Возможные ошибки спецификации модели:
1. Неправильный выбор вида уравнения
регрессии
2. В уравнение регрессии включена лишняя
(незначимая) переменная
3. В уравнении регрессии пропущена
значимая переменная
-
Неправильный выбор вида функции в
уравнении
Пусть на первом этапе была сделана
спецификация модели в виде:
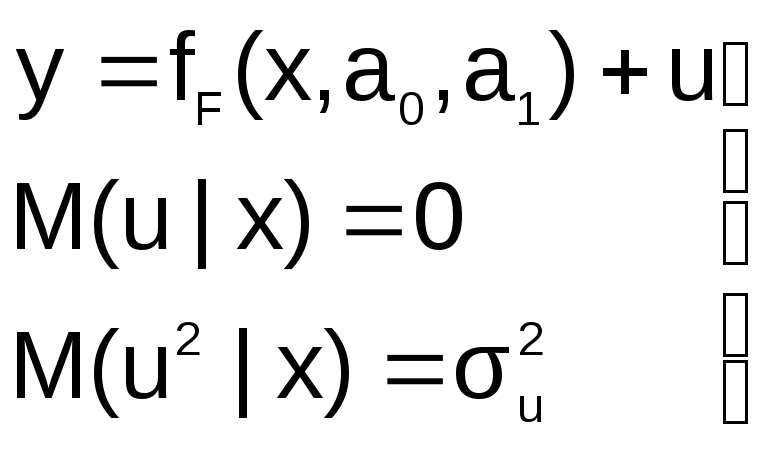
в![]()
которой функция fF(x,a0,a1)
выбрана не верно. Предположим, что
yT=fT(x,a0,a1)+v
– правильный вид функции регрессии.
Тогда справедливо выражение:
И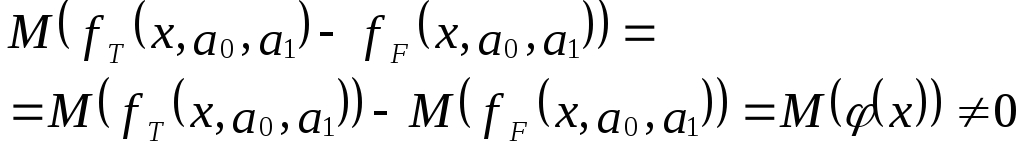 з
з
выражения следует:
Иными словами, математические ожидания
эндогенной переменной, полученные с
помощью функций fT
и fF
не совпадают, т.е. первая предпосылка
теоремы Гаусса-Маркова M(ulx)=0
не выполняется
Следовательно, в результате оценивания
такой модели параметры а0 и а1
будут смещенными
Симптомы наличия ошибки спецификации
первого типа:
1. Несоответствие диаграммы рассеяния,
построенной по имеющейся выборке виду
функции, принятой в спецификации
2. В динамических моделях длительно
сохраняется знак значений оценок
случайных возмущений у смежных (по
номеру t ) уравнений
наблюдений
Именно этот симптом и улавливается
статистикой DW Дарбина–Уотсона!
В силу данного обстоятельства тесту
Дарбина–Уотсона в эконометрике придается
большое значение.
Способ устранения: выбор другой формы
спецификации модели. Например, нелинейная
вместо линейной и т.д.
