На чтение 2 мин Опубликовано Обновлено
При работе с текстовыми файлами, особенно с теми, которые содержат символы нестандартных кодировок, таких как windows 1251, иногда может возникать ошибка «неразрешимый символ 0x98». Эта ошибка означает, что в тексте присутствует символ, который не может быть прочитан или обработан текущей кодировкой.
Чтобы исправить эту ошибку, необходимо произвести конвертацию файла в другую кодировку. Для этого можно воспользоваться различными инструментами и программами, которые позволяют перекодировать текстовые файлы. Например, одним из таких инструментов является утилита iconv, которая доступна для различных операционных систем. С помощью этой утилиты можно перекодировать файл из windows 1251 в другую кодировку, например, UTF-8.
Для того чтобы выполнить перекодировку с помощью утилиты iconv, необходимо открыть командную строку или терминал и ввести следующую команду:
iconv -f windows-1251 -t utf-8 input.txt > output.txt
Где input.txt — это имя исходного файла, который нужно перекодировать, а output.txt — имя файла, в который будет записан результат перекодировки. После выполнения этой команды, файл output.txt будет содержать текст из файла input.txt перекодированный в кодировку UTF-8.
Также существуют и другие инструменты и способы перекодировки текстовых файлов. Один из таких способов — использование текстового редактора, который поддерживает работу с различными кодировками. В этом случае, для перекодировки файла нужно открыть его в редакторе, выбрать нужную кодировку и сохранить файл в новой кодировке.
Просмотров: 7393
Дата последнего изменения: 02.09.2021
Внимание! Приведённые настройки выходят за рамки меню Виртуальной машины. Это означает, что информация — ознакомительная и применять её следует с чётким пониманием того что вы делаете и с собственной ответственностью за совершаемые действия. В нашей техподдержке рассматриваются только вопросы по работе пунктов меню ВМ.
При обновлении старых сайтов в кодировке Windows-1251, созданных в VMBitrix версии 7.4.3 или ниже, могут быть следующие ошибки:
-
Не работает Система обновлений продуктов «1С-Битрикс» – требует наличия параметра
mb_internal_encoding('Windows-1251');в dbconn.php. -
При включенных предупреждениях Система обновлений не работает из-за предупреждения: «PHP Warning: htmlspecialchars(): charset `latin’ not supported, assuming utf-8».
-
Проверка системы выдает ошибку «Строковые функции strtoupper и strtolower работают некорректно».
При обновлении VMBitrix до версии 7.5 и выше данные ошибки в установленных ранее сайтах в кодировке Windows-1251 автоматически не исправляются, поэтому вам нужно исправить их вручную для каждого такого сайта.
-
Добавьте в файл /bitrix/php_interface/dbconn.php сайта строку:
mb_internal_encoding('Windows-1251'); -
В конфигурационном файле Apache для вашего сайта /etc/httpd/bx/conf/bx_ext_[ваш_сайт].conf замените строку:
php_admin_value default_charset latin
на такую:
php_admin_value default_charset cp1251
И перезапустите Apache:
systemctl restart httpd.service
-
Проверьте, есть ли локаль ru_RU.cp1251 в системе. Если ответ 0 – значит локали ru_RU.cp1251 нет, если 1 – есть:
locale -a | grep ru_RU.cp1251 -ic
Если локали ru_RU.cp1251 нет, выполните команду:
localedef -c -i ru_RU -f CP1251 ru_RU.CP1251
-
Далее добавьте в файл /bitrix/php_interface/dbconn.php вашего сайта в кодировке windows-1251 две строки:
setlocale(LC_ALL, 'ru_RU.CP1251' ); setlocale(LC_NUMERIC, 'C' );
И перезапустите Apache:
systemctl restart httpd.service
-
Все готово. Проделайте эти действия для каждого сайта с кодировкой windows-1251, установленного ранее.
Примечание: В VMBitrix 7.5 и выше новые сайты, создаваемые в кодировке Windows-1251, проблем с однобайтовыми кодировками не имеет.
Содержание
- Способ 1: Изменение системного языка
- Способ 2: Изменение параметра использования бета-версии Юникода
- Способ 3: Редактирование реестра
- Способ 4: Замена системного файла
- Способ 5: Проверка целостности системных файлов
- Способ 6: Возвращение Windows к заводским настройкам
- Исправление кодировки в содержании и названиях файлов
- Вопросы и ответы

Способ 1: Изменение системного языка
Чаще всего проблемы с отображением русских букв в Windows 11 связаны с некорректно установленными языковыми параметрами. Подобные дефекты могут появиться как при переименовании файлов, так и в интерфейсах сторонних программ или даже в некоторых частях операционной системы. Соответственно, понадобится проверить вручную языковые настройки и установить нужные, обеспечив тем самым поддержку текстовой кодировки. Универсальную инструкцию по этой теме вы найдете в другой статье на нашем сайте, перейдя по следующей ссылке.
Подробнее: Смена языка интерфейса ОС Windows 11
Способ 2: Изменение параметра использования бета-версии Юникода
Юникод (UTF-8) — стандартное кодирование текста для поддержки многих языков. В Windows 11 предлагается использовать его вместо основных языковых кодировок для каждого отдельного региона. Пользователь может столкнуться с отображением «кракозябр» вместо русских букв как при использовании функции, так и когда она отключена. Поэтому понадобится изменить состояние настройки и переключить кодировку. Для этого достаточно следовать предложенной ниже инструкции.
- Откройте «Пуск» и перейдите в «Параметры», кликнув по значку с изображением шестеренки.
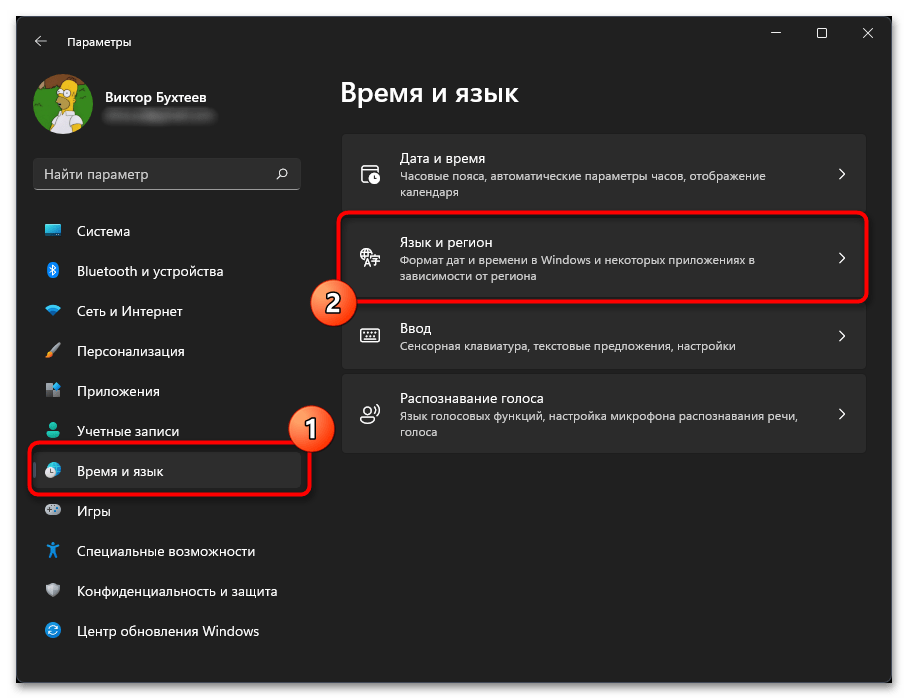
- В новом окне на панели слева выберите раздел «Время и язык», затем щелкните по категории «Язык и регион», чтобы перейти к ней.
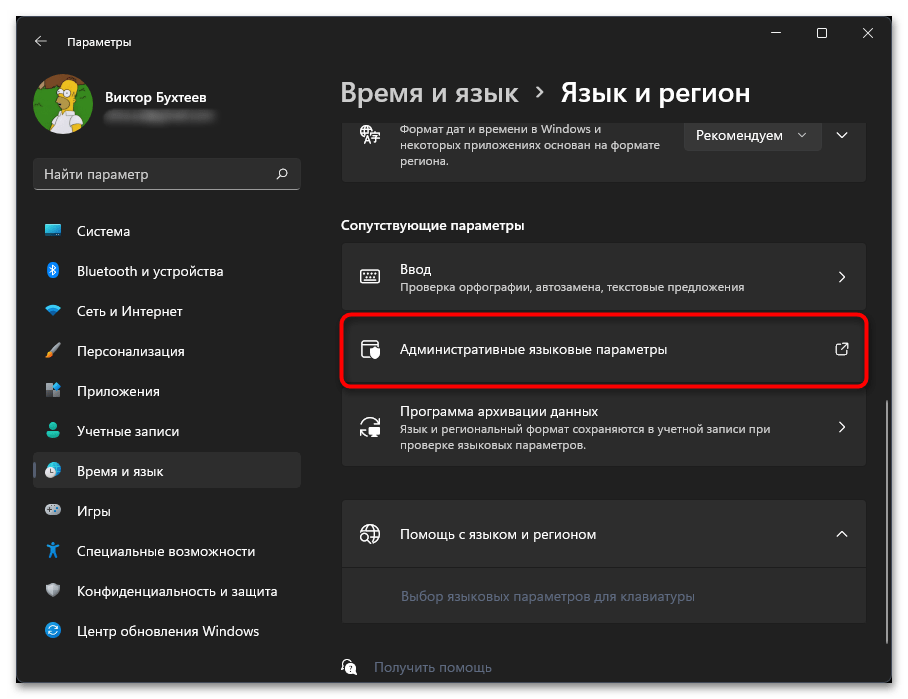
- Нажмите по ссылке «Административные языковые параметры».
