Текст работы размещён без изображений и формул.
Полная версия работы доступна во вкладке «Файлы работы» в формате PDF
В 21 веке не редкостью стало использование биометрических данных вместо обычных паролей, подписей и СМС. Это просто, удобно и практично. Но настолько ли надежны биометрические данные? Для начала стоит разобраться, что же такое биометрия и биометрическая идентификация.
В широком смысле биометрия – это наука о применении математических методов в биологии. Биометрия как наука сложилась чем-то средним между биологией и математикой. Ее развитие связано с превращением биологии как науки описательной в науку точную, основанную на измерениях, на применении количественных оценок. Основными методами биометрии, первоначально заимствованными из математики, были математическая статистика и теория вероятности.
Биометрическая идентификация – использование уникальных признаков человека для его идентификации. Примерами биометрических признаков могут выступать: отпечатки пальцев, лицо, радужная оболочка глаза, геометрия руки, узор вен в ладони, волос и многое другое.
Общие свойства биометрической идентификации:
Плюсы:
идентификатор невозможно забыть, потерять и так далее
затруднена передача идентификатора другому лицу
Минусы:
не 100% результат, ошибки в работе
высокая цена
низкая вандалостойкость, сложнее защитить
низкая скорость работы, процесса считывания (не во всех случаях)
Вероятностный характер работы биометрии:
невозможность достижения 100% достоверности результата
вероятность возникновения ошибки зависит от конкретной системы
Биометрические идентификаторы обеспечивают очень высокие показатели (вероятность несанкционированного доступа – 0,1…0,0001 %, вероятность ложного задержания – доли процентов, время идентификации – единицы секунд), но имеют более высокую стоимость по сравнению со средствами атрибутной идентификации.
Любая система не идеальна и имеет свойство ошибаться. Существует множество разных ситуаций, при которых, система даёт сбои. В качестве примера, рассмотри одну из самых простых ситуаций – верификация. Верификация работает по такому принципу: происходит сравнивание полученного биометрического признака (например, фотография) с уже имеющимся в базе данных. В данном случае она может ошибаться двумя разными способами:
Может сказать: «нет, это не он», но это будет правильный человек
Может сказать: «да, это он», но это будет совершенно другой человек
Ошибки первого и второго рода
Существует 4 разных ситуации реагирования системы на полученные данные:
Первые 2 происходят при нормальном положении дел.
Системе предъявлено изображение правильного человека, и она ответила: «да», это он;
Системе предъявлено изображение другого человека, и она ответила: «нет», это не он;
Системе предъявлено изображение другого человека, и она ответила: «да», это он. Эта ситуация называется ложный допуск, если говорить про контроль доступа. Также её называют ошибка первого рода, а вероятность возникновения такой ситуации обычно именуют FalseAcceptRate (FAR) и измеряют в процентах. Если написано в характеристиках FAR = 1%, это значит, что 1 раз из 100 такая ошибка возникнет;
Системе предъявлено изображение правильного человека, и она ответила: «нет», это не он. Эта ситуация называется ложный отказ. Также её называют ошибка второго рода, а вероятность ситуации обычно именуют FalseRejectRat (FRR) и измеряют в процентах.
Например, при FRR 1% FAR 0,1%. Читается данная запись так: При данном наборе параметров системы с вероятность 1 из 100 будет возникать ситуация ложного отказа, и с вероятностью 1 из 1000 будет возникать ситуация предоставления ложного доступа человеку.
FRR и FAR тесно связаны друг с другом, именно поэтому их пишут вместе.
Степень сходства
Степень сходства — безразмерный показатель сходства сравниваемых объектов. Существует несколько крайних положений, которые она может принимать: 0% — вообще не похож и 100% — очень похож. Но возникает вопрос, что же делать со средними значениями? Тут, в том или ином виде можно задать порог сходства, который определенным способом можно двигать, меняя настройки считывателя. Двигая его влево (к 0%) мы можем добиться того, что система будет менее склонна отказывать доступ, т.е. допускать ситуаций ошибок второго рода. Двигая его вправо (к 100%) мы можем добиться уменьшения количества ошибок первого рода.
У этого параметра нет какого-то идеально правильного единственного положения. Надо понимать, что существуют разные задачи и у каждой свои требования.
Соотношение ошибок FAR и FRR
Их соотношение можно представить в виде гиперболы. Каждая точка этой кривой соответствует определенному положению вещей. Каждая точка ее горизонтальной координаты означает ошибку второго рода (FRR), а вертикальной координаты – ошибку первого рода (FAR).
Чтобы добиться маленькой ошибки второго рода, приходиться платить большой ошибкой первого рода, и наоборот. Существует разные требования и применения соотношения ошибок FAR и FRR.
Например: Для систем с высоким требованием безопасности категорически нельзя дать ложный допуск. Тем самым, приходится платить большим процентом ложных отказов. Проще говоря: мы увеличиваем строгость системы. Она начинает часто отказывать, но тем самым не пропустит чужого.
Совершенно другое применение: для криминальных расследований. Мы должны понять, кто из представленных людей разыскивается, выловить его из толпы. Нам категорически не хочется его случайно пропустить. Для этого, нам нужно сделать низкую вероятность ошибки второго рода, т.е. ложного отказа. Тем самым, приходится платить большой ошибкой первого рода, т.е. система будет отфильтровывать людей, которые ей показались похожими. Для этого применения — это нормально, т.к. потом этих людей уже анализируют вручную. Системе нужно лишь сократить количество рассматриваемых людей.
Идентификация
Идентификация – мы не знаем наперед кто перед нами. Предъявлен какой-то биометрический признак; нужно понять кто из нескольких представленных вариантов, нужный нам человек. При этом от системы ожидается один из ответов:
Кому именно из N числа принадлежит предъявленный признак
Таких признаков нет в базе данных
В идентификации существенную роль играет ошибка первого рода. При сравнении с одним человеком вероятность 1 из 1000 нас устраивает, но, когда людей в базе данных много, большая вероятность, что эта ошибка может возникнуть для каждого из них.
Пример расчета: FRR = 2% FRR = 2%
N = 1 N = 5000
FAR = 0,0001% FAR = 0,5%
Подводя итоги можно сказать:
Для верификации:
нужен низкий FRR
FAR практически не имеет значение
Для идентификации:
нужен низкий FAR
высокий FRR нежелателен
В целом, надо признать, что для идентификации требования намного выше, чем для верификации.
Вывод
Нужно хорошо понимать ограничения и особенности систем биометрической идентификации. Такие системы не являются универсальными решениями, но требуется понимать разницу верификации и идентификации, уметь считать ошибки FAR и FRR. Возможно, в будущем данная технология претерпит значительные изменения и найдет способ снизить процентное соотношение ошибок до минимума.
Оценка качества алгоритмов распознавания лиц
Время на прочтение
15 мин
Количество просмотров 25K
Привет, Хабр!
Мы, в компании NtechLab, занимаемся исследованиями и разработкой продуктов в области распознавания лиц. В процессе внедрения наших решений мы часто сталкиваемся с тем, что заказчики не очень ясно представляют себе требования к точности алгоритма, поэтому и тестирование того или иного решения для их задачи даётся с трудом. Чтобы исправить ситуацию, мы разработали краткое пособие, описывающее основные метрики и подходы к тестированию, которыми хотелось бы поделиться с сообществом Хабра.

В последнее время распознавание лиц вызывает все больше интереса со стороны коммерческого сектора и государства. Однако корректное измерение точности работы таких систем – задача непростая и содержит массу нюансов. К нам постоянно обращаются с запросами на тестирование нашей технологии и пилотными проектами на ее основе, и мы заметили, что часто возникают вопросы с терминологией и методами тестирования алгоритмов применительно к бизнес-задачам. В результате для решения задачи могут быть выбраны неподходящие инструменты, что приводит к финансовым потерям или недополученной прибыли. Мы решили опубликовать эту заметку, чтобы помочь людям освоиться в среде специализированных терминов и сырых данных, окружающих технологии распознавания лиц. Нам хотелось рассказать об основных понятиях в этой области простым и понятным языком. Надеемся, это позволит людям технического и предпринимательского склада говорить на одном языке, лучше понимать сценарии использования распознавания лиц в реальном мире и принимать решения, подтвержденные данными.
