Основной
причиной преобразования аналоговой
информации в дискретную форму стало
невозможность улучшения качества
передачи данных в аналоговой форме.
Поэтому на смену аналоговой техники
передачи пришла цифровая техника. В
этой технике используется дискретная
модуляция исходных, непрерывных во
времени аналоговых процессов.
Рассматриваемый принцип импульсно
кодовой модуляции применяют в телефонии.
В этом случае дискретизация происходит
как по времени, так и по амплитуде.
Амплитуда исходной непрерывной функции
измеряется через заданный период
времени, за счёт этого происходит
дискретизация по времени, затем каждый
замер представляется в виде двоичного
числа, определённой разрядности, что
означает дискретизацию по значению.
Устройство, которое выполняет эту
функцию, называется АЦП. После чего
замеры передаются по линиям связи в
виде 0 и 1. При этом применяется те же
методы кодирования, что и при изначально
дискретной информации. На принимающей
стороне коды преобразуются в исходный
последовательности, а ЦАП производит
декодирование в аналоговый сигнал.
Дискретная
модуляция основана на теории отображения
Найквиста. В соответствии с этой теорией
аналоговая непрерывная функция,
переданная в виде последовательности
ей дискретных значений, может быть точно
восстановлена, если частота её
дискретизации была в 2 и более раз выше
частоты самой высокой гармоники спектра
её функции. В том случае, если это условие
не выполняется, то восстановленная
функция будет существенно отличаться
от исходной.
Ошибка
интерполяции равна разности исходного
задержанного процесса и восстановленного
процесса, причем задержка выбирается
такой, чтобы ошибка была минимальной.
∆инт(t)
= x(t — tопт)
— xв(t).
В
системах с обратной связью задержка
восстановленного сигнала нежелательна.
Она может привести не только к увеличению
ошибок моделирования, но и к потере
устойчивости модели. В этом случае
ошибка определяется как:
∆полн(t)
= x(t) — xв(t)
и
называется полной ошибкой.
Так
как ошибки зависят от времени, то для
их числовой оценки используется
среднеквадратическая ошибка, усредненная
за время Т, в течение которого измеряется
ошибка.
5. Эффективное кодирование, назначения, способы реализации, основные ограничения.
Этот
вид кодирования используется для
уменьшения объемов информации на
носителе — сигнале.
Для
кодирования символов исходного алфавита
используют двоичные коды переменной
длины: чем больше частота символа, тем
короче его код. Эффективность кода
определяется средним числом двоичных
разрядов для кодирования одного символа
– lср
по формуле

где
k – число символов исходного алфавита;
ns
– число двоичных разрядов для кодирования
символа s;
fs
– частота символа s; причем

При
эффективном кодировании существует
предел сжатия, ниже которого не
«спускается» ни один метод эффективного
кодирования — иначе будет потеряна
информация. Этот параметр определяется
предельным значением двоичных разрядов
возможного эффективного кода – lпр:
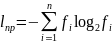
где
n – мощность кодируемого алфавита,
fi
– частота i-го символа кодируемого
алфавита.
Существуют
два классических метода эффективного
кодирования: метод Шеннона-Фано и метод
Хаффмена. Входными данными для обоих
методов является заданное множество
исходных символов для кодирования с их
частотами; результат — эффективные коды.
Метод
Хаффмена построения эффективного кода
реализуется в два этапа: сворачивание
кода и разворачивание кода.
1.
Сворачивание кода.
Формируют
начальную последовательность символов
источника информации путём упорядочивания
по неубыванию вероятностей их появления
на выходе источника. Последние два
символа последовательности объединяют
в один с вероятностью появления на
выходе источника информации, равной
сумме вероятностей появления каждого
из этих символов. Эту операцию повторяют
итеративно до тех пор, пока в
последовательности не останется только
лишь два символа.
2.
Разворачивание кода.
Одному
символу приписываем код 0, а другому 1.
Каждый символ разбивается на две
последовательности в порядке, обратном
порядку сворачивания кода. Эту операцию
повторяют итеративно для каждой из
полученных двух последовательностей
до тех пор, пока имеется последовательность,
состоящая более чем из одного символа.
При этом кодовая комбинация каждой
дочерней последовательности получается
путём приписывания к кодовой комбинации
родительской последовательности символа
0 или 1 справа.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
From Wikipedia, the free encyclopedia
In numerical analysis, computational physics, and simulation, discretization error is the error resulting from the fact that a function of a continuous variable is represented in the computer by a finite number of evaluations, for example, on a lattice. Discretization error can usually be reduced by using a more finely spaced lattice, with an increased computational cost.
Examples[edit]
Discretization error is the principal source of error in methods of finite differences and the pseudo-spectral method of computational physics.
When we define the derivative of  as
as  or
or  , where
, where  is a finitely small number, the difference between the first formula and this approximation is known as discretization error.
is a finitely small number, the difference between the first formula and this approximation is known as discretization error.
[edit]
In signal processing, the analog of discretization is sampling, and results in no loss if the conditions of the sampling theorem are satisfied, otherwise the resulting error is called aliasing.
Discretization error, which arises from finite resolution in the domain, should not be confused with quantization error, which is finite resolution in the range (values), nor in round-off error arising from floating-point arithmetic. Discretization error would occur even if it were possible to represent the values exactly and use exact arithmetic – it is the error from representing a function by its values at a discrete set of points, not an error in these values.[1]
References[edit]
- ^ Higham, Nicholas (2002). Accuracy and Stability of Numerical Algorithms (PDF). Other Titles in Applied Mathematics (2 ed.). SIAM. p. 5. doi:10.1137/1.9780898718027. ISBN 978-0-89871-521-7.
See also[edit]
- Discretization
- Linear multistep method
- Quantization error
Основной
причиной преобразования аналоговой
информации в дискретную форму стало
невозможность улучшения качества
передачи данных в аналоговой форме.
Поэтому на смену аналоговой техники
передачи пришла цифровая техника. В
этой технике используется дискретная
модуляция исходных, непрерывных во
времени аналоговых процессов.
Рассматриваемый принцип импульсно
кодовой модуляции применяют в телефонии.
В этом случае дискретизация происходит
как по времени, так и по амплитуде.
Амплитуда исходной непрерывной функции
измеряется через заданный период
времени, за счёт этого происходит
дискретизация по времени, затем каждый
замер представляется в виде двоичного
числа, определённой разрядности, что
означает дискретизацию по значению.
Устройство, которое выполняет эту
функцию, называется АЦП. После чего
замеры передаются по линиям связи в
виде 0 и 1. При этом применяется те же
методы кодирования, что и при изначально
дискретной информации. На принимающей
стороне коды преобразуются в исходный
последовательности, а ЦАП производит
декодирование в аналоговый сигнал.
Дискретная
модуляция основана на теории отображения
Найквиста. В соответствии с этой теорией
аналоговая непрерывная функция,
переданная в виде последовательности
ей дискретных значений, может быть точно
восстановлена, если частота её
дискретизации была в 2 и более раз выше
частоты самой высокой гармоники спектра
её функции. В том случае, если это условие
не выполняется, то восстановленная
функция будет существенно отличаться
от исходной.
Ошибка
интерполяции равна разности исходного
задержанного процесса и восстановленного
процесса, причем задержка выбирается
такой, чтобы ошибка была минимальной.
∆инт(t)
= x(t — tопт)
— xв(t).
В
системах с обратной связью задержка
восстановленного сигнала нежелательна.
Она может привести не только к увеличению
ошибок моделирования, но и к потере
устойчивости модели. В этом случае
ошибка определяется как:
∆полн(t)
= x(t) — xв(t)
и
называется полной ошибкой.
Так
как ошибки зависят от времени, то для
их числовой оценки используется
среднеквадратическая ошибка, усредненная
за время Т, в течение которого измеряется
ошибка.
5. Эффективное кодирование, назначения, способы реализации, основные ограничения.
Этот
вид кодирования используется для
уменьшения объемов информации на
носителе — сигнале.
Для
кодирования символов исходного алфавита
используют двоичные коды переменной
длины: чем больше частота символа, тем
короче его код. Эффективность кода
определяется средним числом двоичных
разрядов для кодирования одного символа
– lср
по формуле
где
k – число символов исходного алфавита;
ns
– число двоичных разрядов для кодирования
символа s;
fs
– частота символа s; причем
При
эффективном кодировании существует
предел сжатия, ниже которого не
«спускается» ни один метод эффективного
кодирования — иначе будет потеряна
информация. Этот параметр определяется
предельным значением двоичных разрядов
возможного эффективного кода – lпр:
где
n – мощность кодируемого алфавита,
fi
– частота i-го символа кодируемого
алфавита.
Существуют
два классических метода эффективного
кодирования: метод Шеннона-Фано и метод
Хаффмена. Входными данными для обоих
методов является заданное множество
исходных символов для кодирования с их
частотами; результат — эффективные коды.
Метод
Хаффмена построения эффективного кода
реализуется в два этапа: сворачивание
кода и разворачивание кода.
1.
Сворачивание кода.
Формируют
начальную последовательность символов
источника информации путём упорядочивания
по неубыванию вероятностей их появления
на выходе источника. Последние два
символа последовательности объединяют
в один с вероятностью появления на
выходе источника информации, равной
сумме вероятностей появления каждого
из этих символов. Эту операцию повторяют
итеративно до тех пор, пока в
последовательности не останется только
лишь два символа.
2.
Разворачивание кода.
Одному
символу приписываем код 0, а другому 1.
Каждый символ разбивается на две
последовательности в порядке, обратном
порядку сворачивания кода. Эту операцию
повторяют итеративно для каждой из
полученных двух последовательностей
до тех пор, пока имеется последовательность,
состоящая более чем из одного символа.
При этом кодовая комбинация каждой
дочерней последовательности получается
путём приписывания к кодовой комбинации
родительской последовательности символа
0 или 1 справа.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
CFD Solution Analysis: Essentials
Jiyuan Tu, … Chaoqun Liu, in Computational Fluid Dynamics (Third Edition), 2018
Discretisation Error
These errors are due to the difference between the exact solution of the modelled equations and a numerical solution with a limited time and space resolution. They arise because an exact solution to the equation being solved is not obtained but numerically approximated. For a consistent discretization of the algebraic equations, the computed results are expected to become closer to the exact solution of the modelled equations as the number of grid cells is increased. However, the results are strongly affected by the density of the mesh and distribution of the grid nodal points.
We identify two types of discretization errors: local and global (or accumulated). To have an idea about the local error and global error, consider the finite-difference formulation of the derivatives for the transport variable ϕ in space and time at a specified grid nodal point expressed through the Taylor series expansion:
(6.5)∂ϕ∂x=ϕi+1,j−ϕi,jΔx+OΔx︸Truncation errorSpatial derivative
(6.6)∂ϕ∂t=ϕi,jn+1−ϕi,jnΔt+OΔt︸Truncateion errorTime derivative
Termination of the Taylor series expansion in Eqs (6.5) and (6.6) results in the so-called truncation errors involved in the approximation.
The local error is the formulation associated with a single step and provides an idea about the accuracy of the method used. For this error, the accuracy of the numerical solution concerns mainly on the approximation of the spatial derivative. The solution accuracy for a transient problem, however, focuses on the advancement of the transport variable ϕ through time usually characterized by the global error. The representations of the local error and global error are best illustrated in Fig. 6.1. We can observe that the smaller the mesh size or time step in transient problems, the smaller the error, and thus the more accurate the approximation.

