не иметь дела с этим продуктом. При «зависании» компьютера пользователь может даже не сразу понять, что происходит что-то не то, хотя его печальный опыт и заставляет волноваться каждый раз, когда компьютер не выдает быстрой реакции на введенную команду, что также целесообразно иметь в виду. Также опасны могут быть ситуации, при которых пользователь получает неправильные результаты и использует их в своей работе.
Причины ошибок выполнения очень разнообразны, а потому и локализация может оказаться крайне сложной. Все возможные причины ошибок можно разделить на следующие группы:
•неверное определение исходных данных,
•логические ошибки,
•накопление погрешностей результатов вычислений (рис. 10.2).
Н е в е р н о е о п р е д е л е н и е и с х о д н ы х д а н н ы х происходит, если возникают любые ошибки при выполнении операций ввода-вывода: ошибки передачи, ошибки преобразования, ошибки перезаписи и ошибки данных. Причем использование специальных технических средств и программирование с защитой от ошибок (см.§ 2.7) позволяет обнаружить и предотвратить только часть этих ошибок, о чем безусловно не следует забывать.
Л о г и ч е с к и е о ш и б к и имеют разную природу. Так они могут следовать из ошибок, допущенных при проектировании, например, при выборе методов, разработке алгоритмов или определении структуры классов, а могут быть непосредственно внесены при кодировании модуля.
Кпоследней группе относят:
ошибки некорректного использования переменных, например, неудачный выбор типов данных, использование переменных до их инициализации, использование индексов, выходящих за границы определения массивов, нарушения соответствия типов данных при использовании явного или неявного переопределения типа данных, расположенных в памяти при использовании нетипизированных переменных, открытых массивов, объединений, динамической памяти, адресной арифметики и т. п.;
ошибки вычислений, например, некорректные вычисления над неарифметическими переменными, некорректное использование целочисленной арифметики, некорректное преобразование типов данных в процессе вычислений, ошибки, связанные с незнанием приоритетов выполнения операций для арифметических и логических выражений, и т. п.;
ошибки межмодульного интерфейса, например, игнорирование системных соглашений, нарушение типов и последовательности при передачи параметров, несоблюдение единства единиц измерения формальных и фактических параметров, нарушение области действия локальных и глобальных переменных;
другие ошибки кодирования, например, неправильная реализация логики программы при кодировании, игнорирование особенностей или ограничений конкретного языка программирования.
На к о п л е н и е п о г р е ш н о с т е й результатов числовых вычислений возникает, например, при некорректном отбрасывании дробных цифр чисел, некорректном использовании приближенных методов вычислений, игнорировании ограничения разрядной сетки представления вещественных чисел в ЭВМ и т. п.
Все указанные выше причины возникновения ошибок следует иметь в виду в процессе отладки. Кроме того, сложность отладки увеличивается также вследствие влияния следующих факторов:
опосредованного проявления ошибок;
возможности взаимовлияния ошибок;
возможности получения внешне одинаковых проявлений разных ошибок;
отсутствия повторяемости проявлений некоторых ошибок от запуска к запуску – так называемые стохастические ошибки;
возможности устранения внешних проявлений ошибок в исследуемой ситуации при внесении некоторых изменений в программу, например, при включении в программу диагностических фрагментов может аннулироваться или измениться внешнее проявление ошибок;
написания отдельных частей программы разными программистами.
Методы отладки программного обеспечения
Отладка программы в любом случае предполагает обдумывание и логическое осмысление всей имеющейся информации об ошибке. Большинство ошибок можно обнаружить по косвенным признакам посредством тщательного анализа текстов программ и результатов тестирования без получения дополнительной информации. При этом используют различные методы:
ручного тестирования;
индукции;
дедукции;
обратного прослеживания.
Метод ручного тестирования. Это — самый простой и естественный способ данной группы. При обнаружении ошибки необходимо выполнить тестируемую программу вручную, используя тестовый набор, при работе с которым была обнаружена ошибка.
Метод очень эффективен, но не применим для больших программ, программ со сложными вычислениями и в тех случаях, когда ошибка связана с неверным представлением программиста о выполнении некоторых операций.
Данный метод часто используют как составную часть других методов отладки.
Метод индукции. Метод основан на тщательном анализе симптомов ошибки, которые могут проявляться как неверные результаты вычислений или как сообщение об ошибке. Если компьютер просто «зависает», то фрагмент проявления ошибки вычисляют, исходя из последних полученных результатов и действий пользователя. Полученную таким образом информацию организуют и тщательно изучают, просматривая соответствующий фрагмент программы. В результате этих действий выдвигают гипотезы об ошибках, каждую из которых проверяют. Если гипотеза верна, то детализируют информацию об ошибке, иначе — выдвигают другую гипотезу. Последовательность выполнения отладки методом индукции показана на рис. 10.3 в виде схемы алгоритма.
Самый ответственный этап — выявление симптомов ошибки. Организуя данные об ошибке, целесообразно записать все, что известно о ее проявлениях, причем фиксируют, как ситуации, в которых фрагмент с ошибкой выполняется нормально, так и ситуации, в которых ошибка проявляется. Если в результате изучения данных никаких гипотез не появляется, то необходима дополнительная информация об ошибке. Дополнительную информацию можно получить, например, в результате выполнения схожих тестов.
В процессе доказательства пытаются выяснить, все ли проявления ошибки объясняет данная гипотеза, если не все, то либо гипотеза не верна, либо ошибок несколько.
Метод дедукции. По методу дедукции вначале формируют множество причин, которые могли бы вызвать данное проявление ошибки. Затем анализируя причины, исключают те, которые противоречат имеющимся данным. Если все причины исключены, то следует выполнить дополнительное тестирование исследуемого фрагмента. В противном случае наиболее вероятную гипотезу пытаются доказать. Если гипотеза объясняет полученные признаки ошибки, то ошибка найдена, иначе — проверяют следующую причину (рис. 10.4).
Метод обратного прослеживания. Для небольших программ эффективно применение метода обратного прослеживания. Начинают с точки вывода неправильного результата. Для этой точки строится гипотеза о значениях основных переменных, которые могли бы привести к получению имеющегося результата. Далее, исходя из этой гипотезы, делают предложения о значениях переменных в предыдущей точке. Процесс продолжают, пока не обнаружат причину ошибки.
Отладка, или debugging, — это поиск (локализация), анализ и устранение ошибок в программном обеспечении, которые были найдены во время тестирования.
Это простые ошибки, которые в компилируемых языках программирования выявляет компилятор (программа, которая преобразует текст на языке программирования в набор машинных кодов). Если компилятор показывает несколько ошибок, отладку кода начинают с исправления самой первой, так как она может быть причиной других.
В интерпретируемых языках (например Python) текст программы команда за командой переводится в машинный код и сразу исполняется. К моменту обнаружения ошибки часть программы уже может исполниться.
Ошибки связаны с разрешением внешних ссылок. Выявляет компоновщик (редактор связей) при объединении модулей программы. Простой пример — ситуация, когда требуется обращение к подпрограмме другого модуля, но при компоновке она не найдена. Ошибки также просто найти и устранить.
Ошибки, которые обнаруживают операционная система, аппаратные средства или пользователи при выполнении программы. Они считаются непредсказуемыми и проявляются после успешной компиляции и компоновки. Можно выделить четыре вида проявления таких ошибок:
- сообщение об ошибке, которую зафиксировали схемы контроля машинных команд. Это может быть переполнение разрядной сетки (когда старшие разряды результата операции не помещаются в выделенной области памяти), «деление на ноль», нарушение адресации и другие;
- сообщение об ошибке, которую зафиксировала операционная система. Она же, как правило, и документирует ошибку. Это нарушение защиты памяти, отсутствие файла с заданным именем, попытка записи на устройство, защищенное от записи;
- прекращение работы компьютера или зависание. Это и простые ошибки, которые не требуют перезагрузки компьютера, и более сложные, когда нужно выключать ПК;
- получение результатов, которые отличаются от ожидаемых. Программа работает стабильно, но выдает некорректный результат, который пользователь воспринимает за истину.
Ошибки выполнения можно разделить на три большие группы.
Ошибки определения данных или неверное определение исходных данных. Они могут появиться во время выполнения операций ввода-вывода.
К ним относятся:
- ошибки преобразования;
- ошибки данных;
- ошибки перезаписи.
Как правило, использование специальных технических средств для отладки (API-логгеров, логов операционной системы, профилировщиков и пр.) и программирование с защитой от ошибок помогает обнаружить и решить лишь часть из них.
Логические ошибки. Они могут возникать из ошибок, которые были допущены при выборе методов, разработке алгоритмов, определении структуры данных, кодировании модуля.
В эту группу входят:
- ошибки некорректного использования переменных. Сюда относятся неправильный выбор типов данных, использование индексов, выходящих за пределы определения массивов, использование переменных до присвоения переменной начального значения, нарушения соответствия типов данных;
- ошибки вычислений. Это некорректная работа с переменными, неправильное преобразование типов данных в процессе вычислений;
- ошибки взаимодействия модулей или межмодульного интерфейса. Это нарушение типов и последовательности при передаче параметров, области действия локальных и глобальных переменных, несоблюдение единства единиц измерения формальных и фактических параметров;
- неправильная реализация логики при программировании.
Ошибки накопления погрешностей. Могут возникать при неправильном округлении, игнорировании ограничений разрядной сетки, использовании приближенных методов вычислений и т.д.
Отладка программы заключается в тестировании вручную с помощью тестового набора, при работе с которым была допущена ошибка. Несмотря на эффективность, метод не получится использовать для больших программ или программ со сложными вычислениями. Ручное тестирование применяется как составная часть других методов отладки.
В основе отладки системы — тщательный анализ проявлений ошибки. Это могут быть сообщения об ошибке или неверные результаты вычислений. Например, если во время выполнения программы завис компьютер, то, чтобы найти фрагмент проявления ошибки, нужно проанализировать последние действия пользователя. На этапе отладки программы строятся гипотезы, каждая из них проверяется. Если гипотеза подтвердилась, информация об ошибке детализируется, если нет — выдвигаются новые.
Вот как выглядит процесс:

Важно, чтобы выдвинутая гипотеза объясняла все проявления ошибки. Если объясняется только их часть, то либо гипотеза неверна, либо ошибок несколько.
Сначала специалисты предлагают множество причин, по которым могла возникнуть ошибка. Затем анализируют их, исключают противоречащие имеющимся данным. Если все причины были исключены, проводят дополнительное тестирование. В обратном случае наиболее вероятную причину пытаются доказать.