Задачи распознавания лиц
Распознаванием лиц часто называют набор различных задач, например, детектирование лица на фотографии или в видеопотоке, определение пола и возраста, поиск нужного человека среди множества изображений или проверка того, что на двух изображениях один и тот же человек. В этой статье мы остановимся на последних двух задачах и будем их называть, соответственно, идентификация и верификация. Для решения этих задач из изображений извлекаются специальные дескрипторы, или векторы признаков. В этом случае задача идентификации сводится к поиску ближайшего вектора признаков, а верификацию можно реализовать с помощью простого порога расстояний между векторами. Комбинируя эти два действия, можно идентифицировать человека среди набора изображений или принимать решение о том, что его нет среди этих изображений. Такая процедура называется open-set identification (идентификацией на открытом множестве), см. Рис.1.
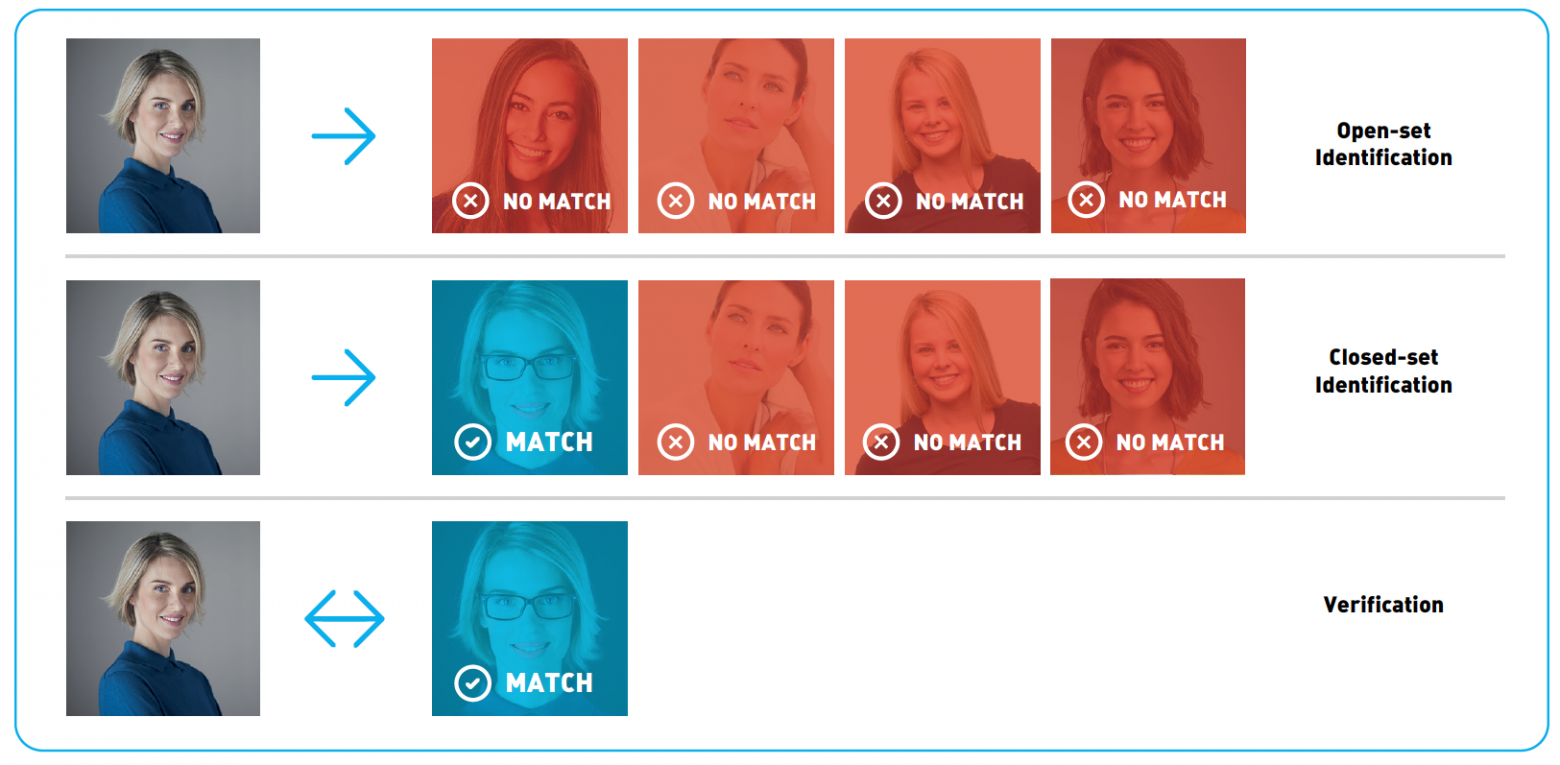
Рис.1 Open-set identification
Для количественной оценки схожести лиц можно использовать расстояние в пространстве векторов признаков. Часто выбирают евклидово или косинусное расстояние, но существуют и другие, более сложные, подходы. Конкретная функция расстояния часто поставляется в составе продукта по распознаванию лиц. Идентификация и верификация возвращают разные результаты и, соответственно, разные метрики применяются для оценки их качества. Мы подробно рассмотрим метрики качества в последующих разделах. Помимо выбора адекватной метрики, для оценки точности алгоритма понадобится размеченный набор изображений (датасет).
Оценка точности
Датасеты
Почти всё современное ПО для распознавания лиц построено на машинном обучении. Алгоритмы обучаются на больших датасетах (наборах данных) с размеченными изображениями. И качество, и природа этих датасетов оказывают существенное влияние на точность. Чем лучше исходные данные, тем лучше алгоритм будет справляться с поставленной задачей.
Естественный способ проверить, что точность алгоритма распознавания лиц соответствует ожиданиям, это измерить точность на отдельном тестовом датасете. Очень важно правильно выбрать этот датасет. В идеальном случае организации стоит обзавестись собственным набором данных, максимально похожим на те изображения, с которыми система будет работать при эксплуатации. Обратите внимание на камеру, условия съемки, возраст, пол и национальность людей, которые попадут в тестовый датасет. Чем более похож тестовый датасет на реальные данные, тем более достоверными будут результаты тестирования. Поэтому часто имеет смысл потратить время и средства для сбора и разметки своего набора данных. Если же это, по какой-то причине, не представляется возможным, можно воспользоваться публичными датасетами, например, LFW и MegaFace. LFW содержит только 6000 пар изображений лиц и не подходит для многих реальных сценариев: в частности, на этом датасете невозможно измерить достаточно низкие уровни ошибок, как мы покажем далее. Датасет MegaFace содержит намного больше изображений и подходит для тестирования алгоритмов распознавания лиц на больших масштабах. Однако и обучающее, и тестовое множество изображений MegaFace’a есть в открытом доступе, поэтому использовать его для тестирования следует с осторожностью.
Альтернативный вариант заключается в использовании результатов тестирования третьим лицом. Такие тестирования проводятся квалифицированными специалистами на больших закрытых датасетах, и их результатам можно доверять. Одним из примеров может служить NIST Face Recognition Vendor Test Ongoing. Это тест, проводимый Национальным Институтом Стандартов и Технологий (NIST) при Министерстве торговли США. “Минус” данного подхода заключается в том, что датасет организации, проводящей тестирование, может существенно отличаться от интересующего сценария использования.
Переобучение
Как мы говорили, машинное обучение лежит в основе современного ПО для распознавания лиц. Одним из распространенных феноменов машинного обучения является т.н. переобучение. Проявляется он в том, что алгоритм показывает хорошие результаты на данных, которые использовались при обучении, но результаты на новых данных получаются значительно хуже.
Рассмотрим конкретный пример: представим себе клиента, который хочет установить пропускную систему с распознаванием лиц. Для этих целей он собирает набор фотографий людей, которым будет разрешен доступ, и обучает алгоритм отличать их от других людей. На испытаниях система показывает хорошие результаты и внедряется в эксплуатацию. Через некоторое время список людей с допуском решают расширить и обнаруживается, что система отказывает новым людям в доступе. Алгоритм тестировался на тех же данных, что и обучался, и никто не проводил измерения точности на новых фотографиях. Это, конечно, утрированный пример, но он позволяет понять проблему.
В некоторых случаях переобучение проявляется не так явно. Допустим, алгоритм обучался на изображениях людей, где превалировала определенная этническая группа. При применении такого алгоритма к лицам другой национальности его точность наверняка упадет. Излишне оптимистичная оценка точности работы алгоритма из-за неправильно проведенного тестирования – очень распространенная ошибка. Всегда следует тестировать алгоритм на новых данных, которые ему предстоит обрабатывать в реальном применении, а не на тех данных, на которых проводилось обучение.