Fig. 6.1. The local and global discretization errors resulting from the finite-difference method at a specified grid nodal point.
We shall illustrate the significance of the discretization error through a worked example below.
Example 6.8
Consider the transient one-dimensional convection-type equation to further illustrate the aspect of discretization error. A fourth-order central difference is employed for the spatial derivative to attain higher accuracy. Using the Euler explicit method, demonstrate the discretization error that is associated with the numerical solution obtained through the first- and second-order approximations to the time derivative at a fixed time step size of Δt = 1/128 accompanied by the variation of two different grid step sizes of Δx = 1 and Δx = 1/2.
Solution: Through the consideration of additional grid nodal points along the spatial direction x and applying the Taylor series expansion, the fourth-order finite-difference approximation can be obtained as
∂ϕ∂x=−ϕi+2+8ϕi+1−8ϕi−1+ϕi−212Δx+OΔx4︸Truncationerror
Substituting the above approximation along with the first-order forward difference to the time derivative yields the following algebraic equation:
ϕin+1−ϕinΔt−u−ϕi+2+8ϕi+1−8ϕi−1+ϕi−212Δx=0
For the second-order approximation of the time derivative, the central difference is employed, in other words,
ϕin+1−ϕin−12Δt−u−ϕi+2+8ϕi+1−8ϕi−1+ϕi−212Δx=0
This newly developed formula is similar to the well-known leapfrog method.
The computed results compared with the exact solution for the first-order and second-order time approximations against two different grid sizes are illustrated in Figs 6.8.1 and 6.8.2.

Fig. 6.8.1. Fourth order grid and first order time approximations of convection-type equation for the variable ϕ with a fixed time step of Δt = 1/128 and two grid sizes of Δx = 1 and Δx = 1/2.

Fig. 6.8.2. Fourth order grid and second order time approximations of convection-type equation for the variable ϕ with a fixed time step of Δt = 1/128 and two grid sizes of Δx = 1 and Δx = 1/2.
Discussion: By increasing the approximation of the time derivative from first order to second order, the numerical simulation for the higher-order time approximation at a grid size of Δx = 1 is shown to be less sensitive to the time step changes with the suppression of wiggles through time (compare the solutions between Figs 6.8.1 and 6.8.2). By halving the grid size to Δx = 1/2, the numerical simulation is stabilized. The solution for the second-order time derivatives converges to the exact solution profile, but the first-order solution retains some oscillatory wiggles around the exact solution profile and is still far from its converged state. In this example, the systematic reduction of the grid step sizes and the use of higher approximation for the time derivative characterize the diminishing contribution of the respective local and global discretization errors.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780081011270000064
Introduction
J. Blazek, in Computational Fluid Dynamics: Principles and Applications (Second Edition), 2005
Each discretisation of the governing equations introduces a certain error – the discretisation error. Several consistency requirements have to be fulfilled by the discretisation scheme in order to ensure that the solution of the discretised equations closely approximates the solution of the original equations. This problem is addressed in the first two parts of Chapter 10. Before a particular numerical solution method is implemented, it is important to know, at least approximately, how the method will influence the stability and the convergence behaviour of the CFD code. It was frequently confirmed that the Von Neumann stability analysis can provide a good assessment of the properties of a numerical scheme. Therefore, the third part of Chapter 10 deals with stability analysis for various model equations.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780080445069500035
Numerical Field Calculation for Charged Particle Optics
Erwin Kasper, in Advances in Imaging and Electron Physics, 2001
5.4.2 Error Analysis and Improvements
In the case of arbitrary triangular meshes, it is difficult to analyse the discretization errors of the approximation (5.66) with (5.72) and (5.75). However, for meshes that are obtained by subdividing along diagonals, as shown in Fig. 5.22 such an analysis is feasible.