Эффективен для небольших программ. Начинается с точки вывода неправильного результата. Для точки выдвигается гипотеза о значениях основных переменных, которые могли привести к ошибке. Далее на основании этой гипотезы строятся предположения о значениях переменных в предыдущей точке. Процесс продолжается до момента, пока не найдут ошибку.
Ранние отладчики, например gdb, представляли собой отдельные программы с интерфейсами командной строки. Более поздние, например первые версии Turbo Debugger, были автономными, но имели собственный графический интерфейс для облегчения работы. Сейчас большинство IDE имеют встроенный отладчик. Он использует такой же интерфейс, как и редактор кода, поэтому можно выполнять отладку в той же среде, которая используется для написания кода.
Отладчик позволяет разработчику контролировать выполнение и проверять (или изменять) состояние программ. Например, можно использовать отладчик для построчного выполнения программы, проверяя по ходу значения переменных. Сравнение фактических и ожидаемых значений переменных или наблюдение за ходом выполнения кода может помочь в отслеживании логических (семантических) ошибок.
Пошаговое выполнение — это набор связанных функций отладчика, позволяющих поэтапно выполнять код.
Команда выполняет очередную инструкцию, а потом приостанавливает процесс, чтобы с помощью отладчика было можно проверить состояние программы. Если в выполняемом операторе есть вызов функции, step into заставляет программу переходить в начало вызываемой функции, где она приостанавливается.
Команда также выполняет очередную инструкцию. Однако когда step into будет входить в вызовы функций и выполнять их строка за строкой, step over выполнит всю функцию, не останавливаясь, и вернет управление после ее выполнения. Команда step over позволяет пропустить функции, если разработчик уверен, что они уже исправлены, или не заинтересован в их отладке в данный момент.
В отличие от step into и step over, step out выполняет не следующую строку кода, а весь оставшийся код функции, исполняемой в настоящее время. После возврата из функции он возвращает управление разработчику. Эта команда полезна, когда специалист случайно вошел в функцию, которую не нужно отлаживать.
Как правило, при пошаговом выполнении можно идти только вперед. Поэтому легко перешагнуть место, которое нужно проверить. Если это произошло, необходимо перезапустить отладку.
У некоторых отладчиков (таких как GDB 7.0, Visual Studio Enterprise Edition 15.5 и более поздних версий) есть возможность вернуться на шаг назад. Это полезно, если пропущена цель либо нужно повторно проверить выполненную инструкцию.
Привет, Вы узнаете про виды ошибок программного обеспечения, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
виды ошибок программного обеспечения, принципы отладки , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance..
1. Отладка программы
Отладка, как мы уже говорили, бывает двух видов:
Синтаксическая отладка. Синтаксические ошибки выявляет компилятор, поэтому исправлять их достаточно легко.
Семантическая (смысловая) отладка. Ее время наступает тогда, когда синтаксических ошибок не осталось, но результаты программа выдает неверные. Здесь компилятор сам ничего выявить не сможет, хотя в среде программирования обычно существуют вспомогательные средства отладки, о которых мы еще поговорим.
Отладка — это процесс локализации и исправления ошибок в программе.
Как бы тщательно мы ни писали, отладка почти всегда занимает больше времени, чем программирование.
2. Локализация ошибок
Локализация — это нахождение места ошибки в программе.
В процессе поиска ошибки мы обычно выполняем одни и те же действия:
- прогоняем программу и получаем результаты;
- сверяем результаты с эталонными и анализируем несоответствие;
- выявляем наличие ошибки, выдвигаем гипотезу о ее характере и месте в программе;
- проверяем текст программы, исправляем ошибку, если мы нашли ее правильно.
Способы обнаружения ошибки:
- Аналитический — имея достаточное представление о структуре программы, просматриваем ее текст вручную, без прогона.
- Экспериментальный — прогоняем программу, используя отладочную печать и средства трассировки, и анализируем результаты ее работы.
Оба способа по-своему удобны и обычно используются совместно.
3.
принципы отладки
Принципы локализации ошибок:
- Большинство ошибок обнаруживается вообще без запуска программы — просто внимательным просматриванием текста.
- Если отладка зашла в тупик и обнаружить ошибку не удается, лучше отложить программу. Когда глаз «замылен», эффективность работы упорно стремится к нулю.
- Чрезвычайно удобные вспомогательные средства — это отладочные механизмы среды разработки: трассировка, промежуточный контроль значений. Можно использовать даже дамп памяти, но такие радикальные действия нужны крайне редко.
- Экспериментирования типа «а что будет, если изменить плюс на минус» — нужно избегать всеми силами. Обычно это не дает результатов, а только больше запутывает процесс отладки, да еще и добавляет новые ошибки.
Принципы исправления ошибок еще больше похожи на законы Мерфи:
- Там, где найдена одна ошибка, возможно, есть и другие.
- Вероятность, что ошибка найдена правильно, никогда не равна ста процентам.
- Наша задача — найти саму ошибку, а не ее симптом.
Это утверждение хочется пояснить. Если программа упорно выдает результат 0,1 вместо эталонного нуля, простым округлением вопрос не решить. Если результат получается отрицательным вместо эталонного положительного, бесполезно брать его по модулю — мы получим вместо решения задачи ерунду с подгонкой.
Исправляя одну ошибку, очень легко внести в программу еще парочку. «Наведенные» ошибки — настоящий бич отладки.
Исправление ошибок зачастую вынуждает нас возвращаться на этап составления программы. Это неприятно, но порой неизбежно.
4. Методы отладки
Силовые методы
- — Использование дампа (распечатки) памяти.Это интересно с познавательной точки зрения: можно досконально разобраться в машинных процессах. Иногда такой подход даже необходим — например, когда речь идет о выделении и высвобождении памяти под динамические переменные с использованием недокументированных возможностей языка. Однако, в большинстве случаев мы получаем огромное количество низкоуровневой информации, разбираться с которой — не пожелаешь и врагу, а результативность поиска — исчезающе низка.
- — Использование отладочной печати в тексте программы — произвольно и в большом количестве.Получать информацию о выполнении каждого оператора тоже небезынтересно. Но здесь мы снова сталкиваемся со слишком большими объемами информации. Кроме того, мы здорово захламляем программу добавочными операторами, получая малочитабельный текст, да еще рискуем внести десяток новых ошибок.
- — Использование автоматических средств отладки — трассировки с отслеживанием промежуточных значений переменых.Пожалуй, это самый распространенный способ отладки. Не нужно только забывать, что это только один из способов, и применять всегда и везде только его — часто невыгодно.
Сложности возникают, когда приходится отслеживать слишком большие структуры данных или огромное их число. Еще проблематичнее трассировать проект, где выполнение каждой подпрограммы приводит к вызову пары десятков других. Но для небольших программ трассировки вполне достаточно.
С точки зрения «правильного» программирования силовые методы плохи тем, что не поощряют анализ задачи.
Суммируя свойства силовых методов, получаем практические советы:
— использовать трассировку и отслеживание значений переменных для небольших проектов, отдельных подпрограмм;
— использовать отладочную печать в небольших количества и «по делу»;
— оставить дамп памяти на самый крайний случай.
Метод индукции — анализ программы от частного к общему.
Просматриваем симптомы ошибки и определяем данные, которые имеют к ней хоть какое-то отношение. Затем, используя тесты, исключаем маловероятные гипотезы, пока не остается одна, которую мы пытаемся уточнить и доказать.
Метод дедукции — от общего к частному.
Выдвигаем гипотезу, которая может объяснить ошибку, пусть и не полностью. Затем при помощи тестов эта гипотеза проверяется и доказывается.
Обратное движение по алгоритму.
Отладка начинается там, где впервые встретился неправильный результат. Затем работа программы прослеживается (мысленно или при помощи тестов) в обратном порядке, пока не будет обнаружено место возможной ошибки.
Метод тестирования.
Давайте рассмотрим процесс локализации ошибки на конкретном примере. Пусть дана небольшая программа, которая выдает значение максимального из трех введенных пользователем чисел.
var
a, b, c: real;
begin
writeln('Программа находит значение максимального из трех введенных чисел');
write('Введите первое число '); readln(a);
write('Введите второе число '); readln(b);
write('Введите третье число '); readln(c);
if (a>b)and(a>c) then
writeln('Наибольшим оказалось первое число ',a:8:2)
else if (b>a)and(a>c) then
writeln('Наибольшим оказалось второе число ',b:8:2)
else
writeln('Наибольшим оказалось третье число ',b:8:2);
end.
Обе выделенные ошибки можно обнаружить невооруженным глазом: первая явно допущена по невнимательности, вторая — из-за того, что скопированную строку не исправили.
Тестовые наборы данных должны учитывать все варианты решения, поэтому выберем следующие наборы чисел:
Данные Ожидаемый результат
a=10; b=-4; c=1 max=a=10
a=-2; b=8; c=4 max=b=8
a=90; b=0; c=90.4 max=c=90.4
В результате выполнения программы мы, однако, получим следующие результаты:
Для a=10; b=-4; c=1:
Наибольшим оказалось первое число 10.00
Для a=-2; b=8; c=4: < pre class=»list»>Наибольшим оказалось третье число 8.00Для a=90; b=0; c=90.4:
Наибольшим оказалось третье число 0.00
Вывод во втором и третьем случаях явно неверен. Будем разбираться.
1. Трассировка и промежуточная наблюдение за переменными
Добавляем промежуточную печать или наблюдение за переменными:
- — вывод a, b, c после ввода (проверяем, правильно ли получили данные)
- — вывод значения каждого из условий (проверяем, правильно ли записали условия)
Листинг программы существенно увеличился и стал вот таким:
var
a, b, c: real;
begin
writeln(‘Программа находит значение максимального из трех введенных чисел’);
write(‘Введите первое число ‘); readln(a);
writeln(‘Вы ввели число ‘,a:8:2); {отл.печать}
write(‘Введите второе число ‘); readln(b);
writeln(‘Вы ввели число ‘,b:8:2); {отл.печать}
write(‘Введите третье число ‘); readln(c);
writeln(‘Вы ввели число ‘,c:8:2); {отл.печать}
writeln(‘a>b=’,a>b,’, a>c=’,a>c,’, (a>b)and(a>c)=’,(a>b)and(a>c)); {отл.печать}
if (a>b)and(a>c) then
writeln(‘Наибольшим оказалось первое число ‘,a:8:2)
else begin
writeln(‘b>a=’,b>a,’, b>c=’,b>c,’, (b>a)and(b>c)=’,(b>a)and(b>c)); {отл.печать}
if (b>a)and(a>c) then
writeln(‘Наибольшим оказалось второе число ‘,b:8:2)
else
writeln(‘Наибольшим оказалось третье число ‘,b:8:2);
end;
end.
В принципе, еще при наборе у нас неплохой шанс отловить ошибку в условии: подобные кусочки кода обычно не перебиваются, а копируются, и если дать себе труд слегка при этом задуматься, ошибку найти легко.
Но давайте считать, что глаз «замылен» совершенно, и найти ошибку не удалось.
Вывод для второго случая получается следующим:
Программа находит значение максимального из трех введенных чисел
Введите первое число -2
Вы ввели число -2.00
Введите второе число 8
Вы ввели число 8.00
Введите третье число 4
Вы ввели число 4.00
a>b=FALSE, a>c=FALSE, (a>b)and(a>c)=FALSE
b>a=TRUE, b>c=TRUE, (b>a)and(b>c)=TRUE
Наибольшим оказалось третье число 8.00
Со вводом все в порядке . Об этом говорит сайт https://intellect.icu . Впрочем, в этом сомнений и так было немного. А вот что касается второй группы операторов печати, то картина вышла интересная: в результате выводится верное число (8.00), но неправильное слово («третье», а не «второе»).
Вероятно, проблемы в выводе результатов. Тщательно проверяем текст и обнаруживаем, что действительно в последнем случае выводится не c, а b. Однако к решению текущей проблемы это не относится: исправив ошибку, мы получаем для чисел -2.0, 8.0, 4.0 следующий результат.
Наибольшим оказалось третье число 4.00
Теперь ошибка локализована до расчетного блока и, после некоторых усилий, мы ее находим и исправляем.
2. Метод индукции
Судя по результатам, ошибка возникает, когда максимальное число — второе или третье (если максимальное — первое, то определяется оно правильно, для доказательства можно програть еще два-три теста).
Просматриваем все, относящееся к переменным b и с. Со вводом никаких проблем не замечено, а что касается вывода — то мы быстро натыкаемся на замену b на с. Исправляем.
Как видно, невыявленные ошибки в программе остаются. Просматриваем расчетный блок: все, что относится к максимальному b (максимум с получается «в противном случае»), и обнаруживаем пресловутую проблему «a>c» вместо «b>c». Программа отлажена.
3. Метод дедукции
Неверные результаты в нашем случае могут получиться из-за ошибки в:
- — вводе данных;
- — расчетном блоке;
- — собственно выводе.
Для доказательства мы можем пользоваться отладочной печатью, трассировкой или просто набором тестов. В любом случае мы выявляем одну ошибку в расчете и одну в выводе.
4. Обратное движение по алгоритму
Зная, что ошибка возникает при выводе результатов, рассматриваем код, начиная с операторов вывода. Сразу же находим лишнюю b в операторе writeln.
Далее, смотрим по конкретной ветке условного оператора, откуда взялся результат. Для значений -2.0, 8.0, 4.0 расчет идет по ветке с условием if (b>a)and(a>c) then… где мы тут же обнаруживаем искомую ошибку.
5. Тестирование
В нашей задаче для самого полного набора данных нужно выбрать такие переменные, что
a > b > c
a > c > b
b > a > c
b > c > a
c > a > b
c > b > a
Анализируя получившиеся в каждом из этих случаев результаты, мы приходим к тому, что проблемы возникают при b>c>a и с — максимальном. Зная эти подробности, мы можем заострить внимание на конкретных участках программы.
Конечно, в реальной работе мы не расписываем так занудно каждый шаг, не прибегаем исключительно к одной методике, да и вообще частенько не задумываемся, каким образом искать ляпы. Теперь, когда мы разобрались со всеми подходами, каждый волен выбрать те из них, которые кажутся самыми удобными.
5. Средства отладки
Помимо методик, хорошо бы иметь представление о средствах, которые помогают нам выявлять ошибки. Это:
1) Аварийная печать — вывод сообщений о ненормальном завершении отдельных блоков и всей программы в целом.
2) Печать в узлах программы — вывод промежуточных значений параметров в местах, выбранных программистом. Обычно, это критичные участки алгоритма (например, значение, от которого зависит дальнейший ход выполнения) или составные части сложных формул (отдельно просчитать и вывести числитель и знаменатель большой дроби).
3) Непосредственное слежение:
- — арифметическое (за тем, чему равны, когда и как изменяются выбранные переменные),
- — логическое (когда и как выполняется выбранная последовательность операторов),
- — контроль выхода индексов за допустимые пределы,
- — отслеживание обращений к переменным,
- — отслеживание обращений к подпрограммам,
- — проверка значений индексов элементов массивов и т.д.
Нынешние среды разработки часто предлагают нам реагировать на возникающую проблему в диалоговом режиме. При этом можно:
- — просмотреть текущие значения переменных, состояние памяти, участок алгоритма, где произошел сбой;
- — прервать выполнение программы;
- — внести в программу изменения и повторно запустить ее (в компиляторных средах для этого потребуется перекомпилировать код, в интерпретаторных выполнение можно продолжить прямо с измененного оператора).
Рис Пример отладки приложения
6. Классификация ошибок
Ошибки в программах могут допускаться от самого начального этапа составления алгоритма решения задачи до окончательного оформления программы. Разновидностей ошибок достаточно много. Рассмотрим некоторые группы ошибок и соответствующие примеры:
Если вы удручены тем, что насажали в текст программы глупых ошибок — не расстраивайтесь. Ошибки вообще не бывают умными, хотя и могут относиться к самым разным частям кода:
- — ошибки обращения к данным,
- — ошибки описания данных,
- — ошибки вычислений,
- — ошибки при сравнении,
- — ошибки в передаче управления,
- — ошибки ввода-вывода,
- — ошибки интерфейса,
- и т д
Классификация ошибок по этапу обработки программы
рис Классификация ошибок этапа выполнения по возможным причинам
Синтаксические ошибки
Синтаксические ошибки зачастую выявляют уже на этапе трансляции. К сожалению, многие ошибки других видов транслятор выявить не в силах, т.к. ему не известен задуманный или требуемый результат работы программы. Отсутствие сообщений транслятора о наличии синтаксических ошибок является необходимым условием правильности программы, но не может свидетельствовать о том, что она даст правильный результат.
Примеры синтаксических ошибок :
- отсутствие знака пунктуации;
- несоответствие количества открывающих и закрывающих скобок;
- неправильно сформированный оператор;
- неправильная запись имени переменной;
- ошибка в написании служебных слов;
- отсутствие условия окончания цикла;
- отсутствие описания массивов и т.п.
Ошибки, которые не обнаруживает транслятор
В случае правильного написания операторов в программе может присутствовать большое количество ошибок, которые транслятор не может обнаружить. Рассмотрим примеры таких ошибок:
Логические ошибки: после проверки заданного условия неправильно указана ветвь алгоритма; неполный перечень возможных условий при решении задачи; один или более блоков алгоритма в программе пропущен.
Ошибки в циклах: неправильно указано начало цикла; неправильно указаны условия окончания цикла; неправильно указано количество повторений цикла; использование бесконечного цикла.
Ошибки ввода-вывода; ошибки при работе с данными: неправильно задан тип данных; организовано считывание меньшего или большего объема данных, чем нужно; неправильно отредактированы данные.
Ошибки в использовании переменных: используются переменных, для которых не указаны начальные значения; ошибочно указана одна переменная вместо другой. Ошибки при работе с массивами: пропущено предварительное обнуление массивов; неправильное описание массивов; индексы массивов следуют в ошибочном порядке.
ошибки безопасности, умышленные и не умышленные уязвимости в системе, открытость к отказам в обслуживании. несанкционированном доступе. екхолы
Ошибки в арифметических операциях: неправильное использование типа переменной (например, для сохранения результата деления используется целочисленная переменная); неправильно определен порядок действий; выполняется деление на нуль; при расчете выполняется попытка извлечения квадратного корня из отрицательного числа; не учитываются значащие разряды числа.
ошибки в архитектуре приложения пприводящие к увеличени технического долга
Методы (пути) снижение ошибок в программировании
- использование тестиования
- использование более простых решений
- использование систем с наименьшим числом составлящих
- использование ранее использованных и проверенных компонентов
- использование более квалифицрованных специалистов
7. Советы отладчику
1) Проверяйте тщательнее: ошибка скорее всего находится не в том месте, в котором кажется.
2) Часто оказывается легче выделить те места программы, ошибок в которых нет, а затем уже искать в остальных.
3) Тщательнее следить за объявлениями констант, типов и переменных, входными данными.
4) При последовательной разработке приходится особенно аккуратно писать драйверы и заглушки — они сами могут быть источником ошибок.
5) Анализировать код, начиная с самых простых вариантов. Чаще всего встречаются ошибки:
— значения входных аргументов принимаются не в том порядке,
— переменная не проинициализирована,
— при повторном прохождении модуля, перемен ная повторно не инициализируется,
— вместо предполагаемого полного копирования структуры данных, копируется только верхний уровень (например, вместо создания новой динамической переменной и присваивания ей нужного значения, адрес тупо копируется из уже существующей переменной),
— скобки в сложном выражении расставлены неправильно.
6) При упорной длительной отладке глаз «замыливается». Хороший прием — обратиться за помощью к другому лицу, чтобы не повторять ошибочных рассуждений. Правда, частенько остается проблемой убедить это другое лицо помочь вам.
7) Ошибка, скорее всего окажется вашей и будет находиться в тексте программы. Гораздо реже она оказывается:
- в компиляторе,
- операционной системе,
- аппаратной части,
- электропроводке в здании и т.д.
Но если вы совершенно уверены, что в программе ошибок нет, просмотрите стандартные модули, к которым она обращается, выясните, не менялась ли версия среды разработки, в конце концов, просто перегрузите компьютер — некоторые проблемы (особенно в DOS-средах, запускаемых из-под Windows) возникают из-за некорректной работы с памятью.
Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
9) Навязчивый поиск одной ошибки почти всегда непродуктивен. Не получается — отложите задачу, возьмитесь за написание следующего модуля, на худой конец займитесь документированием.
10) Старайтесь не жалеть времени, чтобы уясненить причину ошибки. Это поможет вам:
исправить программу,
обнаружить другие ошибки того же типа,
не делать их в дальнейшем.
11) Если вы уже знаете симптомы ошибки, иногда полезно не исправлять ее сразу, а на фоне известного поведения программы поискать другие ляпы.
12) Самые труднообнаруживаемые ошибки — наведенные, то есть те, что были внесены в код при исправлении других.
8. Тестирование
Тестирование — это выполнение программы для набора проверочных входных значений и сравнение полученных результатов с ожидаемыми.
Цель тестирования — проверка и доказательство правильности работы программы. В противном случае — выявление того, что в ней есть ошибки. Тестирование само не показывает местонахождение ошибки и не указывает на ее причины.
Принципы тестирования.
1) Тест — просчитанный вручную пример выполнения программы от исходных данных до ожидаемых результатов расчета. Эти результаты считаются эталонными.
Полномаршрутным будет такое тестирование, при котором каждый линейный участок программы будет пройден хотя бы при выполнении одного теста.
2) При прогоне программы по тестовым начальным данным, полученные результаты нужно сверить с эталонными и проанализировать разницу, если она есть.
3) При разработке тестов нужно учитывать не только правильные, но и неверные исходные данные.
4) Мы должны проверить программу на нежелательные побочные эффекты при задании некоторых исходных данных (деление на ноль, попытка считывания из несуществующего файла и т.д.).
5) Тестирование нужно планировать: заранее выбрать, что мы контролируем и как это сделать лучше. Обычно тесты планируются на этапе алгоритмизации или выбора численного метода решения. Причем, составляя тесты, мы предполагаем, что ошибки в программе есть.
6) Чем больше ошибок в коде мы уже нашли, тем больше вероятность, что мы обнаружим еще не найденные.
Хорошим называют тест, который с большой вероятностью должен обнаруживать ошибки, а удачным — тот, который их обнаружил.
9. Проектирование тестов
Тесты просчитываются вручную, значит, они должны быть достаточно просты для этого.
Тесты должны проверять каждую ветку алгоритма. По возможности, конечно. Так что количество и сложность тестов зависит от сложности программы.
Тесты составляются до кодирования и отладки: во время разработки алгоритма или даже составления математической модели.
Обычно для экономии времени сначала пропускают более простые тесты, а затем более сложные.
Давайте рассмотрим задачу: нужно проверить, попадает ли введенное число в заданный пользователем диапазон.
program Example;
(******************************************************
* Задача: проверить, попадает ли введенное число в *
* заданный пользователем диапазон *
******************************************************)
var
min, max, A, tmp: real;
begin
writeln(‘Программа проверяет, попадают ли введенные пользователем’);
writeln(‘значения в заданный диапазон’);
writeln;
writeln(‘Введите нижнюю границу диапазона ‘); readln(min);
writeln(‘Введите верхнюю границу диапазона ‘); readln(max);
if min>max then begin
writeln(‘Вы перепутали диапазоны, и я их поменяю’);
tmp:=min;
min:=max;
max:=tmp;
end;
repeat
writeln(‘Введите число для проверки (0 — конец работы) ‘); readln(A);
if (A>=min)and(A<=max) then
writeln(‘Число ‘,A,’ попадает в диапазон [‘,min,’..’,max,’]’)
else
writeln(‘Число ‘,A,’ не попадает в диапазон [‘,min,’..’,max,’]’);
until A=0;
writeln;
end.
Если исходить из алгоритма программы, мы должны составить следующие тесты:
ввод границ диапазона
— min< max
— min>max
ввод числа
— A < min (A<>0)
— A > max (A<>0)
— min <= A <= max (A<>0)
— A=0
Как видите, программа очень мала, а тестов для проверки всех ветвей ее алгоритма, требуется довольно много.
10. Стратегии тестирования
1) Тестирование программы как «черного ящика».
Мы знаем только о том, что делает программа, но даже не задумываемся о ее внутренней структуре. Задаем набор входных данных, получаем результаты, сверяем с эталонными.
При этом обнаружить все ошибки мы можем только если составили тесты для всех возможных наборов данных. Естественно, это противоречит экономическим принципам, да и просто достаточно глупо.
«Черным ящиком» удобно тестировать небольшие подпрограммы.
2) Тестирование программы как «белого ящика».
Здесь перед составлением теста мы изучаем логику программы, ее внутреннюю структуру. Тестирование будет считаться удачным, если проверяет программу по всем направлениям. Однако, как мы уже говорили, это требует огромного количества тестов.
На практике мы, как всегда, совместно используем оба принципа.
3) Тестирование программ модульной структуры.
Мы снова возвращаемся к вопросу о структурном программировании. Если вы помните, программы строятся из модулей не в последнюю очередь для того, чтобы их легко было отлаживать и тестировать. Действительно, структурированную программу мы будем тестировать частями. При этом нам нужно:
строить набор тестов;
комбинировать модули для тестирования.
Такое комбинирование может строиться двумя способами:
Пошаговое тестирование — тестируем каждый модуль, присоединяя его к уже оттестированным. При этом можем соединять части программы сверху вниз (нисходящий способ) или снизу вверх (восходящий).
Монолитное тестирование — каждый модуль тестируется отдельно, а затем из них формируется готовая рабочая программа и тестируется уже целиком.
Чтобы протестировать отдельный модуль, нужен модуль-драйвер (всегда один) и модул и-заглушки (этих может быть несколько).
Модуль-драйвер содержит фиксированные исходные данные. Он вызывает тестируемый модуль и отображает (а возможно, и анализирует) результаты.
Модуль-заглушка нужен, если в тестируемом модуле есть вызовы других. Вместо этого вызова управление передается модулю-заглушке, и уже он имитирует необходимые действия.
К сожалению, мы опять сталкиваемся с тем, что драйверы и заглушки сами могут оказаться источником ошибок. Поэтому создаваться они должны с большой осторожностью.
См. также
- ошибки в приложениях , bugs , баг репорт , bug report ,
- Фича
- GIGO
- Патч
- тестирование
- цикломатическая сложность
- баг репорт
- качество программного обеспечения
К сожалению, в одной статье не просто дать все знания про виды ошибок программного обеспечения. Но я — старался.
Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое виды ошибок программного обеспечения, принципы отладки
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Качество и тестирование программного обеспечения. Quality Assurance.
Отладка программы — один их самых сложных
этапов разработки программного
обеспечения, требующий глубокого знания:
-
специфики управления используемыми
техническими средствами, -
операционной системы,
-
среды и языка программирования,
-
реализуемых процессов,
-
природы и специфики различных ошибок,
-
методик отладки и
соответствующих программных средств.
5.2.1. Классификация ошибок.
Отладка — это
процесс локализаций и исправления
ошибок, обнаруженных при тестировании
программного обеспечения. Локализацией
называют процесс
определения оператора программы,
выполнение которого вызвало нарушение
нормального вычислительного процесса.
Для исправления ошибки необходимо
определить ее причину,
т. е. определить
оператор или фрагмент, содержащие
ошибку. Причины ошибок могут быть как
очевидны, так и очень глубоко скрыты.
В целом сложность отладки обусловлена
следующими причинами:
-
требует от программиста
глубоких знаний специфики управления
используемыми техническими средствами,
операционной системы, среды и языка
программирования, реализуемых процессов,
природы и специфики различных ошибок,
методик отладки и соответствующих
программных средств; -
психологически дискомфортна, так как
необходимо искать собственные ошибки
и, как правило, в условиях ограниченного
времени; -
возможно взаимовлияние
ошибок в разных частях программы,
например, за счет затирания области
памяти одного модуля другим из-за ошибок
адресации; -
отсутствуют четко сформулированные
методики отладки.
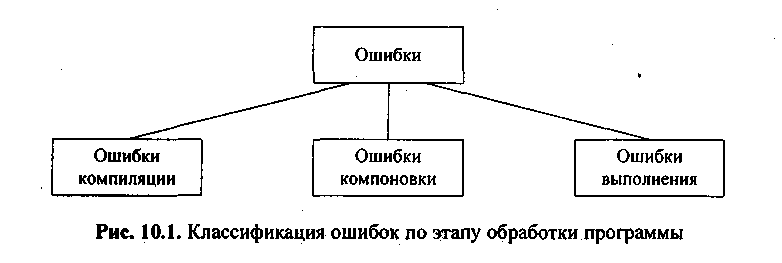
В соответствии с этапом обработки, на
котором проявляются ошибки, различают
(рис. 10.1):
синтаксические ошибки —
ошибки, фиксируемые
компилятором (транслятором,
интерпретатором) при выполнении
синтаксического и частично семантического
анализа программы;
ошибки компоновки — ошибки,
обнаруженные компоновщиком (редактором
связей) при объединении модулей программы;
ошибки выполнения — ошибки,
обнаруженные операционной системой,
аппаратными средствами или пользователем
при выполнении программы.
Синтаксические ошибки.
Синтаксические ошибки
относят к группе самых простых, так как
синтаксис языка, как правило, строго
формализован, и ошибки сопровождаются
развернутым комментарием с указанием
ее местоположения. Определение причин
таких ошибок, как правило, труда не
составляет, и даже при нечетком знании
правил языка за несколько прогонов
удается удалить все ошибки данного
типа.
Следует иметь в виду, что
чем лучше формализованы правила
синтаксиса языка, тем больше ошибок из
общего количества может обнаружить
компилятор и, соответственно, меньше
ошибок будет обнаруживаться на следующих
этапах. В связи с этим говорят о языках
программирования с защищенным
синтаксисом и с незащищенным синтаксисом.
К первым, безусловно, можно отнести
Pascal,
имеющий очень простой и четко определенный
синтаксис, хорошо проверяемый при
компиляции программы, ко вторым — Си со
всеми его модификациями. Чего стоит
хотя бы возможность выполнения
присваивания в условном операторе в
Си, например:
if(c=n)
x=0;/*
в данном случае не
проверятся равенство с и n,
а выполняется присваивание с значения
n,
после чего результат операции сравнивается
с нулем, если программист хотел выполнить
не присваивание, а сравнение, то эта
ошибка будет обнаружена только на этапе
выполнения при получении результатов,
отличающихся от ожидаемых*/
Ошибки компоновки. Ошибки
компоновки, как следует из названия,
связаны с проблемами, обнаруженными
при разрешении внешних ссылок. Например,
предусмотрено обращение к подпрограмме
другого модуля, а при объединении модулей
данная подпрограмма не найдена или не
стыкуются списки параметров. В большинстве
случаев ошибки такого рода также удается
быстро локализовать и устранить.
Ошибки выполнения. К
самой непредсказуемой группе относятся
ошибки выполнения. Прежде всего они
могут иметь разную природу, и соответственно
по-разному проявляться. Часть ошибок
обнаруживается и документируется
операционной системой. Выделяют четыре
способа проявления таких ошибок:
-
появление сообщения об
ошибке, зафиксированной схемами контроля
выполнения машинных команд, например,
переполнении разрядной сетки, ситуации
«деление на ноль», нарушении адресации
и т. п.; -
появление сообщения об ошибке,
обнаруженной операционной системой,
например, нарушении защиты памяти,
попытке записи на устройства,защищенные
от записи, отсутствии файла с заданным
именем и т. п.; -
«зависание» компьютера,
как простое, когда удается завершить
программу без перезагрузки операционной
системы, так и «тяжелое», когда для
продолжения работы необходима
перезагрузка;
-
несовпадение полученных результатов
с ожидаемыми.
Примечание. Отметим,
что, если ошибки этапа выполнения
обнаруживает пользователь, то в двух
первых случаях, получив соответствующее
сообщение, пользователь в зависимости
от своего характера, степени необходимости
и опыта работы за компьютером, либо
попробует понять, что произошло, ища
свою вину, либо обратится за помощью,
либо постарается никогда больше не
иметь дела с этим продуктом. При
«зависании» компьютера пользователь
может даже не сразу понять, что
происходит что-то не то, хотя его печальный
опыт и заставляет волноваться каждый
раз, когда компьютер не выдает быстрой
реакции на введенную команду, что также
целесообразно иметь в виду. Также опасны
могут быть ситуации, при которых
пользователь получает неправильные
результаты и использует их в своей
работе.
Причины ошибок выполнения
очень разнообразны, а потому и локализация
может оказаться крайне сложной. Все
возможные причины ошибок можно разделить
на следующие группы:
-
неверное определение
исходных данных, -
логические ошибки,
-
накопление погрешностей результатов
вычислений (рис. 10.2).
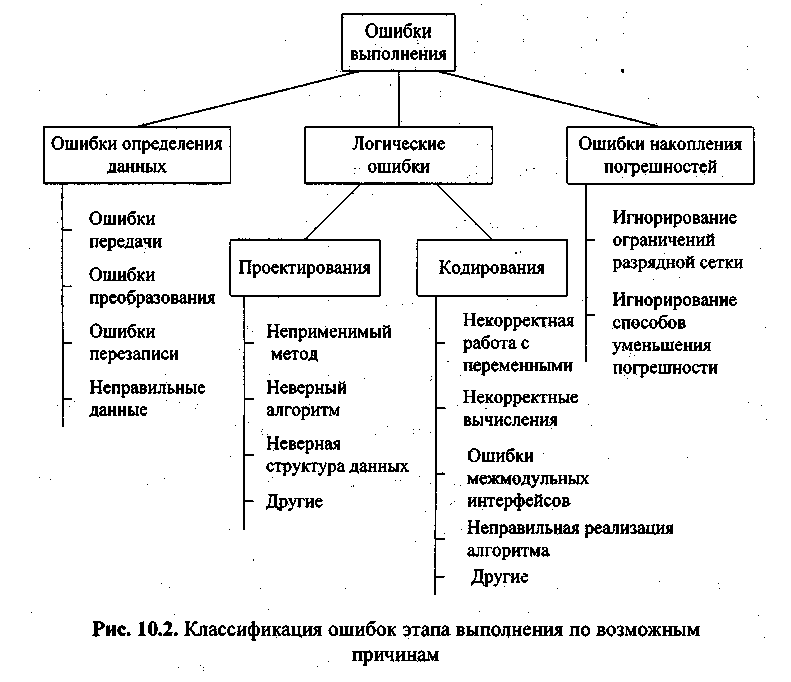
Неверное определение
исходных данных
происходит, если возникают любые
ошибки при выполнении операций
ввода-вывода: ошибки передачи, ошибки
преобразования, ошибки перезаписи и
ошибки данных. Причем использование
специальных технических средств и
программирование с защитой от ошибок
(см. § 2.7) позволяет обнаружить и
предотвратить только часть этих
ошибок, о чем безусловно не следует
забывать.
Логические ошибки
имеют разную природу. Так они могут
следовать из ошибок, допущенных при
проектировании, например, при выборе
методов, разработке алгоритмов или
определении структуры классов, а могут
быть непосредственно внесены при
кодировании модуля. К последней группе
относят:
• ошибки
некорректного использования переменных,
например, неудачный
выбор типов данных, использование
переменных до их инициализации,
использование индексов, выходящих за
границы определения массивов, нарушения
соответствия типов данных при использовании
явного или неявного переопределения
типа данных, расположенных в памяти при