2. В уравнение регрессии включена
лишняя переменная
П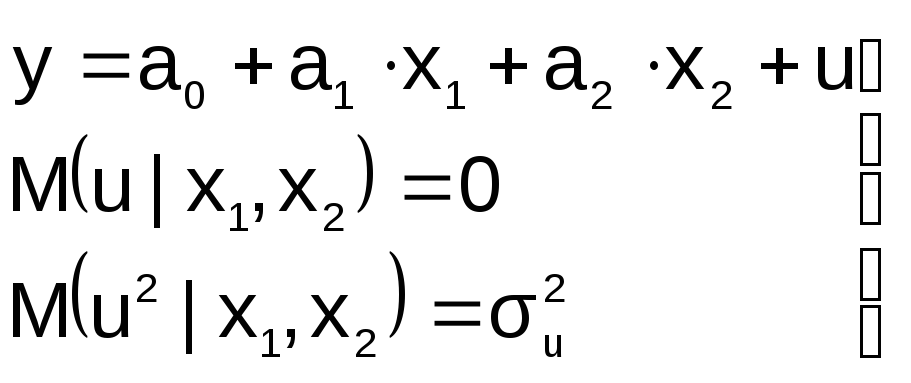 усть
усть
на этапе спецификации в модель включена
«лишняя» переменная, например, X2
«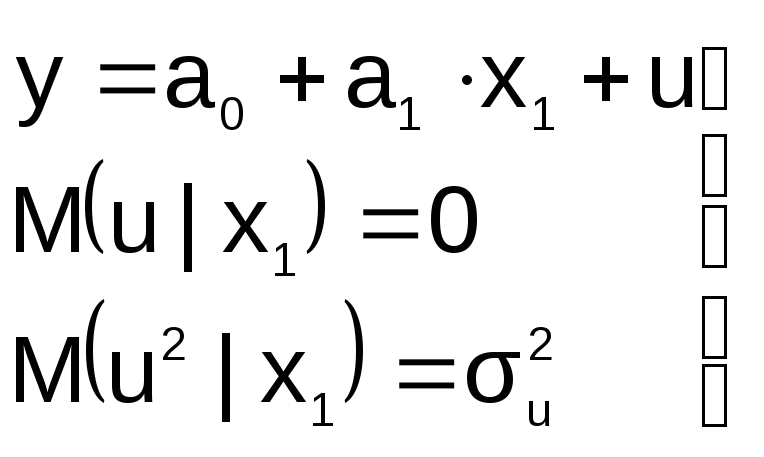 Правильная»
Правильная»
спецификация должна иметь вид:
Последствия:
![]() 1.
1.
Оценки параметров а0, а1, а2
останутся несмещенными, но потеряют
свою эффективность (точность)
2. Увеличивается ошибка прогноза по
модели
как за счет ошибок оценок коэффициентов
и σu,
так и за счет последнего слагаемого.
Это особенно опасно при больших абсолютных
значениях регрессора
Диагностика:
В моделях множественной регрессии
необходимо для каждого коэффициента
уравнения проверять статистическую
гипотезу H0: ai=0.
Вспомним, что для этого достаточно
оценить дробь Стьюдента и сравнить ее
значение с критическим значением
распределения Стьюдента, которое
вычисляется по значению доверительной
вероятности и значению степени свободы
n2 = n – (k+1)
3![]() .
.
В модели не достает важной переменной
Последствия такие же, как и в первом
случае: получаем смещенные оценки
параметров модели
Для устранения необходимо вернуться к
изучению особенностей поведения
экономического объекта, выявить опущенные
переменные и дополнить ими модель
29. Фиктивные переменные и особенности их использования в моделях.
На практике приходится учитывать в
моделях факторы, носящие качественный
характер, значения которых в наблюдениях
не возможно измерить с помощью числовой
шкалы.
Примеры.
Моделирование влияния пола специалистов
на уровень зарплаты.