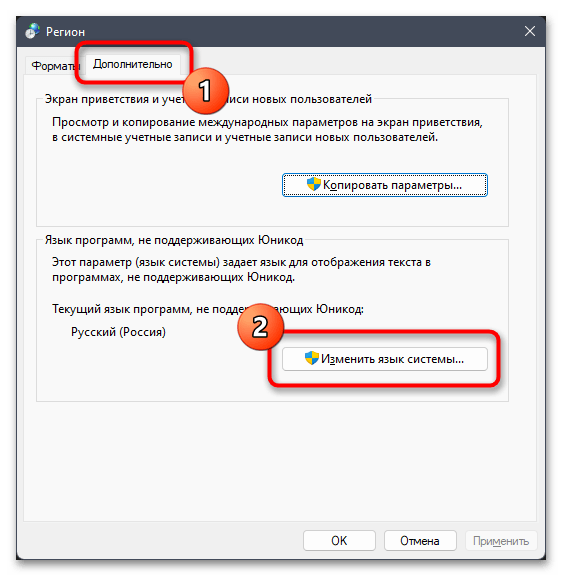
- Отобразится дополнительное окно с названием «Регион», в котором следует выбрать вкладку «Дополнительно» и кликнуть по кнопке «Изменить язык системы».
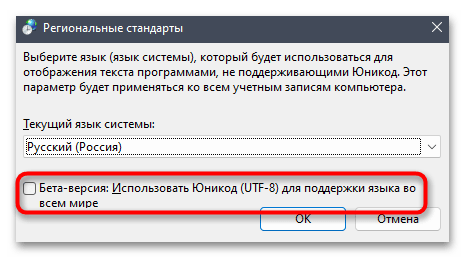
- Поставьте или снимите галочку около пункта «Бета-версия: Использовать Юникод (UTF-8) для поддержки языка во всем мире» в зависимости от того, активна ли она сейчас. Сохраните изменения и отправьте ПК на перезагрузку.
Способ 3: Редактирование реестра
Метод с редактированием реестра несет определенные риски, поскольку будут изменены системные параметры, отвечающие за корректность работы графического интерфейса. Поэтому рекомендуем перед вмешательством обязательно сделать резервную копию и разобраться с тем, как восстановить изначальное состояние реестра, если после применения новых настроек возникнут проблемы с работой ОС.
Подробнее: Восстановление системного реестра Windows 11
После всех подготовительных действий можно переходить непосредственно к настройке реестра. Этот процесс подразумевает проверку текущего языкового параметра с его редактированием или заменой, если это будет необходимо. Внимательно следуйте руководству, чтобы ни на каком из этапов не возникло трудностей.
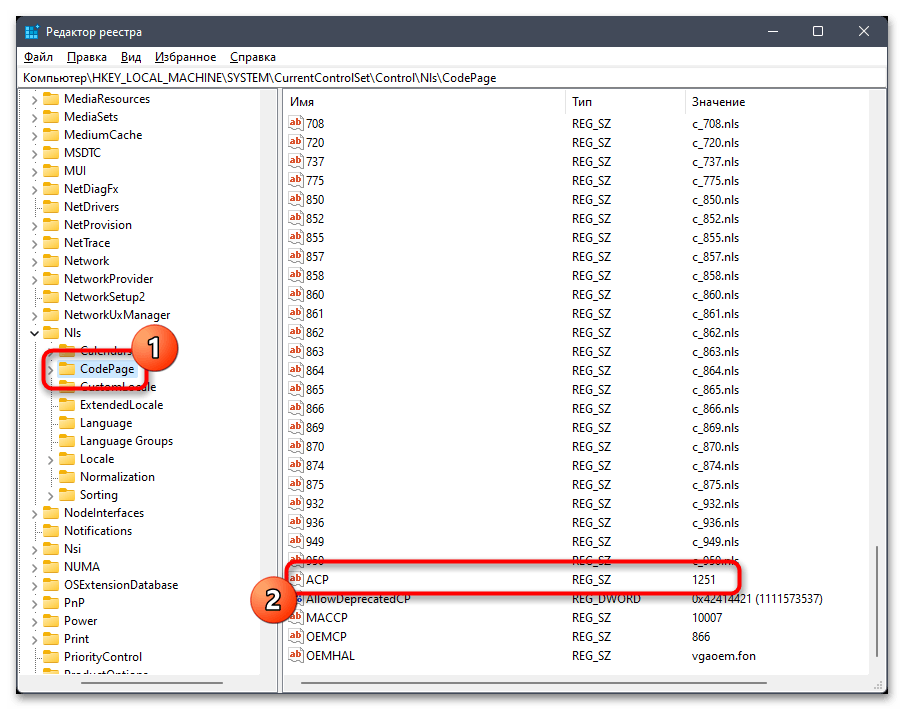
- Откройте «Пуск», через поиск отыщите «Редактор реестра» и запустите данное приложение.
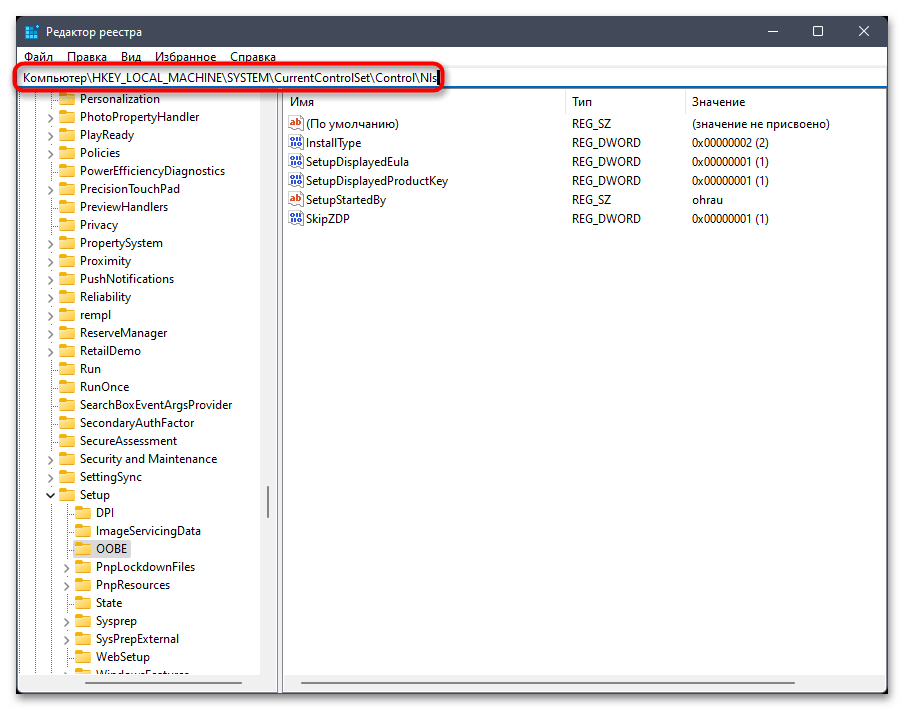
- В его адресную строку вставьте путь
Компьютер\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nlsи перейдите по нему. - На панели слева выберите каталог с названием «CodePage» и внизу списка с параметрами отыщите «ACP». Вам необходимо убедиться в том, что данная настройка имеет значение
1251. - Если это не так, щелкните по параметру дважды и внесите изменение. По завершении обязательно перезагрузите ПК и проверьте, удалось ли такой настройкой исправить «кракозябры».
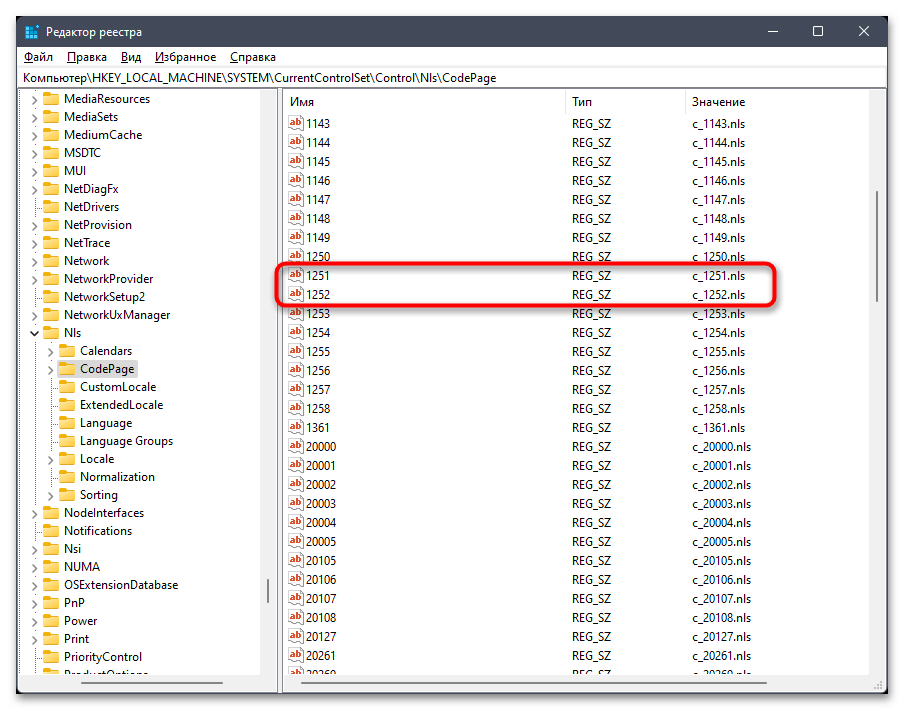
- В случае сохранения ошибки понадобится осуществить подмену файла. Для этого найдите в этой же папке параметры «1251» и «1252». Если каждый из них существует, то «1251» удалите.
