Ошибка
выборки или ошибка репрезентативности
– это разница между знач-ем пок-ля,
получ-го на выборке, и генеральным
параметромом.
Расчет
ошибок позволяет решить одну из главных
проблем орг-ции выборочного наблюдения
— оценить репрезентативность
(представительность) выборочной сов-сти.
Различают среднюю и предельную ошибки
выборки.
Эти 2 вида связаны след соотношением:
![]()
Где
Δ-предельная ошибка выборки;t-коэф-т
доверия. Определяемый в завсим-ти от
ур-ня вероятности;Sx-средняя
ошибка выборки
Величина
средней ошибки выборки рассчитывается
дифференцированно в завис-ти от способа
отбора и процедуры выборки. Так, при
случайном
повторном отборе
средняя ошибка опред-ся по формуле:
![]()
При
бесповторном:
![]()
где
σ2—
выборочная (или генеральная) дисперсия;
σ— выборочное (или генеральное)
среднее квадратическое отклонение;
n—
объем
выборочной совокупности; N
— объем генеральной сов-сти.
Расчет
средней и предельной ошибок выборки
позволяет определить возможные пределы,
в кот будут нах-ся хар-ки генер сов-ти.Н-р,
для выьор средней такие пределы устан-ся
на основе след соотношений:
![]()
Где
μ и х¯-генер и выборочная средние
соответственно,Δх
— предельная ошибка выборочной средней.
Для
типической выборки средняя ошибка
вычисл-ся по формулам:
-при
отборе, пропорциональном объёму
типических групп
![]() (повторный
(повторный
отбор)
![]() (бесповторный
(бесповторный
отбор)
-при
отборе, пропорциональном вариации
признака(не пропорцион-ных объёму групп)
![]() (повторный отбор)
(повторный отбор)
![]() (бесповт отбор)
(бесповт отбор)
При
серийной выборке ср ошибка опр-ся след
обр:
![]() (повт отбор)
(повт отбор)
![]() (бесповт
(бесповт
отбор)
Где
R-число
серий в генер сов-ти;r-число
серий в выборочной сов-ти; σ2—
межгруп дисперсия
28. Определение необходимой численности выборочного наблюдения.
Прежде
чем приступить к проведению выборочного
наблюдения, надо установить необходимую
численность выборки, т.е. объем выборки,
необходимый для того, чтобы обеспечить
результаты выборочного наблюдения с
заранее установленной точностью.
Необходимая
численность выборки (n)
определяется на основе формул предельной
выборки. Так, если выборка повторная,
то n
определяется из формулы
 ,
,
где t-коэфф.
доверия. Чтобы найти необход. числ-ть
выборки (n),
нужно выразить ее из предыд-ей фор-лы,
т.е. n
= =(t2*б2)/r2.
Для бесповторного отбора численность
выборки опред-ся из фор-лы:
 .
.
Необходимая численность выборки
находится путем выражения n
из пред-щей фор-лы: n
= (t2
* б2 *
N)
/ (r2*
N
+ t2
* б2),
где n
– объем выборки, N
– объем генер. сов-ти.
29. Распространение выборочных характеристик на генеральную совокупность.
Распространение
выборочных данных на генер. совок-ть
явл-ся конечной задачей выборочного
наблюдения. Обычно применяется 2 способа
такого распространения: способ прямого
пересчета и способ коэффициентов.
Сп.
прямого пересчета
состоит в том, что ср. величина признака,
найденная посредством выборки, умножается
на число единиц генер. совок-ти.
Сп.
коэфф-ов
применяется тогда, когда выборочное
обслед-е проводится в целях проверки
данных сплошного наблюдения. Сущность
этого метода заключ. в том, что на
основании сопоставления данных сплошного
и данных выбор-го наблюд. устанавливают
% расхождений (% недоучета), кот. и служит
коэфф-ом поправки на данные сплошного
наблюдения.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
1.1. Ошибки
выборочного наблюдения
Средняя
ошибка выборки показывает, как генеральная средняя отклоняется в среднем от выборочной средней в ту или другую сторону. Формула
расчета средней ошибки выборки определяется видом исследуемого признака единиц
совокупности (количественный или альтернативный) и
способом отбора (бесповторный или повторный).
·
Если отбор повторный, а признак количественный
средняя ошибка выборки определяется по формуле
![]() , где
, где ![]() — дисперсия признака в выборочной совокупности
— дисперсия признака в выборочной совокупности
n- число единиц
в выборке
·
Если отбор бесповторный, а признак
количественный
 , где N—
, где N—
число единиц в генеральной совокупности
·
Если отбор повторный, а признак альтернативный
 , где w-выборочная
, где w-выборочная
доля
·
Если отбор бесповторный, а признак
альтернативный