Резюмируя вышесказанное, составим список рекомендаций: не используйте данные, на которых обучался алгоритм при тестировании, используйте специальный закрытый датасет для тестирования. Если это невозможно и вы собираетесь воспользоваться публичным датасетом, убедитесь, что вендор не использовал его в процессе обучения и/или настройки алгоритма. Изучите датасет перед тестированием, подумайте, насколько он близок к тем данным, которые будут поступать при эксплуатации системы.
Метрики
После выбора датасета, следует определиться с метрикой, которая будет использоваться для оценки результатов. В общем случае метрика – это функция, которая принимает на вход результаты работы алгоритма (идентификации или верификации), а на выходе возвращает число, которое соответствует качеству работы алгоритма на конкретном датасете. Использование одного числа для количественного сравнения разных алгоритмов или вендоров позволяет сжато представлять результаты тестирования и облегчает процесс принятия решений. В этом разделе мы рассмотрим метрики, наиболее часто применяемые в распознавании лиц, и обсудим их значение с точки зрения бизнеса.
Верификация
Верификацию лиц можно рассматривать как процесс принятия бинарного решения: “да” (два изображения принадлежат одному человеку), “нет” (на паре фотографий изображены разные люди). Прежде чем разбираться с метриками верификации, полезно понять, как мы можем классифицировать ошибки в подобных задачах. Учитывая, что есть 2 возможных ответа алгоритма и 2 варианта истинного положения вещей, всего возможно 4 исхода:
Рис. 2 Типы ошибок. Цвет фона кодирует истинное отношение между картинками (синий означает “принять”, желтый – “отвергнуть”), цвет рамки соответствует предсказанию алгоритма (синий – “принять”, желтый – “отвергнуть”
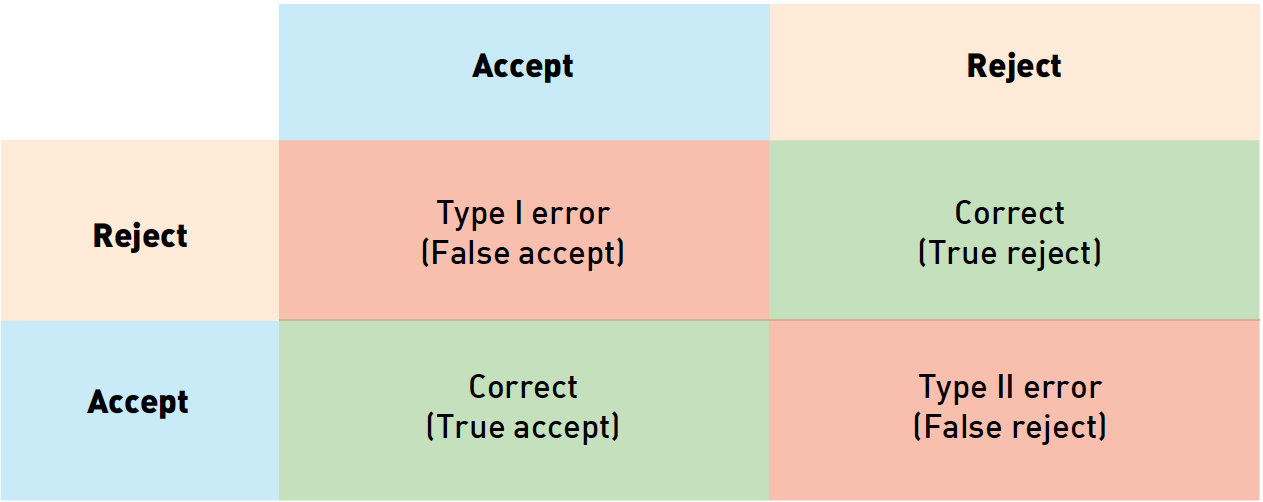
В таблице выше столбцы соответствуют решению алгоритма (синий – принять, желтый – отвергнуть), строки соответствуют истинным значениям (кодируются теми же цветами). Правильные ответы алгоритма отмечены зеленым фоном, ошибочные – красным.
Из этих исходов два соответствуют правильным ответам алгоритма, а два – ошибкам первого и второго рода соответственно. Ошибки первого рода называют «false accept», «false positive» или «false match» (неверно принято), а ошибки второго рода – «false reject», «false negative» или «false non-match» (неверно отвергнуто).
Просуммировав количество ошибок разного рода среди пар изображений в датасете и поделив их на количество пар, мы получим false accept rate (FAR) и false reject rate (FRR). В случае с системой контроля доступа «false positive» соответствует предоставлению доступа человеку, для которого этот доступ не предусмотрен, в то время как «false negative» означает, что система ошибочно отказала в доступе авторизованной персоне. Эти ошибки имеют разную стоимость с точки зрения бизнеса и поэтому рассматриваются отдельно. В примере с контролем доступа «false negative» приводит к тому, что сотруднику службы безопасности надо перепроверить пропуск сотрудника. Предоставление неавторизованного доступа потенциальному нарушителю (false positive) может привести к гораздо худшим последствиям.
Учитывая, что ошибки разного рода связаны с различными рисками, производители ПО для распознавания лиц зачастую дают возможность настроить алгоритм так, чтобы минимизировать один из типов ошибок. Для этого алгоритм возвращает не бинарное значение, а вещественное число, отражающее уверенность алгоритма в своем решении. В таком случае пользователь может самостоятельно выбрать порог и зафиксировать уровень ошибок на определенных значениях.
Для примера рассмотрим «игрушечный» датасет из трех изображений. Пусть изображения 1 и 2 принадлежат одному и тому же человеку, а изображение 3 кому-то еще. Допустим, что программа оценила свою уверенность для каждой из трех пар следующим образом:

Мы специально выбрали значения таким образом, чтобы ни один порог не классифицировал все три пары правильно. В частности, любой порог ниже 0.6 приведет к двум false accept (для пар 2-3 и 1-3). Разумеется, такой результат можно улучшить.
Выбор порога из диапазона от 0.6 до 0.85 приведет к тому, что пара 1-3 будет отвергнута, пара 1-2 по-прежнему будет приниматься, а 2-3 будет ложно приниматься. Если увеличить порог до 0.85-0.9, то пара 1-2 станет ложно отвергаться. Значения порога выше 0.9 приведут к двум true reject (пары 1-3 и 2-3) и одному false reject (1-2). Таким образом, лучшими вариантами выглядят пороги из диапазона 0.6-0.85 (один false accept 2-3) и порог выше 0.9 (приводит к false reject 1-2). Какое значение выбрать в качестве финального, зависит от стоимости ошибок разных типов. В этом примере порог варьируется в широких диапазонах, это связано, в первую очередь, с очень маленьких размеров датасетом и с тем, как мы выбрали значения уверенности алгоритма. Для больших, применяемых для реальных задач датасетов, получились бы существенно более точные значения порога. Зачастую вендоры ПО для распознавания лиц поставляют значения порога по умолчанию для разных FAR, которые вычисляются похожим образом на собственных датасетах вендора.
Также нетрудно заметить, что по мере того как интересующий FAR снижается, требуется все больше и больше положительных пар изображений, чтобы точно вычислить значение порога. Так, для FAR=0.001 нужно по меньшей мере 1000 пар, а для FAR= потребуется уже 1 миллион пар. Собрать и разметить такой датасет непросто, поэтому клиентам, заинтересованным в низких значениях FAR, имеет смысл обратить внимание на публичные бенчмарки, такие как NIST Face Recognition Vendor Test или MegaFace. К последнему следует относиться с осторожностью, так как и обучающая, и тестовая выборки доступны всем желающим, что может привести к излишне оптимистичной оценке точности (см. раздел «Переобучение»).
потребуется уже 1 миллион пар. Собрать и разметить такой датасет непросто, поэтому клиентам, заинтересованным в низких значениях FAR, имеет смысл обратить внимание на публичные бенчмарки, такие как NIST Face Recognition Vendor Test или MegaFace. К последнему следует относиться с осторожностью, так как и обучающая, и тестовая выборки доступны всем желающим, что может привести к излишне оптимистичной оценке точности (см. раздел «Переобучение»).
Типы ошибок различаются по связанной с ними стоимости, и у клиента есть способ смещать баланс в сторону тех или иных ошибок. Для этого надо рассмотреть широкий диапазон значений порога. Удобный способ визуализации точности алгоритма при разных значениях FAR заключается в построении ROC-кривых (англ. receiver operating characteristic, рабочая характеристика приёмника).