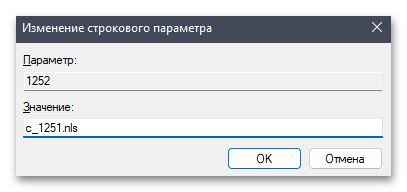
- Для «1252» поменяйте значение на
c_1251.nls, сохраните изменения и снова перезагрузите компьютер.

Если ошибка не исчезла, всегда рекомендуется вернуть настройки по умолчанию, восстановив реестр или самостоятельно воссоздав нужные параметры, изменение которых и производилось ранее.
Способ 4: Замена системного файла
Следующий метод тоже подразумевает изменение системных настроек. При помощи замены файлов можно добиться исправления кодировки, когда язык операционной системы по каким-то причинам распознается некорректно и появляются «кракозябры» вместо нормальных букв. Будьте готовы к тому, что такие изменения тоже могут негативно сказаться на работе ОС, поэтому во время выполнения инструкции соблюдайте все рекомендации по сохранению оригиналов файлов, чтобы в случае чего восстановить все так, как это было ранее.
- Откройте «Проводник» и перейдите по пути
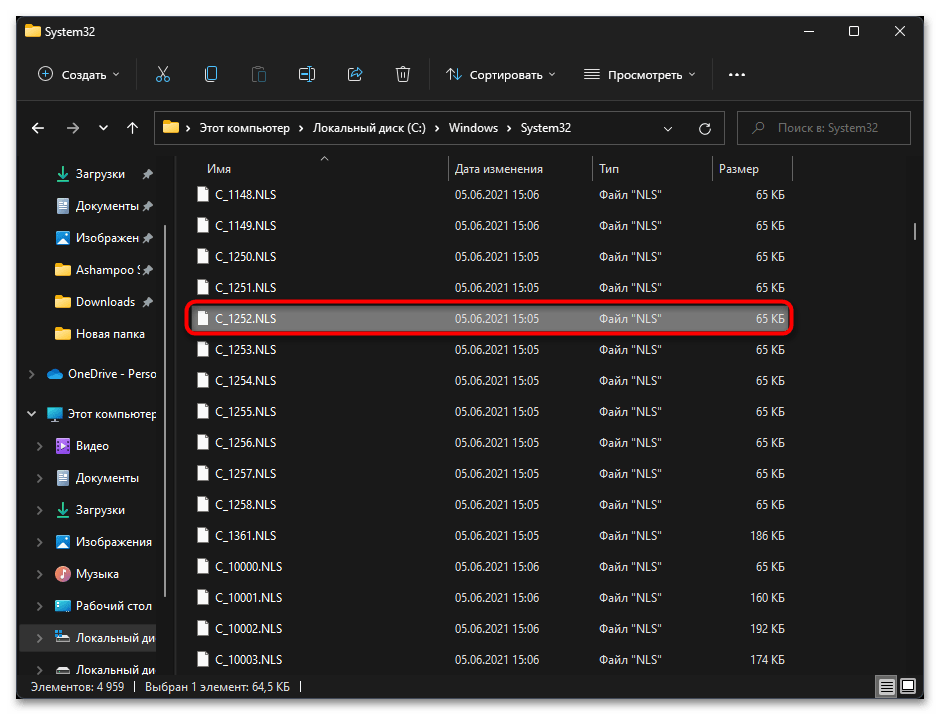
C:/Windows/System32. - В данном каталоге отыщите файл с названием «C_1252.NLS».
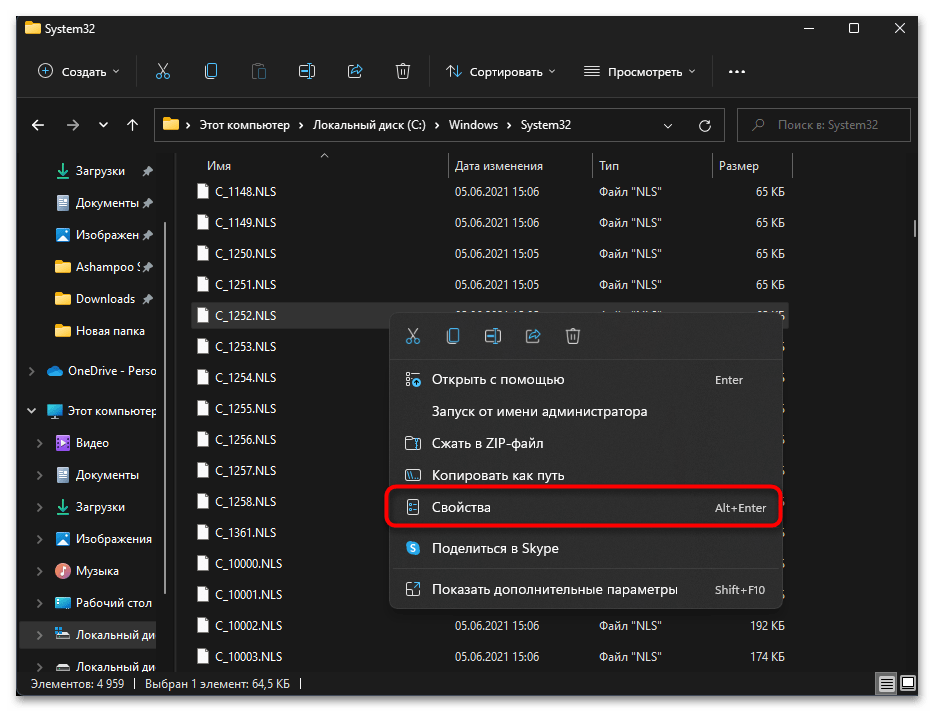
- Для него нужно изменить владельца, чтобы система разрешила переименование и выполнение других действий. Щелкните по файлу правой кнопкой мыши и из контекстного меню выберите пункт «Свойства».
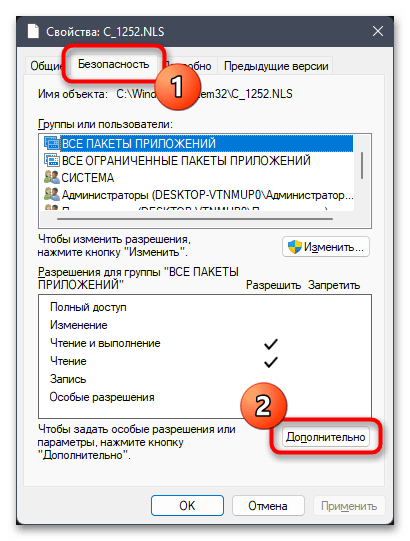
- Перейдите на вкладку «Безопасность» и нажмите по «Дополнительно».
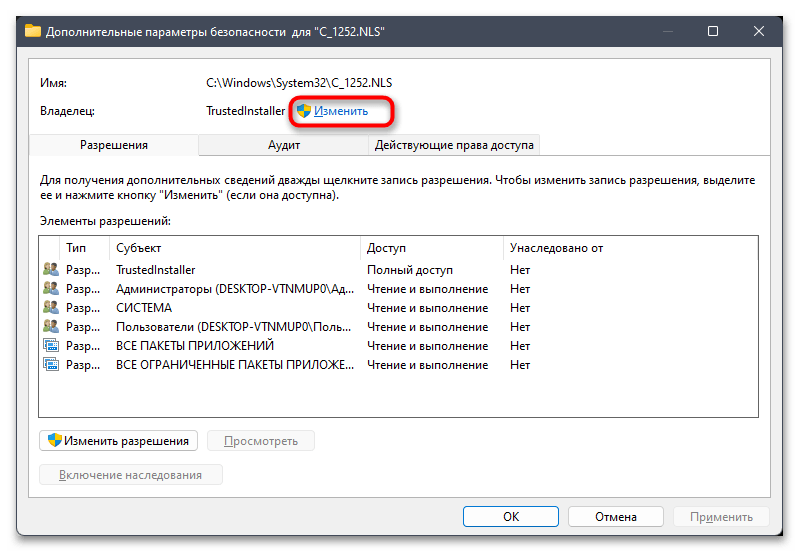
- В новом окне вы увидите текущего владельца файла, коим наверняка будете не вы. Для исправления этой ситуации кликните по «Изменить».