Figure 5.22. Different triangulations of a square-shaped mesh. The points in diagonal directions always have vanishing coefficients. In the traditional form of the FEM only configuration (c) gives the correct results.
According to Eq. (5.72a), the L-coefficients vanish for all neighbors in diagonal directions, regardless of how the bisections into triangles were made, and consequently a five-point formula is found. However, this depends on the mode of subdivision, because the material coefficient s is evaluated at different centroids of triangles. This inconsistency already causes a discretization error of second order, which can easily be removed.
It is favorable to introduce the coefficients
(5.76a)εk±:=εu0+pk/2∓ηqk,v0+qk/2±ηpk,k=1,…,M,η≪1,
if ε(u, v) is discontinuous and
(5.76b)εk′=εk+=εk−=εu0+pk/2,v0+qk/2
for a continuous function. This means that the coefficient is determined not at a centroid but at the midpoint (k′) on the line from point (0) to point (k), as shown in Fig. 5.21. Equation (5.72a) is now replaced by
(5.77)−L0k=εk−γk−+εk+γk+/2,k=1,…,M,
whereupon the second and more general form of Eq. (5.72b) has still to be satisfied. After a corresponding change of notation and some elementary calculations, it is now possible to show that for the homogeneous PDE with A = B = ε and D ≡ Q ≡ 0 the five-point formula (4.60) is obtained, as it should be.
Another source of errors of second order is Eq. 5.75. This is most easily seen for a constant function Q(u, v) = Q0, Eq. 5.75 then simplifying to
(5.78)S0=16Q0∑i=1MDi=Q0ac/3,
ac being the total area of the carrier. For the configurations shown in Fig. 5.22, this takes different values, whereas the L-coefficients remain the same. This is certainly a severe error that must be eliminated by suitable modifications.
A fairly easy way is found by imposing the condition that a function with some free parameters shall become a particular integral of the inhomogenous PDE. An example of such a function is
(5.79a)ϕuv=ϕ0+p2+q2C0+pC1+qC2/4,
where C0, C1, and C2 being the free parameters. We must assume here a linear function ε(u, v), and we write
(5.79b)ε0:=εu0v0,ε′:=εu0+p/2,v0+q/2.
The source function corresponding to Eq. (5.79a) is then found by differentiation
(5.79c)Quv:=Δ⋅ε∇ϕ=ε′3C0+2pC1+2qC2−2ε0C0+R,
where R is the remainder. The latter consists of quadrupole terms with derivatives of ε as coefficients; such terms can be ignored within the framework of the FOFEM. The source at the center, Q0 = ε0C0, can now be used to eliminate the free parameters, the result being
(5.79d)ε′ϕ−ϕ0=p2+q2Q+2−ε′/ε0Q0/8.
Considering Eqs. (5.76b) and (5.77), the total source term becomes
(5.80a)−∑k=1ML0kϕk−ϕ0=S0=∑k=0MC0kQk,
with the source coefficients
(5.80b)C0k=pk2+qk2γk−+γk+/16k=1,…,M,
(5.80c)C00=∑k=1Mpk2+qk2γk−+γk+2−εk′/ε0/16.
If the source function Q(u, v) is discontinuous, like the current density at the surface of a coil, for example, then the following replacements should be made:
(5.81)γk−+γk+Qj→γk−+Qj−+γk++Qj+j=0ork.
All the deficiencies described earlier now vanish, because only those nodes that contribute also to the potential term contribute to the source term. In orthogonal structures the final formulas become independent of the mode of bisection into triangles. Moreover, it can be shown that the mesh formula is now consistent with (Eq. 4.60) in its inhomogeneous form, as it should be.
In spite of these improvements, which can easily be incorporated in FOFEM programs, this method is still not exact in second order, if tilted meshes are taken into account, as must be done in realistic applications. The error can then be reduced only by suitable choice of the meshes. Apart from orthogonal ones, there is a second class of configurations that are obtained by smooth and locally affine deformations of regular hexagonal elements, as is shown in Fig. 5.23. In such a case, the deformations should be small enough such that obtuse angles never appear, as the latter would cause negative potential coefficients. The optimum consists of completely regular elements, whose construction was dealt with in Section 5.1. If abrupt alterations of the mesh sizes cannot be avoided because of unfortunate geometric constraints, then discretization errors of second order must be taken into account.

Figure 5.23. Appropriate mesh construction for the application of the FOFEM by affine distortion of regular hexagonal structures. The hatched area is an example for one of the hexagonal carriers.
All these arguments demonstrate that the FOFEM is not very favorable. The only reason for its frequent use in practice is its simplicity when compared with other methods.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/S1076567001800690
Computational Electromagnetics: The Finite-Difference Time-Domain Method
Allen Taflove, … Melinda Piket-May, in The Electrical Engineering Handbook, 2005
Discretization Error
The design of an effective PML requires balancing the theoretical reflection error R(θ) and the numerical discretization error. For example, equation 9.128 provides σx, max for a polynomial-graded conductivity given a predetermined R(0) and m. If σx, max is too small, the primary reflection from the PML is due to its PEC backing, and equation 9.125 provides a fairly accurate approximation of the reflection error. However, if σx, max is too large, the discretization error due to the FDTD approximation dominates, and the actual reflection error is potentially much higher than what equation 9.125 predicts. Consequently, there is an optimal choice for σx, max that balances reflection from the PEC outer boundary and discretization error.
Through extensive numerical experimentation, Gedney (1996) and He (1997) found that, for a broad range of applications, an optimal choice for a 10-cell-thick, polynomial-graded PML is R(0) ≈ e−16. For a 5-cell-thick PML, R(0) ≈ e−8 is optimal. From equation 9.128, this leads to an optimal σx, max for polynomial grading:
(9.129)σx, opt≈−(m+1)⋅(−16)(2η)⋅(10Δ).=0.8(m+1)ηΔ.
This expression has proven to be adequate for many applications. Its value, however, may be too large when the PML terminates highly elongated resonant structures or sources with a very long time duration. For detailed discussions and examples of PML performance over a wide range of possible loss profiles, see Gedney (1998) and Gedney and Taflove (2000).
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780121709600500463
11th International Symposium on Process Systems Engineering
Sen Huang, … Lorenz T. Biegler, in Computer Aided Chemical Engineering, 2012
Element Mesh Generation:
For the given initial mesh h¯ , initialize the placement of mesh points hopt←h¯, discretization error εrd←+∞; give the amplitude of mesh point disturbance d, tolerence on discretization error εc.
-
Upper-level: Generate an element mesh for dynamic optimization:
-
Disturb placement of mesh points by uniform distribution hiopt ← U[hiopt — d, hiopt + d].
-
Adjust the mesh to match the given time horizon hiopt←tf⋅hiopt/∑i=1Nmaxhiopt
-
Lower-level: Solve problem (2) using mesh hopt .
-
Check error estimate (3) at the solution:
-
If e ≤ εc, save mesh hopt, and the algorithm can stop while enough meshes, say 50 meshes, are obtained; otherwise, if e < εrd, update εrd← e.
-
Go to step 1.
Note that different from the MFE strategy, which solves problem (2) together with the following error estimate:
(4){z˙ti,nonc-hifzti,nonc,yti,nonc,uti,nonc,p≤εc∑i=1NEhi=tf,hi≥0
the simplified MFE does not involve solving such a more constrained and difficult NLP. Instead, the simplified MFE exploits a derivative-free method to look for meshes for accurate discretization.
Let M denote the set of the obtained meshes. The online phase takes advantage of M to generate at low cost the discretization mesh for the current power change demand p. A straightforward way is to use regression methods. A profile can then be obtained, which represents the configuration of the newly generated element mesh. Let config denote the configuration, the placement of the mesh points can be calculated by config(index), where index = 1..NE is the index of mesh points and config(NE) = tf.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780444595065500912
Parallel Efficiency of the Lattice Boltzmann Method for Compressible Flows
Andrew. T. Hsu, … Akin Ecer, in Parallel Computational Fluid Dynamics 2000, 2001
3 NUMERICAL SIMULATION
If we regard the viscous terms and the diffusion terms of the right hand sides of Eqs. (4) and (5) as the discretization error the equations (3-5) become an inviscid Euler system. In fact, the viscosity and diffusivity are of order [τ − (1/2)] l2/∆t, where l is the length of the lattice and ∆t is the unit time. In two previous papers [5,6] we simulated Sod shock-tube problem and two-dimensional shock reflection. The numerical results agree well with exact solutions. In the following, we simulate two more complex flows with strong shocks under the condition τ = l and γ = 1.4.
A double Mach reflection of a strong shock (an normal shock passing a wedge) [14] is calculated on a 360 × 140 hexagonal lattice. Figure 1 shows the density contours at t = 200th iteration. Complex features, such as oblique shocks, contact discontinuity and triple points are well captured and are in good agreement with results obtained by a upwind method [14] and a gas kinetic method [13].