использовании нетипизированных
переменных, открытых массивов, объединений,
динамической памяти, адресной
арифметики и т. п.;
-
ошибки вычислений,
например, некорректные
вычисления над неарифметическими
переменными, некорректное использование
целочисленной арифметики, некорректное
преобразование типов данных в процессе
вычислений, ошибки, связанные с незнанием
приоритетов выполнения операций
для арифметических и логических
выражений, и т. п.; -
ошибки межмодульного
интерфейса, например,
игнорирование системных соглашений,
нарушение типов и последовательности
при передаче параметров, несоблюдение
единства единиц измерения формальных
и фактических параметров, нарушение
области действия локальных и глобальных
переменных; -
другие ошибки
кодирования, например,
неправильная реализация логики
программы при кодировании, игнорирование
особенностей или ограничений
конкретного языка программирования.
Накопление погрешностей
результатов числовых вычислений
возникает, например, при некорректном
отбрасывании дробных цифр чисел,
некорректном использовании приближенных
методов вычислений, игнорировании
ограничения разрядной сетки представления
вещественных чисел в ЭВМ и т. п.
Все указанные выше причины возникновения
ошибок следует иметь в виду в процессе
отладки. Кроме того, сложность отладки
увеличивается также вследствие
влияния следующих факторов:
-
опосредованного проявления ошибок;
-
возможности взаимовлияния ошибок;
-
возможности получения внешне одинаковых
проявлений разных ошибок; -
отсутствия повторяемости
проявлений некоторых ошибок от запуска
к запуску — так называемые стохастические
ошибки; -
возможности устранения
внешних проявлений ошибок в исследуемой
ситуации при внесении некоторых
изменений в программу, например, при
включении в программу диагностических
фрагментов может аннулироваться
или измениться внешнее проявление
ошибок; -
написания отдельных частей программы
разными программистами.
при численном решении алгебраических уравнений — суммарное влияние округлений, сделанных на отдельных шагах вычислительного процесса, на точность полученного решения линейной алгебраич. системы. Наиболее распространенным способом априорной оценки суммарного влияния ошибок округления в численных методах линейной алгебры является схема т. н. обратного анализа. В применении к решению системы линейных алгебраич. уравнений
схема обратного анализа заключается в следующем. Вычисленное прямым методом Мрешение хуи не удовлетворяет (1), но может быть представлено как точное решение возмущенной системы
Качество прямого метода оценивается по наилучшей априорной оценке, к-рую можно дать для норм матрицы и вектора . Такие «наилучшие»и наз. соответственно матрицей и вектором эквивалентного возмущения для метода М.
Если оценки для и имеются, то теоретически ошибка приближенного решения может быть оценена неравенством
Здесь — число обусловленности матрицы А, а матричная норма в (3) предполагается подчиненной векторной норме
В действительности оценка для редко бывает известна, и основной смысл (2) состоит в возможности сравнения качества различных методов. Ниже приводится вид нек-рых типичных оценок для матрицы Для методов с ортогональными преобразованиями и арифметики с плавающей запятой (в системе (1) Аи bсчитаются действительными)
В этой оценке — относительная точность арифметич. операций в ЭВМ,— евклидова матричная норма, f(n) — функция вида , где п- порядок системы. Точные значения константы Си показателя kопределяются такими деталями вычислительного процесса, как способ округления, использование операции накопления скалярных произведений и т. д. Наиболее часто k=1 или 3/2.
В случае методов типа Гаусса в правую часть оценки (4) входит еще множитель , отражающий возможность роста элементов матрицы Ана промежуточных шагах метода по сравнению с первоначальным уровнем (такой рост отсутствует в ортогональных методах). Чтобы уменьшить значение , применяют различные способы выбора ведущего элемента, препятствующие возрастанию элементов матрицы.
Для квадратного корня метода, к-рый применяется обычно в случае положительно определенной матрицы А, получена наиболее сильная оценка
Существуют прямые методы (Жордана, окаймления, сопряженных градиентов), для к-рых непосредственное применение схемы обратного анализа не приводит к эффективным оценкам. В этих случаях при исследовании Н. п. применяются и иные соображения (см. [6] — [9]).
Лит.:[1] Givens W., «TJ. S. Atomic Energy Commiss. Repts. Ser. OR NL», 1954, № 1574; [2] Wilkinson J. H., Rounding errors in algebraic processes, L., 1963; [3] Уилкинсон Д ж. <Х., Алгебраическая проблема собственных значений, пер. с англ., М., 1970; [4] Воеводин В. В., Ошибки округления и устойчивость в прямых методах линейной алгебры, М., 1969; [5] его же, Вычислительные основы линейной алгебры, М., 1977; [6] Peters G., Wilkinsоn J. H., «Communs Assoc. Comput. Math.», 1975, v. 18, № 1, p. 20-24; [7] Вrоуden C. G., «J. Inst. Math, and Appl.», 1974, v. 14, № 2, p. 131-40; [8] Reid J. К., в кн.: Large Sparse Sets of Linear Equations, L.- N. Y., 1971, p. 231 — 254; [9] Икрамов Х. Д., «Ж. вычисл. матем. и матем. физики», 1978, т. 18, № 3, с. 531-45.
X. Д. Икрамов.
Н. п. округления или погрешности метода возникает при решении задач, где решение является результатом большого числа последовательно выполняемых арифметич. операций.
Значительная часть таких задач связана с решением алгебраич. задач, линейных или нелинейных (см. выше). В свою очередь среди алгебраич. задач наиболее распространены задачи, возникающие при аппроксимации дифференциальных уравнений. Этим задачам свойственны нек-рые специфич. особенности.
Н. п. метода решения задачи происходит по тем же или по более простым законам, что и Н. п. вычислительной погрешности; Н. ,п. метода исследуется при оценке метода решения задачи.
При исследовании накопления вычислительной погрешности различают два подхода. В первом случае считают, что вычислительные погрешности на каждом шаге вносятся самым неблагоприятным образом и получают мажорантную оценку погрешности. Во втором случае считают, что эти погрешности случайны с определенным законом распределения.
Характер Н. п. зависит от решаемой задачи, метода решения и ряда других факторов, на первый взгляд могущих показаться несущественными; сюда относятся форма записи чисел в ЭВМ (с фиксированной запятой или с плавающей запятой), порядок выполнения арифметич. операций и т. д. Напр., в задаче вычисления суммы Nчисел
существенен порядок выполнения операций. Пусть вычисления производятся на машине с плавающей запятой с tдвоичными разрядами и все числа лежат в пределах . При непосредственном вычислении с помощью рекуррентной формулы мажорантная оценка погрешности имеет порядок 2-tN. Можно поступить иначе (см. [1]). При вычислении попарных сумм (если N=2l+1 нечетно) полагают . Далее вычисляются их попарные суммы и т. д. При после тшагов образования попарных сумм по формулам
получают мажорантная оценка погрешности порядка
В типичных задачах величины а т вычисляются по формулам, в частности рекуррентным, или поступают последовательно в оперативную память ЭВМ; в этих случаях применение описанного приема приводит к увеличению загрузки памяти ЭВМ. Однако можно организовать последовательность вычислений так, что загрузка оперативной памяти не будет превосходить -log2N ячеек.
При численном решении дифференциальных уравнений возможны следующие случаи. При стремлении шага сетки hк нулю погрешность растет как где . Такие методы решения задач относят к классу неустойчивых. Их применение носит эпизодич. характер.
Для устойчивых методов характерен рост погрешности как Оценка погрешности таких методов обычно производится следующим образом. Строится уравнение относительно возмущения, вносимого или округлением, или погрешностями метода и затем исследуется решение этого уравнения (см. [2], [3]).
В более сложных случаях применяется метод эквивалентных возмущений (см. [1], [4]), развитый в отношении задачи исследования накопления вычислительной погрешности при решении дифференциальных уравнений (см. [3], [5], [6]). Вычисления по нек-рой расчетной схеме с округлениями рассматриваются как вычисления без округлений, но для уравнения с возмущенными коэффициентами. Сравнивая решение исходного сеточного уравнения с решением уравнения с возмущенными коэффициентами получают оценку погрешности.
Уделяется существенное внимание выбору метода по возможности с меньшими значениями qи A(h). При фиксированном методе решения задачи расчетные формулы обычно удается преобразовать к виду, где (см. [3], [5]). Это особенно существенно в случае обыкновенных дифференциальных уравнений, где число шагов в отдельных случаях оказывается очень большим.
Величина (h)может сильно расти с ростом промежутка интегрирования. Поэтому стараются применять методы по возможности с меньшим значением A(h). В случае задачи Коши ошибка округления на каждом конкретном шаге по отношению к последующим шагам может рассматриваться как ошибка в начальном условии. Поэтому нижняя грань (h)зависит от характеристики расхождения близких решений дифференциального уравнения, определяемого уравнением в вариациях.
В случае численного решения обыкновенного дифференциального уравнения уравнение в вариациях имеет вид
и потому при решении задачи на отрезке ( х 0 , X )нельзя рассчитывать на константу A(h)в мажорантной оценке вычислительной погрешности существенно лучшую, чем
Поэтому при решении этой задачи наиболее употребительны однощаговые методы типа Рунге — Кутта или методы типа Адамса (см. [3], [7]), где Н. п. в основном определяется решением уравнения в вариациях.
Для ряда методов главный член погрешности метода накапливается по подобному закону, в то время как вычислительная погрешность накапливается существенно быстрее (см. [3]). Область практич. применимости таких методов оказывается существенно уже.
Накопление вычислительной погрешности существенно зависит от метода, применяемого для решения сеточной задачи. Напр., при решении сеточных краевых задач, соответствующих обыкновенным дифференциальным уравнениям, методами стрельбы и прогонки Н. п. имеет характер A(h)h-q, где qодно и то же. Значения A(h)у этих методов могут отличаться настолько, что в определенной ситуации один из методов становится неприменимым. При решении методом пристрелки сеточной краевой задачи для уравнения Лапласа Н. п. имеет характер с 1/h, с>1, а в случае метода прогонки Ah-q. При вероятностном подходе к исследованию Н. п. в одних случаях априорно предполагают какой-то закон распределения погрешности (см. [2]), в других случаях вводят меру на пространстве рассматриваемых задач и, исходя из этой меры, получают закон распределения погрешностей округления (см. [8], [9]).
При умеренной точности решения задачи мажорантные и вероятностные подходы к оценке накопления вычислительной погрешности обычно дают качественно одинаковые результаты: или в обоих случаях Н. п. происходит в допустимых пределах, или в обоих случаях Н. п. превосходит такие пределы.
Лит.:[1] Воеводин В. В., Вычислительные основы линейной алгебры, М., 1977; [2] Шура-Бура М. Р., «Прикл. матем. и механ.», 1952, т. 16, № 5, с. 575-88; [3] Бахвалов Н. С, Численные методы, 2 изд., М., 1975; [4] Уилкинсон Дж. X., Алгебраическая проблема собственных значений, пер. с англ., М.. 1970; [5] Бахвалов Н. С, в кн.: Вычислительные методы и программирование, в. 1, М., 1962, с, 69-79; [6] Годунов С. К., Рябенький В. С, Разностные схемы, 2 изд., М., 1977; [7] Бахвалов Н. С, «Докл. АН СССР», 1955, т. 104, № 5, с. 683-86; [8] его же, «Ж. вычислит, матем. и матем. физики», 1964; т. 4, № 3, с. 399- 404; [9] Лапшин Е. А., там же, 1971, т. 11, № 6, с.1425-36.
Н. С. Бахвалов.
Математическая энциклопедия. — М.: Советская энциклопедия.
.
1977—1985.
-
Отладка по – классификация ошибок: ошибки компиляции, компоновки, выполнения; причины ошибок выполнения.
Отладка-это
процесс локализации и исправления
ошибок, обнаруженных при тестировании
программного обеспечения. Локализацией
называют
процесс определения оператора программы,
выполнение которого вызвало нарушение
нормального вычислительного процесса.
До исправления ошибки необходимо
определить ее причину,
т. е. определить оператор или фрагмент,
содержащие ошибку. Причины ошибок могут
быть как очевидны, так и очень глубоко
скрыты.
В целом сложность
отладки обусловлена следующими причинами:
• требует от
программиста глубоких знаний специфики
управления используемыми техническими
средствами, операционной системы, среды
и языка программирования, реализуемых
процессов, природы и специфики различных
ошибок, методик отладки и соответствующих
программных средств;
• психологически
дискомфортна, так как необходимо искать
собственные ошибки и, как правило, в
условиях ограниченного времени;
• возможно
взаимовлияние ошибок в разных частях
программы, например, за счет затирания
области памяти одного модуля другим
из-за ошибок адресации;
• отсутствуют
четко сформулированные методики отладки.
В соответствии с
этапом обработки, на котором проявляются
ошибки, различаю:
• синтаксические
ошибки —
ошибки, фиксируемые компилятором
(транслятором, интерпретатором) при
выполнении синтаксического и частично
семантического анализа программы;
•ошибки компоновки
— ошибки,
обнаруженные компоновщиком (редактором
связей) при объединении модулей программы;
•ошибки выполнения
— ошибки,
обнаруженные операционной системой,
аппаратными средствами или пользователем
при выполнении программы.
Синтаксические
ошибки. Синтаксические
ошибки относят к группе самых простых,
так как синтаксис языка, как правило,
строго формализован, и ошибки сопровождаются
развернутым комментарием с указанием
ее местоположения. Определение причин
таких ошибок, как правило, труда не
составляет, и даже при нечетком знании
правил языка за несколько прогонов
удается удалить все ошибки данного
типа.
Следует иметь в
виду, что чем лучше формализованы правила
синтаксиса языка, тем больше ошибок из
общего количества может обнаружить
компилятор и, соответственно, меньше
ошибок будет обнаруживаться на следующих
этапах. В связи с этим говорят о языках
программирования с защищенным синтаксисом
и с незащищенным синтаксисом. К первым,
безусловно, можно отнести Pascal, имеющий
очень простой и четко определенный
синтаксис, хорошо проверяемый при
компиляции программы, ко вторым — Си со
всеми его модификациями. Чего стоит
хотя бы возможность выполнения
присваивания в условном операторе в
Си, например: if (c = n) x = 0; /* в данном случае
не проверятся равенство с и n, а выполняется
присваивание с значения n, после чего
результат операции сравнивается с
нулем, если программист хотел выполнить
не присваивание, а сравнение, то эта
ошибка будет обнаружена только на этапе
выполнения при получении результатов,
отличающихся от ожидаемых */
Ошибки компоновки.
Ошибки
компоновки, как следует из названия,
связаны с проблемами,
обнаруженными при
разрешении внешних ссылок. Например,
предусмотрено обращение к подпрограмме
другого модуля, а при объединении модулей
данная подпрограмма не найдена или не
стыкуются списки параметров. В большинстве
случаев ошибки такого рода также удается
быстро локализовать и устранить.
Ошибки выполнения.
К самой
непредсказуемой группе относятся ошибки
выполнения. Прежде всего они могут иметь
разную природу, и соответственно
по-разному проявляться. Часть ошибок
обнаруживается и документируется
операционной системой. Выделяют четыре
способа проявления таких ошибок:
• появление
сообщения об ошибке, зафиксированной
схемами контроля выполнения машинных
команд, например, переполнении разрядной
сетки, ситуации «деление на ноль»,
нарушении адресации и т. п.;
• появление
сообщения об ошибке, обнаруженной
операционной системой, например,
нарушении защиты памяти, попытке записи
на устройства, защищенные от записи,
отсутствии файла с заданным именем и
т. п.;
• «зависание»
компьютера, как простое, когда удается
завершить программу без перезагрузки
операционной системы, так и «тяжелое»,
когда для продолжения работы необходима
перезагрузка;
• несовпадение
полученных результатов с ожидаемыми.
Причины ошибок
выполнения очень разнообразны, а потому
и локализация может оказаться крайне
сложной. Все возможные причины ошибок
можно разделить на следующие группы:
• неверное
определение исходных данных,
• логические
ошибки,
• накопление
погрешностей результатов вычислений.
Неверное
определение исходных данных
происходит, если возникают любые ошибки
при выполнении операций ввода-вывода:
ошибки передачи, ошибки преобразования,
ошибки перезаписи и ошибки данных.
Причем использование специальных
технических средств и программирование
с защитой от ошибок позволяет обнаружить
и предотвратить только часть этих
ошибок, о чем безусловно не следует
забывать.
Логические ошибки
имеют разную природу. Так они могут
следовать из ошибок, допущенных при
проектировании, например, при выборе
методов, разработке алгоритмов или
определении структуры классов, а могут
быть непосредственно внесены при
кодировании модуля.
К последней группе
относят:
• ошибки
некорректного использования переменных,
например, неудачный выбор типов данных,
использование переменных до их
инициализации, использование индексов,
выходящих за границы определения
массивов, нарушения соответствия типов
данных при использовании явного или
неявного переопределения типа данных,
расположенных в памяти при использовании
нетипизированных переменных, открытых
массивов, объединений, динамической
памяти, адресной арифметики и т. п.;
• ошибки
вычислений,
например, некорректные вычисления над
неарифметическими переменными,
некорректное использование целочисленной
арифметики, некорректное преобразование
типов данных в процессе вычислений,
ошибки, связанные с незнанием приоритетов
выполнения операций для арифметических
и логических выражений, и т. п.;
•ошибки
межмодульного интерфейса,
например, игнорирование системных
соглашений, нарушение типов и
последовательности при передачи
параметров, несоблюдение единства
единиц измерения формальных и фактических
параметров, нарушение области действия
локальных и глобальных переменных;
• другие ошибки
кодирования,
например, неправильная реализация
логики программы при кодировании,
игнорирование особенностей или
ограничений конкретного языка
программирования.
Накопление
погрешностей
результатов числовых вычислений
возникает, например, при некорректном
отбрасывании дробных цифр чисел,
некорректном использовании приближенных
методов вычислений, игнорировании
ограничения разрядной сетки представления
вещественных чисел в ЭВМ и т. п.
Все указанные выше
причины возникновения ошибок следует
иметь в виду в процессе отладки. Кроме
того, сложность отладки увеличивается
также вследствие влияния следующих
факторов:
• опосредованного
проявления ошибок;
• возможности
взаимовлияния ошибок;
• возможности
получения внешне одинаковых проявлений
разных ошибок;
• отсутствия
повторяемости проявлений некоторых
ошибок от запуска к запуску – так
называемые стохастические ошибки;
• возможности
устранения внешних проявлений ошибок
в исследуемой ситуации при внесении
некоторых изменений в программу,
например, при включении в программу
диагностических фрагментов может
аннулироваться или измениться внешнее
проявление ошибок;
• написания
отдельных частей программы разными
программистами.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Отладка программы — один их самых сложных этапов разработки программного обеспечения, требующий глубокого знания:
•специфики управления используемыми техническими средствами,
•операционной системы,
•среды и языка программирования,
•реализуемых процессов,
•природы и специфики различных ошибок,
•методик отладки и соответствующих программных средств.
Отладка — это процесс локализации и исправления ошибок, обнаруженных при тестировании программного обеспечения. Локализацией называют процесс определения оператора программы, выполнение которого вызвало нарушение нормального вычислительного процесса. Доя исправления ошибки необходимо определить ее причину, т. е. определить оператор или фрагмент, содержащие ошибку. Причины ошибок могут быть как очевидны, так и очень глубоко скрыты.
Вцелом сложность отладки обусловлена следующими причинами:
•требует от программиста глубоких знаний специфики управления используемыми техническими средствами, операционной системы, среды и языка программирования, реализуемых процессов, природы и специфики различных ошибок, методик отладки и соответствующих программных средств;
•психологически дискомфортна, так как необходимо искать собственные ошибки и, как правило, в условиях ограниченного времени;
•возможно взаимовлияние ошибок в разных частях программы, например, за счет затирания области памяти одного модуля другим из-за ошибок адресации;
•отсутствуют четко сформулированные методики отладки.
Всоответствии с этапом обработки, на котором проявляются ошибки, различают (рис. 10.1):
синтаксические ошибки — ошибки, фиксируемые компилятором (транслятором, интерпретатором) при выполнении синтаксического и частично семантического анализа программы; ошибки компоновки — ошибки, обнаруженные компоновщиком (редактором связей) при объединении модулей программы;
ошибки выполнения — ошибки, обнаруженные операционной системой, аппаратными средствами или пользователем при выполнении программы.
Синтаксические ошибки. Синтаксические ошибки относят к группе самых простых, так как синтаксис языка, как правило, строго формализован, и ошибки сопровождаются развернутым комментарием с указанием ее местоположения. Определение причин таких ошибок, как правило, труда не составляет, и даже при нечетком знании правил языка за несколько прогонов удается удалить все ошибки данного типа.
Следует иметь в виду, что чем лучше формализованы правила синтаксиса языка, тем больше ошибок из общего количества может обнаружить компилятор и, соответственно, меньше ошибок будет обнаруживаться на следующих этапах. В связи с этим говорят о языках программирования с защищенным синтаксисом и с незащищенным синтаксисом. К первым, безусловно, можно отнести Pascal, имеющий очень простой и четко определенный синтаксис, хорошо проверяемый при компиляции программы, ко вторым — Си со всеми его модификациями. Чего стоит хотя бы возможность выполнения присваивания в условном операторе в Си, например:
if (c = n) x = 0; /* в данном случае не проверятся равенство с и n, а выполняется присваивание с значения n, после чего результат операции сравнивается с нулем, если программист хотел выполнить не присваивание, а сравнение, то эта ошибка будет обнаружена только на этапе выполнения при получении результатов, отличающихся от ожидаемых */
Ошибки компоновки. Ошибки компоновки, как следует из названия, связаны с проблемами,
обнаруженными при разрешении внешних ссылок. Например, предусмотрено обращение к подпрограмме другого модуля, а при объединении модулей данная подпрограмма не найдена или не стыкуются списки параметров. В большинстве случаев ошибки такого рода также удается быстро локализовать и устранить.
Ошибки выполнения. К самой непредсказуемой группе относятся ошибки выполнения. Прежде всего они могут иметь разную природу, и соответственно по-разному проявляться. Часть ошибок обнаруживается и документируется операционной системой. Выделяют четыре способа проявления таких ошибок:
• появление сообщения об ошибке, зафиксированной схемами контроля выполнения машинных команд, например, переполнении разрядной сетки, ситуации «деление на ноль», нарушении адресации и т. п.;
•появление сообщения об ошибке, обнаруженной операционной системой, например, нарушении защиты памяти, попытке записи на устройства, защищенные от записи, отсутствии файла с заданным именем и т. п.;
•«зависание» компьютера, как простое, когда удается завершить программу без перезагрузки операционной системы, так и «тяжелое», когда для продолжения работы необходима перезагрузка;
•несовпадение полученных результатов с ожидаемыми.
Примечание. Отметим, что, если ошибки этапа выполнения обнаруживает пользователь, то в двух первых случаях, получив соответствующее сообщение, пользователь в зависимости от своего характера, степени необходимости и опыта работы за компьютером, либо попробует понять, что произошло, ища свою вину, либо обратится за помощью, либо постарается никогда больше не иметь дела с этим продуктом. При «зависании» компьютера пользователь может даже не сразу понять, что происходит что-то не то, хотя его печальный опыт и заставляет волноваться каждый раз, когда компьютер не выдает быстрой реакции на введенную команду, что также целесообразно иметь в виду. Также опасны могут быть ситуации, при которых пользователь получает неправильные результаты и использует их в своей работе.
Причины ошибок выполнения очень разнообразны, а потому и локализация может оказаться крайне сложной. Все возможные причины ошибок можно разделить на следующие группы:
•неверное определение исходных данных,
•логические ошибки,
•накопление погрешностей результатов вычислений (рис. 10.2).
Н е в е р н о е о п р е д е л е н и е и с х о д н ы х д а н н ы х происходит, если возникают любые ошибки при выполнении операций ввода-вывода: ошибки передачи, ошибки преобразования, ошибки перезаписи и ошибки данных. Причем использование специальных технических средств и программирование с защитой от ошибок (см.§ 2.7) позволяет обнаружить и предотвратить только часть этих ошибок, о чем безусловно не следует забывать.
Л о г и ч е с к и е о ш и б к и имеют разную природу. Так они могут следовать из ошибок, допущенных при проектировании, например, при выборе методов, разработке алгоритмов или определении структуры классов, а могут быть непосредственно внесены при кодировании модуля.
Кпоследней группе относят:
ошибки некорректного использования переменных, например, неудачный выбор типов данных, использование переменных до их инициализации, использование индексов, выходящих за границы определения массивов, нарушения соответствия типов данных при использовании явного или неявного переопределения типа данных, расположенных в памяти при использовании нетипизированных переменных, открытых массивов, объединений, динамической памяти, адресной арифметики и т. п.;
ошибки вычислений, например, некорректные вычисления над неарифметическими переменными, некорректное использование целочисленной арифметики, некорректное преобразование типов данных в процессе вычислений, ошибки, связанные с незнанием приоритетов выполнения операций для арифметических и логических выражений, и т. п.;
ошибки межмодульного интерфейса, например, игнорирование системных соглашений, нарушение типов и последовательности при передачи параметров, несоблюдение единства единиц измерения формальных и фактических параметров, нарушение области действия локальных и глобальных переменных;
другие ошибки кодирования, например, неправильная реализация логики программы при кодировании, игнорирование особенностей или ограничений конкретного языка программирования.
На к о п л е н и е п о г р е ш н о с т е й результатов числовых вычислений возникает, например, при некорректном отбрасывании дробных цифр чисел, некорректном использовании приближенных методов вычислений, игнорировании ограничения разрядной сетки представления вещественных чисел в ЭВМ и т. п.
Все указанные выше причины возникновения ошибок следует иметь в виду в процессе отладки. Кроме того, сложность отладки увеличивается также вследствие влияния следующих факторов:
опосредованного проявления ошибок;
возможности взаимовлияния ошибок;
возможности получения внешне одинаковых проявлений разных ошибок;
отсутствия повторяемости проявлений некоторых ошибок от запуска к запуску – так называемые стохастические ошибки;
возможности устранения внешних проявлений ошибок в исследуемой ситуации при внесении некоторых изменений в программу, например, при включении в программу диагностических фрагментов может аннулироваться или измениться внешнее проявление ошибок;
написания отдельных частей программы разными программистами.
Методы отладки программного обеспечения
Отладка программы в любом случае предполагает обдумывание и логическое осмысление всей имеющейся информации об ошибке. Большинство ошибок можно обнаружить по косвенным признакам посредством тщательного анализа текстов программ и результатов тестирования без получения дополнительной информации. При этом используют различные методы:
ручного тестирования;
индукции;
дедукции;
обратного прослеживания.
Метод ручного тестирования. Это — самый простой и естественный способ данной группы. При обнаружении ошибки необходимо выполнить тестируемую программу вручную, используя тестовый набор, при работе с которым была обнаружена ошибка.
Метод очень эффективен, но не применим для больших программ, программ со сложными вычислениями и в тех случаях, когда ошибка связана с неверным представлением программиста о выполнении некоторых операций.
Данный метод часто используют как составную часть других методов отладки.
Метод индукции. Метод основан на тщательном анализе симптомов ошибки, которые могут проявляться как неверные результаты вычислений или как сообщение об ошибке. Если компьютер просто «зависает», то фрагмент проявления ошибки вычисляют, исходя из последних полученных результатов и действий пользователя. Полученную таким образом информацию организуют и тщательно изучают, просматривая соответствующий фрагмент программы. В результате этих действий выдвигают гипотезы об ошибках, каждую из которых проверяют. Если гипотеза верна, то детализируют информацию об ошибке, иначе — выдвигают другую гипотезу. Последовательность выполнения отладки методом индукции показана на рис. 10.3 в виде схемы алгоритма.
Самый ответственный этап — выявление симптомов ошибки. Организуя данные об ошибке, целесообразно записать все, что известно о ее проявлениях, причем фиксируют, как ситуации, в которых фрагмент с ошибкой выполняется нормально, так и ситуации, в которых ошибка проявляется. Если в результате изучения данных никаких гипотез не появляется, то необходима дополнительная информация об ошибке. Дополнительную информацию можно получить, например, в результате выполнения схожих тестов.
В процессе доказательства пытаются выяснить, все ли проявления ошибки объясняет данная гипотеза, если не все, то либо гипотеза не верна, либо ошибок несколько.
Метод дедукции. По методу дедукции вначале формируют множество причин, которые могли бы вызвать данное проявление ошибки. Затем анализируя причины, исключают те, которые противоречат имеющимся данным. Если все причины исключены, то следует выполнить дополнительное тестирование исследуемого фрагмента. В противном случае наиболее вероятную гипотезу пытаются доказать. Если гипотеза объясняет полученные признаки ошибки, то ошибка найдена, иначе — проверяют следующую причину (рис. 10.4).
Метод обратного прослеживания. Для небольших программ эффективно применение метода обратного прослеживания. Начинают с точки вывода неправильного результата. Для этой точки строится гипотеза о значениях основных переменных, которые могли бы привести к получению имеющегося результата. Далее, исходя из этой гипотезы, делают предложения о значениях переменных в предыдущей точке. Процесс продолжают, пока не обнаружат причину ошибки.
Накопление — ошибка
Cтраница 1
Накопление ошибки от шага к шагу не только увеличивает систематические отклонения между x ( t) и ее дискретным аналогом, но и создает возрастающую погрешность смещения фазы и запаздывание. Поэтому вычисленные значения x ( tk) обычно корректируются путем предсказания ( прогноза) будущих значений x ( t) на основании настоящих и прошлых.
[1]
Накопление ошибок 20 Нижний пояс 47 Новожилов И.В. 9, 191, 227, 376 Ньютон И.
[2]
Накопление антиэкологических ошибок более недопустимо.
[3]
Накопление ошибки счета — В процессе шагового расчета накапливаются ошибки счета, которые, если не принимать специальных мер, могут привести к существенному искажению или даже к полностью неверным результатам. Накопление ошибки связано с рядом причин. Составляющими ошибки счета являются погрешности аппроксимации при решении интегральных задач. Если при рассмотрении стационарного процесса, расчете дисков с использованием конечных соотношений упругости и деформационных теорий пластичности и ползучести задание определенной точности решения дает удовлетворительные результаты при сходящемся процессе, то при повторении этих погрешностей на расчетных этапах и последующем суммировании результатов при шаговом расчете нестационарного процесса накапливается существенная погрешность.
[4]
Вследствие накопления ошибки при развертывании определителя восьмой корень получается близкий к нулю, но не нулевой.
[5]
Чтобы избежать накопления ошибок при откладывании делений, прибегают к следующим приемам.
[6]
Чтобы избежать накопления ошибок при откладывании делений, прибегают к следующим приемам.
[8]
Чтобы избежать накопления ошибок, измерения проводят сериями по 10 — 12 точек в каждой. Первая серия носит разведочный характер.
[10]
Однако при накоплении ошибок в процессе вычислений, выражения, которые алгебраически равны, могут оказаться равными неточно.
[11]
Для избежания такого накопления ошибок в данной работе мы предлагаем пожертвовать мягким корректным учетом вкладов флуктуации разных масштабов и жестко разделить кулонов-ское взаимодействие на Vi и У % — потенциалы, соответствующие ближнему и дальнему вкладам, причем разбиение выполнить таким образом, чтобы носители функций Vi и / 2 не перекрывались.
[12]
В результате такого накопления ошибок вместо предсказанного теорией 10 — 12-кратного выигрыша в точности был получен выигрыш лишь в 4 — 5 раз [ 78, с.
[13]
Существенное влияние на накопление ошибки оказывает погрешность определения величины Аг / при у — — 0, которая при ограниченности экспериментальных данных может оказаться очень значительной.
[14]
Страницы:
1
2
3
4
»
0
C
F
G
H
K
L
N
P
S
T
W
Z
А
Б
В
Г
Д
Е
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Э
Ю
Я
НАКОПЛЕНИЕ ПОГРЕШНОСТИ
Значение НАКОПЛЕНИЕ ПОГРЕШНОСТИ в математической энциклопедии:
при численном решении алгебраических уравнений — суммарное влияние округлений, сделанных на отдельных шагах вычислительного процесса, на точность полученного решения линейной алгебраич. системы. Наиболее распространенным способом априорной оценки суммарного влияния ошибок округления в численных методах линейной алгебры является схема т. н. обратного анализа. В применении к решению системы линейных алгебраич. уравнений