Давайте разберемся, как строятся и анализируются ROC-кривые. Уверенность алгоритма (а следовательно, и порог) принимают значения из фиксированного интервала. Другими словами, эти величины ограничены сверху и снизу. Предположим, что это интервал от 0 до 1. Теперь мы можем измерить количество ошибок, варьируя значение порога от 0 до 1 с небольшим шагом. Так, для каждого значения порога мы получим значения FAR и TAR (true accept rate). Далее мы будет рисовать каждую точку так, чтобы FAR соответствовал оси абсцисс, а TAR – оси ординат.
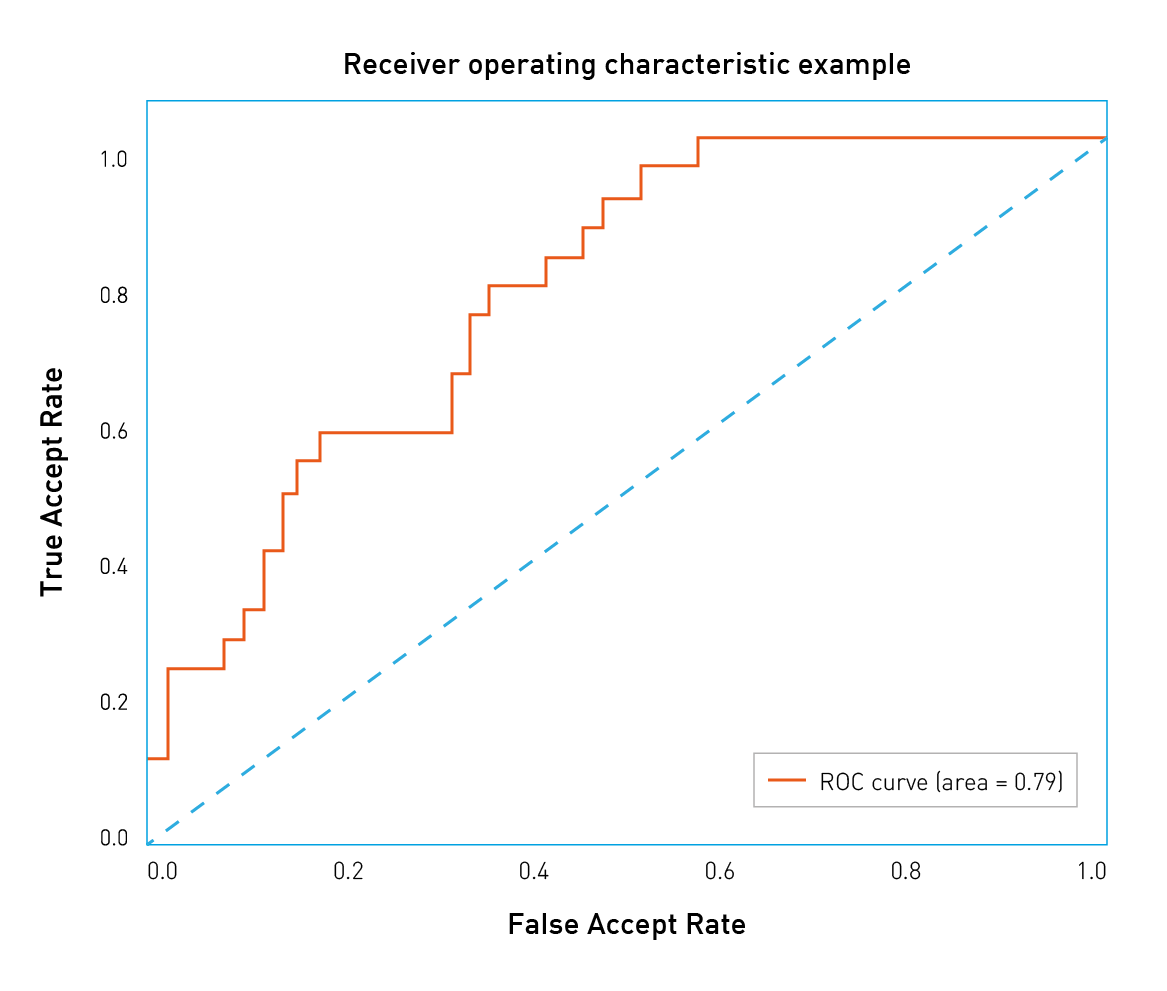
Рис.3 Пример ROC-кривой
Легко заметить, что первая точка будет иметь координаты 1,1. При пороге равном 0 мы принимаем все пары и не отвергаем ни одной. Аналогично, последняя точка будет 0,0: при пороге 1 мы не принимаем ни одной пары и отвергаем все пары. В остальных точках кривая обычно выпуклая. Также можно заметить, что наихудшая кривая лежит примерно на диагонали графика и соответствует случайному угадыванию исхода. С другой стороны, наилучшая возможная кривая образует треугольник с вершинами (0,0) (0,1) и (1,1). Но на датасетах разумного размера такое трудно встретить.

Рис.4 ROC-кривые NIST FRVT
Можно построить подобие RОС-кривых с различными метриками/ошибками на оси. Рассмотрим, например, рисунок 4. На нем видно, что организаторы NIST FRVT по оси Y нарисовали FRR (на рисунке – False non-match rate), а по оси X – FAR (на рисунке – False match rate). В данном конкретном случае лучшие результаты достигнуты кривыми, которые расположены ниже и смещены влево, что соответствует низким показателям FRR и FAR. Поэтому стоит обращать внимание на то, какие величины отложены по осям.
Такой график позволяет легко судить о точности алгоритма при заданном FAR: достаточно найти точку на кривой с координатой Х равной нужному FAR и соответствующее значение TAR. «Качество» ROC-кривой также можно оценить одним числом, для этого надо посчитать площадь под ней. При этом лучшее возможное значение будет 1, а значение 0.5 соответствует случайному угадыванию. Такое число называют ROC AUC (Area Under Curve). Однако следует заметить, что ROC AUC неявно предполагает, что ошибки первого и второго рода однозначны, что не всегда так. В случае если цена ошибок различается, следует обратить внимание на форму кривой и те области, где FAR соответствует бизнес-требованиям.
Идентификация
Второй популярной задачей распознавания лиц является идентификация, или поиск человека среди набора изображений. Результаты поиска сортируются по уверенности алгоритма, и наиболее вероятные совпадения попадают в начало списка. В зависимости от того, присутствует или нет искомый человек в поисковой базе, идентификацию разделяют на две подкатегории: closed-set идентификация (известно, что искомый человек есть в базе) и open-set идентификация (искомого человека может не быть в базе).
Точность (accuracy) является надежной и понятной метрикой для closed-set идентификации. По сути, точность измеряет количество раз, когда нужная персона была среди результатов поиска.
Как это работает на практике? Давайте разбираться. Начнем с формулировки бизнес-требований. Допустим, у нас есть веб-страница, которая может разместить десять результатов поиска. Нам нужно измерить количество раз, которое искомый человек попадает в первые десять ответов алгоритма. Такое число называется Top-N точностью (в данном конкретном случае N равно 10).
Для каждого испытания мы определяем изображение человека, которого будем искать, и галерею, в которой будем искать, так, чтобы галерея содержала хотя бы еще одно изображение этого человека. Мы просматриваем первые десять результатов работы алгоритма поиска и проверяем, есть ли среди них искомый человек. Чтобы получить точность, следует просуммировать все испытания, в которых искомый человек был в результатах поиска, и поделить на общее число испытаний.

Рис 5. Пример идентификации. В этом примере искомый человек появляется в позиции 2, поэтому точность Top-1 равна 0, а Top-2 и далее равна 1.
Open-set идентификация состоит из поиска людей, наиболее похожих на искомое изображение, и определения, является ли кто-то из них искомым человеком на основании уверенности алгоритма. Open-set идентификацию можно рассматривать как комбинацию closed-set идентификации и верификации, поэтому на этой задаче можно применять все те же метрики, что и в задаче верификации. Также нетрудно заметить, что open-set идентификацию можно свести к попарным сравнениям искомого изображения со всеми изображениями из галереи. На практике это не используется из соображений скорости вычислений. ПО для распознавания лиц часто поставляется с быстрыми алгоритмами поиска, которые могут находить среди миллионов лиц похожие за миллисекунды. Попарные сравнения заняли бы намного больше времени.
Практические примеры
В качестве иллюстрации давайте рассмотрим несколько распространенных ситуаций и подходов к тестированию алгоритмов распознавания лиц.
