-
Описание ошибок в машинном переводе
Применение
машинного перевода без настройки на
тематику (или с намеренно неверной
настройкой) служит предметом многочисленных
бродящих по Интернету шуток.
Зачастую
программы машинного перевода понимаются
как какое-то уникальное средство, которое
способно вытеснить живых, мыслящих
переводчиков. Некоторые пользователи
полагают, что, если с помощью компьютера
сегодня можно добыть любые сведения из
многочисленных информационных источников,
от него можно ожидать соответствующей
компетентности также в вопросах
качественной трансформации этих сведений
в любой возможный языковой формат.
Однако
ни для кого не секрет, что такое
преставление крайне ошибочное. Знающие
специалисты, равно как и производители
подобных программ, понимают, что в
действительности ситуация выглядит
иначе. Конечно, рекламируя свои программные
продукты, производители честно признаются,
что качество машинного перевода далеко
от идеального и что получение адекватного
перевода возможно только при вмешательстве
человека, однако не всегда раскрывается
тот факт, что человек, которому предстоит
обработать такой перевод, должен быть
квалифицированным переводчиком и ему
придется потратить массу времени на
придание машинному тексту качества,
достойного профессионального перевода.
И
как бы ни пытались производители
приукрасить достоинства своей продукции,
пользователи многочисленных
онлайн-переводчиков всегда имеют
возможность убедиться в том, что
виртуальные «толмачи» не всегда способны
достойно справляться с поставленными
перед ними задачами. Доказательством
этому служат многочисленные шутки,
переходящие с сайта на сайт и высмеивающие
недостаточную компетентность
онлайн-переводчиков в вопросах
качественного перевода. К числу любимых
развлечений скептически настроенных
пользователей онлайн-переводчиков
относится перевод коротких предложений
или текстов песен в различных направлениях
и сравнение полученного результата с
исходным вариантом. К избитым примерам
относится перевод предложения «Мама
мыла раму» на английский язык, который
звучит как “Mum washed the frame”. Если затем
снова перевести полученное предложение
на русский язык, то разные переводчики
выдают свои результаты: «мама вымыла
структуру» (перевод Translate.ru – компания
PROMT) или «мама помыла рамку» (вариант
Babelfish.yahoo.com). Всем известен также пример
с переводом предложения “My
cat has given birth to four kittens, two yellow, one white and one
black”,
выполненным онлайн-переводчиком компании
PROMT, которое в русскоязычном исполнении
звучит как «Моя
кошка родила четырех котят, два желтых
цвета, одно белое и одного афроамериканца».
Нужно отметить, что разработчики
поработали над усовершенствованием
своего продукта, так как раньше данное
предложение начиналось с абсурдного
«Мой кот родил…», однако радует, что
данный переводчик компетентен в вопросе
политкорректности. К числу подобных
примеров относятся также переводы
различных песен и литературных
произведений, доставляющие немало
веселья экспериментаторам.
Сотрудники
многих фирм на каждом шагу встречаются
с многочисленными примерами абсурдных
переводов, выполненных посредством
онлайн-переводчиков. Зарубежные клиенты,
желающие сделать запрос на перевод, или
коллеги, предлагающие свое сотрудничество
в сфере переводов, часто прибегают к
помощи онлайн-переводчиков, столкнувшись
с необходимостью перевода электронных
сообщений на русский язык.
Например,
однажды сотрудники одной из фирм получили
электронное сообщение следующего
содержания:
Привет
Уважаемые! Пожалуйста, как вы! Надеюсь,
ты штраф и в отличном состоянии health.
I пошел через ваш профиль сегодня на
www.multitran.ru
и я прочитал его и принял в ней интереса,
пожалуйста, если вы не возражаете, я
хотел, чтобы вы напишите мне по этому
ID (***@yahoo.com)
надеются услышать от вас в ближайшее
время, и я буду Жду ваших почту, потому
что я что-то очень важно, чтобы рассказать
вам. Много любви Грейс.
Автор
сообщения сопроводил данное обращение
исходным текстом на английском языке:
Hi
Dear! Please how are you! hope you are fine and in perfect condition
of health. I went through your profile today at www.multitran.ru and
i read it and took interest in it, please if you don’t mind i will
like you to write me on this ID (***@yahoo.com
) hope to hear from you soon, and I will be waiting for your
mail because i have something VERY important to tell you. Lots
of love Grace.
Не
нужно долго гадать, чтобы понять, что
сообщение на русском языке является
результатом работы онлайн-переводчика.
Кстати, путем несложного эксперимента
было установлено, что автором данного
перевода был онлайн-переводчик Google. Это
сообщение является ярким подтверждением
тому, что данный онлайн-переводчик не
особо преуспел в своем деле и вряд ли
может бросить достойный вызов
профессиональному переводчику. Не
вдаваясь в глубокий анализ, можно
отметить, что основным недостатком
онлайн-переводчика является незнание
грамматических правил (в основном это
касается согласования частей речи и
членов предложений), а также неумение
распознавать и корректно переводить
некоторые лексические единицы,
употребленные в рамках заданного
контекста, и устойчивые выражения, в
результате чего, вместо «надеюсь, у Вас
все хорошо», переводчик выдал нелепое
и искажающее смысл предложения выражение
«надеюсь, ты штраф» (слово «fine» было
употреблено в значении «штраф»). Истинная
причина получения таких низкосортных
переводов кроется в том, что программы
машинного перевода не способны учитывать
экстралингвистические факторы. Именно
поэтому многие переводчики дословно
переводят те или иные термины и, кроме
того, не всегда отличают имена собственные
от знаменательных слов.
Ярким
примером этому может послужить перевод
статьи, посвященной Лоре Буш, супруге
бывшего президента Америки, выполненный
с помощью программы-переводчика. Ее
полное имя зазвучало на французском
языке как «le buisson de Laura», то есть «кустарник
Лоры». Программа не распознала фамилию
«Bush» как имя собственное и дословно
перевела ее на французский как «кустарник».
Но вся нелепость этой ситуации заключается
в том, что на французском сленге слово
«buisson» имеет сексуальную коннотацию.
Данные
примеры свидетельствуют о том, что
научить самый современный компьютер
языковой логике значительно сложнее,
чем математическим алгоритмам и логике
статистического анализа. Чтобы создать
в той или иной степени связный машинный
текст, программа может лишь использовать
ограниченный набор определенных
лингвистических алгоритмов, заложенных
в ее базу. Сначала система подвергает
анализу структурные элементы исходного
предложения, затем изменяет его в
соответствии правилами языка и выдает
конечный вариант. Однако как бы ни
пытались производители программ
машинного перевода усовершенствовать
свои разработки, еще ни одна технология
не выдерживала сравнения с теми
алгоритмами перевода и многочисленными
трансформациями, которым учат живых
переводчиков в школах и вузах. Безусловно,
для получения связного текста программу
можно снабдить богатой словарной базой,
включающей устойчивые выражения, а
также подключить специализированные
словари, чтобы переводчик смог перевести
тематические тексты. Но, как показывает
реальный опыт работы с онлайн-переводчиками,
это лишь малая часть того, что необходимо
для обеспечения приемлемого качества.
Основной проблемой таких переводчиков,
равно как и других систем машинного
перевода, является отсутствие фоновых
знаний. Компьютер знает только языковые
соответствия, а ведь переводчику очень
часто приходится выходить за рамки
формального текста и обращаться не к
языковым знаниям, а к экстралингвистическим
факторам, включающим знания о реальном
мире, культуре, истории, технике.
Профессиональные переводчики, особенно
технические, – это очень образованные
люди, и все их знания непосредственно
задействованы в процессе перевода.
Только в таком случае может быть
гарантировано действительно первоклассное
качество переводов. Поэтому если
разработчики сервисов онлайн-перевода
стремятся к предоставлению адекватных,
качественных переводов, они должны
снабдить своих машинных переводчиков
такими же фоновыми знаниями и, главное,
научить их правильно обращаться с
заложенным багажом знаний. Проще говоря,
программа должна понять, что возникла
какая-то проблема, для решения которой
необходимо прибегнуть к дополнительным
знаниям, и правильно сформулировать
запрос к имеющейся базе. Показательным
примером служит перевод на западноевропейские
языки предложений, в которых упоминаются
известные правители или их дети. В таких
предложениях артикль, категория которого
характерна для языков данной языковой
семьи, должен ставиться в зависимости
от общего количества детей. Например,
при переводе выражения «сын царя Федора»
артикль необходимо выбирать в зависимости
от того, сколько сыновей было у царя
Федора.
В
качестве аналогичного примера можно
привести перевод надписи на постаменте
памятника, открытого во Франции в честь
Анны Ярославны, дочери князя Киевского
Ярослава Мудрого. Перевод надписи на
французском языке звучал как «Anne de
Kiev la reine de la France», и все бы ничего, если
бы не лишний артикль. В случае с Францией
«la France» звучит как «единая
Франция», что не искажает смысл. Что
же касается дочери князя, «la reine»
означает, что она единственная за всю
историю королева Франции. Переводчик,
знакомый со всеми нюансами французской
грамматики, не допустил бы такую нелепую
ошибку, а вот для электронного переводчика
– это довольно типичная ошибка.
Чаще
всего подобные шутки связаны с тем, что
программа не распознаёт контекст фразы
и переводит термины дословно, к тому же
не отличая собственных имён от обычных
слов. Тот же переводчик ПРОМТ превращает
«bra-ket
notation» в «примечание Кети лифчика»,
«Lie
algebra» — в «алгебру Лжи», «eccentricity
vector» — в «вектор оригинальности»,
«Shawnee
Smith» в «индеец племени шони Смит» и
т. п. Переводчик
Google, наоборот, слово «rice»
часто принимал за фамилию госсекретаря
США.
А
теперь рассмотрим примеры машинного
перевода отрывков из художественных и
научных текстов.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Библиографическое описание:
Красильникова, В. Г. Анализ качества машинного перевода системами Google Translate и Яндекс.Переводчик (на материале отрывка из научно-популярного издания по медицине) / В. Г. Красильникова, А. Д. Сафронова. — Текст : непосредственный // Молодой ученый. — 2021. — № 23 (365). — С. 492-494. — URL: https://moluch.ru/archive/365/81991/ (дата обращения: 22.09.2023).
В рамках данного исследования был проведён анализ ошибочно переведённых фрагментов машинного перевода на материале отрывка из научно-популярного издания о деменции.Мы выделили массив ошибок, допущенных системами Google Translate и Яндекс.Переводчик, и классифицировали их по трём группам ошибок, связанных с денотативным и жанрово-стилистическим содержанием оригинала, а также с оформлением текста на языке перевода, и постарались объяснить причины их возникновения.
Ключевые слова:
машинный перевод, переводческие ошибки, постредактирование, научно-популярная литература, медицинский дискурс.
Книгоиздание является одним из процессов, подлежащих возможной автоматизации в будущем. На сегодняшний день количество книг, переведённых системами машинного перевода и отредактированных далее человеком слишком мало, чтобы делать выводы об эффективности машинных переводчиков в этой области, однако и разработчики, и представители книжного рынка, и постредакторы машинного перевода позитивно относятся к тому, чтобы делегировать часть переводческих задач автоматизированным системам, тем самым осуществить переквалификацию действующих переводчиков [1, 3, 4, 5, 6].
Мы проанализировали ошибки, допущенные двумя популярными системами машинного перевода. Ошибками в переводе считаются неоправданные переводческие трансформации, нарушение логики изложения на языке перевода и несоблюдение узуса и норм переводящего языка. Для данной работы в качестве основы была выбрана классификация ошибок по Д. М. Бузаджи и соавт. [2]. В ней выделяется четыре крупные группы переводческих ошибок, но поскольку в исследуемом материале не была представлена группа, связанная с нарушениями передачи авторской оценки, было принято решение не учитывать её при демонстрации полученных результатов. Несмотря на тот факт, что в научно-популярной литературе оценочная лексика встречается гораздо чаще, чем в специализированных текстах [2, с. 60], конкретно в анализируемом отрывке изложение материала близится к объективному с нейтральным уровнем экспрессии. Авторы не говорят о себе и не выражают свою позицию по тому или иному вопросу, лишь популяризуют знание. Таким образом, мы ограничились тремя группами переводческих ошибок, а именно:
1) нарушения при передаче денотативного содержания текста;
2) нарушения при передаче стилистических характеристик оригинала;
3) нарушения нормы и узуса ПЯ.
Материалом исследования послужил отрывок из англоязычной научно-популярной книги о деменции [7]: разделы, описывающие деменцию как заболевание, её симптомы и четыре основных вида. Перевод осуществлялся системами Google Translate и Яндекс.Переводчик, которые различаются в своём подходе к данному процессу. Первая система использует нейронный машинный перевод, изредка обращаясь к статистическому подходу; вторая переводит по гибридному типу, выбирая один из вариантов статистического или нейронного перевода для каждого исходного сегмента. Обе системы постоянно обучаются за счёт пополнения учебных корпусов (как правило, это web-тексты) и активного участия пользовательского сообщества в развитии данных систем. Переведённый машинными переводчиками текст подлежал сравнению с опубликованным на русском языке переводом данного произведения [8]. Для удобства сравнения анализируемый текст был разбит на смысловые единства согласно опубликованному переводу. Каждый такой блок, содержащий заголовок, абзац или группу абзацев помещался в поле для исходного текста в интерфейсе машинных переводчиков. Выведенный в поле с переводом текст подлежал дальнейшему количественно-качественному анализу содержащихся в нём ошибок. Текст машинного перевода нами не редактировался.
Всего в переводе от Google Translate было зафиксировано 405 случаев переводческих ошибок (100 %), из которых наибольшую частотность имеет такой вид ошибок, как неточная передача информации: 139 случаев (34.3 %). Далее следуют нарушения при передаче жанрово-стилистических особенностей текста оригинала: 82 случая (20.2 %). Третье место по частотности разделяют калькирование и нарушения узуса ПЯ: по 40 случаев каждого вида (9.9 %). Общее число случаев переводческих ошибок в рамках исследованного материала от Яндекс.Переводчика составило 439 единиц (100 %). Распределение ошибок по частотности аналогично тому, что было у зарубежной системы машинного перевода. Неточная передача информации представлена наиболее часто: 143 случая (32.6 %). Вторыми по частотности являются нарушения при передаче жанрово-стилистических особенностей текста оригинала: 91 случай (20.7 %). Далее следует калькирование: 56 случаев (12.8 %).