схема обратного анализа заключается в следующем. Вычисленное прямым методом Мрешение хуи не удовлетворяет (1), но может быть представлено как точное решение возмущенной системы

Качество прямого метода оценивается по наилучшей априорной оценке, к-рую можно дать для норм матрицы  и вектора
и вектора  . Такие «наилучшие»
. Такие «наилучшие» и
и  наз. соответственно матрицей и вектором эквивалентного возмущения для метода М.
наз. соответственно матрицей и вектором эквивалентного возмущения для метода М.
Если оценки для 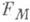 и
и 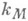 имеются, то теоретически ошибка приближенного решения
имеются, то теоретически ошибка приближенного решения  может быть оценена неравенством
может быть оценена неравенством
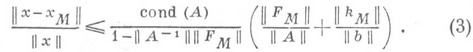
Здесь  — число обусловленности матрицы А, а матричная норма в (3) предполагается подчиненной векторной норме
— число обусловленности матрицы А, а матричная норма в (3) предполагается подчиненной векторной норме 
В действительности оценка для 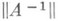 редко бывает известна, и основной смысл (2) состоит в возможности сравнения качества различных методов. Ниже приводится вид нек-рых типичных оценок для матрицы
редко бывает известна, и основной смысл (2) состоит в возможности сравнения качества различных методов. Ниже приводится вид нек-рых типичных оценок для матрицы  Для методов с ортогональными преобразованиями и арифметики с плавающей запятой (в системе (1) Аи bсчитаются действительными)
Для методов с ортогональными преобразованиями и арифметики с плавающей запятой (в системе (1) Аи bсчитаются действительными)