Моделирование доходов граждан от типа
учебного заведения, в котором он получил
образование (государственное, частное,
специализированное,…)
Модель инфляции с учетом различных
видов регулирования со стороны государства
Возможны два подхода к решению задачи:
— построить несколько моделей отдельно
для каждого значения (градации)
качественной переменной
— учесть влияние качественного фактора
в одной модели
Второй способ представляется более
прогрессивным, т.к в этом случае появляется
возможность оценить статистическую
значимость влияния данного фактора на
поведение эндогенной переменной на
фоне других факторов, внесенных в
спецификацию модели
Пример. Изучается зависимость
расходов на образование «С» в «обычных»
и «специализированных» школах в
зависимости от числа учащихся N
Предположим:
-
Зависимость затрат на обучение от
количества учащихся N в
обоих типах школ одинакова
2. Разница в затратах объясняется
необходимостью приобретения
специализированного оборудования для
обучения специальным дисциплинам
Тогда если строить различные модели
для каждого типа школ, то спецификацию
моделей можно записать в виде:
Yo
= a0 +
a1N +u
Ys
= b0 +
a1N +
v
О бе
бе
модели можно объединить, если ввести
переменную d, область
определения которой два целых числа :
0 и 1. При этом:
Спецификация такой модели имеет вид:
Y = a0
+ a1N
+ δd + u
Тогда при d=0 получим Yo
= a0 + a1N
+ u
при d=1 получим Ys
= (a0+δ)
+a1N +
v
d – фиктивная переменная
сдвига
Фиктивные переменные часто применяются
при построении динамических моделей,
когда с определенного момента времени
начинает действовать какой-либо
качественный фактор
Пусть некоторый качественный фактор
имеет несколько градаций (более 2-х)
Введение в модель фиктивных переменных
с несколькими градациями рассмотрим
на примере шанхайских школ, где имеются
4 категории школ: общеобразовательные,
технические, ПТУ и специализированные
Казалось достаточно ввести фиктивную
переменную сдвига d, придав
ей четыре различных значения и проблема
будет решена
Такой подход мало эффективен, т.к не
удается оценить статистическую значимость
влияния каждой градации на значения
эндогенной переменной
В этом случае имеет смысл ввести отдельную
переменную для каждой градации фактора
Н апример:
апример:
Однако, если взять спецификацию модели
в виде:
Y=a0
+ a1d1+a2d2+a3d3+a4d4+a5N+u
при этом всегда верно тождество
d1+d2+d3+d4=1
Это означает, что матрица Х коэффициентов
системы уравнений наблюдений будет
коллинеарной т.к в ней присутствует
столбец из 1, и как следствие отсутствует
возможность применения МНК для оценки
параметров модели.
Предлагается в спецификацию ввести
(к-1) фиктивную переменную (к- кол-во
градаций), сделав одну из градаций
базовой, относительно которой изучать
влияние остальных градаций. Проблемы
мультиколинеарности в этом случае не
возникает
Для учета возможного изменения наклона
графика модели при изменении градации
качественного фактора предлагается
ввести в спецификацию модели еще одно
слагаемое вида «d умноженное
на x»
Вернемся к примеру изучения зависимости
расходов на образование в различных
школах. Для простоты ограничимся лишь
двумя градациями фактора «тип школы»:
d=0 – обычная школа;
d=1 – профессиональная
школа
Спецификацию модели следует записать
в виде:
Y = a0
+ a1N
+ a2*d
+ a3dN
+U
50
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #

Ошибки спецификации эконометрической модели относятся к различным ошибкам, которые могут быть сделаны при выборе и обработке набора независимых переменных для объяснения зависимой переменной.
Когда модель построена, она должна удовлетворять гипотезе правильной спецификации. Это основано на том факте, что независимые переменные, выбранные для модели, способны объяснить независимую переменную. Следовательно, предполагается, что не существует независимой переменной (x), которая могла бы объяснить независимую переменную (y), и что таким образом были бы выбраны переменные, которые позволяют использовать подход правильной модели.
Ошибки спецификации модели
В спецификации модели имеется ряд ошибок, которые можно сгруппировать в три большие группы:
Группа 1: способ работы указан неверно.
- Пропуск соответствующих переменных: Представим, что мы хотим объяснить доходность акций компании Y. Для этого мы выбираем PER, рыночную капитализацию и балансовую стоимость в качестве независимых переменных. Если свободное плавание коррелирует с любой из переменных, содержащихся в модели, ошибка нашей модели будет коррелирована с переменными, включенными в модель. Это может привести к тому, что параметры, оцениваемые моделью, будут несмещенными и непоследовательными. Таким образом, результаты прогнозов и различных тестов, выполненных на модели, будут недействительными.