Табличное отображение ошибок по видам внутри групп для каждой системы машинного перевода выглядит следующим образом:
Таблица 1
Частотность ошибок, допущенных системами машинного перевода
Google
Translate
и
Яндекс.Переводчик
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1.1 |
опущение информации |
17 |
4.2 % |
12 |
2.7 % |
|
1.2 |
добавление информации |
10 |
2.5 % |
3 |
0.7 % |
|
1.3 |
замена информации |
23 |
5.7 % |
30 |
6.8 % |
|
1.4 |
неточная передача информации |
139 |
34.3 % |
143 |
32.6 % |
|
|
|
|
|
|
|
|
2.1. |
нарушения при передаче жанрово-стилистических особенностей текста оригинала |
82 |
20.2 % |
91 |
20.7 % |
|
2.2. |
калькирование |
40 |
9.9 % |
56 |
12.8 % |
|
2.3. |
нарушения узуса ПЯ |
40 |
9.9 % |
39 |
8.9 % |
|
|
|
|
|
|
|
|
3.1. |
ошибки в орфографии и пунктуации |
2 |
0.5 % |
4 |
0.9 % |
|
3.2. |
ошибки при передаче имен собственных при наличии или отсутствии традиционного варианта |
3 |
0.7 % |
4 |
0.9 % |
|
3.3. |
нарушения стилистических норм ПЯ |
37 |
9.1 % |
29 |
6.6 % |
|
3.4. |
ошибки при передаче некоторых цифровых данных |
3 |
0.7 % |
2 |
0.5 % |
|
3.5. |
нарушения требований к оформлению данного типа текстов |
9 |
2.2 % |
26 |
5.9 % |
|
|
|
|
|
|
|
Так как Яндекс.Переводчик обучается на корпусах русских текстов, ожидалось, что перевод от данной системы будет содержать меньшее количество ошибок, однако обе системы выдают переводы одинакового уровня качества, которые безусловно нуждаются в постредактуре. По результатам исследования, 89–92 % текста, генерируемого машинными переводчиками, содержало переводческие ошибки.
Чаще всего допускались ошибки по типу неточной передачи информации из оригинального текста, для избегания которых необходимо владеть таким приёмом переводческих трансформаций как модуляция. Именно распознавание тонких смысловых оттенков значений и логическое развитие оригинальной мысли на переводящем языке недоступно для нейросетей на настоящем этапе их развития. Кроме того, векторное представление слов для текстов научно-популярного медицинского дискурса у нейросетей развито недостаточно, поэтому наблюдаются проблемы с актуальным членением предложения в тексте переводов, что тоже относится к неточной передаче информации. Ошибки дискурсивного характера могут быть связаны с тем, что машинные переводчики, в отличие от реальных, не работают с коммуникативной целью исходного текста. В связи с этим в тексте перевода не соблюдается единая терминология, происходит неуместный переход от научной лексики к разговорно-бытовой, термины претерпевают генерализацию или же идентификация терминов вовсе не осуществляется, и машинный переводчик переходит на лексическое или синтаксическое калькирование. Аналогичные переводческие ошибки наблюдались в терминосодержащих словосочетаниях. Наконец, третья группа ошибок представляла собой нарушения нормы и узуса переводящего языка, но не с точки зрения смыслов, авторских сем, а графического и стилистического оформления текстов на русском языке. Данные переводческие ошибки возникали несистематично, спонтанно. Они обусловлены «шумами», «мусором» в учебных корпусах текстов. Так, в тексте перевода наблюдались лишние пробелы и символы, изменение регистра и нарушения стилистических норм. Такой вид ошибок, как сбои в передаче цифровых данных, в нашем случае объясняется отсутствием в базе корпусов системы синонимов и эквивалентов мер времени, которые, как известно, различаются в англоязычной и русскоязычной культурах.
Системы машинного перевода постепенно набирают популярность среди профессиональных переводчиков благодаря тому, что они способны в значительной степени упростить процесс перевода. Владение навыком работы в таких системах и постредактирования найденных ошибок определяет востребованность современного переводчика и его конкурентоспособность. Это одна из новейших задач в переводческой индустрии. Стоит отметить, что абсолютная замена реальных переводчиков компьютерными программами перевода не предвидится, по крайней мере, в ближайшем будущем. Несмотря на то, что переводчик теперь склонен выбирать и редактировать наиболее оптимальный из предложенных его «коллегой» вариантов, условием качественного машинного перевода остаётся человеческая экспертиза и авторство перевода, в любом случае, принадлежит людям.
Литература:
- Бенюмов, К. «Как думаете, какой запрос самый распространенный?» Глава Google Translate Барак Туровски — о том, как сервис переходит на нейросети [Интервью] / К. Бенюмов — Текст: электронный // Meduza. — 07.03.2017. — URL: https://meduza.io/feature/2017/03/07/kak-dumaete-kakoy-zapros-samyy-rasprostranennyy (дата обращения: 20.03.2021).
- Бузаджи, Д. М. Новый взгляд на классификацию переводческих ошибок / Д. М. Бузаджи, В. В. Гусев, В. К. Ланчиков, Д. В. Псурцев. — Москва: Всероссийский центр переводов, 2009. — 121 c. — Текст: непосредственный.
- Воронович, В. В. Машинный перевод / В. В. Воронович. — Текст: непосредственный // Конспект лекций для студентов 5-го курса специальности «Современные иностранные языки». — Минск: Белорусский государственный университет, 2013.
- Сандалов, Ф. Редакторские тяготы — часть вторая: переводы / Ф. Сандалов. — Текст: электронный // Facebook: [сайт]. — URL: https://www.facebook.com/from.depot/posts/10224120155289932 (дата обращения: 20.03.2021).
- Тарарак, Е. Машина vs Человек. Отберет ли искусственный интеллект хлеб у переводчиков? [Интервью] / Е. Тарарак. — Текст: электронный // Новая газета: [сайт]. — URL: https://novayagazeta.ru/articles/2020/12/13/88357-mashina-vs-chelovek (дата обращения: 20.03.2021).
- Zaretskaya, A. Integration of Machine Translation in CAT Tools: State of the Art, Evaluation and User Attitudes / A. Zaretskaya, P. G. Corpas, M. Seghiri. — Текст: непосредственный // SKASE Journal of Translation and Interpretation. — 2015. — № 8. — С. 76–88.
- Warner, J. A Pocket Guide to Understanding Alzheimer’s Disease and Other Dementias / J. Warner, N. Graham. — Second Edition. — London : Jessica Kingsley Publishers, 2018. — 160 c.
- Грэм, Н. Поговорим о болезни Альцгеймера. Карманный справочник для ухаживающих за близким с деменцией / Н. Грэм, Дж Уорнер. — Москва : Олимп-Бизнес, 2018. — 121 c. — (Как жить (Олимп-Бизнес)
Основные термины (генерируются автоматически): машинный перевод, ошибка, неточная передача информации, переводчик, система, жанрово-стилистическая особенность текста оригинала, нарушение, нарушение нормы, переводящий язык, передача.
Introduction
In order to improve Translation Environment Tools, we need to find objective ways to assess post-editing effort before presenting machine translation output to the translator. In current tools, it is often still the translator that has to decide whether or not the output provided by the machine translation system is worth post-editing, or whether it would be faster to simply translate from scratch (Offersgaard et al., 2008). Letting the post-editors make this decision, however, costs time and effort. It would be much more cost-efficient to have a system capable of pre-assessing MT suitability (Schütz, 2008; Denkowski and Lavie, 2012) by predicting post-editing effort. At the same time, it is still largely unclear how post-editing effort should be defined and measured and whether differences in effort between more and less experienced translators can be observed.
Current systems often make use of product analysis to evaluate post-editing effort, but the question remains whether these methods measure actual effort or not, as a product is a result of a process, not necessarily a reflection of the effort involved in the process itself. Process measures are therefore expected to give a more accurate indication of actual effort, as they measure the effort as it is taking place. When discussing effort, it is also important to take the factor ‘experience’ into account. Student translators have been shown to work differently compared to professional translators, and their attitude toward machine translation is also expected to be different.
In this study, we observe the impact of machine translation errors on different post-editing effort indicators: the often used product effort indicator human-targeted translation error rate (HTER), and some of the commonly used process effort indicators [fixation duration, number of fixations, (average) pause ratio, post-editing duration, and production units].
To collect the data, we set up a post-editing experiment with professional translators and student translators, using keystroke logging and eye-tracking. We first verify whether all effort indicators are influenced by machine translation quality, and then identify the specific types of machine translation errors that have the greatest impact on each of the effort indicators. This study is an extension and improvement of a previous study (Daems et al., 2015), in which only the student data was analyzed and only process effort indicators were observed.
It is hypothesized that, while all effort indicators are expected to be influenced by machine translation quality, the product effort indicator will be impacted by different types of errors than the process indicators, suggesting that product effort indicators in isolation are not a sufficiently accurate measure of actual post-editing effort. We expect there to be overlapping error types between the different process effort indicators, as they are to a certain extent related to one another (Krings, 2001). With regards to experience, it is hypothesized that different machine translation errors impact the effort indicators differently for student translators and for professional translators.
In the following sections, we will first discuss possible measures of post-editing effort, the influence of machine translation quality and the influence of experience.
Related Research
Post-editing effort has been assessed via product analysis (by comparing machine translation output to a reference translation or post-edited sentence) and via process analysis (by observing aspects of the post-editing process, such as duration, production units, pauses, and fixation behavior). These measures will be discussed in more detail in the following paragraphs.
Assessing PE Effort via Product Analysis
Often used automatic metrics like BLEU (Papineni et al., 2002) or METEOR (Banerjee and Lavie, 2005) compare MT output to reference translations to evaluate a machine translation system’s performance. Whereas the values given by such metrics can be used to benchmark and improve MT systems, they are created on the basis of translations made independently of the MT output and thus do not necessarily provide post-editors with valid information about the effort that would be involved in post-editing the output. In addition, a score given by such metrics contains no information about the complexity of specific errors that need to be fixed during post-editing.
More recently, research into machine translation quality estimation (QE) has moved away from the independent reference translations, as used by automatic metrics, to reference post-edited sentences. Many of these QE systems have been trained on HTER data (Snover et al., 2006). HTER measures the edit distance between the MT output and a post-edited version of that MT output. The benefit of using HTER is the fact that it is relatively easy to apply, as it only requires MT output and a post-edited text. The underlying assumption when using HTER for QE is that HTER is an indication of actual post-editing effort (Specia and Farzindar, 2010), which implies that all edits made to MT output by a human are expected to require a comparable amount of effort. However, HTER has one important limitation: as HTER focuses on the final product, it does not take the actual process into account, so its relationship to post-editing effort is questionable. For example, a post-editor can return to the same phrase multiple times during the post-editing process, changing that particular phrase each time, but settling on one specific solution in the end. HTER will indicate how different this final solution is from the original MT output, but it does not take into account all edits made during the process. In addition, the number of edits required to solve an issue does not necessarily correlate with the cognitive demand.
Assessing PE Effort via Process Analysis
According to Krings (2001), there are three main types of process-based post-editing effort. Of these three, the easiest to define and measure is temporal effort: how much time does a post-editor need to turn machine translation output into a high quality translation? The second type of post-editing effort is somewhat harder to measure, namely technical effort. Technical effort includes all physical actions required to post-edit a text, such as deletions, insertions, and reordering. The final type of effort is cognitive effort. It refers to the mental processes and cognitive load in a translator’s mind during post-editing, and can, presumably, be measured via fixation data. While it is important to distinguish between these three types of post-editing effort conceptually, it must be noted that they are, to some extent, related to one another. Temporal effort is determined by a combination of cognitive effort and technical effort, and while an increase in technical effort does not necessarily correspond to an increase in cognitive effort, the technical process is still guided by cognitive processes.
Since effort can be defined in many different ways, researchers have used different methods to measure it. Koponen et al. (2012), for example, inquired into temporal and technical effort. They used a cognitively motivated MT error classification created by Temnikova (2010) and found that more time was needed to post-edit sentences that contained more cognitively demanding errors. They considered the number of keystrokes as well, but found no relationship between the number of keystrokes and the error types. Keystrokes were more strongly influenced by individual differences between participants.
A more direct cognitive measure was used by Jakobsen and Jensen (2008), who looked at fixation duration and the number of fixations during tasks of increasing complexity (from reading to translation). They found longer average fixation durations and a higher number of fixations as the complexity of a task increased. Doherty and O’Brien (2009) looked at the same variables, focusing specifically on the reading of MT output. They found a higher number of fixations when reading bad MT output than when reading good MT output, but they did not find a significant difference between the average fixation durations for both outputs.
Lastly, pauses have also been used a measure of effort. O’Brien (2006), for example, assumed that a higher number of negative translatability indicators (NTIs, i.e., elements in the source texts that are known to be problematic for MT) would be cognitively more demanding for a post-editor. She suggested pause ratio (total time in pauses divided by the total editing duration) as a possible indicator of cognitive effort, but she did not find conclusive evidence for a relationship between pause ratio and the number of NTIs in the source text.
Later, Lacruz et al. (2012) took the number of editing events in a sentence to be an indication of cognitive effort. They introduced the average pause ratio (the average duration per pause in a segment divided by the average duration per word in the segment) as an answer to O’Brien’s (2006) pause ratio, arguing that pause ratio is not sensitive enough as a measure for cognitive activity, as it does not take average pause length into account. While their results were promising, it must be noted that they reported on a case study with only one participant, and that they used a different measure of cognitive demand compared to O’Brien (2006).
Impact of MT Quality
Denkowski and Lavie (2012) made a clear distinction between analyzing MT as a final product and MT fit for post-editing, saying that evaluation methods for the first may not necessarily be appropriate for the latter. It is the latter that the present article will be concerned with: does MT quality have an impact on PE effort, and, if so, which kinds of MT errors have the highest impact on this effort?
The problem has been approached by using human quality ratings ranging from ‘good’ to ‘bad’ (Doherty and O’Brien, 2009; Koponen, 2012; Popovic et al., 2014) and error typologies (Koponen et al., 2012; Stymne et al., 2012).
Doherty and O’Brien (2009), Koponen (2012), and Popovic et al. (2014) used human-assigned sentence ratings with four or five levels, with the highest score indicating that no post-editing was needed and the lowest score indicating that it would be better to translate from scratch. Whereas Popovic et al. (2014) included MT output at all levels in their analysis, Doherty and O’Brien (2009) and Koponen (2012) limited theirs to the MT segments with highest and lowest quality. It is therefore hard to directly compare the three studies. For the lower quality sentences, Koponen (2012) and Popovic et al. (2014) found an increase in the number of word order edits and Doherty and O’Brien (2009) found a higher number of fixations.
Regarding error typologies, Koponen et al. (2012) used the classification proposed by Temnikova (2010), which contains various MT output errors ranked according to cognitive demand, and Stymne et al. (2012) used the classification proposed by Vilar et al. (2006). This difference in classification makes it hard to compare both studies, although they both found word order errors and incorrect words to impact post-editing effort the most: Koponen et al. (2012) studied their relationship with post-editing duration, and Stymne et al. (2012) studied their relationship with fixation duration.
For future work, researchers suggest using more fine-grained error typologies (Koponen et al., 2012; Stymne et al., 2012) and different languages (Koponen et al., 2012; Stymne et al., 2012; Popovic et al., 2014).