Figure 1. Density distribution for Mach 10 reflection shock on lattice 360 × 140 at 200th iteration.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780444506733501147
Numerical Field Calculation for Charged Particle Optics
Erwin Kasper, in Advances in Imaging and Electron Physics, 2001
4.5.4 Evaluation of Series Expansions
If the configuration round a mesh point is irregular as in Fig. 4.12, the analytic derivation of mesh formulas of higher than the second order becomes very tedious. Only very few attempts have been made to overcome this obstacle therefore [8], and usually a discretization error of third order, resulting from irregular boundaries is tolerated as an unsurmountable limit.
A possibility for further development is the series expansion of the potential in terms of suitable trial functions with initially unknown coefficients. These trial functions Tn(r), (n = 1, …, N) should satisfy exactly (or at least very accurately) the PDE to be solved. The expansion coefficients are then found from the condition that the given potentials are assumed at the surrounding points (1, …, N). The potential at the central point is subsequently obtained by evaluation of the now known expansion at this position. Because this concept is rather general, we shall present it here in a form that could also be used in three dimension though this would become laborious.
Let D be a homogeneously linear partial differential operator of second order and DΦ(r) = 0 the PDE to be solved. Then a suitable set of trial functions must be chosen, which are linearly independent and satisfy DTn(r) = 0. The series expansion in question is now
(4.213)Φr=∑n=1NcnTnr.
The condition that the prescribed values ϕj := Φ(rj) (j = 1, …, N) are assumed by this expression requires the solution of a linear system of equations
(4.214)∑n=1NAjncn:=∑n=1NTnrjcn=ϕjj=1,…,N.
We must assume here that the matrix A is nonsingular. Then we can write
(4.215)cn=∑k=1NAnk−1ϕkn=1,…,N,
and introduce this into Eq. (4.213), whereupon our problem is solved. For the central mesh point r0, the condition
(4.216)ϕ0=Φr0=∑k=1N∑n=1NTnr0Ank−1ϕk
is obtained. This is none other than the required mesh formula
(4.217a)ϕ0=∑k=1Nμkϕk
with the coefficients
(4.217b)μk=∑n=1NTnr0Ank−1k=1,…,N.
Apart from this systematic derivation of mesh formulas, this method also offers a way of calculating derivatives
(4.218)∇Φr=∑n=1Ncn∇Tnr
and even derivatives of higher orders, if necessary. These could be used for purposes of field calculation and interpolation. Another essential task is the derivation of mesh formulas for positions at material boundaries, as dealt with in the preceding section.
The situation is shown in Fig. 4.17: we have a surface with normal n and different material coefficients ε1 and ε2 on either side. The numbers N1 and N2of surrounding points may be different and surface points can be used twice. The set of trial functions here will be different, as a constant for the lowest order is unacceptable here. Instead of Eq. (4.213), there are now two series expansions

Figure 4.17. Arbitrary configuration of nodes and corresponding space vectors in the vicinity of a material boundary. Here the numbers N1 = 4 and N2 = 5 were chosen. The vector n is the surface normal at point 0.
(4.219)Φr=ϕ0+∑n=1NkcnkTnrk=1,2
to be used in the two separate domains. We have to calculate two inverse matrices and express the coefficients in terms of potential differences:
(4.220)cnk=∑j=1NkAk−1njϕj−ϕ0k=1,2.
It is now straightforward to write down the continuity condition for the position r0
(4.221)ε1n⋅∇Φ1=ε2n⋅∇Φ2,
leading to
(4.222)ε1∑i=1N1ci1n⋅∇Tir0=ε2∑i=1N2ci2n⋅∇Tir0.
On introducing the coefficients (4.220) into this equation, we obtain a linear relation of the general form
(4.223a)ε1∑j=1N1Fj1ϕj′−ϕ0=ε2∑j=1N2Fj2ϕj−ϕ0
with coefficients
(4.223b)Fjk=∑i=1NkAk−1ijn⋅∇Tir0k=1,2.
It remains to find the discretization of an inhomogeneous linear PDE
(4.224)DΨr=Sr,
S(r) being a given source function. This problem can be reduced to the task of finding any convenient particular solution Ψp(r) of this PDE. When this is found, we can use the above outlined relations because Φ(r) = Ψ(r) − Ψp(r) solves DΦ = 0. This implies that for instance
(4.225)Ψr0=Ψpr0+∑k=1NμkΨrk−Ψprk
follows from Eq. (4.217a), and also Eq. (4.223a) must be modified accordingly. From a purely theoretical standpoint, therefore, all the problems have been solved in principle, but in practice there are numerous obstacles to be overcome.
There are two essential difficulties: the first is that the rank N of the matrix is rather high, and the number of neighbor points is correspondingly large if a certain polynomial order M of the approximation is to be reached: in two dimensions we have N = 2 M + 1, whereas in three dimensions this number is N = (M + l)2. For a large number N, it might become difficult to find suitable neighbor points. The other, more serious problem arises from ill-conditioned or even singular matrices, which may result from an unsuitable choice of configurations. Here we shall outline briefly a method, which has been tested by the author and which gave good results. This method will also exhibit some interesting physical relations.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/S1076567001800689
29th European Symposium on Computer Aided Process Engineering
Hojae Lee, Christos T. Maravelias, in Computer Aided Chemical Engineering, 2019
3 Determining the key model parameter, δ
As mentioned earlier, DCA requires the user to select the discretization step length, δ, in the first stage model. If chosen carefully, the speed and accuracy of DCA can be improved significantly. However, selecting δ’s that bring such results is non trivial.
In order to find the best performing δ, we introduce an error evaluation function denoted as ε(δ). For a given instance, ε(δ) measures the amount of discretization error introduced by the chosen δ, considering how much the shortage of each unit is constraining the objective value.
(10)εδ=1δ∑i∑j∈Jiωijτij−δτ¯ij,ωij=Nij∑iNijDj∑jDj
(11)Dj=∑nλjn∗∀j
(12)Nij=∑nXijn∗∀i,j∈Ji
where, Xijn⁎ is the solution of the LP relaxed model of the first stage, and λjn⁎ is the dual variable associated with the allocation constraints (Eq. 9 in Shah et al. (1993)) in the LP relaxed model.
As shown in Figure 1, ε(δ) is an accurate metric to quantify the amount of discretization error introduced. Specifically, DCA obtains high quality first and third stage solutions, whenever δ’s that lead to low values of ε(δ) are used. Although only shown for two instances, we observed similar results for all other instances tested.

Figure 1. Using the error evaluation function, ε(δ), as a metric to determine δ’s, illustrated for (a) instance 1, and (b) instance 2
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B978012818634350196X
Structured Finite Volume Schemes
J. Blazek, in Computational Fluid Dynamics: Principles and Applications (Second Edition), 2005
4.2.4 Cell-Centred versus Cell-Vertex Schemes
In the preceding three subsections, both the cell-centred and the cell-vertex discretisation methodologies were outlined. The following paragraphs compare the three schemes and give an overview of the, at times controversial, debate about their relative merits.
First, let us consider the accuracy of the discretisations. It follows from the discussion in [4], [21] that the cell-vertex scheme (either with overlapping or dual control volumes) can be made first-order accurate on distorted grids. On Cartesian or on smooth grids (i.e., where the volumes between adjacent cells vary only moderately and which are only slightly skewed), the cell-vertex scheme is second- or higher-order accurate [22], depending on the flux evaluation scheme. In the opposite, the discretisation error of a cell-centred scheme depends strongly on the smoothness of the grid. For example, for an arrangement of the cells sketched in Fig. 4.7, an averaging does not provide the correct value at the midpoint of a face even for a linearly varying function. The consequence is that on a grid with slope discontinuity the discretisation error will not be reduced even when the grid is infinitely refined. As demonstrated in [4], such zero-order errors manifest themselves as oscillations or kinks in isolines, whereas a cell-vertex scheme experiences no problems in the same situation. Nevertheless, on Cartesian or on sufficiently smooth grids, the cell-centred scheme can also reach second- or higher-order accuracy. A further analysis of the discretisation errors were presented in [23]–[26].