- Преобразуемые переменные: Гипотеза регрессионной модели предполагает, что зависимая переменная линейно связана с независимыми переменными. Однако во многих случаях связь между ними не является линейной. Если необходимое преобразование не будет выполнено для независимой переменной, модель не будет иметь правильного соответствия. В качестве примеров преобразования независимых переменных мы можем привести логарифм, квадратный корень или возведение в квадрат среди прочего.
- Плохой сбор выборочных данных: Данные независимых переменных должны быть согласованы со временем, то есть структурных изменений независимых переменных быть не может. Представим, что мы хотим объяснить изменение ВВП в стране X, используя потребление и инвестиции в качестве независимых переменных. Предположим, что в этой стране на государственной земле открыто месторождение нефти, и правительство решает отменить налоги. Это может привести к изменению потребительских привычек страны, которые с этой даты будут сохраняться неопределенно долго. В этом случае мы должны собрать два разных временных ряда и оценить две модели. Одна модель до изменения, другая после. Если бы мы сгруппировали данные в одну выборку и оценили модель, у нас была бы плохо определенная модель, а гипотезы, контрасты и прогнозы были бы неверными.
Группа 2: независимые переменные коррелируют с ошибкой во временном ряду.
- Использование зависимой переменной с запаздыванием в качестве независимой переменной: Использование переменной с запаздыванием означает использование данных тех же переменных, но измеренных за предыдущий период. Предположим, мы используем предыдущую модель ВВП в качестве зависимой переменной. Добавим в модель, помимо потребления и инвестиций, ВВП предыдущего года (GDPт-1). Если ВВП предыдущего года серийно коррелирует с ошибкой, расчетные коэффициенты будут смещены и не будут противоречивыми. Это снова сделает недействительными все проверки гипотез, прогнозы и т. Д.
- Предсказание прошлого: Когда мы измеряем переменную, мы всегда должны брать период перед тем, который мы хотим оценить. Предположим, что наша зависимая переменная — это доходность запаса X, а наша независимая переменная — PER. Предположим далее, что мы берем окончательные данные за февраль. Если мы воспользуемся этим в нашей модели, мы сделаем вывод, что акции с самым высоким PER в конце февраля имели самую высокую доходность в конце февраля. Правильная спецификация модели предполагает использование данных с начала периода для прогнозирования более поздних данных, а не наоборот, как в предыдущем случае. Это называется предсказанием прошлого.
- Измерьте независимую переменную с ошибкой: Предположим, что наша независимая переменная — это доходность акции, а одна из наших независимых переменных — номинальная процентная ставка. Помните, что номинальная процентная ставка — это процентная ставка плюс инфляция. Поскольку инфляционный компонент номинальной процентной ставки не наблюдается в будущем, мы будем измерять переменную с ошибкой. Чтобы правильно измерить процентную ставку, мы должны использовать ожидаемую процентную ставку, которая учитывает ожидаемую инфляцию, а не текущую.
Вы поможете развитию сайта, поделившись страницей с друзьями
4.
Использование
предварительной информации о значениях некоторых параметров. Иногда значения некоторых неизвестных параметров
модели могут быть определены по пробным выборочным наблюдениям, тогда
мультиколлинеарность может быть устранена путем установления значений параметра
у одной коррелирующих переменных. Ограниченность метода – в сложности получения
предварительных значений параметров с высокой точностью.
5.
Преобразование переменных. Для устранения мультиколлинеарности можно
преобразовать переменные, например, путем линеаризации или получения
относительных показателей, а также перехода от номинальных к реальным
показателям (особенно в макроэкономических исследованиях).
При построении модели множественной регрессии с точки
зрения обеспечения ее высокого качества возникают следующие вопросы:
1.
Каковы признаки качественной
модели?
2.
Какие ошибки спецификации могут
быть?