Impact of Translation Experience
The effort involved in post-editing can be expected to be different for professional translators and students on the basis of previous studies in the field of translation and revision research.
Inexperienced translators have been shown to treat the translation task as a mainly lexical task, whereas professional translators pay more attention to coherence and style (Tirkkonen-Condit, 1990; Séguinot, 1991). Students have also been shown to require more time (Tirkkonen-Condit, 1990), and a higher number of fixations and pauses than professional translators while translating (Dragsted, 2010).
A comparable trend is found in revision research. Sommers (1980), for example, found that experts adopt a non-linear strategy, focusing more on meaning and composition, whereas student revisers work on a sentence level and rarely ever reorder or add information. Hayes et al. (1987), too, reported that expert revisers first attend to the global structure of a text, whereas novice revisers attend to the surface level of a text. Revision is seen as a complex process that puts a great demand on working memory. Broekkamp and van den Bergh (1996) found that students were heavily influenced by textual cues during the revision process. For example, if a text contained many grammatical errors, the reviser’s focus switched to solving grammatical issues, and more global issues were ignored.
It remains to be seen whether these findings can be extrapolated to the post-editing process. The study by de Almeida and O’Brien (2010) is, to the best of our knowledge, the only one linking experience to the post-editing process. They found that more experienced translators were faster post-editors and made more essential changes as well as preferential changes.
Hypotheses
In this article, we focus on the following research questions: (i) are all effort indicators influenced by machine translation quality, (ii) is the product effort indicator HTER influenced by different machine translation error types than the process effort indicators, (iii) is there an overlap between the error types that influence the different process effort indicators, and (iv) is the impact of machine translation error types on effort indicators different for student translators than for professional translators?
On the basis of the above-mentioned research, we expect that a decrease in machine translation quality will lead to an increase in post-editing effort, as expressed by an increase in HTER (Specia and Farzindar, 2010), the number of production units1 (Koponen, 2012; Popovic et al., 2014), the number of fixations (Doherty and O’Brien, 2009), post-editing time (Koponen et al., 2012), fixation duration (Stymne et al., 2012), pause ratio (O’Brien, 2006), and a decrease in average pause ratio (Lacruz et al., 2012).
As HTER is a product measure, we expect it to be influenced by different machine translation error types than the process effort indicators, which we expect to be influenced by comparable error types, as they are, to a certain extent, related (Krings, 2001). More specifically, we expect process effort indicators to be influenced most by mistranslations and word order issues (Koponen et al., 2012; Stymne et al., 2012) and lexical or semantic issues (Popovic et al., 2014).
Given the notion that inexperienced revisers focus more on grammatical errors when there is an abundance of grammatical errors (Broekkamp and van den Bergh, 1996), and the fact that student translators treat translation as a lexical task (Tirkkonen-Condit, 1990), we expect students to focus mostly on the grammatical and lexical issues, whereas professional translators are expected to pay more attention to coherence, meaning, and structural issues (Sommers, 1980). This means that we expect to see a greater increase in post-editing effort with students than with professional translators when there is an increase in grammatical and lexical issues in the text, and we expect a greater increase in post-editing effort with professional translators than with students when there is an increase in coherence, meaning, or structural issues.
Materials and Methods
In order to collect both process and product data for translators with different levels of experience, we conducted a study with student and professional translators, registering the post-editing process by means of keystroke logging and eyetracking. As product effort indicator, we measured HTER. As process effort indicators, we measured fixation duration, number of fixations, (average) pause ratio, post-editing duration, and production units.
Participants
Participants were 13 professional translators (3 male and 10 female) and 10 master’s students of translation (2 male and 8 female) at Ghent University who had passed their final English translation examination, meaning that they were ready to start working as professional translators. All participants were native speakers of Dutch. With the exception of one professional translator, who had 2 years of experience, all other translators had experience working as a full-time professional translator between 5 and 18 years. Students’ median age was 23 years (range 21–25), that of the professional translators was 37 years (range 25–51).
All participants had normal or corrected to normal vision. Two students wore contact lenses and one student wore glasses, yet the calibration with the eye tracker was successful for all three. Two professional translators wore lenses. Calibration was problematic for one of the professionals, their sessions with problematic calibration were removed from the data.
The project this study is a part of has been reviewed and approved by the Ethical Committee of the Faculty of Psychology and Educational Sciences at Ghent University. All participants gave written informed consent.
Students reported that they were aware of the existence of MT systems, and sometimes used them as an additional resource, but they had received no explicit post-editing training. Some professional translators had basic experience with post-editing, although none of the translators had ever post-edited an entire text.
All participants performed a LexTALE test (Lemhöfer and Broersma, 2012), which is a word recognition test used in psycholinguistic experiments, so as to assess English proficiency. Other than being an indicator of vocabulary knowledge, it is also an indicator of general English proficiency. As such, it is an important factor to take into account when comparing the translation process of students and professionals. Both groups had very high scores on this test; their scores (professionals mean = 88.27; standard deviation = 9.5; students mean = 88; standard deviation = 7.75) did not differ significantly [t(21) = 0.089, p = 0.47].
Text Selection
Both to avoid specialized text experience playing a role and to control for text complexity as much as possible, 15 newspaper articles with a comparable complexity level were selected from Newsela, a website that offers English newspaper articles at various levels of complexity (as represented by Lexile® scores, which combine syntactic and semantic information). We selected 150/160-word passages from articles with high Lexile® scores (between 1160L and 1190L). To control texts further, we manually compared them for readability, potential translation problems and MT quality. Texts with on average fewer than 15 or more than 20 words per sentence were discarded, as well as texts that contained too many or too few complex compounds, idiomatic expressions, infrequent words or polysemous words. The Dutch MT output was taken from Google Translate (output obtained January 24, 2014), and annotated with a two-step Translation Quality Assessment approach2 (Daems et al., 2013, see also “MT Output Error Analysis”).
We discarded the texts for which the MT output would be too problematic, or not problematic enough, for post-editors, based on the number of structural grammatical problems, lexical issues, logical problems and mistranslated polysemous words. The final corpus consisted of eight newspaper articles, each 7–10 sentences long. The topics of the texts varied, and the texts required no specialist knowledge to be translated.
MT Output Error Analysis
Annotation of the MT Output
To be able to identify the relationship between specific machine translation problems and post-editing effort, two of the authors annotated all translations for quality. Machine translation quality was analyzed from two perspectives.
The first was acceptability, or the adherence to target text and target language norms. This category contained all translation problems that can be identified by looking at the target text (in this case, the machine translation output) without consulting the source text. It consisted of the subcategories of grammar and syntax, lexicon, coherence, style and register, and spelling, which were all further subdivided into subcategories.
The second perspective was adequacy, or the adherence to source text norms. All problems that could be identified by comparing the source text with the target text belonged to this category. Subcategories included deletions and additions (of words or phrases), various types of mistranslations, and meaning shifts.
Each error type was given an error weight ranging from 0 (not a real error, but a change nonetheless, such as an explicitation) to 4 (contradictions and other problems that severely impacted the comprehensibility of the text).
The actual annotation took place in two steps, respecting both perspectives above: in step one the annotators were only given the target text and annotated the text for acceptability, and in step two annotators compared the translations with the source texts and annotated the texts for adequacy. The annotations of both annotators were then compared and discussed and only the annotations which both annotators agreed on were maintained for the final analysis. Annotations were made with the brat rapid annotation tool (Stenetorp et al., 2012).
Overview of Errors in the MT Output
Out of 63 sentences, 60 sentences contained at least one error. There were more acceptability issues (201 instances) than adequacy issues (86 instances). The error categorization described above contained 35 types of acceptability issues and 17 types of adequacy issues, but not all issues were found in the machine translation output3. To be able to perform statistical analyses, some of the error categories were grouped together, so that each error type occurred at least 10 times. The final classification used in this study can be seen in Figure 1.
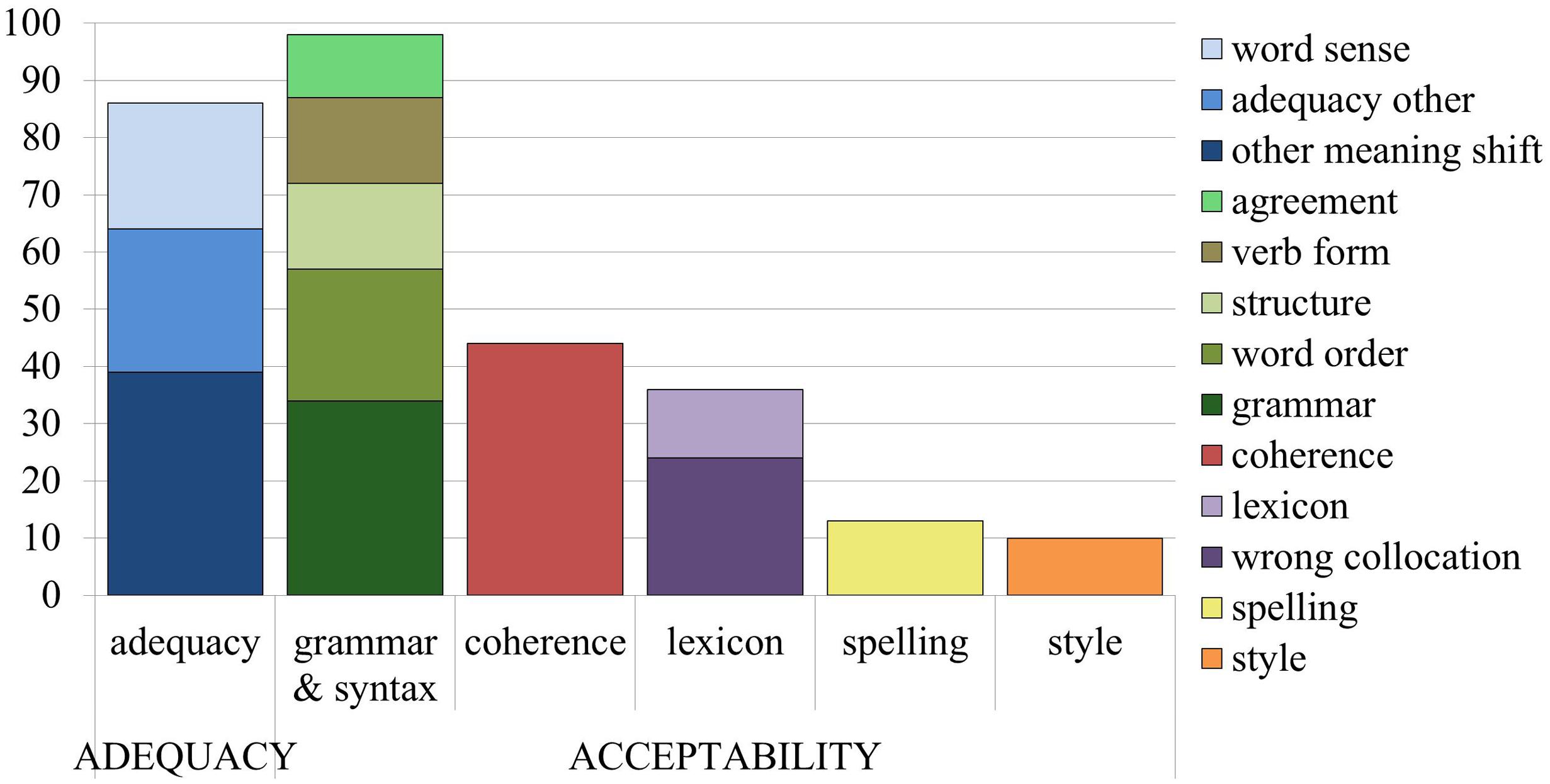
FIGURE 1. Error type frequency in the MT output.
From the perspective of ‘acceptability,’ it was the grammar and syntax category, which turned out to be the most common error category for MT output, with word order issues, structural issues, and incorrect verb forms occurring more than 10 times each. The different types of agreement issues (noun-adjective, article-noun, subject-verb, and reference) were grouped into a new ‘agreement’ category, and the other grammatical issues were contained in a ‘grammar other’ category (superfluous or missing elements). For coherence issues, the category of ‘logical problem’ occurred more than 10 times, but the other categories together (conjunction, missing info, paragraph, and inconsistency) did not occur more than 10 times, so all other coherence categories were grouped together. As for the lexicon, the subcategory of ‘wrong collocation’ appeared often enough to stand alone, while the other subcategories (wrong preposition, named entity, and word non-existent) were grouped into ‘lexicon other.’ All subcategories for style and spelling were merged together into the two main categories, since there were very few instances of these errors.
From the perspective of ‘adequacy,’ other meaning shifts and word sense issues4 occurred frequently enough to be considered as separate categories, while the other subcategories (additions, deletions, misplaced words, function words, part of speech, and inconsistent terminology) were grouped together into ‘adequacy other.’
The most common errors overall are grammatical errors (grammar and syntax), followed closely by adequacy issues.
Procedure
Sessions
The data were gathered during two separate sessions for each participant. The students’ sessions took place in June and July 2014 and the professionals’ sessions took place in April and May 2015.
The first session started with a survey, to gain an idea of participants’ backgrounds, their experience with and attitude toward MT and post-editing, and a LexTALE test. This was followed by a copy task (participants copied a text to get used to the keyboard and screen) and a warm-up task combining post-editing and human translation, so that participants could get used to the environment and the different types of tasks. The actual experiment consisted of two texts that they translated from scratch, and two texts that they post-edited.
The second session started with a warm-up task as well, followed first by post-editing two texts and translating two texts from scratch. The final part of the session consisted of unsupervised retrospection (participants received the texts which they had just translated and were requested to highlight elements they found particularly difficult to translate) and another survey, to obtain insight into participants’ attitude after the experiment.
The order of the texts and tasks was balanced across participants within each group in a Latin square design. Participants were instructed to deliver products of publishable quality, whether they were translating from scratch or post-editing. There was no time limit, and participants could take breaks between texts if so requested, to mimic a natural translation day. All participants had a morning and an afternoon session, though temperature and light conditions remained constant throughout the different sessions, as they took place in a basement room (controlled light is needed for accurate eyetracking data).
Registration Tools
To be able to study all aspects of the translation process, the process was registered with two keystroke logging tools and an EyeLink 1000 eyetracker.
The main keystroke logging tool was the CASMACAT translators’ workbench (Alabau et al., 2013), which is an actual workbench with added mouse tracking and keystroke logging software. A browser plugin directly added the EyeLink fixation data to the CASMACAT logging files. Though not relevant for this particular analysis, we also used the Inputlog keystroke logging tool (Leijten and Van Waes, 2013) to register the usage of external resources during translation and post-editing.
The texts were presented to the participants one by one, with eye tracker calibration taking place before each new text. Only one sentence could be edited at a time, although the entire text was visible and participants could go back and forth through the text. The source text was shown on the left hand side of the screen, the right hand side contained the MT output.