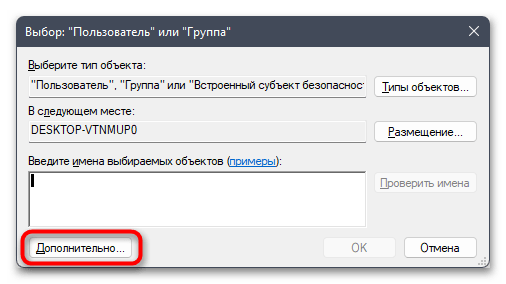
- Можете ввести имя объекта вручную, но в большинстве случаев у пользователя нет информации о том, как точно называется его учетная запись. Поэтому лучше пойти простым путем автоматического поиска, сначала нажав по «Дополнительно».
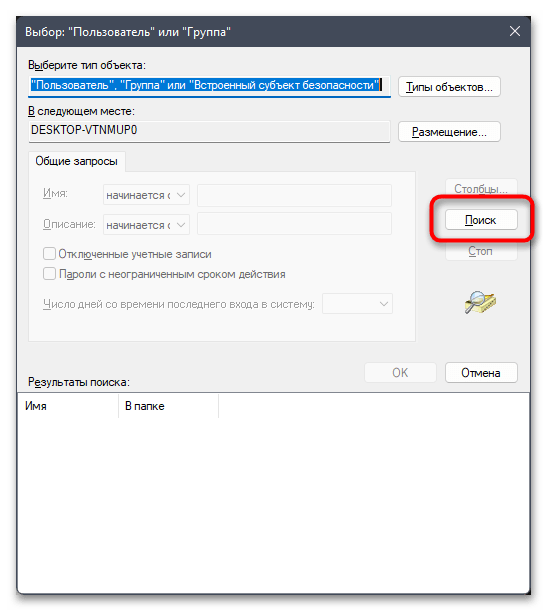
- В следующем окне нажмите кнопку «Поиск».
- Дождитесь загрузки учетных записей и выберите среди них свою. Подтвердите внесение изменений и закройте данное окно.
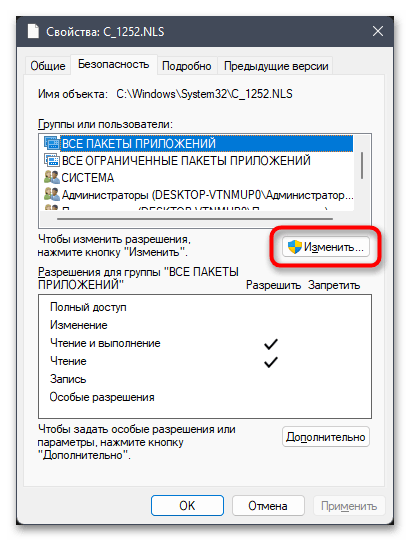
- Остается только добавить полные права доступа к файлу для нового владельца. В окне «Свойств» на вкладке «Безопасность» нажмите по «Изменить».
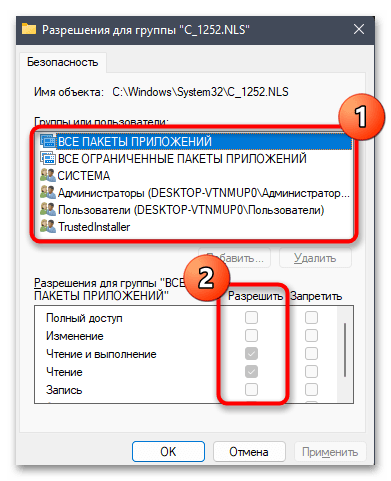
- В списке «Группы или пользователи» выберите свою учетную запись, предоставьте полные права и сохраните изменения.
- Теперь вам нужно переименовать файл «C_1252.NLS». Лучшим вариантом будет изменить его формат, допустим, на текстовый. Если что-то пойдет не так, его всегда можно вернуть к NLS.
- Далее в этой же папке отыщите файл «C_1251.NLS» и создайте его копию на рабочем столе.
- Для данного файла с названием «C_1251.NLS» установите новое, переименовав его на «C_1252.NLS». Если действие недоступно, измените владельца и для этого файла точно так же, как это было показано выше.
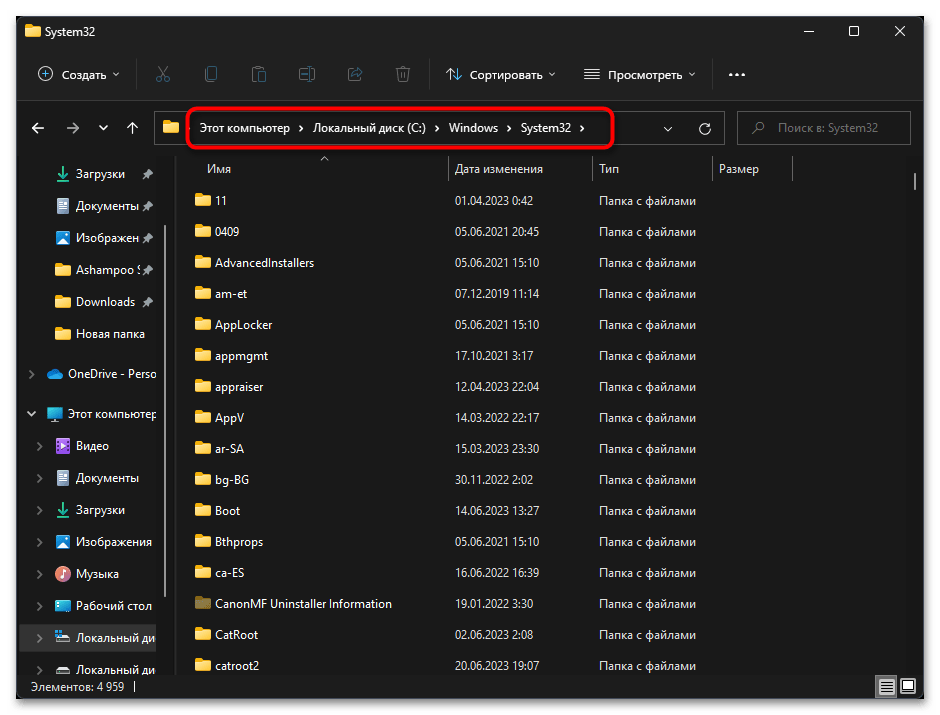

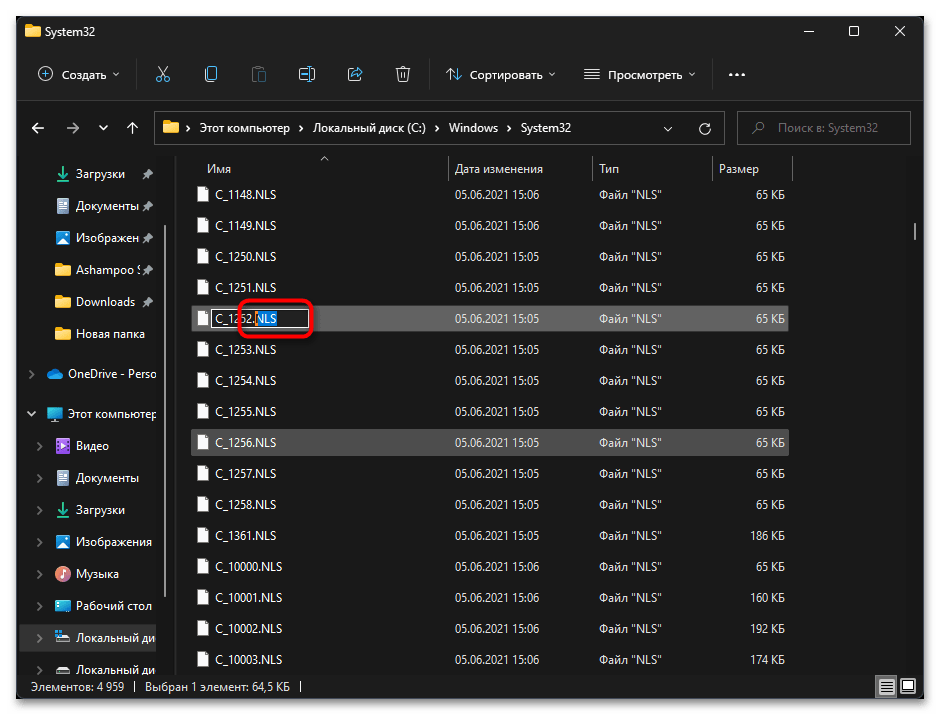
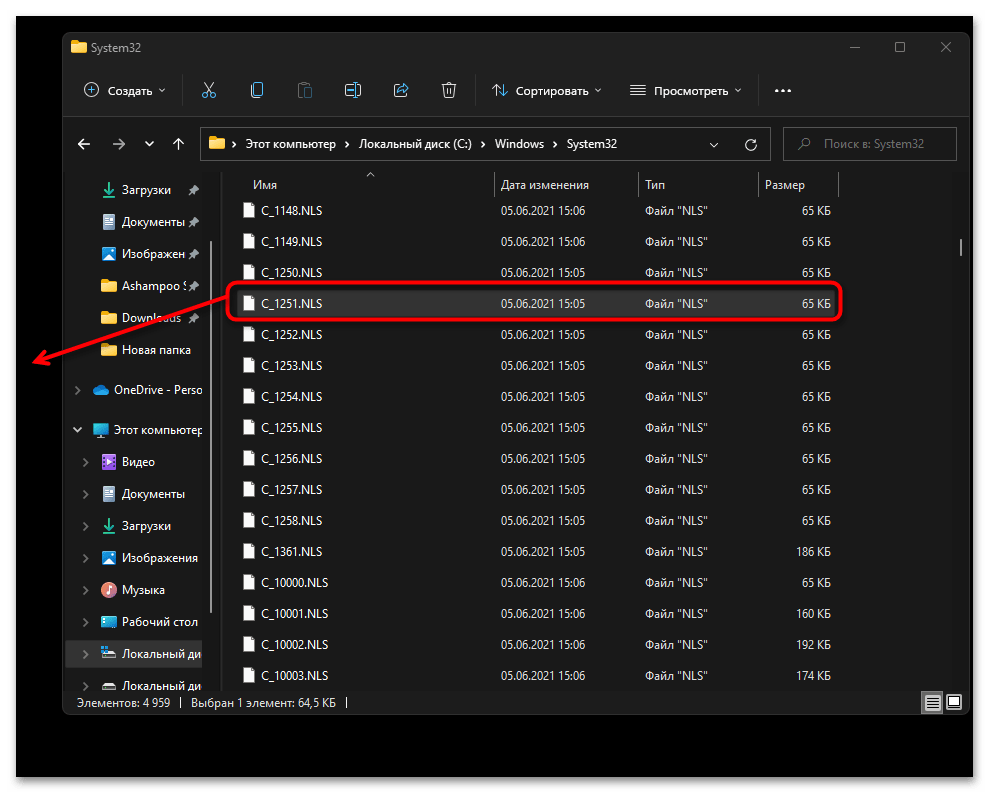
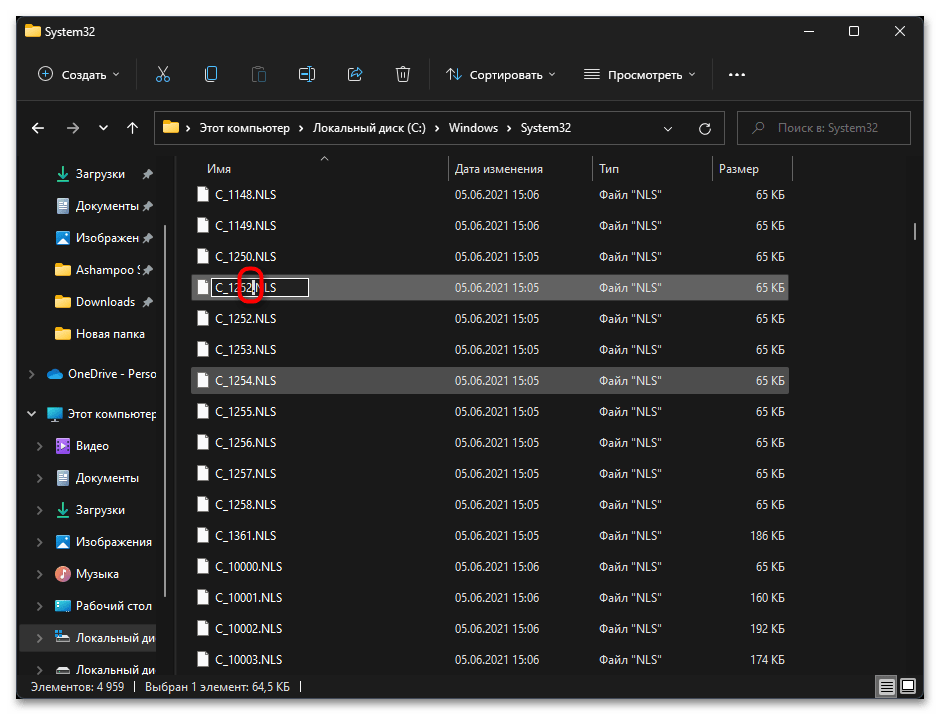