Предельная ошибка выборки— показывающая с определенной степенью вероятности
отклонения средней от выборочной средней.
Предельная ошибка выборки
![]() , где параметр t зависит
, где параметр t зависит
от вероятности
Некоторые значения параметра t приведены
в таблице:
|
Вероятность, p |
0.95 |
0.954 |
0.9876 |
0.9907 |
0.9973 |
0.9999 |
|
Параметр t |
1.96 |
2.0 |
2.5 |
2.6 |
3.0 |
4.0 |
·
Если отбор повторный, а признак количественный
средняя ошибка выборки определяется по формуле
![]() , где
, где ![]() — дисперсия признака в выборочной совокупности
— дисперсия признака в выборочной совокупности
n- число единиц
в выборке
·
Если отбор бесповторный, а признак
количественный
 , где N—
, где N—
число единиц в генеральной совокупности
·
Если отбор повторный, а признак альтернативный
 , где w-выборочная
, где w-выборочная
доля
·
Если отбор бесповторный, а признак
альтернативный

Доверительный интервал для генеральной средней
![]()
Доверительный интервал для
генеральной доли
![]()
Пример расчета доверительного
интервала:
При выборочном обследовании 5% продукции по методу случайного
бесповторного отбора получены данные о содержании сахара в образцах:
|
Сахарность, % |
Число |
|
16-17 17-18 18-19 19-20 20-21 |
10 158 154 50 28 |
|
На основании этих данных вычислите:
1. Средний процент сахаристости.
2. Дисперсию и среднее квадратическое
отклонение.
3. С вероятностью 0.954 возможные пределы среднего значения
сахаристости продукции для всей партии.
4. С вероятностью 0.997 возможный процент продукции высшего
сорта по всей партии, если известно, что из 400 проб, попавших в выборку , 80
ед. отнесены к продукции высшего сорта.
Решение.
1.
Средний процент сахаристости найдем по формуле средней взвешенной
![]() , где xi–
, где xi–
середина i-го интервала
![]() =18,32 %
=18,32 %
2.
Дисперсия
![]()
![]()
![]() =336,49
=336,49
D(X)=336.49–
18.322=0.8676
Среднее квадратическое отклонение
![]() =0,93%
=0,93%
5. Предельная ошибка для
среднего процента сахаристости
![]()
для вероятности 0,954 параметр t=2.0
![]()
Доверительный интервал для среднего значения процента
сахаристости
![]()
![]()
![]()
С вероятностью 0,954 можно утверждать, что в генеральной
совокупности средний процент сахаристости лежит в пределах от 18,23% до 18,41%.
5. Доля продукции высшего сорта в выборочной совокупности
![]()
Предельная ошибка для
доли продукции высшего сорта
![]()
для вероятности 0,997 параметр t=3.0
![]()
Доверительный интервал для доли продукции высшего сорта
![]()
![]()
![]()
С вероятностью 0,997 можно утверждать, что в генеральной
совокупности доля продукции высшего сорта лежит в пределах от 14,0% до 26,0%.
Как говорилось ранее, при определении величины репрезентативной ошибки предполагается, что ошибка регистрации равна нулю. Определение ошибки производится по формулам ошибки выборочной доли и ошибки выборочной средней. Систематическая ошибка репрезентативности возникает вследствие нарушения правил отбора единиц генеральной совокупности, в частности принципа беспристрастного, непреднамеренного отбора. Систематическая ошибка может привести к полной непригодности результатов наблюдений.
Рассмотрим на примере, насколько отличаются выборочные и генеральные показатели по данным об успеваемости студентов (две 10%-е выборки) (табл.2).
Таблица 2
Данные по выборкам
|
Оценка |
Число студентов, чел |
||
|
Генеральная совокупность |
Первая выборка |
Вторая выборка |
|
|
2 3 4 5 |
100 300 520 80 |
9 27 54 10 |
12 29 52 7 |
|
Итого |
1000 |
100 |
100 |
Средний балл для генеральной совокупности