Analysis
The final dataset comprised 721 post-edited sentences, concatenated from all post-editing sessions and enriched with MT quality information. For each sentence, the average error weight per word was calculated by summing up the error weight of all errors found in the sentence and dividing that value by the number of words in the sentence.
The statistical software package R (R Core Team, 2014) was used to analyze the data. We used the lme4 package (Bates et al., 2014) and the lmerTest package (Kuznetsova et al., 2014-48pc) to perform linear mixed effects analyses. In these analyses, statistical models can be built that contain independent variables as well as random effects, i.e., subject or item-specific effects. It is also possible to have more than one independent variable, and to study the interaction effect of independent variables on one another. A statistical model is always tested against a null model, i.e., a model that assumes that there is no effect on the dependent variable. If the created model differs sufficiently from the null model, we can assume that there is an effect from the independent variables on the dependent variables.
In this particular study, we used the various post-editing effort indicators as dependent variables, see Table 1 for an overview of dependent variables with descriptives for student and professional data; The independent variables are machine translation quality and experience. They were included in the models with interaction effect, as we are interested in seeing how machine translation quality has a different influence on effort indicators for students and professional translators. The random effects were participants and sentence codes (a unique id for each source text sentence), because we expected there to be individual differences across participants as well as sentence-inherent effects.
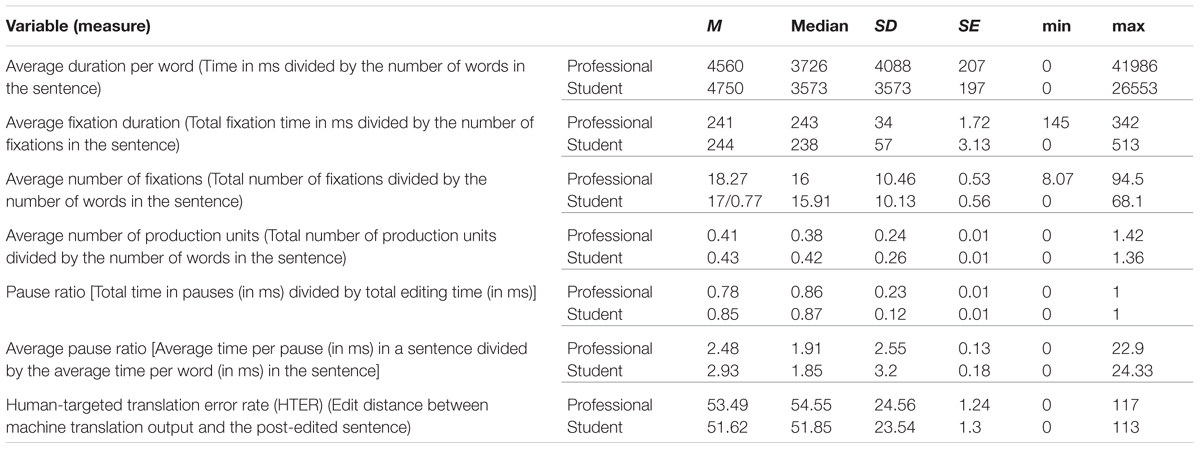
TABLE 1. Overview of dependent variables.
For each of the models discussed below, we started by building a null model with the post-editing effort indicator as dependent variable and participant and sentence code as random effects. This model was then tested against the model containing two predictors (the continuous variable machine translation quality and the categorical variable experience, which was either ‘student’ or ‘professional’), plus interaction effect.
As a measure of model fit, we used Akaike’s Information Criterion (AIC) values (Akaike, 1974). The model with the lower AIC value has a better fit compared to the model with the higher AIC value, especially when the difference between both models is greater than 4 (Burnham and Anderson, 2004), but an AIC value in itself has no absolute meaning, which is why we only included difference in AIC value in the tables.
We looked at the impact of fine- and coarse-grained machine translation quality on different post-editing effort indicators in two different analyses. This was done to first establish whether effort indicators are indeed impacted by machine translation errors, and to verify whether the suggestion by Koponen et al. (2012) and Stymne et al. (2012) to use more fine-grained error typologies really leads to more obvious differences between the different post-editing effort indicators.
The first analysis was the most coarse-grained, in which we used the average total machine translation error weight and experience as predictor variables. For each of the post-editing effort indicators, we built a null model and a model with both predictor variables, which we then compared.
For the fine-grained analysis, we also built separate models for each of the post-editing effort indicators. Here, we added all our adapted machine translation error subcategories as possible predictors. We then tested which of the subcategories were retained by the step-function from the lmerTest package. For each of these significant predictors, we built a separate model, adding experience with interaction effect as a possible additional predictor.
Results
Analysis 1: Coarse-Grained
A summary of the models with average total machine translation error weight and experience plus interaction as possible predictor variables can be found in Table 2. The table contains the dependent variable, i.e., the post-editing effort indicator under scrutiny in the first column, the difference in AIC value between the predictor model and the null model (i.e., model without predictor) in the second column, an overview of the significant or almost significant predictors (i.e., MT error weight and/or experience, with or without interaction effect, with p ≤ 0.05) in the third column, the effect size for each significant predictor in column four, and the p-value to indicate significance in column five. The effect column shows the actual effect that an independent variable has on a dependent variable. For non-significant effects, the table contains ‘n/a.’
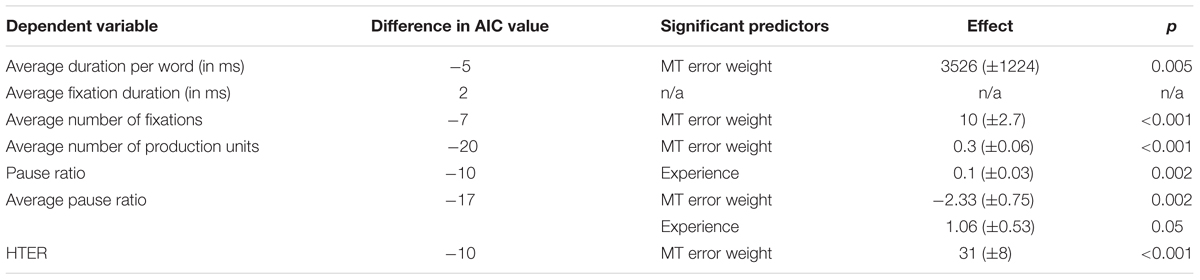
TABLE 2. Summary of mixed models with average total MT error weight and experience plus interaction effect as fixed effects.
For most post-editing effort indicators, machine translation quality has an impact, but experience does not, with the exception of both pause measures. The effect of machine translation quality on the effort indicators is in line with expectations, with a decrease in quality leading to an increase in duration needed (Figure 2), an increase in the number of fixations (Figure 3) and the number of production units (Figure 4), an increase in HTER score (Figure 5), and a decrease in average pause ratio (Figure 6). The post-editing effort indicators on which machine translation quality seems to have no statistically significant impact are average fixation duration and pause ratio. The latter is impacted by experience rather than machine translation quality (Figure 7), whereas the average pause ratio is impacted by experience as well as machine translation quality. Students have a significantly higher pause ratio than professionals, presumably requiring more time to think before changing anything, but also a higher average pause ratio, which is somewhat surprising. It must be noted, however, that the latter effect is not quite significant (p = 0.05) and so it must be interpreted with caution. We further found no significant effect of either machine translation error weight or experience on average fixation duration.
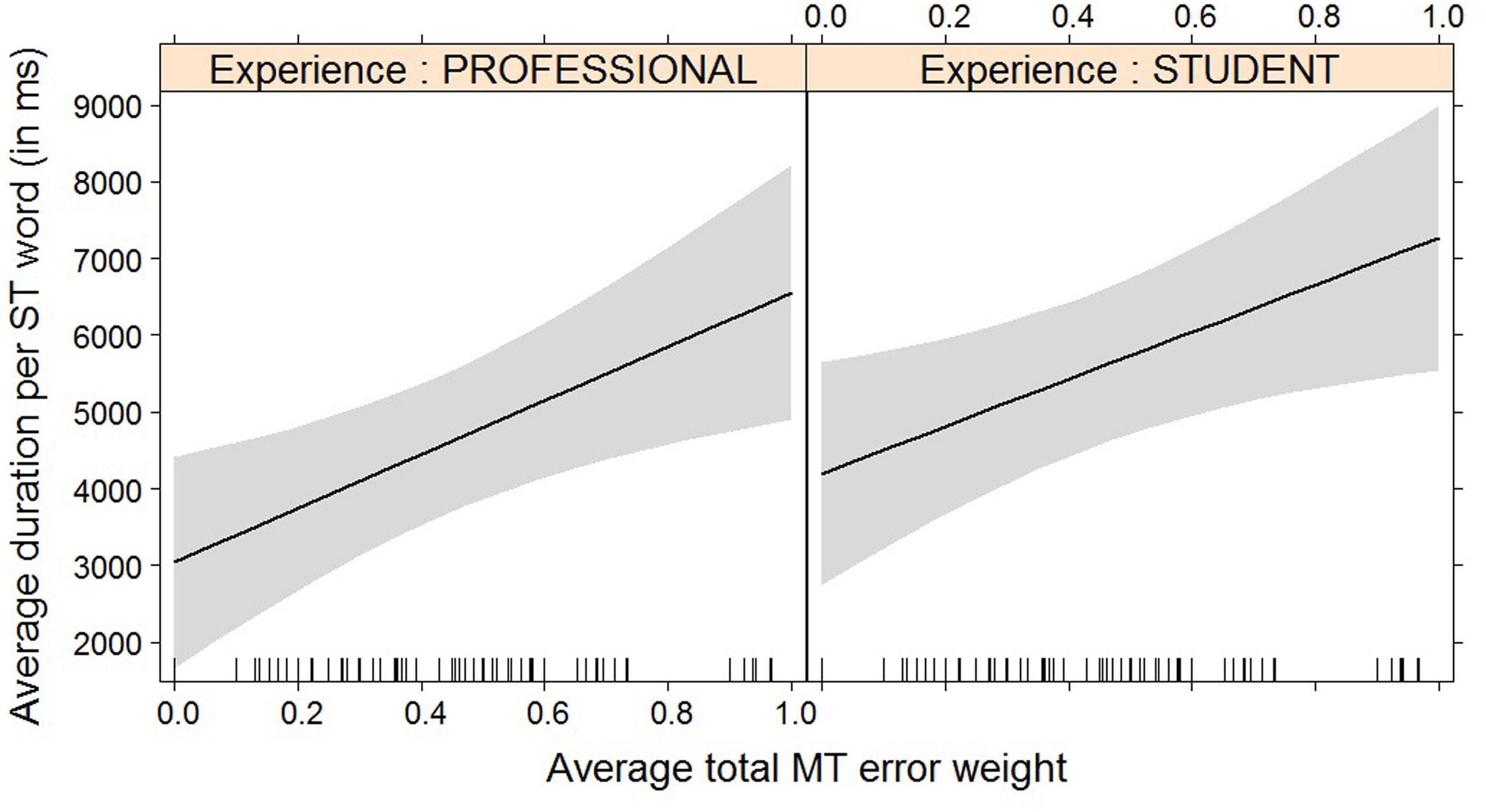
FIGURE 2. Effect plot of total MT error weight on average duration. An increase in average total MT error weight leads to an increase in average duration per ST word, for professionals and students alike.
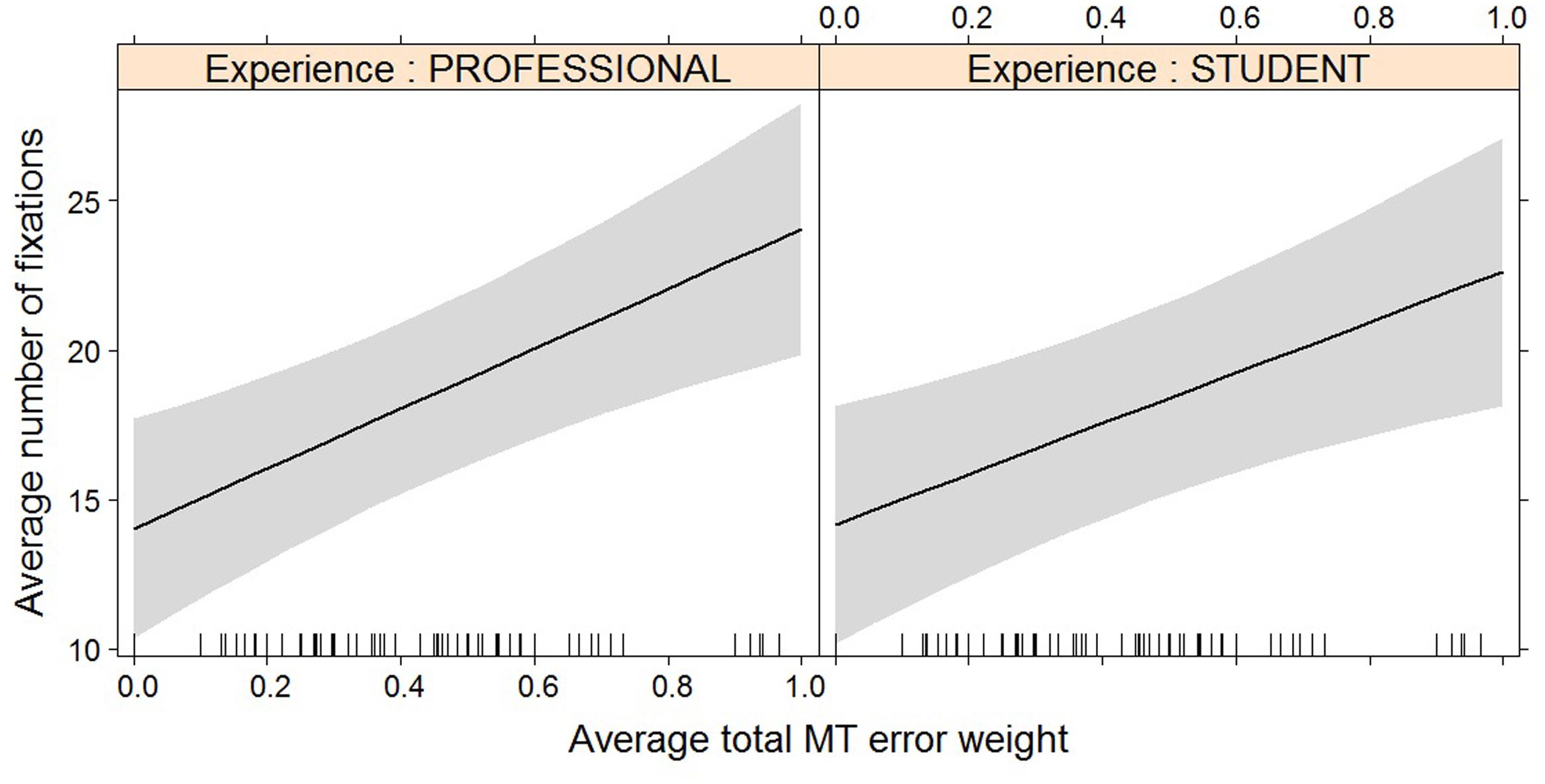
FIGURE 3. Effect plot of total MT error weight on average number of fixations. An increase in average total MT error weight leads to an increase in average number of fixations, for professionals and students alike.