В этой оценке  — относительная точность арифметич. операций в ЭВМ,
— относительная точность арифметич. операций в ЭВМ,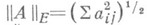 — евклидова матричная норма, f(n) — функция вида
— евклидова матричная норма, f(n) — функция вида 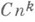 , где п- порядок системы. Точные значения константы Си показателя kопределяются такими деталями вычислительного процесса, как способ округления, использование операции накопления скалярных произведений и т. д. Наиболее часто k=1 или 3/2.
, где п- порядок системы. Точные значения константы Си показателя kопределяются такими деталями вычислительного процесса, как способ округления, использование операции накопления скалярных произведений и т. д. Наиболее часто k=1 или 3/2.
В случае методов типа Гаусса в правую часть оценки (4) входит еще множитель  , отражающий возможность роста элементов матрицы Ана промежуточных шагах метода по сравнению с первоначальным уровнем (такой рост отсутствует в ортогональных методах). Чтобы уменьшить значение
, отражающий возможность роста элементов матрицы Ана промежуточных шагах метода по сравнению с первоначальным уровнем (такой рост отсутствует в ортогональных методах). Чтобы уменьшить значение 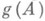 , применяют различные способы выбора ведущего элемента, препятствующие возрастанию элементов матрицы.
, применяют различные способы выбора ведущего элемента, препятствующие возрастанию элементов матрицы.
Для квадратного корня метода, к-рый применяется обычно в случае положительно определенной матрицы А, получена наиболее сильная оценка
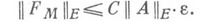
Существуют прямые методы (Жордана, окаймления, сопряженных градиентов), для к-рых непосредственное применение схемы обратного анализа не приводит к эффективным оценкам. В этих случаях при исследовании Н. п. применяются и иные соображения (см. [6] — [9]).
Лит.:[1] Givens W., «TJ. S. Atomic Energy Commiss. Repts. Ser. OR NL», 1954, № 1574; [2] Wilkinson J. H., Rounding errors in algebraic processes, L., 1963; [3] Уилкинсон Д ж. <Х., Алгебраическая проблема собственных значений, пер. с англ., М., 1970; [4] Воеводин В. В., Ошибки округления и устойчивость в прямых методах линейной алгебры, М., 1969; [5] его же, Вычислительные основы линейной алгебры, М., 1977; [6] Peters G., Wilkinsоn J. H., «Communs Assoc. Comput. Math.», 1975, v. 18, № 1, p. 20-24; [7] Вrоуden C. G., «J. Inst. Math, and Appl.», 1974, v. 14, № 2, p. 131-40; [8] Reid J. К., в кн.: Large Sparse Sets of Linear Equations, L.- N. Y., 1971, p. 231 — 254; [9] Икрамов Х. Д., «Ж. вычисл. матем. и матем. физики», 1978, т. 18, № 3, с. 531-45.
X. Д. Икрамов.
Н. п. округления или погрешности метода возникает при решении задач, где решение является результатом большого числа последовательно выполняемых арифметич. операций.
Значительная часть таких задач связана с решением алгебраич. задач, линейных или нелинейных (см. выше). В свою очередь среди алгебраич. задач наиболее распространены задачи, возникающие при аппроксимации дифференциальных уравнений. Этим задачам свойственны нек-рые специфич. особенности.
Н. п. метода решения задачи происходит по тем же или по более простым законам, что и Н. п. вычислительной погрешности; Н. ,п. метода исследуется при оценке метода решения задачи.
При исследовании накопления вычислительной погрешности различают два подхода. В первом случае считают, что вычислительные погрешности на каждом шаге вносятся самым неблагоприятным образом и получают мажорантную оценку погрешности. Во втором случае считают, что эти погрешности случайны с определенным законом распределения.
Характер Н. п. зависит от решаемой задачи, метода решения и ряда других факторов, на первый взгляд могущих показаться несущественными; сюда относятся форма записи чисел в ЭВМ (с фиксированной запятой или с плавающей запятой), порядок выполнения арифметич. операций и т. д. Напр., в задаче вычисления суммы Nчисел 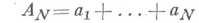
существенен порядок выполнения операций. Пусть вычисления производятся на машине с плавающей запятой с tдвоичными разрядами и все числа лежат в пределах 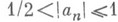 . При непосредственном вычислении
. При непосредственном вычислении 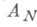 с помощью рекуррентной формулы
с помощью рекуррентной формулы 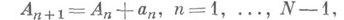 мажорантная оценка погрешности имеет порядок 2-tN. Можно поступить иначе (см. [1]). При вычислении попарных сумм
мажорантная оценка погрешности имеет порядок 2-tN. Можно поступить иначе (см. [1]). При вычислении попарных сумм 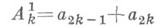 (если N=2l+1 нечетно) полагают
(если N=2l+1 нечетно) полагают  . Далее вычисляются их попарные суммы
. Далее вычисляются их попарные суммы  и т. д. При
и т. д. При 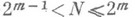 после тшагов образования попарных сумм по формулам
после тшагов образования попарных сумм по формулам

получают 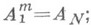 мажорантная оценка погрешности порядка
мажорантная оценка погрешности порядка 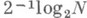
В типичных задачах величины а т вычисляются по формулам, в частности рекуррентным, или поступают последовательно в оперативную память ЭВМ; в этих случаях применение описанного приема приводит к увеличению загрузки памяти ЭВМ. Однако можно организовать последовательность вычислений так, что загрузка оперативной памяти не будет превосходить -log2N ячеек.
При численном решении дифференциальных уравнений возможны следующие случаи. При стремлении шага сетки hк нулю погрешность растет как 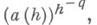 где
где 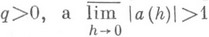 . Такие методы решения задач относят к классу неустойчивых. Их применение носит эпизодич. характер.
. Такие методы решения задач относят к классу неустойчивых. Их применение носит эпизодич. характер.
Для устойчивых методов характерен рост погрешности как  Оценка погрешности таких методов обычно производится следующим образом. Строится уравнение относительно возмущения, вносимого или округлением, или погрешностями метода и затем исследуется решение этого уравнения (см. [2], [3]).
Оценка погрешности таких методов обычно производится следующим образом. Строится уравнение относительно возмущения, вносимого или округлением, или погрешностями метода и затем исследуется решение этого уравнения (см. [2], [3]).
В более сложных случаях применяется метод эквивалентных возмущений (см. [1], [4]), развитый в отношении задачи исследования накопления вычислительной погрешности при решении дифференциальных уравнений (см. [3], [5], [6]). Вычисления по нек-рой расчетной схеме с округлениями рассматриваются как вычисления без округлений, но для уравнения с возмущенными коэффициентами. Сравнивая решение исходного сеточного уравнения с решением уравнения с возмущенными коэффициентами получают оценку погрешности.
Уделяется существенное внимание выбору метода по возможности с меньшими значениями qи A(h). При фиксированном методе решения задачи расчетные формулы обычно удается преобразовать к виду, где  (см. [3], [5]). Это особенно существенно в случае обыкновенных дифференциальных уравнений, где число шагов в отдельных случаях оказывается очень большим.
(см. [3], [5]). Это особенно существенно в случае обыкновенных дифференциальных уравнений, где число шагов в отдельных случаях оказывается очень большим.
Величина (h)может сильно расти с ростом промежутка интегрирования. Поэтому стараются применять методы по возможности с меньшим значением A(h). В случае задачи Коши ошибка округления на каждом конкретном шаге по отношению к последующим шагам может рассматриваться как ошибка в начальном условии. Поэтому нижняя грань (h)зависит от характеристики расхождения близких решений дифференциального уравнения, определяемого уравнением в вариациях.
В случае численного решения обыкновенного дифференциального уравнения 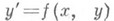 уравнение в вариациях имеет вид
уравнение в вариациях имеет вид
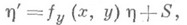
и потому при решении задачи на отрезке ( х 0 , X )нельзя рассчитывать на константу A(h)в мажорантной оценке вычислительной погрешности существенно лучшую, чем
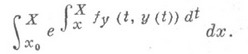
Поэтому при решении этой задачи наиболее употребительны однощаговые методы типа Рунге — Кутта или методы типа Адамса (см. [3], [7]), где Н. п. в основном определяется решением уравнения в вариациях.
Для ряда методов главный член погрешности метода накапливается по подобному закону, в то время как вычислительная погрешность накапливается существенно быстрее (см. [3]). Область практич. применимости таких методов оказывается существенно уже.
Накопление вычислительной погрешности существенно зависит от метода, применяемого для решения сеточной задачи. Напр., при решении сеточных краевых задач, соответствующих обыкновенным дифференциальным уравнениям, методами стрельбы и прогонки Н. п. имеет характер A(h)h-q, где qодно и то же. Значения A(h)у этих методов могут отличаться настолько, что в определенной ситуации один из методов становится неприменимым. При решении методом пристрелки сеточной краевой задачи для уравнения Лапласа Н. п. имеет характер с 1/h, с>1, а в случае метода прогонки Ah-q. При вероятностном подходе к исследованию Н. п. в одних случаях априорно предполагают какой-то закон распределения погрешности (см. [2]), в других случаях вводят меру на пространстве рассматриваемых задач и, исходя из этой меры, получают закон распределения погрешностей округления (см. [8], [9]).
При умеренной точности решения задачи мажорантные и вероятностные подходы к оценке накопления вычислительной погрешности обычно дают качественно одинаковые результаты: или в обоих случаях Н. п. происходит в допустимых пределах, или в обоих случаях Н. п. превосходит такие пределы.
Лит.:[1] Воеводин В. В., Вычислительные основы линейной алгебры, М., 1977; [2] Шура-Бура М. Р., «Прикл. матем. и механ.», 1952, т. 16, № 5, с. 575-88; [3] Бахвалов Н. С, Численные методы, 2 изд., М., 1975; [4] Уилкинсон Дж. X., Алгебраическая проблема собственных значений, пер. с англ., М.. 1970; [5] Бахвалов Н. С, в кн.: Вычислительные методы и программирование, в. 1, М., 1962, с, 69-79; [6] Годунов С. К., Рябенький В. С, Разностные схемы, 2 изд., М., 1977; [7] Бахвалов Н. С, «Докл. АН СССР», 1955, т. 104, № 5, с. 683-86; [8] его же, «Ж. вычислит, матем. и матем. физики», 1964; т. 4, № 3, с. 399- 404; [9] Лапшин Е. А., там же, 1971, т. 11, № 6, с.1425-36.
Н. С. Бахвалов.
при численном решении алгебраических уравнений — суммарное влияние округлений, сделанных на отдельных шагах вычислительного процесса, на точность полученного решения линейной алгебраич. системы. Наиболее распространенным способом априорной оценки суммарного влияния ошибок округления в численных методах линейной алгебры является схема т. н. обратного анализа. В применении к решению системы линейных алгебраич. уравнений схема обратного анализа заключается в следующем. Вычисленное прямым методом Мрешение хуи не удовлетворяет (1), но может быть представлено как точное решение возмущенной системы Качество прямого метода оценивается по наилучшей априорной оценке, к-рую можно дать для норм матрицы и вектора. Такие «наилучшие»и наз. соответственно матрицей и вектором эквивалентного возмущения для метода М. Если оценки для и имеются, то теоретически ошибка приближенного решения может быть оценена неравенством Здесь — число обусловленности матрицы А, а матричная норма в (3) предполагается подчиненной векторной норме В действительности оценка для редко бывает известна, и основной смысл (2) состоит в возможности сравнения качества различных методов. Ниже приводится вид нек-рых типичных оценок для матрицы Для методов с ортогональными преобразованиями и арифметики с плавающей запятой (в системе (1) Аи bсчитаются действительными) В этой оценке — относительная точность арифметич. операций в ЭВМ,- евклидова матричная норма, f(n) — функция вида, где п- порядок системы. Точные значения константы Си показателя kопределяются такими деталями вычислительного процесса, как способ округления, использование операции накопления скалярных произведений и т. д. Наиболее часто k=1 или 3/2. В случае методов типа Гаусса в правую часть оценки (4) входит еще множитель, отражающий возможность роста элементов матрицы Ана промежуточных шагах метода по сравнению с первоначальным уровнем (такой рост отсутствует в ортогональных методах). Чтобы уменьшить значение, применяют различные способы выбора ведущего элемента, препятствующие возрастанию элементов матрицы. Для квадратного корня метода, к-рый применяется обычно в случае положительно определенной матрицы А, получена наиболее сильная оценка Существуют прямые методы (Жордана, окаймления, сопряженных градиентов), для к-рых непосредственное применение схемы обратного анализа не приводит к эффективным оценкам. В этих случаях при исследовании Н. п. применяются и иные соображения (см. — ). Лит.: Givens W., «TJ. S. Atomic Energy Commiss. Repts. Ser. OR NL», 1954, № 1574; Wilkinson J. H., Rounding errors in algebraic processes, L., 1963; Уилкинсон Д ж.
Для устойчивых методов характерен рост погрешности как Оценка погрешности таких методов обычно производится следующим образом. Строится уравнение относительно возмущения, вносимого или округлением, или погрешностями метода и затем исследуется решение этого уравнения (см. , ). В более сложных случаях применяется метод эквивалентных возмущений (см. , ), развитый в отношении задачи исследования накопления вычислительной погрешности при решении дифференциальных уравнений (см. , , ). Вычисления по нек-рой расчетной схеме с округлениями рассматриваются как вычисления без округлений, но для уравнения с возмущенными коэффициентами. Сравнивая решение исходного сеточного уравнения с решением уравнения с возмущенными коэффициентами получают оценку погрешности. Уделяется существенное внимание выбору метода по возможности с меньшими значениями qи A(h). При фиксированном методе решения задачи расчетные формулы обычно удается преобразовать к виду, где (см. , ). Это особенно существенно в случае обыкновенных дифференциальных уравнений, где число шагов в отдельных случаях оказывается очень большим. Величина (h)может сильно расти с ростом промежутка интегрирования. Поэтому стараются применять методы по возможности с меньшим значением A(h). В случае задачи Коши ошибка округления на каждом конкретном шаге по отношению к последующим шагам может рассматриваться как ошибка в начальном условии. Поэтому нижняя грань (h)зависит от характеристики расхождения близких решений дифференциального уравнения, определяемого уравнением в вариациях. В случае численного решения обыкновенного дифференциального уравнения уравнение в вариациях имеет вид и потому при решении задачи на отрезке (х 0 , X)нельзя рассчитывать на константу A(h)в мажорантной оценке вычислительной погрешности существенно лучшую, чем Поэтому при решении этой задачи наиболее употребительны однощаговые методы типа Рунге — Кутта или методы типа Адамса (см. , ), где Н. п. в основном определяется решением уравнения в вариациях. Для ряда методов главный член погрешности метода накапливается по подобному закону, в то время как вычислительная погрешность накапливается существенно быстрее (см. ). Область практич. применимости таких методов оказывается существенно уже. Накопление вычислительной погрешности существенно зависит от метода, применяемого для решения сеточной задачи. Напр., при решении сеточных краевых задач, соответствующих обыкновенным дифференциальным уравнениям, методами стрельбы и прогонки Н. п. имеет характер A(h)h-q, где qодно и то же. Значения A(h)у этих методов могут отличаться настолько, что в определенной ситуации один из методов становится неприменимым. При решении методом пристрелки сеточной краевой задачи для уравнения Лапласа Н. п. имеет характер с 1/h, с>1, а в случае метода прогонки Ah-q. При вероятностном подходе к исследованию Н. п. в одних случаях априорно предполагают какой-то закон распределения погрешности (см. ), в других случаях вводят меру на пространстве рассматриваемых задач и, исходя из этой меры, получают закон распределения погрешностей округления (см. , ). При умеренной точности решения задачи мажорантные и вероятностные подходы к оценке накопления вычислительной погрешности обычно дают качественно одинаковые результаты: или в обоих случаях Н. п. происходит в допустимых пределах, или в обоих случаях Н. п. превосходит такие пределы. Лит.: Воеводин В. В., Вычислительные основы линейной алгебры, М., 1977; Шура-Бура М. Р., «Прикл. матем. и механ.», 1952, т. 16, № 5, с. 575-88; Бахвалов Н. С, Численные методы, 2 изд., М., 1975; Уилкинсон Дж. X., Алгебраическая проблема собственных значений, пер. с англ., М.. 1970; Бахвалов Н. С, в кн.: Вычислительные методы и программирование, в. 1, М., 1962, с, 69-79; Годунов С. К., Рябенький В. С, Разностные схемы, 2 изд., М., 1977; Бахвалов Н. С, «Докл. АН СССР», 1955, т. 104, № 5, с. 683-86; его же, «Ж. вычислит, матем. и матем. физики», 1964; т. 4, № 3, с. 399- 404; Лапшин Е. А., там же, 1971, т. 11, № 6, с.1425-36. Н. С. Бахвалов.
Смотреть значение Накопление Погрешности
в других словарях
Накопление
— накопления, ср. (книжн.). 1. только ед. Действие по глаг. накопить-накоплять и накопиться-накопляться. воды. Первоначальное накопление капитала (исходный пункт создания……..
Толковый словарь Ушакова
Накопление Ср.
— 1. Процесс действия по знач. глаг.: накопить, накопиться. 2. Состояние по знач. глаг.: накопить, накопиться. 3. То, что накоплено.
Толковый словарь Ефремовой
Накопление
— -я; ср.
1. к Накопи́ть — накопи́ться. Н. богатств. Н. знаний. Источники накопления.
2. только мн.: накопле́ния. То, что накоплено; сбережения. Увеличить размеры накоплений……..
Толковый словарь Кузнецова
Накопление
— — 1. увеличение личных капиталов, запасов, имущества; 2.
доля национального
дохода, используемая на пополнение производственных и непроизводственных фондов в……..
Экономический словарь
Накопление — Accumulation
— Ситуация, при которой происходит
рост торговых позиций, созданных ранее. Обычно это происходит за
счет добавления вновь открываемых позиций к уже существующим………
Экономический словарь
Накопление Валовое
— приобретение товаров, произведенных в отчетном
периоде, но не потребленное.
Показатель
счета
Операции с капиталом системы национальных счетов включает……..
Экономический словарь
Накопление Дивиденда
— В страховании жизни: способ урегулирования, содержащийся в условиях полиса по страхованию жизни, предоставляющий возможность оставить на депозитном счете страховой……..
Экономический словарь
Накопление Инвестором Менее 5% Акций Компании, Являющейся Целью Перекупки
— Как только приобретается 5% акций,
покупатель должен представить информацию в Комиссию по ценным
бумагам и
биржам, на соответствующую биржу и в компанию,……..
Экономический словарь
Накопление Основного Капитала Валовое
— вложение средств в основной капитал основные(фонды) для создания нового дохода в будущем.
Экономический словарь
Накопление Основного Капитала, Валовое
— — вложение средств в
основной
капитал (
основные фонды) для создания нового
дохода в будущем. В.н.о.к. состоит из следующих элементов: а)
приобретение……..
Экономический словарь
Накопление Страховое
— ENDOWMENT INSURANCEФорма страхования жизни, сочетающая
СТРАХОВАНИЕ и обязательное
накопление. Отличается от обычного страхования жизни тем, что по истечении определенного……..
Экономический словарь
Накопление, Аккумулирование
— Финансирование корпораций: прибыль, которая не выплачивается в качестве дивидендов, а добавляется к основному капиталу компании. См. также accumulated profits tax. Инвестиции:……..
Экономический словарь
Привлечение, Накопление, Образование Капитала; Прирост Основного Капитала
— Создание или расширение путем накопления сбережений капитала или средств производства (producers goods) — зданий, оборудования, механизмов — необходимых для производства ряда……..
Экономический словарь
Накопление
— — превращение части прибыли в капитал, увеличение запасов материалов, имущества, денежных средств, наращивание капитала, основных средств государством, предприятиями,……..
Юридический словарь
Накопление
— использование части дохода для расширения производства иувеличения на этой основе выпуска продукции и услуг. Размеры накопления итемпы его роста зависят от объема……..
Первоначальное Накопление Капитала
— процесс превращения основной массымелких товаропроизводителей (главным образом крестьян) в наемных рабочихпутем отделения их от средств производства и превращения……..
Большой энциклопедический словарь
Погрешности Измерений
— (ошибки измерений) — отклонения результатовизмерений от истинных значений измеряемой величины. Систематическиепогрешности измерений обусловлены главным образом……..
Большой энциклопедический словарь
Погрешности Средств Измерений
— отклонения метрологических свойств илипараметров средств измерений от номинальных, влияющие на погрешностирезультатов измерений (создающие т. н. инструментальные ошибки измерений).
Большой энциклопедический словарь
Первоначальное Накопление
— — процесс превращения основной массы мелких товаропроизводителей, в основном крестьян, в наемных рабочих. Создание предпринимателями накоплений для последующей организации……..
Исторический словарь
Первоначальное Накопление
— накопление капитала, предшествующее капиталистич. способу производства, делающее этот способ производства исторически возможным и составляющее его отправной, исходный……..
Советская историческая энциклопедия
Валовое Накопление Основного Капитала
— вложение резидентными единицами средств в объекты основного капитала для создания нового дохода в будущем путем использования их в производстве. Валовое накопление основного капитала……..
Социологический словарь
Измерение Ориентированное На Индикатор Погрешности
— — англ. measurement, indicator error,-oriented; нем. Fehlermessung. По В. Торгерсону — измерение, направленное на выявление в реакции опрашиваемых информации об индикаторах или раздражителях,……..
Социологический словарь
Капитала Накопление
— — англ. capital accumulation; нем. Akkumulation. Превращение прибавочной стоимости в капитал, происходящее в процессе расширенного воспроизводства.
Социологический словарь
Капитала Накопление Первоначальное
— — англ. capital accumulation, primitive; нем. Akkumulation, urprungliche. Предшествующий капиталист, способу производства процесс отделения непосредственных производителей (гл. обр. крестьян)……..
Социологический словарь
Капитальное Накопление
— (capital accumulation) — см Накопление капитала.
Социологический словарь
Накопление (или Расширенное Воспроизводство) Капитала
— (accumulation (or expanded or extended reproduction) of capital) (марксизм) — процесс, в ходе которого капитализм развивается посредством найма рабочей силы для производства прибавочной……..
Социологический словарь
Первоначальное Накопление
— (primitive accumulation) (Марксизм) — исторический процесс, посредством которого был накоплен капитал прежде, чем появился капитализм. В «Das Kapital» Маркс задается вопросом,……..
Социологический словарь
Временное Накопление Отходов На Пром-площадке
— — хранение отходов на территории предприятия в специально обустроенных для этих целей местах до момента их использования в последующем технологическом цикле или отправки……..
Экологический словарь
НАКОПЛЕНИЕ
— НАКОПЛЕНИЕ, -я, ср. 1. см. копить, -ся. 2. мн. Накопленная сумма, количество чего-н. Большие накопления. || прил. накопительный, -ая, -ое (спец.). Накопительная ведомость.
Толковый словарь Ожегова
БИОЛОГИЧЕСКОЕ НАКОПЛЕНИЕ
— БИОЛОГИЧЕСКОЕ НАКОПЛЕНИЕ концентрирование (накопление) ряда химических веществ (пестицидов, тяжелых металлов, радионуклидов и др.) в трофических……..
Экологический словарь
при численном решении алгебраических уравнений — суммарное влияние округлений, сделанных на отдельных шагах вычислительного процесса, на точность полученного решения линейной алгебраич. системы. Наиболее распространенным способом априорной оценки суммарного влияния ошибок округления в численных методах линейной алгебры является схема т. н. обратного анализа. В применении к решению системы линейных алгебраич. уравнений
схема обратного анализа заключается в следующем. Вычисленное прямым методом Мрешение хуи не удовлетворяет (1), но может быть представлено как точное решение возмущенной системы
Качество прямого метода оценивается по наилучшей априорной оценке, к-рую можно дать для норм матрицы и вектора . Такие «наилучшие»и наз. соответственно матрицей и вектором эквивалентного возмущения для метода М.
Если оценки для и имеются, то теоретически ошибка приближенного решения может быть оценена неравенством
Здесь — число обусловленности матрицы А, а матричная норма в (3) предполагается подчиненной векторной норме
В действительности оценка для редко бывает известна, и основной смысл (2) состоит в возможности сравнения качества различных методов. Ниже приводится вид нек-рых типичных оценок для матрицы Для методов с ортогональными преобразованиями и арифметики с плавающей запятой (в системе (1) Аи bсчитаются действительными)
В этой оценке — относительная точность арифметич. операций в ЭВМ,![]() — евклидова матричная норма, f(n) — функция вида , где п- порядок системы. Точные значения константы Си показателя kопределяются такими деталями вычислительного процесса, как способ округления, использование операции накопления скалярных произведений и т. д. Наиболее часто k=1 или 3/2.
— евклидова матричная норма, f(n) — функция вида , где п- порядок системы. Точные значения константы Си показателя kопределяются такими деталями вычислительного процесса, как способ округления, использование операции накопления скалярных произведений и т. д. Наиболее часто k=1 или 3/2.
В случае методов типа Гаусса в правую часть оценки (4) входит еще множитель , отражающий возможность роста элементов матрицы Ана промежуточных шагах метода по сравнению с первоначальным уровнем (такой рост отсутствует в ортогональных методах). Чтобы уменьшить значение , применяют различные способы выбора ведущего элемента, препятствующие возрастанию элементов матрицы.
Для квадратного корня метода,
к-рый применяется обычно в случае положительно определенной матрицы А, получена наиболее сильная оценка
Существуют прямые методы (Жордана, окаймления, сопряженных градиентов), для к-рых непосредственное применение схемы обратного анализа не приводит к эффективным оценкам. В этих случаях при исследовании Н. п. применяются и иные соображения (см. — ).
Лит.
: Givens W., «TJ. S. Atomic Energy Commiss. Repts. Ser. OR NL», 1954, № 1574; Wilkinson J. H., Rounding errors in algebraic processes, L., 1963; Уилкинсон Д ж.
X. Д. Икрамов.
Н. п. округления или погрешности метода возникает при решении задач, где решение является результатом большого числа последовательно выполняемых арифметич. операций.
Значительная часть таких задач связана с решением алгебраич. задач, линейных или нелинейных (см. выше). В свою очередь среди алгебраич. задач наиболее распространены задачи, возникающие при аппроксимации дифференциальных уравнений. Этим задачам свойственны нек-рые специфич. особенности.
Н. п. метода решения задачи происходит по тем же или по более простым законам, что и Н. п. вычислительной погрешности; Н. ,п. метода исследуется при оценке метода решения задачи.
При исследовании накопления вычислительной погрешности различают два подхода. В первом случае считают, что вычислительные погрешности на каждом шаге вносятся самым неблагоприятным образом и получают мажорантную оценку погрешности. Во втором случае считают, что эти погрешности случайны с определенным законом распределения.
Характер Н. п. зависит от решаемой задачи, метода решения и ряда других факторов, на первый взгляд могущих показаться несущественными; сюда относятся форма записи чисел в ЭВМ (с фиксированной запятой или с плавающей запятой), порядок выполнения арифметич. операций и т. д. Напр., в задаче вычисления суммы Nчисел
существенен порядок выполнения операций. Пусть вычисления производятся на машине с плавающей запятой с tдвоичными разрядами и все числа лежат в пределах ![]() . При непосредственном вычислении с помощью рекуррентной формулы мажорантная оценка погрешности имеет порядок 2 -t N.
. При непосредственном вычислении с помощью рекуррентной формулы мажорантная оценка погрешности имеет порядок 2 -t N.
Можно поступить иначе (см. ). При вычислении попарных сумм ![]() (если N=2l+1
(если N=2l+1
нечетно) полагают ![]() . Далее вычисляются их попарные суммы и т. д. При после тшагов образования попарных сумм по формулам
. Далее вычисляются их попарные суммы и т. д. При после тшагов образования попарных сумм по формулам
получают мажорантная оценка погрешности порядка
В типичных задачах величины а т
вычисляются по формулам, в частности рекуррентным, или поступают последовательно в оперативную память ЭВМ; в этих случаях применение описанного приема приводит к увеличению загрузки памяти ЭВМ. Однако можно организовать последовательность вычислений так, что загрузка оперативной памяти не будет превосходить -log 2 N ячеек.
При численном решении дифференциальных уравнений возможны следующие случаи. При стремлении шага сетки hк нулю погрешность растет как где ![]() . Такие методы решения задач относят к классу неустойчивых. Их применение носит эпизодич. характер.
. Такие методы решения задач относят к классу неустойчивых. Их применение носит эпизодич. характер.
Для устойчивых методов характерен рост погрешности как Оценка погрешности таких методов обычно производится следующим образом. Строится уравнение относительно возмущения, вносимого или округлением, или погрешностями метода и затем исследуется решение этого уравнения (см. , ).
В более сложных случаях применяется метод эквивалентных возмущений (см. , ), развитый в отношении задачи исследования накопления вычислительной погрешности при решении дифференциальных уравнений (см. , , ). Вычисления по нек-рой расчетной схеме с округлениями рассматриваются как вычисления без округлений, но для уравнения с возмущенными коэффициентами. Сравнивая решение исходного сеточного уравнения с решением уравнения с возмущенными коэффициентами получают оценку погрешности.
Уделяется существенное внимание выбору метода по возможности с меньшими значениями qи A(h).
При фиксированном методе решения задачи расчетные формулы обычно удается преобразовать к виду, где (см. , ). Это особенно существенно в случае обыкновенных дифференциальных уравнений, где число шагов в отдельных случаях оказывается очень большим.
Величина (h)может сильно расти с ростом промежутка интегрирования. Поэтому стараются применять методы по возможности с меньшим значением A(h).
В случае задачи Коши ошибка округления на каждом конкретном шаге по отношению к последующим шагам может рассматриваться как ошибка в начальном условии. Поэтому нижняя грань (h)зависит от характеристики расхождения близких решений дифференциального уравнения, определяемого уравнением в вариациях.
В случае численного решения обыкновенного дифференциального уравнения ![]() уравнение в вариациях имеет вид
уравнение в вариациях имеет вид
и потому при решении задачи на отрезке ( х 0 , X
)нельзя рассчитывать на константу A(h)в мажорантной оценке вычислительной погрешности существенно лучшую, чем