При помощи нехитрых манипуляций вы произвели замену файлов, отвечающих за локализацию в Windows 11. «C_1252.NLS» нужен для нормального отображения английского языка системы, который является основным. При помощи замены мы сделали так, чтобы основным теперь считался русский и кодировка была исправлена в тех местах, где наблюдаются проблемы с отображением букв. Если после перезагрузки компьютера выяснилось, что система функционирует хуже, появились ошибки и сама проблема не была исправлена, верните оригинальные файлы в ту же папку и снова перезагрузите ПК.
Способ 5: Проверка целостности системных файлов
Не стоит исключать тот факт, что появление «кракозябр» вместо нормального отображения букв иногда свидетельствует о том, что в системе нарушена целостность файлов, отвечающих за локализацию или работу с определенными текстовыми кодировками. Самостоятельно проверить вы это не сможете, поэтому доверьте операцию автоматизированным средствам, а именно специальным консольным утилитам. Информацию об их применении вы найдете в материале от другого нашего автора по ссылке ниже.
Подробнее: Использование и восстановление проверки целостности системных файлов в Windows
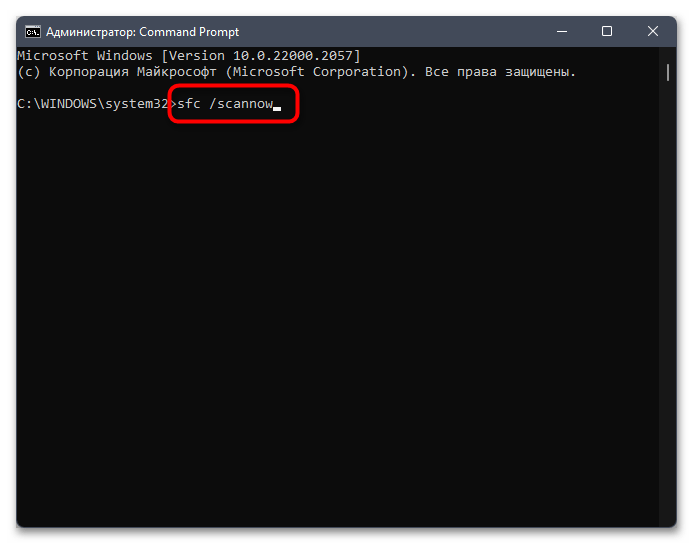
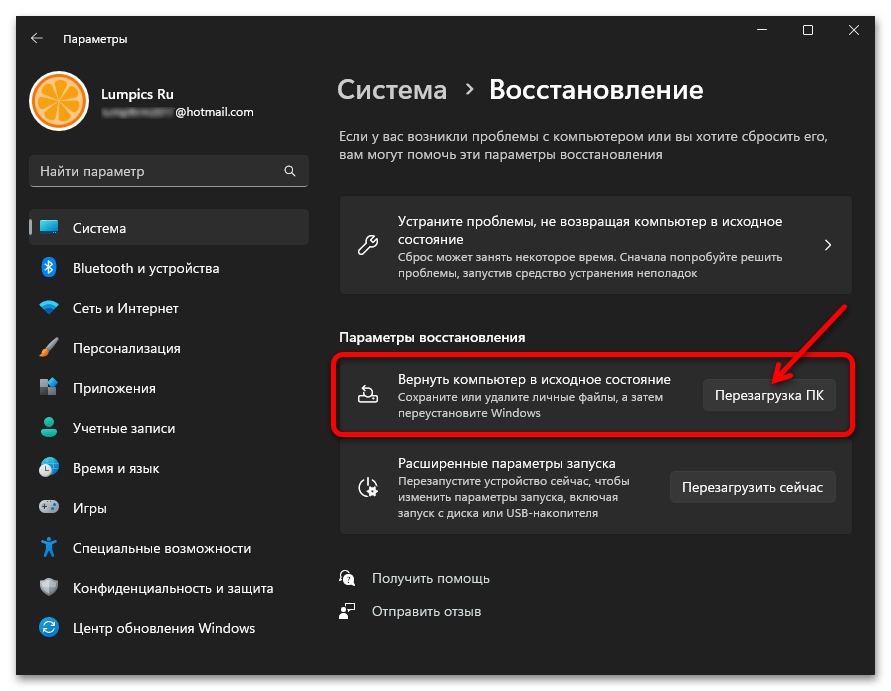
Единственный метод исправления ситуации, который еще не был рассмотрен в рамках данной статьи, подразумевает восстановление стандартного состояния Windows 11, что в большинстве случаев решает самые распространенные системные проблемы. Сделать это можно и полной переустановкой, но куда проще восстановить заводские настройки. Для этого подходит стандартное средство операционной системы, об использовании которого читайте в материале по следующей ссылке.