3.
Каковы последствия ошибок
спецификации?
4.
Какие существуют методы
обнаружения и устранения ошибок спецификации?
Рассмотрим основные признаки качественной модели
множественной регрессии:
1.
Простота. Из двух моделей примерно одинаковых статистических
свойств более качественной является та, которая содержит меньше переменных, или
же более простая по аналитической форме.
2.
Однозначность. Метод вычисления коэффициентов должен быть одинаков
для любых наборов данных.
3.
Максимальное соответствие. Этот признак говорит о том, что основным критерием
качества модели является коэффициент детерминации, отражающий объясненную
моделью вариацию зависимой переменной. Для практического использования выбирают
модель, для которой расчетное значение F-критерия для
коэффициента детерминации б четыре раза больше табличного.
4.
Согласованность с теорией. Получаемые значения коэффициентов должны быть
интерпретируемы с точки зрения экономических явлений и процессов. К примеру,
если строится линейная регрессионная модель спроса на товар, то соответствующий
коэффициент при цене товара должен быть отрицательным.
5.
Хорошие прогнозные качества.
Обязательным условием построения
качественной модели является возможность ее использования для прогнозирования.
Одной из основных ошибок, допускаемых при построении
регрессионной модели, является ошибка спецификации (рис. 4.3).
Под ошибкой спецификации понимается неправильный выбор функциональной формы
модели или набора объясняющих переменных.
Различают следующие виды ошибок спецификации:
1.
Невключение в модель полезной
(значимой) переменной.
2.
Добавление в модель лишней
(незначимой) переменной
3.
Выбор неправильной функциональной
формы модели
Последствия ошибки первого вида (невключение в
модель значимой переменной) заключаются в том, что полученные по МНК оценки
параметров являются смещенными и несостоятельными, а значение коэффициента
детерминации значительно снижаются.
При добавлении в модель лишней переменной
(ошибка второго вида) ухудшаются статистические свойства оценок
коэффициентов, возрастают их дисперсии, что ухудшает прогнозные качества модели
и затрудняет содержательную интерпретацию параметров, однако по сравнению с
другими ошибками ее последствия менее серьезны.
Если же осуществлен неверный выбор
функциональной формы модели, то есть допущена ошибка третьего вида, то
получаемые оценки будут смещенными, качество модели в целом и отдельных
коэффициентов будет невысоким. Это может существенно сказаться на прогнозных
качествах модели.
Ошибки спецификации первого вида можно обнаружить только
по невысокому качеству модели, низким значениям R2.
Обнаружение ошибок спецификации второго вида, если лишней
является только одна переменная, осуществляется на основе расчета t — статистики для коэффициентов. При лишней переменной коэффициент
будет статистически незначим.
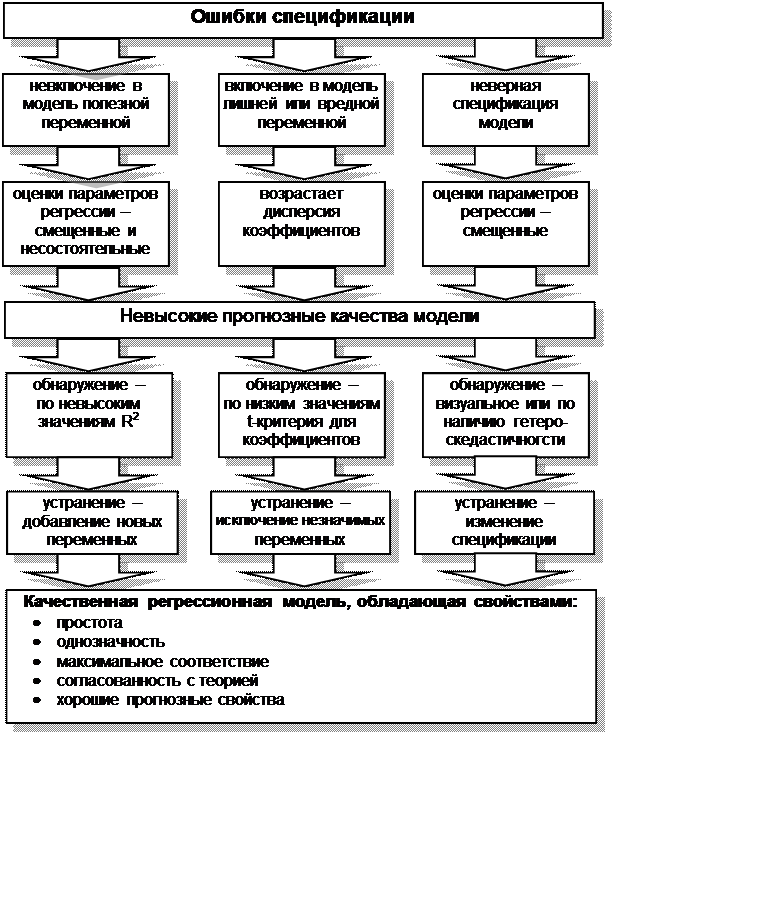
Рис. 4.3 Ошибки спецификации и свойства качественной
регрессионной модели
From Wikipedia, the free encyclopedia
In statistics, model specification is part of the process of building a statistical model: specification consists of selecting an appropriate functional form for the model and choosing which variables to include. For example, given personal income  together with years of schooling
together with years of schooling  and on-the-job experience
and on-the-job experience  , we might specify a functional relationship