Розничный магазин
Допустим, что средний по размеру розничный магазин хочет улучшить свою программу лояльности или уменьшить количество краж. Забавно, но с точки зрения распознавания лиц это примерно одно и то же. Главная задача этого проекта заключается в том, чтобы как можно раньше идентифицировать постоянного покупателя или злоумышленника по изображению с камеры и передать эту информацию продавцу или сотруднику службы безопасности.
Пусть программа лояльности охватывает 100 клиентов. Данную задачу можно рассматривать как пример open-set идентификации. Оценив расходы, отдел маркетинга пришел в выводу, что приемлемый уровень ошибки – принимать одного посетителя за постоянного покупателя за день. Если в день магазин посещает 1000 посетителей, каждый из которых должен быть сверен со списком 100 постоянных клиентов, то необходимый FAR составит  .
.
Определившись с допустимым уровнем ошибки, следует выбрать подходящий датасет для тестирования. Хорошим вариантом было бы разместить камеру в подходящем месте (вендоры могут помочь с конкретным устройством и расположением). Сопоставив транзакции держателей карт постоянного покупателя с изображениями с камеры и проведя ручную фильтрацию, сотрудники магазина могут собрать набор позитивных пар. Также имеет смысл собрать набор изображений случайных посетителей (по одному изображению на человека). Общее количество изображений должно примерно соответствовать количеству посетителей магазина в день. Объединив оба набора, можно получить датасет как «позитивных», так и «негативных» пар.
Для проверки желаемой точности должно хватить около тысячи «позитивных» пар. Комбинируя различных постоянных клиентов и случайных посетителей, можно собрать около 100 000 «негативных» пар.
Следующим шагом будет запустить (или попросить вендора запустить) ПО и получить уверенность алгоритма для каждой пары из датасета. Когда это будет сделано, можно построить ROC-кривую и удостовериться, что количество правильно идентифицированных постоянных клиентов при FAR= соответствует бизнес-требованиям.
соответствует бизнес-требованиям.
E-Gate в аэропорту
Современные аэропорты обслуживают десятки миллионов пассажиров в год, а процедуру паспортного контроля ежедневно проходит около 300 000 человек. Автоматизация этого процесса позволит существенно сократить расходы. С другой стороны, пропустить нарушителя крайне нежелательно, и администрация аэропорта хочет минимизировать риск такого события. FAR= соответствует десяти нарушителям в год и кажется разумным в этой ситуации. Если при данном FAR, FRR составляет 0.1 (что соответствует результатам NtechLab на бенчмарке NIST visa images), то затраты на ручную проверку документов можно будет сократить в десять раз. Однако для того чтобы оценить точность при данном уровне FAR, понадобятся десятки миллионов изображений. Сбор такого большого датасета требует значительных средств и может потребовать дополнительного согласования обработки личных данных. В результате инвестиции в подобную систему могут окупаться чересчур долго. В таком случае имеет смысл обратиться к отчету о тестировании NIST Face Recognition Vendor Test, который содержит датасет с фотографиями с виз. Администрации аэропорта стоит выбирать вендора на основе тестирования на этом датасете, приняв во внимание пассажиропоток.
соответствует десяти нарушителям в год и кажется разумным в этой ситуации. Если при данном FAR, FRR составляет 0.1 (что соответствует результатам NtechLab на бенчмарке NIST visa images), то затраты на ручную проверку документов можно будет сократить в десять раз. Однако для того чтобы оценить точность при данном уровне FAR, понадобятся десятки миллионов изображений. Сбор такого большого датасета требует значительных средств и может потребовать дополнительного согласования обработки личных данных. В результате инвестиции в подобную систему могут окупаться чересчур долго. В таком случае имеет смысл обратиться к отчету о тестировании NIST Face Recognition Vendor Test, который содержит датасет с фотографиями с виз. Администрации аэропорта стоит выбирать вендора на основе тестирования на этом датасете, приняв во внимание пассажиропоток.
Таргетированная почтовая рассылка
До сих пор мы рассматривали примеры, в которых заказчик был заинтересован в низких FAR, однако это не всегда так. Представим себе оборудованный камерой рекламный стенд в крупном торговом центре. Торговый центр имеет собственную программу лояльности и хотел бы идентифицировать ее участников, остановившихся у стенда. Далее этим покупателям можно было бы рассылать таргетированные письма со скидками и интересными предложениями на основании того, что их заинтересовало на стенде.
Допустим, что эксплуатация такой системы обходится в 10 $, при этом около 1000 посетителей в день останавливаются у стенда. Отдел маркетинга оценил прибыль от каждого таргетированного email в 0.0105 $. Нам хотелось бы идентифицировать как можно больше постоянных покупателей и не слишком беспокоить остальных. Чтобы такая рассылка окупилась, точность должна быть равна затратам на стенд, поделенным на количество посетителей и ожидаемый доход от каждого письма. Для нашего примера точность равна  . Администрация торгового центра могла бы собрать датасет способом, описанным в разделе «Розничный магазин», и измерить точность, как описано в разделе «Идентификация». На основании результатов тестирования можно принимать решение, получится ли извлечь ожидаемую выгоду с помощью системы распознавания лиц.
. Администрация торгового центра могла бы собрать датасет способом, описанным в разделе «Розничный магазин», и измерить точность, как описано в разделе «Идентификация». На основании результатов тестирования можно принимать решение, получится ли извлечь ожидаемую выгоду с помощью системы распознавания лиц.
Поддержка видео
В этой заметке мы обсуждали преимущественно работу с изображениями и почти не касались потокового видео. Видео можно рассматривать как последовательность статичных изображений, поэтому метрики и подходы к тестированию точности на изображениях применимы и к видео. Стоит отметить, что обработка потокового видео гораздо более затратна с точки зрения производимых вычислений и накладывает дополнительные ограничения на все этапы распознавания лиц. При работе с видео следует проводить отдельное тестирование производительности, поэтому детали этого процесса не затрагиваются в настоящем тексте.
Частые ошибки
В этом разделе мы хотели бы перечислить распространенные проблемы и ошибки, которые встречаются при тестировании ПО для распознавания лиц, и дать рекомендации, как их избежать.
Тестирование на датасете недостаточного размера
Всегда следует быть аккуратным при выборе датасета для тестирования алгоритмов распознавания лиц. Одним из важнейших свойств датасета является его размер. Размер датасета нужно выбирать, исходя из требований бизнеса и значений FAR/TAR. «Игрушечные» датасеты из нескольких изображений людей из вашего офиса дадут возможность «поиграть» с алгоритмом, измерить его производительность или протестировать нестандартные ситуации, но на их основании нельзя делать выводы о точности алгоритма. Для тестирования точности следует использовать датасеты разумных размеров.
Тестирование при единственном значении порога
Иногда люди тестируют алгоритм распознавания лиц при одном фиксированном пороге (часто выбранном производителем «по умолчанию») и принимают во внимание лишь один тип ошибок. Это неправильно, так как значения порога «по умолчанию» у разных вендоров различаются или выбираются на основе различных значений FAR или TAR. При тестировании следует обращать внимание на оба типа ошибок.
Сравнение результатов на разных датасетах
Датасеты различаются по размерам, качеству и сложности, поэтому результаты работы алгоритмов на разных датасетах невозможно сравнивать. Можно запросто отказаться от лучшего решения только потому, что оно тестировалось на более сложном, чем у конкурента, датасете.
Делать выводы на основе тестирования на единственном датасете
Следует стараться проводить тестирование на нескольких наборах данных. При выборе единственного публичного датасета нельзя быть уверенным, что он не использовался при обучении или настройке алгоритма. В этом случае точность алгоритма будет переоценена. К счастью, вероятность этого события можно снизить, сравнив результаты на разных датасетах.
Выводы
В этой заметке мы описали основные составные части тестирования алгоритмов распознавания лиц: наборы данных, задачи, соответствующие метрики и распространенные сценарии.
Конечно, это далеко не всё, что хотелось бы рассказать о тестировании, и наилучший порядок действий может отличаться при многочисленных исключительных сценариях (команда NtechLab с радостью поможет с ними разобраться). Но мы очень надеемся, что этот текст поможет правильно спланировать тестирование алгоритма, оценить его сильные и слабые стороны и интерпретировать метрики качества с точки зрения бизнес-задач.
В прошлой статье мы рассказывали о самых крупных утечках данных из биометрических Big Data систем в России и за рубежом. Сегодня рассмотрим характерные уязвимости биометрии: естественные ограничения методов идентификации личности с помощью машинного обучения (Machine Learning, ML) и целенаправленные атаки.