Figure 4.7. Cell-centred flux balance on a skewed grid; cross denotes the midpoint of the cell face.
Second, let us compare the three methods and their characteristics at boundaries. It is mainly at the solid wall boundary where the cell-vertex scheme with dual control volumes faces difficulties. Recalling Fig. 4.6 again, it is apparent that only about one half of the control volume is left at the boundary. The integration of fluxes around the faces results in a residual located inside — ideally in the centroid — of the control volume. But, the residual is associated with the node residing directly at the wall. This mismatch leads to increased discretisation error in comparison to the cell-centred scheme. The definition of the dual control volume causes also problems at sharp corners (like trailing edges), which show up as unphysical peaks in pressure or density. Further complications arise, e.g., at coordinate cuts or at periodic boundaries (see Chapter 8), where the fluxes from both parts of the control volume have to be summed up correctly. All cell-vertex schemes also require additional logic, in order to assure a consistent solution at boundary points shared by multiple grid blocks. No such problems appear for cell-centred schemes.
The cell-vertex scheme with overlapping control volumes has an advantage over the dual volume scheme in the treatment of wall boundaries, but it cannot be combined with the popular upwind discretisation methods like TVD, AUSM, or CUSP. The discretisation involves more points than those of the cell-centred and the dual control-volume schemes (27 instead of 7 in 3D), which leads to smearing of discontinuities and memory overhead in the case of an implicit time discretisation.
The last main difference between the cell-centred and the cell-vertex schemes appears for unsteady flow problems. As mentioned earlier in Section 3.2, the cell-vertex schemes require at least an approximate treatment of the mass matrix [27], [28]. On the contrary, the mass matrix can be completely discarded in the case of a cell-centred scheme, because the residual is naturally associated with the centroid of the control volume.
In summary, the cell-vertex scheme with dual control volumes and the cell-centred scheme are numerically very similar in the interior of a stationary flow field. The main differences occur on distorted grids, in the boundary treatment and for unsteady flows. In the last two cases, the cell-centred approach shows advantages over the cell-vertex schemes, which result in a more straightforward implementation in a flow solver.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780080445069500060
Handbook of Numerical Methods for Hyperbolic Problems
A. Chertock, in Handbook of Numerical Analysis, 2017
2.3.1 Accuracy
The two terms in the error estimate (23) may be balanced by choosing an appropriate size of ɛ. Intuitively, it is clear that if the smoothing parameter ɛ is too small in comparison to the minimal distance between particles, the approximate solution defined by (19) will vanish away from the ɛ-neighbourhood of the particles and is thus irrelevant. On the other hand, large values of ɛ will generate unacceptable smoothing errors. Theoretically ɛ is chosen so that the smoothing error and the discretization error are of the same order and it is common to take ɛ∼h (see, e.g., Chertock and Kurganov, 2006, 2009; Hald, 1987; Raviart, 1985). It should be noted, however, that it is not clear what the optimal proportionality constant is. That strongly depends on both the smoothness of the flow and the cut-off function and its value at the origin. It has been also observed in various numerical experiments that the overall accuracy of the particle method can deteriorate over long-time integrations, see, e.g., the discussion in Beale and Majda (1985), Hald (1987), Hald and del Prete (1978), Nordmark (1991), Koumoutsakos (2005), Perlman (1985) and in references therein.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/S1570865916300448
|
|

Макеты страниц
Высокая степень развития рационального интеллекта у человека привела к значительной и печальной потере возможностей его интуиции, которая так необходима сегодня для дальнейшего развития. (Жак Моно, Случайность и необходимость)
Тот, кто не допускает ошибок, не способен познать истину.
Рабиндранат Тагор
В гл. 9 предполагалось, что необходимые для вычислений математические операции реализуются идеально. Когда мы записывали выражение

то молчаливо предполагали, что операции умножения  (идеального аналогового умножения) и интегрирования осуществляются без ошибок. Однако известно, что на практике все чаще и чаще аналоговые операции умножения и интегрирования заменяются численным умножением и интегрированием (после аналого-цифрового преобразования). При огромном количестве исходных данных (когда величина ВТ равна
(идеального аналогового умножения) и интегрирования осуществляются без ошибок. Однако известно, что на практике все чаще и чаще аналоговые операции умножения и интегрирования заменяются численным умножением и интегрированием (после аналого-цифрового преобразования). При огромном количестве исходных данных (когда величина ВТ равна  и более) для вычисления корреляции необходимо найти способ уменьшения числа символов для записи каждого слова, т. е. осуществлять кодирование с минимальным общим числом символов. Следовательно, очень важно изучить влияние дискретизации.
и более) для вычисления корреляции необходимо найти способ уменьшения числа символов для записи каждого слова, т. е. осуществлять кодирование с минимальным общим числом символов. Следовательно, очень важно изучить влияние дискретизации.
10.1. Статистическое изучение влияния дискретизаций
Постановка проблемы.
Прежде всего мы изучим влияние дискретизации на корреляционную функцию, а затем покажем, что некоторые полученные результаты применимы и в более
общем случае. Общая структура дискретного коррелометра может быть представлена в виде блок-схемы, приведенной на рис. 10.1. Это устройство осуществляет оценку  истинной автокорреляционной функции
истинной автокорреляционной функции 

Рис. 10.1.
Оценка отлична в общем случае от истинного значения по двум причинам:
1. Поскольку сигнал x(t) по предположению стационарен и эргодичен, то

Однако при вычислении оценки интервал интегрирования Т не может быть бесконечным, и, следовательно, мы получаем  . Ошибка, порожденная такой заменой, была изучена в гл. 9.
. Ошибка, порожденная такой заменой, была изучена в гл. 9.
2. Очень трудно реализовать запаздывание для непрерывных сигналов и очень легко — для дискретизованных сигналов. Поэтому наиболее часто рассматриваются дискретные сигналы. В этой главе мы изучим ошибку, обусловленную дискретизацией сигналов.
Дискретизация случайной величины.
Определение. Пусть х — случайная величина. Дискретизацией величины х называется шаг дискретизации и  — натуральное число.
— натуральное число.
Плотность вероятности дискретизованной случайной величины. Пусть  — плотность вероятности величины х. Изучим влияние дискретизации на
— плотность вероятности величины х. Изучим влияние дискретизации на 
По определению величины х имеем

Но

где

Отсюда

Следовательно, плотность вероятности дискретизованной случайной величины х записывается в виде

Отсюда

Из последнего выражения следуют два эффекта (рис. 10.2) влияния дискретизации на  :
:
1) эффект фильтрации с помощью фильтра-интегратора на интервале  импульсный отклик которого равен
импульсный отклик которого равен 
2) эффект дискретизации с шагом  т. е. влияние дискретизации с помощью дискретизатора-интегратора.
т. е. влияние дискретизации с помощью дискретизатора-интегратора.
Характеристическая функция дискретизованной случайной величины.
Напомним, что характеристическая функция случайной величины х определяется равенством

Из этого равенства следует соотношение между фурье-образом  плотности вероятности и характеристической функции
плотности вероятности и характеристической функции 

Рис. 10.2.
 . Используя формулу (10.2), вычислим характеристическую функцию
. Используя формулу (10.2), вычислим характеристическую функцию  дискретизованной случайной величины. Запишем выражение (10.2) в виде
дискретизованной случайной величины. Запишем выражение (10.2) в виде

Используя теорему Парсеваля и фурье-образ гребневой функции Дирака, получим

Перейдем в равенстве (10.3) к фурье-образам:

Положив  , получаем искомое выражение
, получаем искомое выражение

Выражение (10.4) позволяет обнаружить по спектру плотности вероятности два эффекта влияния дискретизации, о которых говорилось выше в связи с дискретизацией плотности вероятности:
• эффект фильтрации (рис. 10.3), соответствующий умножению функции  на величину
на величину  ;
;
• эффект дискретизации, соответствующий суммированию спектра после фильтрации с периодичностью 

Очевидно, что дискретизация не изменяет существенно  в окрестности точки
в окрестности точки  кроме случая, когда
кроме случая, когда  для
для  т. е. когда повторяемый таким образом спектр не восстанавливается через промежуток, длина которого больше половины периода (рис. 10.4). Это замечание будет нами использовано в дальнейшем, когда мы распространим его на случай двух случайных величин.
т. е. когда повторяемый таким образом спектр не восстанавливается через промежуток, длина которого больше половины периода (рис. 10.4). Это замечание будет нами использовано в дальнейшем, когда мы распространим его на случай двух случайных величин.