, we might specify a functional relationship  as follows:[1]
as follows:[1]

where  is the unexplained error term that is supposed to comprise independent and identically distributed Gaussian variables.
is the unexplained error term that is supposed to comprise independent and identically distributed Gaussian variables.
The statistician Sir David Cox has said, «How [the] translation from subject-matter problem to statistical model is done is often the most critical part of an analysis».[2]
Specification error and bias[edit]
Specification error occurs when the functional form or the choice of independent variables poorly represent relevant aspects of the true data-generating process. In particular, bias (the expected value of the difference of an estimated parameter and the true underlying value) occurs if an independent variable is correlated with the errors inherent in the underlying process. There are several different possible causes of specification error; some are listed below.
- An inappropriate functional form could be employed.
- A variable omitted from the model may have a relationship with both the dependent variable and one or more of the independent variables (causing omitted-variable bias).[3]
- An irrelevant variable may be included in the model (although this does not create bias, it involves overfitting and so can lead to poor predictive performance).
- The dependent variable may be part of a system of simultaneous equations (giving simultaneity bias).
Additionally, measurement errors may affect the independent variables: while this is not a specification error, it can create statistical bias.
Note that all models will have some specification error. Indeed, in statistics there is a common aphorism that «all models are wrong». In the words of Burnham & Anderson,
«Modeling is an art as well as a science and is directed toward finding a good approximating model … as the basis for statistical inference».[4]
Detection of misspecification[edit]
The Ramsey RESET test can help test for specification error in regression analysis.
In the example given above relating personal income to schooling and job experience, if the assumptions of the model are correct, then the least squares estimates of the parameters  and
and  will be efficient and unbiased. Hence specification diagnostics usually involve testing the first to fourth moment of the residuals.[5]
will be efficient and unbiased. Hence specification diagnostics usually involve testing the first to fourth moment of the residuals.[5]
Model building[edit]
|
This section needs expansion. You can help by adding to it. (February 2019) |
Building a model involves finding a set of relationships to represent the process that is generating the data. This requires avoiding all the sources of misspecification mentioned above.
One approach is to start with a model in general form that relies on a theoretical understanding of the data-generating process. Then the model can be fit to the data and checked for the various sources of misspecification, in a task called statistical model validation. Theoretical understanding can then guide the modification of the model in such a way as to retain theoretical validity while removing the sources of misspecification. But if it proves impossible to find a theoretically acceptable specification that fits the data, the theoretical model may have to be rejected and replaced with another one.