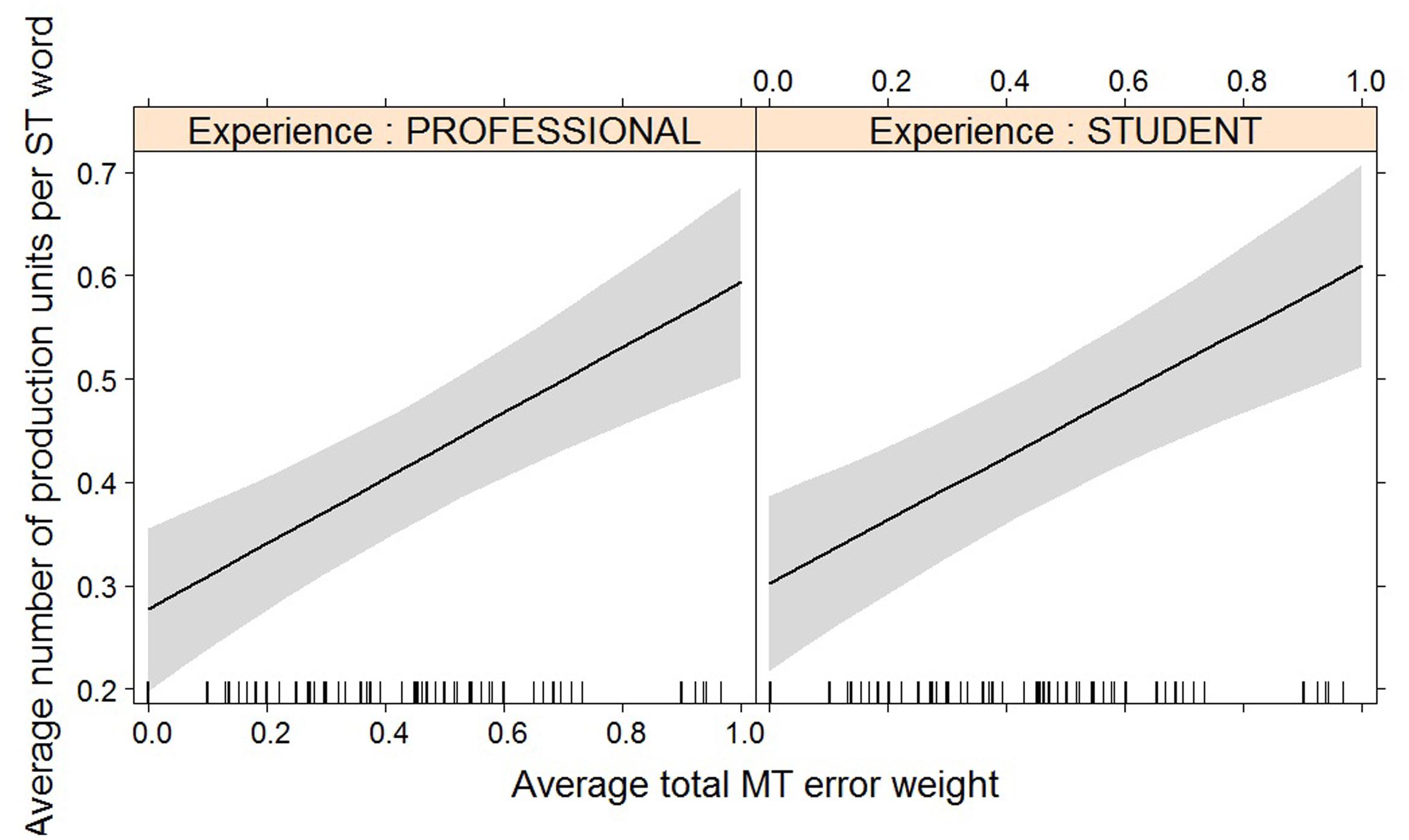
FIGURE 4. Effect plot of total MT error weight on average number of production units. An increase in average total MT error weight leads to an increase in average number of production units, for professionals and students alike.
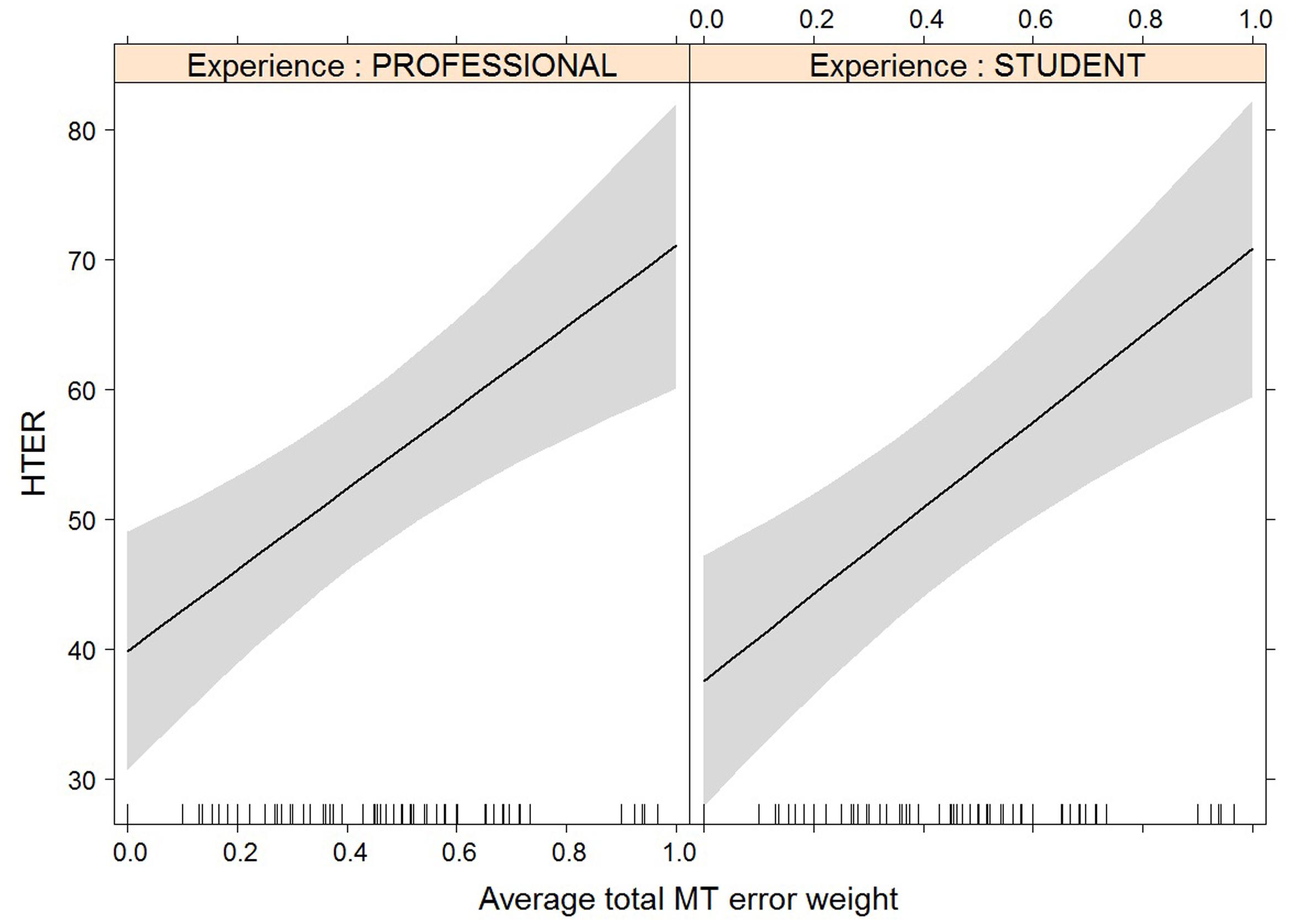
FIGURE 5. Effect plot of total MT error weight on human-targeted translation error rate (HTER). An increase in average total MT error weight leads to an increase in HTER score, for professionals and students alike.
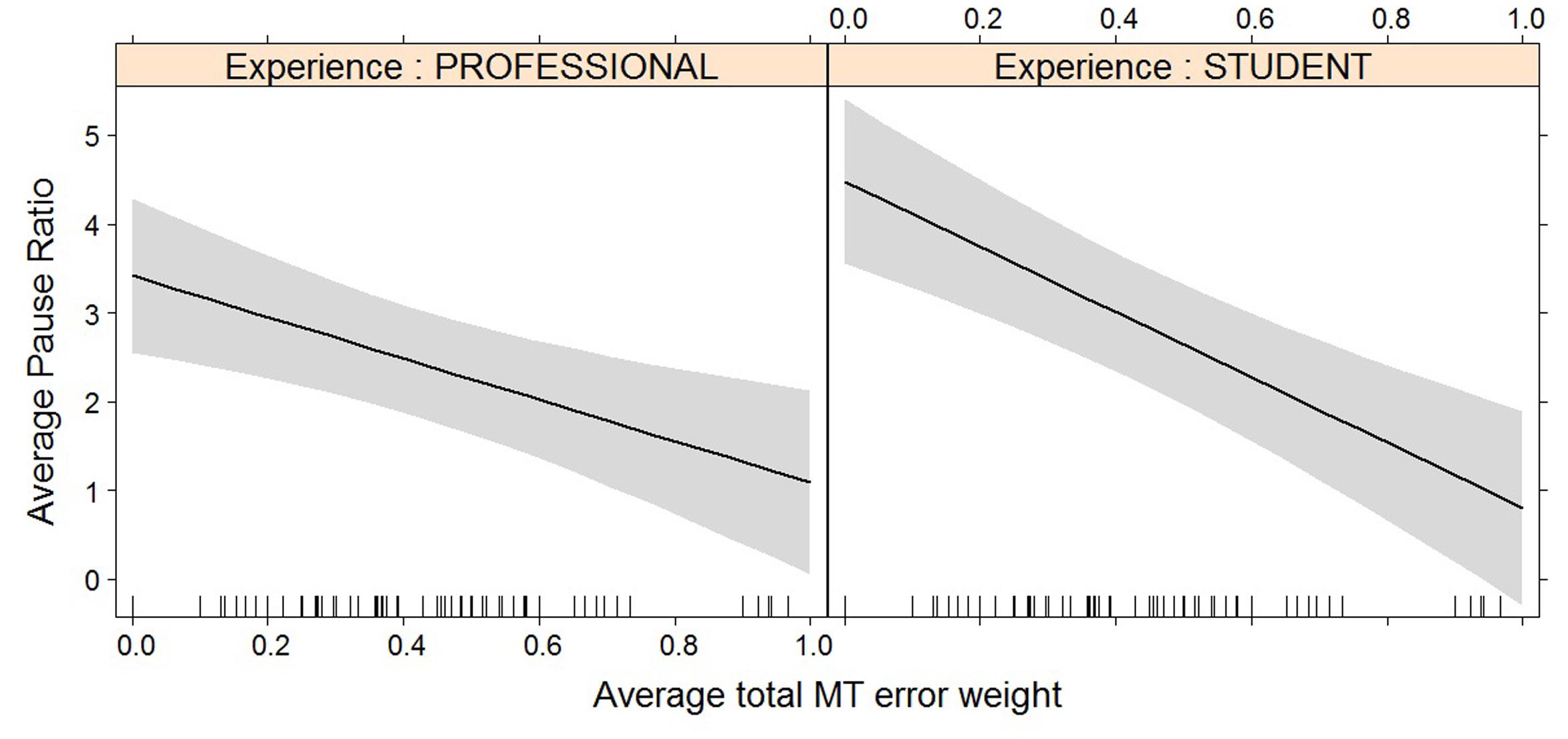
FIGURE 6. Effect plot of total MT error weight on average pause ratio. An increase in average total MT error weight leads to a decrease in average pause ratio, for professionals and students alike.
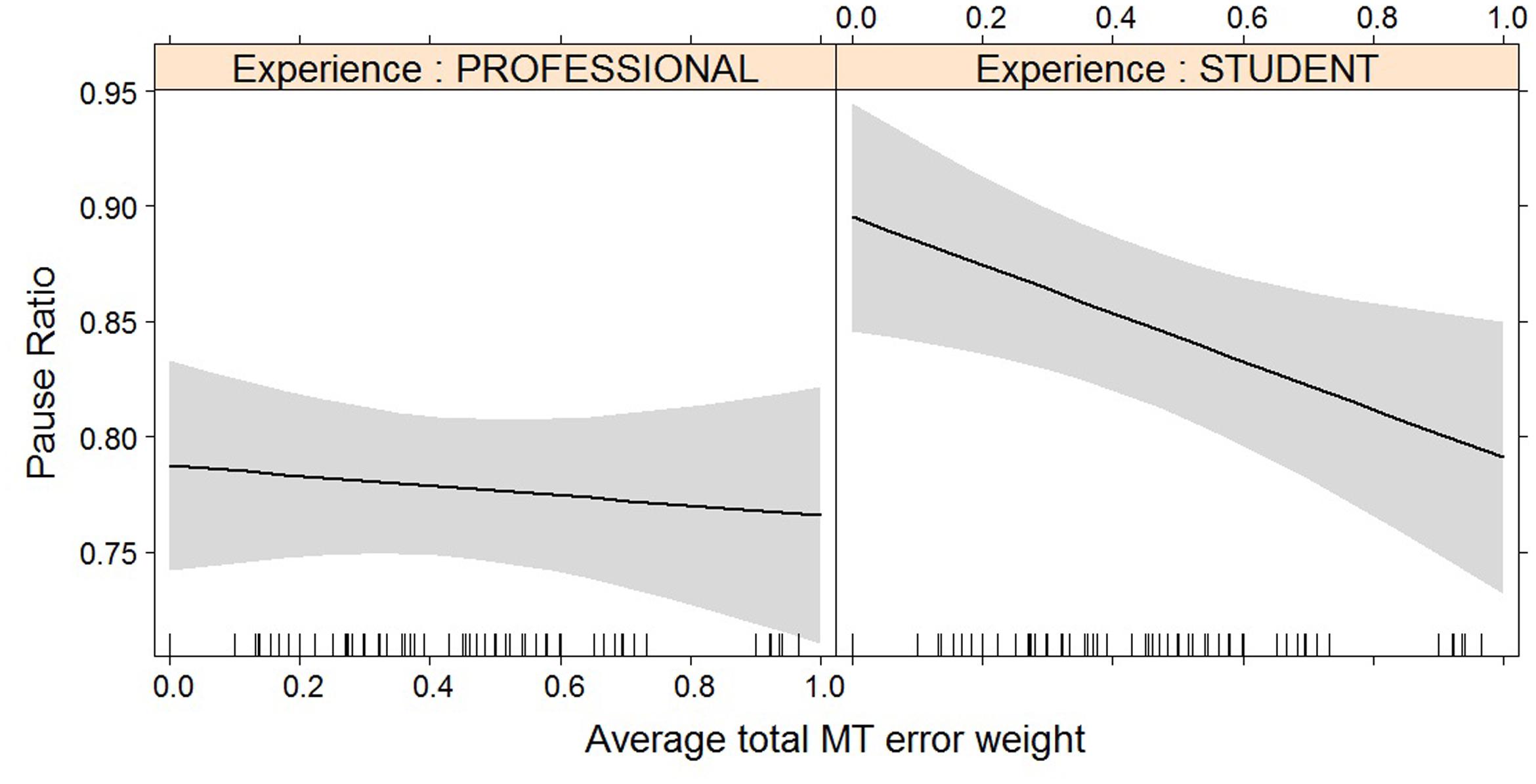
FIGURE 7. Effect plot of total MT error weight on pause ratio. Students show a higher average pause ratio than professional translators; the impact of the increased error weight on pause ratio is not statistically significant.