Рис. 10.3.

Рис. 10.4.
Дискретизация двух случайных величин.
Обобщения. Для того чтобы получить сведения о влиянии дискретизации на момент второго порядка (с целью использования их для корреляционной функции), мы изучим статистические воздействия дискретизации на двумерную случайную величину  Необходимые выкладки аналогичны выкладкам предыдущего раздела. Поэтому мы даем лишь окончательные формулы и обращаем внимание на интересующие нас результаты.
Необходимые выкладки аналогичны выкладкам предыдущего раздела. Поэтому мы даем лишь окончательные формулы и обращаем внимание на интересующие нас результаты.
Совместная плотность вероятности и характеристическая функция двух дискретизованных случайных величин. Используя предыдущие обозначения для двух случайных величин  дискретизованных с шагами
дискретизованных с шагами  получаем формулы
получаем формулы

Влияние дискретизации на момент второго порядка и на корреляцию двух случайных величин. Воздействие фильтрации и дискретизации. Поскольку выражение (10.6) аналогично выражению (10.4), то справедливы все предыдущие заключения о
воздействии фильтрации и дискретизации на характеристическую функцию.
Достаточное условие равенства нулю ошибки дискретизации для момента второго порядка. Согласно известной формуле теории вероятности, имеем

Из выражений (10.6) и (10.7) следует, что выполнение условия

для любых  и любых
и любых  достаточно для выполнения равенства
достаточно для выполнения равенства 
Связь между корреляционными функциями двух дискретизованных и недискретизованных сигналов. Если равенства (10.8) не выполнены, то между  существует более сложная связь. Рассмотрим два случайных стационарных процесса
существует более сложная связь. Рассмотрим два случайных стационарных процесса  Для нахождения соотношения между истинной корреляционной функцией
Для нахождения соотношения между истинной корреляционной функцией

и корреляционной функцией дискретизованных сигналов  можно использовать полученные выше формулы (10.6) и
можно использовать полученные выше формулы (10.6) и  (для сокращения записи иногда
(для сокращения записи иногда  обозначают
обозначают  если такое обозначение не может вызвать неоднозначного толкования).
если такое обозначение не может вызвать неоднозначного толкования).
Бонне, используя формулы (10.6) и (10.7), провел соответствующие вычисления и получил равенства

где 

В большинстве случаев коэффициентом а можно пренебречь, и предыдущая формула для  принимает вид
принимает вид

с точностью до бесконечно малых величин более высокого порядка.
Этот важный результат можно интерпретировать следующим образом. В любом коррелометре с двумя входами дискретизация с шагом  эквивалентна последовательному умножению на
эквивалентна последовательному умножению на  и добавлению двух независимых шумов с дисперсией
и добавлению двух независимых шумов с дисперсией  и корреляционной функцией
и корреляционной функцией  на каждом входе.
на каждом входе.
Итак, схемы, представленные на рис. 10.1 и 10.5, эквивалентны.

Рис. 10.5.
Данный результат согласуется с результатом, полученным Блан-Лапьером: добавление к сигналу шума с точки зрения статистики эквивалентно некоторой дискретизации сигнала.
Из формулы (10.9) следует, что ошибка дискретизации входных сигналов зависит от отношения  Приведем в качестве примера результаты по дискретизации, полученные Бонне [6]:
Приведем в качестве примера результаты по дискретизации, полученные Бонне [6]:

Дискретизация с помощью конечного числа разбиений.
При всех предыдущих вычислениях предполагалось, что число дискретных значений бесконечно. В действительности такое предположение нереализуемо и максимальный уровень дискретизации ограничен сверху конечным числом А. Последнее означает, что каждый раз, когда величина сигнала превосходит А, ему приписывается значение, равное А. Эта процедура эквивалентна усечению плотности вероятности на интервале  . Совокупности вероятностей, содержащиеся на интервалах
. Совокупности вероятностей, содержащиеся на интервалах  , -«проектируются» в точки —А и А. Ошибка, порожденная процедурой усечения, будет мала, если «проектируемые» совокупности вероятностей «малы». Порядок величины, характеризующей «проектируемые» совокупности вероятно
, -«проектируются» в точки —А и А. Ошибка, порожденная процедурой усечения, будет мала, если «проектируемые» совокупности вероятностей «малы». Порядок величины, характеризующей «проектируемые» совокупности вероятно
стей, может быть оценен с помощью неравенства Чебышева  из которого следует, что ошибка, обусловленная заменой бесконечного числа дискретных значений конечным числом, зависит от отношения
из которого следует, что ошибка, обусловленная заменой бесконечного числа дискретных значений конечным числом, зависит от отношения  Согласно Бонне [6], этой ошибкой можно пренебречь, если
Согласно Бонне [6], этой ошибкой можно пренебречь, если 
Итак, мы показали, что ошибка, порожденная дискретизацией, уменьшается с уменьшением отношения  Кроме того, ошибка, порожденная конечностью числа дискретных значений, уменьшается с возрастанием отношения
Кроме того, ошибка, порожденная конечностью числа дискретных значений, уменьшается с возрастанием отношения  Следовательно, уменьшение полной ошибки всегда соответствует увеличению отношения
Следовательно, уменьшение полной ошибки всегда соответствует увеличению отношения  которое равно общему числу уровней дискретизации.
которое равно общему числу уровней дискретизации.
Частный случай.
Коррелометр с двумя уровнями дискретизации (коррелометр с совпадением полярности, коррелометр с подрезанием, коррелометр Фарана и Хилла). В этом частном случае предыдущие формулы принимают относительно простой вид [8]:

где  — нормированная корреляционная функция:
— нормированная корреляционная функция:

В тех случаях (они довольно многочисленны), когда достаточно вычислить нормированные корреляционные функции, переход от  осуществляется с помощью простого соотношения
осуществляется с помощью простого соотношения