2 главные уязвимости биометрических Big Data систем на базе Machine Learning
Прежде всего отметим, что для биометрических систем характерны те же факторы возникновения рисков, как и для любого Big Data проекта. В частности, здесь мы анализировали, почему случаются утечки данных: в основном, виноваты люди (сторонние хакеры или внутренние пользователи), инфраструктурные проблемы, уязвимости программного обеспечения или сторонние сервисы. Однако, помимо этих причин, биометрии свойственны специфические проблемы, непосредственно связанные с самими алгоритмами распознавания личности на базе методов машинного обучения. Поэтому их называют естественными ограничениями биометрических методов идентификации. При этом могут возникнуть ошибки 1-го и 2-го родов по матрице ошибок (confusion matrix) [1]:
- ложное соответствие из-за вторжения злоумышленника, который сумел обмануть ML-алгоритмы распознавания, выдав себя за другого пользователя – вариант False Positive (ложноположительное решение, FP), ошибка 1-го рода;
- ложное несоответствие и отказ в обслуживании, когда ML-модель не смогла распознать легитимного пользователя, не найдя в базе подходящего цифрового шаблона для представленных биометрических персональных данных (БПД) – вариант False Negative (ложноотрицательное решение, FN), ошибка 2-го рода.
Ошибка 2-го рода, в основном, связана с качеством алгоритмов распознавания и/или качеством входных данных. А ошибки 1-го рода, как правило, возникают вследствие атаки подделки, когда фальсифицируется биометрическая черта, используемая в ML-алгоритмах. Например, искусственный палец с нужными отпечатками, трехмерная маска лица или даже реальная часть тела легитимного пользователя, отрезанная от него [1]. Именно такой инцидент произошел с владельцем премиального автомобиля в Малайзии в 2005 году, которого покалечили преступники при попытке угнать его машину [2]. Впрочем, злоумышленники успешно применяют и менее травматичные способы изготовления поддельных биометрических носителей. В частности, хакеры имитируют нужные отпечатки пальцев с помощью силиконовых пленок, графитового порошка и суперклея, а фото лица – гипсовыми копиями головы и масками. Такие методы позволяют обмануть простые биометрические системы идентификации в смартфонах с не слишком сложными ML-алгоритмами и/или не самыми чувствительными датчиками [3].
На самом деле оба варианта ложных срабатываний весьма нежелательны, т.к. влекут за собой неправомерные действия с информацией (в случае FP) или недовольство пользователя (в случае FN), что приводит к репутационным потерям и увеличивает вероятность оттока клиента (Churn Rate).

Как оценить качество распознавания: FAR, FRR и другие метрики биометрии
Для оценки качества распознавания в биометрических системах используются следующие коэффициенты [2]:
- ложного приема (FAR, False Acceptance Rate) – вероятность ложной идентификации, когда ошибочно признается подлинность пользователя, не зарегистрированного в системе;
- ложного совпадения (FMR, False Match Rate) – вероятность того, что входной образец неверно сравнивается с несоответствующим шаблоном в базе данных;
- ложного отклонения (FRR, False Rejection Rate) – вероятность того, что система биоидентификации не признает подлинность зарегистрированного в ней пользователя;
- ложного несовпадения (FNMR, False Non Match Rate) – вероятность ошибки в определении совпадений между входным образцом и соответствующим шаблоном из базы данных;
- отказа в регистрации (FER, Failure to Enrol Rate)– вероятность того, что система не сможет создать шаблон из входных биометрических данных из-за их низкого качества или других помех;
- ошибочного удержания (FTC) – вероятность того, что система не способна определить корректно представленные БПД.
Для количественного расчета вышеперечисленных коэффициентов составляется матрица ошибок распознавания личности по биометрическим данным.
|
Шаблон БПД |
Реальные БПД |
|
|
+ |
— |
|
|
+ |
True Positive (истинно-положительное решение): реальные БПД соответствуют шаблону, положительное решение ML-модели распознавания |
False Positive (ложноположительное решение): ошибка 1-го рода, ML-модель ошибочно идентифицировала личность, распознав реальные БПД соответствующими шаблону другого человека Подсчет коэффициентов FAR, FMR |
|
— |
False Negative (ложноотрицательное решение): ошибка 2-го рода – ML-модель не смогла идентифицировать личность, не распознавав БПД, т.е. не нашла для них соответствующего шаблона Подсчет коэффициентов FRR и FNMR |
True Negative (истинно-отрицательное решение): в базе шаблонов отсутствуют представленные БПД, ML-модель не смогла распознать и идентифицировать незарегистрированного пользователя, что абсолютно корректно |

Какая биометрия самая эффективная: анализ метрик и факторов
Как мы уже рассказывали, биометрические системы на базе Machine Learning работают не по принципу однозначного соответствия представленных БПД ранее сохраненному шаблону. Обычно сравнивающий алгоритм принимает решение о соответствии данных на степени близости представленных образцов к шаблону. Поэтому разработчики ML-модели распознавания стремятся найти баланс между показателями FAR и FRR, варьируя значение этой дельты (порога) близости данных. Например, при уменьшении порога будет меньше ложных несовпадений, но больше ложных приёмов. А высокий порог уменьшит FAR, но увеличит FRR. Для определения этого баланса используют коэффициент EER, при котором ошибки приёма и отклонения эквивалентны и возникают с равной степени вероятности. Считается, что системы с низким EER более точны. Также стоит отметить тенденцию роста чувствительности биометрических приборов, что уменьшает FAR, но увеличивает FRR [2].
Однако, при одинаковом значении FAR более качественной будет та биометрия, у которой FRR меньше. От значений FAR и FRR зависит, с каким количеством пользователей система будет эффективно работать, не раздражая своими ошибками. Это число обычно обратно пропорционально квадратному корню из анализируемого параметра. Например, при FAR, равном 0,01%, и допустимом уровне ошибок не более 1 в день, биометрическую систему целесообразно применять в компаниях со штатом до 100 человек [4]. А вводимая с 2018 года в России единая биометрическая система (ЕБС) предполагает точность распознавания 1 к 10 000 000, т.е. на 10 миллионов случаев возможна одна единственная ошибка распознавания. При этом для идентификации личности ЕБС использует 2 биометрических параметра: трехмерное сканирование лица и голос.
Стоит помнить, что успешность распознавания, а, следовательно, показатели FAR, FRR и прочие метрики оценки эффективности биометрической системы, зависят от характера и количества используемых данных. Разумеется, более надежны многофакторные системы, которые используют сочетание нескольких биометрических параметров, например, рисунок вен на ладонях, особенности радужной оболочки глаз и походки. Однако, такой комплексный подход увеличивает сложность и, соответственно, стоимость реализации. Кроме того, при выборе биометрических методов следует учитывать контекст применения и условия эксплуатации такой Big Data системы [5]. Как сделать это на практике, мы расскажем в следующей статье. Также поговорим про то, как разные биометрические методы отличаются друг от друга. В частности, рассмотрим, насколько будет быстрым и устойчивым к фальсификации определение личности по отпечаткам пальцев, ладоней или изображениям лица и глаз. Еще коснемся некоторых «экзотических» способов идентификации личности: по запахам, сердцебиению и внутренним вибрациям.

А о том, чем выгодна цифровизация процессов на базе биометрических систем машинного обучения и другие вопросы информационной безопасности больших данных, вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- BDAM: Аналитика больших данных для руководителей
- DSEC: Безопасность озера данных Hadoop
Источники
- https://www.osp.ru/os/2012/10/13033122/
- https://ru.wikipedia.org/wiki/Биометрия
- https://habr.com/ru/company/globalsign/blog/435978/
- https://ai-news.ru/2018/11/ne_v_brov_a_v_glaz_kak_rabotaet_biometriya.html
- http://www.techportal.ru/security/biometrics/tekhnologii-biometricheskoy-identifikatsii/
Оценка качества Биометрических систем
Работа
биометрической системы идентификации
пользователя (БСИ) описывается техническими
и ценовыми параметрами. Качество работы
БСИ характеризуется процентом ошибок
при прохождении процедуры допуска. В
БСИ различают ошибки трех видов:
-
FRR
(False Rejection Rate)ошибка первого рода—
вероятность принять «своего» за
«чужого». Обычно в коммерческих
системах эта ошибка выбирается равной
примерно 0,01, поскольку считается, что,
разрешив несколько касаний для «своих»,
можно искусственным способом улучшить
эту ошибку. В ряде случаев (скажем, при
большом потоке, чтобы не создавать
очередей) требуется улучшение FRR до
0,001-0,0001. В системах, присутствующих на
рынке, FRR обычно находится в диапазоне
0,025-0,01. -
FAR
(False Acceptance Rate)ошибка второго рода— вероятность принять «чужого» за
«своего». В представленных на рынке
системах эта ошибка колеблется в
основном от 10-3до 10-6, хотя
есть решения и с FAR = 10-9. Чем больше
данная ошибка, тем грубее работает
система и тем вероятнее проникновение
«чужого»; поэтому в системах с
большим числом пользователей или
транзакций следует ориентироваться
на малые значения FAR.