Analysis 2: Fine-Grained
We obtain a more nuanced picture when studying the results for the fine-grained level analysis in Table 3. We first built a model including all possible machine translation error types as possible predictors for the different post-editing effort indicators. The significant error types are listed in column two, showing that different types of machine translation errors impact different post-editing effort indicators. The more technical effort indicators (number of production units, pause ratio, average pause ratio, and HTER) are mostly impacted by grammatical errors (grammar, structure, word order, and agreement), whereas the more cognitive effort indicators (fixations and duration) are influenced most by coherence and other meaning shifts. We then built a model for each of the significant MT error types separately and added experience plus interaction effect as possible predictors. The significant (p < 0.05) and almost significant (p < 0.06) predictors for these models can be seen in column four, with the actual effect size in column five. For non-significant effects, the table contains ‘n/a.’
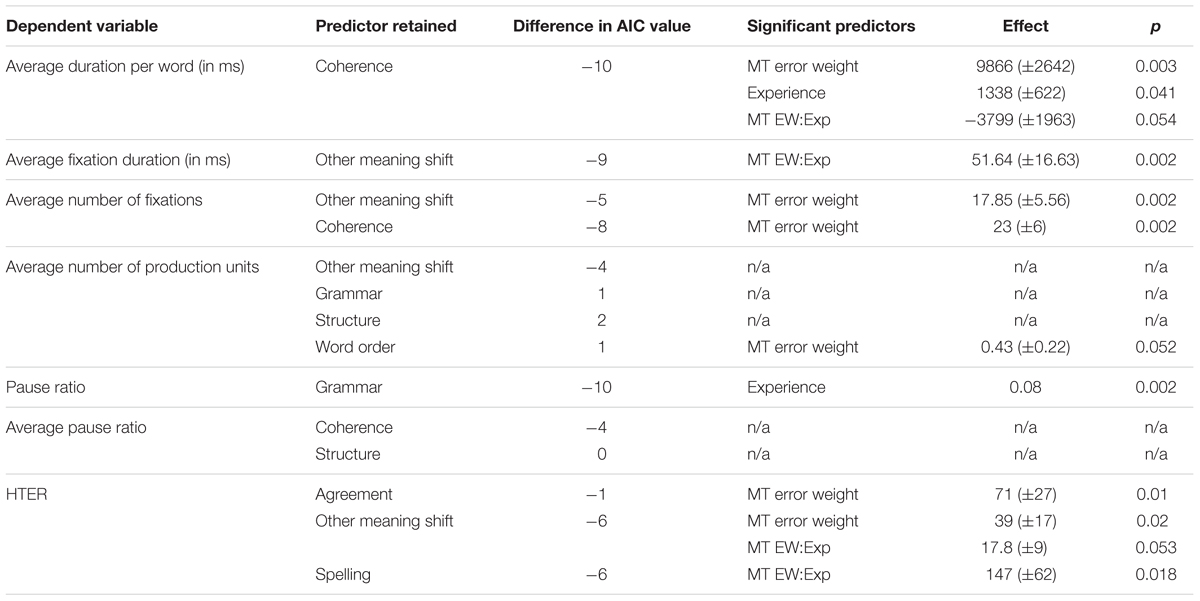
TABLE 3. Summary of mixed models with average MT error weight for the subcategories retained by step-function as fixed effects, and experience plus interaction effect as potential additional fixed effects.
It is interesting to see how experience and/or experience with interaction effect now become relevant for the models with average duration (Figure 8), average fixation duration (Figure 9), and HTER (Figure 10) as dependent variables. In the case of average duration, students seem to be impacted less by an increase in coherence issues than professional translators, although the significance levels are not convincing (the experience effect only just reaches significance, the interaction effect almost reaches significance). In the case of average fixation duration, only students seem to be impacted by an increase in other meaning shifts, whereas the average fixation duration of professional translators remains comparable. The trend for HTER is similar, with students responding more strongly (yet not statistically significantly) to an increase in other meaning shifts than professional translators. In addition, HTER scores for students go up significantly with an increase in spelling errors. In the models for average number of production units and average pause ratio, a few different machine translation error types seem to influence the post-editing effort indicators, but once split into a separate model containing experience with interaction effect as additional predictors, the predictors are no longer significant. The model with word order as predictor variable of the average number of production units approaches significance, but that is the only one.
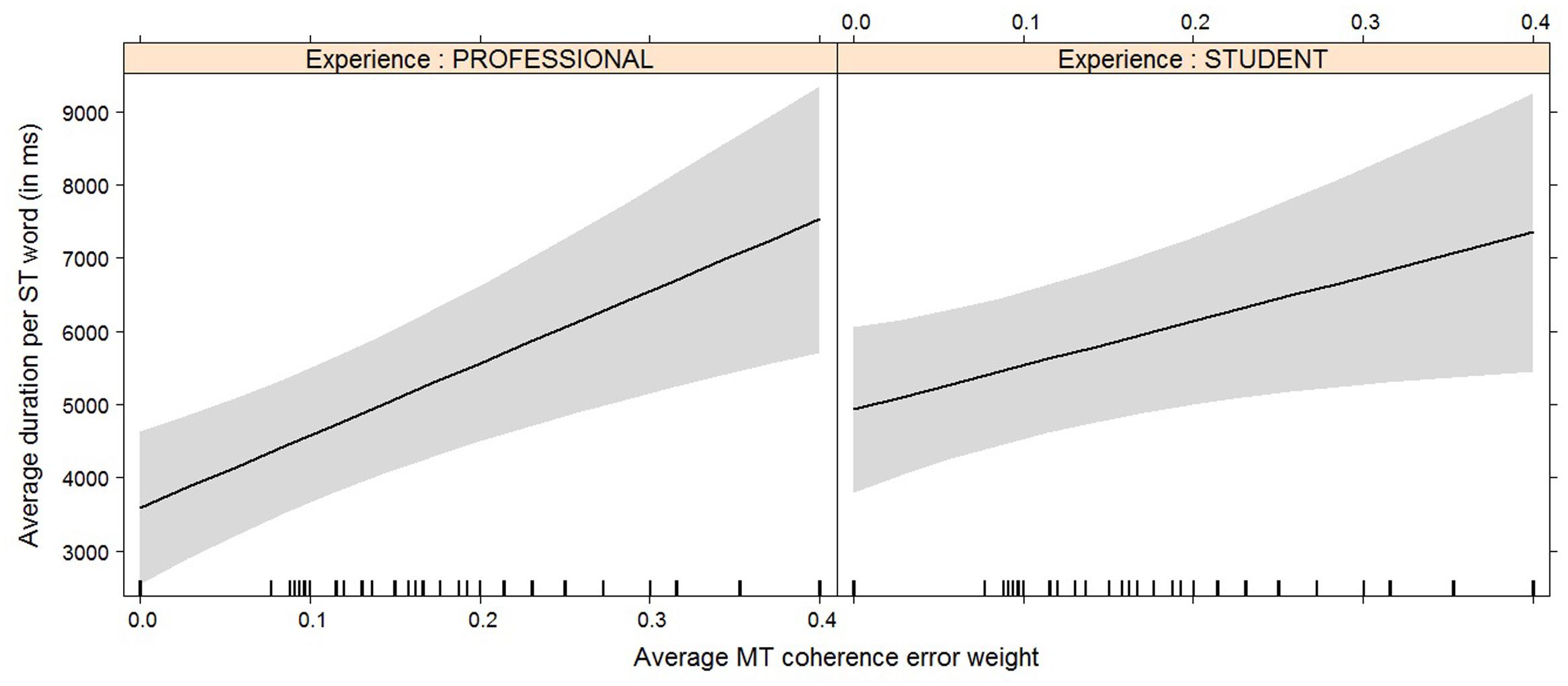
FIGURE 8. Effect plot of MT coherence error weight on average duration. An increase in average MT coherence error weight leads to an increase in the average duration. Students have a higher overall average duration, but the average duration increases somewhat more rapidly for professionals with an increase of MT coherence error weight than it does for students.
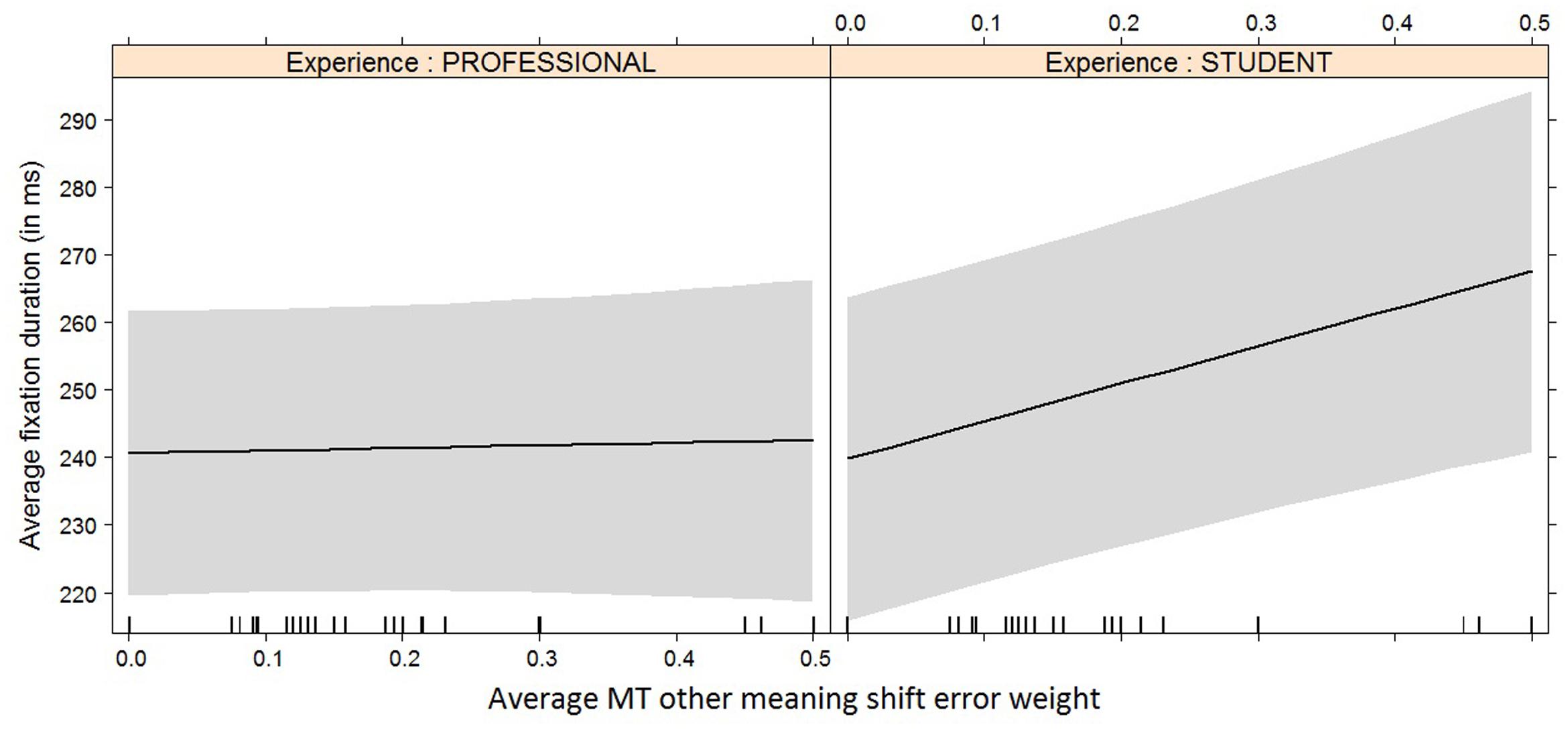
FIGURE 9. Effect plot of MT other meaning shift error weight on average fixation duration. Only the interaction effect is significant: the average fixation duration for students increases more heavily than that of professional translators with an increase in MT other meaning shift error weight.