1
Оглавление
- ПРЕДИСЛОВИЕ РЕДАКТОРА ПЕРЕВОДА
- ВВЕДЕНИЕ
- Глава 1. ФИЗИЧЕСКИЕ ПРЕДСТАВЛЕНИЯ О ШУМАХ КАК О СЛУЧАЙНЫХ ПРОЦЕССАХ
- Глава 2. ПРЕОБРАЗОВАНИЕ ФУРЬЕ
- 2.2. Преобразование Фурье непериодических функций
- 2.3. Преобразование Фурье физических функций
- 2.4. Физический смысл преобразования Фурье
- 2.5. Условия существования преобразования Фурье
- 2.6. Некоторые свойства преобразования Фурье
- 2.7. Несколько функций и их фурье-образы
- 2.8. Частный случай вещественных сигналов
- 2.9. Отрицательные частоты
- 2.10. Аналитический сигнал
- 2.11. Почему выбрано преобразование Фурье?
- 2.12 Физическая реализация фурье-образа. Преобразование Фурье в оптике
- 2.13. Свойства функции sin х/х
- 2.14. Лямбда-функция
- Глава 3. МОЩНОСТЬ И ЭНЕРГИЯ СИГНАЛОВ
- 3.2. Частотная мощность. Спектральная плотность мощности. Спектр мощности
- 3.3. Общее определение спектральной плотности
- 3.4. Теорема Парсеваля
- 3.5. Понятие скалярного произведения и нормы
- Глава 4. ПРЕОБРАЗОВАНИЕ ЛАПЛАСА
- 4.2. Связь между фурье-образом и изображением Лапласа
- Глава 5. СВЕРТКА
- 5.2. Уравнение свертки
- 5.3. Несколько замечаний относительно свертки
- 5.4. Физическая интерпретация свертки
- 5.5. Прямая и обратная задачи, связанные с операцией свертки
- 5.6. Свертка и преобразование Фурье. Теорема Планшереля
- Глава 6. ФИЛЬТРАЦИЯ
- 6.2. Временная фильтрация
- 6.3. Частотная фильтрация («линейная фильтрация» в смысле Блан-Лапьера)
- 6.4. Связь между фильтрацией и сверткой
- 6.5. Физически реализуемые линейные фильтры частоты
- 6.6. Идеальный фильтр
- 6.7. Реализуемые непрерывные аналоговые фильтры [3]
- 6.8. Фильтры с линейным сдвигом фаз
- 6.9. Узкополосные фильтры
- 6.10. Обобщение понятия фильтрации
- Глава 7. ДИСКРЕТИЗАЦИЯ
- 7.2. Теоремы дискретизации
- 7.3. Дискретизация сигналов конечной длительности
- 7.4. Дискретизация фурье-образов
- 7.5. Выбор частоты дискретизации на практике
- 7.6. Противомаскировочный фильтр
- 7.7. Физическая дискретизация. Комбинированная дискретизация
- 7.8. Субдискретизация. Обобщение теоремы Шеннона [9]
- 7.9. Заключение
- Глава 8. КОРРЕЛЯЦИЯ И НЕКОТОРЫЕ ДРУГИЕ ПОНЯТИЯ СТАТИСТИКИ
- 8.2. Величина, характеризующая «связь» между двумя физическими процессами. Случай, когда известна одна реализация физического процесса, наблюдаемая в течение большого интервала времени
- 8.3. Эргодичность
- 8.4. Коэффициент корреляции и теория информации
- 8.5. Практические замечания
- 8.6. Характеристические функции
- 8.7. Спектральная плотность случайного сигнала
- 8.8. Связь между временными представлениями сигналов и спектральными плотностями. Теорема Винера — Хинчина
- 8.9. Функция связи
- 8.10. Распределение Гаусса, или нормальное распределение
- 8.11. Спектральная плотность и центрирование сигналов
- Глава 9. ОЦЕНКА ОШИБОК ИЗМЕРЕНИЙ КОРРЕЛЯЦИОННЫХ ФУНКЦИЙ И СПЕКТРАЛЬНЫХ ПЛОТНОСТЕЙ
- 9.2. Оценка корреляционных функций
- 9.3. Оценка спектральных плотностей
- 9.4. Оценка одномерной плотности вероятности
- 9.5. Последовательное вычисление среднего значения и дисперсии
- 9.6. Физическая интерпретация дисперсии
- 9.7. Идеальный интегратор и низкочастотный фильтр
- 9.8. Дискретные сигналы
- Глава 10. ОШИБКИ ИЗМЕРЕНИЯ КОРРЕЛЯЦИОННЫХ ФУНКЦИЙ ПРИ ДИСКРЕТИЗАЦИИ СИГНАЛОВ
- 10.2. Коррелометры с вспомогательными шумами
- 10.3. Условия на вспомогательные шумы, при которых отсутствует смещение оценки корреляционной функции
- 10.4. Вычисление дисперсии. Состоятельность оценки
- 10.5. Практические приложения
- 10.6. Важное замечание
- 10.7. Замечание относительно генераторов вспомогательных шумов
- Глава 11. ОСНОВНЫЕ СВОЙСТВА КОРРЕЛЯЦИОННЫХ ФУНКЦИЙ И СПЕКТРАЛЬНЫХ ПЛОТНОСТЕЙ
- 11.2. Периодические функции
- 11.3. Переходные функции
- 11.4. Дистрибутивность операций вычисления корреляции и спектральной плотности
- 11.5. Связь между входным и выходным сигналами линейной однородной во времени системы при условии, что входной сигнал является случайным и стационарным 2-го порядка
- Глава 12. ОСНОВНЫЕ ПРИЛОЖЕНИЯ КОРРЕЛЯЦИОННЫХ ФУНКЦИЙ И СПЕКТРАЛЬНЫХ ПЛОТНОСТЕЙ
- 12.2. Обнаружение периодического сигнала с известным периодом на фоне шума
- 12.3. Выделение сигнала на фоне шума. Усреднение
- 12.4. Обнаружение скрытых периодичностей
- 12.5. Получение спектральных плотностей по корреляционным функциям
- 12.6. Измерение динамических характеристик (переходных функций, импульсных характеристик) линейных систем. Идентификация процессов
- 12.7. Измерение когерентности
- 12.8. Применение когерентности к измерению передаточных функций линейных и однородных во времени систем. Спектральная лупа
- 12.9. Измерение временного сдвига двух сигналов
- Глава 13. СПЕКТРАЛЬНЫЙ АНАЛИЗ. ИЗМЕРЕНИЕ СПЕКТРАЛЬНЫХ ПЛОТНОСТЕЙ
- 13.2. Влияние фильтрации, обусловленной дискретизацией спектральной плотности
- 13.3. Дискретизация спектральной плотности, реализуемая на практике
- 13.4. Систематическая ошибка при измерении спектральной плотности
- 13.5. Измерение спектральной плотности
- 13.6. Спектральный анализ методом фильтрации
- 13.7. Измерение спектральной плотности методом фильтрации
- 13.8. Дискретное преобразование Фурье и измерение спектральных плотностей [2, 6, 7]
- 13.9. Вычисление автокорреляционных функций и взаимных корреляционных функций по спектральной плотности
- 13.10. Явление Гиббса
- 13.11. Корреляционный метод спектрального анализа
- 13.12. Корреляционный анализатор спектра
- 13.13. Точность определения спектральной плотности, полученной преобразованием Фурье корреляционной функции [1]
- 13.14. Замечания по поводу применения спектральных анализаторов. Определение оптимальной частоты дискретизации
- Глава 14. ВЕСОВЫЕ ОКНА
- 14.2. Окна, связанные с преобразованием Фурье
- 14.3. Окна, используемые в методе коррелограмм
- 14.4. Окна, применяемые в методе периодограмм
- 14.5. Окна, применяемые в методе фильтрации с возведением в квадрат и усреднением
- 14.6. Основные характеристики временных и спектральных окон
- 14.7. Первое семейство временных весовых окон
- 14.8. Второе семейство временных весовых окон (Метод периодограмм)
- 14.9. Исследование спектра в простом случае
- 14.10. Выбор весовой функции
Московский государственный университет приборостроении и информатики (МГУПИ) Реферат По дисциплине «Информатика» Тема: иск етиза ия и квантование сигналов по ешности иск етиза иииквантования. Выполнил: студент первого курса очной формы обучения, направление 230100 Васильев мит ий Олегович Ст. преп. Каф. ИТ-4 Москва 2011 Министерство Образования и Науки Российской Федерации Проверил: Кукин М.А. 1.Введение В первой половине ХХ века при регистрации и обработке информации использовались, в основном, измерительные приборы и устройства аналогового типа, работающие в реальном масштабе времени, при этом даже для величин, дискретных в силу своей природы, применялось преобразование дискретных сигналов в аналоговую форму. Положение изменилось с распространением микропроцессорной техники и ЭВМ.
Цифровая регистрация и обработка информации оказалась более совершенной и точной, более универсальной, многофункциональной и гибкой. Мощь и простота цифровой обработки сигналов настолько преобладают над аналоговой, что преобразование аналоговых по природе сигналов в цифровую форму стало производственным стандартом. ~2,с.31 2.Види информиции Информация может быть двух видов: дискретная (цифровая) и не- информация прерывная (аналоговая).
Дискретная ~1,с.71 характеризуется последовательными точными значениями некоторой величины, а непрерывная — непрерывным процессом изменения некоторой величины. Непрерывную информацию может, например, выдавать датчик атмосферного давления или датчик скорости автомашины. Дискретную информацию можно получить от любого цифрового индикатора: электронных часов, счетчика магнитофона и т. и.