-
EER
(Equal Error Rates)– равная вероятность
(норма) ошибок первого и второго рода.
Биометрические
технологии
основаны на биометрии, измерении
уникальных характеристик отдельно
взятого человека. Это могут быть как
уникальные признаки, полученные им с
рождения, например: ДНК, отпечатки
пальцев, радужная оболочка глаза; так
и характеристики, приобретённые со
временем или же способные меняться с
возрастом или внешним воздействием,
например: почерк, голос или походка.
Все
биометрические системы работают
практически по одинаковой схеме.
Во-первых, система запоминает образец
биометрической характеристики (это и
называется процессом записи). Во время
записи некоторые биометрические системы
могут попросить сделать несколько
образцов для того, чтобы составить
наиболее точное изображение биометрической
характеристики. Затем полученная
информация обрабатывается и
преобразовывается в математический
код. Кроме того, система может попросить
произвести ещё некоторые действия для
того, чтобы «приписать» биометрический
образец к определённому человеку.
Например, персональный идентификационный
номер (PIN) прикрепляется к определённому
образцу, либо смарт-карта, содержащая
образец, вставляется в считывающее
устройство. В таком случае, снова делается
образец биометрической характеристики
и сравнивается с представленным образцом.
Идентификация по любой биометрической
системе проходит четыре стадии:
-
Запись
– физический или поведенческий образец
запоминается системой; -
Выделение
– уникальная информация выносится из
образца и составляется биометрический
образец; -
Сравнение
– сохраненный образец сравнивается с
представленным; -
Совпадение/несовпадение
— система решает, совпадают ли
биометрические образцы, и выносит
решение.
Подавляющее
большинство людей считают, что в памяти
компьютера хранится образец отпечатка
пальца, голоса человека или картинка
радужной оболочки его глаза. Но на самом
деле в большинстве современных систем
это не так. В специальной базе данных
хранится цифровой код длиной до 1000 бит,
который ассоциируется с конкретным
человеком, имеющим право доступа. Сканер
или любое другое устройство, используемое
в системе, считывает определённый
биологический параметр человека. Далее
он обрабатывает полученное изображение
или звук, преобразовывая их в цифровой
код. Именно этот ключ и сравнивается с
содержимым специальной базы данных для
идентификации личности [19].
Преимущества
биометрической идентификации состоит
в том, что биометрическая защита дает
больший эффект по сравнению, например,
с использованием паролей, смарт-карт,
PIN-кодов, жетонов или технологии
инфраструктуры открытых ключей. Это
объясняется возможностью биометрии
идентифицировать не устройство, но
человека.
Обычные
методы защиты чреваты потерей или кражей
информации, которая становится открытой
для незаконных пользователей.
Исключительный биометрический
идентификатор, например, отпечатки
пальцев, является ключом, не подлежащим
потере [18].
Соседние файлы в папке ГОСЫ
- #
- #
- #
- #
- #
- #
- #
- #
- #
Технология распознавания лиц в видеонаблюдении
Как подобрать подходящую камеру и правильно выбрать место её установки
Системы видеонаблюдения уже давно перестали быть пассивными. Алгоритмы видеоанализа позволяют автоматически извлекать информацию из потока данных от камеры наблюдения. Одной из наиболее востребованных является технология распознавания лиц. В данной статье разберем вопрос выбора камеры для идентификации лица и места ее установки для минимизации ошибок распознавания.
Целевые задачи видеонаблюдения
Идентификация человека – одна из целевых задач видеонаблюдения. Технология распознавания лиц позволяет автоматически осуществлять идентификацию человека за счет алгоритмов видеоанализа.
Функция идентификации лица позволяет с заданной вероятностью выделить из видеопотока лицо человека, находящегося в базе данных системы видеонаблюдения. Помимо идентификации, технология распознавания лиц может фиксировать и другую информацию из видеопотока:
- определение пола
- оценка возраста
- определение расы
- выявление эмоций
- наличие усов / бороды
- наличие очков
- подсчет уникальных посетителей
Таким образом сферы применения технологии распознавания лиц куда шире, чем традиционные задачи расследования произошедших инцидентов. Вот неполный перечень:
- поиск лица в архиве видеонаблюдения
- идентификационный признак для системы контроля и управления доступом
- сбор статистики о посетителях в сфере ритейла
Отдельно следует отметить задачи сохранения приватности, которые (как ни странно!) также могут решаться средствами видеоаналитики. Система видеонаблюдения выделяет на кадре лицо человека и “замыливает” этот участок изображения таким образом, чтобы попавшие в кадр лица невозможно было узнать. Соблюдение приватности при работе видеонаблюдения в общественных зонах могут требоваться как заказчиком такой системы, так и законодательно.
Идентификация и верификация
При распознавании лиц алгоритм выявляет ряд биометрических данных о человеке. Эти данные могут быть использованы по-разному:
- накапливаться в системе для статистики
- сравниваться со всей накопленной базой данных лиц для поиска наиболее близкого совпадения (идентификации)
- сравниваться с эталонными данными для оценки степени соответствия (верификации)
Идентификация, как правило, используется для поиска лиц в архиве. Это позволяет эффективно проводить расследования инцидентов и преступлений. Кроме того, идентификация используется для отслеживания нахождения человека в “белом” или “черном” списке посетителей.
Верификация чаще используется для систем контроля и управления доступом, как один из идентификаторов посетителя.
Ошибки FAR и FRR
Для оценки качества применяемых алгоритмов используются две вероятностных величины: ошибки первого и второго рода. FAR (False Acceptance Rate) – процентный порог, определяющий вероятность того, что один человек может быть принят за другого (ошибка второго рода). FRR (False Rejection Rate) — вероятность того, что человек может быть не распознан системой (ошибка первого рода).
Ошибки FAR и FRR связаны между собой: чем ниже вероятность FAR, тем выше вероятность FRR и наоборот. Поэтому при настройке алгоритма выбирают их оптимальное соотношение для конкретного объекта защиты.
Facе Anti-Spoofing
В системах распознавания лиц необходима защита от попыток обмана (spoofing attack). Это либо попытка подделать идентификационный признак для ошибочной верификации пользователя системой распознавания. Либо попытка избежать идентификации различными методами маскировки лица.
Наиболее продвинутые алгоритмы идентификации используют различные методы Facе Anti-Spoofing.
Выбор системы распознавания лиц
Существует огромное число различных реализаций систем идентификации лиц. Их можно классифицировать по подходам к реализации:
- стандартные алгоритмы
- нейросетевые алгоритмы
А также по месту обработки видеопотока:
- на сервере
- на IP камере
- на видеорегистраторе
Системы распознавания лиц существенно отличаются друг от друга и требует тщательного выбора как по функциональности, так и по качеству идентификации (упомянутым ошибкам первого и второго рода, стойкости к spoofing attack). Наиболее продвинутые системы строятся на базе видеоаналитических модулей VMS систем (Video Management System или Video Management Software). Простейшие алгоритмы могут быть приятным бонусом в относительно бюджетных видеорегистраторах. И те и другие имеют своего потребителя, однако решают задачи разного класса и степени важности для потребителя.
Критерии идентификации лица человека
При планировании системы распознавания лиц необходимо учитывать требования производителя конкретного оборудования или видеоаналитических модулей. Ведь для автоматического распознавания лиц не существует единых государственных или межгосударственных стандартов.