Поэтому при решении этой задачи наиболее употребительны однощаговые методы типа Рунге — Кутта или методы типа Адамса (см. , ), где Н. п. в основном определяется решением уравнения в вариациях.
Для ряда методов главный член погрешности метода накапливается по подобному закону, в то время как вычислительная погрешность накапливается существенно быстрее (см. ). Область практич. применимости таких методов оказывается существенно уже.
Накопление вычислительной погрешности существенно зависит от метода, применяемого для решения сеточной задачи. Напр., при решении сеточных краевых задач, соответствующих обыкновенным дифференциальным уравнениям, методами стрельбы и прогонки Н. п. имеет характер A(h)h -q ,
где qодно и то же. Значения A(h)у этих методов могут отличаться настолько, что в определенной ситуации один из методов становится неприменимым. При решении методом пристрелки сеточной краевой задачи для уравнения Лапласа Н. п. имеет характер с 1/h , с
>1, а в случае метода прогонки Ah -q .
При вероятностном подходе к исследованию Н. п. в одних случаях априорно предполагают какой-то закон распределения погрешности (см. ), в других случаях вводят меру на пространстве рассматриваемых задач и, исходя из этой меры, получают закон распределения погрешностей округления (см. , ).
При умеренной точности решения задачи мажорантные и вероятностные подходы к оценке накопления вычислительной погрешности обычно дают качественно одинаковые результаты: или в обоих случаях Н. п. происходит в допустимых пределах, или в обоих случаях Н. п. превосходит такие пределы.
Лит.
: Воеводин В. В., Вычислительные основы линейной алгебры, М., 1977; Шура-Бура М. Р., «Прикл. матем. и механ.», 1952, т. 16, № 5, с. 575-88; Бахвалов Н. С, Численные методы, 2 изд., М., 1975; Уилкинсон Дж. X., Алгебраическая проблема собственных значений, пер. с англ., М.. 1970; Бахвалов Н. С, в кн.: Вычислительные методы и программирование, в. 1, М., 1962, с, 69-79; Годунов С. К., Рябенький В. С, Разностные схемы, 2 изд., М., 1977; Бахвалов Н. С, «Докл. АН СССР», 1955, т. 104, № 5, с. 683-86; его же, «Ж. вычислит, матем. и матем. физики», 1964; т. 4, № 3, с. 399- 404; Лапшин Е. А., там же, 1971, т. 11, № 6, с.1425-36.
- — отклонения результатов измерений истинных значений измеряемой величины. Систематич…
- — отклонения метрологич. свойств или параметров средств измерений от поминальных, влияющее на погрешности результатов измерений…
Естествознание. Энциклопедический словарь
- — отклонения результатов измерений от истинных значений измеряемой величины. Играют существенную роль при производстве ряда судебных экспертиз…
Криминалистическая энциклопедия
- — : Смотри также: — погрешности средств измерений — погрешности измерений…
- — Смотри…
Энциклопедический словарь по металлургии
- — отклонения метрологических параметров средств измерений от номинальных, влияющие на погрешности результатов измерений…
Энциклопедический словарь по металлургии
- — «…Периодические погрешности — погрешности, значение которых является периодической функцией времени или перемещения указателя измерительного прибора…..
Официальная терминология
- — «…Постоянные погрешности — погрешности, которые длительное время сохраняют свое значение, например в течение времени выполнения всего ряда измерений. Они встречаются наиболее часто…..
Официальная терминология
- — «…Прогрессивные погрешности — непрерывно возрастающие или убывающие погрешности…
Официальная терминология
- — см. Ошибки наблюдений…
Энциклопедический словарь Брокгауза и Евфрона
- — ошибки измерений, отклонения результатов измерений от истинных значений измеряемых величин. Различают систематические, случайные и грубые П. и. …
- — отклонения метрологических свойств или параметров средств измерений от номинальных, влияющие на погрешности результатов измерений, получаемых при помощи этих средств…
Большая Советская энциклопедия
- — разность между результатами измерений и истинным значением измеряемой величины. Относительной погрешностью измерения называется отношение абсолютной погрешности измерения к истинному значению…
Современная энциклопедия
- — отклонения результатов измерений от истинных значений измеряемой величины…
Большой энциклопедический словарь
- — прил., кол-во синонимов: 3 исправивший устранивший неточности устранивший ошибки…
Словарь синонимов
- — прил., кол-во синонимов: 4 исправлявший устранявший изъяны устранявший неточности устранявший ошибки…
Словарь синонимов
«НАКОПЛЕНИЕ ПОГРЕШНОСТИ» в книгах
Технические погрешности
Из книги
Звезды и немного нервно
автора
Технические погрешности
Из книги
Напрасные совершенства и другие виньетки
автора
Жолковский Александр Константинович
Технические погрешности
Рассказы об успешном противостоянии силе не так неправдоподобны, как мы подспудно боимся. Наезд обычно предполагает пассивность жертвы, а потому продумывается лишь на шаг вперед и контрудара не выдерживает. Папа рассказывал об одном таком
Грешки и погрешности
Из книги
Как NASA показало Америке Луну
автора
Рене Ральф
Грешки и погрешности
Несмотря на всю фиктивность своей космической навигации, NASA кичилось потрясающей точностью во всем, что бы ни делало. Девять раз подряд капсулы Аполлонов идеально ложились на лунную орбиту, не нуждаясь в серьезной корректировке курса. Лунный модуль,
Первоначальное накопление капитала. Насильственное обезземеливание крестьян. Накопление богатств.
автора
Первоначальное накопление капитала. Насильственное обезземеливание крестьян. Накопление богатств.
Капиталистическое производство предполагает два основных условия: 1) наличие массы неимущих людей, лично свободных и в то же время лишённых средств производства и
Социалистическое накопление. Накопление и потребление в социалистическом обществе.
Из книги
Политическая экономия
автора
Островитянов Константин Васильевич
Социалистическое накопление. Накопление и потребление в социалистическом обществе.
Источником расширенного социалистического воспроизводства является социалистическое накопление. Социалистическое накопление есть использование части чистого дохода общества,
Погрешности измерений
БСЭ
Погрешности средств измерений
Из книги
Большая Советская Энциклопедия (ПО)
автора
БСЭ
Погрешности УЗИ
Из книги
Восстановление щитовидной железы Руководство для пациентов
автора
Ушаков Андрей Валерьевич
Погрешности УЗИ
Когда из С.-Петербурга ко мне приехала на консультацию пациентка, я увидел сразу три протокола ультразвукового обследования. Все они были сделаны разными специалистами. По-разному описаны. При этом даты исследований отличались друг от друга почти
Приложение 13 Речевые погрешности
Из книги
Искусство добиваться своего
автора
Степанов Сергей Сергеевич
Приложение 13
Речевые погрешности
Даже безобидные на первый взгляд фразы зачастую могут стать серьезным барьером в продвижении по службе. Известный американский специалист по маркетингу Джон Р. Грехем составил список выражений, употребление которых, по его наблюдениям,
Речевые погрешности
Из книги
Сколько вы стоите [Технология успешной карьеры]
автора
Степанов Сергей Сергеевич
Речевые погрешности
Даже безобидные на первый взгляд фразы зачастую могут стать серьезным барьером в продвижении по службе. Известный американский специалист по маркетингу Джон Р. Грехем составил список выражений, употребление которых, по его наблюдениям, не позволило
Губительные погрешности
Из книги
Чёрный лебедь [Под знаком непредсказуемости]
автора
Талеб Нассим Николас
Губительные погрешности
У погрешностей есть такое губительное свойство: чем они значительнее, тем больше их маскирующее воздействие.Никто не видит дохлых крыс, и поэтому чем смертельнее риск, тем менее он явен, ведь пострадавшие исключаются из числа свидетелей. Чем
Погрешности при ориентировании
Из книги
Азбука туризма
автора
Бардин Кирилл Васильевич
Погрешности при ориентировании
Итак, обычная задача на ориентирование, которую приходится решать туристу, состоит в том, что надо прийти из одного пункта в другой, пользуясь только компасом и картой. Местность незнакомая и к тому же закрытая, т. е. лишенная сколько-нибудь
Погрешности: философия
Из книги
автора
Погрешности: философия
На интуитивном уровне мы понимаем, что знание наше во многих случаях не точно. Можно осторожно предположить, что точным наше знание вообще может быть только при дискретной шкале. Можно точно знать, сколько шариков в мешке, но нельзя — каков их вес,
Погрешности: модели
Из книги
автора
Погрешности: модели
Когда мы что-то измеряем, имеющуюся к моменту начала измерений информацию (как осознанная, так и неосознанная) удобно представить в виде моделей объекта или явления. Модель «нулевого уровня» — это модель наличия величины. Мы верим в то, что она есть —
Погрешности: что и как контролировать
Из книги
автора
Погрешности: что и как контролировать
Выбор контролируемых параметров, схемы измерений, метода и объема контроля делается с учетом выходных параметров изделия, его конструкции и технологии, требований и потребностей того, кто применяет контролируемые изделия. Опять же,
Под погрешностью
измерения будем понимать совокупность
всех ошибок измерения.
Ошибки измерений
можно классифицировать на следующие
виды:
Абсолютные и
относительные,
Положительные и
отрицательные,
Постоянные и
пропорциональные,
Случайные и
систематические,
Абсолютная
ошибка
А
y
)
определяется как разность следующих
величин:
А
y
= y
i
— y
ист.
y
i
-y
,
где: y
i – единичный результат измерения;y
ист. – истинный результат измерения;y
– среднее арифметическое значение
результата измерения (далее среднее).
Постоянной
называется абсолютная ошибка,
которая не зависит от значения измеряемой
величины (y
y
).
Ошибка пропорциональная
,
если названная зависимость существует.
Характер ошибки измерения (постоянная
или пропорциональная) определяется
после проведения специальных исследований.
Относительная
ошибка
единичного результата
измерения (В
y
)
рассчитывается как отношение следующих
величин:
Из этой формулы
следует, что величина относительной
ошибки зависит не только от величины
абсолютной ошибки, но и от значения
измеряемой величины. При неизменности
измеряемой величины (y
)
относительную ошибку измерения можно
уменьшить только за счет снижения
величины абсолютной ошибки (А
y
).
При постоянстве абсолютной ошибки
измерения для уменьшения относительной
ошибки измерения можно использовать
прием увеличения значения измеряемой
величины.
Знак ошибки
(положительный или отрицательный)
определяется разницей между единичным
и полученным (средним арифметическим)
результатом измерения:
y
i -y
> 0 (ошибка
положительная
);
y
i -y
< 0 (ошибка
отрицательная
).
Грубая ошибка
измерения (промах) возникает при нарушении
методики измерения. Результат измерения,
содержащий грубую ошибку, обычно
значительно отличается по величине от
других результатов. Наличие грубых
ошибок измерения в выборке устанавливается
только методамиматематической
статистики (при числе повторений
измерения n
>2).
С методами обнаружения грубых ошибок
познакомьтесь самостоятельно в .
К случайным
ошибкам
относят ошибки, которые не
имеют постоянной величины и знака. Такие
ошибки возникают под действием следующих
факторов: не известных исследователю;
известных, но нерегулируемых; постоянно
изменяющихся.
Случайные
ошибки можно оценить только после
проведения измерений.
Количественной
оценкой модуля величины случайной
ошибки измерения могут являться следующие
параметры: выборочная дисперсия
единичных значений и среднего значения;
выборочные абсолютные стандартные
отклонения единичных значений и среднего
значения; выборочные относительные
стандартные отклонения единичных
значений и среднего значения; генеральная
дисперсия единичных значений
),
соответственно, и др.
Случайные ошибки
измерения невозможно исключить, их
можно только уменьшить. Один из основных
способов уменьшения величины случайной
ошибки измерения – это увеличение числа
(объема выборки) единичных измерений
(увеличение величины n
).
Объясняется это тем, что величина
случайных ошибок обратно пропорциональна
величинеn
, например:
 .
.
Систематические
ошибки
– это ошибки с неизменными
величиной и знаком или изменяющиеся по
известному закону. Эти ошибки вызываются
постоянными факторами. Систематические
ошибки можно количественно оценивать,
уменьшать и даже исключать.
Систематические
ошибки классифицируют на ошибки I,IIиIIIтипов.
К систематическим
ошибкам
I
типа
относят ошибки известного происхождения,
которые могут быть до проведения
измерения оценены путем расчета. Эти
ошибки можно исключить, вводя их в
результат измерения в виде поправок.
Примером ошибки такого типа является
ошибка при титрометрическом определении
объемной концентрации раствора, если
титрант был приготовлен при одной
температуре, а измерение концентрации
проводилось при другой. Зная зависимость
плотности титранта от температуры,
можно до проведения измерения рассчитать
изменение объемной концентрации
титранта, связанное с изменением его
температуры, и эту разницу учесть в виде
поправки в результате измерения.
Систематические
ошибки
II
типа
– это ошибки известного происхождения,
которые можно оценить только в ходе
эксперимента или в результате проведения
специальных исследований. К этому типу
ошибок относят инструментальные
(приборные), реактивные, эталонные и др.
ошибки. Познакомьтесь с особенностями
таких ошибок самостоятельно в .
Любой прибор при
его применении в процедуре измерения
вносит в результат измерения свои
приборные ошибки. При этом часть этих
ошибок случайная, а другая часть –
систематическая. Случайные ошибки
приборов отдельно не оценивают, их
оценивают в общей совокупности со всеми
другими случайными ошибками измерения.
Каждый экземпляр
любого прибора имеет свою персональную
систематическую ошибку. Для того чтобы
оценить эту ошибку, необходимо проводить
специальные исследования.
Наиболее надежный
способ оценки приборной систематической
ошибки IIтипа – это сверка
работы приборов по эталонам. Для мерной
посуды (пипетка, бюретка, цилиндры и
др.) проводят специальную процедуру –
калибровку.
На практике наиболее
часто требуется не оценить, а уменьшить
или исключить систематическую ошибку
IIтипа. Самыми распространенными
методами уменьшения систематических
ошибок являютсяметоды релятивизации
и рандомизации
.Познакомьтесь с
этими методами самостоятельно в .
К ошибкам
III
типа
относят ошибки неизвестного
происхождения. Эти ошибки можно обнаружить
только после устранения всех систематических
ошибокIиIIтипов.
К прочим ошибкам
отнесем все другие виды ошибок, не
рассмотренные выше (допускаемые,
возможные предельные ошибки и др.).
Понятие возможных предельных ошибок
применяется в случаях использования
средств измерения и предполагает
максимально возможную по величине
инструментальную ошибку измерения
(реальное же значение ошибки может быть
меньше величины возможной предельной
ошибки).
При использовании
средств измерения можно рассчитать
возможную предельную абсолютную ( )
)
или относительную ( )
)
погрешность измерения. Так, например,
возможная предельная абсолютная
погрешность измерения находится как
сумма возможных предельных случайных
( )
)
и неисключенных систематических ( )
)
ошибок:
 =
=
 +
+
При выборках малого
объема (n
20)
неизвестной генеральной совокупности,
подчиняющейся нормальному закону
распределения, случайные возможные
предельные ошибки измерений можно
оценить следующим образом:
 =
=
 =
= ,
,
где:
 – доверительный интервал для
– доверительный интервал для
соответствующей вероятностиР
;
 –квантиль
–квантиль
распределения Стьюдента для вероятности
Р
и выборки объемомn
или при
числе степеней свободыf
=
n
– 1.
Абсолютная возможная
предельная погрешность измерения в
этом случае будет равна:
 =
=
 +
+ .
.
Если результаты
измерений не подчиняются нормальному
закону распределения, то оценка
погрешностей проводится по другим
формулам.
Определение
величины