Подробнее: Сброс Windows 11 к заводским настройкам
Исправление кодировки в содержании и названиях файлов
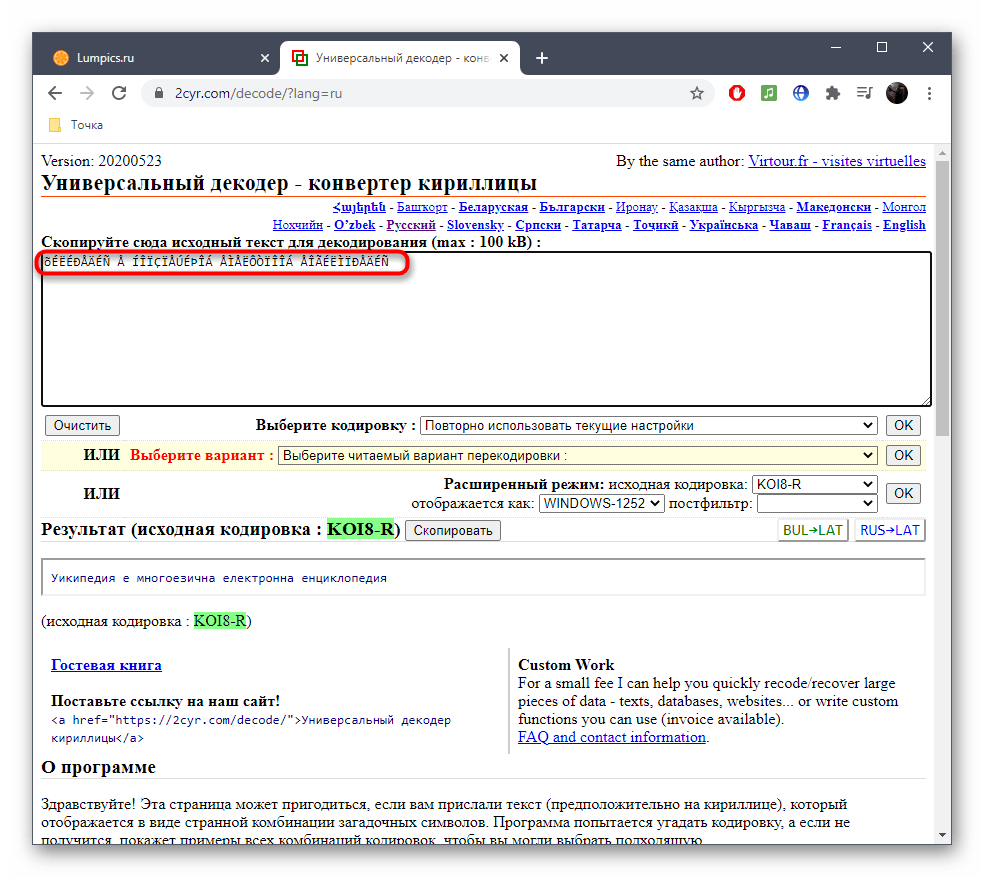
В некоторых случаях пользователь сталкивается с тем, что «кракозябры» отображаются только в названиях конкретных текстовых файлов или после их открытия через текстовые редакторы, когда речь идет о просмотре содержимого. В первую очередь можем порекомендовать сменить текстовый редактор, поскольку не все поддерживают разные кодировки, особенно если речь идет о стандартном «Блокноте». Если это не принесло должного результата, можно попробовать восстановить кодировку через разные онлайн-сервисы. Они поддерживают как загрузку файлов целиком, так и вставку содержимого из буфера обмена.
Подробнее: Исправление кодировки при помощи онлайн-сервисов
Содержание
- Информационные технологии, интернет, веб программирование, IT, Hi-Tech, …
- Кодировка XML
- Ошибки Кодировки XML
- Блокнот Windows
- Выводы
- Кодировки UTF-8 и Windows 1251 — просто о сложном
- Немного теории
- Недостатки и достоинства
- Базы банных
- Htaccess
- forum.clarionlife.net
- XML-файлы в кодовой таблице Windows-1251
- Как настроить кодировку сайта самостоятельно
- Зачем нужна кодировка
- Кодировка влияет на SEO?
- Виды кодировок
- Windows-1251
- Как определить кодировку на сайте
- Если кодировка не отображается
- Где указать кодировку сайта
- Кодировка в мета-теге
- Кодировка в файле httpd.conf
- Кодировка в .htaccess
- Кодировка документа
- Кодировка Базы данных
Информационные технологии, интернет, веб программирование, IT, Hi-Tech, …
Кодировка XML
Здравствуйте, уважаемые посетители сайта okITgo.ru! Продолжаем рассматривать язык разметки XML.
XML документы могут содержать символы, не входящие в ASCII, например норвежские, или французские.
Чтобы избежать ошибок, указывайте кодировку XML, или сохраняйте XML файлы в формате Уникод.
Ошибки Кодировки XML
При загрузке XML документа, Вы можете получить две различные ошибки, указывающие на проблемы с кодировкой:
Неправильный символ был найден в текстовом содержимом.
Вы получаете эту ошибку, если ваш XML содержит символы, не входящие в ASCII, и файл был сохранен как однобайтовый ANSI (или ASCII) без указания кодировки.
Переключение из текущей кодировки в указанную кодировку не поддерживается.
Вы получаете эту ошибку, если ваш XML файл был сохранен как двухбайтовый Уникод (или UTF-16) с указанной однобайтовой кодировкой (например, Windows-1251,
ISO-8859-1, UTF-8).
Вы также получаете эту ошибку, если ваш XML файл был сохранен как однобайтовый ANSI (или ASCII) с указанной двухбайтовой кодировкой (например, UTF-16).
Блокнот Windows
Блокнот Windows сохраняет файлы как однобайтовые ANSI (ASCII) по умолчанию.
Если Вы выберите «Сохранить как…», Вы можете указать двухбайтовый Уникод (UTF-16).
Сохраните XML файл ниже как Уникод (заметьте, что документ не содержит атрибута кодировки):
Света
Вася
Позвони мне завтра!
Файл выше, note_encode_none_u.xml НЕ будет генерировать ошибку. Но если Вы укажете однобайтовую кодировку, то будет.
Кодировка (откройте файл), вызовет сообщение об ошибке:
Следующая кодировка (откройте файл), вызовет сообщение об ошибке:
Следующая кодировка (откройте файл), вызовет сообщение об ошибке:
Следующая кодировка (откройте файл), НЕ будет генерировать ошибку:
Выводы
- Всегда используйте атрибут кодировки XML
- Используйте редактор, который поддерживает кодировки
- Удостоверьтесь, что знаете, какую кодировку использует ваш редактор
- Используйте ту же самую кодировку в атрибуте кодировки
Кодировки UTF-8 и Windows 1251 — просто о сложном

Здравствуйте, уважаемые читатели моего блога. Сегодня мы поговорим с вами про кодировку. Если вы читали мою статью о том, как посмотреть код страницы в браузере, то знаете, что любой документ в интернете хранится не в том виде, в каком мы привыкли его видеть. Он записан при помощи непонятных человеку символов и знаков. С текстом все точно также.
Существует несколько кодировок, а потому, иногда увидев непонятные символы при открытии книги в мобильном приложении или запилив статью на сайт, вы, поменяв кое-какие значения в настройках, увидите привычный глазу алфавит.

Кодировка windows-1251 – что это такое, какое значение она имеет при создании сайта, какие символы будут доступны и является ли она лучшим решением на сегодняшний день? Обо всем этом в сегодняшней статье. Как всегда, простым языком, максимально понятно и с минимальным количеством терминов.
Немного теории
Любой документ на компьютере или в интернете, как я уже сказал, хранится в виде двоичного кода. К примеру, если вы используете кодировку ASCII, то буква «К» будет записана как 10001010, а windows 1251 под этим числом скрывается символ – Љ. В итоге, если браузер или программа обратится к другой таблице и считает вместо ASCII коды windows 1251, то читатель увидит совершенно непонятные ему символ.
Логичен вопрос, нафига было придумывать множество таблиц с кодами? Дело в том, что помимо русского алфавита существует еще и английский, немецкий, китайский. По некоторым подсчетам, существует около 200 000 символов. Хотя, я не очень доверяю этой статистике, вспоминая про японский.
Не забывайте, что для заглавной и строчной буквы нужно придумать свой код, есть запятые, тире и так далее.
Чем больше в таблице символов, тем длиннее код каждого из них, а значит и вес документа становится больше.
Представьте, если бы одна книга весила 4 Гб! Она бы очень долго загружалась, занимала все свободное место на компьютере. Решение о скачивании представлялось бы делом нелегким.
Если вспомнить о сайтах, то вообще страшно подумать, что бы произошло. Каждая страничка открывалась даже на скоростном оптоволокне по часу с лишним! Думаю, мобильные телефоны можно было бы смело выкидывать. Пользоваться ими на улице даже с 4G? Сомневаюсь.
По этим причинам каждый программист в свое время старался придумать свою таблицу символов. Чтобы было удобно для использования и вес сохранялся оптимальным.
Microsoft, к примеру, для русскоязычного сегмента создали windows-1251. В ней, конечно же, есть свои достоинства и недостатки. Как и у любого другого продукта.
Сейчас уже, лишь 2% всех страниц в интернете написано на 1251. Большинство веб-мастеров используют UTF-8. Почему так?