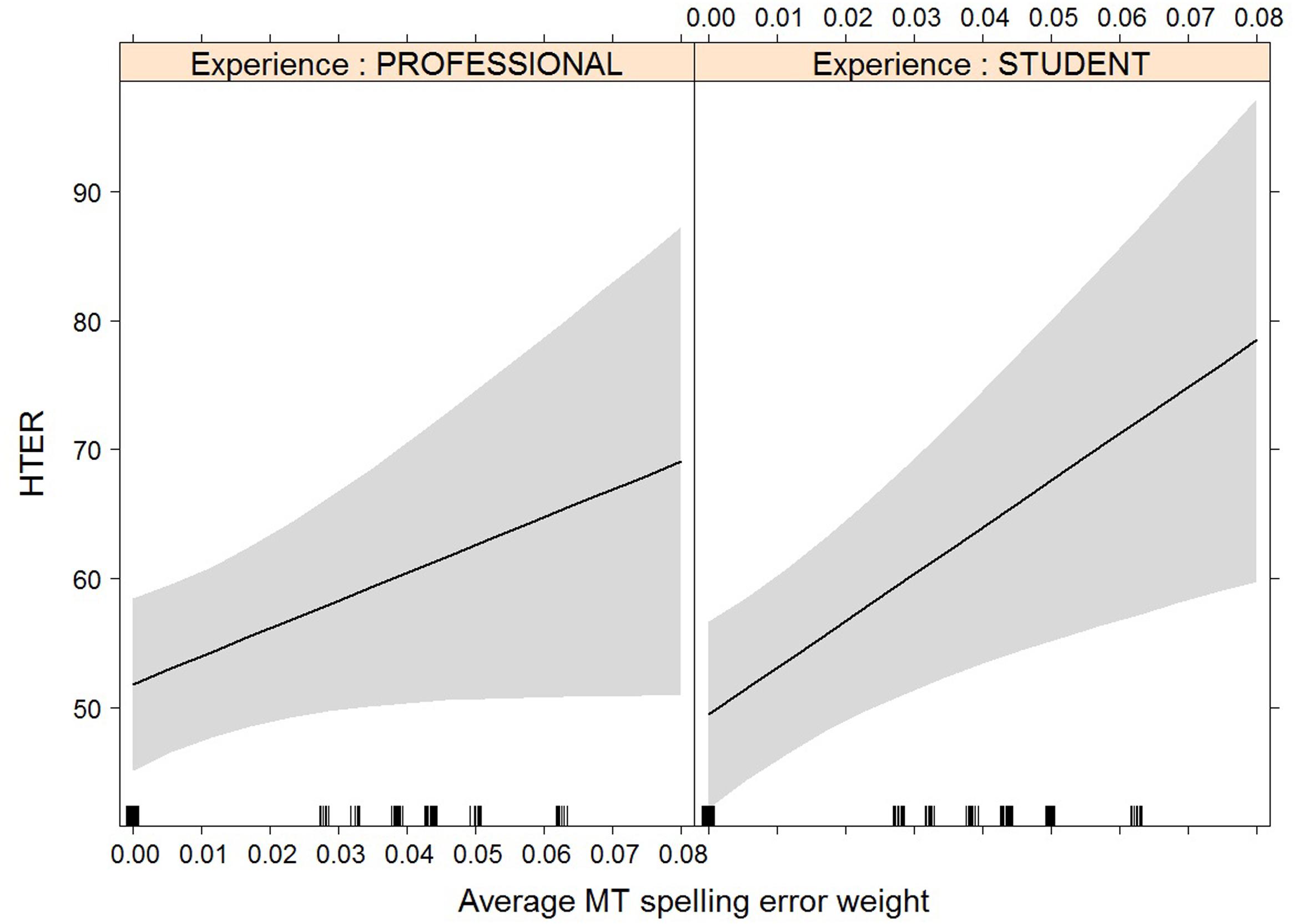
FIGURE 10. Effect plot of MT spelling error weight on HTER. Only the interaction effect is significant: the average HTER for students increases more heavily than that of professional translators with an increase in MT spelling error weight.
Discussion
We expected to find that (i) post-editing effort indicators are influenced by machine translation quality, (ii) the product effort indicator HTER is influenced by other machine translation error types than process effort indicators, (iii) there is an overlap in error types that influence the various process effort indicators, and (iv) the effort indicators of student translators and professional translators respond to different error types in different ways. In order to verify these hypotheses, we studied the impact of machine translation quality on seven types of post-editing effort indicators (six process-based effort indicators and one product-based effort indicator), at two levels of MT quality assessment granularity and we added experience as a predictor.
Hypothesis 1
From the coarse-grained analyses, we learned that post-editing effort indicators can indeed be predicted by machine translation quality, with the exception of average fixation duration and pause ratio.
Previous studies, too, have shown that average fixation duration does not differ significantly for good and bad MT quality (Doherty and O’Brien, 2009; Doherty et al., 2010), and so perhaps average fixation duration is not a good measure of post-editing effort.
For pause ratio, it seems that students require significantly more time in pauses than professional translators, and this effect outweighs the impact of machine translation quality. Perhaps students need more time to think about the correct course of action, whereas this process has been become more automatic for professionals. This confirms previous findings on students’ pause behavior (Dragsted, 2010), and might be an indication that pause ratio measures something else than average pause ratio (Lacruz et al., 2012), as the latter is influenced by machine translation quality.
Hypothesis 2
Most importantly, the fine-grained analysis shows that two out of three predictors (agreement and spelling issues) of the product effort indicator HTER are unique predictors, i.e., they do not appear in the models for any of the other post-editing effort indicators. This seems to offer support for our hypothesis that product effort indicators measure different things than process effort indicators. On the other hand, the HTER predictor ‘other meaning shift’ is shared with a few process effort indicators as well, which means that HTER presumably does manage to measure some of the effort measured by process effort indicators.
Hypothesis 3
Not all process effort indicators seem to be influenced by the same machine translation error types, refuting our third hypothesis. Duration, for example, is influenced most by coherence, whereas fixation duration is influenced by other meaning shifts. The machine translation error types that occur with more than one post-editing effort indicator are coherence issues, other meaning shifts, grammar and structural issues. As ‘other meaning shifts’ also occurred as a predictor of HTER, it would seem that being able to detect these three issue types (coherence issues, other meaning shifts, grammar and structural issues) would be the best way to ensure that as many different types of effort as possible are being taken into account.
The lack of word order issues as an influential category is striking, as we expected them to influence post-editing duration (Koponen et al., 2012), the average fixation duration, and number of fixations (Stymne et al., 2012). A possible explanation for these findings is the fact that our error classification includes error types such as coherence, which was not included in Temnikova’s (2010) classification, and those error types outweigh the effect of commonly used error types such as word order issues. Further research on a larger dataset and different languages is needed to support or refute these claims.
The more detailed findings can largely be explained by existing literature. The number of production units was influenced most by grammatical issues (Alves and Gonçalves, 2013), and fixations were influenced most by other meaning shifts (comparable to mistranslations), as suggested by Stymne et al. (2012). With respect to both pause measures, we found support for the claim made by Lacruz et al. (2012) that average pause ratio does not measure the same as pause ratio suggested by O’Brien (2006). Average pause ratio is influenced by structural issues and coherence issues, whereas pause ratio is influenced by grammatical issues, but this effect is outweighed by the influence of experience.
Hypothesis 4
Regarding experience effects, we expected students to be more heavily influenced by grammatical and lexical issues and professional translators to be more heavily influenced by coherence and structural issues (Sommers, 1980; Hayes et al., 1987; Tirkkonen-Condit, 1990; Séguinot, 1991).
This almost holds true for the average duration per word, where an increase in coherence issues leads to an increase in the time needed and this effect is stronger for professional translators than for students. It must be noted, however, that this interaction effect is not quite significant (p = 0.054).
For the average fixation duration, which is influenced most heavily by other meaning shifts, only the interaction effect between the increase in other meaning shifts and experience is significant. While the average fixation duration for professional translators remains more or less constant as the number of other meaning shifts increases, the average fixation duration for students goes up under the same circumstances.
A comparable trend can be seen with HTER, although the effect here is not significant. This can be an indication that other meaning shifts are cognitively more demanding for students, seeing how it is not an issue they usually focus on during translation. For professional translators, however, spotting and solving these issues is probably more routinised, causing their average fixation duration to remain constant and their HTER scores to be lower (Tirkkonen-Condit, 1990; Séguinot, 1991). Students’ HTER scores were also more heavily influenced by spelling errors. This finding is somewhat harder to explain, as spelling issues are mostly related to compounds and spaces before punctuation, which are both error types that can be expected to be corrected by both students and professional translators. We would have to look at the final translations to see whether this was actually the case.
Experience had no effect on the number of fixations, production units, and average pause ratio, which could indicate that these three predictors measure a different kind of post-editing effort than the other predictors. These findings could be further evaluated by studying the final post-editing product and comparing the quality of student and professional post-editors’ texts.
Limitations
Although we included data from students as well as professional translators, the total dataset remains relatively small. While our fine-grained analysis showed some promising results, it must be noted that with the more fine-grained analysis, fewer observations are taken into account, and so these results need to be interpreted with caution. Further experiments with the same categorisation on more data and different language pairs should be carried out in order to further develop the claims made in this article.
After this paper was written, Google released its neural machine translation for the English-Dutch language pair5. Future experiments will repeat the above analyses with this newer type of machine translation, to see whether the results can be replicated or to discover the ways in which neural machine translation differs from statistical machine translation with regards to its impact on post-editing effort.
Conclusion
We confirmed that machine translation quality has an impact on product and process post-editing effort indicators alike, with the exception of average fixation duration and pause ratio.
While most machine translation error types occur with more than one post-editing effort indicator, two of HTER’s predictors are not shared with any of the other effort indicators, providing some support for our hypothesis that product effort measures do not necessarily measure post-editing effort the way process effort measures do. On the other hand, the various process effort indicators are influenced by different error types. This indicates that the question of what influences post-editing effort depends greatly on which type of effort is meant, with coherence issues, grammatical issues and other meaning shifts being good candidates for effort prediction on the basis of MT quality in the future. This also means that, depending on the type of effort one wishes to reduce, different error type predictors should be used. For example, a language service provider mostly concerned with translation speed should focus on coherence issues, as these had the greatest impact on translation duration.
In contrast with our expectations, experience only had a significant effect on four out of seven effort predictors: average duration per word, average fixation duration with an increase of other meaning shifts, pause ratio, and HTER with an increase of spelling issues. This either means that the other three effort indicators (number of fixations, average pause ratio, and number of production units) measure different types of effort, or that the differences between students and professional translators is smaller than often thought.
Once our determined important error types and their impact have been confirmed in larger studies, this information can – in future work – be used to improve translation tools, by only providing MT output to a translator when the effort to post-edit a sentence is expected to be lower than the effort to translate the sentence from scratch, and by taking into account that post-editor’s level of experience. Additionally, translator training (O’Brien, 2002) that incorporates post-editing can be adapted to make future translators more aware of effortful machine translation errors. By learning how to spot and solve these types of issues, the post-editing process can, in turn, become less strenuous as well.
Author Contributions
JD, LM, SV, and RH discussed and agreed upon the design of the study and analysis. JD and LM performed the text selection and error analysis. LM provided the scripts for the HTER calculation. JD performed the original experiments and statistical analyses. RH offered suggestions related to data collection and improvements of the statistical analysis JD wrote the first draft of the article. LM, SV, and RH provided suggestions for revision. All authors approve the submission of the manuscript in the current state and agree to be accountable for all aspects of the work in ensuring that questions related to the accuracy or integrity of any part of the work are appropriately investigated and resolved.
Funding
This study would not have been possible without the grant awarded by the University College Ghent Research Foundation. We are very grateful for its support.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Footnotes
- ^Given that Koponen et al. (2012) found that keystrokes were more influenced by personal differences rather than differences in effort, we decided to include production units rather than keystrokes. Production units are editing events, i.e., continuous typing activities, that are often defined as units separated from one another by pauses of at least one second (Carl et al., 2016).
- ^Instructions can be found online: users.ugent.be/∼jvdaems/TQA_guidelines_2.0.html
- ^Issues not found in MT output: spelling: capitalization, typo; coherence: inconsistency, paragraph, coherence other; grammar: comparative/superlative, singular/plural; style: long/short sentences, text type; adequacy: contradiction, explicitation, hyperonymy, hyponymy, terminology, time.
- ^Other meaning shifts are adequacy issues that cannot be classified as belonging to one of the other subcategories, and a word sense issue occurs when the wrong meaning of the word has been chosen for the context. For example, the phrase ‘donned shades,’ i.e., ‘put on sunglasses,’ was translated into Dutch as ‘vormden schaduwen’ (created shadows). The translation for ‘donned’ is a case of ‘other meaning shift,’ the translation for ‘shades’ is a word sense issue, ‘shadow’ being a possible translation for ‘shade,’ however, not in this context.
- ^https://nederland.googleblog.com/2017/04/grote-verbetering-voor-het-nederlands.html?m=1
References
Akaike, H. (1974). A new look at the statistical model identification. IEEE Trans. Autom. Control 19, 716–723. doi: 10.2478/pralin-2013-0016
CrossRef Full Text | Google Scholar
Alabau, V., Bonk, R., Buck, C., Carl, M., Casacuberta, F., García-Martínez, M., et al. (2013). CASMACAT: an open source workbench for advanced computer aided translation. Prague Bull. Mathe. Linguist. 100, 101–112. doi: 10.1075/target.25.1.09alv
CrossRef Full Text | Google Scholar
Alves, F., and Gonçalves, J. L. (2013). Investigating the conceptual-procedural distinction in the translation process. Target 25, 107–124.
Google Scholar
Banerjee, S., and Lavie, A. (2005). “METEOR: an automatic metric for MT evaluation with improved correlation with human judgments,” in Proceedings of the Workshop on Intrinsic and Extrinsic Evaluation Measures for MT and/or Summarization at the 43th Annual Meeting of the Association of Computational Linguistics, Ann Arbor, MI.
Google Scholar
Broekkamp, H., and van den Bergh, H. (1996). “Attention strategies in revising a foreign language text,” in Theories, Models and Methodology in Writing Research, eds G. Rijlaarsdam, H. van den Bergh, and M. Couzijn (Amsterdam: Amsterdam University Press), 170–181.
Google Scholar
Burnham, K., and Anderson, D. (2004). Multimodel inference: understanding AIC and BIC in model selection. Sociol. Methods Res. 33, 261–304. doi: 10.1177/0049124104268644
CrossRef Full Text | Google Scholar
Carl, M., Schaeffer, M., and Bangalore, S. (eds). (2016). “The CRITT translation process research database,” in New Directions in Empirical Translation Process Research (Berlin: Springer), 13–54. doi: 10.1007/978-3-319-20358-4_2
CrossRef Full Text | Google Scholar
Daems, J., Macken, L., and Vandepitte, S. (2013). “Quality as the sum of its parts: a two-step approach for the identification of translation problems and translation quality assessment for HT and MT+PE,” in Proceedings of the MT Summit XIV Workshop on Post-editing Technology and Practice, eds S. O’Brien, M. Simard, and L. Specia (Allschwil: European Association for Machine Translation), 63–71.
Daems, J., Vandepitte, S., Hartsuiker, R., and Macken, L. (2015). “The impact of machine translation error types on post-editing effort indicators,” in Proceedings of the Fourth Workshop on Post-Editing Technology and Practice: Association for Machine Translation in the Americas, eds S. O’Brien and M. Simard (Washington, DC: Georgetown University), 31–45.
Google Scholar
de Almeida, G., and O’Brien, S. (2010). “Analysing post-editing performance: correlations with years of translation experience,” in Proceedings of the 14th Annual Conference of the European Association for Machine Translation, Saint-Raphaël.
Google Scholar
Denkowski, M., and Lavie, A. (2012). “Challenges in predicting machine translation utility for human post-editors,” in Proceedings of the Tenth Conference of the Association for Machine Translation in the Americas (AMTA 2012), San Diego, CA.
Google Scholar
Doherty, S., and O’Brien, S. (2009). “Can MT output be evaluated through eye tracking?,” in Proceedings of the MT Summit XII, Ottawa, ON.