зависит от наличия у средства
измерения класса точности. Если средство
измерения не имеет класса точности, тоза величину
 можно принять минимальную цену
можно принять минимальную цену
деления шкалы
(или ее половину) средства
измерения . Для средства измерения с
известным классом точности за величину можно принять абсолютнуюдопускаемую
можно принять абсолютнуюдопускаемую
систематическую ошибку средства
измерения ( ):
):

 .
.
Величина
 рассчитывается исходя из формул,
рассчитывается исходя из формул,
приведенных в табл. 2.
Для многих средств
измерения класс точности указывается
в виде чисел а
10 n
, гдеа
равно 1; 1,5; 2; 2,5; 4; 5; 6 иn
равно 1; 0; -1; -2 и т.д., которые показывают
величину возможной предельной допускаемой
систематической ошибки (Е y
,
доп.
) и специальных знаков,
свидетельствующих о ее типе (относительная,
приведенная, постоянная, пропорциональная).
Если известны
составляющие абсолютной систематической
ошибки среднего арифметического
результата измерения (например, приборная
ошибка, ошибка метода и др.), то ее можно
оценить по формуле
 ,
,
где: m
– число
составляющих систематическую ошибку
среднего результата измерения;
k
– коэффициент,
определяемый вероятностьюР
и числомm
;
 –абсолютная
–абсолютная
систематическая ошибка отдельной
составляющей.
Отдельными
составляющими погрешности можно
пренебрегать при выполнении соответствующих
условий.
Таблица 2
Примеры обозначения
классов точности средств измерения
|
Обозначение точности |
Формула |
Характеристика |
|
|
в |
на |
||
|
|
Приведенная |
||
|
|
Приведенная |
||
|
|
Постоянная |
||
|
c |
Пропорциональная |




Систематическими
ошибками можно пренебрегать, если
выполняется неравенство
 0,8.
0,8.
В этом случае
принимают



 .
.
Случайными ошибками
можно пренебречь при условии
 8.
8.
Для этого случая


.
Чтобы общая
погрешность измерения определялась
только систематическими ошибками,
увеличивают число повторных измерений.
Минимально необходимое для этого число
повторных измерений (n
min) можно
рассчитать только при известном значении
генеральной совокупности единичных
результатов по формуле
 .
.
Оценка погрешностей
измерения зависит не только от условий
измерения, но и от типа измерения (прямое
или косвенное).
Деление измерений
на прямые и косвенные достаточно условно.
В дальнейшем под прямыми измерениями
будем понимать измерения значения
которых берут непосредственно из опытных
данных, например, считывают
со шкалы прибора (широко известный
пример прямого измерения –измерение
температуры термометром). Ккосвенным
измерениям
будем относить
такие, результат которых получают на
основании известной зависимости между
искомой величиной и величинами,
определяемыми в результате прямых
измерений. При этомрезультат
косвенного измеренияполучают расчетным
путем
как значение функции
,
аргументами которой являются результаты
прямых измерений (x
1 ,x
2 ,
…,x
j,. …,x
k).
Необходимо знать,
что ошибки косвенных измерений всегда
больше, чем ошибки отдельных прямых
измерений.
Ошибки косвенных
измерений
оцениваются по
соответствующим законам накопления
ошибок (приk
2).
Закон накопления
случайных ошибок
косвенных измерений
выглядит следующим образом:

 .
.
Закон накопления
возможных предельных абсолютных
систематических ошибок
косвенных
измерений представляется следующими
зависимостями:
 ;
;
 .
.
Закон накопления
возможных предельных относительных
систематических ошибок
косвенных
измерений имеет следующий вид:
 ;
;
 .
.
В случаях, когда
искомая величина (y
) рассчитывается
как функция результатов нескольких
независимых прямых измерений вида ,
,
закон накопления предельных относительных
систематических ошибок косвенных
измерений принимает более простой вид:
 ;
;
 .
.
Ошибки и погрешности
измерений определяют их точность,
воспроизводимость и правильность.
Точность
тем
выше, чем меньше величина погрешности
измерения.
Воспроизводимость
результатов измерений улучшается при
уменьшении случайных ошибок измерений.
Правильность
результата измерений увеличивается
с уменьшением остаточных систематических
ошибок измерений.
Более
подробно с теорией ошибок измерений и
их особенностями познакомьтесь
самостоятельно . Обращаю ваше внимание
на то, что современные формы представления
конечных результатов измерений
обязательно требуют приведения ошибок
или погрешностей измерения (вторичных
данных). При этом погрешности и ошибки
измерений должны представляться числами,
которые содержат не более двух
значащих цифр
.
1.2.10. Обработка косвенных измерений.
При косвенных измерениях искомое значение физической величины Y
находят на основании результатов X
1
,
X
2
, …
X
i
, …
X
n
, прямых измерений других физических величин, связанных с искомой известной функциональной зависимостью φ:
Y
= φ(X
1
, X
2
, … X
i
, …
X
n
). (1.43)
Предполагая, что X
1
,
X
2
, …
X
i
, …
X
n
– исправленные результаты прямых измерений, а методическими погрешностями косвенного измерения можно пренебречь, результат косвенного измерения можно найти непосредственно по формуле (1.43).
Если ΔX
1
,
ΔX
2
, …
ΔX
i
, …
ΔX
n
– погрешности результатов прямых измерений величин X
1
,
X
2
, …
X
i
, …
X
n
, то погрешность Δ результата Y
косвенного измерения в линейном приближении может быть найдена по формуле
Δ
= . (1.44)
Слагаемое
 (1.45)
(1.45)
– составляющую погрешности результата косвенного измерения, вызванная погрешностью ΔX
i
результата X
i
прямого измерения – называют частной погрешностью, а приближенную формулу (1.44) – законом накопления частных погрешностей
. {1К22}
Для оценки погрешности Δ результата косвенного измерения необходимо иметь ту или иную информацию о погрешностях ΔX
1
,
ΔX
2
, …
ΔX
i
, …
ΔX
n
результатов прямых измерений.
Обычно известны предельные значения составляющих погрешностей прямых измерений. Например, для погрешности ΔX
i
известны: предел основной погрешности, пределы дополнительных погрешностей, предел неисключенных остатков систематической погрешности и т.д. Погрешность ΔX
i
равна сумме этих погрешностей:
 ,
,
а предельное значение этой погрешности ΔX i
,п – сумме пределов:
 . (1.46)
. (1.46)
Тогда предельное значение Δ п погрешности результата косвенного измерения P
= 1 можно найти по формуле
Δ п
=  . (1.47)
. (1.47)
Граничное значение Δ г погрешности результата косвенного измерения для доверительной вероятности P
= 0,95 можно найти по приближенной формуле (1.41). С учетом (1.44) и (1.46) получим:
 . (1.48)
. (1.48)
После расчета Δ п или Δ г результат косвенного измерения следует записать с стандартной форме (соответственно, (1.40) или (1.42)). {1П3}
ВОПРОСЫ:
1. Для решения каких задач используются средств измерительной техники? Какие метрологические характеристики
средств измерительной техники Вам известны?
2. По каким признакам классифицируются метрологические характеристики
средств измерительной техники?
3. Какая составляющая погрешности средства измерений называется основной
?
4. Какая составляющая погрешности средства измерений называется дополнительной
?
5. Дайте определения абсолютной, относительной и приведенной погрешности
средства измерений.
6. Дайте определения абсолютной погрешности измерительного преобразователя по входу и выходу
.
7. Как бы Вы экспериментально определили погрешности измерительного преобразователя по входу и выходу
?
8. Как взаимосвязаны абсолютные погрешности измерительного преобразователя по входу и выходу
?
9. Дайте определения аддитивной, мультипликативной и нелинейной составляющих погрешности средства измерительной техники
.
10. Почему нелинейную составляющую погрешности средства измерительной техники
называют иногда погрешностью линейности
? Для каких функций преобразования измерительных преобразователей
это имеет смысл?
11. Какую информацию о погрешности средства измерений дает его класс точности
?
12. Сформулируйте закон накопления частных погрешностей.
13. Сформулируйте задачу суммирования погрешностей.
15. Что такое исправленное значение результата измерения
?
16. Какова цель обработки результатов измерений
?
17. Как рассчитать предельное значение
Δ п
погрешности
результата прямого измерения
для доверительной вероятности P
= 1 и ее граничное значение
Δ г для P
= 0,95?
18. Какое измерение называют косвенным
? Как найти результат косвенного измерения
?
19. Как рассчитать предельное значение
Δ п
погрешности
результата косвенного измерения
для доверительной вероятности P
= 1 и ее граничное значение
Δ г для P
= 0,95?
20. Приведите примеры методических погрешностей прямых и косвенных измерений.
Контрольные работы по подразделу 1.2 приведены в {1КР1}
.
ЛИТЕРАТУРА к разделу 1.
2. МЕТОДЫ ИЗМЕРЕНИЙ ЭЛЕКТРИЧЕСКИХ ВЕЛИЧИН
2.1. Измерение напряжений и токов.
2.1.1. Общие сведения.
При выборе средства измерений электрических напряжений и токов необходимо, прежде всего, учитывать:
Род измеряемой физической величины (напряжение или ток);
Наличие и характер зависимости измеряемой величины от времени на интервале наблюдения (зависит или нет, зависимость представляет собой периодическую или непериодическую функцию и т.д.);
Диапазон возможных значений измеряемой величины;
Измеряемый параметр (среднее значение, действующее значение, максимальное значение на интервале наблюдения, множество мгновенных значений на интервале наблюдения и т.п.);
Частотный диапазон;
Требуемую точность измерений;
Максимальный интервал времени наблюдения.
Кроме того, приходится учитывать диапазоны значений влияющих величин (температуры окружающего воздуха, напряжения питания средства измерений, выходного сопротивления источника сигнала, электромагнитных помех, вибраций, влажности и т.д.), зависящие от условий проведения измерительного эксперимента.
Диапазоны возможных значений напряжений и токов весьма широки. Например, токи могут быть порядка 10 -16 А при измерениях в космосе и порядка 10 5 А — в цепях мощных энергетических установках. В данном разделе рассматриваются, в основном, измерения напряжений и токов в наиболее часто встречающихся на практике диапазонах: от 10 -6 до 10 3 В и от 10 -6 до 10 4 А.
Для измерения напряжений используют аналоговые (электромеханические и электронные) и цифровые вольтметры
{2К1}
, компенсаторы (потенциометры) постоянного и переменного тока, аналоговые и цифровые осциллографы и измерительные системы.
Для измерений токов используют электромеханические амперметры
{2К2}
, а также мультиметры
и измерительные системы, в которых измеряемый ток преобразуется предварительно в пропорциональное ему напряжение. Кроме того, для экспериментального определения токов используют косвенный метод, измеряя напряжение, вызванное прохождением тока через резистор с известным сопротивлением.
2.1.2. Измерение постоянных напряжений электромеханическими приборами.
Для создания вольтметров используют следующие измерительные механизмы
{2К3}
: магнитоэлектрический
{2К4}
, электромагнитный
{2К5}
, электродинамический
{2К6}
, ферродинамический
{2К7}
и электростатический
{2К8}
.
В магнитоэлектрическом измерительном механизме вращающий момент пропорционален току в подвижной катушке. Для построения вольтметра последовательно с обмоткой катушки включают добавочное сопротивление. Измеряемое напряжение, подаваемое на это последовательное соединение, пропорционально току в обмотке; поэтому шкалу прибора можно градуировать в единицах напряжения. Направление вращающего момента зависит от направления тока, поэтому необходимо обращать внимание на полярность подаваемого на вольтметр напряжения.
Входное сопротивление R
вх магнитоэлектрического вольтметра зависит от конечного значения U
к диапазона измерений и тока полного отклонения I
по – тока в обмотке катушки, при котором стрелка прибора отклонится на всю шкалу (установится на отметке U
к). Очевидно, что
R
вх = U
к /I
по. (2.1)
В многопредельных приборах часто нормируют не значение R
вх, а ток I
по. Зная напряжение U
к для используемого в данном эксперименте диапазона измерений, значение R
вх можно рассчитать по формуле (2.1). Например, для вольтметра с U
к = 100 В и I
по = 1 мА R
вх = 10 5 Ом.
Для построения электромагнитных, электродинамических и ферродинамических вольтметров используют аналогичную схему, только добавочное сопротивление включают последовательно с обмоткой неподвижной катушки электромагнитного измерительного механизма или с предварительно последовательно соединенными обмотками подвижной и неподвижной катушек электродинамического или ферродинамического измерительных механизмов. Токи полного отклонения для этих измерительных механизмов обычно существенно больше, чем для магнитоэлектрического, поэтому входные сопротивления вольтметров меньше.
В электростатических вольтметрах используют электростатический измерительный механизм. Измеряемое напряжение подают между изолированными друг от друга неподвижными и подвижными пластинами. Входное сопротивление определяется сопротивлением изоляции (порядка 10 9 Ом).
Наиболее распространенные электромеханические вольтметры с классами точности 0,2. 0,5, 1,0, 1,5 позволяют измерять постоянные напряжения в диапазоне от 0,1 до 10 4 В. Для измерения больших напряжений (обычно более 10 3 В) используют делители напряжения
{2К9}
. Для измерения напряжений менее 0,1 В можно применять магнитоэлектрические гальванометры
{2К10}
и приборы на их основе (например, фотогальванометрические приборы), однако целесообразнее использовать цифровые вольтметры.
2.1.3. Измерение постоянных токов электромеханическими приборами.
Для создания амперметров используют следующие измерительные механизмы
{2К3}
: магнитоэлектрический
{2К4}
, электромагнитный
{2К5}
, электродинамический
{2К6}
и ферродинамический
{2К7}
.
В простейших однопредельных амперметрах цепь измеряемого тока состоит из обмотки подвижной катушки (для магнитоэлектрического измерительного механизма), обмотки неподвижной катушки (для электромагнитного измерительного механизма) или последовательно включенных обмоток подвижной и неподвижной катушек (для электродинамического и ферродинамического измерительных механизмов). Таким образом, в отличие от цепей вольтметров, в них отсутствуют добавочные сопротивления.
Многопредельные амперметры строят на базе однопредельных, используя различные приемы для уменьшения чувствительности. Например, пропуская измеряемый ток через часть обмотки катушки или включая обмотки катушек параллельно. Используют также шунты – резисторы с относительно малыми сопротивлениями, включаемые параллельно обмоткам.
Наиболее распространенные электромеханические амперметры с классами точности 0,2. 0,5, 1,0, 1,5 позволяют измерять постоянные токи в диапазоне от 10 -6 до 10 4 А. Для измерения токов менее 10 -6 А можно применять магнитоэлектрические гальванометры
{2К10}
и приборы на их основе (например, фотогальванометрические приборы).
2.1.4. Измерение переменных токов и напряжений
электромеханическими приборами.
Электромеханические амперметры и вольтметры применяются для измерения действующих значений периодических токов и напряжений. Для их создания используются электромагнитные, электродинамические и ферродинамические, а также электростатические (только для вольтметров) измерительные механизмы. Кроме того, к электромеханическим амперметрам и вольтметрам относят также приборы на основе магнитоэлектрического измерительного механизма с преобразователями переменного тока или напряжения в постоянный ток (выпрямительные и термоэлектрические приборы).
Измерительные цепи электромагнитных, электродинамических и ферродинамических амперметров и вольтметров переменного тока практически не отличаются от цепей аналогичных приборов постоянного тока. Все эти приборы могут быть использованы для измерений как постоянных, так и переменных токов и напряжений.
Мгновенное значение вращающего момента в этих приборах определяется квадратом мгновенного значения тока в обмотках катушек, а положение указателя зависит от среднего значения вращающего момента. Поэтому прибор измеряет действующее (среднеквадратическое) значение измеряемого периодического тока или напряжения независимо от формы кривой. Наиболее распространенные амперметры и вольтметры с классами точности 0,2. 0,5, 1,0, 1,5 позволяют измерять переменные токи от 10 -4 до 10 2 А и напряжения от 0,1 до 600 В в частотном диапазоне от 45 Гц до 5 кГц.
Электростатические вольтметры также могут быть использованы для измерения и постоянных, и действующих значений переменных напряжений независимо от формы кривой, так как мгновенное значение вращающего момента в этих приборах определяется квадратом мгновенного значения измеряемого напряжения. Наиболее распространенные вольтметры с классами точности 0,5, 1,0, 1,5 позволяют измерять переменные напряжения от 1 до 10 5 В в частотном диапазоне от 20 Гц до 10 МГц.
Магнитоэлектрическими амперметрами и вольтметрами, предназначенными для работы в цепях постоянного тока, нельзя измерять действующие значения переменных токов и напряжений. Действительно, мгновенное значение вращающего момента в этих приборах пропорционально мгновенному значению тока в катушке. При синусоидальном токе среднее значение вращающего момента и, соответственно, показание прибора равно нулю. Если ток в катушке имеет постоянную составляющую, то показание прибора пропорционально среднему значению тока в катушке.
Для создания амперметров и вольтметров переменного тока на базе магнитоэлектрического измерительного механизма используют преобразователи переменного тока в постоянный на основе полупроводниковых диодов или термопреобразователей. На рис. 2.1 приведена одна из возможных схем амперметра выпрямительной системы, а на рис. 2.2 – термоэлектрической.
В амперметре выпрямительной системы измеряемый ток i
(t
)
выпрямляется и проходит через обмотку катушки магнитоэлектрического измерительного механизма ИМ. Показание прибора пропорционально среднему по модулю за период T
значению тока:
 . (2.2)
. (2.2)
Значение I
ср пропорционально действующему значению тока, однако коэффициент пропорциональности зависит от вида функции i
(t
).
Все приборы выпрямительной системы градуируются в действующих значениях токов (или напряжений) синусоидальной формы и не предназначены для измерений в цепях с токами произвольной формы.
В амперметре термоэлектрической системы измеряемый ток i
(t
)
проходит через нагреватель термопреобразователя ТП. При его нагреве на свободных концах термопары возникает термо-ЭДС, вызывающая постоянный ток через обмотку катушки магнитоэлектрического измерительного механизма ИМ. Значение этого тока нелинейно зависит от действующего значения I
измеряемого тока i
(t
)
и мало зависит от его формы и спектра.
Схемы вольтметров выпрямительной и термоэлектрической систем отличаются от схем амперметров наличием добавочного сопротивления, включенного последовательно в цепь измеряемого тока i
(t
)
и выполняющего функцию преобразователя измеряемого напряжения в ток.
Наиболее распространенные амперметры и вольтметры выпрямительной системы с классами точности 1,0 и 1,5 позволяют измерять переменные токи от 10 -3 до 10 А и напряжения от 1 до 600 В в частотном диапазоне от 45 Гц до 10 кГц.
Наиболее распространенные амперметры и вольтметры термоэлектрической системы с классами точности 1,0 и 1,5 позволяют измерять переменные токи от 10 -4 до 10 2 А и напряжения от 0,1 до 600 В в частотном диапазоне от 1 Гц до 50 МГц.
Обычно приборы выпрямительной и термоэлектрической систем делают многопредельными и комбинированными, что позволяет использовать их для измерения как переменных, так и постоянных токов и напряжений.
2.1.5. Измерение постоянных напряжений
В отличие от электромеханических аналоговых вольтметров
{2К11}
электронные вольтметры имеют в своем составе усилители напряжения. Информативный параметр измеряемого напряжения преобразуется в этих приборах в постоянный ток в обмотке катушки магнитоэлектрического измерительного механизма {2К4}
, шкала которого градуируется в единицах напряжения.
Усилитель электронного вольтметра должен иметь стабильный коэффициент усиления в определенном частотном диапазоне от некоторой нижней частоты f
н до верхней f
в. Если f
н = 0, то такой усилитель обычно называют усилителем постоянного тока
, а если f
н > 0 и коэффициент усиления равен нулю при f
= 0 – усилителем переменного тока
.
Упрощенная схема электронного вольтметра постоянного тока состоит из трех основных узлов: входного делителя напряжения {2К9}
, усилителя постоянного тока, подключенного к его выходу, и магнитоэлектрического вольтметра. Высокоомный делитель напряжения и усилитель постоянного тока обеспечивают высокое входное сопротивление электронного вольтметра (порядка 1 МОм). Коэффициенты деления и усиления можно дискретно регулировать, что позволяет делать вольтметры многодиапазонными. За счет высокого коэффициента усиления у электронных вольтметров обеспечивается более высокая чувствительность по сравнению с электромеханическими.
Особенностью электронных вольтметров постоянного тока является дрейф показаний
– медленные изменения показаний вольтметра при неизменном измеряемом напряжении {1К14}
, вызванные изменениями параметров элементов схем усилителей постоянного тока. Наиболее существенен дрейф показаний при измерении малых напряжений. Поэтому перед началом измерений необходимо с помощью специальных регулировочных элементов осуществить установку нулевого показания вольтметра при закороченном входе.
Если на рассматриваемый вольтметр подать переменное периодическое напряжение, то в силу свойств магнитоэлектрического измерительного механизма он будет измерять постоянную составляющую этого напряжения, если только переменная составляющая не слишком велика и усилитель вольтметра работает в линейном режиме.
Наиболее распространенные аналоговые электронные вольтметры постоянного тока позволяют измерять напряжения в диапазоне от 10 -6 до 10 3 В. Значения пределов основной приведенной погрешности зависят от диапазона измерений и составляют обычно ± (0,5 – 5,0) %.
2.1.6. Измерение переменных напряжений
аналоговыми электронными вольтметрами.
Аналоговые электронные вольтметры используются в основном для измерения действующих значений периодических напряжений в широком частотном диапазоне.
Основное отличие схемы электронного вольтметра переменного тока от рассмотренной выше схемы вольтметра постоянного тока связано с наличием в нем дополнительного узла – преобразователя информативного параметра переменного напряжения в постоянное. Такие преобразователи часто называют «детекторами».
Различают детекторы амплитудного, среднего по модулю и действующего значений напряжения. Постоянное напряжение на выходе первого пропорционально амплитуде напряжения на его входе, постоянное напряжение на выходе второго – среднему по модулю значению напряжения на входе, а третьего – действующему.
Каждую из трех указанных групп детекторов можно, в свою очередь, разделить на две группы: детекторы с открытым входом и детекторы с закрытым входом. У детекторов с открытым входом выходное напряжение зависит от постоянной составляющей входного напряжения, а у детекторов с закрытым входом – не зависит. Очевидно, если в схеме электронного вольтметра имеется детектор с закрытым входом или усилитель переменного тока, то показания такого вольтметра не зависят от постоянной составляющей измеряемого напряжения. Такой вольтметр выгодно использовать в тех случаях, когда полезную информацию несет только переменная составляющая измеряемого напряжения.
Упрощенные схемы амплитудных детекторов с открытым и с закрытым входами приведены соответственно на рис. 2.3 и 2.4.