Дискретная информация удобнее для обработки человеком, но непрерывная информация часто встречается в практической работе, поэтому необходимо уметь переводить непрерывную информацию в дискретную (дискретизация) и наоборот. Модем (это слово происходит от слов модуляция и демодуляция) представляет собой устройство для такого перевода: он переводит цифровые данные от компьютера в звук или электромагнитные колебания-копии звука и наоборот. 3. Способы представления информации Непрерывный (аналоговый) способ представления информации- представление информации, в котором сигнал на выходе датчика будет меняться вслед за изменениями соответствующей физической величины.
Примером непрерывного сообщения служит человеческая речь, передаваемая модулированной звуковой волной; параметром сигнала в этом случае является давление, создаваемое этой волной в точке нахождения приемника — человеческого уха. Аналоговый способ представления информации имеет недостатки: Точность представления информации определяется точностью измерительного прибора (например, точность числа отображающего напряжение в электрической цепи, зависит от точности вольтметра).
Наличие помех может сильно исказить представляемую информацию. Дискретность (от лат. Йзсгегцзразделенный, прерывистый) — прерывность; противопоставляется непрерывности. Дискретное изменение величины во времени — это изменение, происходящее через определенные промежутки времени (скачками); система целых (в противоположность системе действительных чисел) является дискретной. Дискретный сигнал- сигнал, параметр которого принимает последовательное во времени конечное число значений (при этом все они могут быть пронумерованы). Сообщение, передаваемое с помощью таких сигналов — дискретным сообщением.
Информация передаваемая источником, в этом случае также называется дискретной информацией. 4.Дискретизация Дискретизация — преобразование непрерывной функции в дискретную. Используется в гибридных вычислительных системах и цифровых устройствах при импульсно-кодовой модуляции сигналов в системах передачи данных. При дискретизации только по времени, непрерывный аналоговый сигнал заменяется последовательностью отсчетов, величина которых может быть равна значению сигнала в данный момент времени.
Возможность точного воспроизведения такого представления зависит от интервала времени между отсчетами ЛГ. Согласно теореме Котельникова: 1 Х1 <— где гп«и: — наибольшая частота спектра сигнала. 12,с.51 При переводе непрерывной информации в дискретную важна так называемая частота дискретизации ч, определяющая период (Т=1/ч) определения значения непрерывной величины .
11,с.71 Чем выше частота дискретизации, тем точнее происходит перевод непрерывной информации в дискретную. Но с ростом этой частоты растет и размер дискретных данных, получаемых при таком переводе, и, следовательно, сложность их обработки, передачи и хранения. Однако для повышения точности дискретизации необязательно безграничное увеличение ее частоты. Эту частоту разумно увеличивать только до предела, определяемого теоремой Котельникова. Примером использования этой теоремы являются лазерные компакт-диски, звуковая информация на которых хранится в цифровой форме.
11,с.81 Согласно теореме Котельникова частоту дискретизации нужно выбрать не меньшей 40 КГц (в промышленном стандарте на компакт-диске используется частота 44.1 КГц). При преобразовании дискретной информации в непрерывную, определяющей является скорость этого преобразования: чем она выше, с тем более высокочастотными гармониками получится непрерывная величина. Но чем большие частоты встречаются в этой величине, тем сложнее с ней работать.
Например, обычные телефонные линии предназначены для передачи звуков частотой до 3 КГц. 11,с.8~ Устройства для преобразования непрерывной информации в дискретную обобщающе называются АЦП (аналого-цифровой преобразователь) или АОС (Апа1о8 1о Ирта1 Сопчег~ог, АЛ)), а устройства для преобразования дискретной информации в аналоговую — ЦАП (цифро-аналоговый преобразователь) или ПАС (Иф1а1 1о Апа!о8 Сопчеггог, Р/А).
11,с.81 5. Э ТА ПБТ ДИСКРЕ ТИЗА ЦИИ Область определения функции разбивается точками х1, х2,, хп на отрезки равной длины и на каждом из этих отрезков значение функции принимается постоянным и равным, например, среднему значению на этом отрезке; полученная на этом этапе функция называется ступенчатой. Следующий шаг — проецирование значений «ступенек» на ось значений функции (ось ординат).
11олученная таким образом последовательность значений функции у1, у2,, уп является дискретным представлением непрерывной функции, точность которого можно неограниченно улучшать путем уменьшения длин отрезков разбиения области значений аргумента.[2,с.14~ У1 У» ~ а; ~~.1~,1 Х Рисунок 4 — Дискретизация Ось значений функции можно разбить на отрезки с заданным шагом и отобразить каждый из выделенных отрезков из области определения функции в соответствующий отрезок из множества значений.
В итоге получим конечное множество чисел, определяемых, например, по середине или одной из границ таких отрезков. Таким образом, любое сообщение может быть представлено как дискретное, иначе говоря, последовательностью знаков некоторого алфавита. Возможность дискретизации непрерывного сигнала с любой желаемой точностью (для возрастания точности достаточно уменьшить шаг) принципиально важна с точки зрения информатики. Компьютер — цифровая машина, т.е. внутреннее представление информации в нем дискретно.
Дискретизация входной информации (если она непрерывна) позволяет сделать ее пригодной для компьютерной обработки. Существуют и другие вычислительные машины аналоговые ЭВМ. Они используются обычно для решения задач специального характера и широкой публике практически не известны. Эти ЭВМ в принципе не нуждаются в дискретизации входной информации, так как ее внутренне представление у них непрерывно. В этом случае все наоборот — если внешняя информация дискретна, то ее перед использованием необходимо преобразовать в непрерывную.~2,с.151 б. Квантпвание ~2,с. б-8~ Квантование (англ.
с1папйкайоп) — в информатике разбиение диапазона значений непрерывной или дискретной величины на конечное число интервалов. Существует также векторное квантование — разбиение пространства возможных значений векторной величины на конечное число областей. Квантование часто используется при обработке сигналов, в том числе при сжатии звука и изображений. Простейшим видом квантования является деление целочисленного значения на натуральное число, называемое коэффициентом квантования. Рисунок 1 — Квантованный сигнал Не следует путать квантование с дискретизацией (и, соответственно, шаг квантования с частотой дискретизации).
При дискретизации изменяющаяся во времени величина (сигнал) замеряется с заданной частотой (частотой дискретизации), таким образом, дискретизация разбивает сигнал по временной составляющей (на графике — по горизонтали). Квантование же приводит сигнал к заданным значениям, то есть, разбивает по уровню сигнала (на графике — по вертикали). Сигнал, к которому применены дискретизация и квантование, называется цифровым.
Рисунок 3 — Цифровой сигнал При оцифровке сигнала уровень квантования называют также глубиной дискретизации или битностью. Глубина дискретизации измеряется в битах и обозначает количество бит, выражающих амплитуду сигнала. Чем больше глубина дискретизации, тем точнее цифровой сигнал соответствует аналоговому. В случае однородного квантования глубину дискретизации называют также динамическим диапазоном и измеряют в децибелах (1 бит = 6 дБ). 7.Погрешность квантования Начальный сигнал, приобретенный при амплитудной модуляции, состоит из импульсов, у каких амплитуда может лежать в границах некого ограниченного спектра значений. По данной причине для подготовки такового сигнала к шагу кодировки, когда каждый импульс в потоке преобразовывается в последовательность нулей и единиц, нужно применять ограниченную шкалу значений.
Нельзя 9 ждать, что каждый начальный импульс будет в точности совпадать с одним из значений в избранной шкале. Это значит, что некие импульсы должны быть скорректированы, и при всем этом для их не будет никакой сопровождающей информации, с помощью которой они могли бы в предстоящем быть восстановлены в начальное состояние. Такое несоответствие именуют ошибкой, либо погрешностью квантования.