Google Scholar
Doherty, S., O’Brien, S., and Carl, M. (2010). Eye tracking as an MT evaluation technique. Mach. Transl. 24, 1–13. doi: 10.1007/s10590-010-9070-9
CrossRef Full Text | Google Scholar
Dragsted, B. (2010). “Coordination of reading and writing processes in translation: an eye on uncharted territory,” in Translation and Cognition, eds G. M. Shreve and E. Angelone (Amsterdam: John Benjamins). doi: 10.1075/ata.xv.04dra
CrossRef Full Text | Google Scholar
Hayes, J., Flower, L., Scriver, K., Stratman, J., and Carey, L. (1987). “Cognitive processing in revision,” in Advances in Applied Psycholinguistics: Reading, Writing, and Language Processes, Vol. 2, ed. S. Rosenberg (New York, NY: Cambridge University Press), 176–240.
Jakobsen, A. L., and Jensen, K. T. H. (2008). “Eye movement behaviour across four different types of reading task,” in Looking at Eyes: Eye-Tracking Studies of Reading and Translation Processing, eds S. Göpferich, A. L. Jakobsen, and I. M. Mees (Copenhagen: Samfundslitteratur), 103–124.
Google Scholar
Koponen, M. (2012). “Comparing human perceptions of post-editing effort with post-editing operations,” in Proceedings of the 7th Workshop on Statistical Machine Translation, Montréal, QC.
Google Scholar
Koponen, M., Aziz, W., Ramos, L., and Specia, L. (2012). “Post-editing time as a measure of cognitive effort,” in Proceedings of the AMTA 2012 Workshop on Post-editing Technology and Practice WPTP, San Diego, CA.
Google Scholar
Krings, H. (2001). Repairing Texts: Empirical Investigations of Machine Translation Post-Editing Processes. Trans. G. Koby, G. M. Shreve, K. Mischerikov and S. Litzer. K. Ohio (London: The Kent State University Press).
Google Scholar
Lacruz, I., Shreve, G. M., and Angelone, E. (2012). “Average pause ratio as an indicator of cognitive effort in post-editing: a case study,” in Proceedings of the AMTA 2012 Workshop on Post-Editing Technology and Practice, Stroudsburg, PA.
Google Scholar
Leijten, M., and Van Waes, L. (2013). Keystroke logging in writing research: using inputlog to analyze and visualize writing processes. Writ. Commun. 30, 325–343. doi: 10.1177/0741088313491692
CrossRef Full Text | Google Scholar
Lemhöfer, K., and Broersma, M. (2012). Introducing LexTALE: a quick and valid lexical test for advanced learners of english. Behav. Res. Methods 44, 325–343. doi: 10.3758/s13428-011-0146-0
PubMed Abstract | CrossRef Full Text | Google Scholar
O’Brien, S. (2002). “Teaching post-editing: a proposal for course content,” in Proceedings of the 6th EAMT Workshop Teaching Machine Translation, Manchester.
Google Scholar
O’Brien, S. (2006). Pauses as indicators of cognitive effort in post-editing machine translation output. Across Lang. Cult. 7, 1–21. doi: 10.1556/Acr.7.2006.1.1
CrossRef Full Text | Google Scholar
Offersgaard, L., Povlsen, C., Almsten, L., and Maegaard, B. (2008). “Domain specific MT in use,” in Proceedings of the 12th Annual Conference of the European Association for Machine Translation, HITEC, Hamburg.
Google Scholar
Papineni, K., Roukos, S., Ward, T., and Zhu, W.-J. (2002). “BLEU: a method for automatic evaluation of machine translation,” in Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), Philadelphia, PA.
Google Scholar
Popovic, M., Lommel, A. R., Burchardt, A., Avramidis, E., and Uszkoreit, H. (2014). “Relations between different types of post-editing operations, cognitive effort and temporal effort,” in Proceedings of the Seventeenth Annual Conference of the European Association for Machine Translation (EAMT 14), Dubrovnik.
Google Scholar
R Core Team (2014). R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing.
Google Scholar
Schütz, J. (2008). “Artificial cognitive MT post-editing intelligence,” in Proceedings of the 8th AMTA Conference, Waikiki, HI.
Google Scholar
Séguinot, C. (1991). “A study of student translation strategies,” in Empirical Research in Translation and Intercultural Studies, ed. S. T. Condit (Tübingen: Gunter Narr), 79–88.
Google Scholar
Snover, M., Dorr, B., Schwartz, R., Micciulla, L., and Makhoul, J. (2006). “A study of translation edit rate with targeted human annotation,” in Proceedings of the 7th Conference of the Association for Machine Translation in the Americas, Cambridge.
Google Scholar
Sommers, N. (1980). Revision strategies of student writers and experienced adult writers. Coll. Compos. Commun. 31, 378–388. doi: 10.2307/356588
CrossRef Full Text | Google Scholar
Specia, L., and Farzindar, A. (2010). “Estimating machine translation post-editing effort with HTER,” in Proceedings of the Second Joint EM+CNGL Workshop Bringing MT to the User: Research on Integrating MT in the Translation Industry, Denver, CO.
Google Scholar
Stenetorp, P., Pyysalo, S., Topic, G., Ohta, T., Anaiadou, S., and Tsujii, J. (2012). “brat: a Web-based tool for NLP-assisted text annotation,” in Proceedings of the Demonstrations at the 13th Conference of the European Chapter of the Association for Computational Linguistics, Avignon, 102–107.
Google Scholar
Stymne, S., Danielsson, H., Bremin, S., Hu, H., Karlsson, J., Lillkull, A. P., et al. (2012). “Eye tracking as a tool for machine translation error analysis,” in Proceedings of the International Conference on Language Resources and Evaluation, Istanbul.
Google Scholar
Temnikova, I. (2010). “Cognitive evaluation approach for a controlled language post-editing experiment,” in Proceedings of the 7th International Conference on Language Resources and Evaluation, Valetta.
Google Scholar
Tirkkonen-Condit, S. (1990). “Professional vs. Non-professional translation: a think-aloud protocol study,” in Learning, Keeping and Using Language: Selected Papers from the Eighth World Congress of Applied Linguistics, eds M. A. K. Halliday, J. Gibbons, and H. Nicholas (Amsterdam: John Benjamins), 381–394. doi: 10.1075/z.lkul2.28tir
CrossRef Full Text | Google Scholar
Vilar, D., Xu, J., D’Haro, L. F., and Ney, H. (2006). “Error analysis of machine translation output,” in Proceedings of the 5th International Conference on Language Resources and Evaluation (LREC’06), Genoa.
PubMed Abstract
Лучший комментарий
Скрыть

4k
Эта история приключилась 14 лет назад, когда пользовались старым, добрым промтом. Наша организация была совсем молодая, малооборудованная. И мы просили спонсорскую помощь у спонсоров: манахинь-немок. Было составлено письмо с необходимым оборудованием. Чтобы облегчить перевод и как-то ускорить получение необходимого, текст пропустили через промт. После вручения и прочтения письма у бедных немок глаза из орбит повылазили. Что они при этом говорили, я умолчу. Оказалось, что программа слова: диван и половое покрытие (через запятую), перевела «секс на диване». Теперь мне это «секс» напоминают регулярно, так как я занималась тем переводом.

0
гугл рулит проверил-все действительно так! эпичные ляпы
Комментарий удален

18k

6k
В самом первом он еще и «дорогой» перевел как «моя дорогая». Переводчик что-то знает.

0
Хрень get ride проверил получить поездку

7k
Кира найтли в костюме днища

26k
«Гитлер капут» просто убил!

18k
Да, теперь понятно, откуда берутся меню на русском языке в Китае и Таиланде!

3k
Переводчик как бэ намекает

42k

13k
«Так пойдет?»
Со смокингом прикольно.
А вот дринькать смок ранее было, вместо смокинг — они так выражались, говоря про курить.

1k
Это шедеврально! Однозначно +
Эмма Вуллакотт, 25 сентября 2018 г.
Корреспондент Би-Би-Си по вопросам технологии бизнеса
Качество машинных переводов постоянно улучшается, но ошибки все еще случаются
Несмотря на усовершенствования приложений для перевода, они все еще далеки от идеала. В особенности, это касается редких языков. Могут ли искусственный интеллект и нейронные сети исправить ситуацию?
По данным компании Google, во время чемпионата мира по футболу в России этим летом был зафиксирован резкий рост обращений к сервису Google Translate. Болельщики пытались общаться со своими гостями и фанатами, приехавшими на Чемпионат из других стран.
Особенно часто они искали перевод слов «стадион» и «пиво».
В те дни обычные разговорники не пользовался спросом. Недавнее исследование Британского совета показало, что сегодня примерно две трети респондентов в возрасте от 16 до 34 лет, находясь в чужой языковой среде, пользуются мобильными приложениями для перевода.
Однако несмотря на то, что такие приложения несомненно становятся лучше, целиком полагаться на них пока нельзя. Каждый пятый из опрошенных заявил, что сталкивался с непониманием в отпуске из-за некорректного автоматического перевода.
Данная проблема особенно актуальна для носителей языков национальных меньшинств.
Валлийцы, к примеру, обращали внимание на отдельные случаи особо «грубого» перевода, а именно, одно предупреждение «Ведутся взрывные работы» было переведено как «Gweithwyr yn ffrwydro» или «Рабочие взрываются».
А пользователь Google Translate обнаружил этим летом, что при вводе в поле для перевода слова «собака» 18 раз выдается следующий перевод с языка маори: «На часах Судного дня три минуты до полуночи. Мы видим знаки и колоссальные изменения в мире, свидетельствующие о том, что мы все быстрее приближаемся к концу света и второму пришествию Иисуса».
* «Пирог жены» и «дьявольская вода»: Опасности автоперевода
Так почему же в эпоху сверхмощных компьютеров и «машинного обучения» до сих пор встречаются ошибки при переводе?
Главная проблема заключается в том, что часто слова имеют несколько значений. Такие омографы, как они называются, могут поставить в неловкое положение не только отдыхающих на курортах, но и членов правительства.
Рассмотрим, к примеру, некачественный перевод «Белой книги» (план «Брексит») правительства Великобритании в июле, где фраза «демократические процедуры» была переведена на немецкий как «demokratische Übung», где «Übung» дословно можно перевести как «физическое упражнение».
Чтобы исключить такие ошибки, алгоритмы машинного обучения в приложениях для перевода постоянно дорабатываются. Они сверяются с предыдущими запросами, принимают во внимание контекст, в котором то или иное слово использовалось ранее и подбирают наиболее подходящее его значение.

В начале этого года компания Microsoft объявила, что добилась «человеческого паритета» в плане качества своих переводов. Ряд китайских новостных статей был переведен на английский язык с использованием машинного перевода, и группа независимых экспертов обнаружила, что их качество оказалось не хуже переводов, выполненных двумя профессиональными переводчиками.
По словам Microsoft, данное достижение стало возможным только благодаря использованию глубоких нейронных сетей, а также статистического машинного обучения.
Проще говоря, в основе данного процесса лежит усовершенствование исходного «сырого» варианта перевода путем многократного повторения разных вариантов, их сравнения, сопоставления и обучения. Подобным образом переводу учится и человек.
По словам Сюэдуня Хуаня, в планах научиться соблюдать правила языка при машинном переводе.
Переводческая система уже имеет четкое представление о грамматической структуре предложения в каждом языке, исходя из анализа всех ранее переведенных документов.
Вместо передачи правил перевода с языка на язык вручную, современные переводческие системы рассматривают этот процесс как проблему машинного обучения в процессе перевода текста с языка на язык с учетом ранее выполненных человеком переводов и последних достижений в области прикладной статистики и машинного обучения», – объясняет Сюэдунь Хуань, главный инженер исследовательской группы Microsoft по работе с искусственным интеллектом.
Машинный перевод, качество которого сравнимо с качеством перевода, выполненным человеком, кажется довольно впечатляющим достижением. Но даже в Microsoft признают, что перевод исторических новостных статей – это не то же самое, что и перевод живой беседы, где идиоматические тонкости, акценты и диалектические особенности представляют намного более серьезную проблему.
Наушники с функцией синхронного перевода
В прошлом году Google выпустила беспроводные наушники Pixel Buds (Пиксель Батс) с функцией синхронного переводчика 40 языков – хотя насколько точным может быть перевод – это спорный вопрос.
Нью-йоркский стартап Waverly Labs разработал собственные наушники Pilot с функцией переводчика и приложение для смартфона, которое, по данным компании, может переводить на/с 15 языков практически в режиме реального времени.


Но когда приходится переводить между двумя языками, у которых нет большой базы взаимных переводов, к которой можно было бы обращаться, например, с сингальского языка на язык пушту, задача усложняется.
Можно сначала перевести с сингальского языка на английский, а затем полученный результат – на пушту, но очевидно, что при таком подходе будут появляться указанные выше ошибки.
Описанный выше случай с языком маори и апокалиптическими предсказаниями объясняется в том числе избыточной зависимостью машинных переводов от текстов, которые существуют на обоих интересующих пользователя языках. В случае с английским и маори это была Библия.
«Если вы закладываете в модель для перевода предложения из древнего манускрипта и пытаетесь перевести разговор двух современных людей, модель столкнется со сложностями, потому что и содержание, и стилистика современной разговорной речи очень сильно отличается от того, что можно найти в древних манускриптах», — объясняет разработчик искусственного интеллекта из Facebook Гийом Лампл.
«Кроме того, модель, похоже, будет генерировать сегменты с использованием слов, которые найдет в манускрипте. Нечто подобное, вероятно, может произойти с языками, где не наработана переводческая база, а значительная доля подходящих значений в целом будет приходиться на древние источники».
Тема искусственного интеллекта сегодня очень популярна в творчестве
Проект, над которым Лампл сейчас работает вместе с командой исследователей из Facebook и Сорбонны, может предложить решение этой проблемы.
Они используют исходные тексты, состоящие всего лишь из нескольких сотен тысяч предложений в каждом языке, но не используют предложения, переведенные напрямую.
По существу, эта система принимает во внимание то, как одни слова сочетаются с другими. Например, в английском слова «кот» и «пушистый» используются вместе так же, как в испанском. Система обучается подобным подстановкам слов, и это позволяет ей делать более точные переводы. Затем используются те же техники, что и в случае с переводчиком Microsoft.
По словам Лампла, фактически при помощи такой методики можно не только переводить живые языки, но и расшифровывать мертвые и потерянные.
«Но есть серьезная проблема – недостаток предложений, составленных на этих языках. Например, Манускрипт Войнича (кодекс, написанный предположительно в XV веке, который до сих пор не может быть переведен) состоит всего лишь из нескольких сотен страниц. Этого слишком мало для нашей модели», – говорит он.
При наличии достаточного объема текста система должна справиться с расшифровкой мертвого языка, полагает Лампл.
Эта перспектива открывает и многие другие удивительные возможности. «Мы можем научиться общаться с инопланетянами, – рассуждает Лампл. – Но для начала им придется много говорить, причем на темы, схожие с теми, на которые обычно говорим мы».