Наиболее проработанными являются требования к городским системам видеонаблюдения класса “Безопасный город”, а также для систем транспортной безопасности. Так в Постановление Правительства РФ от 26.09.2016 N 969 “Об утверждении требований к функциональным свойствам технических средств обеспечения транспортной безопасности и Правил обязательной сертификации технических средств обеспечения транспортной безопасности” приведены следующие требования:
34. Функциональные свойства технических систем и средств идентификации физических лиц, указанные в пункте 33 настоящих требований, должны обеспечиваться при следующих условиях:
а) освещенность в плоскости лица – от (100 ± 10) до (1000 ± 50) люкс;
б) неравномерность освещенности лица – не более (50 ± 5) процентов;
в) характеристики видеоизображения:
разрешение видеоизображения, обеспечивающее регистрацию изображений лиц на рабочей дистанции съемки видеокамеры не менее 1,5 метра с расстоянием между центрами глаз (40 ± 2) пикселей (для алгоритмов и аппаратно-программных средств детекции) и (60 ± 2) пикселей (для алгоритмов и аппаратно-программных средств идентификации);
динамический диапазон интенсивности изображения в области лица – не менее 8 бит;
цветность видеоизображения – черно-белое;
частота – не менее 16 кадров в секунду;
г) плотность потока людей – 1 чел/м ;
д) скорость движения – не более 5 км/ч;
е) ракурс лица относительно фронтального ракурса, определяемый в соответствии с ГОСТ Р ИСО/МЭК 19794-5-2013 “Информационные технологии. Биометрия. Форматы обмена биометрическими данными. Часть 5. Данные изображения лица” угловыми координатами поворота, наклона и отклонения лица:
для алгоритмов и аппаратно-программных средств детекции – в диапазоне от 0 до (30 ± 2) градусов;
для алгоритмов и аппаратно-программных средств идентификации – в диапазоне от 0 до (15 ± 2) градусов;
ж) структура фона (подвижный случайно неоднородный фон съемки с перепадами контраста) – от (0,2 ± 0,05) до (0,8 ± 0,05);
з) объем базы данных эталонных изображений лиц – не менее 1000 лиц условно-фронтального типа (в соответствии с ГОСТ Р ИСО/МЭК 19794-5-2013 “Информационные технологии. Биометрия. Форматы обмена биометрическими данными. Часть 5. Данные изображения лица”).
35. В состав технических систем и средств идентификации физических лиц включаются средства регистрации видеоизображений, к которым предъявляются следующие требования:
а) разрешение регистрируемого видеоизображения – не менее 1,2 мегапикселя;
б) частота кадров – не менее 16 кадров в секунду;
в) разрешающая способность – разрешение на рабочей дистанции съемки объектов размером 2 миллиметра и более (значения для области в центре кадра и на расстоянии до одной третьей ширины, высоты и диагоналей кадра от центра включительно);
г) глубина резко отображаемого пространства – не менее 1 метра (для области в центре кадра и на расстоянии до одной третьей ширины, высоты и диагоналей кадра от центра включительно);
д) расстояние между центрами глаз на изображении лица, зарегистрированном на рабочей дистанции съемки, – не менее (60 ± 2) пикселей (для области в центре кадра и на расстоянии до одной третьей ширины, высоты и диагоналей кадра от центра включительно);
е) максимальное отношение “сигнал – шум” (с выключенной функцией автоматического усиления сигнала) – не менее 45 дБ;
ж) дисторсия – не более 5 процентов (по краям кадра – на расстоянии одной третьей ширины, высоты и диагоналей кадра от его центра).
Для обычной (не алгоритмической) идентификации некоторые рекомендации в нормативных документах все же есть. Из отечественных можно вспомнить Р 78.36.008-99 Проектирование и монтаж систем охранного телевидения и домофонов. Рекомендации:

*МРД – минимальная различимая деталь (изображения)
В европейском стандарте BS EN 62676-4:2015 Video surveillance systems for use in security applications. Application guidelines приведены близкие к отечественным рекомендации по плотности пикселей для решения целевой задачи идентификации:
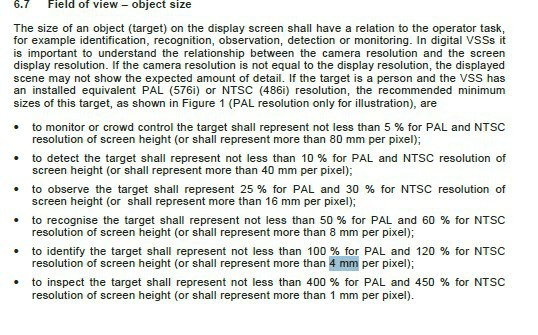
Если же проанализировать требования производителей видеоаналитических модулей, то основными критериями будут:
- число пикселей между глаз
- угол между горизонталью и направлением «лицо — камера» (на сколько лицо “анфас” по вертикале)
- угол между направлением оптической оси камеры и нормалью условной плоскости лица (на сколько лицо “анфас” по горизонтали)

Как выбрать место установки камеры для автоматического распознавания лиц?
Как было сказано выше – наша задача получить изображение лица “анфас”. Исходя из этого нам требуется максимально уменьшать вертикальные и горизонтальные углы, под которыми мы снимаем человека. Для этого при планировании системы видеонаблюдения мы должны:
- определить место, где человек неизбежно окажется при входе на объект с понятным положением головы

- установить камеру напротив входа, по-возможности без смещения относительно центра
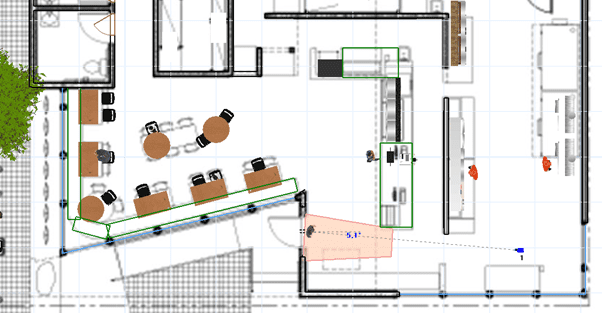
- при возможности – максимально приблизить высоту установки камеры к росту наиболее рослого человека (около 2 метров), однако не слишком низко, чтобы впереди идущий человек не загораживал лицо следующего за ним

- при невозможности установить камеру низко – максимально сместить ее от зоны съемки лица (для уменьшения вертикального угла)
Следует также избегать мест установки камеры, где человек инстинктивно смотрит вниз под ноги: выход или вход с эскалатора, проход через турникеты (человек будет смотреть на считыватель), подъем по ступенькам и т.п. Либо как то привлекать внимание к камере – например размещая рядом с ней экран с выводом изображения с камеры.

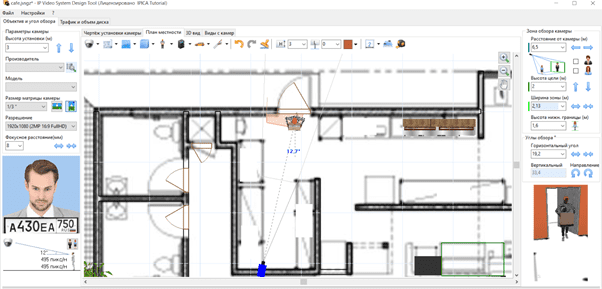
Как подобрать характеристики камеры?
Нас интересуют прежде всего два параметра:
- разрешение камеры
- угол обзора камеры (на который влияют фокусное расстояние и размер матрицы)
Для идентификации нам не подойдут широкоугольные камеры с наличием выраженной дисторсией объектива.
При выборе угла обзора нужно учитывать размер входной зоны, где неизбежно должна оказаться голова входящего на объект человека. Разрешение матрицы нужно выбирать минимально достаточным, чтобы при заданном угле обзора выполнить требование по числу пикселей между глаз человека или аналогичному значению плотности пикселей.


В зависимости от условий съемки нужно подбирать и другие характеристики камеры:
- размер матрицы и ее светочувствительность
- F-число диафрагмы объектива
- величину выдержки электронного затвора
- режим работы диафрагмы и электронного затвора
Тут речь идет о том, что контрастность изображения не должна зависеть от времени суток и изображение не должно быть смазанным из-за быстрого перемещения человека в кадре.
Выводы
Технологии идентификации занимают все большее место в современных системах видеонаблюдения. Для правильного планирования таких систем важно подобрать систему, удовлетворяющую пользователей по соотношению ошибок первого и второго уровня, а также правильно подобрать место установки камеры и ее характеристики. Для этого нужно выяснить критерии идентификации у выбранного производителя и произвести нужные расчеты. Наиболее удобно планировать такие системы в специализированном софте для проектирования систем видеонаблюдения.
Дополнительные материалы
Бесплатная книга с практическими уроками по проектированию видеонаблюдения.
Анонс: Плагин AutoCAD для видеонаблюдения
Рейтинги: топ 10 популярных камер видеонаблюдения
Скачать: 90 дневную версию программы IP Video System Design Tool 10