Недостатки и достоинства
UTF-8, в отличие от windows-1251 универсальная кодировка, в ней содержатся буквы различных алфавитов. Существует даже UTF-128, где есть вообще все языки – теулу, суахили, лаосский, мальтийский и так далее.

UTF-8 победнее, буквы занимают в разы меньше места и занимают всего один байт памяти, как и в 1251. В УТФ есть редкие символы из других языков или специальные символы. Они-то и весят по 5-6 байтов, но в документе используются крайне редко.
Эта кодировка более продумана, а потому ее использует большинство приложений по умолчанию. То есть, если вы не указываете программе, какую кодировку вы используете, то первым делом он проверит именно UTF-8 .
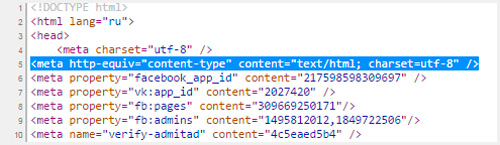
Когда вы создаете html документ для сайта, то указываете браузерам на какую таблицу им обращать внимание при расшифровке записей.
Для этого необходимо вставить в тег head следующие данные. После символов «charset=» идет либо утф, либо виндовс, как в примере ниже.
Если в дальнейшем вы захотите что-то поменять и вставить фразу на албанском, используя эту таблицу расшифровок, то ничего не получится, ведь этого языка кодировка не поддерживает. UTF‑8 без проблем позволит вам это сделать.
Если вас заинтересовало правильное создание сайта, то я могу порекомендовать вам курс Михаила Русакова « Создание и Раскрутка сайта от А до Я ».

Он содержит в себе очень много – 256 уроков, затрагивающих HTML, CSS, JavaScript, PHP, MySQL и XML. Помимо языков программирования вы сможете понять как монетизировать сайт, то есть скорее и больше получать прибыль. Один из немногих курсов, в котором было бы так подробно разъяснено все, что нужно.
Сам я вот уже год обучаюсь в школе блоггеров Александра Борисова . Это занимает в разы больше времени, конца и края пока не видно, но зато не менее исчерпывающе и дисциплинирует. Мотивирует продолжать разработку.
Ну а если возникают вопросы, не нужно искать по интернету. Всегда есть грамотный наставник.

Что-то я отошел от темы. Давайте вернемся к кодировкам.
Базы банных
Когда речь идет о php, все вообще страшно. Я уже рассказывал про базы данных, они используются для ускорения работы сайта. Обычно, вы к ним не обращаетесь, но когда появляется необходимость в переносе сайта становится не по себе.
Сложности случаются у всех, не важно какой у вас опыт работы, стаж и выслуга лет. Некоторые странички в базе могут содержать в себе все доступные символы для виндовс-1251, другие, к примеру, в шаблонах страниц, в другой кодировке.
Пока не нужен перенос все работает и функционирует, хоть и не совсем правильно. Но после переезда начинаются неприятности. В идеале вы должны использовать либо только УТФ, либо виндовс-1251, но по факту всегда и у всех случаются вот такие недочеты.
Чтобы расшифровка согласовалась необходимо вписать код mysql_query(«SET NAMES cp1251»). В этом случае преобразование будет осуществлять по другому протоколу – cp1251.
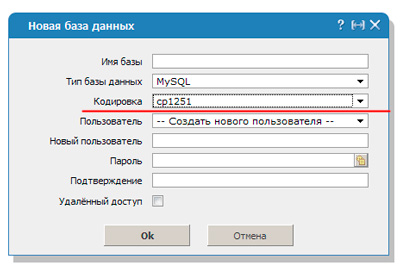
Htaccess
Если на сайте вы настойчиво решили использовать именно 1251, то вам следует найти или создать файл htaccess. Он отвечает за настройки конфигурации. В него придется добавить еще три строчки, чтобы все сошлось.
DefaultLanguage ru; AddDefaultCharset windows-1251; php_value default_charset «cp1251»
Я все же настоятельно рекомендую вам задумать о использовании UTF-8. Он более популярен, прост и богат. Какие бы решения вы не приняли сейчас, важно, чтобы впоследствии можно было все исправить. Добавить англоязычную версию сайта на этой кодировке будет в разы проще. Ничего не нужно исправлять.
Решение остается за вами. Подписывайтесь на рассылку, чтобы узнавать как можно быстрее создавать правильные сайты, где учиться, чтобы не повторять чужих ошибок, а также какие блоггеры получают больше посетителей.
До новых встреч и удачи в ваших начинаниях.
forum.clarionlife.net
Место общения программистов, форум разработчиков БД на Clarion
XML-файлы в кодовой таблице Windows-1251
Сообщение Гость » 27 Август 2004, 13:27
Честно говоря, не знаю, кому может пригодиться .
Мне надо было генерировать (для заказчика) и читать (от заказчика) XML в кодовой таблице Window-1251.
1. Опишем русскую кодировку в CPXML.Inc
2. И заставим выводить данные в windows-1251 (CpXML.clw)
DOMToXMLFile procedure(*Document doc, string path, , UNSIGNED Format = Format:AS_IS)
3. После чего получим XML-файл (например, в Example\XMLParse) в кодировке Windows-1251, вполне отображаемый браузером. Но встаёт другая проблема — эти файлы не читаются кларионовским парсером (Шаблон ‘View XML File’ просто падает при загрузке). Ну что ж, тем хуже для парсера. Возьмём шестнадцатеричный редактор, найдём в модуле C60cpxml.dll текст ‘ISO-8859-1’, заменим на ‘WINDOWS-1251’ и добавим в конец ‘ ‘ .
4. Вопрос с документами в UTF-8 не рассматривается
Когда-то мне пришлось более плотнее исследовать C6 XML Support. Сделал точно такие же изменения как Вы.
Я не понял, тогда в этом случае все O’K, что ли?
С уважением, Семен Попов
А за это отвечает процедура CheckXMLName из CpXML.clw . Можно поставить в первую строку Return(0) — и будут приниматься любые теги
С уважением, Семен Попов
По крайней мере, файлы, созданные обычным текстовым редактором или сформированные программой (в том числе без использования интерфейса) читаются, только и всего. Просто похоже, что используемая библиотека в принципе не поддерживает кодировок, отличных от буржуинских, а это самый простой путь заставить это делать.
Сообщение Гость » 27 Август 2004, 13:34
Кстати, вместо «WINDOWS-1251» можно использовать «MS1251» — такой синтаксис тоже понимают все системы.
Этим самым экономится длина строки (ISO-8859-1 — 10 знаков, WINDOWS-1251 — 12 знаков) при бинарном рпедактировании.
Увы, это строка проверяется при вводе, а не выводе Поэтому приходится пожертвовать следующим полем — US-ASCII .
Ну, у Клариона я не проверял, к сожалению.
У меня был аналогичный случай по основной работе (программные продукты Documentum).
Мы тоже очень долго мучились с проблемой замены в бинарном файле «ISO_8859-1» на название русской кодировки. Мучились как раз из-за ттго, что нужно было уложиться «байт в байт». Проверяли все возможные варианты синтаксиса (кстати, кроме «Windows-1251» еще есть варианты «1251», «CP-1251», «ANSI-1251» и другие).
В итоге долгих экспериментов выяснилось, что «MS1251» читается даже, например, Интернет-Эксплорером.
Собственно говоря, можете проверить — замените в метатеге какой-нибудь HTML-страницы «Windows-1251» на «MS1251» — бедет работать.
Да речь не о Кларионе. Просто для создания DLL использовалась некая сишная библиотека. А в ней есть список допустимый кодовых таблиц, и Windows-1251 в ней НЕТ. Происходит чтение XML и поиск наименования кодовой страницы в списке. Ещё раз — это важно при ЧТЕНИИ XML-файла через кларионовский Support.
И если файл начинается на
,
то именно ‘WINDOWS-1251’ и должен быть в программе. Собственно, путём двухдневных хакерских «экспериментов» и был найден такой вариант.
Возможно, что можно подменить и другие текстовые строки. Кто займётся?
Кстати, попробовал CP-1251 и MS1251, браузер показал ошибку . Файл прилагается.
А вот список кодовых таблиц кириллицы из MSDN
Имя обозначение (алиасы)
Cyrillic (DOS) cp866 ( ibm866 )
Cyrillic (ISO) iso-8859-5 (csISOLatin5, csISOLatinCyrillic, cyrillic, ISO_8859-5, ISO_8859-5:1988, iso-ir-144, l5)
Cyrillic (KOI8-R) koi8-r (koi8-ru)
Cyrillic (KOI8-U) koi8-u
Cyrillic (Windows) windows-1251 (x-cp1251)
Действительно, выдает ошибку.
Получается, что для обычного HTML это работает, а для XML — нет.
Ну, Билл Гейтс — все запутал!
Как настроить кодировку сайта самостоятельно

В статье:
Разбираем, на что влияет кодировка, нужно ли указывать ее самостоятельно, и почему могут появиться так называемые «кракозябры» на сайте.
Зачем нужна кодировка
Кодировка (Charset) — способ отображения кода на экране, соответствие набора символов набору числовых значений. О ней сообщает строка Content-Type и сервер в header запросе.