При подаче на вход амплитудного детектора с открытым входом напряжения u
(t
)
= U
m
sinωt
конденсатор заряжается до напряжения U
m
, которое запирает диод. При этом на выходе детектора сохраняется постоянное напряжение U
m
. Если же подать на вход напряжение произвольной формы, то конденсатор зарядится до максимального положительного значения этого напряжения.
При подаче на вход амплитудного детектора с закрытым входом напряжения u
(t
)
= U
m
sinωt
конденсатор также заряжается до напряжения U
m
и на выходе образуется напряжение u
(t
)
= U
m
+ U
m
sinωt
. Если такое напряжение или пропорциональный ему ток подать на обмотку катушки магнитоэлектрического измерительного механизма, то показания прибора будут зависеть от постоянной составляющей этого напряжения, равной U
m
{2К4}
. При подаче на вход напряжения u
(t
)
= U
ср
+ U
m
sinωt
, где U
ср
– среднее значение напряжения u
(t
)
, конденсатор заряжается до напряжения U
m
+ U
ср
, а на выходе устанавливается напряжение u
(t
)
= U
m
+ U
m
sinωt
, не зависящее от U
ср
.
Примеры детекторов среднего по модулю и действующего значений напряжения были рассмотрены в подразделе 2.1.4 (соответственно рис. 2.1 и 2.2).
Детекторы амплитудного и среднего по модулю значения проще детекторов действующего значения, однако вольтметры на их основе можно использовать только для измерения синусоидальных напряжений. Дело в том, что их показания в зависимости от типа детектора пропорциональны средним по модулю или амплитудным значениям измеряемого напряжения. Поэтому рассматриваемые аналоговые электронные вольтметры можно градуировать в действующих значениях только при определенной форме измеряемого напряжения. Это сделано для наиболее распространенного – синусоидального напряжения.
Наиболее распространенные аналоговые электронные вольтметры позволяют измерять напряжения от 10 -6 до 10 3 В в частотном диапазоне от 10 до 10 9 Гц. Значения пределов основной приведенной погрешности зависят от диапазона измерений и частоты измеряемого напряжения и составляют обычно ± (0,5 – 5,0) %.
Методика измерений с помощью электронных вольтметров отличается от методики применения электромеханических вольтметров. Это связано с наличием в них электронных усилителей с источниками питания напряжениями постоянного тока, работающими, как правило, от сети переменного тока.

Если же зажим 6 соединить с входным зажимом 1 вольтметра и измерять, например, напряжение U
65 , то результат измерения будет искажен напряжением помехи, значение которого зависит от параметров схем замещения рис. 2.5 и 2.6.
При прямом измерении напряжения U
54 помеха будет искажать результат измерения независимо от способа подключения вольтметра. Избежать этого можно при косвенном измерении, измерив напряжения U
64 и U
65 и вычислив U
54 = U
64 — U
65 . Однако точность такого измерения может оказаться недостаточно высокой, особенно если U
64 ≈ U
65 . {2К12}
Что такое «НАКОПЛЕНИЕ ПОГРЕШНОСТИ»? Как правильно пишется данное слово. Понятие и трактовка.
НАКОПЛЕНИЕ ПОГРЕШНОСТИ
при численном решении алгебраических уравнений — суммарное влияние округлений, сделанных на отдельных шагах вычислительного процесса, на точность полученного решения линейной алгебраич. системы. Наиболее распространенным способом априорной оценки суммарного влияния ошибок округления в численных методах линейной алгебры является схема т. н. обратного анализа. В применении к решению системы линейных алгебраич. уравнений схема обратного анализа заключается в следующем. Вычисленное прямым методом Мрешение хуи не удовлетворяет (1), но может быть представлено как точное решение возмущенной системы Качество прямого метода оценивается по наилучшей априорной оценке, к-рую можно дать для норм матрицы и вектора. Такие «наилучшие»и наз. соответственно матрицей и вектором эквивалентного возмущения для метода М. Если оценки для и имеются, то теоретически ошибка приближенного решения может быть оценена неравенством Здесь — число обусловленности матрицы А, а матричная норма в (3) предполагается подчиненной векторной норме В действительности оценка для редко бывает известна, и основной смысл (2) состоит в возможности сравнения качества различных методов. Ниже приводится вид нек-рых типичных оценок для матрицы Для методов с ортогональными преобразованиями и арифметики с плавающей запятой (в системе (1) Аи bсчитаются действительными) В этой оценке — относительная точность арифметич. операций в ЭВМ,- евклидова матричная норма, f(n) — функция вида, где п- порядок системы. Точные значения константы Си показателя kопределяются такими деталями вычислительного процесса, как способ округления, использование операции накопления скалярных произведений и т. д. Наиболее часто k=1 или 3/2. В случае методов типа Гаусса в правую часть оценки (4) входит еще множитель, отражающий возможность роста элементов матрицы Ана промежуточных шагах метода по сравнению с первоначальным уровнем (такой рост отсутствует в ортогональных методах). Чтобы уменьшить значение, применяют различные способы выбора ведущего элемента, препятствующие возрастанию элементов матрицы. Для квадратного корня метода, к-рый применяется обычно в случае положительно определенной матрицы А, получена наиболее сильная оценка Существуют прямые методы (Жордана, окаймления, сопряженных градиентов), для к-рых непосредственное применение схемы обратного анализа не приводит к эффективным оценкам. В этих случаях при исследовании Н. п. применяются и иные соображения (см. — ). Лит.: Givens W., «TJ. S. Atomic Energy Commiss. Repts. Ser. OR NL», 1954, № 1574; Wilkinson J. H., Rounding errors in algebraic processes, L., 1963; Уилкинсон Д ж. устойчивость в прямых методах линейной алгебры, М., 1969; его же, Вычислительные основы линейной алгебры, М., 1977; Peters G., Wilkinsоn J. H., «Communs Assoc. Comput. Math.», 1975, v. 18, № 1, p. 20-24; Вrоуden C. G., «J. Inst. Math, and Appl.», 1974, v. 14, № 2, p. 131-40; Reid J. К., в кн.: Large Sparse Sets of Linear Equations, L.- N. Y., 1971, p. 231 — 254; Икрамов Х. Д., «Ж. вычисл. матем. и матем. физики», 1978, т. 18, № 3, с. 531-45. X. Д. Икрамов. Н. п. округления или погрешности метода возникает при решении задач, где решение является результатом большого числа последовательно выполняемых арифметич. операций. Значительная часть таких задач связана с решением алгебраич. задач, линейных или нелинейных (см. выше). В свою очередь среди алгебраич. задач наиболее распространены задачи, возникающие при аппроксимации дифференциальных уравнений. Этим задачам свойственны нек-рые специфич. особенности. Н. п. метода решения задачи происходит по тем же или по более простым законам, что и Н. п. вычислительной погрешности; Н. ,п. метода исследуется при оценке метода решения задачи. При исследовании накопления вычислительной погрешности различают два подхода. В первом случае считают, что вычислительные погрешности на каждом шаге вносятся самым неблагоприятным образом и получают мажорантную оценку погрешности. Во втором случае считают, что эти погрешности случайны с определенным законом распределения. Характер Н. п. зависит от решаемой задачи, метода решения и ряда других факторов, на первый взгляд могущих показаться несущественными; сюда относятся форма записи чисел в ЭВМ (с фиксированной запятой или с плавающей запятой), порядок выполнения арифметич. операций и т. д. Напр., в задаче вычисления суммы Nчисел существенен порядок выполнения операций. Пусть вычисления производятся на машине с плавающей запятой с tдвоичными разрядами и все числа лежат в пределах. При непосредственном вычислении с помощью рекуррентной формулы мажорантная оценка погрешности имеет порядок 2-tN. Можно поступить иначе (см. ). При вычислении попарных сумм (если N=2l+1 нечетно) полагают. Далее вычисляются их попарные суммы и т. д. При после тшагов образования попарных сумм по формулам получают мажорантная оценка погрешности порядка В типичных задачах величины а т вычисляются по формулам, в частности рекуррентным, или поступают последовательно в оперативную память ЭВМ; в этих случаях применение описанного приема приводит к увеличению загрузки памяти ЭВМ. Однако можно организовать последовательность вычислений так, что загрузка оперативной памяти не будет превосходить -log2N ячеек. При численном решении дифференциальных уравнений возможны следующие случаи. При стремлении шага сетки hк нулю погрешность растет как где. Такие методы решения задач относят к классу неустойчивых. Их применение носит эпизодич. характер.
Для устойчивых методов характерен рост погрешности как Оценка погрешности таких методов обычно производится следующим образом. Строится уравнение относительно возмущения, вносимого или округлением, или погрешностями метода и затем исследуется решение этого уравнения (см. , ). В более сложных случаях применяется метод эквивалентных возмущений (см. , ), развитый в отношении задачи исследования накопления вычислительной погрешности при решении дифференциальных уравнений (см. , , ). Вычисления по нек-рой расчетной схеме с округлениями рассматриваются как вычисления без округлений, но для уравнения с возмущенными коэффициентами. Сравнивая решение исходного сеточного уравнения с решением уравнения с возмущенными коэффициентами получают оценку погрешности. Уделяется существенное внимание выбору метода по возможности с меньшими значениями qи A(h). При фиксированном методе решения задачи расчетные формулы обычно удается преобразовать к виду, где (см. , ). Это особенно существенно в случае обыкновенных дифференциальных уравнений, где число шагов в отдельных случаях оказывается очень большим. Величина (h)может сильно расти с ростом промежутка интегрирования. Поэтому стараются применять методы по возможности с меньшим значением A(h). В случае задачи Коши ошибка округления на каждом конкретном шаге по отношению к последующим шагам может рассматриваться как ошибка в начальном условии. Поэтому нижняя грань (h)зависит от характеристики расхождения близких решений дифференциального уравнения, определяемого уравнением в вариациях. В случае численного решения обыкновенного дифференциального уравнения уравнение в вариациях имеет вид и потому при решении задачи на отрезке (х 0 , X)нельзя рассчитывать на константу A(h)в мажорантной оценке вычислительной погрешности существенно лучшую, чем Поэтому при решении этой задачи наиболее употребительны однощаговые методы типа Рунге — Кутта или методы типа Адамса (см. , ), где Н. п. в основном определяется решением уравнения в вариациях. Для ряда методов главный член погрешности метода накапливается по подобному закону, в то время как вычислительная погрешность накапливается существенно быстрее (см. ). Область практич. применимости таких методов оказывается существенно уже. Накопление вычислительной погрешности существенно зависит от метода, применяемого для решения сеточной задачи. Напр., при решении сеточных краевых задач, соответствующих обыкновенным дифференциальным уравнениям, методами стрельбы и прогонки Н. п. имеет характер A(h)h-q, где qодно и то же. Значения A(h)у этих методов могут отличаться настолько, что в определенной ситуации один из методов становится неприменимым. При решении методом пристрелки сеточной краевой задачи для уравнения Лапласа Н. п. имеет характер с 1/h, с>1, а в случае метода прогонки Ah-q. При вероятностном подходе к исследованию Н. п. в одних случаях априорно предполагают какой-то закон распределения погрешности (см. ), в других случаях вводят меру на пространстве рассматриваемых задач и, исходя из этой меры, получают закон распределения погрешностей округления (см. , ). При умеренной точности решения задачи мажорантные и вероятностные подходы к оценке накопления вычислительной погрешности обычно дают качественно одинаковые результаты: или в обоих случаях Н. п. происходит в допустимых пределах, или в обоих случаях Н. п. превосходит такие пределы. Лит.: Воеводин В. В., Вычислительные основы линейной алгебры, М., 1977; Шура-Бура М. Р., «Прикл. матем. и механ.», 1952, т. 16, № 5, с. 575-88; Бахвалов Н. С, Численные методы, 2 изд., М., 1975; Уилкинсон Дж. X., Алгебраическая проблема собственных значений, пер. с англ., М.. 1970; Бахвалов Н. С, в кн.: Вычислительные методы и программирование, в. 1, М., 1962, с, 69-79; Годунов С. К., Рябенький В. С, Разностные схемы, 2 изд., М., 1977; Бахвалов Н. С, «Докл. АН СССР», 1955, т. 104, № 5, с. 683-86; его же, «Ж. вычислит, матем. и матем. физики», 1964; т. 4, № 3, с. 399- 404; Лапшин Е. А., там же, 1971, т. 11, № 6, с.1425-36. Н. С. Бахвалов.