по первой выборке
по второй выборке


Доля студентов, получивших оценки «4» и «5»:
по генеральной совокупности

по первой выборке
по второй выборке


Разность между показателями выборочной и генеральной совокупности является случайной ошибкой репрезентативности (ошибкой выборки).
Ошибки репрезентативности:




Как видно из расчетов, выборочная средняя и выборочная доля являются случайными величинами, которые могут принимать различные значения в зависимости от того, какие единицы совокупности попали в выборку.
Ошибка выборочной средней представляет собой расхождение (разность) между выборочной средней и генеральной средней , возникающее вследствие несплошного выборочного характера наблюдения. Величина ошибки выборочной средней определяется как предел отклонения от , гарантируемый с заданной вероятностью:


 где — гарантийный коэффициент, зависящий от вероятности ,с которой гарантируется невыход разности за пределы ; — средняя ошибка выборочной средней.
где — гарантийный коэффициент, зависящий от вероятности ,с которой гарантируется невыход разности за пределы ; — средняя ошибка выборочной средней.

Значения гарантийного коэффициента и соответствующие им вероятности приведены в таблице 3. Обычно вероятность принимается равной 0,9545 или 0,9973, а при этом равно соответственно 2 и 3.
Таблица 3
Значения гарантийного коэффициента
|
1,00 1,10 1,20 1,30 1,40 1,50 1,60 1,70 1,80 1,90 2,00 2,10 2,20 2,30 2,40 2,50 2,60 2,70 2,80 2,90 3,00 |
0,6827 0,7287 0,7699 0,8064 0,8385 0,8664 0,8904 0,9109 0,9281 0,9426 0,9545 0,9643 0,9722 0,9786 0,9836 0,9876 0,9907 0,9931 0,9949 0,9963 0,9973 |
выборочный наблюдение статистический ошибка
Средняя ошибка определяется как среднее квадратическое отклонение средней величины в генеральной совокупности (средней генеральной)

В математической статистике доказывается, что величина средней квадратической стандартной ошибки простой случайной повторной выборки может быть определена по формуле:


где — дисперсия признака в генеральной совокупности.
Дисперсия суммы независимых величин равна сумме дисперсий слагаемых
 Если все величины Xi имеют одинаковую дисперсию, то:
Если все величины Xi имеют одинаковую дисперсию, то:
Тогда дисперсия средней будет:

Тогда средняя ошибка при определении средней:

Между дисперсиями в генеральной и выборочной совокупностях существует следующее соотношение:


где — дисперсия признака в выборке.

Если n достаточно велико, то близко к единице и дисперсию в генеральной совокупности можно заменить на дисперсию в выборке.
Тогда средняя ошибка средней в генеральной совокупности может быть как среднее квадратическое отклонение средней величины в выборочной совокупности (средней выборочной)
Средняя ошибка выборочной средней:

Значения средней ошибки выборки определяются по формуле:


где — дисперсия в генеральной совокупности.
Между дисперсиями в генеральной и выборочной совокупностях существует следующее соотношение:


где — дисперсия в выборке.
Если n достаточно велико, то близко к единице и дисперсию в генеральной совокупности можно заменить на дисперсию в выборке.
При повторном отборе средняя ошибка определяется следующим образом:

где — средняя величина дисперсии количественного признака , которая рассчитывается по формуле средней арифметической невзвешенной


или средней арифметической взвешенной:

где fi — статистический вес.
В данном разделе были показаны общие формулы расчета ошибок выборочного наблюдения в статистическом анализе. Однако, в зависимости от способов отбора выборочной совокупности, расчет средней ошибки выборочной средней имеет свои особенности и формулы расчета. Это будет проиллюстрировано в следующем разделе.
2.4. Точность статистического наблюдения
Под точностью статистического наблюдения понимают степень соответствия значения наблюдаемого показателя, вычисленного по материалам обследования, его действительной величине. Расхождение, или разница, между ними называется ошибкой статистического наблюдения.
Различают две группы ошибок:
- ошибки регистрации;
- ошибки репрезентативности.
Ошибки регистрации присущи любому статистическому наблюдению, как сплошному, так и несплошному. Они делятся на случайные ошибки регистрации и систематические ошибки регистрации.
Случайными ошибками регистрации называют ошибки, возникающие вследствие действия случайных факторов. К ним можно отнести различного рода непреднамеренные описки: например, вместо возраста человека «15 лет» указано «5 лет», у Ивановой Марии Петровны в графе пол отмечен «Мужской» и т. п. Такие ошибки легко выявляются методом логического анализа, например, если человеку 8 лет, но имеется высшее образование, а в графе «Семейное положение» указано «Состоит в браке», то, естественно, следует исправить возраст. Если объем исследуемой совокупности велик или велика доля отбора при выборочном наблюдении, случайные ошибки регистрации имеют тенденцию взаимопогашаться вследствие действия закона больших чисел, поскольку ошибки, как правило, разнонаправлены и искажают статистический показатель как в большую, так и в меньшую сторону. При небольшом объеме наблюдения требуется тщательная выверка его результатов — логический анализ данных.
Систематические ошибки регистрации чаще всего имеют однонаправленные искажения: они либо увеличивают, либо уменьшают статистический показатель, и, что характерно, подобная ситуация повторяется от обследования к обследованию. Так, по результатам переписей (практически всех!) число замужних женщин превышает число женатых мужчин — мужчинам приятнее ощущать себя неженатыми, а для женщины как бы «стыдно» быть не замужем. Другой пример, когда человек округляет свой возраст — вместо 32 лет говорит 30, вместо 79-80 и т. п. (это явление широко известно и даже получило свое название — «аккумуляция возрастов»). Систематические ошибки регистрации могут возникать и из-за неточностей измерительных приборов, если сбор информации проводят путем непосредственного наблюдения.
Ошибки репрезентативности присущи только несплошному обследованию. Они также делятся на случайные и систематические ошибки.
Случайные ошибки репрезентативности возникают из-за того, что обследованию подвергается не вся совокупность в целом, а только ее часть, и, следовательно, при несплошном наблюдении они присутствуют всегда. В теории статистики разработаны специальные методы для оценки величин таких ошибок, на их основе для наблюдаемых показателей строят доверительные интервалы, т.д. эти ошибки вычисляются и находятся как бы «под контролем».
Хуже обстоит дело, если наряду со случайными ошибками имеются и ошибки систематические.
Систематические ошибки репрезентативности возникают, если при несплошном наблюдении кардинально нарушаются технологии отбора единиц из генеральной совокупности объектов, но чаще — если в ходе обследования не удается получить информацию обо всех отобранных для наблюдения единицах, например, вследствие отказа отвечать на вопросы анкеты, или если человека не удалось застать дома и т. п.
Ошибки статистического наблюдения для наглядности можно изобразить в виде схемы (рис. 2.1).
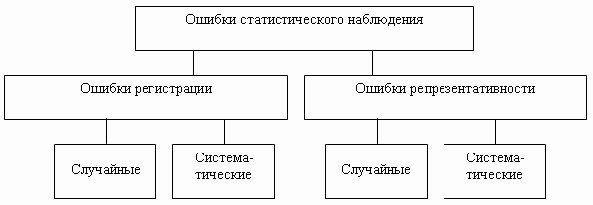
Рис.
2.1.
Виды ошибок статистического наблюдения
Для повышения точности наблюдения необходимо:
- правильно разработать формуляр статистического наблюдения: вопросы должны быть четкими, однозначными, не допускающими двойного толкования;
- иметь хорошо обученный персонал для проведения обследования;
- строго придерживаться выбранной технологии обследования (если проводится несплошное наблюдение) и помнить, что если не удается опросить какую-то конкретную единицу, отобранную для наблюдения, замена ее на другую единицу может привести к возникновению систематической ошибки репрезентативности;
- провести логический анализ данных, основанный на логических взаимосвязях показателей, после сбора всей совокупности анкет или формуляров;
- целесообразно провести и арифметический контроль данных, т.д. заново пересчитать расчетные величины, если какие-либо показатели получаются в результате определенных арифметических действий;
- предпринять определенные меры по восстановлению данных при наличии незаполненных анкет или формуляров либо при получении результатов обследования сделать поправку на неответы респондентов.