Несовпадение кодировок сервера и страницы будет причиной появления ошибок. Если они не совпадают, информация декодируется некорректно, так что контент на сайте будет отображаться в виде набора бессвязных букв, иероглифов и символов, в народе называемых «кракозябрами». Такой текст прочитать невозможно, так что пользователь просто уйдет с сайта и найдет другой ресурс. Или останется, если ему не очень важно содержание:
 Студентка списывала реферат с формулами, а на сайте слетела кодировка. Реальная история
Студентка списывала реферат с формулами, а на сайте слетела кодировка. Реальная история
Google рекомендует всегда указывать сведения о кодировке, чтобы текст точно корректно отображался в браузере пользователя.
Кодировка влияет на SEO?
Разберемся, как кодировка на сайте влияет на индексацию в Яндекс и Google.
«Тип используемой на сайте кодировки не влияет на индексирование сайта. Если ваш сервер не передает в заголовке кодировку, робот Яндекса также определит ее самостоятельно».
Позиция Google такая же. Поисковики не рассматривают Charset как фактор ранжирования или сигнал для индексирования, тем не менее, она косвенно влияет на трафик и позиции.
Если кодировка сервера не совпадает с той, что указана на сайте, пользователи увидят нечитабельные символы вместо контента. На таком сайте сложно что-либо понять, так что скорее всего пользователи сбегут, а на сайте будут расти отказы.
 Пример страницы со слетевшей кодировкой
Пример страницы со слетевшей кодировкой
Поэтому она важна для SEO, хоть и влияет на него косвенно через поведенческие. Пользователи должны видеть читабельный текст на человеческом языке, чтобы работать с сайтом.
Виды кодировок
Существует довольно много видов, но сейчас распространены два:
Unicode Transformation Format — универсальный стандарт кодирования, который работает с символами почти всех языков мира. Символы могут занимать от 1 до 4 байт, такое кодирование позволяет создавать мультиязычные сайты.
Есть несколько вариантов — UTF-8, 16, 32, но чаще используют восьмибитное.
Windows-1251
Этот вид занимает второе место по популярности после UTF-8. Windows-1251 — кодирование для кириллицы, созданное на базе кодировок, использовавшихся в русификаторах операционной системы Windows. В ней есть все символы, которые используются в русской типографике, кроме значка ударения. Символы занимают 1 байт.
Выбор кодировки остается на усмотрение веб-мастера, но UTF-8 используют намного чаще — ее поддерживают все популярные браузеры и распознают поисковики, а еще ее удобнее использовать для сайтов на разных языках.
Как определить кодировку на сайте
Определить кодировку страницы своего или чужого сайта можно через исходный код страницы. Откройте страницу сайта, выберите «Просмотр кода страницы» (сочетание горячих клавиш Ctrl+U» в Google Chrome) и найдите упоминание «charset» внутри тега head.
На странице сайта используется кодировка UTF-8:
 Указание кодировки в коде страницы
Указание кодировки в коде страницы
Узнать вид кодирования можно с помощью «Анализа сайта». Сервис проверяет в том числе и техническую сторону ресурса: анализирует серверную информацию, определяет кодировку, проверяет редиректы и другие пункты.
 Фрагмент анализа серверной информации сайта
Фрагмент анализа серверной информации сайта
С помощью этого же сервиса можно проверить корректность указанного кодирования. Аудит внутренних страниц «Анализа сайта» проверяет кодировку сервера и сравнивает ее с той, которая указана на внутренней странице. Найденные ошибки Анализ покажет в результатах проверки, и вы сразу узнаете, где нужно исправить.
 Отчет о технических данных
Отчет о технических данных
 Кодировка сервера и страницы
Кодировка сервера и страницы
Проверить кодировку еще можно через сервис Validator.w3, о котором писали в статье о проверке валидации кода. Нужная надпись находится внизу страницы.
 Кодировка сайта в валидаторе
Кодировка сайта в валидаторе
Если валидатор не обнаружит Charset, он покажет ошибку:
 Ошибка указания кодировки
Ошибка указания кодировки
Но валидатор работает не точно: он проверяет только синтаксис разметки, поэтому может не показать ошибку, даже если кодирование указано неправильно.
Если кодировка не отображается
Если вы зашли на чужой сайт с абракадаброй, а вам все равно очень интересно почитать контент, то в Справке Google объясняют, как исправить кодирование текста через браузер.
О проблеме возникновения абракадабры на вашем сайте будут сигнализировать метрики поведения: вырастут отказы, уменьшится глубина просмотров. Но скорее всего вы и раньше заметите, что что-то пошло не так.
Главное правило — для всех файлов, скриптов, баз данных сайта и сервера должна быть указана одна кодировка. Ошибка может возникнуть, если вы случайно указали на сайте разные виды кодировки.
Яндекс советует использовать одинаковую кодировку для страниц и кириллических адресов структуры. К примеру, если робот встретит ссылку href=»/корзина» на странице с кодировкой UTF-8, он сохранит ее в этом же UTF-8, так что страница должна быть доступна по адресу «/%D0%BA%D0%BE%D1%80%D0%B7%D0%B8%D0%BD%D0%B0».
Где указать кодировку сайта
Если проблема возникла на вашем сайте, способ исправления зависит от вида сайта. Для одностраничника достаточно указать кодировку в мета-теге страницы, а для большого сайта есть разные варианты:
- кодировка в мета-теге;
- кодировка в .htaccess;
- кодировка документа;
- кодировка в базе данных MySQL.
Кодировка в мета-теге
Добавьте указание кодировки в head файла шаблона сайта.
При создании документа HTML укажите тег meta в начале в блоке head. Некоторые браузеры могут не распознать указание кодировки, если оно будет ниже.
Мета-тег может выглядеть так:
В HTML5 они эквивалентны.
 Тег кодировки в HTML
Тег кодировки в HTML
В темах WordPress обычно тег «charset» с кодировкой указан по умолчанию, но лучше проверить.
Кодировка в файле httpd.conf
Инструкции для сервера находятся в файле httpd.conf, обычно его можно найти на пути «/usr/local/apache/conf/».
Если вам нужно сменить кодировку Windows-1251 на UTF-8, замените строчку «AddDefaultCharset windows-1251» на «AddDefaultCharset utf-8».
Осторожнее: если вы измените в файле кодировку по умолчанию, то она изменится для всех проектов на этом сервере.
Убедитесь, что сервер не передает HTTP-заголовки с конфликтующими кодировками.
Кодировка в .htaccess
Добавьте кодировку в файл .htaccess:
- Откройте панель управления хостингом.
- Перейдите в корневую папку сайта.
- В файле .htaccess добавьте в самое начало код:
- для указания кодировки UTF-8 — AddDefaultCharset UTF-8;
- для указания кодировки Windows-1251 — AddDefaultCharset WINDOWS-1251.
- Перейдите на сайт и очистите кэш браузера.
Кодировка документа
Готовые файлы HTML важно сохранять в нужной кодировке сайта. Узнать текущую кодировку файла можно через Notepad++: откройте файл и зайдите в «Encoding». Меняется она там же: чтобы сменить кодировку на UTF-8, выберите «Convert to UTF-8 without BOOM». Нужно выбрать «без BOOM», чтобы не было пустых символов.
Кодировка Базы данных
Выбирайте нужную кодировку сразу при создании базы данных. Распространенный вариант — «UTF-8 general ci».
Где менять кодировку у БД:
- Кликните по названию нужной базы в утилите управления БД phpMyAdmin и откройте ее.
- Кликните на раздел «Операции»:

- Введите нужную кодировку для базы данных MySQL:
- Перейдите на сайт и очистите кэш.


С новой БД проще, но если вы меняете кодировку у существующей базы, то у созданных таблиц и колонок заданы свои кодировки, которые тоже нужно поменять.
Для всех таблиц, колонок, файлов, сервера и вообще всего, что связано с сайтом, должна быть одна кодировка.
Проблема может не решиться, если все дело в кодировке подключения к базе данных. Что делать:
- Подключитесь к серверу с правами mysql root пользователя:
mysql -u root -p - Выберите нужную базу:
USE имя_базы; - Выполните запрос:
SET NAMES ‘utf8’;
Если вы хотите указать Windows-1251, то пишите не «utf-8», а «cp1251» — обозначение для кодировки Windows-1251 у MySQL.
Чтобы установить UTF-8 по умолчанию, откройте на сервере my.cnf и добавьте следующее:
Вы когда-нибудь сталкивались с проблемами кодировки на сайте?
![]()
In universal windows app, calling Encoding.GetEncoding(«windows-1251») will throw an exception
An exception of type ‘System.ArgumentException’ occurred in mscorlib.ni.dll but was not handled in user code
Additional information: ‘windows-1251’ is not a supported encoding name. For information on defining a custom encoding, see the documentation for the Encoding.RegisterProvider method.
same for euc-kr charset.
![]()
You will likely need to reference the System.Text.Encoding.CodePages package and then use Encoding.RegisterProvider.
This Stack Overflow answer addresses a similar problem. I expect the answer will work for you as well.
The reason this is done was to remove the need to carry encoding data with ever UWP app, even if the apps did not use them.
![]()
![]()
msftgits
transferred this issue from dotnet/corefx
Jan 31, 2020
![]()
msftbot
bot
locked as resolved and limited conversation to collaborators
Jan 1, 2021