A quotation from Karl Popper is apposite here: «Whenever a theory appears to you as the only possible one, take this as a sign that you have neither understood the theory nor the problem which it was intended to solve».[6]
Another approach to model building is to specify several different models as candidates, and then compare those candidate models to each other. The purpose of the comparison is to determine which candidate model is most appropriate for statistical inference. Common criteria for comparing models include the following: R2, Bayes factor, and the likelihood-ratio test together with its generalization relative likelihood. For more on this topic, see statistical model selection.
See also[edit]
- Abductive reasoning
- Conceptual model
- Data analysis
- Data transformation (statistics)
- Design of experiments
- Durbin–Wu–Hausman test
- Exploratory data analysis
- Feature selection
- Heteroscedasticity, second-order statistical misspecification
- Information matrix test
- Model identification
- Principle of Parsimony
- Spurious relationship
- Statistical conclusion validity
- Statistical inference
- Statistical learning theory
Notes[edit]
- ^ This particular example is known as Mincer earnings function.
- ^ Cox, D. R. (2006), Principles of Statistical Inference, Cambridge University Press, p. 197.
- ^ «Quantitative Methods II: Econometrics», College of William & Mary.
- ^ Burnham, K. P.; Anderson, D. R. (2002), Model Selection and Multimodel Inference: A practical information-theoretic approach (2nd ed.), Springer-Verlag, §1.1.
- ^ Long, J. Scott; Trivedi, Pravin K. (1993). «Some specification tests for the linear regression model». In Bollen, Kenneth A.; Long, J. Scott (eds.). Testing Structural Equation Models. SAGE Publishing. pp. 66–110.
- ^ Popper, Karl (1972), Objective Knowledge: An evolutionary approach, Oxford University Press.
Further reading[edit]
- Akaike, Hirotugu (1994), «Implications of informational point of view on the development of statistical science», in Bozdogan, H. (ed.), Proceedings of the First US/JAPAN Conference on The Frontiers of Statistical Modeling: An Informational Approach—Volume 3, Kluwer Academic Publishers, pp. 27–38.
- Asteriou, Dimitrios; Hall, Stephen G. (2011). «Misspecification: Wrong regressors, measurement errors and wrong functional forms». Applied Econometrics (Second ed.). Palgrave Macmillan. pp. 172–197.
- Colegrave, N.; Ruxton, G. D. (2017). «Statistical model specification and power: recommendations on the use of test-qualified pooling in analysis of experimental data». Proceedings of the Royal Society B. 284 (1851): 20161850. doi:10.1098/rspb.2016.1850. PMC 5378071. PMID 28330912.
- Gujarati, Damodar N.; Porter, Dawn C. (2009). «Econometric modeling: Model specification and diagnostic testing». Basic Econometrics (Fifth ed.). McGraw-Hill/Irwin. pp. 467–522. ISBN 978-0-07-337577-9.
- Harrell, Frank (2001), Regression Modeling Strategies, Springer.
- Kmenta, Jan (1986). Elements of Econometrics (Second ed.). New York: Macmillan Publishers. pp. 442–455. ISBN 0-02-365070-2.
- Lehmann, E. L. (1990). «Model specification: The views of Fisher and Neyman, and later developments». Statistical Science. 5 (2): 160–168. doi:10.1214/ss/1177012164.
- MacKinnon, James G. (1992). «Model specification tests and artificial regressions». Journal of Economic Literature. 30 (1): 102–146. JSTOR 2727880.
- Maddala, G. S.; Lahiri, Kajal (2009). «Diagnostic checking, model selection, and specification testing». Introduction to Econometrics (Fourth ed.). Wiley. pp. 401–449. ISBN 978-0-470-01512-4.
- Sapra, Sunil (2005). «A regression error specification test (RESET) for generalized linear models» (PDF). Economics Bulletin. 3 (1): 1–6.